Re: Slow standby snapshot - Mailing list pgsql-hackers
| From | Michail Nikolaev |
|---|---|
| Subject | Re: Slow standby snapshot |
| Date | |
| Msg-id | CANtu0ohzBFTYwdLtcanWo4+794WWUi7LY2rnbHyorJdE8_ZnGg@mail.gmail.com Whole thread |
| In response to | Re: Slow standby snapshot (Michail Nikolaev <michail.nikolaev@gmail.com>) |
| List | pgsql-hackers |
Hello, everyone.
I made a performance test to make sure the patch solves real issues
without performance regression.
Tests are made on 3 VM - one for primary, another - standby, latest
one - pgbench. It is Azure Standard_D16ads_v5 - 16 VCPU, 64GIB RAM,
Fast SSD.
5000 used as a number of connections (it is the max number of
connections for AWS - LEAST({DBInstanceClassMemory/9531392}, 5000)).
Setup:
primary:
max_connections=5000
listen_addresses='*'
fsync=off
standby:
primary_conninfo = 'user=postgres host=10.0.0.4 port=5432
sslmode=prefer sslcompression=0 gssencmode=prefer krbsrvname=postgres
target_session_attrs=any'
hot_standby_feedback = on
max_connections=5000
listen_addresses='*'
fsync=off
The test was run the following way:
# restart both standby and primary
# init fresh DB
./pgbench -h 10.0.0.4 -i -s 10 -U postgres -d postgres
# warm up primary for 10 seconds
./pgbench -h 10.0.0.4 -b simple-update -j 8 -c 16 -P 1 -T 10 -U
postgres postgres
# warm up standby for 10 seconds
./pgbench -h 10.0.0.5 -b select-only -j 8 -c 16 -n -P 1 -T 10 -U
postgres postgres
# then, run at the same(!) time (in parallel):
# simple-update on primary
./pgbench -h 10.0.0.4 -b simple-update -j 8 -c 16 -P 1 -T 180 -U
postgres postgres
# simple-select on standby
./pgbench -h 10.0.0.5 -b select-only -j 8 -c 16 -n -P 1 -T 180 -U
postgres postgres
# then, after 60 seconds after test start - start a long transaction
on the master
./psql -h 10.0.0.4 -c "BEGIN; select txid_current();SELECT
