Hi,
Here's an updated version of this patch series. There's still plenty of
stuff to improve, but it fixes a number of issues I mentioned earlier.
The two most important changes are:
1) handling of projections
Until now queries with projection might have failed, due to not using
the right slot, bogus var references and so on. The code was somewhat
confused because the new node is somewhere in between a scan node and a
sort (or more precisely, it combines both).
I believe this version handles all of this correctly - the code that
initializes the slots/projection info etc. needs serious cleanup, but
should be correct.
2) handling of expressions
The other improvement is handling of expressions - if you have a BRIN
index on an expression, this should now work too. This also includes
correct handling of collations (which the previous patches ignored).
Similarly to the projections, I believe the code is correct but needs
cleanup. In particular, I haven't paid close attention to memory
management, so there might be memory leaks when evaluating expressions.
The last two parts of the patch series (0009 and 0010) are about
testing. 0009 adds a regular regression test with various combinations
(projections, expressions, single- vs. multi-column indexes, ...).
0010 introduces a python script that randomly generates data sets,
indexes and queries. I use it to both test random combinations and to
evaluate performance. I don't expect it to be committed etc. - it's
included only to keep it versioned with the rest of the patch.
I did some basic benchmarking using the 0010 part, to evaluate the how
this works for various cases. The script varies a number of parameters:
- number of rows
- table fill factor
- randomness (how much ranges overlapp)
- pages per range
- limit / offset for queries
- ...
The script forces both a "seqscan" and "brinsort" plan, and collects
timing info.
The results are encouraging, I think. Attached are two charts, plotting
speedup vs. fraction of tuples the query has to sort.
speedup = (seqscan timing / brinsort timing)
fraction = (limit + offset) / (table rows)
A query with "limit 1 offset 0" has fraction ~0.0, query that scans
everything (perhaps because it has no LIMIT/OFFSET) has ~1.0.
For speedup, 1.0 means "no change" while values above 1.0 means the
query gets faster. Both plots have log-scale y-axis.
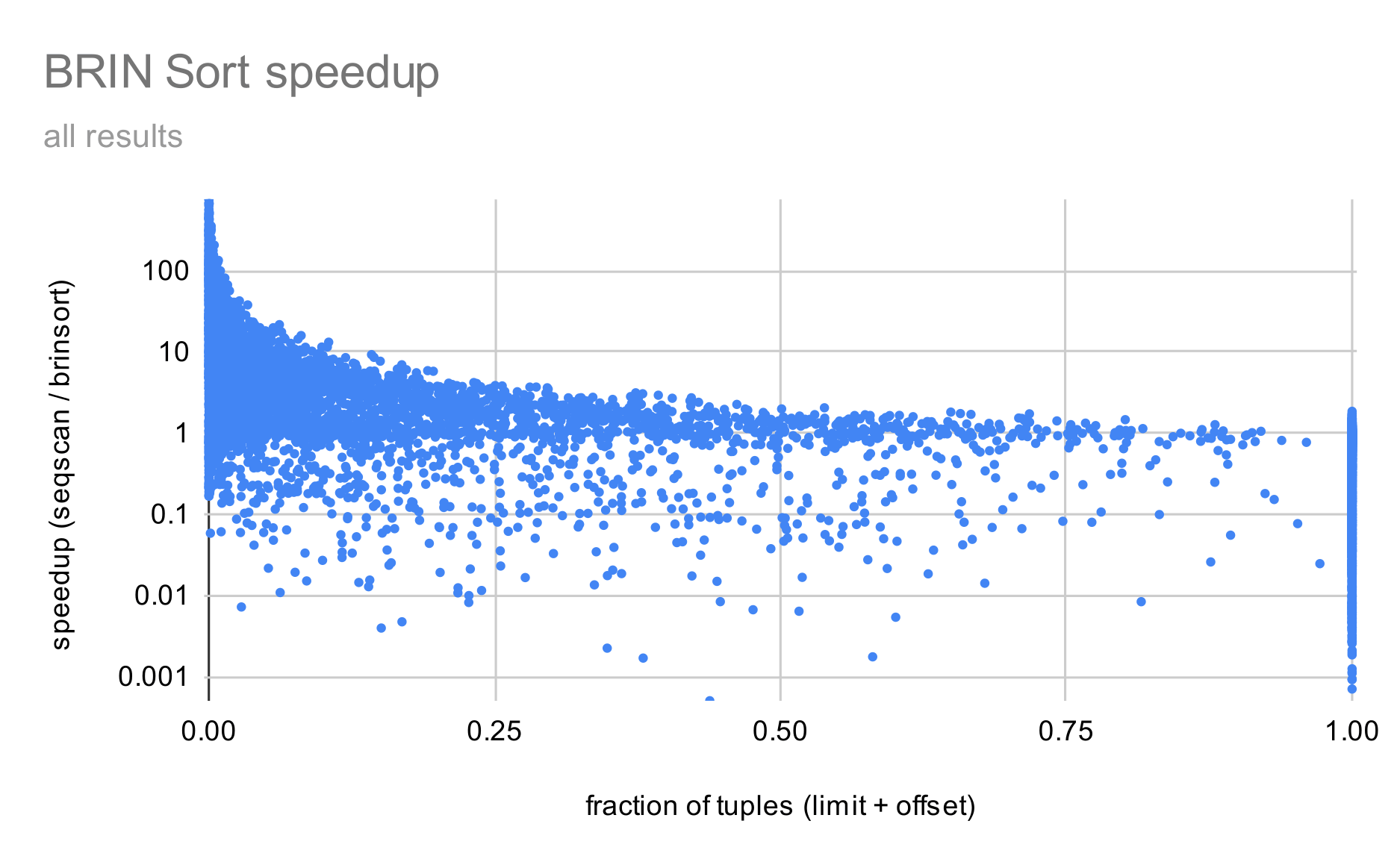
brinsort-all-data.gif shows results for all queries. There's significant
speedup for small values of fraction (i.e. queries with limit, requiring
few rows). This is expected, as this is pretty much the primary use case
for the patch.
The other thing is that the benefits quickly diminish - for fractions
close to 0.0 the potential benefits are huge, but once you cross ~10% of
the table, it's within 10x, for ~25% less than 5x etc.
OTOH there are also a fair number of queries that got slower - those are
the data points below 1.0. I've looked into many of them, and there are
a couple reasons why that can happen:
1) random data set - When the ranges are very wide, BRIN Sort has to
read most of the data, and it ends up sorting almost as many rows as the
sequential scan. But it's more expensive, especially when combined with
the following points.
Note: I don't think is an issue in practice, because BRIN indexes
would suck quite badly on such data, so no one is going to create
such indexes in the first place.
2) tiny ranges - By default ranges are 1MB, but it's possible to make
them much smaller. But BRIN Sort has to read/sort all ranges, and that
gets more expensive with the number of ranges.
Note: I'm not sure there's a way around this, although Matthias
had some interesting ideas about how to keep the ranges sorted.
But ultimately, I think this is fine, as long as it's costed
correctly. For fractions close to 0.0 this is still going to be
a huge win.
3) non-adaptive (and low) watermark_step - The number of sorts makes a
huge difference - in an extreme case we could add the ranges one by one,
with a sort after each. For small limit/offset that works, but for more
rows it's quite pointless.
Note: The adaptive step (adjusted during execution) works great, and
the script sets explicit values mostly to trigger more corner cases.
Also, I wonder if we should force higher values as we progress
through the table - we still don't want to exceed work_mem, but the
larger fraction we scan the more we should prefer larger "batches".
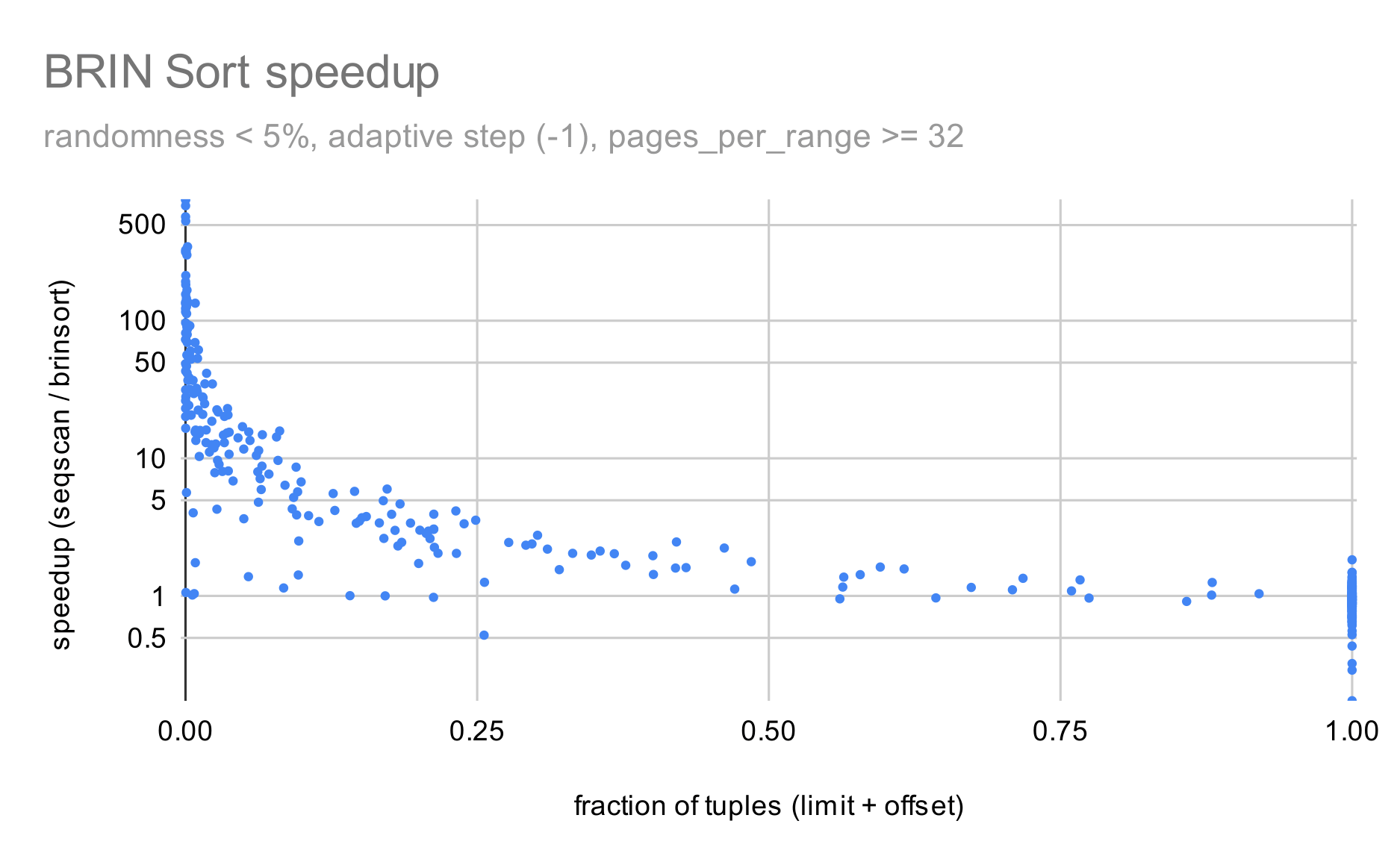
The second "filter" chart (brinsort-filtered-data.gif) shows results
filtered to only show runs with:
- pages_per_range >= 32
- randomness <= 5% (i.e. each range covers about 5% of domain)
- adaptive step (= -1)
And IMO this looks much better - there are almost no slower queries,
except for a bunch of queries that scan all the data.
So, what are the next steps for this patch:
1) cleanup of the existing code (mentioned above)
2) improvement of the costing - This is probably the critical part,
because we need a costing that allows us to identify the queries that
are likely to be faster/slower. I believe this is doable - either now or
using the new opclass-specific stats proposed in a separate patch (and
kept in part 0001 for completeness).
regards
--
Tomas Vondra
EnterpriseDB: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
{kind=link}
{kind=link}