Thread: badly calculated width of emoji in psql
Hi
I am checked an query from https://www.depesz.com/2021/04/01/waiting-for-postgresql-14-add-unistr-function/ article.
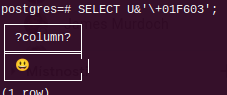
postgres=# SELECT U&'\+01F603';
┌──────────┐
│ ?column? │
╞══════════╡
│ 😃 │
└──────────┘
(1 row)
┌──────────┐
│ ?column? │
╞══════════╡
│ 😃 │
└──────────┘
(1 row)
The result is not correct. Emoji has width 2 chars, but psql calculates with just one char.
Regards
Pavel
On Fri, 2021-04-02 at 10:45 +0200, Pavel Stehule wrote: > I am checked an query from https://www.depesz.com/2021/04/01/waiting-for-postgresql-14-add-unistr-function/ article. > > postgres=# SELECT U&'\+01F603'; > ┌──────────┐ > │ ?column? │ > ╞══════════╡ > │ 😃 │ > └──────────┘ > (1 row) > > > The result is not correct. Emoji has width 2 chars, but psql calculates with just one char. How about this: diff --git a/src/common/wchar.c b/src/common/wchar.c index 6e7d731e02..e2d0d9691c 100644 --- a/src/common/wchar.c +++ b/src/common/wchar.c @@ -673,7 +673,8 @@ ucs_wcwidth(pg_wchar ucs) (ucs >= 0xfe30 && ucs <= 0xfe6f) || /* CJK Compatibility Forms */ (ucs >= 0xff00 && ucs <= 0xff5f) || /* Fullwidth Forms */ (ucs >= 0xffe0 && ucs <= 0xffe6) || - (ucs >= 0x20000 && ucs <= 0x2ffff))); + (ucs >= 0x20000 && ucs <= 0x2ffff) || + (ucs >= 0x1f300 && ucs <= 0x1faff))); /* symbols and emojis */ } /* This is guesswork based on the unicode entries that look like symbols. Yours, Laurenz Albe
pá 2. 4. 2021 v 11:37 odesílatel Laurenz Albe <laurenz.albe@cybertec.at> napsal:
On Fri, 2021-04-02 at 10:45 +0200, Pavel Stehule wrote:
> I am checked an query from https://www.depesz.com/2021/04/01/waiting-for-postgresql-14-add-unistr-function/ article.
>
> postgres=# SELECT U&'\+01F603';
> ┌──────────┐
> │ ?column? │
> ╞══════════╡
> │ 😃 │
> └──────────┘
> (1 row)
>
>
> The result is not correct. Emoji has width 2 chars, but psql calculates with just one char.
How about this:
diff --git a/src/common/wchar.c b/src/common/wchar.c
index 6e7d731e02..e2d0d9691c 100644
--- a/src/common/wchar.c
+++ b/src/common/wchar.c
@@ -673,7 +673,8 @@ ucs_wcwidth(pg_wchar ucs)
(ucs >= 0xfe30 && ucs <= 0xfe6f) || /* CJK Compatibility Forms */
(ucs >= 0xff00 && ucs <= 0xff5f) || /* Fullwidth Forms */
(ucs >= 0xffe0 && ucs <= 0xffe6) ||
- (ucs >= 0x20000 && ucs <= 0x2ffff)));
+ (ucs >= 0x20000 && ucs <= 0x2ffff) ||
+ (ucs >= 0x1f300 && ucs <= 0x1faff))); /* symbols and emojis */
}
/*
This is guesswork based on the unicode entries that look like symbols.
it helps
with this patch, the formatting is correct
Pavel
Yours,
Laurenz Albe
At Fri, 2 Apr 2021 11:51:26 +0200, Pavel Stehule <pavel.stehule@gmail.com> wrote in > with this patch, the formatting is correct I think the hardest point of this issue is that we don't have a reasonable authoritative source that determines character width. And that the presentation is heavily dependent on environment. Unicode 9 and/or 10 defines the character properties "Emoji" and "Emoji_Presentation", and tr51[1] says that > Emoji are generally presented with a square aspect ratio, which > presents a problem for flags. ... > Current practice is for emoji to have a square aspect ratio, deriving > from their origin in Japanese. For interoperability, it is recommended > that this practice be continued with current and future emoji. They > will typically have about the same vertical placement and advance > width as CJK ideographs. For example: Ok, even putting aside flags, the first table in [2] asserts that "#", "*", "0-9" are emoji characters. But we and I think no-one never present them in two-columns. And the table has many mysterious holes I haven't looked into. We could Emoji_Presentation=yes for the purpose, but for example, U+23E9(BLACK RIGHT-POINTING DOUBLE TRIANGLE) has the property Emoji_Presentation=yes but U+23E9(BLACK RIGHT-POINTING DOUBLE TRIANGLE WITH VERTICAL BAR) does not for a reason uncertaion to me. It doesn't look like other than some kind of mistake. About environment, for example, U+23E9 is an emoji, and Emoji_Presentation=yes, but it is shown in one column on my xterm. (I'm not sure what font am I using..) [1] http://www.unicode.org/reports/tr51/ [2] https://unicode.org/Public/13.0.0/ucd/emoji/emoji-data.txt A possible compromise is that we treat all Emoji=yes characters excluding ASCII characters as double-width and manually merge the fragmented regions into reasonably larger chunks. regards. -- Kyotaro Horiguchi NTT Open Source Software Center
po 5. 4. 2021 v 7:07 odesílatel Kyotaro Horiguchi <horikyota.ntt@gmail.com> napsal:
At Fri, 2 Apr 2021 11:51:26 +0200, Pavel Stehule <pavel.stehule@gmail.com> wrote in
> with this patch, the formatting is correct
I think the hardest point of this issue is that we don't have a
reasonable authoritative source that determines character width. And
that the presentation is heavily dependent on environment.
Unicode 9 and/or 10 defines the character properties "Emoji" and
"Emoji_Presentation", and tr51[1] says that
> Emoji are generally presented with a square aspect ratio, which
> presents a problem for flags.
...
> Current practice is for emoji to have a square aspect ratio, deriving
> from their origin in Japanese. For interoperability, it is recommended
> that this practice be continued with current and future emoji. They
> will typically have about the same vertical placement and advance
> width as CJK ideographs. For example:
Ok, even putting aside flags, the first table in [2] asserts that "#",
"*", "0-9" are emoji characters. But we and I think no-one never
present them in two-columns. And the table has many mysterious holes
I haven't looked into.
We could Emoji_Presentation=yes for the purpose, but for example,
U+23E9(BLACK RIGHT-POINTING DOUBLE TRIANGLE) has the property
Emoji_Presentation=yes but U+23E9(BLACK RIGHT-POINTING DOUBLE TRIANGLE
WITH VERTICAL BAR) does not for a reason uncertaion to me. It doesn't
look like other than some kind of mistake.
About environment, for example, U+23E9 is an emoji, and
Emoji_Presentation=yes, but it is shown in one column on my
xterm. (I'm not sure what font am I using..)
[1] http://www.unicode.org/reports/tr51/
[2] https://unicode.org/Public/13.0.0/ucd/emoji/emoji-data.txt
A possible compromise is that we treat all Emoji=yes characters
excluding ASCII characters as double-width and manually merge the
fragmented regions into reasonably larger chunks.
ok
It should be fixed in glibc,
so we can check it
Regards
Pavel
regards.
--
Kyotaro Horiguchi
NTT Open Source Software Center
On Mon, 2021-04-05 at 14:07 +0900, Kyotaro Horiguchi wrote: > At Fri, 2 Apr 2021 11:51:26 +0200, Pavel Stehule <pavel.stehule@gmail.com> wrote in > > with this patch, the formatting is correct > > I think the hardest point of this issue is that we don't have a > reasonable authoritative source that determines character width. And > that the presentation is heavily dependent on environment. > Unicode 9 and/or 10 defines the character properties "Emoji" and > "Emoji_Presentation", and tr51[1] says that > > > Emoji are generally presented with a square aspect ratio, which > > presents a problem for flags. > ... > > Current practice is for emoji to have a square aspect ratio, deriving > > from their origin in Japanese. For interoperability, it is recommended > > that this practice be continued with current and future emoji. They > > will typically have about the same vertical placement and advance > > width as CJK ideographs. For example: > > Ok, even putting aside flags, the first table in [2] asserts that "#", > "*", "0-9" are emoji characters. But we and I think no-one never > present them in two-columns. And the table has many mysterious holes > I haven't looked into. I think that's why Emoji_Presentation is false for those characters -- they _could_ be presented as emoji if the UI should choose to do so, or if an emoji presentation selector is used, but by default a text presentation would be expected. > We could Emoji_Presentation=yes for the purpose, but for example, > U+23E9(BLACK RIGHT-POINTING DOUBLE TRIANGLE) has the property > Emoji_Presentation=yes but U+23E9(BLACK RIGHT-POINTING DOUBLE TRIANGLE > WITH VERTICAL BAR) does not for a reason uncertaion to me. It doesn't > look like other than some kind of mistake. That is strange. > About environment, for example, U+23E9 is an emoji, and > Emoji_Presentation=yes, but it is shown in one column on my > xterm. (I'm not sure what font am I using..) I would guess that's the key issue here. If we choose a particular width for emoji characters, is there anything keeping a terminal's font from doing something different anyway? Furthermore, if the stream contains an emoji presentation selector after a code point that would normally be text, shouldn't we change that glyph to have an emoji "expected width"? I'm wondering if the most correct solution would be to have the user tell the client what width to use, using .psqlrc or something. > A possible compromise is that we treat all Emoji=yes characters > excluding ASCII characters as double-width and manually merge the > fragmented regions into reasonably larger chunks. We could also keep the fragments as-is and generate a full interval table, like common/unicode_combining_table.h. It looks like there's roughly double the number of emoji intervals as combining intervals, so hopefully adding a second binary search wouldn't be noticeably slower. -- In your opinion, would the current one-line patch proposal make things strictly better than they are today, or would it have mixed results? I'm wondering how to help this patch move forward for the current commitfest, or if we should maybe return with feedback for now. --Jacob
st 7. 7. 2021 v 20:03 odesílatel Jacob Champion <pchampion@vmware.com> napsal:
On Mon, 2021-04-05 at 14:07 +0900, Kyotaro Horiguchi wrote:
> At Fri, 2 Apr 2021 11:51:26 +0200, Pavel Stehule <pavel.stehule@gmail.com> wrote in
> > with this patch, the formatting is correct
>
> I think the hardest point of this issue is that we don't have a
> reasonable authoritative source that determines character width. And
> that the presentation is heavily dependent on environment.
> Unicode 9 and/or 10 defines the character properties "Emoji" and
> "Emoji_Presentation", and tr51[1] says that
>
> > Emoji are generally presented with a square aspect ratio, which
> > presents a problem for flags.
> ...
> > Current practice is for emoji to have a square aspect ratio, deriving
> > from their origin in Japanese. For interoperability, it is recommended
> > that this practice be continued with current and future emoji. They
> > will typically have about the same vertical placement and advance
> > width as CJK ideographs. For example:
>
> Ok, even putting aside flags, the first table in [2] asserts that "#",
> "*", "0-9" are emoji characters. But we and I think no-one never
> present them in two-columns. And the table has many mysterious holes
> I haven't looked into.
I think that's why Emoji_Presentation is false for those characters --
they _could_ be presented as emoji if the UI should choose to do so, or
if an emoji presentation selector is used, but by default a text
presentation would be expected.
> We could Emoji_Presentation=yes for the purpose, but for example,
> U+23E9(BLACK RIGHT-POINTING DOUBLE TRIANGLE) has the property
> Emoji_Presentation=yes but U+23E9(BLACK RIGHT-POINTING DOUBLE TRIANGLE
> WITH VERTICAL BAR) does not for a reason uncertaion to me. It doesn't
> look like other than some kind of mistake.
That is strange.
> About environment, for example, U+23E9 is an emoji, and
> Emoji_Presentation=yes, but it is shown in one column on my
> xterm. (I'm not sure what font am I using..)
I would guess that's the key issue here. If we choose a particular
width for emoji characters, is there anything keeping a terminal's font
from doing something different anyway?
Furthermore, if the stream contains an emoji presentation selector
after a code point that would normally be text, shouldn't we change
that glyph to have an emoji "expected width"?
I'm wondering if the most correct solution would be to have the user
tell the client what width to use, using .psqlrc or something.
Gnome terminal does it - VTE does it - there is option how to display chars with not well specified width.
> A possible compromise is that we treat all Emoji=yes characters
> excluding ASCII characters as double-width and manually merge the
> fragmented regions into reasonably larger chunks.
We could also keep the fragments as-is and generate a full interval
table, like common/unicode_combining_table.h. It looks like there's
roughly double the number of emoji intervals as combining intervals, so
hopefully adding a second binary search wouldn't be noticeably slower.
--
In your opinion, would the current one-line patch proposal make things
strictly better than they are today, or would it have mixed results?
I'm wondering how to help this patch move forward for the current
commitfest, or if we should maybe return with feedback for now.
We can check how these chars are printed in most common terminals in modern versions. I am afraid that it can be problematic to find a solution that works everywhere, because some libraries on some platforms are pretty obsolete.
Regards
Pavel
--Jacob
On Wed, Jul 07, 2021 at 06:03:34PM +0000, Jacob Champion wrote: > I would guess that's the key issue here. If we choose a particular > width for emoji characters, is there anything keeping a terminal's font > from doing something different anyway? I'd say that we are doing our best in guessing what it should be, then. One cannot predict how fonts are designed. > We could also keep the fragments as-is and generate a full interval > table, like common/unicode_combining_table.h. It looks like there's > roughly double the number of emoji intervals as combining intervals, so > hopefully adding a second binary search wouldn't be noticeably slower. Hmm. Such things have a cost, and this one sounds costly with a limited impact. What do we gain except a better visibility with psql? > In your opinion, would the current one-line patch proposal make things > strictly better than they are today, or would it have mixed results? > I'm wondering how to help this patch move forward for the current > commitfest, or if we should maybe return with feedback for now. Based on the following list, it seems to me that [u+1f300,u+0x1faff] won't capture everything, like the country flags: http://www.unicode.org/emoji/charts/full-emoji-list.html -- Michael
Attachment
po 19. 7. 2021 v 9:46 odesílatel Michael Paquier <michael@paquier.xyz> napsal:
On Wed, Jul 07, 2021 at 06:03:34PM +0000, Jacob Champion wrote:
> I would guess that's the key issue here. If we choose a particular
> width for emoji characters, is there anything keeping a terminal's font
> from doing something different anyway?
I'd say that we are doing our best in guessing what it should be,
then. One cannot predict how fonts are designed.
> We could also keep the fragments as-is and generate a full interval
> table, like common/unicode_combining_table.h. It looks like there's
> roughly double the number of emoji intervals as combining intervals, so
> hopefully adding a second binary search wouldn't be noticeably slower.
Hmm. Such things have a cost, and this one sounds costly with a
limited impact. What do we gain except a better visibility with psql?
The benefit is correct displaying. I checked impact on server side, and ucs_wcwidth is used just for calculation of error position. Any other usage is only in psql.
Moreover, I checked unicode ranges, and I think so for common languages the performance impact should be zero (because typically use ucs < 0x1100). The possible (but very low) impact can be for some historic languages or special symbols. It has not any impact for ranges that currently return display width 2, because the new range is at the end of list.
I am not sure how wide usage of PQdsplen is outside psql, but I have no reason to think so, so developers will prefer this function over built functionality in any developing environment that supports unicode. So in this case I have a strong opinion to prefer correctness of result against current speed (note: I have an experience from pspg development, where this operation is really on critical path, and I tried do some micro optimization without strong effect - on very big unusual result (very wide, very long (100K rows) the difference was about 500 ms (on pager side, it does nothing else than string operations in this moment)).
Regards
Pavel
> In your opinion, would the current one-line patch proposal make things
> strictly better than they are today, or would it have mixed results?
> I'm wondering how to help this patch move forward for the current
> commitfest, or if we should maybe return with feedback for now.
Based on the following list, it seems to me that [u+1f300,u+0x1faff]
won't capture everything, like the country flags:
http://www.unicode.org/emoji/charts/full-emoji-list.html
--
Michael
On Mon, 2021-07-19 at 16:46 +0900, Michael Paquier wrote: > > In your opinion, would the current one-line patch proposal make things > > strictly better than they are today, or would it have mixed results? > > I'm wondering how to help this patch move forward for the current > > commitfest, or if we should maybe return with feedback for now. > > Based on the following list, it seems to me that [u+1f300,u+0x1faff] > won't capture everything, like the country flags: > http://www.unicode.org/emoji/charts/full-emoji-list.html That could be adapted; the question is if the approach as such is desirable or not. This is necessarily a moving target, at the rate that emojis are created and added to Unicode. My personal feeling is that something simple and perhaps imperfect as my one-liner that may miss some corner cases would be ok, but anything that saps more performance or is complicated would not be worth the effort. Yours, Laurenz Albe
On Mon, 2021-07-19 at 13:13 +0200, Laurenz Albe wrote: > On Mon, 2021-07-19 at 16:46 +0900, Michael Paquier wrote: > > > In your opinion, would the current one-line patch proposal make things > > > strictly better than they are today, or would it have mixed results? > > > I'm wondering how to help this patch move forward for the current > > > commitfest, or if we should maybe return with feedback for now. > > > > Based on the following list, it seems to me that [u+1f300,u+0x1faff] > > won't capture everything, like the country flags: > > https://nam04.safelinks.protection.outlook.com/?url=http%3A%2F%2Fwww.unicode.org%2Femoji%2Fcharts%2Ffull-emoji-list.html&data=04%7C01%7Cpchampion%40vmware.com%7Cbc3f4cff42094f60fa7708d94aa64f11%7Cb39138ca3cee4b4aa4d6cd83d9dd62f0%7C0%7C0%7C637622900429154586%7CUnknown%7CTWFpbGZsb3d8eyJWIjoiMC4wLjAwMDAiLCJQIjoiV2luMzIiLCJBTiI6Ik1haWwiLCJXVCI6Mn0%3D%7C1000&sdata=lfSsqU%2BEiSJrwftt9FL13ib7pw0Mzt5DYl%2BSjL2%2Bm%2F0%3D&reserved=0 On my machine, the regional indicator codes take up one column each (even though they display as a wide uppercase letter), so making them wide would break alignment. This seems to match up with Annex #11 [1]: ED4. East Asian Wide (W): All other characters that are always wide. [...] This category includes characters that have explicit halfwidth counterparts, along with characters that have the [UTS51] property Emoji_Presentation, with the exception of characters that have the [UCD] property Regional_Indicator So for whatever reason, those indicator codes aren't considered East Asian Wide by Unicode (and therefore glibc), even though they are Emoji_Presentation. And glibc appears to be using East Asian Wide as the flag for a 2-column character. glibc 2.31 is based on Unicode 12.1, I think. So if Postgres is built against a Unicode database that's different from the system's, obviously you'll see odd results no matter what we do here. And _all_ of that completely ignores the actual country-flag-combining behavior, which my terminal doesn't do and I assume would be part of a separate conversation entirely, along with things like ZWJ sequences. > That could be adapted; the question is if the approach as such is > desirable or not. This is necessarily a moving target, at the rate > that emojis are created and added to Unicode. Sure. We already have code in the tree that deals with that moving target, though, by parsing apart pieces of the Unicode database. So the added maintenance cost should be pretty low. > My personal feeling is that something simple and perhaps imperfect > as my one-liner that may miss some corner cases would be ok, but > anything that saps more performance or is complicated would not > be worth the effort. Another data point: on my machine (Ubuntu 20.04, glibc 2.31) that additional range not only misses a large number of emoji (e.g. in the 2xxx codepoint range), it incorrectly treats some narrow codepoints as wide (e.g. many in the 1F32x range have Emoji_Presentation set to false). I note that the doc comment for ucs_wcwidth()... > * - Spacing characters in the East Asian Wide (W) or East Asian > * FullWidth (F) category as defined in Unicode Technical > * Report #11 have a column width of 2. ...doesn't match reality anymore. The East Asian width handling was last updated in 2006, it looks like? So I wonder whether fixing the code to match the comment would not only fix the emoji problem but also a bunch of other non-emoji characters. --Jacob [1] http://www.unicode.org/reports/tr11/
On Wed, 2021-07-21 at 00:08 +0000, Jacob Champion wrote: > On Mon, 2021-07-19 at 13:13 +0200, Laurenz Albe wrote: > > That could be adapted; the question is if the approach as such is > > desirable or not. This is necessarily a moving target, at the rate > > that emojis are created and added to Unicode. > > Sure. We already have code in the tree that deals with that moving > target, though, by parsing apart pieces of the Unicode database. So the > added maintenance cost should be pretty low. (I am working on such a patch today and will report back.) --Jacob
On Wed, 2021-07-21 at 00:08 +0000, Jacob Champion wrote: > I note that the doc comment for ucs_wcwidth()... > > > * - Spacing characters in the East Asian Wide (W) or East Asian > > * FullWidth (F) category as defined in Unicode Technical > > * Report #11 have a column width of 2. > > ...doesn't match reality anymore. The East Asian width handling was > last updated in 2006, it looks like? So I wonder whether fixing the > code to match the comment would not only fix the emoji problem but also > a bunch of other non-emoji characters. Attached is my attempt at that. This adds a second interval table, handling not only the emoji range in the original patch but also correcting several non-emoji character ranges which are included in the 13.0 East Asian Wide/Fullwidth sets. Try for example - U+2329 LEFT POINTING ANGLE BRACKET - U+16FE0 TANGUT ITERATION MARK - U+18000 KATAKANA LETTER ARCHAIC E This should work reasonably well for terminals that depend on modern versions of Unicode's EastAsianWidth.txt to figure out character width. I don't know how it behaves on BSD libc or Windows. The new binary search isn't free, but my naive attempt at measuring the performance hit made it look worse than it actually is. Since the measurement function was previously returning an incorrect (too short) width, we used to get a free performance boost by not printing the correct number of alignment/border characters. I'm still trying to figure out how best to isolate the performance changes due to this patch. Pavel, I'd be interested to see what your benchmarks find with this code. Does this fix the original issue for you? --Jacob
Attachment
Hi
čt 22. 7. 2021 v 0:12 odesílatel Jacob Champion <pchampion@vmware.com> napsal:
On Wed, 2021-07-21 at 00:08 +0000, Jacob Champion wrote:
> I note that the doc comment for ucs_wcwidth()...
>
> > * - Spacing characters in the East Asian Wide (W) or East Asian
> > * FullWidth (F) category as defined in Unicode Technical
> > * Report #11 have a column width of 2.
>
> ...doesn't match reality anymore. The East Asian width handling was
> last updated in 2006, it looks like? So I wonder whether fixing the
> code to match the comment would not only fix the emoji problem but also
> a bunch of other non-emoji characters.
Attached is my attempt at that. This adds a second interval table,
handling not only the emoji range in the original patch but also
correcting several non-emoji character ranges which are included in the
13.0 East Asian Wide/Fullwidth sets. Try for example
- U+2329 LEFT POINTING ANGLE BRACKET
- U+16FE0 TANGUT ITERATION MARK
- U+18000 KATAKANA LETTER ARCHAIC E
This should work reasonably well for terminals that depend on modern
versions of Unicode's EastAsianWidth.txt to figure out character width.
I don't know how it behaves on BSD libc or Windows.
