Re: Partitioned checkpointing - Mailing list pgsql-hackers
| From | Takashi Horikawa |
|---|---|
| Subject | Re: Partitioned checkpointing |
| Date | |
| Msg-id | 73FA3881462C614096F815F75628AFCD0355D813@BPXM01GP.gisp.nec.co.jp Whole thread Raw |
| In response to | Partitioned checkpointing (Takashi Horikawa <t-horikawa@aj.jp.nec.com>) |
| Responses |
Re: Partitioned checkpointing
|
| List | pgsql-hackers |
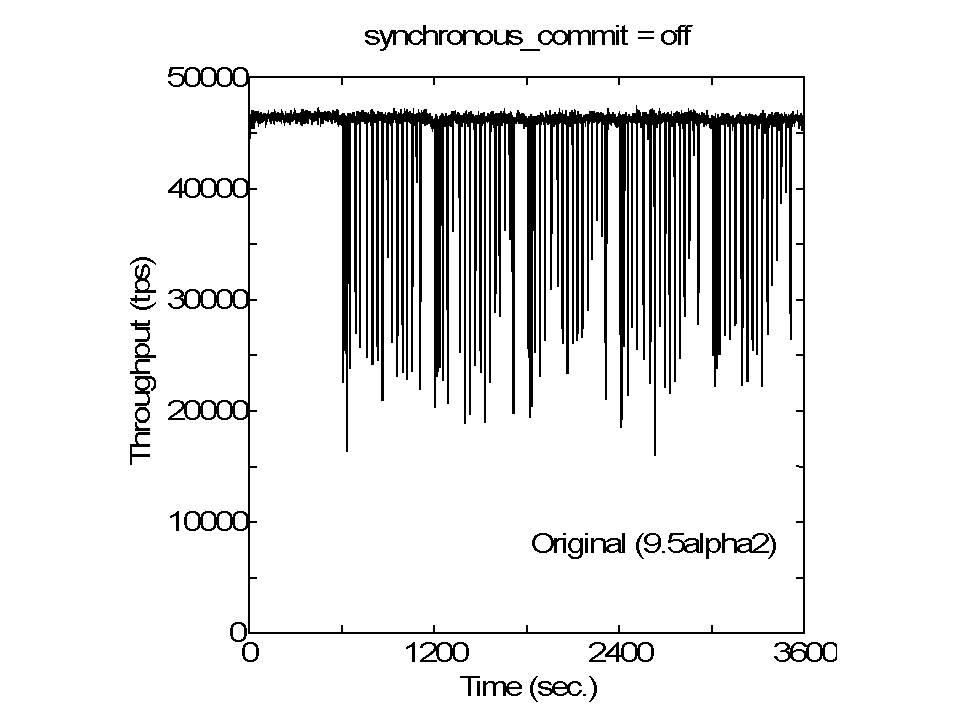
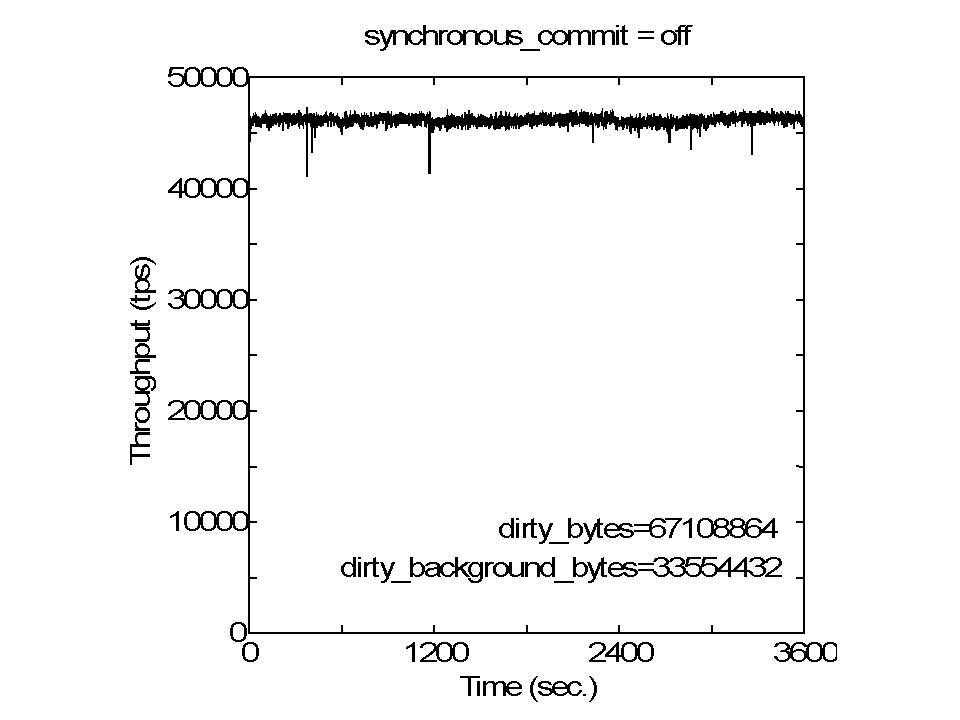
Hi, I wrote: > ... So, honestly, I do not exactly know > why 'Partitioned checkpointing' mitigated the dips in pgbench executions. I have conducted some experiments to clarify why checkpointing brings on performance dip and why partitioned checkpointingmitigated the dip in my experimental setup. Some were finished, only traces of the past knowledge, and the others, I beleive, resulted in a new knowledge. Please find some result graphs, default.JPG, no-flushd.JPG, dirty64M.JPG, dirty512M.JPG, and file_sync_range.JPG, which were obtained with varying some kernel parameters to change the behavior of the flush daemon. At first, it becomes clear that performance dip problem is related to the flush daemon, as it has been said conventionally. When the flush daemon activity was disabled (no-flushd.JPG) during the benchmark execution, performance dips occurred atthe end of checkpoint period. Time variation of the throughput for this case is quite different from that for default setting (default.JPG). When using the partitioned checkpointing, I think that the system had the same kind of behavior, but scale is one-Nth, whereN is the number of partitions. As the checkpoint interval was almost the same as dirty_expire_centisecs (30 seconds), there would be no chance for flushdaemon to work. Since the flush daemon has an important role in performance dip, I changed some kernel parameter dirty_bytes and dirty_background_bytesbased on the conventional knowledge. As to my experimental setup, 512MB, which some blogs recommend to set in dirty_bytes, was not small enough. When 512MB and 256MB were set in dirty_bytes and dirty_background_bytes respectively (dirty512M.JPG), there was no visibleimprovement from the default setting (default.JPG). Meaningful improvement was observed when 64MB and 32MB were set in those parameters (dirty64M.JPG). In a situation in which small values are set in dirty_bytes and dirty_backgound_bytes, a buffer is likely stored in the HDimmediately after the buffer is written in the kernel by the checkpointer. Thus, I tried a quick hack to make the checkpointer invoke write system call to write a dirty buffer immediately followedby invoking store operation for a buffer implemented with sync_file_range() system call. # For reference, I attach the patch. As shown in file_sync_range.JPG, this strategy considered to have been effective. In conclusion, as long as pgbench execution against linux concerns, using sync_file_range() is a promising solution. That is, the checkpointer invokes sync_file_range() to