Thread: Fuzzy substring searching with the pg_trgm extension
Hello.
PostgreSQL has a contrib module named pg_trgm. It is used to the fuzzy
text search. It provides some functions and operators for determining
the similarity of the given texts using trigram matching.
At the moment, in pg_trgm both the similarity function and the %
operator match two strings expecting that they are similar entirely. But
they give bad results if we want to find documents by a query which is
substring of a document.
For this purpose we need a new operator which enables to find strings
that have a fragment most similar to the given string. This patch adds
some functions and operator:
- function substring_similarity - Returns a number that indicates how
similar the first string to the most similar substring of the second
string. The range of the result is zero (indicating that the two strings
are completely dissimilar) to one (indicating that the first string is
identical to substring of the second substring).
- function show_substring_limit - Returns the current similarity
threshold used by the <% operator. This sets the minimum substring
similarity between two phrases.
- function set_substring_limit - Sets the current substring similarity
threshold that is used by the <% operator. The threshold must be between
0 and 1 (default is 0.6). Returns the same value passed in.
- operator <% - Returns true if its arguments have a substring
similarity that is greater than the current substring similarity
threshold set by set_substring_limit. Has an index support.
Substring similarity algorithm
------------------------------
1 - generate trigram arrays for a query string and for a text.
2 - create an array that contains trigrams from both arrays from the
step 1 and contains position (index) for trigrams from the second array.
The array stores the following structure:
typedef struct
{
trgm t; // Trigram
int i; // -1 for the first array and position (index) in
the second array
} ptrgm;
3 - sort the array from the step 2.
4 - search trigrams from a query string in a given text and store a
search result in the new boolean array using the array from the step 2.
5 - calculate similarity using the array from the step 4. In this step
lower and upper indexes of the second array from the step 1 are used. An
upper index is moved in each iteration of the calculation. And a lower
index is moved if current similarity is bigger than a maximum similarity
calculated in previous iterations. In a result lower and upper indexes
point to a substring that has a maxumim similarity value.
Changes
-------
Version was increased to 1.3.
Added some functions into trgm_op.c to calculate substring similarity.
Made some fixes into trgm_gin.c in gin_extract_query_trgm,
gin_trgm_consistent and gin_trgm_triconsistent functions to add GIN
index supporing for <% operator.
Made some fixes into trgm_gist.c in gtrgm_consistent and gtrgm_distance
functions to add GIST index support for <% operator.
Added pg_substring_trgm test.
Tests
-----
I have done tests to show performance of the new operator. Tests have
been done using a table that contains 10254520 records. This table
contains texts that have trigram count between 2 and 121. 214 queries
were done to this table using GIN and GIST indexes and same queries were
done without indexes.
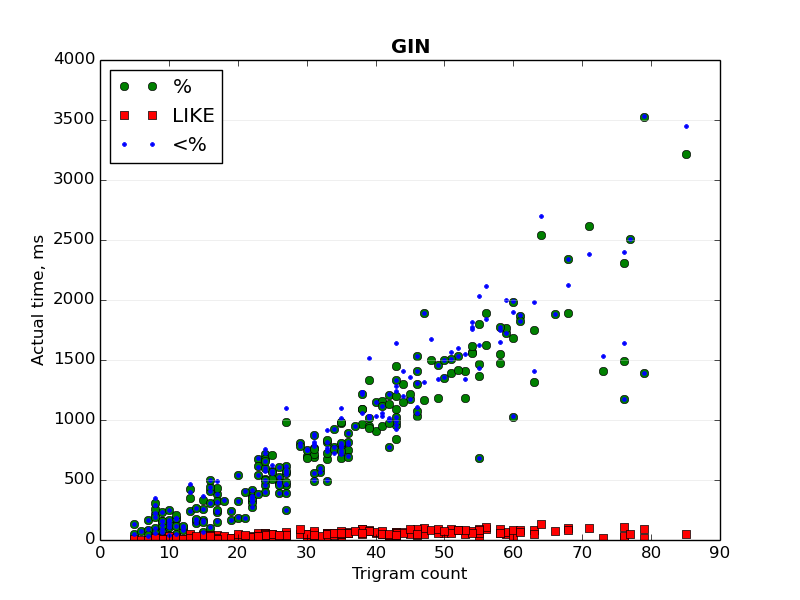
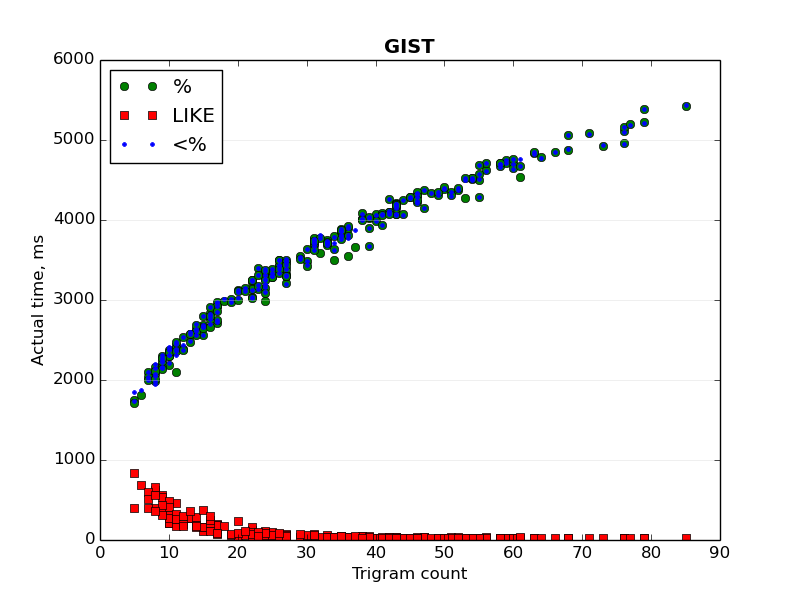
Two graphs ("GIN - index time.png" and "GIST - index time.png") show the
dependence of the actual time of bitmap index scan from the trigram
count of a searched text.
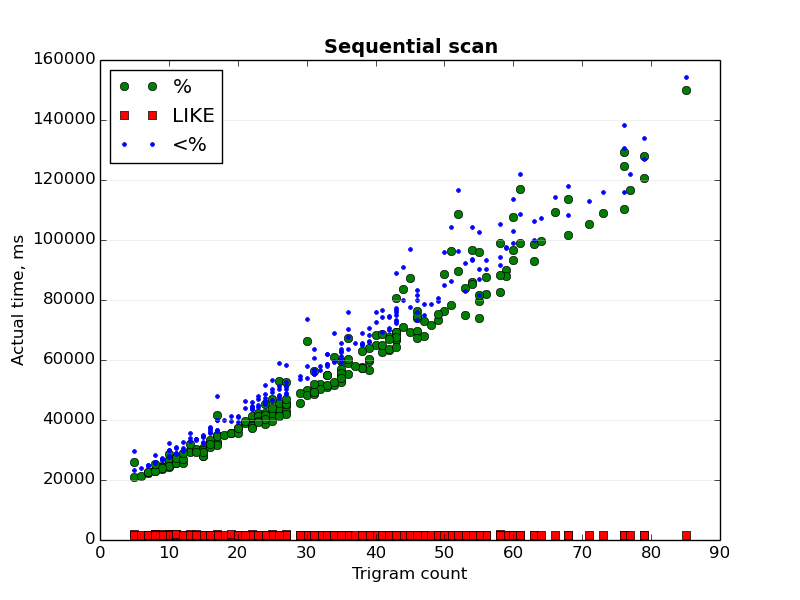
Third graph (Sequential scan.png) shows the dependence of the actual
time of sequential scan from the trigram count of a searched text.
Until now I have not done tests to show performance of the search in
large texts. I can do it if it is interesting.
Alexander Korotkov <a(dot)korotkov(at)postgrespro(dot)ru> is co-author
of the patch. Thank you for review and for help.
--
Artur Zakirov
Postgres Professional: http://www.postgrespro.com
Russian Postgres Company
Attachment
{kind=link}
{kind=link}
{kind=link}
On 18.12.2015 22:43, Artur Zakirov wrote: > Hello. > > PostgreSQL has a contrib module named pg_trgm. It is used to the fuzzy > text search. It provides some functions and operators for determining > the similarity of the given texts using trigram matching. > Sorry, I have forgotten to mark previous message with [PROPOSAL]. I registered the patch in commitfest: https://commitfest.postgresql.org/8/448/ -- Artur Zakirov Postgres Professional: http://www.postgrespro.com Russian Postgres Company
On Fri, Dec 18, 2015 at 10:53 PM, Artur Zakirov <a.zakirov@postgrespro.ru> wrote:
On 18.12.2015 22:43, Artur Zakirov wrote:Hello.Sorry, I have forgotten to mark previous message with [PROPOSAL].
PostgreSQL has a contrib module named pg_trgm. It is used to the fuzzy text search. It provides some functions and operators for determining the similarity of the given texts using trigram matching.
I think, you shouldn't mark thread as [PROPOSAL] since you're providing a full patch.
I registered the patch in commitfest:
https://commitfest.postgresql.org/8/448/
Great.
------
Alexander Korotkov
Postgres Professional: http://www.postgrespro.com
The Russian Postgres Company
On Fri, Dec 18, 2015 at 11:43 AM, Artur Zakirov <a.zakirov@postgrespro.ru> wrote: > Hello. > > PostgreSQL has a contrib module named pg_trgm. It is used to the fuzzy text > search. It provides some functions and operators for determining the > similarity of the given texts using trigram matching. > > At the moment, in pg_trgm both the similarity function and the % operator > match two strings expecting that they are similar entirely. But they give > bad results if we want to find documents by a query which is substring of a > document. This is very interesting. I suspect the index will not be very useful in cases where the full string is much larger than the substring, because the limit will not be met often enough to rule out many rows just based on the index data. I have a pretty good test case to see. Can you update the patch to incorporate the recent changes committed under the thread "Patch: pg_trgm: gin index scan performance for similarity search"? They conflict with your changes. Thanks, Jeff
On 27.12.2015 08:12, Jeff Janes wrote: > This is very interesting. I suspect the index will not be very useful > in cases where the full string is much larger than the substring, > because the limit will not be met often enough to rule out many rows > just based on the index data. I have a pretty good test case to see. > > Can you update the patch to incorporate the recent changes committed > under the thread "Patch: pg_trgm: gin index scan performance for > similarity search"? They conflict with your changes. > > Thanks, > > Jeff > > I updated the patch and attached it. The patch includes source code and regression tests now. It will be very good if you will test it with your case. -- Artur Zakirov Postgres Professional: http://www.postgrespro.com Russian Postgres Company
Attachment
I gave a quick look through the patch and noticed a few minor things
while trying to understand it.
I think the test corpus isn't particularly interesting for how big it
is. I'd rather have (a) a small corpus (say 100 words) with which to do
detailed regression testing, and (b) some larger document for more
extensive testing. I'm not sure (b) is actually necessary.
Overall I think the new functions could stand a lot more commentary.
> --- 104,125 ----
> #define GETARR(x) ( (trgm*)( (char*)x+TRGMHDRSIZE ) )
> #define ARRNELEM(x) ( ( VARSIZE(x) - TRGMHDRSIZE )/sizeof(trgm) )
>
> + #ifdef DIVUNION
> + #define CALCSML(count, len1, len2) ((float4) (count)) / ((float4) ((len1) + (len2) - (count)))
> + #else
> + #define CALCSML(count, len1, len2) ((float4) (count)) / ((float4) (((len1) > (len2)) ? (len1) : (len2)))
> + #endif
This macro has a multiple evaluation gotcha. Maybe we don't really care
because of the limited applicability but I'd put a comment on top.
> /* strange bug at freebsd 5.2.1 and gcc 3.3.3 */
> ! res = (*(int *) &tmpsml == *(int *) &trgm_limit || tmpsml > trgm_limit) ? true : false;
> }
> else if (ISALLTRUE(key))
> { /* non-leaf contains signature */
> --- 288,304 ----
> switch (strategy)
> {
> case SimilarityStrategyNumber:
> ! case SubstringSimilarityStrategyNumber:
> ! /* Similarity search is exact. Substring similarity search is inexact */
> ! *recheck = (strategy == SubstringSimilarityStrategyNumber) ? true : false;
> ! nlimit = (strategy == SimilarityStrategyNumber) ? trgm_limit : trgm_substring_limit;
>
> if (GIST_LEAF(entry))
> { /* all leafs contains orig trgm */
> ! float4 tmpsml = cnt_sml(qtrg, key, *recheck);
>
> /* strange bug at freebsd 5.2.1 and gcc 3.3.3 */
> ! res = (*(int *) &tmpsml == *(int *) &nlimit || tmpsml > nlimit) ? true : false;
What's the compiler bug about? This code and comment were introduced in
cbfa4092bb (May 2004) without any explanation. Do we still need to keep
it, if &nlimit is now a local variable instead of a global? FWIW the
oldest GCC in the buildfarm is 3.4.2/3.4.3 (except for Gaur which uses
GCC 2.95 under HPPA)
BTW you don't need a ternary op just to say "? true : false" -- just
make itres = foo == bar;
which immediately assigns the correct boolean value. (This pattern
occurs in many places both in the original and in your submitted code.
I see no reason to perpetuate it.)
> + Datum
> + set_substring_limit(PG_FUNCTION_ARGS)
> + {
> + float4 nlimit = PG_GETARG_FLOAT4(0);
> +
> + if (nlimit < 0 || nlimit > 1.0)
> + elog(ERROR, "wrong limit, should be between 0 and 1");
Should be an ereport().
> ! static void
> ! protect_out_of_mem(int slen)
> ! {
> ! /*
> ! * Guard against possible overflow in the palloc requests below. (We
> ! * don't worry about the additive constants, since palloc can detect
> ! * requests that are a little above MaxAllocSize --- we just need to
> ! * prevent integer overflow in the multiplications.)
> ! */
> ! if ((Size) (slen / 2) >= (MaxAllocSize / (sizeof(trgm) * 3)) ||
> ! (Size) slen >= (MaxAllocSize / pg_database_encoding_max_length()))
> ! ereport(ERROR,
> ! (errcode(ERRCODE_PROGRAM_LIMIT_EXCEEDED),
> ! errmsg("out of memory")));
> ! }
I think the comment should now be above the function, not inside it.
> ***************
> *** 254,259 **** generate_trgm(char *str, int slen)
> --- 292,534 ----
> return trg;
> }
>
> + /* Trigram with position */
> + typedef struct
> + {
> + trgm t;
> + int i;
> + } ptrgm;
This struct definition could stand a better name, and better member
names. Also, our policy (not always enforced) is to have these near the
top of the file rather than in the middle. If the struct is used in
many places then IMO it's better that it go at the top; if it's used
only in one function I'd say it's okay to have it just after that
function.
> + /*
> + * Make array of positional trigrams from two trigram arrays. The first array
> + * is required substing which positions don't matter and replaced with -1.
> + * The second array is haystack where we search and have to store its
> + * positions.
> + */
> + static ptrgm *
> + make_positional_trgm(trgm *trg1, int len1, trgm *trg2, int len2)
> + {
> + ptrgm *result;
> + int i, len = len1 + len2;
> +
> + result = (ptrgm *) palloc(sizeof(ptrgm) * len);
> +
> + for (i = 0; i < len1; i++)
> + {
> + memcpy(&result[i].t, &trg1[i], sizeof(trgm));
> + result[i].i = -1;
> + }
> +
> + for (i = 0; i < len2; i++)
> + {
> + memcpy(&result[i + len1].t, &trg2[i], sizeof(trgm));
> + result[i + len1].i = i;
> + }
> +
> + return result;
> + }
So the output trigram array is the concatenation of both input trigrams?
That's not quite evident from the comment above the function ... I think
some rephrasing there is in order.
> --- 856,869 ----
> }
> }
>
> ! /* if inexact then len2 is equal to count */
> ! if (inexact)
> ! return CALCSML(count, len1, count);
> ! else
> ! return CALCSML(count, len1, len2);
This is where a ternary op would make better code.CALCSML(count, len1, inexact ? count : len2);
but a better comment would actually explain why we do this, rather than
just stating we do.
> + <row>
> +
<entry><function>show_substring_limit()</function><indexterm><primary>show_substring_limit</primary></indexterm></entry>
> + <entry><type>real</type></entry>
> + <entry>
> + Returns the current similarity threshold used by the <literal><%</>
> + operator. This sets the minimum substring similarity between
> + two phrases.
> + </entry>
> + </row>
> + <row>
> +
<entry><function>set_substring_limit(real)</function><indexterm><primary>set_substring_limit</primary></indexterm></entry>
> + <entry><type>real</type></entry>
> + <entry>
> + Sets the current substring similarity threshold that is used by
> + the <literal><%</> operator. The threshold must be between
> + 0 and 1 (default is 0.6). Returns the same value passed in.
> + </entry>
I don't quite understand why aren't we using a custom GUC variable here.
These already have SHOW and SET support ...
--
Álvaro Herrera http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
Alvaro Herrera <alvherre@2ndquadrant.com> writes:
>> +
<entry><function>show_substring_limit()</function><indexterm><primary>show_substring_limit</primary></indexterm></entry>
>> +
<entry><function>set_substring_limit(real)</function><indexterm><primary>set_substring_limit</primary></indexterm></entry>
> I don't quite understand why aren't we using a custom GUC variable here.
Presumably this is following the existing set_limit() precedent
in pg_trgm. But I tend to agree that that's a crummy precedent
and we should not extend it.
Let's invent a custom GUC for the regular limit, mark show_limit()
and set_limit as deprecated, and then make just a custom GUC for
this other limit.
regards, tom lane
>> ! float4 tmpsml = cnt_sml(qtrg, key, *recheck); >> >> /* strange bug at freebsd 5.2.1 and gcc 3.3.3 */ >> ! res = (*(int *) &tmpsml == *(int *) &nlimit || tmpsml > nlimit) ? true : false; > > What's the compiler bug about? This code and comment were introduced in > cbfa4092bb (May 2004) without any explanation. Do we still need to keep > it, if &nlimit is now a local variable instead of a global? FWIW the > oldest GCC in the buildfarm is 3.4.2/3.4.3 (except for Gaur which uses As I remeber, the problem was with x87 math coprocessor. Compiler (suppose, modern compiler could do it too) keeps tmpsml in internal 80-bit wide register and compares with 32-bit wide float. Of course, it depends on level of optimization and so, result of comparison was differ in optimization enabled and disabled instances. Such strange way I choose to force compiler to use main memory for tmpsml variable. Actually, I don't know better way even now. -- Teodor Sigaev E-mail: teodor@sigaev.ru WWW: http://www.sigaev.ru/
On Sat, Dec 26, 2015 at 9:12 PM, Jeff Janes <jeff.janes@gmail.com> wrote: > On Fri, Dec 18, 2015 at 11:43 AM, Artur Zakirov > <a.zakirov@postgrespro.ru> wrote: >> Hello. >> >> PostgreSQL has a contrib module named pg_trgm. It is used to the fuzzy text >> search. It provides some functions and operators for determining the >> similarity of the given texts using trigram matching. >> >> At the moment, in pg_trgm both the similarity function and the % operator >> match two strings expecting that they are similar entirely. But they give >> bad results if we want to find documents by a query which is substring of a >> document. > > This is very interesting. I suspect the index will not be very useful > in cases where the full string is much larger than the substring, > because the limit will not be met often enough to rule out many rows > just based on the index data. I have a pretty good test case to see. My test case is turning out to be harder to evaluate than I thought, because it was more complicated than I remembered it being. Hopefully I can provide some more feedback on it next week. In the meantime, I had a question about bumping the version to 1.3. Version 1.2 of pg_trgm has never been included in a community release (because it didn't make the 9.5 cutoff). So should we really bump the version to 1.3, or just merge the changes here directly into the existing 1.2 HEAD code? I think it would be pretty odd for 9.5. to come with pg_trgm 1.1 and for 9.6 to come with pg_trgm 1.3. Thanks, Jeff
Jeff Janes <jeff.janes@gmail.com> writes:
> In the meantime, I had a question about bumping the version to 1.3.
> Version 1.2 of pg_trgm has never been included in a community release
> (because it didn't make the 9.5 cutoff). So should we really bump the
> version to 1.3, or just merge the changes here directly into the
> existing 1.2 HEAD code?
> I think it would be pretty odd for 9.5. to come with pg_trgm 1.1 and
> for 9.6 to come with pg_trgm 1.3.
+1 for not bumping the version, if we've not shipped 1.2 yet. There's
enough maintenance overhead in an extension version bump that we should
not do one unnecessarily.
regards, tom lane
On 12.01.2016 02:31, Alvaro Herrera wrote: > I gave a quick look through the patch and noticed a few minor things > while trying to understand it. > > I think the test corpus isn't particularly interesting for how big it > is. I'd rather have (a) a small corpus (say 100 words) with which to do > detailed regression testing, and (b) some larger document for more > extensive testing. I'm not sure (b) is actually necessary. > > Overall I think the new functions could stand a lot more commentary. > Thank you for a review. I will send fixed patch in a few days. -- Artur Zakirov Postgres Professional: http://www.postgrespro.com Russian Postgres Company
On Fri, Dec 18, 2015 at 11:43 AM, Artur Zakirov
<a.zakirov@postgrespro.ru> wrote:
> Hello.
>
> PostgreSQL has a contrib module named pg_trgm. It is used to the fuzzy text
> search. It provides some functions and operators for determining the
> similarity of the given texts using trigram matching.
>
> At the moment, in pg_trgm both the similarity function and the % operator
> match two strings expecting that they are similar entirely. But they give
> bad results if we want to find documents by a query which is substring of a
> document.
>
> For this purpose we need a new operator which enables to find strings that
> have a fragment most similar to the given string. This patch adds some
> functions and operator:
> - function substring_similarity - Returns a number that indicates how
> similar the first string to the most similar substring of the second string.
> The range of the result is zero (indicating that the two strings are
> completely dissimilar) to one (indicating that the first string is identical
> to substring of the second substring).
The behavior of this function is surprising to me.
select substring_similarity('dog' , 'hotdogpound') ;
substring_similarity
---------------------- 0.25
The most similar substring of the second string would be 'dog', which
has a similarity of 1.0 if it were an isolated string.
I think that this function should refrain from calculating the
space-padded trigrams at the beginning and end of its first argument.
Since the first argument is expected to be evaluated as a substring, I
wouldn't take it for granted that the beginning and end of the string
as given are at the beginning and end of a 'word', which is what is
currently being enforced.
Or perhaps the 2nd argument needs to have ghost trigrams computed at
each start and stop when comparing that substring to the full
argument.
If we prefer the current behavior, then I think the explanation needs
to be changed.
Also, should we have a function which indicates the position in the
2nd string at which the most similar match to the 1st argument occurs?
select substring_similarity_pos('dog' , 'hotdogpound') ;
answering: 4
When the long string is much longer, it can be hard to figure out
where the best match was (or the first such match, if there is a
series of ties).
Finally, should there be operators for returning the distance,
analogous to the <-> operator? It is awkward to use an operator for
the boolean and a function to get the distance. Especially when you
use %> and so need swap the order of arguments between the operator
and the function.
We could call them <<-> and <->> , where the first corresponds to <%
and the second to %>
Cheers,
Jeff
I have did some changes to the patch:
- changed version from 1.3 to 1.2
- added check_only parameter to the function
calc_substring_similarity(). If check_only == true then a
calc_substring_similarity() calculates similarity which greater than
pg_trgm.substring_limit variable. This behavior is used in the
substring_similarity_op() and it should increase performance of the
operator. In the substring_similarity() function check_only == false.
On 12.01.2016 02:31, Alvaro Herrera wrote:
> I gave a quick look through the patch and noticed a few minor things
> while trying to understand it.
>
> I think the test corpus isn't particularly interesting for how big it
> is. I'd rather have (a) a small corpus (say 100 words) with which to do
> detailed regression testing, and (b) some larger document for more
> extensive testing. I'm not sure (b) is actually necessary.
>
> Overall I think the new functions could stand a lot more commentary.
I added some comments to new functions iterate_substring_similarity()
and calc_substring_similarity().
>>
>> + #ifdef DIVUNION
>> + #define CALCSML(count, len1, len2) ((float4) (count)) / ((float4) ((len1) + (len2) - (count)))
>> + #else
>> + #define CALCSML(count, len1, len2) ((float4) (count)) / ((float4) (((len1) > (len2)) ? (len1) : (len2)))
>> + #endif
>
> This macro has a multiple evaluation gotcha. Maybe we don't really care
> because of the limited applicability but I'd put a comment on top.
I added a comment to explain various similarity formula.
>
> BTW you don't need a ternary op just to say "? true : false" -- just
> make it
> res = foo == bar;
> which immediately assigns the correct boolean value. (This pattern
> occurs in many places both in the original and in your submitted code.
> I see no reason to perpetuate it.)
>
Fixed all ternary operators.
>
>> + Datum
>> + set_substring_limit(PG_FUNCTION_ARGS)
>> + {
>> + float4 nlimit = PG_GETARG_FLOAT4(0);
>> +
>> + if (nlimit < 0 || nlimit > 1.0)
>> + elog(ERROR, "wrong limit, should be between 0 and 1");
>
> Should be an ereport().
Fixed. But an elog() function occurs in trgm_gin.c and trgm_gist.c also.
I'm not sure that it should be replaced with an ereport().
>
>
>> ! static void
>> ! protect_out_of_mem(int slen)
>> ! {
>> ! /*
>> ! * Guard against possible overflow in the palloc requests below. (We
>> ! * don't worry about the additive constants, since palloc can detect
>> ! * requests that are a little above MaxAllocSize --- we just need to
>> ! * prevent integer overflow in the multiplications.)
>> ! */
>> ! if ((Size) (slen / 2) >= (MaxAllocSize / (sizeof(trgm) * 3)) ||
>> ! (Size) slen >= (MaxAllocSize / pg_database_encoding_max_length()))
>> ! ereport(ERROR,
>> ! (errcode(ERRCODE_PROGRAM_LIMIT_EXCEEDED),
>> ! errmsg("out of memory")));
>> ! }
>
> I think the comment should now be above the function, not inside it.
Fixed.
>>
>> + /* Trigram with position */
>> + typedef struct
>> + {
>> + trgm t;
>> + int i;
>> + } ptrgm;
>
> This struct definition could stand a better name, and better member
> names. Also, our policy (not always enforced) is to have these near the
> top of the file rather than in the middle. If the struct is used in
> many places then IMO it's better that it go at the top; if it's used
> only in one function I'd say it's okay to have it just after that
> function.
Renamed this structure to pos_trgm and move it near the top since this
structure is used in a couple of functions. I renamed member names to
trg and index accordingly.
>
>> + /*
>> + * Make array of positional trigrams from two trigram arrays. The first array
>> + * is required substing which positions don't matter and replaced with -1.
>> + * The second array is haystack where we search and have to store its
>> + * positions.
>> + */
>> + static ptrgm *
>> + make_positional_trgm(trgm *trg1, int len1, trgm *trg2, int len2)
>> + {
>> + ptrgm *result;
>> + int i, len = len1 + len2;
>> +
>> + result = (ptrgm *) palloc(sizeof(ptrgm) * len);
>> +
>> + for (i = 0; i < len1; i++)
>> + {
>> + memcpy(&result[i].t, &trg1[i], sizeof(trgm));
>> + result[i].i = -1;
>> + }
>> +
>> + for (i = 0; i < len2; i++)
>> + {
>> + memcpy(&result[i + len1].t, &trg2[i], sizeof(trgm));
>> + result[i + len1].i = i;
>> + }
>> +
>> + return result;
>> + }
>
> So the output trigram array is the concatenation of both input trigrams?
> That's not quite evident from the comment above the function ... I think
> some rephrasing there is in order.
Rephrased the comment.
>>
>> ! /* if inexact then len2 is equal to count */
>> ! if (inexact)
>> ! return CALCSML(count, len1, count);
>> ! else
>> ! return CALCSML(count, len1, len2);
>
> This is where a ternary op would make better code.
> CALCSML(count, len1, inexact ? count : len2);
> but a better comment would actually explain why we do this, rather than
> just stating we do.
Fixed a code and a comment.
>
>
>> + <row>
>> +
<entry><function>show_substring_limit()</function><indexterm><primary>show_substring_limit</primary></indexterm></entry>
>> + <entry><type>real</type></entry>
>> + <entry>
>> + Returns the current similarity threshold used by the <literal><%</>
>> + operator. This sets the minimum substring similarity between
>> + two phrases.
>> + </entry>
>> + </row>
>> + <row>
>> +
<entry><function>set_substring_limit(real)</function><indexterm><primary>set_substring_limit</primary></indexterm></entry>
>> + <entry><type>real</type></entry>
>> + <entry>
>> + Sets the current substring similarity threshold that is used by
>> + the <literal><%</> operator. The threshold must be between
>> + 0 and 1 (default is 0.6). Returns the same value passed in.
>> + </entry>
>
> I don't quite understand why aren't we using a custom GUC variable here.
> These already have SHOW and SET support ...
>
Added GUC variables:
- pg_trgm.limit
- pg_trgm.substring_limit
I added this variables to the documentation.
show_limit() and set_limit() functions work correctly and they are
marked as deprecated.
--
Artur Zakirov
Postgres Professional: http://www.postgrespro.com
Russian Postgres Company
Attachment
Artur Zakirov wrote: > >I don't quite understand why aren't we using a custom GUC variable here. > >These already have SHOW and SET support ... > > > > Added GUC variables: > - pg_trgm.limit > - pg_trgm.substring_limit > I added this variables to the documentation. > show_limit() and set_limit() functions work correctly and they are marked as > deprecated. Thanks. I'm willing to commit quickly a small patch that only changes the existing function to GUCs, then have a look at a separate patch that adds the new substring operator. Would you split the patch that way? -- Álvaro Herrera http://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On 21.01.2016 00:25, Alvaro Herrera wrote:
> Artur Zakirov wrote:
>>
>> Added GUC variables:
>> - pg_trgm.limit
>> - pg_trgm.substring_limit
>> I added this variables to the documentation.
>> show_limit() and set_limit() functions work correctly and they are marked as
>> deprecated.
>
> Thanks. I'm willing to commit quickly a small patch that only changes
> the existing function to GUCs, then have a look at a separate patch that
> adds the new substring operator. Would you split the patch that way?
>
Sure. I attached two patches. But notice that pg_trgm.limit should be
used with this command:
SHOW "pg_trgm.limit";
If you will use this command:
SHOW pg_trgm.limit;
you will get the error:
ERROR: syntax error at or near "limit"
LINE 1: SHOW pg_trgm.limit;
^
This is because "limit" is keyword I think.
If it is important then GUC variables can have names:
- pg_trgm.sml_limit
- pg_trgm.substring_sml_limit
--
Artur Zakirov
Postgres Professional: http://www.postgrespro.com
Russian Postgres Company
Attachment
On 21.01.2016 00:25, Alvaro Herrera wrote: > Artur Zakirov wrote: > >>> I don't quite understand why aren't we using a custom GUC variable here. >>> These already have SHOW and SET support ... >>> >> >> Added GUC variables: >> - pg_trgm.limit >> - pg_trgm.substring_limit >> I added this variables to the documentation. >> show_limit() and set_limit() functions work correctly and they are marked as >> deprecated. > > Thanks. I'm willing to commit quickly a small patch that only changes > the existing function to GUCs, then have a look at a separate patch that > adds the new substring operator. Would you split the patch that way? > What status of this patch? In commitfest it is "Needs review". Can this patch get the status "Ready for Commiter"? -- Artur Zakirov Postgres Professional: http://www.postgrespro.com Russian Postgres Company
Artur Zakirov wrote: > What status of this patch? In commitfest it is "Needs review". "Needs review" means it needs a reviewer to go over it and, uh, review it. Did I send an email to you prodding you to review patches? I sent such an email to several people from PostgresPro, but I don't remember getting a response from anyone, and honestly I don't see you guys/gal doing much review on-list. If you can please talk to your colleagues so that they look over your patch, while at the same time your review their patches, that would help not only this one patch but everyone else's patches as well. > Can this patch get the status "Ready for Commiter"? Sure, as soon as it has gotten enough review to say it's past the "needs review" phase. Just like all patches. -- Álvaro Herrera http://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On Fri, Jan 29, 2016 at 1:11 PM, Alvaro Herrera <alvherre@2ndquadrant.com> wrote:
Artur Zakirov wrote:
> What status of this patch? In commitfest it is "Needs review".
"Needs review" means it needs a reviewer to go over it and, uh, review
it. Did I send an email to you prodding you to review patches? I sent
such an email to several people from PostgresPro, but I don't remember
getting a response from anyone, and honestly I don't see you guys/gal
doing much review on-list. If you can please talk to your colleagues so
that they look over your patch, while at the same time your review their
patches, that would help not only this one patch but everyone else's
patches as well.
I think Teodor is planning to review these patches.
> Can this patch get the status "Ready for Commiter"?
Sure, as soon as it has gotten enough review to say it's past the "needs
review" phase. Just like all patches.
--
Álvaro Herrera http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services--
Sent via pgsql-hackers mailing list (pgsql-hackers@postgresql.org)
To make changes to your subscription:
http://www.postgresql.org/mailpref/pgsql-hackers
> Sure. I attached two patches. But notice that pg_trgm.limit should be used with
> this command:
> SHOW "pg_trgm.limit";
> If you will use this command:
> SHOW pg_trgm.limit;
> you will get the error:
> ERROR: syntax error at or near "limit"
> LINE 1: SHOW pg_trgm.limit;
> ^
>
> This is because "limit" is keyword I think.
It's easy to fix in gram.y:
@@ -1499,7 +1499,7 @@ set_rest_more: /* Generic SET syntaxes: */ ;
var_name: ColId { $$ = $1; }
- | var_name '.' ColId
+ | var_name '.' ColLabel { $$ = psprintf("%s.%s", $1, $3); } ;
ColId doesn't contain reserved_keyword, it's impossible to change initial part
of var_name to ColId because of a lot of conflicts in grammar but could be easy
changed for second part of var_name. It seems like improvement in any case but
sml_limit or similarity_limit or even similarity_treshold is more preferable
name than just simple limit. In future we could introduce more tresholds/limits.
Also, should get/set_limit emit a warning about deprecation?
Some notices about substring patch itself:
1 trgm2.data contains too much duplicates (like Barkala or Bakalan). Is it
really needed for testing?
2 I'm agree with Jeff Janes about <<-> and <->> operation. They are needed.
(http://www.postgresql.org/message-id/CAMkU=1zynKQfkR-J2_Uq8Lzp0uho8i+LEdFwGt77CzK_tNtN7g@mail.gmail.com)
--
Teodor Sigaev E-mail: teodor@sigaev.ru
WWW: http://www.sigaev.ru/
> The behavior of this function is surprising to me.
>
> select substring_similarity('dog' , 'hotdogpound') ;
>
> substring_similarity
> ----------------------
> 0.25
>
Substring search was desined to search similar word in string:
contrib_regression=# select substring_similarity('dog' , 'hot dogpound') ; substring_similarity
---------------------- 0.75
contrib_regression=# select substring_similarity('dog' , 'hot dog pound') ; substring_similarity
---------------------- 1
It seems to me that users search words in long string. But I'm agree that more
detailed explanation needed and, may be, we need to change feature name to
fuzzywordsearch or something else, I can't imagine how.
>
> Also, should we have a function which indicates the position in the
> 2nd string at which the most similar match to the 1st argument occurs?
>
> select substring_similarity_pos('dog' , 'hotdogpound') ;
>
> answering: 4
Interesting, I think, it will be useful in some cases.
>
> We could call them <<-> and <->> , where the first corresponds to <%
> and the second to %>
Agree
--
Teodor Sigaev E-mail: teodor@sigaev.ru
WWW: http://www.sigaev.ru/
On 29.01.2016 17:15, Teodor Sigaev wrote:
>> The behavior of this function is surprising to me.
>>
>> select substring_similarity('dog' , 'hotdogpound') ;
>>
>> substring_similarity
>> ----------------------
>> 0.25
>>
> Substring search was desined to search similar word in string:
> contrib_regression=# select substring_similarity('dog' , 'hot dogpound') ;
> substring_similarity
> ----------------------
> 0.75
>
> contrib_regression=# select substring_similarity('dog' , 'hot dog
> pound') ;
> substring_similarity
> ----------------------
> 1
> It seems to me that users search words in long string. But I'm agree
> that more detailed explanation needed and, may be, we need to change
> feature name to fuzzywordsearch or something else, I can't imagine how.
>
Thank you for the review. I will rename the function name. Maybe to
subword_similarity()?
>
>>
>> Also, should we have a function which indicates the position in the
>> 2nd string at which the most similar match to the 1st argument occurs?
>>
>> select substring_similarity_pos('dog' , 'hotdogpound') ;
>>
>> answering: 4
> Interesting, I think, it will be useful in some cases.
>
>>
>> We could call them <<-> and <->> , where the first corresponds to <%
>> and the second to %>
> Agree
I will add them.
--
Artur Zakirov
Postgres Professional: http://www.postgrespro.com
Russian Postgres Company
Teodor Sigaev wrote:
> >The behavior of this function is surprising to me.
> >
> >select substring_similarity('dog' , 'hotdogpound') ;
> >
> > substring_similarity
> >----------------------
> > 0.25
> >
> Substring search was desined to search similar word in string:
> contrib_regression=# select substring_similarity('dog' , 'hot dogpound') ;
> substring_similarity
> ----------------------
> 0.75
>
> contrib_regression=# select substring_similarity('dog' , 'hot dog pound') ;
> substring_similarity
> ----------------------
> 1
Hmm, this behavior looks too much like magic to me. I mean, a substring
is a substring -- why are we treating the space as a special character
here?
--
Álvaro Herrera http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On 29.01.2016 18:39, Alvaro Herrera wrote:
> Teodor Sigaev wrote:
>>> The behavior of this function is surprising to me.
>>>
>>> select substring_similarity('dog' , 'hotdogpound') ;
>>>
>>> substring_similarity
>>> ----------------------
>>> 0.25
>>>
>> Substring search was desined to search similar word in string:
>> contrib_regression=# select substring_similarity('dog' , 'hot dogpound') ;
>> substring_similarity
>> ----------------------
>> 0.75
>>
>> contrib_regression=# select substring_similarity('dog' , 'hot dog pound') ;
>> substring_similarity
>> ----------------------
>> 1
>
> Hmm, this behavior looks too much like magic to me. I mean, a substring
> is a substring -- why are we treating the space as a special character
> here?
>
I think, I can rename this function to subword_similarity() and correct
the documentation.
The current behavior is developed to find most similar word in a text.
For example, if we will search just substring (not word) then we will
get the following result:
select substring_similarity('dog', 'dogmatist'); substring_similarity
--------------------- 1
(1 row)
But this is wrong I think. They are completely different words.
For searching a similar substring (not word) in a text maybe another
function should be added?
--
Artur Zakirov
Postgres Professional: http://www.postgrespro.com
Russian Postgres Company
On 29.01.2016 18:58, Artur Zakirov wrote:
> On 29.01.2016 18:39, Alvaro Herrera wrote:
>> Teodor Sigaev wrote:
>>>> The behavior of this function is surprising to me.
>>>>
>>>> select substring_similarity('dog' , 'hotdogpound') ;
>>>>
>>>> substring_similarity
>>>> ----------------------
>>>> 0.25
>>>>
>>> Substring search was desined to search similar word in string:
>>> contrib_regression=# select substring_similarity('dog' , 'hot
>>> dogpound') ;
>>> substring_similarity
>>> ----------------------
>>> 0.75
>>>
>>> contrib_regression=# select substring_similarity('dog' , 'hot dog
>>> pound') ;
>>> substring_similarity
>>> ----------------------
>>> 1
>>
>> Hmm, this behavior looks too much like magic to me. I mean, a substring
>> is a substring -- why are we treating the space as a special character
>> here?
>>
>
> I think, I can rename this function to subword_similarity() and correct
> the documentation.
>
> The current behavior is developed to find most similar word in a text.
> For example, if we will search just substring (not word) then we will
> get the following result:
>
> select substring_similarity('dog', 'dogmatist');
> substring_similarity
> ---------------------
> 1
> (1 row)
>
> But this is wrong I think. They are completely different words.
>
> For searching a similar substring (not word) in a text maybe another
> function should be added?
>
I have changed the patch:
1 - trgm2.data was corrected, duplicates were deleted.
2 - I have added operators <<-> and <->> with GiST index supporting. A
regression test will pass only with the patch
http://www.postgresql.org/message-id/CAPpHfdt19FwQXarYjkzxb3oxmv-KAn3FLuZrooARE_U3H3CV9g@mail.gmail.com
3 - the function substring_similarity() was renamed to subword_similarity().
But there is not a function substring_similarity_pos() yet. It is not
trivial.
--
Artur Zakirov
Postgres Professional: http://www.postgrespro.com
Russian Postgres Company
Attachment
On 01.02.2016 20:12, Artur Zakirov wrote: > > I have changed the patch: > 1 - trgm2.data was corrected, duplicates were deleted. > 2 - I have added operators <<-> and <->> with GiST index supporting. A > regression test will pass only with the patch > http://www.postgresql.org/message-id/CAPpHfdt19FwQXarYjkzxb3oxmv-KAn3FLuZrooARE_U3H3CV9g@mail.gmail.com > > 3 - the function substring_similarity() was renamed to > subword_similarity(). > > But there is not a function substring_similarity_pos() yet. It is not > trivial. > Sorry, in the previous patch was a typo. Here is the fixed patch. -- Artur Zakirov Postgres Professional: http://www.postgrespro.com Russian Postgres Company
Attachment
On 02.02.2016 15:45, Artur Zakirov wrote: > On 01.02.2016 20:12, Artur Zakirov wrote: >> >> I have changed the patch: >> 1 - trgm2.data was corrected, duplicates were deleted. >> 2 - I have added operators <<-> and <->> with GiST index supporting. A >> regression test will pass only with the patch >> http://www.postgresql.org/message-id/CAPpHfdt19FwQXarYjkzxb3oxmv-KAn3FLuZrooARE_U3H3CV9g@mail.gmail.com >> >> >> 3 - the function substring_similarity() was renamed to >> subword_similarity(). >> >> But there is not a function substring_similarity_pos() yet. It is not >> trivial. >> > > Sorry, in the previous patch was a typo. Here is the fixed patch. > I have attached a new version of the patch. It fixes error of operators <->> and %>: - operator <->> did not pass the regression test in CentOS 32 bit (gcc 4.4.7 20120313). - operator %> did not pass the regression test in FreeBSD 32 bit (gcc 4.2.1 20070831). It was because of variable optimization by gcc. In this patch pg_trgm documentation was corrected. Now operators were wrote as %> and <->> (not <% and <<->). There is a problem in adding the substring_similarity_pos() function. It can bring additional overhead. Because we need to store characters position including spaces in addition. Spaces between words are lost in current implementation. Does it actually need? In conclusion, this patch introduces: 1 - functions: - subword_similarity() 2 - operators: - %> - <->> 3 - GUC variables: - pg_trgm.sml_limit - pg_trgm.subword_limit -- Artur Zakirov Postgres Professional: http://www.postgrespro.com Russian Postgres Company
Attachment
>>> The behavior of this function is surprising to me.
>>>
>>> select substring_similarity('dog' , 'hotdogpound') ;
>>>
>>> substring_similarity
>>> ----------------------
>>> 0.25
>>>
>> Substring search was desined to search similar word in string:
>> contrib_regression=# select substring_similarity('dog' , 'hot dogpound') ;
>> substring_similarity
>> ----------------------
>> 0.75
>>
>> contrib_regression=# select substring_similarity('dog' , 'hot dog pound') ;
>> substring_similarity
>> ----------------------
>> 1
>
> Hmm, this behavior looks too much like magic to me. I mean, a substring
> is a substring -- why are we treating the space as a special character
> here?
Because it isn't a regex for substring search. Since implementing, pg_trgm
works over words in string.
contrib_regression=# select similarity('block hole', 'hole black'); similarity
------------ 0.571429
contrib_regression=# select similarity('block hole', 'black hole'); similarity
------------ 0.571429
It ignores spaces between words and word's order.
I agree, that substring_similarity is confusing name, but actually it search
most similar word in second arg to first arg and returns their similarity.
--
Teodor Sigaev E-mail: teodor@sigaev.ru
WWW: http://www.sigaev.ru/
> I have attached a new version of the patch. It fixes error of operators <->> and > %>: > - operator <->> did not pass the regression test in CentOS 32 bit (gcc 4.4.7 > 20120313). > - operator %> did not pass the regression test in FreeBSD 32 bit (gcc 4.2.1 > 20070831). > > It was because of variable optimization by gcc. Fixed with volatile modifier, right? I'm close to push this patches, but I still doubt in names, and I'd like to see comment from English speackers: 1 sml_limit GUC variable (options: similarity_limit, sml_threshold) 2 subword_similarity(). Actually, it finds most similar word (not substring!) from whole string. word_similarity? word_in_string_similarity? substring_similarity_pos() could be a separate patch. -- Teodor Sigaev E-mail: teodor@sigaev.ru WWW: http://www.sigaev.ru/
On Thu, Feb 11, 2016 at 8:11 AM, Teodor Sigaev <teodor@sigaev.ru> wrote: >> I have attached a new version of the patch. It fixes error of operators >> <->> and >> %>: >> - operator <->> did not pass the regression test in CentOS 32 bit (gcc >> 4.4.7 >> 20120313). >> - operator %> did not pass the regression test in FreeBSD 32 bit (gcc >> 4.2.1 >> 20070831). >> >> It was because of variable optimization by gcc. > > > Fixed with volatile modifier, right? > > I'm close to push this patches, but I still doubt in names, and I'd like to > see comment from English speackers: > 1 sml_limit GUC variable (options: similarity_limit, sml_threshold) > 2 subword_similarity(). Actually, it finds most similar word (not > substring!) from whole string. word_similarity? word_in_string_similarity? > At least for this English speaker, substring_similarity is not confusing even if it's not internally accurate, but English is a strange language. Because I want the bike shed to be blue, how does query_string_similarity sound instead? If that's overly precise, then word_similarity would be fine with me. Thanks, -- Mike Rylander
On 11.02.2016 16:11, Teodor Sigaev wrote: >> I have attached a new version of the patch. It fixes error of >> operators <->> and >> %>: >> - operator <->> did not pass the regression test in CentOS 32 bit (gcc >> 4.4.7 >> 20120313). >> - operator %> did not pass the regression test in FreeBSD 32 bit (gcc >> 4.2.1 >> 20070831). >> >> It was because of variable optimization by gcc. > > Fixed with volatile modifier, right? Yes, it was fixes with volatile modifier. > > I'm close to push this patches, but I still doubt in names, and I'd like > to see comment from English speackers: > 1 sml_limit GUC variable (options: similarity_limit, sml_threshold) > 2 subword_similarity(). Actually, it finds most similar word (not > substring!) from whole string. word_similarity? word_in_string_similarity? > > > substring_similarity_pos() could be a separate patch. > -- Artur Zakirov Postgres Professional: http://www.postgrespro.com Russian Postgres Company
On 11.02.2016 16:35, Mike Rylander wrote: > On Thu, Feb 11, 2016 at 8:11 AM, Teodor Sigaev <teodor@sigaev.ru> wrote: >>> I have attached a new version of the patch. It fixes error of operators >>> <->> and >>> %>: >>> - operator <->> did not pass the regression test in CentOS 32 bit (gcc >>> 4.4.7 >>> 20120313). >>> - operator %> did not pass the regression test in FreeBSD 32 bit (gcc >>> 4.2.1 >>> 20070831). >>> >>> It was because of variable optimization by gcc. >> >> >> Fixed with volatile modifier, right? >> >> I'm close to push this patches, but I still doubt in names, and I'd like to >> see comment from English speackers: >> 1 sml_limit GUC variable (options: similarity_limit, sml_threshold) >> 2 subword_similarity(). Actually, it finds most similar word (not >> substring!) from whole string. word_similarity? word_in_string_similarity? >> > > At least for this English speaker, substring_similarity is not > confusing even if it's not internally accurate, but English is a > strange language. > > Because I want the bike shed to be blue, how does > query_string_similarity sound instead? If that's overly precise, then > word_similarity would be fine with me. > > Thanks, > > -- > Mike Rylander > Great. I can change names: 1 - sml_limit to similarity_limit. sml_threshold is difficult to write I think, similarity_limit is more simple. 2 - subword_similarity() to word_similarity(). -- Artur Zakirov Postgres Professional: http://www.postgrespro.com Russian Postgres Company
> 1 - sml_limit to similarity_limit. sml_threshold is difficult to write I think, > similarity_limit is more simple. It seems to me that threshold is right word by meaning. sml_threshold is my choice. > 2 - subword_similarity() to word_similarity(). Agree, according to Mike Rylander opinion in this thread -- Teodor Sigaev E-mail: teodor@sigaev.ru WWW: http://www.sigaev.ru/
On Thu, Feb 11, 2016 at 9:56 AM, Teodor Sigaev <teodor@sigaev.ru> wrote: >> 1 - sml_limit to similarity_limit. sml_threshold is difficult to write I >> think, >> similarity_limit is more simple. > > It seems to me that threshold is right word by meaning. sml_threshold is my > choice. Why abbreviate it like that? Nobody's going to know that "sml" stands for "similarity" without consulting the documentation, and that sucks. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
> On Thu, Feb 11, 2016 at 9:56 AM, Teodor Sigaev <teodor@sigaev.ru> wrote: >>> 1 - sml_limit to similarity_limit. sml_threshold is difficult to write I >>> think, >>> similarity_limit is more simple. >> >> It seems to me that threshold is right word by meaning. sml_threshold is my >> choice. > > Why abbreviate it like that? Nobody's going to know that "sml" stands > for "similarity" without consulting the documentation, and that sucks. Ok, I don't have an objections. I worked a lot on various similarity modules and sml becomes usual for me. That's why I was asking. -- Teodor Sigaev E-mail: teodor@sigaev.ru WWW: http://www.sigaev.ru/
On 12.02.2016 20:56, Teodor Sigaev wrote:
>> On Thu, Feb 11, 2016 at 9:56 AM, Teodor Sigaev <teodor@sigaev.ru> wrote:
>>>> 1 - sml_limit to similarity_limit. sml_threshold is difficult to
>>>> write I
>>>> think,
>>>> similarity_limit is more simple.
>>>
>>> It seems to me that threshold is right word by meaning. sml_threshold
>>> is my
>>> choice.
>>
>> Why abbreviate it like that? Nobody's going to know that "sml" stands
>> for "similarity" without consulting the documentation, and that sucks.
>
> Ok, I don't have an objections. I worked a lot on various similarity
> modules and sml becomes usual for me. That's why I was asking.
>
Hi!
I attached new version of the patch. It fixes names of GUC variables and
functions.
Now the patch introduces:
1 - functions:
- word_similarity()
2 - operators:
- %> (and <%)
- <->> (and <<->)
3 - GUC variables:
- pg_trgm.similarity_threshold
- pg_trgm.word_similarity_threshold
--
Artur Zakirov
Postgres Professional: http://www.postgrespro.com
Russian Postgres Company
Attachment
On Fri, Jan 29, 2016 at 6:15 AM, Teodor Sigaev <teodor@sigaev.ru> wrote:
>> The behavior of this function is surprising to me.
>>
>> select substring_similarity('dog' , 'hotdogpound') ;
>>
>> substring_similarity
>> ----------------------
>> 0.25
>>
> Substring search was desined to search similar word in string:
> contrib_regression=# select substring_similarity('dog' , 'hot dogpound') ;
> substring_similarity
> ----------------------
> 0.75
>
> contrib_regression=# select substring_similarity('dog' , 'hot dog pound') ;
> substring_similarity
> ----------------------
> 1
> It seems to me that users search words in long string. But I'm agree that
> more detailed explanation needed and, may be, we need to change feature name
> to fuzzywordsearch or something else, I can't imagine how.
If we implement my proposed behavior, and I wanted the existing
behavior instead, I could just do:
select substring_similarity(' dog ' , 'hotdogpound');
But with the existing implementation, there isn't anything I could to
switch to the one I want instead. So treating is purely as a substring
is more flexible than treating it as a word match.
The reason I like the option of not treating word boundaries as
special in this case is that often in scientific vocabulary, and in
catalog part numbers, people are pretty inconsistent about whether
they included spaces. "HEK 293", "HEK293", and "HEK-293" could be all
the same thing. So I like to strip out spaces and punctuation on both
sides of operator. Of course I can't do that if there are invisible
un-removable spaces on the substring side.
But, It doesn't sound like I am going to win that debate. Given that,
I don't think we need a different name for the function. I'm fine with
explaining the word-boundary subtlety in the documentation, and
keeping the function name itself simple.
Cheers,
Jeff
Hi Jeff, On 2/25/16 5:00 PM, Jeff Janes wrote: > But, It doesn't sound like I am going to win that debate. Given that, > I don't think we need a different name for the function. I'm fine with > explaining the word-boundary subtlety in the documentation, and > keeping the function name itself simple. It's not clear to me if you are requesting more documentation here or stating that you are happy with it as-is. Care to elaborate? Other than that I think this patch looks to be ready for committer. Any objections? -- -David david@pgmasters.net
On 14.03.2016 18:48, David Steele wrote: > Hi Jeff, > > On 2/25/16 5:00 PM, Jeff Janes wrote: > >> But, It doesn't sound like I am going to win that debate. Given that, >> I don't think we need a different name for the function. I'm fine with >> explaining the word-boundary subtlety in the documentation, and >> keeping the function name itself simple. > > It's not clear to me if you are requesting more documentation here or > stating that you are happy with it as-is. Care to elaborate? > > Other than that I think this patch looks to be ready for committer. Any > objections? > There was some comments about the word-boundary subtlety. But I think it was not enough. I rephrased the explanation of word_similarity() and %>. It is better now. But if it is not correct I can change the explanation. -- Artur Zakirov Postgres Professional: http://www.postgrespro.com Russian Postgres Company
Attachment
On 3/14/16 12:27 PM, Artur Zakirov wrote: > On 14.03.2016 18:48, David Steele wrote: >> Hi Jeff, >> >> On 2/25/16 5:00 PM, Jeff Janes wrote: >> >>> But, It doesn't sound like I am going to win that debate. Given that, >>> I don't think we need a different name for the function. I'm fine with >>> explaining the word-boundary subtlety in the documentation, and >>> keeping the function name itself simple. >> >> It's not clear to me if you are requesting more documentation here or >> stating that you are happy with it as-is. Care to elaborate? >> >> Other than that I think this patch looks to be ready for committer. Any >> objections? >> > > There was some comments about the word-boundary subtlety. But I think it > was not enough. > > I rephrased the explanation of word_similarity() and %>. It is better now. > > But if it is not correct I can change the explanation. Since to only change in the latest patch is to documentation I have marked this "ready for committer". -- -David david@pgmasters.net
On 15.03.2016 17:28, David Steele wrote: > On 3/14/16 12:27 PM, Artur Zakirov wrote: >> On 14.03.2016 18:48, David Steele wrote: >>> Hi Jeff, >>> >>> On 2/25/16 5:00 PM, Jeff Janes wrote: >>> >>>> But, It doesn't sound like I am going to win that debate. Given that, >>>> I don't think we need a different name for the function. I'm fine with >>>> explaining the word-boundary subtlety in the documentation, and >>>> keeping the function name itself simple. >>> >>> It's not clear to me if you are requesting more documentation here or >>> stating that you are happy with it as-is. Care to elaborate? >>> >>> Other than that I think this patch looks to be ready for committer. Any >>> objections? >>> >> >> There was some comments about the word-boundary subtlety. But I think it >> was not enough. >> >> I rephrased the explanation of word_similarity() and %>. It is better now. >> >> But if it is not correct I can change the explanation. > > Since to only change in the latest patch is to documentation I have > marked this "ready for committer". > Thank you! -- Artur Zakirov Postgres Professional: http://www.postgrespro.com Russian Postgres Company
On Mon, Mar 14, 2016 at 9:27 AM, Artur Zakirov <a.zakirov@postgrespro.ru> wrote: > On 14.03.2016 18:48, David Steele wrote: >> >> Hi Jeff, >> >> On 2/25/16 5:00 PM, Jeff Janes wrote: >> >>> But, It doesn't sound like I am going to win that debate. Given that, >>> I don't think we need a different name for the function. I'm fine with >>> explaining the word-boundary subtlety in the documentation, and >>> keeping the function name itself simple. >> >> >> It's not clear to me if you are requesting more documentation here or >> stating that you are happy with it as-is. Care to elaborate? >> >> Other than that I think this patch looks to be ready for committer. Any >> objections? >> > > There was some comments about the word-boundary subtlety. But I think it was > not enough. > > I rephrased the explanation of word_similarity() and %>. It is better now. > > But if it is not correct I can change the explanation. <% and <<-> are not documented at all. Is that a deliberate choice? Since they were added as convenience functions for the user, I think they really need to be in the user documentation. Also, the documentation should probably include <% and <<-> as the "parent" operators and use them in the examples, and only mention %> and <->> in passing, as the commutators. That is because <% and <<-> take their arguments in the same order as word_similarity does. It would be less confusing if the documentation and the examples didn't need to keep changing the argument orders. Cheers, Jeff
2016-03-18 23:46 GMT+03:00 Jeff Janes <jeff.janes@gmail.com>:
<% and <<-> are not documented at all. Is that a deliberate choice?
Since they were added as convenience functions for the user, I think
they really need to be in the user documentation.
I can send a patch a little bit later. I documented %>
and <->> because examples of other operators have the following order:SELECT t, t <-> 'word' AS dist
FROM test_trgm
ORDER BY dist LIMIT 10;
and
SELECT * FROM test_trgm WHERE t LIKE '%foo%bar';
I did not include <% and <<-> because I did not know how to document commutators. But I can fix it.
And honestly the following order:
SELECT 'word' <% t FROM test_trgm;
is more convenient to me too.
Do you know how do not break the line in the operators table in the first column? Now I see:
Operator | Returns
----------------|------------------
text % | boolean
text |
But the following is better:
Operator | Returns
----------------|------------------
text % text | boolean
Also, the documentation should probably include <% and <<-> as the
"parent" operators and use them in the examples, and only mention %>
and <->> in passing, as the commutators. That is because <% and <<->
take their arguments in the same order as word_similarity does. It
would be less confusing if the documentation and the examples didn't
need to keep changing the argument orders.
Cheers,
Jeff
I attached the patch, which fixes the pg_trgm documentation. On 19.03.2016 01:18, Artur Zakirov wrote: > > > 2016-03-18 23:46 GMT+03:00 Jeff Janes <jeff.janes@gmail.com > <mailto:jeff.janes@gmail.com>>: > > > <% and <<-> are not documented at all. Is that a deliberate choice? > Since they were added as convenience functions for the user, I think > they really need to be in the user documentation. > > > I can send a patch a little bit later. I documented %> > and <->> because examples of other operators have the following order: > > SELECT t, t <-> 'word' AS dist > FROM test_trgm > ORDER BY dist LIMIT 10; > > and > > SELECT * FROM test_trgm WHERE t LIKE '%foo%bar'; > > I did not include <% and <<-> because I did not know how to document > commutators. But I can fix it. > > And honestly the following order: > > SELECT 'word' <% t FROM test_trgm; > > is more convenient to me too. > > Do you know how do not break the line in the operators table in the > first column? Now I see: > > Operator| Returns > ----------------|------------------ > text % | boolean > text | > > But the following is better: > > Operator| Returns > ----------------|------------------ > text % text | boolean > > > Also, the documentation should probably include <% and <<-> as the > "parent" operators and use them in the examples, and only mention %> > and <->> in passing, as the commutators. That is because <% and <<-> > take their arguments in the same order as word_similarity does. It > would be less confusing if the documentation and the examples didn't > need to keep changing the argument orders. > > Cheers, > > Jeff > > > > > -- > Artur Zakirov > Postgres Professional: http://www.postgrespro.com > Russian Postgres Company -- Artur Zakirov Postgres Professional: http://www.postgrespro.com Russian Postgres Company