Thread: [pgadmin4][patch] Use pytest test runner for unit tests
yarn test:unit
Attachment
Hey all,Attached is a rather large patch that attempts to introduce the Pytest test runner and Grappah test matcher into our code base. The patch replaces all of the previous python unit tests from the previous design. This is a follow-up from our previous proof of concept and discussion around the idiosyncrasies of our existing test suite.We are motivated to submit this change for the following reasons:1. Having a highly customized test suite increases the learning curve towards contributing to the code base. Pytest is a mature stable python test framework that outside developers are more likely to be familiar with.2. Pytest supports a lot of the features that we've built for our use-cases - out of the box, and with extensive documentation on the matter.3. The lack of ability to run tests individually has become a pain point. Especially when it comes to debugging long running feature tests.Test can be ran with the following command:yarn test:unitPlease let us know what you think and if there are any issues!
(pgadmin4) piranha:web dpage$ yarn test:unit
yarn run v1.3.2
$ yarn run linter && pytest -q pgadmin
$ yarn eslint --no-eslintrc -c .eslintrc.js --ext .js --ext .jsx .
$ /Users/dpage/git/pgadmin4/web/node_modules/.bin/eslint --no-eslintrc -c .eslintrc.js --ext .js --ext .jsx .
Traceback (most recent call last):
File "/Users/dpage/.virtualenvs/pgadmin4/lib/python2.7/site-packages/_pytest/config.py", line 371, in _importconftest
mod = conftestpath.pyimport()
File "/Users/dpage/.virtualenvs/pgadmin4/lib/python2.7/site-packages/py/_path/local.py", line 668, in pyimport
__import__(modname)
File "/Users/dpage/git/pgadmin4/web/pgadmin/__init__.py", line 29, in <module>
from pgadmin.model import db, Role, Server, ServerGroup, \
ImportError: No module named pgadmin.model
ERROR: could not load /Users/dpage/git/pgadmin4/web/pgadmin/conftest.py
error Command failed with exit code 4.
info Visit https://yarnpkg.com/en/docs/cli/run for documentation about this command.
Note: The feature tests are not yet completed. We expect our CI to fail as a result of this patch. We will complete this step soon in a follow-up patch!
Blog: http://pgsnake.blogspot.com
Twitter: @pgsnake
EnterpriseDB UK: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
Here’s a followup patch with the relevant README and Makefile changes. To be clear, both patches need to be applied in succession to run the tests.
The error that you were running into was because the appropriate PYTHONPATH environment variable was not set. We updated the README to reflect that, but haven’t done anything to the code for that
Thanks
Joao && Anthony
Attachment
Here’s a followup patch with the relevant README and Makefile changes. To be clear, both patches need to be applied in succession to run the tests.
The error that you were running into was because the appropriate
PYTHONPATHenvironment variable was not set. We updated the README to reflect that, but haven’t done anything to the code for that
Blog: http://pgsnake.blogspot.com
Twitter: @pgsnake
EnterpriseDB UK: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
On Thu, May 24, 2018 at 5:14 PM, Anthony Emengo <aemengo@pivotal.io> wrote:Here’s a followup patch with the relevant README and Makefile changes. To be clear, both patches need to be applied in succession to run the tests.
The error that you were running into was because the appropriate
PYTHONPATHenvironment variable was not set. We updated the README to reflect that, but haven’t done anything to the code for thatThat really needs to be fixed then. I shouldn't need to do anything beyond activate the appropriate virtual environment (which I had done).--Dave Page
Blog: http://pgsnake.blogspot.com
Twitter: @pgsnake
EnterpriseDB UK: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
Attachment
As part of the development environment we do not see the reasoning behind not add PYTHONPATH to the environment variables, specially because this looks like the way pytest was invisoned.
However please try the following patch instead. We've changed the pytest invocation to assume the relevant dir as part of the directories to load, as well as the docs and Makefile
Blog: http://pgsnake.blogspot.com
Twitter: @pgsnake
EnterpriseDB UK: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
Hello Dave
As part of the development environment we do not see the reasoning behind not add PYTHONPATH to the environment variables, specially because this looks like the way pytest was invisoned.Really? It's one more step that wasn't previously required, and for which there is no good reason when running in a properly configured virtual environment. Not only that, but PYTHONPATH is typically used as a search path to find modules on which the application/script is dependent - not to find the application/script itself. Unconditionally overriding it is likely to lead to problems in some possible configurations (at the very least I would expect to see the Makefile do PYTHONPATH=$PYTHONPATH:$(PWD)/web).
However please try the following patch instead. We've changed the pytest invocation to assume the relevant dir as part of the directories to load, as well as the docs and MakefileSome initial feedback:- The JSON results are no longer being generated.
- The output is *extremely* verbose, showing a lot of seemingly unnecessary info (do we really need to output the source code of failing test cases?). I would suggest that the verbose output be directed to the log, and the visible output should be much more terse along the lines of what it is now.
- There is no summary at the end showing what passed, failed or was skipped. To figure out what to look at, I have to trawl through over 13K lines of output (642KB).
- 69 tests failed for me running test:unit. They were previously all passing.
- It is a *lot* faster - not sure if that's a result of tests failing, but I expect not entirely.- /README was updated, but not /web/regression/README
Hello Hackers,
We have good news, we just finished porting all the tests to pytest/grappa. Please see the attached diff with the multiple commits for this. Bare with us in this HUGE patch. We split it as follow:
0001 - Convert all the Unit Tests to pytest/grappa(Patch previously sent, with some tests that were not running previously
0002 - Change of README, makefile and package.json to use the new syntax
0003 - Convert all the Feature Tests to pytest/grappa
From now on, we can launch 1 test at a time if we want to by using pytest. (In this gist https://gist.github.com/kwmiebach/3fd49612ef7a52b5ce3a there are some examples on how to use it) Because we are using the pytest CLI all the options are made available to use, the community also as a ton of plugins if we ever need something else.
We updated all README’s with the following information as well.
As we discussed previously in order to use the pytest binary directly you need to point the PYTHONPATH to $PGADMIN_SRC/web
If you do not want to do that then you can use it like this web $ python -m pytest -q -s pgadmin
We also changed the feature test, they now are under regression/feature_tests as they do no longer need to be in the application path in order to run.
To address the password issue we added to the makefile
python -m pytest --tb=short -q --json=regression/test_result.json --log-file-level=DEBUG --log-file=regression/regression.log pgadmin
the --tb=short options is the one responsible for removing a chunk of the traceback, making it smaller and hiding the variable printing
Known issues:
- Python 2.7, the library we are using for assertions (Grappa) is failing while trying to assert on strings. We created a PR to the library: https://github.com/grappa-py/grappa/pull/43 as soon as this gets in all the tests should pass
- We found out that the tests in
pgadmin/browser/testswhere not running because they needed SERVER_MODE to be True. We ported these tests but 2 tests are still failingTestResetPassword.test_successandTestChangePassword.test_success. They are currently failing for 2 different reasons, but when we went back tomasterbranch they were also failing. So we kept them with the markxfail, this mark allow us to run the tests and do not report the failure. You can read more one the topic at (https://docs.pytest.org/en/3.6.0/skipping.html). Unfortunately we were not able to correct the issues, if someone could look into these test it would be great. - Jenkins server need a change. Because we now run tests for a single database at a time the Jenkins flow need to change. Our proposal for this is to isolate each database in its own task something similar to the pipeline that we currently use internally:
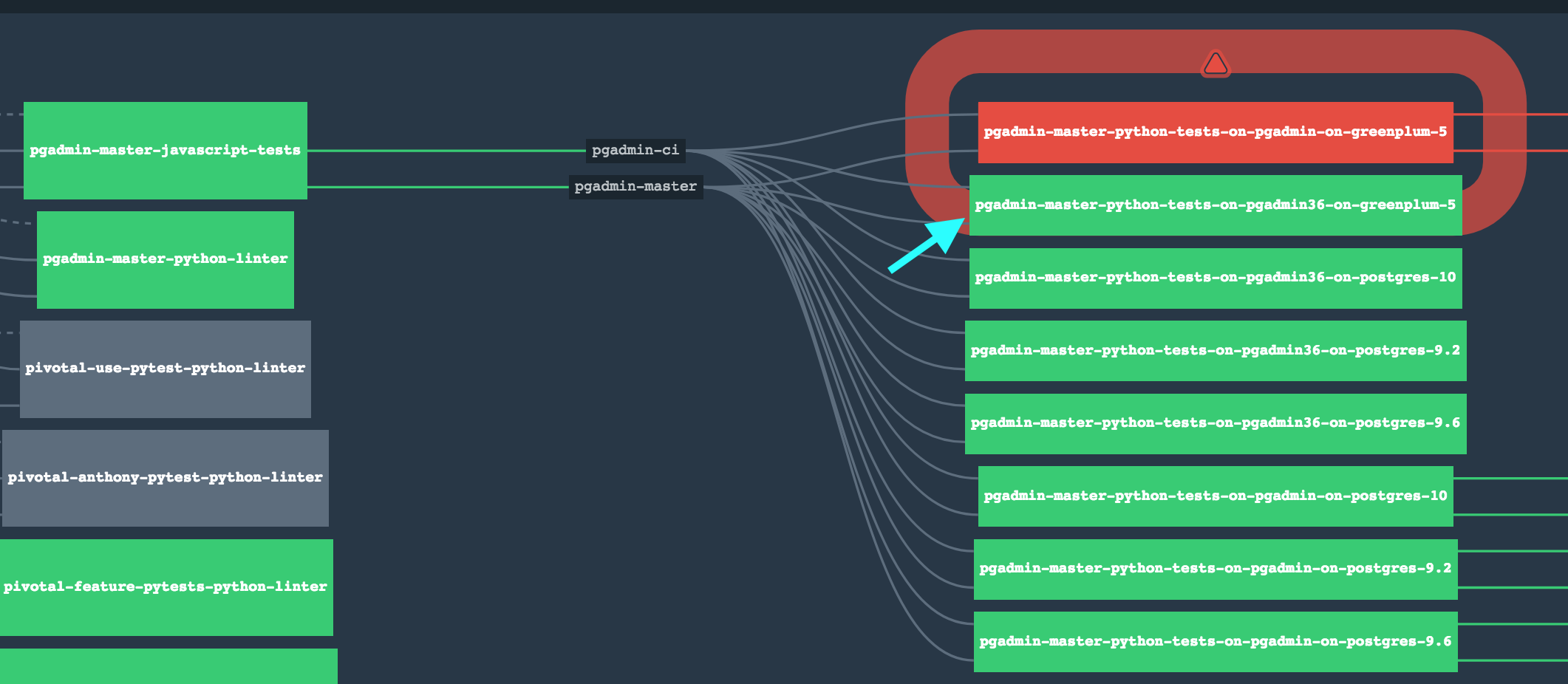
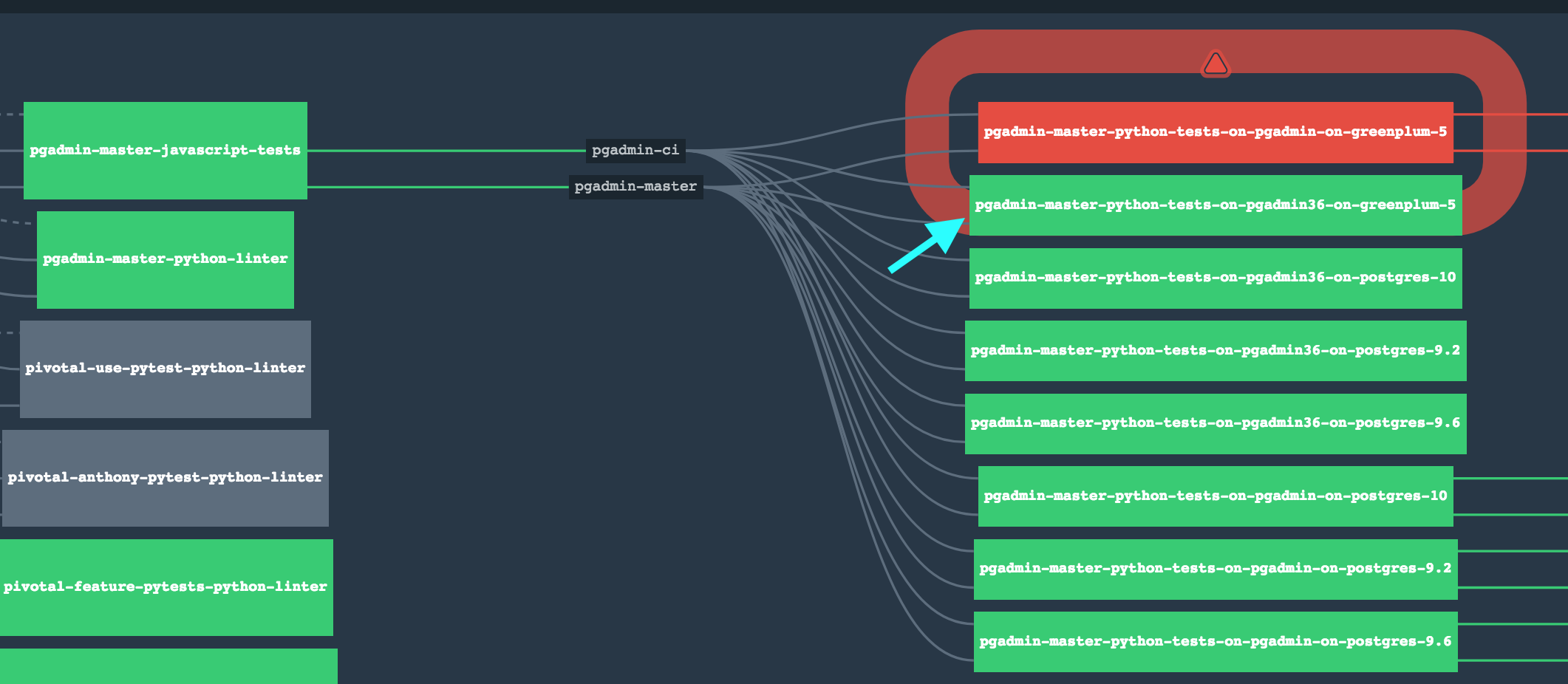
The boxes that we are pointing with the teal arrow represent 1 Python Version Against 1 Database. This can be accomplished using Jenkins as well. In order to accomplish that we are going to generate e Jenkinsfile(https://jenkins.io/doc/book/pipeline/jenkinsfile/) to do this in a more DSL manner, making it easier for us to deploy the pipeline in a more consistent way. The LTS version of jenkins is 2.107.3 the version that we have in CI should be ok, but is always good to be in a LTS version of Jenkins or newer because the community is pretty active.
The idea would be to replace the 5 tasks that we have there and start using a pipeline that will spawn docker containers to isolate the testing between version/database. That is what we do with concourse as we depicted in the previous image.
Does anyone have any thoughts about this?
Thanks
Joao
Attachment
Hello Hackers,
We have good news, we just finished porting all the tests to pytest/grappa. Please see the attached diff with the multiple commits for this. Bare with us in this HUGE patch. We split it as follow:0001 - Convert all the Unit Tests to pytest/grappa(Patch previously sent, with some tests that were not running previously
0002 - Change of README, makefile and package.json to use the new syntax
0003 - Convert all the Feature Tests to pytest/grappaFrom now on, we can launch 1 test at a time if we want to by using pytest. (In this gist https://gist.github.com/
kwmiebach/3fd49612ef7a52b5ce3a there are some examples on how to use it) Because we are using the pytest CLI all the options are made available to use, the community also as a ton of plugins if we ever need something else. We updated all README’s with the following information as well.
As we discussed previously in order to use the pytest binary directly you need to point the
PYTHONPATHto$PGADMIN_SRC/web
If you do not want to do that then you can use it like thisweb $ python -m pytest -q -s pgadminWe also changed the feature test, they now are under
regression/feature_testsas they do no longer need to be in the application path in order to run.
To address the password issue we added to the makefilepython -m pytest --tb=short -q --json=regression/test_result.json --log-file-level=DEBUG --log-file=regression/ regression.log pgadmin the
--tb=shortoptions is the one responsible for removing a chunk of the traceback, making it smaller and hiding the variable printingKnown issues:
- Python 2.7, the library we are using for assertions (Grappa) is failing while trying to assert on strings. We created a PR to the library: https://github.com/grappa-py/
grappa/pull/43 as soon as this gets in all the tests should pass
- We found out that the tests in
pgadmin/browser/testswhere not running because they needed SERVER_MODE to be True. We ported these tests but 2 tests are still failingTestResetPassword.test_successandTestChangePassword.test_. They are currently failing for 2 different reasons, but when we went back tosuccess masterbranch they were also failing. So we kept them with the markxfail, this mark allow us to run the tests and do not report the failure. You can read more one the topic at (https://docs.pytest.org/en/3.6.0/skipping.html). Unfortunately we were not able to correct the issues, if someone could look into these test it would be great.
- Jenkins server need a change. Because we now run tests for a single database at a time the Jenkins flow need to change. Our proposal for this is to isolate each database in its own task something similar to the pipeline that we currently use internally:
The boxes that we are pointing with the teal arrow represent 1 Python Version Against 1 Database. This can be accomplished using Jenkins as well. In order to accomplish that we are going to generate e Jenkinsfile(https://jenkins.
io/doc/book/pipeline/ jenkinsfile/) to do this in a more DSL manner, making it easier for us to deploy the pipeline in a more consistent way. The LTS version of jenkins is 2.107.3 the version that we have in CI should be ok, but is always good to be in a LTS version of Jenkins or newer because the community is pretty active.
The idea would be to replace the 5 tasks that we have there and start using a pipeline that will spawn docker containers to isolate the testing between version/database. That is what we do with concourse as we depicted in the previous image.
Does anyone have any thoughts about this?
Blog: http://pgsnake.blogspot.com
Twitter: @pgsnake
EnterpriseDB UK: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
Attachment
Known issues:
- Python 2.7, the library we are using for assertions (Grappa) is failing while trying to assert on strings. We created a PR to the library: https://github.com/grappa-py/grappa/pull/43 as soon as this gets in all the tests should pass
Any guesses as to the ETA? Given that most of our dev, and our Windows and Mac packages both run on 2.7 at the moment, it's clear that this is a required fix before we can proceed.
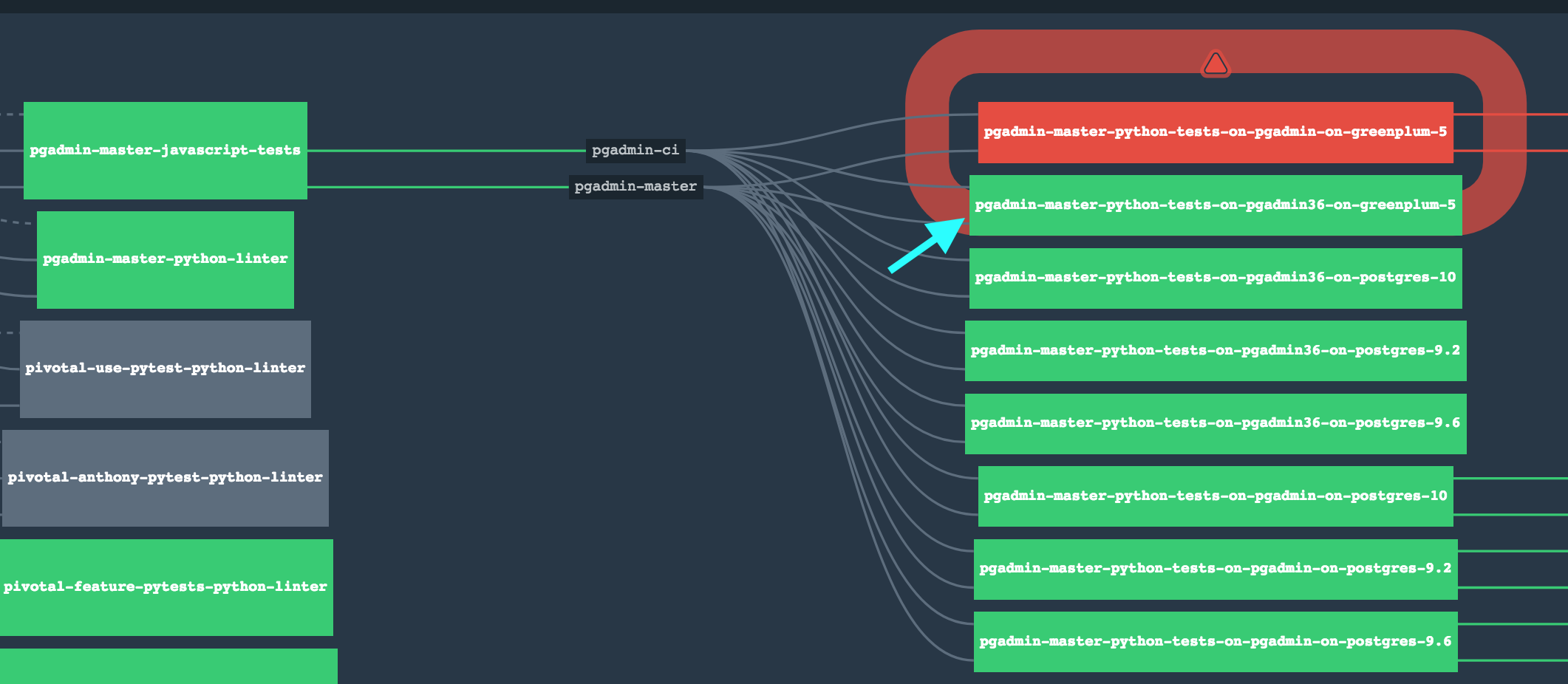
- Jenkins server need a change. Because we now run tests for a single database at a time the Jenkins flow need to change. Our proposal for this is to isolate each database in its own task something similar to the pipeline that we currently use internally:
The boxes that we are pointing with the teal arrow represent 1 Python Version Against 1 Database. This can be accomplished using Jenkins as well. In order to accomplish that we are going to generate e Jenkinsfile(https://jenkins.io/doc/book/pipeline/jenkinsfile/) to do this in a more DSL manner, making it easier for us to deploy the pipeline in a more consistent way. The LTS version of jenkins is 2.107.3 the version that we have in CI should be ok, but is always good to be in a LTS version of Jenkins or newer because the community is pretty active.
The idea would be to replace the 5 tasks that we have there and start using a pipeline that will spawn docker containers to isolate the testing between version/database. That is what we do with concourse as we depicted in the previous image.
Does anyone have any thoughts about this?Well the current public Jenkins system is going away soon, and the new one has had a ton of jobs created that assume the tests run in series automatically against each database server (and is completely different from the current system). I do plan to change that in the longer term, but it requires a change to the way I've been using (and know how to use) Jenkins.
However, the bigger problem for me is that I often run the tests against multiple DB servers on my laptop, without Jenkins. How would that workflow look now?
Attachment
Known issues:
- Python 2.7, the library we are using for assertions (Grappa) is failing while trying to assert on strings. We created a PR to the library: https://github.com/grappa-py/
grappa/pull/43 as soon as this gets in all the tests should pass Any guesses as to the ETA? Given that most of our dev, and our Windows and Mac packages both run on 2.7 at the moment, it's clear that this is a required fix before we can proceed.Attached you can find the patch that bumps grappa to version 0.1.9 that support Python 2.7
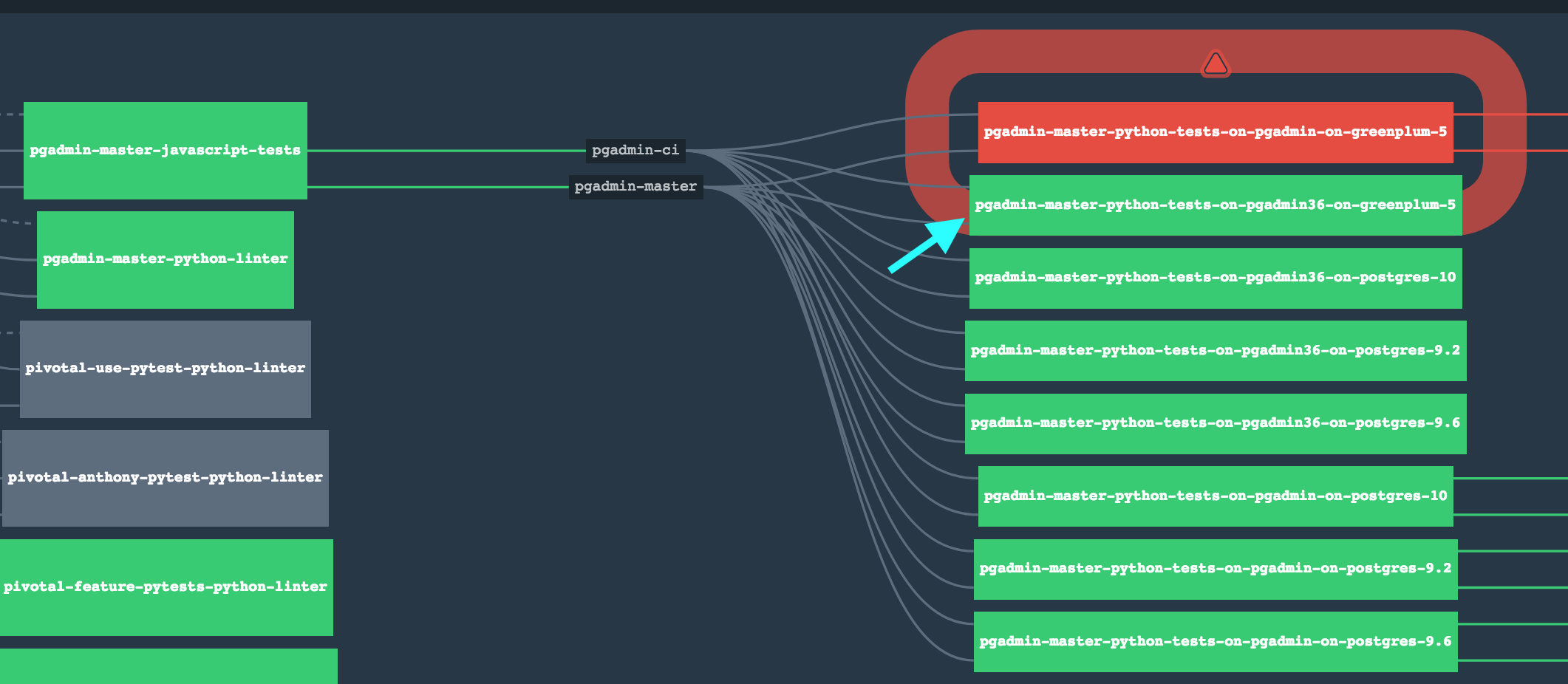
- Jenkins server need a change. Because we now run tests for a single database at a time the Jenkins flow need to change. Our proposal for this is to isolate each database in its own task something similar to the pipeline that we currently use internally:
The boxes that we are pointing with the teal arrow represent 1 Python Version Against 1 Database. This can be accomplished using Jenkins as well. In order to accomplish that we are going to generate e Jenkinsfile(https://jenkins.
io/doc/book/pipeline/ jenkinsfile/) to do this in a more DSL manner, making it easier for us to deploy the pipeline in a more consistent way. The LTS version of jenkins is 2.107.3 the version that we have in CI should be ok, but is always good to be in a LTS version of Jenkins or newer because the community is pretty active.
The idea would be to replace the 5 tasks that we have there and start using a pipeline that will spawn docker containers to isolate the testing between version/database. That is what we do with concourse as we depicted in the previous image.
Does anyone have any thoughts about this?Well the current public Jenkins system is going away soon, and the new one has had a ton of jobs created that assume the tests run in series automatically against each database server (and is completely different from the current system). I do plan to change that in the longer term, but it requires a change to the way I've been using (and know how to use) Jenkins.Do you have a link to the new CI that you can share with us so we can take a pick. We can give some advises on what we believe it is a a good flow for the Continuous Delivery pipeline.
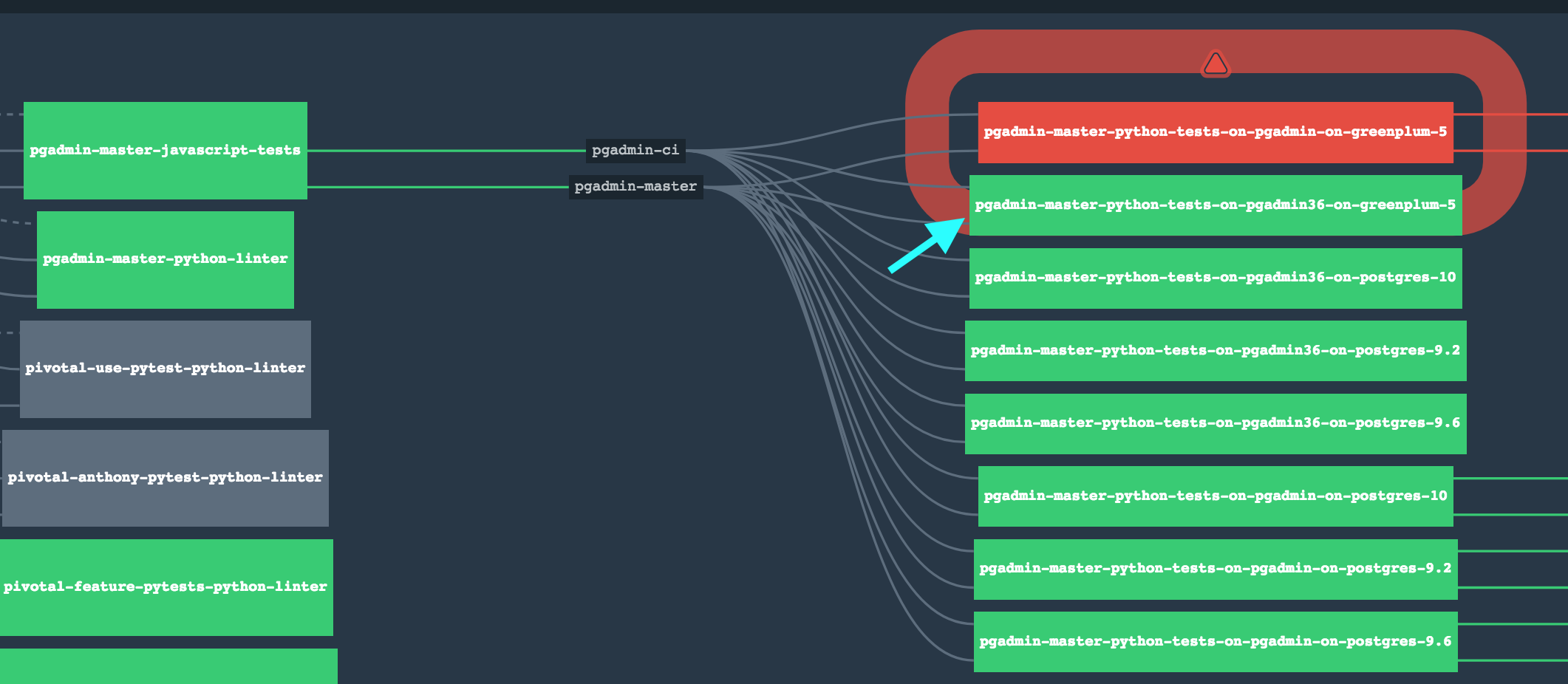
We have some examples from our pipeline that we can share:Script that we use to run the UT + Feature tests on a docker image that has python+yarn+selenium+postgres installed on it:This type of scripts can be added to the Jenkinsfile to create a pipeline step. A good practice in a reproducible pipeline is to use Docker to ensure that every test runs in a clean and predictable environment, this make it easy to reproduce a problem found in testing.
However, the bigger problem for me is that I often run the tests against multiple DB servers on my laptop, without Jenkins. How would that workflow look now?We understand that and it looks like an interesting use case and it could be accomplished by creating a script of something similar that launch the tests multiple times. That is something that we can schedule as a future steps after this patch is reviewed and committed.
Blog: http://pgsnake.blogspot.com
Twitter: @pgsnake
EnterpriseDB UK: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
Attachment
Known issues:
- Python 2.7, the library we are using for assertions (Grappa) is failing while trying to assert on strings. We created a PR to the library: https://github.com/grappa-py/
grappa/pull/43 as soon as this gets in all the tests should pass Any guesses as to the ETA? Given that most of our dev, and our Windows and Mac packages both run on 2.7 at the moment, it's clear that this is a required fix before we can proceed.Attached you can find the patch that bumps grappa to version 0.1.9 that support Python 2.7
- I get the following failure (which is easily fixed in the config file, though that of course, shouldn't be necessary):
E AssertionError: Oops! Something went wrong!
E
E The following assertion was not satisfied
E subject "/Library/PostgreSQL/ ..." should be equal to "/Library/PostgreSQL/ ..."
E
E What we expected
E a value that is equal to "/Library/PostgreSQL/ ..."
E
E What we got instead
E an value of type "str" with data "/Library/PostgreSQL/ ..."
E
E Difference comparison
E > - /Library/PostgreSQL/tablespaces/9.4
E > + /Library/PostgreSQL/tablespaces/9.4/
E > ? +
E
E Where
E File "/Users/dpage/git/pgadmin4/web/pgadmin/browser/server_groups/servers/tablespaces/tests/test_tbspc_get.py", line 75, in test_tablespace_get
Blog: http://pgsnake.blogspot.com
Twitter: @pgsnake
EnterpriseDB UK: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
HiOn Mon, Jun 4, 2018 at 3:26 PM, Joao De Almeida Pereira <jdealmeidapereira@pivotal.io> wrote:Known issues:
- Python 2.7, the library we are using for assertions (Grappa) is failing while trying to assert on strings. We created a PR to the library: https://github.com/grappa-py/grappa/pull/43 as soon as this gets in all the tests should pass
Any guesses as to the ETA? Given that most of our dev, and our Windows and Mac packages both run on 2.7 at the moment, it's clear that this is a required fix before we can proceed.Attached you can find the patch that bumps grappa to version 0.1.9 that support Python 2.7I thought I had replied to this, but apparently not. My apologies...This does seem to fix the issues with Python 2.7. The remaining issues I saw are:- There are a handful of failures with PG 11, however that's not yet supported and Khushboo is working on it. It shouldn't hold up this patch - just mentioning for completeness.
- I get the following failure (which is easily fixed in the config file, though that of course, shouldn't be necessary):E AssertionError: Oops! Something went wrong!
E
E The following assertion was not satisfied
E subject "/Library/PostgreSQL/ ..." should be equal to "/Library/PostgreSQL/ ..."
E
E What we expected
E a value that is equal to "/Library/PostgreSQL/ ..."
E
E What we got instead
E an value of type "str" with data "/Library/PostgreSQL/ ..."
E
E Difference comparison
E > - /Library/PostgreSQL/tablespaces/9.4
E > + /Library/PostgreSQL/tablespaces/9.4/
E > ? +
E
E Where
E File "/Users/dpage/git/pgadmin4/web/pgadmin/browser/server_groups/servers/tablespaces/tests/test_tbspc_get.py", line 75, in test_tablespace_get
Thanks.--Dave Page
Blog: http://pgsnake.blogspot.com
Twitter: @pgsnake
EnterpriseDB UK: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
Attachment
No, because it's firewalled to the nines inside our network. There's no chance I'm making production build machines internet-accessible.
We have some examples from our pipeline that we can share:Script that we use to run the UT + Feature tests on a docker image that has python+yarn+selenium+postgres installed on it:This type of scripts can be added to the Jenkinsfile to create a pipeline step. A good practice in a reproducible pipeline is to use Docker to ensure that every test runs in a clean and predictable environment, this make it easy to reproduce a problem found in testing.Docker is of little use to us here, as 2 of the 4 build platforms cannot be run in Docker (macOS and the Docker container), and the 3rd would be extremely difficult to run that way (Windows)
Attachment
{kind=link}
Hi Dave,No, because it's firewalled to the nines inside our network. There's no chance I'm making production build machines internet-accessible.For a Open Source project, if the community cannot see the place where the tests are running it looses a huge part of the process. We believe that removing this capability will have a negative impact on the development, especially because we do not have a CI/CD. Before the code is merged we will never know if master is broken or not.
We have some examples from our pipeline that we can share:Script that we use to run the UT + Feature tests on a docker image that has python+yarn+selenium+postgres installed on it:This type of scripts can be added to the Jenkinsfile to create a pipeline step. A good practice in a reproducible pipeline is to use Docker to ensure that every test runs in a clean and predictable environment, this make it easy to reproduce a problem found in testing.Docker is of little use to us here, as 2 of the 4 build platforms cannot be run in Docker (macOS and the Docker container), and the 3rd would be extremely difficult to run that way (Windows)The docker files that we are talking about here is to run the tests, and we believe that the tests are all running in a Linux environment.
Blog: http://pgsnake.blogspot.com
Twitter: @pgsnake
EnterpriseDB UK: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
Hi Dave,Attached are four different patches that should be applied in order. Included is a fix for the failing test above.
Blog: http://pgsnake.blogspot.com
Twitter: @pgsnake
EnterpriseDB UK: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
HiOn Tue, Jun 12, 2018 at 3:41 PM, Victoria Henry <vhenry@pivotal.io> wrote:Hi Dave,Attached are four different patches that should be applied in order. Included is a fix for the failing test above.This is no longer failing :-)However, I'm still seeing problems that need to be resolved:- Passwords are still being written to the log file. This is a complete show-stopper.- The regression.log file is empty. I'm now only getting the JSON summary. We really need both - the regression log for diagnostics, and the JSON file for feeding into monitoring systems.- There is still no summary list of tests that failed or were skipped output at the end of the run. This is important because it highlights which tests failed (obviously!) and need investigation, and knowing which ones are skipped at a glance is very useful as they can be skipped due to mis-configuration; e.g. running against a different server than intended, or failing to specify something like a tablespace path which we can then easily see to fix.- I cannot run against servers other than the first one in the config file. We need to run against all that are enabled, and have the output show which one was used for each one as we have now. This may seem trivial, but it's really not - to the point that for some of us it negates the whole point of the patch by giving us more control over which tests are run but removing all control over which database servers they will run against. In my case, this will almost certainly cost even more time; right now I just have to run more tests than I may need but I can do other things at the same time. With this patch I'll have to keep re-running the tests, modifying the config between each run.Thanks.--Dave Page
Blog: http://pgsnake.blogspot.com
Twitter: @pgsnake
EnterpriseDB UK: http://www.enterprisedb.com
The Enterprise PostgreSQL Company