Thread: Add bump memory context type and use it for tuplesorts
Background:
The idea with 40af10b57 (Use Generation memory contexts to store
tuples in sorts) was to reduce the memory wastage in tuplesort.c
caused by aset.c's power-of-2 rounding up behaviour and allow more
tuples to be stored per work_mem in tuplesort.c
Later, in (v16's) c6e0fe1f2a (Improve performance of and reduce
overheads of memory management) that commit reduced the palloc chunk
header overhead down to 8 bytes. For generation.c contexts (as is now
used by non-bounded tuplesorts as of 40af10b57), the overhead was 24
bytes. So this allowed even more tuples to be stored in a work_mem by
reducing the chunk overheads for non-bounded tuplesorts by 2/3rds down
to 16 bytes.
1083f94da (Be smarter about freeing tuples during tuplesorts) removed
the useless pfree() calls from tuplesort.c which pfree'd the tuples
just before we reset the context. So, as of now, we never pfree()
memory allocated to store tuples in non-bounded tuplesorts.
My thoughts are, if we never pfree tuples in tuplesorts, then why
bother having a chunk header at all?
Proposal:
Because of all of what is mentioned above about the current state of
tuplesort, there does not really seem to be much need to have chunk
headers in memory we allocate for tuples at all. Not having these
saves us a further 8 bytes per tuple.
In the attached patch, I've added a bump memory allocator which
allocates chunks without and chunk header. This means the chunks
cannot be pfree'd or realloc'd. That seems fine for the use case for
storing tuples in tuplesort. I've coded bump.c in such a way that when
built with MEMORY_CONTEXT_CHECKING, we *do* have chunk headers. That
should allow us to pick up any bugs that are introduced by any code
which accidentally tries to pfree a bump.c chunk.
I'd expect a bump.c context only to be used for fairly short-lived and
memory that's only used by a small amount of code (e.g. only accessed
from a single .c file, like tuplesort.c). That should reduce the risk
of any code accessing the memory which might be tempted into calling
pfree or some other unsupported function.
Getting away from the complexity of freelists (aset.c) and tracking
allocations per block (generation.c) allows much better allocation
performance. All we need to do is check there's enough space then
bump the free pointer when performing an allocation. See the attached
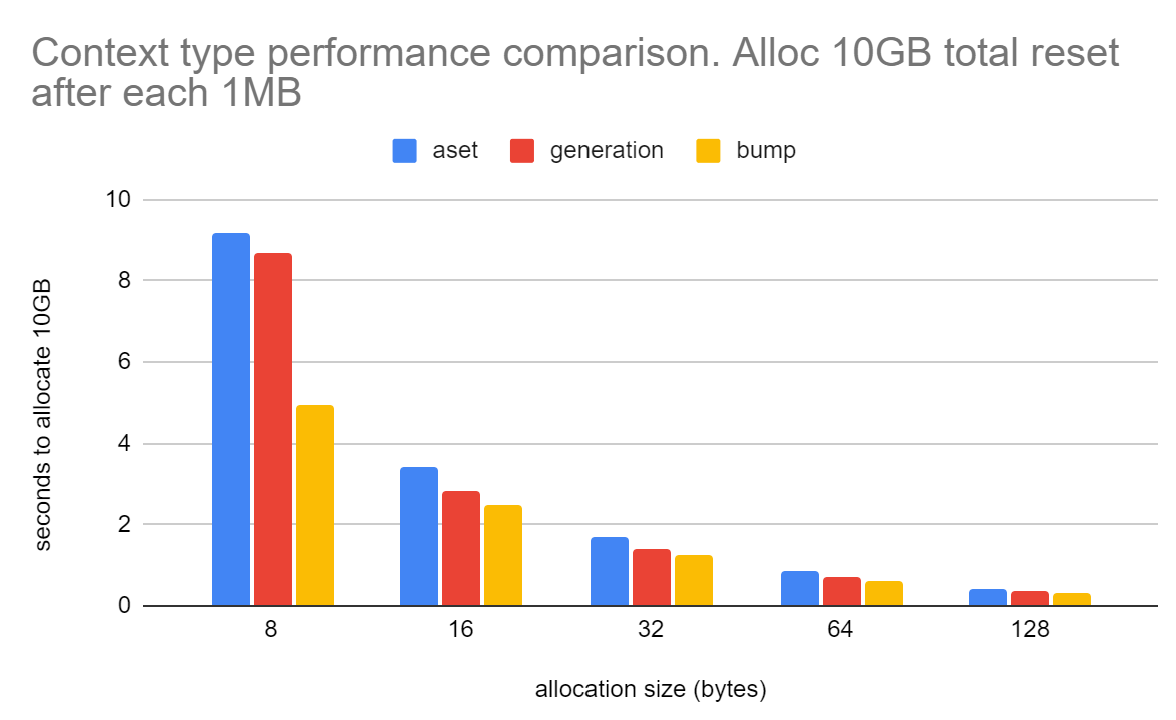
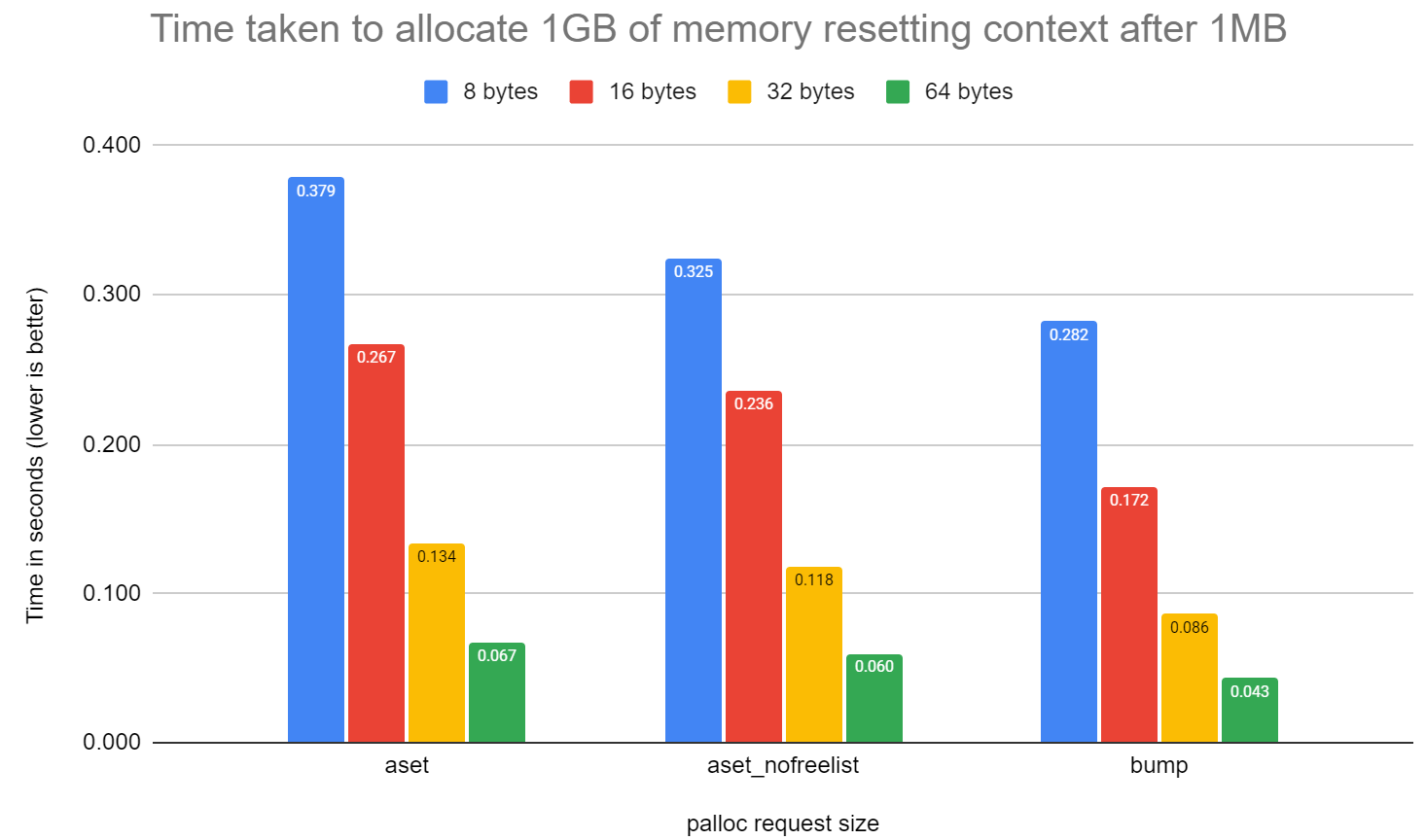
time_to_allocate_10gbs_memory.png to see how bump.c compares to aset.c
and generation.c to allocate 10GBs of memory resetting the context
after 1MB. It's not far off twice as fast in raw allocation speed.
(See 3rd tab in the attached spreadsheet)
Performance:
In terms of the speed of palloc(), the performance tested on an AMD
3990x CPU on Linux for 8-byte chunks:
aset.c 9.19 seconds
generation.c 8.68 seconds
bump.c 4.95 seconds
These numbers were generated by calling:
select stype,chksz,pg_allocate_memory_test_reset(chksz,1024*1024,10::bigint*1024*1024*1024,stype)
from (values(8),(16),(32),(64),(128)) t1(chksz) cross join
(values('aset'),('generation'),('bump')) t2(stype) order by
stype,chksz;
This allocates a total of 10GBs of chunks but calls a context reset
after 1MB so as not to let the memory usage get out of hand. The
function is in the attached membench.patch.txt file.
In terms of performance of tuplesort, there's a small (~5-6%)
performance gain. Not as much as I'd hoped, but I'm also doing a bit
of other work on tuplesort to make it more efficient in terms of CPU,
so I suspect the cache efficiency improvements might be more
pronounced after those.
Please see the attached bump_context_tuplesort_2023-06-27.ods for my
complete benchmark.
One thing that might need more thought is that we're running a bit low
on MemoryContextMethodIDs. I had to use an empty slot that has a bit
pattern like glibc malloc'd chunks sized 128kB. Maybe it's worth
freeing up a bit from the block offset in MemoryChunk. This is
currently 30 bits allowing 1GB offset, but these offsets are always
MAXALIGNED, so we could free up a couple of bits since those 2
lowest-order bits will always be 0 anyway.
I've attached the bump allocator patch and also the script I used to
gather the performance results in the first 2 tabs in the attached
spreadsheet.
David
Attachment
{kind=link}
On Tue, 27 Jun 2023 at 21:19, David Rowley <dgrowleyml@gmail.com> wrote: > I've attached the bump allocator patch and also the script I used to > gather the performance results in the first 2 tabs in the attached > spreadsheet. I've attached a v2 patch which changes the BumpContext a little to remove some of the fields that are not really required. There was no need for the "keeper" field as the keeper block always comes at the end of the BumpContext as these are allocated in a single malloc(). The pointer to the "block" also isn't really needed. This is always the same as the head element in the blocks dlist. David
Attachment
On Tue, Jun 27, 2023 at 09:19:26PM +1200, David Rowley wrote: > Because of all of what is mentioned above about the current state of > tuplesort, there does not really seem to be much need to have chunk > headers in memory we allocate for tuples at all. Not having these > saves us a further 8 bytes per tuple. > > In the attached patch, I've added a bump memory allocator which > allocates chunks without and chunk header. This means the chunks > cannot be pfree'd or realloc'd. That seems fine for the use case for > storing tuples in tuplesort. I've coded bump.c in such a way that when > built with MEMORY_CONTEXT_CHECKING, we *do* have chunk headers. That > should allow us to pick up any bugs that are introduced by any code > which accidentally tries to pfree a bump.c chunk. This is a neat idea. > In terms of performance of tuplesort, there's a small (~5-6%) > performance gain. Not as much as I'd hoped, but I'm also doing a bit > of other work on tuplesort to make it more efficient in terms of CPU, > so I suspect the cache efficiency improvements might be more > pronounced after those. Nice. > One thing that might need more thought is that we're running a bit low > on MemoryContextMethodIDs. I had to use an empty slot that has a bit > pattern like glibc malloc'd chunks sized 128kB. Maybe it's worth > freeing up a bit from the block offset in MemoryChunk. This is > currently 30 bits allowing 1GB offset, but these offsets are always > MAXALIGNED, so we could free up a couple of bits since those 2 > lowest-order bits will always be 0 anyway. I think it'd be okay to steal those bits. AFAICT it'd complicate the macros in memutils_memorychunk.h a bit, but that doesn't seem like such a terrible price to pay to allow us to keep avoiding the glibc bit patterns. > + if (base->sortopt & TUPLESORT_ALLOWBOUNDED) > + tuplen = GetMemoryChunkSpace(tuple); > + else > + tuplen = MAXALIGN(tuple->t_len); nitpick: I see this repeated in a few places, and I wonder if it might deserve a comment. I haven't had a chance to try out your benchmark, but I'm hoping to do so in the near future. -- Nathan Bossart Amazon Web Services: https://aws.amazon.com
On Tue, 11 Jul 2023 at 01:51, David Rowley <dgrowleyml@gmail.com> wrote:
>
> On Tue, 27 Jun 2023 at 21:19, David Rowley <dgrowleyml@gmail.com> wrote:
> > I've attached the bump allocator patch and also the script I used to
> > gather the performance results in the first 2 tabs in the attached
> > spreadsheet.
>
> I've attached a v2 patch which changes the BumpContext a little to
> remove some of the fields that are not really required. There was no
> need for the "keeper" field as the keeper block always comes at the
> end of the BumpContext as these are allocated in a single malloc().
> The pointer to the "block" also isn't really needed. This is always
> the same as the head element in the blocks dlist.
Neat idea, +1.
I think it would make sense to split the "add a bump allocator"
changes from the "use the bump allocator in tuplesort" patches.
Tangent: Do we have specific notes on worst-case memory usage of
memory contexts with various allocation patterns? This new bump
allocator seems to be quite efficient, but in a worst-case allocation
pattern it can still waste about 1/3 of its allocated memory due to
never using free space on previous blocks after an allocation didn't
fit on that block.
It probably isn't going to be a huge problem in general, but this
seems like something that could be documented as a potential problem
when you're looking for which allocator to use and compare it with
other allocators that handle different allocation sizes more
gracefully.
> +++ b/src/backend/utils/mmgr/bump.c
> +BumpBlockIsEmpty(BumpBlock *block)
> +{
> + /* it's empty if the freeptr has not moved */
> + return (block->freeptr == (char *) block + Bump_BLOCKHDRSZ);
> [...]
> +static inline void
> +BumpBlockMarkEmpty(BumpBlock *block)
> +{
> +#if defined(USE_VALGRIND) || defined(CLOBBER_FREED_MEMORY)
> + char *datastart = ((char *) block) + Bump_BLOCKHDRSZ;
These two use different definitions of the start pointer. Is that deliberate?
> +++ b/src/include/utils/tuplesort.h
> @@ -109,7 +109,8 @@ typedef struct TuplesortInstrumentation
> * a pointer to the tuple proper (might be a MinimalTuple or IndexTuple),
> * which is a separate palloc chunk --- we assume it is just one chunk and
> * can be freed by a simple pfree() (except during merge, when we use a
> - * simple slab allocator). SortTuples also contain the tuple's first key
> + * simple slab allocator and when performing a non-bounded sort where we
> + * use a bump allocator). SortTuples also contain the tuple's first key
I'd go with something like the following:
+ * ...(except during merge *where* we use a
+ * simple slab allocator, and during a non-bounded sort where we
+ * use a bump allocator).
Kind regards,
Matthias van de Meent
Neon (https://neon.tech)
On Mon, 6 Nov 2023 at 19:54, Matthias van de Meent <boekewurm+postgres@gmail.com> wrote: > > On Tue, 11 Jul 2023 at 01:51, David Rowley <dgrowleyml@gmail.com> wrote: >> >> On Tue, 27 Jun 2023 at 21:19, David Rowley <dgrowleyml@gmail.com> wrote: >>> I've attached the bump allocator patch and also the script I used to >>> gather the performance results in the first 2 tabs in the attached >>> spreadsheet. >> >> I've attached a v2 patch which changes the BumpContext a little to >> remove some of the fields that are not really required. There was no >> need for the "keeper" field as the keeper block always comes at the >> end of the BumpContext as these are allocated in a single malloc(). >> The pointer to the "block" also isn't really needed. This is always >> the same as the head element in the blocks dlist. >> +++ b/src/backend/utils/mmgr/bump.c >> [...] >> +MemoryContext >> +BumpContextCreate(MemoryContext parent, >> + const char *name, >> + Size minContextSize, >> + Size initBlockSize, >> + Size maxBlockSize) >> [...] >> + /* Determine size of initial block */ >> + allocSize = MAXALIGN(sizeof(BumpContext)) + Bump_BLOCKHDRSZ + >> + if (minContextSize != 0) >> + allocSize = Max(allocSize, minContextSize); >> + else >> + allocSize = Max(allocSize, initBlockSize); Shouldn't this be the following, considering the meaning of "initBlockSize"? + allocSize = MAXALIGN(sizeof(BumpContext)) + Bump_BLOCKHDRSZ + + Bump_CHUNKHDRSZ + initBlockSize; + if (minContextSize != 0) + allocSize = Max(allocSize, minContextSize); >> + * BumpFree >> + * Unsupported. >> [...] >> + * BumpRealloc >> + * Unsupported. Rather than the error, can't we make this a no-op (potentially optionally, or in a different memory context?) What I mean is, I get that it is an easy validator check that the code that uses this context doesn't accidentally leak memory through assumptions about pfree, but this does make this memory context unusable for more generic operations where leaking a little memory is preferred over the overhead of other memory contexts, as MemoryContextReset is quite cheap in the grand scheme of things. E.g. using a bump context in btree descent could speed up queries when we use compare operators that do allocate memory (e.g. numeric, text), because btree operators must not leak memory and thus always have to manually keep track of all allocations, which can be expensive. I understand that allowing pfree/repalloc in bump contexts requires each allocation to have a MemoryChunk prefix in overhead, but I think it's still a valid use case to have a very low overhead allocator with no-op deallocator (except context reset). Do you have performance comparison results between with and without the overhead of MemoryChunk? Kind regards, Matthias van de Meent Neon (https://neon.tech)
Hi,
I wanted to take a look at this patch but it seems to need a rebase,
because of a seemingly trivial conflict in MemoryContextMethodID:
--- src/include/utils/memutils_internal.h
+++ src/include/utils/memutils_internal.h
@@ -123,12 +140,13 @@ typedef enum MemoryContextMethodID
{
MCTX_UNUSED1_ID, /* 000 occurs in never-used memory */
MCTX_UNUSED2_ID, /* glibc malloc'd chunks usually match 001 */
- MCTX_UNUSED3_ID, /* glibc malloc'd chunks > 128kB match 010 */
+ MCTX_BUMP_ID, /* glibc malloc'd chunks > 128kB match 010
+ * XXX? */
MCTX_ASET_ID,
MCTX_GENERATION_ID,
MCTX_SLAB_ID,
MCTX_ALIGNED_REDIRECT_ID,
- MCTX_UNUSED4_ID /* 111 occurs in wipe_mem'd memory */
+ MCTX_UNUSED3_ID /* 111 occurs in wipe_mem'd memory */
} MemoryContextMethodID;
I wasn't paying much attention to these memcontext reworks in 2022, so
my instinct was simply to use one of those "UNUSED" IDs. But after
looking at the 80ef92675823 a bit more, are those IDs really unused? I
mean, we're relying on those values to detect bogus pointers, right? So
if we instead start using those values for a new memory context, won't
we lose the ability to detect those issues?
Maybe I'm completely misunderstanding the implication of those limits,
but doesn't this mean the claim that we can support 8 memory context
types is not quite true, and the limit is 4, because the 4 IDs are
already used for malloc stuff?
One thing that confuses me a bit is that the comments introduced by
80ef92675823 talk about glibc, but the related discussion in [1] talks a
lot about FreeBSD, NetBSD, ... which don't actually use glibc (AFAIK).
So how portable are those unused IDs, actually?
Or am I just too caffeine-deprived and missing something obvious?
regards
[1] https://postgr.es/m/2910981.1665080361@sss.pgh.pa.us
--
Tomas Vondra
EnterpriseDB: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
On 11/6/23 19:54, Matthias van de Meent wrote: > > ... > > Tangent: Do we have specific notes on worst-case memory usage of > memory contexts with various allocation patterns? This new bump > allocator seems to be quite efficient, but in a worst-case allocation > pattern it can still waste about 1/3 of its allocated memory due to > never using free space on previous blocks after an allocation didn't > fit on that block. > It probably isn't going to be a huge problem in general, but this > seems like something that could be documented as a potential problem > when you're looking for which allocator to use and compare it with > other allocators that handle different allocation sizes more > gracefully. > I don't think it's documented anywhere, but I agree it might be an interesting piece of information. It probably did not matter too much when we had just AllocSet, but now we have 3 very different allocators, so maybe we should explain this. When implementing these allocators, it didn't feel that important, because the new allocators started as intended for a very specific part of the code (as in "This piece of code has a very unique allocation pattern, let's develop a custom allocator for it."), but if we feel we want to make it simpler to use the allocators elsewhere ... I think there are two obvious places where to document this - either in the header of each memory context .c file, or a README in the mmgr directory. Or some combination of it. At some point I was thinking about writing a "proper paper" comparing these allocators in a more scientific / thorough way, but I never got to do it. I wonder if that'd be interesting for enough people. regards -- Tomas Vondra EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
Tomas Vondra <tomas.vondra@enterprisedb.com> writes:
> Maybe I'm completely misunderstanding the implication of those limits,
> but doesn't this mean the claim that we can support 8 memory context
> types is not quite true, and the limit is 4, because the 4 IDs are
> already used for malloc stuff?
Well, correct code would still work, but we will take a hit in our
ability to detect bogus chunk pointers if we convert any of the four
remaining bit-patterns to valid IDs. That has costs for debugging.
The particular bit patterns we left unused were calculated to make it
likely that we could detect a malloced-instead-of-palloced chunk (at
least with glibc); but in general, reducing the number of invalid
patterns makes it more likely that a just-plain-bad pointer would
escape detection.
I am less concerned about that than I was in 2022, because people
have already had some time to flush out bugs associated with the
GUC malloc->palloc conversion. Still, maybe we should think harder
about whether we can free up another ID bit before we go eating
more ID types. It's not apparent to me that the "bump context"
idea is valuable enough to foreclose ever adding more context types,
yet it will be pretty close to doing that if we commit it as-is.
If we do kick this can down the road, then I concur with eating 010
next, as it seems the least likely to occur in glibc-malloced
chunks.
> One thing that confuses me a bit is that the comments introduced by
> 80ef92675823 talk about glibc, but the related discussion in [1] talks a
> lot about FreeBSD, NetBSD, ... which don't actually use glibc (AFAIK).
The conclusion was that the specific invalid values didn't matter as
much on the other platforms as they do with glibc. But right now you
have a fifty-fifty chance that a pointer to garbage will look valid.
Do we want to increase those odds?
regards, tom lane
On 2/17/24 00:14, Tom Lane wrote: > Tomas Vondra <tomas.vondra@enterprisedb.com> writes: >> Maybe I'm completely misunderstanding the implication of those limits, >> but doesn't this mean the claim that we can support 8 memory context >> types is not quite true, and the limit is 4, because the 4 IDs are >> already used for malloc stuff? > > Well, correct code would still work, but we will take a hit in our > ability to detect bogus chunk pointers if we convert any of the four > remaining bit-patterns to valid IDs. That has costs for debugging. > The particular bit patterns we left unused were calculated to make it > likely that we could detect a malloced-instead-of-palloced chunk (at > least with glibc); but in general, reducing the number of invalid > patterns makes it more likely that a just-plain-bad pointer would > escape detection. > > I am less concerned about that than I was in 2022, because people > have already had some time to flush out bugs associated with the > GUC malloc->palloc conversion. Still, maybe we should think harder > about whether we can free up another ID bit before we go eating > more ID types. It's not apparent to me that the "bump context" > idea is valuable enough to foreclose ever adding more context types, > yet it will be pretty close to doing that if we commit it as-is. > > If we do kick this can down the road, then I concur with eating 010 > next, as it seems the least likely to occur in glibc-malloced > chunks. > I don't know if the bump context for tuplesorts alone is worth it, but I've been thinking it's not the only place doing something like that. I'm aware of two other places doing this "dense allocation" - spell.c and nodeHash.c. And in those cases it definitely made a big difference (ofc, the question is how big the difference would be now, with all the palloc improvements). But maybe we could switch all those places to a proper memcontext (instead of something built on top of a memory context) ... Of course, the code in spell.c/nodeHash.c is quite stable, so the custom code does not cost much. >> One thing that confuses me a bit is that the comments introduced by >> 80ef92675823 talk about glibc, but the related discussion in [1] talks a >> lot about FreeBSD, NetBSD, ... which don't actually use glibc (AFAIK). > > The conclusion was that the specific invalid values didn't matter as > much on the other platforms as they do with glibc. But right now you > have a fifty-fifty chance that a pointer to garbage will look valid. > Do we want to increase those odds? > Not sure. The ability to detect bogus pointers seems valuable, but is the difference between 4/8 and 3/8 really qualitatively different? If it is, maybe we should try to increase it by simply adding a bit. regards -- Tomas Vondra EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
Tomas Vondra <tomas.vondra@enterprisedb.com> writes:
> On 2/17/24 00:14, Tom Lane wrote:
>> The conclusion was that the specific invalid values didn't matter as
>> much on the other platforms as they do with glibc. But right now you
>> have a fifty-fifty chance that a pointer to garbage will look valid.
>> Do we want to increase those odds?
> Not sure. The ability to detect bogus pointers seems valuable, but is
> the difference between 4/8 and 3/8 really qualitatively different? If it
> is, maybe we should try to increase it by simply adding a bit.
I think it'd be worth taking a fresh look at the bit allocation in the
header word to see if we can squeeze another bit without too much
pain. There's basically no remaining headroom in the current design,
and it starts to seem like we want some. (I'm also wondering whether
the palloc_aligned stuff should have been done some other way than
by consuming a context type ID.)
regards, tom lane
Hi, On 2024-02-16 20:10:48 -0500, Tom Lane wrote: > Tomas Vondra <tomas.vondra@enterprisedb.com> writes: > > On 2/17/24 00:14, Tom Lane wrote: > >> The conclusion was that the specific invalid values didn't matter as > >> much on the other platforms as they do with glibc. But right now you > >> have a fifty-fifty chance that a pointer to garbage will look valid. > >> Do we want to increase those odds? > > > Not sure. The ability to detect bogus pointers seems valuable, but is > > the difference between 4/8 and 3/8 really qualitatively different? If it > > is, maybe we should try to increase it by simply adding a bit. > > I think it'd be worth taking a fresh look at the bit allocation in the > header word to see if we can squeeze another bit without too much > pain. There's basically no remaining headroom in the current design, > and it starts to seem like we want some. I think we could fairly easily "move" some bits around, by restricting the maximum size of a non-external chunk (i.e. allocations coming out of a larger block, not a separate allocation). Right now we reserve 30 bits for the offset from the block header to the allocation. It seems unlikely that it's ever worth having an undivided 1GB block. Even if we wanted something that large - say because we want to use 1GB huge pages to back the block - we could just add a few block headers ever couple hundred MBs. Another avenue is that presumably the chunk<->block header offset always has at least the two lower bits set to zero, so perhaps we could just shift blockoffset right by two bits in MemoryChunkSetHdrMask() and left in MemoryChunkGetBlock()? > (I'm also wondering whether the palloc_aligned stuff should have been done > some other way than by consuming a context type ID.) Possibly, I just don't quite know how. Greetings, Andres Freund
Thanks for having a look at this.
On Tue, 7 Nov 2023 at 07:55, Matthias van de Meent
<boekewurm+postgres@gmail.com> wrote:
> I think it would make sense to split the "add a bump allocator"
> changes from the "use the bump allocator in tuplesort" patches.
I've done this and will post updated patches after replying to the
other comments.
> Tangent: Do we have specific notes on worst-case memory usage of
> memory contexts with various allocation patterns? This new bump
> allocator seems to be quite efficient, but in a worst-case allocation
> pattern it can still waste about 1/3 of its allocated memory due to
> never using free space on previous blocks after an allocation didn't
> fit on that block.
> It probably isn't going to be a huge problem in general, but this
> seems like something that could be documented as a potential problem
> when you're looking for which allocator to use and compare it with
> other allocators that handle different allocation sizes more
> gracefully.
It might be a good idea to document this. The more memory allocator
types we add, the harder it is to decide which one to use when writing
new code.
> > +++ b/src/backend/utils/mmgr/bump.c
> > +BumpBlockIsEmpty(BumpBlock *block)
> > +{
> > + /* it's empty if the freeptr has not moved */
> > + return (block->freeptr == (char *) block + Bump_BLOCKHDRSZ);
> > [...]
> > +static inline void
> > +BumpBlockMarkEmpty(BumpBlock *block)
> > +{
> > +#if defined(USE_VALGRIND) || defined(CLOBBER_FREED_MEMORY)
> > + char *datastart = ((char *) block) + Bump_BLOCKHDRSZ;
>
> These two use different definitions of the start pointer. Is that deliberate?
hmm, I'm not sure if I follow what you mean. Are you talking about
the "datastart" variable and the assignment of block->freeptr (which
you've not quoted?)
> > +++ b/src/include/utils/tuplesort.h
> > @@ -109,7 +109,8 @@ typedef struct TuplesortInstrumentation
> > * a pointer to the tuple proper (might be a MinimalTuple or IndexTuple),
> > * which is a separate palloc chunk --- we assume it is just one chunk and
> > * can be freed by a simple pfree() (except during merge, when we use a
> > - * simple slab allocator). SortTuples also contain the tuple's first key
> > + * simple slab allocator and when performing a non-bounded sort where we
> > + * use a bump allocator). SortTuples also contain the tuple's first key
>
> I'd go with something like the following:
>
> + * ...(except during merge *where* we use a
> + * simple slab allocator, and during a non-bounded sort where we
> + * use a bump allocator).
Adjusted.
On Wed, 26 Jul 2023 at 12:11, Nathan Bossart <nathandbossart@gmail.com> wrote: > I think it'd be okay to steal those bits. AFAICT it'd complicate the > macros in memutils_memorychunk.h a bit, but that doesn't seem like such a > terrible price to pay to allow us to keep avoiding the glibc bit patterns. I've not adjusted anything here and I've kept the patch using the >128KB glibc bit pattern. I think it was a good idea to make our lives easier if someone came to us with a bug report, but it's not like the reserved patterns are guaranteed to cover all malloc implementations. What's there is just to cover the likely candidates. I'd like to avoid adding any bit shift instructions in the code that decodes the hdrmask. > > + if (base->sortopt & TUPLESORT_ALLOWBOUNDED) > > + tuplen = GetMemoryChunkSpace(tuple); > > + else > > + tuplen = MAXALIGN(tuple->t_len); > > nitpick: I see this repeated in a few places, and I wonder if it might > deserve a comment. I ended up adding a macro and a comment in each location that does this. > I haven't had a chance to try out your benchmark, but I'm hoping to do so > in the near future. Great. It would be good to get a 2nd opinion. David
On Fri, 26 Jan 2024 at 01:29, Matthias van de Meent <boekewurm+postgres@gmail.com> wrote: > >> + allocSize = MAXALIGN(sizeof(BumpContext)) + Bump_BLOCKHDRSZ + > >> + if (minContextSize != 0) > >> + allocSize = Max(allocSize, minContextSize); > >> + else > >> + allocSize = Max(allocSize, initBlockSize); > > Shouldn't this be the following, considering the meaning of "initBlockSize"? No, we want to make the blocksize exactly initBlockSize if we can. Not initBlockSize plus all the header stuff. We do it that way for all the other contexts and I agree that it's a good idea as it keeps the malloc request sizes powers of 2. > >> + * BumpFree > >> + * Unsupported. > >> [...] > >> + * BumpRealloc > >> + * Unsupported. > > Rather than the error, can't we make this a no-op (potentially > optionally, or in a different memory context?) Unfortunately not. There are no MemoryChunks on bump chunks so we've no way to determine the context type a given pointer belongs to. I've left the MemoryChunk on there for debug builds so we can get the ERRORs to allow us to fix the broken code that is pfreeing these chunks. > I understand that allowing pfree/repalloc in bump contexts requires > each allocation to have a MemoryChunk prefix in overhead, but I think > it's still a valid use case to have a very low overhead allocator with > no-op deallocator (except context reset). Do you have performance > comparison results between with and without the overhead of > MemoryChunk? Oh right, you've taken this into account. I was hoping not to have the headers otherwise the only gains we see over using generation.c is that of the allocation function being faster. I certainly did do benchmarks in [1] and saw the 338% increase due to the reduction in memory. That massive jump happened by accident as the sort on tenk1 went from not fitting into default 4MB work_mem to fitting in, so what I happened to measure there was the difference of spilling to disk and not. The same could happen for this case, so the overhead of having the chunk headers really depends on what the test is. Probably, "potentially large" is likely a good way to describe the overhead of having chunk headers. However, to a lesser extent, there will be a difference for large sorts as we'll be able to fit more tuples per batch and do fewer batches. The smaller the tuple, the more that will be noticeable as the chunk header is a larger portion of the overall allocation with those. David [1] https://postgr.es/m/CAApHDvoH4ASzsAOyHcxkuY01Qf++8JJ0paw+03dk+W25tQEcNQ@mail.gmail.com
Thanks for taking an interest in this. On Sat, 17 Feb 2024 at 11:46, Tomas Vondra <tomas.vondra@enterprisedb.com> wrote: > I wasn't paying much attention to these memcontext reworks in 2022, so > my instinct was simply to use one of those "UNUSED" IDs. But after > looking at the 80ef92675823 a bit more, are those IDs really unused? I > mean, we're relying on those values to detect bogus pointers, right? So > if we instead start using those values for a new memory context, won't > we lose the ability to detect those issues? I wouldn't say we're "relying" on them. Really there just there to improve debugability. If we call any code that tries to look at the MemoryChunk header of a malloc'd chunk, then we can expect bad things to happen. We no longer have any code which does this. MemoryContextContains() did, and it's now gone. > Maybe I'm completely misunderstanding the implication of those limits, > but doesn't this mean the claim that we can support 8 memory context > types is not quite true, and the limit is 4, because the 4 IDs are > already used for malloc stuff? I think we all expected a bit more pain from the memory context change. I was happy that Tom did the extra work to look at the malloc patterns of glibc, but I think there's been very little gone wrong. The reserved MemoryContextMethodIDs do seem to have allowed [1] to be found, but I guess there'd have been a segfault instead of an ERROR without the reserved IDs. I've attached version 2, now split into 2 patches. 0001 for the bump allocator 0002 to use the new allocator for tuplesorts David [1] https://postgr.es/m/796b65c3-57b7-bddf-b0d5-a8afafb8b627@gmail.com
Attachment
On Tue, 20 Feb 2024 at 10:41, David Rowley <dgrowleyml@gmail.com> wrote:
> On Tue, 7 Nov 2023 at 07:55, Matthias van de Meent
> <boekewurm+postgres@gmail.com> wrote:
> > > +++ b/src/backend/utils/mmgr/bump.c
> > > +BumpBlockIsEmpty(BumpBlock *block)
> > > +{
> > > + /* it's empty if the freeptr has not moved */
> > > + return (block->freeptr == (char *) block + Bump_BLOCKHDRSZ);
> > > [...]
> > > +static inline void
> > > +BumpBlockMarkEmpty(BumpBlock *block)
> > > +{
> > > +#if defined(USE_VALGRIND) || defined(CLOBBER_FREED_MEMORY)
> > > + char *datastart = ((char *) block) + Bump_BLOCKHDRSZ;
> >
> > These two use different definitions of the start pointer. Is that deliberate?
>
> hmm, I'm not sure if I follow what you mean. Are you talking about
> the "datastart" variable and the assignment of block->freeptr (which
> you've not quoted?)
What I meant was that
> (char *) block + Bump_BLOCKHDRSZ
vs
> ((char *) block) + Bump_BLOCKHDRSZ
, when combined with my little experience with pointer addition and
precedence, and a lack of compiler at the ready at that point in time,
I was afraid that "(char *) block + Bump_BLOCKHDRSZ" would be parsed
as "(char *) (block + Bump_BLOCKHDRSZ)", which would get different
offsets across the two statements.
Godbolt has since helped me understand that both are equivalent.
Kind regards,
Matthias van de Meent
On Tue, 20 Feb 2024 at 11:02, David Rowley <dgrowleyml@gmail.com> wrote: > On Fri, 26 Jan 2024 at 01:29, Matthias van de Meent > <boekewurm+postgres@gmail.com> wrote: > > >> + allocSize = MAXALIGN(sizeof(BumpContext)) + Bump_BLOCKHDRSZ + > > >> + if (minContextSize != 0) > > >> + allocSize = Max(allocSize, minContextSize); > > >> + else > > >> + allocSize = Max(allocSize, initBlockSize); > > > > Shouldn't this be the following, considering the meaning of "initBlockSize"? > > No, we want to make the blocksize exactly initBlockSize if we can. Not > initBlockSize plus all the header stuff. We do it that way for all > the other contexts and I agree that it's a good idea as it keeps the > malloc request sizes powers of 2. One part of the reason of my comment was that initBlockSize was ignored in favour of minContextSize if that was configured, regardless of the value of initBlockSize. Is it deliberately ignored when minContextSize is set? > > >> + * BumpFree > > >> + * Unsupported. > > >> [...] > > >> + * BumpRealloc > > >> + * Unsupported. > > > > Rather than the error, can't we make this a no-op (potentially > > optionally, or in a different memory context?) > > Unfortunately not. There are no MemoryChunks on bump chunks so we've > no way to determine the context type a given pointer belongs to. I've > left the MemoryChunk on there for debug builds so we can get the > ERRORs to allow us to fix the broken code that is pfreeing these > chunks. > > > I understand that allowing pfree/repalloc in bump contexts requires > > each allocation to have a MemoryChunk prefix in overhead, but I think > > it's still a valid use case to have a very low overhead allocator with > > no-op deallocator (except context reset). Do you have performance > > comparison results between with and without the overhead of > > MemoryChunk? > > Oh right, you've taken this into account. I was hoping not to have > the headers otherwise the only gains we see over using generation.c is > that of the allocation function being faster. > > [...] The smaller the tuple, the > more that will be noticeable as the chunk header is a larger portion > of the overall allocation with those. I see. Thanks for the explanation. Kind regards, Matthias van de Meent Neon (https://neon.tech)
On Tue, 20 Feb 2024 at 23:52, Matthias van de Meent <boekewurm+postgres@gmail.com> wrote: > What I meant was that > > > (char *) block + Bump_BLOCKHDRSZ > vs > > ((char *) block) + Bump_BLOCKHDRSZ > > , when combined with my little experience with pointer addition and > precedence, and a lack of compiler at the ready at that point in time, > I was afraid that "(char *) block + Bump_BLOCKHDRSZ" would be parsed > as "(char *) (block + Bump_BLOCKHDRSZ)", which would get different > offsets across the two statements. > Godbolt has since helped me understand that both are equivalent. I failed to notice this. I've made them the same regardless to prevent future questions from being raised about the discrepancy between the two. David
On Wed, 21 Feb 2024 at 00:02, Matthias van de Meent <boekewurm+postgres@gmail.com> wrote: > > On Tue, 20 Feb 2024 at 11:02, David Rowley <dgrowleyml@gmail.com> wrote: > > On Fri, 26 Jan 2024 at 01:29, Matthias van de Meent > > <boekewurm+postgres@gmail.com> wrote: > > > >> + allocSize = MAXALIGN(sizeof(BumpContext)) + Bump_BLOCKHDRSZ + > > > >> + if (minContextSize != 0) > > > >> + allocSize = Max(allocSize, minContextSize); > > > >> + else > > > >> + allocSize = Max(allocSize, initBlockSize); > > > > > > Shouldn't this be the following, considering the meaning of "initBlockSize"? > > > > No, we want to make the blocksize exactly initBlockSize if we can. Not > > initBlockSize plus all the header stuff. We do it that way for all > > the other contexts and I agree that it's a good idea as it keeps the > > malloc request sizes powers of 2. > > One part of the reason of my comment was that initBlockSize was > ignored in favour of minContextSize if that was configured, regardless > of the value of initBlockSize. Is it deliberately ignored when > minContextSize is set? Ok, it's a good question. It's to allow finer-grained control over the initial block as it allows it to be a fixed given size without affecting the number that we double for the subsequent blocks. e.g BumpContextCreate(64*1024, 8*1024, 1024*1024); would make the first block 64K and the next block 16K, followed by 32K, 64K ... 1MB. Whereas, BumpContextCreate(0, 8*1024, 1024*1024) will start at 8K, 16K ... 1MB. It seems useful as you might have a good idea of how much memory the common case has and want to do that without having to allocate subsequent blocks, but if slightly more memory is required sometimes, you probably don't want the next malloc to be double the common size, especially if the common size is large. Apart from slab.c, this is how all the other contexts work. It seems best to keep this and not to go against the grain on this as there's more to consider if we opt to change the context types of existing contexts. David
There've been a few changes to the memory allocators in the past week
and some of these changes also need to be applied to bump.c. So, I've
rebased the patches on top of today's master. See attached.
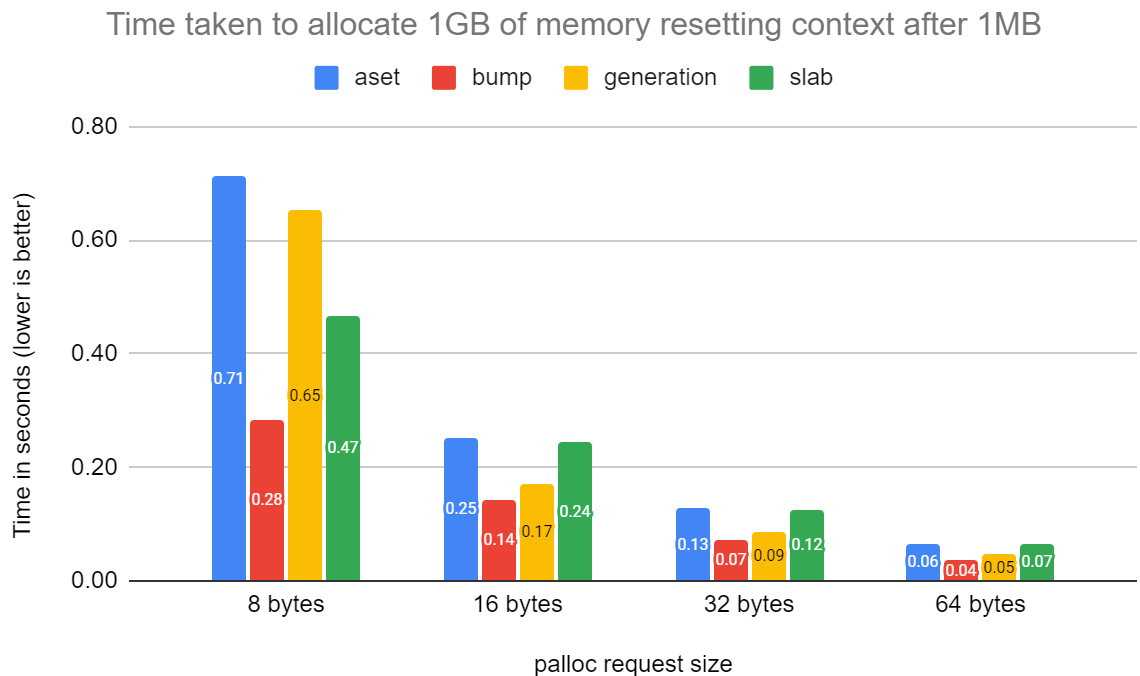
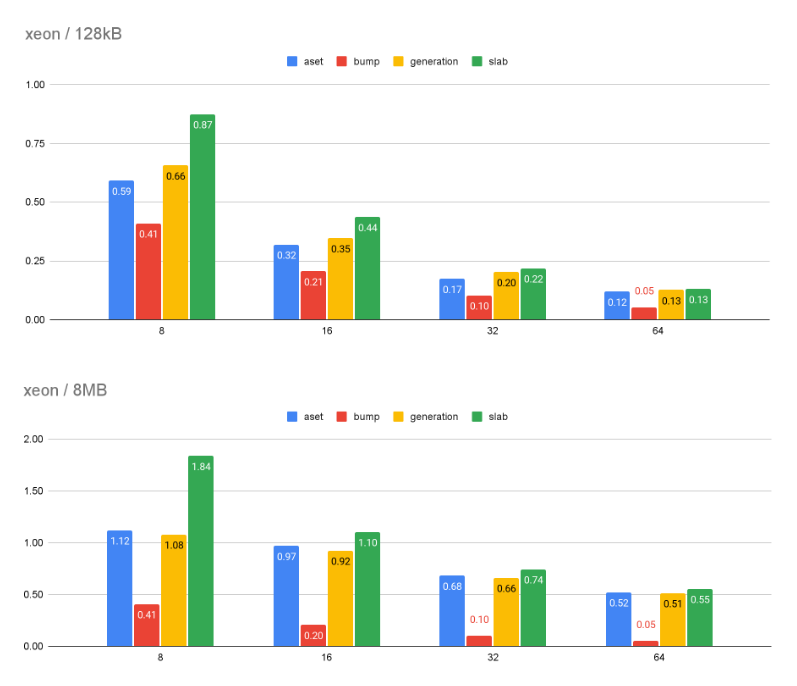
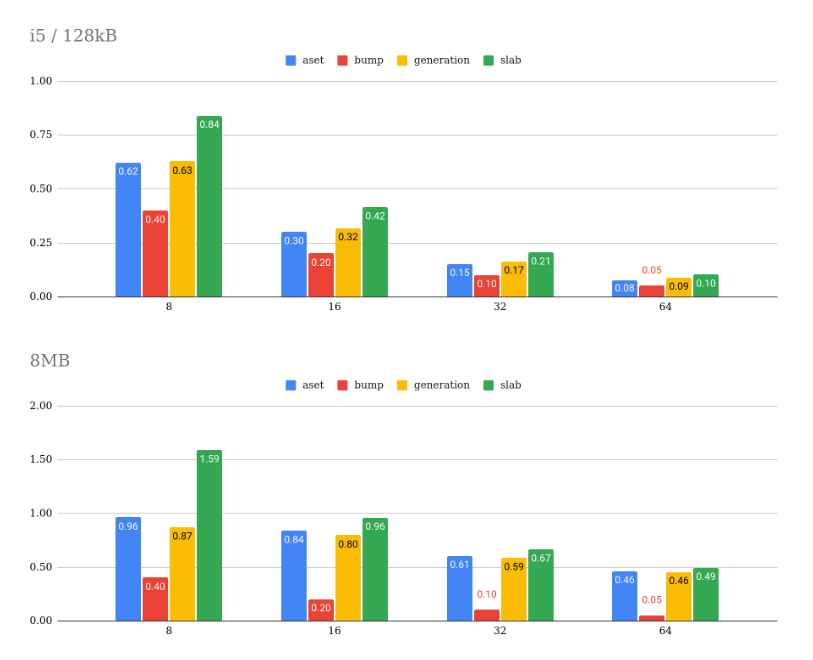
I also re-ran the performance tests to check the allocation
performance against the recently optimised aset, generation and slab
contexts. The attached graph shows the time it took in seconds to
allocate 1GB of memory performing a context reset after 1MB. The
function I ran the test on is in the attached
pg_allocate_memory_test.patch.txt file.
The query I ran was:
select chksz,mtype,pg_allocate_memory_test_reset(chksz,
1024*1024,1024*1024*1024, mtype) from (values(8),(16),(32),(64))
sizes(chksz),(values('aset'),('generation'),('slab'),('bump'))
cxt(mtype) order by mtype,chksz;
David
Attachment
{kind=link}
On Tue, Mar 5, 2024 at 9:42 AM David Rowley <dgrowleyml@gmail.com> wrote:
> performance against the recently optimised aset, generation and slab
> contexts. The attached graph shows the time it took in seconds to
> allocate 1GB of memory performing a context reset after 1MB. The
> function I ran the test on is in the attached
> pg_allocate_memory_test.patch.txt file.
>
> The query I ran was:
>
> select chksz,mtype,pg_allocate_memory_test_reset(chksz,
> 1024*1024,1024*1024*1024, mtype) from (values(8),(16),(32),(64))
> sizes(chksz),(values('aset'),('generation'),('slab'),('bump'))
> cxt(mtype) order by mtype,chksz;
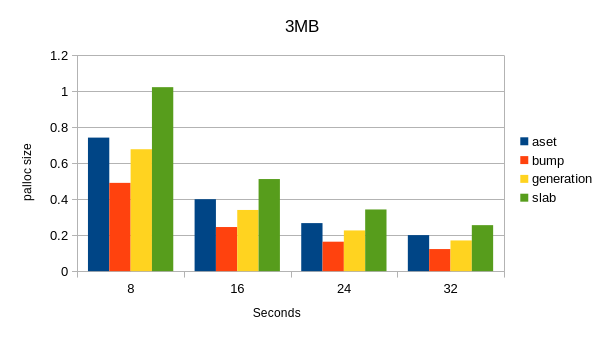
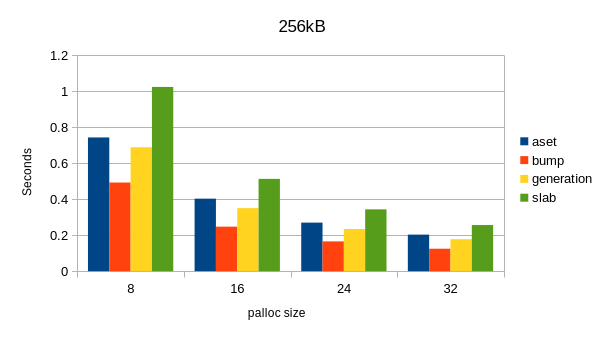
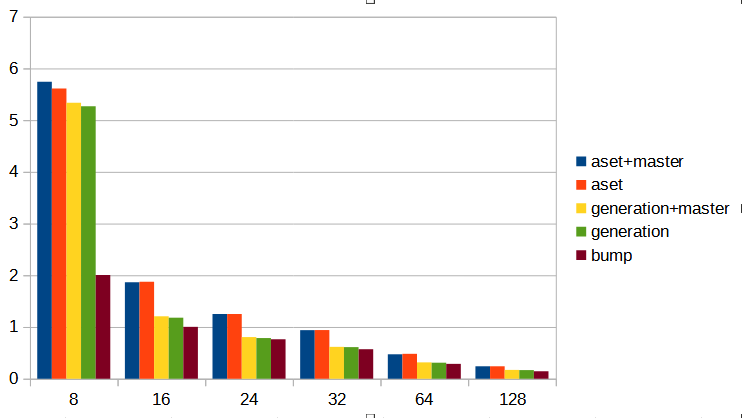
I ran the test function, but using 256kB and 3MB for the reset
frequency, and with 8,16,24,32 byte sizes (patched against a commit
after the recent hot/cold path separation). Images attached. I also
get a decent speedup with the bump context, but not quite as dramatic
as on your machine. It's worth noting that slab is the slowest for me.
This is an Intel i7-10750H.
Attachment
{kind=link}
{kind=link}
On 3/11/24 10:09, John Naylor wrote:
> On Tue, Mar 5, 2024 at 9:42 AM David Rowley <dgrowleyml@gmail.com> wrote:
>> performance against the recently optimised aset, generation and slab
>> contexts. The attached graph shows the time it took in seconds to
>> allocate 1GB of memory performing a context reset after 1MB. The
>> function I ran the test on is in the attached
>> pg_allocate_memory_test.patch.txt file.
>>
>> The query I ran was:
>>
>> select chksz,mtype,pg_allocate_memory_test_reset(chksz,
>> 1024*1024,1024*1024*1024, mtype) from (values(8),(16),(32),(64))
>> sizes(chksz),(values('aset'),('generation'),('slab'),('bump'))
>> cxt(mtype) order by mtype,chksz;
>
> I ran the test function, but using 256kB and 3MB for the reset
> frequency, and with 8,16,24,32 byte sizes (patched against a commit
> after the recent hot/cold path separation). Images attached. I also
> get a decent speedup with the bump context, but not quite as dramatic
> as on your machine. It's worth noting that slab is the slowest for me.
> This is an Intel i7-10750H.
That's interesting! Obviously, I can't miss a benchmarking party like
this, so I ran this on my two machines, and I got very similar results
on both - see the attached charts.
It seems that compared to the other memory context types:
(a) bump context is much faster
(b) slab is considerably slower
I wonder if this is due to the microbenchmark being a particularly poor
fit for Slab (but I don't see why would that be), or if this is simply
how Slab works. I vaguely recall it was meant handle this much better
than AllocSet, both in terms of time and memory usage, but we improved
AllocSet since then, so maybe it's no longer true / needed?
regards
--
Tomas Vondra
EnterpriseDB: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
Attachment
{kind=link}
{kind=link}
On Tue, 12 Mar 2024 at 12:25, Tomas Vondra <tomas.vondra@enterprisedb.com> wrote: > (b) slab is considerably slower It would be interesting to modify SlabReset() to, instead of free()ing the blocks, push the first SLAB_MAXIMUM_EMPTY_BLOCKS of them onto the emptyblocks list. That might give us an idea of how much overhead comes from malloc/free. Having something like this as an option when creating a context might be a good idea. generation.c now keeps 1 "freeblock" which currently does not persist during context resets. Some memory context usages might suit having an option like this. Maybe something like the executor's per-tuple context, which perhaps (c|sh)ould be a generation context... However, saying that, I see you measure it to be slightly slower than aset. David
On Mon, 11 Mar 2024 at 22:09, John Naylor <johncnaylorls@gmail.com> wrote:
> I ran the test function, but using 256kB and 3MB for the reset
> frequency, and with 8,16,24,32 byte sizes (patched against a commit
> after the recent hot/cold path separation). Images attached. I also
> get a decent speedup with the bump context, but not quite as dramatic
> as on your machine. It's worth noting that slab is the slowest for me.
> This is an Intel i7-10750H.
Thanks for trying this out. I didn't check if the performance was
susceptible to the memory size before the reset. It certainly would
be once the allocation crosses some critical threshold of CPU cache
size, but probably it will also be to some extent regarding the number
of actual mallocs that are required underneath.
I see there's some discussion of bump in [1]. Do you still have a
valid use case for bump for performance/memory usage reasons?
The reason I ask is due to what Tom mentioned in [2] ("It's not
apparent to me that the "bump context" idea is valuable enough to
foreclose ever adding more context types"). So, I'm just probing to
find other possible use cases that reinforce the usefulness of bump.
It would be interesting to try it in a few places to see what
performance gains could be had. I've not done much scouting around
the codebase for other uses other than non-bounded tuplesorts.
David
[1] https://postgr.es/m/CANWCAZbxxhysYtrPYZ-wZbDtvRPWoeTe7RQM1g_+4CB8Z6KYSQ@mail.gmail.com
[2] https://postgr.es/m/3537323.1708125284@sss.pgh.pa.us
On Tue, Mar 12, 2024 at 6:41 AM David Rowley <dgrowleyml@gmail.com> wrote: > Thanks for trying this out. I didn't check if the performance was > susceptible to the memory size before the reset. It certainly would > be once the allocation crosses some critical threshold of CPU cache > size, but probably it will also be to some extent regarding the number > of actual mallocs that are required underneath. I neglected to mention it, but the numbers I chose did have the L2/L3 cache in mind, but the reset frequency didn't seem to make much difference. > I see there's some discussion of bump in [1]. Do you still have a > valid use case for bump for performance/memory usage reasons? Yeah, that was part of my motivation for helping test, although my interest is in saving memory in cases of lots of small allocations. It might help if I make this a little more concrete, so I wrote a quick-and-dirty function to measure the bytes used by the proposed TID store and the vacuum's current array. Using bitmaps really shines with a high number of offsets per block, e.g. with about a million sequential blocks, and 49 offsets per block (last parameter is a bound): select * from tidstore_memory(0,1*1001*1000, 1,50); array_mem | ts_mem -----------+---------- 294294000 | 42008576 The break-even point with this scenario is around 7 offsets per block: select * from tidstore_memory(0,1*1001*1000, 1,8); array_mem | ts_mem -----------+---------- 42042000 | 42008576 Below that, the array gets smaller, but the bitmap just has more empty space. Here, 8 million bytes are used by the chunk header in bitmap allocations, so the bump context would help there (I haven't actually tried). Of course, the best allocation is no allocation at all, and I have a draft patch to store up to 3 offsets in the last-level node's pointer array, so for 2 or 3 offsets per block we're smaller than the array again: select * from tidstore_memory(0,1*1001*1000, 1,4); array_mem | ts_mem -----------+--------- 18018000 | 8462336 Sequential blocks are not the worst case scenario for memory use, but this gives an idea of what's involved. So, with aset, on average I still expect to use quite a bit less memory, with some corner cases that use more. The bump context would be some extra insurance to reduce those corner cases, where there are a large number of blocks in play.
On 3/12/24 00:40, David Rowley wrote: > On Tue, 12 Mar 2024 at 12:25, Tomas Vondra > <tomas.vondra@enterprisedb.com> wrote: >> (b) slab is considerably slower > > It would be interesting to modify SlabReset() to, instead of free()ing > the blocks, push the first SLAB_MAXIMUM_EMPTY_BLOCKS of them onto the > emptyblocks list. > > That might give us an idea of how much overhead comes from malloc/free. > > Having something like this as an option when creating a context might > be a good idea. generation.c now keeps 1 "freeblock" which currently > does not persist during context resets. Some memory context usages > might suit having an option like this. Maybe something like the > executor's per-tuple context, which perhaps (c|sh)ould be a generation > context... However, saying that, I see you measure it to be slightly > slower than aset. > IIUC you're suggesting maybe it's a problem we free the blocks during context reset, only to allocate them again shortly after, paying the malloc overhead. This reminded the mempool idea I recently shared in the nearby "scalability bottlenecks" thread [1]. So I decided to give this a try and see how it affects this benchmark. Attached is an updated version of the mempool patch, modifying all the memory contexts (not just AllocSet), including the bump context. And then also PDF with results from the two machines, comparing results without and with the mempool. There's very little impact on small reset values (128kB, 1MB), but pretty massive improvements on the 8MB test (where it's a 2x improvement). Nevertheless, it does not affect the relative performance very much. The bump context is still the fastest, but the gap is much smaller. Considering the mempool serves as a cache in between memory contexts and glibc, eliminating most of the malloc/free calls, and essentially keeping the blocks allocated, I doubt slab is slow because of malloc overhead - at least in the "small" tests (but I haven't looked closer). regards [1] https://www.postgresql.org/message-id/510b887e-c0ce-4a0c-a17a-2c6abb8d9a5c%40enterprisedb.com -- Tomas Vondra EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
Attachment
On Tue, 12 Mar 2024 at 23:57, Tomas Vondra <tomas.vondra@enterprisedb.com> wrote: > Attached is an updated version of the mempool patch, modifying all the > memory contexts (not just AllocSet), including the bump context. And > then also PDF with results from the two machines, comparing results > without and with the mempool. There's very little impact on small reset > values (128kB, 1MB), but pretty massive improvements on the 8MB test > (where it's a 2x improvement). I think it would be good to have something like this. I've done some experiments before with something like this [1]. However, mine was much more trivial. One thing my version did was get rid of the *context* freelist stuff in aset. I wondered if we'd need that anymore as, if I understand correctly, it's just there to stop malloc/free thrashing, which is what the patch aims to do anyway. Aside from that, it's now a little weird that aset.c has that but generation.c and slab.c do not. One thing I found was that in btbeginscan(), we have "so = (BTScanOpaque) palloc(sizeof(BTScanOpaqueData));", which on this machine is 27344 bytes and results in a call to AllocSetAllocLarge() and therefore a malloc(). Ideally, there'd be no malloc() calls in a standard pgbench run, at least once the rel and cat caches have been warmed up. I think there are a few things in your patch that could be improved, here's a quick review. 1. MemoryPoolEntryIndex() could follow the lead of AllocSetFreeIndex(), which is quite well-tuned and has no looping. I think you can get rid of MemoryPoolEntrySize() and just have MemoryPoolEntryIndex() round up to the next power of 2. 2. The following could use "result = Min(MEMPOOL_MIN_BLOCK, pg_nextpower2_size_t(size));" + * should be very low, though (less than MEMPOOL_SIZES, i.e. 14). + */ + result = MEMPOOL_MIN_BLOCK; + while (size > result) + result *= 2; 3. "MemoryPoolFree": I wonder if this is a good name for such a function. Really you want to return it to the pool. "Free" sounds like you're going to free() it. I went for "Fetch" and "Release" which I thought was less confusing. 4. MemoryPoolRealloc(), could this just do nothing if the old and new indexes are the same? 5. It might be good to put a likely() around this: + /* only do this once every MEMPOOL_REBALANCE_DISTANCE allocations */ + if (pool->num_requests < MEMPOOL_REBALANCE_DISTANCE) + return; Otherwise, if that function is inlined then you'll bloat the functions that inline it for not much good reason. Another approach would be to have a static inline function which checks and calls a noinline function that does the work so that the rebalance stuff is never inlined. Overall, I wonder if the rebalance stuff might make performance testing quite tricky. I see: +/* + * How often to rebalance the memory pool buckets (number of allocations). + * This is a tradeoff between the pool being adaptive and more overhead. + */ +#define MEMPOOL_REBALANCE_DISTANCE 25000 Will TPS take a sudden jump after 25k transactions doing the same thing? I'm not saying this shouldn't happen, but... benchmarking is pretty hard already. I wonder if there's something more fine-grained that can be done which makes the pool adapt faster but not all at once. (I've not studied your algorithm for the rebalance.) David [1] https://github.com/david-rowley/postgres/tree/malloccache
On 3/15/24 03:21, David Rowley wrote: > On Tue, 12 Mar 2024 at 23:57, Tomas Vondra > <tomas.vondra@enterprisedb.com> wrote: >> Attached is an updated version of the mempool patch, modifying all the >> memory contexts (not just AllocSet), including the bump context. And >> then also PDF with results from the two machines, comparing results >> without and with the mempool. There's very little impact on small reset >> values (128kB, 1MB), but pretty massive improvements on the 8MB test >> (where it's a 2x improvement). > > I think it would be good to have something like this. I've done some > experiments before with something like this [1]. However, mine was > much more trivial. > Interesting. My thing is a bit more complex because it was not meant to be a cache initially, but more a way to limit the memory allocated by a backend (discussed in [1]), or perhaps even a smaller part of a plan. I only added the caching after I ran into some bottlenecks [2], and malloc turned out to be a scalability issue. > One thing my version did was get rid of the *context* freelist stuff > in aset. I wondered if we'd need that anymore as, if I understand > correctly, it's just there to stop malloc/free thrashing, which is > what the patch aims to do anyway. Aside from that, it's now a little > weird that aset.c has that but generation.c and slab.c do not. > True. I think the "memory pool" shared by all memory contexts would be a more principled way to do this - not only it works for all memory context types, but it's also part of the "regular" cache eviction like everything else (which the context freelist is not). > One thing I found was that in btbeginscan(), we have "so = > (BTScanOpaque) palloc(sizeof(BTScanOpaqueData));", which on this > machine is 27344 bytes and results in a call to AllocSetAllocLarge() > and therefore a malloc(). Ideally, there'd be no malloc() calls in a > standard pgbench run, at least once the rel and cat caches have been > warmed up. > Right. That's exactly what I found in [2], where it's a massive problem with many partitions and many concurrent connections. > I think there are a few things in your patch that could be improved, > here's a quick review. > > 1. MemoryPoolEntryIndex() could follow the lead of > AllocSetFreeIndex(), which is quite well-tuned and has no looping. I > think you can get rid of MemoryPoolEntrySize() and just have > MemoryPoolEntryIndex() round up to the next power of 2. > > 2. The following could use "result = Min(MEMPOOL_MIN_BLOCK, > pg_nextpower2_size_t(size));" > > + * should be very low, though (less than MEMPOOL_SIZES, i.e. 14). > + */ > + result = MEMPOOL_MIN_BLOCK; > + while (size > result) > + result *= 2; > > 3. "MemoryPoolFree": I wonder if this is a good name for such a > function. Really you want to return it to the pool. "Free" sounds > like you're going to free() it. I went for "Fetch" and "Release" > which I thought was less confusing. > > 4. MemoryPoolRealloc(), could this just do nothing if the old and new > indexes are the same? > > 5. It might be good to put a likely() around this: > > + /* only do this once every MEMPOOL_REBALANCE_DISTANCE allocations */ > + if (pool->num_requests < MEMPOOL_REBALANCE_DISTANCE) > + return; > > Otherwise, if that function is inlined then you'll bloat the functions > that inline it for not much good reason. Another approach would be to > have a static inline function which checks and calls a noinline > function that does the work so that the rebalance stuff is never > inlined. > Yes, I agree with all of that. I was a bit lazy when doing the PoC, so I ignored these things. > Overall, I wonder if the rebalance stuff might make performance > testing quite tricky. I see: > > +/* > + * How often to rebalance the memory pool buckets (number of allocations). > + * This is a tradeoff between the pool being adaptive and more overhead. > + */ > +#define MEMPOOL_REBALANCE_DISTANCE 25000 > > Will TPS take a sudden jump after 25k transactions doing the same > thing? I'm not saying this shouldn't happen, but... benchmarking is > pretty hard already. I wonder if there's something more fine-grained > that can be done which makes the pool adapt faster but not all at > once. (I've not studied your algorithm for the rebalance.) > I don't think so, or at least I haven't observed anything like that. My intent was to make the rebalancing fairly frequent but incremental, with each increment doing only a tiny amount of work. It does not do any more malloc/free calls than without the cache - it may just delay them a bit, and the assumption is the rest of the rebalancing (walking the size slots and adjusting counters based on activity since the last run) is super cheap. So it shouldn't be the case that the rebalancing is so expensive to cause a measurable drop in throughput, or something like that. I can imagine spreading it even more (doing it in smaller steps), but on the other hand the interval must not be too short - we need to do enough allocations to provide good "heuristics" how to adjust the cache. BTW it's not directly tied to transactions - it's triggered by block allocations, and each transaction likely needs many of those. regards [1] https://www.postgresql.org/message-id/bd57d9a4c219cc1392665fd5fba61dde8027b3da.camel%40crunchydata.com [2] https://www.postgresql.org/message-id/510b887e-c0ce-4a0c-a17a-2c6abb8d9a5c@enterprisedb.com -- Tomas Vondra EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On Tue, 5 Mar 2024 at 15:42, David Rowley <dgrowleyml@gmail.com> wrote:
> The query I ran was:
>
> select chksz,mtype,pg_allocate_memory_test_reset(chksz,
> 1024*1024,1024*1024*1024, mtype) from (values(8),(16),(32),(64))
> sizes(chksz),(values('aset'),('generation'),('slab'),('bump'))
> cxt(mtype) order by mtype,chksz;
Andres and I were discussing this patch offlist in the context of
"should we have bump". Andres wonders if it would be better to have a
function such as palloc_nofree() (we didn't actually discuss the
name), which for aset, would forego rounding up to the next power of 2
and not bother checking the freelist and only have a chunk header for
MEMORY_CONTEXT_CHECKING builds. For non-MEMORY_CONTEXT_CHECKING
builds, the chunk header could be set to some other context type such
as one of the unused ones or perhaps a dedicated new one that does
something along the lines of BogusFree() which raises an ERROR if
anything tries to pfree or repalloc it.
An advantage of having this instead of bump would be that it could be
used for things such as the parser, where we make a possibly large
series of small allocations and never free them again.
Andres ask me to run some benchmarks to mock up AllocSetAlloc() to
have it not check the freelist to see how the performance of it
compares to BumpAlloc(). I did this in the attached 2 patches. The
0001 patch just #ifdefs that part of AllocSetAlloc out, however
properly implementing this is more complex as aset.c currently stores
the freelist index in the MemoryChunk rather than the chunk_size. I
did this because it saved having to call AllocSetFreeIndex() in
AllocSetFree() which made a meaningful performance improvement in
pfree(). The 0002 patch effectively reverses that change out so that
the chunk_size is stored. Again, these patches are only intended to
demonstrate the performance and check how it compares to bump.
I'm yet uncertain why, but I find that the first time I run the query
quoted above, the aset results are quite a bit slower than on
subsequent runs. Other context types don't seem to suffer from this.
The previous results I sent in [1] were of the initial run after
starting up the database.
The attached graph shows the number of seconds it takes to allocate a
total of 1GBs of memory in various chunk sizes, resetting the context
after 1MBs has been allocated, so as to keep the test sized so it fits
in CPU caches.
I'm not drawing any particular conclusion from the results aside from
it's not quite as fast as bump. I also have some reservations about
how easy it would be to actually use something like palloc_nofree().
For example heap_form_minimal_tuple() does palloc0(). What if I
wanted to call ExecCopySlotMinimalTuple() and use palloc0_nofree().
Would we need new versions of various functions to give us control
over this?
David
[1] https://www.postgresql.org/message-id/CAApHDvr_hGT=kaP0YXbKSNZtbRX+6hUkieCWEn2BULwW1uTr_Q@mail.gmail.com
Attachment
{kind=link}
On 3/25/24 12:41, David Rowley wrote:
> On Tue, 5 Mar 2024 at 15:42, David Rowley <dgrowleyml@gmail.com> wrote:
>> The query I ran was:
>>
>> select chksz,mtype,pg_allocate_memory_test_reset(chksz,
>> 1024*1024,1024*1024*1024, mtype) from (values(8),(16),(32),(64))
>> sizes(chksz),(values('aset'),('generation'),('slab'),('bump'))
>> cxt(mtype) order by mtype,chksz;
>
> Andres and I were discussing this patch offlist in the context of
> "should we have bump". Andres wonders if it would be better to have a
> function such as palloc_nofree() (we didn't actually discuss the
> name), which for aset, would forego rounding up to the next power of 2
> and not bother checking the freelist and only have a chunk header for
> MEMORY_CONTEXT_CHECKING builds. For non-MEMORY_CONTEXT_CHECKING
> builds, the chunk header could be set to some other context type such
> as one of the unused ones or perhaps a dedicated new one that does
> something along the lines of BogusFree() which raises an ERROR if
> anything tries to pfree or repalloc it.
>
> An advantage of having this instead of bump would be that it could be
> used for things such as the parser, where we make a possibly large
> series of small allocations and never free them again.
>
I may be missing something, but I don't quite understand how this would
be simpler to use in places like parser. Wouldn't it require all the
places to start explicitly calling palloc_nofree()? How is that better
than having a specialized memory context?
> Andres ask me to run some benchmarks to mock up AllocSetAlloc() to
> have it not check the freelist to see how the performance of it
> compares to BumpAlloc(). I did this in the attached 2 patches. The
> 0001 patch just #ifdefs that part of AllocSetAlloc out, however
> properly implementing this is more complex as aset.c currently stores
> the freelist index in the MemoryChunk rather than the chunk_size. I
> did this because it saved having to call AllocSetFreeIndex() in
> AllocSetFree() which made a meaningful performance improvement in
> pfree(). The 0002 patch effectively reverses that change out so that
> the chunk_size is stored. Again, these patches are only intended to
> demonstrate the performance and check how it compares to bump.
>
> I'm yet uncertain why, but I find that the first time I run the query
> quoted above, the aset results are quite a bit slower than on
> subsequent runs. Other context types don't seem to suffer from this.
> The previous results I sent in [1] were of the initial run after
> starting up the database.
>
> The attached graph shows the number of seconds it takes to allocate a
> total of 1GBs of memory in various chunk sizes, resetting the context
> after 1MBs has been allocated, so as to keep the test sized so it fits
> in CPU caches.
>
Yeah, strange and interesting. My guess is it's some sort of caching
effect, where the first run has to initialize stuff that's not in any of
the CPU caches yet, likely something specific to AllocSet (freelist?).
Or maybe memory prefetching does not work that well for AllocSet?
I'd try perf-stat, that might tell us more ... but who knows.
Alternatively, it might be some interaction with the glibc allocator.
Have you tried using jemalloc using LD_PRELOAD, or tweaking the glibc
parameters using environment variables? If you feel adventurous, you
might even try the memory pool stuff, although I'm not sure that can
help with the first run.
> I'm not drawing any particular conclusion from the results aside from
> it's not quite as fast as bump. I also have some reservations about
> how easy it would be to actually use something like palloc_nofree().
> For example heap_form_minimal_tuple() does palloc0(). What if I
> wanted to call ExecCopySlotMinimalTuple() and use palloc0_nofree().
> Would we need new versions of various functions to give us control
> over this?
>
That's kinda the problem that I mentioned above - is this really any
simpler/better than just having a separate memory context type? I don't
see what benefits this is supposed to have.
IMHO the idea of having a general purpose memory context and then also
specialized memory contexts for particular allocation patterns is great,
and we should embrace it. Adding more and more special cases into
AllocSet seems to go directly against that idea, makes the code more
complex, and I don't quite see how is that better or easier to use than
having a separate BumpContext ...
Having an AllocSet that mixes chunks that may be freed and chunks that
can't be freed, and have a different context type in the chunk header,
seems somewhat confusing and "not great" for debugging, for example.
regards
--
Tomas Vondra
EnterpriseDB: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
Tomas Vondra <tomas.vondra@enterprisedb.com> writes:
> IMHO the idea of having a general purpose memory context and then also
> specialized memory contexts for particular allocation patterns is great,
> and we should embrace it. Adding more and more special cases into
> AllocSet seems to go directly against that idea, makes the code more
> complex, and I don't quite see how is that better or easier to use than
> having a separate BumpContext ...
I agree with this completely. However, the current design for chunk
headers is mighty restrictive about how many kinds of contexts we can
have. We need to open that back up.
Could we move the knowledge of exactly which context type it is out
of the per-chunk header and keep it in the block header? This'd
require that every context type have a standardized way of finding
the block header from a chunk. We could repurpose the existing
MemoryContextMethodID bits to allow having a small number of different
ways, perhaps.
regards, tom lane
On Tue, 26 Mar 2024 at 03:53, Tom Lane <tgl@sss.pgh.pa.us> wrote: > I agree with this completely. However, the current design for chunk > headers is mighty restrictive about how many kinds of contexts we can > have. We need to open that back up. Andres mentioned how we could do this in [1]. One possible issue with that is that slab.c has no external chunks so would restrict slab to 512MB chunks. I doubt that's ever going to realistically be an issue. That's just not a good use case for slab, so I'd be ok with that. > Could we move the knowledge of exactly which context type it is out > of the per-chunk header and keep it in the block header? This'd > require that every context type have a standardized way of finding > the block header from a chunk. We could repurpose the existing > MemoryContextMethodID bits to allow having a small number of different > ways, perhaps. I wasn't 100% clear on your opinion about using 010 vs expanding the bit-space. Based on the following it sounded like you were not outright rejecting the idea of consuming the 010 pattern. On Sat, 17 Feb 2024 at 12:14, Tom Lane <tgl@sss.pgh.pa.us> wrote: > If we do kick this can down the road, then I concur with eating 010 > next, as it seems the least likely to occur in glibc-malloced > chunks. David [1] https://postgr.es/m/20240217200845.ywlwenjrlbyoc73v@awork3.anarazel.de
David Rowley <dgrowleyml@gmail.com> writes:
> On Tue, 26 Mar 2024 at 03:53, Tom Lane <tgl@sss.pgh.pa.us> wrote:
>> Could we move the knowledge of exactly which context type it is out
>> of the per-chunk header and keep it in the block header?
> I wasn't 100% clear on your opinion about using 010 vs expanding the
> bit-space. Based on the following it sounded like you were not
> outright rejecting the idea of consuming the 010 pattern.
What I said earlier was that 010 was the least bad choice if we
fail to do any expansibility work; but I'm not happy with failing
to do that.
Basically, I'm not happy with consuming the last reasonably-available
pattern for a memory context type that has little claim to being the
Last Context Type We Will Ever Want. Rather than making a further
dent in our ability to detect corrupted chunks, we should do something
towards restoring the expansibility that existed in the original
design. Then we can add bump contexts and whatever else we want.
regards, tom lane
On Mon, 25 Mar 2024 at 22:44, Tom Lane <tgl@sss.pgh.pa.us> wrote: > > David Rowley <dgrowleyml@gmail.com> writes: > > On Tue, 26 Mar 2024 at 03:53, Tom Lane <tgl@sss.pgh.pa.us> wrote: > >> Could we move the knowledge of exactly which context type it is out > >> of the per-chunk header and keep it in the block header? > > > I wasn't 100% clear on your opinion about using 010 vs expanding the > > bit-space. Based on the following it sounded like you were not > > outright rejecting the idea of consuming the 010 pattern. > > What I said earlier was that 010 was the least bad choice if we > fail to do any expansibility work; but I'm not happy with failing > to do that. Okay. > Basically, I'm not happy with consuming the last reasonably-available > pattern for a memory context type that has little claim to being the > Last Context Type We Will Ever Want. Rather than making a further > dent in our ability to detect corrupted chunks, we should do something > towards restoring the expansibility that existed in the original > design. Then we can add bump contexts and whatever else we want. So, would something like the attached make enough IDs available so that we can add the bump context anyway? It extends memory context IDs to 5 bits (32 values), of which - 8 have glibc's malloc pattern of 001/010; - 1 is unused memory's 00000 - 1 is wipe_mem's 11111 - 4 are used by existing contexts (Aset/Generation/Slab/AlignedRedirect) - 18 are newly available. Kind regards, Matthias
Attachment
Matthias van de Meent <boekewurm+postgres@gmail.com> writes:
> On Mon, 25 Mar 2024 at 22:44, Tom Lane <tgl@sss.pgh.pa.us> wrote:
>> Basically, I'm not happy with consuming the last reasonably-available
>> pattern for a memory context type that has little claim to being the
>> Last Context Type We Will Ever Want. Rather than making a further
>> dent in our ability to detect corrupted chunks, we should do something
>> towards restoring the expansibility that existed in the original
>> design. Then we can add bump contexts and whatever else we want.
> So, would something like the attached make enough IDs available so
> that we can add the bump context anyway?
> It extends memory context IDs to 5 bits (32 values), of which
> - 8 have glibc's malloc pattern of 001/010;
> - 1 is unused memory's 00000
> - 1 is wipe_mem's 11111
> - 4 are used by existing contexts (Aset/Generation/Slab/AlignedRedirect)
> - 18 are newly available.
This seems like it would solve the problem for a good long time
to come; and if we ever need more IDs, we could steal one more bit
by requiring the offset to the block header to be a multiple of 8.
(Really, we could just about do that today at little or no cost ...
machines with MAXALIGN less than 8 are very thin on the ground.)
The only objection I can think of is that perhaps this would slow
things down a tad by requiring more complicated shifting/masking.
I wonder if we could redo the performance checks that were done
on the way to accepting the current design.
regards, tom lane
On Thu, 4 Apr 2024 at 22:43, Tom Lane <tgl@sss.pgh.pa.us> wrote: > > Matthias van de Meent <boekewurm+postgres@gmail.com> writes: > > On Mon, 25 Mar 2024 at 22:44, Tom Lane <tgl@sss.pgh.pa.us> wrote: > >> Basically, I'm not happy with consuming the last reasonably-available > >> pattern for a memory context type that has little claim to being the > >> Last Context Type We Will Ever Want. Rather than making a further > >> dent in our ability to detect corrupted chunks, we should do something > >> towards restoring the expansibility that existed in the original > >> design. Then we can add bump contexts and whatever else we want. > > > So, would something like the attached make enough IDs available so > > that we can add the bump context anyway? > > > It extends memory context IDs to 5 bits (32 values), of which > > - 8 have glibc's malloc pattern of 001/010; > > - 1 is unused memory's 00000 > > - 1 is wipe_mem's 11111 > > - 4 are used by existing contexts (Aset/Generation/Slab/AlignedRedirect) > > - 18 are newly available. > > This seems like it would solve the problem for a good long time > to come; and if we ever need more IDs, we could steal one more bit > by requiring the offset to the block header to be a multiple of 8. > (Really, we could just about do that today at little or no cost ... > machines with MAXALIGN less than 8 are very thin on the ground.) Hmm, it seems like a decent idea, but I didn't want to deal with the repercussions of that this late in the cycle when these 2 bits were still relatively easy to get hold of. > The only objection I can think of is that perhaps this would slow > things down a tad by requiring more complicated shifting/masking. > I wonder if we could redo the performance checks that were done > on the way to accepting the current design. I didn't do very extensive testing, but the light performance tests that I did with the palloc performance benchmark patch & script shared above indicate didn't measure an observable negative effect. An adapted version of the test that uses repalloc() to check performance differences in MCXT_METHOD() doesn't show a significant performance difference from master either. That test case is attached as repalloc-performance-test-function.patch.txt. The full set of patches would then accumulate to the attached v5 of the patchset. 0001 is an update of my patch from yesterday, in which I update MemoryContextMethodID infrastructure for more IDs, and use a new naming scheme for unused/reserved IDs. 0002 and 0003 are David's patches, with minor changes to work with 0001 (rebasing, and I moved the location around to keep function declaration in order with memctx ids) Kind regards, Matthias van de Meent
Attachment
{kind=link}
Matthias van de Meent <boekewurm+postgres@gmail.com> writes:
> On Thu, 4 Apr 2024 at 22:43, Tom Lane <tgl@sss.pgh.pa.us> wrote:
>> The only objection I can think of is that perhaps this would slow
>> things down a tad by requiring more complicated shifting/masking.
>> I wonder if we could redo the performance checks that were done
>> on the way to accepting the current design.
> I didn't do very extensive testing, but the light performance tests
> that I did with the palloc performance benchmark patch & script shared
> above indicate didn't measure an observable negative effect.
OK. I did not read the patch very closely, but at least in principle
I have no further objections. David, are you planning to take point
on getting this in?
regards, tom lane
On Sat, 6 Apr 2024 at 03:24, Tom Lane <tgl@sss.pgh.pa.us> wrote: > OK. I did not read the patch very closely, but at least in principle > I have no further objections. David, are you planning to take point > on getting this in? Yes. I'll be looking soon. David
On Sat, 6 Apr 2024 at 02:30, Matthias van de Meent
<boekewurm+postgres@gmail.com> wrote:
>
> On Thu, 4 Apr 2024 at 22:43, Tom Lane <tgl@sss.pgh.pa.us> wrote:
> >
> > Matthias van de Meent <boekewurm+postgres@gmail.com> writes:
> > > It extends memory context IDs to 5 bits (32 values), of which
> > > - 8 have glibc's malloc pattern of 001/010;
> > > - 1 is unused memory's 00000
> > > - 1 is wipe_mem's 11111
> > > - 4 are used by existing contexts (Aset/Generation/Slab/AlignedRedirect)
> > > - 18 are newly available.
> >
> > This seems like it would solve the problem for a good long time
> > to come; and if we ever need more IDs, we could steal one more bit
> > by requiring the offset to the block header to be a multiple of 8.
> > (Really, we could just about do that today at little or no cost ...
> > machines with MAXALIGN less than 8 are very thin on the ground.)
>
> Hmm, it seems like a decent idea, but I didn't want to deal with the
> repercussions of that this late in the cycle when these 2 bits were
> still relatively easy to get hold of.
Thanks for writing the patch.
I think 5 bits is 1 too many. 4 seems fine. I also think you've
reserved too many slots in your patch as I disagree that we need to
reserve the glibc malloc pattern anywhere but in the 1 and 2 slots of
the mcxt_methods[] array. I looked again at the 8 bytes prior to a
glibc malloc'd chunk and I see the lowest 4 bits of the headers
consistently set to 0001 for all powers of 2 starting at 8 up to
65536. 131072 seems to vary and beyond that, they seem to be set to
0010.
With that, there's no increase in the number of reserved slots from
what we have reserved today. Still 4. So having 4 bits instead of 3
bits gives us a total of 12 slots rather than 4 slots. Having 3x
slots seems enough. We might need an extra bit for something else
sometime. I think keeping it up our sleeve is a good idea.
Another reason not to make it 5 bits is that I believe that would make
the mcxt_methods[] array 2304 bytes rather than 576 bytes. 4 bits
makes it 1152 bytes, if I'm counting correctly.
I revised the patch to simplify hdrmask logic. This started with me
having trouble finding the best set of words to document that the
offset is "half the bytes between the chunk and block". So, instead
of doing that, I've just made it so these two fields effectively
overlap. The lowest bit of the block offset is the same bit as the
high bit of what MemoryChunkGetValue returns. I've just added an
Assert to MemoryChunkSetHdrMask to ensure that the low bit is never
set in the offset. Effectively, using this method, there's no new *C*
code to split the values out. However, the compiler will emit one
additional bitwise-AND to implement the following, which I'll express
using fragments from the 0001 patch:
#define MEMORYCHUNK_MAX_BLOCKOFFSET UINT64CONST(0x3FFFFFFF)
+#define MEMORYCHUNK_BLOCKOFFSET_MASK UINT64CONST(0x3FFFFFFE)
#define HdrMaskBlockOffset(hdrmask) \
- (((hdrmask) >> MEMORYCHUNK_BLOCKOFFSET_BASEBIT) & MEMORYCHUNK_MAX_BLOCKOFFSET)
+ (((hdrmask) >> MEMORYCHUNK_BLOCKOFFSET_BASEBIT) &
MEMORYCHUNK_BLOCKOFFSET_MASK)
Previously most compilers would have optimised the bitwise-AND away as
it was effectively similar to doing something like (0xFFFFFFFF >> 16)
& 0xFFFF. The compiler should know that no bits can be masked out by
the bitwise-AND due to the left shift zeroing them all. If you swap
0xFFFF for 0xFFFE then that's no longer true.
I also updated src/backend/utils/mmgr/README to explain this and
adjust the mentions of 3-bits and 61-bits to 4-bits and 60-bits. I
also explained the overlapping part.
I spent quite a bit of time benchmarking this. There is a small
performance regression from widening to 4 bits, but it's not huge.
Please see the 3 attached graphs. All times in the graph are the
average of the time taken for each test over 9 runs.
bump_palloc_reset.png: Shows the results from:
select stype,chksz,avg(pg_allocate_memory_test_reset(chksz,1024*1024,10::bigint*1024*1024*1024,stype))
from (values(8),(16),(32),(64),(128)) t1(chksz)
cross join (values('bump')) t2(stype)
cross join generate_series(1,3) r(run)
group by stype,chksz
order by stype,chksz;
There's no performance regression here. Bump does not have headers so
no extra bits are used anywhere.
aset_palloc_pfree.png: Shows the results from:
select stype,chksz,avg(pg_allocate_memory_test(chksz,1024*1024,10::bigint*1024*1024*1024,stype))
from (values(8),(16),(32),(64),(128)) t1(chksz)
cross join (values('aset')) t2(stype)
cross join generate_series(1,3) r(run)
group by stype,chksz
order by stype,chksz;
This exercises palloc and pfree. Effectively it's allocating 10GB of
memory but starting to pfree before each new palloc after we get to
1MB of concurrent allocations. Because this test calls pfree, we need
to look at the chunk header and into the mcxt_methods[] array. It's
important to test this part.
The graph shows a small performance regression of about 1-2%.
generation_palloc_pfree.png: Same as aset_palloc_pfree.png but for the
generation context. The regression here is slightly more than aset.
Seems to be about 2-3.5%. I don't think this is too surprising as
there's more room for instruction-level parallelism in AllocSetFree()
when calling MemoryChunkGetBlock() than there is in GenerationFree().
In GenerationFree() we get the block and then immediately do
"block->nfree += 1;", whereas in AllocSetFree() we also call
MemoryChunkGetValue().
I've attached an updated set of patches, plus graphs, plus entire
benchmark results as a .txt file.
Note the v6-0003 patch is just v4-0002 renamed so the CFbot applies in
the correct order.
I'm planning on pushing these, pending a final look at 0002 and 0003
on Sunday morning NZ time (UTC+12), likely in about 10 hours time.
David
Attachment
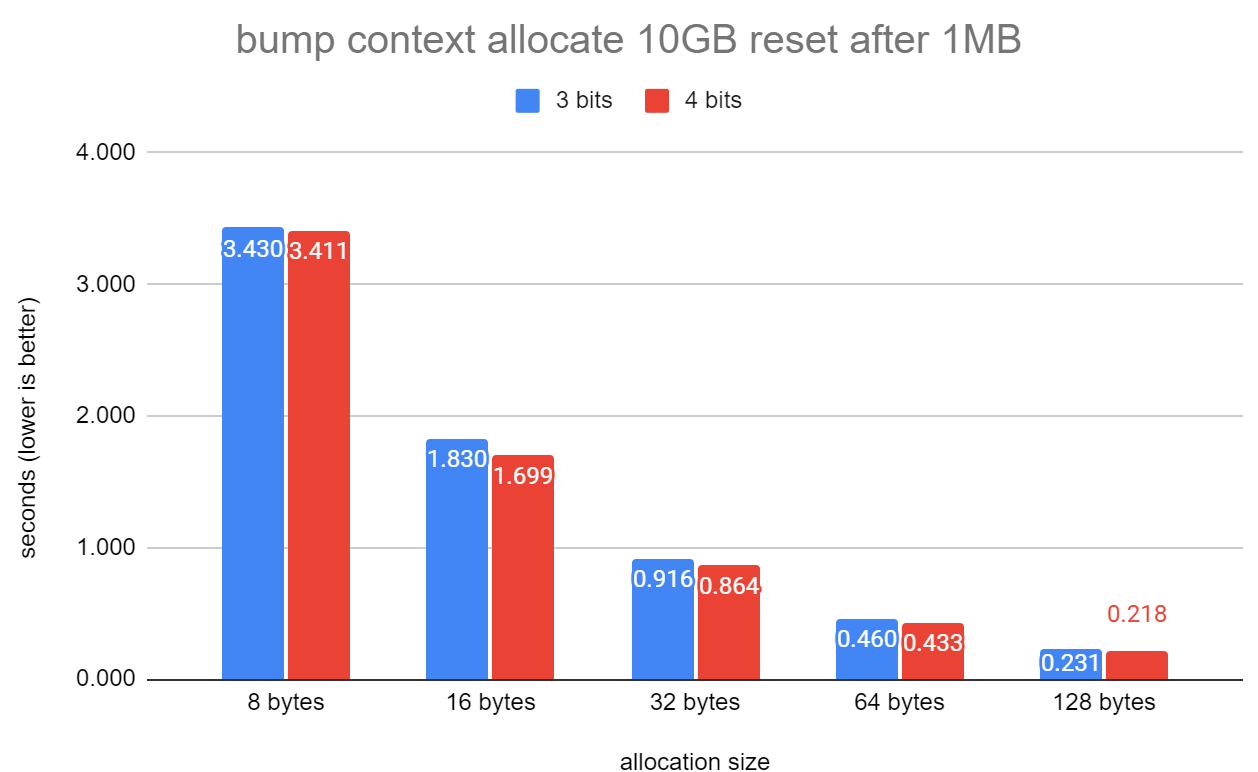{kind=link}
{kind=link}
{kind=link}
On Sat, 6 Apr 2024, 14:36 David Rowley, <dgrowleyml@gmail.com> wrote:
On Sat, 6 Apr 2024 at 02:30, Matthias van de Meent
<boekewurm+postgres@gmail.com> wrote:
>
> On Thu, 4 Apr 2024 at 22:43, Tom Lane <tgl@sss.pgh.pa.us> wrote:
> >
> > Matthias van de Meent <boekewurm+postgres@gmail.com> writes:
> > > It extends memory context IDs to 5 bits (32 values), of which
> > > - 8 have glibc's malloc pattern of 001/010;
> > > - 1 is unused memory's 00000
> > > - 1 is wipe_mem's 11111
> > > - 4 are used by existing contexts (Aset/Generation/Slab/AlignedRedirect)
> > > - 18 are newly available.
> >
> > This seems like it would solve the problem for a good long time
> > to come; and if we ever need more IDs, we could steal one more bit
> > by requiring the offset to the block header to be a multiple of 8.
> > (Really, we could just about do that today at little or no cost ...
> > machines with MAXALIGN less than 8 are very thin on the ground.)
>
> Hmm, it seems like a decent idea, but I didn't want to deal with the
> repercussions of that this late in the cycle when these 2 bits were
> still relatively easy to get hold of.
Thanks for writing the patch.
I think 5 bits is 1 too many. 4 seems fine. I also think you've
reserved too many slots in your patch as I disagree that we need to
reserve the glibc malloc pattern anywhere but in the 1 and 2 slots of
the mcxt_methods[] array. I looked again at the 8 bytes prior to a
glibc malloc'd chunk and I see the lowest 4 bits of the headers
consistently set to 0001 for all powers of 2 starting at 8 up to
65536.
Malloc's docs specify the minimum chunk size at 4*sizeof(void*) and itself uses , so using powers of 2 for chunks would indeed fail to detect 1s in the 4th bit. I suspect you'll get different results when you check the allocation patterns of multiples of 8 bytes, starting from 40, especially on 32-bit arm (where MALLOC_ALIGNMENT is 8 bytes, rather than the 16 bytes on i386 and 64-bit architectures, assuming [0] is accurate)
131072 seems to vary and beyond that, they seem to be set to
0010.
In your updated 0001, you don't seem to fill the RESERVED_GLIBC memctx array entries with BOGUS_MCTX().
With that, there's no increase in the number of reserved slots from
what we have reserved today. Still 4. So having 4 bits instead of 3
bits gives us a total of 12 slots rather than 4 slots. Having 3x
slots seems enough. We might need an extra bit for something else
sometime. I think keeping it up our sleeve is a good idea.
Another reason not to make it 5 bits is that I believe that would make
the mcxt_methods[] array 2304 bytes rather than 576 bytes. 4 bits
makes it 1152 bytes, if I'm counting correctly.
I don't think I understand why this would be relevant when only 5 of the contexts are actually in use (thus in caches). Is that size concern about TLB entries then?
I revised the patch to simplify hdrmask logic. This started with me
having trouble finding the best set of words to document that the
offset is "half the bytes between the chunk and block". So, instead
of doing that, I've just made it so these two fields effectively
overlap. The lowest bit of the block offset is the same bit as the
high bit of what MemoryChunkGetValue returns.
Works for me, I suppose.
I also updated src/backend/utils/mmgr/README to explain this and
adjust the mentions of 3-bits and 61-bits to 4-bits and 60-bits. I
also explained the overlapping part.
Thanks!
On Sun, 7 Apr 2024 at 05:45, Matthias van de Meent <boekewurm+postgres@gmail.com> wrote: > Malloc's docs specify the minimum chunk size at 4*sizeof(void*) and itself uses , so using powers of 2 for chunks wouldindeed fail to detect 1s in the 4th bit. I suspect you'll get different results when you check the allocation patternsof multiples of 8 bytes, starting from 40, especially on 32-bit arm (where MALLOC_ALIGNMENT is 8 bytes, rather thanthe 16 bytes on i386 and 64-bit architectures, assuming [0] is accurate) I'm prepared to be overruled, but I just don't have strong feelings that 32-bit is worth making these reservations for. Especially so given the rate we're filling these slots. The only system that I see the 4th bit change is Cygwin. It doesn't look like a very easy system to protect against pfreeing of malloc'd chunks as the prior 8-bytes seem to vary depending on the malloc'd size and I see all bit patterns there, including the ones we use for our memory contexts. Since we can't protect against every possible bit pattern there, we need to draw the line somewhere. I don't think 32-bit systems are worth reserving these precious slots for. I'd hazard a guess that there are more instances of Postgres running on Windows today than on 32-bit CPUs and we don't seem too worried about the bit-patterns used for Windows. > In your updated 0001, you don't seem to fill the RESERVED_GLIBC memctx array entries with BOGUS_MCTX(). Oops. Thanks >> Another reason not to make it 5 bits is that I believe that would make >> the mcxt_methods[] array 2304 bytes rather than 576 bytes. 4 bits >> makes it 1152 bytes, if I'm counting correctly. > > > I don't think I understand why this would be relevant when only 5 of the contexts are actually in use (thus in caches).Is that size concern about TLB entries then? It's a static const array. I don't want to bloat the binary with something we'll likely never need. If we one day need it, we can reserve another bit using the same overlapping method. >> I revised the patch to simplify hdrmask logic. This started with me >> having trouble finding the best set of words to document that the >> offset is "half the bytes between the chunk and block". So, instead >> of doing that, I've just made it so these two fields effectively >> overlap. The lowest bit of the block offset is the same bit as the >> high bit of what MemoryChunkGetValue returns. > > > Works for me, I suppose. hmm. I don't detect much enthusiasm for it. Personally, I quite like the method as it adds no extra instructions when encoding the MemoryChunk and only a simple bitwise-AND when decoding it. Your method added extra instructions in the encode and decode. I went to great lengths to make this code as fast as possible, so I know which method that I prefer. We often palloc and never do anything that requires the chunk header to be decoded, so not adding extra instructions on the encoding stage is a big win. The only method I see to avoid adding instructions in encoding and decoding is to reduce the bit-space for the MemoryChunkGetValue field to 29 bits. Effectively, that means non-external chunks can only be 512MB rather than 1GB. As far as I know, that just limits slab.c to only being able to do 512MB pallocs as generation.c and aset.c use external chunks well below that threshold. Restricting slab to 512MB is probably far from the end of the world. Anything close to that would be a terrible use case for slab. I was just less keen on using a bit from there as that's a field we allow the context implementation to do what they like with. Having bitspace for 2^30 possible values in there just seems nice given that it can store any possible value from zero up to MaxAllocSize. David
On Sun, 7 Apr 2024, 01:59 David Rowley, <dgrowleyml@gmail.com> wrote:
On Sun, 7 Apr 2024 at 05:45, Matthias van de Meent
<boekewurm+postgres@gmail.com> wrote:
> Malloc's docs specify the minimum chunk size at 4*sizeof(void*) and itself uses , so using powers of 2 for chunks would indeed fail to detect 1s in the 4th bit. I suspect you'll get different results when you check the allocation patterns of multiples of 8 bytes, starting from 40, especially on 32-bit arm (where MALLOC_ALIGNMENT is 8 bytes, rather than the 16 bytes on i386 and 64-bit architectures, assuming [0] is accurate)
I'd hazard a guess that
there are more instances of Postgres running on Windows today than on
32-bit CPUs and we don't seem too worried about the bit-patterns used
for Windows.
Yeah, that is something I had some thoughts about too, but didn't check if there was historical context around. I don't think it's worth bothering right now though.
>> Another reason not to make it 5 bits is that I believe that would make
>> the mcxt_methods[] array 2304 bytes rather than 576 bytes. 4 bits
>> makes it 1152 bytes, if I'm counting correctly.
>
>
> I don't think I understand why this would be relevant when only 5 of the contexts are actually in use (thus in caches). Is that size concern about TLB entries then?
It's a static const array. I don't want to bloat the binary with
something we'll likely never need. If we one day need it, we can
reserve another bit using the same overlapping method.
Fair points.
>> I revised the patch to simplify hdrmask logic. This started with me
>> having trouble finding the best set of words to document that the
>> offset is "half the bytes between the chunk and block". So, instead
>> of doing that, I've just made it so these two fields effectively
>> overlap. The lowest bit of the block offset is the same bit as the
>> high bit of what MemoryChunkGetValue returns.
>
>
> Works for me, I suppose.
hmm. I don't detect much enthusiasm for it.
I had a tiring day leaving me short on enthousiasm, after which I realised there were some things to this patch that would need fixing.
I could've worded this better, but nothing against this code.
-Matthias
On Sat, Apr 6, 2024 at 7:37 PM David Rowley <dgrowleyml@gmail.com> wrote: > I'm planning on pushing these, pending a final look at 0002 and 0003 > on Sunday morning NZ time (UTC+12), likely in about 10 hours time. +1 I haven't looked at v6, but I've tried using it in situ, and it seems to work as well as hoped: https://www.postgresql.org/message-id/CANWCAZZQFfxvzO8yZHFWtQV%2BZ2gAMv1ku16Vu7KWmb5kZQyd1w%40mail.gmail.com
On Sun, 7 Apr 2024 at 22:05, John Naylor <johncnaylorls@gmail.com> wrote: > > On Sat, Apr 6, 2024 at 7:37 PM David Rowley <dgrowleyml@gmail.com> wrote: > > > I'm planning on pushing these, pending a final look at 0002 and 0003 > > on Sunday morning NZ time (UTC+12), likely in about 10 hours time. > > +1 I've now pushed all 3 patches. Thank you for all the reviews on these and for the extra MemoryContextMethodID bit, Matthias. > I haven't looked at v6, but I've tried using it in situ, and it seems > to work as well as hoped: > > https://www.postgresql.org/message-id/CANWCAZZQFfxvzO8yZHFWtQV%2BZ2gAMv1ku16Vu7KWmb5kZQyd1w%40mail.gmail.com I'm already impressed with the radix tree work. Nice to see bump allowing a little more memory to be saved for TID storage. David
On 4/7/24 14:37, David Rowley wrote: > On Sun, 7 Apr 2024 at 22:05, John Naylor <johncnaylorls@gmail.com> wrote: >> >> On Sat, Apr 6, 2024 at 7:37 PM David Rowley <dgrowleyml@gmail.com> wrote: >>> >> I'm planning on pushing these, pending a final look at 0002 and 0003 >>> on Sunday morning NZ time (UTC+12), likely in about 10 hours time. >> >> +1 > > I've now pushed all 3 patches. Thank you for all the reviews on > these and for the extra MemoryContextMethodID bit, Matthias. > >> I haven't looked at v6, but I've tried using it in situ, and it seems >> to work as well as hoped: >> >> https://www.postgresql.org/message-id/CANWCAZZQFfxvzO8yZHFWtQV%2BZ2gAMv1ku16Vu7KWmb5kZQyd1w%40mail.gmail.com > > I'm already impressed with the radix tree work. Nice to see bump > allowing a little more memory to be saved for TID storage. > > David There seems to be some issue with this on 32-bit machines. A couple animals (grison, mamba) already complained about an assert int BumpCheck() during initdb, I get the same crash on my rpi5 running 32-bit debian - see the backtrace attached. I haven't investigated, but I'd considering it works on 64-bit, I guess it's not considering alignment somewhere. I can dig more if needed. regards -- Tomas Vondra EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
Attachment
On 4/7/24 22:35, Tomas Vondra wrote: > On 4/7/24 14:37, David Rowley wrote: >> On Sun, 7 Apr 2024 at 22:05, John Naylor <johncnaylorls@gmail.com> wrote: >>> >>> On Sat, Apr 6, 2024 at 7:37 PM David Rowley <dgrowleyml@gmail.com> wrote: >>>> >>> I'm planning on pushing these, pending a final look at 0002 and 0003 >>>> on Sunday morning NZ time (UTC+12), likely in about 10 hours time. >>> >>> +1 >> >> I've now pushed all 3 patches. Thank you for all the reviews on >> these and for the extra MemoryContextMethodID bit, Matthias. >> >>> I haven't looked at v6, but I've tried using it in situ, and it seems >>> to work as well as hoped: >>> >>> https://www.postgresql.org/message-id/CANWCAZZQFfxvzO8yZHFWtQV%2BZ2gAMv1ku16Vu7KWmb5kZQyd1w%40mail.gmail.com >> >> I'm already impressed with the radix tree work. Nice to see bump >> allowing a little more memory to be saved for TID storage. >> >> David > > There seems to be some issue with this on 32-bit machines. A couple > animals (grison, mamba) already complained about an assert int > BumpCheck() during initdb, I get the same crash on my rpi5 running > 32-bit debian - see the backtrace attached. > > I haven't investigated, but I'd considering it works on 64-bit, I guess > it's not considering alignment somewhere. I can dig more if needed. > I did try running it under valgrind, and there doesn't seem to be anything particularly wrong - just a bit of noise about calculating CRC on uninitialized bytes. regards -- Tomas Vondra EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
Hi,
On 2024-04-07 22:35:47 +0200, Tomas Vondra wrote:
> I haven't investigated, but I'd considering it works on 64-bit, I guess
> it's not considering alignment somewhere. I can dig more if needed.
I think I may the problem:
#define KeeperBlock(set) ((BumpBlock *) ((char *) (set) + sizeof(BumpContext)))
#define IsKeeperBlock(set, blk) (KeeperBlock(set) == (blk))
BumpContextCreate():
...
/* Fill in the initial block's block header */
block = (BumpBlock *) (((char *) set) + MAXALIGN(sizeof(BumpContext)));
/* determine the block size and initialize it */
firstBlockSize = allocSize - MAXALIGN(sizeof(BumpContext));
BumpBlockInit(set, block, firstBlockSize);
...
((MemoryContext) set)->mem_allocated = allocSize;
void
BumpCheck(MemoryContext context)
...
if (IsKeeperBlock(bump, block))
total_allocated += block->endptr - (char *) bump;
...
I suspect that KeeperBlock() isn't returning true, because IsKeeperBlock misses
the MAXALIGN(). I think that about fits with:
> #4 0x008f0088 in BumpCheck (context=0x131e330) at bump.c:808
> 808 Assert(total_allocated == context->mem_allocated);
> (gdb) p total_allocated
> $1 = 8120
> (gdb) p context->mem_allocated
> $2 = 8192
Greetings,
Andres Freund
On 4/7/24 23:09, Andres Freund wrote: > Hi, > > On 2024-04-07 22:35:47 +0200, Tomas Vondra wrote: >> I haven't investigated, but I'd considering it works on 64-bit, I guess >> it's not considering alignment somewhere. I can dig more if needed. > > I think I may the problem: > > > #define KeeperBlock(set) ((BumpBlock *) ((char *) (set) + sizeof(BumpContext))) > #define IsKeeperBlock(set, blk) (KeeperBlock(set) == (blk)) > > BumpContextCreate(): > ... > /* Fill in the initial block's block header */ > block = (BumpBlock *) (((char *) set) + MAXALIGN(sizeof(BumpContext))); > /* determine the block size and initialize it */ > firstBlockSize = allocSize - MAXALIGN(sizeof(BumpContext)); > BumpBlockInit(set, block, firstBlockSize); > ... > ((MemoryContext) set)->mem_allocated = allocSize; > > void > BumpCheck(MemoryContext context) > ... > if (IsKeeperBlock(bump, block)) > total_allocated += block->endptr - (char *) bump; > ... > > I suspect that KeeperBlock() isn't returning true, because IsKeeperBlock misses > the MAXALIGN(). I think that about fits with: > >> #4 0x008f0088 in BumpCheck (context=0x131e330) at bump.c:808 >> 808 Assert(total_allocated == context->mem_allocated); >> (gdb) p total_allocated >> $1 = 8120 >> (gdb) p context->mem_allocated >> $2 = 8192 > Yup, changing it to this: #define KeeperBlock(set) ((BumpBlock *) ((char *) (set) + MAXALIGN(sizeof(BumpContext)))) fixes the issue for me. regards -- Tomas Vondra EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
Tomas Vondra <tomas.vondra@enterprisedb.com> writes:
> Yup, changing it to this:
> #define KeeperBlock(set) ((BumpBlock *) ((char *) (set) +
> MAXALIGN(sizeof(BumpContext))))
> fixes the issue for me.
Mamba is happy with that change, too.
regards, tom lane
> On 8 Apr 2024, at 00:41, Tom Lane <tgl@sss.pgh.pa.us> wrote:
>
> Tomas Vondra <tomas.vondra@enterprisedb.com> writes:
>> Yup, changing it to this:
>
>> #define KeeperBlock(set) ((BumpBlock *) ((char *) (set) +
>> MAXALIGN(sizeof(BumpContext))))
>
>> fixes the issue for me.
>
> Mamba is happy with that change, too.
Unrelated to that one, seems like turaco ran into another issue:
running bootstrap script ... TRAP: failed Assert("total_allocated == context->mem_allocated"), File: "bump.c", Line:
808,PID: 7809
https://buildfarm.postgresql.org/cgi-bin/show_log.pl?nm=turaco&dt=2024-04-07%2022%3A42%3A54
--
Daniel Gustafsson
Hi,
On 2024-04-08 00:55:42 +0200, Daniel Gustafsson wrote:
> > On 8 Apr 2024, at 00:41, Tom Lane <tgl@sss.pgh.pa.us> wrote:
> >
> > Tomas Vondra <tomas.vondra@enterprisedb.com> writes:
> >> Yup, changing it to this:
> >
> >> #define KeeperBlock(set) ((BumpBlock *) ((char *) (set) +
> >> MAXALIGN(sizeof(BumpContext))))
> >
> >> fixes the issue for me.
> >
> > Mamba is happy with that change, too.
>
> Unrelated to that one, seems like turaco ran into another issue:
>
> running bootstrap script ... TRAP: failed Assert("total_allocated == context->mem_allocated"), File: "bump.c", Line:
808,PID: 7809
>
> https://buildfarm.postgresql.org/cgi-bin/show_log.pl?nm=turaco&dt=2024-04-07%2022%3A42%3A54
What makes you think that's unrelated? To me that looks like the same issue?
Greetings,
Andres Freund
On Mon, 8 Apr 2024 at 09:09, Andres Freund <andres@anarazel.de> wrote: > I suspect that KeeperBlock() isn't returning true, because IsKeeperBlock misses > the MAXALIGN(). I think that about fits with: Thanks for investigating that. I've just pushed a fix for the macro and also adjusted a location which was *correctly* calculating the keeper block address manually to use the macro. If I'd used the macro there to start with the Assert likely wouldn't have failed, but there'd have been memory alignment issues. David
> On 8 Apr 2024, at 01:04, Andres Freund <andres@anarazel.de> wrote: > What makes you think that's unrelated? To me that looks like the same issue? Nvm, I misread the assert, ETOOLITTLESLEEP. Sorry for the noise. -- Daniel Gustafsson
Attached is a small patch adding the missing BumpContext description to the
README.
README.
Regards,
Amul
Attachment
> On 16 Apr 2024, at 07:12, Amul Sul <sulamul@gmail.com> wrote: > > Attached is a small patch adding the missing BumpContext description to the > README. Nice catch, we should add it to the README. + pfree'd or realloc'd. I think it's best to avoid mixing API:s, "pfree'd or repalloc'd" keeps it to functions in our API instead. -- Daniel Gustafsson
On Tue, 16 Apr 2024 at 17:13, Amul Sul <sulamul@gmail.com> wrote: > Attached is a small patch adding the missing BumpContext description to the > README. Thanks for noticing and working on the patch. There were a few things that were not quite accurate or are misleading: 1. > +These three memory contexts aim to free memory back to the operating system That's not true for bump. It's the worst of the 4. Worse than aset. It only returns memory when the context is reset/deleted. 2. "These memory contexts were initially developed for ReorderBuffer, but may be useful elsewhere as long as the allocation patterns match." The above isn't true for bump. It was written for tuplesort. I think we can just remove that part now. Slab and generation are both old enough not to care why they were conceived. Also since adding bump, I think the choice of which memory context to use is about 33% harder than it used to be when there were only 3 context types. I think this warrants giving more detail on what these 3 special-purpose memory allocators are good for. I've added more details in the attached patch. This includes more details about freeing malloc'd blocks I've tried to detail out enough of the specialities of the context type without going into extensive detail. My hope is that there will be enough detail for someone to choose the most suitable looking one and head over to the corresponding .c file to find out more. Is that about the right level of detail? David
Attachment
On Mon, 8 Apr 2024 at 00:37, David Rowley <dgrowleyml@gmail.com> wrote: > I've now pushed all 3 patches. Thank you for all the reviews on > these and for the extra MemoryContextMethodID bit, Matthias. I realised earlier today when working on [1] that bump makes a pretty brain-dead move when adding dedicated blocks to the blocks list. The problem is that I opted to not have a current block field in BumpContext and just rely on the head pointer of the blocks list to be the "current" block. The head block is the block we look at to see if we've any space left when new allocations come in. The problem there is when adding a dedicated block in BumpAllocLarge(), the code adds this to the head of the blocks list so that when a new allocation comes in that's normal-sized, the block at the top of the list is full and we have to create a new block for the allocation. The attached fixes this by pushing these large/dedicated blocks to the *tail* of the blocks list. This means the partially filled block remains at the head and is available for any new allocation which will fit. This behaviour is evident by the regression test change that I added earlier today when working on [1]. The 2nd and smaller allocation in that text goes onto the keeper block rather than a new block. I plan to push this tomorrow. David [1] https://git.postgresql.org/gitweb/?p=postgresql.git;a=commit;h=bea97cd02ebb347ab469b78673c2b33a72109669
Attachment
On Tue, Apr 16, 2024 at 3:44 PM David Rowley <dgrowleyml@gmail.com> wrote:
On Tue, 16 Apr 2024 at 17:13, Amul Sul <sulamul@gmail.com> wrote:
> Attached is a small patch adding the missing BumpContext description to the
> README.
Thanks for noticing and working on the patch.
There were a few things that were not quite accurate or are misleading:
1.
> +These three memory contexts aim to free memory back to the operating system
That's not true for bump. It's the worst of the 4. Worse than aset.
It only returns memory when the context is reset/deleted.
2.
"These memory contexts were initially developed for ReorderBuffer, but
may be useful elsewhere as long as the allocation patterns match."
The above isn't true for bump. It was written for tuplesort. I think
we can just remove that part now. Slab and generation are both old
enough not to care why they were conceived.
Also since adding bump, I think the choice of which memory context to
use is about 33% harder than it used to be when there were only 3
context types. I think this warrants giving more detail on what these
3 special-purpose memory allocators are good for. I've added more
details in the attached patch. This includes more details about
freeing malloc'd blocks
I've tried to detail out enough of the specialities of the context
type without going into extensive detail. My hope is that there will
be enough detail for someone to choose the most suitable looking one
and head over to the corresponding .c file to find out more.
Is that about the right level of detail?
Yes, it looks much better now, thank you.
Regards,
Amul