Re: Partitioned checkpointing - Mailing list pgsql-hackers
| From | Takashi Horikawa |
|---|---|
| Subject | Re: Partitioned checkpointing |
| Date | |
| Msg-id | 73FA3881462C614096F815F75628AFCD035590E2@BPXM01GP.gisp.nec.co.jp Whole thread Raw |
| In response to | Re: Partitioned checkpointing (Takashi Horikawa <t-horikawa@aj.jp.nec.com>) |
| List | pgsql-hackers |
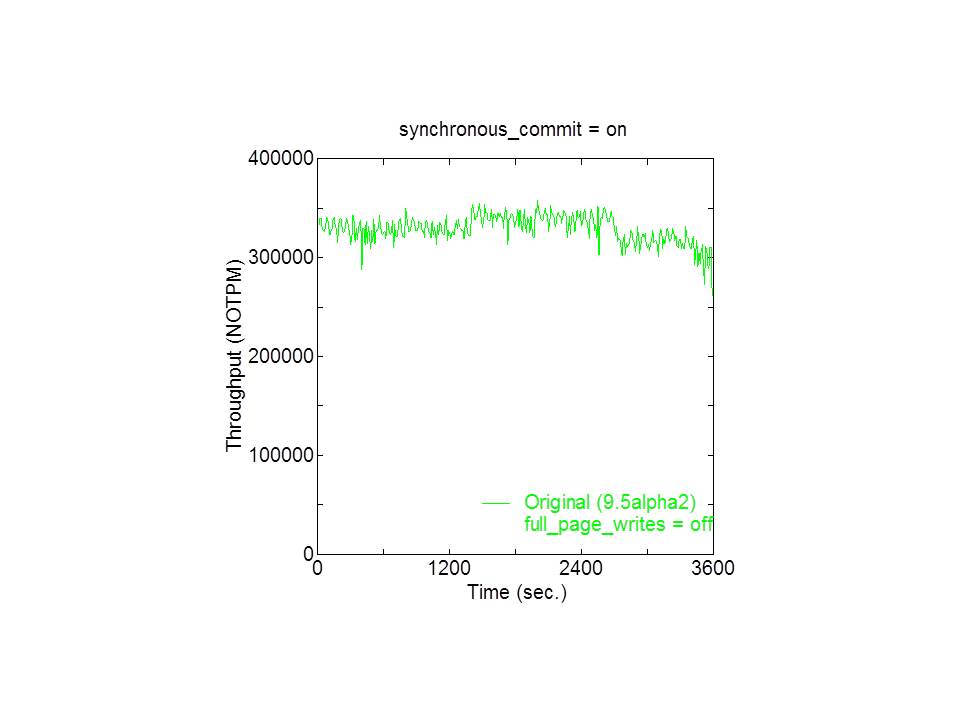
Hi, I wrote: > The original purpose is to mitigate full-page-write rush that occurs at > immediately after the beginning of each checkpoint. > The amount of FPW at each checkpoint is reduced to 1/16 by the > 'Partitioned checkpointing.' Let me show another set of measurement results that clearly illustrates this point. Please find DBT2-sync.jpg and DBT2-sync-FPWoff.jpg. At first, I noticed the performance dip due to checkpointing when I conducted some performance measurement using DBT-2 thatimplements transactions based on the TPC-C specification. As can be seen in DBT2-sync.jpg, original 9.5alpha2 showedsharp dips in throughput periodically. The point here is that I identified that those dips were caused by full-page-write rush that occurs immediately after thebeginning of each checkpoint. As shown in DBT2-sync-FPWoff.jpg; those dips were eliminated when a GUC parameter 'full_page_writes'was set to 'off.' This also indicates that existing mechanism of spreading buffer sync operations overtime was effectively worked. As only difference between original 9.5alpha2 case in DBT2-sync.jpg and DBT2-sync-FPWoff.jpgwas in the setting of 'full_page_writes,' those dips were attributed to the full-page-write as a corollary. The 'Partitioned checkpointing' was implemented to mitigate the dips by spreading full-page-writes over time and was workedexactly as designed (see DBT2-sync.jpg). It also produced good effect for pgbench, thus I have posted an article witha Partitioned-checkpointing.patch to this mailing list. As to pgbench, however, I have found that full-page-writes did not cause the performance dips, because the dips also occurredwhen 'full_page_writes' was set to 'off.' So, honestly, I do not exactly know why 'Partitioned checkpointing' mitigatedthe dips in pgbench executions. However, it is certain that there are some, other than pgbench, workloads for PostgreSQL in which the full-page-write rushcauses performance dips and 'Partitioned checkpointing' is effective to eliminate (or mitigate) them; DBT-2 is an example. And also, 'Partitioned checkpointing' is worth to study why it is effective in pgbench executions. By studying it, it maylead to devising better ways. -- Takashi Horikawa NEC Corporation Knowledge Discovery Research Laboratories > -----Original Message----- > From: pgsql-hackers-owner@postgresql.org > [mailto:pgsql-hackers-owner@postgresql.org] On Behalf Of Takashi Horikawa > Sent: Saturday, September 12, 2015 12:50 PM > To: Simon Riggs; Fabien COELHO > Cc: pgsql-hackers@postgresql.org > Subject: Re: [HACKERS] Partitioned checkpointing > > Hi, > > > I understand that what this patch does is cutting the checkpoint > > of buffers in 16 partitions, each addressing 1/16 of buffers, and each > with > > its own wal-log entry, pacing, fsync and so on. > Right. > However, > > The key point is that we spread out the fsyncs across the whole checkpoint > > period. > this is not the key point of the 'partitioned checkpointing,' I think. > The original purpose is to mitigate full-page-write rush that occurs at > immediately after the beginning of each checkpoint. > The amount of FPW at each checkpoint is reduced to 1/16 by the > 'Partitioned checkpointing.' > > > This method interacts with the current proposal to improve the > > checkpointer behavior by avoiding random I/Os, but it could be combined. > I agree. > > > Splitting with N=16 does nothing to guarantee the partitions are equally > > sized, so there would likely be an imbalance that would reduce the > > effectiveness of the patch. > May be right. > However, current method was designed with considering to split > buffers so as to balance the load as equally as possible; > current patch splits the buffer as > --- > 1st round: b[0], b[p], b[2p], … b[(n-1)p] > 2nd round: b[1], b[p+1], b[2p+1], … b[(n-1)p+1] > … > p-1 th round:b[p-1], b[p+(p-1)], b[2p+(p-1)], … b[(n-1)p+(p-1)] > --- > where N is the number of buffers, > p is the number of partitions, and n = (N / p). > > It would be extremely unbalance if buffers are divided as follow. > --- > 1st round: b[0], b[1], b[2], … b[n-1] > 2nd round: b[n], b[n+1], b[n+2], … b[2n-1] > … > p-1 th round:b[(p-1)n], b[(p-1)n+1], b[(p-1)n+2], … b[(p-1)n+(n-1)] > --- > > > I'm afraid that I miss the point, but > > 2. > > Assign files to one of N batches so we can make N roughly equal sized > > mini-checkpoints > Splitting buffers with considering the file boundary makes FPW related > processing > (in xlog.c and xloginsert.c) complicated intolerably, as 'Partitioned > checkpointing' is strongly related to the decision of whether this buffer > is necessary to FPW or not at the time of inserting the xlog record. > # 'partition id = buffer id % number of partitions' is fairly simple. > > Best regards. > -- > Takashi Horikawa > NEC Corporation > Knowledge Discovery Research Laboratories > > > > > -----Original Message----- > > From: Simon Riggs [mailto:simon@2ndQuadrant.com] > > Sent: Friday, September 11, 2015 10:57 PM > > To: Fabien COELHO > > Cc: Horikawa Takashi(堀川 隆); pgsql-hackers@postgresql.org > > Subject: Re: [HACKERS] Partitioned checkpointing > > > > On 11 September 2015 at 09:07, Fabien COELHO <coelho@cri.ensmp.fr> wrote: > > > > > > > > Some general comments : > > > > > > > > Thanks for the summary Fabien. > > > > > > I understand that what this patch does is cutting the checkpoint > > of buffers in 16 partitions, each addressing 1/16 of buffers, and each > with > > its own wal-log entry, pacing, fsync and so on. > > > > I'm not sure why it would be much better, although I agree that > > it may have some small positive influence on performance, but I'm afraid > > it may also degrade performance in some conditions. So I think that maybe > > a better understanding of why there is a better performance and focus > on > > that could help obtain a more systematic gain. > > > > > > > > I think its a good idea to partition the checkpoint, but not doing it > this > > way. > > > > Splitting with N=16 does nothing to guarantee the partitions are equally > > sized, so there would likely be an imbalance that would reduce the > > effectiveness of the patch. > > > > > > This method interacts with the current proposal to improve the > > checkpointer behavior by avoiding random I/Os, but it could be combined. > > > > I'm wondering whether the benefit you see are linked to the file > > flushing behavior induced by fsyncing more often, in which case it is > quite > > close the "flushing" part of the current "checkpoint continuous flushing" > > patch, and could be redundant/less efficient that what is done there, > > especially as test have shown that the effect of flushing is *much* better > > on sorted buffers. > > > > Another proposal around, suggested by Andres Freund I think, is > > that checkpoint could fsync files while checkpointing and not wait for > the > > end of the checkpoint. I think that it may also be one of the reason why > > your patch does bring benefit, but Andres approach would be more > systematic, > > because there would be no need to fsync files several time (basically > your > > patch issues 16 fsync per file). This suggest that the "partitionning" > > should be done at a lower level, from within the CheckPointBuffers, which > > would take care of fsyncing files some time after writting buffers to > them > > is finished. > > > > > > The idea to do a partial pass through shared buffers and only write a > fraction > > of dirty buffers, then fsync them is a good one. > > > > The key point is that we spread out the fsyncs across the whole checkpoint > > period. > > > > I think we should be writing out all buffers for a particular file in > one > > pass, then issue one fsync per file. >1 fsyncs per file seems a bad idea. > > > > So we'd need logic like this > > 1. Run through shared buffers and analyze the files contained in there > 2. > > Assign files to one of N batches so we can make N roughly equal sized > > mini-checkpoints 3. Make N passes through shared buffers, writing out > files > > assigned to each batch as we go > > > > -- > > > > Simon Riggs http://www.2ndQuadrant.com/ > > PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
Attachment
{kind=link}
{kind=link}
pgsql-hackers by date: