Re: [PoC] Non-volatile WAL buffer - Mailing list pgsql-hackers
| From | Tomas Vondra |
|---|---|
| Subject | Re: [PoC] Non-volatile WAL buffer |
| Date | |
| Msg-id | a4e541cd-4dcc-1047-8972-b7338971412c@enterprisedb.com Whole thread Raw |
| In response to | Re: [PoC] Non-volatile WAL buffer (Takashi Menjo <takashi.menjo@gmail.com>) |
| Responses |
Re: [PoC] Non-volatile WAL buffer
|
| List | pgsql-hackers |
Hi,
These patches no longer apply :-( A rebased version would be nice.
I've been interested in what performance improvements this might bring,
so I've been running some extensive benchmarks on a machine with PMEM
hardware. So let me share some interesting results. (I used commit from
early September, to make the patch apply cleanly.)
Note: The hardware was provided by Intel, and they are interested in
supporting the development and providing access to machines with PMEM to
developers. So if you're interested in this patch & PMEM, but don't have
access to suitable hardware, try contacting Steve Shaw
<steve.shaw@intel.com> who's the person responsible for open source
databases at Intel (he's also the author of HammerDB).
The benchmarks were done on a machine with 2 x Xeon Platinum (24/48
cores), 128GB RAM, NVMe and PMEM SSDs. I did some basic pgbench tests
with different scales (500, 5000, 15000) with and without these patches.
I did some usual tuning (shared buffers, max_wal_size etc.), the most
important changes being:
- maintenance_work_mem = 256MB
- max_connections = 200
- random_page_cost = 1.2
- shared_buffers = 16GB
- work_mem = 64MB
- checkpoint_completion_target = 0.9
- checkpoint_timeout = 20min
- max_wal_size = 96GB
- autovacuum_analyze_scale_factor = 0.1
- autovacuum_vacuum_insert_scale_factor = 0.05
- autovacuum_vacuum_scale_factor = 0.01
- vacuum_cost_limit = 1000
And on the patched version:
- nvwal_size = 128GB
- nvwal_path = … points to the PMEM DAX device …
The machine has multiple SSDs (all Optane-based, IIRC):
- NVMe SSD (Optane)
- PMEM in BTT mode
- PMEM in DAX mode
So I've tested all of them - the data was always on the NVMe device, and
the WAL was placed on one of those devices. That means we have these
four cases to compare:
- nvme - master with WAL on the NVMe SSD
- pmembtt - master with WAL on PMEM in BTT mode
- pmemdax - master with WAL on PMEM in DAX mode
- pmemdax-ntt - patched version with WAL on PMEM in DAX mode
The "nvme" is a bit disadvantaged as it places both data and WAL on the
same device, so consider that while evaluating the results. But for the
smaller data sets this should be fairly negligible, I believe.
I'm not entirely sure whether the "pmemdax" (i.e. unpatched instance
with WAL on PMEM DAX device) is actually safe, but I included it anyway
to see what difference is.
Now let's look at results for the basic data sizes and client counts.
I've also attached some charts to illustrate this. These numbers are tps
averages from 3 runs, each about 30 minutes long.
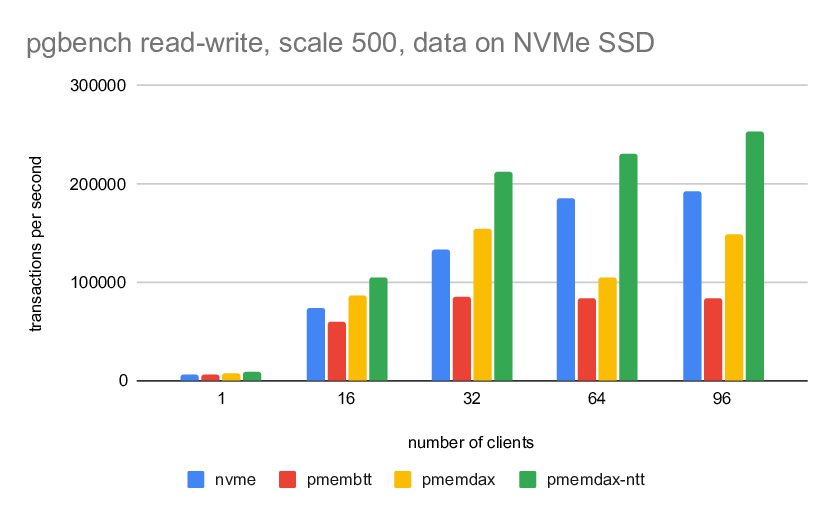
1) scale 500 (fits into shared buffers)
---------------------------------------
wal 1 16 32 64 96
----------------------------------------------------------
nvme 6321 73794 132687 185409 192228
pmembtt 6248 60105 85272 82943 84124
pmemdax 6686 86188 154850 105219 149224
pmemdax-ntt 8062 104887 211722 231085 252593
The NVMe performs well (the single device is not an issue, as there
should be very little non-WAL I/O). The PMBM/BTT has a clear bottleneck
~85k tps. It's interesting the PMEM/DAX performs much worse without the
patch, and the drop at 64 clients. Not sure what that's about.
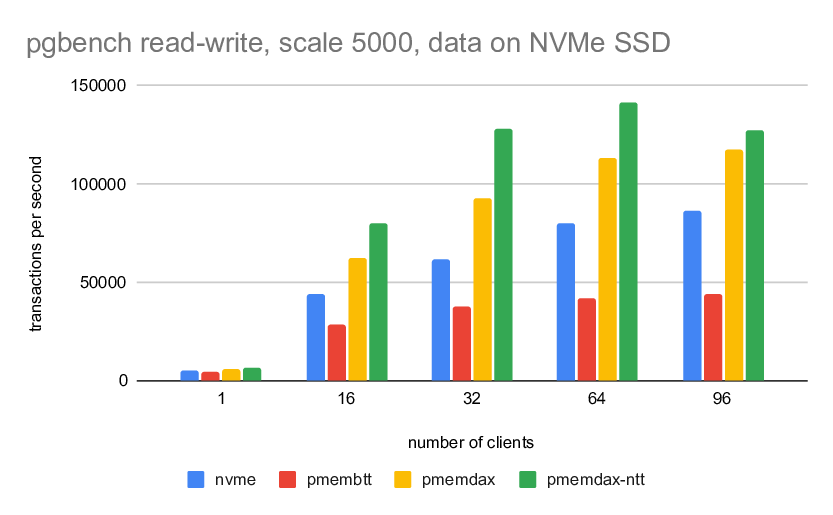
2) scale 5000 (fits into RAM)
-----------------------------
wal 1 16 32 64 96
-----------------------------------------------------------
nvme 4804 43636 61443 79807 86414
pmembtt 4203 28354 37562 41562 43684
pmemdax 5580 62180 92361 112935 117261
pmemdax-ntt 6325 79887 128259 141793 127224
The differences are more significant, compared to the small scale. The
BTT seems to have bottleneck around ~43k tps, the PMEM/DAX dominates.
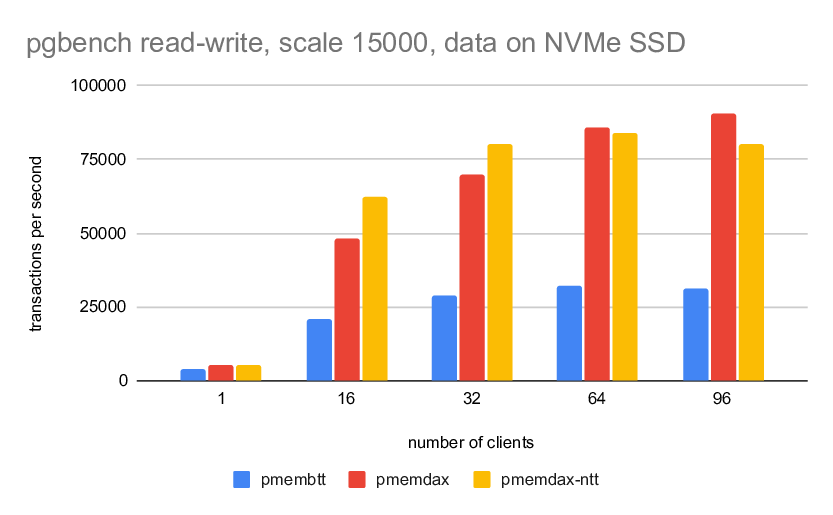
3) scale 15000 (bigger than RAM)
--------------------------------
wal 1 16 32 64 96
-----------------------------------------------------------
pmembtt 3638 20630 28985 32019 31303
pmemdax 5164 48230 69822 85740 90452
pmemdax-ntt 5382 62359 80038 83779 80191
I have not included the nvme results here, because the impact of placing
both data and WAL on the same device was too significant IMHO.
The remaining results seem nice. It's interesting the patched case is a
bit slower than master. Not sure why.
Overall, these results seem pretty nice, I guess. Of course, this does
not say the current patch is the best way to implement this (or whether
it's correct), but it does suggest supporting PMEM might bring sizeable
performance boost.
regards
--
Tomas Vondra
EnterpriseDB: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
Attachment
{kind=link}
{kind=link}
{kind=link}
pgsql-hackers by date: