Re: Add bump memory context type and use it for tuplesorts - Mailing list pgsql-hackers
| From | David Rowley |
|---|---|
| Subject | Re: Add bump memory context type and use it for tuplesorts |
| Date | |
| Msg-id | CAApHDvqUWhOMkUjYXzq95idAwpiPdJLCxxRbf8kV6PYcW5y=Cg@mail.gmail.com Whole thread |
| In response to | Re: Add bump memory context type and use it for tuplesorts (Matthias van de Meent <boekewurm+postgres@gmail.com>) |
| Responses |
Re: Add bump memory context type and use it for tuplesorts
Re: Add bump memory context type and use it for tuplesorts |
| List | pgsql-hackers |
On Sat, 6 Apr 2024 at 02:30, Matthias van de Meent
<boekewurm+postgres@gmail.com> wrote:
>
> On Thu, 4 Apr 2024 at 22:43, Tom Lane <tgl@sss.pgh.pa.us> wrote:
> >
> > Matthias van de Meent <boekewurm+postgres@gmail.com> writes:
> > > It extends memory context IDs to 5 bits (32 values), of which
> > > - 8 have glibc's malloc pattern of 001/010;
> > > - 1 is unused memory's 00000
> > > - 1 is wipe_mem's 11111
> > > - 4 are used by existing contexts (Aset/Generation/Slab/AlignedRedirect)
> > > - 18 are newly available.
> >
> > This seems like it would solve the problem for a good long time
> > to come; and if we ever need more IDs, we could steal one more bit
> > by requiring the offset to the block header to be a multiple of 8.
> > (Really, we could just about do that today at little or no cost ...
> > machines with MAXALIGN less than 8 are very thin on the ground.)
>
> Hmm, it seems like a decent idea, but I didn't want to deal with the
> repercussions of that this late in the cycle when these 2 bits were
> still relatively easy to get hold of.
Thanks for writing the patch.
I think 5 bits is 1 too many. 4 seems fine. I also think you've
reserved too many slots in your patch as I disagree that we need to
reserve the glibc malloc pattern anywhere but in the 1 and 2 slots of
the mcxt_methods[] array. I looked again at the 8 bytes prior to a
glibc malloc'd chunk and I see the lowest 4 bits of the headers
consistently set to 0001 for all powers of 2 starting at 8 up to
65536. 131072 seems to vary and beyond that, they seem to be set to
0010.
With that, there's no increase in the number of reserved slots from
what we have reserved today. Still 4. So having 4 bits instead of 3
bits gives us a total of 12 slots rather than 4 slots. Having 3x
slots seems enough. We might need an extra bit for something else
sometime. I think keeping it up our sleeve is a good idea.
Another reason not to make it 5 bits is that I believe that would make
the mcxt_methods[] array 2304 bytes rather than 576 bytes. 4 bits
makes it 1152 bytes, if I'm counting correctly.
I revised the patch to simplify hdrmask logic. This started with me
having trouble finding the best set of words to document that the
offset is "half the bytes between the chunk and block". So, instead
of doing that, I've just made it so these two fields effectively
overlap. The lowest bit of the block offset is the same bit as the
high bit of what MemoryChunkGetValue returns. I've just added an
Assert to MemoryChunkSetHdrMask to ensure that the low bit is never
set in the offset. Effectively, using this method, there's no new *C*
code to split the values out. However, the compiler will emit one
additional bitwise-AND to implement the following, which I'll express
using fragments from the 0001 patch:
#define MEMORYCHUNK_MAX_BLOCKOFFSET UINT64CONST(0x3FFFFFFF)
+#define MEMORYCHUNK_BLOCKOFFSET_MASK UINT64CONST(0x3FFFFFFE)
#define HdrMaskBlockOffset(hdrmask) \
- (((hdrmask) >> MEMORYCHUNK_BLOCKOFFSET_BASEBIT) & MEMORYCHUNK_MAX_BLOCKOFFSET)
+ (((hdrmask) >> MEMORYCHUNK_BLOCKOFFSET_BASEBIT) &
MEMORYCHUNK_BLOCKOFFSET_MASK)
Previously most compilers would have optimised the bitwise-AND away as
it was effectively similar to doing something like (0xFFFFFFFF >> 16)
& 0xFFFF. The compiler should know that no bits can be masked out by
the bitwise-AND due to the left shift zeroing them all. If you swap
0xFFFF for 0xFFFE then that's no longer true.
I also updated src/backend/utils/mmgr/README to explain this and
adjust the mentions of 3-bits and 61-bits to 4-bits and 60-bits. I
also explained the overlapping part.
I spent quite a bit of time benchmarking this. There is a small
performance regression from widening to 4 bits, but it's not huge.
Please see the 3 attached graphs. All times in the graph are the
average of the time taken for each test over 9 runs.
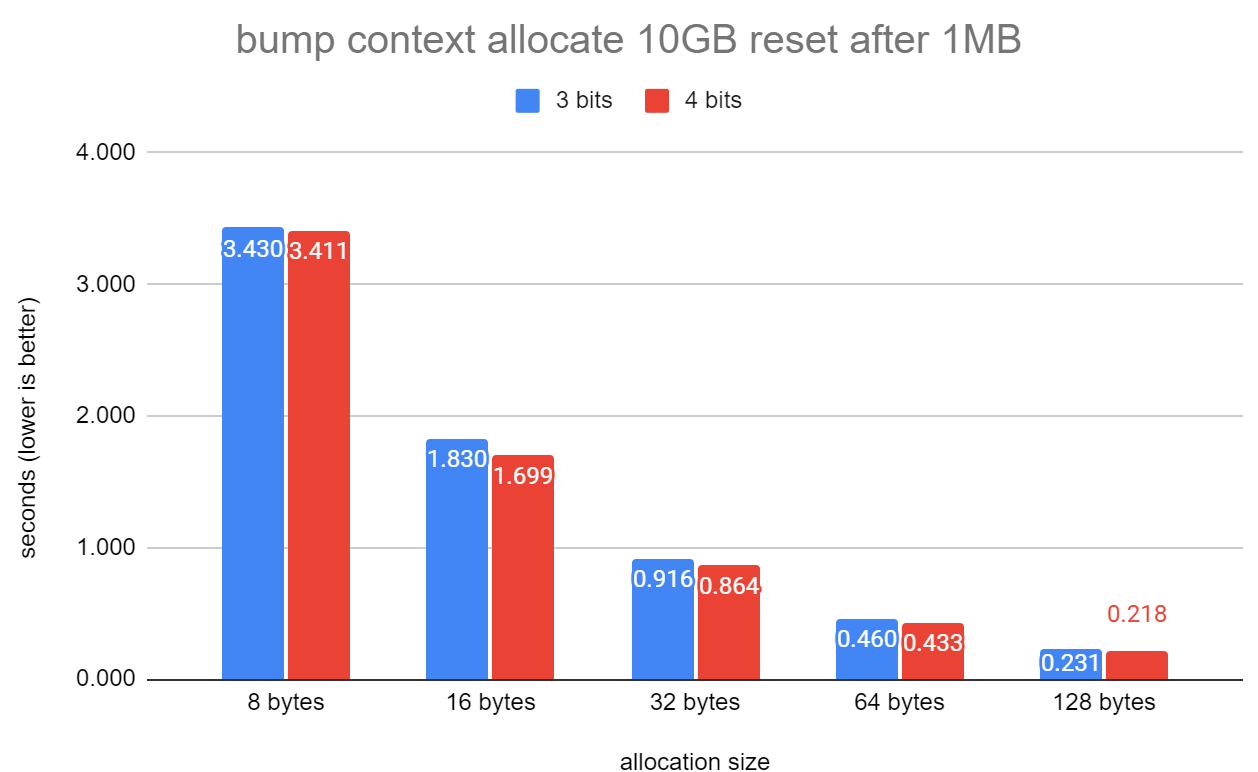
bump_palloc_reset.png: Shows the results from:
select stype,chksz,avg(pg_allocate_memory_test_reset(chksz,1024*1024,10::bigint*1024*1024*1024,stype))
from (values(8),(16),(32),(64),(128)) t1(chksz)
cross join (values('bump')) t2(stype)
cross join generate_series(1,3) r(run)
group by stype,chksz
order by stype,chksz;
There's no performance regression here. Bump does not have headers so
no extra bits are used anywhere.
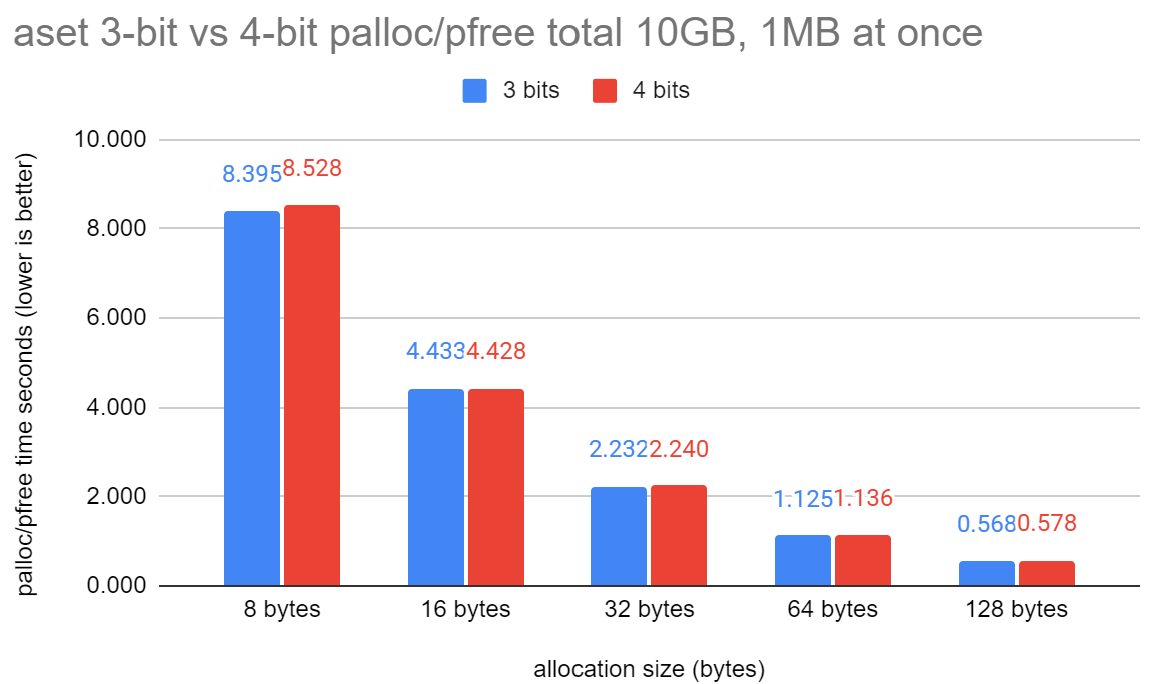
aset_palloc_pfree.png: Shows the results from:
select stype,chksz,avg(pg_allocate_memory_test(chksz,1024*1024,10::bigint*1024*1024*1024,stype))
from (values(8),(16),(32),(64),(128)) t1(chksz)
cross join (values('aset')) t2(stype)
cross join generate_series(1,3) r(run)
group by stype,chksz
order by stype,chksz;
This exercises palloc and pfree. Effectively it's allocating 10GB of
memory but starting to pfree before each new palloc after we get to
1MB of concurrent allocations. Because this test calls pfree, we need
to look at the chunk header and into the mcxt_methods[] array. It's
important to test this part.
The graph shows a small performance regression of about 1-2%.
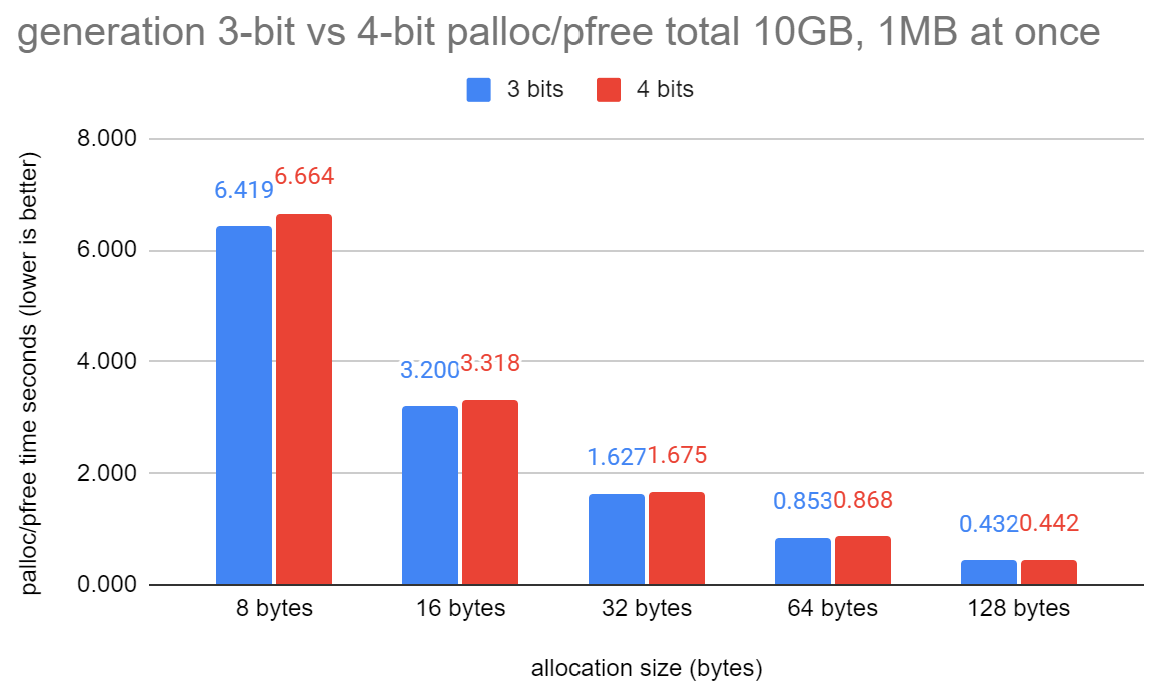
generation_palloc_pfree.png: Same as aset_palloc_pfree.png but for the
generation context. The regression here is slightly more than aset.
Seems to be about 2-3.5%. I don't think this is too surprising as
there's more room for instruction-level parallelism in AllocSetFree()
when calling MemoryChunkGetBlock() than there is in GenerationFree().
In GenerationFree() we get the block and then immediately do
"block->nfree += 1;", whereas in AllocSetFree() we also call
MemoryChunkGetValue().
I've attached an updated set of patches, plus graphs, plus entire
benchmark results as a .txt file.
Note the v6-0003 patch is just v4-0002 renamed so the CFbot applies in
the correct order.
I'm planning on pushing these, pending a final look at 0002 and 0003
on Sunday morning NZ time (UTC+12), likely in about 10 hours time.
David
Attachment
{kind=link}
{kind=link}
{kind=link}
pgsql-hackers by date: