Thread: Proposed Patch to Improve Performance of Multi-Batch Hash Join for Skewed Data Sets
Proposed Patch to Improve Performance of Multi-Batch Hash Join for Skewed Data Sets
We propose a patch that improves hybrid hash join’s performance for large multi-batch joins where the probe relation has skew.
Project name: Histojoin
Patch file: histojoin_v1.patch
This patch implements the Histojoin join algorithm as an optional feature added to the standard Hybrid Hash Join (HHJ). A flag is used to enable or disable the Histojoin features. When Histojoin is disabled, HHJ acts as normal. The Histojoin features allow HHJ to use PostgreSQL’s statistics to do skew aware partitioning. The basic idea is to keep build relation tuples in a small in-memory hash table that have join values that are frequently occurring in the probe relation. This improves performance of HHJ when multiple batches are used by 10% to 50% for skewed data sets. The performance improvements of this patch can be seen in the paper (pages 25-30) at:
http://people.ok.ubc.ca/rlawrenc/histojoin2.pdf
All generators and materials needed to verify these results can be provided.
This is a patch against the HEAD of the repository.
This patch does not contain platform specific code. It compiles and has been tested on our machines in both Windows (MSVC++) and Linux (GCC).
Currently the Histojoin feature is enabled by default and is used whenever HHJ is used and there are Most Common Value (MCV) statistics available on the probe side base relation of the join. To disable this feature simply set the enable_hashjoin_usestatmcvs flag to off in the database configuration file or at run time with the 'set' command.
One potential improvement not included in the patch is that Most Common Value (MCV) statistics are only determined when the probe relation is produced by a scan operator. There is a benefit to using MCVs even when the probe relation is not a base scan, but we were unable to determine how to find statistics from a base relation after other operators are performed.
This patch was created by Bryce Cutt as part of his work on his M.Sc. thesis.
--
Dr. Ramon Lawrence
Assistant Professor, Department of Computer Science, University of British Columbia Okanagan
E-mail: ramon.lawrence@ubc.ca
Attachment
Re: Proposed Patch to Improve Performance of Multi-Batch Hash Join for Skewed Data Sets
On Mon, Oct 20, 2008 at 4:42 PM, Lawrence, Ramon <ramon.lawrence@ubc.ca> wrote: > We propose a patch that improves hybrid hash join's performance for large > multi-batch joins where the probe relation has skew. > > Project name: Histojoin > Patch file: histojoin_v1.patch > > This patch implements the Histojoin join algorithm as an optional feature > added to the standard Hybrid Hash Join (HHJ). A flag is used to enable or > disable the Histojoin features. When Histojoin is disabled, HHJ acts as > normal. The Histojoin features allow HHJ to use PostgreSQL's statistics to > do skew aware partitioning. The basic idea is to keep build relation tuples > in a small in-memory hash table that have join values that are frequently > occurring in the probe relation. This improves performance of HHJ when > multiple batches are used by 10% to 50% for skewed data sets. The > performance improvements of this patch can be seen in the paper (pages > 25-30) at: > > http://people.ok.ubc.ca/rlawrenc/histojoin2.pdf > > All generators and materials needed to verify these results can be provided. > > This is a patch against the HEAD of the repository. > > This patch does not contain platform specific code. It compiles and has > been tested on our machines in both Windows (MSVC++) and Linux (GCC). > > Currently the Histojoin feature is enabled by default and is used whenever > HHJ is used and there are Most Common Value (MCV) statistics available on > the probe side base relation of the join. To disable this feature simply > set the enable_hashjoin_usestatmcvs flag to off in the database > configuration file or at run time with the 'set' command. > > One potential improvement not included in the patch is that Most Common > Value (MCV) statistics are only determined when the probe relation is > produced by a scan operator. There is a benefit to using MCVs even when the > probe relation is not a base scan, but we were unable to determine how to > find statistics from a base relation after other operators are performed. > > This patch was created by Bryce Cutt as part of his work on his M.Sc. > thesis. > > -- > Dr. Ramon Lawrence > Assistant Professor, Department of Computer Science, University of British > Columbia Okanagan > E-mail: ramon.lawrence@ubc.ca I'm interested in trying to review this patch. Having not done patch review before, I can't exactly promise grand results, but if you could provide me with the data to check your results? In the meantime I'll go read the paper. - Josh / eggyknap
Re: Proposed Patch to Improve Performance of Multi-Batch Hash Join for Skewed Data Sets
Joshua, Thank you for offering to review the patch. The easiest way to test would be to generate your own TPC-H data and load it into a database for testing. I have posted the TPC-H generator at: http://people.ok.ubc.ca/rlawrenc/TPCHSkew.zip The generator can produce skewed data sets. It was produced by Microsoft Research. After unzipping, on a Windows machine, you can just run the command: dbgen -s 1 -z 1 This will produce a TPC-H database of scale 1 GB with a Zipfian skew of z=1. More information on the generator is in the document README-S.DOC. Source is provided for the generator, so you should be able to run it on other operating systems as well. The schema DDL is at: http://people.ok.ubc.ca/rlawrenc/tpch_pg_ddl.txt Note that the load time for 1G data is 1-2 hours and for 10G data is about 24 hours. I recommend you do not add the foreign keys until after the data is loaded. The other alternative is to do a pgdump on our data sets. However, the download size would be quite large, and it will take a couple of days for us to get you the data in that form. -- Dr. Ramon Lawrence Assistant Professor, Department of Computer Science, University of British Columbia Okanagan E-mail: ramon.lawrence@ubc.ca > -----Original Message----- > From: Joshua Tolley [mailto:eggyknap@gmail.com] > Sent: November 1, 2008 3:42 PM > To: Lawrence, Ramon > Cc: pgsql-hackers@postgresql.org; Bryce Cutt > Subject: Re: [HACKERS] Proposed Patch to Improve Performance of Multi- > Batch Hash Join for Skewed Data Sets > > On Mon, Oct 20, 2008 at 4:42 PM, Lawrence, Ramon <ramon.lawrence@ubc.ca> > wrote: > > We propose a patch that improves hybrid hash join's performance for > large > > multi-batch joins where the probe relation has skew. > > > > Project name: Histojoin > > Patch file: histojoin_v1.patch > > > > This patch implements the Histojoin join algorithm as an optional > feature > > added to the standard Hybrid Hash Join (HHJ). A flag is used to enable > or > > disable the Histojoin features. When Histojoin is disabled, HHJ acts as > > normal. The Histojoin features allow HHJ to use PostgreSQL's statistics > to > > do skew aware partitioning. The basic idea is to keep build relation > tuples > > in a small in-memory hash table that have join values that are > frequently > > occurring in the probe relation. This improves performance of HHJ when > > multiple batches are used by 10% to 50% for skewed data sets. The > > performance improvements of this patch can be seen in the paper (pages > > 25-30) at: > > > > http://people.ok.ubc.ca/rlawrenc/histojoin2.pdf > > > > All generators and materials needed to verify these results can be > provided. > > > > This is a patch against the HEAD of the repository. > > > > This patch does not contain platform specific code. It compiles and has > > been tested on our machines in both Windows (MSVC++) and Linux (GCC). > > > > Currently the Histojoin feature is enabled by default and is used > whenever > > HHJ is used and there are Most Common Value (MCV) statistics available > on > > the probe side base relation of the join. To disable this feature > simply > > set the enable_hashjoin_usestatmcvs flag to off in the database > > configuration file or at run time with the 'set' command. > > > > One potential improvement not included in the patch is that Most Common > > Value (MCV) statistics are only determined when the probe relation is > > produced by a scan operator. There is a benefit to using MCVs even when > the > > probe relation is not a base scan, but we were unable to determine how > to > > find statistics from a base relation after other operators are > performed. > > > > This patch was created by Bryce Cutt as part of his work on his M.Sc. > > thesis. > > > > -- > > Dr. Ramon Lawrence > > Assistant Professor, Department of Computer Science, University of > British > > Columbia Okanagan > > E-mail: ramon.lawrence@ubc.ca > > I'm interested in trying to review this patch. Having not done patch > review before, I can't exactly promise grand results, but if you could > provide me with the data to check your results? In the meantime I'll > go read the paper. > > - Josh / eggyknap
Re: Proposed Patch to Improve Performance of Multi-Batch Hash Join for Skewed Data Sets
On Sun, Nov 2, 2008 at 4:48 PM, Lawrence, Ramon <ramon.lawrence@ubc.ca> wrote: > Joshua, > > Thank you for offering to review the patch. > > The easiest way to test would be to generate your own TPC-H data and > load it into a database for testing. I have posted the TPC-H generator > at: > > http://people.ok.ubc.ca/rlawrenc/TPCHSkew.zip > > The generator can produce skewed data sets. It was produced by > Microsoft Research. > > After unzipping, on a Windows machine, you can just run the command: > > dbgen -s 1 -z 1 > > This will produce a TPC-H database of scale 1 GB with a Zipfian skew of > z=1. More information on the generator is in the document README-S.DOC. > Source is provided for the generator, so you should be able to run it on > other operating systems as well. > > The schema DDL is at: > > http://people.ok.ubc.ca/rlawrenc/tpch_pg_ddl.txt > > Note that the load time for 1G data is 1-2 hours and for 10G data is > about 24 hours. I recommend you do not add the foreign keys until after > the data is loaded. > > The other alternative is to do a pgdump on our data sets. However, the > download size would be quite large, and it will take a couple of days > for us to get you the data in that form. > > -- > Dr. Ramon Lawrence > Assistant Professor, Department of Computer Science, University of > British Columbia Okanagan > E-mail: ramon.lawrence@ubc.ca I'll try out the TPC-H generator first :) Thanks. - Josh
Re: Proposed Patch to Improve Performance of Multi-Batch Hash Join for Skewed Data Sets
"Lawrence, Ramon" <ramon.lawrence@ubc.ca> writes: > The easiest way to test would be to generate your own TPC-H data and > load it into a database for testing. I have posted the TPC-H generator > at: > http://people.ok.ubc.ca/rlawrenc/TPCHSkew.zip > The generator can produce skewed data sets. It was produced by > Microsoft Research. What alternatives are there for people who do not run Windows? regards, tom lane
Re: Proposed Patch to Improve Performance of Multi-Batch Hash Join for Skewed Data Sets
> From: Tom Lane [mailto:tgl@sss.pgh.pa.us] > What alternatives are there for people who do not run Windows? > > regards, tom lane The TPC-H generator is a standard code base provided at http://www.tpc.org/tpch/. We have been able to compile this code on Linux. However, we were unable to get the Microsoft modifications to this code to compile on Linux (although they are supposed to be portable). So, we just used the Windows version with wine on our test Debian machine. I have also posted the text files for the TPC-H 1G 1Z data set at: http://people.ok.ubc.ca/rlawrenc/tpch1g1z.zip Note that you need to trim the extra characters at the end of the lines for PostgreSQL to read them properly. Since the data takes a while to generate and load, we can also provide a compressed version of the PostgreSQL data directory of the databases with the data already loaded. -- Ramon Lawrence
Re: Proposed Patch to Improve Performance of Multi-Batch Hash Join for Skewed Data Sets
On Mon, Oct 20, 2008 at 03:42:49PM -0700, Lawrence, Ramon wrote:
> We propose a patch that improves hybrid hash join's performance for large
> multi-batch joins where the probe relation has skew.
I'm running into problems with this patch. It applies cleanly, and the
technique you provided for generating sample data works just fine
(though I admit I haven't verified that the expected skew exists in the
data). But the server crashes when I try to load the data. The backtrace
is below, labeled "Backtrace 1"; since it happens in
ExecScanHashMostCommonTuples, I figure it's because of the patch and not
something else odd (unless perhaps my hardware is flakey -- I'll try it
on other hardware as soon as I can, to verify). Note that I'm running
this on Ubuntu 8.10, 32-bit x86, running a kernel Ubuntu labels as
"2.6.27-7-generic #1 SMP". The statement in execution at the time was
"ALTER TABLE SUPPLIER ADD CONSTRAINT SUPPLIER_FK1 FOREIGN KEY
(S_NATIONKEY) references NATION (N_NATIONKEY);"
Further, when I go back into the database in psql, simply issuing a "\d"
command crashes the backend with a similar backtrace, labeled Backtrace
2, below. The query underlying \d and its EXPLAIN output are also
included, just for kicks.
- Josh
*****************************************
BACKTRACE 1
****************************************
Core was generated by `postgres: jtolley jtolley [local] ALTE'.
Program terminated with signal 6, Aborted.
[New process 20407]
#0 0xb80b0430 in __kernel_vsyscall ()
(gdb) bt
#0 0xb80b0430 in __kernel_vsyscall ()
#1 0xb7f22880 in raise () from /lib/tls/i686/cmov/libc.so.6
#2 0xb7f24248 in abort () from /lib/tls/i686/cmov/libc.so.6
#3 0x0831540e in ExceptionalCondition ( conditionName=0x8433274
"!(hjstate->hj_OuterTupleMostCommonValuePartition <
hashtable->nMostCommonTuplePartitions)", errorType=0x834b66d "FailedAssertion", fileName=0x84331d9
"nodeHash.c", lineNumber=880) at assert.c:57
#4 0x081b457b in ExecScanHashMostCommonTuples (hjstate=0x8720a6c,
econtext=0x8720af8) at nodeHash.c:880
#5 0x081b60de in ExecHashJoin (node=0x8720a6c) at nodeHashjoin.c:357
#6 0x081a4748 in ExecProcNode (node=0x8720a6c) at execProcnode.c:406
#7 0x081a242b in standard_ExecutorRun (queryDesc=0x870957c,
direction=ForwardScanDirection, count=1) at execMain.c:1343
#8 0x081c2036 in _SPI_execute_plan (plan=0x87181bc, paramLI=0x0,
snapshot=0x8485300, crosscheck_snapshot=0x0, read_only=1 '\001', fire_triggers=0 '\0', tcount=1) at spi.c:1976
#9 0x081c2350 in SPI_execute_snapshot (plan=0x87181bc, Values=0x0,
Nulls=0x0, snapshot=0x8485300, crosscheck_snapshot=0x0, read_only=<value optimized out>, fire_triggers=<value
optimized
out>, tcount=1) at spi.c:408
#10 0x082e1921 in RI_Initial_Check (trigger=0xbfeb0afc,
fk_rel=0xb5a21938, pk_rel=0xb5a20754) at ri_triggers.c:2763
#11 0x08178613 in ATRewriteTables (wqueue=0xbfeb0d88) at
tablecmds.c:5026
#12 0x0817ef36 in ATController (rel=0xb5a21938, cmds=<value optimized
out>, recurse=<value optimized out>) at tablecmds.c:2294
#13 0x08261dd5 in ProcessUtility (parsetree=0x86ca17c, queryString=0x86c96ec "ALTER TABLE SUPPLIER\nADD CONSTRAINT
SUPPLIER_FK1 FOREIGN KEY (S_NATIONKEY) references NATION
(N_NATIONKEY);", params=0x0, isTopLevel=1 '\001', dest=0x86ca2b4,
completionTag=0xbfeb0fc8 "") at utility.c:569
#14 0x0825e2ae in PortalRunUtility (portal=0x86fadfc,
utilityStmt=0x86ca17c, isTopLevel=<value optimized out>, dest=0x86ca2b4, completionTag=0xbfeb0fc8 "") at
pquery.c:1176
#15 0x0825f2c0 in PortalRunMulti (portal=0x86fadfc, isTopLevel=<value
optimized out>, dest=0x86ca2b4, altdest=0x86ca2b4, completionTag=0xbfeb0fc8 "") at pquery.c:1281
#16 0x0825fb54 in PortalRun (portal=0x86fadfc, count=2147483647,
isTopLevel=6 '\006', dest=0x86ca2b4, altdest=0x86ca2b4, completionTag=0xbfeb0fc8 "") at pquery.c:812
#17 0x0825a757 in exec_simple_query ( query_string=0x86c96ec "ALTER TABLE SUPPLIER\nADD CONSTRAINT
SUPPLIER_FK1 FOREIGN KEY (S_NATIONKEY) references NATION
(N_NATIONKEY);") at postgres.c:992
#18 0x0825bfff in PostgresMain (argc=4, argv=0x8667b08,
username=0x8667ae0 "jtolley") at postgres.c:3569
#19 0x082261cf in ServerLoop () at postmaster.c:3258
#20 0x08227190 in PostmasterMain (argc=1, argv=0x8664250) at
postmaster.c:1031
#21 0x081cc126 in main (argc=1, argv=0x8664250) at main.c:188
(gdb)
*****************************************
BACKTRACE 2
****************************************
Core was generated by `postgres: jtolley jtolley [local] SELE'.
Program terminated with signal 6, Aborted.
[New process 20967]
#0 0xb80b0430 in __kernel_vsyscall ()
(gdb) bt
#0 0xb80b0430 in __kernel_vsyscall ()
#1 0xb7f22880 in raise () from /lib/tls/i686/cmov/libc.so.6
#2 0xb7f24248 in abort () from /lib/tls/i686/cmov/libc.so.6
#3 0x0831540e in ExceptionalCondition ( conditionName=0x8433274
"!(hjstate->hj_OuterTupleMostCommonValuePartition <
hashtable->nMostCommonTuplePartitions)", errorType=0x834b66d "FailedAssertion", fileName=0x84331d9
"nodeHash.c", lineNumber=880) at assert.c:57
#4 0x081b457b in ExecScanHashMostCommonTuples (hjstate=0x86fb320,
econtext=0x86fb3ac) at nodeHash.c:880
#5 0x081b60de in ExecHashJoin (node=0x86fb320) at nodeHashjoin.c:357
#6 0x081a4748 in ExecProcNode (node=0x86fb320) at execProcnode.c:406
#7 0x081bb2a1 in ExecSort (node=0x86fb294) at nodeSort.c:102
#8 0x081a4718 in ExecProcNode (node=0x86fb294) at execProcnode.c:417
#9 0x081a242b in standard_ExecutorRun (queryDesc=0x8706e1c,
direction=ForwardScanDirection, count=0) at execMain.c:1343
#10 0x0825e64c in PortalRunSelect (portal=0x8700e0c, forward=1 '\001',
count=0, dest=0x871db14) at pquery.c:942
#11 0x0825f9ae in PortalRun (portal=0x8700e0c, count=2147483647,
isTopLevel=1 '\001', dest=0x871db14, altdest=0x871db14, completionTag=0xbfeb0fc8 "") at pquery.c:796
#12 0x0825a757 in exec_simple_query ( query_string=0x86cb6f4 "SELECT n.nspname as \"Schema\",\n c.relname
as \"Name\",\n CASE c.relkind WHEN 'r' THEN 'table' WHEN 'v' THEN
'view' WHEN 'i' THEN 'index' WHEN 'S' THEN 'sequence' WHEN 's' THEN
'special' END as \"Type\",\n "...) at postgres.c:992
#13 0x0825bfff in PostgresMain (argc=4, argv=0x8667f58,
username=0x8667f30 "jtolley") at postgres.c:3569
#14 0x082261cf in ServerLoop () at postmaster.c:3258
#15 0x08227190 in PostmasterMain (argc=1, argv=0x8664250) at
postmaster.c:1031
#16 0x081cc126 in main (argc=1, argv=0x8664250) at main.c:188
*****************************************
\d EXPLAIN output
****************************************
jtolley=# explain SELECT n.nspname as "Schema",
jtolley-# c.relname as "Name",
jtolley-# CASE c.relkind WHEN 'r' THEN 'table' WHEN 'v' THEN 'view'
WHEN 'i' THEN 'index' WHEN 'S' THEN 'sequence' WHEN 's' THEN 'special'
END as "Type",
jtolley-# pg_catalog.pg_get_userbyid(c.relowner) as "Owner"
jtolley-# FROM pg_catalog.pg_class c
jtolley-# LEFT JOIN pg_catalog.pg_namespace n ON n.oid =
c.relnamespace
jtolley-# WHERE c.relkind IN ('r','v','S','')
jtolley-# AND n.nspname <> 'pg_catalog'
jtolley-# AND n.nspname !~ '^pg_toast'
jtolley-# AND pg_catalog.pg_table_is_visible(c.oid)
jtolley-# ORDER BY 1,2; QUERY PLAN
--------------------------------------------------------------------------------------------------Sort
(cost=13.02..13.10rows=35 width=133) Sort Key: n.nspname, c.relname -> Hash Join (cost=1.14..12.12 rows=35
width=133) Hash Cond: (c.relnamespace = n.oid) -> Seq Scan on pg_class c (cost=0.00..9.97 rows=35
width=73) Filter: (pg_table_is_visible(oid) AND (relkind = ANY
('{r,v,S,""}'::"char"[]))) -> Hash (cost=1.09..1.09 rows=4 width=68) -> Seq Scan on pg_namespace
n (cost=0.00..1.09 rows=4
width=68) Filter: ((nspname <> 'pg_catalog'::name) AND
(nspname !~ '^pg_toast'::text))
(9 rows)
Re: Proposed Patch to Improve Performance of Multi-Batch Hash Join for Skewed Data Sets
On Mon, Oct 20, 2008 at 03:42:49PM -0700, Lawrence, Ramon wrote: > We propose a patch that improves hybrid hash join's performance for large > multi-batch joins where the probe relation has skew. I also recommend modifying docs/src/sgml/config.sgml to include the enable_hashjoin_usestatmcvs option. - Josh / eggyknap
Re: Proposed Patch to Improve Performance of Multi-Batch Hash Join for Skewed Data Sets
Joshua Tolley <eggyknap@gmail.com> writes:
> On Mon, Oct 20, 2008 at 03:42:49PM -0700, Lawrence, Ramon wrote:
>> We propose a patch that improves hybrid hash join's performance for large
>> multi-batch joins where the probe relation has skew.
> I also recommend modifying docs/src/sgml/config.sgml to include the
> enable_hashjoin_usestatmcvs option.
If the patch is actually a win, why would we bother with such a GUC
at all?
regards, tom lane
Re: Proposed Patch to Improve Performance of Multi-Batch Hash Join for Skewed Data Sets
-----BEGIN PGP SIGNED MESSAGE----- Hash: SHA1 On Wed, Nov 5, 2008 at 8:20 AM, Tom Lane wrote: > Joshua Tolley writes: >> On Mon, Oct 20, 2008 at 03:42:49PM -0700, Lawrence, Ramon wrote: >>> We propose a patch that improves hybrid hash join's performance for large >>> multi-batch joins where the probe relation has skew. > >> I also recommend modifying docs/src/sgml/config.sgml to include the >> enable_hashjoin_usestatmcvs option. > > If the patch is actually a win, why would we bother with such a GUC > at all? > > regards, tom lane Good point. Leaving it in place for patch review purposes is useful, but we can probably lose it in the end. - - Josh / eggyknap -----BEGIN PGP SIGNATURE----- Version: GnuPG v1.4.9 (GNU/Linux) Comment: http://getfiregpg.org iEYEARECAAYFAkkRujsACgkQRiRfCGf1UMNSTACfbpDSQn0HGSVr3jI30GJApcRD YbQAn2VZdI/aIalGBrbn1hlRWPEvbgV5 =LKZ3 -----END PGP SIGNATURE-----
Re: Proposed Patch to Improve Performance of Multi-Batch Hash Join for Skewed Data Sets
The error is causes by me Asserting against the wrong variable. I never noticed this as I apparently did not have assertions turned on on my development machine. That is fixed now and with the new patch version I have attached all assertions are passing with your query and my test queries. I added another assertion to that section of the code so that it is a bit more vigorous in confirming the hash table partition is correct. It does not change the operation of the code. There are two partition counts. One holds the maximum number of buckets in the hash table and the other counts the number of actual buckets created for hash values. I was incorrectly testing against the second one because that was valid before I started using a hash table to store the buckets. The enable_hashjoin_usestatmcvs flag was valuable for my own research and tests and likely useful for your review but Tom is correct that it can be removed in the final version. - Bryce Cutt On Wed, Nov 5, 2008 at 7:22 AM, Joshua Tolley <eggyknap@gmail.com> wrote: > -----BEGIN PGP SIGNED MESSAGE----- > Hash: SHA1 > > On Wed, Nov 5, 2008 at 8:20 AM, Tom Lane wrote: >> Joshua Tolley writes: >>> On Mon, Oct 20, 2008 at 03:42:49PM -0700, Lawrence, Ramon wrote: >>>> We propose a patch that improves hybrid hash join's performance for large >>>> multi-batch joins where the probe relation has skew. >> >>> I also recommend modifying docs/src/sgml/config.sgml to include the >>> enable_hashjoin_usestatmcvs option. >> >> If the patch is actually a win, why would we bother with such a GUC >> at all? >> >> regards, tom lane > > Good point. Leaving it in place for patch review purposes is useful, > but we can probably lose it in the end. > > - - Josh / eggyknap > -----BEGIN PGP SIGNATURE----- > Version: GnuPG v1.4.9 (GNU/Linux) > Comment: http://getfiregpg.org > > iEYEARECAAYFAkkRujsACgkQRiRfCGf1UMNSTACfbpDSQn0HGSVr3jI30GJApcRD > YbQAn2VZdI/aIalGBrbn1hlRWPEvbgV5 > =LKZ3 > -----END PGP SIGNATURE----- >
Attachment
Re: Proposed Patch to Improve Performance of Multi-Batch Hash Join for Skewed Data Sets
On Wed, Nov 05, 2008 at 04:06:11PM -0800, Bryce Cutt wrote: > The error is causes by me Asserting against the wrong variable. I > never noticed this as I apparently did not have assertions turned on > on my development machine. That is fixed now and with the new patch > version I have attached all assertions are passing with your query and > my test queries. I added another assertion to that section of the > code so that it is a bit more vigorous in confirming the hash table > partition is correct. It does not change the operation of the code. > > There are two partition counts. One holds the maximum number of > buckets in the hash table and the other counts the number of actual > buckets created for hash values. I was incorrectly testing against > the second one because that was valid before I started using a hash > table to store the buckets. > > The enable_hashjoin_usestatmcvs flag was valuable for my own research > and tests and likely useful for your review but Tom is correct that it > can be removed in the final version. > > - Bryce Cutt Thanks for the new patch; I'll take a look as soon as I can (prolly tomorrow). - Josh
Re: Proposed Patch to Improve Performance of Multi-Batch Hash Join for Skewed Data Sets
On Wed, Nov 5, 2008 at 5:06 PM, Bryce Cutt <pandasuit@gmail.com> wrote: > The error is causes by me Asserting against the wrong variable. I > never noticed this as I apparently did not have assertions turned on > on my development machine. That is fixed now and with the new patch > version I have attached all assertions are passing with your query and > my test queries. I added another assertion to that section of the > code so that it is a bit more vigorous in confirming the hash table > partition is correct. It does not change the operation of the code. > > There are two partition counts. One holds the maximum number of > buckets in the hash table and the other counts the number of actual > buckets created for hash values. I was incorrectly testing against > the second one because that was valid before I started using a hash > table to store the buckets. > > The enable_hashjoin_usestatmcvs flag was valuable for my own research > and tests and likely useful for your review but Tom is correct that it > can be removed in the final version. > > - Bryce Cutt Well, that builds nicely, lets me import the data, and I've seen a performance improvement with enable_hashjoin_usestatmcvs on vs. off. I plan to test that more formally (though probably not fully to the extent you did in your paper; just enough to feel comfortable that I'm getting similar results). Then I'll spend some time poking in the code, for the relatively little good I feel I can do in that capacity, and I'll also investigate scenarios with particularly inaccurate statistics. Stay tuned. - Josh
Re: Proposed Patch to Improve Performance of Multi-Batch Hash Join for Skewed Data Sets
On Thu, 2008-11-06 at 15:33 -0700, Joshua Tolley wrote: > Stay tuned. Minor question on this patch. AFAICS there is another patch that seems to be aiming at exactly the same use case. Jonah's Bloom filter patch. Shouldn't we have a dust off to see which one is best? Or at least a discussion to test whether they overlap? Perhaps you already did that and I missed it because I'm not very tuned in on this thread. -- Simon Riggs www.2ndQuadrant.comPostgreSQL Training, Services and Support
Re: Proposed Patch to Improve Performance of Multi-Batch Hash Join for Skewed Data Sets
On Thu, Nov 6, 2008 at 3:52 PM, Simon Riggs <simon@2ndquadrant.com> wrote: > > On Thu, 2008-11-06 at 15:33 -0700, Joshua Tolley wrote: > >> Stay tuned. > > Minor question on this patch. AFAICS there is another patch that seems > to be aiming at exactly the same use case. Jonah's Bloom filter patch. > > Shouldn't we have a dust off to see which one is best? Or at least a > discussion to test whether they overlap? Perhaps you already did that > and I missed it because I'm not very tuned in on this thread. > > -- > Simon Riggs www.2ndQuadrant.com > PostgreSQL Training, Services and Support We haven't had that discussion AFAIK, and definitely should. First glance suggests they could coexist peacefully, with proper coaxing. If I understand things properly, Jonah's patch filters tuples early in the join process, and this patch tries to ensure that hash join batches are kept in RAM when they're most likely to be used. So they're orthogonal in purpose, and the patches actually apply *almost* cleanly together. Jonah, any comments? If I continue to have some time to devote, and get through all I think I can do to review this patch, I'll gladly look at Jonah's too, FWIW. - Josh
Re: Proposed Patch to Improve Performance of Multi-Batch Hash Join for Skewed Data Sets
> -----Original Message----- > > Minor question on this patch. AFAICS there is another patch that seems > > to be aiming at exactly the same use case. Jonah's Bloom filter patch. > > > > Shouldn't we have a dust off to see which one is best? Or at least a > > discussion to test whether they overlap? Perhaps you already did that > > and I missed it because I'm not very tuned in on this thread. > > > > -- > > Simon Riggs www.2ndQuadrant.com > > PostgreSQL Training, Services and Support > > We haven't had that discussion AFAIK, and definitely should. First > glance suggests they could coexist peacefully, with proper coaxing. If > I understand things properly, Jonah's patch filters tuples early in > the join process, and this patch tries to ensure that hash join > batches are kept in RAM when they're most likely to be used. So > they're orthogonal in purpose, and the patches actually apply *almost* > cleanly together. Jonah, any comments? If I continue to have some time > to devote, and get through all I think I can do to review this patch, > I'll gladly look at Jonah's too, FWIW. > > - Josh The skew patch and bloom filter patch are orthogonal and can both be applied. The bloom filter patch is a great idea, and it is used in many other database systems. You can use the TPC-H data set to demonstrate that the bloom filter patch will significantly improve performance of multi-batch joins (with or without data skew). Any query that filters a build table before joining on the probe table will show improvements with a bloom filter. For example, select * from customer, orders where customer.c_nationkey = 10 and customer.c_custkey = orders.o_custkey The bloom filter on customer would allow us to avoid probing with orders tuples that cannot possibly find a match due to the selection criteria. This is especially beneficial for multi-batch joins where an orders tuple must be written to disk if its corresponding customer batch is not the in-memory batch. I have no experience reviewing patches, but I would be happy to help contribute/review the bloom filter patch as best I can. -- Dr. Ramon Lawrence Assistant Professor, Department of Computer Science, University of British Columbia Okanagan E-mail: ramon.lawrence@ubc.ca
Re: Proposed Patch to Improve Performance of Multi-Batch Hash Join for Skewed Data Sets
On Thu, Nov 6, 2008 at 5:31 PM, Lawrence, Ramon <ramon.lawrence@ubc.ca> wrote: >> -----Original Message----- >> > Minor question on this patch. AFAICS there is another patch that > seems >> > to be aiming at exactly the same use case. Jonah's Bloom filter > patch. >> > >> > Shouldn't we have a dust off to see which one is best? Or at least a >> > discussion to test whether they overlap? Perhaps you already did > that >> > and I missed it because I'm not very tuned in on this thread. >> > >> > -- >> > Simon Riggs www.2ndQuadrant.com >> > PostgreSQL Training, Services and Support >> >> We haven't had that discussion AFAIK, and definitely should. First >> glance suggests they could coexist peacefully, with proper coaxing. If >> I understand things properly, Jonah's patch filters tuples early in >> the join process, and this patch tries to ensure that hash join >> batches are kept in RAM when they're most likely to be used. So >> they're orthogonal in purpose, and the patches actually apply *almost* >> cleanly together. Jonah, any comments? If I continue to have some time >> to devote, and get through all I think I can do to review this patch, >> I'll gladly look at Jonah's too, FWIW. >> >> - Josh > > The skew patch and bloom filter patch are orthogonal and can both be > applied. The bloom filter patch is a great idea, and it is used in many > other database systems. You can use the TPC-H data set to demonstrate > that the bloom filter patch will significantly improve performance of > multi-batch joins (with or without data skew). > > Any query that filters a build table before joining on the probe table > will show improvements with a bloom filter. For example, > > select * from customer, orders where customer.c_nationkey = 10 and > customer.c_custkey = orders.o_custkey > > The bloom filter on customer would allow us to avoid probing with orders > tuples that cannot possibly find a match due to the selection criteria. > This is especially beneficial for multi-batch joins where an orders > tuple must be written to disk if its corresponding customer batch is not > the in-memory batch. > > I have no experience reviewing patches, but I would be happy to help > contribute/review the bloom filter patch as best I can. > > -- > Dr. Ramon Lawrence > Assistant Professor, Department of Computer Science, University of > British Columbia Okanagan > E-mail: ramon.lawrence@ubc.ca > I've no patch review experience, either -- this is my first one. See http://wiki.postgresql.org/wiki/Reviewing_a_Patch for details on what a reviewer ought to do in general; various patch review discussions on the -hackers list have also proven helpful. As regards this patch specifically, it seems we could merge the two patches into one and consider them together. However, the bloom filter patch is listed as a "Work in Progress" on http://wiki.postgresql.org/wiki/CommitFest_2008-11. Perhaps it needs more work before being considered seriously? Jonah, what do you think would be most helpful? - Josh / eggyknap
Re: Proposed Patch to Improve Performance of Multi-Batch Hash Join for Skewed Data Sets
On Wed, Nov 05, 2008 at 04:06:11PM -0800, Bryce Cutt wrote: > The error is causes by me Asserting against the wrong variable. I > never noticed this as I apparently did not have assertions turned on > on my development machine. That is fixed now and with the new patch > version I have attached all assertions are passing with your query and > my test queries. I added another assertion to that section of the > code so that it is a bit more vigorous in confirming the hash table > partition is correct. It does not change the operation of the code. > > There are two partition counts. One holds the maximum number of > buckets in the hash table and the other counts the number of actual > buckets created for hash values. I was incorrectly testing against > the second one because that was valid before I started using a hash > table to store the buckets. > > The enable_hashjoin_usestatmcvs flag was valuable for my own research > and tests and likely useful for your review but Tom is correct that it > can be removed in the final version. > > - Bryce Cutt > Well, this version seems to work as advertised. Skewed data sets tend to hash join more quickly with this turned on, and data sets with deliberately bad statistics don't perform much differently than with the feature turned off. The patch applies cleanly to CVS HEAD. I don't consider myself qualified to do a decent code review. However I noticed that the comments are all done with // instead of /* ... */. That should probably be changed. To those familiar with code review: is there more I should do to review this? - Josh / eggyknap
Re: Proposed Patch to Improve Performance of Multi-Batch Hash Join for Skewed Data Sets
"Lawrence, Ramon" <ramon.lawrence@ubc.ca> writes:
> We propose a patch that improves hybrid hash join's performance for
> large multi-batch joins where the probe relation has skew.
> ...
> The basic idea
> is to keep build relation tuples in a small in-memory hash table that
> have join values that are frequently occurring in the probe relation.
I looked at this patch a little.
I'm a tad worried about what happens when the values that are frequently
occurring in the outer relation are also frequently occurring in the
inner (which hardly seems an improbable case). Don't you stand a severe
risk of blowing out the in-memory hash table? It doesn't appear to me
that the code has any way to back off once it's decided that a certain
set of join key values are to be treated in-memory. Splitting the main
join into more batches certainly doesn't help with that.
Also, AFAICS the benefit of this patch comes entirely from avoiding dump
and reload of tuples bearing the most common values, which means it's a
significant waste of cycles when there's only one batch. It'd be better
to avoid doing any of the extra work in the single-batch case.
One thought that might address that point as well as the difficulty of
getting stats in nontrivial cases is to wait until we've overrun memory
and are forced to start batching, and at that point determine on-the-fly
which are the most common hash values from inspection of the hash table
as we dump it out. This would amount to optimizing on the basis of
frequency in the *inner* relation not the outer, but offhand I don't see
any strong theoretical basis why that wouldn't be just as good. It
could lose if the first work_mem worth of inner tuples isn't
representative of what follows; but this hardly seems more dangerous
than depending on MCV stats that are for the whole outer relation rather
than the portion of it being selected.
regards, tom lane
Re: Proposed Patch to Improve Performance of Multi-Batch Hash Join for Skewed Data Sets
> -----Original Message----- > From: Tom Lane [mailto:tgl@sss.pgh.pa.us] > I'm a tad worried about what happens when the values that are frequently > occurring in the outer relation are also frequently occurring in the > inner (which hardly seems an improbable case). Don't you stand a severe > risk of blowing out the in-memory hash table? It doesn't appear to me > that the code has any way to back off once it's decided that a certain > set of join key values are to be treated in-memory. Splitting the main > join into more batches certainly doesn't help with that. > > Also, AFAICS the benefit of this patch comes entirely from avoiding dump > and reload of tuples bearing the most common values, which means it's a > significant waste of cycles when there's only one batch. It'd be better > to avoid doing any of the extra work in the single-batch case. > > One thought that might address that point as well as the difficulty of > getting stats in nontrivial cases is to wait until we've overrun memory > and are forced to start batching, and at that point determine on-the-fly > which are the most common hash values from inspection of the hash table > as we dump it out. This would amount to optimizing on the basis of > frequency in the *inner* relation not the outer, but offhand I don't see > any strong theoretical basis why that wouldn't be just as good. It > could lose if the first work_mem worth of inner tuples isn't > representative of what follows; but this hardly seems more dangerous > than depending on MCV stats that are for the whole outer relation rather > than the portion of it being selected. > > regards, tom lane You are correct with both observations. The patch only has a benefit when there is more than one batch. Also, there is a potential issue with MCV hash table overflows if the number of tuples that match the MCVs in the build relation is very large. Bryce has created a patch (attached) that disables the code for one batch joins. This patch also checks for MCV hash table overflows and handles them by "flushing" from the MCV hash table back to the main hash table. The main hash table will then resolve overflows as usual. Note that this will cause the worse case of a build table with all the same values to be handled the same as the current hash code, i.e., it will attempt to re-partition until it eventually gives up and then allocates the entire partition in memory. There may be a better way to handle this case, but the new patch will remain consistent with the current hash join implementation. The issue with determining and using the MCV stats is more challenging than it appears. First, knowing the MCVs of the build table will not help us. What we need are the MCVs of the probe table because by knowing those values we will keep the tuples with those values in the build relation in memory. For example, consider a join between tables Part and LineItem. Assume 1 popular part accounts for 10% of all LineItems. If Part is the build relation and LineItem is the probe relation, then by keeping that 1 part record in memory, we will guarantee that we do not need to write out 10% of LineItem. If a selection occurs on LineItem before the join, it may change the distribution of LineItem (the MCVs) but it is probable that they are still a good estimate of the MCVs in the derived LineItem relation. (We did experiments on trying to sample the first few thousand tuples of the probe relation to dynamically determine the MCVs but generally found this was inaccurate due to non-random samples.) In essence, the goal is to smartly pick the tuples that remain in the in-memory batch before probing begins. Since the number of MCVs is small, incorrectly selecting build tuples to remain in memory has negligible cost. If we assume that LineItem has been filtered so much that it is now smaller than Part and is the build relation then the MCV approach does not apply. There is no skew in Part on partkey (since it is the PK) and knowing the MCV partkeys in LineItem does not help us because they each only join with a single tuple in Part. In this case, the MCV approach should not be used because no benefit is possible, and it will not be used because there will be no MCVs for Part.partkey. The bad case with MCV hash table overflow requires a many-to-many join between the two relations which would not occur on the more typical PK-FK joins. -- Dr. Ramon Lawrence Assistant Professor, Department of Computer Science, University of British Columbia Okanagan E-mail: ramon.lawrence@ubc.ca
Attachment
Re: Proposed Patch to Improve Performance of Multi-Batch Hash Join for Skewed Data Sets
I have to admit that I haven't fully grokked what this patch is about
just yet, so what follows is mostly a coding style review at this
point. It would help a lot if you could add some comments to the new
functions that are being added to explain the purpose of each at a
very high level. There's clearly been a lot of thought put into some
parts of this logic, so it would be worth explaining the reasoning
behind that logic.
This patch applies clearly against CVS HEAD, but does not compile
(please fix the warning, too).
nodeHash.c:88: warning: no previous prototype for 'freezeNextMCVPartiton'
nodeHash.c: In function 'freezeNextMCVPartiton':
nodeHash.c:148: error: 'struct HashJoinTableData' has no member named 'inTupIOs'
I commented out the offending line. It errored out again here:
nodeHashjoin.c: In function 'getMostCommonValues':
nodeHashjoin.c:136: error: wrong type argument to unary plus
After removing the stray + sign, it compiled, but failed the
"rangefuncs" regression test. If you're going to keep the
enable_hashjoin_usestatmvcs() GUC around, you need to patch
rangefuncs.out so that the regression tests pass. I think, however,
that there was some discussion of removing that before the patch is
committed; if so, please do that instead. Keeping the GUC would also
require patching the documentation, which the current patch does not
do.
getMostCommonValues() isn't a good name for a non-static function
because there's nothing to tip the reader off to the fact that it has
something to do with hash joins; compare with the other function names
defined in the same header file. On the flip side, that function has
only one call site, so it should probably be made static and not
declared in the header file at all. Some of the other new functions
need similar treatment. I am also a little suspicious of this bit of
code:
relid = getrelid(((SeqScan *) ((SeqScanState *)
outerPlanState(hjstate))->ps.plan)->scanrelid,
estate->es_range_table); clause = (FuncExprState *) lfirst(list_head(hjstate->hashclauses)); argstate =
(ExprState*) lfirst(list_head(clause->args)); variable = (Var *) argstate->expr;
I'm not very familiar with the hash join code, but it seems like there
are a lot of assumptions being made there about what things are
pointing to what other things. Is this this actually safe? And if it
is, perhaps a comment explaining why?
getMostCommonValues() also appears to be creating and maintaining a
counter called collisionsWhileHashing, but nothing is ever done with
the counter. On a similar note, the variables relattnum, atttype, and
atttypmod don't appear to be necessary; 2 out of 3 of them are only
used once, so maybe inlining the reference and dropping the variable
would make more sense. Also, the if (HeapTupleIsValid(statsTuple))
block encompasses the whole rest of the function, maybe if
(!HeapTupleIsValid(statsTuple)) return?
I don't understand why
hashtable->mostCommonTuplePartition[bucket].tuples and .frozen need to
be initialized to 0. It looks to me like those are in a zero-filled
array that was just allocated, so it shouldn't be necessary to re-zero
them, unless I'm missing something.
freezeNextMCVPartiton is mis-spelled consistently throughout (the last
three letters should be "ion"). I also don't think it makes sense to
enclose everything but the first two lines of that function in an
else-block.
There is some initialization code in ExecHashJoin() that looks like it
belongs in ExecHashTableCreate.
It appears to me that the interface to isAMostCommonValue() could be
simplified by just making it return the partition number. It could
perhaps be renamed something like ExecHashGetMCVPartition().
Does ExecHashTableDestroy() need to explicitly pfree
hashtable->mostCommonTuplePartition and
hashtable->flushOrderedMostCommonTuplePartition? I would think those
would be allocated out of hashCxt - if they aren't, they probably
should be.
Department of minor nitpicks: (1) C++-style comments are not
permitted, (2) function names need to be capitalized like_this() or
LikeThis() but not likeThis(), (3) when defining a function, the
return type should be placed on the line preceding the actual function
name, so that the function name is at the beginning of the line, (4)
curly braces should be avoided around a block containing only one
statement, (5) excessive blank lines should be avoided (for example,
the one in costsize.c is clearly unnecessary, and there's at least one
place where you add two consecutive blank lines), and (6) I believe
the accepted way to write an empty loop is an indented semi-colon on
the next line, rather than {} on the same line as the while.
I will try to do some more substantive testing of this as well.
...Robert
Re: Proposed Patch to Improve Performance of Multi-Batch Hash Join for Skewed Data Sets
Dr. Lawrence: I'm still working on reviewing this patch. I've managed to load the sample TPCH data from tpch1g1z.zip after changing the line endings to UNIX-style and chopping off the trailing vertical bars. (If anyone is interested, I have the results of pg_dump | bzip2 -9 on the resulting database, which I would be happy to upload if someone has server space. It is about 250MB.) But, I'm not sure quite what to do in terms of generating queries. TPCHSkew contains QGEN.EXE, but that seems to require that you provide template queries as input, and I'm not sure where to get the templates. Any suggestions? Thanks, ...Robert
Re: Proposed Patch to Improve Performance of Multi-Batch Hash Join for Skewed Data Sets
Robert, You do not need to use qgen.exe to generate queries as you are not running the TPC-H benchmark test. Attached is an example of the 22 sample TPC-H queries according to the benchmark. We have not tested using the TPC-H queries for this particular patch and only use the TPC-H database as a large, skewed data set. The simpler queries we test involve joins of Part-Lineitem or Supplier-Lineitem such as: Select * from part, lineitem where p_partkey = l_partkey OR Select count(*) from part, lineitem where p_partkey = l_partkey The count(*) version is usually more useful for comparisons as the generation of output tuples on the client side (say with pgadmin) dominates the actual time to complete the query. To isolate query costs, we also test using a simple server-side function. The setup description I have also attached. I would be happy to help in any way I can. Bryce is currently working on an updated patch according to your suggestions. -- Dr. Ramon Lawrence Assistant Professor, Department of Computer Science, University of British Columbia Okanagan E-mail: ramon.lawrence@ubc.ca > -----Original Message----- > From: pgsql-hackers-owner@postgresql.org [mailto:pgsql-hackers- > owner@postgresql.org] On Behalf Of Robert Haas > Sent: December 17, 2008 7:54 PM > To: Lawrence, Ramon > Cc: Tom Lane; pgsql-hackers@postgresql.org; Bryce Cutt > Subject: Re: [HACKERS] Proposed Patch to Improve Performance of Multi- > Batch Hash Join for Skewed Data Sets > > Dr. Lawrence: > > I'm still working on reviewing this patch. I've managed to load the > sample TPCH data from tpch1g1z.zip after changing the line endings to > UNIX-style and chopping off the trailing vertical bars. (If anyone is > interested, I have the results of pg_dump | bzip2 -9 on the resulting > database, which I would be happy to upload if someone has server > space. It is about 250MB.) > > But, I'm not sure quite what to do in terms of generating queries. > TPCHSkew contains QGEN.EXE, but that seems to require that you provide > template queries as input, and I'm not sure where to get the > templates. > > Any suggestions? > > Thanks, > > ...Robert > > -- > Sent via pgsql-hackers mailing list (pgsql-hackers@postgresql.org) > To make changes to your subscription: > http://www.postgresql.org/mailpref/pgsql-hackers
Attachment
Re: Proposed Patch to Improve Performance of Multi-Batch Hash Join for Skewed Data Sets
Robert,
I thoroughly appreciate the constructive criticism.
The compile errors are due to my development process being convoluted.I will endeavor to not waste your time in the
futurewith errors
caused by my development process.
I have updated the code to follow the conventions and suggestions
given. I am now working on adding the requested documentation. I
will not submit the next patch until that is done. The functionality
has not changed so you can performance test with the patch you have.
As for that particularly ugly piece of code. I figured that out while
digging through the selfuncs code. Basically I needed a way to get
the stats tuple for the outer relation join column of the join but to
do that I needed to figure out how to get the actual relation id and
attribute number that was being joined.
I have not yet figured out a better way to do this but I am sure there
is someone on the mailing list with far more knowledge of this than I
have.
I could possibly be more vigorous in testing to make sure the things I
am casting are exactly what I expect. My tests have always been
consistent so far.
I am essentially doing what is done in selfuncs. I believe I could
use the examine_variable() function in selfuncs.c except I would first
need a PlannerInfo and I don't think I can get that from inside the
join initialization code.
- Bryce Cutt
On Mon, Dec 15, 2008 at 8:51 PM, Robert Haas <robertmhaas@gmail.com> wrote:
> I have to admit that I haven't fully grokked what this patch is about
> just yet, so what follows is mostly a coding style review at this
> point. It would help a lot if you could add some comments to the new
> functions that are being added to explain the purpose of each at a
> very high level. There's clearly been a lot of thought put into some
> parts of this logic, so it would be worth explaining the reasoning
> behind that logic.
>
> This patch applies clearly against CVS HEAD, but does not compile
> (please fix the warning, too).
>
> nodeHash.c:88: warning: no previous prototype for 'freezeNextMCVPartiton'
> nodeHash.c: In function 'freezeNextMCVPartiton':
> nodeHash.c:148: error: 'struct HashJoinTableData' has no member named 'inTupIOs'
>
> I commented out the offending line. It errored out again here:
>
> nodeHashjoin.c: In function 'getMostCommonValues':
> nodeHashjoin.c:136: error: wrong type argument to unary plus
>
> After removing the stray + sign, it compiled, but failed the
> "rangefuncs" regression test. If you're going to keep the
> enable_hashjoin_usestatmvcs() GUC around, you need to patch
> rangefuncs.out so that the regression tests pass. I think, however,
> that there was some discussion of removing that before the patch is
> committed; if so, please do that instead. Keeping the GUC would also
> require patching the documentation, which the current patch does not
> do.
>
> getMostCommonValues() isn't a good name for a non-static function
> because there's nothing to tip the reader off to the fact that it has
> something to do with hash joins; compare with the other function names
> defined in the same header file. On the flip side, that function has
> only one call site, so it should probably be made static and not
> declared in the header file at all. Some of the other new functions
> need similar treatment. I am also a little suspicious of this bit of
> code:
>
> relid = getrelid(((SeqScan *) ((SeqScanState *)
> outerPlanState(hjstate))->ps.plan)->scanrelid,
> estate->es_range_table);
> clause = (FuncExprState *) lfirst(list_head(hjstate->hashclauses));
> argstate = (ExprState *) lfirst(list_head(clause->args));
> variable = (Var *) argstate->expr;
>
> I'm not very familiar with the hash join code, but it seems like there
> are a lot of assumptions being made there about what things are
> pointing to what other things. Is this this actually safe? And if it
> is, perhaps a comment explaining why?
>
> getMostCommonValues() also appears to be creating and maintaining a
> counter called collisionsWhileHashing, but nothing is ever done with
> the counter. On a similar note, the variables relattnum, atttype, and
> atttypmod don't appear to be necessary; 2 out of 3 of them are only
> used once, so maybe inlining the reference and dropping the variable
> would make more sense. Also, the if (HeapTupleIsValid(statsTuple))
> block encompasses the whole rest of the function, maybe if
> (!HeapTupleIsValid(statsTuple)) return?
>
> I don't understand why
> hashtable->mostCommonTuplePartition[bucket].tuples and .frozen need to
> be initialized to 0. It looks to me like those are in a zero-filled
> array that was just allocated, so it shouldn't be necessary to re-zero
> them, unless I'm missing something.
>
> freezeNextMCVPartiton is mis-spelled consistently throughout (the last
> three letters should be "ion"). I also don't think it makes sense to
> enclose everything but the first two lines of that function in an
> else-block.
>
> There is some initialization code in ExecHashJoin() that looks like it
> belongs in ExecHashTableCreate.
>
> It appears to me that the interface to isAMostCommonValue() could be
> simplified by just making it return the partition number. It could
> perhaps be renamed something like ExecHashGetMCVPartition().
>
> Does ExecHashTableDestroy() need to explicitly pfree
> hashtable->mostCommonTuplePartition and
> hashtable->flushOrderedMostCommonTuplePartition? I would think those
> would be allocated out of hashCxt - if they aren't, they probably
> should be.
>
> Department of minor nitpicks: (1) C++-style comments are not
> permitted, (2) function names need to be capitalized like_this() or
> LikeThis() but not likeThis(), (3) when defining a function, the
> return type should be placed on the line preceding the actual function
> name, so that the function name is at the beginning of the line, (4)
> curly braces should be avoided around a block containing only one
> statement, (5) excessive blank lines should be avoided (for example,
> the one in costsize.c is clearly unnecessary, and there's at least one
> place where you add two consecutive blank lines), and (6) I believe
> the accepted way to write an empty loop is an indented semi-colon on
> the next line, rather than {} on the same line as the while.
>
> I will try to do some more substantive testing of this as well.
>
> ...Robert
>
Re: Proposed Patch to Improve Performance of Multi-Batch Hash Join for Skewed Data Sets
[Some performance testing.] I ran this query 10x with this patch applied, and then 10x again with enable_hashjoin_usestatmvcs set to false to disable the optimization: select sum(1) from (select * from part, lineitem where p_partkey = l_partkey) x; With the optimization enabled, the query took between 26.6 and 38.3 seconds with an average of 31.6. With the optimization disabled, the query took between 48.3 and 69.0 seconds with an average of 60.0 seconds. It appears that the 100 entries in pg_statistic cover about 32% of l_partkey: tpch=# WITH x AS ( SELECT stanumbers1, array_length(stanumbers1, 1) AS len FROM pg_statistic WHERE starelid='lineitem'::regclass AND staattnum = (SELECT attnum FROM pg_attribute WHERE attrelid='lineitem'::regclassAND attname='l_partkey') ) SELECT sum(x.stanumbers1[y.g]) FROM x, (select generate_series(1, x.len) g from x) y; sum --------0.3276 (1 row) (there's probably a better way to write that query...) stadistinct for l_partkey is 23,050; the actual number of distinct values is 199,919. IOW, 0.0005% of the distinct values account for 32.76% of the table. That's a lot of skew, but not unrealistic - I've seen tables where more than half of the rows were covered by a single value. ...Robert
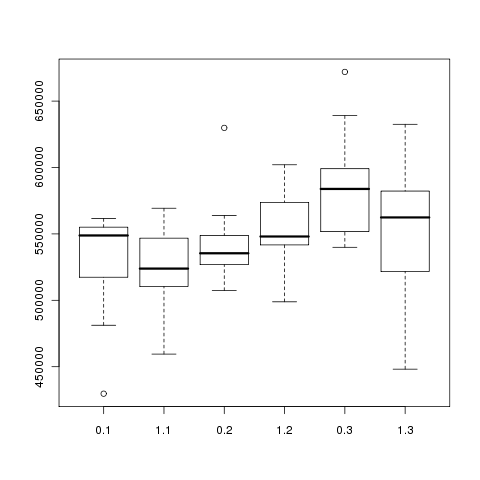
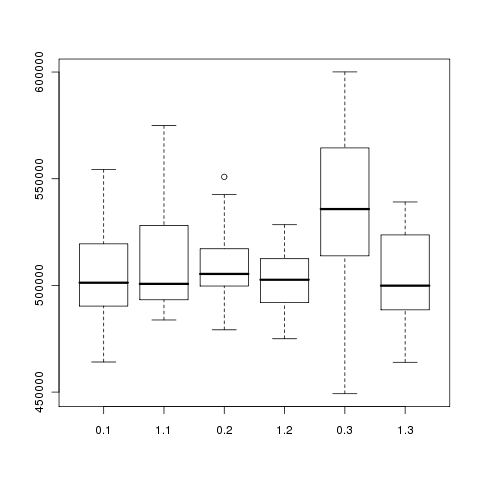
Re: Proposed Patch to Improve Performance of Multi-Batch Hash Join for Skewed Data Sets
On Sun, Dec 21, 2008 at 10:25:59PM -0500, Robert Haas wrote:
> [Some performance testing.]
I (finally!) have a chance to post my performance testing results... my
apologies for the really long delay. <Excuses omitted>
Unfortunately I'm not seeing wonderful speedups with the particular
queries I did in this case. I generated three 1GB datasets, with skews
set at 1, 2, and 3. The test script I wrote turns on enable_usestatmcvs
and runs EXPLAIN ANALYZE on the same query five times. Then it turns
enable_usestatmcvs off, and runs the same query five more times. It does
this with each of the three datasets in turn, and then starts over at
the beginning until I tell it to quit. My results showed a statistically
significant improvement in speed only on the skew == 3 dataset.
I did the same tests twice, once with default_statistics_target set to
10, and once with it set to 100. I've attached boxplots of the total
query times as reported by EXPLAIN ANALYZE ("dst10" in the filename
indicates default_statistics_target was 10, and so on), my results
parsed out of the EXPLAIN ANALYZE output (test.filtered.10 and
test.filtered.100), the results of one-tailed Student's T tests of the
result set (ttests), and the R code to run the tests if anyone's really
interested (t.test.R).
The results data includes six columns: the skew value, whether
enable_usestatmcvs was on or not (represented by a 1 or 0), total times
for each of the three joins that made up the query, and total time for
the query itself. The results above pay attention only to the total
query time.
Finally, the query involved:
SELECT * FROM lineitem l LEFT JOIN part p ON (p.p_partkey = l.l_partkey)
LEFT JOIN orders o ON (o.o_orderkey = l.l_orderky) LEFT JOIN customer c
ON (c.c_custkey = o.o_custkey);
- Josh / eggyknap
Attachment
{kind=link}
{kind=link}
Re: Proposed Patch to Improve Performance of Multi-Batch Hash Join for Skewed Data Sets
Because there is no nice way in PostgreSQL (that I know of) to derive
a histogram after a join (on an intermediate result) currently
usingMostCommonValues is only enabled on a join when the outer (probe)
side is a table scan (seq scan only actually). See
getMostCommonValues (soon to be called
ExecHashJoinGetMostCommonValues) for the logic that determines this.
Here is the result of explain (on a 100MB version of PostgreSQL):
"Hash Left Join (cost=16232.00..91035.00 rows=600000 width=526)"
" Hash Cond: (l.l_partkey = p.p_partkey)"
" -> Hash Left Join (cost=15368.00..75171.00 rows=600000 width=395)"
" Hash Cond: (l.l_orderkey = o.o_orderkey)"
" -> Seq Scan on lineitem l (cost=0.00..17867.00 rows=600000
width=125)"
" -> Hash (cost=8073.00..8073.00 rows=150000 width=270)"
" -> Hash Left Join (cost=700.50..8073.00 rows=150000 width=270)"
" Hash Cond: (o.o_custkey = c.c_custkey)"
" -> Seq Scan on orders o (cost=0.00..4185.00
rows=150000 width=109)"
" -> Hash (cost=513.00..513.00 rows=15000 width=161)"
" -> Seq Scan on customer c
(cost=0.00..513.00 rows=15000 width=161)"
" -> Hash (cost=614.00..614.00 rows=20000 width=131)"
" -> Seq Scan on part p (cost=0.00..614.00 rows=20000 width=131)"
If you take a look at the explain for that join you will see that the
first of the relations joined are orders and customer on custkey.
There is almost no skew in the o_custkey attribute of orders even in
the Z2 dataset so the difference between hashjoin with and without
usingMostCommonValues enabled is quite small.
The second join performed is to join the result of the first join with
lineitem on orderkey. There is no skew at all in the l_orderkey
attribute of lineitem so usingMostCommonValues can not help at all.
The third join performed is to join the result of the second join with
part on partkey. There is a lot of skew in the l_partkey attribute of
lineitem but because the probe side of the third join is an
intermediate from the second join and not a seq scan the algorithm
cannot figure out the MCVs of the probe side.
So on the query presented almost no skew can be exploited on the first
join and no other joins can have their skew exploited at all because
of the order PostgreSQL does the joins in. Basically yes, you would
not see any real benefit from using the most common values on this
query.
We experimented with sampling (mentioned in the paper) to make an
educated guess of MCVs on intermediary results but found that because
a random sample could not be obtained the results were always very
inaccurate. I basically just read a percentage of tuples from the
probe relation before partitioning the build relation, derived the
MCVs in a single pass, wrote the tuples back out to a temp file
(because reading back from here is less expensive than resetting the
probe side tree), then did the join as usual while remembering to read
back from my temp file before reading the rest of the probe side
tuples. Our tests indicate that sampling is not likely a good
solution for deriving MCVs from intermediary results.
In the Java implementation of histojoin we experimented with
exploiting skew in multiple joins of a star join with some success
(detailed in paper). I am not sure how this would be accomplished
nicely in PostgreSQL.
If the cost operators knew how to order the joins to make the best use
of skew in the relations PostgreSQL could use the benefits of
histojoin more often if perhaps doing a join with skew first would
have speed benefits over doing the smaller join first. This change
could be a future addition to PostgreSQL if this patch is accepted.
It relies on getting the stats tuple for the join during the planning
phase (in the cost function) and estimating the benefit that would
have on the join cost.
- Bryce Cutt
On Mon, Dec 22, 2008 at 6:15 AM, Joshua Tolley <eggyknap@gmail.com> wrote:
> On Sun, Dec 21, 2008 at 10:25:59PM -0500, Robert Haas wrote:
>> [Some performance testing.]
>
> I (finally!) have a chance to post my performance testing results... my
> apologies for the really long delay. <Excuses omitted>
>
> Unfortunately I'm not seeing wonderful speedups with the particular
> queries I did in this case. I generated three 1GB datasets, with skews
> set at 1, 2, and 3. The test script I wrote turns on enable_usestatmcvs
> and runs EXPLAIN ANALYZE on the same query five times. Then it turns
> enable_usestatmcvs off, and runs the same query five more times. It does
> this with each of the three datasets in turn, and then starts over at
> the beginning until I tell it to quit. My results showed a statistically
> significant improvement in speed only on the skew == 3 dataset.
>
> I did the same tests twice, once with default_statistics_target set to
> 10, and once with it set to 100. I've attached boxplots of the total
> query times as reported by EXPLAIN ANALYZE ("dst10" in the filename
> indicates default_statistics_target was 10, and so on), my results
> parsed out of the EXPLAIN ANALYZE output (test.filtered.10 and
> test.filtered.100), the results of one-tailed Student's T tests of the
> result set (ttests), and the R code to run the tests if anyone's really
> interested (t.test.R).
>
> The results data includes six columns: the skew value, whether
> enable_usestatmcvs was on or not (represented by a 1 or 0), total times
> for each of the three joins that made up the query, and total time for
> the query itself. The results above pay attention only to the total
> query time.
>
> Finally, the query involved:
>
> SELECT * FROM lineitem l LEFT JOIN part p ON (p.p_partkey = l.l_partkey)
> LEFT JOIN orders o ON (o.o_orderkey = l.l_orderky) LEFT JOIN customer c
> ON (c.c_custkey = o.o_custkey);
>
> - Josh / eggyknap
>
> -----BEGIN PGP SIGNATURE-----
> Version: GnuPG v1.4.9 (GNU/Linux)
>
> iEYEARECAAYFAklPoRYACgkQRiRfCGf1UMNUJgCcCxCRNXJS65nXqMsY2h6PENKF
> YkQAoJlSlaaHd2L5dkFUAc8GPKfKezS5
> =KWfi
> -----END PGP SIGNATURE-----
>
>
Re: Proposed Patch to Improve Performance of Multi-Batch Hash Join for Skewed Data Sets
On Tue, Dec 23, 2008 at 2:21 AM, Bryce Cutt <pandasuit@gmail.com> wrote: > Because there is no nice way in PostgreSQL (that I know of) to derive > a histogram after a join (on an intermediate result) currently > usingMostCommonValues is only enabled on a join when the outer (probe) > side is a table scan (seq scan only actually). See > getMostCommonValues (soon to be called > ExecHashJoinGetMostCommonValues) for the logic that determines this. It's starting to seem to me that the case where this patch provides a benefit is so narrow that I'm not sure it's worth the extra code. Admittedly, when it works, it is pretty dramatic, as in the numbers that I posted previously. I'm OK with the fact that it is restricted to hash joins on a single variable where the probe relation is a sequential scan, because that actually happens pretty frequently, at least in my queries. But, if there's no way to consistently get any benefit out of this when joining more than two tables, then I'm not sure it's worth it. Is it realistic to think that the MCVs of the base relation might still be applicable to the joinrel? It's certainly easy to think of counterexamples, but it might be a good approximation more often than not. ...Robert
Re: Proposed Patch to Improve Performance of Multi-Batch Hash Join for Skewed Data Sets
On Tue, Dec 23, 2008 at 09:22:27AM -0500, Robert Haas wrote: > On Tue, Dec 23, 2008 at 2:21 AM, Bryce Cutt <pandasuit@gmail.com> wrote: > > Because there is no nice way in PostgreSQL (that I know of) to derive > > a histogram after a join (on an intermediate result) currently > > usingMostCommonValues is only enabled on a join when the outer (probe) > > side is a table scan (seq scan only actually). See > > getMostCommonValues (soon to be called > > ExecHashJoinGetMostCommonValues) for the logic that determines this. So my test case of "do a whole bunch of hash joins in a test query" isn't really valid. Makes sense. I did another, more haphazard test on a query with fewer joins, and saw noticeable speedups. > It's starting to seem to me that the case where this patch provides a > benefit is so narrow that I'm not sure it's worth the extra code. Not that anyone asked, but I don't consider myself qualified to render judgement on that point. Code size is, I guess, a maintainability issue, and I'm not terribly experienced maintaining PostgreSQL :) > Is it realistic to think that the MCVs of the base relation might > still be applicable to the joinrel? It's certainly easy to think of > counterexamples, but it might be a good approximation more often than > not. It's equivalent to our assumption that distributions of values in columns in the same table are independent. Making that assumption in this case would probably result in occasional dramatic speed improvements similar to the ones we've seen in less complex joins, offset by just-as-occasional dramatic slowdowns of similar magnitude. In other words, it will increase the variance of our results. - Josh
Re: Proposed Patch to Improve Performance of Multi-Batch Hash Join for Skewed Data Sets
> It's equivalent to our assumption that distributions of values in > columns in the same table are independent. Making that assumption in > this case would probably result in occasional dramatic speed > improvements similar to the ones we've seen in less complex joins, > offset by just-as-occasional dramatic slowdowns of similar magnitude. In > other words, it will increase the variance of our results. Under what circumstances do you think that it would produce a dramatic slowdown? I'm confused. I thought the penalty for picking a bad set of values for the in-memory hash table was pretty small. ...Robert
Re: Proposed Patch to Improve Performance of Multi-BatchHash Join for Skewed Data Sets
> > > Because there is no nice way in PostgreSQL (that I know of) to derive > > > a histogram after a join (on an intermediate result) currently > > > usingMostCommonValues is only enabled on a join when the outer (probe) > > > side is a table scan (seq scan only actually). See > > > getMostCommonValues (soon to be called > > > ExecHashJoinGetMostCommonValues) for the logic that determines this. > > So my test case of "do a whole bunch of hash joins in a test query" > isn't really valid. Makes sense. I did another, more haphazard test on a > query with fewer joins, and saw noticeable speedups. > > > It's starting to seem to me that the case where this patch provides a > > benefit is so narrow that I'm not sure it's worth the extra code. > > Not that anyone asked, but I don't consider myself qualified to render > judgement on that point. Code size is, I guess, a maintainability issue, > and I'm not terribly experienced maintaining PostgreSQL :) > > > Is it realistic to think that the MCVs of the base relation might > > still be applicable to the joinrel? It's certainly easy to think of > > counterexamples, but it might be a good approximation more often than > > not. > > It's equivalent to our assumption that distributions of values in > columns in the same table are independent. Making that assumption in > this case would probably result in occasional dramatic speed > improvements similar to the ones we've seen in less complex joins, > offset by just-as-occasional dramatic slowdowns of similar magnitude. In > other words, it will increase the variance of our results. > > - Josh There is almost zero penalty for selecting incorrect MCV tuples to buffer in memory. Since the number of MCVs is approximately 100, the "overhead" is keeping these 100 tuples in memory where they *might* not be MCVs. The cost is the little extra memory and the checking of the MCVs which is very fast. On the other hand, the benefit is potentially tremendous if the MCV is very common in the probe relation. Every probe tuple that matches the MCV tuple in memory does not have to be written to disk. The potential speedup is directly proportional to the skew. The more skew the more benefit. An analogy is with a page buffering system where one goal is to keep frequently used pages in the buffer. Essentially the goal of this patch is to "pin in memory" the tuples that the join believes will match with the most tuples on the probe side. This reduces I/Os by making more probe relation tuples match during the first read of the probe relation. Regular hash join has no way to guarantee frequently matched build tuples remain memory-resident. The particular join with Customer, Orders, LineItem, and Part is a reasonable test case. There may be two explanations for the results. (I am running tests for this query currently.) First, the time to generate the tuples (select *) may be dominating the query time. Second, as mentioned by Bryce, I expect the issue is that only the join with Customer and Orders exploited the patch. Customer has some skew (but not dramatic) so there would be some speedup. However, the join with Part and LineItem *should* show a benefit but may not because of a limitation of the patch implementation (not the idea). The MCV optimization is only enabled currently when the probe side is a sequential scan. This limitation is due to our current inability to determine a stats tuple of the join attribute on the probe side for other operators. (This should be possible - help please?). Even if this stats tuple is on the base relation and may not exactly reflect the distribution of the intermediate relation on the probe side, it still could be very good. Even if it is not, once again the cost is negligible. In summary, the patch will improve performance of any multi-batch hash join with skew. It is useful right now when the probe relation has skew and is accessed using a sequential scan. It would be useful in even more situations if the code was modified to determine the stats for the join attribute of the probe relation in all cases (even when the probe relation is produced by another operator). -- Dr. Ramon Lawrence Assistant Professor, Department of Computer Science, University of British Columbia Okanagan E-mail: ramon.lawrence@ubc.ca
Re: Proposed Patch to Improve Performance of Multi-Batch Hash Join for Skewed Data Sets
On Tue, Dec 23, 2008 at 10:14:29AM -0500, Robert Haas wrote: > > It's equivalent to our assumption that distributions of values in > > columns in the same table are independent. Making that assumption in > > this case would probably result in occasional dramatic speed > > improvements similar to the ones we've seen in less complex joins, > > offset by just-as-occasional dramatic slowdowns of similar magnitude. In > > other words, it will increase the variance of our results. > > Under what circumstances do you think that it would produce a dramatic > slowdown? I'm confused. I thought the penalty for picking a bad set > of values for the in-memory hash table was pretty small. > > ...Robert I take that back :) I agree with what others have already said, that it shouldn't cause dramatic slowdowns when we get it wrong. - Josh
Re: Proposed Patch to Improve Performance of Multi-BatchHash Join for Skewed Data Sets
> There is almost zero penalty for selecting incorrect MCV tuples to > buffer in memory. Since the number of MCVs is approximately 100, the > "overhead" is keeping these 100 tuples in memory where they *might* not > be MCVs. The cost is the little extra memory and the checking of the > MCVs which is very fast. I looked at this some more. I'm a little concerned about the way we're maintaining the in-memory hash table. Since the highest legal statistics target is now 10,000, it's possible that we could have two orders of magnitude more MCVs than what you're expecting. As I read the code, that could lead to construction of an in-memory hash table with 64K slots. On a 32-bit machine, I believe that works out to 16 bytes per partition (12 and 4), which is a 1MB hash table. That's not necessarily problematic, except that I don't think you're considering the size of the hash table itself when evaluating whether you are blowing out work_mem, and the default size of work_mem is 1MB. I also don't really understand why we're trying to control the size of the hash table by flushing tuples after the fact. Right now, when the in-memory table fills up, we just keep adding tuples to it, which in turn forces us to flush out other tuples to keep the size down. This seems quite inefficient - not only are we doing a lot of unnecessary allocating and freeing, but those flushed slots in the hash table degrade performance (because they don't stop the scan for an empty slot). It seems like we could simplify things considerably by adding tuples to the in-memory hash table only to the point where the next tuple would blow it out. Once we get to that point, we can skip the isAMostCommonValue() test and send any future tuples straight to temp files. (This would also reduce the memory consumption of the in-memory table by a factor of two.) We could potentially improve on this even further if we can estimate in advance how many MCVs we can fit into the in-memory hash table before it gets blown out. If, for example, we have only 1MB of work_mem but there 10,000 MCVs, getMostCommonValues() might decide to only hash the first 1,000 MCVs. Even if we still blow out the in-memory hash table, the earlier MCVs are more frequent than the later MCVs, so the ones that actually make it into the table are likely to be more beneficial. I'm not sure exactly how to do this tuning though, since we'd need to approximate the size of the tuples... I guess the query planner makes some effort to estimate that but I'm not sure how to get at it. > However, the join with Part and LineItem *should* show a benefit but may > not because of a limitation of the patch implementation (not the idea). > The MCV optimization is only enabled currently when the probe side is a > sequential scan. This limitation is due to our current inability to > determine a stats tuple of the join attribute on the probe side for > other operators. (This should be possible - help please?). Not sure how to get at this either, but I'll take a look and see if I can figure it out. Merry Christmas, ...Robert
Re: Proposed Patch to Improve Performance of Multi-BatchHash Join for Skewed Data Sets
> -----Original Message----- > From: Robert Haas [mailto:robertmhaas@gmail.com] > I looked at this some more. I'm a little concerned about the way > we're maintaining the in-memory hash table. Since the highest legal > statistics target is now 10,000, it's possible that we could have two > orders of magnitude more MCVs than what you're expecting. As I read > the code, that could lead to construction of an in-memory hash table > with 64K slots. On a 32-bit machine, I believe that works out to 16 > bytes per partition (12 and 4), which is a 1MB hash table. That's not > necessarily problematic, except that I don't think you're considering > the size of the hash table itself when evaluating whether you are > blowing out work_mem, and the default size of work_mem is 1MB. I totally agree that 10,000 MCVs changes things. Ideally, these 10,000 MCVs should be kept in memory because they will join with the most tuples. However, the size of the MCV hash table (as you point out) can be bigger than work_mem *by itself* not even considering the tuples in the table or in the in-memory batch. Supporting that many MCVs would require more modifications to the hash join algorithm. 100 MCVs should be able to fit in memory though. Since the number of batches is rounded to a power of 2, there is often some hash_table_bytes that are not used by the in-memory batch that can be "used" to store the MCV table. The absolute size of the memory used should also be reasonable (depending on the tuple size in bytes). So, basically, we have a decision to make whether to try support a larger number of MCVs or cap it at a reasonable number like a 100. You can come up with situations where using all 10,000 MCVs is good (for instance if all MCVs have frequency 1/10000), but I expect 100 MCVs will capture the majority of the cases as usually the top 100 MCVs are significantly more frequent than later MCVs. I now also see that the code should be changed to keep track of the MCV bytes separately from hashtable->spaceUsed as this is used to determine when to dynamically increase the number of batches. > I also don't really understand why we're trying to control the size of > the hash table by flushing tuples after the fact. Right now, when the > in-memory table fills up, we just keep adding tuples to it, which in > turn forces us to flush out other tuples to keep the size down. This > seems quite inefficient - not only are we doing a lot of unnecessary > allocating and freeing, but those flushed slots in the hash table > degrade performance (because they don't stop the scan for an empty > slot). It seems like we could simplify things considerably by adding > tuples to the in-memory hash table only to the point where the next > tuple would blow it out. Once we get to that point, we can skip the > isAMostCommonValue() test and send any future tuples straight to temp > files. (This would also reduce the memory consumption of the > in-memory table by a factor of two.) In the ideal case, we select a number of MCVs to support that we know will always fit in memory. The flushing is used to deal with the case where we are doing a many-to-many join and there may be multiple tuples with the given MCV value in the build relation. The issue with building the MCV table is that the hash operator will not be receiving tuples in MCV frequency order. It is possible that the MCV table is filled up with tuples of less frequent MCVs when a more frequent MCV tuple arrives. In that case, we would like to keep the more frequent MCV and bump one of the less frequent MCVs. > We could potentially improve on this even further if we can estimate > in advance how many MCVs we can fit into the in-memory hash table > before it gets blown out. If, for example, we have only 1MB of > work_mem but there 10,000 MCVs, getMostCommonValues() might decide to > only hash the first 1,000 MCVs. Even if we still blow out the > in-memory hash table, the earlier MCVs are more frequent than the > later MCVs, so the ones that actually make it into the table are > likely to be more beneficial. I'm not sure exactly how to do this > tuning though, since we'd need to approximate the size of the > tuples... I guess the query planner makes some effort to estimate that > but I'm not sure how to get at it. The number of batches (nbatch), inner_rel_bytes, and hash_table_bytes are calculated in ExecChooseHashTableSize in nodeHash.c. The number of bytes "free" not allocated to the in-memory batch is then: hash_table_bytes - inner_rel_bytes/nbatch Depending on the power of 2 rounding of nbatch, this may be almost 0 or quite large. You could change the calculation of nbatch or try to resize the in-memory batch, but that opens up a can of worms. It may be best to assume a small number of MCVs 10 or 100. > > > However, the join with Part and LineItem *should* show a benefit but may > > not because of a limitation of the patch implementation (not the idea). > > The MCV optimization is only enabled currently when the probe side is a > > sequential scan. This limitation is due to our current inability to > > determine a stats tuple of the join attribute on the probe side for > > other operators. (This should be possible - help please?). > > Not sure how to get at this either, but I'll take a look and see if I > can figure it out. After more digging, we can extract the original relation id and attribute id of the join attribute using the instance variables varnoold and varoattno of Var. It is documented that these variables are just kept around for debugging, but they are definitely useful here. New code would be: relid = getrelid(variable->varnoold, estate->es_range_table); relattnum = variable->varoattno; Thanks for working with us on the patch. Happy Holidays Everyone, Ramon Lawrence
Re: Proposed Patch to Improve Performance of Multi-BatchHash Join for Skewed Data Sets
> I totally agree that 10,000 MCVs changes things. Ideally, these 10,000 > MCVs should be kept in memory because they will join with the most > tuples. However, the size of the MCV hash table (as you point out) can > be bigger than work_mem *by itself* not even considering the tuples in > the table or in the in-memory batch. > > So, basically, we have a decision to make whether to try support a > larger number of MCVs or cap it at a reasonable number like a 100. You > can come up with situations where using all 10,000 MCVs is good (for > instance if all MCVs have frequency 1/10000), but I expect 100 MCVs will > capture the majority of the cases as usually the top 100 MCVs are > significantly more frequent than later MCVs. I thought about this, but upon due reflection I think it's the wrong approach. Raising work_mem is a pretty common tuning step - it's 4MB even on my small OLTP systems, and in a data-warehousing environment where this optimization will bring the most benefit, it could easily be higher. Furthermore, if someone DOES change the statistics target for that column to 10,000, there's a pretty good chance that they had a reason for doing so (or at the very least it's not for us to assume that they were doing something stupid). I think we need some kind of code to try to tune this based on the actual situation. We might try to size the in-memory hash table to be the largest value that won't increase the total number of batches, but if the number of batches is large then this won't be the right decision. Maybe we should insist on setting aside some minimum percentage of work_mem for the in-memory hash table, and fill it with however many MCVs we think will fit. > The issue with building the MCV table is that the hash operator will not > be receiving tuples in MCV frequency order. It is possible that the MCV > table is filled up with tuples of less frequent MCVs when a more > frequent MCV tuple arrives. In that case, we would like to keep the > more frequent MCV and bump one of the less frequent MCVs. I agree. However, there's no reason at all to assume that the tuples we flush out of the table are any better or worse than the new ones we add back in later. In fact, although it's far from a guarantee, if the order of the tuples in the table is random, then we're more likely to encounter the most common values first. We might as well just keep the ones we had rather than dumping them out and adding in different ones. Err, except, maybe we can't guarantee correctness that way, in the case of a many-to-many join? I don't think there's any way to get around the possibility of a hash-table overflow completely. Besides many-to-many joins, there's also the possibility of hash collisions. The code assumes that anything that hashes to the same 32-bit value as an MCV is in fact an MCV, which is obviously false, but doesn't seem worth worrying about since the chances of a collision are very small and the equality test might be expensive. But clearly we want to minimize overflows as much as we can. ...Robert
Re: Proposed Patch to Improve Performance of Multi-BatchHash Join for Skewed Data Sets
> I thought about this, but upon due reflection I think it's the wrong > approach. Raising work_mem is a pretty common tuning step - it's 4MB > even on my small OLTP systems, and in a data-warehousing environment > where this optimization will bring the most benefit, it could easily > be higher. Furthermore, if someone DOES change the statistics target > for that column to 10,000, there's a pretty good chance that they had > a reason for doing so (or at the very least it's not for us to assume > that they were doing something stupid). I think we need some kind of > code to try to tune this based on the actual situation. > > We might try to size the in-memory hash table to be the largest value > that won't increase the total number of batches, but if the number of > batches is large then this won't be the right decision. Maybe we > should insist on setting aside some minimum percentage of work_mem for > the in-memory hash table, and fill it with however many MCVs we think > will fit. I think that setting aside a minimum percentage of work_mem may be a reasonable approach. For instance, setting aside 1% at even 1 MB work_mem would be 10 KB which is enough to store about 40 MCV tuples of the TPC-H database. Such a small percentage would be very unlikely (but still possible) to change the number of batches used. Then, given the memory allocation and the known tuple size + overhead, only that number of MCVs are selected for the MCV table regardless how many there are. The MCV table size would then increase as work_mem is changed up to a maximum given by the number of MCVs. > I agree. However, there's no reason at all to assume that the tuples > we flush out of the table are any better or worse than the new ones we > add back in later. In fact, although it's far from a guarantee, if > the order of the tuples in the table is random, then we're more likely > to encounter the most common values first. We might as well just keep > the ones we had rather than dumping them out and adding in different > ones. Err, except, maybe we can't guarantee correctness that way, in > the case of a many-to-many join? The code when building the MCV hash table keeps track of the order of insertion of the best MCVs. It then flushes the MCV partitions in decreasing order of frequency of MCVs. Thus, by the end of the build partitioning phase the MCV hash table should only store the most frequent MCV tuples. Even with many-to-many joins as long as we keep all build tuples that have a given MCV in memory, then everything is fine. You would get into problems if you only flushed some of the tuples of a certain MCV but that will not happen. -- Ramon Lawrence
Re: Proposed Patch to Improve Performance of Multi-BatchHash Join for Skewed Data Sets
> I think that setting aside a minimum percentage of work_mem may be a > reasonable approach. For instance, setting aside 1% at even 1 MB > work_mem would be 10 KB which is enough to store about 40 MCV tuples of > the TPC-H database. Such a small percentage would be very unlikely (but > still possible) to change the number of batches used. Then, given the > memory allocation and the known tuple size + overhead, only that number > of MCVs are selected for the MCV table regardless how many there are. > The MCV table size would then increase as work_mem is changed up to a > maximum given by the number of MCVs. Sounds fine. Maybe 2-3% would be better. > The code when building the MCV hash table keeps track of the order of > insertion of the best MCVs. It then flushes the MCV partitions in > decreasing order of frequency of MCVs. Thus, by the end of the build > partitioning phase the MCV hash table should only store the most > frequent MCV tuples. Even with many-to-many joins as long as we keep > all build tuples that have a given MCV in memory, then everything is > fine. You would get into problems if you only flushed some of the > tuples of a certain MCV but that will not happen. OK, I'll read it again - I must not have understood. It would be good to post an updated patch soon, even if not everything has been addressed. ...Robert
Re: Proposed Patch to Improve Performance of Multi-BatchHash Join for Skewed Data Sets
Here is the next patch version. The naming and style concerns have been addressed. The patch now only touches 5 files. 4 of those files are hashjoin specific and 1 is to add a couple lines to a hashjoin specific struct in another file. The code can now find the the MCVs in more cases. Even if the probe side is an operator other than a seq scan (such as another hashjoin) the code can now find the stats tuple for the underlying relation. The new idea of limiting the number of MCVs to a percentage of memory has not been added yet. - Bryce Cutt On Mon, Dec 29, 2008 at 8:55 PM, Robert Haas <robertmhaas@gmail.com> wrote: >> I think that setting aside a minimum percentage of work_mem may be a >> reasonable approach. For instance, setting aside 1% at even 1 MB >> work_mem would be 10 KB which is enough to store about 40 MCV tuples of >> the TPC-H database. Such a small percentage would be very unlikely (but >> still possible) to change the number of batches used. Then, given the >> memory allocation and the known tuple size + overhead, only that number >> of MCVs are selected for the MCV table regardless how many there are. >> The MCV table size would then increase as work_mem is changed up to a >> maximum given by the number of MCVs. > > Sounds fine. Maybe 2-3% would be better. > >> The code when building the MCV hash table keeps track of the order of >> insertion of the best MCVs. It then flushes the MCV partitions in >> decreasing order of frequency of MCVs. Thus, by the end of the build >> partitioning phase the MCV hash table should only store the most >> frequent MCV tuples. Even with many-to-many joins as long as we keep >> all build tuples that have a given MCV in memory, then everything is >> fine. You would get into problems if you only flushed some of the >> tuples of a certain MCV but that will not happen. > > OK, I'll read it again - I must not have understood. > > It would be good to post an updated patch soon, even if not everything > has been addressed. > > ...Robert >
Attachment
Re: Proposed Patch to Improve Performance of Multi-BatchHash Join for Skewed Data Sets
On Tue, Dec 30, 2008 at 12:29 AM, Bryce Cutt <pandasuit@gmail.com> wrote: > Here is the next patch version. Thanks for posting this update. This is definitely getting better, but I still see some style issues. We can work on fixing those once the rest of the details have been finalized. However, one question in this area - isn't ExecHashFreezeNextMCVPartition actually a most common TUPLE partition, rather than a most common VALUE partition (and similarly for ExecHashGetMCVPartition)? I'm not quite sure what to do about this as the names are already quite long - is there some better name for the functions and structure members than MostCommonTuplePartition? Maybe we could call it the in-memory partition and abbreviate it IMPartition throughout. I think that might make things more clear. > The code can now find the the MCVs in more cases. Even if the probe > side is an operator other than a seq scan (such as another hashjoin) > the code can now find the stats tuple for the underlying relation. You're using varnoold in a way that directly contradicts the comment in primnodes.h (essentially, that it's not used for anything other than debugging). I don't think this is a bad thing, but you have to patch the comment. Have you done any performance testing on the impact of this change? > The new idea of limiting the number of MCVs to a percentage of memory > has not been added yet. That's a pretty important change, I think, though it would be nice to have one of the committers chime in here. For those who may not have been following the thread closely, the current implementation's memory usage can go quite a bit higher than work_mem - the in-memory open hash table can be up to 1MB or so (if statistics_target = 10K) plus it can contain up to work_mem of tuples plus each batch can contain another work_mem of tuples. The proposal is to carve out 1-3% of work_mem for the in-memory hash table and leave the rest for the batches, thus hopefully not affecting the # of batches very much. If it doesn't look like the whole MCV list will fit, we'll take a shot at guessing what length prefix of it will. ...Robert
Re: Proposed Patch to Improve Performance of Multi-BatchHash Join for Skewed Data Sets
The latest version of the patch is attached. The revision considerably cleans up the code, especially variable naming consistency. We have adopted the use of IM (in-memory) in variable names for the hash table structures as suggested. Two other implementations changes: 1) The overhead of the hash table has been reduced by allocating an array of pointers instead of an array of structs and only allocating the structs as they are needed to store MCVs. IM buckets are now frozen by first removing all tuples then deleting the struct from memory. This allows more memory to be freed as well as the removal of the frozen field in the IM bucket struct which now makes that struct only 8 bytes on a 32bit machine. If for some reason all IM buckets are frozen all IM struct overhead is removed from memory to further reduce the memory footprint. 2) This patch supports using a set percentage of work_mem (currently 2%) to store the build tuples that join frequently with probe relation tuples. The code only allocates MCVs up to the maximum amount and will flush from the in-memory hash table if the memory is ever exceeded. The code also ensures that the overall join memory used (the MCV hash table and batch 0 in memory) does not exceed spaceAllocated as usual. If this 2% of memory is not used by the MCV hash table then it can be used by batch 0. These changes are mostly relate to style, although some of the cleanup has made the code slightly faster. We would really appreciate help on finalizing this patch, especially in regard to style issues. Thank you for all the help. - Dr. Ramon Lawrence and Bryce Cutt On Sun, Jan 4, 2009 at 6:48 PM, Robert Haas <robertmhaas@gmail.com> wrote: >> 1) Isn't ExecHashFreezeNextMCVPartition actually a most common TUPLE >> partition, rather than a most common VALUE partition (and similarly for >> ExecHashGetMCVPartition)? >> >> A partition stores all tuples that correspond to that MCV value. It is >> usually one for foreign key joins but may be more than one. (Plus, it >> may store other tuples that have the same hash value for the join >> attribute as the MCV value.) > > I guess my point is - check that your variable/function/structure > member naming is consistent between different parts of the code. The > ExecHashGetMCVPartition function accesses structure members called > nMostCommonTuplePartitionHashBuckets, nMostCommonTuplePartition, and > mostCommonTuplePartition. It seems inconsistent that the function > name uses MCVPartition and > the structure members use mostCommonTuplePartition - aren't we talking > about the same thing in both cases? > > And, more to the point, the terminology just seems wrong to me, the > more I think about it. I mean, ExecHashGetMCVParitition is not > finding a partition of the MCVs. It's finding a partition of an > in-memory hash table which we plan to populate with MCVs. That's why > I'm wondering if we should make it ExecHashGetIMPartition, > nIMPartitionHashBuckets, etc. > >> 2) Have you done any performance testing on the impact of this change? >> >> Yes, the ability to use MCVs for more than sequential scans >> significantly improves performance in multi-join cases. The allocation >> of a percentage of memory of only 1% will not affect any performance >> results as all our testing was done with the MCV value of 10 or 100 >> which is significantly below a 1% allocation of work_mem. If anything, >> performance would be improved when using more MCVs. > > That is a very good thing. > >> Finally, any help you can provide on style concerns to make this easier >> to commit would be appreciated. We will put all the effort required >> over the next few days to get this into 8.4. > > If I have time, I might be willing to make a style run over the next > version of the patch after you post it to the list, and just correct > anything I see and repost. This might be faster than sending comments > back and forth, if you are OK with it. I have a day job so this would > probably need to be Tuesday or Wednesday night. My main advice is > "read the diff before you post it". Sometimes things will just pop > out at you that are less obvious when you are head-down in the code. > > Random stuff I notice in v4 patch: make sure all lines fit in 80 > columns (except for long error messages if any), missing space before > closing comment delimiter in ExecHashGetMCVPartition, extraneous blank > line added to nodeHash.c just before the comment that says "and remove > from hash table", comment in ExecHashJoinGetMostCommonValues just > after the get_attstatsslot call is formatted strangely, still extra > curly braces around the calls to > ExecScanHashMostCommonValuePartition/ExecScanHashBucket. > > ...Robert >
Attachment
Re: Proposed Patch to Improve Performance of Multi-BatchHash Join for Skewed Data Sets
> We would really appreciate help on finalizing this patch, especially in > regard to style issues. Thank you for all the help. Here is a cleaned-up version. I fixed a number of whitespace issues, improved a few comments, and rearranged one set of nested if-else statements (hopefully without breaking anything in the process). Josh / eggyknap - Can you rerun your performance tests with this version of the patch? ...Robert
Attachment
Re: Proposed Patch to Improve Performance of Multi-BatchHash Join for Skewed Data Sets
On Tue, Jan 06, 2009 at 11:49:57PM -0500, Robert Haas wrote: > Josh / eggyknap - > > Can you rerun your performance tests with this version of the patch? > > ...Robert Will do, as soon as I can.
Re: Proposed Patch to Improve Performance of Multi-BatchHash Join for Skewed Data Sets
> Here is a cleaned-up version. I fixed a number of whitespace issues, > improved a few comments, and rearranged one set of nested if-else > statements (hopefully without breaking anything in the process). > > Josh / eggyknap - > > Can you rerun your performance tests with this version of the patch? To help with testing, we have constructed a patch specifically for testing. The patch is the same as Robert's version except that it tracks and prints out statistics during the join on how many tuples are affected and has the enable_hashjoin_usestatmcvs variable defined so that it is easy to turn on/off skew handling. This is useful as although the patch reduces the number of I/Os performed, this improvement may not be seen in some queries which are dominated by other cost factors (non-skew joins, CPU time, time to scan input relations, etc.). The sample output looks like this: LI-P Values: 100 Skew: 0.27 Est. tuples: 59986052.00 Batches: 512 Est. Save: 16114709.99 Total Inner Tuples: 2000000 IM Inner Tuples: 83 Batch Zero Inner Tuples: 3941 Batch Zero Potential Inner Tuples: 3941 Total Outer Tuples: 59986052 IM Outer Tuples: 16074146 Batch Zero Outer Tuples: 98778 Batch Zero Potential Outer Tuples: 98778 Total Output Tuples: 59986052 IM Output Tuples: 16074146 Batch Zero Output Tuples: 98778 Batch Zero Potential Output Tuples: 98778 Percentage less tuple IOs than HHJ: 25.98 The other change is that the system calculates the skew and will not use the in-memory skew partition if the skew is less than 1%. Finally, we have attached some performance results for the TPCH 10G data set (skew factors z=1 and z=2). For the Customer-Orders-Lineitem-Part query that Josh was testing, we see no overall time difference that is significant compared to experimental error (although there is I/O benefit for the Lineitem-Part join). This query cost is dominated by the non-skew joins of Customer-Orders and Orders-Lineitem and output tuple construction. The joins with skew, Lineitem-Supplier and Lineitem-Part, show significantly improved performance. Note how the statistics show that the percentage I/O savings is directly proportional to the skew. However, the overall query time savings is always less than this as there are other costs such as reading the relations, performing the hash comparisons, building the output tuples, etc. that are unaffected by the optimization. At this point, we await further feedback on what is necessary to get this patch accepted. We would also like to thank Josh and Robert again for their review time. Sincerely, Ramon Lawrence and Bryce Cutt
Attachment
Re: Proposed Patch to Improve Performance of Multi-BatchHash Join for Skewed Data Sets
On Wed, Jan 7, 2009 at 9:14 AM, Joshua Tolley <eggyknap@gmail.com> wrote: > On Tue, Jan 06, 2009 at 11:49:57PM -0500, Robert Haas wrote: >> Josh / eggyknap - >> >> Can you rerun your performance tests with this version of the patch? >> >> ...Robert > > Will do, as soon as I can. Josh, Have you been able to do anything further with this? I'm attaching a rebased version of this patch with a few further whitespace cleanups. ...Robert
Attachment
Re: Proposed Patch to Improve Performance of Multi-BatchHash Join for Skewed Data Sets
> At this point, we await further feedback on what is necessary to get > this patch accepted. We would also like to thank Josh and Robert again > for their review time. I think what we need here is some very simple testing to demonstrate that this patch demonstrates a speed-up even when the inner side of the join is a joinrel rather than a baserel. Can you suggest a single query against the skewed TPCH dataset that will result in two or more multi-batch hash joins? If so, it should be a simple matter to run that query with and without the patch and verify that the former is faster than the latter. Thanks, ...Robert
Re: Proposed Patch to Improve Performance of Multi-BatchHash Join for Skewed Data Sets
________________________________ From: pgsql-hackers-owner@postgresql.org on behalf of Robert Haas I think what we need here is some very simple testing to demonstrate that this patch demonstrates a speed-up even when the inner side of the join is a joinrel rather than a baserel. Can you suggest a single query against the skewed TPCH dataset that will result in two or more multi-batch hash joins? If so, it should be a simple matter to run that query with and without the patch and verify that the former is faster than the latter. This query will have the outer relation be a joinrel rather than a baserel: select count(*) from supplier, part, lineitem where l_partkey = p_partkey and s_suppkey = l_suppkey; The approach collects statistics on the outer relation (not the inner relation) so the code had to have the ability to determinea stats tuple on a joinrel in addition to a baserel. Joshua sent us some preliminary data with this query and others and indicated that we could post it. He wanted time to cleanit up and re-run some experiments, but the data is generally good and the algorithm performs as expected. I have attachedthis data to the post. Note that the last set of data (although labelled as Z7) is actually an almost zero skewdatabase and represents the worst-case for the algorithm (for most queries the optimization is not even used). -- Ramon Lawrence
Attachment
Re: Proposed Patch to Improve Performance of Multi-BatchHash Join for Skewed Data Sets
On Wed, Feb 18, 2009 at 11:20:03PM -0500, Robert Haas wrote: > On Wed, Jan 7, 2009 at 9:14 AM, Joshua Tolley <eggyknap@gmail.com> wrote: > > On Tue, Jan 06, 2009 at 11:49:57PM -0500, Robert Haas wrote: > >> Josh / eggyknap - > >> > >> Can you rerun your performance tests with this version of the patch? > >> > >> ...Robert > > > > Will do, as soon as I can. > > Josh, > > Have you been able to do anything further with this? > > I'm attaching a rebased version of this patch with a few further > whitespace cleanups. > > ...Robert I keep trying to do testing, but not getting too far, though I did return some test results to the original authors for their review. I'll try to get a more formal response put together (my new daughter will be 24 hours old in a little bit, though, so it might be a while!) - Josh
Re: Proposed Patch to Improve Performance of Multi-BatchHash Join for Skewed Data Sets
On Thu, Feb 19, 2009 at 01:50:55PM -0700, Josh Tolley wrote: > (my new daughter will be 24 hours old in a little bit, though, so it > might be a while!) Pics! Cheers, David. -- David Fetter <david@fetter.org> http://fetter.org/ Phone: +1 415 235 3778 AIM: dfetter666 Yahoo!: dfetter Skype: davidfetter XMPP: david.fetter@gmail.com Remember to vote! Consider donating to Postgres: http://www.postgresql.org/about/donate
Re: Proposed Patch to Improve Performance of Multi-BatchHash Join for Skewed Data Sets
> Joshua sent us some preliminary data with this query and others and indicated that we could post it. He wanted time toclean it up > and re-run some experiments, but the data is generally good and the algorithm performs as expected. I have attached thisdata to the > post. Note that the last set of data (although labelled as Z7) is actually an almost zero skew database and representsthe worst-case > for the algorithm (for most queries the optimization is not even used). Sadly, there seem to be a number of cases in the Z7 database where the optimization makes things significantly worse (specifically, queries 2, 3, and 7, but especially query 3). Have you investigated what is going on there? I had thought that we had sufficient safeguards in place to prevent this optimization from kicking in in cases where it doesn't help, but it seems not. There will certainly be real-world databases that are more like Z7 than Z1. ...Robert
Re: Proposed Patch to Improve Performance of Multi-BatchHash Join for Skewed Data Sets
> -----Original Message----- > From: Robert Haas > Sadly, there seem to be a number of cases in the Z7 database where the > optimization makes things significantly worse (specifically, queries > 2, 3, and 7, but especially query 3). Have you investigated what is > going on there? I had thought that we had sufficient safeguards in > place to prevent this optimization from kicking in in cases where it > doesn't help, but it seems not. There will certainly be real-world > databases that are more like Z7 than Z1. I agree that there should be no noticeable performance difference when the optimization is not used (single batch case or no skew). I think the patch achieves this. The optimization is not used in those cases, but we will review to see if it is the code that by-passes the optimization that is causing a difference. The query #3 timing difference is primarily due to a flaw in the experimental setup. For some reason, query #3 got executed before #4 with the optimization on, and executed after #4 with the optimization off. This skewed the results for all runs (due to buffering issues), but is especially noticeable for Z7. Note how query #4 is always faster for the optimization on version even though the optimization is not actually used for those queries (because they were one batch). I expect that if you run query #3 on Z7 in isolation then the results should be basically identical. I have attached the SQL script that Joshua sent me. The raw data I have posted at: http://people.ok.ubc.ca/rlawrenc/test.output -- Ramon Lawrence
Attachment
Re: Proposed Patch to Improve Performance of Multi-BatchHash Join for Skewed Data Sets
On Wed, Feb 25, 2009 at 12:38 AM, Lawrence, Ramon <ramon.lawrence@ubc.ca> wrote: >> -----Original Message----- >> From: Robert Haas >> Sadly, there seem to be a number of cases in the Z7 database where the >> optimization makes things significantly worse (specifically, queries >> 2, 3, and 7, but especially query 3). Have you investigated what is >> going on there? I had thought that we had sufficient safeguards in >> place to prevent this optimization from kicking in in cases where it >> doesn't help, but it seems not. There will certainly be real-world >> databases that are more like Z7 than Z1. > > I agree that there should be no noticeable performance difference when > the optimization is not used (single batch case or no skew). I think > the patch achieves this. The optimization is not used in those cases, > but we will review to see if it is the code that by-passes the > optimization that is causing a difference. Yeah we need to understand what's going on there. > The query #3 timing difference is primarily due to a flaw in the > experimental setup. For some reason, query #3 got executed before #4 > with the optimization on, and executed after #4 with the optimization > off. This skewed the results for all runs (due to buffering issues), > but is especially noticeable for Z7. Note how query #4 is always faster > for the optimization on version even though the optimization is not > actually used for those queries (because they were one batch). I expect > that if you run query #3 on Z7 in isolation then the results should be > basically identical. > > I have attached the SQL script that Joshua sent me. The raw data I have > posted at: http://people.ok.ubc.ca/rlawrenc/test.output I don't think we're really doing this the right way. EXPLAIN ANALYZE has a measurable effect on the results, and we probably ought to stop the database and drop the VM caches after each query. Are the Z1-Z7 datasets on line someplace? I might be able to rig up a script here. ...Robert
Re: Proposed Patch to Improve Performance of Multi-BatchHash Join for Skewed Data Sets
I haven't been following this thread closely, so pardon if this has been discussed already. The patch doesn't seem to change the cost estimates in the planner at all. Without that, I'd imagine that the planner rarely chooses a multi-batch hash join to begin with. Joshua, in the tests that you've been running, did you have to rig the planner with "enable_mergjoin=off" or similar, to get the queries to use hash joins? -- Heikki Linnakangas EnterpriseDB http://www.enterprisedb.com
Re: Proposed Patch to Improve Performance of Multi-BatchHash Join for Skewed Data Sets
On Thu, Feb 26, 2009 at 4:22 AM, Heikki Linnakangas <heikki.linnakangas@enterprisedb.com> wrote: > I haven't been following this thread closely, so pardon if this has been > discussed already. > > The patch doesn't seem to change the cost estimates in the planner at all. > Without that, I'd imagine that the planner rarely chooses a multi-batch hash > join to begin with. AFAICS, a multi-batch hash join happens when you are joining two big, unsorted paths. The planner essentially compares the cost of sorting the two paths and then merge-joining them versus the cost of a hash join. It doesn't seem to be unusual for the hash join to come out the winner, although admittedly I haven't played with it a ton. You certainly could try to model it in the costing algorithm, but I'm not sure how much benefit you'd get out of it: if you're doing this a lot you're probably better off creating indices. > Joshua, in the tests that you've been running, did you have to rig the > planner with "enable_mergjoin=off" or similar, to get the queries to use > hash joins? I didn't have to fiddle anything, but Josh's tests were more exhaustive. ...Robert
Re: Proposed Patch to Improve Performance of Multi-BatchHash Join for Skewed Data Sets
On Wed, Feb 25, 2009 at 10:24:21PM -0500, Robert Haas wrote: > I don't think we're really doing this the right way. EXPLAIN ANALYZE > has a measurable effect on the results, and we probably ought to stop > the database and drop the VM caches after each query. Are the Z1-Z7 > datasets on line someplace? I might be able to rig up a script here. > > ...Robert They're automatically generated by the dbgen utility, a link to which was originally published somewhere in this thread. That tool creates a few text files suitable (with some tweaking) for a COPY command. I've got the original files... the .tbz I just made is 1.8 GB :) Anyone have someplace they'd like me to drop it? - Josh
Re: Proposed Patch to Improve Performance of Multi-BatchHash Join for Skewed Data Sets
On Thu, Feb 26, 2009 at 08:22:52AM -0500, Robert Haas wrote: > On Thu, Feb 26, 2009 at 4:22 AM, Heikki Linnakangas > <heikki.linnakangas@enterprisedb.com> wrote: > > Joshua, in the tests that you've been running, did you have to rig the > > planner with "enable_mergjoin=off" or similar, to get the queries to use > > hash joins? > > I didn't have to fiddle anything, but Josh's tests were more exhaustive. The planner chose hash joins for the queries I was running, regardless of whether the patch was applied. I didn't have to mess with any settings to get hash joins. - Josh
Re: Proposed Patch to Improve Performance of Multi-BatchHash Join for Skewed Data Sets
Heikki's got a point here: the planner is aware that hashjoin doesn't
like skewed distributions, and it assigns extra cost accordingly if it
can determine that the join key is skewed. (See the "bucketsize" stuff
in cost_hashjoin.) If this patch is accepted we'll want to tweak that
code.
Still, that has little to do with the current gating issue, which is
whether we've convinced ourselves that the patch doesn't cause a
performance decrease for cases in which it's unable to help.
regards, tom lane
Re: Proposed Patch to Improve Performance of Multi-BatchHash Join for Skewed Data Sets
> From: Tom Lane > Heikki's got a point here: the planner is aware that hashjoin doesn't > like skewed distributions, and it assigns extra cost accordingly if it > can determine that the join key is skewed. (See the "bucketsize" stuff > in cost_hashjoin.) If this patch is accepted we'll want to tweak that > code. Those modifications would make the optimizer more likely to select hash join, even with skewed distributions. For the TPC-H data set that we are using the optimizer always picks hash join over merge join (single or multi-batch). Since the current patch does not change the cost function, there is no change in the planning cost. It may or may not be useful to modify the cost function depending on the effect on planning cost. > Still, that has little to do with the current gating issue, which is > whether we've convinced ourselves that the patch doesn't cause a > performance decrease for cases in which it's unable to help. Although we have not seen an overhead when the optimization is by-passed, we are looking at some small code changes that would guarantee that no extra statements are executed for the single batch case. Currently, an if optimization_on check is performed on each probe tuple which, although minor, should be able to be avoided. The patch's author, Bryce Cutt, is defending his Master's thesis Friday morning (on this work), so we will provide some updated code right after that. Since these code changes are small, they should not affect people trying to test the performance of the current patch. -- Ramon Lawrence
Re: Proposed Patch to Improve Performance ofMulti-BatchHash Join for Skewed Data Sets
> They're automatically generated by the dbgen utility, a link to which > was originally published somewhere in this thread. That tool creates a > few text files suitable (with some tweaking) for a COPY command. I've > got the original files... the .tbz I just made is 1.8 GB :) Anyone have > someplace they'd like me to drop it? Just a note that the Z7 data set is really a uniform data set Z0. The generator only accepts skew in the range from Z0 to Z4. The uniform, Z0, data set is typically used when benchmarking data warehouses. It turns out the data is not perfectly uniform as the top 100 suppliers and products represent 2.3% and 1.5% of LineItem. This is just enough skew that the optimization will sometimes be triggered in the multi-batch case (currently 1% skew is the cutoff). I have posted a pg_dump of the TPCH 1G Z0 data set at: http://people.ok.ubc.ca/rlawrenc/tpch1g0z.zip (Note that ownership commands are in the dump and make sure to vacuum analyze after the load.) I can also post the input text files if that is easier. -- Ramon Lawrence
Re: Proposed Patch to Improve Performance ofMulti-BatchHash Join for Skewed Data Sets
> I have posted a pg_dump of the TPCH 1G Z0 data set at: > > http://people.ok.ubc.ca/rlawrenc/tpch1g0z.zip That seems VERY useful - can you post the other ones (Z1, etc.) so I can download them all? Thanks, ...Robert
Re: Proposed Patch to Improve Performance ofMulti-BatchHash Join for Skewed Data Sets
> That seems VERY useful - can you post the other ones (Z1, etc.) so I > can download them all? The Z1 data set is posted at: http://people.ok.ubc.ca/rlawrenc/tpch1g1z.zip I have not generated Z2, Z3, Z4 for 1G, but I can generate the Z2 and Z3 data sets, and in a hour or two they will be at: http://people.ok.ubc.ca/rlawrenc/tpch1g2z.zip http://people.ok.ubc.ca/rlawrenc/tpch1g3z.zip Note that Z3 and Z4 are not really useful as the skew is extreme (98% of the probe relation covered by top 100 values). Using the Z2/Z3 data set should be enough to show the huge win if you do *really* have a skewed data set. BTW, is there any particular form/options of the pg_dump command that I should use to make the dump? -- Ramon Lawrence
Re: Proposed Patch to Improve Performance of Multi-BatchHash Join for Skewed Data Sets
The patch originally modified the cost function but I removed that part before we submitted it to be a bit conservative about our proposed changes. I didn't like that for large plans the statistics were retrieved and calculated many times when finding the optimal query plan. The overhead of the algorithm when the skew optimization is not used ends up being roughly a function call and an if statement per tuple. It would be easy to remove the function call per tuple. Dr. Lawrence has come up with some changes so that when the optimization is turned off, the function call does not happen at all and instead of the if statement happening per tuple it is run just once per join. We have to test this a bit more but it should further reduce the overhead. Hopefully we will have the new patch ready to go this weekend. - Bryce Cutt On Thu, Feb 26, 2009 at 7:45 AM, Tom Lane <tgl@sss.pgh.pa.us> wrote: > Heikki's got a point here: the planner is aware that hashjoin doesn't > like skewed distributions, and it assigns extra cost accordingly if it > can determine that the join key is skewed. (See the "bucketsize" stuff > in cost_hashjoin.) If this patch is accepted we'll want to tweak that > code. > > Still, that has little to do with the current gating issue, which is > whether we've convinced ourselves that the patch doesn't cause a > performance decrease for cases in which it's unable to help. > > regards, tom lane >
Re: Proposed Patch to Improve Performance of Multi-BatchHash Join for Skewed Data Sets
Here is the new patch. Our experiments show no noticeable performance issue when using the patch for cases where the optimization is not used because the number of extra statements executed when the optimization is disabled is insignificant. We have updated the patch to remove a couple of if statements, but this is really minor. The biggest change was to MultiExecHash that avoids an if check per tuple by duplicating the hashing loop. To demonstrate the differences, here is an analysis of the code changes and their impact. Three cases: 1) One batch hash join - Optimization is disabled. Extra statements executed are: - One if (hashtable->nbatch > 1) in ExecHashJoin (line 356 of nodeHashjoin.c) - One if optimization_on in MultiExecHash (line 259 of nodeHash.c) - One if optimization_on in MultiExecHash per probe tuple (line 431 of nodeHashjoin.c) - One if statement in ExecScanHashBucket per probe tuple (line 1071 of nodeHash.c) 2) Multi-batch hash join with limited skew - Optimization is disabled. Extra statements executed are: - One if (hashtable->nbatch > 1) in ExecHashJoin (line 356 of nodeHashjoin.c) - Executes ExecHashJoinDetectSkew method (at line 357 of nodeHashjoin.c) that reads stats tuple for probe relation attribute and determines if skew is above cut-off. In this case, skew is not above cutoff and no extra memory is used. - One if optimization_on in MultiExecHash (line 259 of nodeHash.c) - One if optimization_on in MultiExecHash per probe tuple (line 431 of nodeHashjoin.c) - One if statement in ExecScanHashBucket per probe tuple (line 1071 of nodeHash.c) 3) Multi-batch hash join with skew - Optimization is enabled. Extra statements executed are: - One if (hashtable->nbatch > 1) in ExecHashJoin (line 356 of nodeHashjoin.c) - Executes ExecHashJoinDetectSkew method (at line 357 of nodeHashjoin.c) that reads stats tuple for probe relation attribute and determines there is skew. Allocates space for XXX which is 2% of work_mem. - One if optimization_on in MultiExecHash (line 259 of nodeHash.c) - In MultiExecHash after each tuple is hashed determines if its join attribute value matches one of the MCVs. If it does, it is put in the MCV structure. Cost is the hash and search for each build tuple. - If all IM buckets end up frozen in the build phase (MultiExecHash) because they grow larger than the memory allowed for IM buckets then skew optimization is turned off and the probe phase reverts to Case 2 - For each probe tuple, determines if its value is a MCV by performing hash and quick table lookup. If yes, probes MCV bucket otherwise does regular hash algorithm as usual. - One if statement in ExecScanHashBucket per probe tuple (line 1071 of nodeHash.c) - Additional cost is determining if a tuple is a common tuple (both on build and probe side). This additional cost is dramatically outweighed by avoiding disk I/Os (even if they never hit the disk due to caching). The if statement on line 440 of nodeHashjoin.c (in ExecHashJoin) has been rearranged so that in the single batch case short circuit evaluation requires only the first test in the IF to be checked. The "limited skew" check mentioned in Case 2 above is a simple check in the ExecHashJoinDetectSkew function. - Bryce Cutt On Thu, Feb 26, 2009 at 12:16 PM, Bryce Cutt <pandasuit@gmail.com> wrote: > The patch originally modified the cost function but I removed that > part before we submitted it to be a bit conservative about our > proposed changes. I didn't like that for large plans the statistics > were retrieved and calculated many times when finding the optimal > query plan. > > The overhead of the algorithm when the skew optimization is not used > ends up being roughly a function call and an if statement per tuple. > It would be easy to remove the function call per tuple. Dr. Lawrence > has come up with some changes so that when the optimization is turned > off, the function call does not happen at all and instead of the if > statement happening per tuple it is run just once per join. We have > to test this a bit more but it should further reduce the overhead. > > Hopefully we will have the new patch ready to go this weekend. > > - Bryce Cutt > > > On Thu, Feb 26, 2009 at 7:45 AM, Tom Lane <tgl@sss.pgh.pa.us> wrote: >> Heikki's got a point here: the planner is aware that hashjoin doesn't >> like skewed distributions, and it assigns extra cost accordingly if it >> can determine that the join key is skewed. (See the "bucketsize" stuff >> in cost_hashjoin.) If this patch is accepted we'll want to tweak that >> code. >> >> Still, that has little to do with the current gating issue, which is >> whether we've convinced ourselves that the patch doesn't cause a >> performance decrease for cases in which it's unable to help. >> >> regards, tom lane >> >
Attachment
Re: Proposed Patch to Improve Performance of Multi-BatchHash Join for Skewed Data Sets
Bryce Cutt <pandasuit@gmail.com> writes:
> Here is the new patch.
> Our experiments show no noticeable performance issue when using the
> patch for cases where the optimization is not used because the number
> of extra statements executed when the optimization is disabled is
> insignificant.
> We have updated the patch to remove a couple of if statements, but
> this is really minor. The biggest change was to MultiExecHash that
> avoids an if check per tuple by duplicating the hashing loop.
I think you missed the point of the performance questions. It wasn't
about avoiding extra simple if-tests in the per-tuple loops; a few of
those are certainly not going to add measurable cost given how complex
the code is already. (I really don't think you should be duplicating
hunks of code to avoid adding such tests.) Rather, the concern was that
if we are dedicating a fraction of available work_mem to this purpose,
that reduces the overall efficiency of the regular non-IM code path,
principally by forcing the creation of more batches than would otherwise
be needed. It's not clear whether the savings for IM tuples always
exceeds this additional cost.
After looking over the code a bit, there are two points that
particularly concern me in this connection:
* The IM hashtable is only needed during the first-batch processing;
once we've completed the first pass over the outer relation there is
no longer any need for it, unless I'm misunderstanding things
completely. Therefore it really only competes for space with the
regular first batch. However the damage to nbatches will already have
been done; in effect, we can expect that each subsequent batch will
probably only use (100 - IM_WORK_MEM_PERCENT)% of work_mem. The patch
seems to try to deal with this by keeping IM_WORK_MEM_PERCENT negligibly
small, but surely that's mostly equivalent to fighting with one hand
tied behind your back. I wonder if it'd be better to dedicate all of
work_mem to the MCV hash values during the first pass, rather than
allowing them to compete with the first regular batch.
* The IM hashtable creates an additional reason why nbatch might
increase during the initial scan of the inner relation; in fact, since
it's an effect not modeled in the initial choice of nbatch, it's
probably going to be a major reason for that to happen. Increasing
nbatch on the fly isn't good because it results in extra I/O for tuples
that were previously assigned to what is now the wrong batch. Again,
the only answer the patch has for this is to try not to use enough
of work_mem for it to make a difference. Seems like instead the initial
nbatch estimate needs to account for that.
regards, tom lane
Re: Proposed Patch to Improve Performance of Multi-BatchHash Join for Skewed Data Sets
On Fri, Mar 6, 2009 at 1:57 PM, Tom Lane <tgl@sss.pgh.pa.us> wrote: > Bryce Cutt <pandasuit@gmail.com> writes: >> Here is the new patch. >> Our experiments show no noticeable performance issue when using the >> patch for cases where the optimization is not used because the number >> of extra statements executed when the optimization is disabled is >> insignificant. > >> We have updated the patch to remove a couple of if statements, but >> this is really minor. The biggest change was to MultiExecHash that >> avoids an if check per tuple by duplicating the hashing loop. > > I think you missed the point of the performance questions. It wasn't > about avoiding extra simple if-tests in the per-tuple loops; a few of > those are certainly not going to add measurable cost given how complex > the code is already. (I really don't think you should be duplicating > hunks of code to avoid adding such tests.) Rather, the concern was that Well, at one point we were still trying to verify that (1) the patch actually had a benefit and (2) blowing out the IM hashtable wasn't too horribly nasty. A great deal of improvement has been made in those areas since this was first reviewed. But your questions are completely valid, too. (I don't think anyone ever expressed a concern about the simple if-tests, either.) > if we are dedicating a fraction of available work_mem to this purpose, > that reduces the overall efficiency of the regular non-IM code path, > principally by forcing the creation of more batches than would otherwise > be needed. It's not clear whether the savings for IM tuples always > exceeds this additional cost. > > After looking over the code a bit, there are two points that > particularly concern me in this connection: > > * The IM hashtable is only needed during the first-batch processing; > once we've completed the first pass over the outer relation there is > no longer any need for it, unless I'm misunderstanding things > completely. Therefore it really only competes for space with the > regular first batch. However the damage to nbatches will already have > been done; in effect, we can expect that each subsequent batch will > probably only use (100 - IM_WORK_MEM_PERCENT)% of work_mem. The patch > seems to try to deal with this by keeping IM_WORK_MEM_PERCENT negligibly > small, but surely that's mostly equivalent to fighting with one hand > tied behind your back. I wonder if it'd be better to dedicate all of > work_mem to the MCV hash values during the first pass, rather than > allowing them to compete with the first regular batch. The IM hash table doesn't need to be very large in order to produce a substantial benefit, because there are only going to be ~100 MCVs in the probe table and each of those may well be unique in the build table. But no matter what size you choose for it, there's some danger that it will push us over the edge into more batches, and if the skew doesn't turn out to be enough to make up for that, you lose. I'm not sure there's any way to completely eliminate that unpleasant possibility. > * The IM hashtable creates an additional reason why nbatch might > increase during the initial scan of the inner relation; in fact, since > it's an effect not modeled in the initial choice of nbatch, it's > probably going to be a major reason for that to happen. Increasing > nbatch on the fly isn't good because it results in extra I/O for tuples > that were previously assigned to what is now the wrong batch. Again, > the only answer the patch has for this is to try not to use enough > of work_mem for it to make a difference. Seems like instead the initial > nbatch estimate needs to account for that. ...Robert
Re: Proposed Patch to Improve Performance of Multi-BatchHash Join for Skewed Data Sets
> > I think you missed the point of the performance questions. It wasn't > > about avoiding extra simple if-tests in the per-tuple loops; a few of > > those are certainly not going to add measurable cost given how complex > > the code is already. (I really don't think you should be duplicating > > hunks of code to avoid adding such tests.) Rather, the concern was that > > if we are dedicating a fraction of available work_mem to this purpose, > > that reduces the overall efficiency of the regular non-IM code path, > > principally by forcing the creation of more batches than would otherwise > > be needed. It's not clear whether the savings for IM tuples always > > exceeds this additional cost. I misunderstood the concern. So, there is no issue with the patch when it is disabled (single batch case or multi-batchwith no skew)? There is no memory allocated when the optimization is off, so these cases will not affect thenumber of batches or re-partitioning. > > * The IM hashtable is only needed during the first-batch processing; > > once we've completed the first pass over the outer relation there is > > no longer any need for it, unless I'm misunderstanding things > > completely. Therefore it really only competes for space with the > > regular first batch. However the damage to nbatches will already have > > been done; in effect, we can expect that each subsequent batch will > > probably only use (100 - IM_WORK_MEM_PERCENT)% of work_mem. The patch > > seems to try to deal with this by keeping IM_WORK_MEM_PERCENT negligibly > > small, but surely that's mostly equivalent to fighting with one hand > > tied behind your back. I wonder if it'd be better to dedicate all of > > work_mem to the MCV hash values during the first pass, rather than > > allowing them to compete with the first regular batch. > > The IM hash table doesn't need to be very large in order to produce a > substantial benefit, because there are only going to be ~100 MCVs in > the probe table and each of those may well be unique in the build > table. But no matter what size you choose for it, there's some danger > that it will push us over the edge into more batches, and if the skew > doesn't turn out to be enough to make up for that, you lose. I'm not > sure there's any way to completely eliminate that unpleasant > possibility. Correct - The IM table only competes with the first-batch during processing and is removed after the first pass. Also, ittends to be VERY small as the default of 100 MCVs usually results in 100 tuples being in the IM table which is normallymuch less than 2% of work_mem. We get almost all the benefit with 100-10000 MCVs with little downside risk. Makingthe IM table larger (size of work_mem) is both not possible (not that many MCVs) and has a bigger downside risk ifwe get it wrong. > > * The IM hashtable creates an additional reason why nbatch might > > increase during the initial scan of the inner relation; in fact, since > > it's an effect not modeled in the initial choice of nbatch, it's > > probably going to be a major reason for that to happen. Increasing > > nbatch on the fly isn't good because it results in extra I/O for tuples > > that were previously assigned to what is now the wrong batch. Again, > > the only answer the patch has for this is to try not to use enough > > of work_mem for it to make a difference. Seems like instead the initial > > nbatch estimate needs to account for that. The possibility of the 1-2% IM_WORK_MEM_PERCENT causing a re-batch exists but is very small. The number of batches is calculatedin ExecChooseHashTableSize (costsize.c) as ceil(inner_rel_bytes/work_mem) rounded up to the next power of 2. Thus,hash join already "wastes" some of its work_mem allocation due to rounding. For instance, if nbatch is calculated as3 then rounded up to 4, only 75% of work_mem is used for each batch. This leaves 25% of work_mem "unaccounted for" whichmay be used by the IM table (and also to compensate for build skew). Clearly, if nbatch is exactly 4, then this unaccountedspace is not present and if the optimizer is exact in its estimates, the extra 1-2% may force a re-partition. A solution may be to re-calculate nbatch factoring in the extra 1-2% during ExecHashTableCreate (nodeHashjoin.c) which callsExecChooseHashTableSize again before execution. The decision is whether to modify ExecChooseHashTableSize itself (whichis used during costing) or to make a modified ExecChooseHashTableSize function that is only used once in ExecHashTableCreate. We have tried to change the original code as little as possible, but it is possible to modify ExecChooseHashTableSize andthe hash join cost function to be skew optimization aware. -- Ramon Lawrence
Re: Proposed Patch to Improve Performance of Multi-BatchHash Join for Skewed Data Sets
Bryce Cutt <pandasuit@gmail.com> writes:
> Here is the new patch.
Applied with revisions. I undid some of the "optimizations" that
cluttered the code in order to save a cycle or two per tuple --- as per
previous discussion, that's not what the performance questions were
about. Also, I did not like the terminology "in-memory"/"IM"; it seemed
confusing since the main hash table is in-memory too. I revised the
code to consistently refer to the additional hash table as a "skew"
hashtable and the optimization in general as skew optimization. Hope
that seems reasonable to you --- we could search-and-replace it to
something else if you'd prefer.
For the moment, I didn't really do anything about teaching the planner
to account for this optimization in its cost estimates. The initial
estimate of the number of MCVs that will be specially treated seems to
me to be too high (it's only accurate if the inner relation is unique),
but getting a more accurate estimate seems pretty hard, and it's not
clear it's worth the trouble. Without that, though, you can't tell
what fraction of outer tuples will get the short-circuit treatment.
regards, tom lane
Re: Proposed Patch to Improve Performance of Multi-BatchHash Join for Skewed Data Sets
On Fri, Mar 20, 2009 at 8:14 PM, Tom Lane <tgl@sss.pgh.pa.us> wrote: > Bryce Cutt <pandasuit@gmail.com> writes: >> Here is the new patch. > > Applied with revisions. I undid some of the "optimizations" that > cluttered the code in order to save a cycle or two per tuple --- as per > previous discussion, that's not what the performance questions were > about. Also, I did not like the terminology "in-memory"/"IM"; it seemed > confusing since the main hash table is in-memory too. I revised the > code to consistently refer to the additional hash table as a "skew" > hashtable and the optimization in general as skew optimization. Hope > that seems reasonable to you --- we could search-and-replace it to > something else if you'd prefer. > > For the moment, I didn't really do anything about teaching the planner > to account for this optimization in its cost estimates. The initial > estimate of the number of MCVs that will be specially treated seems to > me to be too high (it's only accurate if the inner relation is unique), > but getting a more accurate estimate seems pretty hard, and it's not > clear it's worth the trouble. Without that, though, you can't tell > what fraction of outer tuples will get the short-circuit treatment. If the inner relation isn't fairly close to unique you shouldn't be using this optimization in the first place. ...Robert
Re: Proposed Patch to Improve Performance of Multi-BatchHash Join for Skewed Data Sets
On Fri, Mar 20, 2009 at 8:45 PM, Bryce Cutt <pandasuit@gmail.com> wrote: > On Fri, Mar 20, 2009 at 5:35 PM, Robert Haas <robertmhaas@gmail.com> wrote: >> If the inner relation isn't fairly close to unique you shouldn't be >> using this optimization in the first place. > Not necessarily true. Seeing as (when the statistics are correct) we > know each of these inner tuples will match with the largest amount of > outer tuples it is just as much of a win per inner tuple as when they > are unique. There is just a chance you will have to give up on the > optimization part way through if too many inner tuples fall into the > new "skew buckets" (formerly IM buckets) and dump the tuples back into > the main buckets. The potential win is still pretty high though. > > - Bryce Cutt Maybe I'm remembering wrong, but I thought the estimating functions assuemd that the inner relation was unique. So if there turn out to be 2, 3, 4, or more copies of each value, the chances of blowing out the skew hash table are almost 100%, I would think... am I wrong? ...Robert
Re: Proposed Patch to Improve Performance of Multi-BatchHash Join for Skewed Data Sets
On Fri, Mar 20, 2009 at 8:45 PM, Bryce Cutt <pandasuit@gmail.com> wrote: > On Fri, Mar 20, 2009 at 5:35 PM, Robert Haas <robertmhaas@gmail.com> wrote: >> If the inner relation isn't fairly close to unique you shouldn't be >> using this optimization in the first place. > Not necessarily true. Seeing as (when the statistics are correct) we > know each of these inner tuples will match with the largest amount of > outer tuples it is just as much of a win per inner tuple as when they > are unique. There is just a chance you will have to give up on the > optimization part way through if too many inner tuples fall into the > new "skew buckets" (formerly IM buckets) and dump the tuples back into > the main buckets. The potential win is still pretty high though. > > - Bryce Cutt Maybe I'm remembering wrong, but I thought the estimating functions assuemd that the inner relation was unique. So if there turn out to be 2, 3, 4, or more copies of each value, the chances of blowing out the skew hash table are almost 100%, I would think... am I wrong? ...Robert
Re: Proposed Patch to Improve Performance of Multi-BatchHash Join for Skewed Data Sets
Not necessarily true. Seeing as (when the statistics are correct) we know each of these inner tuples will match with the largest amount of outer tuples it is just as much of a win per inner tuple as when they are unique. There is just a chance you will have to give up on the optimization part way through if too many inner tuples fall into the new "skew buckets" (formerly IM buckets) and dump the tuples back into the main buckets. The potential win is still pretty high though. - Bryce Cutt On Fri, Mar 20, 2009 at 5:35 PM, Robert Haas <robertmhaas@gmail.com> wrote: > On Fri, Mar 20, 2009 at 8:14 PM, Tom Lane <tgl@sss.pgh.pa.us> wrote: >> Bryce Cutt <pandasuit@gmail.com> writes: >>> Here is the new patch. >> >> Applied with revisions. I undid some of the "optimizations" that >> cluttered the code in order to save a cycle or two per tuple --- as per >> previous discussion, that's not what the performance questions were >> about. Also, I did not like the terminology "in-memory"/"IM"; it seemed >> confusing since the main hash table is in-memory too. I revised the >> code to consistently refer to the additional hash table as a "skew" >> hashtable and the optimization in general as skew optimization. Hope >> that seems reasonable to you --- we could search-and-replace it to >> something else if you'd prefer. >> >> For the moment, I didn't really do anything about teaching the planner >> to account for this optimization in its cost estimates. The initial >> estimate of the number of MCVs that will be specially treated seems to >> me to be too high (it's only accurate if the inner relation is unique), >> but getting a more accurate estimate seems pretty hard, and it's not >> clear it's worth the trouble. Without that, though, you can't tell >> what fraction of outer tuples will get the short-circuit treatment. > > If the inner relation isn't fairly close to unique you shouldn't be > using this optimization in the first place. > > ...Robert >
Re: Proposed Patch to Improve Performance of Multi-BatchHash Join for Skewed Data Sets
The estimation functions assume the inner relation join column is unique. But it freezes (flushes back to the main hash table) one skew bucket at a time in order of least importance so if 100 inner tuples can fit in the skew buckets then the skew buckets are only fully blown out if the best tuple (the single most common value) occurs more than 100 times in the inner relation. And up until that point you still have the tuples in memory that are the best "per tuple worth of memory". But yes, after that point (more than 100 tuples of that best MCV) the entire effort was wasted. The skew buckets are dynamically flushed just like buckets in a dynamic hash join would be. - Bryce Cutt On Fri, Mar 20, 2009 at 5:51 PM, Robert Haas <robertmhaas@gmail.com> wrote: > On Fri, Mar 20, 2009 at 8:45 PM, Bryce Cutt <pandasuit@gmail.com> wrote: >> On Fri, Mar 20, 2009 at 5:35 PM, Robert Haas <robertmhaas@gmail.com> wrote: >>> If the inner relation isn't fairly close to unique you shouldn't be >>> using this optimization in the first place. >> Not necessarily true. Seeing as (when the statistics are correct) we >> know each of these inner tuples will match with the largest amount of >> outer tuples it is just as much of a win per inner tuple as when they >> are unique. There is just a chance you will have to give up on the >> optimization part way through if too many inner tuples fall into the >> new "skew buckets" (formerly IM buckets) and dump the tuples back into >> the main buckets. The potential win is still pretty high though. >> >> - Bryce Cutt > > Maybe I'm remembering wrong, but I thought the estimating functions > assuemd that the inner relation was unique. So if there turn out to > be 2, 3, 4, or more copies of each value, the chances of blowing out > the skew hash table are almost 100%, I would think... am I wrong? > > ...Robert >