Thread: GIN improvements part2: fast scan
Hackes,
attached patch implementing "fast scan" technique for GIN. This is second patch of GIN improvements, see the 1st one here:
This patch allow to skip parts of posting trees when their scan is not necessary. In particular, it solves "frequent_term & rare_term" problem of FTS.
It introduces new interface method pre_consistent which behaves like consistent, but:
1) allows false positives on input (check[])
2) allowed to return false positives
Some example: "frequent_term & rare_term" becomes pretty fast.
create table test as (select to_tsvector('english', 'bbb') as v from generate_series(1,1000000));
insert into test (select to_tsvector('english', 'ddd') from generate_series(1,10));
create index test_idx on test using gin (v);
postgres=# explain analyze select * from test where v @@ to_tsquery('english', 'bbb & ddd');
QUERY PLAN
-----------------------------------------------------------------------------------------------------------------------
Bitmap Heap Scan on test (cost=942.75..7280.63 rows=5000 width=17) (actual time=0.458..0.461 rows=10 loops=1)
Recheck Cond: (v @@ '''bbb'' & ''ddd'''::tsquery)
-> Bitmap Index Scan on test_idx (cost=0.00..941.50 rows=5000 width=0) (actual time=0.449..0.449 rows=10 loops=1)
Index Cond: (v @@ '''bbb'' & ''ddd'''::tsquery)
Total runtime: 0.516 ms
(5 rows)
------
With best regards,
Alexander Korotkov.
With best regards,
Alexander Korotkov.
Attachment
On Sat, Jun 15, 2013 at 2:55 AM, Alexander Korotkov <aekorotkov@gmail.com> wrote:
------
With best regards,
attached patch implementing "fast scan" technique for GIN. This is second patch of GIN improvements, see the 1st one here:This patch allow to skip parts of posting trees when their scan is not necessary. In particular, it solves "frequent_term & rare_term" problem of FTS.It introduces new interface method pre_consistent which behaves like consistent, but:1) allows false positives on input (check[])2) allowed to return false positivesSome example: "frequent_term & rare_term" becomes pretty fast.create table test as (select to_tsvector('english', 'bbb') as v from generate_series(1,1000000));insert into test (select to_tsvector('english', 'ddd') from generate_series(1,10));create index test_idx on test using gin (v);postgres=# explain analyze select * from test where v @@ to_tsquery('english', 'bbb & ddd');QUERY PLAN-----------------------------------------------------------------------------------------------------------------------Bitmap Heap Scan on test (cost=942.75..7280.63 rows=5000 width=17) (actual time=0.458..0.461 rows=10 loops=1)Recheck Cond: (v @@ '''bbb'' & ''ddd'''::tsquery)-> Bitmap Index Scan on test_idx (cost=0.00..941.50 rows=5000 width=0) (actual time=0.449..0.449 rows=10 loops=1)Index Cond: (v @@ '''bbb'' & ''ddd'''::tsquery)Total runtime: 0.516 ms(5 rows)
Attached version of patch has some refactoring and bug fixes.
With best regards,
Alexander Korotkov.
Attachment
On 17.06.2013 15:55, Alexander Korotkov wrote: > On Sat, Jun 15, 2013 at 2:55 AM, Alexander Korotkov<aekorotkov@gmail.com>wrote: > >> attached patch implementing "fast scan" technique for GIN. This is second >> patch of GIN improvements, see the 1st one here: >> >> http://www.postgresql.org/message-id/CAPpHfduxv-iL7aedwPW0W5fXrWGAKfxijWM63_hZujaCRxnmFQ@mail.gmail.com >> This patch allow to skip parts of posting trees when their scan is not >> necessary. In particular, it solves "frequent_term& rare_term" problem of >> FTS. >> It introduces new interface method pre_consistent which behaves like >> consistent, but: >> 1) allows false positives on input (check[]) >> 2) allowed to return false positives >> >> Some example: "frequent_term& rare_term" becomes pretty fast. >> >> create table test as (select to_tsvector('english', 'bbb') as v from >> generate_series(1,1000000)); >> insert into test (select to_tsvector('english', 'ddd') from >> generate_series(1,10)); >> create index test_idx on test using gin (v); >> >> postgres=# explain analyze select * from test where v @@ >> to_tsquery('english', 'bbb& ddd'); >> QUERY PLAN >> >> ----------------------------------------------------------------------------------------------------------------------- >> Bitmap Heap Scan on test (cost=942.75..7280.63 rows=5000 width=17) >> (actual time=0.458..0.461 rows=10 loops=1) >> Recheck Cond: (v @@ '''bbb''& ''ddd'''::tsquery) >> -> Bitmap Index Scan on test_idx (cost=0.00..941.50 rows=5000 >> width=0) (actual time=0.449..0.449 rows=10 loops=1) >> Index Cond: (v @@ '''bbb''& ''ddd'''::tsquery) >> Total runtime: 0.516 ms >> (5 rows) >> > > Attached version of patch has some refactoring and bug fixes. Good timing, I just started looking at this. I think you'll need to explain how this works. There are no docs, and almost no comments. (and this shows how poorly I understand this, but) Why does this require the "additional information" patch? What extra information do you store on-disk, in the additional information? The pre-consistent method is like the consistent method, but it allows false positives. I think that's because during the scan, before having scanned for all the keys, the gin AM doesn't yet know if the tuple contains all of the keys. So it passes the keys it doesn't yet know about as 'true' to pre-consistent. Could that be generalized, to pass a tri-state instead of a boolean for each key to the pre-consistent method? For each key, you would pass "true", "false", or "don't know". I think you could then also speed up queries like "!english & bbb". - Heikki
On Mon, Jun 17, 2013 at 5:09 PM, Heikki Linnakangas <hlinnakangas@vmware.com> wrote:
------
With best regards,
Alexander Korotkov.
On 17.06.2013 15:55, Alexander Korotkov wrote:attached patch implementing "fast scan" technique for GIN. This is secondnecessary. In particular, it solves "frequent_term& rare_term" problem of
patch of GIN improvements, see the 1st one here:
http://www.postgresql.org/message-id/CAPpHfduxv-iL7aedwPW0W5fXrWGAKfxijWM63_hZujaCRxnmFQ@mail.gmail.com
This patch allow to skip parts of posting trees when their scan is notSome example: "frequent_term& rare_term" becomes pretty fast.
FTS.
It introduces new interface method pre_consistent which behaves like
consistent, but:
1) allows false positives on input (check[])
2) allowed to return false positivesto_tsquery('english', 'bbb& ddd');
create table test as (select to_tsvector('english', 'bbb') as v from
generate_series(1,1000000));
insert into test (select to_tsvector('english', 'ddd') from
generate_series(1,10));
create index test_idx on test using gin (v);
postgres=# explain analyze select * from test where v @@
QUERY PLAN
-----------------------------------------------------------------------------------------------------------------------
Bitmap Heap Scan on test (cost=942.75..7280.63 rows=5000 width=17)
(actual time=0.458..0.461 rows=10 loops=1)
Recheck Cond: (v @@ '''bbb''& ''ddd'''::tsquery)
-> Bitmap Index Scan on test_idx (cost=0.00..941.50 rows=5000
width=0) (actual time=0.449..0.449 rows=10 loops=1)
Index Cond: (v @@ '''bbb''& ''ddd'''::tsquery)
Total runtime: 0.516 ms
(5 rows)
Attached version of patch has some refactoring and bug fixes.
Good timing, I just started looking at this.
I think you'll need to explain how this works. There are no docs, and almost no comments.
Sorry for that. I'll post patch with docs and comments in couple days.
(and this shows how poorly I understand this, but) Why does this require the "additional information" patch?
In principle, it doesn't require "additional information" patch. Same optimization could be done without "additional information". The reason why it requires "additional information" patch is that otherwise I have to implement and maintain 2 versions of "fast scan": with and without "additional information".
What extra information do you store on-disk, in the additional information?
It depends on opclass. In regex patch it is part of graph associated with trigram. In fulltext search it is word positions. In array similarity search it could be length of array for better estimation of similarity (not implemented yet). So it's anything which is stored with each ItemPointer and is useful for consistent or index driven sorting (see patch #3).
The pre-consistent method is like the consistent method, but it allows false positives. I think that's because during the scan, before having scanned for all the keys, the gin AM doesn't yet know if the tuple contains all of the keys. So it passes the keys it doesn't yet know about as 'true' to pre-consistent.
Could that be generalized, to pass a tri-state instead of a boolean for each key to the pre-consistent method? For each key, you would pass "true", "false", or "don't know". I think you could then also speed up queries like "!english & bbb".
I would like to illustrate that on example. Imagine you have fulltext query "rare_term & frequent_term". Frequent term has large posting tree while rare term has only small posting list containing iptr1, iptr2 and iptr3. At first we get iptr1 from posting list of rare term, then we would like to check whether we have to scan part of frequent term posting tree where iptr < iptr1. So we call pre_consistent([false, true]), because we know that rare term is not present for iptr < iptr2. pre_consistent returns false. So we can start scanning frequent term posting tree from iptr1. Similarly we can skip lags between iptr1 and iptr2, iptr2 and iptr3, from iptr3 to maximum possible pointer.
And yes, it could be generalized to tri-state instead of a boolean. I had that idea first. But I found superiority of exact "true" quite narrow.
Let's see it on the example. If you have "!term1 & term2" there are few cases:
1) term1 is rare, term2 is frequent => you can exclude only some entries from posting tree of term2, performance benefit will be negligible
2) term1 is frequent, term2 is rare => you should actually scan term2 posting list and then check term1 posting tree like in example about "rare_term & frequent_term", so there is no need of tri-state to handle this situation
3) term1 is frequent, term2 is frequent => this case probably could be optimized by tri-state. But in order to actully skip some parts of term2 posting tree you need item pointers in term1 to go sequential. It seems for me to be very narrow case.
4) term1 is rare, term2 is rare => don't need optimization
BTW, version of patch with some bug fixes is attached.
------
With best regards,
Alexander Korotkov.
Attachment
On 18.06.2013 23:59, Alexander Korotkov wrote: > I would like to illustrate that on example. Imagine you have fulltext query > "rare_term& frequent_term". Frequent term has large posting tree while > rare term has only small posting list containing iptr1, iptr2 and iptr3. At > first we get iptr1 from posting list of rare term, then we would like to > check whether we have to scan part of frequent term posting tree where iptr > < iptr1. So we call pre_consistent([false, true]), because we know that > rare term is not present for iptr< iptr2. pre_consistent returns false. So > we can start scanning frequent term posting tree from iptr1. Similarly we > can skip lags between iptr1 and iptr2, iptr2 and iptr3, from iptr3 to > maximum possible pointer. Thanks, now I understand the rare-term & frequent-term problem. Couldn't you do that with the existing consistent function? I don't see why you need the new pre-consistent function for this. - Heikki
On Wed, Jun 19, 2013 at 11:48 AM, Heikki Linnakangas <hlinnakangas@vmware.com> wrote:
------
With best regards,
Alexander Korotkov.
On 18.06.2013 23:59, Alexander Korotkov wrote:I would like to illustrate that on example. Imagine you have fulltext query"rare_term& frequent_term". Frequent term has large posting tree while
rare term has only small posting list containing iptr1, iptr2 and iptr3. At
first we get iptr1 from posting list of rare term, then we would like to
check whether we have to scan part of frequent term posting tree where iptr
< iptr1. So we call pre_consistent([false, true]), because we know that
rare term is not present for iptr< iptr2. pre_consistent returns false. So
we can start scanning frequent term posting tree from iptr1. Similarly we
can skip lags between iptr1 and iptr2, iptr2 and iptr3, from iptr3 to
maximum possible pointer.
Thanks, now I understand the rare-term & frequent-term problem. Couldn't you do that with the existing consistent function? I don't see why you need the new pre-consistent function for this.
In the case of two entries I can. But in the case of n entries things becomes more complicated. Imagine you have "term_1 & term_2 & ... & term_n" query. When you get some item pointer from term_1 you can skip all the lesser item pointers from term_2, term_3 ... term_n. But if all you have for it is consistent function you have to call it with following check arguments:
1) [false, false, false, ... , false]
2) [false, true, false, ... , false]
3) [false, false, true, ... , false]
4) [false, true, true, ..., false]
......
i.e. you have to call it 2^(n-1) times. But if you know the query specific (i.e. in opclass) it's typically easy to calculate exactly what we need in single pass. That's why I introduced pre_consistent.
With best regards,
Alexander Korotkov.
On Wed, Jun 19, 2013 at 12:30 PM, Alexander Korotkov <aekorotkov@gmail.com> wrote:
------
With best regards,
Alexander Korotkov.
On Wed, Jun 19, 2013 at 11:48 AM, Heikki Linnakangas <hlinnakangas@vmware.com> wrote:On 18.06.2013 23:59, Alexander Korotkov wrote:I would like to illustrate that on example. Imagine you have fulltext query"rare_term& frequent_term". Frequent term has large posting tree while
rare term has only small posting list containing iptr1, iptr2 and iptr3. At
first we get iptr1 from posting list of rare term, then we would like to
check whether we have to scan part of frequent term posting tree where iptr
< iptr1. So we call pre_consistent([false, true]), because we know that
rare term is not present for iptr< iptr2. pre_consistent returns false. So
we can start scanning frequent term posting tree from iptr1. Similarly we
can skip lags between iptr1 and iptr2, iptr2 and iptr3, from iptr3 to
maximum possible pointer.
Thanks, now I understand the rare-term & frequent-term problem. Couldn't you do that with the existing consistent function? I don't see why you need the new pre-consistent function for this.In the case of two entries I can. But in the case of n entries things becomes more complicated. Imagine you have "term_1 & term_2 & ... & term_n" query. When you get some item pointer from term_1 you can skip all the lesser item pointers from term_2, term_3 ... term_n. But if all you have for it is consistent function you have to call it with following check arguments:1) [false, false, false, ... , false]2) [false, true, false, ... , false]3) [false, false, true, ... , false]4) [false, true, true, ..., false]......i.e. you have to call it 2^(n-1) times.
To be precise you don't need the first check argument I listed. So, it's 2^(n-1)-1 calls.
With best regards,
Alexander Korotkov.
On 19.06.2013 11:30, Alexander Korotkov wrote: > On Wed, Jun 19, 2013 at 11:48 AM, Heikki Linnakangas< > hlinnakangas@vmware.com> wrote: > >> On 18.06.2013 23:59, Alexander Korotkov wrote: >> >>> I would like to illustrate that on example. Imagine you have fulltext >>> query >>> "rare_term& frequent_term". Frequent term has large posting tree while >>> >>> rare term has only small posting list containing iptr1, iptr2 and iptr3. >>> At >>> first we get iptr1 from posting list of rare term, then we would like to >>> check whether we have to scan part of frequent term posting tree where >>> iptr >>> < iptr1. So we call pre_consistent([false, true]), because we know that >>> rare term is not present for iptr< iptr2. pre_consistent returns false. >>> So >>> we can start scanning frequent term posting tree from iptr1. Similarly we >>> can skip lags between iptr1 and iptr2, iptr2 and iptr3, from iptr3 to >>> maximum possible pointer. >>> >> >> Thanks, now I understand the rare-term& frequent-term problem. Couldn't >> you do that with the existing consistent function? I don't see why you need >> the new pre-consistent function for this. > > In the case of two entries I can. But in the case of n entries things > becomes more complicated. Imagine you have "term_1& term_2& ...& term_n" > query. When you get some item pointer from term_1 you can skip all the > lesser item pointers from term_2, term_3 ... term_n. But if all you have > for it is consistent function you have to call it with following check > arguments: > 1) [false, false, false, ... , false] > 2) [false, true, false, ... , false] > 3) [false, false, true, ... , false] > 4) [false, true, true, ..., false] > ...... > i.e. you have to call it 2^(n-1) times. But if you know the query specific > (i.e. in opclass) it's typically easy to calculate exactly what we need in > single pass. That's why I introduced pre_consistent. Hmm. So how does that work with the pre-consistent function? Don't you need to call that 2^(n-1)-1 times as well? - Heikki
On Wed, Jun 19, 2013 at 12:49 PM, Heikki Linnakangas <hlinnakangas@vmware.com> wrote:
------
With best regards,
Alexander Korotkov.
On 19.06.2013 11:30, Alexander Korotkov wrote:On 18.06.2013 23:59, Alexander Korotkov wrote:Thanks, now I understand the rare-term& frequent-term problem. Couldn'tI would like to illustrate that on example. Imagine you have fulltext
query
"rare_term& frequent_term". Frequent term has large posting tree while
rare term has only small posting list containing iptr1, iptr2 and iptr3.
At
first we get iptr1 from posting list of rare term, then we would like to
check whether we have to scan part of frequent term posting tree where
iptr
< iptr1. So we call pre_consistent([false, true]), because we know that
rare term is not present for iptr< iptr2. pre_consistent returns false.
So
we can start scanning frequent term posting tree from iptr1. Similarly we
can skip lags between iptr1 and iptr2, iptr2 and iptr3, from iptr3 to
maximum possible pointer.
you do that with the existing consistent function? I don't see why you need
the new pre-consistent function for this.becomes more complicated. Imagine you have "term_1& term_2& ...& term_n"
In the case of two entries I can. But in the case of n entries things
query. When you get some item pointer from term_1 you can skip all the
lesser item pointers from term_2, term_3 ... term_n. But if all you have
for it is consistent function you have to call it with following check
arguments:
1) [false, false, false, ... , false]
2) [false, true, false, ... , false]
3) [false, false, true, ... , false]
4) [false, true, true, ..., false]
......
i.e. you have to call it 2^(n-1) times. But if you know the query specific
(i.e. in opclass) it's typically easy to calculate exactly what we need in
single pass. That's why I introduced pre_consistent.
Hmm. So how does that work with the pre-consistent function? Don't you need to call that 2^(n-1)-1 times as well?
I call pre-consistent once with [false, true, true, ..., true]. Pre-consistent knows that each true passed to it could be false positive. So, if it returns false it guarantees that consistent will be false for all possible combinations.
With best regards,
Alexander Korotkov.
On 19.06.2013 11:56, Alexander Korotkov wrote:
> On Wed, Jun 19, 2013 at 12:49 PM, Heikki Linnakangas<
> hlinnakangas@vmware.com> wrote:
>
>> On 19.06.2013 11:30, Alexander Korotkov wrote:
>>
>>> On Wed, Jun 19, 2013 at 11:48 AM, Heikki Linnakangas<
>>> hlinnakangas@vmware.com> wrote:
>>>
>>> On 18.06.2013 23:59, Alexander Korotkov wrote:
>>>>
>>>> I would like to illustrate that on example. Imagine you have fulltext
>>>>> query
>>>>> "rare_term& frequent_term". Frequent term has large posting tree while
>>>>>
>>>>> rare term has only small posting list containing iptr1, iptr2 and iptr3.
>>>>> At
>>>>> first we get iptr1 from posting list of rare term, then we would like to
>>>>> check whether we have to scan part of frequent term posting tree where
>>>>> iptr
>>>>> < iptr1. So we call pre_consistent([false, true]), because we know
>>>>> that
>>>>> rare term is not present for iptr< iptr2. pre_consistent returns
>>>>> false.
>>>>> So
>>>>> we can start scanning frequent term posting tree from iptr1. Similarly
>>>>> we
>>>>> can skip lags between iptr1 and iptr2, iptr2 and iptr3, from iptr3 to
>>>>> maximum possible pointer.
>>>>>
>>>>>
>>>> Thanks, now I understand the rare-term& frequent-term problem. Couldn't
>>>>
>>>> you do that with the existing consistent function? I don't see why you
>>>> need
>>>> the new pre-consistent function for this.
>>>>
>>>
>>> In the case of two entries I can. But in the case of n entries things
>>> becomes more complicated. Imagine you have "term_1& term_2& ...&
>>> term_n"
>>>
>>> query. When you get some item pointer from term_1 you can skip all the
>>> lesser item pointers from term_2, term_3 ... term_n. But if all you have
>>> for it is consistent function you have to call it with following check
>>> arguments:
>>> 1) [false, false, false, ... , false]
>>> 2) [false, true, false, ... , false]
>>> 3) [false, false, true, ... , false]
>>> 4) [false, true, true, ..., false]
>>> ......
>>> i.e. you have to call it 2^(n-1) times. But if you know the query specific
>>> (i.e. in opclass) it's typically easy to calculate exactly what we need in
>>> single pass. That's why I introduced pre_consistent.
>>>
>>
>> Hmm. So how does that work with the pre-consistent function? Don't you
>> need to call that 2^(n-1)-1 times as well?
>
>
> I call pre-consistent once with [false, true, true, ..., true].
> Pre-consistent knows that each true passed to it could be false positive.
> So, if it returns false it guarantees that consistent will be false for all
> possible combinations.
Ok, I see.
I spent some time pondering this. I'd like to find a way to do something
about this without requiring another user-defined function. A couple of
observations:
1. The profile of that rare-term & frequent-term quest, without any
patch, looks like this:
28,55% postgres ginCompareItemPointers
19,36% postgres keyGetItem
15,20% postgres scanGetItem 7,75% postgres checkcondition_gin 6,25% postgres
gin_tsquery_consistent4,34% postgres TS_execute 3,85% postgres callConsistentFn 3,64% postgres
FunctionCall8Coll 3,19% postgres check_stack_depth 2,60% postgres entryGetNextItem 1,35%
postgres entryGetItem 1,25% postgres MemoryContextReset 1,12% postgres
MemoryContextSwitchTo0,31% libc-2.17.so __memcpy_ssse3_back 0,24% postgres collectMatchesForHeapRow
I was quite surprised by seeing ginCompareItemPointers at the top. It
turns out that it's relatively expensive to do comparisons in the format
we keep item pointers, packed in 6 bytes, in 3 int16s. I hacked together
a patch to convert ItemPointers into uint64s, when dealing with them in
memory. That helped quite a bit.
Another important thing in the above profile is that calling
consistent-function is taking up a lot of resources. And in the example
test case you gave, it's called with the same arguments every time.
Caching the result of consistent-function would be a big win.
I wrote a quick patch to do that caching, and together with the
itempointer hack, I was able to halve the runtime of that test case.
That's impressive, we probably should pursue that low-hanging fruit, but
it's still slower than your "fast scan" patch by a factor of 100x. So
clearly we do need an algorithmic improvement here, along the lines of
your patch, or something similar.
2. There's one trick we could do even without the pre-consistent
function, that would help the particular test case you gave. Suppose
that you have two search terms A and B. If you have just called
consistent on a row that matched term A, but not term B, you can skip
any subsequent rows in the scan that match A but not B. That means that
you can skip over to the next row that matches B. This is essentially
the same thing you do with the pre-consistent function, it's just a
degenerate case of it. That helps as long as the search contains only
one frequent term, but if it contains multiple, then you have to still
stop at every row that matches more than one of the frequent terms.
3. I'm still not totally convinced that we shouldn't just build the
"truth table" by calling the regular consistent function with all the
combinations of matching keys, as discussed above. I think that would
work pretty well in practice, for queries with up to 5-10 frequent
terms. Per the profiling, it probably would make sense to pre-compute
such a table anyway, to avoid calling consistent repeatedly.
4. If we do go with a new function, I'd like to just call it
"consistent" (or consistent2 or something, to keep it separate form the
old consistent function), and pass it a tri-state input for each search
term. It might not be any different for the full-text search
implementation, or any of the other ones for that matter, but I think it
would be a more understandable API.
- Heikki
On Fri, Jun 21, 2013 at 11:43 PM, Heikki Linnakangas <hlinnakangas@vmware.com> wrote:
------
With best regards,
Alexander Korotkov.
Ok, I see.On 19.06.2013 11:56, Alexander Korotkov wrote:On Wed, Jun 19, 2013 at 12:49 PM, Heikki Linnakangas<
hlinnakangas@vmware.com> wrote:On 19.06.2013 11:30, Alexander Korotkov wrote:On Wed, Jun 19, 2013 at 11:48 AM, Heikki Linnakangas<
hlinnakangas@vmware.com> wrote:
On 18.06.2013 23:59, Alexander Korotkov wrote:
I would like to illustrate that on example. Imagine you have fulltextqueryThanks, now I understand the rare-term& frequent-term problem. Couldn't
"rare_term& frequent_term". Frequent term has large posting tree while
rare term has only small posting list containing iptr1, iptr2 and iptr3.
At
first we get iptr1 from posting list of rare term, then we would like to
check whether we have to scan part of frequent term posting tree where
iptr
< iptr1. So we call pre_consistent([false, true]), because we know
that
rare term is not present for iptr< iptr2. pre_consistent returns
false.
So
we can start scanning frequent term posting tree from iptr1. Similarly
we
can skip lags between iptr1 and iptr2, iptr2 and iptr3, from iptr3 to
maximum possible pointer.
you do that with the existing consistent function? I don't see why you
need
the new pre-consistent function for this.
In the case of two entries I can. But in the case of n entries things
becomes more complicated. Imagine you have "term_1& term_2& ...&
term_n"
query. When you get some item pointer from term_1 you can skip all the
lesser item pointers from term_2, term_3 ... term_n. But if all you have
for it is consistent function you have to call it with following check
arguments:
1) [false, false, false, ... , false]
2) [false, true, false, ... , false]
3) [false, false, true, ... , false]
4) [false, true, true, ..., false]
......
i.e. you have to call it 2^(n-1) times. But if you know the query specific
(i.e. in opclass) it's typically easy to calculate exactly what we need in
single pass. That's why I introduced pre_consistent.
Hmm. So how does that work with the pre-consistent function? Don't you
need to call that 2^(n-1)-1 times as well?
I call pre-consistent once with [false, true, true, ..., true].
Pre-consistent knows that each true passed to it could be false positive.
So, if it returns false it guarantees that consistent will be false for all
possible combinations.
I spent some time pondering this. I'd like to find a way to do something about this without requiring another user-defined function. A couple of observations:
1. The profile of that rare-term & frequent-term quest, without any patch, looks like this:
28,55% postgres ginCompareItemPointers
19,36% postgres keyGetItem
15,20% postgres scanGetItem
7,75% postgres checkcondition_gin
6,25% postgres gin_tsquery_consistent
4,34% postgres TS_execute
3,85% postgres callConsistentFn
3,64% postgres FunctionCall8Coll
3,19% postgres check_stack_depth
2,60% postgres entryGetNextItem
1,35% postgres entryGetItem
1,25% postgres MemoryContextReset
1,12% postgres MemoryContextSwitchTo
0,31% libc-2.17.so __memcpy_ssse3_back
0,24% postgres collectMatchesForHeapRow
I was quite surprised by seeing ginCompareItemPointers at the top. It turns out that it's relatively expensive to do comparisons in the format we keep item pointers, packed in 6 bytes, in 3 int16s. I hacked together a patch to convert ItemPointers into uint64s, when dealing with them in memory. That helped quite a bit.
Another important thing in the above profile is that calling consistent-function is taking up a lot of resources. And in the example test case you gave, it's called with the same arguments every time. Caching the result of consistent-function would be a big win.
I wrote a quick patch to do that caching, and together with the itempointer hack, I was able to halve the runtime of that test case. That's impressive, we probably should pursue that low-hanging fruit, but it's still slower than your "fast scan" patch by a factor of 100x. So clearly we do need an algorithmic improvement here, along the lines of your patch, or something similar.
For sure, many advantages can be achieved without "fast scan". For example, sphinx is known to be fast, but it straightforwardly scan each posting list just like GIN now.
2. There's one trick we could do even without the pre-consistent function, that would help the particular test case you gave. Suppose that you have two search terms A and B. If you have just called consistent on a row that matched term A, but not term B, you can skip any subsequent rows in the scan that match A but not B. That means that you can skip over to the next row that matches B. This is essentially the same thing you do with the pre-consistent function, it's just a degenerate case of it. That helps as long as the search contains only one frequent term, but if it contains multiple, then you have to still stop at every row that matches more than one of the frequent terms.
Yes, two terms case is confluent and there is no direct need of preConsistent.
3. I'm still not totally convinced that we shouldn't just build the "truth table" by calling the regular consistent function with all the combinations of matching keys, as discussed above. I think that would work pretty well in practice, for queries with up to 5-10 frequent terms. Per the profiling, it probably would make sense to pre-compute such a table anyway, to avoid calling consistent repeatedly.
Why do you mention 5-10 _frequent_ items? If we have 5-10 frequent items and 20 rare items we would have to create "truth table" of frequent items for each new combination of rare items. For 20 rare items truth combinations can be unique for each item pointer, in that case you would have to calculate small "truth table" of frequent items for each item pointers. And then it can appear to be not so small. I mean it seems to me that we should take into account both "frequent" and "rare" items when talking about "truth table".
4. If we do go with a new function, I'd like to just call it "consistent" (or consistent2 or something, to keep it separate form the old consistent function), and pass it a tri-state input for each search term. It might not be any different for the full-text search implementation, or any of the other ones for that matter, but I think it would be a more understandable API.
Understandable API makes sense. But for now, I can't see even potentional usage of third state (exact false). Also, with preConsistent interface "as is" in some cases we can use old consistent method as both consistent and preConsistent when it implements monotonous boolean function. For example, it's consistent function for opclasses of arrays.
Revised version of patch is attaches with more comments and docs.
With best regards,
Alexander Korotkov.
Attachment
On Tue, Jun 25, 2013 at 2:20 AM, Alexander Korotkov <aekorotkov@gmail.com> wrote:
------
With best regards,
Alexander Korotkov.
4. If we do go with a new function, I'd like to just call it "consistent" (or consistent2 or something, to keep it separate form the old consistent function), and pass it a tri-state input for each search term. It might not be any different for the full-text search implementation, or any of the other ones for that matter, but I think it would be a more understandable API.Understandable API makes sense. But for now, I can't see even potentional usage of third state (exact false).
Typo here. I meant "exact true".
Also, with preConsistent interface "as is" in some cases we can use old consistent method as both consistent and preConsistent when it implements monotonous boolean function. For example, it's consistent function for opclasses of arrays.
Now, I got the point of three state consistent: we can keep only one consistent in opclasses that support new interface. exact true and exact false values will be passed in the case of current patch consistent; exact false and unknown will be passed in the case of current patch preConsistent. That's reasonable.
With best regards,
Alexander Korotkov.
On 28.06.2013 22:31, Alexander Korotkov wrote: > Now, I got the point of three state consistent: we can keep only one > consistent in opclasses that support new interface. exact true and exact > false values will be passed in the case of current patch consistent; exact > false and unknown will be passed in the case of current patch > preConsistent. That's reasonable. I'm going to mark this as "returned with feedback". For the next version, I'd like to see the API changed per above. Also, I'd like us to do something about the tidbitmap overhead, as a separate patch before this, so that we can assess the actual benefit of this patch. And a new test case that demonstrates the I/O benefits. - Heikki
Hi,
this is a follow-up to the message I posted to the thread about
additional info in GIN.
I've applied both ginaddinfo.7.patch and gin_fast_scan.4.patch on commit
b8fd1a09, but I'm observing a lot of failures like this:
STATEMENT: SELECT id FROM messages WHERE body_tsvector @@
plainto_tsquery('english', 'email free') LIMIT 100
ERROR: buffer 238068 is not owned by resource owner Portal
There's a GIN index on messages(body_tsvector). I haven't dug into why
it fails like this.
Tomas
On Sun, Jun 30, 2013 at 3:00 PM, Heikki Linnakangas <hlinnakangas@vmware.com> wrote:
------
With best regards,
Alexander Korotkov.
On 28.06.2013 22:31, Alexander Korotkov wrote:I'm going to mark this as "returned with feedback". For the next version, I'd like to see the API changed per above. Also, I'd like us to do something about the tidbitmap overhead, as a separate patch before this, so that we can assess the actual benefit of this patch. And a new test case that demonstrates the I/O benefits.Now, I got the point of three state consistent: we can keep only one
consistent in opclasses that support new interface. exact true and exact
false values will be passed in the case of current patch consistent; exact
false and unknown will be passed in the case of current patch
preConsistent. That's reasonable.
Revised version of patch is attached.
Changes are so:
1) Patch rebased against packed posting lists, not depends on additional information now.
2) New API with tri-state logic is introduced.
With best regards,
Alexander Korotkov.
Attachment
On 14.11.2013 19:26, Alexander Korotkov wrote: > On Sun, Jun 30, 2013 at 3:00 PM, Heikki Linnakangas <hlinnakangas@vmware.com >> wrote: > >> On 28.06.2013 22:31, Alexander Korotkov wrote: >> >>> Now, I got the point of three state consistent: we can keep only one >>> consistent in opclasses that support new interface. exact true and exact >>> false values will be passed in the case of current patch consistent; exact >>> false and unknown will be passed in the case of current patch >>> preConsistent. That's reasonable. >>> >> >> I'm going to mark this as "returned with feedback". For the next version, >> I'd like to see the API changed per above. Also, I'd like us to do >> something about the tidbitmap overhead, as a separate patch before this, so >> that we can assess the actual benefit of this patch. And a new test case >> that demonstrates the I/O benefits. > > > Revised version of patch is attached. > Changes are so: > 1) Patch rebased against packed posting lists, not depends on additional > information now. > 2) New API with tri-state logic is introduced. Thanks! A couple of thoughts after a 5-minute glance: * documentation * How about defining the tri-state consistent function to also return a tri-state? True would mean that the tuple definitely matches, false means the tuple definitely does not match, and Unknown means it might match. Or does return value true with recheck==true have the same effect? If I understood the patch, right, returning Unknown or True wouldn't actually make any difference, but it's conceivable that we might come up with more optimizations in the future that could take advantage of that. For example, for a query like "foo OR (bar AND baz)", you could immediately return any tuples that match foo, and not bother scanning for bar and baz at all. - Heikki
On Fri, Nov 15, 2013 at 3:25 AM, Rod Taylor <rbt@simple-knowledge.com> wrote:
------
With best regards,
Alexander Korotkov.
I checked out master and put together a test case using a small percentage of production data for a known problem we have with Pg 9.2 and text search scans.A small percentage in this case means 10 million records randomly selected; has a few billion records.Tests ran for master successfully and I recorded timings.
Applied the patch included here to master along with gin-packed-postinglists-14.patch.Run make clean; ./configure; make; make install.make check (All 141 tests passed.)initdb, import dump
The GIN index fails to build with a segfault.
Thanks for testing. See fixed version in thread about packed posting lists.
------
With best regards,
Alexander Korotkov.
On Fri, Nov 15, 2013 at 12:34 AM, Heikki Linnakangas <hlinnakangas@vmware.com> wrote:
------
With best regards,
Alexander Korotkov.
Thanks! A couple of thoughts after a 5-minute glance:On 14.11.2013 19:26, Alexander Korotkov wrote:On Sun, Jun 30, 2013 at 3:00 PM, Heikki Linnakangas <hlinnakangas@vmware.comwrote:On 28.06.2013 22:31, Alexander Korotkov wrote:Now, I got the point of three state consistent: we can keep only one
consistent in opclasses that support new interface. exact true and exact
false values will be passed in the case of current patch consistent; exact
false and unknown will be passed in the case of current patch
preConsistent. That's reasonable.
I'm going to mark this as "returned with feedback". For the next version,
I'd like to see the API changed per above. Also, I'd like us to do
something about the tidbitmap overhead, as a separate patch before this, so
that we can assess the actual benefit of this patch. And a new test case
that demonstrates the I/O benefits.
Revised version of patch is attached.
Changes are so:
1) Patch rebased against packed posting lists, not depends on additional
information now.
2) New API with tri-state logic is introduced.
* documentation
Will provide documented version this week.
* How about defining the tri-state consistent function to also return a tri-state? True would mean that the tuple definitely matches, false means the tuple definitely does not match, and Unknown means it might match. Or does return value true with recheck==true have the same effect? If I understood the patch, right, returning Unknown or True wouldn't actually make any difference, but it's conceivable that we might come up with more optimizations in the future that could take advantage of that. For example, for a query like "foo OR (bar AND baz)", you could immediately return any tuples that match foo, and not bother scanning for bar and baz at all.
The meaning of recheck flag when input contains unknown is undefined now. :)
For instance, we could define it in following ways:
1) Like returning Unknown meaning that consistent with true of false instead of input Unknown could return either true or false.
2) Consistent with true of false instead of input Unknown could return recheck. This meaning is probably logical, but I don't see any usage of it.
I'm not against idea of tri-state returning value for consisted, because it's logical continuation of its tri-state input. However, I don't see usage of distinguish True and Unknown in returning value for now :)
In example you give we can return foo immediately, but we have to create full bitmap. So we anyway will have to scan (bar AND baz). We could skip part of trees for bar and baz. But it's possible only when foo contains large amount of sequential TIDS so we can be sure that we didn't miss any TIDs. This seems to be very narrow use-case for me.
Another point is that one day we probably could immediately return tuples in gingettuple. And with LIMIT clause and no sorting we can don't search for other tuples. However, gingettuple was removed because of reasons of concurrency. And my patches for index-based ordering didn't return it in previous manner: it collects all the results and then returns them one-by-one.
With best regards,
Alexander Korotkov.
I tried again this morning using gin-packed-postinglists-16.patch and gin-fast-scan.6.patch. No crashes during index building.
Pg was compiled with debug enabled in both cases. The data is a ~0.1% random sample of production data (10,000,000 records for the test) with the below structure.
Table "public.kp"
Column | Type | Modifiers
--------+---------+-----------
id | bigint | not null
string | text | not null
score1 | integer |
score2 | integer |
score3 | integer |
score4 | integer |
Indexes:
"kp_pkey" PRIMARY KEY, btree (id)
"kp_string_key" UNIQUE CONSTRAINT, btree (string)
"textsearch_gin_idx" gin (to_tsvector('simple'::regconfig, string)) WHERE score1 IS NOT NULL
All data is in Pg buffer cache for these timings. Words like "the" and "and" are very common (~9% of entries, each) and a word like "hotel" is much less common (~0.2% of entries). Below is the query tested:
SELECT id,string
FROM kp
WHERE score1 IS NOT NULL
AND to_tsvector('simple', string) @@ to_tsquery('simple', ?)
-- ? is substituted with the query strings
ORDER BY score1 DESC, score2 ASC
LIMIT 1000;
Limit (cost=56.04..56.04 rows=1 width=37) (actual time=250.010..250.032 rows=142 loops=1)
-> Sort (cost=56.04..56.04 rows=1 width=37) (actual time=250.008..250.017 rows=142 loops=1)
Sort Key: score1, score2
Sort Method: quicksort Memory: 36kB
-> Bitmap Heap Scan on kp (cost=52.01..56.03 rows=1 width=37) (actual time=249.711..249.945 rows=142 loops=1)
Recheck Cond: ((to_tsvector('simple'::regconfig, string) @@ '''hotel'' & ''and'' & ''the'''::tsquery) AND (score1 IS NOT NULL))
-> Bitmap Index Scan on textsearch_gin_idx (cost=0.00..52.01 rows=1 width=0) (actual time=249.681..249.681 rows=142 loops=1)
Index Cond: (to_tsvector('simple'::regconfig, string) @@ '''hotel'' & ''and'' & ''the'''::tsquery)
Total runtime: 250.096 ms
Times are from \timing on.
MASTER
=======
the: 888.436 ms 926.609 ms 885.502 ms
and: 944.052 ms 937.732 ms 920.050 ms
hotel: 53.992 ms 57.039 ms 65.581 ms
and & the & hotel: 260.308 ms 248.275 ms 248.098 ms
These numbers roughly match what we get with Pg 9.2. The time savings between 'the' and 'and & the & hotel' is mostly heap lookups for the score and the final sort.
The size of the index on disk is about 2% smaller in the patched version.
PATCHED
=======
the: 1055.169 ms 1081.976 ms 1083.021 ms
and: 912.173 ms 949.364 ms 965.261 ms
hotel: 62.591 ms 64.341 ms 62.923 ms
and & the & hotel: 268.577 ms 259.293 ms 257.408 ms
hotel & and & the: 253.574 ms 258.071 ms 250.280 ms
I was hoping that the 'and & the & hotel' case would improve with this patch to be closer to the 'hotel' search, as I thought that was the kind of thing it targeted. Unfortunately, it did not. I actually applied the patches, compiled, initdb/load data, and ran it again thinking I made a mistake.
Reordering the terms 'hotel & and & the' doesn't change the result.
Pg was compiled with debug enabled in both cases. The data is a ~0.1% random sample of production data (10,000,000 records for the test) with the below structure.
Table "public.kp"
Column | Type | Modifiers
--------+---------+-----------
id | bigint | not null
string | text | not null
score1 | integer |
score2 | integer |
score3 | integer |
score4 | integer |
Indexes:
"kp_pkey" PRIMARY KEY, btree (id)
"kp_string_key" UNIQUE CONSTRAINT, btree (string)
"textsearch_gin_idx" gin (to_tsvector('simple'::regconfig, string)) WHERE score1 IS NOT NULL
All data is in Pg buffer cache for these timings. Words like "the" and "and" are very common (~9% of entries, each) and a word like "hotel" is much less common (~0.2% of entries). Below is the query tested:
SELECT id,string
FROM kp
WHERE score1 IS NOT NULL
AND to_tsvector('simple', string) @@ to_tsquery('simple', ?)
-- ? is substituted with the query strings
ORDER BY score1 DESC, score2 ASC
LIMIT 1000;
Limit (cost=56.04..56.04 rows=1 width=37) (actual time=250.010..250.032 rows=142 loops=1)
-> Sort (cost=56.04..56.04 rows=1 width=37) (actual time=250.008..250.017 rows=142 loops=1)
Sort Key: score1, score2
Sort Method: quicksort Memory: 36kB
-> Bitmap Heap Scan on kp (cost=52.01..56.03 rows=1 width=37) (actual time=249.711..249.945 rows=142 loops=1)
Recheck Cond: ((to_tsvector('simple'::regconfig, string) @@ '''hotel'' & ''and'' & ''the'''::tsquery) AND (score1 IS NOT NULL))
-> Bitmap Index Scan on textsearch_gin_idx (cost=0.00..52.01 rows=1 width=0) (actual time=249.681..249.681 rows=142 loops=1)
Index Cond: (to_tsvector('simple'::regconfig, string) @@ '''hotel'' & ''and'' & ''the'''::tsquery)
Total runtime: 250.096 ms
Times are from \timing on.
MASTER
=======
the: 888.436 ms 926.609 ms 885.502 ms
and: 944.052 ms 937.732 ms 920.050 ms
hotel: 53.992 ms 57.039 ms 65.581 ms
and & the & hotel: 260.308 ms 248.275 ms 248.098 ms
These numbers roughly match what we get with Pg 9.2. The time savings between 'the' and 'and & the & hotel' is mostly heap lookups for the score and the final sort.
The size of the index on disk is about 2% smaller in the patched version.
PATCHED
=======
the: 1055.169 ms 1081.976 ms 1083.021 ms
and: 912.173 ms 949.364 ms 965.261 ms
hotel: 62.591 ms 64.341 ms 62.923 ms
and & the & hotel: 268.577 ms 259.293 ms 257.408 ms
hotel & and & the: 253.574 ms 258.071 ms 250.280 ms
I was hoping that the 'and & the & hotel' case would improve with this patch to be closer to the 'hotel' search, as I thought that was the kind of thing it targeted. Unfortunately, it did not. I actually applied the patches, compiled, initdb/load data, and ran it again thinking I made a mistake.
Reordering the terms 'hotel & and & the' doesn't change the result.
On Fri, Nov 15, 2013 at 1:51 AM, Alexander Korotkov <aekorotkov@gmail.com> wrote:
On Fri, Nov 15, 2013 at 3:25 AM, Rod Taylor <rbt@simple-knowledge.com> wrote:I checked out master and put together a test case using a small percentage of production data for a known problem we have with Pg 9.2 and text search scans.A small percentage in this case means 10 million records randomly selected; has a few billion records.Tests ran for master successfully and I recorded timings.
Applied the patch included here to master along with gin-packed-postinglists-14.patch.Run make clean; ./configure; make; make install.make check (All 141 tests passed.)initdb, import dump
The GIN index fails to build with a segfault.Thanks for testing. See fixed version in thread about packed posting lists.
------
With best regards,
Alexander Korotkov.
On Fri, Nov 15, 2013 at 6:57 PM, Rod Taylor <pg@rbt.ca> wrote:
------
With best regards,
Alexander Korotkov.
I tried again this morning using gin-packed-postinglists-16.patch and gin-fast-scan.6.patch. No crashes.
It is about a 0.1% random sample of production data (10,000,000 records) with the below structure. Pg was compiled with debug enabled in both cases.
Table "public.kp"
Column | Type | Modifiers
--------+---------+-----------
id | bigint | not null
string | text | not null
score1 | integer |
score2 | integer |
score3 | integer |
score4 | integer |
Indexes:
"kp_pkey" PRIMARY KEY, btree (id)
"kp_string_key" UNIQUE CONSTRAINT, btree (string)
"textsearch_gin_idx" gin (to_tsvector('simple'::regconfig, string)) WHERE score1 IS NOT NULL
This is a query tested. All data is in Pg buffer cache for these timings. Words like "the" and "and" are very common (~9% of entries, each) and a word like "hotel" is much less common (~0.2% of entries).
SELECT id,string
FROM kp
WHERE score1 IS NOT NULL
AND to_tsvector('simple', string) @@ to_tsquery('simple', ?)
-- ? is substituted with the query strings
ORDER BY score1 DESC, score2 ASC
LIMIT 1000;
Limit (cost=56.04..56.04 rows=1 width=37) (actual time=250.010..250.032 rows=142 loops=1)
-> Sort (cost=56.04..56.04 rows=1 width=37) (actual time=250.008..250.017 rows=142 loops=1)
Sort Key: score1, score2
Sort Method: quicksort Memory: 36kB
-> Bitmap Heap Scan on kp (cost=52.01..56.03 rows=1 width=37) (actual time=249.711..249.945 rows=142 loops=1)
Recheck Cond: ((to_tsvector('simple'::regconfig, string) @@ '''hotel'' & ''and'' & ''the'''::tsquery) AND (score1 IS NOT NULL))
-> Bitmap Index Scan on textsearch_gin_idx (cost=0.00..52.01 rows=1 width=0) (actual time=249.681..249.681 rows=142 loops=1)
Index Cond: (to_tsvector('simple'::regconfig, string) @@ '''hotel'' & ''and'' & ''the'''::tsquery)
Total runtime: 250.096 ms
Times are from \timing on.
MASTER
=======
the: 888.436 ms 926.609 ms 885.502 ms
and: 944.052 ms 937.732 ms 920.050 ms
hotel: 53.992 ms 57.039 ms 65.581 ms
and & the & hotel: 260.308 ms 248.275 ms 248.098 msThese numbers roughly match what we get with Pg 9.2. The time savings between 'the' and 'and & the & hotel' is mostly heap lookups for the score and the final sort.
The size of the index on disk is about 2% smaller in the patched version.
PATCHED
=======
the: 1055.169 ms 1081.976 ms 1083.021 ms
and: 912.173 ms 949.364 ms 965.261 ms
hotel: 62.591 ms 64.341 ms 62.923 ms
and & the & hotel: 268.577 ms 259.293 ms 257.408 mshotel & and & the: 253.574 ms 258.071 ms 250.280 ms
I was hoping that the 'and & the & hotel' case would improve with this patch to be closer to the 'hotel' search, as I thought that was the kind of thing it targeted. Unfortunately, it did not. I actually applied the patches, compiled, initdb/load data, and ran it again thinking I made a mistake.Reordering the terms 'hotel & and & the' doesn't change the result.
Oh, in this path new consistent method isn't implemented for tsvector opclass, for array only. Will be fixed soon.
BTW, was index 2% smaller or 2 times smaller? If it's 2% smaller than I need to know more about your dataset :)
------
With best regards,
Alexander Korotkov.
2%.
It's essentially sentence fragments from 1 to 5 words in length. I wasn't expecting it to be much smaller.10 recent value selections:
white vinegar reduce color running
vinegar cure uti
cane vinegar acidity depends parameter
how remedy fir clogged shower
use vinegar sensitive skin
home remedies removing rust heating
does non raw apple cider
home remedies help maintain healthy
can vinegar mess up your
apple cide vineger ph balance
On Fri, Nov 15, 2013 at 12:51 PM, Alexander Korotkov <aekorotkov@gmail.com> wrote:
On Fri, Nov 15, 2013 at 6:57 PM, Rod Taylor <pg@rbt.ca> wrote:I tried again this morning using gin-packed-postinglists-16.patch and gin-fast-scan.6.patch. No crashes.
It is about a 0.1% random sample of production data (10,000,000 records) with the below structure. Pg was compiled with debug enabled in both cases.
Table "public.kp"
Column | Type | Modifiers
--------+---------+-----------
id | bigint | not null
string | text | not null
score1 | integer |
score2 | integer |
score3 | integer |
score4 | integer |
Indexes:
"kp_pkey" PRIMARY KEY, btree (id)
"kp_string_key" UNIQUE CONSTRAINT, btree (string)
"textsearch_gin_idx" gin (to_tsvector('simple'::regconfig, string)) WHERE score1 IS NOT NULL
This is a query tested. All data is in Pg buffer cache for these timings. Words like "the" and "and" are very common (~9% of entries, each) and a word like "hotel" is much less common (~0.2% of entries).
SELECT id,string
FROM kp
WHERE score1 IS NOT NULL
AND to_tsvector('simple', string) @@ to_tsquery('simple', ?)
-- ? is substituted with the query strings
ORDER BY score1 DESC, score2 ASC
LIMIT 1000;
Limit (cost=56.04..56.04 rows=1 width=37) (actual time=250.010..250.032 rows=142 loops=1)
-> Sort (cost=56.04..56.04 rows=1 width=37) (actual time=250.008..250.017 rows=142 loops=1)
Sort Key: score1, score2
Sort Method: quicksort Memory: 36kB
-> Bitmap Heap Scan on kp (cost=52.01..56.03 rows=1 width=37) (actual time=249.711..249.945 rows=142 loops=1)
Recheck Cond: ((to_tsvector('simple'::regconfig, string) @@ '''hotel'' & ''and'' & ''the'''::tsquery) AND (score1 IS NOT NULL))
-> Bitmap Index Scan on textsearch_gin_idx (cost=0.00..52.01 rows=1 width=0) (actual time=249.681..249.681 rows=142 loops=1)
Index Cond: (to_tsvector('simple'::regconfig, string) @@ '''hotel'' & ''and'' & ''the'''::tsquery)
Total runtime: 250.096 ms
Times are from \timing on.
MASTER
=======
the: 888.436 ms 926.609 ms 885.502 ms
and: 944.052 ms 937.732 ms 920.050 ms
hotel: 53.992 ms 57.039 ms 65.581 ms
and & the & hotel: 260.308 ms 248.275 ms 248.098 msThese numbers roughly match what we get with Pg 9.2. The time savings between 'the' and 'and & the & hotel' is mostly heap lookups for the score and the final sort.
The size of the index on disk is about 2% smaller in the patched version.
PATCHED
=======
the: 1055.169 ms 1081.976 ms 1083.021 ms
and: 912.173 ms 949.364 ms 965.261 ms
hotel: 62.591 ms 64.341 ms 62.923 ms
and & the & hotel: 268.577 ms 259.293 ms 257.408 mshotel & and & the: 253.574 ms 258.071 ms 250.280 ms
I was hoping that the 'and & the & hotel' case would improve with this patch to be closer to the 'hotel' search, as I thought that was the kind of thing it targeted. Unfortunately, it did not. I actually applied the patches, compiled, initdb/load data, and ran it again thinking I made a mistake.Reordering the terms 'hotel & and & the' doesn't change the result.Oh, in this path new consistent method isn't implemented for tsvector opclass, for array only. Will be fixed soon.BTW, was index 2% smaller or 2 times smaller? If it's 2% smaller than I need to know more about your dataset :)
------
With best regards,
Alexander Korotkov.
On Fri, Nov 15, 2013 at 11:18 PM, Rod Taylor <rod.taylor@gmail.com> wrote:
------
With best regards,
Alexander Korotkov.
2%.It's essentially sentence fragments from 1 to 5 words in length. I wasn't expecting it to be much smaller.
10 recent value selections:
white vinegar reduce color running
vinegar cure uti
cane vinegar acidity depends parameter
how remedy fir clogged shower
use vinegar sensitive skin
home remedies removing rust heating
does non raw apple cider
home remedies help maintain healthy
can vinegar mess up your
apple cide vineger ph balance
I didn't get why it's not significantly smaller. Is it possible to share dump?
------
With best regards,
Alexander Korotkov.
On Fri, Nov 15, 2013 at 2:26 PM, Alexander Korotkov <aekorotkov@gmail.com> wrote:
Sorry, I reported that incorrectly. It's not something I was actually looking for and didn't pay much attention to at the time.
On Fri, Nov 15, 2013 at 11:18 PM, Rod Taylor <rod.taylor@gmail.com> wrote:2%.It's essentially sentence fragments from 1 to 5 words in length. I wasn't expecting it to be much smaller.
10 recent value selections:
white vinegar reduce color running
vinegar cure uti
cane vinegar acidity depends parameter
how remedy fir clogged shower
use vinegar sensitive skin
home remedies removing rust heating
does non raw apple cider
home remedies help maintain healthy
can vinegar mess up your
apple cide vineger ph balanceI didn't get why it's not significantly smaller. Is it possible to share dump?
The patched index is 58% of the 9.4 master size. 212 MB instead of 365 MB.
On Fri, Nov 15, 2013 at 11:39 PM, Rod Taylor <rod.taylor@gmail.com> wrote:
------
With best regards,
Alexander Korotkov.
Sorry, I reported that incorrectly. It's not something I was actually looking for and didn't pay much attention to at the time.On Fri, Nov 15, 2013 at 2:26 PM, Alexander Korotkov <aekorotkov@gmail.com> wrote:On Fri, Nov 15, 2013 at 11:18 PM, Rod Taylor <rod.taylor@gmail.com> wrote:2%.It's essentially sentence fragments from 1 to 5 words in length. I wasn't expecting it to be much smaller.
10 recent value selections:
white vinegar reduce color running
vinegar cure uti
cane vinegar acidity depends parameter
how remedy fir clogged shower
use vinegar sensitive skin
home remedies removing rust heating
does non raw apple cider
home remedies help maintain healthy
can vinegar mess up your
apple cide vineger ph balanceI didn't get why it's not significantly smaller. Is it possible to share dump?The patched index is 58% of the 9.4 master size. 212 MB instead of 365 MB.
Good. That's meet my expectations :)
You mention that both master and patched versions was compiled with debug. Was cassert enabled?
With best regards,
Alexander Korotkov.
On 11/14/13, 12:26 PM, Alexander Korotkov wrote: > Revised version of patch is attached. This doesn't build: ginget.c: In function ‘scanPage’: ginget.c:1108:2: warning: implicit declaration of function ‘GinDataLeafPageGetPostingListEnd’ [-Wimplicit-function-declaration] ginget.c:1108:9: warning: assignment makes pointer from integer without a cast [enabled by default] ginget.c:1109:18: error: ‘GinDataLeafIndexCount’ undeclared (first use in this function) ginget.c:1109:18: note: each undeclared identifier is reported only once for each function it appears in ginget.c:1111:3: error: unknown type name ‘GinDataLeafItemIndex’ ginget.c:1111:3: warning: implicit declaration of function ‘GinPageGetIndexes’ [-Wimplicit-function-declaration] ginget.c:1111:57: error: subscripted value is neither array nor pointer nor vector ginget.c:1112:12: error: request for member ‘pageOffset’ in something not a structure or union ginget.c:1115:38: error: request for member ‘iptr’ in something not a structure or union ginget.c:1118:230: error: request for member ‘pageOffset’ in something not a structure or union ginget.c:1119:16: error: request for member ‘iptr’ in something not a structure or union ginget.c:1123:233: error: request for member ‘pageOffset’ in something not a structure or union ginget.c:1136:3: warning: implicit declaration of function ‘ginDataPageLeafReadItemPointer’ [-Wimplicit-function-declaration] ginget.c:1136:7: warning: assignment makes pointer from integer without a cast [enabled by default]
On Sat, Nov 16, 2013 at 12:10 AM, Peter Eisentraut <peter_e@gmx.net> wrote:
------
With best regards,
Alexander Korotkov.
On 11/14/13, 12:26 PM, Alexander Korotkov wrote:This doesn't build:
> Revised version of patch is attached.
ginget.c: In function ‘scanPage’:
ginget.c:1108:2: warning: implicit declaration of function ‘GinDataLeafPageGetPostingListEnd’ [-Wimplicit-function-declaration]
ginget.c:1108:9: warning: assignment makes pointer from integer without a cast [enabled by default]
ginget.c:1109:18: error: ‘GinDataLeafIndexCount’ undeclared (first use in this function)
ginget.c:1109:18: note: each undeclared identifier is reported only once for each function it appears in
ginget.c:1111:3: error: unknown type name ‘GinDataLeafItemIndex’
ginget.c:1111:3: warning: implicit declaration of function ‘GinPageGetIndexes’ [-Wimplicit-function-declaration]
ginget.c:1111:57: error: subscripted value is neither array nor pointer nor vector
ginget.c:1112:12: error: request for member ‘pageOffset’ in something not a structure or union
ginget.c:1115:38: error: request for member ‘iptr’ in something not a structure or union
ginget.c:1118:230: error: request for member ‘pageOffset’ in something not a structure or union
ginget.c:1119:16: error: request for member ‘iptr’ in something not a structure or union
ginget.c:1123:233: error: request for member ‘pageOffset’ in something not a structure or union
ginget.c:1136:3: warning: implicit declaration of function ‘ginDataPageLeafReadItemPointer’ [-Wimplicit-function-declaration]
ginget.c:1136:7: warning: assignment makes pointer from integer without a cast [enabled by default]
This patch is against gin packed posting lists patch. Doesn't compile separately.
With best regards,
Alexander Korotkov.
On Fri, Nov 15, 2013 at 11:42 PM, Alexander Korotkov <aekorotkov@gmail.com> wrote:
------
With best regards,
Alexander Korotkov.
On Fri, Nov 15, 2013 at 11:39 PM, Rod Taylor <rod.taylor@gmail.com> wrote:Sorry, I reported that incorrectly. It's not something I was actually looking for and didn't pay much attention to at the time.On Fri, Nov 15, 2013 at 2:26 PM, Alexander Korotkov <aekorotkov@gmail.com> wrote:On Fri, Nov 15, 2013 at 11:18 PM, Rod Taylor <rod.taylor@gmail.com> wrote:2%.It's essentially sentence fragments from 1 to 5 words in length. I wasn't expecting it to be much smaller.
10 recent value selections:
white vinegar reduce color running
vinegar cure uti
cane vinegar acidity depends parameter
how remedy fir clogged shower
use vinegar sensitive skin
home remedies removing rust heating
does non raw apple cider
home remedies help maintain healthy
can vinegar mess up your
apple cide vineger ph balanceI didn't get why it's not significantly smaller. Is it possible to share dump?The patched index is 58% of the 9.4 master size. 212 MB instead of 365 MB.Good. That's meet my expectations :)You mention that both master and patched versions was compiled with debug. Was cassert enabled?
In the attached version of patch tsvector opclass is enabled to use fastscan. You can retry your tests.
With best regards,
Alexander Korotkov.
Attachment
On Fri, Nov 15, 2013 at 2:42 PM, Alexander Korotkov <aekorotkov@gmail.com> wrote:
gin-fast-scan.6.patch/9.4 master performance
=================
the: 1147.413 ms 1159.360 ms 1122.549 ms
and: 1035.540 ms 999.514 ms 1003.042 ms
hotel: 57.670 ms 61.152 ms 58.862 ms
and & the & hotel: 266.121 ms 256.711 ms 267.011 ms
hotel & and & the: 260.213 ms 254.055 ms 255.611 ms
gin-fast-scan.7.patch
=================
the: 1091.735 ms 1068.909 ms 1076.474 ms
and: 985.690 ms 972.833 ms 948.286 ms
hotel: 60.756 ms 59.028 ms 57.836 ms
and & the & hotel: 50.391 ms 38.715 ms 46.168 ms
hotel & and & the: 45.395 ms 40.880 ms 43.978 ms
On Fri, Nov 15, 2013 at 11:39 PM, Rod Taylor <rod.taylor@gmail.com> wrote:The patched index is 58% of the 9.4 master size. 212 MB instead of 365 MB.Good. That's meet my expectations :)You mention that both master and patched versions was compiled with debug. Was cassert enabled?
Just debug. I try not to do performance tests with assertions on.
Patch 7 gives the results I was looking for on this small sampling of data.
gin-fast-scan.6.patch/9.4 master performance
=================
the: 1147.413 ms 1159.360 ms 1122.549 ms
and: 1035.540 ms 999.514 ms 1003.042 ms
hotel: 57.670 ms 61.152 ms 58.862 ms
and & the & hotel: 266.121 ms 256.711 ms 267.011 ms
hotel & and & the: 260.213 ms 254.055 ms 255.611 ms
gin-fast-scan.7.patch
=================
the: 1091.735 ms 1068.909 ms 1076.474 ms
and: 985.690 ms 972.833 ms 948.286 ms
hotel: 60.756 ms 59.028 ms 57.836 ms
and & the & hotel: 50.391 ms 38.715 ms 46.168 ms
hotel & and & the: 45.395 ms 40.880 ms 43.978 ms
Thanks,
Rod
I checked out master and put together a test case using a small percentage of production data for a known problem we have with Pg 9.2 and text search scans.
A small percentage in this case means 10 million records randomly selected; has a few billion records.Tests ran for master successfully and I recorded timings.
Applied the patch included here to master along with gin-packed-postinglists-14.patch.
Run make clean; ./configure; make; make install.
make check (All 141 tests passed.)
initdb, import dump
The GIN index fails to build with a segfault.
DETAIL: Failed process was running: CREATE INDEX textsearch_gin_idx ON kp USING gin (to_tsvector('simple'::regconfig, string)) WHERE (score1 IS NOT NULL);
#0 XLogCheckBuffer (holdsExclusiveLock=1 '\001', lsn=lsn@entry=0x7fffcf341920, bkpb=bkpb@entry=0x7fffcf341960, rdata=0x468f11 <ginFindLeafPage+529>,
rdata=0x468f11 <ginFindLeafPage+529>) at xlog.c:2339
#1 0x00000000004b9ddd in XLogInsert (rmid=rmid@entry=13 '\r', info=info@entry=16 '\020', rdata=rdata@entry=0x7fffcf341bf0) at xlog.c:936
#2 0x0000000000468a9e in createPostingTree (index=0x7fa4e8d31030, items=items@entry=0xfb55680, nitems=nitems@entry=762,
buildStats=buildStats@entry=0x7fffcf343dd0) at gindatapage.c:1324
#3 0x00000000004630c0 in buildFreshLeafTuple (buildStats=0x7fffcf343dd0, nitem=762, items=0xfb55680, category=<optimized out>, key=34078256,
attnum=<optimized out>, ginstate=0x7fffcf341df0) at gininsert.c:281
#4 ginEntryInsert (ginstate=ginstate@entry=0x7fffcf341df0, attnum=<optimized out>, key=34078256, category=<optimized out>, items=0xfb55680, nitem=762,
buildStats=buildStats@entry=0x7fffcf343dd0) at gininsert.c:351
#5 0x00000000004635b0 in ginbuild (fcinfo=<optimized out>) at gininsert.c:531
#6 0x0000000000718637 in OidFunctionCall3Coll (functionId=functionId@entry=2738, collation=collation@entry=0, arg1=arg1@entry=140346257507968,
arg2=arg2@entry=140346257510448, arg3=arg3@entry=32826432) at fmgr.c:1649
#7 0x00000000004ce1da in index_build (heapRelation=heapRelation@entry=0x7fa4e8d30680, indexRelation=indexRelation@entry=0x7fa4e8d31030,
indexInfo=indexInfo@entry=0x1f4e440, isprimary=isprimary@entry=0 '\000', isreindex=isreindex@entry=0 '\000') at index.c:1963
#8 0x00000000004ceeaa in index_create (heapRelation=heapRelation@entry=0x7fa4e8d30680,
indexRelationName=indexRelationName@entry=0x1f4e660 "textsearch_gin_knn_idx", indexRelationId=16395, indexRelationId@entry=0,
relFileNode=<optimized out>, indexInfo=indexInfo@entry=0x1f4e440, indexColNames=indexColNames@entry=0x1f4f728,
accessMethodObjectId=accessMethodObjectId@entry=2742, tableSpaceId=tableSpaceId@entry=0, collationObjectId=collationObjectId@entry=0x1f4fcc8,
classObjectId=classObjectId@entry=0x1f4fce0, coloptions=coloptions@entry=0x1f4fcf8, reloptions=reloptions@entry=0, isprimary=0 '\000',
isconstraint=0 '\000', deferrable=0 '\000', initdeferred=0 '\000', allow_system_table_mods=0 '\000', skip_build=0 '\000', concurrent=0 '\000',
is_internal=0 '\000') at index.c:1082
#9 0x0000000000546a78 in DefineIndex (stmt=<optimized out>, indexRelationId=indexRelationId@entry=0, is_alter_table=is_alter_table@entry=0 '\000',
check_rights=check_rights@entry=1 '\001', skip_build=skip_build@entry=0 '\000', quiet=quiet@entry=0 '\000') at indexcmds.c:594
#10 0x000000000065147e in ProcessUtilitySlow (parsetree=parsetree@entry=0x1f7fb68,
queryString=0x1f7eb10 "CREATE INDEX textsearch_gin_idx ON kp USING gin (to_tsvector('simple'::regconfig, string)) WHERE (score1 IS NOT NULL);", context=<optimized out>, params=params@entry=0x0, completionTag=completionTag@entry=0x7fffcf344c10 "", dest=<optimized out>) at utility.c:1163
#11 0x000000000065079e in standard_ProcessUtility (parsetree=0x1f7fb68, queryString=<optimized out>, context=<optimized out>, params=0x0,
dest=<optimized out>, completionTag=0x7fffcf344c10 "") at utility.c:873
#12 0x000000000064de61 in PortalRunUtility (portal=portal@entry=0x1f4c350, utilityStmt=utilityStmt@entry=0x1f7fb68, isTopLevel=isTopLevel@entry=1 '\001',
dest=dest@entry=0x1f7ff08, completionTag=completionTag@entry=0x7fffcf344c10 "") at pquery.c:1187
#13 0x000000000064e9e5 in PortalRunMulti (portal=portal@entry=0x1f4c350, isTopLevel=isTopLevel@entry=1 '\001', dest=dest@entry=0x1f7ff08,
altdest=altdest@entry=0x1f7ff08, completionTag=completionTag@entry=0x7fffcf344c10 "") at pquery.c:1318
#14 0x000000000064f459 in PortalRun (portal=portal@entry=0x1f4c350, count=count@entry=9223372036854775807, isTopLevel=isTopLevel@entry=1 '\001',
dest=dest@entry=0x1f7ff08, altdest=altdest@entry=0x1f7ff08, completionTag=completionTag@entry=0x7fffcf344c10 "") at pquery.c:816
#15 0x000000000064d2d5 in exec_simple_query (
query_string=0x1f7eb10 "CREATE INDEX textsearch_gin_idx ON kp USING gin (to_tsvector('simple'::regconfig, string)) WHERE (score1 IS NOT NULL);") at postgres.c:1048
#16 PostgresMain (argc=<optimized out>, argv=argv@entry=0x1f2ad40, dbname=0x1f2abf8 "rbt", username=<optimized out>) at postgres.c:3992
#17 0x000000000045b1b4 in BackendRun (port=0x1f47280) at postmaster.c:4085
#18 BackendStartup (port=0x1f47280) at postmaster.c:3774
#19 ServerLoop () at postmaster.c:1585
#20 0x000000000060d031 in PostmasterMain (argc=argc@entry=3, argv=argv@entry=0x1f28b20) at postmaster.c:1240
#21 0x000000000045bb25 in main (argc=3, argv=0x1f28b20) at main.c:196
On Thu, Nov 14, 2013 at 12:26 PM, Alexander Korotkov <aekorotkov@gmail.com> wrote:
On Sun, Jun 30, 2013 at 3:00 PM, Heikki Linnakangas <hlinnakangas@vmware.com> wrote:On 28.06.2013 22:31, Alexander Korotkov wrote:I'm going to mark this as "returned with feedback". For the next version, I'd like to see the API changed per above. Also, I'd like us to do something about the tidbitmap overhead, as a separate patch before this, so that we can assess the actual benefit of this patch. And a new test case that demonstrates the I/O benefits.Now, I got the point of three state consistent: we can keep only one
consistent in opclasses that support new interface. exact true and exact
false values will be passed in the case of current patch consistent; exact
false and unknown will be passed in the case of current patch
preConsistent. That's reasonable.Revised version of patch is attached.Changes are so:1) Patch rebased against packed posting lists, not depends on additional information now.2) New API with tri-state logic is introduced.------
With best regards,
Alexander Korotkov.
--
Sent via pgsql-hackers mailing list (pgsql-hackers@postgresql.org)
To make changes to your subscription:
http://www.postgresql.org/mailpref/pgsql-hackers
I tried again this morning using gin-packed-postinglists-16.patch and gin-fast-scan.6.patch. No crashes.
It is about a 0.1% random sample of production data (10,000,000 records) with the below structure. Pg was compiled with debug enabled in both cases.
Table "public.kp"
Column | Type | Modifiers
--------+---------+-----------
id | bigint | not null
string | text | not null
score1 | integer |
score2 | integer |
score3 | integer |
score4 | integer |
Indexes:
"kp_pkey" PRIMARY KEY, btree (id)
"kp_string_key" UNIQUE CONSTRAINT, btree (string)
"textsearch_gin_idx" gin (to_tsvector('simple'::regconfig, string)) WHERE score1 IS NOT NULL
This is a query tested. All data is in Pg buffer cache for these timings. Words like "the" and "and" are very common (~9% of entries, each) and a word like "hotel" is much less common (~0.2% of entries).
SELECT id,string
FROM kp
WHERE score1 IS NOT NULL
AND to_tsvector('simple', string) @@ to_tsquery('simple', ?)
-- ? is substituted with the query strings
ORDER BY score1 DESC, score2 ASC
LIMIT 1000;
Limit (cost=56.04..56.04 rows=1 width=37) (actual time=250.010..250.032 rows=142 loops=1)
-> Sort (cost=56.04..56.04 rows=1 width=37) (actual time=250.008..250.017 rows=142 loops=1)
Sort Key: score1, score2
Sort Method: quicksort Memory: 36kB
-> Bitmap Heap Scan on kp (cost=52.01..56.03 rows=1 width=37) (actual time=249.711..249.945 rows=142 loops=1)
Recheck Cond: ((to_tsvector('simple'::regconfig, string) @@ '''hotel'' & ''and'' & ''the'''::tsquery) AND (score1 IS NOT NULL))
-> Bitmap Index Scan on textsearch_gin_idx (cost=0.00..52.01 rows=1 width=0) (actual time=249.681..249.681 rows=142 loops=1)
Index Cond: (to_tsvector('simple'::regconfig, string) @@ '''hotel'' & ''and'' & ''the'''::tsquery)
Total runtime: 250.096 ms
Times are from \timing on.
MASTER
=======
the: 888.436 ms 926.609 ms 885.502 ms
and: 944.052 ms 937.732 ms 920.050 ms
hotel: 53.992 ms 57.039 ms 65.581 ms
and & the & hotel: 260.308 ms 248.275 ms 248.098 ms
These numbers roughly match what we get with Pg 9.2. The time savings between 'the' and 'and & the & hotel' is mostly heap lookups for the score and the final sort.
The size of the index on disk is about 2% smaller in the patched version.
PATCHED
=======
the: 1055.169 ms 1081.976 ms 1083.021 ms
and: 912.173 ms 949.364 ms 965.261 ms
hotel: 62.591 ms 64.341 ms 62.923 ms
and & the & hotel: 268.577 ms 259.293 ms 257.408 ms
hotel & and & the: 253.574 ms 258.071 ms 250.280 ms
I was hoping that the 'and & the & hotel' case would improve with this patch to be closer to the 'hotel' search, as I thought that was the kind of thing it targeted. Unfortunately, it did not. I actually applied the patches, compiled, initdb/load data, and ran it again thinking I made a mistake.
Reordering the terms 'hotel & and & the' doesn't change the result.
On Fri, Nov 15, 2013 at 1:51 AM, Alexander Korotkov <aekorotkov@gmail.com> wrote:
On Fri, Nov 15, 2013 at 3:25 AM, Rod Taylor <rbt@simple-knowledge.com> wrote:I checked out master and put together a test case using a small percentage of production data for a known problem we have with Pg 9.2 and text search scans.A small percentage in this case means 10 million records randomly selected; has a few billion records.Tests ran for master successfully and I recorded timings.
Applied the patch included here to master along with gin-packed-postinglists-14.patch.Run make clean; ./configure; make; make install.make check (All 141 tests passed.)initdb, import dump
The GIN index fails to build with a segfault.Thanks for testing. See fixed version in thread about packed posting lists.
------
With best regards,
Alexander Korotkov.
On Fri, Nov 15, 2013 at 11:19 AM, Alexander Korotkov <aekorotkov@gmail.com> wrote:
------
With best regards,
Alexander Korotkov.
On Fri, Nov 15, 2013 at 12:34 AM, Heikki Linnakangas <hlinnakangas@vmware.com> wrote:Thanks! A couple of thoughts after a 5-minute glance:On 14.11.2013 19:26, Alexander Korotkov wrote:On Sun, Jun 30, 2013 at 3:00 PM, Heikki Linnakangas <hlinnakangas@vmware.comwrote:On 28.06.2013 22:31, Alexander Korotkov wrote:Now, I got the point of three state consistent: we can keep only one
consistent in opclasses that support new interface. exact true and exact
false values will be passed in the case of current patch consistent; exact
false and unknown will be passed in the case of current patch
preConsistent. That's reasonable.
I'm going to mark this as "returned with feedback". For the next version,
I'd like to see the API changed per above. Also, I'd like us to do
something about the tidbitmap overhead, as a separate patch before this, so
that we can assess the actual benefit of this patch. And a new test case
that demonstrates the I/O benefits.
Revised version of patch is attached.
Changes are so:
1) Patch rebased against packed posting lists, not depends on additional
information now.
2) New API with tri-state logic is introduced.
* documentationWill provide documented version this week.* How about defining the tri-state consistent function to also return a tri-state? True would mean that the tuple definitely matches, false means the tuple definitely does not match, and Unknown means it might match. Or does return value true with recheck==true have the same effect? If I understood the patch, right, returning Unknown or True wouldn't actually make any difference, but it's conceivable that we might come up with more optimizations in the future that could take advantage of that. For example, for a query like "foo OR (bar AND baz)", you could immediately return any tuples that match foo, and not bother scanning for bar and baz at all.The meaning of recheck flag when input contains unknown is undefined now. :)For instance, we could define it in following ways:1) Like returning Unknown meaning that consistent with true of false instead of input Unknown could return either true or false.2) Consistent with true of false instead of input Unknown could return recheck. This meaning is probably logical, but I don't see any usage of it.I'm not against idea of tri-state returning value for consisted, because it's logical continuation of its tri-state input. However, I don't see usage of distinguish True and Unknown in returning value for now :)In example you give we can return foo immediately, but we have to create full bitmap. So we anyway will have to scan (bar AND baz). We could skip part of trees for bar and baz. But it's possible only when foo contains large amount of sequential TIDS so we can be sure that we didn't miss any TIDs. This seems to be very narrow use-case for me.Another point is that one day we probably could immediately return tuples in gingettuple. And with LIMIT clause and no sorting we can don't search for other tuples. However, gingettuple was removed because of reasons of concurrency. And my patches for index-based ordering didn't return it in previous manner: it collects all the results and then returns them one-by-one.
I'm trying to make fastscan work with GinFuzzySearchLimit. Then I figure out that I don't understand how GinFuzzySearchLimit works. Why with GinFuzzySearchLimit startScan can return without doing startScanKey? Is it a bug?
With best regards,
Alexander Korotkov.
On Wed, Nov 20, 2013 at 3:06 AM, Alexander Korotkov <aekorotkov@gmail.com> wrote:
------
With best regards,
Alexander Korotkov.
On Fri, Nov 15, 2013 at 11:19 AM, Alexander Korotkov <aekorotkov@gmail.com> wrote:On Fri, Nov 15, 2013 at 12:34 AM, Heikki Linnakangas <hlinnakangas@vmware.com> wrote:Thanks! A couple of thoughts after a 5-minute glance:On 14.11.2013 19:26, Alexander Korotkov wrote:On Sun, Jun 30, 2013 at 3:00 PM, Heikki Linnakangas <hlinnakangas@vmware.comwrote:On 28.06.2013 22:31, Alexander Korotkov wrote:Now, I got the point of three state consistent: we can keep only one
consistent in opclasses that support new interface. exact true and exact
false values will be passed in the case of current patch consistent; exact
false and unknown will be passed in the case of current patch
preConsistent. That's reasonable.
I'm going to mark this as "returned with feedback". For the next version,
I'd like to see the API changed per above. Also, I'd like us to do
something about the tidbitmap overhead, as a separate patch before this, so
that we can assess the actual benefit of this patch. And a new test case
that demonstrates the I/O benefits.
Revised version of patch is attached.
Changes are so:
1) Patch rebased against packed posting lists, not depends on additional
information now.
2) New API with tri-state logic is introduced.
* documentationWill provide documented version this week.* How about defining the tri-state consistent function to also return a tri-state? True would mean that the tuple definitely matches, false means the tuple definitely does not match, and Unknown means it might match. Or does return value true with recheck==true have the same effect? If I understood the patch, right, returning Unknown or True wouldn't actually make any difference, but it's conceivable that we might come up with more optimizations in the future that could take advantage of that. For example, for a query like "foo OR (bar AND baz)", you could immediately return any tuples that match foo, and not bother scanning for bar and baz at all.The meaning of recheck flag when input contains unknown is undefined now. :)For instance, we could define it in following ways:1) Like returning Unknown meaning that consistent with true of false instead of input Unknown could return either true or false.2) Consistent with true of false instead of input Unknown could return recheck. This meaning is probably logical, but I don't see any usage of it.I'm not against idea of tri-state returning value for consisted, because it's logical continuation of its tri-state input. However, I don't see usage of distinguish True and Unknown in returning value for now :)In example you give we can return foo immediately, but we have to create full bitmap. So we anyway will have to scan (bar AND baz). We could skip part of trees for bar and baz. But it's possible only when foo contains large amount of sequential TIDS so we can be sure that we didn't miss any TIDs. This seems to be very narrow use-case for me.Another point is that one day we probably could immediately return tuples in gingettuple. And with LIMIT clause and no sorting we can don't search for other tuples. However, gingettuple was removed because of reasons of concurrency. And my patches for index-based ordering didn't return it in previous manner: it collects all the results and then returns them one-by-one.I'm trying to make fastscan work with GinFuzzySearchLimit. Then I figure out that I don't understand how GinFuzzySearchLimit works. Why with GinFuzzySearchLimit startScan can return without doing startScanKey? Is it a bug?
Revised version of patch is attached. Changes are so:
1) Support for GinFuzzySearchLimit.
2) Some documentation.
Question about GinFuzzySearchLimit is still relevant.
------
With best regards,
Alexander Korotkov.
Attachment
On Thu, Nov 21, 2013 at 12:14 AM, Alexander Korotkov <aekorotkov@gmail.com> wrote:
------
With best regards,
Alexander Korotkov.
On Wed, Nov 20, 2013 at 3:06 AM, Alexander Korotkov <aekorotkov@gmail.com> wrote:On Fri, Nov 15, 2013 at 11:19 AM, Alexander Korotkov <aekorotkov@gmail.com> wrote:On Fri, Nov 15, 2013 at 12:34 AM, Heikki Linnakangas <hlinnakangas@vmware.com> wrote:Thanks! A couple of thoughts after a 5-minute glance:On 14.11.2013 19:26, Alexander Korotkov wrote:On Sun, Jun 30, 2013 at 3:00 PM, Heikki Linnakangas <hlinnakangas@vmware.comwrote:On 28.06.2013 22:31, Alexander Korotkov wrote:Now, I got the point of three state consistent: we can keep only one
consistent in opclasses that support new interface. exact true and exact
false values will be passed in the case of current patch consistent; exact
false and unknown will be passed in the case of current patch
preConsistent. That's reasonable.
I'm going to mark this as "returned with feedback". For the next version,
I'd like to see the API changed per above. Also, I'd like us to do
something about the tidbitmap overhead, as a separate patch before this, so
that we can assess the actual benefit of this patch. And a new test case
that demonstrates the I/O benefits.
Revised version of patch is attached.
Changes are so:
1) Patch rebased against packed posting lists, not depends on additional
information now.
2) New API with tri-state logic is introduced.
* documentationWill provide documented version this week.* How about defining the tri-state consistent function to also return a tri-state? True would mean that the tuple definitely matches, false means the tuple definitely does not match, and Unknown means it might match. Or does return value true with recheck==true have the same effect? If I understood the patch, right, returning Unknown or True wouldn't actually make any difference, but it's conceivable that we might come up with more optimizations in the future that could take advantage of that. For example, for a query like "foo OR (bar AND baz)", you could immediately return any tuples that match foo, and not bother scanning for bar and baz at all.The meaning of recheck flag when input contains unknown is undefined now. :)For instance, we could define it in following ways:1) Like returning Unknown meaning that consistent with true of false instead of input Unknown could return either true or false.2) Consistent with true of false instead of input Unknown could return recheck. This meaning is probably logical, but I don't see any usage of it.I'm not against idea of tri-state returning value for consisted, because it's logical continuation of its tri-state input. However, I don't see usage of distinguish True and Unknown in returning value for now :)In example you give we can return foo immediately, but we have to create full bitmap. So we anyway will have to scan (bar AND baz). We could skip part of trees for bar and baz. But it's possible only when foo contains large amount of sequential TIDS so we can be sure that we didn't miss any TIDs. This seems to be very narrow use-case for me.Another point is that one day we probably could immediately return tuples in gingettuple. And with LIMIT clause and no sorting we can don't search for other tuples. However, gingettuple was removed because of reasons of concurrency. And my patches for index-based ordering didn't return it in previous manner: it collects all the results and then returns them one-by-one.I'm trying to make fastscan work with GinFuzzySearchLimit. Then I figure out that I don't understand how GinFuzzySearchLimit works. Why with GinFuzzySearchLimit startScan can return without doing startScanKey? Is it a bug?Revised version of patch is attached. Changes are so:1) Support for GinFuzzySearchLimit.2) Some documentation.Question about GinFuzzySearchLimit is still relevant.
Attached version is rebased against last version of packed posting lists.
With best regards,
Alexander Korotkov.
Attachment
On 01/14/2014 05:35 PM, Alexander Korotkov wrote: > On Thu, Nov 21, 2013 at 12:14 AM, Alexander Korotkov > <aekorotkov@gmail.com>wrote: > >> Revised version of patch is attached. Changes are so: >> 1) Support for GinFuzzySearchLimit. >> 2) Some documentation. >> Question about GinFuzzySearchLimit is still relevant. >> > > Attached version is rebased against last version of packed posting lists. Quick question: the ginEnableFastScan is just for debugging/testing purposes, right? There's no reason anyone would turn that off in production. We should remove it before committing, but I guess it's useful while we're still hacking.. - Heikki
On Tue, Jan 14, 2014 at 11:07 PM, Heikki Linnakangas <hlinnakangas@vmware.com> wrote:
------
With best regards,
Alexander Korotkov.
On 01/14/2014 05:35 PM, Alexander Korotkov wrote:Revised version of patch is attached. Changes are so:
1) Support for GinFuzzySearchLimit.
2) Some documentation.
Question about GinFuzzySearchLimit is still relevant.
Attached version is rebased against last version of packed posting lists.
Quick question: the ginEnableFastScan is just for debugging/testing purposes, right? There's no reason anyone would turn that off in production.
We should remove it before committing, but I guess it's useful while we're still hacking..
Yes, ginEnableFastScan is for debugging and testing.
With best regards,
Alexander Korotkov.
On 01/14/2014 05:35 PM, Alexander Korotkov wrote:
> Attached version is rebased against last version of packed posting lists.
Thanks!
I think we're missing a trick with multi-key queries. We know that when
multiple scan keys are used, they are ANDed together, so we can do the
skip optimization even without the new tri-state consistent function.
To get started, I propose the three attached patches. These only
implement the optimization for the multi-key case, which doesn't require
any changes to the consistent functions and hence no catalog changes.
Admittedly this isn't anywhere near as useful in practice as the single
key case, but let's go for the low-hanging fruit first. This
nevertheless introduces some machinery that will be needed by the full
patch anyway.
I structured the code somewhat differently than your patch. There is no
separate fast-path for the case where the optimization applies. Instead,
I'm passing the advancePast variable all the way down to where the next
batch of items are loaded from the posting tree. keyGetItem is now
responsible for advancing the entry streams, and the logic in
scanGetItem has been refactored so that it advances advancePast
aggressively, as soon as one of the key streams let us conclude that no
items < a certain point can match.
scanGetItem might yet need to be refactored when we get to the full
preconsistent check stuff, but one step at a time.
The first patch is the most interesting one, and contains the
scanGetItem changes. The second patch allows seeking to the right
segment in a posting tree page, and the third allows starting the
posting tree scan from root, when skipping items (instead of just
following the right-links).
Here are some simple performance test results, demonstrating the effect
of each of these patches. This is a best-case scenario. I don't think
these patches has any adverse effects even in the worst-case scenario,
although I haven't actually tried hard to measure that. The used this to
create a test table:
create table foo (intarr int[]);
-- Every row contains 0 (frequent term), and a unique number.
insert into foo select array[0,g] from generate_series(1, 10000000) g;
-- Add another tuple with 0, 1 combo physically to the end of the table.
insert into foo values (array[0,1]);
The query I used is this:
postgres=# select count(*) from foo where intarr @> array[0] and intarr
@> array[1];
count
-------
2
(1 row)
I measured the time that query takes, and the number of pages hit, using
"explain (analyze, buffers true) ...".
patches time (ms) buffers
---
unpatched 650 1316
patch 1 0.52 1316
patches 1+2 0.50 1316
patches 1+2+3 0.13 15
So, the second patch isn't doing much in this particular case. But it's
trivial, and I think it will make a difference in other queries where
you have the opportunity skip, but return a lot of tuples overall.
In summary, these are fairly small patches, and useful on their, so I
think these should be committed now. But please take a look and see if
the logic in scanGetItem/keyGetItem looks correct to you. After this, I
think the main fast scan logic will go into keyGetItem.
PS. I find it a bit surprising that in your patch, you're completely
bailing out if there are any partial-match keys involved. Is there some
fundamental reason for that, or just not implemented?
- Heikki
Attachment
On 23.1.2014 17:22, Heikki Linnakangas wrote:
> On 01/14/2014 05:35 PM, Alexander Korotkov wrote:
>> Attached version is rebased against last version of packed posting lists.
>
> Thanks!
>
> I think we're missing a trick with multi-key queries. We know that when
> multiple scan keys are used, they are ANDed together, so we can do the
> skip optimization even without the new tri-state consistent function.
>
> To get started, I propose the three attached patches. These only
> implement the optimization for the multi-key case, which doesn't require
> any changes to the consistent functions and hence no catalog changes.
> Admittedly this isn't anywhere near as useful in practice as the single
> key case, but let's go for the low-hanging fruit first. This
> nevertheless introduces some machinery that will be needed by the full
> patch anyway.
>
> I structured the code somewhat differently than your patch. There is no
> separate fast-path for the case where the optimization applies. Instead,
> I'm passing the advancePast variable all the way down to where the next
> batch of items are loaded from the posting tree. keyGetItem is now
> responsible for advancing the entry streams, and the logic in
> scanGetItem has been refactored so that it advances advancePast
> aggressively, as soon as one of the key streams let us conclude that no
> items < a certain point can match.
>
> scanGetItem might yet need to be refactored when we get to the full
> preconsistent check stuff, but one step at a time.
>
>
> The first patch is the most interesting one, and contains the
> scanGetItem changes. The second patch allows seeking to the right
> segment in a posting tree page, and the third allows starting the
> posting tree scan from root, when skipping items (instead of just
> following the right-links).
>
> Here are some simple performance test results, demonstrating the effect
> of each of these patches. This is a best-case scenario. I don't think
> these patches has any adverse effects even in the worst-case scenario,
> although I haven't actually tried hard to measure that. The used this to
> create a test table:
>
> create table foo (intarr int[]);
> -- Every row contains 0 (frequent term), and a unique number.
> insert into foo select array[0,g] from generate_series(1, 10000000) g;
> -- Add another tuple with 0, 1 combo physically to the end of the table.
> insert into foo values (array[0,1]);
>
> The query I used is this:
>
> postgres=# select count(*) from foo where intarr @> array[0] and intarr
> @> array[1];
> count
> -------
> 2
> (1 row)
>
> I measured the time that query takes, and the number of pages hit, using
> "explain (analyze, buffers true) ...".
>
> patches time (ms) buffers
> ---
> unpatched 650 1316
> patch 1 0.52 1316
> patches 1+2 0.50 1316
> patches 1+2+3 0.13 15
>
> So, the second patch isn't doing much in this particular case. But it's
> trivial, and I think it will make a difference in other queries where
> you have the opportunity skip, but return a lot of tuples overall.
>
> In summary, these are fairly small patches, and useful on their, so I
> think these should be committed now. But please take a look and see if
> the logic in scanGetItem/keyGetItem looks correct to you. After this, I
> think the main fast scan logic will go into keyGetItem.
>
> PS. I find it a bit surprising that in your patch, you're completely
> bailing out if there are any partial-match keys involved. Is there some
> fundamental reason for that, or just not implemented?
I've done some initial testing (with all the three patches applied)
today to see if there are any crashes or obvious failures and found none
so far. The only issue I've noticed is this LOG message in ginget.c:
elog(LOG, "entryLoadMoreItems, %u/%u, skip: %d", ItemPointerGetBlockNumber(&advancePast),
ItemPointerGetOffsetNumber(&advancePast), !stepright);
which produces enormous amount of messages. I suppose that was used for
debugging purposes and shouldn't be there?
I plan to do more thorough testing over the weekend, but I'd like to
make sure I understand what to expect. My understanding is that this
patch should:
- give the same results as the current code (e.g. the fulltext should not return different rows / change the ts_rank
etc.)
- improve the performance of fulltext queries
Are there any obvious rules what queries will benefit most from this?
The queries generated by the tool I'm using for testing are mostly of
this form:
SELECT id FROM messages WHERE body_tsvector @ plainto_tsquery('english', 'word1 word2 ...') ORDER BY ts_rank(...)
DESCLIMIT :n;
with varying number of words and LIMIT values. During the testing today
I haven't noticed any obvious performance difference, but I haven't
spent much time on that.
regards
Tomas
On Fri, Jan 24, 2014 at 6:48 AM, Tomas Vondra <tv@fuzzy.cz> wrote:
------
With best regards,
Alexander Korotkov.
make sure I understand what to expect. My understanding is that thisI plan to do more thorough testing over the weekend, but I'd like to
patch should:
- give the same results as the current code (e.g. the fulltext should
not return different rows / change the ts_rank etc.)
- improve the performance of fulltext queries
Are there any obvious rules what queries will benefit most from this?
The queries generated by the tool I'm using for testing are mostly of
this form:
SELECT id FROM messages
WHERE body_tsvector @ plainto_tsquery('english', 'word1 word2 ...')
ORDER BY ts_rank(...) DESC LIMIT :n;
with varying number of words and LIMIT values. During the testing today
I haven't noticed any obvious performance difference, but I haven't
spent much time on that.
These patches optimizes only query with multiple WHERE clauses. For instance:
SELECT id FROM messages
WHERE body_tsvector @ plainto_tsquery('english', 'word1') AND body_tsvector @ plainto_tsquery('english', 'word2')
ORDER BY ts_rank(...) DESC LIMIT :n;
WHERE body_tsvector @ plainto_tsquery('english', 'word1') AND body_tsvector @ plainto_tsquery('english', 'word2')
ORDER BY ts_rank(...) DESC LIMIT :n;
Optimizations inside single clause will be provided as separate patch.
------
With best regards,
Alexander Korotkov.
On Thu, Jan 23, 2014 at 8:22 PM, Heikki Linnakangas <hlinnakangas@vmware.com> wrote:
------
With best regards,
Alexander Korotkov.
On 01/14/2014 05:35 PM, Alexander Korotkov wrote:Thanks!Attached version is rebased against last version of packed posting lists.
I think we're missing a trick with multi-key queries. We know that when multiple scan keys are used, they are ANDed together, so we can do the skip optimization even without the new tri-state consistent function.
To get started, I propose the three attached patches. These only implement the optimization for the multi-key case, which doesn't require any changes to the consistent functions and hence no catalog changes. Admittedly this isn't anywhere near as useful in practice as the single key case, but let's go for the low-hanging fruit first. This nevertheless introduces some machinery that will be needed by the full patch anyway.
I structured the code somewhat differently than your patch. There is no separate fast-path for the case where the optimization applies. Instead, I'm passing the advancePast variable all the way down to where the next batch of items are loaded from the posting tree. keyGetItem is now responsible for advancing the entry streams, and the logic in scanGetItem has been refactored so that it advances advancePast aggressively, as soon as one of the key streams let us conclude that no items < a certain point can match.
scanGetItem might yet need to be refactored when we get to the full preconsistent check stuff, but one step at a time.
The first patch is the most interesting one, and contains the scanGetItem changes. The second patch allows seeking to the right segment in a posting tree page, and the third allows starting the posting tree scan from root, when skipping items (instead of just following the right-links).
Here are some simple performance test results, demonstrating the effect of each of these patches. This is a best-case scenario. I don't think these patches has any adverse effects even in the worst-case scenario, although I haven't actually tried hard to measure that. The used this to create a test table:
create table foo (intarr int[]);
-- Every row contains 0 (frequent term), and a unique number.
insert into foo select array[0,g] from generate_series(1, 10000000) g;
-- Add another tuple with 0, 1 combo physically to the end of the table.
insert into foo values (array[0,1]);
The query I used is this:
postgres=# select count(*) from foo where intarr @> array[0] and intarr @> array[1];
count
-------
2
(1 row)
I measured the time that query takes, and the number of pages hit, using "explain (analyze, buffers true) ...".
patches time (ms) buffers
---
unpatched 650 1316
patch 1 0.52 1316
patches 1+2 0.50 1316
patches 1+2+3 0.13 15
So, the second patch isn't doing much in this particular case. But it's trivial, and I think it will make a difference in other queries where you have the opportunity skip, but return a lot of tuples overall.
In summary, these are fairly small patches, and useful on their, so I think these should be committed now. But please take a look and see if the logic in scanGetItem/keyGetItem looks correct to you. After this, I think the main fast scan logic will go into keyGetItem.
Good, thanks! Now I can reimplement fast scan basing on this patches.
PS. I find it a bit surprising that in your patch, you're completely bailing out if there are any partial-match keys involved. Is there some fundamental reason for that, or just not implemented?
Just not implemented. I think there is two possible approaches to handle it:
1) Handle partial-match keys like OR on matching keys.
2) Implement keyAdvancePast for bitmap.
First approach seems to be useful with low number of keys. Probably, we should implement automatic switching between them.
With best regards,
Alexander Korotkov.
On 01/24/2014 01:58 PM, Alexander Korotkov wrote: > On Thu, Jan 23, 2014 at 8:22 PM, Heikki Linnakangas <hlinnakangas@vmware.com >> wrote: > >> In summary, these are fairly small patches, and useful on their, so I >> think these should be committed now. But please take a look and see if the >> logic in scanGetItem/keyGetItem looks correct to you. After this, I think >> the main fast scan logic will go into keyGetItem. > > Good, thanks! Now I can reimplement fast scan basing on this patches. I hope we're not wasting effort doing the same thing, but I was also hacking that; here's what I got. It applies on top of the previous set of patches. I decided to focus on the ginget.c changes, and worry about the catalog changes later. Instead, I added an abstraction for calling the ternary consistent function, with a shim implementation that checks if there is only one UNKNOWN argument, and tries the regular boolean consistent function "both ways" for the UNKNOWN argument. That's the same strategy we were already using when dealing with a key with one lossy page, so I refactored that to also use the new ternary consistent function. That abstraction can be used to do other optimizations in the future. For example, building the truth table like I suggested a long time ago, or simply checking for some common cases, like if the consistent function implements plain AND logic. Or caching the results of expensive consistent functions. And obviously, that is where the call to the opclass-provided tri-state consistent function will go to. Then, I rewrote keyGetItem to make use of the ternary consistent function, to perform the "pre-consistent" check. That is the core logic from your patch. Currently (ie. without the patch), we loop through all the entries, and advance them to the next item pointer > advancePast, and then perform the consistent check for the smallest item among those. With the patch, we first determine the smallest item pointer among the entries with curItem > advancePast, and call that minItem. The others are considered as "unknown", as they might contain an item X where advancePast < X < minItem. Normally, we would have to load the next item from that entry to determine if X exists, but we can skip it if the ternary pre-consistent function says that X cannot match anyway. In addition to that, I'm using the ternary consistent function to check if minItem is a match, even if we haven't loaded all the entries yet. That's less important, but I think for something like "rare1 | (rare2 & frequent)" it might be useful. It would allow us to skip fetching 'frequent', when we already know that 'rare1' matches for the current item. I'm not sure if that's worth the cycles, but it seemed like an obvious thing to do, now that we have the ternary consistent function. (hmm, I should put the above paragraphs in a comment in the patch) This isn't exactly the same structure as in your patch, but I found the concept easier to understand when written this way. I did not implement the sorting of the entries. It seems like a sensible thing to do, but I'd like to see a test case that shows the difference before bothering with it. If we do it, a binary heap probably makes more sense than keeping the array fully sorted. There's one tradeoff here that should be mentioned: In most cases, it's extremely cheap to fetch the next item from an entry stream. We load a page worth of items into the array, so it's just a matter of pulling the next item from the array. Instead of trying to "refute" such items based on other entries, would it be better to load them and call the consistent function the normal way for them? Refuting might slash all the entries in one consistent check, but OTOH, when refuting fails, the consistent check was a waste of cycles. If we only tried to refute items when the alternative would be to load a new page, there would be less change of a performance regression from this patch. Anyway, how does this patch look to you? Did I get the logic correct? Do you have some test data and/or queries that you could share easily? - Heikki
Attachment
On 23.1.2014 17:22, Heikki Linnakangas wrote:
> I measured the time that query takes, and the number of pages hit, using
> "explain (analyze, buffers true) ...".
>
> patches time (ms) buffers
> ---
> unpatched 650 1316
> patch 1 0.52 1316
> patches 1+2 0.50 1316
> patches 1+2+3 0.13 15
>
> So, the second patch isn't doing much in this particular case. But it's
> trivial, and I think it will make a difference in other queries where
> you have the opportunity skip, but return a lot of tuples overall.
>
> In summary, these are fairly small patches, and useful on their, so I
> think these should be committed now. But please take a look and see if
> the logic in scanGetItem/keyGetItem looks correct to you. After this, I
> think the main fast scan logic will go into keyGetItem.
Hi,
I've done some testing of the three patches today, and I've ran into an
infinite loop caused by the third patch. I don't know why exactly it
gets stuck, but with patches #1+#2 it works fine, and after applying #3
it runs infinitely.
I can't point to a particular line / condition causing this, but this is
wthat I see in 'perf top'
54.16% postgres [.] gingetbitmap 32.38% postgres [.] ginPostingListDecodeAllSegments 3.03%
libc-2.17.so [.] 0x000000000007fb88
I've tracked it down to this loop in ginget.c:840 (I've added the
logging for debugging / demonstration purposes):
=====================================================================
elog(WARNING, "scanning entries");
elog(WARNING, "advacepast=(%u,%d)", BlockIdGetBlockNumber(&advancePast.ip_blkid),
advancePast.ip_posid);
while (entry->isFinished == FALSE && ginCompareItemPointers(&entry->curItem, &advancePast) <= 0) {
elog(WARNING,"current=(%u,%d)", BlockIdGetBlockNumber(&entry->curItem.ip_blkid),
entry->curItem.ip_posid); entryGetItem(ginstate, entry, advancePast); }
elog(WARNING, "entries scanned");
=====================================================================
which is executed repeatedly, but the last invocation gets stuck and
produces this output:
WARNING: scanning entries WARNING: advacepast=(172058,0) LOG: entryLoadMoreItems, 172058/0, skip: 1
WARNING: getting item current=(171493,7) WARNING: getting item current=(116833,2) WARNING: getting item
current=(116833,3) WARNING: getting item current=(116833,4) WARNING: getting item current=(116833,5) WARNING:
gettingitem current=(116838,1) WARNING: getting item current=(116838,2)
... increasing sequence of block IDs ...
WARNING: getting item current=(170743,5) WARNING: getting item current=(170746,4) WARNING: getting item
current=(171493,7) LOG: entryLoadMoreItems, 172058/0, skip: 1 WARNING: getting item current=(116833,2) WARNING:
gettingitem current=(116833,3) WARNING: getting item current=(116833,4) WARNING: getting item current=(116833,5)
... and repeat
=====================================================================
Not sure what went wrong, though - I suspect it does not set the
isFinished flag or something like that, but I don't know where/when
should that happen.
This is rather easy to reproduce - download the dump I already provided
two weeks ago [http://www.fuzzy.cz/tmp/message-b.data.gz] and load it
into a simple table:
CREATE TABLE msgs (body tsvector); COPY msgs FROM '/tmp/message-b.data'; CREATE INDEX msgidx ON msgs USING
gin(body); ANALYZE msgs;
And then run this query:
SELECT body FROM msgs WHERE body @@ plainto_tsquery('english','string | x') AND body @@
plainto_tsquery('english','versions| equivalent') AND body @@ plainto_tsquery('english','usually | contain');
It should run infinitely. I suspect it's not perfectly stable, i.e, the
this query may work fine / another one will block. In that case try to
run this [http://www.fuzzy.cz/tmp/random-queries.sql] - it's a file with
1000 generated queries, at least one of them should block (that's how I
discovered the issue).
regards
Tomas
On 01/25/2014 09:44 PM, Tomas Vondra wrote: > This is rather easy to reproduce - download the dump I already provided > two weeks ago [http://www.fuzzy.cz/tmp/message-b.data.gz] and load it > into a simple table: > > CREATE TABLE msgs (body tsvector); > COPY msgs FROM '/tmp/message-b.data'; > CREATE INDEX msgidx ON msgs USING gin(body); > ANALYZE msgs; > > And then run this query: > > SELECT body FROM msgs > WHERE body @@ plainto_tsquery('english','string | x') > AND body @@ plainto_tsquery('english','versions | equivalent') > AND body @@ plainto_tsquery('english','usually | contain'); > > It should run infinitely. I suspect it's not perfectly stable, i.e, the > this query may work fine / another one will block. In that case try to > run this [http://www.fuzzy.cz/tmp/random-queries.sql] - it's a file with > 1000 generated queries, at least one of them should block (that's how I > discovered the issue). Thanks, that's a great test suite! Indeed, it did get stuck for me as well. I tracked it down to a logic bug in entryGetItem; an && should've been ||. Also, it tickled an assertion in the debug LOG statement that bleated "entryLoadMoreItems, %u/%u, skip: %d" (I was using ItemPointerGetBlockNumber, which contains a check that the argument is a valid item pointer, which it isn't always in this case). Fixed that too. Attached is a new version of the patch set, with those bugs fixed. One interesting detail that I noticed while testing that query: Using EXPLAIN (BUFFERS) shows that we're actually accessing *more* pages with the patches than without it. The culprit is patch #3, which makes us re-descend the posting tree from root, rather than just stepping right from current page. I was very surprised by that at first - the patch was supposed to *reduce* the number of page's accessed, by not having to walk through all the leaf pages. But in this case, even when you're skipping some items, almost always the next item you're interested in is on the next posting tree page, so re-descending the tree is a waste and you land on the right sibling of the original page anyway. It's not a big waste, though. The upper levels of the tree are almost certainly in cache, so it's just a matter of some extra lw-locking and binary searching, which is cheap compared to actually decoding and copying all the items from the correct page. Indeed, I couldn't see any meaningful difference in query time with or without the patch. (I'm sure a different query that allows skipping more would show the patch to be a win - this was a worst case scenario) Alexander's patch contained a more complicated method for re-finding the right leaf page. It ascended the tree back up the same path it was originally descended, which is potentially faster if the tree is many-levels deep, and you only skip forward a little. In practice, posting trees are very compact, so to have a tree taller than 2 levels, it must contain millions of items. A 4-level tree would be humongous. So I don't think it's worth the complexity to try anything smarter than just re-descending from root. However, that difference in implementation shows up in EXPLAIN (BUFFERS) output; since Alexander's patch kept the stack of upper pages pinned, ascending and descending the tree did not increase the counters of pages accessed (I believe; I didn't actually test it), while descending from root does. - Heikki
Attachment
Hi!
On 25.1.2014 22:21, Heikki Linnakangas wrote:
> Attached is a new version of the patch set, with those bugs fixed.
I've done a bunch of tests with all the 4 patches applied, and it seems
to work now. I've done tests with various conditions (AND/OR, number of
words, number of conditions) and I so far I did not get any crashes,
infinite loops or anything like that.
I've also compared the results to 9.3 - by dumping the database and
running the same set of queries on both machines, and indeed I got 100%
match.
I also did some performance tests, and that's when I started to worry.
For example, I generated and ran 1000 queries that look like this:
SELECT id FROM messages
WHERE body_tsvector @@ to_tsquery('english','(header & 53 & 32 &
useful & dropped)')
ORDER BY ts_rank(body_tsvector, to_tsquery('english','(header & 53 &
32 & useful & dropped)')) DESC;
i.e. in this case the query always was 5 words connected by AND. This
query is a pretty common pattern for fulltext search - sort by a list of
words and give me the best ranked results.
On 9.3, the script was running for ~23 seconds, on patched HEAD it was
~40. It's perfectly reproducible, I've repeated the test several times
with exactly the same results. The test is CPU bound, there's no I/O
activity at all. I got the same results with more queries (~100k).
Attached is a simple chart with x-axis used for durations measured on
9.3.2, y-axis used for durations measured on patched HEAD. It's obvious
a vast majority of queries is up to 2x slower - that's pretty obvious
from the chart.
Only about 50 queries are faster on HEAD, and >700 queries are more than
50% slower on HEAD (i.e. if the query took 100ms on 9.3, it takes >150ms
on HEAD).
Typically, the EXPLAIN ANALYZE looks something like this (on 9.3):
http://explain.depesz.com/s/5tv
and on HEAD (same query):
http://explain.depesz.com/s/1lI
Clearly the main difference is in the "Bitmap Index Scan" which takes
60ms on 9.3 and 120ms on HEAD.
On 9.3 the "perf top" looks like this:
34.79% postgres [.] gingetbitmap
28.96% postgres [.] ginCompareItemPointers
9.36% postgres [.] TS_execute
5.36% postgres [.] check_stack_depth
3.57% postgres [.] FunctionCall8Coll
while on 9.4 it looks like this:
28.20% postgres [.] gingetbitmap
21.17% postgres [.] TS_execute
8.08% postgres [.] check_stack_depth
7.11% postgres [.] FunctionCall8Coll
4.34% postgres [.] shimTriConsistentFn
Not sure how to interpret that, though. For example where did the
ginCompareItemPointers go? I suspect it's thanks to inlining, and that
it might be related to the performance decrease. Or maybe not.
I've repeated the test several times, checked all I could think of, but
I've found nothing so far. The flags were exactly the same in both cases
(just --enable-debug and nothing else).
regards
Tomas
Attachment
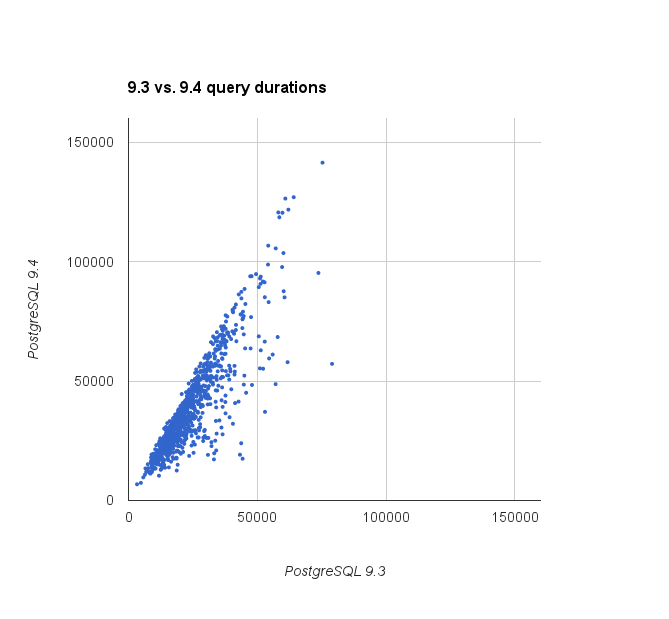{kind=link}
On 2014-01-26 07:24:58 +0100, Tomas Vondra wrote: > Not sure how to interpret that, though. For example where did the > ginCompareItemPointers go? I suspect it's thanks to inlining, and that > it might be related to the performance decrease. Or maybe not. Try recompiling with CFLAGS="-fno-omit-frame-pointers -O2" and then use perf record -g. That gives you a hierarchical profile which often makes such questions easier to answer. Greetings, Andres Freund -- Andres Freund http://www.2ndQuadrant.com/PostgreSQL Development, 24x7 Support, Training & Services
On 01/26/2014 08:24 AM, Tomas Vondra wrote:
> Hi!
>
> On 25.1.2014 22:21, Heikki Linnakangas wrote:
>> Attached is a new version of the patch set, with those bugs fixed.
>
> I've done a bunch of tests with all the 4 patches applied, and it seems
> to work now. I've done tests with various conditions (AND/OR, number of
> words, number of conditions) and I so far I did not get any crashes,
> infinite loops or anything like that.
>
> I've also compared the results to 9.3 - by dumping the database and
> running the same set of queries on both machines, and indeed I got 100%
> match.
>
> I also did some performance tests, and that's when I started to worry.
>
> For example, I generated and ran 1000 queries that look like this:
>
> SELECT id FROM messages
> WHERE body_tsvector @@ to_tsquery('english','(header & 53 & 32 &
> useful & dropped)')
> ORDER BY ts_rank(body_tsvector, to_tsquery('english','(header & 53 &
> 32 & useful & dropped)')) DESC;
>
> i.e. in this case the query always was 5 words connected by AND. This
> query is a pretty common pattern for fulltext search - sort by a list of
> words and give me the best ranked results.
>
> On 9.3, the script was running for ~23 seconds, on patched HEAD it was
> ~40. It's perfectly reproducible, I've repeated the test several times
> with exactly the same results. The test is CPU bound, there's no I/O
> activity at all. I got the same results with more queries (~100k).
>
> Attached is a simple chart with x-axis used for durations measured on
> 9.3.2, y-axis used for durations measured on patched HEAD. It's obvious
> a vast majority of queries is up to 2x slower - that's pretty obvious
> from the chart.
>
> Only about 50 queries are faster on HEAD, and >700 queries are more than
> 50% slower on HEAD (i.e. if the query took 100ms on 9.3, it takes >150ms
> on HEAD).
>
> Typically, the EXPLAIN ANALYZE looks something like this (on 9.3):
>
> http://explain.depesz.com/s/5tv
>
> and on HEAD (same query):
>
> http://explain.depesz.com/s/1lI
>
> Clearly the main difference is in the "Bitmap Index Scan" which takes
> 60ms on 9.3 and 120ms on HEAD.
>
> On 9.3 the "perf top" looks like this:
>
> 34.79% postgres [.] gingetbitmap
> 28.96% postgres [.] ginCompareItemPointers
> 9.36% postgres [.] TS_execute
> 5.36% postgres [.] check_stack_depth
> 3.57% postgres [.] FunctionCall8Coll
>
> while on 9.4 it looks like this:
>
> 28.20% postgres [.] gingetbitmap
> 21.17% postgres [.] TS_execute
> 8.08% postgres [.] check_stack_depth
> 7.11% postgres [.] FunctionCall8Coll
> 4.34% postgres [.] shimTriConsistentFn
>
> Not sure how to interpret that, though. For example where did the
> ginCompareItemPointers go? I suspect it's thanks to inlining, and that
> it might be related to the performance decrease. Or maybe not.
Yeah, inlining makes it disappear from the profile, and spreads that
time to the functions calling it.
The profile tells us that the consistent function is called a lot more
than before. That is expected - with the fast scan feature, we're
calling consistent not only for potential matches, but also to refute
TIDs based on just a few entries matching. If that's effective, it
allows us to skip many TIDs and avoid consistent calls, which
compensates, but if it's not effective, it's just overhead.
I would actually expect it to be fairly effective for that query, so
that's a bit surprising. I added counters to see where the calls are
coming from, and it seems that about 80% of the calls are actually
coming from this little the feature I explained earlier:
> In addition to that, I'm using the ternary consistent function to check
> if minItem is a match, even if we haven't loaded all the entries yet.
> That's less important, but I think for something like "rare1 | (rare2 &
> frequent)" it might be useful. It would allow us to skip fetching
> 'frequent', when we already know that 'rare1' matches for the current
> item. I'm not sure if that's worth the cycles, but it seemed like an
> obvious thing to do, now that we have the ternary consistent function.
So, that clearly isn't worth the cycles :-). At least not with an
expensive consistent function; it might be worthwhile if we pre-build
the truth-table, or cache the results of the consistent function.
Attached is a quick patch to remove that, on top of all the other
patches, if you want to test the effect.
- Heikki
Attachment
On 26.1.2014 17:14, Heikki Linnakangas wrote:
>
> I would actually expect it to be fairly effective for that query, so
> that's a bit surprising. I added counters to see where the calls are
> coming from, and it seems that about 80% of the calls are actually
> coming from this little the feature I explained earlier:
>
>> In addition to that, I'm using the ternary consistent function to check
>> if minItem is a match, even if we haven't loaded all the entries yet.
>> That's less important, but I think for something like "rare1 | (rare2 &
>> frequent)" it might be useful. It would allow us to skip fetching
>> 'frequent', when we already know that 'rare1' matches for the current
>> item. I'm not sure if that's worth the cycles, but it seemed like an
>> obvious thing to do, now that we have the ternary consistent function.
>
> So, that clearly isn't worth the cycles :-). At least not with an
> expensive consistent function; it might be worthwhile if we pre-build
> the truth-table, or cache the results of the consistent function.
>
> Attached is a quick patch to remove that, on top of all the other
> patches, if you want to test the effect.
Indeed, the patch significantly improved the performance. The total
runtime is almost exactly the same as on 9.3 (~22 seconds for 1000
queries). The timing chart (patched vs. 9.3) is attached.
A table with number of queries with duration ratio below some threshold
looks like this:
threshold | count | percentage
-------------------------------------
0.5 | 3 | 0.3%
0.75 | 45 | 4.5%
0.9 | 224 | 22.4%
1.0 | 667 | 66.7%
1.05 | 950 | 95.0%
1.1 | 992 | 99.2%
A ratio is just a measure of how much time it took compared to 9.3
ratio = (duration on patched HEAD) / (duration on 9.3)
The table is cumulative, e.g. values in the 0.9 row mean that for 224
queries the duration with the patches was below 90% of the duration on 9.3.
IMHO the table suggests with the last patch we're fine - majority of
queries (~66%) is faster than on 9.3, and the tail is very short. There
are just 2 queries that took more than 15% longer, compared to 9.3. And
we're talking about 20ms vs. 30ms, so chances are this is just a random
noise.
So IMHO we can go ahead, and maybe tune this a bit more in the future.
regards
Tomas
Attachment
{kind=link}
On Sun, Jan 26, 2014 at 8:14 PM, Heikki Linnakangas <hlinnakangas@vmware.com> wrote:
------
With best regards,
Alexander Korotkov.
Yeah, inlining makes it disappear from the profile, and spreads that time to the functions calling it.On 01/26/2014 08:24 AM, Tomas Vondra wrote:Hi!
On 25.1.2014 22:21, Heikki Linnakangas wrote:Attached is a new version of the patch set, with those bugs fixed.
I've done a bunch of tests with all the 4 patches applied, and it seems
to work now. I've done tests with various conditions (AND/OR, number of
words, number of conditions) and I so far I did not get any crashes,
infinite loops or anything like that.
I've also compared the results to 9.3 - by dumping the database and
running the same set of queries on both machines, and indeed I got 100%
match.
I also did some performance tests, and that's when I started to worry.
For example, I generated and ran 1000 queries that look like this:
SELECT id FROM messages
WHERE body_tsvector @@ to_tsquery('english','(header & 53 & 32 &
useful & dropped)')
ORDER BY ts_rank(body_tsvector, to_tsquery('english','(header & 53 &
32 & useful & dropped)')) DESC;
i.e. in this case the query always was 5 words connected by AND. This
query is a pretty common pattern for fulltext search - sort by a list of
words and give me the best ranked results.
On 9.3, the script was running for ~23 seconds, on patched HEAD it was
~40. It's perfectly reproducible, I've repeated the test several times
with exactly the same results. The test is CPU bound, there's no I/O
activity at all. I got the same results with more queries (~100k).
Attached is a simple chart with x-axis used for durations measured on
9.3.2, y-axis used for durations measured on patched HEAD. It's obvious
a vast majority of queries is up to 2x slower - that's pretty obvious
from the chart.
Only about 50 queries are faster on HEAD, and >700 queries are more than
50% slower on HEAD (i.e. if the query took 100ms on 9.3, it takes >150ms
on HEAD).
Typically, the EXPLAIN ANALYZE looks something like this (on 9.3):
http://explain.depesz.com/s/5tv
and on HEAD (same query):
http://explain.depesz.com/s/1lI
Clearly the main difference is in the "Bitmap Index Scan" which takes
60ms on 9.3 and 120ms on HEAD.
On 9.3 the "perf top" looks like this:
34.79% postgres [.] gingetbitmap
28.96% postgres [.] ginCompareItemPointers
9.36% postgres [.] TS_execute
5.36% postgres [.] check_stack_depth
3.57% postgres [.] FunctionCall8Coll
while on 9.4 it looks like this:
28.20% postgres [.] gingetbitmap
21.17% postgres [.] TS_execute
8.08% postgres [.] check_stack_depth
7.11% postgres [.] FunctionCall8Coll
4.34% postgres [.] shimTriConsistentFn
Not sure how to interpret that, though. For example where did the
ginCompareItemPointers go? I suspect it's thanks to inlining, and that
it might be related to the performance decrease. Or maybe not.
The profile tells us that the consistent function is called a lot more than before. That is expected - with the fast scan feature, we're calling consistent not only for potential matches, but also to refute TIDs based on just a few entries matching. If that's effective, it allows us to skip many TIDs and avoid consistent calls, which compensates, but if it's not effective, it's just overhead.
I would actually expect it to be fairly effective for that query, so that's a bit surprising. I added counters to see where the calls are coming from, and it seems that about 80% of the calls are actually coming from this little the feature I explained earlier:So, that clearly isn't worth the cycles :-). At least not with an expensive consistent function; it might be worthwhile if we pre-build the truth-table, or cache the results of the consistent function.In addition to that, I'm using the ternary consistent function to check
if minItem is a match, even if we haven't loaded all the entries yet.
That's less important, but I think for something like "rare1 | (rare2 &
frequent)" it might be useful. It would allow us to skip fetching
'frequent', when we already know that 'rare1' matches for the current
item. I'm not sure if that's worth the cycles, but it seemed like an
obvious thing to do, now that we have the ternary consistent function.
Attached is a quick patch to remove that, on top of all the other patches, if you want to test the effect.
Every single change you did in fast scan seems to be reasonable, but testing shows that something went wrong. Simple test with 3 words of different selectivities.
After applying your patches:
# select count(*) from fts_test where fti @@ plainto_tsquery('english', 'gin index select');
count
───────
627
(1 row)
Time: 21,252 ms
In original fast-scan:
# select count(*) from fts_test where fti @@ plainto_tsquery('english', 'gin index select');
count
───────
627
(1 row)
Time: 3,382 ms
I'm trying to get deeper into it.
With best regards,
Alexander Korotkov.
On Mon, Jan 27, 2014 at 2:32 PM, Alexander Korotkov <aekorotkov@gmail.com> wrote:
------
With best regards,
Alexander Korotkov.
On Sun, Jan 26, 2014 at 8:14 PM, Heikki Linnakangas <hlinnakangas@vmware.com> wrote:Yeah, inlining makes it disappear from the profile, and spreads that time to the functions calling it.On 01/26/2014 08:24 AM, Tomas Vondra wrote:Hi!
On 25.1.2014 22:21, Heikki Linnakangas wrote:Attached is a new version of the patch set, with those bugs fixed.
I've done a bunch of tests with all the 4 patches applied, and it seems
to work now. I've done tests with various conditions (AND/OR, number of
words, number of conditions) and I so far I did not get any crashes,
infinite loops or anything like that.
I've also compared the results to 9.3 - by dumping the database and
running the same set of queries on both machines, and indeed I got 100%
match.
I also did some performance tests, and that's when I started to worry.
For example, I generated and ran 1000 queries that look like this:
SELECT id FROM messages
WHERE body_tsvector @@ to_tsquery('english','(header & 53 & 32 &
useful & dropped)')
ORDER BY ts_rank(body_tsvector, to_tsquery('english','(header & 53 &
32 & useful & dropped)')) DESC;
i.e. in this case the query always was 5 words connected by AND. This
query is a pretty common pattern for fulltext search - sort by a list of
words and give me the best ranked results.
On 9.3, the script was running for ~23 seconds, on patched HEAD it was
~40. It's perfectly reproducible, I've repeated the test several times
with exactly the same results. The test is CPU bound, there's no I/O
activity at all. I got the same results with more queries (~100k).
Attached is a simple chart with x-axis used for durations measured on
9.3.2, y-axis used for durations measured on patched HEAD. It's obvious
a vast majority of queries is up to 2x slower - that's pretty obvious
from the chart.
Only about 50 queries are faster on HEAD, and >700 queries are more than
50% slower on HEAD (i.e. if the query took 100ms on 9.3, it takes >150ms
on HEAD).
Typically, the EXPLAIN ANALYZE looks something like this (on 9.3):
http://explain.depesz.com/s/5tv
and on HEAD (same query):
http://explain.depesz.com/s/1lI
Clearly the main difference is in the "Bitmap Index Scan" which takes
60ms on 9.3 and 120ms on HEAD.
On 9.3 the "perf top" looks like this:
34.79% postgres [.] gingetbitmap
28.96% postgres [.] ginCompareItemPointers
9.36% postgres [.] TS_execute
5.36% postgres [.] check_stack_depth
3.57% postgres [.] FunctionCall8Coll
while on 9.4 it looks like this:
28.20% postgres [.] gingetbitmap
21.17% postgres [.] TS_execute
8.08% postgres [.] check_stack_depth
7.11% postgres [.] FunctionCall8Coll
4.34% postgres [.] shimTriConsistentFn
Not sure how to interpret that, though. For example where did the
ginCompareItemPointers go? I suspect it's thanks to inlining, and that
it might be related to the performance decrease. Or maybe not.
The profile tells us that the consistent function is called a lot more than before. That is expected - with the fast scan feature, we're calling consistent not only for potential matches, but also to refute TIDs based on just a few entries matching. If that's effective, it allows us to skip many TIDs and avoid consistent calls, which compensates, but if it's not effective, it's just overhead.
I would actually expect it to be fairly effective for that query, so that's a bit surprising. I added counters to see where the calls are coming from, and it seems that about 80% of the calls are actually coming from this little the feature I explained earlier:So, that clearly isn't worth the cycles :-). At least not with an expensive consistent function; it might be worthwhile if we pre-build the truth-table, or cache the results of the consistent function.In addition to that, I'm using the ternary consistent function to check
if minItem is a match, even if we haven't loaded all the entries yet.
That's less important, but I think for something like "rare1 | (rare2 &
frequent)" it might be useful. It would allow us to skip fetching
'frequent', when we already know that 'rare1' matches for the current
item. I'm not sure if that's worth the cycles, but it seemed like an
obvious thing to do, now that we have the ternary consistent function.
Attached is a quick patch to remove that, on top of all the other patches, if you want to test the effect.Every single change you did in fast scan seems to be reasonable, but testing shows that something went wrong. Simple test with 3 words of different selectivities.After applying your patches:# select count(*) from fts_test where fti @@ plainto_tsquery('english', 'gin index select');count───────627(1 row)Time: 21,252 msIn original fast-scan:# select count(*) from fts_test where fti @@ plainto_tsquery('english', 'gin index select');count───────627(1 row)Time: 3,382 msI'm trying to get deeper into it.
I had two guesses about why it's become so slower than in my original fast-scan:
1) Not using native consistent function
2) Not sorting entries
I attach two patches which rollback these two features (sorry for awful quality of second). Native consistent function accelerates thing significantly, as expected. Tt seems that sorting entries have almost no effect. However it's still not as fast as initial fast-scan:
# select count(*) from fts_test where fti @@ plainto_tsquery('english', 'gin index select');
count
───────
627
(1 row)
Time: 5,381 ms
Tomas, could you rerun your tests with first and both these patches applied against patches by Heikki?
With best regards,
Alexander Korotkov.
Attachment
On Sun, Jan 26, 2014 at 8:14 PM, Heikki Linnakangas <hlinnakangas@vmware.com> wrote:
------
With best regards,
Alexander Korotkov.
So, that clearly isn't worth the cycles :-). At least not with an expensive consistent function; it might be worthwhile if we pre-build the truth-table, or cache the results of the consistent function.In addition to that, I'm using the ternary consistent function to check
if minItem is a match, even if we haven't loaded all the entries yet.
That's less important, but I think for something like "rare1 | (rare2 &
frequent)" it might be useful. It would allow us to skip fetching
'frequent', when we already know that 'rare1' matches for the current
item. I'm not sure if that's worth the cycles, but it seemed like an
obvious thing to do, now that we have the ternary consistent function.
I believe cache consistent function results is quite same as lazy truth-table. I think it's a good option to use with two-state consistent function. However, I don't think it's a reason to refuse from three-state consistent function because number of entries could be large.
With best regards,
Alexander Korotkov.
On 27.1.2014 16:30, Alexander Korotkov wrote:
> On Mon, Jan 27, 2014 at 2:32 PM, Alexander Korotkov
> <aekorotkov@gmail.com <mailto:aekorotkov@gmail.com>> wrote:
>
> I attach two patches which rollback these two features (sorry for awful
> quality of second). Native consistent function accelerates thing
> significantly, as expected. Tt seems that sorting entries have almost no
> effect. However it's still not as fast as initial fast-scan:
>
> # select count(*) from fts_test where fti @@ plainto_tsquery('english',
> 'gin index select');
> count
> ───────
> 627
> (1 row)
>
> Time: 5,381 ms
>
> Tomas, could you rerun your tests with first and both these patches
> applied against patches by Heikki?
Done, and the results are somewhat disappointing.
I've generated 1000 queries with either 3 or 6 words, based on how often
they occur in the documents. For example 1% means there's 1% of
documents containing the word. In this case, I've used ranges 0-2%, 1-3%
and 3-9%.
Which gives six combinations
| 0-2% | 1-3% | 3-9% |
--------------------------------
3 words | | | |
--------------------------------
6 words | | | |
--------------------------------
Each word had ~5% probability to be negated (i.e. "!" in front of it).
So these queries are a bit different than the ones I ran yesterday.
Then I ran those scripts on:
* 9.3
* 9.4 with Heikki's patches (9.4-heikki)
* 9.4 with Heikki's and first patch (9.4-alex-1)
* 9.4 with Heikki's and both patches (9.4-alex-2)
I've always created a new DB, loaded the data, done VACUUM (FREEZE,
ANALYZE) and then ran the script 5x but only measured the fifth run.
The full results are available here (and attached as ODT, but just the
numbers without the charts)
https://docs.google.com/spreadsheet/ccc?key=0Alm8ruV3ChcgdHJfZTdOY2JBSlkwZjNuWGlIaGM0REE
On all the charts the x-axis is "how long it took without the patch" and
y-axis means "how much longer it took with the patch". 1 means exactly
the same, >1 slower, <1 faster. Sometimes one (or both) of the axes is
log-scale. The durations are in microseconds (i.e. 1e-6 sec).
I'll analyze the results for 3-words first.
The Heikki's patch seems fine, at least compared to 9.3. See for example
the heikki-vs-9.3.png image. This is the case with 3 words, each
contained in less than 2% of documents (i.e. rare words). Vast majority
of the queries is much faster, and the ~1.0 results are below 1
milisecond, which is somewhat tricky to measure.
Now, see alexander-1.png / alexander-2.png, for one / both of the
patches, compared to results with Heikki's patches. Not really good,
IMHO, especially for the first patch - most of the queries is much
slower, even by an order of magnitude. The second patch fixes the worst
cases, but does not really make it better than 9.4-heikki.
It however gets better as the words become more common. See for example
alexander-common-words.png - which once again compares 9.4-alex-1 vs.
9.4-heikki on 3 words in the 3-9% range. This time the performance is
rather consistently better.
On 6 words the results are similar, i.e bad with rare words but getting
better on the more common ones. Except that in this case it never gets
better than 9.4-heikki.
I can provide the queries but without the dataset I'm testing this on,
that's pretty useless. I'll try to analyze this a bit more later today,
but I'm afraid I don't have the necessary insight.
regards
Tomas
Attachment
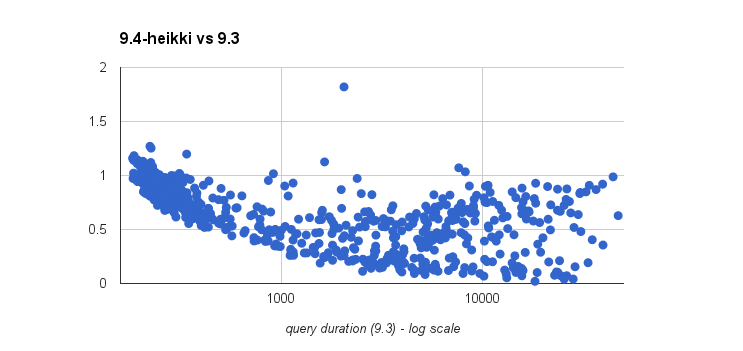{kind=link}
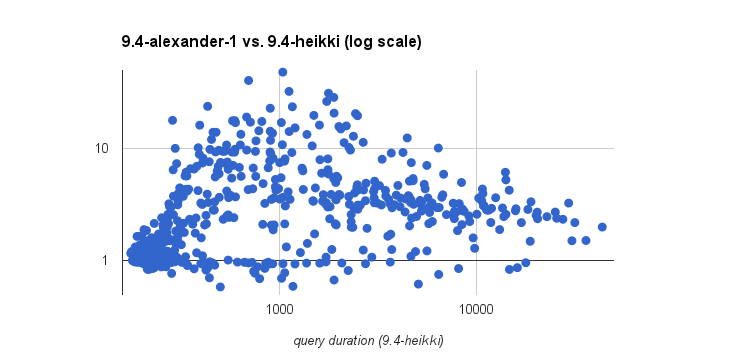{kind=link}
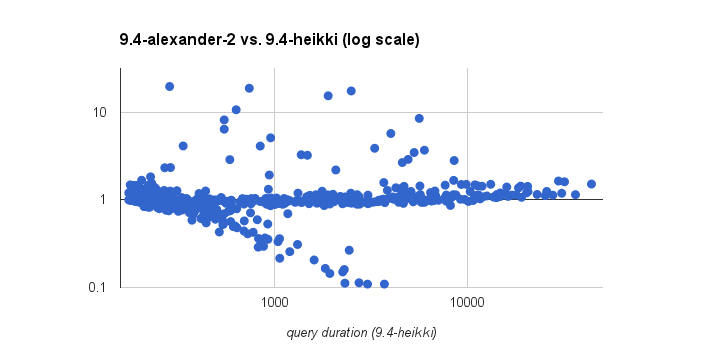{kind=link}
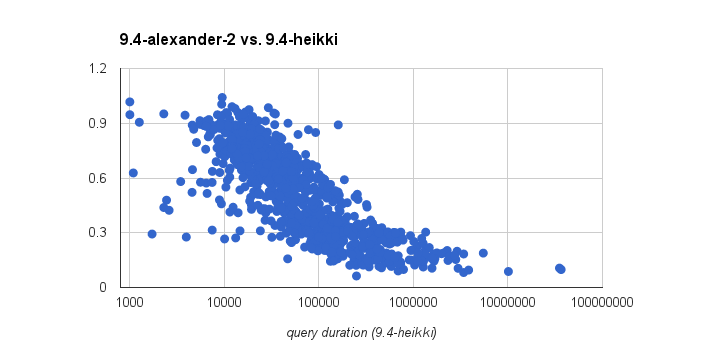{kind=link}
On 01/28/2014 05:54 AM, Tomas Vondra wrote: > Then I ran those scripts on: > > * 9.3 > * 9.4 with Heikki's patches (9.4-heikki) > * 9.4 with Heikki's and first patch (9.4-alex-1) > * 9.4 with Heikki's and both patches (9.4-alex-2) It would be good to also test with unpatched 9.4 (ie. git master). The packed posting lists patch might account for a large part of the differences between 9.3 and the patched 9.4 versions. - Heikki
On 28.1.2014 08:29, Heikki Linnakangas wrote: > On 01/28/2014 05:54 AM, Tomas Vondra wrote: >> Then I ran those scripts on: >> >> * 9.3 >> * 9.4 with Heikki's patches (9.4-heikki) >> * 9.4 with Heikki's and first patch (9.4-alex-1) >> * 9.4 with Heikki's and both patches (9.4-alex-2) > > It would be good to also test with unpatched 9.4 (ie. git master). The > packed posting lists patch might account for a large part of the > differences between 9.3 and the patched 9.4 versions. > > - Heikki > Hi, the e-mail I sent yesterday apparently did not make it into the list, probably because of the attachments, so I'll just link them this time. I added the results from 9.4 master to the spreadsheet: https://docs.google.com/spreadsheet/ccc?key=0Alm8ruV3ChcgdHJfZTdOY2JBSlkwZjNuWGlIaGM0REE It's a bit cumbersome to analyze though, so I've quickly hacked up a simple jqplot page that allows comparing the results. It's available here: http://www.fuzzy.cz/tmp/gin/ It's likely there are some quirks and issues - let me know about them. The ODT with the data is available here: http://www.fuzzy.cz/tmp/gin/gin-scan-benchmarks.ods Three quick basic observations: (1) The current 9.4 master is consistently better than 9.3 by about 15% on rare words, and up to 30% on common words. Seethe charts for 6-word queries: http://www.fuzzy.cz/tmp/gin/6-words-rare-94-vs-93.png http://www.fuzzy.cz/tmp/gin/6-words-rare-94-vs-93.png With 3-word queries the effects are even stronger & clearer, especially with the common words. (2) Heikki's patches seem to work OK, i.e. improve the performance, but only with rare words. http://www.fuzzy.cz/tmp/gin/heikki-vs-94-rare.png With 3 words the impact is much stronger than with 6 words, presumably because it depends on how frequent the combinationof words is (~ multiplication of probabilities). See http://www.fuzzy.cz/tmp/gin/heikki-vs-94-3-common-words.png http://www.fuzzy.cz/tmp/gin/heikki-vs-94-6-common-words.png for comparison of 9.4 master vs. 9.4+heikki's patches. (3) A file with explain plans for 4 queries suffering ~2x slowdown, and explain plans with 9.4 master and Heikki's patchesis available here: http://www.fuzzy.cz/tmp/gin/queries.txt All the queries have 6 common words, and the explain plans look just fine to me - exactly like the plans for other queries. Two things now caught my eye. First some of these queries actually have words repeated - either exactly like "database& database" or in negated form like "!anything & anything". Second, while generating the queries, I use "dumb"frequency, where only exact matches count. I.e. "write != written" etc. But the actual number of hits may be muchhigher - for example "write" matches exactly just 5% documents, but using @@ it matches more than 20%. I don't know if that's the actual cause though. regards Tomas
{kind=link}
{kind=link}
{kind=link}
{kind=link}
On 01/30/2014 01:53 AM, Tomas Vondra wrote: > (3) A file with explain plans for 4 queries suffering ~2x slowdown, > and explain plans with 9.4 master and Heikki's patches is available > here: > > http://www.fuzzy.cz/tmp/gin/queries.txt > > All the queries have 6 common words, and the explain plans look > just fine to me - exactly like the plans for other queries. > > Two things now caught my eye. First some of these queries actually > have words repeated - either exactly like "database & database" or > in negated form like "!anything & anything". Second, while > generating the queries, I use "dumb" frequency, where only exact > matches count. I.e. "write != written" etc. But the actual number > of hits may be much higher - for example "write" matches exactly > just 5% documents, but using @@ it matches more than 20%. > > I don't know if that's the actual cause though. I tried these queries with the data set you posted here: http://www.postgresql.org/message-id/52E4141E.60609@fuzzy.cz. The reason for the slowdown is the extra consistent calls it causes. That's expected - the patch certainly does call consistent in situations where it didn't before, and if the "pre-consistent" checks are not able to eliminate many tuples, you lose. So, what can we do to mitigate that? Some ideas: 1. Implement the catalog changes from Alexander's patch. That ought to remove the overhead, as you only need to call the consistent function once, not "both ways". OTOH, currently we only call the consistent function if there is only one unknown column. If with the catalog changes, we always call the consistent function even if there are more unknown columns, we might end up calling it even more often. 2. Cache the result of the consistent function. 3. Make the consistent function cheaper. (How? Magic?) 4. Use some kind of a heuristic, and stop doing the pre-consistent checks if they're not effective. Not sure what the heuristic would look like. The caching we could easily do. It's very simple and very effective, as long as the number of number of entries is limited. The amount of space required to cache all combinations grows exponentially, so it's only feasible for up to 10 or so entries. - Heikki
On 01/30/2014 01:53 AM, Tomas Vondra wrote: > (3) A file with explain plans for 4 queries suffering ~2x slowdown, > and explain plans with 9.4 master and Heikki's patches is available > here: > > http://www.fuzzy.cz/tmp/gin/queries.txt > > All the queries have 6 common words, and the explain plans look > just fine to me - exactly like the plans for other queries. > > Two things now caught my eye. First some of these queries actually > have words repeated - either exactly like "database & database" or > in negated form like "!anything & anything". Second, while > generating the queries, I use "dumb" frequency, where only exact > matches count. I.e. "write != written" etc. But the actual number > of hits may be much higher - for example "write" matches exactly > just 5% documents, but using @@ it matches more than 20%. > > I don't know if that's the actual cause though. Ok, here's another variant of these patches. Compared to git master, it does three things: 1. It adds the concept of ternary consistent function internally, but no catalog changes. It's implemented by calling the regular boolean consistent function "both ways". 2. Use a binary heap to get the "next" item from the entries in a scan. I'm pretty sure this makes sense, because arguably it makes the code more readable, and reduces the number of item pointer comparisons significantly for queries with a lot of entries. 3. Only perform the pre-consistent check to try skipping entries, if we don't already have the next item from the entry loaded in the array. This is a tradeoff, you will lose some of the performance gain you might get from pre-consistent checks, but it also limits the performance loss you might get from doing useless pre-consistent checks. So taken together, I would expect this patch to make some of the performance gains less impressive, but also limit the loss we saw with some of the other patches. Tomas, could you run your test suite with this patch, please? - Heikki
Attachment
On 2.2.2014 11:45, Heikki Linnakangas wrote: > On 01/30/2014 01:53 AM, Tomas Vondra wrote: >> (3) A file with explain plans for 4 queries suffering ~2x slowdown, >> and explain plans with 9.4 master and Heikki's patches is available >> here: >> >> http://www.fuzzy.cz/tmp/gin/queries.txt >> >> All the queries have 6 common words, and the explain plans look >> just fine to me - exactly like the plans for other queries. >> >> Two things now caught my eye. First some of these queries actually >> have words repeated - either exactly like "database & database" or >> in negated form like "!anything & anything". Second, while >> generating the queries, I use "dumb" frequency, where only exact >> matches count. I.e. "write != written" etc. But the actual number >> of hits may be much higher - for example "write" matches exactly >> just 5% documents, but using @@ it matches more than 20%. >> >> I don't know if that's the actual cause though. > > Ok, here's another variant of these patches. Compared to git master, it > does three things: > > 1. It adds the concept of ternary consistent function internally, but no > catalog changes. It's implemented by calling the regular boolean > consistent function "both ways". > > 2. Use a binary heap to get the "next" item from the entries in a scan. > I'm pretty sure this makes sense, because arguably it makes the code > more readable, and reduces the number of item pointer comparisons > significantly for queries with a lot of entries. > > 3. Only perform the pre-consistent check to try skipping entries, if we > don't already have the next item from the entry loaded in the array. > This is a tradeoff, you will lose some of the performance gain you might > get from pre-consistent checks, but it also limits the performance loss > you might get from doing useless pre-consistent checks. > > So taken together, I would expect this patch to make some of the > performance gains less impressive, but also limit the loss we saw with > some of the other patches. > > Tomas, could you run your test suite with this patch, please? Sure, will do. Do I get it right that this should be applied instead of the four patches you've posted earlier? Tomas
On 3.2.2014 00:13, Tomas Vondra wrote: > On 2.2.2014 11:45, Heikki Linnakangas wrote: >> On 01/30/2014 01:53 AM, Tomas Vondra wrote: >>> (3) A file with explain plans for 4 queries suffering ~2x slowdown, >>> and explain plans with 9.4 master and Heikki's patches is available >>> here: >>> >>> http://www.fuzzy.cz/tmp/gin/queries.txt >>> >>> All the queries have 6 common words, and the explain plans look >>> just fine to me - exactly like the plans for other queries. >>> >>> Two things now caught my eye. First some of these queries actually >>> have words repeated - either exactly like "database & database" or >>> in negated form like "!anything & anything". Second, while >>> generating the queries, I use "dumb" frequency, where only exact >>> matches count. I.e. "write != written" etc. But the actual number >>> of hits may be much higher - for example "write" matches exactly >>> just 5% documents, but using @@ it matches more than 20%. >>> >>> I don't know if that's the actual cause though. >> >> Ok, here's another variant of these patches. Compared to git master, it >> does three things: >> >> 1. It adds the concept of ternary consistent function internally, but no >> catalog changes. It's implemented by calling the regular boolean >> consistent function "both ways". >> >> 2. Use a binary heap to get the "next" item from the entries in a scan. >> I'm pretty sure this makes sense, because arguably it makes the code >> more readable, and reduces the number of item pointer comparisons >> significantly for queries with a lot of entries. >> >> 3. Only perform the pre-consistent check to try skipping entries, if we >> don't already have the next item from the entry loaded in the array. >> This is a tradeoff, you will lose some of the performance gain you might >> get from pre-consistent checks, but it also limits the performance loss >> you might get from doing useless pre-consistent checks. >> >> So taken together, I would expect this patch to make some of the >> performance gains less impressive, but also limit the loss we saw with >> some of the other patches. >> >> Tomas, could you run your test suite with this patch, please? > > Sure, will do. Do I get it right that this should be applied instead of > the four patches you've posted earlier? So, I was curious and did a basic testing - I've repeated the tests on current HEAD and 'HEAD with the new patch'. The complete data are available at [http://www.fuzzy.cz/tmp/gin/gin-scan-benchmarks.ods] and I've updated the charts at [http://www.fuzzy.cz/tmp/gin/] too. Look for branches named 9.4-head-2 and 9.4-heikki-2. To me it seems that: (1) The main issue was that with common words, it used to be much slower than HEAD (or 9.3). This seems to be fixed, i.e. it's not slower than before. See http://www.fuzzy.cz/tmp/gin/3-common-words.png (previous patch) http://www.fuzzy.cz/tmp/gin/3-common-words-new.png (new patch) for comparison vs. 9.4 HEAD. With the new patch there's no slowdown, which seems nice. Compared to 9.3 it looks like this: http://www.fuzzy.cz/tmp/gin/3-common-words-new-vs-93.png so there's a significant speedup (thanks to the modified layout). (2) The question is whether the new patch works fine on rare words. See this for comparison of the patches against HEAD: http://www.fuzzy.cz/tmp/gin/3-rare-words.png http://www.fuzzy.cz/tmp/gin/3-rare-words-new.png and this is the comparison of the two patches: http://www.fuzzy.cz/tmp/gin/patches-rare-words.png That seems fine to me - some queries are slower, but we're talking about queries taking 1 or 2 ms, so the measurement error is probably the main cause of the differences. (3) With higher numbers of frequent words, the differences (vs. HEAD or the previous patch) are not that dramatic as in (1) - the new patch is consistently by ~20% faster. Tomas
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Attachment
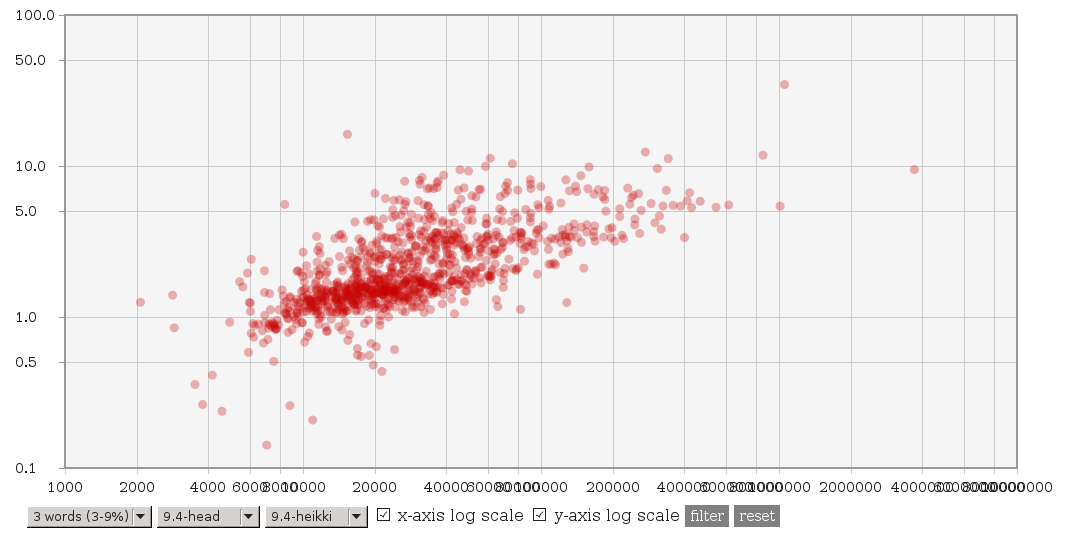{kind=link}
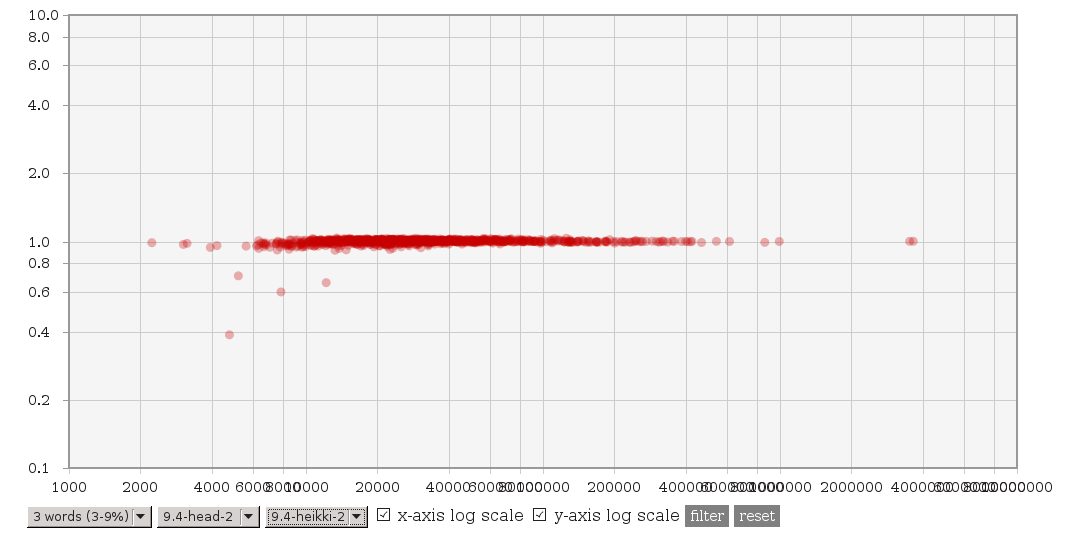{kind=link}
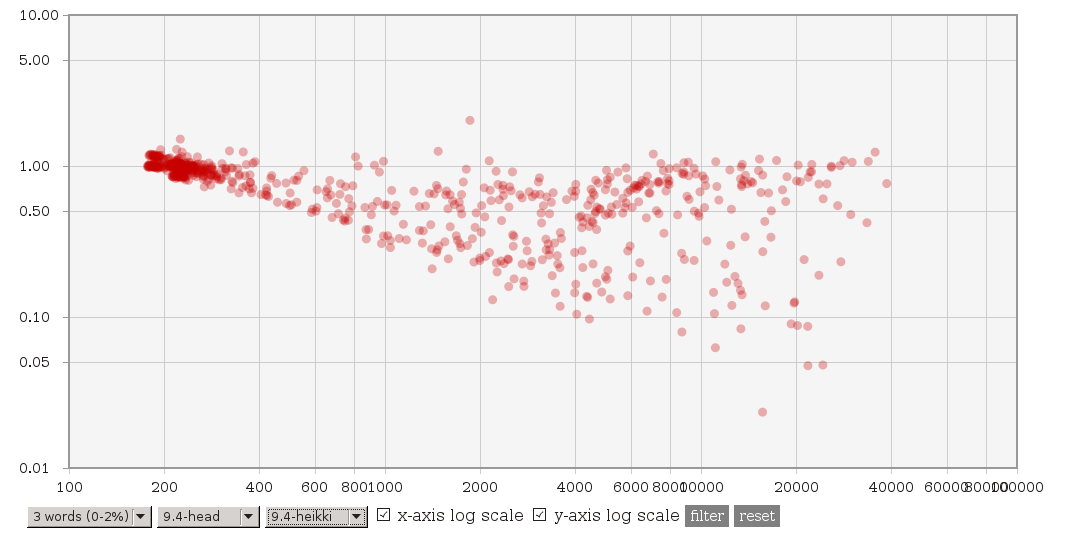{kind=link}
{kind=link}
{kind=link}
{kind=link}
Tomasa, it'd be nice if you use real data in your testing. One very good application of gin fast-scan is dramatic performance improvement of hstore/jsonb @> operator, see slides 57, 58 http://www.sai.msu.su/~megera/postgres/talks/hstore-dublin-2013.pdf. I'd like not to lost this benefit :) Oleg PS. I used data delicious-rss-1250k.gz from http://randomwalker.info/data/delicious/ On Mon, Feb 3, 2014 at 5:44 AM, Tomas Vondra <tv@fuzzy.cz> wrote: > On 3.2.2014 00:13, Tomas Vondra wrote: >> On 2.2.2014 11:45, Heikki Linnakangas wrote: >>> On 01/30/2014 01:53 AM, Tomas Vondra wrote: >>>> (3) A file with explain plans for 4 queries suffering ~2x slowdown, >>>> and explain plans with 9.4 master and Heikki's patches is available >>>> here: >>>> >>>> http://www.fuzzy.cz/tmp/gin/queries.txt >>>> >>>> All the queries have 6 common words, and the explain plans look >>>> just fine to me - exactly like the plans for other queries. >>>> >>>> Two things now caught my eye. First some of these queries actually >>>> have words repeated - either exactly like "database & database" or >>>> in negated form like "!anything & anything". Second, while >>>> generating the queries, I use "dumb" frequency, where only exact >>>> matches count. I.e. "write != written" etc. But the actual number >>>> of hits may be much higher - for example "write" matches exactly >>>> just 5% documents, but using @@ it matches more than 20%. >>>> >>>> I don't know if that's the actual cause though. >>> >>> Ok, here's another variant of these patches. Compared to git master, it >>> does three things: >>> >>> 1. It adds the concept of ternary consistent function internally, but no >>> catalog changes. It's implemented by calling the regular boolean >>> consistent function "both ways". >>> >>> 2. Use a binary heap to get the "next" item from the entries in a scan. >>> I'm pretty sure this makes sense, because arguably it makes the code >>> more readable, and reduces the number of item pointer comparisons >>> significantly for queries with a lot of entries. >>> >>> 3. Only perform the pre-consistent check to try skipping entries, if we >>> don't already have the next item from the entry loaded in the array. >>> This is a tradeoff, you will lose some of the performance gain you might >>> get from pre-consistent checks, but it also limits the performance loss >>> you might get from doing useless pre-consistent checks. >>> >>> So taken together, I would expect this patch to make some of the >>> performance gains less impressive, but also limit the loss we saw with >>> some of the other patches. >>> >>> Tomas, could you run your test suite with this patch, please? >> >> Sure, will do. Do I get it right that this should be applied instead of >> the four patches you've posted earlier? > > So, I was curious and did a basic testing - I've repeated the tests on > current HEAD and 'HEAD with the new patch'. The complete data are > available at [http://www.fuzzy.cz/tmp/gin/gin-scan-benchmarks.ods] and > I've updated the charts at [http://www.fuzzy.cz/tmp/gin/] too. > > Look for branches named 9.4-head-2 and 9.4-heikki-2. > > To me it seems that: > > (1) The main issue was that with common words, it used to be much > slower than HEAD (or 9.3). This seems to be fixed, i.e. it's not > slower than before. See > > http://www.fuzzy.cz/tmp/gin/3-common-words.png (previous patch) > http://www.fuzzy.cz/tmp/gin/3-common-words-new.png (new patch) > > for comparison vs. 9.4 HEAD. With the new patch there's no slowdown, > which seems nice. Compared to 9.3 it looks like this: > > http://www.fuzzy.cz/tmp/gin/3-common-words-new-vs-93.png > > so there's a significant speedup (thanks to the modified layout). > > (2) The question is whether the new patch works fine on rare words. See > this for comparison of the patches against HEAD: > > http://www.fuzzy.cz/tmp/gin/3-rare-words.png > http://www.fuzzy.cz/tmp/gin/3-rare-words-new.png > > and this is the comparison of the two patches: > > http://www.fuzzy.cz/tmp/gin/patches-rare-words.png > > That seems fine to me - some queries are slower, but we're talking > about queries taking 1 or 2 ms, so the measurement error is probably > the main cause of the differences. > > (3) With higher numbers of frequent words, the differences (vs. HEAD or > the previous patch) are not that dramatic as in (1) - the new patch > is consistently by ~20% faster. > > Tomas > > > -- > Sent via pgsql-hackers mailing list (pgsql-hackers@postgresql.org) > To make changes to your subscription: > http://www.postgresql.org/mailpref/pgsql-hackers >
Hi Oleg, On 3 Únor 2014, 7:53, Oleg Bartunov wrote: > Tomasa, it'd be nice if you use real data in your testing. I'm using a mailing list archive (the benchmark is essentially a simple search engine on top of the archive, implemented using built-in full-text). So I think this is a quite 'real' dataset, not something synthetic. The queries are generated, of course, but I strived to make them as real as possible. Sure, this is not a hstore-centric benchmark, but the thread is about GIN indexes, so I think it's fair. > One very good application of gin fast-scan is dramatic performance > improvement of hstore/jsonb @> operator, see slides 57, 58 > http://www.sai.msu.su/~megera/postgres/talks/hstore-dublin-2013.pdf. > I'd like not to lost this benefit :) Yes, that's something we could/should test, probably. Sadly I don't have a dataset or a complete real-world test case at hand. Any ideas? I certainly agree that it'd be very sad to lose the performance gain for hstore/json. OTOH my fear is that to achieve that gain, we'll noticeably slow down other important use cases (e.g. full-text search), which is one of the reasons why I was doing the tests. regards Tomas
On 03/02/14 02:44, Tomas Vondra wrote: > (2) The question is whether the new patch works fine on rare words. See > this for comparison of the patches against HEAD: > > http://www.fuzzy.cz/tmp/gin/3-rare-words.png > http://www.fuzzy.cz/tmp/gin/3-rare-words-new.png > > and this is the comparison of the two patches: > > http://www.fuzzy.cz/tmp/gin/patches-rare-words.png > > That seems fine to me - some queries are slower, but we're talking > about queries taking 1 or 2 ms, so the measurement error is probably > the main cause of the differences. > > (3) With higher numbers of frequent words, the differences (vs. HEAD or > the previous patch) are not that dramatic as in (1) - the new patch > is consistently by ~20% faster. Just thinking, this is about one algorithm is being better or frequent words and another algorithm being better at rare words... we do have this information (at least or tsvector) in the statistics, would it be possible to just call the "consistent" function more often if the statistics gives signs that it actually is a frequent word? Jesper - heavily dependent on tsvector-searches, with both frequent and rare words.
On Mon, Jan 27, 2014 at 7:30 PM, Alexander Korotkov <aekorotkov@gmail.com> wrote:
------
With best regards,
Alexander Korotkov.
On Mon, Jan 27, 2014 at 2:32 PM, Alexander Korotkov <aekorotkov@gmail.com> wrote:On Sun, Jan 26, 2014 at 8:14 PM, Heikki Linnakangas <hlinnakangas@vmware.com> wrote:Yeah, inlining makes it disappear from the profile, and spreads that time to the functions calling it.On 01/26/2014 08:24 AM, Tomas Vondra wrote:Hi!
On 25.1.2014 22:21, Heikki Linnakangas wrote:Attached is a new version of the patch set, with those bugs fixed.
I've done a bunch of tests with all the 4 patches applied, and it seems
to work now. I've done tests with various conditions (AND/OR, number of
words, number of conditions) and I so far I did not get any crashes,
infinite loops or anything like that.
I've also compared the results to 9.3 - by dumping the database and
running the same set of queries on both machines, and indeed I got 100%
match.
I also did some performance tests, and that's when I started to worry.
For example, I generated and ran 1000 queries that look like this:
SELECT id FROM messages
WHERE body_tsvector @@ to_tsquery('english','(header & 53 & 32 &
useful & dropped)')
ORDER BY ts_rank(body_tsvector, to_tsquery('english','(header & 53 &
32 & useful & dropped)')) DESC;
i.e. in this case the query always was 5 words connected by AND. This
query is a pretty common pattern for fulltext search - sort by a list of
words and give me the best ranked results.
On 9.3, the script was running for ~23 seconds, on patched HEAD it was
~40. It's perfectly reproducible, I've repeated the test several times
with exactly the same results. The test is CPU bound, there's no I/O
activity at all. I got the same results with more queries (~100k).
Attached is a simple chart with x-axis used for durations measured on
9.3.2, y-axis used for durations measured on patched HEAD. It's obvious
a vast majority of queries is up to 2x slower - that's pretty obvious
from the chart.
Only about 50 queries are faster on HEAD, and >700 queries are more than
50% slower on HEAD (i.e. if the query took 100ms on 9.3, it takes >150ms
on HEAD).
Typically, the EXPLAIN ANALYZE looks something like this (on 9.3):
http://explain.depesz.com/s/5tv
and on HEAD (same query):
http://explain.depesz.com/s/1lI
Clearly the main difference is in the "Bitmap Index Scan" which takes
60ms on 9.3 and 120ms on HEAD.
On 9.3 the "perf top" looks like this:
34.79% postgres [.] gingetbitmap
28.96% postgres [.] ginCompareItemPointers
9.36% postgres [.] TS_execute
5.36% postgres [.] check_stack_depth
3.57% postgres [.] FunctionCall8Coll
while on 9.4 it looks like this:
28.20% postgres [.] gingetbitmap
21.17% postgres [.] TS_execute
8.08% postgres [.] check_stack_depth
7.11% postgres [.] FunctionCall8Coll
4.34% postgres [.] shimTriConsistentFn
Not sure how to interpret that, though. For example where did the
ginCompareItemPointers go? I suspect it's thanks to inlining, and that
it might be related to the performance decrease. Or maybe not.
The profile tells us that the consistent function is called a lot more than before. That is expected - with the fast scan feature, we're calling consistent not only for potential matches, but also to refute TIDs based on just a few entries matching. If that's effective, it allows us to skip many TIDs and avoid consistent calls, which compensates, but if it's not effective, it's just overhead.
I would actually expect it to be fairly effective for that query, so that's a bit surprising. I added counters to see where the calls are coming from, and it seems that about 80% of the calls are actually coming from this little the feature I explained earlier:So, that clearly isn't worth the cycles :-). At least not with an expensive consistent function; it might be worthwhile if we pre-build the truth-table, or cache the results of the consistent function.In addition to that, I'm using the ternary consistent function to check
if minItem is a match, even if we haven't loaded all the entries yet.
That's less important, but I think for something like "rare1 | (rare2 &
frequent)" it might be useful. It would allow us to skip fetching
'frequent', when we already know that 'rare1' matches for the current
item. I'm not sure if that's worth the cycles, but it seemed like an
obvious thing to do, now that we have the ternary consistent function.
Attached is a quick patch to remove that, on top of all the other patches, if you want to test the effect.Every single change you did in fast scan seems to be reasonable, but testing shows that something went wrong. Simple test with 3 words of different selectivities.After applying your patches:# select count(*) from fts_test where fti @@ plainto_tsquery('english', 'gin index select');count───────627(1 row)Time: 21,252 msIn original fast-scan:# select count(*) from fts_test where fti @@ plainto_tsquery('english', 'gin index select');count───────627(1 row)Time: 3,382 msI'm trying to get deeper into it.I had two guesses about why it's become so slower than in my original fast-scan:1) Not using native consistent function2) Not sorting entriesI attach two patches which rollback these two features (sorry for awful quality of second). Native consistent function accelerates thing significantly, as expected. Tt seems that sorting entries have almost no effect. However it's still not as fast as initial fast-scan:# select count(*) from fts_test where fti @@ plainto_tsquery('english', 'gin index select');count───────627(1 row)Time: 5,381 msTomas, could you rerun your tests with first and both these patches applied against patches by Heikki?
I found my patch "0005-Ternary-consistent-implementation.patch" to be completely wrong. It introduces ternary consistent function to opclass, but don't uses it, because I forgot to include ginlogic.c change into patch. So, it shouldn't make any impact on performance. However, testing results with that patch significantly differs. That makes me very uneasy. Can we now reproduce exact same?
Right version of these two patches in one against current head is attached. I've rerun tests with it, results are /mnt/sas-raid10/gin-testing/queries/9.4-fast-scan-10. Could you rerun postprocessing including graph drawing?
Sometimes test cases are not what we expect. For example:
=# explain SELECT id FROM messages WHERE body_tsvector @@ to_tsquery('english','(5alpha1-initdb''d)');
QUERY PLAN
─────────────────────────────────────────────────────────────────────────────────────────────────────────
Bitmap Heap Scan on messages (cost=84.00..88.01 rows=1 width=4)
Recheck Cond: (body_tsvector @@ '''5alpha1-initdb'' & ''5alpha1'' & ''initdb'' & ''d'''::tsquery)
-> Bitmap Index Scan on messages_body_tsvector_idx (cost=0.00..84.00 rows=1 width=0)
Index Cond: (body_tsvector @@ '''5alpha1-initdb'' & ''5alpha1'' & ''initdb'' & ''d'''::tsquery)
Planning time: 0.257 ms
(5 rows)
5alpha1-initdb'd is 3 gin entries with different frequencies.
Also, these patches are not intended to change relevance ordering speed. When number of results are high, most of time is relevance calculating and sorting. I propose to remove ORDER BY clause from test cases to see scan speed more clear.
I've dump of postgresql.org search queries from Magnus. We can add them to our test case.
With best regards,
Alexander Korotkov.
Attachment
Hi Alexander,
On 3 Únor 2014, 15:31, Alexander Korotkov wrote:
>
> I found my patch "0005-Ternary-consistent-implementation.patch" to be
> completely wrong. It introduces ternary consistent function to opclass,
> but
> don't uses it, because I forgot to include ginlogic.c change into patch.
> So, it shouldn't make any impact on performance. However, testing results
> with that patch significantly differs. That makes me very uneasy. Can we
> now reproduce exact same?
Do I understand it correctly that the 0005 patch should give exactly the
same performance as the 9.4-heikki branch (as it was applied on it, and
effectively did no change). This wasn't exactly what I measured, although
the differences were not that significant.
I can rerun the tests, if that's what you're asking for. I'll improve the
test a bit - e.g. I plan to average multiple runs, to filter out random
noise (which might be significant for such short queries).
> Right version of these two patches in one against current head is
> attached.
> I've rerun tests with it, results are
> /mnt/sas-raid10/gin-testing/queries/9.4-fast-scan-10. Could you rerun
> postprocessing including graph drawing?
Yes, I'll do that. However I'll have to rerun the other tests too, because
the
previous runs were done on a different machine.
I'm a bit confused right now. The previous patches (0005 + 0007) were
supposed
to be applied on top of the 4 from Heikki (0001-0004), right? AFAIK those
were
not commited yet, so why is this version against HEAD?
To summarize, I know of these patch sets:
9.4-heikki (old version) 0001-Optimize-GIN-multi-key-queries.patch
0002-Further-optimize-the-multi-key-GIN-searches.patch 0003-Further-optimize-GIN-multi-key-searches.patch
0004-Add-the-concept-of-a-ternary-consistent-check-and-us.patch
9.4-alex-1 (based on 9.4-heikki) 0005-Ternary-consistent-implementation.patch
9.4-alex-1 (based on 9.4-alex-1) 0006-Sort-entries.patch
9.4-heikki (new version) gin-ternary-logic+binary-heap+preconsistent-only-on-new-page.patch
9.4-alex-2 (new version) gin-fast-scan.10.patch.gz
Or did I get that wrong?
> Sometimes test cases are not what we expect. For example:
>
> =# explain SELECT id FROM messages WHERE body_tsvector @@
> to_tsquery('english','(5alpha1-initdb''d)');
> QUERY PLAN
>
> ────────────────────────────────────────────────────────────────────────────────
> Bitmap Heap Scan on messages (cost=84.00..88.01 rows=1 width=4)
> Recheck Cond: (body_tsvector @@ '''5alpha1-initdb'' & ''5alpha1'' &
> ''initdb'' & ''d'''::tsquery)
> -> Bitmap Index Scan on messages_body_tsvector_idx (cost=0.00..84.00
> rows=1 width=0)
> Index Cond: (body_tsvector @@ '''5alpha1-initdb'' & ''5alpha1'' &
> ''initdb'' & ''d'''::tsquery)
> Planning time: 0.257 ms
> (5 rows)
>
> 5alpha1-initdb'd is 3 gin entries with different frequencies.
Why do you find that strange? The way the query is formed or the way it's
evaluated?
The query generator certainly is not perfect, so it may produce some
strange queries.
> Also, these patches are not intended to change relevance ordering speed.
> When number of results are high, most of time is relevance calculating and
> sorting. I propose to remove ORDER BY clause from test cases to see scan
> speed more clear.
Sure, I can do that. Or maybe one set of queries with ORDER BY, the other
one without it.
> I've dump of postgresql.org search queries from Magnus. We can add them to
> our test case.
You mean search queries from the search for mailing list archives? Sure,
we add that.
Tomas
On Thu, Jan 30, 2014 at 8:38 PM, Heikki Linnakangas <hlinnakangas@vmware.com> wrote:
------
With best regards,
Alexander Korotkov.
On 01/30/2014 01:53 AM, Tomas Vondra wrote:I tried these queries with the data set you posted here: http://www.postgresql.org/message-id/52E4141E.60609@fuzzy.cz. The reason for the slowdown is the extra consistent calls it causes. That's expected - the patch certainly does call consistent in situations where it didn't before, and if the "pre-consistent" checks are not able to eliminate many tuples, you lose.(3) A file with explain plans for 4 queries suffering ~2x slowdown,
and explain plans with 9.4 master and Heikki's patches is available
here:
http://www.fuzzy.cz/tmp/gin/queries.txt
All the queries have 6 common words, and the explain plans look
just fine to me - exactly like the plans for other queries.
Two things now caught my eye. First some of these queries actually
have words repeated - either exactly like "database & database" or
in negated form like "!anything & anything". Second, while
generating the queries, I use "dumb" frequency, where only exact
matches count. I.e. "write != written" etc. But the actual number
of hits may be much higher - for example "write" matches exactly
just 5% documents, but using @@ it matches more than 20%.
I don't know if that's the actual cause though.
So, what can we do to mitigate that? Some ideas:
1. Implement the catalog changes from Alexander's patch. That ought to remove the overhead, as you only need to call the consistent function once, not "both ways". OTOH, currently we only call the consistent function if there is only one unknown column. If with the catalog changes, we always call the consistent function even if there are more unknown columns, we might end up calling it even more often.
2. Cache the result of the consistent function.
3. Make the consistent function cheaper. (How? Magic?)
4. Use some kind of a heuristic, and stop doing the pre-consistent checks if they're not effective. Not sure what the heuristic would look like.
I'm fiddling around with following idea of such heuristic:
1) Sort entries ascending by estimate of TIDs number. Assume number of entries to be n.
2) Sequentially call ternary consistent with first m of GIN_FALSE and rest n-m of GIN_MAYBE until it returns GIN_FALSE.
3) Decide whether to use fast-scan depending on number of TIDs in first m entries and number of TIDs in rest (n-m) entries. Something like number_of_TIDs_in_frist_m_entries * k < number_of_TIDs_in_rest_n-m_entries where k is some quotient.
For sure, it rough method, but it should be fast. Without natural implementation of ternary consistent function algorithm will be slightly different: only m values close to n should be checked.
I'm going to implement this heuristic against last version of your patch.
With best regards,
Alexander Korotkov.
On Mon, Feb 3, 2014 at 7:24 PM, Tomas Vondra <tv@fuzzy.cz> wrote:
------
With best regards,
Alexander Korotkov.
On 3 Únor 2014, 15:31, Alexander Korotkov wrote:Do I understand it correctly that the 0005 patch should give exactly the
>
> I found my patch "0005-Ternary-consistent-implementation.patch" to be
> completely wrong. It introduces ternary consistent function to opclass,
> but
> don't uses it, because I forgot to include ginlogic.c change into patch.
> So, it shouldn't make any impact on performance. However, testing results
> with that patch significantly differs. That makes me very uneasy. Can we
> now reproduce exact same?
same performance as the 9.4-heikki branch (as it was applied on it, and
effectively did no change). This wasn't exactly what I measured, although
the differences were not that significant.
Do I undestand correctly it's 9.4-heikki and 9.4-alex-1 here:
In some queries it differs in times. I wonder why.
I can rerun the tests, if that's what you're asking for. I'll improve the
test a bit - e.g. I plan to average multiple runs, to filter out random
noise (which might be significant for such short queries).Yes, I'll do that. However I'll have to rerun the other tests too, because
> Right version of these two patches in one against current head is
> attached.
> I've rerun tests with it, results are
> /mnt/sas-raid10/gin-testing/queries/9.4-fast-scan-10. Could you rerun
> postprocessing including graph drawing?
the
previous runs were done on a different machine.
I'm a bit confused right now. The previous patches (0005 + 0007) were
supposed
to be applied on top of the 4 from Heikki (0001-0004), right? AFAIK those
were
not commited yet, so why is this version against HEAD?
To summarize, I know of these patch sets:
9.4-heikki (old version)
0001-Optimize-GIN-multi-key-queries.patch
0002-Further-optimize-the-multi-key-GIN-searches.patch
0003-Further-optimize-GIN-multi-key-searches.patch
0004-Add-the-concept-of-a-ternary-consistent-check-and-us.patch
9.4-alex-1 (based on 9.4-heikki)
0005-Ternary-consistent-implementation.patch
9.4-alex-1 (based on 9.4-alex-1)
0006-Sort-entries.patch
From these patches I only need to compare 9.4-heikki (old version) and 9.4-alex-1 to release my doubts.
9.4-heikki (new version)
gin-ternary-logic+binary-heap+preconsistent-only-on-new-page.patch
9.4-alex-2 (new version)
gin-fast-scan.10.patch.gz
Or did I get that wrong?
Only you mentioned 9.4-alex-1 twice. I afraid to have some mess in numbering.
> Sometimes test cases are not what we expect. For example:Why do you find that strange? The way the query is formed or the way it's
>
> =# explain SELECT id FROM messages WHERE body_tsvector @@
> to_tsquery('english','(5alpha1-initdb''d)');
> QUERY PLAN
>
> ────────────────────────────────────────────────────────────────────────────────
> Bitmap Heap Scan on messages (cost=84.00..88.01 rows=1 width=4)
> Recheck Cond: (body_tsvector @@ '''5alpha1-initdb'' & ''5alpha1'' &
> ''initdb'' & ''d'''::tsquery)
> -> Bitmap Index Scan on messages_body_tsvector_idx (cost=0.00..84.00
> rows=1 width=0)
> Index Cond: (body_tsvector @@ '''5alpha1-initdb'' & ''5alpha1'' &
> ''initdb'' & ''d'''::tsquery)
> Planning time: 0.257 ms
> (5 rows)
>
> 5alpha1-initdb'd is 3 gin entries with different frequencies.
evaluated?
The query generator certainly is not perfect, so it may produce some
strange queries.
I just mean that in this case 3 words doesn't mean 3 gin entries.
> Also, these patches are not intended to change relevance ordering speed.Sure, I can do that. Or maybe one set of queries with ORDER BY, the other
> When number of results are high, most of time is relevance calculating and
> sorting. I propose to remove ORDER BY clause from test cases to see scan
> speed more clear.
one without it.
Good.
You mean search queries from the search for mailing list archives? Sure,
we add that.
Yes. I'll transform it into tsquery and send you privately.
------
With best regards,
Alexander Korotkov.
On 3 Únor 2014, 17:08, Alexander Korotkov wrote: > On Mon, Feb 3, 2014 at 7:24 PM, Tomas Vondra <tv@fuzzy.cz> wrote: > >> On 3 Únor 2014, 15:31, Alexander Korotkov wrote: >> > >> > I found my patch "0005-Ternary-consistent-implementation.patch" to be >> > completely wrong. It introduces ternary consistent function to >> opclass, >> > but >> > don't uses it, because I forgot to include ginlogic.c change into >> patch. >> > So, it shouldn't make any impact on performance. However, testing >> results >> > with that patch significantly differs. That makes me very uneasy. Can >> we >> > now reproduce exact same? >> >> Do I understand it correctly that the 0005 patch should give exactly the >> same performance as the 9.4-heikki branch (as it was applied on it, and >> effectively did no change). This wasn't exactly what I measured, >> although >> the differences were not that significant. >> > > Do I undestand correctly it's 9.4-heikki and 9.4-alex-1 here: > http://www.fuzzy.cz/tmp/gin/# Yes. > In some queries it differs in times. I wonder why. Not sure. > I can rerun the tests, if that's what you're asking for. I'll improve the >> test a bit - e.g. I plan to average multiple runs, to filter out random >> noise (which might be significant for such short queries). >> >> > Right version of these two patches in one against current head is >> > attached. >> > I've rerun tests with it, results are >> > /mnt/sas-raid10/gin-testing/queries/9.4-fast-scan-10. Could you rerun >> > postprocessing including graph drawing? >> >> Yes, I'll do that. However I'll have to rerun the other tests too, >> because >> the >> previous runs were done on a different machine. >> >> I'm a bit confused right now. The previous patches (0005 + 0007) were >> supposed >> to be applied on top of the 4 from Heikki (0001-0004), right? AFAIK >> those >> were >> not commited yet, so why is this version against HEAD? >> >> To summarize, I know of these patch sets: >> >> 9.4-heikki (old version) >> 0001-Optimize-GIN-multi-key-queries.patch >> 0002-Further-optimize-the-multi-key-GIN-searches.patch >> 0003-Further-optimize-GIN-multi-key-searches.patch >> 0004-Add-the-concept-of-a-ternary-consistent-check-and-us.patch >> >> 9.4-alex-1 (based on 9.4-heikki) >> 0005-Ternary-consistent-implementation.patch >> >> 9.4-alex-1 (based on 9.4-alex-1) >> 0006-Sort-entries.patch >> > > From these patches I only need to compare 9.4-heikki (old version) and > 9.4-alex-1 to release my doubts. OK, understood. > > 9.4-heikki (new version) >> gin-ternary-logic+binary-heap+preconsistent-only-on-new-page.patch >> >> 9.4-alex-2 (new version) >> gin-fast-scan.10.patch.gz >> >> Or did I get that wrong? >> > > Only you mentioned 9.4-alex-1 twice. I afraid to have some mess in > numbering. You're right. It should have been like this: 9.4-alex-1 (based on 9.4-heikki) 0005-Ternary-consistent-implementation.patch 9.4-alex-2 (based on 9.4-alex-1) 0006-Sort-entries.patch 9.4-alex-3 (new version, not yet tested) gin-fast-scan.10.patch.gz > > > Sometimes test cases are not what we expect. For example: >> > >> > =# explain SELECT id FROM messages WHERE body_tsvector @@ >> > to_tsquery('english','(5alpha1-initdb''d)'); >> > QUERY PLAN >> > >> > >> ──────────────────────────────────────────────────────────────────────────────── >> > Bitmap Heap Scan on messages (cost=84.00..88.01 rows=1 width=4) >> > Recheck Cond: (body_tsvector @@ '''5alpha1-initdb'' & ''5alpha1'' & >> > ''initdb'' & ''d'''::tsquery) >> > -> Bitmap Index Scan on messages_body_tsvector_idx >> (cost=0.00..84.00 >> > rows=1 width=0) >> > Index Cond: (body_tsvector @@ '''5alpha1-initdb'' & >> ''5alpha1'' >> & >> > ''initdb'' & ''d'''::tsquery) >> > Planning time: 0.257 ms >> > (5 rows) >> > >> > 5alpha1-initdb'd is 3 gin entries with different frequencies. >> >> Why do you find that strange? The way the query is formed or the way >> it's >> evaluated? >> >> The query generator certainly is not perfect, so it may produce some >> strange queries. >> > > I just mean that in this case 3 words doesn't mean 3 gin entries. Isn't that expected? I mean, that's what to_tsquery may do, right? Tomas
On Mon, Feb 3, 2014 at 8:19 PM, Tomas Vondra <tv@fuzzy.cz> wrote:
------
With best regards,
Alexander Korotkov.
> > Sometimes test cases are not what we expect. For example:>> >Isn't that expected? I mean, that's what to_tsquery may do, right?
>> > =# explain SELECT id FROM messages WHERE body_tsvector @@
>> > to_tsquery('english','(5alpha1-initdb''d)');
>> > QUERY PLAN
>> >
>> >
>> ────────────────────────────────────────────────────────────────────────────────
>> > Bitmap Heap Scan on messages (cost=84.00..88.01 rows=1 width=4)
>> > Recheck Cond: (body_tsvector @@ '''5alpha1-initdb'' & ''5alpha1'' &
>> > ''initdb'' & ''d'''::tsquery)
>> > -> Bitmap Index Scan on messages_body_tsvector_idx
>> (cost=0.00..84.00
>> > rows=1 width=0)
>> > Index Cond: (body_tsvector @@ '''5alpha1-initdb'' &
>> ''5alpha1''
>> &
>> > ''initdb'' & ''d'''::tsquery)
>> > Planning time: 0.257 ms
>> > (5 rows)
>> >
>> > 5alpha1-initdb'd is 3 gin entries with different frequencies.
>>
>> Why do you find that strange? The way the query is formed or the way
>> it's
>> evaluated?
>>
>> The query generator certainly is not perfect, so it may produce some
>> strange queries.
>>
>
> I just mean that in this case 3 words doesn't mean 3 gin entries.
Everything is absolutely correct. :-) It just may be not what do you expect if you aren't getting into details.
With best regards,
Alexander Korotkov.
On 3 Únor 2014, 19:18, Alexander Korotkov wrote:
> On Mon, Feb 3, 2014 at 8:19 PM, Tomas Vondra <tv@fuzzy.cz> wrote:
>
>> > > Sometimes test cases are not what we expect. For example:
>> >> >
>> >> > =# explain SELECT id FROM messages WHERE body_tsvector @@
>> >> > to_tsquery('english','(5alpha1-initdb''d)');
>> >> > QUERY PLAN
>> >> >
>> >> >
>> >>
>> ────────────────────────────────────────────────────────────────────────────────
>> >> > Bitmap Heap Scan on messages (cost=84.00..88.01 rows=1 width=4)
>> >> > Recheck Cond: (body_tsvector @@ '''5alpha1-initdb'' &
>> ''5alpha1'' &
>> >> > ''initdb'' & ''d'''::tsquery)
>> >> > -> Bitmap Index Scan on messages_body_tsvector_idx
>> >> (cost=0.00..84.00
>> >> > rows=1 width=0)
>> >> > Index Cond: (body_tsvector @@ '''5alpha1-initdb'' &
>> >> ''5alpha1''
>> >> &
>> >> > ''initdb'' & ''d'''::tsquery)
>> >> > Planning time: 0.257 ms
>> >> > (5 rows)
>> >> >
>> >> > 5alpha1-initdb'd is 3 gin entries with different frequencies.
>> >>
>> >> Why do you find that strange? The way the query is formed or the way
>> >> it's
>> >> evaluated?
>> >>
>> >> The query generator certainly is not perfect, so it may produce some
>> >> strange queries.
>> >>
>> >
>> > I just mean that in this case 3 words doesn't mean 3 gin entries.
>>
>> Isn't that expected? I mean, that's what to_tsquery may do, right?
>>
>
> Everything is absolutely correct. :-) It just may be not what do you
> expect
> if you aren't getting into details.
Well, that's not how I designed the benchmark. I haven't based the
benchmark on GIN entries, but on 'natural' words, to simulate real
queries. I understand using GIN terms might get "more consistent" results
(e.g. 3 GIN terms with given frequency) than the current approach.
However this was partially a goal, to cover wider range of cases. Also,
that's why the benchmark works with relative speedup - comparing the query
duration with and without the patch.
Tomas
On Mon, Feb 3, 2014 at 6:31 PM, Alexander Korotkov <aekorotkov@gmail.com> wrote:
------
With best regards,
Alexander Korotkov.
On Mon, Jan 27, 2014 at 7:30 PM, Alexander Korotkov <aekorotkov@gmail.com> wrote:On Mon, Jan 27, 2014 at 2:32 PM, Alexander Korotkov <aekorotkov@gmail.com> wrote:On Sun, Jan 26, 2014 at 8:14 PM, Heikki Linnakangas <hlinnakangas@vmware.com> wrote:Yeah, inlining makes it disappear from the profile, and spreads that time to the functions calling it.On 01/26/2014 08:24 AM, Tomas Vondra wrote:Hi!
On 25.1.2014 22:21, Heikki Linnakangas wrote:Attached is a new version of the patch set, with those bugs fixed.
I've done a bunch of tests with all the 4 patches applied, and it seems
to work now. I've done tests with various conditions (AND/OR, number of
words, number of conditions) and I so far I did not get any crashes,
infinite loops or anything like that.
I've also compared the results to 9.3 - by dumping the database and
running the same set of queries on both machines, and indeed I got 100%
match.
I also did some performance tests, and that's when I started to worry.
For example, I generated and ran 1000 queries that look like this:
SELECT id FROM messages
WHERE body_tsvector @@ to_tsquery('english','(header & 53 & 32 &
useful & dropped)')
ORDER BY ts_rank(body_tsvector, to_tsquery('english','(header & 53 &
32 & useful & dropped)')) DESC;
i.e. in this case the query always was 5 words connected by AND. This
query is a pretty common pattern for fulltext search - sort by a list of
words and give me the best ranked results.
On 9.3, the script was running for ~23 seconds, on patched HEAD it was
~40. It's perfectly reproducible, I've repeated the test several times
with exactly the same results. The test is CPU bound, there's no I/O
activity at all. I got the same results with more queries (~100k).
Attached is a simple chart with x-axis used for durations measured on
9.3.2, y-axis used for durations measured on patched HEAD. It's obvious
a vast majority of queries is up to 2x slower - that's pretty obvious
from the chart.
Only about 50 queries are faster on HEAD, and >700 queries are more than
50% slower on HEAD (i.e. if the query took 100ms on 9.3, it takes >150ms
on HEAD).
Typically, the EXPLAIN ANALYZE looks something like this (on 9.3):
http://explain.depesz.com/s/5tv
and on HEAD (same query):
http://explain.depesz.com/s/1lI
Clearly the main difference is in the "Bitmap Index Scan" which takes
60ms on 9.3 and 120ms on HEAD.
On 9.3 the "perf top" looks like this:
34.79% postgres [.] gingetbitmap
28.96% postgres [.] ginCompareItemPointers
9.36% postgres [.] TS_execute
5.36% postgres [.] check_stack_depth
3.57% postgres [.] FunctionCall8Coll
while on 9.4 it looks like this:
28.20% postgres [.] gingetbitmap
21.17% postgres [.] TS_execute
8.08% postgres [.] check_stack_depth
7.11% postgres [.] FunctionCall8Coll
4.34% postgres [.] shimTriConsistentFn
Not sure how to interpret that, though. For example where did the
ginCompareItemPointers go? I suspect it's thanks to inlining, and that
it might be related to the performance decrease. Or maybe not.
The profile tells us that the consistent function is called a lot more than before. That is expected - with the fast scan feature, we're calling consistent not only for potential matches, but also to refute TIDs based on just a few entries matching. If that's effective, it allows us to skip many TIDs and avoid consistent calls, which compensates, but if it's not effective, it's just overhead.
I would actually expect it to be fairly effective for that query, so that's a bit surprising. I added counters to see where the calls are coming from, and it seems that about 80% of the calls are actually coming from this little the feature I explained earlier:So, that clearly isn't worth the cycles :-). At least not with an expensive consistent function; it might be worthwhile if we pre-build the truth-table, or cache the results of the consistent function.In addition to that, I'm using the ternary consistent function to check
if minItem is a match, even if we haven't loaded all the entries yet.
That's less important, but I think for something like "rare1 | (rare2 &
frequent)" it might be useful. It would allow us to skip fetching
'frequent', when we already know that 'rare1' matches for the current
item. I'm not sure if that's worth the cycles, but it seemed like an
obvious thing to do, now that we have the ternary consistent function.
Attached is a quick patch to remove that, on top of all the other patches, if you want to test the effect.Every single change you did in fast scan seems to be reasonable, but testing shows that something went wrong. Simple test with 3 words of different selectivities.After applying your patches:# select count(*) from fts_test where fti @@ plainto_tsquery('english', 'gin index select');count───────627(1 row)Time: 21,252 msIn original fast-scan:# select count(*) from fts_test where fti @@ plainto_tsquery('english', 'gin index select');count───────627(1 row)Time: 3,382 msI'm trying to get deeper into it.I had two guesses about why it's become so slower than in my original fast-scan:1) Not using native consistent function2) Not sorting entriesI attach two patches which rollback these two features (sorry for awful quality of second). Native consistent function accelerates thing significantly, as expected. Tt seems that sorting entries have almost no effect. However it's still not as fast as initial fast-scan:# select count(*) from fts_test where fti @@ plainto_tsquery('english', 'gin index select');count───────627(1 row)Time: 5,381 msTomas, could you rerun your tests with first and both these patches applied against patches by Heikki?I found my patch "0005-Ternary-consistent-implementation.patch" to be completely wrong. It introduces ternary consistent function to opclass, but don't uses it, because I forgot to include ginlogic.c change into patch. So, it shouldn't make any impact on performance. However, testing results with that patch significantly differs. That makes me very uneasy. Can we now reproduce exact same?Right version of these two patches in one against current head is attached. I've rerun tests with it, results are /mnt/sas-raid10/gin-testing/queries/9.4-fast-scan-10. Could you rerun postprocessing including graph drawing?Sometimes test cases are not what we expect. For example:=# explain SELECT id FROM messages WHERE body_tsvector @@ to_tsquery('english','(5alpha1-initdb''d)');QUERY PLAN─────────────────────────────────────────────────────────────────────────────────────────────────────────Bitmap Heap Scan on messages (cost=84.00..88.01 rows=1 width=4)Recheck Cond: (body_tsvector @@ '''5alpha1-initdb'' & ''5alpha1'' & ''initdb'' & ''d'''::tsquery)-> Bitmap Index Scan on messages_body_tsvector_idx (cost=0.00..84.00 rows=1 width=0)Index Cond: (body_tsvector @@ '''5alpha1-initdb'' & ''5alpha1'' & ''initdb'' & ''d'''::tsquery)Planning time: 0.257 ms(5 rows)5alpha1-initdb'd is 3 gin entries with different frequencies.Also, these patches are not intended to change relevance ordering speed. When number of results are high, most of time is relevance calculating and sorting. I propose to remove ORDER BY clause from test cases to see scan speed more clear.I've dump of postgresql.org search queries from Magnus. We can add them to our test case.
It turns out that version 10 contained bug in ternary consistent function implementation for tsvector. Fixed in attached version.
With best regards,
Alexander Korotkov.
Attachment
On Wed, Feb 5, 2014 at 1:23 AM, Alexander Korotkov <aekorotkov@gmail.com> wrote:
------
With best regards,
Alexander Korotkov.
On Mon, Feb 3, 2014 at 6:31 PM, Alexander Korotkov <aekorotkov@gmail.com> wrote:On Mon, Jan 27, 2014 at 7:30 PM, Alexander Korotkov <aekorotkov@gmail.com> wrote:On Mon, Jan 27, 2014 at 2:32 PM, Alexander Korotkov <aekorotkov@gmail.com> wrote:Every single change you did in fast scan seems to be reasonable, but testing shows that something went wrong. Simple test with 3 words of different selectivities.After applying your patches:# select count(*) from fts_test where fti @@ plainto_tsquery('english', 'gin index select');count───────627(1 row)Time: 21,252 msIn original fast-scan:# select count(*) from fts_test where fti @@ plainto_tsquery('english', 'gin index select');count───────627(1 row)Time: 3,382 msI'm trying to get deeper into it.I had two guesses about why it's become so slower than in my original fast-scan:1) Not using native consistent function2) Not sorting entriesI attach two patches which rollback these two features (sorry for awful quality of second). Native consistent function accelerates thing significantly, as expected. Tt seems that sorting entries have almost no effect. However it's still not as fast as initial fast-scan:# select count(*) from fts_test where fti @@ plainto_tsquery('english', 'gin index select');count───────627(1 row)Time: 5,381 msTomas, could you rerun your tests with first and both these patches applied against patches by Heikki?I found my patch "0005-Ternary-consistent-implementation.patch" to be completely wrong. It introduces ternary consistent function to opclass, but don't uses it, because I forgot to include ginlogic.c change into patch. So, it shouldn't make any impact on performance. However, testing results with that patch significantly differs. That makes me very uneasy. Can we now reproduce exact same?Right version of these two patches in one against current head is attached. I've rerun tests with it, results are /mnt/sas-raid10/gin-testing/queries/9.4-fast-scan-10. Could you rerun postprocessing including graph drawing?Sometimes test cases are not what we expect. For example:=# explain SELECT id FROM messages WHERE body_tsvector @@ to_tsquery('english','(5alpha1-initdb''d)');QUERY PLAN─────────────────────────────────────────────────────────────────────────────────────────────────────────Bitmap Heap Scan on messages (cost=84.00..88.01 rows=1 width=4)Recheck Cond: (body_tsvector @@ '''5alpha1-initdb'' & ''5alpha1'' & ''initdb'' & ''d'''::tsquery)-> Bitmap Index Scan on messages_body_tsvector_idx (cost=0.00..84.00 rows=1 width=0)Index Cond: (body_tsvector @@ '''5alpha1-initdb'' & ''5alpha1'' & ''initdb'' & ''d'''::tsquery)Planning time: 0.257 ms(5 rows)5alpha1-initdb'd is 3 gin entries with different frequencies.Also, these patches are not intended to change relevance ordering speed. When number of results are high, most of time is relevance calculating and sorting. I propose to remove ORDER BY clause from test cases to see scan speed more clear.I've dump of postgresql.org search queries from Magnus. We can add them to our test case.It turns out that version 10 contained bug in ternary consistent function implementation for tsvector. Fixed in attached version.
Attached patch is "light" version of fast scan. It does extra consistent function calls only on startScanKey, no extra calls during scan of the index.
It finds subset of rarest entries absence of which guarantee false consistent function result.
I've run real-life tests based of postgresql.org logs (33318 queries). Here is a table with summary time of running whole test case.
=# select method, sum(time) from test_result group by method order by method;
method | sum
---------------------+------------------
fast-scan-11 | 126916.111999999
fast-scan-light | 137321.211
heikki | 466751.693
heikki-true-ternary | 454113.623999997
master | 446976.288
(6 rows)
where 'heikki' is gin-ternary-logic binary-heap preconsistent-only-on-new-page.patch and 'heikki-true-ternary' is version with my catalog changes promoting ternary consistent function to opclass.
We can see fast-scan-light gives almost same performance benefit on "&" queries. However, I test only CPU effect, not IO effect.
Any thoughts?
With best regards,
Alexander Korotkov.
Attachment
On 02/05/2014 12:42 PM, Alexander Korotkov wrote:
> Attached patch is "light" version of fast scan. It does extra consistent
> function calls only on startScanKey, no extra calls during scan of the
> index.
> It finds subset of rarest entries absence of which guarantee false
> consistent function result.
Sounds good. Since the extra consistent calls are only performed at
startup, it's unlikely to cause any noticeable performance regression,
even when it's not helping.
> I've run real-life tests based of postgresql.org logs (33318 queries). Here
> is a table with summary time of running whole test case.
>
> =# select method, sum(time) from test_result group by method order by
> method;
> method | sum
> ---------------------+------------------
> fast-scan-11 | 126916.111999999
> fast-scan-light | 137321.211
> heikki | 466751.693
> heikki-true-ternary | 454113.623999997
> master | 446976.288
> (6 rows)
>
> where 'heikki' is gin-ternary-logic binary-heap
> preconsistent-only-on-new-page.patch and 'heikki-true-ternary' is version
> with my catalog changes promoting ternary consistent function to opclass.
Looks good.
> We can see fast-scan-light gives almost same performance benefit on "&"
> queries. However, I test only CPU effect, not IO effect.
> Any thoughts?
This test doesn't handle lossy-pages correctly:
> /*
> * Check if all items marked as scanEntryUseForSkip is not present in
> * minItem. If so, we can correct advancePast.
> */
> if (ginCompareItemPointers(&minItem, &minItemSkip) < 0)
> {
> advancePast = minItemSkip;
> advancePast.ip_posid--;
> continue;
> }
>
If minItemSkip is a lossy page, we skip all exact items on the same
page. That's wrong, here's a test case to demonstrate:
CREATE TABLE foo (ts tsvector);
INSERT INTO foo SELECT to_tsvector('foo bar'||g) from generate_series(1,
1000000) g;
CREATE INDEX i_foo ON foo USING gin (ts);
set work_mem='64'; -- to force lossy pages
-- should return 111111
select count(*) from foo where ts @@ to_tsquery('foo & bar4:*');
After some fiddling (including fixing the above), I ended up with the
attached version of your patch. I still left out the catalog changes,
again not because I don't think we should have them, but to split this
into smaller patches that can be reviewed separately. I extended the
"both ways" shim function to work with more than one "maybe" input. Of
course, that is O(n^2), where n is the number of "maybe" arguments, so
that won't scale, but it's OK for testing purposes. And many if not most
real world queries, too.
I had a very hard time understanding what it really means for an entry
to be in the scanEntryUseForSkip array. What does it mean to "use" an
entry for skipping?
So I refactored that logic, to hopefully make it more clear. In essence,
the entries are divided into two groups, required and other items. If
none of the entries in the required set are true, then we know that the
overall qual cannot match. See the comments for a more detailed
explanation. I'm not wedded to the term "required" here; one might think
that *all* the entries in the required set must be TRUE for a match,
while it's actually that at least one of them must be TRUE.
In keyGetItem, we fetch the minimum item among all the entries in the
requiredEntries set. That's the next item we're going to return,
regardless of any items in otherEntries set. But before calling the
consistent function, we advance the other entries up to that point, so
that we know whether to pass TRUE or FALSE to the consistent function.
IOW, otherEntries only provide extra information for the consistent
function to decide if we have a match or not - they don't affect which
items we return to the caller.
I think this is pretty close to committable state now. I'm slightly
disappointed that we can't do the skipping in more scenarios. For
example, in "foo & bar", we can currently skip "bar" entry up to the
next "foo", but we cannot skip "foo" up to the next "bar". But this is
fairly simple, and since we sort the entries by estimated frequency,
should already cover all the pathological "rare & frequent" type
queries. So that's OK.
- Heikki
Attachment
On Thu, Feb 6, 2014 at 2:21 PM, Heikki Linnakangas <hlinnakangas@vmware.com> wrote:
------
With best regards,
Alexander Korotkov.
On 02/05/2014 12:42 PM, Alexander Korotkov wrote:Sounds good. Since the extra consistent calls are only performed at startup, it's unlikely to cause any noticeable performance regression, even when it's not helping.Attached patch is "light" version of fast scan. It does extra consistent
function calls only on startScanKey, no extra calls during scan of the
index.
It finds subset of rarest entries absence of which guarantee false
consistent function result.Looks good.I've run real-life tests based of postgresql.org logs (33318 queries). Here
is a table with summary time of running whole test case.
=# select method, sum(time) from test_result group by method order by
method;
method | sum
---------------------+------------------
fast-scan-11 | 126916.111999999
fast-scan-light | 137321.211
heikki | 466751.693
heikki-true-ternary | 454113.623999997
master | 446976.288
(6 rows)
where 'heikki' is gin-ternary-logic binary-heap
preconsistent-only-on-new-page.patch and 'heikki-true-ternary' is version
with my catalog changes promoting ternary consistent function to opclass.This test doesn't handle lossy-pages correctly:We can see fast-scan-light gives almost same performance benefit on "&"
queries. However, I test only CPU effect, not IO effect.
Any thoughts?/*
* Check if all items marked as scanEntryUseForSkip is not present in
* minItem. If so, we can correct advancePast.
*/
if (ginCompareItemPointers(&minItem, &minItemSkip) < 0)
{
advancePast = minItemSkip;
advancePast.ip_posid--;
continue;
}
If minItemSkip is a lossy page, we skip all exact items on the same page. That's wrong, here's a test case to demonstrate:
CREATE TABLE foo (ts tsvector);
INSERT INTO foo SELECT to_tsvector('foo bar'||g) from generate_series(1, 1000000) g;
CREATE INDEX i_foo ON foo USING gin (ts);
set work_mem='64'; -- to force lossy pages
-- should return 111111
select count(*) from foo where ts @@ to_tsquery('foo & bar4:*');
After some fiddling (including fixing the above), I ended up with the attached version of your patch. I still left out the catalog changes, again not because I don't think we should have them, but to split this into smaller patches that can be reviewed separately. I extended the "both ways" shim function to work with more than one "maybe" input. Of course, that is O(n^2), where n is the number of "maybe" arguments, so that won't scale, but it's OK for testing purposes. And many if not most real world queries, too.
I had a very hard time understanding what it really means for an entry to be in the scanEntryUseForSkip array. What does it mean to "use" an entry for skipping?
So I refactored that logic, to hopefully make it more clear. In essence, the entries are divided into two groups, required and other items. If none of the entries in the required set are true, then we know that the overall qual cannot match. See the comments for a more detailed explanation. I'm not wedded to the term "required" here; one might think that *all* the entries in the required set must be TRUE for a match, while it's actually that at least one of them must be TRUE.
In keyGetItem, we fetch the minimum item among all the entries in the requiredEntries set. That's the next item we're going to return, regardless of any items in otherEntries set. But before calling the consistent function, we advance the other entries up to that point, so that we know whether to pass TRUE or FALSE to the consistent function. IOW, otherEntries only provide extra information for the consistent function to decide if we have a match or not - they don't affect which items we return to the caller.
I think this is pretty close to committable state now. I'm slightly disappointed that we can't do the skipping in more scenarios. For example, in "foo & bar", we can currently skip "bar" entry up to the next "foo", but we cannot skip "foo" up to the next "bar". But this is fairly simple, and since we sort the entries by estimated frequency, should already cover all the pathological "rare & frequent" type queries. So that's OK.
Sorry for my scanty explanation. Your version of patch looks good for me. I've rerun my testcase:
=# select method, sum(time) from test_result group by method order by method;
method | sum
------------------------+------------------
fast-scan-11 | 126916.111999999
fast-scan-light | 137321.211
fast-scan-light-heikki | 138168.028000001
heikki | 466751.693
heikki-tru-ternary | 454113.623999997
master | 446976.288
tri-state | 444725.515
(7 rows)
Difference is very small. For me, it looks ready for commit.
With best regards,
Alexander Korotkov.
On 02/06/2014 01:22 PM, Alexander Korotkov wrote: > Difference is very small. For me, it looks ready for commit. Great, committed! Now, to review the catalog changes... - Heikki
On Fri, Feb 7, 2014 at 5:33 PM, Heikki Linnakangas <hlinnakangas@vmware.com> wrote:
------
With best regards,
Alexander Korotkov.
On 02/06/2014 01:22 PM, Alexander Korotkov wrote:Great, committed!Difference is very small. For me, it looks ready for commit.
Now, to review the catalog changes...
I've rebased catalog changes with last master. Patch is attached. I've rerun my test suite with both last master ('committed') and attached patch ('ternary-consistent').
method | sum
------------------------+------------------
committed | 143491.715000001
fast-scan-11 | 126916.111999999
fast-scan-light | 137321.211
fast-scan-light-heikki | 138168.028000001
master | 446976.288
ternary-consistent | 125923.514
I explain regression in last master by change of MAX_MAYBE_ENTRIES from 8 to 4. However I'm not sure why ternary-consistent show so good results. Probably it's because some optimizations you did in committed version which wasn't visible because of change of MAX_MAYBE_ENTRIES.
I'm not sure about decision to reserve separate procedure number for ternary consistent. Probably, it would be better to add ginConfig method. It would be useful for post 9.4 improvements.
With best regards,
Alexander Korotkov.
Attachment
On 3.2.2014 07:53, Oleg Bartunov wrote: > Tomasa, it'd be nice if you use real data in your testing. > > One very good application of gin fast-scan is dramatic performance > improvement of hstore/jsonb @> operator, see slides 57, 58 > http://www.sai.msu.su/~megera/postgres/talks/hstore-dublin-2013.pdf. > I'd like not to lost this benefit :) > > Oleg > > PS. I used data delicious-rss-1250k.gz from > http://randomwalker.info/data/delicious/ Hi Oleg, I'm working on extending the GIN testing to include this test (and I'll use it to test both for GIN and hstore-v2 patches). I do have the dataset, but I need the queries too - how did you generate the queries for your benchmark? Do you have some query generator at hand? In your Dublin talk I see just this query type select count(*) from hs where h @> 'tags=>{{term=>NYC}}'; but that seems inadequate for representative benchmark. Are there other types of queries that need to be tested / might be interesting? E.g. queries with multiple search terms etc.? regards Tommas
On Sun, February 9, 2014 22:35, Tomas Vondra wrote: > On 3.2.2014 07:53, Oleg Bartunov wrote: >> PS. I used data delicious-rss-1250k.gz from >> http://randomwalker.info/data/delicious/ > > I'm working on extending the GIN testing to include this test (and I'll > use it to test both for GIN and hstore-v2 patches). > > I do have the dataset, but I need the queries too - how did you generate > the queries for your benchmark? Do you have some query generator at hand? > > In your Dublin talk I see just this query type > > select count(*) from hs where h @> 'tags=>{{term=>NYC}}'; > > but that seems inadequate for representative benchmark. Are there other > types of queries that need to be tested / might be interesting? E.g. > queries with multiple search terms etc.? > There is the hstore operators table (Table F-6) that you can perhaps use to generate queries? (I am working on this too.) At least it contains already a handful of queries. To get at the bits in that table, perhaps the perl program attached here helps: http://www.postgresql.org/message-id/f29d70631e2046655c40dfcfce6db3c3.squirrel@webmail.xs4all.nl YMMV, I guess... Erik Rijkers
On 9.2.2014 22:51, Erik Rijkers wrote: > On Sun, February 9, 2014 22:35, Tomas Vondra wrote: >> On 3.2.2014 07:53, Oleg Bartunov wrote: >>> PS. I used data delicious-rss-1250k.gz from >>> http://randomwalker.info/data/delicious/ >> >> I'm working on extending the GIN testing to include this test (and I'll >> use it to test both for GIN and hstore-v2 patches). >> >> I do have the dataset, but I need the queries too - how did you generate >> the queries for your benchmark? Do you have some query generator at hand? >> >> In your Dublin talk I see just this query type >> >> select count(*) from hs where h @> 'tags=>{{term=>NYC}}'; >> >> but that seems inadequate for representative benchmark. Are there other >> types of queries that need to be tested / might be interesting? E.g. >> queries with multiple search terms etc.? >> > > There is the hstore operators table (Table F-6) that you can perhaps use to generate queries? (I am working on this too.) > At least it contains already a handful of queries. > > To get at the bits in that table, perhaps the perl program attached here helps: > > http://www.postgresql.org/message-id/f29d70631e2046655c40dfcfce6db3c3.squirrel@webmail.xs4all.nl > > YMMV, I guess... It seems to me the purpose of the program is to demonstrate some differences between expected and actual result of an operator. If that's true then it's not really of much use - it's not a query generator. I need a script that generates large number of 'reasonable' queries, i.e. queries that make sense and resemble what the users actually do. Tomas
On 9.2.2014 11:11, Alexander Korotkov wrote:
> On Fri, Feb 7, 2014 at 5:33 PM, Heikki Linnakangas
> <hlinnakangas@vmware.com <mailto:hlinnakangas@vmware.com>> wrote:
>
> On 02/06/2014 01:22 PM, Alexander Korotkov wrote:
>
> Difference is very small. For me, it looks ready for commit.
>
>
> Great, committed!
>
> Now, to review the catalog changes...
>
>
> I've rebased catalog changes with last master. Patch is attached. I've
> rerun my test suite with both last master ('committed') and attached
> patch ('ternary-consistent').
>
> method | sum
> ------------------------+------------------
> committed | 143491.715000001
> fast-scan-11 | 126916.111999999
> fast-scan-light | 137321.211
> fast-scan-light-heikki | 138168.028000001
> master | 446976.288
> ternary-consistent | 125923.514
>
Hi,
I've repeated the benchmarks - it took a few days to process that, but
here are the results. And IMHO it looks 100% fine.
I've tested all the patches since 25/01/2014, mostly because of
curiosity but also for comparison with current patches. So these are the
patches (name + date of the message with the patch):
heikki-20140125 0001 + 0002 + 0003 + 0004
heikki-20140126 load-all-entries-before-consistent-check-1
alexander-20140127-1 0001 + 0002 + 0003 + 0004 + 0005
alexander-20140127-2 0001 + 0002 + 0003 + 0004 + 0005 + 0006
heikki-20140202 ternary-logic + binary-heap
+ preconsistent-only-on-new-page
alexander-20140203 fast-scan-10
alexander-20140204 fast-scan-11
alexander-20140205 fast-scan-light
heikki-20140206 fast-scan-light-heikki1 (comitted 07/02)
alexander-20140209 ternary-consistent
I've tested both 9.3 and master for comparison. Package with all the
patches is available here: http://www.fuzzy.cz/tmp/gin/patches.tgz
The results are available on http://www.fuzzy.cz/tmp/gin/ as before.
I've tested these datasets:
3-words-common
3-words-common + ORDER BY
3-words-medium
3-words-medium + ORDER BY
3-words-rare
3-words-rare + ORDER BY
6-words-common
6-words-common + ORDER BY
6-words-medium
6-words-medium
6-words-rare
6-words-rare + ORDER BY
postgres-queries
postgres-queries + ORDER BY
I.e. basically the same queries as before, except that I've added a
version without "ORDER BY" clause. The main difference is that I added a
"postgres-queries" dataset with 33k real-world queries collected from
search at postgresql.org.
Another improvement is that instead of a single measurement, I've ran
the tests 10x, then threw away the first run and computed average,
median, min, max and stddev. You can choose the value to plot under the
chart.
The files with results for the 'postgres-queries' are ~70MB, which makes
viewing the dataset on the web a major PITA (first it takes very long to
download it, then it hogs the browser). So don't do that unless you want
to punish yourself for something bad you've done.
An alternative way to view the data is using a simple gnuplot charts. In
that case get http://www.fuzzy.cz/tmp/gin/plots.tgz. There's always a
.plot and .data file for each dataset/value combination. The dataset is
always "speedup vs. master"
Looking ad the postgres-queries results (attached), I see almost no
differences between these patches:
alexander-20140204 fast-scan-11
alexander-20140205 fast-scan-light
heikki-20140206 fast-scan-light-heikki1 (comitted 07/02)
alexander-20140209 ternary-consistent
And the same is true for the other tests - see the attached gnuplot
charts for a few of the tests.
So IMHO this looks quite great, no need for worries. Let me know if you
have any questions / would like to see another chart.
regards
Tomas
Attachment
{kind=link}
{kind=link}
{kind=link}
{kind=link}
On 02/09/2014 12:11 PM, Alexander Korotkov wrote:
> I've rebased catalog changes with last master. Patch is attached. I've
> rerun my test suite with both last master ('committed') and attached
> patch ('ternary-consistent').
Thanks!
> method | sum
> ------------------------+------------------
> committed | 143491.715000001
> fast-scan-11 | 126916.111999999
> fast-scan-light | 137321.211
> fast-scan-light-heikki | 138168.028000001
> master | 446976.288
> ternary-consistent | 125923.514
>
> I explain regression in last master by change of MAX_MAYBE_ENTRIES from 8
> to 4.
Yeah, probably. I set MAX_MAYBE_ENTRIES to 8 in initial versions to make
sure we get similar behavior in Tomas' tests that used 6 search terms.
But I always felt that it was too large for real queries, once we have
the catalog changes, that's why I lowered to 4 when committing. If an
opclass benefits greatly from fast scan, it should provide the ternary
consistent function, and not rely on the shim implementation.
> I'm not sure about decision to reserve separate procedure number for
> ternary consistent. Probably, it would be better to add ginConfig method.
> It would be useful for post 9.4 improvements.
Hmm, it might be useful for an opclass to provide both, a boolean and
ternary consistent function, if the boolean version is significantly
more efficient when all the arguments are TRUE/FALSE. OTOH, you could
also do a quick check through the array to see if there are any MAYBE
arguments, within the consistent function. But I'm inclined to keep the
possibility to provide both versions. As long as we support the boolean
version at all, there's not much difference in terms of the amount of
code to support having them both for the same opclass.
A ginConfig could be useful for many other things, but I don't think
it's worth adding it now.
What's the difference between returning GIN_MAYBE and GIN_TRUE+recheck?
We discussed that earlier, but didn't reach any conclusion. That needs
to be clarified in the docs. One possibility is to document that they're
equivalent. Another is to forbid one of them. Yet another is to assign a
different meaning to each.
I've been thinking that it might be useful to define them so that a
MAYBE result from the tri-consistent function means that it cannot
decide if you have a match or not, because some of the inputs were
MAYBE. And TRUE+recheck means that even if all the MAYBE inputs were
passed as TRUE or FALSE, the result would be the same, TRUE+recheck. The
practical difference would be that if the tri-consistent function
returns TRUE+recheck, ginget.c wouldn't need to bother fetching the
other entries, it could just return the entry with recheck=true
immediately. While with MAYBE result, it would fetch the other entries
and call tri-consistent again. ginget.c doesn't currently use the
tri-consistent function that way - it always fetches all the entries for
a potential match before calling tri-consistent, but it could. I had it
do that in some of the patch versions, but Tomas' testing showed that it
was a big loss on some queries, because the consistent function was
called much more often. Still, something like that might be sensible in
the future, so it might be good to distinguish those cases in the API
now. Note that ginarrayproc is already using the return values like
that: in GinContainedStrategy, it always returns TRUE+recheck regardless
of the inputs, but in other cases it uses GIN_MAYBE.
- Heikki
On Thu, Feb 20, 2014 at 1:48 PM, Heikki Linnakangas <hlinnakangas@vmware.com> wrote:
------
With best regards,
Alexander Korotkov.
On 02/09/2014 12:11 PM, Alexander Korotkov wrote:Thanks!I've rebased catalog changes with last master. Patch is attached. I've
rerun my test suite with both last master ('committed') and attached
patch ('ternary-consistent').Yeah, probably. I set MAX_MAYBE_ENTRIES to 8 in initial versions to make sure we get similar behavior in Tomas' tests that used 6 search terms. But I always felt that it was too large for real queries, once we have the catalog changes, that's why I lowered to 4 when committing. If an opclass benefits greatly from fast scan, it should provide the ternary consistent function, and not rely on the shim implementation.method | sum
------------------------+------------------
committed | 143491.715000001
fast-scan-11 | 126916.111999999
fast-scan-light | 137321.211
fast-scan-light-heikki | 138168.028000001
master | 446976.288
ternary-consistent | 125923.514
I explain regression in last master by change of MAX_MAYBE_ENTRIES from 8
to 4.Hmm, it might be useful for an opclass to provide both, a boolean and ternary consistent function, if the boolean version is significantly more efficient when all the arguments are TRUE/FALSE. OTOH, you could also do a quick check through the array to see if there are any MAYBE arguments, within the consistent function. But I'm inclined to keep the possibility to provide both versions. As long as we support the boolean version at all, there's not much difference in terms of the amount of code to support having them both for the same opclass.I'm not sure about decision to reserve separate procedure number for
ternary consistent. Probably, it would be better to add ginConfig method.
It would be useful for post 9.4 improvements.
A ginConfig could be useful for many other things, but I don't think it's worth adding it now.
What's the difference between returning GIN_MAYBE and GIN_TRUE+recheck? We discussed that earlier, but didn't reach any conclusion. That needs to be clarified in the docs. One possibility is to document that they're equivalent. Another is to forbid one of them. Yet another is to assign a different meaning to each.
I've been thinking that it might be useful to define them so that a MAYBE result from the tri-consistent function means that it cannot decide if you have a match or not, because some of the inputs were MAYBE. And TRUE+recheck means that even if all the MAYBE inputs were passed as TRUE or FALSE, the result would be the same, TRUE+recheck. The practical difference would be that if the tri-consistent function returns TRUE+recheck, ginget.c wouldn't need to bother fetching the other entries, it could just return the entry with recheck=true immediately. While with MAYBE result, it would fetch the other entries and call tri-consistent again. ginget.c doesn't currently use the tri-consistent function that way - it always fetches all the entries for a potential match before calling tri-consistent, but it could. I had it do that in some of the patch versions, but Tomas' testing showed that it was a big loss on some queries, because the consistent function was called much more often. Still, something like that might be sensible in the future, so it might be good to distinguish those cases in the API now. Note that ginarrayproc is already using the return values like that: in GinContainedStrategy, it always returns TRUE+recheck regardless of the inputs, but in other cases it uses GIN_MAYBE.
Next revision of patch is attached.
In this version opclass should provide at least one consistent function: binary or ternary. It's expected to achieve best performance when opclass provide both of them. However, tests shows opposite :( I've to recheck it carefully.
I've removed recheck flag from ternary consistent function. It have to return GIN_MAYBE instead.
------
With best regards,
Alexander Korotkov.
Attachment
On Thu, Feb 27, 2014 at 1:07 AM, Alexander Korotkov <aekorotkov@gmail.com> wrote:
On Thu, Feb 20, 2014 at 1:48 PM, Heikki Linnakangas <hlinnakangas@vmware.com> wrote:On 02/09/2014 12:11 PM, Alexander Korotkov wrote:Thanks!I've rebased catalog changes with last master. Patch is attached. I've
rerun my test suite with both last master ('committed') and attached
patch ('ternary-consistent').Yeah, probably. I set MAX_MAYBE_ENTRIES to 8 in initial versions to make sure we get similar behavior in Tomas' tests that used 6 search terms. But I always felt that it was too large for real queries, once we have the catalog changes, that's why I lowered to 4 when committing. If an opclass benefits greatly from fast scan, it should provide the ternary consistent function, and not rely on the shim implementation.method | sum
------------------------+------------------
committed | 143491.715000001
fast-scan-11 | 126916.111999999
fast-scan-light | 137321.211
fast-scan-light-heikki | 138168.028000001
master | 446976.288
ternary-consistent | 125923.514
I explain regression in last master by change of MAX_MAYBE_ENTRIES from 8
to 4.Hmm, it might be useful for an opclass to provide both, a boolean and ternary consistent function, if the boolean version is significantly more efficient when all the arguments are TRUE/FALSE. OTOH, you could also do a quick check through the array to see if there are any MAYBE arguments, within the consistent function. But I'm inclined to keep the possibility to provide both versions. As long as we support the boolean version at all, there's not much difference in terms of the amount of code to support having them both for the same opclass.I'm not sure about decision to reserve separate procedure number for
ternary consistent. Probably, it would be better to add ginConfig method.
It would be useful for post 9.4 improvements.
A ginConfig could be useful for many other things, but I don't think it's worth adding it now.
What's the difference between returning GIN_MAYBE and GIN_TRUE+recheck? We discussed that earlier, but didn't reach any conclusion. That needs to be clarified in the docs. One possibility is to document that they're equivalent. Another is to forbid one of them. Yet another is to assign a different meaning to each.
I've been thinking that it might be useful to define them so that a MAYBE result from the tri-consistent function means that it cannot decide if you have a match or not, because some of the inputs were MAYBE. And TRUE+recheck means that even if all the MAYBE inputs were passed as TRUE or FALSE, the result would be the same, TRUE+recheck. The practical difference would be that if the tri-consistent function returns TRUE+recheck, ginget.c wouldn't need to bother fetching the other entries, it could just return the entry with recheck=true immediately. While with MAYBE result, it would fetch the other entries and call tri-consistent again. ginget.c doesn't currently use the tri-consistent function that way - it always fetches all the entries for a potential match before calling tri-consistent, but it could. I had it do that in some of the patch versions, but Tomas' testing showed that it was a big loss on some queries, because the consistent function was called much more often. Still, something like that might be sensible in the future, so it might be good to distinguish those cases in the API now. Note that ginarrayproc is already using the return values like that: in GinContainedStrategy, it always returns TRUE+recheck regardless of the inputs, but in other cases it uses GIN_MAYBE.Next revision of patch is attached.In this version opclass should provide at least one consistent function: binary or ternary. It's expected to achieve best performance when opclass provide both of them. However, tests shows opposite :( I've to recheck it carefully.
However, it's not!
This revision of patch completes my test case in 123330 ms. This is slightly faster than previous revision.
------
With best regards,
Alexander Korotkov.
With best regards,
Alexander Korotkov.
Hi all,
a quick question that just occured to me - do you plan to tweak the cost
estimation fot GIN indexes, in this patch?
IMHO it would be appropriate, given the improvements and gains, but it
seems to me gincostestimate() was not touched by this patch.
I just ran into this while testing some jsonb stuff, and after creating
a GIN and GIST indexes on the same column, I get these two plans:
=======================================================================
db=# explain analyze select count(*) from messages_2 where headers ?
'x-virus-scanned';
QUERY PLAN
------------------------------------------------------------------------Aggregate (cost=1068.19..1068.20 rows=1
width=0)(actual
time=400.149..400.150 rows=1 loops=1) -> Bitmap Heap Scan on messages_2 (cost=10.44..1067.50 rows=278
width=0) (actual time=27.974..395.840 rows=70499 loops=1) Recheck Cond: (headers ? 'x-virus-scanned'::text)
Rows Removed by Index Recheck: 33596 Heap Blocks: exact=40978 -> Bitmap Index Scan on
messages_2_gist_idx (cost=0.00..10.37
rows=278 width=0) (actual time=21.762..21.762 rows=104095 loops=1) Index Cond: (headers ?
'x-virus-scanned'::text)Planningtime: 0.052 msTotal runtime: 400.179 ms
(9 rows)
Time: 400,467 ms
db=# drop index messages_2_gist_idx;
DROP INDEX
db=# explain analyze select count(*) from messages_2 where headers ?
'x-virus-scanned'; QUERY PLAN
------------------------------------------------------------------------Aggregate (cost=1083.91..1083.92 rows=1
width=0)(actual
time=39.130..39.130 rows=1 loops=1) -> Bitmap Heap Scan on messages_2 (cost=26.16..1083.22 rows=278
width=0) (actual time=11.285..36.248 rows=70499 loops=1) Recheck Cond: (headers ? 'x-virus-scanned'::text)
Heap Blocks: exact=23896 -> Bitmap Index Scan on messages_2_gin_idx (cost=0.00..26.09
rows=278 width=0) (actual time=7.974..7.974 rows=70499 loops=1) Index Cond: (headers ?
'x-virus-scanned'::text)Planningtime: 0.064 msTotal runtime: 39.160 ms
(8 rows)
Time: 39,509 ms
=======================================================================
So while the GIN plans seems to be just slightly expensive than GIN,
it's actually way faster.
Granted, most won't have GIN and GIST index on the same column at the
same time, but bad cost estimate may cause other issues. Maybe I could
achieve this by tweaking the various cost GUCs, but ISTM that tweaking
the cost estimation would be appropriate.
regards
Tomas
On 02/26/2014 11:25 PM, Alexander Korotkov wrote:
> On Thu, Feb 27, 2014 at 1:07 AM, Alexander Korotkov <aekorotkov@gmail.com>wrote:
>
>> On Thu, Feb 20, 2014 at 1:48 PM, Heikki Linnakangas <
>> hlinnakangas@vmware.com> wrote:
>>
>>> On 02/09/2014 12:11 PM, Alexander Korotkov wrote:
>>>
>>>> I've rebased catalog changes with last master. Patch is attached. I've
>>>> rerun my test suite with both last master ('committed') and attached
>>>> patch ('ternary-consistent').
>>>>
>>>
>>> Thanks!
>>>
>>>
>>> method | sum
>>>> ------------------------+------------------
>>>> committed | 143491.715000001
>>>> fast-scan-11 | 126916.111999999
>>>> fast-scan-light | 137321.211
>>>> fast-scan-light-heikki | 138168.028000001
>>>> master | 446976.288
>>>> ternary-consistent | 125923.514
>>>>
>>>> I explain regression in last master by change of MAX_MAYBE_ENTRIES from 8
>>>> to 4.
>>>>
>>>
>>> Yeah, probably. I set MAX_MAYBE_ENTRIES to 8 in initial versions to make
>>> sure we get similar behavior in Tomas' tests that used 6 search terms. But
>>> I always felt that it was too large for real queries, once we have the
>>> catalog changes, that's why I lowered to 4 when committing. If an opclass
>>> benefits greatly from fast scan, it should provide the ternary consistent
>>> function, and not rely on the shim implementation.
>>>
>>>
>>> I'm not sure about decision to reserve separate procedure number for
>>>> ternary consistent. Probably, it would be better to add ginConfig method.
>>>> It would be useful for post 9.4 improvements.
>>>>
>>>
>>> Hmm, it might be useful for an opclass to provide both, a boolean and
>>> ternary consistent function, if the boolean version is significantly more
>>> efficient when all the arguments are TRUE/FALSE. OTOH, you could also do a
>>> quick check through the array to see if there are any MAYBE arguments,
>>> within the consistent function. But I'm inclined to keep the possibility to
>>> provide both versions. As long as we support the boolean version at all,
>>> there's not much difference in terms of the amount of code to support
>>> having them both for the same opclass.
>>>
>>> A ginConfig could be useful for many other things, but I don't think it's
>>> worth adding it now.
>>>
>>>
>>> What's the difference between returning GIN_MAYBE and GIN_TRUE+recheck?
>>> We discussed that earlier, but didn't reach any conclusion. That needs to
>>> be clarified in the docs. One possibility is to document that they're
>>> equivalent. Another is to forbid one of them. Yet another is to assign a
>>> different meaning to each.
>>>
>>> I've been thinking that it might be useful to define them so that a MAYBE
>>> result from the tri-consistent function means that it cannot decide if you
>>> have a match or not, because some of the inputs were MAYBE. And
>>> TRUE+recheck means that even if all the MAYBE inputs were passed as TRUE or
>>> FALSE, the result would be the same, TRUE+recheck. The practical difference
>>> would be that if the tri-consistent function returns TRUE+recheck, ginget.c
>>> wouldn't need to bother fetching the other entries, it could just return
>>> the entry with recheck=true immediately. While with MAYBE result, it would
>>> fetch the other entries and call tri-consistent again. ginget.c doesn't
>>> currently use the tri-consistent function that way - it always fetches all
>>> the entries for a potential match before calling tri-consistent, but it
>>> could. I had it do that in some of the patch versions, but Tomas' testing
>>> showed that it was a big loss on some queries, because the consistent
>>> function was called much more often. Still, something like that might be
>>> sensible in the future, so it might be good to distinguish those cases in
>>> the API now. Note that ginarrayproc is already using the return values like
>>> that: in GinContainedStrategy, it always returns TRUE+recheck regardless of
>>> the inputs, but in other cases it uses GIN_MAYBE.
>>
>>
>> Next revision of patch is attached.
>>
>> In this version opclass should provide at least one consistent function:
>> binary or ternary. It's expected to achieve best performance when opclass
>> provide both of them. However, tests shows opposite :( I've to recheck it
>> carefully.
>>
>
> However, it's not!
> This revision of patch completes my test case in 123330 ms. This is
> slightly faster than previous revision.
Great. Committed, I finally got around to it.
Some minor changes: I reworded the docs and also updated the table of
support functions in xindex.sgml. I refactored the query in
opr_sanity.sql, to make it easier to read, and to check more carefully
that the required support functions are present. I also added a runtime
check to avoid crashing if neither is present.
A few things we ought to still discuss:
* I just noticed that the dummy trueTriConsistentFn returns GIN_MAYBE,
rather than GIN_TRUE. The equivalent boolean version returns 'true'
without recheck. Is that a typo, or was there some reason for the
discrepancy?
* Come to think of it, I'm not too happy with the name GinLogicValue.
It's too vague. It ought to include "ternary" or "tri-value" or
something like that. How about renaming it to "GinTernaryValue" or just
"GinTernary"? Any better suggestion for the name?
* This patch added a triConsistent function for array and tsvector
opclasses. Were you planning to submit a patch to do that for the rest
of the opclasses, like pg_trgm? (it's getting awfully late for that...)
- Heikki
On 03/12/2014 12:09 AM, Tomas Vondra wrote:
> Hi all,
>
> a quick question that just occured to me - do you plan to tweak the cost
> estimation fot GIN indexes, in this patch?
>
> IMHO it would be appropriate, given the improvements and gains, but it
> seems to me gincostestimate() was not touched by this patch.
Good point. We have done two major changes to GIN in this release cycle:
changed the data page format and made it possible to skip items without
fetching all the keys ("fast scan"). gincostestimate doesn't know about
either change.
Adjusting gincostestimate for the more compact data page format seems
easy. When I hacked on that, I assumed all along that gincostestimate
doesn't need to be changed as the index will just be smaller, which will
be taken into account automatically. But now that I look at
gincostestimate, it assumes that the size of one item on a posting tree
page is a constant 6 bytes (SizeOfIptrData), which is no longer true.
I'll go fix that.
Adjusting for the effects of skipping is harder. gincostestimate needs
to do the same preparation steps as startScanKey: sort the query keys by
frequency, and call consistent function to split the keys intao
"required" and "additional" sets. And then model that the "additional"
entries only need to be fetched when the other keys match. That's doable
in principle, but requires a bunch of extra code.
Alexander, any thoughts on that? It's getting awfully late to add new
code for that, but it sure would be nice somehow take fast scan into
account.
- Heikki
<div dir="ltr"><div class="gmail_extra"><div class="gmail_quote">On Wed, Mar 12, 2014 at 8:29 PM, Heikki Linnakangas
<spandir="ltr"><<a href="mailto:hlinnakangas@vmware.com" target="_blank">hlinnakangas@vmware.com</a>></span>
wrote:<br/><blockquote class="gmail_quote" style="margin:0px 0px 0px
0.8ex;border-left-width:1px;border-left-color:rgb(204,204,204);border-left-style:solid;padding-left:1ex"><div
class="">On03/12/2014 12:09 AM, Tomas Vondra wrote:<br /><blockquote class="gmail_quote" style="margin:0px 0px 0px
0.8ex;border-left-width:1px;border-left-color:rgb(204,204,204);border-left-style:solid;padding-left:1ex">Hi all,<br
/><br/> a quick question that just occured to me - do you plan to tweak the cost<br /> estimation fot GIN indexes, in
thispatch?<br /><br /> IMHO it would be appropriate, given the improvements and gains, but it<br /> seems to me
gincostestimate()was not touched by this patch.<br /></blockquote><br /></div> Good point. We have done two major
changesto GIN in this release cycle: changed the data page format and made it possible to skip items without fetching
allthe keys ("fast scan"). gincostestimate doesn't know about either change.<br /><br /> Adjusting gincostestimate for
themore compact data page format seems easy. When I hacked on that, I assumed all along that gincostestimate doesn't
needto be changed as the index will just be smaller, which will be taken into account automatically. But now that I
lookat gincostestimate, it assumes that the size of one item on a posting tree page is a constant 6 bytes
(SizeOfIptrData),which is no longer true. I'll go fix that.<br /><br /> Adjusting for the effects of skipping is
harder.gincostestimate needs to do the same preparation steps as startScanKey: sort the query keys by frequency, and
callconsistent function to split the keys intao "required" and "additional" sets. And then model that the "additional"
entriesonly need to be fetched when the other keys match. That's doable in principle, but requires a bunch of extra
code.<br/><br /> Alexander, any thoughts on that? It's getting awfully late to add new code for that, but it sure would
benice somehow take fast scan into account.</blockquote><div class="gmail_quote"><br /></div><div class="gmail_quote">
Preparationwe do in startScanKey requires knowledge of estimate size of posting lists/trees. We do this estimate by
traversalto leaf pages. I think gincostestimate is expected to be way more cheap. So, we probably need so more rough
estimatethere, don't we?</div><br />------<br />With best regards,<br />Alexander Korotkov.<br /></div></div></div>
On Wed, Mar 12, 2014 at 8:02 PM, Heikki Linnakangas <hlinnakangas@vmware.com> wrote:
------
With best regards,
Alexander Korotkov.
Great. Committed, I finally got around to it.On 02/26/2014 11:25 PM, Alexander Korotkov wrote:On Thu, Feb 27, 2014 at 1:07 AM, Alexander Korotkov <aekorotkov@gmail.com>wrote:On Thu, Feb 20, 2014 at 1:48 PM, Heikki Linnakangas <
hlinnakangas@vmware.com> wrote:On 02/09/2014 12:11 PM, Alexander Korotkov wrote:I've rebased catalog changes with last master. Patch is attached. I've
rerun my test suite with both last master ('committed') and attached
patch ('ternary-consistent').
Thanks!
method | sum------------------------+------------------
committed | 143491.715000001
fast-scan-11 | 126916.111999999
fast-scan-light | 137321.211
fast-scan-light-heikki | 138168.028000001
master | 446976.288
ternary-consistent | 125923.514
I explain regression in last master by change of MAX_MAYBE_ENTRIES from 8
to 4.
Yeah, probably. I set MAX_MAYBE_ENTRIES to 8 in initial versions to make
sure we get similar behavior in Tomas' tests that used 6 search terms. But
I always felt that it was too large for real queries, once we have the
catalog changes, that's why I lowered to 4 when committing. If an opclass
benefits greatly from fast scan, it should provide the ternary consistent
function, and not rely on the shim implementation.
I'm not sure about decision to reserve separate procedure number forternary consistent. Probably, it would be better to add ginConfig method.
It would be useful for post 9.4 improvements.
Hmm, it might be useful for an opclass to provide both, a boolean and
ternary consistent function, if the boolean version is significantly more
efficient when all the arguments are TRUE/FALSE. OTOH, you could also do a
quick check through the array to see if there are any MAYBE arguments,
within the consistent function. But I'm inclined to keep the possibility to
provide both versions. As long as we support the boolean version at all,
there's not much difference in terms of the amount of code to support
having them both for the same opclass.
A ginConfig could be useful for many other things, but I don't think it's
worth adding it now.
What's the difference between returning GIN_MAYBE and GIN_TRUE+recheck?
We discussed that earlier, but didn't reach any conclusion. That needs to
be clarified in the docs. One possibility is to document that they're
equivalent. Another is to forbid one of them. Yet another is to assign a
different meaning to each.
I've been thinking that it might be useful to define them so that a MAYBE
result from the tri-consistent function means that it cannot decide if you
have a match or not, because some of the inputs were MAYBE. And
TRUE+recheck means that even if all the MAYBE inputs were passed as TRUE or
FALSE, the result would be the same, TRUE+recheck. The practical difference
would be that if the tri-consistent function returns TRUE+recheck, ginget.c
wouldn't need to bother fetching the other entries, it could just return
the entry with recheck=true immediately. While with MAYBE result, it would
fetch the other entries and call tri-consistent again. ginget.c doesn't
currently use the tri-consistent function that way - it always fetches all
the entries for a potential match before calling tri-consistent, but it
could. I had it do that in some of the patch versions, but Tomas' testing
showed that it was a big loss on some queries, because the consistent
function was called much more often. Still, something like that might be
sensible in the future, so it might be good to distinguish those cases in
the API now. Note that ginarrayproc is already using the return values like
that: in GinContainedStrategy, it always returns TRUE+recheck regardless of
the inputs, but in other cases it uses GIN_MAYBE.
Next revision of patch is attached.
In this version opclass should provide at least one consistent function:
binary or ternary. It's expected to achieve best performance when opclass
provide both of them. However, tests shows opposite :( I've to recheck it
carefully.
However, it's not!
This revision of patch completes my test case in 123330 ms. This is
slightly faster than previous revision.
Some minor changes: I reworded the docs and also updated the table of support functions in xindex.sgml. I refactored the query in opr_sanity.sql, to make it easier to read, and to check more carefully that the required support functions are present. I also added a runtime check to avoid crashing if neither is present.
A few things we ought to still discuss:
* I just noticed that the dummy trueTriConsistentFn returns GIN_MAYBE, rather than GIN_TRUE. The equivalent boolean version returns 'true' without recheck. Is that a typo, or was there some reason for the discrepancy?
Actually, there is not difference in current implementation, But I implemented it so that trueTriConsistentFn can correctly work with shimBoolConsistentFn. In this case it should return GIN_MAYBE in case when it have no GIN_MAYBE in the input (as analogue of setting recheck flag). So, it could return GIN_TRUE only if it checked that input has GIN_MAYBE. However, checking would be just wasting of cycles. So I end up with just GIN_MAYBE :-)
* Come to think of it, I'm not too happy with the name GinLogicValue. It's too vague. It ought to include "ternary" or "tri-value" or something like that. How about renaming it to "GinTernaryValue" or just "GinTernary"? Any better suggestion for the name?
Probably we could call this just "TernaryValue" hoping that one day it would be useful outside of gin?
* This patch added a triConsistent function for array and tsvector opclasses. Were you planning to submit a patch to do that for the rest of the opclasses, like pg_trgm? (it's getting awfully late for that...)
Yes. I can try to get it into 9.4 if it's possible.
With best regards,
Alexander Korotkov.
On Wed, Mar 12, 2014 at 1:52 PM, Alexander Korotkov <aekorotkov@gmail.com> wrote: >> * This patch added a triConsistent function for array and tsvector >> opclasses. Were you planning to submit a patch to do that for the rest of >> the opclasses, like pg_trgm? (it's getting awfully late for that...) > > Yes. I can try to get it into 9.4 if it's possible. It seems to me that we'd be wise to push that to 9.5 at this point. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On 03/12/2014 07:42 PM, Alexander Korotkov wrote: > Preparation we do in startScanKey requires knowledge of estimate size of > posting lists/trees. We do this estimate by traversal to leaf pages. I > think gincostestimate is expected to be way more cheap. So, we probably > need so more rough estimate there, don't we? Yeah, maybe. We do something similar for b-tree MIN/MAX currently, but with a lot of keys, it could be a lot more expensive to traverse down to all of them. I wonder if we could easily at least catch the common skewed cases, where e.g the logic of the consistent function is to AND all the keys. The opclass would know that, but we would somehow need to pass down the information to gincostestimate. - Heikki
On 03/12/2014 07:52 PM, Alexander Korotkov wrote: >> > >> >* I just noticed that the dummy trueTriConsistentFn returns GIN_MAYBE, >> >rather than GIN_TRUE. The equivalent boolean version returns 'true' without >> >recheck. Is that a typo, or was there some reason for the discrepancy? >> > > Actually, there is not difference in current implementation, But I > implemented it so that trueTriConsistentFn can correctly work > with shimBoolConsistentFn. In this case it should return GIN_MAYBE in case > when it have no GIN_MAYBE in the input (as analogue of setting recheck > flag). So, it could return GIN_TRUE only if it checked that input has > GIN_MAYBE. However, checking would be just wasting of cycles. So I end up > with just GIN_MAYBE :-) I don't understand that. As it is, it's inconsistent with the boolean trueConsistent function. trueConsistent always returns TRUE with recheck=false. And in GIN_SEARCH_MODE_EVERYTHING mode, there are no regular scan keys. - Heikki
On Thu, Mar 13, 2014 at 8:58 PM, Heikki Linnakangas <hlinnakangas@vmware.com> wrote:
On 03/12/2014 07:52 PM, Alexander Korotkov wrote:I don't understand that. As it is, it's inconsistent with the boolean trueConsistent function. trueConsistent always returns TRUE with recheck=false. And in GIN_SEARCH_MODE_EVERYTHING mode, there are no regular scan keys.>Actually, there is not difference in current implementation, But I
>* I just noticed that the dummy trueTriConsistentFn returns GIN_MAYBE,
>rather than GIN_TRUE. The equivalent boolean version returns 'true' without
>recheck. Is that a typo, or was there some reason for the discrepancy?
>
implemented it so that trueTriConsistentFn can correctly work
with shimBoolConsistentFn. In this case it should return GIN_MAYBE in case
when it have no GIN_MAYBE in the input (as analogue of setting recheck
flag). So, it could return GIN_TRUE only if it checked that input has
GIN_MAYBE. However, checking would be just wasting of cycles. So I end up
with just GIN_MAYBE :-)
Ok, I see. I just messed it up.
------
With best regards,
Alexander Korotkov.
With best regards,
Alexander Korotkov.
On 12 March 2014 16:29, Heikki Linnakangas <hlinnakangas@vmware.com> wrote:
> Good point. We have done two major changes to GIN in this release cycle:
> changed the data page format and made it possible to skip items without
> fetching all the keys ("fast scan"). gincostestimate doesn't know about
> either change.
Did this cost estimation issue get fixed? If not, and if this is due
for 9.5, can this be removed from the 9.4 open items list?
Thom
On 09/25/2014 09:05 PM, Thom Brown wrote:
> On 12 March 2014 16:29, Heikki Linnakangas <hlinnakangas@vmware.com> wrote:
>> Good point. We have done two major changes to GIN in this release cycle:
>> changed the data page format and made it possible to skip items without
>> fetching all the keys ("fast scan"). gincostestimate doesn't know about
>> either change.
>
> Did this cost estimation issue get fixed?
Nope.
> If not, and if this is due for 9.5, can this be removed from the 9.4 open items list?
Removed and moved to the TODO list. It's a pity, but no-one seems to
have a great idea on what to do about the cost estimation, nor interest
in working on it.
- Heikki