Thread: Slow standby snapshot
Hi,
I recently ran into a problem in one of our production postgresql cluster. I had noticed lock contention on procarray lock on standby, which causes WAL replay lag growth.
To reproduce this, you can do the following:
1) set max_connections to big number, like 100000
2) begin a transaction on primary
3) start pgbench workload on primary and on standby
After a while it will be possible to see KnownAssignedXidsGetAndSetXmin in perf top consuming abount 75 % of CPU.
%%
PerfTop: 1060 irqs/sec kernel: 0.0% exact: 0.0% [4000Hz cycles:u], (target_pid: 273361)
-------------------------------------------------------------------------------
73.92% postgres [.] KnownAssignedXidsGetAndSetXmin
1.40% postgres [.] base_yyparse
0.96% postgres [.] LWLockAttemptLock
0.84% postgres [.] hash_search_with_hash_value
0.84% postgres [.] AtEOXact_GUC
0.72% postgres [.] ResetAllOptions
0.70% postgres [.] AllocSetAlloc
0.60% postgres [.] _bt_compare
0.55% postgres [.] core_yylex
0.42% libc-2.27.so [.] __strlen_avx2
0.23% postgres [.] LWLockRelease
0.19% postgres [.] MemoryContextAllocZeroAligned
0.18% postgres [.] expression_tree_walker.part.3
0.18% libc-2.27.so [.] __memmove_avx_unaligned_erms
0.17% postgres [.] PostgresMain
0.17% postgres [.] palloc
0.17% libc-2.27.so [.] _int_malloc
0.17% postgres [.] set_config_option
0.17% postgres [.] ScanKeywordLookup
0.16% postgres [.] _bt_checkpage
%%
We have tried to fix this by using BitMapSet instead of boolean array KnownAssignedXidsValid, but this does not help too much.
Instead, using a doubly linked list helps a little more, we got +1000 tps on pgbench workload with patched postgresql. The general idea of this patch is that, instead of memorizing which elements in KnownAssignedXids are valid, lets maintain a doubly linked list of them. This solution will work in exactly the same way, except that taking a snapshot on the replica is now O(running transaction) instead of O(head - tail) which is significantly faster under some workloads. The patch helps to reduce CPU usage of KnownAssignedXidsGetAndSetXmin to ~48% instead of ~74%, but does eliminate it from perf top.
The problem is better reproduced on PG13 since PG14 has some snapshot optimization.
Thanks!
Best regards, reshke
I recently ran into a problem in one of our production postgresql cluster. I had noticed lock contention on procarray lock on standby, which causes WAL replay lag growth.
To reproduce this, you can do the following:
1) set max_connections to big number, like 100000
2) begin a transaction on primary
3) start pgbench workload on primary and on standby
After a while it will be possible to see KnownAssignedXidsGetAndSetXmin in perf top consuming abount 75 % of CPU.
%%
PerfTop: 1060 irqs/sec kernel: 0.0% exact: 0.0% [4000Hz cycles:u], (target_pid: 273361)
-------------------------------------------------------------------------------
73.92% postgres [.] KnownAssignedXidsGetAndSetXmin
1.40% postgres [.] base_yyparse
0.96% postgres [.] LWLockAttemptLock
0.84% postgres [.] hash_search_with_hash_value
0.84% postgres [.] AtEOXact_GUC
0.72% postgres [.] ResetAllOptions
0.70% postgres [.] AllocSetAlloc
0.60% postgres [.] _bt_compare
0.55% postgres [.] core_yylex
0.42% libc-2.27.so [.] __strlen_avx2
0.23% postgres [.] LWLockRelease
0.19% postgres [.] MemoryContextAllocZeroAligned
0.18% postgres [.] expression_tree_walker.part.3
0.18% libc-2.27.so [.] __memmove_avx_unaligned_erms
0.17% postgres [.] PostgresMain
0.17% postgres [.] palloc
0.17% libc-2.27.so [.] _int_malloc
0.17% postgres [.] set_config_option
0.17% postgres [.] ScanKeywordLookup
0.16% postgres [.] _bt_checkpage
%%
We have tried to fix this by using BitMapSet instead of boolean array KnownAssignedXidsValid, but this does not help too much.
Instead, using a doubly linked list helps a little more, we got +1000 tps on pgbench workload with patched postgresql. The general idea of this patch is that, instead of memorizing which elements in KnownAssignedXids are valid, lets maintain a doubly linked list of them. This solution will work in exactly the same way, except that taking a snapshot on the replica is now O(running transaction) instead of O(head - tail) which is significantly faster under some workloads. The patch helps to reduce CPU usage of KnownAssignedXidsGetAndSetXmin to ~48% instead of ~74%, but does eliminate it from perf top.
The problem is better reproduced on PG13 since PG14 has some snapshot optimization.
Thanks!
Best regards, reshke
sorry, forgot to add a patch to the letter
чт, 20 мая 2021 г. в 13:52, Кирилл Решке <reshkekirill@gmail.com>:
Hi,
I recently ran into a problem in one of our production postgresql cluster. I had noticed lock contention on procarray lock on standby, which causes WAL replay lag growth.
To reproduce this, you can do the following:
1) set max_connections to big number, like 100000
2) begin a transaction on primary
3) start pgbench workload on primary and on standby
After a while it will be possible to see KnownAssignedXidsGetAndSetXmin in perf top consuming abount 75 % of CPU.
%%
PerfTop: 1060 irqs/sec kernel: 0.0% exact: 0.0% [4000Hz cycles:u], (target_pid: 273361)
-------------------------------------------------------------------------------
73.92% postgres [.] KnownAssignedXidsGetAndSetXmin
1.40% postgres [.] base_yyparse
0.96% postgres [.] LWLockAttemptLock
0.84% postgres [.] hash_search_with_hash_value
0.84% postgres [.] AtEOXact_GUC
0.72% postgres [.] ResetAllOptions
0.70% postgres [.] AllocSetAlloc
0.60% postgres [.] _bt_compare
0.55% postgres [.] core_yylex
0.42% libc-2.27.so [.] __strlen_avx2
0.23% postgres [.] LWLockRelease
0.19% postgres [.] MemoryContextAllocZeroAligned
0.18% postgres [.] expression_tree_walker.part.3
0.18% libc-2.27.so [.] __memmove_avx_unaligned_erms
0.17% postgres [.] PostgresMain
0.17% postgres [.] palloc
0.17% libc-2.27.so [.] _int_malloc
0.17% postgres [.] set_config_option
0.17% postgres [.] ScanKeywordLookup
0.16% postgres [.] _bt_checkpage
%%
We have tried to fix this by using BitMapSet instead of boolean array KnownAssignedXidsValid, but this does not help too much.
Instead, using a doubly linked list helps a little more, we got +1000 tps on pgbench workload with patched postgresql. The general idea of this patch is that, instead of memorizing which elements in KnownAssignedXids are valid, lets maintain a doubly linked list of them. This solution will work in exactly the same way, except that taking a snapshot on the replica is now O(running transaction) instead of O(head - tail) which is significantly faster under some workloads. The patch helps to reduce CPU usage of KnownAssignedXidsGetAndSetXmin to ~48% instead of ~74%, but does eliminate it from perf top.
The problem is better reproduced on PG13 since PG14 has some snapshot optimization.
Thanks!
Best regards, reshke
Attachment
)Hello.
> I recently ran into a problem in one of our production postgresql cluster.
> I had noticed lock contention on procarray lock on standby, which causes WAL
> replay lag growth.
Yes, I saw the same issue on my production cluster.
> 1) set max_connections to big number, like 100000
I made the tests with a more realistic value - 5000. It is valid value
for Amazon RDS for example (default is
LEAST({DBInstanceClassMemory/9531392}, 5000)).
The test looks like this:
pgbench -i -s 10 -U postgres -d postgres
pgbench -b select-only -p 6543 -j 1 -c 50 -n -P 1 -T 18000 -U postgres postgres
pgbench -b simple-update -j 1 -c 50 -n -P 1 -T 18000 -U postgres postgres
long transaction on primary - begin;select txid_current();
perf top -p <pid of some standby>
So, on postgres 14 (master) non-patched version looks like this:
5.13% postgres [.] KnownAssignedXidsGetAndSetXmin
4.61% postgres [.] pg_checksum_block
2.54% postgres [.] AllocSetAlloc
2.44% postgres [.] base_yyparse
It is too much to spend 5-6% of CPU running throw an array :) I think
it should be fixed for both the 13 and 14 versions.
The patched version like this (was unable to notice
KnownAssignedXidsGetAndSetXmin):
3.08% postgres [.] pg_checksum_block
2.89% postgres [.] AllocSetAlloc
2.66% postgres [.] base_yyparse
2.00% postgres [.] MemoryContextAllocZeroAligned
On postgres 13 non patched version looks even worse (definitely need
to be fixed in my opinion):
26.44% postgres [.] KnownAssignedXidsGetAndSetXmin
2.17% postgres [.] base_yyparse
2.01% postgres [.] AllocSetAlloc
1.55% postgres [.] MemoryContextAllocZeroAligned
But your patch does not apply to REL_13_STABLE. Could you please
provide two versions?
Also, there are warnings while building with patch:
procarray.c:4595:9: warning: ISO C90 forbids mixed
declarations and code [-Wdeclaration-after-statement]
4595 | int prv = -1;
| ^~~
procarray.c: In function ‘KnownAssignedXidsGetOldestXmin’:
procarray.c:5056:5: warning: variable ‘tail’ set but not used
[-Wunused-but-set-variable]
5056 | tail;
| ^~~~
procarray.c:5067:38: warning: ‘i’ is used uninitialized in
this function [-Wuninitialized]
5067 | i = KnownAssignedXidsValidDLL[i].nxt;
Some of them are clear errors, so, please recheck the code.
Also, maybe it is better to reduce the invasivity by using a more
simple approach. For example, use the first bit to mark xid as valid
and the last 7 bit (128 values) as an optimistic offset to the next
valid xid (jump by 127 steps in the worse scenario).
What do you think?
Also, it is a good idea to register the patch in the commitfest app
(https://commitfest.postgresql.org/).
Thanks,
Michail.
Hello, Kirill. > Also, maybe it is better to reduce the invasivity by using a more > simple approach. For example, use the first bit to mark xid as valid > and the last 7 bit (128 values) as an optimistic offset to the next > valid xid (jump by 127 steps in the worse scenario). > What do you think? I have tried such an approach but looks like it is not effective, probably because of CPU caching issues. I have looked again at your patch, ut seems like it has a lot of issues at the moment: * error in KnownAssignedXidsGetOldestXmin, `i` is uninitialized, logic is wrong * error in compressing function (```KnownAssignedXidsValidDLL[compress_index].prv = prv;```, `prv` is never updated) * probably other errors? * compilation warnings * looks a little complex logic with `KAX_DLL_ENTRY_INVALID` * variable\methods placing is bad (see `KAX_E_INVALID` and others) * need to update documentation about KnownAssignedXidsValid, see ```To keep individual deletions cheap, we need to allow gaps in the array``` in procarray.c * formatting is broken Do you have plans to update it? If not - I could try to rewrite it. Also, what is about to add a patch to commitfest? Thanks, Michail.
Hello.
> I have tried such an approach but looks like it is not effective,
> probably because of CPU caching issues.
It was a mistake by me. I have repeated the approach and got good
results with small and a non-invasive patch.
The main idea is simple optimistic optimization - store offset to next
valid entry. So, in most cases, we could just skip all the gaps.
Of course, it adds some additional impact for workloads without long
(few seconds) transactions but it is almost not detectable (because of
CPU caches).
* TEST
The next testing setup was used:
max_connections=5000 (taken from real RDS installation)
pgbench -i -s 10 -U postgres -d postgres
# emulate typical OLTP load
pgbench -b simple-update -j 1 -c 50 -n -P 1 -T 18000 -U postgres postgres
#emulate typical cache load on replica
pgbench -b select-only -p 6543 -j 1 -c 50 -n -P 1 -T 18000 -U postgres postgres
# emulate some typical long transactions up to 60 seconds on primary
echo "\set t random(0, 60)
BEGIN;
select txid_current();
select pg_sleep(:t);
COMMIT;" > slow_transactions.bench
pgbench -f /home/nkey/pg/slow_transactions.bench -p 5432 -j 1 -c 10 -n
-P 1 -T 18000 -U postgres postgres
* RESULTS
*REL_13_STABLE* - 23.02% vs 0.76%
non-patched:
23.02% postgres [.] KnownAssignedXidsGetAndSetXmin
2.56% postgres [.] base_yyparse
2.15% postgres [.] AllocSetAlloc
1.68% postgres [.] MemoryContextAllocZeroAligned
1.51% postgres [.] hash_search_with_hash_value
1.26% postgres [.] SearchCatCacheInternal
1.03% postgres [.] hash_bytes
0.92% postgres [.] pg_checksum_block
0.89% postgres [.] expression_tree_walker
0.81% postgres [.] core_yylex
0.69% postgres [.] palloc
0.68% [kernel] [k] do_syscall_64
0.59% postgres [.] _bt_compare
0.54% postgres [.] new_list
patched:
3.09% postgres [.] base_yyparse
3.00% postgres [.] AllocSetAlloc
2.01% postgres [.] MemoryContextAllocZeroAligned
1.89% postgres [.] SearchCatCacheInternal
1.80% postgres [.] hash_search_with_hash_value
1.27% postgres [.] expression_tree_walker
1.27% postgres [.] pg_checksum_block
1.18% postgres [.] hash_bytes
1.10% postgres [.] core_yylex
0.96% [kernel] [k] do_syscall_64
0.86% postgres [.] palloc
0.84% postgres [.] _bt_compare
0.79% postgres [.] new_list
0.76% postgres [.] KnownAssignedXidsGetAndSetXmin
*MASTER* - 6.16% vs ~0%
(includes snapshot scalability optimization by Andres Freund (1))
non-patched:
6.16% postgres [.] KnownAssignedXidsGetAndSetXmin
3.05% postgres [.] AllocSetAlloc
2.59% postgres [.] base_yyparse
1.95% postgres [.] hash_search_with_hash_value
1.87% postgres [.] MemoryContextAllocZeroAligned
1.85% postgres [.] SearchCatCacheInternal
1.27% postgres [.] hash_bytes
1.16% postgres [.] expression_tree_walker
1.06% postgres [.] core_yylex
0.94% [kernel] [k] do_syscall_64
patched:
3.35% postgres [.] base_yyparse
2.84% postgres [.] AllocSetAlloc
1.89% postgres [.] hash_search_with_hash_value
1.82% postgres [.] MemoryContextAllocZeroAligned
1.79% postgres [.] SearchCatCacheInternal
1.49% postgres [.] pg_checksum_block
1.26% postgres [.] hash_bytes
1.26% postgres [.] expression_tree_walker
1.08% postgres [.] core_yylex
1.04% [kernel] [k] do_syscall_64
0.81% postgres [.] palloc
Looks like it is possible to get a significant TPS increase on a very
typical standby workload.
Currently, I have no environment to measure TPS accurately. Could you
please try it on yours?
I have attached two versions of the patch - for master and REL_13_STABLE.
Also, I am going to add a patch to commitfest (2).
Thanks,
MIchail.
(1): https://commitfest.postgresql.org/29/2500/
(2): https://commitfest.postgresql.org/34/3271/
Attachment
Hi, On 2021-08-03 00:07:23 +0300, Michail Nikolaev wrote: > The main idea is simple optimistic optimization - store offset to next > valid entry. So, in most cases, we could just skip all the gaps. > Of course, it adds some additional impact for workloads without long > (few seconds) transactions but it is almost not detectable (because of > CPU caches). I'm doubtful that that's really the right direction. For workloads that are replay heavy we already often can see the cost of maintaining the known xids datastructures show up significantly - not surprising, given the datastructure. And for standby workloads with active primaries the cost of searching through the array in all backends is noticeable as well. I think this needs a bigger data structure redesign. Greetings, Andres Freund
Hi, > 3 авг. 2021 г., в 03:01, Andres Freund <andres@anarazel.de> написал(а): > > Hi, > > On 2021-08-03 00:07:23 +0300, Michail Nikolaev wrote: >> The main idea is simple optimistic optimization - store offset to next >> valid entry. So, in most cases, we could just skip all the gaps. >> Of course, it adds some additional impact for workloads without long >> (few seconds) transactions but it is almost not detectable (because of >> CPU caches). > > I'm doubtful that that's really the right direction. For workloads that > are replay heavy we already often can see the cost of maintaining the > known xids datastructures show up significantly - not surprising, given > the datastructure. And for standby workloads with active primaries the > cost of searching through the array in all backends is noticeable as > well. I think this needs a bigger data structure redesign. KnownAssignedXids implements simple membership test idea. What kind of redesign would you suggest? Proposed optimisationmakes it close to optimal, but needs eventual compression. Maybe use a hashtable of running transactions? It will be slightly faster when adding\removing single transactions. But muchworse when doing KnownAssignedXidsRemove(). Maybe use a tree? (AVL\RB or something like that) It will be slightly better, because it does not need eventual compressionlike exiting array. Best regards, Andrey Borodin.
Hi, On 2021-08-03 10:33:50 +0500, Andrey Borodin wrote: > > 3 авг. 2021 г., в 03:01, Andres Freund <andres@anarazel.de> написал(а): > > On 2021-08-03 00:07:23 +0300, Michail Nikolaev wrote: > >> The main idea is simple optimistic optimization - store offset to next > >> valid entry. So, in most cases, we could just skip all the gaps. > >> Of course, it adds some additional impact for workloads without long > >> (few seconds) transactions but it is almost not detectable (because of > >> CPU caches). > > > > I'm doubtful that that's really the right direction. For workloads that > > are replay heavy we already often can see the cost of maintaining the > > known xids datastructures show up significantly - not surprising, given > > the datastructure. And for standby workloads with active primaries the > > cost of searching through the array in all backends is noticeable as > > well. I think this needs a bigger data structure redesign. > > KnownAssignedXids implements simple membership test idea. What kind of > redesign would you suggest? Proposed optimisation makes it close to optimal, > but needs eventual compression. Binary searches are very ineffecient on modern CPUs (unpredictable memory accesses, unpredictable branches). We constantly need to do binary searches during replay to remove xids from the array. I don't see how you can address that with just the current datastructure. > Maybe use a hashtable of running transactions? It will be slightly faster > when adding\removing single transactions. But much worse when doing > KnownAssignedXidsRemove(). Why would it be worse for KnownAssignedXidsRemove()? Were you intending to write KnownAssignedXidsGet[AndSetXmin]()? > Maybe use a tree? (AVL\RB or something like that) It will be slightly better, because it does not need eventual compressionlike exiting array. I'm not entirely sure what datastructure would work best. I can see something like a radix tree work well, or a skiplist style approach. Or a hashtable: I'm not sure that we need to care as much about the cost of KnownAssignedXidsGetAndSetXmin() - for one, the caching we now have makes that less frequent. But more importantly, it'd not be hard to maintain an occasionally (or opportunistically) maintained denser version for GetSnapshotData() - there's only a single writer, making the concurrency issues a lot simpler. Greetings, Andres Freund
Hello, Andres. Thanks for your feedback. >> Maybe use a hashtable of running transactions? It will be slightly faster >> when adding\removing single transactions. But much worse when doing >> KnownAssignedXidsRemove(). > Why would it be worse for KnownAssignedXidsRemove()? Were you intending to > write KnownAssignedXidsGet[AndSetXmin]()? It is actually was a hashtable in 2010. It was replaced by Simon Riggs in 2871b4618af1acc85665eec0912c48f8341504c4. > I'm not sure that we need to care as much about the cost of > KnownAssignedXidsGetAndSetXmin() - for one, the caching we now have makes that > less frequent. It is still about 5-7% of CPU for a typical workload, a considerable amount for me. And a lot of systems still work on 12 and 13. The proposed approach eliminates KnownAssignedXidsGetAndSetXmin from the top by a small changeset. > But more importantly, it'd not be hard to maintain an > occasionally (or opportunistically) maintained denser version for > GetSnapshotData() - there's only a single writer, making the concurrency > issues a lot simpler. Could you please explain it in more detail? Single writer and GetSnapshotData() already exclusively hold ProcArrayLock at the moment of KnownAssignedXidsRemove, KnownAssignedXidsGetAndSetXmin, and sometimes KnownAssignedXidsAdd. BTW, the tiny thing we could also fix now is (comment from code): > (We could dispense with the spinlock if we were to > * create suitable memory access barrier primitives and use those instead.) > * The spinlock must be taken to read or write the head/tail pointers unless > * the caller holds ProcArrayLock exclusively. Thanks, Michail.
Hi, On 2021-08-03 22:23:58 +0300, Michail Nikolaev wrote: > > I'm not sure that we need to care as much about the cost of > > KnownAssignedXidsGetAndSetXmin() - for one, the caching we now have makes that > > less frequent. > > It is still about 5-7% of CPU for a typical workload, a considerable > amount for me. I'm not saying we shouldn't optimize things. Just that it's less pressing. And what kind of price we're willing to optimize may have changed. > And a lot of systems still work on 12 and 13. I don't see us backporting performance improvements around this to 12 and 13, so I don't think that matters much... We've done that a few times, but usually when there's some accidentally quadratic behaviour or such. > > But more importantly, it'd not be hard to maintain an > > occasionally (or opportunistically) maintained denser version for > > GetSnapshotData() - there's only a single writer, making the concurrency > > issues a lot simpler. > > Could you please explain it in more detail? > Single writer and GetSnapshotData() already exclusively hold > ProcArrayLock at the moment of KnownAssignedXidsRemove, > KnownAssignedXidsGetAndSetXmin, and sometimes KnownAssignedXidsAdd. GetSnapshotData() only locks ProcArrayLock in shared mode. The problem is that we don't want to add a lot of work KnownAssignedXidsAdd/Remove, because very often nobody will build a snapshot for that moment and building a sorted, gap-free, linear array of xids isn't cheap. In my experience it's more common to be bottlenecked by replay CPU performance than on replica snapshot building. During recovery, where there's only one writer to the procarray / known xids, it might not be hard to opportunistically build a dense version of the known xids whenever a snapshot is built. Greetings, Andres Freund
Hello, Andres. Thanks for the feedback again. > The problem is that we don't want to add a lot of work > KnownAssignedXidsAdd/Remove, because very often nobody will build a snapshot > for that moment and building a sorted, gap-free, linear array of xids isn't > cheap. In my experience it's more common to be bottlenecked by replay CPU > performance than on replica snapshot building. Yes, but my patch adds almost the smallest possible amount for KnownAssignedXidsAdd/Remove - a single write to the array by index. It differs from the first version in this thread which is based on linked lists. The "next valid offset" is just "optimistic optimization" - it means "you could safely skip KnownAssignedXidsNext[i] while finding the next valid". But KnownAssignedXidsNext is not updated by Add/Remove. > During recovery, where there's only one writer to the procarray / known xids, > it might not be hard to opportunistically build a dense version of the known > xids whenever a snapshot is built. AFAIU the patch does exactly the same. On the first snapshot building, offsets to the next valid entry are set. So, a dense version is created on-demand. And this version is reused (even partly if something was removed) on the next snapshot building. > I'm not entirely sure what datastructure would work best. I can see something > like a radix tree work well, or a skiplist style approach. Or a hashtable: We could try to use some other structure (for example - linked hash map) - but the additional cost (memory management, links, hash calculation) will probably significantly reduce performance. And it is a much harder step to perform. So, I think "next valid offset" optimization is a good trade-off for now: * KnownAssignedXidsAdd/Remove are almost not affected in their complexity * KnownAssignedXidsGetAndSetXmin is eliminated from the CPU top on typical read scenario - so, more TPS, less ProcArrayLock contention * it complements GetSnapshotData() scalability - now on standby * changes are small Thanks, Michail.
On Tue, Aug 10, 2021 at 12:45:17AM +0300, Michail Nikolaev wrote: > Thanks for the feedback again. From what I can see, there has been some feedback from Andres here, and the thread is idle for six weeks now, so I have marked this patch as RwF in the CF app. -- Michael
Attachment
Hello, Andres. Could you please clarify how to better deal with the situation? According to your previous letter, I think there was some misunderstanding regarding the latest patch version (but I am not sure). Because as far as understand provided optimization (lazily calculated optional offset to the next valid xid) fits into your wishes. It was described in the previous letter in more detail. And now it is not clear for me how to move forward :) There is an option to try to find some better data structure (like some tricky linked hash map) but it is going to be huge changes without any confidence to get a more effective version (because provided changes make the structure pretty effective). Another option I see - use optimization from the latest patch version and get a significant TPS increase (5-7%) for the typical standby read scenario. Patch is small and does not affect other scenarios in a negative way. Probably I could make an additional set of some performance tests and provide some simulation to prove that pg_atomic_uint32-related code is correct (if required). Or just leave the issue and hope someone else will try to fix it in the future :) Thanks a lot, Michail.
Sorry for so late reply. I've been thinking about possible approaches.
KnownAssignedXids over hashtable in fact was implemented long before and rejected [0].
> 3 авг. 2021 г., в 22:35, Andres Freund <andres@anarazel.de> написал(а):
>
> On 2021-08-03 10:33:50 +0500, Andrey Borodin wrote:
>>> 3 авг. 2021 г., в 03:01, Andres Freund <andres@anarazel.de> написал(а):
>>> On 2021-08-03 00:07:23 +0300, Michail Nikolaev wrote:
>>>> The main idea is simple optimistic optimization - store offset to next
>>>> valid entry. So, in most cases, we could just skip all the gaps.
>>>> Of course, it adds some additional impact for workloads without long
>>>> (few seconds) transactions but it is almost not detectable (because of
>>>> CPU caches).
>>>
>>> I'm doubtful that that's really the right direction. For workloads that
>>> are replay heavy we already often can see the cost of maintaining the
>>> known xids datastructures show up significantly - not surprising, given
>>> the datastructure. And for standby workloads with active primaries the
>>> cost of searching through the array in all backends is noticeable as
>>> well. I think this needs a bigger data structure redesign.
>>
>> KnownAssignedXids implements simple membership test idea. What kind of
>> redesign would you suggest? Proposed optimisation makes it close to optimal,
>> but needs eventual compression.
>
> Binary searches are very ineffecient on modern CPUs (unpredictable memory
> accesses, unpredictable branches). We constantly need to do binary searches
> during replay to remove xids from the array. I don't see how you can address
> that with just the current datastructure.
Current patch addresses another problem. In presence of old enough transaction enumeration of KnownAssignedXids with
sharedlock prevents adding new transactions with exclusive lock. And recovery effectively pauses.
Binary searches can consume 10-15 cache misses, which is unreasonable amount of memory waits. But that's somewhat
differentproblem.
Also binsearch is not that expensive when we compress KnownAssignedXids often.
>> Maybe use a hashtable of running transactions? It will be slightly faster
>> when adding\removing single transactions. But much worse when doing
>> KnownAssignedXidsRemove().
>
> Why would it be worse for KnownAssignedXidsRemove()? Were you intending to
> write KnownAssignedXidsGet[AndSetXmin]()?
I was thinking about inefficient KnownAssignedXidsRemovePreceding() in hashtable. But, probably, this is not so
frequentoperation.
>> Maybe use a tree? (AVL\RB or something like that) It will be slightly better, because it does not need eventual
compressionlike exiting array.
>
> I'm not entirely sure what datastructure would work best. I can see something
> like a radix tree work well, or a skiplist style approach. Or a hashtable:
>
> I'm not sure that we need to care as much about the cost of
> KnownAssignedXidsGetAndSetXmin() - for one, the caching we now have makes that
> less frequent. But more importantly, it'd not be hard to maintain an
> occasionally (or opportunistically) maintained denser version for
> GetSnapshotData() - there's only a single writer, making the concurrency
> issues a lot simpler.
I've been prototyping Radix tree for a while.
Here every 4 xids are summarized my minimum Xid and number of underlying Xids. Of cause 4 is arbitrary number,
summarizationarea must be of cacheline size.
┌───────┐
│ 1 / 9 │
├───────┴────┐
│ └────┐
│ └────┐
│ └────┐
▼ └───▶
┌───────────────────────────────┐
│ 1 / 3 | 5 / 0 | 9 / 3 | D / 3 │
├───────┬───────┬────────┬──────┴────┐
│ └─┐ └───┐ └────┐ └─────┐
│ └─┐ └──┐ └────┐ └─────┐
│ └─┐ └──┐ └────┐ └────┐
▼ └─┐ └──┐ └───┐ └────┐
┌───────────────▼────────────┴─▶────────────┴──▶───────────┴───▶
│ 1 | 2 | | 4 | | | | | 9 | | B | C | D | E | F | │
└──────────────────────────────────────────────────────────────┘
Bottom layer is current array (TransactionId *KnownAssignedXids).
When we remove Xid we need theoretical minimum of cachelines touched. I'd say 5-7 instead of 10-15 of binsearch (in
caseof millions of entries in KnownAssignedXids).
Enumerating running Xids is not that difficult too: we will need to scan O(xip) memory, not whole KnownAssignedXids
array.
But the overall complexity of this approach does not seem good to me.
All in all, I think using proposed "KnownAssignedXidsNext" patch solves real problem and the problem of binary searches
shouldbe addressed by compressing KnownAssignedXids more often.
Currently we do not compress array
if (nelements < 4 * PROCARRAY_MAXPROCS || // It's not that big yet OR
nelements < 2 * pArray->numKnownAssignedXids) // It's contains less than a half of a bloat
return;
From my POV arbitrary number 4 is just too high.
Summary: I think ("KnownAssignedXidsNext" patch + compressing KnownAssignedXids more often) is better than major
KnownAssignedXidsredesign.
Best regards, Andrey Borodin.
[0] https://github.com/postgres/postgres/commit/2871b4618af1acc85665eec0912c48f8341504c4
Hello, Andrey. Thanks for your feedback. > Current patch addresses another problem. In presence of old enough transaction enumeration of KnownAssignedXids with sharedlock prevents adding new transactions with exclusive lock. And recovery effectively pauses. Actually, I see two problems here (caused by the presence of old long transactions). The first one is lock contention which causes recovery pauses. The second one - just high CPU usage on standby by KnownAssignedXidsGetAndSetXmin. > All in all, I think using proposed "KnownAssignedXidsNext" patch solves real problem and the problem of binary searchesshould be addressed by compressing KnownAssignedXids more often. I updated the patch a little. KnownAssignedXidsGetAndSetXmin now causes fewer cache misses because some values are stored in variables (registers). I think it is better to not lean on the compiler here because of `volatile` args. Also, I have added some comments. Best regards, Michail.
Attachment
Hello, everyone.
I made a performance test to make sure the patch solves real issues
without performance regression.
Tests are made on 3 VM - one for primary, another - standby, latest
one - pgbench. It is Azure Standard_D16ads_v5 - 16 VCPU, 64GIB RAM,
Fast SSD.
5000 used as a number of connections (it is the max number of
connections for AWS - LEAST({DBInstanceClassMemory/9531392}, 5000)).
Setup:
primary:
max_connections=5000
listen_addresses='*'
fsync=off
standby:
primary_conninfo = 'user=postgres host=10.0.0.4 port=5432
sslmode=prefer sslcompression=0 gssencmode=prefer krbsrvname=postgres
target_session_attrs=any'
hot_standby_feedback = on
max_connections=5000
listen_addresses='*'
fsync=off
The test was run the following way:
# restart both standby and primary
# init fresh DB
./pgbench -h 10.0.0.4 -i -s 10 -U postgres -d postgres
# warm up primary for 10 seconds
./pgbench -h 10.0.0.4 -b simple-update -j 8 -c 16 -P 1 -T 10 -U
postgres postgres
# warm up standby for 10 seconds
./pgbench -h 10.0.0.5 -b select-only -j 8 -c 16 -n -P 1 -T 10 -U
postgres postgres
# then, run at the same(!) time (in parallel):
# simple-update on primary
./pgbench -h 10.0.0.4 -b simple-update -j 8 -c 16 -P 1 -T 180 -U
postgres postgres
# simple-select on standby
./pgbench -h 10.0.0.5 -b select-only -j 8 -c 16 -n -P 1 -T 180 -U
postgres postgres
# then, after 60 seconds after test start - start a long transaction
on the master
./psql -h 10.0.0.4 -c "BEGIN; select txid_current();SELECT
pg_sleep(5);COMMIT;" -U postgres postgres
I made 3 runs for both the patched and vanilla versions (current
master branch). One run of the patched version was retried because of
a significant difference in TPS (it is vCPU on VM with neighborhoods,
so, probably some isolation issue).
The result on the primary is about 23k-25k TPS for both versions.
So, graphics show a significant reduction of TPS on the secondary
while the long transaction is active (about 10%).
The patched version solves the issue without any noticeable regression
in the case of short-only transactions.
Also, transactions could be much shorted to reduce CPU - a few seconds
is enough.
Also, this is `perf diff` between `with` and `without` long
transaction recording.
Vanilla (+ 10.26% of KnownAssignedXidsGetAndSetXmin):
0.22% +10.26% postgres [.]
KnownAssignedXidsGetAndSetXmin
3.39% +0.68% [kernel.kallsyms] [k]
_raw_spin_unlock_irqrestore
2.66% -0.61% libc-2.31.so [.] 0x0000000000045dc1
3.77% -0.50% postgres [.] base_yyparse
3.43% -0.45% [kernel.kallsyms] [k] finish_task_switch
0.41% +0.36% postgres [.] pg_checksum_page
0.61% +0.31% [kernel.kallsyms] [k] copy_user_generic_string
Patched (+ 0.22%):
2.26% -0.40% [kernel.kallsyms] [k] _raw_spin_unlock_irqrestore
0.78% +0.39% [kernel.kallsyms] [k] copy_user_generic_string
0.22% +0.26% postgres [.] KnownAssignedXidsGetAndSetXmin
0.23% +0.20% postgres [.] ScanKeywordLookup
3.77% +0.19% postgres [.] base_yyparse
0.64% +0.19% postgres [.] pg_checksum_page
3.63% -0.18% [kernel.kallsyms] [k] finish_task_switch
If someone knows any additional performance tests that need to be done
- please share.
Best regards,
Michail.
Attachment
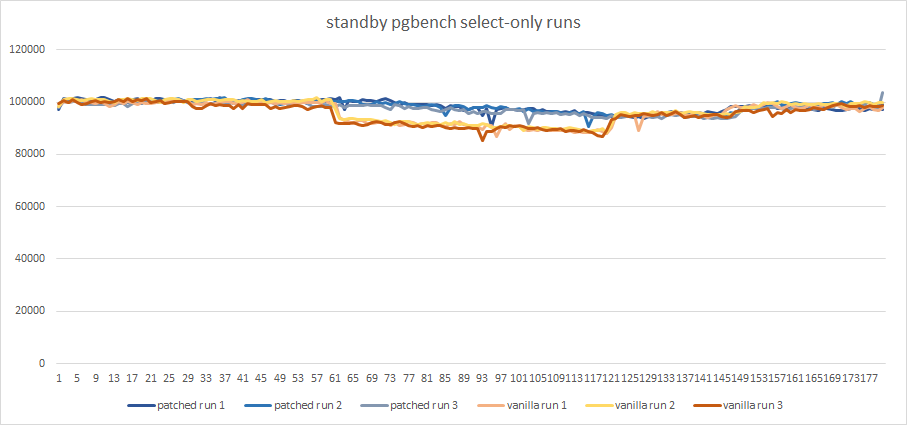{kind=link}
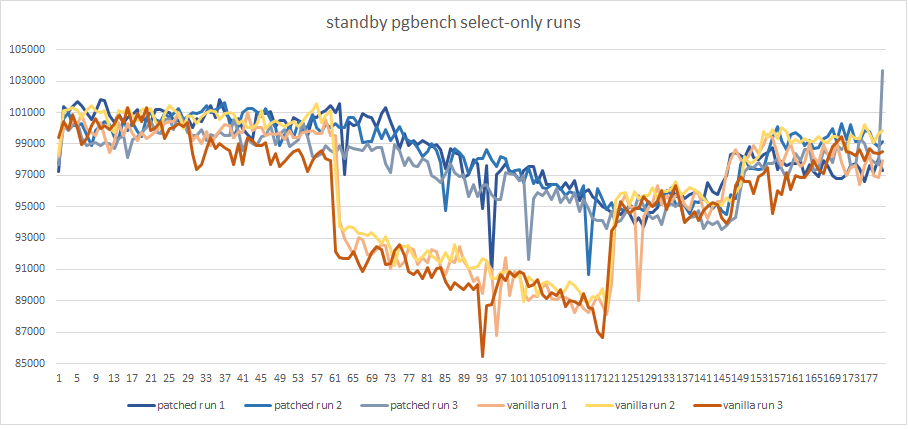{kind=link}
{kind=link}
On Wed, Nov 10, 2021 at 12:16 AM Michail Nikolaev <michail.nikolaev@gmail.com> wrote: > I updated the patch a little. KnownAssignedXidsGetAndSetXmin now > causes fewer cache misses because some values are stored in variables > (registers). I think it is better to not lean on the compiler here > because of `volatile` args. > Also, I have added some comments. It looks like KnownAssignedXidsNext doesn't have to be pg_atomic_uint32. I see it only gets read with pg_atomic_read_u32() and written with pg_atomic_write_u32(). Existing code believes that read/write of 32-bit values is atomic. So, you can use just uint32 instead of pg_atomic_uint32. ------ Regards, Alexander Korotkov
Hello, Alexander. Thanks for your review. > It looks like KnownAssignedXidsNext doesn't have to be > pg_atomic_uint32. I see it only gets read with pg_atomic_read_u32() > and written with pg_atomic_write_u32(). Existing code believes that > read/write of 32-bit values is atomic. So, you can use just uint32 > instead of pg_atomic_uint32. Fixed. Looks better now, yeah. Also, I added an additional (not depending on KnownAssignedXidsNext feature) commit replacing the spinlock with a memory barrier. It goes to Simon Riggs and Tom Lane at 2010: > (We could dispense with the spinlock if we were to > create suitable memory access barrier primitives and use those instead.) Now it is possible to avoid additional spinlock on each KnownAssignedXidsGetAndSetXmin. I have not measured the performance impact of this particular change yet (and it is not easy to reliable measure impact less than 0.5% probably), but I think it is worth adding. We need to protect only the head pointer because the tail is updated only with exclusive ProcArrayLock. BTW should I provide a separate patch for this? So, now we have a pretty successful benchmark for the typical use-case and some additional investigation had been done. So, I think I’ll re-add the patch to the commitfest app. Thanks, Michail
Attachment
> 21 нояб. 2021 г., в 23:58, Michail Nikolaev <michail.nikolaev@gmail.com> написал(а): > > <v3-0001-memory-barrier-instead-of-spinlock.patch> Write barrier must be issued after write, not before. Don't we need to issue read barrier too? Best regards, Andrey Borodin.
Hello, Andrey. > Write barrier must be issued after write, not before. > Don't we need to issue read barrier too? The write barrier is issued after the changes to KnownAssignedXidsNext and KnownAssignedXidsValid arrays and before the update of headKnownAssignedXids. So, it seems to be correct. We make sure once the CPU sees changes of headKnownAssignedXids - underlying arrays contain all the required data. Thanks, Michail.
> On 22 Nov 2021, at 14:05, Michail Nikolaev <michail.nikolaev@gmail.com> wrote: > >> Write barrier must be issued after write, not before. >> Don't we need to issue read barrier too? > > The write barrier is issued after the changes to KnownAssignedXidsNext > and KnownAssignedXidsValid arrays and before the update of > headKnownAssignedXids. > So, it seems to be correct. We make sure once the CPU sees changes of > headKnownAssignedXids - underlying arrays contain all the required > data. Patch on barrier seems too complicated to me right now. I’d propose to focus on KnowAssignedXidsNext patch: it’s clean, simpleand effective. I’ve rebased the patch so that it does not depend on previous step. Please check out it’s current state, if you are OK withit - let’s mark the patch Ready for Committer. Just maybe slightly better commit message would make the patch easierto understand. Thanks! Best regards, Andrey Borodin.
Attachment
Hello, Andrey. Thanks for your efforts. > Patch on barrier seems too complicated to me right now. I’d propose to focus on KnowAssignedXidsNext patch: it’s clean,simple and effective. I'll extract it to the separated patch later. > I’ve rebased the patch so that it does not depend on previous step. Please check out it’s current state, if you are OKwith it - let’s mark the patch Ready for Committer. Just maybe slightly better commit message would make the patch easierto understand. Everything seems to be correct. Best regards, Michail.
Hello. Just an updated commit message. Thanks, Michail.
Attachment
Hello, Simon. Sorry for calling you directly, but you know the subject better than anyone else. It is related to your work from 2010 - replacing KnownAssignedXidsHash with the KnownAssignedXids array. I have added additional optimization to the data structure you implemented. Initially, it was caused by the huge usage of CPU (70%+) for KnownAssignedXidsGetAndSetXmin in case of long (few seconds) transactions on primary and high (few thousands) max_connections in Postgres 11. After snapshot scalability optimization by Andres Freund (2), it is not so crucial but still provides a significant performance impact (+10% TPS) for a typical workload, see benchmark (3). Last patch version is here - (4). Does such optimisation look worth committing? Thanks in advance, Michail. [1]: https://github.com/postgres/postgres/commit/2871b4618af1acc85665eec0912c48f8341504c4#diff-8879f0173be303070ab7931db7c757c96796d84402640b9e386a4150ed97b179 [2]: https://commitfest.postgresql.org/29/2500/ [3]: https://www.postgresql.org/message-id/flat/CANtu0ohzBFTYwdLtcanWo4%2B794WWUi7LY2rnbHyorJdE8_ZnGg%40mail.gmail.com#379c1be7b8134ada5a574078d51b64c6 [4]: https://www.postgresql.org/message-id/flat/CANtu0ogzo4MsR7My9%2BNhu3to5%3Dy7G9zSzUbxfWYOn9W5FfHjTA%40mail.gmail.com#341a3c3b033f69b260120b3173a66382
> On 1 Apr 2022, at 04:18, Michail Nikolaev <michail.nikolaev@gmail.com> wrote: > > Hello. > > Just an updated commit message. I've looked into v5. IMO the purpose of KnownAssignedXidsNext would be slightly more obvious if it was named KnownAssignedXidsNextOffset. Also please consider some editorialisation: s/high value/big number/g KnownAssignedXidsNext[] is updating while taking the snapshot. -> KnownAssignedXidsNext[] is updated during taking the snapshot. O(N) next call -> amortized O(N) on next call Is it safe on all platforms to do "KnownAssignedXidsNext[prev] = n;" while only holding shared lock? I think it is, per Alexander'scomment, but maybe let's document it? Thank you! Thanks! Best regards, Andrey Borodin.
Hello, Andrey. > I've looked into v5. Thanks! Patch is updated accordingly your remarks. Best regards, Michail.
Attachment
> On 20 Jul 2022, at 02:12, Michail Nikolaev <michail.nikolaev@gmail.com> wrote: > >> I've looked into v5. > Thanks! > > Patch is updated accordingly your remarks. The patch seems Ready for Committer from my POV. Thanks! Best regards, Andrey Borodin.
At Tue, 26 Jul 2022 23:09:16 +0500, Andrey Borodin <x4mmm@yandex-team.ru> wrote in > > > > On 20 Jul 2022, at 02:12, Michail Nikolaev <michail.nikolaev@gmail.com> wrote: > > > >> I've looked into v5. > > Thanks! > > > > Patch is updated accordingly your remarks. > > The patch seems Ready for Committer from my POV. + * is s updated during taking the snapshot. The KnownAssignedXidsNextOffset + * contains not an offset to the next valid xid but a number which tends to + * the offset to next valid xid. KnownAssignedXidsNextOffset[] values read Is there still a reason why the array stores the distnace to the next valid element instead of the index number of the next valid index? It seems to me that that was in an intention to reduce the size of the offset array but it is int32[] which is far wider than TOTAL_MAX_CACHED_SUBXIDS. It seems to me storing the index itself is simpler and maybe faster by the cycles to perform addition. regards. -- Kyotaro Horiguchi NTT Open Source Software Center
On Wed, 27 Jul 2022 at 08:08, Kyotaro Horiguchi <horikyota.ntt@gmail.com> wrote: > > At Tue, 26 Jul 2022 23:09:16 +0500, Andrey Borodin <x4mmm@yandex-team.ru> wrote in > > > > > > > On 20 Jul 2022, at 02:12, Michail Nikolaev <michail.nikolaev@gmail.com> wrote: > > > > > >> I've looked into v5. > > > Thanks! > > > > > > Patch is updated accordingly your remarks. > > > > The patch seems Ready for Committer from my POV. > > + * is s updated during taking the snapshot. The KnownAssignedXidsNextOffset > + * contains not an offset to the next valid xid but a number which tends to > + * the offset to next valid xid. KnownAssignedXidsNextOffset[] values read > > Is there still a reason why the array stores the distnace to the next > valid element instead of the index number of the next valid index? It > seems to me that that was in an intention to reduce the size of the > offset array but it is int32[] which is far wider than > TOTAL_MAX_CACHED_SUBXIDS. > > It seems to me storing the index itself is simpler and maybe faster by > the cycles to perform addition. I'm inclined to think this is all too much. All of this optimization makes sense when the array spreads out horribly, but we should be just avoiding that in the first place by compressing more often. The original coded frequency of compression was just a guess and was never tuned later. A simple patch like this seems to hit the main concern, aiming to keep the array from spreading out and impacting snapshot performance for SELECTs, yet not doing it so often that the startup process has a higher burden of work. -- Simon Riggs http://www.EnterpriseDB.com/
Attachment
Hello. Thanks to everyone for the review. > It seems to me storing the index itself is simpler and maybe faster by > the cycles to perform addition. Yes, first version used 1-byte for offset with maximum value of 255. Agreed, looks like there is no sense to store offsets now. > A simple patch like this seems to hit the main concern, aiming to keep > the array from spreading out and impacting snapshot performance for > SELECTs, yet not doing it so often that the startup process has a > higher burden of work. Nice, I'll do performance testing for both versions and master branch as baseline. Thanks, Michail.
On Fri, 29 Jul 2022 at 18:24, Michail Nikolaev <michail.nikolaev@gmail.com> wrote: > > A simple patch like this seems to hit the main concern, aiming to keep > > the array from spreading out and impacting snapshot performance for > > SELECTs, yet not doing it so often that the startup process has a > > higher burden of work. > > Nice, I'll do performance testing for both versions and master branch > as baseline. The objective of all patches is to touch the smallest number of cachelines when accessing the KnownAssignedXacts array. The trade-off is to keep the array small with the minimum number of compressions, so that normal snapshots don't feel the contention and so that the Startup process doesn't slow down because of the extra compression work. The values I've chosen in the recent patch are just guesses at what we'll need to reduce it to, so there may be some benefit in varying those numbers to see the effects. It did also occur to me that we might need a separate process to perform the compressions, which we might be able to give to WALWriter. -- Simon Riggs http://www.EnterpriseDB.com/
> On 29 Jul 2022, at 20:08, Simon Riggs <simon.riggs@enterprisedb.com> wrote: > > A simple patch like this seems to hit the main concern, aiming to keep > the array from spreading out and impacting snapshot performance for > SELECTs, yet not doing it so often that the startup process has a > higher burden of work. The idea to compress more often seem viable. But this might make some other workloads pathological. Some KnownAssignedXids routines now can become quadratic in case of lots of subtransactions. KnownAssignedXidsRemoveTree() only compress with probability 1/8, but it is still O(N*N). IMO original patch (with next pointer) is much safer in terms of unexpected performance degradation. Thanks! Best regards, Andrey Borodin.
On Tue, 2 Aug 2022 at 12:32, Andrey Borodin <x4mmm@yandex-team.ru> wrote: > KnownAssignedXidsRemoveTree() only compress with probability 1/8, but it is still O(N*N). Currently it is O(NlogS), not quite as bad as O(N^2). Since each xid in the tree is always stored to the right, it should be possible to make that significantly better by starting each binary search from the next element, rather than the start of the array. Something like the attached might help, but we can probably make that cache conscious to improve things even more. -- Simon Riggs http://www.EnterpriseDB.com/
Attachment
At Tue, 2 Aug 2022 16:18:44 +0100, Simon Riggs <simon.riggs@enterprisedb.com> wrote in > On Tue, 2 Aug 2022 at 12:32, Andrey Borodin <x4mmm@yandex-team.ru> wrote: > > > KnownAssignedXidsRemoveTree() only compress with probability 1/8, but it is still O(N*N). > > Currently it is O(NlogS), not quite as bad as O(N^2). > > Since each xid in the tree is always stored to the right, it should be > possible to make that significantly better by starting each binary > search from the next element, rather than the start of the array. > Something like the attached might help, but we can probably make that > cache conscious to improve things even more. The original complaint is KnownAssignedXidsGetAndSetXmin can get very slow for large max_connections. I'm not sure what was happening on the KAXidsArray at the time precisely, but if the array starts with a large number of invalid entries (I guess it is likely), and the variable "start" were available to the function (that is, it were placed in procArray), that strategy seems to work for this case. With this strategy we can avoid compression if only the relatively narrow range in the array is occupied. regards. -- Kyotaro Horiguchi NTT Open Source Software Center
> On 2 Aug 2022, at 20:18, Simon Riggs <simon.riggs@enterprisedb.com> wrote: > > On Tue, 2 Aug 2022 at 12:32, Andrey Borodin <x4mmm@yandex-team.ru> wrote: > >> KnownAssignedXidsRemoveTree() only compress with probability 1/8, but it is still O(N*N). > > Currently it is O(NlogS), not quite as bad as O(N^2). Consider workload when we have a big number of simultaneously active xids. Number of calls to KnownAssignedXidsRemoveTree()is proportional to number of these xids. And the complexity of KnownAssignedXidsRemoveTree() is proportional to the number of these xids, because each call to KnownAssignedXidsRemoveTree()might evenly run compression (which will not compress much). Compression is not an answer to performance problems - because it might be burden itself. Instead we can make compressionunneeded to make a snapshot's xids-in-progress list. > Since each xid in the tree is always stored to the right, it should be > possible to make that significantly better by starting each binary > search from the next element, rather than the start of the array. > Something like the attached might help, but we can probably make that > cache conscious to improve things even more. As Kyotaro-san correctly mentioned - performance degradation happened in KnownAssignedXidsGetAndSetXmin() which does notdo binary search. > On 3 Aug 2022, at 06:04, Kyotaro Horiguchi <horikyota.ntt@gmail.com> wrote: > > The original complaint is KnownAssignedXidsGetAndSetXmin can get very > slow for large max_connections. I'm not sure what was happening on the > KAXidsArray at the time precisely, but if the array starts with a > large number of invalid entries (I guess it is likely), and the > variable "start" were available to the function (that is, it were > placed in procArray), that strategy seems to work for this case. With > this strategy we can avoid compression if only the relatively narrow > range in the array is occupied. This applies to only one workload - all transactions are very short. If we have a tiny fraction of mid or long transactions- this heuristics does not help anymore. Thank you! Best regards, Andrey Borodin.
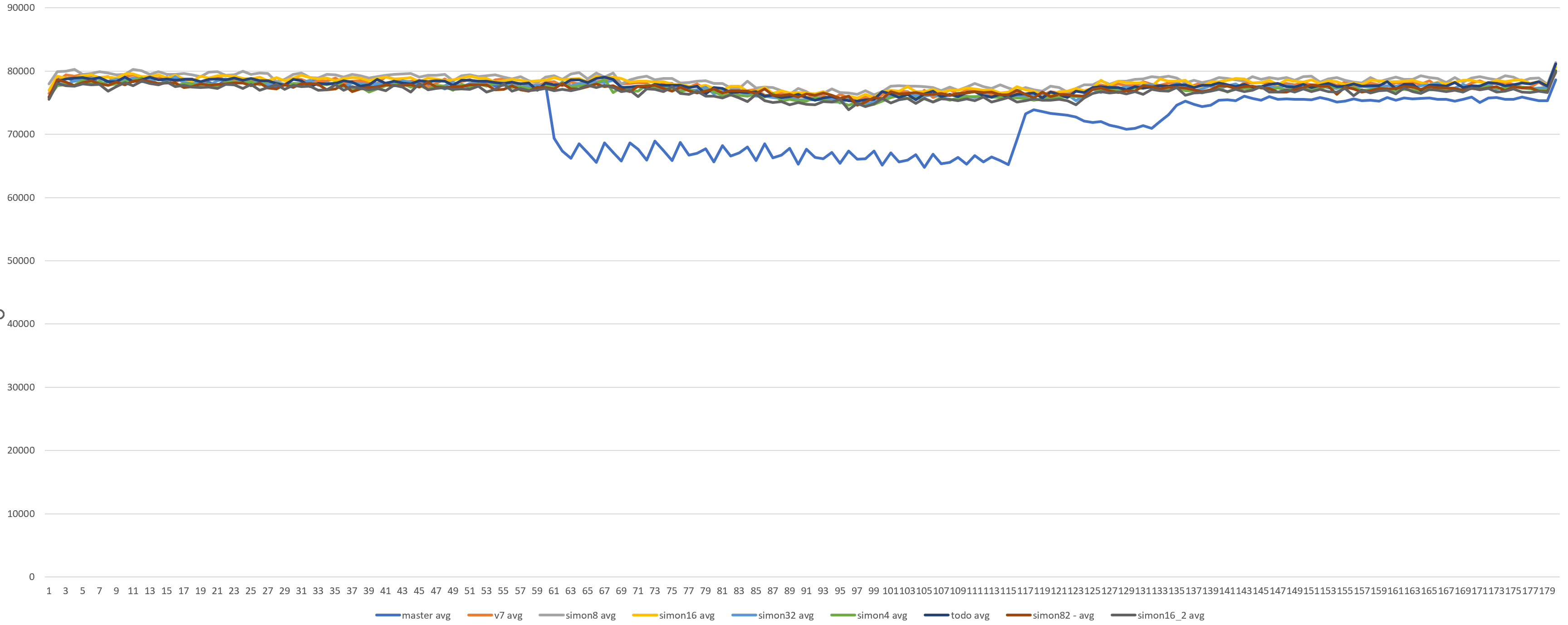
Hello, everyone. > It seems to me storing the index itself is simpler and maybe faster by > the cycles to perform addition. Done in v7. > Since each xid in the tree is always stored to the right, it should be > possible to make that significantly better by starting each binary > search from the next element, rather than the start of the array. Also, looks like it is better to go with `tail = Max(start, pArray->tailKnownAssignedXids)` (in v1-0001-TODO.patch) Performance tests show Simon's approach solves the issue without significant difference in performance comparing to my version. I need some additional time to provide statistically significant best coefficients (how often to go compression, minimum number of invalid xids to start compression). Thanks, Michail.
Attachment
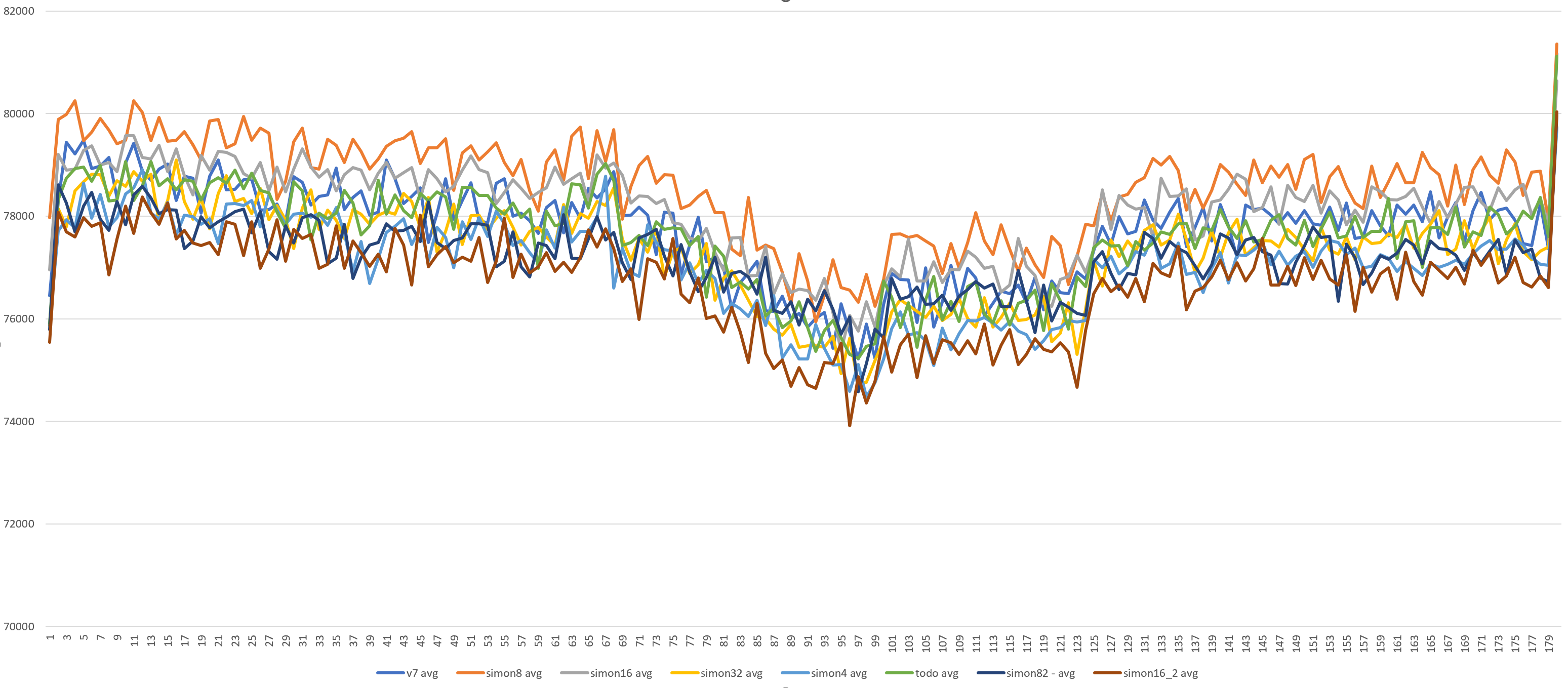
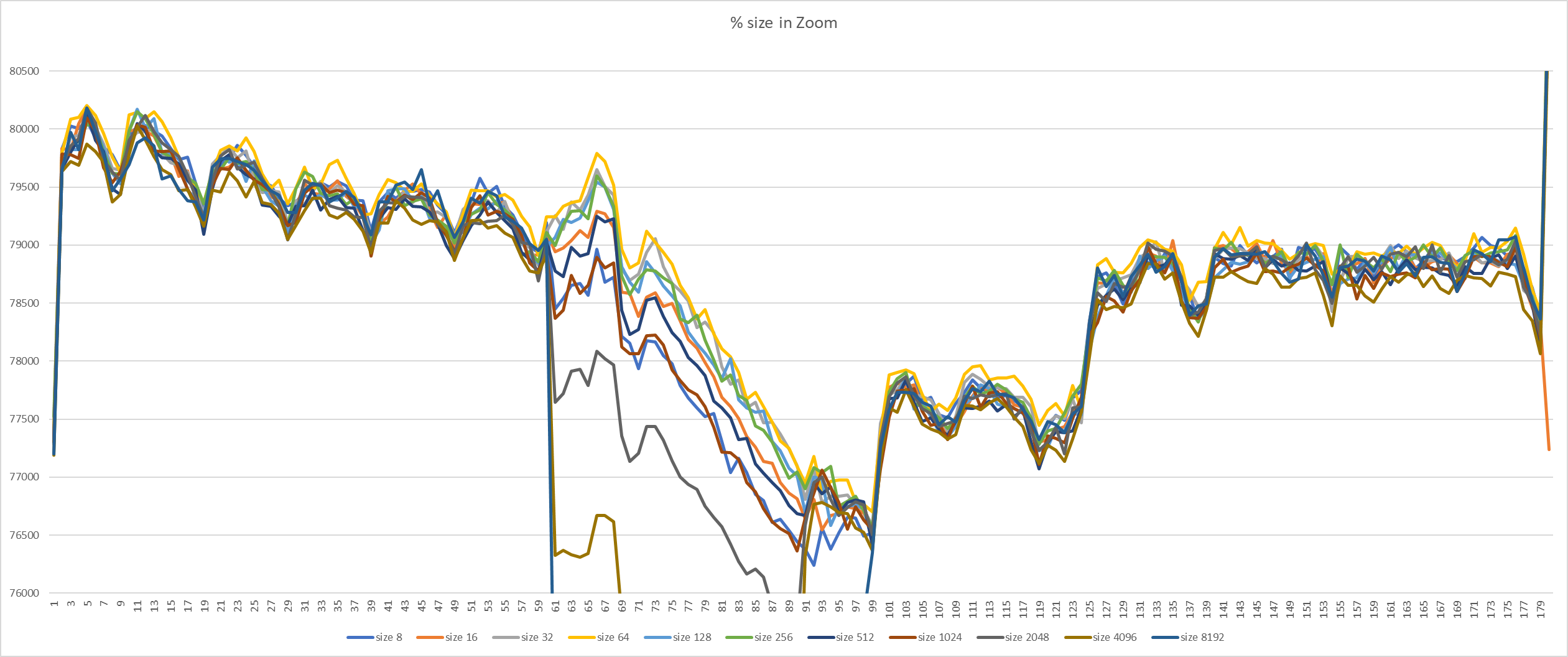
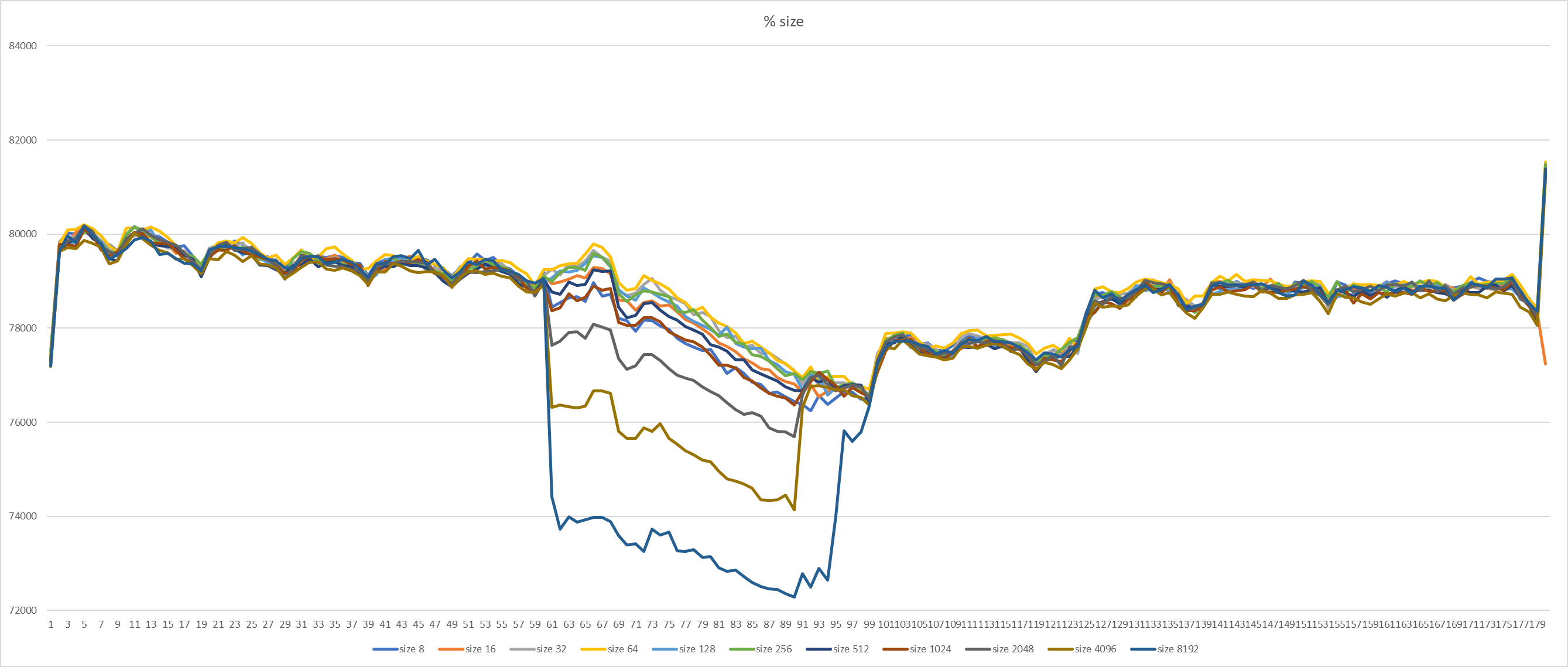
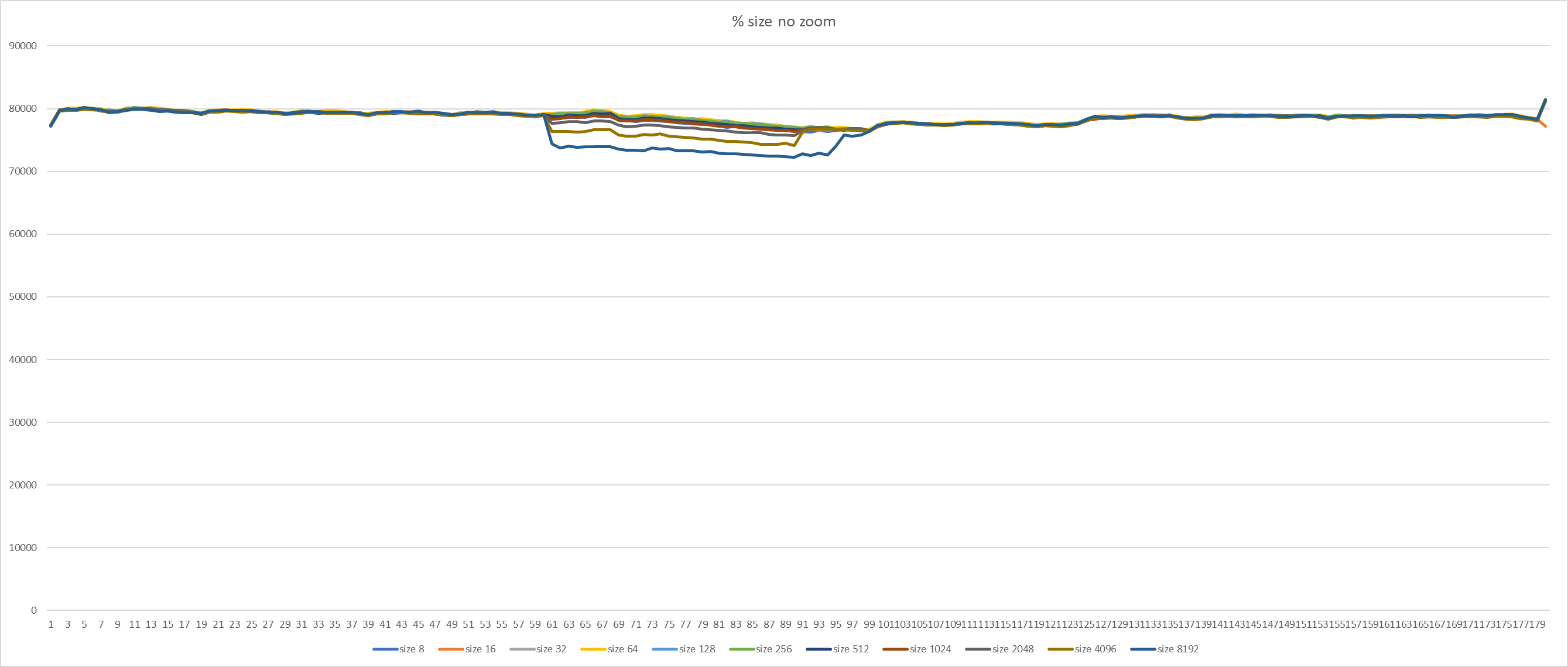
{kind=link}
{kind=link}
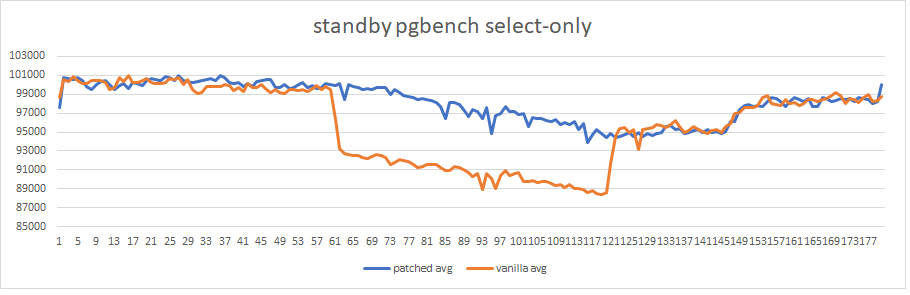
Hello everyone. To find the best frequency for calling KnownAssignedXidsCompress in Simon's patch, I made a set of benchmarks. It looks like each 8th xid is a little bit often. Setup and method is the same as previous (1). 16-core machines, max_connections = 5000. Tests were running for about a day, 220 runs in total (each version for 20 times, evenly distributed throughout the day). Staring from 60th second, 30 seconds-long transaction was started on primary. Graphs in attachment. So, looks like 64 is the best value here. It gives even a little bit more TPS than smaller values. Yes, such benchmark does not cover all possible cases, but it is better to measure at least something when selecting constants :) If someone has an idea of different benchmark scenarios - please share them. So, updated version (with 64 and some commit message) in attachment too. [1]: https://www.postgresql.org/message-id/flat/CANtu0ohzBFTYwdLtcanWo4%2B794WWUi7LY2rnbHyorJdE8_ZnGg%40mail.gmail.com#379c1be7b8134ada5a574078d51b64c6
Attachment
{kind=link}
{kind=link}
{kind=link}
On Fri, 16 Sept 2022 at 17:08, Michail Nikolaev <michail.nikolaev@gmail.com> wrote: > > Hello everyone. > > To find the best frequency for calling KnownAssignedXidsCompress in > Simon's patch, I made a set of benchmarks. It looks like each 8th xid > is a little bit often. > > Setup and method is the same as previous (1). 16-core machines, > max_connections = 5000. Tests were running for about a day, 220 runs > in total (each version for 20 times, evenly distributed throughout the > day). > > Staring from 60th second, 30 seconds-long transaction was started on primary. > > Graphs in attachment. So, looks like 64 is the best value here. It > gives even a little bit more TPS than smaller values. > > Yes, such benchmark does not cover all possible cases, but it is > better to measure at least something when selecting constants :) This is very good and clear, thank you. > If someone has an idea of different benchmark scenarios - please share them. > So, updated version (with 64 and some commit message) in attachment too. > > [1]: https://www.postgresql.org/message-id/flat/CANtu0ohzBFTYwdLtcanWo4%2B794WWUi7LY2rnbHyorJdE8_ZnGg%40mail.gmail.com#379c1be7b8134ada5a574078d51b64c6 I've cleaned up the comments and used a #define for the constant. IMHO this is ready for commit. I will add it to the next CF. -- Simon Riggs http://www.EnterpriseDB.com/
Attachment
On Sat, Sep 17, 2022 at 6:27 PM Simon Riggs <simon.riggs@enterprisedb.com> wrote: > I've cleaned up the comments and used a #define for the constant. > > IMHO this is ready for commit. I will add it to the next CF. FYI This had many successful cfbot runs but today it blew up on Windows when the assertion TransactionIdPrecedesOrEquals(safeXid, snap->xmin) failed: https://api.cirrus-ci.com/v1/artifact/task/5311549010083840/crashlog/crashlog-postgres.exe_1c40_2022-11-08_00-20-28-110.txt
Hi, On 2022-11-09 11:42:36 +1300, Thomas Munro wrote: > On Sat, Sep 17, 2022 at 6:27 PM Simon Riggs > <simon.riggs@enterprisedb.com> wrote: > > I've cleaned up the comments and used a #define for the constant. > > > > IMHO this is ready for commit. I will add it to the next CF. > > FYI This had many successful cfbot runs but today it blew up on > Windows when the assertion TransactionIdPrecedesOrEquals(safeXid, > snap->xmin) failed: > > https://api.cirrus-ci.com/v1/artifact/task/5311549010083840/crashlog/crashlog-postgres.exe_1c40_2022-11-08_00-20-28-110.txt I don't immediately see how that could be connected to this patch - afaict that crash wasn't during recovery, and the modified functions should only be active during hot standby. Greetings, Andres Freund
On Wed, Nov 9, 2022 at 1:54 PM Andres Freund <andres@anarazel.de> wrote: > On 2022-11-09 11:42:36 +1300, Thomas Munro wrote: > > On Sat, Sep 17, 2022 at 6:27 PM Simon Riggs > > <simon.riggs@enterprisedb.com> wrote: > > > I've cleaned up the comments and used a #define for the constant. > > > > > > IMHO this is ready for commit. I will add it to the next CF. > > > > FYI This had many successful cfbot runs but today it blew up on > > Windows when the assertion TransactionIdPrecedesOrEquals(safeXid, > > snap->xmin) failed: > > > > https://api.cirrus-ci.com/v1/artifact/task/5311549010083840/crashlog/crashlog-postgres.exe_1c40_2022-11-08_00-20-28-110.txt > > I don't immediately see how that could be connected to this patch - afaict > that crash wasn't during recovery, and the modified functions should only be > active during hot standby. Indeed, sorry for the noise.
Simon Riggs <simon.riggs@enterprisedb.com> writes:
> I've cleaned up the comments and used a #define for the constant.
> IMHO this is ready for commit. I will add it to the next CF.
I looked at this a little. It's a simple enough patch, and if it
solves the problem then I sure like it better than the previous
ideas in this thread.
However ... I tried to reproduce the original complaint, and
failed entirely. I do see KnownAssignedXidsGetAndSetXmin
eating a bit of time in the standby backends, but it's under 1%
and doesn't seem to be rising over time. Perhaps we've already
applied some optimization that ameliorates the problem? But
I tested v13 as well as HEAD, and got the same results.
regards, tom lane
BTW, while nosing around this code I came across this statement
(procarray.c, about line 4550 in HEAD):
* ... To add XIDs to the array, we just insert
* them into slots to the right of the head pointer and then advance the head
* pointer. This wouldn't require any lock at all, except that on machines
* with weak memory ordering we need to be careful that other processors
* see the array element changes before they see the head pointer change.
* We handle this by using a spinlock to protect reads and writes of the
* head/tail pointers. (We could dispense with the spinlock if we were to
* create suitable memory access barrier primitives and use those instead.)
* The spinlock must be taken to read or write the head/tail pointers unless
* the caller holds ProcArrayLock exclusively.
Nowadays we've *got* those primitives. Can we get rid of
known_assigned_xids_lck, and if so would it make a meaningful
difference in this scenario?
regards, tom lane
On Tue, 15 Nov 2022 at 23:06, Tom Lane <tgl@sss.pgh.pa.us> wrote: > > BTW, while nosing around this code I came across this statement > (procarray.c, about line 4550 in HEAD): > > * ... To add XIDs to the array, we just insert > * them into slots to the right of the head pointer and then advance the head > * pointer. This wouldn't require any lock at all, except that on machines > * with weak memory ordering we need to be careful that other processors > * see the array element changes before they see the head pointer change. > * We handle this by using a spinlock to protect reads and writes of the > * head/tail pointers. (We could dispense with the spinlock if we were to > * create suitable memory access barrier primitives and use those instead.) > * The spinlock must be taken to read or write the head/tail pointers unless > * the caller holds ProcArrayLock exclusively. > > Nowadays we've *got* those primitives. Can we get rid of > known_assigned_xids_lck, and if so would it make a meaningful > difference in this scenario? I think you could do that *as well*, since it does act as an overhead but that is not related to the main issues: * COMMITs: xids are removed from the array by performing a binary search - this gets more and more expensive as the array gets wider * SNAPSHOTs: scanning the array for snapshots becomes more expensive as the array gets wider Hence more frequent compression is effective at reducing the overhead. But too frequent compression slows down the startup process, which can't then keep up. So we're just looking for an optimal frequency of compression for any given workload. -- Simon Riggs http://www.EnterpriseDB.com/
Hi, On 2022-11-15 23:14:42 +0000, Simon Riggs wrote: > * COMMITs: xids are removed from the array by performing a binary > search - this gets more and more expensive as the array gets wider > * SNAPSHOTs: scanning the array for snapshots becomes more expensive > as the array gets wider > > Hence more frequent compression is effective at reducing the overhead. > But too frequent compression slows down the startup process, which > can't then keep up. > So we're just looking for an optimal frequency of compression for any > given workload. What about making the behaviour adaptive based on the amount of wasted effort during those two operations, rather than just a hardcoded "emptiness" factor? It's common that basically no snapshots are taken, and constantly compressing in that case is likely going to be wasted effort. The heuristic the patch adds to KnownAssignedXidsRemoveTree() seems somewhat misplaced to me. When called from ProcArrayApplyXidAssignment() we probably should always compress - it'll only be issued when a substantial amount of subxids have been assigned, so there'll be a bunch of cleanup work. It makes more sense from ExpireTreeKnownAssignedTransactionIds(), since it will very commonly called for individual xids - but even then, we afaict should take into account how many xids we've just expired. I don't think the xids % KAX_COMPRESS_FREQUENCY == 0 filter is a good idea - if you have a workload with plenty subxids you might end up never compressing because xids divisible by KAX_COMPRESS_FREQUENCY will end up as a subxid most/all of the time. Re cost of processing at COMMITs: We do a fresh binary search for each subxid right now. There's a lot of locality in the xids that can be expired. Perhaps we could have a cache for the position of the latest value in KnownAssignedXidsSearch() and search linearly if the distance from the last looked up value isn't large? Greetings, Andres
Andres Freund <andres@anarazel.de> writes:
> On 2022-11-15 23:14:42 +0000, Simon Riggs wrote:
>> Hence more frequent compression is effective at reducing the overhead.
>> But too frequent compression slows down the startup process, which
>> can't then keep up.
>> So we're just looking for an optimal frequency of compression for any
>> given workload.
> What about making the behaviour adaptive based on the amount of wasted effort
> during those two operations, rather than just a hardcoded "emptiness" factor?
Not quite sure how we could do that, given that those things aren't even
happening in the same process. But yeah, it does feel like the proposed
approach is only going to be optimal over a small range of conditions.
> I don't think the xids % KAX_COMPRESS_FREQUENCY == 0 filter is a good idea -
> if you have a workload with plenty subxids you might end up never compressing
> because xids divisible by KAX_COMPRESS_FREQUENCY will end up as a subxid
> most/all of the time.
Yeah, I didn't think that was too safe either. It'd be more reliable
to use a static counter to skip all but every N'th compress attempt
(something we could do inside KnownAssignedXidsCompress itself, instead
of adding warts at the call sites).
regards, tom lane
Simon Riggs <simon.riggs@enterprisedb.com> writes:
> but that is not related to the main issues:
> * COMMITs: xids are removed from the array by performing a binary
> search - this gets more and more expensive as the array gets wider
> * SNAPSHOTs: scanning the array for snapshots becomes more expensive
> as the array gets wider
Right. The case complained of in this thread is SNAPSHOT cost,
since that's what KnownAssignedXidsGetAndSetXmin is used for.
> Hence more frequent compression is effective at reducing the overhead.
> But too frequent compression slows down the startup process, which
> can't then keep up.
> So we're just looking for an optimal frequency of compression for any
> given workload.
Hmm. I wonder if my inability to detect a problem is because the startup
process does keep ahead of the workload on my machine, while it fails
to do so on the OP's machine. I've only got a 16-CPU machine at hand,
which probably limits the ability of the primary to saturate the standby's
startup process. If that's accurate, reducing the frequency of
compression attempts could be counterproductive in my workload range.
It would help the startup process when that is the bottleneck --- but
that wasn't what the OP complained of, so I'm not sure it helps him
either.
It seems like maybe what we should do is just drop the "nelements < 4 *
PROCARRAY_MAXPROCS" part of the existing heuristic, which is clearly
dangerous with large max_connection settings, and in any case doesn't
have a clear connection to either the cost of scanning or the cost
of compressing. Or we could replace that with a hardwired constant,
like "nelements < 400".
regards, tom lane
Hi, On 2022-11-15 23:14:42 +0000, Simon Riggs wrote: > On Tue, 15 Nov 2022 at 23:06, Tom Lane <tgl@sss.pgh.pa.us> wrote: > > > > BTW, while nosing around this code I came across this statement > > (procarray.c, about line 4550 in HEAD): > > > > * ... To add XIDs to the array, we just insert > > * them into slots to the right of the head pointer and then advance the head > > * pointer. This wouldn't require any lock at all, except that on machines > > * with weak memory ordering we need to be careful that other processors > > * see the array element changes before they see the head pointer change. > > * We handle this by using a spinlock to protect reads and writes of the > > * head/tail pointers. (We could dispense with the spinlock if we were to > > * create suitable memory access barrier primitives and use those instead.) > > * The spinlock must be taken to read or write the head/tail pointers unless > > * the caller holds ProcArrayLock exclusively. > > > > Nowadays we've *got* those primitives. Can we get rid of > > known_assigned_xids_lck, and if so would it make a meaningful > > difference in this scenario? Forgot to reply to this part: I'm confused by the explanation of the semantics of the spinlock: "The spinlock must be taken to read or write the head/tail pointers unless the caller holds ProcArrayLock exclusively." makes it sound like it'd be valid to modify the KnownAssignedXids without holding ProcArrayLock exclusively. Doesn't that contradict only needing the spinlock because of memory ordering? And when would it be valid to do any modifications of KnownAssignedXids without holding ProcArrayLock exclusively? Concurrent readers of KnownAssignedXids will operate on a snapshot of head/tail (the spinlock is only ever held to query them). Afaict any such modification would be racy, because subsequent modifications of KnownAssignedXids could overwrite contents of KnownAssignedXids that another backend is in the process of reading, based on the stale snapshot of head/tail. To me it sounds like known_assigned_xids_lck is pointless and the talk about memory barriers a red herring, since all modifications have to happen with ProcArrayLock held exlusively and all reads with ProcArrayLock held in share mode. It can't be legal to modify head/tail or the contents of the array outside of that. And lwlocks provide sufficient barrier semantics. > I think you could do that *as well*, since it does act as an overhead > but that is not related to the main issues I think it might be a bigger effect than one might immediately think. Because the spinlock will typically be on the same cacheline as head/tail, and because every spinlock acquisition requires the cacheline to be modified (and thus owned mexlusively) by the current core, uses of head/tail will very commonly be cache misses even in workloads without a lot of KAX activity. Greetings, Andres Freund
Hi, On 2022-11-15 19:15:15 -0500, Tom Lane wrote: > Andres Freund <andres@anarazel.de> writes: > > On 2022-11-15 23:14:42 +0000, Simon Riggs wrote: > >> Hence more frequent compression is effective at reducing the overhead. > >> But too frequent compression slows down the startup process, which > >> can't then keep up. > >> So we're just looking for an optimal frequency of compression for any > >> given workload. > > > What about making the behaviour adaptive based on the amount of wasted effort > > during those two operations, rather than just a hardcoded "emptiness" factor? > > Not quite sure how we could do that, given that those things aren't even > happening in the same process. I'm not certain what the best approach is, but I don't think the not-the-same-process part is a blocker. Approach 1: We could have an atomic variable in ProcArrayStruct that counts the amount of wasted effort and have processes update it whenever they've wasted a meaningful amount of effort. Something like counting the skipped elements in KnownAssignedXidsGetAndSetXmin in a function local static variable and updating the shared counter whenever that reaches Approach 2: Perform conditional cleanup in non-startup processes - I think that'd actually be ok, as long as ProcArrayLock is held exlusively. We could count the amount of skipped elements in KnownAssignedXidsGetAndSetXmin() in a local variable, and whenever that gets too high, conditionally acquire ProcArrayLock lock exlusively at the end of GetSnapshotData() and compress KAX. Reset the local variable independent of getting the lock or not, to avoid causing a lot of contention. The nice part is that this would work even without the startup making process. The not nice part that it'd require a bit of code study to figure out whether it's safe to modify KAX from outside the startup process. > But yeah, it does feel like the proposed > approach is only going to be optimal over a small range of conditions. In particular, it doesn't adapt at all to workloads that don't replay all that much, but do compute a lot of snapshots. Greetings, Andres Freund
Andres Freund <andres@anarazel.de> writes:
> To me it sounds like known_assigned_xids_lck is pointless and the talk about
> memory barriers a red herring, since all modifications have to happen with
> ProcArrayLock held exlusively and all reads with ProcArrayLock held in share
> mode. It can't be legal to modify head/tail or the contents of the array
> outside of that. And lwlocks provide sufficient barrier semantics.
No ... RecordKnownAssignedTransactionIds calls KnownAssignedXidsAdd
with exclusive_lock = false, and in the typical case that will not
acquire ProcArrayLock at all. Since there's only one writer, that
seems safe enough, and I believe the commentary's claim that we
really just need to be sure the head-pointer update is seen
after the array updates.
regards, tom lane
Hi, On 2022-11-15 19:46:26 -0500, Tom Lane wrote: > Andres Freund <andres@anarazel.de> writes: > > To me it sounds like known_assigned_xids_lck is pointless and the talk about > > memory barriers a red herring, since all modifications have to happen with > > ProcArrayLock held exlusively and all reads with ProcArrayLock held in share > > mode. It can't be legal to modify head/tail or the contents of the array > > outside of that. And lwlocks provide sufficient barrier semantics. > > No ... RecordKnownAssignedTransactionIds calls KnownAssignedXidsAdd > with exclusive_lock = false, and in the typical case that will not > acquire ProcArrayLock at all. Since there's only one writer, that > seems safe enough, and I believe the commentary's claim that we > really just need to be sure the head-pointer update is seen > after the array updates. Oh, right. I focussed to much on the part of the comment quoted in your email. I still think it's misleading for the comment to say that the tail can be modified with the spinlock - I don't see how that'd ever be correct. Nor could head be safely decreased with just the spinlock. Too bad, that seems to make the idea of compressing in other backends a non-starter unfortunately :(. Although - are we really gaining that much by avoiding ProcArrayLock in the RecordKnownAssignedTransactionIds() case? It only happens when latestObservedXid is increased, and we'll remove them at commit with the exclusive lock held. Afaict that's the only KAX access that doesn't also require ProcArrayLock? Greetings, Andres Freund
On Wed, 16 Nov 2022 at 00:15, Tom Lane <tgl@sss.pgh.pa.us> wrote: > > Andres Freund <andres@anarazel.de> writes: > > On 2022-11-15 23:14:42 +0000, Simon Riggs wrote: > >> Hence more frequent compression is effective at reducing the overhead. > >> But too frequent compression slows down the startup process, which > >> can't then keep up. > >> So we're just looking for an optimal frequency of compression for any > >> given workload. > > > What about making the behaviour adaptive based on the amount of wasted effort > > during those two operations, rather than just a hardcoded "emptiness" factor? > > Not quite sure how we could do that, given that those things aren't even > happening in the same process. But yeah, it does feel like the proposed > approach is only going to be optimal over a small range of conditions. I have not been able to think of a simple way to autotune it. > > I don't think the xids % KAX_COMPRESS_FREQUENCY == 0 filter is a good idea - > > if you have a workload with plenty subxids you might end up never compressing > > because xids divisible by KAX_COMPRESS_FREQUENCY will end up as a subxid > > most/all of the time. > > Yeah, I didn't think that was too safe either. > It'd be more reliable > to use a static counter to skip all but every N'th compress attempt > (something we could do inside KnownAssignedXidsCompress itself, instead > of adding warts at the call sites). I was thinking exactly that myself, for the reason of keeping it all inside KnownAssignedXidsCompress(). -- Simon Riggs http://www.EnterpriseDB.com/
Hello everyone. > However ... I tried to reproduce the original complaint, and > failed entirely. I do see KnownAssignedXidsGetAndSetXmin > eating a bit of time in the standby backends, but it's under 1% > and doesn't seem to be rising over time. Perhaps we've already > applied some optimization that ameliorates the problem? But > I tested v13 as well as HEAD, and got the same results. > Hmm. I wonder if my inability to detect a problem is because the startup > process does keep ahead of the workload on my machine, while it fails > to do so on the OP's machine. I've only got a 16-CPU machine at hand, > which probably limits the ability of the primary to saturate the standby's > startup process. Yes, optimization by Andres Freund made things much better, but the impact is still noticeable. I was also using 16CPU machine - but two of them (primary and standby). Here are the scripts I was using (1) for benchmark - maybe it could help. > Nowadays we've *got* those primitives. Can we get rid of > known_assigned_xids_lck, and if so would it make a meaningful > difference in this scenario? I was trying it already - but was unable to find real benefits for it. WIP patch in attachment. Hm, I see I have sent it to list, but it absent in archives... Just quote from it: > First potential positive effect I could see is > (TransactionIdIsInProgress -> KnownAssignedXidsSearch) locking but > seems like it is not on standby hotpath. > Second one - locking for KnownAssignedXidsGetAndSetXmin (build > snapshot). But I was unable to measure impact. It wasn’t visible > separately in (3) test. > Maybe someone knows scenario causing known_assigned_xids_lck or > TransactionIdIsInProgress become bottleneck on standby? The latest question is still actual :) > I think it might be a bigger effect than one might immediately think. Because > the spinlock will typically be on the same cacheline as head/tail, and because > every spinlock acquisition requires the cacheline to be modified (and thus > owned mexlusively) by the current core, uses of head/tail will very commonly > be cache misses even in workloads without a lot of KAX activity. I was trying to find some way to practically achieve any noticeable impact here, but unsuccessfully. >> But yeah, it does feel like the proposed >> approach is only going to be optimal over a small range of conditions. > In particular, it doesn't adapt at all to workloads that don't replay all that > much, but do compute a lot of snapshots. The approach (2) was optimized to avoid any additional work for anyone except non-startup processes (approach with offsets to skip gaps while building snapshot). [1]: https://gist.github.com/michail-nikolaev/e1dfc70bdd7cfd1b902523dbb3db2f28 [2]: https://www.postgresql.org/message-id/flat/CANtu0ogzo4MsR7My9%2BNhu3to5%3Dy7G9zSzUbxfWYOn9W5FfHjTA%40mail.gmail.com#341a3c3b033f69b260120b3173a66382 -- Michail Nikolaev
Attachment
Hello. On Wed, Nov 16, 2022 at 3:44 AM Andres Freund <andres@anarazel.de> wrote: > Approach 1: > We could have an atomic variable in ProcArrayStruct that counts the amount of > wasted effort and have processes update it whenever they've wasted a > meaningful amount of effort. Something like counting the skipped elements in > KnownAssignedXidsGetAndSetXmin in a function local static variable and > updating the shared counter whenever that reaches I made the WIP patch for that approach and some initial tests. It seems like it works pretty well. At least it is better than previous ways for standbys without high read only load. Both patch and graph in attachments. Strange numbers is a limit of wasted work to perform compression. I have used the same (1) testing script and configuration as before (two 16-CPU machines, long transaction on primary at 60th second, simple-update and select-only for pgbench). If such approach looks committable - I could do more careful performance testing to find the best value for WASTED_SNAPSHOT_WORK_LIMIT_TO_COMPRESS. [1]: https://gist.github.com/michail-nikolaev/e1dfc70bdd7cfd1b902523dbb3db2f28 -- Michail Nikolaev
Attachment
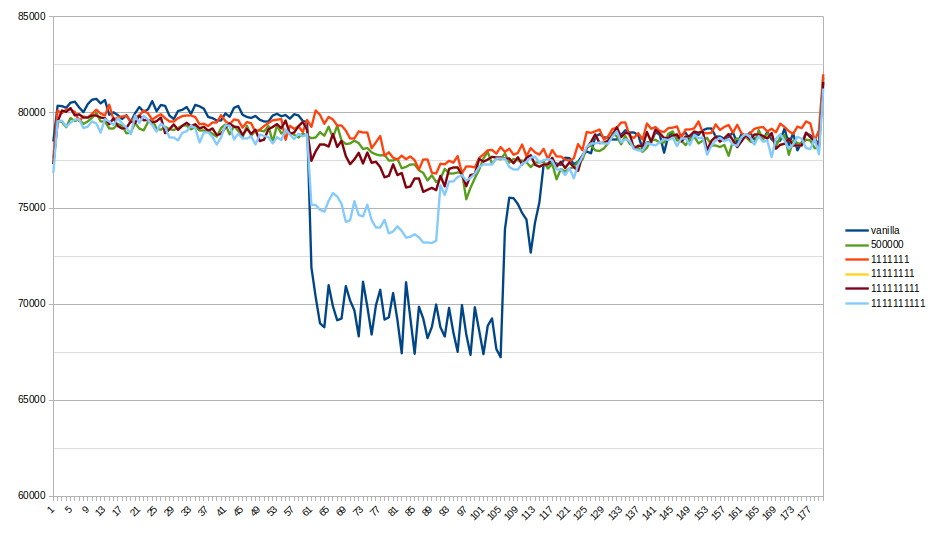{kind=link}
Oops, wrong image, this is correct one. But is 1-run tests, so it shows only basic correlation,
Attachment
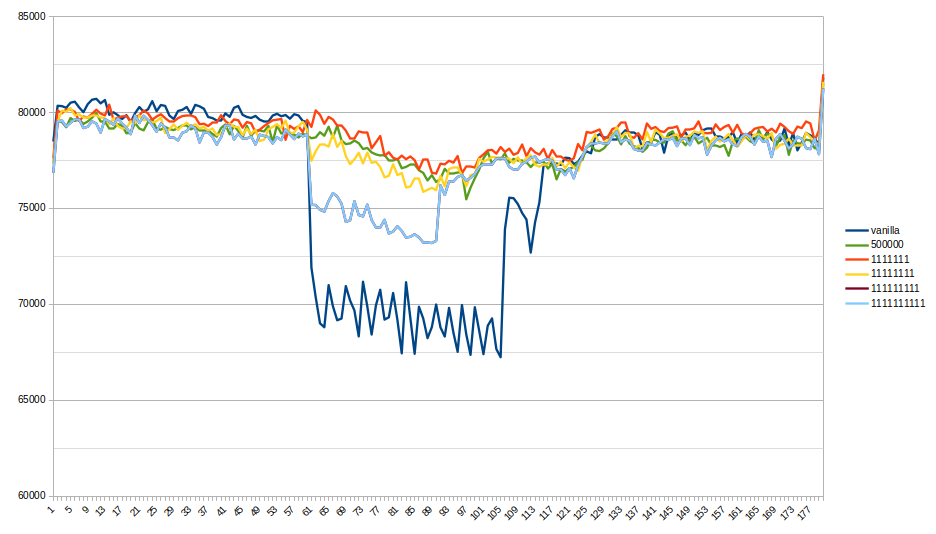{kind=link}
Oh, seems like it is not my day :) The image fixed again.
Attachment
{kind=link}
On Sun, 20 Nov 2022 at 13:45, Michail Nikolaev <michail.nikolaev@gmail.com> wrote: > If such approach looks committable - I could do more careful > performance testing to find the best value for > WASTED_SNAPSHOT_WORK_LIMIT_TO_COMPRESS. Nice patch. We seem to have replaced one magic constant with another, so not sure if this is autotuning, but I like it much better than what we had before (i.e. better than my prev patch). Few thoughts 1. I was surprised that you removed the limits on size and just had the wasted work limit. If there is no read traffic that will mean we hardly ever compress, which means the removal of xids at commit will get slower over time. I would prefer that we forced compression on a regular basis, such as every time we process an XLOG_RUNNING_XACTS message (every 15s), as well as when we hit certain size limits. 2. If there is lots of read traffic but no changes flowing, it would also make sense to force compression when the startup process goes idle rather than wait for the work to be wasted first. Quick patch to add those two compression events also. That should favour the smaller wasted work limits. -- Simon Riggs http://www.EnterpriseDB.com/
Attachment
Simon Riggs <simon.riggs@enterprisedb.com> writes:
> We seem to have replaced one magic constant with another, so not sure
> if this is autotuning, but I like it much better than what we had
> before (i.e. better than my prev patch).
Yeah, the magic constant is still magic, even if it looks like it's
not terribly sensitive to the exact value.
> 1. I was surprised that you removed the limits on size and just had
> the wasted work limit. If there is no read traffic that will mean we
> hardly ever compress, which means the removal of xids at commit will
> get slower over time. I would prefer that we forced compression on a
> regular basis, such as every time we process an XLOG_RUNNING_XACTS
> message (every 15s), as well as when we hit certain size limits.
> 2. If there is lots of read traffic but no changes flowing, it would
> also make sense to force compression when the startup process goes
> idle rather than wait for the work to be wasted first.
If we do those things, do we need a wasted-work counter at all?
I still suspect that 90% of the problem is the max_connections
dependency in the existing heuristic, because of the fact that
you have to push max_connections to the moon before it becomes
a measurable problem. If we do
- if (nelements < 4 * PROCARRAY_MAXPROCS ||
- nelements < 2 * pArray->numKnownAssignedXids)
+ if (nelements < 2 * pArray->numKnownAssignedXids)
and then add the forced compressions you suggest, where
does that put us?
Also, if we add more forced compressions, it seems like we should have
a short-circuit for a forced compression where there's nothing to do.
So more or less like
nelements = head - tail;
if (!force)
{
if (nelements < 2 * pArray->numKnownAssignedXids)
return;
}
else
{
if (nelements == pArray->numKnownAssignedXids)
return;
}
I'm also wondering why there's not an
Assert(compress_index == pArray->numKnownAssignedXids);
after the loop, to make sure our numKnownAssignedXids tracking
is sane.
regards, tom lane
On Tue, 22 Nov 2022 at 16:28, Tom Lane <tgl@sss.pgh.pa.us> wrote:
>
> Simon Riggs <simon.riggs@enterprisedb.com> writes:
> > We seem to have replaced one magic constant with another, so not sure
> > if this is autotuning, but I like it much better than what we had
> > before (i.e. better than my prev patch).
>
> Yeah, the magic constant is still magic, even if it looks like it's
> not terribly sensitive to the exact value.
>
> > 1. I was surprised that you removed the limits on size and just had
> > the wasted work limit. If there is no read traffic that will mean we
> > hardly ever compress, which means the removal of xids at commit will
> > get slower over time. I would prefer that we forced compression on a
> > regular basis, such as every time we process an XLOG_RUNNING_XACTS
> > message (every 15s), as well as when we hit certain size limits.
>
> > 2. If there is lots of read traffic but no changes flowing, it would
> > also make sense to force compression when the startup process goes
> > idle rather than wait for the work to be wasted first.
>
> If we do those things, do we need a wasted-work counter at all?
>
> I still suspect that 90% of the problem is the max_connections
> dependency in the existing heuristic, because of the fact that
> you have to push max_connections to the moon before it becomes
> a measurable problem. If we do
>
> - if (nelements < 4 * PROCARRAY_MAXPROCS ||
> - nelements < 2 * pArray->numKnownAssignedXids)
> + if (nelements < 2 * pArray->numKnownAssignedXids)
>
> and then add the forced compressions you suggest, where
> does that put us?
The forced compressions I propose happen
* when idle - since we have time to do it when that happens, which
happens often since most workloads are bursty
* every 15s - since we already have lock
which is overall much less often than every 64 commits, as benchmarked
by Michail.
I didn't mean to imply that superceded the wasted work approach, it
was meant to be in addition to.
The wasted work counter works well to respond to heavy read-only
traffic and also avoids wasted compressions for write-heavy workloads.
So I still like it the best.
> Also, if we add more forced compressions, it seems like we should have
> a short-circuit for a forced compression where there's nothing to do.
> So more or less like
>
> nelements = head - tail;
> if (!force)
> {
> if (nelements < 2 * pArray->numKnownAssignedXids)
> return;
> }
> else
> {
> if (nelements == pArray->numKnownAssignedXids)
> return;
> }
+1
> I'm also wondering why there's not an
>
> Assert(compress_index == pArray->numKnownAssignedXids);
>
> after the loop, to make sure our numKnownAssignedXids tracking
> is sane.
+1
--
Simon Riggs http://www.EnterpriseDB.com/
Simon Riggs <simon.riggs@enterprisedb.com> writes:
> On Tue, 22 Nov 2022 at 16:28, Tom Lane <tgl@sss.pgh.pa.us> wrote:
>> If we do those things, do we need a wasted-work counter at all?
> The wasted work counter works well to respond to heavy read-only
> traffic and also avoids wasted compressions for write-heavy workloads.
> So I still like it the best.
This argument presumes that maintenance of the counter is free,
which it surely is not. I don't know how bad contention on that
atomically-updated variable could get, but it seems like it could
be an issue when lots of processes are acquiring snapshots.
regards, tom lane
On Tue, 22 Nov 2022 at 16:53, Tom Lane <tgl@sss.pgh.pa.us> wrote: > > Simon Riggs <simon.riggs@enterprisedb.com> writes: > > On Tue, 22 Nov 2022 at 16:28, Tom Lane <tgl@sss.pgh.pa.us> wrote: > >> If we do those things, do we need a wasted-work counter at all? > > > The wasted work counter works well to respond to heavy read-only > > traffic and also avoids wasted compressions for write-heavy workloads. > > So I still like it the best. > > This argument presumes that maintenance of the counter is free, > which it surely is not. I don't know how bad contention on that > atomically-updated variable could get, but it seems like it could > be an issue when lots of processes are acquiring snapshots. I understand. I was assuming that you and Andres liked that approach. In the absence of that approach, falling back to a counter that compresses every N xids would be best, in addition to the two new forced compression events. -- Simon Riggs http://www.EnterpriseDB.com/
Hello, everyone. I have tried to put it all together. > In the absence of that approach, falling back to a counter that > compresses every N xids would be best, in addition to the two new > forced compression events. Done. > Also, if we add more forced compressions, it seems like we should have > a short-circuit for a forced compression where there's nothing to do. Done. > I'm also wondering why there's not an > > Assert(compress_index == pArray->numKnownAssignedXids); > > after the loop, to make sure our numKnownAssignedXids tracking > is sane. Done. > * when idle - since we have time to do it when that happens, which > happens often since most workloads are bursty I have added getting of ProcArrayLock for this case. Also, I have added maximum frequency as 1 per second to avoid contention with heavy read load in case of small, episodic but regular WAL traffic (WakeupRecovery() for each 100ms for example). Or it is useless? > It'd be more reliable > to use a static counter to skip all but every N'th compress attempt > (something we could do inside KnownAssignedXidsCompress itself, instead > of adding warts at the call sites). Done. I have added “reason” enum for calling KnownAssignedXidsCompress to keep it as much clean as possible. But not sure that I was successful here. Also, I think while we still in the context, it is good to add: * Simon's optimization (1) for KnownAssignedXidsRemoveTree (it is simple and effective for some situations without any seen drawbacks) * Maybe my patch (2) for replacing known_assigned_xids_lck with memory barrier? New version in attach. Running benchmarks now. Preliminary result in attachments (16CPU, 5000 max_connections, now 64 active connections instead of 16). Also, interesting moment - with 64 connections, vanilla version is unable to recover its performance after 30-sec transaction on primary. [1]: https://www.postgresql.org/message-id/flat/CANbhV-Ey8HRYPvnvQnsZAteCfzN3VHVhZVKfWMYcnjMnSzs4dQ%40mail.gmail.com#05993cf2bc87e35e0dff38fec26b9805 [2]: https://www.postgresql.org/message-id/flat/CANtu0oiPoSdQsjRd6Red5WMHi1E83d2%2B-bM9J6dtWR3c5Tap9g%40mail.gmail.com#cc4827dee902978f93278732435e8521 -- Michail Nikolaev
Attachment
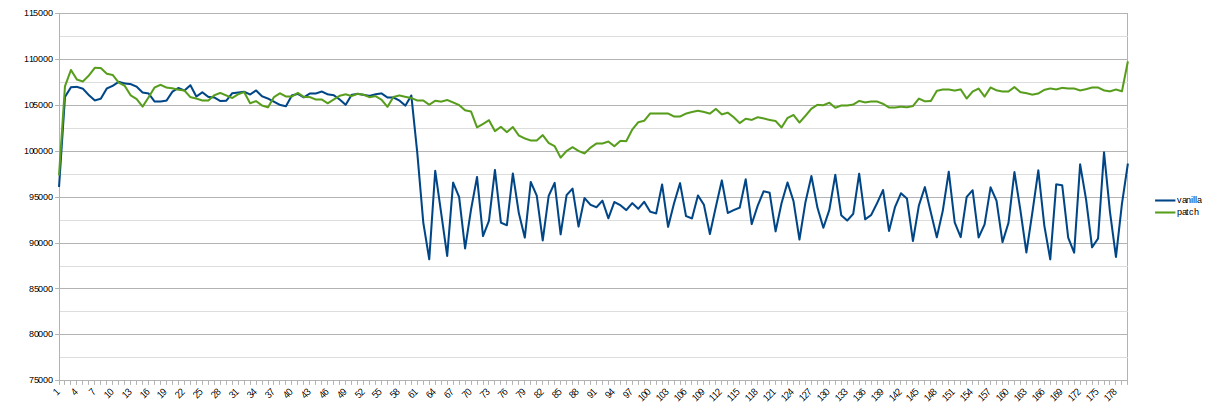{kind=link}
Hello, everyone. Benchmarks for the last version of patch are ready. Executed on two 16CPU machines (AMD EPYC 7763), 5000 max_connections. Staring from the 60th second, 30 seconds-long transaction was started on primary. Setup is the same as in (1), scripts here - (2). For most of the tests, simple-update and simple-select pgbench scenarios were used on primary and standby. For one of the tests - just “SELECT txid_current();” and “SELECT 1;” accordingly. The name of the line is KAX_COMPRESS_FREQUENCY value. For 16 connections, 64, 128 and 256 are the best ones. For 32 - 32, 64, 12, 256. For 64 - a little bit tricky story. 128 and 256 are best, but 1024-4096 can be faster some small period of time with continuing degradation. Still not sure why. Three different run sets in attachment, one with start of long transaction on 20th second. For 128 - anything < 1024 is good. For “txid_current+select 1” case - the same. Also, in all the cases, patched version is better than current master. And for master (and some big values of KAX_COMPRESS_FREQUENCY) version it is not possible for performance to recover, probably caches and locking goes into some bad, but stable pattern. So, I think it is better to go 128 here. [1]: https://www.postgresql.org/message-id/flat/CANtu0ohzBFTYwdLtcanWo4%2B794WWUi7LY2rnbHyorJdE8_ZnGg%40mail.gmail.com#379c1be7b8134ada5a574078d51b64c6 [2]: https://gist.github.com/michail-nikolaev/e1dfc70bdd7cfd1b902523dbb3db2f28 -- Michail Nikolaev.
Attachment
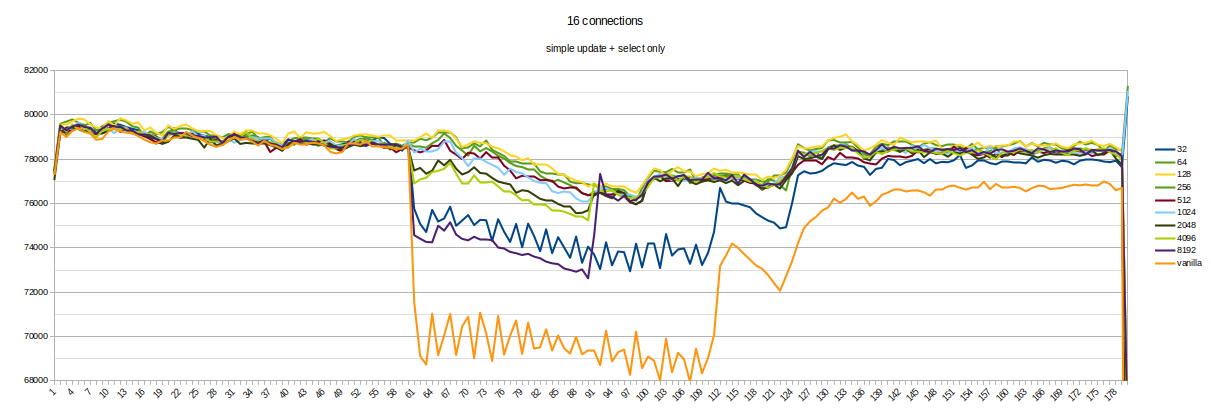{kind=link}
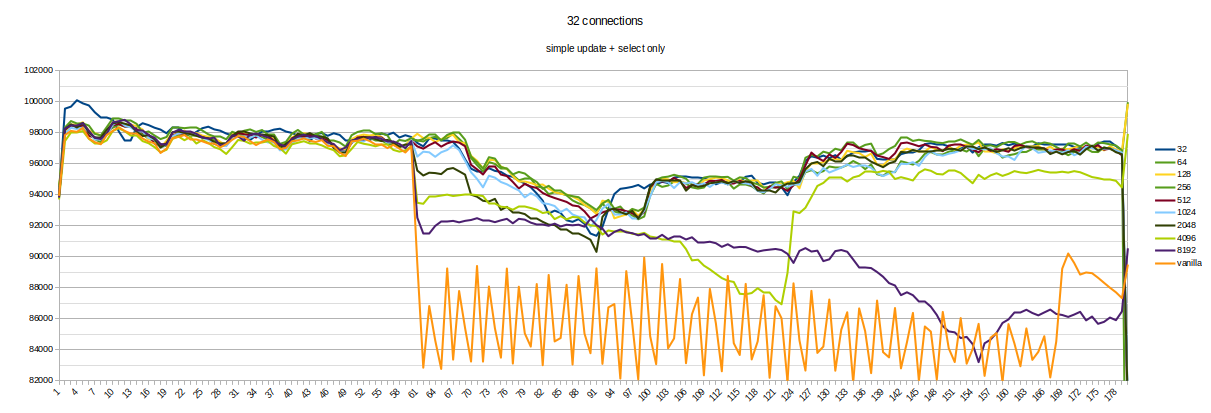{kind=link}
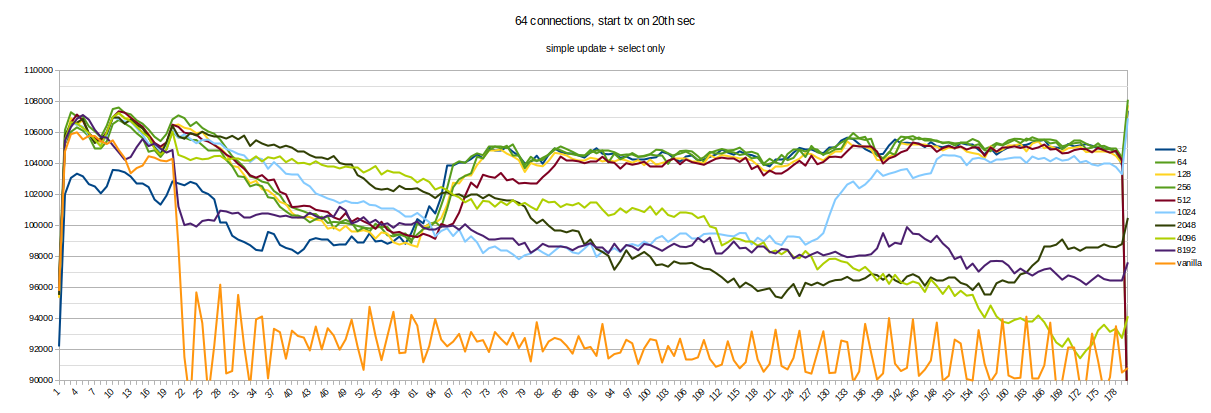{kind=link}
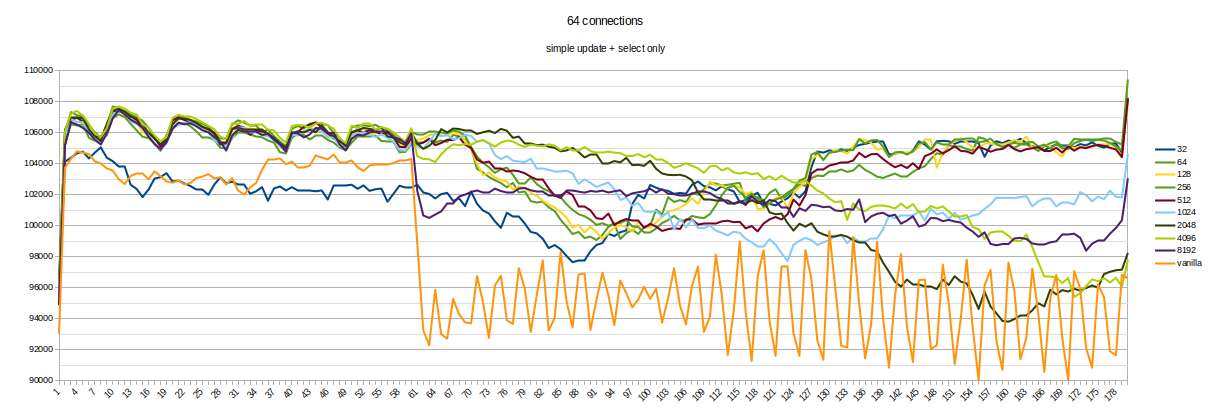{kind=link}
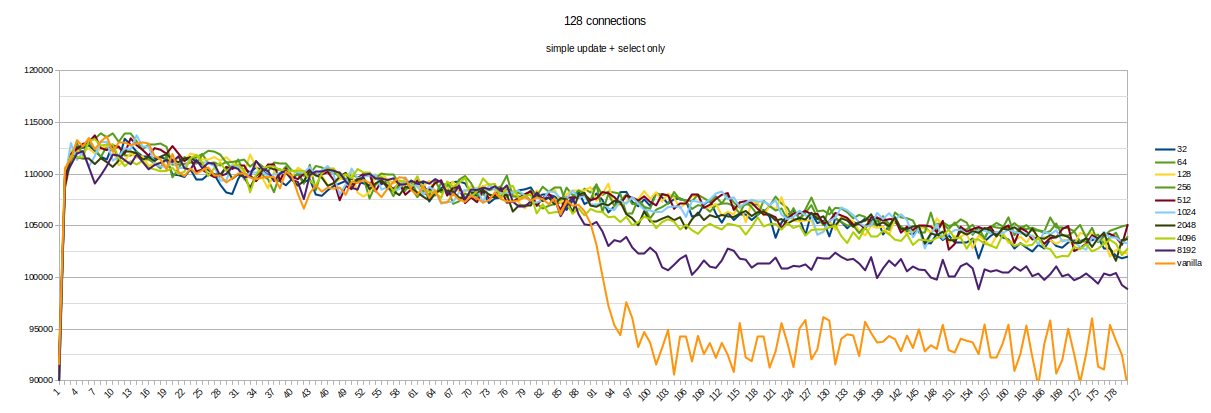{kind=link}
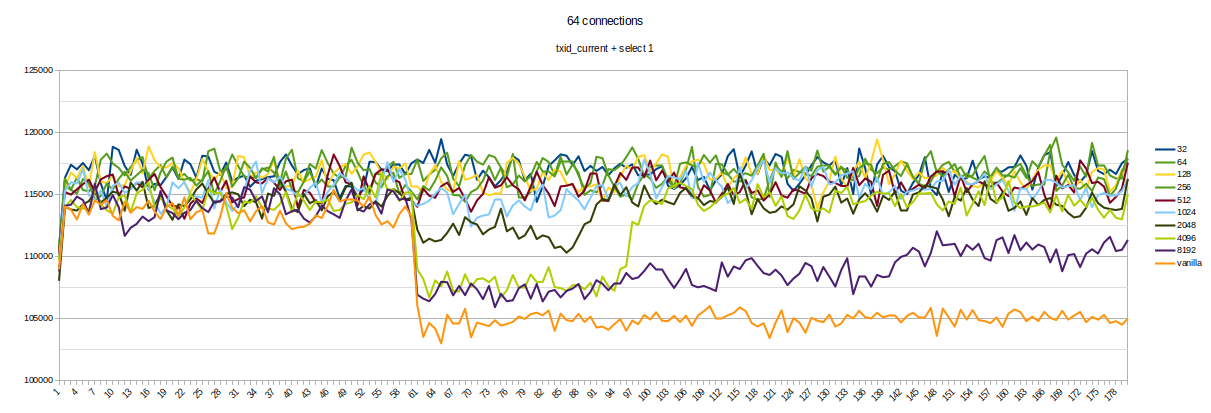{kind=link}
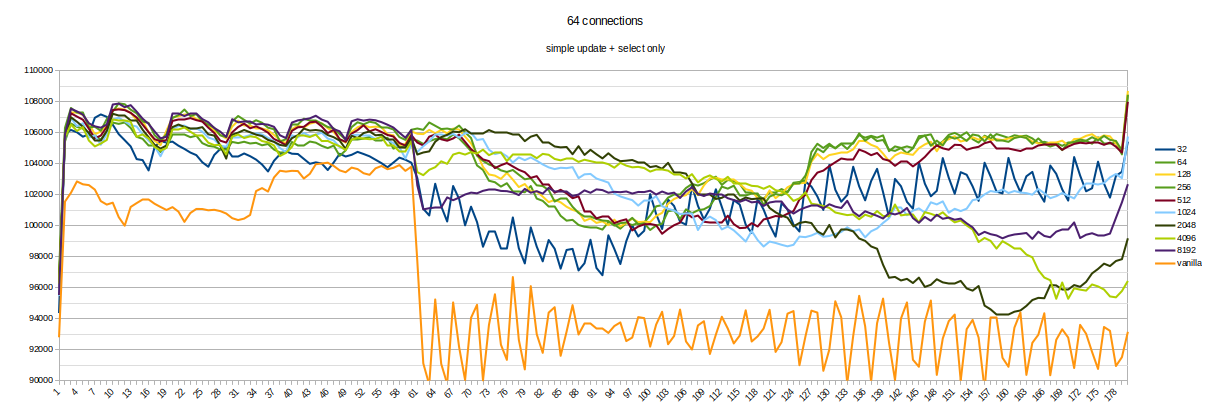{kind=link}
Michail Nikolaev <michail.nikolaev@gmail.com> writes:
>> * when idle - since we have time to do it when that happens, which
>> happens often since most workloads are bursty
> I have added getting of ProcArrayLock for this case.
That seems like a fairly bad idea: it will add extra contention
on ProcArrayLock, and I see no real strong argument that the path
can't get traversed often enough for that to matter. It would
likely be better for KnownAssignedXidsCompress to obtain the lock
for itself, only after it knows there is something worth doing.
(This ties back to previous discussion: the comment claiming it's
safe to read head/tail because we have the lock is misguided.
It's safe because we're the only process that changes them.
So we can make the heuristic decision before acquiring lock.)
While you could use the "reason" code to decide whether you need
to take the lock, it might be better to add a separate boolean
argument specifying whether the caller already has the lock.
Beyond that, I don't see any issues except cosmetic ones.
> Also, I think while we still in the context, it is good to add:
> * Simon's optimization (1) for KnownAssignedXidsRemoveTree (it is
> simple and effective for some situations without any seen drawbacks)
> * Maybe my patch (2) for replacing known_assigned_xids_lck with memory barrier?
Doesn't seem like we have any hard evidence in favor of either of
those being worth doing. We especially haven't any evidence that
they'd still be worth doing after this patch. I'd be willing to
make the memory barrier change anyway, because that seems like
a simple change that can't hurt. I'm less enthused about the
patch at (1) because of the complexity it adds.
regards, tom lane
I wrote:
> That seems like a fairly bad idea: it will add extra contention
> on ProcArrayLock, and I see no real strong argument that the path
> can't get traversed often enough for that to matter. It would
> likely be better for KnownAssignedXidsCompress to obtain the lock
> for itself, only after it knows there is something worth doing.
Since we're running out of time in the current commitfest,
I went ahead and changed that, and made the cosmetic fixes
I wanted, and pushed.
regards, tom lane
Hello, Tom. > Since we're running out of time in the current commitfest, > I went ahead and changed that, and made the cosmetic fixes > I wanted, and pushed. Great, thanks! The small thing I was thinking to add in KnownAssignedXidsCompress is the assertion like Assert(MyBackendType == B_STARTUP); Just to make it more clear that locking is not the only thing required for the call. > I'd be willing to > make the memory barrier change anyway, because that seems like > a simple change that can't hurt. I'm going to create a separate commit fest entry for it, ok? Best regards, Michail.
Michail Nikolaev <michail.nikolaev@gmail.com> writes:
> The small thing I was thinking to add in KnownAssignedXidsCompress is
> the assertion like
> Assert(MyBackendType == B_STARTUP);
Mmm ... given where the call sites are, we have got lots more problems
than this if some non-startup process reaches them. I'm not sure this
is worth the trouble, but if it is, I'd put it in the callers.
>> I'd be willing to
>> make the memory barrier change anyway, because that seems like
>> a simple change that can't hurt.
> I'm going to create a separate commit fest entry for it, ok?
Right, since I closed this one already.
regards, tom lane
On Tue, 29 Nov 2022 at 20:46, Tom Lane <tgl@sss.pgh.pa.us> wrote: > > I wrote: > > That seems like a fairly bad idea: it will add extra contention > > on ProcArrayLock, and I see no real strong argument that the path > > can't get traversed often enough for that to matter. It would > > likely be better for KnownAssignedXidsCompress to obtain the lock > > for itself, only after it knows there is something worth doing. > > Since we're running out of time in the current commitfest, > I went ahead and changed that, and made the cosmetic fixes > I wanted, and pushed. That is a complete patch from multiple angles; very happy here. Thanks for a great job. -- Simon Riggs http://www.EnterpriseDB.com/