The new binary search isn't free, but my naive attempt at measuring the
performance hit made it look worse than it actually is. Since the
measurement function was previously returning an incorrect (too short)
width, we used to get a free performance boost by not printing the
correct number of alignment/border characters. I'm still trying to
figure out how best to isolate the performance changes due to this
patch.
Pavel, I'd be interested to see what your benchmarks find with this
code. Does this fix the original issue for you?
I can confirm that the original issue is fixed.
I tested performance
I had three data sets
1. typical data - mix ascii and utf characters typical for czech language - 25K lines - there is very small slowdown 2ms from 24 to 26ms (stored file of this result has 3MB)
2. the worst case - this reports has only emoji 1000 chars * 10K rows - there is more significant slowdown - from 160 ms to 220 ms (stored file has 39MB)
3. a little bit of obscure datasets generated by \x and select * from pg_proc - it has 99K lines - and there are a lot of unicode decorations (borders). The line has 17K chars. (the stored file has 1.7GB)
In this dataset I see a slowdown from 4300 to 4700 ms.
In all cases, the data are in memory (in filesystem cache). I tested load to pspg.
9% looks too high, but in absolute time it is 400ms for 99K lines and very untypical data, or 2ms for more typical results., 2ms are nothing (for interactive work). More - this is from a pspg perspective. In psql there can be overhead of network, protocol processing, formatting, and more and more, and psql doesn't need to calculate display width of decorations (borders), what is the reason for slowdowns in pspg.
Pavel
--Jacob
On Fri, 2021-07-23 at 17:42 +0200, Pavel Stehule wrote:
> čt 22. 7. 2021 v 0:12 odesílatel Jacob Champion <pchampion@vmware.com> napsal:
> >
> > Pavel, I'd be interested to see what your benchmarks find with this
> > code. Does this fix the original issue for you?
>
> I can confirm that the original issue is fixed.
Great!
> I tested performance
>
> I had three data sets
>
> 1. typical data - mix ascii and utf characters typical for czech
> language - 25K lines - there is very small slowdown 2ms from 24 to
> 26ms (stored file of this result has 3MB)
>
> 2. the worst case - this reports has only emoji 1000 chars * 10K rows
> - there is more significant slowdown - from 160 ms to 220 ms (stored
> file has 39MB)
I assume the stored file size has grown with this patch, since we're
now printing the correct number of spacing/border characters?
> 3. a little bit of obscure datasets generated by \x and select * from
> pg_proc - it has 99K lines - and there are a lot of unicode
> decorations (borders). The line has 17K chars. (the stored file has
> 1.7GB)
> In this dataset I see a slowdown from 4300 to 4700 ms.
These results are lining up fairly well with my profiling. To isolate
the effects of the new algorithm (as opposed to printing time) I
redirected to /dev/null:
psql postgres -c "select repeat(unistr('\u115D'), 10000000);" > /dev/null
This is what I expect to be the worst case for the new patch: a huge
string consisting of nothing but \u115D, which is in the first interval
and therefore takes the maximum number of iterations during the binary
search.
For that command, the wall time slowdown with this patch was about
240ms (from 1.128s to 1.366s, or 21% slower). Callgrind shows an
increase of 18% in the number of instructions executed with the
interval table patch, all of it coming from PQdsplen (no surprise).
PQdsplen itself has a 36% increase in instruction count for that run.
I also did a microbenchmark of PQdsplen (code attached, requires Google
Benchmark [1]). The three cases I tested were standard ASCII
characters, a smiley-face emoji, and the worst-case \u115F character.
Without the patch:
------------------------------------------------------------
Benchmark Time CPU Iterations
------------------------------------------------------------
...
BM_Ascii_mean 4.97 ns 4.97 ns 5
BM_Ascii_median 4.97 ns 4.97 ns 5
BM_Ascii_stddev 0.035 ns 0.035 ns 5
...
BM_Emoji_mean 6.30 ns 6.30 ns 5
BM_Emoji_median 6.30 ns 6.30 ns 5
BM_Emoji_stddev 0.045 ns 0.045 ns 5
...
BM_Worst_mean 12.4 ns 12.4 ns 5
BM_Worst_median 12.4 ns 12.4 ns 5
BM_Worst_stddev 0.038 ns 0.038 ns 5
With the patch:
------------------------------------------------------------
Benchmark Time CPU Iterations
------------------------------------------------------------
...
BM_Ascii_mean 4.59 ns 4.59 ns 5
BM_Ascii_median 4.60 ns 4.60 ns 5
BM_Ascii_stddev 0.069 ns 0.068 ns 5
...
BM_Emoji_mean 11.8 ns 11.8 ns 5
BM_Emoji_median 11.8 ns 11.8 ns 5
BM_Emoji_stddev 0.059 ns 0.059 ns 5
...
BM_Worst_mean 18.5 ns 18.5 ns 5
BM_Worst_median 18.5 ns 18.5 ns 5
BM_Worst_stddev 0.077 ns 0.077 ns 5
So an incredibly tiny improvement in the ASCII case, which is
reproducible across multiple runs and not just a fluke (I assume
because the code is smaller now and has better cache line
characteristics?). A ~90% slowdown for the emoji case, and a ~50%
slowdown for the worst-performing characters. That seems perfectly
reasonable considering we're talking about dozens of nanoseconds.
> 9% looks too high, but in absolute time it is 400ms for 99K lines and
> very untypical data, or 2ms for more typical results., 2ms are
> nothing (for interactive work). More - this is from a pspg
> perspective. In psql there can be overhead of network, protocol
> processing, formatting, and more and more, and psql doesn't need to
> calculate display width of decorations (borders), what is the reason
> for slowdowns in pspg.
Yeah. Considering the alignment code is for user display, the absolute
performance is going to dominate, and I don't see any red flags so far.
If you're regularly dealing with unbelievably huge amounts of emoji, I
think the amount of extra time we're seeing here is unlikely to be a
problem. If it is, you can always turn alignment off. (Do you rely on
horizontal alignment for lines with millions of characters, anyway?)
Laurenz, Michael, what do you think?
--Jacob
[1] https://github.com/google/benchmark
Attachment
čt 22. 7. 2021 v 0:12 odesílatel Jacob Champion <pchampion@vmware.com> napsal:
On Wed, 2021-07-21 at 00:08 +0000, Jacob Champion wrote:
> I note that the doc comment for ucs_wcwidth()...
>
> > * - Spacing characters in the East Asian Wide (W) or East Asian
> > * FullWidth (F) category as defined in Unicode Technical
> > * Report #11 have a column width of 2.
>
> ...doesn't match reality anymore. The East Asian width handling was
> last updated in 2006, it looks like? So I wonder whether fixing the
> code to match the comment would not only fix the emoji problem but also
> a bunch of other non-emoji characters.
Attached is my attempt at that. This adds a second interval table,
handling not only the emoji range in the original patch but also
correcting several non-emoji character ranges which are included in the
13.0 East Asian Wide/Fullwidth sets. Try for example
- U+2329 LEFT POINTING ANGLE BRACKET
- U+16FE0 TANGUT ITERATION MARK
- U+18000 KATAKANA LETTER ARCHAIC E
This should work reasonably well for terminals that depend on modern
versions of Unicode's EastAsianWidth.txt to figure out character width.
I don't know how it behaves on BSD libc or Windows.
The new binary search isn't free, but my naive attempt at measuring the
performance hit made it look worse than it actually is. Since the
measurement function was previously returning an incorrect (too short)
width, we used to get a free performance boost by not printing the
correct number of alignment/border characters. I'm still trying to
figure out how best to isolate the performance changes due to this
patch.
Pavel, I'd be interested to see what your benchmarks find with this
code. Does this fix the original issue for you?
This patch fixed badly formatted tables with emoji.
I checked this patch, and it is correct and a step forward, because it dynamically sets intervals of double wide characters, and the code is more readable.
I checked and performance, and although there is measurable slowdown, it is negligible in absolute values. Previous code was a little bit faster - it checked less ranges, but was not fully correct and up to date.
The patching was without problems
There are no regress tests, but I am not sure so they are necessary for this case.
make check-world passed without problems
I'll mark this patch as ready for committer
Regards
Pavel
--Jacob
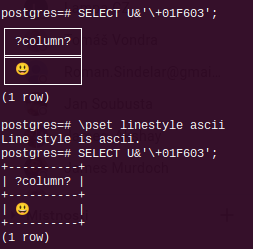
I tried this patch on and MacOS11/iterm2 and RHEL 7 (ssh'd from the Mac, in case that matters) and the example shown at the top of the thread shows no difference:
john.naylor=# \pset border 2
Border style is 2.
john.naylor=# SELECT U&'\+01F603';
+----------+
| ?column? |
+----------+
| 😃 |
+----------+
(1 row)
Border style is 2.
john.naylor=# SELECT U&'\+01F603';
+----------+
| ?column? |
+----------+
| 😃 |
+----------+
(1 row)
(In case it doesn't render locally, the right bar in the result cell is still shifted to the right.
What is the expected context to show a behavior change? Does one need some specific terminal or setting?
čt 12. 8. 2021 v 18:36 odesílatel John Naylor <john.naylor@enterprisedb.com> napsal:
I tried this patch on and MacOS11/iterm2 and RHEL 7 (ssh'd from the Mac, in case that matters) and the example shown at the top of the thread shows no difference:john.naylor=# \pset border 2
Border style is 2.
john.naylor=# SELECT U&'\+01F603';
+----------+
| ?column? |
+----------+
| 😃 |
+----------+
(1 row)
did you run make clean?
when I executed just patch & make, it didn't work
(In case it doesn't render locally, the right bar in the result cell is still shifted to the right.What is the expected context to show a behavior change? Does one need some specific terminal or setting?
I assigned screenshots
Attachment
{kind=link}
{kind=link}
On Thu, 2021-08-12 at 12:36 -0400, John Naylor wrote: > I tried this patch on and MacOS11/iterm2 and RHEL 7 (ssh'd from the Mac, in case that matters) and the example shown atthe top of the thread shows no difference: > > john.naylor=# \pset border 2 > Border style is 2. > john.naylor=# SELECT U&'\+01F603'; > +----------+ > | ?column? | > +----------+ > | 😃 | > +----------+ > (1 row) > > (In case it doesn't render locally, the right bar in the result cell is still shifted to the right. > > What is the expected context to show a behavior change? There shouldn't be anything special. (If your terminal was set up to display emoji in single columns, that would cause alignment issues, but in the opposite direction to the one you're seeing.) > Does one need some specific terminal or setting? In your case, an incorrect number of spaces are being printed, so it shouldn't have anything to do with your terminal settings. Was this a clean build? Perhaps I've introduced (or exacerbated) a dependency bug in the Makefile? The patch doing nothing is a surprising result given the code change. --Jacob
> did you run make clean?
>
> when I executed just patch & make, it didn't work
I did not, but I always have --enable-depend on. I tried again with make clean, and ccache -C just in case, and it works now.
On Thu, Aug 12, 2021 at 12:54 PM Jacob Champion <pchampion@vmware.com> wrote:
> Was this a clean build? Perhaps I've introduced (or exacerbated) a
> dependency bug in the Makefile? The patch doing nothing is a surprising
> result given the code change.
Yeah, given that Pavel had the same issue, that's a possibility. I don't recall that happening with other unicode patches I've tested.
--
John Naylor
EDB: http://www.enterprisedb.com
The patch looks pretty good to me. I just have a stylistic suggestion which I've attached as a text file. There are also some outdated comments that are not the responsibility of this patch, but I kind of want to fix them now:
* - Hangul Jamo medial vowels and final consonants (U+1160-U+11FF)
* have a column width of 0.
We got rid of this range in d8594d123c1, which is correct.
* - Other format characters (general category code Cf in the Unicode
* database) and ZERO WIDTH SPACE (U+200B) have a column width of 0.
We don't treat Cf the same as Me or Mn, and I believe that's deliberate. We also no longer have the exception for zero-width space.
It seems the consensus so far is that performance is not an issue, and I'm inclined to agree.
I'm a bit concerned about the build dependencies not working right, but it's not clear it's even due to the patch. I'll spend some time investigating next week.
-- * - Hangul Jamo medial vowels and final consonants (U+1160-U+11FF)
* have a column width of 0.
We got rid of this range in d8594d123c1, which is correct.
* - Other format characters (general category code Cf in the Unicode
* database) and ZERO WIDTH SPACE (U+200B) have a column width of 0.
We don't treat Cf the same as Me or Mn, and I believe that's deliberate. We also no longer have the exception for zero-width space.
It seems the consensus so far is that performance is not an issue, and I'm inclined to agree.
I'm a bit concerned about the build dependencies not working right, but it's not clear it's even due to the patch. I'll spend some time investigating next week.
Attachment
On Thu, 2021-08-12 at 17:13 -0400, John Naylor wrote:
> The patch looks pretty good to me. I just have a stylistic suggestion
> which I've attached as a text file.
Getting rid of the "clever addition" looks much better to me, thanks. I
haven't verified the changes to the doc comment, but your description
seems reasonable.
> I'm a bit concerned about the build dependencies not working right,
> but it's not clear it's even due to the patch. I'll spend some time
> investigating next week.
If I vandalize src/common/wchar.c on HEAD, say by deleting the contents
of pg_wchar_table, and then run `make install`, then libpq doesn't get
rebuilt and there's no effect on the frontend. The postgres executable
does get rebuilt for the backend.
It looks like src/interfaces/libpq/Makefile doesn't have a dependency
on libpgcommon (or libpgport, for that matter). For comparison,
src/backend/Makefile has this:
OBJS = \
$(LOCALOBJS) \
$(SUBDIROBJS) \
$(top_builddir)/src/common/libpgcommon_srv.a \
$(top_builddir)/src/port/libpgport_srv.a
So I think that's a bug that needs to be fixed independently, whether
this patch goes in or not.
--Jacob
On Thu, Aug 12, 2021 at 05:13:31PM -0400, John Naylor wrote: > I'm a bit concerned about the build dependencies not working right, but > it's not clear it's even due to the patch. I'll spend some time > investigating next week. How large do libpgcommon deliverables get with this patch? Skimming through the patch, that just looks like a couple of bytes, still. -- Michael
Attachment
On Sun, Aug 15, 2021 at 10:45 PM Michael Paquier <michael@paquier.xyz> wrote:
>
> On Thu, Aug 12, 2021 at 05:13:31PM -0400, John Naylor wrote:
> > I'm a bit concerned about the build dependencies not working right, but
> > it's not clear it's even due to the patch. I'll spend some time
> > investigating next week.
>
> How large do libpgcommon deliverables get with this patch? Skimming
> through the patch, that just looks like a couple of bytes, still.
More like a couple thousand bytes. That's because the width of mbinterval doubled. If this is not desirable, we could teach the scripts to adjust the width of the interval type depending on the largest character they saw.
--
John Naylor
EDB: http://www.enterprisedb.com
On Mon, 2021-08-16 at 11:24 -0400, John Naylor wrote: > > On Sun, Aug 15, 2021 at 10:45 PM Michael Paquier <michael@paquier.xyz> wrote: > > > How large do libpgcommon deliverables get with this patch? Skimming > > through the patch, that just looks like a couple of bytes, still. > > More like a couple thousand bytes. That's because the width > of mbinterval doubled. If this is not desirable, we could teach the > scripts to adjust the width of the interval type depending on the > largest character they saw. True. Note that the combining character table currently excludes codepoints outside of the BMP, so if someone wants combinations in higher planes to be handled correctly in the future, the mbinterval for that table may have to be widened anyway. --Jacob
On Mon, Aug 16, 2021 at 1:04 PM Jacob Champion <pchampion@vmware.com> wrote:
>
> On Mon, 2021-08-16 at 11:24 -0400, John Naylor wrote:
> >
> > On Sun, Aug 15, 2021 at 10:45 PM Michael Paquier <michael@paquier.xyz> wrote:
> >
> > > How large do libpgcommon deliverables get with this patch? Skimming
> > > through the patch, that just looks like a couple of bytes, still.
> >
> > More like a couple thousand bytes. That's because the width
> > of mbinterval doubled. If this is not desirable, we could teach the
> > scripts to adjust the width of the interval type depending on the
> > largest character they saw.
>
> True. Note that the combining character table currently excludes
> codepoints outside of the BMP, so if someone wants combinations in
> higher planes to be handled correctly in the future, the mbinterval for
> that table may have to be widened anyway.
Hmm, somehow it escaped my attention that the combining character table script explicitly excludes those. There's no comment about it. Maybe best to ask Peter E. (CC'd)
Peter, does the combining char table exclude values > 0xFFFF for size reasons, correctness, or some other consideration?
--
John Naylor
EDB: http://www.enterprisedb.com
--
John Naylor
EDB: http://www.enterprisedb.com
I wrote:
> On Sun, Aug 15, 2021 at 10:45 PM Michael Paquier <michael@paquier.xyz> wrote:
> >
> > On Thu, Aug 12, 2021 at 05:13:31PM -0400, John Naylor wrote:
> > > I'm a bit concerned about the build dependencies not working right, but
> > > it's not clear it's even due to the patch. I'll spend some time
> > > investigating next week.
> >
> > How large do libpgcommon deliverables get with this patch? Skimming
> > through the patch, that just looks like a couple of bytes, still.
>
> More like a couple thousand bytes. That's because the width of mbinterval doubled. If this is not desirable, we could teach the scripts to adjust the width of the interval type depending on the largest character they saw.
For src/common/libpgcommon.a, in a non-assert / non-debug build:
> >
> > On Thu, Aug 12, 2021 at 05:13:31PM -0400, John Naylor wrote:
> > > I'm a bit concerned about the build dependencies not working right, but
> > > it's not clear it's even due to the patch. I'll spend some time
> > > investigating next week.
> >
> > How large do libpgcommon deliverables get with this patch? Skimming
> > through the patch, that just looks like a couple of bytes, still.
>
> More like a couple thousand bytes. That's because the width of mbinterval doubled. If this is not desirable, we could teach the scripts to adjust the width of the interval type depending on the largest character they saw.
For src/common/libpgcommon.a, in a non-assert / non-debug build:
master: 254912
patch: 256432
And if I go further and remove the limit on the largest character in the combining table, I get 257248, which is still a relatively small difference.
And if I go further and remove the limit on the largest character in the combining table, I get 257248, which is still a relatively small difference.
I had a couple further thoughts:
1. The coding historically used normal comparison and branching for everything, but recently it only does that to detect control characters, and then goes through a binary search (and with this patch, two binary searches) for everything else. Although the performance regression of the current patch seems negligible, we could use almost the same branches to fast-path printable ascii text, like this:
+ /* fast path for printable ASCII characters */
+ if (ucs >= 0x20 || ucs < 0x7f)
+ return 1;
+
/* test for 8-bit control characters */
if (ucs == 0)
return 0;
- if (ucs < 0x20 || (ucs >= 0x7f && ucs < 0xa0) || ucs > 0x0010ffff)
+ if (ucs < 0xa0 || ucs > 0x0010ffff)
return -1;
+ if (ucs >= 0x20 || ucs < 0x7f)
+ return 1;
+
/* test for 8-bit control characters */
if (ucs == 0)
return 0;
- if (ucs < 0x20 || (ucs >= 0x7f && ucs < 0xa0) || ucs > 0x0010ffff)
+ if (ucs < 0xa0 || ucs > 0x0010ffff)
return -1;
2. As written, the patch adds a script that's very close to an existing one, and emits a new file that has the same type of contents as an existing one, both of which are #included in one place. I wonder if we should consider having just one script that ingests both files and emits one file. All we need is for mbinterval to encode the character width, but we can probably do that with a bitfield like the normprops table to save space. Then, we only do one binary search. Opinions?
On 16.08.21 22:06, John Naylor wrote: > Peter, does the combining char table exclude values > 0xFFFF for size > reasons, correctness, or some other consideration? I don't remember a reason, other than perhaps making the generated table match the previous manual table in scope. IIRC, the previous table was ancient, so perhaps from the days before higher Unicode values were universally supported in the code.
On Thu, 2021-08-19 at 13:49 -0400, John Naylor wrote: > I had a couple further thoughts: > > 1. The coding historically used normal comparison and branching for > everything, but recently it only does that to detect control > characters, and then goes through a binary search (and with this > patch, two binary searches) for everything else. Although the > performance regression of the current patch seems negligible, If I'm reading the code correctly, ASCII characters don't go through the binary searches; they're already short-circuited at the beginning of mbbisearch(). On my machine that's enough for the patch to be a performance _improvement_ for ASCII, not a regression. Does adding another short-circuit at the top improve the microbenchmarks noticeably? I assumed the compiler had pretty well optimized all that already. > we could use almost the same branches to fast-path printable ascii > text, like this: > > + /* fast path for printable ASCII characters */ > + if (ucs >= 0x20 || ucs < 0x7f) > + return 1; Should be && instead of ||, I think. > + > /* test for 8-bit control characters */ > if (ucs == 0) > return 0; > > - if (ucs < 0x20 || (ucs >= 0x7f && ucs < 0xa0) || ucs > 0x0010ffff) > + if (ucs < 0xa0 || ucs > 0x0010ffff) > return -1; > > 2. As written, the patch adds a script that's very close to an > existing one, and emits a new file that has the same type of contents > as an existing one, both of which are #included in one place. I > wonder if we should consider having just one script that ingests both > files and emits one file. All we need is for mbinterval to encode the > character width, but we can probably do that with a bitfield like the > normprops table to save space. Then, we only do one binary search. > Opinions? I guess it just depends on what the end result looks/performs like. We'd save seven hops or so in the worst case? --Jacob
On Thu, Aug 19, 2021 at 8:05 PM Jacob Champion <pchampion@vmware.com> wrote:
>
> On Thu, 2021-08-19 at 13:49 -0400, John Naylor wrote:
> > I had a couple further thoughts:
> >
> > 1. The coding historically used normal comparison and branching for
> > everything, but recently it only does that to detect control
> > characters, and then goes through a binary search (and with this
> > patch, two binary searches) for everything else. Although the
> > performance regression of the current patch seems negligible,
>
> If I'm reading the code correctly, ASCII characters don't go through
> the binary searches; they're already short-circuited at the beginning
> of mbbisearch(). On my machine that's enough for the patch to be a
> performance _improvement_ for ASCII, not a regression.
I had assumed that there would be a function call, but looking at the assembly, it's inlined, so you're right.
> Should be && instead of ||, I think.
Yes, you're quite right. Clearly I didn't test it. :-) But given the previous, I won't pursue this further.
> > 2. As written, the patch adds a script that's very close to an
> > existing one, and emits a new file that has the same type of contents
> > as an existing one, both of which are #included in one place. I
> > wonder if we should consider having just one script that ingests both
> > files and emits one file. All we need is for mbinterval to encode the
> > character width, but we can probably do that with a bitfield like the
> > normprops table to save space. Then, we only do one binary search.
> > Opinions?
>
> I guess it just depends on what the end result looks/performs like.
> We'd save seven hops or so in the worst case?
Something like that. Attached is what I had in mind (using real patches to see what the CF bot thinks):
0001 is a simple renaming
0002 puts the char width inside the mbinterval so we can put arbitrary values there
0003 is Jacob's patch adjusted to use the same binary search as for combining characters
0004 removes the ancient limit on combining characters, so the following works now:
SELECT U&'\+0102E1\+0102E0';
+----------+
| ?column? |
+----------+
| 𐋡𐋠 |
+----------+
(1 row)
I think the adjustments to 0003 result in a cleaner and more extensible design, but a case could be made otherwise. The former combining table script is a bit more complex than the sum of its former self and Jacob's proposed new script, but just slightly.
>
> On Thu, 2021-08-19 at 13:49 -0400, John Naylor wrote:
> > I had a couple further thoughts:
> >
> > 1. The coding historically used normal comparison and branching for
> > everything, but recently it only does that to detect control
> > characters, and then goes through a binary search (and with this
> > patch, two binary searches) for everything else. Although the
> > performance regression of the current patch seems negligible,
>
> If I'm reading the code correctly, ASCII characters don't go through
> the binary searches; they're already short-circuited at the beginning
> of mbbisearch(). On my machine that's enough for the patch to be a
> performance _improvement_ for ASCII, not a regression.
I had assumed that there would be a function call, but looking at the assembly, it's inlined, so you're right.
> Should be && instead of ||, I think.
Yes, you're quite right. Clearly I didn't test it. :-) But given the previous, I won't pursue this further.
> > 2. As written, the patch adds a script that's very close to an
> > existing one, and emits a new file that has the same type of contents
> > as an existing one, both of which are #included in one place. I
> > wonder if we should consider having just one script that ingests both
> > files and emits one file. All we need is for mbinterval to encode the
> > character width, but we can probably do that with a bitfield like the
> > normprops table to save space. Then, we only do one binary search.
> > Opinions?
>
> I guess it just depends on what the end result looks/performs like.
> We'd save seven hops or so in the worst case?
Something like that. Attached is what I had in mind (using real patches to see what the CF bot thinks):
0001 is a simple renaming
0002 puts the char width inside the mbinterval so we can put arbitrary values there
0003 is Jacob's patch adjusted to use the same binary search as for combining characters
0004 removes the ancient limit on combining characters, so the following works now:
SELECT U&'\+0102E1\+0102E0';
+----------+
| ?column? |
+----------+
| 𐋡𐋠 |
+----------+
(1 row)
I think the adjustments to 0003 result in a cleaner and more extensible design, but a case could be made otherwise. The former combining table script is a bit more complex than the sum of its former self and Jacob's proposed new script, but just slightly.
Also, I checked the behavior of this comment that I proposed to remove upthread:
- * - Other format characters (general category code Cf in the Unicode
- * database) and ZERO WIDTH SPACE (U+200B) have a column width of 0.
- * database) and ZERO WIDTH SPACE (U+200B) have a column width of 0.
We don't handle the latter in our current setup:
SELECT U&'foo\200Bbar';
+----------+
| ?column? |
+----------+
| foobar |
+----------+
(1 row)
+----------+
| ?column? |
+----------+
| foobar |
+----------+
(1 row)
Not sure if we should do anything about this. It was an explicit exception years ago in our vendored manual table, but is not labeled as such in the official Unicode files.
Attachment
I plan to commit my proposed v2 this week unless I hear reservations about my adjustments, or bikeshedding. I'm thinking of squashing 0001 and 0002.
--
John Naylor
EDB: http://www.enterprisedb.com
--
John Naylor
EDB: http://www.enterprisedb.com
On Fri, 2021-08-20 at 13:05 -0400, John Naylor wrote:
> On Thu, Aug 19, 2021 at 8:05 PM Jacob Champion <pchampion@vmware.com> wrote:
> > I guess it just depends on what the end result looks/performs like.
> > We'd save seven hops or so in the worst case?
>
> Something like that. Attached is what I had in mind (using real
> patches to see what the CF bot thinks):
>
> 0001 is a simple renaming
> 0002 puts the char width inside the mbinterval so we can put arbitrary values there
0002 introduces a mixed declarations/statements warning for
ucs_wcwidth(). Other than that, LGTM overall.
> --- a/src/common/wchar.c
> +++ b/src/common/wchar.c
> @@ -583,9 +583,9 @@ pg_utf_mblen(const unsigned char *s)
>
> struct mbinterval
> {
> - unsigned short first;
> - unsigned short last;
> - signed short width;
> + unsigned int first;
> + unsigned int last:21;
> + signed int width:4;
> };
Oh, right -- my patch moved mbinterval from short to int, but should I
have used uint32 instead? It would only matter in theory for the
`first` member now that the bitfields are there.
> I think the adjustments to 0003 result in a cleaner and more
> extensible design, but a case could be made otherwise. The former
> combining table script is a bit more complex than the sum of its
> former self and Jacob's proposed new script, but just slightly.
The microbenchmark says it's also more performant, so +1 to your
version.
Does there need to be any sanity check for overlapping ranges between
the combining and fullwidth sets? The Unicode data on a dev's machine
would have to be broken somehow for that to happen, but it could
potentially go undetected for a while if it did.
> Also, I checked the behavior of this comment that I proposed to remove upthread:
>
> - * - Other format characters (general category code Cf in the Unicode
> - * database) and ZERO WIDTH SPACE (U+200B) have a column width of 0.
>
> We don't handle the latter in our current setup:
>
> SELECT U&'foo\200Bbar';
> +----------+
> | ?column? |
> +----------+
> | foobar |
> +----------+
> (1 row)
>
> Not sure if we should do anything about this. It was an explicit
> exception years ago in our vendored manual table, but is not labeled
> as such in the official Unicode files.
I'm wary of changing too many things at once, but it does seem like we
should be giving that codepoint a width of 0.
On Tue, 2021-08-24 at 12:05 -0400, John Naylor wrote:
> I plan to commit my proposed v2 this week unless I hear reservations
> about my adjustments, or bikeshedding. I'm thinking of squashing 0001
> and 0002.
+1
Thanks!
--Jacob
On Tue, Aug 24, 2021 at 1:50 PM Jacob Champion <pchampion@vmware.com> wrote:
>
> On Fri, 2021-08-20 at 13:05 -0400, John Naylor wrote:
> > On Thu, Aug 19, 2021 at 8:05 PM Jacob Champion <pchampion@vmware.com> wrote:
> > > I guess it just depends on what the end result looks/performs like.
> > > We'd save seven hops or so in the worst case?
> >
> > Something like that. Attached is what I had in mind (using real
> > patches to see what the CF bot thinks):
> >
> > 0001 is a simple renaming
> > 0002 puts the char width inside the mbinterval so we can put arbitrary values there
>
> 0002 introduces a mixed declarations/statements warning for
> ucs_wcwidth(). Other than that, LGTM overall.
I didn't see that warning with clang 12, either with or without assertions, but I do see it on gcc 11. Fixed, and pushed 0001 and 0002. I decided against squashing them, since my original instinct was correct -- the header changes too much for git to consider it the same file, which may make archeology harder.
> > --- a/src/common/wchar.c
> > +++ b/src/common/wchar.c
> > @@ -583,9 +583,9 @@ pg_utf_mblen(const unsigned char *s)
> >
> > struct mbinterval
> > {
> > - unsigned short first;
> > - unsigned short last;
> > - signed short width;
> > + unsigned int first;
> > + unsigned int last:21;
> > + signed int width:4;
> > };
>
> Oh, right -- my patch moved mbinterval from short to int, but should I
> have used uint32 instead? It would only matter in theory for the
> `first` member now that the bitfields are there.
I'm not sure it would matter, but the usual type for codepoints is unsigned.
> > I think the adjustments to 0003 result in a cleaner and more
> > extensible design, but a case could be made otherwise. The former
> > combining table script is a bit more complex than the sum of its
> > former self and Jacob's proposed new script, but just slightly.
>
> The microbenchmark says it's also more performant, so +1 to your
> version.
>
> Does there need to be any sanity check for overlapping ranges between
> the combining and fullwidth sets? The Unicode data on a dev's machine
> would have to be broken somehow for that to happen, but it could
> potentially go undetected for a while if it did.
Thanks for testing again! The sanity check sounds like a good idea, so I'll work on that and push soon.
>
> On Fri, 2021-08-20 at 13:05 -0400, John Naylor wrote:
> > On Thu, Aug 19, 2021 at 8:05 PM Jacob Champion <pchampion@vmware.com> wrote:
> > > I guess it just depends on what the end result looks/performs like.
> > > We'd save seven hops or so in the worst case?
> >
> > Something like that. Attached is what I had in mind (using real
> > patches to see what the CF bot thinks):
> >
> > 0001 is a simple renaming
> > 0002 puts the char width inside the mbinterval so we can put arbitrary values there
>
> 0002 introduces a mixed declarations/statements warning for
> ucs_wcwidth(). Other than that, LGTM overall.
I didn't see that warning with clang 12, either with or without assertions, but I do see it on gcc 11. Fixed, and pushed 0001 and 0002. I decided against squashing them, since my original instinct was correct -- the header changes too much for git to consider it the same file, which may make archeology harder.
> > --- a/src/common/wchar.c
> > +++ b/src/common/wchar.c
> > @@ -583,9 +583,9 @@ pg_utf_mblen(const unsigned char *s)
> >
> > struct mbinterval
> > {
> > - unsigned short first;
> > - unsigned short last;
> > - signed short width;
> > + unsigned int first;
> > + unsigned int last:21;
> > + signed int width:4;
> > };
>
> Oh, right -- my patch moved mbinterval from short to int, but should I
> have used uint32 instead? It would only matter in theory for the
> `first` member now that the bitfields are there.
I'm not sure it would matter, but the usual type for codepoints is unsigned.
> > I think the adjustments to 0003 result in a cleaner and more
> > extensible design, but a case could be made otherwise. The former
> > combining table script is a bit more complex than the sum of its
> > former self and Jacob's proposed new script, but just slightly.
>
> The microbenchmark says it's also more performant, so +1 to your
> version.
>
> Does there need to be any sanity check for overlapping ranges between
> the combining and fullwidth sets? The Unicode data on a dev's machine
> would have to be broken somehow for that to happen, but it could
> potentially go undetected for a while if it did.
Thanks for testing again! The sanity check sounds like a good idea, so I'll work on that and push soon.
On Tue, Aug 24, 2021 at 1:50 PM Jacob Champion <pchampion@vmware.com> wrote:
>
> Does there need to be any sanity check for overlapping ranges between
> the combining and fullwidth sets? The Unicode data on a dev's machine
> would have to be broken somehow for that to happen, but it could
> potentially go undetected for a while if it did.
It turns out I should have done that to begin with. In the Unicode data, it apparently happens that a character can be both combining and wide, and that will cause ranges to overlap in my scheme:
302A..302D;W # Mn [4] IDEOGRAPHIC LEVEL TONE MARK..IDEOGRAPHIC ENTERING TONE MARK
>
> Does there need to be any sanity check for overlapping ranges between
> the combining and fullwidth sets? The Unicode data on a dev's machine
> would have to be broken somehow for that to happen, but it could
> potentially go undetected for a while if it did.
It turns out I should have done that to begin with. In the Unicode data, it apparently happens that a character can be both combining and wide, and that will cause ranges to overlap in my scheme:
302A..302D;W # Mn [4] IDEOGRAPHIC LEVEL TONE MARK..IDEOGRAPHIC ENTERING TONE MARK
{0x3000, 0x303E, 2},
{0x302A, 0x302D, 0},
3099..309A;W # Mn [2] COMBINING KATAKANA-HIRAGANA VOICED SOUND MARK..COMBINING KATAKANA-HIRAGANA SEMI-VOICED SOUND MARK
{0x302A, 0x302D, 0},
3099..309A;W # Mn [2] COMBINING KATAKANA-HIRAGANA VOICED SOUND MARK..COMBINING KATAKANA-HIRAGANA SEMI-VOICED SOUND MARK
{0x3099, 0x309A, 0},
{0x3099, 0x30FF, 2},
Going by the above, Jacob's patch from July 21 just happened to be correct by chance since the combining character search happened first.
It seems the logical thing to do is revert my 0001 and 0002 and go back to something much closer to Jacob's patch, plus a big comment explaining that the order in which the searches happen matters.
The EastAsianWidth.txt does have combining property "Mn" in the comment above, so it's tempting to just read that (plus we could read just one file for these properties). However, it seems risky to rely on comments, since their presence and format is probably less stable than the data format.
--
John Naylor
EDB: http://www.enterprisedb.com
{0x3099, 0x30FF, 2},
Going by the above, Jacob's patch from July 21 just happened to be correct by chance since the combining character search happened first.
It seems the logical thing to do is revert my 0001 and 0002 and go back to something much closer to Jacob's patch, plus a big comment explaining that the order in which the searches happen matters.
The EastAsianWidth.txt does have combining property "Mn" in the comment above, so it's tempting to just read that (plus we could read just one file for these properties). However, it seems risky to rely on comments, since their presence and format is probably less stable than the data format.
--
John Naylor
EDB: http://www.enterprisedb.com
I wrote:
> On Tue, Aug 24, 2021 at 1:50 PM Jacob Champion <pchampion@vmware.com> wrote:
> It seems the logical thing to do is revert my 0001 and 0002 and go back to something much closer to Jacob's patch, plus a big comment explaining that the order in which the searches happen matters.
I pushed Jacob's patch with the addendum I shared upthread, plus a comment about search order. I also took the liberty of changing the author in the CF app to Jacob. Later I'll push detecting non-spacing characters beyond the BMP.
--
John Naylor
EDB: http://www.enterprisedb.com
> On Tue, Aug 24, 2021 at 1:50 PM Jacob Champion <pchampion@vmware.com> wrote:
> It seems the logical thing to do is revert my 0001 and 0002 and go back to something much closer to Jacob's patch, plus a big comment explaining that the order in which the searches happen matters.
I pushed Jacob's patch with the addendum I shared upthread, plus a comment about search order. I also took the liberty of changing the author in the CF app to Jacob. Later I'll push detecting non-spacing characters beyond the BMP.
--
John Naylor
EDB: http://www.enterprisedb.com
On Wed, 2021-08-25 at 16:15 -0400, John Naylor wrote: > On Tue, Aug 24, 2021 at 1:50 PM Jacob Champion <pchampion@vmware.com> wrote: > > > > Does there need to be any sanity check for overlapping ranges between > > the combining and fullwidth sets? The Unicode data on a dev's machine > > would have to be broken somehow for that to happen, but it could > > potentially go undetected for a while if it did. > > It turns out I should have done that to begin with. In the Unicode > data, it apparently happens that a character can be both combining > and wide, and that will cause ranges to overlap in my scheme: I was looking for overlaps in my review, but I skipped right over that, sorry... On Thu, 2021-08-26 at 11:12 -0400, John Naylor wrote: > I pushed Jacob's patch with the addendum I shared upthread, plus a > comment about search order. I also took the liberty of changing the > author in the CF app to Jacob. Later I'll push detecting non-spacing > characters beyond the BMP. Thanks! --Jacob
čt 26. 8. 2021 v 17:25 odesílatel Jacob Champion <pchampion@vmware.com> napsal:
On Wed, 2021-08-25 at 16:15 -0400, John Naylor wrote:
> On Tue, Aug 24, 2021 at 1:50 PM Jacob Champion <pchampion@vmware.com> wrote:
> >
> > Does there need to be any sanity check for overlapping ranges between
> > the combining and fullwidth sets? The Unicode data on a dev's machine
> > would have to be broken somehow for that to happen, but it could
> > potentially go undetected for a while if it did.
>
> It turns out I should have done that to begin with. In the Unicode
> data, it apparently happens that a character can be both combining
> and wide, and that will cause ranges to overlap in my scheme:
I was looking for overlaps in my review, but I skipped right over that,
sorry...
On Thu, 2021-08-26 at 11:12 -0400, John Naylor wrote:
> I pushed Jacob's patch with the addendum I shared upthread, plus a
> comment about search order. I also took the liberty of changing the
> author in the CF app to Jacob. Later I'll push detecting non-spacing
> characters beyond the BMP.
Thanks!
Great, thanks
Pavel
--Jacob