Thread: Error on pgbench logs
Hello!
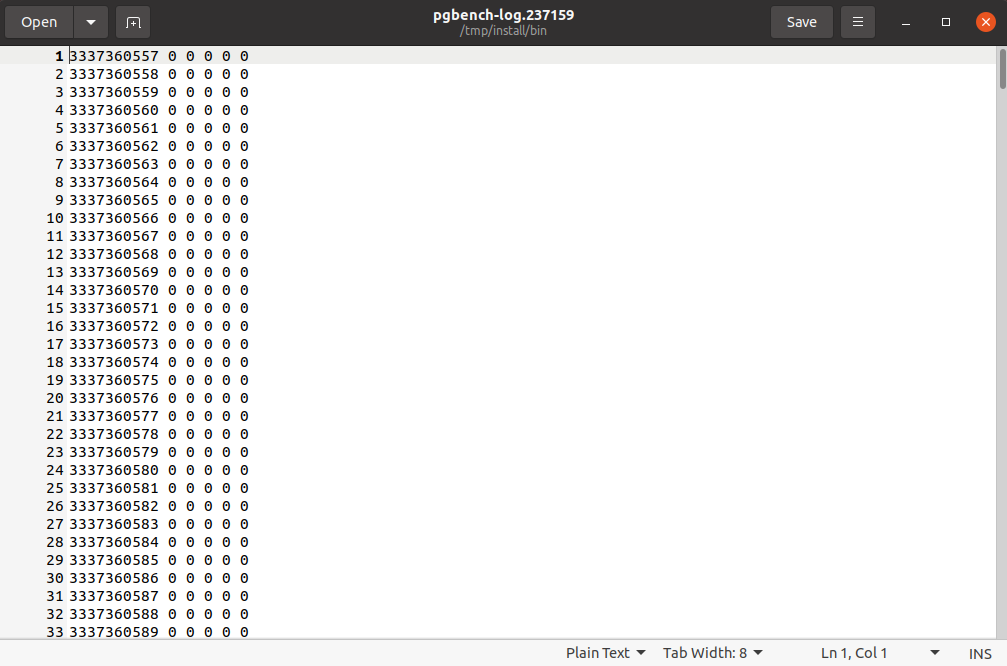
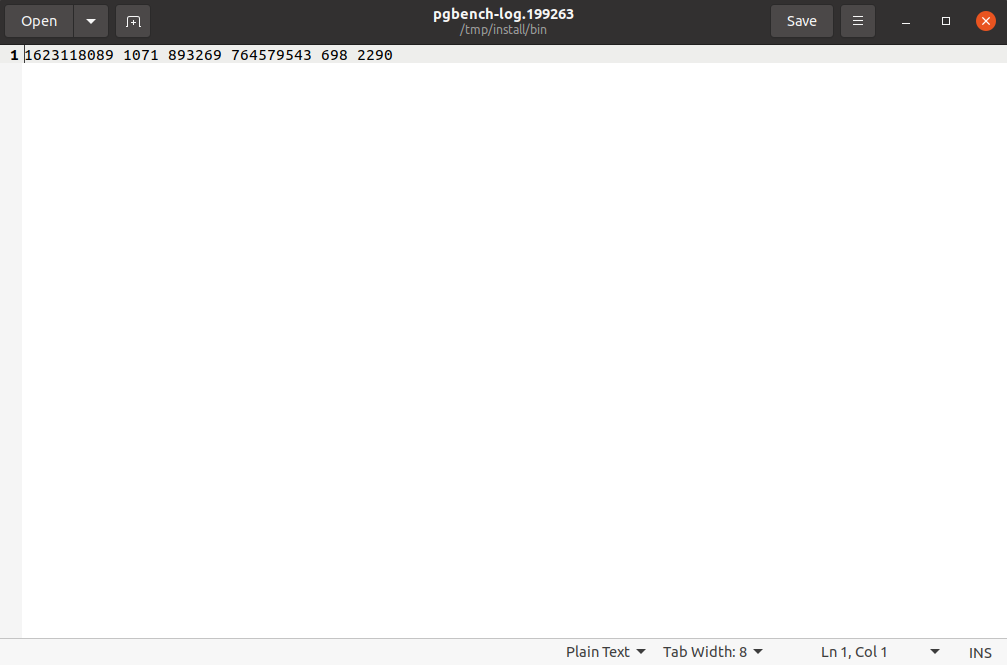
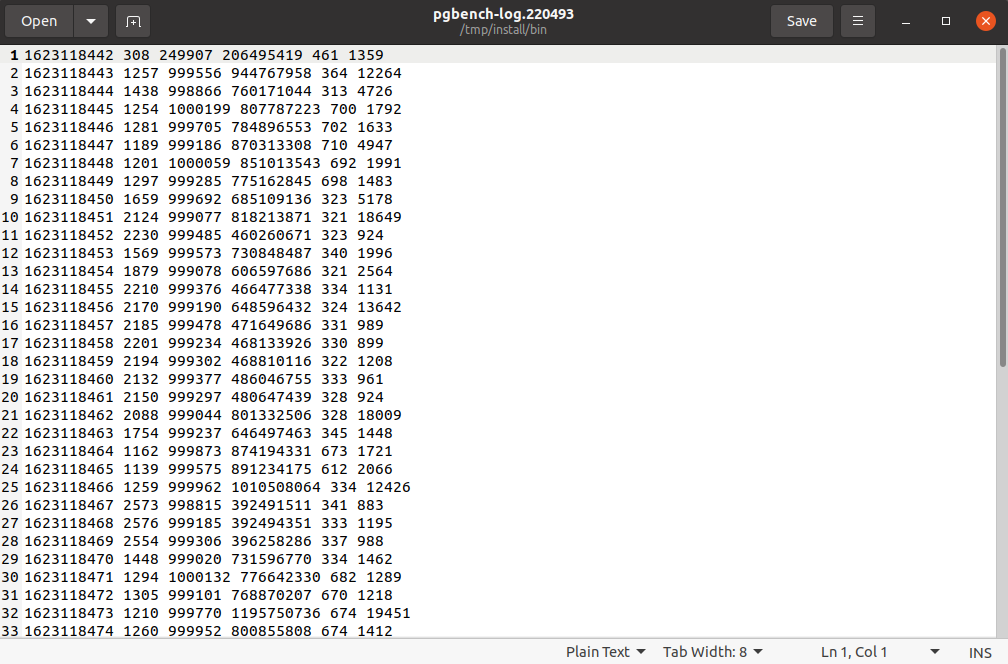
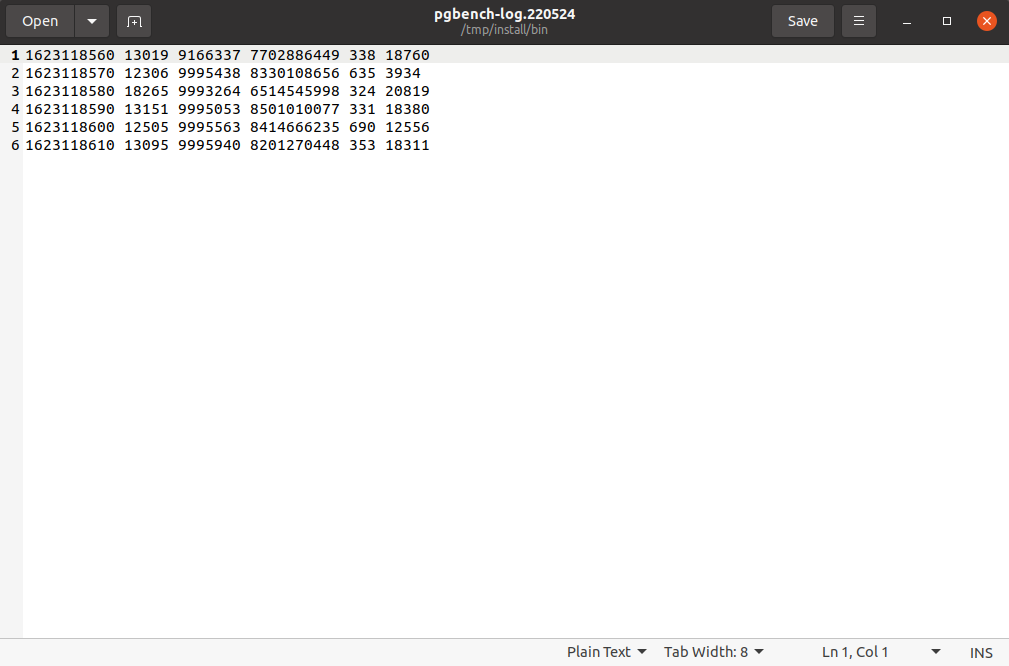
While I was using pgbench from the master branch, I discovered an error on pgbench logs.
When I run pgbench, the log file contains a lot of redundant 0s.
I ran git bisect and found out that this error occured since the commit 547f04e7348b6ed992bd4a197d39661fe7c25097 (Mar 10, 2021).
I ran the tests below on the problematic commit and the commit before it. (I used Debian 10.9 and Ubuntu 20.04)
=====
./pg_ctl -D /tmp/data init
./pg_ctl -D /tmp/data start
./pgbench -i -s 1 postgres
./pgbench -r -c 1 -j 1 -T 1 --aggregate-interval 1 -l --log-prefix pgbench-log postgres
./pgbench -r -c 2 -j 4 -T 60 --aggregate-interval 1 -l --log-prefix pgbench-log postgres
./pgbench -r -c 2 -j 4 -T 60 --aggregate-interval 10 -l --log-prefix pgbench-log postgres
=====
The result screenshots are in the attachments.
(I didn't attach the problematic 60 second log file which was bigger than 1GB.)
Please take a look at this issue.
Thank you!
Regards,
YoungHwan
While I was using pgbench from the master branch, I discovered an error on pgbench logs.
When I run pgbench, the log file contains a lot of redundant 0s.
I ran git bisect and found out that this error occured since the commit 547f04e7348b6ed992bd4a197d39661fe7c25097 (Mar 10, 2021).
I ran the tests below on the problematic commit and the commit before it. (I used Debian 10.9 and Ubuntu 20.04)
=====
./pg_ctl -D /tmp/data init
./pg_ctl -D /tmp/data start
./pgbench -i -s 1 postgres
./pgbench -r -c 1 -j 1 -T 1 --aggregate-interval 1 -l --log-prefix pgbench-log postgres
./pgbench -r -c 2 -j 4 -T 60 --aggregate-interval 1 -l --log-prefix pgbench-log postgres
./pgbench -r -c 2 -j 4 -T 60 --aggregate-interval 10 -l --log-prefix pgbench-log postgres
=====
The result screenshots are in the attachments.
(I didn't attach the problematic 60 second log file which was bigger than 1GB.)
Please take a look at this issue.
Thank you!
Regards,
YoungHwan
Attachment
{kind=link}
{kind=link}
{kind=link}
{kind=link}
At Tue, 8 Jun 2021 12:09:47 +0900, YoungHwan Joo <rulyox@gmail.com> wrote in
> Hello!
>
> While I was using pgbench from the master branch, I discovered an error on
> pgbench logs.
> When I run pgbench, the log file contains a lot of redundant 0s.
>
> I ran git bisect and found out that this error occured since the commit
> 547f04e7348b6ed992bd4a197d39661fe7c25097 (Mar 10, 2021).
Ugh! Thanks for the hunting!
The cause is that the time unit is changed to usec but the patch
forgot to convert agg_interval into the same unit in doLog. I tempted
to change it into pg_time_usec_t but it seems that it is better that
the unit is same with other similar variables like duration.
So I think that the attached fix works for you. (However, I'm not sure
the emitted log is correct or not, though..)
I didn't check for the similar bugs for other variables yet.
> I ran the tests below on the problematic commit and the commit before it.
> (I used Debian 10.9 and Ubuntu 20.04)
>
> =====
> ./pg_ctl -D /tmp/data init
> ./pg_ctl -D /tmp/data start
>
> ./pgbench -i -s 1 postgres
>
> ./pgbench -r -c 1 -j 1 -T 1 --aggregate-interval 1 -l --log-prefix
> pgbench-log postgres
> ./pgbench -r -c 2 -j 4 -T 60 --aggregate-interval 1 -l --log-prefix
> pgbench-log postgres
> ./pgbench -r -c 2 -j 4 -T 60 --aggregate-interval 10 -l --log-prefix
> pgbench-log postgres
> =====
>
> The result screenshots are in the attachments.
> (I didn't attach the problematic 60 second log file which was bigger than
> 1GB.)
>
> Please take a look at this issue.
>
> Thank you!
>
> Regards,
> YoungHwan
regards.
--
Kyotaro Horiguchi
NTT Open Source Software Center
diff --git a/src/bin/pgbench/pgbench.c b/src/bin/pgbench/pgbench.c
index dc84b7b9b7..c68dfa1806 100644
--- a/src/bin/pgbench/pgbench.c
+++ b/src/bin/pgbench/pgbench.c
@@ -3799,7 +3799,7 @@ doLog(TState *thread, CState *st,
* e.g. --rate=0.1).
*/
- while (agg->start_time + agg_interval <= now)
+ while (agg->start_time + agg_interval * 1000000 <= now)
{
/* print aggregated report to logfile */
fprintf(logfile, INT64_FORMAT " " INT64_FORMAT " %.0f %.0f %.0f %.0f",
@@ -3822,7 +3822,7 @@ doLog(TState *thread, CState *st,
fputc('\n', logfile);
/* reset data and move to next interval */
- initStats(agg, agg->start_time + agg_interval);
+ initStats(agg, agg->start_time + agg_interval * 1000000);
}
/* accumulate the current transaction */
On Tue, Jun 08, 2021 at 06:59:04PM +0900, Kyotaro Horiguchi wrote: > The cause is that the time unit is changed to usec but the patch > forgot to convert agg_interval into the same unit in doLog. I tempted > to change it into pg_time_usec_t but it seems that it is better that > the unit is same with other similar variables like duration. As the option remains in seconds, I think that it is simpler to keep it as an int, and do the conversion where need be. It would be good to document that agg_interval is in seconds where the variable is defined. - while (agg->start_time + agg_interval <= now) + while (agg->start_time + agg_interval * 1000000 <= now) In need of a cast with (int64), no? The other things are "progress" and "duration". These look correctly handled to me. -- Michael
Attachment
Hello Michael, >> The cause is that the time unit is changed to usec but the patch >> forgot to convert agg_interval into the same unit in doLog. I tempted >> to change it into pg_time_usec_t but it seems that it is better that >> the unit is same with other similar variables like duration. > > As the option remains in seconds, I think that it is simpler to keep > it as an int, and do the conversion where need be. It would be good > to document that agg_interval is in seconds where the variable is > defined. > > - while (agg->start_time + agg_interval <= now) > + while (agg->start_time + agg_interval * 1000000 <= now) > > In need of a cast with (int64), no? Yes, it would be better. In practice I would not expect the interval to be large enough to trigger an overflow (maxint µs is about 36 minutes). > The other things are "progress" and "duration". These look correctly > handled to me. Hmmm… What about tests? I'm pretty sure that I wrote a test about time sensitive features with a 2 seconds run (-T, -P, maybe these aggregates as well), but the test needed to be quite loose so as to pass on slow/heavy loaded hosts, and was removed at some point on the ground that it was somehow imprecise. I'm not sure whether it is worth to try again. -- Fabien.
Bonjour Michaël, Here is an updated patch. While having a look at Kyotaro-san patch, I noticed that the aggregate stuff did not print the last aggregate. I think that it is a side effect of switching the precision from per-second to per-µs. I've done an attempt at also fixing that which seems to work. -- Fabien.
Attachment
On Thu, Jun 10, 2021 at 11:29:30PM +0200, Fabien COELHO wrote: > + /* flush remaining stats */ > + if (!logged && latency == 0.0) > + logAgg(logfile, agg); You are right, this is missing the final stats. Why the choice of latency here for the check? That's just to make the difference between the case where doLog() is called while processing the benchmark for the end of the transaction and the case where doLog() is called once a thread ends, no? Wouldn't it be better to do a final push of the states once a thread reaches CSTATE_FINISHED or CSTATE_ABORTED instead? -- Michael
Attachment
At Fri, 11 Jun 2021 15:23:41 +0900, Michael Paquier <michael@paquier.xyz> wrote in > On Thu, Jun 10, 2021 at 11:29:30PM +0200, Fabien COELHO wrote: > > + /* flush remaining stats */ > > + if (!logged && latency == 0.0) > > + logAgg(logfile, agg); > > You are right, this is missing the final stats. Why the choice of > latency here for the check? That's just to make the difference > between the case where doLog() is called while processing the > benchmark for the end of the transaction and the case where doLog() is > called once a thread ends, no? Wouldn't it be better to do a final > push of the states once a thread reaches CSTATE_FINISHED or > CSTATE_ABORTED instead? Doesn't threadRun already doing that? -- Kyotaro Horiguchi NTT Open Source Software Center
At Fri, 11 Jun 2021 15:56:55 +0900 (JST), Kyotaro Horiguchi <horikyota.ntt@gmail.com> wrote in > Doesn't threadRun already doing that? (s/Does/Is) That's once per thread, sorry for the noise. regards. -- Kyotaro Horiguchi NTT Open Source Software Center
Bonjour Michaël, >> + /* flush remaining stats */ >> + if (!logged && latency == 0.0) >> + logAgg(logfile, agg); > > You are right, this is missing the final stats. Why the choice of > latency here for the check? For me zero latency really says that there is no actual transaction to count, so it is a good trigger for the closing call. I did not wish to add a new "flush" parameter, or a specific function. I agree that it looks strange, though. > That's just to make the difference between the case where doLog() is > called while processing the benchmark for the end of the transaction and > the case where doLog() is called once a thread ends, no? Yes. > Wouldn't it be better to do a final push of the states once a thread > reaches CSTATE_FINISHED or CSTATE_ABORTED instead? The call was already in place at the end of threadRun and had just become ineffective. I did not wish to revisit its place and change the overall structure, it is just a bug fix. I agree that it could be done differently with the added logAgg function which could be called directly. Attached another version which does that. -- Fabien.
Attachment
On Fri, 11 Jun 2021 16:09:10 +0200 (CEST)
Fabien COELHO <coelho@cri.ensmp.fr> wrote:
>
> Bonjour Michaël,
>
> >> + /* flush remaining stats */
> >> + if (!logged && latency == 0.0)
> >> + logAgg(logfile, agg);
> >
> > You are right, this is missing the final stats. Why the choice of
> > latency here for the check?
>
> For me zero latency really says that there is no actual transaction to
> count, so it is a good trigger for the closing call. I did not wish to add
> a new "flush" parameter, or a specific function. I agree that it looks
> strange, though.
It will not work if the transaction is skipped, in which case latency is 0.0.
It would work if we check also "skipped" as bellow.
+ if (!logged && !skipped && latency == 0.0)
However, it still might not work if the latency is so small so that we could
observe latency == 0.0. I observed this when I used a script that contained
only a meta command. This is not usual and would be a corner case, though.
> > Wouldn't it be better to do a final push of the states once a thread
> > reaches CSTATE_FINISHED or CSTATE_ABORTED instead?
>
> The call was already in place at the end of threadRun and had just become
> ineffective. I did not wish to revisit its place and change the overall
> structure, it is just a bug fix. I agree that it could be done differently
> with the added logAgg function which could be called directly. Attached
> another version which does that.
/* log aggregated but not yet reported transactions */
doLog(thread, state, &aggs, false, 0, 0);
+ logAgg(thread->logfile, &aggs);
I think we don't have to call doLog() before logAgg(). If we call doLog(),
we will count an extra transaction that is not actually processed because
accumStats() is called in this.
Regards,
Yugo Nagata
--
Yugo NAGATA <nagata@sraoss.co.jp>
On Thu, 10 Jun 2021 23:29:30 +0200 (CEST) Fabien COELHO <coelho@cri.ensmp.fr> wrote: > > Bonjour Michaël, > > Here is an updated patch. While having a look at Kyotaro-san patch, I > noticed that the aggregate stuff did not print the last aggregate. I think > that it is a side effect of switching the precision from per-second to > per-µs. I've done an attempt at also fixing that which seems to work. This is just out of curiosity. + while ((next = agg->start_time + agg_interval * INT64CONST(1000000)) <= now) I can find the similar code to convert "seconds" to "us" using casting like end_time = threads[0].create_time + (int64) 1000000 * duration; or next_report = last_report + (int64) 1000000 * progress; Is there a reason use INT64CONST instead of (int64)? Do these imply the same effect? Sorry, if this is a dumb question... Regards, Yugo Nagata -- Yugo NAGATA <nagata@sraoss.co.jp>
> + while ((next = agg->start_time + agg_interval * INT64CONST(1000000)) <= now) > > I can find the similar code to convert "seconds" to "us" using casting like > > end_time = threads[0].create_time + (int64) 1000000 * duration; > > or > > next_report = last_report + (int64) 1000000 * progress; > > Is there a reason use INT64CONST instead of (int64)? Do these imply the same effect? I guess that the macros does 1000000LL or something similar to directly create an int64 constant. It is necessary if the constant would overflow a usual 32 bits C integer, whereas the cast is sufficient if there is no overflow. Maybe I c/should have used the previous approach. > Sorry, if this is a dumb question... Nope. -- Fabien.
>> + while ((next = agg->start_time + agg_interval * INT64CONST(1000000))
>> <= now)
>>
>> I can find the similar code to convert "seconds" to "us" using casting
>> like
>>
>> end_time = threads[0].create_time + (int64) 1000000 * duration;
>>
>> or
>>
>> next_report = last_report + (int64) 1000000 * progress;
>>
>> Is there a reason use INT64CONST instead of (int64)? Do these imply
>> the same effect?
>
> I guess that the macros does 1000000LL or something similar to
> directly create an int64 constant. It is necessary if the constant
> would overflow a usual 32 bits C integer, whereas the cast is
> sufficient if there is no overflow. Maybe I c/should have used the
> previous approach.
I think using INT64CONST to create a 64-bit constant is the standard
practice in PostgreSQL.
commit 9d6b160d7db76809f0c696d9073f6955dd5a973a
Author: Tom Lane <tgl@sss.pgh.pa.us>
Date: Fri Sep 1 15:14:18 2017 -0400
Make [U]INT64CONST safe for use in #if conditions.
Instead of using a cast to force the constant to be the right width,
assume we can plaster on an L, UL, LL, or ULL suffix as appropriate.
The old approach to this is very hoary, dating from before we were
willing to require compilers to have working int64 types.
This fix makes the PG_INT64_MIN, PG_INT64_MAX, and PG_UINT64_MAX
constants safe to use in preprocessor conditions, where a cast
doesn't work. Other symbolic constants that might be defined using
[U]INT64CONST are likewise safer than before.
Also fix the SIZE_MAX macro to be similarly safe, if we are forced
to provide a definition for that. The test added in commit 2e70d6b5e
happens to do what we want even with the hack "(size_t) -1" definition,
but we could easily get burnt on other tests in future.
Back-patch to all supported branches, like the previous commits.
Discussion: https://postgr.es/m/15883.1504278595@sss.pgh.pa.us
Best regards,
--
Tatsuo Ishii
SRA OSS, Inc. Japan
English: http://www.sraoss.co.jp/index_en.php
Japanese:http://www.sraoss.co.jp
On Sun, Jun 13, 2021 at 03:07:51AM +0900, Yugo NAGATA wrote: > It will not work if the transaction is skipped, in which case latency is 0.0. > It would work if we check also "skipped" as bellow. > > + if (!logged && !skipped && latency == 0.0) > > However, it still might not work if the latency is so small so that we could > observe latency == 0.0. I observed this when I used a script that contained > only a meta command. This is not usual and would be a corner case, though. Hmm. I am not sure to completely follow the idea here. It would be good to make this code less confusing than it is now. > /* log aggregated but not yet reported transactions */ > doLog(thread, state, &aggs, false, 0, 0); > + logAgg(thread->logfile, &aggs); > > I think we don't have to call doLog() before logAgg(). If we call doLog(), > we will count an extra transaction that is not actually processed because > accumStats() is called in this. Yes, calling both is weird. Is using logAgg() directly in the context actually right when it comes to sample_rate? We may not log anything on HEAD if sample_rate is enabled, but we would finish by logging something all the time with this patch. If I am following this code correctly, we don't care about accumStats() in the code path of a thread we are done with, right? -- Michael
Attachment
Hello Michaël, >> I think we don't have to call doLog() before logAgg(). If we call doLog(), >> we will count an extra transaction that is not actually processed because >> accumStats() is called in this. > > Yes, calling both is weird. The motivation to call doLog is to catch up zeros on slow rates, so as to avoid holes in the log, including at the end of the run. This "trick" was already used by the code. I agree that it would record a non existant transaction, which is not desirable. I wanted to avoid a special parameter, but this seems unrealistic. > Is using logAgg() directly in the context actually right when it comes > to sample_rate? The point is just to trigger the last display, which is not triggered by the previous I think because of the precision: the start of the run is not exactly the start of the thread. > We may not log anything on HEAD if sample_rate is enabled, but we would > finish by logging something all the time with this patch. I do not get it. > If I am following this code correctly, we don't care about accumStats() > in the code path of a thread we are done with, right? Yes. Attached a v3 which adds a boolean to distinguish recording vs flushing. -- Fabien.
On Tue, 15 Jun 2021 10:05:29 +0200 (CEST) Fabien COELHO <coelho@cri.ensmp.fr> wrote: > > Hello Michaël, > > >> I think we don't have to call doLog() before logAgg(). If we call doLog(), > >> we will count an extra transaction that is not actually processed because > >> accumStats() is called in this. > > > > Yes, calling both is weird. > > The motivation to call doLog is to catch up zeros on slow rates, so as to > avoid holes in the log, including at the end of the run. This "trick" was > already used by the code. I agree that it would record a non existant > transaction, which is not desirable. I wanted to avoid a special > parameter, but this seems unrealistic. > > > Is using logAgg() directly in the context actually right when it comes > > to sample_rate? > > The point is just to trigger the last display, which is not triggered by > the previous I think because of the precision: the start of the run is > not exactly the start of the thread. > > > We may not log anything on HEAD if sample_rate is enabled, but we would > > finish by logging something all the time with this patch. > > I do not get it. It was not a problem because --sampling-rate --aggregate-interval cannot be used at the same time. > > If I am following this code correctly, we don't care about accumStats() > > in the code path of a thread we are done with, right? > > Yes. > > Attached a v3 which adds a boolean to distinguish recording vs flushing. Sorry, but I can't find any patach attached... -- Yugo NAGATA <nagata@sraoss.co.jp>
On Tue, Jun 15, 2021 at 05:15:14PM +0900, Yugo NAGATA wrote: > On Tue, 15 Jun 2021 10:05:29 +0200 (CEST) Fabien COELHO <coelho@cri.ensmp.fr> wrote: > It was not a problem because --sampling-rate --aggregate-interval cannot be > used at the same time. Yep, you are right, thanks. I have missed that both options cannot be specified at the same time. -- Michael
Attachment
> Attached a v3 which adds a boolean to distinguish recording vs flushing. Better with the attachement… sorry for the noise. -- Fabien.
Attachment
On Tue, 15 Jun 2021 18:01:18 +0900 Michael Paquier <michael@paquier.xyz> wrote: > On Tue, Jun 15, 2021 at 05:15:14PM +0900, Yugo NAGATA wrote: > > On Tue, 15 Jun 2021 10:05:29 +0200 (CEST) Fabien COELHO <coelho@cri.ensmp.fr> wrote: > > It was not a problem because --sampling-rate --aggregate-interval cannot be > > used at the same time. > > Yep, you are right, thanks. I have missed that both options cannot be > specified at the same time. Maybe, adding Assert(sample_rate == 0.0 || agg_interval == 0) or moving the check of sample_rate into the else block could improve code readability? -- Yugo NAGATA <nagata@sraoss.co.jp>
On Tue, 15 Jun 2021 11:38:00 +0200 (CEST) Fabien COELHO <coelho@cri.ensmp.fr> wrote: > > > Attached a v3 which adds a boolean to distinguish recording vs flushing. I am fine with this version, but I think it would be better if we have a comment explaining what "tx" is for. Also, how about adding Assert(tx) instead of using "else if (tx)" because we are assuming that tx is always true when agg_interval is not used, right? -- Yugo NAGATA <nagata@sraoss.co.jp>
On Tue, Jun 15, 2021 at 09:53:06PM +0900, Yugo NAGATA wrote: > I am fine with this version, but I think it would be better if we have a comment > explaining what "tx" is for. > > Also, how about adding Assert(tx) instead of using "else if (tx)" because > we are assuming that tx is always true when agg_interval is not used, right? Agreed on both points. From what I get, this code could be clarified much more, and perhaps partially refactored to have less spaghetti code between the point where we call it at the end of a thread or when gathering stats of a transaction mid-run, but that's not something to do post-beta1. I am not completely sure that the result would be worth it either. Let's document things and let's the readers know better the assumptions this area of the code relies on, for clarity. The dependency between agg_interval and sample_rate is one of those things, somebody needs now to look at the option parsing why only one is possible at the time. Using an extra tx flag to track what to do after the loop for the aggregate print to the log file is an improvement in this direction. -- Michael
Attachment
Michaël-san, Yugo-san, >> I am fine with this version, but I think it would be better if we have >> a comment explaining what "tx" is for. Yes. Done. >> Also, how about adding Assert(tx) instead of using "else if (tx)" because >> we are assuming that tx is always true when agg_interval is not used, right? Ok. Done. > Agreed on both points. From what I get, this code could be clarified > much more, I agree that the code is a little bit awkward. > and perhaps partially refactored to have less spaghetti > code between the point where we call it at the end of a thread or when > gathering stats of a transaction mid-run, but that's not something to > do post-beta1. Yep. > I am not completely sure that the result would be worth it either. I'm not either. > Let's document things and let's the readers know better the > assumptions this area of the code relies on, for clarity. Sure. > The dependency between agg_interval and sample_rate is one of those > things, somebody needs now to look at the option parsing why only one is > possible at the time. Actually it would work if both are mixed: the code would aggregate a sample. However it does not look very useful to do that, so it is arbitrary forbidden. Not sure whether this is that useful to prevent this use case. > Using an extra tx flag to track what to do after the loop for the > aggregate print to the log file is an improvement in this direction. Yep. Attached v4 improves comments and moves tx as an assert. -- Fabien.
Attachment
On Wed, Jun 16, 2021 at 08:58:17AM +0200, Fabien COELHO wrote: > Actually it would work if both are mixed: the code would aggregate a sample. > However it does not look very useful to do that, so it is arbitrary > forbidden. Not sure whether this is that useful to prevent this use case. Okay, noted. > Attached v4 improves comments and moves tx as an assert. Thanks. I have not tested in details but that looks rather sane to me at quick glance. I'll look at that more tomorrow. > + * The function behaviors changes depending on sample_rate (a fraction of > + * transaction is reported) and agg_interval (transactions are aggregated > + * over the interval and reported once). The first part of this sentence has an incorrect grammar. -- Michael
Attachment
>> + * The function behaviors changes depending on sample_rate (a fraction of >> + * transaction is reported) and agg_interval (transactions are aggregated >> + * over the interval and reported once). > > The first part of this sentence has an incorrect grammar. Indeed. v5 attempts to improve comments. -- Fabien.