Thread: [PoC] Non-volatile WAL buffer
Dear hackers,
I propose "non-volatile WAL buffer," a proof-of-concept new feature. It
enables WAL records to be durable without output to WAL segment files by
residing on persistent memory (PMEM) instead of DRAM. It improves database
performance by reducing copies of WAL and shortening the time of write
transactions.
I attach the first patchset that can be applied to PostgreSQL 12.0 (refs/
tags/REL_12_0). Please see README.nvwal (added by the patch 0003) to use
the new feature.
PMEM [1] is fast, non-volatile, and byte-addressable memory installed into
DIMM slots. Such products have been already available. For example, an
NVDIMM-N is a type of PMEM module that contains both DRAM and NAND flash.
It can be accessed like a regular DRAM, but on power loss, it can save its
contents into flash area. On power restore, it performs the reverse, that
is, the contents are copied back into DRAM. PMEM also has been already
supported by major operating systems such as Linux and Windows, and new
open-source libraries such as Persistent Memory Development Kit (PMDK) [2].
Furthermore, several DBMSes have started to support PMEM.
It's time for PostgreSQL. PMEM is faster than a solid state disk and
naively can be used as a block storage. However, we cannot gain much
performance in that way because it is so fast that the overhead of
traditional software stacks now becomes unignorable, such as user buffers,
filesystems, and block layers. Non-volatile WAL buffer is a work to make
PostgreSQL PMEM-aware, that is, accessing directly to PMEM as a RAM to
bypass such overhead and achieve the maximum possible benefit. I believe
WAL is one of the most important modules to be redesigned for PMEM because
it has assumed slow disks such as HDDs and SSDs but PMEM is not so.
This work is inspired by "Non-volatile Memory Logging" talked in PGCon
2016 [3] to gain more benefit from PMEM than my and Yoshimi's previous
work did [4][5]. I submitted a talk proposal for PGCon in this year, and
have measured and analyzed performance of my PostgreSQL with non-volatile
WAL buffer, comparing with the original one that uses PMEM as "a faster-
than-SSD storage." I will talk about the results if accepted.
Best regards,
Takashi Menjo
[1] Persistent Memory (SNIA)
https://www.snia.org/PM
[2] Persistent Memory Development Kit (pmem.io)
https://pmem.io/pmdk/
[3] Non-volatile Memory Logging (PGCon 2016)
https://www.pgcon.org/2016/schedule/track/Performance/945.en.html
[4] Introducing PMDK into PostgreSQL (PGCon 2018)
https://www.pgcon.org/2018/schedule/events/1154.en.html
[5] Applying PMDK to WAL operations for persistent memory (pgsql-hackers)
https://www.postgresql.org/message-id/C20D38E97BCB33DAD59E3A1@lab.ntt.co.jp
--
Takashi Menjo <takashi.menjou.vg@hco.ntt.co.jp>
NTT Software Innovation Center
Attachment
Hello, +1 on the idea. By quickly looking at the patch, I notice that there are no tests. Is it possible to emulate somthing without the actual hardware, at least for testing purposes? -- Fabien.
On 24/01/2020 10:06, Takashi Menjo wrote: > I propose "non-volatile WAL buffer," a proof-of-concept new feature. It > enables WAL records to be durable without output to WAL segment files by > residing on persistent memory (PMEM) instead of DRAM. It improves database > performance by reducing copies of WAL and shortening the time of write > transactions. > > I attach the first patchset that can be applied to PostgreSQL 12.0 (refs/ > tags/REL_12_0). Please see README.nvwal (added by the patch 0003) to use > the new feature. I have the same comments on this that I had on the previous patch, see: https://www.postgresql.org/message-id/2aec6e2a-6a32-0c39-e4e2-aad854543aa8%40iki.fi - Heikki
Hello Fabien, Thank you for your +1 :) > Is it possible to emulate somthing without the actual hardware, at least > for testing purposes? Yes, you can emulate PMEM using DRAM on Linux, via "memmap=nnG!ssG" kernel parameter. Please see [1] and [2] for emulation details. If your emulation does not work well, please check if the kernel configuration options (like CONFIG_ FOOBAR) for PMEM and DAX (in [1] and [3]) are set up properly. Best regards, Takashi [1] How to Emulate Persistent Memory Using Dynamic Random-access Memory (DRAM) https://software.intel.com/en-us/articles/how-to-emulate-persistent-memory-on-an-intel-architecture-server [2] how_to_choose_the_correct_memmap_kernel_parameter_for_pmem_on_your_system https://nvdimm.wiki.kernel.org/how_to_choose_the_correct_memmap_kernel_parameter_for_pmem_on_your_system [3] Persistent Memory Wiki https://nvdimm.wiki.kernel.org/ -- Takashi Menjo <takashi.menjou.vg@hco.ntt.co.jp> NTT Software Innovation Center
Hello Heikki, > I have the same comments on this that I had on the previous patch, see: > > https://www.postgresql.org/message-id/2aec6e2a-6a32-0c39-e4e2-aad854543aa8%40iki.fi Thanks. I re-read your messages [1][2]. What you meant, AFAIU, is how about using memory-mapped WAL segment files as WAL buffers, and switching CPU instructions or msync() depending on whether the segment files are on PMEM or not, to sync inserted WAL records. It sounds reasonable, but I'm sorry that I haven't tested such a program yet. I'll try it to compare with my non-volatile WAL buffer. For now, I'm a little worried about the overhead of mmap()/munmap() for each WAL segment file. You also told a SIGBUS problem of memory-mapped I/O. I think it's true for reading from bad memory blocks, as you mentioned, and also true for writing to such blocks [3]. Handling SIGBUS properly or working around it is future work. Best regards, Takashi [1] https://www.postgresql.org/message-id/83eafbfd-d9c5-6623-2423-7cab1be3888c%40iki.fi [2] https://www.postgresql.org/message-id/2aec6e2a-6a32-0c39-e4e2-aad854543aa8%40iki.fi [3] https://pmem.io/2018/11/26/bad-blocks.htm -- Takashi Menjo <takashi.menjou.vg@hco.ntt.co.jp> NTT Software Innovation Center
On Mon, Jan 27, 2020 at 2:01 AM Takashi Menjo <takashi.menjou.vg@hco.ntt.co.jp> wrote: > It sounds reasonable, but I'm sorry that I haven't tested such a program > yet. I'll try it to compare with my non-volatile WAL buffer. For now, I'm > a little worried about the overhead of mmap()/munmap() for each WAL segment > file. I guess the question here is how the cost of one mmap() and munmap() pair per WAL segment (normally 16MB) compares to the cost of one write() per block (normally 8kB). It could be that mmap() is a more expensive call than read(), but by a small enough margin that the vastly reduced number of system calls makes it a winner. But that's just speculation, because I don't know how heavy mmap() actually is. I have a different concern. I think that, right now, when we reuse a WAL segment, we write entire blocks at a time, so the old contents of the WAL segment are overwritten without ever being read. But that behavior might not be maintained when using mmap(). It might be that as soon as we write the first byte to a mapped page, the old contents have to be faulted into memory. Indeed, it's unclear how it could be otherwise, since the VM page must be made read-write at that point and the system cannot know that we will overwrite the whole page. But reading in the old contents of a recycled WAL file just to overwrite them seems like it would be disastrously expensive. A related, but more minor, concern is whether there are any differences in in the write-back behavior when modifying a mapped region vs. using write(). Either way, the same pages of the same file will get dirtied, but the kernel might not have the same idea in either case about when the changed pages should be written back down to disk, and that could make a big difference to performance. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
Hello Robert, I think our concerns are roughly classified into two: (1) Performance (2) Consistency And your "different concern" is rather into (2), I think. I'm also worried about it, but I have no good answer for now. I suppose mmap(flags|=MAP_SHARED) called by multiple backendprocesses for the same file works consistently for both PMEM and non-PMEM devices. However, I have not found anyevidence such as specification documents yet. I also made a tiny program calling memcpy() and msync() on the same mmap()-ed file but mutually distinct address range inparallel, and found that there was no corrupted data. However, that result does not ensure any consistency I'm worriedabout. I could give it up if there *were* corrupted data... So I will go to (1) first. I will test the way Heikki told us to answer whether the cost of mmap() and munmap() per WALsegment, etc, is reasonable or not. If it really is, then I will go to (2). Best regards, Takashi -- Takashi Menjo <takashi.menjou.vg@hco.ntt.co.jp> NTT Software Innovation Center
On Tue, Jan 28, 2020 at 3:28 AM Takashi Menjo <takashi.menjou.vg@hco.ntt.co.jp> wrote: > I think our concerns are roughly classified into two: > > (1) Performance > (2) Consistency > > And your "different concern" is rather into (2), I think. Actually, I think it was mostly a performance concern (writes triggering lots of reading) but there might be a consistency issue as well. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
Hi, On 2020-01-27 13:54:38 -0500, Robert Haas wrote: > On Mon, Jan 27, 2020 at 2:01 AM Takashi Menjo > <takashi.menjou.vg@hco.ntt.co.jp> wrote: > > It sounds reasonable, but I'm sorry that I haven't tested such a program > > yet. I'll try it to compare with my non-volatile WAL buffer. For now, I'm > > a little worried about the overhead of mmap()/munmap() for each WAL segment > > file. > > I guess the question here is how the cost of one mmap() and munmap() > pair per WAL segment (normally 16MB) compares to the cost of one > write() per block (normally 8kB). It could be that mmap() is a more > expensive call than read(), but by a small enough margin that the > vastly reduced number of system calls makes it a winner. But that's > just speculation, because I don't know how heavy mmap() actually is. mmap()/munmap() on a regular basis does have pretty bad scalability impacts. I don't think they'd fully hit us, because we're not in a threaded world however. My issue with the proposal to go towards mmap()/munmap() is that I think doing so forcloses a lot of improvements. Even today, on fast storage, using the open_datasync is faster (at least when somehow hitting the O_DIRECT path, which isn't that easy these days) - and that's despite it being really unoptimized. I think our WAL scalability is a serious issue. There's a fair bit that we can improve by just fix without really changing the way we do IO: - Split WALWriteLock into one lock for writing and one for flushing the WAL. Right now we prevent other sessions from writing out WAL - even to other segments - when one session is doing a WAL flush. But there's absolutely no need for that. - Stop increasing the size of the flush request to the max when flushing WAL (cf "try to write/flush later additions to XLOG as well" in XLogFlush()) - that currently reduces throughput in OLTP workloads quite noticably. It made some sense in the spinning disk times, but I don't think it does for a halfway decent SSD. By writing the maximum ready to write, we hold the lock for longer, increasing latency for the committing transaction *and* preventing more WAL from being written. - We should immediately ask the OS to flush writes for full XLOG pages back to the OS. Right now the IO for that will never be started before the commit comes around in an OLTP workload, which means that we just waste the time between the XLogWrite() and the commit. That'll gain us 2-3x, I think. But after that I think we're going to have to actually change more fundamentally how we do IO for WAL writes. Using async IO I can do like 18k individual durable 8kb writes (using O_DSYNC) a second, at a queue depth of 32. On my laptop. If I make it 4k writes, it's 22k. That's not directly comparable with postgres WAL flushes, of course, as it's all separate blocks, whereas WAL will often end up overwriting the last block. But it doesn't at all account for group commits either, which we *constantly* end up doing. Postgres manages somewhere between ~450 (multiple users) ~800 (single user) individually durable WAL writes / sec on the same hardware. Yes, that's more than an order of magnitude less. Of course some of that is just that postgres does more than just IO - but that's not effect on the order of a magnitude. So, why am I bringing this up in this thread? Only because I do not see a way to actually utilize non-pmem hardware to a much higher degree than we are doing now by using mmap(). Doing so requires using direct IO, which is fundamentally incompatible with using mmap(). > I have a different concern. I think that, right now, when we reuse a > WAL segment, we write entire blocks at a time, so the old contents of > the WAL segment are overwritten without ever being read. But that > behavior might not be maintained when using mmap(). It might be that > as soon as we write the first byte to a mapped page, the old contents > have to be faulted into memory. Indeed, it's unclear how it could be > otherwise, since the VM page must be made read-write at that point and > the system cannot know that we will overwrite the whole page. But > reading in the old contents of a recycled WAL file just to overwrite > them seems like it would be disastrously expensive. Yea, that's a serious concern. > A related, but more minor, concern is whether there are any > differences in in the write-back behavior when modifying a mapped > region vs. using write(). Either way, the same pages of the same file > will get dirtied, but the kernel might not have the same idea in > either case about when the changed pages should be written back down > to disk, and that could make a big difference to performance. I don't think there's a significant difference in case of linux - no idea about others. And either way we probably should force the kernels hand to start flushing much sooner. Greetings, Andres Freund
Dear hackers, I made another WIP patchset to mmap WAL segments as WAL buffers. Note that this is not a non-volatile WAL buffer patchsetbut its competitor. I am measuring and analyzing the performance of this patchset to compare with my N.V.WAL buffer. Please wait for a several more days for the result report... Best regards, Takashi -- Takashi Menjo <takashi.menjou.vg@hco.ntt.co.jp> NTT Software Innovation Center > -----Original Message----- > From: Robert Haas <robertmhaas@gmail.com> > Sent: Wednesday, January 29, 2020 6:00 AM > To: Takashi Menjo <takashi.menjou.vg@hco.ntt.co.jp> > Cc: Heikki Linnakangas <hlinnaka@iki.fi>; pgsql-hackers@postgresql.org > Subject: Re: [PoC] Non-volatile WAL buffer > > On Tue, Jan 28, 2020 at 3:28 AM Takashi Menjo <takashi.menjou.vg@hco.ntt.co.jp> wrote: > > I think our concerns are roughly classified into two: > > > > (1) Performance > > (2) Consistency > > > > And your "different concern" is rather into (2), I think. > > Actually, I think it was mostly a performance concern (writes triggering lots of reading) but there might be a > consistency issue as well. > > -- > Robert Haas > EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
Attachment
Dear hackers, I applied my patchset that mmap()-s WAL segments as WAL buffers to refs/tags/REL_12_0, and measured and analyzed its performancewith pgbench. Roughly speaking, When I used *SSD and ext4* to store WAL, it was "obviously worse" than the originalREL_12_0. VTune told me that the CPU time of memcpy() called by CopyXLogRecordToWAL() got larger than before. WhenI used *NVDIMM-N and ext4 with filesystem DAX* to store WAL, however, it achieved "not bad" performance compared withour previous patchset and non-volatile WAL buffer. Each CPU time of XLogInsert() and XLogFlush() was reduced like asnon-volatile WAL buffer. So I think mmap()-ing WAL segments as WAL buffers is not such a bad idea as long as we use PMEM, at least NVDIMM-N. Excuse me but for now I'd keep myself not talking about how much the performance was, because the mmap()-ing patchset isWIP so there might be bugs which wrongfully "improve" or "degrade" performance. Also we need to know persistent memoryprogramming and related features such as filesystem DAX, huge page faults, and WAL persistence with cache flush andmemory barrier instructions to explain why the performance improved. I'd talk about all the details at the appropriatetime and place. (The conference, or here later...) Best regards, Takashi -- Takashi Menjo <takashi.menjou.vg@hco.ntt.co.jp> NTT Software Innovation Center > -----Original Message----- > From: Takashi Menjo <takashi.menjou.vg@hco.ntt.co.jp> > Sent: Monday, February 10, 2020 6:30 PM > To: 'Robert Haas' <robertmhaas@gmail.com>; 'Heikki Linnakangas' <hlinnaka@iki.fi> > Cc: 'pgsql-hackers@postgresql.org' <pgsql-hackers@postgresql.org> > Subject: RE: [PoC] Non-volatile WAL buffer > > Dear hackers, > > I made another WIP patchset to mmap WAL segments as WAL buffers. Note that this is not a non-volatile WAL > buffer patchset but its competitor. I am measuring and analyzing the performance of this patchset to compare > with my N.V.WAL buffer. > > Please wait for a several more days for the result report... > > Best regards, > Takashi > > -- > Takashi Menjo <takashi.menjou.vg@hco.ntt.co.jp> NTT Software Innovation Center > > > -----Original Message----- > > From: Robert Haas <robertmhaas@gmail.com> > > Sent: Wednesday, January 29, 2020 6:00 AM > > To: Takashi Menjo <takashi.menjou.vg@hco.ntt.co.jp> > > Cc: Heikki Linnakangas <hlinnaka@iki.fi>; pgsql-hackers@postgresql.org > > Subject: Re: [PoC] Non-volatile WAL buffer > > > > On Tue, Jan 28, 2020 at 3:28 AM Takashi Menjo <takashi.menjou.vg@hco.ntt.co.jp> wrote: > > > I think our concerns are roughly classified into two: > > > > > > (1) Performance > > > (2) Consistency > > > > > > And your "different concern" is rather into (2), I think. > > > > Actually, I think it was mostly a performance concern (writes > > triggering lots of reading) but there might be a consistency issue as well. > > > > -- > > Robert Haas > > EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL > > Company
Menjo-san, On Mon, Feb 17, 2020 at 1:13 PM Takashi Menjo <takashi.menjou.vg@hco.ntt.co.jp> wrote: > I applied my patchset that mmap()-s WAL segments as WAL buffers to refs/tags/REL_12_0, and measured and analyzed its performancewith pgbench. Roughly speaking, When I used *SSD and ext4* to store WAL, it was "obviously worse" than the originalREL_12_0. I apologize for not having any opinion on the patches themselves, but let me point out that it's better to base these patches on HEAD (master branch) than REL_12_0, because all new code is committed to the master branch, whereas stable branches such as REL_12_0 only receive bug fixes. Do you have any specific reason to be working on REL_12_0? Thanks, Amit
Hello Amit, > I apologize for not having any opinion on the patches themselves, but let me point out that it's better to base these > patches on HEAD (master branch) than REL_12_0, because all new code is committed to the master branch, > whereas stable branches such as REL_12_0 only receive bug fixes. Do you have any specific reason to be working > on REL_12_0? Yes, because I think it's human-friendly to reproduce and discuss performance measurement. Of course I know all new acceptedpatches are merged into master's HEAD, not stable branches and not even release tags, so I'm aware of rebasing mypatchset onto master sooner or later. However, if someone, including me, says that s/he applies my patchset to "master"and measures its performance, we have to pay attention to which commit the "master" really points to. Although wehave sha1 hashes to specify which commit, we should check whether the specific commit on master has patches affecting performanceor not because master's HEAD gets new patches day by day. On the other hand, a release tag clearly points thecommit all we probably know. Also we can check more easily the features and improvements by using release notes and usermanuals. Best regards, Takashi -- Takashi Menjo <takashi.menjou.vg@hco.ntt.co.jp> NTT Software Innovation Center > -----Original Message----- > From: Amit Langote <amitlangote09@gmail.com> > Sent: Monday, February 17, 2020 1:39 PM > To: Takashi Menjo <takashi.menjou.vg@hco.ntt.co.jp> > Cc: Robert Haas <robertmhaas@gmail.com>; Heikki Linnakangas <hlinnaka@iki.fi>; PostgreSQL-development > <pgsql-hackers@postgresql.org> > Subject: Re: [PoC] Non-volatile WAL buffer > > Menjo-san, > > On Mon, Feb 17, 2020 at 1:13 PM Takashi Menjo <takashi.menjou.vg@hco.ntt.co.jp> wrote: > > I applied my patchset that mmap()-s WAL segments as WAL buffers to refs/tags/REL_12_0, and measured and > analyzed its performance with pgbench. Roughly speaking, When I used *SSD and ext4* to store WAL, it was > "obviously worse" than the original REL_12_0. > > I apologize for not having any opinion on the patches themselves, but let me point out that it's better to base these > patches on HEAD (master branch) than REL_12_0, because all new code is committed to the master branch, > whereas stable branches such as REL_12_0 only receive bug fixes. Do you have any specific reason to be working > on REL_12_0? > > Thanks, > Amit
Hello, On Mon, Feb 17, 2020 at 4:16 PM Takashi Menjo <takashi.menjou.vg@hco.ntt.co.jp> wrote: > Hello Amit, > > > I apologize for not having any opinion on the patches themselves, but let me point out that it's better to base these > > patches on HEAD (master branch) than REL_12_0, because all new code is committed to the master branch, > > whereas stable branches such as REL_12_0 only receive bug fixes. Do you have any specific reason to be working > > on REL_12_0? > > Yes, because I think it's human-friendly to reproduce and discuss performance measurement. Of course I know all new acceptedpatches are merged into master's HEAD, not stable branches and not even release tags, so I'm aware of rebasing mypatchset onto master sooner or later. However, if someone, including me, says that s/he applies my patchset to "master"and measures its performance, we have to pay attention to which commit the "master" really points to. Although wehave sha1 hashes to specify which commit, we should check whether the specific commit on master has patches affecting performanceor not because master's HEAD gets new patches day by day. On the other hand, a release tag clearly points thecommit all we probably know. Also we can check more easily the features and improvements by using release notes and usermanuals. Thanks for clarifying. I see where you're coming from. While I do sometimes see people reporting numbers with the latest stable release' branch, that's normally just one of the baselines. The more important baseline for ongoing development is the master branch's HEAD, which is also what people volunteering to test your patches would use. Anyone who reports would have to give at least two numbers -- performance with a branch's HEAD without patch applied and that with patch applied -- which can be enough in most cases to see the difference the patch makes. Sure, the numbers might change on each report, but that's fine I'd think. If you continue to develop against the stable branch, you might miss to notice impact from any relevant developments in the master branch, even developments which possibly require rethinking the architecture of your own changes, although maybe that rarely occurs. Thanks, Amit
Hi, On 2020-02-17 13:12:37 +0900, Takashi Menjo wrote: > I applied my patchset that mmap()-s WAL segments as WAL buffers to > refs/tags/REL_12_0, and measured and analyzed its performance with > pgbench. Roughly speaking, When I used *SSD and ext4* to store WAL, > it was "obviously worse" than the original REL_12_0. VTune told me > that the CPU time of memcpy() called by CopyXLogRecordToWAL() got > larger than before. FWIW, this might largely be because of page faults. In contrast to before we wouldn't reuse the same pages (because they've been munmap()/mmap()ed), so the first time they're touched, we'll incur page faults. Did you try mmap()ing with MAP_POPULATE? It's probably also worthwhile to try to use MAP_HUGETLB. Still doubtful it's the right direction, but I'd rather have good numbers to back me up :) Greetings, Andres Freund
Dear Amit, Thank you for your advice. Exactly, it's so to speak "do as the hackers do when in pgsql"... I'm rebasing my branch onto master. I'll submit an updated patchset and performance report later. Best regards, Takashi -- Takashi Menjo <takashi.menjou.vg@hco.ntt.co.jp> NTT Software Innovation Center > -----Original Message----- > From: Amit Langote <amitlangote09@gmail.com> > Sent: Monday, February 17, 2020 5:21 PM > To: Takashi Menjo <takashi.menjou.vg@hco.ntt.co.jp> > Cc: Robert Haas <robertmhaas@gmail.com>; Heikki Linnakangas <hlinnaka@iki.fi>; PostgreSQL-development > <pgsql-hackers@postgresql.org> > Subject: Re: [PoC] Non-volatile WAL buffer > > Hello, > > On Mon, Feb 17, 2020 at 4:16 PM Takashi Menjo <takashi.menjou.vg@hco.ntt.co.jp> wrote: > > Hello Amit, > > > > > I apologize for not having any opinion on the patches themselves, > > > but let me point out that it's better to base these patches on HEAD > > > (master branch) than REL_12_0, because all new code is committed to > > > the master branch, whereas stable branches such as REL_12_0 only receive bug fixes. Do you have any > specific reason to be working on REL_12_0? > > > > Yes, because I think it's human-friendly to reproduce and discuss performance measurement. Of course I know > all new accepted patches are merged into master's HEAD, not stable branches and not even release tags, so I'm > aware of rebasing my patchset onto master sooner or later. However, if someone, including me, says that s/he > applies my patchset to "master" and measures its performance, we have to pay attention to which commit the > "master" really points to. Although we have sha1 hashes to specify which commit, we should check whether the > specific commit on master has patches affecting performance or not because master's HEAD gets new patches day > by day. On the other hand, a release tag clearly points the commit all we probably know. Also we can check more > easily the features and improvements by using release notes and user manuals. > > Thanks for clarifying. I see where you're coming from. > > While I do sometimes see people reporting numbers with the latest stable release' branch, that's normally just one > of the baselines. > The more important baseline for ongoing development is the master branch's HEAD, which is also what people > volunteering to test your patches would use. Anyone who reports would have to give at least two numbers -- > performance with a branch's HEAD without patch applied and that with patch applied -- which can be enough in > most cases to see the difference the patch makes. Sure, the numbers might change on each report, but that's fine > I'd think. If you continue to develop against the stable branch, you might miss to notice impact from any relevant > developments in the master branch, even developments which possibly require rethinking the architecture of your > own changes, although maybe that rarely occurs. > > Thanks, > Amit
Dear hackers,
I rebased my non-volatile WAL buffer's patchset onto master. A new v2 patchset is attached to this mail.
I also measured performance before and after patchset, varying -c/--client and -j/--jobs options of pgbench, for each
scalingfactor s = 50 or 1000. The results are presented in the following tables and the attached charts. Conditions,
steps,and other details will be shown later.
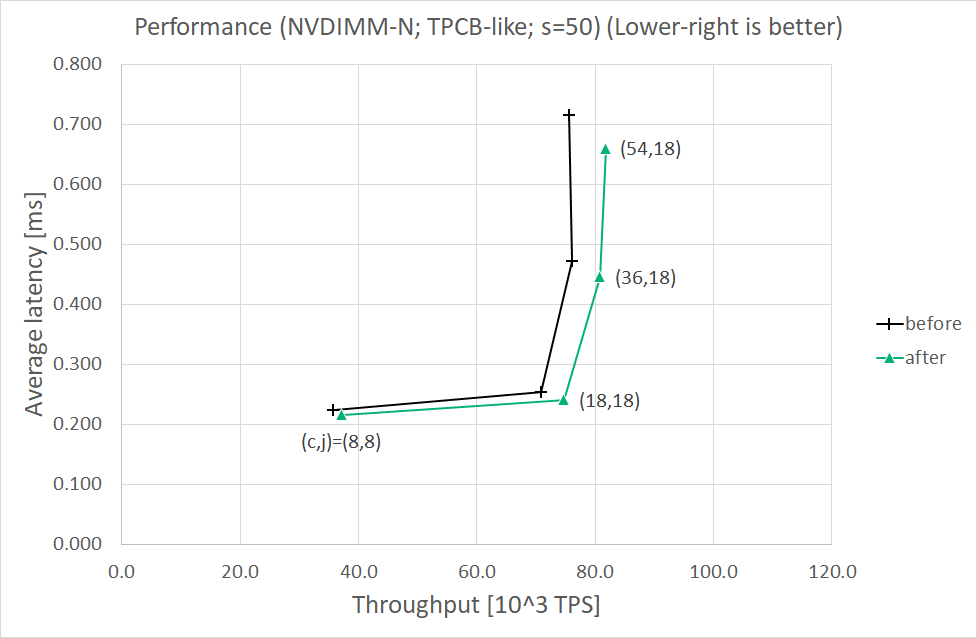
Results (s=50)
==============
Throughput [10^3 TPS] Average latency [ms]
( c, j) before after before after
------- --------------------- ---------------------
( 8, 8) 35.7 37.1 (+3.9%) 0.224 0.216 (-3.6%)
(18,18) 70.9 74.7 (+5.3%) 0.254 0.241 (-5.1%)
(36,18) 76.0 80.8 (+6.3%) 0.473 0.446 (-5.7%)
(54,18) 75.5 81.8 (+8.3%) 0.715 0.660 (-7.7%)
Results (s=1000)
================
Throughput [10^3 TPS] Average latency [ms]
( c, j) before after before after
------- --------------------- ---------------------
( 8, 8) 37.4 40.1 (+7.3%) 0.214 0.199 (-7.0%)
(18,18) 79.3 86.7 (+9.3%) 0.227 0.208 (-8.4%)
(36,18) 87.2 95.5 (+9.5%) 0.413 0.377 (-8.7%)
(54,18) 86.8 94.8 (+9.3%) 0.622 0.569 (-8.5%)
Both throughput and average latency are improved for each scaling factor. Throughput seemed to almost reach the upper
limitwhen (c,j)=(36,18).
The percentage in s=1000 case looks larger than in s=50 case. I think larger scaling factor leads to less contentions
onthe same tables and/or indexes, that is, less lock and unlock operations. In such a situation, write-ahead logging
appearsto be more significant for performance.
Conditions
==========
- Use one physical server having 2 NUMA nodes (node 0 and 1)
- Pin postgres (server processes) to node 0 and pgbench to node 1
- 18 cores and 192GiB DRAM per node
- Use an NVMe SSD for PGDATA and an interleaved 6-in-1 NVDIMM-N set for pg_wal
- Both are installed on the server-side node, that is, node 0
- Both are formatted with ext4
- NVDIMM-N is mounted with "-o dax" option to enable Direct Access (DAX)
- Use the attached postgresql.conf
- Two new items nvwal_path and nvwal_size are used only after patch
Steps
=====
For each (c,j) pair, I did the following steps three times then I found the median of the three as a final result shown
inthe tables above.
(1) Run initdb with proper -D and -X options; and also give --nvwal-path and --nvwal-size options after patch
(2) Start postgres and create a database for pgbench tables
(3) Run "pgbench -i -s ___" to create tables (s = 50 or 1000)
(4) Stop postgres, remount filesystems, and start postgres again
(5) Execute pg_prewarm extension for all the four pgbench tables
(6) Run pgbench during 30 minutes
pgbench command line
====================
$ pgbench -h /tmp -p 5432 -U username -r -M prepared -T 1800 -c ___ -j ___ dbname
I gave no -b option to use the built-in "TPC-B (sort-of)" query.
Software
========
- Distro: Ubuntu 18.04
- Kernel: Linux 5.4 (vanilla kernel)
- C Compiler: gcc 7.4.0
- PMDK: 1.7
- PostgreSQL: d677550 (master on Mar 3, 2020)
Hardware
========
- System: HPE ProLiant DL380 Gen10
- CPU: Intel Xeon Gold 6154 (Skylake) x 2sockets
- DRAM: DDR4 2666MHz {32GiB/ch x 6ch}/socket x 2sockets
- NVDIMM-N: DDR4 2666MHz {16GiB/ch x 6ch}/socket x 2sockets
- NVMe SSD: Intel Optane DC P4800X Series SSDPED1K750GA
Best regards,
Takashi
--
Takashi Menjo <takashi.menjou.vg@hco.ntt.co.jp>
NTT Software Innovation Center
> -----Original Message-----
> From: Takashi Menjo <takashi.menjou.vg@hco.ntt.co.jp>
> Sent: Thursday, February 20, 2020 6:30 PM
> To: 'Amit Langote' <amitlangote09@gmail.com>
> Cc: 'Robert Haas' <robertmhaas@gmail.com>; 'Heikki Linnakangas' <hlinnaka@iki.fi>; 'PostgreSQL-development'
> <pgsql-hackers@postgresql.org>
> Subject: RE: [PoC] Non-volatile WAL buffer
>
> Dear Amit,
>
> Thank you for your advice. Exactly, it's so to speak "do as the hackers do when in pgsql"...
>
> I'm rebasing my branch onto master. I'll submit an updated patchset and performance report later.
>
> Best regards,
> Takashi
>
> --
> Takashi Menjo <takashi.menjou.vg@hco.ntt.co.jp> NTT Software Innovation Center
>
> > -----Original Message-----
> > From: Amit Langote <amitlangote09@gmail.com>
> > Sent: Monday, February 17, 2020 5:21 PM
> > To: Takashi Menjo <takashi.menjou.vg@hco.ntt.co.jp>
> > Cc: Robert Haas <robertmhaas@gmail.com>; Heikki Linnakangas
> > <hlinnaka@iki.fi>; PostgreSQL-development
> > <pgsql-hackers@postgresql.org>
> > Subject: Re: [PoC] Non-volatile WAL buffer
> >
> > Hello,
> >
> > On Mon, Feb 17, 2020 at 4:16 PM Takashi Menjo <takashi.menjou.vg@hco.ntt.co.jp> wrote:
> > > Hello Amit,
> > >
> > > > I apologize for not having any opinion on the patches themselves,
> > > > but let me point out that it's better to base these patches on
> > > > HEAD (master branch) than REL_12_0, because all new code is
> > > > committed to the master branch, whereas stable branches such as
> > > > REL_12_0 only receive bug fixes. Do you have any
> > specific reason to be working on REL_12_0?
> > >
> > > Yes, because I think it's human-friendly to reproduce and discuss
> > > performance measurement. Of course I know
> > all new accepted patches are merged into master's HEAD, not stable
> > branches and not even release tags, so I'm aware of rebasing my
> > patchset onto master sooner or later. However, if someone, including
> > me, says that s/he applies my patchset to "master" and measures its
> > performance, we have to pay attention to which commit the "master"
> > really points to. Although we have sha1 hashes to specify which
> > commit, we should check whether the specific commit on master has patches affecting performance or not
> because master's HEAD gets new patches day by day. On the other hand, a release tag clearly points the commit
> all we probably know. Also we can check more easily the features and improvements by using release notes and
> user manuals.
> >
> > Thanks for clarifying. I see where you're coming from.
> >
> > While I do sometimes see people reporting numbers with the latest
> > stable release' branch, that's normally just one of the baselines.
> > The more important baseline for ongoing development is the master
> > branch's HEAD, which is also what people volunteering to test your
> > patches would use. Anyone who reports would have to give at least two
> > numbers -- performance with a branch's HEAD without patch applied and
> > that with patch applied -- which can be enough in most cases to see
> > the difference the patch makes. Sure, the numbers might change on
> > each report, but that's fine I'd think. If you continue to develop against the stable branch, you might miss to
> notice impact from any relevant developments in the master branch, even developments which possibly require
> rethinking the architecture of your own changes, although maybe that rarely occurs.
> >
> > Thanks,
> > Amit
Attachment
{kind=link}
{kind=link}
Dear Andres,
Thank you for your advice about MAP_POPULATE flag. I rebased my msync patchset onto master and added a commit to
appendthat flag
when mmap. A new v2 patchset is attached to this mail. Note that this patchset is NOT non-volatile WAL buffer's one.
I also measured performance of the following three versions, varying -c/--client and -j/--jobs options of pgbench, for
eachscaling
factor s = 50 or 1000.
- Before patchset (say "before")
- After patchset except patch 0005 not to use MAP_POPULATE ("after (no populate)")
- After full patchset to use MAP_POPULATE ("after (populate)")
The results are presented in the following tables and the attached charts. Conditions, steps, and other details will
beshown
later. Note that, unlike the measurement of non-volatile WAL buffer I sent recently [1], I used an NVMe SSD for pg_wal
toevaluate
this patchset with traditional mmap-ed files, that is, direct access (DAX) is not supported and there are page caches.
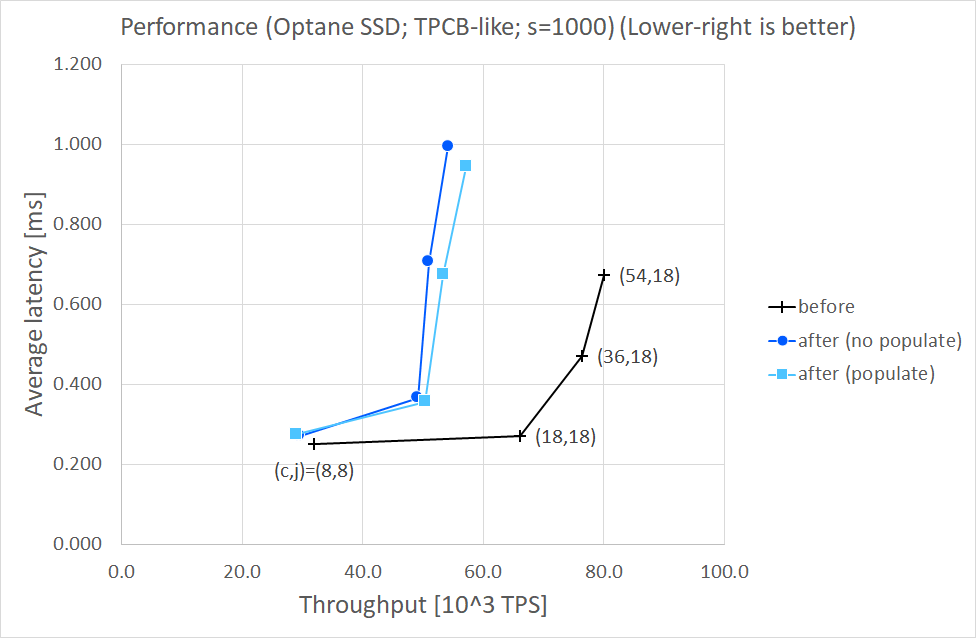
Results (s=50)
==============
Throughput [10^3 TPS]
( c, j) before after after
(no populate) (populate)
------- -------------------------------------
( 8, 8) 30.9 28.1 (- 9.2%) 28.3 (- 8.6%)
(18,18) 61.5 46.1 (-25.0%) 47.7 (-22.3%)
(36,18) 67.0 45.9 (-31.5%) 48.4 (-27.8%)
(54,18) 68.3 47.0 (-31.3%) 49.6 (-27.5%)
Average Latency [ms]
( c, j) before after after
(no populate) (populate)
------- --------------------------------------
( 8, 8) 0.259 0.285 (+10.0%) 0.283 (+ 9.3%)
(18,18) 0.293 0.391 (+33.4%) 0.377 (+28.7%)
(36,18) 0.537 0.784 (+46.0%) 0.744 (+38.5%)
(54,18) 0.790 1.149 (+45.4%) 1.090 (+38.0%)
Results (s=1000)
================
Throghput [10^3 TPS]
( c, j) before after after
(no populate) (populate)
------- ------------------------------------
( 8, 8) 32.0 29.6 (- 7.6%) 29.1 (- 9.0%)
(18,18) 66.1 49.2 (-25.6%) 50.4 (-23.7%)
(36,18) 76.4 51.0 (-33.3%) 53.4 (-30.1%)
(54,18) 80.1 54.3 (-32.2%) 57.2 (-28.6%)
Average latency [10^3 TPS]
( c, j) before after after
(no populate) (populate)
------- --------------------------------------
( 8, 8) 0.250 0.271 (+ 8.4%) 0.275 (+10.0%)
(18,18) 0.272 0.366 (+34.6%) 0.357 (+31.3%)
(36,18) 0.471 0.706 (+49.9%) 0.674 (+43.1%)
(54,18) 0.674 0.995 (+47.6%) 0.944 (+40.1%)
I'd say MAP_POPULATE made performance a little better in large #clients cases, comparing "populate" with "no populate".
However,
comparing "after" with "before", I found both throughput and average latency degraded. VTune told me that "after
(populate)"still
spent larger CPU time for memcpy-ing WAL records into mmap-ed segments than "before".
I also made a microbenchmark to see the behavior of mmap and msync. I found that:
- A major fault occured at mmap with MAP_POPULATE, instead at first access to the mmap-ed space.
- Some minor faults also occured at mmap with MAP_POPULATE, and no additional fault occured when I loaded from the
mmap-edspace.
But once I stored to that space, a minor fault occured.
- When I stored to the page that had been msync-ed, a minor fault occurred.
So I think one of the remaining causes of performance degrade is minor faults when mmap-ed pages get dirtied. And it
seemsnot to
be solved by MAP_POPULATE only, as far as I see.
Conditions
==========
- Use one physical server having 2 NUMA nodes (node 0 and 1)
- Pin postgres (server processes) to node 0 and pgbench to node 1
- 18 cores and 192GiB DRAM per node
- Use two NVMe SSDs; one for PGDATA, another for pg_wal
- Both are installed on the server-side node, that is, node 0
- Both are formatted with ext4
- Use the attached postgresql.conf
Steps
=====
For each (c,j) pair, I did the following steps three times then I found the median of the three as a final result shown
inthe
tables above.
(1) Run initdb with proper -D and -X options
(2) Start postgres and create a database for pgbench tables
(3) Run "pgbench -i -s ___" to create tables (s = 50 or 1000)
(4) Stop postgres, remount filesystems, and start postgres again
(5) Execute pg_prewarm extension for all the four pgbench tables
(6) Run pgbench during 30 minutes
pgbench command line
====================
$ pgbench -h /tmp -p 5432 -U username -r -M prepared -T 1800 -c ___ -j ___ dbname
I gave no -b option to use the built-in "TPC-B (sort-of)" query.
Software
========
- Distro: Ubuntu 18.04
- Kernel: Linux 5.4 (vanilla kernel)
- C Compiler: gcc 7.4.0
- PMDK: 1.7
- PostgreSQL: d677550 (master on Mar 3, 2020)
Hardware
========
- System: HPE ProLiant DL380 Gen10
- CPU: Intel Xeon Gold 6154 (Skylake) x 2sockets
- DRAM: DDR4 2666MHz {32GiB/ch x 6ch}/socket x 2sockets
- NVMe SSD: Intel Optane DC P4800X Series SSDPED1K750GA x2
Best regards,
Takashi
[1] https://www.postgresql.org/message-id/002701d5fd03$6e1d97a0$4a58c6e0$@hco.ntt.co.jp_1
--
Takashi Menjo <takashi.menjou.vg@hco.ntt.co.jp>
NTT Software Innovation Center
> -----Original Message-----
> From: Andres Freund <andres@anarazel.de>
> Sent: Thursday, February 20, 2020 2:04 PM
> To: Takashi Menjo <takashi.menjou.vg@hco.ntt.co.jp>
> Cc: 'Robert Haas' <robertmhaas@gmail.com>; 'Heikki Linnakangas' <hlinnaka@iki.fi>;
> pgsql-hackers@postgresql.org
> Subject: Re: [PoC] Non-volatile WAL buffer
>
> Hi,
>
> On 2020-02-17 13:12:37 +0900, Takashi Menjo wrote:
> > I applied my patchset that mmap()-s WAL segments as WAL buffers to
> > refs/tags/REL_12_0, and measured and analyzed its performance with
> > pgbench. Roughly speaking, When I used *SSD and ext4* to store WAL,
> > it was "obviously worse" than the original REL_12_0. VTune told me
> > that the CPU time of memcpy() called by CopyXLogRecordToWAL() got
> > larger than before.
>
> FWIW, this might largely be because of page faults. In contrast to before we wouldn't reuse the same pages
> (because they've been munmap()/mmap()ed), so the first time they're touched, we'll incur page faults. Did you
> try mmap()ing with MAP_POPULATE? It's probably also worthwhile to try to use MAP_HUGETLB.
>
> Still doubtful it's the right direction, but I'd rather have good numbers to back me up :)
>
> Greetings,
>
> Andres Freund
Attachment
- v2-0001-Preallocate-more-WAL-segments.patch
- v2-0002-Use-WAL-segments-as-WAL-buffers.patch
- v2-0003-Lazy-unmap-WAL-segments.patch
- v2-0004-Speculative-map-WAL-segments.patch
- v2-0005-Map-WAL-segments-with-MAP_POPULATE-if-non-DAX.patch
- msync-performance-s50.png
- msync-performance-s1000.png
- postgresql.conf
{kind=link}
{kind=link}
Dear hackers,
I update my non-volatile WAL buffer's patchset to v3. Now we can use it in streaming replication mode.
Updates from v2:
- walreceiver supports non-volatile WAL buffer
Now walreceiver stores received records directly to non-volatile WAL buffer if applicable.
- pg_basebackup supports non-volatile WAL buffer
Now pg_basebackup copies received WAL segments onto non-volatile WAL buffer if you run it with "nvwal" mode (-Fn).
You should specify a new NVWAL path with --nvwal-path option. The path will be written to postgresql.auto.conf or
recovery.conf. The size of the new NVWAL is same as the master's one.
Best regards,
Takashi
--
Takashi Menjo <takashi.menjou.vg@hco.ntt.co.jp>
NTT Software Innovation Center
> -----Original Message-----
> From: Takashi Menjo <takashi.menjou.vg@hco.ntt.co.jp>
> Sent: Wednesday, March 18, 2020 5:59 PM
> To: 'PostgreSQL-development' <pgsql-hackers@postgresql.org>
> Cc: 'Robert Haas' <robertmhaas@gmail.com>; 'Heikki Linnakangas' <hlinnaka@iki.fi>; 'Amit Langote'
> <amitlangote09@gmail.com>
> Subject: RE: [PoC] Non-volatile WAL buffer
>
> Dear hackers,
>
> I rebased my non-volatile WAL buffer's patchset onto master. A new v2 patchset is attached to this mail.
>
> I also measured performance before and after patchset, varying -c/--client and -j/--jobs options of pgbench, for
> each scaling factor s = 50 or 1000. The results are presented in the following tables and the attached charts.
> Conditions, steps, and other details will be shown later.
>
>
> Results (s=50)
> ==============
> Throughput [10^3 TPS] Average latency [ms]
> ( c, j) before after before after
> ------- --------------------- ---------------------
> ( 8, 8) 35.7 37.1 (+3.9%) 0.224 0.216 (-3.6%)
> (18,18) 70.9 74.7 (+5.3%) 0.254 0.241 (-5.1%)
> (36,18) 76.0 80.8 (+6.3%) 0.473 0.446 (-5.7%)
> (54,18) 75.5 81.8 (+8.3%) 0.715 0.660 (-7.7%)
>
>
> Results (s=1000)
> ================
> Throughput [10^3 TPS] Average latency [ms]
> ( c, j) before after before after
> ------- --------------------- ---------------------
> ( 8, 8) 37.4 40.1 (+7.3%) 0.214 0.199 (-7.0%)
> (18,18) 79.3 86.7 (+9.3%) 0.227 0.208 (-8.4%)
> (36,18) 87.2 95.5 (+9.5%) 0.413 0.377 (-8.7%)
> (54,18) 86.8 94.8 (+9.3%) 0.622 0.569 (-8.5%)
>
>
> Both throughput and average latency are improved for each scaling factor. Throughput seemed to almost reach
> the upper limit when (c,j)=(36,18).
>
> The percentage in s=1000 case looks larger than in s=50 case. I think larger scaling factor leads to less
> contentions on the same tables and/or indexes, that is, less lock and unlock operations. In such a situation,
> write-ahead logging appears to be more significant for performance.
>
>
> Conditions
> ==========
> - Use one physical server having 2 NUMA nodes (node 0 and 1)
> - Pin postgres (server processes) to node 0 and pgbench to node 1
> - 18 cores and 192GiB DRAM per node
> - Use an NVMe SSD for PGDATA and an interleaved 6-in-1 NVDIMM-N set for pg_wal
> - Both are installed on the server-side node, that is, node 0
> - Both are formatted with ext4
> - NVDIMM-N is mounted with "-o dax" option to enable Direct Access (DAX)
> - Use the attached postgresql.conf
> - Two new items nvwal_path and nvwal_size are used only after patch
>
>
> Steps
> =====
> For each (c,j) pair, I did the following steps three times then I found the median of the three as a final result
shown
> in the tables above.
>
> (1) Run initdb with proper -D and -X options; and also give --nvwal-path and --nvwal-size options after patch
> (2) Start postgres and create a database for pgbench tables
> (3) Run "pgbench -i -s ___" to create tables (s = 50 or 1000)
> (4) Stop postgres, remount filesystems, and start postgres again
> (5) Execute pg_prewarm extension for all the four pgbench tables
> (6) Run pgbench during 30 minutes
>
>
> pgbench command line
> ====================
> $ pgbench -h /tmp -p 5432 -U username -r -M prepared -T 1800 -c ___ -j ___ dbname
>
> I gave no -b option to use the built-in "TPC-B (sort-of)" query.
>
>
> Software
> ========
> - Distro: Ubuntu 18.04
> - Kernel: Linux 5.4 (vanilla kernel)
> - C Compiler: gcc 7.4.0
> - PMDK: 1.7
> - PostgreSQL: d677550 (master on Mar 3, 2020)
>
>
> Hardware
> ========
> - System: HPE ProLiant DL380 Gen10
> - CPU: Intel Xeon Gold 6154 (Skylake) x 2sockets
> - DRAM: DDR4 2666MHz {32GiB/ch x 6ch}/socket x 2sockets
> - NVDIMM-N: DDR4 2666MHz {16GiB/ch x 6ch}/socket x 2sockets
> - NVMe SSD: Intel Optane DC P4800X Series SSDPED1K750GA
>
>
> Best regards,
> Takashi
>
> --
> Takashi Menjo <takashi.menjou.vg@hco.ntt.co.jp> NTT Software Innovation Center
>
> > -----Original Message-----
> > From: Takashi Menjo <takashi.menjou.vg@hco.ntt.co.jp>
> > Sent: Thursday, February 20, 2020 6:30 PM
> > To: 'Amit Langote' <amitlangote09@gmail.com>
> > Cc: 'Robert Haas' <robertmhaas@gmail.com>; 'Heikki Linnakangas' <hlinnaka@iki.fi>;
> 'PostgreSQL-development'
> > <pgsql-hackers@postgresql.org>
> > Subject: RE: [PoC] Non-volatile WAL buffer
> >
> > Dear Amit,
> >
> > Thank you for your advice. Exactly, it's so to speak "do as the hackers do when in pgsql"...
> >
> > I'm rebasing my branch onto master. I'll submit an updated patchset and performance report later.
> >
> > Best regards,
> > Takashi
> >
> > --
> > Takashi Menjo <takashi.menjou.vg@hco.ntt.co.jp> NTT Software
> > Innovation Center
> >
> > > -----Original Message-----
> > > From: Amit Langote <amitlangote09@gmail.com>
> > > Sent: Monday, February 17, 2020 5:21 PM
> > > To: Takashi Menjo <takashi.menjou.vg@hco.ntt.co.jp>
> > > Cc: Robert Haas <robertmhaas@gmail.com>; Heikki Linnakangas
> > > <hlinnaka@iki.fi>; PostgreSQL-development
> > > <pgsql-hackers@postgresql.org>
> > > Subject: Re: [PoC] Non-volatile WAL buffer
> > >
> > > Hello,
> > >
> > > On Mon, Feb 17, 2020 at 4:16 PM Takashi Menjo <takashi.menjou.vg@hco.ntt.co.jp> wrote:
> > > > Hello Amit,
> > > >
> > > > > I apologize for not having any opinion on the patches
> > > > > themselves, but let me point out that it's better to base these
> > > > > patches on HEAD (master branch) than REL_12_0, because all new
> > > > > code is committed to the master branch, whereas stable branches
> > > > > such as
> > > > > REL_12_0 only receive bug fixes. Do you have any
> > > specific reason to be working on REL_12_0?
> > > >
> > > > Yes, because I think it's human-friendly to reproduce and discuss
> > > > performance measurement. Of course I know
> > > all new accepted patches are merged into master's HEAD, not stable
> > > branches and not even release tags, so I'm aware of rebasing my
> > > patchset onto master sooner or later. However, if someone,
> > > including me, says that s/he applies my patchset to "master" and
> > > measures its performance, we have to pay attention to which commit the "master"
> > > really points to. Although we have sha1 hashes to specify which
> > > commit, we should check whether the specific commit on master has
> > > patches affecting performance or not
> > because master's HEAD gets new patches day by day. On the other hand,
> > a release tag clearly points the commit all we probably know. Also we
> > can check more easily the features and improvements by using release notes and user manuals.
> > >
> > > Thanks for clarifying. I see where you're coming from.
> > >
> > > While I do sometimes see people reporting numbers with the latest
> > > stable release' branch, that's normally just one of the baselines.
> > > The more important baseline for ongoing development is the master
> > > branch's HEAD, which is also what people volunteering to test your
> > > patches would use. Anyone who reports would have to give at least
> > > two numbers -- performance with a branch's HEAD without patch
> > > applied and that with patch applied -- which can be enough in most
> > > cases to see the difference the patch makes. Sure, the numbers
> > > might change on each report, but that's fine I'd think. If you
> > > continue to develop against the stable branch, you might miss to
> > notice impact from any relevant developments in the master branch,
> > even developments which possibly require rethinking the architecture of your own changes, although maybe that
> rarely occurs.
> > >
> > > Thanks,
> > > Amit
Attachment
Dear hackers,
I update my non-volatile WAL buffer's patchset to v3. Now we can use it in streaming replication mode.
Updates from v2:
- walreceiver supports non-volatile WAL buffer
Now walreceiver stores received records directly to non-volatile WAL buffer if applicable.
- pg_basebackup supports non-volatile WAL buffer
Now pg_basebackup copies received WAL segments onto non-volatile WAL buffer if you run it with "nvwal" mode (-Fn).
You should specify a new NVWAL path with --nvwal-path option. The path will be written to postgresql.auto.conf or recovery.conf. The size of the new NVWAL is same as the master's one.
Best regards,
Takashi
--
Takashi Menjo <takashi.menjou.vg@hco.ntt.co.jp>
NTT Software Innovation Center
> -----Original Message-----
> From: Takashi Menjo <takashi.menjou.vg@hco.ntt.co.jp>
> Sent: Wednesday, March 18, 2020 5:59 PM
> To: 'PostgreSQL-development' <pgsql-hackers@postgresql.org>
> Cc: 'Robert Haas' <robertmhaas@gmail.com>; 'Heikki Linnakangas' <hlinnaka@iki.fi>; 'Amit Langote'
> <amitlangote09@gmail.com>
> Subject: RE: [PoC] Non-volatile WAL buffer
>
> Dear hackers,
>
> I rebased my non-volatile WAL buffer's patchset onto master. A new v2 patchset is attached to this mail.
>
> I also measured performance before and after patchset, varying -c/--client and -j/--jobs options of pgbench, for
> each scaling factor s = 50 or 1000. The results are presented in the following tables and the attached charts.
> Conditions, steps, and other details will be shown later.
>
>
> Results (s=50)
> ==============
> Throughput [10^3 TPS] Average latency [ms]
> ( c, j) before after before after
> ------- --------------------- ---------------------
> ( 8, 8) 35.7 37.1 (+3.9%) 0.224 0.216 (-3.6%)
> (18,18) 70.9 74.7 (+5.3%) 0.254 0.241 (-5.1%)
> (36,18) 76.0 80.8 (+6.3%) 0.473 0.446 (-5.7%)
> (54,18) 75.5 81.8 (+8.3%) 0.715 0.660 (-7.7%)
>
>
> Results (s=1000)
> ================
> Throughput [10^3 TPS] Average latency [ms]
> ( c, j) before after before after
> ------- --------------------- ---------------------
> ( 8, 8) 37.4 40.1 (+7.3%) 0.214 0.199 (-7.0%)
> (18,18) 79.3 86.7 (+9.3%) 0.227 0.208 (-8.4%)
> (36,18) 87.2 95.5 (+9.5%) 0.413 0.377 (-8.7%)
> (54,18) 86.8 94.8 (+9.3%) 0.622 0.569 (-8.5%)
>
>
> Both throughput and average latency are improved for each scaling factor. Throughput seemed to almost reach
> the upper limit when (c,j)=(36,18).
>
> The percentage in s=1000 case looks larger than in s=50 case. I think larger scaling factor leads to less
> contentions on the same tables and/or indexes, that is, less lock and unlock operations. In such a situation,
> write-ahead logging appears to be more significant for performance.
>
>
> Conditions
> ==========
> - Use one physical server having 2 NUMA nodes (node 0 and 1)
> - Pin postgres (server processes) to node 0 and pgbench to node 1
> - 18 cores and 192GiB DRAM per node
> - Use an NVMe SSD for PGDATA and an interleaved 6-in-1 NVDIMM-N set for pg_wal
> - Both are installed on the server-side node, that is, node 0
> - Both are formatted with ext4
> - NVDIMM-N is mounted with "-o dax" option to enable Direct Access (DAX)
> - Use the attached postgresql.conf
> - Two new items nvwal_path and nvwal_size are used only after patch
>
>
> Steps
> =====
> For each (c,j) pair, I did the following steps three times then I found the median of the three as a final result shown
> in the tables above.
>
> (1) Run initdb with proper -D and -X options; and also give --nvwal-path and --nvwal-size options after patch
> (2) Start postgres and create a database for pgbench tables
> (3) Run "pgbench -i -s ___" to create tables (s = 50 or 1000)
> (4) Stop postgres, remount filesystems, and start postgres again
> (5) Execute pg_prewarm extension for all the four pgbench tables
> (6) Run pgbench during 30 minutes
>
>
> pgbench command line
> ====================
> $ pgbench -h /tmp -p 5432 -U username -r -M prepared -T 1800 -c ___ -j ___ dbname
>
> I gave no -b option to use the built-in "TPC-B (sort-of)" query.
>
>
> Software
> ========
> - Distro: Ubuntu 18.04
> - Kernel: Linux 5.4 (vanilla kernel)
> - C Compiler: gcc 7.4.0
> - PMDK: 1.7
> - PostgreSQL: d677550 (master on Mar 3, 2020)
>
>
> Hardware
> ========
> - System: HPE ProLiant DL380 Gen10
> - CPU: Intel Xeon Gold 6154 (Skylake) x 2sockets
> - DRAM: DDR4 2666MHz {32GiB/ch x 6ch}/socket x 2sockets
> - NVDIMM-N: DDR4 2666MHz {16GiB/ch x 6ch}/socket x 2sockets
> - NVMe SSD: Intel Optane DC P4800X Series SSDPED1K750GA
>
>
> Best regards,
> Takashi
>
> --
> Takashi Menjo <takashi.menjou.vg@hco.ntt.co.jp> NTT Software Innovation Center
>
> > -----Original Message-----
> > From: Takashi Menjo <takashi.menjou.vg@hco.ntt.co.jp>
> > Sent: Thursday, February 20, 2020 6:30 PM
> > To: 'Amit Langote' <amitlangote09@gmail.com>
> > Cc: 'Robert Haas' <robertmhaas@gmail.com>; 'Heikki Linnakangas' <hlinnaka@iki.fi>;
> 'PostgreSQL-development'
> > <pgsql-hackers@postgresql.org>
> > Subject: RE: [PoC] Non-volatile WAL buffer
> >
> > Dear Amit,
> >
> > Thank you for your advice. Exactly, it's so to speak "do as the hackers do when in pgsql"...
> >
> > I'm rebasing my branch onto master. I'll submit an updated patchset and performance report later.
> >
> > Best regards,
> > Takashi
> >
> > --
> > Takashi Menjo <takashi.menjou.vg@hco.ntt.co.jp> NTT Software
> > Innovation Center
> >
> > > -----Original Message-----
> > > From: Amit Langote <amitlangote09@gmail.com>
> > > Sent: Monday, February 17, 2020 5:21 PM
> > > To: Takashi Menjo <takashi.menjou.vg@hco.ntt.co.jp>
> > > Cc: Robert Haas <robertmhaas@gmail.com>; Heikki Linnakangas
> > > <hlinnaka@iki.fi>; PostgreSQL-development
> > > <pgsql-hackers@postgresql.org>
> > > Subject: Re: [PoC] Non-volatile WAL buffer
> > >
> > > Hello,
> > >
> > > On Mon, Feb 17, 2020 at 4:16 PM Takashi Menjo <takashi.menjou.vg@hco.ntt.co.jp> wrote:
> > > > Hello Amit,
> > > >
> > > > > I apologize for not having any opinion on the patches
> > > > > themselves, but let me point out that it's better to base these
> > > > > patches on HEAD (master branch) than REL_12_0, because all new
> > > > > code is committed to the master branch, whereas stable branches
> > > > > such as
> > > > > REL_12_0 only receive bug fixes. Do you have any
> > > specific reason to be working on REL_12_0?
> > > >
> > > > Yes, because I think it's human-friendly to reproduce and discuss
> > > > performance measurement. Of course I know
> > > all new accepted patches are merged into master's HEAD, not stable
> > > branches and not even release tags, so I'm aware of rebasing my
> > > patchset onto master sooner or later. However, if someone,
> > > including me, says that s/he applies my patchset to "master" and
> > > measures its performance, we have to pay attention to which commit the "master"
> > > really points to. Although we have sha1 hashes to specify which
> > > commit, we should check whether the specific commit on master has
> > > patches affecting performance or not
> > because master's HEAD gets new patches day by day. On the other hand,
> > a release tag clearly points the commit all we probably know. Also we
> > can check more easily the features and improvements by using release notes and user manuals.
> > >
> > > Thanks for clarifying. I see where you're coming from.
> > >
> > > While I do sometimes see people reporting numbers with the latest
> > > stable release' branch, that's normally just one of the baselines.
> > > The more important baseline for ongoing development is the master
> > > branch's HEAD, which is also what people volunteering to test your
> > > patches would use. Anyone who reports would have to give at least
> > > two numbers -- performance with a branch's HEAD without patch
> > > applied and that with patch applied -- which can be enough in most
> > > cases to see the difference the patch makes. Sure, the numbers
> > > might change on each report, but that's fine I'd think. If you
> > > continue to develop against the stable branch, you might miss to
> > notice impact from any relevant developments in the master branch,
> > even developments which possibly require rethinking the architecture of your own changes, although maybe that
> rarely occurs.
> > >
> > > Thanks,
> > > Amit
Attachment
Hi Takashi,
Thank you for the patch and work on accelerating PG performance with NVM. I applied the patch and made some performance test based on the patch v4. I stored database data files on NVMe SSD and stored WAL file on Intel PMem (NVM). I used two methods to store WAL file(s):
1. Leverage your patch to access PMem with libpmem (NVWAL patch).
2. Access PMem with legacy filesystem interface, that means use PMem as ordinary block device, no PG patch is required to access PMem (Storage over App Direct).
I tried two insert scenarios:
A. Insert small record (length of record to be inserted is 24 bytes), I think it is similar as your test
B. Insert large record (length of record to be inserted is 328 bytes)
My original purpose is to see higher performance gain in scenario B as it is more write intensive on WAL. But I observed that NVWAL patch method had ~5% performance improvement compared with Storage over App Direct method in scenario A, while had ~20% performance degradation in scenario B.
I made further investigation on the test. I found that NVWAL patch can improve performance of XlogFlush function, but it may impact performance of CopyXlogRecordToWAL function. It may be related to the higher latency of memcpy to Intel PMem comparing with DRAM. Here are key data in my test:
Scenario A (length of record to be inserted: 24 bytes per record):
==============================
NVWAL SoAD
------------------------------------ ------- -------
Througput (10^3 TPS) 310.5 296.0
CPU Time % of CopyXlogRecordToWAL 0.4 0.2
CPU Time % of XLogInsertRecord 1.5 0.8
CPU Time % of XLogFlush 2.1 9.6
Scenario B (length of record to be inserted: 328 bytes per record):
==============================
NVWAL SoAD
------------------------------------ ------- -------
Througput (10^3 TPS) 13.0 16.9
CPU Time % of CopyXlogRecordToWAL 3.0 1.6
CPU Time % of XLogInsertRecord 23.0 16.4
CPU Time % of XLogFlush 2.3 5.9
Best Regards,
Gang
From: Takashi Menjo <takashi.menjo@gmail.com>
Sent: Thursday, September 10, 2020 4:01 PM
To: Takashi Menjo <takashi.menjou.vg@hco.ntt.co.jp>
Cc: pgsql-hackers@postgresql.org
Subject: Re: [PoC] Non-volatile WAL buffer
Rebased.
2020年6月24日(水) 16:44 Takashi Menjo <takashi.menjou.vg@hco.ntt.co.jp>:
Dear hackers,
I update my non-volatile WAL buffer's patchset to v3. Now we can use it in streaming replication mode.
Updates from v2:
- walreceiver supports non-volatile WAL buffer
Now walreceiver stores received records directly to non-volatile WAL buffer if applicable.
- pg_basebackup supports non-volatile WAL buffer
Now pg_basebackup copies received WAL segments onto non-volatile WAL buffer if you run it with "nvwal" mode (-Fn).
You should specify a new NVWAL path with --nvwal-path option. The path will be written to postgresql.auto.conf or recovery.conf. The size of the new NVWAL is same as the master's one.
Best regards,
Takashi
--
Takashi Menjo <takashi.menjou.vg@hco.ntt.co.jp>
NTT Software Innovation Center
> -----Original Message-----
> From: Takashi Menjo <takashi.menjou.vg@hco.ntt.co.jp>
> Sent: Wednesday, March 18, 2020 5:59 PM
> To: 'PostgreSQL-development' <pgsql-hackers@postgresql.org>
> Cc: 'Robert Haas' <robertmhaas@gmail.com>; 'Heikki Linnakangas' <hlinnaka@iki.fi>; 'Amit Langote'
> <amitlangote09@gmail.com>
> Subject: RE: [PoC] Non-volatile WAL buffer
>
> Dear hackers,
>
> I rebased my non-volatile WAL buffer's patchset onto master. A new v2 patchset is attached to this mail.
>
> I also measured performance before and after patchset, varying -c/--client and -j/--jobs options of pgbench, for
> each scaling factor s = 50 or 1000. The results are presented in the following tables and the attached charts.
> Conditions, steps, and other details will be shown later.
>
>
> Results (s=50)
> ==============
> Throughput [10^3 TPS] Average latency [ms]
> ( c, j) before after before after
> ------- --------------------- ---------------------
> ( 8, 8) 35.7 37.1 (+3.9%) 0.224 0.216 (-3.6%)
> (18,18) 70.9 74.7 (+5.3%) 0.254 0.241 (-5.1%)
> (36,18) 76.0 80.8 (+6.3%) 0.473 0.446 (-5.7%)
> (54,18) 75.5 81.8 (+8.3%) 0.715 0.660 (-7.7%)
>
>
> Results (s=1000)
> ================
> Throughput [10^3 TPS] Average latency [ms]
> ( c, j) before after before after
> ------- --------------------- ---------------------
> ( 8, 8) 37.4 40.1 (+7.3%) 0.214 0.199 (-7.0%)
> (18,18) 79.3 86.7 (+9.3%) 0.227 0.208 (-8.4%)
> (36,18) 87.2 95.5 (+9.5%) 0.413 0.377 (-8.7%)
> (54,18) 86.8 94.8 (+9.3%) 0.622 0.569 (-8.5%)
>
>
> Both throughput and average latency are improved for each scaling factor. Throughput seemed to almost reach
> the upper limit when (c,j)=(36,18).
>
> The percentage in s=1000 case looks larger than in s=50 case. I think larger scaling factor leads to less
> contentions on the same tables and/or indexes, that is, less lock and unlock operations. In such a situation,
> write-ahead logging appears to be more significant for performance.
>
>
> Conditions
> ==========
> - Use one physical server having 2 NUMA nodes (node 0 and 1)
> - Pin postgres (server processes) to node 0 and pgbench to node 1
> - 18 cores and 192GiB DRAM per node
> - Use an NVMe SSD for PGDATA and an interleaved 6-in-1 NVDIMM-N set for pg_wal
> - Both are installed on the server-side node, that is, node 0
> - Both are formatted with ext4
> - NVDIMM-N is mounted with "-o dax" option to enable Direct Access (DAX)
> - Use the attached postgresql.conf
> - Two new items nvwal_path and nvwal_size are used only after patch
>
>
> Steps
> =====
> For each (c,j) pair, I did the following steps three times then I found the median of the three as a final result shown
> in the tables above.
>
> (1) Run initdb with proper -D and -X options; and also give --nvwal-path and --nvwal-size options after patch
> (2) Start postgres and create a database for pgbench tables
> (3) Run "pgbench -i -s ___" to create tables (s = 50 or 1000)
> (4) Stop postgres, remount filesystems, and start postgres again
> (5) Execute pg_prewarm extension for all the four pgbench tables
> (6) Run pgbench during 30 minutes
>
>
> pgbench command line
> ====================
> $ pgbench -h /tmp -p 5432 -U username -r -M prepared -T 1800 -c ___ -j ___ dbname
>
> I gave no -b option to use the built-in "TPC-B (sort-of)" query.
>
>
> Software
> ========
> - Distro: Ubuntu 18.04
> - Kernel: Linux 5.4 (vanilla kernel)
> - C Compiler: gcc 7.4.0
> - PMDK: 1.7
> - PostgreSQL: d677550 (master on Mar 3, 2020)
>
>
> Hardware
> ========
> - System: HPE ProLiant DL380 Gen10
> - CPU: Intel Xeon Gold 6154 (Skylake) x 2sockets
> - DRAM: DDR4 2666MHz {32GiB/ch x 6ch}/socket x 2sockets
> - NVDIMM-N: DDR4 2666MHz {16GiB/ch x 6ch}/socket x 2sockets
> - NVMe SSD: Intel Optane DC P4800X Series SSDPED1K750GA
>
>
> Best regards,
> Takashi
>
> --
> Takashi Menjo <takashi.menjou.vg@hco.ntt.co.jp> NTT Software Innovation Center
>
> > -----Original Message-----
> > From: Takashi Menjo <takashi.menjou.vg@hco.ntt.co.jp>
> > Sent: Thursday, February 20, 2020 6:30 PM
> > To: 'Amit Langote' <amitlangote09@gmail.com>
> > Cc: 'Robert Haas' <robertmhaas@gmail.com>; 'Heikki Linnakangas' <hlinnaka@iki.fi>;
> 'PostgreSQL-development'
> > <pgsql-hackers@postgresql.org>
> > Subject: RE: [PoC] Non-volatile WAL buffer
> >
> > Dear Amit,
> >
> > Thank you for your advice. Exactly, it's so to speak "do as the hackers do when in pgsql"...
> >
> > I'm rebasing my branch onto master. I'll submit an updated patchset and performance report later.
> >
> > Best regards,
> > Takashi
> >
> > --
> > Takashi Menjo <takashi.menjou.vg@hco.ntt.co.jp> NTT Software
> > Innovation Center
> >
> > > -----Original Message-----
> > > From: Amit Langote <amitlangote09@gmail.com>
> > > Sent: Monday, February 17, 2020 5:21 PM
> > > To: Takashi Menjo <takashi.menjou.vg@hco.ntt.co.jp>
> > > Cc: Robert Haas <robertmhaas@gmail.com>; Heikki Linnakangas
> > > <hlinnaka@iki.fi>; PostgreSQL-development
> > > <pgsql-hackers@postgresql.org>
> > > Subject: Re: [PoC] Non-volatile WAL buffer
> > >
> > > Hello,
> > >
> > > On Mon, Feb 17, 2020 at 4:16 PM Takashi Menjo <takashi.menjou.vg@hco.ntt.co.jp> wrote:
> > > > Hello Amit,
> > > >
> > > > > I apologize for not having any opinion on the patches
> > > > > themselves, but let me point out that it's better to base these
> > > > > patches on HEAD (master branch) than REL_12_0, because all new
> > > > > code is committed to the master branch, whereas stable branches
> > > > > such as
> > > > > REL_12_0 only receive bug fixes. Do you have any
> > > specific reason to be working on REL_12_0?
> > > >
> > > > Yes, because I think it's human-friendly to reproduce and discuss
> > > > performance measurement. Of course I know
> > > all new accepted patches are merged into master's HEAD, not stable
> > > branches and not even release tags, so I'm aware of rebasing my
> > > patchset onto master sooner or later. However, if someone,
> > > including me, says that s/he applies my patchset to "master" and
> > > measures its performance, we have to pay attention to which commit the "master"
> > > really points to. Although we have sha1 hashes to specify which
> > > commit, we should check whether the specific commit on master has
> > > patches affecting performance or not
> > because master's HEAD gets new patches day by day. On the other hand,
> > a release tag clearly points the commit all we probably know. Also we
> > can check more easily the features and improvements by using release notes and user manuals.
> > >
> > > Thanks for clarifying. I see where you're coming from.
> > >
> > > While I do sometimes see people reporting numbers with the latest
> > > stable release' branch, that's normally just one of the baselines.
> > > The more important baseline for ongoing development is the master
> > > branch's HEAD, which is also what people volunteering to test your
> > > patches would use. Anyone who reports would have to give at least
> > > two numbers -- performance with a branch's HEAD without patch
> > > applied and that with patch applied -- which can be enough in most
> > > cases to see the difference the patch makes. Sure, the numbers
> > > might change on each report, but that's fine I'd think. If you
> > > continue to develop against the stable branch, you might miss to
> > notice impact from any relevant developments in the master branch,
> > even developments which possibly require rethinking the architecture of your own changes, although maybe that
> rarely occurs.
> > >
> > > Thanks,
> > > Amit
--
Takashi Menjo <takashi.menjo@gmail.com>
Hi Takashi,
Thank you for the patch and work on accelerating PG performance with NVM. I applied the patch and made some performance test based on the patch v4. I stored database data files on NVMe SSD and stored WAL file on Intel PMem (NVM). I used two methods to store WAL file(s):
1. Leverage your patch to access PMem with libpmem (NVWAL patch).
2. Access PMem with legacy filesystem interface, that means use PMem as ordinary block device, no PG patch is required to access PMem (Storage over App Direct).
I tried two insert scenarios:
A. Insert small record (length of record to be inserted is 24 bytes), I think it is similar as your test
B. Insert large record (length of record to be inserted is 328 bytes)
My original purpose is to see higher performance gain in scenario B as it is more write intensive on WAL. But I observed that NVWAL patch method had ~5% performance improvement compared with Storage over App Direct method in scenario A, while had ~20% performance degradation in scenario B.
I made further investigation on the test. I found that NVWAL patch can improve performance of XlogFlush function, but it may impact performance of CopyXlogRecordToWAL function. It may be related to the higher latency of memcpy to Intel PMem comparing with DRAM. Here are key data in my test:
Scenario A (length of record to be inserted: 24 bytes per record):
==============================
NVWAL SoAD
------------------------------------ ------- -------
Througput (10^3 TPS) 310.5 296.0
CPU Time % of CopyXlogRecordToWAL 0.4 0.2
CPU Time % of XLogInsertRecord 1.5 0.8
CPU Time % of XLogFlush 2.1 9.6
Scenario B (length of record to be inserted: 328 bytes per record):
==============================
NVWAL SoAD
------------------------------------ ------- -------
Througput (10^3 TPS) 13.0 16.9
CPU Time % of CopyXlogRecordToWAL 3.0 1.6
CPU Time % of XLogInsertRecord 23.0 16.4
CPU Time % of XLogFlush 2.3 5.9
Best Regards,
Gang
From: Takashi Menjo <takashi.menjo@gmail.com>
Sent: Thursday, September 10, 2020 4:01 PM
To: Takashi Menjo <takashi.menjou.vg@hco.ntt.co.jp>
Cc: pgsql-hackers@postgresql.org
Subject: Re: [PoC] Non-volatile WAL buffer
Rebased.
2020年6月24日(水) 16:44 Takashi Menjo <takashi.menjou.vg@hco.ntt.co.jp>:
Dear hackers,
I update my non-volatile WAL buffer's patchset to v3. Now we can use it in streaming replication mode.
Updates from v2:
- walreceiver supports non-volatile WAL buffer
Now walreceiver stores received records directly to non-volatile WAL buffer if applicable.
- pg_basebackup supports non-volatile WAL buffer
Now pg_basebackup copies received WAL segments onto non-volatile WAL buffer if you run it with "nvwal" mode (-Fn).
You should specify a new NVWAL path with --nvwal-path option. The path will be written to postgresql.auto.conf or recovery.conf. The size of the new NVWAL is same as the master's one.
Best regards,
Takashi
--
Takashi Menjo <takashi.menjou.vg@hco.ntt.co.jp>
NTT Software Innovation Center
> -----Original Message-----
> From: Takashi Menjo <takashi.menjou.vg@hco.ntt.co.jp>
> Sent: Wednesday, March 18, 2020 5:59 PM
> To: 'PostgreSQL-development' <pgsql-hackers@postgresql.org>
> Cc: 'Robert Haas' <robertmhaas@gmail.com>; 'Heikki Linnakangas' <hlinnaka@iki.fi>; 'Amit Langote'
> <amitlangote09@gmail.com>
> Subject: RE: [PoC] Non-volatile WAL buffer
>
> Dear hackers,
>
> I rebased my non-volatile WAL buffer's patchset onto master. A new v2 patchset is attached to this mail.
>
> I also measured performance before and after patchset, varying -c/--client and -j/--jobs options of pgbench, for
> each scaling factor s = 50 or 1000. The results are presented in the following tables and the attached charts.
> Conditions, steps, and other details will be shown later.
>
>
> Results (s=50)
> ==============
> Throughput [10^3 TPS] Average latency [ms]
> ( c, j) before after before after
> ------- --------------------- ---------------------
> ( 8, 8) 35.7 37.1 (+3.9%) 0.224 0.216 (-3.6%)
> (18,18) 70.9 74.7 (+5.3%) 0.254 0.241 (-5.1%)
> (36,18) 76.0 80.8 (+6.3%) 0.473 0.446 (-5.7%)
> (54,18) 75.5 81.8 (+8.3%) 0.715 0.660 (-7.7%)
>
>
> Results (s=1000)
> ================
> Throughput [10^3 TPS] Average latency [ms]
> ( c, j) before after before after
> ------- --------------------- ---------------------
> ( 8, 8) 37.4 40.1 (+7.3%) 0.214 0.199 (-7.0%)
> (18,18) 79.3 86.7 (+9.3%) 0.227 0.208 (-8.4%)
> (36,18) 87.2 95.5 (+9.5%) 0.413 0.377 (-8.7%)
> (54,18) 86.8 94.8 (+9.3%) 0.622 0.569 (-8.5%)
>
>
> Both throughput and average latency are improved for each scaling factor. Throughput seemed to almost reach
> the upper limit when (c,j)=(36,18).
>
> The percentage in s=1000 case looks larger than in s=50 case. I think larger scaling factor leads to less
> contentions on the same tables and/or indexes, that is, less lock and unlock operations. In such a situation,
> write-ahead logging appears to be more significant for performance.
>
>
> Conditions
> ==========
> - Use one physical server having 2 NUMA nodes (node 0 and 1)
> - Pin postgres (server processes) to node 0 and pgbench to node 1
> - 18 cores and 192GiB DRAM per node
> - Use an NVMe SSD for PGDATA and an interleaved 6-in-1 NVDIMM-N set for pg_wal
> - Both are installed on the server-side node, that is, node 0
> - Both are formatted with ext4
> - NVDIMM-N is mounted with "-o dax" option to enable Direct Access (DAX)
> - Use the attached postgresql.conf
> - Two new items nvwal_path and nvwal_size are used only after patch
>
>
> Steps
> =====
> For each (c,j) pair, I did the following steps three times then I found the median of the three as a final result shown
> in the tables above.
>
> (1) Run initdb with proper -D and -X options; and also give --nvwal-path and --nvwal-size options after patch
> (2) Start postgres and create a database for pgbench tables
> (3) Run "pgbench -i -s ___" to create tables (s = 50 or 1000)
> (4) Stop postgres, remount filesystems, and start postgres again
> (5) Execute pg_prewarm extension for all the four pgbench tables
> (6) Run pgbench during 30 minutes
>
>
> pgbench command line
> ====================
> $ pgbench -h /tmp -p 5432 -U username -r -M prepared -T 1800 -c ___ -j ___ dbname
>
> I gave no -b option to use the built-in "TPC-B (sort-of)" query.
>
>
> Software
> ========
> - Distro: Ubuntu 18.04
> - Kernel: Linux 5.4 (vanilla kernel)
> - C Compiler: gcc 7.4.0
> - PMDK: 1.7
> - PostgreSQL: d677550 (master on Mar 3, 2020)
>
>
> Hardware
> ========
> - System: HPE ProLiant DL380 Gen10
> - CPU: Intel Xeon Gold 6154 (Skylake) x 2sockets
> - DRAM: DDR4 2666MHz {32GiB/ch x 6ch}/socket x 2sockets
> - NVDIMM-N: DDR4 2666MHz {16GiB/ch x 6ch}/socket x 2sockets
> - NVMe SSD: Intel Optane DC P4800X Series SSDPED1K750GA
>
>
> Best regards,
> Takashi
>
> --
> Takashi Menjo <takashi.menjou.vg@hco.ntt.co.jp> NTT Software Innovation Center
>
> > -----Original Message-----
> > From: Takashi Menjo <takashi.menjou.vg@hco.ntt.co.jp>
> > Sent: Thursday, February 20, 2020 6:30 PM
> > To: 'Amit Langote' <amitlangote09@gmail.com>
> > Cc: 'Robert Haas' <robertmhaas@gmail.com>; 'Heikki Linnakangas' <hlinnaka@iki.fi>;
> 'PostgreSQL-development'
> > <pgsql-hackers@postgresql.org>
> > Subject: RE: [PoC] Non-volatile WAL buffer
> >
> > Dear Amit,
> >
> > Thank you for your advice. Exactly, it's so to speak "do as the hackers do when in pgsql"...
> >
> > I'm rebasing my branch onto master. I'll submit an updated patchset and performance report later.
> >
> > Best regards,
> > Takashi
> >
> > --
> > Takashi Menjo <takashi.menjou.vg@hco.ntt.co.jp> NTT Software
> > Innovation Center
> >
> > > -----Original Message-----
> > > From: Amit Langote <amitlangote09@gmail.com>
> > > Sent: Monday, February 17, 2020 5:21 PM
> > > To: Takashi Menjo <takashi.menjou.vg@hco.ntt.co.jp>
> > > Cc: Robert Haas <robertmhaas@gmail.com>; Heikki Linnakangas
> > > <hlinnaka@iki.fi>; PostgreSQL-development
> > > <pgsql-hackers@postgresql.org>
> > > Subject: Re: [PoC] Non-volatile WAL buffer
> > >
> > > Hello,
> > >
> > > On Mon, Feb 17, 2020 at 4:16 PM Takashi Menjo <takashi.menjou.vg@hco.ntt.co.jp> wrote:
> > > > Hello Amit,
> > > >
> > > > > I apologize for not having any opinion on the patches
> > > > > themselves, but let me point out that it's better to base these
> > > > > patches on HEAD (master branch) than REL_12_0, because all new
> > > > > code is committed to the master branch, whereas stable branches
> > > > > such as
> > > > > REL_12_0 only receive bug fixes. Do you have any
> > > specific reason to be working on REL_12_0?
> > > >
> > > > Yes, because I think it's human-friendly to reproduce and discuss
> > > > performance measurement. Of course I know
> > > all new accepted patches are merged into master's HEAD, not stable
> > > branches and not even release tags, so I'm aware of rebasing my
> > > patchset onto master sooner or later. However, if someone,
> > > including me, says that s/he applies my patchset to "master" and
> > > measures its performance, we have to pay attention to which commit the "master"
> > > really points to. Although we have sha1 hashes to specify which
> > > commit, we should check whether the specific commit on master has
> > > patches affecting performance or not
> > because master's HEAD gets new patches day by day. On the other hand,
> > a release tag clearly points the commit all we probably know. Also we
> > can check more easily the features and improvements by using release notes and user manuals.
> > >
> > > Thanks for clarifying. I see where you're coming from.
> > >
> > > While I do sometimes see people reporting numbers with the latest
> > > stable release' branch, that's normally just one of the baselines.
> > > The more important baseline for ongoing development is the master
> > > branch's HEAD, which is also what people volunteering to test your
> > > patches would use. Anyone who reports would have to give at least
> > > two numbers -- performance with a branch's HEAD without patch
> > > applied and that with patch applied -- which can be enough in most
> > > cases to see the difference the patch makes. Sure, the numbers
> > > might change on each report, but that's fine I'd think. If you
> > > continue to develop against the stable branch, you might miss to
> > notice impact from any relevant developments in the master branch,
> > even developments which possibly require rethinking the architecture of your own changes, although maybe that
> rarely occurs.
> > >
> > > Thanks,
> > > Amit
--
Takashi Menjo <takashi.menjo@gmail.com>
Hi Gang,
I have tried to but yet cannot reproduce performance degrade you reported when inserting 328-byte records. So I think
thecondition of you and me would be different, such as steps to reproduce, postgresql.conf, installation setup, and so
on.
My results and condition are as follows. May I have your condition in more detail? Note that I refer to your "Storage
overApp Direct" as my "Original (PMEM)" and "NVWAL patch" to "Non-volatile WAL buffer."
Best regards,
Takashi
# Results
See the attached figure. In short, Non-volatile WAL buffer got better performance than Original (PMEM).
# Steps
Note that I ran postgres server and pgbench in a single-machine system but separated two NUMA nodes. PMEM and PCI SSD
forthe server process are on the server-side NUMA node.
01) Create a PMEM namespace (sudo ndctl create-namespace -f -t pmem -m fsdax -M dev -e namespace0.0)
02) Make an ext4 filesystem for PMEM then mount it with DAX option (sudo mkfs.ext4 -q -F /dev/pmem0 ; sudo mount -o dax
/dev/pmem0/mnt/pmem0)
03) Make another ext4 filesystem for PCIe SSD then mount it (sudo mkfs.ext4 -q -F /dev/nvme0n1 ; sudo mount
/dev/nvme0n1/mnt/nvme0n1)
04) Make /mnt/pmem0/pg_wal directory for WAL
05) Make /mnt/nvme0n1/pgdata directory for PGDATA
06) Run initdb (initdb --locale=C --encoding=UTF8 -X /mnt/pmem0/pg_wal ...)
- Also give -P /mnt/pmem0/pg_wal/nvwal -Q 81920 in the case of Non-volatile WAL buffer
07) Edit postgresql.conf as the attached one
- Please remove nvwal_* lines in the case of Original (PMEM)
08) Start postgres server process on NUMA node 0 (numactl -N 0 -m 0 -- pg_ctl -l pg.log start)
09) Create a database (createdb --locale=C --encoding=UTF8)
10) Initialize pgbench tables with s=50 (pgbench -i -s 50)
11) Change # characters of "filler" column of "pgbench_history" table to 300 (ALTER TABLE pgbench_history ALTER filler
TYPEcharacter(300);)
- This would make the row size of the table 328 bytes
12) Stop the postgres server process (pg_ctl -l pg.log -m smart stop)
13) Remount the PMEM and the PCIe SSD
14) Start postgres server process on NUMA node 0 again (numactl -N 0 -m 0 -- pg_ctl -l pg.log start)
15) Run pg_prewarm for all the four pgbench_* tables
16) Run pgbench on NUMA node 1 for 30 minutes (numactl -N 1 -m 1 -- pgbench -r -M prepared -T 1800 -c __ -j __)
- It executes the default tpcb-like transactions
I repeated all the steps three times for each (c,j) then got the median "tps = __ (including connections establishing)"
ofthe three as throughput and the "latency average = __ ms " of that time as average latency.
# Environment variables
export PGHOST=/tmp
export PGPORT=5432
export PGDATABASE="$USER"
export PGUSER="$USER"
export PGDATA=/mnt/nvme0n1/pgdata
# Setup
- System: HPE ProLiant DL380 Gen10
- CPU: Intel Xeon Gold 6240M x2 sockets (18 cores per socket; HT disabled by BIOS)
- DRAM: DDR4 2933MHz 192GiB/socket x2 sockets (32 GiB per channel x 6 channels per socket)
- Optane PMem: Apache Pass, AppDirect Mode, DDR4 2666MHz 1.5TiB/socket x2 sockets (256 GiB per channel x 6 channels per
socket;interleaving enabled)
- PCIe SSD: DC P4800X Series SSDPED1K750GA
- Distro: Ubuntu 20.04.1
- C compiler: gcc 9.3.0
- libc: glibc 2.31
- Linux kernel: 5.7 (vanilla)
- Filesystem: ext4 (DAX enabled when using Optane PMem)
- PMDK: 1.9
- PostgreSQL (Original): 14devel (200f610: Jul 26, 2020)
- PostgreSQL (Non-volatile WAL buffer): 14devel (200f610: Jul 26, 2020) + non-volatile WAL buffer patchset v4
--
Takashi Menjo <takashi.menjou.vg@hco.ntt.co.jp>
NTT Software Innovation Center
> -----Original Message-----
> From: Takashi Menjo <takashi.menjo@gmail.com>
> Sent: Thursday, September 24, 2020 2:38 AM
> To: Deng, Gang <gang.deng@intel.com>
> Cc: pgsql-hackers@postgresql.org; Takashi Menjo <takashi.menjou.vg@hco.ntt.co.jp>
> Subject: Re: [PoC] Non-volatile WAL buffer
>
> Hello Gang,
>
> Thank you for your report. I have not taken care of record size deeply yet, so your report is very interesting. I
will
> also have a test like yours then post results here.
>
> Regards,
> Takashi
>
>
> 2020年9月21日(月) 14:14 Deng, Gang <gang.deng@intel.com <mailto:gang.deng@intel.com> >:
>
>
> Hi Takashi,
>
>
>
> Thank you for the patch and work on accelerating PG performance with NVM. I applied the patch and made
> some performance test based on the patch v4. I stored database data files on NVMe SSD and stored WAL file on
> Intel PMem (NVM). I used two methods to store WAL file(s):
>
> 1. Leverage your patch to access PMem with libpmem (NVWAL patch).
>
> 2. Access PMem with legacy filesystem interface, that means use PMem as ordinary block device, no
> PG patch is required to access PMem (Storage over App Direct).
>
>
>
> I tried two insert scenarios:
>
> A. Insert small record (length of record to be inserted is 24 bytes), I think it is similar as your test
>
> B. Insert large record (length of record to be inserted is 328 bytes)
>
>
>
> My original purpose is to see higher performance gain in scenario B as it is more write intensive on WAL.
> But I observed that NVWAL patch method had ~5% performance improvement compared with Storage over App
> Direct method in scenario A, while had ~20% performance degradation in scenario B.
>
>
>
> I made further investigation on the test. I found that NVWAL patch can improve performance of XlogFlush
> function, but it may impact performance of CopyXlogRecordToWAL function. It may be related to the higher
> latency of memcpy to Intel PMem comparing with DRAM. Here are key data in my test:
>
>
>
> Scenario A (length of record to be inserted: 24 bytes per record):
>
> ==============================
>
> NVWAL
> SoAD
>
> ------------------------------------ ------- -------
>
> Througput (10^3 TPS) 310.5
> 296.0
>
> CPU Time % of CopyXlogRecordToWAL 0.4 0.2
>
> CPU Time % of XLogInsertRecord 1.5 0.8
>
> CPU Time % of XLogFlush 2.1 9.6
>
>
>
> Scenario B (length of record to be inserted: 328 bytes per record):
>
> ==============================
>
> NVWAL
> SoAD
>
> ------------------------------------ ------- -------
>
> Througput (10^3 TPS) 13.0
> 16.9
>
> CPU Time % of CopyXlogRecordToWAL 3.0 1.6
>
> CPU Time % of XLogInsertRecord 23.0 16.4
>
> CPU Time % of XLogFlush 2.3 5.9
>
>
>
> Best Regards,
>
> Gang
>
>
>
> From: Takashi Menjo <takashi.menjo@gmail.com <mailto:takashi.menjo@gmail.com> >
> Sent: Thursday, September 10, 2020 4:01 PM
> To: Takashi Menjo <takashi.menjou.vg@hco.ntt.co.jp <mailto:takashi.menjou.vg@hco.ntt.co.jp> >
> Cc: pgsql-hackers@postgresql.org <mailto:pgsql-hackers@postgresql.org>
> Subject: Re: [PoC] Non-volatile WAL buffer
>
>
>
> Rebased.
>
>
>
>
>
> 2020年6月24日(水) 16:44 Takashi Menjo <takashi.menjou.vg@hco.ntt.co.jp
> <mailto:takashi.menjou.vg@hco.ntt.co.jp> >:
>
> Dear hackers,
>
> I update my non-volatile WAL buffer's patchset to v3. Now we can use it in streaming replication
> mode.
>
> Updates from v2:
>
> - walreceiver supports non-volatile WAL buffer
> Now walreceiver stores received records directly to non-volatile WAL buffer if applicable.
>
> - pg_basebackup supports non-volatile WAL buffer
> Now pg_basebackup copies received WAL segments onto non-volatile WAL buffer if you run it with
> "nvwal" mode (-Fn).
> You should specify a new NVWAL path with --nvwal-path option. The path will be written to
> postgresql.auto.conf or recovery.conf. The size of the new NVWAL is same as the master's one.
>
>
> Best regards,
> Takashi
>
> --
> Takashi Menjo <takashi.menjou.vg@hco.ntt.co.jp <mailto:takashi.menjou.vg@hco.ntt.co.jp> >
> NTT Software Innovation Center
>
> > -----Original Message-----
> > From: Takashi Menjo <takashi.menjou.vg@hco.ntt.co.jp
> <mailto:takashi.menjou.vg@hco.ntt.co.jp> >
> > Sent: Wednesday, March 18, 2020 5:59 PM
> > To: 'PostgreSQL-development' <pgsql-hackers@postgresql.org
> <mailto:pgsql-hackers@postgresql.org> >
> > Cc: 'Robert Haas' <robertmhaas@gmail.com <mailto:robertmhaas@gmail.com> >; 'Heikki
> Linnakangas' <hlinnaka@iki.fi <mailto:hlinnaka@iki.fi> >; 'Amit Langote'
> > <amitlangote09@gmail.com <mailto:amitlangote09@gmail.com> >
> > Subject: RE: [PoC] Non-volatile WAL buffer
> >
> > Dear hackers,
> >
> > I rebased my non-volatile WAL buffer's patchset onto master. A new v2 patchset is attached
> to this mail.
> >
> > I also measured performance before and after patchset, varying -c/--client and -j/--jobs
> options of pgbench, for
> > each scaling factor s = 50 or 1000. The results are presented in the following tables and the
> attached charts.
> > Conditions, steps, and other details will be shown later.
> >
> >
> > Results (s=50)
> > ==============
> > Throughput [10^3 TPS] Average latency [ms]
> > ( c, j) before after before after
> > ------- --------------------- ---------------------
> > ( 8, 8) 35.7 37.1 (+3.9%) 0.224 0.216 (-3.6%)
> > (18,18) 70.9 74.7 (+5.3%) 0.254 0.241 (-5.1%)
> > (36,18) 76.0 80.8 (+6.3%) 0.473 0.446 (-5.7%)
> > (54,18) 75.5 81.8 (+8.3%) 0.715 0.660 (-7.7%)
> >
> >
> > Results (s=1000)
> > ================
> > Throughput [10^3 TPS] Average latency [ms]
> > ( c, j) before after before after
> > ------- --------------------- ---------------------
> > ( 8, 8) 37.4 40.1 (+7.3%) 0.214 0.199 (-7.0%)
> > (18,18) 79.3 86.7 (+9.3%) 0.227 0.208 (-8.4%)
> > (36,18) 87.2 95.5 (+9.5%) 0.413 0.377 (-8.7%)
> > (54,18) 86.8 94.8 (+9.3%) 0.622 0.569 (-8.5%)
> >
> >
> > Both throughput and average latency are improved for each scaling factor. Throughput seemed
> to almost reach
> > the upper limit when (c,j)=(36,18).
> >
> > The percentage in s=1000 case looks larger than in s=50 case. I think larger scaling factor
> leads to less
> > contentions on the same tables and/or indexes, that is, less lock and unlock operations. In such
> a situation,
> > write-ahead logging appears to be more significant for performance.
> >
> >
> > Conditions
> > ==========
> > - Use one physical server having 2 NUMA nodes (node 0 and 1)
> > - Pin postgres (server processes) to node 0 and pgbench to node 1
> > - 18 cores and 192GiB DRAM per node
> > - Use an NVMe SSD for PGDATA and an interleaved 6-in-1 NVDIMM-N set for pg_wal
> > - Both are installed on the server-side node, that is, node 0
> > - Both are formatted with ext4
> > - NVDIMM-N is mounted with "-o dax" option to enable Direct Access (DAX)
> > - Use the attached postgresql.conf
> > - Two new items nvwal_path and nvwal_size are used only after patch
> >
> >
> > Steps
> > =====
> > For each (c,j) pair, I did the following steps three times then I found the median of the three as
> a final result shown
> > in the tables above.
> >
> > (1) Run initdb with proper -D and -X options; and also give --nvwal-path and --nvwal-size
> options after patch
> > (2) Start postgres and create a database for pgbench tables
> > (3) Run "pgbench -i -s ___" to create tables (s = 50 or 1000)
> > (4) Stop postgres, remount filesystems, and start postgres again
> > (5) Execute pg_prewarm extension for all the four pgbench tables
> > (6) Run pgbench during 30 minutes
> >
> >
> > pgbench command line
> > ====================
> > $ pgbench -h /tmp -p 5432 -U username -r -M prepared -T 1800 -c ___ -j ___ dbname
> >
> > I gave no -b option to use the built-in "TPC-B (sort-of)" query.
> >
> >
> > Software
> > ========
> > - Distro: Ubuntu 18.04
> > - Kernel: Linux 5.4 (vanilla kernel)
> > - C Compiler: gcc 7.4.0
> > - PMDK: 1.7
> > - PostgreSQL: d677550 (master on Mar 3, 2020)
> >
> >
> > Hardware
> > ========
> > - System: HPE ProLiant DL380 Gen10
> > - CPU: Intel Xeon Gold 6154 (Skylake) x 2sockets
> > - DRAM: DDR4 2666MHz {32GiB/ch x 6ch}/socket x 2sockets
> > - NVDIMM-N: DDR4 2666MHz {16GiB/ch x 6ch}/socket x 2sockets
> > - NVMe SSD: Intel Optane DC P4800X Series SSDPED1K750GA
> >
> >
> > Best regards,
> > Takashi
> >
> > --
> > Takashi Menjo <takashi.menjou.vg@hco.ntt.co.jp <mailto:takashi.menjou.vg@hco.ntt.co.jp> >
> NTT Software Innovation Center
> >
> > > -----Original Message-----
> > > From: Takashi Menjo <takashi.menjou.vg@hco.ntt.co.jp
> <mailto:takashi.menjou.vg@hco.ntt.co.jp> >
> > > Sent: Thursday, February 20, 2020 6:30 PM
> > > To: 'Amit Langote' <amitlangote09@gmail.com <mailto:amitlangote09@gmail.com> >
> > > Cc: 'Robert Haas' <robertmhaas@gmail.com <mailto:robertmhaas@gmail.com> >; 'Heikki
> Linnakangas' <hlinnaka@iki.fi <mailto:hlinnaka@iki.fi> >;
> > 'PostgreSQL-development'
> > > <pgsql-hackers@postgresql.org <mailto:pgsql-hackers@postgresql.org> >
> > > Subject: RE: [PoC] Non-volatile WAL buffer
> > >
> > > Dear Amit,
> > >
> > > Thank you for your advice. Exactly, it's so to speak "do as the hackers do when in pgsql"...
> > >
> > > I'm rebasing my branch onto master. I'll submit an updated patchset and performance report
> later.
> > >
> > > Best regards,
> > > Takashi
> > >
> > > --
> > > Takashi Menjo <takashi.menjou.vg@hco.ntt.co.jp <mailto:takashi.menjou.vg@hco.ntt.co.jp>
> > NTT Software
> > > Innovation Center
> > >
> > > > -----Original Message-----
> > > > From: Amit Langote <amitlangote09@gmail.com <mailto:amitlangote09@gmail.com> >
> > > > Sent: Monday, February 17, 2020 5:21 PM
> > > > To: Takashi Menjo <takashi.menjou.vg@hco.ntt.co.jp
> <mailto:takashi.menjou.vg@hco.ntt.co.jp> >
> > > > Cc: Robert Haas <robertmhaas@gmail.com <mailto:robertmhaas@gmail.com> >; Heikki
> Linnakangas
> > > > <hlinnaka@iki.fi <mailto:hlinnaka@iki.fi> >; PostgreSQL-development
> > > > <pgsql-hackers@postgresql.org <mailto:pgsql-hackers@postgresql.org> >
> > > > Subject: Re: [PoC] Non-volatile WAL buffer
> > > >
> > > > Hello,
> > > >
> > > > On Mon, Feb 17, 2020 at 4:16 PM Takashi Menjo <takashi.menjou.vg@hco.ntt.co.jp
> <mailto:takashi.menjou.vg@hco.ntt.co.jp> > wrote:
> > > > > Hello Amit,
> > > > >
> > > > > > I apologize for not having any opinion on the patches
> > > > > > themselves, but let me point out that it's better to base these
> > > > > > patches on HEAD (master branch) than REL_12_0, because all new
> > > > > > code is committed to the master branch, whereas stable branches
> > > > > > such as
> > > > > > REL_12_0 only receive bug fixes. Do you have any
> > > > specific reason to be working on REL_12_0?
> > > > >
> > > > > Yes, because I think it's human-friendly to reproduce and discuss
> > > > > performance measurement. Of course I know
> > > > all new accepted patches are merged into master's HEAD, not stable
> > > > branches and not even release tags, so I'm aware of rebasing my
> > > > patchset onto master sooner or later. However, if someone,
> > > > including me, says that s/he applies my patchset to "master" and
> > > > measures its performance, we have to pay attention to which commit the "master"
> > > > really points to. Although we have sha1 hashes to specify which
> > > > commit, we should check whether the specific commit on master has
> > > > patches affecting performance or not
> > > because master's HEAD gets new patches day by day. On the other hand,
> > > a release tag clearly points the commit all we probably know. Also we
> > > can check more easily the features and improvements by using release notes and user
> manuals.
> > > >
> > > > Thanks for clarifying. I see where you're coming from.
> > > >
> > > > While I do sometimes see people reporting numbers with the latest
> > > > stable release' branch, that's normally just one of the baselines.
> > > > The more important baseline for ongoing development is the master
> > > > branch's HEAD, which is also what people volunteering to test your
> > > > patches would use. Anyone who reports would have to give at least
> > > > two numbers -- performance with a branch's HEAD without patch
> > > > applied and that with patch applied -- which can be enough in most
> > > > cases to see the difference the patch makes. Sure, the numbers
> > > > might change on each report, but that's fine I'd think. If you
> > > > continue to develop against the stable branch, you might miss to
> > > notice impact from any relevant developments in the master branch,
> > > even developments which possibly require rethinking the architecture of your own changes,
> although maybe that
> > rarely occurs.
> > > >
> > > > Thanks,
> > > > Amit
>
>
>
>
>
>
> --
>
> Takashi Menjo <takashi.menjo@gmail.com <mailto:takashi.menjo@gmail.com> >
>
>
>
> --
>
> Takashi Menjo <takashi.menjo@gmail.com <mailto:takashi.menjo@gmail.com> >
Attachment
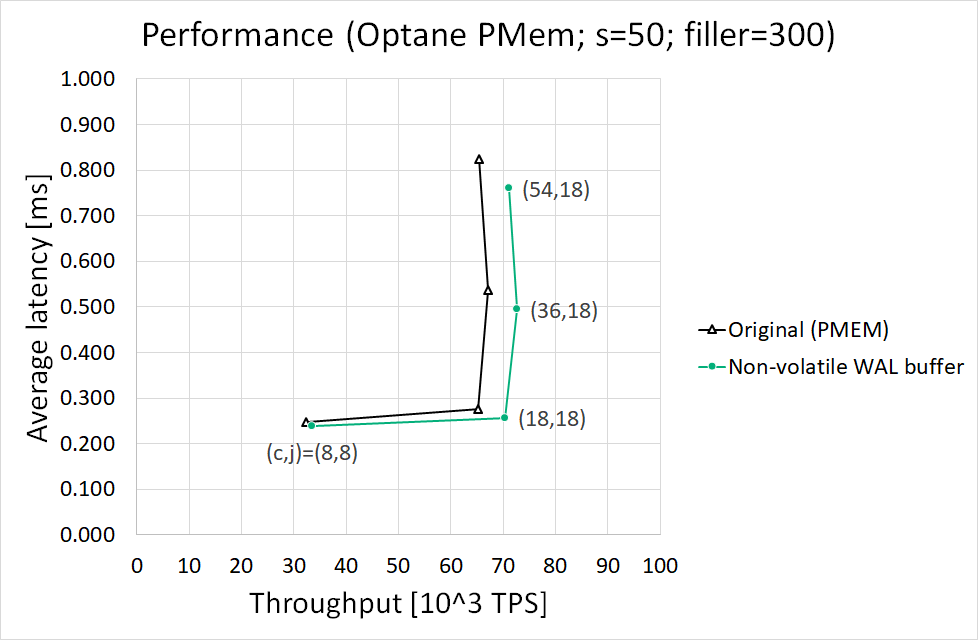{kind=link}
Hi Takashi,
There are some differences between our HW/SW configuration and test steps. I attached postgresql.conf I used for your
reference.I would like to try postgresql.conf and steps you provided in the later days to see if I can find cause.
I also ran pgbench and postgres server on the same server but on different NUMA node, and ensure server process and
PMEMon the same NUMA node. I used similar steps are yours from step 1 to 9. But some difference in later steps, major
ofthem are:
In step 10), I created a database and table for test by:
#create database:
psql -c "create database insert_bench;"
#create table:
psql -d insert_bench -c "create table test(crt_time timestamp, info text default
'75feba6d5ca9ff65d09af35a67fe962a4e3fa5ef279f94df6696bee65f4529a4bbb03ae56c3b5b86c22b447fc48da894740ed1a9d518a9646b3a751a57acaca1142ccfc945b1082b40043e3f83f8b7605b5a55fcd7eb8fc1d0475c7fe465477da47d96957849327731ae76322f440d167725d2e2bbb60313150a4f69d9a8c9e86f9d79a742e7a35bf159f670e54413fb89ff81b8e5e8ab215c3ddfd00bb6aeb4');"
in step 15), I did not use pg_prewarm, but just ran pg_bench for 180 seconds to warm up.
In step 16), I ran pgbench using command: pgbench -M prepared -n -r -P 10 -f ./test.sql -T 600 -c _ -j _ insert_bench.
(test.sqlcan be found in attachment)
For HW/SW conf, the major differences are:
CPU: I used Xeon 8268 (24c@2.9Ghz, HT enabled)
OS Distro: CentOS 8.2.2004
Kernel: 4.18.0-193.6.3.el8_2.x86_64
GCC: 8.3.1
Best regards
Gang
-----Original Message-----
From: Takashi Menjo <takashi.menjou.vg@hco.ntt.co.jp>
Sent: Tuesday, October 6, 2020 4:49 PM
To: Deng, Gang <gang.deng@intel.com>
Cc: pgsql-hackers@postgresql.org; 'Takashi Menjo' <takashi.menjo@gmail.com>
Subject: RE: [PoC] Non-volatile WAL buffer
Hi Gang,
I have tried to but yet cannot reproduce performance degrade you reported when inserting 328-byte records. So I think
thecondition of you and me would be different, such as steps to reproduce, postgresql.conf, installation setup, and so
on.
My results and condition are as follows. May I have your condition in more detail? Note that I refer to your "Storage
overApp Direct" as my "Original (PMEM)" and "NVWAL patch" to "Non-volatile WAL buffer."
Best regards,
Takashi
# Results
See the attached figure. In short, Non-volatile WAL buffer got better performance than Original (PMEM).
# Steps
Note that I ran postgres server and pgbench in a single-machine system but separated two NUMA nodes. PMEM and PCI SSD
forthe server process are on the server-side NUMA node.
01) Create a PMEM namespace (sudo ndctl create-namespace -f -t pmem -m fsdax -M dev -e namespace0.0)
02) Make an ext4 filesystem for PMEM then mount it with DAX option (sudo mkfs.ext4 -q -F /dev/pmem0 ; sudo mount -o dax
/dev/pmem0/mnt/pmem0)
03) Make another ext4 filesystem for PCIe SSD then mount it (sudo mkfs.ext4 -q -F /dev/nvme0n1 ; sudo mount
/dev/nvme0n1/mnt/nvme0n1)
04) Make /mnt/pmem0/pg_wal directory for WAL
05) Make /mnt/nvme0n1/pgdata directory for PGDATA
06) Run initdb (initdb --locale=C --encoding=UTF8 -X /mnt/pmem0/pg_wal ...)
- Also give -P /mnt/pmem0/pg_wal/nvwal -Q 81920 in the case of Non-volatile WAL buffer
07) Edit postgresql.conf as the attached one
- Please remove nvwal_* lines in the case of Original (PMEM)
08) Start postgres server process on NUMA node 0 (numactl -N 0 -m 0 -- pg_ctl -l pg.log start)
09) Create a database (createdb --locale=C --encoding=UTF8)
10) Initialize pgbench tables with s=50 (pgbench -i -s 50)
11) Change # characters of "filler" column of "pgbench_history" table to 300 (ALTER TABLE pgbench_history ALTER filler
TYPEcharacter(300);)
- This would make the row size of the table 328 bytes
12) Stop the postgres server process (pg_ctl -l pg.log -m smart stop)
13) Remount the PMEM and the PCIe SSD
14) Start postgres server process on NUMA node 0 again (numactl -N 0 -m 0 -- pg_ctl -l pg.log start)
15) Run pg_prewarm for all the four pgbench_* tables
16) Run pgbench on NUMA node 1 for 30 minutes (numactl -N 1 -m 1 -- pgbench -r -M prepared -T 1800 -c __ -j __)
- It executes the default tpcb-like transactions
I repeated all the steps three times for each (c,j) then got the median "tps = __ (including connections establishing)"
ofthe three as throughput and the "latency average = __ ms " of that time as average latency.
# Environment variables
export PGHOST=/tmp
export PGPORT=5432
export PGDATABASE="$USER"
export PGUSER="$USER"
export PGDATA=/mnt/nvme0n1/pgdata
# Setup
- System: HPE ProLiant DL380 Gen10
- CPU: Intel Xeon Gold 6240M x2 sockets (18 cores per socket; HT disabled by BIOS)
- DRAM: DDR4 2933MHz 192GiB/socket x2 sockets (32 GiB per channel x 6 channels per socket)
- Optane PMem: Apache Pass, AppDirect Mode, DDR4 2666MHz 1.5TiB/socket x2 sockets (256 GiB per channel x 6 channels per
socket;interleaving enabled)
- PCIe SSD: DC P4800X Series SSDPED1K750GA
- Distro: Ubuntu 20.04.1
- C compiler: gcc 9.3.0
- libc: glibc 2.31
- Linux kernel: 5.7 (vanilla)
- Filesystem: ext4 (DAX enabled when using Optane PMem)
- PMDK: 1.9
- PostgreSQL (Original): 14devel (200f610: Jul 26, 2020)
- PostgreSQL (Non-volatile WAL buffer): 14devel (200f610: Jul 26, 2020) + non-volatile WAL buffer patchset v4
--
Takashi Menjo <takashi.menjou.vg@hco.ntt.co.jp> NTT Software Innovation Center
> -----Original Message-----
> From: Takashi Menjo <takashi.menjo@gmail.com>
> Sent: Thursday, September 24, 2020 2:38 AM
> To: Deng, Gang <gang.deng@intel.com>
> Cc: pgsql-hackers@postgresql.org; Takashi Menjo
> <takashi.menjou.vg@hco.ntt.co.jp>
> Subject: Re: [PoC] Non-volatile WAL buffer
>
> Hello Gang,
>
> Thank you for your report. I have not taken care of record size deeply
> yet, so your report is very interesting. I will also have a test like yours then post results here.
>
> Regards,
> Takashi
>
>
> 2020年9月21日(月) 14:14 Deng, Gang <gang.deng@intel.com <mailto:gang.deng@intel.com> >:
>
>
> Hi Takashi,
>
>
>
> Thank you for the patch and work on accelerating PG performance with
> NVM. I applied the patch and made some performance test based on the
> patch v4. I stored database data files on NVMe SSD and stored WAL file on Intel PMem (NVM). I used two methods to
storeWAL file(s):
>
> 1. Leverage your patch to access PMem with libpmem (NVWAL patch).
>
> 2. Access PMem with legacy filesystem interface, that means use PMem as ordinary block device, no
> PG patch is required to access PMem (Storage over App Direct).
>
>
>
> I tried two insert scenarios:
>
> A. Insert small record (length of record to be inserted is 24 bytes), I think it is similar as your test
>
> B. Insert large record (length of record to be inserted is 328 bytes)
>
>
>
> My original purpose is to see higher performance gain in scenario B as it is more write intensive on WAL.
> But I observed that NVWAL patch method had ~5% performance improvement
> compared with Storage over App Direct method in scenario A, while had ~20% performance degradation in scenario B.
>
>
>
> I made further investigation on the test. I found that NVWAL patch
> can improve performance of XlogFlush function, but it may impact
> performance of CopyXlogRecordToWAL function. It may be related to the higher latency of memcpy to Intel PMem
comparingwith DRAM. Here are key data in my test:
>
>
>
> Scenario A (length of record to be inserted: 24 bytes per record):
>
> ==============================
>
>
> NVWAL SoAD
>
> ------------------------------------ ------- -------
>
> Througput (10^3 TPS) 310.5
> 296.0
>
> CPU Time % of CopyXlogRecordToWAL 0.4 0.2
>
> CPU Time % of XLogInsertRecord 1.5 0.8
>
> CPU Time % of XLogFlush 2.1 9.6
>
>
>
> Scenario B (length of record to be inserted: 328 bytes per record):
>
> ==============================
>
>
> NVWAL SoAD
>
> ------------------------------------ ------- -------
>
> Througput (10^3 TPS) 13.0
> 16.9
>
> CPU Time % of CopyXlogRecordToWAL 3.0 1.6
>
> CPU Time % of XLogInsertRecord 23.0 16.4
>
> CPU Time % of XLogFlush 2.3 5.9
>
>
>
> Best Regards,
>
> Gang
>
>
>
> From: Takashi Menjo <takashi.menjo@gmail.com <mailto:takashi.menjo@gmail.com> >
> Sent: Thursday, September 10, 2020 4:01 PM
> To: Takashi Menjo <takashi.menjou.vg@hco.ntt.co.jp <mailto:takashi.menjou.vg@hco.ntt.co.jp> >
> Cc: pgsql-hackers@postgresql.org <mailto:pgsql-hackers@postgresql.org>
> Subject: Re: [PoC] Non-volatile WAL buffer
>
>
>
> Rebased.
>
>
>
>
>
> 2020年6月24日(水) 16:44 Takashi Menjo <takashi.menjou.vg@hco.ntt.co.jp
> <mailto:takashi.menjou.vg@hco.ntt.co.jp> >:
>
> Dear hackers,
>
> I update my non-volatile WAL buffer's patchset to v3. Now we can
> use it in streaming replication mode.
>
> Updates from v2:
>
> - walreceiver supports non-volatile WAL buffer
> Now walreceiver stores received records directly to non-volatile WAL buffer if applicable.
>
> - pg_basebackup supports non-volatile WAL buffer
> Now pg_basebackup copies received WAL segments onto non-volatile WAL
> buffer if you run it with "nvwal" mode (-Fn).
> You should specify a new NVWAL path with --nvwal-path option. The
> path will be written to postgresql.auto.conf or recovery.conf. The size of the new NVWAL is same as the master's
one.
>
>
> Best regards,
> Takashi
>
> --
> Takashi Menjo <takashi.menjou.vg@hco.ntt.co.jp <mailto:takashi.menjou.vg@hco.ntt.co.jp> >
> NTT Software Innovation Center
>
> > -----Original Message-----
> > From: Takashi Menjo <takashi.menjou.vg@hco.ntt.co.jp
> <mailto:takashi.menjou.vg@hco.ntt.co.jp> >
> > Sent: Wednesday, March 18, 2020 5:59 PM
> > To: 'PostgreSQL-development' <pgsql-hackers@postgresql.org
> <mailto:pgsql-hackers@postgresql.org> >
> > Cc: 'Robert Haas' <robertmhaas@gmail.com
> <mailto:robertmhaas@gmail.com> >; 'Heikki Linnakangas' <hlinnaka@iki.fi <mailto:hlinnaka@iki.fi> >; 'Amit Langote'
> > <amitlangote09@gmail.com <mailto:amitlangote09@gmail.com> >
> > Subject: RE: [PoC] Non-volatile WAL buffer
> >
> > Dear hackers,
> >
> > I rebased my non-volatile WAL buffer's patchset onto master. A
> new v2 patchset is attached to this mail.
> >
> > I also measured performance before and after patchset, varying
> -c/--client and -j/--jobs options of pgbench, for
> > each scaling factor s = 50 or 1000. The results are presented in
> the following tables and the attached charts.
> > Conditions, steps, and other details will be shown later.
> >
> >
> > Results (s=50)
> > ==============
> > Throughput [10^3 TPS] Average latency [ms]
> > ( c, j) before after before after
> > ------- --------------------- ---------------------
> > ( 8, 8) 35.7 37.1 (+3.9%) 0.224 0.216 (-3.6%)
> > (18,18) 70.9 74.7 (+5.3%) 0.254 0.241 (-5.1%)
> > (36,18) 76.0 80.8 (+6.3%) 0.473 0.446 (-5.7%)
> > (54,18) 75.5 81.8 (+8.3%) 0.715 0.660 (-7.7%)
> >
> >
> > Results (s=1000)
> > ================
> > Throughput [10^3 TPS] Average latency [ms]
> > ( c, j) before after before after
> > ------- --------------------- ---------------------
> > ( 8, 8) 37.4 40.1 (+7.3%) 0.214 0.199 (-7.0%)
> > (18,18) 79.3 86.7 (+9.3%) 0.227 0.208 (-8.4%)
> > (36,18) 87.2 95.5 (+9.5%) 0.413 0.377 (-8.7%)
> > (54,18) 86.8 94.8 (+9.3%) 0.622 0.569 (-8.5%)
> >
> >
> > Both throughput and average latency are improved for each scaling
> factor. Throughput seemed to almost reach
> > the upper limit when (c,j)=(36,18).
> >
> > The percentage in s=1000 case looks larger than in s=50 case. I
> think larger scaling factor leads to less
> > contentions on the same tables and/or indexes, that is, less lock
> and unlock operations. In such a situation,
> > write-ahead logging appears to be more significant for performance.
> >
> >
> > Conditions
> > ==========
> > - Use one physical server having 2 NUMA nodes (node 0 and 1)
> > - Pin postgres (server processes) to node 0 and pgbench to node 1
> > - 18 cores and 192GiB DRAM per node
> > - Use an NVMe SSD for PGDATA and an interleaved 6-in-1 NVDIMM-N set for pg_wal
> > - Both are installed on the server-side node, that is, node 0
> > - Both are formatted with ext4
> > - NVDIMM-N is mounted with "-o dax" option to enable Direct Access (DAX)
> > - Use the attached postgresql.conf
> > - Two new items nvwal_path and nvwal_size are used only after patch
> >
> >
> > Steps
> > =====
> > For each (c,j) pair, I did the following steps three times then I
> found the median of the three as a final result shown
> > in the tables above.
> >
> > (1) Run initdb with proper -D and -X options; and also give
> --nvwal-path and --nvwal-size options after patch
> > (2) Start postgres and create a database for pgbench tables
> > (3) Run "pgbench -i -s ___" to create tables (s = 50 or 1000)
> > (4) Stop postgres, remount filesystems, and start postgres again
> > (5) Execute pg_prewarm extension for all the four pgbench tables
> > (6) Run pgbench during 30 minutes
> >
> >
> > pgbench command line
> > ====================
> > $ pgbench -h /tmp -p 5432 -U username -r -M prepared -T 1800 -c ___ -j ___ dbname
> >
> > I gave no -b option to use the built-in "TPC-B (sort-of)" query.
> >
> >
> > Software
> > ========
> > - Distro: Ubuntu 18.04
> > - Kernel: Linux 5.4 (vanilla kernel)
> > - C Compiler: gcc 7.4.0
> > - PMDK: 1.7
> > - PostgreSQL: d677550 (master on Mar 3, 2020)
> >
> >
> > Hardware
> > ========
> > - System: HPE ProLiant DL380 Gen10
> > - CPU: Intel Xeon Gold 6154 (Skylake) x 2sockets
> > - DRAM: DDR4 2666MHz {32GiB/ch x 6ch}/socket x 2sockets
> > - NVDIMM-N: DDR4 2666MHz {16GiB/ch x 6ch}/socket x 2sockets
> > - NVMe SSD: Intel Optane DC P4800X Series SSDPED1K750GA
> >
> >
> > Best regards,
> > Takashi
> >
> > --
> > Takashi Menjo <takashi.menjou.vg@hco.ntt.co.jp
> <mailto:takashi.menjou.vg@hco.ntt.co.jp> > NTT Software Innovation Center
> >
> > > -----Original Message-----
> > > From: Takashi Menjo <takashi.menjou.vg@hco.ntt.co.jp
> <mailto:takashi.menjou.vg@hco.ntt.co.jp> >
> > > Sent: Thursday, February 20, 2020 6:30 PM
> > > To: 'Amit Langote' <amitlangote09@gmail.com <mailto:amitlangote09@gmail.com> >
> > > Cc: 'Robert Haas' <robertmhaas@gmail.com
> <mailto:robertmhaas@gmail.com> >; 'Heikki Linnakangas' <hlinnaka@iki.fi <mailto:hlinnaka@iki.fi> >;
> > 'PostgreSQL-development'
> > > <pgsql-hackers@postgresql.org <mailto:pgsql-hackers@postgresql.org> >
> > > Subject: RE: [PoC] Non-volatile WAL buffer
> > >
> > > Dear Amit,
> > >
> > > Thank you for your advice. Exactly, it's so to speak "do as the hackers do when in pgsql"...
> > >
> > > I'm rebasing my branch onto master. I'll submit an updated
> patchset and performance report later.
> > >
> > > Best regards,
> > > Takashi
> > >
> > > --
> > > Takashi Menjo <takashi.menjou.vg@hco.ntt.co.jp
> <mailto:takashi.menjou.vg@hco.ntt.co.jp>
> > NTT Software
> > > Innovation Center
> > >
> > > > -----Original Message-----
> > > > From: Amit Langote <amitlangote09@gmail.com <mailto:amitlangote09@gmail.com> >
> > > > Sent: Monday, February 17, 2020 5:21 PM
> > > > To: Takashi Menjo <takashi.menjou.vg@hco.ntt.co.jp
> <mailto:takashi.menjou.vg@hco.ntt.co.jp> >
> > > > Cc: Robert Haas <robertmhaas@gmail.com
> <mailto:robertmhaas@gmail.com> >; Heikki Linnakangas
> > > > <hlinnaka@iki.fi <mailto:hlinnaka@iki.fi> >; PostgreSQL-development
> > > > <pgsql-hackers@postgresql.org <mailto:pgsql-hackers@postgresql.org> >
> > > > Subject: Re: [PoC] Non-volatile WAL buffer
> > > >
> > > > Hello,
> > > >
> > > > On Mon, Feb 17, 2020 at 4:16 PM Takashi Menjo
> <takashi.menjou.vg@hco.ntt.co.jp <mailto:takashi.menjou.vg@hco.ntt.co.jp> > wrote:
> > > > > Hello Amit,
> > > > >
> > > > > > I apologize for not having any opinion on the patches
> > > > > > themselves, but let me point out that it's better to base these
> > > > > > patches on HEAD (master branch) than REL_12_0, because all new
> > > > > > code is committed to the master branch, whereas stable branches
> > > > > > such as
> > > > > > REL_12_0 only receive bug fixes. Do you have any
> > > > specific reason to be working on REL_12_0?
> > > > >
> > > > > Yes, because I think it's human-friendly to reproduce and discuss
> > > > > performance measurement. Of course I know
> > > > all new accepted patches are merged into master's HEAD, not stable
> > > > branches and not even release tags, so I'm aware of rebasing my
> > > > patchset onto master sooner or later. However, if someone,
> > > > including me, says that s/he applies my patchset to "master" and
> > > > measures its performance, we have to pay attention to which commit the "master"
> > > > really points to. Although we have sha1 hashes to specify which
> > > > commit, we should check whether the specific commit on master has
> > > > patches affecting performance or not
> > > because master's HEAD gets new patches day by day. On the other hand,
> > > a release tag clearly points the commit all we probably know. Also we
> > > can check more easily the features and improvements by using
> release notes and user manuals.
> > > >
> > > > Thanks for clarifying. I see where you're coming from.
> > > >
> > > > While I do sometimes see people reporting numbers with the latest
> > > > stable release' branch, that's normally just one of the baselines.
> > > > The more important baseline for ongoing development is the master
> > > > branch's HEAD, which is also what people volunteering to test your
> > > > patches would use. Anyone who reports would have to give at least
> > > > two numbers -- performance with a branch's HEAD without patch
> > > > applied and that with patch applied -- which can be enough in most
> > > > cases to see the difference the patch makes. Sure, the numbers
> > > > might change on each report, but that's fine I'd think. If you
> > > > continue to develop against the stable branch, you might miss to
> > > notice impact from any relevant developments in the master branch,
> > > even developments which possibly require rethinking the
> architecture of your own changes, although maybe that
> > rarely occurs.
> > > >
> > > > Thanks,
> > > > Amit
>
>
>
>
>
>
> --
>
> Takashi Menjo <takashi.menjo@gmail.com
> <mailto:takashi.menjo@gmail.com> >
>
>
>
> --
>
> Takashi Menjo <takashi.menjo@gmail.com
> <mailto:takashi.menjo@gmail.com> >
Attachment
Hi Gang,
Thanks. I have tried to reproduce performance degrade, using your configuration, query, and steps. And today, I got
someresults that Original (PMEM) achieved better performance than Non-volatile WAL buffer on my Ubuntu environment. Now
Iwork for further investigation.
Best regards,
Takashi
--
Takashi Menjo <takashi.menjou.vg@hco.ntt.co.jp>
NTT Software Innovation Center
> -----Original Message-----
> From: Deng, Gang <gang.deng@intel.com>
> Sent: Friday, October 9, 2020 3:10 PM
> To: Takashi Menjo <takashi.menjou.vg@hco.ntt.co.jp>
> Cc: pgsql-hackers@postgresql.org; 'Takashi Menjo' <takashi.menjo@gmail.com>
> Subject: RE: [PoC] Non-volatile WAL buffer
>
> Hi Takashi,
>
> There are some differences between our HW/SW configuration and test steps. I attached postgresql.conf I used
> for your reference. I would like to try postgresql.conf and steps you provided in the later days to see if I can find
> cause.
>
> I also ran pgbench and postgres server on the same server but on different NUMA node, and ensure server process
> and PMEM on the same NUMA node. I used similar steps are yours from step 1 to 9. But some difference in later
> steps, major of them are:
>
> In step 10), I created a database and table for test by:
> #create database:
> psql -c "create database insert_bench;"
> #create table:
> psql -d insert_bench -c "create table test(crt_time timestamp, info text default
> '75feba6d5ca9ff65d09af35a67fe962a4e3fa5ef279f94df6696bee65f4529a4bbb03ae56c3b5b86c22b447fc
> 48da894740ed1a9d518a9646b3a751a57acaca1142ccfc945b1082b40043e3f83f8b7605b5a55fcd7eb8fc1
> d0475c7fe465477da47d96957849327731ae76322f440d167725d2e2bbb60313150a4f69d9a8c9e86f9d7
> 9a742e7a35bf159f670e54413fb89ff81b8e5e8ab215c3ddfd00bb6aeb4');"
>
> in step 15), I did not use pg_prewarm, but just ran pg_bench for 180 seconds to warm up.
> In step 16), I ran pgbench using command: pgbench -M prepared -n -r -P 10 -f ./test.sql -T 600 -c _ -j _
> insert_bench. (test.sql can be found in attachment)
>
> For HW/SW conf, the major differences are:
> CPU: I used Xeon 8268 (24c@2.9Ghz, HT enabled) OS Distro: CentOS 8.2.2004
> Kernel: 4.18.0-193.6.3.el8_2.x86_64
> GCC: 8.3.1
>
> Best regards
> Gang
>
> -----Original Message-----
> From: Takashi Menjo <takashi.menjou.vg@hco.ntt.co.jp>
> Sent: Tuesday, October 6, 2020 4:49 PM
> To: Deng, Gang <gang.deng@intel.com>
> Cc: pgsql-hackers@postgresql.org; 'Takashi Menjo' <takashi.menjo@gmail.com>
> Subject: RE: [PoC] Non-volatile WAL buffer
>
> Hi Gang,
>
> I have tried to but yet cannot reproduce performance degrade you reported when inserting 328-byte records. So
> I think the condition of you and me would be different, such as steps to reproduce, postgresql.conf, installation
> setup, and so on.
>
> My results and condition are as follows. May I have your condition in more detail? Note that I refer to your "Storage
> over App Direct" as my "Original (PMEM)" and "NVWAL patch" to "Non-volatile WAL buffer."
>
> Best regards,
> Takashi
>
>
> # Results
> See the attached figure. In short, Non-volatile WAL buffer got better performance than Original (PMEM).
>
> # Steps
> Note that I ran postgres server and pgbench in a single-machine system but separated two NUMA nodes. PMEM
> and PCI SSD for the server process are on the server-side NUMA node.
>
> 01) Create a PMEM namespace (sudo ndctl create-namespace -f -t pmem -m fsdax -M dev -e namespace0.0)
> 02) Make an ext4 filesystem for PMEM then mount it with DAX option (sudo mkfs.ext4 -q -F /dev/pmem0 ; sudo
> mount -o dax /dev/pmem0 /mnt/pmem0)
> 03) Make another ext4 filesystem for PCIe SSD then mount it (sudo mkfs.ext4 -q -F /dev/nvme0n1 ; sudo mount
> /dev/nvme0n1 /mnt/nvme0n1)
> 04) Make /mnt/pmem0/pg_wal directory for WAL
> 05) Make /mnt/nvme0n1/pgdata directory for PGDATA
> 06) Run initdb (initdb --locale=C --encoding=UTF8 -X /mnt/pmem0/pg_wal ...)
> - Also give -P /mnt/pmem0/pg_wal/nvwal -Q 81920 in the case of Non-volatile WAL buffer
> 07) Edit postgresql.conf as the attached one
> - Please remove nvwal_* lines in the case of Original (PMEM)
> 08) Start postgres server process on NUMA node 0 (numactl -N 0 -m 0 -- pg_ctl -l pg.log start)
> 09) Create a database (createdb --locale=C --encoding=UTF8)
> 10) Initialize pgbench tables with s=50 (pgbench -i -s 50)
> 11) Change # characters of "filler" column of "pgbench_history" table to 300 (ALTER TABLE pgbench_history
> ALTER filler TYPE character(300);)
> - This would make the row size of the table 328 bytes
> 12) Stop the postgres server process (pg_ctl -l pg.log -m smart stop)
> 13) Remount the PMEM and the PCIe SSD
> 14) Start postgres server process on NUMA node 0 again (numactl -N 0 -m 0 -- pg_ctl -l pg.log start)
> 15) Run pg_prewarm for all the four pgbench_* tables
> 16) Run pgbench on NUMA node 1 for 30 minutes (numactl -N 1 -m 1 -- pgbench -r -M prepared -T 1800 -c __
> -j __)
> - It executes the default tpcb-like transactions
>
> I repeated all the steps three times for each (c,j) then got the median "tps = __ (including connections
> establishing)" of the three as throughput and the "latency average = __ ms " of that time as average latency.
>
> # Environment variables
> export PGHOST=/tmp
> export PGPORT=5432
> export PGDATABASE="$USER"
> export PGUSER="$USER"
> export PGDATA=/mnt/nvme0n1/pgdata
>
> # Setup
> - System: HPE ProLiant DL380 Gen10
> - CPU: Intel Xeon Gold 6240M x2 sockets (18 cores per socket; HT disabled by BIOS)
> - DRAM: DDR4 2933MHz 192GiB/socket x2 sockets (32 GiB per channel x 6 channels per socket)
> - Optane PMem: Apache Pass, AppDirect Mode, DDR4 2666MHz 1.5TiB/socket x2 sockets (256 GiB per channel
> x 6 channels per socket; interleaving enabled)
> - PCIe SSD: DC P4800X Series SSDPED1K750GA
> - Distro: Ubuntu 20.04.1
> - C compiler: gcc 9.3.0
> - libc: glibc 2.31
> - Linux kernel: 5.7 (vanilla)
> - Filesystem: ext4 (DAX enabled when using Optane PMem)
> - PMDK: 1.9
> - PostgreSQL (Original): 14devel (200f610: Jul 26, 2020)
> - PostgreSQL (Non-volatile WAL buffer): 14devel (200f610: Jul 26, 2020) + non-volatile WAL buffer patchset
> v4
>
> --
> Takashi Menjo <takashi.menjou.vg@hco.ntt.co.jp> NTT Software Innovation Center
>
> > -----Original Message-----
> > From: Takashi Menjo <takashi.menjo@gmail.com>
> > Sent: Thursday, September 24, 2020 2:38 AM
> > To: Deng, Gang <gang.deng@intel.com>
> > Cc: pgsql-hackers@postgresql.org; Takashi Menjo
> > <takashi.menjou.vg@hco.ntt.co.jp>
> > Subject: Re: [PoC] Non-volatile WAL buffer
> >
> > Hello Gang,
> >
> > Thank you for your report. I have not taken care of record size deeply
> > yet, so your report is very interesting. I will also have a test like yours then post results here.
> >
> > Regards,
> > Takashi
> >
> >
> > 2020年9月21日(月) 14:14 Deng, Gang <gang.deng@intel.com <mailto:gang.deng@intel.com> >:
> >
> >
> > Hi Takashi,
> >
> >
> >
> > Thank you for the patch and work on accelerating PG performance with
> > NVM. I applied the patch and made some performance test based on the
> > patch v4. I stored database data files on NVMe SSD and stored WAL file on Intel PMem (NVM). I used two
> methods to store WAL file(s):
> >
> > 1. Leverage your patch to access PMem with libpmem (NVWAL patch).
> >
> > 2. Access PMem with legacy filesystem interface, that means use PMem as ordinary block device, no
> > PG patch is required to access PMem (Storage over App Direct).
> >
> >
> >
> > I tried two insert scenarios:
> >
> > A. Insert small record (length of record to be inserted is 24 bytes), I think it is similar as your test
> >
> > B. Insert large record (length of record to be inserted is 328 bytes)
> >
> >
> >
> > My original purpose is to see higher performance gain in scenario B as it is more write intensive on WAL.
> > But I observed that NVWAL patch method had ~5% performance improvement
> > compared with Storage over App Direct method in scenario A, while had ~20% performance degradation in
> scenario B.
> >
> >
> >
> > I made further investigation on the test. I found that NVWAL patch
> > can improve performance of XlogFlush function, but it may impact
> > performance of CopyXlogRecordToWAL function. It may be related to the higher latency of memcpy to Intel
> PMem comparing with DRAM. Here are key data in my test:
> >
> >
> >
> > Scenario A (length of record to be inserted: 24 bytes per record):
> >
> > ==============================
> >
> >
> > NVWAL SoAD
> >
> > ------------------------------------ ------- -------
> >
> > Througput (10^3 TPS) 310.5
> > 296.0
> >
> > CPU Time % of CopyXlogRecordToWAL 0.4 0.2
> >
> > CPU Time % of XLogInsertRecord 1.5 0.8
> >
> > CPU Time % of XLogFlush 2.1 9.6
> >
> >
> >
> > Scenario B (length of record to be inserted: 328 bytes per record):
> >
> > ==============================
> >
> >
> > NVWAL SoAD
> >
> > ------------------------------------ ------- -------
> >
> > Througput (10^3 TPS) 13.0
> > 16.9
> >
> > CPU Time % of CopyXlogRecordToWAL 3.0 1.6
> >
> > CPU Time % of XLogInsertRecord 23.0 16.4
> >
> > CPU Time % of XLogFlush 2.3 5.9
> >
> >
> >
> > Best Regards,
> >
> > Gang
> >
> >
> >
> > From: Takashi Menjo <takashi.menjo@gmail.com <mailto:takashi.menjo@gmail.com> >
> > Sent: Thursday, September 10, 2020 4:01 PM
> > To: Takashi Menjo <takashi.menjou.vg@hco.ntt.co.jp <mailto:takashi.menjou.vg@hco.ntt.co.jp> >
> > Cc: pgsql-hackers@postgresql.org <mailto:pgsql-hackers@postgresql.org>
> > Subject: Re: [PoC] Non-volatile WAL buffer
> >
> >
> >
> > Rebased.
> >
> >
> >
> >
> >
> > 2020年6月24日(水) 16:44 Takashi Menjo <takashi.menjou.vg@hco.ntt.co.jp
> > <mailto:takashi.menjou.vg@hco.ntt.co.jp> >:
> >
> > Dear hackers,
> >
> > I update my non-volatile WAL buffer's patchset to v3. Now we can
> > use it in streaming replication mode.
> >
> > Updates from v2:
> >
> > - walreceiver supports non-volatile WAL buffer
> > Now walreceiver stores received records directly to non-volatile WAL buffer if applicable.
> >
> > - pg_basebackup supports non-volatile WAL buffer
> > Now pg_basebackup copies received WAL segments onto non-volatile WAL
> > buffer if you run it with "nvwal" mode (-Fn).
> > You should specify a new NVWAL path with --nvwal-path option. The
> > path will be written to postgresql.auto.conf or recovery.conf. The size of the new NVWAL is same as the
> master's one.
> >
> >
> > Best regards,
> > Takashi
> >
> > --
> > Takashi Menjo <takashi.menjou.vg@hco.ntt.co.jp <mailto:takashi.menjou.vg@hco.ntt.co.jp> >
> > NTT Software Innovation Center
> >
> > > -----Original Message-----
> > > From: Takashi Menjo <takashi.menjou.vg@hco.ntt.co.jp
> > <mailto:takashi.menjou.vg@hco.ntt.co.jp> >
> > > Sent: Wednesday, March 18, 2020 5:59 PM
> > > To: 'PostgreSQL-development' <pgsql-hackers@postgresql.org
> > <mailto:pgsql-hackers@postgresql.org> >
> > > Cc: 'Robert Haas' <robertmhaas@gmail.com
> > <mailto:robertmhaas@gmail.com> >; 'Heikki Linnakangas' <hlinnaka@iki.fi <mailto:hlinnaka@iki.fi> >; 'Amit
> Langote'
> > > <amitlangote09@gmail.com <mailto:amitlangote09@gmail.com> >
> > > Subject: RE: [PoC] Non-volatile WAL buffer
> > >
> > > Dear hackers,
> > >
> > > I rebased my non-volatile WAL buffer's patchset onto master. A
> > new v2 patchset is attached to this mail.
> > >
> > > I also measured performance before and after patchset, varying
> > -c/--client and -j/--jobs options of pgbench, for
> > > each scaling factor s = 50 or 1000. The results are presented in
> > the following tables and the attached charts.
> > > Conditions, steps, and other details will be shown later.
> > >
> > >
> > > Results (s=50)
> > > ==============
> > > Throughput [10^3 TPS] Average latency [ms]
> > > ( c, j) before after before after
> > > ------- --------------------- ---------------------
> > > ( 8, 8) 35.7 37.1 (+3.9%) 0.224 0.216 (-3.6%)
> > > (18,18) 70.9 74.7 (+5.3%) 0.254 0.241 (-5.1%)
> > > (36,18) 76.0 80.8 (+6.3%) 0.473 0.446 (-5.7%)
> > > (54,18) 75.5 81.8 (+8.3%) 0.715 0.660 (-7.7%)
> > >
> > >
> > > Results (s=1000)
> > > ================
> > > Throughput [10^3 TPS] Average latency [ms]
> > > ( c, j) before after before after
> > > ------- --------------------- ---------------------
> > > ( 8, 8) 37.4 40.1 (+7.3%) 0.214 0.199 (-7.0%)
> > > (18,18) 79.3 86.7 (+9.3%) 0.227 0.208 (-8.4%)
> > > (36,18) 87.2 95.5 (+9.5%) 0.413 0.377 (-8.7%)
> > > (54,18) 86.8 94.8 (+9.3%) 0.622 0.569 (-8.5%)
> > >
> > >
> > > Both throughput and average latency are improved for each scaling
> > factor. Throughput seemed to almost reach
> > > the upper limit when (c,j)=(36,18).
> > >
> > > The percentage in s=1000 case looks larger than in s=50 case. I
> > think larger scaling factor leads to less
> > > contentions on the same tables and/or indexes, that is, less lock
> > and unlock operations. In such a situation,
> > > write-ahead logging appears to be more significant for performance.
> > >
> > >
> > > Conditions
> > > ==========
> > > - Use one physical server having 2 NUMA nodes (node 0 and 1)
> > > - Pin postgres (server processes) to node 0 and pgbench to node 1
> > > - 18 cores and 192GiB DRAM per node
> > > - Use an NVMe SSD for PGDATA and an interleaved 6-in-1 NVDIMM-N set for pg_wal
> > > - Both are installed on the server-side node, that is, node 0
> > > - Both are formatted with ext4
> > > - NVDIMM-N is mounted with "-o dax" option to enable Direct Access (DAX)
> > > - Use the attached postgresql.conf
> > > - Two new items nvwal_path and nvwal_size are used only after patch
> > >
> > >
> > > Steps
> > > =====
> > > For each (c,j) pair, I did the following steps three times then I
> > found the median of the three as a final result shown
> > > in the tables above.
> > >
> > > (1) Run initdb with proper -D and -X options; and also give
> > --nvwal-path and --nvwal-size options after patch
> > > (2) Start postgres and create a database for pgbench tables
> > > (3) Run "pgbench -i -s ___" to create tables (s = 50 or 1000)
> > > (4) Stop postgres, remount filesystems, and start postgres again
> > > (5) Execute pg_prewarm extension for all the four pgbench tables
> > > (6) Run pgbench during 30 minutes
> > >
> > >
> > > pgbench command line
> > > ====================
> > > $ pgbench -h /tmp -p 5432 -U username -r -M prepared -T 1800 -c ___ -j ___ dbname
> > >
> > > I gave no -b option to use the built-in "TPC-B (sort-of)" query.
> > >
> > >
> > > Software
> > > ========
> > > - Distro: Ubuntu 18.04
> > > - Kernel: Linux 5.4 (vanilla kernel)
> > > - C Compiler: gcc 7.4.0
> > > - PMDK: 1.7
> > > - PostgreSQL: d677550 (master on Mar 3, 2020)
> > >
> > >
> > > Hardware
> > > ========
> > > - System: HPE ProLiant DL380 Gen10
> > > - CPU: Intel Xeon Gold 6154 (Skylake) x 2sockets
> > > - DRAM: DDR4 2666MHz {32GiB/ch x 6ch}/socket x 2sockets
> > > - NVDIMM-N: DDR4 2666MHz {16GiB/ch x 6ch}/socket x 2sockets
> > > - NVMe SSD: Intel Optane DC P4800X Series SSDPED1K750GA
> > >
> > >
> > > Best regards,
> > > Takashi
> > >
> > > --
> > > Takashi Menjo <takashi.menjou.vg@hco.ntt.co.jp
> > <mailto:takashi.menjou.vg@hco.ntt.co.jp> > NTT Software Innovation Center
> > >
> > > > -----Original Message-----
> > > > From: Takashi Menjo <takashi.menjou.vg@hco.ntt.co.jp
> > <mailto:takashi.menjou.vg@hco.ntt.co.jp> >
> > > > Sent: Thursday, February 20, 2020 6:30 PM
> > > > To: 'Amit Langote' <amitlangote09@gmail.com <mailto:amitlangote09@gmail.com> >
> > > > Cc: 'Robert Haas' <robertmhaas@gmail.com
> > <mailto:robertmhaas@gmail.com> >; 'Heikki Linnakangas' <hlinnaka@iki.fi <mailto:hlinnaka@iki.fi> >;
> > > 'PostgreSQL-development'
> > > > <pgsql-hackers@postgresql.org <mailto:pgsql-hackers@postgresql.org> >
> > > > Subject: RE: [PoC] Non-volatile WAL buffer
> > > >
> > > > Dear Amit,
> > > >
> > > > Thank you for your advice. Exactly, it's so to speak "do as the hackers do when in pgsql"...
> > > >
> > > > I'm rebasing my branch onto master. I'll submit an updated
> > patchset and performance report later.
> > > >
> > > > Best regards,
> > > > Takashi
> > > >
> > > > --
> > > > Takashi Menjo <takashi.menjou.vg@hco.ntt.co.jp
> > <mailto:takashi.menjou.vg@hco.ntt.co.jp>
> > > NTT Software
> > > > Innovation Center
> > > >
> > > > > -----Original Message-----
> > > > > From: Amit Langote <amitlangote09@gmail.com <mailto:amitlangote09@gmail.com> >
> > > > > Sent: Monday, February 17, 2020 5:21 PM
> > > > > To: Takashi Menjo <takashi.menjou.vg@hco.ntt.co.jp
> > <mailto:takashi.menjou.vg@hco.ntt.co.jp> >
> > > > > Cc: Robert Haas <robertmhaas@gmail.com
> > <mailto:robertmhaas@gmail.com> >; Heikki Linnakangas
> > > > > <hlinnaka@iki.fi <mailto:hlinnaka@iki.fi> >; PostgreSQL-development
> > > > > <pgsql-hackers@postgresql.org <mailto:pgsql-hackers@postgresql.org> >
> > > > > Subject: Re: [PoC] Non-volatile WAL buffer
> > > > >
> > > > > Hello,
> > > > >
> > > > > On Mon, Feb 17, 2020 at 4:16 PM Takashi Menjo
> > <takashi.menjou.vg@hco.ntt.co.jp <mailto:takashi.menjou.vg@hco.ntt.co.jp> > wrote:
> > > > > > Hello Amit,
> > > > > >
> > > > > > > I apologize for not having any opinion on the patches
> > > > > > > themselves, but let me point out that it's better to base these
> > > > > > > patches on HEAD (master branch) than REL_12_0, because all new
> > > > > > > code is committed to the master branch, whereas stable branches
> > > > > > > such as
> > > > > > > REL_12_0 only receive bug fixes. Do you have any
> > > > > specific reason to be working on REL_12_0?
> > > > > >
> > > > > > Yes, because I think it's human-friendly to reproduce and discuss
> > > > > > performance measurement. Of course I know
> > > > > all new accepted patches are merged into master's HEAD, not stable
> > > > > branches and not even release tags, so I'm aware of rebasing my
> > > > > patchset onto master sooner or later. However, if someone,
> > > > > including me, says that s/he applies my patchset to "master" and
> > > > > measures its performance, we have to pay attention to which commit the "master"
> > > > > really points to. Although we have sha1 hashes to specify which
> > > > > commit, we should check whether the specific commit on master has
> > > > > patches affecting performance or not
> > > > because master's HEAD gets new patches day by day. On the other hand,
> > > > a release tag clearly points the commit all we probably know. Also we
> > > > can check more easily the features and improvements by using
> > release notes and user manuals.
> > > > >
> > > > > Thanks for clarifying. I see where you're coming from.
> > > > >
> > > > > While I do sometimes see people reporting numbers with the latest
> > > > > stable release' branch, that's normally just one of the baselines.
> > > > > The more important baseline for ongoing development is the master
> > > > > branch's HEAD, which is also what people volunteering to test your
> > > > > patches would use. Anyone who reports would have to give at least
> > > > > two numbers -- performance with a branch's HEAD without patch
> > > > > applied and that with patch applied -- which can be enough in most
> > > > > cases to see the difference the patch makes. Sure, the numbers
> > > > > might change on each report, but that's fine I'd think. If you
> > > > > continue to develop against the stable branch, you might miss to
> > > > notice impact from any relevant developments in the master branch,
> > > > even developments which possibly require rethinking the
> > architecture of your own changes, although maybe that
> > > rarely occurs.
> > > > >
> > > > > Thanks,
> > > > > Amit
> >
> >
> >
> >
> >
> >
> > --
> >
> > Takashi Menjo <takashi.menjo@gmail.com
> > <mailto:takashi.menjo@gmail.com> >
> >
> >
> >
> > --
> >
> > Takashi Menjo <takashi.menjo@gmail.com
> > <mailto:takashi.menjo@gmail.com> >
I had a new look at this thread today, trying to figure out where we are. I'm a bit confused. One thing we have established: mmap()ing WAL files performs worse than the current method, if pg_wal is not on a persistent memory device. This is because the kernel faults in existing content of each page, even though we're overwriting everything. That's unfortunate. I was hoping that mmap() would be a good option even without persistent memory hardware. I wish we could tell the kernel to zero the pages instead of reading them from the file. Maybe clear the file with ftruncate() before mmapping it? That should not be problem with a real persistent memory device, however (or when emulating it with DRAM). With DAX, the storage is memory-mapped directly and there is no page cache, and no pre-faulting. Because of that, I'm baffled by what the v4-0002-Non-volatile-WAL-buffer.patch does. If I understand it correctly, it puts the WAL buffers in a separate file, which is stored on the NVRAM. Why? I realize that this is just a Proof of Concept, but I'm very much not interested in anything that requires the DBA to manage a second WAL location. Did you test the mmap() patches with persistent memory hardware? Did you compare that with the pmem patchset, on the same hardware? If there's a meaningful performance difference between the two, what's causing it? - Heikki
I appreciate your patience. I reproduced the results you reported to me, on my environment.
First of all, the condition you gave to me was a little unstable on my environment, so I made the values of {max_,min_,nv}wal_size larger and the pre-warm duration longer to get stable performance. I didn't modify your table and query, and benchmark duration.
Under the stable condition, Original (PMEM) still got better performance than Non-volatile WAL Buffer. To sum up, the reason was that Non-volatile WAL Buffer on Optane PMem spent much more time than Original (PMEM) for XLogInsert when using your table and query. It offset the improvement of XLogFlush, and degraded performance in total. VTune told me that Non-volatile WAL Buffer took more CPU time than Original (PMEM) for (XLogInsert => XLogInsertRecord => CopyXLogRecordsToWAL =>) memcpy while it took less time for XLogFlush. This profile was very similar to the one you reported.
In general, when WAL buffers are on Optane PMem rather than DRAM, it is obvious that it takes more time to memcpy WAL records into the buffers because Optane PMem is a little slower than DRAM. In return for that, Non-volatile WAL Buffer reduces the time to let the records hit to devices because it doesn't need to write them out of the buffers to somewhere else, but just need to flush out of CPU caches to the underlying memory-mapped file.
Your report shows that Non-volatile WAL Buffer on Optane PMem is not good for certain kinds of transactions, and is good for others. I have tried to fix how to insert and flush WAL records, or the configurations or constants that could change performance such as NUM_XLOGINSERT_LOCKS, but Non-volatile WAL Buffer have not achieved better performance than Original (PMEM) yet when using your table and query. I will continue to work on this issue and will report if I have any update.
By the way, did your performance progress reported by pgbench with -P option get down to zero when you run Non-volatile WAL Buffer? If so, your {max_,min_,nv}wal_size might be too small or your checkpoint configurations might be not appropriate. Could you check your results again?
Best regards,
Takashi
Hi,
These patches no longer apply :-( A rebased version would be nice.
I've been interested in what performance improvements this might bring,
so I've been running some extensive benchmarks on a machine with PMEM
hardware. So let me share some interesting results. (I used commit from
early September, to make the patch apply cleanly.)
Note: The hardware was provided by Intel, and they are interested in
supporting the development and providing access to machines with PMEM to
developers. So if you're interested in this patch & PMEM, but don't have
access to suitable hardware, try contacting Steve Shaw
<steve.shaw@intel.com> who's the person responsible for open source
databases at Intel (he's also the author of HammerDB).
The benchmarks were done on a machine with 2 x Xeon Platinum (24/48
cores), 128GB RAM, NVMe and PMEM SSDs. I did some basic pgbench tests
with different scales (500, 5000, 15000) with and without these patches.
I did some usual tuning (shared buffers, max_wal_size etc.), the most
important changes being:
- maintenance_work_mem = 256MB
- max_connections = 200
- random_page_cost = 1.2
- shared_buffers = 16GB
- work_mem = 64MB
- checkpoint_completion_target = 0.9
- checkpoint_timeout = 20min
- max_wal_size = 96GB
- autovacuum_analyze_scale_factor = 0.1
- autovacuum_vacuum_insert_scale_factor = 0.05
- autovacuum_vacuum_scale_factor = 0.01
- vacuum_cost_limit = 1000
And on the patched version:
- nvwal_size = 128GB
- nvwal_path = … points to the PMEM DAX device …
The machine has multiple SSDs (all Optane-based, IIRC):
- NVMe SSD (Optane)
- PMEM in BTT mode
- PMEM in DAX mode
So I've tested all of them - the data was always on the NVMe device, and
the WAL was placed on one of those devices. That means we have these
four cases to compare:
- nvme - master with WAL on the NVMe SSD
- pmembtt - master with WAL on PMEM in BTT mode
- pmemdax - master with WAL on PMEM in DAX mode
- pmemdax-ntt - patched version with WAL on PMEM in DAX mode
The "nvme" is a bit disadvantaged as it places both data and WAL on the
same device, so consider that while evaluating the results. But for the
smaller data sets this should be fairly negligible, I believe.
I'm not entirely sure whether the "pmemdax" (i.e. unpatched instance
with WAL on PMEM DAX device) is actually safe, but I included it anyway
to see what difference is.
Now let's look at results for the basic data sizes and client counts.
I've also attached some charts to illustrate this. These numbers are tps
averages from 3 runs, each about 30 minutes long.
1) scale 500 (fits into shared buffers)
---------------------------------------
wal 1 16 32 64 96
----------------------------------------------------------
nvme 6321 73794 132687 185409 192228
pmembtt 6248 60105 85272 82943 84124
pmemdax 6686 86188 154850 105219 149224
pmemdax-ntt 8062 104887 211722 231085 252593
The NVMe performs well (the single device is not an issue, as there
should be very little non-WAL I/O). The PMBM/BTT has a clear bottleneck
~85k tps. It's interesting the PMEM/DAX performs much worse without the
patch, and the drop at 64 clients. Not sure what that's about.
2) scale 5000 (fits into RAM)
-----------------------------
wal 1 16 32 64 96
-----------------------------------------------------------
nvme 4804 43636 61443 79807 86414
pmembtt 4203 28354 37562 41562 43684
pmemdax 5580 62180 92361 112935 117261
pmemdax-ntt 6325 79887 128259 141793 127224
The differences are more significant, compared to the small scale. The
BTT seems to have bottleneck around ~43k tps, the PMEM/DAX dominates.
3) scale 15000 (bigger than RAM)
--------------------------------
wal 1 16 32 64 96
-----------------------------------------------------------
pmembtt 3638 20630 28985 32019 31303
pmemdax 5164 48230 69822 85740 90452
pmemdax-ntt 5382 62359 80038 83779 80191
I have not included the nvme results here, because the impact of placing
both data and WAL on the same device was too significant IMHO.
The remaining results seem nice. It's interesting the patched case is a
bit slower than master. Not sure why.
Overall, these results seem pretty nice, I guess. Of course, this does
not say the current patch is the best way to implement this (or whether
it's correct), but it does suggest supporting PMEM might bring sizeable
performance boost.
regards
--
Tomas Vondra
EnterpriseDB: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
Attachment
{kind=link}
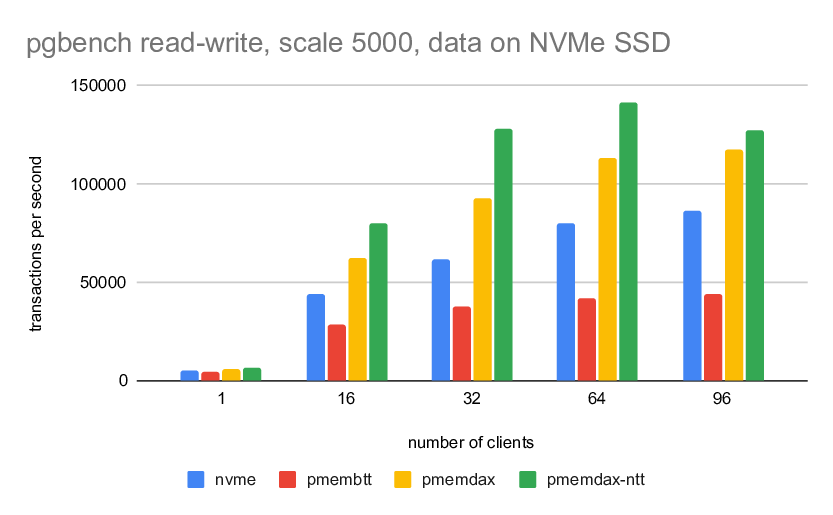{kind=link}
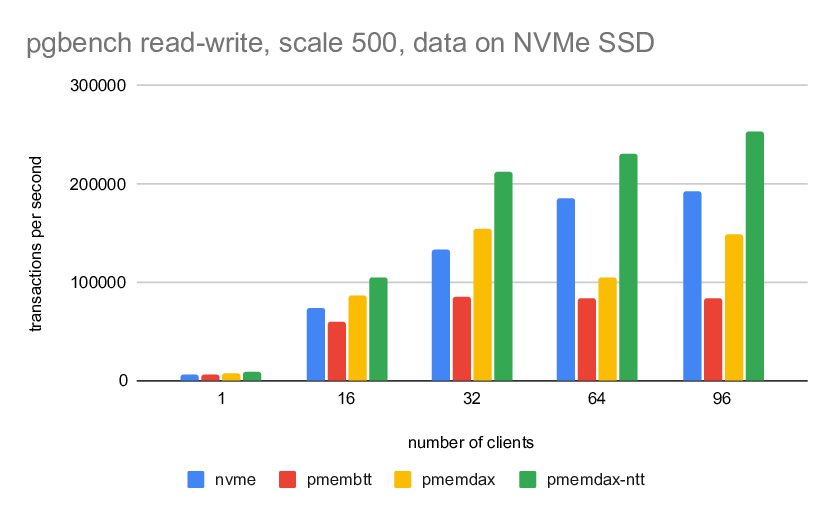{kind=link}
Hi, On 10/30/20 6:57 AM, Takashi Menjo wrote: > Hi Heikki, > >> I had a new look at this thread today, trying to figure out where >> we are. > > I'm a bit confused. >> >> One thing we have established: mmap()ing WAL files performs worse >> than the current method, if pg_wal is not on a persistent memory >> device. This is because the kernel faults in existing content of >> each page, even though we're overwriting everything. > > Yes. In addition, after a certain page (in the sense of OS page) is > msync()ed, another page fault will occur again when something is > stored into that page. > >> That's unfortunate. I was hoping that mmap() would be a good option >> even without persistent memory hardware. I wish we could tell the >> kernel to zero the pages instead of reading them from the file. >> Maybe clear the file with ftruncate() before mmapping it? > > The area extended by ftruncate() appears as if it were zero-filled > [1]. Please note that it merely "appears as if." It might not be > actually zero-filled as data blocks on devices, so pre-allocating > files should improve transaction performance. At least, on Linux 5.7 > and ext4, it takes more time to store into the mapped file just > open(O_CREAT)ed and ftruncate()d than into the one filled already and > actually. > Does is really matter that it only appears zero-filled? I think Heikki's point was that maybe ftruncate() would prevent the kernel from faulting the existing page content when we're overwriting it. Not sure I understand what the benchmark with ext4 was doing, exactly. How was that measured? Might be interesting to have some simple benchmarking tool to demonstrate this (I believe a small standalone tool written in C should do the trick). >> That should not be problem with a real persistent memory device, >> however (or when emulating it with DRAM). With DAX, the storage is >> memory-mapped directly and there is no page cache, and no >> pre-faulting. > > Yes, with filesystem DAX, there is no page cache for file data. A > page fault still occurs but for each 2MiB DAX hugepage, so its > overhead decreases compared with 4KiB page fault. Such a DAX > hugepage fault is only applied to DAX-mapped files and is different > from a general transparent hugepage fault. > I don't follow - if there are page faults even when overwriting all the data, I'd say it's still an issue even with 2MB DAX pages. How big is the difference between 4kB and 2MB pages? Not sure I understand how is this different from general THP fault? >> Because of that, I'm baffled by what the >> v4-0002-Non-volatile-WAL-buffer.patch does. If I understand it >> correctly, it puts the WAL buffers in a separate file, which is >> stored on the NVRAM. Why? I realize that this is just a Proof of >> Concept, but I'm very much not interested in anything that requires >> the DBA to manage a second WAL location. Did you test the mmap() >> patches with persistent memory hardware? Did you compare that with >> the pmem patchset, on the same hardware? If there's a meaningful >> performance difference between the two, what's causing it? > Yes, this patchset puts the WAL buffers into the file specified by > "nvwal_path" in postgresql.conf. > > Why this patchset puts the buffers into the separated file, not > existing segment files in PGDATA/pg_wal, is because it reduces the > overhead due to system calls such as open(), mmap(), munmap(), and > close(). It open()s and mmap()s the file "nvwal_path" once, and keeps > that file mapped while running. On the other hand, as for the > patchset mmap()ing the segment files, a backend process should > munmap() and close() the current mapped file and open() and mmap() > the new one for each time the inserting location for that process > goes over segments. This causes the performance difference between > the two. > I kinda agree with Heikki here - having to manage yet another location for WAL data is rather inconvenient. We should aim not to make the life of DBAs unnecessarily difficult, IMO. I wonder how significant the syscall overhead is - can you show share some numbers? I don't see any such results in this thread, so I'm not sure if it means losing 1% or 10% throughput. Also, maybe there are alternative ways to reduce the overhead? For example, we can increase the size of the WAL segment, and with 1GB segments we'd do 1/64 of syscalls. Or maybe we could do some of this asynchronously - request a segment ahead, and let another process do the actual work etc. so that the running process does not wait. Do I understand correctly that the patch removes "regular" WAL buffers and instead writes the data into the non-volatile PMEM buffer, without writing that to the WAL segments at all (unless in archiving mode)? Firstly, I guess many (most?) instances will have to write the WAL segments anyway because of PITR/backups, so I'm not sure we can save much here. But more importantly - doesn't that mean the nvwal_size value is essentially a hard limit? With max_wal_size, it's a soft limit i.e. we're allowed to temporarily use more WAL when needed. But with a pre-allocated file, that's clearly not possible. So what would happen in those cases? Also, is it possible to change nvwal_size? I haven't tried, but I wonder what happens with the current contents of the file. regards -- Tomas Vondra EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
Hi,
On 11/23/20 3:01 AM, Tomas Vondra wrote:
> Hi,
>
> On 10/30/20 6:57 AM, Takashi Menjo wrote:
>> Hi Heikki,
>>
>>> I had a new look at this thread today, trying to figure out where
>>> we are.
>>
>> I'm a bit confused.
>>>
>>> One thing we have established: mmap()ing WAL files performs worse
>>> than the current method, if pg_wal is not on a persistent memory
>>> device. This is because the kernel faults in existing content of
>>> each page, even though we're overwriting everything.
>>
>> Yes. In addition, after a certain page (in the sense of OS page) is
>> msync()ed, another page fault will occur again when something is
>> stored into that page.
>>
>>> That's unfortunate. I was hoping that mmap() would be a good option
>>> even without persistent memory hardware. I wish we could tell the
>>> kernel to zero the pages instead of reading them from the file.
>>> Maybe clear the file with ftruncate() before mmapping it?
>>
>> The area extended by ftruncate() appears as if it were zero-filled
>> [1]. Please note that it merely "appears as if." It might not be
>> actually zero-filled as data blocks on devices, so pre-allocating
>> files should improve transaction performance. At least, on Linux 5.7
>> and ext4, it takes more time to store into the mapped file just
>> open(O_CREAT)ed and ftruncate()d than into the one filled already and
>> actually.
>>
>
> Does is really matter that it only appears zero-filled? I think Heikki's
> point was that maybe ftruncate() would prevent the kernel from faulting
> the existing page content when we're overwriting it.
>
> Not sure I understand what the benchmark with ext4 was doing, exactly.
> How was that measured? Might be interesting to have some simple
> benchmarking tool to demonstrate this (I believe a small standalone tool
> written in C should do the trick).
>
One more thought about this - if ftruncate() is not enough to convince
the mmap() to not load existing data from the file, what about not
reusing the WAL segments at all? I haven't tried, though.
>>> That should not be problem with a real persistent memory device,
>>> however (or when emulating it with DRAM). With DAX, the storage is
>>> memory-mapped directly and there is no page cache, and no
>>> pre-faulting.
>>
>> Yes, with filesystem DAX, there is no page cache for file data. A
>> page fault still occurs but for each 2MiB DAX hugepage, so its
>> overhead decreases compared with 4KiB page fault. Such a DAX
>> hugepage fault is only applied to DAX-mapped files and is different
>> from a general transparent hugepage fault.
>>
>
> I don't follow - if there are page faults even when overwriting all the
> data, I'd say it's still an issue even with 2MB DAX pages. How big is
> the difference between 4kB and 2MB pages?
>
> Not sure I understand how is this different from general THP fault?
>
>>> Because of that, I'm baffled by what the
>>> v4-0002-Non-volatile-WAL-buffer.patch does. If I understand it
>>> correctly, it puts the WAL buffers in a separate file, which is
>>> stored on the NVRAM. Why? I realize that this is just a Proof of
>>> Concept, but I'm very much not interested in anything that requires
>>> the DBA to manage a second WAL location. Did you test the mmap()
>>> patches with persistent memory hardware? Did you compare that with
>>> the pmem patchset, on the same hardware? If there's a meaningful
>>> performance difference between the two, what's causing it?
>
>> Yes, this patchset puts the WAL buffers into the file specified by
>> "nvwal_path" in postgresql.conf.
>>
>> Why this patchset puts the buffers into the separated file, not
>> existing segment files in PGDATA/pg_wal, is because it reduces the
>> overhead due to system calls such as open(), mmap(), munmap(), and
>> close(). It open()s and mmap()s the file "nvwal_path" once, and keeps
>> that file mapped while running. On the other hand, as for the
>> patchset mmap()ing the segment files, a backend process should
>> munmap() and close() the current mapped file and open() and mmap()
>> the new one for each time the inserting location for that process
>> goes over segments. This causes the performance difference between
>> the two.
>>
>
> I kinda agree with Heikki here - having to manage yet another location
> for WAL data is rather inconvenient. We should aim not to make the life
> of DBAs unnecessarily difficult, IMO.
>
> I wonder how significant the syscall overhead is - can you show share
> some numbers? I don't see any such results in this thread, so I'm not
> sure if it means losing 1% or 10% throughput.
>
> Also, maybe there are alternative ways to reduce the overhead? For
> example, we can increase the size of the WAL segment, and with 1GB
> segments we'd do 1/64 of syscalls. Or maybe we could do some of this
> asynchronously - request a segment ahead, and let another process do the
> actual work etc. so that the running process does not wait.
>
>
> Do I understand correctly that the patch removes "regular" WAL buffers
> and instead writes the data into the non-volatile PMEM buffer, without
> writing that to the WAL segments at all (unless in archiving mode)?
>
> Firstly, I guess many (most?) instances will have to write the WAL
> segments anyway because of PITR/backups, so I'm not sure we can save
> much here.
>
> But more importantly - doesn't that mean the nvwal_size value is
> essentially a hard limit? With max_wal_size, it's a soft limit i.e.
> we're allowed to temporarily use more WAL when needed. But with a
> pre-allocated file, that's clearly not possible. So what would happen in
> those cases?
>
> Also, is it possible to change nvwal_size? I haven't tried, but I wonder
> what happens with the current contents of the file.
>
I've been thinking about the current design (which essentially places
the WAL buffers on PMEM) a bit more. I wonder whether that's actually
the right design ...
The way I understand the current design is that we're essentially
switching from this architecture:
clients -> wal buffers (DRAM) -> wal segments (storage)
to this
clients -> wal buffers (PMEM)
(Assuming there we don't have to write segments because of archiving.)
The first thing to consider is that PMEM is actually somewhat slower
than DRAM, the difference is roughly 100ns vs. 300ns (see [1] and [2]).
From this POV it's a bit strange that we're moving the WAL buffer to a
slower medium.
Of course, PMEM is significantly faster than other storage types (e.g.
order of magnitude faster than flash) and we're eliminating the need to
write the WAL from PMEM in some cases, and that may help.
The second thing I notice is that PMEM does not seem to handle many
clients particularly well - if you look at Figure 2 in [2], you'll see
that there's a clear drop-off in write bandwidth after only a few
clients. For DRAM there's no such issue. (The total PMEM bandwidth seems
much worse than for DRAM too.)
So I wonder if using PMEM for the WAL buffer is the right way forward.
AFAIK the WAL buffer is quite concurrent (multiple clients writing
data), which seems to contradict the PMEM vs. DRAM trade-offs.
The design I've originally expected would look more like this
clients -> wal buffers (DRAM) -> wal segments (PMEM DAX)
i.e. mostly what we have now, but instead of writing the WAL segments
"the usual way" we'd write them using mmap/memcpy, without fsync.
I suppose that's what Heikki meant too, but I'm not sure.
regards
[1] https://pmem.io/2019/12/19/performance.html
[2] https://arxiv.org/pdf/1904.01614.pdf
--
Tomas Vondra
EnterpriseDB: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
From: Tomas Vondra <tomas.vondra@enterprisedb.com> > So I wonder if using PMEM for the WAL buffer is the right way forward. > AFAIK the WAL buffer is quite concurrent (multiple clients writing > data), which seems to contradict the PMEM vs. DRAM trade-offs. > > The design I've originally expected would look more like this > > clients -> wal buffers (DRAM) -> wal segments (PMEM DAX) > > i.e. mostly what we have now, but instead of writing the WAL segments > "the usual way" we'd write them using mmap/memcpy, without fsync. > > I suppose that's what Heikki meant too, but I'm not sure. SQL Server probably does so. Please see the following page and the links in "Next steps" section. I'm saying "probably"because the document doesn't clearly state whether SQL Server memcpys data from DRAM log cache to non-volatilelog cache only for transaction commits or for all log cache writes. I presume the former. Add persisted log buffer to a database https://docs.microsoft.com/en-us/sql/relational-databases/databases/add-persisted-log-buffer?view=sql-server-ver15 -------------------------------------------------- With non-volatile, tail of the log storage the pattern is memcpy to LC memcpy to NV LC Set status Return control to caller (commit is now valid) ... With this new functionality, we use a region of memory which is mapped to a file on a DAX volume to hold that buffer. Sincethe memory hosted by the DAX volume is already persistent, we have no need to perform a separate flush, and can immediatelycontinue with processing the next operation. Data is flushed from this buffer to more traditional storage in thebackground. -------------------------------------------------- Regards Takayuki Tsunakawa
On 11/24/20 7:34 AM, tsunakawa.takay@fujitsu.com wrote: > From: Tomas Vondra <tomas.vondra@enterprisedb.com> >> So I wonder if using PMEM for the WAL buffer is the right way forward. >> AFAIK the WAL buffer is quite concurrent (multiple clients writing >> data), which seems to contradict the PMEM vs. DRAM trade-offs. >> >> The design I've originally expected would look more like this >> >> clients -> wal buffers (DRAM) -> wal segments (PMEM DAX) >> >> i.e. mostly what we have now, but instead of writing the WAL segments >> "the usual way" we'd write them using mmap/memcpy, without fsync. >> >> I suppose that's what Heikki meant too, but I'm not sure. > > SQL Server probably does so. Please see the following page and the links in "Next steps" section. I'm saying "probably"because the document doesn't clearly state whether SQL Server memcpys data from DRAM log cache to non-volatilelog cache only for transaction commits or for all log cache writes. I presume the former. > > > Add persisted log buffer to a database > https://docs.microsoft.com/en-us/sql/relational-databases/databases/add-persisted-log-buffer?view=sql-server-ver15 > -------------------------------------------------- > With non-volatile, tail of the log storage the pattern is > > memcpy to LC > memcpy to NV LC > Set status > Return control to caller (commit is now valid) > ... > > With this new functionality, we use a region of memory which is mapped to a file on a DAX volume to hold that buffer. Sincethe memory hosted by the DAX volume is already persistent, we have no need to perform a separate flush, and can immediatelycontinue with processing the next operation. Data is flushed from this buffer to more traditional storage in thebackground. > -------------------------------------------------- > Interesting, thanks for the likn. If I understand [1] correctly, they essentially do this: clients -> buffers (DRAM) -> buffers (PMEM) -> wal (storage) that is, they insert the PMEM buffer between the LC (in DRAM) and traditional (non-PMEM) storage, so that a commit does not need to do any fsyncs etc. It seems to imply the memcpy between DRAM and PMEM happens right when writing the WAL, but I guess that's not strictly required - we might just as well do that in the background, I think. It's interesting that they only place the tail of the log on PMEM, i.e. the PMEM buffer has limited size, and the rest of the log is not on PMEM. It's a bit as if we inserted a PMEM buffer between our wal buffers and the WAL segments, and kept the WAL segments on regular storage. That could work, but I'd bet they did that because at that time the NV devices were much smaller, and placing the whole log on PMEM was not quite possible. So it might be unnecessarily complicated, considering the PMEM device capacity is much higher now. So I'd suggest we simply try this: clients -> buffers (DRAM) -> wal segments (PMEM) I plan to do some hacking and maybe hack together some simple tools to benchmarks various approaches. regards [1] https://docs.microsoft.com/en-us/archive/blogs/bobsql/how-it-works-it-just-runs-faster-non-volatile-memory-sql-server-tail-of-log-caching-on-nvdimm -- Tomas Vondra EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
From: Tomas Vondra <tomas.vondra@enterprisedb.com> > It's interesting that they only place the tail of the log on PMEM, i.e. > the PMEM buffer has limited size, and the rest of the log is not on > PMEM. It's a bit as if we inserted a PMEM buffer between our wal buffers > and the WAL segments, and kept the WAL segments on regular storage. That > could work, but I'd bet they did that because at that time the NV > devices were much smaller, and placing the whole log on PMEM was not > quite possible. So it might be unnecessarily complicated, considering > the PMEM device capacity is much higher now. > > So I'd suggest we simply try this: > > clients -> buffers (DRAM) -> wal segments (PMEM) > > I plan to do some hacking and maybe hack together some simple tools to > benchmarks various approaches. I'm in favor of your approach. Yes, Intel PMEM were available in 128/256/512 GB when I checked last year. That's more thanenough to place all WAL segments, so a small PMEM wal buffer is not necessary. I'm excited to see Postgres gain morepower. Regards Takayuki Tsunakawa
I'm not entirely sure whether the "pmemdax" (i.e. unpatched instance
with WAL on PMEM DAX device) is actually safe, but I included it anyway
to see what difference is.
On 11/25/20 1:27 AM, tsunakawa.takay@fujitsu.com wrote: > From: Tomas Vondra <tomas.vondra@enterprisedb.com> >> It's interesting that they only place the tail of the log on PMEM, >> i.e. the PMEM buffer has limited size, and the rest of the log is >> not on PMEM. It's a bit as if we inserted a PMEM buffer between our >> wal buffers and the WAL segments, and kept the WAL segments on >> regular storage. That could work, but I'd bet they did that because >> at that time the NV devices were much smaller, and placing the >> whole log on PMEM was not quite possible. So it might be >> unnecessarily complicated, considering the PMEM device capacity is >> much higher now. >> >> So I'd suggest we simply try this: >> >> clients -> buffers (DRAM) -> wal segments (PMEM) >> >> I plan to do some hacking and maybe hack together some simple tools >> to benchmarks various approaches. > > I'm in favor of your approach. Yes, Intel PMEM were available in > 128/256/512 GB when I checked last year. That's more than enough to > place all WAL segments, so a small PMEM wal buffer is not necessary. > I'm excited to see Postgres gain more power. > Cool. FWIW I'm not 100% sure it's the right approach, but I think it's worth testing. In the worst case we'll discover that this architecture does not allow fully leveraging PMEM benefits, or maybe it won't work for some other reason and the approach proposed here will work better. Let's play a bit and we'll see. I have hacked a very simple patch doing this (essentially replacing open/write/close calls in xlog.c with pmem calls). It's a bit rough but seems good enough for testing/experimenting. I'll polish it a bit, do some benchmarks, and share some numbers in a day or two. regards -- Tomas Vondra EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On 11/25/20 2:10 AM, Ashwin Agrawal wrote: > On Sun, Nov 22, 2020 at 5:23 PM Tomas Vondra <tomas.vondra@enterprisedb.com> > wrote: > >> I'm not entirely sure whether the "pmemdax" (i.e. unpatched instance >> with WAL on PMEM DAX device) is actually safe, but I included it anyway >> to see what difference is. > > I am curious to learn more on this aspect. Kernels have provided support > for "pmemdax" mode so what part is unsafe in stack. > I do admit I'm not 100% certain about this, so I err on the side of caution. While discussing this with Steve Shaw, he suggested that applications may get broken because DAX devices don't behave like block devices in some respects (atomicity, addressability, ...). > Reading the numbers it seems only at smaller scale modified PostgreSQL is > giving enhanced benefit over unmodified PostgreSQL with "pmemdax". For most > of other cases the numbers are pretty close between these two setups, so > curious to learn, why even modify PostgreSQL if unmodified PostgreSQL can > provide similar benefit with just DAX mode. > That's a valid questions, but I wouldn't say the ~20% difference on the medium scale is negligible. And it's possible that for the larger scales the primary bottleneck is the storage used for data directory, not WAL (notice that nvme is missing for the large scale). Of course, it's faster than flash storage but the PMEM costs more too, and when you pay $$$ for hardware you probably want to get as much benefit from it as possible. [1] https://ark.intel.com/content/www/us/en/ark/products/203879/intel-optane-persistent-memory-200-series-128gb-pmem-module.html regards -- Tomas Vondra EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
Hi,
Here's the "simple patch" that I'm currently experimenting with. It
essentially replaces open/close/write/fsync with pmem calls
(map/unmap/memcpy/persist variants), and it's by no means committable.
But it works well enough for experiments / measurements, etc.
The numbers (5-minute pgbench runs on scale 500) look like this:
master/btt master/dax ntt simple
-----------------------------------------------------------
1 5469 7402 7977 6746
16 48222 80869 107025 82343
32 73974 158189 214718 158348
64 85921 154540 225715 164248
96 150602 221159 237008 217253
A chart illustrating these results is attached. The four columns are
showing unpatched master with WAL on a pmem device, in BTT or DAX modes,
"ntt" is the patch submitted to this thread, and "simple" is the patch
I've hacked together.
As expected, the BTT case performs poorly (compared to the rest).
The "master/dax" and "simple" perform about the same. There are some
differences, but those may be attributed to noise. The NTT patch does
outperform these cases by ~20-40% in some cases.
The question is why. I recall suggestions this is due to page faults
when writing data into the WAL, but I did experiment with various
settings that I think should prevent that (e.g. disabling WAL reuse
and/or disabling zeroing the segments) but that made no measurable
difference.
So I've added some primitive instrumentation to the code, counting the
calls and measuring duration for each of the PMEM operations, and
printing the stats regularly into log (after ~1M ops).
Typical results from a run with a single client look like this (slightly
formatted/wrapped for e-mail):
PMEM STATS
COUNT total 1000000 map 30 unmap 20
memcpy 510210 persist 489740
TIME total 0 map 931080 unmap 188750
memcpy 4938866752 persist 187846686
LENGTH memcpy 4337647616 persist 329824672
This shows that a majority of the 1M calls is memcpy/persist, the rest
is mostly negligible - both in terms of number of calls and duration.
The time values are in nanoseconds, BTW.
So for example we did 30 map_file calls, taking ~0.9ms in total, and the
unmap calls took even less time. So the direct impact of map/unmap calls
is rather negligible, I think.
The dominant part is clearly the memcpy (~5s) and persist (~2s). It's
not much per call, but it's overall it costs much more than the map and
unmap calls.
Finally, let's look at the LENGTH, which is a sum of the ranges either
copied to PMEM (memcpy) or fsynced (persist). Those are in bytes, and
the memcpy value is way higher than the persist one. In this particular
case, it's something like 4.3MB vs. 300kB, so an order of magnitude.
It's entirely possible this is a bug/measurement error in the patch. I'm
not all that familiar with the XLOG stuff, so maybe I did some silly
mistake somewhere.
But I think it might be also explained by the fact that XLogWrite()
always writes the WAL in a multiple of 8kB pages. Which is perfectly
reasonable for regular block-oriented storage, but pmem/dax is exactly
about not having to do that - PMEM is byte-addressable. And with pgbech,
the individual WAL records are tiny, so having to instead write/flush
the whole 8kB page (or more of them) repeatedly, as we append the WAL
records, seems a bit wasteful. So I wonder if this is why the trivial
patch does not show any benefits.
regards
--
Tomas Vondra
EnterpriseDB: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
Attachment
{kind=link}
On 26/11/2020 21:27, Tomas Vondra wrote: > Hi, > > Here's the "simple patch" that I'm currently experimenting with. It > essentially replaces open/close/write/fsync with pmem calls > (map/unmap/memcpy/persist variants), and it's by no means committable. > But it works well enough for experiments / measurements, etc. > > The numbers (5-minute pgbench runs on scale 500) look like this: > > master/btt master/dax ntt simple > ----------------------------------------------------------- > 1 5469 7402 7977 6746 > 16 48222 80869 107025 82343 > 32 73974 158189 214718 158348 > 64 85921 154540 225715 164248 > 96 150602 221159 237008 217253 > > A chart illustrating these results is attached. The four columns are > showing unpatched master with WAL on a pmem device, in BTT or DAX modes, > "ntt" is the patch submitted to this thread, and "simple" is the patch > I've hacked together. > > As expected, the BTT case performs poorly (compared to the rest). > > The "master/dax" and "simple" perform about the same. There are some > differences, but those may be attributed to noise. The NTT patch does > outperform these cases by ~20-40% in some cases. > > The question is why. I recall suggestions this is due to page faults > when writing data into the WAL, but I did experiment with various > settings that I think should prevent that (e.g. disabling WAL reuse > and/or disabling zeroing the segments) but that made no measurable > difference. The page faults are only a problem when mmap() is used *without* DAX. Takashi tried a patch earlier to mmap() WAL segments and insert WAL to them directly. See 0002-Use-WAL-segments-as-WAL-buffers.patch at https://www.postgresql.org/message-id/000001d5dff4%24995ed180%24cc1c7480%24%40hco.ntt.co.jp_1. Could you test that patch too, please? Using your nomenclature, that patch skips wal_buffers and does: clients -> wal segments (PMEM DAX) He got good results with that with DAX, but otherwise it performed worse. And then we discussed why that might be, and the page fault hypothesis was brought up. I think 0002-Use-WAL-segments-as-WAL-buffers.patch is the most promising approach here. But because it's slower without DAX, we need to keep the current code for non-DAX systems. Unfortunately it means that we need to maintain both implementations, selectable with a GUC or some DAX detection magic. The question then is whether the code complexity is worth the performance gin on DAX-enabled systems. Andres was not excited about mmapping the WAL segments because of performance reasons. I'm not sure how much of his critique applies if we keep supporting both methods and only use mmap() if so configured. - Heikki
On 11/26/20 9:59 PM, Heikki Linnakangas wrote: > On 26/11/2020 21:27, Tomas Vondra wrote: >> Hi, >> >> Here's the "simple patch" that I'm currently experimenting with. It >> essentially replaces open/close/write/fsync with pmem calls >> (map/unmap/memcpy/persist variants), and it's by no means committable. >> But it works well enough for experiments / measurements, etc. >> >> The numbers (5-minute pgbench runs on scale 500) look like this: >> >> master/btt master/dax ntt simple >> ----------------------------------------------------------- >> 1 5469 7402 7977 6746 >> 16 48222 80869 107025 82343 >> 32 73974 158189 214718 158348 >> 64 85921 154540 225715 164248 >> 96 150602 221159 237008 217253 >> >> A chart illustrating these results is attached. The four columns are >> showing unpatched master with WAL on a pmem device, in BTT or DAX modes, >> "ntt" is the patch submitted to this thread, and "simple" is the patch >> I've hacked together. >> >> As expected, the BTT case performs poorly (compared to the rest). >> >> The "master/dax" and "simple" perform about the same. There are some >> differences, but those may be attributed to noise. The NTT patch does >> outperform these cases by ~20-40% in some cases. >> >> The question is why. I recall suggestions this is due to page faults >> when writing data into the WAL, but I did experiment with various >> settings that I think should prevent that (e.g. disabling WAL reuse >> and/or disabling zeroing the segments) but that made no measurable >> difference. > > The page faults are only a problem when mmap() is used *without* DAX. > > Takashi tried a patch earlier to mmap() WAL segments and insert WAL to > them directly. See 0002-Use-WAL-segments-as-WAL-buffers.patch at > https://www.postgresql.org/message-id/000001d5dff4%24995ed180%24cc1c7480%24%40hco.ntt.co.jp_1. > Could you test that patch too, please? Using your nomenclature, that > patch skips wal_buffers and does: > > clients -> wal segments (PMEM DAX) > > He got good results with that with DAX, but otherwise it performed > worse. And then we discussed why that might be, and the page fault > hypothesis was brought up. > D'oh, I haven't noticed there's a patch doing that. This thread has so many different patches - which is good, but a bit confusing. > I think 0002-Use-WAL-segments-as-WAL-buffers.patch is the most promising > approach here. But because it's slower without DAX, we need to keep the > current code for non-DAX systems. Unfortunately it means that we need to > maintain both implementations, selectable with a GUC or some DAX > detection magic. The question then is whether the code complexity is > worth the performance gin on DAX-enabled systems. > Sure, I can give it a spin. The question is whether it applies to current master, or whether some sort of rebase is needed. I'll try. > Andres was not excited about mmapping the WAL segments because of > performance reasons. I'm not sure how much of his critique applies if we > keep supporting both methods and only use mmap() if so configured. > Yeah. I don't think we can just discard the current approach, there are far too many OS variants that even if Linux is happy one of the other critters won't be. regards -- Tomas Vondra EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On 11/26/20 10:19 PM, Tomas Vondra wrote: > > > On 11/26/20 9:59 PM, Heikki Linnakangas wrote: >> On 26/11/2020 21:27, Tomas Vondra wrote: >>> Hi, >>> >>> Here's the "simple patch" that I'm currently experimenting with. It >>> essentially replaces open/close/write/fsync with pmem calls >>> (map/unmap/memcpy/persist variants), and it's by no means committable. >>> But it works well enough for experiments / measurements, etc. >>> >>> The numbers (5-minute pgbench runs on scale 500) look like this: >>> >>> master/btt master/dax ntt simple >>> ----------------------------------------------------------- >>> 1 5469 7402 7977 6746 >>> 16 48222 80869 107025 82343 >>> 32 73974 158189 214718 158348 >>> 64 85921 154540 225715 164248 >>> 96 150602 221159 237008 217253 >>> >>> A chart illustrating these results is attached. The four columns are >>> showing unpatched master with WAL on a pmem device, in BTT or DAX modes, >>> "ntt" is the patch submitted to this thread, and "simple" is the patch >>> I've hacked together. >>> >>> As expected, the BTT case performs poorly (compared to the rest). >>> >>> The "master/dax" and "simple" perform about the same. There are some >>> differences, but those may be attributed to noise. The NTT patch does >>> outperform these cases by ~20-40% in some cases. >>> >>> The question is why. I recall suggestions this is due to page faults >>> when writing data into the WAL, but I did experiment with various >>> settings that I think should prevent that (e.g. disabling WAL reuse >>> and/or disabling zeroing the segments) but that made no measurable >>> difference. >> >> The page faults are only a problem when mmap() is used *without* DAX. >> >> Takashi tried a patch earlier to mmap() WAL segments and insert WAL to >> them directly. See 0002-Use-WAL-segments-as-WAL-buffers.patch at >> https://www.postgresql.org/message-id/000001d5dff4%24995ed180%24cc1c7480%24%40hco.ntt.co.jp_1. >> Could you test that patch too, please? Using your nomenclature, that >> patch skips wal_buffers and does: >> >> clients -> wal segments (PMEM DAX) >> >> He got good results with that with DAX, but otherwise it performed >> worse. And then we discussed why that might be, and the page fault >> hypothesis was brought up. >> > > D'oh, I haven't noticed there's a patch doing that. This thread has so > many different patches - which is good, but a bit confusing. > >> I think 0002-Use-WAL-segments-as-WAL-buffers.patch is the most promising >> approach here. But because it's slower without DAX, we need to keep the >> current code for non-DAX systems. Unfortunately it means that we need to >> maintain both implementations, selectable with a GUC or some DAX >> detection magic. The question then is whether the code complexity is >> worth the performance gin on DAX-enabled systems. >> > > Sure, I can give it a spin. The question is whether it applies to > current master, or whether some sort of rebase is needed. I'll try. > Unfortunately, that patch seems to fail for me :-( The patches seem to be for PG12, so I applied them on REL_12_STABLE (all the parts 0001-0005) and then I did this: LIBS="-lpmem" ./configure --prefix=/home/tomas/pg-12-pmem --enable-debug make -s install initdb -X /opt/pmemdax/benchmarks/wal -D /opt/nvme/benchmarks/data pg_ctl -D /opt/nvme/benchmarks/data/ -l pg.log start createdb test pgbench -i -s 500 test which however fails after just about 70k rows generated (PQputline failed), and the pg.log says this: PANIC: could not open or mmap file "pg_wal/000000010000000000000006": No such file or directory CONTEXT: COPY pgbench_accounts, line 721000 STATEMENT: copy pgbench_accounts from stdin Takashi-san, can you check and provide a fixed version? Ideally, I'll take a look too, but I'm not familiar with this patch so it may take more time. regards -- Tomas Vondra EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On 11/27/20 1:02 AM, Tomas Vondra wrote:
>
> Unfortunately, that patch seems to fail for me :-(
>
> The patches seem to be for PG12, so I applied them on REL_12_STABLE (all
> the parts 0001-0005) and then I did this:
>
> LIBS="-lpmem" ./configure --prefix=/home/tomas/pg-12-pmem --enable-debug
> make -s install
>
> initdb -X /opt/pmemdax/benchmarks/wal -D /opt/nvme/benchmarks/data
>
> pg_ctl -D /opt/nvme/benchmarks/data/ -l pg.log start
>
> createdb test
> pgbench -i -s 500 test
>
>
> which however fails after just about 70k rows generated (PQputline
> failed), and the pg.log says this:
>
> PANIC: could not open or mmap file
> "pg_wal/000000010000000000000006": No such file or directory
> CONTEXT: COPY pgbench_accounts, line 721000
> STATEMENT: copy pgbench_accounts from stdin
>
> Takashi-san, can you check and provide a fixed version? Ideally, I'll
> take a look too, but I'm not familiar with this patch so it may take
> more time.
>
I did try to get this working today, unsuccessfully. I did manage to
apply the 0002 part separately on REL_12_0 (there's one trivial rejected
chunk), but I still get the same failure. In fact, when built with
assertions, I can't even get initdb to pass :-(
I do get this:
TRAP: FailedAssertion("!(page->xlp_pageaddr == ptr - (ptr % 8192))",
File: "xlog.c", Line: 1813)
The values involved here are
xlp_pageaddr = 16777216
ptr = 20971520
so the page seems to be at the very beginning of the second WAL segment,
but the pointer is somewhere later. A full backtrace is attached.
I'll continue investigating this, but the xlog code is not particularly
easy to understand in general, so it may take time.
regards
--
Tomas Vondra
EnterpriseDB: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
Attachment
Hi,
I think I've managed to get the 0002 patch [1] rebased to master and
working (with help from Masahiko Sawada). It's not clear to me how it
could have worked as submitted - my theory is that an incomplete patch
was submitted by mistake, or something like that.
Unfortunately, the benchmark results were kinda disappointing. For a
pgbench on scale 500 (fits into shared buffers), an average of three
5-minute runs looks like this:
branch 1 16 32 64 96
----------------------------------------------------------------
master 7291 87704 165310 150437 224186
ntt 7912 106095 213206 212410 237819
simple-no-buffers 7654 96544 115416 95828 103065
NTT refers to the patch from September 10, pre-allocating a large WAL
file on PMEM, and simple-no-buffers is the simpler patch simply removing
the WAL buffers and writing directly to a mmap-ed WAL segment on PMEM.
Note: The patch is just replacing the old implementation with mmap.
That's good enough for experiments like this, but we probably want to
keep the old one for setups without PMEM. But it's good enough for
testing, benchmarking etc.
Unfortunately, the results for this simple approach are pretty bad. Not
only compared to the "ntt" patch, but even to master. I'm not entirely
sure what's the root cause, but I have a couple hypotheses:
1) bug in the patch - That's clearly a possibility, although I've tried
tried to eliminate this possibility.
2) PMEM is slower than DRAM - From what I know, PMEM is much faster than
NVMe storage, but still much slower than DRAM (both in terms of latency
and bandwidth, see [2] for some data). It's not terrible, but the
latency is maybe 2-3x higher - not a huge difference, but may matter for
WAL buffers?
3) PMEM does not handle parallel writes well - If you look at [2],
Figure 4(b), you'll see that the throughput actually *drops" as the
number of threads increase. That's pretty strange / annoying, because
that's how we write into WAL buffers - each thread writes it's own data,
so parallelism is not something we can get rid of.
I've added some simple profiling, to measure number of calls / time for
each operation (use -DXLOG_DEBUG_STATS to enable). It accumulates data
for each backend, and logs the counts every 1M ops.
Typical stats from a concurrent run looks like this:
xlog stats cnt 43000000
map cnt 100 time 5448333 unmap cnt 100 time 3730963
memcpy cnt 985964 time 1550442272 len 15150499
memset cnt 0 time 0 len 0
persist cnt 13836 time 10369617 len 16292182
The times are in nanoseconds, so this says the backend did 100 mmap and
unmap calls, taking ~10ms in total. There were ~14k pmem_persist calls,
taking 10ms in total. And the most time (~1.5s) was used by pmem_memcpy
copying about 15MB of data. That's quite a lot :-(
My conclusion from this is that eliminating WAL buffers and writing WAL
directly to PMEM (by memcpy to mmap-ed WAL segments) is probably not the
right approach.
I suppose we should keep WAL buffers, and then just write the data to
mmap-ed WAL segments on PMEM. Which I think is what the NTT patch does,
except that it allocates one huge file on PMEM and writes to that
(instead of the traditional WAL segments).
So I decided to try how it'd work with writing to regular WAL segments,
mmap-ed ad hoc. The pmem-with-wal-buffers-master.patch patch does that,
and the results look a bit nicer:
branch 1 16 32 64 96
----------------------------------------------------------------
master 7291 87704 165310 150437 224186
ntt 7912 106095 213206 212410 237819
simple-no-buffers 7654 96544 115416 95828 103065
with-wal-buffers 7477 95454 181702 140167 214715
So, much better than the version without WAL buffers, somewhat better
than master (except for 64/96 clients), but still not as good as NTT.
At this point I was wondering how could the NTT patch be faster when
it's doing roughly the same thing. I'm sire there are some differences,
but it seemed strange. The main difference seems to be that it only maps
one large file, and only once. OTOH the alternative "simple" patch maps
segments one by one, in each backend. Per the debug stats the map/unmap
calls are fairly cheap, but maybe it interferes with the memcpy somehow.
So I did an experiment by increasing the size of the WAL segments. I
chose to try with 521MB and 1024MB, and the results with 1GB look like this:
branch 1 16 32 64 96
----------------------------------------------------------------
master 6635 88524 171106 163387 245307
ntt 7909 106826 217364 223338 242042
simple-no-buffers 7871 101575 199403 188074 224716
with-wal-buffers 7643 101056 206911 223860 261712
So yeah, there's a clear difference. It changes the values for "master"
a bit, but both the "simple" patches (with and without) WAL buffers are
much faster. The with-wal-buffers is almost equal to the NTT patch,
which was using 96GB file. I presume larger WAL segments would get even
closer, if we supported them.
I'll continue investigating this, but my conclusion so far seem to be
that we can't really replace WAL buffers with PMEM - that seems to
perform much worse.
The question is what to do about the segment size. Can we reduce the
overhead of mmap-ing individual segments, so that this works even for
smaller WAL segments, to make this useful for common instances (not
everyone wants to run with 1GB WAL). Or whether we need to adopt the
design with a large file, mapped just once.
Another question is whether it's even worth the extra complexity. On
16MB segments the difference between master and NTT patch seems to be
non-trivial, but increasing the WAL segment size kinda reduces that. So
maybe just using File I/O on PMEM DAX filesystem seems good enough.
Alternatively, maybe we could switch to libpmemblk, which should
eliminate the filesystem overhead at least.
I'm also wondering if WAL is the right usage for PMEM. Per [2] there's a
huge read-write assymmetry (the writes being way slower), and their
recommendation (in "Observation 3" is)
The read-write asymmetry of PMem im-plies the necessity of avoiding
writes as much as possible for PMem.
So maybe we should not be trying to use PMEM for WAL, which is pretty
write-heavy (and in most cases even write-only).
I'll continue investigating this, but I'd welcome some feedback and
thoughts about this.
Attached are:
* patches.tgz - all three patches discussed here, rebased to master
* bench.tgz - benchmarking scripts / config files I used
* pmem.pdf - charts illustrating results between the patches, and also
showing the impact of the increased WAL segments
regards
[1]
https://www.postgresql.org/message-id/000001d5dff4%24995ed180%24cc1c7480%24%40hco.ntt.co.jp_1
[2] https://arxiv.org/pdf/2005.07658.pdf (Lessons learned from the early
performance evaluation of IntelOptane DC Persistent Memory in DBMS)
--
Tomas Vondra
EnterpriseDB: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
Attachment
On Thu, Jan 7, 2021 at 2:16 AM Tomas Vondra <tomas.vondra@enterprisedb.com> wrote: > > Hi, > > I think I've managed to get the 0002 patch [1] rebased to master and > working (with help from Masahiko Sawada). It's not clear to me how it > could have worked as submitted - my theory is that an incomplete patch > was submitted by mistake, or something like that. > > Unfortunately, the benchmark results were kinda disappointing. For a > pgbench on scale 500 (fits into shared buffers), an average of three > 5-minute runs looks like this: > > branch 1 16 32 64 96 > ---------------------------------------------------------------- > master 7291 87704 165310 150437 224186 > ntt 7912 106095 213206 212410 237819 > simple-no-buffers 7654 96544 115416 95828 103065 > > NTT refers to the patch from September 10, pre-allocating a large WAL > file on PMEM, and simple-no-buffers is the simpler patch simply removing > the WAL buffers and writing directly to a mmap-ed WAL segment on PMEM. > > Note: The patch is just replacing the old implementation with mmap. > That's good enough for experiments like this, but we probably want to > keep the old one for setups without PMEM. But it's good enough for > testing, benchmarking etc. > > Unfortunately, the results for this simple approach are pretty bad. Not > only compared to the "ntt" patch, but even to master. I'm not entirely > sure what's the root cause, but I have a couple hypotheses: > > 1) bug in the patch - That's clearly a possibility, although I've tried > tried to eliminate this possibility. > > 2) PMEM is slower than DRAM - From what I know, PMEM is much faster than > NVMe storage, but still much slower than DRAM (both in terms of latency > and bandwidth, see [2] for some data). It's not terrible, but the > latency is maybe 2-3x higher - not a huge difference, but may matter for > WAL buffers? > > 3) PMEM does not handle parallel writes well - If you look at [2], > Figure 4(b), you'll see that the throughput actually *drops" as the > number of threads increase. That's pretty strange / annoying, because > that's how we write into WAL buffers - each thread writes it's own data, > so parallelism is not something we can get rid of. > > I've added some simple profiling, to measure number of calls / time for > each operation (use -DXLOG_DEBUG_STATS to enable). It accumulates data > for each backend, and logs the counts every 1M ops. > > Typical stats from a concurrent run looks like this: > > xlog stats cnt 43000000 > map cnt 100 time 5448333 unmap cnt 100 time 3730963 > memcpy cnt 985964 time 1550442272 len 15150499 > memset cnt 0 time 0 len 0 > persist cnt 13836 time 10369617 len 16292182 > > The times are in nanoseconds, so this says the backend did 100 mmap and > unmap calls, taking ~10ms in total. There were ~14k pmem_persist calls, > taking 10ms in total. And the most time (~1.5s) was used by pmem_memcpy > copying about 15MB of data. That's quite a lot :-( It might also be interesting if we can see how much time spent on each logging function, such as XLogInsert(), XLogWrite(), and XLogFlush(). > > My conclusion from this is that eliminating WAL buffers and writing WAL > directly to PMEM (by memcpy to mmap-ed WAL segments) is probably not the > right approach. > > I suppose we should keep WAL buffers, and then just write the data to > mmap-ed WAL segments on PMEM. Which I think is what the NTT patch does, > except that it allocates one huge file on PMEM and writes to that > (instead of the traditional WAL segments). > > So I decided to try how it'd work with writing to regular WAL segments, > mmap-ed ad hoc. The pmem-with-wal-buffers-master.patch patch does that, > and the results look a bit nicer: > > branch 1 16 32 64 96 > ---------------------------------------------------------------- > master 7291 87704 165310 150437 224186 > ntt 7912 106095 213206 212410 237819 > simple-no-buffers 7654 96544 115416 95828 103065 > with-wal-buffers 7477 95454 181702 140167 214715 > > So, much better than the version without WAL buffers, somewhat better > than master (except for 64/96 clients), but still not as good as NTT. > > At this point I was wondering how could the NTT patch be faster when > it's doing roughly the same thing. I'm sire there are some differences, > but it seemed strange. The main difference seems to be that it only maps > one large file, and only once. OTOH the alternative "simple" patch maps > segments one by one, in each backend. Per the debug stats the map/unmap > calls are fairly cheap, but maybe it interferes with the memcpy somehow. > While looking at the two methods: NTT and simple-no-buffer, I realized that in XLogFlush(), NTT patch flushes (by pmem_flush() and pmem_drain()) WAL without acquiring WALWriteLock whereas simple-no-buffer patch acquires WALWriteLock to do that (pmem_persist()). I wonder if this also affected the performance differences between those two methods since WALWriteLock serializes the operations. With PMEM, multiple backends can concurrently flush the records if the memory region is not overlapped? If so, flushing WAL without WALWriteLock would be a big benefit. > So I did an experiment by increasing the size of the WAL segments. I > chose to try with 521MB and 1024MB, and the results with 1GB look like this: > > branch 1 16 32 64 96 > ---------------------------------------------------------------- > master 6635 88524 171106 163387 245307 > ntt 7909 106826 217364 223338 242042 > simple-no-buffers 7871 101575 199403 188074 224716 > with-wal-buffers 7643 101056 206911 223860 261712 > > So yeah, there's a clear difference. It changes the values for "master" > a bit, but both the "simple" patches (with and without) WAL buffers are > much faster. The with-wal-buffers is almost equal to the NTT patch, > which was using 96GB file. I presume larger WAL segments would get even > closer, if we supported them. > > I'll continue investigating this, but my conclusion so far seem to be > that we can't really replace WAL buffers with PMEM - that seems to > perform much worse. > > The question is what to do about the segment size. Can we reduce the > overhead of mmap-ing individual segments, so that this works even for > smaller WAL segments, to make this useful for common instances (not > everyone wants to run with 1GB WAL). Or whether we need to adopt the > design with a large file, mapped just once. > > Another question is whether it's even worth the extra complexity. On > 16MB segments the difference between master and NTT patch seems to be > non-trivial, but increasing the WAL segment size kinda reduces that. So > maybe just using File I/O on PMEM DAX filesystem seems good enough. > Alternatively, maybe we could switch to libpmemblk, which should > eliminate the filesystem overhead at least. I think the performance improvement by NTT patch with the 16MB WAL segment, the most common WAL segment size, is very good (150437 vs. 212410 with 64 clients). But maybe evaluating writing WAL segment files on PMEM DAX filesystem is also worth, as you mentioned, if we don't do that yet. Also, I'm interested in why the through-put of NTT patch saturated at 32 clients, which is earlier than the master's one (96 clients). How many CPU cores are there on the machine you used? > I'm also wondering if WAL is the right usage for PMEM. Per [2] there's a > huge read-write assymmetry (the writes being way slower), and their > recommendation (in "Observation 3" is) > > The read-write asymmetry of PMem im-plies the necessity of avoiding > writes as much as possible for PMem. > > So maybe we should not be trying to use PMEM for WAL, which is pretty > write-heavy (and in most cases even write-only). I think using PMEM for WAL is cost-effective but it leverages the only low-latency (sequential) write, but not other abilities such as fine-grained access and low-latency random write. If we want to exploit its all ability we might need some drastic changes to logging protocol while considering storing data on PMEM. Regards, -- Masahiko Sawada EnterpriseDB: https://www.enterprisedb.com/
On 1/21/21 3:17 AM, Masahiko Sawada wrote: > On Thu, Jan 7, 2021 at 2:16 AM Tomas Vondra > <tomas.vondra@enterprisedb.com> wrote: >> >> Hi, >> >> I think I've managed to get the 0002 patch [1] rebased to master and >> working (with help from Masahiko Sawada). It's not clear to me how it >> could have worked as submitted - my theory is that an incomplete patch >> was submitted by mistake, or something like that. >> >> Unfortunately, the benchmark results were kinda disappointing. For a >> pgbench on scale 500 (fits into shared buffers), an average of three >> 5-minute runs looks like this: >> >> branch 1 16 32 64 96 >> ---------------------------------------------------------------- >> master 7291 87704 165310 150437 224186 >> ntt 7912 106095 213206 212410 237819 >> simple-no-buffers 7654 96544 115416 95828 103065 >> >> NTT refers to the patch from September 10, pre-allocating a large WAL >> file on PMEM, and simple-no-buffers is the simpler patch simply removing >> the WAL buffers and writing directly to a mmap-ed WAL segment on PMEM. >> >> Note: The patch is just replacing the old implementation with mmap. >> That's good enough for experiments like this, but we probably want to >> keep the old one for setups without PMEM. But it's good enough for >> testing, benchmarking etc. >> >> Unfortunately, the results for this simple approach are pretty bad. Not >> only compared to the "ntt" patch, but even to master. I'm not entirely >> sure what's the root cause, but I have a couple hypotheses: >> >> 1) bug in the patch - That's clearly a possibility, although I've tried >> tried to eliminate this possibility. >> >> 2) PMEM is slower than DRAM - From what I know, PMEM is much faster than >> NVMe storage, but still much slower than DRAM (both in terms of latency >> and bandwidth, see [2] for some data). It's not terrible, but the >> latency is maybe 2-3x higher - not a huge difference, but may matter for >> WAL buffers? >> >> 3) PMEM does not handle parallel writes well - If you look at [2], >> Figure 4(b), you'll see that the throughput actually *drops" as the >> number of threads increase. That's pretty strange / annoying, because >> that's how we write into WAL buffers - each thread writes it's own data, >> so parallelism is not something we can get rid of. >> >> I've added some simple profiling, to measure number of calls / time for >> each operation (use -DXLOG_DEBUG_STATS to enable). It accumulates data >> for each backend, and logs the counts every 1M ops. >> >> Typical stats from a concurrent run looks like this: >> >> xlog stats cnt 43000000 >> map cnt 100 time 5448333 unmap cnt 100 time 3730963 >> memcpy cnt 985964 time 1550442272 len 15150499 >> memset cnt 0 time 0 len 0 >> persist cnt 13836 time 10369617 len 16292182 >> >> The times are in nanoseconds, so this says the backend did 100 mmap and >> unmap calls, taking ~10ms in total. There were ~14k pmem_persist calls, >> taking 10ms in total. And the most time (~1.5s) was used by pmem_memcpy >> copying about 15MB of data. That's quite a lot :-( > > It might also be interesting if we can see how much time spent on each > logging function, such as XLogInsert(), XLogWrite(), and XLogFlush(). > Yeah, we could extend it to that, that's fairly mechanical thing. Bbut maybe that could be visible in a regular perf profile. Also, I suppose most of the time will be used by the pmem calls, shown in the stats. >> >> My conclusion from this is that eliminating WAL buffers and writing WAL >> directly to PMEM (by memcpy to mmap-ed WAL segments) is probably not the >> right approach. >> >> I suppose we should keep WAL buffers, and then just write the data to >> mmap-ed WAL segments on PMEM. Which I think is what the NTT patch does, >> except that it allocates one huge file on PMEM and writes to that >> (instead of the traditional WAL segments). >> >> So I decided to try how it'd work with writing to regular WAL segments, >> mmap-ed ad hoc. The pmem-with-wal-buffers-master.patch patch does that, >> and the results look a bit nicer: >> >> branch 1 16 32 64 96 >> ---------------------------------------------------------------- >> master 7291 87704 165310 150437 224186 >> ntt 7912 106095 213206 212410 237819 >> simple-no-buffers 7654 96544 115416 95828 103065 >> with-wal-buffers 7477 95454 181702 140167 214715 >> >> So, much better than the version without WAL buffers, somewhat better >> than master (except for 64/96 clients), but still not as good as NTT. >> >> At this point I was wondering how could the NTT patch be faster when >> it's doing roughly the same thing. I'm sire there are some differences, >> but it seemed strange. The main difference seems to be that it only maps >> one large file, and only once. OTOH the alternative "simple" patch maps >> segments one by one, in each backend. Per the debug stats the map/unmap >> calls are fairly cheap, but maybe it interferes with the memcpy somehow. >> > > While looking at the two methods: NTT and simple-no-buffer, I realized > that in XLogFlush(), NTT patch flushes (by pmem_flush() and > pmem_drain()) WAL without acquiring WALWriteLock whereas > simple-no-buffer patch acquires WALWriteLock to do that > (pmem_persist()). I wonder if this also affected the performance > differences between those two methods since WALWriteLock serializes > the operations. With PMEM, multiple backends can concurrently flush > the records if the memory region is not overlapped? If so, flushing > WAL without WALWriteLock would be a big benefit. > That's a very good question - it's quite possible the WALWriteLock is not really needed, because the processes are actually "writing" the WAL directly to PMEM. So it's a bit confusing, because it's only really concerned about making sure it's flushed. And yes, multiple processes certainly can write to PMEM at the same time, in fact it's a requirement to get good throughput I believe. My understanding is we need ~8 processes, at least that's what I heard from people with more PMEM experience. TBH I'm not convinced the code in the "simple-no-buffer" code (coming from the 0002 patch) is actually correct. Essentially, consider the backend needs to do a flush, but does not have a segment mapped. So it maps it and calls pmem_drain() on it. But does that actually flush anything? Does it properly flush changes done by other processes that may not have called pmem_drain() yet? I find this somewhat suspicious and I'd bet all processes that did write something have to call pmem_drain(). >> So I did an experiment by increasing the size of the WAL segments. I >> chose to try with 521MB and 1024MB, and the results with 1GB look like this: >> >> branch 1 16 32 64 96 >> ---------------------------------------------------------------- >> master 6635 88524 171106 163387 245307 >> ntt 7909 106826 217364 223338 242042 >> simple-no-buffers 7871 101575 199403 188074 224716 >> with-wal-buffers 7643 101056 206911 223860 261712 >> >> So yeah, there's a clear difference. It changes the values for "master" >> a bit, but both the "simple" patches (with and without) WAL buffers are >> much faster. The with-wal-buffers is almost equal to the NTT patch, >> which was using 96GB file. I presume larger WAL segments would get even >> closer, if we supported them. >> >> I'll continue investigating this, but my conclusion so far seem to be >> that we can't really replace WAL buffers with PMEM - that seems to >> perform much worse. >> >> The question is what to do about the segment size. Can we reduce the >> overhead of mmap-ing individual segments, so that this works even for >> smaller WAL segments, to make this useful for common instances (not >> everyone wants to run with 1GB WAL). Or whether we need to adopt the >> design with a large file, mapped just once. >> >> Another question is whether it's even worth the extra complexity. On >> 16MB segments the difference between master and NTT patch seems to be >> non-trivial, but increasing the WAL segment size kinda reduces that. So >> maybe just using File I/O on PMEM DAX filesystem seems good enough. >> Alternatively, maybe we could switch to libpmemblk, which should >> eliminate the filesystem overhead at least. > > I think the performance improvement by NTT patch with the 16MB WAL > segment, the most common WAL segment size, is very good (150437 vs. > 212410 with 64 clients). But maybe evaluating writing WAL segment > files on PMEM DAX filesystem is also worth, as you mentioned, if we > don't do that yet. > Well, not sure. I think the question is still open whether it's actually safe to run on DAX, which does not have atomic writes of 512B sectors, and I think we rely on that e.g. for pg_config. But maybe for WAL that's not an issue. > Also, I'm interested in why the through-put of NTT patch saturated at > 32 clients, which is earlier than the master's one (96 clients). How > many CPU cores are there on the machine you used? > From what I know, this is somewhat expected for PMEM devices, for a bunch of reasons: 1) The memory bandwidth is much lower than for DRAM (maybe ~10-20%), so it takes fewer processes to saturate it. 2) Internally, the PMEM has a 256B buffer for writes, used for combining etc. With too many processes sending writes, it becomes to look more random, which is harmful for throughput. When combined, this means the performance starts dropping at certain number of threads, and the optimal number of threads is rather low (something like 5-10). This is very different behavior compared to DRAM. There's a nice overview and measurements in this paper: Building blocks for persistent memory / How to get the most out of your new memory? Alexander van Renen, Lukas Vogel, Viktor Leis, Thomas Neumann & Alfons Kemper https://link.springer.com/article/10.1007/s00778-020-00622-9 >> I'm also wondering if WAL is the right usage for PMEM. Per [2] there's a >> huge read-write assymmetry (the writes being way slower), and their >> recommendation (in "Observation 3" is) >> >> The read-write asymmetry of PMem im-plies the necessity of avoiding >> writes as much as possible for PMem. >> >> So maybe we should not be trying to use PMEM for WAL, which is pretty >> write-heavy (and in most cases even write-only). > > I think using PMEM for WAL is cost-effective but it leverages the only > low-latency (sequential) write, but not other abilities such as > fine-grained access and low-latency random write. If we want to > exploit its all ability we might need some drastic changes to logging > protocol while considering storing data on PMEM. > True. I think investigating whether it's sensible to use PMEM for this purpose. It may turn out that replacing the DRAM WAL buffers with writes directly to PMEM is not economical, and aggregating data in a DRAM buffer is better :-( regards -- Tomas Vondra EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
Hi,
Let me share some numbers from a few more tests. I've been experimenting
with two optimization ideas - alignment and non-temporal writes.
The first idea (alignment) is not entirely unique to PMEM - we have a
bunch of places where we align stuff to cacheline, and the same thing
does apply to PMEM. The cache lines are 64B, so I've tweaked the WAL
format to align records accordingly - the header sizes are a multiple of
64B, and the space is reserved in 64B chunks. It's a bit crude, but good
enough for experiments, I think. This means the WAL format would not be
compatible, and there's additional overhead (not sure how much).
The second idea is somewhat specific to PMEM - the pmem_memcpy provided
by libpmem allows specifying flags, determining whether the data should
go to CPU cache or not, whether it should be flushed, etc. So far the
code was using
pmem_memcpy(..., PMEM_F_MEM_NOFLUSH);
following the idea that caching data in CPU cache and then flushing it
in larger chunks is more efficient. I heard some recommendations to use
non-temporal writes (which should not use CPU cache), so I tested that
switching to
pmem_memcpy(..., PMEM_F_NON_TEMPORAL);
The experimental patches doing these things are attached, as usual.
The results are a bit better than for the preceding patches, but only by
a couple percent. That's a bit disappointing. Attached is a PDF with
charts for the three WAL segment sizes as before.
It's possible the patches are introducing some internal bottleneck, so I
plan to focus on profiling and optimizing them next. I'd welcome some
feedback with ideas what might be wrong, of course ;-)
regards
--
Tomas Vondra
EnterpriseDB: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
Attachment
On 22.01.2021 5:32, Tomas Vondra wrote: > > > On 1/21/21 3:17 AM, Masahiko Sawada wrote: >> On Thu, Jan 7, 2021 at 2:16 AM Tomas Vondra >> <tomas.vondra@enterprisedb.com> wrote: >>> >>> Hi, >>> >>> I think I've managed to get the 0002 patch [1] rebased to master and >>> working (with help from Masahiko Sawada). It's not clear to me how it >>> could have worked as submitted - my theory is that an incomplete patch >>> was submitted by mistake, or something like that. >>> >>> Unfortunately, the benchmark results were kinda disappointing. For a >>> pgbench on scale 500 (fits into shared buffers), an average of three >>> 5-minute runs looks like this: >>> >>> branch 1 16 32 64 96 >>> ---------------------------------------------------------------- >>> master 7291 87704 165310 150437 224186 >>> ntt 7912 106095 213206 212410 237819 >>> simple-no-buffers 7654 96544 115416 95828 103065 >>> >>> NTT refers to the patch from September 10, pre-allocating a large WAL >>> file on PMEM, and simple-no-buffers is the simpler patch simply >>> removing >>> the WAL buffers and writing directly to a mmap-ed WAL segment on PMEM. >>> >>> Note: The patch is just replacing the old implementation with mmap. >>> That's good enough for experiments like this, but we probably want to >>> keep the old one for setups without PMEM. But it's good enough for >>> testing, benchmarking etc. >>> >>> Unfortunately, the results for this simple approach are pretty bad. Not >>> only compared to the "ntt" patch, but even to master. I'm not entirely >>> sure what's the root cause, but I have a couple hypotheses: >>> >>> 1) bug in the patch - That's clearly a possibility, although I've tried >>> tried to eliminate this possibility. >>> >>> 2) PMEM is slower than DRAM - From what I know, PMEM is much faster >>> than >>> NVMe storage, but still much slower than DRAM (both in terms of latency >>> and bandwidth, see [2] for some data). It's not terrible, but the >>> latency is maybe 2-3x higher - not a huge difference, but may matter >>> for >>> WAL buffers? >>> >>> 3) PMEM does not handle parallel writes well - If you look at [2], >>> Figure 4(b), you'll see that the throughput actually *drops" as the >>> number of threads increase. That's pretty strange / annoying, because >>> that's how we write into WAL buffers - each thread writes it's own >>> data, >>> so parallelism is not something we can get rid of. >>> >>> I've added some simple profiling, to measure number of calls / time for >>> each operation (use -DXLOG_DEBUG_STATS to enable). It accumulates data >>> for each backend, and logs the counts every 1M ops. >>> >>> Typical stats from a concurrent run looks like this: >>> >>> xlog stats cnt 43000000 >>> map cnt 100 time 5448333 unmap cnt 100 time 3730963 >>> memcpy cnt 985964 time 1550442272 len 15150499 >>> memset cnt 0 time 0 len 0 >>> persist cnt 13836 time 10369617 len 16292182 >>> >>> The times are in nanoseconds, so this says the backend did 100 mmap >>> and >>> unmap calls, taking ~10ms in total. There were ~14k pmem_persist calls, >>> taking 10ms in total. And the most time (~1.5s) was used by pmem_memcpy >>> copying about 15MB of data. That's quite a lot :-( >> >> It might also be interesting if we can see how much time spent on each >> logging function, such as XLogInsert(), XLogWrite(), and XLogFlush(). >> > > Yeah, we could extend it to that, that's fairly mechanical thing. Bbut > maybe that could be visible in a regular perf profile. Also, I suppose > most of the time will be used by the pmem calls, shown in the stats. > >>> >>> My conclusion from this is that eliminating WAL buffers and writing WAL >>> directly to PMEM (by memcpy to mmap-ed WAL segments) is probably not >>> the >>> right approach. >>> >>> I suppose we should keep WAL buffers, and then just write the data to >>> mmap-ed WAL segments on PMEM. Which I think is what the NTT patch does, >>> except that it allocates one huge file on PMEM and writes to that >>> (instead of the traditional WAL segments). >>> >>> So I decided to try how it'd work with writing to regular WAL segments, >>> mmap-ed ad hoc. The pmem-with-wal-buffers-master.patch patch does that, >>> and the results look a bit nicer: >>> >>> branch 1 16 32 64 96 >>> ---------------------------------------------------------------- >>> master 7291 87704 165310 150437 224186 >>> ntt 7912 106095 213206 212410 237819 >>> simple-no-buffers 7654 96544 115416 95828 103065 >>> with-wal-buffers 7477 95454 181702 140167 214715 >>> >>> So, much better than the version without WAL buffers, somewhat better >>> than master (except for 64/96 clients), but still not as good as NTT. >>> >>> At this point I was wondering how could the NTT patch be faster when >>> it's doing roughly the same thing. I'm sire there are some differences, >>> but it seemed strange. The main difference seems to be that it only >>> maps >>> one large file, and only once. OTOH the alternative "simple" patch maps >>> segments one by one, in each backend. Per the debug stats the map/unmap >>> calls are fairly cheap, but maybe it interferes with the memcpy >>> somehow. >>> >> >> While looking at the two methods: NTT and simple-no-buffer, I realized >> that in XLogFlush(), NTT patch flushes (by pmem_flush() and >> pmem_drain()) WAL without acquiring WALWriteLock whereas >> simple-no-buffer patch acquires WALWriteLock to do that >> (pmem_persist()). I wonder if this also affected the performance >> differences between those two methods since WALWriteLock serializes >> the operations. With PMEM, multiple backends can concurrently flush >> the records if the memory region is not overlapped? If so, flushing >> WAL without WALWriteLock would be a big benefit. >> > > That's a very good question - it's quite possible the WALWriteLock is > not really needed, because the processes are actually "writing" the > WAL directly to PMEM. So it's a bit confusing, because it's only > really concerned about making sure it's flushed. > > And yes, multiple processes certainly can write to PMEM at the same > time, in fact it's a requirement to get good throughput I believe. My > understanding is we need ~8 processes, at least that's what I heard > from people with more PMEM experience. > > TBH I'm not convinced the code in the "simple-no-buffer" code (coming > from the 0002 patch) is actually correct. Essentially, consider the > backend needs to do a flush, but does not have a segment mapped. So it > maps it and calls pmem_drain() on it. > > But does that actually flush anything? Does it properly flush changes > done by other processes that may not have called pmem_drain() yet? I > find this somewhat suspicious and I'd bet all processes that did write > something have to call pmem_drain(). > > >>> So I did an experiment by increasing the size of the WAL segments. I >>> chose to try with 521MB and 1024MB, and the results with 1GB look >>> like this: >>> >>> branch 1 16 32 64 96 >>> ---------------------------------------------------------------- >>> master 6635 88524 171106 163387 245307 >>> ntt 7909 106826 217364 223338 242042 >>> simple-no-buffers 7871 101575 199403 188074 224716 >>> with-wal-buffers 7643 101056 206911 223860 261712 >>> >>> So yeah, there's a clear difference. It changes the values for "master" >>> a bit, but both the "simple" patches (with and without) WAL buffers are >>> much faster. The with-wal-buffers is almost equal to the NTT patch, >>> which was using 96GB file. I presume larger WAL segments would get even >>> closer, if we supported them. >>> >>> I'll continue investigating this, but my conclusion so far seem to be >>> that we can't really replace WAL buffers with PMEM - that seems to >>> perform much worse. >>> >>> The question is what to do about the segment size. Can we reduce the >>> overhead of mmap-ing individual segments, so that this works even for >>> smaller WAL segments, to make this useful for common instances (not >>> everyone wants to run with 1GB WAL). Or whether we need to adopt the >>> design with a large file, mapped just once. >>> >>> Another question is whether it's even worth the extra complexity. On >>> 16MB segments the difference between master and NTT patch seems to be >>> non-trivial, but increasing the WAL segment size kinda reduces that. So >>> maybe just using File I/O on PMEM DAX filesystem seems good enough. >>> Alternatively, maybe we could switch to libpmemblk, which should >>> eliminate the filesystem overhead at least. >> >> I think the performance improvement by NTT patch with the 16MB WAL >> segment, the most common WAL segment size, is very good (150437 vs. >> 212410 with 64 clients). But maybe evaluating writing WAL segment >> files on PMEM DAX filesystem is also worth, as you mentioned, if we >> don't do that yet. >> > > Well, not sure. I think the question is still open whether it's > actually safe to run on DAX, which does not have atomic writes of 512B > sectors, and I think we rely on that e.g. for pg_config. But maybe for > WAL that's not an issue. > >> Also, I'm interested in why the through-put of NTT patch saturated at >> 32 clients, which is earlier than the master's one (96 clients). How >> many CPU cores are there on the machine you used? >> > > From what I know, this is somewhat expected for PMEM devices, for a > bunch of reasons: > > 1) The memory bandwidth is much lower than for DRAM (maybe ~10-20%), > so it takes fewer processes to saturate it. > > 2) Internally, the PMEM has a 256B buffer for writes, used for > combining etc. With too many processes sending writes, it becomes to > look more random, which is harmful for throughput. > > When combined, this means the performance starts dropping at certain > number of threads, and the optimal number of threads is rather low > (something like 5-10). This is very different behavior compared to DRAM. > > There's a nice overview and measurements in this paper: > > Building blocks for persistent memory / How to get the most out of > your new memory? > Alexander van Renen, Lukas Vogel, Viktor Leis, Thomas Neumann & Alfons > Kemper > > https://link.springer.com/article/10.1007/s00778-020-00622-9 > > >>> I'm also wondering if WAL is the right usage for PMEM. Per [2] >>> there's a >>> huge read-write assymmetry (the writes being way slower), and their >>> recommendation (in "Observation 3" is) >>> >>> The read-write asymmetry of PMem im-plies the necessity of >>> avoiding >>> writes as much as possible for PMem. >>> >>> So maybe we should not be trying to use PMEM for WAL, which is pretty >>> write-heavy (and in most cases even write-only). >> >> I think using PMEM for WAL is cost-effective but it leverages the only >> low-latency (sequential) write, but not other abilities such as >> fine-grained access and low-latency random write. If we want to >> exploit its all ability we might need some drastic changes to logging >> protocol while considering storing data on PMEM. >> > > True. I think investigating whether it's sensible to use PMEM for this > purpose. It may turn out that replacing the DRAM WAL buffers with > writes directly to PMEM is not economical, and aggregating data in a > DRAM buffer is better :-( > > > regards > I have heard from several DBMS experts that appearance of huge and cheap non-volatile memory can make a revolution in database system architecture. If all database can fit in non-volatile memory, then we do not need buffers, WAL, ... But although multi-terabyte NVM announces were made by IBM several years ago, I do not know about some successful DBMS prototypes with new architecture. I tried to understand why... It was very interesting to me to read this thread, which is actually started in 2016 with "Non-volatile Memory Logging" presentation at PGCon. As far as I understand from Tomas result right now using PMEM for WAL doesn't provide some substantial increase of performance. But the main advantage of PMEM from my point of view is that it allows to avoid write-ahead logging at all! Certainly we need to change our algorithms to make it possible. Speaking about Postgres, we have to rewrite all indexes + heap and throw away buffer manager + WAL. What can be used instead of standard B-Tree? For example there is description of multiword-CAS approach: http://justinlevandoski.org/papers/mwcas.pdf and BzTree implementation on top of it: https://www.cc.gatech.edu/~jarulraj/papers/2018.bztree.vldb.pdf There is free BzTree implementation at github: git@github.com:sfu-dis/bztree.git I tried to adopt it for Postgres. It was not so easy because: 1. It was written in modern C++ (-std=c++14) 2. It supports multithreading, but not mutliprocess access So I have to patch code of this library instead of just using it: git@github.com:postgrespro/bztree.git I have not tested yet most iterating case: access to PMEM through PMDK. And I do not have hardware for such tests. But first results are also seem to be interesting: PMwCAS is kind of lockless algorithm and it shows much better scaling at NUMA host comparing with standard Postgres. I have done simple parallel insertion test: multiple clients are inserting data with random keys. To make competition with vanilla Postgres more honest I used unlogged table: create unlogged table t(pk int, payload int); create index on t using bztree(pk); randinsert.sql: insert into t (payload,pk) values (generate_series(1,1000),random()*1000000000); pgbench -f randinsert.sql -c N -j N -M prepared -n -t 1000 -P 1 postgres So each client is inserting one million records. The target system has 160 virtual and 80 real cores with 256GB of RAM. Results (TPS) are the following: N nbtree bztree 1 540 455 10 993 2237 100 1479 5025 So bztree is more than 3 times faster for 100 clients. Just for comparison: result for inserting in this table without index is 10k TPS. I am going then try to play with PMEM. If results will be promising, then it is possible to think about reimplementation of heap and WAL-less Postgres! I am sorry, that my post has no direct relation to the topic of this thread (Non-volatile WAL buffer). It seems to be that it is better to use PMEM to eliminate WAL at all instead of optimizing it. Certainly, I realize that WAL plays very important role in Postgres: archiving and replication are based on WAL. So even if we can live without WAL, it is still not clear whether we really want to live without it. One more idea: using multiword CAS approach requires us to make changes as editing sequences. Such editing sequence is actually ready WAL records. So implementors of access methods do not have to do double work: update data structure in memory and create correspondent WAL records. Moreover, PMwCAS operations are atomic: we can replay or revert them in case of fault. So there is no need in FPW (full page writes) which have very noticeable impact on WAL size and database performance. -- Konstantin Knizhnik Postgres Professional: http://www.postgrespro.com The Russian Postgres Company
On Fri, Jan 22, 2021 at 11:32 AM Tomas Vondra <tomas.vondra@enterprisedb.com> wrote: > > > > On 1/21/21 3:17 AM, Masahiko Sawada wrote: > > On Thu, Jan 7, 2021 at 2:16 AM Tomas Vondra > > <tomas.vondra@enterprisedb.com> wrote: > >> > >> Hi, > >> > >> I think I've managed to get the 0002 patch [1] rebased to master and > >> working (with help from Masahiko Sawada). It's not clear to me how it > >> could have worked as submitted - my theory is that an incomplete patch > >> was submitted by mistake, or something like that. > >> > >> Unfortunately, the benchmark results were kinda disappointing. For a > >> pgbench on scale 500 (fits into shared buffers), an average of three > >> 5-minute runs looks like this: > >> > >> branch 1 16 32 64 96 > >> ---------------------------------------------------------------- > >> master 7291 87704 165310 150437 224186 > >> ntt 7912 106095 213206 212410 237819 > >> simple-no-buffers 7654 96544 115416 95828 103065 > >> > >> NTT refers to the patch from September 10, pre-allocating a large WAL > >> file on PMEM, and simple-no-buffers is the simpler patch simply removing > >> the WAL buffers and writing directly to a mmap-ed WAL segment on PMEM. > >> > >> Note: The patch is just replacing the old implementation with mmap. > >> That's good enough for experiments like this, but we probably want to > >> keep the old one for setups without PMEM. But it's good enough for > >> testing, benchmarking etc. > >> > >> Unfortunately, the results for this simple approach are pretty bad. Not > >> only compared to the "ntt" patch, but even to master. I'm not entirely > >> sure what's the root cause, but I have a couple hypotheses: > >> > >> 1) bug in the patch - That's clearly a possibility, although I've tried > >> tried to eliminate this possibility. > >> > >> 2) PMEM is slower than DRAM - From what I know, PMEM is much faster than > >> NVMe storage, but still much slower than DRAM (both in terms of latency > >> and bandwidth, see [2] for some data). It's not terrible, but the > >> latency is maybe 2-3x higher - not a huge difference, but may matter for > >> WAL buffers? > >> > >> 3) PMEM does not handle parallel writes well - If you look at [2], > >> Figure 4(b), you'll see that the throughput actually *drops" as the > >> number of threads increase. That's pretty strange / annoying, because > >> that's how we write into WAL buffers - each thread writes it's own data, > >> so parallelism is not something we can get rid of. > >> > >> I've added some simple profiling, to measure number of calls / time for > >> each operation (use -DXLOG_DEBUG_STATS to enable). It accumulates data > >> for each backend, and logs the counts every 1M ops. > >> > >> Typical stats from a concurrent run looks like this: > >> > >> xlog stats cnt 43000000 > >> map cnt 100 time 5448333 unmap cnt 100 time 3730963 > >> memcpy cnt 985964 time 1550442272 len 15150499 > >> memset cnt 0 time 0 len 0 > >> persist cnt 13836 time 10369617 len 16292182 > >> > >> The times are in nanoseconds, so this says the backend did 100 mmap and > >> unmap calls, taking ~10ms in total. There were ~14k pmem_persist calls, > >> taking 10ms in total. And the most time (~1.5s) was used by pmem_memcpy > >> copying about 15MB of data. That's quite a lot :-( > > > > It might also be interesting if we can see how much time spent on each > > logging function, such as XLogInsert(), XLogWrite(), and XLogFlush(). > > > > Yeah, we could extend it to that, that's fairly mechanical thing. Bbut > maybe that could be visible in a regular perf profile. Also, I suppose > most of the time will be used by the pmem calls, shown in the stats. > > >> > >> My conclusion from this is that eliminating WAL buffers and writing WAL > >> directly to PMEM (by memcpy to mmap-ed WAL segments) is probably not the > >> right approach. > >> > >> I suppose we should keep WAL buffers, and then just write the data to > >> mmap-ed WAL segments on PMEM. Which I think is what the NTT patch does, > >> except that it allocates one huge file on PMEM and writes to that > >> (instead of the traditional WAL segments). > >> > >> So I decided to try how it'd work with writing to regular WAL segments, > >> mmap-ed ad hoc. The pmem-with-wal-buffers-master.patch patch does that, > >> and the results look a bit nicer: > >> > >> branch 1 16 32 64 96 > >> ---------------------------------------------------------------- > >> master 7291 87704 165310 150437 224186 > >> ntt 7912 106095 213206 212410 237819 > >> simple-no-buffers 7654 96544 115416 95828 103065 > >> with-wal-buffers 7477 95454 181702 140167 214715 > >> > >> So, much better than the version without WAL buffers, somewhat better > >> than master (except for 64/96 clients), but still not as good as NTT. > >> > >> At this point I was wondering how could the NTT patch be faster when > >> it's doing roughly the same thing. I'm sire there are some differences, > >> but it seemed strange. The main difference seems to be that it only maps > >> one large file, and only once. OTOH the alternative "simple" patch maps > >> segments one by one, in each backend. Per the debug stats the map/unmap > >> calls are fairly cheap, but maybe it interferes with the memcpy somehow. > >> > > > > While looking at the two methods: NTT and simple-no-buffer, I realized > > that in XLogFlush(), NTT patch flushes (by pmem_flush() and > > pmem_drain()) WAL without acquiring WALWriteLock whereas > > simple-no-buffer patch acquires WALWriteLock to do that > > (pmem_persist()). I wonder if this also affected the performance > > differences between those two methods since WALWriteLock serializes > > the operations. With PMEM, multiple backends can concurrently flush > > the records if the memory region is not overlapped? If so, flushing > > WAL without WALWriteLock would be a big benefit. > > > > That's a very good question - it's quite possible the WALWriteLock is > not really needed, because the processes are actually "writing" the WAL > directly to PMEM. So it's a bit confusing, because it's only really > concerned about making sure it's flushed. > > And yes, multiple processes certainly can write to PMEM at the same > time, in fact it's a requirement to get good throughput I believe. My > understanding is we need ~8 processes, at least that's what I heard from > people with more PMEM experience. Thanks, that's good to know. > > TBH I'm not convinced the code in the "simple-no-buffer" code (coming > from the 0002 patch) is actually correct. Essentially, consider the > backend needs to do a flush, but does not have a segment mapped. So it > maps it and calls pmem_drain() on it. > > But does that actually flush anything? Does it properly flush changes > done by other processes that may not have called pmem_drain() yet? I > find this somewhat suspicious and I'd bet all processes that did write > something have to call pmem_drain(). Yeah, in terms of experiments at least it's good to find out that the approach mmapping each WAL segment is not good at performance. > > > >> So I did an experiment by increasing the size of the WAL segments. I > >> chose to try with 521MB and 1024MB, and the results with 1GB look like this: > >> > >> branch 1 16 32 64 96 > >> ---------------------------------------------------------------- > >> master 6635 88524 171106 163387 245307 > >> ntt 7909 106826 217364 223338 242042 > >> simple-no-buffers 7871 101575 199403 188074 224716 > >> with-wal-buffers 7643 101056 206911 223860 261712 > >> > >> So yeah, there's a clear difference. It changes the values for "master" > >> a bit, but both the "simple" patches (with and without) WAL buffers are > >> much faster. The with-wal-buffers is almost equal to the NTT patch, > >> which was using 96GB file. I presume larger WAL segments would get even > >> closer, if we supported them. > >> > >> I'll continue investigating this, but my conclusion so far seem to be > >> that we can't really replace WAL buffers with PMEM - that seems to > >> perform much worse. > >> > >> The question is what to do about the segment size. Can we reduce the > >> overhead of mmap-ing individual segments, so that this works even for > >> smaller WAL segments, to make this useful for common instances (not > >> everyone wants to run with 1GB WAL). Or whether we need to adopt the > >> design with a large file, mapped just once. > >> > >> Another question is whether it's even worth the extra complexity. On > >> 16MB segments the difference between master and NTT patch seems to be > >> non-trivial, but increasing the WAL segment size kinda reduces that. So > >> maybe just using File I/O on PMEM DAX filesystem seems good enough. > >> Alternatively, maybe we could switch to libpmemblk, which should > >> eliminate the filesystem overhead at least. > > > > I think the performance improvement by NTT patch with the 16MB WAL > > segment, the most common WAL segment size, is very good (150437 vs. > > 212410 with 64 clients). But maybe evaluating writing WAL segment > > files on PMEM DAX filesystem is also worth, as you mentioned, if we > > don't do that yet. > > > > Well, not sure. I think the question is still open whether it's actually > safe to run on DAX, which does not have atomic writes of 512B sectors, > and I think we rely on that e.g. for pg_config. But maybe for WAL that's > not an issue. I think we can use the Block Translation Table (BTT) driver that provides atomic sector updates. > > > Also, I'm interested in why the through-put of NTT patch saturated at > > 32 clients, which is earlier than the master's one (96 clients). How > > many CPU cores are there on the machine you used? > > > > From what I know, this is somewhat expected for PMEM devices, for a > bunch of reasons: > > 1) The memory bandwidth is much lower than for DRAM (maybe ~10-20%), so > it takes fewer processes to saturate it. > > 2) Internally, the PMEM has a 256B buffer for writes, used for combining > etc. With too many processes sending writes, it becomes to look more > random, which is harmful for throughput. > > When combined, this means the performance starts dropping at certain > number of threads, and the optimal number of threads is rather low > (something like 5-10). This is very different behavior compared to DRAM. Makes sense. > > There's a nice overview and measurements in this paper: > > Building blocks for persistent memory / How to get the most out of your > new memory? > Alexander van Renen, Lukas Vogel, Viktor Leis, Thomas Neumann & Alfons > Kemper > > https://link.springer.com/article/10.1007/s00778-020-00622-9 Thank you. I'll read it. > > > >> I'm also wondering if WAL is the right usage for PMEM. Per [2] there's a > >> huge read-write assymmetry (the writes being way slower), and their > >> recommendation (in "Observation 3" is) > >> > >> The read-write asymmetry of PMem im-plies the necessity of avoiding > >> writes as much as possible for PMem. > >> > >> So maybe we should not be trying to use PMEM for WAL, which is pretty > >> write-heavy (and in most cases even write-only). > > > > I think using PMEM for WAL is cost-effective but it leverages the only > > low-latency (sequential) write, but not other abilities such as > > fine-grained access and low-latency random write. If we want to > > exploit its all ability we might need some drastic changes to logging > > protocol while considering storing data on PMEM. > > > > True. I think investigating whether it's sensible to use PMEM for this > purpose. It may turn out that replacing the DRAM WAL buffers with writes > directly to PMEM is not economical, and aggregating data in a DRAM > buffer is better :-( Yes. I think it might be interesting to do an analysis of the bottlenecks of NTT patch by perf etc. If bottlenecks are moved to other places by removing WALWriteLock during flush, it's probably a good sign for further performance improvements. IIRC WALWriteLock is one of the main bottlenecks on OLTP workload, although my memory might already be out of date. Regards, -- Masahiko Sawada EDB: https://www.enterprisedb.com/
On Fri, Jan 22, 2021 at 11:32 AM Tomas Vondra
<tomas.vondra@enterprisedb.com> wrote:
>
>
>
> On 1/21/21 3:17 AM, Masahiko Sawada wrote:
> > On Thu, Jan 7, 2021 at 2:16 AM Tomas Vondra
> > <tomas.vondra@enterprisedb.com> wrote:
> >>
> >> Hi,
> >>
> >> I think I've managed to get the 0002 patch [1] rebased to master and
> >> working (with help from Masahiko Sawada). It's not clear to me how it
> >> could have worked as submitted - my theory is that an incomplete patch
> >> was submitted by mistake, or something like that.
> >>
> >> Unfortunately, the benchmark results were kinda disappointing. For a
> >> pgbench on scale 500 (fits into shared buffers), an average of three
> >> 5-minute runs looks like this:
> >>
> >> branch 1 16 32 64 96
> >> ----------------------------------------------------------------
> >> master 7291 87704 165310 150437 224186
> >> ntt 7912 106095 213206 212410 237819
> >> simple-no-buffers 7654 96544 115416 95828 103065
> >>
> >> NTT refers to the patch from September 10, pre-allocating a large WAL
> >> file on PMEM, and simple-no-buffers is the simpler patch simply removing
> >> the WAL buffers and writing directly to a mmap-ed WAL segment on PMEM.
> >>
> >> Note: The patch is just replacing the old implementation with mmap.
> >> That's good enough for experiments like this, but we probably want to
> >> keep the old one for setups without PMEM. But it's good enough for
> >> testing, benchmarking etc.
> >>
> >> Unfortunately, the results for this simple approach are pretty bad. Not
> >> only compared to the "ntt" patch, but even to master. I'm not entirely
> >> sure what's the root cause, but I have a couple hypotheses:
> >>
> >> 1) bug in the patch - That's clearly a possibility, although I've tried
> >> tried to eliminate this possibility.
> >>
> >> 2) PMEM is slower than DRAM - From what I know, PMEM is much faster than
> >> NVMe storage, but still much slower than DRAM (both in terms of latency
> >> and bandwidth, see [2] for some data). It's not terrible, but the
> >> latency is maybe 2-3x higher - not a huge difference, but may matter for
> >> WAL buffers?
> >>
> >> 3) PMEM does not handle parallel writes well - If you look at [2],
> >> Figure 4(b), you'll see that the throughput actually *drops" as the
> >> number of threads increase. That's pretty strange / annoying, because
> >> that's how we write into WAL buffers - each thread writes it's own data,
> >> so parallelism is not something we can get rid of.
> >>
> >> I've added some simple profiling, to measure number of calls / time for
> >> each operation (use -DXLOG_DEBUG_STATS to enable). It accumulates data
> >> for each backend, and logs the counts every 1M ops.
> >>
> >> Typical stats from a concurrent run looks like this:
> >>
> >> xlog stats cnt 43000000
> >> map cnt 100 time 5448333 unmap cnt 100 time 3730963
> >> memcpy cnt 985964 time 1550442272 len 15150499
> >> memset cnt 0 time 0 len 0
> >> persist cnt 13836 time 10369617 len 16292182
> >>
> >> The times are in nanoseconds, so this says the backend did 100 mmap and
> >> unmap calls, taking ~10ms in total. There were ~14k pmem_persist calls,
> >> taking 10ms in total. And the most time (~1.5s) was used by pmem_memcpy
> >> copying about 15MB of data. That's quite a lot :-(
> >
> > It might also be interesting if we can see how much time spent on each
> > logging function, such as XLogInsert(), XLogWrite(), and XLogFlush().
> >
>
> Yeah, we could extend it to that, that's fairly mechanical thing. Bbut
> maybe that could be visible in a regular perf profile. Also, I suppose
> most of the time will be used by the pmem calls, shown in the stats.
>
> >>
> >> My conclusion from this is that eliminating WAL buffers and writing WAL
> >> directly to PMEM (by memcpy to mmap-ed WAL segments) is probably not the
> >> right approach.
> >>
> >> I suppose we should keep WAL buffers, and then just write the data to
> >> mmap-ed WAL segments on PMEM. Which I think is what the NTT patch does,
> >> except that it allocates one huge file on PMEM and writes to that
> >> (instead of the traditional WAL segments).
> >>
> >> So I decided to try how it'd work with writing to regular WAL segments,
> >> mmap-ed ad hoc. The pmem-with-wal-buffers-master.patch patch does that,
> >> and the results look a bit nicer:
> >>
> >> branch 1 16 32 64 96
> >> ----------------------------------------------------------------
> >> master 7291 87704 165310 150437 224186
> >> ntt 7912 106095 213206 212410 237819
> >> simple-no-buffers 7654 96544 115416 95828 103065
> >> with-wal-buffers 7477 95454 181702 140167 214715
> >>
> >> So, much better than the version without WAL buffers, somewhat better
> >> than master (except for 64/96 clients), but still not as good as NTT.
> >>
> >> At this point I was wondering how could the NTT patch be faster when
> >> it's doing roughly the same thing. I'm sire there are some differences,
> >> but it seemed strange. The main difference seems to be that it only maps
> >> one large file, and only once. OTOH the alternative "simple" patch maps
> >> segments one by one, in each backend. Per the debug stats the map/unmap
> >> calls are fairly cheap, but maybe it interferes with the memcpy somehow.
> >>
> >
> > While looking at the two methods: NTT and simple-no-buffer, I realized
> > that in XLogFlush(), NTT patch flushes (by pmem_flush() and
> > pmem_drain()) WAL without acquiring WALWriteLock whereas
> > simple-no-buffer patch acquires WALWriteLock to do that
> > (pmem_persist()). I wonder if this also affected the performance
> > differences between those two methods since WALWriteLock serializes
> > the operations. With PMEM, multiple backends can concurrently flush
> > the records if the memory region is not overlapped? If so, flushing
> > WAL without WALWriteLock would be a big benefit.
> >
>
> That's a very good question - it's quite possible the WALWriteLock is
> not really needed, because the processes are actually "writing" the WAL
> directly to PMEM. So it's a bit confusing, because it's only really
> concerned about making sure it's flushed.
>
> And yes, multiple processes certainly can write to PMEM at the same
> time, in fact it's a requirement to get good throughput I believe. My
> understanding is we need ~8 processes, at least that's what I heard from
> people with more PMEM experience.
Thanks, that's good to know.
>
> TBH I'm not convinced the code in the "simple-no-buffer" code (coming
> from the 0002 patch) is actually correct. Essentially, consider the
> backend needs to do a flush, but does not have a segment mapped. So it
> maps it and calls pmem_drain() on it.
>
> But does that actually flush anything? Does it properly flush changes
> done by other processes that may not have called pmem_drain() yet? I
> find this somewhat suspicious and I'd bet all processes that did write
> something have to call pmem_drain().
Yeah, in terms of experiments at least it's good to find out that the
approach mmapping each WAL segment is not good at performance.
>
>
> >> So I did an experiment by increasing the size of the WAL segments. I
> >> chose to try with 521MB and 1024MB, and the results with 1GB look like this:
> >>
> >> branch 1 16 32 64 96
> >> ----------------------------------------------------------------
> >> master 6635 88524 171106 163387 245307
> >> ntt 7909 106826 217364 223338 242042
> >> simple-no-buffers 7871 101575 199403 188074 224716
> >> with-wal-buffers 7643 101056 206911 223860 261712
> >>
> >> So yeah, there's a clear difference. It changes the values for "master"
> >> a bit, but both the "simple" patches (with and without) WAL buffers are
> >> much faster. The with-wal-buffers is almost equal to the NTT patch,
> >> which was using 96GB file. I presume larger WAL segments would get even
> >> closer, if we supported them.
> >>
> >> I'll continue investigating this, but my conclusion so far seem to be
> >> that we can't really replace WAL buffers with PMEM - that seems to
> >> perform much worse.
> >>
> >> The question is what to do about the segment size. Can we reduce the
> >> overhead of mmap-ing individual segments, so that this works even for
> >> smaller WAL segments, to make this useful for common instances (not
> >> everyone wants to run with 1GB WAL). Or whether we need to adopt the
> >> design with a large file, mapped just once.
> >>
> >> Another question is whether it's even worth the extra complexity. On
> >> 16MB segments the difference between master and NTT patch seems to be
> >> non-trivial, but increasing the WAL segment size kinda reduces that. So
> >> maybe just using File I/O on PMEM DAX filesystem seems good enough.
> >> Alternatively, maybe we could switch to libpmemblk, which should
> >> eliminate the filesystem overhead at least.
> >
> > I think the performance improvement by NTT patch with the 16MB WAL
> > segment, the most common WAL segment size, is very good (150437 vs.
> > 212410 with 64 clients). But maybe evaluating writing WAL segment
> > files on PMEM DAX filesystem is also worth, as you mentioned, if we
> > don't do that yet.
> >
>
> Well, not sure. I think the question is still open whether it's actually
> safe to run on DAX, which does not have atomic writes of 512B sectors,
> and I think we rely on that e.g. for pg_config. But maybe for WAL that's
> not an issue.
I think we can use the Block Translation Table (BTT) driver that
provides atomic sector updates.
>
> > Also, I'm interested in why the through-put of NTT patch saturated at
> > 32 clients, which is earlier than the master's one (96 clients). How
> > many CPU cores are there on the machine you used?
> >
>
> From what I know, this is somewhat expected for PMEM devices, for a
> bunch of reasons:
>
> 1) The memory bandwidth is much lower than for DRAM (maybe ~10-20%), so
> it takes fewer processes to saturate it.
>
> 2) Internally, the PMEM has a 256B buffer for writes, used for combining
> etc. With too many processes sending writes, it becomes to look more
> random, which is harmful for throughput.
>
> When combined, this means the performance starts dropping at certain
> number of threads, and the optimal number of threads is rather low
> (something like 5-10). This is very different behavior compared to DRAM.
Makes sense.
>
> There's a nice overview and measurements in this paper:
>
> Building blocks for persistent memory / How to get the most out of your
> new memory?
> Alexander van Renen, Lukas Vogel, Viktor Leis, Thomas Neumann & Alfons
> Kemper
>
> https://link.springer.com/article/10.1007/s00778-020-00622-9
Thank you. I'll read it.
>
>
> >> I'm also wondering if WAL is the right usage for PMEM. Per [2] there's a
> >> huge read-write assymmetry (the writes being way slower), and their
> >> recommendation (in "Observation 3" is)
> >>
> >> The read-write asymmetry of PMem im-plies the necessity of avoiding
> >> writes as much as possible for PMem.
> >>
> >> So maybe we should not be trying to use PMEM for WAL, which is pretty
> >> write-heavy (and in most cases even write-only).
> >
> > I think using PMEM for WAL is cost-effective but it leverages the only
> > low-latency (sequential) write, but not other abilities such as
> > fine-grained access and low-latency random write. If we want to
> > exploit its all ability we might need some drastic changes to logging
> > protocol while considering storing data on PMEM.
> >
>
> True. I think investigating whether it's sensible to use PMEM for this
> purpose. It may turn out that replacing the DRAM WAL buffers with writes
> directly to PMEM is not economical, and aggregating data in a DRAM
> buffer is better :-(
Yes. I think it might be interesting to do an analysis of the
bottlenecks of NTT patch by perf etc. If bottlenecks are moved to
other places by removing WALWriteLock during flush, it's probably a
good sign for further performance improvements. IIRC WALWriteLock is
one of the main bottlenecks on OLTP workload, although my memory might
already be out of date.
Regards,
--
Masahiko Sawada
EDB: https://www.enterprisedb.com/
Dear everyone,I'm sorry for the late reply. I rebase my two patchsets onto the latest master 411ae64.The one patchset prefixed with v4 is for non-volatile WAL buffer; the other prefixed with v3 is for msync.I will reply to your thankful feedbacks one by one within days. Please wait for a moment.Best regards,Takashi01/25/2021(Mon) 11:56 Masahiko Sawada <sawada.mshk@gmail.com>:On Fri, Jan 22, 2021 at 11:32 AM Tomas Vondra
<tomas.vondra@enterprisedb.com> wrote:
>
>
>
> On 1/21/21 3:17 AM, Masahiko Sawada wrote:
> > On Thu, Jan 7, 2021 at 2:16 AM Tomas Vondra
> > <tomas.vondra@enterprisedb.com> wrote:
> >>
> >> Hi,
> >>
> >> I think I've managed to get the 0002 patch [1] rebased to master and
> >> working (with help from Masahiko Sawada). It's not clear to me how it
> >> could have worked as submitted - my theory is that an incomplete patch
> >> was submitted by mistake, or something like that.
> >>
> >> Unfortunately, the benchmark results were kinda disappointing. For a
> >> pgbench on scale 500 (fits into shared buffers), an average of three
> >> 5-minute runs looks like this:
> >>
> >> branch 1 16 32 64 96
> >> ----------------------------------------------------------------
> >> master 7291 87704 165310 150437 224186
> >> ntt 7912 106095 213206 212410 237819
> >> simple-no-buffers 7654 96544 115416 95828 103065
> >>
> >> NTT refers to the patch from September 10, pre-allocating a large WAL
> >> file on PMEM, and simple-no-buffers is the simpler patch simply removing
> >> the WAL buffers and writing directly to a mmap-ed WAL segment on PMEM.
> >>
> >> Note: The patch is just replacing the old implementation with mmap.
> >> That's good enough for experiments like this, but we probably want to
> >> keep the old one for setups without PMEM. But it's good enough for
> >> testing, benchmarking etc.
> >>
> >> Unfortunately, the results for this simple approach are pretty bad. Not
> >> only compared to the "ntt" patch, but even to master. I'm not entirely
> >> sure what's the root cause, but I have a couple hypotheses:
> >>
> >> 1) bug in the patch - That's clearly a possibility, although I've tried
> >> tried to eliminate this possibility.
> >>
> >> 2) PMEM is slower than DRAM - From what I know, PMEM is much faster than
> >> NVMe storage, but still much slower than DRAM (both in terms of latency
> >> and bandwidth, see [2] for some data). It's not terrible, but the
> >> latency is maybe 2-3x higher - not a huge difference, but may matter for
> >> WAL buffers?
> >>
> >> 3) PMEM does not handle parallel writes well - If you look at [2],
> >> Figure 4(b), you'll see that the throughput actually *drops" as the
> >> number of threads increase. That's pretty strange / annoying, because
> >> that's how we write into WAL buffers - each thread writes it's own data,
> >> so parallelism is not something we can get rid of.
> >>
> >> I've added some simple profiling, to measure number of calls / time for
> >> each operation (use -DXLOG_DEBUG_STATS to enable). It accumulates data
> >> for each backend, and logs the counts every 1M ops.
> >>
> >> Typical stats from a concurrent run looks like this:
> >>
> >> xlog stats cnt 43000000
> >> map cnt 100 time 5448333 unmap cnt 100 time 3730963
> >> memcpy cnt 985964 time 1550442272 len 15150499
> >> memset cnt 0 time 0 len 0
> >> persist cnt 13836 time 10369617 len 16292182
> >>
> >> The times are in nanoseconds, so this says the backend did 100 mmap and
> >> unmap calls, taking ~10ms in total. There were ~14k pmem_persist calls,
> >> taking 10ms in total. And the most time (~1.5s) was used by pmem_memcpy
> >> copying about 15MB of data. That's quite a lot :-(
> >
> > It might also be interesting if we can see how much time spent on each
> > logging function, such as XLogInsert(), XLogWrite(), and XLogFlush().
> >
>
> Yeah, we could extend it to that, that's fairly mechanical thing. Bbut
> maybe that could be visible in a regular perf profile. Also, I suppose
> most of the time will be used by the pmem calls, shown in the stats.
>
> >>
> >> My conclusion from this is that eliminating WAL buffers and writing WAL
> >> directly to PMEM (by memcpy to mmap-ed WAL segments) is probably not the
> >> right approach.
> >>
> >> I suppose we should keep WAL buffers, and then just write the data to
> >> mmap-ed WAL segments on PMEM. Which I think is what the NTT patch does,
> >> except that it allocates one huge file on PMEM and writes to that
> >> (instead of the traditional WAL segments).
> >>
> >> So I decided to try how it'd work with writing to regular WAL segments,
> >> mmap-ed ad hoc. The pmem-with-wal-buffers-master.patch patch does that,
> >> and the results look a bit nicer:
> >>
> >> branch 1 16 32 64 96
> >> ----------------------------------------------------------------
> >> master 7291 87704 165310 150437 224186
> >> ntt 7912 106095 213206 212410 237819
> >> simple-no-buffers 7654 96544 115416 95828 103065
> >> with-wal-buffers 7477 95454 181702 140167 214715
> >>
> >> So, much better than the version without WAL buffers, somewhat better
> >> than master (except for 64/96 clients), but still not as good as NTT.
> >>
> >> At this point I was wondering how could the NTT patch be faster when
> >> it's doing roughly the same thing. I'm sire there are some differences,
> >> but it seemed strange. The main difference seems to be that it only maps
> >> one large file, and only once. OTOH the alternative "simple" patch maps
> >> segments one by one, in each backend. Per the debug stats the map/unmap
> >> calls are fairly cheap, but maybe it interferes with the memcpy somehow.
> >>
> >
> > While looking at the two methods: NTT and simple-no-buffer, I realized
> > that in XLogFlush(), NTT patch flushes (by pmem_flush() and
> > pmem_drain()) WAL without acquiring WALWriteLock whereas
> > simple-no-buffer patch acquires WALWriteLock to do that
> > (pmem_persist()). I wonder if this also affected the performance
> > differences between those two methods since WALWriteLock serializes
> > the operations. With PMEM, multiple backends can concurrently flush
> > the records if the memory region is not overlapped? If so, flushing
> > WAL without WALWriteLock would be a big benefit.
> >
>
> That's a very good question - it's quite possible the WALWriteLock is
> not really needed, because the processes are actually "writing" the WAL
> directly to PMEM. So it's a bit confusing, because it's only really
> concerned about making sure it's flushed.
>
> And yes, multiple processes certainly can write to PMEM at the same
> time, in fact it's a requirement to get good throughput I believe. My
> understanding is we need ~8 processes, at least that's what I heard from
> people with more PMEM experience.
Thanks, that's good to know.
>
> TBH I'm not convinced the code in the "simple-no-buffer" code (coming
> from the 0002 patch) is actually correct. Essentially, consider the
> backend needs to do a flush, but does not have a segment mapped. So it
> maps it and calls pmem_drain() on it.
>
> But does that actually flush anything? Does it properly flush changes
> done by other processes that may not have called pmem_drain() yet? I
> find this somewhat suspicious and I'd bet all processes that did write
> something have to call pmem_drain().
Yeah, in terms of experiments at least it's good to find out that the
approach mmapping each WAL segment is not good at performance.
>
>
> >> So I did an experiment by increasing the size of the WAL segments. I
> >> chose to try with 521MB and 1024MB, and the results with 1GB look like this:
> >>
> >> branch 1 16 32 64 96
> >> ----------------------------------------------------------------
> >> master 6635 88524 171106 163387 245307
> >> ntt 7909 106826 217364 223338 242042
> >> simple-no-buffers 7871 101575 199403 188074 224716
> >> with-wal-buffers 7643 101056 206911 223860 261712
> >>
> >> So yeah, there's a clear difference. It changes the values for "master"
> >> a bit, but both the "simple" patches (with and without) WAL buffers are
> >> much faster. The with-wal-buffers is almost equal to the NTT patch,
> >> which was using 96GB file. I presume larger WAL segments would get even
> >> closer, if we supported them.
> >>
> >> I'll continue investigating this, but my conclusion so far seem to be
> >> that we can't really replace WAL buffers with PMEM - that seems to
> >> perform much worse.
> >>
> >> The question is what to do about the segment size. Can we reduce the
> >> overhead of mmap-ing individual segments, so that this works even for
> >> smaller WAL segments, to make this useful for common instances (not
> >> everyone wants to run with 1GB WAL). Or whether we need to adopt the
> >> design with a large file, mapped just once.
> >>
> >> Another question is whether it's even worth the extra complexity. On
> >> 16MB segments the difference between master and NTT patch seems to be
> >> non-trivial, but increasing the WAL segment size kinda reduces that. So
> >> maybe just using File I/O on PMEM DAX filesystem seems good enough.
> >> Alternatively, maybe we could switch to libpmemblk, which should
> >> eliminate the filesystem overhead at least.
> >
> > I think the performance improvement by NTT patch with the 16MB WAL
> > segment, the most common WAL segment size, is very good (150437 vs.
> > 212410 with 64 clients). But maybe evaluating writing WAL segment
> > files on PMEM DAX filesystem is also worth, as you mentioned, if we
> > don't do that yet.
> >
>
> Well, not sure. I think the question is still open whether it's actually
> safe to run on DAX, which does not have atomic writes of 512B sectors,
> and I think we rely on that e.g. for pg_config. But maybe for WAL that's
> not an issue.
I think we can use the Block Translation Table (BTT) driver that
provides atomic sector updates.
>
> > Also, I'm interested in why the through-put of NTT patch saturated at
> > 32 clients, which is earlier than the master's one (96 clients). How
> > many CPU cores are there on the machine you used?
> >
>
> From what I know, this is somewhat expected for PMEM devices, for a
> bunch of reasons:
>
> 1) The memory bandwidth is much lower than for DRAM (maybe ~10-20%), so
> it takes fewer processes to saturate it.
>
> 2) Internally, the PMEM has a 256B buffer for writes, used for combining
> etc. With too many processes sending writes, it becomes to look more
> random, which is harmful for throughput.
>
> When combined, this means the performance starts dropping at certain
> number of threads, and the optimal number of threads is rather low
> (something like 5-10). This is very different behavior compared to DRAM.
Makes sense.
>
> There's a nice overview and measurements in this paper:
>
> Building blocks for persistent memory / How to get the most out of your
> new memory?
> Alexander van Renen, Lukas Vogel, Viktor Leis, Thomas Neumann & Alfons
> Kemper
>
> https://link.springer.com/article/10.1007/s00778-020-00622-9
Thank you. I'll read it.
>
>
> >> I'm also wondering if WAL is the right usage for PMEM. Per [2] there's a
> >> huge read-write assymmetry (the writes being way slower), and their
> >> recommendation (in "Observation 3" is)
> >>
> >> The read-write asymmetry of PMem im-plies the necessity of avoiding
> >> writes as much as possible for PMem.
> >>
> >> So maybe we should not be trying to use PMEM for WAL, which is pretty
> >> write-heavy (and in most cases even write-only).
> >
> > I think using PMEM for WAL is cost-effective but it leverages the only
> > low-latency (sequential) write, but not other abilities such as
> > fine-grained access and low-latency random write. If we want to
> > exploit its all ability we might need some drastic changes to logging
> > protocol while considering storing data on PMEM.
> >
>
> True. I think investigating whether it's sensible to use PMEM for this
> purpose. It may turn out that replacing the DRAM WAL buffers with writes
> directly to PMEM is not economical, and aggregating data in a DRAM
> buffer is better :-(
Yes. I think it might be interesting to do an analysis of the
bottlenecks of NTT patch by perf etc. If bottlenecks are moved to
other places by removing WALWriteLock during flush, it's probably a
good sign for further performance improvements. IIRC WALWriteLock is
one of the main bottlenecks on OLTP workload, although my memory might
already be out of date.
Regards,
--
Masahiko Sawada
EDB: https://www.enterprisedb.com/--Takashi Menjo <takashi.menjo@gmail.com>
Attachment
- v4-0001-Support-GUCs-for-external-WAL-buffer.patch
- v4-0005-README-for-non-volatile-WAL-buffer.patch
- v4-0003-walreceiver-supports-non-volatile-WAL-buffer.patch
- v4-0004-pg_basebackup-supports-non-volatile-WAL-buffer.patch
- v4-0002-Non-volatile-WAL-buffer.patch
- v4-0006-More-log-when-using-NVWAL.patch
- v3-0001-Revert-Use-vectored-I-O-to-fill-new-WAL-segments.patch
- v3-0004-Lazy-unmap-WAL-segments.patch
- v3-0002-Preallocate-more-WAL-segments.patch
- v3-0005-Speculative-map-WAL-segments.patch
- v3-0003-Use-WAL-segments-as-WAL-buffers.patch
- v3-0006-Map-WAL-segments-with-MAP_POPULATE-if-non-DAX.patch
- v3-0007-Set-wal_buffers-to-the-same-pages-as-WAL-segment.patch
- v3-0008-Create-a-new-WAL-segment-just-before-mapping.patch
- v3-0010-Revert-Speculative-map-WAL-segments.patch
- v3-0009-Do-not-open-an-existing-WAL-segment-when-creating.patch
Dear everyone,Sorry but I forgot to attach my patchsets... Please see the files attached to this mail. Please also note that they contain some fixes.Best regards,Takashi2021年1月26日(火) 17:46 Takashi Menjo <takashi.menjo@gmail.com>:Dear everyone,I'm sorry for the late reply. I rebase my two patchsets onto the latest master 411ae64.The one patchset prefixed with v4 is for non-volatile WAL buffer; the other prefixed with v3 is for msync.I will reply to your thankful feedbacks one by one within days. Please wait for a moment.Best regards,Takashi01/25/2021(Mon) 11:56 Masahiko Sawada <sawada.mshk@gmail.com>:On Fri, Jan 22, 2021 at 11:32 AM Tomas Vondra
<tomas.vondra@enterprisedb.com> wrote:
>
>
>
> On 1/21/21 3:17 AM, Masahiko Sawada wrote:
> > On Thu, Jan 7, 2021 at 2:16 AM Tomas Vondra
> > <tomas.vondra@enterprisedb.com> wrote:
> >>
> >> Hi,
> >>
> >> I think I've managed to get the 0002 patch [1] rebased to master and
> >> working (with help from Masahiko Sawada). It's not clear to me how it
> >> could have worked as submitted - my theory is that an incomplete patch
> >> was submitted by mistake, or something like that.
> >>
> >> Unfortunately, the benchmark results were kinda disappointing. For a
> >> pgbench on scale 500 (fits into shared buffers), an average of three
> >> 5-minute runs looks like this:
> >>
> >> branch 1 16 32 64 96
> >> ----------------------------------------------------------------
> >> master 7291 87704 165310 150437 224186
> >> ntt 7912 106095 213206 212410 237819
> >> simple-no-buffers 7654 96544 115416 95828 103065
> >>
> >> NTT refers to the patch from September 10, pre-allocating a large WAL
> >> file on PMEM, and simple-no-buffers is the simpler patch simply removing
> >> the WAL buffers and writing directly to a mmap-ed WAL segment on PMEM.
> >>
> >> Note: The patch is just replacing the old implementation with mmap.
> >> That's good enough for experiments like this, but we probably want to
> >> keep the old one for setups without PMEM. But it's good enough for
> >> testing, benchmarking etc.
> >>
> >> Unfortunately, the results for this simple approach are pretty bad. Not
> >> only compared to the "ntt" patch, but even to master. I'm not entirely
> >> sure what's the root cause, but I have a couple hypotheses:
> >>
> >> 1) bug in the patch - That's clearly a possibility, although I've tried
> >> tried to eliminate this possibility.
> >>
> >> 2) PMEM is slower than DRAM - From what I know, PMEM is much faster than
> >> NVMe storage, but still much slower than DRAM (both in terms of latency
> >> and bandwidth, see [2] for some data). It's not terrible, but the
> >> latency is maybe 2-3x higher - not a huge difference, but may matter for
> >> WAL buffers?
> >>
> >> 3) PMEM does not handle parallel writes well - If you look at [2],
> >> Figure 4(b), you'll see that the throughput actually *drops" as the
> >> number of threads increase. That's pretty strange / annoying, because
> >> that's how we write into WAL buffers - each thread writes it's own data,
> >> so parallelism is not something we can get rid of.
> >>
> >> I've added some simple profiling, to measure number of calls / time for
> >> each operation (use -DXLOG_DEBUG_STATS to enable). It accumulates data
> >> for each backend, and logs the counts every 1M ops.
> >>
> >> Typical stats from a concurrent run looks like this:
> >>
> >> xlog stats cnt 43000000
> >> map cnt 100 time 5448333 unmap cnt 100 time 3730963
> >> memcpy cnt 985964 time 1550442272 len 15150499
> >> memset cnt 0 time 0 len 0
> >> persist cnt 13836 time 10369617 len 16292182
> >>
> >> The times are in nanoseconds, so this says the backend did 100 mmap and
> >> unmap calls, taking ~10ms in total. There were ~14k pmem_persist calls,
> >> taking 10ms in total. And the most time (~1.5s) was used by pmem_memcpy
> >> copying about 15MB of data. That's quite a lot :-(
> >
> > It might also be interesting if we can see how much time spent on each
> > logging function, such as XLogInsert(), XLogWrite(), and XLogFlush().
> >
>
> Yeah, we could extend it to that, that's fairly mechanical thing. Bbut
> maybe that could be visible in a regular perf profile. Also, I suppose
> most of the time will be used by the pmem calls, shown in the stats.
>
> >>
> >> My conclusion from this is that eliminating WAL buffers and writing WAL
> >> directly to PMEM (by memcpy to mmap-ed WAL segments) is probably not the
> >> right approach.
> >>
> >> I suppose we should keep WAL buffers, and then just write the data to
> >> mmap-ed WAL segments on PMEM. Which I think is what the NTT patch does,
> >> except that it allocates one huge file on PMEM and writes to that
> >> (instead of the traditional WAL segments).
> >>
> >> So I decided to try how it'd work with writing to regular WAL segments,
> >> mmap-ed ad hoc. The pmem-with-wal-buffers-master.patch patch does that,
> >> and the results look a bit nicer:
> >>
> >> branch 1 16 32 64 96
> >> ----------------------------------------------------------------
> >> master 7291 87704 165310 150437 224186
> >> ntt 7912 106095 213206 212410 237819
> >> simple-no-buffers 7654 96544 115416 95828 103065
> >> with-wal-buffers 7477 95454 181702 140167 214715
> >>
> >> So, much better than the version without WAL buffers, somewhat better
> >> than master (except for 64/96 clients), but still not as good as NTT.
> >>
> >> At this point I was wondering how could the NTT patch be faster when
> >> it's doing roughly the same thing. I'm sire there are some differences,
> >> but it seemed strange. The main difference seems to be that it only maps
> >> one large file, and only once. OTOH the alternative "simple" patch maps
> >> segments one by one, in each backend. Per the debug stats the map/unmap
> >> calls are fairly cheap, but maybe it interferes with the memcpy somehow.
> >>
> >
> > While looking at the two methods: NTT and simple-no-buffer, I realized
> > that in XLogFlush(), NTT patch flushes (by pmem_flush() and
> > pmem_drain()) WAL without acquiring WALWriteLock whereas
> > simple-no-buffer patch acquires WALWriteLock to do that
> > (pmem_persist()). I wonder if this also affected the performance
> > differences between those two methods since WALWriteLock serializes
> > the operations. With PMEM, multiple backends can concurrently flush
> > the records if the memory region is not overlapped? If so, flushing
> > WAL without WALWriteLock would be a big benefit.
> >
>
> That's a very good question - it's quite possible the WALWriteLock is
> not really needed, because the processes are actually "writing" the WAL
> directly to PMEM. So it's a bit confusing, because it's only really
> concerned about making sure it's flushed.
>
> And yes, multiple processes certainly can write to PMEM at the same
> time, in fact it's a requirement to get good throughput I believe. My
> understanding is we need ~8 processes, at least that's what I heard from
> people with more PMEM experience.
Thanks, that's good to know.
>
> TBH I'm not convinced the code in the "simple-no-buffer" code (coming
> from the 0002 patch) is actually correct. Essentially, consider the
> backend needs to do a flush, but does not have a segment mapped. So it
> maps it and calls pmem_drain() on it.
>
> But does that actually flush anything? Does it properly flush changes
> done by other processes that may not have called pmem_drain() yet? I
> find this somewhat suspicious and I'd bet all processes that did write
> something have to call pmem_drain().
Yeah, in terms of experiments at least it's good to find out that the
approach mmapping each WAL segment is not good at performance.
>
>
> >> So I did an experiment by increasing the size of the WAL segments. I
> >> chose to try with 521MB and 1024MB, and the results with 1GB look like this:
> >>
> >> branch 1 16 32 64 96
> >> ----------------------------------------------------------------
> >> master 6635 88524 171106 163387 245307
> >> ntt 7909 106826 217364 223338 242042
> >> simple-no-buffers 7871 101575 199403 188074 224716
> >> with-wal-buffers 7643 101056 206911 223860 261712
> >>
> >> So yeah, there's a clear difference. It changes the values for "master"
> >> a bit, but both the "simple" patches (with and without) WAL buffers are
> >> much faster. The with-wal-buffers is almost equal to the NTT patch,
> >> which was using 96GB file. I presume larger WAL segments would get even
> >> closer, if we supported them.
> >>
> >> I'll continue investigating this, but my conclusion so far seem to be
> >> that we can't really replace WAL buffers with PMEM - that seems to
> >> perform much worse.
> >>
> >> The question is what to do about the segment size. Can we reduce the
> >> overhead of mmap-ing individual segments, so that this works even for
> >> smaller WAL segments, to make this useful for common instances (not
> >> everyone wants to run with 1GB WAL). Or whether we need to adopt the
> >> design with a large file, mapped just once.
> >>
> >> Another question is whether it's even worth the extra complexity. On
> >> 16MB segments the difference between master and NTT patch seems to be
> >> non-trivial, but increasing the WAL segment size kinda reduces that. So
> >> maybe just using File I/O on PMEM DAX filesystem seems good enough.
> >> Alternatively, maybe we could switch to libpmemblk, which should
> >> eliminate the filesystem overhead at least.
> >
> > I think the performance improvement by NTT patch with the 16MB WAL
> > segment, the most common WAL segment size, is very good (150437 vs.
> > 212410 with 64 clients). But maybe evaluating writing WAL segment
> > files on PMEM DAX filesystem is also worth, as you mentioned, if we
> > don't do that yet.
> >
>
> Well, not sure. I think the question is still open whether it's actually
> safe to run on DAX, which does not have atomic writes of 512B sectors,
> and I think we rely on that e.g. for pg_config. But maybe for WAL that's
> not an issue.
I think we can use the Block Translation Table (BTT) driver that
provides atomic sector updates.
>
> > Also, I'm interested in why the through-put of NTT patch saturated at
> > 32 clients, which is earlier than the master's one (96 clients). How
> > many CPU cores are there on the machine you used?
> >
>
> From what I know, this is somewhat expected for PMEM devices, for a
> bunch of reasons:
>
> 1) The memory bandwidth is much lower than for DRAM (maybe ~10-20%), so
> it takes fewer processes to saturate it.
>
> 2) Internally, the PMEM has a 256B buffer for writes, used for combining
> etc. With too many processes sending writes, it becomes to look more
> random, which is harmful for throughput.
>
> When combined, this means the performance starts dropping at certain
> number of threads, and the optimal number of threads is rather low
> (something like 5-10). This is very different behavior compared to DRAM.
Makes sense.
>
> There's a nice overview and measurements in this paper:
>
> Building blocks for persistent memory / How to get the most out of your
> new memory?
> Alexander van Renen, Lukas Vogel, Viktor Leis, Thomas Neumann & Alfons
> Kemper
>
> https://link.springer.com/article/10.1007/s00778-020-00622-9
Thank you. I'll read it.
>
>
> >> I'm also wondering if WAL is the right usage for PMEM. Per [2] there's a
> >> huge read-write assymmetry (the writes being way slower), and their
> >> recommendation (in "Observation 3" is)
> >>
> >> The read-write asymmetry of PMem im-plies the necessity of avoiding
> >> writes as much as possible for PMem.
> >>
> >> So maybe we should not be trying to use PMEM for WAL, which is pretty
> >> write-heavy (and in most cases even write-only).
> >
> > I think using PMEM for WAL is cost-effective but it leverages the only
> > low-latency (sequential) write, but not other abilities such as
> > fine-grained access and low-latency random write. If we want to
> > exploit its all ability we might need some drastic changes to logging
> > protocol while considering storing data on PMEM.
> >
>
> True. I think investigating whether it's sensible to use PMEM for this
> purpose. It may turn out that replacing the DRAM WAL buffers with writes
> directly to PMEM is not economical, and aggregating data in a DRAM
> buffer is better :-(
Yes. I think it might be interesting to do an analysis of the
bottlenecks of NTT patch by perf etc. If bottlenecks are moved to
other places by removing WALWriteLock during flush, it's probably a
good sign for further performance improvements. IIRC WALWriteLock is
one of the main bottlenecks on OLTP workload, although my memory might
already be out of date.
Regards,
--
Masahiko Sawada
EDB: https://www.enterprisedb.com/--Takashi Menjo <takashi.menjo@gmail.com>--Takashi Menjo <takashi.menjo@gmail.com>
Dear everyone, Tomas,First of all, the "v4" patchset for non-volatile WAL buffer attached to the previous mail is actually v5... Please read "v4" as "v5."Then, to Tomas:Thank you for your crash report you gave on Nov 27, 2020, regarding msync patchset. I applied the latest msync patchset v3 attached to the previous to master 411ae64 (on Jan18, 2021) then tested it, and I got no error when pgbench -i -s 500. Please try it if necessary.Best regards,Takashi2021年1月26日(火) 17:52 Takashi Menjo <takashi.menjo@gmail.com>:Dear everyone,Sorry but I forgot to attach my patchsets... Please see the files attached to this mail. Please also note that they contain some fixes.Best regards,Takashi2021年1月26日(火) 17:46 Takashi Menjo <takashi.menjo@gmail.com>:Dear everyone,I'm sorry for the late reply. I rebase my two patchsets onto the latest master 411ae64.The one patchset prefixed with v4 is for non-volatile WAL buffer; the other prefixed with v3 is for msync.I will reply to your thankful feedbacks one by one within days. Please wait for a moment.Best regards,Takashi01/25/2021(Mon) 11:56 Masahiko Sawada <sawada.mshk@gmail.com>:On Fri, Jan 22, 2021 at 11:32 AM Tomas Vondra
<tomas.vondra@enterprisedb.com> wrote:
>
>
>
> On 1/21/21 3:17 AM, Masahiko Sawada wrote:
> > On Thu, Jan 7, 2021 at 2:16 AM Tomas Vondra
> > <tomas.vondra@enterprisedb.com> wrote:
> >>
> >> Hi,
> >>
> >> I think I've managed to get the 0002 patch [1] rebased to master and
> >> working (with help from Masahiko Sawada). It's not clear to me how it
> >> could have worked as submitted - my theory is that an incomplete patch
> >> was submitted by mistake, or something like that.
> >>
> >> Unfortunately, the benchmark results were kinda disappointing. For a
> >> pgbench on scale 500 (fits into shared buffers), an average of three
> >> 5-minute runs looks like this:
> >>
> >> branch 1 16 32 64 96
> >> ----------------------------------------------------------------
> >> master 7291 87704 165310 150437 224186
> >> ntt 7912 106095 213206 212410 237819
> >> simple-no-buffers 7654 96544 115416 95828 103065
> >>
> >> NTT refers to the patch from September 10, pre-allocating a large WAL
> >> file on PMEM, and simple-no-buffers is the simpler patch simply removing
> >> the WAL buffers and writing directly to a mmap-ed WAL segment on PMEM.
> >>
> >> Note: The patch is just replacing the old implementation with mmap.
> >> That's good enough for experiments like this, but we probably want to
> >> keep the old one for setups without PMEM. But it's good enough for
> >> testing, benchmarking etc.
> >>
> >> Unfortunately, the results for this simple approach are pretty bad. Not
> >> only compared to the "ntt" patch, but even to master. I'm not entirely
> >> sure what's the root cause, but I have a couple hypotheses:
> >>
> >> 1) bug in the patch - That's clearly a possibility, although I've tried
> >> tried to eliminate this possibility.
> >>
> >> 2) PMEM is slower than DRAM - From what I know, PMEM is much faster than
> >> NVMe storage, but still much slower than DRAM (both in terms of latency
> >> and bandwidth, see [2] for some data). It's not terrible, but the
> >> latency is maybe 2-3x higher - not a huge difference, but may matter for
> >> WAL buffers?
> >>
> >> 3) PMEM does not handle parallel writes well - If you look at [2],
> >> Figure 4(b), you'll see that the throughput actually *drops" as the
> >> number of threads increase. That's pretty strange / annoying, because
> >> that's how we write into WAL buffers - each thread writes it's own data,
> >> so parallelism is not something we can get rid of.
> >>
> >> I've added some simple profiling, to measure number of calls / time for
> >> each operation (use -DXLOG_DEBUG_STATS to enable). It accumulates data
> >> for each backend, and logs the counts every 1M ops.
> >>
> >> Typical stats from a concurrent run looks like this:
> >>
> >> xlog stats cnt 43000000
> >> map cnt 100 time 5448333 unmap cnt 100 time 3730963
> >> memcpy cnt 985964 time 1550442272 len 15150499
> >> memset cnt 0 time 0 len 0
> >> persist cnt 13836 time 10369617 len 16292182
> >>
> >> The times are in nanoseconds, so this says the backend did 100 mmap and
> >> unmap calls, taking ~10ms in total. There were ~14k pmem_persist calls,
> >> taking 10ms in total. And the most time (~1.5s) was used by pmem_memcpy
> >> copying about 15MB of data. That's quite a lot :-(
> >
> > It might also be interesting if we can see how much time spent on each
> > logging function, such as XLogInsert(), XLogWrite(), and XLogFlush().
> >
>
> Yeah, we could extend it to that, that's fairly mechanical thing. Bbut
> maybe that could be visible in a regular perf profile. Also, I suppose
> most of the time will be used by the pmem calls, shown in the stats.
>
> >>
> >> My conclusion from this is that eliminating WAL buffers and writing WAL
> >> directly to PMEM (by memcpy to mmap-ed WAL segments) is probably not the
> >> right approach.
> >>
> >> I suppose we should keep WAL buffers, and then just write the data to
> >> mmap-ed WAL segments on PMEM. Which I think is what the NTT patch does,
> >> except that it allocates one huge file on PMEM and writes to that
> >> (instead of the traditional WAL segments).
> >>
> >> So I decided to try how it'd work with writing to regular WAL segments,
> >> mmap-ed ad hoc. The pmem-with-wal-buffers-master.patch patch does that,
> >> and the results look a bit nicer:
> >>
> >> branch 1 16 32 64 96
> >> ----------------------------------------------------------------
> >> master 7291 87704 165310 150437 224186
> >> ntt 7912 106095 213206 212410 237819
> >> simple-no-buffers 7654 96544 115416 95828 103065
> >> with-wal-buffers 7477 95454 181702 140167 214715
> >>
> >> So, much better than the version without WAL buffers, somewhat better
> >> than master (except for 64/96 clients), but still not as good as NTT.
> >>
> >> At this point I was wondering how could the NTT patch be faster when
> >> it's doing roughly the same thing. I'm sire there are some differences,
> >> but it seemed strange. The main difference seems to be that it only maps
> >> one large file, and only once. OTOH the alternative "simple" patch maps
> >> segments one by one, in each backend. Per the debug stats the map/unmap
> >> calls are fairly cheap, but maybe it interferes with the memcpy somehow.
> >>
> >
> > While looking at the two methods: NTT and simple-no-buffer, I realized
> > that in XLogFlush(), NTT patch flushes (by pmem_flush() and
> > pmem_drain()) WAL without acquiring WALWriteLock whereas
> > simple-no-buffer patch acquires WALWriteLock to do that
> > (pmem_persist()). I wonder if this also affected the performance
> > differences between those two methods since WALWriteLock serializes
> > the operations. With PMEM, multiple backends can concurrently flush
> > the records if the memory region is not overlapped? If so, flushing
> > WAL without WALWriteLock would be a big benefit.
> >
>
> That's a very good question - it's quite possible the WALWriteLock is
> not really needed, because the processes are actually "writing" the WAL
> directly to PMEM. So it's a bit confusing, because it's only really
> concerned about making sure it's flushed.
>
> And yes, multiple processes certainly can write to PMEM at the same
> time, in fact it's a requirement to get good throughput I believe. My
> understanding is we need ~8 processes, at least that's what I heard from
> people with more PMEM experience.
Thanks, that's good to know.
>
> TBH I'm not convinced the code in the "simple-no-buffer" code (coming
> from the 0002 patch) is actually correct. Essentially, consider the
> backend needs to do a flush, but does not have a segment mapped. So it
> maps it and calls pmem_drain() on it.
>
> But does that actually flush anything? Does it properly flush changes
> done by other processes that may not have called pmem_drain() yet? I
> find this somewhat suspicious and I'd bet all processes that did write
> something have to call pmem_drain().
Yeah, in terms of experiments at least it's good to find out that the
approach mmapping each WAL segment is not good at performance.
>
>
> >> So I did an experiment by increasing the size of the WAL segments. I
> >> chose to try with 521MB and 1024MB, and the results with 1GB look like this:
> >>
> >> branch 1 16 32 64 96
> >> ----------------------------------------------------------------
> >> master 6635 88524 171106 163387 245307
> >> ntt 7909 106826 217364 223338 242042
> >> simple-no-buffers 7871 101575 199403 188074 224716
> >> with-wal-buffers 7643 101056 206911 223860 261712
> >>
> >> So yeah, there's a clear difference. It changes the values for "master"
> >> a bit, but both the "simple" patches (with and without) WAL buffers are
> >> much faster. The with-wal-buffers is almost equal to the NTT patch,
> >> which was using 96GB file. I presume larger WAL segments would get even
> >> closer, if we supported them.
> >>
> >> I'll continue investigating this, but my conclusion so far seem to be
> >> that we can't really replace WAL buffers with PMEM - that seems to
> >> perform much worse.
> >>
> >> The question is what to do about the segment size. Can we reduce the
> >> overhead of mmap-ing individual segments, so that this works even for
> >> smaller WAL segments, to make this useful for common instances (not
> >> everyone wants to run with 1GB WAL). Or whether we need to adopt the
> >> design with a large file, mapped just once.
> >>
> >> Another question is whether it's even worth the extra complexity. On
> >> 16MB segments the difference between master and NTT patch seems to be
> >> non-trivial, but increasing the WAL segment size kinda reduces that. So
> >> maybe just using File I/O on PMEM DAX filesystem seems good enough.
> >> Alternatively, maybe we could switch to libpmemblk, which should
> >> eliminate the filesystem overhead at least.
> >
> > I think the performance improvement by NTT patch with the 16MB WAL
> > segment, the most common WAL segment size, is very good (150437 vs.
> > 212410 with 64 clients). But maybe evaluating writing WAL segment
> > files on PMEM DAX filesystem is also worth, as you mentioned, if we
> > don't do that yet.
> >
>
> Well, not sure. I think the question is still open whether it's actually
> safe to run on DAX, which does not have atomic writes of 512B sectors,
> and I think we rely on that e.g. for pg_config. But maybe for WAL that's
> not an issue.
I think we can use the Block Translation Table (BTT) driver that
provides atomic sector updates.
>
> > Also, I'm interested in why the through-put of NTT patch saturated at
> > 32 clients, which is earlier than the master's one (96 clients). How
> > many CPU cores are there on the machine you used?
> >
>
> From what I know, this is somewhat expected for PMEM devices, for a
> bunch of reasons:
>
> 1) The memory bandwidth is much lower than for DRAM (maybe ~10-20%), so
> it takes fewer processes to saturate it.
>
> 2) Internally, the PMEM has a 256B buffer for writes, used for combining
> etc. With too many processes sending writes, it becomes to look more
> random, which is harmful for throughput.
>
> When combined, this means the performance starts dropping at certain
> number of threads, and the optimal number of threads is rather low
> (something like 5-10). This is very different behavior compared to DRAM.
Makes sense.
>
> There's a nice overview and measurements in this paper:
>
> Building blocks for persistent memory / How to get the most out of your
> new memory?
> Alexander van Renen, Lukas Vogel, Viktor Leis, Thomas Neumann & Alfons
> Kemper
>
> https://link.springer.com/article/10.1007/s00778-020-00622-9
Thank you. I'll read it.
>
>
> >> I'm also wondering if WAL is the right usage for PMEM. Per [2] there's a
> >> huge read-write assymmetry (the writes being way slower), and their
> >> recommendation (in "Observation 3" is)
> >>
> >> The read-write asymmetry of PMem im-plies the necessity of avoiding
> >> writes as much as possible for PMem.
> >>
> >> So maybe we should not be trying to use PMEM for WAL, which is pretty
> >> write-heavy (and in most cases even write-only).
> >
> > I think using PMEM for WAL is cost-effective but it leverages the only
> > low-latency (sequential) write, but not other abilities such as
> > fine-grained access and low-latency random write. If we want to
> > exploit its all ability we might need some drastic changes to logging
> > protocol while considering storing data on PMEM.
> >
>
> True. I think investigating whether it's sensible to use PMEM for this
> purpose. It may turn out that replacing the DRAM WAL buffers with writes
> directly to PMEM is not economical, and aggregating data in a DRAM
> buffer is better :-(
Yes. I think it might be interesting to do an analysis of the
bottlenecks of NTT patch by perf etc. If bottlenecks are moved to
other places by removing WALWriteLock during flush, it's probably a
good sign for further performance improvements. IIRC WALWriteLock is
one of the main bottlenecks on OLTP workload, although my memory might
already be out of date.
Regards,
--
Masahiko Sawada
EDB: https://www.enterprisedb.com/--Takashi Menjo <takashi.menjo@gmail.com>--Takashi Menjo <takashi.menjo@gmail.com>--Takashi Menjo <takashi.menjo@gmail.com>
On 1/25/21 3:56 AM, Masahiko Sawada wrote:
>>
>> ...
>>
>> On 1/21/21 3:17 AM, Masahiko Sawada wrote:
>>> ...
>>>
>>> While looking at the two methods: NTT and simple-no-buffer, I realized
>>> that in XLogFlush(), NTT patch flushes (by pmem_flush() and
>>> pmem_drain()) WAL without acquiring WALWriteLock whereas
>>> simple-no-buffer patch acquires WALWriteLock to do that
>>> (pmem_persist()). I wonder if this also affected the performance
>>> differences between those two methods since WALWriteLock serializes
>>> the operations. With PMEM, multiple backends can concurrently flush
>>> the records if the memory region is not overlapped? If so, flushing
>>> WAL without WALWriteLock would be a big benefit.
>>>
>>
>> That's a very good question - it's quite possible the WALWriteLock is
>> not really needed, because the processes are actually "writing" the WAL
>> directly to PMEM. So it's a bit confusing, because it's only really
>> concerned about making sure it's flushed.
>>
>> And yes, multiple processes certainly can write to PMEM at the same
>> time, in fact it's a requirement to get good throughput I believe. My
>> understanding is we need ~8 processes, at least that's what I heard from
>> people with more PMEM experience.
>
> Thanks, that's good to know.
>
>>
>> TBH I'm not convinced the code in the "simple-no-buffer" code (coming
>> from the 0002 patch) is actually correct. Essentially, consider the
>> backend needs to do a flush, but does not have a segment mapped. So it
>> maps it and calls pmem_drain() on it.
>>
>> But does that actually flush anything? Does it properly flush changes
>> done by other processes that may not have called pmem_drain() yet? I
>> find this somewhat suspicious and I'd bet all processes that did write
>> something have to call pmem_drain().
>
For the record, from what I learned / been told by engineers with PMEM
experience, calling pmem_drain() should properly flush changes done by
other processes. So it should be sufficient to do that in XLogFlush(),
from a single process.
My understanding is that we have about three challenges here:
(a) we still need to track how far we flushed, so this needs to be
protected by some lock anyway (although perhaps a much smaller section
of the function)
(b) pmem_drain() flushes all the changes, so it flushes even "future"
part of the WAL after the requested LSN, which may negatively affects
performance I guess. So I wonder if pmem_persist would be a better fit,
as it allows specifying a range that should be persisted.
(c) As mentioned before, PMEM behaves differently with concurrent
access, i.e. it reaches peak throughput with relatively low number of
threads wroting data, and then the throughput drops quite quickly. I'm
not sure if the same thing applies to pmem_drain() too - if it does, we
may need something like we have for insertions, i.e. a handful of locks
allowing limited number of concurrent inserts.
> Yeah, in terms of experiments at least it's good to find out that the
> approach mmapping each WAL segment is not good at performance.
>
Right. The problem with small WAL segments seems to be that each mmap
causes the TLB to be thrown away, which means a lot of expensive cache
misses. As the mmap needs to be done by each backend writing WAL, this
is particularly bad with small WAL segments. The NTT patch works around
that by doing just a single mmap.
I wonder if we could pre-allocate and mmap small segments, and keep them
mapped and just rename the underlying files when recycling them. That'd
keep the regular segment files, as expected by various tools, etc. The
question is what would happen when we temporarily need more WAL, etc.
>>>
>>> ...
>>>
>>> I think the performance improvement by NTT patch with the 16MB WAL
>>> segment, the most common WAL segment size, is very good (150437 vs.
>>> 212410 with 64 clients). But maybe evaluating writing WAL segment
>>> files on PMEM DAX filesystem is also worth, as you mentioned, if we
>>> don't do that yet.
>>>
>>
>> Well, not sure. I think the question is still open whether it's actually
>> safe to run on DAX, which does not have atomic writes of 512B sectors,
>> and I think we rely on that e.g. for pg_config. But maybe for WAL that's
>> not an issue.
>
> I think we can use the Block Translation Table (BTT) driver that
> provides atomic sector updates.
>
But we have benchmarked that, see my message from 2020/11/26, which
shows this table:
master/btt master/dax ntt simple
-----------------------------------------------------------
1 5469 7402 7977 6746
16 48222 80869 107025 82343
32 73974 158189 214718 158348
64 85921 154540 225715 164248
96 150602 221159 237008 217253
Clearly, BTT is quite expensive. Maybe there's a way to tune that at
filesystem/kernel level, I haven't tried that.
>>
>>>> I'm also wondering if WAL is the right usage for PMEM. Per [2] there's a
>>>> huge read-write assymmetry (the writes being way slower), and their
>>>> recommendation (in "Observation 3" is)
>>>>
>>>> The read-write asymmetry of PMem im-plies the necessity of avoiding
>>>> writes as much as possible for PMem.
>>>>
>>>> So maybe we should not be trying to use PMEM for WAL, which is pretty
>>>> write-heavy (and in most cases even write-only).
>>>
>>> I think using PMEM for WAL is cost-effective but it leverages the only
>>> low-latency (sequential) write, but not other abilities such as
>>> fine-grained access and low-latency random write. If we want to
>>> exploit its all ability we might need some drastic changes to logging
>>> protocol while considering storing data on PMEM.
>>>
>>
>> True. I think investigating whether it's sensible to use PMEM for this
>> purpose. It may turn out that replacing the DRAM WAL buffers with writes
>> directly to PMEM is not economical, and aggregating data in a DRAM
>> buffer is better :-(
>
> Yes. I think it might be interesting to do an analysis of the
> bottlenecks of NTT patch by perf etc. If bottlenecks are moved to
> other places by removing WALWriteLock during flush, it's probably a
> good sign for further performance improvements. IIRC WALWriteLock is
> one of the main bottlenecks on OLTP workload, although my memory might
> already be out of date.
>
I think WALWriteLock itself (i.e. acquiring/releasing it) is not an
issue - the problem is that writing the WAL to persistent storage itself
is expensive, and we're waiting to that.
So it's not clear to me if removing the lock (and allowing multiple
processes to do pmem_drain concurrently) can actually help, considering
pmem_drain() should flush writes from other processes anyway.
But as I said, that is just my theory - I might be entirely wrong, it'd
be good to hack XLogFlush a bit and try it out.
regards
--
Tomas Vondra
EnterpriseDB: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
From: Tomas Vondra <tomas.vondra@enterprisedb.com> > (c) As mentioned before, PMEM behaves differently with concurrent > access, i.e. it reaches peak throughput with relatively low number of > threads wroting data, and then the throughput drops quite quickly. I'm > not sure if the same thing applies to pmem_drain() too - if it does, we > may need something like we have for insertions, i.e. a handful of locks > allowing limited number of concurrent inserts. > I think WALWriteLock itself (i.e. acquiring/releasing it) is not an > issue - the problem is that writing the WAL to persistent storage itself > is expensive, and we're waiting to that. > > So it's not clear to me if removing the lock (and allowing multiple > processes to do pmem_drain concurrently) can actually help, considering > pmem_drain() should flush writes from other processes anyway. I may be out of the track, but HPE's benchmark using Oracle 18c, placing the REDO log file on Intel PMEM in App Direct mode,showed only 27% performance increase compared to even "SAS" SSD. https://h20195.www2.hpe.com/v2/getdocument.aspx?docname=a00074230enw The just-released Oracle 21c has started support for placing data files on PMEM, eliminating the overhead of buffer cache. It's interesting that this new feature is categorized in "Manageability", not "Performance and scalability." https://docs.oracle.com/en/database/oracle/oracle-database/21/nfcon/persistent-memory-database-258797846.html They recommend placing REDO logs on DAX-aware file systems. I ownder what's behind this. https://docs.oracle.com/en/database/oracle/oracle-database/21/admin/using-PMEM-db-support.html#GUID-D230B9CF-1845-4833-9BF7-43E9F15B7113 "You can use PMEM Filestore for database datafiles and control files. For performance reasons, Oracle recommends that youstore redo log files as independent files in a DAX-aware filesystem such as EXT4/XFS." Regards Takayuki Tsunakawa
I'd answer your questions. (Not all for now, sorry.)
> Do I understand correctly that the patch removes "regular" WAL buffers and instead writes the data into the non-volatile PMEM buffer, without writing that to the WAL segments at all (unless in archiving mode)?
> Firstly, I guess many (most?) instances will have to write the WAL segments anyway because of PITR/backups, so I'm not sure we can save much here.
Mostly yes. My "non-volatile WAL buffer" patchset removes regular volatile WAL buffers and brings non-volatile ones. All the WAL will get into the non-volatile buffers and persist there. No write out of the buffers to WAL segment files is required. However in archiving mode or in a case of buffer full (described later), both of the non-volatile buffers and the segment files are used.
In archiving mode with my patchset, for each time one segment (16MB default) is fixed on the non-volatile buffers, that segment is written to a segment file asynchronously (by XLogBackgroundFlush). Then it will be archived by existing archiving functionality.
> But more importantly - doesn't that mean the nvwal_size value is essentially a hard limit? With max_wal_size, it's a soft limit i.e. we're allowed to temporarily use more WAL when needed. But with a pre-allocated file, that's clearly not possible. So what would happen in those cases?
Yes, nvwal_size is a hard limit, and I see it's a major weak point of my patchset.
When all non-volatile WAL buffers are filled, the oldest segment on the buffers is written (by XLogWrite) to a regular WAL segment file, then those buffers are cleared (by AdvanceXLInsertBuffer) for new records. All WAL record insertions to the buffers block until that write and clear are complete. Due to that, all write transactions also block.
To make the matter worse, if a checkpoint eventually occurs in such a buffer full case, record insertions would block for a certain time at the end of the checkpoint because a large amount of the non-volatile buffers will be cleared (see PreallocNonVolatileXlogBuffer). From a client view, it would look as if the postgres server freezes for a while.
Proper checkpointing would prevent such cases, but it could be hard to control. When I reproduced the Gang's case reported in this thread, such buffer full and freeze occured.
> Also, is it possible to change nvwal_size? I haven't tried, but I wonder what happens with the current contents of the file.
The value of nvwal_size should be equal to the actual size of nvwal_path file when postgres starts up. If not equal, postgres will panic at MapNonVolatileXLogBuffer (see nv_xlog_buffer.c), and the WAL contents on the file will remain as it was. So, if an admin accidentally changes the nvwal_size value, they just cannot get postgres up.
The file size may be extended/shrunk offline by truncate(1) command, but the WAL contents on the file also should be moved to the proper offset because the insertion/recovery offset is calculated by modulo, that is, record's LSN % nvwal_size; otherwise we lose WAL. An offline tool to do such an operation might be required, but is not yet.
> The way I understand the current design is that we're essentially switching from this architecture:
>
> clients -> wal buffers (DRAM) -> wal segments (storage)
>
> to this
>
> clients -> wal buffers (PMEM)
>
> (Assuming there we don't have to write segments because of archiving.)
Yes. Let me describe how current PostgreSQL design is and how the patchsets and works talked in this thread changes it, AFAIU:
- Current PostgreSQL:
clients -[memcpy]-> buffers (DRAM) -[write]-> segments (disk)
- Patch "pmem-with-wal-buffers-master.patch" Tomas posted:
clients -[memcpy]-> buffers (DRAM) -[pmem_memcpy]-> mmap-ed segments (PMEM)
- My "non-volatile WAL buffer" patchset:
clients -[pmem_memcpy(*)]-> buffers (PMEM)
- My another patchset mmap-ing segments as buffers:
clients -[pmem_memcpy(*)]-> mmap-ed segments as buffers (PMEM)
- "Non-volatile Memory Logging" in PGcon 2016 [1][2][3]:
clients -[memcpy]-> buffers (WC[4] DRAM as pseudo PMEM) -[async write]-> segments (disk)
(* or memcpy + pmem_flush)
And I'd say that our previous work "Introducing PMDK into PostgreSQL" talked in PGCon 2018 [5] and its patchset [6 for the latest] are based on the same idea as Tomas's patch above.
That's all for this mail. Please be patient for the next mail.
Best regards,
Takashi
[1] https://www.pgcon.org/2016/schedule/track/Performance/945.en.html
[2] https://github.com/meistervonperf/postgresql-NVM-logging
[3] https://github.com/meistervonperf/pseudo-pram
[4] https://www.kernel.org/doc/html/latest/x86/pat.html
[5] https://pgcon.org/2018/schedule/events/1154.en.html
[6] https://www.postgresql.org/message-id/CAOwnP3ONd9uXPXKoc5AAfnpCnCyOna1ru6sU=eY_4WfMjaKG9A@mail.gmail.com
On Thu, Jan 28, 2021 at 1:41 AM Tomas Vondra
<tomas.vondra@enterprisedb.com> wrote:
>
> On 1/25/21 3:56 AM, Masahiko Sawada wrote:
> >>
> >> ...
> >>
> >> On 1/21/21 3:17 AM, Masahiko Sawada wrote:
> >>> ...
> >>>
> >>> While looking at the two methods: NTT and simple-no-buffer, I realized
> >>> that in XLogFlush(), NTT patch flushes (by pmem_flush() and
> >>> pmem_drain()) WAL without acquiring WALWriteLock whereas
> >>> simple-no-buffer patch acquires WALWriteLock to do that
> >>> (pmem_persist()). I wonder if this also affected the performance
> >>> differences between those two methods since WALWriteLock serializes
> >>> the operations. With PMEM, multiple backends can concurrently flush
> >>> the records if the memory region is not overlapped? If so, flushing
> >>> WAL without WALWriteLock would be a big benefit.
> >>>
> >>
> >> That's a very good question - it's quite possible the WALWriteLock is
> >> not really needed, because the processes are actually "writing" the WAL
> >> directly to PMEM. So it's a bit confusing, because it's only really
> >> concerned about making sure it's flushed.
> >>
> >> And yes, multiple processes certainly can write to PMEM at the same
> >> time, in fact it's a requirement to get good throughput I believe. My
> >> understanding is we need ~8 processes, at least that's what I heard from
> >> people with more PMEM experience.
> >
> > Thanks, that's good to know.
> >
> >>
> >> TBH I'm not convinced the code in the "simple-no-buffer" code (coming
> >> from the 0002 patch) is actually correct. Essentially, consider the
> >> backend needs to do a flush, but does not have a segment mapped. So it
> >> maps it and calls pmem_drain() on it.
> >>
> >> But does that actually flush anything? Does it properly flush changes
> >> done by other processes that may not have called pmem_drain() yet? I
> >> find this somewhat suspicious and I'd bet all processes that did write
> >> something have to call pmem_drain().
> >
> For the record, from what I learned / been told by engineers with PMEM
> experience, calling pmem_drain() should properly flush changes done by
> other processes. So it should be sufficient to do that in XLogFlush(),
> from a single process.
>
> My understanding is that we have about three challenges here:
>
> (a) we still need to track how far we flushed, so this needs to be
> protected by some lock anyway (although perhaps a much smaller section
> of the function)
>
> (b) pmem_drain() flushes all the changes, so it flushes even "future"
> part of the WAL after the requested LSN, which may negatively affects
> performance I guess. So I wonder if pmem_persist would be a better fit,
> as it allows specifying a range that should be persisted.
>
> (c) As mentioned before, PMEM behaves differently with concurrent
> access, i.e. it reaches peak throughput with relatively low number of
> threads wroting data, and then the throughput drops quite quickly. I'm
> not sure if the same thing applies to pmem_drain() too - if it does, we
> may need something like we have for insertions, i.e. a handful of locks
> allowing limited number of concurrent inserts.
Thanks. That's a good summary.
>
>
> > Yeah, in terms of experiments at least it's good to find out that the
> > approach mmapping each WAL segment is not good at performance.
> >
> Right. The problem with small WAL segments seems to be that each mmap
> causes the TLB to be thrown away, which means a lot of expensive cache
> misses. As the mmap needs to be done by each backend writing WAL, this
> is particularly bad with small WAL segments. The NTT patch works around
> that by doing just a single mmap.
>
> I wonder if we could pre-allocate and mmap small segments, and keep them
> mapped and just rename the underlying files when recycling them. That'd
> keep the regular segment files, as expected by various tools, etc. The
> question is what would happen when we temporarily need more WAL, etc.
>
> >>>
> >>> ...
> >>>
> >>> I think the performance improvement by NTT patch with the 16MB WAL
> >>> segment, the most common WAL segment size, is very good (150437 vs.
> >>> 212410 with 64 clients). But maybe evaluating writing WAL segment
> >>> files on PMEM DAX filesystem is also worth, as you mentioned, if we
> >>> don't do that yet.
> >>>
> >>
> >> Well, not sure. I think the question is still open whether it's actually
> >> safe to run on DAX, which does not have atomic writes of 512B sectors,
> >> and I think we rely on that e.g. for pg_config. But maybe for WAL that's
> >> not an issue.
> >
> > I think we can use the Block Translation Table (BTT) driver that
> > provides atomic sector updates.
> >
>
> But we have benchmarked that, see my message from 2020/11/26, which
> shows this table:
>
> master/btt master/dax ntt simple
> -----------------------------------------------------------
> 1 5469 7402 7977 6746
> 16 48222 80869 107025 82343
> 32 73974 158189 214718 158348
> 64 85921 154540 225715 164248
> 96 150602 221159 237008 217253
>
> Clearly, BTT is quite expensive. Maybe there's a way to tune that at
> filesystem/kernel level, I haven't tried that.
I missed your mail. Yeah, BTT seems to be quite expensive.
>
> >>
> >>>> I'm also wondering if WAL is the right usage for PMEM. Per [2] there's a
> >>>> huge read-write assymmetry (the writes being way slower), and their
> >>>> recommendation (in "Observation 3" is)
> >>>>
> >>>> The read-write asymmetry of PMem im-plies the necessity of avoiding
> >>>> writes as much as possible for PMem.
> >>>>
> >>>> So maybe we should not be trying to use PMEM for WAL, which is pretty
> >>>> write-heavy (and in most cases even write-only).
> >>>
> >>> I think using PMEM for WAL is cost-effective but it leverages the only
> >>> low-latency (sequential) write, but not other abilities such as
> >>> fine-grained access and low-latency random write. If we want to
> >>> exploit its all ability we might need some drastic changes to logging
> >>> protocol while considering storing data on PMEM.
> >>>
> >>
> >> True. I think investigating whether it's sensible to use PMEM for this
> >> purpose. It may turn out that replacing the DRAM WAL buffers with writes
> >> directly to PMEM is not economical, and aggregating data in a DRAM
> >> buffer is better :-(
> >
> > Yes. I think it might be interesting to do an analysis of the
> > bottlenecks of NTT patch by perf etc. If bottlenecks are moved to
> > other places by removing WALWriteLock during flush, it's probably a
> > good sign for further performance improvements. IIRC WALWriteLock is
> > one of the main bottlenecks on OLTP workload, although my memory might
> > already be out of date.
> >
>
> I think WALWriteLock itself (i.e. acquiring/releasing it) is not an
> issue - the problem is that writing the WAL to persistent storage itself
> is expensive, and we're waiting to that.
>
> So it's not clear to me if removing the lock (and allowing multiple
> processes to do pmem_drain concurrently) can actually help, considering
> pmem_drain() should flush writes from other processes anyway.
>
> But as I said, that is just my theory - I might be entirely wrong, it'd
> be good to hack XLogFlush a bit and try it out.
>
>
I've done some performance benchmarks with the master and NTT v4
patch. Let me share the results.
pgbench setup:
* scale factor = 2000
* duration = 600 sec
* clients = 32, 64, 96
NVWAL setup:
* nvwal_size = 50GB
* max_wal_size = 50GB
* min_wal_size = 50GB
The whole database fits in shared_buffers and WAL segment file size is 16MB.
The results are:
master NTT master-unlogged
32 113209 67107 154298
64 144880 54289 178883
96 151405 50562 180018
"master-unlogged" is the same setup as "master" except for using
unlogged tables (using --unlogged-tables pgbench option). The TPS
increased by about 20% compared to "master" case (i.g., logged table
case). The reason why I experimented unlogged table case as well is
that we can think these results as an ideal performance if we were
able to write WAL records in 0 sec. IOW, even if the PMEM patch would
significantly improve WAL logging performance, I think it could not
exceed this performance. But hope is that if we currently have a
performance bottle-neck in WAL logging (.e.g, locking and writing
WAL), removing or minimizing WAL logging would bring a chance to
further improve performance by eliminating the new-coming bottle-neck.
As we can see from the above result, apparently, the performance of
“ntt” case was not good in this evaluation. I've not reviewed the
patch in-depth yet but something might be wrong with the v4 patch or
PMEM configuration I did on my environment is wrong.
Besides, I've checked the main wait events on each experiment using
pg_wait_sampling. Here are the top 5 wait events on "master" case
excluding wait events on the main function of auxiliary processes:
event_type | event | sum
------------+----------------------+-------
Client | ClientRead | 46902
LWLock | WALWrite | 33405
IPC | ProcArrayGroupUpdate | 8855
LWLock | WALInsert | 3215
LWLock | ProcArray | 3022
We can see the wait event on WALWrite lwlock acquisition happened many
times and it was the primary wait event. On the other hand, In
"master-unlogged" case, I got:
event_type | event | sum
------------+----------------------+-------
Client | ClientRead | 59871
IPC | ProcArrayGroupUpdate | 17528
LWLock | ProcArray | 4317
LWLock | XactSLRU | 3705
IPC | XactGroupUpdate | 3045
LWLock of WAL logging disappeared.
The result of "ntt" case is:
event_type | event | sum
------------+----------------------+--------
LWLock | WALInsert | 126487
Client | ClientRead | 12173
LWLock | BufferContent | 4480
Lock | transactionid | 2017
IPC | ProcArrayGroupUpdate | 924
The wait event on WALWrite lwlock disappeared. Instead, there were
many wait events on WALInsert lwlock. I've not investigated this
result yet. This could be because the v4 patch acquires WALInsert lock
more than necessary or writing WAL records to PMEM took more time than
writing to DRAM as Tomas mentioned before.
If the PMEM patch introduces a new WAL file (called nwwal file in the
patch) and writes a normal WAL segment file based on nvwal file, I
think it doesn't necessarily need to follow the current WAL segment
file format (i.g., sequential writes to 8kB each block). I think there
is a better algorithm to write WAL records to PMEM more efficiently
like this paper proposing[1].
Finally, I realized while using the PMEM patch that with a large nvwal
file, PostgreSQL server takes a long time to start since it
initializes nvwal file. In my environment, nvwal size is 50GB and it
took 1 min to startup. This could lead to downtime in production.
[1] https://jianh.web.engr.illinois.edu/papers/jian-vldb15.pdf
--
Masahiko Sawada
EDB: https://www.enterprisedb.com/
From: Masahiko Sawada <sawada.mshk@gmail.com> > I've done some performance benchmarks with the master and NTT v4 > patch. Let me share the results. > ... > master NTT master-unlogged > 32 113209 67107 154298 > 64 144880 54289 178883 > 96 151405 50562 180018 > > "master-unlogged" is the same setup as "master" except for using > unlogged tables (using --unlogged-tables pgbench option). The TPS > increased by about 20% compared to "master" case (i.g., logged table > case). The reason why I experimented unlogged table case as well is > that we can think these results as an ideal performance if we were > able to write WAL records in 0 sec. IOW, even if the PMEM patch would > significantly improve WAL logging performance, I think it could not > exceed this performance. But hope is that if we currently have a > performance bottle-neck in WAL logging (.e.g, locking and writing > WAL), removing or minimizing WAL logging would bring a chance to > further improve performance by eliminating the new-coming bottle-neck. Could you tell us the specifics of the storage for WAL, e.g., SSD/HDD, the interface is NVMe/SAS/SATA, read-write throughputand latency (on the product catalog), and the product model? Was the WAL stored on a storage device separate from the other files? I want to know if the comparison is as fair as possible. I guess that in the NTT (PMEM) case, the WAL traffic is not affected by the I/Os of the other files. What would the comparison look like between master and unlogged-master if you place WAL on a DAX-aware filesystem like xfsor ext4 on PMEM, which Oracle recommends as REDO log storage? That is, if we place the WAL on the fastest storage configurationpossible, what would be the difference between the logged and unlogged? I'm asking these to know if we consider it worthwhile to make further efforts in special code for WAL on PMEM. > Besides, I've checked the main wait events on each experiment using > pg_wait_sampling. Here are the top 5 wait events on "master" case > excluding wait events on the main function of auxiliary processes: > > event_type | event | sum > ------------+----------------------+------- > Client | ClientRead | 46902 > LWLock | WALWrite | 33405 > IPC | ProcArrayGroupUpdate | 8855 > LWLock | WALInsert | 3215 > LWLock | ProcArray | 3022 > > We can see the wait event on WALWrite lwlock acquisition happened many > times and it was the primary wait event. > > The result of "ntt" case is: > > event_type | event | sum > ------------+----------------------+-------- > LWLock | WALInsert | 126487 > Client | ClientRead | 12173 > LWLock | BufferContent | 4480 > Lock | transactionid | 2017 > IPC | ProcArrayGroupUpdate | 924 > > The wait event on WALWrite lwlock disappeared. Instead, there were > many wait events on WALInsert lwlock. I've not investigated this > result yet. This could be because the v4 patch acquires WALInsert lock > more than necessary or writing WAL records to PMEM took more time than > writing to DRAM as Tomas mentioned before. Increasing NUM_XLOGINSERT_LOCKS might improve the result, but I don't have much hope because PMEM appears to have limitedconcurrency... Regards Takayuki Tsunakawa
From: Takashi Menjo <takashi.menjo@gmail.com> > I made a new page at PostgreSQL Wiki to gather and summarize information and discussion about PMEM-backed WAL designs andimplementations. Some parts of the page are TBD. I will continue to maintain the page. Requests are welcome. > > Persistent Memory for WAL > https://wiki.postgresql.org/wiki/Persistent_Memory_for_WAL Thank you for putting together the information. In "Allocates WAL buffers on shared buffers", "shared buffers" should be DRAM because shared buffers in Postgres means thebuffer cache for database data. I haven't tracked the whole thread, but could you collect information like the following? I think such (partly basic) informationwill be helpful to decide whether it's worth casting more efforts into complex code, or it's enough to place WALon DAX-aware filesystems and tune the filesystem. * What approaches other DBMSs take, and their performance gains (Oracle, SQL Server, HANA, Cassandra, etc.) The same DBMS should take different approaches depending on the file type: Oracle recommends different things to data filesand REDO logs. * The storage capabilities of PMEM compared to the fast(est) alternatives such as NVMe SSD (read/write IOPS, latency, throughput,concurrency, which may be posted on websites like Tom's Hardware or SNIA) * What's the situnation like on Windows? Regards Takayuki Tsunakawa
In "Allocates WAL buffers on shared buffers", "shared buffers" should be DRAM because shared buffers in Postgres means the buffer cache for database data.
I haven't tracked the whole thread, but could you collect information like the following? I think such (partly basic) information will be helpful to decide whether it's worth casting more efforts into complex code, or it's enough to place WAL on DAX-aware filesystems and tune the filesystem.
* What approaches other DBMSs take, and their performance gains (Oracle, SQL Server, HANA, Cassandra, etc.)
The same DBMS should take different approaches depending on the file type: Oracle recommends different things to data files and REDO logs.
* The storage capabilities of PMEM compared to the fast(est) alternatives such as NVMe SSD (read/write IOPS, latency, throughput, concurrency, which may be posted on websites like Tom's Hardware or SNIA)
* What's the situnation like on Windows?
Hi Sawada, Thank you for your performance report. First, I'd say that the latest v5 non-volatile WAL buffer patchset looks not bad itself. I made a performance test for the v5 and got better performance than the original (non-patched) one and our previous work. See the attached figure for results. I think steps and/or setups of Tomas's, yours, and mine could be different, leading to the different performance results. So I show my steps and setups for my performance test. Please see the tail of this mail for them. Also, I write performance tips to the PMEM page at PostgreSQL wiki [1]. I wish it could be helpful to improve performance. Regards, Takashi [1] https://wiki.postgresql.org/wiki/Persistent_Memory_for_WAL#Performance_tips # Environment variables export PGHOST=/tmp export PGPORT=5432 export PGDATABASE="$USER" export PGUSER="$USER" export PGDATA=/mnt/nvme0n1/pgdata # Steps Note that I ran postgres server and pgbench in a single-machine system but separated two NUMA nodes. PMEM and PCI SSD for the server process are on the server-side NUMA node. 01) Create a PMEM namespace (sudo ndctl create-namespace -f -t pmem -m fsdax -M dev -e namespace0.0) 02) Make an ext4 filesystem for PMEM then mount it with DAX option (sudo mkfs.ext4 -q -F /dev/pmem0 ; sudo mount -o dax /dev/pmem0 /mnt/pmem0) 03) Make another ext4 filesystem for PCIe SSD then mount it (sudo mkfs.ext4 -q -F /dev/nvme0n1 ; sudo mount /dev/nvme0n1 /mnt/nvme0n1) 04) Make /mnt/pmem0/pg_wal directory for WAL 05) Make /mnt/nvme0n1/pgdata directory for PGDATA 06) Run initdb (initdb --locale=C --encoding=UTF8 -X /mnt/pmem0/pg_wal ...) - Also give -P /mnt/pmem0/pg_wal/nvwal -Q 81920 in the case of "Non-volatile WAL buffer" 07) Edit postgresql.conf as the attached one 08) Start postgres server process on NUMA node 0 (numactl -N 0 -m 0 -- pg_ctl -l pg.log start) 09) Create a database (createdb --locale=C --encoding=UTF8) 10) Initialize pgbench tables with s=50 (pgbench -i -s 50) 11) Stop the postgres server process (pg_ctl -l pg.log -m smart stop) 12) Remount the PMEM and the PCIe SSD 13) Start postgres server process on NUMA node 0 again (numactl -N 0 -m 0 -- pg_ctl -l pg.log start) 14) Run pg_prewarm for all the four pgbench_* tables 15) Run pgbench on NUMA node 1 for 30 minutes (numactl -N 1 -m 1 -- pgbench -r -M prepared -T 1800 -c __ -j __) - It executes the default tpcb-like transactions I repeated all the steps three times for each (c,j) then got the median "tps = __ (including connections establishing)" of the three as throughput and the "latency average = __ ms " of that time as average latency. # Setup - System: HPE ProLiant DL380 Gen10 - CPU: Intel Xeon Gold 6240M x2 sockets (18 cores per socket; HT disabled by BIOS) - DRAM: DDR4 2933MHz 192GiB/socket x2 sockets (32 GiB per channel x 6 channels per socket) - Optane PMem: Apache Pass, AppDirect Mode, DDR4 2666MHz 1.5TiB/socket x2 sockets (256 GiB per channel x 6 channels per socket; interleaving enabled) - PCIe SSD: DC P4800X Series SSDPED1K750GA - Distro: Ubuntu 20.04.1 - C compiler: gcc 9.3.0 - libc: glibc 2.31 - Linux kernel: 5.7.0 (built by myself) - Filesystem: ext4 (DAX enabled when using Optane PMem) - PMDK: 1.9 (built by myself) - PostgreSQL (Original): 9e7dbe3369cd8f5b0136c53b817471002505f934 (Jan 18, 2021 @ master) - PostgreSQL (Mapped WAL file): Original + v5 of "Applying PMDK to WAL operations for persistent memory" [2] - PostgreSQL (Non-volatile WAL buffer): Original + v5 of "Non-volatile WAL buffer" [3]; please read the files' prefix "v4-" as "v5-" [2] https://www.postgresql.org/message-id/CAOwnP3O3O1GbHpddUAzT%3DCP3aMpX99%3D1WtBAfsRZYe2Ui53MFQ%40mail.gmail.com [3] https://www.postgresql.org/message-id/CAOwnP3Oz4CnKp0-_KU-x5irr9pBqPNkk7pjwZE5Pgo8i1CbFGg%40mail.gmail.com -- Takashi Menjo <takashi.menjo@gmail.com>
Attachment
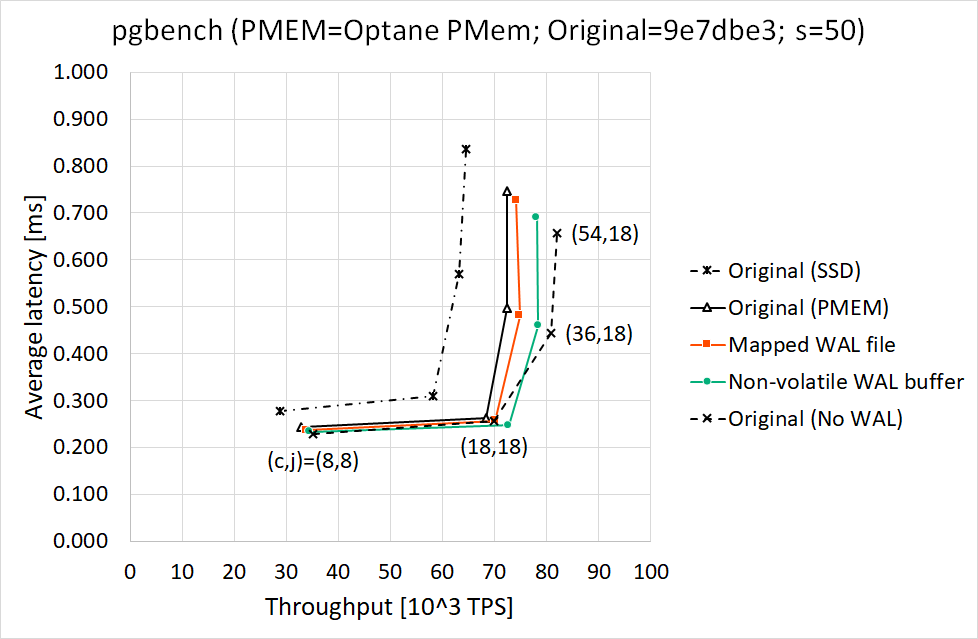{kind=link}
On 1/22/21 5:04 PM, Konstantin Knizhnik wrote: > ... > > I have heard from several DBMS experts that appearance of huge and > cheap non-volatile memory can make a revolution in database system > architecture. If all database can fit in non-volatile memory, then we > do not need buffers, WAL, ...> > But although multi-terabyte NVM announces were made by IBM several > years ago, I do not know about some successful DBMS prototypes with new > architecture. > > I tried to understand why... > IMHO those predictions are a bit too optimistic, because they often assume PMEM behavior is mostly similar to DRAM, except for the extra persistence. But that's not quite true - throughput with PMEM is much lower in general, peak throughput is reached with few processes (and then drops quickly) etc. But over the last few years we were focused on optimizing for exactly the opposite - systems with many CPU cores and processes, because that's what maximizes DRAM throughput. I'm not saying a revolution is not possible, but it'll probably require quite significant rethinking of the whole architecture, and it may take multiple PMEM generations until the performance improves enough to make this economical. Some systems are probably more suitable for this (e.g. Redis is doing most of the work in a single process, IIRC). The other challenge of course is availability of the hardware - most users run on whatever is widely available at cloud providers. And PMEM is unlikely to get there very soon, I'd guess. Until that happens, the pressure from these customers will be (naturally) fairly low. Perhaps someone will develop hardware appliances for on-premise setups, as was quite common in the past. Not sure. > It was very interesting to me to read this thread, which is actually > started in 2016 with "Non-volatile Memory Logging" presentation at PGCon. > As far as I understand from Tomas result right now using PMEM for WAL > doesn't provide some substantial increase of performance. > At the moment, I'd probably agree. It's quite possible the PoC patches are missing some optimizations and the difference might be better, but even then the performance increase seems fairly modest and limited to certainly workloads. > But the main advantage of PMEM from my point of view is that it allows > to avoid write-ahead logging at all! No, PMEM certainly does not allow avoiding write-ahead logging - we still need to handle e.g. recovery after a crash, when the data files are in unknown / corrupted state. Not to mention that WAL is used for physical and logical replication (and thus HA), and so on. > Certainly we need to change our algorithms to make it possible. Speaking > about Postgres, we have to rewrite all indexes + heap > and throw away buffer manager + WAL. > The problem with removing buffer manager and just writing everything directly to PMEM is the worse latency/throughput (compared to DRAM). It's probably much more efficient to combine multiple writes into RAM and then do one (much slower) write to persistent storage, than pay the higher latency for every write. It might make sense for data sets that are larger than DRAM but can fit into PMEM. But that seems like fairly rare case, and even then it may be more efficient to redesign the schema to fit into RAM somehow (sharding, partitioning, ...). > What can be used instead of standard B-Tree? > For example there is description of multiword-CAS approach: > > http://justinlevandoski.org/papers/mwcas.pdf > > and BzTree implementation on top of it: > > https://www.cc.gatech.edu/~jarulraj/papers/2018.bztree.vldb.pdf > > There is free BzTree implementation at github: > > git@github.com:sfu-dis/bztree.git > > I tried to adopt it for Postgres. It was not so easy because: > 1. It was written in modern C++ (-std=c++14) > 2. It supports multithreading, but not mutliprocess access > > So I have to patch code of this library instead of just using it: > > git@github.com:postgrespro/bztree.git > > I have not tested yet most iterating case: access to PMEM through PMDK. > And I do not have hardware for such tests. > But first results are also seem to be interesting: PMwCAS is kind of > lockless algorithm and it shows much better scaling at > NUMA host comparing with standard Postgres. > > I have done simple parallel insertion test: multiple clients are > inserting data with random keys. > To make competition with vanilla Postgres more honest I used unlogged > table: > > create unlogged table t(pk int, payload int); > create index on t using bztree(pk); > > randinsert.sql: > insert into t (payload,pk) values > (generate_series(1,1000),random()*1000000000); > > pgbench -f randinsert.sql -c N -j N -M prepared -n -t 1000 -P 1 postgres > > So each client is inserting one million records. > The target system has 160 virtual and 80 real cores with 256GB of RAM. > Results (TPS) are the following: > > N nbtree bztree > 1 540 455 > 10 993 2237 > 100 1479 5025 > > So bztree is more than 3 times faster for 100 clients. > Just for comparison: result for inserting in this table without index is > 10k TPS. > I'm not familiar with bztree, but I agree novel indexing structures are an interesting topic on their own. I only quickly skimmed the bztree paper, but it seems it might be useful even on DRAM (assuming it will work with replication etc.). The other "problem" with placing data files (tables, indexes) on PMEM and making this code PMEM-aware is that these writes generally happen asynchronously in the background, so the impact on transaction rate is fairly low. This is why all the patches in this thread try to apply PMEM on the WAL logging / flushing, which is on the critical path. > I am going then try to play with PMEM. > If results will be promising, then it is possible to think about > reimplementation of heap and WAL-less Postgres! > > I am sorry, that my post has no direct relation to the topic of this > thread (Non-volatile WAL buffer). > It seems to be that it is better to use PMEM to eliminate WAL at all > instead of optimizing it. > Certainly, I realize that WAL plays very important role in Postgres: > archiving and replication are based on WAL. So even if we can live > without WAL, it is still not clear whether we really want to live > without it. > > One more idea: using multiword CAS approach requires us to make changes > as editing sequences. > Such editing sequence is actually ready WAL records. So implementors of > access methods do not have to do > double work: update data structure in memory and create correspondent > WAL records. Moreover, PMwCAS operations are atomic: > we can replay or revert them in case of fault. So there is no need in > FPW (full page writes) which have very noticeable impact on WAL size and > database performance. > regards -- Tomas Vondra EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
Thank you for your feedback. On 19.02.2021 6:25, Tomas Vondra wrote: > On 1/22/21 5:04 PM, Konstantin Knizhnik wrote: >> ... >> >> I have heard from several DBMS experts that appearance of huge and >> cheap non-volatile memory can make a revolution in database system >> architecture. If all database can fit in non-volatile memory, then we >> do not need buffers, WAL, ...> >> But although multi-terabyte NVM announces were made by IBM several >> years ago, I do not know about some successful DBMS prototypes with new >> architecture. >> >> I tried to understand why... >> > IMHO those predictions are a bit too optimistic, because they often > assume PMEM behavior is mostly similar to DRAM, except for the extra > persistence. But that's not quite true - throughput with PMEM is much > lower Actually it is not completely true. There are several types of NVDIMMs. Most popular now is NVDIMM-N which is just combination of DRAM and flash. Speed it the same as of normal DRAM, but size of such memory is also comparable with DRAM. So I do not think that it is perspective approach. And definitely speed of Intel Optane memory is much slower than of DRAM. >> But the main advantage of PMEM from my point of view is that it allows >> to avoid write-ahead logging at all! > No, PMEM certainly does not allow avoiding write-ahead logging - we > still need to handle e.g. recovery after a crash, when the data files > are in unknown / corrupted state. It is possible to avoid write-ahead logging if we use special algorithms (like PMwCAS) which ensures atomicity of updates. > The problem with removing buffer manager and just writing everything > directly to PMEM is the worse latency/throughput (compared to DRAM). > It's probably much more efficient to combine multiple writes into RAM > and then do one (much slower) write to persistent storage, than pay the > higher latency for every write. > > It might make sense for data sets that are larger than DRAM but can fit > into PMEM. But that seems like fairly rare case, and even then it may be > more efficient to redesign the schema to fit into RAM somehow (sharding, > partitioning, ...). Certainly avoid buffering will make sense only if speed of accessing PMEM will be comparable with DRAM. > So I have to patch code of this library instead of just using it: > > git@github.com:postgrespro/bztree.git > > I have not tested yet most iterating case: access to PMEM through PMDK. > And I do not have hardware for such tests. > But first results are also seem to be interesting: PMwCAS is kind of > lockless algorithm and it shows much better scaling at > NUMA host comparing with standard Postgres. > > I have done simple parallel insertion test: multiple clients are > inserting data with random keys. > To make competition with vanilla Postgres more honest I used unlogged > table: > > create unlogged table t(pk int, payload int); > create index on t using bztree(pk); > > randinsert.sql: > insert into t (payload,pk) values > (generate_series(1,1000),random()*1000000000); > > pgbench -f randinsert.sql -c N -j N -M prepared -n -t 1000 -P 1 postgres > > So each client is inserting one million records. > The target system has 160 virtual and 80 real cores with 256GB of RAM. > Results (TPS) are the following: > > N nbtree bztree > 1 540 455 > 10 993 2237 > 100 1479 5025 > > So bztree is more than 3 times faster for 100 clients. > Just for comparison: result for inserting in this table without index is > 10k TPS. > > I'm not familiar with bztree, but I agree novel indexing structures are > an interesting topic on their own. I only quickly skimmed the bztree > paper, but it seems it might be useful even on DRAM (assuming it will > work with replication etc.). > > The other "problem" with placing data files (tables, indexes) on PMEM > and making this code PMEM-aware is that these writes generally happen > asynchronously in the background, so the impact on transaction rate is > fairly low. This is why all the patches in this thread try to apply PMEM > on the WAL logging / flushing, which is on the critical path. I want to make an update on my prototype. Unfortunately my attempt to use bztree with PMEM failed, because of two problems: 1. Used libpmemobj/bztree libraries are not compatible with Postgres architecture. Them support concurrent access, but by multiple threads within one process (widely use thread-local variables). The traditional Postgres approach (initialize shared data structures in postmaster (shared_preload_libraries) and inherit it by forked child processes) doesn't work for libpmemobj. If child doesn't open pmem itself, then any access to it cause crash. And in case of openning pmem by child, it is assigned different virtual memory address. But bztree and pmwcas implementations expect that addresses are the same in all clients. 2. There is some bug in bztree/pmwcas implementation which cause its own test to hang in case of multithreaded access in persistence mode. I tried to find the reason of the problem but didn;t succeed yet: PMwCAS implementation is very non-trivial). So I just compared single threaded performance of bztree test: with Intel Optane it was about two times worser than with volatile memory. I still wonder if using bztree just as in-memory index will be interested because it is scaling much better than Postgres B-Tree and even our own PgPro in_memory extension. But certainly volatile index has very limited usages. Also full support of all Postgres types in bztree requires a lot of efforts (right now I support only equality comparison). -- Konstantin Knizhnik Postgres Professional: http://www.postgrespro.com The Russian Postgres Company