Thread: Partitioned checkpointing
Hi All,
Recently, I have found a paper titled "Segmented Fussy Checkpointing for
Main Memory Databases" published in 1996 at ACM symposium on Applied
Computing, which inspired me to implement a similar mechanism in PostgreSQL.
Since the early evaluation results obtained from a 16 core server was beyond
my expectation, I have decided to submit a patch to be open for discussion
by community members interested in this mechanism.
Attached patch is a PoC (or mayby prototype) implementation of a partitioned
checkpointing on 9.5alpha2 The term 'partitioned' is used here instead of
'segmented' because I feel 'segmented' is somewhat confusable with 'xlog
segment,' etc. In contrast, the term 'partitioned' is not as it implies
almost the same concept of 'buffer partition,' thus I think it is suitable.
Background and my motivation is that performance dip due to checkpoint is a
major concern, and thus it is valuable to mitigate this issue. In fact, many
countermeasures have been attempted against this issue. As far as I know,
those countermeasures so far focus mainly on mitigating the adverse impact
due to disk writes to implement the buffer sync; recent highly regarded
'checkpointer continuous flushing' is a typical example. On the other hand,
I don't feel that another source of the performance dip has been heartily
addressed; full-page-write rush, which I call here, would be a major issue.
That is, the average size of transaction log (XLOG) records jumps up sharply
immediately after the beginning of each checkpoint, resulting in the
saturation of WAL write path including disk(s) for $PGDATA/pg_xlog and WAL
buffers.
In the following, I will describe early evaluation results and mechanism of
the partitioned checkpointing briefly.
1. Performance evaluation
1.1 Experimental setup
The configuration of the server machine was as follows.
CPU: Intel E5-2650 v2 (8 cores/chip) @ 2.60GHz x 2
Memory: 64GB
OS: Linux 2.6.32-504.12.2.el6.x86_64 (CentOS)
Storage: raid1 of 4 HDs (write back assumed using BBU) for $PGDATA/pg_xlog
raid1 of 2 SSDs for $PGDATA (other than pg_xlog)
PostgreSQL settings
shared_buffers = 28GB
wal_buffers = 64MB
checkpoint_timeout = 10min
max_wal_size = 128GB
min_wal_size = 8GB
checkpoint_completion_target = 0.9
benchmark
pgbench -M prepared -N -P 1 -T 3600
The scaling factor was 1000. Both the number of clients (-c option) and
threads (-j option) were 120 for sync. commit case and 96 for async. commit
(synchronous_commit = off) case. These are chosen because maximum
throughputs were obtained under these conditions.
The server was connected to a client machine on which pgbench client program
run with a 1G ether. Since the client machine was not saturated in the
measurement and thus hardly affected the results, details of the client
machine are not described here.
1.2 Early results
The measurement results shown here are latency average, latency stddev, and
throughput (tps), which are the output of the pgbench program.
1.2.1 synchronous_commit = on
(a) 9.5alpha2(original)
latency average: 2.852 ms
latency stddev: 6.010 ms
tps = 42025.789717 (including connections establishing)
tps = 42026.137247 (excluding connections establishing)
(b) 9.5alpha2 with partitioned checkpointing
latency average: 2.815 ms
latency stddev: 2.317 ms
tps = 42575.301137 (including connections establishing)
tps = 42575.677907 (excluding connections establishing)
1.2.2 synchronous_commit = off
(a) 9.5alpha2(original)
latency average: 2.136 ms
latency stddev: 5.422 ms
tps = 44870.897907 (including connections establishing)
tps = 44871.215792 (excluding connections establishing)
(b) 9.5alpha2 with partitioned checkpointing
latency average: 2.085 ms
latency stddev: 1.529 ms
tps = 45974.617724 (including connections establishing)
tps = 45974.973604 (excluding connections establishing)
1.3 Summary
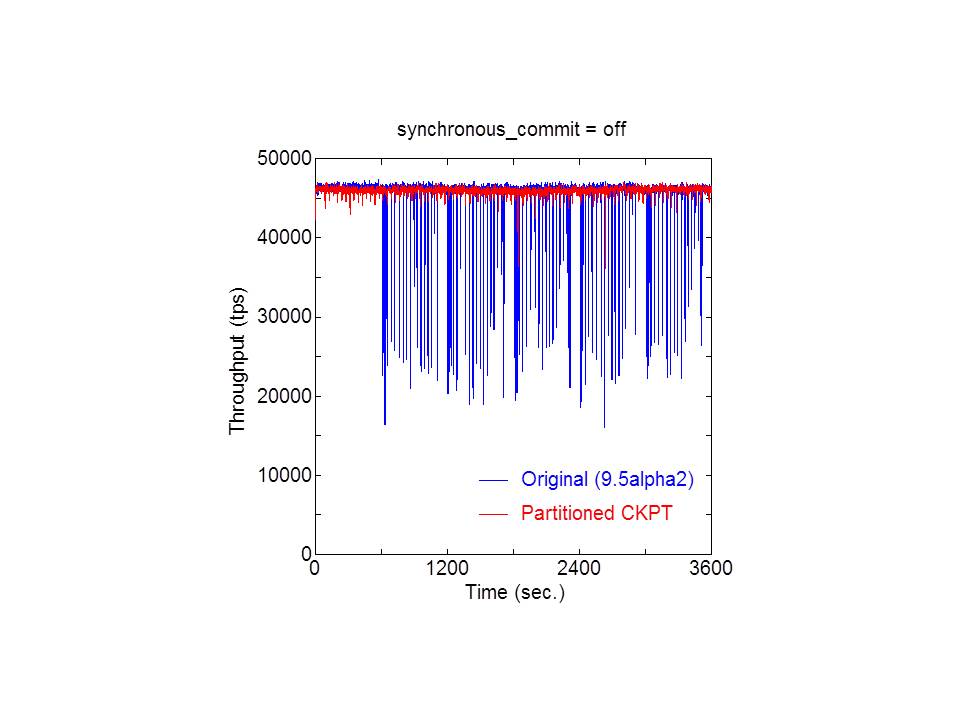
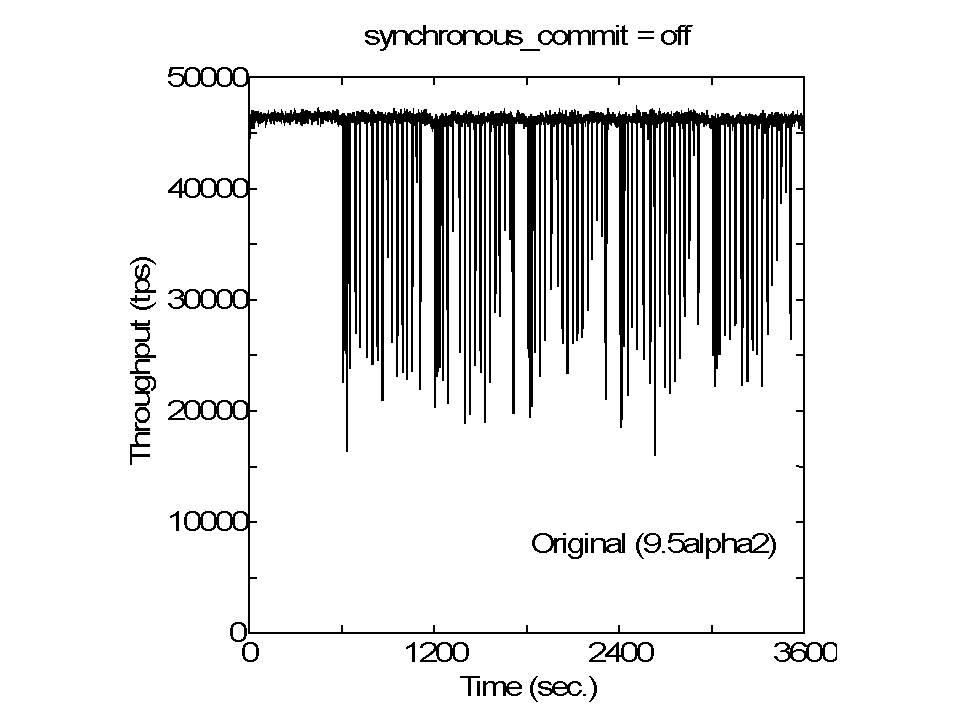
The partitioned checkpointing produced great improvement (reduction) in
latency stddev and slight improvement in latency average and tps; there was
no performance degradation. Therefore, there is an effect to stabilize the
operation in this partitioned checkpointing. In fact, the throughput
variation, obtained by -P 1 option, shows that the dips were mitigated in
both magnitude and frequency.
# Since I'm not sure whether it is OK to send an email to this mailing with
attaching some files other than patch, I refrain now from attaching raw
results (200K bytes of text/case) and result graphs in .jpg or .epsf format
illustrating the throughput variations to this email. If it is OK, I'm
pleased to show the results in those formats.
2. Mechanism
Imaginably, 'partitioned checkpointing' conducts buffer sync not for all
buffers at once but for the buffers belonging to one partition at one
invocation of the checkpointer. In the following description, the number of
partitions is expressed by N. (N is fixed to 16 in the attached patch).
2.1 Principles of operations
In order to preserve the semantics of the traditional checkpointing, the
checkpointer invocation interval is changed to checkpoint_timeout / N. The
checkpointer carries out the buffer sync for the buffer partition 0 at the
first invocation, and then for the buffer partition 1 at the second
invocation, and so on. When the turn of the the buffer partition N-1 comes,
i.e. the last round of a series of buffer sync, the checkpointer carries out
the buffer sync for the buffer partition and other usual checkpoint
operations, coded in CheckPointGuts() in xlog.c.
The principle is that, roughly speaking, 1) checkpointing for the buffer
partition 0 corresponds to the beginning of the traditional checkpointing,
where the XLOG location (LSN) is obtained and set to RedoRecPtr, and 2)
checkpointing for the buffer partition N - 1 corresponds to the end of the
traditional checkpointing, where the WAL files that are no longer need (up
to the previous log segment of that specified by the RedoRecPtr value) are
deleted or recycled.
A role of RedoRecPtr indicating the threshold to determine whether FPW is
necessary or not is moved to a new N-element array of XLogRecPtr, as the
threshold for each buffer is different among partitions. The n-th element of
the array is updated when the buffer sync for partition n is carried out.
2.2 Drawbacks
The 'partitioned checkpointing' works effectively in such situation that the
checkpointer is invoked by hitting the checkpoint_timeout; performance dip
is mitigated and the WAL size is not changed (in avarage).
On the other hand, when the checkpointer is invoked by another trigger event
than timeout, traditional checkpoint procedure which syncs all buffers at
once will take place, resulting in performance dip. Also the WAL size for
that checkpoint period (until the next invocation of the checkpointer) will
theoritically increase to 1.5 times of that of usual case because of the
increase in the FPW.
My opinion is that this is not serious because it is preferable for
checkpointer to be invoked by the timeout, and thus usual systems are
supposed to be tuned to work under such condition that is prefarable for the
'partitioned checkpointing.'
3. Conclusion
The 'partitioned checkpointing' mechanism is expected to be effective for
mitigating the performance dip due to checkpoint. In particular, it is
noteworthy that the effect was observed on a server machine that use SSDs
for $PGDATA, for which seek optimizations are not believed effective.
Therefore, this mechanism is worth to further investigation aiming to
implement in future PostgreSQL.
--
Takashi Horikawa
NEC Corporation
Knowledge Discovery Research Laboratories
Attachment
Hello Takashi-san,
I suggest that you have a look at the following patch submitted in June:
https://commitfest.postgresql.org/6/260/
And these two threads:
http://www.postgresql.org/message-id/flat/alpine.DEB.2.10.1408251900211.11151@sto/
http://www.postgresql.org/message-id/flat/alpine.DEB.2.10.1506011320000.28433@sto/
Including many performance figures under different condition in the second
thread. I'm not sure how it would interact with what you are proposing,
but it is also focussing on improving postgres availability especially on
HDD systems by changing how the checkpointer write buffers with sorting
and flushing.
Also, you may consider running some tests about the latest version of this
patch onto your hardware, to complement Amit tests?
--
Fabien.
> I don't feel that another source of the performance dip has been heartily
> addressed; full-page-write rush, which I call here, would be a major issue.
> That is, the average size of transaction log (XLOG) records jumps up sharply
> immediately after the beginning of each checkpoint, resulting in the
> saturation of WAL write path including disk(s) for $PGDATA/pg_xlog and WAL
> buffers.
On this point, you may have a look at this item:
https://commitfest.postgresql.org/5/283/
--
Fabien.
> Feel free to do that. 200kB is well below this list's limits. (I'm not > sure how easy it is to open .epsf files in today's systems, but .jpg or > other raster image formats are pretty common.) Thanks for your comment. Please find two result graphs (for sync and async commit cases) in .jpg format. I think it is obvious that performance dips were mitigated in both magnitude and frequency by introducing the partitionedcheckpointing. (In passing) one correction for my previous email. > Storage: raid1 of 4 HDs (write back assumed using BBU) for $PGDATA/pg_xlog > raid1 of 2 SSDs for $PGDATA (other than pg_xlog) 'raid1' is wrong and 'raid0' is correct. -- Takashi Horikawa NEC Corporation Knowledge Discovery Research Laboratories > -----Original Message----- > From: Alvaro Herrera [mailto:pgsql-hackers-owner@postgresql.org] > Sent: Friday, September 11, 2015 12:03 AM > To: Horikawa Takashi(堀川 隆) > Subject: Re: [HACKERS] Partitioned checkpointing > > Takashi Horikawa wrote: > > > # Since I'm not sure whether it is OK to send an email to this mailing > > with attaching some files other than patch, I refrain now from > > attaching raw results (200K bytes of text/case) and result graphs in > > .jpg or .epsf format illustrating the throughput variations to this > > email. If it is OK, I'm pleased to show the results in those formats. > > Feel free to do that. 200kB is well below this list's limits. (I'm not > sure how easy it is to open .epsf files in today's systems, but .jpg or > other raster image formats are pretty common.) > > -- > Álvaro Herrera
Attachment
{kind=link}
{kind=link}
Fabien, Thanks for your comment. I'll check them and try to examine what is the same and what is different. -- Takashi Horikawa NEC Corporation Knowledge Discovery Research Laboratories > -----Original Message----- > From: pgsql-hackers-owner@postgresql.org > [mailto:pgsql-hackers-owner@postgresql.org] On Behalf Of Fabien COELHO > Sent: Thursday, September 10, 2015 7:33 PM > To: Horikawa Takashi(堀川 隆) > Cc: pgsql-hackers@postgresql.org > Subject: Re: [HACKERS] Partitioned checkpointing > > > > > I don't feel that another source of the performance dip has been > > heartily addressed; full-page-write rush, which I call here, would be > a major issue. > > That is, the average size of transaction log (XLOG) records jumps up > > sharply immediately after the beginning of each checkpoint, resulting > > in the saturation of WAL write path including disk(s) for > > $PGDATA/pg_xlog and WAL buffers. > > On this point, you may have a look at this item: > > https://commitfest.postgresql.org/5/283/ > > -- > Fabien. > > > -- > Sent via pgsql-hackers mailing list (pgsql-hackers@postgresql.org) > To make changes to your subscription: > http://www.postgresql.org/mailpref/pgsql-hackers
Hello Takashi-san, I wanted to do some tests with this POC patch. For this purpose, it would be nice to have a guc which would allow to activate or not this feature. Could you provide a patch with such a guc? I would suggest to have the number of partitions as a guc, so that choosing 1 would basically reflect the current behavior. Some general comments : I understand that what this patch does is cutting the checkpoint of buffers in 16 partitions, each addressing 1/16 of buffers, and each with its own wal-log entry, pacing, fsync and so on. I'm not sure why it would be much better, although I agree that it may have some small positive influence on performance, but I'm afraid it may also degrade performance in some conditions. So I think that maybe a better understanding of why there is a better performance and focus on that could help obtain a more systematic gain. This method interacts with the current proposal to improve the checkpointer behavior by avoiding random I/Os, but it could be combined. I'm wondering whether the benefit you see are linked to the file flushing behavior induced by fsyncing more often, in which case it is quite close the "flushing" part of the current "checkpoint continuous flushing" patch, and could be redundant/less efficient that what is done there, especially as test have shown that the effect of flushing is *much* better on sorted buffers. Another proposal around, suggested by Andres Freund I think, is that checkpoint could fsync files while checkpointing and not wait for the end of the checkpoint. I think that it may also be one of the reason why your patch does bring benefit, but Andres approach would be more systematic, because there would be no need to fsync files several time (basically your patch issues 16 fsync per file). This suggest that the "partitionning" should be done at a lower level, from within the CheckPointBuffers, which would take care of fsyncing files some time after writting buffers to them is finished. -- Fabien.
On 11 September 2015 at 09:07, Fabien COELHO <coelho@cri.ensmp.fr> wrote:
--
Some general comments :
Thanks for the summary Fabien.
I understand that what this patch does is cutting the checkpoint of buffers in 16 partitions, each addressing 1/16 of buffers, and each with its own wal-log entry, pacing, fsync and so on.
I'm not sure why it would be much better, although I agree that it may have some small positive influence on performance, but I'm afraid it may also degrade performance in some conditions. So I think that maybe a better understanding of why there is a better performance and focus on that could help obtain a more systematic gain.
I think its a good idea to partition the checkpoint, but not doing it this way.
Splitting with N=16 does nothing to guarantee the partitions are equally sized, so there would likely be an imbalance that would reduce the effectiveness of the patch.
This method interacts with the current proposal to improve the checkpointer behavior by avoiding random I/Os, but it could be combined.
I'm wondering whether the benefit you see are linked to the file flushing behavior induced by fsyncing more often, in which case it is quite close the "flushing" part of the current "checkpoint continuous flushing" patch, and could be redundant/less efficient that what is done there, especially as test have shown that the effect of flushing is *much* better on sorted buffers.
Another proposal around, suggested by Andres Freund I think, is that checkpoint could fsync files while checkpointing and not wait for the end of the checkpoint. I think that it may also be one of the reason why your patch does bring benefit, but Andres approach would be more systematic, because there would be no need to fsync files several time (basically your patch issues 16 fsync per file). This suggest that the "partitionning" should be done at a lower level, from within the CheckPointBuffers, which would take care of fsyncing files some time after writting buffers to them is finished.
The idea to do a partial pass through shared buffers and only write a fraction of dirty buffers, then fsync them is a good one.
The key point is that we spread out the fsyncs across the whole checkpoint period.
I think we should be writing out all buffers for a particular file in one pass, then issue one fsync per file. >1 fsyncs per file seems a bad idea.
So we'd need logic like this
1. Run through shared buffers and analyze the files contained in there
2. Assign files to one of N batches so we can make N roughly equal sized mini-checkpoints
3. Make N passes through shared buffers, writing out files assigned to each batch as we go
Simon Riggs http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On 09/11/2015 03:56 PM, Simon Riggs wrote: > > The idea to do a partial pass through shared buffers and only write a > fraction of dirty buffers, then fsync them is a good one. > > The key point is that we spread out the fsyncs across the whole > checkpoint period. I doubt that's really what we want to do, as it defeats one of the purposes of spread checkpoints. With spread checkpoints, we write the data to the page cache, and then let the OS to actually write the data to the disk. This is handled by the kernel, which marks the data as expired after some time (say, 30 seconds) and then flushes them to disk. The goal is to have everything already written to disk when we call fsync at the beginning of the next checkpoint, so that the fsync are cheap and don't cause I/O issues. What you propose (spreading the fsyncs) significantly changes that, because it minimizes the amount of time the OS has for writing the data to disk in the background to 1/N. That's a significant change, and I'd bet it's for the worse. > > I think we should be writing out all buffers for a particular file > in one pass, then issue one fsync per file. >1 fsyncs per file seems > a bad idea. > > So we'd need logic like this > 1. Run through shared buffers and analyze the files contained in there > 2. Assign files to one of N batches so we can make N roughly equal sized > mini-checkpoints > 3. Make N passes through shared buffers, writing out files assigned to > each batch as we go What I think might work better is actually keeping the write/fsync phases we have now, but instead of postponing the fsyncs until the next checkpoint we might spread them after the writes. So with target=0.5 we'd do the writes in the first half, then the fsyncs in the other half. Of course, we should sort the data like you propose, and issue the fsyncs in the same order (so that the OS has time to write them to the devices). I wonder how much the original paper (written in 1996) is effectively obsoleted by spread checkpoints, but the benchmark results posted by Horikawa-san suggest there's a possible gain. But perhaps partitioning the checkpoints is not the best approach? regards -- Tomas Vondra http://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
Hello Simon, > The idea to do a partial pass through shared buffers and only write a > fraction of dirty buffers, then fsync them is a good one. Sure. > The key point is that we spread out the fsyncs across the whole checkpoint > period. Yes, this is really Andres suggestion, as I understood it. > I think we should be writing out all buffers for a particular file in one > pass, then issue one fsync per file. >1 fsyncs per file seems a bad idea. This is one of the things done in the "checkpoint continuous flushing" patch, as buffers are sorted, they are written per file, and in order within a file, which help getting sequencial writes instead of random writes. See https://commitfest.postgresql.org/6/260/ However for now the final fsync is not called, but Linux is told that the written buffers must be flushed, which is akin to an "asynchronous fsync", i.e. it asks to move data but does not wait for the data to be actually written, as a blocking fsync would. Andres suggestion, which has some common points to Takashi-san patch, is to also integrate the fsync in the buffer writing process. There are some details to think about, because probably it is not a a good to issue an fsync right after the corresponding writes, it is better to wait for some delay before doing so, so the implementation is not straightforward. -- Fabien.
Hi, Partitioned checkpoint have the significant disadvantage that it increases random write io by the number of passes. Which is a bad idea, *especially* on SSDs. > >So we'd need logic like this > >1. Run through shared buffers and analyze the files contained in there > >2. Assign files to one of N batches so we can make N roughly equal sized > >mini-checkpoints > >3. Make N passes through shared buffers, writing out files assigned to > >each batch as we go That's essentially what Fabien's sorting patch does by sorting all writes. > What I think might work better is actually keeping the write/fsync phases we > have now, but instead of postponing the fsyncs until the next checkpoint we > might spread them after the writes. So with target=0.5 we'd do the writes in > the first half, then the fsyncs in the other half. Of course, we should sort > the data like you propose, and issue the fsyncs in the same order (so that > the OS has time to write them to the devices). I think the approach in Fabien's patch of enforcing that there's not very much dirty data to flush by forcing early cache flushes is better. Having gigabytes worth of dirty data in the OS page cache can have massive negative impact completely independent of fsyncs. > I wonder how much the original paper (written in 1996) is effectively > obsoleted by spread checkpoints, but the benchmark results posted by > Horikawa-san suggest there's a possible gain. But perhaps partitioning the > checkpoints is not the best approach? I think it's likely that the patch will have only a very small effect if applied ontop of Fabien's patch (which'll require some massaging I'm sure). Greetings, Andres Freund
Hello Fabien, > I wanted to do some tests with this POC patch. For this purpose, it would > be nice to have a guc which would allow to activate or not this feature. Thanks. > Could you provide a patch with such a guc? I would suggest to have the number > of partitions as a guc, so that choosing 1 would basically reflect the > current behavior. Sure. Please find the attached patch. A guc parameter named 'checkpoint_partitions' is added. This can be set to 1, 2, 4, 8, or 16. Default is 16. (It is trivial at this present, I think.) And some definitions are moved from bufmgr.h to xlog.h. It would be also trivial. Best regards. -- Takashi Horikawa NEC Corporation Knowledge Discovery Research Laboratories
Attachment
Hi, > I understand that what this patch does is cutting the checkpoint > of buffers in 16 partitions, each addressing 1/16 of buffers, and each with > its own wal-log entry, pacing, fsync and so on. Right. However, > The key point is that we spread out the fsyncs across the whole checkpoint > period. this is not the key point of the 'partitioned checkpointing,' I think. The original purpose is to mitigate full-page-write rush that occurs at immediately after the beginning of each checkpoint. The amount of FPW at each checkpoint is reduced to 1/16 by the 'Partitioned checkpointing.' > This method interacts with the current proposal to improve the > checkpointer behavior by avoiding random I/Os, but it could be combined. I agree. > Splitting with N=16 does nothing to guarantee the partitions are equally > sized, so there would likely be an imbalance that would reduce the > effectiveness of the patch. May be right. However, current method was designed with considering to split buffers so as to balance the load as equally as possible; current patch splits the buffer as --- 1st round: b[0], b[p], b[2p], … b[(n-1)p] 2nd round: b[1], b[p+1], b[2p+1], … b[(n-1)p+1] … p-1 th round:b[p-1], b[p+(p-1)], b[2p+(p-1)], … b[(n-1)p+(p-1)] --- where N is the number of buffers, p is the number of partitions, and n = (N / p). It would be extremely unbalance if buffers are divided as follow. --- 1st round: b[0], b[1], b[2], … b[n-1] 2nd round: b[n], b[n+1], b[n+2], … b[2n-1] … p-1 th round:b[(p-1)n], b[(p-1)n+1], b[(p-1)n+2], … b[(p-1)n+(n-1)] --- I'm afraid that I miss the point, but > 2. > Assign files to one of N batches so we can make N roughly equal sized > mini-checkpoints Splitting buffers with considering the file boundary makes FPW related processing (in xlog.c and xloginsert.c) complicated intolerably, as 'Partitioned checkpointing' is strongly related to the decision of whether this buffer is necessary to FPW or not at the time of inserting the xlog record. # 'partition id = buffer id % number of partitions' is fairly simple. Best regards. -- Takashi Horikawa NEC Corporation Knowledge Discovery Research Laboratories > -----Original Message----- > From: Simon Riggs [mailto:simon@2ndQuadrant.com] > Sent: Friday, September 11, 2015 10:57 PM > To: Fabien COELHO > Cc: Horikawa Takashi(堀川 隆); pgsql-hackers@postgresql.org > Subject: Re: [HACKERS] Partitioned checkpointing > > On 11 September 2015 at 09:07, Fabien COELHO <coelho@cri.ensmp.fr> wrote: > > > > Some general comments : > > > > Thanks for the summary Fabien. > > > I understand that what this patch does is cutting the checkpoint > of buffers in 16 partitions, each addressing 1/16 of buffers, and each with > its own wal-log entry, pacing, fsync and so on. > > I'm not sure why it would be much better, although I agree that > it may have some small positive influence on performance, but I'm afraid > it may also degrade performance in some conditions. So I think that maybe > a better understanding of why there is a better performance and focus on > that could help obtain a more systematic gain. > > > > I think its a good idea to partition the checkpoint, but not doing it this > way. > > Splitting with N=16 does nothing to guarantee the partitions are equally > sized, so there would likely be an imbalance that would reduce the > effectiveness of the patch. > > > This method interacts with the current proposal to improve the > checkpointer behavior by avoiding random I/Os, but it could be combined. > > I'm wondering whether the benefit you see are linked to the file > flushing behavior induced by fsyncing more often, in which case it is quite > close the "flushing" part of the current "checkpoint continuous flushing" > patch, and could be redundant/less efficient that what is done there, > especially as test have shown that the effect of flushing is *much* better > on sorted buffers. > > Another proposal around, suggested by Andres Freund I think, is > that checkpoint could fsync files while checkpointing and not wait for the > end of the checkpoint. I think that it may also be one of the reason why > your patch does bring benefit, but Andres approach would be more systematic, > because there would be no need to fsync files several time (basically your > patch issues 16 fsync per file). This suggest that the "partitionning" > should be done at a lower level, from within the CheckPointBuffers, which > would take care of fsyncing files some time after writting buffers to them > is finished. > > > The idea to do a partial pass through shared buffers and only write a fraction > of dirty buffers, then fsync them is a good one. > > The key point is that we spread out the fsyncs across the whole checkpoint > period. > > I think we should be writing out all buffers for a particular file in one > pass, then issue one fsync per file. >1 fsyncs per file seems a bad idea. > > So we'd need logic like this > 1. Run through shared buffers and analyze the files contained in there 2. > Assign files to one of N batches so we can make N roughly equal sized > mini-checkpoints 3. Make N passes through shared buffers, writing out files > assigned to each batch as we go > > -- > > Simon Riggs http://www.2ndQuadrant.com/ > PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
Hello Andres, Thank you for discussion. It’s nice for me to discuss here. > Partitioned checkpoint have the significant disadvantage that it increases > random write io by the number of passes. Which is a bad idea, > *especially* on SSDs. I’m curious about the conclusion that the Partitioned Checkpinting increases random write io by the number of passes. The order of buffer syncs in original checkpointing is as follows. b[0], b[1], ….. , b[N-1] where b[i] means buffer[i], N is the number of buffers. (To make the story simple, starting point of buffer sync determined by the statement ‘buf_id = StrategySyncStart(NULL, NULL);’ in BufferSync() is ignored here. If it is important in this discussion, please note that.) While partitioned checkpointing is as follows. 1st round b[0], b[p], b[2p], … b[(n-1)p] 2nd round b[1], b[p+1], b[2p+1], … b[(n-1)p+1] … last round b[p-1], b[p+(p-1)], b[2p+(p-1)], … b[(n-1)p+(p-1)] where p is the number of partitions and n = (N / p). I think important here is that the ‘Partitioned checkpointing’ does not change (increase) the total number of buffer writes. I wonder why the sequence of b[0], b[1], ….. , b[N-1] is less random than that of b[0], b[p], b[2p], … b[(n-1)p]. I think there is no relationship between the neighboring buffers, like b[0] and b[1]. Is this wrong? Also, I believe that random ‘PAGE’ writes are not harmful for SSDs. (Buffer sync is carried out in the unit of 8 Kbyte page.) Harmful for SSDs is partial write (write size is less than PAGE size) because it increases the write-amplitude of the SSD, resulting in shortening its lifetime. On the other hand, IIRC, random ‘PAGE’ writes do not increase the write amplitude. Wearleveling algorithm of the SSD should effectively handle random ‘PAGE’ writes. > I think it's likely that the patch will have only a very small effect if > applied ontop of Fabien's patch (which'll require some massaging I'm sure). It may be true or not. Who knows? I think only detail experimentations tell the truth. Best regards. -- Takashi Horikawa NEC Corporation Knowledge Discovery Research Laboratories > -----Original Message----- > From: pgsql-hackers-owner@postgresql.org > [mailto:pgsql-hackers-owner@postgresql.org] On Behalf Of Andres Freund > Sent: Saturday, September 12, 2015 1:30 AM > To: Tomas Vondra > Cc: pgsql-hackers@postgresql.org > Subject: Re: [HACKERS] Partitioned checkpointing > > Hi, > > Partitioned checkpoint have the significant disadvantage that it increases > random write io by the number of passes. Which is a bad idea, > *especially* on SSDs. > > > >So we'd need logic like this > > >1. Run through shared buffers and analyze the files contained in > > >there 2. Assign files to one of N batches so we can make N roughly > > >equal sized mini-checkpoints 3. Make N passes through shared buffers, > > >writing out files assigned to each batch as we go > > That's essentially what Fabien's sorting patch does by sorting all writes. > > > What I think might work better is actually keeping the write/fsync > > phases we have now, but instead of postponing the fsyncs until the > > next checkpoint we might spread them after the writes. So with > > target=0.5 we'd do the writes in the first half, then the fsyncs in > > the other half. Of course, we should sort the data like you propose, > > and issue the fsyncs in the same order (so that the OS has time to write > them to the devices). > > I think the approach in Fabien's patch of enforcing that there's not very > much dirty data to flush by forcing early cache flushes is better. Having > gigabytes worth of dirty data in the OS page cache can have massive negative > impact completely independent of fsyncs. > > > I wonder how much the original paper (written in 1996) is effectively > > obsoleted by spread checkpoints, but the benchmark results posted by > > Horikawa-san suggest there's a possible gain. But perhaps partitioning > > the checkpoints is not the best approach? > > I think it's likely that the patch will have only a very small effect if > applied ontop of Fabien's patch (which'll require some massaging I'm sure). > > Greetings, > > Andres Freund > > > -- > Sent via pgsql-hackers mailing list (pgsql-hackers@postgresql.org) To make > changes to your subscription: > http://www.postgresql.org/mailpref/pgsql-hackers
Hello Fabien,
I wrote:
> A guc parameter named 'checkpoint_partitions' is added.