pg_sleep(5);COMMIT;" -U postgres postgres
I made 3 runs for both the patched and vanilla versions (current
master branch). One run of the patched version was retried because of
a significant difference in TPS (it is vCPU on VM with neighborhoods,
so, probably some isolation issue).
The result on the primary is about 23k-25k TPS for both versions.
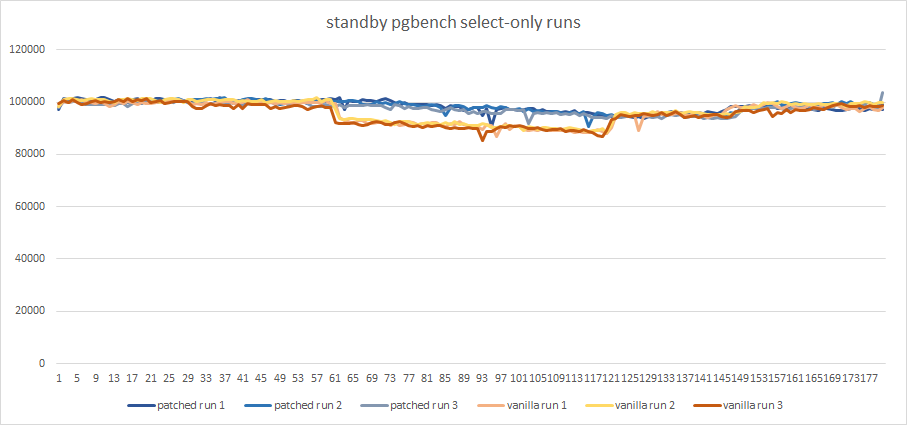
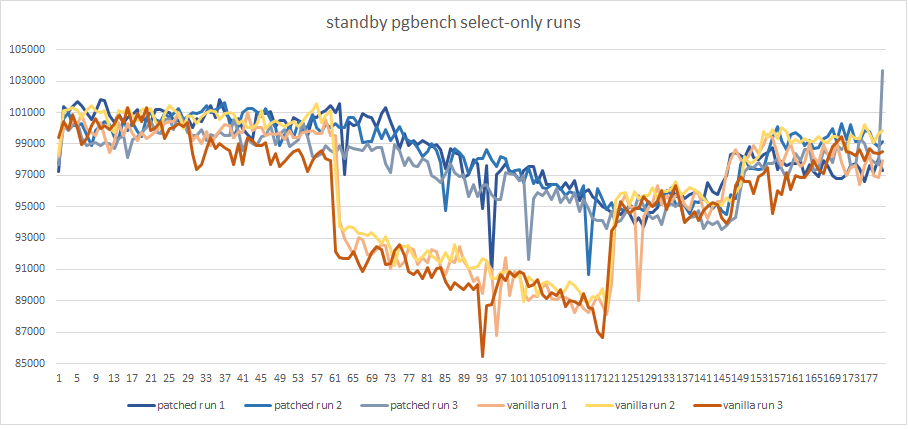
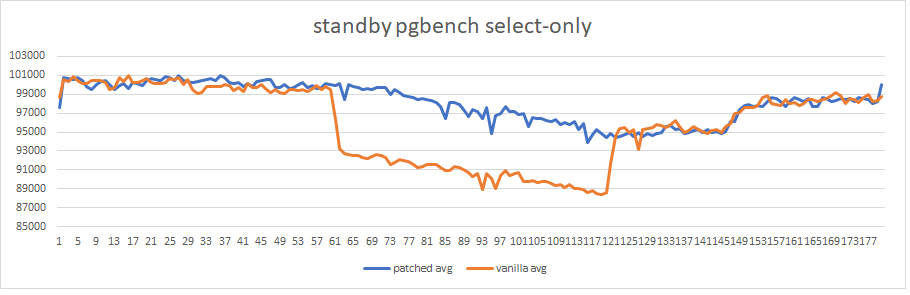
So, graphics show a significant reduction of TPS on the secondary
while the long transaction is active (about 10%).
The patched version solves the issue without any noticeable regression
in the case of short-only transactions.
Also, transactions could be much shorted to reduce CPU - a few seconds
is enough.
Also, this is `perf diff` between `with` and `without` long
transaction recording.
Vanilla (+ 10.26% of KnownAssignedXidsGetAndSetXmin):
0.22% +10.26% postgres [.]
KnownAssignedXidsGetAndSetXmin
3.39% +0.68% [kernel.kallsyms] [k]
_raw_spin_unlock_irqrestore
2.66% -0.61% libc-2.31.so [.] 0x0000000000045dc1
3.77% -0.50% postgres [.] base_yyparse
3.43% -0.45% [kernel.kallsyms] [k] finish_task_switch
0.41% +0.36% postgres [.] pg_checksum_page
0.61% +0.31% [kernel.kallsyms] [k] copy_user_generic_string
Patched (+ 0.22%):
2.26% -0.40% [kernel.kallsyms] [k] _raw_spin_unlock_irqrestore
0.78% +0.39% [kernel.kallsyms] [k] copy_user_generic_string
0.22% +0.26% postgres [.] KnownAssignedXidsGetAndSetXmin
0.23% +0.20% postgres [.] ScanKeywordLookup
3.77% +0.19% postgres [.] base_yyparse
0.64% +0.19% postgres [.] pg_checksum_page
3.63% -0.18% [kernel.kallsyms] [k] finish_task_switch
If someone knows any additional performance tests that need to be done
- please share.
Best regards,
Michail.
Attachment
{kind=link}
{kind=link}
{kind=link}
pgsql-hackers by date: