Thread: Avoid LWLockWaitForVar() for currently held WAL insertion lock in WaitXLogInsertionsToFinish()
Avoid LWLockWaitForVar() for currently held WAL insertion lock in WaitXLogInsertionsToFinish()
From
Bharath Rupireddy
Date:
Hi, While working on something else, I noticed that WaitXLogInsertionsToFinish() goes the LWLockWaitForVar() route even for a process that's holding a WAL insertion lock. Typically, a process holding WAL insertion lock reaches WaitXLogInsertionsToFinish() when it's in need of WAL buffer pages for its insertion and waits for other older in-progress WAL insertions to finish. This fact guarantees that the process holding a WAL insertion lock will never have its insertingAt less than 'upto'. With that said, here's a small improvement I can think of, that is, to avoid calling LWLockWaitForVar() for the WAL insertion lock the caller of WaitXLogInsertionsToFinish() currently holds. Since LWLockWaitForVar() does a bunch of things - holds interrupts, does atomic reads, acquires and releases wait list lock and so on, avoiding it may be a good idea IMO. I'm attaching a patch herewith. Here's the cirrus-ci tests - https://github.com/BRupireddy/postgres/tree/avoid_LWLockWaitForVar_for_currently_held_wal_ins_lock_v1. Thoughts? -- Bharath Rupireddy PostgreSQL Contributors Team RDS Open Source Databases Amazon Web Services: https://aws.amazon.com
Attachment
Re: Avoid LWLockWaitForVar() for currently held WAL insertion lock in WaitXLogInsertionsToFinish()
From
Andres Freund
Date:
Hi, On 2022-11-24 18:13:10 +0530, Bharath Rupireddy wrote: > With that said, here's a small improvement I can think of, that is, to > avoid calling LWLockWaitForVar() for the WAL insertion lock the caller > of WaitXLogInsertionsToFinish() currently holds. Since > LWLockWaitForVar() does a bunch of things - holds interrupts, does > atomic reads, acquires and releases wait list lock and so on, avoiding > it may be a good idea IMO. That doesn't seem like a big win. We're still going to call LWLockWaitForVar() for all the other locks. I think we could improve this code more significantly by avoiding the call to LWLockWaitForVar() for all locks that aren't acquired or don't have a conflicting insertingAt, that'd require just a bit more work to handle systems without tear-free 64bit writes/reads. The easiest way would probably be to just make insertingAt a 64bit atomic, that transparently does the required work to make even non-atomic read/writes tear free. Then we could trivially avoid the spinlock in LWLockConflictsWithVar(), LWLockReleaseClearVar() and with just a bit more work add a fastpath to LWLockUpdateVar(). We don't need to acquire the wait list lock if there aren't any waiters. I'd bet that start to have visible effects in a workload with many small records. Greetings, Andres Freund
Re: Avoid LWLockWaitForVar() for currently held WAL insertion lock in WaitXLogInsertionsToFinish()
From
Bharath Rupireddy
Date:
On Fri, Nov 25, 2022 at 12:16 AM Andres Freund <andres@anarazel.de> wrote: > > Hi, > > On 2022-11-24 18:13:10 +0530, Bharath Rupireddy wrote: > > With that said, here's a small improvement I can think of, that is, to > > avoid calling LWLockWaitForVar() for the WAL insertion lock the caller > > of WaitXLogInsertionsToFinish() currently holds. Since > > LWLockWaitForVar() does a bunch of things - holds interrupts, does > > atomic reads, acquires and releases wait list lock and so on, avoiding > > it may be a good idea IMO. > > That doesn't seem like a big win. We're still going to call LWLockWaitForVar() > for all the other locks. > > I think we could improve this code more significantly by avoiding the call to > LWLockWaitForVar() for all locks that aren't acquired or don't have a > conflicting insertingAt, that'd require just a bit more work to handle systems > without tear-free 64bit writes/reads. > > The easiest way would probably be to just make insertingAt a 64bit atomic, > that transparently does the required work to make even non-atomic read/writes > tear free. Then we could trivially avoid the spinlock in > LWLockConflictsWithVar(), LWLockReleaseClearVar() and with just a bit more > work add a fastpath to LWLockUpdateVar(). We don't need to acquire the wait > list lock if there aren't any waiters. > > I'd bet that start to have visible effects in a workload with many small > records. Thanks Andres! I quickly came up with the attached patch. I also ran an insert test [1], below are the results. I also attached the results graph. The cirrus-ci is happy with the patch - https://github.com/BRupireddy/postgres/tree/wal_insertion_lock_improvements_v1_2. Please let me know if the direction of the patch seems right. clients HEAD PATCHED 1 1354 1499 2 1451 1464 4 3069 3073 8 5712 5797 16 11331 11157 32 22020 22074 64 41742 42213 128 71300 76638 256 103652 118944 512 111250 161582 768 99544 161987 1024 96743 164161 2048 72711 156686 4096 54158 135713 [1] ./configure --prefix=$PWD/inst/ CFLAGS="-O3" > install.log && make -j 8 install > install.log 2>&1 & cd inst/bin ./pg_ctl -D data -l logfile stop rm -rf data logfile free -m sudo su -c 'sync; echo 3 > /proc/sys/vm/drop_caches' free -m ./initdb -D data ./pg_ctl -D data -l logfile start ./psql -d postgres -c 'ALTER SYSTEM SET shared_buffers = "8GB";' ./psql -d postgres -c 'ALTER SYSTEM SET max_wal_size = "16GB";' ./psql -d postgres -c 'ALTER SYSTEM SET max_connections = "4096";' ./pg_ctl -D data -l logfile restart ./pgbench -i -s 1 -d postgres ./psql -d postgres -c "ALTER TABLE pgbench_accounts DROP CONSTRAINT pgbench_accounts_pkey;" cat << EOF >> insert.sql \set aid random(1, 10 * :scale) \set delta random(1, 100000 * :scale) INSERT INTO pgbench_accounts (aid, bid, abalance) VALUES (:aid, :aid, :delta); EOF ulimit -S -n 5000 for c in 1 2 4 8 16 32 64 128 256 512 768 1024 2048 4096; do echo -n "$c ";./pgbench -n -M prepared -U ubuntu postgres -f insert.sql -c$c -j$c -T5 2>&1|grep '^tps'|awk '{print $3}';done -- Bharath Rupireddy PostgreSQL Contributors Team RDS Open Source Databases Amazon Web Services: https://aws.amazon.com
Attachment
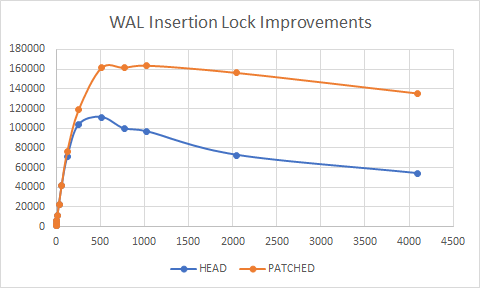{kind=link}
Re: Avoid LWLockWaitForVar() for currently held WAL insertion lock in WaitXLogInsertionsToFinish()
From
Andres Freund
Date:
On 2022-11-25 16:54:19 +0530, Bharath Rupireddy wrote: > On Fri, Nov 25, 2022 at 12:16 AM Andres Freund <andres@anarazel.de> wrote: > > I think we could improve this code more significantly by avoiding the call to > > LWLockWaitForVar() for all locks that aren't acquired or don't have a > > conflicting insertingAt, that'd require just a bit more work to handle systems > > without tear-free 64bit writes/reads. > > > > The easiest way would probably be to just make insertingAt a 64bit atomic, > > that transparently does the required work to make even non-atomic read/writes > > tear free. Then we could trivially avoid the spinlock in > > LWLockConflictsWithVar(), LWLockReleaseClearVar() and with just a bit more > > work add a fastpath to LWLockUpdateVar(). We don't need to acquire the wait > > list lock if there aren't any waiters. > > > > I'd bet that start to have visible effects in a workload with many small > > records. > > Thanks Andres! I quickly came up with the attached patch. I also ran > an insert test [1], below are the results. I also attached the results > graph. The cirrus-ci is happy with the patch - > https://github.com/BRupireddy/postgres/tree/wal_insertion_lock_improvements_v1_2. > Please let me know if the direction of the patch seems right. > clients HEAD PATCHED > 1 1354 1499 > 2 1451 1464 > 4 3069 3073 > 8 5712 5797 > 16 11331 11157 > 32 22020 22074 > 64 41742 42213 > 128 71300 76638 > 256 103652 118944 > 512 111250 161582 > 768 99544 161987 > 1024 96743 164161 > 2048 72711 156686 > 4096 54158 135713 Nice. > From 293e789f9c1a63748147acd613c556961f1dc5c4 Mon Sep 17 00:00:00 2001 > From: Bharath Rupireddy <bharath.rupireddyforpostgres@gmail.com> > Date: Fri, 25 Nov 2022 10:53:56 +0000 > Subject: [PATCH v1] WAL Insertion Lock Improvements > > --- > src/backend/access/transam/xlog.c | 8 +++-- > src/backend/storage/lmgr/lwlock.c | 56 +++++++++++++++++-------------- > src/include/storage/lwlock.h | 7 ++-- > 3 files changed, 41 insertions(+), 30 deletions(-) > > diff --git a/src/backend/access/transam/xlog.c b/src/backend/access/transam/xlog.c > index a31fbbff78..b3f758abb3 100644 > --- a/src/backend/access/transam/xlog.c > +++ b/src/backend/access/transam/xlog.c > @@ -376,7 +376,7 @@ typedef struct XLogwrtResult > typedef struct > { > LWLock lock; > - XLogRecPtr insertingAt; > + pg_atomic_uint64 insertingAt; > XLogRecPtr lastImportantAt; > } WALInsertLock; > > @@ -1482,6 +1482,10 @@ WaitXLogInsertionsToFinish(XLogRecPtr upto) > { > XLogRecPtr insertingat = InvalidXLogRecPtr; > > + /* Quickly check and continue if no one holds the lock. */ > + if (!IsLWLockHeld(&WALInsertLocks[i].l.lock)) > + continue; I'm not sure this is quite right - don't we need a memory barrier. But I don't see a reason to not just leave this code as-is. I think this should be optimized entirely in lwlock.c I'd probably split the change to an atomic from other changes either way. Greetings, Andres Freund
WAL Insertion Lock Improvements (was: Re: Avoid LWLockWaitForVar() for currently held WAL insertion lock in WaitXLogInsertionsToFinish())
From
Bharath Rupireddy
Date:
On Fri, Dec 2, 2022 at 6:10 AM Andres Freund <andres@anarazel.de> wrote: > > On 2022-11-25 16:54:19 +0530, Bharath Rupireddy wrote: > > On Fri, Nov 25, 2022 at 12:16 AM Andres Freund <andres@anarazel.de> wrote: > > > I think we could improve this code more significantly by avoiding the call to > > > LWLockWaitForVar() for all locks that aren't acquired or don't have a > > > conflicting insertingAt, that'd require just a bit more work to handle systems > > > without tear-free 64bit writes/reads. > > > > > > The easiest way would probably be to just make insertingAt a 64bit atomic, > > > that transparently does the required work to make even non-atomic read/writes > > > tear free. Then we could trivially avoid the spinlock in > > > LWLockConflictsWithVar(), LWLockReleaseClearVar() and with just a bit more > > > work add a fastpath to LWLockUpdateVar(). We don't need to acquire the wait > > > list lock if there aren't any waiters. > > > > > > I'd bet that start to have visible effects in a workload with many small > > > records. > > > > Thanks Andres! I quickly came up with the attached patch. I also ran > > an insert test [1], below are the results. I also attached the results > > graph. The cirrus-ci is happy with the patch - > > https://github.com/BRupireddy/postgres/tree/wal_insertion_lock_improvements_v1_2. > > Please let me know if the direction of the patch seems right. > > clients HEAD PATCHED > > 1 1354 1499 > > 2 1451 1464 > > 4 3069 3073 > > 8 5712 5797 > > 16 11331 11157 > > 32 22020 22074 > > 64 41742 42213 > > 128 71300 76638 > > 256 103652 118944 > > 512 111250 161582 > > 768 99544 161987 > > 1024 96743 164161 > > 2048 72711 156686 > > 4096 54158 135713 > > Nice. Thanks for taking a look at it. > > From 293e789f9c1a63748147acd613c556961f1dc5c4 Mon Sep 17 00:00:00 2001 > > From: Bharath Rupireddy <bharath.rupireddyforpostgres@gmail.com> > > Date: Fri, 25 Nov 2022 10:53:56 +0000 > > Subject: [PATCH v1] WAL Insertion Lock Improvements > > > > --- > > src/backend/access/transam/xlog.c | 8 +++-- > > src/backend/storage/lmgr/lwlock.c | 56 +++++++++++++++++-------------- > > src/include/storage/lwlock.h | 7 ++-- > > 3 files changed, 41 insertions(+), 30 deletions(-) > > > > diff --git a/src/backend/access/transam/xlog.c b/src/backend/access/transam/xlog.c > > index a31fbbff78..b3f758abb3 100644 > > --- a/src/backend/access/transam/xlog.c > > +++ b/src/backend/access/transam/xlog.c > > @@ -376,7 +376,7 @@ typedef struct XLogwrtResult > > typedef struct > > { > > LWLock lock; > > - XLogRecPtr insertingAt; > > + pg_atomic_uint64 insertingAt; > > XLogRecPtr lastImportantAt; > > } WALInsertLock; > > > > @@ -1482,6 +1482,10 @@ WaitXLogInsertionsToFinish(XLogRecPtr upto) > > { > > XLogRecPtr insertingat = InvalidXLogRecPtr; > > > > + /* Quickly check and continue if no one holds the lock. */ > > + if (!IsLWLockHeld(&WALInsertLocks[i].l.lock)) > > + continue; > > I'm not sure this is quite right - don't we need a memory barrier. But I don't > see a reason to not just leave this code as-is. I think this should be > optimized entirely in lwlock.c Actually, we don't need that at all as LWLockWaitForVar() will return immediately if the lock is free. So, I removed it. > I'd probably split the change to an atomic from other changes either way. Done. I've added commit messages to each of the patches. I've also brought the patch from [1] here as 0003. Thoughts? [1] https://www.postgresql.org/message-id/CALj2ACXtQdrGXtb%3DrbUOXddm1wU1vD9z6q_39FQyX0166dq%3D%3DA%40mail.gmail.com -- Bharath Rupireddy PostgreSQL Contributors Team RDS Open Source Databases Amazon Web Services: https://aws.amazon.com
Attachment
Re: WAL Insertion Lock Improvements (was: Re: Avoid LWLockWaitForVar() for currently held WAL insertion lock in WaitXLogInsertionsToFinish())
From
Nathan Bossart
Date:
On Fri, Dec 02, 2022 at 04:32:38PM +0530, Bharath Rupireddy wrote: > On Fri, Dec 2, 2022 at 6:10 AM Andres Freund <andres@anarazel.de> wrote: >> I'm not sure this is quite right - don't we need a memory barrier. But I don't >> see a reason to not just leave this code as-is. I think this should be >> optimized entirely in lwlock.c > > Actually, we don't need that at all as LWLockWaitForVar() will return > immediately if the lock is free. So, I removed it. I briefly looked at the latest patch set, and I'm curious how this change avoids introducing memory ordering bugs. Perhaps I am missing something obvious. -- Nathan Bossart Amazon Web Services: https://aws.amazon.com
Re: WAL Insertion Lock Improvements (was: Re: Avoid LWLockWaitForVar() for currently held WAL insertion lock in WaitXLogInsertionsToFinish())
From
Andres Freund
Date:
Hi,
FWIW, I don't see an advantage in 0003. If it allows us to make something else
simpler / faster, cool, but on its own it doesn't seem worthwhile.
On 2022-12-02 16:31:58 -0800, Nathan Bossart wrote:
> On Fri, Dec 02, 2022 at 04:32:38PM +0530, Bharath Rupireddy wrote:
> > On Fri, Dec 2, 2022 at 6:10 AM Andres Freund <andres@anarazel.de> wrote:
> >> I'm not sure this is quite right - don't we need a memory barrier. But I don't
> >> see a reason to not just leave this code as-is. I think this should be
> >> optimized entirely in lwlock.c
> >
> > Actually, we don't need that at all as LWLockWaitForVar() will return
> > immediately if the lock is free. So, I removed it.
>
> I briefly looked at the latest patch set, and I'm curious how this change
> avoids introducing memory ordering bugs. Perhaps I am missing something
> obvious.
I'm a bit confused too - the comment above talks about LWLockWaitForVar(), but
the patches seem to optimize LWLockUpdateVar().
