Thread: [PATCH] Refactoring of LWLock tranches
Hello hackers!
This patch contains LWLocks changes from pg_stat_activity thread
and I think it deserves a separate thread.
The goal is to split LWLocks from one array to logical pieces (with separate
tranches) for better monitoring and debug purposes. Each type of LWLock
will have its own tranche and a associated name.
I fixed problems with EXEC_BACKEND. Another parts require a some discussion so
I didn't touch them yet.
On Sep 2, 2015, at 9:45 PM, Robert Haas <robertmhaas@gmail.com> wrote:On Tue, Sep 1, 2015 at 6:43 PM, andres@anarazel.de <andres@anarazel.de> wrote:Why a new tranche for each of these? And it can't be correct that each
has the same base?
I complained about the same-base problem before. Apparently, that got ignored.
The idea to create an individual tranches for individual LWLocks have
come from Heikki Linnakangas and I also think that tranche is a good place to keep
LWLock name. Base of these tranches points to MainLWLockArray and T_ID
macros keeps the old behavior for them. But I don't insist on the current implementation
here.
Attachment
Hi, On 2015-09-05 12:48:12 +0300, Ildus Kurbangaliev wrote: > Another parts require a some discussion so I didn't touch them yet. At this point I don't see any point in further review until these are addressed. > The idea to create an individual tranches for individual LWLocks have > come from Heikki Linnakangas and I also think that tranche is a good place to keep > LWLock name. I think it's rather ugly. > Base of these tranches points to MainLWLockArray And that's just plain wrong. The base of a tranche ought to point to the first lwlock in it. Greetings, Andres Freund
On Sep 6, 2015, at 2:36 PM, andres@anarazel.de wrote:On 2015-09-05 12:48:12 +0300, Ildus Kurbangaliev wrote:Another parts require a some discussion so I didn't touch them yet.
At this point I don't see any point in further review until these are
addressed.The idea to create an individual tranches for individual LWLocks have
come from Heikki Linnakangas and I also think that tranche is a good place to keep
LWLock name.
I think it's rather ugly.Base of these tranches points to MainLWLockArray
And that's just plain wrong. The base of a tranche ought to point to the
first lwlock in it.
Ok, I've kept only one tranche for individual LWLocks
On Sep 2, 2015, at 1:43 AM, andres@anarazel.de wrote:I don't really like the tranche model as in the patch right now. I'd
rather have in a way that we have one tranch for all the individual
lwlocks, where the tranche points to an array of names alongside the
tranche's name. And then for the others we just supply the tranche name,
but leave the name array empty, whereas a name can be generated.
Maybe I don't understand something here, but why add extra field to all tranches
if we need only one array (especially the array for individual LWLocks).
----
Attachment
On 2015-09-06 22:57:04 +0300, Ildus Kurbangaliev wrote:
> Ok, I've kept only one tranche for individual LWLocks
But you've added the lock names as a statically sized array to all
tranches? Why not just a pointer to an array that's either NULL ('not
individualy named locks') or appropriately sized?
> > I don't really like the tranche model as in the patch right now. I'd
> > rather have in a way that we have one tranch for all the individual
> > lwlocks, where the tranche points to an array of names alongside the
> > tranche's name. And then for the others we just supply the tranche name,
> > but leave the name array empty, whereas a name can be generated.
>
> Maybe I don't understand something here, but why add extra field to all tranches
> if we need only one array (especially the array for individual LWLocks).
It's cheap to add an optional pointer field to an individual
tranche. It'll be far less cheap to extend the max number of
tranches. But it's also just ugly to to use a tranche per lock - they're
intended to describe 'runs' of locks.
Greetings,
Andres Freund
On Sun, 6 Sep 2015 23:18:02 +0200
"andres@anarazel.de" <andres@anarazel.de> wrote:
> On 2015-09-06 22:57:04 +0300, Ildus Kurbangaliev wrote:
> > Ok, I've kept only one tranche for individual LWLocks
>
> But you've added the lock names as a statically sized array to all
> tranches? Why not just a pointer to an array that's either NULL ('not
> individualy named locks') or appropriately sized?
A tranche contains only the tranche name. Yes, it's statically sized,
because we need to know an exact space in shared memory for it. This
name is enough to describe all LWLocks in that tranche (except main
tranche), because they have one type (for example BufferMgrLocks).
In main tranche this field contains 'main' (like now) and
an additional array is used for determining a name for LWLock. If you
suggest keep a pointer to this array in main tranche (and NULL for
others) then I have no objections to do that.
So generally the code is similar to code that we have in Postgres now
except the tranches located in shared memory and created by backends.
>
> > > I don't really like the tranche model as in the patch right now.
> > > I'd rather have in a way that we have one tranch for all the
> > > individual lwlocks, where the tranche points to an array of names
> > > alongside the tranche's name. And then for the others we just
> > > supply the tranche name, but leave the name array empty, whereas
> > > a name can be generated.
> >
> > Maybe I don't understand something here, but why add extra field to
> > all tranches if we need only one array (especially the array for
> > individual LWLocks).
>
> It's cheap to add an optional pointer field to an individual
> tranche. It'll be far less cheap to extend the max number of
> tranches. But it's also just ugly to to use a tranche per lock -
> they're intended to describe 'runs' of locks.
The current patch exactly does that - contains 'runs' of locks.
----
Ildus Kurbangaliev
Postgres Professional: http://www.postgrespro.com
<http://www.postgrespro.com/> The Russian Postgres Company
Added changes related to the latest master (for individual LWLocks definitions)
Attachment
On Sun, Sep 13, 2015 at 12:43 PM, Ildus Kurbangaliev <i.kurbangaliev@postgrespro.ru> wrote: > Added changes related to the latest master (for individual LWLocks > definitions) If I haven't said this clearly enough already, I'm not OK with changing the tranche name from char * to a fixed-size character array. Nor am I OK with limiting the maximum number of tranches to 64. I worked hard to set this system up so that it did not have limits on the number of tranches or the lengths of their names, and I don't see any good reason to add those limitations now. I would like to avoid adding an argument to every call to SimpleLruInit(). It's already got two arguments that are basically names; let's avoid introducing a third one. Instead, let's decide on a naming convention that we ca use for both locks and shared memory segments. We haven't worried about that much in the past because this stuff was only exposed to developers, but that's changing now. So let's come up with something that will be nice for users and adopt a uniform convention. I don't think it should be NameOfSubsystemLocks as you have it here. That's too easy to confuse with heavyweight locks. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On Sep 13, 2015, at 11:32 PM, Robert Haas <robertmhaas@gmail.com> wrote:On Sun, Sep 13, 2015 at 12:43 PM, Ildus Kurbangaliev
<i.kurbangaliev@postgrespro.ru> wrote:Added changes related to the latest master (for individual LWLocks
definitions)
If I haven't said this clearly enough already, I'm not OK with
changing the tranche name from char * to a fixed-size character array.
Nor am I OK with limiting the maximum number of tranches to 64. I
worked hard to set this system up so that it did not have limits on
the number of tranches or the lengths of their names, and I don't see
any good reason to add those limitations now.
Yes, that is because I tried to go with current convention working with
shmem in Postgres (there are one function that returns the size and
others that initialize that memory). But I like your suggestion about
API functions, in that case number of tranches and locks will be known
during the initialization.
----
On Sun, Sep 13, 2015 at 5:05 PM, Ildus Kurbangaliev <i.kurbangaliev@postgrespro.ru> wrote: > Yes, that is because I tried to go with current convention working with > shmem in Postgres (there are one function that returns the size and > others that initialize that memory). But I like your suggestion about > API functions, in that case number of tranches and locks will be known > during the initialization. I also want to leave the door open to tranches that are registered after initialization. At that point, it's too late to put a tranche in shared memory, but you can still use DSM. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On Mon, 14 Sep 2015 06:32:22 -0400 Robert Haas <robertmhaas@gmail.com> wrote: > On Sun, Sep 13, 2015 at 5:05 PM, Ildus Kurbangaliev > <i.kurbangaliev@postgrespro.ru> wrote: > > Yes, that is because I tried to go with current convention working > > with shmem in Postgres (there are one function that returns the > > size and others that initialize that memory). But I like your > > suggestion about API functions, in that case number of tranches and > > locks will be known during the initialization. > > I also want to leave the door open to tranches that are registered > after initialization. At that point, it's too late to put a tranche > in shared memory, but you can still use DSM. > We can hold some extra space in LWLockTrancheArray, add some function for unregistering a tranche, and reuse free items in LWLockTrancheId later. ---- Ildus Kurbangaliev Postgres Professional: http://www.postgrespro.com The Russian Postgres Company
On Tue, Sep 15, 2015 at 12:44 PM, Ildus Kurbangaliev <i.kurbangaliev@postgrespro.ru> wrote: > On Mon, 14 Sep 2015 06:32:22 -0400 > Robert Haas <robertmhaas@gmail.com> wrote: > >> On Sun, Sep 13, 2015 at 5:05 PM, Ildus Kurbangaliev >> <i.kurbangaliev@postgrespro.ru> wrote: >> > Yes, that is because I tried to go with current convention working >> > with shmem in Postgres (there are one function that returns the >> > size and others that initialize that memory). But I like your >> > suggestion about API functions, in that case number of tranches and >> > locks will be known during the initialization. >> >> I also want to leave the door open to tranches that are registered >> after initialization. At that point, it's too late to put a tranche >> in shared memory, but you can still use DSM. > > We can hold some extra space in LWLockTrancheArray, add some > function for unregistering a tranche, and reuse free items in > LWLockTrancheId later. We could, but since that would be strictly more annoying and less flexible than what we've already got, why would we? -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On 2015-09-15 14:39:51 -0400, Robert Haas wrote: > We could, but since that would be strictly more annoying and less > flexible than what we've already got, why would we? I don't find the current approach of having to define tranches in every backend all that convenient. It also completely breaks down if you want to display locks from tranches that are only visible within a subset of the backends - not that unlikely given that shared_preload_libraries is a PITA. Greetings, Andres Freund
On Tue, Sep 15, 2015 at 2:44 PM, andres@anarazel.de <andres@anarazel.de> wrote: > On 2015-09-15 14:39:51 -0400, Robert Haas wrote: >> We could, but since that would be strictly more annoying and less >> flexible than what we've already got, why would we? > > I don't find the current approach of having to define tranches in every > backend all that convenient. Sure. That's why I proposed a way to define them across all backends during postmaster startup. However, I'd like that way to be in addition to what works now, not instead of it. That way, you can do it the convenient way if it applies, and the inconvenient way is still there if you really need it. > It also completely breaks down if you want > to display locks from tranches that are only visible within a subset of > the backends - not that unlikely given that shared_preload_libraries is > a PITA. True. I don't really see that as a big deal. We can expect that most people will register tranches at startup, and the names will be available. If they don't, then the tranche name will have to be listed as something like extension, or maybe extension-tranche-123. I'm not prepared to revoke the ability to create tranches later for the convenience of this mechanism; the reporting mechanism has to adapt itself to what the code can support, not the other way around. Actually, I think it might very well be a good idea to fold all non-core tranches together under "extension" anyway for wait reporting purposes. The reason is that we are debating whether to report the wait event information as 1 byte or 4 bytes. The tranche ID by itself is 4 bytes, and lwlocks are not the only kind of wait event we need to be able to report. Unless we're prepared to make the wait-reporting stuff use more than 4 bytes, and therefore require a locking protocol (which I'm not keen about for reasons discussed upthread), we're not going to be able to report the full range of values anyway. My proposal is to have about 50 possible wait events for lwlocks: one for each individual lwlock, one for each builtin tranche, and one for everything else. That easily fits in one byte with plenty of room left over for all of the other stuff I want to report. If we've got four bytes, it's even simpler. If users of this facility can't distinguish a wait on an lwlock created by extension A from a wait on an lwlock created by extension B, I don't really care. That's going to be a really, really rare case: how many extensions use lwlocks anyway? How many of them use them enough to cause significant contention? Yeah, it could happen, but not often. Something pretty simple, dumb, and cheap here still figures to offer a lot of benefit. In fact, probably *more* benefit than a more complex, more general system. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On Tue, 15 Sep 2015 14:39:51 -0400 Robert Haas <robertmhaas@gmail.com> wrote: > On Tue, Sep 15, 2015 at 12:44 PM, Ildus Kurbangaliev > <i.kurbangaliev@postgrespro.ru> wrote: > > On Mon, 14 Sep 2015 06:32:22 -0400 > > Robert Haas <robertmhaas@gmail.com> wrote: > > > >> On Sun, Sep 13, 2015 at 5:05 PM, Ildus Kurbangaliev > >> <i.kurbangaliev@postgrespro.ru> wrote: > >> > Yes, that is because I tried to go with current convention > >> > working with shmem in Postgres (there are one function that > >> > returns the size and others that initialize that memory). But I > >> > like your suggestion about API functions, in that case number of > >> > tranches and locks will be known during the initialization. > >> > >> I also want to leave the door open to tranches that are registered > >> after initialization. At that point, it's too late to put a > >> tranche in shared memory, but you can still use DSM. > > > > We can hold some extra space in LWLockTrancheArray, add some > > function for unregistering a tranche, and reuse free items in > > LWLockTrancheId later. > > We could, but since that would be strictly more annoying and less > flexible than what we've already got, why would we? > Yes, probably. I'm going to change API calls as you suggested earlier. How you do think the tranches registration after initialization should look like? ---- Ildus Kurbangaliev Postgres Professional: http://www.postgrespro.com The Russian Postgres Company
On Tue, Sep 22, 2015 at 5:16 AM, Ildus Kurbangaliev <i.kurbangaliev@postgrespro.ru> wrote: > Yes, probably. > I'm going to change API calls as you suggested earlier. > How you do think the tranches registration after initialization should > look like? I don't see any need to change anything there. The idea there is that an extension allocates a tranche ID and are responsible for making sure that every backend that uses that tranche finds out about the ID that was chosen and registers a matching tranche definition. How to do that is the extension's problem. Maybe eventually we'll provide some tools to make that easier, but that's separate from the work we're trying to do here. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
Robert Haas wrote: > On Tue, Sep 22, 2015 at 5:16 AM, Ildus Kurbangaliev > <i.kurbangaliev@postgrespro.ru> wrote: > > Yes, probably. > > I'm going to change API calls as you suggested earlier. > > How you do think the tranches registration after initialization should > > look like? > > I don't see any need to change anything there. The idea there is that > an extension allocates a tranche ID and are responsible for making > sure that every backend that uses that tranche finds out about the ID > that was chosen and registers a matching tranche definition. How to > do that is the extension's problem. Maybe eventually we'll provide > some tools to make that easier, but that's separate from the work > we're trying to do here. FWIW I had assumed, when you created the tranche stuff, that SLRU users would all allocate their lwlocks from a tranche provided by slru.c itself, and the locks would be stored in the slru Ctl struct. Does that not work for some reason? -- Álvaro Herrera http://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On Wed, Sep 23, 2015 at 11:22 AM, Alvaro Herrera <alvherre@2ndquadrant.com> wrote: > Robert Haas wrote: >> On Tue, Sep 22, 2015 at 5:16 AM, Ildus Kurbangaliev >> <i.kurbangaliev@postgrespro.ru> wrote: >> > Yes, probably. >> > I'm going to change API calls as you suggested earlier. >> > How you do think the tranches registration after initialization should >> > look like? >> >> I don't see any need to change anything there. The idea there is that >> an extension allocates a tranche ID and are responsible for making >> sure that every backend that uses that tranche finds out about the ID >> that was chosen and registers a matching tranche definition. How to >> do that is the extension's problem. Maybe eventually we'll provide >> some tools to make that easier, but that's separate from the work >> we're trying to do here. > > FWIW I had assumed, when you created the tranche stuff, that SLRU users > would all allocate their lwlocks from a tranche provided by slru.c > itself, and the locks would be stored in the slru Ctl struct. Does that > not work for some reason? I think that should work and that it's a good idea. I think it's just a case of nobody having done the work. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On Wed, 23 Sep 2015 11:46:00 -0400 Robert Haas <robertmhaas@gmail.com> wrote: > On Wed, Sep 23, 2015 at 11:22 AM, Alvaro Herrera > <alvherre@2ndquadrant.com> wrote: > > Robert Haas wrote: > >> On Tue, Sep 22, 2015 at 5:16 AM, Ildus Kurbangaliev > >> <i.kurbangaliev@postgrespro.ru> wrote: > >> > Yes, probably. > >> > I'm going to change API calls as you suggested earlier. > >> > How you do think the tranches registration after initialization > >> > should look like? > >> > >> I don't see any need to change anything there. The idea there is > >> that an extension allocates a tranche ID and are responsible for > >> making sure that every backend that uses that tranche finds out > >> about the ID that was chosen and registers a matching tranche > >> definition. How to do that is the extension's problem. Maybe > >> eventually we'll provide some tools to make that easier, but > >> that's separate from the work we're trying to do here. > > > > FWIW I had assumed, when you created the tranche stuff, that SLRU > > users would all allocate their lwlocks from a tranche provided by > > slru.c itself, and the locks would be stored in the slru Ctl > > struct. Does that not work for some reason? > > I think that should work and that it's a good idea. I think it's just > a case of nobody having done the work. > There is a patch that splits SLRU LWLocks to separate tranches and moves them to SLRU Ctl. It does some work from the main patch from this thread, but can be commited separately. It also simplifies lwlock.c. -- Ildus Kurbangaliev Postgres Professional: http://www.postgrespro.com Russian Postgres Company
Attachment
On Fri, Nov 6, 2015 at 6:27 AM, Ildus Kurbangaliev <i.kurbangaliev@postgrespro.ru> wrote: > There is a patch that splits SLRU LWLocks to separate tranches and > moves them to SLRU Ctl. It does some work from the main patch from > this thread, but can be commited separately. It also simplifies > lwlock.c. Thanks. I like the direction this is going. - char *ptr; - Size offset; - int slotno; + char *ptr; + Size offset; + int slotno; + int tranche_id; + LWLockPadded *locks; Please don't introduce this kind of churn. pgindent will undo it. This isn't going to work for EXEC_BACKEND builds, I think. It seems to rely on the LWLockRegisterTranche() performed !IsUnderPostmaster being inherited by subsequent children, which won't work under EXEC_BACKEND. Instead, store the tranche ID in SlruSharedData. Move the LWLockRegisterTranche call out from the (!IsUnderPostmaster) case and call it based on the tranche ID from SlruSharedData. I would just drop the add_postfix stuff. I think it's fine if the names of the shared memory checks are just "CLOG" etc. rather than "CLOG Slru Ctl", and similarly I think the locks can be registered without the "Locks" suffix. It'll be clear from context that they are locks. I suggest also that we just change all of these names to be lower case, though I realize that's a debatable and cosmetic point. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On 11/06/2015 08:53 PM, Robert Haas wrote: > On Fri, Nov 6, 2015 at 6:27 AM, Ildus Kurbangaliev > <i.kurbangaliev@postgrespro.ru> wrote: >> There is a patch that splits SLRU LWLocks to separate tranches and >> moves them to SLRU Ctl. It does some work from the main patch from >> this thread, but can be commited separately. It also simplifies >> lwlock.c. > Thanks. I like the direction this is going. > > - char *ptr; > - Size offset; > - int slotno; > + char *ptr; > + Size offset; > + int slotno; > + int tranche_id; > + LWLockPadded *locks; > > Please don't introduce this kind of churn. pgindent will undo it. > > This isn't going to work for EXEC_BACKEND builds, I think. It seems > to rely on the LWLockRegisterTranche() performed !IsUnderPostmaster > being inherited by subsequent children, which won't work under > EXEC_BACKEND. Instead, store the tranche ID in SlruSharedData. Move > the LWLockRegisterTranche call out from the (!IsUnderPostmaster) case > and call it based on the tranche ID from SlruSharedData. > > I would just drop the add_postfix stuff. I think it's fine if the > names of the shared memory checks are just "CLOG" etc. rather than > "CLOG Slru Ctl", and similarly I think the locks can be registered > without the "Locks" suffix. It'll be clear from context that they are > locks. I suggest also that we just change all of these names to be > lower case, though I realize that's a debatable and cosmetic point. > Thanks for the review. I've attached a new version of SLRU patch. I've removed add_postfix and fixed EXEC_BACKEND case. -- Ildus Kurbangaliev Postgres Professional: http://www.postgrespro.com Russian Postgres Company
Attachment
Ildus Kurbangaliev wrote: > Thanks for the review. I've attached a new version of SLRU patch. I've > removed add_postfix and fixed EXEC_BACKEND case. Thanks. Please do not use "committs" in commit_ts.c; people didn't like the abbreviated name without the underscore. But then, why are we abbreviating here? We could keep it complete and with a space instead of underscore, so why not use just "commit timestamp", because it's just a string, right? In multixact.c, is there a reason to have underscore in the strings? We could substitute it with a space and it'd look prettier; but really, we could also keep those names parallel to subdirectory names by using the already existing string parameter as name here, and not add another one. I also imagined that the Slru's ControlLock itself would be part of the tranche, and not just the per-buffer locks. That requires a bit more churn, but seems reasonable. Why do we have two per-buffer loops in SimpleLruInit? I mean, why not add the LWLockInitialize call to the second one? I'm up to speed on how the LWLockTranche API works -- does assigning to tranche_name a pstrdup string work okay? Is the pstrdup really necessary? > /* Initialize our shared state struct */ > diff --git a/src/backend/access/transam/slru.c b/src/backend/access/transam/slru.c > index 90c7cf5..868b35a 100644 > --- a/src/backend/access/transam/slru.c > +++ b/src/backend/access/transam/slru.c > @@ -157,6 +157,8 @@ SimpleLruShmemSize(int nslots, int nlsns) > if (nlsns > 0) > sz += MAXALIGN(nslots * nlsns * sizeof(XLogRecPtr)); /* group_lsn[] */ > > + sz += MAXALIGN(nslots * sizeof(LWLockPadded)); /* lwlocks[] */ > + > return BUFFERALIGN(sz) + BLCKSZ * nslots; > } What is the "lwlocks[]" comment supposed to mean? I don't think there's a struct member with that name, is there? Uhm, actually, why do we keep buffer_locks[] at all? This arrangement seems pretty odd, where if I understand correctly we have one array which is the tranche and another array which points to each item in the tranche ... -- Álvaro Herrera http://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On Nov 9, 2015, at 7:56 PM, Alvaro Herrera <alvherre@2ndquadrant.com> wrote:Ildus Kurbangaliev wrote:Thanks for the review. I've attached a new version of SLRU patch. I've
removed add_postfix and fixed EXEC_BACKEND case.
Thanks.
Please do not use "committs" in commit_ts.c; people didn't like the
abbreviated name without the underscore. But then, why are we
abbreviating here? We could keep it complete and with a space instead
of underscore, so why not use just "commit timestamp", because it's just
a string, right?
In multixact.c, is there a reason to have underscore in the strings? We
could substitute it with a space and it'd look prettier; but really, we
could also keep those names parallel to subdirectory names by using the
already existing string parameter as name here, and not add another one.
I do not insist on concrete names or a case here, but I think that identifiers are more
useful when they don't contain spaces. For example that name will be exposed later
in other places and can be part of some longer string.
Why do we have two per-buffer loops in SimpleLruInit? I mean, why not
add the LWLockInitialize call to the second one?
Thanks. I didn't see that.
I'm up to speed on how the LWLockTranche API works -- does assigning to
tranche_name a pstrdup string work okay? Is the pstrdup really
necessary?
I think pstrdup can be removed here.
/* Initialize our shared state struct */
diff --git a/src/backend/access/transam/slru.c b/src/backend/access/transam/slru.c
index 90c7cf5..868b35a 100644
--- a/src/backend/access/transam/slru.c
+++ b/src/backend/access/transam/slru.c
@@ -157,6 +157,8 @@ SimpleLruShmemSize(int nslots, int nlsns)
if (nlsns > 0)
sz += MAXALIGN(nslots * nlsns * sizeof(XLogRecPtr)); /* group_lsn[] */
+ sz += MAXALIGN(nslots * sizeof(LWLockPadded)); /* lwlocks[] */
+
return BUFFERALIGN(sz) + BLCKSZ * nslots;
}
What is the "lwlocks[]" comment supposed to mean? I don't think there's
a struct member with that name, is there?
It just means that we are allocating memory for an array of lwlocks,
i'll change it.
Uhm, actually, why do we keep buffer_locks[] at all? This arrangement
seems pretty odd, where if I understand correctly we have one array
which is the tranche and another array which points to each item in the
tranche ...
Actually yes, that is a good idea.
----
On 11/09/2015 10:32 PM, Ildus Kurbangaliev wrote: > >> On Nov 9, 2015, at 7:56 PM, Alvaro Herrera <alvherre@2ndquadrant.com> wrote: >> >> Ildus Kurbangaliev wrote: >> >>> Thanks for the review. I've attached a new version of SLRU patch. I've >>> removed add_postfix and fixed EXEC_BACKEND case. >> >> Thanks. >> >> Please do not use "committs" in commit_ts.c; people didn't like the >> abbreviated name without the underscore. But then, why are we >> abbreviating here? We could keep it complete and with a space instead >> of underscore, so why not use just "commit timestamp", because it's just >> a string, right? >> >> In multixact.c, is there a reason to have underscore in the strings? We >> could substitute it with a space and it'd look prettier; but really, we >> could also keep those names parallel to subdirectory names by using the >> already existing string parameter as name here, and not add another one. > > I do not insist on concrete names or a case here, but I think that identifiers are more > useful when they don't contain spaces. For example that name will be exposed later > in other places and can be part of some longer string. > >> >> Why do we have two per-buffer loops in SimpleLruInit? I mean, why not >> add the LWLockInitialize call to the second one? > > Thanks. I didn't see that. > >> >> I'm up to speed on how the LWLockTranche API works -- does assigning to >> tranche_name a pstrdup string work okay? Is the pstrdup really >> necessary? > > I think pstrdup can be removed here. > >> >>> /* Initialize our shared state struct */ >>> diff --git a/src/backend/access/transam/slru.c b/src/backend/access/transam/slru.c >>> index 90c7cf5..868b35a 100644 >>> --- a/src/backend/access/transam/slru.c >>> +++ b/src/backend/access/transam/slru.c >>> @@ -157,6 +157,8 @@ SimpleLruShmemSize(int nslots, int nlsns) >>> if (nlsns > 0) >>> sz += MAXALIGN(nslots * nlsns * sizeof(XLogRecPtr)); /* group_lsn[] */ >>> >>> + sz += MAXALIGN(nslots * sizeof(LWLockPadded)); /* lwlocks[] */ >>> + >>> return BUFFERALIGN(sz) + BLCKSZ * nslots; >>> } >> >> What is the "lwlocks[]" comment supposed to mean? I don't think there's >> a struct member with that name, is there? > > It just means that we are allocating memory for an array of lwlocks, > i'll change it. > >> >> Uhm, actually, why do we keep buffer_locks[] at all? This arrangement >> seems pretty odd, where if I understand correctly we have one array >> which is the tranche and another array which points to each item in the >> tranche ... > > Actually yes, that is a good idea. Attached a new version of the patch that moves SLRU tranches and LWLocks to SLRU control structs. `buffer_locks` field now contains LWLocks itself, so we have some economy of the memory here. `pstrdup` removed in SimpleLruInit. I didn't change names from the previous patch yet, but I don't mind if they'll be changed. -- Ildus Kurbangaliev Postgres Professional: http://www.postgrespro.com Russian Postgres Company
Attachment
On Wed, Nov 11, 2015 at 6:50 AM, Ildus Kurbangaliev <i.kurbangaliev@postgrespro.ru> wrote: > Attached a new version of the patch that moves SLRU tranches and LWLocks to > SLRU control structs. > > `buffer_locks` field now contains LWLocks itself, so we have some economy of > the memory here. `pstrdup` removed in SimpleLruInit. I didn't > change names from the previous patch yet, but I don't mind if they'll > be changed. I've committed this with some modifications. I did a little bit of renaming, and I stored a copy of the SLRU name in shared memory. Otherwise, we're relying on the fact that a static string will be at the same backend-private address in every process, which is a dangerous assumption at best. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On Thu, 12 Nov 2015 14:59:59 -0500 Robert Haas <robertmhaas@gmail.com> wrote: > On Wed, Nov 11, 2015 at 6:50 AM, Ildus Kurbangaliev > <i.kurbangaliev@postgrespro.ru> wrote: > > Attached a new version of the patch that moves SLRU tranches and LWLocks to > > SLRU control structs. > > > > `buffer_locks` field now contains LWLocks itself, so we have some economy of > > the memory here. `pstrdup` removed in SimpleLruInit. I didn't > > change names from the previous patch yet, but I don't mind if they'll > > be changed. > > I've committed this with some modifications. I did a little bit of > renaming, and I stored a copy of the SLRU name in shared memory. > Otherwise, we're relying on the fact that a static string will be at > the same backend-private address in every process, which is a > dangerous assumption at best. Thanks! That's very inspiring. I have some questions about next steps on other tranches. First of all, I think we can have two API calls, something like: 1) LWLockRequestTranche(char *tranche_name, int locks_count) 2) LWLockGetTranche(char *tranche_name) LWLockRequestTranche reserve an item in main tranches array in shared memory, and allocates space for name, LWLockTranche and LWLocks. There is first question. It is ok if this call will be from *ShmemSize functions? We keep those requests, calculate a required size in LWLockShmemSize (by moving this call to the end) and create all these tranches in CreateLWLocks. And the second issue. We have tranches created manually by backends (xlog, now SLRU), and they located in their shared memory. I suggest for them just reserving an item in the tranches array with LWLockRequestTranche(NULL, 0). About tranches that are creating after Postgres initialization I suggest don't keep them in the shared memory, just to use a local array like in the current implementation. Their name will not be read, we can determine by id that they are not in shared memory, and show "other" in pg_stat_activity and other places. ----- Ildus Kurbangaliev Postgres Professional: http://www.postgrespro.com Russian Postgres Company
On Fri, Nov 13, 2015 at 11:37 AM, Ildus Kurbangaliev <i.kurbangaliev@postgrespro.ru> wrote: > Thanks! That's very inspiring. Cool. It was great work; I am very happy with how it turned out. > I have some questions about next steps on other tranches. > First of all, I think we can have two API calls, something like: > > 1) LWLockRequestTranche(char *tranche_name, int locks_count) > 2) LWLockGetTranche(char *tranche_name) > > LWLockRequestTranche reserve an item in main tranches array in shared memory, and > allocates space for name, LWLockTranche and LWLocks. There is first question. It is > ok if this call will be from *ShmemSize functions? We keep those requests, > calculate a required size in LWLockShmemSize (by moving this call to the end) > and create all these tranches in CreateLWLocks. I think what we should do about the buffer locks is polish up this patch and get it applied: http://www.postgresql.org/message-id/20150907175909.GD5084@alap3.anarazel.de I think it needs to be adapted to use predefined constants for the tranche IDs instead of hardcoded values, maybe based on the attached tranche-constants.patch. This approach could be extended for the other stuff in the main tranche, and I think that would be cleaner than inventing LWLockRequestTranche as you are proposing. Just make the tranche IDs constants, and then the rest fits nicely into the framework we've already got. Also, I think we should rip all the volatile qualifiers out of bufmgr.c, using the second attached patch, devolatileize-bufmgr.patch. The comment claiming that we need this because spinlocks aren't compiler barriers is obsolete. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
Attachment
On 2015-11-15 16:24:24 -0500, Robert Haas wrote:
> I think it needs to be adapted to use predefined constants for the
> tranche IDs instead of hardcoded values, maybe based on the attached
> tranche-constants.patch.
Yea, that part is clearly not ok. Let me look at the patch.
> Also, I think we should rip all the volatile qualifiers out of
> bufmgr.c, using the second attached patch, devolatileize-bufmgr.patch.
> The comment claiming that we need this because spinlocks aren't
> compiler barriers is obsolete.
Same here.
> @@ -457,7 +457,7 @@ CreateLWLocks(void)
> LWLockCounter = (int *) ((char *) MainLWLockArray - 3 * sizeof(int));
> LWLockCounter[0] = NUM_FIXED_LWLOCKS;
> LWLockCounter[1] = numLocks;
> - LWLockCounter[2] = 1; /* 0 is the main array */
> + LWLockCounter[2] = LWTRANCHE_LAST_BUILTIN_ID + 1;
> }
Man this LWLockCounter[0] stuff is just awful. Absolutely nothing that
needs to be fixed here, but here it really should be fixed someday.
> /*
> + * We reserve a few predefined tranche IDs. These values will never be
> + * returned by LWLockNewTrancheId.
> + */
> +#define LWTRANCHE_MAIN 0
> +#define LWTRANCHE_BUFFER_CONTENT 1
> +#define LWTRANCHE_BUFFER_IO_IN_PROGRESS 2
> +#define LWTRANCHE_LAST_BUILTIN_ID LWTRANCHE_BUFFER_IO_IN_PROGRESS
Nitpick: I'm inclined to use an enum to avoid having to adjust the last
builtin id when adding a new builtin tranche.
Besides that minor thing I think this works for me. We might
independently want something making adding non-builtin tranches easier,
but that's really just independent.
> From 9e7f9219b5e752da46be0e26a0be074191ae8f62 Mon Sep 17 00:00:00 2001
> From: Robert Haas <rhaas@postgresql.org>
> Date: Sun, 15 Nov 2015 10:24:03 -0500
> Subject: [PATCH 1/3] De-volatile-ize.
I very strongly think this should be done. It's painful having to
cast-away volatile, and it de-optimizes a fair bit of performance
relevant code.
> /* local state for StartBufferIO and related functions */
> /* local state for StartBufferIO and related functions */
> -static volatile BufferDesc *InProgressBuf = NULL;
> +static BufferDesc *InProgressBuf = NULL;
> static bool IsForInput;
>
> /* local state for LockBufferForCleanup */
> -static volatile BufferDesc *PinCountWaitBuf = NULL;
> +static BufferDesc *PinCountWaitBuf = NULL;
Hm. These could also be relevant for sigsetjmp et al. Haven't found
relevant code tho.
> - volatile BufferDesc *bufHdr;
> + BufferDesc *bufHdr;
> Block bufBlock;
Looks mis-indented now, similarly in a bunch of other places. Maybe
pg-indent afterwards?
> /*
> * Header spinlock is enough to examine BM_DIRTY, see comment in
> @@ -1707,7 +1707,7 @@ BufferSync(int flags)
> num_written = 0;
> while (num_to_scan-- > 0)
> {
> - volatile BufferDesc *bufHdr = GetBufferDescriptor(buf_id);
> + BufferDesc *bufHdr = GetBufferDescriptor(buf_id);
>
This case has some theoretical behavioural implications: As
bufHdr->flags is accessed without a spinlock the compiler might re-use
an older value. But that's ok: a) there's no old value it really could
use b) the whole race-condition exists anyway, and the comment in the
body explains why that's ok.
> BlockNumber
> BufferGetBlockNumber(Buffer buffer)
> {
> - volatile BufferDesc *bufHdr;
> + BufferDesc *bufHdr;
>
> Assert(BufferIsPinned(buffer));
>
> @@ -2346,7 +2346,7 @@ void
> BufferGetTag(Buffer buffer, RelFileNode *rnode, ForkNumber *forknum,
> BlockNumber *blknum)
> {
> - volatile BufferDesc *bufHdr;
> + BufferDesc *bufHdr;
> /* Do the same checks as BufferGetBlockNumber. */
> Assert(BufferIsPinned(buffer));
> @@ -2382,7 +2382,7 @@ BufferGetTag(Buffer buffer, RelFileNode *rnode, ForkNumber *forknum,
> * as the second parameter. If not, pass NULL.
> */
> static void
> -FlushBuffer(volatile BufferDesc *buf, SMgrRelation reln)
> +FlushBuffer(BufferDesc *buf, SMgrRelation reln)
> {
> XLogRecPtr recptr;
> ErrorContextCallback errcallback;
> @@ -2520,7 +2520,7 @@ RelationGetNumberOfBlocksInFork(Relation relation, ForkNumber forkNum)
> bool
> BufferIsPermanent(Buffer buffer)
> {
> - volatile BufferDesc *bufHdr;
> + BufferDesc *bufHdr;
These require that the buffer is pinned (a barrier implying
operation). The pin prevents the contents from changing in a relevant
manner, the barrier implied in the pin forces the core's view to be
non-stale.
> @@ -2613,7 +2613,7 @@ DropRelFileNodeBuffers(RelFileNodeBackend rnode, ForkNumber forkNum,
>
> for (i = 0; i < NBuffers; i++)
> {
> - volatile BufferDesc *bufHdr = GetBufferDescriptor(i);
> + BufferDesc *bufHdr = GetBufferDescriptor(i);
> /*
> * We can make this a tad faster by prechecking the buffer tag before
> @@ -2703,7 +2703,7 @@ DropRelFileNodesAllBuffers(RelFileNodeBackend *rnodes, int nnodes)
> for (i = 0; i < NBuffers; i++)
> {
> RelFileNode *rnode = NULL;
> - volatile BufferDesc *bufHdr = GetBufferDescriptor(i);
> + BufferDesc *bufHdr = GetBufferDescriptor(i);
>
> /*
> * As in DropRelFileNodeBuffers, an unlocked precheck should be safe
> @@ -2767,7 +2767,7 @@ DropDatabaseBuffers(Oid dbid)
>
> for (i = 0; i < NBuffers; i++)
> {
> - volatile BufferDesc *bufHdr = GetBufferDescriptor(i);
> + BufferDesc *bufHdr = GetBufferDescriptor(i);
> @@ -2863,7 +2863,7 @@ void
> FlushRelationBuffers(Relation rel)
> {
> int i;
> - volatile BufferDesc *bufHdr;
> + BufferDesc *bufHdr;
>
> /* Open rel at the smgr level if not already done */
> RelationOpenSmgr(rel);
> @@ -2955,7 +2955,7 @@ void
> FlushDatabaseBuffers(Oid dbid)
> {
> int i;
> - volatile BufferDesc *bufHdr;
> + BufferDesc *bufHdr;
These all are correct based on the premise that some heavy lock -
implying a barrier - prevents new blocks with relevant tags from being
loaded into s_b. And it's fine if some other backend concurrently writes
out the buffer before we do - we'll notice that in the re-check after
So, looks good to me.
Andres
On Sun, 15 Nov 2015 16:24:24 -0500 Robert Haas <robertmhaas@gmail.com> wrote: > > I have some questions about next steps on other tranches. > > First of all, I think we can have two API calls, something like: > > > > 1) LWLockRequestTranche(char *tranche_name, int locks_count) > > 2) LWLockGetTranche(char *tranche_name) > > > > LWLockRequestTranche reserve an item in main tranches array in shared memory, and > > allocates space for name, LWLockTranche and LWLocks. There is first question. It is > > ok if this call will be from *ShmemSize functions? We keep those requests, > > calculate a required size in LWLockShmemSize (by moving this call to the end) > > and create all these tranches in CreateLWLocks. > > I think what we should do about the buffer locks is polish up this > patch and get it applied: > > http://www.postgresql.org/message-id/20150907175909.GD5084@alap3.anarazel.de > > I think it needs to be adapted to use predefined constants for the > tranche IDs instead of hardcoded values, maybe based on the attached > tranche-constants.patch. This approach could be extended for the > other stuff in the main tranche, and I think that would be cleaner > than inventing LWLockRequestTranche as you are proposing. Just make > the tranche IDs constants, and then the rest fits nicely into the > framework we've already got. What if just create a control struct in shared memory like in other places? BufferDescriptors and BufferBlocks can be kept there along with tranches definitions and lwlocks. Buffer locks that are located in MainLWLockArray by offset can be moved there too. -- Ildus Kurbangaliev Postgres Professional: http://www.postgrespro.com Russian Postgres Company
On Sun, Nov 15, 2015 at 7:20 PM, andres@anarazel.de <andres@anarazel.de> wrote: >> /* >> + * We reserve a few predefined tranche IDs. These values will never be >> + * returned by LWLockNewTrancheId. >> + */ >> +#define LWTRANCHE_MAIN 0 >> +#define LWTRANCHE_BUFFER_CONTENT 1 >> +#define LWTRANCHE_BUFFER_IO_IN_PROGRESS 2 >> +#define LWTRANCHE_LAST_BUILTIN_ID LWTRANCHE_BUFFER_IO_IN_PROGRESS > > Nitpick: I'm inclined to use an enum to avoid having to adjust the last > builtin id when adding a new builtin tranche. I prefer to do it this way because sometimes enums require a cast. But if you do the work, I'm not going to fight you over this. (If I do the work, on the other hand, ...) > Looks mis-indented now, similarly in a bunch of other places. Maybe > pg-indent afterwards? pgindent doesn't change anything for me. > So, looks good to me. Great. Committed. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On Mon, Nov 16, 2015 at 7:32 AM, Ildus Kurbangaliev <i.kurbangaliev@postgrespro.ru> wrote: > What if just create a control struct in shared memory like in other places? BufferDescriptors > and BufferBlocks can be kept there along with tranches definitions > and lwlocks. Buffer locks that are located in MainLWLockArray by offset > can be moved there too. Yeah, we could do that, but what's the advantage of it? The alignment of the buffer descriptors is kinda finnicky and matters to performance, so it seems better not to prefix them with something that might perturb it. If we just rebase Andres' patch over what I just committed and add in something so that the buffer numbers are fed from #defines or an enum instead of being random integers, I think we're done. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On Mon, 16 Nov 2015 18:55:55 -0500 Robert Haas <robertmhaas@gmail.com> wrote: > On Mon, Nov 16, 2015 at 7:32 AM, Ildus Kurbangaliev > <i.kurbangaliev@postgrespro.ru> wrote: > > What if just create a control struct in shared memory like in other places? BufferDescriptors > > and BufferBlocks can be kept there along with tranches definitions > > and lwlocks. Buffer locks that are located in MainLWLockArray by offset > > can be moved there too. > > Yeah, we could do that, but what's the advantage of it? The alignment > of the buffer descriptors is kinda finnicky and matters to > performance, so it seems better not to prefix them with something that > might perturb it. If we just rebase Andres' patch over what I just > committed and add in something so that the buffer numbers are fed from > #defines or an enum instead of being random integers, I think we're > done. I created a little patch on top of Andres' patch as example. I see several advantages: 1) We can avoid constants, and use a standard steps for tranches creation. 2) We have only one global variable (BufferCtl) 3) Tranches moved to shared memory, so we won't need to do an additional work here. 4) Also we can kept buffer locks from MainLWLockArray there (that was done in attached patch). -- Ildus Kurbangaliev Postgres Professional: http://www.postgrespro.com Russian Postgres Company
Attachment
On 2015-11-17 14:14:50 +0300, Ildus Kurbangaliev wrote:
> 1) We can avoid constants, and use a standard steps for tranches
> creation.
The constants are actually a bit useful, to easily determine
builtin/non-builtin stuff.
> 2) We have only one global variable (BufferCtl)
Don't see the advantage. This adds another, albeit predictable,
indirection in frequent callsites. There's no architectural advantage in
avoiding these.
> 3) Tranches moved to shared memory, so we won't need to do
> an additional work here.
I can see some benefit, but it also doesn't seem like a huge benefit.
> 4) Also we can kept buffer locks from MainLWLockArray there (that was done
> in attached patch).
That's the 'blockLocks' thing? That's a pretty bad name. These are
buffer mapping locks. And this seems like a separate patch, separately
debated.
> + if (!foundCtl)
> {
> - int i;
> + /* Align descriptors to a cacheline boundary. */
> + ctl->base.bufferDescriptors = (void *) CACHELINEALIGN(ShmemAlloc(
> + NBuffers * sizeof(BufferDescPadded) + PG_CACHE_LINE_SIZE));
> +
> + ctl->base.bufferBlocks = (char *) ShmemAlloc(NBuffers * (Size) BLCKSZ);
I'm going to entirely veto this.
> + strncpy(ctl->IOLWLockTrancheName, "buffer_io",
> + BUFMGR_MAX_NAME_LENGTH);
> + strncpy(ctl->contentLWLockTrancheName, "buffer_content",
> + BUFMGR_MAX_NAME_LENGTH);
> + strncpy(ctl->blockLWLockTrancheName, "buffer_blocks",
> + BUFMGR_MAX_NAME_LENGTH);
> +
> + ctl->IOLocks = (LWLockMinimallyPadded *) ShmemAlloc(
> + sizeof(LWLockMinimallyPadded) * NBuffers);
This should be cacheline aligned.
> - buf->io_in_progress_lock = LWLockAssign();
> - buf->content_lock = LWLockAssign();
> + LWLockInitialize(BufferDescriptorGetContentLock(buf),
> + ctl->contentLWLockTrancheId);
> + LWLockInitialize(&ctl->IOLocks[i].lock,
> + ctl->IOLWLockTrancheId);
Seems weird to use the macro accessing content locks, but not IO locks.
> /* Note: these two macros only work on shared buffers, not local ones! */
> -#define BufHdrGetBlock(bufHdr) ((Block) (BufferBlocks + ((Size) (bufHdr)->buf_id) * BLCKSZ))
> +#define BufHdrGetBlock(bufHdr) ((Block) (BufferCtl->bufferBlocks + ((Size) (bufHdr)->buf_id) * BLCKSZ))
That's the additional indirection I'm talking about.
> @@ -353,9 +353,6 @@ NumLWLocks(void)
> /* Predefined LWLocks */
> numLocks = NUM_FIXED_LWLOCKS;
>
> - /* bufmgr.c needs two for each shared buffer */
> - numLocks += 2 * NBuffers;
> -
> /* proc.c needs one for each backend or auxiliary process */
> numLocks += MaxBackends + NUM_AUXILIARY_PROCS;
Didn't you also move the buffer mapping locks... ?
> diff --git a/src/include/storage/buf_internals.h b/src/include/storage/buf_internals.h
> index 521ee1c..e1795dc 100644
> --- a/src/include/storage/buf_internals.h
> +++ b/src/include/storage/buf_internals.h
> @@ -95,6 +95,7 @@ typedef struct buftag
> (a).forkNum == (b).forkNum \
> )
>
> +
> /*
unrelated change.
> * The shared buffer mapping table is partitioned to reduce contention.
> * To determine which partition lock a given tag requires, compute the tag's
> @@ -104,10 +105,9 @@ typedef struct buftag
> #define BufTableHashPartition(hashcode) \
> ((hashcode) % NUM_BUFFER_PARTITIONS)
> #define BufMappingPartitionLock(hashcode) \
> - (&MainLWLockArray[BUFFER_MAPPING_LWLOCK_OFFSET + \
> - BufTableHashPartition(hashcode)].lock)
> + (&((BufferCtlData *)BufferCtl)->blockLocks[BufTableHashPartition(hashcode)].lock)
> #define BufMappingPartitionLockByIndex(i) \
> - (&MainLWLockArray[BUFFER_MAPPING_LWLOCK_OFFSET + (i)].lock)
> + (&((BufferCtlData *)BufferCtl)->blockLocks[i].lock)
Again, unnecessary indirections.
> +/* Maximum length of a bufmgr lock name */
> +#define BUFMGR_MAX_NAME_LENGTH 32
If we were to do this I'd just use NAMEDATALEN.
> +/*
> + * Base control struct for the buffer manager data
> + * Located in shared memory.
> + *
> + * BufferCtl variable points to BufferCtlBase because of only
> + * the backend code knows about BufferDescPadded, LWLock and
> + * others structures and the same time it must be usable in
> + * the frontend code.
> + */
> +typedef struct BufferCtlData
> +{
> + BufferCtlBase base;
Eeek. What's the point here?
Andres
Thank you for the review. I've made changes according to your comments.
I don't stick on current names in the patch.
I've removed all unnecerrary indirections, and added cache aligning
to LWLock arrays.
On Tue, 17 Nov 2015 19:36:13 +0100
"andres@anarazel.de" <andres@anarazel.de> wrote:
> On 2015-11-17 14:14:50 +0300, Ildus Kurbangaliev wrote:
> > 1) We can avoid constants, and use a standard steps for tranches
> > creation.
>
> The constants are actually a bit useful, to easily determine
> builtin/non-builtin stuff.
Maybe I'm missing something here, but I don't see much difference with
other tranches, created in Postgres startup. In my opinion they are also
pretty much builtin.
>
> > 2) We have only one global variable (BufferCtl)
>
> Don't see the advantage. This adds another, albeit predictable,
> indirection in frequent callsites. There's no architectural advantage
> in avoiding these.
>
> > 3) Tranches moved to shared memory, so we won't need to do
> > an additional work here.
>
> I can see some benefit, but it also doesn't seem like a huge benefit.
The moving base tranches to shared memory has been discussed many times.
The point is using them later in pg_stat_activity and other monitoring
views.
>
>
> > 4) Also we can kept buffer locks from MainLWLockArray there (that
> > was done in attached patch).
>
> That's the 'blockLocks' thing? That's a pretty bad name. These are
> buffer mapping locks. And this seems like a separate patch, separately
> debated.
Changed to BufMappingPartitionLWLocks. If this patch is all about
separating LWLocks of the buffer manager, why not use one patch for this
task?
>
> > + if (!foundCtl)
> > {
> > - int i;
> > + /* Align descriptors to a cacheline boundary. */
> > + ctl->base.bufferDescriptors = (void *)
> > CACHELINEALIGN(ShmemAlloc(
> > + NBuffers * sizeof(BufferDescPadded) +
> > PG_CACHE_LINE_SIZE)); +
> > + ctl->base.bufferBlocks = (char *)
> > ShmemAlloc(NBuffers * (Size) BLCKSZ);
>
> I'm going to entirely veto this.
>
> > + strncpy(ctl->IOLWLockTrancheName, "buffer_io",
> > + BUFMGR_MAX_NAME_LENGTH);
> > + strncpy(ctl->contentLWLockTrancheName,
> > "buffer_content",
> > + BUFMGR_MAX_NAME_LENGTH);
> > + strncpy(ctl->blockLWLockTrancheName,
> > "buffer_blocks",
> > + BUFMGR_MAX_NAME_LENGTH);
> > +
> > + ctl->IOLocks = (LWLockMinimallyPadded *)
> > ShmemAlloc(
> > + sizeof(LWLockMinimallyPadded) *
> > NBuffers);
>
> This should be cacheline aligned.
Fixed
>
> > - buf->io_in_progress_lock = LWLockAssign();
> > - buf->content_lock = LWLockAssign();
> > +
> > LWLockInitialize(BufferDescriptorGetContentLock(buf),
> > + ctl->contentLWLockTrancheId);
> > + LWLockInitialize(&ctl->IOLocks[i].lock,
> > + ctl->IOLWLockTrancheId);
>
> Seems weird to use the macro accessing content locks, but not IO
> locks.
Fixed
>
> > /* Note: these two macros only work on shared buffers, not local
> > ones! */ -#define BufHdrGetBlock(bufHdr) ((Block)
> > (BufferBlocks + ((Size) (bufHdr)->buf_id) * BLCKSZ)) +#define
> > BufHdrGetBlock(bufHdr) ((Block) (BufferCtl->bufferBlocks +
> > ((Size) (bufHdr)->buf_id) * BLCKSZ))
>
> That's the additional indirection I'm talking about.
>
> > @@ -353,9 +353,6 @@ NumLWLocks(void)
> > /* Predefined LWLocks */
> > numLocks = NUM_FIXED_LWLOCKS;
> >
> > - /* bufmgr.c needs two for each shared buffer */
> > - numLocks += 2 * NBuffers;
> > -
> > /* proc.c needs one for each backend or auxiliary process
> > */ numLocks += MaxBackends + NUM_AUXILIARY_PROCS;
>
> Didn't you also move the buffer mapping locks... ?
>
> > diff --git a/src/include/storage/buf_internals.h
> > b/src/include/storage/buf_internals.h index 521ee1c..e1795dc 100644
> > --- a/src/include/storage/buf_internals.h
> > +++ b/src/include/storage/buf_internals.h
> > @@ -95,6 +95,7 @@ typedef struct buftag
> > (a).forkNum == (b).forkNum \
> > )
> >
> > +
> > /*
>
> unrelated change.
>
> > * The shared buffer mapping table is partitioned to reduce
> > contention.
> > * To determine which partition lock a given tag requires, compute
> > the tag's @@ -104,10 +105,9 @@ typedef struct buftag
> > #define BufTableHashPartition(hashcode) \
> > ((hashcode) % NUM_BUFFER_PARTITIONS)
> > #define BufMappingPartitionLock(hashcode) \
> > - (&MainLWLockArray[BUFFER_MAPPING_LWLOCK_OFFSET + \
> > - BufTableHashPartition(hashcode)].lock)
> > + (&((BufferCtlData
> > *)BufferCtl)->blockLocks[BufTableHashPartition(hashcode)].lock)
> > #define BufMappingPartitionLockByIndex(i) \
> > - (&MainLWLockArray[BUFFER_MAPPING_LWLOCK_OFFSET + (i)].lock)
> > + (&((BufferCtlData *)BufferCtl)->blockLocks[i].lock)
>
> Again, unnecessary indirections.
Fixed
>
> > +/* Maximum length of a bufmgr lock name */
> > +#define BUFMGR_MAX_NAME_LENGTH 32
>
> If we were to do this I'd just use NAMEDATALEN.
Fixed
>
> > +/*
> > + * Base control struct for the buffer manager data
> > + * Located in shared memory.
> > + *
> > + * BufferCtl variable points to BufferCtlBase because of only
> > + * the backend code knows about BufferDescPadded, LWLock and
> > + * others structures and the same time it must be usable in
> > + * the frontend code.
> > + */
> > +typedef struct BufferCtlData
> > +{
> > + BufferCtlBase base;
>
> Eeek. What's the point here?
The point was using BufferCtlBase in the backend and frontend code.
The frontend code doesn't know about LWLock and other structures.
Anyway I've removed this code.
--
Ildus Kurbangaliev
Postgres Professional: http://www.postgrespro.com
Russian Postgres Company
Attachment
On Thu, Nov 19, 2015 at 9:04 AM, Ildus Kurbangaliev <i.kurbangaliev@postgrespro.ru> wrote: > The moving base tranches to shared memory has been discussed many times. > The point is using them later in pg_stat_activity and other monitoring > views. I'm not in agreement with this idea. Actually, I'd prefer that the tranches live in backend-private memory, not shared memory, so that we could for example add backend-local counters to them if desired. The SLRU patch is the first time we've put them in shared memory, but it would be easy to keep only the things that the tranche needs to point to in shared memory and put the tranche itself back in each backend, which I tend to think is what we should do. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On November 19, 2015 8:09:38 AM PST, Robert Haas <robertmhaas@gmail.com> wrote: >On Thu, Nov 19, 2015 at 9:04 AM, Ildus Kurbangaliev ><i.kurbangaliev@postgrespro.ru> wrote: >> The moving base tranches to shared memory has been discussed many >times. >> The point is using them later in pg_stat_activity and other >monitoring >> views. > >I'm not in agreement with this idea. Actually, I'd prefer that the >tranches live in backend-private memory, not shared memory, so that we >could for example add backend-local counters to them if desired. I don't buy that argument. It'd be nearly trivial to have a backend_tranchestats array, indexed by the tranche id, for suchcounters. It's really not particularly convenient to allocate tranches right now. You have to store at least the identifier in sharedmemory and then redo the registration in each process. Otherwise some processes can't identify them. Which of ratherinconvenient of you want to register some at runtime --- Please excuse brevity and formatting - I am writing this on my mobile phone.
On Thu, Nov 19, 2015 at 11:30 AM, Andres Freund <andres@anarazel.de> wrote: > On November 19, 2015 8:09:38 AM PST, Robert Haas <robertmhaas@gmail.com> wrote: >>On Thu, Nov 19, 2015 at 9:04 AM, Ildus Kurbangaliev >><i.kurbangaliev@postgrespro.ru> wrote: >>> The moving base tranches to shared memory has been discussed many >>times. >>> The point is using them later in pg_stat_activity and other >>monitoring >>> views. >> >>I'm not in agreement with this idea. Actually, I'd prefer that the >>tranches live in backend-private memory, not shared memory, so that we >>could for example add backend-local counters to them if desired. > > I don't buy that argument. It'd be nearly trivial to have a backend_tranchestats array, indexed by the tranche id, forsuch counters. Hmm, true. > It's really not particularly convenient to allocate tranches right now. You have to store at least the identifier in sharedmemory and then redo the registration in each process. Otherwise some processes can't identify them. Which of ratherinconvenient of you want to register some at runtime Sure, that's why we're proposing to use an enum or a list of #defines for that. I don't see a need to do any more than that. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On 2015-11-19 14:58:05 -0500, Robert Haas wrote: > On Thu, Nov 19, 2015 at 11:30 AM, Andres Freund <andres@anarazel.de> wrote: > > It's really not particularly convenient to allocate tranches right > > now. You have to store at least the identifier in shared memory and > > then redo the registration in each process. Otherwise some processes > > can't identify them. Which of rather inconvenient of you want to > > register some at runtime > > Sure, that's why we're proposing to use an enum or a list of #defines > for that. I don't see a need to do any more than that. That works fine for builtin stuff, but not at all for extensions doing it. If you do register locks at runtime, instead of shared_preload_library - something you surely agree makes some things easier by not requiring a restart - you really don't have any way to force the registration to happen in each backend.
On Thu, Nov 19, 2015 at 4:26 PM, Andres Freund <andres@anarazel.de> wrote: > On 2015-11-19 14:58:05 -0500, Robert Haas wrote: >> On Thu, Nov 19, 2015 at 11:30 AM, Andres Freund <andres@anarazel.de> wrote: >> > It's really not particularly convenient to allocate tranches right >> > now. You have to store at least the identifier in shared memory and >> > then redo the registration in each process. Otherwise some processes >> > can't identify them. Which of rather inconvenient of you want to >> > register some at runtime >> >> Sure, that's why we're proposing to use an enum or a list of #defines >> for that. I don't see a need to do any more than that. > > That works fine for builtin stuff, but not at all for extensions doing > it. > > If you do register locks at runtime, instead of shared_preload_library - > something you surely agree makes some things easier by not requiring a > restart - you really don't have any way to force the registration to > happen in each backend. I'm not exactly clear what you are proposing. Pick some relatively small cap on the number of tranches and put an array of them in shared memory? Blech. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On Thu, 19 Nov 2015 11:09:38 -0500 Robert Haas <robertmhaas@gmail.com> wrote: > On Thu, Nov 19, 2015 at 9:04 AM, Ildus Kurbangaliev > <i.kurbangaliev@postgrespro.ru> wrote: > > The moving base tranches to shared memory has been discussed many > > times. The point is using them later in pg_stat_activity and other > > monitoring views. > > I'm not in agreement with this idea. Actually, I'd prefer that the > tranches live in backend-private memory, not shared memory, so that we > could for example add backend-local counters to them if desired. The > SLRU patch is the first time we've put them in shared memory, but it > would be easy to keep only the things that the tranche needs to point > to in shared memory and put the tranche itself back in each backend, > which I tend to think is what we should do. > We keep limited number of LWLocks in base shared memory, why not keep their thanches in shared memory too? Other tranches can be in local memory, we just have to save somewhere highest id of these tranches. We have not so many of possible builtin tranches, excluding the SLRU tranches, there will be only seven: three for buffer manager, one for each of proc.c, slot.c, lock manager and predicate lock manager. -- Ildus Kurbangaliev Postgres Professional: http://www.postgrespro.com Russian Postgres Company
On Fri, Nov 20, 2015 at 6:53 AM, Ildus Kurbangaliev <i.kurbangaliev@postgrespro.ru> wrote: > We keep limited number of LWLocks in base shared memory, why not keep > their thanches in shared memory too? Other tranches can be in local > memory, we just have to save somewhere highest id of these tranches. I just don't see it buying us anything. The tranches are small and contain only a handful of values. The values need to be present in shared memory but the tranches themselves don't. Now, if it's convenient to put them in shared memory and doesn't cause us any other problems, then maybe there's no real downside. But it's not clear to me that there's any upside either. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On Mon, 23 Nov 2015 12:12:23 -0500 Robert Haas <robertmhaas@gmail.com> wrote: > On Fri, Nov 20, 2015 at 6:53 AM, Ildus Kurbangaliev > <i.kurbangaliev@postgrespro.ru> wrote: > > We keep limited number of LWLocks in base shared memory, why not > > keep their thanches in shared memory too? Other tranches can be in > > local memory, we just have to save somewhere highest id of these > > tranches. > > I just don't see it buying us anything. The tranches are small and > contain only a handful of values. The values need to be present in > shared memory but the tranches themselves don't. > > Now, if it's convenient to put them in shared memory and doesn't cause > us any other problems, then maybe there's no real downside. But it's > not clear to me that there's any upside either. > I see. Since tranche names are always in shared memory or static strings, then maybe we should just create global static char * array with fixed length for names (something like `char *LWLockTrancheNames[NUM_LWLOCK_BUILTIN_TRANCHES]`)? It will be just enough for monitoring purposes, and doesn't matter where a tranche is located. We will have a name pointer for built-in tranches only, and fixed length of this array will not be a problem since we know exact count of them. -- Ildus Kurbangaliev Postgres Professional: http://www.postgrespro.com Russian Postgres Company
On 2015-11-15 16:24:24 -0500, Robert Haas wrote: > I think what we should do about the buffer locks is polish up this > patch and get it applied: > > http://www.postgresql.org/message-id/20150907175909.GD5084@alap3.anarazel.de > > I think it needs to be adapted to use predefined constants for the > tranche IDs instead of hardcoded values, maybe based on the attached > tranche-constants.patch. Here's two patches doing that. The first is an adaption of your constants patch, using an enum and also converting xlog.c's locks. The second is the separation into distinct tranches. One thing to call out is that an "oversized" s_lock can now make BufferDesc exceed 64 bytes, right now that's just the case when it's larger than 4 bytes. I'm not sure if that's cause for real concern, given that it's not very concurrent or ancient platforms where that's the case. http://archives.postgresql.org/message-id/20150915020625.GI9666%40alap3.anarazel.de would alleviate that concern again, as it collapses flags, usage_count, buf_hdr_lock and refcount into one 32 bit int... Greetings, Andres Freund
Attachment
On Sat, Dec 12, 2015 at 1:17 PM, andres@anarazel.de <andres@anarazel.de> wrote: > On 2015-11-15 16:24:24 -0500, Robert Haas wrote: >> I think what we should do about the buffer locks is polish up this >> patch and get it applied: >> >> http://www.postgresql.org/message-id/20150907175909.GD5084@alap3.anarazel.de >> >> I think it needs to be adapted to use predefined constants for the >> tranche IDs instead of hardcoded values, maybe based on the attached >> tranche-constants.patch. > > Here's two patches doing that. The first is an adaption of your > constants patch, using an enum and also converting xlog.c's locks. The > second is the separation into distinct tranches. Personally, I prefer the #define approach to the enum, but I can live with doing it this way. Other than that, I think these patches look good, although if it's OK with you I would like to make a pass over the comments and the commit messages which seem to me that they could benefit from a bit of editing (but not much substantive change). > One thing to call out is that an "oversized" s_lock can now make > BufferDesc exceed 64 bytes, right now that's just the case when it's > larger than 4 bytes. I'm not sure if that's cause for real concern, > given that it's not very concurrent or ancient platforms where that's > the case. > http://archives.postgresql.org/message-id/20150915020625.GI9666%40alap3.anarazel.de > would alleviate that concern again, as it collapses flags, usage_count, > buf_hdr_lock and refcount into one 32 bit int... I don't think that would be worth worrying about even if we didn't have a plan in mind that would make it go away again, and even less so given that we do have such a plan. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On 2015-12-12 21:15:52 -0500, Robert Haas wrote: > On Sat, Dec 12, 2015 at 1:17 PM, andres@anarazel.de <andres@anarazel.de> wrote: > > Here's two patches doing that. The first is an adaption of your > > constants patch, using an enum and also converting xlog.c's locks. The > > second is the separation into distinct tranches. > > Personally, I prefer the #define approach to the enum, but I can live > with doing it this way. I think the lack needing to adjust the 'last defined' var is worth it... > Other than that, I think these patches look > good, although if it's OK with you I would like to make a pass over > the comments and the commit messages which seem to me that they could > benefit from a bit of editing (but not much substantive change). Sounds good to me. You'll then commit that? > > One thing to call out is that an "oversized" s_lock can now make > > BufferDesc exceed 64 bytes, right now that's just the case when it's > > larger than 4 bytes. I'm not sure if that's cause for real concern, > > given that it's not very concurrent or ancient platforms where that's > > the case. > > http://archives.postgresql.org/message-id/20150915020625.GI9666%40alap3.anarazel.de > > would alleviate that concern again, as it collapses flags, usage_count, > > buf_hdr_lock and refcount into one 32 bit int... > > I don't think that would be worth worrying about even if we didn't > have a plan in mind that would make it go away again, and even less so > given that we do have such a plan. Ok cool. I'm not particularly concerned either, just didn't want to slip that in without having it called out. Andres
On Sun, Dec 13, 2015 at 6:35 AM, andres@anarazel.de <andres@anarazel.de> wrote: > On 2015-12-12 21:15:52 -0500, Robert Haas wrote: >> On Sat, Dec 12, 2015 at 1:17 PM, andres@anarazel.de <andres@anarazel.de> wrote: >> > Here's two patches doing that. The first is an adaption of your >> > constants patch, using an enum and also converting xlog.c's locks. The >> > second is the separation into distinct tranches. >> >> Personally, I prefer the #define approach to the enum, but I can live >> with doing it this way. > > I think the lack needing to adjust the 'last defined' var is worth it... > >> Other than that, I think these patches look >> good, although if it's OK with you I would like to make a pass over >> the comments and the commit messages which seem to me that they could >> benefit from a bit of editing (but not much substantive change). > > Sounds good to me. You'll then commit that? Yes. Done! In terms of this project overall, NumLWLocks() now knows about only four categories of stuff: fixed lwlocks, backend locks (proc.c), replication slot locks, and locks needed by extensions. I think it'd probably be fine to move the backend locks into PGPROC directly, and the replication slot locks into ReplicationSlot. I don't know if that will improve performance but it doesn't seem like it should regress anything, though we should probably test that. I'm not sure what to do about extension-requested locks - maybe give those their own tranche somehow? I think we should also look at tranche-ifying the locks counted in NUM_FIXED_LWLOCKS but not NUM_INDIVIDUAL_LWLOCKS. That's basically just the lock manager locks and the predicate lock manager locks. That would get us to a place where every lock in the system has a descriptive name, either via the tranche or because it's an individually named lock, which sounds excellent. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On Tue, 15 Dec 2015 13:56:30 -0500 Robert Haas <robertmhaas@gmail.com> wrote: > On Sun, Dec 13, 2015 at 6:35 AM, andres@anarazel.de > <andres@anarazel.de> wrote: > > On 2015-12-12 21:15:52 -0500, Robert Haas wrote: > >> On Sat, Dec 12, 2015 at 1:17 PM, andres@anarazel.de > >> <andres@anarazel.de> wrote: > >> > Here's two patches doing that. The first is an adaption of your > >> > constants patch, using an enum and also converting xlog.c's > >> > locks. The second is the separation into distinct tranches. > >> > >> Personally, I prefer the #define approach to the enum, but I can > >> live with doing it this way. > > > > I think the lack needing to adjust the 'last defined' var is worth > > it... > >> Other than that, I think these patches look > >> good, although if it's OK with you I would like to make a pass over > >> the comments and the commit messages which seem to me that they > >> could benefit from a bit of editing (but not much substantive > >> change). > > > > Sounds good to me. You'll then commit that? > > Yes. Done! > > In terms of this project overall, NumLWLocks() now knows about only > four categories of stuff: fixed lwlocks, backend locks (proc.c), > replication slot locks, and locks needed by extensions. I think it'd > probably be fine to move the backend locks into PGPROC directly, and > the replication slot locks into ReplicationSlot. I don't know if that > will improve performance but it doesn't seem like it should regress > anything, though we should probably test that. I'm not sure what to > do about extension-requested locks - maybe give those their own > tranche somehow? > > I think we should also look at tranche-ifying the locks counted in > NUM_FIXED_LWLOCKS but not NUM_INDIVIDUAL_LWLOCKS. That's basically > just the lock manager locks and the predicate lock manager locks. > That would get us to a place where every lock in the system has a > descriptive name, either via the tranche or because it's an > individually named lock, which sounds excellent. > There is a patch that moves backend LWLocks into PGPROC and to a separate tranche. I did tests, and it doesn't regress and the same time doesn't improve performance on my computer. -- Ildus Kurbangaliev Postgres Professional: http://www.postgrespro.com Russian Postgres Company
Attachment
On Thu, Dec 24, 2015 at 5:50 PM, Ildus Kurbangaliev <i.kurbangaliev@postgrespro.ru> wrote:
>
> On Tue, 15 Dec 2015 13:56:30 -0500
> Robert Haas <robertmhaas@gmail.com> wrote:
>
> > On Sun, Dec 13, 2015 at 6:35 AM, andres@anarazel.de
> > <andres@anarazel.de> wrote:
> > > On 2015-12-12 21:15:52 -0500, Robert Haas wrote:
> > >> On Sat, Dec 12, 2015 at 1:17 PM, andres@anarazel.de
> > >> <andres@anarazel.de> wrote:
> > >> > Here's two patches doing that. The first is an adaption of your
> > >> > constants patch, using an enum and also converting xlog.c's
> > >> > locks. The second is the separation into distinct tranches.
> > >>
> > >> Personally, I prefer the #define approach to the enum, but I can
> > >> live with doing it this way.
> > >
> > > I think the lack needing to adjust the 'last defined' var is worth
> > > it...
> > >> Other than that, I think these patches look
> > >> good, although if it's OK with you I would like to make a pass over
> > >> the comments and the commit messages which seem to me that they
> > >> could benefit from a bit of editing (but not much substantive
> > >> change).
> > >
> > > Sounds good to me. You'll then commit that?
> >
> > Yes. Done!
> >
> > In terms of this project overall, NumLWLocks() now knows about only
> > four categories of stuff: fixed lwlocks, backend locks (proc.c),
> > replication slot locks, and locks needed by extensions. I think it'd
> > probably be fine to move the backend locks into PGPROC directly, and
> > the replication slot locks into ReplicationSlot. I don't know if that
> > will improve performance but it doesn't seem like it should regress
> > anything, though we should probably test that. I'm not sure what to
> > do about extension-requested locks - maybe give those their own
> > tranche somehow?
> >
> > I think we should also look at tranche-ifying the locks counted in
> > NUM_FIXED_LWLOCKS but not NUM_INDIVIDUAL_LWLOCKS. That's basically
> > just the lock manager locks and the predicate lock manager locks.
> > That would get us to a place where every lock in the system has a
> > descriptive name, either via the tranche or because it's an
> > individually named lock, which sounds excellent.
> >
>
> There is a patch that moves backend LWLocks into PGPROC and to a
> separate tranche.
>
> On Tue, 15 Dec 2015 13:56:30 -0500
> Robert Haas <robertmhaas@gmail.com> wrote:
>
> > On Sun, Dec 13, 2015 at 6:35 AM, andres@anarazel.de
> > <andres@anarazel.de> wrote:
> > > On 2015-12-12 21:15:52 -0500, Robert Haas wrote:
> > >> On Sat, Dec 12, 2015 at 1:17 PM, andres@anarazel.de
> > >> <andres@anarazel.de> wrote:
> > >> > Here's two patches doing that. The first is an adaption of your
> > >> > constants patch, using an enum and also converting xlog.c's
> > >> > locks. The second is the separation into distinct tranches.
> > >>
> > >> Personally, I prefer the #define approach to the enum, but I can
> > >> live with doing it this way.
> > >
> > > I think the lack needing to adjust the 'last defined' var is worth
> > > it...
> > >> Other than that, I think these patches look
> > >> good, although if it's OK with you I would like to make a pass over
> > >> the comments and the commit messages which seem to me that they
> > >> could benefit from a bit of editing (but not much substantive
> > >> change).
> > >
> > > Sounds good to me. You'll then commit that?
> >
> > Yes. Done!
> >
> > In terms of this project overall, NumLWLocks() now knows about only
> > four categories of stuff: fixed lwlocks, backend locks (proc.c),
> > replication slot locks, and locks needed by extensions. I think it'd
> > probably be fine to move the backend locks into PGPROC directly, and
> > the replication slot locks into ReplicationSlot. I don't know if that
> > will improve performance but it doesn't seem like it should regress
> > anything, though we should probably test that. I'm not sure what to
> > do about extension-requested locks - maybe give those their own
> > tranche somehow?
> >
> > I think we should also look at tranche-ifying the locks counted in
> > NUM_FIXED_LWLOCKS but not NUM_INDIVIDUAL_LWLOCKS. That's basically
> > just the lock manager locks and the predicate lock manager locks.
> > That would get us to a place where every lock in the system has a
> > descriptive name, either via the tranche or because it's an
> > individually named lock, which sounds excellent.
> >
>
> There is a patch that moves backend LWLocks into PGPROC and to a
> separate tranche.
>
1.
@@ -437,6 +440,13 @@ InitProcessPhase2(void)
{
Assert(MyProc != NULL);
+ /* Register and initialize fields of ProcLWLockTranche */
+ ProcLWLockTranche.name = "proc";
+ ProcLWLockTranche.array_base = (char *) (ProcGlobal->allProcs) +
+ offsetof(PGPROC, backendLock);
+ ProcLWLockTranche.array_stride = sizeof(PGPROC);
+ LWLockRegisterTranche(LWTRANCHE_PROC, &ProcLWLockTranche);
+
I think this will not work for Auxilary processes as they won't
call InitProcessPhase2(). It is better to initialize it in
InitProcGlobal() and then propagate it to backends for EXEC_BACKEND
cases as we do for ProcStructLock, AuxiliaryProcs.
2.
@@ -213,6 +213,7 @@ typedef enum BuiltinTrancheIds
LWTRANCHE_WAL_INSERT,
LWTRANCHE_BUFFER_CONTENT,
LWTRANCHE_BUFFER_IO_IN_PROGRESS,
+ LWTRANCHE_PROC,
LWTRANCHE_FIRST_USER_DEFINED
} BuiltinTrancheIds;
Other trancheids are based on the name of their corresponding
LWLock, don't you think it is better to name it as
LWTRANCHE_BACKEND for the sake of consistency? Also consider
changing name at other places in patch for this tranche.
On Wed, Dec 16, 2015 at 12:26 AM, Robert Haas <robertmhaas@gmail.com> wrote:
>
>
> In terms of this project overall, NumLWLocks() now knows about only
> four categories of stuff: fixed lwlocks, backend locks (proc.c),
> replication slot locks, and locks needed by extensions. I think it'd
> probably be fine to move the backend locks into PGPROC directly, and
> the replication slot locks into ReplicationSlot.
>
>
> In terms of this project overall, NumLWLocks() now knows about only
> four categories of stuff: fixed lwlocks, backend locks (proc.c),
> replication slot locks, and locks needed by extensions. I think it'd
> probably be fine to move the backend locks into PGPROC directly, and
> the replication slot locks into ReplicationSlot.
>
IIdus has written a patch to move backend locks into PGPROC which
I am reviewing and will do performance tests once he responds to
my review comments and I have written a patch to move replication
slot locks into ReplicationSlot which is attached with this mail.
Attachment
On Mon, Dec 28, 2015 at 3:17 AM, Amit Kapila <amit.kapila16@gmail.com> wrote: > 2. > @@ -213,6 +213,7 @@ typedef enum BuiltinTrancheIds > LWTRANCHE_WAL_INSERT, > LWTRANCHE_BUFFER_CONTENT, > LWTRANCHE_BUFFER_IO_IN_PROGRESS, > + LWTRANCHE_PROC, > LWTRANCHE_FIRST_USER_DEFINED > } BuiltinTrancheIds; > > Other trancheids are based on the name of their corresponding > LWLock, don't you think it is better to name it as > LWTRANCHE_BACKEND for the sake of consistency? Also consider > changing name at other places in patch for this tranche. Hmm, don't think I agree with this. I think LWTRANCHE_PROC is better. Remember, backendLock is intended to distinguish thatobject from everything else in the PGPROC; but here we're trying to distinguish stuff in the PGPROC from stuff in other data structures altogether. That's an important distinction. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On Tue, Dec 29, 2015 at 2:26 PM, Amit Kapila <amit.kapila16@gmail.com> wrote:
On Wed, Dec 16, 2015 at 12:26 AM, Robert Haas <robertmhaas@gmail.com> wrote:
>
>
> In terms of this project overall, NumLWLocks() now knows about only
> four categories of stuff: fixed lwlocks, backend locks (proc.c),
> replication slot locks, and locks needed by extensions. I think it'd
> probably be fine to move the backend locks into PGPROC directly, and
> the replication slot locks into ReplicationSlot.>IIdus has written a patch to move backend locks into PGPROC whichI am reviewing and will do performance tests once he responds tomy review comments and I have written a patch to move replicationslot locks into ReplicationSlot which is attached with this mail.
Going further on this work, I have written a patch for separating the
tranches for extensions. The basic idea is to expose two new API's,
first to request a new tranche and second to assign a lock from that
tranche.
RequestAddinLWLockTranche(const char *tranche_name, int num_lwlocks)will be used by extensions to request a new tranche with specified number
of locks, this will be used instead of current API RequestAddinLWLocks().
We need to remember this information for each extension and then
during startup we need to create separate tranches and still have locks
for extensions in the MainLWLockArray such that the base for each
tranche will point to the locks corresponding to that tranche. As for
each proc/backend, we need to register the tranche separately, the
information of newly formed tranches needs to be passed to backends
via save/restore_backend_variables mechanism for EXEC_BACKEND
builds.
LWLock *LWLockAssignFromTranche(const char *tranche_name) willassign a lock for the specified tranche. This also ensures that no
more than requested number of LWLocks can be assigned from a
specified tranche.
Also I have retained NUM_USER_DEFINED_LWLOCKS in
MainLWLockArray so that if any extensions want to assign a LWLock
after startup, it can be used from this pool. The tranche for such locks
will be reported as main.
This is based on the suggestions by Robert in the mail:
Thoughts?
Attachment
On Thu, Dec 31, 2015 at 5:06 PM, Amit Kapila <amit.kapila16@gmail.com> wrote:
>
> On Tue, Dec 29, 2015 at 2:26 PM, Amit Kapila <amit.kapila16@gmail.com> wrote:
>>
>> On Wed, Dec 16, 2015 at 12:26 AM, Robert Haas <robertmhaas@gmail.com> wrote:
>> >
>> >
I have moved this patch to new CF as the work is still in
progress.
On 12/31/2015 06:36 AM, Amit Kapila wrote: > Going further on this work, I have written a patch for separating the > tranches for extensions. The basic idea is to expose two new API's, > first to request a new tranche and second to assign a lock from that > tranche. > RequestAddinLWLockTranche(const char *tranche_name, int num_lwlocks) > will be used by extensions to request a new tranche with specified number > of locks, this will be used instead of current API RequestAddinLWLocks(). > We need to remember this information for each extension and then > during startup we need to create separate tranches and still have locks > for extensions in the MainLWLockArray such that the base for each > tranche will point to the locks corresponding to that tranche. As for > each proc/backend, we need to register the tranche separately, the > information of newly formed tranches needs to be passed to backends > via save/restore_backend_variables mechanism for EXEC_BACKEND > builds. > LWLock *LWLockAssignFromTranche(const char *tranche_name) will > assign a lock for the specified tranche. This also ensures that no > more than requested number of LWLocks can be assigned from a > specified tranche. > > Also I have retained NUM_USER_DEFINED_LWLOCKS in > MainLWLockArray so that if any extensions want to assign a LWLock > after startup, it can be used from this pool. The tranche for such locks > will be reported as main. > > This is based on the suggestions by Robert in the mail: > http://www.postgresql.org/message-id/CA+TgmoashjaQeSK1bEm-GGc8OWFyLhvOrH=4KJfvKRFt9YkBWQ@mail.gmail.com > > Thoughts? > +1 for the idea. However, RequestAddinLWLocks and LWLockAssign are used by extensions outside of the main tree, so I think it would be better to deprecate the methods for starters with a log statement. NUM_USER_DEFINED_LWLOCKS aren't enough in many cases, so the existing functionality needs to be maintained during the deprecation period. If extensions needs to upgrade to the new API I think LWLockAssign should be removed. doc/src/sgml/xfunc.sgml needs an update on how the new API should be used. Best regards, Jesper
On Thu, Dec 31, 2015 at 7:42 PM, Jesper Pedersen <jesper.pedersen@redhat.com> wrote:
+1 for the idea.On 12/31/2015 06:36 AM, Amit Kapila wrote:Going further on this work, I have written a patch for separating the
tranches for extensions. The basic idea is to expose two new API's,
first to request a new tranche and second to assign a lock from that
tranche.
RequestAddinLWLockTranche(const char *tranche_name, int num_lwlocks)
will be used by extensions to request a new tranche with specified number
of locks, this will be used instead of current API RequestAddinLWLocks().
We need to remember this information for each extension and then
during startup we need to create separate tranches and still have locks
for extensions in the MainLWLockArray such that the base for each
tranche will point to the locks corresponding to that tranche. As for
each proc/backend, we need to register the tranche separately, the
information of newly formed tranches needs to be passed to backends
via save/restore_backend_variables mechanism for EXEC_BACKEND
builds.
LWLock *LWLockAssignFromTranche(const char *tranche_name) will
assign a lock for the specified tranche. This also ensures that no
more than requested number of LWLocks can be assigned from a
specified tranche.
Also I have retained NUM_USER_DEFINED_LWLOCKS in
MainLWLockArray so that if any extensions want to assign a LWLock
after startup, it can be used from this pool. The tranche for such locks
will be reported as main.
This is based on the suggestions by Robert in the mail:
http://www.postgresql.org/message-id/CA+TgmoashjaQeSK1bEm-GGc8OWFyLhvOrH=4KJfvKRFt9YkBWQ@mail.gmail.com
Thoughts?
Thanks.
However, RequestAddinLWLocks and LWLockAssign are used by extensions outside of the main tree, so I think it would be better to deprecate the methods for starters with a log statement.
NUM_USER_DEFINED_LWLOCKS aren't enough in many cases, so the existing functionality needs to be maintained during the deprecation period.
If extensions needs to upgrade to the new API I think LWLockAssign should be removed.
Let take the decision about old API's, once the new API's got reviewed.
We can either remove old API's or use log message to warn users or
mention them as deprecated in docs.
doc/src/sgml/xfunc.sgml needs an update on how the new API should be used.
Agreed, will do it in next version of patch.
On Thu, Dec 31, 2015 at 3:36 AM, Amit Kapila <amit.kapila16@gmail.com> wrote: > Going further on this work, I have written a patch for separating the > tranches for extensions. The basic idea is to expose two new API's, > first to request a new tranche and second to assign a lock from that > tranche. > RequestAddinLWLockTranche(const char *tranche_name, int num_lwlocks) > will be used by extensions to request a new tranche with specified number > of locks, this will be used instead of current API RequestAddinLWLocks(). I like this idea. > LWLock *LWLockAssignFromTranche(const char *tranche_name) will > assign a lock for the specified tranche. This also ensures that no > more than requested number of LWLocks can be assigned from a > specified tranche. However, this seems like an awkward API, because if there are many LWLocks you're going to need to look up the tranche name many times, and then you're going to need to make an array of pointers to them somehow, introducing a thoroughly unnecessary layer of indirection. Instead, I suggest just having a function LWLockPadded *GetLWLockAddinTranche(const char *tranche_name) that returns a pointer to the base of the array. > Also I have retained NUM_USER_DEFINED_LWLOCKS in > MainLWLockArray so that if any extensions want to assign a LWLock > after startup, it can be used from this pool. The tranche for such locks > will be reported as main. I don't like this. I think we should get rid of NUM_USER_DEFINED_LWLOCKS altogether. It's just an accident waiting to happen, and I don't think there are enough people using LWLocks from extensions that we'll annoy very many people by breaking backward compatibility here. If we are going to care about backward compatibility, then I think the old-style lwlocks should go in their own tranche, not main. But personally, I think it'd be better to just force a hard break and make people switch to using the new APIs. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On Mon, Jan 4, 2016 at 4:49 AM, Robert Haas <robertmhaas@gmail.com> wrote:
>
> On Thu, Dec 31, 2015 at 3:36 AM, Amit Kapila <amit.kapila16@gmail.com> wrote:
> > LWLock *LWLockAssignFromTranche(const char *tranche_name) will
> > assign a lock for the specified tranche. This also ensures that no
> > more than requested number of LWLocks can be assigned from a
> > specified tranche.
>
> However, this seems like an awkward API, because if there are many
> LWLocks you're going to need to look up the tranche name many times,
> and then you're going to need to make an array of pointers to them
> somehow, introducing a thoroughly unnecessary layer of indirection.
> Instead, I suggest just having a function LWLockPadded
> *GetLWLockAddinTranche(const char *tranche_name) that returns a
> pointer to the base of the array.
>
> > Also I have retained NUM_USER_DEFINED_LWLOCKS in
> > MainLWLockArray so that if any extensions want to assign a LWLock
> > after startup, it can be used from this pool. The tranche for such locks
> > will be reported as main.
>
> I don't like this. I think we should get rid of
> NUM_USER_DEFINED_LWLOCKS altogether. It's just an accident waiting to
> happen, and I don't think there are enough people using LWLocks from
> extensions that we'll annoy very many people by breaking backward
> compatibility here. If we are going to care about backward
> compatibility, then I think the old-style lwlocks should go in their
> own tranche, not main. But personally, I think it'd be better to just
> force a hard break and make people switch to using the new APIs.
>
>
> On Thu, Dec 31, 2015 at 3:36 AM, Amit Kapila <amit.kapila16@gmail.com> wrote:
> > LWLock *LWLockAssignFromTranche(const char *tranche_name) will
> > assign a lock for the specified tranche. This also ensures that no
> > more than requested number of LWLocks can be assigned from a
> > specified tranche.
>
> However, this seems like an awkward API, because if there are many
> LWLocks you're going to need to look up the tranche name many times,
> and then you're going to need to make an array of pointers to them
> somehow, introducing a thoroughly unnecessary layer of indirection.
> Instead, I suggest just having a function LWLockPadded
> *GetLWLockAddinTranche(const char *tranche_name) that returns a
> pointer to the base of the array.
>
If we do that way, then user of API needs to maintain the interlock
guarantee that the requested number of locks is same as allocations
done from that tranche and also if it is not allocating all the
LWLocks in one function, it needs to save the base address of the
array and then allocate from it by maintaining some counter.
I agree that looking up for tranche names multiple times is not good,
if there are many number of lwlocks, but that is done at startup
time and not at operation-level. Also if we look currently at
the extensions in contrib, then just one of them allocactes one
LWLock in this fashion, now there could be extnsions apart from
extensions in contrib, but not sure if they require many number of
LWLocks, so I feel it is better to give an API which is more
convinient for user to use.
> > Also I have retained NUM_USER_DEFINED_LWLOCKS in
> > MainLWLockArray so that if any extensions want to assign a LWLock
> > after startup, it can be used from this pool. The tranche for such locks
> > will be reported as main.
>
> I don't like this. I think we should get rid of
> NUM_USER_DEFINED_LWLOCKS altogether. It's just an accident waiting to
> happen, and I don't think there are enough people using LWLocks from
> extensions that we'll annoy very many people by breaking backward
> compatibility here. If we are going to care about backward
> compatibility, then I think the old-style lwlocks should go in their
> own tranche, not main. But personally, I think it'd be better to just
> force a hard break and make people switch to using the new APIs.
>
One point to think before removing it altogether, is that the new API's
provide a way to allocate LWLocks at the startup-time and if any user
wants to allocate a new LWLock after start-up, it will not be possible
with the proposed API's. Do you think for such cases, we should ask
user to use it the way we have exposed or do you have something else
in mind?
On Mon, Jan 4, 2016 at 1:20 AM, Amit Kapila <amit.kapila16@gmail.com> wrote: > On Mon, Jan 4, 2016 at 4:49 AM, Robert Haas <robertmhaas@gmail.com> wrote: >> On Thu, Dec 31, 2015 at 3:36 AM, Amit Kapila <amit.kapila16@gmail.com> >> wrote: >> > LWLock *LWLockAssignFromTranche(const char *tranche_name) will >> > assign a lock for the specified tranche. This also ensures that no >> > more than requested number of LWLocks can be assigned from a >> > specified tranche. >> >> However, this seems like an awkward API, because if there are many >> LWLocks you're going to need to look up the tranche name many times, >> and then you're going to need to make an array of pointers to them >> somehow, introducing a thoroughly unnecessary layer of indirection. >> Instead, I suggest just having a function LWLockPadded >> *GetLWLockAddinTranche(const char *tranche_name) that returns a >> pointer to the base of the array. > > If we do that way, then user of API needs to maintain the interlock > guarantee that the requested number of locks is same as allocations > done from that tranche and also if it is not allocating all the > LWLocks in one function, it needs to save the base address of the > array and then allocate from it by maintaining some counter. > I agree that looking up for tranche names multiple times is not good, > if there are many number of lwlocks, but that is done at startup > time and not at operation-level. Also if we look currently at > the extensions in contrib, then just one of them allocactes one > LWLock in this fashion, now there could be extnsions apart from > extensions in contrib, but not sure if they require many number of > LWLocks, so I feel it is better to give an API which is more > convinient for user to use. Well, I agree with you that we should provide the most convenient API possible, but I don't agree that yours is more convenient than the one I proposed. I think it is less convenient. In most cases, if the user asks for a large number of LWLocks, they aren't going to be each for a different purpose - they will all be for the same purpose, like one per buffer or one per hash partition. The case where the user wants to allocate 8 lwlocks from an extension, each for a different purpose, and spread those allocations across a bunch of different functions probably does not exist. *Maybe* there is somebody allocating lwlocks from an extension for unrelated purposes, but I'd be willing to bet that, if so, all of those allocations happen one right after the other in a single function, because anything else would be completely nuts. >> > Also I have retained NUM_USER_DEFINED_LWLOCKS in >> > MainLWLockArray so that if any extensions want to assign a LWLock >> > after startup, it can be used from this pool. The tranche for such >> > locks >> > will be reported as main. >> >> I don't like this. I think we should get rid of >> NUM_USER_DEFINED_LWLOCKS altogether. It's just an accident waiting to >> happen, and I don't think there are enough people using LWLocks from >> extensions that we'll annoy very many people by breaking backward >> compatibility here. If we are going to care about backward >> compatibility, then I think the old-style lwlocks should go in their >> own tranche, not main. But personally, I think it'd be better to just >> force a hard break and make people switch to using the new APIs. > > One point to think before removing it altogether, is that the new API's > provide a way to allocate LWLocks at the startup-time and if any user > wants to allocate a new LWLock after start-up, it will not be possible > with the proposed API's. Do you think for such cases, we should ask > user to use it the way we have exposed or do you have something else > in mind? Allocating a new lock after startup mostly doesn't work, because there will be at most 3 available and sometimes less. And even if it does work, it often isn't very useful because you probably need some other shared memory space as well - otherwise, what is the lock protecting? And that space might not be available either. I'd be interested in knowing whether there are cases where useful extensions can be loaded apart from shared_preload_libraries because of NUM_USER_DEFINED_LWLOCKS and our tendency to allocate a little bit of extra shared memory, but my suspicion is that it rarely works out and is too flaky to be useful to anybody. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On Mon, Jan 4, 2016 at 8:28 PM, Robert Haas <robertmhaas@gmail.com> wrote:
>
> On Mon, Jan 4, 2016 at 1:20 AM, Amit Kapila <amit.kapila16@gmail.com> wrote:
> > On Mon, Jan 4, 2016 at 4:49 AM, Robert Haas <robertmhaas@gmail.com> wrote:
> >> On Thu, Dec 31, 2015 at 3:36 AM, Amit Kapila <amit.kapila16@gmail.com>
> >> wrote:
> >> > LWLock *LWLockAssignFromTranche(const char *tranche_name) will
> >> > assign a lock for the specified tranche. This also ensures that no
> >> > more than requested number of LWLocks can be assigned from a
> >> > specified tranche.
> >>
> >> However, this seems like an awkward API, because if there are many
> >> LWLocks you're going to need to look up the tranche name many times,
> >> and then you're going to need to make an array of pointers to them
> >> somehow, introducing a thoroughly unnecessary layer of indirection.
> >> Instead, I suggest just having a function LWLockPadded
> >> *GetLWLockAddinTranche(const char *tranche_name) that returns a
> >> pointer to the base of the array.
> >
> > If we do that way, then user of API needs to maintain the interlock
> > guarantee that the requested number of locks is same as allocations
> > done from that tranche and also if it is not allocating all the
> > LWLocks in one function, it needs to save the base address of the
> > array and then allocate from it by maintaining some counter.
> > I agree that looking up for tranche names multiple times is not good,
> > if there are many number of lwlocks, but that is done at startup
> > time and not at operation-level. Also if we look currently at
> > the extensions in contrib, then just one of them allocactes one
> > LWLock in this fashion, now there could be extnsions apart from
> > extensions in contrib, but not sure if they require many number of
> > LWLocks, so I feel it is better to give an API which is more
> > convinient for user to use.
>
> Well, I agree with you that we should provide the most convenient API
> possible, but I don't agree that yours is more convenient than the one
> I proposed. I think it is less convenient. In most cases, if the
> user asks for a large number of LWLocks, they aren't going to be each
> for a different purpose - they will all be for the same purpose, like
> one per buffer or one per hash partition. The case where the user
> wants to allocate 8 lwlocks from an extension, each for a different
> purpose, and spread those allocations across a bunch of different
> functions probably does not exist.
Probably, but the point is to make user of API do what he or she wants
>
> *Maybe* there is somebody
> allocating lwlocks from an extension for unrelated purposes, but I'd
> be willing to bet that, if so, all of those allocations happen one
> right after the other in a single function, because anything else
> would be completely nuts.
>
> >> > Also I have retained NUM_USER_DEFINED_LWLOCKS in
> >> > MainLWLockArray so that if any extensions want to assign a LWLock
> >> > after startup, it can be used from this pool. The tranche for such
> >> > locks
> >> > will be reported as main.
> >>
>
> I'd be interested in knowing whether there are cases where useful
> extensions can be loaded apart from shared_preload_libraries because
> of NUM_USER_DEFINED_LWLOCKS and our tendency to allocate a little bit
> of extra shared memory, but my suspicion is that it rarely works out
> and is too flaky to be useful to anybody.
>
>
> On Mon, Jan 4, 2016 at 1:20 AM, Amit Kapila <amit.kapila16@gmail.com> wrote:
> > On Mon, Jan 4, 2016 at 4:49 AM, Robert Haas <robertmhaas@gmail.com> wrote:
> >> On Thu, Dec 31, 2015 at 3:36 AM, Amit Kapila <amit.kapila16@gmail.com>
> >> wrote:
> >> > LWLock *LWLockAssignFromTranche(const char *tranche_name) will
> >> > assign a lock for the specified tranche. This also ensures that no
> >> > more than requested number of LWLocks can be assigned from a
> >> > specified tranche.
> >>
> >> However, this seems like an awkward API, because if there are many
> >> LWLocks you're going to need to look up the tranche name many times,
> >> and then you're going to need to make an array of pointers to them
> >> somehow, introducing a thoroughly unnecessary layer of indirection.
> >> Instead, I suggest just having a function LWLockPadded
> >> *GetLWLockAddinTranche(const char *tranche_name) that returns a
> >> pointer to the base of the array.
> >
> > If we do that way, then user of API needs to maintain the interlock
> > guarantee that the requested number of locks is same as allocations
> > done from that tranche and also if it is not allocating all the
> > LWLocks in one function, it needs to save the base address of the
> > array and then allocate from it by maintaining some counter.
> > I agree that looking up for tranche names multiple times is not good,
> > if there are many number of lwlocks, but that is done at startup
> > time and not at operation-level. Also if we look currently at
> > the extensions in contrib, then just one of them allocactes one
> > LWLock in this fashion, now there could be extnsions apart from
> > extensions in contrib, but not sure if they require many number of
> > LWLocks, so I feel it is better to give an API which is more
> > convinient for user to use.
>
> Well, I agree with you that we should provide the most convenient API
> possible, but I don't agree that yours is more convenient than the one
> I proposed. I think it is less convenient. In most cases, if the
> user asks for a large number of LWLocks, they aren't going to be each
> for a different purpose - they will all be for the same purpose, like
> one per buffer or one per hash partition. The case where the user
> wants to allocate 8 lwlocks from an extension, each for a different
> purpose, and spread those allocations across a bunch of different
> functions probably does not exist.
Probably, but the point is to make user of API do what he or she wants
to accomplish without much knowledge of underlying stuff. However,
I think it is not too much details for user to know, so I have changed the
API as per your suggestion.
>
> *Maybe* there is somebody
> allocating lwlocks from an extension for unrelated purposes, but I'd
> be willing to bet that, if so, all of those allocations happen one
> right after the other in a single function, because anything else
> would be completely nuts.
>
> >> > Also I have retained NUM_USER_DEFINED_LWLOCKS in
> >> > MainLWLockArray so that if any extensions want to assign a LWLock
> >> > after startup, it can be used from this pool. The tranche for such
> >> > locks
> >> > will be reported as main.
> >>
>
> I'd be interested in knowing whether there are cases where useful
> extensions can be loaded apart from shared_preload_libraries because
> of NUM_USER_DEFINED_LWLOCKS and our tendency to allocate a little bit
> of extra shared memory, but my suspicion is that it rarely works out
> and is too flaky to be useful to anybody.
>
I am not aware of such cases, however the reason I have kept it was for
backward-compatability, but now I have removed it in the attached patch.
Apart from that, I have updated the docs to reflect the changes related
to new API's.
Fe things to Note -
Some change is needed in LWLockCounter[1] if this goes after 2
other patches (separate tranche for PGProcs and separate tranche
for ReplicationSlots). Also, LWLockAssign() can be removed after
those patches
Attachment
On 01/05/2016 08:04 AM, Amit Kapila wrote:
> I am not aware of such cases, however the reason I have kept it was for
> backward-compatability, but now I have removed it in the attached patch.
>
> Apart from that, I have updated the docs to reflect the changes related
> to new API's.
>
xfunc.sgml:
+ after allocating LWLocks, verify that the number of
allocated
+ LWLocks is same as requested;
Did you mean to put this check in ?
lwlock.c:
+ * GetLWLockAddinTranche - returns the base address of LWLock from the
+ * specified tranche.
+ *
+ * Caller needs to retrieve the requested number of LWLocks starting from
+ * the base lock address returned by this API. This can be used for
+ * tranches that are requested by using RequestAddinLWLockTranche() API.
+ */
+LWLockPadded *
+GetLWLockAddinTranche(const char *tranche_name)
+{
I understand why the signature is the way it is, but
LWLock *
GetLWLockAddinTranche(const char *tranche_name)
would be nicer to work with for extensions IMHO. Not likely worth the
trouble though.
Thanks for working on this.
Best regards, Jesper
On Tue, Jan 5, 2016 at 8:54 AM, Jesper Pedersen <jesper.pedersen@redhat.com> wrote: > LWLock * > GetLWLockAddinTranche(const char *tranche_name) > > would be nicer to work with for extensions IMHO. Not likely worth the > trouble though. That change would be easy to make, but would tend to make performance worse for anyone who uses more than 1 lock. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On Sun, Dec 13, 2015 at 12:35:34PM +0100, Andres Freund wrote: > > > One thing to call out is that an "oversized" s_lock can now make > > > BufferDesc exceed 64 bytes, right now that's just the case when it's > > > larger than 4 bytes. I'm not sure if that's cause for real concern, > > > given that it's not very concurrent or ancient platforms where that's > > > the case. > > > http://archives.postgresql.org/message-id/20150915020625.GI9666%40alap3.anarazel.de > > > would alleviate that concern again, as it collapses flags, usage_count, > > > buf_hdr_lock and refcount into one 32 bit int... > > > > I don't think that would be worth worrying about even if we didn't > > have a plan in mind that would make it go away again, and even less so > > given that we do have such a plan. > > Ok cool. I'm not particularly concerned either, just didn't want to slip > that in without having it called out. Uh, didn't you and I work in 9.5 to make sure the BufferDesc was 64-byte aligned to avoid double-CPU cache invalidation that was causing performance problems on a server you were testing? -- Bruce Momjian <bruce@momjian.us> http://momjian.us EnterpriseDB http://enterprisedb.com + As you are, so once was I. As I am, so you will be. + + Roman grave inscription +
On 2016-01-05 10:28:25 -0500, Bruce Momjian wrote: > On Sun, Dec 13, 2015 at 12:35:34PM +0100, Andres Freund wrote: > > > > One thing to call out is that an "oversized" s_lock can now make > > > > BufferDesc exceed 64 bytes, right now that's just the case when it's > > > > larger than 4 bytes. I'm not sure if that's cause for real concern, > > > > given that it's not very concurrent or ancient platforms where that's > > > > the case. > > > > http://archives.postgresql.org/message-id/20150915020625.GI9666%40alap3.anarazel.de > > > > would alleviate that concern again, as it collapses flags, usage_count, > > > > buf_hdr_lock and refcount into one 32 bit int... > > > > > > I don't think that would be worth worrying about even if we didn't > > > have a plan in mind that would make it go away again, and even less so > > > given that we do have such a plan. > > > > Ok cool. I'm not particularly concerned either, just didn't want to slip > > that in without having it called out. > > Uh, didn't you and I work in 9.5 to make sure the BufferDesc was 64-byte > aligned to avoid double-CPU cache invalidation that was causing > performance problems on a server you were testing? Yes? But it's ok sizewise on the common platforms? Andres
On Tue, Jan 5, 2016 at 04:31:15PM +0100, Andres Freund wrote: > On 2016-01-05 10:28:25 -0500, Bruce Momjian wrote: > > On Sun, Dec 13, 2015 at 12:35:34PM +0100, Andres Freund wrote: > > > > > One thing to call out is that an "oversized" s_lock can now make > > > > > BufferDesc exceed 64 bytes, right now that's just the case when it's > > > > > larger than 4 bytes. I'm not sure if that's cause for real concern, > > > > > given that it's not very concurrent or ancient platforms where that's > > > > > the case. > > > > > http://archives.postgresql.org/message-id/20150915020625.GI9666%40alap3.anarazel.de > > > > > would alleviate that concern again, as it collapses flags, usage_count, > > > > > buf_hdr_lock and refcount into one 32 bit int... > > > > > > > > I don't think that would be worth worrying about even if we didn't > > > > have a plan in mind that would make it go away again, and even less so > > > > given that we do have such a plan. > > > > > > Ok cool. I'm not particularly concerned either, just didn't want to slip > > > that in without having it called out. > > > > Uh, didn't you and I work in 9.5 to make sure the BufferDesc was 64-byte > > aligned to avoid double-CPU cache invalidation that was causing > > performance problems on a server you were testing? > > Yes? But it's ok sizewise on the common platforms? What is the uncommon part? I guess I missed that. -- Bruce Momjian <bruce@momjian.us> http://momjian.us EnterpriseDB http://enterprisedb.com + As you are, so once was I. As I am, so you will be. + + Roman grave inscription +
On 2016-01-05 10:40:13 -0500, Bruce Momjian wrote: > On Tue, Jan 5, 2016 at 04:31:15PM +0100, Andres Freund wrote: > > On 2016-01-05 10:28:25 -0500, Bruce Momjian wrote: > > Yes? But it's ok sizewise on the common platforms? > > What is the uncommon part? I guess I missed that. http://archives.postgresql.org/message-id/20151212181702.GH17938%40alap3.anarazel.de
On Tue, Jan 5, 2016 at 04:42:24PM +0100, Andres Freund wrote: > On 2016-01-05 10:40:13 -0500, Bruce Momjian wrote: > > On Tue, Jan 5, 2016 at 04:31:15PM +0100, Andres Freund wrote: > > > On 2016-01-05 10:28:25 -0500, Bruce Momjian wrote: > > > Yes? But it's ok sizewise on the common platforms? > > > > What is the uncommon part? I guess I missed that. > > http://archives.postgresql.org/message-id/20151212181702.GH17938%40alap3.anarazel.de Yes, I saw that, and the URL in the email, but what is the uncommon case? -- Bruce Momjian <bruce@momjian.us> http://momjian.us EnterpriseDB http://enterprisedb.com + As you are, so once was I. As I am, so you will be. + + Roman grave inscription +
On 2016-01-05 10:48:43 -0500, Bruce Momjian wrote: > On Tue, Jan 5, 2016 at 04:42:24PM +0100, Andres Freund wrote: > > On 2016-01-05 10:40:13 -0500, Bruce Momjian wrote: > > > On Tue, Jan 5, 2016 at 04:31:15PM +0100, Andres Freund wrote: > > > > On 2016-01-05 10:28:25 -0500, Bruce Momjian wrote: > > > > Yes? But it's ok sizewise on the common platforms? > > > > > > What is the uncommon part? I guess I missed that. > > > > http://archives.postgresql.org/message-id/20151212181702.GH17938%40alap3.anarazel.de > > Yes, I saw that, and the URL in the email, but what is the uncommon > case? Are you asking which platforms s_lock is larger than a char? If so, grep s_lock.h for typedefs. If not, I'm not following what you're asking for?
On Tue, Jan 5, 2016 at 04:53:26PM +0100, Andres Freund wrote: > On 2016-01-05 10:48:43 -0500, Bruce Momjian wrote: > > On Tue, Jan 5, 2016 at 04:42:24PM +0100, Andres Freund wrote: > > > On 2016-01-05 10:40:13 -0500, Bruce Momjian wrote: > > > > On Tue, Jan 5, 2016 at 04:31:15PM +0100, Andres Freund wrote: > > > > > On 2016-01-05 10:28:25 -0500, Bruce Momjian wrote: > > > > > Yes? But it's ok sizewise on the common platforms? > > > > > > > > What is the uncommon part? I guess I missed that. > > > > > > http://archives.postgresql.org/message-id/20151212181702.GH17938%40alap3.anarazel.de > > > > Yes, I saw that, and the URL in the email, but what is the uncommon > > case? > > Are you asking which platforms s_lock is larger than a char? If so, grep > s_lock.h for typedefs. If not, I'm not following what you're asking for? Yes, that is the information I was looing for. I see s_lock defined as int-sized on Itanium, ARM, PowerPC, MIPS, m32r, PA-RISC, Windows, Sunstudio. -- Bruce Momjian <bruce@momjian.us> http://momjian.us EnterpriseDB http://enterprisedb.com + As you are, so once was I. As I am, so you will be. + + Roman grave inscription +
On Tue, Jan 5, 2016 at 7:24 PM, Jesper Pedersen <jesper.pedersen@redhat.com> wrote:
>
> On 01/05/2016 08:04 AM, Amit Kapila wrote:
>>
>> I am not aware of such cases, however the reason I have kept it was for
>> backward-compatability, but now I have removed it in the attached patch.
>>
>> Apart from that, I have updated the docs to reflect the changes related
>> to new API's.
>>
>
> xfunc.sgml:
>
> + after allocating LWLocks, verify that the number of allocated
> + LWLocks is same as requested;
>
> Did you mean to put this check in ?
>
>
> On 01/05/2016 08:04 AM, Amit Kapila wrote:
>>
>> I am not aware of such cases, however the reason I have kept it was for
>> backward-compatability, but now I have removed it in the attached patch.
>>
>> Apart from that, I have updated the docs to reflect the changes related
>> to new API's.
>>
>
> xfunc.sgml:
>
> + after allocating LWLocks, verify that the number of allocated
> + LWLocks is same as requested;
>
> Did you mean to put this check in ?
>
Yes, it is good to check, right now I have added Assert in code as
I think it is a dev problem to over-allocate the lwlocks.
On Mon, Dec 28, 2015 at 4:47 PM, Amit Kapila <amit.kapila16@gmail.com> wrote:
On Thu, Dec 24, 2015 at 5:50 PM, Ildus Kurbangaliev <i.kurbangaliev@postgrespro.ru> wrote:
> >
>
> There is a patch that moves backend LWLocks into PGPROC and to a
> separate tranche.>1.@@ -437,6 +440,13 @@ InitProcessPhase2(void){Assert(MyProc != NULL);+ /* Register and initialize fields of ProcLWLockTranche */+ ProcLWLockTranche.name = "proc";+ ProcLWLockTranche.array_base = (char *) (ProcGlobal->allProcs) ++ offsetof(PGPROC, backendLock);+ ProcLWLockTranche.array_stride = sizeof(PGPROC);+ LWLockRegisterTranche(LWTRANCHE_PROC, &ProcLWLockTranche);+I think this will not work for Auxilary processes as they won'tcall InitProcessPhase2(). It is better to initialize it inInitProcGlobal() and then propagate it to backends for EXEC_BACKENDcases as we do for ProcStructLock, AuxiliaryProcs.
That idea won't work as we need to separately register tranche for
each process. The other wayout could be to do it in CreateSharedProcArray()
which will be quite similar to what we do for other tranches and
it will cover all kind of processes. Attached patch fixes this problem.
I have considered to separately do it in InitProcessPhase2() and
InitAuxiliaryProcess(), but then the registration will be done twice for some
of the processes like bootstrap and same is true if we do this InitProcess()
instead of InitProcessPhase2() and I think it won't be similar to what
we do for other tranches.
I have done the performance testing of the attached patch and the
results are attached with this mail. The main tests conducted are
pgbench read-write and read-only tests and the results indicate that
this patch doesn't introduce any regression, though you will see some
cases where the performance is better with patch by ~5% and then
regressed by 2~3%, but I think it is more of a noise, then anything
else.
Attachment
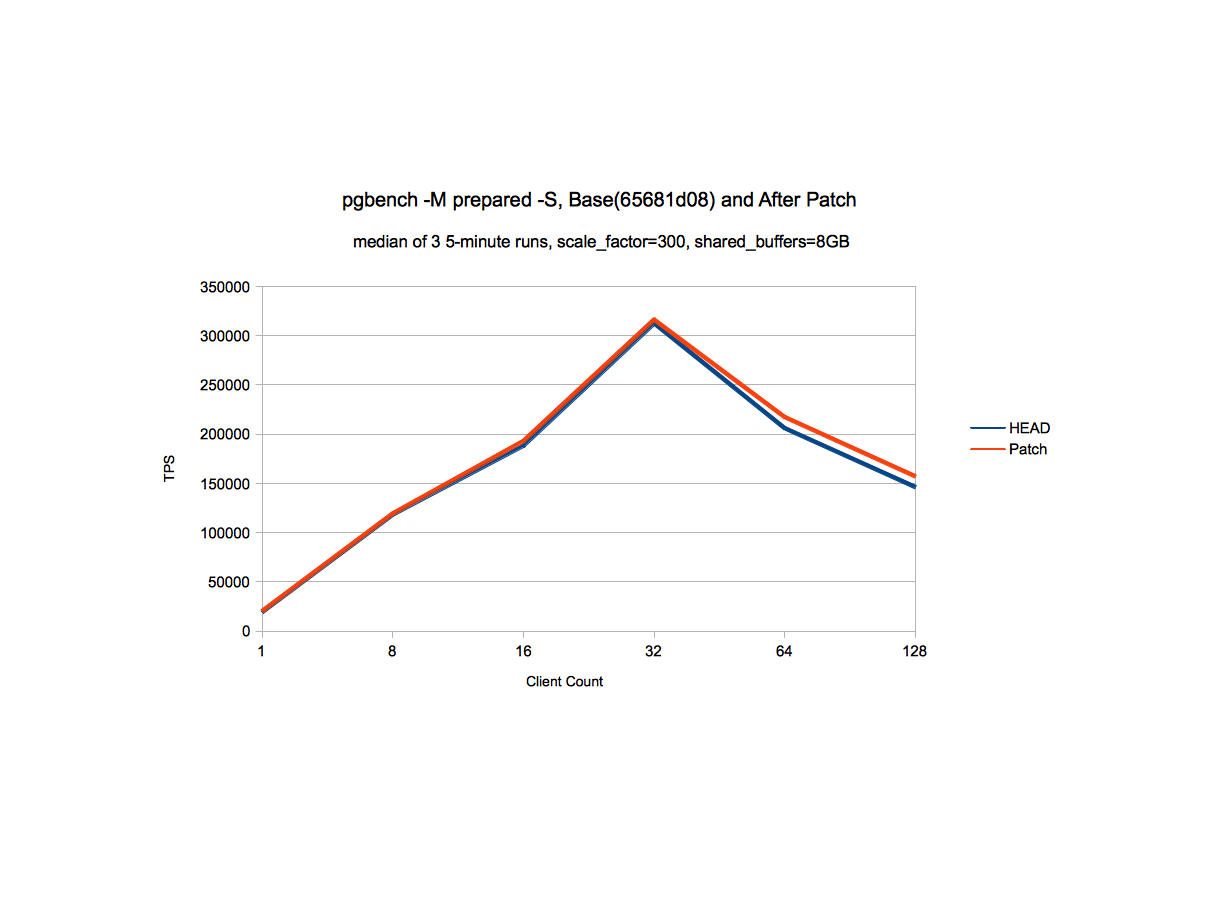{kind=link}
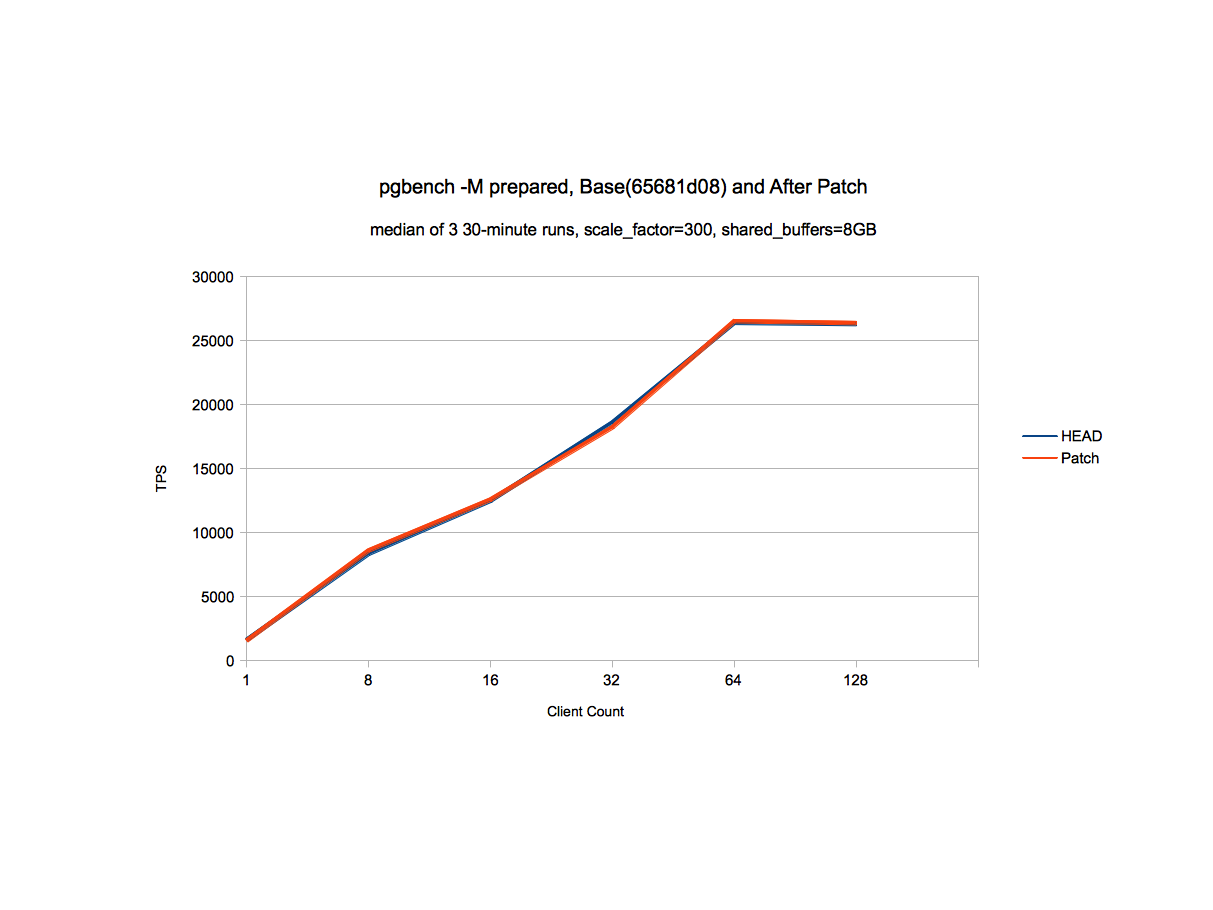{kind=link}
So far as I can tell, there are three patches in flight here: * replication slot IO lwlocks * ability of extensions to request tranches dynamically * PGPROC The first one hasn't been reviewed at all, but the other two have seen a bit of discussion and evolution. Is anyone doing any more reviewing? -- Álvaro Herrera http://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On Thu, Jan 21, 2016 at 3:07 AM, Alvaro Herrera <alvherre@2ndquadrant.com> wrote:
>
> So far as I can tell, there are three patches in flight here:
>
>
> So far as I can tell, there are three patches in flight here:
>
Yes, thats right.
> * replication slot IO lwlocks
> * ability of extensions to request tranches dynamically
> * PGPROC
>
> The first one hasn't been reviewed at all, but the other two have seen a
> bit of discussion and evolution.
>
The last one "PGProc" has been reviewed and all the reported problems
have been fixed. It is "Ready For Committer".
On Thu, Jan 21, 2016 at 12:37 AM, Alvaro Herrera <alvherre@2ndquadrant.com> wrote:
So far as I can tell, there are three patches in flight here:
* replication slot IO lwlocks
* ability of extensions to request tranches dynamically
* PGPROC
The first one hasn't been reviewed at all, but the other two have seen a
bit of discussion and evolution. Is anyone doing any more reviewing?
I'd like to add another one: fixed tranche id for each SLRU.
And I'm going to make review over others.
Alexander Korotkov
Postgres Professional: http://www.postgrespro.com
The Russian Postgres Company
Attachment
On Mon, Jan 4, 2016 at 5:58 PM, Robert Haas <robertmhaas@gmail.com> wrote:
Well, I agree with you that we should provide the most convenient APIOn Mon, Jan 4, 2016 at 1:20 AM, Amit Kapila <amit.kapila16@gmail.com> wrote:
> If we do that way, then user of API needs to maintain the interlock
> guarantee that the requested number of locks is same as allocations
> done from that tranche and also if it is not allocating all the
> LWLocks in one function, it needs to save the base address of the
> array and then allocate from it by maintaining some counter.
> I agree that looking up for tranche names multiple times is not good,
> if there are many number of lwlocks, but that is done at startup
> time and not at operation-level. Also if we look currently at
> the extensions in contrib, then just one of them allocactes one
> LWLock in this fashion, now there could be extnsions apart from
> extensions in contrib, but not sure if they require many number of
> LWLocks, so I feel it is better to give an API which is more
> convinient for user to use.
possible, but I don't agree that yours is more convenient than the one
I proposed. I think it is less convenient. In most cases, if the
user asks for a large number of LWLocks, they aren't going to be each
for a different purpose - they will all be for the same purpose, like
one per buffer or one per hash partition. The case where the user
wants to allocate 8 lwlocks from an extension, each for a different
purpose, and spread those allocations across a bunch of different
functions probably does not exist. *Maybe* there is somebody
allocating lwlocks from an extension for unrelated purposes, but I'd
be willing to bet that, if so, all of those allocations happen one
right after the other in a single function, because anything else
would be completely nuts.
I'm not sure if we should return LWLockPadded*.
+LWLockPadded *
+GetLWLockAddinTranche(const char *tranche_name)
It would be nice to isolate extension from knowledge about padding. Could we one day change it from LWLockPadded * to LWLockMinimallyPadded * or any?
+LWLock **
+GetLWLockAddinTranche(const char *tranche_name)
Could we use this signature?
>> > Also I have retained NUM_USER_DEFINED_LWLOCKS in
>> > MainLWLockArray so that if any extensions want to assign a LWLock
>> > after startup, it can be used from this pool. The tranche for such
>> > locks
>> > will be reported as main.
>>
>> I don't like this. I think we should get rid of
>> NUM_USER_DEFINED_LWLOCKS altogether. It's just an accident waiting to
>> happen, and I don't think there are enough people using LWLocks from
>> extensions that we'll annoy very many people by breaking backward
>> compatibility here. If we are going to care about backward
>> compatibility, then I think the old-style lwlocks should go in their
>> own tranche, not main. But personally, I think it'd be better to just
>> force a hard break and make people switch to using the new APIs.
>
> One point to think before removing it altogether, is that the new API's
> provide a way to allocate LWLocks at the startup-time and if any user
> wants to allocate a new LWLock after start-up, it will not be possible
> with the proposed API's. Do you think for such cases, we should ask
> user to use it the way we have exposed or do you have something else
> in mind?
Allocating a new lock after startup mostly doesn't work, because there
will be at most 3 available and sometimes less. And even if it does
work, it often isn't very useful because you probably need some other
shared memory space as well - otherwise, what is the lock protecting?
And that space might not be available either.
I'd be interested in knowing whether there are cases where useful
extensions can be loaded apart from shared_preload_libraries because
of NUM_USER_DEFINED_LWLOCKS and our tendency to allocate a little bit
of extra shared memory, but my suspicion is that it rarely works out
and is too flaky to be useful to anybody.
+1 for dropping old API
I don't think it's useful to have LWLocks without having shared memory.
There is another thing I'd like extensions to be able to do. It would be nice if extensions could use dynamic shared memory instead of static. Then extensions could use shared memory without being in shared_preload_libraries. But if extension register DSM, then there is no way to tell other backends to use it for that extension. Also DSM would be deallocated when all backends detached from it. This it out of scope for this patch though.
------
Alexander Korotkov
Postgres Professional: http://www.postgrespro.com
The Russian Postgres Company
Alexander Korotkov
Postgres Professional: http://www.postgrespro.com
The Russian Postgres Company
On Fri, Jan 8, 2016 at 11:22 PM, Amit Kapila <amit.kapila16@gmail.com> wrote: > That idea won't work as we need to separately register tranche for > each process. The other wayout could be to do it in CreateSharedProcArray() > which will be quite similar to what we do for other tranches and > it will cover all kind of processes. Attached patch fixes this problem. > > I have considered to separately do it in InitProcessPhase2() and > InitAuxiliaryProcess(), but then the registration will be done twice for > some > of the processes like bootstrap and same is true if we do this InitProcess() > instead of InitProcessPhase2() and I think it won't be similar to what > we do for other tranches. > > I have done the performance testing of the attached patch and the > results are attached with this mail. The main tests conducted are > pgbench read-write and read-only tests and the results indicate that > this patch doesn't introduce any regression, though you will see some > cases where the performance is better with patch by ~5% and then > regressed by 2~3%, but I think it is more of a noise, then anything > else. Committed. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On Fri, Jan 29, 2016 at 6:59 AM, Alexander Korotkov <a.korotkov@postgrespro.ru> wrote: > On Thu, Jan 21, 2016 at 12:37 AM, Alvaro Herrera <alvherre@2ndquadrant.com> > wrote: >> So far as I can tell, there are three patches in flight here: >> >> * replication slot IO lwlocks >> * ability of extensions to request tranches dynamically >> * PGPROC >> >> The first one hasn't been reviewed at all, but the other two have seen a >> bit of discussion and evolution. Is anyone doing any more reviewing? > > I'd like to add another one: fixed tranche id for each SLRU. +1 for this. The patch looks good and I will commit it if nobody objects. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On Tue, Jan 5, 2016 at 4:04 PM, Amit Kapila <amit.kapila16@gmail.com> wrote:
Probably, but the point is to make user of API do what he or she wantsOn Mon, Jan 4, 2016 at 8:28 PM, Robert Haas <robertmhaas@gmail.com> wrote:
>
> On Mon, Jan 4, 2016 at 1:20 AM, Amit Kapila <amit.kapila16@gmail.com> wrote:
> > On Mon, Jan 4, 2016 at 4:49 AM, Robert Haas <robertmhaas@gmail.com> wrote:
> >> On Thu, Dec 31, 2015 at 3:36 AM, Amit Kapila <amit.kapila16@gmail.com>
> >> wrote:
> >> > LWLock *LWLockAssignFromTranche(const char *tranche_name) will
> >> > assign a lock for the specified tranche. This also ensures that no
> >> > more than requested number of LWLocks can be assigned from a
> >> > specified tranche.
> >>
> >> However, this seems like an awkward API, because if there are many
> >> LWLocks you're going to need to look up the tranche name many times,
> >> and then you're going to need to make an array of pointers to them
> >> somehow, introducing a thoroughly unnecessary layer of indirection.
> >> Instead, I suggest just having a function LWLockPadded
> >> *GetLWLockAddinTranche(const char *tranche_name) that returns a
> >> pointer to the base of the array.
> >
> > If we do that way, then user of API needs to maintain the interlock
> > guarantee that the requested number of locks is same as allocations
> > done from that tranche and also if it is not allocating all the
> > LWLocks in one function, it needs to save the base address of the
> > array and then allocate from it by maintaining some counter.
> > I agree that looking up for tranche names multiple times is not good,
> > if there are many number of lwlocks, but that is done at startup
> > time and not at operation-level. Also if we look currently at
> > the extensions in contrib, then just one of them allocactes one
> > LWLock in this fashion, now there could be extnsions apart from
> > extensions in contrib, but not sure if they require many number of
> > LWLocks, so I feel it is better to give an API which is more
> > convinient for user to use.
>
> Well, I agree with you that we should provide the most convenient API
> possible, but I don't agree that yours is more convenient than the one
> I proposed. I think it is less convenient. In most cases, if the
> user asks for a large number of LWLocks, they aren't going to be each
> for a different purpose - they will all be for the same purpose, like
> one per buffer or one per hash partition. The case where the user
> wants to allocate 8 lwlocks from an extension, each for a different
> purpose, and spread those allocations across a bunch of different
> functions probably does not exist.to accomplish without much knowledge of underlying stuff. However,I think it is not too much details for user to know, so I have changed theAPI as per your suggestion.
>
> *Maybe* there is somebody
> allocating lwlocks from an extension for unrelated purposes, but I'd
> be willing to bet that, if so, all of those allocations happen one
> right after the other in a single function, because anything else
> would be completely nuts.
>
> >> > Also I have retained NUM_USER_DEFINED_LWLOCKS in
> >> > MainLWLockArray so that if any extensions want to assign a LWLock
> >> > after startup, it can be used from this pool. The tranche for such
> >> > locks
> >> > will be reported as main.
> >>
>
> I'd be interested in knowing whether there are cases where useful
> extensions can be loaded apart from shared_preload_libraries because
> of NUM_USER_DEFINED_LWLOCKS and our tendency to allocate a little bit
> of extra shared memory, but my suspicion is that it rarely works out
> and is too flaky to be useful to anybody.
>I am not aware of such cases, however the reason I have kept it was forbackward-compatability, but now I have removed it in the attached patch.Apart from that, I have updated the docs to reflect the changes relatedto new API's.Fe things to Note -Some change is needed in LWLockCounter[1] if this goes after 2other patches (separate tranche for PGProcs and separate tranchefor ReplicationSlots). Also, LWLockAssign() can be removed afterthose patches
Also couple of minor comments from me.
I think this
+ StrNCpy(LWLockTrancheRequestArray[LWLockTrancheRequestsCount].tranche_name, tranche_name, strlen(tranche_name) + 1);
should be
+ StrNCpy(LWLockTrancheRequestArray[LWLockTrancheRequestsCount].tranche_name, tranche_name, sizeof(LWLockTrancheRequestArray[LWLockTrancheRequestsCount].tranche_name));
And as far as I know english "it's" should be "its" in the sentence below.
+ from <function>_PG_init</>. Tranche repersents an array of LWLocks and
+ can be accessed by it's name. First parameter <literal>tranche_name</>
Alexander Korotkov
Postgres Professional: http://www.postgrespro.com
The Russian Postgres Company
On Tue, Dec 29, 2015 at 11:56 AM, Amit Kapila <amit.kapila16@gmail.com> wrote:
On Wed, Dec 16, 2015 at 12:26 AM, Robert Haas <robertmhaas@gmail.com> wrote:
>
>
> In terms of this project overall, NumLWLocks() now knows about only
> four categories of stuff: fixed lwlocks, backend locks (proc.c),
> replication slot locks, and locks needed by extensions. I think it'd
> probably be fine to move the backend locks into PGPROC directly, and
> the replication slot locks into ReplicationSlot.>IIdus has written a patch to move backend locks into PGPROC whichI am reviewing and will do performance tests once he responds tomy review comments and I have written a patch to move replicationslot locks into ReplicationSlot which is attached with this mail.
This patch looks good for me.
It compiles without warnings, passes regression tests.
I also did small testing of replication slots in order to check that it works correctly.
Alexander Korotkov
Postgres Professional: http://www.postgrespro.com
The Russian Postgres Company
On Fri, Jan 29, 2016 at 6:21 PM, Alexander Korotkov <a.korotkov@postgrespro.ru> wrote:
On Mon, Jan 4, 2016 at 5:58 PM, Robert Haas <robertmhaas@gmail.com> wrote:On Mon, Jan 4, 2016 at 1:20 AM, Amit Kapila <amit.kapila16@gmail.com> wrote:> If we do that way, then user of API needs to maintain the interlock
> guarantee that the requested number of locks is same as allocations
> done from that tranche and also if it is not allocating all the
> LWLocks in one function, it needs to save the base address of the
> array and then allocate from it by maintaining some counter.
> I agree that looking up for tranche names multiple times is not good,
> if there are many number of lwlocks, but that is done at startup
> time and not at operation-level. Also if we look currently at
> the extensions in contrib, then just one of them allocactes one
> LWLock in this fashion, now there could be extnsions apart from
> extensions in contrib, but not sure if they require many number of
> LWLocks, so I feel it is better to give an API which is more
> convinient for user to use.Well, I agree with you that we should provide the most convenient API
possible, but I don't agree that yours is more convenient than the one
I proposed. I think it is less convenient. In most cases, if the
user asks for a large number of LWLocks, they aren't going to be each
for a different purpose - they will all be for the same purpose, like
one per buffer or one per hash partition. The case where the user
wants to allocate 8 lwlocks from an extension, each for a different
purpose, and spread those allocations across a bunch of different
functions probably does not exist. *Maybe* there is somebody
allocating lwlocks from an extension for unrelated purposes, but I'd
be willing to bet that, if so, all of those allocations happen one
right after the other in a single function, because anything else
would be completely nuts.I'm not sure if we should return LWLockPadded*.+LWLockPadded *
+GetLWLockAddinTranche(const char *tranche_name)It would be nice to isolate extension from knowledge about padding. Could we one day change it from LWLockPadded * to LWLockMinimallyPadded * or any?
Valid point, but I think there is an advantage of exposing padded
structure as well which is that if extension owner wants
LWLockPadded for some performance reason or otherwise (like
currently SlruSharedData is using), it can use this API as it is.
+LWLock **
+GetLWLockAddinTranche(const char *tranche_name)Could we use this signature?
I think we can do this way as well. There is some discussion
upthread [1] about the signature of API where the current API has
been thought of as a better API.
I think we can expose it in many ways like the v1 version of patch or
the way it has been discussed and done in latest patch or in the
way you are suggesting and each has its pros and cons. It seems
to me we should leave this point at committers discretion unless,
there is clear win for any kind of API or more people are in favour of one
kind of signature over other.
With Regards,
Amit Kapila.
EnterpriseDB: http://www.enterprisedb.com
On Fri, Jan 29, 2016 at 6:55 PM, Alexander Korotkov <a.korotkov@postgrespro.ru> wrote:
Also couple of minor comments from me.I think this+ StrNCpy(LWLockTrancheRequestArray[LWLockTrancheRequestsCount].tranche_name, tranche_name, strlen(tranche_name) + 1);should be+ StrNCpy(LWLockTrancheRequestArray[LWLockTrancheRequestsCount].tranche_name, tranche_name, sizeof(LWLockTrancheRequestArray[LWLockTrancheRequestsCount].tranche_name));
I think you are right, otherwise it might try to copy more, how
about
StrNCpy(LWLockTrancheRequestArray[LWLockTrancheRequestsCount].tranche_name, tranche_name, Min (strlen(tranche_name) + 1, sizeof(LWLockTrancheRequestArray[LWLockTrancheRequestsCount].tranche_name)));
And as far as I know english "it's" should be "its" in the sentence below.+ from <function>_PG_init</>. Tranche repersents an array of LWLocks and
+ can be accessed by it's name. First parameter <literal>tranche_name</>
Right, will change.
On Fri, Jan 29, 2016 at 6:47 PM, Robert Haas <robertmhaas@gmail.com> wrote:
>
> On Fri, Jan 29, 2016 at 6:59 AM, Alexander Korotkov
> <a.korotkov@postgrespro.ru> wrote:
> > On Thu, Jan 21, 2016 at 12:37 AM, Alvaro Herrera <alvherre@2ndquadrant.com>
> > wrote:
> >> So far as I can tell, there are three patches in flight here:
> >>
> >> * replication slot IO lwlocks
> >> * ability of extensions to request tranches dynamically
> >> * PGPROC
> >>
> >> The first one hasn't been reviewed at all, but the other two have seen a
> >> bit of discussion and evolution. Is anyone doing any more reviewing?
> >
> > I'd like to add another one: fixed tranche id for each SLRU.
>
> +1 for this. The patch looks good and I will commit it if nobody objects.
>
>
> On Fri, Jan 29, 2016 at 6:59 AM, Alexander Korotkov
> <a.korotkov@postgrespro.ru> wrote:
> > On Thu, Jan 21, 2016 at 12:37 AM, Alvaro Herrera <alvherre@2ndquadrant.com>
> > wrote:
> >> So far as I can tell, there are three patches in flight here:
> >>
> >> * replication slot IO lwlocks
> >> * ability of extensions to request tranches dynamically
> >> * PGPROC
> >>
> >> The first one hasn't been reviewed at all, but the other two have seen a
> >> bit of discussion and evolution. Is anyone doing any more reviewing?
> >
> > I'd like to add another one: fixed tranche id for each SLRU.
>
> +1 for this. The patch looks good and I will commit it if nobody objects.
>
+1. Patch looks good to me as well, but I have one related question:
Is there a reason why we should not assign ReplicationOrigins a
fixed tranche id and then we might want to even get away with
LWLockRegisterTranche()?
On Sat, Jan 30, 2016 at 10:58 AM, Amit Kapila <amit.kapila16@gmail.com> wrote:
On Fri, Jan 29, 2016 at 6:47 PM, Robert Haas <robertmhaas@gmail.com> wrote:
>
> On Fri, Jan 29, 2016 at 6:59 AM, Alexander Korotkov
> <a.korotkov@postgrespro.ru> wrote:
> > On Thu, Jan 21, 2016 at 12:37 AM, Alvaro Herrera <alvherre@2ndquadrant.com>
> > wrote:
> >> So far as I can tell, there are three patches in flight here:
> >>
> >> * replication slot IO lwlocks
> >> * ability of extensions to request tranches dynamically
> >> * PGPROC
> >>
> >> The first one hasn't been reviewed at all, but the other two have seen a
> >> bit of discussion and evolution. Is anyone doing any more reviewing?
> >
> > I'd like to add another one: fixed tranche id for each SLRU.
>
> +1 for this. The patch looks good and I will commit it if nobody objects.
>+1. Patch looks good to me as well, but I have one related question:Is there a reason why we should not assign ReplicationOrigins afixed tranche id and then we might want to even get away withLWLockRegisterTranche()?
+1. I think we should do this.
------
Alexander Korotkov
Postgres Professional: http://www.postgrespro.com
The Russian Postgres Company
Alexander Korotkov
Postgres Professional: http://www.postgrespro.com
The Russian Postgres Company
On Sat, Jan 30, 2016 at 12:23 PM, Amit Kapila <amit.kapila16@gmail.com> wrote:
On Fri, Jan 29, 2016 at 6:55 PM, Alexander Korotkov <a.korotkov@postgrespro.ru> wrote:Also couple of minor comments from me.I think this+ StrNCpy(LWLockTrancheRequestArray[LWLockTrancheRequestsCount].tranche_name, tranche_name, strlen(tranche_name) + 1);should be+ StrNCpy(LWLockTrancheRequestArray[LWLockTrancheRequestsCount].tranche_name, tranche_name, sizeof(LWLockTrancheRequestArray[LWLockTrancheRequestsCount].tranche_name));I think you are right, otherwise it might try to copy more, howaboutStrNCpy(LWLockTrancheRequestArray[LWLockTrancheRequestsCount].tranche_name, tranche_name, Min (strlen(tranche_name) + 1, sizeof(LWLockTrancheRequestArray[LWLockTrancheRequestsCount].tranche_name)));
Changed as per your suggestion, rather than using Min,
because I saw most code places uses directly sizeof for
StrNCpy(), so lets be consistent.
And as far as I know english "it's" should be "its" in the sentence below.+ from <function>_PG_init</>. Tranche repersents an array of LWLocks and
+ can be accessed by it's name. First parameter <literal>tranche_name</>Right, will change.
Fixed.
Attachment
On Sat, Jan 30, 2016 at 2:15 PM, Alexander Korotkov <a.korotkov@postgrespro.ru> wrote:
>
> On Sat, Jan 30, 2016 at 10:58 AM, Amit Kapila <amit.kapila16@gmail.com> wrote:
>>
>> On Fri, Jan 29, 2016 at 6:47 PM, Robert Haas <robertmhaas@gmail.com> wrote:
>> >
>> > On Fri, Jan 29, 2016 at 6:59 AM, Alexander Korotkov
>> > <a.korotkov@postgrespro.ru> wrote:
>> > > On Thu, Jan 21, 2016 at 12:37 AM, Alvaro Herrera <alvherre@2ndquadrant.com>
>> > > wrote:
>> > >> So far as I can tell, there are three patches in flight here:
>> > >>
>> > >> * replication slot IO lwlocks
>> > >> * ability of extensions to request tranches dynamically
>> > >> * PGPROC
>> > >>
>> > >> The first one hasn't been reviewed at all, but the other two have seen a
>> > >> bit of discussion and evolution. Is anyone doing any more reviewing?
>> > >
>> > > I'd like to add another one: fixed tranche id for each SLRU.
>> >
>> > +1 for this. The patch looks good and I will commit it if nobody objects.
>> >
>>
>> +1. Patch looks good to me as well, but I have one related question:
>> Is there a reason why we should not assign ReplicationOrigins a
>> fixed tranche id and then we might want to even get away with
>> LWLockRegisterTranche()?
>
>
> +1. I think we should do this.
>
>
> On Sat, Jan 30, 2016 at 10:58 AM, Amit Kapila <amit.kapila16@gmail.com> wrote:
>>
>> On Fri, Jan 29, 2016 at 6:47 PM, Robert Haas <robertmhaas@gmail.com> wrote:
>> >
>> > On Fri, Jan 29, 2016 at 6:59 AM, Alexander Korotkov
>> > <a.korotkov@postgrespro.ru> wrote:
>> > > On Thu, Jan 21, 2016 at 12:37 AM, Alvaro Herrera <alvherre@2ndquadrant.com>
>> > > wrote:
>> > >> So far as I can tell, there are three patches in flight here:
>> > >>
>> > >> * replication slot IO lwlocks
>> > >> * ability of extensions to request tranches dynamically
>> > >> * PGPROC
>> > >>
>> > >> The first one hasn't been reviewed at all, but the other two have seen a
>> > >> bit of discussion and evolution. Is anyone doing any more reviewing?
>> > >
>> > > I'd like to add another one: fixed tranche id for each SLRU.
>> >
>> > +1 for this. The patch looks good and I will commit it if nobody objects.
>> >
>>
>> +1. Patch looks good to me as well, but I have one related question:
>> Is there a reason why we should not assign ReplicationOrigins a
>> fixed tranche id and then we might want to even get away with
>> LWLockRegisterTranche()?
>
>
> +1. I think we should do this.
>
Okay, Attached patch assigns fixed trancheid for ReplicationOrigins.
I don't think we can remove LWLockRegisterTranche(), as that will be
required for assigning transcheid's for extensions, so didn't change that
part of code.
Attachment
On Mon, Feb 1, 2016 at 10:26 AM, Amit Kapila <amit.kapila16@gmail.com> wrote:
On Sat, Jan 30, 2016 at 2:15 PM, Alexander Korotkov <a.korotkov@postgrespro.ru> wrote:
>
> On Sat, Jan 30, 2016 at 10:58 AM, Amit Kapila <amit.kapila16@gmail.com> wrote:
>>
>> On Fri, Jan 29, 2016 at 6:47 PM, Robert Haas <robertmhaas@gmail.com> wrote:
>> >
>> > On Fri, Jan 29, 2016 at 6:59 AM, Alexander Korotkov
>> > <a.korotkov@postgrespro.ru> wrote:
>> > > On Thu, Jan 21, 2016 at 12:37 AM, Alvaro Herrera <alvherre@2ndquadrant.com>
>> > > wrote:
>> > >> So far as I can tell, there are three patches in flight here:
>> > >>
>> > >> * replication slot IO lwlocks
>> > >> * ability of extensions to request tranches dynamically
>> > >> * PGPROC
>> > >>
>> > >> The first one hasn't been reviewed at all, but the other two have seen a
>> > >> bit of discussion and evolution. Is anyone doing any more reviewing?
>> > >
>> > > I'd like to add another one: fixed tranche id for each SLRU.
>> >
>> > +1 for this. The patch looks good and I will commit it if nobody objects.
>> >
>>
>> +1. Patch looks good to me as well, but I have one related question:
>> Is there a reason why we should not assign ReplicationOrigins a
>> fixed tranche id and then we might want to even get away with
>> LWLockRegisterTranche()?
>
>
> +1. I think we should do this.
>Okay, Attached patch assigns fixed trancheid for ReplicationOrigins.I don't think we can remove LWLockRegisterTranche(), as that will berequired for assigning transcheid's for extensions, so didn't change thatpart of code.
OK. This one looks good for me too.
Alexander Korotkov
Postgres Professional: http://www.postgrespro.com
The Russian Postgres Company
On Mon, Feb 1, 2016 at 3:47 AM, Alexander Korotkov <a.korotkov@postgrespro.ru> wrote: > OK. This one looks good for me too. All right, I pushed both this and the other one as a single commit, since they were so closely related and the second only one line. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On Tue, Feb 2, 2016 at 5:24 PM, Robert Haas <robertmhaas@gmail.com> wrote:
>
> On Mon, Feb 1, 2016 at 3:47 AM, Alexander Korotkov
> <a.korotkov@postgrespro.ru> wrote:
> > OK. This one looks good for me too.
>
> All right, I pushed both this and the other one as a single commit,
> since they were so closely related and the second only one line.
>
>
> On Mon, Feb 1, 2016 at 3:47 AM, Alexander Korotkov
> <a.korotkov@postgrespro.ru> wrote:
> > OK. This one looks good for me too.
>
> All right, I pushed both this and the other one as a single commit,
> since they were so closely related and the second only one line.
>
Thank you!
On Tue, Feb 2, 2016 at 2:54 PM, Robert Haas <robertmhaas@gmail.com> wrote:
On Mon, Feb 1, 2016 at 3:47 AM, Alexander Korotkov
<a.korotkov@postgrespro.ru> wrote:
> OK. This one looks good for me too.
All right, I pushed both this and the other one as a single commit,
since they were so closely related and the second only one line.
Great, thanks!
It seems that we have only extension tranches patch pending in this thread.
Alexander Korotkov
Postgres Professional: http://www.postgrespro.com
The Russian Postgres Company
On Mon, Feb 1, 2016 at 12:27 AM, Amit Kapila <amit.kapila16@gmail.com> wrote:
> Fixed.
This patch doesn't build:
./xfunc.sgml: int lwlock_count = 0;
Tabs appear in SGML/XML files
The #define NUM_LWLOCKS 1 just seems totally unnecessary, as does int
lwlock_count = 0. You're only assigning one lock! I'd just do
RequestAddinLWLockTranche("pg_stat_statements locks", 1); pgss->lock =
GetLWLockAddinTranche("pg_stat_statements locks")->lock; and call it
good.
I think we shouldn't foreclose the idea of core users of this facility
by using names like NumLWLocksByLoadableModules(). Why can't an
in-core client use this API? I think instead of calling these "addin
tranches" we should call them "named tranches"; thus public APIs
RequestNamedLWLockTranche()
and GetNamedLWLockTranche(), and private variables
NamedLWLockTrancheRequests, NamedLWLockTrancheRequestsAllocated, etc.
In fact,
I do not see an obvious reason why the two looks in CreateLWLocks()
that end with "} while (++i < LWLockTrancheRequestsCount);" could not
be merged, and I believe that would be cleaner than what you've got
now. Similarly, the two loops in GetLWLockAddinTranche() could also
be merged. Just keep a running total and return it when you find a
match.
I think it would be a good idea to merge LWLockAddInTrancheShmemSize
into LWLockShmemSize. I don't see why that function can't compute a
grand total and return it.
Overall, I think this is on the right track, but it still needs some
work to make it cleaner.
--
Robert Haas
EnterpriseDB: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
Robert Haas wrote: > Overall, I think this is on the right track, but it still needs some > work to make it cleaner. We've committed a large number of patches in this item this cycle. I think it's fair to mark it as Committed. Can somebody submit a new one to the next commitfest? -- Álvaro Herrera http://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On Tue, Feb 2, 2016 at 9:04 AM, Alvaro Herrera <alvherre@2ndquadrant.com> wrote: > Robert Haas wrote: >> Overall, I think this is on the right track, but it still needs some >> work to make it cleaner. > > We've committed a large number of patches in this item this cycle. I > think it's fair to mark it as Committed. Can somebody submit a new one > to the next commitfest? I plan to keep working with the patch authors on this patch during the inter-CF period, but have no objection to it being considered as Committed for CF purposes. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On Tue, Feb 2, 2016 at 7:19 PM, Robert Haas <robertmhaas@gmail.com> wrote:
>
> On Mon, Feb 1, 2016 at 12:27 AM, Amit Kapila <amit.kapila16@gmail.com> wrote:
> > Fixed.
>
> This patch doesn't build:
>
> ./xfunc.sgml: int lwlock_count = 0;
> Tabs appear in SGML/XML files
>
> The #define NUM_LWLOCKS 1 just seems totally unnecessary, as does int
> lwlock_count = 0. You're only assigning one lock! I'd just do
> RequestAddinLWLockTranche("pg_stat_statements locks", 1); pgss->lock =
> GetLWLockAddinTranche("pg_stat_statements locks")->lock; and call it
> good.
>
> I think we shouldn't foreclose the idea of core users of this facility
> by using names like NumLWLocksByLoadableModules(). Why can't an
> in-core client use this API? I think instead of calling these "addin
> tranches" we should call them "named tranches"; thus public APIs
> RequestNamedLWLockTranche()
> and GetNamedLWLockTranche(), and private variables
> NamedLWLockTrancheRequests, NamedLWLockTrancheRequestsAllocated, etc.
> In fact,
>
> I do not see an obvious reason why the two looks in CreateLWLocks()
> that end with "} while (++i < LWLockTrancheRequestsCount);" could not
> be merged, and I believe that would be cleaner than what you've got
> now. Similarly, the two loops in GetLWLockAddinTranche() could also
> be merged. Just keep a running total and return it when you find a
> match.
>
> I think it would be a good idea to merge LWLockAddInTrancheShmemSize
> into LWLockShmemSize. I don't see why that function can't compute a
> grand total and return it.
>
>
> On Mon, Feb 1, 2016 at 12:27 AM, Amit Kapila <amit.kapila16@gmail.com> wrote:
> > Fixed.
>
> This patch doesn't build:
>
> ./xfunc.sgml: int lwlock_count = 0;
> Tabs appear in SGML/XML files
>
Changed the documentation and now I am not getting build failure.
> The #define NUM_LWLOCKS 1 just seems totally unnecessary, as does int
> lwlock_count = 0. You're only assigning one lock! I'd just do
> RequestAddinLWLockTranche("pg_stat_statements locks", 1); pgss->lock =
> GetLWLockAddinTranche("pg_stat_statements locks")->lock; and call it
> good.
>
Changed as per suggestion.
> I think we shouldn't foreclose the idea of core users of this facility
> by using names like NumLWLocksByLoadableModules(). Why can't an
> in-core client use this API? I think instead of calling these "addin
> tranches" we should call them "named tranches"; thus public APIs
> RequestNamedLWLockTranche()
> and GetNamedLWLockTranche(), and private variables
> NamedLWLockTrancheRequests, NamedLWLockTrancheRequestsAllocated, etc.
> In fact,
>
Changed as per suggestion.
> I do not see an obvious reason why the two looks in CreateLWLocks()
> that end with "} while (++i < LWLockTrancheRequestsCount);" could not
> be merged, and I believe that would be cleaner than what you've got
> now. Similarly, the two loops in GetLWLockAddinTranche() could also
> be merged. Just keep a running total and return it when you find a
> match.
>
> I think it would be a good idea to merge LWLockAddInTrancheShmemSize
> into LWLockShmemSize. I don't see why that function can't compute a
> grand total and return it.
>
Agreed with both the points and changed as per suggestion.
Attachment
On Thu, Feb 4, 2016 at 7:00 AM, Amit Kapila <amit.kapila16@gmail.com> wrote: > [ new patch ] I've committed this after heavy rewriting. In particular, I merged two loops, used local variables to get rid of the very long and quite repetitive lines, and did various cleanup on the documentation and comments. I think we ought to move the buffer mapping, lock manager, and predicate lock manager locks into their own tranches also, perhaps using this new named-tranche facility. In addition, I think we should get rid of NumLWLocks(). It's no longer calculating anything; it just returns NUM_FIXED_LWLOCKS, and with the changes described in the first sentence of this paragraph, it will simply return NUM_INDIVIDUAL_LWLOCKS. We don't need a function just to do that; the assignment it does can be moved to the relevant caller. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On Fri, Feb 5, 2016 at 3:17 AM, Robert Haas <robertmhaas@gmail.com> wrote:
>
> On Thu, Feb 4, 2016 at 7:00 AM, Amit Kapila <amit.kapila16@gmail.com> wrote:
> > [ new patch ]
>
> I've committed this after heavy rewriting. In particular, I merged
> two loops, used local variables to get rid of the very long and quite
> repetitive lines, and did various cleanup on the documentation and
> comments.
>
>
> On Thu, Feb 4, 2016 at 7:00 AM, Amit Kapila <amit.kapila16@gmail.com> wrote:
> > [ new patch ]
>
> I've committed this after heavy rewriting. In particular, I merged
> two loops, used local variables to get rid of the very long and quite
> repetitive lines, and did various cleanup on the documentation and
> comments.
>
I think there is a typo in the committed code, patch to fix the same
is attached.
Attachment
On Thu, Feb 4, 2016 at 11:30 PM, Amit Kapila <amit.kapila16@gmail.com> wrote: > On Fri, Feb 5, 2016 at 3:17 AM, Robert Haas <robertmhaas@gmail.com> wrote: >> >> On Thu, Feb 4, 2016 at 7:00 AM, Amit Kapila <amit.kapila16@gmail.com> >> wrote: >> > [ new patch ] >> >> I've committed this after heavy rewriting. In particular, I merged >> two loops, used local variables to get rid of the very long and quite >> repetitive lines, and did various cleanup on the documentation and >> comments. >> > > I think there is a typo in the committed code, patch to fix the same > is attached. Thanks! Committed. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On Fri, Feb 5, 2016 at 3:17 AM, Robert Haas <robertmhaas@gmail.com> wrote:
>
>
> I think we ought to move the buffer mapping, lock manager, and
> predicate lock manager locks into their own tranches also, perhaps
> using this new named-tranche facility.
>
>
> I think we ought to move the buffer mapping, lock manager, and
> predicate lock manager locks into their own tranches also, perhaps
> using this new named-tranche facility.
>
Makes sense and attached patch implements it using new named
tranches facility. One thing to note is that to make it work on
EXEC_BACKEND builds, I have passed the individual LWLock
array via save-restore backendparams mechanism. Now instead
we could have initialised the LWLock arrays in each backend at
start-up and I have tried to analyse that way as well, but we need
to use NamedLWLockTrancheArray instead ofNamedLWLockTrancheRequestArray in GetNamedLWLockTranche()
and not only that, we also need to store number of locks
information in NamedLWLockTrancheArray as well. So it seems
it is better to use save-restore backendparams mechanism for
passing LWLock arrays.
> In addition, I think we should
> get rid of NumLWLocks(). It's no longer calculating anything; it just
> returns NUM_FIXED_LWLOCKS, and with the changes described in the first
> sentence of this paragraph, it will simply return
> NUM_INDIVIDUAL_LWLOCKS. We don't need a function just to do that; the
> assignment it does can be moved to the relevant caller.
>
> get rid of NumLWLocks(). It's no longer calculating anything; it just
> returns NUM_FIXED_LWLOCKS, and with the changes described in the first
> sentence of this paragraph, it will simply return
> NUM_INDIVIDUAL_LWLOCKS. We don't need a function just to do that; the
> assignment it does can be moved to the relevant caller.
>
Agreed and we don't even need an array of LWLockCounter's, just one
counter is sufficient for tranches. Apart from this function
LWLockAssign() seems redundant to me after new implementation
of named tranches, so I have removed that as well.
Attachment
On Tue, Feb 9, 2016 at 7:53 AM, Amit Kapila <amit.kapila16@gmail.com> wrote: > On Fri, Feb 5, 2016 at 3:17 AM, Robert Haas <robertmhaas@gmail.com> wrote: >> I think we ought to move the buffer mapping, lock manager, and >> predicate lock manager locks into their own tranches also, perhaps >> using this new named-tranche facility. > > Makes sense and attached patch implements it using new named > tranches facility. One thing to note is that to make it work on > EXEC_BACKEND builds, I have passed the individual LWLock > array via save-restore backendparams mechanism. Now instead > we could have initialised the LWLock arrays in each backend at > start-up and I have tried to analyse that way as well, but we need > to use NamedLWLockTrancheArray instead of > NamedLWLockTrancheRequestArray in GetNamedLWLockTranche() > and not only that, we also need to store number of locks > information in NamedLWLockTrancheArray as well. So it seems > it is better to use save-restore backendparams mechanism for > passing LWLock arrays. I'm not very keen on the way this puts RequestNamedTranches() into miscinit.c. That doesn't really seem like it goes there, and I feel like each subsystem should be responsible for requesting its own named tranche rather than having it be centralized like this. I think it might be helpful to split this into two patches. The first would remove LWLockAssign() and NumLWLocks() and related bits, and would use NUM_FIXED_LWLOCKS any place we currently call NumLWLocks(). The second would add the named tranches for the three kinds of locks included in NUM_FIXED_LWLOCKS and then replace NUM_FIXED_LWLOCKS with NUM_INDIVIDUAL_LWLOCKS. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On Tue, Feb 9, 2016 at 11:05 PM, Robert Haas <robertmhaas@gmail.com> wrote:
>
> On Tue, Feb 9, 2016 at 7:53 AM, Amit Kapila <amit.kapila16@gmail.com> wrote:
> > On Fri, Feb 5, 2016 at 3:17 AM, Robert Haas <robertmhaas@gmail.com> wrote:
> >> I think we ought to move the buffer mapping, lock manager, and
> >> predicate lock manager locks into their own tranches also, perhaps
> >> using this new named-tranche facility.
> >
> > Makes sense and attached patch implements it using new named
> > tranches facility. One thing to note is that to make it work on
> > EXEC_BACKEND builds, I have passed the individual LWLock
> > array via save-restore backendparams mechanism. Now instead
> > we could have initialised the LWLock arrays in each backend at
> > start-up and I have tried to analyse that way as well, but we need
> > to use NamedLWLockTrancheArray instead of
> > NamedLWLockTrancheRequestArray in GetNamedLWLockTranche()
> > and not only that, we also need to store number of locks
> > information in NamedLWLockTrancheArray as well. So it seems
> > it is better to use save-restore backendparams mechanism for
> > passing LWLock arrays.
>
> I'm not very keen on the way this puts RequestNamedTranches() into
> miscinit.c. That doesn't really seem like it goes there, and I feel
> like each subsystem should be responsible for requesting its own named
> tranche rather than having it be centralized like this.
>
>
> On Tue, Feb 9, 2016 at 7:53 AM, Amit Kapila <amit.kapila16@gmail.com> wrote:
> > On Fri, Feb 5, 2016 at 3:17 AM, Robert Haas <robertmhaas@gmail.com> wrote:
> >> I think we ought to move the buffer mapping, lock manager, and
> >> predicate lock manager locks into their own tranches also, perhaps
> >> using this new named-tranche facility.
> >
> > Makes sense and attached patch implements it using new named
> > tranches facility. One thing to note is that to make it work on
> > EXEC_BACKEND builds, I have passed the individual LWLock
> > array via save-restore backendparams mechanism. Now instead
> > we could have initialised the LWLock arrays in each backend at
> > start-up and I have tried to analyse that way as well, but we need
> > to use NamedLWLockTrancheArray instead of
> > NamedLWLockTrancheRequestArray in GetNamedLWLockTranche()
> > and not only that, we also need to store number of locks
> > information in NamedLWLockTrancheArray as well. So it seems
> > it is better to use save-restore backendparams mechanism for
> > passing LWLock arrays.
>
> I'm not very keen on the way this puts RequestNamedTranches() into
> miscinit.c. That doesn't really seem like it goes there, and I feel
> like each subsystem should be responsible for requesting its own named
> tranche rather than having it be centralized like this.
>
The reason for using centralized way is that we need to request
named tranches before initialization of shared memory and as far as
I can see, currently there is no way in the subsystems where they can
issue such a request, so one possibility is that we introduce new API's
like InitBufferLWLocks(), InitLmgrLWLocks(), InitPredicateLWLocks()
in respective subsystem and call them in
CreateSharedMemoryAndSemaphores() before shared memoryinitialization. Does by doing that way addresses your concern?
> I think it might be helpful to split this into two patches. The first
> would remove LWLockAssign() and NumLWLocks() and related bits, and
> would use NUM_FIXED_LWLOCKS any place we currently call NumLWLocks().
> I think it might be helpful to split this into two patches. The first
> would remove LWLockAssign() and NumLWLocks() and related bits, and
> would use NUM_FIXED_LWLOCKS any place we currently call NumLWLocks().
Okay, attached patch does that.
Attachment
On Wed, Feb 10, 2016 at 1:32 AM, Amit Kapila <amit.kapila16@gmail.com> wrote:
> The reason for using centralized way is that we need to request
> named tranches before initialization of shared memory and as far as
> I can see, currently there is no way in the subsystems where they can
> issue such a request, so one possibility is that we introduce new API's
> like InitBufferLWLocks(), InitLmgrLWLocks(), InitPredicateLWLocks()
> in respective subsystem and call them in
> CreateSharedMemoryAndSemaphores() before shared memory
> initialization. Does by doing that way addresses your concern?
Well, if we're going to have new functions like that, I think the
place to call them from is PostmasterMain() just before
process_shared_preload_libraries(). After all, if extensions were
requesting tranches, they'd do it from
process_shared_preload_libraries(), so it seems like the right place.
However, since the number of locks we need for each of these
subsystems is fixed at compile time, it seems a bit of a shame to have
to do something about them at runtime. I wonder if we should just
hard-code this in CreateLWLocks() instead of trying to use the
named-tranche facility. That is, where that function does this:
MainLWLockTranche.name = "main"; MainLWLockTranche.array_base = MainLWLockArray; MainLWLockTranche.array_stride
=sizeof(LWLockPadded); LWLockRegisterTranche(LWTRANCHE_MAIN, &MainLWLockTranche);
...register four tranches instead. And where it does this:
/* Initialize all fixed LWLocks in main array */ for (id = 0, lock = MainLWLockArray; id < numLocks; id++,
lock++) LWLockInitialize(&lock->lock, LWTRANCHE_MAIN);
...have four loops instead, each initializing with a different tranche
ID. Then the current method of computing the location of those locks
would still work just fine; the code changes would be a lot more
isolated, and we wouldn't have to do runtime save-and-restore of more
variables on Windows.
--
Robert Haas
EnterpriseDB: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
On Wed, Feb 10, 2016 at 8:51 PM, Robert Haas <robertmhaas@gmail.com> wrote:
>
> On Wed, Feb 10, 2016 at 1:32 AM, Amit Kapila <amit.kapila16@gmail.com> wrote:
> > The reason for using centralized way is that we need to request
> > named tranches before initialization of shared memory and as far as
> > I can see, currently there is no way in the subsystems where they can
> > issue such a request, so one possibility is that we introduce new API's
> > like InitBufferLWLocks(), InitLmgrLWLocks(), InitPredicateLWLocks()
> > in respective subsystem and call them in
> > CreateSharedMemoryAndSemaphores() before shared memory
> > initialization. Does by doing that way addresses your concern?
>
> Well, if we're going to have new functions like that, I think the
> place to call them from is PostmasterMain() just before
> process_shared_preload_libraries(). After all, if extensions were
> requesting tranches, they'd do it from
> process_shared_preload_libraries(), so it seems like the right place.
>
> However, since the number of locks we need for each of these
> subsystems is fixed at compile time, it seems a bit of a shame to have
> to do something about them at runtime. I wonder if we should just
> hard-code this in CreateLWLocks() instead of trying to use the
> named-tranche facility. That is, where that function does this:
>
> MainLWLockTranche.name = "main";
> MainLWLockTranche.array_base = MainLWLockArray;
> MainLWLockTranche.array_stride = sizeof(LWLockPadded);
> LWLockRegisterTranche(LWTRANCHE_MAIN, &MainLWLockTranche);
>
> ...register four tranches instead. And where it does this:
>
> /* Initialize all fixed LWLocks in main array */
> for (id = 0, lock = MainLWLockArray; id < numLocks; id++, lock++)
> LWLockInitialize(&lock->lock, LWTRANCHE_MAIN);
>
> ...have four loops instead, each initializing with a different tranche
> ID. Then the current method of computing the location of those locks
> would still work just fine; the code changes would be a lot more
> isolated, and we wouldn't have to do runtime save-and-restore of more
> variables on Windows.
>
>
> On Wed, Feb 10, 2016 at 1:32 AM, Amit Kapila <amit.kapila16@gmail.com> wrote:
> > The reason for using centralized way is that we need to request
> > named tranches before initialization of shared memory and as far as
> > I can see, currently there is no way in the subsystems where they can
> > issue such a request, so one possibility is that we introduce new API's
> > like InitBufferLWLocks(), InitLmgrLWLocks(), InitPredicateLWLocks()
> > in respective subsystem and call them in
> > CreateSharedMemoryAndSemaphores() before shared memory
> > initialization. Does by doing that way addresses your concern?
>
> Well, if we're going to have new functions like that, I think the
> place to call them from is PostmasterMain() just before
> process_shared_preload_libraries(). After all, if extensions were
> requesting tranches, they'd do it from
> process_shared_preload_libraries(), so it seems like the right place.
>
Initially I also thought like that, but on further analysis I found that
we also need to request the tranches from InitCommunication() as
that gets called from initdb path.
> However, since the number of locks we need for each of these
> subsystems is fixed at compile time, it seems a bit of a shame to have
> to do something about them at runtime. I wonder if we should just
> hard-code this in CreateLWLocks() instead of trying to use the
> named-tranche facility. That is, where that function does this:
>
> MainLWLockTranche.name = "main";
> MainLWLockTranche.array_base = MainLWLockArray;
> MainLWLockTranche.array_stride = sizeof(LWLockPadded);
> LWLockRegisterTranche(LWTRANCHE_MAIN, &MainLWLockTranche);
>
> ...register four tranches instead. And where it does this:
>
> /* Initialize all fixed LWLocks in main array */
> for (id = 0, lock = MainLWLockArray; id < numLocks; id++, lock++)
> LWLockInitialize(&lock->lock, LWTRANCHE_MAIN);
>
> ...have four loops instead, each initializing with a different tranche
> ID. Then the current method of computing the location of those locks
> would still work just fine; the code changes would be a lot more
> isolated, and we wouldn't have to do runtime save-and-restore of more
> variables on Windows.
>
Sounds sensible, however after changes, CreateLWLocks() started
looking unreadable, so moved initialization and registration of tranches
to separate functions.
Increased number of tranches allocated in LWLockTrancheArray, as
now the LWTRANCHE_FIRST_USER_DEFINED is already greater
than 16.
Attachment
On Thu, Feb 11, 2016 at 3:15 AM, Amit Kapila <amit.kapila16@gmail.com> wrote: > Sounds sensible, however after changes, CreateLWLocks() started > looking unreadable, so moved initialization and registration of tranches > to separate functions. Seems good. > Increased number of tranches allocated in LWLockTrancheArray, as > now the LWTRANCHE_FIRST_USER_DEFINED is already greater > than 16. OK, cool. + int numIndividualLocks = NUM_INDIVIDUAL_LWLOCKS; + int numBufMappingLocks = NUM_BUFFER_PARTITIONS; + int numLmgrLocks = NUM_LOCK_PARTITIONS; + int i; This doesn't seem like it's buying us anything. Can't we just use the constants directly? + BufMappingLWLockTranche.name = "Buffer Mapping Locks"; We've not been very consistent about how we name our tranches. If we're going to try to expose this information to users, we're going to need to do better. We've got these names: main clog commit_timestamp subtrans multixact_offset multixact_member async oldserxid WALInsertLocks Buffer Content Locks Buffer IO Locks ReplicationOrigins Replication Slot IO Locks proc Personally, I prefer the style of all lower case, words separated with semicolons where necessary, the word "locks" left out. That way we can display wait events as something like lwlock:<name of tranche> and not have the word "lock" in there twice. I don't think it does much good to try to make these names "user friendly" because, fundamentally, these are internal pieces of the system and you won't know what they are unless you do. So I'd prefer to make them look like identifiers. If we adopt that style, then I think the new tranches created by this patch should be named buffer_mapping, lock_manager, and predicate_lock_manager and then, probably as a separate patch, we should rename the rest to match that style (buffer_content, buffer_io, replication_origin, replication_slot_io). -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On Thu, Feb 11, 2016 at 6:45 PM, Robert Haas <robertmhaas@gmail.com> wrote:
>
> On Thu, Feb 11, 2016 at 3:15 AM, Amit Kapila <amit.kapila16@gmail.com> wrote:
> > Sounds sensible, however after changes, CreateLWLocks() started
> > looking unreadable, so moved initialization and registration of tranches
> > to separate functions.
>
> Seems good.
>
> > Increased number of tranches allocated in LWLockTrancheArray, as
> > now the LWTRANCHE_FIRST_USER_DEFINED is already greater
> > than 16.
>
> OK, cool.
>
> + int numIndividualLocks = NUM_INDIVIDUAL_LWLOCKS;
> + int numBufMappingLocks = NUM_BUFFER_PARTITIONS;
> + int numLmgrLocks = NUM_LOCK_PARTITIONS;
> + int i;
>
> This doesn't seem like it's buying us anything. Can't we just use the
> constants directly?
>
> + BufMappingLWLockTranche.name = "Buffer Mapping Locks";
>
> We've not been very consistent about how we name our tranches. If
> we're going to try to expose this information to users, we're going to
> need to do better. We've got these names:
>
> main
> clog
> commit_timestamp
> subtrans
> multixact_offset
> multixact_member
> async
> oldserxid
> WALInsertLocks
> Buffer Content Locks
> Buffer IO Locks
> ReplicationOrigins
> Replication Slot IO Locks
> proc
>
> Personally, I prefer the style of all lower case, words separated with
> semicolons where necessary, the word "locks" left out. That way we
> can display wait events as something like lwlock:<name of tranche> and
> not have the word "lock" in there twice. I don't think it does much
> good to try to make these names "user friendly" because,
> fundamentally, these are internal pieces of the system and you won't
> know what they are unless you do. So I'd prefer to make them look
> like identifiers. If we adopt that style, then I think the new
> tranches created by this patch should be named buffer_mapping,
> lock_manager, and predicate_lock_manager
>
> On Thu, Feb 11, 2016 at 3:15 AM, Amit Kapila <amit.kapila16@gmail.com> wrote:
> > Sounds sensible, however after changes, CreateLWLocks() started
> > looking unreadable, so moved initialization and registration of tranches
> > to separate functions.
>
> Seems good.
>
> > Increased number of tranches allocated in LWLockTrancheArray, as
> > now the LWTRANCHE_FIRST_USER_DEFINED is already greater
> > than 16.
>
> OK, cool.
>
> + int numIndividualLocks = NUM_INDIVIDUAL_LWLOCKS;
> + int numBufMappingLocks = NUM_BUFFER_PARTITIONS;
> + int numLmgrLocks = NUM_LOCK_PARTITIONS;
> + int i;
>
> This doesn't seem like it's buying us anything. Can't we just use the
> constants directly?
>
Yes, we can use the constants. The reason I have used variables
was they need to be used at couple of places, but I think using
constants directly also doesn't harm, so changed accordingly.
> + BufMappingLWLockTranche.name = "Buffer Mapping Locks";
>
> We've not been very consistent about how we name our tranches. If
> we're going to try to expose this information to users, we're going to
> need to do better. We've got these names:
>
> main
> clog
> commit_timestamp
> subtrans
> multixact_offset
> multixact_member
> async
> oldserxid
> WALInsertLocks
> Buffer Content Locks
> Buffer IO Locks
> ReplicationOrigins
> Replication Slot IO Locks
> proc
>
> Personally, I prefer the style of all lower case, words separated with
> semicolons where necessary, the word "locks" left out. That way we
> can display wait events as something like lwlock:<name of tranche> and
> not have the word "lock" in there twice. I don't think it does much
> good to try to make these names "user friendly" because,
> fundamentally, these are internal pieces of the system and you won't
> know what they are unless you do. So I'd prefer to make them look
> like identifiers. If we adopt that style, then I think the new
> tranches created by this patch should be named buffer_mapping,
> lock_manager, and predicate_lock_manager
Okay, changed as per suggestion.
> and then, probably as a
> separate patch, we should rename the rest to match that style
> (buffer_content, buffer_io, replication_origin, replication_slot_io).
>
Sure, will send these changes as a separate patch.
> separate patch, we should rename the rest to match that style
> (buffer_content, buffer_io, replication_origin, replication_slot_io).
>
Sure, will send these changes as a separate patch.
Attachment
On Thu, Feb 11, 2016 at 12:10 PM, Amit Kapila <amit.kapila16@gmail.com> wrote: > Okay, changed as per suggestion. Looks good to me; committed. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On Fri, Feb 12, 2016 at 12:39 AM, Robert Haas <robertmhaas@gmail.com> wrote:
>
> On Thu, Feb 11, 2016 at 12:10 PM, Amit Kapila <amit.kapila16@gmail.com> wrote:
> > Okay, changed as per suggestion.
>
> Looks good to me; committed.
>
>
> On Thu, Feb 11, 2016 at 12:10 PM, Amit Kapila <amit.kapila16@gmail.com> wrote:
> > Okay, changed as per suggestion.
>
> Looks good to me; committed.
>
Thanks!
Attached patch changes the name of some of the existing tranches
as suggested by you upthread.
Attachment
On Thu, Feb 11, 2016 at 11:03 PM, Amit Kapila <amit.kapila16@gmail.com> wrote: > Attached patch changes the name of some of the existing tranches > as suggested by you upthread. Committed. Woohoo! -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company