Thread: Polyphase merge is obsolete
The beauty of the polyphase merge algorithm is that it allows reusing input tapes as output tapes efficiently. So if you have N tape drives, you can keep them all busy throughout the merge. That doesn't matter, when we can easily have as many "tape drives" as we want. In PostgreSQL, a tape drive consumes just a few kB of memory, for the buffers. With the patch being discussed to allow a tape to be "paused" between write passes [1], we don't even keep the tape buffers around, when a tape is not actively read written to, so all it consumes is the memory needed for the LogicalTape struct. The number of *input* tapes we can use in each merge pass is still limited, by the memory needed for the tape buffers and the merge heap, but only one output tape is active at any time. The inactive output tapes consume very few resources. So the whole idea of trying to efficiently reuse input tapes as output tapes is pointless. Let's switch over to a simple k-way balanced merge. Because it's simpler. If you're severely limited on memory, like when sorting 1GB of data with work_mem='1MB' or less, it's also slightly faster. I'm not too excited about the performance aspect, because in the typical case of a single-pass merge, there's no difference. But it would be worth changing on simplicity grounds, since we're mucking around in tuplesort.c anyway. I came up with the attached patch to do that. This patch applies on top of my latest "Logical tape pause/resume" patches [1]. It includes changes to the logtape.c interface, that make it possible to create and destroy LogicalTapes in a tapeset on the fly. I believe this will also come handy for Peter's parallel tuplesort patch set. [1] Logical tape pause/resume, https://www.postgresql.org/message-id/55b3b7ae-8dec-b188-b8eb-e07604052351%40iki.fi PS. I finally bit the bullet and got self a copy of The Art of Computer Programming, Vol 3, 2nd edition. In section 5.4 on External Sorting, Knuth says: " When this book was first written, magnetic tapes were abundant and disk drives were expensive. But disks became enormously better during the 1980s, and by the late 1990s they had almost completely replaced magnetic tape units on most of the world's computer systems. Therefore the once-crucial topic of tape merging has become of limited relevance to current needs. Yet many of the patterns are quite beautiful, and the associated algorithms reflect some of the best research done in computer science during its early days; the techniques are just too nice to be discarded abruptly onto the rubbish heap of history. Indeed, the ways in which these methods blend theory with practice are especially instructive. Therefore merging patterns are discussed carefully and completely below, in what may be their last grand appearance before they accept the final curtain call. " Yep, the polyphase and other merge patterns are beautiful. I enjoyed reading through those sections. Now let's put them to rest in PostgreSQL. - Heikki
Attachment
Heikki Linnakangas <hlinnaka@iki.fi> writes:
> The beauty of the polyphase merge algorithm is that it allows reusing
> input tapes as output tapes efficiently ... So the whole idea of trying to
> efficiently reuse input tapes as output tapes is pointless.
It's been awhile since I looked at that code, but I'm quite certain that
it *never* thought it was dealing with actual tapes. Rather, the point of
sticking with polyphase merge was that it allowed efficient incremental
re-use of temporary disk files, so that the maximum on-disk footprint was
only about equal to the volume of data to be sorted, rather than being a
multiple of that. Have we thrown that property away?
regards, tom lane
On 10/12/2016 08:27 PM, Tom Lane wrote: > Heikki Linnakangas <hlinnaka@iki.fi> writes: >> The beauty of the polyphase merge algorithm is that it allows reusing >> input tapes as output tapes efficiently ... So the whole idea of trying to >> efficiently reuse input tapes as output tapes is pointless. > > It's been awhile since I looked at that code, but I'm quite certain that > it *never* thought it was dealing with actual tapes. Rather, the point of > sticking with polyphase merge was that it allowed efficient incremental > re-use of temporary disk files, so that the maximum on-disk footprint was > only about equal to the volume of data to be sorted, rather than being a > multiple of that. Have we thrown that property away? No, there's no difference to that behavior. logtape.c takes care of incremental re-use of disk space, regardless of the merging pattern. - Heikki
On Wed, Oct 12, 2016 at 10:16 AM, Heikki Linnakangas <hlinnaka@iki.fi> wrote: > Let's switch over to a simple k-way balanced merge. Because it's simpler. If > you're severely limited on memory, like when sorting 1GB of data with > work_mem='1MB' or less, it's also slightly faster. I'm not too excited about > the performance aspect, because in the typical case of a single-pass merge, > there's no difference. But it would be worth changing on simplicity grounds, > since we're mucking around in tuplesort.c anyway. This analysis seems sound. I suppose we might as well simplify things while we're at it. -- Peter Geoghegan
On Wed, Oct 12, 2016 at 10:16 AM, Heikki Linnakangas <hlinnaka@iki.fi> wrote: > The number of *input* tapes we can use in each merge pass is still limited, > by the memory needed for the tape buffers and the merge heap, but only one > output tape is active at any time. The inactive output tapes consume very > few resources. So the whole idea of trying to efficiently reuse input tapes > as output tapes is pointless I picked this up again. The patch won't apply cleanly. Can you rebase? Also, please look at my bugfix for logtape.c free block management [1] before doing so, as that might be prerequisite. Finally, I don't think that the Logical tape pause/resume idea is compelling. Is it hard to not do that, but still do everything else that you propose here? That's what I lean towards doing right now. Anyway, efficient use of tapes certainly mattered a lot more when rewinding meant sitting around for a magnetic tape deck to physically rewind. There is another algorithm in AoCP Vol III that lets us write to tapes backwards, actually, which is motivated by similar obsolete considerations about hardware. Why not write while we rewind, to avoid doing nothing else while rewinding?! Perhaps this patch should make a clean break from the "rewinding" terminology. Perhaps you should rename LogicalTapeRewindForRead() to LogicalTapePrepareForRead(), and so on. It's already a bit awkward that that routine is called LogicalTapeRewindForRead(), because it behaves significantly differently when a tape is frozen, and because the whole point of logtape.c is space reuse that is completely dissimilar to rewinding. (Space reuse is thus totally unlike how polyphase merge is supposed to reuse space, which is all about rewinding, and isn't nearly as eager. Same applies to K-way balanced merge, of course.) I think that the "rewinding" terminology does more harm than good, now that it doesn't even help the Knuth reader to match Knuth's remarks to what's going on in tuplesort.c. Just a thought. > Let's switch over to a simple k-way balanced merge. Because it's simpler. If > you're severely limited on memory, like when sorting 1GB of data with > work_mem='1MB' or less, it's also slightly faster. I'm not too excited about > the performance aspect, because in the typical case of a single-pass merge, > there's no difference. But it would be worth changing on simplicity grounds, > since we're mucking around in tuplesort.c anyway. I actually think that the discontinuities in the merge scheduling are worse than you suggest here. There doesn't have to be as extreme a difference between work_mem and the size of input as you describe here. As an example: create table seq_tab(t int); insert into seq_tab select generate_series(1, 10000000); set work_mem = '4MB'; select count(distinct t) from seq_tab; The trace_sort output ends like this: 30119/2017-01-16 17:17:05 PST LOG: begin datum sort: workMem = 4096, randomAccess = f 30119/2017-01-16 17:17:05 PST LOG: switching to external sort with 16 tapes: CPU: user: 0.07 s, system: 0.00 s, elapsed: 0.06 s 30119/2017-01-16 17:17:05 PST LOG: starting quicksort of run 1: CPU: user: 0.07 s, system: 0.00 s, elapsed: 0.06 s 30119/2017-01-16 17:17:05 PST LOG: finished quicksort of run 1: CPU: user: 0.07 s, system: 0.00 s, elapsed: 0.07 s *** SNIP *** 30119/2017-01-16 17:17:08 PST LOG: finished writing run 58 to tape 0: CPU: user: 2.50 s, system: 0.27 s, elapsed: 2.78 s 30119/2017-01-16 17:17:08 PST LOG: using 4095 KB of memory for read buffers among 15 input tapes 30119/2017-01-16 17:17:08 PST LOG: finished 1-way merge step: CPU: user: 2.52 s, system: 0.28 s, elapsed: 2.80 s 30119/2017-01-16 17:17:08 PST LOG: finished 4-way merge step: CPU: user: 2.58 s, system: 0.30 s, elapsed: 2.89 s 30119/2017-01-16 17:17:08 PST LOG: finished 14-way merge step: CPU: user: 2.86 s, system: 0.34 s, elapsed: 3.20 s 30119/2017-01-16 17:17:08 PST LOG: finished 14-way merge step: CPU: user: 3.09 s, system: 0.41 s, elapsed: 3.51 s 30119/2017-01-16 17:17:09 PST LOG: finished 15-way merge step: CPU: user: 3.61 s, system: 0.52 s, elapsed: 4.14 s 30119/2017-01-16 17:17:09 PST LOG: performsort done (except 15-way final merge): CPU: user: 3.61 s, system: 0.52 s, elapsed: 4.14 s 30119/2017-01-16 17:17:10 PST LOG: external sort ended, 14678 disk blocks used: CPU: user: 4.93 s, system: 0.57 s, elapsed: 5.51 s (This is the test case that Cy posted earlier today, for the bug that was just fixed in master.) The first 1-way merge step is clearly kind of a waste of time. We incur no actual comparisons during this "merge", since there is only one real run from each input tape (all other active tapes contain only dummy runs). We are, in effect, just shoveling the tuples from that single run from one tape to another (from one range in the underlying logtape.c BufFile space to another). I've seen this quite a lot before, over the years, while working on sorting. It's not that big of a deal, but it's a degenerate case that illustrates how polyphase merge can do badly. What's probably of more concern here is that the final on-the-fly merge we see merges 15 input runs, but 10 of the inputs only have runs that are sized according to how much we could quicksort at once (actually, I should say 11 out of 15, what with that 1-way merge). So, 4 of those runs are far larger, which is not great. ISTM that having the merge be "balanced" is pretty important, at least as far as multi-pass sorts in the year 2017 go. Still, I agree with you that this patch is much more about refactoring than about performance, and I agree that the refactoring is worthwhile. I just think that you may have somewhat underestimated how much this could help when we're low on memory, but not ridiculously so. It doesn't seem necessary to prove this, though. (We need only verify that there are no regressions.) That's all I have right now. [1] https://commitfest.postgresql.org/13/955/ -- Peter Geoghegan
On Mon, Jan 16, 2017 at 5:56 PM, Peter Geoghegan <pg@heroku.com> wrote: > On Wed, Oct 12, 2016 at 10:16 AM, Heikki Linnakangas <hlinnaka@iki.fi> wrote: >> The number of *input* tapes we can use in each merge pass is still limited, >> by the memory needed for the tape buffers and the merge heap, but only one >> output tape is active at any time. The inactive output tapes consume very >> few resources. So the whole idea of trying to efficiently reuse input tapes >> as output tapes is pointless > > I picked this up again. The patch won't apply cleanly. Can you rebase? Since we have an awful lot of stuff in the last CF, and this patch doesn't seem particularly strategic, I've marked it "Returned with Feedback". Thanks -- Peter Geoghegan
On Mon, Feb 27, 2017 at 2:45 PM, Peter Geoghegan <pg@bowt.ie> wrote: > Since we have an awful lot of stuff in the last CF, and this patch > doesn't seem particularly strategic, I've marked it "Returned with > Feedback". I noticed that this is in the upcoming CF 1 for v11. I'm signed up to review. I'd like to point out that replacement selection is also obsolete, which is something I brought up recently [1]. I don't actually have any feature-driven reason to want to kill replacement selection - it's just an annoyance at this point. I do think that RS is more deserving of being killed than Polyphase merge, because it actually costs users something to continue to support it. The replacement_sort_tuples GUC particularly deserves to be removed. It would be nice if killing RS was put in scope here. I'd appreciate it, at least, since it would simplify the heap routines noticeably. The original analysis that led to adding replacement_sort_tuples was based on certain performance characteristics of merging that have since changed by quite a bit, due to our work for v10. [1] postgr.es/m/CAH2-WzmmNjG_K0R9nqYwMq3zjyJJK+hCbiZYNGhAy-Zyjs64GQ@mail.gmail.com -- Peter Geoghegan
On Wed, Aug 30, 2017 at 2:54 PM, Peter Geoghegan <pg@bowt.ie> wrote: > I noticed that this is in the upcoming CF 1 for v11. I'm signed up to review. > > I'd like to point out that replacement selection is also obsolete, > which is something I brought up recently [1]. I don't actually have > any feature-driven reason to want to kill replacement selection - it's > just an annoyance at this point. I do think that RS is more deserving > of being killed than Polyphase merge, because it actually costs users > something to continue to support it. The replacement_sort_tuples GUC > particularly deserves to be removed. > > It would be nice if killing RS was put in scope here. I'd appreciate > it, at least, since it would simplify the heap routines noticeably. > The original analysis that led to adding replacement_sort_tuples was > based on certain performance characteristics of merging that have > since changed by quite a bit, due to our work for v10. These are separate topics. They should each be discussed on their own thread. Please don't hijack this thread to talk about something else. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On Wed, Aug 30, 2017 at 12:48 PM, Robert Haas <robertmhaas@gmail.com> wrote: > These are separate topics. They should each be discussed on their own > thread. Please don't hijack this thread to talk about something else. I don't think that that is a fair summary. Heikki has done a number of things in this area, of which this is only the latest. I'm saying "hey, have you thought about RS too?". Whether or not I'm "hijacking" this thread is, at best, ambiguous. -- Peter Geoghegan
Hi, I planned to do some benchmarking on this patch, but apparently the patch no longer applies. Rebase please? regards -- Tomas Vondra http://www.2ndQuadrant.com PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services -- Sent via pgsql-hackers mailing list (pgsql-hackers@postgresql.org) To make changes to your subscription: http://www.postgresql.org/mailpref/pgsql-hackers
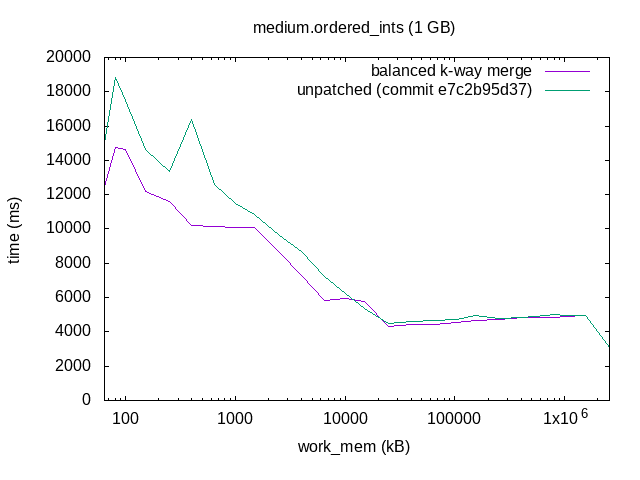
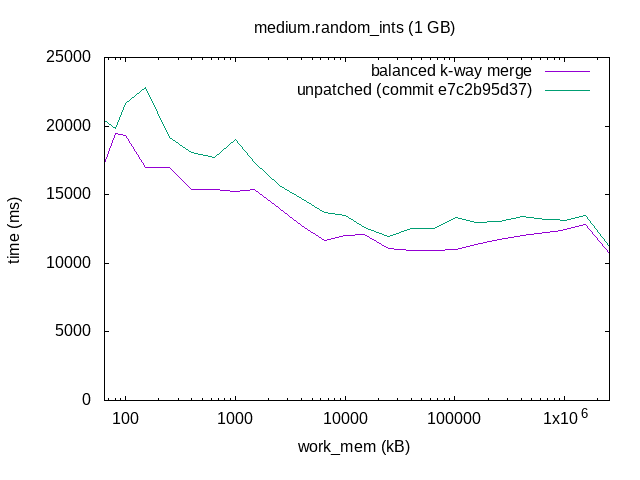
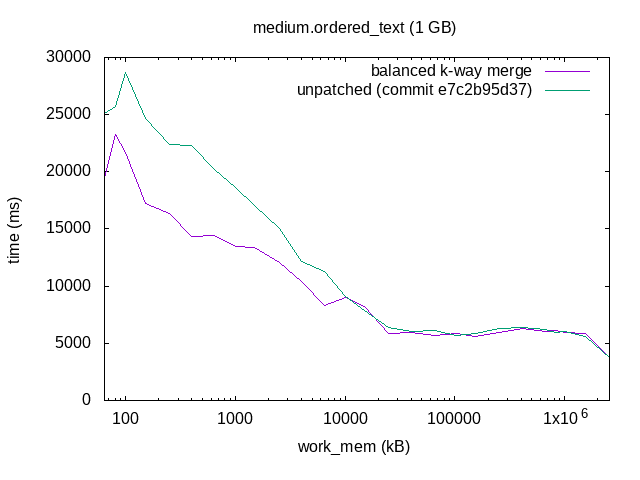
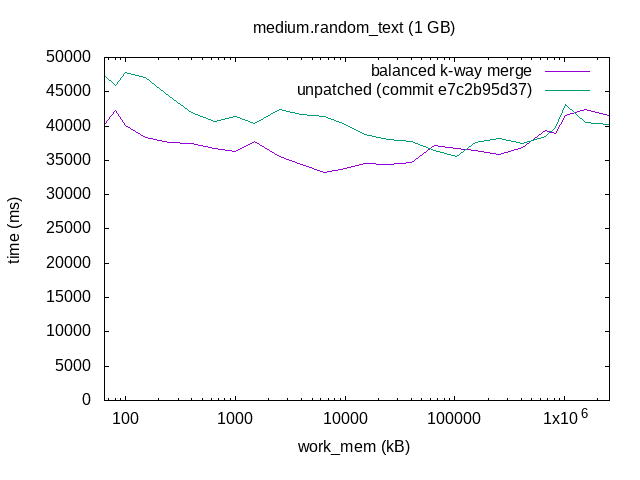
On 11/09/2017 13:37, Tomas Vondra wrote: > I planned to do some benchmarking on this patch, but apparently the > patch no longer applies. Rebase please? Here's a rebase of this. Sorry to keep you waiting :-). I split the patch into two, one patch to refactor the logtape.c APIs, and another to change the merge algorithm. With the new logtape.c API, you can create and destroy LogicalTapes in a tape set on the fly, which simplified the new hash agg spilling code somewhat. I think that's nice, even without the sort merge algorithm change. I did some benchmarking too. I used four data sets: ordered integers, random integers, ordered text, and random text, with 1 GB of data in each. I sorted those datasets with different work_mem settings, and plotted the results. I only ran each combination once, and all on my laptop, so there's a fair amount of noise in individual data points. The trend is clear, though. The results show that this makes sorting faster with small work_mem settings. As work_mem grows so that there's only one merge pass, there's no difference. The rightmost data points are with work_mem='2500 MB', so that the data fits completely in work_mem and you get a quicksort. That's unaffected by the patch. I've attached the test scripts I used for the plots, although they are quite messy and not very automated. I don't expect them to be very helpful to anyone, but might as well have it archived. - Heikki
Attachment
{kind=link}
{kind=link}
{kind=link}
{kind=link}
On 22/10/2020 14:48, Heikki Linnakangas wrote: > On 11/09/2017 13:37, Tomas Vondra wrote: >> I planned to do some benchmarking on this patch, but apparently the >> patch no longer applies. Rebase please? > > Here's a rebase of this. Sorry to keep you waiting :-). Here's an updated version that fixes one bug: The CFBot was reporting a failure on the FreeBSD system [1]. It turned out to be an out-of-memory issue caused by an underflow bug in the calculation of the size of the tape read buffer size. With a small work_mem size, the memory left for tape buffers was negative, and that wrapped around to a very large number. I believe that was not caught by the other systems, because the other ones had enough memory for the incorrectly-sized buffers anyway. That was the case on my laptop at least. It did cause a big slowdown in the 'tuplesort' regression test though, which I hadn't noticed. The fix for that bug is here as a separate patch for easier review, but I'll squash it before committing. [1] https://cirrus-ci.com/task/6699842091089920 - Heikki
Attachment
On 1/22/21 5:19 PM, Heikki Linnakangas wrote: > On 22/10/2020 14:48, Heikki Linnakangas wrote: >> On 11/09/2017 13:37, Tomas Vondra wrote: >>> I planned to do some benchmarking on this patch, but apparently the >>> patch no longer applies. Rebase please? >> >> Here's a rebase of this. Sorry to keep you waiting :-). I am amused that the wait here was 3+ years! > Here's an updated version that fixes one bug: We're near the end of the CF and this has not really seen any review after a long hiatus. I'll move this to the next CF on April 30 unless I hear objections. Regards, -- -David david@pgmasters.net
On 3/25/21 9:41 AM, David Steele wrote: > On 1/22/21 5:19 PM, Heikki Linnakangas wrote: >> On 22/10/2020 14:48, Heikki Linnakangas wrote: >>> On 11/09/2017 13:37, Tomas Vondra wrote: >>>> I planned to do some benchmarking on this patch, but apparently the >>>> patch no longer applies. Rebase please? >>> >>> Here's a rebase of this. Sorry to keep you waiting :-). > > I am amused that the wait here was 3+ years! > >> Here's an updated version that fixes one bug: > > We're near the end of the CF and this has not really seen any review > after a long hiatus. I'll move this to the next CF on April 30 unless I > hear objections. Oops, I meant March 30. Regards, -- -David david@pgmasters.net
On Sat, Jan 23, 2021 at 3:49 AM Heikki Linnakangas <hlinnaka@iki.fi> wrote: > > On 22/10/2020 14:48, Heikki Linnakangas wrote: > > On 11/09/2017 13:37, Tomas Vondra wrote: > >> I planned to do some benchmarking on this patch, but apparently the > >> patch no longer applies. Rebase please? > > > > Here's a rebase of this. Sorry to keep you waiting :-). > > Here's an updated version that fixes one bug: > > The CFBot was reporting a failure on the FreeBSD system [1]. It turned > out to be an out-of-memory issue caused by an underflow bug in the > calculation of the size of the tape read buffer size. With a small > work_mem size, the memory left for tape buffers was negative, and that > wrapped around to a very large number. I believe that was not caught by > the other systems, because the other ones had enough memory for the > incorrectly-sized buffers anyway. That was the case on my laptop at > least. It did cause a big slowdown in the 'tuplesort' regression test > though, which I hadn't noticed. > > The fix for that bug is here as a separate patch for easier review, but > I'll squash it before committing. The patch does not apply on Head anymore, could you rebase and post a patch. I'm changing the status to "Waiting for Author". Regards, Vignesh
On 14/07/2021 15:12, vignesh C wrote: > On Sat, Jan 23, 2021 at 3:49 AM Heikki Linnakangas <hlinnaka@iki.fi> wrote: >> Here's an updated version that fixes one bug: >> >> The CFBot was reporting a failure on the FreeBSD system [1]. It turned >> out to be an out-of-memory issue caused by an underflow bug in the >> calculation of the size of the tape read buffer size. With a small >> work_mem size, the memory left for tape buffers was negative, and that >> wrapped around to a very large number. I believe that was not caught by >> the other systems, because the other ones had enough memory for the >> incorrectly-sized buffers anyway. That was the case on my laptop at >> least. It did cause a big slowdown in the 'tuplesort' regression test >> though, which I hadn't noticed. >> >> The fix for that bug is here as a separate patch for easier review, but >> I'll squash it before committing. > > The patch does not apply on Head anymore, could you rebase and post a > patch. I'm changing the status to "Waiting for Author". Here's a rebased version. I also squashed that little bug fix from previous patch set. - Heikki
Attachment
On Wed, Jul 14, 2021 at 06:04:14PM +0300, Heikki Linnakangas wrote: > On 14/07/2021 15:12, vignesh C wrote: > > On Sat, Jan 23, 2021 at 3:49 AM Heikki Linnakangas <hlinnaka@iki.fi> wrote: > > > Here's an updated version that fixes one bug: > > > > > > The CFBot was reporting a failure on the FreeBSD system [1]. It turned > > > out to be an out-of-memory issue caused by an underflow bug in the > > > calculation of the size of the tape read buffer size. With a small > > > work_mem size, the memory left for tape buffers was negative, and that > > > wrapped around to a very large number. I believe that was not caught by > > > the other systems, because the other ones had enough memory for the > > > incorrectly-sized buffers anyway. That was the case on my laptop at > > > least. It did cause a big slowdown in the 'tuplesort' regression test > > > though, which I hadn't noticed. > > > > > > The fix for that bug is here as a separate patch for easier review, but > > > I'll squash it before committing. > > > > The patch does not apply on Head anymore, could you rebase and post a > > patch. I'm changing the status to "Waiting for Author". > > Here's a rebased version. I also squashed that little bug fix from previous > patch set. > Hi, This patch does not apply, can you submit a rebased version? -- Jaime Casanova Director de Servicios Profesionales SystemGuards - Consultores de PostgreSQL
On Fri, Sep 10, 2021 at 11:35 PM Jaime Casanova <jcasanov@systemguards.com.ec> wrote:
On Wed, Jul 14, 2021 at 06:04:14PM +0300, Heikki Linnakangas wrote:
> On 14/07/2021 15:12, vignesh C wrote:
> > On Sat, Jan 23, 2021 at 3:49 AM Heikki Linnakangas <hlinnaka@iki.fi> wrote:
> > > Here's an updated version that fixes one bug:
> > >
> > > The CFBot was reporting a failure on the FreeBSD system [1]. It turned
> > > out to be an out-of-memory issue caused by an underflow bug in the
> > > calculation of the size of the tape read buffer size. With a small
> > > work_mem size, the memory left for tape buffers was negative, and that
> > > wrapped around to a very large number. I believe that was not caught by
> > > the other systems, because the other ones had enough memory for the
> > > incorrectly-sized buffers anyway. That was the case on my laptop at
> > > least. It did cause a big slowdown in the 'tuplesort' regression test
> > > though, which I hadn't noticed.
> > >
> > > The fix for that bug is here as a separate patch for easier review, but
> > > I'll squash it before committing.
> >
> > The patch does not apply on Head anymore, could you rebase and post a
> > patch. I'm changing the status to "Waiting for Author".
>
> Here's a rebased version. I also squashed that little bug fix from previous
> patch set.
>
Hi,
This patch does not apply, can you submit a rebased version?
--
Jaime Casanova
Director de Servicios Profesionales
SystemGuards - Consultores de PostgreSQL
Hi,
+ * Algorithm 5.4.2D),
I think the above 'Before PostgreSQL 14' should be 'Before PostgreSQL 15' now that PostgreSQL 14 has been released.
+static int64
+merge_read_buffer_size(int64 avail_mem, int nInputTapes, int nInputRuns,
+ int maxOutputTapes)
+merge_read_buffer_size(int64 avail_mem, int nInputTapes, int nInputRuns,
+ int maxOutputTapes)
For memory to allocate, I think uint64 can be used (instead of int64).
Cheers
On Sat, Sep 11, 2021 at 01:35:27AM -0500, Jaime Casanova wrote: > On Wed, Jul 14, 2021 at 06:04:14PM +0300, Heikki Linnakangas wrote: > > On 14/07/2021 15:12, vignesh C wrote: > > > On Sat, Jan 23, 2021 at 3:49 AM Heikki Linnakangas <hlinnaka@iki.fi> wrote: > > > > Here's an updated version that fixes one bug: > > > > > > > > The CFBot was reporting a failure on the FreeBSD system [1]. It turned > > > > out to be an out-of-memory issue caused by an underflow bug in the > > > > calculation of the size of the tape read buffer size. With a small > > > > work_mem size, the memory left for tape buffers was negative, and that > > > > wrapped around to a very large number. I believe that was not caught by > > > > the other systems, because the other ones had enough memory for the > > > > incorrectly-sized buffers anyway. That was the case on my laptop at > > > > least. It did cause a big slowdown in the 'tuplesort' regression test > > > > though, which I hadn't noticed. > > > > > > > > The fix for that bug is here as a separate patch for easier review, but > > > > I'll squash it before committing. > > > > > > The patch does not apply on Head anymore, could you rebase and post a > > > patch. I'm changing the status to "Waiting for Author". > > > > Here's a rebased version. I also squashed that little bug fix from previous > > patch set. > > > > Hi, > > This patch does not apply, can you submit a rebased version? > BTW, I'm marking this one as "waiting on author" -- Jaime Casanova Director de Servicios Profesionales SystemGuards - Consultores de PostgreSQL
On 16/09/2021 00:12, Jaime Casanova wrote: > On Sat, Sep 11, 2021 at 01:35:27AM -0500, Jaime Casanova wrote: >> On Wed, Jul 14, 2021 at 06:04:14PM +0300, Heikki Linnakangas wrote: >>> On 14/07/2021 15:12, vignesh C wrote: >>>> On Sat, Jan 23, 2021 at 3:49 AM Heikki Linnakangas <hlinnaka@iki.fi> wrote: >>>>> Here's an updated version that fixes one bug: >>>>> >>>>> The CFBot was reporting a failure on the FreeBSD system [1]. It turned >>>>> out to be an out-of-memory issue caused by an underflow bug in the >>>>> calculation of the size of the tape read buffer size. With a small >>>>> work_mem size, the memory left for tape buffers was negative, and that >>>>> wrapped around to a very large number. I believe that was not caught by >>>>> the other systems, because the other ones had enough memory for the >>>>> incorrectly-sized buffers anyway. That was the case on my laptop at >>>>> least. It did cause a big slowdown in the 'tuplesort' regression test >>>>> though, which I hadn't noticed. >>>>> >>>>> The fix for that bug is here as a separate patch for easier review, but >>>>> I'll squash it before committing. >>>> >>>> The patch does not apply on Head anymore, could you rebase and post a >>>> patch. I'm changing the status to "Waiting for Author". >>> >>> Here's a rebased version. I also squashed that little bug fix from previous >>> patch set. >>> >> >> Hi, >> >> This patch does not apply, can you submit a rebased version? > > BTW, I'm marking this one as "waiting on author" Thanks, here's another rebase. - Heikki
Attachment
On Wed, Sep 15, 2021 at 5:35 PM Heikki Linnakangas <hlinnaka@iki.fi> wrote:
> Thanks, here's another rebase.
>
> - Heikki
I've had a chance to review and test out the v5 patches.
0001 is a useful simplification. Nothing in 0002 stood out as needing comment.
I've done some performance testing of master versus both patches applied. The full results and test script are attached, but I'll give a summary here. A variety of value distributions were tested, with work_mem from 1MB to 16MB, plus 2GB which will not use external sort at all. I settled on 2 million records for the sort, to have something large enough to work with but also keep the test time reasonable. That works out to about 130MB on disk. We have recent improvements to datum sort, so I used both single values and all values in the SELECT list.
The system was on a Westmere-era Xeon with gcc 4.8. pg_prewarm was run on the input tables. The raw measurements were reduced to the minimum of five runs.
I can confirm that sort performance is improved with small values of work_mem. That was not the motivating reason for the patch, but it's a nice bonus. Even as high as 16MB work_mem, it's possible some of the 4-6% differences represent real improvement and not just noise or binary effects, but it's much more convincing at 4MB and below, with 25-30% faster with non-datum integer sorts at 1MB work_mem. The nominal regressions seem within the noise level, with one exception that only showed up in one set of measurements (-10.89% in the spreadsheet). I'm not sure what to make of that since it only happens in one combination of factors and nowhere else.
On Sat, Sep 11, 2021 at 4:28 AM Zhihong Yu <zyu@yugabyte.com> wrote:
> + * Before PostgreSQL 14, we used the polyphase merge algorithm (Knuth's
> + * Algorithm 5.4.2D),
>
> I think the above 'Before PostgreSQL 14' should be 'Before PostgreSQL 15' now that PostgreSQL 14 has been released.
>
> +static int64
> +merge_read_buffer_size(int64 avail_mem, int nInputTapes, int nInputRuns,
> + int maxOutputTapes)
>
> For memory to allocate, I think uint64 can be used (instead of int64).
int64 is used elsewhere in this file, and I see now reason to do otherwise.
Aside from s/14/15/ for the version as noted above, I've marked it Ready for Committer.
--
John Naylor
EDB: http://www.enterprisedb.com
Attachment
On Tue, Oct 5, 2021 at 10:25 AM John Naylor <john.naylor@enterprisedb.com> wrote: > int64 is used elsewhere in this file, and I see now reason to do otherwise. Right. The point of using int64 in tuplesort.c is that the values may become negative in certain edge-cases. The whole LACKMEM() concept that tuplesort.c uses to enforce work_mem limits sometimes allows the implementation to use slightly more memory than theoretically allowable. That's how we get negative values. -- Peter Geoghegan
On 05/10/2021 20:24, John Naylor wrote: > I've had a chance to review and test out the v5 patches. Thanks! I fixed the stray reference to PostgreSQL 14 that Zhihong mentioned, and pushed. > I've done some performance testing of master versus both patches > applied. The full results and test script are attached, but I'll give a > summary here. A variety of value distributions were tested, with > work_mem from 1MB to 16MB, plus 2GB which will not use external sort at > all. I settled on 2 million records for the sort, to have something > large enough to work with but also keep the test time reasonable. That > works out to about 130MB on disk. We have recent improvements to datum > sort, so I used both single values and all values in the SELECT list. > > The system was on a Westmere-era Xeon with gcc 4.8. pg_prewarm was run > on the input tables. The raw measurements were reduced to the minimum of > five runs. > > I can confirm that sort performance is improved with small values of > work_mem. That was not the motivating reason for the patch, but it's a > nice bonus. Even as high as 16MB work_mem, it's possible some of the > 4-6% differences represent real improvement and not just noise or binary > effects, but it's much more convincing at 4MB and below, with 25-30% > faster with non-datum integer sorts at 1MB work_mem. The nominal > regressions seem within the noise level, with one exception that only > showed up in one set of measurements (-10.89% in the spreadsheet). I'm > not sure what to make of that since it only happens in one combination > of factors and nowhere else. That's a bit odd, but given how many data points there are, I think we can write it off as random noise. - Heikki
On 18.10.21 14:15, Heikki Linnakangas wrote: > On 05/10/2021 20:24, John Naylor wrote: >> I've had a chance to review and test out the v5 patches. > > Thanks! I fixed the stray reference to PostgreSQL 14 that Zhihong > mentioned, and pushed. AFAICT, this thread updated the API of LogicalTapeSetCreate() in PG15, but did not adequately update the function header comment. The comment still mentions the "shared" argument, which has been removed. There is a new "preallocate" argument that is not mentioned at all. Also, it's not easy to match the actual callers to the call variants described in the comment. Could someone who remembers this work perhaps look this over and update the comment?
On 19/11/2022 13:00, Peter Eisentraut wrote: > On 18.10.21 14:15, Heikki Linnakangas wrote: >> On 05/10/2021 20:24, John Naylor wrote: >>> I've had a chance to review and test out the v5 patches. >> >> Thanks! I fixed the stray reference to PostgreSQL 14 that Zhihong >> mentioned, and pushed. > > AFAICT, this thread updated the API of LogicalTapeSetCreate() in PG15, > but did not adequately update the function header comment. The comment > still mentions the "shared" argument, which has been removed. There is > a new "preallocate" argument that is not mentioned at all. Also, it's > not easy to match the actual callers to the call variants described in > the comment. Could someone who remembers this work perhaps look this > over and update the comment? Is the attached more readable? I'm not 100% sure of the "preallocate" argument. If I understand correctly, you should pass true if you are writing multiple tapes at the same time, and false otherwise. HashAgg passed true, tuplesort passes false. However, it's not clear to me why we couldn't just always do the preallocation. It seems pretty harmless even if it's not helpful. Or do it when there are multiple writer tapes, and not otherwise. The parameter was added in commit 0758964963 so presumably there was a reason, but at a quick glance at the thread that led to that commit, I couldn't see what it was. - Heikki
Attachment
On 21.11.22 00:57, Heikki Linnakangas wrote: > On 19/11/2022 13:00, Peter Eisentraut wrote: >> On 18.10.21 14:15, Heikki Linnakangas wrote: >>> On 05/10/2021 20:24, John Naylor wrote: >>>> I've had a chance to review and test out the v5 patches. >>> >>> Thanks! I fixed the stray reference to PostgreSQL 14 that Zhihong >>> mentioned, and pushed. >> >> AFAICT, this thread updated the API of LogicalTapeSetCreate() in PG15, >> but did not adequately update the function header comment. The comment >> still mentions the "shared" argument, which has been removed. There is >> a new "preallocate" argument that is not mentioned at all. Also, it's >> not easy to match the actual callers to the call variants described in >> the comment. Could someone who remembers this work perhaps look this >> over and update the comment? > > Is the attached more readable? That looks better, thanks. > I'm not 100% sure of the "preallocate" argument. If I understand > correctly, you should pass true if you are writing multiple tapes at the > same time, and false otherwise. HashAgg passed true, tuplesort passes > false. However, it's not clear to me why we couldn't just always do the > preallocation. It seems pretty harmless even if it's not helpful. Or do > it when there are multiple writer tapes, and not otherwise. The > parameter was added in commit 0758964963 so presumably there was a > reason, but at a quick glance at the thread that led to that commit, I > couldn't see what it was. Right, these are the kinds of questions such a comment ought to answer. Let's see if anyone chimes in here, otherwise let's complain in the original thread, since it had nothing to do with this one.
On 21.11.22 10:29, Peter Eisentraut wrote: > On 21.11.22 00:57, Heikki Linnakangas wrote: >> On 19/11/2022 13:00, Peter Eisentraut wrote: >>> On 18.10.21 14:15, Heikki Linnakangas wrote: >>>> On 05/10/2021 20:24, John Naylor wrote: >>>>> I've had a chance to review and test out the v5 patches. >>>> >>>> Thanks! I fixed the stray reference to PostgreSQL 14 that Zhihong >>>> mentioned, and pushed. >>> >>> AFAICT, this thread updated the API of LogicalTapeSetCreate() in PG15, >>> but did not adequately update the function header comment. The comment >>> still mentions the "shared" argument, which has been removed. There is >>> a new "preallocate" argument that is not mentioned at all. Also, it's >>> not easy to match the actual callers to the call variants described in >>> the comment. Could someone who remembers this work perhaps look this >>> over and update the comment? >> >> Is the attached more readable? > > That looks better, thanks. > >> I'm not 100% sure of the "preallocate" argument. If I understand >> correctly, you should pass true if you are writing multiple tapes at >> the same time, and false otherwise. HashAgg passed true, tuplesort >> passes false. However, it's not clear to me why we couldn't just >> always do the preallocation. It seems pretty harmless even if it's not >> helpful. Or do it when there are multiple writer tapes, and not >> otherwise. The parameter was added in commit 0758964963 so presumably >> there was a reason, but at a quick glance at the thread that led to >> that commit, I couldn't see what it was. > > Right, these are the kinds of questions such a comment ought to answer. > > Let's see if anyone chimes in here, otherwise let's complain in the > original thread, since it had nothing to do with this one. So nothing has happened. Let's get your changes about the removed "shared" argument committed, and we can figure out the "preallocated" thing separately.
On 16/01/2023 12:23, Peter Eisentraut wrote: > On 21.11.22 10:29, Peter Eisentraut wrote: >> On 21.11.22 00:57, Heikki Linnakangas wrote: >>> On 19/11/2022 13:00, Peter Eisentraut wrote: >>>> AFAICT, this thread updated the API of LogicalTapeSetCreate() in PG15, >>>> but did not adequately update the function header comment. The comment >>>> still mentions the "shared" argument, which has been removed. There is >>>> a new "preallocate" argument that is not mentioned at all. Also, it's >>>> not easy to match the actual callers to the call variants described in >>>> the comment. Could someone who remembers this work perhaps look this >>>> over and update the comment? >>> >>> Is the attached more readable? >> >> That looks better, thanks. >> >>> I'm not 100% sure of the "preallocate" argument. If I understand >>> correctly, you should pass true if you are writing multiple tapes at >>> the same time, and false otherwise. HashAgg passed true, tuplesort >>> passes false. However, it's not clear to me why we couldn't just >>> always do the preallocation. It seems pretty harmless even if it's not >>> helpful. Or do it when there are multiple writer tapes, and not >>> otherwise. The parameter was added in commit 0758964963 so presumably >>> there was a reason, but at a quick glance at the thread that led to >>> that commit, I couldn't see what it was. >> >> Right, these are the kinds of questions such a comment ought to answer. >> >> Let's see if anyone chimes in here, otherwise let's complain in the >> original thread, since it had nothing to do with this one. > > So nothing has happened. Let's get your changes about the removed > "shared" argument committed, and we can figure out the "preallocated" > thing separately. Ok, pushed. I included the brief comment on "preallocated", but it would be nice to improve it further, per the above discussion. Thanks! - Heikki