I think it'd be safe to optimize LWLockConflictsWithVar(), due to some
pre-existing, quite crufty, code. LWLockConflictsWithVar() says:
* Test first to see if it the slot is free right now.
*
* XXX: the caller uses a spinlock before this, so we don't need a memory
* barrier here as far as the current usage is concerned. But that might
* not be safe in general.
which happens to be true in the single, indirect, caller:
/* Read the current insert position */
SpinLockAcquire(&Insert->insertpos_lck);
bytepos = Insert->CurrBytePos;
SpinLockRelease(&Insert->insertpos_lck);
reservedUpto = XLogBytePosToEndRecPtr(bytepos);
I think at the very least we ought to have a comment in
WaitXLogInsertionsToFinish() highlighting this.
It's not at all clear to me that the proposed fast-path for LWLockUpdateVar()
is safe. I think at the very least we could end up missing waiters that we
should have woken up.
I think it ought to be safe to do something like
pg_atomic_exchange_u64()..
if (!(pg_atomic_read_u32(&lock->state) & LW_FLAG_HAS_WAITERS))
return;
because the pg_atomic_exchange_u64() will provide the necessary memory
barrier.
Greetings,
Andres Freund
Re: WAL Insertion Lock Improvements (was: Re: Avoid LWLockWaitForVar() for currently held WAL insertion lock in WaitXLogInsertionsToFinish())
From
Bharath Rupireddy
Date:
On Tue, Dec 6, 2022 at 12:00 AM Andres Freund <andres@anarazel.de> wrote:
>
> FWIW, I don't see an advantage in 0003. If it allows us to make something else
> simpler / faster, cool, but on its own it doesn't seem worthwhile.
Thanks. I will discard it.
> I think it'd be safe to optimize LWLockConflictsWithVar(), due to some
> pre-existing, quite crufty, code. LWLockConflictsWithVar() says:
>
> * Test first to see if it the slot is free right now.
> *
> * XXX: the caller uses a spinlock before this, so we don't need a memory
> * barrier here as far as the current usage is concerned. But that might
> * not be safe in general.
>
> which happens to be true in the single, indirect, caller:
>
> /* Read the current insert position */
> SpinLockAcquire(&Insert->insertpos_lck);
> bytepos = Insert->CurrBytePos;
> SpinLockRelease(&Insert->insertpos_lck);
> reservedUpto = XLogBytePosToEndRecPtr(bytepos);
>
> I think at the very least we ought to have a comment in
> WaitXLogInsertionsToFinish() highlighting this.
So, using a spinlock ensures no memory ordering occurs while reading
lock->state in LWLockConflictsWithVar()? How does spinlock that gets
acquired and released in the caller WaitXLogInsertionsToFinish()
itself and the memory barrier in the called function
LWLockConflictsWithVar() relate here? Can you please help me
understand this a bit?
> It's not at all clear to me that the proposed fast-path for LWLockUpdateVar()
> is safe. I think at the very least we could end up missing waiters that we
> should have woken up.
>
> I think it ought to be safe to do something like
>
> pg_atomic_exchange_u64()..
> if (!(pg_atomic_read_u32(&lock->state) & LW_FLAG_HAS_WAITERS))
> return;
pg_atomic_exchange_u64(&lock->state, exchange_with_what_?. Exchange
will change the value no?
> because the pg_atomic_exchange_u64() will provide the necessary memory
> barrier.
I'm reading some comments [1], are these also true for 64-bit atomic
CAS? Does it mean that an atomic CAS operation inherently provides a
memory barrier? Can you please point me if it's described better
somewhere else?
[1]
* Full barrier semantics.
*/
static inline uint32
pg_atomic_exchange_u32(volatile pg_atomic_uint32 *ptr,
/*
* Get and clear the flags that are set for this backend. Note that
* pg_atomic_exchange_u32 is a full barrier, so we're guaranteed that the
* read of the barrier generation above happens before we atomically
* extract the flags, and that any subsequent state changes happen
* afterward.
--
Bharath Rupireddy
PostgreSQL Contributors Team
RDS Open Source Databases
Amazon Web Services: https://aws.amazon.com
Re: WAL Insertion Lock Improvements (was: Re: Avoid LWLockWaitForVar() for currently held WAL insertion lock in WaitXLogInsertionsToFinish())
From
Andres Freund
Date:
Hi, On 2022-12-08 12:29:54 +0530, Bharath Rupireddy wrote: > On Tue, Dec 6, 2022 at 12:00 AM Andres Freund <andres@anarazel.de> wrote: > > I think it'd be safe to optimize LWLockConflictsWithVar(), due to some > > pre-existing, quite crufty, code. LWLockConflictsWithVar() says: > > > > * Test first to see if it the slot is free right now. > > * > > * XXX: the caller uses a spinlock before this, so we don't need a memory > > * barrier here as far as the current usage is concerned. But that might > > * not be safe in general. > > > > which happens to be true in the single, indirect, caller: > > > > /* Read the current insert position */ > > SpinLockAcquire(&Insert->insertpos_lck); > > bytepos = Insert->CurrBytePos; > > SpinLockRelease(&Insert->insertpos_lck); > > reservedUpto = XLogBytePosToEndRecPtr(bytepos); > > > > I think at the very least we ought to have a comment in > > WaitXLogInsertionsToFinish() highlighting this. > > So, using a spinlock ensures no memory ordering occurs while reading > lock->state in LWLockConflictsWithVar()? No, a spinlock *does* imply ordering. But your patch does remove several of the spinlock acquisitions (via LWLockWaitListLock()). And moved the assignment in LWLockUpdateVar() out from under the spinlock. If you remove spinlock operations (or other barrier primitives), you need to make sure that such modifications don't break the required memory ordering. > How does spinlock that gets acquired and released in the caller > WaitXLogInsertionsToFinish() itself and the memory barrier in the called > function LWLockConflictsWithVar() relate here? Can you please help me > understand this a bit? The caller's barrier means that we'll see values that are at least as "up to date" as at the time of the barrier (it's a bit more complicated than that, a barrier always needs to be paired with another barrier). > > It's not at all clear to me that the proposed fast-path for LWLockUpdateVar() > > is safe. I think at the very least we could end up missing waiters that we > > should have woken up. > > > > I think it ought to be safe to do something like > > > > pg_atomic_exchange_u64().. > > if (!(pg_atomic_read_u32(&lock->state) & LW_FLAG_HAS_WAITERS)) > > return; > > pg_atomic_exchange_u64(&lock->state, exchange_with_what_?. Exchange will > change the value no? Not lock->state, but the atomic passed to LWLockUpdateVar(), which we do want to update. An pg_atomic_exchange_u64() includes a memory barrier. > > because the pg_atomic_exchange_u64() will provide the necessary memory > > barrier. > > I'm reading some comments [1], are these also true for 64-bit atomic > CAS? Yes. See /* ---- * The 64 bit operations have the same semantics as their 32bit counterparts * if they are available. Check the corresponding 32bit function for * documentation. * ---- */ > Does it mean that an atomic CAS operation inherently provides a > memory barrier? Yes. > Can you please point me if it's described better somewhere else? I'm not sure what you'd like to have described more extensively, tbh. Greetings, Andres Freund
Re: WAL Insertion Lock Improvements (was: Re: Avoid LWLockWaitForVar() for currently held WAL insertion lock in WaitXLogInsertionsToFinish())
From
Bharath Rupireddy
Date:
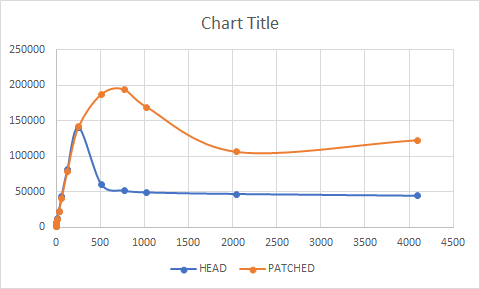
On Tue, Dec 6, 2022 at 12:00 AM Andres Freund <andres@anarazel.de> wrote: > > Hi Thanks for reviewing. > FWIW, I don't see an advantage in 0003. If it allows us to make something else > simpler / faster, cool, but on its own it doesn't seem worthwhile. I've discarded this change. > On 2022-12-02 16:31:58 -0800, Nathan Bossart wrote: > > On Fri, Dec 02, 2022 at 04:32:38PM +0530, Bharath Rupireddy wrote: > > > On Fri, Dec 2, 2022 at 6:10 AM Andres Freund <andres@anarazel.de> wrote: > > >> I'm not sure this is quite right - don't we need a memory barrier. But I don't > > >> see a reason to not just leave this code as-is. I think this should be > > >> optimized entirely in lwlock.c > > > > > > Actually, we don't need that at all as LWLockWaitForVar() will return > > > immediately if the lock is free. So, I removed it. > > > > I briefly looked at the latest patch set, and I'm curious how this change > > avoids introducing memory ordering bugs. Perhaps I am missing something > > obvious. > > I'm a bit confused too - the comment above talks about LWLockWaitForVar(), but > the patches seem to optimize LWLockUpdateVar(). > > I think it'd be safe to optimize LWLockConflictsWithVar(), due to some > pre-existing, quite crufty, code. LWLockConflictsWithVar() says: > > * Test first to see if it the slot is free right now. > * > * XXX: the caller uses a spinlock before this, so we don't need a memory > * barrier here as far as the current usage is concerned. But that might > * not be safe in general. > > which happens to be true in the single, indirect, caller: > > /* Read the current insert position */ > SpinLockAcquire(&Insert->insertpos_lck); > bytepos = Insert->CurrBytePos; > SpinLockRelease(&Insert->insertpos_lck); > reservedUpto = XLogBytePosToEndRecPtr(bytepos); > > I think at the very least we ought to have a comment in > WaitXLogInsertionsToFinish() highlighting this. Done. > It's not at all clear to me that the proposed fast-path for LWLockUpdateVar() > is safe. I think at the very least we could end up missing waiters that we > should have woken up. > > I think it ought to be safe to do something like > > pg_atomic_exchange_u64().. > if (!(pg_atomic_read_u32(&lock->state) & LW_FLAG_HAS_WAITERS)) > return; > > because the pg_atomic_exchange_u64() will provide the necessary memory > barrier. Done. I'm attaching the v3 patch with the above review comments addressed. Hopefully, no memory ordering issues now. FWIW, I've added it to CF https://commitfest.postgresql.org/42/4141/. Test results with the v3 patch and insert workload are the same as that of the earlier run - TPS starts to scale at higher clients as expected after 512 clients and peaks at 2X with 2048 and 4096 clients. HEAD: 1 1380.411086 2 1358.378988 4 2701.974332 8 5925.380744 16 10956.501237 32 20877.513953 64 40838.046774 128 70251.744161 256 108114.321299 512 120478.988268 768 99140.425209 1024 93645.984364 2048 70111.159909 4096 55541.804826 v3 PATCHED: 1 1493.800209 2 1569.414953 4 3154.186605 8 5965.578904 16 11912.587645 32 22720.964908 64 42001.094528 128 78361.158983 256 110457.926232 512 148941.378393 768 167256.590308 1024 155510.675372 2048 147499.376882 4096 119375.457779 -- Bharath Rupireddy PostgreSQL Contributors Team RDS Open Source Databases Amazon Web Services: https://aws.amazon.com
Attachment
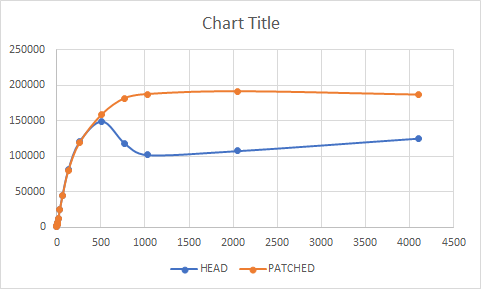
On Tue, Jan 24, 2023 at 7:00 PM Bharath Rupireddy <bharath.rupireddyforpostgres@gmail.com> wrote: > > I'm attaching the v3 patch with the above review comments addressed. > Hopefully, no memory ordering issues now. FWIW, I've added it to CF > https://commitfest.postgresql.org/42/4141/. > > Test results with the v3 patch and insert workload are the same as > that of the earlier run - TPS starts to scale at higher clients as > expected after 512 clients and peaks at 2X with 2048 and 4096 clients. > > HEAD: > 1 1380.411086 > 2 1358.378988 > 4 2701.974332 > 8 5925.380744 > 16 10956.501237 > 32 20877.513953 > 64 40838.046774 > 128 70251.744161 > 256 108114.321299 > 512 120478.988268 > 768 99140.425209 > 1024 93645.984364 > 2048 70111.159909 > 4096 55541.804826 > > v3 PATCHED: > 1 1493.800209 > 2 1569.414953 > 4 3154.186605 > 8 5965.578904 > 16 11912.587645 > 32 22720.964908 > 64 42001.094528 > 128 78361.158983 > 256 110457.926232 > 512 148941.378393 > 768 167256.590308 > 1024 155510.675372 > 2048 147499.376882 > 4096 119375.457779 I slightly modified the comments and attached the v4 patch for further review. I also took perf report - there's a clear reduction in the functions that are affected by the patch - LWLockWaitListLock, WaitXLogInsertionsToFinish, LWLockWaitForVar and LWLockConflictsWithVar. Note that I compiled the source code with -ggdb for capturing symbols for perf, still the benefit stands at > 2X for a higher number of clients. HEAD: + 16.87% 0.01% postgres [.] CommitTransactionCommand + 16.86% 0.00% postgres [.] finish_xact_command + 16.81% 0.01% postgres [.] CommitTransaction + 15.09% 0.20% postgres [.] LWLockWaitListLock + 14.53% 0.01% postgres [.] WaitXLogInsertionsToFinish + 14.51% 0.02% postgres [.] LWLockWaitForVar + 11.70% 11.63% postgres [.] pg_atomic_read_u32_impl + 11.66% 0.08% postgres [.] pg_atomic_read_u32 + 9.96% 0.03% postgres [.] LWLockConflictsWithVar + 4.78% 0.00% postgres [.] LWLockQueueSelf + 1.91% 0.01% postgres [.] pg_atomic_fetch_or_u32 + 1.91% 1.89% postgres [.] pg_atomic_fetch_or_u32_impl + 1.73% 0.00% postgres [.] XLogInsert + 1.69% 0.01% postgres [.] XLogInsertRecord + 1.41% 0.01% postgres [.] LWLockRelease + 1.37% 0.47% postgres [.] perform_spin_delay + 1.11% 1.11% postgres [.] spin_delay + 1.10% 0.03% postgres [.] exec_bind_message + 0.91% 0.00% postgres [.] WALInsertLockRelease + 0.91% 0.00% postgres [.] LWLockReleaseClearVar + 0.72% 0.02% postgres [.] LWLockAcquire + 0.60% 0.00% postgres [.] LWLockDequeueSelf + 0.58% 0.00% postgres [.] GetTransactionSnapshot 0.58% 0.49% postgres [.] GetSnapshotData + 0.58% 0.00% postgres [.] WALInsertLockAcquire + 0.55% 0.00% postgres [.] XactLogCommitRecord TPS (compiled with -ggdb for capturing symbols for perf) 1 1392.512967 2 1435.899119 4 3104.091923 8 6159.305522 16 11477.641780 32 22701.000718 64 41662.425880 128 23743.426209 256 89837.651619 512 65164.221500 768 66015.733370 1024 56421.223080 2048 52909.018072 4096 40071.146985 PATCHED: + 2.19% 0.05% postgres [.] LWLockWaitListLock + 2.10% 0.01% postgres [.] LWLockQueueSelf + 1.73% 1.71% postgres [.] pg_atomic_read_u32_impl + 1.73% 0.02% postgres [.] pg_atomic_read_u32 + 1.72% 0.02% postgres [.] LWLockRelease + 1.65% 0.04% postgres [.] exec_bind_message + 1.43% 0.00% postgres [.] XLogInsert + 1.42% 0.01% postgres [.] WaitXLogInsertionsToFinish + 1.40% 0.03% postgres [.] LWLockWaitForVar + 1.38% 0.02% postgres [.] XLogInsertRecord + 0.93% 0.03% postgres [.] LWLockAcquireOrWait + 0.91% 0.00% postgres [.] GetTransactionSnapshot + 0.91% 0.79% postgres [.] GetSnapshotData + 0.91% 0.00% postgres [.] WALInsertLockRelease + 0.91% 0.00% postgres [.] LWLockReleaseClearVar + 0.53% 0.02% postgres [.] ExecInitModifyTable TPS (compiled with -ggdb for capturing symbols for perf) 1 1295.296611 2 1459.079162 4 2865.688987 8 5533.724983 16 10771.697842 32 20557.499312 64 39436.423783 128 42555.639048 256 73139.060227 512 124649.665196 768 131162.826976 1024 132185.160007 2048 117377.586644 4096 88240.336940 -- Bharath Rupireddy PostgreSQL Contributors Team RDS Open Source Databases Amazon Web Services: https://aws.amazon.com
Attachment
+ pg_atomic_exchange_u64(valptr, val); nitpick: I'd add a (void) at the beginning of these calls to pg_atomic_exchange_u64() so that it's clear that we are discarding the return value. + /* + * Update the lock variable atomically first without having to acquire wait + * list lock, so that if anyone looking for the lock will have chance to + * grab it a bit quickly. + * + * NB: Note the use of pg_atomic_exchange_u64 as opposed to just + * pg_atomic_write_u64 to update the value. Since pg_atomic_exchange_u64 is + * a full barrier, we're guaranteed that the subsequent atomic read of lock + * state to check if it has any waiters happens after we set the lock + * variable to new value here. Without a barrier, we could end up missing + * waiters that otherwise should have been woken up. + */ + pg_atomic_exchange_u64(valptr, val); + + /* + * Quick exit when there are no waiters. This avoids unnecessary lwlock's + * wait list lock acquisition and release. + */ + if ((pg_atomic_read_u32(&lock->state) & LW_FLAG_HAS_WAITERS) == 0) + return; I think this makes sense. A waiter could queue itself after the exchange, but it'll recheck after queueing. IIUC this is basically how this works today. We update the value and release the lock before waking up any waiters, so the same principle applies. Overall, I think this patch is in reasonable shape. -- Nathan Bossart Amazon Web Services: https://aws.amazon.com
On Thu, Feb 9, 2023 at 3:36 AM Nathan Bossart <nathandbossart@gmail.com> wrote: > > + pg_atomic_exchange_u64(valptr, val); > > nitpick: I'd add a (void) at the beginning of these calls to > pg_atomic_exchange_u64() so that it's clear that we are discarding the > return value. I did that in the attached v5 patch although it's a mix elsewhere; some doing explicit return value cast with (void) and some not. > + /* > + * Update the lock variable atomically first without having to acquire wait > + * list lock, so that if anyone looking for the lock will have chance to > + * grab it a bit quickly. > + * > + * NB: Note the use of pg_atomic_exchange_u64 as opposed to just > + * pg_atomic_write_u64 to update the value. Since pg_atomic_exchange_u64 is > + * a full barrier, we're guaranteed that the subsequent atomic read of lock > + * state to check if it has any waiters happens after we set the lock > + * variable to new value here. Without a barrier, we could end up missing > + * waiters that otherwise should have been woken up. > + */ > + pg_atomic_exchange_u64(valptr, val); > + > + /* > + * Quick exit when there are no waiters. This avoids unnecessary lwlock's > + * wait list lock acquisition and release. > + */ > + if ((pg_atomic_read_u32(&lock->state) & LW_FLAG_HAS_WAITERS) == 0) > + return; > > I think this makes sense. A waiter could queue itself after the exchange, > but it'll recheck after queueing. IIUC this is basically how this works > today. We update the value and release the lock before waking up any > waiters, so the same principle applies. Yes, a waiter right after self-queuing (LWLockQueueSelf) checks for the value (LWLockConflictsWithVar) before it goes and waits until awakened in LWLockWaitForVar. A waiter added to the queue is guaranteed to be woken up by the LWLockUpdateVar but before that the lock value is set and we have pg_atomic_exchange_u64 as a memory barrier, so no memory reordering. Essentially, the order of these operations aren't changed. The benefit that we're seeing is from avoiding LWLock's waitlist lock for reading and updating the lock value relying on 64-bit atomics. > Overall, I think this patch is in reasonable shape. Thanks for reviewing. Please see the attached v5 patch. -- Bharath Rupireddy PostgreSQL Contributors Team RDS Open Source Databases Amazon Web Services: https://aws.amazon.com
Attachment
On Thu, Feb 09, 2023 at 11:51:28AM +0530, Bharath Rupireddy wrote: > On Thu, Feb 9, 2023 at 3:36 AM Nathan Bossart <nathandbossart@gmail.com> wrote: >> Overall, I think this patch is in reasonable shape. > > Thanks for reviewing. Please see the attached v5 patch. I'm marking this as ready-for-committer. I think a couple of the comments could use some small adjustments, but that probably doesn't need to hold up this patch. -- Nathan Bossart Amazon Web Services: https://aws.amazon.com
Hi Andres Freund
This patch improves performance significantly,Commitfest 2023-03 is coming to an end,Is it not submitted yet since the patch still needs to be improved?
Best wish
发件人: Nathan Bossart <nathandbossart@gmail.com>
发送时间: 2023年2月21日 13:49
收件人: Bharath Rupireddy <bharath.rupireddyforpostgres@gmail.com>
抄送: Andres Freund <andres@anarazel.de>; PostgreSQL Hackers <pgsql-hackers@lists.postgresql.org>
主题: Re: WAL Insertion Lock Improvements
发送时间: 2023年2月21日 13:49
收件人: Bharath Rupireddy <bharath.rupireddyforpostgres@gmail.com>
抄送: Andres Freund <andres@anarazel.de>; PostgreSQL Hackers <pgsql-hackers@lists.postgresql.org>
主题: Re: WAL Insertion Lock Improvements
On Thu, Feb 09, 2023 at 11:51:28AM +0530, Bharath Rupireddy wrote:
> On Thu, Feb 9, 2023 at 3:36 AM Nathan Bossart <nathandbossart@gmail.com> wrote:
>> Overall, I think this patch is in reasonable shape.
>
> Thanks for reviewing. Please see the attached v5 patch.
I'm marking this as ready-for-committer. I think a couple of the comments
could use some small adjustments, but that probably doesn't need to hold up
this patch.
--
Nathan Bossart
Amazon Web Services: https://aws.amazon.com
> On Thu, Feb 9, 2023 at 3:36 AM Nathan Bossart <nathandbossart@gmail.com> wrote:
>> Overall, I think this patch is in reasonable shape.
>
> Thanks for reviewing. Please see the attached v5 patch.
I'm marking this as ready-for-committer. I think a couple of the comments
could use some small adjustments, but that probably doesn't need to hold up
this patch.
--
Nathan Bossart
Amazon Web Services: https://aws.amazon.com
On Mon, Feb 20, 2023 at 09:49:48PM -0800, Nathan Bossart wrote:
> I'm marking this as ready-for-committer. I think a couple of the comments
> could use some small adjustments, but that probably doesn't need to hold up
> this patch.
Apologies. I was planning to have a thorough look at this patch but
life got in the way and I have not been able to study what's happening
on this thread this close to the feature freeze.
Anyway, I am attaching two modules I have written for the sake of this
thread while beginning my lookup of the patch:
- lwlock_test.tar.gz, validation module for LWLocks with variable
waits. This module can be loaded with shared_preload_libraries to
have two LWLocks and two variables in shmem, then have 2 backends play
ping-pong with each other's locks. An isolation test may be possible,
though I have not thought hard about it. Just use a SQL sequence like
that, for example, with N > 1 (see README):
Backend 1: SELECT lwlock_test_acquire();
Backend 2: SELECT lwlock_test_wait(N);
Backend 1: SELECT lwlock_test_update(N);
Backend 1: SELECT lwlock_test_release();
- custom_wal.tar.gz, thin wrapper for LogLogicalMessage() able to
generate N records of size M bytes in a single SQL call. This can be
used to generate records of various sizes for benchmarking, limiting
the overhead of individual calls to pg_logical_emit_message_bytea().
I have begun gathering numbers with WAL records of various size and
length, using pgbench like:
$ cat script.sql
\set record_size 1
\set record_number 5000
SELECT custom_wal(:record_size, :record_number);
$ pgbench -n -c 500 -t 100 -f script.sql
So this limits most the overhead of behind parsing, planning, and most
of the INSERT logic.
I have been trying to get some reproducible numbers, but I think that
I am going to need a bigger maching than what I have been using for
the last few days, up to 400 connections. It is worth noting that
00d1e02b may influence a bit the results, so we may want to have more
numbers with that in place particularly with INSERTs, and one of the
tests used upthread uses single row INSERTs.
Another question I had: would it be worth having some tests with
pg_wal/ mounted to a tmpfs so as I/O would not be a bottleneck? It
should be instructive to get more measurement with a fixed number of
transactions and a rather high amount of concurrent connections (1k at
least?), where the contention would be on the variable waits. My
first impression is that records should not be too small if you want
to see more the effects of this patch, either.
Looking at the patch.. LWLockConflictsWithVar() and
LWLockReleaseClearVar() are the trivial bits. These are OK.
+ * NB: Note the use of pg_atomic_exchange_u64 as opposed to just
+ * pg_atomic_write_u64 to update the value. Since pg_atomic_exchange_u64 is
+ * a full barrier, we're guaranteed that the subsequent shared memory
+ * reads/writes, if any, happen after we reset the lock variable.
This mentions that the subsequent read/write operations are safe, so
this refers to anything happening after the variable is reset. As
a full barrier, should be also mention that this is also ordered with
respect to anything that the caller did before clearing the variable?
From this perspective using pg_atomic_exchange_u64() makes sense to me
in LWLockReleaseClearVar().
+ * XXX: Use of a spinlock at the beginning of this function to read
+ * current insert position implies memory ordering. That means that
+ * the immediate loads and stores to shared memory (for instance,
+ * in LWLockUpdateVar called via LWLockWaitForVar) don't need an
+ * explicit memory barrier as far as the current usage is
+ * concerned. But that might not be safe in general.
*/
What's the part where this is not safe? Based on what I see, this
code path is safe because of the previous spinlock. This is the same
comment as at the beginning of LWLockConflictsWithVar(). Is that
something that we ought to document at the top of LWLockWaitForVar()
as well? We have one caller of this function currently, but there may
be more in the future.
- * you're about to write out.
+ * you're about to write out. Using an atomic variable for insertingAt avoids
+ * taking any explicit lock for reads and writes.
Hmm. Not sure that we need to comment at all.
-LWLockUpdateVar(LWLock *lock, uint64 *valptr, uint64 val)
+LWLockUpdateVar(LWLock *lock, pg_atomic_uint64 *valptr, uint64 val)
[...]
Assert(pg_atomic_read_u32(&lock->state) & LW_VAL_EXCLUSIVE);
- /* Update the lock's value */
- *valptr = val;
The sensitive change is in LWLockUpdateVar(). I am not completely
sure to understand this removal, though. Does that influence the case
where there are waiters?
Another thing I was wondering about: how much does the fast-path used
in LWLockUpdateVar() influence the performance numbers? Am I right to
guess that it counts for most of the gain seen? Or could it be that
the removal of the spin lock in
LWLockConflictsWithVar()/LWLockWaitForVar() the point that has the
highest effect?
--
Michael
Attachment
On Mon, Apr 10, 2023 at 9:38 AM Michael Paquier <michael@paquier.xyz> wrote: > > I have been trying to get some reproducible numbers, but I think that > I am going to need a bigger maching than what I have been using for > the last few days, up to 400 connections. It is worth noting that > 00d1e02b may influence a bit the results, so we may want to have more > numbers with that in place particularly with INSERTs, and one of the > tests used upthread uses single row INSERTs. I ran performance tests on the patch with different use-cases. Clearly the patch reduces burden on LWLock's waitlist lock (evident from perf reports [1]). However, to see visible impact in the output, the txns must be generating small (between 16 bytes to 2 KB) amounts of WAL in a highly concurrent manner, check the results below (FWIW, I've zipped and attached perf images for better illustration along with test setup). When the txns are generating a small amount of WAL i.e. between 16 bytes to 2 KB in a highly concurrent manner, the benefit is clearly visible in the TPS more than 2.3X improvement. When the txns are generating more WAL i.e. more than 2 KB, the gain from reduced burden on waitlist lock is offset by increase in the wait/release for WAL insertion locks and no visible benefit is seen. As the amount of WAL each txn generates increases, it looks like the benefit gained from reduced burden on waitlist lock is offset by increase in the wait for WAL insertion locks. Note that I've used pg_logical_emit_message() for ease of understanding about the txns generating various amounts of WAL, but the pattern is the same if txns are generating various amounts of WAL say with inserts. test-case 1: -T5, WAL ~16 bytes clients HEAD PATCHED 1 1437 1352 2 1376 1419 4 2919 2774 8 5875 6371 16 11148 12242 32 22108 23532 64 41414 46478 128 85304 85235 256 83771 152901 512 61970 141021 768 56514 118899 1024 51784 110960 2048 39141 84150 4096 16901 45759 test-case 1: -t1000, WAL ~16 bytes clients HEAD PATCHED 1 1417 1333 2 1363 1791 4 2978 2970 8 5954 6198 16 11179 11164 32 23742 24043 64 45537 44103 128 84683 91762 256 80369 146293 512 61080 132079 768 57236 118046 1024 53497 114574 2048 46423 93588 4096 42067 85790 test-case 2: -T5, WAL ~256 bytes clients HEAD PATCHED 1 1521 1386 2 1647 1637 4 3088 3270 8 6011 5631 16 12778 10317 32 24117 20006 64 43966 38199 128 72660 67936 256 93096 121261 512 57247 142418 768 53782 126218 1024 50279 109153 2048 35109 91602 4096 21184 39848 test-case 2: -t1000, WAL ~256 bytes clients HEAD PATCHED 1 1265 1389 2 1522 1258 4 2802 2775 8 5875 5422 16 11664 10853 32 21961 22145 64 44304 40851 128 73278 80494 256 91172 122287 512 60966 136734 768 56590 125050 1024 52481 124341 2048 47878 104760 4096 42838 94121 test-case 3: -T5, WAL 512 bytes clients HEAD PATCHED 1 1464 1284 2 1520 1381 4 2985 2877 8 6237 5261 16 11296 10621 32 22257 20789 64 40548 37243 128 66507 59891 256 92516 97506 512 56404 119716 768 51127 112482 1024 48463 103484 2048 38079 81424 4096 18977 40942 test-case 3: -t1000, WAL 512 bytes clients HEAD PATCHED 1 1452 1434 2 1604 1649 4 3051 2971 8 5967 5650 16 10471 10702 32 20257 20899 64 39412 36750 128 62767 61110 256 81050 89768 512 56888 122786 768 51238 114444 1024 48972 106867 2048 43451 98847 4096 40018 111079 test-case 4: -T5, WAL 1024 bytes clients HEAD PATCHED 1 1405 1395 2 1638 1607 4 3176 3207 8 6271 6024 16 11653 11103 32 20530 20260 64 34313 32367 128 55939 52079 256 74355 76420 512 56506 90983 768 50088 100410 1024 44589 99025 2048 39640 90931 4096 20942 36035 test-case 4: -t1000, WAL 1024 bytes clients HEAD PATCHED 1 1330 1304 2 1615 1366 4 3117 2667 8 6179 5390 16 10524 10426 32 19819 18620 64 34844 29731 128 52180 48869 256 73284 71396 512 55714 96014 768 49336 108100 1024 46113 102789 2048 44627 104721 4096 44979 106189 test-case 5: -T5, WAL 2048 bytes clients HEAD PATCHED 1 1407 1377 2 1518 1559 4 2589 2870 8 4883 5493 16 9075 9201 32 15957 16295 64 27471 25029 128 37493 38642 256 46369 45787 512 61755 62836 768 59144 68419 1024 52495 68933 2048 48608 72500 4096 26463 61252 test-case 5: -t1000, WAL 2048 bytes clients HEAD PATCHED 1 1289 1366 2 1489 1628 4 2960 3036 8 5536 5965 16 9248 10399 32 15770 18140 64 27626 27800 128 36817 39483 256 48533 52105 512 64453 64007 768 59146 64160 1024 57637 61756 2048 59063 62109 4096 58268 61206 test-case 6: -T5, WAL 4096 bytes clients HEAD PATCHED 1 1322 1325 2 1504 1551 4 2811 2880 8 5330 5159 16 8625 8315 32 12820 13534 64 19737 19965 128 26298 24633 256 34630 29939 512 34382 36669 768 33421 33316 1024 33525 32821 2048 37053 37752 4096 37334 39114 test-case 6: -t1000, WAL 4096 bytes clients HEAD PATCHED 1 1212 1371 2 1383 1566 4 2858 2967 8 5092 5035 16 8233 8486 32 13353 13678 64 19052 20072 128 24803 24726 256 34065 33139 512 31590 32029 768 31432 31404 1024 31357 31366 2048 31465 31508 4096 32157 32180 test-case 7: -T5, WAL 8192 bytes clients HEAD PATCHED 1 1287 1233 2 1552 1521 4 2658 2617 8 4680 4532 16 6732 7110 32 9649 9198 64 13276 12042 128 17100 17187 256 17408 17448 512 16595 16358 768 16599 16500 1024 16975 17300 2048 19073 19137 4096 21368 21735 test-case 7: -t1000, WAL 8192 bytes clients HEAD PATCHED 1 1144 1190 2 1414 1395 4 2618 2438 8 4645 4485 16 6766 7001 32 9620 9804 64 12943 13023 128 15904 17148 256 16645 16035 512 15800 15796 768 15788 15810 1024 15814 15817 2048 17775 17771 4096 31715 31682 > Looking at the patch.. LWLockConflictsWithVar() and > LWLockReleaseClearVar() are the trivial bits. These are OK. Hm, the crux of the patch is avoiding LWLock's waitlist lock for reading/writing the lock variable. Essentially, they are important bits. > + * NB: Note the use of pg_atomic_exchange_u64 as opposed to just > + * pg_atomic_write_u64 to update the value. Since pg_atomic_exchange_u64 is > + * a full barrier, we're guaranteed that the subsequent shared memory > + * reads/writes, if any, happen after we reset the lock variable. > > This mentions that the subsequent read/write operations are safe, so > this refers to anything happening after the variable is reset. As > a full barrier, should be also mention that this is also ordered with > respect to anything that the caller did before clearing the variable? > From this perspective using pg_atomic_exchange_u64() makes sense to me > in LWLockReleaseClearVar(). Wordsmithed that comment a bit. > + * XXX: Use of a spinlock at the beginning of this function to read > + * current insert position implies memory ordering. That means that > + * the immediate loads and stores to shared memory (for instance, > + * in LWLockUpdateVar called via LWLockWaitForVar) don't need an > + * explicit memory barrier as far as the current usage is > + * concerned. But that might not be safe in general. > */ > What's the part where this is not safe? Based on what I see, this > code path is safe because of the previous spinlock. This is the same > comment as at the beginning of LWLockConflictsWithVar(). Is that > something that we ought to document at the top of LWLockWaitForVar() > as well? We have one caller of this function currently, but there may > be more in the future. 'But that might not be safe in general' applies only for LWLockWaitForVar not for WaitXLogInsertionsToFinish for sure. My bad. If there's another caller for LWLockWaitForVar without any spinlock, that's when the LWLockWaitForVar needs to have an explicit memory barrier. Per a comment upthread https://www.postgresql.org/message-id/20221205183007.s72oygp63s43dqyz%40awork3.anarazel.de, I had a note in WaitXLogInsertionsToFinish before LWLockWaitForVar. I now have modified that comment. > - * you're about to write out. > + * you're about to write out. Using an atomic variable for insertingAt avoids > + * taking any explicit lock for reads and writes. > > Hmm. Not sure that we need to comment at all. Removed. I was being verbose. One who understands pg_atomic_uint64 can get to that point easily. > -LWLockUpdateVar(LWLock *lock, uint64 *valptr, uint64 val) > +LWLockUpdateVar(LWLock *lock, pg_atomic_uint64 *valptr, uint64 val) > [...] > Assert(pg_atomic_read_u32(&lock->state) & LW_VAL_EXCLUSIVE); > > - /* Update the lock's value */ > - *valptr = val; > > The sensitive change is in LWLockUpdateVar(). I am not completely > sure to understand this removal, though. Does that influence the case > where there are waiters? I'll send about this in a follow-up email to not overload this response with too much data. > Another thing I was wondering about: how much does the fast-path used > in LWLockUpdateVar() influence the performance numbers? Am I right to > guess that it counts for most of the gain seen? I'll send about this in a follow-up email to not overload this response with too much data. > Or could it be that > the removal of the spin lock in > LWLockConflictsWithVar()/LWLockWaitForVar() the point that has the > highest effect? I'll send about this in a follow-up email to not overload this response with too much data. I've addressed the above review comments and attached the v6 patch. [1] test-case 1: -T5, WAL ~16 bytes HEAD: + 81.52% 0.03% postgres [.] __vstrfmon_l_internal + 81.52% 0.00% postgres [.] startup_hacks + 81.52% 0.00% postgres [.] PostmasterMain + 63.95% 1.01% postgres [.] LWLockWaitListLock + 61.93% 0.02% postgres [.] WaitXLogInsertionsToFinish + 61.89% 0.05% postgres [.] LWLockWaitForVar + 48.83% 48.33% postgres [.] pg_atomic_read_u32_impl + 48.78% 0.40% postgres [.] pg_atomic_read_u32 + 43.19% 0.12% postgres [.] LWLockConflictsWithVar + 19.81% 0.01% postgres [.] LWLockQueueSelf + 7.86% 2.46% postgres [.] perform_spin_delay + 6.14% 6.06% postgres [.] spin_delay + 5.82% 0.01% postgres [.] pg_atomic_fetch_or_u32 + 5.81% 5.76% postgres [.] pg_atomic_fetch_or_u32_impl + 4.00% 0.01% postgres [.] XLogInsert + 3.93% 0.03% postgres [.] XLogInsertRecord + 2.13% 0.02% postgres [.] LWLockRelease + 2.10% 0.03% postgres [.] LWLockAcquire + 1.92% 0.00% postgres [.] LWLockDequeueSelf + 1.87% 0.01% postgres [.] WALInsertLockAcquire + 1.68% 0.04% postgres [.] LWLockAcquireOrWait + 1.64% 0.01% postgres [.] pg_analyze_and_rewrite_fixedparams + 1.62% 0.00% postgres [.] WALInsertLockRelease + 1.62% 0.00% postgres [.] LWLockReleaseClearVar + 1.55% 0.01% postgres [.] parse_analyze_fixedparams + 1.51% 0.00% postgres [.] transformTopLevelStmt + 1.50% 0.00% postgres [.] transformOptionalSelectInto + 1.50% 0.01% postgres [.] transformStmt + 1.47% 0.02% postgres [.] transformSelectStmt + 1.29% 0.01% postgres [.] XactLogCommitRecord test-case 1: -T5, WAL ~16 bytes PATCHED: + 74.49% 0.04% postgres [.] __vstrfmon_l_internal + 74.49% 0.00% postgres [.] startup_hacks + 74.49% 0.00% postgres [.] PostmasterMain + 51.60% 0.01% postgres [.] finish_xact_command + 51.60% 0.02% postgres [.] CommitTransactionCommand + 51.37% 0.03% postgres [.] CommitTransaction + 49.43% 0.05% postgres [.] RecordTransactionCommit + 46.55% 0.05% postgres [.] XLogFlush + 46.37% 0.85% postgres [.] LWLockWaitListLock + 43.79% 0.02% postgres [.] LWLockQueueSelf + 38.87% 0.03% postgres [.] WaitXLogInsertionsToFinish + 38.79% 0.11% postgres [.] LWLockWaitForVar + 34.99% 34.49% postgres [.] pg_atomic_read_u32_impl + 34.93% 0.35% postgres [.] pg_atomic_read_u32 + 6.99% 2.12% postgres [.] perform_spin_delay + 6.64% 0.01% postgres [.] XLogInsert + 6.54% 0.06% postgres [.] XLogInsertRecord + 6.26% 0.08% postgres [.] LWLockAcquireOrWait + 5.31% 5.22% postgres [.] spin_delay + 4.23% 0.04% postgres [.] LWLockRelease + 3.74% 0.01% postgres [.] pg_atomic_fetch_or_u32 + 3.73% 3.68% postgres [.] pg_atomic_fetch_or_u32_impl + 3.33% 0.06% postgres [.] LWLockAcquire + 2.97% 0.01% postgres [.] pg_plan_queries + 2.95% 0.01% postgres [.] WALInsertLockAcquire + 2.94% 0.02% postgres [.] planner + 2.94% 0.01% postgres [.] pg_plan_query + 2.92% 0.01% postgres [.] LWLockDequeueSelf + 2.89% 0.04% postgres [.] standard_planner + 2.81% 0.00% postgres [.] WALInsertLockRelease + 2.80% 0.00% postgres [.] LWLockReleaseClearVar + 2.38% 0.07% postgres [.] subquery_planner + 2.35% 0.01% postgres [.] XactLogCommitRecord -- Bharath Rupireddy PostgreSQL Contributors Team RDS Open Source Databases Amazon Web Services: https://aws.amazon.com
Attachment
On Mon, May 8, 2023 at 5:57 PM Bharath Rupireddy
<bharath.rupireddyforpostgres@gmail.com> wrote:
>
> On Mon, Apr 10, 2023 at 9:38 AM Michael Paquier <michael@paquier.xyz> wrote:
>
> > -LWLockUpdateVar(LWLock *lock, uint64 *valptr, uint64 val)
> > +LWLockUpdateVar(LWLock *lock, pg_atomic_uint64 *valptr, uint64 val)
> > [...]
> > Assert(pg_atomic_read_u32(&lock->state) & LW_VAL_EXCLUSIVE);
> >
> > - /* Update the lock's value */
> > - *valptr = val;
> >
> > The sensitive change is in LWLockUpdateVar(). I am not completely
> > sure to understand this removal, though. Does that influence the case
> > where there are waiters?
>
> I'll send about this in a follow-up email to not overload this
> response with too much data.
It helps the case when there are no waiters. IOW, it updates value
without waitlist lock when there are no waiters, so no extra waitlist
lock acquisition/release just to update the value. In turn, it helps
the other backend wanting to flush the WAL looking for the new updated
value of insertingAt in WaitXLogInsertionsToFinish(), now the flushing
backend can get the new value faster.
> > Another thing I was wondering about: how much does the fast-path used
> > in LWLockUpdateVar() influence the performance numbers? Am I right to
> > guess that it counts for most of the gain seen?
>
> I'll send about this in a follow-up email to not overload this
> response with too much data.
The fastpath exit in LWLockUpdateVar() doesn't seem to influence the
results much, see below results. However, it avoids waitlist lock
acquisition when there are no waiters.
test-case 1: -T5, WAL ~16 bytes
clients HEAD PATCHED with fastpath PATCHED no fast path
1 1482 1486 1457
2 1617 1620 1569
4 3174 3233 3031
8 6136 6365 5725
16 12566 12269 11685
32 24284 23621 23177
64 50135 45528 46653
128 94903 89791 89103
256 82289 152915 152835
512 62498 138838 142084
768 57083 125074 126768
1024 51308 113593 115930
2048 41084 88764 85110
4096 19939 42257 43917
> > Or could it be that
> > the removal of the spin lock in
> > LWLockConflictsWithVar()/LWLockWaitForVar() the point that has the
> > highest effect?
>
> I'll send about this in a follow-up email to not overload this
> response with too much data.
Out of 3 functions that got rid of waitlist lock
LWLockConflictsWithVar/LWLockWaitForVar, LWLockUpdateVar,
LWLockReleaseClearVar, perf reports tell that the biggest gain (for
the use-cases that I've tried) is for
LWLockConflictsWithVar/LWLockWaitForVar:
test-case 1: -T5, WAL ~16 bytes
HEAD:
+ 61.89% 0.05% postgres [.] LWLockWaitForVar
+ 43.19% 0.12% postgres [.] LWLockConflictsWithVar
+ 1.62% 0.00% postgres [.] LWLockReleaseClearVar
PATCHED:
+ 38.79% 0.11% postgres [.] LWLockWaitForVar
0.40% 0.02% postgres [.] LWLockConflictsWithVar
+ 2.80% 0.00% postgres [.] LWLockReleaseClearVar
test-case 6: -T5, WAL 4096 bytes
HEAD:
+ 29.66% 0.07% postgres [.] LWLockWaitForVar
+ 20.94% 0.08% postgres [.] LWLockConflictsWithVar
0.19% 0.03% postgres [.] LWLockUpdateVar
PATCHED:
+ 3.95% 0.08% postgres [.] LWLockWaitForVar
0.19% 0.03% postgres [.] LWLockConflictsWithVar
+ 1.73% 0.00% postgres [.] LWLockReleaseClearVar
--
Bharath Rupireddy
PostgreSQL Contributors Team
RDS Open Source Databases
Amazon Web Services: https://aws.amazon.com
On Mon, May 08, 2023 at 05:57:09PM +0530, Bharath Rupireddy wrote: > I ran performance tests on the patch with different use-cases. Clearly > the patch reduces burden on LWLock's waitlist lock (evident from perf > reports [1]). However, to see visible impact in the output, the txns > must be generating small (between 16 bytes to 2 KB) amounts of WAL in > a highly concurrent manner, check the results below (FWIW, I've zipped > and attached perf images for better illustration along with test > setup). > > When the txns are generating a small amount of WAL i.e. between 16 > bytes to 2 KB in a highly concurrent manner, the benefit is clearly > visible in the TPS more than 2.3X improvement. When the txns are > generating more WAL i.e. more than 2 KB, the gain from reduced burden > on waitlist lock is offset by increase in the wait/release for WAL > insertion locks and no visible benefit is seen. > > As the amount of WAL each txn generates increases, it looks like the > benefit gained from reduced burden on waitlist lock is offset by > increase in the wait for WAL insertion locks. Nice. > test-case 1: -T5, WAL ~16 bytes > test-case 1: -t1000, WAL ~16 bytes I wonder if it's worth doing a couple of long-running tests, too. -- Nathan Bossart Amazon Web Services: https://aws.amazon.com
On Mon, May 08, 2023 at 04:04:10PM -0700, Nathan Bossart wrote: > On Mon, May 08, 2023 at 05:57:09PM +0530, Bharath Rupireddy wrote: >> test-case 1: -T5, WAL ~16 bytes >> test-case 1: -t1000, WAL ~16 bytes > > I wonder if it's worth doing a couple of long-running tests, too. Yes, 5s or 1000 transactions per client is too small, though it shows that things are going in the right direction. (Will reply to the rest in a bit..) -- Michael
Attachment
On Tue, May 9, 2023 at 9:02 AM Michael Paquier <michael@paquier.xyz> wrote: > > On Mon, May 08, 2023 at 04:04:10PM -0700, Nathan Bossart wrote: > > On Mon, May 08, 2023 at 05:57:09PM +0530, Bharath Rupireddy wrote: > >> test-case 1: -T5, WAL ~16 bytes > >> test-case 1: -t1000, WAL ~16 bytes > > > > I wonder if it's worth doing a couple of long-running tests, too. > > Yes, 5s or 1000 transactions per client is too small, though it shows > that things are going in the right direction. I'll pick a test case that generates a reasonable amount of WAL 256 bytes. What do you think of the following? test-case 2: -T900, WAL ~256 bytes (for c in 1 2 4 8 16 32 64 128 256 512 768 1024 2048 4096 - takes 3.5hrs) test-case 2: -t1000000, WAL ~256 bytes If okay, I'll fire the tests. -- Bharath Rupireddy PostgreSQL Contributors Team RDS Open Source Databases Amazon Web Services: https://aws.amazon.com
On Tue, May 09, 2023 at 09:24:14AM +0530, Bharath Rupireddy wrote: > I'll pick a test case that generates a reasonable amount of WAL 256 > bytes. What do you think of the following? > > test-case 2: -T900, WAL ~256 bytes (for c in 1 2 4 8 16 32 64 128 256 > 512 768 1024 2048 4096 - takes 3.5hrs) > test-case 2: -t1000000, WAL ~256 bytes > > If okay, I'll fire the tests. Sounds like a sensible duration, yes. What's your setting for min/max_wal_size? I assume that there are still 16GB throttled with target_completion at 0.9? -- Michael
Attachment
On Tue, May 9, 2023 at 9:27 AM Michael Paquier <michael@paquier.xyz> wrote: > > On Tue, May 09, 2023 at 09:24:14AM +0530, Bharath Rupireddy wrote: > > I'll pick a test case that generates a reasonable amount of WAL 256 > > bytes. What do you think of the following? > > > > test-case 2: -T900, WAL ~256 bytes (for c in 1 2 4 8 16 32 64 128 256 > > 512 768 1024 2048 4096 - takes 3.5hrs) > > test-case 2: -t1000000, WAL ~256 bytes > > > > If okay, I'll fire the tests. > > Sounds like a sensible duration, yes. What's your setting for > min/max_wal_size? I assume that there are still 16GB throttled with > target_completion at 0.9? Below is the configuration I've been using. I have been keeping the checkpoints away so far to get expected numbers. Probably, something that I should modify for this long run? Change checkpoint_timeout to 15 min or so? max_wal_size=64GB checkpoint_timeout=1d shared_buffers=8GB max_connections=5000 -- Bharath Rupireddy PostgreSQL Contributors Team RDS Open Source Databases Amazon Web Services: https://aws.amazon.com
On Tue, May 09, 2023 at 09:34:56AM +0530, Bharath Rupireddy wrote: > Below is the configuration I've been using. I have been keeping the > checkpoints away so far to get expected numbers. Probably, something > that I should modify for this long run? Change checkpoint_timeout to > 15 min or so? > > max_wal_size=64GB > checkpoint_timeout=1d > shared_buffers=8GB > max_connections=5000 Noted. Something like that should be OK IMO, with all the checkpoints generated based on the volume generated. With records that have a fixed size, this should, I assume, lead to results that could be compared across runs, even if the patched code would lead to more checkpoints generated. -- Michael
Attachment
On Mon, May 08, 2023 at 08:18:04PM +0530, Bharath Rupireddy wrote: > On Mon, May 8, 2023 at 5:57 PM Bharath Rupireddy > <bharath.rupireddyforpostgres@gmail.com> wrote: >> On Mon, Apr 10, 2023 at 9:38 AM Michael Paquier <michael@paquier.xyz> wrote: >>> The sensitive change is in LWLockUpdateVar(). I am not completely >>> sure to understand this removal, though. Does that influence the case >>> where there are waiters? >> >> I'll send about this in a follow-up email to not overload this >> response with too much data. > > It helps the case when there are no waiters. IOW, it updates value > without waitlist lock when there are no waiters, so no extra waitlist > lock acquisition/release just to update the value. In turn, it helps > the other backend wanting to flush the WAL looking for the new updated > value of insertingAt in WaitXLogInsertionsToFinish(), now the flushing > backend can get the new value faster. Sure, which is what the memory barrier given by exchange_u64 guarantees. My thoughts on this one is that I am not completely sure to understand that we won't miss any waiters that should have been awaken. > The fastpath exit in LWLockUpdateVar() doesn't seem to influence the > results much, see below results. However, it avoids waitlist lock > acquisition when there are no waiters. > > test-case 1: -T5, WAL ~16 bytes > clients HEAD PATCHED with fastpath PATCHED no fast path > 64 50135 45528 46653 > 128 94903 89791 89103 > 256 82289 152915 152835 > 512 62498 138838 142084 > 768 57083 125074 126768 > 1024 51308 113593 115930 > 2048 41084 88764 85110 > 4096 19939 42257 43917 Considering that there could be a few percents of noise mixed into that, that's not really surprising as the workload is highly concurrent on inserts so the fast path won't really shine :) Should we split this patch into two parts, as they aim at tackling two different cases then? One for LWLockConflictsWithVar() and LWLockReleaseClearVar() which are the straight-forward pieces (using one pg_atomic_write_u64() in LWLockUpdateVar instead), then a second for LWLockUpdateVar()? Also, the fast path treatment in LWLockUpdateVar() may show some better benefits when there are really few backends and a bunch of very little records? Still, even that sounds a bit limited.. > Out of 3 functions that got rid of waitlist lock > LWLockConflictsWithVar/LWLockWaitForVar, LWLockUpdateVar, > LWLockReleaseClearVar, perf reports tell that the biggest gain (for > the use-cases that I've tried) is for > LWLockConflictsWithVar/LWLockWaitForVar: > > test-case 6: -T5, WAL 4096 bytes > HEAD: > + 29.66% 0.07% postgres [.] LWLockWaitForVar > + 20.94% 0.08% postgres [.] LWLockConflictsWithVar > 0.19% 0.03% postgres [.] LWLockUpdateVar > > PATCHED: > + 3.95% 0.08% postgres [.] LWLockWaitForVar > 0.19% 0.03% postgres [.] LWLockConflictsWithVar > + 1.73% 0.00% postgres [.] LWLockReleaseClearVar Indeed. -- Michael
Attachment
On Tue, May 09, 2023 at 02:10:20PM +0900, Michael Paquier wrote: > Should we split this patch into two parts, as they aim at tackling two > different cases then? One for LWLockConflictsWithVar() and > LWLockReleaseClearVar() which are the straight-forward pieces > (using one pg_atomic_write_u64() in LWLockUpdateVar instead), then > a second for LWLockUpdateVar()? I have been studying that a bit more, and I'd like to take this suggestion back. Apologies for the noise. -- Michael
Attachment
On Mon, May 08, 2023 at 05:57:09PM +0530, Bharath Rupireddy wrote:
> Note that I've used pg_logical_emit_message() for ease of
> understanding about the txns generating various amounts of WAL, but
> the pattern is the same if txns are generating various amounts of WAL
> say with inserts.
Sounds good to me to just rely on that for some comparison numbers.
+ * NB: LWLockConflictsWithVar (which is called from
+ * LWLockWaitForVar) relies on the spinlock used above in this
+ * function and doesn't use a memory barrier.
This patch adds the following comment in WaitXLogInsertionsToFinish()
because lwlock.c on HEAD mentions that:
/*
* Test first to see if it the slot is free right now.
*
* XXX: the caller uses a spinlock before this, so we don't need a memory
* barrier here as far as the current usage is concerned. But that might
* not be safe in general.
*/
Should it be something where we'd better be noisy about at the top of
LWLockWaitForVar()? We don't want to add a memory barrier at the
beginning of LWLockConflictsWithVar(), still it strikes me that
somebody that aims at using LWLockWaitForVar() may miss this point
because LWLockWaitForVar() is the routine published in lwlock.h, not
LWLockConflictsWithVar(). This does not need to be really
complicated, say a note at the top of LWLockWaitForVar() among the
lines of (?):
"Be careful that LWLockConflictsWithVar() does not include a memory
barrier, hence the caller of this function may want to rely on an
explicit barrier or a spinlock to avoid memory ordering issues."
>> + * NB: Note the use of pg_atomic_exchange_u64 as opposed to just
>> + * pg_atomic_write_u64 to update the value. Since pg_atomic_exchange_u64 is
>> + * a full barrier, we're guaranteed that the subsequent shared memory
>> + * reads/writes, if any, happen after we reset the lock variable.
>>
>> This mentions that the subsequent read/write operations are safe, so
>> this refers to anything happening after the variable is reset. As
>> a full barrier, should be also mention that this is also ordered with
>> respect to anything that the caller did before clearing the variable?
>> From this perspective using pg_atomic_exchange_u64() makes sense to me
>> in LWLockReleaseClearVar().
>
> Wordsmithed that comment a bit.
- * Set the variable's value before releasing the lock, that prevents race
- * a race condition wherein a new locker acquires the lock, but hasn't yet
- * set the variables value.
[...]
+ * NB: pg_atomic_exchange_u64 is used here as opposed to just
+ * pg_atomic_write_u64 to update the variable. Since pg_atomic_exchange_u64
+ * is a full barrier, we're guaranteed that all loads and stores issued
+ * prior to setting the variable are completed before any loads or stores
+ * issued after setting the variable.
This is the same explanation as LWLockUpdateVar(), except that we
lose the details explaining why we are doing the update before
releasing the lock.
It took me some time, but I have been able to deploy a big box to see
the effect of this patch at a rather large scale (64 vCPU, 512G of
memory), with the following test characteristics for HEAD and v6:
- TPS comparison with pgbench and pg_logical_emit_message().
- Record sizes of 16, 64, 256, 1k, 4k and 16k.
- Clients and jobs equal at 4, 16, 64, 256, 512, 1024, 2048, 4096.
- Runs of 3 mins for each of the 48 combinations, meaning 96 runs in
total.
And here are the results I got:
message_size_b | 16 | 64 | 256 | 1024 | 4096 | 16k
------------------|--------|--------|--------|--------|-------|-------
head_4_clients | 3026 | 2965 | 2846 | 2880 | 2778 | 2412
head_16_clients | 12087 | 11287 | 11670 | 11100 | 9003 | 5608
head_64_clients | 42995 | 44005 | 43592 | 35437 | 21533 | 11273
head_256_clients | 106775 | 109233 | 104201 | 80759 | 42118 | 16254
head_512_clients | 153849 | 156950 | 142915 | 99288 | 57714 | 16198
head_1024_clients | 122102 | 123895 | 114248 | 117317 | 62270 | 16261
head_2048_clients | 126730 | 115594 | 109671 | 119564 | 62454 | 16298
head_4096_clients | 111564 | 111697 | 119164 | 123483 | 62430 | 16140
v6_4_clients | 2893 | 2917 | 3087 | 2904 | 2786 | 2262
v6_16_clients | 12097 | 11387 | 11579 | 11242 | 9228 | 5661
v6_64_clients | 45124 | 46533 | 42275 | 36124 | 21696 | 11386
v6_256_clients | 121500 | 125732 | 104328 | 78989 | 41949 | 16254
v6_512_clients | 164120 | 174743 | 146677 | 98110 | 60228 | 16171
v6_1024_clients | 168990 | 180710 | 149894 | 117431 | 62271 | 16259
v6_2048_clients | 165426 | 162893 | 146322 | 132476 | 62468 | 16274
v6_4096_clients | 161283 | 158732 | 162474 | 135636 | 62461 | 16030
These tests are not showing me any degradation, and a correlation
between the record size and the number of clients where the TPS begins
to show a difference between HEAD and v6 of the patch. In short the
shorter the record, the better performance gets at a lower client
number, still this required at least 256~512 clients with even
messages of 16bytes. At the end I'm cool with that.
--
Michael
Attachment
On Tue, May 9, 2023 at 9:24 AM Bharath Rupireddy <bharath.rupireddyforpostgres@gmail.com> wrote: > > On Tue, May 9, 2023 at 9:02 AM Michael Paquier <michael@paquier.xyz> wrote: > > > > On Mon, May 08, 2023 at 04:04:10PM -0700, Nathan Bossart wrote: > > > On Mon, May 08, 2023 at 05:57:09PM +0530, Bharath Rupireddy wrote: > > >> test-case 1: -T5, WAL ~16 bytes > > >> test-case 1: -t1000, WAL ~16 bytes > > > > > > I wonder if it's worth doing a couple of long-running tests, too. > > > > Yes, 5s or 1000 transactions per client is too small, though it shows > > that things are going in the right direction. > > I'll pick a test case that generates a reasonable amount of WAL 256 > bytes. What do you think of the following? > > test-case 2: -T900, WAL ~256 bytes (for c in 1 2 4 8 16 32 64 128 256 > 512 768 1024 2048 4096 - takes 3.5hrs) > test-case 2: -t1000000, WAL ~256 bytes > > If okay, I'll fire the tests. test-case 2: -T900, WAL ~256 bytes - ran for about 3.5 hours and the more than 3X improvement in TPS is seen - 3.11X @ 512 3.79 @ 768, 3.47 @ 1024, 2.27 @ 2048, 2.77 @ 4096 test-case 2: -T900, WAL ~256 bytes clients HEAD PATCHED 1 1394 1351 2 1551 1445 4 3104 2881 8 5974 5774 16 12154 11319 32 22438 21606 64 43689 40567 128 80726 77993 256 139987 141638 512 60108 187126 768 51188 194406 1024 48766 169353 2048 46617 105961 4096 44163 122697 test-case 2: -t1000000, WAL ~256 bytes - ran for more than 12 hours and the maximum improvement is 1.84X @ 1024 client. test-case 2: -t1000000, WAL ~256 bytes clients HEAD PATCHED 1 1454 1500 2 1657 1612 4 3223 3224 8 6305 6295 16 12447 12260 32 24855 24335 64 45229 44386 128 80752 79518 256 120663 119083 512 149546 159396 768 118298 181732 1024 101829 187492 2048 107506 191378 4096 125130 186728 -- Bharath Rupireddy PostgreSQL Contributors Team RDS Open Source Databases Amazon Web Services: https://aws.amazon.com
Attachment
{kind=link}
{kind=link}
On Wed, May 10, 2023 at 10:40:20PM +0530, Bharath Rupireddy wrote: > test-case 2: -T900, WAL ~256 bytes - ran for about 3.5 hours and the > more than 3X improvement in TPS is seen - 3.11X @ 512 3.79 @ 768, 3.47 > @ 1024, 2.27 @ 2048, 2.77 @ 4096 > > [...] > > test-case 2: -t1000000, WAL ~256 bytes - ran for more than 12 hours > and the maximum improvement is 1.84X @ 1024 client. Thanks. So that's pretty close to what I was seeing when it comes to this message size where you see much more effects under a number of clients of at least 512~. Any of these tests have been using fsync = on, I assume. I think that disabling fsync or just mounting pg_wal to a tmpfs should show the same pattern for larger record sizes (after 1k of message size the curve begins to go down with 512~ clients). -- Michael
Attachment
On Wed, May 10, 2023 at 09:04:47PM +0900, Michael Paquier wrote: > It took me some time, but I have been able to deploy a big box to see > the effect of this patch at a rather large scale (64 vCPU, 512G of > memory), with the following test characteristics for HEAD and v6: > - TPS comparison with pgbench and pg_logical_emit_message(). > - Record sizes of 16, 64, 256, 1k, 4k and 16k. > - Clients and jobs equal at 4, 16, 64, 256, 512, 1024, 2048, 4096. > - Runs of 3 mins for each of the 48 combinations, meaning 96 runs in > total. > > And here are the results I got: > message_size_b | 16 | 64 | 256 | 1024 | 4096 | 16k > ------------------|--------|--------|--------|--------|-------|------- > head_4_clients | 3026 | 2965 | 2846 | 2880 | 2778 | 2412 > head_16_clients | 12087 | 11287 | 11670 | 11100 | 9003 | 5608 > head_64_clients | 42995 | 44005 | 43592 | 35437 | 21533 | 11273 > head_256_clients | 106775 | 109233 | 104201 | 80759 | 42118 | 16254 > head_512_clients | 153849 | 156950 | 142915 | 99288 | 57714 | 16198 > head_1024_clients | 122102 | 123895 | 114248 | 117317 | 62270 | 16261 > head_2048_clients | 126730 | 115594 | 109671 | 119564 | 62454 | 16298 > head_4096_clients | 111564 | 111697 | 119164 | 123483 | 62430 | 16140 > v6_4_clients | 2893 | 2917 | 3087 | 2904 | 2786 | 2262 > v6_16_clients | 12097 | 11387 | 11579 | 11242 | 9228 | 5661 > v6_64_clients | 45124 | 46533 | 42275 | 36124 | 21696 | 11386 > v6_256_clients | 121500 | 125732 | 104328 | 78989 | 41949 | 16254 > v6_512_clients | 164120 | 174743 | 146677 | 98110 | 60228 | 16171 > v6_1024_clients | 168990 | 180710 | 149894 | 117431 | 62271 | 16259 > v6_2048_clients | 165426 | 162893 | 146322 | 132476 | 62468 | 16274 > v6_4096_clients | 161283 | 158732 | 162474 | 135636 | 62461 | 16030 Another thing I was wondering is if it would be able to see a difference by reducing the I/O pressure. After mounting pg_wal to a tmpfs, I am getting the following table: message_size_b | 16 | 64 | 256 | 1024 | 4096 | 16000 -------------------+--------+--------+--------+--------+--------+------- head_4_clients | 86476 | 86592 | 84645 | 76784 | 57887 | 30199 head_16_clients | 277006 | 278431 | 263238 | 228614 | 143880 | 67237 head_64_clients | 373972 | 370082 | 352217 | 297377 | 190974 | 96843 head_256_clients | 144510 | 147077 | 146281 | 189059 | 156294 | 88345 head_512_clients | 122863 | 119054 | 127790 | 162187 | 142771 | 84109 head_1024_clients | 140802 | 138728 | 147200 | 172449 | 138022 | 81054 head_2048_clients | 175950 | 164143 | 154070 | 161432 | 128205 | 76732 head_4096_clients | 161438 | 158666 | 152057 | 139520 | 113955 | 69335 v6_4_clients | 87356 | 86985 | 83933 | 76397 | 57352 | 30084 v6_16_clients | 277466 | 280125 | 259733 | 224916 | 143832 | 66589 v6_64_clients | 388352 | 386188 | 362358 | 302719 | 190353 | 96687 v6_256_clients | 365797 | 360114 | 337135 | 266851 | 172252 | 88898 v6_512_clients | 339751 | 332384 | 308182 | 249624 | 158868 | 84258 v6_1024_clients | 301294 | 295140 | 276769 | 226034 | 148392 | 80909 v6_2048_clients | 268846 | 261001 | 247110 | 205332 | 137271 | 76299 v6_4096_clients | 229322 | 227049 | 217271 | 183708 | 124888 | 69263 This shows more difference from 64 clients up to 4k records, without degradation noticed across the board. -- Michael
Attachment
On Thu, May 11, 2023 at 11:56 AM Michael Paquier <michael@paquier.xyz> wrote: > > On Wed, May 10, 2023 at 09:04:47PM +0900, Michael Paquier wrote: > > It took me some time, but I have been able to deploy a big box to see > > the effect of this patch at a rather large scale (64 vCPU, 512G of > > memory), with the following test characteristics for HEAD and v6: > > - TPS comparison with pgbench and pg_logical_emit_message(). > > - Record sizes of 16, 64, 256, 1k, 4k and 16k. > > - Clients and jobs equal at 4, 16, 64, 256, 512, 1024, 2048, 4096. > > - Runs of 3 mins for each of the 48 combinations, meaning 96 runs in > > total. > > > > And here are the results I got: > > message_size_b | 16 | 64 | 256 | 1024 | 4096 | 16k > > ------------------|--------|--------|--------|--------|-------|------- > > head_4_clients | 3026 | 2965 | 2846 | 2880 | 2778 | 2412 > > head_16_clients | 12087 | 11287 | 11670 | 11100 | 9003 | 5608 > > head_64_clients | 42995 | 44005 | 43592 | 35437 | 21533 | 11273 > > head_256_clients | 106775 | 109233 | 104201 | 80759 | 42118 | 16254 > > head_512_clients | 153849 | 156950 | 142915 | 99288 | 57714 | 16198 > > head_1024_clients | 122102 | 123895 | 114248 | 117317 | 62270 | 16261 > > head_2048_clients | 126730 | 115594 | 109671 | 119564 | 62454 | 16298 > > head_4096_clients | 111564 | 111697 | 119164 | 123483 | 62430 | 16140 > > v6_4_clients | 2893 | 2917 | 3087 | 2904 | 2786 | 2262 > > v6_16_clients | 12097 | 11387 | 11579 | 11242 | 9228 | 5661 > > v6_64_clients | 45124 | 46533 | 42275 | 36124 | 21696 | 11386 > > v6_256_clients | 121500 | 125732 | 104328 | 78989 | 41949 | 16254 > > v6_512_clients | 164120 | 174743 | 146677 | 98110 | 60228 | 16171 > > v6_1024_clients | 168990 | 180710 | 149894 | 117431 | 62271 | 16259 > > v6_2048_clients | 165426 | 162893 | 146322 | 132476 | 62468 | 16274 > > v6_4096_clients | 161283 | 158732 | 162474 | 135636 | 62461 | 16030 > > Another thing I was wondering is if it would be able to see a > difference by reducing the I/O pressure. After mounting pg_wal to a > tmpfs, I am getting the following table: > message_size_b | 16 | 64 | 256 | 1024 | 4096 | 16000 > -------------------+--------+--------+--------+--------+--------+------- > head_4_clients | 86476 | 86592 | 84645 | 76784 | 57887 | 30199 > head_16_clients | 277006 | 278431 | 263238 | 228614 | 143880 | 67237 > head_64_clients | 373972 | 370082 | 352217 | 297377 | 190974 | 96843 > head_256_clients | 144510 | 147077 | 146281 | 189059 | 156294 | 88345 > head_512_clients | 122863 | 119054 | 127790 | 162187 | 142771 | 84109 > head_1024_clients | 140802 | 138728 | 147200 | 172449 | 138022 | 81054 > head_2048_clients | 175950 | 164143 | 154070 | 161432 | 128205 | 76732 > head_4096_clients | 161438 | 158666 | 152057 | 139520 | 113955 | 69335 > v6_4_clients | 87356 | 86985 | 83933 | 76397 | 57352 | 30084 > v6_16_clients | 277466 | 280125 | 259733 | 224916 | 143832 | 66589 > v6_64_clients | 388352 | 386188 | 362358 | 302719 | 190353 | 96687 > v6_256_clients | 365797 | 360114 | 337135 | 266851 | 172252 | 88898 > v6_512_clients | 339751 | 332384 | 308182 | 249624 | 158868 | 84258 > v6_1024_clients | 301294 | 295140 | 276769 | 226034 | 148392 | 80909 > v6_2048_clients | 268846 | 261001 | 247110 | 205332 | 137271 | 76299 > v6_4096_clients | 229322 | 227049 | 217271 | 183708 | 124888 | 69263 > > This shows more difference from 64 clients up to 4k records, without > degradation noticed across the board. Impressive. I further covered the following test cases. There's a clear gain with the patch i.e. reducing burden on LWLock's waitlist lock is helping out. fsync=off, -T120: message_size_b | 16 | 64 | 256 | 1024 | 4096 | 16384 -------------------+--------+--------+--------+--------+--------+-------- head_1_clients | 33609 | 33862 | 32975 | 29722 | 21842 | 10606 head_2_clients | 60583 | 60524 | 57833 | 53582 | 38583 | 20120 head_4_clients | 115209 | 114012 | 114077 | 102991 | 73452 | 39179 head_8_clients | 181786 | 177592 | 174404 | 155350 | 98642 | 41406 head_16_clients | 313750 | 309024 | 295375 | 253101 | 159328 | 73617 head_32_clients | 406456 | 416809 | 400527 | 344573 | 213756 | 96322 head_64_clients | 199619 | 197948 | 198871 | 208606 | 221751 | 107762 head_128_clients | 108576 | 108727 | 107606 | 112137 | 173998 | 106976 head_256_clients | 75303 | 74983 | 73986 | 76100 | 148209 | 98080 head_512_clients | 62559 | 60189 | 59588 | 61102 | 131803 | 90534 head_768_clients | 55650 | 54486 | 54813 | 55515 | 120707 | 88009 head_1024_clients | 54709 | 52395 | 51672 | 52910 | 113904 | 86116 head_2048_clients | 48640 | 47098 | 46787 | 47582 | 98394 | 80766 head_4096_clients | 43205 | 42709 | 42591 | 43649 | 88903 | 72362 v6_1_clients | 33337 | 32877 | 31880 | 29372 | 21695 | 10596 v6_2_clients | 60125 | 60682 | 58770 | 53709 | 38390 | 20266 v6_4_clients | 115338 | 114053 | 114232 | 93527 | 74409 | 40437 v6_8_clients | 179472 | 183899 | 175474 | 154547 | 101807 | 43508 v6_16_clients | 318181 | 318580 | 296591 | 258094 | 159351 | 74758 v6_32_clients | 439681 | 447005 | 428459 | 367307 | 218511 | 97635 v6_64_clients | 473440 | 478388 | 464287 | 394825 | 244365 | 109194 v6_128_clients | 384433 | 412694 | 405916 | 366046 | 232421 | 110274 v6_256_clients | 312480 | 303635 | 291900 | 307573 | 206784 | 104171 v6_512_clients | 218560 | 189207 | 216267 | 252513 | 186762 | 97918 v6_768_clients | 168432 | 155493 | 145941 | 226616 | 178178 | 95435 v6_1024_clients | 150300 | 132078 | 134657 | 224515 | 172950 | 94356 v6_2048_clients | 126941 | 120189 | 120702 | 195684 | 158683 | 88055 v6_4096_clients | 163993 | 140795 | 139702 | 170149 | 139740 | 78907 pg_wal on tmpfs, -T180: message_size_b | 16 | 64 | 256 | 1024 | 4096 | 16384 -------------------+--------+--------+--------+--------+--------+-------- head_1_clients | 32956 | 32766 | 32244 | 29772 | 22094 | 11212 head_2_clients | 60093 | 60382 | 58825 | 53812 | 39764 | 20953 head_4_clients | 117178 | 104986 | 112060 | 103416 | 75588 | 39753 head_8_clients | 177556 | 179926 | 173413 | 156684 | 107727 | 42001 head_16_clients | 311033 | 313842 | 298362 | 261298 | 165293 | 76183 head_32_clients | 425750 | 433988 | 419193 | 370925 | 227392 | 101638 head_64_clients | 227463 | 219832 | 221421 | 235603 | 236601 | 113677 head_128_clients | 117188 | 116847 | 118414 | 123605 | 194533 | 111480 head_256_clients | 80596 | 80541 | 79130 | 83949 | 167529 | 102401 head_512_clients | 64912 | 63610 | 63209 | 65554 | 146882 | 94936 head_768_clients | 59050 | 57082 | 57061 | 58966 | 133336 | 92389 head_1024_clients | 56880 | 54951 | 54864 | 56554 | 125270 | 90893 head_2048_clients | 52148 | 49603 | 50422 | 50692 | 110789 | 86659 head_4096_clients | 47001 | 46992 | 46075 | 47793 | 99617 | 77762 v6_1_clients | 32915 | 32854 | 31676 | 29341 | 21956 | 11220 v6_2_clients | 59592 | 59146 | 58106 | 53235 | 38973 | 20943 v6_4_clients | 113947 | 114897 | 97349 | 104630 | 73628 | 40719 v6_8_clients | 177996 | 179673 | 176190 | 156831 | 104183 | 42884 v6_16_clients | 312284 | 317065 | 300130 | 268788 | 165765 | 77299 v6_32_clients | 443101 | 450025 | 436774 | 380398 | 229081 | 101916 v6_64_clients | 450794 | 469633 | 470252 | 411374 | 253232 | 113722 v6_128_clients | 413357 | 399514 | 386713 | 364070 | 236133 | 112780 v6_256_clients | 264674 | 252701 | 268273 | 296090 | 208050 | 105477 v6_512_clients | 196481 | 154815 | 158316 | 238805 | 188363 | 99507 v6_768_clients | 139839 | 132645 | 131391 | 219846 | 179226 | 97808 v6_1024_clients | 124540 | 119543 | 120140 | 206740 | 174657 | 96629 v6_2048_clients | 118793 | 113033 | 113881 | 190997 | 161421 | 91888 v6_4096_clients | 156341 | 156971 | 131391 | 177024 | 146564 | 84096 --enable-atomics=no, -T60: message_size_b | 16 | 64 | 256 | 1024 | 4096 | 16384 -------------------+-------+-------+-------+-------+-------+------- head_1_clients | 1701 | 1686 | 1636 | 1693 | 1523 | 1331 head_2_clients | 1751 | 1712 | 1698 | 1769 | 1690 | 1579 head_4_clients | 3328 | 3370 | 3405 | 3495 | 3107 | 2713 head_8_clients | 6580 | 6521 | 6459 | 6370 | 5470 | 4253 head_16_clients | 13433 | 13476 | 12986 | 11461 | 9249 | 6313 head_32_clients | 25697 | 26729 | 24879 | 20862 | 14344 | 9454 head_64_clients | 51499 | 48322 | 46297 | 35224 | 20970 | 13241 head_128_clients | 56777 | 57177 | 59129 | 47687 | 27591 | 16007 head_256_clients | 9555 | 10041 | 9526 | 9830 | 13179 | 15776 head_512_clients | 5795 | 5871 | 5809 | 5954 | 5828 | 15647 head_768_clients | 4322 | 4366 | 4782 | 4624 | 4853 | 12959 head_1024_clients | 4003 | 3789 | 3647 | 3865 | 4160 | 7991 head_2048_clients | 2687 | 2573 | 2569 | 2829 | 2918 | 5462 head_4096_clients | 1694 | 1802 | 1813 | 1948 | 2256 | 5862 v6_1_clients | 1560 | 1595 | 1690 | 1621 | 1526 | 1374 v6_2_clients | 1737 | 1736 | 1738 | 1663 | 1601 | 1568 v6_4_clients | 3575 | 3583 | 3449 | 3137 | 3157 | 2788 v6_8_clients | 6660 | 6900 | 6802 | 6158 | 5605 | 4521 v6_16_clients | 14084 | 12991 | 13485 | 12628 | 10025 | 6211 v6_32_clients | 26408 | 24652 | 24672 | 21441 | 14966 | 9753 v6_64_clients | 49537 | 47703 | 45583 | 33524 | 21476 | 13259 v6_128_clients | 86938 | 79745 | 73740 | 53007 | 34863 | 15901 v6_256_clients | 20391 | 21433 | 21730 | 30836 | 43821 | 15891 v6_512_clients | 13128 | 12181 | 12309 | 11596 | 14744 | 15851 v6_768_clients | 10511 | 9942 | 9713 | 9373 | 10181 | 15964 v6_1024_clients | 9264 | 8745 | 8031 | 7500 | 8762 | 15198 v6_2048_clients | 6070 | 5724 | 5939 | 5987 | 5513 | 10828 v6_4096_clients | 4322 | 4035 | 3616 | 3637 | 5628 | 10970 --enable-spinlocks=no, -T60: message_size_b | 16 | 64 | 256 | 1024 | 4096 | 16384 -------------------+--------+--------+--------+--------+-------+------- head_1_clients | 1644 | 1716 | 1701 | 1636 | 1569 | 1368 head_2_clients | 1779 | 1875 | 1728 | 1728 | 1770 | 1568 head_4_clients | 3448 | 3569 | 3330 | 3324 | 3319 | 2780 head_8_clients | 6159 | 6996 | 6893 | 6401 | 6308 | 4423 head_16_clients | 13195 | 13810 | 13139 | 12892 | 10744 | 6714 head_32_clients | 26752 | 26834 | 25749 | 21739 | 18071 | 9706 head_64_clients | 52303 | 49759 | 47785 | 36625 | 26993 | 13685 head_128_clients | 98325 | 89753 | 83276 | 62302 | 38515 | 16005 head_256_clients | 128075 | 124396 | 111059 | 97165 | 56941 | 15779 head_512_clients | 140908 | 132622 | 126363 | 119113 | 62572 | 15919 head_768_clients | 118694 | 111764 | 109464 | 120368 | 62129 | 15905 head_1024_clients | 102542 | 99007 | 94291 | 109485 | 62680 | 16039 head_2048_clients | 57994 | 57003 | 57410 | 60350 | 62487 | 16091 head_4096_clients | 33995 | 32944 | 34174 | 33483 | 61071 | 15655 v6_1_clients | 1743 | 1711 | 1722 | 1655 | 1588 | 1378 v6_2_clients | 1714 | 1830 | 1767 | 1667 | 1725 | 1518 v6_4_clients | 3638 | 3602 | 3594 | 3452 | 3216 | 2713 v6_8_clients | 7047 | 6671 | 7148 | 6342 | 5577 | 4573 v6_16_clients | 13885 | 13247 | 13951 | 13037 | 10570 | 6391 v6_32_clients | 27766 | 27230 | 27079 | 22911 | 17152 | 9700 v6_64_clients | 50748 | 51548 | 47852 | 36479 | 27232 | 13290 v6_128_clients | 97611 | 89554 | 85009 | 67349 | 37046 | 16005 v6_256_clients | 124475 | 128603 | 108888 | 95277 | 55021 | 15785 v6_512_clients | 181639 | 176544 | 152852 | 120914 | 62674 | 15921 v6_768_clients | 188600 | 180691 | 158997 | 128740 | 62402 | 15979 v6_1024_clients | 191845 | 180830 | 161597 | 143032 | 62426 | 15985 v6_2048_clients | 179227 | 168906 | 173510 | 149689 | 62721 | 16090 v6_4096_clients | 156613 | 152795 | 154231 | 134587 | 62245 | 15781 --enable-atomics=no --enable-spinlocks=no, -T60: message_size_b | 16 | 64 | 256 | 1024 | 4096 | 16384 -------------------+-------+-------+-------+-------+-------+------- head_1_clients | 1644 | 1768 | 1726 | 1698 | 1544 | 1344 head_2_clients | 1805 | 1829 | 1746 | 1869 | 1730 | 1565 head_4_clients | 3562 | 3606 | 3571 | 3656 | 3145 | 2704 head_8_clients | 6921 | 7051 | 6774 | 6676 | 5999 | 4425 head_16_clients | 13418 | 13998 | 13634 | 12640 | 9782 | 6440 head_32_clients | 21716 | 21690 | 21124 | 18977 | 14050 | 9168 head_64_clients | 27085 | 26498 | 26108 | 23048 | 17843 | 13278 head_128_clients | 26704 | 26373 | 25845 | 24056 | 19777 | 15922 head_256_clients | 24694 | 24586 | 24148 | 22525 | 23523 | 15852 head_512_clients | 21364 | 21143 | 20697 | 20334 | 21770 | 15870 head_768_clients | 16985 | 16618 | 16544 | 16511 | 17360 | 15945 head_1024_clients | 13133 | 13640 | 13521 | 13716 | 14202 | 16020 head_2048_clients | 8051 | 8140 | 7711 | 8673 | 9027 | 15091 head_4096_clients | 4692 | 4549 | 4924 | 4908 | 6853 | 14752 v6_1_clients | 1676 | 1722 | 1781 | 1681 | 1527 | 1394 v6_2_clients | 1868 | 1706 | 1868 | 1842 | 1762 | 1573 v6_4_clients | 3668 | 3591 | 3449 | 3556 | 3309 | 2707 v6_8_clients | 7279 | 6818 | 6842 | 6846 | 5888 | 4283 v6_16_clients | 13604 | 13364 | 14099 | 12851 | 9959 | 6271 v6_32_clients | 22899 | 22453 | 22488 | 20127 | 15970 | 8915 v6_64_clients | 33289 | 32943 | 32280 | 28683 | 22885 | 13215 v6_128_clients | 43614 | 42954 | 41336 | 36660 | 29107 | 15928 v6_256_clients | 46542 | 46593 | 45673 | 41064 | 38759 | 15850 v6_512_clients | 36303 | 35923 | 34640 | 32828 | 38359 | 15913 v6_768_clients | 29654 | 29822 | 29317 | 28703 | 34194 | 15903 v6_1024_clients | 25871 | 25219 | 25801 | 25099 | 29323 | 16015 v6_2048_clients | 16497 | 17041 | 16401 | 17128 | 19656 | 15962 v6_4096_clients | 10067 | 10873 | 10702 | 10540 | 12909 | 16041 -- Bharath Rupireddy PostgreSQL Contributors Team RDS Open Source Databases Amazon Web Services: https://aws.amazon.com
On Fri, May 12, 2023 at 07:35:20AM +0530, Bharath Rupireddy wrote: > --enable-atomics=no, -T60: > --enable-spinlocks=no, -T60: > --enable-atomics=no --enable-spinlocks=no, -T60: Thanks for these extra tests, I have not done these specific cases but the profiles look similar to what I've seen myself. If I recall correctly the fallback implementation of atomics just uses spinlocks internally to force the barriers required. -- Michael
Attachment
On Wed, May 10, 2023 at 5:34 PM Michael Paquier <michael@paquier.xyz> wrote:
>
> + * NB: LWLockConflictsWithVar (which is called from
> + * LWLockWaitForVar) relies on the spinlock used above in this
> + * function and doesn't use a memory barrier.
>
> This patch adds the following comment in WaitXLogInsertionsToFinish()
> because lwlock.c on HEAD mentions that:
> /*
> * Test first to see if it the slot is free right now.
> *
> * XXX: the caller uses a spinlock before this, so we don't need a memory
> * barrier here as far as the current usage is concerned. But that might
> * not be safe in general.
> */
>
> Should it be something where we'd better be noisy about at the top of
> LWLockWaitForVar()? We don't want to add a memory barrier at the
> beginning of LWLockConflictsWithVar(), still it strikes me that
> somebody that aims at using LWLockWaitForVar() may miss this point
> because LWLockWaitForVar() is the routine published in lwlock.h, not
> LWLockConflictsWithVar(). This does not need to be really
> complicated, say a note at the top of LWLockWaitForVar() among the
> lines of (?):
> "Be careful that LWLockConflictsWithVar() does not include a memory
> barrier, hence the caller of this function may want to rely on an
> explicit barrier or a spinlock to avoid memory ordering issues."
+1. Now, we have comments in 3 places to warn about the
LWLockConflictsWithVar not using memory barrier - one in
WaitXLogInsertionsToFinish, one in LWLockWaitForVar and another one
(existing) in LWLockConflictsWithVar specifying where exactly a memory
barrier is needed if the caller doesn't use a spinlock. Looks fine to
me.
> + * NB: pg_atomic_exchange_u64 is used here as opposed to just
> + * pg_atomic_write_u64 to update the variable. Since pg_atomic_exchange_u64
> + * is a full barrier, we're guaranteed that all loads and stores issued
> + * prior to setting the variable are completed before any loads or stores
> + * issued after setting the variable.
>
> This is the same explanation as LWLockUpdateVar(), except that we
> lose the details explaining why we are doing the update before
> releasing the lock.
I think what I have so far seems more verbose explaining what a
barrier does and all that. I honestly think we don't need to be that
verbose, thanks to README.barrier.
I simplified those 2 comments as the following:
* NB: pg_atomic_exchange_u64, having full barrier semantics will ensure
* the variable is updated before releasing the lock.
* NB: pg_atomic_exchange_u64, having full barrier semantics will ensure
* the variable is updated before waking up waiters.
Please find the attached v7 patch.
--
Bharath Rupireddy
PostgreSQL Contributors Team
RDS Open Source Databases
Amazon Web Services: https://aws.amazon.com
Attachment
On Thu, May 18, 2023 at 11:18:25AM +0530, Bharath Rupireddy wrote: > I think what I have so far seems more verbose explaining what a > barrier does and all that. I honestly think we don't need to be that > verbose, thanks to README.barrier. Agreed. This file is a mine of information. > I simplified those 2 comments as the following: > > * NB: pg_atomic_exchange_u64, having full barrier semantics will ensure > * the variable is updated before releasing the lock. > > * NB: pg_atomic_exchange_u64, having full barrier semantics will ensure > * the variable is updated before waking up waiters. > > Please find the attached v7 patch. Nit. These sentences seem to be worded a bit weirdly to me. How about: "pg_atomic_exchange_u64 has full barrier semantics, ensuring that the variable is updated before (releasing the lock|waking up waiters)." + * Be careful that LWLockConflictsWithVar() does not include a memory barrier, + * hence the caller of this function may want to rely on an explicit barrier or + * a spinlock to avoid memory ordering issues. Thanks, this addition looks OK to me. -- Michael
Attachment
On Fri, May 19, 2023 at 12:24 PM Michael Paquier <michael@paquier.xyz> wrote:
>
> On Thu, May 18, 2023 at 11:18:25AM +0530, Bharath Rupireddy wrote:
> > I think what I have so far seems more verbose explaining what a
> > barrier does and all that. I honestly think we don't need to be that
> > verbose, thanks to README.barrier.
>
> Agreed. This file is a mine of information.
>
> > I simplified those 2 comments as the following:
> >
> > * NB: pg_atomic_exchange_u64, having full barrier semantics will ensure
> > * the variable is updated before releasing the lock.
> >
> > * NB: pg_atomic_exchange_u64, having full barrier semantics will ensure
> > * the variable is updated before waking up waiters.
> >
> > Please find the attached v7 patch.
>
> Nit. These sentences seem to be worded a bit weirdly to me. How
> about:
> "pg_atomic_exchange_u64 has full barrier semantics, ensuring that the
> variable is updated before (releasing the lock|waking up waiters)."
I get it. How about the following similar to what
ProcessProcSignalBarrier() has?
+ * Note that pg_atomic_exchange_u64 is a full barrier, so we're guaranteed
+ * that the variable is updated before waking up waiters.
+ */
+ * Note that pg_atomic_exchange_u64 is a full barrier, so we're guaranteed
+ * that the variable is updated before releasing the lock.
*/
Please find the attached v8 patch with the above change.
--
Bharath Rupireddy
PostgreSQL Contributors Team
RDS Open Source Databases
Amazon Web Services: https://aws.amazon.com
Attachment
On Fri, May 19, 2023 at 08:34:16PM +0530, Bharath Rupireddy wrote: > I get it. How about the following similar to what > ProcessProcSignalBarrier() has? > > + * Note that pg_atomic_exchange_u64 is a full barrier, so we're guaranteed > + * that the variable is updated before waking up waiters. > + */ > > + * Note that pg_atomic_exchange_u64 is a full barrier, so we're guaranteed > + * that the variable is updated before releasing the lock. > */ > > Please find the attached v8 patch with the above change. Simpler and consistent, nice. I don't have much more to add, so I have switched the patch as RfC. -- Michael
Attachment
On Mon, May 22, 2023 at 09:26:25AM +0900, Michael Paquier wrote: > Simpler and consistent, nice. I don't have much more to add, so I > have switched the patch as RfC. While at PGcon, Andres has asked me how many sockets are in the environment I used for the tests, and lscpu tells me the following, which is more than 1: CPU(s): 64 On-line CPU(s) list: 0-63 Core(s) per socket: 16 Socket(s): 2 NUMA node(s): 2 @Andres: Were there any extra tests you wanted to be run for more input? -- Michael
Attachment
On Wed, May 31, 2023 at 5:05 PM Michael Paquier <michael@paquier.xyz> wrote: > > On Mon, May 22, 2023 at 09:26:25AM +0900, Michael Paquier wrote: > > Simpler and consistent, nice. I don't have much more to add, so I > > have switched the patch as RfC. > > While at PGcon, Andres has asked me how many sockets are in the > environment I used for the tests, I'm glad to know that the feature was discussed at PGCon. > and lscpu tells me the following, > which is more than 1: > CPU(s): 64 > On-line CPU(s) list: 0-63 > Core(s) per socket: 16 > Socket(s): 2 > NUMA node(s): 2 Mine says this: CPU(s): 96 On-line CPU(s) list: 0-95 Core(s) per socket: 24 Socket(s): 2 NUMA: NUMA node(s): 2 NUMA node0 CPU(s): 0-23,48-71 NUMA node1 CPU(s): 24-47,72-95 > @Andres: Were there any extra tests you wanted to be run for more > input? @Andres Freund please let us know your thoughts. -- Bharath Rupireddy PostgreSQL Contributors Team RDS Open Source Databases Amazon Web Services: https://aws.amazon.com
On Mon, Jun 05, 2023 at 08:00:00AM +0530, Bharath Rupireddy wrote: > On Wed, May 31, 2023 at 5:05 PM Michael Paquier <michael@paquier.xyz> wrote: >> @Andres: Were there any extra tests you wanted to be run for more >> input? > > @Andres Freund please let us know your thoughts. Err, ping. It seems like this thread is waiting on input from you, Andres? -- Michael
Attachment
On 2023-07-11 09:20:45 +0900, Michael Paquier wrote: > On Mon, Jun 05, 2023 at 08:00:00AM +0530, Bharath Rupireddy wrote: > > On Wed, May 31, 2023 at 5:05 PM Michael Paquier <michael@paquier.xyz> wrote: > >> @Andres: Were there any extra tests you wanted to be run for more > >> input? > > > > @Andres Freund please let us know your thoughts. > > Err, ping. It seems like this thread is waiting on input from you, > Andres? Looking. Sorry for not getting to this earlier. - Andres
Hi,
On 2023-07-13 14:04:31 -0700, Andres Freund wrote:
> From b74b6e953cb5a7e7ea1a89719893f6ce9e231bba Mon Sep 17 00:00:00 2001
> From: Bharath Rupireddy <bharath.rupireddyforpostgres@gmail.com>
> Date: Fri, 19 May 2023 15:00:21 +0000
> Subject: [PATCH v8] Optimize WAL insertion lock acquisition and release
>
> This commit optimizes WAL insertion lock acquisition and release
> in the following way:
I think this commit does too many things at once.
> 1. WAL insertion lock's variable insertingAt is currently read and
> written with the help of lwlock's wait list lock to avoid
> torn-free reads/writes. This wait list lock can become a point of
> contention on a highly concurrent write workloads. Therefore, make
> insertingAt a 64-bit atomic which inherently provides torn-free
> reads/writes.
"inherently" is a bit strong, given that we emulate 64bit atomics where not
available...
> 2. LWLockUpdateVar currently acquires lwlock's wait list lock even when
> there are no waiters at all. Add a fastpath exit to LWLockUpdateVar when
> there are no waiters to avoid unnecessary locking.
I don't think there's enough of an explanation for why this isn't racy.
The reason it's, I think, safe, is that anyone using LWLockConflictsWithVar()
will do so twice in a row, with a barrier inbetween. But that really relies on
what I explain in the paragraph below:
> It also adds notes on why LWLockConflictsWithVar doesn't need a
> memory barrier as far as its current usage is concerned.
I don't think:
* NB: LWLockConflictsWithVar (which is called from
* LWLockWaitForVar) relies on the spinlock used above in this
* function and doesn't use a memory barrier.
helps to understand why any of this is safe to a meaningful degree.
The existing comments aren't obviously aren't sufficient to explain this, but
the reason it's, I think, safe today, is that we are only waiting for
insertions that started before WaitXLogInsertionsToFinish() was called. The
lack of memory barriers in the loop means that we might see locks as "unused"
that have *since* become used, which is fine, because they only can be for
later insertions that we wouldn't want to wait on anyway.
Not taking a lock to acquire the current insertingAt value means that we might
see older insertingAt value. Which should also be fine, because if we read a
too old value, we'll add ourselves to the queue, which contains atomic
operations.
> diff --git a/src/backend/storage/lmgr/lwlock.c b/src/backend/storage/lmgr/lwlock.c
> index 59347ab951..82266e6897 100644
> --- a/src/backend/storage/lmgr/lwlock.c
> +++ b/src/backend/storage/lmgr/lwlock.c
> @@ -1547,9 +1547,8 @@ LWLockAcquireOrWait(LWLock *lock, LWLockMode mode)
> * *result is set to true if the lock was free, and false otherwise.
> */
> static bool
> -LWLockConflictsWithVar(LWLock *lock,
> - uint64 *valptr, uint64 oldval, uint64 *newval,
> - bool *result)
> +LWLockConflictsWithVar(LWLock *lock, pg_atomic_uint64 *valptr, uint64 oldval,
> + uint64 *newval, bool *result)
> {
> bool mustwait;
> uint64 value;
> @@ -1572,13 +1571,11 @@ LWLockConflictsWithVar(LWLock *lock,
> *result = false;
>
> /*
> - * Read value using the lwlock's wait list lock, as we can't generally
> - * rely on atomic 64 bit reads/stores. TODO: On platforms with a way to
> - * do atomic 64 bit reads/writes the spinlock should be optimized away.
> + * Reading the value atomically ensures that we don't need any explicit
> + * locking. Note that in general, 64 bit atomic APIs in postgres inherently
> + * provide explicit locking for the platforms without atomics support.
> */
This comment seems off to me. Using atomics doesn't guarantee not needing
locking. It just guarantees that we are reading a non-torn value.
> @@ -1605,9 +1602,14 @@ LWLockConflictsWithVar(LWLock *lock,
> *
> * Note: this function ignores shared lock holders; if the lock is held
> * in shared mode, returns 'true'.
> + *
> + * Be careful that LWLockConflictsWithVar() does not include a memory barrier,
> + * hence the caller of this function may want to rely on an explicit barrier or
> + * a spinlock to avoid memory ordering issues.
> */
s/careful/aware/?
s/spinlock/implied barrier via spinlock or lwlock/?
Greetings,
Andres
On Fri, Jul 14, 2023 at 4:17 AM Andres Freund <andres@anarazel.de> wrote: > > Hi, > > On 2023-07-13 14:04:31 -0700, Andres Freund wrote: > > From b74b6e953cb5a7e7ea1a89719893f6ce9e231bba Mon Sep 17 00:00:00 2001 > > From: Bharath Rupireddy <bharath.rupireddyforpostgres@gmail.com> > > Date: Fri, 19 May 2023 15:00:21 +0000 > > Subject: [PATCH v8] Optimize WAL insertion lock acquisition and release > > > > This commit optimizes WAL insertion lock acquisition and release > > in the following way: > > I think this commit does too many things at once. I've split the patch into three - 1) Make insertingAt 64-bit atomic. 2) Have better commenting on why there's no memory barrier or spinlock in and around LWLockWaitForVar call sites. 3) Have a quick exit for LWLockUpdateVar. > > 1. WAL insertion lock's variable insertingAt is currently read and > > written with the help of lwlock's wait list lock to avoid > > torn-free reads/writes. This wait list lock can become a point of > > contention on a highly concurrent write workloads. Therefore, make > > insertingAt a 64-bit atomic which inherently provides torn-free > > reads/writes. > > "inherently" is a bit strong, given that we emulate 64bit atomics where not > available... Modified. > > 2. LWLockUpdateVar currently acquires lwlock's wait list lock even when > > there are no waiters at all. Add a fastpath exit to LWLockUpdateVar when > > there are no waiters to avoid unnecessary locking. > > I don't think there's enough of an explanation for why this isn't racy. > > The reason it's, I think, safe, is that anyone using LWLockConflictsWithVar() > will do so twice in a row, with a barrier inbetween. But that really relies on > what I explain in the paragraph below: The twice-in-a-row lock acquisition protocol used by LWLockWaitForVar is helping us out have quick exit in LWLockUpdateVar. Because, LWLockWaitForVar ensures that they are added to the wait queue even if LWLockUpdateVar thinks that there aren't waiters. Is my understanding correct here? > > It also adds notes on why LWLockConflictsWithVar doesn't need a > > memory barrier as far as its current usage is concerned. > > I don't think: > * NB: LWLockConflictsWithVar (which is called from > * LWLockWaitForVar) relies on the spinlock used above in this > * function and doesn't use a memory barrier. > > helps to understand why any of this is safe to a meaningful degree. > > The existing comments aren't obviously aren't sufficient to explain this, but > the reason it's, I think, safe today, is that we are only waiting for > insertions that started before WaitXLogInsertionsToFinish() was called. The > lack of memory barriers in the loop means that we might see locks as "unused" > that have *since* become used, which is fine, because they only can be for > later insertions that we wouldn't want to wait on anyway. Right. > Not taking a lock to acquire the current insertingAt value means that we might > see older insertingAt value. Which should also be fine, because if we read a > too old value, we'll add ourselves to the queue, which contains atomic > operations. Right. An older value adds ourselves to the queue in LWLockWaitForVar, and we should be woken up eventually by LWLockUpdateVar. This matches with my understanding. I used more or less your above wording in 0002 patch. > > /* > > - * Read value using the lwlock's wait list lock, as we can't generally > > - * rely on atomic 64 bit reads/stores. TODO: On platforms with a way to > > - * do atomic 64 bit reads/writes the spinlock should be optimized away. > > + * Reading the value atomically ensures that we don't need any explicit > > + * locking. Note that in general, 64 bit atomic APIs in postgres inherently > > + * provide explicit locking for the platforms without atomics support. > > */ > > This comment seems off to me. Using atomics doesn't guarantee not needing > locking. It just guarantees that we are reading a non-torn value. Modified the comment. > > @@ -1605,9 +1602,14 @@ LWLockConflictsWithVar(LWLock *lock, > > * > > * Note: this function ignores shared lock holders; if the lock is held > > * in shared mode, returns 'true'. > > + * > > + * Be careful that LWLockConflictsWithVar() does not include a memory barrier, > > + * hence the caller of this function may want to rely on an explicit barrier or > > + * a spinlock to avoid memory ordering issues. > > */ > > s/careful/aware/? > > s/spinlock/implied barrier via spinlock or lwlock/? Done. -- Bharath Rupireddy PostgreSQL Contributors Team RDS Open Source Databases Amazon Web Services: https://aws.amazon.com
Attachment
On Thu, Jul 20, 2023 at 02:38:29PM +0530, Bharath Rupireddy wrote: > On Fri, Jul 14, 2023 at 4:17 AM Andres Freund <andres@anarazel.de> wrote: >> I think this commit does too many things at once. > > I've split the patch into three - 1) Make insertingAt 64-bit atomic. > 2) Have better commenting on why there's no memory barrier or spinlock > in and around LWLockWaitForVar call sites. 3) Have a quick exit for > LWLockUpdateVar. FWIW, I was kind of already OK with 0001, as it shows most of the gains observed while 0003 had a limited impact: https://www.postgresql.org/message-id/CALj2ACWgeOPEKVY-TEPvno%3DVatyzrb-vEEP8hN7QqrQ%3DyPRupA%40mail.gmail.com It is kind of a no-brainer to replace the spinlocks with atomic reads and writes there. >> I don't think: >> * NB: LWLockConflictsWithVar (which is called from >> * LWLockWaitForVar) relies on the spinlock used above in this >> * function and doesn't use a memory barrier. >> >> helps to understand why any of this is safe to a meaningful degree. >> >> The existing comments aren't obviously aren't sufficient to explain this, but >> the reason it's, I think, safe today, is that we are only waiting for >> insertions that started before WaitXLogInsertionsToFinish() was called. The >> lack of memory barriers in the loop means that we might see locks as "unused" >> that have *since* become used, which is fine, because they only can be for >> later insertions that we wouldn't want to wait on anyway. > > Right. FWIW, I always have a hard time coming back to this code and see it rely on undocumented assumptions with code in lwlock.c while we need to keep an eye in xlog.c (we take a spinlock there while the variable wait logic relies on it for ordering @-@). So the proposal of getting more documentation in place via 0002 goes in the right direction. >> This comment seems off to me. Using atomics doesn't guarantee not needing >> locking. It just guarantees that we are reading a non-torn value. > > Modified the comment. - /* - * Read value using the lwlock's wait list lock, as we can't generally - * rely on atomic 64 bit reads/stores. TODO: On platforms with a way to - * do atomic 64 bit reads/writes the spinlock should be optimized away. - */ - LWLockWaitListLock(lock); - value = *valptr; - LWLockWaitListUnlock(lock); + /* Reading atomically avoids getting a torn value */ + value = pg_atomic_read_u64(valptr); Should this specify that this is specifically important for platforms where reading a uint64 could lead to a torn value read, if you apply this term in this context? Sounding picky, I would make that a bit longer, say something like that: "Reading this value atomically is safe even on platforms where uint64 cannot be read without observing a torn value." Only xlogprefetcher.c uses the term "torn" for a value by the way, but for a write. >>> @@ -1605,9 +1602,14 @@ LWLockConflictsWithVar(LWLock *lock, >>> * >>> * Note: this function ignores shared lock holders; if the lock is held >>> * in shared mode, returns 'true'. >>> + * >>> + * Be careful that LWLockConflictsWithVar() does not include a memory barrier, >>> + * hence the caller of this function may want to rely on an explicit barrier or >>> + * a spinlock to avoid memory ordering issues. >>> */ >> >> s/careful/aware/? >> >> s/spinlock/implied barrier via spinlock or lwlock/? > > Done. Okay to mention a LWLock here, even if the sole caller of this routine relies on a spinlock. 0001 looks OK-ish seen from here. Thoughts? -- Michael
Attachment
On Fri, Jul 21, 2023 at 11:29 AM Michael Paquier <michael@paquier.xyz> wrote:
>
> + /* Reading atomically avoids getting a torn value */
> + value = pg_atomic_read_u64(valptr);
>
> Should this specify that this is specifically important for platforms
> where reading a uint64 could lead to a torn value read, if you apply
> this term in this context? Sounding picky, I would make that a bit
> longer, say something like that:
> "Reading this value atomically is safe even on platforms where uint64
> cannot be read without observing a torn value."
>
> Only xlogprefetcher.c uses the term "torn" for a value by the way, but
> for a write.
Done.
> 0001 looks OK-ish seen from here. Thoughts?
Yes, it looks safe to me too. FWIW, 0001 essentially implements what
an existing TODO comment introduced by commit 008608b9d5106 says:
/*
* Read value using the lwlock's wait list lock, as we can't generally
* rely on atomic 64 bit reads/stores. TODO: On platforms with a way to
* do atomic 64 bit reads/writes the spinlock should be optimized away.
*/
I'm attaching v10 patch set here - 0001 has modified the comment as
above, no other changes in patch set.
--
Bharath Rupireddy
PostgreSQL Contributors Team
RDS Open Source Databases
Amazon Web Services: https://aws.amazon.com
Attachment
On Sat, Jul 22, 2023 at 01:08:49PM +0530, Bharath Rupireddy wrote: > Yes, it looks safe to me too. 0001 has been now applied. I have done more tests while looking at this patch since yesterday and was surprised to see higher TPS numbers on HEAD with the same tests as previously, and the patch was still shining with more than 256 clients. > FWIW, 0001 essentially implements what > an existing TODO comment introduced by commit 008608b9d5106 says: We really need to do something in terms of documentation with something like 0002, so I'll try to look at that next. Regarding 0003, I don't know. I think that we'd better look more into cases where it shows actual benefits for specific workloads (like workloads with a fixed rate of read and/or write operations?). -- Michael
Attachment
Hi, On 2023-07-25 16:43:16 +0900, Michael Paquier wrote: > On Sat, Jul 22, 2023 at 01:08:49PM +0530, Bharath Rupireddy wrote: > > Yes, it looks safe to me too. > > 0001 has been now applied. I have done more tests while looking at > this patch since yesterday and was surprised to see higher TPS numbers > on HEAD with the same tests as previously, and the patch was still > shining with more than 256 clients. > > > FWIW, 0001 essentially implements what > > an existing TODO comment introduced by commit 008608b9d5106 says: > > We really need to do something in terms of documentation with > something like 0002, so I'll try to look at that next. Regarding > 0003, I don't know. I think that we'd better look more into cases > where it shows actual benefits for specific workloads (like workloads > with a fixed rate of read and/or write operations?). FWIW, I'm working on a patch that replaces WAL insert locks as a whole, because they don't scale all that well. If there's no very clear improvements, I'm not sure it's worth putting too much effort into polishing them all that much. Greetings, Andres Freund
Hi, On 2023-07-25 16:43:16 +0900, Michael Paquier wrote: > On Sat, Jul 22, 2023 at 01:08:49PM +0530, Bharath Rupireddy wrote: > > Yes, it looks safe to me too. > > 0001 has been now applied. I have done more tests while looking at > this patch since yesterday and was surprised to see higher TPS numbers > on HEAD with the same tests as previously, and the patch was still > shining with more than 256 clients. Just a small heads up: I just rebased my aio tree over the commit and promptly, on the first run, saw a hang. I did some debugging on that. Unfortunately repeated runs haven't repeated that hang, despite quite a bit of trying. The symptom I was seeing is that all running backends were stuck in LWLockWaitForVar(), even though the value they're waiting for had changed. Which obviously "shouldn't be possible". It's of course possible that this is AIO specific, but I didn't see anything in stacks to suggest that. I do wonder if this possibly exposed an undocumented prior dependency on the value update always happening under the list lock. Greetings, Andres Freund
On Tue, Jul 25, 2023 at 12:57:37PM -0700, Andres Freund wrote: > I just rebased my aio tree over the commit and promptly, on the first run, saw > a hang. I did some debugging on that. Unfortunately repeated runs haven't > repeated that hang, despite quite a bit of trying. > > The symptom I was seeing is that all running backends were stuck in > LWLockWaitForVar(), even though the value they're waiting for had > changed. Which obviously "shouldn't be possible". Hmm. I've also spent a few days looking at this past report that made the LWLock part what it is today, but I don't quite see immediately how it would be possible to reach a state where all the backends are waiting for an update that's not happening: https://www.postgresql.org/message-id/CAMkU=1zLztROwH3B42OXSB04r9ZMeSk3658qEn4_8+b+K3E7nQ@mail.gmail.com All the assumptions of this code and its dependencies with xloginsert.c are hard to come by. > It's of course possible that this is AIO specific, but I didn't see anything > in stacks to suggest that. Or AIO handles the WAL syncs so quickly that it has more chances in showing a race condition here? > I do wonder if this possibly exposed an undocumented prior dependency on the > value update always happening under the list lock. I would not be surprised by that. -- Michael
Attachment
On Tue, Jul 25, 2023 at 09:49:01AM -0700, Andres Freund wrote: > FWIW, I'm working on a patch that replaces WAL insert locks as a whole, > because they don't scale all that well. What were you looking at here? Just wondering. -- Michael
Attachment
Hi, On 2023-07-26 07:40:31 +0900, Michael Paquier wrote: > On Tue, Jul 25, 2023 at 09:49:01AM -0700, Andres Freund wrote: > > FWIW, I'm working on a patch that replaces WAL insert locks as a whole, > > because they don't scale all that well. > > What were you looking at here? Just wondering. Here's what I had written offlist a few days ago: > The basic idea is to have a ringbuffer of in-progress insertions. The > acquisition of a position in the ringbuffer is done at the same time as > advancing the reserved LSN, using a 64bit xadd. The trick that makes that > possible is to use the high bits of the atomic for the position in the > ringbuffer. The point of using the high bits is that they wrap around, without > affecting the rest of the value. > > Of course, when using xadd, we can't keep the "prev" pointer in the > atomic. That's where the ringbuffer comes into play. Whenever one inserter has > determined the byte pos of its insertion, it updates the "prev byte pos" in > the *next* ringbuffer entry. > > Of course that means that insertion N+1 needs to wait for N to set the prev > position - but that happens very quickly. In my very hacky prototype the > relevant path (which for now just spins) is reached very rarely, even when > massively oversubscribed. While I've not implemented that, N+1 could actually > do the first "iteration" in CopyXLogRecordToWAL() before it needs the prev > position, the COMP_CRC32C() could happen "inside" the buffer. > > > There's a fair bit of trickyness in turning that into something working, of > course :). Ensuring that the ring buffer of insertions doesn't wrap around is > non-trivial. Nor is trivial to ensure that the "reduced" space LSN in the > atomic can't overflow. > > I do wish MAX_BACKENDS were smaller... > > > Until last night I thought all my schemes would continue to need something > like the existing WAL insertion locks, to implement > WALInsertLockAcquireExclusive(). > > But I think I came up with an idea to do away with that (not even prototyped > yet): Use one bit in the atomic that indicates that no new insertions are > allowed. Whenever the xadd finds that old value actually was locked, it > "aborts" the insertion, and instead waits for a condition variable (or > something similar). Of course that's after modifying the atomic - to deal with > that the "lock holder" reverts all modifications that have been made to the > atomic when releasing the "lock", they weren't actually successful and all > those backends will retry. > > Except that this doesn't quite suffice - XLogInsertRecord() needs to be able > to "roll back", when it finds that we now need to log FPIs. I can't quite see > how to make that work with what I describe above. The only idea I have so far > is to just waste the space with a NOOP record - it should be pretty rare. At > least if we updated RedoRecPtr eagerly (or just stopped this stupid business > of having an outdated backend-local copy). > > > > My prototype shows this idea to be promising. It's a tad slower at low > concurrency, but much better at high concurrency. I think most if not all of > the low-end overhead isn't inherent, but comes from having both old and new > infrastructure in place (as well as a lot of debugging cruft). Greetings, Andres Freund
On Tue, Jul 25, 2023 at 04:43:16PM +0900, Michael Paquier wrote: > We really need to do something in terms of documentation with > something like 0002, so I'll try to look at that next. I have applied a slightly-tweaked version of 0002 as of 66d86d4 to improve a bit the documentation of the area, and switched the CF entry as committed. (I got interested in what Andres has seen on his latest AIO branch, so I have a few extra benchmarks running in the background on HEAD, but nothing able to freeze all the backends yet waiting for a variable update. These are still running now.) -- Michael
Attachment
On Wed, Jul 26, 2023 at 1:27 AM Andres Freund <andres@anarazel.de> wrote: > > > 0001 has been now applied. I have done more tests while looking at > > this patch since yesterday and was surprised to see higher TPS numbers > > on HEAD with the same tests as previously, and the patch was still > > shining with more than 256 clients. > > Just a small heads up: > > I just rebased my aio tree over the commit and promptly, on the first run, saw > a hang. I did some debugging on that. Unfortunately repeated runs haven't > repeated that hang, despite quite a bit of trying. Hm. Please share workload details, test scripts, system info and any special settings for running in my setup. > The symptom I was seeing is that all running backends were stuck in > LWLockWaitForVar(), even though the value they're waiting for had > changed. Which obviously "shouldn't be possible". Were the backends stuck there indefinitely? IOW, did they get into a deadlock? > It's of course possible that this is AIO specific, but I didn't see anything > in stacks to suggest that. > > I do wonder if this possibly exposed an undocumented prior dependency on the > value update always happening under the list lock. I'm going through the other thread mentioned by Michael Paquier. I'm wondering if the deadlock issue illustrated here https://www.postgresql.org/message-id/55BB50D3.9000702%40iki.fi is showing up again, because 71e4cc6b8e reduced the contention on waitlist lock and made things *a bit* faster. -- Bharath Rupireddy PostgreSQL Contributors Team RDS Open Source Databases Amazon Web Services: https://aws.amazon.com
On Tue, Jul 25, 2023 at 04:43:16PM +0900, Michael Paquier wrote: > 0001 has been now applied. I have done more tests while looking at > this patch since yesterday and was surprised to see higher TPS numbers > on HEAD with the same tests as previously, and the patch was still > shining with more than 256 clients. I found this code when searching for callers that use atomic exchanges as atomic writes with barriers (for a separate thread [0]). Can't we use pg_atomic_write_u64() here since the locking functions that follow should serve as barriers? I've attached a patch to demonstrate what I'm thinking. This might be more performant, although maybe less so after commit 64b1fb5. Am I missing something obvious here? If not, I might rerun the benchmarks to see whether it makes any difference. [0] https://www.postgresql.org/message-id/flat/20231110205128.GB1315705%40nathanxps13 -- Nathan Bossart Amazon Web Services: https://aws.amazon.com
Attachment
On Mon, Dec 18, 2023 at 10:00:29PM -0600, Nathan Bossart wrote: > I found this code when searching for callers that use atomic exchanges as > atomic writes with barriers (for a separate thread [0]). Can't we use > pg_atomic_write_u64() here since the locking functions that follow should > serve as barriers? The full barrier guaranteed by pg_atomic_exchange_u64() in LWLockUpdateVar() was also necessary for the shortcut based on read_u32() to see if there are no waiters, but it has been discarded in the later versions of the patch because it did not influence performance under heavy WAL inserts. So you mean to rely on the full barriers taken by the fetches in LWLockRelease() and LWLockWaitListLock()? Hmm, I got the impression that pg_atomic_exchange_u64() with its full barrier was necessary in these two paths so as all the loads and stores are completed *before* updating these variables. So I am not sure to get why it would be safe to switch to a write with no barrier. > I've attached a patch to demonstrate what I'm thinking. This might be more > performant, although maybe less so after commit 64b1fb5. Am I missing > something obvious here? If not, I might rerun the benchmarks to see > whether it makes any difference. I was wondering as well if the numbers we got upthread would go up after what you have committed to improve the exchanges. :) Any change in this area should be strictly benchmarked. -- Michael