> This can be set to 1, 2, 4, 8, or 16.
> Default is 16. (It is trivial at this present, I think.)
I've noticed that the behavior in 'checkpoint_partitions = 1' is not the
same as that of original 9.5alpha2.
Attached 'partitioned-checkpointing-v3.patch' fixed the bug, thus please use
it.
I'm sorry for that.
PS. The result graphs I sent was obtained using original 9.5alpha2, and thus
that results is unrelated to this bug.
As to 'partitioned checkpointing' case, the results shown in that graph
is probably worth than bug-fix version.
Best regards.
--
Takashi Horikawa
NEC Corporation
Knowledge Discovery Research Laboratories
> -----Original Message-----
> From: pgsql-hackers-owner@postgresql.org
> [mailto:pgsql-hackers-owner@postgresql.org] On Behalf Of Takashi Horikawa
> Sent: Saturday, September 12, 2015 11:50 AM
> To: Fabien COELHO
> Cc: pgsql-hackers@postgresql.org
> Subject: Re: [HACKERS] Partitioned checkpointing
>
> Hello Fabien,
>
> > I wanted to do some tests with this POC patch. For this purpose, it
would
> > be nice to have a guc which would allow to activate or not this feature.
> Thanks.
>
> > Could you provide a patch with such a guc? I would suggest to have the
> number
> > of partitions as a guc, so that choosing 1 would basically reflect the
> > current behavior.
> Sure.
> Please find the attached patch.
>
> A guc parameter named 'checkpoint_partitions' is added.
> This can be set to 1, 2, 4, 8, or 16.
> Default is 16. (It is trivial at this present, I think.)
>
> And some definitions are moved from bufmgr.h to xlog.h.
> It would be also trivial.
>
> Best regards.
> --
> Takashi Horikawa
> NEC Corporation
> Knowledge Discovery Research Laboratories
Attachment
> As to 'partitioned checkpointing' case, the results shown in that graph > is probably worth than bug-fix version. ^^^^^ worse Sorry for typo. -- Takashi Horikawa NEC Corporation Knowledge Discovery Research Laboratories > -----Original Message----- > From: pgsql-hackers-owner@postgresql.org > [mailto:pgsql-hackers-owner@postgresql.org] On Behalf Of Takashi Horikawa > Sent: Saturday, September 12, 2015 11:36 PM > To: Fabien COELHO > Cc: pgsql-hackers@postgresql.org > Subject: Re: [HACKERS] Partitioned checkpointing > > Hello Fabien, > > I wrote: > > A guc parameter named 'checkpoint_partitions' is added. > > This can be set to 1, 2, 4, 8, or 16. > > Default is 16. (It is trivial at this present, I think.) > I've noticed that the behavior in 'checkpoint_partitions = 1' is not the > same as that of original 9.5alpha2. > Attached 'partitioned-checkpointing-v3.patch' fixed the bug, thus please > use > it. > I'm sorry for that. > > PS. The result graphs I sent was obtained using original 9.5alpha2, and > thus > that results is unrelated to this bug. > As to 'partitioned checkpointing' case, the results shown in that graph > is probably worth than bug-fix version. > > Best regards. > -- > Takashi Horikawa > NEC Corporation > Knowledge Discovery Research Laboratories > > > > -----Original Message----- > > From: pgsql-hackers-owner@postgresql.org > > [mailto:pgsql-hackers-owner@postgresql.org] On Behalf Of Takashi > Horikawa > > Sent: Saturday, September 12, 2015 11:50 AM > > To: Fabien COELHO > > Cc: pgsql-hackers@postgresql.org > > Subject: Re: [HACKERS] Partitioned checkpointing > > > > Hello Fabien, > > > > > I wanted to do some tests with this POC patch. For this purpose, it > would > > > be nice to have a guc which would allow to activate or not this feature. > > Thanks. > > > > > Could you provide a patch with such a guc? I would suggest to have the > > number > > > of partitions as a guc, so that choosing 1 would basically reflect the > > > current behavior. > > Sure. > > Please find the attached patch. > > > > A guc parameter named 'checkpoint_partitions' is added. > > This can be set to 1, 2, 4, 8, or 16. > > Default is 16. (It is trivial at this present, I think.) > > > > And some definitions are moved from bufmgr.h to xlog.h. > > It would be also trivial. > > > > Best regards. > > -- > > Takashi Horikawa > > NEC Corporation > > Knowledge Discovery Research Laboratories
Hi, I wrote: > The original purpose is to mitigate full-page-write rush that occurs at > immediately after the beginning of each checkpoint. > The amount of FPW at each checkpoint is reduced to 1/16 by the > 'Partitioned checkpointing.' Let me show another set of measurement results that clearly illustrates this point. Please find DBT2-sync.jpg and DBT2-sync-FPWoff.jpg. At first, I noticed the performance dip due to checkpointing when I conducted some performance measurement using DBT-2 thatimplements transactions based on the TPC-C specification. As can be seen in DBT2-sync.jpg, original 9.5alpha2 showedsharp dips in throughput periodically. The point here is that I identified that those dips were caused by full-page-write rush that occurs immediately after thebeginning of each checkpoint. As shown in DBT2-sync-FPWoff.jpg; those dips were eliminated when a GUC parameter 'full_page_writes'was set to 'off.' This also indicates that existing mechanism of spreading buffer sync operations overtime was effectively worked. As only difference between original 9.5alpha2 case in DBT2-sync.jpg and DBT2-sync-FPWoff.jpgwas in the setting of 'full_page_writes,' those dips were attributed to the full-page-write as a corollary. The 'Partitioned checkpointing' was implemented to mitigate the dips by spreading full-page-writes over time and was workedexactly as designed (see DBT2-sync.jpg). It also produced good effect for pgbench, thus I have posted an article witha Partitioned-checkpointing.patch to this mailing list. As to pgbench, however, I have found that full-page-writes did not cause the performance dips, because the dips also occurredwhen 'full_page_writes' was set to 'off.' So, honestly, I do not exactly know why 'Partitioned checkpointing' mitigatedthe dips in pgbench executions. However, it is certain that there are some, other than pgbench, workloads for PostgreSQL in which the full-page-write rushcauses performance dips and 'Partitioned checkpointing' is effective to eliminate (or mitigate) them; DBT-2 is an example. And also, 'Partitioned checkpointing' is worth to study why it is effective in pgbench executions. By studying it, it maylead to devising better ways. -- Takashi Horikawa NEC Corporation Knowledge Discovery Research Laboratories > -----Original Message----- > From: pgsql-hackers-owner@postgresql.org > [mailto:pgsql-hackers-owner@postgresql.org] On Behalf Of Takashi Horikawa > Sent: Saturday, September 12, 2015 12:50 PM > To: Simon Riggs; Fabien COELHO > Cc: pgsql-hackers@postgresql.org > Subject: Re: [HACKERS] Partitioned checkpointing > > Hi, > > > I understand that what this patch does is cutting the checkpoint > > of buffers in 16 partitions, each addressing 1/16 of buffers, and each > with > > its own wal-log entry, pacing, fsync and so on. > Right. > However, > > The key point is that we spread out the fsyncs across the whole checkpoint > > period. > this is not the key point of the 'partitioned checkpointing,' I think. > The original purpose is to mitigate full-page-write rush that occurs at > immediately after the beginning of each checkpoint. > The amount of FPW at each checkpoint is reduced to 1/16 by the > 'Partitioned checkpointing.' > > > This method interacts with the current proposal to improve the > > checkpointer behavior by avoiding random I/Os, but it could be combined. > I agree. > > > Splitting with N=16 does nothing to guarantee the partitions are equally > > sized, so there would likely be an imbalance that would reduce the > > effectiveness of the patch. > May be right. > However, current method was designed with considering to split > buffers so as to balance the load as equally as possible; > current patch splits the buffer as > --- > 1st round: b[0], b[p], b[2p], … b[(n-1)p] > 2nd round: b[1], b[p+1], b[2p+1], … b[(n-1)p+1] > … > p-1 th round:b[p-1], b[p+(p-1)], b[2p+(p-1)], … b[(n-1)p+(p-1)] > --- > where N is the number of buffers, > p is the number of partitions, and n = (N / p). > > It would be extremely unbalance if buffers are divided as follow. > --- > 1st round: b[0], b[1], b[2], … b[n-1] > 2nd round: b[n], b[n+1], b[n+2], … b[2n-1] > … > p-1 th round:b[(p-1)n], b[(p-1)n+1], b[(p-1)n+2], … b[(p-1)n+(n-1)] > --- > > > I'm afraid that I miss the point, but > > 2. > > Assign files to one of N batches so we can make N roughly equal sized > > mini-checkpoints > Splitting buffers with considering the file boundary makes FPW related > processing > (in xlog.c and xloginsert.c) complicated intolerably, as 'Partitioned > checkpointing' is strongly related to the decision of whether this buffer > is necessary to FPW or not at the time of inserting the xlog record. > # 'partition id = buffer id % number of partitions' is fairly simple. > > Best regards. > -- > Takashi Horikawa > NEC Corporation > Knowledge Discovery Research Laboratories > > > > > -----Original Message----- > > From: Simon Riggs [mailto:simon@2ndQuadrant.com] > > Sent: Friday, September 11, 2015 10:57 PM > > To: Fabien COELHO > > Cc: Horikawa Takashi(堀川 隆); pgsql-hackers@postgresql.org > > Subject: Re: [HACKERS] Partitioned checkpointing > > > > On 11 September 2015 at 09:07, Fabien COELHO <coelho@cri.ensmp.fr> wrote: > > > > > > > > Some general comments : > > > > > > > > Thanks for the summary Fabien. > > > > > > I understand that what this patch does is cutting the checkpoint > > of buffers in 16 partitions, each addressing 1/16 of buffers, and each > with > > its own wal-log entry, pacing, fsync and so on. > > > > I'm not sure why it would be much better, although I agree that > > it may have some small positive influence on performance, but I'm afraid > > it may also degrade performance in some conditions. So I think that maybe > > a better understanding of why there is a better performance and focus > on > > that could help obtain a more systematic gain. > > > > > > > > I think its a good idea to partition the checkpoint, but not doing it > this > > way. > > > > Splitting with N=16 does nothing to guarantee the partitions are equally > > sized, so there would likely be an imbalance that would reduce the > > effectiveness of the patch. > > > > > > This method interacts with the current proposal to improve the > > checkpointer behavior by avoiding random I/Os, but it could be combined. > > > > I'm wondering whether the benefit you see are linked to the file > > flushing behavior induced by fsyncing more often, in which case it is > quite > > close the "flushing" part of the current "checkpoint continuous flushing" > > patch, and could be redundant/less efficient that what is done there, > > especially as test have shown that the effect of flushing is *much* better > > on sorted buffers. > > > > Another proposal around, suggested by Andres Freund I think, is > > that checkpoint could fsync files while checkpointing and not wait for > the > > end of the checkpoint. I think that it may also be one of the reason why > > your patch does bring benefit, but Andres approach would be more > systematic, > > because there would be no need to fsync files several time (basically > your > > patch issues 16 fsync per file). This suggest that the "partitionning" > > should be done at a lower level, from within the CheckPointBuffers, which > > would take care of fsyncing files some time after writting buffers to > them > > is finished. > > > > > > The idea to do a partial pass through shared buffers and only write a > fraction > > of dirty buffers, then fsync them is a good one. > > > > The key point is that we spread out the fsyncs across the whole checkpoint > > period. > > > > I think we should be writing out all buffers for a particular file in > one > > pass, then issue one fsync per file. >1 fsyncs per file seems a bad idea. > > > > So we'd need logic like this > > 1. Run through shared buffers and analyze the files contained in there > 2. > > Assign files to one of N batches so we can make N roughly equal sized > > mini-checkpoints 3. Make N passes through shared buffers, writing out > files > > assigned to each batch as we go > > > > -- > > > > Simon Riggs http://www.2ndQuadrant.com/ > > PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
Attachment
{kind=link}
{kind=link}
Hello Takashi-san,
> I've noticed that the behavior in 'checkpoint_partitions = 1' is not the
> same as that of original 9.5alpha2. Attached
> 'partitioned-checkpointing-v3.patch' fixed the bug, thus please use it.
I've done two sets of run on an old box (16 GB, 8 cores, RAID1 HDD)
with "pgbench -M prepared -N -j 2 -c 4 ..." and analysed per second traces
(-P 1) for 4 versions : sort+flush patch fully on, sort+flush patch full
off (should be equivalent to head), partition patch v3 with 1 partition
(should also be equivalent to head), partition patch v3 with 16
partitions.
I ran two configurations :
small: shared_buffers = 2GB checkpoint_timeout = 300s checkpoint_completion_target = 0.8 pgbench's scale = 120,
time= 4000
medium: shared_buffers = 4GB max_wal_size = 5GB checkpoint_timeout = 30min checkpoint_completion_target = 0.8
pgbench'sscale = 300, time = 7500
* full speed run performance
average tps +- standard deviation (percent of under 10 tps seconds)
small medium 1. flush+sort : 751 +- 415 ( 0.2) 984 +- 500 ( 0.3) 2. no
flush/sort: 188 +- 508 (83.6) 252 +- 551 (77.0) 3. 1 partition : 183 +- 518 (85.6) 232 +- 535 (78.3) 4. 16
partitions: 179 +- 462 (81.1) 196 +- 492 (80.9)
Although 2 & 3 should be equivalent, there seems to be a lower performance
with 1 partition, but it is pretty close and it may not be significant.
The 16 partitions seems to show significant lower tps performance,
especially for the medium case. Although the stddev is a little bit better
for the small case, as suggested by the lower off-line figure, but
relatively higher with the medium case (stddev = 2.5 * average).
There is no comparision with the flush & sort activated.
* throttled performance (-R 100/200 -L 100)
percent of late transactions - above 100 ms or not even started as the system is much too behind schedule.
small-100 small-200 medium-100 1. flush+sort : 1.0 1.9 1.9 2. no
flush/sort: 31.5 49.8 27.1 3. 1 partition : 32.3 49.0 27.0 4. 16 partitions : 32.9
48.0 31.5
2 & 3 seem pretty equivalent, as expected. The 16 partitions seem to
slightly degrade availability on average. Yet again, no comparison with
flush & sort activated.
From these runs, I would advise against applying the checkpoint
partitionning patch: there is no consistent benefit on the basic harware
I'm using on this test. I think that it make sense, because fsyncing
random I/O several times instead of one has little impact.
Now, once I/O are not random, that is with some kind of combined patch,
this is another question. I would rather go with Andres suggestion to
fsync once per file, when writing to a file is completed, because
partitionning as such would reduce the effectiveness of sorting buffers.
I think that it would be interesting if you could test the sort/flush
patch on the same high-end system that you used for testing your partition
patch.
--
Fabien.
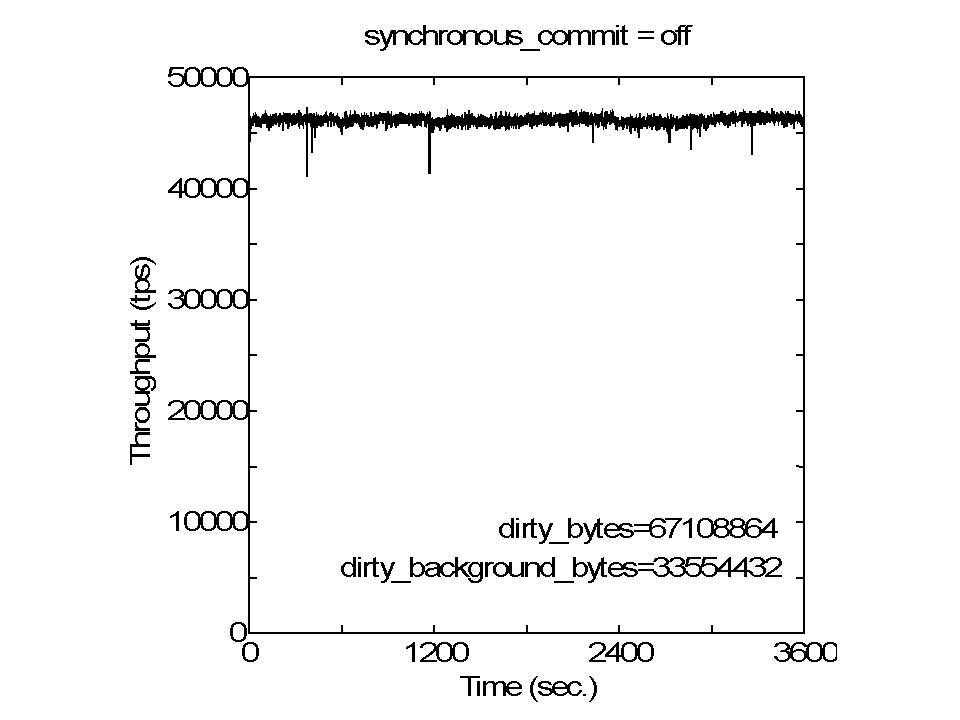
Hi, I wrote: > ... So, honestly, I do not exactly know > why 'Partitioned checkpointing' mitigated the dips in pgbench executions. I have conducted some experiments to clarify why checkpointing brings on performance dip and why partitioned checkpointingmitigated the dip in my experimental setup. Some were finished, only traces of the past knowledge, and the others, I beleive, resulted in a new knowledge. Please find some result graphs, default.JPG, no-flushd.JPG, dirty64M.JPG, dirty512M.JPG, and file_sync_range.JPG, which were obtained with varying some kernel parameters to change the behavior of the flush daemon. At first, it becomes clear that performance dip problem is related to the flush daemon, as it has been said conventionally. When the flush daemon activity was disabled (no-flushd.JPG) during the benchmark execution, performance dips occurred atthe end of checkpoint period. Time variation of the throughput for this case is quite different from that for default setting (default.JPG). When using the partitioned checkpointing, I think that the system had the same kind of behavior, but scale is one-Nth, whereN is the number of partitions. As the checkpoint interval was almost the same as dirty_expire_centisecs (30 seconds), there would be no chance for flushdaemon to work. Since the flush daemon has an important role in performance dip, I changed some kernel parameter dirty_bytes and dirty_background_bytesbased on the conventional knowledge. As to my experimental setup, 512MB, which some blogs recommend to set in dirty_bytes, was not small enough. When 512MB and 256MB were set in dirty_bytes and dirty_background_bytes respectively (dirty512M.JPG), there was no visibleimprovement from the default setting (default.JPG). Meaningful improvement was observed when 64MB and 32MB were set in those parameters (dirty64M.JPG). In a situation in which small values are set in dirty_bytes and dirty_backgound_bytes, a buffer is likely stored in the HDimmediately after the buffer is written in the kernel by the checkpointer. Thus, I tried a quick hack to make the checkpointer invoke write system call to write a dirty buffer immediately followedby invoking store operation for a buffer implemented with sync_file_range() system call. # For reference, I attach the patch. As shown in file_sync_range.JPG, this strategy considered to have been effective. In conclusion, as long as pgbench execution against linux concerns, using sync_file_range() is a promising solution. That is, the checkpointer invokes sync_file_range() to store a buffer immediately after it writes the buffer in the kernel. -- Takashi Horikawa NEC Corporation Knowledge Discovery Research Laboratories > -----Original Message----- > From: Horikawa Takashi(堀川 隆) > Sent: Monday, September 14, 2015 6:43 PM > To: Simon Riggs; Fabien COELHO > Cc: pgsql-hackers@postgresql.org > Subject: RE: [HACKERS] Partitioned checkpointing > > Hi, > > I wrote: > > The original purpose is to mitigate full-page-write rush that occurs at > > immediately after the beginning of each checkpoint. > > The amount of FPW at each checkpoint is reduced to 1/16 by the > > 'Partitioned checkpointing.' > Let me show another set of measurement results that clearly illustrates > this point. Please find DBT2-sync.jpg and DBT2-sync-FPWoff.jpg. > > At first, I noticed the performance dip due to checkpointing when I conducted > some performance measurement using DBT-2 that implements transactions based > on the TPC-C specification. As can be seen in DBT2-sync.jpg, original > 9.5alpha2 showed sharp dips in throughput periodically. > > The point here is that I identified that those dips were caused by > full-page-write rush that occurs immediately after the beginning of each > checkpoint. As shown in DBT2-sync-FPWoff.jpg; those dips were eliminated > when a GUC parameter 'full_page_writes' was set to 'off.' This also > indicates that existing mechanism of spreading buffer sync operations over > time was effectively worked. As only difference between original 9.5alpha2 > case in DBT2-sync.jpg and DBT2-sync-FPWoff.jpg was in the setting of > 'full_page_writes,' those dips were attributed to the full-page-write as > a corollary. > > The 'Partitioned checkpointing' was implemented to mitigate the dips by > spreading full-page-writes over time and was worked exactly as designed > (see DBT2-sync.jpg). It also produced good effect for pgbench, thus I have > posted an article with a Partitioned-checkpointing.patch to this mailing > list. > > As to pgbench, however, I have found that full-page-writes did not cause > the performance dips, because the dips also occurred when > 'full_page_writes' was set to 'off.' So, honestly, I do not exactly know > why 'Partitioned checkpointing' mitigated the dips in pgbench executions. > > However, it is certain that there are some, other than pgbench, workloads > for PostgreSQL in which the full-page-write rush causes performance dips > and 'Partitioned checkpointing' is effective to eliminate (or mitigate) > them; DBT-2 is an example. > > And also, 'Partitioned checkpointing' is worth to study why it is effective > in pgbench executions. By studying it, it may lead to devising better ways. > -- > Takashi Horikawa > NEC Corporation > Knowledge Discovery Research Laboratories > > > > -----Original Message----- > > From: pgsql-hackers-owner@postgresql.org > > [mailto:pgsql-hackers-owner@postgresql.org] On Behalf Of Takashi > Horikawa > > Sent: Saturday, September 12, 2015 12:50 PM > > To: Simon Riggs; Fabien COELHO > > Cc: pgsql-hackers@postgresql.org > > Subject: Re: [HACKERS] Partitioned checkpointing > > > > Hi, > > > > > I understand that what this patch does is cutting the checkpoint > > > of buffers in 16 partitions, each addressing 1/16 of buffers, and each > > with > > > its own wal-log entry, pacing, fsync and so on. > > Right. > > However, > > > The key point is that we spread out the fsyncs across the whole checkpoint > > > period. > > this is not the key point of the 'partitioned checkpointing,' I think. > > The original purpose is to mitigate full-page-write rush that occurs at > > immediately after the beginning of each checkpoint. > > The amount of FPW at each checkpoint is reduced to 1/16 by the > > 'Partitioned checkpointing.' > > > > > This method interacts with the current proposal to improve the > > > checkpointer behavior by avoiding random I/Os, but it could be combined. > > I agree. > > > > > Splitting with N=16 does nothing to guarantee the partitions are equally > > > sized, so there would likely be an imbalance that would reduce the > > > effectiveness of the patch. > > May be right. > > However, current method was designed with considering to split > > buffers so as to balance the load as equally as possible; > > current patch splits the buffer as > > --- > > 1st round: b[0], b[p], b[2p], … b[(n-1)p] > > 2nd round: b[1], b[p+1], b[2p+1], … b[(n-1)p+1] > > … > > p-1 th round:b[p-1], b[p+(p-1)], b[2p+(p-1)], … b[(n-1)p+(p-1)] > > --- > > where N is the number of buffers, > > p is the number of partitions, and n = (N / p). > > > > It would be extremely unbalance if buffers are divided as follow. > > --- > > 1st round: b[0], b[1], b[2], … b[n-1] > > 2nd round: b[n], b[n+1], b[n+2], … b[2n-1] > > … > > p-1 th round:b[(p-1)n], b[(p-1)n+1], b[(p-1)n+2], … b[(p-1)n+(n-1)] > > --- > > > > > > I'm afraid that I miss the point, but > > > 2. > > > Assign files to one of N batches so we can make N roughly equal sized > > > mini-checkpoints > > Splitting buffers with considering the file boundary makes FPW related > > processing > > (in xlog.c and xloginsert.c) complicated intolerably, as 'Partitioned > > checkpointing' is strongly related to the decision of whether this buffer > > is necessary to FPW or not at the time of inserting the xlog record. > > # 'partition id = buffer id % number of partitions' is fairly simple. > > > > Best regards. > > -- > > Takashi Horikawa > > NEC Corporation > > Knowledge Discovery Research Laboratories > > > > > > > > > -----Original Message----- > > > From: Simon Riggs [mailto:simon@2ndQuadrant.com] > > > Sent: Friday, September 11, 2015 10:57 PM > > > To: Fabien COELHO > > > Cc: Horikawa Takashi(堀川 隆); pgsql-hackers@postgresql.org > > > Subject: Re: [HACKERS] Partitioned checkpointing > > > > > > On 11 September 2015 at 09:07, Fabien COELHO <coelho@cri.ensmp.fr> > wrote: > > > > > > > > > > > > Some general comments : > > > > > > > > > > > > Thanks for the summary Fabien. > > > > > > > > > I understand that what this patch does is cutting the checkpoint > > > of buffers in 16 partitions, each addressing 1/16 of buffers, and each > > with > > > its own wal-log entry, pacing, fsync and so on. > > > > > > I'm not sure why it would be much better, although I agree that > > > it may have some small positive influence on performance, but I'm afraid > > > it may also degrade performance in some conditions. So I think that > maybe > > > a better understanding of why there is a better performance and focus > > on > > > that could help obtain a more systematic gain. > > > > > > > > > > > > I think its a good idea to partition the checkpoint, but not doing it > > this > > > way. > > > > > > Splitting with N=16 does nothing to guarantee the partitions are equally > > > sized, so there would likely be an imbalance that would reduce the > > > effectiveness of the patch. > > > > > > > > > This method interacts with the current proposal to improve the > > > checkpointer behavior by avoiding random I/Os, but it could be combined. > > > > > > I'm wondering whether the benefit you see are linked to the file > > > flushing behavior induced by fsyncing more often, in which case it is > > quite > > > close the "flushing" part of the current "checkpoint continuous > flushing" > > > patch, and could be redundant/less efficient that what is done there, > > > especially as test have shown that the effect of flushing is *much* > better > > > on sorted buffers. > > > > > > Another proposal around, suggested by Andres Freund I think, is > > > that checkpoint could fsync files while checkpointing and not wait for > > the > > > end of the checkpoint. I think that it may also be one of the reason > why > > > your patch does bring benefit, but Andres approach would be more > > systematic, > > > because there would be no need to fsync files several time (basically > > your > > > patch issues 16 fsync per file). This suggest that the "partitionning" > > > should be done at a lower level, from within the CheckPointBuffers, > which > > > would take care of fsyncing files some time after writting buffers to > > them > > > is finished. > > > > > > > > > The idea to do a partial pass through shared buffers and only write > a > > fraction > > > of dirty buffers, then fsync them is a good one. > > > > > > The key point is that we spread out the fsyncs across the whole checkpoint > > > period. > > > > > > I think we should be writing out all buffers for a particular file in > > one > > > pass, then issue one fsync per file. >1 fsyncs per file seems a bad > idea. > > > > > > So we'd need logic like this > > > 1. Run through shared buffers and analyze the files contained in there > > 2. > > > Assign files to one of N batches so we can make N roughly equal sized > > > mini-checkpoints 3. Make N passes through shared buffers, writing out > > files > > > assigned to each batch as we go > > > > > > -- > > > > > > Simon Riggs http://www.2ndQuadrant.com/ > > > PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
Attachment
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Hello,
These are interesting runs.
> In a situation in which small values are set in dirty_bytes and
> dirty_backgound_bytes, a buffer is likely stored in the HD immediately
> after the buffer is written in the kernel by the checkpointer. Thus, I
> tried a quick hack to make the checkpointer invoke write system call to
> write a dirty buffer immediately followed by invoking store operation
> for a buffer implemented with sync_file_range() system call. # For
> reference, I attach the patch. As shown in file_sync_range.JPG, this
> strategy considered to have been effective.
Indeed. This approach is part of this current patch:
https://commitfest.postgresql.org/6/260/
Basically, what you do is to call sync_file_range on each block, and you
tested on a high-end system probably with a lot of BBU disk cache, which I
guess allows the disk to reorder writes so as to benefit from sequential
write performance.
> In conclusion, as long as pgbench execution against linux concerns,
> using sync_file_range() is a promising solution.
I found that calling sync_file_range for every block could degrade
performance a bit under some conditions, at least onmy low-end systems
(just a [raid] disk, no significant disk cache in front of it), so the
above patch aggregates neighboring writes so as to issue less
sync_file_range calls.
> That is, the checkpointer invokes sync_file_range() to store a buffer
> immediately after it writes the buffer in the kernel.
Yep. It is interesting that sync_file_range alone improves stability a lot
on your high-end system, although sorting is mandatory for low-end
systems.
My interpretation, already stated above, is that the hardware does the
sorting on the cached data at the disk level in your system.
--
Fabien.