Re: [pgadmin4][patch] Initial patch to decouple from ACI Tree - Mailing list pgadmin-hackers
| From | Khushboo Vashi |
|---|---|
| Subject | Re: [pgadmin4][patch] Initial patch to decouple from ACI Tree |
| Date | |
| Msg-id | CAFOhELcTvnyB+0d7SauaR8NzxF1kFfCAtqA3Fswj=Um=Y71Z9g@mail.gmail.com Whole thread |
| In response to | Re: [pgadmin4][patch] Initial patch to decouple from ACI Tree (Joao De Almeida Pereira <jdealmeidapereira@pivotal.io>) |
| List | pgadmin-hackers |
Hi Hackers,
Be prepared this is going to be a big email.
Objectives of this patch:
- Start the work to split ACI from pgAdmin code
- Add more tests around the front end components
- Start the discussion on application architecture
1. Start the work to split ACI from pgAdmin code
Why
This journey started on our first attempt to store state of the current tree, so that when a user accessed again pgAdmin
there would be no need to reopen all the nodes and make the flow better. Another problem users brought to us was related
to the UI behavior when the number of objects was too big.In order to do implement this features we would have to play around with aciTree or some functions from our code that
called and leveraged the aciTree functionalities. To do this we needed to have some confidence that our changes would
implement correctly the new feature and it would not break the current functionality.
The process that we used was first extract the functions that interacted with the tree, wrap them with
tests and then refactor them in some way. While doing this work we realized that the tree started spreading roots
throughout the majority of the application.How
Options:
- Rewrite the front end
- One bang replace ACI Tree without change on the application
- Create an abstraction layer between ACI Tree and the application
1. Rewrite the front end
Pros Const Achieve decoupling by recreating the frontend Cost is too high Do not rely on deprecated or unmaintained libraries Turn around is too long One shot change 2. One bang replace ACI Tree
Pros Const Achieve decoupling by recreating the frontend Cost is too high Does not achieve the decoupling unless we change the application Need to create an adaptor No garantee of success One shot change 3. Create an abstraction layer between ACI Tree and the application
Pros Const Achieve decoupling of the application and the tree 90% of the time on Code archaeology Lower cost Ability to change or keep ACI Tree, decision TBD Can be done in a iterative way We decided that options 3 looked more attractive specially because we could do it in a iterative way.
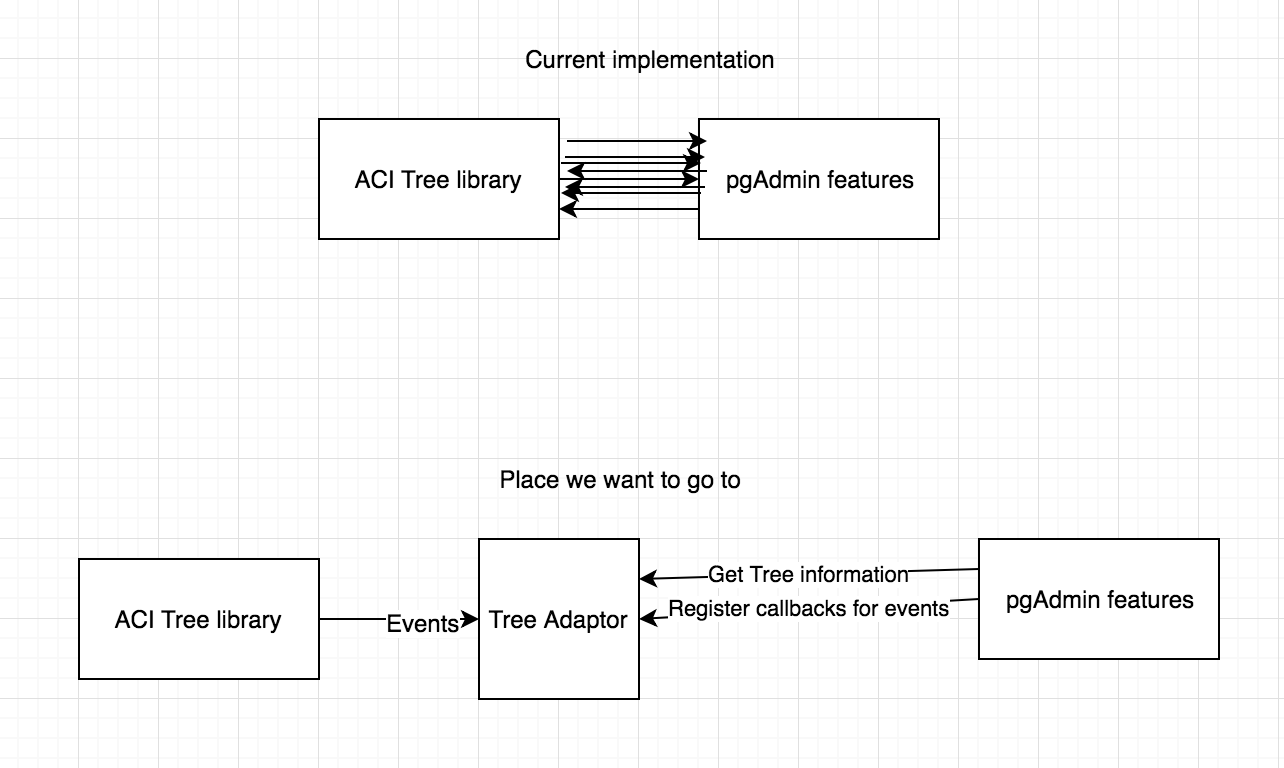
The next image depicts the current state of the interactions between the application and the ACI and the place we want
to be in.
for retrieving of data from the ACI Tree that then is used in different ways.
Because we are doing this in a iterative process we need to keep the current tree working and create our adaptor next
to it. In order to do that we created a new property onPGBrowserclass calledtreeMenuand when ACI Tree receives
the node information we also populate the new Tree with all the needed information.This approach allow us not to worry, for now, with data retrieval, URL system and other issues that should be addressed
in the future when the adaptor is done.This first patch tries to deal with the low hanging fruit, functions that are triggered by events from ACI Tree.
Cases like registering to events and triggering events need to be handled in the future as well.2. Add more tests around the front end components
Why
Go Fast Forever: https://builttoadapt.io/why-
tdd-489fdcdda05e
I think this is a very good summary of why do we need tests in our applications.3. Start the discussion on application architecture
Why should we care about location of files inside a our application?
Why is this way better the another?
These are 2 good questions that have very lengthy answers. Trying to more or less summarize the answers we care about
the location of the files, because we want our application to communicate intent and there are always pros and cons
on all the decisions that we make.At this point the application structure follows our menu, this approach eventually make is easier to follow the code
but at the same time if the menu changes down the line, will we change the structure of our folders?
The proposal that we do with the last diff of this patch is to change to a structure that slices vertically the
application. This way we can understand intent behind the code and more easily find what we are looking for.In the current structure if you want to see the tables code you need to go to
pgAdmin/browser/server_groups/this is a huge path to remember and to get to. Whatservers/databases/schemas/ tables/
do we win with this? If we open pgAdmin we know which nodes to click in order to get to tables. But for development
every time that you are looking for a specific functionality you need to run the application, navigate the menu so that
you know where you can find the code. This doesn’t sound very appealing.What if our structure would look like this:
- web - tables - controller - get_nodes.py - get_sql.py - __init__.py - frontend - component - ddl_component.js - services - table-service.js - schemas - servers - ....
This would saves us time because all the information that we need is what are we working on and everything is right there.
Menu driven structure Intent Driven Structure Pros: Pros: Already in place Explicitly shows features Self contained features Self contained features Support for drop in features Support for drop in features Cons: Cons: Follows the menu, and it could change Need to change current code Hard to find features Some additional plumbing might be needed Drop in features need to be placed in a specific location according to the menu location What are your thought about this architecture?
Around minute 7 of this video Uncle Bob shows an application written
in rails to talk about architecture. It is a long KeyNote if you are curious I would advise you to see the full video.
His approach to architecture of the application is pretty interesting.
Patches
0001 Change the order of the shims on the shim file
Simple change that orders the shims inside the shim file
0002 New tree implementation
This is the first version of our Tree implementation. At this point is a very simple tree without no abstractions and
with code that eventually is not very performant, but this is only the first iteration and we are trying to follow the
Last Responsible Moment Principle.What can you find in this patch:
- Creation of
PGBrowser.treeMenu- Initial version of the Tree Adaptor
web/pgadmin/static/js/tree/tree.js - TreeFake test double that can replace the Tree for testing purposes
- Tests. As an interesting asside because Fake’s need to behave like the real object you will noticed that there are
tests for this type of double and they the same as of the real object.0003 Extract, Test and Refactor Methods
This is the patch that contains the change that we talked a in the objectives. It touches in a subset of the places
whereitemDatafunction is called. To have a sense of progress the following image depicts, on the left all places
where this functions can be found in the code and on the right the places where it still remains after this patch.But this patch is not only related to the ACI Tree, it also creates some abstractions from code that we found repeated.
Some examples of this are the dialogs for Backup and Restore, where the majority of the logic was common, so we created
inweb/pgadmin/static/js/3 different objects:alertify/
A FactoryDialogFactorythat is responsible for creating newDialogand these dialogs will use theDialogWrapper.This is also a good example of the Last Responsible Moment Principle,
inDialogthere are still some functions that are used in a Recover and Backup scenario. When we have more examples
we will be able to, if we want, to extract that into another function.While doing some code refactoring we found out that the Right Click Menu as some checks that can be centralized. Examples
of these are checks for Enable/Disable of an option of the display of the Create/Edit/Drop option in some menus.
Checkweb/pgadmin/static/js/menu/for more information. This simplified code like:canCreate: function(itemData, item, data) { - //If check is false then , we will allow create menu - if (data && data.check == false) - return true; - - var t = pgBrowser.tree, i = item, d = itemData; - // To iterate over tree to check parent node - while (i) { - // If it is schema then allow user to create domain - if (_.indexOf(['schema'], d._type) > -1) - return true; - - if ('coll-domain' == d._type) { - //Check if we are not child of catalog - var prev_i = t.hasParent(i) ? t.parent(i) : null, - prev_d = prev_i ? t.itemData(prev_i) : null; - if( prev_d._type == 'catalog') { - return false; - } else { - return true; - } - } - i = t.hasParent(i) ? t.parent(i) : null; - d = i ? t.itemData(i) : null; - } - // by default we do not want to allow create menu - return true; + return canCreate.canCreate(pgBrowser, 'coll-domain', item, data); }This refactor was made in a couple of places throughout the code.
Another refactor that had to be done was the creation of the functions
getTreeNodeHierarchyFromElemenandt getTreeNodeHierarchyFromIdentithat replace the oldfier getTreeNodeHierarchy. This implementation was done
because for the time being we have 2 different types of trees and calls to them.The rest of the changes resulted from our process of refactoring that we are following:
- Find a location where
itemDatais used- Extract that into a function outside of the current code
- Wrap it with tests
- When we have enough confidence on the tests, we refactor the function to use the new Tree
- We refactor the function to become more readable
- Start over
0004 Architecture
The proposed structure is our vision for the application, this is not the state we will be in when this patch lands.
For now the only change we are doing is move the javascript intostatic/js/FEATURE_NAME. This is a first step in the
direction that we would like to see the product heading.Even if we decide to keep using the same architecture the move of Javascript to a centralized place will
not break any plugability as webpack can retrieve all the Javascript from any place in the code.Have a nice weekend
Joao
Attachment
pgadmin-hackers by date: