Thread: 7.1 vs. 7.2 on AIX 5L
Hi, I have made a new version of pgbench which allows not to update branches and tellers tables, which should significantly reduce the contentions. (See attached patches against current. Note that the paches also includes changes removing CHECKPOINT command while running in initialization mode (pgbench -i)). With the patches you could specify -N option not to update branches and tellers tables. With the new pgbench, I ran a test with current and 7.1 and saw not-so-small differences. Any idea to get better performance on 7.2 and AIX 5L combo? 7.2 with lwlock.patch rev.2 7.1.3 AIX 5L 4way with 4GB RAM testing script is same as my previous postings (except -N for pgbench, of course).
Tatsuo Ishii wrote: > > Hi, > > I have made a new version of pgbench which allows not to update > branches and tellers tables, which should significantly reduce the > contentions. (See attached patches against current. Note that the > paches also includes changes removing CHECKPOINT command while > running in initialization mode (pgbench -i)). With the patches you > could specify -N option not to update branches and tellers tables. > > With the new pgbench, I ran a test with current and 7.1 and saw > not-so-small differences. Any idea to get better performance on 7.2 > and AIX 5L combo? > > 7.2 with lwlock.patch rev.2 > 7.1.3 > AIX 5L 4way with 4GB RAM > testing script is same as my previous postings (except -N for pgbench, > of course). > > ------------------------------------------------------------------------ > Name: pgbench.patch > pgbench.patch Type: Plain Text (Text/Plain) > Encoding: 7bit > > Name: result-Jan-09.png > result-Jan-09.png Type: PNG Image (image/png) > Encoding: base64 Could you add some labels to lines as Tom did ? We can only guess which line is which. -------------- Hannu
> Could you add some labels to lines as Tom did ? > > We can only guess which line is which. I thought I already added labels. 7.1 is "+"(green one), and 7.2 is "rhombus"(red one). -- Tatsuo Ishii
Tatsuo Ishii <t-ishii@sra.co.jp> writes:
> I have made a new version of pgbench which allows not to update
> branches and tellers tables, which should significantly reduce the
> contentions.
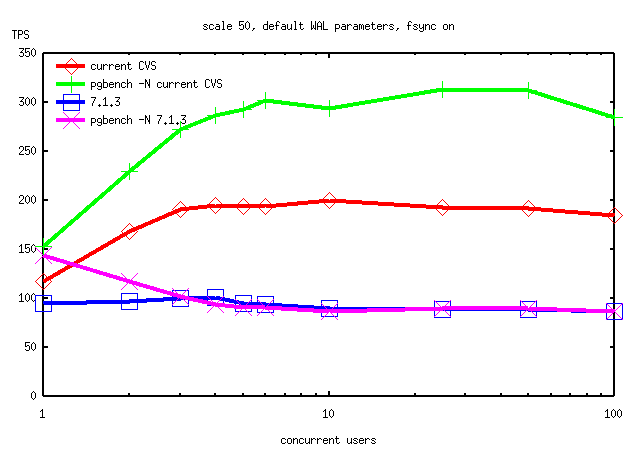
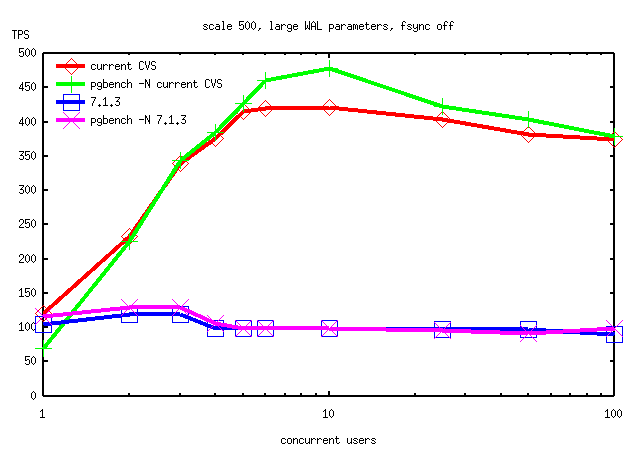
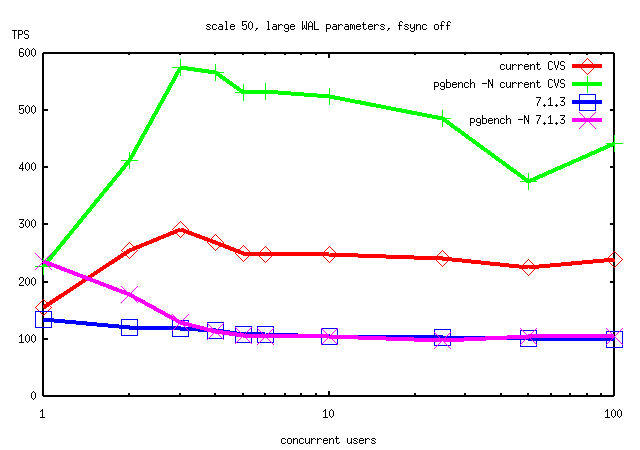
I used this version of pgbench in some fresh runs on RedHat's 4-way SMP
Linux box. I did several test runs under varying conditions (pgbench
scale 500 or 50, checkpoint_segments/wal_files either default 3/0 or
30/5, fsync on or off). I compared current CVS tip (including the
now-committed lwlock rev 2 patch) to 7.1.3. The results are attached.
As you can see, current beats 7.1 pretty much across the board on that
hardware. The reason seems to be revealed by looking at vmstat output.
Typical "vmstat 5" output for 7.1.3 (here in a 6-client pgbench -N
run) is
procs memory swap io system cpu
r b w swpd free buff cache si so bi bo in cs us sy id
1 0 0 0 108444 8920 4917092 0 0 213 0 170 4814 0 1 99
1 0 0 0 103592 8948 4921912 0 0 234 357 230 4811 1 1 98
0 0 0 0 98776 8968 4926704 0 0 233 428 235 4854 1 1 97
0 0 0 0 94300 8980 4931168 0 0 216 423 229 4809 1 2 97
0 0 0 0 89960 8984 4935504 0 0 209 771 421 4723 2 2 96
0 0 0 0 69280 9016 4956140 0 0 205 842 457 4645 1 2 96
The system is capable of much greater I/O rates, so neither disks nor
CPUs are exactly exerting themselves here. In contrast, 7.2 shows:
procs memory swap io system cpu
r b w swpd free buff cache si so bi bo in cs us sy id
2 0 0 0 2927344 9148 1969356 0 0 0 5772 102 13753 61 32 7
7 0 0 0 3042272 9148 1969716 0 0 0 2267 2400 14083 58 32 10
5 0 0 0 3042168 9148 1970100 0 0 0 2734 1028 12994 53 37 11
I think that 7.1's poor showing here is undoubtedly due to the spinlock
backoff algorithm it used --- there is no other way to explain 99% idle
CPU than that all of the backends are caught in 10-msec select() waits.
> With the new pgbench, I ran a test with current and 7.1 and saw
> not-so-small differences. Any idea to get better performance on 7.2
> and AIX 5L combo?
I'm thinking more and more that there must be something weird about the
cs() routine that we use for spinlocks on AIX. Could someone dig into
that and find exactly what it does and whether it's got any performance
issues?
regards, tom lane
Attachment
{kind=link}
{kind=link}
{kind=link}
Tom Lane wrote: > Tatsuo Ishii <t-ishii@sra.co.jp> writes: > > I have made a new version of pgbench which allows not to update > > branches and tellers tables, which should significantly reduce the > > contentions. > > I used this version of pgbench in some fresh runs on RedHat's 4-way SMP > Linux box. I did several test runs under varying conditions (pgbench > scale 500 or 50, checkpoint_segments/wal_files either default 3/0 or > 30/5, fsync on or off). I compared current CVS tip (including the > now-committed lwlock rev 2 patch) to 7.1.3. The results are attached. > As you can see, current beats 7.1 pretty much across the board on that > hardware. The reason seems to be revealed by looking at vmstat output. > Typical "vmstat 5" output for 7.1.3 (here in a 6-client pgbench -N > run) is Those are dramatic graphs. Is it the WAL increase that made 7.2 much faster? -- Bruce Momjian | http://candle.pha.pa.us pgman@candle.pha.pa.us | (610) 853-3000+ If your life is a hard drive, | 830 Blythe Avenue + Christ can be your backup. | Drexel Hill, Pennsylvania19026
> > With the new pgbench, I ran a test with current and 7.1 and saw > > not-so-small differences. Any idea to get better performance on 7.2 > > and AIX 5L combo? > > I'm thinking more and more that there must be something weird about the > cs() routine that we use for spinlocks on AIX. Could someone dig into > that and find exactly what it does and whether it's got any performance > issues? The manual page sais: Note: The cs subroutine is only provided to support binary compatibility with AIX Version 3 applications. When writingnew applications, it is not recommended to use this subroutine; it may cause reduced performance in the future.Applications should use the compare_and_swap subroutine, unless they need to use unaligned memory locations. I once tried to replace cs() with compare_and_swap() but saw worse performance for the limited testing I did (probably on a single CPU). Maybe the "threat" that performance will be reduced is actually true on AIX 5 now. The thing would imho now be for Tatsuo to try to replace cs with compare_and_swap, and see what happens on AIX 5. Andreas PS: Would the __powerpc__ assembly work on AIX machines ?
> > I'm thinking more and more that there must be something weird about the > > cs() routine that we use for spinlocks on AIX. Could someone dig into > > that and find exactly what it does and whether it's got any performance > > issues? > > The manual page sais: > > Note: The cs subroutine is only provided to support binary compatibility with > AIX Version 3 applications. When writing new applications, it is not > recommended to use this subroutine; it may cause reduced performance in the > future. Applications should use the compare_and_swap subroutine, unless they > need to use unaligned memory locations. > > I once tried to replace cs() with compare_and_swap() but saw worse performance > for the limited testing I did (probably on a single CPU). Maybe the "threat" > that performance will be reduced is actually true on AIX 5 now. > > The thing would imho now be for Tatsuo to try to replace cs with compare_and_swap, > and see what happens on AIX 5. > > Andreas > > PS: Would the __powerpc__ assembly work on AIX machines ? > I wish I could do that but... From the manual page of compare_and_swap (see below): What I'm not sure is this part: > Note If compare_and_swap is used as a locking primitive, insert an > isync at the start of any critical sections; What is "isync"? Also, how I can implement calling compare_and_swap in the assembly language? -- Tatsuo Ishii ----------------------------------------------------------------------- boolean_t compare_and_swap ( word_addr, old_val_addr, new_val) atomic_p word_addr; int *old_val_addr; int new_val; Description The compare_and_swap subroutine performs an atomic operation which compares the contents of a single word variable with a stored old value; If the values are equal, a new value is stored in the single word variable and TRUE is returned; otherwise, the old value is set to the current value of the single word variable and FALSE is returned; The compare_and_swap subroutine is useful when a word value must be updated only if it has not been changed since it was last read; Note The word containing the single word variable must be aligned on a full word boundary Note If compare_and_swap is used as a locking primitive, insert anisync at the start of any critical sections; Parameters word_addr Specifies the address of the single word variable. old_val_addr Specifies the address of the old value to be checked against (and conditionally updated with) the value of the single word variable. new_val Specifies the new value to be conditionally assigned to the single word variable. Return Values TRUE Indicates that the single word variable was equal to the old value, and has been set to the new value. FALSE Indicates that the single word variable was not equal to the old value, and that its current value has been returned in the location where the old value was previously stored. Implementation Specifics Implementation Specifics The compare_and_swap subroutine is part of the Base Operating System (BOS) Runtime Related Information The fetch_and_add (fetch_and_add Subroutine) subroutine, fetch_and_and (fetch_and_and or fetch_and_or Subroutine) subroutine, fetch_and_or (fetch_and_and or fetch_and_or Subroutine) subroutine.
Tatsuo Ishii <t-ishii@sra.co.jp> writes:
> [ compare_and_swap man page ]
Looks kinda baroque. What about the referenced fetch_and_or routine?
If that's atomic it might be closer to TAS semantics.
regards, tom lane
> > What is "isync"? Also, how I can implement calling > > sorry no idea :-( > > > compare_and_swap in the assembly language? > > In assembly language you would do the locking yourself, > the code would be identical, or at least very similar to > the __APPLE__ __ppc__ code. > > sample lock code supplied in the PowerPC > Architecture book (page 254): > > unlock: sync > stw 0, lock_location > blr > > In the unlock case the sync is all that is necessary to make all changes > protected by the lock globally visible. Note that no lwarx or stwcx. is > needed. > > lock: > 1: lwarx r5, lock_location > cmpiw r5, 0 > bne 2f: > stwcx. 1, lock_location > bne 1b > isync > blr > 2: need to indicate the lock is already locked (could spin if you want to > in this case or put on a sleep queue) > blr > > isync only affects the running processor. I have tried LinuxPPC's TAS code but AIX's assembler complains that lwarx and stwcx are unsupported op. So it seems that we need to tweak your code actually. -- Tatsuo Ishii
> > isync only affects the running processor. > > I have tried LinuxPPC's TAS code but AIX's assembler complains that > lwarx and stwcx are unsupported op. So it seems that we need to tweak > your code actually. The problem is, that the default on AIX is to produce architecture independent code (arch=COM). Unfortunately not all AIX architectures seem to have these instructions. With arch=ppc it works (two lines adjusted .globl .tas and .tas:). My worry is, that the Architecture book sais that the isync is necessary on SMP. I wonder why that would not also apply to LinuxPPC or Apple. Andreas
"Zeugswetter Andreas SB SD" <ZeugswetterA@spardat.at> writes:
> The problem is, that the default on AIX is to produce architecture
> independent code (arch=COM). Unfortunately not all AIX architectures
> seem to have these instructions.
AIX does more than one architecture? Hmm, s_lock.h doesn't know that...
> With arch=ppc it works (two lines
> adjusted .globl .tas and .tas:). My worry is, that the Architecture
> book sais that the isync is necessary on SMP. I wonder why that would
> not also apply to LinuxPPC or Apple.
I doubt we've had anyone test on SMP PPC machines, other than Tatsuo's
tests on AIX. Worse, I'd imagine that any failures from a missing sync
instruction would be rare and tough to reproduce. So there may indeed
be a lurking problem here.
regards, tom lane
Tom writes: > "Zeugswetter Andreas SB SD" <ZeugswetterA@spardat.at> writes: > > The problem is, that the default on AIX is to produce architecture > > independent code (arch=COM). Unfortunately not all AIX architectures > > seem to have these instructions. > > AIX does more than one architecture? Hmm, s_lock.h doesn't > know that... It does not need to, since all of them currently use cs(). The compilers by default generate executables that run on all of the different processors (they are all Risc). Andreas
Um, and then there's darwin on the dual g4's.... SMP POSIX code on PPC is not limited to AIX and Linux (ugh). freebsd 5.0 is rumored to be smp and run on ppc as well. alex
Tom wrote: > > [ compare_and_swap man page ] > > Looks kinda baroque. What about the referenced fetch_and_or routine? > If that's atomic it might be closer to TAS semantics. Thanks for the hint! Tatsuo, can you try the performance of fetch_and_or on your machine ? Replace the cs() line in s_lock.h with the following: <-- #define TAS(lock) cs((int *) (lock), 0, 1) --> #define TAS(lock) fetch_and_or(lock, 1) On my machine the various implemtations have the following runtimes: (with a modified s_lock test that does not sleep, and SPINS_PER_DELAY 100000) with LinuxPPC asm: 1m5.16s (Which may not work relyably on SMP) with cs: 1m12.25s with fetch_and_or: 1m26.71s I don't know if that is enough difference to worry about. Andreas
> On my machine the various implemtations have the following runtimes: > (with a modified s_lock test that does not sleep, and > SPINS_PER_DELAY 100000) > > with LinuxPPC asm: 1m5.16s (Which may not work relyably on SMP) > with cs: 1m12.25s > with fetch_and_or: 1m26.71s Aah, there we have it. Same test on a slower 4Way SMP: with LinuxPPC asm: 2m9.340s with cs: 10m11.15s with fetch_and_or: 3m55.19s These numbers look more alarming. Unfortunately the man page for fetch_and_or does not mention anything about using it as a locking primitive. It is documented atomic though, so I guess that is enough. Andreas
> > On my machine the various implemtations have the following runtimes: > > (with a modified s_lock test that does not sleep, and > > SPINS_PER_DELAY 100000) > > > > with LinuxPPC asm: 1m5.16s (Which may not work relyably on SMP) > > with cs: 1m12.25s > > with fetch_and_or: 1m26.71s > > Aah, there we have it. Same test on a slower 4Way SMP: > > with LinuxPPC asm: 2m9.340s > with cs: 10m11.15s > with fetch_and_or: 3m55.19s > > These numbers look more alarming. > Unfortunately the man page for fetch_and_or does not mention anything > about using it as a locking primitive. It is documented atomic though, > so I guess that is enough. > > Andreas > I did several times of pgbenhc -c 10 -t 20 with the modification you suggested and once got a hung (all backends sleeping with the status showing "COMMIT"). Also I had an eror: NOTICE: LockRelease: no such lock I'm afraid now the locking is broken. Will look into more. -- Tatsuo Ishii
"Zeugswetter Andreas SB SD" <ZeugswetterA@spardat.at> writes:
> Unfortunately the man page for fetch_and_or does not mention anything
> about using it as a locking primitive. It is documented atomic though,
> so I guess that is enough.
