Thread: DocBook 5.2
DocBook 5.2 is around the corner [1], we use DocBook 4.5 which is 'feature frozen' since 2006, and there are even ideas for DocBook 6.x [2].
I want to inform you that I'm working on an upgrade of our documentation to DocBook 5.2. Major steps have been done, but I need some more time before I can publish a first working draft. Please keep me informed, if someone else is working on the same issue.J. Purtz
[1]: https://github.com/docbook/docbook/releases/tag/5.2CR3
[2]: https://github.com/docbook/docbook/issues?q=is%3Aissue+is%3Aopen+label%3Av6
On 2022-Sep-04, Jürgen Purtz wrote: > DocBook 5.2 is around the corner [1], we use DocBook 4.5 which is 'feature > frozen' since 2006, and there are even ideas for DocBook 6.x [2]. What changes? I doubt we'll want to adopt a new version immediately after release, since we want to stay compatible with older systems. But recently I had an issue with a tag that would have worked with 5.0 and didn't with 4.5, so let's hear what the benefits are. -- Álvaro Herrera PostgreSQL Developer — https://www.EnterpriseDB.com/ "I'm always right, but sometimes I'm more right than other times." (Linus Torvalds)
On 04.09.22 17:39, Alvaro Herrera wrote: > What changes? > I doubt we'll want to adopt a new version immediately after release, > since we want to stay compatible with older systems. The migration isn't a matter of days. It's a huge step because nearly all files are touched and we have to act carefully to deliver (nearly) identical HTML, PDF, ... files as before. As a preview of the ongoing the actual README.md file is attached. Jürgen Purtz
Attachment
> On 5 Sep 2022, at 11:50, Jürgen Purtz <juergen@purtz.de> wrote: > > On 04.09.22 17:39, Alvaro Herrera wrote: >> What changes? >> I doubt we'll want to adopt a new version immediately after release, >> since we want to stay compatible with older systems. > > The migration isn't a matter of days. It's a huge step because nearly all files are touched and we have to act carefullyto deliver (nearly) identical HTML, PDF, ... files as before. As a preview of the ongoing the actual README.md fileis attached. Will the markup be similar enough to not carry a significant risk of introducing pain for backpatching doc patches? -- Daniel Gustafsson https://vmware.com/
On 05.09.22 11:59, Daniel Gustafsson wrote:
> Will the markup be similar enough to not carry a significant risk of
> introducing pain for backpatching doc patches?
There are many changes. Most of them are systematically and others are
individual, which is more painful. To give you an impression what
typically changes, here is the diff of an arbitrary file. The
HTML-output looks quite good - as far as I have seen.
diff --git a/doc/src/sgml/xtypes.sgml b/doc/src/sgml/xtypes.sgml
index e67e5bdf4c..6b6e6eb059 100644
--- a/doc/src/sgml/xtypes.sgml
+++ b/doc/src/sgml/xtypes.sgml
@@ -1,6 +1,6 @@
<!-- doc/src/sgml/xtypes.sgml -->
- <sect1 id="xtypes">
+ <sect1 xml:id="xtypes">
<title>User-Defined Types</title>
<indexterm zone="xtypes">
@@ -72,7 +72,7 @@ typedef struct Complex {
write a complete and robust parser for that representation as your
input function. For instance:
-<programlisting><![CDATA[
+<programlisting>
PG_FUNCTION_INFO_V1(complex_in);
Datum
@@ -83,23 +83,23 @@ complex_in(PG_FUNCTION_ARGS)
y;
Complex *result;
- if (sscanf(str, " ( %lf , %lf )", &x, &y) != 2)
+ if (sscanf(str, " ( %lf , %lf )", &x, &y) != 2)
ereport(ERROR,
(errcode(ERRCODE_INVALID_TEXT_REPRESENTATION),
errmsg("invalid input syntax for type %s: \"%s\"",
"complex", str)));
result = (Complex *) palloc(sizeof(Complex));
- result->x = x;
- result->y = y;
+ result->x = x;
+ result->y = y;
PG_RETURN_POINTER(result);
}
-]]>
+
</programlisting>
The output function can simply be:
-<programlisting><![CDATA[
+<programlisting>
PG_FUNCTION_INFO_V1(complex_out);
Datum
@@ -108,10 +108,10 @@ complex_out(PG_FUNCTION_ARGS)
Complex *complex = (Complex *) PG_GETARG_POINTER(0);
char *result;
- result = psprintf("(%g,%g)", complex->x, complex->y);
+ result = psprintf("(%g,%g)", complex->x, complex->y);
PG_RETURN_CSTRING(result);
}
-]]>
+
</programlisting>
</para>
@@ -132,7 +132,7 @@ complex_out(PG_FUNCTION_ARGS)
<type>complex</type>, we will piggy-back on the binary I/O converters
for type <type>float8</type>:
-<programlisting><![CDATA[
+<programlisting>
PG_FUNCTION_INFO_V1(complex_recv);
Datum
@@ -142,8 +142,8 @@ complex_recv(PG_FUNCTION_ARGS)
Complex *result;
result = (Complex *) palloc(sizeof(Complex));
- result->x = pq_getmsgfloat8(buf);
- result->y = pq_getmsgfloat8(buf);
+ result->x = pq_getmsgfloat8(buf);
+ result->y = pq_getmsgfloat8(buf);
PG_RETURN_POINTER(result);
}
@@ -155,12 +155,12 @@ complex_send(PG_FUNCTION_ARGS)
Complex *complex = (Complex *) PG_GETARG_POINTER(0);
StringInfoData buf;
- pq_begintypsend(&buf);
- pq_sendfloat8(&buf, complex->x);
- pq_sendfloat8(&buf, complex->y);
- PG_RETURN_BYTEA_P(pq_endtypsend(&buf));
+ pq_begintypsend(&buf);
+ pq_sendfloat8(&buf, complex->x);
+ pq_sendfloat8(&buf, complex->y);
+ PG_RETURN_BYTEA_P(pq_endtypsend(&buf));
}
-]]>
+
</programlisting>
</para>
@@ -237,7 +237,7 @@ CREATE TYPE complex (
If the internal representation of the data type is variable-length, the
internal representation must follow the standard layout for
variable-length
data: the first four bytes must be a <type>char[4]</type> field
which is
- never accessed directly (customarily named
<structfield>vl_len_</structfield>). You
+ never accessed directly (customarily named <varname
remap="structfield">vl_len_</varname>). You
must use the <function>SET_VARSIZE()</function> macro to store the
total
size of the datum (including the length field itself) in this field
and <function>VARSIZE()</function> to retrieve it. (These macros exist
@@ -249,7 +249,7 @@ CREATE TYPE complex (
<xref linkend="sql-createtype"/> command.
</para>
- <sect2 id="xtypes-toast">
+ <sect2 xml:id="xtypes-toast">
<title>TOAST Considerations</title>
<indexterm>
<primary>TOAST</primary>
@@ -258,8 +258,7 @@ CREATE TYPE complex (
<para>
If the values of your data type vary in size (in internal form), it's
- usually desirable to make the data type <acronym>TOAST</acronym>-able
(see <xref
- linkend="storage-toast"/>). You should do this even if the values are
always
+ usually desirable to make the data type <acronym>TOAST</acronym>-able
(see <xref linkend="storage-toast"/>). You should do this even if the
values are always
too small to be compressed or stored externally, because
<acronym>TOAST</acronym> can save space on small data too, by
reducing header
overhead.
@@ -290,7 +289,7 @@ CREATE TYPE complex (
<note>
<para>
- Older code frequently declares <structfield>vl_len_</structfield> as an
+ Older code frequently declares <varname
remap="structfield">vl_len_</varname> as an
<type>int32</type> field instead of <type>char[4]</type>. This is
OK as long as
the struct definition has other fields that have at least
<type>int32</type>
alignment. But it is dangerous to use such a struct definition when
On 2022-Sep-05, Jürgen Purtz wrote: > - <sect1 id="xtypes"> > + <sect1 xml:id="xtypes"> > <title>User-Defined Types</title> OK, these seem quite significant changes that are likely to cause great pain. So I repeat my question, what are the benefits of making this change? They better be very very substantial. -- Álvaro Herrera Breisgau, Deutschland — https://www.EnterpriseDB.com/ "The Gord often wonders why people threaten never to come back after they've been told never to return" (www.actsofgord.com)
On 2022-Sep-05, Jürgen Purtz wrote:
> - <sect1 id="xtypes">
> + <sect1 xml:id="xtypes">
> <title>User-Defined Types</title>
OK, these seem quite significant changes that are likely to cause great
pain. So I repeat my question, what are the benefits of making this
change? They better be very very substantial.
--
Le lun. 5 sept. 2022 à 13:14, Alvaro Herrera <alvherre@alvh.no-ip.org> a écrit :On 2022-Sep-05, Jürgen Purtz wrote:
> - <sect1 id="xtypes">
> + <sect1 xml:id="xtypes">
> <title>User-Defined Types</title>
OK, these seem quite significant changes that are likely to cause great
pain. So I repeat my question, what are the benefits of making this
change? They better be very very substantial.I totally agree with Alvaro.They will also cause massive pain for translators. There are already some changes that were pretty bad for me. For example, when all the tables in func.sgml were modified. In v15, I also remember massive changes on protocol.sgml. I won't complain if there is a significant benefit for readers, which is why I didn't complain for func.sgml even if it meant I had to translate it all over again. But if there's a massive change over the whole manual for a strictly limited benefit, I guess there won't be enough motivation for me to translate it all over again.
--Guillaume.
The goal of the migration is an approximation to today's technology, especially programming interfaces and standards, to be able to use and interact with nowadays tools. Of course, this leads to internal technical changes. It is not intended to change anything at the readers surface. In that respect, it is comparable with the sgml to xml conversion.
- The introduction of RELAX NG instead of DTDs leads to a much richer controlling of the sgml files.
- The introduction of namespaces instead of a DOCTYPE definition offers the possibility to integrate tags of other namespaces into our documentation, eg.: MathML, XInclude, XLink, ... .
- The changes during the migration consist mainly in a renaming of tag-names. The most important for us is 'ulink'.
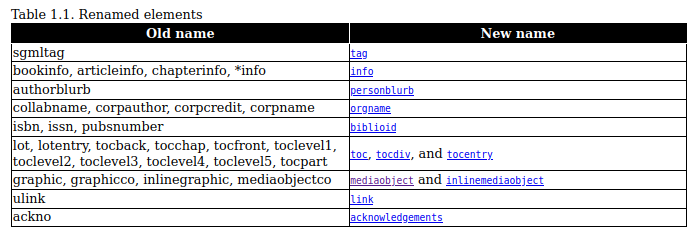
- After the migration the validation is much stricter than before. Because we have used tags in a more or less 'individual' style, especially when describing commands, there are a lot of violations against the RELAX NG schema. Modifications caused by such problems are those, which will create the most pain - for back-patching as well as for translators.
- Possibly the pain for translators decreases significantly by using the same migration scripts on their already translated sgml files.
- I don't understand where the pain for back-patching is when the attribute 'id' changes to 'xml:id'. It is very unlikely that the id of a section or another tag will change, or something else in such lines. In nearly all cases such lines will keep as they are, back-patching will not be necessary at such places.
What is the alternative to a migration? DocBook 4.5 forever?
--
J. Purtz
Attachment
On 05.09.22 11:50, Jürgen Purtz wrote: > Therefore, we should consider to introduce another validator. During the migration phase, > we have used **jing**. It's Java, it's fast, the error messages are very precise. But there > are many others:https://relaxng.org/#validators. Should we possibly provide multiple > validators in doc/src/sgml/Makefile? If you follow the links on that page, it appears that all the projects other than jing are abandoned. Even jing has a very sporadic release history (2015 -> 2018 -> 2022). Last year at FOSDEM I gave a talk about the state of the DocBook toolchain [0], where I found that there is pretty much no tooling available for Relax-NG. So it's great that there is a 2022 release of jing, but before we can consider relying on that, it might be nice to see a bit more of a track record. (And we should also wait a little to make it trickle in stable packages for common operating systems.) [0]: https://ftp.fau.de/fosdem/2021/D.docs/ttdpostgresdocbook.webm
On 06.09.22 21:28, Peter Eisentraut wrote: > On 05.09.22 11:50, Jürgen Purtz wrote: >> Therefore, we should consider to introduce another validator. During >> the migration phase, >> we have used **jing**. It's Java, it's fast, the error messages are >> very precise. But there >> are many others:https://relaxng.org/#validators. Should we possibly >> provide multiple >> validators in doc/src/sgml/Makefile? > > If you follow the links on that page, it appears that all the projects > other than jing are abandoned. Even jing has a very sporadic release > history (2015 -> 2018 -> 2022). Last year at FOSDEM I gave a talk > about the state of the DocBook toolchain [0], where I found that there > is pretty much no tooling available for Relax-NG. So it's great that > there is a 2022 release of jing, but before we can consider relying on > that, it might be nice to see a bit more of a track record. (And we > should also wait a little to make it trickle in stable packages for > common operating systems.) > > [0]: https://ftp.fau.de/fosdem/2021/D.docs/ttdpostgresdocbook.webm > > The work on the migration has reached a stage where the resulting files validates against the Relax NG schema and HTML output is generated, see attached README,md, conv.sh, and doRealModifications.sh. If you want to test the suite, I recommend the use of jing for the validation process. The generation of PDF and Epub shows an unacceptable runtime behavior. An intentionally reduced postgres.sgml file (up to about 100 pages of output) creates the expected pdf and epub output. After some work on this problem I don't have any idea how to solve it. During the sgml-to-xml conversion we faced a similar problem and solved it with an additional xsl-script. Can someone support me? -- J. Purtz
Attachment
On Mon, Sep 5, 2022 at 01:15:08PM +0200, Álvaro Herrera wrote: > On 2022-Sep-05, Jürgen Purtz wrote: > > > - <sect1 id="xtypes"> > > + <sect1 xml:id="xtypes"> > > <title>User-Defined Types</title> > > OK, these seem quite significant changes that are likely to cause great > pain. So I repeat my question, what are the benefits of making this > change? They better be very very substantial. Would we be converting docs for all supported versions of Postgres to use DocBook 5.2, or just the most current version? If the later, we would find backpatching a pain for five years. -- Bruce Momjian <bruce@momjian.us> https://momjian.us EDB https://enterprisedb.com Indecision is a decision. Inaction is an action. Mark Batterson
Bruce Momjian <bruce@momjian.us> writes:
> On Mon, Sep 5, 2022 at 01:15:08PM +0200, Álvaro Herrera wrote:
>> OK, these seem quite significant changes that are likely to cause great
>> pain. So I repeat my question, what are the benefits of making this
>> change? They better be very very substantial.
> Would we be converting docs for all supported versions of Postgres to
> use DocBook 5.2, or just the most current version? If the later, we
> would find backpatching a pain for five years.
Yeah, I think we'd have to convert all the supported versions to
make this palatable. If the conversion is sufficiently automated,
that might not be a big lift. (If it's *not* automated, I think
the change would never get off the ground even for HEAD, because
the docs are too much of a moving target.)
regards, tom lane
On Mon, Sep 26, 2022 at 05:42:32PM -0400, Tom Lane wrote: > Bruce Momjian <bruce@momjian.us> writes: > > On Mon, Sep 5, 2022 at 01:15:08PM +0200, Álvaro Herrera wrote: > >> OK, these seem quite significant changes that are likely to cause great > >> pain. So I repeat my question, what are the benefits of making this > >> change? They better be very very substantial. > > > Would we be converting docs for all supported versions of Postgres to > > use DocBook 5.2, or just the most current version? If the later, we > > would find backpatching a pain for five years. > > Yeah, I think we'd have to convert all the supported versions to > make this palatable. If the conversion is sufficiently automated, > that might not be a big lift. (If it's *not* automated, I think > the change would never get off the ground even for HEAD, because > the docs are too much of a moving target.) +1 -- Bruce Momjian <bruce@momjian.us> https://momjian.us EDB https://enterprisedb.com Indecision is a decision. Inaction is an action. Mark Batterson
Yeah, I think we'd have to convert all the supported versions to make this palatable. If the conversion is sufficiently automated, that might not be a big lift. (If it's *not* automated, I think the change would never get off the ground even for HEAD, because the docs are too much of a moving target.)+1
The process is totally automated. There are general steps which work for every DocBook 4.x book. And there are Postgres-specific steps (doRealModifictions.sh) which looks for individual patterns per file. This is the critical part. Currently it's tested only with HEAD. My expectation is, that it should work also for translations to other languages because the patterns contain only elements and attributes, no text. But if they run against older versions it's likely that we need some changes or additional patterns. I'm willing to work on this if a) there is a consensus in the community that the work should go on and b) someone helps me to resolve the reported unacceptable runtime problem during PDF generation.
--
J. Purtz
Yeah, I think we'd have to convert all the supported versions to make this palatable. If the conversion is sufficiently automated, that might not be a big lift. (If it's *not* automated, I think the change would never get off the ground even for HEAD, because the docs are too much of a moving target.)+1The process is totally automated. There are general steps which work for every DocBook 4.x book. And there are Postgres-specific steps (doRealModifictions.sh) which looks for individual patterns per file. This is the critical part. Currently it's tested only with HEAD. My expectation is, that it should work also for translations to other languages because the patterns contain only elements and attributes, no text. But if they run against older versions it's likely that we need some changes or additional patterns. I'm willing to work on this if a) there is a consensus in the community that the work should go on and b) someone helps me to resolve the reported unacceptable runtime problem during PDF generation.
--
J. Purtz
DocBook 5.2 is published [1] [2].
This mail contains a new version of the PostgreSQL migration scripts (DocBook 4.5 format to 5.2 format). They are developed for PG versions 13 up to 17. Please see README.md for details. The generated output looks good at first glance, but: a) I don't have an idea how to guarantee that it looks REALLY identical at ALL places. Everyone is invited to search differences. b) pdf (resp. 'fo') cannot be generated. It seems to be a performance issue - a small number of test-pages works well. Concerning this issue I need help from someone with good xslt knowledge. c) On my laptop epub cannot be generated (for version 4.5 as well as for 5.2). dbtoepub is a ruby program.
Development and testing was done only at an Ubuntu 22.04 laptop. For those who want to see the results quickly, download [3] (converted sgml, html, and man files, 8MB) or [4] (plus postgres-full.xml, postgres.txt, html single page, 16 MB). The two files remain online for some days.
J. Purtz
[1] https://www.oasis-open.org/2024/02/13/the-docbook-schema-version-5-2-oasis-standard-published/
[2] https://github.com/docbook/docbook/releases/tag/5.2
[3] https://purtz.de/sgml_17beta1.zip
[4] https://purtz.de/sgml_17beta1_huge.zip
Attachment
On 27.09.22 09:12, Jürgen Purtz wrote:Yeah, I think we'd have to convert all the supported versions to make this palatable. If the conversion is sufficiently automated, that might not be a big lift. (If it's *not* automated, I think the change would never get off the ground even for HEAD, because the docs are too much of a moving target.)+1The process is totally automated. There are general steps which work for every DocBook 4.x book. And there are Postgres-specific steps (doRealModifictions.sh) which looks for individual patterns per file. This is the critical part. Currently it's tested only with HEAD. My expectation is, that it should work also for translations to other languages because the patterns contain only elements and attributes, no text. But if they run against older versions it's likely that we need some changes or additional patterns. I'm willing to work on this if a) there is a consensus in the community that the work should go on and b) someone helps me to resolve the reported unacceptable runtime problem during PDF generation.
--
J. Purtz
DocBook 5.2 is published [1] [2].
This mail contains a new version of the PostgreSQL migration scripts (DocBook 4.5 format to 5.2 format). They are developed for PG versions 13 up to 17. Please see README.md for details. The generated output looks good at first glance, but: a) I don't have an idea how to guarantee that it looks REALLY identical at ALL places. Everyone is invited to search differences. b) pdf (resp. 'fo') cannot be generated. It seems to be a performance issue - a small number of test-pages works well. Concerning this issue I need help from someone with good xslt knowledge. c) On my laptop epub cannot be generated (for version 4.5 as well as for 5.2). dbtoepub is a ruby program.
Development and testing was done only at an Ubuntu 22.04 laptop. For those who want to see the results quickly, download [3] (converted sgml, html, and man files, 8MB) or [4] (plus postgres-full.xml, postgres.txt, html single page, 16 MB). The two files remain online for some days.
J. Purtz
[1] https://www.oasis-open.org/2024/02/13/the-docbook-schema-version-5-2-oasis-standard-published/
[2] https://github.com/docbook/docbook/releases/tag/5.2
[3] https://purtz.de/sgml_17beta1.zip
[4] https://purtz.de/sgml_17beta1_huge.zip
Compared to my last mail, the scripts have changed regarding the following topics:
- They use the current Docbook stylesheets 1.79.2 instead of 1.79.1 (cdn instead of sourceforge)
- All PG-stylesheets declare and use the Docbook namespace
- Implementation of different checks via 'diff'
- Elapsed time for all documentation generation targets is slightly better than with Docbook 4.5, especially for PDF generation
The README.md file reports the currently know problems and TODOs.
For those who want to see the results quickly, there is [1] for some time which contains migrated sgml, html, man, and PDF for 17beta2.
[1] https://purtz.de/sgml_17beta2.zip (27MB)
J. Purtz
Attachment
=?UTF-8?Q?J=C3=BCrgen_Purtz?= <juergen@purtz.de> writes:
> [ conversion to DocBook 5.2 ]
I took another look at this issue, and found that no Red Hat distro is
yet shipping DocBook 5.2; not even Fedora 40 which is bleeding edge.
So I would have to obtain and manually install the relevant DTDs
and style sheets, as would a lot of other contributors. I'm less
familiar with the Debian ecosystem but AFAICT they are shipping
even older docbook packages than Red Hat.
In short, making this conversion now would destroy most contributors'
ability to build the docs at all. Not to mention packagers, who
generally don't have the option to use stuff not yet blessed by their
distro. Since we've lately been encouraging packagers to build the
docs for themselves, that part is likely to be a pain point long
after it stops being one for average contributors.
I don't see how we can migrate to 5.2 until it becomes a lot more
widespread in standard distros.
regards, tom lane
I took another look at this issue, and found that no Red Hat distro is yet shipping DocBook 5.2; not even Fedora 40 which is bleeding edge. So I would have to obtain and manually install the relevant DTDs and style sheets, as would a lot of other contributors. I'm less familiar with the Debian ecosystem but AFAICT they are shipping even older docbook packages than Red Hat. In short, making this conversion now would destroy most contributors' ability to build the docs at all. Not to mention packagers, who generally don't have the option to use stuff not yet blessed by their distro. Since we've lately been encouraging packagers to build the docs for themselves, that part is likely to be a pain point long after it stops being one for average contributors. I don't see how we can migrate to 5.2 until it becomes a lot more widespread in standard distros. regards, tom lane
For me it's understandable that Red Hat and others hesitate to integrate DocBook into their distros. The DocBook people spread their results across a lot of sites: docbook, oasis, sourceforge, github, cdn, ... (DTD, XML-schema, Relax-NG; xslt1.0, xslt2.0, xslt3.0; with/without namespace; ...) and even mix it with secondary literature in a less transparent way. It's hard to understand which parts are the necessary core of their product.
For the PG community I would like to raise the question: Do we need DocBook in the distro of any operating system? In the past we developed some stylesheets to adopt DocBook to our needs. They are part of PG's distro and refer to the standard with statements like <xsl:import href="http://docbook.sourceforge.net/release/xsl/current/xxxx/docbook.xsl"/>. With the migration to db5.x the links change to <xsl:import href="http://cdn.docbook.org/release/xsl/1.79.2/xxxx/docbook.xsl"/>. Hence we don't need any additional local stylesheet outside of our own distro. Concerning DTD/schema/relax-ng: In db5.2 there is no DTD nor a XML-schema, for validation we need only the Relax-NG file 'docbook.rng'. This file is available at https://docs.oasis-open.org/docbook/docbook/v5.2/os/rng/docbook.rng (during the conversion-process I used a local copy).
I assume we don't need any operating system distro of DocBook. Please correct me, if I'm wrong.
---
J. Purtz
On 06.09.24 10:50, Jürgen Purtz wrote: > For the PG community I would like to raise the question: Do we need > DocBook in the distro of any operating system? In the past we developed > some stylesheets to adopt DocBook to our needs. They are part of PG's > distro and refer to the standard with statements like <xsl:import > href="http://docbook.sourceforge.net/release/xsl/current/xxxx/docbook.xsl"/>. With the migration to db5.x the links changeto <xsl:import href="http://cdn.docbook.org/release/xsl/1.79.2/xxxx/docbook.xsl"/>. Hence we don't need any additionallocal stylesheet outside of our own distro. Concerning DTD/schema/relax-ng: In db5.2 there is no DTD nor a XML-schema,for validation we need only the Relax-NG file 'docbook.rng'. This file is available at https://docs.oasis-open.org/docbook/docbook/v5.2/os/rng/docbook.rng(during the conversion-process I used a local copy). > > I assume we don't need any operating system distro of DocBook. Please > correct me, if I'm wrong. Note that we run xsltproc with the --nonet option. So stylesheet and schema need to be available as local files. Downloading these on-the-fly during the build process has been found to be unreliable, and it's also not sound software supply chain hygiene.