Thread: PATCH: Using BRIN indexes for sorted output
Hi,
There have been a couple discussions about using BRIN indexes for
sorting - in fact this was mentioned even in the "Improving Indexing
Performance" unconference session this year (don't remember by whom).
But I haven't seen any patches, so here's one.
The idea is that we can use information about ranges to split the table
into smaller parts that can be sorted in smaller chunks. For example if
you have a tiny 2MB table with two ranges, with values in [0,100] and
[101,200] intervals, then it's clear we can sort the first range, output
tuples, and then sort/output the second range.
The attached patch builds "BRIN Sort" paths/plans, closely resembling
index scans, only for BRIN indexes. And this special type of index scan
does what was mentioned above - incrementally sorts the data. It's a bit
more complicated because of overlapping ranges, ASC/DESC, NULL etc.
This is disabled by default, using a GUC enable_brinsort (you may need
to tweak other GUCs to disable parallel plans etc.).
A trivial example, demonstrating the benefits:
create table t (a int) with (fillfactor = 10);
insert into t select i from generate_series(1,10000000) s(i);
First, a simple LIMIT query:
explain (analyze, costs off) select * from t order by a limit 10;
QUERY PLAN
------------------------------------------------------------------------
Limit (actual time=1879.768..1879.770 rows=10 loops=1)
-> Sort (actual time=1879.767..1879.768 rows=10 loops=1)
Sort Key: a
Sort Method: top-N heapsort Memory: 25kB
-> Seq Scan on t
(actual time=0.007..1353.110 rows=10000000 loops=1)
Planning Time: 0.083 ms
Execution Time: 1879.786 ms
(7 rows)
QUERY PLAN
------------------------------------------------------------------------
Limit (actual time=1.217..1.219 rows=10 loops=1)
-> BRIN Sort using t_a_idx on t
(actual time=1.216..1.217 rows=10 loops=1)
Sort Key: a
Planning Time: 0.084 ms
Execution Time: 1.234 ms
(5 rows)
That's a pretty nice improvement - of course, this is thanks to having a
perfectly sequential, and the difference can be almost arbitrary by
making the table smaller/larger. Similarly, if the table gets less
sequential (making ranges to overlap), the BRIN plan will be more
expensive. Feel free to experiment with other data sets.
However, not only the LIMIT queries can improve - consider a sort of the
whole table:
test=# explain (analyze, costs off) select * from t order by a;
QUERY PLAN
-------------------------------------------------------------------------
Sort (actual time=2806.468..3487.213 rows=10000000 loops=1)
Sort Key: a
Sort Method: external merge Disk: 117528kB
-> Seq Scan on t (actual time=0.018..1498.754 rows=10000000 loops=1)
Planning Time: 0.110 ms
Execution Time: 3766.825 ms
(6 rows)
test=# explain (analyze, costs off) select * from t order by a;
QUERY PLAN
----------------------------------------------------------------------------------
BRIN Sort using t_a_idx on t (actual time=1.210..2670.875 rows=10000000
loops=1)
Sort Key: a
Planning Time: 0.073 ms
Execution Time: 2939.324 ms
(4 rows)
Right - not a huge difference, but still a nice 25% speedup, mostly due
to not having to spill data to disk and sorting smaller amounts of data.
There's a bunch of issues with this initial version of the patch,
usually described in XXX comments in the relevant places.6)
1) The paths are created in build_index_paths() because that's what
creates index scans (which the new path resembles). But that is expected
to produce IndexPath, not BrinSortPath, so it's not quite correct.
Should be somewhere "higher" I guess.
2) BRIN indexes don't have internal ordering, i.e. ASC/DESC and NULLS
FIRST/LAST does not really matter for them. The patch just generates
paths for all 4 combinations (or tries to). Maybe there's a better way.
3) I'm not quite sure the separation of responsibilities between
opfamily and opclass is optimal. I added a new amproc, but maybe this
should be split differently. At the moment only minmax indexes have
this, but adding this to minmax-multi should be trivial.
4) The state changes in nodeBrinSort is a bit confusing. Works, but may
need cleanup and refactoring. Ideas welcome.
5) The costing is essentially just plain cost_index. I have some ideas
about BRIN costing in general, which I'll post in a separate thread (as
it's not specific to this patch).
6) At the moment this only picks one of the index keys, specified in the
ORDER BY clause. I think we can generalize this to multiple keys, but
thinking about multi-key ranges was a bit too much for me. The good
thing is this nicely combines with IncrementalSort.
7) Only plain index keys for the ORDER BY keys, no expressions. Should
not be hard to fix, though.
8) Parallel version is not supported, but I think it shouldn't be
possible. Just make the leader build the range info, and then let the
workers to acquire/sort ranges and merge them by Gather Merge.
9) I was also thinking about leveraging other indexes to quickly
eliminate ranges that need to be sorted. The node does evaluate filter,
of course, but only after reading the tuple from the range. But imagine
we allow BrinSort to utilize BRIN indexes to evaluate the filter - in
that case we might skip many ranges entirely. Essentially like a bitmap
index scan does, except that building the bitmap incrementally with BRIN
is trivial - you can quickly check if a particular range matches or not.
With other indexes (e.g. btree) you essentially need to evaluate the
filter completely, and only then you can look at the bitmap. Which seems
rather against the idea of this patch, which is about low startup cost.
Of course, the condition might be very selective, but then you probably
can just fetch the matching tuples and do a Sort.
regards
--
Tomas Vondra
EnterpriseDB: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
Attachment
On Sat, Oct 15, 2022 at 5:34 AM Tomas Vondra <tomas.vondra@enterprisedb.com> wrote:
Hi,
There have been a couple discussions about using BRIN indexes for
sorting - in fact this was mentioned even in the "Improving Indexing
Performance" unconference session this year (don't remember by whom).
But I haven't seen any patches, so here's one.
The idea is that we can use information about ranges to split the table
into smaller parts that can be sorted in smaller chunks. For example if
you have a tiny 2MB table with two ranges, with values in [0,100] and
[101,200] intervals, then it's clear we can sort the first range, output
tuples, and then sort/output the second range.
The attached patch builds "BRIN Sort" paths/plans, closely resembling
index scans, only for BRIN indexes. And this special type of index scan
does what was mentioned above - incrementally sorts the data. It's a bit
more complicated because of overlapping ranges, ASC/DESC, NULL etc.
This is disabled by default, using a GUC enable_brinsort (you may need
to tweak other GUCs to disable parallel plans etc.).
A trivial example, demonstrating the benefits:
create table t (a int) with (fillfactor = 10);
insert into t select i from generate_series(1,10000000) s(i);
First, a simple LIMIT query:
explain (analyze, costs off) select * from t order by a limit 10;
QUERY PLAN
------------------------------------------------------------------------
Limit (actual time=1879.768..1879.770 rows=10 loops=1)
-> Sort (actual time=1879.767..1879.768 rows=10 loops=1)
Sort Key: a
Sort Method: top-N heapsort Memory: 25kB
-> Seq Scan on t
(actual time=0.007..1353.110 rows=10000000 loops=1)
Planning Time: 0.083 ms
Execution Time: 1879.786 ms
(7 rows)
QUERY PLAN
------------------------------------------------------------------------
Limit (actual time=1.217..1.219 rows=10 loops=1)
-> BRIN Sort using t_a_idx on t
(actual time=1.216..1.217 rows=10 loops=1)
Sort Key: a
Planning Time: 0.084 ms
Execution Time: 1.234 ms
(5 rows)
That's a pretty nice improvement - of course, this is thanks to having a
perfectly sequential, and the difference can be almost arbitrary by
making the table smaller/larger. Similarly, if the table gets less
sequential (making ranges to overlap), the BRIN plan will be more
expensive. Feel free to experiment with other data sets.
However, not only the LIMIT queries can improve - consider a sort of the
whole table:
test=# explain (analyze, costs off) select * from t order by a;
QUERY PLAN
-------------------------------------------------------------------------
Sort (actual time=2806.468..3487.213 rows=10000000 loops=1)
Sort Key: a
Sort Method: external merge Disk: 117528kB
-> Seq Scan on t (actual time=0.018..1498.754 rows=10000000 loops=1)
Planning Time: 0.110 ms
Execution Time: 3766.825 ms
(6 rows)
test=# explain (analyze, costs off) select * from t order by a;
QUERY PLAN
----------------------------------------------------------------------------------
BRIN Sort using t_a_idx on t (actual time=1.210..2670.875 rows=10000000
loops=1)
Sort Key: a
Planning Time: 0.073 ms
Execution Time: 2939.324 ms
(4 rows)
Right - not a huge difference, but still a nice 25% speedup, mostly due
to not having to spill data to disk and sorting smaller amounts of data.
There's a bunch of issues with this initial version of the patch,
usually described in XXX comments in the relevant places.6)
1) The paths are created in build_index_paths() because that's what
creates index scans (which the new path resembles). But that is expected
to produce IndexPath, not BrinSortPath, so it's not quite correct.
Should be somewhere "higher" I guess.
2) BRIN indexes don't have internal ordering, i.e. ASC/DESC and NULLS
FIRST/LAST does not really matter for them. The patch just generates
paths for all 4 combinations (or tries to). Maybe there's a better way.
3) I'm not quite sure the separation of responsibilities between
opfamily and opclass is optimal. I added a new amproc, but maybe this
should be split differently. At the moment only minmax indexes have
this, but adding this to minmax-multi should be trivial.
4) The state changes in nodeBrinSort is a bit confusing. Works, but may
need cleanup and refactoring. Ideas welcome.
5) The costing is essentially just plain cost_index. I have some ideas
about BRIN costing in general, which I'll post in a separate thread (as
it's not specific to this patch).
6) At the moment this only picks one of the index keys, specified in the
ORDER BY clause. I think we can generalize this to multiple keys, but
thinking about multi-key ranges was a bit too much for me. The good
thing is this nicely combines with IncrementalSort.
7) Only plain index keys for the ORDER BY keys, no expressions. Should
not be hard to fix, though.
8) Parallel version is not supported, but I think it shouldn't be
possible. Just make the leader build the range info, and then let the
workers to acquire/sort ranges and merge them by Gather Merge.
9) I was also thinking about leveraging other indexes to quickly
eliminate ranges that need to be sorted. The node does evaluate filter,
of course, but only after reading the tuple from the range. But imagine
we allow BrinSort to utilize BRIN indexes to evaluate the filter - in
that case we might skip many ranges entirely. Essentially like a bitmap
index scan does, except that building the bitmap incrementally with BRIN
is trivial - you can quickly check if a particular range matches or not.
With other indexes (e.g. btree) you essentially need to evaluate the
filter completely, and only then you can look at the bitmap. Which seems
rather against the idea of this patch, which is about low startup cost.
Of course, the condition might be very selective, but then you probably
can just fetch the matching tuples and do a Sort.
regards
--
Tomas Vondra
EnterpriseDB: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
Hi,
I am still going over the patch.
Minor: for #8, I guess you meant `it should be possible` .
Cheers
On 10/15/22 15:46, Zhihong Yu wrote: >... > 8) Parallel version is not supported, but I think it shouldn't be > possible. Just make the leader build the range info, and then let the > workers to acquire/sort ranges and merge them by Gather Merge. > ... > Hi, > I am still going over the patch. > > Minor: for #8, I guess you meant `it should be possible` . > Yes, I meant to say it should be possible. Sorry for the confusion. regards -- Tomas Vondra EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On Sat, Oct 15, 2022 at 8:23 AM Tomas Vondra <tomas.vondra@enterprisedb.com> wrote:
On 10/15/22 15:46, Zhihong Yu wrote:
>...
> 8) Parallel version is not supported, but I think it shouldn't be
> possible. Just make the leader build the range info, and then let the
> workers to acquire/sort ranges and merge them by Gather Merge.
> ...
> Hi,
> I am still going over the patch.
>
> Minor: for #8, I guess you meant `it should be possible` .
>
Yes, I meant to say it should be possible. Sorry for the confusion.
regards
--
Tomas Vondra
EnterpriseDB: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
Hi,
For brin_minmax_ranges, looking at the assignment to gottuple and reading gottuple, it seems variable gottuple can be omitted - we can check tup directly.
+ /* Maybe mark the range as processed. */
+ range->processed |= mark_processed;
+ range->processed |= mark_processed;
`Maybe` can be dropped.
For brinsort_load_tuples(), do we need to check for interrupts inside the loop ?
Similar question for subsequent methods involving loops, such as brinsort_load_unsummarized_ranges.
Cheers
On 10/15/22 14:33, Tomas Vondra wrote: > Hi, > > ... > > There's a bunch of issues with this initial version of the patch, > usually described in XXX comments in the relevant places.6) > > ... I forgot to mention one important issue in my list yesterday, and that's memory consumption. The way the patch is coded now, the new BRIN support function (brin_minmax_ranges) produces information about *all* ranges in one go, which may be an issue. The worst case is 32TB table, with 1-page BRIN ranges, which means ~4 billion ranges. The info is an array of ~32B structs, so this would require ~128GB of RAM. With the default 128-page ranges, it's still be ~1GB, which is quite a lot. We could have a discussion about what's the reasonable size of BRIN ranges on such large tables (e.g. building a bitmap on 4 billion ranges is going to be "not cheap" so this is likely pretty rare). But we should not introduce new nodes that ignore work_mem, so we need a way to deal with such cases somehow. The easiest solution likely is to check this while planning - we can check the table size, calculate the number of BRIN ranges, and check that the range info fits into work_mem, and just not create the path when it gets too large. That's what we did for HashAgg, although that decision was unreliable because estimating GROUP BY cardinality is hard. The wrinkle here is that counting just the range info (BrinRange struct) does not include the values for by-reference types. We could use average width - that's just an estimate, though. A more comprehensive solution seems to be to allow requesting chunks of the BRIN ranges. So that we'd get "slices" of ranges and we'd process those. So for example if you have 1000 ranges, and you can only handle 100 at a time, we'd do 10 loops, each requesting 100 ranges. This has another problem - we do care about "overlaps", and we can't really know if the overlapping ranges will be in the same "slice" easily. The chunks would be sorted (for example) by maxval. But there can be a range with much higher maxval (thus in some future slice), but very low minval (thus intersecting with ranges in the current slice). Imagine ranges with these minval/maxval values, sorted by maxval: [101,200] [201,300] [301,400] [150,500] and let's say we can only process 2-range slices. So we'll get the first two, but both of them intersect with the very last range. We could always include all the intersecting ranges into the slice, but what if there are too many very "wide" ranges? So I think this will need to switch to an iterative communication with the BRIN index - instead of asking "give me info about all the ranges", we'll need a way to - request the next range (sorted by maxval) - request the intersecting ranges one by one (sorted by minval) Of course, the BRIN side will have some of the same challenges with tracking the info without breaking the work_mem limit, but I suppose it can store the info into a tuplestore/tuplesort, and use that instead of plain in-memory array. Alternatively, it could just return those, and BrinSort would use that. OTOH it seems cleaner to have some sort of API, especially if we want to support e.g. minmax-multi opclasses, that have a more complicated concept of "intersection". regards -- Tomas Vondra EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On Sun, Oct 16, 2022 at 6:51 AM Tomas Vondra <tomas.vondra@enterprisedb.com> wrote:
On 10/15/22 14:33, Tomas Vondra wrote:
> Hi,
>
> ...
>
> There's a bunch of issues with this initial version of the patch,
> usually described in XXX comments in the relevant places.6)
>
> ...
I forgot to mention one important issue in my list yesterday, and that's
memory consumption. The way the patch is coded now, the new BRIN support
function (brin_minmax_ranges) produces information about *all* ranges in
one go, which may be an issue. The worst case is 32TB table, with 1-page
BRIN ranges, which means ~4 billion ranges. The info is an array of ~32B
structs, so this would require ~128GB of RAM. With the default 128-page
ranges, it's still be ~1GB, which is quite a lot.
We could have a discussion about what's the reasonable size of BRIN
ranges on such large tables (e.g. building a bitmap on 4 billion ranges
is going to be "not cheap" so this is likely pretty rare). But we should
not introduce new nodes that ignore work_mem, so we need a way to deal
with such cases somehow.
The easiest solution likely is to check this while planning - we can
check the table size, calculate the number of BRIN ranges, and check
that the range info fits into work_mem, and just not create the path
when it gets too large. That's what we did for HashAgg, although that
decision was unreliable because estimating GROUP BY cardinality is hard.
The wrinkle here is that counting just the range info (BrinRange struct)
does not include the values for by-reference types. We could use average
width - that's just an estimate, though.
A more comprehensive solution seems to be to allow requesting chunks of
the BRIN ranges. So that we'd get "slices" of ranges and we'd process
those. So for example if you have 1000 ranges, and you can only handle
100 at a time, we'd do 10 loops, each requesting 100 ranges.
This has another problem - we do care about "overlaps", and we can't
really know if the overlapping ranges will be in the same "slice"
easily. The chunks would be sorted (for example) by maxval. But there
can be a range with much higher maxval (thus in some future slice), but
very low minval (thus intersecting with ranges in the current slice).
Imagine ranges with these minval/maxval values, sorted by maxval:
[101,200]
[201,300]
[301,400]
[150,500]
and let's say we can only process 2-range slices. So we'll get the first
two, but both of them intersect with the very last range.
We could always include all the intersecting ranges into the slice, but
what if there are too many very "wide" ranges?
So I think this will need to switch to an iterative communication with
the BRIN index - instead of asking "give me info about all the ranges",
we'll need a way to
- request the next range (sorted by maxval)
- request the intersecting ranges one by one (sorted by minval)
Of course, the BRIN side will have some of the same challenges with
tracking the info without breaking the work_mem limit, but I suppose it
can store the info into a tuplestore/tuplesort, and use that instead of
plain in-memory array. Alternatively, it could just return those, and
BrinSort would use that. OTOH it seems cleaner to have some sort of API,
especially if we want to support e.g. minmax-multi opclasses, that have
a more complicated concept of "intersection".
regards
--
Tomas Vondra
EnterpriseDB: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
Hi,
In your example involving [150,500], can this range be broken down into 4 ranges, ending in 200, 300, 400 and 500, respectively ?
That way, there is no intersection among the ranges.
bq. can store the info into a tuplestore/tuplesort
Wouldn't this involve disk accesses which may reduce the effectiveness of BRIN sort ?
Cheers
On 10/16/22 03:36, Zhihong Yu wrote: > > > On Sat, Oct 15, 2022 at 8:23 AM Tomas Vondra > <tomas.vondra@enterprisedb.com <mailto:tomas.vondra@enterprisedb.com>> > wrote: > > On 10/15/22 15:46, Zhihong Yu wrote: > >... > > 8) Parallel version is not supported, but I think it shouldn't be > > possible. Just make the leader build the range info, and then > let the > > workers to acquire/sort ranges and merge them by Gather Merge. > > ... > > Hi, > > I am still going over the patch. > > > > Minor: for #8, I guess you meant `it should be possible` . > > > > Yes, I meant to say it should be possible. Sorry for the confusion. > > > > regards > > -- > Tomas Vondra > EnterpriseDB: http://www.enterprisedb.com <http://www.enterprisedb.com> > The Enterprise PostgreSQL Company > > Hi, > > For brin_minmax_ranges, looking at the assignment to gottuple and > reading gottuple, it seems variable gottuple can be omitted - we can > check tup directly. > > + /* Maybe mark the range as processed. */ > + range->processed |= mark_processed; > > `Maybe` can be dropped. > No, because the "mark_processed" may be false. So we may not mark it as processed in some cases. > For brinsort_load_tuples(), do we need to check for interrupts inside > the loop ? > Similar question for subsequent methods involving loops, such > as brinsort_load_unsummarized_ranges. > We could/should, although most of the loops should be very short. regrds -- Tomas Vondra EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On 10/16/22 16:01, Zhihong Yu wrote: > > > On Sun, Oct 16, 2022 at 6:51 AM Tomas Vondra > <tomas.vondra@enterprisedb.com <mailto:tomas.vondra@enterprisedb.com>> > wrote: > > On 10/15/22 14:33, Tomas Vondra wrote: > > Hi, > > > > ... > > > > There's a bunch of issues with this initial version of the patch, > > usually described in XXX comments in the relevant places.6) > > > > ... > > I forgot to mention one important issue in my list yesterday, and that's > memory consumption. The way the patch is coded now, the new BRIN support > function (brin_minmax_ranges) produces information about *all* ranges in > one go, which may be an issue. The worst case is 32TB table, with 1-page > BRIN ranges, which means ~4 billion ranges. The info is an array of ~32B > structs, so this would require ~128GB of RAM. With the default 128-page > ranges, it's still be ~1GB, which is quite a lot. > > We could have a discussion about what's the reasonable size of BRIN > ranges on such large tables (e.g. building a bitmap on 4 billion ranges > is going to be "not cheap" so this is likely pretty rare). But we should > not introduce new nodes that ignore work_mem, so we need a way to deal > with such cases somehow. > > The easiest solution likely is to check this while planning - we can > check the table size, calculate the number of BRIN ranges, and check > that the range info fits into work_mem, and just not create the path > when it gets too large. That's what we did for HashAgg, although that > decision was unreliable because estimating GROUP BY cardinality is hard. > > The wrinkle here is that counting just the range info (BrinRange struct) > does not include the values for by-reference types. We could use average > width - that's just an estimate, though. > > A more comprehensive solution seems to be to allow requesting chunks of > the BRIN ranges. So that we'd get "slices" of ranges and we'd process > those. So for example if you have 1000 ranges, and you can only handle > 100 at a time, we'd do 10 loops, each requesting 100 ranges. > > This has another problem - we do care about "overlaps", and we can't > really know if the overlapping ranges will be in the same "slice" > easily. The chunks would be sorted (for example) by maxval. But there > can be a range with much higher maxval (thus in some future slice), but > very low minval (thus intersecting with ranges in the current slice). > > Imagine ranges with these minval/maxval values, sorted by maxval: > > [101,200] > [201,300] > [301,400] > [150,500] > > and let's say we can only process 2-range slices. So we'll get the first > two, but both of them intersect with the very last range. > > We could always include all the intersecting ranges into the slice, but > what if there are too many very "wide" ranges? > > So I think this will need to switch to an iterative communication with > the BRIN index - instead of asking "give me info about all the ranges", > we'll need a way to > > - request the next range (sorted by maxval) > - request the intersecting ranges one by one (sorted by minval) > > Of course, the BRIN side will have some of the same challenges with > tracking the info without breaking the work_mem limit, but I suppose it > can store the info into a tuplestore/tuplesort, and use that instead of > plain in-memory array. Alternatively, it could just return those, and > BrinSort would use that. OTOH it seems cleaner to have some sort of API, > especially if we want to support e.g. minmax-multi opclasses, that have > a more complicated concept of "intersection". > > > regards > > -- > Tomas Vondra > EnterpriseDB: http://www.enterprisedb.com <http://www.enterprisedb.com> > The Enterprise PostgreSQL Company > > Hi, > In your example involving [150,500], can this range be broken down into > 4 ranges, ending in 200, 300, 400 and 500, respectively ? > That way, there is no intersection among the ranges. > Not really, I think. These "value ranges" map to "page ranges" and how would you split those? I mean, you know values [150,500] map to blocks [0,127]. You split the values into [150,200], [201,300], [301,400]. How do you split the page range [0,127]? Also, splitting a range into more ranges is likely making the issue worse, because it increases the number of ranges, right? And I mean, much worse, because imagine a "wide" range that overlaps with every other range - the number of ranges would explode. It's not clear to me at which point you'd make the split. At the beginning, right after loading the ranges from BRIN index? A lot of that may be unnecessary, in case the range is loaded as a "non-intersecting" range. Try to formulate the whole algorithm. Maybe I'm missing something. The current algorithm is something like this: 1. request info about ranges from the BRIN opclass 2. sort them by maxval and minval 3. NULLS FIRST: read all ranges that might have NULLs => output 4. read the next range (by maxval) into tuplesort (if no more ranges, go to (9)) 5. load all tuples from "splill" tuplestore, compare to maxval 6. load all tuples from no-summarized ranges (first range only) (into tuplesort/tuplestore, depending on maxval comparison) 7. load all intersecting ranges (with minval < current maxval) (into tuplesort/tuplestore, depending on maxval comparison) 8. sort the tuplesort, output all tuples, then back to (4) 9. NULLS LAST: read all ranges that might have NULLs => output 10. done For "DESC" ordering the process is almost the same, except that we swap minval/maxval in most places. > bq. can store the info into a tuplestore/tuplesort > > Wouldn't this involve disk accesses which may reduce the effectiveness > of BRIN sort ? Yes, it might. But the question is whether the result is still faster than alternative plans (e.g. seqscan+sort), and those are likely to do even more I/O. Moreover, for "regular" cases this shouldn't be a significant issue, because the stuff will fit into work_mem and so there'll be no I/O. But it'll handle those extreme cases gracefully. regards -- Tomas Vondra EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
Tomas Vondra <tomas.vondra@enterprisedb.com> writes:
> I forgot to mention one important issue in my list yesterday, and that's
> memory consumption.
TBH, this is all looking like vastly more complexity than benefit.
It's going to be impossible to produce a reliable cost estimate
given all the uncertainty, and I fear that will end in picking
BRIN-based sorting when it's not actually a good choice.
The examples you showed initially are cherry-picked to demonstrate
the best possible case, which I doubt has much to do with typical
real-world tables. It would be good to see what happens with
not-perfectly-sequential data before even deciding this is worth
spending more effort on. It also seems kind of unfair to decide
that the relevant comparison point is a seqscan rather than a
btree indexscan.
regards, tom lane
On Sun, Oct 16, 2022 at 7:33 AM Tomas Vondra <tomas.vondra@enterprisedb.com> wrote:
On 10/16/22 16:01, Zhihong Yu wrote:
>
>
> On Sun, Oct 16, 2022 at 6:51 AM Tomas Vondra
> <tomas.vondra@enterprisedb.com <mailto:tomas.vondra@enterprisedb.com>>
> wrote:
>
> On 10/15/22 14:33, Tomas Vondra wrote:
> > Hi,
> >
> > ...
> >
> > There's a bunch of issues with this initial version of the patch,
> > usually described in XXX comments in the relevant places.6)
> >
> > ...
>
> I forgot to mention one important issue in my list yesterday, and that's
> memory consumption. The way the patch is coded now, the new BRIN support
> function (brin_minmax_ranges) produces information about *all* ranges in
> one go, which may be an issue. The worst case is 32TB table, with 1-page
> BRIN ranges, which means ~4 billion ranges. The info is an array of ~32B
> structs, so this would require ~128GB of RAM. With the default 128-page
> ranges, it's still be ~1GB, which is quite a lot.
>
> We could have a discussion about what's the reasonable size of BRIN
> ranges on such large tables (e.g. building a bitmap on 4 billion ranges
> is going to be "not cheap" so this is likely pretty rare). But we should
> not introduce new nodes that ignore work_mem, so we need a way to deal
> with such cases somehow.
>
> The easiest solution likely is to check this while planning - we can
> check the table size, calculate the number of BRIN ranges, and check
> that the range info fits into work_mem, and just not create the path
> when it gets too large. That's what we did for HashAgg, although that
> decision was unreliable because estimating GROUP BY cardinality is hard.
>
> The wrinkle here is that counting just the range info (BrinRange struct)
> does not include the values for by-reference types. We could use average
> width - that's just an estimate, though.
>
> A more comprehensive solution seems to be to allow requesting chunks of
> the BRIN ranges. So that we'd get "slices" of ranges and we'd process
> those. So for example if you have 1000 ranges, and you can only handle
> 100 at a time, we'd do 10 loops, each requesting 100 ranges.
>
> This has another problem - we do care about "overlaps", and we can't
> really know if the overlapping ranges will be in the same "slice"
> easily. The chunks would be sorted (for example) by maxval. But there
> can be a range with much higher maxval (thus in some future slice), but
> very low minval (thus intersecting with ranges in the current slice).
>
> Imagine ranges with these minval/maxval values, sorted by maxval:
>
> [101,200]
> [201,300]
> [301,400]
> [150,500]
>
> and let's say we can only process 2-range slices. So we'll get the first
> two, but both of them intersect with the very last range.
>
> We could always include all the intersecting ranges into the slice, but
> what if there are too many very "wide" ranges?
>
> So I think this will need to switch to an iterative communication with
> the BRIN index - instead of asking "give me info about all the ranges",
> we'll need a way to
>
> - request the next range (sorted by maxval)
> - request the intersecting ranges one by one (sorted by minval)
>
> Of course, the BRIN side will have some of the same challenges with
> tracking the info without breaking the work_mem limit, but I suppose it
> can store the info into a tuplestore/tuplesort, and use that instead of
> plain in-memory array. Alternatively, it could just return those, and
> BrinSort would use that. OTOH it seems cleaner to have some sort of API,
> especially if we want to support e.g. minmax-multi opclasses, that have
> a more complicated concept of "intersection".
>
>
> regards
>
> --
> Tomas Vondra
> EnterpriseDB: http://www.enterprisedb.com <http://www.enterprisedb.com>
> The Enterprise PostgreSQL Company
>
> Hi,
> In your example involving [150,500], can this range be broken down into
> 4 ranges, ending in 200, 300, 400 and 500, respectively ?
> That way, there is no intersection among the ranges.
>
Not really, I think. These "value ranges" map to "page ranges" and how
would you split those? I mean, you know values [150,500] map to blocks
[0,127]. You split the values into [150,200], [201,300], [301,400]. How
do you split the page range [0,127]?
Also, splitting a range into more ranges is likely making the issue
worse, because it increases the number of ranges, right? And I mean,
much worse, because imagine a "wide" range that overlaps with every
other range - the number of ranges would explode.
It's not clear to me at which point you'd make the split. At the
beginning, right after loading the ranges from BRIN index? A lot of that
may be unnecessary, in case the range is loaded as a "non-intersecting"
range.
Try to formulate the whole algorithm. Maybe I'm missing something.
The current algorithm is something like this:
1. request info about ranges from the BRIN opclass
2. sort them by maxval and minval
3. NULLS FIRST: read all ranges that might have NULLs => output
4. read the next range (by maxval) into tuplesort
(if no more ranges, go to (9))
5. load all tuples from "splill" tuplestore, compare to maxval
6. load all tuples from no-summarized ranges (first range only)
(into tuplesort/tuplestore, depending on maxval comparison)
7. load all intersecting ranges (with minval < current maxval)
(into tuplesort/tuplestore, depending on maxval comparison)
8. sort the tuplesort, output all tuples, then back to (4)
9. NULLS LAST: read all ranges that might have NULLs => output
10. done
For "DESC" ordering the process is almost the same, except that we swap
minval/maxval in most places.
Hi,
Thanks for the quick reply.
I don't have good answer w.r.t. splitting the page range [0,127] now. Let me think more about it.
The 10 step flow (subject to changes down the road) should be either given in the description of the patch or, written as comment inside the code.
This would help people grasp the concept much faster.
BTW splill seems to be a typo - I assume you meant spill.
Cheers
On 10/16/22 16:41, Tom Lane wrote:
> Tomas Vondra <tomas.vondra@enterprisedb.com> writes:
>> I forgot to mention one important issue in my list yesterday, and that's
>> memory consumption.
>
> TBH, this is all looking like vastly more complexity than benefit.
> It's going to be impossible to produce a reliable cost estimate
> given all the uncertainty, and I fear that will end in picking
> BRIN-based sorting when it's not actually a good choice.
>
Maybe. If it turns out the estimates we have are insufficient to make
good planning decisions, that's life.
As I wrote in my message, I know the BRIN costing is a bit shaky in
general (not just for this new operation), and I intend to propose some
improvement in a separate patch.
I think the main issue with BRIN costing is that we have no stats about
the ranges, and we can't estimate how many ranges we'll really end up
accessing. If you have 100 rows, will that be 1 range or 100 ranges? Or
for the BRIN Sort, how many overlapping ranges will there be?
I intend to allow index AMs to collect custom statistics, and the BRIN
minmax opfamily would collect e.g. this:
1) number of non-summarized ranges
2) number of all-nulls ranges
3) number of has-nulls ranges
4) average number of overlaps (given a random range, how many other
ranges intersect with it)
5) how likely is it for a row to hit multiple ranges (cross-check
sample rows vs. ranges)
I believe this will allow much better / more reliable BRIN costing (the
number of overlaps is particularly useful for the this patch).
> The examples you showed initially are cherry-picked to demonstrate
> the best possible case, which I doubt has much to do with typical
> real-world tables. It would be good to see what happens with
> not-perfectly-sequential data before even deciding this is worth
> spending more effort on.
Yes, the example was trivial "happy case" example. Obviously, the
performance degrades as the data become more random (with ranges wider),
forcing the BRIN Sort to read / sort more tuples.
But let's see an example with less correlated data, say, like this:
create table t (a int) with (fillfactor = 10);
insert into t select i + 10000 * random()
from generate_series(1,10000000) s(i);
With the fillfactor=10, there are ~2500 values per 1MB range, so this
means each range overlaps with ~4 more. The results then look like this:
1) select * from t order by a;
seqscan+sort: 4437 ms
brinsort: 4233 ms
2) select * from t order by a limit 10;
seqscan+sort: 1859 ms
brinsort: 4 ms
If you increase the random factor from 10000 to 100000 (so, 40 ranges),
the seqscan timings remain about the same, while brinsort gets to 5200
and 20 ms. And with 1M, it's ~6000 and 300 ms.
Only at 5000000, where we pretty much read 1/2 the table because the
ranges intersect, we get the same timing as the seqscan (for the LIMIT
query). The "full sort" query is more like 5000 vs. 6600 ms, so slower
but not by a huge amount.
Yes, this is a very simple example. I can do more tests with other
datasets (larger/smaller, different distribution, ...).
> It also seems kind of unfair to decide
> that the relevant comparison point is a seqscan rather than a
> btree indexscan.
>
I don't think it's all that unfair. How likely is it to have both a BRIN
and btree index on the same column? And even if you do have such indexes
(say, on different sets of keys), we kinda already have this costing
issue with index and bitmap index scans.
regards
--
Tomas Vondra
EnterpriseDB: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
On 10/16/22 16:42, Zhihong Yu wrote: > ... > > I don't have good answer w.r.t. splitting the page range [0,127] now. > Let me think more about it. > Sure, no problem. > The 10 step flow (subject to changes down the road) should be either > given in the description of the patch or, written as comment inside the > code. > This would help people grasp the concept much faster. True. I'll add it to the next version of the pach. regards -- Tomas Vondra EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On Sun, 16 Oct 2022 at 16:42, Tom Lane <tgl@sss.pgh.pa.us> wrote: > > It also seems kind of unfair to decide > that the relevant comparison point is a seqscan rather than a > btree indexscan. I think the comparison against full table scan seems appropriate, as the benefit of BRIN is less space usage when compared to other indexes, and better IO selectivity than full table scans. A btree easily requires 10x the space of a normal BRIN index, and may require a lot of random IO whilst scanning. This BRIN-sorted scan would have a much lower random IO cost during its scan, and would help bridge the performance gap between having index that supports ordered retrieval, and no index at all, which is especially steep in large tables. I think that BRIN would be an alternative to btree as a provider of sorted data, even when the table is not 100% clustered. This BRIN-assisted table sort can help reduce the amount of data that is accessed in top-N sorts significantly, both at the index and at the relation level, without having the space overhead of "all sortable columns get a btree index". If BRIN gets its HOT optimization back, the benefits would be even larger, as we would then have an index that can speed up top-N sorts without bloating other indexes, and at very low disk footprint. Columns that are only occasionally accessed in a sorted manner could then get BRIN minmax indexes to support this sort, at minimal overhead to the rest of the application. Kind regards, Matthias van de Meent
First of all, it's really great to see that this is being worked on.
On Sun, 16 Oct 2022 at 16:34, Tomas Vondra
<tomas.vondra@enterprisedb.com> wrote:
> Try to formulate the whole algorithm. Maybe I'm missing something.
>
> The current algorithm is something like this:
>
> 1. request info about ranges from the BRIN opclass
> 2. sort them by maxval and minval
Why sort on maxval and minval? That seems wasteful for effectively all
sorts, where range sort on minval should suffice: If you find a range
that starts at 100 in a list of ranges sorted at minval, you've
processed all values <100. You can't make a similar comparison when
that range is sorted on maxvals.
> 3. NULLS FIRST: read all ranges that might have NULLs => output
> 4. read the next range (by maxval) into tuplesort
> (if no more ranges, go to (9))
> 5. load all tuples from "splill" tuplestore, compare to maxval
Instead of this, shouldn't an update to tuplesort that allows for
restarting the sort be better than this? Moving tuples that we've
accepted into BRINsort state but not yet returned around seems like a
waste of cycles, and I can't think of a reason why it can't work.
> 6. load all tuples from no-summarized ranges (first range only)
> (into tuplesort/tuplestore, depending on maxval comparison)
> 7. load all intersecting ranges (with minval < current maxval)
> (into tuplesort/tuplestore, depending on maxval comparison)
> 8. sort the tuplesort, output all tuples, then back to (4)
> 9. NULLS LAST: read all ranges that might have NULLs => output
> 10. done
>
> For "DESC" ordering the process is almost the same, except that we swap
> minval/maxval in most places.
When I was thinking about this feature at the PgCon unconference, I
was thinking about it more along the lines of the following system
(for ORDER BY col ASC NULLS FIRST):
1. prepare tuplesort Rs (for Rangesort) for BRIN tuples, ordered by
[has_nulls, min ASC]
2. scan info about ranges from BRIN, store them in Rs.
3. Finalize the sorting of Rs.
4. prepare tuplesort Ts (for Tuplesort) for sorting on the specified
column ordering.
5. load all tuples from no-summarized ranges into Ts'
6. while Rs has a block range Rs' with has_nulls:
- Remove Rs' from Rs
- store the tuples of Rs' range in Ts.
We now have all tuples with NULL in our sorted set; max_sorted = (NULL)
7. Finalize the Ts sorted set.
8. While the next tuple Ts' in the Ts tuplesort <= max_sorted
- Remove Ts' from Ts
- Yield Ts'
Now, all tuples up to and including max_sorted are yielded.
9. If there are no more ranges in Rs:
- Yield all remaining tuples from Ts, then return.
10. "un-finalize" Ts, so that we can start adding tuples to that tuplesort.
This is different from Tomas' implementation, as he loads the
tuples into a new tuplestore.
11. get the next item from Rs: Rs'
- remove Rs' from Rs
- assign Rs' min value to max_sorted
- store the tuples of Rs' range in Ts
12. while the next item Rs' from Rs has a min value of max_sorted:
- remove Rs' from Rs
- store the tuples of Rs' range in Ts
13. The 'new' value from the next item from Rs is stored in
max_sorted. If no such item exists, max_sorted is assigned a sentinel
value (+INF)
14. Go to Step 7
This set of operations requires a restarting tuplesort for Ts, but I
don't think that would result in many API changes for tuplesort. It
reduces the overhead of large overlapping ranges, as it doesn't need
to copy all tuples that have been read from disk but have not yet been
returned.
The maximum cost of this tuplesort would be the cost of sorting a
seqscanned table, plus sorting the relevant BRIN ranges, plus the 1
extra compare per tuple and range that are needed to determine whether
the range or tuple should be extracted from the tuplesort. The minimum
cost would be the cost of sorting all BRIN ranges, plus sorting all
tuples in one of the index's ranges.
Kind regards,
Matthias van de Meent
PS. Are you still planning on giving the HOT optimization for BRIN a
second try? I'm fairly confident that my patch at [0] would fix the
issue that lead to the revert of that feature, but it introduced ABI
changes after the feature freeze and thus it didn't get in. The patch
might need some polishing, but I think it shouldn't take too much
extra effort to get into PG16.
[0] https://www.postgresql.org/message-id/CAEze2Wi9%3DBay_%3DrTf8Z6WPgZ5V0tDOayszQJJO%3DR_9aaHvr%2BTg%40mail.gmail.com
On 10/16/22 22:17, Matthias van de Meent wrote: > First of all, it's really great to see that this is being worked on. > > On Sun, 16 Oct 2022 at 16:34, Tomas Vondra > <tomas.vondra@enterprisedb.com> wrote: >> Try to formulate the whole algorithm. Maybe I'm missing something. >> >> The current algorithm is something like this: >> >> 1. request info about ranges from the BRIN opclass >> 2. sort them by maxval and minval > > Why sort on maxval and minval? That seems wasteful for effectively all > sorts, where range sort on minval should suffice: If you find a range > that starts at 100 in a list of ranges sorted at minval, you've > processed all values <100. You can't make a similar comparison when > that range is sorted on maxvals. > Because that allows to identify overlapping ranges quickly. Imagine you have the ranges sorted by maxval, which allows you to add tuples in small increments. But how do you know there's not a range (possibly with arbitrarily high maxval), that however overlaps with the range we're currently processing? Consider these ranges sorted by maxval range #1 [0,100] range #2 [101,200] range #3 [150,250] ... range #1000000 [190,1000000000] processing the range #1 is simple, because there are no overlapping ranges. When processing range #2, that's not the case - the following range #3 is overlapping too, so we need to load the tuples too. But there may be other ranges (in arbitrary distance) also overlapping. So we either have to cross-check everything with everything - that's O(N^2) so not great, or we can invent a way to eliminate ranges that can't overlap. The patch does that by having two arrays - one sorted by maxval, one sorted by minval. After proceeding to the next range by maxval (using the first array), the minval-sorted array is used to detect overlaps. This can be done quickly, because we only care for new matches since the previous range, so we can remember the index to the array and start from it. And we can stop once the minval exceeds the maxval for the range in the first step. Because we'll only sort tuples up to that point. >> 3. NULLS FIRST: read all ranges that might have NULLs => output >> 4. read the next range (by maxval) into tuplesort >> (if no more ranges, go to (9)) >> 5. load all tuples from "splill" tuplestore, compare to maxval > > Instead of this, shouldn't an update to tuplesort that allows for > restarting the sort be better than this? Moving tuples that we've > accepted into BRINsort state but not yet returned around seems like a > waste of cycles, and I can't think of a reason why it can't work. > I don't understand what you mean by "update to tuplesort". Can you elaborate? The point of spilling them into a tuplestore is to make the sort cheaper by not sorting tuples that can't possibly be produced, because the value exceeds the current maxval. Consider ranges sorted by maxval [0,1000] [500,1500] [1001,2000] ... We load tuples from [0,1000] and use 1000 as "threshold" up to which we can sort. But we have to load tuples from the overlapping range(s) too, e.g. from [500,1500] except that all tuples with values > 1000 can't be produced (because there might be yet more ranges intersecting with that part). So why sort these tuples at all? Imagine imperfectly correlated table where each range overlaps with ~10 other ranges. If we feed all of that into the tuplestore, we're now sorting 11x the amount of data. Or maybe I just don't understand what you mean. >> 6. load all tuples from no-summarized ranges (first range only) >> (into tuplesort/tuplestore, depending on maxval comparison) >> 7. load all intersecting ranges (with minval < current maxval) >> (into tuplesort/tuplestore, depending on maxval comparison) >> 8. sort the tuplesort, output all tuples, then back to (4) >> 9. NULLS LAST: read all ranges that might have NULLs => output >> 10. done >> >> For "DESC" ordering the process is almost the same, except that we swap >> minval/maxval in most places. > > When I was thinking about this feature at the PgCon unconference, I > was thinking about it more along the lines of the following system > (for ORDER BY col ASC NULLS FIRST): > > 1. prepare tuplesort Rs (for Rangesort) for BRIN tuples, ordered by > [has_nulls, min ASC] > 2. scan info about ranges from BRIN, store them in Rs. > 3. Finalize the sorting of Rs. > 4. prepare tuplesort Ts (for Tuplesort) for sorting on the specified > column ordering. > 5. load all tuples from no-summarized ranges into Ts' > 6. while Rs has a block range Rs' with has_nulls: > - Remove Rs' from Rs > - store the tuples of Rs' range in Ts. > We now have all tuples with NULL in our sorted set; max_sorted = (NULL) > 7. Finalize the Ts sorted set. > 8. While the next tuple Ts' in the Ts tuplesort <= max_sorted > - Remove Ts' from Ts > - Yield Ts' > Now, all tuples up to and including max_sorted are yielded. > 9. If there are no more ranges in Rs: > - Yield all remaining tuples from Ts, then return. > 10. "un-finalize" Ts, so that we can start adding tuples to that tuplesort. > This is different from Tomas' implementation, as he loads the > tuples into a new tuplestore. > 11. get the next item from Rs: Rs' > - remove Rs' from Rs > - assign Rs' min value to max_sorted > - store the tuples of Rs' range in Ts I don't think this works, because we may get a range (Rs') with very high maxval (thus read very late from Rs), but with very low minval. AFAICS max_sorted must never go back, and this breaks it. > 12. while the next item Rs' from Rs has a min value of max_sorted: > - remove Rs' from Rs > - store the tuples of Rs' range in Ts > 13. The 'new' value from the next item from Rs is stored in > max_sorted. If no such item exists, max_sorted is assigned a sentinel > value (+INF) > 14. Go to Step 7 > > This set of operations requires a restarting tuplesort for Ts, but I > don't think that would result in many API changes for tuplesort. It > reduces the overhead of large overlapping ranges, as it doesn't need > to copy all tuples that have been read from disk but have not yet been > returned. > > The maximum cost of this tuplesort would be the cost of sorting a > seqscanned table, plus sorting the relevant BRIN ranges, plus the 1 > extra compare per tuple and range that are needed to determine whether > the range or tuple should be extracted from the tuplesort. The minimum > cost would be the cost of sorting all BRIN ranges, plus sorting all > tuples in one of the index's ranges. > I'm not a tuplesort expert, but my assumption it's better to sort smaller amounts of rows - which is why the patch sorts only the rows it knows it can actually output. > Kind regards, > > Matthias van de Meent > > PS. Are you still planning on giving the HOT optimization for BRIN a > second try? I'm fairly confident that my patch at [0] would fix the > issue that lead to the revert of that feature, but it introduced ABI > changes after the feature freeze and thus it didn't get in. The patch > might need some polishing, but I think it shouldn't take too much > extra effort to get into PG16. > Thanks for reminding me, I'll take a look before the next CF. regards -- Tomas Vondra EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On Mon, 17 Oct 2022 at 05:43, Tomas Vondra <tomas.vondra@enterprisedb.com> wrote: > > On 10/16/22 22:17, Matthias van de Meent wrote: > > On Sun, 16 Oct 2022 at 16:34, Tomas Vondra > > <tomas.vondra@enterprisedb.com> wrote: > >> Try to formulate the whole algorithm. Maybe I'm missing something. > >> > >> The current algorithm is something like this: > >> > >> 1. request info about ranges from the BRIN opclass > >> 2. sort them by maxval and minval > > > > Why sort on maxval and minval? That seems wasteful for effectively all > > sorts, where range sort on minval should suffice: If you find a range > > that starts at 100 in a list of ranges sorted at minval, you've > > processed all values <100. You can't make a similar comparison when > > that range is sorted on maxvals. > > Because that allows to identify overlapping ranges quickly. > > Imagine you have the ranges sorted by maxval, which allows you to add > tuples in small increments. But how do you know there's not a range > (possibly with arbitrarily high maxval), that however overlaps with the > range we're currently processing? Why do we need to identify overlapping ranges specifically? If you sort by minval, it becomes obvious that any subsequent range cannot contain values < the minval of the next range in the list, allowing you to emit any values less than the next, unprocessed, minmax range's minval. > >> 3. NULLS FIRST: read all ranges that might have NULLs => output > >> 4. read the next range (by maxval) into tuplesort > >> (if no more ranges, go to (9)) > >> 5. load all tuples from "splill" tuplestore, compare to maxval > > > > Instead of this, shouldn't an update to tuplesort that allows for > > restarting the sort be better than this? Moving tuples that we've > > accepted into BRINsort state but not yet returned around seems like a > > waste of cycles, and I can't think of a reason why it can't work. > > > > I don't understand what you mean by "update to tuplesort". Can you > elaborate? Tuplesort currently only allows the following workflow: you to load tuples, then call finalize, then extract tuples. There is currently no way to add tuples once you've started extracting them. For my design to work efficiently or without hacking into the internals of tuplesort, we'd need a way to restart or 'un-finalize' the tuplesort so that it returns to the 'load tuples' phase. Because all data of the previous iteration is already sorted, adding more data shouldn't be too expensive. > The point of spilling them into a tuplestore is to make the sort cheaper > by not sorting tuples that can't possibly be produced, because the value > exceeds the current maxval. Consider ranges sorted by maxval > [...] > > Or maybe I just don't understand what you mean. If we sort the ranges by minval like this: 1. [0,1000] 2. [0,999] 3. [50,998] 4. [100,997] 5. [100,996] 6. [150,995] Then we can load and sort the values for range 1 and 2, and emit all values up to (not including) 50 - the minval of the next, not-yet-loaded range in the ordered list of ranges. Then add the values from range 3 to the set of tuples we have yet to output; sort; and then emit valus up to 100 (range 4's minval), etc. This reduces the amount of tuples in the tuplesort to the minimum amount needed to output any specific value. If the ranges are sorted and loaded by maxval, like your algorithm expects: 1. [150,995] 2. [100,996] 3. [100,997] 4. [50,998] 5. [0,999] 6. [0,1000] We need to load all ranges into the sort before it could start emitting any tuples, as all ranges overlap with the first range. > > [algo] > > I don't think this works, because we may get a range (Rs') with very > high maxval (thus read very late from Rs), but with very low minval. > AFAICS max_sorted must never go back, and this breaks it. max_sorted cannot go back, because it is the min value of the next range in the list of ranges sorted by min value; see also above. There is a small issue in my algorithm where I use <= for yielding values where it should be <, where initialization of max_value to NULL is then be incorrect, but apart from that I don't think there are any issues with the base algorithm. > > The maximum cost of this tuplesort would be the cost of sorting a > > seqscanned table, plus sorting the relevant BRIN ranges, plus the 1 > > extra compare per tuple and range that are needed to determine whether > > the range or tuple should be extracted from the tuplesort. The minimum > > cost would be the cost of sorting all BRIN ranges, plus sorting all > > tuples in one of the index's ranges. > > > > I'm not a tuplesort expert, but my assumption it's better to sort > smaller amounts of rows - which is why the patch sorts only the rows it > knows it can actually output. I see that the two main differences between our designs are in answering these questions: - How do we select table ranges for processing? - How do we handle tuples that we know we can't output yet? For the first, I think the differences are explained above. The main drawback of your selection algorithm seems to be that your algorithm's worst-case is "all ranges overlap", whereas my algorithm's worst case is "all ranges start at the same value", which is only a subset of your worst case. For the second, the difference is whether we choose to sort the tuples that are out-of-bounds, but are already in the working set due to being returned from a range overlapping with the current bound. My algorithm tries to reduce the overhead of increasing the sort boundaries by also sorting the out-of-bound data, allowing for O(n-less-than-newbound) overhead of extending the bounds (total complexity for whole sort O(n-out-of-bound)), and O(n log n) processing of all tuples during insertion. Your algorithm - if I understand it correctly - seems to optimize for faster results within the current bound by not sorting the out-of-bounds data with O(1) processing when out-of-bounds, at the cost of needing O(n-out-of-bound-tuples) operations when the maxval / max_sorted boundary is increased, with a complexity of O(n*m) for an average of n out-of-bound tuples and m bound updates. Lastly, there is the small difference in how the ranges are extracted from BRIN: I prefer and mention an iterative approach where the tuples are extracted from the index and loaded into a tuplesort in some iterative fashion (which spills to disk and does not need all tuples to reside in memory), whereas your current approach was mentioned as (paraphrasing) 'allocate all this data in one chunk and hope that there is enough memory available'. I think this is not so much a disagreement in best approach, but mostly a case of what could be made to work; so in later updates I hope we'll see improvements here. Kind regards, Matthias van de Meent
On 10/17/22 16:00, Matthias van de Meent wrote: > On Mon, 17 Oct 2022 at 05:43, Tomas Vondra > <tomas.vondra@enterprisedb.com> wrote: >> >> On 10/16/22 22:17, Matthias van de Meent wrote: >>> On Sun, 16 Oct 2022 at 16:34, Tomas Vondra >>> <tomas.vondra@enterprisedb.com> wrote: >>>> Try to formulate the whole algorithm. Maybe I'm missing something. >>>> >>>> The current algorithm is something like this: >>>> >>>> 1. request info about ranges from the BRIN opclass >>>> 2. sort them by maxval and minval >>> >>> Why sort on maxval and minval? That seems wasteful for effectively all >>> sorts, where range sort on minval should suffice: If you find a range >>> that starts at 100 in a list of ranges sorted at minval, you've >>> processed all values <100. You can't make a similar comparison when >>> that range is sorted on maxvals. >> >> Because that allows to identify overlapping ranges quickly. >> >> Imagine you have the ranges sorted by maxval, which allows you to add >> tuples in small increments. But how do you know there's not a range >> (possibly with arbitrarily high maxval), that however overlaps with the >> range we're currently processing? > > Why do we need to identify overlapping ranges specifically? If you > sort by minval, it becomes obvious that any subsequent range cannot > contain values < the minval of the next range in the list, allowing > you to emit any values less than the next, unprocessed, minmax range's > minval. > D'oh! I think you're right, it should be possible to do this with only sort by minval. And it might actually be better way to do that. I think I chose the "maxval" ordering because it seemed reasonable. Looking at the current range and using the maxval as the threshold seemed reasonable. But it leads to a bunch of complexity with the intersecting ranges, and I never reconsidered this choice. Silly me. >>>> 3. NULLS FIRST: read all ranges that might have NULLs => output >>>> 4. read the next range (by maxval) into tuplesort >>>> (if no more ranges, go to (9)) >>>> 5. load all tuples from "splill" tuplestore, compare to maxval >>> >>> Instead of this, shouldn't an update to tuplesort that allows for >>> restarting the sort be better than this? Moving tuples that we've >>> accepted into BRINsort state but not yet returned around seems like a >>> waste of cycles, and I can't think of a reason why it can't work. >>> >> >> I don't understand what you mean by "update to tuplesort". Can you >> elaborate? > > Tuplesort currently only allows the following workflow: you to load > tuples, then call finalize, then extract tuples. There is currently no > way to add tuples once you've started extracting them. > > For my design to work efficiently or without hacking into the > internals of tuplesort, we'd need a way to restart or 'un-finalize' > the tuplesort so that it returns to the 'load tuples' phase. Because > all data of the previous iteration is already sorted, adding more data > shouldn't be too expensive. > Not sure. I still think it's better to limit the amount of data we have in the tuplesort. Even if the tuplesort can efficiently skip the already sorted part, it'll still occupy disk space, possibly even force the data to disk etc. (We'll still have to write that into a tuplestore, but that should be relatively small and short-lived/recycled). FWIW I wonder if the assumption that tuplesort can quickly skip already sorted data holds e.g. for tuplesorts much larger than work_mem, but I haven't checked that. I'd also like to include some more info in the explain, like how many times we did a sort, and what was the largest amount of data we sorted. Although, maybe that could be tracked by tracking the tuplesort size of the last sort. Considering the tuplesort does not currently support this, I'll probably stick to the existing approach with separate tuplestore. There's enough complexity in the patch already, I think. The only thing we'll need with the minval ordering is the ability to "peek ahead" to the next minval (which is going to be the threshold used to route values either to tuplesort or tuplestore). >> The point of spilling them into a tuplestore is to make the sort cheaper >> by not sorting tuples that can't possibly be produced, because the value >> exceeds the current maxval. Consider ranges sorted by maxval >> [...] >> >> Or maybe I just don't understand what you mean. > > If we sort the ranges by minval like this: > > 1. [0,1000] > 2. [0,999] > 3. [50,998] > 4. [100,997] > 5. [100,996] > 6. [150,995] > > Then we can load and sort the values for range 1 and 2, and emit all > values up to (not including) 50 - the minval of the next, > not-yet-loaded range in the ordered list of ranges. Then add the > values from range 3 to the set of tuples we have yet to output; sort; > and then emit valus up to 100 (range 4's minval), etc. This reduces > the amount of tuples in the tuplesort to the minimum amount needed to > output any specific value. > > If the ranges are sorted and loaded by maxval, like your algorithm expects: > > 1. [150,995] > 2. [100,996] > 3. [100,997] > 4. [50,998] > 5. [0,999] > 6. [0,1000] > > We need to load all ranges into the sort before it could start > emitting any tuples, as all ranges overlap with the first range. > Right, thanks - I get this now. >>> [algo] >> >> I don't think this works, because we may get a range (Rs') with very >> high maxval (thus read very late from Rs), but with very low minval. >> AFAICS max_sorted must never go back, and this breaks it. > > max_sorted cannot go back, because it is the min value of the next > range in the list of ranges sorted by min value; see also above. > > There is a small issue in my algorithm where I use <= for yielding > values where it should be <, where initialization of max_value to NULL > is then be incorrect, but apart from that I don't think there are any > issues with the base algorithm. > >>> The maximum cost of this tuplesort would be the cost of sorting a >>> seqscanned table, plus sorting the relevant BRIN ranges, plus the 1 >>> extra compare per tuple and range that are needed to determine whether >>> the range or tuple should be extracted from the tuplesort. The minimum >>> cost would be the cost of sorting all BRIN ranges, plus sorting all >>> tuples in one of the index's ranges. >>> >> >> I'm not a tuplesort expert, but my assumption it's better to sort >> smaller amounts of rows - which is why the patch sorts only the rows it >> knows it can actually output. > > I see that the two main differences between our designs are in > answering these questions: > > - How do we select table ranges for processing? > - How do we handle tuples that we know we can't output yet? > > For the first, I think the differences are explained above. The main > drawback of your selection algorithm seems to be that your algorithm's > worst-case is "all ranges overlap", whereas my algorithm's worst case > is "all ranges start at the same value", which is only a subset of > your worst case. > Right, those are very good points. > For the second, the difference is whether we choose to sort the tuples > that are out-of-bounds, but are already in the working set due to > being returned from a range overlapping with the current bound. > My algorithm tries to reduce the overhead of increasing the sort > boundaries by also sorting the out-of-bound data, allowing for > O(n-less-than-newbound) overhead of extending the bounds (total > complexity for whole sort O(n-out-of-bound)), and O(n log n) > processing of all tuples during insertion. > Your algorithm - if I understand it correctly - seems to optimize for > faster results within the current bound by not sorting the > out-of-bounds data with O(1) processing when out-of-bounds, at the > cost of needing O(n-out-of-bound-tuples) operations when the maxval / > max_sorted boundary is increased, with a complexity of O(n*m) for an > average of n out-of-bound tuples and m bound updates. > Right. I wonder if we these are actually complementary approaches, and we could/should pick between them depending on how many rows we expect to consume. My focus was LIMIT queries, so I favored the approach with the lowest startup cost. I haven't quite planned for this to work so well even in full-sort cases. That kinda surprised me (I wonder if the very large tuplesorts - compared to work_mem - would hurt this, though). > Lastly, there is the small difference in how the ranges are extracted > from BRIN: I prefer and mention an iterative approach where the tuples > are extracted from the index and loaded into a tuplesort in some > iterative fashion (which spills to disk and does not need all tuples > to reside in memory), whereas your current approach was mentioned as > (paraphrasing) 'allocate all this data in one chunk and hope that > there is enough memory available'. I think this is not so much a > disagreement in best approach, but mostly a case of what could be made > to work; so in later updates I hope we'll see improvements here. > Right. I think I mentioned this in my post [1], where I also envisioned some sort of iterative approach. And I think you're right the approach with ordering by minval is naturally more suitable because it just consumes the single sequence of ranges. regards [1] https://www.postgresql.org/message-id/1a7c2ff5-a855-64e9-0272-1f9947f8a558%40enterprisedb.com -- Tomas Vondra EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
Hi, here's an updated/reworked version of the patch, on top of the "BRIN statistics" patch as 0001 (because some of the stuff is useful, but we can ignore this part in this thread). Warning: I realized the new node is somewhat broken when it comes to projection and matching the indexed column, most likely because the targetlists are wired/processed incorrectly or something like that. So when experimenting with this, just index the first column of the table and don't do anything requiring a projection. I'll get this fixed, but I've been focusing on the other stuff. I'm not particularly familiar with this tlist/project stuff, so any help is welcome. The main change in this version is the adoption of multiple ideas suggested by Matthias in his earlier responses. Firstly, this changes how the index opclass passes information to the executor node. Instead of using a plain array, we now use a tuplesort. This addresses the memory consumption issues with large number of ranges, and it also simplifies the sorting etc. which is now handled by the tuplesort. The support procedure simply fills a tuplesort and then hands it over to the caller (more or less). Secondly, instead of ordering the ranges by maxval, this orders them by minval (as suggested by Matthias), which greatly simplifies the code because we don't need to detect overlapping ranges etc. More precisely, the ranges are sorted to get this ordering - not yet summarized ranges - ranges sorted by (minval, blkno) - all-nulls ranges This particular ordering is beneficial for the algorithm, which does two passes over the ranges. For the NULLS LAST case (i.e. the default), we do this: - produce tuples with non-NULL values, ordered by the value - produce tuples with NULL values (arbitrary order) And each of these phases does a separate pass over the ranges (I'll get to that in a minute). And the ordering is tailored to this. Note: For DESC we'd sort by maxval, and for NULLS FIRST the phases would happen in the opposite order, but those are details. Let's assume ASC ordering with NULLS LAST, unless stated otherwise. The idea here is that all not-summarized ranges need to be processed always, both when processing NULLs and non-NULL values, which happens as two separate passes over ranges. The all-null ranges don't need to be processed during the non-NULL pass, and we can terminate this pass early once we hit the first null-only range. So placing them last helps with this. The regular ranges are ordered by minval, as dictated by the algorithm (which is now described in nodeBrinSort.c comment), but we also sort them by blkno to make this a bit more sequential (but this only matters for ranges with the same minval, and that's probably rare, but the extra sort key is also cheap so why not). I mentioned we do two separate passes - one for non-NULL values, one for NULL values. That may be somewhat inefficient, because in extreme cases we might end up scanning the whole table twice (imagine BRIN ranges where each range has both regular values and NULLs). It might be possible to do all of this in a single pass, at least in some cases - for example while scanning ranges, we might stash NULL rows into a tuplestore, so that the second pass is not needed. That assumes there are not too many such rows (otherwise we might need to write and then read many rows, outweighing the cost of just doing two passes). This should be possible to estimate/cost fairly well, I think, and the comment in nodeBrinSort actually presents some ideas about this. And we can't do that for the NULLS FIRST case, because if we stash the non-NULL rows somewhere, we won't be able to do the "incremental" sort, i.e. we might just do regular Sort right away. So I've kept this simple approach with two passes for now. This still uses the approach with spilling tuples to a tuplestore, and only sorting rows that we know are safe to output. I still think this is a good approach, for the reasons I explained before, but changing this is not hard so we can experiment. There's however a related question - how quickly should we increment the minval value, serving as a watermark? One option is to go to the next distinct minval value - but that may result in excessive number of tiny sorts, because the number ranges and rows between the old and new minval values tends to be small. Another negative consequence is that this may cause of lot of spilling (and re-spilling), because we only consume tiny number of rows from the tuplestore after incrementing the watermark. Or we can do larger steps, skipping some of the minval values, so that more rows quality into the sort. Of course, too large step means we'll exceed work_mem and switch to an on-disk sort, which we probably don't want. Also, this may be the wrong thing to do for LIMIT queries, that only need a couple rows, and a tiny sort is fine (because we won't do too many of them). Patch 0004 introduces a new GUC called brinsort_watermark_step, that can be used to experiment with this. By default it's set to '1' which means we simply progress to the next minval value. Then 0005 tries to customize this based on statistics - we estimate the number of rows we expect to get for each minval increment to "add" and then pick just a step value not to overflow work_mem. This happens in create_brinsort_plan, and the comment explains the main weakness - the way the number of rows is estimated is somewhat naive, as it just divides reltuples by number of ranges. But I have a couple ideas about what statistics we might collect, explained in 0001 in the comment at brin_minmax_stats. But there's another option - we can tune the step based on past sorts. If we see the sorts are doing on-disk sort, maybe try doing smaller steps. Patch 0006 implements a very simple variant of this. There's a couple ideas about how it might be improved, mentioned in the comment at brinsort_adjust_watermark_step. There's also patch 0003, which extends the EXPLAIN output with a counters tracking the number of sorts, counts of on-disk/in-memory sorts, space used, number of rows sorted/spilled, and so on. This is useful when analyzing e.g. the effect of higher/lower watermark steps, discussed in the preceding paragraphs. regards -- Tomas Vondra EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
Attachment
- 0001-Allow-index-AMs-to-build-and-use-custom-sta-20221022.patch
- 0002-Allow-BRIN-indexes-to-produce-sorted-output-20221022.patch
- 0003-wip-brinsort-explain-stats-20221022.patch
- 0004-wip-multiple-watermark-steps-20221022.patch
- 0005-wip-adjust-watermark-step-20221022.patch
- 0006-wip-adaptive-watermark-step-20221022.patch
On Sat, Oct 15, 2022 at 02:33:50PM +0200, Tomas Vondra wrote:
> Of course, if there are e.g. BTREE indexes this is going to be slower,
> but people are unlikely to have both index types on the same column.
On Sun, Oct 16, 2022 at 05:48:31PM +0200, Tomas Vondra wrote:
> I don't think it's all that unfair. How likely is it to have both a BRIN
> and btree index on the same column? And even if you do have such indexes
Note that we (at my work) use unique, btree indexes on multiple columns
for INSERT ON CONFLICT into the most-recent tables: UNIQUE(a,b,c,...),
plus a separate set of indexes on all tables, used for searching:
BRIN(a) and BTREE(b). I'd hope that the costing is accurate enough to
prefer the btree index for searching the most-recent table, if that's
what's faster (for example, if columns b and c are specified).
> + /* There must not be any TID scan in progress yet. */
> + Assert(node->ss.ss_currentScanDesc == NULL);
> +
> + /* Initialize the TID range scan, for the provided block range. */
> + if (node->ss.ss_currentScanDesc == NULL)
> + {
Why is this conditional on the condition that was just Assert()ed ?
>
> +void
> +cost_brinsort(BrinSortPath *path, PlannerInfo *root, double loop_count,
> + bool partial_path)
It's be nice to refactor existing code to avoid this part being so
duplicitive.
> + * In some situations (particularly with OR'd index conditions) we may
> + * have scan_clauses that are not equal to, but are logically implied by,
> + * the index quals; so we also try a predicate_implied_by() check to see
Isn't that somewhat expensive ?
If that's known, then it'd be good to say that in the documentation.
> + {
> + {"enable_brinsort", PGC_USERSET, QUERY_TUNING_METHOD,
> + gettext_noop("Enables the planner's use of BRIN sort plans."),
> + NULL,
> + GUC_EXPLAIN
> + },
> + &enable_brinsort,
> + false,
I think new GUCs should be enabled during patch development.
Maybe in a separate 0002 patch "for CI only not for commit".
That way "make check" at least has a chance to hit that new code paths.
Also, note that indxpath.c had the var initialized to true.
> + attno = (i + 1);
> + nranges = (nblocks / pagesPerRange);
> + node->bs_phase = (nullsFirst) ? BRINSORT_LOAD_NULLS : BRINSORT_LOAD_RANGE;
I'm curious why you have parenthesis these places ?
> +#ifndef NODEBrinSort_H
> +#define NODEBrinSort_H
NODEBRIN_SORT would be more consistent with NODEINCREMENTALSORT.
But I'd prefer NODE_* - otherwise it looks like NO DEBRIN.
This needed a bunch of work needed to pass any of the regression tests -
even with the feature set to off.
. meson.build needs the same change as the corresponding ./Makefile.
. guc missing from postgresql.conf.sample
. brin_validate.c is missing support for the opr function.
I gather you're planning on changing this part (?) but this allows to
pass tests for now.
. mingw is warning about OidIsValid(pointer) in nodeBrinSort.c.
https://cirrus-ci.com/task/5771227447951360?logs=mingw_cross_warning#L969
. Uninitialized catalog attribute.
. Some typos in your other patches: "heuristics heuristics". ste.
lest (least).
--
Justin
Attachment
On 10/24/22 06:32, Justin Pryzby wrote:
> On Sat, Oct 15, 2022 at 02:33:50PM +0200, Tomas Vondra wrote:
>> Of course, if there are e.g. BTREE indexes this is going to be slower,
>> but people are unlikely to have both index types on the same column.
>
> On Sun, Oct 16, 2022 at 05:48:31PM +0200, Tomas Vondra wrote:
>> I don't think it's all that unfair. How likely is it to have both a BRIN
>> and btree index on the same column? And even if you do have such indexes
>
> Note that we (at my work) use unique, btree indexes on multiple columns
> for INSERT ON CONFLICT into the most-recent tables: UNIQUE(a,b,c,...),
> plus a separate set of indexes on all tables, used for searching:
> BRIN(a) and BTREE(b). I'd hope that the costing is accurate enough to
> prefer the btree index for searching the most-recent table, if that's
> what's faster (for example, if columns b and c are specified).
>
Well, the costing is very crude at the moment - at the moment it's
pretty much just a copy of the existing BRIN costing. And the cost is
likely going to increase, because brinsort needs to do regular BRIN
bitmap scan (more or less) and then also a sort (which is an extra cost,
of course). So if it works now, I don't see why would brinsort break it.
Moreover, if you don't have ORDER BY in the query, I don't see why would
we create a brinsort at all.
But if you could test this once the costing gets improved, that'd be
very valuable.
>> + /* There must not be any TID scan in progress yet. */
>> + Assert(node->ss.ss_currentScanDesc == NULL);
>> +
>> + /* Initialize the TID range scan, for the provided block range. */
>> + if (node->ss.ss_currentScanDesc == NULL)
>> + {
>
> Why is this conditional on the condition that was just Assert()ed ?
>
Yeah, that's a mistake, due to how the code evolved.
>>
>> +void
>> +cost_brinsort(BrinSortPath *path, PlannerInfo *root, double loop_count,
>> + bool partial_path)
>
> It's be nice to refactor existing code to avoid this part being so
> duplicitive.
>
>> + * In some situations (particularly with OR'd index conditions) we may
>> + * have scan_clauses that are not equal to, but are logically implied by,
>> + * the index quals; so we also try a predicate_implied_by() check to see
>
> Isn't that somewhat expensive ?
>
> If that's known, then it'd be good to say that in the documentation.
>
Some of this is probably a residue from create_indexscan_path and may
not be needed for this new node.
>> + {
>> + {"enable_brinsort", PGC_USERSET, QUERY_TUNING_METHOD,
>> + gettext_noop("Enables the planner's use of BRIN sort plans."),
>> + NULL,
>> + GUC_EXPLAIN
>> + },
>> + &enable_brinsort,
>> + false,
>
> I think new GUCs should be enabled during patch development.
> Maybe in a separate 0002 patch "for CI only not for commit".
> That way "make check" at least has a chance to hit that new code paths.
>
> Also, note that indxpath.c had the var initialized to true.
>
Good point.
>> + attno = (i + 1);
>> + nranges = (nblocks / pagesPerRange);
>> + node->bs_phase = (nullsFirst) ? BRINSORT_LOAD_NULLS : BRINSORT_LOAD_RANGE;
>
> I'm curious why you have parenthesis these places ?
>
Not sure, it seemed more readable when writing the code I guess.
>> +#ifndef NODEBrinSort_H
>> +#define NODEBrinSort_H
>
> NODEBRIN_SORT would be more consistent with NODEINCREMENTALSORT.
> But I'd prefer NODE_* - otherwise it looks like NO DEBRIN.
>
Yeah, stupid search/replace on the indescan code, which was used as a
starting point.
> This needed a bunch of work needed to pass any of the regression tests -
> even with the feature set to off.
>
> . meson.build needs the same change as the corresponding ./Makefile.
> . guc missing from postgresql.conf.sample
> . brin_validate.c is missing support for the opr function.
> I gather you're planning on changing this part (?) but this allows to
> pass tests for now.
> . mingw is warning about OidIsValid(pointer) in nodeBrinSort.c.
> https://cirrus-ci.com/task/5771227447951360?logs=mingw_cross_warning#L969
> . Uninitialized catalog attribute.
> . Some typos in your other patches: "heuristics heuristics". ste.
> lest (least).
>
Thanks, I'll get this fixed. I've posted the patch as a PoC to showcase
it and gather some feedback, I should have mentioned it's incomplete in
these ways.
regards
--
Tomas Vondra
EnterpriseDB: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
Fwiw tuplesort does do something like what you want for the top-k case. At least it used to last I looked -- not sure if it went out with the tapesort ... For top-k it inserts new tuples into the heap data structure and then pops the top element out of the hash. That keeps a fixed number of elements in the heap. It's always inserting and removing at the same time. I don't think it would be very hard to add a tuplesort interface to access that behaviour. For something like BRIN you would sort the ranges by minvalue then insert all the tuples for each range. Before inserting tuples for a new range you would first pop out all the tuples that are < the minvalue for the new range. I'm not sure how you handle degenerate BRIN indexes that behave terribly. Like, if many BRIN ranges covered the entire key range. Perhaps there would be a clever way to spill the overflow and switch to quicksort for the spilled tuples without wasting lots of work already done and without being too inefficient.
On 11/16/22 22:52, Greg Stark wrote: > Fwiw tuplesort does do something like what you want for the top-k > case. At least it used to last I looked -- not sure if it went out > with the tapesort ... > > For top-k it inserts new tuples into the heap data structure and then > pops the top element out of the hash. That keeps a fixed number of > elements in the heap. It's always inserting and removing at the same > time. I don't think it would be very hard to add a tuplesort interface > to access that behaviour. > Bounded sorts are still there, implemented using a heap (which is what you're talking about, I think). I actually looked at it some time ago, and it didn't look like a particularly good match for the general case (without explicit LIMIT). Bounded sorts require specifying number of tuples, and then discard the remaining tuples. But you don't know how many tuples you'll actually find until the next minval - you have to keep them all. Maybe we could feed the tuples into a (sorted) heap incrementally, and consume tuples until the next minval value. I'm not against exploring that idea, but it certainly requires more work than just slapping some interface to existing code. > For something like BRIN you would sort the ranges by minvalue then > insert all the tuples for each range. Before inserting tuples for a > new range you would first pop out all the tuples that are < the > minvalue for the new range. > Well, yeah. That's pretty much exactly what the last version of this patch (from October 23) does. > I'm not sure how you handle degenerate BRIN indexes that behave > terribly. Like, if many BRIN ranges covered the entire key range. > Perhaps there would be a clever way to spill the overflow and switch > to quicksort for the spilled tuples without wasting lots of work > already done and without being too inefficient. In two ways: 1) Don't have such BRIN index - if it has many degraded ranges, it's bound to perform poorly even for WHERE conditions. We've lived with this until now, I don't think this makes the issue any worse. 2) Improving statistics for BRIN indexes - until now the BRIN costing is very crude, we have almost no information about how wide the ranges are, how much they overlap, etc. The 0001 part (discussed in a thread [1]) aims to provide much better statistics. Yes, the costing still doesn't use that information very much. regards [1] https://commitfest.postgresql.org/40/3952/ -- Tomas Vondra EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
Hi, On 2022-11-17 00:52:35 +0100, Tomas Vondra wrote: > Well, yeah. That's pretty much exactly what the last version of this > patch (from October 23) does. That version unfortunately doesn't build successfully: https://cirrus-ci.com/task/5108789846736896 [03:02:48.641] Duplicate OIDs detected: [03:02:48.641] 9979 [03:02:48.641] 9980 [03:02:48.641] found 2 duplicate OID(s) in catalog data Greetings, Andres Freund
Hi,
Here's an updated version of this patch series. There's still plenty of
stuff to improve, but it fixes a number of issues I mentioned earlier.
The two most important changes are:
1) handling of projections
Until now queries with projection might have failed, due to not using
the right slot, bogus var references and so on. The code was somewhat
confused because the new node is somewhere in between a scan node and a
sort (or more precisely, it combines both).
I believe this version handles all of this correctly - the code that
initializes the slots/projection info etc. needs serious cleanup, but
should be correct.
2) handling of expressions
The other improvement is handling of expressions - if you have a BRIN
index on an expression, this should now work too. This also includes
correct handling of collations (which the previous patches ignored).
Similarly to the projections, I believe the code is correct but needs
cleanup. In particular, I haven't paid close attention to memory
management, so there might be memory leaks when evaluating expressions.
The last two parts of the patch series (0009 and 0010) are about
testing. 0009 adds a regular regression test with various combinations
(projections, expressions, single- vs. multi-column indexes, ...).
0010 introduces a python script that randomly generates data sets,
indexes and queries. I use it to both test random combinations and to
evaluate performance. I don't expect it to be committed etc. - it's
included only to keep it versioned with the rest of the patch.
I did some basic benchmarking using the 0010 part, to evaluate the how
this works for various cases. The script varies a number of parameters:
- number of rows
- table fill factor
- randomness (how much ranges overlapp)
- pages per range
- limit / offset for queries
- ...
The script forces both a "seqscan" and "brinsort" plan, and collects
timing info.
The results are encouraging, I think. Attached are two charts, plotting
speedup vs. fraction of tuples the query has to sort.
speedup = (seqscan timing / brinsort timing)
fraction = (limit + offset) / (table rows)
A query with "limit 1 offset 0" has fraction ~0.0, query that scans
everything (perhaps because it has no LIMIT/OFFSET) has ~1.0.
For speedup, 1.0 means "no change" while values above 1.0 means the
query gets faster. Both plots have log-scale y-axis.
brinsort-all-data.gif shows results for all queries. There's significant
speedup for small values of fraction (i.e. queries with limit, requiring
few rows). This is expected, as this is pretty much the primary use case
for the patch.
The other thing is that the benefits quickly diminish - for fractions
close to 0.0 the potential benefits are huge, but once you cross ~10% of
the table, it's within 10x, for ~25% less than 5x etc.
OTOH there are also a fair number of queries that got slower - those are
the data points below 1.0. I've looked into many of them, and there are
a couple reasons why that can happen:
1) random data set - When the ranges are very wide, BRIN Sort has to
read most of the data, and it ends up sorting almost as many rows as the
sequential scan. But it's more expensive, especially when combined with
the following points.
Note: I don't think is an issue in practice, because BRIN indexes
would suck quite badly on such data, so no one is going to create
such indexes in the first place.
2) tiny ranges - By default ranges are 1MB, but it's possible to make
them much smaller. But BRIN Sort has to read/sort all ranges, and that
gets more expensive with the number of ranges.
Note: I'm not sure there's a way around this, although Matthias
had some interesting ideas about how to keep the ranges sorted.
But ultimately, I think this is fine, as long as it's costed
correctly. For fractions close to 0.0 this is still going to be
a huge win.
3) non-adaptive (and low) watermark_step - The number of sorts makes a
huge difference - in an extreme case we could add the ranges one by one,
with a sort after each. For small limit/offset that works, but for more
rows it's quite pointless.
Note: The adaptive step (adjusted during execution) works great, and
the script sets explicit values mostly to trigger more corner cases.
Also, I wonder if we should force higher values as we progress
through the table - we still don't want to exceed work_mem, but the
larger fraction we scan the more we should prefer larger "batches".
The second "filter" chart (brinsort-filtered-data.gif) shows results
filtered to only show runs with:
- pages_per_range >= 32
- randomness <= 5% (i.e. each range covers about 5% of domain)
- adaptive step (= -1)
And IMO this looks much better - there are almost no slower queries,
except for a bunch of queries that scan all the data.
So, what are the next steps for this patch:
1) cleanup of the existing code (mentioned above)
2) improvement of the costing - This is probably the critical part,
because we need a costing that allows us to identify the queries that
are likely to be faster/slower. I believe this is doable - either now or
using the new opclass-specific stats proposed in a separate patch (and
kept in part 0001 for completeness).
regards
--
Tomas Vondra
EnterpriseDB: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
Attachment
- brinsort-filtered-data.gif
- brinsort-all-data.gif
- 0001-Allow-index-AMs-to-build-and-use-custom-sta-20230206.patch
- 0002-wip-introduce-debug_brin_stats-20230206.patch
- 0003-wip-introduce-debug_brin_cross_check-20230206.patch
- 0004-Allow-BRIN-indexes-to-produce-sorted-output-20230206.patch
- 0005-wip-brinsort-explain-stats-20230206.patch
- 0006-wip-multiple-watermark-steps-20230206.patch
- 0007-wip-adjust-watermark-step-20230206.patch
- 0008-wip-adaptive-watermark-step-20230206.patch
- 0009-wip-add-brin_sort.sql-test-20230206.patch
- 0010-wip-test-generator-script-20230206.patch
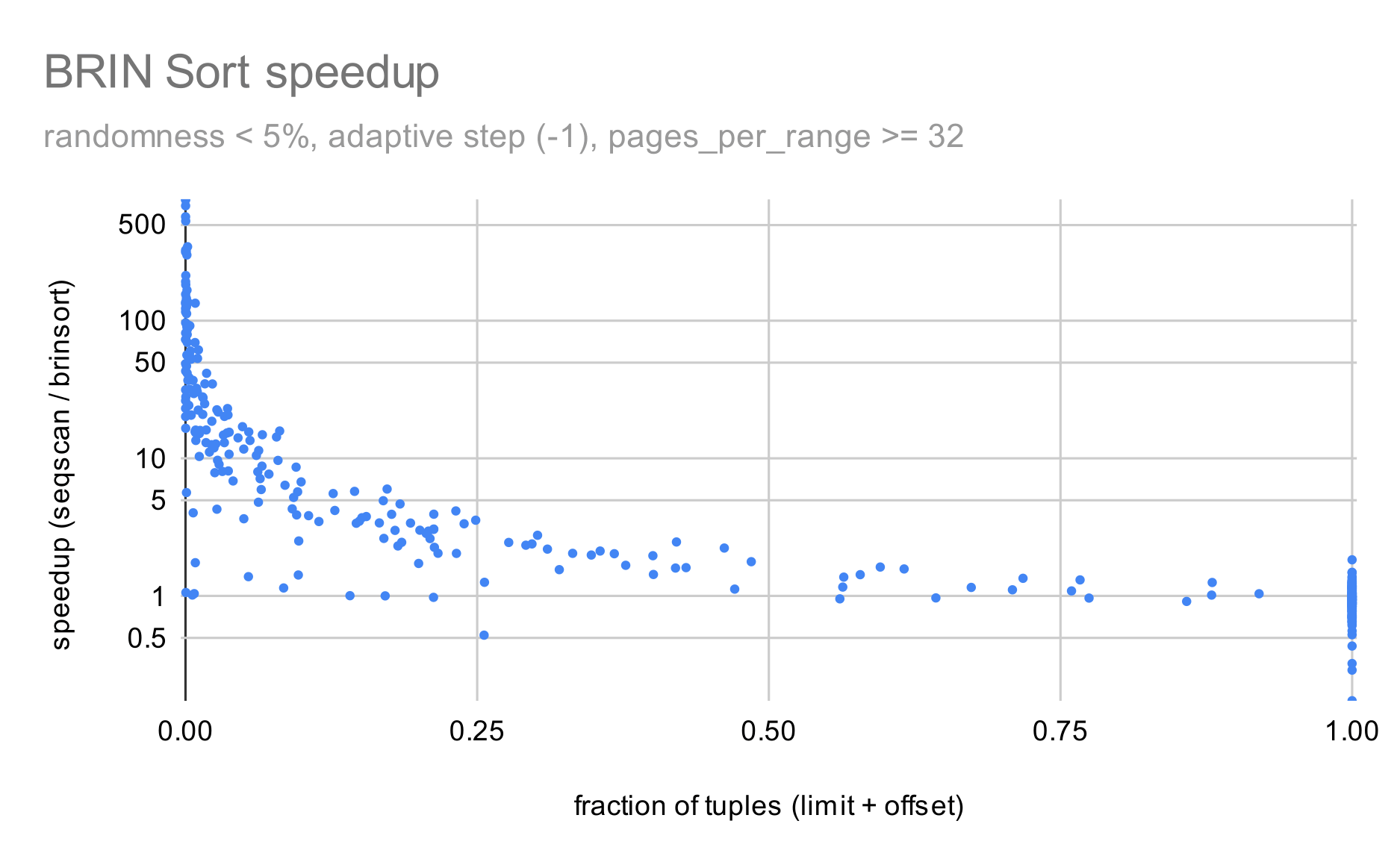{kind=link}
{kind=link}
Hi, Rebased version of the patches, fixing only minor conflicts. regards -- Tomas Vondra EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
Attachment
- 0001-Allow-index-AMs-to-build-and-use-custom-sta-20230216.patch
- 0002-wip-introduce-debug_brin_stats-20230216.patch
- 0003-wip-introduce-debug_brin_cross_check-20230216.patch
- 0004-Allow-BRIN-indexes-to-produce-sorted-output-20230216.patch
- 0005-wip-brinsort-explain-stats-20230216.patch
- 0006-wip-multiple-watermark-steps-20230216.patch
- 0007-wip-adjust-watermark-step-20230216.patch
- 0008-wip-adaptive-watermark-step-20230216.patch
- 0009-wip-add-brin_sort.sql-test-20230216.patch
- 0010-wip-test-generator-script-20230216.patch
On Thu, Feb 16, 2023 at 03:07:59PM +0100, Tomas Vondra wrote:
> Rebased version of the patches, fixing only minor conflicts.
Per cfbot, the patch fails on 32 bit builds.
+ERROR: count mismatch: 0 != 1000
And causes warnings in mingw cross-compile.
On Sun, Oct 23, 2022 at 11:32:37PM -0500, Justin Pryzby wrote:
> I think new GUCs should be enabled during patch development.
> Maybe in a separate 0002 patch "for CI only not for commit".
> That way "make check" at least has a chance to hit that new code
> paths.
>
> Also, note that indxpath.c had the var initialized to true.
In your patch, the amstats guc is still being set to false during
startup by the guc machinery. And the tests crash everywhere if it's
set to on:
TRAP: failed Assert("(nmatches_unique >= 1) && (nmatches_unique <= unique[nvalues-1])"), File:
"../src/backend/access/brin/brin_minmax.c",Line: 644, PID: 25519
> . Some typos in your other patches: "heuristics heuristics". ste.
> lest (least).
These are still present.
--
Justin
On 2/16/23 17:10, Justin Pryzby wrote:
> On Thu, Feb 16, 2023 at 03:07:59PM +0100, Tomas Vondra wrote:
>> Rebased version of the patches, fixing only minor conflicts.
>
> Per cfbot, the patch fails on 32 bit builds.
> +ERROR: count mismatch: 0 != 1000
>
> And causes warnings in mingw cross-compile.
>
There was a silly mistake in trying to store block numbers as bigint
when sorting the ranges, instead of uint32. That happens to work on
64-bit systems, but on 32-bit systems it produces bogus block.
The attached should fix that - it passes on 32-bit arm, even with
valgrind and all that.
> On Sun, Oct 23, 2022 at 11:32:37PM -0500, Justin Pryzby wrote:
>> I think new GUCs should be enabled during patch development.
>> Maybe in a separate 0002 patch "for CI only not for commit".
>> That way "make check" at least has a chance to hit that new code
>> paths.
>>
>> Also, note that indxpath.c had the var initialized to true.
>
> In your patch, the amstats guc is still being set to false during
> startup by the guc machinery. And the tests crash everywhere if it's
> set to on:
>
> TRAP: failed Assert("(nmatches_unique >= 1) && (nmatches_unique <= unique[nvalues-1])"), File:
"../src/backend/access/brin/brin_minmax.c",Line: 644, PID: 25519
>
Right, that was a silly thinko in building the stats, and I found a
couple more issues nearby. Should be fixed in the attached version.
>> . Some typos in your other patches: "heuristics heuristics". ste.
>> lest (least).
>
> These are still present.
Thanks for reminding me, those should be fixed too now.
regards
--
Tomas Vondra
EnterpriseDB: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
Attachment
- 0001-Allow-index-AMs-to-build-and-use-custom-sta-20230218.patch
- 0002-wip-introduce-debug_brin_stats-20230218.patch
- 0003-wip-introduce-debug_brin_cross_check-20230218.patch
- 0004-Allow-BRIN-indexes-to-produce-sorted-output-20230218.patch
- 0005-wip-brinsort-explain-stats-20230218.patch
- 0006-wip-multiple-watermark-steps-20230218.patch
- 0007-wip-adjust-watermark-step-20230218.patch
- 0008-wip-adaptive-watermark-step-20230218.patch
- 0009-wip-add-brin_sort.sql-test-20230218.patch
- 0010-wip-test-generator-script-20230218.patch
cfbot complained there's one more place triggering a compiler warning on 32-bit systems, so here's a version fixing that. I've also added a copy of the regression tests but using the indexam stats added in 0001. This is just a copy of the already existing regression tests, just with enable_indexam_stats=true - this should catch some of the issues that went mostly undetected in the earlier patch versions. regards -- Tomas Vondra EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
Attachment
- 0001-Allow-index-AMs-to-build-and-use-custom-s-20230218-2.patch
- 0002-wip-introduce-debug_brin_stats-20230218-2.patch
- 0003-wip-introduce-debug_brin_cross_check-20230218-2.patch
- 0004-Allow-BRIN-indexes-to-produce-sorted-outp-20230218-2.patch
- 0005-wip-brinsort-explain-stats-20230218-2.patch
- 0006-wip-multiple-watermark-steps-20230218-2.patch
- 0007-wip-adjust-watermark-step-20230218-2.patch
- 0008-wip-adaptive-watermark-step-20230218-2.patch
- 0009-wip-add-brinsort-regression-tests-20230218-2.patch
- 0010-wip-add-brinsort-amstats-regression-tests-20230218-2.patch
- 0011-wip-test-generator-script-20230218-2.patch
Are (any of) these patches targetting v16 ? typos: ar we - we are? morestly - mostly interstect - intersect > + * XXX We don't sort the bins, so just do binary sort. For large number of values > + * this might be an issue, for small number of values a linear search is fine. "binary sort" is wrong? > + * only half of there ranges, thus 1/2. This can be extended to randomly half of *these* ranges ? > From 7b3307c27b35ece119feab4891f03749250e454b Mon Sep 17 00:00:00 2001 > From: Tomas Vondra <tomas.vondra@postgresql.org> > Date: Mon, 17 Oct 2022 18:39:28 +0200 > Subject: [PATCH 01/11] Allow index AMs to build and use custom statistics I think the idea can also apply to btree - currently, correlation is considered to be a property of a column, but not an index. But that fails to distinguish between a freshly built index, and an index with out of order heap references, which can cause an index scan to be a lot more expensive. I implemented per-index correlation stats way back when: https://www.postgresql.org/message-id/flat/20160524173914.GA11880%40telsasoft.com See also: https://www.postgresql.org/message-id/14438.1512499811@sss.pgh.pa.us With my old test case: Index scan is 3x slower than bitmap scan, but index scan is costed as being cheaper: postgres=# explain analyze SELECT * FROM t WHERE i>11 AND i<55; Index Scan using t_i_idx on t (cost=0.43..21153.74 rows=130912 width=8) (actual time=0.107..222.737 rows=128914 loops=1) postgres=# SET enable_indexscan =no; postgres=# explain analyze SELECT * FROM t WHERE i>11 AND i<55; Bitmap Heap Scan on t (cost=2834.28..26895.96 rows=130912 width=8) (actual time=16.830..69.860 rows=128914 loops=1) If it's clustered, then the index scan is almost twice as fast, and the costs are more consistent with the associated time. The planner assumes that the indexes are freshly built... postgres=# CLUSTER t USING t_i_idx ; postgres=# explain analyze SELECT * FROM t WHERE i>11 AND i<55; Index Scan using t_i_idx on t (cost=0.43..20121.74 rows=130912 width=8) (actual time=0.084..117.549 rows=128914 loops=1) -- Justin
On 2/18/23 19:51, Justin Pryzby wrote: > Are (any of) these patches targetting v16 ? > Probably not. Maybe if there's more feedback / scrutiny, but I'm not sure one commitfest is enough to polish the patch (especially considering I haven't done much on the costing yet). > typos: > ar we - we are? > morestly - mostly > interstect - intersect > >> + * XXX We don't sort the bins, so just do binary sort. For large number of values >> + * this might be an issue, for small number of values a linear search is fine. > > "binary sort" is wrong? > >> + * only half of there ranges, thus 1/2. This can be extended to randomly > > half of *these* ranges ? > Thanks, I'll fix those. >> From 7b3307c27b35ece119feab4891f03749250e454b Mon Sep 17 00:00:00 2001 >> From: Tomas Vondra <tomas.vondra@postgresql.org> >> Date: Mon, 17 Oct 2022 18:39:28 +0200 >> Subject: [PATCH 01/11] Allow index AMs to build and use custom statistics > > I think the idea can also apply to btree - currently, correlation is > considered to be a property of a column, but not an index. But that > fails to distinguish between a freshly built index, and an index with > out of order heap references, which can cause an index scan to be a lot > more expensive. > > I implemented per-index correlation stats way back when: > https://www.postgresql.org/message-id/flat/20160524173914.GA11880%40telsasoft.com > > See also: > https://www.postgresql.org/message-id/14438.1512499811@sss.pgh.pa.us > > With my old test case: > > Index scan is 3x slower than bitmap scan, but index scan is costed as > being cheaper: > > postgres=# explain analyze SELECT * FROM t WHERE i>11 AND i<55; > Index Scan using t_i_idx on t (cost=0.43..21153.74 rows=130912 width=8) (actual time=0.107..222.737 rows=128914 loops=1) > > postgres=# SET enable_indexscan =no; > postgres=# explain analyze SELECT * FROM t WHERE i>11 AND i<55; > Bitmap Heap Scan on t (cost=2834.28..26895.96 rows=130912 width=8) (actual time=16.830..69.860 rows=128914 loops=1) > > If it's clustered, then the index scan is almost twice as fast, and the > costs are more consistent with the associated time. The planner assumes > that the indexes are freshly built... > > postgres=# CLUSTER t USING t_i_idx ; > postgres=# explain analyze SELECT * FROM t WHERE i>11 AND i<55; > Index Scan using t_i_idx on t (cost=0.43..20121.74 rows=130912 width=8) (actual time=0.084..117.549 rows=128914 loops=1) > Yeah, the concept of indexam statistics certainly applies to other index types, and for btree we might collect information about correlation etc. I haven't looked at the 2017 patch, but it seems reasonable. regards -- Tomas Vondra EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On Sat, 18 Feb 2023 at 16:55, Tomas Vondra <tomas.vondra@enterprisedb.com> wrote: > > cfbot complained there's one more place triggering a compiler warning on > 32-bit systems, so here's a version fixing that. > > I've also added a copy of the regression tests but using the indexam > stats added in 0001. This is just a copy of the already existing > regression tests, just with enable_indexam_stats=true - this should > catch some of the issues that went mostly undetected in the earlier > patch versions. Comments on 0001, mostly comments and patch design: > +range_minval_cmp(const void *a, const void *b, void *arg) > [...] > +range_maxval_cmp(const void *a, const void *b, void *arg) > [...] > +range_values_cmp(const void *a, const void *b, void *arg) Can the arguments of these functions be modified into the types they are expected to receive? If not, could you add a comment on why that's not possible? I don't think it's good practise to "just" use void* for arguments to cast them to more concrete types in the next lines without an immediate explanation. > + * Statistics calculated by index AM (e.g. BRIN for ranges, etc.). Could you please expand on this? We do have GIST support for ranges, too. > + * brin_minmax_stats > + * Calculate custom statistics for a BRIN minmax index. > + * > + * At the moment this calculates: > + * > + * - number of summarized/not-summarized and all/has nulls ranges I think statistics gathering of an index should be done at the AM level, not attribute level. The docs currently suggest that the user builds one BRIN index with 16 columns instead of 16 BRIN indexes with one column each, which would make the statistics gathering use 16x more IO if the scanned data cannot be reused. It is possible to build BRIN indexes on more than one column with more than one opclass family like `USING brin (id int8_minmax_ops, id int8_bloom_ops)`. This would mean various duplicate statistics fields, no? It seems to me that it's more useful to do the null- and n_summarized on the index level instead of duplicating that inside the opclass. > + for (heapBlk = 0; heapBlk < nblocks; heapBlk += pagesPerRange) I am not familiar with the frequency of max-sized relations, but this would go into an infinite loop for pagesPerRange values >1 for max-sized relations due to BlockNumber wraparound. I think there should be some additional overflow checks here. > +/* > + * get_attstaindexam > + * > + * Given the table and attribute number of a column, get the index AM > + * statistics. Return NULL if no data available. > + * Shouldn't this be "given the index and attribute number" instead of "the table and attribute number"? I think we need to be compatible with indexes on expression here, so that we don't fail to create (or use) statistics for an index `USING brin ( (int8range(my_min_column, my_max_column, '[]')) range_inclusion_ops)` when we implement stats for range_inclusion_ops. > + * Alternative to brin_minmax_match_tuples_to_ranges2, leveraging ordering Does this function still exist? . I'm planning on reviewing the other patches, and noticed that a lot of the patches are marked WIP. Could you share a status on those, because currently that status is unknown: Are these patches you don't plan on including, or are these patches only (or mostly) included for debugging? Kind regards, Matthias van de Meent
On 2/23/23 15:19, Matthias van de Meent wrote: > On Sat, 18 Feb 2023 at 16:55, Tomas Vondra > <tomas.vondra@enterprisedb.com> wrote: >> >> cfbot complained there's one more place triggering a compiler warning on >> 32-bit systems, so here's a version fixing that. >> >> I've also added a copy of the regression tests but using the indexam >> stats added in 0001. This is just a copy of the already existing >> regression tests, just with enable_indexam_stats=true - this should >> catch some of the issues that went mostly undetected in the earlier >> patch versions. > > > Comments on 0001, mostly comments and patch design: > >> +range_minval_cmp(const void *a, const void *b, void *arg) >> [...] >> +range_maxval_cmp(const void *a, const void *b, void *arg) >> [...] >> +range_values_cmp(const void *a, const void *b, void *arg) > > Can the arguments of these functions be modified into the types they > are expected to receive? If not, could you add a comment on why that's > not possible? > I don't think it's good practise to "just" use void* for arguments to > cast them to more concrete types in the next lines without an > immediate explanation. > The reason is that that's what qsort() expects. If you change that to actual data types, you'll get compile-time warnings. I agree this may need better comments, though. >> + * Statistics calculated by index AM (e.g. BRIN for ranges, etc.). > > Could you please expand on this? We do have GIST support for ranges, too. > Expand in what way? This is meant to be AM-specific, so if GiST wants to collect some additional stats, it's free to do so - perhaps some of the ideas from the stats collected for BRIN would be applicable, but it's also bound to the index structure. >> + * brin_minmax_stats >> + * Calculate custom statistics for a BRIN minmax index. >> + * >> + * At the moment this calculates: >> + * >> + * - number of summarized/not-summarized and all/has nulls ranges > > I think statistics gathering of an index should be done at the AM > level, not attribute level. The docs currently suggest that the user > builds one BRIN index with 16 columns instead of 16 BRIN indexes with > one column each, which would make the statistics gathering use 16x > more IO if the scanned data cannot be reused. > Why? The row sample is collected only once and used for building all the index AM stats - it doesn't really matter if we analyze 16 single-column indexes or 1 index with 16 columns. Yes, we'll need to scan more indexes, but the with 16 columns the summaries will be larger so the total amount of I/O will be almost the same I think. Or maybe I don't understand what I/O you're talking about? > It is possible to build BRIN indexes on more than one column with more > than one opclass family like `USING brin (id int8_minmax_ops, id > int8_bloom_ops)`. This would mean various duplicate statistics fields, > no? > It seems to me that it's more useful to do the null- and n_summarized > on the index level instead of duplicating that inside the opclass. I don't think it's worth it. The amount of data this would save is tiny, and it'd only apply to cases where the index includes the same attribute multiple times, and that's pretty rare I think. I don't think it's worth the extra complexity. > >> + for (heapBlk = 0; heapBlk < nblocks; heapBlk += pagesPerRange) > > I am not familiar with the frequency of max-sized relations, but this > would go into an infinite loop for pagesPerRange values >1 for > max-sized relations due to BlockNumber wraparound. I think there > should be some additional overflow checks here. > Good point, but that's a pre-existing issue. We do this same loop in a number of places. >> +/* >> + * get_attstaindexam >> + * >> + * Given the table and attribute number of a column, get the index AM >> + * statistics. Return NULL if no data available. >> + * > > Shouldn't this be "given the index and attribute number" instead of > "the table and attribute number"? > I think we need to be compatible with indexes on expression here, so > that we don't fail to create (or use) statistics for an index `USING > brin ( (int8range(my_min_column, my_max_column, '[]')) > range_inclusion_ops)` when we implement stats for range_inclusion_ops. > >> + * Alternative to brin_minmax_match_tuples_to_ranges2, leveraging ordering > > Does this function still exist? > Yes, but only in 0003 - it's a "brute-force" algorithm used as a cross-check the result of the optimized algorithm in 0001. You're right it should not be referenced in the comment. > > I'm planning on reviewing the other patches, and noticed that a lot of > the patches are marked WIP. Could you share a status on those, because > currently that status is unknown: Are these patches you don't plan on > including, or are these patches only (or mostly) included for > debugging? > I think the WIP label is a bit misleading, I used it mostly to mark patches that are not meant to be committed on their own. A quick overview: 0002-wip-introduce-debug_brin_stats-20230218-2.patch 0003-wip-introduce-debug_brin_cross_check-20230218-2.patch Not meant for commit, used mostly during development/debugging, by adding debug logging and/or cross-check to validate the results. I think it's fine to ignore those during review. 0005-wip-brinsort-explain-stats-20230218-2.patch This needs more work. It does what it's meant to do (show info about the brinsort node), but I'm not very happy with the formatting etc. Review and suggestions welcome. 0006-wip-multiple-watermark-steps-20230218-2.patch 0007-wip-adjust-watermark-step-20230218-2.patch 0008-wip-adaptive-watermark-step-20230218-2.patch Ultimately this should be merged into 0004 (which does the actual brinsort), I think 0006 is the way to go, but I kept all the patches to show the incremental evolution (and allow comparisons). 0006 adds a GUC to specify how many ranges to add in each round, 0005 adjusts that based on statistics during planning and 0006 does that adaptively during execution. 0009-wip-add-brinsort-regression-tests-20230218-2.patch 0010-wip-add-brinsort-amstats-regression-tests-20230218-2.patch These need to move to the earlier parts. The tests are rather expensive so we'll need to reduce it somehow. 0011-wip-test-generator-script-20230218-2.patch Not intended for commit, I only included it to keep it as part of the patch series. regards -- Tomas Vondra EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On Thu, 23 Feb 2023 at 16:22, Tomas Vondra <tomas.vondra@enterprisedb.com> wrote: > > On 2/23/23 15:19, Matthias van de Meent wrote: >> Comments on 0001, mostly comments and patch design: One more comment: >>> + range->min_value = bval->bv_values[0]; >>> + range->max_value = bval->bv_values[1]; This produces dangling pointers for minmax indexes on by-ref types such as text and bytea, due to the memory context of the decoding tuple being reset every iteration. :-( > >> +range_values_cmp(const void *a, const void *b, void *arg) > > > > Can the arguments of these functions be modified into the types they > > are expected to receive? If not, could you add a comment on why that's > > not possible? > > The reason is that that's what qsort() expects. If you change that to > actual data types, you'll get compile-time warnings. I agree this may > need better comments, though. Thanks in advance. > >> + * Statistics calculated by index AM (e.g. BRIN for ranges, etc.). > > > > Could you please expand on this? We do have GIST support for ranges, too. > > > > Expand in what way? This is meant to be AM-specific, so if GiST wants to > collect some additional stats, it's free to do so - perhaps some of the > ideas from the stats collected for BRIN would be applicable, but it's > also bound to the index structure. I don't quite understand the flow of the comment, as I don't clearly see what the "BRIN for ranges" tries to refer to. In my view, that makes it a bad example which needs further explanation or rewriting, aka "expanding on". > >> + * brin_minmax_stats > >> + * Calculate custom statistics for a BRIN minmax index. > >> + * > >> + * At the moment this calculates: > >> + * > >> + * - number of summarized/not-summarized and all/has nulls ranges > > > > I think statistics gathering of an index should be done at the AM > > level, not attribute level. The docs currently suggest that the user > > builds one BRIN index with 16 columns instead of 16 BRIN indexes with > > one column each, which would make the statistics gathering use 16x > > more IO if the scanned data cannot be reused. > > > > Why? The row sample is collected only once and used for building all the > index AM stats - it doesn't really matter if we analyze 16 single-column > indexes or 1 index with 16 columns. Yes, we'll need to scan more > indexes, but the with 16 columns the summaries will be larger so the > total amount of I/O will be almost the same I think. > > Or maybe I don't understand what I/O you're talking about? With the proposed patch, we do O(ncols_statsenabled) scans over the BRIN index. Each scan reads all ncol columns of all block ranges from disk, so in effect the data scan does on the order of O(ncols_statsenabled * ncols * nranges) IOs, or O(n^2) on cols when all columns have statistics enabled. > > It is possible to build BRIN indexes on more than one column with more > > than one opclass family like `USING brin (id int8_minmax_ops, id > > int8_bloom_ops)`. This would mean various duplicate statistics fields, > > no? > > It seems to me that it's more useful to do the null- and n_summarized > > on the index level instead of duplicating that inside the opclass. > > I don't think it's worth it. The amount of data this would save is tiny, > and it'd only apply to cases where the index includes the same attribute > multiple times, and that's pretty rare I think. I don't think it's worth > the extra complexity. Not necessarily, it was just an example of where we'd save IO. Note that the current gathering method already retrieves all tuple attribute data, so from a basic processing perspective we'd save some time decoding as well. > > > > I'm planning on reviewing the other patches, and noticed that a lot of > > the patches are marked WIP. Could you share a status on those, because > > currently that status is unknown: Are these patches you don't plan on > > including, or are these patches only (or mostly) included for > > debugging? > > > > I think the WIP label is a bit misleading, I used it mostly to mark > patches that are not meant to be committed on their own. A quick overview: > > [...] Thanks for the explanation, that's quite helpful. I'll see to further reviewing 0004 and 0005 when I have additional time. Kind regards, Matthias van de Meent.
On 2/23/23 17:44, Matthias van de Meent wrote: > On Thu, 23 Feb 2023 at 16:22, Tomas Vondra > <tomas.vondra@enterprisedb.com> wrote: >> >> On 2/23/23 15:19, Matthias van de Meent wrote: >>> Comments on 0001, mostly comments and patch design: > > One more comment: > >>>> + range->min_value = bval->bv_values[0]; >>>> + range->max_value = bval->bv_values[1]; > > This produces dangling pointers for minmax indexes on by-ref types > such as text and bytea, due to the memory context of the decoding > tuple being reset every iteration. :-( > Yeah, that sounds like a bug. Also a sign the tests should have some by-ref data types (presumably there are none, as that would certainly trip some asserts etc.). >>>> +range_values_cmp(const void *a, const void *b, void *arg) >>> >>> Can the arguments of these functions be modified into the types they >>> are expected to receive? If not, could you add a comment on why that's >>> not possible? >> >> The reason is that that's what qsort() expects. If you change that to >> actual data types, you'll get compile-time warnings. I agree this may >> need better comments, though. > > Thanks in advance. > >>>> + * Statistics calculated by index AM (e.g. BRIN for ranges, etc.). >>> >>> Could you please expand on this? We do have GIST support for ranges, too. >>> >> >> Expand in what way? This is meant to be AM-specific, so if GiST wants to >> collect some additional stats, it's free to do so - perhaps some of the >> ideas from the stats collected for BRIN would be applicable, but it's >> also bound to the index structure. > > I don't quite understand the flow of the comment, as I don't clearly > see what the "BRIN for ranges" tries to refer to. In my view, that > makes it a bad example which needs further explanation or rewriting, > aka "expanding on". > Ah, right. Yeah, the "BRIN for ranges" wording is a bit misleading. It should really say only BRIN, but I was focused on the minmax use case, so I mentioned the ranges. >>>> + * brin_minmax_stats >>>> + * Calculate custom statistics for a BRIN minmax index. >>>> + * >>>> + * At the moment this calculates: >>>> + * >>>> + * - number of summarized/not-summarized and all/has nulls ranges >>> >>> I think statistics gathering of an index should be done at the AM >>> level, not attribute level. The docs currently suggest that the user >>> builds one BRIN index with 16 columns instead of 16 BRIN indexes with >>> one column each, which would make the statistics gathering use 16x >>> more IO if the scanned data cannot be reused. >>> >> >> Why? The row sample is collected only once and used for building all the >> index AM stats - it doesn't really matter if we analyze 16 single-column >> indexes or 1 index with 16 columns. Yes, we'll need to scan more >> indexes, but the with 16 columns the summaries will be larger so the >> total amount of I/O will be almost the same I think. >> >> Or maybe I don't understand what I/O you're talking about? > > With the proposed patch, we do O(ncols_statsenabled) scans over the > BRIN index. Each scan reads all ncol columns of all block ranges from > disk, so in effect the data scan does on the order of > O(ncols_statsenabled * ncols * nranges) IOs, or O(n^2) on cols when > all columns have statistics enabled. > I don't think that's the number of I/O operations we'll do, because we always read the whole BRIN tuple at once. So I believe it should rather be something like O(ncols_statsenabled * nranges) assuming nranges is the number of page ranges. But even that's likely a significant overestimate because most of the tuples will be served from shared buffers. Considering how tiny BRIN indexes are, this is likely orders of magnitude less I/O than we expend on sampling rows from the table. I mean, with the default statistics target we read ~30000 pages (~240MB) or more just to sample the rows. Randomly, while the BRIN index is likely scanned mostly sequentially. Maybe there are cases where this would be an issue, but I haven't seen one when working on this patch (and I did a lot of experiments). I'd like to see one before we start optimizing it ... This also reminds me that the issues I actually saw (e.g. memory consumption) would be made worse by processing all columns at once, because then you need to keep more columns in memory. >>> It is possible to build BRIN indexes on more than one column with more >>> than one opclass family like `USING brin (id int8_minmax_ops, id >>> int8_bloom_ops)`. This would mean various duplicate statistics fields, >>> no? >>> It seems to me that it's more useful to do the null- and n_summarized >>> on the index level instead of duplicating that inside the opclass. >> >> I don't think it's worth it. The amount of data this would save is tiny, >> and it'd only apply to cases where the index includes the same attribute >> multiple times, and that's pretty rare I think. I don't think it's worth >> the extra complexity. > > Not necessarily, it was just an example of where we'd save IO. > Note that the current gathering method already retrieves all tuple > attribute data, so from a basic processing perspective we'd save some > time decoding as well. > [shrug] I still think it's a negligible fraction of the time. >>> >>> I'm planning on reviewing the other patches, and noticed that a lot of >>> the patches are marked WIP. Could you share a status on those, because >>> currently that status is unknown: Are these patches you don't plan on >>> including, or are these patches only (or mostly) included for >>> debugging? >>> >> >> I think the WIP label is a bit misleading, I used it mostly to mark >> patches that are not meant to be committed on their own. A quick overview: >> >> [...] > > Thanks for the explanation, that's quite helpful. I'll see to further > reviewing 0004 and 0005 when I have additional time. > Cool, thank you! regards -- Tomas Vondra EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On 2023-Feb-23, Matthias van de Meent wrote: > > + for (heapBlk = 0; heapBlk < nblocks; heapBlk += pagesPerRange) > > I am not familiar with the frequency of max-sized relations, but this > would go into an infinite loop for pagesPerRange values >1 for > max-sized relations due to BlockNumber wraparound. I think there > should be some additional overflow checks here. They are definitely not very common -- BlockNumber wraps around at 32 TB IIUC. But yeah, I guess it is a possibility, and perhaps we should find a way to write these loops in a more robust manner. -- Álvaro Herrera Breisgau, Deutschland — https://www.EnterpriseDB.com/ "World domination is proceeding according to plan" (Andrew Morton)
On 2/24/23 09:39, Alvaro Herrera wrote:
> On 2023-Feb-23, Matthias van de Meent wrote:
>
>>> + for (heapBlk = 0; heapBlk < nblocks; heapBlk += pagesPerRange)
>>
>> I am not familiar with the frequency of max-sized relations, but this
>> would go into an infinite loop for pagesPerRange values >1 for
>> max-sized relations due to BlockNumber wraparound. I think there
>> should be some additional overflow checks here.
>
> They are definitely not very common -- BlockNumber wraps around at 32 TB
> IIUC. But yeah, I guess it is a possibility, and perhaps we should find
> a way to write these loops in a more robust manner.
>
I guess the easiest fix would be to do the arithmetic in 64 bits. That'd
eliminate the overflow.
Alternatively, we could do something like
prevHeapBlk = 0;
for (heapBlk = 0; (heapBlk < nblocks) && (prevHeapBlk <= heapBlk);
heapBlk += pagesPerRange)
{
...
prevHeapBlk = heapBlk;
}
regards
--
Tomas Vondra
EnterpriseDB: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
On 2023-Feb-24, Tomas Vondra wrote:
> I guess the easiest fix would be to do the arithmetic in 64 bits. That'd
> eliminate the overflow.
Yeah, that might be easy to set up. We then don't have to worry about
it until BlockNumber is enlarged to 64 bits ... but by that time surely
we can just grow it again to a 128 bit loop variable.
> Alternatively, we could do something like
>
> prevHeapBlk = 0;
> for (heapBlk = 0; (heapBlk < nblocks) && (prevHeapBlk <= heapBlk);
> heapBlk += pagesPerRange)
> {
> ...
> prevHeapBlk = heapBlk;
> }
I think a formulation of this kind has the benefit that it works after
BlockNumber is enlarged to 64 bits, and doesn't have to be changed ever
again (assuming it is correct).
... if pagesPerRange is not a whole divisor of MaxBlockNumber, I think
this will neglect the last range in the table.
--
Álvaro Herrera Breisgau, Deutschland — https://www.EnterpriseDB.com/
On 2/24/23 16:14, Alvaro Herrera wrote:
> On 2023-Feb-24, Tomas Vondra wrote:
>
>> I guess the easiest fix would be to do the arithmetic in 64 bits. That'd
>> eliminate the overflow.
>
> Yeah, that might be easy to set up. We then don't have to worry about
> it until BlockNumber is enlarged to 64 bits ... but by that time surely
> we can just grow it again to a 128 bit loop variable.
>
>> Alternatively, we could do something like
>>
>> prevHeapBlk = 0;
>> for (heapBlk = 0; (heapBlk < nblocks) && (prevHeapBlk <= heapBlk);
>> heapBlk += pagesPerRange)
>> {
>> ...
>> prevHeapBlk = heapBlk;
>> }
>
> I think a formulation of this kind has the benefit that it works after
> BlockNumber is enlarged to 64 bits, and doesn't have to be changed ever
> again (assuming it is correct).
>
Did anyone even propose doing that? I suspect this is unlikely to be the
only place that'd might be broken by that.
> ... if pagesPerRange is not a whole divisor of MaxBlockNumber, I think
> this will neglect the last range in the table.
>
Why would it? Let's say BlockNumber is uint8, i.e. 255 max. And there
are 10 pages per range. That's 25 "full" ranges, and the last range
being just 5 pages. So we get into
prevHeapBlk = 240
heapBlk = 250
and we read the last 5 pages. And then we update
prevHeapBlk = 250
heapBlk = (250 + 10) % 255 = 5
and we don't do that loop. Or did I get this wrong, somehow?
regards
--
Tomas Vondra
EnterpriseDB: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
On Fri, 24 Feb 2023 at 17:04, Tomas Vondra <tomas.vondra@enterprisedb.com> wrote: > > On 2/24/23 16:14, Alvaro Herrera wrote: > > ... if pagesPerRange is not a whole divisor of MaxBlockNumber, I think > > this will neglect the last range in the table. > > > > Why would it? Let's say BlockNumber is uint8, i.e. 255 max. And there > are 10 pages per range. That's 25 "full" ranges, and the last range > being just 5 pages. So we get into > > prevHeapBlk = 240 > heapBlk = 250 > > and we read the last 5 pages. And then we update > > prevHeapBlk = 250 > heapBlk = (250 + 10) % 255 = 5 > > and we don't do that loop. Or did I get this wrong, somehow? The result is off-by-one due to (u)int8 overflows being mod-256, but apart from that your result is accurate. The condition only stops the loop when we wrap around or when we go past the last block, but no earlier than that. Kind regards, Matthias van de Meent
On Thu, 23 Feb 2023 at 19:48, Tomas Vondra <tomas.vondra@enterprisedb.com> wrote: > > On 2/23/23 17:44, Matthias van de Meent wrote: > > On Thu, 23 Feb 2023 at 16:22, Tomas Vondra > > <tomas.vondra@enterprisedb.com> wrote: > >> > >> On 2/23/23 15:19, Matthias van de Meent wrote: > >>> Comments on 0001, mostly comments and patch design: > > > > One more comment: > > > >>>> + range->min_value = bval->bv_values[0]; > >>>> + range->max_value = bval->bv_values[1]; > > > > This produces dangling pointers for minmax indexes on by-ref types > > such as text and bytea, due to the memory context of the decoding > > tuple being reset every iteration. :-( > > > > Yeah, that sounds like a bug. Also a sign the tests should have some > by-ref data types (presumably there are none, as that would certainly > trip some asserts etc.). I'm not sure we currently trip asserts, as the data we store in the memory context is very limited, making it unlikely we actually release the memory region back to the OS. I did get assertion failures by adding the attached patch, but I don't think that's something we can do in the final release. > > With the proposed patch, we do O(ncols_statsenabled) scans over the > > BRIN index. Each scan reads all ncol columns of all block ranges from > > disk, so in effect the data scan does on the order of > > O(ncols_statsenabled * ncols * nranges) IOs, or O(n^2) on cols when > > all columns have statistics enabled. > > > > I don't think that's the number of I/O operations we'll do, because we > always read the whole BRIN tuple at once. So I believe it should rather > be something like > > O(ncols_statsenabled * nranges) > > assuming nranges is the number of page ranges. But even that's likely a > significant overestimate because most of the tuples will be served from > shared buffers. We store some data per index attribute, which makes the IO required for a single indexed range proportional to the number of index attributes. If we then scan the index a number of times proportional to the number of attributes, the cumulative IO load of statistics gathering for that index is quadratic on the number of attributes, not linear, right? > Considering how tiny BRIN indexes are, this is likely orders of > magnitude less I/O than we expend on sampling rows from the table. I > mean, with the default statistics target we read ~30000 pages (~240MB) > or more just to sample the rows. Randomly, while the BRIN index is > likely scanned mostly sequentially. Mostly agreed; except I think it's not too difficult to imagine a BRIN index that is on that scale; with as an example the bloom filters that easily take up several hundreds of bytes. With the default configuration of 128 pages_per_range, n_distinct_per_range of -0.1, and false_positive_rate of 0.01, the bloom filter size is 4.36 KiB - each indexed item on its own page. It is still only 1% of the original table's size, but there are enough tables that are larger than 24GB that this could be a significant issue. Note that most of my concerns are related to our current documentation's statement that there are no demerits to multi-column BRIN indexes: """ 11.3. Multicolumn Indexes [...] The only reason to have multiple BRIN indexes instead of one multicolumn BRIN index on a single table is to have a different pages_per_range storage parameter. """ Wide BRIN indexes add IO overhead for single-attribute scans when compared to single-attribute indexes, so having N single-attribute index scans to build statistics the statistics on an N-attribute index is not great. > Maybe there are cases where this would be an issue, but I haven't seen > one when working on this patch (and I did a lot of experiments). I'd > like to see one before we start optimizing it ... I'm not only worried about optimizing it, I'm also worried that we're putting this abstraction at the wrong level in a way that is difficult to modify. > This also reminds me that the issues I actually saw (e.g. memory > consumption) would be made worse by processing all columns at once, > because then you need to keep more columns in memory. Yes, I that can be a valid concern, but don't we already do similar things in the current table statistics gathering? Kind regards, Matthias van de Meent
On 2/24/23 19:03, Matthias van de Meent wrote: > On Thu, 23 Feb 2023 at 19:48, Tomas Vondra > <tomas.vondra@enterprisedb.com> wrote: >> >> On 2/23/23 17:44, Matthias van de Meent wrote: >>> On Thu, 23 Feb 2023 at 16:22, Tomas Vondra >>> <tomas.vondra@enterprisedb.com> wrote: >>>> >>>> On 2/23/23 15:19, Matthias van de Meent wrote: >>>>> Comments on 0001, mostly comments and patch design: >>> >>> One more comment: >>> >>>>>> + range->min_value = bval->bv_values[0]; >>>>>> + range->max_value = bval->bv_values[1]; >>> >>> This produces dangling pointers for minmax indexes on by-ref types >>> such as text and bytea, due to the memory context of the decoding >>> tuple being reset every iteration. :-( >>> >> >> Yeah, that sounds like a bug. Also a sign the tests should have some >> by-ref data types (presumably there are none, as that would certainly >> trip some asserts etc.). > > I'm not sure we currently trip asserts, as the data we store in the > memory context is very limited, making it unlikely we actually release > the memory region back to the OS. > I did get assertion failures by adding the attached patch, but I don't > think that's something we can do in the final release. > But we should randomize the memory if we ever do pfree(), and it's strange valgrind didn't complain when I ran tests with it. But yeah, I'll take a look and see if we can add some tests covering this. >>> With the proposed patch, we do O(ncols_statsenabled) scans over the >>> BRIN index. Each scan reads all ncol columns of all block ranges from >>> disk, so in effect the data scan does on the order of >>> O(ncols_statsenabled * ncols * nranges) IOs, or O(n^2) on cols when >>> all columns have statistics enabled. >>> >> >> I don't think that's the number of I/O operations we'll do, because we >> always read the whole BRIN tuple at once. So I believe it should rather >> be something like >> >> O(ncols_statsenabled * nranges) >> >> assuming nranges is the number of page ranges. But even that's likely a >> significant overestimate because most of the tuples will be served from >> shared buffers. > > We store some data per index attribute, which makes the IO required > for a single indexed range proportional to the number of index > attributes. > If we then scan the index a number of times proportional to the number > of attributes, the cumulative IO load of statistics gathering for that > index is quadratic on the number of attributes, not linear, right? > Ah, OK. I was focusing on number of I/O operations while you're talking about amount of I/O performed. You're right the amount of I/O is quadratic, but I think what's more interesting is the comparison of the alternative ANALYZE approaches. The current simple approach does a multiple of the I/O amount, linear to the number of attributes. Which is not great, ofc. >> Considering how tiny BRIN indexes are, this is likely orders of >> magnitude less I/O than we expend on sampling rows from the table. I >> mean, with the default statistics target we read ~30000 pages (~240MB) >> or more just to sample the rows. Randomly, while the BRIN index is >> likely scanned mostly sequentially. > > Mostly agreed; except I think it's not too difficult to imagine a BRIN > index that is on that scale; with as an example the bloom filters that > easily take up several hundreds of bytes. > > With the default configuration of 128 pages_per_range, > n_distinct_per_range of -0.1, and false_positive_rate of 0.01, the > bloom filter size is 4.36 KiB - each indexed item on its own page. It > is still only 1% of the original table's size, but there are enough > tables that are larger than 24GB that this could be a significant > issue. > Right, it's certainly true BRIN indexes may be made fairly large (either by using something like bloom or by making the ranges much smaller). But those are exactly the indexes where building statistics for all columns at once is going to cause issues with memory usage etc. Note: Obviously, that depends on how much data per range we need to keep in memory. For bloom I doubt we'd actually want to keep all the filters, we'd probably calculate just some statistics (e.g. number of bits set), so maybe the memory consumption is not that bad. In fact, for such indexes the memory consumption may already be an issue even when analyzing the index column by column. My feeling is we'll need to do something about that, e.g. by reading only a sample of the ranges, or something like that. That might help with the I/O too, I guess. > Note that most of my concerns are related to our current > documentation's statement that there are no demerits to multi-column > BRIN indexes: > > """ > 11.3. Multicolumn Indexes > > [...] The only reason to have multiple BRIN indexes instead of one > multicolumn BRIN index on a single table is to have a different > pages_per_range storage parameter. > """ > True, we may need to clarify this in the documentation. > Wide BRIN indexes add IO overhead for single-attribute scans when > compared to single-attribute indexes, so having N single-attribute > index scans to build statistics the statistics on an N-attribute index > is not great. > Perhaps, but it's not like the alternative is perfect either (complexity, memory consumption, ...). IMHO it's a reasonable tradeoff. >> Maybe there are cases where this would be an issue, but I haven't seen >> one when working on this patch (and I did a lot of experiments). I'd >> like to see one before we start optimizing it ... > > I'm not only worried about optimizing it, I'm also worried that we're > putting this abstraction at the wrong level in a way that is difficult > to modify. > Yeah, that's certainly a valid concern. I admit I only did the minimum amount of work on this part, as I was focused on the sorting part. >> This also reminds me that the issues I actually saw (e.g. memory >> consumption) would be made worse by processing all columns at once, >> because then you need to keep more columns in memory. > > Yes, I that can be a valid concern, but don't we already do similar > things in the current table statistics gathering? > Not really, I think. We sample a bunch of rows once, but then we build statistics on this sample for each attribute / expression independently. We could of course read the whole index into memory and then run the analysis, but I think tuples tend to be much smaller (thanks to TOAST etc.) and we only really scan a limited amount of them (30k). But if we're concerned about the I/O, the BRIN is likely fairly large, so maybe reading it into memory at once is not a great idea. It's be more similar if we sampled sampled the BRIN ranges - I think we'll have to do something like that anyway. regards -- Tomas Vondra EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On 2/24/23 20:14, Tomas Vondra wrote: > > > On 2/24/23 19:03, Matthias van de Meent wrote: >> On Thu, 23 Feb 2023 at 19:48, Tomas Vondra >> <tomas.vondra@enterprisedb.com> wrote: >>> >>> On 2/23/23 17:44, Matthias van de Meent wrote: >>>> On Thu, 23 Feb 2023 at 16:22, Tomas Vondra >>>> <tomas.vondra@enterprisedb.com> wrote: >>>>> >>>>> On 2/23/23 15:19, Matthias van de Meent wrote: >>>>>> Comments on 0001, mostly comments and patch design: >>>> >>>> One more comment: >>>> >>>>>>> + range->min_value = bval->bv_values[0]; >>>>>>> + range->max_value = bval->bv_values[1]; >>>> >>>> This produces dangling pointers for minmax indexes on by-ref types >>>> such as text and bytea, due to the memory context of the decoding >>>> tuple being reset every iteration. :-( >>>> >>> >>> Yeah, that sounds like a bug. Also a sign the tests should have some >>> by-ref data types (presumably there are none, as that would certainly >>> trip some asserts etc.). >> >> I'm not sure we currently trip asserts, as the data we store in the >> memory context is very limited, making it unlikely we actually release >> the memory region back to the OS. >> I did get assertion failures by adding the attached patch, but I don't >> think that's something we can do in the final release. >> > > But we should randomize the memory if we ever do pfree(), and it's > strange valgrind didn't complain when I ran tests with it. But yeah, > I'll take a look and see if we can add some tests covering this. > There was no patch to trigger the assertions, but the attached patches should fix that, I think. It pretty much just does datumCopy() after reading the BRIN tuple from disk. It's interesting I've been unable to hit the usual asserts checking freed memory etc. even with text columns etc. I guess the BRIN tuple memory happens to be aligned in a way that just happens to work. It howver triggered an assert failure in minval_end, because it didn't use the proper comparator. regards -- Tomas Vondra EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
Attachment
- 0001-Allow-index-AMs-to-build-and-use-custom-sta-20230225.patch
- 0002-wip-introduce-debug_brin_stats-20230225.patch
- 0003-wip-introduce-debug_brin_cross_check-20230225.patch
- 0004-Allow-BRIN-indexes-to-produce-sorted-output-20230225.patch
- 0005-wip-brinsort-explain-stats-20230225.patch
- 0006-wip-multiple-watermark-steps-20230225.patch
- 0007-wip-adjust-watermark-step-20230225.patch
- 0008-wip-adaptive-watermark-step-20230225.patch
- 0009-wip-add-brinsort-regression-tests-20230225.patch
- 0010-wip-add-brinsort-amstats-regression-tests-20230225.patch
- 0011-wip-test-generator-script-20230225.patch
On Fri, 24 Feb 2023, 20:14 Tomas Vondra, <tomas.vondra@enterprisedb.com> wrote: > > On 2/24/23 19:03, Matthias van de Meent wrote: > > On Thu, 23 Feb 2023 at 19:48, Tomas Vondra > >> Yeah, that sounds like a bug. Also a sign the tests should have some > >> by-ref data types (presumably there are none, as that would certainly > >> trip some asserts etc.). > > > > I'm not sure we currently trip asserts, as the data we store in the > > memory context is very limited, making it unlikely we actually release > > the memory region back to the OS. > > I did get assertion failures by adding the attached patch, but I don't > > think that's something we can do in the final release. > > > > But we should randomize the memory if we ever do pfree(), and it's > strange valgrind didn't complain when I ran tests with it. Well, we don't clean up the decoding tuple immediately after our last iteration, so the memory context (and the last tuple's attributes) are still valid memory addresses. And, assuming that min/max values for all brin ranges all have the same max-aligned length, the attribute pointers are likely to point to the same offset within the decoding tuple's memory context's memory segment, which would mean the dangling pointers still point to valid memory - just not memory with the contents they expected to be pointing to. > >> Considering how tiny BRIN indexes are, this is likely orders of > >> magnitude less I/O than we expend on sampling rows from the table. I > >> mean, with the default statistics target we read ~30000 pages (~240MB) > >> or more just to sample the rows. Randomly, while the BRIN index is > >> likely scanned mostly sequentially. > > > > Mostly agreed; except I think it's not too difficult to imagine a BRIN > > index that is on that scale; with as an example the bloom filters that > > easily take up several hundreds of bytes. > > > > With the default configuration of 128 pages_per_range, > > n_distinct_per_range of -0.1, and false_positive_rate of 0.01, the > > bloom filter size is 4.36 KiB - each indexed item on its own page. It > > is still only 1% of the original table's size, but there are enough > > tables that are larger than 24GB that this could be a significant > > issue. > > > > Right, it's certainly true BRIN indexes may be made fairly large (either > by using something like bloom or by making the ranges much smaller). But > those are exactly the indexes where building statistics for all columns > at once is going to cause issues with memory usage etc. > > Note: Obviously, that depends on how much data per range we need to keep > in memory. For bloom I doubt we'd actually want to keep all the filters, > we'd probably calculate just some statistics (e.g. number of bits set), > so maybe the memory consumption is not that bad. Yes, I was thinking something along the same lines for bloom as well. Something like 'average number of bits set' (or: histogram number of bits set), and/or for each bit a count (or %) how many times it is set, etc. > >> Maybe there are cases where this would be an issue, but I haven't seen > >> one when working on this patch (and I did a lot of experiments). I'd > >> like to see one before we start optimizing it ... > > > > I'm not only worried about optimizing it, I'm also worried that we're > > putting this abstraction at the wrong level in a way that is difficult > > to modify. > > > > Yeah, that's certainly a valid concern. I admit I only did the minimum > amount of work on this part, as I was focused on the sorting part. > > >> This also reminds me that the issues I actually saw (e.g. memory > >> consumption) would be made worse by processing all columns at once, > >> because then you need to keep more columns in memory. > > > > Yes, I that can be a valid concern, but don't we already do similar > > things in the current table statistics gathering? > > > > Not really, I think. We sample a bunch of rows once, but then we build > statistics on this sample for each attribute / expression independently. > We could of course read the whole index into memory and then run the > analysis, but I think tuples tend to be much smaller (thanks to TOAST > etc.) and we only really scan a limited amount of them (30k). Just to note, with default settings, sampling 30k index entries from BRIN would cover ~29 GiB of a table. This isn't a lot, but it also isn't exactly a small table. I think that it would be difficult to get accurate avg_overlap statistics for some shapes of BRIN data... > But if we're concerned about the I/O, the BRIN is likely fairly large, > so maybe reading it into memory at once is not a great idea. Agreed, we can't always expect that the interesting parts of the BRIN index always fit in the available memory. Kind regards, Matthias van de Meent
Hi,
On Thu, 23 Feb 2023 at 17:44, Matthias van de Meent
<boekewurm+postgres@gmail.com> wrote:
>
> I'll see to further reviewing 0004 and 0005 when I have additional time.
Some initial comments on 0004:
> +/*
> + * brin_minmax_ranges
> + * Load the BRIN ranges and sort them.
> + */
> +Datum
> +brin_minmax_ranges(PG_FUNCTION_ARGS)
> +{
Like in 0001, this seems to focus on only single columns. Can't we put
the scan and sort infrastructure in brin, and put the weight- and
compare-operators in the opclasses? I.e.
brin_minmax_minorder(PG_FUNCTION_ARGS=brintuple) -> range.min and
brin_minmax_maxorder(PG_FUNCTION_ARGS=brintuple) -> range.max, and a
brin_minmax_compare(order, order) -> int? I'm thinking of something
similar to GIST's distance operators, which would make implementing
ordering by e.g. `pointcolumn <-> (1, 2)::point` implementable in the
brin infrastructure.
Note: One big reason I don't really like the current
brin_minmax_ranges (and the analyze code in 0001) is because it breaks
the operatorclass-vs-index abstraction layer. Operator classes don't
(shouldn't) know or care about which attribute number they have, nor
what the index does with the data.
Scanning the index is not something that I expect the operator class
to do, I expect that the index code organizes the scan, and forwards
the data to the relevant operator classes.
Scanning the index N times for N attributes can be excused if there
are good reasons, but I'd rather have that decision made in the
index's core code rather than at the design level.
> +/*
> + * XXX Does it make sense (is it possible) to have a sort by more than one
> + * column, using a BRIN index?
> + */
Yes, even if only one prefix column is included in the BRIN index
(e.g. `company` in `ORDER BY company, date`, the tuplesort with table
tuples can add additional sorting without first reading the whole
table, potentially (likely) reducing the total resource usage of the
query. That utilizes the same idea as incremental sorts, but with the
caveat that the input sort order is approximately likely but not at
all guaranteed. So, even if the range sort is on a single index
column, we can still do the table's tuplesort on all ORDER BY
attributes, as long as a prefix of ORDER BY columns are included in
the BRIN index.
> + /*
> + * XXX We can be a bit smarter for LIMIT queries - once we
> + * know we have more rows in the tuplesort than we need to
> + * output, we can stop spilling - those rows are not going
> + * to be needed. We can discard the tuplesort (no need to
> + * respill) and stop spilling.
> + */
Shouldn't that be "discard the tuplestore"?
> +#define BRIN_PROCNUM_RANGES 12 /* optional */
It would be useful to add documentation for this in this patch.
Kind regards,
Matthias van de Meent.
On 2023-Feb-24, Tomas Vondra wrote: > On 2/24/23 16:14, Alvaro Herrera wrote: > > I think a formulation of this kind has the benefit that it works after > > BlockNumber is enlarged to 64 bits, and doesn't have to be changed ever > > again (assuming it is correct). > > Did anyone even propose doing that? I suspect this is unlikely to be the > only place that'd might be broken by that. True about other places also needing fixes, and no I haven't see anyone; but while 32 TB does seem very far away to us now, it might be not *that* far away. So I think doing it the other way is better. > > ... if pagesPerRange is not a whole divisor of MaxBlockNumber, I think > > this will neglect the last range in the table. > > Why would it? Let's say BlockNumber is uint8, i.e. 255 max. And there > are 10 pages per range. That's 25 "full" ranges, and the last range > being just 5 pages. So we get into > > prevHeapBlk = 240 > heapBlk = 250 > > and we read the last 5 pages. And then we update > > prevHeapBlk = 250 > heapBlk = (250 + 10) % 255 = 5 > > and we don't do that loop. Or did I get this wrong, somehow? I stand corrected. -- Álvaro Herrera 48°01'N 7°57'E — https://www.EnterpriseDB.com/
Hi,
I finally had time to look at this patch again. There's a bit of bitrot,
so here's a rebased version (no other changes).
[more comments inline]
On 2/27/23 16:40, Matthias van de Meent wrote:
> Hi,
>
> On Thu, 23 Feb 2023 at 17:44, Matthias van de Meent
> <boekewurm+postgres@gmail.com> wrote:
>>
>> I'll see to further reviewing 0004 and 0005 when I have additional time.
>
> Some initial comments on 0004:
>
>> +/*
>> + * brin_minmax_ranges
>> + * Load the BRIN ranges and sort them.
>> + */
>> +Datum
>> +brin_minmax_ranges(PG_FUNCTION_ARGS)
>> +{
>
> Like in 0001, this seems to focus on only single columns. Can't we put
> the scan and sort infrastructure in brin, and put the weight- and
> compare-operators in the opclasses? I.e.
> brin_minmax_minorder(PG_FUNCTION_ARGS=brintuple) -> range.min and
> brin_minmax_maxorder(PG_FUNCTION_ARGS=brintuple) -> range.max, and a
> brin_minmax_compare(order, order) -> int? I'm thinking of something
> similar to GIST's distance operators, which would make implementing
> ordering by e.g. `pointcolumn <-> (1, 2)::point` implementable in the
> brin infrastructure.
>
> Note: One big reason I don't really like the current
> brin_minmax_ranges (and the analyze code in 0001) is because it breaks
> the operatorclass-vs-index abstraction layer. Operator classes don't
> (shouldn't) know or care about which attribute number they have, nor
> what the index does with the data.
> Scanning the index is not something that I expect the operator class
> to do, I expect that the index code organizes the scan, and forwards
> the data to the relevant operator classes.
> Scanning the index N times for N attributes can be excused if there
> are good reasons, but I'd rather have that decision made in the
> index's core code rather than at the design level.
>
I think you're right. It'd be more appropriate to have most of the core
scanning logic in brin.c, and then delegate only some minor decisions to
the opclass. Like, comparisons, extraction of min/max from ranges etc.
However, it's not quite clear to me is what you mean by the weight- and
compare-operators? That is, what are
- brin_minmax_minorder(PG_FUNCTION_ARGS=brintuple) -> range.min
- brin_minmax_maxorder(PG_FUNCTION_ARGS=brintuple) -> range.max
- brin_minmax_compare(order, order) -> int
supposed to do? Or what does "PG_FUNCTION_ARGS=brintuple" mean?
In principle we just need a procedure that tells us min/max for a given
page range - I guess that's what the minorder/maxorder functions do? But
why would we need the compare one? We're comparing by the known data
type, so we can just delegate the comparison to that, no?
Also, the existence of these opclass procedures should be enough to
identify the opclasses which can support this.
>> +/*
>> + * XXX Does it make sense (is it possible) to have a sort by more than one
>> + * column, using a BRIN index?
>> + */
>
> Yes, even if only one prefix column is included in the BRIN index
> (e.g. `company` in `ORDER BY company, date`, the tuplesort with table
> tuples can add additional sorting without first reading the whole
> table, potentially (likely) reducing the total resource usage of the
> query. That utilizes the same idea as incremental sorts, but with the
> caveat that the input sort order is approximately likely but not at
> all guaranteed. So, even if the range sort is on a single index
> column, we can still do the table's tuplesort on all ORDER BY
> attributes, as long as a prefix of ORDER BY columns are included in
> the BRIN index.
>
That's now quite what I meant, though. When I mentioned sorting by more
than one column, I meant using a multi-column BRIN index on those
columns. Something like this:
CREATE TABLE t (a int, b int);
INSERT INTO t ...
CREATE INDEX ON t USING brin (a,b);
SELECT * FROM t ORDER BY a, b;
Now, what I think you described is using BRIN to sort by "a", and then
do incremental sort for "b". What I had in mind is whether it's possible
to use BRIN to sort by "b" too.
I was suspecting it might be made to work, but now that I think about it
again it probably can't - BRIN pretty much sorts the columns separately,
it's not like having an ordering by (a,b) - first by "a", then "b".
>> + /*
>> + * XXX We can be a bit smarter for LIMIT queries - once we
>> + * know we have more rows in the tuplesort than we need to
>> + * output, we can stop spilling - those rows are not going
>> + * to be needed. We can discard the tuplesort (no need to
>> + * respill) and stop spilling.
>> + */
>
> Shouldn't that be "discard the tuplestore"?
>
Yeah, definitely.
>> +#define BRIN_PROCNUM_RANGES 12 /* optional */
>
> It would be useful to add documentation for this in this patch.
>
Right, this should be documented in doc/src/sgml/brin.sgml.
regards
--
Tomas Vondra
EnterpriseDB: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
On Fri, 7 Jul 2023 at 20:26, Tomas Vondra <tomas.vondra@enterprisedb.com> wrote:
>
> Hi,
>
> I finally had time to look at this patch again. There's a bit of bitrot,
> so here's a rebased version (no other changes).
Thanks!
> On 2/27/23 16:40, Matthias van de Meent wrote:
> > Some initial comments on 0004:
> >
> >> +/*
> >> + * brin_minmax_ranges
> >> + * Load the BRIN ranges and sort them.
> >> + */
> >> +Datum
> >> +brin_minmax_ranges(PG_FUNCTION_ARGS)
> >> +{
> >
> > Like in 0001, this seems to focus on only single columns. Can't we put
> > the scan and sort infrastructure in brin, and put the weight- and
> > compare-operators in the opclasses? I.e.
> > brin_minmax_minorder(PG_FUNCTION_ARGS=brintuple) -> range.min and
> > brin_minmax_maxorder(PG_FUNCTION_ARGS=brintuple) -> range.max, and a
> > brin_minmax_compare(order, order) -> int? I'm thinking of something
> > similar to GIST's distance operators, which would make implementing
> > ordering by e.g. `pointcolumn <-> (1, 2)::point` implementable in the
> > brin infrastructure.
> >
>
> However, it's not quite clear to me is what you mean by the weight- and
> compare-operators? That is, what are
>
> - brin_minmax_minorder(PG_FUNCTION_ARGS=brintuple) -> range.min
> - brin_minmax_maxorder(PG_FUNCTION_ARGS=brintuple) -> range.max
> - brin_minmax_compare(order, order) -> int
>
> supposed to do? Or what does "PG_FUNCTION_ARGS=brintuple" mean?
_minorder/_maxorder is for extracting the minimum/maximum relative
order of each range, used for ASC/DESC sorting of operator results
(e.g. to support ORDER BY <->(box_column, '(1,2)'::point) DESC).
PG_FUNCTION_ARGS is mentioned because of PG calling conventions;
though I did forget to describe the second operator argument for the
distance function. We might also want to use only one such "order
extraction function" with DESC/ASC indicated by an argument.
> In principle we just need a procedure that tells us min/max for a given
> page range - I guess that's what the minorder/maxorder functions do? But
> why would we need the compare one? We're comparing by the known data
> type, so we can just delegate the comparison to that, no?
Is there a comparison function for any custom orderable type that we
can just use? GIST distance ordering uses floats, and I don't quite
like that from a user perspective, as it makes ordering operations
imprecise. I'd rather allow (but discourage) any type with its own
compare function.
> Also, the existence of these opclass procedures should be enough to
> identify the opclasses which can support this.
Agreed.
> >> +/*
> >> + * XXX Does it make sense (is it possible) to have a sort by more than one
> >> + * column, using a BRIN index?
> >> + */
> >
> > Yes, even if only one prefix column is included in the BRIN index
> > (e.g. `company` in `ORDER BY company, date`, the tuplesort with table
> > tuples can add additional sorting without first reading the whole
> > table, potentially (likely) reducing the total resource usage of the
> > query. That utilizes the same idea as incremental sorts, but with the
> > caveat that the input sort order is approximately likely but not at
> > all guaranteed. So, even if the range sort is on a single index
> > column, we can still do the table's tuplesort on all ORDER BY
> > attributes, as long as a prefix of ORDER BY columns are included in
> > the BRIN index.
> >
>
> That's now quite what I meant, though. When I mentioned sorting by more
> than one column, I meant using a multi-column BRIN index on those
> columns. Something like this:
>
> CREATE TABLE t (a int, b int);
> INSERT INTO t ...
> CREATE INDEX ON t USING brin (a,b);
>
> SELECT * FROM t ORDER BY a, b;
>
> Now, what I think you described is using BRIN to sort by "a", and then
> do incremental sort for "b". What I had in mind is whether it's possible
> to use BRIN to sort by "b" too.
>
> I was suspecting it might be made to work, but now that I think about it
> again it probably can't - BRIN pretty much sorts the columns separately,
> it's not like having an ordering by (a,b) - first by "a", then "b".
I imagine it would indeed be limited to an extremely small subset of
cases, and probably not worth the effort to implement in an initial
version.
Kind regards,
Matthias van de Meent
Neon (https://neon.tech)
On 7/10/23 12:22, Matthias van de Meent wrote:
> On Fri, 7 Jul 2023 at 20:26, Tomas Vondra <tomas.vondra@enterprisedb.com> wrote:
>>
>> Hi,
>>
>> I finally had time to look at this patch again. There's a bit of bitrot,
>> so here's a rebased version (no other changes).
>
> Thanks!
>
>> On 2/27/23 16:40, Matthias van de Meent wrote:
>>> Some initial comments on 0004:
>>>
>>>> +/*
>>>> + * brin_minmax_ranges
>>>> + * Load the BRIN ranges and sort them.
>>>> + */
>>>> +Datum
>>>> +brin_minmax_ranges(PG_FUNCTION_ARGS)
>>>> +{
>>>
>>> Like in 0001, this seems to focus on only single columns. Can't we put
>>> the scan and sort infrastructure in brin, and put the weight- and
>>> compare-operators in the opclasses? I.e.
>>> brin_minmax_minorder(PG_FUNCTION_ARGS=brintuple) -> range.min and
>>> brin_minmax_maxorder(PG_FUNCTION_ARGS=brintuple) -> range.max, and a
>>> brin_minmax_compare(order, order) -> int? I'm thinking of something
>>> similar to GIST's distance operators, which would make implementing
>>> ordering by e.g. `pointcolumn <-> (1, 2)::point` implementable in the
>>> brin infrastructure.
>>>
>>
>> However, it's not quite clear to me is what you mean by the weight- and
>> compare-operators? That is, what are
>>
>> - brin_minmax_minorder(PG_FUNCTION_ARGS=brintuple) -> range.min
>> - brin_minmax_maxorder(PG_FUNCTION_ARGS=brintuple) -> range.max
>> - brin_minmax_compare(order, order) -> int
>>
>> supposed to do? Or what does "PG_FUNCTION_ARGS=brintuple" mean?
>
> _minorder/_maxorder is for extracting the minimum/maximum relative
> order of each range, used for ASC/DESC sorting of operator results
> (e.g. to support ORDER BY <->(box_column, '(1,2)'::point) DESC).
> PG_FUNCTION_ARGS is mentioned because of PG calling conventions;
> though I did forget to describe the second operator argument for the
> distance function. We might also want to use only one such "order
> extraction function" with DESC/ASC indicated by an argument.
>
I'm still not sure I understand what "minimum/maximum relative order"
is. Isn't it the same as returning min/max value that can appear in the
range? Although, that wouldn't work for points/boxes.
>> In principle we just need a procedure that tells us min/max for a given
>> page range - I guess that's what the minorder/maxorder functions do? But
>> why would we need the compare one? We're comparing by the known data
>> type, so we can just delegate the comparison to that, no?
>
> Is there a comparison function for any custom orderable type that we
> can just use? GIST distance ordering uses floats, and I don't quite
> like that from a user perspective, as it makes ordering operations
> imprecise. I'd rather allow (but discourage) any type with its own
> compare function.
>
I haven't really thought about geometric types, just about minmax and
minmax-multi. It's not clear to me what the benefit for these types be.
I mean, we can probably sort points lexicographically, but is anyone
doing that in queries? It seems useless for order by distance.
>> Also, the existence of these opclass procedures should be enough to
>> identify the opclasses which can support this.
>
> Agreed.
>
>>>> +/*
>>>> + * XXX Does it make sense (is it possible) to have a sort by more than one
>>>> + * column, using a BRIN index?
>>>> + */
>>>
>>> Yes, even if only one prefix column is included in the BRIN index
>>> (e.g. `company` in `ORDER BY company, date`, the tuplesort with table
>>> tuples can add additional sorting without first reading the whole
>>> table, potentially (likely) reducing the total resource usage of the
>>> query. That utilizes the same idea as incremental sorts, but with the
>>> caveat that the input sort order is approximately likely but not at
>>> all guaranteed. So, even if the range sort is on a single index
>>> column, we can still do the table's tuplesort on all ORDER BY
>>> attributes, as long as a prefix of ORDER BY columns are included in
>>> the BRIN index.
>>>
>>
>> That's now quite what I meant, though. When I mentioned sorting by more
>> than one column, I meant using a multi-column BRIN index on those
>> columns. Something like this:
>>
>> CREATE TABLE t (a int, b int);
>> INSERT INTO t ...
>> CREATE INDEX ON t USING brin (a,b);
>>
>> SELECT * FROM t ORDER BY a, b;
>>
>> Now, what I think you described is using BRIN to sort by "a", and then
>> do incremental sort for "b". What I had in mind is whether it's possible
>> to use BRIN to sort by "b" too.
>>
>> I was suspecting it might be made to work, but now that I think about it
>> again it probably can't - BRIN pretty much sorts the columns separately,
>> it's not like having an ordering by (a,b) - first by "a", then "b".
>
> I imagine it would indeed be limited to an extremely small subset of
> cases, and probably not worth the effort to implement in an initial
> version.
>
OK, let's stick to order by a single column.
regards
--
Tomas Vondra
EnterpriseDB: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
On Mon, 10 Jul 2023 at 13:43, Tomas Vondra <tomas.vondra@enterprisedb.com> wrote: > On 7/10/23 12:22, Matthias van de Meent wrote: >> On Fri, 7 Jul 2023 at 20:26, Tomas Vondra <tomas.vondra@enterprisedb.com> wrote: >>> However, it's not quite clear to me is what you mean by the weight- and >>> compare-operators? That is, what are >>> >>> - brin_minmax_minorder(PG_FUNCTION_ARGS=brintuple) -> range.min >>> - brin_minmax_maxorder(PG_FUNCTION_ARGS=brintuple) -> range.max >>> - brin_minmax_compare(order, order) -> int >>> >>> supposed to do? Or what does "PG_FUNCTION_ARGS=brintuple" mean? >> >> _minorder/_maxorder is for extracting the minimum/maximum relative >> order of each range, used for ASC/DESC sorting of operator results >> (e.g. to support ORDER BY <->(box_column, '(1,2)'::point) DESC). >> PG_FUNCTION_ARGS is mentioned because of PG calling conventions; >> though I did forget to describe the second operator argument for the >> distance function. We might also want to use only one such "order >> extraction function" with DESC/ASC indicated by an argument. >> > > I'm still not sure I understand what "minimum/maximum relative order" > is. Isn't it the same as returning min/max value that can appear in the > range? Although, that wouldn't work for points/boxes. Kind of. For single-dimensional opclasses (minmax, minmax_multi) we only need to extract the normal min/max values for ASC/DESC sorts, which are readily available in the summary. But for multi-dimensional and distance searches (nearest neighbour) we need to calculate the distance between the indexed value(s) and the origin value to compare the summary against, and the order would thus be asc/desc on distance - a distance which may not be precisely represented by float types - thus 'relative order' with its own order operation. >>> In principle we just need a procedure that tells us min/max for a given >>> page range - I guess that's what the minorder/maxorder functions do? But >>> why would we need the compare one? We're comparing by the known data >>> type, so we can just delegate the comparison to that, no? >> >> Is there a comparison function for any custom orderable type that we >> can just use? GIST distance ordering uses floats, and I don't quite >> like that from a user perspective, as it makes ordering operations >> imprecise. I'd rather allow (but discourage) any type with its own >> compare function. >> > > I haven't really thought about geometric types, just about minmax and > minmax-multi. It's not clear to me what the benefit for these types be. > I mean, we can probably sort points lexicographically, but is anyone > doing that in queries? It seems useless for order by distance. Yes, that's why you would sort them by distance, where the distance is generated by the opclass as min/max distance between the summary and the distance's origin, and then inserted into the tuplesort. (previously) >>> I finally had time to look at this patch again. There's a bit of bitrot, >>> so here's a rebased version (no other changes). It seems like you forgot to attach the rebased patch, so unless you're actively working on updating the patchset right now, could you send the rebase to make CFBot happy? Kind regards, Matthias van de Meent Neon (https://neon.tech/)
On 7/10/23 14:38, Matthias van de Meent wrote: > On Mon, 10 Jul 2023 at 13:43, Tomas Vondra > <tomas.vondra@enterprisedb.com> wrote: >> On 7/10/23 12:22, Matthias van de Meent wrote: >>> On Fri, 7 Jul 2023 at 20:26, Tomas Vondra <tomas.vondra@enterprisedb.com> wrote: >>>> However, it's not quite clear to me is what you mean by the weight- and >>>> compare-operators? That is, what are >>>> >>>> - brin_minmax_minorder(PG_FUNCTION_ARGS=brintuple) -> range.min >>>> - brin_minmax_maxorder(PG_FUNCTION_ARGS=brintuple) -> range.max >>>> - brin_minmax_compare(order, order) -> int >>>> >>>> supposed to do? Or what does "PG_FUNCTION_ARGS=brintuple" mean? >>> >>> _minorder/_maxorder is for extracting the minimum/maximum relative >>> order of each range, used for ASC/DESC sorting of operator results >>> (e.g. to support ORDER BY <->(box_column, '(1,2)'::point) DESC). >>> PG_FUNCTION_ARGS is mentioned because of PG calling conventions; >>> though I did forget to describe the second operator argument for the >>> distance function. We might also want to use only one such "order >>> extraction function" with DESC/ASC indicated by an argument. >>> >> >> I'm still not sure I understand what "minimum/maximum relative order" >> is. Isn't it the same as returning min/max value that can appear in the >> range? Although, that wouldn't work for points/boxes. > > Kind of. For single-dimensional opclasses (minmax, minmax_multi) we > only need to extract the normal min/max values for ASC/DESC sorts, > which are readily available in the summary. But for multi-dimensional > and distance searches (nearest neighbour) we need to calculate the > distance between the indexed value(s) and the origin value to compare > the summary against, and the order would thus be asc/desc on distance > - a distance which may not be precisely represented by float types - > thus 'relative order' with its own order operation. > Can you give some examples of such data / queries, and how would it leverage the BRIN sort stuff? For distance searches, I imagine this as data indexed by BRIN inclusion opclass, which creates a bounding box. We could return closest/furthest point on the bounding box (from the point used in the query). Which seems a bit like a R-tree ... But I have no idea what would this do for multi-dimensional searches, or what would those searches do? How would you sort such data other than lexicographically? Which I think is covered by the current BRIN Sort, because the data is either stored as multiple columns, in which case we use the BRIN on the first column. Or it's indexed using BRIN minmax as a tuple of values, but then it's sorted lexicographically. >>>> In principle we just need a procedure that tells us min/max for a given >>>> page range - I guess that's what the minorder/maxorder functions do? But >>>> why would we need the compare one? We're comparing by the known data >>>> type, so we can just delegate the comparison to that, no? >>> >>> Is there a comparison function for any custom orderable type that we >>> can just use? GIST distance ordering uses floats, and I don't quite >>> like that from a user perspective, as it makes ordering operations >>> imprecise. I'd rather allow (but discourage) any type with its own >>> compare function. >>> >> >> I haven't really thought about geometric types, just about minmax and >> minmax-multi. It's not clear to me what the benefit for these types be. >> I mean, we can probably sort points lexicographically, but is anyone >> doing that in queries? It seems useless for order by distance. > > Yes, that's why you would sort them by distance, where the distance is > generated by the opclass as min/max distance between the summary and > the distance's origin, and then inserted into the tuplesort. > OK, so the query says "order by distance from point X" and we calculate the min/max distance of values in a given page range. > (previously) >>>> I finally had time to look at this patch again. There's a bit of bitrot, >>>> so here's a rebased version (no other changes). > > It seems like you forgot to attach the rebased patch, so unless you're > actively working on updating the patchset right now, could you send > the rebase to make CFBot happy? > Yeah, I forgot about the attachment. So here it is. regards -- Tomas Vondra EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
Attachment
- 0001-Allow-index-AMs-to-build-and-use-custom-sta-20230710.patch
- 0002-wip-introduce-debug_brin_stats-20230710.patch
- 0003-wip-introduce-debug_brin_cross_check-20230710.patch
- 0004-Allow-BRIN-indexes-to-produce-sorted-output-20230710.patch
- 0005-wip-brinsort-explain-stats-20230710.patch
- 0006-wip-multiple-watermark-steps-20230710.patch
- 0007-wip-adjust-watermark-step-20230710.patch
- 0008-wip-adaptive-watermark-step-20230710.patch
- 0009-wip-add-brinsort-regression-tests-20230710.patch
- 0010-wip-add-brinsort-amstats-regression-tests-20230710.patch
- 0011-wip-test-generator-script-20230710.patch
On Mon, 10 Jul 2023 at 17:09, Tomas Vondra <tomas.vondra@enterprisedb.com> wrote: > On 7/10/23 14:38, Matthias van de Meent wrote: >> Kind of. For single-dimensional opclasses (minmax, minmax_multi) we >> only need to extract the normal min/max values for ASC/DESC sorts, >> which are readily available in the summary. But for multi-dimensional >> and distance searches (nearest neighbour) we need to calculate the >> distance between the indexed value(s) and the origin value to compare >> the summary against, and the order would thus be asc/desc on distance >> - a distance which may not be precisely represented by float types - >> thus 'relative order' with its own order operation. >> > > Can you give some examples of such data / queries, and how would it > leverage the BRIN sort stuff? Order by distance would be `ORDER BY box <-> '(1, 2)'::point ASC`, and the opclass would then decide that `<->(box, point) ASC` means it has to return the closest distance from the point to the summary, for some measure of 'distance' (this case L2, <#> other types, etc.). For DESC, that would return the distance from `'(1,2)'::point` to the furthest edge of the summary away from that point. Etc. > For distance searches, I imagine this as data indexed by BRIN inclusion > opclass, which creates a bounding box. We could return closest/furthest > point on the bounding box (from the point used in the query). Which > seems a bit like a R-tree ... Kind of; it would allow us to utilize such orderings without the expensive 1 tuple = 1 index entry and without scanning the full table before getting results. No tree involved, just a sequential scan on the index to allow some sketch-based pre-sort on the data. Again, this would work similar to how GiST's internal pages work: each downlink in GiST contains a summary of the entries on the downlinked page, and distance searches use a priority queue where the priority is the distance of the opclass-provided distance operator - lower distance means higher priority. For BRIN, we'd have to build a priority queue for the whole table at once, but presorting table sections is part of the design of BRIN sort, right? > But I have no idea what would this do for multi-dimensional searches, or > what would those searches do? How would you sort such data other than > lexicographically? Which I think is covered by the current BRIN Sort, > because the data is either stored as multiple columns, in which case we > use the BRIN on the first column. Or it's indexed using BRIN minmax as a > tuple of values, but then it's sorted lexicographically. Yes, just any BRIN summary that allows distance operators and the like should be enough MINMAX is easy to understand, and box inclusion are IMO also fairly easy to understand. >>> I haven't really thought about geometric types, just about minmax and >>> minmax-multi. It's not clear to me what the benefit for these types be. >>> I mean, we can probably sort points lexicographically, but is anyone >>> doing that in queries? It seems useless for order by distance. >> >> Yes, that's why you would sort them by distance, where the distance is >> generated by the opclass as min/max distance between the summary and >> the distance's origin, and then inserted into the tuplesort. >> > > OK, so the query says "order by distance from point X" and we calculate > the min/max distance of values in a given page range. Yes, and because it's BRIN that's an approximation, which should generally be fine. Kind regards, Matthias van de Meent Neon (https://neon.tech/)
On 7/10/23 18:18, Matthias van de Meent wrote: > On Mon, 10 Jul 2023 at 17:09, Tomas Vondra > <tomas.vondra@enterprisedb.com> wrote: >> On 7/10/23 14:38, Matthias van de Meent wrote: >>> Kind of. For single-dimensional opclasses (minmax, minmax_multi) we >>> only need to extract the normal min/max values for ASC/DESC sorts, >>> which are readily available in the summary. But for multi-dimensional >>> and distance searches (nearest neighbour) we need to calculate the >>> distance between the indexed value(s) and the origin value to compare >>> the summary against, and the order would thus be asc/desc on distance >>> - a distance which may not be precisely represented by float types - >>> thus 'relative order' with its own order operation. >>> >> >> Can you give some examples of such data / queries, and how would it >> leverage the BRIN sort stuff? > > Order by distance would be `ORDER BY box <-> '(1, 2)'::point ASC`, and > the opclass would then decide that `<->(box, point) ASC` means it has > to return the closest distance from the point to the summary, for some > measure of 'distance' (this case L2, <#> other types, etc.). For DESC, > that would return the distance from `'(1,2)'::point` to the furthest > edge of the summary away from that point. Etc. > Thanks. >> For distance searches, I imagine this as data indexed by BRIN inclusion >> opclass, which creates a bounding box. We could return closest/furthest >> point on the bounding box (from the point used in the query). Which >> seems a bit like a R-tree ... > > Kind of; it would allow us to utilize such orderings without the > expensive 1 tuple = 1 index entry and without scanning the full table > before getting results. No tree involved, just a sequential scan on > the index to allow some sketch-based pre-sort on the data. Again, this > would work similar to how GiST's internal pages work: each downlink in > GiST contains a summary of the entries on the downlinked page, and > distance searches use a priority queue where the priority is the > distance of the opclass-provided distance operator - lower distance > means higher priority. Yes, that's roughly how I understood this too - a tradeoff that won't give the same performance as GiST, but much smaller and cheaper to maintain. > For BRIN, we'd have to build a priority queue > for the whole table at once, but presorting table sections is part of > the design of BRIN sort, right? Yes, that's kinda the whole point of BRIN sort. > >> But I have no idea what would this do for multi-dimensional searches, or >> what would those searches do? How would you sort such data other than >> lexicographically? Which I think is covered by the current BRIN Sort, >> because the data is either stored as multiple columns, in which case we >> use the BRIN on the first column. Or it's indexed using BRIN minmax as a >> tuple of values, but then it's sorted lexicographically. > > Yes, just any BRIN summary that allows distance operators and the like > should be enough MINMAX is easy to understand, and box inclusion are > IMO also fairly easy to understand. > True. If minmax is interpreted as inclusion with a simple 1D points, it kinda does the same thing. (Of course, minmax work with data types that don't have distances, but there's similarity.) >>>> I haven't really thought about geometric types, just about minmax and >>>> minmax-multi. It's not clear to me what the benefit for these types be. >>>> I mean, we can probably sort points lexicographically, but is anyone >>>> doing that in queries? It seems useless for order by distance. >>> >>> Yes, that's why you would sort them by distance, where the distance is >>> generated by the opclass as min/max distance between the summary and >>> the distance's origin, and then inserted into the tuplesort. >>> >> >> OK, so the query says "order by distance from point X" and we calculate >> the min/max distance of values in a given page range. > > Yes, and because it's BRIN that's an approximation, which should > generally be fine. > Approximation in what sense? My understanding was we'd get a range of distances that we know covers all rows in that range. So the results should be accurate, no? regards -- Tomas Vondra EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On Mon, 10 Jul 2023 at 22:04, Tomas Vondra <tomas.vondra@enterprisedb.com> wrote: > On 7/10/23 18:18, Matthias van de Meent wrote: >> On Mon, 10 Jul 2023 at 17:09, Tomas Vondra >> <tomas.vondra@enterprisedb.com> wrote: >>> On 7/10/23 14:38, Matthias van de Meent wrote: >>>>> I haven't really thought about geometric types, just about minmax and >>>>> minmax-multi. It's not clear to me what the benefit for these types be. >>>>> I mean, we can probably sort points lexicographically, but is anyone >>>>> doing that in queries? It seems useless for order by distance. >>>> >>>> Yes, that's why you would sort them by distance, where the distance is >>>> generated by the opclass as min/max distance between the summary and >>>> the distance's origin, and then inserted into the tuplesort. >>>> >>> >>> OK, so the query says "order by distance from point X" and we calculate >>> the min/max distance of values in a given page range. >> >> Yes, and because it's BRIN that's an approximation, which should >> generally be fine. >> > > Approximation in what sense? My understanding was we'd get a range of > distances that we know covers all rows in that range. So the results > should be accurate, no? The distance is going to be accurate only to the degree that the summary can produce accurate distances for the datapoints it represents. That can be quite imprecise due to the nature of the contained datapoints: a summary of the points (-1, -1) and (1, 1) will have a minimum distance of 0 to the origin, where the summary (-1, 0) and (-1, 0.5) would have a much more accurate distance of 1. The point I was making is that the summary can only approximate the distance, and that approximation is fine w.r.t. the BRIN sort algoritm. Kind regards, Matthias van de Meent Neon (https://neon.tech/)
On 7/11/23 13:20, Matthias van de Meent wrote: > On Mon, 10 Jul 2023 at 22:04, Tomas Vondra > <tomas.vondra@enterprisedb.com> wrote: >> On 7/10/23 18:18, Matthias van de Meent wrote: >>> On Mon, 10 Jul 2023 at 17:09, Tomas Vondra >>> <tomas.vondra@enterprisedb.com> wrote: >>>> On 7/10/23 14:38, Matthias van de Meent wrote: >>>>>> I haven't really thought about geometric types, just about minmax and >>>>>> minmax-multi. It's not clear to me what the benefit for these types be. >>>>>> I mean, we can probably sort points lexicographically, but is anyone >>>>>> doing that in queries? It seems useless for order by distance. >>>>> >>>>> Yes, that's why you would sort them by distance, where the distance is >>>>> generated by the opclass as min/max distance between the summary and >>>>> the distance's origin, and then inserted into the tuplesort. >>>>> >>>> >>>> OK, so the query says "order by distance from point X" and we calculate >>>> the min/max distance of values in a given page range. >>> >>> Yes, and because it's BRIN that's an approximation, which should >>> generally be fine. >>> >> >> Approximation in what sense? My understanding was we'd get a range of >> distances that we know covers all rows in that range. So the results >> should be accurate, no? > > The distance is going to be accurate only to the degree that the > summary can produce accurate distances for the datapoints it > represents. That can be quite imprecise due to the nature of the > contained datapoints: a summary of the points (-1, -1) and (1, 1) will > have a minimum distance of 0 to the origin, where the summary (-1, 0) > and (-1, 0.5) would have a much more accurate distance of 1. Ummm, I'm probably missing something, or maybe my mental model of this is just wrong, but why would the distance for the second summary be more accurate? Or what does "more accurate" mean? Is that about the range of distances for the summary? For the first range the summary is a bounding box [(-1,1), (1,1)] so all we know the points may have distance in range [0, sqrt(2)]. While for the second summary it's [1, sqrt(1.25)]. > The point I was making is that the summary can only approximate the > distance, and that approximation is fine w.r.t. the BRIN sort > algoritm. > I think as long as the approximation (whatever it means) does not cause differences in results (compared to not using an index), it's OK. regards -- Tomas Vondra EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On Fri, 14 Jul 2023 at 16:21, Tomas Vondra <tomas.vondra@enterprisedb.com> wrote: > > > > > On 7/11/23 13:20, Matthias van de Meent wrote: >> On Mon, 10 Jul 2023 at 22:04, Tomas Vondra >> <tomas.vondra@enterprisedb.com> wrote: >>> Approximation in what sense? My understanding was we'd get a range of >>> distances that we know covers all rows in that range. So the results >>> should be accurate, no? >> >> The distance is going to be accurate only to the degree that the >> summary can produce accurate distances for the datapoints it >> represents. That can be quite imprecise due to the nature of the >> contained datapoints: a summary of the points (-1, -1) and (1, 1) will >> have a minimum distance of 0 to the origin, where the summary (-1, 0) >> and (-1, 0.5) would have a much more accurate distance of 1. > > Ummm, I'm probably missing something, or maybe my mental model of this > is just wrong, but why would the distance for the second summary be more > accurate? Or what does "more accurate" mean? > > Is that about the range of distances for the summary? For the first > range the summary is a bounding box [(-1,1), (1,1)] so all we know the > points may have distance in range [0, sqrt(2)]. While for the second > summary it's [1, sqrt(1.25)]. Yes; I was trying to refer to the difference between what results you get from the summary vs what results you get from the actual datapoints: In this case, for finding points which are closest to the origin, the first bounding box has a less accurate estimate than the second. > > The point I was making is that the summary can only approximate the > > distance, and that approximation is fine w.r.t. the BRIN sort > > algoritm. > > > > I think as long as the approximation (whatever it means) does not cause > differences in results (compared to not using an index), it's OK. Agreed. Kind regards, Matthias van de Meent Neon (https://neon.tech)
On 7/14/23 16:42, Matthias van de Meent wrote: > On Fri, 14 Jul 2023 at 16:21, Tomas Vondra > <tomas.vondra@enterprisedb.com> wrote: >> >> >> >> >> On 7/11/23 13:20, Matthias van de Meent wrote: >>> On Mon, 10 Jul 2023 at 22:04, Tomas Vondra >>> <tomas.vondra@enterprisedb.com> wrote: >>>> Approximation in what sense? My understanding was we'd get a range of >>>> distances that we know covers all rows in that range. So the results >>>> should be accurate, no? >>> >>> The distance is going to be accurate only to the degree that the >>> summary can produce accurate distances for the datapoints it >>> represents. That can be quite imprecise due to the nature of the >>> contained datapoints: a summary of the points (-1, -1) and (1, 1) will >>> have a minimum distance of 0 to the origin, where the summary (-1, 0) >>> and (-1, 0.5) would have a much more accurate distance of 1. >> >> Ummm, I'm probably missing something, or maybe my mental model of this >> is just wrong, but why would the distance for the second summary be more >> accurate? Or what does "more accurate" mean? >> >> Is that about the range of distances for the summary? For the first >> range the summary is a bounding box [(-1,1), (1,1)] so all we know the >> points may have distance in range [0, sqrt(2)]. While for the second >> summary it's [1, sqrt(1.25)]. > > Yes; I was trying to refer to the difference between what results you > get from the summary vs what results you get from the actual > datapoints: In this case, for finding points which are closest to the > origin, the first bounding box has a less accurate estimate than the > second. > OK. I think regular minmax indexes have a similar issue with non-distance ordering, because we don't know if the min/max values are still in the page range (or deleted/updated). >>> The point I was making is that the summary can only approximate the >>> distance, and that approximation is fine w.r.t. the BRIN sort >>> algoritm. >>> >> >> I think as long as the approximation (whatever it means) does not cause >> differences in results (compared to not using an index), it's OK. > I haven't written any code yet, but I think if we don't try to find the exact min/max distances for the summary (e.g. by calculating the closest point exactly) but rather "estimates" that are guaranteed to bound the actual min/max, that's good enough for the sorting. For the max, this probably is not an issue, as we can just calculate distance for the corners and use a maximum of that. At least with reasonable euclidean distance ... in 2D I'm imagining the bounding box summary as a rectangle, with the "max distance" being a minimum radius of a circle containing it (the rectangle). For min we're looking for the largest radius not intersecting with the box, which seems harder to calculate I think. However, now that I'm thinking about it - don't (SP-)GiST indexes already do pretty much exactly this? regards -- Tomas Vondra EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
Hello,
> Parallel version is not supported, but I think it should be possible.
@Tomas are you working on this ? If not, I would like to give it a try.
> static void
> AssertCheckRanges(BrinSortState *node)
> {
> #ifdef USE_ASSERT_CHECKING
>
> #endif
> }
I guess it should not be empty at the ongoing development stage.
Attached a small modification of the patch with a draft of the docs.
Regards,
Sergey Dudoladov
Attachment
On 8/2/23 17:25, Sergey Dudoladov wrote:
> Hello,
>
>> Parallel version is not supported, but I think it should be possible.
>
> @Tomas are you working on this ? If not, I would like to give it a try.
>
Feel free to try. Just keep it in a separate part/patch, to make it
easier to combine the work later.
>> static void
>> AssertCheckRanges(BrinSortState *node)
>> {
>> #ifdef USE_ASSERT_CHECKING
>>
>> #endif
>> }
>
> I guess it should not be empty at the ongoing development stage.
>
> Attached a small modification of the patch with a draft of the docs.
>
Thanks. FWIW it's generally better to always post the whole patch
series, otherwise the cfbot gets confused as it's unable to combine
stuff from different messages.
regards
--
Tomas Vondra
EnterpriseDB: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
On Wed, 2 Aug 2023 at 21:34, Tomas Vondra <tomas.vondra@enterprisedb.com> wrote:
>
>
>
> On 8/2/23 17:25, Sergey Dudoladov wrote:
> > Hello,
> >
> >> Parallel version is not supported, but I think it should be possible.
> >
> > @Tomas are you working on this ? If not, I would like to give it a try.
> >
>
> Feel free to try. Just keep it in a separate part/patch, to make it
> easier to combine the work later.
>
> >> static void
> >> AssertCheckRanges(BrinSortState *node)
> >> {
> >> #ifdef USE_ASSERT_CHECKING
> >>
> >> #endif
> >> }
> >
> > I guess it should not be empty at the ongoing development stage.
> >
> > Attached a small modification of the patch with a draft of the docs.
> >
>
> Thanks. FWIW it's generally better to always post the whole patch
> series, otherwise the cfbot gets confused as it's unable to combine
> stuff from different messages.
Are we planning to take this patch forward? It has been nearly 5
months since the last discussion on this. If the interest has gone
down and if there are no plans to handle this I'm thinking of
returning this commitfest entry in this commitfest and can be opened
when there is more interest.
Regards,
Vignesh
On Sun, 21 Jan 2024 at 07:32, vignesh C <vignesh21@gmail.com> wrote:
>
> On Wed, 2 Aug 2023 at 21:34, Tomas Vondra <tomas.vondra@enterprisedb.com> wrote:
> >
> >
> >
> > On 8/2/23 17:25, Sergey Dudoladov wrote:
> > > Hello,
> > >
> > >> Parallel version is not supported, but I think it should be possible.
> > >
> > > @Tomas are you working on this ? If not, I would like to give it a try.
> > >
> >
> > Feel free to try. Just keep it in a separate part/patch, to make it
> > easier to combine the work later.
> >
> > >> static void
> > >> AssertCheckRanges(BrinSortState *node)
> > >> {
> > >> #ifdef USE_ASSERT_CHECKING
> > >>
> > >> #endif
> > >> }
> > >
> > > I guess it should not be empty at the ongoing development stage.
> > >
> > > Attached a small modification of the patch with a draft of the docs.
> > >
> >
> > Thanks. FWIW it's generally better to always post the whole patch
> > series, otherwise the cfbot gets confused as it's unable to combine
> > stuff from different messages.
>
> Are we planning to take this patch forward? It has been nearly 5
> months since the last discussion on this. If the interest has gone
> down and if there are no plans to handle this I'm thinking of
> returning this commitfest entry in this commitfest and can be opened
> when there is more interest.
Since the author or no one else showed interest in taking it forward
and the patch had no activity for more than 5 months, I have changed
the status to RWF. Feel free to add a new CF entry when someone is
planning to resume work more actively by starting off with a rebased
version.
Regards,
Vignesh