You could disassemble it and see if it includes that "isync" instruction
or not.
Given Tatsuo's later report, I'm afraid the answer is "not".
regards, tom lane
> NOTICE: LockRelease: no such lock > > I'm afraid now the locking is broken. Will look into more. Next try would be _check_lock (found in sys/atomic_op.h): Description (from man page) The _check_lock subroutine performs an atomic (uninterruptible) sequence of operations. The compare_and_swap subroutine is similar, but does not issue synchronization instructions and therefore is inappropriate for updating lock words. replace the TAS define with: #define TAS(lock) _check_lock(lock, 0, 1) > with LinuxPPC asm: 2m9.340s > with cs: 10m11.15s > with fetch_and_or: 3m55.19s with _check_lock: 3m29.990s I think that the culprit may also be the S_UNLOCK (use _clear_lock) ? Andreas
"Zeugswetter Andreas SB SD" <ZeugswetterA@spardat.at> writes:
> I think that the culprit may also be the S_UNLOCK (use _clear_lock) ?
If isync is anything like the MB instruction on Alpha (ie, force memory
updates to occur before proceeding), then it must be used in S_UNLOCK
as well as S_LOCK. All updates done within the spinlocked section must
reach memory before another processor is allowed to acquire the lock.
regards, tom lane
> > NOTICE: LockRelease: no such lock > > > > I'm afraid now the locking is broken. Will look into more. > > Next try would be _check_lock (found in sys/atomic_op.h): > > Description (from man page) > > The _check_lock subroutine performs an atomic (uninterruptible) sequence of > operations. The compare_and_swap subroutine is similar, but does not issue > synchronization instructions and therefore is inappropriate for updating lock > words. > > replace the TAS define with: > #define TAS(lock) _check_lock(lock, 0, 1) > > > with LinuxPPC asm: 2m9.340s > > with cs: 10m11.15s > > with fetch_and_or: 3m55.19s > > with _check_lock: 3m29.990s > > I think that the culprit may also be the S_UNLOCK (use _clear_lock) ? Thanks. I will try with it. BTW, I'm still wondering why 7.2 is slower than 7.1 on AIX. Tom said cs() is responsible for that. But not only 7.2 but 7.1 uses cs(). It seems cs() does not explain the difference of the performance. -- Tatsuo Ishii
> Thanks. I will try with it. > > BTW, I'm still wondering why 7.2 is slower than 7.1 on AIX. Tom said > cs() is responsible for that. But not only 7.2 but 7.1 uses cs(). It > seems cs() does not explain the difference of the performance. cs() may be used more heavily on 7.2 --- not sure. -- Bruce Momjian | http://candle.pha.pa.us pgman@candle.pha.pa.us | (610) 853-3000+ If your life is a hard drive, | 830 Blythe Avenue + Christ can be your backup. | Drexel Hill, Pennsylvania19026
> that the extra cost would be enough to notice. And indeed we haven't > been able to measure any penalty on Linux, HPUX, nor BSD (right Bruce?). Right. -- Bruce Momjian | http://candle.pha.pa.us pgman@candle.pha.pa.us | (610) 853-3000+ If your life is a hard drive, | 830 Blythe Avenue + Christ can be your backup. | Drexel Hill, Pennsylvania19026
Bruce Momjian <pgman@candle.pha.pa.us> writes:
>> BTW, I'm still wondering why 7.2 is slower than 7.1 on AIX. Tom said
>> cs() is responsible for that. But not only 7.2 but 7.1 uses cs(). It
>> seems cs() does not explain the difference of the performance.
> cs() may be used more heavily on 7.2 --- not sure.
Most of the places that were SpinLockAcquire ... SpinRelease on 7.1 are
now LWLockAcquire ... LWLockRelease on 7.2. And each of LWLockAcquire
and LWLockRelease does a SpinLockAcquire + SpinRelease + some other
computation. So there's no doubt that we expend more cycles; cycles
that are wasted in a pure-single-backend scenario. However, if the
spinlock operations are as cheap as they should be, it's hard to believe
that the extra cost would be enough to notice. And indeed we haven't
been able to measure any penalty on Linux, HPUX, nor BSD (right Bruce?).
So I'm still suspicious that our cs()-based spinlock for AIX is carrying
some unexpected cost.
regards, tom lane
Added to TODO: * Evaluate AIX cs() spinlock macro for performance optimizations (Tatsuo) --------------------------------------------------------------------------- Tatsuo Ishii wrote: > > > NOTICE: LockRelease: no such lock > > > > > > I'm afraid now the locking is broken. Will look into more. > > > > Next try would be _check_lock (found in sys/atomic_op.h): > > > > Description (from man page) > > > > The _check_lock subroutine performs an atomic (uninterruptible) sequence of > > operations. The compare_and_swap subroutine is similar, but does not issue > > synchronization instructions and therefore is inappropriate for updating lock > > words. > > > > replace the TAS define with: > > #define TAS(lock) _check_lock(lock, 0, 1) > > > > > with LinuxPPC asm: 2m9.340s > > > with cs: 10m11.15s > > > with fetch_and_or: 3m55.19s > > > > with _check_lock: 3m29.990s > > > > I think that the culprit may also be the S_UNLOCK (use _clear_lock) ? > > Thanks. I will try with it. > > BTW, I'm still wondering why 7.2 is slower than 7.1 on AIX. Tom said > cs() is responsible for that. But not only 7.2 but 7.1 uses cs(). It > seems cs() does not explain the difference of the performance. > -- > Tatsuo Ishii > > ---------------------------(end of broadcast)--------------------------- > TIP 4: Don't 'kill -9' the postmaster > -- Bruce Momjian | http://candle.pha.pa.us pgman@candle.pha.pa.us | (610) 853-3000+ If your life is a hard drive, | 830 Blythe Avenue + Christ can be your backup. | Drexel Hill, Pennsylvania19026
Tom, Can I use the fourth graph (scale=50, fsync=on) to show how 7.2 could outperform 7.1 on SMP boxes? I'm going to make a presentation at Net&Com 2002 (http://expo.nikkeibp.co.jp/netcom/web/e/index.html) the day after tomorrow. -- Tatsuo Ishii > I used this version of pgbench in some fresh runs on RedHat's 4-way SMP > Linux box. I did several test runs under varying conditions (pgbench > scale 500 or 50, checkpoint_segments/wal_files either default 3/0 or > 30/5, fsync on or off). I compared current CVS tip (including the > now-committed lwlock rev 2 patch) to 7.1.3. The results are attached. > As you can see, current beats 7.1 pretty much across the board on that > hardware. The reason seems to be revealed by looking at vmstat output. > Typical "vmstat 5" output for 7.1.3 (here in a 6-client pgbench -N > run) is > > procs memory swap io system cpu > r b w swpd free buff cache si so bi bo in cs us sy id > 1 0 0 0 108444 8920 4917092 0 0 213 0 170 4814 0 1 99 > 1 0 0 0 103592 8948 4921912 0 0 234 357 230 4811 1 1 98 > 0 0 0 0 98776 8968 4926704 0 0 233 428 235 4854 1 1 97 > 0 0 0 0 94300 8980 4931168 0 0 216 423 229 4809 1 2 97 > 0 0 0 0 89960 8984 4935504 0 0 209 771 421 4723 2 2 96 > 0 0 0 0 69280 9016 4956140 0 0 205 842 457 4645 1 2 96 > > The system is capable of much greater I/O rates, so neither disks nor > CPUs are exactly exerting themselves here. In contrast, 7.2 shows: > > procs memory swap io system cpu > r b w swpd free buff cache si so bi bo in cs us sy id > 2 0 0 0 2927344 9148 1969356 0 0 0 5772 102 13753 61 32 7 > 7 0 0 0 3042272 9148 1969716 0 0 0 2267 2400 14083 58 32 10 > 5 0 0 0 3042168 9148 1970100 0 0 0 2734 1028 12994 53 37 11 > > I think that 7.1's poor showing here is undoubtedly due to the spinlock > backoff algorithm it used --- there is no other way to explain 99% idle > CPU than that all of the backends are caught in 10-msec select() waits. > > > With the new pgbench, I ran a test with current and 7.1 and saw > > not-so-small differences. Any idea to get better performance on 7.2 > > and AIX 5L combo? > > I'm thinking more and more that there must be something weird about the > cs() routine that we use for spinlocks on AIX. Could someone dig into > that and find exactly what it does and whether it's got any performance > issues? > > regards, tom lane >