Thread: BitmapHeapScan streaming read user and prelim refactoring
Hi, Attached is a patch set which refactors BitmapHeapScan such that it can use the streaming read API [1]. It also resolves the long-standing FIXME in the BitmapHeapScan code suggesting that the skip fetch optimization should be pushed into the table AMs. Additionally, it moves table scan initialization to after the index scan and bitmap initialization. patches 0001-0002 are assorted cleanup needed later in the set. patches 0003 moves the table scan initialization to after bitmap creation patch 0004 is, I think, a bug fix. see [2]. patches 0005-0006 push the skip fetch optimization into the table AMs patches 0007-0009 change the control flow of BitmapHeapNext() to match that required by the streaming read API patch 0010 is the streaming read code not yet in master patch 0011 is the actual bitmapheapscan streaming read user. patches 0001-0009 apply on top of master but 0010 and 0011 must be applied on top of a commit before a 21d9c3ee4ef74e2 (until a rebased version of the streaming read API is on the mailing list). The caveat is that these patches introduce breaking changes to two table AM functions for bitmapheapscan: table_scan_bitmap_next_block() and table_scan_bitmap_next_tuple(). A TBMIterateResult used to be threaded through both of these functions and used in BitmapHeapNext(). This patch set removes all references to TBMIterateResults from BitmapHeapNext. Because the streaming read API requires the callback to specify the next block, BitmapHeapNext() can no longer pass a TBMIterateResult to table_scan_bitmap_next_block(). More subtly, table_scan_bitmap_next_block() used to return false if there were no more visible tuples on the page or if the block that was requested was not valid. With these changes, table_scan_bitmap_next_block() will only return false when the bitmap has been exhausted and the scan can end. In order to use the streaming read API, the user must be able to request the blocks it needs without requiring synchronous feedback per block. Thus, this table AM function must change its meaning. I think the way the patches are split up could be improved. I will think more about this. There are also probably a few mistakes with which comments are updated in which patches in the set. - Melanie [1] https://www.postgresql.org/message-id/flat/CA%2BhUKGJkOiOCa%2Bmag4BF%2BzHo7qo%3Do9CFheB8%3Dg6uT5TUm2gkvA%40mail.gmail.com [2] https://www.postgresql.org/message-id/CAAKRu_bxrXeZ2rCnY8LyeC2Ls88KpjWrQ%2BopUrXDRXdcfwFZGA%40mail.gmail.com
Attachment
- v1-0003-BitmapHeapScan-begin-scan-after-bitmap-setup.patch
- v1-0002-BitmapHeapScan-set-can_skip_fetch-later.patch
- v1-0001-Remove-table_scan_bitmap_next_tuple-parameter-tbm.patch
- v1-0005-Update-BitmapAdjustPrefetchIterator-parameter-typ.patch
- v1-0004-BitmapPrefetch-use-prefetch-block-recheck-for-ski.patch
- v1-0006-Push-BitmapHeapScan-skip-fetch-optimization-into-.patch
- v1-0008-Reduce-scope-of-BitmapHeapScan-tbmiterator-local-.patch
- v1-0009-Make-table_scan_bitmap_next_block-async-friendly.patch
- v1-0007-BitmapHeapScan-scan-desc-counts-lossy-and-exact-p.patch
- v1-0010-Streaming-Read-API.patch
- v1-0011-BitmapHeapScan-uses-streaming-read-API.patch
> On Feb 13, 2024, at 3:11 PM, Melanie Plageman <melanieplageman@gmail.com> wrote: Thanks for the patch... > Attached is a patch set which refactors BitmapHeapScan such that it > can use the streaming read API [1]. It also resolves the long-standing > FIXME in the BitmapHeapScan code suggesting that the skip fetch > optimization should be pushed into the table AMs. Additionally, it > moves table scan initialization to after the index scan and bitmap > initialization. > > patches 0001-0002 are assorted cleanup needed later in the set. > patches 0003 moves the table scan initialization to after bitmap creation > patch 0004 is, I think, a bug fix. see [2]. > patches 0005-0006 push the skip fetch optimization into the table AMs > patches 0007-0009 change the control flow of BitmapHeapNext() to match > that required by the streaming read API > patch 0010 is the streaming read code not yet in master > patch 0011 is the actual bitmapheapscan streaming read user. > > patches 0001-0009 apply on top of master but 0010 and 0011 must be > applied on top of a commit before a 21d9c3ee4ef74e2 (until a rebased > version of the streaming read API is on the mailing list). I followed your lead and applied them to 6a8ffe812d194ba6f4f26791b6388a4837d17d6c. `make check` worked fine, though I expectyou know that already. > The caveat is that these patches introduce breaking changes to two > table AM functions for bitmapheapscan: table_scan_bitmap_next_block() > and table_scan_bitmap_next_tuple(). You might want an independent perspective on how much of a hassle those breaking changes are, so I took a stab at that. Having written a custom proprietary TAM for postgresql 15 here at EDB, and having ported it and released it for postgresql16, I thought I'd try porting it to the the above commit with your patches. Even without your patches, I alreadysee breaking changes coming from commit f691f5b80a85c66d715b4340ffabb503eb19393e, which creates a similar amount ofbreakage for me as does your patches. Dealing with the combined breakage might amount to a day of work, including testing,half of which I think I've already finished. In other words, it doesn't seem like a big deal. Were postgresql 17 shaping up to be compatible with TAMs written for 16, your patch would change that qualitatively, butsince things are already incompatible, I think you're in the clear. > A TBMIterateResult used to be threaded through both of these functions > and used in BitmapHeapNext(). This patch set removes all references to > TBMIterateResults from BitmapHeapNext. Because the streaming read API > requires the callback to specify the next block, BitmapHeapNext() can > no longer pass a TBMIterateResult to table_scan_bitmap_next_block(). > > More subtly, table_scan_bitmap_next_block() used to return false if > there were no more visible tuples on the page or if the block that was > requested was not valid. With these changes, > table_scan_bitmap_next_block() will only return false when the bitmap > has been exhausted and the scan can end. In order to use the streaming > read API, the user must be able to request the blocks it needs without > requiring synchronous feedback per block. Thus, this table AM function > must change its meaning. > > I think the way the patches are split up could be improved. I will > think more about this. There are also probably a few mistakes with > which comments are updated in which patches in the set. I look forward to the next version of the patch set. Thanks again for working on this. — Mark Dilger EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On Tue, Feb 13, 2024 at 11:34 PM Mark Dilger <mark.dilger@enterprisedb.com> wrote: > > > On Feb 13, 2024, at 3:11 PM, Melanie Plageman <melanieplageman@gmail.com> wrote: > > Thanks for the patch... > > > Attached is a patch set which refactors BitmapHeapScan such that it > > can use the streaming read API [1]. It also resolves the long-standing > > FIXME in the BitmapHeapScan code suggesting that the skip fetch > > optimization should be pushed into the table AMs. Additionally, it > > moves table scan initialization to after the index scan and bitmap > > initialization. > > > > patches 0001-0002 are assorted cleanup needed later in the set. > > patches 0003 moves the table scan initialization to after bitmap creation > > patch 0004 is, I think, a bug fix. see [2]. > > patches 0005-0006 push the skip fetch optimization into the table AMs > > patches 0007-0009 change the control flow of BitmapHeapNext() to match > > that required by the streaming read API > > patch 0010 is the streaming read code not yet in master > > patch 0011 is the actual bitmapheapscan streaming read user. > > > > patches 0001-0009 apply on top of master but 0010 and 0011 must be > > applied on top of a commit before a 21d9c3ee4ef74e2 (until a rebased > > version of the streaming read API is on the mailing list). > > I followed your lead and applied them to 6a8ffe812d194ba6f4f26791b6388a4837d17d6c. `make check` worked fine, though Iexpect you know that already. Thanks for taking a look! > > The caveat is that these patches introduce breaking changes to two > > table AM functions for bitmapheapscan: table_scan_bitmap_next_block() > > and table_scan_bitmap_next_tuple(). > > You might want an independent perspective on how much of a hassle those breaking changes are, so I took a stab at that. Having written a custom proprietary TAM for postgresql 15 here at EDB, and having ported it and released it for postgresql16, I thought I'd try porting it to the the above commit with your patches. Even without your patches, I alreadysee breaking changes coming from commit f691f5b80a85c66d715b4340ffabb503eb19393e, which creates a similar amount ofbreakage for me as does your patches. Dealing with the combined breakage might amount to a day of work, including testing,half of which I think I've already finished. In other words, it doesn't seem like a big deal. > > Were postgresql 17 shaping up to be compatible with TAMs written for 16, your patch would change that qualitatively, butsince things are already incompatible, I think you're in the clear. Oh, good to know! I'm very happy to have the perspective of a table AM author. Just curious, did your table AM implement table_scan_bitmap_next_block() and table_scan_bitmap_next_tuple(), and, if so, did you use the TBMIterateResult? Since it is not used in BitmapHeapNext() in my version, table AMs would have to change how they use TBMIterateResults anyway. But I assume they could add it to a table AM specific scan descriptor if they want access to a TBMIterateResult of their own making in both table_san_bitmap_next_block() and next_tuple()? - Melanie
> On Feb 14, 2024, at 6:47 AM, Melanie Plageman <melanieplageman@gmail.com> wrote: > > Just curious, did your table AM implement > table_scan_bitmap_next_block() and table_scan_bitmap_next_tuple(), > and, if so, did you use the TBMIterateResult? Since it is not used in > BitmapHeapNext() in my version, table AMs would have to change how > they use TBMIterateResults anyway. But I assume they could add it to a > table AM specific scan descriptor if they want access to a > TBMIterateResult of their own making in both > table_san_bitmap_next_block() and next_tuple()? My table AM does implement those two functions and does use the TBMIterateResult *tbmres argument, yes. I would deal withthe issue in very much the same way that your patches modify heapam. I don't really have any additional comments aboutthat. — Mark Dilger EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
Hi,
On 2024-02-13 18:11:25 -0500, Melanie Plageman wrote:
> Attached is a patch set which refactors BitmapHeapScan such that it
> can use the streaming read API [1]. It also resolves the long-standing
> FIXME in the BitmapHeapScan code suggesting that the skip fetch
> optimization should be pushed into the table AMs. Additionally, it
> moves table scan initialization to after the index scan and bitmap
> initialization.
Thanks for working on this! While I have some quibbles with details, I think
this is quite a bit of progress in the right direction.
> patches 0001-0002 are assorted cleanup needed later in the set.
> patches 0003 moves the table scan initialization to after bitmap creation
> patch 0004 is, I think, a bug fix. see [2].
I'd not quite call it a bugfix, it's not like it leads to wrong
behaviour. Seems more like an optimization. But whatever :)
> The caveat is that these patches introduce breaking changes to two
> table AM functions for bitmapheapscan: table_scan_bitmap_next_block()
> and table_scan_bitmap_next_tuple().
That's to be expected, I don't think it's worth worrying about. Right now a
bunch of TAMs can't implement bitmap scans, this goes a fair bit towards
allowing that...
> From d6dd6eb21dcfbc41208f87d1d81ffe3960130889 Mon Sep 17 00:00:00 2001
> From: Melanie Plageman <melanieplageman@gmail.com>
> Date: Mon, 12 Feb 2024 18:50:29 -0500
> Subject: [PATCH v1 03/11] BitmapHeapScan begin scan after bitmap setup
>
> There is no reason for table_beginscan_bm() to begin the actual scan of
> the underlying table in ExecInitBitmapHeapScan(). We can begin the
> underlying table scan after the index scan has been completed and the
> bitmap built.
>
> The one use of the scan descriptor during initialization was
> ExecBitmapHeapInitializeWorker(), which set the scan descriptor snapshot
> with one from an array in the parallel state. This overwrote the
> snapshot set in table_beginscan_bm().
>
> By saving that worker snapshot as a member in the BitmapHeapScanState
> during initialization, it can be restored in table_beginscan_bm() after
> returning from the table AM specific begin scan function.
I don't understand what the point of passing two different snapshots to
table_beginscan_bm() is. What does that even mean? Why can't we just use the
correct snapshot initially?
> From a3f62e4299663d418531ae61bb16ea39f0836fac Mon Sep 17 00:00:00 2001
> From: Melanie Plageman <melanieplageman@gmail.com>
> Date: Mon, 12 Feb 2024 19:03:24 -0500
> Subject: [PATCH v1 04/11] BitmapPrefetch use prefetch block recheck for skip
> fetch
>
> Previously BitmapPrefetch() used the recheck flag for the current block
> to determine whether or not it could skip prefetching the proposed
> prefetch block. It makes more sense for it to use the recheck flag from
> the TBMIterateResult for the prefetch block instead.
I'd mention the commit that introduced the current logic and link to the
the thread that you started about this.
> From d56be7741765d93002649ef912ef4b8256a5b9af Mon Sep 17 00:00:00 2001
> From: Melanie Plageman <melanieplageman@gmail.com>
> Date: Mon, 12 Feb 2024 19:04:48 -0500
> Subject: [PATCH v1 05/11] Update BitmapAdjustPrefetchIterator parameter type
> to BlockNumber
>
> BitmapAdjustPrefetchIterator() only used the blockno member of the
> passed in TBMIterateResult to ensure that the prefetch iterator and
> regular iterator stay in sync. Pass it the BlockNumber only. This will
> allow us to move away from using the TBMIterateResult outside of table
> AM specific code.
Hm - I'm not convinced this is a good direction - doesn't that arguably
*increase* TAM awareness? Perhaps it doesn't make much sense to use bitmap
heap scans in a TAM without blocks, but still.
> From 202b16d3a381210e8dbee69e68a8310be8ee11d2 Mon Sep 17 00:00:00 2001
> From: Melanie Plageman <melanieplageman@gmail.com>
> Date: Mon, 12 Feb 2024 20:15:05 -0500
> Subject: [PATCH v1 06/11] Push BitmapHeapScan skip fetch optimization into
> table AM
>
> This resolves the long-standing FIXME in BitmapHeapNext() which said that
> the optmization to skip fetching blocks of the underlying table when
> none of the column data was needed should be pushed into the table AM
> specific code.
Long-standing? Sure, it's old enough to walk, but we have FIXMEs that are old
enough to drink, at least in some countries. :)
> The table AM agnostic functions for prefetching still need to know if
> skipping fetching is permitted for this scan. However, this dependency
> will be removed when that prefetching code is removed in favor of the
> upcoming streaming read API.
> ---
> src/backend/access/heap/heapam.c | 10 +++
> src/backend/access/heap/heapam_handler.c | 29 +++++++
> src/backend/executor/nodeBitmapHeapscan.c | 100 ++++++----------------
> src/include/access/heapam.h | 2 +
> src/include/access/tableam.h | 17 ++--
> src/include/nodes/execnodes.h | 6 --
> 6 files changed, 74 insertions(+), 90 deletions(-)
>
> diff --git a/src/backend/access/heap/heapam.c b/src/backend/access/heap/heapam.c
> index 707460a5364..7aae1ecf0a9 100644
> --- a/src/backend/access/heap/heapam.c
> +++ b/src/backend/access/heap/heapam.c
> @@ -955,6 +955,8 @@ heap_beginscan(Relation relation, Snapshot snapshot,
> scan->rs_base.rs_flags = flags;
> scan->rs_base.rs_parallel = parallel_scan;
> scan->rs_strategy = NULL; /* set in initscan */
> + scan->vmbuffer = InvalidBuffer;
> + scan->empty_tuples = 0;
These don't follow the existing naming pattern for HeapScanDescData. While I
explicitly dislike the practice of adding prefixes to struct members, I don't
think mixing conventions within a single struct improves things.
I also think it'd be good to note in comments that the vm buffer currently is
only used for bitmap heap scans, otherwise one might think they'd also be used
for normal scans, where we don't need them, because of the page level flag.
Also, perhaps worth renaming "empty_tuples" to something indicating that it's
the number of empty tuples to be returned later? num_empty_tuples_pending or
such? Or the current "return_empty_tuples".
> @@ -1043,6 +1045,10 @@ heap_rescan(TableScanDesc sscan, ScanKey key, bool set_params,
> if (BufferIsValid(scan->rs_cbuf))
> ReleaseBuffer(scan->rs_cbuf);
>
> + if (BufferIsValid(scan->vmbuffer))
> + ReleaseBuffer(scan->vmbuffer);
> + scan->vmbuffer = InvalidBuffer;
It does not matter one iota here, but personally I prefer moving the write
inside the if, as dirtying the cacheline after we just figured out whe
> diff --git a/src/backend/executor/nodeBitmapHeapscan.c b/src/backend/executor/nodeBitmapHeapscan.c
> index 9372b49bfaa..c0fb06c9688 100644
> --- a/src/backend/executor/nodeBitmapHeapscan.c
> +++ b/src/backend/executor/nodeBitmapHeapscan.c
> @@ -108,6 +108,7 @@ BitmapHeapNext(BitmapHeapScanState *node)
> */
> if (!node->initialized)
> {
> + bool can_skip_fetch;
> /*
> * We can potentially skip fetching heap pages if we do not need any
> * columns of the table, either for checking non-indexable quals or
Pretty sure pgindent will move this around.
> +++ b/src/include/access/tableam.h
> @@ -62,6 +62,7 @@ typedef enum ScanOptions
>
> /* unregister snapshot at scan end? */
> SO_TEMP_SNAPSHOT = 1 << 9,
> + SO_CAN_SKIP_FETCH = 1 << 10,
> } ScanOptions;
Would be nice to add a comment explaining what this flag means.
> From 500c84019b982a1e6c8b8dd40240c8510d83c287 Mon Sep 17 00:00:00 2001
> From: Melanie Plageman <melanieplageman@gmail.com>
> Date: Tue, 13 Feb 2024 10:05:04 -0500
> Subject: [PATCH v1 07/11] BitmapHeapScan scan desc counts lossy and exact
> pages
>
> Future commits will remove the TBMIterateResult from BitmapHeapNext(),
> pushing it into the table AM-specific code. So we will have to keep
> track of the number of lossy and exact pages in the scan descriptor.
> Doing this change to lossy/exact page counting in a separate commit just
> simplifies the diff.
> ---
> src/backend/access/heap/heapam.c | 2 ++
> src/backend/access/heap/heapam_handler.c | 9 +++++++++
> src/backend/executor/nodeBitmapHeapscan.c | 18 +++++++++++++-----
> src/include/access/relscan.h | 4 ++++
> 4 files changed, 28 insertions(+), 5 deletions(-)
>
> diff --git a/src/backend/access/heap/heapam.c b/src/backend/access/heap/heapam.c
> index 7aae1ecf0a9..88b4aad5820 100644
> --- a/src/backend/access/heap/heapam.c
> +++ b/src/backend/access/heap/heapam.c
> @@ -957,6 +957,8 @@ heap_beginscan(Relation relation, Snapshot snapshot,
> scan->rs_strategy = NULL; /* set in initscan */
> scan->vmbuffer = InvalidBuffer;
> scan->empty_tuples = 0;
> + scan->rs_base.lossy_pages = 0;
> + scan->rs_base.exact_pages = 0;
>
> /*
> * Disable page-at-a-time mode if it's not a MVCC-safe snapshot.
> diff --git a/src/backend/access/heap/heapam_handler.c b/src/backend/access/heap/heapam_handler.c
> index baba09c87c0..6e85ef7a946 100644
> --- a/src/backend/access/heap/heapam_handler.c
> +++ b/src/backend/access/heap/heapam_handler.c
> @@ -2242,6 +2242,15 @@ heapam_scan_bitmap_next_block(TableScanDesc scan,
> Assert(ntup <= MaxHeapTuplesPerPage);
> hscan->rs_ntuples = ntup;
>
> + /* Only count exact and lossy pages with visible tuples */
> + if (ntup > 0)
> + {
> + if (tbmres->ntuples >= 0)
> + scan->exact_pages++;
> + else
> + scan->lossy_pages++;
> + }
> +
> return ntup > 0;
> }
>
> diff --git a/src/backend/executor/nodeBitmapHeapscan.c b/src/backend/executor/nodeBitmapHeapscan.c
> index c0fb06c9688..19d115de06f 100644
> --- a/src/backend/executor/nodeBitmapHeapscan.c
> +++ b/src/backend/executor/nodeBitmapHeapscan.c
> @@ -53,6 +53,8 @@
> #include "utils/spccache.h"
>
> static TupleTableSlot *BitmapHeapNext(BitmapHeapScanState *node);
> +static inline void BitmapAccumCounters(BitmapHeapScanState *node,
> + TableScanDesc scan);
> static inline void BitmapDoneInitializingSharedState(ParallelBitmapHeapState *pstate);
> static inline void BitmapAdjustPrefetchIterator(BitmapHeapScanState *node,
> BlockNumber blockno);
> @@ -234,11 +236,6 @@ BitmapHeapNext(BitmapHeapScanState *node)
> continue;
> }
>
> - if (tbmres->ntuples >= 0)
> - node->exact_pages++;
> - else
> - node->lossy_pages++;
> -
> /* Adjust the prefetch target */
> BitmapAdjustPrefetchTarget(node);
> }
> @@ -315,9 +312,20 @@ BitmapHeapNext(BitmapHeapScanState *node)
> /*
> * if we get here it means we are at the end of the scan..
> */
> + BitmapAccumCounters(node, scan);
> return ExecClearTuple(slot);
> }
>
> +static inline void
> +BitmapAccumCounters(BitmapHeapScanState *node,
> + TableScanDesc scan)
> +{
> + node->exact_pages += scan->exact_pages;
> + scan->exact_pages = 0;
> + node->lossy_pages += scan->lossy_pages;
> + scan->lossy_pages = 0;
> +}
> +
I don't think this is quite right - you're calling BitmapAccumCounters() only
when the scan doesn't return anything anymore, but there's no guarantee
that'll ever be reached. E.g. a bitmap heap scan below a limit node. I think
this needs to be in a) ExecEndBitmapHeapScan() b) ExecReScanBitmapHeapScan()
> /*
> * BitmapDoneInitializingSharedState - Shared state is initialized
> *
> diff --git a/src/include/access/relscan.h b/src/include/access/relscan.h
> index 521043304ab..b74e08dd745 100644
> --- a/src/include/access/relscan.h
> +++ b/src/include/access/relscan.h
> @@ -40,6 +40,10 @@ typedef struct TableScanDescData
> ItemPointerData rs_mintid;
> ItemPointerData rs_maxtid;
>
> + /* Only used for Bitmap table scans */
> + long exact_pages;
> + long lossy_pages;
> +
> /*
> * Information about type and behaviour of the scan, a bitmask of members
> * of the ScanOptions enum (see tableam.h).
I wonder if this really is the best place for the data to be accumulated. This
requires the accounting to be implemented in each AM, which doesn't obviously
seem required. Why can't the accounting continue to live in
nodeBitmapHeapscan.c, to be done after each table_scan_bitmap_next_block()
call?
> From 555743e4bc885609d20768f7f2990c6ba69b13a9 Mon Sep 17 00:00:00 2001
> From: Melanie Plageman <melanieplageman@gmail.com>
> Date: Tue, 13 Feb 2024 10:57:07 -0500
> Subject: [PATCH v1 09/11] Make table_scan_bitmap_next_block() async friendly
>
> table_scan_bitmap_next_block() previously returned false if we did not
> wish to call table_scan_bitmap_next_tuple() on the tuples on the page.
> This could happen when there were no visible tuples on the page or, due
> to concurrent activity on the table, the block returned by the iterator
> is past the known end of the table.
This sounds a bit like the block is actually past the end of the table,
but in reality this happens if the block is past the end of the table as it
was when the scan was started. Somehow that feels significant, but I don't
really know why I think that.
> diff --git a/src/backend/access/heap/heapam.c b/src/backend/access/heap/heapam.c
> index 88b4aad5820..d8569373987 100644
> --- a/src/backend/access/heap/heapam.c
> +++ b/src/backend/access/heap/heapam.c
> @@ -959,6 +959,8 @@ heap_beginscan(Relation relation, Snapshot snapshot,
> scan->empty_tuples = 0;
> scan->rs_base.lossy_pages = 0;
> scan->rs_base.exact_pages = 0;
> + scan->rs_base.shared_tbmiterator = NULL;
> + scan->rs_base.tbmiterator = NULL;
>
> /*
> * Disable page-at-a-time mode if it's not a MVCC-safe snapshot.
> @@ -1051,6 +1053,18 @@ heap_rescan(TableScanDesc sscan, ScanKey key, bool set_params,
> ReleaseBuffer(scan->vmbuffer);
> scan->vmbuffer = InvalidBuffer;
>
> + if (scan->rs_base.rs_flags & SO_TYPE_BITMAPSCAN)
> + {
> + if (scan->rs_base.shared_tbmiterator)
> + tbm_end_shared_iterate(scan->rs_base.shared_tbmiterator);
> +
> + if (scan->rs_base.tbmiterator)
> + tbm_end_iterate(scan->rs_base.tbmiterator);
> + }
> +
> + scan->rs_base.shared_tbmiterator = NULL;
> + scan->rs_base.tbmiterator = NULL;
> +
> /*
> * reinitialize scan descriptor
> */
If every AM would need to implement this, perhaps this shouldn't be done here,
but in generic code?
> --- a/src/backend/access/heap/heapam_handler.c
> +++ b/src/backend/access/heap/heapam_handler.c
> @@ -2114,17 +2114,49 @@ heapam_estimate_rel_size(Relation rel, int32 *attr_widths,
>
> static bool
> heapam_scan_bitmap_next_block(TableScanDesc scan,
> - TBMIterateResult *tbmres)
> + bool *recheck, BlockNumber *blockno)
> {
> HeapScanDesc hscan = (HeapScanDesc) scan;
> - BlockNumber block = tbmres->blockno;
> + BlockNumber block;
> Buffer buffer;
> Snapshot snapshot;
> int ntup;
> + TBMIterateResult *tbmres;
>
> hscan->rs_cindex = 0;
> hscan->rs_ntuples = 0;
>
> + *blockno = InvalidBlockNumber;
> + *recheck = true;
> +
> + do
> + {
> + if (scan->shared_tbmiterator)
> + tbmres = tbm_shared_iterate(scan->shared_tbmiterator);
> + else
> + tbmres = tbm_iterate(scan->tbmiterator);
> +
> + if (tbmres == NULL)
> + {
> + /* no more entries in the bitmap */
> + Assert(hscan->empty_tuples == 0);
> + return false;
> + }
> +
> + /*
> + * Ignore any claimed entries past what we think is the end of the
> + * relation. It may have been extended after the start of our scan (we
> + * only hold an AccessShareLock, and it could be inserts from this
> + * backend). We don't take this optimization in SERIALIZABLE
> + * isolation though, as we need to examine all invisible tuples
> + * reachable by the index.
> + */
> + } while (!IsolationIsSerializable() && tbmres->blockno >= hscan->rs_nblocks);
Hm. Isn't it a problem that we have no CHECK_FOR_INTERRUPTS() in this loop?
> @@ -2251,7 +2274,14 @@ heapam_scan_bitmap_next_block(TableScanDesc scan,
> scan->lossy_pages++;
> }
>
> - return ntup > 0;
> + /*
> + * Return true to indicate that a valid block was found and the bitmap is
> + * not exhausted. If there are no visible tuples on this page,
> + * hscan->rs_ntuples will be 0 and heapam_scan_bitmap_next_tuple() will
> + * return false returning control to this function to advance to the next
> + * block in the bitmap.
> + */
> + return true;
> }
Why can't we fetch the next block immediately?
> @@ -201,46 +197,23 @@ BitmapHeapNext(BitmapHeapScanState *node)
> can_skip_fetch);
> }
>
> - node->tbmiterator = tbmiterator;
> - node->shared_tbmiterator = shared_tbmiterator;
> + scan->tbmiterator = tbmiterator;
> + scan->shared_tbmiterator = shared_tbmiterator;
It seems a bit odd that this code modifies the scan descriptor, instead of
passing the iterator, or perhaps better the bitmap itself, to
table_beginscan_bm()?
> diff --git a/src/include/access/relscan.h b/src/include/access/relscan.h
> index b74e08dd745..bf7ee044268 100644
> --- a/src/include/access/relscan.h
> +++ b/src/include/access/relscan.h
> @@ -16,6 +16,7 @@
>
> #include "access/htup_details.h"
> #include "access/itup.h"
> +#include "nodes/tidbitmap.h"
I'd like to avoid exposing this to everything including relscan.h. I think we
could just forward declare the structs and use them here to avoid that?
> From aac60985d6bc70bfedf77a77ee3c512da87bfcb1 Mon Sep 17 00:00:00 2001
> From: Melanie Plageman <melanieplageman@gmail.com>
> Date: Tue, 13 Feb 2024 14:27:57 -0500
> Subject: [PATCH v1 11/11] BitmapHeapScan uses streaming read API
>
> Remove all of the code to do prefetching from BitmapHeapScan code and
> rely on the streaming read API prefetching. Heap table AM implements a
> streaming read callback which uses the iterator to get the next valid
> block that needs to be fetched for the streaming read API.
> ---
> src/backend/access/gin/ginget.c | 15 +-
> src/backend/access/gin/ginscan.c | 7 +
> src/backend/access/heap/heapam.c | 71 +++++
> src/backend/access/heap/heapam_handler.c | 78 +++--
> src/backend/executor/nodeBitmapHeapscan.c | 328 +---------------------
> src/backend/nodes/tidbitmap.c | 80 +++---
> src/include/access/heapam.h | 2 +
> src/include/access/tableam.h | 14 +-
> src/include/nodes/execnodes.h | 19 --
> src/include/nodes/tidbitmap.h | 8 +-
> 10 files changed, 178 insertions(+), 444 deletions(-)
>
> diff --git a/src/backend/access/gin/ginget.c b/src/backend/access/gin/ginget.c
> index 0b4f2ebadb6..3ce28078a6f 100644
> --- a/src/backend/access/gin/ginget.c
> +++ b/src/backend/access/gin/ginget.c
> @@ -373,7 +373,10 @@ restartScanEntry:
> if (entry->matchBitmap)
> {
> if (entry->matchIterator)
> + {
> tbm_end_iterate(entry->matchIterator);
> + pfree(entry->matchResult);
> + }
> entry->matchIterator = NULL;
> tbm_free(entry->matchBitmap);
> entry->matchBitmap = NULL;
> @@ -386,6 +389,7 @@ restartScanEntry:
> if (entry->matchBitmap && !tbm_is_empty(entry->matchBitmap))
> {
> entry->matchIterator = tbm_begin_iterate(entry->matchBitmap);
> + entry->matchResult = palloc0(TBM_ITERATE_RESULT_SIZE);
Do we actually have to use palloc0? TBM_ITERATE_RESULT_SIZE ain't small, so
zeroing all of it isn't free.
> +static BlockNumber bitmapheap_pgsr_next_single(PgStreamingRead *pgsr, void *pgsr_private,
> + void *per_buffer_data);
Is it correct to have _single in the name here? Aren't we also using for
parallel scans?
> +static BlockNumber
> +bitmapheap_pgsr_next_single(PgStreamingRead *pgsr, void *pgsr_private,
> + void *per_buffer_data)
> +{
> + TBMIterateResult *tbmres = per_buffer_data;
> + HeapScanDesc hdesc = (HeapScanDesc) pgsr_private;
> +
> + for (;;)
> + {
> + if (hdesc->rs_base.shared_tbmiterator)
> + tbm_shared_iterate(hdesc->rs_base.shared_tbmiterator, tbmres);
> + else
> + tbm_iterate(hdesc->rs_base.tbmiterator, tbmres);
> +
> + /* no more entries in the bitmap */
> + if (!BlockNumberIsValid(tbmres->blockno))
> + return InvalidBlockNumber;
> +
> + /*
> + * Ignore any claimed entries past what we think is the end of the
> + * relation. It may have been extended after the start of our scan (we
> + * only hold an AccessShareLock, and it could be inserts from this
> + * backend). We don't take this optimization in SERIALIZABLE
> + * isolation though, as we need to examine all invisible tuples
> + * reachable by the index.
> + */
> + if (!IsolationIsSerializable() && tbmres->blockno >= hdesc->rs_nblocks)
> + continue;
> +
> +
> + if (hdesc->rs_base.rs_flags & SO_CAN_SKIP_FETCH &&
> + !tbmres->recheck &&
> + VM_ALL_VISIBLE(hdesc->rs_base.rs_rd, tbmres->blockno, &hdesc->vmbuffer))
> + {
> + hdesc->empty_tuples += tbmres->ntuples;
> + continue;
> + }
> +
> + return tbmres->blockno;
> + }
> +
> + /* not reachable */
> + Assert(false);
> +}
Need to check for interrupts somewhere here.
> @@ -124,15 +119,6 @@ BitmapHeapNext(BitmapHeapScanState *node)
There's still a comment in BitmapHeapNext talking about prefetching with two
iterators etc. That seems outdated now.
> /*
> * tbm_iterate - scan through next page of a TIDBitmap
> *
> - * Returns a TBMIterateResult representing one page, or NULL if there are
> - * no more pages to scan. Pages are guaranteed to be delivered in numerical
> - * order. If result->ntuples < 0, then the bitmap is "lossy" and failed to
> - * remember the exact tuples to look at on this page --- the caller must
> - * examine all tuples on the page and check if they meet the intended
> - * condition. If result->recheck is true, only the indicated tuples need
> - * be examined, but the condition must be rechecked anyway. (For ease of
> - * testing, recheck is always set true when ntuples < 0.)
> + * Caller must pass in a TBMIterateResult to be filled.
> + *
> + * Pages are guaranteed to be delivered in numerical order. tbmres->blockno is
> + * set to InvalidBlockNumber when there are no more pages to scan. If
> + * tbmres->ntuples < 0, then the bitmap is "lossy" and failed to remember the
> + * exact tuples to look at on this page --- the caller must examine all tuples
> + * on the page and check if they meet the intended condition. If
> + * tbmres->recheck is true, only the indicated tuples need be examined, but the
> + * condition must be rechecked anyway. (For ease of testing, recheck is always
> + * set true when ntuples < 0.)
> */
> -TBMIterateResult *
> -tbm_iterate(TBMIterator *iterator)
> +void
> +tbm_iterate(TBMIterator *iterator, TBMIterateResult *tbmres)
Hm - it seems a tad odd that we later have to find out if the scan is done
iterating by checking if blockno is valid, when tbm_iterate already knew. But
I guess the code would be a bit uglier if we needed the result of
tbm_[shared_]iterate(), due to the two functions.
Right now ExecEndBitmapHeapScan() frees the tbm before it does table_endscan()
- which seems problematic, as heap_endscan() will do stuff like
tbm_end_iterate(), which imo shouldn't be called after the tbm has been freed,
even if that works today.
It seems a bit confusing that your changes seem to treat
BitmapHeapScanState->initialized as separate from ->scan, even though afaict
scan should be NULL iff initialized is false and vice versa.
Independent of your patches, but brr, it's ugly that
BitmapShouldInitializeSharedState() blocks.
Greetings,
Andres Freund
Thank you so much for this thorough review!!!!
On Wed, Feb 14, 2024 at 2:42 PM Andres Freund <andres@anarazel.de> wrote:
>
>
> On 2024-02-13 18:11:25 -0500, Melanie Plageman wrote:
>
> > From d6dd6eb21dcfbc41208f87d1d81ffe3960130889 Mon Sep 17 00:00:00 2001
> > From: Melanie Plageman <melanieplageman@gmail.com>
> > Date: Mon, 12 Feb 2024 18:50:29 -0500
> > Subject: [PATCH v1 03/11] BitmapHeapScan begin scan after bitmap setup
> >
> > There is no reason for table_beginscan_bm() to begin the actual scan of
> > the underlying table in ExecInitBitmapHeapScan(). We can begin the
> > underlying table scan after the index scan has been completed and the
> > bitmap built.
> >
> > The one use of the scan descriptor during initialization was
> > ExecBitmapHeapInitializeWorker(), which set the scan descriptor snapshot
> > with one from an array in the parallel state. This overwrote the
> > snapshot set in table_beginscan_bm().
> >
> > By saving that worker snapshot as a member in the BitmapHeapScanState
> > during initialization, it can be restored in table_beginscan_bm() after
> > returning from the table AM specific begin scan function.
>
> I don't understand what the point of passing two different snapshots to
> table_beginscan_bm() is. What does that even mean? Why can't we just use the
> correct snapshot initially?
Indeed. Honestly, it was an unlabeled TODO for me. I wasn't quite sure
how to get the same behavior as in master. Fixed in attached v2.
Now the parallel worker still restores and registers that snapshot in
ExecBitmapHeapInitializeWorker() and then saves it in the
BitmapHeapScanState. We then pass SO_TEMP_SNAPSHOT as an extra flag
(to set rs_flags) to table_beginscan_bm() if there is a parallel
worker snapshot saved in the BitmapHeapScanState.
> > From a3f62e4299663d418531ae61bb16ea39f0836fac Mon Sep 17 00:00:00 2001
> > From: Melanie Plageman <melanieplageman@gmail.com>
> > Date: Mon, 12 Feb 2024 19:03:24 -0500
> > Subject: [PATCH v1 04/11] BitmapPrefetch use prefetch block recheck for skip
> > fetch
> >
> > Previously BitmapPrefetch() used the recheck flag for the current block
> > to determine whether or not it could skip prefetching the proposed
> > prefetch block. It makes more sense for it to use the recheck flag from
> > the TBMIterateResult for the prefetch block instead.
>
> I'd mention the commit that introduced the current logic and link to the
> the thread that you started about this.
Done
> > From d56be7741765d93002649ef912ef4b8256a5b9af Mon Sep 17 00:00:00 2001
> > From: Melanie Plageman <melanieplageman@gmail.com>
> > Date: Mon, 12 Feb 2024 19:04:48 -0500
> > Subject: [PATCH v1 05/11] Update BitmapAdjustPrefetchIterator parameter type
> > to BlockNumber
> >
> > BitmapAdjustPrefetchIterator() only used the blockno member of the
> > passed in TBMIterateResult to ensure that the prefetch iterator and
> > regular iterator stay in sync. Pass it the BlockNumber only. This will
> > allow us to move away from using the TBMIterateResult outside of table
> > AM specific code.
>
> Hm - I'm not convinced this is a good direction - doesn't that arguably
> *increase* TAM awareness? Perhaps it doesn't make much sense to use bitmap
> heap scans in a TAM without blocks, but still.
This is removed in later commits and is an intermediate state to try
and move the TBMIterateResult out of BitmapHeapNext(). I can find
another way to achieve this if it is important.
> > From 202b16d3a381210e8dbee69e68a8310be8ee11d2 Mon Sep 17 00:00:00 2001
> > From: Melanie Plageman <melanieplageman@gmail.com>
> > Date: Mon, 12 Feb 2024 20:15:05 -0500
> > Subject: [PATCH v1 06/11] Push BitmapHeapScan skip fetch optimization into
> > table AM
> >
> > This resolves the long-standing FIXME in BitmapHeapNext() which said that
> > the optmization to skip fetching blocks of the underlying table when
> > none of the column data was needed should be pushed into the table AM
> > specific code.
>
> Long-standing? Sure, it's old enough to walk, but we have FIXMEs that are old
> enough to drink, at least in some countries. :)
;) I've updated the commit message. Though it is longstanding in that
it predates Melanie + Postgres.
> > The table AM agnostic functions for prefetching still need to know if
> > skipping fetching is permitted for this scan. However, this dependency
> > will be removed when that prefetching code is removed in favor of the
> > upcoming streaming read API.
>
> > ---
> > src/backend/access/heap/heapam.c | 10 +++
> > src/backend/access/heap/heapam_handler.c | 29 +++++++
> > src/backend/executor/nodeBitmapHeapscan.c | 100 ++++++----------------
> > src/include/access/heapam.h | 2 +
> > src/include/access/tableam.h | 17 ++--
> > src/include/nodes/execnodes.h | 6 --
> > 6 files changed, 74 insertions(+), 90 deletions(-)
> >
> > diff --git a/src/backend/access/heap/heapam.c b/src/backend/access/heap/heapam.c
> > index 707460a5364..7aae1ecf0a9 100644
> > --- a/src/backend/access/heap/heapam.c
> > +++ b/src/backend/access/heap/heapam.c
> > @@ -955,6 +955,8 @@ heap_beginscan(Relation relation, Snapshot snapshot,
> > scan->rs_base.rs_flags = flags;
> > scan->rs_base.rs_parallel = parallel_scan;
> > scan->rs_strategy = NULL; /* set in initscan */
> > + scan->vmbuffer = InvalidBuffer;
> > + scan->empty_tuples = 0;
>
> These don't follow the existing naming pattern for HeapScanDescData. While I
> explicitly dislike the practice of adding prefixes to struct members, I don't
> think mixing conventions within a single struct improves things.
I've updated the names. What does rs even stand for?
> I also think it'd be good to note in comments that the vm buffer currently is
> only used for bitmap heap scans, otherwise one might think they'd also be used
> for normal scans, where we don't need them, because of the page level flag.
Done.
> Also, perhaps worth renaming "empty_tuples" to something indicating that it's
> the number of empty tuples to be returned later? num_empty_tuples_pending or
> such? Or the current "return_empty_tuples".
Done.
> > @@ -1043,6 +1045,10 @@ heap_rescan(TableScanDesc sscan, ScanKey key, bool set_params,
> > if (BufferIsValid(scan->rs_cbuf))
> > ReleaseBuffer(scan->rs_cbuf);
> >
> > + if (BufferIsValid(scan->vmbuffer))
> > + ReleaseBuffer(scan->vmbuffer);
> > + scan->vmbuffer = InvalidBuffer;
>
> It does not matter one iota here, but personally I prefer moving the write
> inside the if, as dirtying the cacheline after we just figured out whe
I've now followed this convention throughout my patchset in the places
where I noticed it.
> > diff --git a/src/backend/executor/nodeBitmapHeapscan.c b/src/backend/executor/nodeBitmapHeapscan.c
> > index 9372b49bfaa..c0fb06c9688 100644
> > --- a/src/backend/executor/nodeBitmapHeapscan.c
> > +++ b/src/backend/executor/nodeBitmapHeapscan.c
> > @@ -108,6 +108,7 @@ BitmapHeapNext(BitmapHeapScanState *node)
> > */
> > if (!node->initialized)
> > {
> > + bool can_skip_fetch;
> > /*
> > * We can potentially skip fetching heap pages if we do not need any
> > * columns of the table, either for checking non-indexable quals or
>
> Pretty sure pgindent will move this around.
This is gone now, but I have pgindented all the commits so it
shouldn't be a problem again.
> > +++ b/src/include/access/tableam.h
> > @@ -62,6 +62,7 @@ typedef enum ScanOptions
> >
> > /* unregister snapshot at scan end? */
> > SO_TEMP_SNAPSHOT = 1 << 9,
> > + SO_CAN_SKIP_FETCH = 1 << 10,
> > } ScanOptions;
>
> Would be nice to add a comment explaining what this flag means.
Done.
> > From 500c84019b982a1e6c8b8dd40240c8510d83c287 Mon Sep 17 00:00:00 2001
> > From: Melanie Plageman <melanieplageman@gmail.com>
> > Date: Tue, 13 Feb 2024 10:05:04 -0500
> > Subject: [PATCH v1 07/11] BitmapHeapScan scan desc counts lossy and exact
> > pages
> >
> > Future commits will remove the TBMIterateResult from BitmapHeapNext(),
> > pushing it into the table AM-specific code. So we will have to keep
> > track of the number of lossy and exact pages in the scan descriptor.
> > Doing this change to lossy/exact page counting in a separate commit just
> > simplifies the diff.
>
> > ---
> > src/backend/access/heap/heapam.c | 2 ++
> > src/backend/access/heap/heapam_handler.c | 9 +++++++++
> > src/backend/executor/nodeBitmapHeapscan.c | 18 +++++++++++++-----
> > src/include/access/relscan.h | 4 ++++
> > 4 files changed, 28 insertions(+), 5 deletions(-)
> >
> > diff --git a/src/backend/access/heap/heapam.c b/src/backend/access/heap/heapam.c
> > index 7aae1ecf0a9..88b4aad5820 100644
> > --- a/src/backend/access/heap/heapam.c
> > +++ b/src/backend/access/heap/heapam.c
> > @@ -957,6 +957,8 @@ heap_beginscan(Relation relation, Snapshot snapshot,
> > scan->rs_strategy = NULL; /* set in initscan */
> > scan->vmbuffer = InvalidBuffer;
> > scan->empty_tuples = 0;
> > + scan->rs_base.lossy_pages = 0;
> > + scan->rs_base.exact_pages = 0;
> >
> > /*
> > * Disable page-at-a-time mode if it's not a MVCC-safe snapshot.
> > diff --git a/src/backend/access/heap/heapam_handler.c b/src/backend/access/heap/heapam_handler.c
> > index baba09c87c0..6e85ef7a946 100644
> > --- a/src/backend/access/heap/heapam_handler.c
> > +++ b/src/backend/access/heap/heapam_handler.c
> > @@ -2242,6 +2242,15 @@ heapam_scan_bitmap_next_block(TableScanDesc scan,
> > Assert(ntup <= MaxHeapTuplesPerPage);
> > hscan->rs_ntuples = ntup;
> >
> > + /* Only count exact and lossy pages with visible tuples */
> > + if (ntup > 0)
> > + {
> > + if (tbmres->ntuples >= 0)
> > + scan->exact_pages++;
> > + else
> > + scan->lossy_pages++;
> > + }
> > +
> > return ntup > 0;
> > }
> >
> > diff --git a/src/backend/executor/nodeBitmapHeapscan.c b/src/backend/executor/nodeBitmapHeapscan.c
> > index c0fb06c9688..19d115de06f 100644
> > --- a/src/backend/executor/nodeBitmapHeapscan.c
> > +++ b/src/backend/executor/nodeBitmapHeapscan.c
> > @@ -53,6 +53,8 @@
> > #include "utils/spccache.h"
> >
> > static TupleTableSlot *BitmapHeapNext(BitmapHeapScanState *node);
> > +static inline void BitmapAccumCounters(BitmapHeapScanState *node,
> > + TableScanDesc scan);
> > static inline void BitmapDoneInitializingSharedState(ParallelBitmapHeapState *pstate);
> > static inline void BitmapAdjustPrefetchIterator(BitmapHeapScanState *node,
> > BlockNumber blockno);
> > @@ -234,11 +236,6 @@ BitmapHeapNext(BitmapHeapScanState *node)
> > continue;
> > }
> >
> > - if (tbmres->ntuples >= 0)
> > - node->exact_pages++;
> > - else
> > - node->lossy_pages++;
> > -
> > /* Adjust the prefetch target */
> > BitmapAdjustPrefetchTarget(node);
> > }
> > @@ -315,9 +312,20 @@ BitmapHeapNext(BitmapHeapScanState *node)
> > /*
> > * if we get here it means we are at the end of the scan..
> > */
> > + BitmapAccumCounters(node, scan);
> > return ExecClearTuple(slot);
> > }
> >
> > +static inline void
> > +BitmapAccumCounters(BitmapHeapScanState *node,
> > + TableScanDesc scan)
> > +{
> > + node->exact_pages += scan->exact_pages;
> > + scan->exact_pages = 0;
> > + node->lossy_pages += scan->lossy_pages;
> > + scan->lossy_pages = 0;
> > +}
> > +
>
> I don't think this is quite right - you're calling BitmapAccumCounters() only
> when the scan doesn't return anything anymore, but there's no guarantee
> that'll ever be reached. E.g. a bitmap heap scan below a limit node. I think
> this needs to be in a) ExecEndBitmapHeapScan() b) ExecReScanBitmapHeapScan()
The scan descriptor isn't available in ExecEnd/ReScanBitmapHeapScan().
So, if we count in the scan descriptor we can't accumulate into the
BitmapHeapScanState there. The reason to count in the scan descriptor
is that it is in the table AM where we know if we have a lossy or
exact page -- and we only have the scan descriptor not the
BitmapHeapScanState in the table AM.
I added a call to BitmapAccumCounters before the tuple is returned for
correctness in this version (not ideal, I realize). See below for
thoughts about what we could do instead.
> > /*
> > * BitmapDoneInitializingSharedState - Shared state is initialized
> > *
> > diff --git a/src/include/access/relscan.h b/src/include/access/relscan.h
> > index 521043304ab..b74e08dd745 100644
> > --- a/src/include/access/relscan.h
> > +++ b/src/include/access/relscan.h
> > @@ -40,6 +40,10 @@ typedef struct TableScanDescData
> > ItemPointerData rs_mintid;
> > ItemPointerData rs_maxtid;
> >
> > + /* Only used for Bitmap table scans */
> > + long exact_pages;
> > + long lossy_pages;
> > +
> > /*
> > * Information about type and behaviour of the scan, a bitmask of members
> > * of the ScanOptions enum (see tableam.h).
>
> I wonder if this really is the best place for the data to be accumulated. This
> requires the accounting to be implemented in each AM, which doesn't obviously
> seem required. Why can't the accounting continue to live in
> nodeBitmapHeapscan.c, to be done after each table_scan_bitmap_next_block()
> call?
Yes, I would really prefer not to do it in the table AM. But, we only
count exact and lossy pages for which at least one or more tuples were
visible (change this and you'll see tests fail). So, we need to decide
if we are going to increment the counters somewhere where we have
access to that information. In the case of heap, that is really only
once I have the value of ntup in heapam_scan_bitmap_next_block(). To
get that information back out to BitmapHeapNext(), I considered adding
another parameter to heapam_scan_bitmap_next_block() -- maybe an enum
like this:
/*
* BitmapHeapScans's bitmaps can choose to store per page information in a
* lossy or exact way. Exact pages in the bitmap have the individual tuple
* offsets that need to be visited while lossy pages in the bitmap have only the
* block number of the page.
*/
typedef enum BitmapBlockResolution
{
BITMAP_BLOCK_NO_VISIBLE,
BITMAP_BLOCK_LOSSY,
BITMAP_BLOCK_EXACT,
} BitmapBlockResolution;
which we then use to increment the counter. But while I was writing
this code, I found myself narrating in the comment that the reason
this had to be set inside of the table AM is that only the table AM
knows if it wants to count the block as lossy, exact, or not count it.
So, that made me question if it really should be in the
BitmapHeapScanState.
I also explored passing the table scan descriptor to
show_tidbitmap_info() -- but that had its own problems.
> > From 555743e4bc885609d20768f7f2990c6ba69b13a9 Mon Sep 17 00:00:00 2001
> > From: Melanie Plageman <melanieplageman@gmail.com>
> > Date: Tue, 13 Feb 2024 10:57:07 -0500
> > Subject: [PATCH v1 09/11] Make table_scan_bitmap_next_block() async friendly
> >
> > table_scan_bitmap_next_block() previously returned false if we did not
> > wish to call table_scan_bitmap_next_tuple() on the tuples on the page.
> > This could happen when there were no visible tuples on the page or, due
> > to concurrent activity on the table, the block returned by the iterator
> > is past the known end of the table.
>
> This sounds a bit like the block is actually past the end of the table,
> but in reality this happens if the block is past the end of the table as it
> was when the scan was started. Somehow that feels significant, but I don't
> really know why I think that.
I have tried to update the commit message to make it clearer. I was
actually wondering: now that we do table_beginscan_bm() in
BitmapHeapNext() instead of ExecInitBitmapHeapScan(), have we reduced
or eliminated the opportunity for this to be true? initscan() sets
rs_nblocks and that now happens much later.
> > diff --git a/src/backend/access/heap/heapam.c b/src/backend/access/heap/heapam.c
> > index 88b4aad5820..d8569373987 100644
> > --- a/src/backend/access/heap/heapam.c
> > +++ b/src/backend/access/heap/heapam.c
> > @@ -959,6 +959,8 @@ heap_beginscan(Relation relation, Snapshot snapshot,
> > scan->empty_tuples = 0;
> > scan->rs_base.lossy_pages = 0;
> > scan->rs_base.exact_pages = 0;
> > + scan->rs_base.shared_tbmiterator = NULL;
> > + scan->rs_base.tbmiterator = NULL;
> >
> > /*
> > * Disable page-at-a-time mode if it's not a MVCC-safe snapshot.
> > @@ -1051,6 +1053,18 @@ heap_rescan(TableScanDesc sscan, ScanKey key, bool set_params,
> > ReleaseBuffer(scan->vmbuffer);
> > scan->vmbuffer = InvalidBuffer;
> >
> > + if (scan->rs_base.rs_flags & SO_TYPE_BITMAPSCAN)
> > + {
> > + if (scan->rs_base.shared_tbmiterator)
> > + tbm_end_shared_iterate(scan->rs_base.shared_tbmiterator);
> > +
> > + if (scan->rs_base.tbmiterator)
> > + tbm_end_iterate(scan->rs_base.tbmiterator);
> > + }
> > +
> > + scan->rs_base.shared_tbmiterator = NULL;
> > + scan->rs_base.tbmiterator = NULL;
> > +
> > /*
> > * reinitialize scan descriptor
> > */
>
> If every AM would need to implement this, perhaps this shouldn't be done here,
> but in generic code?
Fixed.
> > --- a/src/backend/access/heap/heapam_handler.c
> > +++ b/src/backend/access/heap/heapam_handler.c
> > @@ -2114,17 +2114,49 @@ heapam_estimate_rel_size(Relation rel, int32 *attr_widths,
> >
> > static bool
> > heapam_scan_bitmap_next_block(TableScanDesc scan,
> > - TBMIterateResult *tbmres)
> > + bool *recheck, BlockNumber *blockno)
> > {
> > HeapScanDesc hscan = (HeapScanDesc) scan;
> > - BlockNumber block = tbmres->blockno;
> > + BlockNumber block;
> > Buffer buffer;
> > Snapshot snapshot;
> > int ntup;
> > + TBMIterateResult *tbmres;
> >
> > hscan->rs_cindex = 0;
> > hscan->rs_ntuples = 0;
> >
> > + *blockno = InvalidBlockNumber;
> > + *recheck = true;
> > +
> > + do
> > + {
> > + if (scan->shared_tbmiterator)
> > + tbmres = tbm_shared_iterate(scan->shared_tbmiterator);
> > + else
> > + tbmres = tbm_iterate(scan->tbmiterator);
> > +
> > + if (tbmres == NULL)
> > + {
> > + /* no more entries in the bitmap */
> > + Assert(hscan->empty_tuples == 0);
> > + return false;
> > + }
> > +
> > + /*
> > + * Ignore any claimed entries past what we think is the end of the
> > + * relation. It may have been extended after the start of our scan (we
> > + * only hold an AccessShareLock, and it could be inserts from this
> > + * backend). We don't take this optimization in SERIALIZABLE
> > + * isolation though, as we need to examine all invisible tuples
> > + * reachable by the index.
> > + */
> > + } while (!IsolationIsSerializable() && tbmres->blockno >= hscan->rs_nblocks);
>
> Hm. Isn't it a problem that we have no CHECK_FOR_INTERRUPTS() in this loop?
Yes. fixed.
> > @@ -2251,7 +2274,14 @@ heapam_scan_bitmap_next_block(TableScanDesc scan,
> > scan->lossy_pages++;
> > }
> >
> > - return ntup > 0;
> > + /*
> > + * Return true to indicate that a valid block was found and the bitmap is
> > + * not exhausted. If there are no visible tuples on this page,
> > + * hscan->rs_ntuples will be 0 and heapam_scan_bitmap_next_tuple() will
> > + * return false returning control to this function to advance to the next
> > + * block in the bitmap.
> > + */
> > + return true;
> > }
>
> Why can't we fetch the next block immediately?
We don't know that we want another block until we've gone through this
page and seen there were no visible tuples, so we'd somehow have to
jump back up to the top of the function to get the next block -- which
is basically what is happening in my revised control flow. We call
heapam_scan_bitmap_next_tuple() and rs_ntuples is 0, so we end up
calling heapam_scan_bitmap_next_block() right away.
> > @@ -201,46 +197,23 @@ BitmapHeapNext(BitmapHeapScanState *node)
> >
can_skip_fetch);
> > }
> >
> > - node->tbmiterator = tbmiterator;
> > - node->shared_tbmiterator = shared_tbmiterator;
> > + scan->tbmiterator = tbmiterator;
> > + scan->shared_tbmiterator = shared_tbmiterator;
>
> It seems a bit odd that this code modifies the scan descriptor, instead of
> passing the iterator, or perhaps better the bitmap itself, to
> table_beginscan_bm()?
On rescan we actually will have initialized = false and make new
iterators but have the old scan descriptor. So, we need to be able to
set the iterator in the scan to the new iterator.
> > diff --git a/src/include/access/relscan.h b/src/include/access/relscan.h
> > index b74e08dd745..bf7ee044268 100644
> > --- a/src/include/access/relscan.h
> > +++ b/src/include/access/relscan.h
> > @@ -16,6 +16,7 @@
> >
> > #include "access/htup_details.h"
> > #include "access/itup.h"
> > +#include "nodes/tidbitmap.h"
>
> I'd like to avoid exposing this to everything including relscan.h. I think we
> could just forward declare the structs and use them here to avoid that?
Done
> > From aac60985d6bc70bfedf77a77ee3c512da87bfcb1 Mon Sep 17 00:00:00 2001
> > From: Melanie Plageman <melanieplageman@gmail.com>
> > Date: Tue, 13 Feb 2024 14:27:57 -0500
> > Subject: [PATCH v1 11/11] BitmapHeapScan uses streaming read API
> >
> > Remove all of the code to do prefetching from BitmapHeapScan code and
> > rely on the streaming read API prefetching. Heap table AM implements a
> > streaming read callback which uses the iterator to get the next valid
> > block that needs to be fetched for the streaming read API.
> > ---
> > src/backend/access/gin/ginget.c | 15 +-
> > src/backend/access/gin/ginscan.c | 7 +
> > src/backend/access/heap/heapam.c | 71 +++++
> > src/backend/access/heap/heapam_handler.c | 78 +++--
> > src/backend/executor/nodeBitmapHeapscan.c | 328 +---------------------
> > src/backend/nodes/tidbitmap.c | 80 +++---
> > src/include/access/heapam.h | 2 +
> > src/include/access/tableam.h | 14 +-
> > src/include/nodes/execnodes.h | 19 --
> > src/include/nodes/tidbitmap.h | 8 +-
> > 10 files changed, 178 insertions(+), 444 deletions(-)
> >
> > diff --git a/src/backend/access/gin/ginget.c b/src/backend/access/gin/ginget.c
> > index 0b4f2ebadb6..3ce28078a6f 100644
> > --- a/src/backend/access/gin/ginget.c
> > +++ b/src/backend/access/gin/ginget.c
> > @@ -373,7 +373,10 @@ restartScanEntry:
> > if (entry->matchBitmap)
> > {
> > if (entry->matchIterator)
> > + {
> > tbm_end_iterate(entry->matchIterator);
> > + pfree(entry->matchResult);
> > + }
> > entry->matchIterator = NULL;
> > tbm_free(entry->matchBitmap);
> > entry->matchBitmap = NULL;
> > @@ -386,6 +389,7 @@ restartScanEntry:
> > if (entry->matchBitmap && !tbm_is_empty(entry->matchBitmap))
> > {
> > entry->matchIterator = tbm_begin_iterate(entry->matchBitmap);
> > + entry->matchResult = palloc0(TBM_ITERATE_RESULT_SIZE);
>
> Do we actually have to use palloc0? TBM_ITERATE_RESULT_SIZE ain't small, so
> zeroing all of it isn't free.
Tests actually did fail when I didn't use palloc0.
This code is different now though. There are a few new patches in v2
that 1) make the offsets array in the TBMIterateResult fixed size and
then this makes it possible to 2) make matchResult an inline member of
the GinScanEntry. I have a TODO in the code asking if setting blockno
in the TBMIterateResult to InvalidBlockNumber is sufficient
"resetting".
> > +static BlockNumber bitmapheap_pgsr_next_single(PgStreamingRead *pgsr, void *pgsr_private,
> > + void *per_buffer_data);
>
> Is it correct to have _single in the name here? Aren't we also using for
> parallel scans?
Right. I had a separate parallel version and then deleted it. This is now fixed.
> > +static BlockNumber
> > +bitmapheap_pgsr_next_single(PgStreamingRead *pgsr, void *pgsr_private,
> > + void *per_buffer_data)
> > +{
> > + TBMIterateResult *tbmres = per_buffer_data;
> > + HeapScanDesc hdesc = (HeapScanDesc) pgsr_private;
> > +
> > + for (;;)
> > + {
> > + if (hdesc->rs_base.shared_tbmiterator)
> > + tbm_shared_iterate(hdesc->rs_base.shared_tbmiterator, tbmres);
> > + else
> > + tbm_iterate(hdesc->rs_base.tbmiterator, tbmres);
> > +
> > + /* no more entries in the bitmap */
> > + if (!BlockNumberIsValid(tbmres->blockno))
> > + return InvalidBlockNumber;
> > +
> > + /*
> > + * Ignore any claimed entries past what we think is the end of the
> > + * relation. It may have been extended after the start of our scan (we
> > + * only hold an AccessShareLock, and it could be inserts from this
> > + * backend). We don't take this optimization in SERIALIZABLE
> > + * isolation though, as we need to examine all invisible tuples
> > + * reachable by the index.
> > + */
> > + if (!IsolationIsSerializable() && tbmres->blockno >= hdesc->rs_nblocks)
> > + continue;
> > +
> > +
> > + if (hdesc->rs_base.rs_flags & SO_CAN_SKIP_FETCH &&
> > + !tbmres->recheck &&
> > + VM_ALL_VISIBLE(hdesc->rs_base.rs_rd, tbmres->blockno, &hdesc->vmbuffer))
> > + {
> > + hdesc->empty_tuples += tbmres->ntuples;
> > + continue;
> > + }
> > +
> > + return tbmres->blockno;
> > + }
> > +
> > + /* not reachable */
> > + Assert(false);
> > +}
>
> Need to check for interrupts somewhere here.
Done.
> > @@ -124,15 +119,6 @@ BitmapHeapNext(BitmapHeapScanState *node)
>
> There's still a comment in BitmapHeapNext talking about prefetching with two
> iterators etc. That seems outdated now.
Fixed.
> > /*
> > * tbm_iterate - scan through next page of a TIDBitmap
> > *
> > - * Returns a TBMIterateResult representing one page, or NULL if there are
> > - * no more pages to scan. Pages are guaranteed to be delivered in numerical
> > - * order. If result->ntuples < 0, then the bitmap is "lossy" and failed to
> > - * remember the exact tuples to look at on this page --- the caller must
> > - * examine all tuples on the page and check if they meet the intended
> > - * condition. If result->recheck is true, only the indicated tuples need
> > - * be examined, but the condition must be rechecked anyway. (For ease of
> > - * testing, recheck is always set true when ntuples < 0.)
> > + * Caller must pass in a TBMIterateResult to be filled.
> > + *
> > + * Pages are guaranteed to be delivered in numerical order. tbmres->blockno is
> > + * set to InvalidBlockNumber when there are no more pages to scan. If
> > + * tbmres->ntuples < 0, then the bitmap is "lossy" and failed to remember the
> > + * exact tuples to look at on this page --- the caller must examine all tuples
> > + * on the page and check if they meet the intended condition. If
> > + * tbmres->recheck is true, only the indicated tuples need be examined, but the
> > + * condition must be rechecked anyway. (For ease of testing, recheck is always
> > + * set true when ntuples < 0.)
> > */
> > -TBMIterateResult *
> > -tbm_iterate(TBMIterator *iterator)
> > +void
> > +tbm_iterate(TBMIterator *iterator, TBMIterateResult *tbmres)
>
> Hm - it seems a tad odd that we later have to find out if the scan is done
> iterating by checking if blockno is valid, when tbm_iterate already knew. But
> I guess the code would be a bit uglier if we needed the result of
> tbm_[shared_]iterate(), due to the two functions.
Yes.
> Right now ExecEndBitmapHeapScan() frees the tbm before it does table_endscan()
> - which seems problematic, as heap_endscan() will do stuff like
> tbm_end_iterate(), which imo shouldn't be called after the tbm has been freed,
> even if that works today.
I've flipped the order -- I end the scan then free the bitmap.
> It seems a bit confusing that your changes seem to treat
> BitmapHeapScanState->initialized as separate from ->scan, even though afaict
> scan should be NULL iff initialized is false and vice versa.
I thought so too, but it seems on rescan that the node->initialized is
set to false but the scan is reused. So, we want to only make a new
scan descriptor if it is truly the beginning of a new scan.
- Melanie
Attachment
- v2-0003-BitmapHeapScan-begin-scan-after-bitmap-setup.patch
- v2-0001-Remove-table_scan_bitmap_next_tuple-parameter-tbm.patch
- v2-0004-BitmapPrefetch-use-prefetch-block-recheck-for-ski.patch
- v2-0002-BitmapHeapScan-set-can_skip_fetch-later.patch
- v2-0005-Update-BitmapAdjustPrefetchIterator-parameter-typ.patch
- v2-0007-BitmapHeapScan-scan-desc-counts-lossy-and-exact-p.patch
- v2-0006-Push-BitmapHeapScan-skip-fetch-optimization-into-.patch
- v2-0008-Reduce-scope-of-BitmapHeapScan-tbmiterator-local-.patch
- v2-0009-Make-table_scan_bitmap_next_block-async-friendly.patch
- v2-0011-Separate-TBM-Shared-Iterator-and-TBMIterateResult.patch
- v2-0012-Streaming-Read-API.patch
- v2-0010-Hard-code-TBMIterateResult-offsets-array-size.patch
- v2-0013-BitmapHeapScan-uses-streaming-read-API.patch
In the attached v3, I've reordered the commits, updated some errant comments, and improved the commit messages. I've also made some updates to the TIDBitmap API that seem like a clarity improvement to the API in general. These also reduce the diff for GIN when separating the TBMIterateResult from the TBM[Shared]Iterator. And these TIDBitmap API changes are now all in their own commits (previously those were in the same commit as adding the BitmapHeapScan streaming read user). The three outstanding issues I see in the patch set are: 1) the lossy and exact page counters issue described in my previous email 2) the TODO in the TIDBitmap API changes about being sure that setting TBMIterateResult->blockno to InvalidBlockNumber is sufficient for indicating an invalid TBMIterateResult (and an exhausted bitmap) 3) the streaming read API is not committed yet, so the last two patches are not "done" - Melanie
Attachment
- v3-0001-BitmapHeapScan-begin-scan-after-bitmap-creation.patch
- v3-0002-BitmapHeapScan-set-can_skip_fetch-later.patch
- v3-0003-Push-BitmapHeapScan-skip-fetch-optimization-into-.patch
- v3-0004-BitmapPrefetch-use-prefetch-block-recheck-for-ski.patch
- v3-0005-Update-BitmapAdjustPrefetchIterator-parameter-typ.patch
- v3-0006-BitmapHeapScan-scan-desc-counts-lossy-and-exact-p.patch
- v3-0007-Reduce-scope-of-BitmapHeapScan-tbmiterator-local-.patch
- v3-0008-Remove-table_scan_bitmap_next_tuple-parameter-tbm.patch
- v3-0009-Make-table_scan_bitmap_next_block-async-friendly.patch
- v3-0010-Hard-code-TBMIterateResult-offsets-array-size.patch
- v3-0011-Separate-TBM-Shared-Iterator-and-TBMIterateResult.patch
- v3-0012-Streaming-Read-API.patch
- v3-0013-BitmapHeapScan-uses-streaming-read-API.patch
On Fri, Feb 16, 2024 at 12:35:59PM -0500, Melanie Plageman wrote: > In the attached v3, I've reordered the commits, updated some errant > comments, and improved the commit messages. > > I've also made some updates to the TIDBitmap API that seem like a > clarity improvement to the API in general. These also reduce the diff > for GIN when separating the TBMIterateResult from the > TBM[Shared]Iterator. And these TIDBitmap API changes are now all in > their own commits (previously those were in the same commit as adding > the BitmapHeapScan streaming read user). > > The three outstanding issues I see in the patch set are: > 1) the lossy and exact page counters issue described in my previous > email I've resolved this. I added a new patch to the set which starts counting even pages with no visible tuples toward lossy and exact pages. After an off-list conversation with Andres, it seems that this omission in master may not have been intentional. Once we have only two types of pages to differentiate between (lossy and exact [no longer have to care about "has no visible tuples"]), it is easy enough to pass a "lossy" boolean paramater to table_scan_bitmap_next_block(). I've done this in the attached v4. - Melanie
Attachment
- v4-0004-BitmapPrefetch-use-prefetch-block-recheck-for-ski.patch
- v4-0001-BitmapHeapScan-begin-scan-after-bitmap-creation.patch
- v4-0002-BitmapHeapScan-set-can_skip_fetch-later.patch
- v4-0003-Push-BitmapHeapScan-skip-fetch-optimization-into-.patch
- v4-0005-Update-BitmapAdjustPrefetchIterator-parameter-typ.patch
- v4-0006-EXPLAIN-Bitmap-table-scan-also-count-no-visible-t.patch
- v4-0007-table_scan_bitmap_next_block-returns-lossy-or-exa.patch
- v4-0008-Reduce-scope-of-BitmapHeapScan-tbmiterator-local-.patch
- v4-0009-Remove-table_scan_bitmap_next_tuple-parameter-tbm.patch
- v4-0010-Make-table_scan_bitmap_next_block-async-friendly.patch
- v4-0011-Hard-code-TBMIterateResult-offsets-array-size.patch
- v4-0012-Separate-TBM-Shared-Iterator-and-TBMIterateResult.patch
- v4-0013-Streaming-Read-API.patch
- v4-0014-BitmapHeapScan-uses-streaming-read-API.patch
On Mon, Feb 26, 2024 at 08:50:28PM -0500, Melanie Plageman wrote: > On Fri, Feb 16, 2024 at 12:35:59PM -0500, Melanie Plageman wrote: > > In the attached v3, I've reordered the commits, updated some errant > > comments, and improved the commit messages. > > > > I've also made some updates to the TIDBitmap API that seem like a > > clarity improvement to the API in general. These also reduce the diff > > for GIN when separating the TBMIterateResult from the > > TBM[Shared]Iterator. And these TIDBitmap API changes are now all in > > their own commits (previously those were in the same commit as adding > > the BitmapHeapScan streaming read user). > > > > The three outstanding issues I see in the patch set are: > > 1) the lossy and exact page counters issue described in my previous > > email > > I've resolved this. I added a new patch to the set which starts counting > even pages with no visible tuples toward lossy and exact pages. After an > off-list conversation with Andres, it seems that this omission in master > may not have been intentional. > > Once we have only two types of pages to differentiate between (lossy and > exact [no longer have to care about "has no visible tuples"]), it is > easy enough to pass a "lossy" boolean paramater to > table_scan_bitmap_next_block(). I've done this in the attached v4. Thomas posted a new version of the Streaming Read API [1], so here is a rebased v5. This should make it easier to review as it can be applied on top of master. - Melanie [1] https://www.postgresql.org/message-id/CA%2BhUKGJtLyxcAEvLhVUhgD4fMQkOu3PDaj8Qb9SR_UsmzgsBpQ%40mail.gmail.com
Attachment
- v5-0001-BitmapHeapScan-begin-scan-after-bitmap-creation.patch
- v5-0002-BitmapHeapScan-set-can_skip_fetch-later.patch
- v5-0003-Push-BitmapHeapScan-skip-fetch-optimization-into-.patch
- v5-0004-BitmapPrefetch-use-prefetch-block-recheck-for-ski.patch
- v5-0005-Update-BitmapAdjustPrefetchIterator-parameter-typ.patch
- v5-0006-EXPLAIN-Bitmap-table-scan-also-count-no-visible-t.patch
- v5-0007-table_scan_bitmap_next_block-returns-lossy-or-exa.patch
- v5-0008-Reduce-scope-of-BitmapHeapScan-tbmiterator-local-.patch
- v5-0009-Remove-table_scan_bitmap_next_tuple-parameter-tbm.patch
- v5-0010-Make-table_scan_bitmap_next_block-async-friendly.patch
- v5-0011-Hard-code-TBMIterateResult-offsets-array-size.patch
- v5-0012-Separate-TBM-Shared-Iterator-and-TBMIterateResult.patch
- v5-0013-Streaming-Read-API.patch
- v5-0014-BitmapHeapScan-uses-streaming-read-API.patch
Hi, I haven't looked at the code very closely yet, but I decided to do some basic benchmarks to see if/how this refactoring affects behavior. Attached is a simple .sh script that 1) creates a table with one of a couple basic data distributions (uniform, linear, ...), with an index on top 2) runs a simple query with a where condition matching a known fraction of the table (0 - 100%), and measures duration 3) the query is forced to use bitmapscan by disabling other options 4) there's a couple parameters the script varies (work_mem, parallel workers, ...), the script drops caches etc. 5) I only have results for table with 1M rows, which is ~320MB, so not huge. I'm running this for larger data set, but that will take time. I did this on my two "usual" machines - i5 and xeon. Both have flash storage, although i5 is SATA and xeon has NVMe. I won't share the raw results, because the CSV is like 5MB - ping me off-list if you need the file, ofc. Attached is PDF summarizing the results as a pivot table, with results for "master" and "patched" builds. The interesting bit is the last column, which shows whether the patch makes it faster (green) or slower (red). The results seem pretty mixed, on both machines. If you focus on the uncached results (pages 4 and 8-9), there's both runs that are much faster (by a factor of 2-5x) and slower (similar factor). Of course, these results are with forced bitmap scans, so the question is if those regressions even matter - maybe we'd use a different scan type, making these changes less severe. So I logged "optimal plan" for each run, tracking the scan type the optimizer would really pick without all the enable_* GUCs. And the -optimal.pdf shows only results for the runs where the optimal plan uses the bitmap scan. And yes, while the impact of the changes (in either direction) is reduced, it's still very much there. What's a bit surprising to me is that these regressions affect runs with effective_io_concurrency=0 in particular, which traditionally meant to not do any prefetching / async stuff. I've perceived the patch mostly as refactoring, so have not really expected such massive impact on these cases. So I wonder if the refactoring means that we're actually doing some sort amount of prefetching even with e_i_c=0. I'm not sure that'd be great, I assume people have valid reasons to disable prefetching ... regards -- Tomas Vondra EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
Attachment
On Wed, Feb 28, 2024 at 8:22 AM Tomas Vondra <tomas.vondra@enterprisedb.com> wrote: > > Hi, > > I haven't looked at the code very closely yet, but I decided to do some > basic benchmarks to see if/how this refactoring affects behavior. > > Attached is a simple .sh script that > > 1) creates a table with one of a couple basic data distributions > (uniform, linear, ...), with an index on top > > 2) runs a simple query with a where condition matching a known fraction > of the table (0 - 100%), and measures duration > > 3) the query is forced to use bitmapscan by disabling other options > > 4) there's a couple parameters the script varies (work_mem, parallel > workers, ...), the script drops caches etc. > > 5) I only have results for table with 1M rows, which is ~320MB, so not > huge. I'm running this for larger data set, but that will take time. > > > I did this on my two "usual" machines - i5 and xeon. Both have flash > storage, although i5 is SATA and xeon has NVMe. I won't share the raw > results, because the CSV is like 5MB - ping me off-list if you need the > file, ofc. I haven't looked at your results in detail yet. I plan to dig into this more later today. But, I was wondering if it was easy for you to run the shorter tests on just the commits before the last https://github.com/melanieplageman/postgres/tree/bhs_pgsr i.e. patches 0001-0013. Patch 0014 implements the streaming read user and removes all of the existing prefetch code. I would be interested to know if the behavior with just the preliminary refactoring differs at all. - Melanie
On 2/28/24 15:38, Melanie Plageman wrote: > On Wed, Feb 28, 2024 at 8:22 AM Tomas Vondra > <tomas.vondra@enterprisedb.com> wrote: >> >> Hi, >> >> I haven't looked at the code very closely yet, but I decided to do some >> basic benchmarks to see if/how this refactoring affects behavior. >> >> Attached is a simple .sh script that >> >> 1) creates a table with one of a couple basic data distributions >> (uniform, linear, ...), with an index on top >> >> 2) runs a simple query with a where condition matching a known fraction >> of the table (0 - 100%), and measures duration >> >> 3) the query is forced to use bitmapscan by disabling other options >> >> 4) there's a couple parameters the script varies (work_mem, parallel >> workers, ...), the script drops caches etc. >> >> 5) I only have results for table with 1M rows, which is ~320MB, so not >> huge. I'm running this for larger data set, but that will take time. >> >> >> I did this on my two "usual" machines - i5 and xeon. Both have flash >> storage, although i5 is SATA and xeon has NVMe. I won't share the raw >> results, because the CSV is like 5MB - ping me off-list if you need the >> file, ofc. > > I haven't looked at your results in detail yet. I plan to dig into > this more later today. But, I was wondering if it was easy for you to > run the shorter tests on just the commits before the last > https://github.com/melanieplageman/postgres/tree/bhs_pgsr > i.e. patches 0001-0013. Patch 0014 implements the streaming read user > and removes all of the existing prefetch code. I would be interested > to know if the behavior with just the preliminary refactoring differs > at all. > Sure, I can do that. It'll take a couple hours to get the results, I'll share them when I have them. regards -- Tomas Vondra EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On 2/28/24 15:56, Tomas Vondra wrote: >> ... > > Sure, I can do that. It'll take a couple hours to get the results, I'll > share them when I have them. > Here are the results with only patches 0001 - 0012 applied (i.e. without the patch introducing the streaming read API, and the patch switching the bitmap heap scan to use it). The changes in performance don't disappear entirely, but the scale is certainly much smaller - both in the complete results for all runs, and for the "optimal" runs that would actually pick bitmapscan. FWIW I'm not implying the patch must 100% maintain the current behavior, or anything like that. At this point I'm more motivated to understand if this change in behavior is expected and/or what this means for users. regards -- Tomas Vondra EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
Attachment
On Wed, Feb 28, 2024 at 2:23 PM Tomas Vondra <tomas.vondra@enterprisedb.com> wrote: > > On 2/28/24 15:56, Tomas Vondra wrote: > >> ... > > > > Sure, I can do that. It'll take a couple hours to get the results, I'll > > share them when I have them. > > > > Here are the results with only patches 0001 - 0012 applied (i.e. without > the patch introducing the streaming read API, and the patch switching > the bitmap heap scan to use it). > > The changes in performance don't disappear entirely, but the scale is > certainly much smaller - both in the complete results for all runs, and > for the "optimal" runs that would actually pick bitmapscan. Hmm. I'm trying to think how my refactor could have had this impact. It seems like all the most notable regressions are with 4 parallel workers. What do the numeric column labels mean across the top (2,4,8,16...) -- are they related to "matches"? And if so, what does that mean? - Melanie
On 2/28/24 21:06, Melanie Plageman wrote: > On Wed, Feb 28, 2024 at 2:23 PM Tomas Vondra > <tomas.vondra@enterprisedb.com> wrote: >> >> On 2/28/24 15:56, Tomas Vondra wrote: >>>> ... >>> >>> Sure, I can do that. It'll take a couple hours to get the results, I'll >>> share them when I have them. >>> >> >> Here are the results with only patches 0001 - 0012 applied (i.e. without >> the patch introducing the streaming read API, and the patch switching >> the bitmap heap scan to use it). >> >> The changes in performance don't disappear entirely, but the scale is >> certainly much smaller - both in the complete results for all runs, and >> for the "optimal" runs that would actually pick bitmapscan. > > Hmm. I'm trying to think how my refactor could have had this impact. > It seems like all the most notable regressions are with 4 parallel > workers. What do the numeric column labels mean across the top > (2,4,8,16...) -- are they related to "matches"? And if so, what does > that mean? > That's the number of distinct values matched by the query, which should be an approximation of the number of matching rows. The number of distinct values in the data set differs by data set, but for 1M rows it's roughly like this: uniform: 10k linear: 10k cyclic: 100 So for example matches=128 means ~1% of rows for uniform/linear, and 100% for cyclic data sets. As for the possible cause, I think it's clear most of the difference comes from the last patch that actually switches bitmap heap scan to the streaming read API. That's mostly expected/understandable, although we probably need to look into the regressions or cases with e_i_c=0. To analyze the 0001-0012 patches, maybe it'd be helpful to run tests for individual patches. I can try doing that tomorrow. It'll have to be a limited set of tests, to reduce the time, but might tell us whether it's due to a single patch or multiple patches. regards -- Tomas Vondra EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On Wed, Feb 28, 2024 at 6:17 PM Tomas Vondra <tomas.vondra@enterprisedb.com> wrote: > > > > On 2/28/24 21:06, Melanie Plageman wrote: > > On Wed, Feb 28, 2024 at 2:23 PM Tomas Vondra > > <tomas.vondra@enterprisedb.com> wrote: > >> > >> On 2/28/24 15:56, Tomas Vondra wrote: > >>>> ... > >>> > >>> Sure, I can do that. It'll take a couple hours to get the results, I'll > >>> share them when I have them. > >>> > >> > >> Here are the results with only patches 0001 - 0012 applied (i.e. without > >> the patch introducing the streaming read API, and the patch switching > >> the bitmap heap scan to use it). > >> > >> The changes in performance don't disappear entirely, but the scale is > >> certainly much smaller - both in the complete results for all runs, and > >> for the "optimal" runs that would actually pick bitmapscan. > > > > Hmm. I'm trying to think how my refactor could have had this impact. > > It seems like all the most notable regressions are with 4 parallel > > workers. What do the numeric column labels mean across the top > > (2,4,8,16...) -- are they related to "matches"? And if so, what does > > that mean? > > > > That's the number of distinct values matched by the query, which should > be an approximation of the number of matching rows. The number of > distinct values in the data set differs by data set, but for 1M rows > it's roughly like this: > > uniform: 10k > linear: 10k > cyclic: 100 > > So for example matches=128 means ~1% of rows for uniform/linear, and > 100% for cyclic data sets. Ah, thank you for the explanation. I also looked at your script after having sent this email and saw that it is clear in your script what "matches" is. > As for the possible cause, I think it's clear most of the difference > comes from the last patch that actually switches bitmap heap scan to the > streaming read API. That's mostly expected/understandable, although we > probably need to look into the regressions or cases with e_i_c=0. Right, I'm mostly surprised about the regressions for patches 0001-0012. Re eic 0: Thomas Munro and I chatted off-list, and you bring up a great point about eic 0. In old bitmapheapscan code eic 0 basically disabled prefetching but with the streaming read API, it will still issue fadvises when eic is 0. That is an easy one line fix. Thomas prefers to fix it by always avoiding an fadvise for the last buffer in a range before issuing a read (since we are about to read it anyway, best not fadvise it too). This will fix eic 0 and also cut one system call from each invocation of the streaming read machinery. > To analyze the 0001-0012 patches, maybe it'd be helpful to run tests for > individual patches. I can try doing that tomorrow. It'll have to be a > limited set of tests, to reduce the time, but might tell us whether it's > due to a single patch or multiple patches. Yes, tomorrow I planned to start trying to repro some of the "red" cases myself. Any one of the commits could cause a slight regression but a 3.5x regression is quite surprising, so I might focus on trying to repro that locally and then narrow down which patch causes it. For the non-cached regressions, perhaps the commit to use the correct recheck flag (0004) when prefetching could be the culprit. And for the cached regressions, my money is on the commit which changes the whole control flow of BitmapHeapNext() and the next_block() and next_tuple() functions (0010). - Melanie
On 2/29/24 00:40, Melanie Plageman wrote: > On Wed, Feb 28, 2024 at 6:17 PM Tomas Vondra > <tomas.vondra@enterprisedb.com> wrote: >> >> >> >> On 2/28/24 21:06, Melanie Plageman wrote: >>> On Wed, Feb 28, 2024 at 2:23 PM Tomas Vondra >>> <tomas.vondra@enterprisedb.com> wrote: >>>> >>>> On 2/28/24 15:56, Tomas Vondra wrote: >>>>>> ... >>>>> >>>>> Sure, I can do that. It'll take a couple hours to get the results, I'll >>>>> share them when I have them. >>>>> >>>> >>>> Here are the results with only patches 0001 - 0012 applied (i.e. without >>>> the patch introducing the streaming read API, and the patch switching >>>> the bitmap heap scan to use it). >>>> >>>> The changes in performance don't disappear entirely, but the scale is >>>> certainly much smaller - both in the complete results for all runs, and >>>> for the "optimal" runs that would actually pick bitmapscan. >>> >>> Hmm. I'm trying to think how my refactor could have had this impact. >>> It seems like all the most notable regressions are with 4 parallel >>> workers. What do the numeric column labels mean across the top >>> (2,4,8,16...) -- are they related to "matches"? And if so, what does >>> that mean? >>> >> >> That's the number of distinct values matched by the query, which should >> be an approximation of the number of matching rows. The number of >> distinct values in the data set differs by data set, but for 1M rows >> it's roughly like this: >> >> uniform: 10k >> linear: 10k >> cyclic: 100 >> >> So for example matches=128 means ~1% of rows for uniform/linear, and >> 100% for cyclic data sets. > > Ah, thank you for the explanation. I also looked at your script after > having sent this email and saw that it is clear in your script what > "matches" is. > >> As for the possible cause, I think it's clear most of the difference >> comes from the last patch that actually switches bitmap heap scan to the >> streaming read API. That's mostly expected/understandable, although we >> probably need to look into the regressions or cases with e_i_c=0. > > Right, I'm mostly surprised about the regressions for patches 0001-0012. > > Re eic 0: Thomas Munro and I chatted off-list, and you bring up a > great point about eic 0. In old bitmapheapscan code eic 0 basically > disabled prefetching but with the streaming read API, it will still > issue fadvises when eic is 0. That is an easy one line fix. Thomas > prefers to fix it by always avoiding an fadvise for the last buffer in > a range before issuing a read (since we are about to read it anyway, > best not fadvise it too). This will fix eic 0 and also cut one system > call from each invocation of the streaming read machinery. > >> To analyze the 0001-0012 patches, maybe it'd be helpful to run tests for >> individual patches. I can try doing that tomorrow. It'll have to be a >> limited set of tests, to reduce the time, but might tell us whether it's >> due to a single patch or multiple patches. > > Yes, tomorrow I planned to start trying to repro some of the "red" > cases myself. Any one of the commits could cause a slight regression > but a 3.5x regression is quite surprising, so I might focus on trying > to repro that locally and then narrow down which patch causes it. > > For the non-cached regressions, perhaps the commit to use the correct > recheck flag (0004) when prefetching could be the culprit. And for the > cached regressions, my money is on the commit which changes the whole > control flow of BitmapHeapNext() and the next_block() and next_tuple() > functions (0010). > I do have some partial results, comparing the patches. I only ran one of the more affected workloads (cyclic) on the xeon, attached is a PDF comparing master and the 0001-0014 patches. The percentages are timing vs. the preceding patch (green - faster, red - slower). This suggests only patches 0010 and 0014 affect performance, the rest is just noise. I'll see if I can do more runs and get data from the other machine (seems it's more significant on old SATA SSDs). regards -- Tomas Vondra EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
Attachment
On Thu, Feb 29, 2024 at 7:54 AM Tomas Vondra <tomas.vondra@enterprisedb.com> wrote: > > > > On 2/29/24 00:40, Melanie Plageman wrote: > > On Wed, Feb 28, 2024 at 6:17 PM Tomas Vondra > > <tomas.vondra@enterprisedb.com> wrote: > >> > >> > >> > >> On 2/28/24 21:06, Melanie Plageman wrote: > >>> On Wed, Feb 28, 2024 at 2:23 PM Tomas Vondra > >>> <tomas.vondra@enterprisedb.com> wrote: > >>>> > >>>> On 2/28/24 15:56, Tomas Vondra wrote: > >>>>>> ... > >>>>> > >>>>> Sure, I can do that. It'll take a couple hours to get the results, I'll > >>>>> share them when I have them. > >>>>> > >>>> > >>>> Here are the results with only patches 0001 - 0012 applied (i.e. without > >>>> the patch introducing the streaming read API, and the patch switching > >>>> the bitmap heap scan to use it). > >>>> > >>>> The changes in performance don't disappear entirely, but the scale is > >>>> certainly much smaller - both in the complete results for all runs, and > >>>> for the "optimal" runs that would actually pick bitmapscan. > >>> > >>> Hmm. I'm trying to think how my refactor could have had this impact. > >>> It seems like all the most notable regressions are with 4 parallel > >>> workers. What do the numeric column labels mean across the top > >>> (2,4,8,16...) -- are they related to "matches"? And if so, what does > >>> that mean? > >>> > >> > >> That's the number of distinct values matched by the query, which should > >> be an approximation of the number of matching rows. The number of > >> distinct values in the data set differs by data set, but for 1M rows > >> it's roughly like this: > >> > >> uniform: 10k > >> linear: 10k > >> cyclic: 100 > >> > >> So for example matches=128 means ~1% of rows for uniform/linear, and > >> 100% for cyclic data sets. > > > > Ah, thank you for the explanation. I also looked at your script after > > having sent this email and saw that it is clear in your script what > > "matches" is. > > > >> As for the possible cause, I think it's clear most of the difference > >> comes from the last patch that actually switches bitmap heap scan to the > >> streaming read API. That's mostly expected/understandable, although we > >> probably need to look into the regressions or cases with e_i_c=0. > > > > Right, I'm mostly surprised about the regressions for patches 0001-0012. > > > > Re eic 0: Thomas Munro and I chatted off-list, and you bring up a > > great point about eic 0. In old bitmapheapscan code eic 0 basically > > disabled prefetching but with the streaming read API, it will still > > issue fadvises when eic is 0. That is an easy one line fix. Thomas > > prefers to fix it by always avoiding an fadvise for the last buffer in > > a range before issuing a read (since we are about to read it anyway, > > best not fadvise it too). This will fix eic 0 and also cut one system > > call from each invocation of the streaming read machinery. > > > >> To analyze the 0001-0012 patches, maybe it'd be helpful to run tests for > >> individual patches. I can try doing that tomorrow. It'll have to be a > >> limited set of tests, to reduce the time, but might tell us whether it's > >> due to a single patch or multiple patches. > > > > Yes, tomorrow I planned to start trying to repro some of the "red" > > cases myself. Any one of the commits could cause a slight regression > > but a 3.5x regression is quite surprising, so I might focus on trying > > to repro that locally and then narrow down which patch causes it. > > > > For the non-cached regressions, perhaps the commit to use the correct > > recheck flag (0004) when prefetching could be the culprit. And for the > > cached regressions, my money is on the commit which changes the whole > > control flow of BitmapHeapNext() and the next_block() and next_tuple() > > functions (0010). > > > > I do have some partial results, comparing the patches. I only ran one of > the more affected workloads (cyclic) on the xeon, attached is a PDF > comparing master and the 0001-0014 patches. The percentages are timing > vs. the preceding patch (green - faster, red - slower). Just confirming: the results are for uncached? - Melanie
On 2/29/24 22:19, Melanie Plageman wrote: > On Thu, Feb 29, 2024 at 7:54 AM Tomas Vondra > <tomas.vondra@enterprisedb.com> wrote: >> >> >> >> On 2/29/24 00:40, Melanie Plageman wrote: >>> On Wed, Feb 28, 2024 at 6:17 PM Tomas Vondra >>> <tomas.vondra@enterprisedb.com> wrote: >>>> >>>> >>>> >>>> On 2/28/24 21:06, Melanie Plageman wrote: >>>>> On Wed, Feb 28, 2024 at 2:23 PM Tomas Vondra >>>>> <tomas.vondra@enterprisedb.com> wrote: >>>>>> >>>>>> On 2/28/24 15:56, Tomas Vondra wrote: >>>>>>>> ... >>>>>>> >>>>>>> Sure, I can do that. It'll take a couple hours to get the results, I'll >>>>>>> share them when I have them. >>>>>>> >>>>>> >>>>>> Here are the results with only patches 0001 - 0012 applied (i.e. without >>>>>> the patch introducing the streaming read API, and the patch switching >>>>>> the bitmap heap scan to use it). >>>>>> >>>>>> The changes in performance don't disappear entirely, but the scale is >>>>>> certainly much smaller - both in the complete results for all runs, and >>>>>> for the "optimal" runs that would actually pick bitmapscan. >>>>> >>>>> Hmm. I'm trying to think how my refactor could have had this impact. >>>>> It seems like all the most notable regressions are with 4 parallel >>>>> workers. What do the numeric column labels mean across the top >>>>> (2,4,8,16...) -- are they related to "matches"? And if so, what does >>>>> that mean? >>>>> >>>> >>>> That's the number of distinct values matched by the query, which should >>>> be an approximation of the number of matching rows. The number of >>>> distinct values in the data set differs by data set, but for 1M rows >>>> it's roughly like this: >>>> >>>> uniform: 10k >>>> linear: 10k >>>> cyclic: 100 >>>> >>>> So for example matches=128 means ~1% of rows for uniform/linear, and >>>> 100% for cyclic data sets. >>> >>> Ah, thank you for the explanation. I also looked at your script after >>> having sent this email and saw that it is clear in your script what >>> "matches" is. >>> >>>> As for the possible cause, I think it's clear most of the difference >>>> comes from the last patch that actually switches bitmap heap scan to the >>>> streaming read API. That's mostly expected/understandable, although we >>>> probably need to look into the regressions or cases with e_i_c=0. >>> >>> Right, I'm mostly surprised about the regressions for patches 0001-0012. >>> >>> Re eic 0: Thomas Munro and I chatted off-list, and you bring up a >>> great point about eic 0. In old bitmapheapscan code eic 0 basically >>> disabled prefetching but with the streaming read API, it will still >>> issue fadvises when eic is 0. That is an easy one line fix. Thomas >>> prefers to fix it by always avoiding an fadvise for the last buffer in >>> a range before issuing a read (since we are about to read it anyway, >>> best not fadvise it too). This will fix eic 0 and also cut one system >>> call from each invocation of the streaming read machinery. >>> >>>> To analyze the 0001-0012 patches, maybe it'd be helpful to run tests for >>>> individual patches. I can try doing that tomorrow. It'll have to be a >>>> limited set of tests, to reduce the time, but might tell us whether it's >>>> due to a single patch or multiple patches. >>> >>> Yes, tomorrow I planned to start trying to repro some of the "red" >>> cases myself. Any one of the commits could cause a slight regression >>> but a 3.5x regression is quite surprising, so I might focus on trying >>> to repro that locally and then narrow down which patch causes it. >>> >>> For the non-cached regressions, perhaps the commit to use the correct >>> recheck flag (0004) when prefetching could be the culprit. And for the >>> cached regressions, my money is on the commit which changes the whole >>> control flow of BitmapHeapNext() and the next_block() and next_tuple() >>> functions (0010). >>> >> >> I do have some partial results, comparing the patches. I only ran one of >> the more affected workloads (cyclic) on the xeon, attached is a PDF >> comparing master and the 0001-0014 patches. The percentages are timing >> vs. the preceding patch (green - faster, red - slower). > > Just confirming: the results are for uncached? > Yes, cyclic data set, uncached case. I picked this because it seemed like one of the most affected cases. Do you want me to test some other cases too? regards -- Tomas Vondra EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On 2/29/24 23:44, Tomas Vondra wrote: > > ... > >>> >>> I do have some partial results, comparing the patches. I only ran one of >>> the more affected workloads (cyclic) on the xeon, attached is a PDF >>> comparing master and the 0001-0014 patches. The percentages are timing >>> vs. the preceding patch (green - faster, red - slower). >> >> Just confirming: the results are for uncached? >> > > Yes, cyclic data set, uncached case. I picked this because it seemed > like one of the most affected cases. Do you want me to test some other > cases too? > BTW I decided to look at the data from a slightly different angle and compare the behavior with increasing effective_io_concurrency. Attached are charts for three "uncached" cases: * uniform, work_mem=4MB, workers_per_gather=0 * linear-fuzz, work_mem=4MB, workers_per_gather=0 * uniform, work_mem=4MB, workers_per_gather=4 Each page has charts for master and patched build (with all patches). I think there's a pretty obvious difference in how increasing e_i_c affects the two builds: 1) On master there's clear difference between eic=0 and eic=1 cases, but on the patched build there's literally no difference - for example the "uniform" distribution is clearly not great for prefetching, but eic=0 regresses to eic=1 poor behavior). Note: This is where the the "red bands" in the charts come from. 2) For some reason, the prefetching with eic>1 perform much better with the patches, except for with very low selectivity values (close to 0%). Not sure why this is happening - either the overhead is much lower (which would matter on these "adversarial" data distribution, but how could that be when fadvise is not free), or it ends up not doing any prefetching (but then what about (1)?). 3) I'm not sure about the linear-fuzz case, the only explanation I have we're able to skip almost all of the prefetches (and read-ahead likely works pretty well here). regards -- Tomas Vondra EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
Attachment
On Thu, Feb 29, 2024 at 5:44 PM Tomas Vondra
<tomas.vondra@enterprisedb.com> wrote:
>
>
>
> On 2/29/24 22:19, Melanie Plageman wrote:
> > On Thu, Feb 29, 2024 at 7:54 AM Tomas Vondra
> > <tomas.vondra@enterprisedb.com> wrote:
> >>
> >>
> >>
> >> On 2/29/24 00:40, Melanie Plageman wrote:
> >>> On Wed, Feb 28, 2024 at 6:17 PM Tomas Vondra
> >>> <tomas.vondra@enterprisedb.com> wrote:
> >>>>
> >>>>
> >>>>
> >>>> On 2/28/24 21:06, Melanie Plageman wrote:
> >>>>> On Wed, Feb 28, 2024 at 2:23 PM Tomas Vondra
> >>>>> <tomas.vondra@enterprisedb.com> wrote:
> >>>>>>
> >>>>>> On 2/28/24 15:56, Tomas Vondra wrote:
> >>>>>>>> ...
> >>>>>>>
> >>>>>>> Sure, I can do that. It'll take a couple hours to get the results, I'll
> >>>>>>> share them when I have them.
> >>>>>>>
> >>>>>>
> >>>>>> Here are the results with only patches 0001 - 0012 applied (i.e. without
> >>>>>> the patch introducing the streaming read API, and the patch switching
> >>>>>> the bitmap heap scan to use it).
> >>>>>>
> >>>>>> The changes in performance don't disappear entirely, but the scale is
> >>>>>> certainly much smaller - both in the complete results for all runs, and
> >>>>>> for the "optimal" runs that would actually pick bitmapscan.
> >>>>>
> >>>>> Hmm. I'm trying to think how my refactor could have had this impact.
> >>>>> It seems like all the most notable regressions are with 4 parallel
> >>>>> workers. What do the numeric column labels mean across the top
> >>>>> (2,4,8,16...) -- are they related to "matches"? And if so, what does
> >>>>> that mean?
> >>>>>
> >>>>
> >>>> That's the number of distinct values matched by the query, which should
> >>>> be an approximation of the number of matching rows. The number of
> >>>> distinct values in the data set differs by data set, but for 1M rows
> >>>> it's roughly like this:
> >>>>
> >>>> uniform: 10k
> >>>> linear: 10k
> >>>> cyclic: 100
> >>>>
> >>>> So for example matches=128 means ~1% of rows for uniform/linear, and
> >>>> 100% for cyclic data sets.
> >>>
> >>> Ah, thank you for the explanation. I also looked at your script after
> >>> having sent this email and saw that it is clear in your script what
> >>> "matches" is.
> >>>
> >>>> As for the possible cause, I think it's clear most of the difference
> >>>> comes from the last patch that actually switches bitmap heap scan to the
> >>>> streaming read API. That's mostly expected/understandable, although we
> >>>> probably need to look into the regressions or cases with e_i_c=0.
> >>>
> >>> Right, I'm mostly surprised about the regressions for patches 0001-0012.
> >>>
> >>> Re eic 0: Thomas Munro and I chatted off-list, and you bring up a
> >>> great point about eic 0. In old bitmapheapscan code eic 0 basically
> >>> disabled prefetching but with the streaming read API, it will still
> >>> issue fadvises when eic is 0. That is an easy one line fix. Thomas
> >>> prefers to fix it by always avoiding an fadvise for the last buffer in
> >>> a range before issuing a read (since we are about to read it anyway,
> >>> best not fadvise it too). This will fix eic 0 and also cut one system
> >>> call from each invocation of the streaming read machinery.
> >>>
> >>>> To analyze the 0001-0012 patches, maybe it'd be helpful to run tests for
> >>>> individual patches. I can try doing that tomorrow. It'll have to be a
> >>>> limited set of tests, to reduce the time, but might tell us whether it's
> >>>> due to a single patch or multiple patches.
> >>>
> >>> Yes, tomorrow I planned to start trying to repro some of the "red"
> >>> cases myself. Any one of the commits could cause a slight regression
> >>> but a 3.5x regression is quite surprising, so I might focus on trying
> >>> to repro that locally and then narrow down which patch causes it.
> >>>
> >>> For the non-cached regressions, perhaps the commit to use the correct
> >>> recheck flag (0004) when prefetching could be the culprit. And for the
> >>> cached regressions, my money is on the commit which changes the whole
> >>> control flow of BitmapHeapNext() and the next_block() and next_tuple()
> >>> functions (0010).
> >>>
> >>
> >> I do have some partial results, comparing the patches. I only ran one of
> >> the more affected workloads (cyclic) on the xeon, attached is a PDF
> >> comparing master and the 0001-0014 patches. The percentages are timing
> >> vs. the preceding patch (green - faster, red - slower).
> >
> > Just confirming: the results are for uncached?
> >
>
> Yes, cyclic data set, uncached case. I picked this because it seemed
> like one of the most affected cases. Do you want me to test some other
> cases too?
So, I actually may have found the source of at least part of the
regression with 0010. I was able to reproduce the regression with
patch 0010 applied for the unached case with 4 workers and eic 8 and
100000000 rows for the cyclic dataset. I see it for all number of
matches. The regression went away (for this specific example) when I
moved the BitmapAdjustPrefetchIterator call back up to before the call
to table_scan_bitmap_next_block() like this:
diff --git a/src/backend/executor/nodeBitmapHeapscan.c
b/src/backend/executor/nodeBitmapHeapscan.c
index f7ecc060317..268996bdeea 100644
--- a/src/backend/executor/nodeBitmapHeapscan.c
+++ b/src/backend/executor/nodeBitmapHeapscan.c
@@ -279,6 +279,8 @@ BitmapHeapNext(BitmapHeapScanState *node)
}
new_page:
+ BitmapAdjustPrefetchIterator(node, node->blockno);
+
if (!table_scan_bitmap_next_block(scan, &node->recheck,
&lossy, &node->blockno))
break;
@@ -287,7 +289,6 @@ new_page:
else
node->exact_pages++;
- BitmapAdjustPrefetchIterator(node, node->blockno);
/* Adjust the prefetch target */
BitmapAdjustPrefetchTarget(node);
}
It makes sense this would fix it. I haven't tried all the combinations
you tried. Do you mind running your tests with the new code? I've
pushed it into this branch.
https://github.com/melanieplageman/postgres/commits/bhs_pgsr/
Note that this will fix none of the issues with 0014 because that has
removed all of the old prefetching code anyway.
Thank you sooo much for running these to begin with and then helping
me figure out what is going on!
- Melanie
On Thu, Feb 29, 2024 at 6:44 PM Tomas Vondra <tomas.vondra@enterprisedb.com> wrote: > > On 2/29/24 23:44, Tomas Vondra wrote: > > > > ... > > > >>> > >>> I do have some partial results, comparing the patches. I only ran one of > >>> the more affected workloads (cyclic) on the xeon, attached is a PDF > >>> comparing master and the 0001-0014 patches. The percentages are timing > >>> vs. the preceding patch (green - faster, red - slower). > >> > >> Just confirming: the results are for uncached? > >> > > > > Yes, cyclic data set, uncached case. I picked this because it seemed > > like one of the most affected cases. Do you want me to test some other > > cases too? > > > > BTW I decided to look at the data from a slightly different angle and > compare the behavior with increasing effective_io_concurrency. Attached > are charts for three "uncached" cases: > > * uniform, work_mem=4MB, workers_per_gather=0 > * linear-fuzz, work_mem=4MB, workers_per_gather=0 > * uniform, work_mem=4MB, workers_per_gather=4 > > Each page has charts for master and patched build (with all patches). I > think there's a pretty obvious difference in how increasing e_i_c > affects the two builds: Wow! These visualizations make it exceptionally clear. I want to go to the Vondra school of data visualizations for performance results! > 1) On master there's clear difference between eic=0 and eic=1 cases, but > on the patched build there's literally no difference - for example the > "uniform" distribution is clearly not great for prefetching, but eic=0 > regresses to eic=1 poor behavior). Yes, so eic=0 and eic=1 are identical with the streaming read API. That is, eic 0 does not disable prefetching. Thomas is going to update the streaming read API to avoid issuing an fadvise for the last block in a range before issuing a read -- which would mean no prefetching with eic 0 and eic 1. Not doing prefetching with eic 1 actually seems like the right behavior -- which would be different than what master is doing, right? Hopefully this fixes the clear difference between master and the patched version at eic 0. > 2) For some reason, the prefetching with eic>1 perform much better with > the patches, except for with very low selectivity values (close to 0%). > Not sure why this is happening - either the overhead is much lower > (which would matter on these "adversarial" data distribution, but how > could that be when fadvise is not free), or it ends up not doing any > prefetching (but then what about (1)?). For the uniform with four parallel workers, eic == 0 being worse than master makes sense for the above reason. But I'm not totally sure why eic == 1 would be worse with the patch than with master. Both are doing a (somewhat useless) prefetch. With very low selectivity, you are less likely to get readahead (right?) and similarly less likely to be able to build up > 8kB IOs -- which is one of the main value propositions of the streaming read code. I imagine that this larger read benefit is part of why the performance is better at higher selectivities with the patch. This might be a silly experiment, but we could try decreasing MAX_BUFFERS_PER_TRANSFER on the patched version and see if the performance gains go away. > 3) I'm not sure about the linear-fuzz case, the only explanation I have > we're able to skip almost all of the prefetches (and read-ahead likely > works pretty well here). I started looking at the data generated by linear-fuzz to understand exactly what effect the fuzz was having but haven't had time to really understand the characteristics of this dataset. In the original results, I thought uncached linear-fuzz and linear had similar results (performance improvement from master). What do you expect with linear vs linear-fuzz? - Melanie
On 3/1/24 02:18, Melanie Plageman wrote: > On Thu, Feb 29, 2024 at 6:44 PM Tomas Vondra > <tomas.vondra@enterprisedb.com> wrote: >> >> On 2/29/24 23:44, Tomas Vondra wrote: >>> >>> ... >>> >>>>> >>>>> I do have some partial results, comparing the patches. I only ran one of >>>>> the more affected workloads (cyclic) on the xeon, attached is a PDF >>>>> comparing master and the 0001-0014 patches. The percentages are timing >>>>> vs. the preceding patch (green - faster, red - slower). >>>> >>>> Just confirming: the results are for uncached? >>>> >>> >>> Yes, cyclic data set, uncached case. I picked this because it seemed >>> like one of the most affected cases. Do you want me to test some other >>> cases too? >>> >> >> BTW I decided to look at the data from a slightly different angle and >> compare the behavior with increasing effective_io_concurrency. Attached >> are charts for three "uncached" cases: >> >> * uniform, work_mem=4MB, workers_per_gather=0 >> * linear-fuzz, work_mem=4MB, workers_per_gather=0 >> * uniform, work_mem=4MB, workers_per_gather=4 >> >> Each page has charts for master and patched build (with all patches). I >> think there's a pretty obvious difference in how increasing e_i_c >> affects the two builds: > > Wow! These visualizations make it exceptionally clear. I want to go to > the Vondra school of data visualizations for performance results! > Welcome to my lecture on how to visualize data. The process has about four simple steps: 1) collect data for a lot of potentially interesting cases 2) load them into excel / google sheets / ... 3) slice and dice them into charts that you understand / can explain 4) every now and then there's something you can't understand / explain Thank you for attending my lecture ;-) No homework today. >> 1) On master there's clear difference between eic=0 and eic=1 cases, but >> on the patched build there's literally no difference - for example the >> "uniform" distribution is clearly not great for prefetching, but eic=0 >> regresses to eic=1 poor behavior). > > Yes, so eic=0 and eic=1 are identical with the streaming read API. > That is, eic 0 does not disable prefetching. Thomas is going to update > the streaming read API to avoid issuing an fadvise for the last block > in a range before issuing a read -- which would mean no prefetching > with eic 0 and eic 1. Not doing prefetching with eic 1 actually seems > like the right behavior -- which would be different than what master > is doing, right? > I don't think we should stop doing prefetching for eic=1, or at least not based just on these charts. I suspect these "uniform" charts are not a great example for the prefetching, because it's about distribution of individual rows, and even a small fraction of rows may match most of the pages. It's great for finding strange behaviors / corner cases, but probably not a sufficient reason to change the default. I think it makes sense to issue a prefetch one page ahead, before reading/processing the preceding one, and it's fairly conservative setting, and I assume the default was chosen for a reason / after discussion. My suggestion would be to keep the master behavior unless not practical, and then maybe discuss changing the details later. The patch is already complicated enough, better to leave that discussion for later. > Hopefully this fixes the clear difference between master and the > patched version at eic 0. > >> 2) For some reason, the prefetching with eic>1 perform much better with >> the patches, except for with very low selectivity values (close to 0%). >> Not sure why this is happening - either the overhead is much lower >> (which would matter on these "adversarial" data distribution, but how >> could that be when fadvise is not free), or it ends up not doing any >> prefetching (but then what about (1)?). > > For the uniform with four parallel workers, eic == 0 being worse than > master makes sense for the above reason. But I'm not totally sure why > eic == 1 would be worse with the patch than with master. Both are > doing a (somewhat useless) prefetch. > Right. > With very low selectivity, you are less likely to get readahead > (right?) and similarly less likely to be able to build up > 8kB IOs -- > which is one of the main value propositions of the streaming read > code. I imagine that this larger read benefit is part of why the > performance is better at higher selectivities with the patch. This > might be a silly experiment, but we could try decreasing > MAX_BUFFERS_PER_TRANSFER on the patched version and see if the > performance gains go away. > Sure, I can do that. Do you have any particular suggestion what value to use for MAX_BUFFERS_PER_TRANSFER? I'll also try to add a better version of uniform, where the selectivity matches more closely to pages, not rows. >> 3) I'm not sure about the linear-fuzz case, the only explanation I have >> we're able to skip almost all of the prefetches (and read-ahead likely >> works pretty well here). > > I started looking at the data generated by linear-fuzz to understand > exactly what effect the fuzz was having but haven't had time to really > understand the characteristics of this dataset. In the original > results, I thought uncached linear-fuzz and linear had similar results > (performance improvement from master). What do you expect with linear > vs linear-fuzz? > I don't know, TBH. My intent was to have a data set with correlated data, either perfectly (linear) or with some noise (linear-fuzz). But it's not like I spent too much thinking about it. It's more a case of throwing stuff at the wall, seeing what sticks. regards -- Tomas Vondra EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On Fri, Mar 1, 2024 at 9:05 AM Tomas Vondra <tomas.vondra@enterprisedb.com> wrote: > > On 3/1/24 02:18, Melanie Plageman wrote: > > On Thu, Feb 29, 2024 at 6:44 PM Tomas Vondra > > <tomas.vondra@enterprisedb.com> wrote: > >> > >> On 2/29/24 23:44, Tomas Vondra wrote: > >> 1) On master there's clear difference between eic=0 and eic=1 cases, but > >> on the patched build there's literally no difference - for example the > >> "uniform" distribution is clearly not great for prefetching, but eic=0 > >> regresses to eic=1 poor behavior). > > > > Yes, so eic=0 and eic=1 are identical with the streaming read API. > > That is, eic 0 does not disable prefetching. Thomas is going to update > > the streaming read API to avoid issuing an fadvise for the last block > > in a range before issuing a read -- which would mean no prefetching > > with eic 0 and eic 1. Not doing prefetching with eic 1 actually seems > > like the right behavior -- which would be different than what master > > is doing, right? > > I don't think we should stop doing prefetching for eic=1, or at least > not based just on these charts. I suspect these "uniform" charts are not > a great example for the prefetching, because it's about distribution of > individual rows, and even a small fraction of rows may match most of the > pages. It's great for finding strange behaviors / corner cases, but > probably not a sufficient reason to change the default. Yes, I would like to see results from a data set where selectivity is more correlated to pages/heap fetches. But, I'm not sure I see how that is related to prefetching when eic = 1. > I think it makes sense to issue a prefetch one page ahead, before > reading/processing the preceding one, and it's fairly conservative > setting, and I assume the default was chosen for a reason / after > discussion. Yes, I suppose the overhead of an fadvise does not compare to the IO latency of synchronously reading that block. Actually, I bet the regression I saw by accidentally moving BitmapAdjustPrefetchIterator() after table_scan_bitmap_next_block() would be similar to the regression introduced by making eic = 1 not prefetch. When you think about IO concurrency = 1, it doesn't imply prefetching to me. But, I think we want to do the right thing and have parity with master. > My suggestion would be to keep the master behavior unless not practical, > and then maybe discuss changing the details later. The patch is already > complicated enough, better to leave that discussion for later. Agreed. Speaking of which, we need to add back use of tablespace IO concurrency for the streaming read API (which is used by BitmapHeapScan in master). > > With very low selectivity, you are less likely to get readahead > > (right?) and similarly less likely to be able to build up > 8kB IOs -- > > which is one of the main value propositions of the streaming read > > code. I imagine that this larger read benefit is part of why the > > performance is better at higher selectivities with the patch. This > > might be a silly experiment, but we could try decreasing > > MAX_BUFFERS_PER_TRANSFER on the patched version and see if the > > performance gains go away. > > Sure, I can do that. Do you have any particular suggestion what value to > use for MAX_BUFFERS_PER_TRANSFER? I think setting it to 1 would be the same as always master -- doing only 8kB reads. The only thing about that is that I imagine the other streaming read code has some overhead which might end up being a regression on balance even with the prefetching if we aren't actually using the ranges/vectored capabilities of the streaming read interface. Maybe if you just run it for one of the very obvious performance improvement cases? I can also try this locally. > I'll also try to add a better version of uniform, where the selectivity > matches more closely to pages, not rows. This would be great. - Melanie
On 3/1/24 17:51, Melanie Plageman wrote: > On Fri, Mar 1, 2024 at 9:05 AM Tomas Vondra > <tomas.vondra@enterprisedb.com> wrote: >> >> On 3/1/24 02:18, Melanie Plageman wrote: >>> On Thu, Feb 29, 2024 at 6:44 PM Tomas Vondra >>> <tomas.vondra@enterprisedb.com> wrote: >>>> >>>> On 2/29/24 23:44, Tomas Vondra wrote: >>>> 1) On master there's clear difference between eic=0 and eic=1 cases, but >>>> on the patched build there's literally no difference - for example the >>>> "uniform" distribution is clearly not great for prefetching, but eic=0 >>>> regresses to eic=1 poor behavior). >>> >>> Yes, so eic=0 and eic=1 are identical with the streaming read API. >>> That is, eic 0 does not disable prefetching. Thomas is going to update >>> the streaming read API to avoid issuing an fadvise for the last block >>> in a range before issuing a read -- which would mean no prefetching >>> with eic 0 and eic 1. Not doing prefetching with eic 1 actually seems >>> like the right behavior -- which would be different than what master >>> is doing, right? >> >> I don't think we should stop doing prefetching for eic=1, or at least >> not based just on these charts. I suspect these "uniform" charts are not >> a great example for the prefetching, because it's about distribution of >> individual rows, and even a small fraction of rows may match most of the >> pages. It's great for finding strange behaviors / corner cases, but >> probably not a sufficient reason to change the default. > > Yes, I would like to see results from a data set where selectivity is > more correlated to pages/heap fetches. But, I'm not sure I see how > that is related to prefetching when eic = 1. > OK, I'll make that happen. >> I think it makes sense to issue a prefetch one page ahead, before >> reading/processing the preceding one, and it's fairly conservative >> setting, and I assume the default was chosen for a reason / after >> discussion. > > Yes, I suppose the overhead of an fadvise does not compare to the IO > latency of synchronously reading that block. Actually, I bet the > regression I saw by accidentally moving BitmapAdjustPrefetchIterator() > after table_scan_bitmap_next_block() would be similar to the > regression introduced by making eic = 1 not prefetch. > > When you think about IO concurrency = 1, it doesn't imply prefetching > to me. But, I think we want to do the right thing and have parity with > master. > Just to be sure we're on the same page regarding what eic=1 means, consider a simple sequence of pages: A, B, C, D, E, ... With the current "master" code, eic=1 means we'll issue a prefetch for B and then read+process A. And then issue prefetch for C and read+process B, and so on. It's always one page ahead. Yes, if the page is already in memory, the fadvise is just overhead. It may happen for various reasons (say, read-ahead). But it's just this one case, I'd bet in other cases eic=1 would be a win. >> My suggestion would be to keep the master behavior unless not practical, >> and then maybe discuss changing the details later. The patch is already >> complicated enough, better to leave that discussion for later. > > Agreed. Speaking of which, we need to add back use of tablespace IO > concurrency for the streaming read API (which is used by > BitmapHeapScan in master). > +1 >>> With very low selectivity, you are less likely to get readahead >>> (right?) and similarly less likely to be able to build up > 8kB IOs -- >>> which is one of the main value propositions of the streaming read >>> code. I imagine that this larger read benefit is part of why the >>> performance is better at higher selectivities with the patch. This >>> might be a silly experiment, but we could try decreasing >>> MAX_BUFFERS_PER_TRANSFER on the patched version and see if the >>> performance gains go away. >> >> Sure, I can do that. Do you have any particular suggestion what value to >> use for MAX_BUFFERS_PER_TRANSFER? > > I think setting it to 1 would be the same as always master -- doing > only 8kB reads. The only thing about that is that I imagine the other > streaming read code has some overhead which might end up being a > regression on balance even with the prefetching if we aren't actually > using the ranges/vectored capabilities of the streaming read > interface. Maybe if you just run it for one of the very obvious > performance improvement cases? I can also try this locally. > OK, I'll try with 1, and then we can adjust. >> I'll also try to add a better version of uniform, where the selectivity >> matches more closely to pages, not rows. > > This would be great. > regards -- Tomas Vondra EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On Thu, Feb 29, 2024 at 7:29 PM Melanie Plageman <melanieplageman@gmail.com> wrote: > > On Thu, Feb 29, 2024 at 5:44 PM Tomas Vondra > <tomas.vondra@enterprisedb.com> wrote: > > > > > > > > On 2/29/24 22:19, Melanie Plageman wrote: > > > On Thu, Feb 29, 2024 at 7:54 AM Tomas Vondra > > > <tomas.vondra@enterprisedb.com> wrote: > > >> > > >> > > >> > > >> On 2/29/24 00:40, Melanie Plageman wrote: > > >>> On Wed, Feb 28, 2024 at 6:17 PM Tomas Vondra > > >>> <tomas.vondra@enterprisedb.com> wrote: > > >>>> > > >>>> > > >>>> > > >>>> On 2/28/24 21:06, Melanie Plageman wrote: > > >>>>> On Wed, Feb 28, 2024 at 2:23 PM Tomas Vondra > > >>>>> <tomas.vondra@enterprisedb.com> wrote: > > >>>>>> > > >>>>>> On 2/28/24 15:56, Tomas Vondra wrote: > > >>>>>>>> ... > > >>>>>>> > > >>>>>>> Sure, I can do that. It'll take a couple hours to get the results, I'll > > >>>>>>> share them when I have them. > > >>>>>>> > > >>>>>> > > >>>>>> Here are the results with only patches 0001 - 0012 applied (i.e. without > > >>>>>> the patch introducing the streaming read API, and the patch switching > > >>>>>> the bitmap heap scan to use it). > > >>>>>> > > >>>>>> The changes in performance don't disappear entirely, but the scale is > > >>>>>> certainly much smaller - both in the complete results for all runs, and > > >>>>>> for the "optimal" runs that would actually pick bitmapscan. > > >>>>> > > >>>>> Hmm. I'm trying to think how my refactor could have had this impact. > > >>>>> It seems like all the most notable regressions are with 4 parallel > > >>>>> workers. What do the numeric column labels mean across the top > > >>>>> (2,4,8,16...) -- are they related to "matches"? And if so, what does > > >>>>> that mean? > > >>>>> > > >>>> > > >>>> That's the number of distinct values matched by the query, which should > > >>>> be an approximation of the number of matching rows. The number of > > >>>> distinct values in the data set differs by data set, but for 1M rows > > >>>> it's roughly like this: > > >>>> > > >>>> uniform: 10k > > >>>> linear: 10k > > >>>> cyclic: 100 > > >>>> > > >>>> So for example matches=128 means ~1% of rows for uniform/linear, and > > >>>> 100% for cyclic data sets. > > >>> > > >>> Ah, thank you for the explanation. I also looked at your script after > > >>> having sent this email and saw that it is clear in your script what > > >>> "matches" is. > > >>> > > >>>> As for the possible cause, I think it's clear most of the difference > > >>>> comes from the last patch that actually switches bitmap heap scan to the > > >>>> streaming read API. That's mostly expected/understandable, although we > > >>>> probably need to look into the regressions or cases with e_i_c=0. > > >>> > > >>> Right, I'm mostly surprised about the regressions for patches 0001-0012. > > >>> > > >>> Re eic 0: Thomas Munro and I chatted off-list, and you bring up a > > >>> great point about eic 0. In old bitmapheapscan code eic 0 basically > > >>> disabled prefetching but with the streaming read API, it will still > > >>> issue fadvises when eic is 0. That is an easy one line fix. Thomas > > >>> prefers to fix it by always avoiding an fadvise for the last buffer in > > >>> a range before issuing a read (since we are about to read it anyway, > > >>> best not fadvise it too). This will fix eic 0 and also cut one system > > >>> call from each invocation of the streaming read machinery. > > >>> > > >>>> To analyze the 0001-0012 patches, maybe it'd be helpful to run tests for > > >>>> individual patches. I can try doing that tomorrow. It'll have to be a > > >>>> limited set of tests, to reduce the time, but might tell us whether it's > > >>>> due to a single patch or multiple patches. > > >>> > > >>> Yes, tomorrow I planned to start trying to repro some of the "red" > > >>> cases myself. Any one of the commits could cause a slight regression > > >>> but a 3.5x regression is quite surprising, so I might focus on trying > > >>> to repro that locally and then narrow down which patch causes it. > > >>> > > >>> For the non-cached regressions, perhaps the commit to use the correct > > >>> recheck flag (0004) when prefetching could be the culprit. And for the > > >>> cached regressions, my money is on the commit which changes the whole > > >>> control flow of BitmapHeapNext() and the next_block() and next_tuple() > > >>> functions (0010). > > >>> > > >> > > >> I do have some partial results, comparing the patches. I only ran one of > > >> the more affected workloads (cyclic) on the xeon, attached is a PDF > > >> comparing master and the 0001-0014 patches. The percentages are timing > > >> vs. the preceding patch (green - faster, red - slower). > > > > > > Just confirming: the results are for uncached? > > > > > > > Yes, cyclic data set, uncached case. I picked this because it seemed > > like one of the most affected cases. Do you want me to test some other > > cases too? > > So, I actually may have found the source of at least part of the > regression with 0010. I was able to reproduce the regression with > patch 0010 applied for the unached case with 4 workers and eic 8 and > 100000000 rows for the cyclic dataset. I see it for all number of > matches. The regression went away (for this specific example) when I > moved the BitmapAdjustPrefetchIterator call back up to before the call > to table_scan_bitmap_next_block() like this: > > diff --git a/src/backend/executor/nodeBitmapHeapscan.c > b/src/backend/executor/nodeBitmapHeapscan.c > index f7ecc060317..268996bdeea 100644 > --- a/src/backend/executor/nodeBitmapHeapscan.c > +++ b/src/backend/executor/nodeBitmapHeapscan.c > @@ -279,6 +279,8 @@ BitmapHeapNext(BitmapHeapScanState *node) > } > > new_page: > + BitmapAdjustPrefetchIterator(node, node->blockno); > + > if (!table_scan_bitmap_next_block(scan, &node->recheck, > &lossy, &node->blockno)) > break; > > @@ -287,7 +289,6 @@ new_page: > else > node->exact_pages++; > > - BitmapAdjustPrefetchIterator(node, node->blockno); > /* Adjust the prefetch target */ > BitmapAdjustPrefetchTarget(node); > } > > It makes sense this would fix it. I haven't tried all the combinations > you tried. Do you mind running your tests with the new code? I've > pushed it into this branch. > https://github.com/melanieplageman/postgres/commits/bhs_pgsr/ Hold the phone on this one. I realized why I moved BitmapAdjustPrefetchIterator after table_scan_bitmap_next_block() in the first place -- master calls BitmapAdjustPrefetchIterator after the tbm_iterate() for the current block -- otherwise with eic = 1, it considers the prefetch iterator behind the current block iterator. I'm going to go through and figure out what order this must be done in and fix it. - Melanie
On 3/1/24 18:08, Tomas Vondra wrote: > > On 3/1/24 17:51, Melanie Plageman wrote: >> On Fri, Mar 1, 2024 at 9:05 AM Tomas Vondra >> <tomas.vondra@enterprisedb.com> wrote: >>> >>> On 3/1/24 02:18, Melanie Plageman wrote: >>>> On Thu, Feb 29, 2024 at 6:44 PM Tomas Vondra >>>> <tomas.vondra@enterprisedb.com> wrote: >>>>> >>>>> On 2/29/24 23:44, Tomas Vondra wrote: >>>>> 1) On master there's clear difference between eic=0 and eic=1 cases, but >>>>> on the patched build there's literally no difference - for example the >>>>> "uniform" distribution is clearly not great for prefetching, but eic=0 >>>>> regresses to eic=1 poor behavior). >>>> >>>> Yes, so eic=0 and eic=1 are identical with the streaming read API. >>>> That is, eic 0 does not disable prefetching. Thomas is going to update >>>> the streaming read API to avoid issuing an fadvise for the last block >>>> in a range before issuing a read -- which would mean no prefetching >>>> with eic 0 and eic 1. Not doing prefetching with eic 1 actually seems >>>> like the right behavior -- which would be different than what master >>>> is doing, right? >>> >>> I don't think we should stop doing prefetching for eic=1, or at least >>> not based just on these charts. I suspect these "uniform" charts are not >>> a great example for the prefetching, because it's about distribution of >>> individual rows, and even a small fraction of rows may match most of the >>> pages. It's great for finding strange behaviors / corner cases, but >>> probably not a sufficient reason to change the default. >> >> Yes, I would like to see results from a data set where selectivity is >> more correlated to pages/heap fetches. But, I'm not sure I see how >> that is related to prefetching when eic = 1. >> > > OK, I'll make that happen. > Here's a PDF with charts for a dataset where the row selectivity is more correlated to selectivity of pages. I'm attaching the updated script, with the SQL generating the data set. But the short story is all rows on a single page have the same random value, so the selectivity of rows and pages should be the same. The first page has results for the original "uniform", the second page is the new "uniform-pages" data set. There are 4 charts, for master/patched and 0/4 parallel workers. Overall the behavior is the same, but for the "uniform-pages" it's much more gradual (with respect to row selectivity). I think that's expected. As for how this is related to eic=1 - I think my point was that these are "adversary" data sets, most likely to show regressions. This applies especially to the "uniform" data set, because as the row selectivity grows, it's more and more likely it's right after to the current one, and so a read-ahead would likely do the trick. Also, this is forcing a bitmap scan plan - it's possible many of these cases would use some other scan type, making the regression somewhat irrelevant. Not entirely, because we make planning mistakes and for robustness reasons it's good to keep the regression small. But that's just how I think about it now. I don't think I have some grand theory that'd dictate we have to do prefetching for eic=1. regards -- Tomas Vondra EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
Attachment
On Fri, Mar 1, 2024 at 2:31 PM Melanie Plageman <melanieplageman@gmail.com> wrote: > > On Thu, Feb 29, 2024 at 7:29 PM Melanie Plageman > <melanieplageman@gmail.com> wrote: > > > > On Thu, Feb 29, 2024 at 5:44 PM Tomas Vondra > > <tomas.vondra@enterprisedb.com> wrote: > > > > > > > > > > > > On 2/29/24 22:19, Melanie Plageman wrote: > > > > On Thu, Feb 29, 2024 at 7:54 AM Tomas Vondra > > > > <tomas.vondra@enterprisedb.com> wrote: > > > >> > > > >> > > > >> > > > >> On 2/29/24 00:40, Melanie Plageman wrote: > > > >>> On Wed, Feb 28, 2024 at 6:17 PM Tomas Vondra > > > >>> <tomas.vondra@enterprisedb.com> wrote: > > > >>>> > > > >>>> > > > >>>> > > > >>>> On 2/28/24 21:06, Melanie Plageman wrote: > > > >>>>> On Wed, Feb 28, 2024 at 2:23 PM Tomas Vondra > > > >>>>> <tomas.vondra@enterprisedb.com> wrote: > > > >>>>>> > > > >>>>>> On 2/28/24 15:56, Tomas Vondra wrote: > > > >>>>>>>> ... > > > >>>>>>> > > > >>>>>>> Sure, I can do that. It'll take a couple hours to get the results, I'll > > > >>>>>>> share them when I have them. > > > >>>>>>> > > > >>>>>> > > > >>>>>> Here are the results with only patches 0001 - 0012 applied (i.e. without > > > >>>>>> the patch introducing the streaming read API, and the patch switching > > > >>>>>> the bitmap heap scan to use it). > > > >>>>>> > > > >>>>>> The changes in performance don't disappear entirely, but the scale is > > > >>>>>> certainly much smaller - both in the complete results for all runs, and > > > >>>>>> for the "optimal" runs that would actually pick bitmapscan. > > > >>>>> > > > >>>>> Hmm. I'm trying to think how my refactor could have had this impact. > > > >>>>> It seems like all the most notable regressions are with 4 parallel > > > >>>>> workers. What do the numeric column labels mean across the top > > > >>>>> (2,4,8,16...) -- are they related to "matches"? And if so, what does > > > >>>>> that mean? > > > >>>>> > > > >>>> > > > >>>> That's the number of distinct values matched by the query, which should > > > >>>> be an approximation of the number of matching rows. The number of > > > >>>> distinct values in the data set differs by data set, but for 1M rows > > > >>>> it's roughly like this: > > > >>>> > > > >>>> uniform: 10k > > > >>>> linear: 10k > > > >>>> cyclic: 100 > > > >>>> > > > >>>> So for example matches=128 means ~1% of rows for uniform/linear, and > > > >>>> 100% for cyclic data sets. > > > >>> > > > >>> Ah, thank you for the explanation. I also looked at your script after > > > >>> having sent this email and saw that it is clear in your script what > > > >>> "matches" is. > > > >>> > > > >>>> As for the possible cause, I think it's clear most of the difference > > > >>>> comes from the last patch that actually switches bitmap heap scan to the > > > >>>> streaming read API. That's mostly expected/understandable, although we > > > >>>> probably need to look into the regressions or cases with e_i_c=0. > > > >>> > > > >>> Right, I'm mostly surprised about the regressions for patches 0001-0012. > > > >>> > > > >>> Re eic 0: Thomas Munro and I chatted off-list, and you bring up a > > > >>> great point about eic 0. In old bitmapheapscan code eic 0 basically > > > >>> disabled prefetching but with the streaming read API, it will still > > > >>> issue fadvises when eic is 0. That is an easy one line fix. Thomas > > > >>> prefers to fix it by always avoiding an fadvise for the last buffer in > > > >>> a range before issuing a read (since we are about to read it anyway, > > > >>> best not fadvise it too). This will fix eic 0 and also cut one system > > > >>> call from each invocation of the streaming read machinery. > > > >>> > > > >>>> To analyze the 0001-0012 patches, maybe it'd be helpful to run tests for > > > >>>> individual patches. I can try doing that tomorrow. It'll have to be a > > > >>>> limited set of tests, to reduce the time, but might tell us whether it's > > > >>>> due to a single patch or multiple patches. > > > >>> > > > >>> Yes, tomorrow I planned to start trying to repro some of the "red" > > > >>> cases myself. Any one of the commits could cause a slight regression > > > >>> but a 3.5x regression is quite surprising, so I might focus on trying > > > >>> to repro that locally and then narrow down which patch causes it. > > > >>> > > > >>> For the non-cached regressions, perhaps the commit to use the correct > > > >>> recheck flag (0004) when prefetching could be the culprit. And for the > > > >>> cached regressions, my money is on the commit which changes the whole > > > >>> control flow of BitmapHeapNext() and the next_block() and next_tuple() > > > >>> functions (0010). > > > >>> > > > >> > > > >> I do have some partial results, comparing the patches. I only ran one of > > > >> the more affected workloads (cyclic) on the xeon, attached is a PDF > > > >> comparing master and the 0001-0014 patches. The percentages are timing > > > >> vs. the preceding patch (green - faster, red - slower). > > > > > > > > Just confirming: the results are for uncached? > > > > > > > > > > Yes, cyclic data set, uncached case. I picked this because it seemed > > > like one of the most affected cases. Do you want me to test some other > > > cases too? > > > > So, I actually may have found the source of at least part of the > > regression with 0010. I was able to reproduce the regression with > > patch 0010 applied for the unached case with 4 workers and eic 8 and > > 100000000 rows for the cyclic dataset. I see it for all number of > > matches. The regression went away (for this specific example) when I > > moved the BitmapAdjustPrefetchIterator call back up to before the call > > to table_scan_bitmap_next_block() like this: > > > > diff --git a/src/backend/executor/nodeBitmapHeapscan.c > > b/src/backend/executor/nodeBitmapHeapscan.c > > index f7ecc060317..268996bdeea 100644 > > --- a/src/backend/executor/nodeBitmapHeapscan.c > > +++ b/src/backend/executor/nodeBitmapHeapscan.c > > @@ -279,6 +279,8 @@ BitmapHeapNext(BitmapHeapScanState *node) > > } > > > > new_page: > > + BitmapAdjustPrefetchIterator(node, node->blockno); > > + > > if (!table_scan_bitmap_next_block(scan, &node->recheck, > > &lossy, &node->blockno)) > > break; > > > > @@ -287,7 +289,6 @@ new_page: > > else > > node->exact_pages++; > > > > - BitmapAdjustPrefetchIterator(node, node->blockno); > > /* Adjust the prefetch target */ > > BitmapAdjustPrefetchTarget(node); > > } > > > > It makes sense this would fix it. I haven't tried all the combinations > > you tried. Do you mind running your tests with the new code? I've > > pushed it into this branch. > > https://github.com/melanieplageman/postgres/commits/bhs_pgsr/ > > Hold the phone on this one. I realized why I moved > BitmapAdjustPrefetchIterator after table_scan_bitmap_next_block() in > the first place -- master calls BitmapAdjustPrefetchIterator after the > tbm_iterate() for the current block -- otherwise with eic = 1, it > considers the prefetch iterator behind the current block iterator. I'm > going to go through and figure out what order this must be done in and > fix it. So, I investigated this further, and, as far as I can tell, for parallel bitmapheapscan the timing around when workers decrement prefetch_pages causes the performance differences with patch 0010 applied. It makes very little sense to me, but some of the queries I borrowed from your regression examples are up to 30% slower when this code from BitmapAdjustPrefetchIterator() is after table_scan_bitmap_next_block() instead of before it. SpinLockAcquire(&pstate->mutex); if (pstate->prefetch_pages > 0) pstate->prefetch_pages--; SpinLockRelease(&pstate->mutex); I did some stracing and did see much more time spent in futex/wait with this code after the call to table_scan_bitmap_next_block() vs before it. (table_scan_bitmap_next_block()) calls ReadBuffer()). In my branch, I've now moved only the parallel prefetch_pages-- code to before table_scan_bitmap_next_block(). https://github.com/melanieplageman/postgres/tree/bhs_pgsr I'd be interested to know if you see the regressions go away with 0010 applied (commit message "Make table_scan_bitmap_next_block() async friendly" and sha bfdcbfee7be8e2c461). - Melanie
On Sat, Mar 2, 2024 at 10:05 AM Tomas Vondra <tomas.vondra@enterprisedb.com> wrote: > > Here's a PDF with charts for a dataset where the row selectivity is more > correlated to selectivity of pages. I'm attaching the updated script, > with the SQL generating the data set. But the short story is all rows on > a single page have the same random value, so the selectivity of rows and > pages should be the same. > > The first page has results for the original "uniform", the second page > is the new "uniform-pages" data set. There are 4 charts, for > master/patched and 0/4 parallel workers. Overall the behavior is the > same, but for the "uniform-pages" it's much more gradual (with respect > to row selectivity). I think that's expected. Cool! Thanks for doing this. I have convinced myself that Thomas' forthcoming patch which will eliminate prefetching with eic = 0 will fix the eic 0 blue line regressions. The eic = 1 with four parallel workers is more confusing. And it seems more noticeably bad with your randomized-pages dataset. Regarding your earlier question: > Just to be sure we're on the same page regarding what eic=1 means, > consider a simple sequence of pages: A, B, C, D, E, ... > > With the current "master" code, eic=1 means we'll issue a prefetch for B > and then read+process A. And then issue prefetch for C and read+process > B, and so on. It's always one page ahead. Yes, that is what I mean for eic = 1 > As for how this is related to eic=1 - I think my point was that these > are "adversary" data sets, most likely to show regressions. This applies > especially to the "uniform" data set, because as the row selectivity > grows, it's more and more likely it's right after to the current one, > and so a read-ahead would likely do the trick. No, I think you're right that eic=1 should prefetch. As you say, with high selectivity, a bitmap plan is likely not the best one anyway, so not prefetching in order to preserve the performance of those cases seems silly. - Melanie
On 3/2/24 23:28, Melanie Plageman wrote: > On Sat, Mar 2, 2024 at 10:05 AM Tomas Vondra > <tomas.vondra@enterprisedb.com> wrote: >> >> Here's a PDF with charts for a dataset where the row selectivity is more >> correlated to selectivity of pages. I'm attaching the updated script, >> with the SQL generating the data set. But the short story is all rows on >> a single page have the same random value, so the selectivity of rows and >> pages should be the same. >> >> The first page has results for the original "uniform", the second page >> is the new "uniform-pages" data set. There are 4 charts, for >> master/patched and 0/4 parallel workers. Overall the behavior is the >> same, but for the "uniform-pages" it's much more gradual (with respect >> to row selectivity). I think that's expected. > > Cool! Thanks for doing this. I have convinced myself that Thomas' > forthcoming patch which will eliminate prefetching with eic = 0 will > fix the eic 0 blue line regressions. The eic = 1 with four parallel > workers is more confusing. And it seems more noticeably bad with your > randomized-pages dataset. > > Regarding your earlier question: > >> Just to be sure we're on the same page regarding what eic=1 means, >> consider a simple sequence of pages: A, B, C, D, E, ... >> >> With the current "master" code, eic=1 means we'll issue a prefetch for B >> and then read+process A. And then issue prefetch for C and read+process >> B, and so on. It's always one page ahead. > > Yes, that is what I mean for eic = 1 > >> As for how this is related to eic=1 - I think my point was that these >> are "adversary" data sets, most likely to show regressions. This applies >> especially to the "uniform" data set, because as the row selectivity >> grows, it's more and more likely it's right after to the current one, >> and so a read-ahead would likely do the trick. > > No, I think you're right that eic=1 should prefetch. As you say, with > high selectivity, a bitmap plan is likely not the best one anyway, so > not prefetching in order to preserve the performance of those cases > seems silly. > I was just trying to respond do this from an earlier message: > Yes, I would like to see results from a data set where selectivity is > more correlated to pages/heap fetches. But, I'm not sure I see how > that is related to prefetching when eic = 1. And in that same message you also said "Not doing prefetching with eic 1 actually seems like the right behavior". Hence my argument we should not stop prefetching for eic=1. But maybe I'm confused - it seems agree eic=1 should prefetch, and that uniform data set may not be a good argument against that. regards -- Tomas Vondra EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On 3/2/24 23:11, Melanie Plageman wrote: > On Fri, Mar 1, 2024 at 2:31 PM Melanie Plageman > <melanieplageman@gmail.com> wrote: >> >> ... >> >> Hold the phone on this one. I realized why I moved >> BitmapAdjustPrefetchIterator after table_scan_bitmap_next_block() in >> the first place -- master calls BitmapAdjustPrefetchIterator after the >> tbm_iterate() for the current block -- otherwise with eic = 1, it >> considers the prefetch iterator behind the current block iterator. I'm >> going to go through and figure out what order this must be done in and >> fix it. > > So, I investigated this further, and, as far as I can tell, for > parallel bitmapheapscan the timing around when workers decrement > prefetch_pages causes the performance differences with patch 0010 > applied. It makes very little sense to me, but some of the queries I > borrowed from your regression examples are up to 30% slower when this > code from BitmapAdjustPrefetchIterator() is after > table_scan_bitmap_next_block() instead of before it. > > SpinLockAcquire(&pstate->mutex); > if (pstate->prefetch_pages > 0) > pstate->prefetch_pages--; > SpinLockRelease(&pstate->mutex); > > I did some stracing and did see much more time spent in futex/wait > with this code after the call to table_scan_bitmap_next_block() vs > before it. (table_scan_bitmap_next_block()) calls ReadBuffer()). > > In my branch, I've now moved only the parallel prefetch_pages-- code > to before table_scan_bitmap_next_block(). > https://github.com/melanieplageman/postgres/tree/bhs_pgsr > I'd be interested to know if you see the regressions go away with 0010 > applied (commit message "Make table_scan_bitmap_next_block() async > friendly" and sha bfdcbfee7be8e2c461). > I'll give this a try once the runs with MAX_BUFFERS_PER_TRANSFER=1 complete. But it seems really bizarre that simply moving this code a little bit would cause such a regression ... regards -- Tomas Vondra EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On Sat, Mar 2, 2024 at 5:41 PM Tomas Vondra <tomas.vondra@enterprisedb.com> wrote: > > > > On 3/2/24 23:28, Melanie Plageman wrote: > > On Sat, Mar 2, 2024 at 10:05 AM Tomas Vondra > > <tomas.vondra@enterprisedb.com> wrote: > >> > >> Here's a PDF with charts for a dataset where the row selectivity is more > >> correlated to selectivity of pages. I'm attaching the updated script, > >> with the SQL generating the data set. But the short story is all rows on > >> a single page have the same random value, so the selectivity of rows and > >> pages should be the same. > >> > >> The first page has results for the original "uniform", the second page > >> is the new "uniform-pages" data set. There are 4 charts, for > >> master/patched and 0/4 parallel workers. Overall the behavior is the > >> same, but for the "uniform-pages" it's much more gradual (with respect > >> to row selectivity). I think that's expected. > > > > Cool! Thanks for doing this. I have convinced myself that Thomas' > > forthcoming patch which will eliminate prefetching with eic = 0 will > > fix the eic 0 blue line regressions. The eic = 1 with four parallel > > workers is more confusing. And it seems more noticeably bad with your > > randomized-pages dataset. > > > > Regarding your earlier question: > > > >> Just to be sure we're on the same page regarding what eic=1 means, > >> consider a simple sequence of pages: A, B, C, D, E, ... > >> > >> With the current "master" code, eic=1 means we'll issue a prefetch for B > >> and then read+process A. And then issue prefetch for C and read+process > >> B, and so on. It's always one page ahead. > > > > Yes, that is what I mean for eic = 1 > > > >> As for how this is related to eic=1 - I think my point was that these > >> are "adversary" data sets, most likely to show regressions. This applies > >> especially to the "uniform" data set, because as the row selectivity > >> grows, it's more and more likely it's right after to the current one, > >> and so a read-ahead would likely do the trick. > > > > No, I think you're right that eic=1 should prefetch. As you say, with > > high selectivity, a bitmap plan is likely not the best one anyway, so > > not prefetching in order to preserve the performance of those cases > > seems silly. > > > > I was just trying to respond do this from an earlier message: > > > Yes, I would like to see results from a data set where selectivity is > > more correlated to pages/heap fetches. But, I'm not sure I see how > > that is related to prefetching when eic = 1. > > And in that same message you also said "Not doing prefetching with eic 1 > actually seems like the right behavior". Hence my argument we should not > stop prefetching for eic=1. > > But maybe I'm confused - it seems agree eic=1 should prefetch, and that > uniform data set may not be a good argument against that. Yep, we agree. I was being confusing and wrong :) I just wanted to make sure the thread had a clear consensus that, yes, it is the right thing to do to prefetch blocks for bitmap heap scans when effective_io_concurrency = 1. - Melanie
On Sat, Mar 2, 2024 at 5:51 PM Tomas Vondra <tomas.vondra@enterprisedb.com> wrote: > > On 3/2/24 23:11, Melanie Plageman wrote: > > On Fri, Mar 1, 2024 at 2:31 PM Melanie Plageman > > <melanieplageman@gmail.com> wrote: > >> > >> ... > >> > >> Hold the phone on this one. I realized why I moved > >> BitmapAdjustPrefetchIterator after table_scan_bitmap_next_block() in > >> the first place -- master calls BitmapAdjustPrefetchIterator after the > >> tbm_iterate() for the current block -- otherwise with eic = 1, it > >> considers the prefetch iterator behind the current block iterator. I'm > >> going to go through and figure out what order this must be done in and > >> fix it. > > > > So, I investigated this further, and, as far as I can tell, for > > parallel bitmapheapscan the timing around when workers decrement > > prefetch_pages causes the performance differences with patch 0010 > > applied. It makes very little sense to me, but some of the queries I > > borrowed from your regression examples are up to 30% slower when this > > code from BitmapAdjustPrefetchIterator() is after > > table_scan_bitmap_next_block() instead of before it. > > > > SpinLockAcquire(&pstate->mutex); > > if (pstate->prefetch_pages > 0) > > pstate->prefetch_pages--; > > SpinLockRelease(&pstate->mutex); > > > > I did some stracing and did see much more time spent in futex/wait > > with this code after the call to table_scan_bitmap_next_block() vs > > before it. (table_scan_bitmap_next_block()) calls ReadBuffer()). > > > > In my branch, I've now moved only the parallel prefetch_pages-- code > > to before table_scan_bitmap_next_block(). > > https://github.com/melanieplageman/postgres/tree/bhs_pgsr > > I'd be interested to know if you see the regressions go away with 0010 > > applied (commit message "Make table_scan_bitmap_next_block() async > > friendly" and sha bfdcbfee7be8e2c461). > > > > I'll give this a try once the runs with MAX_BUFFERS_PER_TRANSFER=1 > complete. But it seems really bizarre that simply moving this code a > little bit would cause such a regression ... Yes, it is bizarre. It also might not be a reproducible performance difference on the cases besides the one I was testing (cyclic dataset, uncached, eic=8, matches 16+, distinct=100, rows=100000000, 4 parallel workers). But even if it only affects that one case, it still had a major, reproducible performance impact to move those 5 lines before and after table_scan_bitmap_next_block(). The same number of reads and fadvises are being issued overall. However, I did notice that the pread calls are skewed when the those lines of code are after table_scan_bitmap_next_block() -- fewer of the workers are doing more of the reads. Perhaps this explains what is taking longer. Why those workers would end up doing more of the reads, I don't quite know. - Melanie
On 3/1/24 17:51, Melanie Plageman wrote: > On Fri, Mar 1, 2024 at 9:05 AM Tomas Vondra > <tomas.vondra@enterprisedb.com> wrote: >> >> On 3/1/24 02:18, Melanie Plageman wrote: >>> On Thu, Feb 29, 2024 at 6:44 PM Tomas Vondra >>> <tomas.vondra@enterprisedb.com> wrote: >>>> >>>> On 2/29/24 23:44, Tomas Vondra wrote: >>>> 1) On master there's clear difference between eic=0 and eic=1 cases, but >>>> on the patched build there's literally no difference - for example the >>>> "uniform" distribution is clearly not great for prefetching, but eic=0 >>>> regresses to eic=1 poor behavior). >>> >>> Yes, so eic=0 and eic=1 are identical with the streaming read API. >>> That is, eic 0 does not disable prefetching. Thomas is going to update >>> the streaming read API to avoid issuing an fadvise for the last block >>> in a range before issuing a read -- which would mean no prefetching >>> with eic 0 and eic 1. Not doing prefetching with eic 1 actually seems >>> like the right behavior -- which would be different than what master >>> is doing, right? >> >> I don't think we should stop doing prefetching for eic=1, or at least >> not based just on these charts. I suspect these "uniform" charts are not >> a great example for the prefetching, because it's about distribution of >> individual rows, and even a small fraction of rows may match most of the >> pages. It's great for finding strange behaviors / corner cases, but >> probably not a sufficient reason to change the default. > > Yes, I would like to see results from a data set where selectivity is > more correlated to pages/heap fetches. But, I'm not sure I see how > that is related to prefetching when eic = 1. > >> I think it makes sense to issue a prefetch one page ahead, before >> reading/processing the preceding one, and it's fairly conservative >> setting, and I assume the default was chosen for a reason / after >> discussion. > > Yes, I suppose the overhead of an fadvise does not compare to the IO > latency of synchronously reading that block. Actually, I bet the > regression I saw by accidentally moving BitmapAdjustPrefetchIterator() > after table_scan_bitmap_next_block() would be similar to the > regression introduced by making eic = 1 not prefetch. > > When you think about IO concurrency = 1, it doesn't imply prefetching > to me. But, I think we want to do the right thing and have parity with > master. > >> My suggestion would be to keep the master behavior unless not practical, >> and then maybe discuss changing the details later. The patch is already >> complicated enough, better to leave that discussion for later. > > Agreed. Speaking of which, we need to add back use of tablespace IO > concurrency for the streaming read API (which is used by > BitmapHeapScan in master). > >>> With very low selectivity, you are less likely to get readahead >>> (right?) and similarly less likely to be able to build up > 8kB IOs -- >>> which is one of the main value propositions of the streaming read >>> code. I imagine that this larger read benefit is part of why the >>> performance is better at higher selectivities with the patch. This >>> might be a silly experiment, but we could try decreasing >>> MAX_BUFFERS_PER_TRANSFER on the patched version and see if the >>> performance gains go away. >> >> Sure, I can do that. Do you have any particular suggestion what value to >> use for MAX_BUFFERS_PER_TRANSFER? > > I think setting it to 1 would be the same as always master -- doing > only 8kB reads. The only thing about that is that I imagine the other > streaming read code has some overhead which might end up being a > regression on balance even with the prefetching if we aren't actually > using the ranges/vectored capabilities of the streaming read > interface. Maybe if you just run it for one of the very obvious > performance improvement cases? I can also try this locally. > Here's some results from a build with #define MAX_BUFFERS_PER_TRANSFER 1 There are three columns: - master - patched (original patches, with MAX_BUFFERS_PER_TRANSFER=128kB) - patched-single (MAX_BUFFERS_PER_TRANSFER=8kB) The color scales are always branch compared to master. I think the expectation was that setting the transfer to 1 would make it closer to master, reducing some of the regressions. But in practice the effect is the opposite. - In "cached" runs, this eliminates the small improvements (light green), but leaves the regressions behind. - In "uncached" runs, this exacerbates the regressions, particularly for low selectivities (small values of matches). I don't have a good intuition on why this would be happening :-( regards -- Tomas Vondra EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
Attachment
On Sat, Mar 2, 2024 at 6:59 PM Tomas Vondra <tomas.vondra@enterprisedb.com> wrote: > > > > On 3/1/24 17:51, Melanie Plageman wrote: > > On Fri, Mar 1, 2024 at 9:05 AM Tomas Vondra > > <tomas.vondra@enterprisedb.com> wrote: > >> > >> On 3/1/24 02:18, Melanie Plageman wrote: > >>> On Thu, Feb 29, 2024 at 6:44 PM Tomas Vondra > >>> <tomas.vondra@enterprisedb.com> wrote: > >>>> > >>>> On 2/29/24 23:44, Tomas Vondra wrote: > >>>> 1) On master there's clear difference between eic=0 and eic=1 cases, but > >>>> on the patched build there's literally no difference - for example the > >>>> "uniform" distribution is clearly not great for prefetching, but eic=0 > >>>> regresses to eic=1 poor behavior). > >>> > >>> Yes, so eic=0 and eic=1 are identical with the streaming read API. > >>> That is, eic 0 does not disable prefetching. Thomas is going to update > >>> the streaming read API to avoid issuing an fadvise for the last block > >>> in a range before issuing a read -- which would mean no prefetching > >>> with eic 0 and eic 1. Not doing prefetching with eic 1 actually seems > >>> like the right behavior -- which would be different than what master > >>> is doing, right? > >> > >> I don't think we should stop doing prefetching for eic=1, or at least > >> not based just on these charts. I suspect these "uniform" charts are not > >> a great example for the prefetching, because it's about distribution of > >> individual rows, and even a small fraction of rows may match most of the > >> pages. It's great for finding strange behaviors / corner cases, but > >> probably not a sufficient reason to change the default. > > > > Yes, I would like to see results from a data set where selectivity is > > more correlated to pages/heap fetches. But, I'm not sure I see how > > that is related to prefetching when eic = 1. > > > >> I think it makes sense to issue a prefetch one page ahead, before > >> reading/processing the preceding one, and it's fairly conservative > >> setting, and I assume the default was chosen for a reason / after > >> discussion. > > > > Yes, I suppose the overhead of an fadvise does not compare to the IO > > latency of synchronously reading that block. Actually, I bet the > > regression I saw by accidentally moving BitmapAdjustPrefetchIterator() > > after table_scan_bitmap_next_block() would be similar to the > > regression introduced by making eic = 1 not prefetch. > > > > When you think about IO concurrency = 1, it doesn't imply prefetching > > to me. But, I think we want to do the right thing and have parity with > > master. > > > >> My suggestion would be to keep the master behavior unless not practical, > >> and then maybe discuss changing the details later. The patch is already > >> complicated enough, better to leave that discussion for later. > > > > Agreed. Speaking of which, we need to add back use of tablespace IO > > concurrency for the streaming read API (which is used by > > BitmapHeapScan in master). > > > >>> With very low selectivity, you are less likely to get readahead > >>> (right?) and similarly less likely to be able to build up > 8kB IOs -- > >>> which is one of the main value propositions of the streaming read > >>> code. I imagine that this larger read benefit is part of why the > >>> performance is better at higher selectivities with the patch. This > >>> might be a silly experiment, but we could try decreasing > >>> MAX_BUFFERS_PER_TRANSFER on the patched version and see if the > >>> performance gains go away. > >> > >> Sure, I can do that. Do you have any particular suggestion what value to > >> use for MAX_BUFFERS_PER_TRANSFER? > > > > I think setting it to 1 would be the same as always master -- doing > > only 8kB reads. The only thing about that is that I imagine the other > > streaming read code has some overhead which might end up being a > > regression on balance even with the prefetching if we aren't actually > > using the ranges/vectored capabilities of the streaming read > > interface. Maybe if you just run it for one of the very obvious > > performance improvement cases? I can also try this locally. > > > > Here's some results from a build with > > #define MAX_BUFFERS_PER_TRANSFER 1 > > There are three columns: > > - master > - patched (original patches, with MAX_BUFFERS_PER_TRANSFER=128kB) > - patched-single (MAX_BUFFERS_PER_TRANSFER=8kB) > > The color scales are always branch compared to master. > > I think the expectation was that setting the transfer to 1 would make it > closer to master, reducing some of the regressions. But in practice the > effect is the opposite. > > - In "cached" runs, this eliminates the small improvements (light > green), but leaves the regressions behind. For cached runs, I actually would expect that MAX_BUFFERS_PER_TRANSFER would eliminate the regressions. Pinning more buffers will only hurt us for cached workloads. This is evidence that we may need to control the number of pinned buffers differently when there has been a run of fully cached blocks. > - In "uncached" runs, this exacerbates the regressions, particularly for > low selectivities (small values of matches). For the uncached runs, I actually expected it to eliminate the performance gains that we saw with the patches applied. With MAX_BUFFERS_PER_TRANSFER=1, we don't get the benefit of larger IOs and fewer system calls but we still have the overhead of the streaming read machinery. I was hoping to prove that the performance improvements we saw with all the patches applied were due to MAX_BUFFERS_PER_TRANSFER being > 1 causing fewer, bigger reads. It did eliminate some performance gains, however, primarily for cyclic-fuzz at lower selectivities. I am a little confused by this part because with lower selectivities there are likely fewer consecutive blocks that can be combined into one IO. And, on average, we still see a lot of performance improvements that were not eliminated by MAX_BUFFERS_PER_TRANSFER = 1. Hmm. - Melanie
On 3/3/24 00:39, Melanie Plageman wrote: > On Sat, Mar 2, 2024 at 5:51 PM Tomas Vondra > <tomas.vondra@enterprisedb.com> wrote: >> >> On 3/2/24 23:11, Melanie Plageman wrote: >>> On Fri, Mar 1, 2024 at 2:31 PM Melanie Plageman >>> <melanieplageman@gmail.com> wrote: >>>> >>>> ... >>>> >>>> Hold the phone on this one. I realized why I moved >>>> BitmapAdjustPrefetchIterator after table_scan_bitmap_next_block() in >>>> the first place -- master calls BitmapAdjustPrefetchIterator after the >>>> tbm_iterate() for the current block -- otherwise with eic = 1, it >>>> considers the prefetch iterator behind the current block iterator. I'm >>>> going to go through and figure out what order this must be done in and >>>> fix it. >>> >>> So, I investigated this further, and, as far as I can tell, for >>> parallel bitmapheapscan the timing around when workers decrement >>> prefetch_pages causes the performance differences with patch 0010 >>> applied. It makes very little sense to me, but some of the queries I >>> borrowed from your regression examples are up to 30% slower when this >>> code from BitmapAdjustPrefetchIterator() is after >>> table_scan_bitmap_next_block() instead of before it. >>> >>> SpinLockAcquire(&pstate->mutex); >>> if (pstate->prefetch_pages > 0) >>> pstate->prefetch_pages--; >>> SpinLockRelease(&pstate->mutex); >>> >>> I did some stracing and did see much more time spent in futex/wait >>> with this code after the call to table_scan_bitmap_next_block() vs >>> before it. (table_scan_bitmap_next_block()) calls ReadBuffer()). >>> >>> In my branch, I've now moved only the parallel prefetch_pages-- code >>> to before table_scan_bitmap_next_block(). >>> https://github.com/melanieplageman/postgres/tree/bhs_pgsr >>> I'd be interested to know if you see the regressions go away with 0010 >>> applied (commit message "Make table_scan_bitmap_next_block() async >>> friendly" and sha bfdcbfee7be8e2c461). >>> >> >> I'll give this a try once the runs with MAX_BUFFERS_PER_TRANSFER=1 >> complete. But it seems really bizarre that simply moving this code a >> little bit would cause such a regression ... > > Yes, it is bizarre. It also might not be a reproducible performance > difference on the cases besides the one I was testing (cyclic dataset, > uncached, eic=8, matches 16+, distinct=100, rows=100000000, 4 parallel > workers). But even if it only affects that one case, it still had a > major, reproducible performance impact to move those 5 lines before > and after table_scan_bitmap_next_block(). > > The same number of reads and fadvises are being issued overall. > However, I did notice that the pread calls are skewed when the those > lines of code are after table_scan_bitmap_next_block() -- fewer of > the workers are doing more of the reads. Perhaps this explains what is > taking longer. Why those workers would end up doing more of the reads, > I don't quite know. > > - Melanie I do have some numbers with e44505ce179e442bd50664c85a31a1805e13514a, and I don't see any such effect - it performs pretty much exactly like the v6 patches. I used a slightly different visualization, plotting the timings on a scatter plot, so values on diagonal mean "same performance" while values above/below mean speedup/slowdown. This is a bit more compact than the tables with color scales, and it makes it harder (impossible) to see patterns (e.g. changes depending on eic). But for evaluating if there's a shift overall it still works, and it also shows clusters. So more a complementary & simpler visualization. There are three charts 1) master-patched.png - master vs. v6 patches 2) master-locks.png - master vs. e44505ce 3) patched-locks.png - v6 patches vs. e44505ce There's virtually no difference between (1) and (2) - same pattern of regressions and speedups, almost as a copy. That's confirmed by (3) where pretty much all values are exactly on the diagonal, with only a couple outliers. I'm not sure why you see a 30% difference with the change. I wonder if that might be due to some issue in the environment? Are you running in a VM, or something like that? regards -- Tomas Vondra EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
Attachment
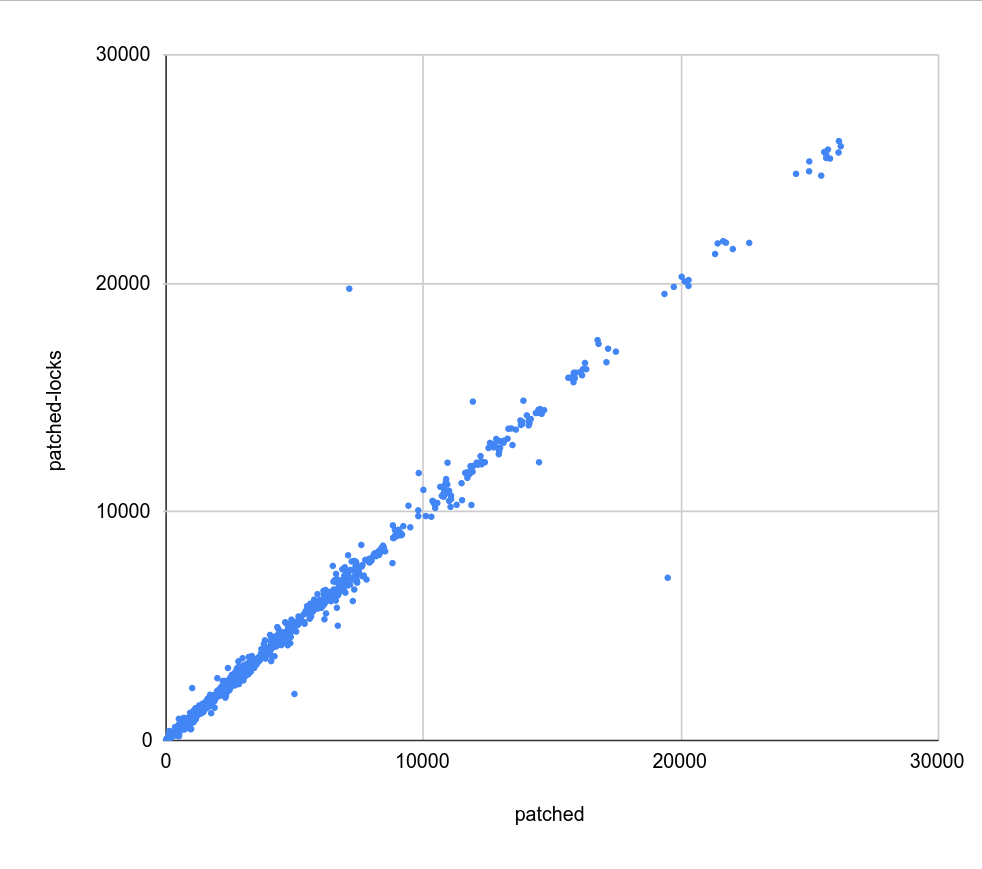{kind=link}
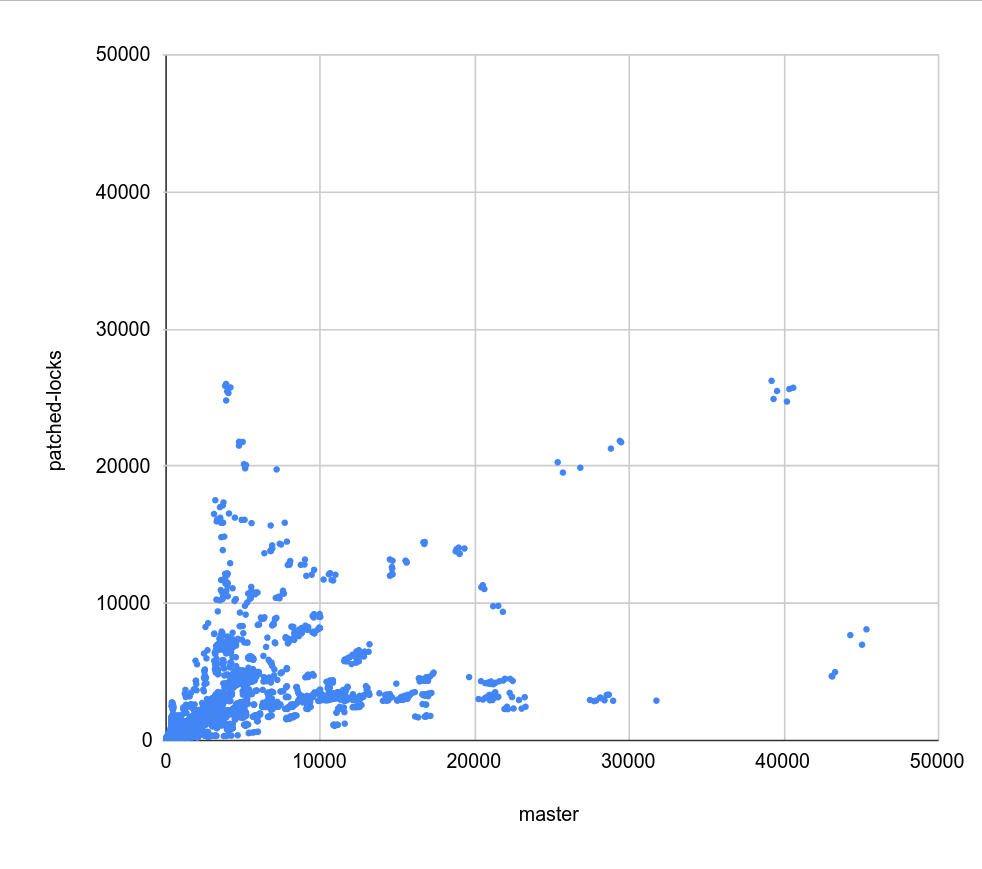{kind=link}
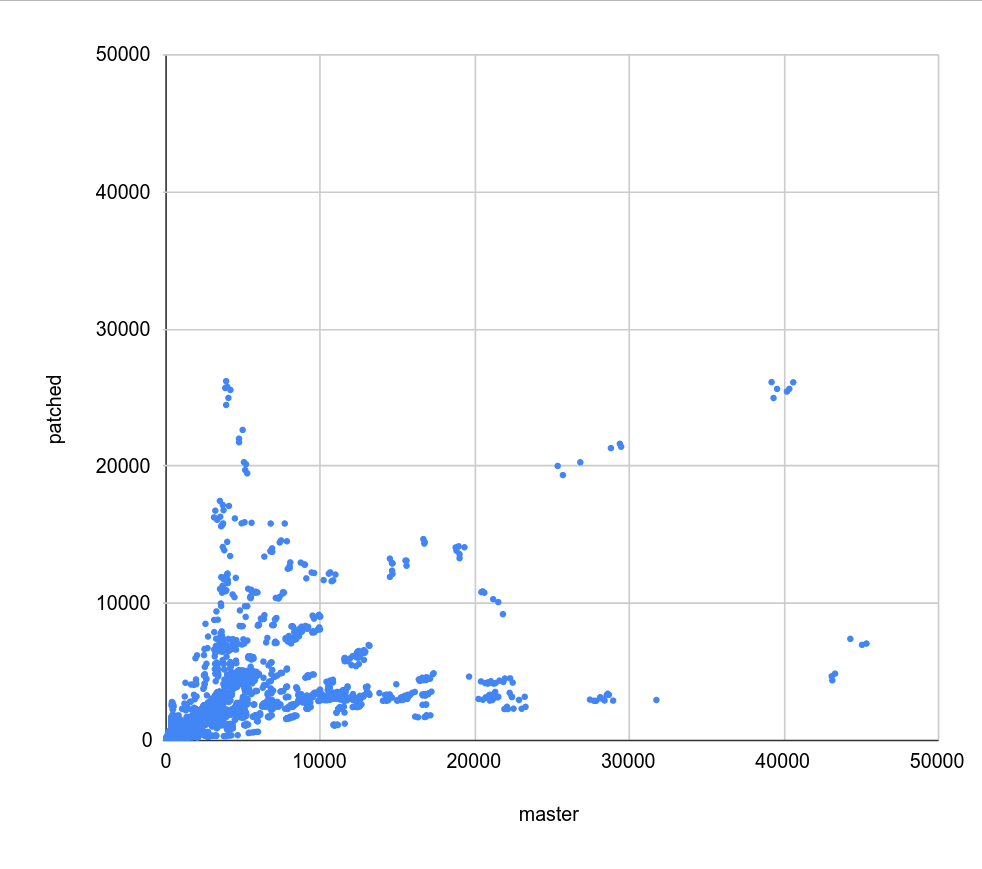{kind=link}
(Adding Dilip, the original author of the parallel bitmap heap scan patch all those years ago, in case you remember anything about the snapshot stuff below.) On 27/02/2024 16:22, Melanie Plageman wrote: > On Mon, Feb 26, 2024 at 08:50:28PM -0500, Melanie Plageman wrote: >> On Fri, Feb 16, 2024 at 12:35:59PM -0500, Melanie Plageman wrote: >>> In the attached v3, I've reordered the commits, updated some errant >>> comments, and improved the commit messages. >>> >>> I've also made some updates to the TIDBitmap API that seem like a >>> clarity improvement to the API in general. These also reduce the diff >>> for GIN when separating the TBMIterateResult from the >>> TBM[Shared]Iterator. And these TIDBitmap API changes are now all in >>> their own commits (previously those were in the same commit as adding >>> the BitmapHeapScan streaming read user). >>> >>> The three outstanding issues I see in the patch set are: >>> 1) the lossy and exact page counters issue described in my previous >>> email >> >> I've resolved this. I added a new patch to the set which starts counting >> even pages with no visible tuples toward lossy and exact pages. After an >> off-list conversation with Andres, it seems that this omission in master >> may not have been intentional. >> >> Once we have only two types of pages to differentiate between (lossy and >> exact [no longer have to care about "has no visible tuples"]), it is >> easy enough to pass a "lossy" boolean paramater to >> table_scan_bitmap_next_block(). I've done this in the attached v4. > > Thomas posted a new version of the Streaming Read API [1], so here is a > rebased v5. This should make it easier to review as it can be applied on > top of master. Lots of discussion happening on the performance results but it seems that there is no performance impact with the preliminary patches up to v5-0013-Streaming-Read-API.patch. I'm focusing purely on those preliminary patches now, because I think they're worthwhile cleanups independent of the streaming read API. Andres already commented on the snapshot stuff on an earlier patch version, and that's much nicer with this version. However, I don't understand why a parallel bitmap heap scan needs to do anything at all with the snapshot, even before these patches. The parallel worker infrastructure already passes the active snapshot from the leader to the parallel worker. Why does bitmap heap scan code need to do that too? I disabled that with: > --- a/src/backend/executor/nodeBitmapHeapscan.c > +++ b/src/backend/executor/nodeBitmapHeapscan.c > @@ -874,7 +874,9 @@ ExecBitmapHeapInitializeWorker(BitmapHeapScanState *node, > pstate = shm_toc_lookup(pwcxt->toc, node->ss.ps.plan->plan_node_id, false); > node->pstate = pstate; > > +#if 0 > node->worker_snapshot = RestoreSnapshot(pstate->phs_snapshot_data); > Assert(IsMVCCSnapshot(node->worker_snapshot)); > RegisterSnapshot(node->worker_snapshot); > +#endif > } and ran "make check-world". All the tests passed. To be even more sure, I added some code there to assert that the serialized version of node->ss.ps.state->es_snapshot is equal to pstate->phs_snapshot_data, and all the tests passed with that too. I propose that we just remove the code in BitmapHeapScan to serialize the snapshot, per attached patch. -- Heikki Linnakangas Neon (https://neon.tech)
Attachment
On Wed, Mar 13, 2024 at 7:04 PM Heikki Linnakangas <hlinnaka@iki.fi> wrote: > > (Adding Dilip, the original author of the parallel bitmap heap scan > patch all those years ago, in case you remember anything about the > snapshot stuff below.) > > On 27/02/2024 16:22, Melanie Plageman wrote: > Andres already commented on the snapshot stuff on an earlier patch > version, and that's much nicer with this version. However, I don't > understand why a parallel bitmap heap scan needs to do anything at all > with the snapshot, even before these patches. The parallel worker > infrastructure already passes the active snapshot from the leader to the > parallel worker. Why does bitmap heap scan code need to do that too? Yeah thinking on this now it seems you are right that the parallel infrastructure is already passing the active snapshot so why do we need it again. Then I checked other low scan nodes like indexscan and seqscan and it seems we are doing the same things there as well. Check for SerializeSnapshot() in table_parallelscan_initialize() and index_parallelscan_initialize() which are being called from ExecSeqScanInitializeDSM() and ExecIndexScanInitializeDSM() respectively. -- Regards, Dilip Kumar EnterpriseDB: http://www.enterprisedb.com
On Wed, Mar 13, 2024 at 11:39 AM Dilip Kumar <dilipbalaut@gmail.com> wrote: > > Andres already commented on the snapshot stuff on an earlier patch > > version, and that's much nicer with this version. However, I don't > > understand why a parallel bitmap heap scan needs to do anything at all > > with the snapshot, even before these patches. The parallel worker > > infrastructure already passes the active snapshot from the leader to the > > parallel worker. Why does bitmap heap scan code need to do that too? > > Yeah thinking on this now it seems you are right that the parallel > infrastructure is already passing the active snapshot so why do we > need it again. Then I checked other low scan nodes like indexscan and > seqscan and it seems we are doing the same things there as well. > Check for SerializeSnapshot() in table_parallelscan_initialize() and > index_parallelscan_initialize() which are being called from > ExecSeqScanInitializeDSM() and ExecIndexScanInitializeDSM() > respectively. I remember thinking about this when I was writing very early parallel query code. It seemed to me that there must be some reason why the EState has a snapshot, as opposed to just using the active snapshot, and so I took care to propagate that snapshot, which is used for the leader's scans, to the worker scans also. Now, if the EState doesn't need to contain a snapshot, then all of that mechanism is unnecessary, but I don't see how it can be right for the leader to do table_beginscan() using estate->es_snapshot and the worker to use the active snapshot. -- Robert Haas EDB: http://www.enterprisedb.com
On 3/13/24 14:34, Heikki Linnakangas wrote: > ... > > Lots of discussion happening on the performance results but it seems > that there is no performance impact with the preliminary patches up to > v5-0013-Streaming-Read-API.patch. I'm focusing purely on those > preliminary patches now, because I think they're worthwhile cleanups > independent of the streaming read API. > Not quite true - the comparison I shared on 29/2 [1] shows a serious regression caused by the 0010 patch. We've been investigating this with Melanie off list, but we don't have any clear findings yet (except that it's clearly due to moving BitmapAdjustPrefetchIterator() a bit down. But if we revert this (and move the BitmapAdjustPrefetchIterator back), the regression should disappear, and we can merge these preparatory patches. We'll have to deal with the regression (or something very similar) when merging the remaining patches. regards [1] https://www.postgresql.org/message-id/91090d58-7d3f-4447-9425-f24ba66e292a%40enterprisedb.com -- Tomas Vondra EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On Sun, Mar 3, 2024 at 11:41 AM Tomas Vondra
<tomas.vondra@enterprisedb.com> wrote:
> On 3/2/24 23:28, Melanie Plageman wrote:
> > On Sat, Mar 2, 2024 at 10:05 AM Tomas Vondra
> > <tomas.vondra@enterprisedb.com> wrote:
> >> With the current "master" code, eic=1 means we'll issue a prefetch for B
> >> and then read+process A. And then issue prefetch for C and read+process
> >> B, and so on. It's always one page ahead.
> >
> > Yes, that is what I mean for eic = 1
I spent quite a few days thinking about the meaning of eic=0 and eic=1
for streaming_read.c v7[1], to make it agree with the above and with
master. Here's why I was confused:
Both eic=0 and eic=1 are expected to generate at most 1 physical I/O
at a time, or I/O queue depth 1 if you want to put it that way. But
this isn't just about concurrency of I/O, it's also about computation.
Duh.
eic=0 means that the I/O is not concurrent with executor computation.
So, to annotate an excerpt from [1]'s random.txt, we have:
effective_io_concurrency = 0, range size = 1
unpatched patched
==============================================================================
pread(43,...,8192,0x58000) = 8192 pread(82,...,8192,0x58000) = 8192
*** executor now has page at 0x58000 to work on ***
pread(43,...,8192,0xb0000) = 8192 pread(82,...,8192,0xb0000) = 8192
*** executor now has page at 0xb0000 to work on ***
eic=1 means that a single I/O is started and then control is returned
to the executor code to do useful work concurrently with the
background read that we assume is happening:
effective_io_concurrency = 1, range size = 1
unpatched patched
==============================================================================
pread(43,...,8192,0x58000) = 8192 pread(82,...,8192,0x58000) = 8192
posix_fadvise(43,0xb0000,0x2000,...) posix_fadvise(82,0xb0000,0x2000,...)
*** executor now has page at 0x58000 to work on ***
pread(43,...,8192,0xb0000) = 8192 pread(82,...,8192,0xb0000) = 8192
posix_fadvise(43,0x108000,0x2000,...) posix_fadvise(82,0x108000,0x2000,...)
*** executor now has page at 0xb0000 to work on ***
pread(43,...,8192,0x108000) = 8192 pread(82,...,8192,0x108000) = 8192
posix_fadvise(43,0x160000,0x2000,...) posix_fadvise(82,0x160000,0x2000,...)
In other words, 'concurrency' doesn't mean 'number of I/Os running
concurrently with each other', it means 'number of I/Os running
concurrently with computation', and when you put it that way, 0 and 1
are different.
Note that the first read is a bit special: by the time the consumer is
ready to pull a buffer out of the stream when we don't have a buffer
ready yet, it is too late to issue useful advice, so we don't bother.
FWIW I think even in the AIO future we would have a synchronous read
in that specific place, at least when using io_method=worker, because
it would be stupid to ask another process to read a block for us that
we want right now and then wait for it wake us up when it's done.
Note that even when we aren't issuing any advice because eic=0 or
because we detected sequential access and we believe the kernel can do
a better job than us, we still 'look ahead' (= call the callback to
see which block numbers are coming down the pipe), but only as far as
we need to coalesce neighbouring blocks. (I deliberately avoid using
the word "prefetch" except in very general discussions because it
means different things to different layers of the code, hence talk of
"look ahead" and "advice".) That's how we get this change:
effective_io_concurrency = 0, range size = 4
unpatched patched
==============================================================================
pread(43,...,8192,0x58000) = 8192 pread(82,...,8192,0x58000) = 8192
pread(43,...,8192,0x5a000) = 8192 preadv(82,...,2,0x5a000) = 16384
pread(43,...,8192,0x5c000) = 8192 pread(82,...,8192,0x5e000) = 8192
pread(43,...,8192,0x5e000) = 8192 preadv(82,...,4,0xb0000) = 32768
pread(43,...,8192,0xb0000) = 8192 preadv(82,...,4,0x108000) = 32768
pread(43,...,8192,0xb2000) = 8192 preadv(82,...,4,0x160000) = 32768
And then once we introduce eic > 0 to the picture with neighbouring
blocks that can be coalesced, "patched" starts to diverge even more
from "unpatched" because it tracks the number of wide I/Os in
progress, not the number of single blocks.
[1] https://www.postgresql.org/message-id/CA+hUKGLJi+c5jB3j6UvkgMYHky-qu+LPCsiNahUGSa5Z4DvyVA@mail.gmail.com
On Wed, Mar 13, 2024 at 9:25 PM Robert Haas <robertmhaas@gmail.com> wrote: > > On Wed, Mar 13, 2024 at 11:39 AM Dilip Kumar <dilipbalaut@gmail.com> wrote: > > > Andres already commented on the snapshot stuff on an earlier patch > > > version, and that's much nicer with this version. However, I don't > > > understand why a parallel bitmap heap scan needs to do anything at all > > > with the snapshot, even before these patches. The parallel worker > > > infrastructure already passes the active snapshot from the leader to the > > > parallel worker. Why does bitmap heap scan code need to do that too? > > > > Yeah thinking on this now it seems you are right that the parallel > > infrastructure is already passing the active snapshot so why do we > > need it again. Then I checked other low scan nodes like indexscan and > > seqscan and it seems we are doing the same things there as well. > > Check for SerializeSnapshot() in table_parallelscan_initialize() and > > index_parallelscan_initialize() which are being called from > > ExecSeqScanInitializeDSM() and ExecIndexScanInitializeDSM() > > respectively. > > I remember thinking about this when I was writing very early parallel > query code. It seemed to me that there must be some reason why the > EState has a snapshot, as opposed to just using the active snapshot, > and so I took care to propagate that snapshot, which is used for the > leader's scans, to the worker scans also. Now, if the EState doesn't > need to contain a snapshot, then all of that mechanism is unnecessary, > but I don't see how it can be right for the leader to do > table_beginscan() using estate->es_snapshot and the worker to use the > active snapshot. Yeah, that's a very valid point. So I think now Heikki/Melanie might have got an answer to their question, about the thought process behind serializing the snapshot for each scan node. And the same thing is followed for BitmapHeapNode as well. -- Regards, Dilip Kumar EnterpriseDB: http://www.enterprisedb.com
On 14/03/2024 06:54, Dilip Kumar wrote: > On Wed, Mar 13, 2024 at 9:25 PM Robert Haas <robertmhaas@gmail.com> wrote: >> >> On Wed, Mar 13, 2024 at 11:39 AM Dilip Kumar <dilipbalaut@gmail.com> wrote: >>>> Andres already commented on the snapshot stuff on an earlier patch >>>> version, and that's much nicer with this version. However, I don't >>>> understand why a parallel bitmap heap scan needs to do anything at all >>>> with the snapshot, even before these patches. The parallel worker >>>> infrastructure already passes the active snapshot from the leader to the >>>> parallel worker. Why does bitmap heap scan code need to do that too? >>> >>> Yeah thinking on this now it seems you are right that the parallel >>> infrastructure is already passing the active snapshot so why do we >>> need it again. Then I checked other low scan nodes like indexscan and >>> seqscan and it seems we are doing the same things there as well. >>> Check for SerializeSnapshot() in table_parallelscan_initialize() and >>> index_parallelscan_initialize() which are being called from >>> ExecSeqScanInitializeDSM() and ExecIndexScanInitializeDSM() >>> respectively. >> >> I remember thinking about this when I was writing very early parallel >> query code. It seemed to me that there must be some reason why the >> EState has a snapshot, as opposed to just using the active snapshot, >> and so I took care to propagate that snapshot, which is used for the >> leader's scans, to the worker scans also. Now, if the EState doesn't >> need to contain a snapshot, then all of that mechanism is unnecessary, >> but I don't see how it can be right for the leader to do >> table_beginscan() using estate->es_snapshot and the worker to use the >> active snapshot. > > Yeah, that's a very valid point. So I think now Heikki/Melanie might > have got an answer to their question, about the thought process behind > serializing the snapshot for each scan node. And the same thing is > followed for BitmapHeapNode as well. I see. Thanks, understanding the thought process helps. So when a parallel table or index scan runs in the executor as part of a query, we could just use the active snapshot. But there are some other callers of parallel table scans that don't use the executor, namely parallel index builds. For those it makes sense to pass the snapshot for the scan independent of the active snapshot. A parallel bitmap heap scan isn't really a parallel scan as far as the table AM is concerned, though. It's more like an independent bitmap heap scan in each worker process, nodeBitmapHeapscan.c does all the coordination of which blocks to scan. So I think that table_parallelscan_initialize() was the wrong role model, and we should still remove the snapshot serialization code from nodeBitmapHeapscan.c. Digging deeper into the question of whether es_snapshot == GetActiveSnapshot() is a valid assumption: <deep dive> es_snapshot is copied from the QueryDesc in standard_ExecutorStart(). Looking at the callers of ExecutorStart(), they all get the QueryDesc by calling CreateQueryDesc() with GetActiveSnapshot(). And I don't see any callers changing the active snapshot between the ExecutorStart() and ExecutorRun() calls either. In pquery.c, we explicitly PushActiveSnapshot(queryDesc->snapshot) before calling ExecutorRun(). So no live bug here AFAICS, es_snapshot == GetActiveSnapshot() holds. _SPI_execute_plan() has code to deal with the possibility that the active snapshot is not set. That seems fishy; do we really support SPI without any snapshot? I'm inclined to turn that into an error. I ran the regression tests with an "Assert(ActiveSnapshotSet())" there, and everything worked. If es_snapshot was different from the active snapshot, things would get weird, even without parallel query. The scans would use es_snapshot for the visibility checks, but any functions you execute in quals would use the active snapshot. We could double down on that assumption, and remove es_snapshot altogether and use GetActiveSnapshot() instead. And perhaps add "PushActiveSnapshot(queryDesc->snapshot)" to ExecutorRun(). </deep dive> In summary, this es_snapshot stuff is a bit confusing and could use some cleanup. But for now, I'd like to just add some assertions and a comments about this, and remove the snapshot serialization from bitmap heap scan node, to make it consistent with other non-parallel scan nodes (it's not really a parallel scan as far as the table AM is concerned). See attached patch, which is the same as previous patch with some extra assertions. -- Heikki Linnakangas Neon (https://neon.tech)
Attachment
On Thu, Mar 14, 2024 at 4:07 PM Heikki Linnakangas <hlinnaka@iki.fi> wrote: > > > Yeah, that's a very valid point. So I think now Heikki/Melanie might > > have got an answer to their question, about the thought process behind > > serializing the snapshot for each scan node. And the same thing is > > followed for BitmapHeapNode as well. > > I see. Thanks, understanding the thought process helps. > > So when a parallel table or index scan runs in the executor as part of a > query, we could just use the active snapshot. But there are some other > callers of parallel table scans that don't use the executor, namely > parallel index builds. For those it makes sense to pass the snapshot for > the scan independent of the active snapshot. Right > A parallel bitmap heap scan isn't really a parallel scan as far as the > table AM is concerned, though. It's more like an independent bitmap heap > scan in each worker process, nodeBitmapHeapscan.c does all the > coordination of which blocks to scan. So I think that > table_parallelscan_initialize() was the wrong role model, and we should > still remove the snapshot serialization code from nodeBitmapHeapscan.c. I think that seems right. > Digging deeper into the question of whether es_snapshot == > GetActiveSnapshot() is a valid assumption: > > <deep dive> > > es_snapshot is copied from the QueryDesc in standard_ExecutorStart(). > Looking at the callers of ExecutorStart(), they all get the QueryDesc by > calling CreateQueryDesc() with GetActiveSnapshot(). And I don't see any > callers changing the active snapshot between the ExecutorStart() and > ExecutorRun() calls either. In pquery.c, we explicitly > PushActiveSnapshot(queryDesc->snapshot) before calling ExecutorRun(). So > no live bug here AFAICS, es_snapshot == GetActiveSnapshot() holds. > > _SPI_execute_plan() has code to deal with the possibility that the > active snapshot is not set. That seems fishy; do we really support SPI > without any snapshot? I'm inclined to turn that into an error. I ran the > regression tests with an "Assert(ActiveSnapshotSet())" there, and > everything worked. IMHO, we can call SPI_Connect() and SPI_Execute() from any C extension, so I don't think there we can guarantee that the snapshot must be set, do we? > If es_snapshot was different from the active snapshot, things would get > weird, even without parallel query. The scans would use es_snapshot for > the visibility checks, but any functions you execute in quals would use > the active snapshot. > > We could double down on that assumption, and remove es_snapshot > altogether and use GetActiveSnapshot() instead. And perhaps add > "PushActiveSnapshot(queryDesc->snapshot)" to ExecutorRun(). > > </deep dive> > > In summary, this es_snapshot stuff is a bit confusing and could use some > cleanup. But for now, I'd like to just add some assertions and a > comments about this, and remove the snapshot serialization from bitmap > heap scan node, to make it consistent with other non-parallel scan nodes > (it's not really a parallel scan as far as the table AM is concerned). > See attached patch, which is the same as previous patch with some extra > assertions. Maybe for now we can just handle this specific case to remove the snapshot serializing for the BitmapHeapScan as you are doing in the patch. After looking into the code your theory seems correct that we are just copying the ActiveSnapshot while building the query descriptor and from there we are copying into the Estate so logically there should not be any reason for these two to be different. -- Regards, Dilip Kumar EnterpriseDB: http://www.enterprisedb.com
On Thu, Mar 14, 2024 at 6:37 AM Heikki Linnakangas <hlinnaka@iki.fi> wrote: > If es_snapshot was different from the active snapshot, things would get > weird, even without parallel query. The scans would use es_snapshot for > the visibility checks, but any functions you execute in quals would use > the active snapshot. Hmm, that's an interesting point. The case where the query is suspended and resumed - i.e. cursors are used - probably needs more analysis. In that case, perhaps there's more room for the snapshots to diverge. -- Robert Haas EDB: http://www.enterprisedb.com
On 14/03/2024 14:34, Robert Haas wrote:
> On Thu, Mar 14, 2024 at 6:37 AM Heikki Linnakangas <hlinnaka@iki.fi> wrote:
>> If es_snapshot was different from the active snapshot, things would get
>> weird, even without parallel query. The scans would use es_snapshot for
>> the visibility checks, but any functions you execute in quals would use
>> the active snapshot.
>
> Hmm, that's an interesting point.
>
> The case where the query is suspended and resumed - i.e. cursors are
> used - probably needs more analysis. In that case, perhaps there's
> more room for the snapshots to diverge.
The portal code is pretty explicit about it, the ExecutorRun() call in
PortalRunSelect() looks like this:
PushActiveSnapshot(queryDesc->snapshot);
ExecutorRun(queryDesc, direction, (uint64) count,
portal->run_once);
nprocessed = queryDesc->estate->es_processed;
PopActiveSnapshot();
I looked at all the callers of ExecutorRun(), and they all have the
active snapshot equal to queryDesc->snapshot, either because they called
CreateQueryDesc() with the active snapshot before ExecutorRun(), or they
set the active snapshot like above.
--
Heikki Linnakangas
Neon (https://neon.tech)
On Thu, Mar 14, 2024 at 9:00 AM Heikki Linnakangas <hlinnaka@iki.fi> wrote: > The portal code is pretty explicit about it, the ExecutorRun() call in > PortalRunSelect() looks like this: > > PushActiveSnapshot(queryDesc->snapshot); > ExecutorRun(queryDesc, direction, (uint64) count, > portal->run_once); > nprocessed = queryDesc->estate->es_processed; > PopActiveSnapshot(); > > I looked at all the callers of ExecutorRun(), and they all have the > active snapshot equal to queryDesc->snapshot, either because they called > CreateQueryDesc() with the active snapshot before ExecutorRun(), or they > set the active snapshot like above. Well, maybe there's a bunch of code cleanup possible, then. -- Robert Haas EDB: http://www.enterprisedb.com
On 14/03/2024 12:55, Dilip Kumar wrote: > On Thu, Mar 14, 2024 at 4:07 PM Heikki Linnakangas <hlinnaka@iki.fi> wrote: >> _SPI_execute_plan() has code to deal with the possibility that the >> active snapshot is not set. That seems fishy; do we really support SPI >> without any snapshot? I'm inclined to turn that into an error. I ran the >> regression tests with an "Assert(ActiveSnapshotSet())" there, and >> everything worked. > > IMHO, we can call SPI_Connect() and SPI_Execute() from any C > extension, so I don't think there we can guarantee that the snapshot > must be set, do we? I suppose, although the things you could do without a snapshot would be pretty limited. The query couldn't access any tables. Could it even look up functions in the parser? Not sure. > Maybe for now we can just handle this specific case to remove the > snapshot serializing for the BitmapHeapScan as you are doing in the > patch. After looking into the code your theory seems correct that we > are just copying the ActiveSnapshot while building the query > descriptor and from there we are copying into the Estate so logically > there should not be any reason for these two to be different. Ok, committed that for now. Thanks for looking! -- Heikki Linnakangas Neon (https://neon.tech)
On 3/13/24 23:38, Thomas Munro wrote: > On Sun, Mar 3, 2024 at 11:41 AM Tomas Vondra > <tomas.vondra@enterprisedb.com> wrote: >> On 3/2/24 23:28, Melanie Plageman wrote: >>> On Sat, Mar 2, 2024 at 10:05 AM Tomas Vondra >>> <tomas.vondra@enterprisedb.com> wrote: >>>> With the current "master" code, eic=1 means we'll issue a prefetch for B >>>> and then read+process A. And then issue prefetch for C and read+process >>>> B, and so on. It's always one page ahead. >>> >>> Yes, that is what I mean for eic = 1 > > I spent quite a few days thinking about the meaning of eic=0 and eic=1 > for streaming_read.c v7[1], to make it agree with the above and with > master. Here's why I was confused: > > Both eic=0 and eic=1 are expected to generate at most 1 physical I/O > at a time, or I/O queue depth 1 if you want to put it that way. But > this isn't just about concurrency of I/O, it's also about computation. > Duh. > > eic=0 means that the I/O is not concurrent with executor computation. > So, to annotate an excerpt from [1]'s random.txt, we have: > > effective_io_concurrency = 0, range size = 1 > unpatched patched > ============================================================================== > pread(43,...,8192,0x58000) = 8192 pread(82,...,8192,0x58000) = 8192 > *** executor now has page at 0x58000 to work on *** > pread(43,...,8192,0xb0000) = 8192 pread(82,...,8192,0xb0000) = 8192 > *** executor now has page at 0xb0000 to work on *** > > eic=1 means that a single I/O is started and then control is returned > to the executor code to do useful work concurrently with the > background read that we assume is happening: > > effective_io_concurrency = 1, range size = 1 > unpatched patched > ============================================================================== > pread(43,...,8192,0x58000) = 8192 pread(82,...,8192,0x58000) = 8192 > posix_fadvise(43,0xb0000,0x2000,...) posix_fadvise(82,0xb0000,0x2000,...) > *** executor now has page at 0x58000 to work on *** > pread(43,...,8192,0xb0000) = 8192 pread(82,...,8192,0xb0000) = 8192 > posix_fadvise(43,0x108000,0x2000,...) posix_fadvise(82,0x108000,0x2000,...) > *** executor now has page at 0xb0000 to work on *** > pread(43,...,8192,0x108000) = 8192 pread(82,...,8192,0x108000) = 8192 > posix_fadvise(43,0x160000,0x2000,...) posix_fadvise(82,0x160000,0x2000,...) > > In other words, 'concurrency' doesn't mean 'number of I/Os running > concurrently with each other', it means 'number of I/Os running > concurrently with computation', and when you put it that way, 0 and 1 > are different. > Interesting. For some reason I thought with eic=1 we'd issue the fadvise for page #2 before pread of page #1, so that there'd be 2 IO requests in flight at the same time for a bit of time ... it'd give the fadvise more time to actually get the data into page cache. > Note that the first read is a bit special: by the time the consumer is > ready to pull a buffer out of the stream when we don't have a buffer > ready yet, it is too late to issue useful advice, so we don't bother. > FWIW I think even in the AIO future we would have a synchronous read > in that specific place, at least when using io_method=worker, because > it would be stupid to ask another process to read a block for us that > we want right now and then wait for it wake us up when it's done. > > Note that even when we aren't issuing any advice because eic=0 or > because we detected sequential access and we believe the kernel can do > a better job than us, we still 'look ahead' (= call the callback to > see which block numbers are coming down the pipe), but only as far as > we need to coalesce neighbouring blocks. (I deliberately avoid using > the word "prefetch" except in very general discussions because it > means different things to different layers of the code, hence talk of > "look ahead" and "advice".) That's how we get this change: > > effective_io_concurrency = 0, range size = 4 > unpatched patched > ============================================================================== > pread(43,...,8192,0x58000) = 8192 pread(82,...,8192,0x58000) = 8192 > pread(43,...,8192,0x5a000) = 8192 preadv(82,...,2,0x5a000) = 16384 > pread(43,...,8192,0x5c000) = 8192 pread(82,...,8192,0x5e000) = 8192 > pread(43,...,8192,0x5e000) = 8192 preadv(82,...,4,0xb0000) = 32768 > pread(43,...,8192,0xb0000) = 8192 preadv(82,...,4,0x108000) = 32768 > pread(43,...,8192,0xb2000) = 8192 preadv(82,...,4,0x160000) = 32768 > > And then once we introduce eic > 0 to the picture with neighbouring > blocks that can be coalesced, "patched" starts to diverge even more > from "unpatched" because it tracks the number of wide I/Os in > progress, not the number of single blocks. > So, IIUC this means (1) the patched code is more aggressive wrt prefetching (because we prefetch more data overall, because master would prefetch N pages and patched prefetches N ranges, each of which may be multiple pages. And (2) it's not easy to quantify how much more aggressive it is, because it depends on how we happen to coalesce the pages into ranges. Do I understand this correctly? regards -- Tomas Vondra EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On Thu, Mar 14, 2024 at 03:32:04PM +0200, Heikki Linnakangas wrote: > On 14/03/2024 12:55, Dilip Kumar wrote: > > On Thu, Mar 14, 2024 at 4:07 PM Heikki Linnakangas <hlinnaka@iki.fi> wrote: > > > _SPI_execute_plan() has code to deal with the possibility that the > > > active snapshot is not set. That seems fishy; do we really support SPI > > > without any snapshot? I'm inclined to turn that into an error. I ran the > > > regression tests with an "Assert(ActiveSnapshotSet())" there, and > > > everything worked. > > > > IMHO, we can call SPI_Connect() and SPI_Execute() from any C > > extension, so I don't think there we can guarantee that the snapshot > > must be set, do we? > > I suppose, although the things you could do without a snapshot would be > pretty limited. The query couldn't access any tables. Could it even look up > functions in the parser? Not sure. > > > Maybe for now we can just handle this specific case to remove the > > snapshot serializing for the BitmapHeapScan as you are doing in the > > patch. After looking into the code your theory seems correct that we > > are just copying the ActiveSnapshot while building the query > > descriptor and from there we are copying into the Estate so logically > > there should not be any reason for these two to be different. > > Ok, committed that for now. Thanks for looking! Attached v6 is rebased over your new commit. It also has the "fix" in 0010 which moves BitmapAdjustPrefetchIterator() back above table_scan_bitmap_next_block(). I've also updated the Streaming Read API commit (0013) to Thomas' v7 version from [1]. This has the update that we theorize should address some of the regressions in the bitmapheapscan streaming read user in 0014. - Melanie [1] https://www.postgresql.org/message-id/CA%2BhUKGLJi%2Bc5jB3j6UvkgMYHky-qu%2BLPCsiNahUGSa5Z4DvyVA%40mail.gmail.com
Attachment
- v6-0001-BitmapHeapScan-begin-scan-after-bitmap-creation.patch
- v6-0002-BitmapHeapScan-set-can_skip_fetch-later.patch
- v6-0003-Push-BitmapHeapScan-skip-fetch-optimization-into-.patch
- v6-0004-BitmapPrefetch-use-prefetch-block-recheck-for-ski.patch
- v6-0005-Update-BitmapAdjustPrefetchIterator-parameter-typ.patch
- v6-0006-EXPLAIN-Bitmap-table-scan-also-count-no-visible-t.patch
- v6-0007-table_scan_bitmap_next_block-returns-lossy-or-exa.patch
- v6-0008-Reduce-scope-of-BitmapHeapScan-tbmiterator-local-.patch
- v6-0009-Remove-table_scan_bitmap_next_tuple-parameter-tbm.patch
- v6-0010-Make-table_scan_bitmap_next_block-async-friendly.patch
- v6-0011-Hard-code-TBMIterateResult-offsets-array-size.patch
- v6-0012-Separate-TBM-Shared-Iterator-and-TBMIterateResult.patch
- v6-0013-v7-Streaming-Read-API.patch
- v6-0014-BitmapHeapScan-uses-streaming-read-API.patch
On Fri, Mar 15, 2024 at 3:18 AM Tomas Vondra <tomas.vondra@enterprisedb.com> wrote: > So, IIUC this means (1) the patched code is more aggressive wrt > prefetching (because we prefetch more data overall, because master would > prefetch N pages and patched prefetches N ranges, each of which may be > multiple pages. And (2) it's not easy to quantify how much more > aggressive it is, because it depends on how we happen to coalesce the > pages into ranges. > > Do I understand this correctly? Yes. Parallelism must prevent coalescing here though. Any parallel aware executor node that allocates block numbers to workers without trying to preserve ranges will. That not only hides the opportunity to coalesce reads, it also makes (globally) sequential scans look random (ie locally they are more random), so that our logic to avoid issuing advice for sequential scan won't work, and we'll inject extra useless or harmful (?) fadvise calls. I don't know what to do about that yet, but it seems like a subject for future research. Should we recognise sequential scans with a window (like Linux does), instead of strictly next-block detection (like some other OSes do)? Maybe a shared streaming read that all workers pull blocks from, so it can see what's going on? I think the latter would be strictly more like what the ad hoc BHS prefetching code in master is doing, but I don't know if it'd be over-engineering, or hard to do for some reason. Another aspect of per-backend streaming reads in one parallel query that don't know about each other is that they will all have their own effective_io_concurrency limit. That is a version of a problem that comes up again and again in parallel query, to be solved by the grand unified resource control system of the future.
On 3/14/24 19:16, Melanie Plageman wrote: > On Thu, Mar 14, 2024 at 03:32:04PM +0200, Heikki Linnakangas wrote: >> ... >> >> Ok, committed that for now. Thanks for looking! > > Attached v6 is rebased over your new commit. It also has the "fix" in > 0010 which moves BitmapAdjustPrefetchIterator() back above > table_scan_bitmap_next_block(). I've also updated the Streaming Read API > commit (0013) to Thomas' v7 version from [1]. This has the update that > we theorize should address some of the regressions in the bitmapheapscan > streaming read user in 0014. > Should I rerun the benchmarks with these new patches, to see if it really helps with the regressions? regards -- Tomas Vondra EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On Thu, Mar 14, 2024 at 5:26 PM Tomas Vondra <tomas.vondra@enterprisedb.com> wrote: > > On 3/14/24 19:16, Melanie Plageman wrote: > > On Thu, Mar 14, 2024 at 03:32:04PM +0200, Heikki Linnakangas wrote: > >> ... > >> > >> Ok, committed that for now. Thanks for looking! > > > > Attached v6 is rebased over your new commit. It also has the "fix" in > > 0010 which moves BitmapAdjustPrefetchIterator() back above > > table_scan_bitmap_next_block(). I've also updated the Streaming Read API > > commit (0013) to Thomas' v7 version from [1]. This has the update that > > we theorize should address some of the regressions in the bitmapheapscan > > streaming read user in 0014. > > > > Should I rerun the benchmarks with these new patches, to see if it > really helps with the regressions? That would be awesome! I will soon send out a summary of what we investigated off-list about 0010 (though we didn't end up concluding anything). My "fix" (leaving BitmapAdjustPrefetchIterator() above table_scan_bitmap_next_block()) eliminates the regression in 0010 on the one example that I repro'd upthread, but it would be good to know if it eliminates the regressions across some other tests. I think it would be worthwhile to run the subset of tests which seemed to fare the worst on 0010 against the patches 0001-0010-- cyclic uncached on your xeon machine with 4 parallel workers, IIRC -- even the 1 million scale would do the trick, I think. And then separately run the subset of tests which seemed to do the worst on 0014. There were several groups of issues across the different tests, but I think that the uniform pages data test would be relevant to use. It showed the regressions with eic 0. As for the other regressions showing with 0014, I think we would want to see at least one with fully-in-shared-buffers and one with fully uncached. Some of the fixes were around pinning fewer buffers when the blocks were already in shared buffers. - Melanie
Hi, On 2024-03-14 17:39:30 -0400, Melanie Plageman wrote: > I will soon send out a summary of what we investigated off-list about > 0010 (though we didn't end up concluding anything). My "fix" (leaving > BitmapAdjustPrefetchIterator() above table_scan_bitmap_next_block()) > eliminates the regression in 0010 on the one example that I repro'd > upthread, but it would be good to know if it eliminates the > regressions across some other tests. I spent a good amount of time looking into this with Melanie. After a bunch of wrong paths I think I found the issue: We end up prefetching blocks we have already read. Notably this happens even as-is on master - just not as frequently as after moving BitmapAdjustPrefetchIterator(). From what I can tell the prefetching in parallel bitmap heap scans is thoroughly broken. I added some tracking of the last block read, the last block prefetched to ParallelBitmapHeapState and found that with a small effective_io_concurrency we end up with ~18% of prefetches being of blocks we already read! After moving the BitmapAdjustPrefetchIterator() to rises to 86%, no wonder it's slower... The race here seems fairly substantial - we're moving the two iterators independently from each other, in multiple processes, without useful locking. I'm inclined to think this is a bug we ought to fix in the backbranches. Greetings, Andres Freund
On Fri, Mar 15, 2024 at 5:14 PM Andres Freund <andres@anarazel.de> wrote: > > Hi, > > On 2024-03-14 17:39:30 -0400, Melanie Plageman wrote: > > I will soon send out a summary of what we investigated off-list about > > 0010 (though we didn't end up concluding anything). My "fix" (leaving > > BitmapAdjustPrefetchIterator() above table_scan_bitmap_next_block()) > > eliminates the regression in 0010 on the one example that I repro'd > > upthread, but it would be good to know if it eliminates the > > regressions across some other tests. > > I spent a good amount of time looking into this with Melanie. After a bunch of > wrong paths I think I found the issue: We end up prefetching blocks we have > already read. Notably this happens even as-is on master - just not as > frequently as after moving BitmapAdjustPrefetchIterator(). > > From what I can tell the prefetching in parallel bitmap heap scans is > thoroughly broken. I added some tracking of the last block read, the last > block prefetched to ParallelBitmapHeapState and found that with a small > effective_io_concurrency we end up with ~18% of prefetches being of blocks we > already read! After moving the BitmapAdjustPrefetchIterator() to rises to 86%, > no wonder it's slower... > > The race here seems fairly substantial - we're moving the two iterators > independently from each other, in multiple processes, without useful locking. > > I'm inclined to think this is a bug we ought to fix in the backbranches. Thinking about how to fix this, perhaps we could keep the current max block number in the ParallelBitmapHeapState and then when prefetching, workers could loop calling tbm_shared_iterate() until they've found a block at least prefetch_pages ahead of the current block. They wouldn't need to read the current max value from the parallel state on each iteration. Even checking it once and storing that value in a local variable prevented prefetching blocks after reading them in my example repro of the issue. - Melanie
Hi, On 2024-03-15 18:42:29 -0400, Melanie Plageman wrote: > On Fri, Mar 15, 2024 at 5:14 PM Andres Freund <andres@anarazel.de> wrote: > > On 2024-03-14 17:39:30 -0400, Melanie Plageman wrote: > > I spent a good amount of time looking into this with Melanie. After a bunch of > > wrong paths I think I found the issue: We end up prefetching blocks we have > > already read. Notably this happens even as-is on master - just not as > > frequently as after moving BitmapAdjustPrefetchIterator(). > > > > From what I can tell the prefetching in parallel bitmap heap scans is > > thoroughly broken. I added some tracking of the last block read, the last > > block prefetched to ParallelBitmapHeapState and found that with a small > > effective_io_concurrency we end up with ~18% of prefetches being of blocks we > > already read! After moving the BitmapAdjustPrefetchIterator() to rises to 86%, > > no wonder it's slower... > > > > The race here seems fairly substantial - we're moving the two iterators > > independently from each other, in multiple processes, without useful locking. > > > > I'm inclined to think this is a bug we ought to fix in the backbranches. > > Thinking about how to fix this, perhaps we could keep the current max > block number in the ParallelBitmapHeapState and then when prefetching, > workers could loop calling tbm_shared_iterate() until they've found a > block at least prefetch_pages ahead of the current block. They > wouldn't need to read the current max value from the parallel state on > each iteration. Even checking it once and storing that value in a > local variable prevented prefetching blocks after reading them in my > example repro of the issue. That would address some of the worst behaviour, but it doesn't really seem to address the underlying problem of the two iterators being modified independently. ISTM the proper fix would be to protect the state of the iterators with a single lock, rather than pushing down the locking into the bitmap code. OTOH, we'll only need one lock going forward, so being economic in the effort of fixing this is also important. Greetings, Andres Freund
On 3/16/24 20:12, Andres Freund wrote: > Hi, > > On 2024-03-15 18:42:29 -0400, Melanie Plageman wrote: >> On Fri, Mar 15, 2024 at 5:14 PM Andres Freund <andres@anarazel.de> wrote: >>> On 2024-03-14 17:39:30 -0400, Melanie Plageman wrote: >>> I spent a good amount of time looking into this with Melanie. After a bunch of >>> wrong paths I think I found the issue: We end up prefetching blocks we have >>> already read. Notably this happens even as-is on master - just not as >>> frequently as after moving BitmapAdjustPrefetchIterator(). >>> >>> From what I can tell the prefetching in parallel bitmap heap scans is >>> thoroughly broken. I added some tracking of the last block read, the last >>> block prefetched to ParallelBitmapHeapState and found that with a small >>> effective_io_concurrency we end up with ~18% of prefetches being of blocks we >>> already read! After moving the BitmapAdjustPrefetchIterator() to rises to 86%, >>> no wonder it's slower... >>> >>> The race here seems fairly substantial - we're moving the two iterators >>> independently from each other, in multiple processes, without useful locking. >>> >>> I'm inclined to think this is a bug we ought to fix in the backbranches. >> >> Thinking about how to fix this, perhaps we could keep the current max >> block number in the ParallelBitmapHeapState and then when prefetching, >> workers could loop calling tbm_shared_iterate() until they've found a >> block at least prefetch_pages ahead of the current block. They >> wouldn't need to read the current max value from the parallel state on >> each iteration. Even checking it once and storing that value in a >> local variable prevented prefetching blocks after reading them in my >> example repro of the issue. > > That would address some of the worst behaviour, but it doesn't really seem to > address the underlying problem of the two iterators being modified > independently. ISTM the proper fix would be to protect the state of the > iterators with a single lock, rather than pushing down the locking into the > bitmap code. OTOH, we'll only need one lock going forward, so being economic > in the effort of fixing this is also important. > Can you share some details about how you identified the problem, counted the prefetches that happen too late, etc? I'd like to try to reproduce this to understand the issue better. If I understand correctly, what may happen is that a worker reads blocks from the "prefetch" iterator, but before it manages to issue the posix_fadvise, some other worker already did pread. Or can the iterators get "out of sync" in a more fundamental way? If my understanding is correct, why would a single lock solve that? Yes, we'd advance the iterators at the same time, but surely we'd not issue the fadvise calls while holding the lock, and the prefetch/fadvise for a particular block could still happen in different workers. I suppose a dirty PoC fix should not be too difficult, and it'd allow us to check if it works. regards -- Tomas Vondra EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
Hi, On 2024-03-16 21:25:18 +0100, Tomas Vondra wrote: > On 3/16/24 20:12, Andres Freund wrote: > > That would address some of the worst behaviour, but it doesn't really seem to > > address the underlying problem of the two iterators being modified > > independently. ISTM the proper fix would be to protect the state of the > > iterators with a single lock, rather than pushing down the locking into the > > bitmap code. OTOH, we'll only need one lock going forward, so being economic > > in the effort of fixing this is also important. > > > > Can you share some details about how you identified the problem, counted > the prefetches that happen too late, etc? I'd like to try to reproduce > this to understand the issue better. There's two aspects. Originally I couldn't reliably reproduce the regression with Melanie's repro on my laptop. I finally was able to do so after I a) changed the block device's read_ahead_kb to 0 b) used effective_io_concurrency=1 That made the difference between the BitmapAdjustPrefetchIterator() locations very significant, something like 2.3s vs 12s. Besides a lot of other things, I finally added debugging fprintfs printing the pid, (prefetch, read), block number. Even looking at tiny excerpts of the large amount of output that generates shows that two iterators were out of sync. > If I understand correctly, what may happen is that a worker reads blocks > from the "prefetch" iterator, but before it manages to issue the > posix_fadvise, some other worker already did pread. Or can the iterators > get "out of sync" in a more fundamental way? I agree that the current scheme of two shared iterators being used has some fairly fundamental raciness. But I suspect there's more than that going on right now. Moving BitmapAdjustPrefetchIterator() to later drastically increases the raciness because it means table_scan_bitmap_next_block() happens between increasing the "real" and the "prefetch" iterators. An example scenario that, I think, leads to the iterators being out of sync, without there being races between iterator advancement and completing prefetching: start: real -> block 0 prefetch -> block 0 prefetch_pages = 0 prefetch_target = 1 W1: tbm_shared_iterate(real) -> block 0 W2: tbm_shared_iterate(real) -> block 1 W1: BitmapAdjustPrefetchIterator() -> tbm_shared_iterate(prefetch) -> 0 W2: BitmapAdjustPrefetchIterator() -> tbm_shared_iterate(prefetch) -> 1 W1: read block 0 W2: read block 1 W1: BitmapPrefetch() -> prefetch_pages++ -> 1, tbm_shared_iterate(prefetch) -> 2, prefetch block 2 W2: BitmapPrefetch() -> nothing, as prefetch_pages == prefetch_target W1: tbm_shared_iterate(real) -> block 2 W2: tbm_shared_iterate(real) -> block 3 W2: BitmapAdjustPrefetchIterator() -> prefetch_pages-- W2: read block 3 W2: BitmapPrefetch() -> prefetch_pages++, tbm_shared_iterate(prefetch) -> 3, prefetch block 3 So afaict here we end up prefetching a block that the *same process* just had read. ISTM that the idea of somehow "catching up" in BitmapAdjustPrefetchIterator(), separately from advancing the "real" iterator, is pretty ugly for non-parallel BHS and just straight up broken in the parallel case. Greetings, Andres Freund
On 3/14/24 22:39, Melanie Plageman wrote: > On Thu, Mar 14, 2024 at 5:26 PM Tomas Vondra > <tomas.vondra@enterprisedb.com> wrote: >> >> On 3/14/24 19:16, Melanie Plageman wrote: >>> On Thu, Mar 14, 2024 at 03:32:04PM +0200, Heikki Linnakangas wrote: >>>> ... >>>> >>>> Ok, committed that for now. Thanks for looking! >>> >>> Attached v6 is rebased over your new commit. It also has the "fix" in >>> 0010 which moves BitmapAdjustPrefetchIterator() back above >>> table_scan_bitmap_next_block(). I've also updated the Streaming Read API >>> commit (0013) to Thomas' v7 version from [1]. This has the update that >>> we theorize should address some of the regressions in the bitmapheapscan >>> streaming read user in 0014. >>> >> >> Should I rerun the benchmarks with these new patches, to see if it >> really helps with the regressions? > > That would be awesome! > OK, here's a couple charts comparing the effect of v6 patches to master. These are from 1M and 10M data sets, same as the runs presented earlier in this thread (the 10M is still running, but should be good enough for this kind of visual comparison). I have results for individual patches, but 0001-0013 behave virtually the same, so the charts show only 0012 and 0014 (vs master). Instead of a table with color scale (used before), I used simple scatter plots as a more compact / concise visualization. It's impossible to identify patterns (e.g. serial vs. parallel runs), but for the purpose of this comparison that does not matter. And then I'll use a chart plotting "relative" time compared to master (I find it easier to judge the relative difference than with scatter plot). 1) absolute-all - all runs (scatter plot) 2) absolute-optimal - runs where the planner would pick bitmapscan 3) relative-all - all runs (duration relative to master) 4) relative-optimal - relative, runs where bitmapscan would be picked The 0012 results are a pretty clear sign the "refactoring patches" behave exactly the same as master. There are a couple outliers (in either direction), but I'd attribute those to random noise and too few runs to smooth it out for a particular combination (especially for 10M). What is even more obvious is that 0014 behaves *VERY* differently. I'm not sure if this is a good thing or a problem is debatable/unclear. I'm sure we don't want to cause regressions, but perhaps those are due to the prefetch issue discussed elsewhere in this thread (identified by Andres and Melanie). There are also many cases that got much faster, but the question is whether this is due to better efficiency or maybe the new code being more aggressive in some way (not sure). It's however interesting the differences are way more significant (both in terms of frequency and scale) on the older machine with SATA SSDs. regards -- Tomas Vondra EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
Attachment
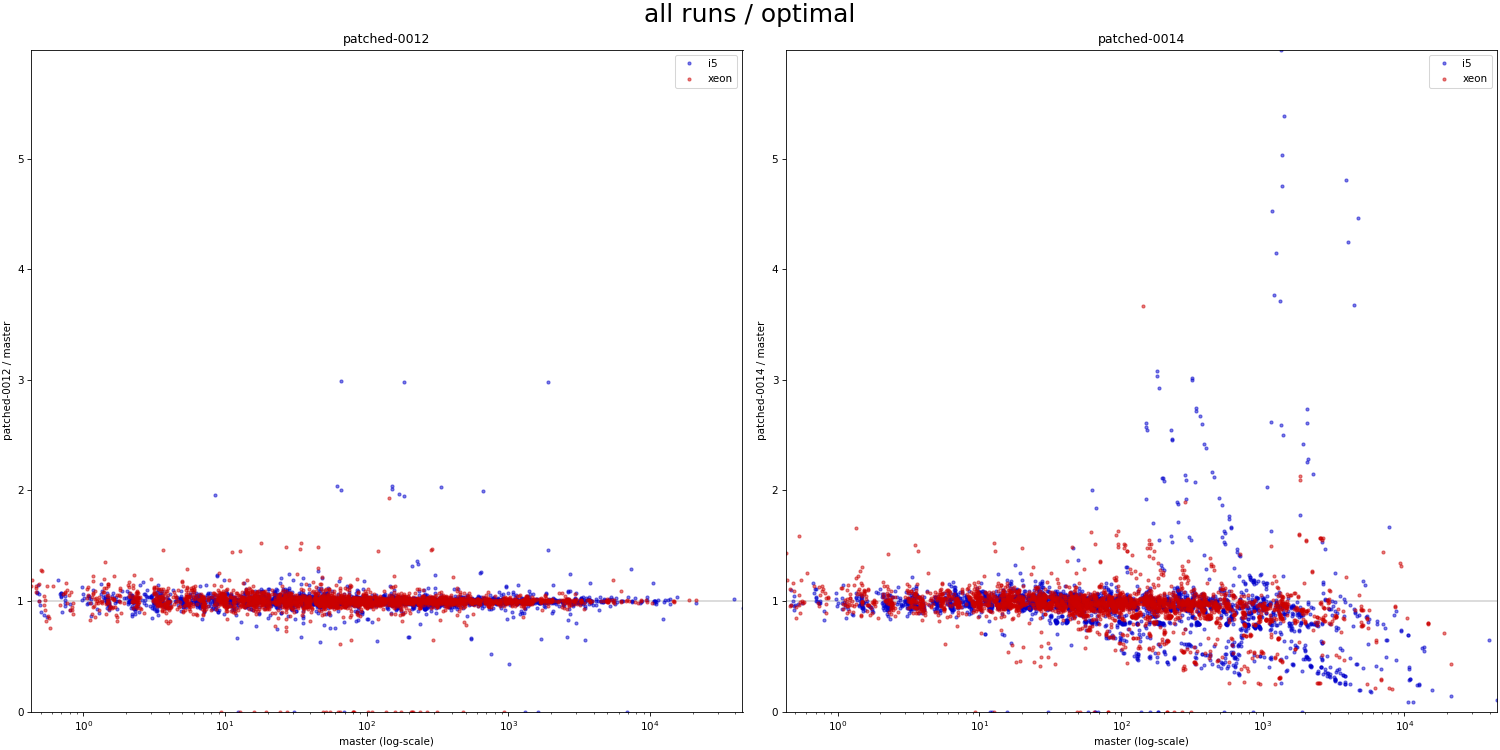{kind=link}
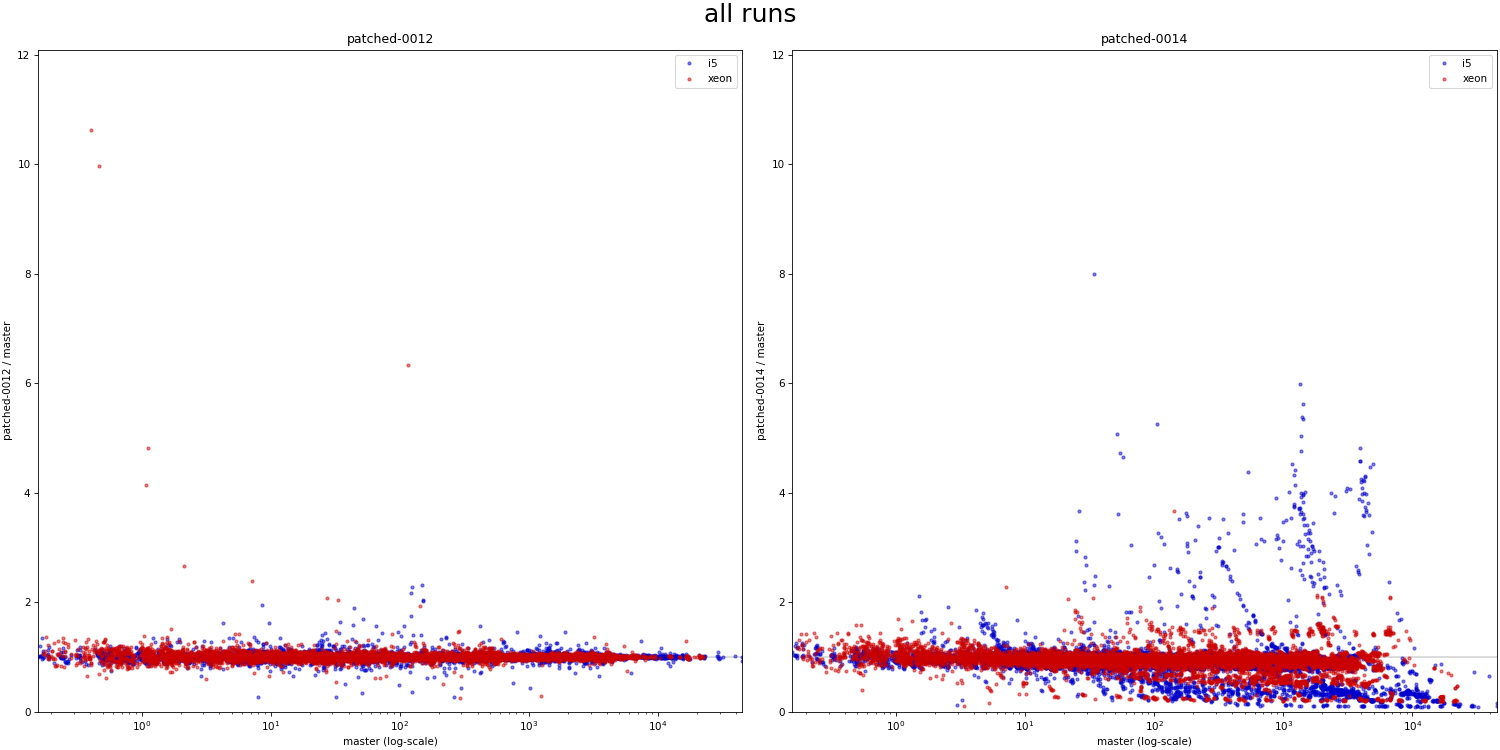{kind=link}
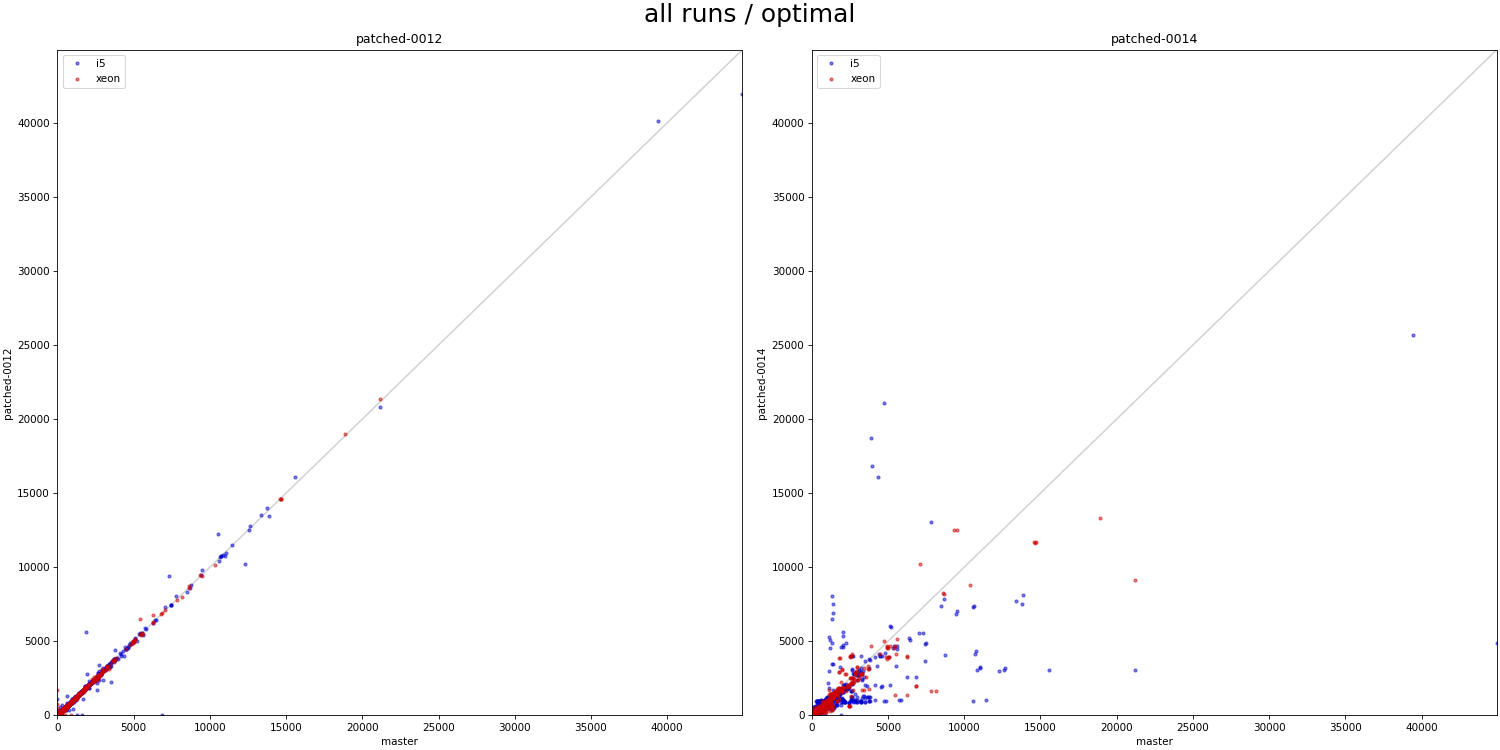{kind=link}
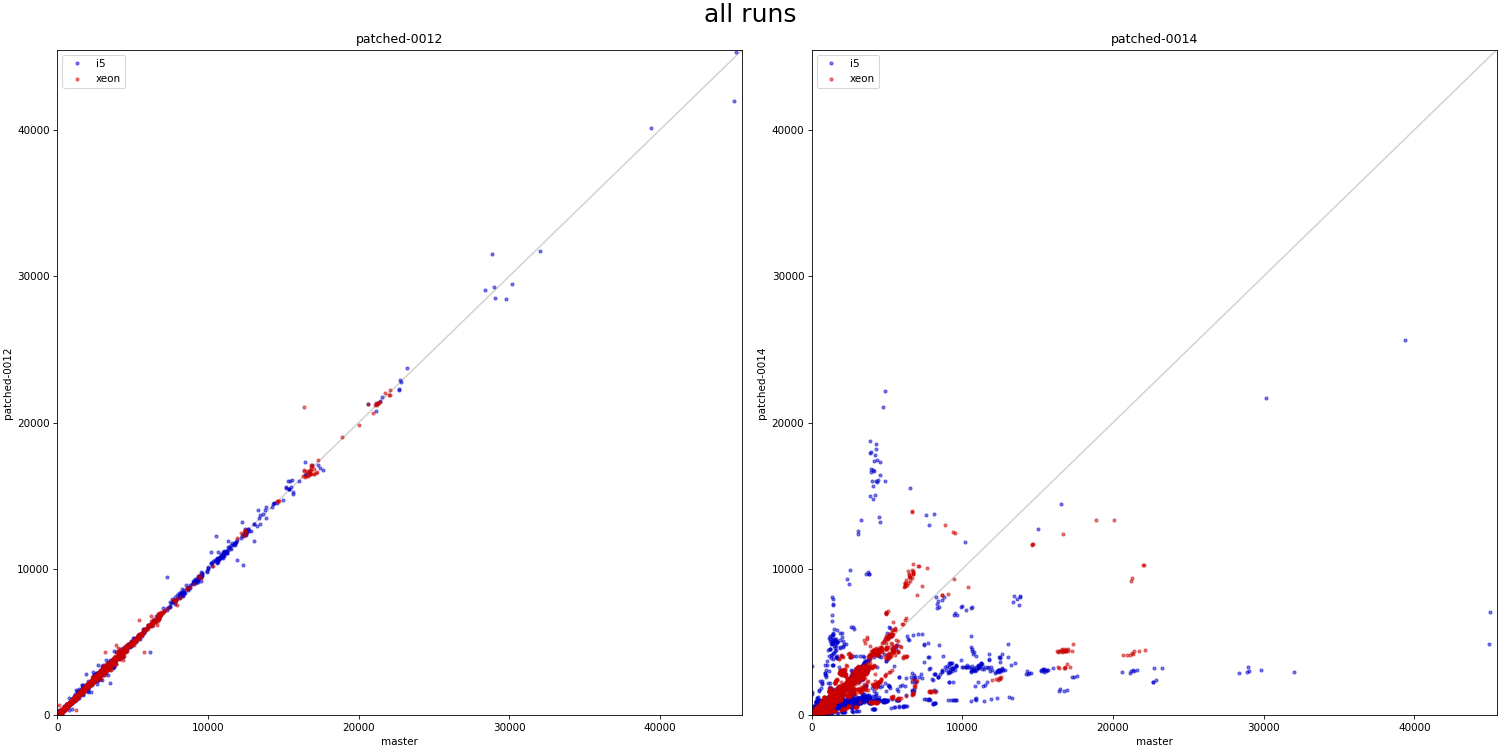{kind=link}
On 3/17/24 17:38, Andres Freund wrote: > Hi, > > On 2024-03-16 21:25:18 +0100, Tomas Vondra wrote: >> On 3/16/24 20:12, Andres Freund wrote: >>> That would address some of the worst behaviour, but it doesn't really seem to >>> address the underlying problem of the two iterators being modified >>> independently. ISTM the proper fix would be to protect the state of the >>> iterators with a single lock, rather than pushing down the locking into the >>> bitmap code. OTOH, we'll only need one lock going forward, so being economic >>> in the effort of fixing this is also important. >>> >> >> Can you share some details about how you identified the problem, counted >> the prefetches that happen too late, etc? I'd like to try to reproduce >> this to understand the issue better. > > There's two aspects. Originally I couldn't reliably reproduce the regression > with Melanie's repro on my laptop. I finally was able to do so after I > a) changed the block device's read_ahead_kb to 0 > b) used effective_io_concurrency=1 > > That made the difference between the BitmapAdjustPrefetchIterator() locations > very significant, something like 2.3s vs 12s. > Interesting. I haven't thought about read_ahead_kb, but in hindsight it makes sense it affects these cases. OTOH I did not set it to 0 on either machine (the 6xSATA RAID0 has it at 12288, for example) and yet that's how we found the regressions. For eic it makes perfect sense that setting it to 1 is particularly vulnerable to this issue - it only takes a small "desynchronization" of the two iterators for the prefetch to "fall behind" and frequently prefetch blocks we already read. > Besides a lot of other things, I finally added debugging fprintfs printing the > pid, (prefetch, read), block number. Even looking at tiny excerpts of the > large amount of output that generates shows that two iterators were out of > sync. > Thanks. I did experiment with fprintf, but it's quite cumbersome, so I was hoping you came up with some smart way to trace this king of stuff. For example I was wondering if ebpf would be a more convenient way. > >> If I understand correctly, what may happen is that a worker reads blocks >> from the "prefetch" iterator, but before it manages to issue the >> posix_fadvise, some other worker already did pread. Or can the iterators >> get "out of sync" in a more fundamental way? > > I agree that the current scheme of two shared iterators being used has some > fairly fundamental raciness. But I suspect there's more than that going on > right now. > > Moving BitmapAdjustPrefetchIterator() to later drastically increases the > raciness because it means table_scan_bitmap_next_block() happens between > increasing the "real" and the "prefetch" iterators. > > An example scenario that, I think, leads to the iterators being out of sync, > without there being races between iterator advancement and completing > prefetching: > > start: > real -> block 0 > prefetch -> block 0 > prefetch_pages = 0 > prefetch_target = 1 > > W1: tbm_shared_iterate(real) -> block 0 > W2: tbm_shared_iterate(real) -> block 1 > W1: BitmapAdjustPrefetchIterator() -> tbm_shared_iterate(prefetch) -> 0 > W2: BitmapAdjustPrefetchIterator() -> tbm_shared_iterate(prefetch) -> 1 > W1: read block 0 > W2: read block 1 > W1: BitmapPrefetch() -> prefetch_pages++ -> 1, tbm_shared_iterate(prefetch) -> 2, prefetch block 2 > W2: BitmapPrefetch() -> nothing, as prefetch_pages == prefetch_target > > W1: tbm_shared_iterate(real) -> block 2 > W2: tbm_shared_iterate(real) -> block 3 > > W2: BitmapAdjustPrefetchIterator() -> prefetch_pages-- > W2: read block 3 > W2: BitmapPrefetch() -> prefetch_pages++, tbm_shared_iterate(prefetch) -> 3, prefetch block 3 > > So afaict here we end up prefetching a block that the *same process* just had > read. > Uh, that's very weird. I'd understood if there's some cross-process issue, but if this happens in a single process ... strange. > ISTM that the idea of somehow "catching up" in BitmapAdjustPrefetchIterator(), > separately from advancing the "real" iterator, is pretty ugly for non-parallel > BHS and just straight up broken in the parallel case. > Yeah, I agree with the feeling it's an ugly fix. Definitely seems more like fixing symptoms than the actual problem. regards -- Tomas Vondra EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On 3/17/24 20:36, Tomas Vondra wrote:
>
> ...
>
>> Besides a lot of other things, I finally added debugging fprintfs printing the
>> pid, (prefetch, read), block number. Even looking at tiny excerpts of the
>> large amount of output that generates shows that two iterators were out of
>> sync.
>>
>
> Thanks. I did experiment with fprintf, but it's quite cumbersome, so I
> was hoping you came up with some smart way to trace this king of stuff.
> For example I was wondering if ebpf would be a more convenient way.
>
FWIW I just realized why I failed to identify this "late prefetch" issue
during my investigation. I was experimenting with instrumenting this by
adding a LD_PRELOAD library, logging all pread/fadvise calls. But the
FilePrefetch call is skipped in the page is already in shared buffers,
so this case "disappeared" during processing which matched the two calls
by doing an "inner join".
That being said, I think tracing this using LD_PRELOAD or perf may be
more convenient way to see what's happening. For example I ended up
doing this:
perf record -a -e syscalls:sys_enter_fadvise64 \
-e syscalls:sys_exit_fadvise64 \
-e syscalls:sys_enter_pread64 \
-e syscalls:sys_exit_pread64
perf script -ns
Alternatively, perf-trace can be used and prints the filename too (but
time has ms resolution only). Processing this seems comparable to the
fprintf approach.
It still has the issue that some of the fadvise calls may be absent if
the prefetch iterator gets too far behind, but I think that can be
detected / measured by simply counting the fadvise calls, and comparing
them to pread calls. We expect these to be about the same, so
(#pread - #fadvise) / #fadvise
is a measure of how many were "late" and skipped.
It also seems better than fprintf because it traces the actual syscalls,
not just calls to glibc wrappers. For example I saw this
postgres 54769 [001] 33768.771524828:
syscalls:sys_enter_pread64: ..., pos: 0x30d04000
postgres 54769 [001] 33768.771526867:
syscalls:sys_exit_pread64: 0x2000
postgres 54820 [000] 33768.771527473:
syscalls:sys_enter_fadvise64: ..., offset: 0x30d04000, ...
postgres 54820 [000] 33768.771528320:
syscalls:sys_exit_fadvise64: 0x0
which is clearly a case where we issue fadvise after pread of the same
block already completed.
regards
--
Tomas Vondra
EnterpriseDB: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
On 14/02/2024 21:42, Andres Freund wrote: > On 2024-02-13 18:11:25 -0500, Melanie Plageman wrote: >> patch 0004 is, I think, a bug fix. see [2]. > > I'd not quite call it a bugfix, it's not like it leads to wrong > behaviour. Seems more like an optimization. But whatever :) It sure looks like bug to me, albeit a very minor one. Certainly not an optimization, it doesn't affect performance in any way, only what EXPLAIN reports. So committed and backported that to all supported branches. -- Heikki Linnakangas Neon (https://neon.tech)
On Sun, Mar 17, 2024 at 3:21 PM Tomas Vondra <tomas.vondra@enterprisedb.com> wrote: > > On 3/14/24 22:39, Melanie Plageman wrote: > > On Thu, Mar 14, 2024 at 5:26 PM Tomas Vondra > > <tomas.vondra@enterprisedb.com> wrote: > >> > >> On 3/14/24 19:16, Melanie Plageman wrote: > >>> On Thu, Mar 14, 2024 at 03:32:04PM +0200, Heikki Linnakangas wrote: > >>>> ... > >>>> > >>>> Ok, committed that for now. Thanks for looking! > >>> > >>> Attached v6 is rebased over your new commit. It also has the "fix" in > >>> 0010 which moves BitmapAdjustPrefetchIterator() back above > >>> table_scan_bitmap_next_block(). I've also updated the Streaming Read API > >>> commit (0013) to Thomas' v7 version from [1]. This has the update that > >>> we theorize should address some of the regressions in the bitmapheapscan > >>> streaming read user in 0014. > >>> > >> > >> Should I rerun the benchmarks with these new patches, to see if it > >> really helps with the regressions? > > > > That would be awesome! > > > > OK, here's a couple charts comparing the effect of v6 patches to master. > These are from 1M and 10M data sets, same as the runs presented earlier > in this thread (the 10M is still running, but should be good enough for > this kind of visual comparison). Thanks for doing this! > What is even more obvious is that 0014 behaves *VERY* differently. I'm > not sure if this is a good thing or a problem is debatable/unclear. I'm > sure we don't want to cause regressions, but perhaps those are due to > the prefetch issue discussed elsewhere in this thread (identified by > Andres and Melanie). There are also many cases that got much faster, but > the question is whether this is due to better efficiency or maybe the > new code being more aggressive in some way (not sure). Are these with the default effective_io_concurrency (1)? If so, the "effective" prefetch distance in many cases will be higher with the streaming read code applied. With effective_io_concurrency 1, "max_ios" will always be 1, but the number of blocks prefetched may exceed this (up to MAX_BUFFERS_PER_TRANSFER) because the streaming read code is always trying to build bigger IOs. And, if prefetching, it will prefetch IOs not yet in shared buffers before reading them. It's hard to tell without going into a specific repro why this would cause some queries to be much slower. In the forced bitmapheapscan, it would make sense that more prefetching is worse -- which is why a bitmapheapscan plan wouldn't have been chosen. But in the optimal cases, it is unclear why it would be worse. I don't think there is any way it could be the issue Andres identified, because there is only one iterator. Nothing to get out of sync. It could be that the fadvises are being issued too close to the reads and aren't effective enough at covering up read latency on slower, older hardware. But that doesn't explain why master would sometimes be faster. Probably the only thing we can do is get into a repro. It would, of course, be easiest to do this with a serial query. I can dig into the scripts you shared earlier and try to find a good repro. Because the regressions may have shifted with Thomas' new version, it would help if you shared a category (cyclic/uniform/etc, parallel or serial, eic value, work mem, etc) where you now see the most regressions. - Melanie
On Mon, Mar 18, 2024 at 02:10:28PM +0200, Heikki Linnakangas wrote: > On 14/02/2024 21:42, Andres Freund wrote: > > On 2024-02-13 18:11:25 -0500, Melanie Plageman wrote: > > > patch 0004 is, I think, a bug fix. see [2]. > > > > I'd not quite call it a bugfix, it's not like it leads to wrong > > behaviour. Seems more like an optimization. But whatever :) > > It sure looks like bug to me, albeit a very minor one. Certainly not an > optimization, it doesn't affect performance in any way, only what EXPLAIN > reports. So committed and backported that to all supported branches. I've attached v7 rebased over this commit. - Melanie
Attachment
- v7-0001-BitmapHeapScan-begin-scan-after-bitmap-creation.patch
- v7-0002-BitmapHeapScan-set-can_skip_fetch-later.patch
- v7-0003-Push-BitmapHeapScan-skip-fetch-optimization-into-.patch
- v7-0004-BitmapPrefetch-use-prefetch-block-recheck-for-ski.patch
- v7-0005-Update-BitmapAdjustPrefetchIterator-parameter-typ.patch
- v7-0006-table_scan_bitmap_next_block-returns-lossy-or-exa.patch
- v7-0007-Reduce-scope-of-BitmapHeapScan-tbmiterator-local-.patch
- v7-0008-Remove-table_scan_bitmap_next_tuple-parameter-tbm.patch
- v7-0009-Make-table_scan_bitmap_next_block-async-friendly.patch
- v7-0010-Hard-code-TBMIterateResult-offsets-array-size.patch
- v7-0011-Separate-TBM-Shared-Iterator-and-TBMIterateResult.patch
- v7-0012-v7-Streaming-Read-API.patch
- v7-0013-BitmapHeapScan-uses-streaming-read-API.patch
On 3/18/24 15:47, Melanie Plageman wrote: > On Sun, Mar 17, 2024 at 3:21 PM Tomas Vondra > <tomas.vondra@enterprisedb.com> wrote: >> >> On 3/14/24 22:39, Melanie Plageman wrote: >>> On Thu, Mar 14, 2024 at 5:26 PM Tomas Vondra >>> <tomas.vondra@enterprisedb.com> wrote: >>>> >>>> On 3/14/24 19:16, Melanie Plageman wrote: >>>>> On Thu, Mar 14, 2024 at 03:32:04PM +0200, Heikki Linnakangas wrote: >>>>>> ... >>>>>> >>>>>> Ok, committed that for now. Thanks for looking! >>>>> >>>>> Attached v6 is rebased over your new commit. It also has the "fix" in >>>>> 0010 which moves BitmapAdjustPrefetchIterator() back above >>>>> table_scan_bitmap_next_block(). I've also updated the Streaming Read API >>>>> commit (0013) to Thomas' v7 version from [1]. This has the update that >>>>> we theorize should address some of the regressions in the bitmapheapscan >>>>> streaming read user in 0014. >>>>> >>>> >>>> Should I rerun the benchmarks with these new patches, to see if it >>>> really helps with the regressions? >>> >>> That would be awesome! >>> >> >> OK, here's a couple charts comparing the effect of v6 patches to master. >> These are from 1M and 10M data sets, same as the runs presented earlier >> in this thread (the 10M is still running, but should be good enough for >> this kind of visual comparison). > > Thanks for doing this! > >> What is even more obvious is that 0014 behaves *VERY* differently. I'm >> not sure if this is a good thing or a problem is debatable/unclear. I'm >> sure we don't want to cause regressions, but perhaps those are due to >> the prefetch issue discussed elsewhere in this thread (identified by >> Andres and Melanie). There are also many cases that got much faster, but >> the question is whether this is due to better efficiency or maybe the >> new code being more aggressive in some way (not sure). > > Are these with the default effective_io_concurrency (1)? If so, the > "effective" prefetch distance in many cases will be higher with the > streaming read code applied. With effective_io_concurrency 1, > "max_ios" will always be 1, but the number of blocks prefetched may > exceed this (up to MAX_BUFFERS_PER_TRANSFER) because the streaming > read code is always trying to build bigger IOs. And, if prefetching, > it will prefetch IOs not yet in shared buffers before reading them. > No, it's a mix of runs with random combinations of these parameters: dataset: uniform uniform_pages linear linear_fuzz cyclic cyclic_fuzz workers: 0 4 work_mem: 128kB 4MB 64MB eic: 0 1 8 16 32 selectivity: 0-100% I can either share the data (~70MB of CSV) or generate charts for results with some filter. > It's hard to tell without going into a specific repro why this would > cause some queries to be much slower. In the forced bitmapheapscan, it > would make sense that more prefetching is worse -- which is why a > bitmapheapscan plan wouldn't have been chosen. But in the optimal > cases, it is unclear why it would be worse. > Yes, not sure about the optimal cases. I'll wait for the 10M runs to complete, and then we can look for some patterns. > I don't think there is any way it could be the issue Andres > identified, because there is only one iterator. Nothing to get out of > sync. It could be that the fadvises are being issued too close to the > reads and aren't effective enough at covering up read latency on > slower, older hardware. But that doesn't explain why master would > sometimes be faster. > Ah, right, thanks for the clarification. I forgot the streaming read API does not use the two-iterator approach. > Probably the only thing we can do is get into a repro. It would, of > course, be easiest to do this with a serial query. I can dig into the > scripts you shared earlier and try to find a good repro. Because the > regressions may have shifted with Thomas' new version, it would help > if you shared a category (cyclic/uniform/etc, parallel or serial, eic > value, work mem, etc) where you now see the most regressions. > OK, I've restarted the tests for only 0012 and 0014 patches, and I'll wait for these to complete - I don't want to be looking for patterns until we have enough data to smooth this out. regards -- Tomas Vondra EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On 18/03/2024 17:19, Melanie Plageman wrote:
> I've attached v7 rebased over this commit.
Thanks!
> v7-0001-BitmapHeapScan-begin-scan-after-bitmap-creation.patch
If we delayed table_beginscan_bm() call further, after starting the TBM
iterator, we could skip it altogether when the iterator is empty.
That's a further improvement, doesn't need to be part of this patch set.
Just caught my eye while reading this.
> v7-0003-Push-BitmapHeapScan-skip-fetch-optimization-into-.patch
I suggest to avoid the double negative with SO_CAN_SKIP_FETCH, and call
the flag e.g. SO_NEED_TUPLE.
As yet another preliminary patch before the streaming read API, it would
be nice to move the prefetching code to heapam.c too.
What's the point of having separate table_scan_bitmap_next_block() and
table_scan_bitmap_next_tuple() functions anymore? The AM owns the TBM
iterator now. The executor node updates the lossy/exact page counts, but
that's the only per-page thing it does now.
> /*
> * If this is the first scan of the underlying table, create the table
> * scan descriptor and begin the scan.
> */
> if (!scan)
> {
> uint32 extra_flags = 0;
>
> /*
> * We can potentially skip fetching heap pages if we do not need
> * any columns of the table, either for checking non-indexable
> * quals or for returning data. This test is a bit simplistic, as
> * it checks the stronger condition that there's no qual or return
> * tlist at all. But in most cases it's probably not worth working
> * harder than that.
> */
> if (node->ss.ps.plan->qual == NIL && node->ss.ps.plan->targetlist == NIL)
> extra_flags |= SO_CAN_SKIP_FETCH;
>
> scan = node->ss.ss_currentScanDesc = table_beginscan_bm(
> node->ss.ss_currentRelation,
> node->ss.ps.state->es_snapshot,
> 0,
> NULL,
> extra_flags);
> }
>
> scan->tbmiterator = tbmiterator;
> scan->shared_tbmiterator = shared_tbmiterator;
How about passing the iterator as an argument to table_beginscan_bm()?
You'd then need some other function to change the iterator on rescan,
though. Not sure what exactly to do here, but feels that this part of
the API is not fully thought-out. Needs comments at least, to explain
who sets tbmiterator / shared_tbmiterator and when. For comparison, for
a TID scan there's a separate scan_set_tidrange() table AM function.
Maybe follow that example and introduce scan_set_tbm_iterator().
It's bit awkward to have separate tbmiterator and shared_tbmiterator
fields. Could regular and shared iterators be merged, or wrapped under a
common interface?
--
Heikki Linnakangas
Neon (https://neon.tech)
On 3/18/24 16:55, Tomas Vondra wrote: > > ... > > OK, I've restarted the tests for only 0012 and 0014 patches, and I'll > wait for these to complete - I don't want to be looking for patterns > until we have enough data to smooth this out. > > I now have results for 1M and 10M runs on the two builds (0012 and 0014), attached is a chart for relative performance plotting (0014 timing) / (0012 timing) for "optimal' runs that would pick bitmapscan on their own. There's nothing special about the config - I reduced the random_page_cost to 1.5-2.0 to reflect both machines have flash storage, etc. Overall, the chart is pretty consistent with what I shared on Sunday. Most of the results are fine (0014 is close to 0012 or faster), but there's a bunch of cases that are much slower. Interestingly enough, almost all of them are on the i5 machine, almost none of the xeon. My guess is this is about the SSD type (SATA vs. NVMe). Attached if table of ~50 worst regressions (by the metric above), and it's interesting the worst regressions are with eic=0 and eic=1. I decided to look at the first case (eic=0), and the timings are quite stable - there are three runs for each build, with timings close to the average (see below the table). Attached is a script that reproduces this on both machines, but the difference is much more significant on i5 (~5x) compared to xeon (~2x). I haven't investigated what exactly is happening and why, hopefully the script will allow you to reproduce this independently. I plan to take a look, but I don't know when I'll have time for this. FWIW if the script does not reproduce this on your machines, I might be able to give you access to the i5 machine. Let me know. regards -- Tomas Vondra EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
Attachment
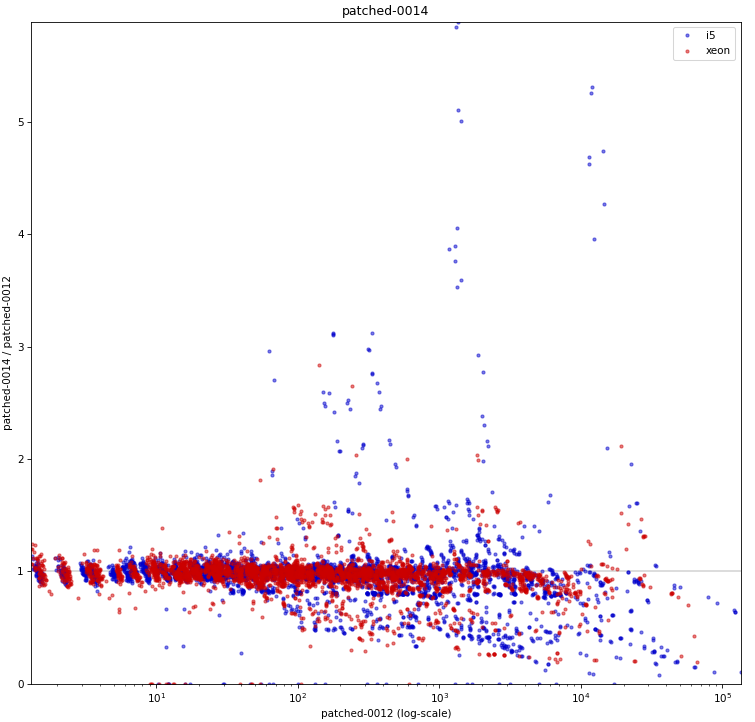{kind=link}
On 3/18/24 16:19, Melanie Plageman wrote: > On Mon, Mar 18, 2024 at 02:10:28PM +0200, Heikki Linnakangas wrote: >> On 14/02/2024 21:42, Andres Freund wrote: >>> On 2024-02-13 18:11:25 -0500, Melanie Plageman wrote: >>>> patch 0004 is, I think, a bug fix. see [2]. >>> >>> I'd not quite call it a bugfix, it's not like it leads to wrong >>> behaviour. Seems more like an optimization. But whatever :) >> >> It sure looks like bug to me, albeit a very minor one. Certainly not an >> optimization, it doesn't affect performance in any way, only what EXPLAIN >> reports. So committed and backported that to all supported branches. > > I've attached v7 rebased over this commit. > I've started a new set of benchmarks with v7 (on top of f69319f2f1), but unfortunately that results in about 15% of the queries failing with: ERROR: prefetch and main iterators are out of sync Reproducing it is pretty simple (at least on my laptop). Simply apply 0001-0011, and then do this: ====================================================================== create table test_table (a bigint, b bigint, c text) with (fillfactor = 25); insert into test_table select 10000 * random(), i, md5(random()::text) from generate_series(1, 1000000) s(i); create index on test_table(a); vacuum analyze ; checkpoint; set work_mem = '128kB'; set effective_io_concurrency = 8; set random_page_cost = 2; set max_parallel_workers_per_gather = 0; explain select * from test_table where a >= 1 and a <= 512; explain analyze select * from test_table where a >= 1 and a <= 512; ERROR: prefetch and main iterators are out of sync ====================================================================== I haven't investigated this, but it seems to get broken by this patch: v7-0009-Make-table_scan_bitmap_next_block-async-friendly.patch I wonder if there are some additional changes aside from the rebase. regards -- Tomas Vondra EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On 3/14/24 19:16, Melanie Plageman wrote: > ... > > Attached v6 is rebased over your new commit. It also has the "fix" in > 0010 which moves BitmapAdjustPrefetchIterator() back above > table_scan_bitmap_next_block(). I've also updated the Streaming Read API > commit (0013) to Thomas' v7 version from [1]. This has the update that > we theorize should address some of the regressions in the bitmapheapscan > streaming read user in 0014. > Based on the recent discussions in this thread I've been wondering how does the readahead setting for the device affect the behavior, so I've modified the script to test different values for this parameter too. Considering the bug in the v7 patch (reported yesterday elsewhere in this thread), I had to use the v6 version for now. I don't think it makes much difference, the important parts of the patch do not change. The complete results are far too large to include here (multiple MBs), so I'll only include results for a small subset of parameters (one dataset on i5), and some scatter charts with all results to show the overall behavior. (I only have results for 1M rows so far). Complete results (including the raw CSV etc.) are available in a git repo, along with jupyter notebooks that I started using for experiments and building the other charts: https://github.com/tvondra/jupyterlab-projects/tree/master If you look at the attached PDF table, the first half is for serial execution (no parallelism), the second half is with 4 workers. And there are 3 different readahead settings 0, 1536 and 12288 (and then different eic values for each readahead value). The readahead values are chosen as "disabled", 6x128kB and the default that was set by the kernel (or wherever it comes from). There are pretty clear patterns: * serial runs with disabled readahead - The patch causes fairly serious regressions (compared to master), if eic>0. * serial runs with enabled readahead - there's still some regression for lower matches values. Presumably, at higher values (which means larger fraction of the table matches) the readahead kicks in, leaving the lower values as if readahead was not enabled. * parallel runs - The regression is much smaller, either because the parallel workers issue requests almost as if there was readahead, or maybe it implicitly disrupts the readahead. Not sure. The other datasets are quite similar, feel free to check the git repo for complete results. One possible caveat is that maybe this affects only cases that would not actually use bitmap scans? But if you check the attached scatter charts (PNG), that only show results for cases where the planner would actually pick bitmap scans on it's own, there are plenty such cases. For the 0012 patch (chart on left), there's almost no such problem - the results are very close to master. Similarly, there are regressions even on the chart with readahead, but it's far less frequent/significant. The question is whether readahead=0 is even worth worrying about? If disabling readahead causes serious regressions even on master (clearly visible in the PDF table), would anyone actually run with it disabled? But I'm not sure that argument is very sound. Surely there are cases where readahead may not detect a pattern, or where it's not supported for some arbitrary reason (e.g. I didn't have much luck with this on ZFS, perhaps other filesystems have similar limitations). But also what about direct I/O? Surely that won't have readahead by kernel, right? regards -- Tomas Vondra EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
Attachment
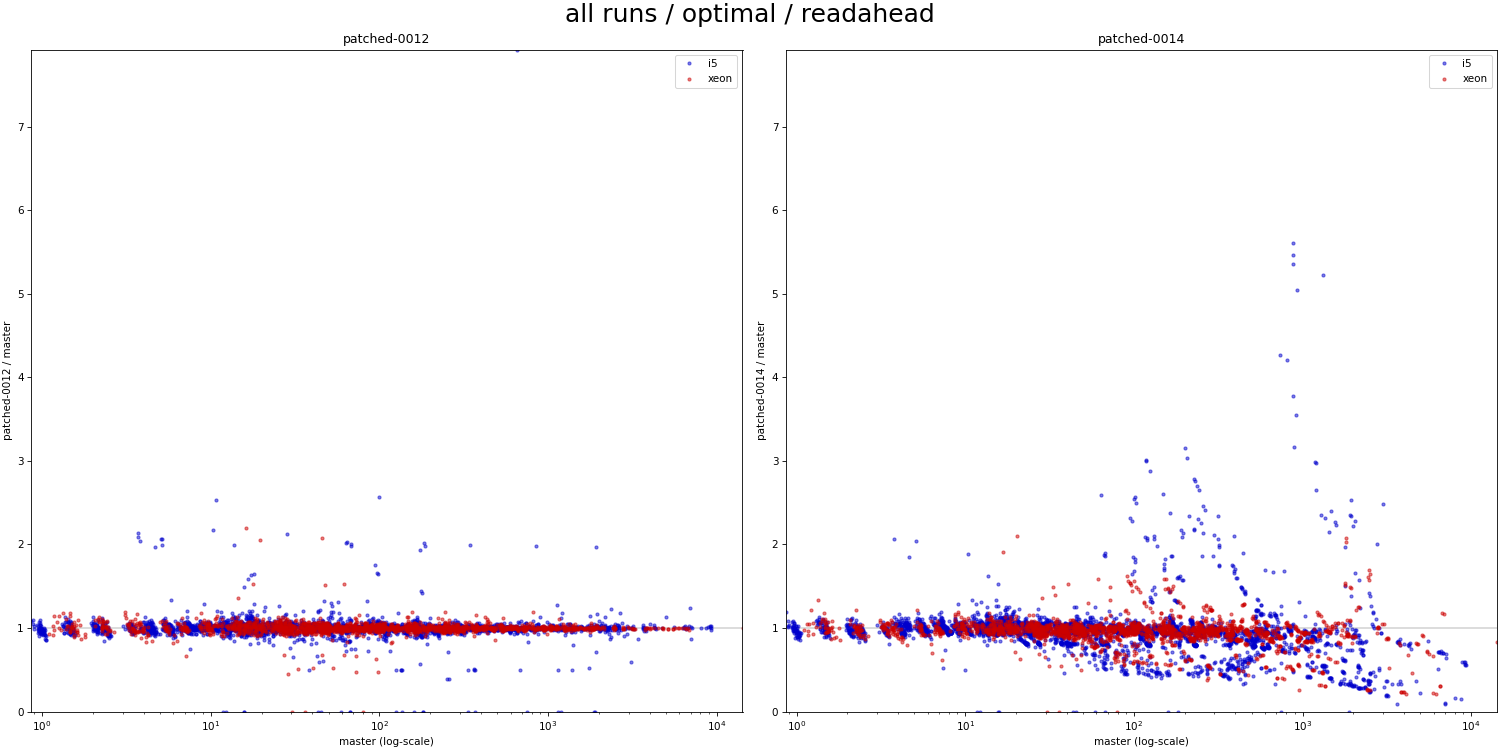{kind=link}
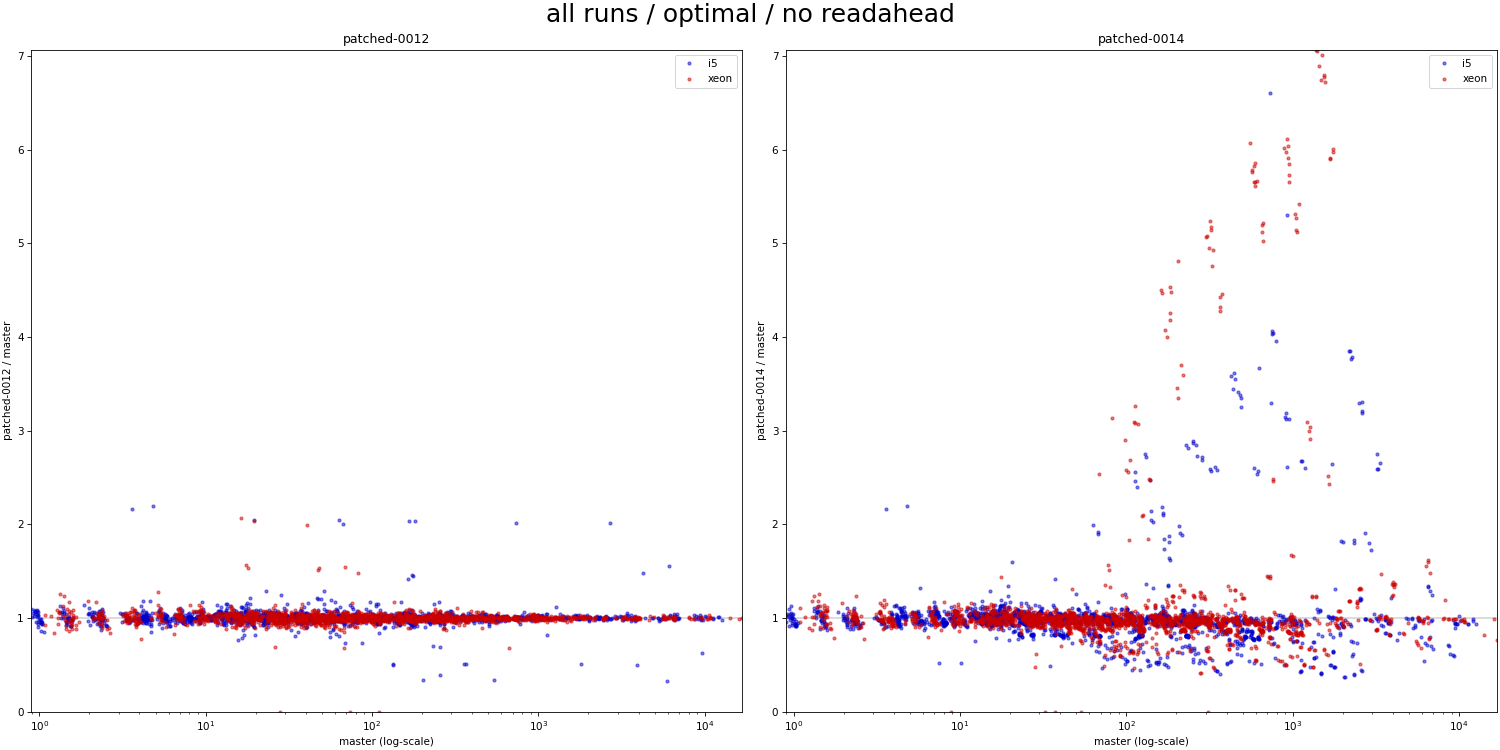{kind=link}
On Tue, Mar 19, 2024 at 02:33:35PM +0200, Heikki Linnakangas wrote:
> On 18/03/2024 17:19, Melanie Plageman wrote:
> > I've attached v7 rebased over this commit.
>
> If we delayed table_beginscan_bm() call further, after starting the TBM
> iterator, we could skip it altogether when the iterator is empty.
>
> That's a further improvement, doesn't need to be part of this patch set.
> Just caught my eye while reading this.
Hmm. You mean like until after the first call to tbm_[shared]_iterate()?
AFAICT, tbm_begin_iterate() doesn't tell us anything about whether or
not the iterator is "empty". Do you mean cases when the bitmap has no
blocks in it? It seems like we should be able to tell that from the
TIDBitmap.
>
> > v7-0003-Push-BitmapHeapScan-skip-fetch-optimization-into-.patch
>
> I suggest to avoid the double negative with SO_CAN_SKIP_FETCH, and call the
> flag e.g. SO_NEED_TUPLE.
Agreed. Done in attached v8. Though I wondered if it was a bit weird
that the flag is set in the common case and not set in the uncommon
case...
> As yet another preliminary patch before the streaming read API, it would be
> nice to move the prefetching code to heapam.c too.
I've done this, but I can say it is not very pretty. see 0013. I had to
add a bunch of stuff to TableScanDescData and HeapScanDescData which are
only used for bitmapheapscans. I don't know if it makes the BHS
streaming read user patch easier to review, but I don't think what I
have in 0013 is committable to Postgres. Maybe there was another way I
could have approached it. Let me know what you think.
In addition to bloating the table descriptors, note that it was
difficult to avoid one semantic change -- with 0013, we no longer
prefetch or adjust prefetch target when emitting each empty tuple --
though I think this is could actually be desirable.
> What's the point of having separate table_scan_bitmap_next_block() and
> table_scan_bitmap_next_tuple() functions anymore? The AM owns the TBM
> iterator now. The executor node updates the lossy/exact page counts, but
> that's the only per-page thing it does now.
Oh, interesting. Good point. I've done this in 0015. If you like the way
it turned out, I can probably rebase this back into an earlier point in
the set and end up dropping some of the other incremental changes (e.g.
0008).
> > /*
> > * If this is the first scan of the underlying table, create the table
> > * scan descriptor and begin the scan.
> > */
> > if (!scan)
> > {
> > uint32 extra_flags = 0;
> >
> > /*
> > * We can potentially skip fetching heap pages if we do not need
> > * any columns of the table, either for checking non-indexable
> > * quals or for returning data. This test is a bit simplistic, as
> > * it checks the stronger condition that there's no qual or return
> > * tlist at all. But in most cases it's probably not worth working
> > * harder than that.
> > */
> > if (node->ss.ps.plan->qual == NIL && node->ss.ps.plan->targetlist == NIL)
> > extra_flags |= SO_CAN_SKIP_FETCH;
> >
> > scan = node->ss.ss_currentScanDesc = table_beginscan_bm(
> > node->ss.ss_currentRelation,
> > node->ss.ps.state->es_snapshot,
> > 0,
> > NULL,
> > extra_flags);
> > }
> >
> > scan->tbmiterator = tbmiterator;
> > scan->shared_tbmiterator = shared_tbmiterator;
>
> How about passing the iterator as an argument to table_beginscan_bm()? You'd
> then need some other function to change the iterator on rescan, though. Not
> sure what exactly to do here, but feels that this part of the API is not
> fully thought-out. Needs comments at least, to explain who sets tbmiterator
> / shared_tbmiterator and when. For comparison, for a TID scan there's a
> separate scan_set_tidrange() table AM function. Maybe follow that example
> and introduce scan_set_tbm_iterator().
I've spent quite a bit of time playing around with the code trying to
make it less terrible than what I had before.
On rescan, we have to actually make the whole bitmap and iterator. And,
we don't have what we need to do that in table_rescan()/heap_rescan().
From what I can tell, scan_set_tidrange() is useful because it can be
called from both the beginscan and rescan functions without invoking it
directly from TidNext().
In our case, any wrapper function we wrote would basically just assign
the iterator to the scan in BitmapHeapNext().
I've reorganized this code structure a bit, so see if you like it more
now. I rebased the changes into some of the other patches, so you'll
just have to look at the result and see what you think.
> It's bit awkward to have separate tbmiterator and shared_tbmiterator fields.
> Could regular and shared iterators be merged, or wrapped under a common
> interface?
This is a good idea. I've done that in 0014. It made the code nicer, but
I just wonder if it will add too much overhead.
- Melanie
On Fri, Mar 22, 2024 at 08:22:11PM -0400, Melanie Plageman wrote: > On Tue, Mar 19, 2024 at 02:33:35PM +0200, Heikki Linnakangas wrote: > > On 18/03/2024 17:19, Melanie Plageman wrote: > > > I've attached v7 rebased over this commit. > > > > If we delayed table_beginscan_bm() call further, after starting the TBM > > iterator, we could skip it altogether when the iterator is empty. > > > > That's a further improvement, doesn't need to be part of this patch set. > > Just caught my eye while reading this. > > Hmm. You mean like until after the first call to tbm_[shared]_iterate()? > AFAICT, tbm_begin_iterate() doesn't tell us anything about whether or > not the iterator is "empty". Do you mean cases when the bitmap has no > blocks in it? It seems like we should be able to tell that from the > TIDBitmap. > > > > > > v7-0003-Push-BitmapHeapScan-skip-fetch-optimization-into-.patch > > > > I suggest to avoid the double negative with SO_CAN_SKIP_FETCH, and call the > > flag e.g. SO_NEED_TUPLE. > > Agreed. Done in attached v8. Though I wondered if it was a bit weird > that the flag is set in the common case and not set in the uncommon > case... v8 actually attached this time
Attachment
- v8-0001-BitmapHeapScan-begin-scan-after-bitmap-creation.patch
- v8-0002-BitmapHeapScan-set-can_skip_fetch-later.patch
- v8-0003-Push-BitmapHeapScan-skip-fetch-optimization-into-.patch
- v8-0004-BitmapPrefetch-use-prefetch-block-recheck-for-ski.patch
- v8-0005-Update-BitmapAdjustPrefetchIterator-parameter-typ.patch
- v8-0006-table_scan_bitmap_next_block-returns-lossy-or-exa.patch
- v8-0007-Reduce-scope-of-BitmapHeapScan-tbmiterator-local-.patch
- v8-0008-Remove-table_scan_bitmap_next_tuple-parameter-tbm.patch
- v8-0009-Make-table_scan_bitmap_next_block-async-friendly.patch
- v8-0010-Hard-code-TBMIterateResult-offsets-array-size.patch
- v8-0011-table_scan_bitmap_next_block-counts-lossy-and-exa.patch
- v8-0012-Separate-TBM-Shared-Iterator-and-TBMIterateResult.patch
- v8-0013-Push-BitmapHeapScan-prefetch-code-into-heapam.c.patch
- v8-0014-Unify-parallel-and-serial-BitmapHeapScan-iterator.patch
- v8-0015-Remove-table_scan_bitmap_next_block.patch
- v8-0016-v7-Streaming-Read-API.patch
- v8-0017-BitmapHeapScan-uses-streaming-read-API.patch
On 3/23/24 01:26, Melanie Plageman wrote: > On Fri, Mar 22, 2024 at 08:22:11PM -0400, Melanie Plageman wrote: >> On Tue, Mar 19, 2024 at 02:33:35PM +0200, Heikki Linnakangas wrote: >>> On 18/03/2024 17:19, Melanie Plageman wrote: >>>> I've attached v7 rebased over this commit. >>> >>> If we delayed table_beginscan_bm() call further, after starting the TBM >>> iterator, we could skip it altogether when the iterator is empty. >>> >>> That's a further improvement, doesn't need to be part of this patch set. >>> Just caught my eye while reading this. >> >> Hmm. You mean like until after the first call to tbm_[shared]_iterate()? >> AFAICT, tbm_begin_iterate() doesn't tell us anything about whether or >> not the iterator is "empty". Do you mean cases when the bitmap has no >> blocks in it? It seems like we should be able to tell that from the >> TIDBitmap. >> >>> >>>> v7-0003-Push-BitmapHeapScan-skip-fetch-optimization-into-.patch >>> >>> I suggest to avoid the double negative with SO_CAN_SKIP_FETCH, and call the >>> flag e.g. SO_NEED_TUPLE. >> >> Agreed. Done in attached v8. Though I wondered if it was a bit weird >> that the flag is set in the common case and not set in the uncommon >> case... > > v8 actually attached this time I tried to run the benchmarks with v8, but unfortunately it crashes for me very quickly (I've only seen 0015 to crash, so I guess the bug is in that patch). The backtrace attached, this doesn't seem right: (gdb) p hscan->rs_cindex $1 = 543516018 regards -- Tomas Vondra EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
Attachment
On Sun, Mar 24, 2024 at 01:36:19PM +0100, Tomas Vondra wrote: > > > On 3/23/24 01:26, Melanie Plageman wrote: > > On Fri, Mar 22, 2024 at 08:22:11PM -0400, Melanie Plageman wrote: > >> On Tue, Mar 19, 2024 at 02:33:35PM +0200, Heikki Linnakangas wrote: > >>> On 18/03/2024 17:19, Melanie Plageman wrote: > >>>> I've attached v7 rebased over this commit. > >>> > >>> If we delayed table_beginscan_bm() call further, after starting the TBM > >>> iterator, we could skip it altogether when the iterator is empty. > >>> > >>> That's a further improvement, doesn't need to be part of this patch set. > >>> Just caught my eye while reading this. > >> > >> Hmm. You mean like until after the first call to tbm_[shared]_iterate()? > >> AFAICT, tbm_begin_iterate() doesn't tell us anything about whether or > >> not the iterator is "empty". Do you mean cases when the bitmap has no > >> blocks in it? It seems like we should be able to tell that from the > >> TIDBitmap. > >> > >>> > >>>> v7-0003-Push-BitmapHeapScan-skip-fetch-optimization-into-.patch > >>> > >>> I suggest to avoid the double negative with SO_CAN_SKIP_FETCH, and call the > >>> flag e.g. SO_NEED_TUPLE. > >> > >> Agreed. Done in attached v8. Though I wondered if it was a bit weird > >> that the flag is set in the common case and not set in the uncommon > >> case... > > > > v8 actually attached this time > > I tried to run the benchmarks with v8, but unfortunately it crashes for > me very quickly (I've only seen 0015 to crash, so I guess the bug is in > that patch). > > The backtrace attached, this doesn't seem right: > > (gdb) p hscan->rs_cindex > $1 = 543516018 Thanks for reporting this! I hadn't seen it crash on my machine, so I didn't realize that I was no longer initializing rs_cindex and rs_ntuples on the first call to heapam_bitmap_next_tuple() (since heapam_bitmap_next_block() wasn't being called first). I've done this in attached v9. I haven't had a chance yet to reproduce the regressions you saw in the streaming read user patch or to look closely at the performance results. I don't anticipate the streaming read user will have any performance differences in this v9 from v6, since I haven't yet rebased in Thomas' latest streaming read API changes nor addressed any other potential regression sources. I tried rebasing in Thomas' latest version today and something is causing a crash that I have yet to figure out. v10 of this patchset will have his latest version once I get that fixed. I wanted to share this version with what I think is a bug fix for the crash you saw first. - Melanie
Attachment
- v9-0001-BitmapHeapScan-begin-scan-after-bitmap-creation.patch
- v9-0002-BitmapHeapScan-set-can_skip_fetch-later.patch
- v9-0003-Push-BitmapHeapScan-skip-fetch-optimization-into-.patch
- v9-0004-BitmapPrefetch-use-prefetch-block-recheck-for-ski.patch
- v9-0005-Update-BitmapAdjustPrefetchIterator-parameter-typ.patch
- v9-0006-table_scan_bitmap_next_block-returns-lossy-or-exa.patch
- v9-0007-Reduce-scope-of-BitmapHeapScan-tbmiterator-local-.patch
- v9-0008-Remove-table_scan_bitmap_next_tuple-parameter-tbm.patch
- v9-0009-Make-table_scan_bitmap_next_block-async-friendly.patch
- v9-0010-table_scan_bitmap_next_block-counts-lossy-and-exa.patch
- v9-0011-Hard-code-TBMIterateResult-offsets-array-size.patch
- v9-0012-Separate-TBM-Shared-Iterator-and-TBMIterateResult.patch
- v9-0013-Push-BitmapHeapScan-prefetch-code-into-heapam.c.patch
- v9-0014-Unify-parallel-and-serial-BitmapHeapScan-iterator.patch
- v9-0015-Remove-table_scan_bitmap_next_block.patch
- v9-0016-v7-Streaming-Read-API.patch
- v9-0017-BitmapHeapScan-uses-streaming-read-API.patch
On 3/24/24 18:38, Melanie Plageman wrote: > On Sun, Mar 24, 2024 at 01:36:19PM +0100, Tomas Vondra wrote: >> >> >> On 3/23/24 01:26, Melanie Plageman wrote: >>> On Fri, Mar 22, 2024 at 08:22:11PM -0400, Melanie Plageman wrote: >>>> On Tue, Mar 19, 2024 at 02:33:35PM +0200, Heikki Linnakangas wrote: >>>>> On 18/03/2024 17:19, Melanie Plageman wrote: >>>>>> I've attached v7 rebased over this commit. >>>>> >>>>> If we delayed table_beginscan_bm() call further, after starting the TBM >>>>> iterator, we could skip it altogether when the iterator is empty. >>>>> >>>>> That's a further improvement, doesn't need to be part of this patch set. >>>>> Just caught my eye while reading this. >>>> >>>> Hmm. You mean like until after the first call to tbm_[shared]_iterate()? >>>> AFAICT, tbm_begin_iterate() doesn't tell us anything about whether or >>>> not the iterator is "empty". Do you mean cases when the bitmap has no >>>> blocks in it? It seems like we should be able to tell that from the >>>> TIDBitmap. >>>> >>>>> >>>>>> v7-0003-Push-BitmapHeapScan-skip-fetch-optimization-into-.patch >>>>> >>>>> I suggest to avoid the double negative with SO_CAN_SKIP_FETCH, and call the >>>>> flag e.g. SO_NEED_TUPLE. >>>> >>>> Agreed. Done in attached v8. Though I wondered if it was a bit weird >>>> that the flag is set in the common case and not set in the uncommon >>>> case... >>> >>> v8 actually attached this time >> >> I tried to run the benchmarks with v8, but unfortunately it crashes for >> me very quickly (I've only seen 0015 to crash, so I guess the bug is in >> that patch). >> >> The backtrace attached, this doesn't seem right: >> >> (gdb) p hscan->rs_cindex >> $1 = 543516018 > > Thanks for reporting this! I hadn't seen it crash on my machine, so I > didn't realize that I was no longer initializing rs_cindex and > rs_ntuples on the first call to heapam_bitmap_next_tuple() (since > heapam_bitmap_next_block() wasn't being called first). I've done this in > attached v9. > OK, I've restarted the tests with v9. > I haven't had a chance yet to reproduce the regressions you saw in the > streaming read user patch or to look closely at the performance results. So you tried to reproduce it and didn't hit the issue? Or didn't have time to look into that yet? FWIW with v7 it failed almost immediately (only a couple queries until hitting one triggering the issue), but v9 that's not the case (hundreds of queries without an error). > I don't anticipate the streaming read user will have any performance > differences in this v9 from v6, since I haven't yet rebased in Thomas' > latest streaming read API changes nor addressed any other potential > regression sources. > OK, understood. It'll be interesting to see the behavior with the new version of Thomas' patch. I however wonder what the plan with these patches is - do we still plan to get some of this into v17? It seems to me we're getting uncomfortably close to the end of the cycle, with a fairly incomplete idea of how it affects performance. Which is why I've been focusing more on the refactoring patches (up to 0015), to make sure those don't cause regressions if committed. And I think that's generally true. But for the main StreamingRead API the situation is very different. > I tried rebasing in Thomas' latest version today and something is > causing a crash that I have yet to figure out. v10 of this patchset will > have his latest version once I get that fixed. I wanted to share this > version with what I think is a bug fix for the crash you saw first. > Understood. I'll let the tests with v9 run for now. regards -- Tomas Vondra EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On Sun, Mar 24, 2024 at 2:22 PM Tomas Vondra <tomas.vondra@enterprisedb.com> wrote: > > On 3/24/24 18:38, Melanie Plageman wrote: > > I haven't had a chance yet to reproduce the regressions you saw in the > > streaming read user patch or to look closely at the performance results. > > So you tried to reproduce it and didn't hit the issue? Or didn't have > time to look into that yet? FWIW with v7 it failed almost immediately > (only a couple queries until hitting one triggering the issue), but v9 > that's not the case (hundreds of queries without an error). I haven't started trying to reproduce it yet. > I however wonder what the plan with these patches is - do we still plan > to get some of this into v17? It seems to me we're getting uncomfortably > close to the end of the cycle, with a fairly incomplete idea of how it > affects performance. > > Which is why I've been focusing more on the refactoring patches (up to > 0015), to make sure those don't cause regressions if committed. And I > think that's generally true. Thank you for testing the refactoring patches with this in mind! Out of the refactoring patches, I think there is a subset of them that have independent value without the streaming read user. I think it is worth committing the first few patches because they remove a table AM layering violation. IMHO, all of the patches up to "Make table_scan_bitmap_next_block() async friendly" make the code nicer and better. And, if folks like the patch "Remove table_scan_bitmap_next_block()", then I think I could rebase that back in on top of "Make table_scan_bitmap_next_block() async friendly". This would mean table AMs would only have to implement one callback (table_scan_bitmap_next_tuple()) which I also think is a net improvement and simplification. The other refactoring patches may not be interesting without the streaming read user. > But for the main StreamingRead API the situation is very different. My intent for the bitmapheapscan streaming read user was to get it into 17, but I'm not sure that looks likely. The main issues Thomas is looking into right now are related to regressions for a fully cached scan (noticeable with the pg_prewarm streaming read user). With all of these fixed, I anticipate we will still see enough behavioral differences with the bitmapheap scan streaming read user that it may not be committable in time. Though, I have yet to work on reproducing the regressions with the BHS streaming read user mostly because I was focused on getting the refactoring ready and not as much because the streaming read API is unstable. - Melanie
On 3/24/24 21:12, Melanie Plageman wrote: > On Sun, Mar 24, 2024 at 2:22 PM Tomas Vondra > <tomas.vondra@enterprisedb.com> wrote: >> >> On 3/24/24 18:38, Melanie Plageman wrote: >>> I haven't had a chance yet to reproduce the regressions you saw in the >>> streaming read user patch or to look closely at the performance results. >> >> So you tried to reproduce it and didn't hit the issue? Or didn't have >> time to look into that yet? FWIW with v7 it failed almost immediately >> (only a couple queries until hitting one triggering the issue), but v9 >> that's not the case (hundreds of queries without an error). > > I haven't started trying to reproduce it yet. > >> I however wonder what the plan with these patches is - do we still plan >> to get some of this into v17? It seems to me we're getting uncomfortably >> close to the end of the cycle, with a fairly incomplete idea of how it >> affects performance. >> >> Which is why I've been focusing more on the refactoring patches (up to >> 0015), to make sure those don't cause regressions if committed. And I >> think that's generally true. > > Thank you for testing the refactoring patches with this in mind! Out > of the refactoring patches, I think there is a subset of them that > have independent value without the streaming read user. I think it is > worth committing the first few patches because they remove a table AM > layering violation. IMHO, all of the patches up to "Make > table_scan_bitmap_next_block() async friendly" make the code nicer and > better. And, if folks like the patch "Remove > table_scan_bitmap_next_block()", then I think I could rebase that back > in on top of "Make table_scan_bitmap_next_block() async friendly". > This would mean table AMs would only have to implement one callback > (table_scan_bitmap_next_tuple()) which I also think is a net > improvement and simplification. > > The other refactoring patches may not be interesting without the > streaming read user. > I admit not reviewing the individual patches very closely yet, but this matches how I understood them - that at least some are likely an improvement on their own, not just as a refactoring preparing for the switch to streaming reads. We only have ~2 weeks left, so it's probably time to focus on getting at least those improvements committed. I see Heikki was paying way more attention to the patches than me, though ... BTW when you say "up to 'Make table_scan_bitmap_next_block() async friendly'" do you mean including that patch, or that this is the first patch that is not one of the independently useful patches. (I took a quick look at the first couple patches and I appreciate that you keep separate patches with small cosmetic changes to keep the actual patch smaller and easier to understand.) >> But for the main StreamingRead API the situation is very different. > > My intent for the bitmapheapscan streaming read user was to get it > into 17, but I'm not sure that looks likely. The main issues Thomas is > looking into right now are related to regressions for a fully cached > scan (noticeable with the pg_prewarm streaming read user). With all of > these fixed, I anticipate we will still see enough behavioral > differences with the bitmapheap scan streaming read user that it may > not be committable in time. Though, I have yet to work on reproducing > the regressions with the BHS streaming read user mostly because I was > focused on getting the refactoring ready and not as much because the > streaming read API is unstable. > I don't have a very good intuition regarding impact of the streaming API patch on performance. I haven't been following that thread very closely, but AFAICS there wasn't much discussion about that - perhaps it happened offlist, not sure. So who knows, really? Which is why I started looking at this patch instead - it seemed easier to benchmark with a somewhat realistic workload. But yeah, there certainly were significant behavior changes, and it's unlikely that whatever Thomas did in v8 made them go away. FWIW I certainly am *not* suggesting there must be no behavior changes, that's simply not possible. I'm not even suggesting no queries must get slower - given the dependence on storage, I think some regressions are pretty much inevitable. But it's still be good to know the regressions are reasonably rare exceptions rather than the common case, and that's not what I'm seeing ... regards -- Tomas Vondra EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On Sun, Mar 24, 2024 at 5:59 PM Tomas Vondra <tomas.vondra@enterprisedb.com> wrote: > > BTW when you say "up to 'Make table_scan_bitmap_next_block() async > friendly'" do you mean including that patch, or that this is the first > patch that is not one of the independently useful patches. I think the code is easier to understand with "Make table_scan_bitmap_next_block() async friendly". Prior to that commit, table_scan_bitmap_next_block() could return false even when the bitmap has more blocks and expects the caller to handle this and invoke it again. I think that interface is very confusing. The downside of the code in that state is that the code for prefetching is still in the BitmapHeapNext() code and the code for getting the current block is in the heap AM-specific code. I took a stab at fixing this in v9's 0013, but the outcome wasn't very attractive. What I will do tomorrow is reorder and group the commits such that all of the commits that are useful independent of streaming read are first (I think 0014 and 0015 are independently valuable but they are on top of some things that are only useful to streaming read because they are more recently requested changes). I think I can actually do a bit of simplification in terms of how many commits there are and what is in each. Just to be clear, v9 is still reviewable. I am just going to go back and change what is included in each commit. > (I took a quick look at the first couple patches and I appreciate that > you keep separate patches with small cosmetic changes to keep the actual > patch smaller and easier to understand.) Thanks!
On Sun, Mar 24, 2024 at 06:37:20PM -0400, Melanie Plageman wrote: > On Sun, Mar 24, 2024 at 5:59 PM Tomas Vondra > <tomas.vondra@enterprisedb.com> wrote: > > > > BTW when you say "up to 'Make table_scan_bitmap_next_block() async > > friendly'" do you mean including that patch, or that this is the first > > patch that is not one of the independently useful patches. > > I think the code is easier to understand with "Make > table_scan_bitmap_next_block() async friendly". Prior to that commit, > table_scan_bitmap_next_block() could return false even when the bitmap > has more blocks and expects the caller to handle this and invoke it > again. I think that interface is very confusing. The downside of the > code in that state is that the code for prefetching is still in the > BitmapHeapNext() code and the code for getting the current block is in > the heap AM-specific code. I took a stab at fixing this in v9's 0013, > but the outcome wasn't very attractive. > > What I will do tomorrow is reorder and group the commits such that all > of the commits that are useful independent of streaming read are first > (I think 0014 and 0015 are independently valuable but they are on top > of some things that are only useful to streaming read because they are > more recently requested changes). I think I can actually do a bit of > simplification in terms of how many commits there are and what is in > each. Just to be clear, v9 is still reviewable. I am just going to go > back and change what is included in each commit. So, attached v10 does not include the new version of streaming read API. I focused instead on the refactoring patches commit regrouping I mentioned here. I realized "Remove table_scan_bitmap_next_block()" can't easily be moved down below "Push BitmapHeapScan prefetch code into heapam.c" because we have to do BitmapAdjustPrefetchTarget() and BitmapAdjustPrefetchIterator() on either side of getting the next block (via table_scan_bitmap_next_block()). "Push BitmapHeapScan prefetch code into heapam.c" isn't very nice because it adds a lot of bitmapheapscan specific members to TableScanDescData and HeapScanDescData. I thought about wrapping all of those members in some kind of BitmapHeapScanTableState struct -- but I don't like that because the members are spread out across HeapScanDescData and TableScanDescData so not all of them would go in BitmapHeapScanTableState. I could move the ones I put in HeapScanDescData back into TableScanDescData and then wrap that in a BitmapHeapScanTableState. I haven't done that in this version. I did manage to move "Unify parallel and serial BitmapHeapScan iterator interfaces" down below the line of patches which are only useful if the streaming read user also goes in. In attached v10, all patches up to and including "Unify parallel and serial BitmapHeapScan iterator interfaces" (0010) are proposed for master with or without the streaming read API. 0010 does add additional indirection and thus pointer dereferencing for accessing the iterators, which doesn't feel good. But, it does simplify the code. Perhaps it is worth renaming the existing TableScanDescData->rs_parallel (a ParallelTableScanDescData) to something like rs_seq_parallel. It is only for sequential scans and scans of tables when building indexes but the comments say it is for parallel scans in general. There is a similar member in HeapScanDescData called rs_parallelworkerdata. - Melanie
Attachment
- v10-0001-BitmapHeapScan-begin-scan-after-bitmap-creation.patch
- v10-0002-BitmapHeapScan-set-can_skip_fetch-later.patch
- v10-0003-Push-BitmapHeapScan-skip-fetch-optimization-into.patch
- v10-0004-BitmapPrefetch-use-prefetch-block-recheck-for-sk.patch
- v10-0005-Update-BitmapAdjustPrefetchIterator-parameter-ty.patch
- v10-0006-table_scan_bitmap_next_block-returns-lossy-or-ex.patch
- v10-0007-Reduce-scope-of-BitmapHeapScan-tbmiterator-local.patch
- v10-0008-Remove-table_scan_bitmap_next_tuple-parameter-tb.patch
- v10-0009-Make-table_scan_bitmap_next_block-async-friendly.patch
- v10-0010-Unify-parallel-and-serial-BitmapHeapScan-iterato.patch
- v10-0011-table_scan_bitmap_next_block-counts-lossy-and-ex.patch
- v10-0012-Hard-code-TBMIterateResult-offsets-array-size.patch
- v10-0013-Separate-TBM-Shared-Iterator-and-TBMIterateResul.patch
- v10-0014-Push-BitmapHeapScan-prefetch-code-into-heapam.c.patch
- v10-0015-Remove-table_scan_bitmap_next_block.patch
- v10-0016-v7-Streaming-Read-API.patch
- v10-0017-BitmapHeapScan-uses-streaming-read-API.patch
On Mon, Mar 25, 2024 at 12:07:09PM -0400, Melanie Plageman wrote: > On Sun, Mar 24, 2024 at 06:37:20PM -0400, Melanie Plageman wrote: > > On Sun, Mar 24, 2024 at 5:59 PM Tomas Vondra > > <tomas.vondra@enterprisedb.com> wrote: > > > > > > BTW when you say "up to 'Make table_scan_bitmap_next_block() async > > > friendly'" do you mean including that patch, or that this is the first > > > patch that is not one of the independently useful patches. > > > > I think the code is easier to understand with "Make > > table_scan_bitmap_next_block() async friendly". Prior to that commit, > > table_scan_bitmap_next_block() could return false even when the bitmap > > has more blocks and expects the caller to handle this and invoke it > > again. I think that interface is very confusing. The downside of the > > code in that state is that the code for prefetching is still in the > > BitmapHeapNext() code and the code for getting the current block is in > > the heap AM-specific code. I took a stab at fixing this in v9's 0013, > > but the outcome wasn't very attractive. > > > > What I will do tomorrow is reorder and group the commits such that all > > of the commits that are useful independent of streaming read are first > > (I think 0014 and 0015 are independently valuable but they are on top > > of some things that are only useful to streaming read because they are > > more recently requested changes). I think I can actually do a bit of > > simplification in terms of how many commits there are and what is in > > each. Just to be clear, v9 is still reviewable. I am just going to go > > back and change what is included in each commit. > > So, attached v10 does not include the new version of streaming read API. > I focused instead on the refactoring patches commit regrouping I > mentioned here. Attached v11 has the updated Read Stream API Thomas sent this morning [1]. No other changes. - Melanie [1] https://www.postgresql.org/message-id/CA%2BhUKGJTwrS7F%3DuJPx3SeigMiQiW%2BLJaOkjGyZdCntwyMR%3DuAw%40mail.gmail.com
Attachment
- v11-0001-BitmapHeapScan-begin-scan-after-bitmap-creation.patch
- v11-0002-BitmapHeapScan-set-can_skip_fetch-later.patch
- v11-0003-Push-BitmapHeapScan-skip-fetch-optimization-into.patch
- v11-0004-BitmapPrefetch-use-prefetch-block-recheck-for-sk.patch
- v11-0005-Update-BitmapAdjustPrefetchIterator-parameter-ty.patch
- v11-0006-table_scan_bitmap_next_block-returns-lossy-or-ex.patch
- v11-0007-Reduce-scope-of-BitmapHeapScan-tbmiterator-local.patch
- v11-0008-Remove-table_scan_bitmap_next_tuple-parameter-tb.patch
- v11-0009-Make-table_scan_bitmap_next_block-async-friendly.patch
- v11-0010-Unify-parallel-and-serial-BitmapHeapScan-iterato.patch
- v11-0011-table_scan_bitmap_next_block-counts-lossy-and-ex.patch
- v11-0012-Hard-code-TBMIterateResult-offsets-array-size.patch
- v11-0013-Separate-TBM-Shared-Iterator-and-TBMIterateResul.patch
- v11-0014-Push-BitmapHeapScan-prefetch-code-into-heapam.c.patch
- v11-0015-Remove-table_scan_bitmap_next_block.patch
- v11-0016-v10-Read-Stream-API.patch
- v11-0017-BitmapHeapScan-uses-read-stream-API.patch
With the unexplained but apparently somewhat systematic regression patterns on certain tests and settings, I wonder if they might be due to read_stream.c trying to form larger reads, making it a bit lazier. It tries to see what the next block will be before issuing the fadvise. I think that means that with small I/O concurrency settings, there might be contrived access patterns where it loses, and needs effective_io_concurrency to be set one notch higher to keep up, or something like that. One way to test that idea would be to run the tests with io_combine_limit = 1 (meaning 1 block). It issues advise eagerly when io_combine_limit is reached, so I suppose it should be exactly as eager as master. The only difference then should be that it automatically suppresses sequential fadvise calls.
On 3/28/24 06:20, Thomas Munro wrote: > With the unexplained but apparently somewhat systematic regression > patterns on certain tests and settings, I wonder if they might be due > to read_stream.c trying to form larger reads, making it a bit lazier. > It tries to see what the next block will be before issuing the > fadvise. I think that means that with small I/O concurrency settings, > there might be contrived access patterns where it loses, and needs > effective_io_concurrency to be set one notch higher to keep up, or > something like that. Yes, I think we've speculated this might be the root cause before, but IIRC we didn't manage to verify it actually is the problem. FWIW I don't think the tests use synthetic data, but I don't think it's particularly contrived. > One way to test that idea would be to run the > tests with io_combine_limit = 1 (meaning 1 block). It issues advise > eagerly when io_combine_limit is reached, so I suppose it should be > exactly as eager as master. The only difference then should be that > it automatically suppresses sequential fadvise calls. Sure, I'll give that a try. What are some good values to test? Perhaps 32 and 1, i.e. the default and "no coalescing"? If this turns out to be the problem, does that mean we would consider using a more conservative default value? Is there some "auto tuning" we could do? For example, could we reduce the value combine limit if we start not finding buffers in memory, or something like that? I recognize this may not be possible with buffered I/O, due to not having any insight into page cache. And maybe it's misguided anyway, because how would we know if the right response is to increase or reduce the combine limit? Anyway, doesn't the combine limit work against the idea that effective_io_concurrency is "prefetch distance"? With eic=32 I'd expect we issue prefetch 32 pages ahead, i.e. if we prefetch page X, we should then process 32 pages before we actually need X (and we expect the page to already be in memory, thanks to the gap). But with the combine limit set to 32, is this still true? I've tried going through read_stream_* to determine how this will behave, but read_stream_look_ahead/read_stream_start_pending_read does not make this very clear. I'll have to experiment with some tracing. regards -- Tomas Vondra EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On Fri, Mar 29, 2024 at 7:01 AM Tomas Vondra
<tomas.vondra@enterprisedb.com> wrote:
> On 3/28/24 06:20, Thomas Munro wrote:
> > With the unexplained but apparently somewhat systematic regression
> > patterns on certain tests and settings, I wonder if they might be due
> > to read_stream.c trying to form larger reads, making it a bit lazier.
> > It tries to see what the next block will be before issuing the
> > fadvise. I think that means that with small I/O concurrency settings,
> > there might be contrived access patterns where it loses, and needs
> > effective_io_concurrency to be set one notch higher to keep up, or
> > something like that.
>
> Yes, I think we've speculated this might be the root cause before, but
> IIRC we didn't manage to verify it actually is the problem.
Another factor could be the bug in master that allows it to get out of
sync -- can it allow *more* concurrency than it intended to? Or fewer
hints, but somehow that goes faster because of the
stepping-on-kernel-toes problem?
> > One way to test that idea would be to run the
> > tests with io_combine_limit = 1 (meaning 1 block). It issues advise
> > eagerly when io_combine_limit is reached, so I suppose it should be
> > exactly as eager as master. The only difference then should be that
> > it automatically suppresses sequential fadvise calls.
>
> Sure, I'll give that a try. What are some good values to test? Perhaps
> 32 and 1, i.e. the default and "no coalescing"?
Thanks! Yeah. The default is actually 16, computed backwards from
128kB. (Explanation: POSIX requires 16 as minimum IOV_MAX, ie number
of vectors acceptable to writev/readv and related functions, though
actual acceptable number is usually much higher, and it also seems to
be a conservative acceptable number for hardware scatter/gather lists
in various protocols, ie if doing direct I/O, the transfer won't be
chopped up into more than one physical I/O command because the disk
and DMA engine can handle it as a single I/O in theory at least.
Actual limit on random SSDs might be more like 33, a weird number but
that's what I'm seeing; Mr Axboe wrote a nice short article[1] to get
some starting points for terminology on that topic on Linux. Also,
just anecdotally, returns seem to diminish after that with huge
transfers of buffered I/O so it seems like an OK number if you have to
pick one; but IDK, YMMV, subject for future research as direct I/O
grows in relevance, hence GUC.)
> If this turns out to be the problem, does that mean we would consider
> using a more conservative default value? Is there some "auto tuning" we
> could do? For example, could we reduce the value combine limit if we
> start not finding buffers in memory, or something like that?
Hmm, not sure... I like that number for seq scans. I also like
auto-tuning. But it seems to me that *if* the problem is that we're
not allowing ourselves as many concurrent I/Os as master BHS because
we're waiting to see if the next block is consecutive, that might
indicate that the distance needs to be higher so that we can have a
better chance to see the 'edge' (the non-contiguous next block) and
start the I/O, not that the io_combine_limit needs to be lower. But I
could be way off, given the fuzziness on this problem so far...
> Anyway, doesn't the combine limit work against the idea that
> effective_io_concurrency is "prefetch distance"? With eic=32 I'd expect
> we issue prefetch 32 pages ahead, i.e. if we prefetch page X, we should
> then process 32 pages before we actually need X (and we expect the page
> to already be in memory, thanks to the gap). But with the combine limit
> set to 32, is this still true?
Hmm. It's different. (1) Master BHS has prefetch_maximum, which is
indeed directly taken from the eic setting, while read_stream.c is
prepared to look much ahead further than that (potentially as far as
max_pinned_buffers) if it's been useful recently, to find
opportunities to coalesce and start I/O. (2) Master BHS has
prefetch_target to control the look-ahead window, which starts small
and ramps up until it hits prefetch_maximum, while read_stream.c has
distance which goes up and down according to a more complex algorithm
described at the top.
> I've tried going through read_stream_* to determine how this will
> behave, but read_stream_look_ahead/read_stream_start_pending_read does
> not make this very clear. I'll have to experiment with some tracing.
I'm going to try to set up something like your experiment here too,
and figure out some way to visualise or trace what's going on...
The differences come from (1) multi-block I/Os, requiring two separate
numbers: how many blocks ahead we're looking, and how many I/Os are
running, and (2) being more aggressive about trying to reach the
desired I/O level. Let me try to describe the approach again.
"distance" is the size of a window that we're searching for
opportunities to start I/Os. read_stream_look_ahead() will keep
looking ahead until we already have max_ios I/Os running, or we hit
the end of that window. That's the two conditions in the while loop
at the top:
while (stream->ios_in_progress < stream->max_ios &&
stream->pinned_buffers + stream->pending_read_nblocks <
stream->distance)
If that window is not large enough, we won't be able to find enough
I/Os to reach max_ios. So, every time we finish up starting a random
(non-sequential) I/O, we increase the distance, widening the window
until it can hopefully reach the I/O goal. (I call that behaviour C
in the comments and code.) In other words, master BHS can only find
opportunities to start I/Os in a smaller window, and can only reach
the full I/O concurrency target if they are right next to each other
in that window, but read_stream.c will look much further ahead, but
only if that has recently proven to be useful.
If we find I/Os that need doing, but they're all sequential, the
window size moves towards io_combine_limit, because we know that
issuing advice won't help, so there is no point in making the window
wider than one maximum-sized I/O. For example, sequential scans or
bitmap heapscans with lots of consecutive page bits fall into this
pattern. (Behaviour B in the code comments.) This is a pattern that
master BHS doesn't have anything like.
If we find that we don't need to do any I/O, we slowly move the window
size towards 1 (also the initial value) as there is no point in doing
anything special as it can't help. In contrast, master BHS never
shrinks its prefetch_target, it only goes up until it hits eic.
[1] https://kernel.dk/when-2mb-turns-into-512k.pdf
On 3/27/24 20:37, Melanie Plageman wrote:
> On Mon, Mar 25, 2024 at 12:07:09PM -0400, Melanie Plageman wrote:
>> On Sun, Mar 24, 2024 at 06:37:20PM -0400, Melanie Plageman wrote:
>>> On Sun, Mar 24, 2024 at 5:59 PM Tomas Vondra
>>> <tomas.vondra@enterprisedb.com> wrote:
>>>>
>>>> BTW when you say "up to 'Make table_scan_bitmap_next_block() async
>>>> friendly'" do you mean including that patch, or that this is the first
>>>> patch that is not one of the independently useful patches.
>>>
>>> I think the code is easier to understand with "Make
>>> table_scan_bitmap_next_block() async friendly". Prior to that commit,
>>> table_scan_bitmap_next_block() could return false even when the bitmap
>>> has more blocks and expects the caller to handle this and invoke it
>>> again. I think that interface is very confusing. The downside of the
>>> code in that state is that the code for prefetching is still in the
>>> BitmapHeapNext() code and the code for getting the current block is in
>>> the heap AM-specific code. I took a stab at fixing this in v9's 0013,
>>> but the outcome wasn't very attractive.
>>>
>>> What I will do tomorrow is reorder and group the commits such that all
>>> of the commits that are useful independent of streaming read are first
>>> (I think 0014 and 0015 are independently valuable but they are on top
>>> of some things that are only useful to streaming read because they are
>>> more recently requested changes). I think I can actually do a bit of
>>> simplification in terms of how many commits there are and what is in
>>> each. Just to be clear, v9 is still reviewable. I am just going to go
>>> back and change what is included in each commit.
>>
>> So, attached v10 does not include the new version of streaming read API.
>> I focused instead on the refactoring patches commit regrouping I
>> mentioned here.
>
> Attached v11 has the updated Read Stream API Thomas sent this morning
> [1]. No other changes.
>
I think there's some sort of bug, triggering this assert in heapam
Assert(BufferGetBlockNumber(hscan->rs_cbuf) == tbmres->blockno);
I haven't looked for the root cause, and it's not exactly deterministic,
but try this:
create table t (a int, b text);
insert into t select 10000 * random(), md5(i::text)
from generate_series(1,10000000) s(i);^C
create index on t (a);
explain analyze select * from t where a = 200;
explain analyze select * from t where a < 200;
and then vary the condition a bit (different values, inequalities,
etc.). For me it hits the assert in a couple tries.
regards
--
Tomas Vondra
EnterpriseDB: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
Attachment
On Fri, Mar 29, 2024 at 10:43 AM Tomas Vondra
<tomas.vondra@enterprisedb.com> wrote:
> I think there's some sort of bug, triggering this assert in heapam
>
> Assert(BufferGetBlockNumber(hscan->rs_cbuf) == tbmres->blockno);
Thanks for the repro. I can't seem to reproduce it (still trying) but
I assume this is with Melanie's v11 patch set which had
v11-0016-v10-Read-Stream-API.patch.
Would you mind removing that commit and instead applying the v13
stream_read.c patches[1]? v10 stream_read.c was a little confused
about random I/O combining, which I fixed with a small adjustment to
the conditions for the "if" statement right at the end of
read_stream_look_ahead(). Sorry about that. The fixed version, with
eic=4, with your test query using WHERE a < a, ends its scan with:
...
posix_fadvise(32,0x28aee000,0x4000,POSIX_FADV_WILLNEED) = 0 (0x0)
pread(32,"\0\0\0\0@4\M-5:\0\0\^D\0\M-x\^A"...,40960,0x28acc000) = 40960 (0xa000)
posix_fadvise(32,0x28af4000,0x4000,POSIX_FADV_WILLNEED) = 0 (0x0)
pread(32,"\0\0\0\0\^XC\M-6:\0\0\^D\0\M-x"...,32768,0x28ad8000) = 32768 (0x8000)
posix_fadvise(32,0x28afc000,0x4000,POSIX_FADV_WILLNEED) = 0 (0x0)
pread(32,"\0\0\0\0\M-XQ\M-7:\0\0\^D\0\M-x"...,24576,0x28ae4000) = 24576 (0x6000)
posix_fadvise(32,0x28b02000,0x8000,POSIX_FADV_WILLNEED) = 0 (0x0)
pread(32,"\0\0\0\0\M^@3\M-8:\0\0\^D\0\M-x"...,16384,0x28aee000) = 16384 (0x4000)
pread(32,"\0\0\0\0\M-`\M-:\M-8:\0\0\^D\0"...,16384,0x28af4000) = 16384 (0x4000)
pread(32,"\0\0\0\0po\M-9:\0\0\^D\0\M-x\^A"...,16384,0x28afc000) = 16384 (0x4000)
pread(32,"\0\0\0\0\M-P\M-v\M-9:\0\0\^D\0"...,32768,0x28b02000) = 32768 (0x8000)
In other words it's able to coalesce, but v10 was a bit b0rked in that
respect and wouldn't do as well at that. Then if you set
io_combine_limit = 1, it looks more like master, eg lots of little
reads, but not as many fadvises as master because of sequential
access:
...
posix_fadvise(32,0x28af4000,0x2000,POSIX_FADV_WILLNEED) = 0 (0x0) -+
pread(32,...,8192,0x28ae8000) = 8192 (0x2000) |
pread(32,...,8192,0x28aee000) = 8192 (0x2000) |
posix_fadvise(32,0x28afc000,0x2000,POSIX_FADV_WILLNEED) = 0 (0x0) ---+
pread(32,...,8192,0x28af0000) = 8192 (0x2000) | |
pread(32,...,8192,0x28af4000) = 8192 (0x2000) <--------------------+ |
posix_fadvise(32,0x28b02000,0x2000,POSIX_FADV_WILLNEED) = 0 (0x0) -----+
pread(32,...,8192,0x28af6000) = 8192 (0x2000) | |
pread(32,...,8192,0x28afc000) = 8192 (0x2000) <----------------------+ |
pread(32,...,8192,0x28afe000) = 8192 (0x2000) }-- no advice |
pread(32,...,8192,0x28b02000) = 8192 (0x2000) <------------------------+
pread(32,...,8192,0x28b04000) = 8192 (0x2000) }
pread(32,...,8192,0x28b06000) = 8192 (0x2000) }-- no advice
pread(32,...,8192,0x28b08000) = 8192 (0x2000) }
It becomes slightly less eager to start I/Os as soon as
io_combine_limit > 1, because when it has hit max_ios, if ... <thinks>
yeah if the average block that it can combine is bigger than 4, an
arbitrary number from:
max_pinned_buffers = Max(max_ios * 4, io_combine_limit);
.... then it can run out of look ahead window before it can reach
max_ios (aka eic), so that's a kind of arbitrary/bogus I/O depth
constraint, which is another way of saying what I was saying earlier:
maybe it just needs more distance. So let's see the average combined
I/O length in your test query... for me it works out to 27,169 bytes.
But I think there must be times when it runs out of window due to
clustering. So you could also try increasing that 4->8 to see what
happens to performance.
[1] https://www.postgresql.org/message-id/CA%2BhUKG%2B5UofvseJWv6YqKmuc_%3Drguc7VqKcNEG1eawKh3MzHXQ%40mail.gmail.com
On 3/29/24 02:12, Thomas Munro wrote: > On Fri, Mar 29, 2024 at 10:43 AM Tomas Vondra > <tomas.vondra@enterprisedb.com> wrote: >> I think there's some sort of bug, triggering this assert in heapam >> >> Assert(BufferGetBlockNumber(hscan->rs_cbuf) == tbmres->blockno); > > Thanks for the repro. I can't seem to reproduce it (still trying) but > I assume this is with Melanie's v11 patch set which had > v11-0016-v10-Read-Stream-API.patch. > > Would you mind removing that commit and instead applying the v13 > stream_read.c patches[1]? v10 stream_read.c was a little confused > about random I/O combining, which I fixed with a small adjustment to > the conditions for the "if" statement right at the end of > read_stream_look_ahead(). Sorry about that. The fixed version, with > eic=4, with your test query using WHERE a < a, ends its scan with: > I'll give that a try. Unfortunately unfortunately the v11 still has the problem I reported about a week ago: ERROR: prefetch and main iterators are out of sync So I can't run the full benchmarks :-( but master vs. streaming read API should work, I think. regards -- Tomas Vondra EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On Sat, Mar 30, 2024 at 12:17 AM Thomas Munro <thomas.munro@gmail.com> wrote: > eic unpatched patched > 0 4172 9572 > 1 30846 10376 > 2 18435 5562 > 4 18980 3503 > 8 18980 2680 > 16 18976 3233 ... but the patched version gets down to a low number for eic=0 too if you turn up the blockdev --setra so that it also gets Linux RA treatment, making it the clear winner on all eic settings. Patched doesn't improve. So, for low IOPS storage at least, when you're on the borderline between random and sequential, ie bitmap with a lot of 1s in it, it seems there are cases where patched doesn't trigger Linux RA but unpatched does, and you can tune your way out of that, and then there are cases where the IOPS limit is reached due to small reads, but patched does better because of larger I/Os that are likely under the same circumstances. Does that make sense?
On 3/29/24 14:36, Thomas Munro wrote: > On Sat, Mar 30, 2024 at 12:17 AM Thomas Munro <thomas.munro@gmail.com> wrote: >> eic unpatched patched >> 0 4172 9572 >> 1 30846 10376 >> 2 18435 5562 >> 4 18980 3503 >> 8 18980 2680 >> 16 18976 3233 > > ... but the patched version gets down to a low number for eic=0 too if > you turn up the blockdev --setra so that it also gets Linux RA > treatment, making it the clear winner on all eic settings. Patched > doesn't improve. So, for low IOPS storage at least, when you're on > the borderline between random and sequential, ie bitmap with a lot of > 1s in it, it seems there are cases where patched doesn't trigger Linux > RA but unpatched does, and you can tune your way out of that, and then > there are cases where the IOPS limit is reached due to small reads, > but patched does better because of larger I/Os that are likely under > the same circumstances. Does that make sense? I think you meant "unpatched version gets down" in the first sentence, right? Still, it seems clear this changes the interaction with readahead done by the kernel. However, you seem to focus only on eic=0/eic=1 cases, but IIRC that was just an example. There are regression with higher eic values too. I do have some early results from the benchmarks - it's just from the NVMe machine, with 1M tables (~300MB), and it's just one incomplete run (so there might be some noise etc.). Attached is a PDF with charts for different subsets of the runs: - optimal (would optimizer pick bitmapscan or not) - readahead (yes/no) - workers (serial vs. 4 workers) - combine limit (8kB / 128kB) The most interesting cases are first two rows, i.e. optimal plans. Either with readahead enabled (first row) or disabled (second row). Two observations: * The combine limit seems to have negligible impact. There's no visible difference between combine_limit=8kB and 128kB. * Parallel queries seem to work about the same as master (especially for optimal cases, but even for not optimal ones). The optimal plans with kernel readahead (two charts in the first row) look fairly good. There are a couple regressed cases, but a bunch of faster ones too. The optimal plans without kernel read ahead (two charts in the second row) perform pretty poorly - there are massive regressions. But I think the obvious reason is that the streaming read API skips prefetches for sequential access patterns, relying on kernel to do the readahead. But if the kernel readahead is disabled for the device, that obviously can't happen ... I think the question is how much we can (want to) rely on the readahead to be done by the kernel. Maybe there should be some flag to force issuing fadvise even for sequential patterns, perhaps at the tablespace level? I don't recall seeing a system with disabled readahead, but I'm sure there are cases where it may not really work - it clearly can't work with direct I/O, but I've also not been very successful with prefetching on ZFS. The non-optimal plans (second half of the charts) shows about the same behavior, but the regressions are more frequent / significant. I'm also attaching results for the 5k "optimal" runs, showing the timing for master and patched build, sorted by (patched/master). The most significant regressions are with readahead=0, but if you filter that out you'll see the regressions affect a mix of data sets, not just the uniformly random data used as example before. On 3/29/24 12:17, Thomas Munro wrote: > ... > On the other hand this might be a pretty unusual data distribution. > People who store random numbers or hashes or whatever probably don't > really search for ranges of them (unless they're trying to mine > bitcoins in SQL). I dunno. Maybe we need more realistic tests, or > maybe we're just discovering all the things that are bad about the > pre-existing code. I certainly admit the data sets are synthetic and perhaps adversarial. My intent was to cover a wide range of data sets, to trigger even less common cases. It's certainly up to debate how serious the regressions on those data sets are in practice, I'm not suggesting "this strange data set makes it slower than master, so we can't commit this". But I'd also point that what matters is the access pattern, not the exact query generating it. I agree people probably don't do random numbers or hashes with range conditions, but that's irrelevant - what it's all about the page access pattern. If you have IPv4 addresses and query that, that's likely going to be pretty random, for example. regards -- Tomas Vondra EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
Attachment
On Sat, Mar 30, 2024 at 4:53 AM Tomas Vondra <tomas.vondra@enterprisedb.com> wrote: > Two observations: > > * The combine limit seems to have negligible impact. There's no visible > difference between combine_limit=8kB and 128kB. > > * Parallel queries seem to work about the same as master (especially for > optimal cases, but even for not optimal ones). > > > The optimal plans with kernel readahead (two charts in the first row) > look fairly good. There are a couple regressed cases, but a bunch of > faster ones too. Thanks for doing this! > The optimal plans without kernel read ahead (two charts in the second > row) perform pretty poorly - there are massive regressions. But I think > the obvious reason is that the streaming read API skips prefetches for > sequential access patterns, relying on kernel to do the readahead. But > if the kernel readahead is disabled for the device, that obviously can't > happen ... Right, it does seem that this whole concept is sensitive on the 'borderline' between sequential and random, and this patch changes that a bit and we lose some. It's becoming much clearer to me that master is already exposing weird kinks, and the streaming version is mostly better, certainly on low IOPS systems. I suspect that there must be queries in the wild that would run much faster with eic=0 than eic=1 today due to that, and while the streaming version also loses in some cases, it seems that it mostly loses because of not triggering RA, which can at least be improved by increasing the RA window. On the flip side, master is more prone to running out of IOPS and there is no way to tune your way out of that. > I think the question is how much we can (want to) rely on the readahead > to be done by the kernel. ... We already rely on it everywhere, for basic things like sequential scan. > ... Maybe there should be some flag to force > issuing fadvise even for sequential patterns, perhaps at the tablespace > level? ... Yeah, I've wondered about trying harder to "second guess" the Linux RA. At the moment, read_stream.c detects *exactly* sequential reads (see seq_blocknum) to suppress advice, but if we knew/guessed the RA window size, we could (1) detect it with the same window that Linux will use to detect it, and (2) [new realisation from yesterday's testing] we could even "tickle" it to wake it up in certain cases where it otherwise wouldn't, by temporarily using a smaller io_combine_limit if certain patterns come along. I think that sounds like madness (I suspect that any place where the latter would help is a place where you could turn RA up a bit higher for the same effect without weird kludges), or another way to put it would be to call it "overfitting" to the pre-existing quirks; but maybe it's a future research idea... > I don't recall seeing a system with disabled readahead, but I'm > sure there are cases where it may not really work - it clearly can't > work with direct I/O, ... Right, for direct I/O everything is slow right now including seq scan. We need to start asynchronous reads in the background (imagine literally just a bunch of background "I/O workers" running preadv() on your behalf to get your future buffers ready for you, or equivalently Linux io_uring). That's the real goal of this project: restructuring so we have the information we need to do that, ie teach every part of PostgreSQL to predict the future in a standard and centralised way. Should work out better than RA heuristics, because we're not just driving in a straight line, we can turn corners too. > ... but I've also not been very successful with > prefetching on ZFS. posix_favise() did not do anything in OpenZFS before 2.2, maybe you have an older version? > I certainly admit the data sets are synthetic and perhaps adversarial. > My intent was to cover a wide range of data sets, to trigger even less > common cases. It's certainly up to debate how serious the regressions on > those data sets are in practice, I'm not suggesting "this strange data > set makes it slower than master, so we can't commit this". Right, yeah. Thanks! Your initial results seemed discouraging, but looking closer I'm starting to feel a lot more positive about streaming BHS.
On Sat, Mar 30, 2024 at 10:39 AM Thomas Munro <thomas.munro@gmail.com> wrote: > On Sat, Mar 30, 2024 at 4:53 AM Tomas Vondra > <tomas.vondra@enterprisedb.com> wrote: > > ... Maybe there should be some flag to force > > issuing fadvise even for sequential patterns, perhaps at the tablespace > > level? ... > > Yeah, I've wondered about trying harder to "second guess" the Linux > RA. At the moment, read_stream.c detects *exactly* sequential reads > (see seq_blocknum) to suppress advice, but if we knew/guessed the RA > window size, we could (1) detect it with the same window that Linux > will use to detect it, and (2) [new realisation from yesterday's > testing] we could even "tickle" it to wake it up in certain cases > where it otherwise wouldn't, by temporarily using a smaller > io_combine_limit if certain patterns come along. I think that sounds > like madness (I suspect that any place where the latter would help is > a place where you could turn RA up a bit higher for the same effect > without weird kludges), or another way to put it would be to call it > "overfitting" to the pre-existing quirks; but maybe it's a future > research idea... I guess I missed a step when responding that suggestion: I don't think we could have an "issue advice always" flag, because it doesn't seem to work out as well as letting the kernel do it, and a global flag like that would affect everything else including sequential scans (once the streaming seq scan patch goes in). But suppose we could do that, maybe even just for BHS. In my little test yesterday had to issue a lot of them, patched eic=4, to beat the kernel's RA with unpatched eic=0: eic unpatched patched 0 4172 9572 1 30846 10376 2 18435 5562 4 18980 3503 So if we forced fadvise to be issued with a GUC, it still wouldn't be good enough in this case. So we might need to try to understand what exactly is waking the RA up for unpatched but not patched, and try to tickle it by doing a little less I/O combining (for example just setting io_combine_limit=1 gives the same number for eic=0, a major clue), but that seems to be going down a weird path, and tuning such a copying algorithm seems too hard.
On 3/29/24 23:03, Thomas Munro wrote: > On Sat, Mar 30, 2024 at 10:39 AM Thomas Munro <thomas.munro@gmail.com> wrote: >> On Sat, Mar 30, 2024 at 4:53 AM Tomas Vondra >> <tomas.vondra@enterprisedb.com> wrote: >>> ... Maybe there should be some flag to force >>> issuing fadvise even for sequential patterns, perhaps at the tablespace >>> level? ... >> >> Yeah, I've wondered about trying harder to "second guess" the Linux >> RA. At the moment, read_stream.c detects *exactly* sequential reads >> (see seq_blocknum) to suppress advice, but if we knew/guessed the RA >> window size, we could (1) detect it with the same window that Linux >> will use to detect it, and (2) [new realisation from yesterday's >> testing] we could even "tickle" it to wake it up in certain cases >> where it otherwise wouldn't, by temporarily using a smaller >> io_combine_limit if certain patterns come along. I think that sounds >> like madness (I suspect that any place where the latter would help is >> a place where you could turn RA up a bit higher for the same effect >> without weird kludges), or another way to put it would be to call it >> "overfitting" to the pre-existing quirks; but maybe it's a future >> research idea... > I don't know if I'd call this overfitting - yes, we certainly don't want to tailor this code to only work with the linux RA, but OTOH it's the RA is what most systems do. And if we plan to rely on that, we probably have to "respect" how it works ... Moving to a "clean" approach that however triggers regressions does not seem like a great thing for users. I'm not saying the goal has to be "no regressions", that would be rather impossible. At this point I still try to understand what's causing this. BTW are you suggesting that increasing the RA distance could maybe fix the regressions? I can give it a try, but I was assuming that 128kB readahead would be enough for combine_limit=8kB. > I guess I missed a step when responding that suggestion: I don't think > we could have an "issue advice always" flag, because it doesn't seem > to work out as well as letting the kernel do it, and a global flag > like that would affect everything else including sequential scans > (once the streaming seq scan patch goes in). But suppose we could do > that, maybe even just for BHS. In my little test yesterday had to > issue a lot of them, patched eic=4, to beat the kernel's RA with > unpatched eic=0: > > eic unpatched patched > 0 4172 9572 > 1 30846 10376 > 2 18435 5562 > 4 18980 3503 > > So if we forced fadvise to be issued with a GUC, it still wouldn't be > good enough in this case. So we might need to try to understand what > exactly is waking the RA up for unpatched but not patched, and try to > tickle it by doing a little less I/O combining (for example just > setting io_combine_limit=1 gives the same number for eic=0, a major > clue), but that seems to be going down a weird path, and tuning such a > copying algorithm seems too hard. Hmmm. I admit I didn't think about the "always prefetch" flag too much, but I did imagine it'd only affect some places (e.g. BHS, but not for sequential scans). If it could be done by lowering the combine limit, that could work too - in fact, I was wondering if we should have combine limit as a tablespace parameter too. But I think adding such knobs should be only the last resort - I myself don't know how to set these parameters, how could we expect users to pick good values? Better to have something that "just works". I admit I never 100% understood when exactly the kernel RA kicks in, but I always thought it's enough for the patterns to be only "close enough" to sequential. Isn't the problem that this only skips fadvise for 100% sequential patterns, but keeps prefetching for cases the RA would deal on it's own? So maybe we should either relax the conditions when to skip fadvise, or combine even pages that are not perfectly sequential (I'm not sure if that's possible only for fadvise), though. regards -- Tomas Vondra EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On 3/29/24 22:39, Thomas Munro wrote: > ... > >> I don't recall seeing a system with disabled readahead, but I'm >> sure there are cases where it may not really work - it clearly can't >> work with direct I/O, ... > > Right, for direct I/O everything is slow right now including seq scan. > We need to start asynchronous reads in the background (imagine > literally just a bunch of background "I/O workers" running preadv() on > your behalf to get your future buffers ready for you, or equivalently > Linux io_uring). That's the real goal of this project: restructuring > so we have the information we need to do that, ie teach every part of > PostgreSQL to predict the future in a standard and centralised way. > Should work out better than RA heuristics, because we're not just > driving in a straight line, we can turn corners too. > >> ... but I've also not been very successful with >> prefetching on ZFS. > > posix_favise() did not do anything in OpenZFS before 2.2, maybe you > have an older version? > Sorry, I meant the prefetch (readahead) built into ZFS. I may be wrong but I don't think the regular RA (in linux kernel) works for ZFS, right? I was wondering if we could use this (posix_fadvise) to improve that, essentially by issuing fadvise even for sequential patterns. But now that I think about that, if posix_fadvise works since 2.2, maybe RA works too now?) regards -- Tomas Vondra EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On Sat, Mar 30, 2024 at 12:40 PM Tomas Vondra
<tomas.vondra@enterprisedb.com> wrote:
> Sorry, I meant the prefetch (readahead) built into ZFS. I may be wrong
> but I don't think the regular RA (in linux kernel) works for ZFS, right?
Right, it separate page cache ("ARC") and prefetch settings:
https://openzfs.github.io/openzfs-docs/Performance%20and%20Tuning/Module%20Parameters.html
That's probably why Linux posix_fadvise didn't affect it, well that
and the fact, at a wild guess, that Solaris didn't have that system
call...
> I was wondering if we could use this (posix_fadvise) to improve that,
> essentially by issuing fadvise even for sequential patterns. But now
> that I think about that, if posix_fadvise works since 2.2, maybe RA
> works too now?)
It should work fine. I am planning to look into this a bit some day
soon -- I think there may be some interesting interactions between
systems with big pages/records like ZFS/BTRFS/... and io_combine_limit
that might offer interesting optimisation tweak opportunities, but
first things first...
On Sat, Mar 30, 2024 at 12:34 PM Tomas Vondra <tomas.vondra@enterprisedb.com> wrote: > Hmmm. I admit I didn't think about the "always prefetch" flag too much, > but I did imagine it'd only affect some places (e.g. BHS, but not for > sequential scans). If it could be done by lowering the combine limit, > that could work too - in fact, I was wondering if we should have combine > limit as a tablespace parameter too. Good idea! Will add. Planning to commit the basic patch very soon, I'm just thinking about what to do with Heikki's recent optimisation feedback (ie can it be done as follow-up, he thinks so, I'm thinking about that today as time is running short). > But I think adding such knobs should be only the last resort - I myself > don't know how to set these parameters, how could we expect users to > pick good values? Better to have something that "just works". Agreed. > I admit I never 100% understood when exactly the kernel RA kicks in, but > I always thought it's enough for the patterns to be only "close enough" > to sequential. Isn't the problem that this only skips fadvise for 100% > sequential patterns, but keeps prefetching for cases the RA would deal > on it's own? So maybe we should either relax the conditions when to skip > fadvise, or combine even pages that are not perfectly sequential (I'm > not sure if that's possible only for fadvise), though. Yes that might be worth considering, if we know/guess what the OS RA window size is for a tablespace. I will post a patch for that for consideration/testing as a potential follow-up as it's super easy, just for experimentation. I just fear that it's getting into the realms of "hard to explain/understand" but on the other hand I guess we already have the mechanism and have to explain it.
On Fri, Mar 29, 2024 at 12:05:15PM +0100, Tomas Vondra wrote: > > > On 3/29/24 02:12, Thomas Munro wrote: > > On Fri, Mar 29, 2024 at 10:43 AM Tomas Vondra > > <tomas.vondra@enterprisedb.com> wrote: > >> I think there's some sort of bug, triggering this assert in heapam > >> > >> Assert(BufferGetBlockNumber(hscan->rs_cbuf) == tbmres->blockno); > > > > Thanks for the repro. I can't seem to reproduce it (still trying) but > > I assume this is with Melanie's v11 patch set which had > > v11-0016-v10-Read-Stream-API.patch. > > > > Would you mind removing that commit and instead applying the v13 > > stream_read.c patches[1]? v10 stream_read.c was a little confused > > about random I/O combining, which I fixed with a small adjustment to > > the conditions for the "if" statement right at the end of > > read_stream_look_ahead(). Sorry about that. The fixed version, with > > eic=4, with your test query using WHERE a < a, ends its scan with: > > > > I'll give that a try. Unfortunately unfortunately the v11 still has the > problem I reported about a week ago: > > ERROR: prefetch and main iterators are out of sync > > So I can't run the full benchmarks :-( but master vs. streaming read API > should work, I think. Odd, I didn't notice you reporting this ERROR popping up. Now that I take a look, v11 (at least, maybe also v10) had this very sill mistake: if (scan->bm_parallel == NULL && scan->rs_pf_bhs_iterator && hscan->pfblockno > hscan->rs_base.blockno) elog(ERROR, "prefetch and main iterators are out of sync"); It errors out if the prefetch block is ahead of the current block -- which is the opposite of what we want. I've fixed this in attached v12. This version also has v13 of the streaming read API. I noticed one mistake in my bitmapheap scan streaming read user -- it freed the streaming read object at the wrong time. I don't know if this was causing any other issues, but it at least is fixed in this version. - Melanie
Attachment
- v12-0001-BitmapHeapScan-begin-scan-after-bitmap-creation.patch
- v12-0002-BitmapHeapScan-set-can_skip_fetch-later.patch
- v12-0003-Push-BitmapHeapScan-skip-fetch-optimization-into.patch
- v12-0004-BitmapPrefetch-use-prefetch-block-recheck-for-sk.patch
- v12-0005-Update-BitmapAdjustPrefetchIterator-parameter-ty.patch
- v12-0006-table_scan_bitmap_next_block-returns-lossy-or-ex.patch
- v12-0007-Reduce-scope-of-BitmapHeapScan-tbmiterator-local.patch
- v12-0008-Remove-table_scan_bitmap_next_tuple-parameter-tb.patch
- v12-0009-Make-table_scan_bitmap_next_block-async-friendly.patch
- v12-0010-Unify-parallel-and-serial-BitmapHeapScan-iterato.patch
- v12-0011-table_scan_bitmap_next_block-counts-lossy-and-ex.patch
- v12-0012-Hard-code-TBMIterateResult-offsets-array-size.patch
- v12-0013-Separate-TBM-Shared-Iterator-and-TBMIterateResul.patch
- v12-0014-Push-BitmapHeapScan-prefetch-code-into-heapam.c.patch
- v12-0015-Remove-table_scan_bitmap_next_block.patch
- v12-0016-v13-Streaming-Read-API.patch
- v12-0017-BitmapHeapScan-uses-read-stream-API.patch
On Sun, Mar 31, 2024 at 11:45:51AM -0400, Melanie Plageman wrote: > On Fri, Mar 29, 2024 at 12:05:15PM +0100, Tomas Vondra wrote: > > > > > > On 3/29/24 02:12, Thomas Munro wrote: > > > On Fri, Mar 29, 2024 at 10:43 AM Tomas Vondra > > > <tomas.vondra@enterprisedb.com> wrote: > > >> I think there's some sort of bug, triggering this assert in heapam > > >> > > >> Assert(BufferGetBlockNumber(hscan->rs_cbuf) == tbmres->blockno); > > > > > > Thanks for the repro. I can't seem to reproduce it (still trying) but > > > I assume this is with Melanie's v11 patch set which had > > > v11-0016-v10-Read-Stream-API.patch. > > > > > > Would you mind removing that commit and instead applying the v13 > > > stream_read.c patches[1]? v10 stream_read.c was a little confused > > > about random I/O combining, which I fixed with a small adjustment to > > > the conditions for the "if" statement right at the end of > > > read_stream_look_ahead(). Sorry about that. The fixed version, with > > > eic=4, with your test query using WHERE a < a, ends its scan with: > > > > > > > I'll give that a try. Unfortunately unfortunately the v11 still has the > > problem I reported about a week ago: > > > > ERROR: prefetch and main iterators are out of sync > > > > So I can't run the full benchmarks :-( but master vs. streaming read API > > should work, I think. > > Odd, I didn't notice you reporting this ERROR popping up. Now that I > take a look, v11 (at least, maybe also v10) had this very sill mistake: > > if (scan->bm_parallel == NULL && > scan->rs_pf_bhs_iterator && > hscan->pfblockno > hscan->rs_base.blockno) > elog(ERROR, "prefetch and main iterators are out of sync"); > > It errors out if the prefetch block is ahead of the current block -- > which is the opposite of what we want. I've fixed this in attached v12. > > This version also has v13 of the streaming read API. I noticed one > mistake in my bitmapheap scan streaming read user -- it freed the > streaming read object at the wrong time. I don't know if this was > causing any other issues, but it at least is fixed in this version. Attached v13 is rebased over master (which includes the streaming read API now). I also reset the streaming read object on rescan instead of creating a new one each time. I don't know how much chance any of this has of going in to 17 now, but I thought I would start looking into the regression repro Tomas provided in [1]. I'm also not sure if I should try and group the commits into fewer commits now or wait until I have some idea of whether or not the approach in 0013 and 0014 is worth pursuing. - Melanie [1] https://www.postgresql.org/message-id/5d5954ed-6f43-4f1a-8e19-ece75b2b7362%40enterprisedb.com
Attachment
- v13-0001-BitmapHeapScan-begin-scan-after-bitmap-creation.patch
- v13-0002-BitmapHeapScan-set-can_skip_fetch-later.patch
- v13-0003-Push-BitmapHeapScan-skip-fetch-optimization-into.patch
- v13-0004-BitmapPrefetch-use-prefetch-block-recheck-for-sk.patch
- v13-0005-Update-BitmapAdjustPrefetchIterator-parameter-ty.patch
- v13-0006-table_scan_bitmap_next_block-returns-lossy-or-ex.patch
- v13-0007-Reduce-scope-of-BitmapHeapScan-tbmiterator-local.patch
- v13-0008-Remove-table_scan_bitmap_next_tuple-parameter-tb.patch
- v13-0009-Make-table_scan_bitmap_next_block-async-friendly.patch
- v13-0010-Unify-parallel-and-serial-BitmapHeapScan-iterato.patch
- v13-0011-table_scan_bitmap_next_block-counts-lossy-and-ex.patch
- v13-0012-Hard-code-TBMIterateResult-offsets-array-size.patch
- v13-0013-Separate-TBM-Shared-Iterator-and-TBMIterateResul.patch
- v13-0014-Push-BitmapHeapScan-prefetch-code-into-heapam.c.patch
- v13-0015-Remove-table_scan_bitmap_next_block.patch
- v13-0016-BitmapHeapScan-uses-read-stream-API.patch
On 4/4/24 00:57, Melanie Plageman wrote: > On Sun, Mar 31, 2024 at 11:45:51AM -0400, Melanie Plageman wrote: >> On Fri, Mar 29, 2024 at 12:05:15PM +0100, Tomas Vondra wrote: >>> >>> >>> On 3/29/24 02:12, Thomas Munro wrote: >>>> On Fri, Mar 29, 2024 at 10:43 AM Tomas Vondra >>>> <tomas.vondra@enterprisedb.com> wrote: >>>>> I think there's some sort of bug, triggering this assert in heapam >>>>> >>>>> Assert(BufferGetBlockNumber(hscan->rs_cbuf) == tbmres->blockno); >>>> >>>> Thanks for the repro. I can't seem to reproduce it (still trying) but >>>> I assume this is with Melanie's v11 patch set which had >>>> v11-0016-v10-Read-Stream-API.patch. >>>> >>>> Would you mind removing that commit and instead applying the v13 >>>> stream_read.c patches[1]? v10 stream_read.c was a little confused >>>> about random I/O combining, which I fixed with a small adjustment to >>>> the conditions for the "if" statement right at the end of >>>> read_stream_look_ahead(). Sorry about that. The fixed version, with >>>> eic=4, with your test query using WHERE a < a, ends its scan with: >>>> >>> >>> I'll give that a try. Unfortunately unfortunately the v11 still has the >>> problem I reported about a week ago: >>> >>> ERROR: prefetch and main iterators are out of sync >>> >>> So I can't run the full benchmarks :-( but master vs. streaming read API >>> should work, I think. >> >> Odd, I didn't notice you reporting this ERROR popping up. Now that I >> take a look, v11 (at least, maybe also v10) had this very sill mistake: >> >> if (scan->bm_parallel == NULL && >> scan->rs_pf_bhs_iterator && >> hscan->pfblockno > hscan->rs_base.blockno) >> elog(ERROR, "prefetch and main iterators are out of sync"); >> >> It errors out if the prefetch block is ahead of the current block -- >> which is the opposite of what we want. I've fixed this in attached v12. >> >> This version also has v13 of the streaming read API. I noticed one >> mistake in my bitmapheap scan streaming read user -- it freed the >> streaming read object at the wrong time. I don't know if this was >> causing any other issues, but it at least is fixed in this version. > > Attached v13 is rebased over master (which includes the streaming read > API now). I also reset the streaming read object on rescan instead of > creating a new one each time. > > I don't know how much chance any of this has of going in to 17 now, but > I thought I would start looking into the regression repro Tomas provided > in [1]. > My personal opinion is that we should try to get in as many of the the refactoring patches as possible, but I think it's probably too late for the actual switch to the streaming API. If someone else feels like committing that part, I won't stand in the way, but I'm not quite convinced it won't cause regressions. Maybe it's OK but I'd need more time to do more tests, collect data, and so on. And I don't think we have that, especially considering we'd still need to commit the other parts first. > I'm also not sure if I should try and group the commits into fewer > commits now or wait until I have some idea of whether or not the > approach in 0013 and 0014 is worth pursuing. > You mean whether to pursue the approach in general, or for v17? I think it looks like the right approach, but for v17 see above :-( As for merging, I wouldn't do that. I looked at the commits and while some of them seem somewhat "trivial", I really like how you organized the commits, and kept those that just "move" code around, and those that actually change stuff. It's much easier to understand, IMO. I went through the first ~10 commits, and added some review - either as a separate commit, when possible, in the code as XXX comment, and also in the commit message. The code tweaks are utterly trivial (whitespace or indentation to make the line shorter). It shouldn't take much time to deal with those, I think. I think the main focus should be updating the commit messages. If it was only a single patch, I'd probably try to write the messages myself, but with this many patches it'd be great if you could update those and I'll review that before commit. I always struggle with writing commit messages myself, and it takes me ages to write a good one (well, I think the message is good, but who knows ...). But I think a good message should be concise enough to explain what and why it's done. It may reference a thread for all the gory details, but the basic reasoning should be in the commit message. For example the message for "BitmapPrefetch use prefetch block recheck for skip fetch" now says that it "makes more sense to do X" but does not really say why that's the case. The linked message does, but it'd be good to have that in the message (because how would I know how much of the thread to read?). Also, it'd be very helpful if you could update the author & reviewed-by fields. I'll review those before commit, ofc, but I admit I lost track of who reviewed which part. I'd focus on the first ~8-9 commits or so for now, we can commit more if things go reasonably well. regards -- Tomas Vondra EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
Attachment
- v14-0001-BitmapHeapScan-begin-scan-after-bitmap-creation.patch
- v14-0002-review.patch
- v14-0003-BitmapHeapScan-set-can_skip_fetch-later.patch
- v14-0004-Push-BitmapHeapScan-skip-fetch-optimization-into.patch
- v14-0005-BitmapPrefetch-use-prefetch-block-recheck-for-sk.patch
- v14-0006-Update-BitmapAdjustPrefetchIterator-parameter-ty.patch
- v14-0007-table_scan_bitmap_next_block-returns-lossy-or-ex.patch
- v14-0008-review.patch
- v14-0009-Reduce-scope-of-BitmapHeapScan-tbmiterator-local.patch
- v14-0010-review.patch
- v14-0011-Remove-table_scan_bitmap_next_tuple-parameter-tb.patch
- v14-0012-Make-table_scan_bitmap_next_block-async-friendly.patch
- v14-0013-Unify-parallel-and-serial-BitmapHeapScan-iterato.patch
- v14-0014-table_scan_bitmap_next_block-counts-lossy-and-ex.patch
- v14-0015-Hard-code-TBMIterateResult-offsets-array-size.patch
- v14-0016-Separate-TBM-Shared-Iterator-and-TBMIterateResul.patch
- v14-0017-Push-BitmapHeapScan-prefetch-code-into-heapam.c.patch
- v14-0018-Remove-table_scan_bitmap_next_block.patch
- v14-0019-BitmapHeapScan-uses-read-stream-API.patch
On Thu, Apr 04, 2024 at 04:35:45PM +0200, Tomas Vondra wrote: > > > On 4/4/24 00:57, Melanie Plageman wrote: > > On Sun, Mar 31, 2024 at 11:45:51AM -0400, Melanie Plageman wrote: > >> On Fri, Mar 29, 2024 at 12:05:15PM +0100, Tomas Vondra wrote: > >>> > >>> > >>> On 3/29/24 02:12, Thomas Munro wrote: > >>>> On Fri, Mar 29, 2024 at 10:43 AM Tomas Vondra > >>>> <tomas.vondra@enterprisedb.com> wrote: > >>>>> I think there's some sort of bug, triggering this assert in heapam > >>>>> > >>>>> Assert(BufferGetBlockNumber(hscan->rs_cbuf) == tbmres->blockno); > >>>> > >>>> Thanks for the repro. I can't seem to reproduce it (still trying) but > >>>> I assume this is with Melanie's v11 patch set which had > >>>> v11-0016-v10-Read-Stream-API.patch. > >>>> > >>>> Would you mind removing that commit and instead applying the v13 > >>>> stream_read.c patches[1]? v10 stream_read.c was a little confused > >>>> about random I/O combining, which I fixed with a small adjustment to > >>>> the conditions for the "if" statement right at the end of > >>>> read_stream_look_ahead(). Sorry about that. The fixed version, with > >>>> eic=4, with your test query using WHERE a < a, ends its scan with: > >>>> > >>> > >>> I'll give that a try. Unfortunately unfortunately the v11 still has the > >>> problem I reported about a week ago: > >>> > >>> ERROR: prefetch and main iterators are out of sync > >>> > >>> So I can't run the full benchmarks :-( but master vs. streaming read API > >>> should work, I think. > >> > >> Odd, I didn't notice you reporting this ERROR popping up. Now that I > >> take a look, v11 (at least, maybe also v10) had this very sill mistake: > >> > >> if (scan->bm_parallel == NULL && > >> scan->rs_pf_bhs_iterator && > >> hscan->pfblockno > hscan->rs_base.blockno) > >> elog(ERROR, "prefetch and main iterators are out of sync"); > >> > >> It errors out if the prefetch block is ahead of the current block -- > >> which is the opposite of what we want. I've fixed this in attached v12. > >> > >> This version also has v13 of the streaming read API. I noticed one > >> mistake in my bitmapheap scan streaming read user -- it freed the > >> streaming read object at the wrong time. I don't know if this was > >> causing any other issues, but it at least is fixed in this version. > > > > Attached v13 is rebased over master (which includes the streaming read > > API now). I also reset the streaming read object on rescan instead of > > creating a new one each time. > > > > I don't know how much chance any of this has of going in to 17 now, but > > I thought I would start looking into the regression repro Tomas provided > > in [1]. > > > > My personal opinion is that we should try to get in as many of the the > refactoring patches as possible, but I think it's probably too late for > the actual switch to the streaming API. Cool. In the attached v15, I have dropped all commits that are related to the streaming read API and included *only* commits that are beneficial to master. A few of the commits are merged or reordered as well. While going through the commits with this new goal in mind (forget about the streaming read API for now), I realized that it doesn't make much sense to just eliminate the layering violation for the current block and leave it there for the prefetch block. I had de-prioritized solving this when I thought we would just delete the prefetch code and replace it with the streaming read. Now that we aren't doing that, I've spent the day trying to resolve the issues with pushing the prefetch code into heapam.c that I cited in [1]. 0010 - 0013 are the result of this. They are not very polished yet and need more cleanup and review (especially 0011, which is probably too large), but I am happy with the solution I came up with. Basically, there are too many members needed for bitmap heap scan to put them all in the HeapScanDescData (don't want to bloat it). So, I've made a new BitmapHeapScanDescData and associated begin/rescan/end() functions In the end, with all patches applied, BitmapHeapNext() loops invoking table_scan_bitmap_next_tuple() and table AMs can implement that however they choose. > > I'm also not sure if I should try and group the commits into fewer > > commits now or wait until I have some idea of whether or not the > > approach in 0013 and 0014 is worth pursuing. > > > > You mean whether to pursue the approach in general, or for v17? I think > it looks like the right approach, but for v17 see above :-( > > As for merging, I wouldn't do that. I looked at the commits and while > some of them seem somewhat "trivial", I really like how you organized > the commits, and kept those that just "move" code around, and those that > actually change stuff. It's much easier to understand, IMO. > > I went through the first ~10 commits, and added some review - either as > a separate commit, when possible, in the code as XXX comment, and also > in the commit message. The code tweaks are utterly trivial (whitespace > or indentation to make the line shorter). It shouldn't take much time to > deal with those, I think. Attached v15 incorporates your v14-0002-review. For your v14-0008-review, I actually ended up removing that commit because once I removed everything that was for streaming read API, it became redundant with another commit. For your v14-0010-review, we actually can't easily get rid of those local variables because we make the iterators before we make the scan descriptors and the commit following that commit moves the iterators from the BitmapHeapScanState to the scan descriptor. > I think the main focus should be updating the commit messages. If it was > only a single patch, I'd probably try to write the messages myself, but > with this many patches it'd be great if you could update those and I'll > review that before commit. I did my best to update the commit messages to be less specific and more focused on "why should I care". I found myself wanting to explain why I implemented something the way I did and then getting back into the implementation details again. I'm not sure if I suceeded in having less details and more substance. > I always struggle with writing commit messages myself, and it takes me > ages to write a good one (well, I think the message is good, but who > knows ...). But I think a good message should be concise enough to > explain what and why it's done. It may reference a thread for all the > gory details, but the basic reasoning should be in the commit message. > For example the message for "BitmapPrefetch use prefetch block recheck > for skip fetch" now says that it "makes more sense to do X" but does not > really say why that's the case. The linked message does, but it'd be > good to have that in the message (because how would I know how much of > the thread to read?). I fixed that particular one. I tried to take that feedback and apply it to other commit messages. I don't know how successful I was... > Also, it'd be very helpful if you could update the author & reviewed-by > fields. I'll review those before commit, ofc, but I admit I lost track > of who reviewed which part. I have updated reviewers. I didn't add reviewers on the ones that haven't really been reviewed yet. > I'd focus on the first ~8-9 commits or so for now, we can commit more if > things go reasonably well. Sounds good. I will spend cleanup time on 0010-0013 tomorrow but would love to know if you agree with the direction before I spend more time. - Melanie [1] https://www.postgresql.org/message-id/20240323002211.on5vb5ulk6lsdb2u%40liskov
Attachment
- v15-0001-BitmapHeapScan-begin-scan-after-bitmap-creation.patch
- v15-0002-BitmapHeapScan-set-can_skip_fetch-later.patch
- v15-0003-Push-BitmapHeapScan-skip-fetch-optimization-into.patch
- v15-0004-BitmapPrefetch-use-prefetch-block-recheck-for-sk.patch
- v15-0005-Update-BitmapAdjustPrefetchIterator-parameter-ty.patch
- v15-0006-Reduce-scope-of-BitmapHeapScan-tbmiterator-local.patch
- v15-0007-table_scan_bitmap_next_block-counts-lossy-and-ex.patch
- v15-0008-Remove-table_scan_bitmap_next_tuple-parameter-tb.patch
- v15-0009-Make-table_scan_bitmap_next_block-async-friendly.patch
- v15-0010-Unify-parallel-and-serial-BitmapHeapScan-iterato.patch
- v15-0011-Push-BitmapHeapScan-prefetch-code-into-heapam.c.patch
- v15-0012-Move-BitmapHeapScan-initialization-to-helper.patch
- v15-0013-Remove-table_scan_bitmap_next_block.patch
On Fri, Apr 05, 2024 at 04:06:34AM -0400, Melanie Plageman wrote: > On Thu, Apr 04, 2024 at 04:35:45PM +0200, Tomas Vondra wrote: > > > > > > On 4/4/24 00:57, Melanie Plageman wrote: > > > On Sun, Mar 31, 2024 at 11:45:51AM -0400, Melanie Plageman wrote: > > >> On Fri, Mar 29, 2024 at 12:05:15PM +0100, Tomas Vondra wrote: > > >>> > > >>> > > >>> On 3/29/24 02:12, Thomas Munro wrote: > > >>>> On Fri, Mar 29, 2024 at 10:43 AM Tomas Vondra > > >>>> <tomas.vondra@enterprisedb.com> wrote: > > >>>>> I think there's some sort of bug, triggering this assert in heapam > > >>>>> > > >>>>> Assert(BufferGetBlockNumber(hscan->rs_cbuf) == tbmres->blockno); > > >>>> > > >>>> Thanks for the repro. I can't seem to reproduce it (still trying) but > > >>>> I assume this is with Melanie's v11 patch set which had > > >>>> v11-0016-v10-Read-Stream-API.patch. > > >>>> > > >>>> Would you mind removing that commit and instead applying the v13 > > >>>> stream_read.c patches[1]? v10 stream_read.c was a little confused > > >>>> about random I/O combining, which I fixed with a small adjustment to > > >>>> the conditions for the "if" statement right at the end of > > >>>> read_stream_look_ahead(). Sorry about that. The fixed version, with > > >>>> eic=4, with your test query using WHERE a < a, ends its scan with: > > >>>> > > >>> > > >>> I'll give that a try. Unfortunately unfortunately the v11 still has the > > >>> problem I reported about a week ago: > > >>> > > >>> ERROR: prefetch and main iterators are out of sync > > >>> > > >>> So I can't run the full benchmarks :-( but master vs. streaming read API > > >>> should work, I think. > > >> > > >> Odd, I didn't notice you reporting this ERROR popping up. Now that I > > >> take a look, v11 (at least, maybe also v10) had this very sill mistake: > > >> > > >> if (scan->bm_parallel == NULL && > > >> scan->rs_pf_bhs_iterator && > > >> hscan->pfblockno > hscan->rs_base.blockno) > > >> elog(ERROR, "prefetch and main iterators are out of sync"); > > >> > > >> It errors out if the prefetch block is ahead of the current block -- > > >> which is the opposite of what we want. I've fixed this in attached v12. > > >> > > >> This version also has v13 of the streaming read API. I noticed one > > >> mistake in my bitmapheap scan streaming read user -- it freed the > > >> streaming read object at the wrong time. I don't know if this was > > >> causing any other issues, but it at least is fixed in this version. > > > > > > Attached v13 is rebased over master (which includes the streaming read > > > API now). I also reset the streaming read object on rescan instead of > > > creating a new one each time. > > > > > > I don't know how much chance any of this has of going in to 17 now, but > > > I thought I would start looking into the regression repro Tomas provided > > > in [1]. > > > > > > > My personal opinion is that we should try to get in as many of the the > > refactoring patches as possible, but I think it's probably too late for > > the actual switch to the streaming API. > > Cool. In the attached v15, I have dropped all commits that are related > to the streaming read API and included *only* commits that are > beneficial to master. A few of the commits are merged or reordered as > well. > > While going through the commits with this new goal in mind (forget about > the streaming read API for now), I realized that it doesn't make much > sense to just eliminate the layering violation for the current block and > leave it there for the prefetch block. I had de-prioritized solving this > when I thought we would just delete the prefetch code and replace it > with the streaming read. > > Now that we aren't doing that, I've spent the day trying to resolve the > issues with pushing the prefetch code into heapam.c that I cited in [1]. > 0010 - 0013 are the result of this. They are not very polished yet and > need more cleanup and review (especially 0011, which is probably too > large), but I am happy with the solution I came up with. > > Basically, there are too many members needed for bitmap heap scan to put > them all in the HeapScanDescData (don't want to bloat it). So, I've made > a new BitmapHeapScanDescData and associated begin/rescan/end() functions > > In the end, with all patches applied, BitmapHeapNext() loops invoking > table_scan_bitmap_next_tuple() and table AMs can implement that however > they choose. > > > > I'm also not sure if I should try and group the commits into fewer > > > commits now or wait until I have some idea of whether or not the > > > approach in 0013 and 0014 is worth pursuing. > > > > > > > You mean whether to pursue the approach in general, or for v17? I think > > it looks like the right approach, but for v17 see above :-( > > > > As for merging, I wouldn't do that. I looked at the commits and while > > some of them seem somewhat "trivial", I really like how you organized > > the commits, and kept those that just "move" code around, and those that > > actually change stuff. It's much easier to understand, IMO. > > > > I went through the first ~10 commits, and added some review - either as > > a separate commit, when possible, in the code as XXX comment, and also > > in the commit message. The code tweaks are utterly trivial (whitespace > > or indentation to make the line shorter). It shouldn't take much time to > > deal with those, I think. > > Attached v15 incorporates your v14-0002-review. > > For your v14-0008-review, I actually ended up removing that commit > because once I removed everything that was for streaming read API, it > became redundant with another commit. > > For your v14-0010-review, we actually can't easily get rid of those > local variables because we make the iterators before we make the scan > descriptors and the commit following that commit moves the iterators > from the BitmapHeapScanState to the scan descriptor. > > > I think the main focus should be updating the commit messages. If it was > > only a single patch, I'd probably try to write the messages myself, but > > with this many patches it'd be great if you could update those and I'll > > review that before commit. > > I did my best to update the commit messages to be less specific and more > focused on "why should I care". I found myself wanting to explain why I > implemented something the way I did and then getting back into the > implementation details again. I'm not sure if I suceeded in having less > details and more substance. > > > I always struggle with writing commit messages myself, and it takes me > > ages to write a good one (well, I think the message is good, but who > > knows ...). But I think a good message should be concise enough to > > explain what and why it's done. It may reference a thread for all the > > gory details, but the basic reasoning should be in the commit message. > > For example the message for "BitmapPrefetch use prefetch block recheck > > for skip fetch" now says that it "makes more sense to do X" but does not > > really say why that's the case. The linked message does, but it'd be > > good to have that in the message (because how would I know how much of > > the thread to read?). > > I fixed that particular one. I tried to take that feedback and apply it > to other commit messages. I don't know how successful I was... > > > Also, it'd be very helpful if you could update the author & reviewed-by > > fields. I'll review those before commit, ofc, but I admit I lost track > > of who reviewed which part. > > I have updated reviewers. I didn't add reviewers on the ones that > haven't really been reviewed yet. > > > I'd focus on the first ~8-9 commits or so for now, we can commit more if > > things go reasonably well. > > Sounds good. I will spend cleanup time on 0010-0013 tomorrow but would > love to know if you agree with the direction before I spend more time. In attached v16, I've split out 0010-0013 into 0011-0017. I think it is much easier to understand. While I was doing that, I realized that I should remove the call to table_rescan() from ExecReScanBitmapHeapScan() and just rely on the new table_rescan_bm() invoked from BitmapHeapNext(). That is done in the attached. 0010-0018 still need comments updated but I focused on getting the split out, reviewable version of them ready. I'll add comments (especially to 0011 table AM functions) tomorrow. I also have to double-check if I should add any asserts for table AMs about having implemented all of the new begin/re/endscan() functions. - Melanie
Attachment
- v16-0001-BitmapHeapScan-begin-scan-after-bitmap-creation.patch
- v16-0002-BitmapHeapScan-set-can_skip_fetch-later.patch
- v16-0003-Push-BitmapHeapScan-skip-fetch-optimization-into.patch
- v16-0004-BitmapPrefetch-use-prefetch-block-recheck-for-sk.patch
- v16-0005-Update-BitmapAdjustPrefetchIterator-parameter-ty.patch
- v16-0006-Reduce-scope-of-BitmapHeapScan-tbmiterator-local.patch
- v16-0007-table_scan_bitmap_next_block-counts-lossy-and-ex.patch
- v16-0008-Remove-table_scan_bitmap_next_tuple-parameter-tb.patch
- v16-0009-Make-table_scan_bitmap_next_block-async-friendly.patch
- v16-0010-Unify-parallel-and-serial-BitmapHeapScan-iterato.patch
- v16-0011-Add-BitmapHeapScanDesc-and-scan-functions.patch
- v16-0012-BitmapHeapScan-initialize-some-prefetch-state-el.patch
- v16-0013-BitmapHeapScan-begin-iteration-in-rescan.patch
- v16-0014-Move-BitmapHeapScan-current-block-iterator-to-Bi.patch
- v16-0015-Lift-and-shift-BitmapHeapScan-prefetch-funcs-to-.patch
- v16-0016-Push-BitmapHeapScan-prefetch-code-into-heap-AM.patch
- v16-0017-Move-BitmapHeapScan-initialization-to-helper.patch
- v16-0018-Remove-table_scan_bitmap_next_block.patch
On 4/6/24 01:53, Melanie Plageman wrote: > On Fri, Apr 05, 2024 at 04:06:34AM -0400, Melanie Plageman wrote: >> On Thu, Apr 04, 2024 at 04:35:45PM +0200, Tomas Vondra wrote: >>> >>> >>> On 4/4/24 00:57, Melanie Plageman wrote: >>>> On Sun, Mar 31, 2024 at 11:45:51AM -0400, Melanie Plageman wrote: >>>>> On Fri, Mar 29, 2024 at 12:05:15PM +0100, Tomas Vondra wrote: >>>>>> >>>>>> >>>>>> On 3/29/24 02:12, Thomas Munro wrote: >>>>>>> On Fri, Mar 29, 2024 at 10:43 AM Tomas Vondra >>>>>>> <tomas.vondra@enterprisedb.com> wrote: >>>>>>>> I think there's some sort of bug, triggering this assert in heapam >>>>>>>> >>>>>>>> Assert(BufferGetBlockNumber(hscan->rs_cbuf) == tbmres->blockno); >>>>>>> >>>>>>> Thanks for the repro. I can't seem to reproduce it (still trying) but >>>>>>> I assume this is with Melanie's v11 patch set which had >>>>>>> v11-0016-v10-Read-Stream-API.patch. >>>>>>> >>>>>>> Would you mind removing that commit and instead applying the v13 >>>>>>> stream_read.c patches[1]? v10 stream_read.c was a little confused >>>>>>> about random I/O combining, which I fixed with a small adjustment to >>>>>>> the conditions for the "if" statement right at the end of >>>>>>> read_stream_look_ahead(). Sorry about that. The fixed version, with >>>>>>> eic=4, with your test query using WHERE a < a, ends its scan with: >>>>>>> >>>>>> >>>>>> I'll give that a try. Unfortunately unfortunately the v11 still has the >>>>>> problem I reported about a week ago: >>>>>> >>>>>> ERROR: prefetch and main iterators are out of sync >>>>>> >>>>>> So I can't run the full benchmarks :-( but master vs. streaming read API >>>>>> should work, I think. >>>>> >>>>> Odd, I didn't notice you reporting this ERROR popping up. Now that I >>>>> take a look, v11 (at least, maybe also v10) had this very sill mistake: >>>>> >>>>> if (scan->bm_parallel == NULL && >>>>> scan->rs_pf_bhs_iterator && >>>>> hscan->pfblockno > hscan->rs_base.blockno) >>>>> elog(ERROR, "prefetch and main iterators are out of sync"); >>>>> >>>>> It errors out if the prefetch block is ahead of the current block -- >>>>> which is the opposite of what we want. I've fixed this in attached v12. >>>>> >>>>> This version also has v13 of the streaming read API. I noticed one >>>>> mistake in my bitmapheap scan streaming read user -- it freed the >>>>> streaming read object at the wrong time. I don't know if this was >>>>> causing any other issues, but it at least is fixed in this version. >>>> >>>> Attached v13 is rebased over master (which includes the streaming read >>>> API now). I also reset the streaming read object on rescan instead of >>>> creating a new one each time. >>>> >>>> I don't know how much chance any of this has of going in to 17 now, but >>>> I thought I would start looking into the regression repro Tomas provided >>>> in [1]. >>>> >>> >>> My personal opinion is that we should try to get in as many of the the >>> refactoring patches as possible, but I think it's probably too late for >>> the actual switch to the streaming API. >> >> Cool. In the attached v15, I have dropped all commits that are related >> to the streaming read API and included *only* commits that are >> beneficial to master. A few of the commits are merged or reordered as >> well. >> >> While going through the commits with this new goal in mind (forget about >> the streaming read API for now), I realized that it doesn't make much >> sense to just eliminate the layering violation for the current block and >> leave it there for the prefetch block. I had de-prioritized solving this >> when I thought we would just delete the prefetch code and replace it >> with the streaming read. >> >> Now that we aren't doing that, I've spent the day trying to resolve the >> issues with pushing the prefetch code into heapam.c that I cited in [1]. >> 0010 - 0013 are the result of this. They are not very polished yet and >> need more cleanup and review (especially 0011, which is probably too >> large), but I am happy with the solution I came up with. >> >> Basically, there are too many members needed for bitmap heap scan to put >> them all in the HeapScanDescData (don't want to bloat it). So, I've made >> a new BitmapHeapScanDescData and associated begin/rescan/end() functions >> >> In the end, with all patches applied, BitmapHeapNext() loops invoking >> table_scan_bitmap_next_tuple() and table AMs can implement that however >> they choose. >> >>>> I'm also not sure if I should try and group the commits into fewer >>>> commits now or wait until I have some idea of whether or not the >>>> approach in 0013 and 0014 is worth pursuing. >>>> >>> >>> You mean whether to pursue the approach in general, or for v17? I think >>> it looks like the right approach, but for v17 see above :-( >>> >>> As for merging, I wouldn't do that. I looked at the commits and while >>> some of them seem somewhat "trivial", I really like how you organized >>> the commits, and kept those that just "move" code around, and those that >>> actually change stuff. It's much easier to understand, IMO. >>> >>> I went through the first ~10 commits, and added some review - either as >>> a separate commit, when possible, in the code as XXX comment, and also >>> in the commit message. The code tweaks are utterly trivial (whitespace >>> or indentation to make the line shorter). It shouldn't take much time to >>> deal with those, I think. >> >> Attached v15 incorporates your v14-0002-review. >> >> For your v14-0008-review, I actually ended up removing that commit >> because once I removed everything that was for streaming read API, it >> became redundant with another commit. >> >> For your v14-0010-review, we actually can't easily get rid of those >> local variables because we make the iterators before we make the scan >> descriptors and the commit following that commit moves the iterators >> from the BitmapHeapScanState to the scan descriptor. >> >>> I think the main focus should be updating the commit messages. If it was >>> only a single patch, I'd probably try to write the messages myself, but >>> with this many patches it'd be great if you could update those and I'll >>> review that before commit. >> >> I did my best to update the commit messages to be less specific and more >> focused on "why should I care". I found myself wanting to explain why I >> implemented something the way I did and then getting back into the >> implementation details again. I'm not sure if I suceeded in having less >> details and more substance. >> >>> I always struggle with writing commit messages myself, and it takes me >>> ages to write a good one (well, I think the message is good, but who >>> knows ...). But I think a good message should be concise enough to >>> explain what and why it's done. It may reference a thread for all the >>> gory details, but the basic reasoning should be in the commit message. >>> For example the message for "BitmapPrefetch use prefetch block recheck >>> for skip fetch" now says that it "makes more sense to do X" but does not >>> really say why that's the case. The linked message does, but it'd be >>> good to have that in the message (because how would I know how much of >>> the thread to read?). >> >> I fixed that particular one. I tried to take that feedback and apply it >> to other commit messages. I don't know how successful I was... >> >>> Also, it'd be very helpful if you could update the author & reviewed-by >>> fields. I'll review those before commit, ofc, but I admit I lost track >>> of who reviewed which part. >> >> I have updated reviewers. I didn't add reviewers on the ones that >> haven't really been reviewed yet. >> >>> I'd focus on the first ~8-9 commits or so for now, we can commit more if >>> things go reasonably well. >> >> Sounds good. I will spend cleanup time on 0010-0013 tomorrow but would >> love to know if you agree with the direction before I spend more time. > > In attached v16, I've split out 0010-0013 into 0011-0017. I think it is > much easier to understand. > Damn it, I went through the whole patch series, adding a couple review comments and tweaks, and was just about to share my version, but you bet me to it ;-) Anyway, I've attached it as .tgz in order to not confuse cfbot. All the review comments are marked with XXX, so grep for that in the patches. There's two separate patches - the first one suggests a code change, so it was better to not merge that with your code. The second has just a couple XXX comments, I'm not sure why I kept it separate. A couple review comments: * I think 0001-0009 are 99% ready to. I reworded some of the commit messages a bit - I realize it's a bit bold, considering you're native speaker and I'm not. If you could check I didn't make it worse, that would be great. * I'm not sure extra_flags is the right way to pass the flag in 0003. The "extra_" name is a bit weird, and no other table AM functions do it this way and pass explicit bool flags instead. So my first "review" commit does it like that. Do you agree it's better that way? * The one question I'm somewhat unsure about is why Tom chose to use the "wrong" recheck flag in the 2017 commit, when the correct recheck flag is readily available. Surely that had a reason, right? But I can't think of one ... > While I was doing that, I realized that I should remove the call to > table_rescan() from ExecReScanBitmapHeapScan() and just rely on the new > table_rescan_bm() invoked from BitmapHeapNext(). That is done in the > attached. > > 0010-0018 still need comments updated but I focused on getting the split > out, reviewable version of them ready. I'll add comments (especially to > 0011 table AM functions) tomorrow. I also have to double-check if I > should add any asserts for table AMs about having implemented all of the > new begin/re/endscan() functions. > I added a couple more comments for those patches (10-12). Chances are the split in v16 clarifies some of my questions, but it'll have to wait till the morning ... regards -- Tomas Vondra EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
Attachment
On Sat, Apr 06, 2024 at 02:51:45AM +0200, Tomas Vondra wrote:
>
>
> On 4/6/24 01:53, Melanie Plageman wrote:
> > On Fri, Apr 05, 2024 at 04:06:34AM -0400, Melanie Plageman wrote:
> >> On Thu, Apr 04, 2024 at 04:35:45PM +0200, Tomas Vondra wrote:
> >>> On 4/4/24 00:57, Melanie Plageman wrote:
> >>>> On Sun, Mar 31, 2024 at 11:45:51AM -0400, Melanie Plageman wrote:
> >>> I'd focus on the first ~8-9 commits or so for now, we can commit more if
> >>> things go reasonably well.
> >>
> >> Sounds good. I will spend cleanup time on 0010-0013 tomorrow but would
> >> love to know if you agree with the direction before I spend more time.
> >
> > In attached v16, I've split out 0010-0013 into 0011-0017. I think it is
> > much easier to understand.
> >
>
> Anyway, I've attached it as .tgz in order to not confuse cfbot. All the
> review comments are marked with XXX, so grep for that in the patches.
> There's two separate patches - the first one suggests a code change, so
> it was better to not merge that with your code. The second has just a
> couple XXX comments, I'm not sure why I kept it separate.
>
> A couple review comments:
>
> * I think 0001-0009 are 99% ready to. I reworded some of the commit
> messages a bit - I realize it's a bit bold, considering you're native
> speaker and I'm not. If you could check I didn't make it worse, that
> would be great.
Attached v17 has *only* patches 0001-0009 with these changes. I will
work on applying the remaining patches, addressing feedback, and adding
comments next.
I have reviewed and incorporated all of your feedback on these patches.
Attached v17 is your exact patches with 1 or 2 *very* slight tweaks to
commit messages (comma splice removal and single word adjustments) as
well as the changes listed below:
I have changed the following:
- 0003 added an assert that rs_empty_tuples_pending is 0 on rescan and
endscan
- 0004 (your 0005)-- I followed up with Tom, but for now I have just
removed the XXX and also reworded the message a bit
- 0006 (your 0007) fixed up the variable name (you changed valid ->
valid_block but it had gotten changed back)
I have open questions on the following:
- 0003: should it be SO_NEED_TUPLES and need_tuples (instead of
SO_NEED_TUPLE and need_tuple)?
- 0009 (your 0010)
- Should I mention in the commit message that we added blockno and
pfblockno in the BitmapHeapScanState only for validation or is that
too specific?
- Should I mention that a future (imminent) commit will remove the
iterators from TableScanDescData and put them in HeapScanDescData? I
imagine folks don't want those there, but it is easier for the
progression of commits to put them there first and then move them
- I'm worried this comment is vague and or potentially not totally
correct. Should we remove it? I don't think we have conclusive proof
that this is true.
/*
* Adjusting the prefetch iterator before invoking
* table_scan_bitmap_next_block() keeps prefetch distance higher across
* the parallel workers.
*/
> * I'm not sure extra_flags is the right way to pass the flag in 0003.
> The "extra_" name is a bit weird, and no other table AM functions do it
> this way and pass explicit bool flags instead. So my first "review"
> commit does it like that. Do you agree it's better that way?
Yes.
> * The one question I'm somewhat unsure about is why Tom chose to use the
> "wrong" recheck flag in the 2017 commit, when the correct recheck flag
> is readily available. Surely that had a reason, right? But I can't think
> of one ...
See above.
> > While I was doing that, I realized that I should remove the call to
> > table_rescan() from ExecReScanBitmapHeapScan() and just rely on the new
> > table_rescan_bm() invoked from BitmapHeapNext(). That is done in the
> > attached.
> >
> > 0010-0018 still need comments updated but I focused on getting the split
> > out, reviewable version of them ready. I'll add comments (especially to
> > 0011 table AM functions) tomorrow. I also have to double-check if I
> > should add any asserts for table AMs about having implemented all of the
> > new begin/re/endscan() functions.
> >
>
> I added a couple more comments for those patches (10-12). Chances are
> the split in v16 clarifies some of my questions, but it'll have to wait
> till the morning ...
Will address this in next mail.
- Melanie
Attachment
- v17-0001-BitmapHeapScan-begin-scan-after-bitmap-creation.patch
- v17-0002-BitmapHeapScan-postpone-setting-can_skip_fetch.patch
- v17-0003-Push-BitmapHeapScan-skip-fetch-optimization-into.patch
- v17-0004-Use-prefetch-block-recheck-value-to-determine-sk.patch
- v17-0005-Change-BitmapAdjustPrefetchIterator-to-accept-Bl.patch
- v17-0006-BitmapHeapScan-Reduce-scope-of-tbmiterator-local.patch
- v17-0007-table_scan_bitmap_next_block-counts-lossy-and-ex.patch
- v17-0008-Remove-table_scan_bitmap_next_tuple-parameter-tb.patch
- v17-0009-Make-table_scan_bitmap_next_block-async-friendly.patch
On 4/6/24 02:51, Tomas Vondra wrote:
>
> * The one question I'm somewhat unsure about is why Tom chose to use the
> "wrong" recheck flag in the 2017 commit, when the correct recheck flag
> is readily available. Surely that had a reason, right? But I can't think
> of one ...
>
I've been wondering about this a bit more, so I decided to experiment
and try to construct a case for which the current code prefetches the
wrong blocks, and the patch fixes that. But I haven't been very
successful so far :-(
My understanding was that the current code should do the wrong thing if
I alternate all-visible and not-all-visible pages. This understanding is
not correct, as I learned, because the thing that needs to change is the
recheck flag, not visibility :-( I'm still posting what I tried, perhaps
you will have an idea how to alter it to demonstrate the incorrect
behavior with current master.
The test was very simple:
create table t (a int, b int) with (fillfactor=10);
insert into t select mod((i/22),2), (i/22)
from generate_series(0,1000) s(i);
create index on t (a);
which creates a table with 46 pages, 22 rows per page, column "a"
alternates between 0/1 on pages, column "b" increments on each page (so
"b" identifies page).
and then
delete from t where mod(b,8) = 0;
which deletes tuples on pages 0, 8, 16, 24, 32, 40, so these pages will
need to be prefetched as not-all-visible by this query
explain analyze select count(1) from t where a = 0
when forced to do bitmap heap scan. The other even-numbered pages remain
all-visible. I added a bit of logging into BitmapPrefetch(), but even
with master I get this:
LOG: prefetching block 8 0 current block 6 0
LOG: prefetching block 16 0 current block 14 0
LOG: prefetching block 24 0 current block 22 0
LOG: prefetching block 32 0 current block 30 0
LOG: prefetching block 40 0 current block 38 0
So it prefetches the correct pages (the other value is the recheck flag
for that block from the iterator result).
Turns out (and I realize the comment about the assumption actually
states that, I just failed to understand it) the thing that would have
to differ for the blocks is the recheck flag.
But that can't actually happen because that's set by the AM/opclass and
the built-in ones do essentially this:
.../hash.c: scan->xs_recheck = true;
.../nbtree.c: scan->xs_recheck = false;
gist opclasses (e.g. btree_gist):
/* All cases served by this function are exact */
*recheck = false;
spgist opclasses (e.g. geo_spgist):
/* All tests are exact. */
out->recheck = false;
If there's an opclass that alters the recheck flag, it's well hidden and
I missed it.
Anyway, after this exercise and learning more about the recheck flag, I
think I agree the assumption is unnecessary. It's pretty harmless
because none of the built-in opclasses alters the recheck flag, but the
correct recheck flag is readily available. I'm still a bit puzzled why
the 2017 commit even relied on this assumption, though.
regards
--
Tomas Vondra
EnterpriseDB: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
On 4/6/24 15:40, Melanie Plageman wrote: > On Sat, Apr 06, 2024 at 02:51:45AM +0200, Tomas Vondra wrote: >> >> >> On 4/6/24 01:53, Melanie Plageman wrote: >>> On Fri, Apr 05, 2024 at 04:06:34AM -0400, Melanie Plageman wrote: >>>> On Thu, Apr 04, 2024 at 04:35:45PM +0200, Tomas Vondra wrote: >>>>> On 4/4/24 00:57, Melanie Plageman wrote: >>>>>> On Sun, Mar 31, 2024 at 11:45:51AM -0400, Melanie Plageman wrote: >>>>> I'd focus on the first ~8-9 commits or so for now, we can commit more if >>>>> things go reasonably well. >>>> >>>> Sounds good. I will spend cleanup time on 0010-0013 tomorrow but would >>>> love to know if you agree with the direction before I spend more time. >>> >>> In attached v16, I've split out 0010-0013 into 0011-0017. I think it is >>> much easier to understand. >>> >> >> Anyway, I've attached it as .tgz in order to not confuse cfbot. All the >> review comments are marked with XXX, so grep for that in the patches. >> There's two separate patches - the first one suggests a code change, so >> it was better to not merge that with your code. The second has just a >> couple XXX comments, I'm not sure why I kept it separate. >> >> A couple review comments: >> >> * I think 0001-0009 are 99% ready to. I reworded some of the commit >> messages a bit - I realize it's a bit bold, considering you're native >> speaker and I'm not. If you could check I didn't make it worse, that >> would be great. > > Attached v17 has *only* patches 0001-0009 with these changes. I will > work on applying the remaining patches, addressing feedback, and adding > comments next. > > I have reviewed and incorporated all of your feedback on these patches. > Attached v17 is your exact patches with 1 or 2 *very* slight tweaks to > commit messages (comma splice removal and single word adjustments) as > well as the changes listed below: > > I have changed the following: > > - 0003 added an assert that rs_empty_tuples_pending is 0 on rescan and > endscan > OK > - 0004 (your 0005)-- I followed up with Tom, but for now I have just > removed the XXX and also reworded the message a bit > After the exercise I described a couple minutes ago, I think I'm convinced the assumption is unnecessary and we should use the correct recheck. Not that it'd make any difference in practice, considering none of the opclasses ever changes the recheck. Maybe the most prudent thing would be to skip this commit and maybe leave this for later, but I'm not forcing you to do that if it would mean a lot of disruption for the following patches. > - 0006 (your 0007) fixed up the variable name (you changed valid -> > valid_block but it had gotten changed back) > OK > I have open questions on the following: > > - 0003: should it be SO_NEED_TUPLES and need_tuples (instead of > SO_NEED_TUPLE and need_tuple)? > I think SO_NEED_TUPLES is more accurate, as we need all tuples from the block. But either would work. > - 0009 (your 0010) > - Should I mention in the commit message that we added blockno and > pfblockno in the BitmapHeapScanState only for validation or is that > too specific? > For the commit message I'd say it's too specific, I'd put it in the comment before the struct. > - Should I mention that a future (imminent) commit will remove the > iterators from TableScanDescData and put them in HeapScanDescData? I > imagine folks don't want those there, but it is easier for the > progression of commits to put them there first and then move them > I'd try not to mention future commits as justification too often, if we don't know that the future commit lands shortly after. > - I'm worried this comment is vague and or potentially not totally > correct. Should we remove it? I don't think we have conclusive proof > that this is true. > /* > * Adjusting the prefetch iterator before invoking > * table_scan_bitmap_next_block() keeps prefetch distance higher across > * the parallel workers. > */ > TBH it's not clear to me what "higher across parallel workers" means. But it sure shouldn't claim things that we think may not be correct. I don't have a good idea how to reword it, though. > >> * I'm not sure extra_flags is the right way to pass the flag in 0003. >> The "extra_" name is a bit weird, and no other table AM functions do it >> this way and pass explicit bool flags instead. So my first "review" >> commit does it like that. Do you agree it's better that way? > > Yes. > Cool >> * The one question I'm somewhat unsure about is why Tom chose to use the >> "wrong" recheck flag in the 2017 commit, when the correct recheck flag >> is readily available. Surely that had a reason, right? But I can't think >> of one ... > > See above. > >>> While I was doing that, I realized that I should remove the call to >>> table_rescan() from ExecReScanBitmapHeapScan() and just rely on the new >>> table_rescan_bm() invoked from BitmapHeapNext(). That is done in the >>> attached. >>> >>> 0010-0018 still need comments updated but I focused on getting the split >>> out, reviewable version of them ready. I'll add comments (especially to >>> 0011 table AM functions) tomorrow. I also have to double-check if I >>> should add any asserts for table AMs about having implemented all of the >>> new begin/re/endscan() functions. >>> >> >> I added a couple more comments for those patches (10-12). Chances are >> the split in v16 clarifies some of my questions, but it'll have to wait >> till the morning ... > > Will address this in next mail. > OK, thanks. If think 0001-0008 are ready to go, with some minor tweaks per above (tuple vs. tuples etc.), and the question about the recheck flag. If you can do these tweaks, I'll get that committed today and we can try to get a couple more patches in tomorrow. Sounds reasonable? regards -- Tomas Vondra EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
Melanie Plageman <melanieplageman@gmail.com> writes:
> On Sat, Apr 06, 2024 at 02:51:45AM +0200, Tomas Vondra wrote:
>> * The one question I'm somewhat unsure about is why Tom chose to use the
>> "wrong" recheck flag in the 2017 commit, when the correct recheck flag
>> is readily available. Surely that had a reason, right? But I can't think
>> of one ...
> See above.
Hi, I hadn't been paying attention to this thread, but Melanie pinged
me off-list about this question. I think it's just a flat-out
oversight in 7c70996eb. Looking at the mailing list thread
(particularly [1][2]), it seems that Alexander hadn't really addressed
the question of when to prefetch at all, but just skipped prefetch if
the current page was skippable:
+ /*
+ * If we did not need to fetch the current page,
+ * we probably will not need to fetch the next.
+ */
+ return;
It looks like I noticed that we could check the appropriate VM bits,
but failed to notice that we could easily check the appropriate
recheck flag as well. Feel free to change it.
regards, tom lane
[1] https://www.postgresql.org/message-id/a6434d5c-ed8d-b09c-a7c3-b2d1677e35b3%40postgrespro.ru
[2] https://www.postgresql.org/message-id/5974.1509573988%40sss.pgh.pa.us
On Sat, Apr 06, 2024 at 04:57:51PM +0200, Tomas Vondra wrote: > On 4/6/24 15:40, Melanie Plageman wrote: > > On Sat, Apr 06, 2024 at 02:51:45AM +0200, Tomas Vondra wrote: > >> > >> > >> On 4/6/24 01:53, Melanie Plageman wrote: > >>> On Fri, Apr 05, 2024 at 04:06:34AM -0400, Melanie Plageman wrote: > >>>> On Thu, Apr 04, 2024 at 04:35:45PM +0200, Tomas Vondra wrote: > >>>>> On 4/4/24 00:57, Melanie Plageman wrote: > >>>>>> On Sun, Mar 31, 2024 at 11:45:51AM -0400, Melanie Plageman wrote: > >>>>> I'd focus on the first ~8-9 commits or so for now, we can commit more if > >>>>> things go reasonably well. > >>>> > >>>> Sounds good. I will spend cleanup time on 0010-0013 tomorrow but would > >>>> love to know if you agree with the direction before I spend more time. > >>> > >>> In attached v16, I've split out 0010-0013 into 0011-0017. I think it is > >>> much easier to understand. > >>> > >> > >> Anyway, I've attached it as .tgz in order to not confuse cfbot. All the > >> review comments are marked with XXX, so grep for that in the patches. > >> There's two separate patches - the first one suggests a code change, so > >> it was better to not merge that with your code. The second has just a > >> couple XXX comments, I'm not sure why I kept it separate. > >> > >> A couple review comments: > >> > >> * I think 0001-0009 are 99% ready to. I reworded some of the commit > >> messages a bit - I realize it's a bit bold, considering you're native > >> speaker and I'm not. If you could check I didn't make it worse, that > >> would be great. > > > > Attached v17 has *only* patches 0001-0009 with these changes. I will > > work on applying the remaining patches, addressing feedback, and adding > > comments next. > > > > I have reviewed and incorporated all of your feedback on these patches. > > Attached v17 is your exact patches with 1 or 2 *very* slight tweaks to > > commit messages (comma splice removal and single word adjustments) as > > well as the changes listed below: > > > > I have open questions on the following: > > > > - 0003: should it be SO_NEED_TUPLES and need_tuples (instead of > > SO_NEED_TUPLE and need_tuple)? > > > > I think SO_NEED_TUPLES is more accurate, as we need all tuples from the > block. But either would work. Attached v18 changes it to TUPLES/tuples > > > - 0009 (your 0010) > > - Should I mention in the commit message that we added blockno and > > pfblockno in the BitmapHeapScanState only for validation or is that > > too specific? > > > > For the commit message I'd say it's too specific, I'd put it in the > comment before the struct. It is in the comment for the struct > > - I'm worried this comment is vague and or potentially not totally > > correct. Should we remove it? I don't think we have conclusive proof > > that this is true. > > /* > > * Adjusting the prefetch iterator before invoking > > * table_scan_bitmap_next_block() keeps prefetch distance higher across > > * the parallel workers. > > */ > > > > TBH it's not clear to me what "higher across parallel workers" means. > But it sure shouldn't claim things that we think may not be correct. I > don't have a good idea how to reword it, though. I realized it makes more sense to add a FIXME (I used XXX. I'm not when to use what) with a link to the message where Andres describes why he thinks it is a bug. If we plan on fixing it, it is good to have a record of that. And it makes it easier to put a clear and accurate comment. Done in 0009. > OK, thanks. If think 0001-0008 are ready to go, with some minor tweaks > per above (tuple vs. tuples etc.), and the question about the recheck > flag. If you can do these tweaks, I'll get that committed today and we > can try to get a couple more patches in tomorrow. Sounds good. - Melanie
Attachment
- v18-0001-BitmapHeapScan-begin-scan-after-bitmap-creation.patch
- v18-0002-BitmapHeapScan-postpone-setting-can_skip_fetch.patch
- v18-0003-Push-BitmapHeapScan-skip-fetch-optimization-into.patch
- v18-0004-Use-prefetch-block-recheck-value-to-determine-sk.patch
- v18-0005-Change-BitmapAdjustPrefetchIterator-to-accept-Bl.patch
- v18-0006-BitmapHeapScan-Reduce-scope-of-tbmiterator-local.patch
- v18-0007-table_scan_bitmap_next_block-counts-lossy-and-ex.patch
- v18-0008-Remove-table_scan_bitmap_next_tuple-parameter-tb.patch
- v18-0009-Make-table_scan_bitmap_next_block-async-friendly.patch
On Sat, Apr 06, 2024 at 12:04:23PM -0400, Melanie Plageman wrote: > On Sat, Apr 06, 2024 at 04:57:51PM +0200, Tomas Vondra wrote: > > On 4/6/24 15:40, Melanie Plageman wrote: > > > On Sat, Apr 06, 2024 at 02:51:45AM +0200, Tomas Vondra wrote: > > >> > > >> > > >> On 4/6/24 01:53, Melanie Plageman wrote: > > >>> On Fri, Apr 05, 2024 at 04:06:34AM -0400, Melanie Plageman wrote: > > >>>> On Thu, Apr 04, 2024 at 04:35:45PM +0200, Tomas Vondra wrote: > > >>>>> On 4/4/24 00:57, Melanie Plageman wrote: > > >>>>>> On Sun, Mar 31, 2024 at 11:45:51AM -0400, Melanie Plageman wrote: > > >>>>> I'd focus on the first ~8-9 commits or so for now, we can commit more if > > >>>>> things go reasonably well. > > >>>> > > >>>> Sounds good. I will spend cleanup time on 0010-0013 tomorrow but would > > >>>> love to know if you agree with the direction before I spend more time. > > >>> > > >>> In attached v16, I've split out 0010-0013 into 0011-0017. I think it is > > >>> much easier to understand. > > >>> > > >> > > >> Anyway, I've attached it as .tgz in order to not confuse cfbot. All the > > >> review comments are marked with XXX, so grep for that in the patches. > > >> There's two separate patches - the first one suggests a code change, so > > >> it was better to not merge that with your code. The second has just a > > >> couple XXX comments, I'm not sure why I kept it separate. > > >> > > >> A couple review comments: > > >> > > >> * I think 0001-0009 are 99% ready to. I reworded some of the commit > > >> messages a bit - I realize it's a bit bold, considering you're native > > >> speaker and I'm not. If you could check I didn't make it worse, that > > >> would be great. > > > > > > Attached v17 has *only* patches 0001-0009 with these changes. I will > > > work on applying the remaining patches, addressing feedback, and adding > > > comments next. > > > > > > I have reviewed and incorporated all of your feedback on these patches. > > > Attached v17 is your exact patches with 1 or 2 *very* slight tweaks to > > > commit messages (comma splice removal and single word adjustments) as > > > well as the changes listed below: > > > > > > I have open questions on the following: > > > > > > - 0003: should it be SO_NEED_TUPLES and need_tuples (instead of > > > SO_NEED_TUPLE and need_tuple)? > > > > > > > I think SO_NEED_TUPLES is more accurate, as we need all tuples from the > > block. But either would work. > > Attached v18 changes it to TUPLES/tuples > > > > > > - 0009 (your 0010) > > > - Should I mention in the commit message that we added blockno and > > > pfblockno in the BitmapHeapScanState only for validation or is that > > > too specific? > > > > > > > For the commit message I'd say it's too specific, I'd put it in the > > comment before the struct. > > It is in the comment for the struct > > > > - I'm worried this comment is vague and or potentially not totally > > > correct. Should we remove it? I don't think we have conclusive proof > > > that this is true. > > > /* > > > * Adjusting the prefetch iterator before invoking > > > * table_scan_bitmap_next_block() keeps prefetch distance higher across > > > * the parallel workers. > > > */ > > > > > > > TBH it's not clear to me what "higher across parallel workers" means. > > But it sure shouldn't claim things that we think may not be correct. I > > don't have a good idea how to reword it, though. > > I realized it makes more sense to add a FIXME (I used XXX. I'm not when > to use what) with a link to the message where Andres describes why he > thinks it is a bug. If we plan on fixing it, it is good to have a record > of that. And it makes it easier to put a clear and accurate comment. > Done in 0009. > > > OK, thanks. If think 0001-0008 are ready to go, with some minor tweaks > > per above (tuple vs. tuples etc.), and the question about the recheck > > flag. If you can do these tweaks, I'll get that committed today and we > > can try to get a couple more patches in tomorrow. Attached v19 rebases the rest of the commits from v17 over the first nine patches from v18. All patches 0001-0009 are unchanged from v18. I have made updates and done cleanup on 0010-0021. - Melanie
Attachment
- v19-0018-Lift-and-shift-BitmapHeapScan-prefetch-funcs-to-.patch
- v19-0001-BitmapHeapScan-begin-scan-after-bitmap-creation.patch
- v19-0002-BitmapHeapScan-postpone-setting-can_skip_fetch.patch
- v19-0003-Push-BitmapHeapScan-skip-fetch-optimization-into.patch
- v19-0004-Use-prefetch-block-recheck-value-to-determine-sk.patch
- v19-0005-Change-BitmapAdjustPrefetchIterator-to-accept-Bl.patch
- v19-0006-BitmapHeapScan-Reduce-scope-of-tbmiterator-local.patch
- v19-0007-table_scan_bitmap_next_block-counts-lossy-and-ex.patch
- v19-0008-Remove-table_scan_bitmap_next_tuple-parameter-tb.patch
- v19-0009-Make-table_scan_bitmap_next_block-async-friendly.patch
- v19-0010-Add-UnifiedTBMIterator-common-interface-for-TBMI.patch
- v19-0011-BitmapHeapScan-initialize-some-prefetch-state-el.patch
- v19-0012-BitmapHeapScan-Use-UnifiedTBMIterator.patch
- v19-0013-BitmapHeapScan-rescan-in-BitmapHeapNext.patch
- v19-0014-Add-table-AM-callbacks-for-Bitmap-Table-Scans.patch
- v19-0015-Add-BitmapHeapScanDesc-and-scan-functions.patch
- v19-0016-BitmapHeapScan-manage-iteration-in-heap-BM-funct.patch
- v19-0017-Move-BitmapHeapScan-current-block-iterator-to-Bi.patch
- v19-0019-Push-BitmapHeapScan-prefetch-code-into-heap-AM.patch
- v19-0020-Move-BitmapHeapScan-initialization-to-helper.patch
- v19-0021-Remove-table_scan_bitmap_next_block.patch
On 4/6/24 23:34, Melanie Plageman wrote: > ... >> >> I realized it makes more sense to add a FIXME (I used XXX. I'm not when >> to use what) with a link to the message where Andres describes why he >> thinks it is a bug. If we plan on fixing it, it is good to have a record >> of that. And it makes it easier to put a clear and accurate comment. >> Done in 0009. >> >>> OK, thanks. If think 0001-0008 are ready to go, with some minor tweaks >>> per above (tuple vs. tuples etc.), and the question about the recheck >>> flag. If you can do these tweaks, I'll get that committed today and we >>> can try to get a couple more patches in tomorrow. > > Attached v19 rebases the rest of the commits from v17 over the first > nine patches from v18. All patches 0001-0009 are unchanged from v18. I > have made updates and done cleanup on 0010-0021. > I've pushed 0001-0005, I'll get back to this tomorrow and see how much more we can get in for v17. What bothers me on 0006-0008 is that the justification in the commit messages is "future commit will do something". I think it's fine to have a separate "prepareatory" patches (I really like how you structured the patches this way), but it'd be good to have them right before that "future" commit - I'd like not to have one in v17 and then the "future commit" in v18, because that's annoying complication for backpatching, (and probably also when implementing the AM?) etc. AFAICS for v19, the "future commit" for all three patches (0006-0008) is 0012, which introduces the unified iterator. Is that correct? Also, for 0008 I'm not sure we could even split it between v17 and v18, because even if heapam did not use the iterator, what if some other AM uses it? Without 0012 it'd be a problem for the AM, no? Would it make sense to move 0009 before these three patches? That seems like a meaningful change on it's own, right? FWIW I don't think it's very likely I'll commit the UnifiedTBMIterator stuff. I do agree with the idea in general, but I think I'd need more time to think about the details. Sorry about that ... regards -- Tomas Vondra EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On Sun, Apr 07, 2024 at 02:27:43AM +0200, Tomas Vondra wrote:
> On 4/6/24 23:34, Melanie Plageman wrote:
> > ...
> >>
> >> I realized it makes more sense to add a FIXME (I used XXX. I'm not when
> >> to use what) with a link to the message where Andres describes why he
> >> thinks it is a bug. If we plan on fixing it, it is good to have a record
> >> of that. And it makes it easier to put a clear and accurate comment.
> >> Done in 0009.
> >>
> >>> OK, thanks. If think 0001-0008 are ready to go, with some minor tweaks
> >>> per above (tuple vs. tuples etc.), and the question about the recheck
> >>> flag. If you can do these tweaks, I'll get that committed today and we
> >>> can try to get a couple more patches in tomorrow.
> >
> > Attached v19 rebases the rest of the commits from v17 over the first
> > nine patches from v18. All patches 0001-0009 are unchanged from v18. I
> > have made updates and done cleanup on 0010-0021.
> >
>
> I've pushed 0001-0005, I'll get back to this tomorrow and see how much
> more we can get in for v17.
Thanks! I thought about it a bit more, and I got worried about the
Assert(scan->rs_empty_tuples_pending == 0);
in heap_rescan() and heap_endscan().
I was worried if we don't complete the scan it could end up tripping
incorrectly.
I tried to come up with a query which didn't end up emitting all of the
tuples on the page (using a LIMIT clause), but I struggled to come up
with an example that qualified for the skip fetch optimization and also
returned before completing the scan.
I could work a bit harder tomorrow to try and come up with something.
However, I think it might be safer to just change these to:
scan->rs_empty_tuples_pending = 0
> What bothers me on 0006-0008 is that the justification in the commit
> messages is "future commit will do something". I think it's fine to have
> a separate "prepareatory" patches (I really like how you structured the
> patches this way), but it'd be good to have them right before that
> "future" commit - I'd like not to have one in v17 and then the "future
> commit" in v18, because that's annoying complication for backpatching,
> (and probably also when implementing the AM?) etc.
Yes, I was thinking about this also.
> AFAICS for v19, the "future commit" for all three patches (0006-0008) is
> 0012, which introduces the unified iterator. Is that correct?
Actually, those patches (v19 0006-0008) were required for v19 0009,
which is why I put them directly before it. 0009 eliminates use of the
TBMIterateResult for control flow in BitmapHeapNext().
I've rephrased the commit messages to not mention future commits and
instead focus on what the changes in the commit are enabling.
v19-0006 actually squashed very easily with v19-0009 and is actually
probably better that way. It is still easy to understand IMO.
In v20, I've attached just the functionality from v19 0006-0009 but in
three patches instead of four.
> Also, for 0008 I'm not sure we could even split it between v17 and v18,
> because even if heapam did not use the iterator, what if some other AM
> uses it? Without 0012 it'd be a problem for the AM, no?
The iterators in the TableScanDescData were introduced in v19-0009. It
is okay for other AMs to use it. In fact, they will want to use it. It
is still initialized and set up in BitmapHeapNext(). They would just
need to call tbm_iterate()/tbm_shared_iterate() on it.
As for how table AMs will cope without the TBMIterateResult passed to
table_scan_bitmap_next_tuple() (which is what v19 0008 did): they can
save the location of the tuples to be scanned somewhere in their scan
descriptor. Heap AM already did this and actually didn't use the
TBMIterateResult at all.
> Would it make sense to move 0009 before these three patches? That seems
> like a meaningful change on it's own, right?
Since v19 0009 requires these patches, I don't think we could do that.
I think up to and including 0009 would be an improvement in clarity and
function.
As for all the patches after 0009, I've dropped them from this version.
We are out of time, and they need more thought.
After we decided not to pursue streaming bitmapheapscan for 17, I wanted
to make sure we removed the prefetch code table AM violation -- since we
weren't deleting that code. So what started out as me looking for a way
to clean up one commit ended up becoming a much larger project. Sorry
about that last minute code explosion! I do think there is a way to do
it right and make it nice. Also that violation would be gone if we
figure out how to get streaming bitmapheapscan behaving correctly.
So, there's just more motivation to make streaming bitmapheapscan
awesome for 18!
Given all that, I've only included the three patches I think we are
considering (former v19 0006-0008). They are largely the same as you saw
them last except for squashing the two commits I mentioned above and
updating all of the commit messages.
> FWIW I don't think it's very likely I'll commit the UnifiedTBMIterator
> stuff. I do agree with the idea in general, but I think I'd need more
> time to think about the details. Sorry about that ...
Yes, that makes total sense. I 100% agree.
I do think the UnifiedTBMIterator (maybe the name is not good, though)
is a good way to simplify the BitmapHeapScan code and is applicable to
any future TIDBitmap user with both a parallel and serial
implementation. So, there's a nice, small patch I can register for July.
Thanks again for taking time to work on this!
- Melanie
Attachment
On 4/7/24 06:17, Melanie Plageman wrote: > On Sun, Apr 07, 2024 at 02:27:43AM +0200, Tomas Vondra wrote: >> On 4/6/24 23:34, Melanie Plageman wrote: >>> ... >>>> >>>> I realized it makes more sense to add a FIXME (I used XXX. I'm not when >>>> to use what) with a link to the message where Andres describes why he >>>> thinks it is a bug. If we plan on fixing it, it is good to have a record >>>> of that. And it makes it easier to put a clear and accurate comment. >>>> Done in 0009. >>>> >>>>> OK, thanks. If think 0001-0008 are ready to go, with some minor tweaks >>>>> per above (tuple vs. tuples etc.), and the question about the recheck >>>>> flag. If you can do these tweaks, I'll get that committed today and we >>>>> can try to get a couple more patches in tomorrow. >>> >>> Attached v19 rebases the rest of the commits from v17 over the first >>> nine patches from v18. All patches 0001-0009 are unchanged from v18. I >>> have made updates and done cleanup on 0010-0021. >>> >> >> I've pushed 0001-0005, I'll get back to this tomorrow and see how much >> more we can get in for v17. > > Thanks! I thought about it a bit more, and I got worried about the > > Assert(scan->rs_empty_tuples_pending == 0); > > in heap_rescan() and heap_endscan(). > > I was worried if we don't complete the scan it could end up tripping > incorrectly. > > I tried to come up with a query which didn't end up emitting all of the > tuples on the page (using a LIMIT clause), but I struggled to come up > with an example that qualified for the skip fetch optimization and also > returned before completing the scan. > > I could work a bit harder tomorrow to try and come up with something. > However, I think it might be safer to just change these to: > > scan->rs_empty_tuples_pending = 0 > Hmmm, good point. I haven't tried, but wouldn't something like "SELECT 1 FROM t WHERE column = X LIMIT 1" do the trick? Probably in a join, as a correlated subquery? It seemed OK to me and the buildfarm did not turn red, so I'd leave this until after the code freeze. >> What bothers me on 0006-0008 is that the justification in the commit >> messages is "future commit will do something". I think it's fine to have >> a separate "prepareatory" patches (I really like how you structured the >> patches this way), but it'd be good to have them right before that >> "future" commit - I'd like not to have one in v17 and then the "future >> commit" in v18, because that's annoying complication for backpatching, >> (and probably also when implementing the AM?) etc. > > Yes, I was thinking about this also. > Good we're on the same page. >> AFAICS for v19, the "future commit" for all three patches (0006-0008) is >> 0012, which introduces the unified iterator. Is that correct? > > Actually, those patches (v19 0006-0008) were required for v19 0009, > which is why I put them directly before it. 0009 eliminates use of the > TBMIterateResult for control flow in BitmapHeapNext(). > Ah, OK. Thanks for the clarification. > I've rephrased the commit messages to not mention future commits and > instead focus on what the changes in the commit are enabling. > > v19-0006 actually squashed very easily with v19-0009 and is actually > probably better that way. It is still easy to understand IMO. > > In v20, I've attached just the functionality from v19 0006-0009 but in > three patches instead of four. > Good. I'll take a look today. >> Also, for 0008 I'm not sure we could even split it between v17 and v18, >> because even if heapam did not use the iterator, what if some other AM >> uses it? Without 0012 it'd be a problem for the AM, no? > > The iterators in the TableScanDescData were introduced in v19-0009. It > is okay for other AMs to use it. In fact, they will want to use it. It > is still initialized and set up in BitmapHeapNext(). They would just > need to call tbm_iterate()/tbm_shared_iterate() on it. > > As for how table AMs will cope without the TBMIterateResult passed to > table_scan_bitmap_next_tuple() (which is what v19 0008 did): they can > save the location of the tuples to be scanned somewhere in their scan > descriptor. Heap AM already did this and actually didn't use the > TBMIterateResult at all. > The reason I feel a bit uneasy about putting this in TableScanDescData is I see that struct as a "description of the scan" (~input parameters defining what the scan should do), while for runtime state we have ScanState in execnodes.h. But maybe I'm wrong - I see we have similar runtime state in the other scan descriptors (like xs_itup/xs_hitup, kill prior tuple in index scans etc.). >> Would it make sense to move 0009 before these three patches? That seems >> like a meaningful change on it's own, right? > > Since v19 0009 requires these patches, I don't think we could do that. > I think up to and including 0009 would be an improvement in clarity and > function. Right, thanks for the correction. > > As for all the patches after 0009, I've dropped them from this version. > We are out of time, and they need more thought. > +1 > After we decided not to pursue streaming bitmapheapscan for 17, I wanted > to make sure we removed the prefetch code table AM violation -- since we > weren't deleting that code. So what started out as me looking for a way > to clean up one commit ended up becoming a much larger project. Sorry > about that last minute code explosion! I do think there is a way to do > it right and make it nice. Also that violation would be gone if we > figure out how to get streaming bitmapheapscan behaving correctly. > > So, there's just more motivation to make streaming bitmapheapscan > awesome for 18! > > Given all that, I've only included the three patches I think we are > considering (former v19 0006-0008). They are largely the same as you saw > them last except for squashing the two commits I mentioned above and > updating all of the commit messages. > Right. I do think the patches make sensible changes in principle, but the later parts need more refinement so let's not rush it. >> FWIW I don't think it's very likely I'll commit the UnifiedTBMIterator >> stuff. I do agree with the idea in general, but I think I'd need more >> time to think about the details. Sorry about that ... > > Yes, that makes total sense. I 100% agree. > > I do think the UnifiedTBMIterator (maybe the name is not good, though) > is a good way to simplify the BitmapHeapScan code and is applicable to > any future TIDBitmap user with both a parallel and serial > implementation. So, there's a nice, small patch I can register for July. > > Thanks again for taking time to work on this! > Yeah, The name seems a bit awkward ... but I don't have a better idea. I like how it "isolates" the complexity and makes the BHS code simpler and easier to understand. regards -- Tomas Vondra EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On Sun, Apr 7, 2024 at 7:38 AM Tomas Vondra <tomas.vondra@enterprisedb.com> wrote: > > On 4/7/24 06:17, Melanie Plageman wrote: > >> What bothers me on 0006-0008 is that the justification in the commit > >> messages is "future commit will do something". I think it's fine to have > >> a separate "prepareatory" patches (I really like how you structured the > >> patches this way), but it'd be good to have them right before that > >> "future" commit - I'd like not to have one in v17 and then the "future > >> commit" in v18, because that's annoying complication for backpatching, > >> (and probably also when implementing the AM?) etc. > > > > Yes, I was thinking about this also. > > > > Good we're on the same page. Having thought about this some more I think we need to stop here for 17. v20-0001 and v20-0002 both make changes to the table AM API that seem bizarre and unjustifiable without the other changes. Like, here we changed all your parameters because someday we are going to do something! You're welcome! Also, the iterators in the TableScanDescData might be something I could live with in the source code for a couple months before we make the rest of the changes in July+. But, adding them does push the TableScanDescData->rs_parallel member into the second cacheline, which will be true in versions of Postgres people are using for years. I didn't perf test, but seems bad. So, yes, unfortunately, I think we should pick up on the BHS saga in a few months. Or, actually, we should start focusing on that parallel BHS + 0 readahead bug and whether or not we are going to fix it. Sorry for the about-face. - Melanie
On 4/7/24 15:11, Melanie Plageman wrote: > On Sun, Apr 7, 2024 at 7:38 AM Tomas Vondra > <tomas.vondra@enterprisedb.com> wrote: >> >> On 4/7/24 06:17, Melanie Plageman wrote: >>>> What bothers me on 0006-0008 is that the justification in the commit >>>> messages is "future commit will do something". I think it's fine to have >>>> a separate "prepareatory" patches (I really like how you structured the >>>> patches this way), but it'd be good to have them right before that >>>> "future" commit - I'd like not to have one in v17 and then the "future >>>> commit" in v18, because that's annoying complication for backpatching, >>>> (and probably also when implementing the AM?) etc. >>> >>> Yes, I was thinking about this also. >>> >> >> Good we're on the same page. > > Having thought about this some more I think we need to stop here for > 17. v20-0001 and v20-0002 both make changes to the table AM API that > seem bizarre and unjustifiable without the other changes. Like, here > we changed all your parameters because someday we are going to do > something! You're welcome! > OK, I think that's essentially the "temporary breakage" that should not span multiple releases, I mentioned ~yesterday. I appreciate you're careful about this. > Also, the iterators in the TableScanDescData might be something I > could live with in the source code for a couple months before we make > the rest of the changes in July+. But, adding them does push the > TableScanDescData->rs_parallel member into the second cacheline, which > will be true in versions of Postgres people are using for years. I > didn't perf test, but seems bad. > I haven't though about how it affects cachelines, TBH. I'd expect it to have minimal impact, because while it makes this struct larger it should make some other struct (used in essentially the same places) smaller. So I'd guess this to be a zero sum game, but perhaps I'm wrong. For me the main question was "Is this the right place for this, even if it's only temporary?" > So, yes, unfortunately, I think we should pick up on the BHS saga in a > few months. Or, actually, we should start focusing on that parallel > BHS + 0 readahead bug and whether or not we are going to fix it. > Yes, the July CF is a good time to focus on this, early in the cycle. > Sorry for the about-face. > No problem. I very much prefer this over something that may not be quite ready yet. regards -- Tomas Vondra EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On Sun, Apr 7, 2024 at 7:38 AM Tomas Vondra <tomas.vondra@enterprisedb.com> wrote: > > > > On 4/7/24 06:17, Melanie Plageman wrote: > > On Sun, Apr 07, 2024 at 02:27:43AM +0200, Tomas Vondra wrote: > >> On 4/6/24 23:34, Melanie Plageman wrote: > >>> ... > >>>> > >>>> I realized it makes more sense to add a FIXME (I used XXX. I'm not when > >>>> to use what) with a link to the message where Andres describes why he > >>>> thinks it is a bug. If we plan on fixing it, it is good to have a record > >>>> of that. And it makes it easier to put a clear and accurate comment. > >>>> Done in 0009. > >>>> > >>>>> OK, thanks. If think 0001-0008 are ready to go, with some minor tweaks > >>>>> per above (tuple vs. tuples etc.), and the question about the recheck > >>>>> flag. If you can do these tweaks, I'll get that committed today and we > >>>>> can try to get a couple more patches in tomorrow. > >>> > >>> Attached v19 rebases the rest of the commits from v17 over the first > >>> nine patches from v18. All patches 0001-0009 are unchanged from v18. I > >>> have made updates and done cleanup on 0010-0021. > >>> > >> > >> I've pushed 0001-0005, I'll get back to this tomorrow and see how much > >> more we can get in for v17. > > > > Thanks! I thought about it a bit more, and I got worried about the > > > > Assert(scan->rs_empty_tuples_pending == 0); > > > > in heap_rescan() and heap_endscan(). > > > > I was worried if we don't complete the scan it could end up tripping > > incorrectly. > > > > I tried to come up with a query which didn't end up emitting all of the > > tuples on the page (using a LIMIT clause), but I struggled to come up > > with an example that qualified for the skip fetch optimization and also > > returned before completing the scan. > > > > I could work a bit harder tomorrow to try and come up with something. > > However, I think it might be safer to just change these to: > > > > scan->rs_empty_tuples_pending = 0 > > > > Hmmm, good point. I haven't tried, but wouldn't something like "SELECT 1 > FROM t WHERE column = X LIMIT 1" do the trick? Probably in a join, as a > correlated subquery? Unfortunately (or fortunately, I guess) that exact thing won't work because even constant values in the target list disqualify it for the skip fetch optimization. Being a bit too lazy to look at planner code this morning, I removed the target list requirement like this: - need_tuples = (node->ss.ps.plan->qual != NIL || - node->ss.ps.plan->targetlist != NIL); + need_tuples = (node->ss.ps.plan->qual != NIL); And can easily trip the assert with this: create table foo (a int); insert into foo select i from generate_series(1,10)i; create index on foo(a); vacuum foo; select 1 from (select 2 from foo limit 3); Anyway, I don't know if we could find a query that does actually hit this. The only bitmap heap scan queries in the regress suite that meet the BitmapHeapScanState->ss.ps.plan->targetlist == NIL condition are aggregates (all are count(*)). I'll dig a bit more later, but do you think this is worth adding an open item for? Even though I don't have a repro yet? - Melanie
On Sun, Apr 7, 2024 at 10:10 AM Tomas Vondra
<tomas.vondra@enterprisedb.com> wrote:
>
> On 4/7/24 15:11, Melanie Plageman wrote:
>
> > Also, the iterators in the TableScanDescData might be something I
> > could live with in the source code for a couple months before we make
> > the rest of the changes in July+. But, adding them does push the
> > TableScanDescData->rs_parallel member into the second cacheline, which
> > will be true in versions of Postgres people are using for years. I
> > didn't perf test, but seems bad.
> >
>
> I haven't though about how it affects cachelines, TBH. I'd expect it to
> have minimal impact, because while it makes this struct larger it should
> make some other struct (used in essentially the same places) smaller. So
> I'd guess this to be a zero sum game, but perhaps I'm wrong.
Yea, to be honest, I didn't do extensive analysis. I just ran `pahole
-C TableScanDescData` with the patch and on master and further
convinced myself the whole thing was a bad idea.
> For me the main question was "Is this the right place for this, even if
> it's only temporary?"
Yep.
> > So, yes, unfortunately, I think we should pick up on the BHS saga in a
> > few months. Or, actually, we should start focusing on that parallel
> > BHS + 0 readahead bug and whether or not we are going to fix it.
> >
>
> Yes, the July CF is a good time to focus on this, early in the cycle.
I've pushed the entry to the next CF. Even though some of the patches
were committed, I think it makes more sense to leave the CF item open
until at least the prefetch table AM violation is removed. Then we
could make a new CF entry for the streaming read user.
When I get a chance, I'll post a full set of the outstanding patches
to this thread -- including the streaming read-related refactoring and
user.
Oh, and, side note, in my previous email [1] about the
empty_tuples_pending assert, I should mention that you need
set enable_seqscan = off
set enable_indexscan = off
to force bitmpaheapscan and get the plan for my fake repro.
- Melanie
[1] https://www.postgresql.org/message-id/CAAKRu_Zg8Bj66OZD46Jd-ksh02OGrPR8z0JLPQqEZNEHASi6uw%40mail.gmail.com
On 4/7/24 16:24, Melanie Plageman wrote: > On Sun, Apr 7, 2024 at 7:38 AM Tomas Vondra > <tomas.vondra@enterprisedb.com> wrote: >> >> >> >> On 4/7/24 06:17, Melanie Plageman wrote: >>> On Sun, Apr 07, 2024 at 02:27:43AM +0200, Tomas Vondra wrote: >>>> On 4/6/24 23:34, Melanie Plageman wrote: >>>>> ... >>>>>> >>>>>> I realized it makes more sense to add a FIXME (I used XXX. I'm not when >>>>>> to use what) with a link to the message where Andres describes why he >>>>>> thinks it is a bug. If we plan on fixing it, it is good to have a record >>>>>> of that. And it makes it easier to put a clear and accurate comment. >>>>>> Done in 0009. >>>>>> >>>>>>> OK, thanks. If think 0001-0008 are ready to go, with some minor tweaks >>>>>>> per above (tuple vs. tuples etc.), and the question about the recheck >>>>>>> flag. If you can do these tweaks, I'll get that committed today and we >>>>>>> can try to get a couple more patches in tomorrow. >>>>> >>>>> Attached v19 rebases the rest of the commits from v17 over the first >>>>> nine patches from v18. All patches 0001-0009 are unchanged from v18. I >>>>> have made updates and done cleanup on 0010-0021. >>>>> >>>> >>>> I've pushed 0001-0005, I'll get back to this tomorrow and see how much >>>> more we can get in for v17. >>> >>> Thanks! I thought about it a bit more, and I got worried about the >>> >>> Assert(scan->rs_empty_tuples_pending == 0); >>> >>> in heap_rescan() and heap_endscan(). >>> >>> I was worried if we don't complete the scan it could end up tripping >>> incorrectly. >>> >>> I tried to come up with a query which didn't end up emitting all of the >>> tuples on the page (using a LIMIT clause), but I struggled to come up >>> with an example that qualified for the skip fetch optimization and also >>> returned before completing the scan. >>> >>> I could work a bit harder tomorrow to try and come up with something. >>> However, I think it might be safer to just change these to: >>> >>> scan->rs_empty_tuples_pending = 0 >>> >> >> Hmmm, good point. I haven't tried, but wouldn't something like "SELECT 1 >> FROM t WHERE column = X LIMIT 1" do the trick? Probably in a join, as a >> correlated subquery? > > Unfortunately (or fortunately, I guess) that exact thing won't work > because even constant values in the target list disqualify it for the > skip fetch optimization. > > Being a bit too lazy to look at planner code this morning, I removed > the target list requirement like this: > > - need_tuples = (node->ss.ps.plan->qual != NIL || > - node->ss.ps.plan->targetlist != NIL); > + need_tuples = (node->ss.ps.plan->qual != NIL); > > And can easily trip the assert with this: > > create table foo (a int); > insert into foo select i from generate_series(1,10)i; > create index on foo(a); > vacuum foo; > select 1 from (select 2 from foo limit 3); > > Anyway, I don't know if we could find a query that does actually hit > this. The only bitmap heap scan queries in the regress suite that meet > the > BitmapHeapScanState->ss.ps.plan->targetlist == NIL > condition are aggregates (all are count(*)). > > I'll dig a bit more later, but do you think this is worth adding an > open item for? Even though I don't have a repro yet? > Try this: create table t (a int, b int) with (fillfactor=10); insert into t select mod((i/22),2), (i/22) from generate_series(0,1000) S(i); create index on t(a); vacuum analyze t; set enable_indexonlyscan = off; set enable_seqscan = off; explain (analyze, verbose) select 1 from (values (1)) s(x) where exists (select * from t where a = x); KABOOM! #2 0x000078a16ac5fafe in __GI_raise (sig=sig@entry=6) at ../sysdeps/posix/raise.c:26 #3 0x000078a16ac4887f in __GI_abort () at abort.c:79 #4 0x0000000000bb2c5a in ExceptionalCondition (conditionName=0xc42ba8 "scan->rs_empty_tuples_pending == 0", fileName=0xc429c8 "heapam.c", lineNumber=1090) at assert.c:66 #5 0x00000000004f68bb in heap_endscan (sscan=0x19af3a0) at heapam.c:1090 #6 0x000000000077a94c in table_endscan (scan=0x19af3a0) at ../../../src/include/access/tableam.h:1001 So yeah, this assert is not quite correct. It's not breaking anything at the moment, so we can fix it now or add it as an open item. regards -- Tomas Vondra EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On Sun, Apr 7, 2024 at 10:42 AM Tomas Vondra <tomas.vondra@enterprisedb.com> wrote: > > > > On 4/7/24 16:24, Melanie Plageman wrote: > >>> Thanks! I thought about it a bit more, and I got worried about the > >>> > >>> Assert(scan->rs_empty_tuples_pending == 0); > >>> > >>> in heap_rescan() and heap_endscan(). > >>> > >>> I was worried if we don't complete the scan it could end up tripping > >>> incorrectly. > >>> > >>> I tried to come up with a query which didn't end up emitting all of the > >>> tuples on the page (using a LIMIT clause), but I struggled to come up > >>> with an example that qualified for the skip fetch optimization and also > >>> returned before completing the scan. > >>> > >>> I could work a bit harder tomorrow to try and come up with something. > >>> However, I think it might be safer to just change these to: > >>> > >>> scan->rs_empty_tuples_pending = 0 > >>> > >> > >> Hmmm, good point. I haven't tried, but wouldn't something like "SELECT 1 > >> FROM t WHERE column = X LIMIT 1" do the trick? Probably in a join, as a > >> correlated subquery? > > > > Unfortunately (or fortunately, I guess) that exact thing won't work > > because even constant values in the target list disqualify it for the > > skip fetch optimization. > > > > Being a bit too lazy to look at planner code this morning, I removed > > the target list requirement like this: > > > > - need_tuples = (node->ss.ps.plan->qual != NIL || > > - node->ss.ps.plan->targetlist != NIL); > > + need_tuples = (node->ss.ps.plan->qual != NIL); > > > > And can easily trip the assert with this: > > > > create table foo (a int); > > insert into foo select i from generate_series(1,10)i; > > create index on foo(a); > > vacuum foo; > > select 1 from (select 2 from foo limit 3); > > > > Anyway, I don't know if we could find a query that does actually hit > > this. The only bitmap heap scan queries in the regress suite that meet > > the > > BitmapHeapScanState->ss.ps.plan->targetlist == NIL > > condition are aggregates (all are count(*)). > > > > I'll dig a bit more later, but do you think this is worth adding an > > open item for? Even though I don't have a repro yet? > > > > Try this: > > create table t (a int, b int) with (fillfactor=10); > insert into t select mod((i/22),2), (i/22) from generate_series(0,1000) > S(i); > create index on t(a); > vacuum analyze t; > > set enable_indexonlyscan = off; > set enable_seqscan = off; > explain (analyze, verbose) select 1 from (values (1)) s(x) where exists > (select * from t where a = x); > > KABOOM! Ooo fancy query! Good job. > #2 0x000078a16ac5fafe in __GI_raise (sig=sig@entry=6) at > ../sysdeps/posix/raise.c:26 > #3 0x000078a16ac4887f in __GI_abort () at abort.c:79 > #4 0x0000000000bb2c5a in ExceptionalCondition (conditionName=0xc42ba8 > "scan->rs_empty_tuples_pending == 0", fileName=0xc429c8 "heapam.c", > lineNumber=1090) at assert.c:66 > #5 0x00000000004f68bb in heap_endscan (sscan=0x19af3a0) at heapam.c:1090 > #6 0x000000000077a94c in table_endscan (scan=0x19af3a0) at > ../../../src/include/access/tableam.h:1001 > > So yeah, this assert is not quite correct. It's not breaking anything at > the moment, so we can fix it now or add it as an open item. I've added an open item [1], because what's one open item when you can have two? (me) - Melanie [1] https://wiki.postgresql.org/wiki/PostgreSQL_17_Open_Items#Open_Issues
On Sun, Apr 7, 2024 at 10:42 PM Tomas Vondra <tomas.vondra@enterprisedb.com> wrote:
create table t (a int, b int) with (fillfactor=10);
insert into t select mod((i/22),2), (i/22) from generate_series(0,1000)
S(i);
create index on t(a);
vacuum analyze t;
set enable_indexonlyscan = off;
set enable_seqscan = off;
explain (analyze, verbose) select 1 from (values (1)) s(x) where exists
(select * from t where a = x);
KABOOM!
FWIW, it seems to me that this assert could be triggered in cases where,
during a join, not all inner tuples need to be scanned before skipping to
next outer tuple. This can happen for 'single_match' or anti-join.
The query provided by Tomas is an example of 'single_match' case. Here
is a query for anti-join that can also trigger this assert.
explain (analyze, verbose)
select t1.a from t t1 left join t t2 on t2.a = 1 where t2.a is null;
server closed the connection unexpectedly
Thanks
Richard
during a join, not all inner tuples need to be scanned before skipping to
next outer tuple. This can happen for 'single_match' or anti-join.
The query provided by Tomas is an example of 'single_match' case. Here
is a query for anti-join that can also trigger this assert.
explain (analyze, verbose)
select t1.a from t t1 left join t t2 on t2.a = 1 where t2.a is null;
server closed the connection unexpectedly
Thanks
Richard
On Sun, Apr 07, 2024 at 10:54:56AM -0400, Melanie Plageman wrote: > I've added an open item [1], because what's one open item when you can > have two? (me) And this is still an open item as of today. What's the plan to move forward here? -- Michael
Attachment
On 4/18/24 09:10, Michael Paquier wrote: > On Sun, Apr 07, 2024 at 10:54:56AM -0400, Melanie Plageman wrote: >> I've added an open item [1], because what's one open item when you can >> have two? (me) > > And this is still an open item as of today. What's the plan to move > forward here? AFAIK the plan is to replace the asserts with actually resetting the rs_empty_tuples_pending field to 0, as suggested by Melanie a week ago. I assume she was busy with the post-freeze AM reworks last week, so this was on a back burner. regards -- Tomas Vondra EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On Thu, Apr 18, 2024 at 5:39 AM Tomas Vondra <tomas.vondra@enterprisedb.com> wrote: > > On 4/18/24 09:10, Michael Paquier wrote: > > On Sun, Apr 07, 2024 at 10:54:56AM -0400, Melanie Plageman wrote: > >> I've added an open item [1], because what's one open item when you can > >> have two? (me) > > > > And this is still an open item as of today. What's the plan to move > > forward here? > > AFAIK the plan is to replace the asserts with actually resetting the > rs_empty_tuples_pending field to 0, as suggested by Melanie a week ago. > I assume she was busy with the post-freeze AM reworks last week, so this > was on a back burner. yep, sorry. Also I took a few days off. I'm just catching up today. I want to pop in one of Richard or Tomas' examples as a test, since it seems like it would add some coverage. I will have a patch soon. - Melanie
On Mon, Apr 22, 2024 at 1:01 PM Melanie Plageman <melanieplageman@gmail.com> wrote: > > On Thu, Apr 18, 2024 at 5:39 AM Tomas Vondra > <tomas.vondra@enterprisedb.com> wrote: > > > > On 4/18/24 09:10, Michael Paquier wrote: > > > On Sun, Apr 07, 2024 at 10:54:56AM -0400, Melanie Plageman wrote: > > >> I've added an open item [1], because what's one open item when you can > > >> have two? (me) > > > > > > And this is still an open item as of today. What's the plan to move > > > forward here? > > > > AFAIK the plan is to replace the asserts with actually resetting the > > rs_empty_tuples_pending field to 0, as suggested by Melanie a week ago. > > I assume she was busy with the post-freeze AM reworks last week, so this > > was on a back burner. > > yep, sorry. Also I took a few days off. I'm just catching up today. I > want to pop in one of Richard or Tomas' examples as a test, since it > seems like it would add some coverage. I will have a patch soon. The patch with a fix is attached. I put the test in src/test/regress/sql/join.sql. It isn't the perfect location because it is testing something exercisable with a join but not directly related to the fact that it is a join. I also considered src/test/regress/sql/select.sql, but it also isn't directly related to the query being a SELECT query. If there is a better place for a test of a bitmap heap scan edge case, let me know. One other note: there is some concurrency effect in the parallel schedule group containing "join" where you won't trip the assert if all the tests in that group in the parallel schedule are run. But, if you would like to verify that the test exercises the correct code, just reduce the group containing "join". - Melanie
Attachment
On 4/23/24 18:05, Melanie Plageman wrote: > On Mon, Apr 22, 2024 at 1:01 PM Melanie Plageman > <melanieplageman@gmail.com> wrote: >> >> On Thu, Apr 18, 2024 at 5:39 AM Tomas Vondra >> <tomas.vondra@enterprisedb.com> wrote: >>> >>> On 4/18/24 09:10, Michael Paquier wrote: >>>> On Sun, Apr 07, 2024 at 10:54:56AM -0400, Melanie Plageman wrote: >>>>> I've added an open item [1], because what's one open item when you can >>>>> have two? (me) >>>> >>>> And this is still an open item as of today. What's the plan to move >>>> forward here? >>> >>> AFAIK the plan is to replace the asserts with actually resetting the >>> rs_empty_tuples_pending field to 0, as suggested by Melanie a week ago. >>> I assume she was busy with the post-freeze AM reworks last week, so this >>> was on a back burner. >> >> yep, sorry. Also I took a few days off. I'm just catching up today. I >> want to pop in one of Richard or Tomas' examples as a test, since it >> seems like it would add some coverage. I will have a patch soon. > > The patch with a fix is attached. I put the test in > src/test/regress/sql/join.sql. It isn't the perfect location because > it is testing something exercisable with a join but not directly > related to the fact that it is a join. I also considered > src/test/regress/sql/select.sql, but it also isn't directly related to > the query being a SELECT query. If there is a better place for a test > of a bitmap heap scan edge case, let me know. > I don't see a problem with adding this to join.sql - why wouldn't this count as something related to a join? Sure, it's not like this code matters only for joins, but if you look at join.sql that applies to a number of other tests (e.g. there are a couple btree tests). That being said, it'd be good to explain in the comment why we're testing this particular plan, not just what the plan looks like. > One other note: there is some concurrency effect in the parallel > schedule group containing "join" where you won't trip the assert if > all the tests in that group in the parallel schedule are run. But, if > you would like to verify that the test exercises the correct code, > just reduce the group containing "join". > That is ... interesting. Doesn't that mean that most test runs won't actually detect the problem? That would make the test a bit useless. regards -- Tomas Vondra EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On Tue, Apr 23, 2024 at 6:43 PM Tomas Vondra <tomas.vondra@enterprisedb.com> wrote: > > On 4/23/24 18:05, Melanie Plageman wrote: > > The patch with a fix is attached. I put the test in > > src/test/regress/sql/join.sql. It isn't the perfect location because > > it is testing something exercisable with a join but not directly > > related to the fact that it is a join. I also considered > > src/test/regress/sql/select.sql, but it also isn't directly related to > > the query being a SELECT query. If there is a better place for a test > > of a bitmap heap scan edge case, let me know. > > I don't see a problem with adding this to join.sql - why wouldn't this > count as something related to a join? Sure, it's not like this code > matters only for joins, but if you look at join.sql that applies to a > number of other tests (e.g. there are a couple btree tests). I suppose it's true that other tests in this file use joins to test other code. I guess if we limited join.sql to containing tests of join implementation, it would be rather small. I just imagined it would be nice if tests were grouped by what they were testing -- not how they were testing it. > That being said, it'd be good to explain in the comment why we're > testing this particular plan, not just what the plan looks like. You mean I should explain in the test comment why I included the EXPLAIN plan output? (because it needs to contain a bitmapheapscan to actually be testing anything) I do have a detailed explanation in my test comment of why this particular query exercises the code we want to test. > > One other note: there is some concurrency effect in the parallel > > schedule group containing "join" where you won't trip the assert if > > all the tests in that group in the parallel schedule are run. But, if > > you would like to verify that the test exercises the correct code, > > just reduce the group containing "join". > > > > That is ... interesting. Doesn't that mean that most test runs won't > actually detect the problem? That would make the test a bit useless. Yes, I should really have thought about it more. After further investigation, I found that the reason it doesn't trip the assert when the join test is run concurrently with other tests is that the SELECT query doesn't use the skip fetch optimization because the VACUUM doesn't set the pages all visible in the VM. In this case, it's because the tuples' xmins are not before VacuumCutoffs->OldestXmin (which is derived from GetOldestNonRemovableTransactionId()). After thinking about it more, I suppose we can't add a test that relies on the relation being all visible in the VM in a group in the parallel schedule. I'm not sure this edge case is important enough to merit its own group or an isolation test. What do you think? - Melanie
On Wed, Apr 24, 2024 at 4:46 PM Melanie Plageman <melanieplageman@gmail.com> wrote: > > On Tue, Apr 23, 2024 at 6:43 PM Tomas Vondra > <tomas.vondra@enterprisedb.com> wrote: > > > > On 4/23/24 18:05, Melanie Plageman wrote: > > > One other note: there is some concurrency effect in the parallel > > > schedule group containing "join" where you won't trip the assert if > > > all the tests in that group in the parallel schedule are run. But, if > > > you would like to verify that the test exercises the correct code, > > > just reduce the group containing "join". > > > > > > > That is ... interesting. Doesn't that mean that most test runs won't > > actually detect the problem? That would make the test a bit useless. > > Yes, I should really have thought about it more. After further > investigation, I found that the reason it doesn't trip the assert when > the join test is run concurrently with other tests is that the SELECT > query doesn't use the skip fetch optimization because the VACUUM > doesn't set the pages all visible in the VM. In this case, it's > because the tuples' xmins are not before VacuumCutoffs->OldestXmin > (which is derived from GetOldestNonRemovableTransactionId()). > > After thinking about it more, I suppose we can't add a test that > relies on the relation being all visible in the VM in a group in the > parallel schedule. I'm not sure this edge case is important enough to > merit its own group or an isolation test. What do you think? Andres rightly pointed out to me off-list that if I just used a temp table, the table would only be visible to the testing backend anyway. I've done that in the attached v2. Now the test is deterministic. - Melanie
Attachment
Melanie Plageman <melanieplageman@gmail.com> writes:
> On Wed, Apr 24, 2024 at 4:46 PM Melanie Plageman
> <melanieplageman@gmail.com> wrote:
>> After thinking about it more, I suppose we can't add a test that
>> relies on the relation being all visible in the VM in a group in the
>> parallel schedule. I'm not sure this edge case is important enough to
>> merit its own group or an isolation test. What do you think?
> Andres rightly pointed out to me off-list that if I just used a temp
> table, the table would only be visible to the testing backend anyway.
> I've done that in the attached v2. Now the test is deterministic.
Hmm, is that actually true? There's no more reason to think a tuple
in a temp table is old enough to be visible to all other sessions
than one in any other table. It could be all right if we had a
special-case rule for setting all-visible in temp tables. Which
indeed I thought we had, but I can't find any evidence of that in
vacuumlazy.c, nor did a trawl of the commit log turn up anything
promising. Am I just looking in the wrong place?
regards, tom lane
I wrote:
> Hmm, is that actually true? There's no more reason to think a tuple
> in a temp table is old enough to be visible to all other sessions
> than one in any other table. It could be all right if we had a
> special-case rule for setting all-visible in temp tables. Which
> indeed I thought we had, but I can't find any evidence of that in
> vacuumlazy.c, nor did a trawl of the commit log turn up anything
> promising. Am I just looking in the wrong place?
Ah, never mind that --- I must be looking in the wrong place.
Direct experimentation proves that VACUUM will set all-visible bits
for temp tables even in the presence of concurrent transactions.
regards, tom lane
On Thu, Apr 25, 2024 at 7:57 PM Tom Lane <tgl@sss.pgh.pa.us> wrote: > > I wrote: > > Hmm, is that actually true? There's no more reason to think a tuple > > in a temp table is old enough to be visible to all other sessions > > than one in any other table. It could be all right if we had a > > special-case rule for setting all-visible in temp tables. Which > > indeed I thought we had, but I can't find any evidence of that in > > vacuumlazy.c, nor did a trawl of the commit log turn up anything > > promising. Am I just looking in the wrong place? > > Ah, never mind that --- I must be looking in the wrong place. > Direct experimentation proves that VACUUM will set all-visible bits > for temp tables even in the presence of concurrent transactions. If this seems correct to you, are you okay with the rest of the fix and test? We could close this open item once the patch is acceptable. - Melanie
> On 26 Apr 2024, at 15:04, Melanie Plageman <melanieplageman@gmail.com> wrote: > If this seems correct to you, are you okay with the rest of the fix > and test? We could close this open item once the patch is acceptable. From reading the discussion and the patch this seems like the right fix to me. Does the test added here aptly cover 04e72ed617be in terms its functionality? -- Daniel Gustafsson
On 4/30/24 14:07, Daniel Gustafsson wrote: >> On 26 Apr 2024, at 15:04, Melanie Plageman <melanieplageman@gmail.com> wrote: > >> If this seems correct to you, are you okay with the rest of the fix >> and test? We could close this open item once the patch is acceptable. > > From reading the discussion and the patch this seems like the right fix to me. I agree. > Does the test added here aptly cover 04e72ed617be in terms its functionality? > AFAIK the test fails without the fix and works with it, so I believe it does cover the relevant functionality. regards -- Tomas Vondra EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On 4/24/24 22:46, Melanie Plageman wrote: > On Tue, Apr 23, 2024 at 6:43 PM Tomas Vondra > <tomas.vondra@enterprisedb.com> wrote: >> >> On 4/23/24 18:05, Melanie Plageman wrote: >>> The patch with a fix is attached. I put the test in >>> src/test/regress/sql/join.sql. It isn't the perfect location because >>> it is testing something exercisable with a join but not directly >>> related to the fact that it is a join. I also considered >>> src/test/regress/sql/select.sql, but it also isn't directly related to >>> the query being a SELECT query. If there is a better place for a test >>> of a bitmap heap scan edge case, let me know. >> >> I don't see a problem with adding this to join.sql - why wouldn't this >> count as something related to a join? Sure, it's not like this code >> matters only for joins, but if you look at join.sql that applies to a >> number of other tests (e.g. there are a couple btree tests). > > I suppose it's true that other tests in this file use joins to test > other code. I guess if we limited join.sql to containing tests of join > implementation, it would be rather small. I just imagined it would be > nice if tests were grouped by what they were testing -- not how they > were testing it. > >> That being said, it'd be good to explain in the comment why we're >> testing this particular plan, not just what the plan looks like. > > You mean I should explain in the test comment why I included the > EXPLAIN plan output? (because it needs to contain a bitmapheapscan to > actually be testing anything) > No, I meant that the comment before the test describes a couple requirements the plan needs to meet (no need to process all inner tuples, bitmapscan eligible for skip_fetch on outer side, ...), but it does not explain why we're testing that plan. I could get to that by doing git-blame to see what commit added this code, and then read the linked discussion. Perhaps that's enough, but maybe the comment could say something like "verify we properly discard tuples on rescans" or something like that? regards -- Tomas Vondra EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On Thu, May 2, 2024 at 5:37 PM Tomas Vondra <tomas.vondra@enterprisedb.com> wrote: > > > > On 4/24/24 22:46, Melanie Plageman wrote: > > On Tue, Apr 23, 2024 at 6:43 PM Tomas Vondra > > <tomas.vondra@enterprisedb.com> wrote: > >> > >> On 4/23/24 18:05, Melanie Plageman wrote: > >>> The patch with a fix is attached. I put the test in > >>> src/test/regress/sql/join.sql. It isn't the perfect location because > >>> it is testing something exercisable with a join but not directly > >>> related to the fact that it is a join. I also considered > >>> src/test/regress/sql/select.sql, but it also isn't directly related to > >>> the query being a SELECT query. If there is a better place for a test > >>> of a bitmap heap scan edge case, let me know. > >> > >> I don't see a problem with adding this to join.sql - why wouldn't this > >> count as something related to a join? Sure, it's not like this code > >> matters only for joins, but if you look at join.sql that applies to a > >> number of other tests (e.g. there are a couple btree tests). > > > > I suppose it's true that other tests in this file use joins to test > > other code. I guess if we limited join.sql to containing tests of join > > implementation, it would be rather small. I just imagined it would be > > nice if tests were grouped by what they were testing -- not how they > > were testing it. > > > >> That being said, it'd be good to explain in the comment why we're > >> testing this particular plan, not just what the plan looks like. > > > > You mean I should explain in the test comment why I included the > > EXPLAIN plan output? (because it needs to contain a bitmapheapscan to > > actually be testing anything) > > > > No, I meant that the comment before the test describes a couple > requirements the plan needs to meet (no need to process all inner > tuples, bitmapscan eligible for skip_fetch on outer side, ...), but it > does not explain why we're testing that plan. > > I could get to that by doing git-blame to see what commit added this > code, and then read the linked discussion. Perhaps that's enough, but > maybe the comment could say something like "verify we properly discard > tuples on rescans" or something like that? Attached is v3. I didn't use your exact language because the test wouldn't actually verify that we properly discard the tuples. Whether or not the empty tuples are all emitted, it just resets the counter to 0. I decided to go with "exercise" instead. - Melanie
Attachment
On 5/10/24 21:48, Melanie Plageman wrote: > On Thu, May 2, 2024 at 5:37 PM Tomas Vondra > <tomas.vondra@enterprisedb.com> wrote: >> >> >> >> On 4/24/24 22:46, Melanie Plageman wrote: >>> On Tue, Apr 23, 2024 at 6:43 PM Tomas Vondra >>> <tomas.vondra@enterprisedb.com> wrote: >>>> >>>> On 4/23/24 18:05, Melanie Plageman wrote: >>>>> The patch with a fix is attached. I put the test in >>>>> src/test/regress/sql/join.sql. It isn't the perfect location because >>>>> it is testing something exercisable with a join but not directly >>>>> related to the fact that it is a join. I also considered >>>>> src/test/regress/sql/select.sql, but it also isn't directly related to >>>>> the query being a SELECT query. If there is a better place for a test >>>>> of a bitmap heap scan edge case, let me know. >>>> >>>> I don't see a problem with adding this to join.sql - why wouldn't this >>>> count as something related to a join? Sure, it's not like this code >>>> matters only for joins, but if you look at join.sql that applies to a >>>> number of other tests (e.g. there are a couple btree tests). >>> >>> I suppose it's true that other tests in this file use joins to test >>> other code. I guess if we limited join.sql to containing tests of join >>> implementation, it would be rather small. I just imagined it would be >>> nice if tests were grouped by what they were testing -- not how they >>> were testing it. >>> >>>> That being said, it'd be good to explain in the comment why we're >>>> testing this particular plan, not just what the plan looks like. >>> >>> You mean I should explain in the test comment why I included the >>> EXPLAIN plan output? (because it needs to contain a bitmapheapscan to >>> actually be testing anything) >>> >> >> No, I meant that the comment before the test describes a couple >> requirements the plan needs to meet (no need to process all inner >> tuples, bitmapscan eligible for skip_fetch on outer side, ...), but it >> does not explain why we're testing that plan. >> >> I could get to that by doing git-blame to see what commit added this >> code, and then read the linked discussion. Perhaps that's enough, but >> maybe the comment could say something like "verify we properly discard >> tuples on rescans" or something like that? > > Attached is v3. I didn't use your exact language because the test > wouldn't actually verify that we properly discard the tuples. Whether > or not the empty tuples are all emitted, it just resets the counter to > 0. I decided to go with "exercise" instead. > I did go over the v3 patch, did a bunch of tests, and I think it's fine and ready to go. The one thing that might need some minor tweaks is the commit message. 1) Isn't the subject "Remove incorrect assert" a bit misleading, as the patch does not simply remove an assert, but replaces it with a reset of the field the assert used to check? (The commit message does not mention this either, at least not explicitly.) 2) The "heap AM-specific bitmap heap scan code" sounds a bit strange to me, isn't the first "heap" unnecessary? regards -- Tomas Vondra EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On Sat, May 11, 2024 at 3:18 PM Tomas Vondra <tomas.vondra@enterprisedb.com> wrote: > > On 5/10/24 21:48, Melanie Plageman wrote: > > Attached is v3. I didn't use your exact language because the test > > wouldn't actually verify that we properly discard the tuples. Whether > > or not the empty tuples are all emitted, it just resets the counter to > > 0. I decided to go with "exercise" instead. > > > > I did go over the v3 patch, did a bunch of tests, and I think it's fine > and ready to go. The one thing that might need some minor tweaks is the > commit message. > > 1) Isn't the subject "Remove incorrect assert" a bit misleading, as the > patch does not simply remove an assert, but replaces it with a reset of > the field the assert used to check? (The commit message does not mention > this either, at least not explicitly.) I've updated the commit message. > 2) The "heap AM-specific bitmap heap scan code" sounds a bit strange to > me, isn't the first "heap" unnecessary? bitmap heap scan has been used to refer to bitmap table scans, as the name wasn't changed from heap when the table AM API was added (e.g. BitmapHeapNext() is used by all table AMs doing bitmap table scans). 04e72ed617be specifically pushed the skip fetch optimization into heap implementations of bitmap table scan callbacks, so it was important to make this distinction. I've changed the commit message to say heap AM implementations of bitmap table scan callbacks. While looking at the patch again, I wondered if I should set enable_material=false in the test. It doesn't matter from the perspective of exercising the correct code; however, I wasn't sure if disabling materialization would make the test more resilient against future planner changes which could cause it to incorrectly fail. - Melanie
Attachment
On Mon, May 13, 2024 at 10:05:03AM -0400, Melanie Plageman wrote: > Remove the assert and reset the field on which it previously asserted to > avoid incorrectly emitting NULL-filled tuples from a previous scan on > rescan. > - Assert(scan->rs_empty_tuples_pending == 0); > + scan->rs_empty_tuples_pending = 0; Perhaps this should document the reason why the reset is done in these two paths rather than let the reader guess it? And this is about avoiding emitting some tuples from a previous scan. > +SET enable_indexonlyscan = off; > +set enable_indexscan = off; > +SET enable_seqscan = off; Nit: adjusting the casing of the second SET here. -- Michael
Attachment
On Tue, May 14, 2024 at 2:18 AM Michael Paquier <michael@paquier.xyz> wrote: > > On Mon, May 13, 2024 at 10:05:03AM -0400, Melanie Plageman wrote: > > Remove the assert and reset the field on which it previously asserted to > > avoid incorrectly emitting NULL-filled tuples from a previous scan on > > rescan. > > > - Assert(scan->rs_empty_tuples_pending == 0); > > + scan->rs_empty_tuples_pending = 0; > > Perhaps this should document the reason why the reset is done in these > two paths rather than let the reader guess it? And this is about > avoiding emitting some tuples from a previous scan. I've added a comment to heap_rescan() in the attached v5. Doing so made me realize that we shouldn't bother resetting it in heap_endscan(). Doing so is perhaps more confusing, because it implies that field may somehow be used later. I've removed the reset of rs_empty_tuples_pending from heap_endscan(). > > +SET enable_indexonlyscan = off; > > +set enable_indexscan = off; > > +SET enable_seqscan = off; > > Nit: adjusting the casing of the second SET here. I've fixed this. I've also set enable_material off as I mentioned I might in my earlier mail. - Melanie
Attachment
On 5/14/24 19:42, Melanie Plageman wrote: > On Tue, May 14, 2024 at 2:18 AM Michael Paquier <michael@paquier.xyz> wrote: >> >> On Mon, May 13, 2024 at 10:05:03AM -0400, Melanie Plageman wrote: >>> Remove the assert and reset the field on which it previously asserted to >>> avoid incorrectly emitting NULL-filled tuples from a previous scan on >>> rescan. >> >>> - Assert(scan->rs_empty_tuples_pending == 0); >>> + scan->rs_empty_tuples_pending = 0; >> >> Perhaps this should document the reason why the reset is done in these >> two paths rather than let the reader guess it? And this is about >> avoiding emitting some tuples from a previous scan. > > I've added a comment to heap_rescan() in the attached v5. Doing so > made me realize that we shouldn't bother resetting it in > heap_endscan(). Doing so is perhaps more confusing, because it implies > that field may somehow be used later. I've removed the reset of > rs_empty_tuples_pending from heap_endscan(). > +1 >>> +SET enable_indexonlyscan = off; >>> +set enable_indexscan = off; >>> +SET enable_seqscan = off; >> >> Nit: adjusting the casing of the second SET here. > > I've fixed this. I've also set enable_material off as I mentioned I > might in my earlier mail. > I'm not sure this (setting more and more GUCs to prevent hypothetical plan changes) is a good practice. Because how do you know the plan does not change for some other unexpected reason, possibly in the future? IMHO if the test requires a specific plan, it's better to do an actual "explain (rows off, costs off)" to check that. regards -- Tomas Vondra EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On Tue, May 14, 2024 at 2:33 PM Tomas Vondra <tomas.vondra@enterprisedb.com> wrote: > > On 5/14/24 19:42, Melanie Plageman wrote: > > I've fixed this. I've also set enable_material off as I mentioned I > > might in my earlier mail. > > > > I'm not sure this (setting more and more GUCs to prevent hypothetical > plan changes) is a good practice. Because how do you know the plan does > not change for some other unexpected reason, possibly in the future? Sure. So, you think it is better not to have enable_material = false? > IMHO if the test requires a specific plan, it's better to do an actual > "explain (rows off, costs off)" to check that. When you say "rows off", do you mean do something to ensure that it doesn't return tuples? Because I don't see a ROWS option for EXPLAIN in the docs. - Melanie
On 5/14/24 20:40, Melanie Plageman wrote: > On Tue, May 14, 2024 at 2:33 PM Tomas Vondra > <tomas.vondra@enterprisedb.com> wrote: >> >> On 5/14/24 19:42, Melanie Plageman wrote: >>> I've fixed this. I've also set enable_material off as I mentioned I >>> might in my earlier mail. >>> >> >> I'm not sure this (setting more and more GUCs to prevent hypothetical >> plan changes) is a good practice. Because how do you know the plan does >> not change for some other unexpected reason, possibly in the future? > > Sure. So, you think it is better not to have enable_material = false? > Right. Unless it's actually needed to force the necessary plan. >> IMHO if the test requires a specific plan, it's better to do an actual >> "explain (rows off, costs off)" to check that. > > When you say "rows off", do you mean do something to ensure that it > doesn't return tuples? Because I don't see a ROWS option for EXPLAIN > in the docs. > Sorry, I meant to hide the cardinality estimates in the explain, but I got confused. "COSTS OFF" is enough. regards -- Tomas Vondra EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On Tue, May 14, 2024 at 2:44 PM Tomas Vondra <tomas.vondra@enterprisedb.com> wrote: > > On 5/14/24 20:40, Melanie Plageman wrote: > > On Tue, May 14, 2024 at 2:33 PM Tomas Vondra > > <tomas.vondra@enterprisedb.com> wrote: > >> > >> On 5/14/24 19:42, Melanie Plageman wrote: > >>> I've fixed this. I've also set enable_material off as I mentioned I > >>> might in my earlier mail. > >>> > >> > >> I'm not sure this (setting more and more GUCs to prevent hypothetical > >> plan changes) is a good practice. Because how do you know the plan does > >> not change for some other unexpected reason, possibly in the future? > > > > Sure. So, you think it is better not to have enable_material = false? > > > > Right. Unless it's actually needed to force the necessary plan. Attached v6 does not use enable_material = false (as it is not needed). - Melanie
Attachment
On 2024-May-14, Tomas Vondra wrote:
> On 5/14/24 19:42, Melanie Plageman wrote:
>
> >>> +SET enable_indexonlyscan = off;
> >>> +set enable_indexscan = off;
> >>> +SET enable_seqscan = off;
> >>
> >> Nit: adjusting the casing of the second SET here.
> >
> > I've fixed this. I've also set enable_material off as I mentioned I
> > might in my earlier mail.
>
> I'm not sure this (setting more and more GUCs to prevent hypothetical
> plan changes) is a good practice. Because how do you know the plan does
> not change for some other unexpected reason, possibly in the future?
I wonder why it resets enable_indexscan at all. I see that this query
first tries a seqscan, then if you disable that it tries an index only
scan, and if you disable that you get the expected bitmap indexscan.
But an indexscan doesn't seem to be in the cards.
> IMHO if the test requires a specific plan, it's better to do an actual
> "explain (rows off, costs off)" to check that.
That's already in the patch, right?
I do wonder how do we _know_ that the test is testing what it wants to
test:
QUERY PLAN
─────────────────────────────────────────────────────────
Nested Loop Anti Join
-> Seq Scan on skip_fetch t1
-> Materialize
-> Bitmap Heap Scan on skip_fetch t2
Recheck Cond: (a = 1)
-> Bitmap Index Scan on skip_fetch_a_idx
Index Cond: (a = 1)
Is it because of the shape of the index condition? Maybe it's worth
explaining in the comments for the tests.
BTW, I was running the explain while desultorily enabling and disabling
these GUCs and hit this assertion failure:
#4 0x000055e6c72afe28 in ExceptionalCondition (conditionName=conditionName@entry=0x55e6c731a928
"scan->rs_empty_tuples_pending== 0",
fileName=fileName@entry=0x55e6c731a3b0
"../../../../../../../../../pgsql/source/master/src/backend/access/heap/heapam.c",lineNumber=lineNumber@entry=1219)
at ../../../../../../../../../pgsql/source/master/src/backend/utils/error/assert.c:66
#5 0x000055e6c6e2e0c7 in heap_endscan (sscan=0x55e6c7b63e28) at
../../../../../../../../../pgsql/source/master/src/backend/access/heap/heapam.c:1219
#6 0x000055e6c6fb35a7 in ExecEndPlan (estate=0x55e6c7a7e9d0, planstate=<optimized out>) at
../../../../../../../../pgsql/source/master/src/backend/executor/execMain.c:1485
#7 standard_ExecutorEnd (queryDesc=0x55e6c7a736b8) at
../../../../../../../../pgsql/source/master/src/backend/executor/execMain.c:501
#8 0x000055e6c6f4d9aa in ExplainOnePlan (plannedstmt=plannedstmt@entry=0x55e6c7a735a8, into=into@entry=0x0,
es=es@entry=0x55e6c7a448b8,
queryString=queryString@entry=0x55e6c796c210 "EXPLAIN (analyze, verbose, COSTS OFF) SELECT t1.a FROM skip_fetch t1
LEFTJOIN skip_fetch t2 ON t2.a = 1 WHERE t2.a IS NULL;", params=params@entry=0x0,
queryEnv=queryEnv@entry=0x0, planduration=0x7ffe8a291848, bufusage=0x0, mem_counters=0x0) at
../../../../../../../../pgsql/source/master/src/backend/commands/explain.c:770
#9 0x000055e6c6f4e257 in standard_ExplainOneQuery (query=<optimized out>, cursorOptions=2048, into=0x0,
es=0x55e6c7a448b8,
queryString=0x55e6c796c210 "EXPLAIN (analyze, verbose, COSTS OFF) SELECT t1.a FROM skip_fetch t1 LEFT JOIN
skip_fetcht2 ON t2.a = 1 WHERE t2.a IS NULL;", params=0x0, queryEnv=0x0)
at ../../../../../../../../pgsql/source/master/src/backend/commands/explain.c:502
I couldn't reproduce it again, though -- and for sure I don't know what
it means. All three GUCs are set false in the core.
--
Álvaro Herrera PostgreSQL Developer — https://www.EnterpriseDB.com/
"Here's a general engineering tip: if the non-fun part is too complex for you
to figure out, that might indicate the fun part is too ambitious." (John Naylor)
https://postgr.es/m/CAFBsxsG4OWHBbSDM%3DsSeXrQGOtkPiOEOuME4yD7Ce41NtaAD9g%40mail.gmail.com
On 2024-May-14, Alvaro Herrera wrote: > BTW, I was running the explain while desultorily enabling and disabling > these GUCs and hit this assertion failure: > > #4 0x000055e6c72afe28 in ExceptionalCondition (conditionName=conditionName@entry=0x55e6c731a928 "scan->rs_empty_tuples_pending== 0", > fileName=fileName@entry=0x55e6c731a3b0 "../../../../../../../../../pgsql/source/master/src/backend/access/heap/heapam.c",lineNumber=lineNumber@entry=1219) > at ../../../../../../../../../pgsql/source/master/src/backend/utils/error/assert.c:66 Ah, I see now that this is precisely the assertion that this patch removes. Nevermind ... -- Álvaro Herrera PostgreSQL Developer — https://www.EnterpriseDB.com/ "This is what I like so much about PostgreSQL. Most of the surprises are of the "oh wow! That's cool" Not the "oh shit!" kind. :)" Scott Marlowe, http://archives.postgresql.org/pgsql-admin/2008-10/msg00152.php
On Tue, May 14, 2024 at 4:05 PM Alvaro Herrera <alvherre@alvh.no-ip.org> wrote: > > On 2024-May-14, Tomas Vondra wrote: > > I wonder why it resets enable_indexscan at all. I see that this query > first tries a seqscan, then if you disable that it tries an index only > scan, and if you disable that you get the expected bitmap indexscan. > But an indexscan doesn't seem to be in the cards. Ah, yes. That is true. I think I added that when, in an older version of the test, I had a query that did try an index scan before bitmap heap scan. I've removed that guc from the attached v7. > > IMHO if the test requires a specific plan, it's better to do an actual > > "explain (rows off, costs off)" to check that. > > That's already in the patch, right? Yep. > I do wonder how do we _know_ that the test is testing what it wants to > test: > QUERY PLAN > ───────────────────────────────────────────────────────── > Nested Loop Anti Join > -> Seq Scan on skip_fetch t1 > -> Materialize > -> Bitmap Heap Scan on skip_fetch t2 > Recheck Cond: (a = 1) > -> Bitmap Index Scan on skip_fetch_a_idx > Index Cond: (a = 1) > > Is it because of the shape of the index condition? Maybe it's worth > explaining in the comments for the tests. There is a comment in the test that explains what it is exercising and how. We include the explain output (the plan) to ensure it is still using a bitmap heap scan. The test exercises the skip fetch optimization in bitmap heap scan when not all of the inner tuples are emitted. Without the patch, the test fails, so it is protection against someone adding back that assert in the future. It is not protection against someone deleting the line scan->rs_empty_tuples_pending = 0 That is, it doesn't verify that the empty unused tuples count is discarded. Do you think that is necessary? - Melanie
Attachment
Procedural comment: It's better to get this patch committed with an imperfect test case than to have it miss beta1. ...Robert
On 2024-May-14, Melanie Plageman wrote: > On Tue, May 14, 2024 at 4:05 PM Alvaro Herrera <alvherre@alvh.no-ip.org> wrote: > > I do wonder how do we _know_ that the test is testing what it wants to > > test: > We include the explain output (the plan) to ensure it is still > using a bitmap heap scan. The test exercises the skip fetch > optimization in bitmap heap scan when not all of the inner tuples are > emitted. I meant -- the query returns an empty resultset, so how do we know it's the empty resultset that we want and not a different empty resultset that happens to be identical? (This is probably not a critical point anyhow.) > Without the patch, the test fails, so it is protection against someone > adding back that assert in the future. It is not protection against > someone deleting the line > scan->rs_empty_tuples_pending = 0 > That is, it doesn't verify that the empty unused tuples count is > discarded. Do you think that is necessary? I don't think that's absolutely necessary. I suspect there are thousands of lines that you could delete that would break things, with no test directly raising red flags. At this point I would go with the RMT's recommendation of pushing this now to make sure the bug is fixed for beta1, even if the test is imperfect. You can always polish the test afterwards if you feel like it ... -- Álvaro Herrera 48°01'N 7°57'E — https://www.EnterpriseDB.com/ "No necesitamos banderas No reconocemos fronteras" (Jorge González)
On Sun, Apr 7, 2024 at 12:17 AM Melanie Plageman <melanieplageman@gmail.com> wrote: > > After we decided not to pursue streaming bitmapheapscan for 17, I wanted > to make sure we removed the prefetch code table AM violation -- since we > weren't deleting that code. So what started out as me looking for a way > to clean up one commit ended up becoming a much larger project. Sorry > about that last minute code explosion! I do think there is a way to do > it right and make it nice. Also that violation would be gone if we > figure out how to get streaming bitmapheapscan behaving correctly. > > So, there's just more motivation to make streaming bitmapheapscan > awesome for 18! Attached v21 is the rest of the patches to make bitmap heap scan use the read stream API. Don't be alarmed by the 20 patches in the set. I tried to keep the individual patches as small and easy to review as possible. Patches 0001-0003 implement the async-friendly behavior needed both to push down the VM lookups for prefetching and eventually to use the read stream API. Patches 0004-0006 add and make use of a common interface for the shared and private (parallel and serial) bitmap iterator per Heikki's suggestion in [1]. Patches 0008 - 0012 make new scan descriptors for bitmap table scans and the heap AM implementation. It is not possible to remove the layering violations mentioned for bitmap table scans in tableam.h without passing more bitmap-specific parameters to table_begin/end/rescan(). Because bitmap heap scans use a fairly reduced set of the members in the HeapScanDescData, it made sense to enable specialized scan descriptors for bitmap table scans. 0013 pushes the primary iterator setup down into heap code. 0014 and 0015 push all of the prefetch code down into heap AM code as suggested by Heikki in [1]. 0017 removes scan_bitmap_next_block() per Heikki's suggestion in [1]. After all of these patches, we've removed the layering violations mentioned previously in tableam.h. There is no use of the visibility map anymore in generic bitmap table scan code. Almost all block-specific logic is gone. The table AMs own the iterator almost completely. The one relic of iterator ownership is that for parallel bitmap heap scan, a single process must scan the index, construct the bitmap, and call tbm_prepare_shared_iterate() to set up the iterator for all the processes. I didn't see a way to push this down (because to build the bitmap we have to scan the index and call ExecProcNode()). I wonder if this creates an odd split of responsibilities. I could use some other synchronization mechanism to communicate which process built the bitmap in the generic bitmap table scan code and thus should set up the iterator in the heap implementation, but that sounds like a pretty bad idea. Also, I'm not sure how a non-block-based table AM would use TBMIterators (or even TIDBitmap) anyway. As a side note, I've started naming all new structs in the bitmap table scan code with the `BitmapTableScan` convention. It seems like it might be a good time to rename the executor node from BitmapHeapScanState to BitmapTableScanState. I didn't because I wondered if I also needed to rename the file (nodeBitmapHeapscan.c -> nodeBitmapTablescan.c) and update all other places using the `BitmapHeapScan` convention. Patches 0018 and 0019 make some changes to the TIDBitmap API to support having multiple TBMIterateResults at the same time instead of reusing the same one when iterating. With async execution we may have more than one TBMIterateResult at a time. There is one MTODO in the whole patch set -- in 0019 -- related to resetting state in the TBMIterateResult. See that patch for the full question. And, finally, 0020 uses the read stream API and removes all the bespoke prefetching code from bitmap heap scan. Assuming we all get to a happy place with the code up until 0020, the next step is to go back and investigate the performance regression with bitmap heap scan and the read stream API first reported by Tomas Vondra in [2]. I'd be very happy for code review on any of the patches, answers to my questions above, or help investigating the regression Tomas found. - Melanie [1] https://www.postgresql.org/message-id/5a172d1e-d69c-409a-b1fa-6521214c81c2%40iki.fi [2] https://www.postgresql.org/message-id/5d5954ed-6f43-4f1a-8e19-ece75b2b7362@enterprisedb.com
Attachment
- v21-0001-table_scan_bitmap_next_block-counts-lossy-and-ex.patch
- v21-0003-Make-table_scan_bitmap_next_block-async-friendly.patch
- v21-0004-Add-common-interface-for-TBMIterators.patch
- v21-0002-Remove-table_scan_bitmap_next_tuple-parameter-tb.patch
- v21-0005-BitmapHeapScan-initialize-some-prefetch-state-el.patch
- v21-0006-BitmapHeapScan-uses-unified-iterator.patch
- v21-0007-BitmapHeapScan-Make-prefetch-sync-error-more-det.patch
- v21-0008-Push-current-scan-descriptor-into-specialized-sc.patch
- v21-0012-Update-variable-names-in-bitmap-scan-descriptors.patch
- v21-0009-Remove-ss_current-prefix-from-ss_currentScanDesc.patch
- v21-0010-Add-scan_in_progress-to-BitmapHeapScanState.patch
- v21-0011-Make-new-bitmap-table-scan-and-bitmap-heap-scan-.patch
- v21-0013-BitmapHeapScan-Push-primary-iterator-setup-into-.patch
- v21-0014-BitmapHeapScan-lift-and-shift-prefetch-functions.patch
- v21-0016-BitmapHeapScan-move-per-scan-setup-into-a-helper.patch
- v21-0015-BitmapHeapScan-Push-prefetch-code-into-heap-AM.patch
- v21-0018-Hard-code-TBMIterateResult-offsets-array-size.patch
- v21-0017-Remove-table-AM-callback-scan_bitmap_next_block.patch
- v21-0019-Separate-TBMIterator-and-TBMIterateResult.patch
- v21-0020-Use-streaming-I-O-in-Bitmap-Heap-Scans.patch
On Fri, Jun 14, 2024 at 7:56 PM Melanie Plageman <melanieplageman@gmail.com> wrote: > > Attached v21 is the rest of the patches to make bitmap heap scan use > the read stream API. ---snip--- > The one relic of iterator ownership is that for parallel bitmap heap > scan, a single process must scan the index, construct the bitmap, and > call tbm_prepare_shared_iterate() to set up the iterator for all the > processes. I didn't see a way to push this down (because to build the > bitmap we have to scan the index and call ExecProcNode()). I wonder if > this creates an odd split of responsibilities. I could use some other > synchronization mechanism to communicate which process built the > bitmap in the generic bitmap table scan code and thus should set up > the iterator in the heap implementation, but that sounds like a pretty > bad idea. Also, I'm not sure how a non-block-based table AM would use > TBMIterators (or even TIDBitmap) anyway. I tinkered around with this some more and actually came up with a solution to my primary concern with the code structure. Attached is v22. It still needs the performance regression investigation mentioned in my previous email, but I feel more confident in the layering of the iterator ownership I ended up with. Because the patch numbers have changed, below is a summary of the contents with the new patch numbers: Patches 0001-0003 implement the async-friendly behavior needed both to push down the VM lookups for prefetching and eventually to use the read stream API. Patches 0004-0006 add and make use of a common interface for the shared and private bitmap iterators per Heikki's suggestion in [1]. Patches 0008 - 0012 make new scan descriptors for bitmap table scans and the heap AM implementation. 0013 and 0014 push all of the prefetch code down into heap AM code as suggested by Heikki in [1]. 0016 removes scan_bitmap_next_block() per Heikki's suggestion in [1]. Patches 0017 and 0018 make some changes to the TIDBitmap API to support having multiple TBMIterateResults at the same time instead of reusing the same one when iterating. 0019 uses the read stream API and removes all the bespoke prefetching code from bitmap heap scan. - Melanie [1] https://www.postgresql.org/message-id/5a172d1e-d69c-409a-b1fa-6521214c81c2%40iki.fi
Attachment
- v22-0005-BitmapHeapScan-initialize-some-prefetch-state-el.patch
- v22-0002-Remove-table_scan_bitmap_next_tuple-parameter-tb.patch
- v22-0003-Make-table_scan_bitmap_next_block-async-friendly.patch
- v22-0001-table_scan_bitmap_next_block-counts-lossy-and-ex.patch
- v22-0004-Add-common-interface-for-TBMIterators.patch
- v22-0006-BitmapHeapScan-uses-unified-iterator.patch
- v22-0007-BitmapHeapScan-Make-prefetch-sync-error-more-det.patch
- v22-0008-Push-current-scan-descriptor-into-specialized-sc.patch
- v22-0009-Remove-ss_current-prefix-from-ss_currentScanDesc.patch
- v22-0010-Add-scan_in_progress-to-BitmapHeapScanState.patch
- v22-0012-Update-variable-names-in-bitmap-scan-descriptors.patch
- v22-0011-Make-new-bitmap-table-scan-and-bitmap-heap-scan-.patch
- v22-0013-BitmapHeapScan-lift-and-shift-prefetch-functions.patch
- v22-0014-BitmapHeapScan-Push-prefetch-code-into-heap-AM.patch
- v22-0015-BitmapHeapScan-move-per-scan-setup-into-a-helper.patch
- v22-0016-Remove-table-AM-callback-scan_bitmap_next_block.patch
- v22-0018-Separate-TBMIterator-and-TBMIterateResult.patch
- v22-0017-Hard-code-TBMIterateResult-offsets-array-size.patch
- v22-0019-Use-streaming-I-O-in-Bitmap-Heap-Scans.patch
Hi, I went through v22 to remind myself of what the patches do and do some basic review - I have some simple questions / comments for now, nothing major. I've kept the comments in separate 'review' patches, it does not seem worth copying here. regards -- Tomas Vondra EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
Attachment
- v22b-0001-table_scan_bitmap_next_block-counts-lossy-and-e.patch
- v22b-0002-review.patch
- v22b-0003-Remove-table_scan_bitmap_next_tuple-parameter-t.patch
- v22b-0004-Make-table_scan_bitmap_next_block-async-friendl.patch
- v22b-0005-review.patch
- v22b-0006-Add-common-interface-for-TBMIterators.patch
- v22b-0007-review.patch
- v22b-0008-BitmapHeapScan-initialize-some-prefetch-state-e.patch
- v22b-0009-BitmapHeapScan-uses-unified-iterator.patch
- v22b-0010-review.patch
- v22b-0011-BitmapHeapScan-Make-prefetch-sync-error-more-de.patch
- v22b-0012-Push-current-scan-descriptor-into-specialized-s.patch
- v22b-0013-review.patch
- v22b-0014-Remove-ss_current-prefix-from-ss_currentScanDes.patch
- v22b-0015-Add-scan_in_progress-to-BitmapHeapScanState.patch
- v22b-0016-Make-new-bitmap-table-scan-and-bitmap-heap-scan.patch
- v22b-0017-review.patch
- v22b-0018-Update-variable-names-in-bitmap-scan-descriptor.patch
- v22b-0019-review.patch
- v22b-0020-BitmapHeapScan-lift-and-shift-prefetch-function.patch
- v22b-0021-BitmapHeapScan-Push-prefetch-code-into-heap-AM.patch
- v22b-0022-review.patch
- v22b-0023-BitmapHeapScan-move-per-scan-setup-into-a-helpe.patch
- v22b-0024-Remove-table-AM-callback-scan_bitmap_next_block.patch
- v22b-0025-review.patch
- v22b-0026-Hard-code-TBMIterateResult-offsets-array-size.patch
- v22b-0027-review.patch
- v22b-0028-Separate-TBMIterator-and-TBMIterateResult.patch
- v22b-0029-Use-streaming-I-O-in-Bitmap-Heap-Scans.patch
On Tue, Jun 18, 2024 at 6:02 PM Tomas Vondra
<tomas.vondra@enterprisedb.com> wrote:
>
> I went through v22 to remind myself of what the patches do and do some
> basic review - I have some simple questions / comments for now, nothing
> major. I've kept the comments in separate 'review' patches, it does not
> seem worth copying here.
Thanks so much for the review!
I've implemented your feedback in attached v23 except for what I
mention below. I have not gone through each patch in the new set very
carefully after making the changes because I think we should resolve
the question of adding the new table scan descriptor before I do that.
A change there will require a big rebase. Then I can go through each
patch very carefully.
From your v22b-0005-review.patch:
src/backend/executor/nodeBitmapHeapscan.c | 14 ++++++++++++++
src/include/access/tableam.h | 2 ++
2 files changed, 16 insertions(+)
diff --git a/src/backend/executor/nodeBitmapHeapscan.c
b/src/backend/executor/nodeBitmapHeapscan.c
index e8b4a754434..6d7ef9ced19 100644
--- a/src/backend/executor/nodeBitmapHeapscan.c
+++ b/src/backend/executor/nodeBitmapHeapscan.c
@@ -270,6 +270,20 @@ new_page:
BitmapAdjustPrefetchIterator(node);
+ /*
+ * XXX I'm a bit unsure if this needs to be handled using
goto. Wouldn't
+ * it be simpler / easier to understand to have two nested loops?
+ *
+ * while (true)
+ * if (!table_scan_bitmap_next_block(...)) { break; }
+ * while (table_scan_bitmap_next_tuple(...)) {
+ * ... process tuples ...
+ * }
+ *
+ * But I haven't tried implementing this.
+ */
if (!table_scan_bitmap_next_block(scan, &node->blockno, &node->recheck,
&node->lossy_pages,
&node->exact_pages))
break;
We need to call table_scan_bimtap_next_block() the first time we call
BitmapHeapNext() on each scan but all subsequent invocations of
BitmapHeapNext() must call table_scan_bitmap_next_tuple() first each
-- because we return from BitmapHeapNext() to yield a tuple even when
there are more tuples on the page. I tried refactoring this a few
different ways and personally found the goto most clear.
From your v22b-0010-review.patch:
@@ -557,6 +559,8 @@ ExecReScanBitmapHeapScan(BitmapHeapScanState *node)
table_rescan(node->ss.ss_currentScanDesc, NULL);
/* release bitmaps and buffers if any */
+ /* XXX seems it should not be right after the comment, also shouldn't
+ * we still reset the prefetch_iterator field to NULL? */
tbm_end_iterate(&node->prefetch_iterator);
if (node->tbm)
tbm_free(node->tbm);
prefetch_iterator is a TBMIterator which is stored in the struct (as
opposed to having a pointer to it stored in the struct).
tbm_end_iterate() sets the actual private and shared iterator pointers
to NULL.
From your v22b-0017-review.patch
diff --git a/src/include/access/relscan.h b/src/include/access/relscan.h
index 036ef29e7d5..9c711ce0eb0 100644
--- a/src/include/access/relscan.h
+++ b/src/include/access/relscan.h
@@ -52,6 +52,13 @@ typedef struct TableScanDescData
} TableScanDescData;
typedef struct TableScanDescData *TableScanDesc;
+/*
+ * XXX I don't understand why we should have this special node if we
+ * don't have special nodes for other scan types.
In this case, up until the final commit (using the read stream
interface), there are six fields required by bitmap heap scan that are
not needed by any other user of HeapScanDescData. There are also
several members of HeapScanDescData that are not needed by bitmap heap
scans and all of the setup in initscan() for those fields is not
required for bitmap heap scans.
Also, because the BitmapHeapScanDesc needs information like the
ParallelBitmapHeapState and prefetch_maximum (for use in prefetching),
the scan_begin() callback would have to take those as parameters. I
thought adding so much bitmap table scan-specific information to the
generic table scan callbacks was a bad idea.
Once we add the read stream API code, the number of fields required
for bitmap heap scan that are in the scan descriptor goes down to
three. So, perhaps we could justify having that many bitmap heap
scan-specific fields in the HeapScanDescData.
Though, I actually think we could start moving toward having
specialized scan descriptors if the requirements for that scan type
are appreciably different. I can't think of new code that would be
added to the HeapScanDescData that would have to be duplicated over to
specialized scan descriptors.
With the final read stream state, I can see the argument for bloating
the HeapScanDescData with three extra members and avoiding making new
scan descriptors. But, for the intermediate patches which have all of
the bitmap prefetch members pushed down into the HeapScanDescData, I
think it is really not okay. Six members only for bitmap heap scans
and two bitmap-specific members to begin_scan() seems bad.
What I thought we plan to do is commit the refactoring patches
sometime after the branch for 18 is cut and leave the final read
stream patch uncommitted so we can do performance testing on it. If
you think it is okay to have the six member bloated HeapScanDescData
in master until we push the read stream code, I am okay with removing
the BitmapTableScanDesc and BitmapHeapScanDesc.
+ * XXX Also, maybe this should do the naming convention with Data at
+ * the end (mostly for consistency).
+ */
typedef struct BitmapTableScanDesc
{
Relation rs_rd; /* heap relation descriptor */
I really want to move away from these Data typedefs. I find them so
confusing as a developer, but it's hard to justify ripping out the
existing ones because of code churn. If we add new scan descriptors, I
had really hoped to start using a different pattern.
From your v22b-0025-review.patch
diff --git a/src/backend/access/table/tableamapi.c
b/src/backend/access/table/tableamapi.c
index a47527d490a..379b7df619e 100644
--- a/src/backend/access/table/tableamapi.c
+++ b/src/backend/access/table/tableamapi.c
@@ -91,6 +91,9 @@ GetTableAmRoutine(Oid amhandler)
Assert(routine->relation_estimate_size != NULL);
+ /* XXX shouldn't this check that _block is not set without _tuple?
+ * Also, the commit message says _block is "local helper" but then
+ * why would it be part of TableAmRoutine? */
Assert(routine->scan_sample_next_block != NULL);
Assert(routine->scan_sample_next_tuple != NULL);
scan_bitmap_next_block() is removed as a table AM callback here, so we
don't check if it is set. We do still check if scan_bitmap_next_tuple
is set if amgetbitmap is not NULL. heapam_scan_bitmap_next_block() is
now a local helper for heapam_scan_bitmap_next_tuple(). Perhaps I
should change the name to something like heap_scan_bitmap_next_block()
to make it clear it is not an implementation of a table AM callback?
- Melanie
Attachment
- v23-0005-BitmapHeapScan-initialize-some-prefetch-state-el.patch
- v23-0002-Remove-table_scan_bitmap_next_tuple-parameter-tb.patch
- v23-0003-Make-table_scan_bitmap_next_block-async-friendly.patch
- v23-0001-table_scan_bitmap_next_block-counts-lossy-and-ex.patch
- v23-0004-Add-common-interface-for-TBMIterators.patch
- v23-0006-BitmapHeapScan-uses-unified-iterator.patch
- v23-0009-Remove-ss_current-prefix-from-ss_currentScanDesc.patch
- v23-0007-BitmapHeapScan-Make-prefetch-sync-error-more-det.patch
- v23-0010-Add-scan_in_progress-to-BitmapHeapScanState.patch
- v23-0008-Push-current-scan-descriptor-into-specialized-sc.patch
- v23-0011-Make-new-bitmap-table-scan-and-bitmap-heap-scan-.patch
- v23-0012-Update-variable-names-in-bitmap-scan-descriptors.patch
- v23-0015-BitmapHeapScan-move-per-scan-setup-into-a-helper.patch
- v23-0013-BitmapHeapScan-lift-and-shift-prefetch-functions.patch
- v23-0016-Remove-table-AM-callback-scan_bitmap_next_block.patch
- v23-0017-Hard-code-TBMIterateResult-offsets-array-size.patch
- v23-0019-Use-streaming-I-O-in-Bitmap-Heap-Scans.patch
- v23-0018-Separate-TBMIterator-and-TBMIterateResult.patch
- v23-0014-BitmapHeapScan-Push-prefetch-code-into-heap-AM.patch
On 6/19/24 17:55, Melanie Plageman wrote:
> On Tue, Jun 18, 2024 at 6:02 PM Tomas Vondra
> <tomas.vondra@enterprisedb.com> wrote:
>>
>> I went through v22 to remind myself of what the patches do and do some
>> basic review - I have some simple questions / comments for now, nothing
>> major. I've kept the comments in separate 'review' patches, it does not
>> seem worth copying here.
>
> Thanks so much for the review!
>
> I've implemented your feedback in attached v23 except for what I
> mention below. I have not gone through each patch in the new set very
> carefully after making the changes because I think we should resolve
> the question of adding the new table scan descriptor before I do that.
> A change there will require a big rebase. Then I can go through each
> patch very carefully.
>
> From your v22b-0005-review.patch:
>
> src/backend/executor/nodeBitmapHeapscan.c | 14 ++++++++++++++
> src/include/access/tableam.h | 2 ++
> 2 files changed, 16 insertions(+)
>
> diff --git a/src/backend/executor/nodeBitmapHeapscan.c
> b/src/backend/executor/nodeBitmapHeapscan.c
> index e8b4a754434..6d7ef9ced19 100644
> --- a/src/backend/executor/nodeBitmapHeapscan.c
> +++ b/src/backend/executor/nodeBitmapHeapscan.c
> @@ -270,6 +270,20 @@ new_page:
>
> BitmapAdjustPrefetchIterator(node);
>
> + /*
> + * XXX I'm a bit unsure if this needs to be handled using
> goto. Wouldn't
> + * it be simpler / easier to understand to have two nested loops?
> + *
> + * while (true)
> + * if (!table_scan_bitmap_next_block(...)) { break; }
> + * while (table_scan_bitmap_next_tuple(...)) {
> + * ... process tuples ...
> + * }
> + *
> + * But I haven't tried implementing this.
> + */
> if (!table_scan_bitmap_next_block(scan, &node->blockno, &node->recheck,
> &node->lossy_pages,
> &node->exact_pages))
> break;
>
> We need to call table_scan_bimtap_next_block() the first time we call
> BitmapHeapNext() on each scan but all subsequent invocations of
> BitmapHeapNext() must call table_scan_bitmap_next_tuple() first each
> -- because we return from BitmapHeapNext() to yield a tuple even when
> there are more tuples on the page. I tried refactoring this a few
> different ways and personally found the goto most clear.
>
OK, I haven't tried refactoring this myself, so you're probably right.
> From your v22b-0010-review.patch:
>
> @@ -557,6 +559,8 @@ ExecReScanBitmapHeapScan(BitmapHeapScanState *node)
> table_rescan(node->ss.ss_currentScanDesc, NULL);
>
> /* release bitmaps and buffers if any */
> + /* XXX seems it should not be right after the comment, also shouldn't
> + * we still reset the prefetch_iterator field to NULL? */
> tbm_end_iterate(&node->prefetch_iterator);
> if (node->tbm)
> tbm_free(node->tbm);
>
> prefetch_iterator is a TBMIterator which is stored in the struct (as
> opposed to having a pointer to it stored in the struct).
> tbm_end_iterate() sets the actual private and shared iterator pointers
> to NULL.
>
Ah, right.
> From your v22b-0017-review.patch
>
> diff --git a/src/include/access/relscan.h b/src/include/access/relscan.h
> index 036ef29e7d5..9c711ce0eb0 100644
> --- a/src/include/access/relscan.h
> +++ b/src/include/access/relscan.h
> @@ -52,6 +52,13 @@ typedef struct TableScanDescData
> } TableScanDescData;
> typedef struct TableScanDescData *TableScanDesc;
>
> +/*
> + * XXX I don't understand why we should have this special node if we
> + * don't have special nodes for other scan types.
>
> In this case, up until the final commit (using the read stream
> interface), there are six fields required by bitmap heap scan that are
> not needed by any other user of HeapScanDescData. There are also
> several members of HeapScanDescData that are not needed by bitmap heap
> scans and all of the setup in initscan() for those fields is not
> required for bitmap heap scans.
>
> Also, because the BitmapHeapScanDesc needs information like the
> ParallelBitmapHeapState and prefetch_maximum (for use in prefetching),
> the scan_begin() callback would have to take those as parameters. I
> thought adding so much bitmap table scan-specific information to the
> generic table scan callbacks was a bad idea.
>
> Once we add the read stream API code, the number of fields required
> for bitmap heap scan that are in the scan descriptor goes down to
> three. So, perhaps we could justify having that many bitmap heap
> scan-specific fields in the HeapScanDescData.
>
> Though, I actually think we could start moving toward having
> specialized scan descriptors if the requirements for that scan type
> are appreciably different. I can't think of new code that would be
> added to the HeapScanDescData that would have to be duplicated over to
> specialized scan descriptors.
>
> With the final read stream state, I can see the argument for bloating
> the HeapScanDescData with three extra members and avoiding making new
> scan descriptors. But, for the intermediate patches which have all of
> the bitmap prefetch members pushed down into the HeapScanDescData, I
> think it is really not okay. Six members only for bitmap heap scans
> and two bitmap-specific members to begin_scan() seems bad.
>
> What I thought we plan to do is commit the refactoring patches
> sometime after the branch for 18 is cut and leave the final read
> stream patch uncommitted so we can do performance testing on it. If
> you think it is okay to have the six member bloated HeapScanDescData
> in master until we push the read stream code, I am okay with removing
> the BitmapTableScanDesc and BitmapHeapScanDesc.
>
I admit I don't have a very good idea what the ideal / desired state
look like. My comment is motivated solely by the feeling that it seems
strange to have one struct serving most scan types, and then a special
struct for one particular scan type ...
> + * XXX Also, maybe this should do the naming convention with Data at
> + * the end (mostly for consistency).
> + */
> typedef struct BitmapTableScanDesc
> {
> Relation rs_rd; /* heap relation descriptor */
>
> I really want to move away from these Data typedefs. I find them so
> confusing as a developer, but it's hard to justify ripping out the
> existing ones because of code churn. If we add new scan descriptors, I
> had really hoped to start using a different pattern.
>
Perhaps, I understand that. I'm not a huge fan of Data structs myself,
but I'm not sure it's a great idea to do both things in the same area of
code. That's guaranteed to be confusing for everyone ...
If we want to move away from that, I'd rather rename the nearby structs
and accept the code churn.
> From your v22b-0025-review.patch
>
> diff --git a/src/backend/access/table/tableamapi.c
> b/src/backend/access/table/tableamapi.c
> index a47527d490a..379b7df619e 100644
> --- a/src/backend/access/table/tableamapi.c
> +++ b/src/backend/access/table/tableamapi.c
> @@ -91,6 +91,9 @@ GetTableAmRoutine(Oid amhandler)
>
> Assert(routine->relation_estimate_size != NULL);
>
> + /* XXX shouldn't this check that _block is not set without _tuple?
> + * Also, the commit message says _block is "local helper" but then
> + * why would it be part of TableAmRoutine? */
> Assert(routine->scan_sample_next_block != NULL);
> Assert(routine->scan_sample_next_tuple != NULL);
>
> scan_bitmap_next_block() is removed as a table AM callback here, so we
> don't check if it is set. We do still check if scan_bitmap_next_tuple
> is set if amgetbitmap is not NULL. heapam_scan_bitmap_next_block() is
> now a local helper for heapam_scan_bitmap_next_tuple(). Perhaps I
> should change the name to something like heap_scan_bitmap_next_block()
> to make it clear it is not an implementation of a table AM callback?
>
I'm quite confused by this. How could it not be am AM callback when it's
in the AM routine?
regards
--
Tomas Vondra
EnterpriseDB: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
On 2024-Jun-14, Melanie Plageman wrote: > Subject: [PATCH v21 12/20] Update variable names in bitmap scan descriptors > > The previous commit which added BitmapTableScanDesc and > BitmapHeapScanDesc used the existing member names from TableScanDescData > and HeapScanDescData for diff clarity. This commit renames the members > -- in many cases by removing the rs_ prefix which is not relevant or > needed here. *Cough* Why? It makes grepping for struct members useless. I'd rather keep these prefixes, as they allow easier code exploration. (Sometimes when I need to search for uses of some field with a name that's too common, I add a prefix to the name and let the compiler guide me to them. But that's a waste of time ...) Thanks, -- Álvaro Herrera Breisgau, Deutschland — https://www.EnterpriseDB.com/ "Cuando mañana llegue pelearemos segun lo que mañana exija" (Mowgli)
On Wed, Jun 19, 2024 at 12:38 PM Tomas Vondra
<tomas.vondra@enterprisedb.com> wrote:
>
>
>
> On 6/19/24 17:55, Melanie Plageman wrote:
> > On Tue, Jun 18, 2024 at 6:02 PM Tomas Vondra
> > <tomas.vondra@enterprisedb.com> wrote:
>
> > From your v22b-0017-review.patch
> >
> > diff --git a/src/include/access/relscan.h b/src/include/access/relscan.h
> > index 036ef29e7d5..9c711ce0eb0 100644
> > --- a/src/include/access/relscan.h
> > +++ b/src/include/access/relscan.h
> > @@ -52,6 +52,13 @@ typedef struct TableScanDescData
> > } TableScanDescData;
> > typedef struct TableScanDescData *TableScanDesc;
> >
> > +/*
> > + * XXX I don't understand why we should have this special node if we
> > + * don't have special nodes for other scan types.
> >
> > In this case, up until the final commit (using the read stream
> > interface), there are six fields required by bitmap heap scan that are
> > not needed by any other user of HeapScanDescData. There are also
> > several members of HeapScanDescData that are not needed by bitmap heap
> > scans and all of the setup in initscan() for those fields is not
> > required for bitmap heap scans.
> >
> > Also, because the BitmapHeapScanDesc needs information like the
> > ParallelBitmapHeapState and prefetch_maximum (for use in prefetching),
> > the scan_begin() callback would have to take those as parameters. I
> > thought adding so much bitmap table scan-specific information to the
> > generic table scan callbacks was a bad idea.
> >
> > Once we add the read stream API code, the number of fields required
> > for bitmap heap scan that are in the scan descriptor goes down to
> > three. So, perhaps we could justify having that many bitmap heap
> > scan-specific fields in the HeapScanDescData.
> >
> > Though, I actually think we could start moving toward having
> > specialized scan descriptors if the requirements for that scan type
> > are appreciably different. I can't think of new code that would be
> > added to the HeapScanDescData that would have to be duplicated over to
> > specialized scan descriptors.
> >
> > With the final read stream state, I can see the argument for bloating
> > the HeapScanDescData with three extra members and avoiding making new
> > scan descriptors. But, for the intermediate patches which have all of
> > the bitmap prefetch members pushed down into the HeapScanDescData, I
> > think it is really not okay. Six members only for bitmap heap scans
> > and two bitmap-specific members to begin_scan() seems bad.
> >
> > What I thought we plan to do is commit the refactoring patches
> > sometime after the branch for 18 is cut and leave the final read
> > stream patch uncommitted so we can do performance testing on it. If
> > you think it is okay to have the six member bloated HeapScanDescData
> > in master until we push the read stream code, I am okay with removing
> > the BitmapTableScanDesc and BitmapHeapScanDesc.
> >
>
> I admit I don't have a very good idea what the ideal / desired state
> look like. My comment is motivated solely by the feeling that it seems
> strange to have one struct serving most scan types, and then a special
> struct for one particular scan type ...
I see what you are saying. We could make BitmapTableScanDesc inherit
from TableScanDescData which would be similar to what we do with other
things like the executor scan nodes themselves. We would waste space
and LOC with initializing the unneeded members, but it might seem less
weird.
Whether we want the specialized scan descriptors at all is probably
the bigger question, though.
The top level BitmapTableScanDesc is motivated by wanting fewer bitmap
table scan specific members passed to scan_begin(). And the
BitmapHeapScanDesc is motivated by this plus wanting to avoid bloating
the HeapScanDescData.
If you look at at HEAD~1 (with my patches applied) and think you would
be okay with
1) the contents of the BitmapHeapScanDesc being in the HeapScanDescData and
2) the extra bitmap table scan-specific parameters in scan_begin_bm()
being passed to scan_begin()
then I will remove the specialized scan descriptors.
The final state (with the read stream) will still have three bitmap
heap scan-specific members in the HeapScanDescData.
Would it help if I do a version like this so you can see what it is like?
> > + * XXX Also, maybe this should do the naming convention with Data at
> > + * the end (mostly for consistency).
> > + */
> > typedef struct BitmapTableScanDesc
> > {
> > Relation rs_rd; /* heap relation descriptor */
> >
> > I really want to move away from these Data typedefs. I find them so
> > confusing as a developer, but it's hard to justify ripping out the
> > existing ones because of code churn. If we add new scan descriptors, I
> > had really hoped to start using a different pattern.
> >
>
> Perhaps, I understand that. I'm not a huge fan of Data structs myself,
> but I'm not sure it's a great idea to do both things in the same area of
> code. That's guaranteed to be confusing for everyone ...
>
> If we want to move away from that, I'd rather rename the nearby structs
> and accept the code churn.
Makes sense. I'll do a patch to get rid of the typedefs and rename
TableScanDescData -> TableScanDesc (also for the heap scan desc) if we
end up keeping the specialized scan descriptors.
> > From your v22b-0025-review.patch
> >
> > diff --git a/src/backend/access/table/tableamapi.c
> > b/src/backend/access/table/tableamapi.c
> > index a47527d490a..379b7df619e 100644
> > --- a/src/backend/access/table/tableamapi.c
> > +++ b/src/backend/access/table/tableamapi.c
> > @@ -91,6 +91,9 @@ GetTableAmRoutine(Oid amhandler)
> >
> > Assert(routine->relation_estimate_size != NULL);
> >
> > + /* XXX shouldn't this check that _block is not set without _tuple?
> > + * Also, the commit message says _block is "local helper" but then
> > + * why would it be part of TableAmRoutine? */
> > Assert(routine->scan_sample_next_block != NULL);
> > Assert(routine->scan_sample_next_tuple != NULL);
> >
> > scan_bitmap_next_block() is removed as a table AM callback here, so we
> > don't check if it is set. We do still check if scan_bitmap_next_tuple
> > is set if amgetbitmap is not NULL. heapam_scan_bitmap_next_block() is
> > now a local helper for heapam_scan_bitmap_next_tuple(). Perhaps I
> > should change the name to something like heap_scan_bitmap_next_block()
> > to make it clear it is not an implementation of a table AM callback?
> >
>
> I'm quite confused by this. How could it not be am AM callback when it's
> in the AM routine?
I removed the callback for getting the next block. Now,
BitmapHeapNext() just calls table_scan_bitmap_next_tuple() and the
table AM is responsible for advancing to the next block when the
current block is out of tuples. In the new code structure, there isn't
much point in having a separate table_scan_bitmap_next_block()
callback. Advancing the iterator to get the next block assignment is
already pushed into the table AM itself. So, getting the next block
can be an internal detail of how the table AM gets the next tuple.
Heikki actually originally suggested it, and I thought it made sense.
- Melanie
Thanks for taking a look at my patches, Álvaro! On Wed, Jun 19, 2024 at 12:51 PM Alvaro Herrera <alvherre@alvh.no-ip.org> wrote: > > On 2024-Jun-14, Melanie Plageman wrote: > > > Subject: [PATCH v21 12/20] Update variable names in bitmap scan descriptors > > > > The previous commit which added BitmapTableScanDesc and > > BitmapHeapScanDesc used the existing member names from TableScanDescData > > and HeapScanDescData for diff clarity. This commit renames the members > > -- in many cases by removing the rs_ prefix which is not relevant or > > needed here. > > *Cough* Why? It makes grepping for struct members useless. I'd rather > keep these prefixes, as they allow easier code exploration. (Sometimes > when I need to search for uses of some field with a name that's too > common, I add a prefix to the name and let the compiler guide me to > them. But that's a waste of time ...) If we want to make it possible to use no tools and only manually grep for struct members, that means we can never reuse struct member names. Across a project of our size, that seems like a very serious restriction. Adding prefixes in struct members makes it harder to read code -- both because it makes the names longer and because people are more prone to abbreviate the meaningful parts of the struct member name to make the whole name shorter. While I understand we as a project want to make it possible to hack on Postgres without an IDE or a set of vim plugins a mile long, I also think we have to make some compromises for readability. Most commonly used text editors have LSP (language server protocol) support and should allow for meaningful identification of the usages of a struct member even if it has the same name as a member of another struct. That being said, I'm not unreasonable. If we have decided we can not reuse struct member names, I will change my patch. - Melanie
On 19/06/2024 18:55, Melanie Plageman wrote:
> On Tue, Jun 18, 2024 at 6:02 PM Tomas Vondra
> <tomas.vondra@enterprisedb.com> wrote:
>>
>> I went through v22 to remind myself of what the patches do and do some
>> basic review - I have some simple questions / comments for now, nothing
>> major. I've kept the comments in separate 'review' patches, it does not
>> seem worth copying here.
>
> Thanks so much for the review!
>
> I've implemented your feedback in attached v23 except for what I
> mention below. I have not gone through each patch in the new set very
> carefully after making the changes because I think we should resolve
> the question of adding the new table scan descriptor before I do that.
> A change there will require a big rebase. Then I can go through each
> patch very carefully.
Had a quick look at this after a long pause. I only looked at the first
few, hoping that reviewing them would allow you to commit at least some
of them, making the rest easier.
v23-0001-table_scan_bitmap_next_block-counts-lossy-and-ex.patch
Looks good to me. (I'm not sure if this would be a net positive change
on its own, but it's needed by the later patch so OK)
v23-0002-Remove-table_scan_bitmap_next_tuple-parameter-tb.patch
LGTM
v23-0003-Make-table_scan_bitmap_next_block-async-friendly.patch
> @@ -1955,19 +1954,26 @@ table_relation_estimate_size(Relation rel, int32 *attr_widths,
> */
>
> /*
> - * Prepare to fetch / check / return tuples from `tbmres->blockno` as part of a
> - * bitmap table scan. `scan` needs to have been started via
> - * table_beginscan_bm(). Returns false if there are no tuples to be found on
> - * the page, true otherwise. `lossy_pages` is incremented if the block's
> - * representation in the bitmap is lossy; otherwise, `exact_pages` is
> - * incremented.
> + * Prepare to fetch / check / return tuples as part of a bitmap table scan.
> + * `scan` needs to have been started via table_beginscan_bm(). Returns false if
> + * there are no more blocks in the bitmap, true otherwise. `lossy_pages` is
> + * incremented if the block's representation in the bitmap is lossy; otherwise,
> + * `exact_pages` is incremented.
> + *
> + * `recheck` is set by the table AM to indicate whether or not the tuples
> + * from this block should be rechecked. Tuples from lossy pages will always
> + * need to be rechecked, but some non-lossy pages' tuples may also require
> + * recheck.
> + *
> + * `blockno` is only used in bitmap table scan code to validate that the
> + * prefetch block is staying ahead of the current block.
> *
> * Note, this is an optionally implemented function, therefore should only be
> * used after verifying the presence (at plan time or such).
> */
> static inline bool
> table_scan_bitmap_next_block(TableScanDesc scan,
> - struct TBMIterateResult *tbmres,
> + BlockNumber *blockno, bool *recheck,
> long *lossy_pages,
> long *exact_pages)
> {
The new comment doesn't really explain what *blockno means. Is it an
input or output parameter? How is it used with the prefetching?
v23-0004-Add-common-interface-for-TBMIterators.patch
> +/*
> + * Start iteration on a shared or private bitmap iterator. Note that tbm will
> + * only be provided by private BitmapHeapScan callers. dsa and dsp will only be
> + * provided by parallel BitmapHeapScan callers. For shared callers, one process
> + * must already have called tbm_prepare_shared_iterate() to create and set up
> + * the TBMSharedIteratorState. The TBMIterator is passed by reference to
> + * accommodate callers who would like to allocate it inside an existing struct.
> + */
> +void
> +tbm_begin_iterate(TBMIterator *iterator, TIDBitmap *tbm,
> + dsa_area *dsa, dsa_pointer dsp)
> +{
> + Assert(iterator);
> +
> + iterator->private_iterator = NULL;
> + iterator->shared_iterator = NULL;
> + iterator->exhausted = false;
> +
> + /* Allocate a private iterator and attach the shared state to it */
> + if (DsaPointerIsValid(dsp))
> + iterator->shared_iterator = tbm_attach_shared_iterate(dsa, dsp);
> + else
> + iterator->private_iterator = tbm_begin_private_iterate(tbm);
> +}
Hmm, I haven't looked at how this is used the later patches, but a
function signature where some parameters are used or not depending on
the situation seems a bit awkward. Perhaps it would be better to let the
caller call tbm_attach_shared_iterate(dsa, dsp) or
tbm_begin_private_iterate(tbm), and provide a function to turn that into
a TBMIterator? Something like:
TBMIterator *tbm_iterator_from_shared_iterator(TBMSharedIterator *);
TBMIterator *tbm_iterator_from_private_iterator(TBMPrivateIterator *);
Does tbm_iterator() really need the 'exhausted' flag? The private and
shared variants work without one.
+1 on this patch in general, and I have no objections to its current
form either, the above are just suggestions to consider.
v23-0006-BitmapHeapScan-uses-unified-iterator.patch
Makes sense. (Might be better to squash this with the previous patch)
v23-0007-BitmapHeapScan-Make-prefetch-sync-error-more-det.patch
LGTM
v23-0008-Push-current-scan-descriptor-into-specialized-sc.patch
v23-0009-Remove-ss_current-prefix-from-ss_currentScanDesc.patch
LGTM. I would squash these together.
v23-0010-Add-scan_in_progress-to-BitmapHeapScanState.patch
> --- a/src/include/nodes/execnodes.h
> +++ b/src/include/nodes/execnodes.h
> @@ -1804,6 +1804,7 @@ typedef struct ParallelBitmapHeapState
> * prefetch_target current target prefetch distance
> * prefetch_maximum maximum value for prefetch_target
> * initialized is node is ready to iterate
> + * scan_in_progress is this a rescan
> * pstate shared state for parallel bitmap scan
> * recheck do current page's tuples need recheck
> * blockno used to validate pf and current block in sync
> @@ -1824,6 +1825,7 @@ typedef struct BitmapHeapScanState
> int prefetch_target;
> int prefetch_maximum;
> bool initialized;
> + bool scan_in_progress;
> ParallelBitmapHeapState *pstate;
> bool recheck;
> BlockNumber blockno;
Hmm, the "is this a rescan" comment sounds inaccurate, because it is set
as soon as the scan is started, not only when rescanning. Other than
that, LGTM.
--
Heikki Linnakangas
Neon (https://neon.tech)
On Wed, Jun 19, 2024 at 2:21 PM Melanie Plageman
<melanieplageman@gmail.com> wrote:
> If we want to make it possible to use no tools and only manually grep
> for struct members, that means we can never reuse struct member names.
> Across a project of our size, that seems like a very serious
> restriction. Adding prefixes in struct members makes it harder to read
> code -- both because it makes the names longer and because people are
> more prone to abbreviate the meaningful parts of the struct member
> name to make the whole name shorter.
I don't think we should go so far as to never reuse a structure member
name. But I also do use 'git grep' a lot to find stuff, and I don't
appreciate it when somebody names a key piece of machinery 'x' or 'n'
or something, especially when references to that thing could
reasonably occur almost anywhere in the source code. So if somebody is
creating a struct whose names are fairly generic and reasonably short,
I like the idea of using a prefix for those names. If the structure
members are things like that_thing_i_stored_behind_the_fridge (which
is long) or cytokine (which is non-generic) then they're greppable
anyway and it doesn't really matter. But surely changing something
like rs_flags to just flags is just making everyone's life harder:
[robert.haas pgsql]$ git grep rs_flags | wc -l
38
[robert.haas pgsql]$ git grep flags | wc -l
6348
--
Robert Haas
EDB: http://www.enterprisedb.com
Robert Haas <robertmhaas@gmail.com> writes:
> On Wed, Jun 19, 2024 at 2:21 PM Melanie Plageman
> <melanieplageman@gmail.com> wrote:
>> If we want to make it possible to use no tools and only manually grep
>> for struct members, that means we can never reuse struct member names.
>> Across a project of our size, that seems like a very serious
>> restriction. Adding prefixes in struct members makes it harder to read
>> code -- both because it makes the names longer and because people are
>> more prone to abbreviate the meaningful parts of the struct member
>> name to make the whole name shorter.
> I don't think we should go so far as to never reuse a structure member
> name. But I also do use 'git grep' a lot to find stuff, and I don't
> appreciate it when somebody names a key piece of machinery 'x' or 'n'
> or something, especially when references to that thing could
> reasonably occur almost anywhere in the source code. So if somebody is
> creating a struct whose names are fairly generic and reasonably short,
> I like the idea of using a prefix for those names. If the structure
> members are things like that_thing_i_stored_behind_the_fridge (which
> is long) or cytokine (which is non-generic) then they're greppable
> anyway and it doesn't really matter. But surely changing something
> like rs_flags to just flags is just making everyone's life harder:
I'm with Robert here: I care quite a lot about the greppability of
field names. I'm not arguing for prefixes everywhere, but I don't
think we should strip out prefixes we've already created, especially
if the result will be to have extremely generic field names.
regards, tom lane
On Mon, Aug 26, 2024 at 10:49 AM Tom Lane <tgl@sss.pgh.pa.us> wrote: > > Robert Haas <robertmhaas@gmail.com> writes: > > On Wed, Jun 19, 2024 at 2:21 PM Melanie Plageman > > <melanieplageman@gmail.com> wrote: > >> If we want to make it possible to use no tools and only manually grep > >> for struct members, that means we can never reuse struct member names. > >> Across a project of our size, that seems like a very serious > >> restriction. Adding prefixes in struct members makes it harder to read > >> code -- both because it makes the names longer and because people are > >> more prone to abbreviate the meaningful parts of the struct member > >> name to make the whole name shorter. > > > I don't think we should go so far as to never reuse a structure member > > name. But I also do use 'git grep' a lot to find stuff, and I don't > > appreciate it when somebody names a key piece of machinery 'x' or 'n' > > or something, especially when references to that thing could > > reasonably occur almost anywhere in the source code. So if somebody is > > creating a struct whose names are fairly generic and reasonably short, > > I like the idea of using a prefix for those names. If the structure > > members are things like that_thing_i_stored_behind_the_fridge (which > > is long) or cytokine (which is non-generic) then they're greppable > > anyway and it doesn't really matter. But surely changing something > > like rs_flags to just flags is just making everyone's life harder: > > I'm with Robert here: I care quite a lot about the greppability of > field names. I'm not arguing for prefixes everywhere, but I don't > think we should strip out prefixes we've already created, especially > if the result will be to have extremely generic field names. Okay, got it -- folks like the prefixes. I'm picking this patch set back up again after a long pause and I will restore all prefixes. What does the rs_* in the HeapScanDescData stand for, though? - Melanie
On Sat, Sep 28, 2024 at 8:13 AM Melanie Plageman <melanieplageman@gmail.com> wrote: > For the top-level TableScanDescData, I suggest we use a union with the > members of each scan type in it in anonymous structs (see 0001). Just by the way, you can't use anonymous structs or unions in C99 (that was added to C11), but most compilers accept them silently unless you use eg -std=c99. Some buildfarm animal or other would bleat about that (ask me how I know), but out CI doesn't pick it up :-( Maybe we should fix that. That's why you see a lot of code around that accesses unions through a member with a name like "u", because the author was shaking her fist at the god of standards and steadfastly refusing to think of a name. It's a shame in cases where you want to retrofit a union into existing code without having to adjust the code that accesses one of the members...
On Tue, Oct 8, 2024 at 4:56 PM Thomas Munro <thomas.munro@gmail.com> wrote: > > Just by the way, you can't use anonymous structs or unions in C99 > (that was added to C11), but most compilers accept them silently > unless you use eg -std=c99. Some buildfarm animal or other would > bleat about that (ask me how I know), but out CI doesn't pick it up > :-( Maybe we should fix that. That's why you see a lot of code > around that accesses unions through a member with a name like "u", > because the author was shaking her fist at the god of standards and > steadfastly refusing to think of a name. It's a shame in cases where > you want to retrofit a union into existing code without having to > adjust the code that accesses one of the members... Wow, that is terrible news. I fact-checked this with ast-grep, and you are right -- we don't use anonymous unions or structs. Perhaps this isn't the time or place but 1) I was under the impression we sometimes did things not allowed in C99 if they were really useful 2) remind me what we are waiting for to die so that we can use features from C11? - Melanie
Hi,
I took a quick look on the first couple parts of this series, up to
0007. I only have a couple minor review comments:
1) 0001
I find it a bit weird that we use ntuples to determine if it's exact or
lossy. Not an issue caused by this patch, of course, but maybe we could
improve that somehow? I mean this:
if (tbmres->ntuples >= 0)
(*exact_pages)++;
else
(*lossy_pages)++;
Also, maybe consider manually wrapping long lines - I haven't tried, but
I guess pgindent did not wrap this. I mean this line, for example:
... whitespace ... &node->stats.lossy_pages, &node->stats.exact_pages))
2) 0003
The "tidr" name is not particularly clear, IMO. Maybe just "range" would
be better?
+ struct
+ {
+ ItemPointerData rs_mintid;
+ ItemPointerData rs_maxtid;
+ } tidr;
Isn't it a bit strange that this patch remove tmbres from
heapam_scan_bitmap_next_block, when it was already removed from
table_scan_bitmap_next_tuple in the previous commit? Does it make sense
to separate it like this? (Maybe it does, not sure.)
I find this not very clear:
+ * recheck do current page's tuples need recheck
+ * blockno used to validate pf and current block in sync
+ * pfblockno used to validate pf stays ahead of current block
The "blockno" sounds weird - shouldn't it say "are in sync"? Also, not
clear what "pf" stands for without context (sure, it's "prefetch"). But
Why not to not write "prefetch_blockno" or something like that?
3) 0006
Seems unnecessary to keep this as separate commit, it's just log
message improvement. I'd merge it to the earlier patch.
4) 0007
Seems fine to me in principle. This adds "subclass" similar to what we
do for plan nodes, except that states are not derived from Node. But
it's the same approach.
Why not to do
scan = (HeapScanDesc *) bscan;
instead of
scan = &bscan->rs_heap_base;
I think the simple cast is what we do for the plan nodes, and we even do
it this way in the opposite direction in a couple places:
BitmapHeapScanDesc *bscan = (BitmapHeapScanDesc *) scan;
BTW would it be a good idea for heapam_scan_bitmap_next_block to check
the passed "scan" has SO_TYPE_BITMAPSCAN? We haven't been checking that
so far I think, but we only had a single struct ...
regards
--
Tomas Vondra
On Sat, Oct 19, 2024 at 2:18 AM Melanie Plageman
<melanieplageman@gmail.com> wrote:
>
> On Wed, Oct 16, 2024 at 11:09 AM Tomas Vondra <tomas@vondra.me> wrote:
> >
>
> Thanks for the review!
>
> >
> > 1) 0001
> >
> > I find it a bit weird that we use ntuples to determine if it's exact or
> > lossy. Not an issue caused by this patch, of course, but maybe we could
> > improve that somehow? I mean this:
> >
> > if (tbmres->ntuples >= 0)
> > (*exact_pages)++;
> > else
> > (*lossy_pages)++;
>
> I agree. The most straightforward solution would be to add a boolean
> `lossy` to TBMIterateResult.
>
> In some ways, I think it would make it a bit more clear because the
> situation with TBMIterateResult->recheck is already a bit confusing.
> It recheck is true if either 1: the Bitmap is lossy and we cannot use
> TBMIterateResult->offsets for this page or 2: the original query has a
> qual requiring recheck
>
> In the body of BitmapHeapNext() it says "if we are using lossy info,
> we have to recheck the qual conditions at every tuple". And in
> heapam_bitmap_next_block(), when the bitmap is lossy it says "bitmap
> is lossy, so we must examine each line pointer on the page. But we can
> ignore HOT chains, since we'll check each tuple anyway"
>
> I must admit I don't quite understand the connection between a lossy
> bitmap and needing to recheck the qual condition. Once we've gone to
> the underlying data, why do we need to recheck each tuple unless the
> qual requires it? It seems like PageTableEntry->recheck is usually
> passed as true for hash indexes and false for btree indexes. So maybe
> it has something to do with the index type?
>
> Anyway, adding a `lossy` member can be another patch. I just wanted to
> check if that was the solution you were thinking of.
>
> On a somewhat related note, I included a patch to alter the test at
> the top of heapam_bitmap_next_tuple()
>
> if (hscan->rs_cindex < 0 || hscan->rs_cindex >= hscan->rs_ntuples)
>
> I don't really see how rs_cindex could ever be < 0 for bitmap heap
> scans. But, I'm not confident enough about this to commit the patch
> really (obviously tests pass with the Assertion I added -- but still).
>
> > Also, maybe consider manually wrapping long lines - I haven't tried, but
> > I guess pgindent did not wrap this. I mean this line, for example:
> >
> > ... whitespace ... &node->stats.lossy_pages, &node->stats.exact_pages))
>
> Ah, yes. pgindent indeed does not help with this. I have now gone
> through every commit and used
>
> git diff origin/master | grep -E '^(\+|diff)' | sed 's/^+//' | expand
> -t4 | awk "length > 78 || /^diff/"
>
> from the committing wiki :)
>
> > 2) 0003
> >
> > The "tidr" name is not particularly clear, IMO. Maybe just "range" would
> > be better?
>
> I've updated this.
>
> > + struct
> > + {
> > + ItemPointerData rs_mintid;
> > + ItemPointerData rs_maxtid;
> > + } tidr;
> >
> > Isn't it a bit strange that this patch remove tmbres from
> > heapam_scan_bitmap_next_block, when it was already removed from
> > table_scan_bitmap_next_tuple in the previous commit? Does it make sense
> > to separate it like this? (Maybe it does, not sure.)
>
> I've combined them.
>
> > I find this not very clear:
> >
> > + * recheck do current page's tuples need recheck
> > + * blockno used to validate pf and current block in sync
> > + * pfblockno used to validate pf stays ahead of current block
> >
> > The "blockno" sounds weird - shouldn't it say "are in sync"? Also, not
> > clear what "pf" stands for without context (sure, it's "prefetch"). But
> > Why not to not write "prefetch_blockno" or something like that?
>
> Fixed.
>
> > 3) 0006
> >
> > Seems unnecessary to keep this as separate commit, it's just log
> > message improvement. I'd merge it to the earlier patch.
>
> Done.
>
> > 4) 0007
> >
> > Seems fine to me in principle. This adds "subclass" similar to what we
> > do for plan nodes, except that states are not derived from Node. But
> > it's the same approach.
> >
> > Why not to do
> >
> > scan = (HeapScanDesc *) bscan;
> >
> > instead of
> >
> > scan = &bscan->rs_heap_base;
> >
> > I think the simple cast is what we do for the plan nodes, and we even do
> > it this way in the opposite direction in a couple places:
> >
> > BitmapHeapScanDesc *bscan = (BitmapHeapScanDesc *) scan;
>
> Yea, in the reverse case, there is no way to refer to a specific
> member (because we are casting something of the parent type to the
> child type). But when we are casting from the child type to the parent
> type and can actually refer to a member, it seems preferable to
> explicitly refer to the member in case anyone ever inserts a member
> above rs_heap_base. However, for consistency with other places in the
> code, I've changed it as you suggested.
>
> Additionally, I've gone through an made a number of stylistic changes
> to conform more closely to existing styles (adding back more rs_
> prefixes and typedef'ing BitmapHeapScanDescData * as
> BitmapHeapScanDesc [despite how sad it makes me]).
>
> > BTW would it be a good idea for heapam_scan_bitmap_next_block to check
> > the passed "scan" has SO_TYPE_BITMAPSCAN? We haven't been checking that
> > so far I think, but we only had a single struct ...
>
> Good point. I've done this.
>
> I plan to commit 0002 and 0003 next week. I'm interested if you think
> 0001 is correct.
> I may also commit 0004-0006 as I feel they are ready too.
Are we planning to commit this refactoring? I think this refactoring
makes the overall code of BitmapHeapNext() quite clean and readable.
I haven't read all patches but 0001-0006 including 0009 makes this
code quite clean and readable. I like the refactoring of merging of
the shared iterator and the private iterator also.
--
Regards,
Dilip Kumar
EnterpriseDB: http://www.enterprisedb.com
On Sat, Oct 19, 2024 at 5:48 AM Melanie Plageman
<melanieplageman@gmail.com> wrote:
> I plan to commit 0002 and 0003 next week. I'm interested if you think
> 0001 is correct.
> I may also commit 0004-0006 as I feel they are ready too.
I noticed an oversight on master, which I think was introduced by the
0005 patch. In ExecReScanBitmapHeapScan:
- if (scan->st.bitmap.rs_shared_iterator)
- {
- tbm_end_shared_iterate(scan->st.bitmap.rs_shared_iterator);
- scan->st.bitmap.rs_shared_iterator = NULL;
- }
-
- if (scan->st.bitmap.rs_iterator)
- {
- tbm_end_private_iterate(scan->st.bitmap.rs_iterator);
- scan->st.bitmap.rs_iterator = NULL;
- }
+ tbm_end_iterate(&scan->st.rs_tbmiterator);
I don't think it's safe to call tbm_end_iterate directly on
scan->st.rs_tbmiterator, as it may have already been cleaned up by
this point.
Here is a query that triggers a SIGSEGV fault on master.
create table t (a int);
insert into t values (1), (2);
create index on t (a);
set enable_seqscan to off;
set enable_indexscan to off;
select * from t t1 left join t t2 on t1.a in (select a from t t3 where
t2.a > 1);
I think we need to check whether rs_tbmiterator is NULL before calling
tbm_end_iterate on it, like below.
--- a/src/backend/executor/nodeBitmapHeapscan.c
+++ b/src/backend/executor/nodeBitmapHeapscan.c
@@ -572,9 +572,11 @@ ExecReScanBitmapHeapScan(BitmapHeapScanState *node)
if (scan)
{
/*
- * End iteration on iterators saved in scan descriptor.
+ * End iteration on iterators saved in scan descriptor, if they
+ * haven't already been cleaned up.
*/
- tbm_end_iterate(&scan->st.rs_tbmiterator);
+ if (!tbm_exhausted(&scan->st.rs_tbmiterator))
+ tbm_end_iterate(&scan->st.rs_tbmiterator);
/* rescan to release any page pin */
table_rescan(node->ss.ss_currentScanDesc, NULL);
Thanks
Richard
On Thu, Dec 19, 2024 at 6:15 PM Richard Guo <guofenglinux@gmail.com> wrote:
> I think we need to check whether rs_tbmiterator is NULL before calling
> tbm_end_iterate on it, like below.
>
> --- a/src/backend/executor/nodeBitmapHeapscan.c
> +++ b/src/backend/executor/nodeBitmapHeapscan.c
> @@ -572,9 +572,11 @@ ExecReScanBitmapHeapScan(BitmapHeapScanState *node)
> if (scan)
> {
> /*
> - * End iteration on iterators saved in scan descriptor.
> + * End iteration on iterators saved in scan descriptor, if they
> + * haven't already been cleaned up.
> */
> - tbm_end_iterate(&scan->st.rs_tbmiterator);
> + if (!tbm_exhausted(&scan->st.rs_tbmiterator))
> + tbm_end_iterate(&scan->st.rs_tbmiterator);
>
> /* rescan to release any page pin */
> table_rescan(node->ss.ss_currentScanDesc, NULL);
This change may also be needed in ExecEndBitmapHeapScan().
Thanks
Richard
On Thu, Dec 19, 2024 at 10:12 AM Richard Guo <guofenglinux@gmail.com> wrote:
>
> On Thu, Dec 19, 2024 at 6:15 PM Richard Guo <guofenglinux@gmail.com> wrote:
> > I think we need to check whether rs_tbmiterator is NULL before calling
> > tbm_end_iterate on it, like below.
> >
> > --- a/src/backend/executor/nodeBitmapHeapscan.c
> > +++ b/src/backend/executor/nodeBitmapHeapscan.c
> > @@ -572,9 +572,11 @@ ExecReScanBitmapHeapScan(BitmapHeapScanState *node)
> > if (scan)
> > {
> > /*
> > - * End iteration on iterators saved in scan descriptor.
> > + * End iteration on iterators saved in scan descriptor, if they
> > + * haven't already been cleaned up.
> > */
> > - tbm_end_iterate(&scan->st.rs_tbmiterator);
> > + if (!tbm_exhausted(&scan->st.rs_tbmiterator))
> > + tbm_end_iterate(&scan->st.rs_tbmiterator);
> >
> > /* rescan to release any page pin */
> > table_rescan(node->ss.ss_currentScanDesc, NULL);
>
> This change may also be needed in ExecEndBitmapHeapScan().
Thanks, Richard! I'm working on the fix and adding the test case you found.
- Melanie
On Thu, Dec 19, 2024 at 10:23 AM Melanie Plageman
<melanieplageman@gmail.com> wrote:
>
> On Thu, Dec 19, 2024 at 10:12 AM Richard Guo <guofenglinux@gmail.com> wrote:
> >
> > On Thu, Dec 19, 2024 at 6:15 PM Richard Guo <guofenglinux@gmail.com> wrote:
> > > I think we need to check whether rs_tbmiterator is NULL before calling
> > > tbm_end_iterate on it, like below.
> > >
> > > --- a/src/backend/executor/nodeBitmapHeapscan.c
> > > +++ b/src/backend/executor/nodeBitmapHeapscan.c
> > > @@ -572,9 +572,11 @@ ExecReScanBitmapHeapScan(BitmapHeapScanState *node)
> > > if (scan)
> > > {
> > > /*
> > > - * End iteration on iterators saved in scan descriptor.
> > > + * End iteration on iterators saved in scan descriptor, if they
> > > + * haven't already been cleaned up.
> > > */
> > > - tbm_end_iterate(&scan->st.rs_tbmiterator);
> > > + if (!tbm_exhausted(&scan->st.rs_tbmiterator))
> > > + tbm_end_iterate(&scan->st.rs_tbmiterator);
> > >
> > > /* rescan to release any page pin */
> > > table_rescan(node->ss.ss_currentScanDesc, NULL);
> >
> > This change may also be needed in ExecEndBitmapHeapScan().
>
> Thanks, Richard! I'm working on the fix and adding the test case you found.
Okay, pushed. Thanks so much, Richard. I also noticed another
oversight and fixed it.
- Melanie
Hi, On Thu, 30 Jan 2025 at 00:38, Melanie Plageman <melanieplageman@gmail.com> wrote: > > On Wed, Jan 22, 2025 at 4:24 PM Melanie Plageman > <melanieplageman@gmail.com> wrote: > > > > 0001 is just the refactoring to push the setup into a helper. > > 0002-0003 are required refactoring of the TBMIterateResult and > > TBMIterator to support the read stream API. > > 0004 implements using the read stream API and removing the old prefetching code. > > 0005 removes the table_scan_bitmap_next_block() callback, as it is not > > really used anymore in BitmapHeapNext() to get the next block. > > > > I could use review feedback on all of them. 0001 should be ready to > > push once I get some review. > > Bilal mentioned offlist that 0001 had some indentation issues in one > of the comments. v27 attached. I have no other comments, 0001 LGTM. -- Regards, Nazir Bilal Yavuz Microsoft
On Tue, Mar 19, 2024 at 4:34 PM Tomas Vondra <tomas.vondra@enterprisedb.com> wrote: > > On 3/18/24 16:55, Tomas Vondra wrote: > > > > ... > > > > OK, I've restarted the tests for only 0012 and 0014 patches, and I'll > > wait for these to complete - I don't want to be looking for patterns > > until we have enough data to smooth this out. > > > > > > I now have results for 1M and 10M runs on the two builds (0012 and > 0014), attached is a chart for relative performance plotting > > (0014 timing) / (0012 timing) > > for "optimal' runs that would pick bitmapscan on their own. There's > nothing special about the config - I reduced the random_page_cost to > 1.5-2.0 to reflect both machines have flash storage, etc. > > Overall, the chart is pretty consistent with what I shared on Sunday. > Most of the results are fine (0014 is close to 0012 or faster), but > there's a bunch of cases that are much slower. Interestingly enough, > almost all of them are on the i5 machine, almost none of the xeon. My > guess is this is about the SSD type (SATA vs. NVMe). > > Attached if table of ~50 worst regressions (by the metric above), and > it's interesting the worst regressions are with eic=0 and eic=1. > > I decided to look at the first case (eic=0), and the timings are quite > stable - there are three runs for each build, with timings close to the > average (see below the table). > > Attached is a script that reproduces this on both machines, but the > difference is much more significant on i5 (~5x) compared to xeon (~2x). > > I haven't investigated what exactly is happening and why, hopefully the > script will allow you to reproduce this independently. I plan to take a > look, but I don't know when I'll have time for this. > > FWIW if the script does not reproduce this on your machines, I might be > able to give you access to the i5 machine. Let me know. I had this particular email on this thread bookmarked so I could go back and investigate the regression. The patch set has changed since these benchmarks were run. And, I honestly no longer remember what 0014 and 0012 were. There are four remaining patches in the set I posted earlier today in [1]. All of them are directly related to bitmap heap scan using the streaming read interface (i.e. not useful on their own). Therefore, it is time to investigate if we should merge streaming read bitmap heap scan. I ran the query included in the reproducer in this mail a dozen times on master and with the patches in [1] and the average speedup with my patch is 12%. So, at least for this query, I don't see a regression. What do you think about rerunning these old benchmarks to see what they look like now? - Melanie [1] https://www.postgresql.org/message-id/CAAKRu_as499kHb9B4B4%3D%2Bc%2B4p%2BOF_Bibd4KEdoqyBgjEaEUdgA%40mail.gmail.com
On 1/30/25 21:36, Melanie Plageman wrote: > > ... > > Attached v28 is rebased and has a few updates/cleanup. All patches in > the set need review and I need to do some benchmarking of v28-0003. > > - Melanie Hi, I've been re-running the benchmarks on v28 on Melanie's request. The tests are still running, but here's what I have so far. The results are pretty large, I've pushed them here: https://github.com/tvondra/bitmapscan-tests I've decommissioned the small "i5" machine and replaced it with a new ryzen 9900x one. I kept the "old" storage (SSD SATA RAID), but other than that it's much more capable. That might explain some of the differences in benchmark results. So now I have these two machines: xeon: 2x E5-2699v4 - nvme: WD Ultrastar DC SN640 960GB ryzen: Ryzen 9 9900X - data: Samsung SSD 990 PRO 1TB (NVME) - raid-nvme: 4x Samsung SSD 990 PRO 1TB (RAID0, NVME) - raid-sata: 4x Intel DC S3700 (RAID0) See the PDFs for the usual "colored pivot table" visualization, or the raw CSV files. The pivot table shows results for various combinations of parameters, the columns are for different patches and values of the effective_io_concurrency GUC. The columns on the right compare results to the previous patch, i.e. it shows how the query duration changes after applying the patch. I didn't have time to do a particularly detailed analysis yet, or try to investigate the regressions. But some basic observations. 1) xeon ------- This machine only has a single type of storage (NVMe SSD), and the results looks really good. Most of the chart is "green" i.e. the patch makes queries faster, and the regressions are random, for the very short queries, and it seems random / no pattern. Which means this is likely random noise, nothing to worry about. There's one minor issue that I failed to test the 0004 patch due to a bug in the script, so the PDF only compares master, 0001, 0002 and 0003. But that should not matter too much, because 0003 is the main change. There are "gaps" for tests on the 100M data set that are still running, but I think I'll abort those, it'd take many days to complete and it doesn't seem we'd learn very much. 2) ryzen -------- This "new" machine has multiple types of storage. The cached results (be it in shared buffers or in page cache) are not very interesting. 0003 helps a bit (~15%), but other than that it's just random noise. The "uncached" results starting on page 23 are much more interesting. In general 0001, 0002 and 0004 have little impact, it seems just random noise. So in the rest I'll focus on 0003. For the single nvme device (device: data), it seems mostly fine. It's green, even though there are a couple "localized regressions" for eic=0. I haven't looked into those yet. For the nvme RAID (device: raid-nvme), it's looks almost exactly the same, except that with parallel query (page 27) there's a clear area of regression with eic=1 (look for "column" of red cells). That's a bit unfortunate, because eic=1 is the default value. For the SATA SSD RAID (device: raid-sata), it's similar - a couple regressions for eic=0, just like for NVMe. But then there's also a couple regressions for higher eic values, usually for queries with selective conditions. Overall, I think this looks good. It might be a good idea to look into some of the regressions, but ultimately the read stream relies on a heuristic to determine how far ahead to read etc. And each heuristics has counter examples. So the presence of regressions is guaranteed, it should not be a reason to reject a patch on its own. There's one more thing to consider when looking at those results - the script *forces* the use of bitmap index scan, even if the planner would not pick it on it's own. The ryzen-filtered.pdf shows only results when that would be the case (i.e. the optimizer would pick bitmapscan). Most of the regressions are gone, simply because it'd do index scan, seqscan. Of course, this is not perfect - planning mistakes happen, and it would be nice to not regress more than before. The plan choice depends also on the cost parameters, and maybe with different values we'd pick bitmap scans more often. Anyway, the results look sensible. It might be good to investigate some of the regressions, and I'll try doing that if I find the time. But I don't think that's necessarily a blocker - every patch of this type will have a hardware where the heuristics doesn't quite do the right thing by default. Which is why we have GUCs to tune it if appropriate. regards -- Tomas Vondra
On Sun, Feb 9, 2025 at 9:27 AM Tomas Vondra <tomas@vondra.me> wrote:
>
>
> 2) ryzen
> --------
>
> This "new" machine has multiple types of storage. The cached results (be
> it in shared buffers or in page cache) are not very interesting. 0003
> helps a bit (~15%), but other than that it's just random noise.
>
> The "uncached" results starting on page 23 are much more interesting. In
> general 0001, 0002 and 0004 have little impact, it seems just random
> noise. So in the rest I'll focus on 0003.
>
> For the single nvme device (device: data), it seems mostly fine. It's
> green, even though there are a couple "localized regressions" for eic=0.
> I haven't looked into those yet.
>
> For the nvme RAID (device: raid-nvme), it's looks almost exactly the
> same, except that with parallel query (page 27) there's a clear area of
> regression with eic=1 (look for "column" of red cells). That's a bit
> unfortunate, because eic=1 is the default value.
It'll be hard to look into all of these, so I think I'll focus on
trying to reproduce something with eic=1 that I can reproduce on my
machine. So far, I can reproduce a regression with the following and
the data file attached.
# initdb and get set up with shared_buffers 1GB
psql -c "create table bitmap_scan_test (a bigint, b bigint, c text)
with (fillfactor = 25)"
psql -c "copy bitmap_scan_test from '/tmp/bitmap_scan_test.data'"
psql -c "create index on bitmap_scan_test (a)"
psql -c "vacuum analyze"
psql -c "checkpoint"
pg_ctl stop
echo 3 | sudo tee /proc/sys/vm/drop_caches
pg_ctl start
psql -c "SET max_parallel_workers_per_gather = 4;" \
-c "SET effective_io_concurrency = 1;" \
-c "SET parallel_setup_cost = 0;" \
-c "SET parallel_tuple_cost = 0;" \
-c "SET enable_seqscan = off;" \
-c "SET enable_indexscan = off;" \
-c "SET work_mem = 65536;"
psql -c "EXPLAIN SELECT * FROM bitmap_scan_test WHERE (a BETWEEN -33
AND 10015) OFFSET 1000000;"
psql -c "SELECT * FROM bitmap_scan_test WHERE (a BETWEEN -33 AND
10015) OFFSET 1000000;"
It's not a huge regression and planner doesn't naturally pick parallel
bitmap heap scan for this, but I don't have a SATA drive right now, so
I focused on something I could reproduce.
One thing I noticed when I was playing around with the script is that
depending on the values chosen by random(), there were differences in
timing. From your script, it looks like the $from and $to won't be the
same for master and the patch each time (they are set in the inner
most nesting level, below where $build is set). Am I understanding
correctly?
> Anyway, the results look sensible. It might be good to investigate some
> of the regressions, and I'll try doing that if I find the time. But I
> don't think that's necessarily a blocker - every patch of this type will
> have a hardware where the heuristics doesn't quite do the right thing by
> default. Which is why we have GUCs to tune it if appropriate.
Yea, I definitely won't be able to look into all of the regressions.
So, I guess we have to ask if we are willing to make the tradeoff.
- Melanie
On 2/10/25 19:02, Melanie Plageman wrote: > On Sun, Feb 9, 2025 at 9:27 AM Tomas Vondra <tomas@vondra.me> wrote: >> >> >> 2) ryzen >> -------- >> >> This "new" machine has multiple types of storage. The cached results (be >> it in shared buffers or in page cache) are not very interesting. 0003 >> helps a bit (~15%), but other than that it's just random noise. >> >> The "uncached" results starting on page 23 are much more interesting. In >> general 0001, 0002 and 0004 have little impact, it seems just random >> noise. So in the rest I'll focus on 0003. >> >> For the single nvme device (device: data), it seems mostly fine. It's >> green, even though there are a couple "localized regressions" for eic=0. >> I haven't looked into those yet. >> >> For the nvme RAID (device: raid-nvme), it's looks almost exactly the >> same, except that with parallel query (page 27) there's a clear area of >> regression with eic=1 (look for "column" of red cells). That's a bit >> unfortunate, because eic=1 is the default value. > > It'll be hard to look into all of these, so I think I'll focus on > trying to reproduce something with eic=1 that I can reproduce on my > machine. So far, I can reproduce a regression with the following and > the data file attached. > Yes, that approach makes perfect sense. I don't think anyone can investigate all the regressions, it's enough to investigate one specimen for each of the main "patterns". > # initdb and get set up with shared_buffers 1GB > psql -c "create table bitmap_scan_test (a bigint, b bigint, c text) > with (fillfactor = 25)" > psql -c "copy bitmap_scan_test from '/tmp/bitmap_scan_test.data'" > psql -c "create index on bitmap_scan_test (a)" > psql -c "vacuum analyze" > psql -c "checkpoint" > > pg_ctl stop > echo 3 | sudo tee /proc/sys/vm/drop_caches > pg_ctl start > psql -c "SET max_parallel_workers_per_gather = 4;" \ > -c "SET effective_io_concurrency = 1;" \ > -c "SET parallel_setup_cost = 0;" \ > -c "SET parallel_tuple_cost = 0;" \ > -c "SET enable_seqscan = off;" \ > -c "SET enable_indexscan = off;" \ > -c "SET work_mem = 65536;" > > psql -c "EXPLAIN SELECT * FROM bitmap_scan_test WHERE (a BETWEEN -33 > AND 10015) OFFSET 1000000;" > psql -c "SELECT * FROM bitmap_scan_test WHERE (a BETWEEN -33 AND > 10015) OFFSET 1000000;" > > It's not a huge regression and planner doesn't naturally pick parallel > bitmap heap scan for this, but I don't have a SATA drive right now, so > I focused on something I could reproduce. > > One thing I noticed when I was playing around with the script is that > depending on the values chosen by random(), there were differences in > timing. From your script, it looks like the $from and $to won't be the > same for master and the patch each time (they are set in the inner > most nesting level, below where $build is set). Am I understanding > correctly? > Yes. The values for the WHERE conditions are generated randomly, and the idea is that it evens out for multiple runs. Maybe not with only 3 runs per query, but it should be good enough to show patterns (e.g. when the runs with eic=1 show regression). >> Anyway, the results look sensible. It might be good to investigate some >> of the regressions, and I'll try doing that if I find the time. But I >> don't think that's necessarily a blocker - every patch of this type will >> have a hardware where the heuristics doesn't quite do the right thing by >> default. Which is why we have GUCs to tune it if appropriate. > > Yea, I definitely won't be able to look into all of the regressions. > So, I guess we have to ask if we are willing to make the tradeoff. > I'm at peace with that. Certainly for the "localized" regressions, and cases when bitmapheapscan would not be picked. The eic=1 case makes me a bit more nervous, because it's default and affects NVMe storage. Would be good to know why is that, or perhaps consider bumping up eic default. Not sure. regards -- Tomas Vondra
On Mon, Feb 10, 2025 at 1:02 PM Melanie Plageman <melanieplageman@gmail.com> wrote: > > It'll be hard to look into all of these, so I think I'll focus on > trying to reproduce something with eic=1 that I can reproduce on my > machine. So far, I can reproduce a regression with the following and > the data file attached. > > # initdb and get set up with shared_buffers 1GB > psql -c "create table bitmap_scan_test (a bigint, b bigint, c text) > with (fillfactor = 25)" > psql -c "copy bitmap_scan_test from '/tmp/bitmap_scan_test.data'" > psql -c "create index on bitmap_scan_test (a)" > psql -c "vacuum analyze" > psql -c "checkpoint" > > pg_ctl stop > echo 3 | sudo tee /proc/sys/vm/drop_caches > pg_ctl start > psql -c "SET max_parallel_workers_per_gather = 4;" \ > -c "SET effective_io_concurrency = 1;" \ > -c "SET parallel_setup_cost = 0;" \ > -c "SET parallel_tuple_cost = 0;" \ > -c "SET enable_seqscan = off;" \ > -c "SET enable_indexscan = off;" \ > -c "SET work_mem = 65536;" > > psql -c "EXPLAIN SELECT * FROM bitmap_scan_test WHERE (a BETWEEN -33 > AND 10015) OFFSET 1000000;" > psql -c "SELECT * FROM bitmap_scan_test WHERE (a BETWEEN -33 AND > 10015) OFFSET 1000000;" I think I figured out why there is a regression. On master, parallel bitmap heap scans seem to end up cheating effective_io_concurrency. What you expect to see with effective_io_concurrency == 1 is a single pread followed by a single fadvise. We can prefetch up to one block before reading the next block. This is what you see on both the patch and master with a serial bitmap heap scan. This is also what you see with the patch if you strace a participating parallel bitmap heap scan process. On master, however, you do not see this 1-1 interleaving for parallel bitmap heap scan. On master we typically issue many fadvises in a row followed by a few preads in a row. For example: fadvise64 fadvise64 fadvise64 fadvise64 pread64 fadvise64 fadvise64 pread64 pread64 fadvise64 On master, while executing this query, the leader did more than 2000 runs of > 1 fadvise or pread in a row. With the patch, there are essentially none. On master, parallel bitmap heap scans' prefetching behavior is controlled by some shared pstate members, prefetch_target and prefetch_pages. Prefetching is supposed to be allowed only up to prefetch_target -- which is capped at effective_io_concurrency. Incrementing and decrementing these variables is not based on whether or not the process actually did a read or a prefetch -- only on the values of those shared memory variables. I think what is happening due to quirks of CPU scheduling is that some of the processes are actually issuing more consecutive reads and prefetches and another process is incrementing and decrementing those values in a way that makes this possible. This effectively increases effective_io_concurrency for parallel bitmap heap scans on master. The patch can't really compete because it is interleaving every read with an fadvise -- preventing readahead. I don't really know what to do about this. The behavior of master parallel bitmap heap scan can be emulated with the patch by increasing effective_io_concurrency. But, IIRC we didn't want to do that for some reason? Not only does effective_io_concurrency == 1 negatively affect read ahead, but it also prevents read combining regardless of the io_combine_limit. - Melanie
On Mon, Feb 10, 2025 at 1:11 PM Tomas Vondra <tomas@vondra.me> wrote: > Certainly for the "localized" regressions, and cases when bitmapheapscan > would not be picked. The eic=1 case makes me a bit more nervous, because > it's default and affects NVMe storage. Would be good to know why is > that, or perhaps consider bumping up eic default. Not sure. I'm relatively upset by the fact that effective_io_concurrency is measured in units that are, AFAIUI, completely stupid. The original idea was that you would set it to the number of spindles you have. But from what I have heard, that didn't actually work: you needed to set it to a significantly higher number. But in 2025, you probably don't even have spindles any more, because you're probably on SSD or some other modern storage medium rather than a rotating hard drive. And if you do have spindles, do you know how many you have? Is that even a meaningful concept? I am not saying that it's this patch's job to replace effective_io_concurrency with something better. I think adopting the streaming read interface is pretty important, and if it works out that we should also change the default effective_io_concurrency from 1 to 2 or 17 or 42715 in the same release, fine. But I think that in the slightly longer term, it would be a really good idea for someone to propose a more sensible model. It's hard to think of a clearer case of a parameter being rendered meaningless by the march of technology. The closest analogue that comes to mind is our sorting implementation used to have a hard coded number of tape drives, when the underlying implementation was a bunch of files all on the same filesystem, but that wasn't a user-settable parameter. -- Robert Haas EDB: http://www.enterprisedb.com
On Mon, Feb 10, 2025 at 4:24 PM Robert Haas <robertmhaas@gmail.com> wrote: > > On Mon, Feb 10, 2025 at 1:11 PM Tomas Vondra <tomas@vondra.me> wrote: > > Certainly for the "localized" regressions, and cases when bitmapheapscan > > would not be picked. The eic=1 case makes me a bit more nervous, because > > it's default and affects NVMe storage. Would be good to know why is > > that, or perhaps consider bumping up eic default. Not sure. > > I'm relatively upset by the fact that effective_io_concurrency is > measured in units that are, AFAIUI, completely stupid. The original > idea was that you would set it to the number of spindles you have. But > from what I have heard, that didn't actually work: you needed to set > it to a significantly higher number. But in 2025, you probably don't > even have spindles any more, because you're probably on SSD or some > other modern storage medium rather than a rotating hard drive. And if > you do have spindles, do you know how many you have? Is that even a > meaningful concept? I had taken to thinking of it as "queue depth". But I think that's not really accurate. Do you know why we set it to 1 as the default? I thought it was because the default should be just prefetch one block ahead. But if it was meant to be spindles, was it that most people had one spindle (I don't really know what a spindle is)? > I am not saying that it's this patch's job to replace > effective_io_concurrency with something better. I think adopting the > streaming read interface is pretty important, and if it works out that > we should also change the default effective_io_concurrency from 1 to 2 > or 17 or 42715 in the same release, fine. Yes, I think we should probably change it to be higher. However, this exercise today made me realize that it is going to be pretty difficult to completely emulate the IO behavior of parallel bitmap heap scans on master with this patch. The way the different processes and the two iterators happened to interact had all sorts of random side effects. (See, for example, this [1] bug we discovered and didn't end up fixing because it would be hard and we figured we would replace this all with the read stream API). > But I think that in the > slightly longer term, it would be a really good idea for someone to > propose a more sensible model. It's hard to think of a clearer case of > a parameter being rendered meaningless by the march of technology. The > closest analogue that comes to mind is our sorting implementation used > to have a hard coded number of tape drives, when the underlying > implementation was a bunch of files all on the same filesystem, but > that wasn't a user-settable parameter. I imagine if I said that we should start calling it prefetch_distance, you would say that no one would know what to configure it to and that would be just as bad. - Melanie [1] https://www.postgresql.org/message-id/20240315211449.en2jcmdqxv5o6tlz%40alap3.anarazel.de
Hi, On 2025-02-10 16:24:25 -0500, Robert Haas wrote: > On Mon, Feb 10, 2025 at 1:11 PM Tomas Vondra <tomas@vondra.me> wrote: > > Certainly for the "localized" regressions, and cases when bitmapheapscan > > would not be picked. The eic=1 case makes me a bit more nervous, because > > it's default and affects NVMe storage. Would be good to know why is > > that, or perhaps consider bumping up eic default. Not sure. > > I'm relatively upset by the fact that effective_io_concurrency is > measured in units that are, AFAIUI, completely stupid. The original > idea was that you would set it to the number of spindles you have. But > from what I have heard, that didn't actually work: you needed to set > it to a significantly higher number. Which isn't too surprising. I think there are a few main reasons #spindles was way too low: 1) Decent interfaces to rotating media benefit very substantially from having multiple requests in flight, for each spindle. The disk can reorder the actual disk access so they each can be executed without needing on average half a rotation for each request. Similar reordering can also happen on the OS level, even if not quite to the same degree of benefit. 2) Even if each spindle could only execute one IO request, you still want to start those requests substantially earlier than allowed by effective_io_concurrency=#spindles, to allow for the IOs to complete. With e.g. bitmap heap scans, there often are sequences of blocks that can be read together in one IO. 3) A single spindle commonly had multiple platters and a disk could read from multiple platters within a single rotation. However, I'm not so sure that the unit of effective_io_concurrency is really the main issue. It IMO makes sense to limit the max number of requests one scan can trigger, to prevent one scan from completely swamping the IO request queue for the next several seconds (trivially possible without a limit on smaller cloud storage disks with low iops). It's plausible that we would want to separately control the "distance" from the currently "consumed" position position and the maximum-io-requests-in-flight. But I think we might be able to come up with a tuning algorithm that can tune the distance based on the observed latency and "consumption" speed. I think what we eventually should get rid of is the "effective_" prefix. My understanding is that basically there to denote that we don't really have an idea what concurrency is achieved, as posix_fadvise() neither tells us if IO was necessary in the first place, nor whether multiple blocks could be read in one IO, nor when IO has completed. The read_stream implementation already has redefined effective_io_concurrency to only count one IO for a multi-block read. Of course that doesn't mean we shouldn't change the default (we very clearly should) or the documentation for the GUC. Greetings, Andres Freund
On Mon, Feb 10, 2025 at 4:41 PM Melanie Plageman <melanieplageman@gmail.com> wrote: > I had taken to thinking of it as "queue depth". But I think that's not > really accurate. Do you know why we set it to 1 as the default? I > thought it was because the default should be just prefetch one block > ahead. But if it was meant to be spindles, was it that most people had > one spindle (I don't really know what a spindle is)? AFAIK, we're imagining that people are running PostgreSQL on a hard drive like the one my desktop machine had when I was in college, which indeed only had one spindle. There were one or possibly several magnetic platters rotating around a single point. But today, nobody has that, certainly not on a production machine. For instance if you are using RAID or LVM you have several drives hooked up together, so that would be multiple spindles even if all of them were HDDs, but probably they are all SSDs which don't have spindles anyway. If you are on a virtual machine you have a slice of the underlying machine's I/O and whatever that is it's probably something more complicated than a single spindle. To be fair, I guess the concept of effective_io_concurrency isn't completely meaningless if you think about it as the number of simultaneous I/O requests that can be in flight at a time. But I still think it's true that it's hard to make any reasonable guess as to how you should set this value to get good performance. Maybe people who work as consultants and configure lots of systems have good intuition here, but anybody else is probably either not going to know about this parameter or flail around trying to figure out how to set it. It might be interesting to try some experiments on a real small VM from some cloud provider and see what value is optimal there these days. Then we could set the default to that value or perhaps somewhat more. -- Robert Haas EDB: http://www.enterprisedb.com
On 2/12/25 20:08, Robert Haas wrote: > On Mon, Feb 10, 2025 at 4:41 PM Melanie Plageman > <melanieplageman@gmail.com> wrote: >> I had taken to thinking of it as "queue depth". But I think that's not >> really accurate. Do you know why we set it to 1 as the default? I >> thought it was because the default should be just prefetch one block >> ahead. But if it was meant to be spindles, was it that most people had >> one spindle (I don't really know what a spindle is)? > > AFAIK, we're imagining that people are running PostgreSQL on a hard > drive like the one my desktop machine had when I was in college, which > indeed only had one spindle. There were one or possibly several > magnetic platters rotating around a single point. But today, nobody > has that, certainly not on a production machine. For instance if you > are using RAID or LVM you have several drives hooked up together, so > that would be multiple spindles even if all of them were HDDs, but > probably they are all SSDs which don't have spindles anyway. If you > are on a virtual machine you have a slice of the underlying machine's > I/O and whatever that is it's probably something more complicated than > a single spindle. I think we've abandoned the idea that effective_io_concurrency has anything to do with the number of spindles - it was always a bit wrong because even spinning rust had TCQ/NCQ (i.e. ability to optimize head movement for a queue of requests). But it completely lost the meaning with flash storage. And in PG13 we even stopped "recalculating" the prefetch distance, and use raw effective_io_concurrency. > > To be fair, I guess the concept of effective_io_concurrency isn't > completely meaningless if you think about it as the number of > simultaneous I/O requests that can be in flight at a time. But I still > think it's true that it's hard to make any reasonable guess as to how > you should set this value to get good performance. Maybe people who > work as consultants and configure lots of systems have good intuition > here, but anybody else is probably either not going to know about this > parameter or flail around trying to figure out how to set it. > Yes, the "queue depth" interpretation seems to be much more accurate than "number of spindles". > It might be interesting to try some experiments on a real small VM > from some cloud provider and see what value is optimal there these > days. Then we could set the default to that value or perhaps somewhat > more. > AFAICS the "1" value is simply one of the many "defensive" defaults in our sample config. It's much more likely to help than cause harm, even on smaller/older systems, but for many systems a higher value would be more appropriate. There's usually a huge initial benefit (say, going to 16 or 32), and then the benefits diminish fairly quickly. regards -- Tomas Vondra
On Wed, Feb 12, 2025 at 3:07 PM Tomas Vondra <tomas@vondra.me> wrote: > AFAICS the "1" value is simply one of the many "defensive" defaults in > our sample config. It's much more likely to help than cause harm, even > on smaller/older systems, but for many systems a higher value would be > more appropriate. There's usually a huge initial benefit (say, going to > 16 or 32), and then the benefits diminish fairly quickly. I'm happy to see us change the value to something that is likely to be good for most people. I think it's OK if people on very tiny systems need to change a few defaults for optimum performance. We should keep in mind that people do sometimes run PostgreSQL on fairly small VMs and not go crazy with it, but there's no reason to pretend that the typical database runs on a Raspberry Pi. -- Robert Haas EDB: http://www.enterprisedb.com
On Sun, Feb 9, 2025 at 9:27 AM Tomas Vondra <tomas@vondra.me> wrote: > > For the nvme RAID (device: raid-nvme), it's looks almost exactly the > same, except that with parallel query (page 27) there's a clear area of > regression with eic=1 (look for "column" of red cells). That's a bit > unfortunate, because eic=1 is the default value. So, I feel pretty confident after even more analysis today with Thomas Munro that all of the parallel cases with effective_io_concurrency == 1 are because master cheats effective_io_concurrency. Therefore, I'm not too worried about those for now. We probably will have to increase effective_io_concurrency before merging this patch, though. Thomas mentioned this to me off-list, and I think he's right. We likely need to rethink the way parallel bitmap heap scan workers get block assignments for reading and prefetching to make it more similar to parallel sequential scan. The workers should probably get assignments of a range of blocks. On master, each worker does end up issuing reads/fadvises for a bunch of blocks in a row -- even though that isn't the intent of the parallel bitmap table scan implementation. We are losing some of that with the patch -- but only because it is behaving as you would expect given the implementation and design. I don't consider that a blocker, though. > For the SATA SSD RAID (device: raid-sata), it's similar - a couple > regressions for eic=0, just like for NVMe. But then there's also a > couple regressions for higher eic values, usually for queries with > selective conditions. I started trying to reproduce the regressions you saw on your SATA devices for higher eic values. I was focusing just on serial bitmap heap scan -- since that doesn't have the problems mentioned above. I don't have a SATA drive, but I used dmsetup to add a 10ms delay to my nvme drive. Unfortunately, that did the opposite of reproduce the issue. With dm delay 10ms, the patch is 5 times faster than master. - Melanie
On Thu, Feb 13, 2025 at 1:40 PM Melanie Plageman <melanieplageman@gmail.com> wrote: > On Sun, Feb 9, 2025 at 9:27 AM Tomas Vondra <tomas@vondra.me> wrote: > > For the nvme RAID (device: raid-nvme), it's looks almost exactly the > > same, except that with parallel query (page 27) there's a clear area of > > regression with eic=1 (look for "column" of red cells). That's a bit > > unfortunate, because eic=1 is the default value. > > So, I feel pretty confident after even more analysis today with Thomas > Munro that all of the parallel cases with effective_io_concurrency == > 1 are because master cheats effective_io_concurrency. Therefore, I'm > not too worried about those for now. We probably will have to increase > effective_io_concurrency before merging this patch, though. Yeah. Not only did we see it issuing up to 20 or so unauthorised overlapping POSIX_FADV_WILLNEED calls, but in the case we studied they didn't really do anything at all because it was *postfetching* (!), ie issuing advice for blocks it had already read. The I/O was sequential (reading all or most blocks in order), so the misdirected advice at least kept out of the kernel's way, and it did some really effective readahead. Meanwhile the stream version played by the rules and respected eic=1, staying only one block ahead. We know that advice for sequential blocks blocks readahead, so that seems to explain the red for that parameter/test permutation. (Hypothesis based on some quick reading: I guess kernel pages faulted in that way don't get marked with the internal "readahead was here" flag, which would normally cause the following pread() to trigger more asynchronous readahead with ever larger physical size). But that code in master is also *trying* to do exactly what we're doing, it's just failing because of some combination of bugs in the parallel scan code (?). It would be absurd to call it the winner: we're setting out with the same goal, but for that particular set of parameters and test setup, apparently two (?) bugs make a right. Melanie mentioned that some other losing cases also involved unauthorised amounts of overlapping advice, except there it was random and beneficial and the iterators didn't get out of sync with each other, so again it beat us in a few red patches, seemingly with a different accidental behaviour. Meanwhile we obediently trundled along with just 1 concurrent I/O or whatever, and lost. On top of that, read_stream.c is also *trying* to avoid issuing advice for access patterns that look sequential, and *trying* to do I/O combining, which all works OK in serial BHS, but it breaks down in parallel because: > Thomas mentioned this to me off-list, and I think he's right. We > likely need to rethink the way parallel bitmap heap scan workers get > block assignments for reading and prefetching to make it more similar > to parallel sequential scan. The workers should probably get > assignments of a range of blocks. On master, each worker does end up > issuing reads/fadvises for a bunch of blocks in a row -- even though > that isn't the intent of the parallel bitmap table scan > implementation. We are losing some of that with the patch -- but only > because it is behaving as you would expect given the implementation > and design. I don't consider that a blocker, though. + /* + * The maximum number of tuples per page is not large (typically 256 with + * 8K pages, or 1024 with 32K pages). So there's not much point in making + * the per-page bitmaps variable size. We just legislate that the size is + * this: + */ + OffsetNumber offsets[MaxHeapTuplesPerPage]; } TBMIterateResult; Seems to be 291? So sizeof(TBMIterateResult) must be somewhere around 588 bytes? There's one of those for every buffer, and we'll support queues of up to effective_io_concurrency (1-1000) * io_combine_limit (1-128?), which would require ~75MB of per-buffer-data with maximum settings That's a lot of memory to have to touch as you whizz around the circular queue even when you don't really need it. With more typical numbers like 10 * 32 it's ~90kB, which I guess is OK. I wonder if it would be worth trying to put a small object in there instead that could be expanded to the results later, cf f6bef362 for TIDStore, but I'm not sure if it's a blocker, just an observation.
On 2/13/25 01:40, Melanie Plageman wrote: > On Sun, Feb 9, 2025 at 9:27 AM Tomas Vondra <tomas@vondra.me> wrote: >> >> For the nvme RAID (device: raid-nvme), it's looks almost exactly the >> same, except that with parallel query (page 27) there's a clear area of >> regression with eic=1 (look for "column" of red cells). That's a bit >> unfortunate, because eic=1 is the default value. > > So, I feel pretty confident after even more analysis today with Thomas > Munro that all of the parallel cases with effective_io_concurrency == > 1 are because master cheats effective_io_concurrency. Therefore, I'm > not too worried about those for now. We probably will have to increase > effective_io_concurrency before merging this patch, though. > > Thomas mentioned this to me off-list, and I think he's right. We > likely need to rethink the way parallel bitmap heap scan workers get > block assignments for reading and prefetching to make it more similar > to parallel sequential scan. The workers should probably get > assignments of a range of blocks. On master, each worker does end up > issuing reads/fadvises for a bunch of blocks in a row -- even though > that isn't the intent of the parallel bitmap table scan > implementation. We are losing some of that with the patch -- but only > because it is behaving as you would expect given the implementation > and design. I don't consider that a blocker, though. > Agreed. If this is due to master doing something wrong (and either prefetching more, or failing to prefetch), that's not the fault of this patch. People might perceive this as a regression, but increasing the default eic value would fix that. BTW I recall we ran into issues with prefetching and parallel workers about a year ago [1]. Is this the same issue, or something new? [1] https://www.postgresql.org/message-id/20240315211449.en2jcmdqxv5o6tlz%40alap3.anarazel.de >> For the SATA SSD RAID (device: raid-sata), it's similar - a couple >> regressions for eic=0, just like for NVMe. But then there's also a >> couple regressions for higher eic values, usually for queries with >> selective conditions. > > I started trying to reproduce the regressions you saw on your SATA > devices for higher eic values. I was focusing just on serial bitmap > heap scan -- since that doesn't have the problems mentioned above. I > don't have a SATA drive, but I used dmsetup to add a 10ms delay to my > nvme drive. Unfortunately, that did the opposite of reproduce the > issue. With dm delay 10ms, the patch is 5 times faster than master. > I'm not quite sure at which point does dm-setup add the delay. Does it affect the fadvise call too, or just the I/O if the page is not already in page cache? regards -- Tomas Vondra
On 2/13/25 05:15, Thomas Munro wrote: > On Thu, Feb 13, 2025 at 1:40 PM Melanie Plageman > <melanieplageman@gmail.com> wrote: >> On Sun, Feb 9, 2025 at 9:27 AM Tomas Vondra <tomas@vondra.me> wrote: >>> For the nvme RAID (device: raid-nvme), it's looks almost exactly the >>> same, except that with parallel query (page 27) there's a clear area of >>> regression with eic=1 (look for "column" of red cells). That's a bit >>> unfortunate, because eic=1 is the default value. >> >> So, I feel pretty confident after even more analysis today with Thomas >> Munro that all of the parallel cases with effective_io_concurrency == >> 1 are because master cheats effective_io_concurrency. Therefore, I'm >> not too worried about those for now. We probably will have to increase >> effective_io_concurrency before merging this patch, though. > > Yeah. Not only did we see it issuing up to 20 or so unauthorised > overlapping POSIX_FADV_WILLNEED calls, but in the case we studied they > didn't really do anything at all because it was *postfetching* (!), ie > issuing advice for blocks it had already read. The I/O was sequential > (reading all or most blocks in order), so the misdirected advice at > least kept out of the kernel's way, and it did some really effective > readahead. Meanwhile the stream version played by the rules and > respected eic=1, staying only one block ahead. We know that advice for > sequential blocks blocks readahead, so that seems to explain the red > for that parameter/test permutation. (Hypothesis based on some > quick reading: I guess kernel pages faulted in that way don't get > marked with the internal "readahead was here" flag, which would > normally cause the following pread() to trigger more asynchronous > readahead with ever larger physical size). But that code > in master is also *trying* to do exactly what we're doing, it's just > failing because of some combination of bugs in the parallel scan code > (?). It would be absurd to call it the winner: we're setting out > with the same goal, but for that particular set of parameters and test > setup, apparently two (?) bugs make a right. Melanie mentioned that > some other losing cases also involved unauthorised amounts of > overlapping advice, except there it was random and beneficial and the > iterators didn't get out of sync with each other, so again it beat us > in a few red patches, seemingly with a different accidental behaviour. > Meanwhile we obediently trundled along with just 1 concurrent I/O or > whatever, and lost. > Makes sense, likely explains the differences. And I agree we should not hold this against this patch series, it's master that's doing something wrong. And in most of these cases we'd not even do bitmap scan anyway, I think, it only happens because we forced the plan. BTW how are you investigating those I/O requests? strace? iosnoop? perf? Something else? > On top of that, read_stream.c is also *trying* to avoid issuing advice > for access patterns that look sequential, and *trying* to do I/O > combining, which all works OK in serial BHS, but it breaks down in > parallel because: > >> Thomas mentioned this to me off-list, and I think he's right. We >> likely need to rethink the way parallel bitmap heap scan workers get >> block assignments for reading and prefetching to make it more similar >> to parallel sequential scan. The workers should probably get >> assignments of a range of blocks. On master, each worker does end up >> issuing reads/fadvises for a bunch of blocks in a row -- even though >> that isn't the intent of the parallel bitmap table scan >> implementation. We are losing some of that with the patch -- but only >> because it is behaving as you would expect given the implementation >> and design. I don't consider that a blocker, though. > > + /* > + * The maximum number of tuples per page is not large (typically 256 with > + * 8K pages, or 1024 with 32K pages). So there's not much point in making > + * the per-page bitmaps variable size. We just legislate that the size is > + * this: > + */ > + OffsetNumber offsets[MaxHeapTuplesPerPage]; > } TBMIterateResult; > > Seems to be 291? So sizeof(TBMIterateResult) must be somewhere > around 588 bytes? There's one of those for every buffer, and we'll > support queues of up to effective_io_concurrency (1-1000) * > io_combine_limit (1-128?), which would require ~75MB of > per-buffer-data with maximum settings That's a lot of memory to have > to touch as you whizz around the circular queue even when you don't > really need it. With more typical numbers like 10 * 32 it's ~90kB, > which I guess is OK. I wonder if it would be worth trying to put a > small object in there instead that could be expanded to the results > later, cf f6bef362 for TIDStore, but I'm not sure if it's a blocker, > just an observation. Not sure I follow. Doesn't f6bef362 do quite the opposite, i.e. removing the repalloc() calls and replacing that with a local on-stack buffer sized for MaxOffsetNumber items? Which I think is 2048 for 8kB pages? Note: Is it correct to use MaxHeapTuplesPerPage for TBMIterateResult, or should it not be tied to heap? I don't have a clear opinion on sizing the offsets buffer - whether it should be static (like above) or dynamic (expanded using repalloc). But I'd probably be more worried about efficiency for "normal" configs than about memory usage when everything is maxed out. The 75MB is not negligible, but it's also not terrible for machines that would need such values for these GUCs. Saving memory is nice, but if it meant "normal" configs spend much more time on resizing the buffers, that doesn't seem like a good tradeoff to me. The one thing I'd be worried about is if the allocations get too large and can no longer be cached by the memory context (and doing malloc every time). But I don't think that's the case here, it'd need to be larger than 8kB. regards -- Tomas Vondra
On Thu, Feb 13, 2025 at 7:08 AM Tomas Vondra <tomas@vondra.me> wrote: > > > > On 2/13/25 01:40, Melanie Plageman wrote: > > On Sun, Feb 9, 2025 at 9:27 AM Tomas Vondra <tomas@vondra.me> wrote: > >> > >> For the nvme RAID (device: raid-nvme), it's looks almost exactly the > >> same, except that with parallel query (page 27) there's a clear area of > >> regression with eic=1 (look for "column" of red cells). That's a bit > >> unfortunate, because eic=1 is the default value. > > > > So, I feel pretty confident after even more analysis today with Thomas > > Munro that all of the parallel cases with effective_io_concurrency == > > 1 are because master cheats effective_io_concurrency. Therefore, I'm > > not too worried about those for now. We probably will have to increase > > effective_io_concurrency before merging this patch, though. > > > > Thomas mentioned this to me off-list, and I think he's right. We > > likely need to rethink the way parallel bitmap heap scan workers get > > block assignments for reading and prefetching to make it more similar > > to parallel sequential scan. The workers should probably get > > assignments of a range of blocks. On master, each worker does end up > > issuing reads/fadvises for a bunch of blocks in a row -- even though > > that isn't the intent of the parallel bitmap table scan > > implementation. We are losing some of that with the patch -- but only > > because it is behaving as you would expect given the implementation > > and design. I don't consider that a blocker, though. > > > > Agreed. If this is due to master doing something wrong (and either > prefetching more, or failing to prefetch), that's not the fault of this > patch. People might perceive this as a regression, but increasing the > default eic value would fix that. > > BTW I recall we ran into issues with prefetching and parallel workers > about a year ago [1]. Is this the same issue, or something new? > > [1] > https://www.postgresql.org/message-id/20240315211449.en2jcmdqxv5o6tlz%40alap3.anarazel.de Th postfetching is the same issue as you linked in [1]. > >> For the SATA SSD RAID (device: raid-sata), it's similar - a couple > >> regressions for eic=0, just like for NVMe. But then there's also a > >> couple regressions for higher eic values, usually for queries with > >> selective conditions. > > > > I started trying to reproduce the regressions you saw on your SATA > > devices for higher eic values. I was focusing just on serial bitmap > > heap scan -- since that doesn't have the problems mentioned above. I > > don't have a SATA drive, but I used dmsetup to add a 10ms delay to my > > nvme drive. Unfortunately, that did the opposite of reproduce the > > issue. With dm delay 10ms, the patch is 5 times faster than master. > > > > I'm not quite sure at which point does dm-setup add the delay. Does it > affect the fadvise call too, or just the I/O if the page is not already > in page cache? So dmsetup adds the delay only when the page is not found in kernel buffer cache -- actually below the filesystem before issuing it to the block device. reads, writes, and flushes can be delayed (I delayed all three by 10ms). fadvises can't since they are above that level. - Melanie
On 2/10/25 23:31, Melanie Plageman wrote: > On Mon, Feb 10, 2025 at 4:22 PM Melanie Plageman > <melanieplageman@gmail.com> wrote: >> >> I don't really know what to do about this. The behavior of master >> parallel bitmap heap scan can be emulated with the patch by increasing >> effective_io_concurrency. But, IIRC we didn't want to do that for some >> reason? >> Not only does effective_io_concurrency == 1 negatively affect read >> ahead, but it also prevents read combining regardless of the >> io_combine_limit. > > Would a sensible default be something like 4? > Could be. It would perform much better for most systems I think, but it's still a fairly conservative value so unlikely to cause regressions. If we wanted to validate the value, what tests do you think would be appropriate? What about just running the same tests with different eic values, and pick a reasonable value based on that? One that helps, but before it stats causing regressions. FWIW I don't think we need to do this before pushing the patches, as long as we do both. AFAIK there'll be an "apparent regression" no matter the order of changes. > I did some self-review on the patches and cleaned up the commit > messages etc. Attached is v29. > I reviewed v29 today, and I think it's pretty much ready to go. The one part where I don't quite get is 0001, which replaces a FLEXIBLE_ARRAY_MEMBER array with a fixed-length array. It's not wrong, but I don't quite see the benefits / clarity. And I think Thomas might be right we may want to make this dynamic, to save memory. Not a blocker, but I'd probably skip 0001 (unless it's required by the later parts, I haven't checked/tried). Other than that, I think this is ready. regards -- Tomas Vondra
On Thu, Feb 13, 2025 at 10:46 AM Tomas Vondra <tomas@vondra.me> wrote: > > I reviewed v29 today, and I think it's pretty much ready to go. > > The one part where I don't quite get is 0001, which replaces a > FLEXIBLE_ARRAY_MEMBER array with a fixed-length array. It's not wrong, > but I don't quite see the benefits / clarity. And I think Thomas might > be right we may want to make this dynamic, to save memory. > > Not a blocker, but I'd probably skip 0001 (unless it's required by the > later parts, I haven't checked/tried). So, on master, it already pallocs an array of size MAX_TUPLES_PER_PAGE (which is hard-coded in the tidbitmap API to MaxHeapTuplesPerPage) -- see tbm_begin_private_iterate(). So we always palloc the same amount of memory. The reason I changed it from a flexible sized array to a fixed size is that we weren't using the flexibility and having a flexible sized array in the TBMIterateResult meant it couldn't be nested in another struct. Since I have to separate the TBMIterateResult and TBMIterator to implement the read stream API for BHS, once I separate them, I nest the TBMIterateResult in the GinScanEntry. If the array of offsets is flexible sized, then I would have to manage that memory separately in GIN code for the TBMIterateResult.. So, 0001 isn't a change in the amount of memory allocated. With the read stream API, these TBMIterateResults are palloc'd just like we palloc'd one in master. However, we have to have more than one at a time. - Melanie
On 2/13/25 17:01, Melanie Plageman wrote: > On Thu, Feb 13, 2025 at 10:46 AM Tomas Vondra <tomas@vondra.me> wrote: >> >> I reviewed v29 today, and I think it's pretty much ready to go. >> >> The one part where I don't quite get is 0001, which replaces a >> FLEXIBLE_ARRAY_MEMBER array with a fixed-length array. It's not wrong, >> but I don't quite see the benefits / clarity. And I think Thomas might >> be right we may want to make this dynamic, to save memory. >> >> Not a blocker, but I'd probably skip 0001 (unless it's required by the >> later parts, I haven't checked/tried). > > So, on master, it already pallocs an array of size MAX_TUPLES_PER_PAGE > (which is hard-coded in the tidbitmap API to MaxHeapTuplesPerPage) -- > see tbm_begin_private_iterate(). > > So we always palloc the same amount of memory. The reason I changed it > from a flexible sized array to a fixed size is that we weren't using > the flexibility and having a flexible sized array in the > TBMIterateResult meant it couldn't be nested in another struct. Since > I have to separate the TBMIterateResult and TBMIterator to implement > the read stream API for BHS, once I separate them, I nest the > TBMIterateResult in the GinScanEntry. If the array of offsets is > flexible sized, then I would have to manage that memory separately in > GIN code for the TBMIterateResult.. > > So, 0001 isn't a change in the amount of memory allocated. > > With the read stream API, these TBMIterateResults are palloc'd just > like we palloc'd one in master. However, we have to have more than one > at a time. > I know it's not changing how much memory we allocate (compared to master). I haven't thought about the GinScanEntry - yes, flexible array member would make this a bit more complex. I don't want to bikeshed this - I'll leave the decision about 0001 to you. I'm OK with both options. regards -- Tomas Vondra
On Thu, Feb 13, 2025 at 11:28 AM Tomas Vondra <tomas@vondra.me> wrote: > > On 2/13/25 17:01, Melanie Plageman wrote: > > On Thu, Feb 13, 2025 at 10:46 AM Tomas Vondra <tomas@vondra.me> wrote: > >> > >> I reviewed v29 today, and I think it's pretty much ready to go. > >> > >> The one part where I don't quite get is 0001, which replaces a > >> FLEXIBLE_ARRAY_MEMBER array with a fixed-length array. It's not wrong, > >> but I don't quite see the benefits / clarity. And I think Thomas might > >> be right we may want to make this dynamic, to save memory. > >> > >> Not a blocker, but I'd probably skip 0001 (unless it's required by the > >> later parts, I haven't checked/tried). > > > > So, on master, it already pallocs an array of size MAX_TUPLES_PER_PAGE > > (which is hard-coded in the tidbitmap API to MaxHeapTuplesPerPage) -- > > see tbm_begin_private_iterate(). > > > > So we always palloc the same amount of memory. The reason I changed it > > from a flexible sized array to a fixed size is that we weren't using > > the flexibility and having a flexible sized array in the > > TBMIterateResult meant it couldn't be nested in another struct. Since > > I have to separate the TBMIterateResult and TBMIterator to implement > > the read stream API for BHS, once I separate them, I nest the > > TBMIterateResult in the GinScanEntry. If the array of offsets is > > flexible sized, then I would have to manage that memory separately in > > GIN code for the TBMIterateResult.. > > > > So, 0001 isn't a change in the amount of memory allocated. > > > > With the read stream API, these TBMIterateResults are palloc'd just > > like we palloc'd one in master. However, we have to have more than one > > at a time. > > > > I know it's not changing how much memory we allocate (compared to > master). I haven't thought about the GinScanEntry - yes, flexible array > member would make this a bit more complex. Oh, I see. I didn't understand Thomas' proposal. I don't know how hard it would be to make tidbitmap allocate the offsets on-demand. I'd need to investigate more. But probably not worth it for this patch. - Melanie
Hi,
Thomas, there's a bit relevant to you at the bottom.
Melanie chatted with me about the performance regressions in Tomas' benchmarks
of the patch. I experimented some and I think I found a few interesting
pieces.
I looked solely at cyclic, wm=4096, matches=8, eic=16 as I wanted to
narrow down what I was looking at as much as possible, and as that seemed a
significant regression.
I was able to reproduce the regression with the patch, although the noise was
very high.
My first attempt at reducing the noise was using MAP_POPULATE, as I was seeing
a lot of time spent in page fault related code, and that help stabilize the
output some.
After I couldn't really make sense of the different perf characteristics
looking at the explain analyze or iostat, so I switched to profiling. As part
of my profiling steps, I:
- bind postgres to a single core
- set the cpu governor to performance
- disable CPU idle just for that core (disabling it for all cores sometimes
leads to slowness due to less clock boost headroom)
- try both with turbo boost on/off
With all of those applied, the performance difference almost vanished. Weird,
huh!
Normally CPUs only clock down when idle. That includes waiting for IO if that
wait period is long enough.
That made me look more at strace. Which shows this interesting difference
between master and the patch:
The chosen excerpts are randomly picked, but the pattern is similar
throughout execution of the query:
master:
pread64(52, "\0\0\0\0\260\7|\17\0\0\4\0x\0\200\30\0 \4 \0\0\0\0\260\237\222\0`\237\222\0"..., 8192, 339271680) = 8192
<0.000010>
fadvise64(52, 339402752, 8192, POSIX_FADV_WILLNEED) = 0 <0.000008>
pread64(52, "\0\0\0\0h\10|\17\0\0\4\0x\0\200\30\0 \4 \0\0\0\0\260\237\222\0`\237\222\0"..., 8192, 339279872) = 8192
<0.000011>
fadvise64(52, 339410944, 8192, POSIX_FADV_WILLNEED) = 0 <0.000008>
pread64(52, "\0\0\0\0 \t|\17\0\0\4\0x\0\200\30\0 \4 \0\0\0\0\260\237\222\0`\237\222\0"..., 8192, 339288064) = 8192
<0.000011>
fadvise64(52, 339419136, 8192, POSIX_FADV_WILLNEED) = 0 <0.000011>
pread64(52, "\0\0\0\0\330\t|\17\0\0\4\0x\0\200\30\0 \4 \0\0\0\0\260\237\222\0`\237\222\0"..., 8192, 339296256) = 8192
<0.000011>
fadvise64(52, 339427328, 8192, POSIX_FADV_WILLNEED) = 0 <0.000008>
With the patch:
fadvise64(52, 332365824, 131072, POSIX_FADV_WILLNEED) = 0 <0.000021>
pread64(52, "\0\0\0\0(\223x\17\0\0\4\0x\0\200\30\0 \4 \0\0\0\0\260\237\222\0`\237\222\0"..., 131072, 329220096) =
131072<0.000161>
pread64(52, "\0\0\0\0\250\236x\17\0\0\4\0x\0\200\30\0 \4 \0\0\0\0\260\237\222\0`\237\222\0"..., 131072, 329351168) =
131072<0.000401>
pread64(52, "\0\0\0\0@\252x\17\0\0\4\0x\0\200\30\0 \4 \0\0\0\0\260\237\222\0`\237\222\0"..., 65536, 329482240) = 65536
<0.000044>
pread64(52, "\0\0\0\0\0\250y\17\0\0\4\0x\0\200\30\0 \4 \0\0\0\0\260\237\222\0`\237\222\0"..., 131072, 332365824) =
131072<0.000079>
pread64(52, "\0\0\0\0\200\263y\17\0\0\4\0x\0\200\30\0 \4 \0\0\0\0\260\237\222\0`\237\222\0"..., 131072, 332496896) =
131072<0.000336>
fadvise64(52, 335781888, 131072, POSIX_FADV_WILLNEED) = 0 <0.000021>
pread64(52, "\0\0\0\0\0\277y\17\0\0\4\0x\0\200\30\0 \4 \0\0\0\0\260\237\222\0`\237\222\0"..., 131072, 332627968) =
131072<0.000091>
pread64(52, "\0\0\0\0\230\312y\17\0\0\4\0x\0\200\30\0 \4 \0\0\0\0\260\237\222\0`\237\222\0"..., 131072, 332759040) =
131072<0.000399>
pread64(52, "\0\0\0\0\30\326y\17\0\0\4\0x\0\200\30\0 \4 \0\0\0\0\260\237\222\0`\237\222\0"..., 65536, 332890112) =
65536<0.000046>
pread64(52, "\0\0\0\0\220\324z\17\0\0\4\0x\0\200\30\0 \4 \0\0\0\0\260\237\222\0`\237\222\0"..., 131072, 335781888) =
131072<0.000081>
pread64(52, "\0\0\0\0(\340z\17\0\0\4\0x\0\200\30\0 \4 \0\0\0\0\260\237\222\0`\237\222\0"..., 131072, 335912960) =
131072<0.000335>
fadvise64(52, 339197952, 131072, POSIX_FADV_WILLNEED) = 0 <0.000021>
There are a few interesting observations here:
- The patch does allow us to make larger reads, nice!
- With the patch we do *not* fadvise some of the blocks, the read stream
sequentialness logic prevents it.
- With the patch there are occasional IOs that are *much* slower. E.g. the
last pread64 is a lot slower than the two preceding ones.
Which I think explains what's happening. Because we don't fadvise all the
time, we have to synchronously wait for some IOs. Because of those slower IOs,
the CPU has time to go into an idle state. Slowing the whole query down.
If I disable that:
diff --git i/src/backend/storage/aio/read_stream.c w/src/backend/storage/aio/read_stream.c
index e4414b2e915..e58585c4e02 100644
--- i/src/backend/storage/aio/read_stream.c
+++ w/src/backend/storage/aio/read_stream.c
@@ -242,8 +242,9 @@ read_stream_start_pending_read(ReadStream *stream, bool suppress_advice)
* isn't a strictly sequential pattern, then we'll issue advice.
*/
if (!suppress_advice &&
- stream->advice_enabled &&
- stream->pending_read_blocknum != stream->seq_blocknum)
+ stream->advice_enabled
+ // && stream->pending_read_blocknum != stream->seq_blocknum
+ )
flags = READ_BUFFERS_ISSUE_ADVICE;
else
flags = 0;
I see *much* improved times.
Without cpu idle tuning:
master: 111ms
patch: 128ms
patch, with disabled seq detection: 68ms
Suddenly making the patch a huge win.
ISTM that disabling posix_fadvise() just because of a single sequential IO is
too aggressive. A pattern of two sequential reads, gap of more than a few
blocks, two sequential reads, ... will afaict never do useful readahead in
linux, because it needs a page cache access nearby already read data to start
doing readahead. But that means we encounter ynchronous-blocking-read.
Thomas, what lead to disabling advice this aggressively? Particularly because
heapam.c disables advice alltogether, it isn't entirely obvious why that's
good?
I suspect this might also affect the behaviour in the vacuum read stream case.
I think we'll need to add some logic in read stream that only disables advice
after a longer sequential sequence. Writing logic for that shouldn't be too
hard, I think? Determining the concrete cutoffs is probably harder, although I
think even fairly simplistic logic will be "good enough".
Greetings,
Andres Freund
On Fri, Feb 14, 2025 at 5:52 AM Melanie Plageman <melanieplageman@gmail.com> wrote: > On Thu, Feb 13, 2025 at 11:28 AM Tomas Vondra <tomas@vondra.me> wrote: > > On 2/13/25 17:01, Melanie Plageman wrote: > > I know it's not changing how much memory we allocate (compared to > > master). I haven't thought about the GinScanEntry - yes, flexible array > > member would make this a bit more complex. > > Oh, I see. I didn't understand Thomas' proposal. I don't know how hard > it would be to make tidbitmap allocate the offsets on-demand. I'd need > to investigate more. But probably not worth it for this patch. No, what I meant was: It would be nice to try to hold only one uncompressed result set in memory at a time, like we achieved in the vacuum patches. The consumer expands them from a tiny object when the associated buffer pops out the other end. That should be possible here too, right, because the bitmap is immutable and long lived, so you should be able to stream (essentially) pointers into its internal guts. The current patch streams the uncompressed data itself, and thus has to reserve space for the maximum possible amount of it, and also forces you to think about fixed sizes. I think if you want "consumer does the expanding" and also "dynamic size" and also "consumer provides memory to avoid palloc churn", then you might need two new functions: "how much memory would I need to expand this thing?" and a "please expand it right here, it has the amount of space you told me!". Then I guess the consumer could keep recycling the same piece of memory, and repalloc() if it's not big enough. Or something like that. Yeah I guess you could in theory also stream pointers to individual uncompressed result objects allocated with palloc(), that is point a point in the per-buffer-data and make the consumer free it, but that has other problems (less locality, allocator churn, need cleanup/destructor mechanism for when the streams is reset or destroyed early, still has lots of uncompressed copies of data in memory *sometimes*) and is not what I was imagining.
On Fri, Feb 14, 2025 at 11:50 AM Thomas Munro <thomas.munro@gmail.com> wrote: > Yeah I guess you could in theory also stream pointers to individual > uncompressed result objects allocated with palloc(), that is point a > point in the per-buffer-data and make the consumer free it, but that > has other problems (less locality, allocator churn, need Sorry, typing too fast, I meant to write: "that is, put a pointer in the per-buffer-data and make the consumer free it".
Hi, On 2025-02-14 10:04:41 +0100, Jakub Wartak wrote: > Is there any reason we couldn't have new pg_test_iorates (similiar to > other pg_test_* proggies), that would literally do this and calibrate > best e_io_c during initdb and put the result into postgresql.auto.conf > (pg_test_iorates --adjust-auto-conf) , that way we would avoid user > questions on how to come with optimal value? Unfortunately I think this is a lot easier said than done: - The optimal depth depends a lot on your IO patterns, there's a lot of things between fully sequential and fully random. You'd really need to test different IO sizes and different patterns. The test matrix for that gets pretty big. - The performance characteristics of storage heavily changes over time. This is particularly true in cloud environments, where disk/VM combinations will be "burstable", allowing higher throughput for a while, but then not anymore. Measureing during either of those states will not be great for the other state. - e_io_c is per-query-node, but impacts the whole system. If you set e_io_c=1000 on a disk with a metered IOPS of say 1k/s you might get a slightly higher throughput for a bitmap heap scan, but also your commit latency in concurrent will go through the roof, because your fdatasync() will be behind a queue of 1k reads that all are throttled. Greetings, Andres Freund
On 2/14/25 18:14, Andres Freund wrote: > Hi, > > On 2025-02-14 10:04:41 +0100, Jakub Wartak wrote: >> Is there any reason we couldn't have new pg_test_iorates (similiar to >> other pg_test_* proggies), that would literally do this and calibrate >> best e_io_c during initdb and put the result into postgresql.auto.conf >> (pg_test_iorates --adjust-auto-conf) , that way we would avoid user >> questions on how to come with optimal value? > > Unfortunately I think this is a lot easier said than done: > > - The optimal depth depends a lot on your IO patterns, there's a lot of things > between fully sequential and fully random. > > You'd really need to test different IO sizes and different patterns. The > test matrix for that gets pretty big. > > - The performance characteristics of storage heavily changes over time. > > This is particularly true in cloud environments, where disk/VM combinations > will be "burstable", allowing higher throughput for a while, but then not > anymore. Measureing during either of those states will not be great for the > other state. > > - e_io_c is per-query-node, but impacts the whole system. If you set > e_io_c=1000 on a disk with a metered IOPS of say 1k/s you might get a > slightly higher throughput for a bitmap heap scan, but also your commit > latency in concurrent will go through the roof, because your fdatasync() > will be behind a queue of 1k reads that all are throttled. > All of this is true, ofc, but maybe it's better to have a tool providing at least some advice? I'd imagine pg_test_fsync is affected by many of those issues too (considering both are about I/O). I'd definitely not want initdb to do this automatically, though. Getting good numbers is fairly expensive (in time and I/O), can be flaky, etc. But maybe having a tool that gives you a bunch of numbers, as input for manual tuning, would be good enough? As you say, it's not just about the hardware (and how that changes over time because of "burst" credits etc.), but also about the workload. Would it be possible to track something, and adjust this dynamically over time? And then adjust the prefetch distance in some adaptive way? Perhaps it's a bit naive, but say we know what % of requests is handled from cache, how long it took, etc. We opportunistically increase the prefetch distance, and check the cache hit ratio after a while. Did it help (% increased, consumed less time), maybe try another step. If not, maybe try prefetching less? regards -- Tomas Vondra
On 2/14/25 18:31, Melanie Plageman wrote: > io_combine_limit 1, effective_io_concurrency 16, read ahead kb 16 > > On Fri, Feb 14, 2025 at 12:18 PM Tomas Vondra <tomas@vondra.me> wrote: >> >> Based on off-list discussion with Melanie, I ran a modified version of >> the benchmark, with these changes: > > Thanks! It looks like the worst offender is io_combine_limit 1 (128 > kB), effective_io_concurrency 16, read_ahead_kb 16. This is a > combination that people shouldn't run in practice I think -- an > io_combine_limit larger than read ahead. > > But we do still see regressions with io_combine_limit 1, > effective_io_concurrency 16 at other read_ahead_kb values. Therefore > I'd be interested to see that subset (ioc 1, eic 16, diff read ahead > values) with the attached patch. > >> FWIW this does not change anything in the detection of sequential access >> patterns, discussed nearby, because the benchmarks started before Andres >> looked into that. If needed, I can easily rerun these tests, I just need >> a patch to apply. > > Attached a patch that has all the commits squashed + removes > sequential detection. > OK, it's running. I didn't limit the benchmarks any further, it seems useful to have "full" comparison with the last run. I expect to have the results in ~48 hours, i.e. by Monday. regards -- Tomas Vondra
Hi, On 2025-02-14 18:36:37 +0100, Tomas Vondra wrote: > All of this is true, ofc, but maybe it's better to have a tool providing > at least some advice I agree, a tool like that would be useful! One difficulty is that the relevant parameter space is really large, making it hard to keep the runtime in a reasonable range... > ? I'd imagine pg_test_fsync is affected by many of > those issues too (considering both are about I/O). I think pg_test_fsync is a bit less affected, because it doens't have a high queue depth, so it doesn't reach limits quite as quickly as something doing higher queue depth IO. Orthogonal aside: pg_test_fsync's numbers are not particularly helpful: - It e.g. tests O_SYNC, O_DSYNC with O_DIRECT, while testing fsync/fdatasync with buffered IO. But all the sync methods apply for both buffered and direct IO. And of course it'd be helpful to note what's being used, since postgres can do either... - Only tests O_SYNC, not O_DSYNC with larger write sizes, even though that information is a lot more relevant for O_DSYNC (since O_SYNC is useless) - Only tests write sizes of up to 16kB, even though larger writes are extremely common and performance critical... There's more, but it's already a long enough aside. > I'd definitely not want initdb to do this automatically, though. Getting > good numbers is fairly expensive (in time and I/O), can be flaky, etc. Yea. > But maybe having a tool that gives you a bunch of numbers, as input for > manual tuning, would be good enough? I think it'd be useful. I'd perhaps make it an SQL callable tool though, so it can be run in cloud environments. > As you say, it's not just about the hardware (and how that changes over > time because of "burst" credits etc.), but also about the workload. > Would it be possible to track something, and adjust this dynamically > over time? And then adjust the prefetch distance in some adaptive way? Yes, I do think so! It's not trivial, but I think we eventually do want it. Melanie has worked on this a fair bit, fwiw. My current thinking is that we'd want something very roughly like TCP BBR. Basically, it predicts the currently available bandwidth not just via lost packets - the traditional approach - but also by building a continually updated model of "bytes in flight" and latency and uses that to predict what the achievable bandwidth is. There are two snags on the way there: 1) Timestamps aren't cheap, so we probably can't do this for every IO. Modern NICs can associate timestamps with packets on a hardware level, we don't have that luxury. 2) It's not always easy to know an accurate completion timestamp. E.g. if a backend fired off a bunch of reads via io_uring and then is busy doing CPU bound work, we don't know how long ago the requests already completed. We probably can approximate that though. Or we could use a background process or timer interrupt to add a timestamp to IOs. > Perhaps it's a bit naive, but say we know what % of requests is handled > from cache, how long it took, etc. We opportunistically increase the > prefetch distance, and check the cache hit ratio after a while. Did it > help (% increased, consumed less time), maybe try another step. If not, > maybe try prefetching less? I don't immediately understand how you can use cache hit ratio here? We only will read data if it was a cache miss, after all? And we keep buffers pinned, so they can't be thrown out. Greetings, Andres Freund
Hi, On 2025-02-14 18:18:47 +0100, Tomas Vondra wrote: > FWIW this does not change anything in the detection of sequential access > patterns, discussed nearby, because the benchmarks started before Andres > looked into that. If needed, I can easily rerun these tests, I just need > a patch to apply. > > But if there really is some sort of issue, it'd make sense why it's much > worse on the older SATA SSDs, while NVMe devices perform somewhat > better. Because AFAICS the NVMe devices are better at handling random > I/O with shorter queues. I think the results are complicated because there are two counteracting factors influencing performance: 1) read stream doing larger reads -> considerably faster 2) read stream not doing prefetching -> more IO stalls 1) will be a a bigger boon on disks where you're not bottlenecked as much by interface limits. Whereas SATA is limited to ~500MB/s, NVMe started out at 3GB/s. So this gain will matter more on NVMes. At least on my machine 2) is what causes CPU idle states to kick in, which is what causes a good bit of the slowdown. How expensive the idle states are, how quickly they kick in, etc seems to depend a lot on CPU model, bios settings and "platform settings" (mainboard manufacturer settings). The worse a disk is at random IO, the longer the stalls are (adding time), the deeper idle state can be reached (further increasing latency). I.e. SATA will be worse. It might be interesting to run the benchmark with cpu idle stats disabled, at least on the subset of cores you run the test on. E.g. cpupower -c 13 idle-set -D1 will disable idle states that have a transition time worse than 1us for core 13. Sometimes disabling idle states for all cores will have deliterious effects, due to reducing the thermal budget for turbo boost. E.g. on my older workstation a core can boost to 3.4GHz if the whole system is at -E and only 3GHz at -D0. Instead of disabling idle states, you could also just monitor them (cpupower monitor <benchmark> or turbostat --quiet <benchmark>). Greetings, Andres Freund
On Fri, Feb 14, 2025 at 7:16 PM Andres Freund <andres@anarazel.de> wrote:
Hi,
> On 2025-02-14 18:36:37 +0100, Tomas Vondra wrote:
> > All of this is true, ofc, but maybe it's better to have a tool providing
> > at least some advice
>
> I agree, a tool like that would be useful!
>
> One difficulty is that the relevant parameter space is really large, making it
> hard to keep the runtime in a reasonable range...
It doesn't need to be perfect for sure. I was to abandon this proposal
(argument for dynamic/burstable IO is hard to argue with), but saw
some data that made me write this. I have a strong feeling that the
whole effort of the community might go unnoticed if real-world
configuration e_io_c stays at what it is today. Distribution of e_io_c
values on real world installations is more like below:
1 66%
200 17%
300 3%
16 2%
8 1%
200 seems to be EDB thingy. As per [1] even Flex has 1 by default.
I've asked R1 model and it literally told me to set this:
Example for SSDs: effective_io_concurrency = 200
Example for HDDs: effective_io_concurrency = 2
Funny, so the current default (1) is saying to me like: use half of
the platters in HDD in 2026+ (that's when people will start to
pg_upgrade) potentially on PCIe Gen 6.0 NVMEs by then :^)
> > I'd definitely not want initdb to do this automatically, though. Getting
> > good numbers is fairly expensive (in time and I/O), can be flaky, etc.
>
> Yea.
Why not? We are not talking about perfect results. If we would
constraint it to just few seconds and cap it (to still get something
conservative but still allow getting higher e_io_c where it might
matter), this would allow read streaming (and it's consumers such as
this $thread) and AIO to at least give some chance to shine , wouldn't
it ? I do understand the value should be conservative, but without at
least values of 4..8 hardly anyone will notice the benefits (?)
Wouldn't be MIN(best_estimated_eioc/VCPUs < 1 ? 1 :
best_estimated_eioc/VCPUs, 8) saner?
After all it could be anything in the OS, that could tell hint us too
(like /sys with nr_requests or queue_depth)
I cannot stop thinking how wasteful that e_io_c=1 seems to be with all
those IO stalls, context_switches, and You have mentioned even that
CPU power-saving idling impact too.
> > But maybe having a tool that gives you a bunch of numbers, as input for
> > manual tuning, would be good enough?
>
> I think it'd be useful. I'd perhaps make it an SQL callable tool though, so
> it can be run in cloud environments.
Right, you could even make it SQL callable and still run it when
initdb runs. It could take a max_runtime parameter too to limit its
max duration (longer the measurement the more accurate the result).
> > As you say, it's not just about the hardware (and how that changes over
> > time because of "burst" credits etc.), but also about the workload.
> > Would it be possible to track something, and adjust this dynamically
> > over time? And then adjust the prefetch distance in some adaptive way?
>
> Yes, I do think so! It's not trivial, but I think we eventually do want it.
>
> Melanie has worked on this a fair bit, fwiw.
>
> My current thinking is that we'd want something very roughly like TCP
> BBR. Basically, it predicts the currently available bandwidth not just via
> lost packets - the traditional approach - but also by building a continually
> updated model of "bytes in flight" and latency and uses that to predict what
> the achievable bandwidth is.[..]
Sadly that doesn't sound like PG18, right? (or I missed some thread,
I've tried to watch Melanie's presentation though )
-J.
[1] -
https://learn.microsoft.com/en-us/azure/postgresql/flexible-server/server-parameters-table-resource-usage-asynchronous-behavior?pivots=postgresql-17
On Thu, Feb 13, 2025 at 5:51 PM Thomas Munro <thomas.munro@gmail.com> wrote: > > On Fri, Feb 14, 2025 at 5:52 AM Melanie Plageman > <melanieplageman@gmail.com> wrote: > > On Thu, Feb 13, 2025 at 11:28 AM Tomas Vondra <tomas@vondra.me> wrote: > > > On 2/13/25 17:01, Melanie Plageman wrote: > > > I know it's not changing how much memory we allocate (compared to > > > master). I haven't thought about the GinScanEntry - yes, flexible array > > > member would make this a bit more complex. > > > > Oh, I see. I didn't understand Thomas' proposal. I don't know how hard > > it would be to make tidbitmap allocate the offsets on-demand. I'd need > > to investigate more. But probably not worth it for this patch. > > No, what I meant was: It would be nice to try to hold only one > uncompressed result set in memory at a time, like we achieved in the > vacuum patches. The consumer expands them from a tiny object when the > associated buffer pops out the other end. That should be possible > here too, right, because the bitmap is immutable and long lived, so > you should be able to stream (essentially) pointers into its internal > guts. The current patch streams the uncompressed data itself, and > thus has to reserve space for the maximum possible amount of it, and > also forces you to think about fixed sizes. Attached v30 makes the tuple offset extraction happen later as you suggested. It turns out that none of the users need to worry much about allocating and freeing -- I was able to have all users make an offsets array on the stack. Personally I don't think we should worry about making a smaller array when fewer offsets are needed. Even without the read stream API, in bitmap heap scan, delaying extraction of the offsets lets us skip doing so for the prefetch iterator -- so that's kind of cool. Anyway, we are going to get rid of the prefetch iterator, so I won't belabor the point. I was worried the patch would be too big of a change to the tidbitmap API for this late in the cycle, but it turned out to be a small patch. I'd be interested in what folks think. - Melanie
Attachment
On Fri, Feb 14, 2025 at 9:32 AM Andres Freund <andres@anarazel.de> wrote: > I think we'll need to add some logic in read stream that only disables advice > after a longer sequential sequence. Writing logic for that shouldn't be too > hard, I think? Determining the concrete cutoffs is probably harder, although I > think even fairly simplistic logic will be "good enough". (Sorry for taking time to respond, I had to try some bogus things first before I hit on a principled answer.) Yeah, it is far too stupid. I think I have figured out the ideal cutoff: just keep issuing advice for a given sequential run of blocks until the pread() end of the stream catches up with the *start* of it, if ever (ie until the kernel sees the actual sequential reads). That turned out to require only a small tweak and one new variable. It avoids those stalls on reads of sequential clusters > io_combine_limit, with no change in behaviour for pure sequential streams and random streams containing sequential clusters <= io_combine_limit that I'd previously been fixating on. I've added a patch for that to the v2 of my read stream improvements series[1] for experimentation... will post shortly. I also see a couple of other reasons why streaming BHS can be less aggressive with I/O than master: the silly arbitrary buffer queue cap, there's already a patch in the series for that but I have a slightly better one now and plan to commit it today, and silly heuristics for look-ahead distance reduction also related to sequential detection, which I'll explain with a patch on the other thread. All of these are cases where I was basically a bit too chicken to open the throttle all the way in early versions. Will post those at [1] too after lunch... more soon... [1] https://www.postgresql.org/message-id/flat/CA%2BhUKGK_%3D4CVmMHvsHjOVrK6t4F%3DLBpFzsrr3R%2BaJYN8kcTfWg%40mail.gmail.com
On Wed, Feb 19, 2025 at 6:03 PM Thomas Munro <thomas.munro@gmail.com> wrote: > > On Fri, Feb 14, 2025 at 9:32 AM Andres Freund <andres@anarazel.de> wrote: > > I think we'll need to add some logic in read stream that only disables advice > > after a longer sequential sequence. Writing logic for that shouldn't be too > > hard, I think? Determining the concrete cutoffs is probably harder, although I > > think even fairly simplistic logic will be "good enough". > > (Sorry for taking time to respond, I had to try some bogus things > first before I hit on a principled answer.) > > Yeah, it is far too stupid. I think I have figured out the ideal > cutoff: just keep issuing advice for a given sequential run of blocks > until the pread() end of the stream catches up with the *start* of it, > if ever (ie until the kernel sees the actual sequential reads). So like fadvise blocks 2,3,4,5, but then we see pread block 2 so stop fadvising for that run of blocks? > That turned out to require only a small tweak and one new variable. It > avoids those stalls on reads of sequential clusters > > io_combine_limit, with no change in behaviour for pure sequential > streams and random streams containing sequential clusters <= > io_combine_limit that I'd previously been fixating on. Hmm. My understanding must be incorrect because I don't see how this would behave differently for these two IO patterns fadvise 2,3,4,5, pread 2 fadvise 2,100,717,999, pread 2 > I've added a > patch for that to the v2 of my read stream improvements series[1] for > experimentation... will post shortly. I don't think you've posted those yet. I'd like to confirm that these work as expected before we merge the bitmap heap scan code. > I also see a couple of other reasons why streaming BHS can be less > aggressive with I/O than master: the silly arbitrary buffer queue cap, > there's already a patch in the series for that but I have a slightly > better one now and plan to commit it today, and silly heuristics for > look-ahead distance reduction also related to sequential detection, > which I'll explain with a patch on the other thread. All of these are > cases where I was basically a bit too chicken to open the throttle all > the way in early versions. Will post those at [1] too after lunch... > more soon... I'd like to hear more about the buffer queue cap, as I can't say I remember what that is. I'd also be interested to see how these other patches affect the BHS performance. Other than that, we need to decide on effective_io_concurrency defaults, which has also been discussed on this thread. - Melanie
On Sun, Feb 16, 2025 at 7:29 AM Tomas Vondra <tomas@vondra.me> wrote: > > On 2/16/25 02:15, Tomas Vondra wrote: > > > > ... > > > > OK, I've uploaded the results to the github repository as usual > > > > https://github.com/tvondra/bitmapscan-tests/tree/main/20250214-184807 > > > > and I've generated the same PDF reports, with the colored comparison. > > > > If you compare the pivot tables (I opened the "same" PDF from the two > > runs and flip between them using alt-tab, which makes the interesting > > regions easy to spot), the change is very clear. > > > > Disabling the sequential detection greatly reduces the scope of > > regressions. That looks pretty great, IMO. > > > > It also seems to lose some speedups, especially with io_combine_limit=1 > > and eic=1. I'm not sure why, if that's expected, etc. Yea, I don't know why these would change with vs without sequential detection. Honestly, for serial bitmap heap scan, I would assume that eic 1, io_combine_limit 1 would be the same as master (i.e. issuing at least the one fadvise and no additional latency introduced by trying to combine IOs). So both the speedup and slowdown are a bit surprising to me. > > There still remain areas of regression, but most of them are for cases > > that'd use index scan (tiny fraction of rows scanned), or with > > read-ahead=4096 (and not for the lower settings). > > > > The read-ahead dependence is actually somewhat interesting, because I > > realized the RAID array has this set to 8192 by default, i.e. even > > higher than 4096 where it regresses. I suppose mdadm does that, or > > something, I don't know how the default is calculated. But I assume it > > depends on the number of devices, so larger arrays might have even > > higher read-ahead values. Are the readahead regressions you are talking about the ones with io_combine_limit > 1 and effective_io_concurrency 0 (at higher readahead values)? With these, we expect that no fadvises and higher readahead values means the OS will do good readahead for us. But somehow the read combining seems to be interfering with this. This is curious. It seems like it must have something to do with the way the kernel is calculating readahead size. While the linux kernel readahead readme [1] is not particularly easy to understand, there are some parts that stick out to me: * The size of the async tail is determined by subtracting the size that * was explicitly requested from the determined request size, unless * this would be less than zero - then zero is used. I wonder if somehow the larger IO requests are foiling readahead. Honestly, I don't know how far we can get trying to figure this out. And explicitly reverse engineering this may backfire in other ways. - Melanie [1] https://github.com/torvalds/linux/blob/master/mm/readahead.c
On Wed, Feb 19, 2025 at 8:29 AM Jakub Wartak <jakub.wartak@enterprisedb.com> wrote: > > On Fri, Feb 14, 2025 at 7:16 PM Andres Freund <andres@anarazel.de> wrote: > > > Melanie has worked on this a fair bit, fwiw. > > > > My current thinking is that we'd want something very roughly like TCP > > BBR. Basically, it predicts the currently available bandwidth not just via > > lost packets - the traditional approach - but also by building a continually > > updated model of "bytes in flight" and latency and uses that to predict what > > the achievable bandwidth is.[..] > > Sadly that doesn't sound like PG18, right? (or I missed some thread, > I've tried to watch Melanie's presentation though ) Yes, I spent about a year researching this. My final algorithm didn't make it into a presentation, but the basic idea was to track how the prefetch distance was affecting throughput on a per IO basis and push the prefetch distance up when doing so was increasing throughput and down when throughput isn't increasing. Doing this in a sawtooth pattern ultimately would allow the prefetch distance to adapt to changing system resources. The actual algorithm was more complicated than this, but that was the basic premise. It worked well in simulations. - Melanie
On Wed, Feb 19, 2025 at 4:14 PM Melanie Plageman <melanieplageman@gmail.com> wrote: > > Attached v30 makes the tuple offset extraction happen later as you > suggested. It turns out that none of the users need to worry much > about allocating and freeing -- I was able to have all users make an > offsets array on the stack. Personally I don't think we should worry > about making a smaller array when fewer offsets are needed. > > Even without the read stream API, in bitmap heap scan, delaying > extraction of the offsets lets us skip doing so for the prefetch > iterator -- so that's kind of cool. Anyway, we are going to get rid of > the prefetch iterator, so I won't belabor the point. > > I was worried the patch would be too big of a change to the tidbitmap > API for this late in the cycle, but it turned out to be a small patch. > I'd be interested in what folks think. Attached v31 has some updates after self-review and some off-list feedback from Andres. They're minor changes, so I won't enumerate them. - Melanie
Attachment
On Fri, Feb 21, 2025 at 11:17 AM Melanie Plageman <melanieplageman@gmail.com> wrote: > [v31-0001-Delay-extraction-of-TIDBitmap-per-page-offsets.patch] Nice patch, seems like a straightforward win with the benefits you explained: less work done under a lock, less work done in the second iterator if the rest of this stuff doesn't make it in yet, and less space used assuming it does. My only comment is that I'm not sure about this type: +/* + * The tuple OffsetNumbers extracted from a single page in the bitmap. + */ +typedef OffsetNumber TBMOffsets[TBM_MAX_TUPLES_PER_PAGE]; It's used for a stack object, but it's also used as a degraded pointer here: +extern void tbm_extract_page_tuple(TBMIterateResult *iteritem, + TBMOffsets offsets); Maybe a personal style question but degraded pointers aren't my favourite C feature. A couple of alternatives, I am not sure how good they are: Would this output variable be better wrapped up in a new struct for better API clarity? If so, shouldn't such a struct also hold ntuples itself, since that really goes with the offsets it's holding? If so, could iteritem->ntuples then be replaced with a boolean iteritem->lossy, since all you really need to be able to check is whether it has offsets to give you, instead of using -1 and -2 for that? Or as a variation without a new struct, would it be better to take that output array as a plain pointer to OffsetNumber and max_offsets, and return ntuples (ie how many were filled in, cf commit f6bef362), for the caller to use in a loop or stash somewhere, with an additional comment that TBM_MAX_TUPLES_PER_PAGE is guaranteed to be enough, for convenience eg for arrays on the stack?
Thanks for the review! While editing this, I found a few things I could improve. For one, I actually wasn't using the parallel state member that I had added as a parameter to one of the table AM callbacks. So, I was able to remove that. On Thu, Feb 20, 2025 at 7:32 PM Thomas Munro <thomas.munro@gmail.com> wrote: > > On Fri, Feb 21, 2025 at 11:17 AM Melanie Plageman > <melanieplageman@gmail.com> wrote: > > [v31-0001-Delay-extraction-of-TIDBitmap-per-page-offsets.patch] > > +/* > + * The tuple OffsetNumbers extracted from a single page in the bitmap. > + */ > +typedef OffsetNumber TBMOffsets[TBM_MAX_TUPLES_PER_PAGE]; > > It's used for a stack object, but it's also used as a degraded pointer here: > > +extern void tbm_extract_page_tuple(TBMIterateResult *iteritem, > + > TBMOffsets offsets); > > Maybe a personal style question but degraded pointers aren't my > favourite C feature. A couple of alternatives, I am not sure how good > they are: Would this output variable be better wrapped up in a new > struct for better API clarity? If so, shouldn't such a struct also > hold ntuples itself, since that really goes with the offsets it's > holding? If so, could iteritem->ntuples then be replaced with a > boolean iteritem->lossy, since all you really need to be able to check > is whether it has offsets to give you, instead of using -1 and -2 for > that? Yea, I think this is a good point. I made a new struct which has ntuples and the offsets array as you suggested. I think it's much nicer than using -2 :) I do worry a bit about the ntuples value in the new struct being uninitialized. Before, tbm_iterate() filled in TBMIterateResult.ntuples, so you knew that once you had a TBMIterateResult at all, ntuples was valid. Now you make a TBMPageOffsets and until you call tbm_extract_page_tuple() on it, TBMPageOffsets->ntuples is garbage. It's probably okay though. I have the caller initialize TBMPageOffsets to -1 when I think this might be an issue. > Or as a variation without a new struct, would it be better to > take that output array as a plain pointer to OffsetNumber and > max_offsets, and return ntuples (ie how many were filled in, cf commit > f6bef362), for the caller to use in a loop or stash somewhere, with an > additional comment that TBM_MAX_TUPLES_PER_PAGE is guaranteed to be > enough, for convenience eg for arrays on the stack? I thought about doing this, but in the end I decided against this approach. If we wanted to make it easy to palloc arrays of different sizes and have tbm_extract_page_tuple extract that many tuples into the array, we'd have to change more of the code anyway because tbm_extract_page_tuple is what tells us how many tuples there are to begin with. We could save this somewhere while filling in the PagetableEntries initially, but that is a bigger change. And, passing a length would also mean more callers would have to know about TBM_MAX_TUPLES_PER_PAGE, which I think is already kind of a hack since it is defined as MaxHeapTuplesPerPage. - Melanie
Attachment
On Fri, Feb 21, 2025 at 5:00 PM Melanie Plageman <melanieplageman@gmail.com> wrote: > > I thought about doing this, but in the end I decided against this > approach. If we wanted to make it easy to palloc arrays of different > sizes and have tbm_extract_page_tuple extract that many tuples into > the array, we'd have to change more of the code anyway because > tbm_extract_page_tuple is what tells us how many tuples there are to > begin with. We could save this somewhere while filling in the > PagetableEntries initially, but that is a bigger change. > > And, passing a length would also mean more callers would have to know > about TBM_MAX_TUPLES_PER_PAGE, which I think is already kind of a hack > since it is defined as MaxHeapTuplesPerPage. I changed my mind. I think since the struct I added was only used for tbm_extract_page_tuple(), it was a bit weird. I also think it is okay for callers to use TBM_MAX_TUPLES_PER_PAGE. I ended up revising this to use the same API you implemented for TIDStore in TidStoreGetBlockOffsets(). The caller passes an array and the size of the array and tbm_extract_page_tuple() fills in that many offsets and returns the total number of offsets. It avoids adding a new struct and means callers could pass a different value than TBM_MAX_TUPLES_PER_PAGE. Overall, I like it. - Melanie
Attachment
On Mon, Feb 24, 2025 at 11:18 AM Melanie Plageman <melanieplageman@gmail.com> wrote: > > I changed my mind. I think since the struct I added was only used for > tbm_extract_page_tuple(), it was a bit weird. I also think it is okay > for callers to use TBM_MAX_TUPLES_PER_PAGE. I ended up revising this > to use the same API you implemented for TIDStore in > TidStoreGetBlockOffsets(). The caller passes an array and the size of > the array and tbm_extract_page_tuple() fills in that many offsets and > returns the total number of offsets. It avoids adding a new struct and > means callers could pass a different value than > TBM_MAX_TUPLES_PER_PAGE. Overall, I like it. Okay, I've pushed those patches. All that remains in attached v34 are the patches to implement using the read stream API. I'll wait to push until the patches to modify the read stream API sequential detection are in. I was thinking about what the default value should be for effective_io_concurrency, and I looked back at Tomas' results. It definitely should be > 1. But, there are cases where 16 is a regression. So, perhaps it would be good to run some tests trying out 4 and 8 once we have a fixed up sequential detection algorithm. - Melanie
Attachment
On Mon, Feb 24, 2025 at 5:07 PM Melanie Plageman <melanieplageman@gmail.com> wrote: > > I was thinking about what the default value should be for > effective_io_concurrency, and I looked back at Tomas' results. It > definitely should be > 1. But, there are cases where 16 is a > regression. So, perhaps it would be good to run some tests trying out > 4 and 8 once we have a fixed up sequential detection algorithm. I ran some experiments on master with datasets and access patterns derived from Tomas' original bitmap heap scan benchmarking scripts to try and identify a good default effective IO concurrency value on master. The takeaway is that I think 16 is a good default effectio_io_concurrency value. I've attached an image with two charts of the effects of different effective_io_concurrency values on query duration. The top are results from a cloud VM with approx 3ms random read completion latency. The bottom are results from a local nvme SSD. The results you see are only for queries for which the optimal plan was a bitmap heap scan. All results are for a 1,000,000 row (~0.5 GB total size given fillfactor) dataset. The uniform dataset has 10,000 distinct values uniformly distributed throughout the relation, so I/O should be pretty random. The cyclic dataset has 100 distinct values banded every 10,000 rows. So, rows where a = 1 would be something like row 1-100, 10,000-10,100, 20,000-20,100, etc. So there are intermittent ranges of sequential values that match. "matches" determines how big the range is in the WHERE clause. In this query, $from and $to are based on the number of matches and the number of distinct values. So a higher matches value means more of the table matches. SELECT * FROM bitmap_scan_test WHERE (a BETWEEN $from AND $to) OFFSET $rows; I also tested the linear data distribution -- which had 10,000 distinct values starting with 0, each value repeating 100 times, and linearly increasing to 10,000. None of these queries chose bitmap heap scan as the optimal plan, so they are not pictured in the results. I've displayed the results for the uncached workload (data was evicted from kernel buffer cache before doing each query). I also ran the same queries with OS caching and shared buffer caching. There was no meaningful difference. I was mostly confirming that there was no regression there with higher effective_io_concurrency values. - Melanie
Attachment
{kind=link}
On Mon, Mar 10, 2025 at 3:06 PM Melanie Plageman <melanieplageman@gmail.com> wrote: > > I ran some experiments on master with datasets and access patterns > derived from Tomas' original bitmap heap scan benchmarking scripts to > try and identify a good default effective IO concurrency value on > master. I've attached one more set of charts for cloud storage that includes effective_io_concurrency 0 (no prefetching) so that you can see that 0 is actually better than the current default of 1. - Melanie
Attachment
{kind=link}
On Mon, Mar 10, 2025 at 3:06 PM Melanie Plageman <melanieplageman@gmail.com> wrote: > > The takeaway is that I think 16 is a good default effectio_io_concurrency value. Attached v35 0003-0005 is the same as v34 but is on top of two new commits: 0001 increases the default effective_io_concurrency to 16 and 0002 adds a READ_STREAM_RANDOM flag which disables sequential detection and is used by bitmap heap scan. - Melanie
Attachment
Hi, On 2025-03-10 19:45:38 -0400, Melanie Plageman wrote: > From 7b35b1144bddf202fb4d56a9b783751a0945ba0e Mon Sep 17 00:00:00 2001 > From: Melanie Plageman <melanieplageman@gmail.com> > Date: Mon, 10 Mar 2025 17:17:38 -0400 > Subject: [PATCH v35 1/5] Increase default effective_io_concurrency to 16 > > The default effective_io_concurrency has been 1 since it was introduced > in b7b8f0b6096d2ab6e. Referencing the associated discussion [1], it > seems 1 was chosen as a conservative value that seemed unlikely to cause > regressions. 16 years... > Experimentation on high latency cloud storage as well as fast, local > nvme storage (see Discussion link) shows that even slightly higher values > improve query timings substantially. 1 actually performs worse than 0. > With effective_io_concurrency 1, we are not prefetching enough to avoid > I/O stalls, but we are issuing extra syscalls. Makes sense. > Moreover, when bitmap heap scan is converted to using the read stream > API, a prefetch distance of 1 will prevent read combining which is quite > detrimental to performance. Hm? This one surprises me. Doesn't the read stream code take some pains to still perform IO combining when effective_io_concurrency=1? It does work for seqscans, for example? > The new default is 16, which should be more appropriate in the general > case while still avoiding flooding low IOPs devices with I/O requests. Maybe s/in the general case/for common hardware/? > [1] https://www.postgresql.org/message-id/flat/FDDBA24E-FF4D-4654-BA75-692B3BA71B97%40enterprisedb.com > > Discussion: https://postgr.es/m/CAAKRu_Z%2BJa-mwXebOoOERMMUMvJeRhzTjad4dSThxG0JLXESxw%40mail.gmail.com > --- > doc/src/sgml/config.sgml | 38 +++++++++---------- > src/backend/utils/misc/postgresql.conf.sample | 2 +- > src/include/storage/bufmgr.h | 2 +- > 3 files changed, 19 insertions(+), 23 deletions(-) > > diff --git a/doc/src/sgml/config.sgml b/doc/src/sgml/config.sgml > index d2fa5f7d1a9..8c4409fc8bf 100644 > --- a/doc/src/sgml/config.sgml > +++ b/doc/src/sgml/config.sgml > @@ -2577,36 +2577,32 @@ include_dir 'conf.d' > Sets the number of concurrent disk I/O operations that > <productname>PostgreSQL</productname> expects can be executed > simultaneously. Raising this value will increase the number of I/O > - operations that any individual <productname>PostgreSQL</productname> session > - attempts to initiate in parallel. The allowed range is 1 to 1000, > - or zero to disable issuance of asynchronous I/O requests. Currently, > - this setting only affects bitmap heap scans. > + operations that any individual <productname>PostgreSQL</productname> > + session attempts to initiate in parallel. The allowed range is > + <literal>1</literal> to <literal>1000</literal>, or > + <literal>0</literal> to disable issuance of asynchronous I/O requests. > + The default is <literal>16</literal> on supported systems, otherwise > + <literal>0</literal>. Currently, this setting only affects bitmap heap > + scans. > </para> I'd probably use this as an occasion to remove "Currently, this setting only affects bitmap heap" sentence - afaict it's been wrong for a while and got more wrong since vacuum started to use read streams... > <para> > - For magnetic drives, a good starting point for this setting is the > - number of separate > - drives comprising a RAID 0 stripe or RAID 1 mirror being used for the > - database. (For RAID 5 the parity drive should not be counted.) > - However, if the database is often busy with multiple queries issued in > - concurrent sessions, lower values may be sufficient to keep the disk > - array busy. A value higher than needed to keep the disks busy will > - only result in extra CPU overhead. > - SSDs and other memory-based storage can often process many > - concurrent requests, so the best value might be in the hundreds. Afaict this whole paragraph was *never* correct... Obviously that's not criticism of your removing it ;) > + Higher values will have the most impact on higher latency storage > + where queries otherwise experience noticeable I/O stalls and on > + devices with high IOPs. Higher values than needed to satisfy the query > + or keep the device busy can be expected to only introduce extra CPU > + overhead. > </para> I'd say unnecessarily high values also can increase IO latency. Greetings, Andres Freund
Thanks for taking a look. I've pushed the patch to increase the default effective_io_concurrency. On Tue, Mar 11, 2025 at 8:07 PM Andres Freund <andres@anarazel.de> wrote: > > On 2025-03-10 19:45:38 -0400, Melanie Plageman wrote: > > From 7b35b1144bddf202fb4d56a9b783751a0945ba0e Mon Sep 17 00:00:00 2001 > > From: Melanie Plageman <melanieplageman@gmail.com> > > Date: Mon, 10 Mar 2025 17:17:38 -0400 > > Subject: [PATCH v35 1/5] Increase default effective_io_concurrency to 16 > > > Moreover, when bitmap heap scan is converted to using the read stream > > API, a prefetch distance of 1 will prevent read combining which is quite > > detrimental to performance. > > Hm? This one surprises me. Doesn't the read stream code take some pains to > still perform IO combining when effective_io_concurrency=1? It does work for > seqscans, for example? I went back and tried to figure out what I meant by this. When Thomas and I were investigating various BHS regressions, we did see that effective_io_concurrency 1 performed particularly badly on the read stream branch (as compared to master). One thing we noticed was very little read combining (especially for parallel bitmap heap scan, but that's a separate bundle of issues). Re-reading the read stream code, though, you are right that we should have no issue read combining when eic is 1. In that case, with the default io_combine_limit, max pinned buffers will be 32, which is definitely enough for read combining. Anyway, I've removed this text from the commit message. > > diff --git a/doc/src/sgml/config.sgml b/doc/src/sgml/config.sgml > > index d2fa5f7d1a9..8c4409fc8bf 100644 > > --- a/doc/src/sgml/config.sgml <-- snip--> > > + <literal>0</literal> to disable issuance of asynchronous I/O requests. > > + The default is <literal>16</literal> on supported systems, otherwise > > + <literal>0</literal>. Currently, this setting only affects bitmap heap > > + scans. > > </para> > > I'd probably use this as an occasion to remove "Currently, this setting only > affects bitmap heap" sentence - afaict it's been wrong for a while and got > more wrong since vacuum started to use read streams... Well, technically vacuum uses maintenance_io_concurrency. Bitmap heap scan is the only one using effective_io_concurrency for prefetching (since sequential scan doesn't do prefetching). So, it is technically true. Sequential scans will try to combine IOs only up to the io_combine_limit so effective_io_concurrency doesn't really matter for them. I removed this sentence anyway, though. Other read stream users (including non-in-core ones) could start using effective_io_concurrency and then it might be more confusing anyway. - Melanie
On Wed, Mar 12, 2025 at 9:02 PM Melanie Plageman <melanieplageman@gmail.com> wrote: > > Thanks for taking a look. I've pushed the patch to increase the > default effective_io_concurrency. Cool, anything > 1 is just better. Just quick question, so now we have: #define DEFAULT_EFFECTIVE_IO_CONCURRENCY 16 #define DEFAULT_MAINTENANCE_IO_CONCURRENCY 10 Shouldn't maintenance be now also at the same value (16) instead of 10? Also, fc34b0d9de27 (5 years ago by Thomas) states about m_io_c: "Use the new setting in heapam.c instead of the hard-coded formula effective_io_concurrency + 10 introduced by commit 558a9165e08.", so there was always assumption that m_io_c > e_io_c (?) Now it's kind of inconsistent to see bitmap heap scans pushing more IOPs than recovery(!)/ANALYZE/VACUUM or am I missing something? No pressure to change, just asking what Your thoughts are. -J.
On Thu, Mar 13, 2025 at 5:46 AM Jakub Wartak <jakub.wartak@enterprisedb.com> wrote: > > Cool, anything > 1 is just better. Just quick question, so now we have: > > #define DEFAULT_EFFECTIVE_IO_CONCURRENCY 16 > #define DEFAULT_MAINTENANCE_IO_CONCURRENCY 10 > > Shouldn't maintenance be now also at the same value (16) instead of > 10? Also, fc34b0d9de27 (5 years ago by Thomas) states about m_io_c: > "Use the new setting in heapam.c instead of the hard-coded formula > effective_io_concurrency + 10 introduced by commit 558a9165e08.", so > there was always assumption that m_io_c > e_io_c (?) Now it's kind of > inconsistent to see bitmap heap scans pushing more IOPs than > recovery(!)/ANALYZE/VACUUM or am I missing something? No pressure to > change, just asking what Your thoughts are. Yea, I'm not really sure what if any relationship the two GUCs should have to one another. As long as they are in the same ballpark, since they are tuning for the same machine, I don't see any reason their values need to be adjusted together. However, if it is confusing for maintenance_io_concurrency default to be 10 while effective_io_concurrency default is 16, I'm happy to change it. I just don't quite know what I would write in the commit message. "it seemed confusing that they weren't the same?" - Melanie
On Mon, Mar 10, 2025 at 7:45 PM Melanie Plageman <melanieplageman@gmail.com> wrote: > > Attached v35 0003-0005 is the same as v34 but is on top of two new > commits: 0001 increases the default effective_io_concurrency to 16 and > 0002 adds a READ_STREAM_RANDOM flag which disables sequential > detection and is used by bitmap heap scan. Attached v36 is built on top of the read stream updates Thomas posted earlier today in [1]. I've been doing some performance testing and from what I see, we've closed the major gaps. The case I was most concerned about was cyclic data (narrow bands of sequential data in a larger random dataset) with reasonable values for io_combine_limit, effective_io_concurrency, and OS read ahead. I've attached a chart which compares the query time for master, my original bitmap heap scan streaming read user "og", the bitmap heap scan streaming read user with sequential detection turned off completely "random", and the bitmap heap scan streaming read user with the updated read stream changes Thomas posted today "rsupdate". You can see that it eliminates the regression. For some of the other cases, because we still do sequential detection with Thomas' changes, we sometimes pause prefetching which means if you have turned off OS read ahead, then it'll be slower than without the read stream user. That's okay, though -- in the vastly more common case of OS readahead being enabled, we can avoid unnecessary prefetching and beat current master. Overall, I feel pretty good about merging this once Thomas merges the read stream patches. - Melanie [1] https://www.postgresql.org/message-id/CA%2BhUKGKH2mwj%3DmpCobC4ZyBdR4ToW2hpQcYFDivj40fxf4yQow%40mail.gmail.com
Attachment
- v36-0005-Support-buffer-forwarding-in-read_stream.c.patch
- v36-0002-Respect-pin-limits-accurately-in-read_stream.c.patch
- v36-0001-Improve-buffer-manager-API-for-backend-pin-limit.patch
- v36-0003-Improve-read-stream-advice-for-large-random-chun.patch
- v36-0004-Look-ahead-more-when-sequential-in-read_stream.c.patch
- v36-0006-Support-buffer-forwarding-in-StartReadBuffers.patch
- v36-0007-Separate-TBM-Shared-Private-Iterator-and-TBMIter.patch
- v36-0009-Remove-table-AM-callback-scan_bitmap_next_block.patch
- v36-0008-BitmapHeapScan-uses-the-read-stream-API.patch
- cyclic_eic16_ioc16_ra4096.png
{kind=link}
On Thu, Mar 13, 2025 at 5:41 PM Melanie Plageman <melanieplageman@gmail.com> wrote: > > Overall, I feel pretty good about merging this once Thomas merges the > read stream patches. This was committed in 944e81bf99db2b5b70b, 2b73a8cd33b745c, and c3953226a07527a1e2. I've marked it as committed in the CF app. As we continue to test the feature in the coming weeks, we can enhance the read stream API with any updates needed. - Melanie
Hi, On 2025-03-15 10:43:45 -0400, Melanie Plageman wrote: > On Thu, Mar 13, 2025 at 5:41 PM Melanie Plageman > <melanieplageman@gmail.com> wrote: > > > > Overall, I feel pretty good about merging this once Thomas merges the > > read stream patches. > > This was committed in 944e81bf99db2b5b70b, 2b73a8cd33b745c, and > c3953226a07527a1e2. > I've marked it as committed in the CF app. > > As we continue to test the feature in the coming weeks, we can enhance > the read stream API with any updates needed. Really excited about this. This work has made read streams way better, making it much easier to add future read stream users to other places! Greetings, Andres Freund
On Thu, Mar 13, 2025 at 9:34 PM Melanie Plageman <melanieplageman@gmail.com> wrote: > On Thu, Mar 13, 2025 at 5:46 AM Jakub Wartak > <jakub.wartak@enterprisedb.com> wrote: > > > > Cool, anything > 1 is just better. Just quick question, so now we have: > > > > #define DEFAULT_EFFECTIVE_IO_CONCURRENCY 16 > > #define DEFAULT_MAINTENANCE_IO_CONCURRENCY 10 > > > > Shouldn't maintenance be now also at the same value (16) instead of > > 10? Also, fc34b0d9de27 (5 years ago by Thomas) states about m_io_c: > > "Use the new setting in heapam.c instead of the hard-coded formula > > effective_io_concurrency + 10 introduced by commit 558a9165e08.", so > > there was always assumption that m_io_c > e_io_c (?) Now it's kind of > > inconsistent to see bitmap heap scans pushing more IOPs than > > recovery(!)/ANALYZE/VACUUM or am I missing something? No pressure to > > change, just asking what Your thoughts are. > > Yea, I'm not really sure what if any relationship the two GUCs should > have to one another. > As long as they are in the same ballpark, since > they are tuning for the same machine, I don't see any reason their > values need to be adjusted together. However, if it is confusing for > maintenance_io_concurrency default to be 10 while > effective_io_concurrency default is 16, I'm happy to change it. Hi Melanie, dunno, I've just asked if it isn't suspicious to anyone except me else that e_io_c > m_io_c rather than e_io_c <= m_io_c. My understanding was always that to tune max IO queue depth you would do this: a. up to N backends (up to max_connections; usually much lower) * e_io_c b. autovacuum_max_workers * m_io_c c. just one (standby/recovering) * m_io_c The thing (for me) is: if we are allowing for much higher IOPS "a" scenario, then why standby cannot use just the same (if not higher) IOPS for prefetching in "c" scenario. After all, it is a much more critical and sensitive thing (lag). > I just don't quite know what I would write in the commit message. "it seemed confusing that they weren't the same?" "To keep with the historical legacy of maintenance_io_concurrency being traditionally higher than effective_io_concurrency ..." OK, so right, nobody else commented on this, so maybe it's just me and it was just a question after all. -J.
On Mon, Mar 17, 2025 at 3:44 AM Jakub Wartak <jakub.wartak@enterprisedb.com> wrote: > > dunno, I've just asked if it isn't suspicious to anyone except me else > that e_io_c > m_io_c rather than e_io_c <= m_io_c. My understanding > was always that to tune max IO queue depth you would do this: > a. up to N backends (up to max_connections; usually much lower) * e_io_c > b. autovacuum_max_workers * m_io_c > c. just one (standby/recovering) * m_io_c > > The thing (for me) is: if we are allowing for much higher IOPS "a" > scenario, then why standby cannot use just the same (if not higher) > IOPS for prefetching in "c" scenario. After all, it is a much more > critical and sensitive thing (lag). This sounds quite reasonable to me. Given I just changed the default effective_io_concurrency to 16, what value would you say is reasonable for maintenance_io_concurrency? I based the eic change off of experimentation -- seeing where the benefits flatlined for a certain class of query on a couple different kinds of machines with different IO latencies. I don't feel strongly that we need to be as rigorous for maintenance_io_concurrency, but I'm also not sure 160 seems reasonable (which would be the same ratio as before). - Melanie
Hi, On 2025-03-17 14:52:02 -0400, Melanie Plageman wrote: > I don't feel strongly that we need to be as rigorous for > maintenance_io_concurrency, but I'm also not sure 160 seems reasonable > (which would be the same ratio as before). I'd lean towards just setting them to the same value for now. Greetings, Andres Freund
On Mon, Mar 17, 2025 at 2:55 PM Andres Freund <andres@anarazel.de> wrote: > > On 2025-03-17 14:52:02 -0400, Melanie Plageman wrote: > > I don't feel strongly that we need to be as rigorous for > > maintenance_io_concurrency, but I'm also not sure 160 seems reasonable > > (which would be the same ratio as before). > > I'd lean towards just setting them to the same value for now. Cool, here's the patch I intend to commit. I had a bit of trouble clearly explaining the situation in the commit message which is why I didn't directly commit it. If no one has ideas on how to clarify it by tomorrow, I'll just push it. - Melanie
Attachment
On Mon, Mar 17, 2025 at 10:46 PM Melanie Plageman <melanieplageman@gmail.com> wrote: > > On Mon, Mar 17, 2025 at 2:55 PM Andres Freund <andres@anarazel.de> wrote: > > > > On 2025-03-17 14:52:02 -0400, Melanie Plageman wrote: > > > I don't feel strongly that we need to be as rigorous for > > > maintenance_io_concurrency, but I'm also not sure 160 seems reasonable > > > (which would be the same ratio as before). > > > > I'd lean towards just setting them to the same value for now. > > Cool, here's the patch I intend to commit. I had a bit of trouble > clearly explaining the situation in the commit message which is why I > didn't directly commit it. If no one has ideas on how to clarify it > by tomorrow, I'll just push it. Hi Melanie, same (160 is probably way too high for default m_io_c on default/small systems with s_b=128MB, but the same value is probably fine), so +1. One may say that higher m_io_c may hurt , but at least for startup/recovery performance see image [1] (from thread [2]) - it shows running it on NVMe with m_io_c=128 and being faster than default =10 and later Tomas V. pushed it even into value of "500" [3]. Hope that helps. -J. [1] https://www.postgresql.org/message-id/attachment/116928/trandomuuids-without-FPW-1.5kTPS_lagOverSize.csv-comments.png [2] https://www.postgresql.org/message-id/VI1PR0701MB69608CBCE44D80857E59572EF6CA0%40VI1PR0701MB6960.eurprd07.prod.outlook.com [3] https://www.postgresql.org/message-id/c5d52837-6256-0556-ac8c-d6d3d558820a%40enterprisedb.com
{kind=link}
Hello Melanie,
15.03.2025 16:43, Melanie Plageman wrote:
15.03.2025 16:43, Melanie Plageman wrote:
On Thu, Mar 13, 2025 at 5:41 PM Melanie Plageman <melanieplageman@gmail.com> wrote:Overall, I feel pretty good about merging this once Thomas merges the read stream patches.This was committed in 944e81bf99db2b5b70b, 2b73a8cd33b745c, and c3953226a07527a1e2. I've marked it as committed in the CF app.
It looks like that change made the bitmapops test unstable (on slow animals?): [1], [2], [3].
I've reproduced such test failures when running
TESTS=$(printf 'bitmapops %.0s' `seq 50`) make -s check-tests
under Valgrind:
...
ok 17 - bitmapops 52719 ms
not ok 18 - bitmapops 57566 ms
ok 19 - bitmapops 60179 ms
ok 20 - bitmapops 32927 ms
ok 21 - bitmapops 45127 ms
ok 22 - bitmapops 42924 ms
ok 23 - bitmapops 61035 ms
ok 24 - bitmapops 56316 ms
ok 25 - bitmapops 52874 ms
not ok 26 - bitmapops 67468 ms
ok 27 - bitmapops 55605 ms
ok 28 - bitmapops 24021 ms
...
diff -U3 /home/vagrant/postgresql/src/test/regress/expected/bitmapops.out /home/vagrant/postgresql/src/test/regress/results/bitmapops.out
--- /home/vagrant/postgresql/src/test/regress/expected/bitmapops.out 2025-03-16 01:37:52.716885600 -0700
+++ /home/vagrant/postgresql/src/test/regress/results/bitmapops.out 2025-03-22 03:47:54.014702406 -0700
@@ -24,14 +24,14 @@
SELECT count(*) FROM bmscantest WHERE a = 1 AND b = 1;
count
-------
- 23
+ 18
(1 row)
-- Test bitmap-or.
SELECT count(*) FROM bmscantest WHERE a = 1 OR b = 1;
count
-------
- 2485
+ 1044
(1 row)
-- clean up
diff -U3 /home/vagrant/postgresql/src/test/regress/expected/bitmapops.out /home/vagrant/postgresql/src/test/regress/results/bitmapops.out
--- /home/vagrant/postgresql/src/test/regress/expected/bitmapops.out 2025-03-16 01:37:52.716885600 -0700
+++ /home/vagrant/postgresql/src/test/regress/results/bitmapops.out 2025-03-22 03:54:53.129549597 -0700
@@ -31,7 +31,7 @@
SELECT count(*) FROM bmscantest WHERE a = 1 OR b = 1;
count
-------
- 2485
+ 1044
(1 row)
git bisect for this deviation has pointed at 2b73a8cd3.
[1] https://buildfarm.postgresql.org/cgi-bin/show_log.pl?nm=skink&dt=2025-03-16%2010%3A34%3A17
[2] https://buildfarm.postgresql.org/cgi-bin/show_log.pl?nm=flaviventris&dt=2025-03-17%2020%3A07%3A43
[3] https://buildfarm.postgresql.org/cgi-bin/show_log.pl?nm=skink&dt=2025-03-17%2001%3A16%3A02
Best regards,
Alexander Lakhin
Neon (https://neon.tech)
Hi, On 2025-03-22 22:00:00 +0200, Alexander Lakhin wrote: > 15.03.2025 16:43, Melanie Plageman wrote: > > On Thu, Mar 13, 2025 at 5:41 PM Melanie Plageman > > <melanieplageman@gmail.com> wrote: > > > Overall, I feel pretty good about merging this once Thomas merges the > > > read stream patches. > > This was committed in 944e81bf99db2b5b70b, 2b73a8cd33b745c, and > > c3953226a07527a1e2. > > I've marked it as committed in the CF app. > > It looks like that change made the bitmapops test unstable (on slow animals?): [1], [2], [3]. > I've reproduced such test failures when running > TESTS=$(printf 'bitmapops %.0s' `seq 50`) make -s check-tests > under Valgrind: > ... > ok 17 - bitmapops 52719 ms > not ok 18 - bitmapops 57566 ms > ok 19 - bitmapops 60179 ms > ok 20 - bitmapops 32927 ms > ok 21 - bitmapops 45127 ms > ok 22 - bitmapops 42924 ms > ok 23 - bitmapops 61035 ms > ok 24 - bitmapops 56316 ms > ok 25 - bitmapops 52874 ms > not ok 26 - bitmapops 67468 ms > ok 27 - bitmapops 55605 ms > ok 28 - bitmapops 24021 ms > ... > > diff -U3 /home/vagrant/postgresql/src/test/regress/expected/bitmapops.out > /home/vagrant/postgresql/src/test/regress/results/bitmapops.out > --- /home/vagrant/postgresql/src/test/regress/expected/bitmapops.out 2025-03-16 01:37:52.716885600 -0700 > +++ /home/vagrant/postgresql/src/test/regress/results/bitmapops.out 2025-03-22 03:47:54.014702406 -0700 > @@ -24,14 +24,14 @@ > SELECT count(*) FROM bmscantest WHERE a = 1 AND b = 1; > count > ------- > - 23 > + 18 > (1 row) Is it possible that this is the bug reported here: https://postgr.es/m/873c33c5-ef9e-41f6-80b2-2f5e11869f1c%40garret.ru I.e. that the all-visible logic in bitmap heapscans is fundamentally broken? I can reproduce different results on a fast machien by just putting a VACUUM FREEZE bmscantest after the CREATE INDEXes in bitmapops.sql. After I disable the all-visible logic in bitmapheap_stream_read_next(), I can't observe such a difference anymore. Greetings, Andres Freund
Hi, On 2025-03-22 16:14:11 -0400, Andres Freund wrote: > On 2025-03-22 22:00:00 +0200, Alexander Lakhin wrote: > > @@ -24,14 +24,14 @@ > > SELECT count(*) FROM bmscantest WHERE a = 1 AND b = 1; > > count > > ------- > > - 23 > > + 18 > > (1 row) > > Is it possible that this is the bug reported here: > https://postgr.es/m/873c33c5-ef9e-41f6-80b2-2f5e11869f1c%40garret.ru > > I.e. that the all-visible logic in bitmap heapscans is fundamentally broken? > > I can reproduce different results on a fast machien by just putting a VACUUM > FREEZE bmscantest after the CREATE INDEXes in bitmapops.sql. After I disable > the all-visible logic in bitmapheap_stream_read_next(), I can't observe such a > difference anymore. Hm, it's clearly related to the all-visible path, but I think the bug is actually independent of what was reported there. The bug you reported is perfectly reproducible, without any concurrency, after all. Here's a smaller reproducer: CREATE TABLE bmscantest (a int, t text); INSERT INTO bmscantest SELECT (r%53), 'foooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooo' FROM generate_series(1,70000) r; CREATE INDEX i_bmtest_a ON bmscantest(a); set enable_indexscan=false; set enable_seqscan=false; -- Lower work_mem to trigger use of lossy bitmaps set work_mem = 64; SELECT count(*) FROM bmscantest WHERE a = 1; vacuum freeze bmscantest; SELECT count(*) FROM bmscantest WHERE a = 1; -- clean up DROP TABLE bmscantest; The first SELECT reports 1321, the second 572 tuples. Greetings, Andres Freund
Hi,
On 2025-03-22 16:42:42 -0400, Andres Freund wrote:
> Hm, it's clearly related to the all-visible path, but I think the bug is
> actually independent of what was reported there. The bug you reported is
> perfectly reproducible, without any concurrency, after all.
>
> Here's a smaller reproducer:
>
> CREATE TABLE bmscantest (a int, t text);
>
> INSERT INTO bmscantest
> SELECT (r%53),
'foooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooo'
> FROM generate_series(1,70000) r;
>
> CREATE INDEX i_bmtest_a ON bmscantest(a);
> set enable_indexscan=false;
> set enable_seqscan=false;
>
> -- Lower work_mem to trigger use of lossy bitmaps
> set work_mem = 64;
>
> SELECT count(*) FROM bmscantest WHERE a = 1;
> vacuum freeze bmscantest;
> SELECT count(*) FROM bmscantest WHERE a = 1;
>
> -- clean up
> DROP TABLE bmscantest;
>
>
> The first SELECT reports 1321, the second 572 tuples.
The problem is that sometimes recheck is performed for pending empty
tuples. The comment about empty tuples says:
/*
* Bitmap is exhausted. Time to emit empty tuples if relevant. We emit
* all empty tuples at the end instead of emitting them per block we
* skip fetching. This is necessary because the streaming read API
* will only return TBMIterateResults for blocks actually fetched.
* When we skip fetching a block, we keep track of how many empty
* tuples to emit at the end of the BitmapHeapScan. We do not recheck
* all NULL tuples.
*/
*recheck = false;
return bscan->rs_empty_tuples_pending > 0;
But we actually emit empty tuples at each page boundary:
/*
* Out of range? If so, nothing more to look at on this page
*/
while (hscan->rs_cindex >= hscan->rs_ntuples)
{
/*
* Emit empty tuples before advancing to the next block
*/
if (bscan->rs_empty_tuples_pending > 0)
{
/*
* If we don't have to fetch the tuple, just return nulls.
*/
ExecStoreAllNullTuple(slot);
bscan->rs_empty_tuples_pending--;
return true;
}
/*
* Returns false if the bitmap is exhausted and there are no further
* blocks we need to scan.
*/
if (!BitmapHeapScanNextBlock(scan, recheck, lossy_pages, exact_pages))
return false;
}
So we don't just process tuples at the end of the scan, but at each page
boundary.
This leads to wrong results whenever there is a rs_empty_tuples_pending > 0
after a previous page that needed rechecks, because nothing will reset
*recheck = false.
And indeed, if I add a *recheck = false in that inside the
/*
* Emit empty tuples before advancing to the next block
*/
if (bscan->rs_empty_tuples_pending > 0)
{
the problem goes away.
A fix should do slightly more, given that the "at the end" comment is wrong.
But I'm wondering if it's worth fixing it, or if we should just rip the logic
out alltogether, due to the whole VM checking being unsound as we learned in
the thread I referenced earlie, without even bothering to fix the bug here.
Greetings,
Andres Freund
On Sat, Mar 22, 2025 at 5:04 PM Andres Freund <andres@anarazel.de> wrote:
>
> The problem is that sometimes recheck is performed for pending empty
> tuples. The comment about empty tuples says:
>
> /*
> * Bitmap is exhausted. Time to emit empty tuples if relevant. We emit
> * all empty tuples at the end instead of emitting them per block we
> * skip fetching. This is necessary because the streaming read API
> * will only return TBMIterateResults for blocks actually fetched.
> * When we skip fetching a block, we keep track of how many empty
> * tuples to emit at the end of the BitmapHeapScan. We do not recheck
> * all NULL tuples.
> */
> *recheck = false;
> return bscan->rs_empty_tuples_pending > 0;
>
> But we actually emit empty tuples at each page boundary:
>
> /*
> * Out of range? If so, nothing more to look at on this page
> */
> while (hscan->rs_cindex >= hscan->rs_ntuples)
> {
> /*
> * Emit empty tuples before advancing to the next block
> */
> if (bscan->rs_empty_tuples_pending > 0)
> {
> /*
> * If we don't have to fetch the tuple, just return nulls.
> */
> ExecStoreAllNullTuple(slot);
> bscan->rs_empty_tuples_pending--;
> return true;
> }
>
> /*
> * Returns false if the bitmap is exhausted and there are no further
> * blocks we need to scan.
> */
> if (!BitmapHeapScanNextBlock(scan, recheck, lossy_pages, exact_pages))
> return false;
> }
>
> So we don't just process tuples at the end of the scan, but at each page
> boundary.
Whoops! I think an earlier version of the patch did emit all the empty
tuples at the end, but I changed the control flow without moving the
recheck = false and removing/modifying that comment. Quite
embarrassing.
> This leads to wrong results whenever there is a rs_empty_tuples_pending > 0
> after a previous page that needed rechecks, because nothing will reset
> *recheck = false.
>
> And indeed, if I add a *recheck = false in that inside the
> /*
> * Emit empty tuples before advancing to the next block
> */
> if (bscan->rs_empty_tuples_pending > 0)
> {
> the problem goes away.
>
>
> A fix should do slightly more, given that the "at the end" comment is wrong.
>
> But I'm wondering if it's worth fixing it, or if we should just rip the logic
> out alltogether, due to the whole VM checking being unsound as we learned in
> the thread I referenced earlie, without even bothering to fix the bug here.
Perhaps it is better I just fix it since ripping out the skip fetch
optimization has to be backported and even though that will look very
different on master than on backbranches, I wonder if people will look
for a "clean" commit on master which removes the feature.
- Melanie
On Sun, Mar 23, 2025 at 1:27 PM Melanie Plageman <melanieplageman@gmail.com> wrote: > > Perhaps it is better I just fix it since ripping out the skip fetch > optimization has to be backported and even though that will look very > different on master than on backbranches, I wonder if people will look > for a "clean" commit on master which removes the feature. This is the patch I intend to commit to fix this assuming my CI passes and there are no objections. I did add a bit of coverage for this in bitmapops.sql. I'm not sure if that is the right thing to do since that coverage should be removed when we remove skip fetch and there is no point in adding the extra query and vacuum freeze if we don't have the skip fetch optimization. - Melanie
Attachment
On Mon, Mar 24, 2025 at 12:14 PM Melanie Plageman <melanieplageman@gmail.com> wrote: > > This is the patch I intend to commit to fix this assuming my CI passes > and there are no objections. And pushed in aea916fe555a3 - Melanie
On Thu, Feb 13, 2025 at 1:40 PM Melanie Plageman <melanieplageman@gmail.com> wrote: > Thomas mentioned this to me off-list, and I think he's right. We > likely need to rethink the way parallel bitmap heap scan workers get > block assignments for reading and prefetching to make it more similar > to parallel sequential scan. The workers should probably get > assignments of a range of blocks. On master, each worker does end up > issuing reads/fadvises for a bunch of blocks in a row -- even though > that isn't the intent of the parallel bitmap table scan > implementation. We are losing some of that with the patch -- but only > because it is behaving as you would expect given the implementation > and design. I don't consider that a blocker, though. I had a crack at this one a few weeks back, and wanted to share some thoughts. Getting sequential block range allocation work was easy (0001), but ramp-down at this level as a parallel query fairness strategy seems to be fundamentally incompatible with AIO. 0002 was an abandoned attempt before I got lost for a while researching the futility of it all. See further down. I gave up for v18. Of course we already have this problem in v18, but 0001 would magnify it. Whether gaining I/O combining is worth losing some parallel fairness, IDK, but it can wait... With just the 0001 patch, io_workers=1 and two parallel processes, you can trace the IO worker to see the ramp-up in each parallel worker and the maximised I/O combining, but also the abrupt and unfair end-of-scan: tmunro@x1:~/projects/postgresql/build$ strace -p 377335 -e trace=preadv,pread64 -s0 strace: Process 377335 attached pread64(16, ""..., 8192, 720896) = 8192 pread64(16, ""..., 8192, 729088) = 8192 pread64(16, ""..., 16384, 737280) = 16384 pread64(16, ""..., 16384, 753664) = 16384 pread64(16, ""..., 32768, 802816) = 32768 pread64(16, ""..., 32768, 770048) = 32768 pread64(16, ""..., 65536, 835584) = 65536 pread64(16, ""..., 65536, 901120) = 65536 pread64(16, ""..., 131072, 966656) = 131072 pread64(16, ""..., 131072, 1228800) = 131072 pread64(16, ""..., 131072, 1097728) = 131072 pread64(16, ""..., 131072, 1490944) = 131072 pread64(16, ""..., 131072, 1359872) = 131072 pread64(16, ""..., 131072, 1753088) = 131072 pread64(16, ""..., 131072, 1884160) = 131072 pread64(16, ""..., 131072, 1622016) = 131072 pread64(16, ""..., 131072, 2015232) = 131072 preadv(16, [...], 7, 2146304) = 131072 preadv(16, [...], 7, 2277376) = 131072 pread64(16, ""..., 131072, 2539520) = 131072 pread64(16, ""..., 131072, 2408448) = 131072 pread64(16, ""..., 98304, 2801664) = 98304 pread64(16, ""..., 131072, 2670592) = 131072 For real parallel query fairness, I wonder if we should think about a work stealing approach. Let me sketch out a simple idea first, and explain why it's still not enough, and then sketch out a bigger idea: Imagine a thing called WorkQueueSet in shared memory that contains a WorkQueue for each worker, and then a function wqs_get_next_object(&state->tidbitmap_wqs, &object) that looks in your own backend's queue first, and if there is nothing, it calls a registered callback that tries to fill your queue up (the current TBM iterator logic becomes that callback in this case, and the per-backend WorkQueue replaces the little array that I added in the attached 0001 patch), and if that doesn't work it tries to steal from everyone else's queue, and if that fails then there really is no more work to be done and your scan is finished. That should be perfectly fair, not just approximately fair under certain assumptions (that are now false) like ramp down schemes. *If* we can figure out how to make the interlocking so lightweight that the common case of consuming from your own uncontended work queue is practically as fast as reading out of a local array... (I have a few ideas about that part but this is already long enough...) But that only provides ramp-down for the block number ranges *entering* each worker's ReadStream. Our goal is to make the workers run out of work as close in time as possible, and their work begins when buffers *exit* each worker's ReadStream. Thought experiment: what if we could also steal blocks/buffers that someone else's ReadStream holds, whether already valid, referenced by an inflight I/O, or waiting to be combined with more blocks in the pending read? The buffer manager can already deal with any and all races at its level and do the right thing, but we'd somehow need to make sure the theft victim doesn't also process that block. The ReadStream's buffer queue could be integrated with your backend's WorkQueue in a WorkQueueSet in shared memory, so that others can steal your stuff, and read_stream_next_buffer() would have to discard anything that has been stolen between entering and exiting the stream. The common non-stolen case would have to be extremely cheap, read barriers and ordering tricks I guess. (This is basically a new take on an idea I have mentioned before, parallel-aware ReadStream, except that all previous versions collapsed in a heap of lock contention and other design problems. Work stealing seems to offer a way to keep everything almost as it is now, except in a few weird corner cases at end-of-stream when new magic fires up only if required. It also seems to be such a broadly useful technique that I'd want a general purpose thing, not just a ReadStream internal trick.) Putting both things together, I'm wondering about *two* levels of WorkQueueSet for stuff like Seq Scan and BHS. 1. Preserve I/O combining opportunities: The ReadStream's block number callback uses WorkQueueSet to hand out block numbers as described a couple of paragraphs above (perhaps WORK_QUEUE_TYPE_BLOCK_RANGE would be a built-in mode with queue elements [blockno, nblocks] so you can consume from them and dequeue once depleted to implement tableam.c's parallel seq block allocator, with the callback working just as it does now except with the ramp-down part removed, and tidbitmap.c would use WORK_QUEUE_TYPE_BLOB to traffic TBMWorkQueueItem objects replacing the current TBMIteratorResult). 2. Fairness: The ReadStream is put into a mode that attaches to your backend's WorkQueue in a second WorkQueueSet, and uses it for buffers and per-buffer-data. This allowing other ReadStreams in other processes attached to the same WorkQueueSet to steal stuff. In the common case, there's no stealing, but at stream end you get perfect fairness. I suspect that a generic work stealing component would find many other uses. I can think of quite a few, but here's one: It might be able to fix the PHJ unmatched scan unfairness problem, within the constraints of our existing executor model. Thought experiment: PHJ_BATCH_PROBE and PHJ_BATCH_SCAN are merged into one phase. Each worker emits already joined tuples from a WorkQueueSet (IDK how they hold tuples exactly, this is hand-waving level). The callback that pulls those tuples into your backend's WorkQueue does the actual joining and sets the match bit, which has the crucial property that you can know when all all bits are set without waiting, and then the callback can switch to feeding unmatched tuples into the work queue for FULL/RIGHT joins, and every worker can participate. No weird detach-and-drop-to-single-process, no wait, no deadlock risk. The callback's batch size would become a new source of unfairness when performing the join, so perhaps you need two levels of WorkQueueSet, one for pre-joined tuples and one for post-joined tuples, and only when both are completely exhausted do you have all match bits (there is a small extra complication: I think you need a concept of 'dequeued but busy' when moving items from pre-joined to post-joined, and a CV so you can wait for that condition to clear, or something like that, but that's a guaranteed-progress wait and only used in a very rare edge case; if I'm making in mistake in all this it may be related to this type of thing, but I'm not seeing anything unsolvable). Note that I didn't say you could take over other workers' scans, which we definitely *can't* do with our current executor model, I'm just saying that if there is no stealable work left, matching must be finished. If that sounds expensive, one thought is that it also provides a tidy solution to my old conundrum "how to do batch-oriented outer scan with the timing and control needed to drive software memory prefetching", ie without falling down the executor volcano by calling ExecProcNode() between prefetches; I strongly suspect that would provide so much speedup that it could easily pay for the cost of the extra steps, again assuming we can make the uncontended case blindingly fast. Maybe, IDK, I could be missing things... Anyway, that was a long explanation for why I didn't come up with an easy patch to teach PBHS not to destroy I/O combining opportunities for v18 :-) The short version is that 0001 does address the immediate problem we identified, but also helped me see the bigger picture a little bit more clearly and find a few interesting connections. Parallel query and I/O streaming are just not the best of friends, yet. R&D needed.
Attachment
On Mon, Apr 7, 2025 at 7:34 PM Thomas Munro <thomas.munro@gmail.com> wrote: > > On Thu, Feb 13, 2025 at 1:40 PM Melanie Plageman > <melanieplageman@gmail.com> wrote: > > Thomas mentioned this to me off-list, and I think he's right. We > > likely need to rethink the way parallel bitmap heap scan workers get > > block assignments for reading and prefetching to make it more similar > > to parallel sequential scan. The workers should probably get > > assignments of a range of blocks. On master, each worker does end up > > issuing reads/fadvises for a bunch of blocks in a row -- even though > > that isn't the intent of the parallel bitmap table scan > > implementation. We are losing some of that with the patch -- but only > > because it is behaving as you would expect given the implementation > > and design. I don't consider that a blocker, though. > > I had a crack at this one a few weeks back, and wanted to share some > thoughts. Fwiw, I've had reasonably good results, in a similar situation, by just batching + double-buffering. Since you're using AIO (as Melanie points out) there should be no real penalty to having a single worker request the next batch of blocks, when the current block is used up. Then you can separate "reading" from "prefetching": whoever reads the last block in the current batch, prefetches the next batch. This way, you could preserve your existing "reading" logic, and you wouldn't need to create several new, related queues. James
On Wed, Apr 9, 2025 at 1:46 PM James Hunter <james.hunter.pg@gmail.com> wrote:
> On Mon, Apr 7, 2025 at 7:34 PM Thomas Munro <thomas.munro@gmail.com> wrote:
> > On Thu, Feb 13, 2025 at 1:40 PM Melanie Plageman
> > <melanieplageman@gmail.com> wrote:
> > > Thomas mentioned this to me off-list, and I think he's right. We
> > > likely need to rethink the way parallel bitmap heap scan workers get
> > > block assignments for reading and prefetching to make it more similar
> > > to parallel sequential scan. The workers should probably get
> > > assignments of a range of blocks. On master, each worker does end up
> > > issuing reads/fadvises for a bunch of blocks in a row -- even though
> > > that isn't the intent of the parallel bitmap table scan
> > > implementation. We are losing some of that with the patch -- but only
> > > because it is behaving as you would expect given the implementation
> > > and design. I don't consider that a blocker, though.
> >
> > I had a crack at this one a few weeks back, and wanted to share some
> > thoughts.
>
> Fwiw, I've had reasonably good results, in a similar situation, by
> just batching + double-buffering.
>
> Since you're using AIO (as Melanie points out) there should be no real
> penalty to having a single worker request the next batch of blocks,
> when the current block is used up.
>
> Then you can separate "reading" from "prefetching": whoever reads the
> last block in the current batch, prefetches the next batch.
I'm trying to understand. IIUC you're suggesting putting the blocks
coming *out* of a worker's ReadStream into a single common shmem queue
for any worker to consume (can't do this for block numbers coming *in*
to the ReadStreams or you're describing what we already have in
master, all mechanical sympathy for I/O out the window). Don't you
have to release the buffers you just streamed after putting their the
block numbers in a common shmem queue, hope they don't get evicted,
repin them when you pop one out, and also contend on the queue for
every block? What if you go to that queue to find a block, find it is
empty, but actually another backend still has an I/O in progress that
you have no way of knowing about? Suppose you do know about it
somehow, so now you have to wait for it to complete the IO before you
can help, but generally speaking it's against the law to wait for
parallel workers unless you can prove they'll come back (for example
there might be another node in the plan where they are waiting for
*you*, deadlock, game over), and even if you could wait safely. If
you don't wait, you just threw parallel fairness out the window.
Hence desire to make all relevant materials for progress at
end-of-scan eligible for work stealing.
What I'm speculating about is not a true generalised work stealing or
scheduling system (take for example Intel TBB[1] and various other
parallel computing architectures going back decades), so I'm using the
term pretty loosely: we can't generally chop all of our executor work
up into tiny tasks and have any thread run any of them at any time to
make progress (that'd be a nice goal but you basically have to blow
the executor up with dynamite and then reassemble all the atoms into
coroutines/continuations/tasks (or various similar-ish concepts) to
achieve something like that, probably after you first make all of
PostgreSQL multi-threaded unless you want to do it with your shoelaces
tied together, and then take a very long holiday). Probably by
mentioning work stealing I made it sound more complicated than
necessary, but hear me out:
A tiny, delimited, node-local kind of work stealing could replace (now
non-viable) ramp-down schemes, but workers would only have to fight
over the remaining scraps once their own queue can't be refilled. The
two key things I'm interested in here are: (1) per-worker queues
preserve block locality in the "first level" WorkQueueSet I was
talking about, to feed io_combine_limit-friendly block number streams
into their ReadStreams and only disturb that when data runs out and
stealing becomes necessary for the last few blocks in the scan, and
(2) at both levels a known-in-advance finite space can hold the
maximum possible unfair allocation to each worker, with certain
caveats. Those are: this logic only kicks in at end of scan when you
can be guaranteed to "get them all" without ever having to wait for
data buffered in the executor state of some other worker (data that is
completely unreachable to peers in our executor model), assuming, and
this is a hard requirement, they are coming from the same source in
all workers (in this case the shared memory bitmap, which you lock
while advancing the shared iterator, and a subgoal of 0001 was to
amortise that locking). It means there's a finite known number of
items that other workers can possibly have in their per-worker queue
that you definitely have enough space for, so wait-free progress
towards the global end-of-scan is guaranteed in every worker after it
reaches the point of stealing. For something a bit like the 0001
patch I posted, it can't be more than _BATCH_SIZE + io_combine_limit
-1 for the lower WorkQueueSet that feeds block numbers into each
worker's ReadStream. Something like Parallel Seq Scan involves an
extra curveball: I don't think you can do it with individual blocks or
IO sized chunks because that would be huge and inefficient. PSS works
with massive block ranges that could be 1MB or whatever IIRC (good),
but I think you could probably represent those ranges as special queue
items {blockno, nblocks} and modify them in place until depleted. For
the second-level WorkQueueSet I was handwaving about, well the
ReadStream queue is also of fixed size, so if your own ReadStream
can't pull any more blocks out of the lower WorkQueueSet to chew on
(including stealing), and it can't steal any buffers from peer
ReadStreams connected to the same second-level WorkQueueSet, then the
scan truly is finished. You never gave up I/O combining until the
end, and you never gave up the ability to distribute the final
parallel granules of work (here: pages, could be/should be tuples but
let's not get carried away) one-at-a-time to whoever could help, you
didn't have to do any new cache line ping pong until the last few
blocks, and no one ever had to wait for a peer.
I admit this all sounds kinda complicated and maybe there is a much
simpler way to achieve the twin goals of maximising I/O combining AND
parallel query fairness. I should probably try stuff before
speculating much more. My main goal in writing these brain dumps was
to highlight at least what I think the problem to be solved is, as I
understood it so far anyway, after a first round of failure at
teaching PBHS the new ways. Maybe the particular idea sketched out
above sucks or doesn't work for some reason, IDK, but I hope at least
the framing might be useful... not too many have had the privilege and
pain of working on both parallel query and the new I/O stuff, and the
feature collision is new territory, so I wanted to share some ideas
about the problem space and solicit better ideas :-)
[1] https://en.wikipedia.org/wiki/Threading_Building_Blocks
On Wed, Apr 9, 2025 at 11:00 PM Thomas Munro <thomas.munro@gmail.com> wrote: > > On Wed, Apr 9, 2025 at 1:46 PM James Hunter <james.hunter.pg@gmail.com> wrote: > > On Mon, Apr 7, 2025 at 7:34 PM Thomas Munro <thomas.munro@gmail.com> wrote: > > > On Thu, Feb 13, 2025 at 1:40 PM Melanie Plageman > > > <melanieplageman@gmail.com> wrote: > > > > Thomas mentioned this to me off-list, and I think he's right. We > > > > likely need to rethink the way parallel bitmap heap scan workers get > > > > block assignments for reading and prefetching to make it more similar > > > > to parallel sequential scan. The workers should probably get > > > > assignments of a range of blocks. On master, each worker does end up > > > > issuing reads/fadvises for a bunch of blocks in a row -- even though > > > > that isn't the intent of the parallel bitmap table scan > > > > implementation. We are losing some of that with the patch -- but only > > > > because it is behaving as you would expect given the implementation > > > > and design. I don't consider that a blocker, though. > > > > > > I had a crack at this one a few weeks back, and wanted to share some > > > thoughts. > > > > Fwiw, I've had reasonably good results, in a similar situation, by > > just batching + double-buffering. > > > > Since you're using AIO (as Melanie points out) there should be no real > > penalty to having a single worker request the next batch of blocks, > > when the current block is used up. > > > > Then you can separate "reading" from "prefetching": whoever reads the > > last block in the current batch, prefetches the next batch. > > I'm trying to understand. IIUC you're suggesting putting the blocks > coming *out* of a worker's ReadStream into a single common shmem queue > for any worker to consume (can't do this for block numbers coming *in* > to the ReadStreams or you're describing what we already have in > master, all mechanical sympathy for I/O out the window). I am looking at the pre-streaming code, in PG 17, as I am not familiar with the PG 18 "streaming" code. Back in PG 17, nodeBitmapHeapscan.c maintained two shared TBM iterators, for PQ. One of the iterators was the actual, "fetch" iterator; the other was the "prefetch" iterator, which kept some distance ahead of the "fetch" iterator (to hide read latency). In general, I find PG's "streaming" interface to be an awkward way of thinking about prefetching. But in this specific case, what are you trying to solve? Is it contention on the shared "iteration" state? Or is it finding an efficient way to issue lots of async reads? Or is it trying to issue async reads for blocks laid out consecutively on disk? (Is that what you mean by "mechanical sympathy for I/O"?) > Don't you > have to release the buffers you just streamed after putting their the > block numbers in a common shmem queue, hope they don't get evicted, > repin them when you pop one out, Yes, sure. If they do get evicted, then you were prefetching too far ahead, right? Unpinning + repinning keeps the buffer pool more "fair," at the cost of atomic updates + contention. CPUs are happy to evict prefetched data, they don't care if you've had the chance to use them. > and also contend on the queue for > every block? No, because you can read a batch of blocks out to process-local memory, at one time. Use the standard pattern: lock shared state, read a batch of work from shared state to local state, unlock shared state. Contention is amortized over the batch; by picking a reasonable batch size, you typically make contention small enough that it doesn't matter. > What if you go to that queue to find a block, find it is > empty, but actually another backend still has an I/O in progress that > you have no way of knowing about? Any time you try to read a buffer from the buffer pool, there's a chance some other backend still has an I/O in progress on it, right? Existing PG code just has everyone wait for the I/O to complete. This ends up being what you want to do, anyway... > Suppose you do know about it > somehow, so now you have to wait for it to complete the IO before you > can help, but generally speaking it's against the law to wait for > parallel workers unless you can prove they'll come back (for example > there might be another node in the plan where they are waiting for > *you*, deadlock, game over), and even if you could wait safely. My confusion here is probably due to my unfamiliarity with how you're handling async I/Os, but once some backend has issued an aync I/O, don't most async I/O frameworks complete the I/O on their own? Certainly the O/S is going to memcpy() the block into some destination address. Why can't the first backend to wait for I/O completion also be responsible for setting the buffer header bits appropriately? Basically, let whatever backend first needs the block be responsible for processing the I/O completion. Since waiting for an I/O completion is a blocking, synchronous operation, how is deadlock possible? > If > you don't wait, you just threw parallel fairness out the window. > Hence desire to make all relevant materials for progress at > end-of-scan eligible for work stealing. I may have misunderstood the context of this discussion, but isn't this all about *async* I/O? (If it's not async, what does "prefetch" mean?) With async I/O, there's no reason why the entity that issues the I/O also has to process its completion. (MySQL, for example, IIRC, uses a dedicated thread pool to process completions.) You just need *some* backend to issue a batch of async reads, on behalf of *all* backends. And then whenever a particular backend needs one of the blocks including in that async batch of reads, it waits for the async read to complete. And if there's no outstanding async read, then (I think this can be handled fairly well using existing PG code) it just issues a new, synchronous read. I think this is just what "prefetch" means. For example, if you ask the CPU to prefetch address 0xf00 into L1 cache, the CPU doesn't worry about whether that address was actually loaded in time, or whether it gets read by the same or a different thread. You have an in-flight, async operation; and then whenever someone needs the result, they block (or not) depending on whether the async operation already completed. > What I'm speculating about is not a true generalised work stealing or > scheduling system (take for example Intel TBB[1] and various other > parallel computing architectures going back decades), so I'm using the > term pretty loosely: we can't generally chop all of our executor work > up into tiny tasks and have any thread run any of them at any time to > make progress (that'd be a nice goal but you basically have to blow > the executor up with dynamite and then reassemble all the atoms into > coroutines/continuations/tasks (or various similar-ish concepts) to > achieve something like that, probably after you first make all of > PostgreSQL multi-threaded unless you want to do it with your shoelaces > tied together, and then take a very long holiday). Probably by > mentioning work stealing I made it sound more complicated than > necessary, but hear me out: I don't have an opinion about chopping up (CPU) work , but my point is that I/Os go to a different resource -- they have a different queue. So you don't usually *need* to chop up *I/O* work. Assuming you can saturate I/O bandwidth / fill the I/O queue using a single thread, then you don't need to worry about all of the above -- at least not for I/Os! And, for CPU, you can typically get away with maintaining a single global queue, and just copying (sequential) batches of work from the global queue into thread- or process- local memory. Why do you want to chop up and reassemble work? Is this CPU work or I/O work? > A tiny, delimited, node-local kind of work stealing could replace (now > non-viable) ramp-down schemes, I guess, for I/Os, the only work-stealing I think about is to handle I/O completions. And that part, at least, can be done (as sketched above) by having backends complete async I/Os inside ReadBuffer(). > I admit this all sounds kinda complicated and maybe there is a much > simpler way to achieve the twin goals of maximising I/O combining AND > parallel query fairness. I tend to think that the two goals are so much in conflict, that it's not worth trying to apply cleverness to get them to agree on things... What I mean is, if you have to take inputs from multiple parties, combine them, sort them, and then produce a Run-Length-Encoding of the result, then there's always going to be lots of contention. And you'll also have to deal with increased latency: should I wait to see if more blocks come in, to see if it lets me combine I/Os, or should I send the batch now? But, if you just do the most naive thing possible (which is my suggestion!), then whatever backend's turn it is to advance the prefetch iterator, it advances it by (let's say) 50 blocks. It can then try to combine those 50 blocks, with no contention or added complexity. Might that be sufficient? I think that, generally, there are only a few techniques that work consistently for concurrency / async operations. And these techniques are necessarily primitive, they are blunt tools. It sounds like you are working on a subtle, complex, refined solution... and I am just doubtful that any such solution will end up being efficient. It is hard to create a complex concurrent execution model that's also fast. For example, simple batching is the solution to a lot of problems. Any time you process a batch of stuff, you amortize any fixed costs over the size of the batch. This is a blunt tool, but it always works. Also, work stealing is great, and one of the nicest ways to steal work is the "async/await" or "coroutines" model, where someone -- we don't care who! -- sends an async request; and then, at some point in the future, someone (else? we don't care!) waits for that async request to complete. And if there's more work to be done, to complete the async request, then whoever waits first does that work. So you steal work from the thread/process that needs that work to be done -- very nice. This is also a blunt tool, but it works. With PG, specifically, waiting for a read into buffer pool to complete seems to go through the same interface as actually performing that read. So this helps you out for prefetch -- which is always best-effort, it's not the prefetch operation's job to ensure that the prefetched data doesn't get evicted -- because you really don't even need to track async reads after you've issued them! This lets PG prefetch behave like CPU prefetch. James
On Fri, Apr 11, 2025 at 5:50 AM James Hunter <james.hunter.pg@gmail.com> wrote: > I am looking at the pre-streaming code, in PG 17, as I am not familiar > with the PG 18 "streaming" code. Back in PG 17, nodeBitmapHeapscan.c > maintained two shared TBM iterators, for PQ. One of the iterators was > the actual, "fetch" iterator; the other was the "prefetch" iterator, > which kept some distance ahead of the "fetch" iterator (to hide read > latency). We're talking at cross-purposes. The new streaming BHS isn't just issuing probabilistic hints about future access obtained from a second iterator. It has just one shared iterator connected up to the workers' ReadStreams. Each worker pulls a disjoint set of blocks out of its stream, possibly running a bunch of IOs in the background as required. The stream replaces the old ReadBuffer() call, and the old PrefetchBuffer() call and a bunch of dubious iterator synchronisation logic are deleted. These are now real IOs running in the background and for the *exact* blocks you will consume; posix_fadvise() was just a stepping towards AIO that tolerated sloppy synchronisation including being entirely wrong. If you additionally teach the iterator to work in batches, as my 0001 patch (which I didn't propose for v18) showed, then one worker might end up processing (say) 10 blocks at end-of-scan while all the other workers have finished the node, and maybe the whole query. That'd be unfair. "Ramp-down" ... 8, 4, 2, 1 has been used in one or two other places in parallel-aware nodes with internal batching as a kind of fudge to help them finish CPU work around the same time if you're lucky, and my 0002 patch shows that NOT working here. I suspect the concept itself is defunct: it no longer narrows the CPU work completion time range across workers at all well due to the elastic streams sitting in between. Any naive solution that requires cooperation/waiting for another worker to hand over final scraps of work originally allocated to it (and I don't mean the IO completion part, that all just works just fine as you say, a lot of engineering went into the buffer manager to make that true, for AIO but also in the preceding decades... what I mean here is: how do you even know which block to read?) is probably a deadlock risk. Essays have been written on the topic if you are interested. All the rest of our conversation makes no sense without that context :-) > > I admit this all sounds kinda complicated and maybe there is a much > > simpler way to achieve the twin goals of maximising I/O combining AND > > parallel query fairness. > > I tend to think that the two goals are so much in conflict, that it's > not worth trying to apply cleverness to get them to agree on things... I don't give up so easily :-)
On Thu, Apr 10, 2025 at 8:15 PM Thomas Munro <thomas.munro@gmail.com> wrote: > > On Fri, Apr 11, 2025 at 5:50 AM James Hunter <james.hunter.pg@gmail.com> wrote: > > I am looking at the pre-streaming code, in PG 17, as I am not familiar > > with the PG 18 "streaming" code. Back in PG 17, nodeBitmapHeapscan.c > > maintained two shared TBM iterators, for PQ. One of the iterators was > > the actual, "fetch" iterator; the other was the "prefetch" iterator, > > which kept some distance ahead of the "fetch" iterator (to hide read > > latency). > > We're talking at cross-purposes. > > The new streaming BHS isn't just issuing probabilistic hints about > future access obtained from a second iterator. It has just one shared > iterator connected up to the workers' ReadStreams. Each worker pulls > a disjoint set of blocks out of its stream, possibly running a bunch > of IOs in the background as required. The stream replaces the old > ReadBuffer() call, and the old PrefetchBuffer() call and a bunch of > dubious iterator synchronisation logic are deleted. Thanks for the clarification -- I realize I am very late to this conversation (as I rejoined a PostgreSQL-related team only within the past year), but I think this whole "ReadStream" project is misguided. Of course, late feedback is a burden, but I think our discussion here (and, in the future, if you try to "ReadStream" BTree index pages, themselves) illustrates my point. In this specific case, you are proposing a lot of complexity, but it's not at all clear to me: why? I see two orthogonal problems, in processing Bitmap Heap pages in parallel: (1) we need to prefetch enough pages, far enough in advance, to hide read latency; (2) later, every parallel worker needs to be given a set of pages to process, in a way that minimizes contention. The easiest way to hand out work to parallel workers (and often the best) is to maintain a single, shared, global work queue. Just put whatever pages you prefetch into a FIFO queue, and let each worker pull one piece of "work" off that queue. In this was, there's no "ramp-down" problem. If you find that contention on this shared queue becomes a bottleneck, then you just pull *n* pieces of work, in a batch. Then the "ramp-down" problem is limited to "n", instead of just 1. Often, one can find a suitable value of n that simultaneously makes contention effectively zero, while avoiding "ramp-down" problems; say n = 10. So much for popping from the shared queue. Pushing to the shared queue is also easy, because you have async reads. Anytime a worker pops a (batch of) work item(s) off the shared queue, it checks to see if the queue is still large enough. If not, it issues the appropriate prefetch / "ReadStream" calls. A single shared queue is easiest, but sometimes there's no way to prevent it from becoming a bottleneck. In that case, one typically partitions the input at startup, gives each worker its own partition, and waits for all workers to complete. In this, second, model, workers are entirely independent, so there is no contention: we scale out perfectly. The problem, as you've pointed out, is that one worker might finish its own work long before another; and then the worker that finished its work is idle and therefore wasted. This is why a single shared queue is so nice, because it avoids workers being idle. But I am confused by your proposal, which seems to be trying to get the behavior of a single shared queue, but implemented with the added complexity of multiple queues. Why not just use a single queue? > These are now > real IOs running in the background and for the *exact* blocks you will > consume; posix_fadvise() was just a stepping towards AIO that > tolerated sloppy synchronisation including being entirely wrong. It has never been clear to me why prefetching the exact blocks you'll later consume is seen as a *benefit*, rather than a *cost*. I'm not aware of any prefetch interface, other than PG's "ReadStream," that insists on this. But that's a separate discussion... > If > you additionally teach the iterator to work in batches, as my 0001 > patch (which I didn't propose for v18) showed, then one worker might > end up processing (say) 10 blocks at end-of-scan while all the other > workers have finished the node, and maybe the whole query. The standard solution to the problem you describe here is to pick a batch size small enough that you don't care. For example, no matter what you do, it will always be possible for one worker to end up processing *1* extra block, end of scan. If 1 is OK, but 10 is too large, then I would try 5. AFAIU, the argument for larger batches is to reduce contention; and the argument for smaller batches is to reduce amount of time workers are idle, at end of query. The problem seems amenable to a static solution -- there should be a value of n that satisfies both restrictions. Otherwise, we'd implicitly be saying that contention is very slow, compared to the time it takes a worker to process a block; while also saying that it takes workers a long time to process each block. For example, if you figure 10 us to process each block, then a batch of size n = 10 gives each worker 100 us of CPU time, between when it needs to acquire the global mutex, to get the next batch of work. Does this make contention low enough? And then, if you figure that a parallel query has to run >= 100 ms, to make PQ worthwhile, then the "idle" time is at most 100 us / 100 ms = 0.1 percent, and therefore inconsequential. > That'd be > unfair. "Ramp-down" ... 8, 4, 2, 1 has been used in one or two other > places in parallel-aware nodes with internal batching as a kind of > fudge to help them finish CPU work around the same time if you're > lucky, and my 0002 patch shows that NOT working here. I suspect the > concept itself is defunct: it no longer narrows the CPU work > completion time range across workers at all well due to the elastic > streams sitting in between. I think you are arguing that a single shared queue won't work, but it's not clear to me why it won't. Maybe the problem is these elastic streams? What I don't understand is -- and I apologize again for interjecting myself into this conversation so late -- why do you want or need multiple streams? Logically, every PG scan is a single stream of blocks, and parallel workers just pull batches of work off that single stream. Suppose the "ReadStream" order for a Bitmap Heap Scan is blocks: 0, 2, 1, 3, 4, 6, 5, 7, 8, 10, 9, 11, ... Why would we want or need to affinitize reads to a particular worker? These are the blocks to be read; this is the order in which they need to be read. Any worker can issue any read, because we are using async I/O. > Any naive solution that requires > cooperation/waiting for another worker to hand over final scraps of > work originally allocated to it (and I don't mean the IO completion > part, that all just works just fine as you say, a lot of engineering > went into the buffer manager to make that true, for AIO but also in > the preceding decades... You have lost me here. Every fork() / join() algorithm requires waiting for a worker to hand over the final scraps of work allocated to it, and AFAIK, no one has ever worried about deadlock risk from fork() / join()... > what I mean here is: how do you even know > which block to read?) is probably a deadlock risk. Essays have been > written on the topic if you are interested. I think this may be where we are talking at cross purposes. Well, reading a block is an async operation, right? And a parallel Bitmap Heap Scan visits exactly the same pages as its serial variant. Every worker acquires the shared queue's mutex. It pops n blocks off the shared queue. If the shared queue is now too small, it iterates the "ReadStream" to get *m* more page IDs, issues async reads for those pages, and pushes them on the shared queue. The worker then releases the mutex. If by "read" you mean, "issue an async read," then you know which block to read by visiting the (shared) "ReadStream". if, instead, you mean, "process a block," then you know because you popped it off the shared queue. > All the rest of our conversation makes no sense without that context :-) I think I am still missing something, but I am not sure what. For example, I can't see how deadlock would be a problem... > > > I admit this all sounds kinda complicated and maybe there is a much > > > simpler way to achieve the twin goals of maximising I/O combining AND > > > parallel query fairness. > > > > I tend to think that the two goals are so much in conflict, that it's > > not worth trying to apply cleverness to get them to agree on things... > > I don't give up so easily :-) Now that I think about the problem more -- "maximizing I/O combining" is orthogonal to "parallel query fairness," right? Parallel query fairness involves splitting up CPU via small batches. Maximizing I/O combining involves making I/O more efficient, by issuing large batches. However, there's no reason I can see why the *I/O batch* needs to resemble the *CPU batch*. If maximizing I/O combining leads me to issue a batch of 1,000 reads at a time, then so what? These are all async reads! The "unlucky" worker issues its 1,000 reads, then gets on with its life. If parallel query fairness leads me to *process* a batch of 10 blocks at a time -- then, again, so what? CPU and I/O are independent resources. Why not just prefetch / read-stream 1,000 blocks at a time, while processing (using CPU) 10 blocks at a time? Wouldn't that achieve your twin goals, without requiring multiple queues / streams / etc.? Thanks, James
Hi, On 2025-04-14 09:58:19 -0700, James Hunter wrote: > Of course, late feedback is a burden, but I think our discussion here > (and, in the future, if you try to "ReadStream" BTree index pages, > themselves) illustrates my point. FWIW, it's quite conceivable that we'll want to use non-readstream prefetching for some cases where "heuristic" prefetching is easier. I think prefetching of btree pages is one of those cases. The read stream based API provides a single point of adjusting the readahead logic, implementing read-combining etc, without needing to know about that in the user of the read stream. > I see two orthogonal problems, in processing Bitmap Heap pages in > parallel: (1) we need to prefetch enough pages, far enough in advance, > to hide read latency; (2) later, every parallel worker needs to be > given a set of pages to process, in a way that minimizes contention. > > The easiest way to hand out work to parallel workers (and often the > best) is to maintain a single, shared, global work queue. Just put > whatever pages you prefetch into a FIFO queue, and let each worker > pull one piece of "work" off that queue. In this was, there's no > "ramp-down" problem. If you just issue prefetch requests separately you'll get no read combining - and it turns out that that is a really rather significant loss, both on the storage layer and just due to the syscall overhead. So you do need to perform batching when issuing IO. Which in turn requires a bit of rampup logic etc. > If you find that contention on this shared queue becomes a bottleneck, > then you just pull *n* pieces of work, in a batch. Then the > "ramp-down" problem is limited to "n", instead of just 1. Often, one > can find a suitable value of n that simultaneously makes contention > effectively zero, while avoiding "ramp-down" problems; say n = 10. > > So much for popping from the shared queue. Pushing to the shared queue > is also easy, because you have async reads. Anytime a worker pops a > (batch of) work item(s) off the shared queue, it checks to see if the > queue is still large enough. If not, it issues the appropriate > prefetch / "ReadStream" calls. > > A single shared queue is easiest, but sometimes there's no way to > prevent it from becoming a bottleneck. In that case, one typically > partitions the input at startup, gives each worker its own partition, > and waits for all workers to complete. In this, second, model, workers > are entirely independent, so there is no contention: we scale out > perfectly. The problem, as you've pointed out, is that one worker > might finish its own work long before another; and then the worker > that finished its work is idle and therefore wasted. > > This is why a single shared queue is so nice, because it avoids > workers being idle. But I am confused by your proposal, which seems to > be trying to get the behavior of a single shared queue, but > implemented with the added complexity of multiple queues. > > Why not just use a single queue? Accessing buffers in a maximally interleaved way, which is what a single queue would give you, adds a good bit of overhead when you have a lot of memory, because e.g. TLB hit rate is minimized. > > These are now > > real IOs running in the background and for the *exact* blocks you will > > consume; posix_fadvise() was just a stepping towards AIO that > > tolerated sloppy synchronisation including being entirely wrong. > > It has never been clear to me why prefetching the exact blocks you'll > later consume is seen as a *benefit*, rather than a *cost*. I'm not > aware of any prefetch interface, other than PG's "ReadStream," that > insists on this. But that's a separate discussion... It (randomly ordered): a) reduces wasted IO b) makes things like IO combining a lot easier c) makes it a lot easier to adaptively control readahead distance, because you have information about 1) the # in-flight IOs 2) the # completed IOs 3) current position 4) reada d) provides *per-stream* control over readahead. You want to be only as aggressive about prefetching as you need to be, which very well can differ between different parts of a query tree. e) provides one central point to implement readahead logic As I said above, that's not to say that we'll only ever want to do readahead via a the read stream interface. Greetings, Andres Freund
On Thu, Apr 10, 2025 at 11:15 PM Thomas Munro <thomas.munro@gmail.com> wrote: > The new streaming BHS isn't just issuing probabilistic hints about > future access obtained from a second iterator. It has just one shared > iterator connected up to the workers' ReadStreams. Each worker pulls > a disjoint set of blocks out of its stream, possibly running a bunch > of IOs in the background as required. It feels to me like the problem here is that the shared iterator is connected to unshared read-streams. If you make a shared read-stream object and connect the shared iterator to that instead, does that solve this whole problem, or is there more to it? -- Robert Haas EDB: http://www.enterprisedb.com
Thanks for the comments! On Tue, Apr 15, 2025 at 3:11 AM Andres Freund <andres@anarazel.de> wrote: > > Hi, > > On 2025-04-14 09:58:19 -0700, James Hunter wrote: > > I see two orthogonal problems, in processing Bitmap Heap pages in > > parallel: (1) we need to prefetch enough pages, far enough in advance, > > to hide read latency; (2) later, every parallel worker needs to be > > given a set of pages to process, in a way that minimizes contention. > > > > The easiest way to hand out work to parallel workers (and often the > > best) is to maintain a single, shared, global work queue. Just put > > whatever pages you prefetch into a FIFO queue, and let each worker > > pull one piece of "work" off that queue. In this was, there's no > > "ramp-down" problem. > > If you just issue prefetch requests separately you'll get no read combining - > and it turns out that that is a really rather significant loss, both on the > storage layer and just due to the syscall overhead. So you do need to perform > batching when issuing IO. Which in turn requires a bit of rampup logic etc. Right, so if you need to do batching anyway, contention on a shared queue will be minimal, because it's amortized over the batch size. I agree about ramp *up* logic, I just don't see the need for ramp *down* logic. > > This is why a single shared queue is so nice, because it avoids > > workers being idle. But I am confused by your proposal, which seems to > > be trying to get the behavior of a single shared queue, but > > implemented with the added complexity of multiple queues. > > > > Why not just use a single queue? > > Accessing buffers in a maximally interleaved way, which is what a single queue > would give you, adds a good bit of overhead when you have a lot of memory, > because e.g. TLB hit rate is minimized. Well that's trade-off, right? As you point out, you need to do batching when issuing reads, to allow for read combining. The larger your batch, the more reads you can combine -- the more efficient your I/O, etc. But the larger your batch, the less locality you get in memory. You always have to choose a batch size large enough to hide I/O latency, plus allow, I guess, for read combining. I suspect that will blow out your TLB more than letting 8 parallel workers share the same queue. Not to mention the complexity (as Thomas has described very nicely, in this thread) of trying to partition+affinitize async read requests to individual parallel workers. (Consider "ramp-down" for a moment: the "problem" here is just that one parallel worker issued a batch of async reads , near the end of the query; and since the worker is affinitized to the async read, all other workers pack up and go home, leaving a single worker to process this last batch. If, instead, we just used a single queue, then there would be no need for "ramp-down" logic, because async reads would go into a single queue/pool, and not be affinitized to a single, "unlucky" worker.) > > It has never been clear to me why prefetching the exact blocks you'll > > later consume is seen as a *benefit*, rather than a *cost*. I'm not > > aware of any prefetch interface, other than PG's "ReadStream," that > > insists on this. But that's a separate discussion... > > ... > > As I said above, that's not to say that we'll only ever want to do readahead > via a the read stream interface. Well that's my point: since, I believe, we'll ultimately want a "heuristic" prefetch, which will be incompatible with the new read stream interface... we'll end up writing and supporting two different prefetch interfaces. It has never been clear to me that the advantages of having this second, read-stream, prefetch interface outweigh the costs of having to write and maintain two separate interfaces, to do pretty much the same thing. If we *didn't* need the "heuristic" interface, then I could be convinced that the "read-stream" interface was a good choice. But since we'll (eventually) need the "heuristic" interface, anyway, it's not clear to me that the benefits outweigh the costs of implementing this "read-stream" interface, as well. Thanks, James
On Tue, Apr 15, 2025 at 5:44 AM Robert Haas <robertmhaas@gmail.com> wrote: > On Thu, Apr 10, 2025 at 11:15 PM Thomas Munro <thomas.munro@gmail.com> wrote: > > The new streaming BHS isn't just issuing probabilistic hints about > > future access obtained from a second iterator. It has just one shared > > iterator connected up to the workers' ReadStreams. Each worker pulls > > a disjoint set of blocks out of its stream, possibly running a bunch > > of IOs in the background as required. > > It feels to me like the problem here is that the shared iterator is > connected to unshared read-streams. If you make a shared read-stream > object and connect the shared iterator to that instead, does that > solve this whole problem, or is there more to it? More or less, yeah, just put the whole ReadStream object in shared memory, pin an LWLock on it and call it a parallel-aware or shared ReadStream. But how do you make the locking not terrible? My "work stealing" brain dump was imagining a way to achieve the same net effect, except NOT have to acquire an exclusive lock for every buffer you pull out of the stream. I was speculating that we could achieve zero locking for most of the stream without any cache line ping pong, but a cunning read barrier scheme could detect when you've been flipped into a slower coordination mode by another backend and need to turn on some locking and fight over the last handful of buffers. And I was also observing that if you can figure out to make it general and reusable enough, we have more unsolved problems like this in unrelated parallel query code not even involving streams. It's a tiny more approachable subset of the old "data buffered in other workers" problem, as I think you called it once.
On Wed, Apr 16, 2025 at 12:31 AM Thomas Munro <thomas.munro@gmail.com> wrote: > More or less, yeah, just put the whole ReadStream object in shared > memory, pin an LWLock on it and call it a parallel-aware or shared > ReadStream. But how do you make the locking not terrible? > > My "work stealing" brain dump was imagining a way to achieve the same > net effect, except NOT have to acquire an exclusive lock for every > buffer you pull out of the stream. I was speculating that we could > achieve zero locking for most of the stream without any cache line > ping pong, but a cunning read barrier scheme could detect when you've > been flipped into a slower coordination mode by another backend and > need to turn on some locking and fight over the last handful of > buffers. And I was also observing that if you can figure out to make > it general and reusable enough, we have more unsolved problems like > this in unrelated parallel query code not even involving streams. > It's a tiny more approachable subset of the old "data buffered in > other workers" problem, as I think you called it once. Maybe the work stealing stuff can hide inside the ReadStream? e.g. a ParallelReadStream is really one ReadStream per participant, each with a separate lock. Mostly you only touch your own, but if necessary you can poke your fingers into other people's ReadStreams. -- Robert Haas EDB: http://www.enterprisedb.com