Thread: Changing WAL Header to reduce contention during ReserveXLogInsertLocation()
Comments in ReserveXLogInsertLocation() says "* This is the performance critical part of XLogInsert that must be serialized * across backends. The rest can happen mostly in parallel. Try to keep this * section as short as possible, insertpos_lck can be heavily contended on a * busy system." We've worked out a way of reducing contention during ReserveXLogInsertLocation() by using atomic operations. The mechanism requires that we remove the xl_prev field in each WAL record. This also has the effect of reducing WAL volume by a few %. Currently, we store the start location of the previous WAL record in the xl_prev field of the WAL record header. Typically, redo recovery is a forward moving process and hence we don't ever need to consult xl_prev and read WAL backwards (there is one exception, more on that later [1]). So in theory, we should be able to remove this field completely without compromising any functionality or correctness. But the presence of xl_prev field enables us to guard against torn WAL pages, when a WAL record starts on a sector boundary. In case of a torn page, even though the WAL page looks sane, the WAL record could actually be a stale record retained from the older, recycled WAL file. The system usually guards against this by comparing xl_prev field stored in the WAL record header with the WAL location of the previous record read. Any mismatch is treated as end-of-WAL-stream. So we can't completely remove xl_prev field, without giving up some functionality. But we don't really need to store the 8-byte previous WAL pointer in order to detect torn pages. Something else which can tell us that the WAL record does not belong to current WAL segno would be enough as well. I propose that we replace it with a much smaller 2-byte field (let's call it xl_walid). The "xl_walid" (or whatever we decide to call it) is the low order 16-bits of the WAL segno to which the WAL record belongs. While reading WAL, we always match that the "xl_walid" value stored in the WAL record matches with the current WAL segno's lower order 16-bits and if not, then consider that as the end of the stream. For this to work, we must ensure that WAL files are either recycled in such a way that the "xl_walid" of the previous (to be recycled) WAL differs from the new WAL or we zero-out the new WAL file. Seems quite easy to do with the existing infrastructure. Because of padding and alignment, replacing 8-byte xl_prev with 2-byte xl_walid effectively reduces the WAL record header by a full 8-bytes on a 64-bit machine. Obviously, this reduces the amount of WAL produced and transferred to the standby. On a pgbench test, we see about 3-5% reduction in WAL traffic, though in some tests higher - depending on workload. There is yet another important benefit of removing the xl_prev field. We no longer need to track PrevBytePos field in XLogCtlInsert. The insertpos_lck spinlock is now only guarding CurrBytePos. So we can replace that with an atomic 64-bit integer and completely remove the spinlock. The comment at the top of ReserveXLogInsertLocation() clearly mentions the importance of keeping the critical section as small as possible and this patch achieves that by using atomic variables. Pavan ran some micro-benchmarks to measure the effectiveness of the approach. I (Pavan) wrote a wrapper on top of ReserveXLogInsertLocation() and exposed that as a SQL-callable function. I then used pgbench with 1-16 clients where each client effectively calls ReserveXLogInsertLocation() 1M times. Following are the results from the master and the patched code, averaged across 5 runs. The tests are done on a i2.2xlarge AWS instance. HEAD 1 ... 24.24 tps 2 ... 18.12 tps 4 ... 10.95 tps 8 ... 9.05 tps 16 ... 8.44 tps As you would notice, the spinlock contention is immediately evident even when running with just 2 clients and gets worse with 4 or more clients. Patched 1 ... 35.08 tps 2 ... 31.99 tps 4 ... 30.48 tps 8 ... 40.44 tps 16 ... 50.14 tps The patched code on the other hand scales to higher numbers of clients much better. Those are microbenchmarks. You need to run a multi-CPU workload with heavy WAL inserts to show benefits. [1] pg_rewind is the only exception which uses xl_prev to find the previous checkpoint record. But we can always start from the beginning of the WAL segment and read forward until we find the checkpoint record. The patch does just the same and passes pg_rewind's tap tests. Patch credit: Simon Riggs and Pavan Deolasee -- Simon Riggs http://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
Attachment
Re: Changing WAL Header to reduce contention during ReserveXLogInsertLocation()
From
Alexander Kuzmenkov
Date:
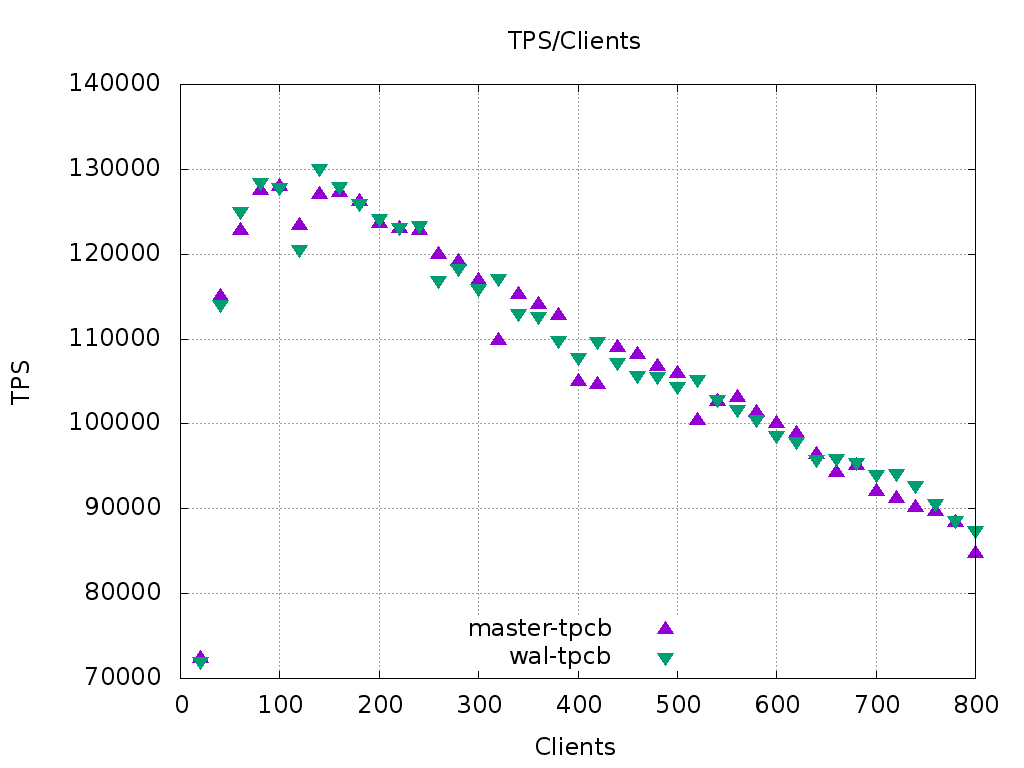
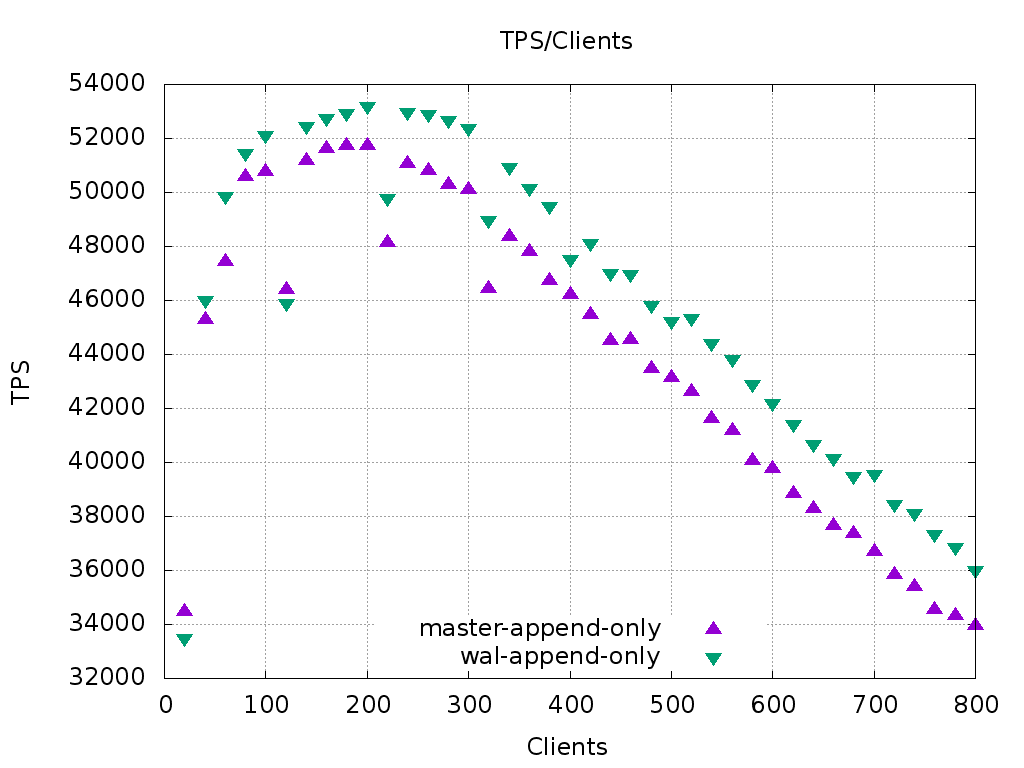
Hi Simon, Pavan, I tried benchmarking your patch. I ran pgbench on a 72-core machine with a simple append-only script: BEGIN; INSERT INTO pgbench_history (tid, bid, aid, delta, mtime) VALUES (:tid, :bid, :aid, :delta, CURRENT_TIMESTAMP); ---- the insert repeated 20 times total ------- END; I can see an increase in transaction throughput of about 5%. Please see the attached graph 'append-only.png' On the default tpcb-like benchmark, there is no meaningful change in performance, as shown in 'tpcb.png' Looking at the code, your changes seem reasonable to me. Some nitpicks: XLogSegNoLowOrderMask -- this macro is not really needed, XLogSegNoToSegID is enough (pg_resetwal should be changed to use the latter, too). The loop in findLastCheckpoint looks complex to me. It would be easier to read with two loops, the outer one iterating over the segments and the inner one iterating over the records. >+ uint16 xl_walid; /* lowest 16 bits of the WAL file to which this >+ record belongs */ I'd put a high-level description here, the low-level details are hidden behind macros anyway. Something like this: /* identifier of the WAL segment to which this record belongs. Used to detect stale WAL records in a reused segment. */ >+ * Make sure the above heavily-contended spinlock and byte positions are >+ * on their own cache line. In particular, the RedoRecPtr and full page This comment in the definition of XLogCtlInsert mentions the spinlock that is no more. The signature of InstallXLogFileSegment looks overloaded now, not sure how to simplify it. We could have two versions, one that looks for the free slot and another that reuses the existing file. Also, it seems to me that the lock doesn't have to be acquired inside this function, it can be done by the caller. -- Alexander Kuzmenkov Postgres Professional: http://www.postgrespro.com The Russian Postgres Company
Attachment
{kind=link}
{kind=link}
Re: Changing WAL Header to reduce contention during ReserveXLogInsertLocation()
From
Robert Haas
Date:
On Sat, Dec 30, 2017 at 5:32 AM, Simon Riggs <simon@2ndquadrant.com> wrote: > So we can't completely remove xl_prev field, without giving up some > functionality. But we don't really need to store the 8-byte previous > WAL pointer in order to detect torn pages. Something else which can > tell us that the WAL record does not belong to current WAL segno would > be enough as well. I propose that we replace it with a much smaller > 2-byte field (let's call it xl_walid). The "xl_walid" (or whatever we > decide to call it) is the low order 16-bits of the WAL segno to which > the WAL record belongs. While reading WAL, we always match that the > "xl_walid" value stored in the WAL record matches with the current WAL > segno's lower order 16-bits and if not, then consider that as the end > of the stream. > > For this to work, we must ensure that WAL files are either recycled in > such a way that the "xl_walid" of the previous (to be recycled) WAL > differs from the new WAL or we zero-out the new WAL file. Seems quite > easy to do with the existing infrastructure. I have some reservations about whether this makes the mechanism less reliable. It seems that an 8-byte field would have almost no chance of matching by accident even if the location was filled with random bytes, but with a 2-byte field it's not that unlikely. Of course, we also have xl_crc, so I'm not sure whether there's any chance of real harm... -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
Robert Haas <robertmhaas@gmail.com> writes:
> On Sat, Dec 30, 2017 at 5:32 AM, Simon Riggs <simon@2ndquadrant.com> wrote:
>> So we can't completely remove xl_prev field, without giving up some
>> functionality. But we don't really need to store the 8-byte previous
>> WAL pointer in order to detect torn pages. Something else which can
>> tell us that the WAL record does not belong to current WAL segno would
>> be enough as well. I propose that we replace it with a much smaller
>> 2-byte field (let's call it xl_walid). The "xl_walid" (or whatever we
>> decide to call it) is the low order 16-bits of the WAL segno to which
>> the WAL record belongs. While reading WAL, we always match that the
>> "xl_walid" value stored in the WAL record matches with the current WAL
>> segno's lower order 16-bits and if not, then consider that as the end
>> of the stream.
>>
>> For this to work, we must ensure that WAL files are either recycled in
>> such a way that the "xl_walid" of the previous (to be recycled) WAL
>> differs from the new WAL or we zero-out the new WAL file. Seems quite
>> easy to do with the existing infrastructure.
> I have some reservations about whether this makes the mechanism less
> reliable.
Yeah, it scares me too. The xl_prev field is our only way of detecting
that we're looking at old WAL data when we cross a sector boundary.
I have no faith that we can prevent old WAL data from reappearing in the
file system across an OS crash, so I find Simon's assertion that we can
dodge the problem through file manipulation to be simply unbelievable.
If we could be sure that the WAL page size was no larger than the file
system's write quantum, then checking xlp_pageaddr would be sufficient
to detect stale WAL data. But I'm afraid 8K is way too big for that;
so we need to be able to recognize page tears within-page.
> Of course, we also have xl_crc, so I'm not sure whether there's any
> chance of real harm...
The CRC only tells you that you have a valid WAL record, it won't clue
you in that it's old data you shouldn't replay. If the previous WAL
record crossed the torn-page boundary, then you should have gotten a
CRC failure on that record --- but if the previous record ended at a
sector boundary, recognizing that the new record has an old xl_prev is
our ONLY defense against replaying stale data.
regards, tom lane
I wrote:
> Robert Haas <robertmhaas@gmail.com> writes:
>> On Sat, Dec 30, 2017 at 5:32 AM, Simon Riggs <simon@2ndquadrant.com> wrote:
>>> For this to work, we must ensure that WAL files are either recycled in
>>> such a way that the "xl_walid" of the previous (to be recycled) WAL
>>> differs from the new WAL or we zero-out the new WAL file. Seems quite
>>> easy to do with the existing infrastructure.
> I have no faith that we can prevent old WAL data from reappearing in the
> file system across an OS crash, so I find Simon's assertion that we can
> dodge the problem through file manipulation to be simply unbelievable.
Forgot to say: if we *could* do it reliably, it would likely add
significant I/O traffic, eg an extra zeroing pass for every WAL segment.
That's a pretty heavy performance price to set against whatever win
we might get from contention reduction.
regards, tom lane
Re: Changing WAL Header to reduce contention duringReserveXLogInsertLocation()
From
Andres Freund
Date:
On 2018-01-12 10:45:54 -0500, Tom Lane wrote: > Robert Haas <robertmhaas@gmail.com> writes: > > On Sat, Dec 30, 2017 at 5:32 AM, Simon Riggs <simon@2ndquadrant.com> wrote: > > I have some reservations about whether this makes the mechanism less > > reliable. > > Yeah, it scares me too. Same here. > The xl_prev field is our only way of detecting that we're looking at > old WAL data when we cross a sector boundary. Right. I wonder if it be reasonable to move that to a page's header instead of individual records? To avoid torn page issues we'd have to reduce the page size to a sector size, but I'm not sure that's that bad? > > Of course, we also have xl_crc, so I'm not sure whether there's any > > chance of real harm... > > The CRC only tells you that you have a valid WAL record, it won't clue > you in that it's old data you shouldn't replay. Yea, I don't like relying on the CRC alone at all. Greetings, Andres Freund
Andres Freund <andres@anarazel.de> writes:
> On 2018-01-12 10:45:54 -0500, Tom Lane wrote:
>> The xl_prev field is our only way of detecting that we're looking at
>> old WAL data when we cross a sector boundary.
> Right. I wonder if it be reasonable to move that to a page's header
> instead of individual records? To avoid torn page issues we'd have to
> reduce the page size to a sector size, but I'm not sure that's that bad?
Giving up a dozen or two bytes out of every 512 sounds like quite an
overhead. Also, this'd mean that a much larger fraction of WAL records
need to be split across page boundaries, which I'd expect to produce a
performance hit in itself --- a page crossing has to complicate figuring
out how much space we need for the record.
regards, tom lane
Re: Changing WAL Header to reduce contention duringReserveXLogInsertLocation()
From
Andres Freund
Date:
On 2018-01-12 17:24:54 -0500, Tom Lane wrote: > Andres Freund <andres@anarazel.de> writes: > > On 2018-01-12 10:45:54 -0500, Tom Lane wrote: > >> The xl_prev field is our only way of detecting that we're looking at > >> old WAL data when we cross a sector boundary. > > > Right. I wonder if it be reasonable to move that to a page's header > > instead of individual records? To avoid torn page issues we'd have to > > reduce the page size to a sector size, but I'm not sure that's that bad? > > Giving up a dozen or two bytes out of every 512 sounds like quite an > overhead. It's not nothing, that's true. But if it avoids 8 bytes in every record, that'd probably at least as much in most usecases. > Also, this'd mean that a much larger fraction of WAL records > need to be split across page boundaries, which I'd expect to produce a > performance hit in itself --- a page crossing has to complicate figuring > out how much space we need for the record. It does increase the computation a bit, see XLogBytePosToRecPtr(). I'd guess that more of the overhead would come from the xlog buffer management though. Greetings, Andres Freund
Andres Freund <andres@anarazel.de> writes:
> On 2018-01-12 17:24:54 -0500, Tom Lane wrote:
>> Andres Freund <andres@anarazel.de> writes:
>>> Right. I wonder if it be reasonable to move that to a page's header
>>> instead of individual records? To avoid torn page issues we'd have to
>>> reduce the page size to a sector size, but I'm not sure that's that bad?
>> Giving up a dozen or two bytes out of every 512 sounds like quite an
>> overhead.
> It's not nothing, that's true. But if it avoids 8 bytes in every record,
> that'd probably at least as much in most usecases.
Fair point. I don't have a very good handle on what "typical" WAL record
sizes are, but we might be fine with that --- some quick counting on the
fingers says we'd break even with an average record size of ~160 bytes,
and be ahead below that.
We'd need to investigate the page-crossing overhead carefully though.
regards, tom lane
Re: Changing WAL Header to reduce contention duringReserveXLogInsertLocation()
From
Andres Freund
Date:
On 2018-01-12 17:43:00 -0500, Tom Lane wrote:
> Andres Freund <andres@anarazel.de> writes:
> > On 2018-01-12 17:24:54 -0500, Tom Lane wrote:
> >> Andres Freund <andres@anarazel.de> writes:
> >>> Right. I wonder if it be reasonable to move that to a page's header
> >>> instead of individual records? To avoid torn page issues we'd have to
> >>> reduce the page size to a sector size, but I'm not sure that's that bad?
>
> >> Giving up a dozen or two bytes out of every 512 sounds like quite an
> >> overhead.
>
> > It's not nothing, that's true. But if it avoids 8 bytes in every record,
> > that'd probably at least as much in most usecases.
>
> Fair point. I don't have a very good handle on what "typical" WAL record
> sizes are, but we might be fine with that --- some quick counting on the
> fingers says we'd break even with an average record size of ~160 bytes,
> and be ahead below that.
This is far from a definitive answer, but here's some data:
pgbench -i -s 100 -q:
Type N (%) Record size (%) FPI size (%)
Combined size (%)
---- - --- ----------- --- -------- ---
------------- ---
Total 308958 1077269060 [84.19%] 202269468 [15.81%]
1279538528 [100%]
So here records are really large, which makes sense, given it's
largelyinitialization of data. With wal_compression that'd probably look
different, but still commonly spanning multiple pages.
pgbench -M prepared -c 16 -j 16 -T 100
Type N (%) Record size (%) FPI size (%)
Combined size (%)
---- - --- ----------- --- -------- ---
------------- ---
Total 14228881 947824170 [100.00%] 8192 [0.00%]
947832362 [100%]
Here we're at 66 bytes...
> We'd need to investigate the page-crossing overhead carefully though.
agreed.
Greetings,
Andres Freund
Re: Changing WAL Header to reduce contention during ReserveXLogInsertLocation()
From
Claudio Freire
Date:
On Sat, Dec 30, 2017 at 7:32 AM, Simon Riggs <simon@2ndquadrant.com> wrote:
So we can't completely remove xl_prev field, without giving up some
functionality. But we don't really need to store the 8-byte previous
WAL pointer in order to detect torn pages. Something else which can
tell us that the WAL record does not belong to current WAL segno would
be enough as well. I propose that we replace it with a much smaller
2-byte field (let's call it xl_walid). The "xl_walid" (or whatever we
decide to call it) is the low order 16-bits of the WAL segno to which
the WAL record belongs. While reading WAL, we always match that the
"xl_walid" value stored in the WAL record matches with the current WAL
segno's lower order 16-bits and if not, then consider that as the end
of the stream.
For this to work, we must ensure that WAL files are either recycled in
such a way that the "xl_walid" of the previous (to be recycled) WAL
differs from the new WAL or we zero-out the new WAL file. Seems quite
easy to do with the existing infrastructure.
Or, you can use the lower 16-bits of the previous record's CRC
Re: Changing WAL Header to reduce contention during ReserveXLogInsertLocation()
From
Claudio Freire
Date:
On Fri, Jan 12, 2018 at 8:43 PM, Claudio Freire <klaussfreire@gmail.com> wrote:
On Sat, Dec 30, 2017 at 7:32 AM, Simon Riggs <simon@2ndquadrant.com> wrote:So we can't completely remove xl_prev field, without giving up some
functionality. But we don't really need to store the 8-byte previous
WAL pointer in order to detect torn pages. Something else which can
tell us that the WAL record does not belong to current WAL segno would
be enough as well. I propose that we replace it with a much smaller
2-byte field (let's call it xl_walid). The "xl_walid" (or whatever we
decide to call it) is the low order 16-bits of the WAL segno to which
the WAL record belongs. While reading WAL, we always match that the
"xl_walid" value stored in the WAL record matches with the current WAL
segno's lower order 16-bits and if not, then consider that as the end
of the stream.
For this to work, we must ensure that WAL files are either recycled in
such a way that the "xl_walid" of the previous (to be recycled) WAL
differs from the new WAL or we zero-out the new WAL file. Seems quite
easy to do with the existing infrastructure.Or, you can use the lower 16-bits of the previous record's CRC
Sorry, missed the whole point. Of the *first* record's CRC
Claudio Freire <klaussfreire@gmail.com> writes:
> On Sat, Dec 30, 2017 at 7:32 AM, Simon Riggs <simon@2ndquadrant.com> wrote:
>> So we can't completely remove xl_prev field, without giving up some
>> functionality.
> Or, you can use the lower 16-bits of the previous record's CRC
Hmm ... that is an interesting idea, but I'm not sure it helps much
towards Simon's actual objective. AIUI the core problem here is the
contention involved in retrieving the previous WAL record's address.
Changing things so that we need the previous record's CRC isn't really
gonna improve that --- if anything, it'll be worse, because the
record's address can (in principle) be known sooner than its CRC.
Still, if we were just looking to shave some bits off of WAL record
headers, it might be possible to do something with this idea.
regards, tom lane
Re: Changing WAL Header to reduce contention during ReserveXLogInsertLocation()
From
Claudio Freire
Date:
On Fri, Jan 12, 2018 at 10:49 PM, Tom Lane <tgl@sss.pgh.pa.us> wrote:
Claudio Freire <klaussfreire@gmail.com> writes:
> On Sat, Dec 30, 2017 at 7:32 AM, Simon Riggs <simon@2ndquadrant.com> wrote:
>> So we can't completely remove xl_prev field, without giving up some
>> functionality.
> Or, you can use the lower 16-bits of the previous record's CRC
Hmm ... that is an interesting idea, but I'm not sure it helps much
towards Simon's actual objective. AIUI the core problem here is the
contention involved in retrieving the previous WAL record's address.
Changing things so that we need the previous record's CRC isn't really
gonna improve that --- if anything, it'll be worse, because the
record's address can (in principle) be known sooner than its CRC.
Still, if we were just looking to shave some bits off of WAL record
headers, it might be possible to do something with this idea.
regards, tom lane
I later realized. That's why I corrected myself to the first record, not the previous.
Now, that assumes there's enough entropy in CRC values to actually make good use of those 16 bits... there may not. WAL segments are highly compressible after all.
So, maybe a hash of the LSN of the first record instead? That should be guaranteed to have good entropy (given a good hash).
In any case, there are many rather good alternatives to the segment number that should be reasonably safe from consistent collisions with garbage data.
Re: Changing WAL Header to reduce contention during ReserveXLogInsertLocation()
From
Simon Riggs
Date:
On 12 January 2018 at 15:45, Tom Lane <tgl@sss.pgh.pa.us> wrote: >> I have some reservations about whether this makes the mechanism less >> reliable. > > Yeah, it scares me too. The xl_prev field is our only way of detecting > that we're looking at old WAL data when we cross a sector boundary. > I have no faith that we can prevent old WAL data from reappearing in the > file system across an OS crash, so I find Simon's assertion that we can > dodge the problem through file manipulation to be simply unbelievable. Not really sure what you mean by "file manipulation". Maybe the proposal wasn't clear. We need a way of detecting that we are looking at old WAL data. More specifically, we need to know whether we are looking at a current file or an older file. My main assertion here is that the detection only needs to happen at file-level, not at record level, so it is OK to lose some bits of information without changing our ability to protect data - they were not being used productively. Let's do the math to see if it is believable, or not. The new two byte value is protected by CRC. The 2 byte value repeats every 32768 WAL files. Any bit error in that value that made it appear to be a current value would need to have a rare set of circumstances. 1. We would need to suffer a bit error that did not get caught by the CRC. 2. An old WAL record would need to occur right on the boundary of the last WAL record. 3. The bit error would need to occur within the 2 byte value. WAL records are usually fairly long, but so this has a Probability of <1/16 4. The bit error would need to change an old value to the current value of the new 2 byte field. If the current value is N, and the previous value is M, then a single bit error that takes M -> N can only happen if N-M is divisible by 2. The maximum probability of an issue would occur when we reuse WAL every 3 files, so probability of such a change would be 1/16. If the distance between M and N is not a power of two then a single bit error cannot change M into N. So what probability do we assign to the situation that M and N are exactly a power of two apart? So the probability of this occurring requires a single undetectable bit error and would then happen less than 1 in 256 times, but arguably much less. Notice that this probability is therefore at least 2 orders of magnitude smaller than the chance that a single bit error occurs and simply corrupts data, a mere rounding error in risk. I don't find that unbelievable at all. If you still do, then I would borrow Andres' idea of using the page header. If we copy the new 2 byte value into the page header, we can use that to match against in the case of error. XLogPageHeaderData can be extended by 2 bytes without increasing its size when using 8 byte alignment. The new 2 byte value is the same anywhere in the file, so that works quickly and easily. And it doesn't increase the size of the header. So with that change it looks completely viable. -- Simon Riggs http://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
Re: Changing WAL Header to reduce contention duringReserveXLogInsertLocation()
From
Michael Paquier
Date:
On Sat, Jan 13, 2018 at 03:40:01PM +0000, Simon Riggs wrote: > The new two byte value is protected by CRC. The 2 byte value repeats > every 32768 WAL files. Any bit error in that value that made it appear > to be a current value would need to have a rare set of circumstances. If you use the two lower bytes of the segment number, then this gets repeated every 64k segments, no? In terms of space this represents 500GB worth of WAL segments with a default segment size. Hence the more PostgreSQL scales, the more there is a risk of collision, and I am pretty sure that there are already deployments around allocating hundreds of gigs worth of space for the WAL partition. There are no problems of this class if using the 8-byte field xl_prev. It seems to me that we don't want to take any risks here. -- Michael
Attachment
Re: Changing WAL Header to reduce contention during ReserveXLogInsertLocation()
From
Pavan Deolasee
Date:
On Thu, Feb 1, 2018 at 11:05 AM, Michael Paquier <michael.paquier@gmail.com> wrote:
On Sat, Jan 13, 2018 at 03:40:01PM +0000, Simon Riggs wrote:
> The new two byte value is protected by CRC. The 2 byte value repeats
> every 32768 WAL files. Any bit error in that value that made it appear
> to be a current value would need to have a rare set of circumstances.
If you use the two lower bytes of the segment number, then this gets
repeated every 64k segments, no? In terms of space this represents
500GB worth of WAL segments with a default segment size. Hence the more
PostgreSQL scales, the more there is a risk of collision, and I am
pretty sure that there are already deployments around allocating
hundreds of gigs worth of space for the WAL partition. There are no
problems of this class if using the 8-byte field xl_prev. It seems to
me that we don't want to take any risks here.
This particular piece of the patch deals with that:
@@ -3496,6 +3495,16 @@ InstallXLogFileSegment(XLogSegNo *segno, char *tmppath,
return false;
}
(*segno)++;
+
+ /*
+ * If avoid_conflicting_walid is true, then we must not recycle the
+ * WAL files so that the old and the recycled WAL segnos have the
+ * same lower order 16-bits.
+ */
+ if (avoid_conflicting_walid &&
+ XLogSegNoToSegID(tmpsegno) == XLogSegNoToSegID(*segno))
+ (*segno)++;
+
XLogFilePath(path, ThisTimeLineID, *segno, wal_segment_size);
}
}
For example, old WAL file 000000010000000000000001 will NEVER be reused as 000000010000000000010001. So even if there are any intact old WAL records in the recycled file, they will be detected correctly during replay since the SegID stored in the WAL record will not match the SegID as derived from the WAL file segment number. The replay code does this for every WAL record it sees.
There were some concerns about bit-flipping, which may inadvertently SegID stored in the carried over WAL record so that it now matches with the current WAL files' SegID, but TBH I don't see why we can't trust CRC to detect that. Because if we can't, then there would be other problems during WAL replay.
--
Thanks,
Pavan
Pavan Deolasee http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Training & Services
PostgreSQL Development, 24x7 Support, Training & Services
Re: Changing WAL Header to reduce contention during ReserveXLogInsertLocation()
From
Robert Haas
Date:
On Thu, Feb 1, 2018 at 1:00 AM, Pavan Deolasee <pavan.deolasee@gmail.com> wrote: > IMHO we're missing a point here. When xl_prev is changed to a 2-byte value > (as the patch suggests), the risk only comes when an old WAL file is > recycled for some future WAL file and the old and the future WAL file's > segment numbers share the same low order 16-bits. Now as the patch stands, > we take precaution to never reuse a WAL file with conflicting low order > bits. You and Simon seem to be assuming that the only case we need to worry about is when the old segment had an xl_prev value at the same offset, and you may be right, but if that is guaranteed, I don't understand why it's guaranteed. Why couldn't that offset in the old WAL file been in the middle of a WAL record and thus subject to containing any random garbage? If we know that, at the same offset in the previous WAL file, there was definitely an xl_prev pointer, then it seems like some trick like what you're proposing might work, although I'm not sure of the details. But if that could've been something else -- like the middle of a WAL record -- then that doesn't really help. Our chance of a false match is pretty much just 2^-nbits. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
Re: Changing WAL Header to reduce contention during ReserveXLogInsertLocation()
From
Simon Riggs
Date:
On 1 February 2018 at 18:55, Robert Haas <robertmhaas@gmail.com> wrote: > On Thu, Feb 1, 2018 at 1:00 AM, Pavan Deolasee <pavan.deolasee@gmail.com> wrote: >> IMHO we're missing a point here. When xl_prev is changed to a 2-byte value >> (as the patch suggests), the risk only comes when an old WAL file is >> recycled for some future WAL file and the old and the future WAL file's >> segment numbers share the same low order 16-bits. Now as the patch stands, >> we take precaution to never reuse a WAL file with conflicting low order >> bits. > > You and Simon seem to be assuming that the only case we need to worry > about is when the old segment had an xl_prev value at the same offset, > and you may be right, but if that is guaranteed, I don't understand > why it's guaranteed. Why couldn't that offset in the old WAL file > been in the middle of a WAL record and thus subject to containing any > random garbage? Yes, it would be about 99% of the time. But you have it backwards - we are not assuming that case. That is the only case that has risk - the one where an old WAL record starts at exactly the place the latest one stops. Otherwise the rest of the WAL record will certainly fail the CRC check, since it will effectively have random data in it, as you say. I didn't even include that aspect in the calculation of the risk. > If we know that, at the same offset in the previous WAL file, there > was definitely an xl_prev pointer, then it seems like some trick like > what you're proposing might work, although I'm not sure of the > details. But if that could've been something else -- like the middle > of a WAL record -- then that doesn't really help. Our chance of a > false match is pretty much just 2^-nbits. The full 8 bytes of the xl_prev pointer aren't working for a living. More isn't better, always. If we really can't persuade you of that, it doesn't sink the patch. We can have the WAL pointer itself - it wouldn't save space but it would at least alleviate the spinlock. -- Simon Riggs http://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
Re: Changing WAL Header to reduce contention duringReserveXLogInsertLocation()
From
Michael Paquier
Date:
On Fri, Feb 02, 2018 at 12:21:49AM +0000, Simon Riggs wrote: > Yes, it would be about 99% of the time. When it comes to recovery, I don't think that 99% is a guarantee sufficient. (Wondering about the maths behind such a number as well.) > But you have it backwards - we are not assuming that case. That is the > only case that has risk - the one where an old WAL record starts at > exactly the place the latest one stops. Otherwise the rest of the WAL > record will certainly fail the CRC check, since it will effectively > have random data in it, as you say. Your patch assumes that a single WAL segment recycling is fine to escape based on the file name, but you need to think beyond that. It seems to me that your assumption is wrong if the tail of a segment gets reused after more cycles than a single one, which could happen when doing recovery from an archive, where segments used could have junk in them. So you actually *increase* the odds of problems if a segment is forcibly switched and archived, then reused in recovery after being fetched from an archive. Since 9.4, the tail of WAL segments is filled with zeros so this brings more confidence, but I think that we cannot exchange the existing reliability with performance. So like others have expressed on this thread, the approach taken does not sound good to me, because we increase the risks of junk WAL records being used during recovery, just for the sake of performance. An approach that could be better is to replace XLogRecord->xl_prev by a new field in XLogPageHeaderData which tracks XLogRecPtr for the previous page, say xlp_prevpageaddr, and use that for all sanity checks that xlogreader.c is doing. If I can count with my fingers correctly, SizeOfXLogLongPHD is 40 bytes long, and SizeOfXLogShortPHD is 24 bytes, so even with an increase of 8 bytes for the page header you gain space as one record is usually much likely less than a full xlog page if you remove xl_prev. -- Michael
Attachment
Re: Changing WAL Header to reduce contention during ReserveXLogInsertLocation()
From
Robert Haas
Date:
On Thu, Feb 1, 2018 at 7:21 PM, Simon Riggs <simon@2ndquadrant.com> wrote: > Yes, it would be about 99% of the time. > > But you have it backwards - we are not assuming that case. That is the > only case that has risk - the one where an old WAL record starts at > exactly the place the latest one stops. Otherwise the rest of the WAL > record will certainly fail the CRC check, since it will effectively > have random data in it, as you say. OK, I get it now. Thanks for explaining. I think I understand now why you think this problem can be solved just by controlling the way we recycle segments, but I'm still not sure if that can really be made fully reliable. Michael seems concerned about what might happen after multiple recyclings, and Tom has raised the issue of old data reappearing after a crash. I do agree that it would be nice if we could make it work - saving 8 bytes per WAL record would be significant. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
Re: Changing WAL Header to reduce contention during ReserveXLogInsertLocation()
From
Pavan Deolasee
Date:
On Fri, Feb 2, 2018 at 9:07 PM, Robert Haas <robertmhaas@gmail.com> wrote:
Thanks,On Thu, Feb 1, 2018 at 7:21 PM, Simon Riggs <simon@2ndquadrant.com> wrote:
> Yes, it would be about 99% of the time.
>
> But you have it backwards - we are not assuming that case. That is the
> only case that has risk - the one where an old WAL record starts at
> exactly the place the latest one stops. Otherwise the rest of the WAL
> record will certainly fail the CRC check, since it will effectively
> have random data in it, as you say.
OK, I get it now. Thanks for explaining. I think I understand now
why you think this problem can be solved just by controlling the way
we recycle segments, but I'm still not sure if that can really be made
fully reliable. Michael seems concerned about what might happen after
multiple recyclings, and Tom has raised the issue of old data
reappearing after a crash.
I'm not sure if Michael has spotted a real problem or was that just a concern. He himself later rightly pointed out that when a WAL file is switched, the old file is filled with zeros. So I don't see a problem there. May be I am missing something and Michael can explain further.
Regarding Tom's concerns, that could be a problem if a file system crash survives a name change, but not the subsequent data written to the file. For this to be a problem, WAL file A is renamed to B and then renamed to C. File A and C share the same low order bits. Further upon file system crash, the file is correctly named as C, but the data written *before* the rename operation is lost. Is that a real possibility? Can we delay reusing low order bits a little further to address this problem? Of course, if the file system crash can survive many renames and still resurrect old data several renames before, then we shall have the same problem.
Pavan
--
Pavan Deolasee http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Training & Services
PostgreSQL Development, 24x7 Support, Training & Services
Re: Changing WAL Header to reduce contention duringReserveXLogInsertLocation()
From
Michael Paquier
Date:
On Mon, Feb 12, 2018 at 04:33:51PM +0530, Pavan Deolasee wrote: > I'm not sure if Michael has spotted a real problem or was that just a > concern. He himself later rightly pointed out that when a WAL file is > switched, the old file is filled with zeros. So I don't see a problem > there. May be I am missing something and Michael can explain further. Sorry for my late reply here. I have been eyeballing the code for some time to be sure that I was not missing something. A new segment is filled with zeros when it is freshly created (see XLogFileInit), or when doing a forced segment switch, but the checkpointer just renames the old files which could perfectly contain past data which is reused afterwards. So after doing one recycling cycle, the old data should be overwritten when a second recycling cycle happens. One thing that worries me though is related to timeline switches. The last, partial, WAL segment may still have garbage data. Since 9.5 the segment is being renamed with a dedicated suffix, but the file could be renamed if an operator is willing to finish replay up to the end of the timeline where this file is the last one, and it could have junk data that your checks rely on. There may be other things I have not considered, but at least that's one problem. -- Michael
Attachment
Re: Changing WAL Header to reduce contention duringReserveXLogInsertLocation()
From
Peter Eisentraut
Date:
On 2/1/18 19:21, Simon Riggs wrote: > If we really can't persuade you of that, it doesn't sink the patch. We > can have the WAL pointer itself - it wouldn't save space but it would > at least alleviate the spinlock. Do you want to send in an alternative patch that preserves the WAL pointer and only changes the locking? -- Peter Eisentraut http://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
Re: Changing WAL Header to reduce contention during ReserveXLogInsertLocation()
From
Pavan Deolasee
Date:
On Fri, Mar 9, 2018 at 8:49 PM, Peter Eisentraut <peter.eisentraut@2ndquadrant.com> wrote:
On 2/1/18 19:21, Simon Riggs wrote:
> If we really can't persuade you of that, it doesn't sink the patch. We
> can have the WAL pointer itself - it wouldn't save space but it would
> at least alleviate the spinlock.
Do you want to send in an alternative patch that preserves the WAL
pointer and only changes the locking?
Sorry for the delay. Here is an updated patch which now replaces xl_prev with xl_curr, thus providing similar safeguards against corrupted or torn WAL pages, but still providing benefits of atomic operations.
Patched:
======
#clients #tps
1 34.195311
2 29.001584
4 31.712009
8 35.489272
16 41.950044
Master:
======
#clients #tps
1 24.128004
2 12.326135
4 8.334143
8 16.035699
16 8.502794
Thanks,
Pavan
Pavan Deolasee http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Training & Services
PostgreSQL Development, 24x7 Support, Training & Services
Attachment
Re: Changing WAL Header to reduce contention during ReserveXLogInsertLocation()
From
Simon Riggs
Date:
On 2 February 2018 at 02:17, Michael Paquier <michael.paquier@gmail.com> wrote: > On Fri, Feb 02, 2018 at 12:21:49AM +0000, Simon Riggs wrote: >> Yes, it would be about 99% of the time. > > When it comes to recovery, I don't think that 99% is a guarantee > sufficient. (Wondering about the maths behind such a number as well.) > >> But you have it backwards - we are not assuming that case. That is the >> only case that has risk - the one where an old WAL record starts at >> exactly the place the latest one stops. Otherwise the rest of the WAL >> record will certainly fail the CRC check, since it will effectively >> have random data in it, as you say. > > Your patch assumes that a single WAL segment recycling is fine to > escape based on the file name, but you need to think beyond that. It > seems to me that your assumption is wrong if the tail of a segment gets > reused after more cycles than a single one, which could happen when > doing recovery from an archive, where segments used could have junk in > them. So you actually *increase* the odds of problems if a segment is > forcibly switched and archived, then reused in recovery after being > fetched from an archive. This seems to be a pivotal point in your argument, yet it is just an assertion. Please explain for the archive why you think the odds increase in the way you describe. Thanks -- Simon Riggs http://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
Re: Changing WAL Header to reduce contention during ReserveXLogInsertLocation()
From
Simon Riggs
Date:
On 23 March 2018 at 08:35, Pavan Deolasee <pavan.deolasee@gmail.com> wrote: > > > On Fri, Mar 9, 2018 at 8:49 PM, Peter Eisentraut > <peter.eisentraut@2ndquadrant.com> wrote: >> >> On 2/1/18 19:21, Simon Riggs wrote: >> > If we really can't persuade you of that, it doesn't sink the patch. We >> > can have the WAL pointer itself - it wouldn't save space but it would >> > at least alleviate the spinlock. >> >> Do you want to send in an alternative patch that preserves the WAL >> pointer and only changes the locking? >> > > Sorry for the delay. Here is an updated patch which now replaces xl_prev > with xl_curr, thus providing similar safeguards against corrupted or torn > WAL pages, but still providing benefits of atomic operations. > > I repeated the same set of tests and the results are almost similar. These > tests are done on a different AWS instance though and hence not comparable > to previous tests. What we do in these tests is essentially call > ReserveXLogInsertLocation() 1M times to reserve 256 bytes each time, in a > single select statement (the function is exported and a SQL-callable routine > is added for the purpose of the tests) > > Patched: > ====== > #clients #tps > 1 34.195311 > 2 29.001584 > 4 31.712009 > 8 35.489272 > 16 41.950044 > > Master: > ====== > #clients #tps > 1 24.128004 > 2 12.326135 > 4 8.334143 > 8 16.035699 > 16 8.502794 > > So that's pretty good improvement across the spectrum. So it shows clear benefit for both bulk actions and OLTP, with no regressions. No objection exists to the approach used in the patch, so I'm now ready to commit this. Last call for objections? -- Simon Riggs http://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
Re: Changing WAL Header to reduce contention duringReserveXLogInsertLocation()
From
Michael Paquier
Date:
On Fri, Mar 23, 2018 at 09:04:55AM +0000, Simon Riggs wrote: > So it shows clear benefit for both bulk actions and OLTP, with no regressions. > > No objection exists to the approach used in the patch, so I'm now > ready to commit this. > > Last call for objections? Please hold on. It is Friday evening here. First I cannot take the time to articulate an answer you are requesting on the other thread part. Second, the latest version of the patch has been sent from Pavan a couple of hours ago, and you are proposing to commit it in a message sent 29 minutes after the last version has been sent. Let's cool down a bit and take some time for reviews, please. You still have one week until the end of the commit fest anyway. Thanks, -- Michael
Attachment
Re: Changing WAL Header to reduce contention during ReserveXLogInsertLocation()
From
Simon Riggs
Date:
On 23 March 2018 at 09:22, Michael Paquier <michael@paquier.xyz> wrote: > On Fri, Mar 23, 2018 at 09:04:55AM +0000, Simon Riggs wrote: >> So it shows clear benefit for both bulk actions and OLTP, with no regressions. >> >> No objection exists to the approach used in the patch, so I'm now >> ready to commit this. >> >> Last call for objections? > > Please hold on. It is Friday evening here. First I cannot take the > time to articulate an answer you are requesting on the other thread > part. Second, the latest version of the patch has been sent from Pavan > a couple of hours ago, and you are proposing to commit it in a message > sent 29 minutes after the last version has been sent. > > Let's cool down a bit and take some time for reviews, please. You still > have one week until the end of the commit fest anyway. Your assumption that I would commit a new patch that was 29 mins old is frankly pretty ridiculous, so yes, lets keep calm. Enjoy your weekend and I'll be happy to read your review on Monday. -- Simon Riggs http://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
Re: Changing WAL Header to reduce contention duringReserveXLogInsertLocation()
From
Andres Freund
Date:
On 2018-03-23 11:06:48 +0000, Simon Riggs wrote: > Your assumption that I would commit a new patch that was 29 mins old > is frankly pretty ridiculous, so yes, lets keep calm. Uh.
Re: Changing WAL Header to reduce contention duringReserveXLogInsertLocation()
From
Michael Paquier
Date:
On Fri, Mar 23, 2018 at 11:06:48AM +0000, Simon Riggs wrote: > Your assumption that I would commit a new patch that was 29 mins old > is frankly pretty ridiculous, so yes, lets keep calm. When a committer says that a patch is "ready for commit" and that he calls for "last objections", I am understanding that you would be ready to commit the patch from the moment such an email has been sent. Am I the only one to think so? Now let's look at the numbers: - The last patch sent is a v2, which implements a completely new approach compared to v1. This is a non-trivial patch which touches sensitive parts of the code. - v2 has been sent exactly two weeks after the last email exchanged on this thread. - Per the data publicly available, it took less than 30 minutes to review the patch, and there are zero comments about its contents. I do patch review on a more-or-less daily basis, and look at threads on hackers on a daily basis, but I really rarely see such an "efficient" review pattern. You and Pavan have likely discussed the patch offline, but nobody can guess what has been discussed and what have been the arguments exchanged. > Enjoy your weekend and I'll be happy to read your review on Monday. Er. So this basically means that I need to do a commitment to look at this patch in such a short time frame? If you are asking for reviews, doing such requests by asking a proper question rather than by implying it in an affirmation would seem more adapted to me, so this email bit is making me uncomfortable. My apologies if I am not able to catch the nuance in those words. -- Michael
Attachment
Re: Changing WAL Header to reduce contention during ReserveXLogInsertLocation()
From
Simon Riggs
Date:
I suggest we focus on the engineering. I've not discussed this patch with Pavan offline. On 23 March 2018 at 23:32, Michael Paquier <michael@paquier.xyz> wrote: > On Fri, Mar 23, 2018 at 11:06:48AM +0000, Simon Riggs wrote: >> Your assumption that I would commit a new patch that was 29 mins old >> is frankly pretty ridiculous, so yes, lets keep calm. > > When a committer says that a patch is "ready for commit" and that he > calls for "last objections", I am understanding that you would be ready > to commit the patch from the moment such an email has been sent. Am I > the only one to think so? Now let's look at the numbers: > - The last patch sent is a v2, which implements a completely new > approach compared to v1. This is a non-trivial patch which touches > sensitive parts of the code. > - v2 has been sent exactly two weeks after the last email exchanged on > this thread. > - Per the data publicly available, it took less than 30 minutes to > review the patch, and there are zero comments about its contents. > I do patch review on a more-or-less daily basis, and look at threads on > hackers on a daily basis, but I really rarely see such an "efficient" > review pattern. You and Pavan have likely discussed the patch offline, > but nobody can guess what has been discussed and what have been the > arguments exchanged. > >> Enjoy your weekend and I'll be happy to read your review on Monday. > > Er. So this basically means that I need to do a commitment to look at > this patch in such a short time frame? If you are asking for reviews, > doing such requests by asking a proper question rather than by implying > it in an affirmation would seem more adapted to me, so this email bit is > making me uncomfortable. My apologies if I am not able to catch the > nuance in those words. > -- > Michael -- Simon Riggs http://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
Re: Changing WAL Header to reduce contention during ReserveXLogInsertLocation()
From
Robert Haas
Date:
On Sat, Mar 24, 2018 at 7:42 AM, Simon Riggs <simon@2ndquadrant.com> wrote: > I suggest we focus on the engineering. I've not discussed this patch > with Pavan offline. Well then proposing to commit moments after it's been posted is ridiculous. That's exactly the opposite of "focusing on the engineering". This is a patch about which multiple people have expressed concerns. You're trying to jam a heavily redesigned version in at the last minute without adequate review. Please don't do that. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
Re: Changing WAL Header to reduce contention during ReserveXLogInsertLocation()
From
Simon Riggs
Date:
On 24 March 2018 at 11:58, Robert Haas <robertmhaas@gmail.com> wrote: > On Sat, Mar 24, 2018 at 7:42 AM, Simon Riggs <simon@2ndquadrant.com> wrote: >> I suggest we focus on the engineering. I've not discussed this patch >> with Pavan offline. > > Well then proposing to commit moments after it's been posted is > ridiculous. That's exactly the opposite of "focusing on the > engineering". > > This is a patch about which multiple people have expressed concerns. > You're trying to jam a heavily redesigned version in at the last > minute without adequate review. Please don't do that. All presumption on your part. Don't tell me what I think and then diss me for that. If you have engineering comments, please make them. -- Simon Riggs http://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
Re: Changing WAL Header to reduce contention during ReserveXLogInsertLocation()
From
Robert Haas
Date:
On Sat, Mar 24, 2018 at 8:11 AM, Simon Riggs <simon@2ndquadrant.com> wrote: > On 24 March 2018 at 11:58, Robert Haas <robertmhaas@gmail.com> wrote: >> On Sat, Mar 24, 2018 at 7:42 AM, Simon Riggs <simon@2ndquadrant.com> wrote: >>> I suggest we focus on the engineering. I've not discussed this patch >>> with Pavan offline. >> >> Well then proposing to commit moments after it's been posted is >> ridiculous. That's exactly the opposite of "focusing on the >> engineering". >> >> This is a patch about which multiple people have expressed concerns. >> You're trying to jam a heavily redesigned version in at the last >> minute without adequate review. Please don't do that. > > All presumption on your part. Don't tell me what I think and then diss > me for that. It is of course true that I can't know your internal mental state with certainty, but I don't think it is presumptuous to suppose that a person who says they're going to commit a patch that hasn't been reviewed intends to commit a patch that hasn't been reviewed. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
Re: Changing WAL Header to reduce contention during ReserveXLogInsertLocation()
From
Pavan Deolasee
Date:
On Sat, Mar 24, 2018 at 5:28 PM, Robert Haas <robertmhaas@gmail.com> wrote:
This is a patch about which multiple people have expressed concerns.
You're trying to jam a heavily redesigned version in at the last
minute without adequate review. Please don't do that.
1. Replacing 8-byte xl_prev with 2-byte xl_walid in order to reduce the size of the WAL record header
2. Changing XLogCtlInsert.CurrBytePos to use atomic operations in order to reduce the spinlock contention.
--
Most people expressed concerns regarding 1, but there were none regarding 2. Now it's possible that the entire attention got diverted to 1 and nobody really studied 2 in detail. Or may be 2 is mostly non-contentious, given the results of micro benchmarks.
So what I've done in v2 is to just deal with part 2 i.e. replace access to CurrBytePos with atomic operations, based on the following suggestion by Simon.
On 2/1/18 19:21, Simon Riggs wrote:
> If we really can't persuade you of that, it doesn't sink the patch. We
> can have the WAL pointer itself - it wouldn't save space but it would
> at least alleviate the spinlock.
This gives us the same level of guarantee that xl_prev used to offer, yet help us use atomic operations. I'll be happy if we can look at that particular change and see if there are any holes there.
Thanks,
Pavan
Pavan Deolasee http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Training & Services
PostgreSQL Development, 24x7 Support, Training & Services
Re: Changing WAL Header to reduce contention during ReserveXLogInsertLocation()
From
Simon Riggs
Date:
On 24 March 2018 at 12:19, Robert Haas <robertmhaas@gmail.com> wrote: > On Sat, Mar 24, 2018 at 8:11 AM, Simon Riggs <simon@2ndquadrant.com> wrote: >> On 24 March 2018 at 11:58, Robert Haas <robertmhaas@gmail.com> wrote: >>> On Sat, Mar 24, 2018 at 7:42 AM, Simon Riggs <simon@2ndquadrant.com> wrote: >>>> I suggest we focus on the engineering. I've not discussed this patch >>>> with Pavan offline. >>> >>> Well then proposing to commit moments after it's been posted is >>> ridiculous. That's exactly the opposite of "focusing on the >>> engineering". >>> >>> This is a patch about which multiple people have expressed concerns. >>> You're trying to jam a heavily redesigned version in at the last >>> minute without adequate review. Please don't do that. >> >> All presumption on your part. Don't tell me what I think and then diss >> me for that. > > It is of course true that I can't know your internal mental state with > certainty, but I don't think it is presumptuous to suppose that a > person who says they're going to commit a patch that hasn't been > reviewed intends to commit a patch that hasn't been reviewed. It seems you really are more intent on talking about my actions than on discussing the patch. Probably would have been better to read what I've actually said beforehand. If you have anything further to say, make it a formal complaint offlist so we can discuss engineering here. -- Simon Riggs http://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
Re: Changing WAL Header to reduce contention duringReserveXLogInsertLocation()
From
Michael Paquier
Date:
On Sat, Mar 24, 2018 at 12:37:21PM +0000, Simon Riggs wrote: > If you have anything further to say, make it a formal complaint > offlist so we can discuss engineering here. Commit fest operations and patch reviews concern the community. There is always something to learn for other people following the mailing lists if a patch is thought to be handled incorrectly, so as the same kind of errors are less repeated in the future. End of the digression from my side, let's go back to development work. -- Michael
Attachment
Re: Changing WAL Header to reduce contention during ReserveXLogInsertLocation()
From
Andrew Dunstan
Date:
On Sat, Mar 24, 2018 at 11:01 PM, Pavan Deolasee <pavan.deolasee@gmail.com> wrote: > > > TBH this is not a heavily redesigned version. There were two parts to the > original patch: > > 1. Replacing 8-byte xl_prev with 2-byte xl_walid in order to reduce the size > of the WAL record header > 2. Changing XLogCtlInsert.CurrBytePos to use atomic operations in order to > reduce the spinlock contention. > > Most people expressed concerns regarding 1, but there were none regarding 2. > Now it's possible that the entire attention got diverted to 1 and nobody > really studied 2 in detail. Or may be 2 is mostly non-contentious, given the > results of micro benchmarks. > > So what I've done in v2 is to just deal with part 2 i.e. replace access to > CurrBytePos with atomic operations, based on the following suggestion by > Simon. > > On 2/1/18 19:21, Simon Riggs wrote: >> If we really can't persuade you of that, it doesn't sink the patch. We >> can have the WAL pointer itself - it wouldn't save space but it would >> at least alleviate the spinlock. > > This gives us the same level of guarantee that xl_prev used to offer, yet > help us use atomic operations. I'll be happy if we can look at that > particular change and see if there are any holes there. > Leaving aside the arguments about process, the patch is pretty small and fairly straightforward. Given the claimed performance gains that's a nice bang for the buck. I haven't seen any obvious holes, but this is surely a case for as many eyeballs as possible. Some of the comments read a little oddly. We should talk about what we are doing or not doing, but not about what we used to do and don't do any longer, ISTM. e.g. instead of explaining that we used to have a spinlock and don't have one any longer, just explain why we don't need a spinlock. All the regression and TAP tests pass happily. cheers andrew -- Andrew Dunstan https://www.2ndQuadrant.com PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
Re: Changing WAL Header to reduce contention during ReserveXLogInsertLocation()
From
Robert Haas
Date:
On Tue, Mar 27, 2018 at 6:35 AM, Andrew Dunstan
<andrew.dunstan@2ndquadrant.com> wrote:
> Leaving aside the arguments about process, the patch is pretty small
> and fairly straightforward. Given the claimed performance gains that's
> a nice bang for the buck.
>
> I haven't seen any obvious holes, but this is surely a case for as
> many eyeballs as possible.
Taking a look at this version, I think the key thing we have to decide
is whether we're comfortable with this:
--- a/src/include/access/xlogrecord.h
+++ b/src/include/access/xlogrecord.h
@@ -42,7 +42,7 @@ typedef struct XLogRecord
{
uint32 xl_tot_len; /* total len of entire record */
TransactionId xl_xid; /* xact id */
- XLogRecPtr xl_prev; /* ptr to previous record in log */
+ XLogRecPtr xl_curr; /* ptr to this record in log */
uint8 xl_info; /* flag bits, see below */
RmgrId xl_rmid; /* resource manager for this record */
/* 2 bytes of padding here, initialize to zero */
I don't see any comments in the patch explaining why this substitution
is just as safe as what we had before, and I think it has only very
briefly been commented upon by Pavan, who remarked that it provided
similar protection to what we have today. That's fair enough, but I
think a little more analysis of this point would be good. Can we
think of any possible downsides to making this change? I think there
are basically two issues:
1. Does it materially increase the chance of a bogus checksum match in
any plausible situation?
2. Does the new logic in pg_rewind to search backward for a checkpoint
work reliably, and will it be slow?
I don't know of a problem in either regard, but I wonder if anyone
else can think of anything.
--
Robert Haas
EnterpriseDB: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
Robert Haas <robertmhaas@gmail.com> writes:
> Taking a look at this version, I think the key thing we have to decide
> is whether we're comfortable with this:
> --- a/src/include/access/xlogrecord.h
> +++ b/src/include/access/xlogrecord.h
> @@ -42,7 +42,7 @@ typedef struct XLogRecord
> {
> uint32 xl_tot_len; /* total len of entire record */
> TransactionId xl_xid; /* xact id */
> - XLogRecPtr xl_prev; /* ptr to previous record in log */
> + XLogRecPtr xl_curr; /* ptr to this record in log */
> uint8 xl_info; /* flag bits, see below */
> RmgrId xl_rmid; /* resource manager for this record */
> /* 2 bytes of padding here, initialize to zero */
> I don't see any comments in the patch explaining why this substitution
> is just as safe as what we had before, and I think it has only very
> briefly been commented upon by Pavan, who remarked that it provided
> similar protection to what we have today. That's fair enough, but I
> think a little more analysis of this point would be good.
I had not noticed that in the kerfuffle over the more extreme version,
but I think this is a different route to breaking the same guarantees.
The point of the xl_prev links is, essentially, to allow verification
that we are reading a coherent series of WAL records, ie that record B
which appears to follow record A actually is supposed to follow it.
This throws away that cross-check just as effectively as the other patch
did, leaving us reliant solely on the per-record CRCs. CRCs are good,
but they do have a false-positive rate.
An example of a case where xl_prev makes one feel a lot more comfortable
is the WAL-segment-switch option. The fact that the first record of the
next WAL file links back to the XLOG_SWITCH record is evidence that
ignoring multiple megabytes of WAL was indeed the intended thing to do.
An xl_curr field cannot provide any evidence as to whether WAL records
were missed.
> 2. Does the new logic in pg_rewind to search backward for a checkpoint
> work reliably, and will it be slow?
If you have to search backwards, this breaks it. Full stop.
regards, tom lane
Re: Changing WAL Header to reduce contention during ReserveXLogInsertLocation()
From
Simon Riggs
Date:
On 27 March 2018 at 14:58, Tom Lane <tgl@sss.pgh.pa.us> wrote: > The point of the xl_prev links is, essentially, to allow verification > that we are reading a coherent series of WAL records, ie that record B > which appears to follow record A actually is supposed to follow it. > This throws away that cross-check just as effectively as the other patch > did, leaving us reliant solely on the per-record CRCs. CRCs are good, > but they do have a false-positive rate. You aren't reliant solely on the CRC. If you have a false-positive CRC then xl_curr allows you to validate the record, just as you would with xl_prev. The xl_curr value points to itself using just as many bits as the xl_prev field, so the probability of false validation is the same as now. xl_prev does allow you to verify that the WAL records form an unbroken chain. The question is whether that has value because it certainly has a very clear cost in terms of write performance. Is there some danger that we would skip records? Where does that risk come from? If someone *wanted* to skip records for whatever reason, they could achieve that with both xl_prev or xl_curr, so there is no difference there. > An example of a case where xl_prev makes one feel a lot more comfortable > is the WAL-segment-switch option. The fact that the first record of the > next WAL file links back to the XLOG_SWITCH record is evidence that > ignoring multiple megabytes of WAL was indeed the intended thing to do. > An xl_curr field cannot provide any evidence as to whether WAL records > were missed. That's a good point, though very frequently unused since streaming replication. We can handle XLOG_SWITCH as a special case. Perhaps we can make each file header point back to the previous WAL record. >> 2. Does the new logic in pg_rewind to search backward for a checkpoint >> work reliably, and will it be slow? > > If you have to search backwards, this breaks it. Full stop. You don't have to search backwards. We only need to locate the last checkpoint record. -- Simon Riggs http://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
Re: Changing WAL Header to reduce contention during ReserveXLogInsertLocation()
From
Pavan Deolasee
Date:
On Tue, Mar 27, 2018 at 7:28 PM, Tom Lane <tgl@sss.pgh.pa.us> wrote:
I had not noticed that in the kerfuffle over the more extreme version,
but I think this is a different route to breaking the same guarantees.
The point of the xl_prev links is, essentially, to allow verification
that we are reading a coherent series of WAL records, ie that record B
which appears to follow record A actually is supposed to follow it.
This throws away that cross-check just as effectively as the other patch
did, leaving us reliant solely on the per-record CRCs. CRCs are good,
but they do have a false-positive rate.
An example of a case where xl_prev makes one feel a lot more comfortable
is the WAL-segment-switch option. The fact that the first record of the
next WAL file links back to the XLOG_SWITCH record is evidence that
ignoring multiple megabytes of WAL was indeed the intended thing to do.
An xl_curr field cannot provide any evidence as to whether WAL records
were missed.
TBH I still don't see why this does not provide the same guarantee that the current code provides, but given the concerns expressed by others, I am not gonna pursue beyond a point. But one last time :-)
The current code uses xl_prev to cross-verify the record B, read after record A, indeed follows A and has a valid back-link to A. This deals with problems where B might actually be an old WAL record, carried over from a stale WAL file.
Now if we store xl_curr, we can definitely guarantee that B is ahead of A because B->xl_curr will be greater than A->xl_curr (otherwise we bail out). So that deals with the problem of stale WAL records. In addition, we also know where A ends (we can deduce that even for XLOG_SWITCH records knowing where the next record will start after the switch) and hence we know where B should start. So we read at B and also confirm that B->xl_curr matches B's position. If it does not, we declare end-of-WAL and bail out. So where is the problem?
> 2. Does the new logic in pg_rewind to search backward for a checkpoint
> work reliably, and will it be slow?
If you have to search backwards, this breaks it. Full stop.
A <- B <- C <- CHKPT <- D <- E <- F <- G
So today, if we want to find last checkpoint prio to G, we go through the back-links until we find the first checkpoint record. In the proposed code, we read forward the current WAL segment, remember the last CHKPT record seen and once we see G, we know we have found the prior checkpoint. If the checkpoint does not exist in the current WAL, we read forward the previous WAL and return the last checkpoint record in that WAL and so on. So in the worst case, we might read a WAL segment extra before we find the checkpoint record. That's not ideal but not too bad given that only pg_rewind needs this and that too only once.
So today, if we want to find last checkpoint prio to G, we go through the back-links until we find the first checkpoint record. In the proposed code, we read forward the current WAL segment, remember the last CHKPT record seen and once we see G, we know we have found the prior checkpoint. If the checkpoint does not exist in the current WAL, we read forward the previous WAL and return the last checkpoint record in that WAL and so on. So in the worst case, we might read a WAL segment extra before we find the checkpoint record. That's not ideal but not too bad given that only pg_rewind needs this and that too only once.
Thanks,
Pavan
--
Pavan Deolasee http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Training & Services
PostgreSQL Development, 24x7 Support, Training & Services
Simon Riggs <simon@2ndquadrant.com> writes:
> On 27 March 2018 at 14:58, Tom Lane <tgl@sss.pgh.pa.us> wrote:
>> The point of the xl_prev links is, essentially, to allow verification
>> that we are reading a coherent series of WAL records, ie that record B
>> which appears to follow record A actually is supposed to follow it.
>> This throws away that cross-check just as effectively as the other patch
>> did, leaving us reliant solely on the per-record CRCs. CRCs are good,
>> but they do have a false-positive rate.
> You aren't reliant solely on the CRC.
> If you have a false-positive CRC then xl_curr allows you to validate
> the record, just as you would with xl_prev. The xl_curr value points
> to itself using just as many bits as the xl_prev field, so the
> probability of false validation is the same as now.
No. xl_curr says that this record is where it thinks it should be.
It fails to provide indication as to which record it should follow,
and that in my opinion is important context-sensitivity that xl_curr
would lack.
The XLOG_SWITCH example speaks to this. Now that we have variable
wal segment size, it is not an ironclad certainty that all onlookers
agree as to where the segment boundaries are. Suppose someone reads
an XLOG_SWITCH, and thinks it means "skip to the next 16MB boundary"
whereas the writer thought it meant "skip to the next 8MB boundary".
With xl_prev, the prev-link mismatch will clue that reader that
something is wrong. With xl_curr, there is no mismatch to detect,
and the reader will go happily on its way having missed 8MB worth
of WAL.
The impression I have, without having really studied the details,
is that all of the patches proposed in this thread are trying to
buy concurrency by removing context-sensitivity of the WAL headers.
I do not think that's a good idea.
regards, tom lane
Pavan Deolasee <pavan.deolasee@gmail.com> writes:
> On Tue, Mar 27, 2018 at 7:28 PM, Tom Lane <tgl@sss.pgh.pa.us> wrote:
>> If you have to search backwards, this breaks it. Full stop.
> We don't really need to fetch the previous record. We really need to find
> the last checkpoint prior to a given LSN. That can be done by reading WAL
> segments forward. It can be a little slow, but hopefully not a whole lot.
This is ignoring the possibility of damaged data in between, ie
A ... B ... CHKPT ... C ... a few zeroed pages ... D ... CHKPT ... E ... F
If A is the start of the WAL segment, and you ask what's the last
checkpoint before F, you will get the wrong answer. Or, if you're
paranoid and verify that you can follow the chain all the way to F,
you'll fail ... needlessly, and in a case where we previously succeeded.
regards, tom lane
Re: Changing WAL Header to reduce contention during ReserveXLogInsertLocation()
From
Robert Haas
Date:
On Tue, Mar 27, 2018 at 11:41 AM, Tom Lane <tgl@sss.pgh.pa.us> wrote: > Pavan Deolasee <pavan.deolasee@gmail.com> writes: >> On Tue, Mar 27, 2018 at 7:28 PM, Tom Lane <tgl@sss.pgh.pa.us> wrote: >>> If you have to search backwards, this breaks it. Full stop. > >> We don't really need to fetch the previous record. We really need to find >> the last checkpoint prior to a given LSN. That can be done by reading WAL >> segments forward. It can be a little slow, but hopefully not a whole lot. > > This is ignoring the possibility of damaged data in between, ie > > A ... B ... CHKPT ... C ... a few zeroed pages ... D ... CHKPT ... E ... F > > If A is the start of the WAL segment, and you ask what's the last > checkpoint before F, you will get the wrong answer. Or, if you're > paranoid and verify that you can follow the chain all the way to F, > you'll fail ... needlessly, and in a case where we previously succeeded. It's hard for me to believe that this case matters very much. If you're trying to run pg_rewind on a system where the WAL segments contain a few zeroed pages, you're probably going to be hosed anyway, if not by this particular thing then by something else. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
Robert Haas <robertmhaas@gmail.com> writes:
> On Tue, Mar 27, 2018 at 11:41 AM, Tom Lane <tgl@sss.pgh.pa.us> wrote:
>> This is ignoring the possibility of damaged data in between, ie
>> A ... B ... CHKPT ... C ... a few zeroed pages ... D ... CHKPT ... E ... F
> It's hard for me to believe that this case matters very much. If
> you're trying to run pg_rewind on a system where the WAL segments
> contain a few zeroed pages, you're probably going to be hosed anyway,
> if not by this particular thing then by something else.
Well, the point of checkpoints is that WAL data before the last one
should no longer matter anymore, isn't it?
But really this is just one illustration of the point, which is that
changing the WAL header definition as proposed *does* cost us reliability.
We can argue about whether better concurrency in WAL insertion is
worth that price, but claiming that the price is zero is flat wrong.
For me, the more important issue is that checking xl_prev not only
validates that the record is where it is supposed to be, but that you
arrived at it correctly. Replacing it with xl_curr would keep the
guarantee of the former (in fact likely make it stronger); but we'd
completely lose the latter.
regards, tom lane
Re: Changing WAL Header to reduce contention during ReserveXLogInsertLocation()
From
Andrew Dunstan
Date:
On Wed, Mar 28, 2018 at 1:21 AM, Pavan Deolasee <pavan.deolasee@gmail.com> wrote: > > > TBH I still don't see why this does not provide the same guarantee that the > current code provides, but given the concerns expressed by others, I am not > gonna pursue beyond a point. But one last time :-) > > The current code uses xl_prev to cross-verify the record B, read after > record A, indeed follows A and has a valid back-link to A. This deals with > problems where B might actually be an old WAL record, carried over from a > stale WAL file. > > Now if we store xl_curr, we can definitely guarantee that B is ahead of A > because B->xl_curr will be greater than A->xl_curr (otherwise we bail out). > So that deals with the problem of stale WAL records. In addition, we also > know where A ends (we can deduce that even for XLOG_SWITCH records knowing > where the next record will start after the switch) and hence we know where B > should start. So we read at B and also confirm that B->xl_curr matches B's > position. If it does not, we declare end-of-WAL and bail out. So where is > the problem? > This seems to have got a bit lost in subsequent discussion. >> >> > 2. Does the new logic in pg_rewind to search backward for a checkpoint >> > work reliably, and will it be slow? >> >> If you have to search backwards, this breaks it. Full stop. > > > We don't really need to fetch the previous record. We really need to find > the last checkpoint prior to a given LSN. That can be done by reading WAL > segments forward. It can be a little slow, but hopefully not a whole lot. > > A <- B <- C <- CHKPT <- D <- E <- F <- G > > So today, if we want to find last checkpoint prio to G, we go through the > back-links until we find the first checkpoint record. In the proposed code, > we read forward the current WAL segment, remember the last CHKPT record seen > and once we see G, we know we have found the prior checkpoint. If the > checkpoint does not exist in the current WAL, we read forward the previous > WAL and return the last checkpoint record in that WAL and so on. So in the > worst case, we might read a WAL segment extra before we find the checkpoint > record. That's not ideal but not too bad given that only pg_rewind needs > this and that too only once. > Some degree of slowdown in pg_rewind seems an acceptable price to pay as long as it doesn't introduce errors. cheers andrew -- Andrew Dunstan https://www.2ndQuadrant.com PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
Re: Changing WAL Header to reduce contention duringReserveXLogInsertLocation()
From
Michael Paquier
Date:
On Tue, Mar 27, 2018 at 02:02:10PM -0400, Tom Lane wrote: > Robert Haas <robertmhaas@gmail.com> writes: >> On Tue, Mar 27, 2018 at 11:41 AM, Tom Lane <tgl@sss.pgh.pa.us> wrote: >>> This is ignoring the possibility of damaged data in between, ie >>> A ... B ... CHKPT ... C ... a few zeroed pages ... D ... CHKPT ... E ... F > >> It's hard for me to believe that this case matters very much. If >> you're trying to run pg_rewind on a system where the WAL segments >> contain a few zeroed pages, you're probably going to be hosed anyway, >> if not by this particular thing then by something else. > > Well, the point of checkpoints is that WAL data before the last one > should no longer matter anymore, isn't it? I have to agree with Tom here. If you force pg_rewind to replay more WAL records from a checkpoint older than the checkpoint prior to where WAL has forked at promotion then you have a risk of losing data. Remember, this comes close to the recent thread where we discussed that keeping in pg_wal WAL segments worth more than the last completed checkpoints could lead to corruption if you try to replay from that, which led to 4b0d28d. -- Michael
Attachment
Re: Changing WAL Header to reduce contention during ReserveXLogInsertLocation()
From
Robert Haas
Date:
On Tue, Mar 27, 2018 at 10:06 PM, Michael Paquier <michael@paquier.xyz> wrote: > On Tue, Mar 27, 2018 at 02:02:10PM -0400, Tom Lane wrote: >> Robert Haas <robertmhaas@gmail.com> writes: >>> On Tue, Mar 27, 2018 at 11:41 AM, Tom Lane <tgl@sss.pgh.pa.us> wrote: >>>> This is ignoring the possibility of damaged data in between, ie >>>> A ... B ... CHKPT ... C ... a few zeroed pages ... D ... CHKPT ... E ... F >> >>> It's hard for me to believe that this case matters very much. If >>> you're trying to run pg_rewind on a system where the WAL segments >>> contain a few zeroed pages, you're probably going to be hosed anyway, >>> if not by this particular thing then by something else. >> >> Well, the point of checkpoints is that WAL data before the last one >> should no longer matter anymore, isn't it? > > I have to agree with Tom here. If you force pg_rewind to replay more > WAL records from a checkpoint older than the checkpoint prior to where > WAL has forked at promotion then you have a risk of losing data. Oh! I see now. Good point. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
Re: Changing WAL Header to reduce contention duringReserveXLogInsertLocation()
From
Michael Paquier
Date:
On Tue, Mar 27, 2018 at 10:09:59PM -0400, Robert Haas wrote: >> I have to agree with Tom here. If you force pg_rewind to replay more >> WAL records from a checkpoint older than the checkpoint prior to where >> WAL has forked at promotion then you have a risk of losing data. > > Oh! I see now. Good point. Something that would address the issue would be to enforce a segment switch after each checkpoint, but that's a high price to pay on mostly idle systems with large WAL segments, which is not appealing either, and this even if the checkpoint skip logic has been fixed in v10 with the concept of "important" WAL records. -- Michael
Attachment
Re: Changing WAL Header to reduce contention during ReserveXLogInsertLocation()
From
Andrew Dunstan
Date:
On Wed, Mar 28, 2018 at 12:57 PM, Michael Paquier <michael@paquier.xyz> wrote: > On Tue, Mar 27, 2018 at 10:09:59PM -0400, Robert Haas wrote: >>> I have to agree with Tom here. If you force pg_rewind to replay more >>> WAL records from a checkpoint older than the checkpoint prior to where >>> WAL has forked at promotion then you have a risk of losing data. >> >> Oh! I see now. Good point. > > Something that would address the issue would be to enforce a segment > switch after each checkpoint, but that's a high price to pay on mostly > idle systems with large WAL segments, which is not appealing either, and > this even if the checkpoint skip logic has been fixed in v10 with the > concept of "important" WAL records. If the system is mostly idle would it really matter that much? cheers andrew -- Andrew Dunstan https://www.2ndQuadrant.com PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
Re: Changing WAL Header to reduce contention during ReserveXLogInsertLocation()
From
Pavan Deolasee
Date:
On Wed, Mar 28, 2018 at 7:36 AM, Michael Paquier <michael@paquier.xyz> wrote:
On Tue, Mar 27, 2018 at 02:02:10PM -0400, Tom Lane wrote:
>
> Well, the point of checkpoints is that WAL data before the last one
> should no longer matter anymore, isn't it?
I have to agree with Tom here. If you force pg_rewind to replay more
WAL records from a checkpoint older than the checkpoint prior to where
WAL has forked at promotion then you have a risk of losing data.
Yeah, we should not do that. The patch surely does not intend to replay any more WAL than what we do today. The idea is to just use a different mechanism to find the prior checkpoint. But we should surely find the latest prior checkpoint. In the rare scenario that Tom showed, we should just throw an error and fix the patch if it's not doing that already.
Thanks,
Pavan
Pavan Deolasee http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Training & Services
PostgreSQL Development, 24x7 Support, Training & Services
Re: Changing WAL Header to reduce contention duringReserveXLogInsertLocation()
From
Michael Paquier
Date:
On Wed, Mar 28, 2018 at 02:13:19PM +1030, Andrew Dunstan wrote: > On Wed, Mar 28, 2018 at 12:57 PM, Michael Paquier <michael@paquier.xyz> wrote: >> Something that would address the issue would be to enforce a segment >> switch after each checkpoint, but that's a high price to pay on mostly >> idle systems with large WAL segments, which is not appealing either, and >> this even if the checkpoint skip logic has been fixed in v10 with the >> concept of "important" WAL records. > > If the system is mostly idle would it really matter that much? We cannot assume that all archive commands support compression, even if the rest of a forcibly switched segment is filled with zeros, so that would cause extra I/O effort for such instances. I see quite a lot of downsides to that. -- Michael
Attachment
Re: Changing WAL Header to reduce contention during ReserveXLogInsertLocation()
From
Robert Haas
Date:
On Tue, Mar 27, 2018 at 11:53 PM, Pavan Deolasee <pavan.deolasee@gmail.com> wrote: > Yeah, we should not do that. The patch surely does not intend to replay any > more WAL than what we do today. The idea is to just use a different > mechanism to find the prior checkpoint. But we should surely find the latest > prior checkpoint. In the rare scenario that Tom showed, we should just throw > an error and fix the patch if it's not doing that already. It's not clear to me that there is any reasonable fix short of giving up on this approach altogether. But I might be missing something. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
Re: Changing WAL Header to reduce contention duringReserveXLogInsertLocation()
From
Michael Paquier
Date:
On Wed, Mar 28, 2018 at 08:50:21PM -0400, Robert Haas wrote: > On Tue, Mar 27, 2018 at 11:53 PM, Pavan Deolasee <pavan.deolasee@gmail.com> wrote: >> Yeah, we should not do that. The patch surely does not intend to replay any >> more WAL than what we do today. The idea is to just use a different >> mechanism to find the prior checkpoint. But we should surely find the latest >> prior checkpoint. In the rare scenario that Tom showed, we should just throw >> an error and fix the patch if it's not doing that already. > > It's not clear to me that there is any reasonable fix short of giving > up on this approach altogether. But I might be missing something. One way to get things done right is to scan recursively segments instead of records. Not impossible but this introduces more code churns in pg_rewind's findLastCheckpoint which is now dead-simple as it just need to look at things backwards. This way you can know as well what is the real last checkpoint as you know as well what's the point where WAL has forked. So for multiple checkpoints on the same segment, the lookup just needs to happen up to the point where WAL has forked, while keeping track of the last checkpoint record found. If we would want to keep compatibility with backward searches, it may be nice to keep a mostly-compatible API layer in xlogreader.c. Now I have honestly not thought about that much. And there may be other tools which rely on being able to do backward searches. Breaking compatibility for them could cause wraith because that would mean less availability when running a rewind-like operation. This thread makes me wonder as well if we are overlooking other things... -- Michael
Attachment
Re: Changing WAL Header to reduce contention during ReserveXLogInsertLocation()
From
Simon Riggs
Date:
On 29 March 2018 at 01:50, Robert Haas <robertmhaas@gmail.com> wrote: > On Tue, Mar 27, 2018 at 11:53 PM, Pavan Deolasee > <pavan.deolasee@gmail.com> wrote: >> Yeah, we should not do that. The patch surely does not intend to replay any >> more WAL than what we do today. The idea is to just use a different >> mechanism to find the prior checkpoint. But we should surely find the latest >> prior checkpoint. In the rare scenario that Tom showed, we should just throw >> an error and fix the patch if it's not doing that already. > > It's not clear to me that there is any reasonable fix short of giving > up on this approach altogether. But I might be missing something. (Sorry to come back to this late) Yes, a few things have been been missed in this discussion. Michael's point is invalid. The earlier discussion said that *replay* of WAL earlier than the last checkpoint could lead to corruption, but this doesn't mean the records themselves are in some way damaged structurally, only that their content can lead to inconsistency in the database. The xl_curr proposal does not replay WAL records it only searches thru them to locate the last checkpoint. Tom also said "Well, the point of checkpoints is that WAL data before the last one should no longer matter anymore, isn't it?". WAL Files prior to the one containing the last checkpoint can be discarded, but checkpoints themselves do nothing to invalidate the WAL records before the checkpoint. Tom's point that a corruption in the WAL file could prevent pg_rewind from locating a record is valid, but misses something. If the WAL file contained corruption AFTER the last checkpoint this would already in the current code prevent pg_rewind from moving backwards to find the last checkpoint. So whether you go forwards or backwards it is possible to be blocked by corrupt WAL records. Most checkpoints are far enough apart that there is only one checkpoint record in any WAL file and it could be anywhere in the file, so the expected number of records to be searched by forwards or backwards scans is equal. And the probability that corruption occurs before or after the record is also equal. Given the above points, I don't see any reason to believe that the forwards search mechanism proposed is faulty, decreases robustness or is even slower. Overall, the loss of links between WAL records is not a loss of robustness. XLOG_SWITCH is a costly operation and mostly unusable these days, so shouldn't be a reason to shy away from this patch. We don't jump around in WAL in any other way, so sequential records are just fine. So IMHO the proposed approach is still very much viable. I know the approach is new and surprising but I thought about it a lot before proposing it and I couldn't see any holes; still can't. Please give this some thought so we can get comfortable with this idea and increase performance as a result. Thanks. -- Simon Riggs http://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
Simon Riggs <simon@2ndquadrant.com> writes:
> I know the approach is new and surprising but I thought about it a lot
> before proposing it and I couldn't see any holes; still can't. Please
> give this some thought so we can get comfortable with this idea and
> increase performance as a result. Thanks.
The long and the short of it is that this is a very dangerous-looking
proposal, we are at the tail end of a development cycle, and there are
~100 other patches remaining in the commitfest that also have claims
on our attention in the short time that's left. If you're expecting
people to spend more time thinking about this now, I feel you're being
unreasonable.
Also, I will say it once more: this change DOES decrease robustness.
It's like blockchain without the chain aspect, or git commits without
a parent pointer. We are not only interested in whether individual
WAL records are valid, but whether they form a consistent series.
Cross-checking xl_prev provides some measure of confidence about that;
xl_curr offers none.
regards, tom lane
Re: Changing WAL Header to reduce contention duringReserveXLogInsertLocation()
From
Tomas Vondra
Date:
On 03/29/2018 06:42 PM, Tom Lane wrote: > Simon Riggs <simon@2ndquadrant.com> writes: >> I know the approach is new and surprising but I thought about it a lot >> before proposing it and I couldn't see any holes; still can't. Please >> give this some thought so we can get comfortable with this idea and >> increase performance as a result. Thanks. > > The long and the short of it is that this is a very dangerous-looking > proposal, we are at the tail end of a development cycle, and there are > ~100 other patches remaining in the commitfest that also have claims > on our attention in the short time that's left. If you're expecting > people to spend more time thinking about this now, I feel you're being > unreasonable. > I agree. > Also, I will say it once more: this change DOES decrease robustness. > It's like blockchain without the chain aspect, or git commits without > a parent pointer. We are not only interested in whether individual > WAL records are valid, but whether they form a consistent series. > Cross-checking xl_prev provides some measure of confidence about that; > xl_curr offers none. > Not sure. If each WAL record has xl_curr, then we know to which position the record belongs (after verifying the checksum). And we do know the size of each WAL record, so we should be able to deduce if two records are immediately after each other. Which I think is enough to rebuild the chain of WAL records. To defeat this, this would need to happen: a) the WAL record gets written to a different location b) the xl_curr gets corrupted in sync with (a) c) the WAL checksum gets corrupted in sync with (b) d) the record overwrites existing record (same size/boundaries) That seems very much like xl_prev. regards -- Tomas Vondra http://www.2ndQuadrant.com PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
Re: Changing WAL Header to reduce contention during ReserveXLogInsertLocation()
From
Robert Haas
Date:
On Thu, Mar 29, 2018 at 1:13 PM, Tomas Vondra <tomas.vondra@2ndquadrant.com> wrote: > On 03/29/2018 06:42 PM, Tom Lane wrote: >> The long and the short of it is that this is a very dangerous-looking >> proposal, we are at the tail end of a development cycle, and there are >> ~100 other patches remaining in the commitfest that also have claims >> on our attention in the short time that's left. If you're expecting >> people to spend more time thinking about this now, I feel you're being >> unreasonable. > > I agree. +1. >> Also, I will say it once more: this change DOES decrease robustness. >> It's like blockchain without the chain aspect, or git commits without >> a parent pointer. We are not only interested in whether individual >> WAL records are valid, but whether they form a consistent series. >> Cross-checking xl_prev provides some measure of confidence about that; >> xl_curr offers none. > > Not sure. > > If each WAL record has xl_curr, then we know to which position the > record belongs (after verifying the checksum). And we do know the size > of each WAL record, so we should be able to deduce if two records are > immediately after each other. Which I think is enough to rebuild the > chain of WAL records. > > To defeat this, this would need to happen: > > a) the WAL record gets written to a different location > b) the xl_curr gets corrupted in sync with (a) > c) the WAL checksum gets corrupted in sync with (b) > d) the record overwrites existing record (same size/boundaries) > > That seems very much like xl_prev. I don't think so, because this ignores, for example, timeline switches, or multiple clusters accidentally sharing an archive directory. TBH, I'm not entirely sure how likely corruption would be under this proposal in practice, but I think Tom's got the right idea on a theoretical level. As he says, there's a reason why things like block chains and git commits include something about the previous record in what gets hashed to create the identifier for the new record. It ties those things together in a way that doesn't happen otherwise. If somebody proposed changing git so that the SHA identifier for a commit didn't hash the commit ID for the previous commit, that would break the security of the system in all kinds of ways: for example, an adversary could maliciously edit an old commit by just changing its SHA identifier and that of its immediate descendent. No other commit IDs would change and integrity checks would not fail -- there would be no easy way to notice that something bad had happened. Now, in our case, the chances of problems are clearly a lot more remote because of the way that WAL records are packed into files. Every WAL record has a place where it's supposed to appear in the WAL stream, and positions in the WAL stream are never intentionally recycled (except in PITR scenarios, I guess). Because of that, the proposed xl_curr check provides a pretty strong cross-check on the validity of a record even without xl_prev. I think there is an argument to be made - as Simon is doing - that this check is in fact strong enough that it's good enough for government work. He might be right. But he might also be wrong, because I think Tom is unquestionably correct when he says that this is weakening the check. What I'm not sure about is whether it's being weakened enough that it's actually going to cause problems in practice. Given where we are in the release cycle, I'd prefer to defer that question to next cycle. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
Re: Changing WAL Header to reduce contention during ReserveXLogInsertLocation()
From
Simon Riggs
Date:
On 29 March 2018 at 18:13, Tomas Vondra <tomas.vondra@2ndquadrant.com> wrote: > On 03/29/2018 06:42 PM, Tom Lane wrote: >> Simon Riggs <simon@2ndquadrant.com> writes: >>> I know the approach is new and surprising but I thought about it a lot >>> before proposing it and I couldn't see any holes; still can't. Please >>> give this some thought so we can get comfortable with this idea and >>> increase performance as a result. Thanks. >> >> The long and the short of it is that this is a very dangerous-looking >> proposal, we are at the tail end of a development cycle, and there are >> ~100 other patches remaining in the commitfest that also have claims >> on our attention in the short time that's left. If you're expecting >> people to spend more time thinking about this now, I feel you're being >> unreasonable. >> > > I agree. We require consensus on such things for good reason. Risk is an issue and everyone must be comfortable. If its a good idea now it will still be a good idea in the next cycle. >> Also, I will say it once more: this change DOES decrease robustness. >> It's like blockchain without the chain aspect, or git commits without >> a parent pointer. We are not only interested in whether individual >> WAL records are valid, but whether they form a consistent series. >> Cross-checking xl_prev provides some measure of confidence about that; >> xl_curr offers none. >> > > Not sure. > > If each WAL record has xl_curr, then we know to which position the > record belongs (after verifying the checksum). And we do know the size > of each WAL record, so we should be able to deduce if two records are > immediately after each other. Which I think is enough to rebuild the > chain of WAL records. > > To defeat this, this would need to happen: > > a) the WAL record gets written to a different location > b) the xl_curr gets corrupted in sync with (a) > c) the WAL checksum gets corrupted in sync with (b) > d) the record overwrites existing record (same size/boundaries) > > That seems very much like xl_prev. That's how I see it. But I also see that it feels different to what we had before and that takes time to either come up with a concrete, quantifiable reason not to, or accept that it is OK. So given my observation that no technical objection remains, I'm happy to move this to next CF to give us more time and less risk. -- Simon Riggs http://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
Re: Changing WAL Header to reduce contention duringReserveXLogInsertLocation()
From
Tomas Vondra
Date:
On 03/29/2018 08:02 PM, Robert Haas wrote: > On Thu, Mar 29, 2018 at 1:13 PM, Tomas Vondra > <tomas.vondra@2ndquadrant.com> wrote: >> On 03/29/2018 06:42 PM, Tom Lane wrote: >>> The long and the short of it is that this is a very dangerous-looking >>> proposal, we are at the tail end of a development cycle, and there are >>> ~100 other patches remaining in the commitfest that also have claims >>> on our attention in the short time that's left. If you're expecting >>> people to spend more time thinking about this now, I feel you're being >>> unreasonable. >> >> I agree. > > +1. > >>> Also, I will say it once more: this change DOES decrease robustness. >>> It's like blockchain without the chain aspect, or git commits without >>> a parent pointer. We are not only interested in whether individual >>> WAL records are valid, but whether they form a consistent series. >>> Cross-checking xl_prev provides some measure of confidence about that; >>> xl_curr offers none. >> >> Not sure. >> >> If each WAL record has xl_curr, then we know to which position the >> record belongs (after verifying the checksum). And we do know the size >> of each WAL record, so we should be able to deduce if two records are >> immediately after each other. Which I think is enough to rebuild the >> chain of WAL records. >> >> To defeat this, this would need to happen: >> >> a) the WAL record gets written to a different location >> b) the xl_curr gets corrupted in sync with (a) >> c) the WAL checksum gets corrupted in sync with (b) >> d) the record overwrites existing record (same size/boundaries) >> >> That seems very much like xl_prev. > > I don't think so, because this ignores, for example, timeline > switches, or multiple clusters accidentally sharing an archive > directory. > I'm curious? How does xl_prev prevents either of those issues (in a way that xl_curr would not)? > TBH, I'm not entirely sure how likely corruption would be under this > proposal in practice, but I think Tom's got the right idea on a > theoretical level. As he says, there's a reason why things like > block chains and git commits include something about the previous > record in what gets hashed to create the identifier for the new > record. It ties those things together in a way that doesn't happen > otherwise. If somebody proposed changing git so that the SHA > identifier for a commit didn't hash the commit ID for the previous > commit, that would break the security of the system in all kinds of > ways: for example, an adversary could maliciously edit an old commit > by just changing its SHA identifier and that of its immediate > descendent. No other commit IDs would change and integrity checks > would not fail -- there would be no easy way to notice that something > bad had happened. > That seems like a rather poor analogy, because we're not protected against such adversarial modifications with xl_prev either. I can damage the previous WAL record, update its checksum and you won't notice anything. My understanding is that xl_curr and xl_prev give us pretty much the same amount of information, except that xl_prev provides it explicitly while with xl_curr it's implicit and we need to deduce it. > Now, in our case, the chances of problems are clearly a lot more > remote because of the way that WAL records are packed into files. > Every WAL record has a place where it's supposed to appear in the WAL > stream, and positions in the WAL stream are never intentionally > recycled (except in PITR scenarios, I guess). Because of that, the > proposed xl_curr check provides a pretty strong cross-check on the > validity of a record even without xl_prev. I think there is an > argument to be made - as Simon is doing - that this check is in fact > strong enough that it's good enough for government work. He might be Is he? I think the claims in this thread were pretty much that xl_curr and xl_prev provide the same level of protection. > right. But he might also be wrong, because I think Tom is > unquestionably correct when he says that this is weakening the check. > What I'm not sure about is whether it's being weakened enough that > it's actually going to cause problems in practice. Given where we are > in the release cycle, I'd prefer to defer that question to next cycle. > Perhaps. I guess the ultimate argument would be an example where xl_prev does provides protection that xl_curr does not. There have been a couple of examples presented in this thread, but I don't think either of them actually shows the xl_prev superiority (or I missed that). regards -- Tomas Vondra http://www.2ndQuadrant.com PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
Re: Changing WAL Header to reduce contention during ReserveXLogInsertLocation()
From
Simon Riggs
Date:
On 29 March 2018 at 19:02, Robert Haas <robertmhaas@gmail.com> wrote: > >>> Also, I will say it once more: this change DOES decrease robustness. >>> It's like blockchain without the chain aspect, or git commits without >>> a parent pointer. We are not only interested in whether individual >>> WAL records are valid, but whether they form a consistent series. >>> Cross-checking xl_prev provides some measure of confidence about that; >>> xl_curr offers none. >> >> Not sure. >> >> If each WAL record has xl_curr, then we know to which position the >> record belongs (after verifying the checksum). And we do know the size >> of each WAL record, so we should be able to deduce if two records are >> immediately after each other. Which I think is enough to rebuild the >> chain of WAL records. >> >> To defeat this, this would need to happen: >> >> a) the WAL record gets written to a different location >> b) the xl_curr gets corrupted in sync with (a) >> c) the WAL checksum gets corrupted in sync with (b) >> d) the record overwrites existing record (same size/boundaries) >> >> That seems very much like xl_prev. > > I don't think so, because this ignores, for example, timeline > switches, or multiple clusters accidentally sharing an archive > directory. I'm not hearing any actual technical problems. > Given where we are > in the release cycle, I'd prefer to defer that question to next cycle. Accepted, on the basis of risk. -- Simon Riggs http://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
Re: Changing WAL Header to reduce contention during ReserveXLogInsertLocation()
From
Simon Riggs
Date:
On 29 March 2018 at 21:03, Tomas Vondra <tomas.vondra@2ndquadrant.com> wrote: > > On 03/29/2018 08:02 PM, Robert Haas wrote: >> On Thu, Mar 29, 2018 at 1:13 PM, Tomas Vondra >> <tomas.vondra@2ndquadrant.com> wrote: >>> On 03/29/2018 06:42 PM, Tom Lane wrote: >>>> The long and the short of it is that this is a very dangerous-looking >>>> proposal, we are at the tail end of a development cycle, and there are >>>> ~100 other patches remaining in the commitfest that also have claims >>>> on our attention in the short time that's left. If you're expecting >>>> people to spend more time thinking about this now, I feel you're being >>>> unreasonable. >>> >>> I agree. >> >> +1. >> >>>> Also, I will say it once more: this change DOES decrease robustness. >>>> It's like blockchain without the chain aspect, or git commits without >>>> a parent pointer. We are not only interested in whether individual >>>> WAL records are valid, but whether they form a consistent series. >>>> Cross-checking xl_prev provides some measure of confidence about that; >>>> xl_curr offers none. >>> >>> Not sure. >>> >>> If each WAL record has xl_curr, then we know to which position the >>> record belongs (after verifying the checksum). And we do know the size >>> of each WAL record, so we should be able to deduce if two records are >>> immediately after each other. Which I think is enough to rebuild the >>> chain of WAL records. >>> >>> To defeat this, this would need to happen: >>> >>> a) the WAL record gets written to a different location >>> b) the xl_curr gets corrupted in sync with (a) >>> c) the WAL checksum gets corrupted in sync with (b) >>> d) the record overwrites existing record (same size/boundaries) >>> >>> That seems very much like xl_prev. >> >> I don't think so, because this ignores, for example, timeline >> switches, or multiple clusters accidentally sharing an archive >> directory. >> > > I'm curious? How does xl_prev prevents either of those issues (in a way > that xl_curr would not)? > >> TBH, I'm not entirely sure how likely corruption would be under this >> proposal in practice, but I think Tom's got the right idea on a >> theoretical level. As he says, there's a reason why things like >> block chains and git commits include something about the previous >> record in what gets hashed to create the identifier for the new >> record. It ties those things together in a way that doesn't happen >> otherwise. If somebody proposed changing git so that the SHA >> identifier for a commit didn't hash the commit ID for the previous >> commit, that would break the security of the system in all kinds of >> ways: for example, an adversary could maliciously edit an old commit >> by just changing its SHA identifier and that of its immediate >> descendent. No other commit IDs would change and integrity checks >> would not fail -- there would be no easy way to notice that something >> bad had happened. >> > > That seems like a rather poor analogy, because we're not protected > against such adversarial modifications with xl_prev either. I can damage > the previous WAL record, update its checksum and you won't notice anything. > > My understanding is that xl_curr and xl_prev give us pretty much the > same amount of information, except that xl_prev provides it explicitly > while with xl_curr it's implicit and we need to deduce it. > >> Now, in our case, the chances of problems are clearly a lot more >> remote because of the way that WAL records are packed into files. >> Every WAL record has a place where it's supposed to appear in the WAL >> stream, and positions in the WAL stream are never intentionally >> recycled (except in PITR scenarios, I guess). Because of that, the >> proposed xl_curr check provides a pretty strong cross-check on the >> validity of a record even without xl_prev. I think there is an >> argument to be made - as Simon is doing - that this check is in fact >> strong enough that it's good enough for government work. He might be > > Is he? I think the claims in this thread were pretty much that xl_curr > and xl_prev provide the same level of protection. Yes, the blockchain analogy breaks down because we don't include previous CRC, only xl_prev. The existing WAL format is easy enough to repair, falsify etc. You've still got to keep your WAL data secure. So the image of a CSI-style chain-of-evidence thing happening isn't technical reality. You could change the existing format to include the previous CRC in the calculation of the current record's CRC. I'd be happy with that as an option, just as much as I'd support an option for high performance as I've proposed here. But bear in mind that including the CRC would mean that you couldn't repair data damaged by data corruption because it would mean all WAL after the corrupt page would be effectively scrambled. -- Simon Riggs http://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
Tomas Vondra <tomas.vondra@2ndquadrant.com> writes:
> If each WAL record has xl_curr, then we know to which position the
> record belongs (after verifying the checksum). And we do know the size
> of each WAL record, so we should be able to deduce if two records are
> immediately after each other.
Per my point earlier, XLOG_SWITCH is sufficient to defeat that argument.
Also consider a timeline fork. It's really hard to be sure which record
in the old timeline is the direct ancestor of the first one in the new
if you lack xl_prev:
A1 -> B1 -> C1 -> D1
\
B2 -> C2 -> D2
If you happened to get confused and think that C2 is the first in its
timeline, diverging off the old line after B1 not A1, there would be
nothing about C2 to disabuse you of your error.
Now, those cases could be fixed: you could imagine inserting a
"continuation record" after an XLOG_SWITCH or timeline fork, which would
carry a checkable back-link to where it came from, and then we'd arguably
not need to pay the price of back-links during normal sequential
insertion. Still, this approach only fixes the cases where we think to
apply it in advance.
regards, tom lane
Re: Changing WAL Header to reduce contention duringReserveXLogInsertLocation()
From
Tomas Vondra
Date:
On 03/29/2018 11:18 PM, Tom Lane wrote: > Tomas Vondra <tomas.vondra@2ndquadrant.com> writes: >> If each WAL record has xl_curr, then we know to which position the >> record belongs (after verifying the checksum). And we do know the size >> of each WAL record, so we should be able to deduce if two records are >> immediately after each other. > > Per my point earlier, XLOG_SWITCH is sufficient to defeat that argument. But the SWITCH record will be the last record in the WAL segment (and if there happens to be a WAL record after it, it will have invalid xl_curr pointer). And the next valid record will be the first one in the next WAL segment. So why wouldn't that be enough information? > Also consider a timeline fork. It's really hard to be sure which record > in the old timeline is the direct ancestor of the first one in the new > if you lack xl_prev: > > A1 -> B1 -> C1 -> D1 > \ > B2 -> C2 -> D2 > > If you happened to get confused and think that C2 is the first in its > timeline, diverging off the old line after B1 not A1, there would be > nothing about C2 to disabuse you of your error. Doesn't that mean the B1 and B2 have to be exactly the same size? Otherwise there would be a gap between B1/C2 or B2/C1, and the xl_curr would be enough to detect this. And how could xl_prev detect it? AFAIK XLogRecPtr does not include TimeLineID, so xl_prev would be the same for both B1 and B2. I admit WAL internals are not an are I'm particularly familiar with, though, so I may be missing something utterly obvious. regards -- Tomas Vondra http://www.2ndQuadrant.com PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
Re: Changing WAL Header to reduce contention during ReserveXLogInsertLocation()
From
Simon Riggs
Date:
On 29 March 2018 at 23:16, Tomas Vondra <tomas.vondra@2ndquadrant.com> wrote: > > > On 03/29/2018 11:18 PM, Tom Lane wrote: >> Tomas Vondra <tomas.vondra@2ndquadrant.com> writes: >>> If each WAL record has xl_curr, then we know to which position the >>> record belongs (after verifying the checksum). And we do know the size >>> of each WAL record, so we should be able to deduce if two records are >>> immediately after each other. >> >> Per my point earlier, XLOG_SWITCH is sufficient to defeat that argument. > > But the SWITCH record will be the last record in the WAL segment (and if > there happens to be a WAL record after it, it will have invalid xl_curr > pointer). And the next valid record will be the first one in the next > WAL segment. So why wouldn't that be enough information? > >> Also consider a timeline fork. It's really hard to be sure which record >> in the old timeline is the direct ancestor of the first one in the new >> if you lack xl_prev: >> >> A1 -> B1 -> C1 -> D1 >> \ >> B2 -> C2 -> D2 >> >> If you happened to get confused and think that C2 is the first in its >> timeline, diverging off the old line after B1 not A1, there would be >> nothing about C2 to disabuse you of your error. > > Doesn't that mean the B1 and B2 have to be exactly the same size? > Otherwise there would be a gap between B1/C2 or B2/C1, and the xl_curr > would be enough to detect this. > > And how could xl_prev detect it? AFAIK XLogRecPtr does not include > TimeLineID, so xl_prev would be the same for both B1 and B2. > > I admit WAL internals are not an are I'm particularly familiar with, > though, so I may be missing something utterly obvious. Timeline history files know the LSN at which they fork. I can imagine losing the timeline branch point metadata because of corruption or other disaster, but getting the LSN slightly wrong sounds strange. If it was slightly wrong and yet still a valid LSN, xl_prev provides no protection about that. The timeline branch point is already marked by specific records in WAL, so if you forgot the LSN completely you would search for those and then you'd know. xl_prev wouldn't assist you in that search. Agree with points about XLOG_SWITCH, adding again the observation that they are no longer used for replication and if they are used as well as replication, have a bad effect on performance. I think it would be easily possible to add some more detail to the WAL stream if needed. -- Simon Riggs http://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
Re: Changing WAL Header to reduce contention duringReserveXLogInsertLocation()
From
Heikki Linnakangas
Date:
On 27/03/18 21:02, Tom Lane wrote: > Robert Haas <robertmhaas@gmail.com> writes: >> On Tue, Mar 27, 2018 at 11:41 AM, Tom Lane <tgl@sss.pgh.pa.us> wrote: >>> This is ignoring the possibility of damaged data in between, ie >>> A ... B ... CHKPT ... C ... a few zeroed pages ... D ... CHKPT ... E ... F > >> It's hard for me to believe that this case matters very much. If >> you're trying to run pg_rewind on a system where the WAL segments >> contain a few zeroed pages, you're probably going to be hosed anyway, >> if not by this particular thing then by something else. > > Well, the point of checkpoints is that WAL data before the last one > should no longer matter anymore, isn't it? > > But really this is just one illustration of the point, which is that > changing the WAL header definition as proposed *does* cost us reliability. > We can argue about whether better concurrency in WAL insertion is > worth that price, but claiming that the price is zero is flat wrong. > > For me, the more important issue is that checking xl_prev not only > validates that the record is where it is supposed to be, but that you > arrived at it correctly. Replacing it with xl_curr would keep the > guarantee of the former (in fact likely make it stronger); but we'd > completely lose the latter. Yeah, removing xl_prev would certainly remove a useful cross-check from the format. Maybe it would be worth it, I don't think it's that critical. And adding some extra information in the page or segment headers might alleviate that. But let's go back to why we're considering this. The idea was to optimize this block: > /* > * The duration the spinlock needs to be held is minimized by minimizing > * the calculations that have to be done while holding the lock. The > * current tip of reserved WAL is kept in CurrBytePos, as a byte position > * that only counts "usable" bytes in WAL, that is, it excludes all WAL > * page headers. The mapping between "usable" byte positions and physical > * positions (XLogRecPtrs) can be done outside the locked region, and > * because the usable byte position doesn't include any headers, reserving > * X bytes from WAL is almost as simple as "CurrBytePos += X". > */ > SpinLockAcquire(&Insert->insertpos_lck); > > startbytepos = Insert->CurrBytePos; > endbytepos = startbytepos + size; > prevbytepos = Insert->PrevBytePos; > Insert->CurrBytePos = endbytepos; > Insert->PrevBytePos = startbytepos; > > SpinLockRelease(&Insert->insertpos_lck); One trick that we could do is to replace that with a 128-bit atomic compare-and-swap instruction. Modern 64-bit Intel systems have that, it's called CMPXCHG16B. Don't know about other architectures. An atomic fetch-and-add, as envisioned in the comment above, would presumably be better, but I suspect that a compare-and-swap would be good enough to move the bottleneck elsewhere again. - Heikki
Re: Changing WAL Header to reduce contention during ReserveXLogInsertLocation()
From
Robert Haas
Date:
On Thu, Mar 29, 2018 at 5:18 PM, Tom Lane <tgl@sss.pgh.pa.us> wrote: > Tomas Vondra <tomas.vondra@2ndquadrant.com> writes: >> If each WAL record has xl_curr, then we know to which position the >> record belongs (after verifying the checksum). And we do know the size >> of each WAL record, so we should be able to deduce if two records are >> immediately after each other. > > Per my point earlier, XLOG_SWITCH is sufficient to defeat that argument. > Also consider a timeline fork. It's really hard to be sure which record > in the old timeline is the direct ancestor of the first one in the new > if you lack xl_prev: > > A1 -> B1 -> C1 -> D1 > \ > B2 -> C2 -> D2 > > If you happened to get confused and think that C2 is the first in its > timeline, diverging off the old line after B1 not A1, there would be > nothing about C2 to disabuse you of your error. But, as Simon correctly points out, if xl_prev is the only thing that's saving us from disaster, that's rather fragile. All it's cross-checking is the length of the previous WAL record, and that could easily match by accident: there aren't *that* many bits of entropy in the length of a WAL record. As he also points out, I think also correctly, if we really want a strong check that the chain of WAL records is continuous and unbroken, we ought to be including the CRC from the previous WAL record, not just the length. Another thing that's bothering me is this: surely there could be (if there isn't already) something *else* that tells us whether we've switched timelines at the wrong place. I mean, if nothing else, we could dictate that the first WAL record after a timeline switch must be XLOG_TIMELINE_SWITCH or something like that, and then if you try to change timelines and don't find that record (with the correct previous TLI), you know something's messed up. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
Heikki Linnakangas <hlinnaka@iki.fi> writes:
> But let's go back to why we're considering this. The idea was to
> optimize this block:
> ...
> One trick that we could do is to replace that with a 128-bit atomic
> compare-and-swap instruction. Modern 64-bit Intel systems have that,
> it's called CMPXCHG16B. Don't know about other architectures. An atomic
> fetch-and-add, as envisioned in the comment above, would presumably be
> better, but I suspect that a compare-and-swap would be good enough to
> move the bottleneck elsewhere again.
+1 for taking a look at that. A bit of experimentation shows that
recent gcc and clang can generate that instruction using
__sync_bool_compare_and_swap or __sync_val_compare_and_swap
on an __int128 value.
regards, tom lane
Re: Changing WAL Header to reduce contention duringReserveXLogInsertLocation()
From
Andres Freund
Date:
On 2018-04-03 09:56:24 -0400, Tom Lane wrote: > Heikki Linnakangas <hlinnaka@iki.fi> writes: > > But let's go back to why we're considering this. The idea was to > > optimize this block: > > ... > > One trick that we could do is to replace that with a 128-bit atomic > > compare-and-swap instruction. Modern 64-bit Intel systems have that, > > it's called CMPXCHG16B. Don't know about other architectures. An atomic > > fetch-and-add, as envisioned in the comment above, would presumably be > > better, but I suspect that a compare-and-swap would be good enough to > > move the bottleneck elsewhere again. > > +1 for taking a look at that. A bit of experimentation shows that > recent gcc and clang can generate that instruction using > __sync_bool_compare_and_swap or __sync_val_compare_and_swap > on an __int128 value. The problem will presumably be that early opteron AMD64s lacked that instruction. I'm not sure which distributions still target them (windows dropped support a few years ago), but we should make sure that neither the necessary dispatch code isn't going to add so much overhead it's eating into our margin, nor that the generated code SIGILLs on such platforms. Greetings, Andres Freund
Re: Changing WAL Header to reduce contention duringReserveXLogInsertLocation()
From
Heikki Linnakangas
Date:
On 03/04/18 19:20, Andres Freund wrote: > On 2018-04-03 09:56:24 -0400, Tom Lane wrote: >> Heikki Linnakangas <hlinnaka@iki.fi> writes: >>> But let's go back to why we're considering this. The idea was to >>> optimize this block: >>> ... >>> One trick that we could do is to replace that with a 128-bit atomic >>> compare-and-swap instruction. Modern 64-bit Intel systems have that, >>> it's called CMPXCHG16B. Don't know about other architectures. An atomic >>> fetch-and-add, as envisioned in the comment above, would presumably be >>> better, but I suspect that a compare-and-swap would be good enough to >>> move the bottleneck elsewhere again. >> >> +1 for taking a look at that. A bit of experimentation shows that >> recent gcc and clang can generate that instruction using >> __sync_bool_compare_and_swap or __sync_val_compare_and_swap >> on an __int128 value. > > The problem will presumably be that early opteron AMD64s lacked that > instruction. I'm not sure which distributions still target them (windows > dropped support a few years ago), but we should make sure that neither > the necessary dispatch code isn't going to add so much overhead it's > eating into our margin, nor that the generated code SIGILLs on such > platforms. Yeah. I'll mark this as "returned with feedback" in the commitfest. The way forward is to test if we can get the same performance benefit from switching to CMPXCHG16B, and keep the WAL format unchanged. If not, then we can continue discussing the WAL format and the tradeoffs with xl_prev, but let's take the easy way out if we can. - Heikki
Re: Changing WAL Header to reduce contention during ReserveXLogInsertLocation()
From
Simon Riggs
Date:
On 9 July 2018 at 14:49, Heikki Linnakangas <hlinnaka@iki.fi> wrote: > On 03/04/18 19:20, Andres Freund wrote: >> >> On 2018-04-03 09:56:24 -0400, Tom Lane wrote: >>> >>> Heikki Linnakangas <hlinnaka@iki.fi> writes: >>>> >>>> But let's go back to why we're considering this. The idea was to >>>> optimize this block: >>>> ... >>>> One trick that we could do is to replace that with a 128-bit atomic >>>> compare-and-swap instruction. Modern 64-bit Intel systems have that, >>>> it's called CMPXCHG16B. Don't know about other architectures. An atomic >>>> fetch-and-add, as envisioned in the comment above, would presumably be >>>> better, but I suspect that a compare-and-swap would be good enough to >>>> move the bottleneck elsewhere again. >>> >>> >>> +1 for taking a look at that. A bit of experimentation shows that >>> recent gcc and clang can generate that instruction using >>> __sync_bool_compare_and_swap or __sync_val_compare_and_swap >>> on an __int128 value. >> >> >> The problem will presumably be that early opteron AMD64s lacked that >> instruction. I'm not sure which distributions still target them (windows >> dropped support a few years ago), but we should make sure that neither >> the necessary dispatch code isn't going to add so much overhead it's >> eating into our margin, nor that the generated code SIGILLs on such >> platforms. > > > Yeah. > > I'll mark this as "returned with feedback" in the commitfest. The way > forward is to test if we can get the same performance benefit from switching > to CMPXCHG16B, and keep the WAL format unchanged. If not, then we can > continue discussing the WAL format and the tradeoffs with xl_prev, but let's > take the easy way out if we can. Agreed. Were you working on this? Or was anybody else? -- Simon Riggs http://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
Re: Changing WAL Header to reduce contention duringReserveXLogInsertLocation()
From
Heikki Linnakangas
Date:
On 09/07/18 18:57, Simon Riggs wrote: > On 9 July 2018 at 14:49, Heikki Linnakangas <hlinnaka@iki.fi> wrote: >> I'll mark this as "returned with feedback" in the commitfest. The way >> forward is to test if we can get the same performance benefit from switching >> to CMPXCHG16B, and keep the WAL format unchanged. If not, then we can >> continue discussing the WAL format and the tradeoffs with xl_prev, but let's >> take the easy way out if we can. > > Agreed. Were you working on this? Or was anybody else? Not me. - Heikki
Re: Changing WAL Header to reduce contention duringReserveXLogInsertLocation()
From
Peter Eisentraut
Date:
On 09.07.18 15:49, Heikki Linnakangas wrote: > The way > forward is to test if we can get the same performance benefit from > switching to CMPXCHG16B, and keep the WAL format unchanged. I have implemented this. I didn't see any performance benefit using the benchmark that Alexander Kuzmenkov outlined earlier in the thread. (But I also didn't see a great benefit for the originally proposed patch, so maybe I'm not doing this right or this particular hardware doesn't benefit from it as much.) I'm attaching the patches and scripts here if someone else wants to do more testing. The first patch adds a zoo of 128-bit atomics support. It's consistent with (a.k.a. copy-and-pasted from) the existing 32- and 64-bit set, but it's not the complete set, only as much as was necessary for this exercise. The second patch then makes use of that in the WAL code under discussion. pgbench invocations were: pgbench -i -I t bench pgbench -n -c $N -j $N -M prepared -f pgbench-wal-cas.sql -T 60 bench for N from 1 to 32. Note: With gcc (at least versions 7 and 8) you need to use some non-default -march setting to get 128-bit atomics to work. (Otherwise the configure test fails and the fallback implementation is used.) I have found the minimum to be -march=nocona. But different -march settings actually affect the benchmark performance, so be sure to test the baseline with the same -march setting. Recommended configure invocation: ./configure ... CC='gcc -march=whatever' clang appears to work out of the box. Also, curiously my gcc installations provide 128-bit __sync_val_compare_and_swap() but not 128-bit __atomic_compare_exchange_n() in spite of what the documentation indicates. So independent of whether this approach actually provides any benefit, the 128-bit atomics support seems a bit wobbly. (I'm also wondering why we are using __sync_val_compare_and_swap() rather than __sync_bool_compare_and_swap(), since all we're doing with the return value is emulate the bool version anyway.) -- Peter Eisentraut http://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services