store a buffer immediately after it writes the buffer in the kernel. -- Takashi Horikawa NEC Corporation Knowledge Discovery Research Laboratories > -----Original Message----- > From: Horikawa Takashi(堀川 隆) > Sent: Monday, September 14, 2015 6:43 PM > To: Simon Riggs; Fabien COELHO > Cc: pgsql-hackers@postgresql.org > Subject: RE: [HACKERS] Partitioned checkpointing > > Hi, > > I wrote: > > The original purpose is to mitigate full-page-write rush that occurs at > > immediately after the beginning of each checkpoint. > > The amount of FPW at each checkpoint is reduced to 1/16 by the > > 'Partitioned checkpointing.' > Let me show another set of measurement results that clearly illustrates > this point. Please find DBT2-sync.jpg and DBT2-sync-FPWoff.jpg. > > At first, I noticed the performance dip due to checkpointing when I conducted > some performance measurement using DBT-2 that implements transactions based > on the TPC-C specification. As can be seen in DBT2-sync.jpg, original > 9.5alpha2 showed sharp dips in throughput periodically. > > The point here is that I identified that those dips were caused by > full-page-write rush that occurs immediately after the beginning of each > checkpoint. As shown in DBT2-sync-FPWoff.jpg; those dips were eliminated > when a GUC parameter 'full_page_writes' was set to 'off.' This also > indicates that existing mechanism of spreading buffer sync operations over > time was effectively worked. As only difference between original 9.5alpha2 > case in DBT2-sync.jpg and DBT2-sync-FPWoff.jpg was in the setting of > 'full_page_writes,' those dips were attributed to the full-page-write as > a corollary. > > The 'Partitioned checkpointing' was implemented to mitigate the dips by > spreading full-page-writes over time and was worked exactly as designed > (see DBT2-sync.jpg). It also produced good effect for pgbench, thus I have > posted an article with a Partitioned-checkpointing.patch to this mailing > list. > > As to pgbench, however, I have found that full-page-writes did not cause > the performance dips, because the dips also occurred when > 'full_page_writes' was set to 'off.' So, honestly, I do not exactly know > why 'Partitioned checkpointing' mitigated the dips in pgbench executions. > > However, it is certain that there are some, other than pgbench, workloads > for PostgreSQL in which the full-page-write rush causes performance dips > and 'Partitioned checkpointing' is effective to eliminate (or mitigate) > them; DBT-2 is an example. > > And also, 'Partitioned checkpointing' is worth to study why it is effective > in pgbench executions. By studying it, it may lead to devising better ways. > -- > Takashi Horikawa > NEC Corporation > Knowledge Discovery Research Laboratories > > > > -----Original Message----- > > From: pgsql-hackers-owner@postgresql.org > > [mailto:pgsql-hackers-owner@postgresql.org] On Behalf Of Takashi > Horikawa > > Sent: Saturday, September 12, 2015 12:50 PM > > To: Simon Riggs; Fabien COELHO > > Cc: pgsql-hackers@postgresql.org > > Subject: Re: [HACKERS] Partitioned checkpointing > > > > Hi, > > > > > I understand that what this patch does is cutting the checkpoint > > > of buffers in 16 partitions, each addressing 1/16 of buffers, and each > > with > > > its own wal-log entry, pacing, fsync and so on. > > Right. > > However, > > > The key point is that we spread out the fsyncs across the whole checkpoint > > > period. > > this is not the key point of the 'partitioned checkpointing,' I think. > > The original purpose is to mitigate full-page-write rush that occurs at > > immediately after the beginning of each checkpoint. > > The amount of FPW at each checkpoint is reduced to 1/16 by the > > 'Partitioned checkpointing.' > > > > > This method interacts with the current proposal to improve the > > > checkpointer behavior by avoiding random I/Os, but it could be combined. > > I agree. > > > > > Splitting with N=16 does nothing to guarantee the partitions are equally > > > sized, so there would likely be an imbalance that would reduce the > > > effectiveness of the patch. > > May be right. > > However, current method was designed with considering to split > > buffers so as to balance the load as equally as possible; > > current patch splits the buffer as > > --- > > 1st round: b[0], b[p], b[2p], … b[(n-1)p] > > 2nd round: b[1], b[p+1], b[2p+1], … b[(n-1)p+1] > > … > > p-1 th round:b[p-1], b[p+(p-1)], b[2p+(p-1)], … b[(n-1)p+(p-1)] > > --- > > where N is the number of buffers, > > p is the number of partitions, and n = (N / p). > > > > It would be extremely unbalance if buffers are divided as follow. > > --- > > 1st round: b[0], b[1], b[2], … b[n-1] > > 2nd round: b[n], b[n+1], b[n+2], … b[2n-1] > > … > > p-1 th round:b[(p-1)n], b[(p-1)n+1], b[(p-1)n+2], … b[(p-1)n+(n-1)] > > --- > > > > > > I'm afraid that I miss the point, but > > > 2. > > > Assign files to one of N batches so we can make N roughly equal sized > > > mini-checkpoints > > Splitting buffers with considering the file boundary makes FPW related > > processing > > (in xlog.c and xloginsert.c) complicated intolerably, as 'Partitioned > > checkpointing' is strongly related to the decision of whether this buffer > > is necessary to FPW or not at the time of inserting the xlog record. > > # 'partition id = buffer id % number of partitions' is fairly simple. > > > > Best regards. > > -- > > Takashi Horikawa > > NEC Corporation > > Knowledge Discovery Research Laboratories > > > > > > > > > -----Original Message----- > > > From: Simon Riggs [mailto:simon@2ndQuadrant.com] > > > Sent: Friday, September 11, 2015 10:57 PM > > > To: Fabien COELHO > > > Cc: Horikawa Takashi(堀川 隆); pgsql-hackers@postgresql.org > > > Subject: Re: [HACKERS] Partitioned checkpointing > > > > > > On 11 September 2015 at 09:07, Fabien COELHO <coelho@cri.ensmp.fr> > wrote: > > > > > > > > > > > > Some general comments : > > > > > > > > > > > > Thanks for the summary Fabien. > > > > > > > > > I understand that what this patch does is cutting the checkpoint > > > of buffers in 16 partitions, each addressing 1/16 of buffers, and each > > with > > > its own wal-log entry, pacing, fsync and so on. > > > > > > I'm not sure why it would be much better, although I agree that > > > it may have some small positive influence on performance, but I'm afraid > > > it may also degrade performance in some conditions. So I think that > maybe > > > a better understanding of why there is a better performance and focus > > on > > > that could help obtain a more systematic gain. > > > > > > > > > > > > I think its a good idea to partition the checkpoint, but not doing it > > this > > > way. > > > > > > Splitting with N=16 does nothing to guarantee the partitions are equally > > > sized, so there would likely be an imbalance that would reduce the > > > effectiveness of the patch. > > > > > > > > > This method interacts with the current proposal to improve the > > > checkpointer behavior by avoiding random I/Os, but it could be combined. > > > > > > I'm wondering whether the benefit you see are linked to the file > > > flushing behavior induced by fsyncing more often, in which case it is > > quite > > > close the "flushing" part of the current "checkpoint continuous > flushing" > > > patch, and could be redundant/less efficient that what is done there, > > > especially as test have shown that the effect of flushing is *much* > better > > > on sorted buffers. > > > > > > Another proposal around, suggested by Andres Freund I think, is > > > that checkpoint could fsync files while checkpointing and not wait for > > the > > > end of the checkpoint. I think that it may also be one of the reason > why > > > your patch does bring benefit, but Andres approach would be more > > systematic, > > > because there would be no need to fsync files several time (basically > > your > > > patch issues 16 fsync per file). This suggest that the "partitionning" > > > should be done at a lower level, from within the CheckPointBuffers, > which > > > would take care of fsyncing files some time after writting buffers to > > them > > > is finished. > > > > > > > > > The idea to do a partial pass through shared buffers and only write > a > > fraction > > > of dirty buffers, then fsync them is a good one. > > > > > > The key point is that we spread out the fsyncs across the whole checkpoint > > > period. > > > > > > I think we should be writing out all buffers for a particular file in > > one > > > pass, then issue one fsync per file. >1 fsyncs per file seems a bad > idea. > > > > > > So we'd need logic like this > > > 1. Run through shared buffers and analyze the files contained in there > > 2. > > > Assign files to one of N batches so we can make N roughly equal sized > > > mini-checkpoints 3. Make N passes through shared buffers, writing out > > files > > > assigned to each batch as we go > > > > > > -- > > > > > > Simon Riggs http://www.2ndQuadrant.com/ > > > PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
Attachment
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
pgsql-hackers by date: