Thread: [pgadmin4][patch] Initial patch to decouple from ACI Tree
- on backup.js: menu_enabled, menu_enabled_server, start_backup_global_server, backup_objects
- on datagrid.js: show_data_grid, get_panel_title, show_query_tool
Attachment
Hi Hackers,Attached you can find the patch that will start to decouple pgAdmin from ACITree library.This patch is intended to be merged after 3.0, because we do not want to cause any entropy or delay the release, but we want to start the discussion and show some code.This job that we started is a massive tech debt chore that will take some time to finalize and we would love the help of the community to do it.Summary of the patch:0001 patch:- Creates a new tree that will allow us to create a separation between the application and ACI Tree- Creates a Fake Tree (Test double, for reference on the available test doubles: https://martinfowler.com/bliki/TestDouble.html) that can be used to inplace to replace the ACITree and also encapsulate the new tree behavior on our tests - Adds tests for all the tree functionalities0002 patch:- Extracts, refactors, adds tests and remove dependency from ACI Tree on:- getTreeNodeHierarchy
- on backup.js: menu_enabled, menu_enabled_server, start_backup_global_server, backup_objects
- on datagrid.js: show_data_grid, get_panel_title, show_query_tool- Start using sprintf-js as Underscore.String is deprecating sprintf functionThis patch represents only 10 calls to ACITree.itemData out of 176 that are spread around our codeIn Depth look on the process behind the patch:We started writing this patch with the idea that we need to decouple pgAdmin4 from ACITree, because ACITree is no longer supported, the documentation is non existent and ACITree is no longer being actively developed.Our process:1. We "randomly" selected a function that is part of the ACITree. From this point we decided to replace that function with our own version. The function that we choose was "itemData".The function gives us all the "data" that a specific node of the tree find.Given in order to replace the tree we would need to have a function that would give us the same information. We had 2 options:a) Create a tree with a function called itemDataPros:- At first view this was the simpler solution- Would keep the status quoCons:- Not a OOP approach- Not very flexibleb) Create a tree that would return a node given an ID and then the node would be responsible for giving it's data.Pros:- OOP Approach- More flexible and we do not need to bring the tree around, just a nodeCons:- Break the current status quoGiven these 2 options we decided to go for a more OOP approach creating a Tree and a TreeNode classes, that in the future will be renamed to ACITreeWrapper and TreeNode.2. After we decided on the starting point we searched for occurrences of the function "itemData" and we found out that there were 303 occurrences of "itemData" in the code and roughly 176 calls to the function itself (some of the hits were variable names).3. We selected the first file on the search and found the function that was responsible for calling the itemData function.4. Extracted the function to a separate file5. Wrap this function with tests6. Refactor the function to ES6, give more declarative names to variables and break the functions into smaller chunks7. When all the tests were passing we replaced ACITree with our Tree8. We ensured that all tests were passing9. Remove function from the original file and use the new function10. Ensure everything still works11. Find the next function and execute from step 4 until all the functions are replaced, refactored and tested.As you can see by the process this is a pretty huge undertake, because of the number of calls to the function. This is just the first step on the direction of completely isolating the ACITree so that we can solve the problem with a large number of elements on the tree.What is on our radar that we need to address:- Finish the complete decoupling of the ACITree- Performance of the current tree implementation- Tweak the naming of the Tree class to explicitly tell us this is to use only with ACITree.ThanksJoao
Blog: http://pgsnake.blogspot.com
Twitter: @pgsnake
EnterpriseDB UK: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
Khushboo, Murtuza,Can you spend some time reviewing this please? I've started playing with it as well - the first thing that's irking me somewhat is the lack of comments. Descriptive function names are all well and good, but sometimes a little more is needed, especially for less experienced developers or newcomers to the application!
--On Mon, Apr 2, 2018 at 7:45 PM, Joao De Almeida Pereira <jdealmeidapereira@pivotal.io> wrote:Hi Hackers,Attached you can find the patch that will start to decouple pgAdmin from ACITree library.This patch is intended to be merged after 3.0, because we do not want to cause any entropy or delay the release, but we want to start the discussion and show some code.This job that we started is a massive tech debt chore that will take some time to finalize and we would love the help of the community to do it.Summary of the patch:0001 patch:- Creates a new tree that will allow us to create a separation between the application and ACI Tree- Creates a Fake Tree (Test double, for reference on the available test doubles: https://martinfowler.com/bliki/TestDouble.html) that can be used to inplace to replace the ACITree and also encapsulate the new tree behavior on our tests - Adds tests for all the tree functionalities0002 patch:- Extracts, refactors, adds tests and remove dependency from ACI Tree on:- getTreeNodeHierarchy
- on backup.js: menu_enabled, menu_enabled_server, start_backup_global_server, backup_objects
- on datagrid.js: show_data_grid, get_panel_title, show_query_tool- Start using sprintf-js as Underscore.String is deprecating sprintf functionThis patch represents only 10 calls to ACITree.itemData out of 176 that are spread around our codeIn Depth look on the process behind the patch:We started writing this patch with the idea that we need to decouple pgAdmin4 from ACITree, because ACITree is no longer supported, the documentation is non existent and ACITree is no longer being actively developed.Our process:1. We "randomly" selected a function that is part of the ACITree. From this point we decided to replace that function with our own version. The function that we choose was "itemData".The function gives us all the "data" that a specific node of the tree find.Given in order to replace the tree we would need to have a function that would give us the same information. We had 2 options:a) Create a tree with a function called itemDataPros:- At first view this was the simpler solution- Would keep the status quoCons:- Not a OOP approach- Not very flexibleb) Create a tree that would return a node given an ID and then the node would be responsible for giving it's data.Pros:- OOP Approach- More flexible and we do not need to bring the tree around, just a nodeCons:- Break the current status quoGiven these 2 options we decided to go for a more OOP approach creating a Tree and a TreeNode classes, that in the future will be renamed to ACITreeWrapper and TreeNode.2. After we decided on the starting point we searched for occurrences of the function "itemData" and we found out that there were 303 occurrences of "itemData" in the code and roughly 176 calls to the function itself (some of the hits were variable names).3. We selected the first file on the search and found the function that was responsible for calling the itemData function.4. Extracted the function to a separate file5. Wrap this function with tests6. Refactor the function to ES6, give more declarative names to variables and break the functions into smaller chunks7. When all the tests were passing we replaced ACITree with our Tree8. We ensured that all tests were passing9. Remove function from the original file and use the new function10. Ensure everything still works11. Find the next function and execute from step 4 until all the functions are replaced, refactored and tested.As you can see by the process this is a pretty huge undertake, because of the number of calls to the function. This is just the first step on the direction of completely isolating the ACITree so that we can solve the problem with a large number of elements on the tree.What is on our radar that we need to address:- Finish the complete decoupling of the ACITree- Performance of the current tree implementation- Tweak the naming of the Tree class to explicitly tell us this is to use only with ACITree.ThanksJoaoDave Page
Blog: http://pgsnake.blogspot.com
Twitter: @pgsnake
EnterpriseDB UK: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
Hi Hackers,Attached you can find the patch that will start to decouple pgAdmin from ACITree library.This patch is intended to be merged after 3.0, because we do not want to cause any entropy or delay the release, but we want to start the discussion and show some code.This job that we started is a massive tech debt chore that will take some time to finalize and we would love the help of the community to do it.Summary of the patch:0001 patch:- Creates a new tree that will allow us to create a separation between the application and ACI Tree- Creates a Fake Tree (Test double, for reference on the available test doubles: https://martinfowler.com/bliki/TestDouble.html) that can be used to inplace to replace the ACITree and also encapsulate the new tree behavior on our tests - Adds tests for all the tree functionalities0002 patch:- Extracts, refactors, adds tests and remove dependency from ACI Tree on:- getTreeNodeHierarchy
- on backup.js: menu_enabled, menu_enabled_server, start_backup_global_server, backup_objects
- on datagrid.js: show_data_grid, get_panel_title, show_query_tool- Start using sprintf-js as Underscore.String is deprecating sprintf functionThis patch represents only 10 calls to ACITree.itemData out of 176 that are spread around our codeIn Depth look on the process behind the patch:We started writing this patch with the idea that we need to decouple pgAdmin4 from ACITree, because ACITree is no longer supported, the documentation is non existent and ACITree is no longer being actively developed.Our process:1. We "randomly" selected a function that is part of the ACITree. From this point we decided to replace that function with our own version. The function that we choose was "itemData".The function gives us all the "data" that a specific node of the tree find.Given in order to replace the tree we would need to have a function that would give us the same information. We had 2 options:a) Create a tree with a function called itemDataPros:- At first view this was the simpler solution- Would keep the status quoCons:- Not a OOP approach- Not very flexibleb) Create a tree that would return a node given an ID and then the node would be responsible for giving it's data.Pros:- OOP Approach- More flexible and we do not need to bring the tree around, just a nodeCons:- Break the current status quoGiven these 2 options we decided to go for a more OOP approach creating a Tree and a TreeNode classes, that in the future will be renamed to ACITreeWrapper and TreeNode.2. After we decided on the starting point we searched for occurrences of the function "itemData" and we found out that there were 303 occurrences of "itemData" in the code and roughly 176 calls to the function itself (some of the hits were variable names).3. We selected the first file on the search and found the function that was responsible for calling the itemData function.4. Extracted the function to a separate file5. Wrap this function with tests6. Refactor the function to ES6, give more declarative names to variables and break the functions into smaller chunks7. When all the tests were passing we replaced ACITree with our Tree8. We ensured that all tests were passing9. Remove function from the original file and use the new function10. Ensure everything still works11. Find the next function and execute from step 4 until all the functions are replaced, refactored and tested.As you can see by the process this is a pretty huge undertake, because of the number of calls to the function. This is just the first step on the direction of completely isolating the ACITree so that we can solve the problem with a large number of elements on the tree.What is on our radar that we need to address:- Finish the complete decoupling of the ACITree- Performance of the current tree implementation- Tweak the naming of the Tree class to explicitly tell us this is to use only with ACITree.ThanksJoao
Hi Joao,Can you please rebase the second patch?Thanks,KhushbooOn Tue, Apr 3, 2018 at 12:15 AM, Joao De Almeida Pereira <jdealmeidapereira@pivotal.io> wrote:Hi Hackers,Attached you can find the patch that will start to decouple pgAdmin from ACITree library.This patch is intended to be merged after 3.0, because we do not want to cause any entropy or delay the release, but we want to start the discussion and show some code.This job that we started is a massive tech debt chore that will take some time to finalize and we would love the help of the community to do it.Summary of the patch:0001 patch:- Creates a new tree that will allow us to create a separation between the application and ACI Tree- Creates a Fake Tree (Test double, for reference on the available test doubles: https://martinfowler.com/bliki/TestDouble.html) that can be used to inplace to replace the ACITree and also encapsulate the new tree behavior on our tests- Adds tests for all the tree functionalities0002 patch:- Extracts, refactors, adds tests and remove dependency from ACI Tree on:- getTreeNodeHierarchy
- on backup.js: menu_enabled, menu_enabled_server, start_backup_global_server, backup_objects
- on datagrid.js: show_data_grid, get_panel_title, show_query_tool- Start using sprintf-js as Underscore.String is deprecating sprintf functionThis patch represents only 10 calls to ACITree.itemData out of 176 that are spread around our codeIn Depth look on the process behind the patch:We started writing this patch with the idea that we need to decouple pgAdmin4 from ACITree, because ACITree is no longer supported, the documentation is non existent and ACITree is no longer being actively developed.Our process:1. We "randomly" selected a function that is part of the ACITree. From this point we decided to replace that function with our own version. The function that we choose was "itemData".The function gives us all the "data" that a specific node of the tree find.Given in order to replace the tree we would need to have a function that would give us the same information. We had 2 options:a) Create a tree with a function called itemDataPros:- At first view this was the simpler solution- Would keep the status quoCons:- Not a OOP approach- Not very flexibleb) Create a tree that would return a node given an ID and then the node would be responsible for giving it's data.Pros:- OOP Approach- More flexible and we do not need to bring the tree around, just a nodeCons:- Break the current status quoGiven these 2 options we decided to go for a more OOP approach creating a Tree and a TreeNode classes, that in the future will be renamed to ACITreeWrapper and TreeNode.2. After we decided on the starting point we searched for occurrences of the function "itemData" and we found out that there were 303 occurrences of "itemData" in the code and roughly 176 calls to the function itself (some of the hits were variable names).3. We selected the first file on the search and found the function that was responsible for calling the itemData function.4. Extracted the function to a separate file5. Wrap this function with tests6. Refactor the function to ES6, give more declarative names to variables and break the functions into smaller chunks7. When all the tests were passing we replaced ACITree with our Tree8. We ensured that all tests were passing9. Remove function from the original file and use the new function10. Ensure everything still works11. Find the next function and execute from step 4 until all the functions are replaced, refactored and tested.As you can see by the process this is a pretty huge undertake, because of the number of calls to the function. This is just the first step on the direction of completely isolating the ACITree so that we can solve the problem with a large number of elements on the tree.What is on our radar that we need to address:- Finish the complete decoupling of the ACITree- Performance of the current tree implementation- Tweak the naming of the Tree class to explicitly tell us this is to use only with ACITree.ThanksJoao
Attachment
Hi Khushboo,Attached you can find both patches rebasedThanksOn Thu, Apr 5, 2018 at 6:31 AM Khushboo Vashi <khushboo.vashi@enterprisedb.com> wrote: Hi Joao,Can you please rebase the second patch?Thanks,KhushbooOn Tue, Apr 3, 2018 at 12:15 AM, Joao De Almeida Pereira <jdealmeidapereira@pivotal.io> wrote:Hi Hackers,Attached you can find the patch that will start to decouple pgAdmin from ACITree library.This patch is intended to be merged after 3.0, because we do not want to cause any entropy or delay the release, but we want to start the discussion and show some code.This job that we started is a massive tech debt chore that will take some time to finalize and we would love the help of the community to do it.Summary of the patch:0001 patch:- Creates a new tree that will allow us to create a separation between the application and ACI Tree- Creates a Fake Tree (Test double, for reference on the available test doubles: https://martinfowler.com/bliki/TestDouble.html) that can be used to inplace to replace the ACITree and also encapsulate the new tree behavior on our tests - Adds tests for all the tree functionalities0002 patch:- Extracts, refactors, adds tests and remove dependency from ACI Tree on:- getTreeNodeHierarchy
- on backup.js: menu_enabled, menu_enabled_server, start_backup_global_server, backup_objects
- on datagrid.js: show_data_grid, get_panel_title, show_query_tool- Start using sprintf-js as Underscore.String is deprecating sprintf functionThis patch represents only 10 calls to ACITree.itemData out of 176 that are spread around our codeIn Depth look on the process behind the patch:We started writing this patch with the idea that we need to decouple pgAdmin4 from ACITree, because ACITree is no longer supported, the documentation is non existent and ACITree is no longer being actively developed.Our process:1. We "randomly" selected a function that is part of the ACITree. From this point we decided to replace that function with our own version. The function that we choose was "itemData".The function gives us all the "data" that a specific node of the tree find.Given in order to replace the tree we would need to have a function that would give us the same information. We had 2 options:a) Create a tree with a function called itemDataPros:- At first view this was the simpler solution- Would keep the status quoCons:- Not a OOP approach- Not very flexibleb) Create a tree that would return a node given an ID and then the node would be responsible for giving it's data.Pros:- OOP Approach- More flexible and we do not need to bring the tree around, just a nodeCons:- Break the current status quoGiven these 2 options we decided to go for a more OOP approach creating a Tree and a TreeNode classes, that in the future will be renamed to ACITreeWrapper and TreeNode.2. After we decided on the starting point we searched for occurrences of the function "itemData" and we found out that there were 303 occurrences of "itemData" in the code and roughly 176 calls to the function itself (some of the hits were variable names).3. We selected the first file on the search and found the function that was responsible for calling the itemData function.4. Extracted the function to a separate file5. Wrap this function with tests6. Refactor the function to ES6, give more declarative names to variables and break the functions into smaller chunks7. When all the tests were passing we replaced ACITree with our Tree8. We ensured that all tests were passing9. Remove function from the original file and use the new function10. Ensure everything still works11. Find the next function and execute from step 4 until all the functions are replaced, refactored and tested.As you can see by the process this is a pretty huge undertake, because of the number of calls to the function. This is just the first step on the direction of completely isolating the ACITree so that we can solve the problem with a large number of elements on the tree.What is on our radar that we need to address:- Finish the complete decoupling of the ACITree- Performance of the current tree implementation- Tweak the naming of the Tree class to explicitly tell us this is to use only with ACITree.ThanksJoao
Hello Murtuza/Dave,
Yes now the extracted functions are spread into different files. The intent would be to make the files as small as possible, and also to group and name them in a way that would be easy to understand what each file is doing without the need of opening it.
As a example:static/js/backup will contain all the backup related functionality
inside of this folder we can see the file:menu_utils.js At this moment in time we decided to group all the functions that are related to the menu, but we can split that also if we believe it is easier to see.
static/js/datagrid folder contains all the datagrid related functionality
Inside of the folder we can see the files:get_panel_title.js is responsible for retrieving the name of the panelshow_data.js is responsible for showing the datagridshow_query_tool.js is responsible for showing the query tool
Does this structure make sense?
Can you give an example of a comment that you think is missing and that could help?
As a personal note, unless the algorithm is very obscure or very complicated, I believe that if the code needs comments it is a signal that something needs to change in terms of naming, structure of the part in question. This being said, I am open to add some comments that might help people.
Thanks
Joao
Hi Joao,Patch looks good and working as expected.I also agree with Dave, Can we please add some comments in each file which can help us to understand the flow, I'm saying because now the code is segregated in so many separate files it will be hard to keep track of the flow from one file to another when debugging.--Regards,On Thu, Apr 5, 2018 at 7:08 PM, Joao De Almeida Pereira <jdealmeidapereira@pivotal.io> wrote:Hi Khushboo,Attached you can find both patches rebasedThanksOn Thu, Apr 5, 2018 at 6:31 AM Khushboo Vashi <khushboo.vashi@enterprisedb.com> wrote:Hi Joao,Can you please rebase the second patch?Thanks,KhushbooOn Tue, Apr 3, 2018 at 12:15 AM, Joao De Almeida Pereira <jdealmeidapereira@pivotal.io> wrote:Hi Hackers,Attached you can find the patch that will start to decouple pgAdmin from ACITree library.This patch is intended to be merged after 3.0, because we do not want to cause any entropy or delay the release, but we want to start the discussion and show some code.This job that we started is a massive tech debt chore that will take some time to finalize and we would love the help of the community to do it.Summary of the patch:0001 patch:- Creates a new tree that will allow us to create a separation between the application and ACI Tree- Creates a Fake Tree (Test double, for reference on the available test doubles: https://martinfowler.com/bliki/TestDouble.html) that can be used to inplace to replace the ACITree and also encapsulate the new tree behavior on our tests- Adds tests for all the tree functionalities0002 patch:- Extracts, refactors, adds tests and remove dependency from ACI Tree on:- getTreeNodeHierarchy
- on backup.js: menu_enabled, menu_enabled_server, start_backup_global_server, backup_objects
- on datagrid.js: show_data_grid, get_panel_title, show_query_tool- Start using sprintf-js as Underscore.String is deprecating sprintf functionThis patch represents only 10 calls to ACITree.itemData out of 176 that are spread around our codeIn Depth look on the process behind the patch:We started writing this patch with the idea that we need to decouple pgAdmin4 from ACITree, because ACITree is no longer supported, the documentation is non existent and ACITree is no longer being actively developed.Our process:1. We "randomly" selected a function that is part of the ACITree. From this point we decided to replace that function with our own version. The function that we choose was "itemData".The function gives us all the "data" that a specific node of the tree find.Given in order to replace the tree we would need to have a function that would give us the same information. We had 2 options:a) Create a tree with a function called itemDataPros:- At first view this was the simpler solution- Would keep the status quoCons:- Not a OOP approach- Not very flexibleb) Create a tree that would return a node given an ID and then the node would be responsible for giving it's data.Pros:- OOP Approach- More flexible and we do not need to bring the tree around, just a nodeCons:- Break the current status quoGiven these 2 options we decided to go for a more OOP approach creating a Tree and a TreeNode classes, that in the future will be renamed to ACITreeWrapper and TreeNode.2. After we decided on the starting point we searched for occurrences of the function "itemData" and we found out that there were 303 occurrences of "itemData" in the code and roughly 176 calls to the function itself (some of the hits were variable names).3. We selected the first file on the search and found the function that was responsible for calling the itemData function.4. Extracted the function to a separate file5. Wrap this function with tests6. Refactor the function to ES6, give more declarative names to variables and break the functions into smaller chunks7. When all the tests were passing we replaced ACITree with our Tree8. We ensured that all tests were passing9. Remove function from the original file and use the new function10. Ensure everything still works11. Find the next function and execute from step 4 until all the functions are replaced, refactored and tested.As you can see by the process this is a pretty huge undertake, because of the number of calls to the function. This is just the first step on the direction of completely isolating the ACITree so that we can solve the problem with a large number of elements on the tree.What is on our radar that we need to address:- Finish the complete decoupling of the ACITree- Performance of the current tree implementation- Tweak the naming of the Tree class to explicitly tell us this is to use only with ACITree.ThanksJoao
Hello Murtuza/Dave,
Yes now the extracted functions are spread into different files. The intent would be to make the files as small as possible, and also to group and name them in a way that would be easy to understand what each file is doing without the need of opening it.
As a example:static/js/backupwill contain all the backup related functionality inside of this folder we can see the file:
menu_utils.jsAt this moment in time we decided to group all the functions that are related to the menu, but we can split that also if we believe it is easier to see.
static/js/datagridfolder contains all the datagrid related functionality
Inside of the folder we can see the files:
get_panel_title.jsis responsible for retrieving the name of the panelshow_data.jsis responsible for showing the datagridshow_query_tool.jsis responsible for showing the query toolDoes this structure make sense?
Can you give an example of a comment that you think is missing and that could help?As a personal note, unless the algorithm is very obscure or very complicated, I believe that if the code needs comments it is a signal that something needs to change in terms of naming, structure of the part in question. This being said, I am open to add some comments that might help people.
Thanks
Joao
On Fri, Apr 6, 2018 at 4:48 AM Murtuza Zabuawala <murtuza.zabuawala@enterprisedb.com> wrote: Hi Joao,Patch looks good and working as expected.I also agree with Dave, Can we please add some comments in each file which can help us to understand the flow, I'm saying because now the code is segregated in so many separate files it will be hard to keep track of the flow from one file to another when debugging.--Regards,On Thu, Apr 5, 2018 at 7:08 PM, Joao De Almeida Pereira <jdealmeidapereira@pivotal.io> wrote:Hi Khushboo,Attached you can find both patches rebasedThanksOn Thu, Apr 5, 2018 at 6:31 AM Khushboo Vashi <khushboo.vashi@enterprisedb.com> wrote: Hi Joao,Can you please rebase the second patch?Thanks,KhushbooOn Tue, Apr 3, 2018 at 12:15 AM, Joao De Almeida Pereira <jdealmeidapereira@pivotal.io> wrote:Hi Hackers,Attached you can find the patch that will start to decouple pgAdmin from ACITree library.This patch is intended to be merged after 3.0, because we do not want to cause any entropy or delay the release, but we want to start the discussion and show some code.This job that we started is a massive tech debt chore that will take some time to finalize and we would love the help of the community to do it.Summary of the patch:0001 patch:- Creates a new tree that will allow us to create a separation between the application and ACI Tree- Creates a Fake Tree (Test double, for reference on the available test doubles: https://martinfowler.com/bliki/TestDouble.html) that can be used to inplace to replace the ACITree and also encapsulate the new tree behavior on our tests - Adds tests for all the tree functionalities0002 patch:- Extracts, refactors, adds tests and remove dependency from ACI Tree on:- getTreeNodeHierarchy
- on backup.js: menu_enabled, menu_enabled_server, start_backup_global_server, backup_objects
- on datagrid.js: show_data_grid, get_panel_title, show_query_tool- Start using sprintf-js as Underscore.String is deprecating sprintf functionThis patch represents only 10 calls to ACITree.itemData out of 176 that are spread around our codeIn Depth look on the process behind the patch:We started writing this patch with the idea that we need to decouple pgAdmin4 from ACITree, because ACITree is no longer supported, the documentation is non existent and ACITree is no longer being actively developed.Our process:1. We "randomly" selected a function that is part of the ACITree. From this point we decided to replace that function with our own version. The function that we choose was "itemData".The function gives us all the "data" that a specific node of the tree find.Given in order to replace the tree we would need to have a function that would give us the same information. We had 2 options:a) Create a tree with a function called itemDataPros:- At first view this was the simpler solution- Would keep the status quoCons:- Not a OOP approach- Not very flexibleb) Create a tree that would return a node given an ID and then the node would be responsible for giving it's data.Pros:- OOP Approach- More flexible and we do not need to bring the tree around, just a nodeCons:- Break the current status quoGiven these 2 options we decided to go for a more OOP approach creating a Tree and a TreeNode classes, that in the future will be renamed to ACITreeWrapper and TreeNode.2. After we decided on the starting point we searched for occurrences of the function "itemData" and we found out that there were 303 occurrences of "itemData" in the code and roughly 176 calls to the function itself (some of the hits were variable names).3. We selected the first file on the search and found the function that was responsible for calling the itemData function.4. Extracted the function to a separate file5. Wrap this function with tests6. Refactor the function to ES6, give more declarative names to variables and break the functions into smaller chunks7. When all the tests were passing we replaced ACITree with our Tree8. We ensured that all tests were passing9. Remove function from the original file and use the new function10. Ensure everything still works11. Find the next function and execute from step 4 until all the functions are replaced, refactored and tested.As you can see by the process this is a pretty huge undertake, because of the number of calls to the function. This is just the first step on the direction of completely isolating the ACITree so that we can solve the problem with a large number of elements on the tree.What is on our radar that we need to address:- Finish the complete decoupling of the ACITree- Performance of the current tree implementation- Tweak the naming of the Tree class to explicitly tell us this is to use only with ACITree.ThanksJoao
Hi Joao,I have reviewed your patch and have some suggestions.On Sat, Apr 7, 2018 at 12:43 AM, Joao De Almeida Pereira <jdealmeidapereira@pivotal.io> wrote:Hello Murtuza/Dave,
Yes now the extracted functions are spread into different files. The intent would be to make the files as small as possible, and also to group and name them in a way that would be easy to understand what each file is doing without the need of opening it.
As a example:static/js/backupwill contain all the backup related functionality inside of this folder we can see the file:
menu_utils.jsAt this moment in time we decided to group all the functions that are related to the menu, but we can split that also if we believe it is easier to see.It's really very good to see the separated code for backup module. As we have done for backup, we would like do it for other PG utilities like restore, maintenance etc.Considering this, we should separate the code in a way that some of the common functionalities can be used for other modules like menu (as you have mentioned above), dialogue factory etc.Also, I think these functionalities should be in their respective static folder instead of pgadmin/static.
static/js/datagridfolder contains all the datagrid related functionalitySame as backup module, this should be in it's respective static/js folder.Inside of the folder we can see the files:
get_panel_title.jsis responsible for retrieving the name of the panelshow_data.jsis responsible for showing the datagridshow_query_tool.jsis responsible for showing the query toolDoes this structure make sense?
Can you give an example of a comment that you think is missing and that could help?As a personal note, unless the algorithm is very obscure or very complicated, I believe that if the code needs comments it is a signal that something needs to change in terms of naming, structure of the part in question. This being said, I am open to add some comments that might help people.
You are right, with the help of naming convention and structure of the code, any one can get the idea about the code. But it is very useful to understand the codevery easily with the proper comments especially when there are multiple developers working on a single project.I found some of the places where it would be great to have comments.- treeMenu: new tree.Tree() in a browser.js- tree.js (especially Tree class)
Thanks
JoaoThanks,KhushbooOn Fri, Apr 6, 2018 at 4:48 AM Murtuza Zabuawala <murtuza.zabuawala@enterprisedb.com> wrote:Hi Joao,Patch looks good and working as expected.I also agree with Dave, Can we please add some comments in each file which can help us to understand the flow, I'm saying because now the code is segregated in so many separate files it will be hard to keep track of the flow from one file to another when debugging.--Regards,On Thu, Apr 5, 2018 at 7:08 PM, Joao De Almeida Pereira <jdealmeidapereira@pivotal.io> wrote:Hi Khushboo,Attached you can find both patches rebasedThanksOn Thu, Apr 5, 2018 at 6:31 AM Khushboo Vashi <khushboo.vashi@enterprisedb.com> wrote:Hi Joao,Can you please rebase the second patch?Thanks,KhushbooOn Tue, Apr 3, 2018 at 12:15 AM, Joao De Almeida Pereira <jdealmeidapereira@pivotal.io> wrote:Hi Hackers,Attached you can find the patch that will start to decouple pgAdmin from ACITree library.This patch is intended to be merged after 3.0, because we do not want to cause any entropy or delay the release, but we want to start the discussion and show some code.This job that we started is a massive tech debt chore that will take some time to finalize and we would love the help of the community to do it.Summary of the patch:0001 patch:- Creates a new tree that will allow us to create a separation between the application and ACI Tree- Creates a Fake Tree (Test double, for reference on the available test doubles: https://martinfowler.com/bliki/TestDouble.html) that can be used to inplace to replace the ACITree and also encapsulate the new tree behavior on our tests- Adds tests for all the tree functionalities0002 patch:- Extracts, refactors, adds tests and remove dependency from ACI Tree on:- getTreeNodeHierarchy
- on backup.js: menu_enabled, menu_enabled_server, start_backup_global_server, backup_objects
- on datagrid.js: show_data_grid, get_panel_title, show_query_tool- Start using sprintf-js as Underscore.String is deprecating sprintf functionThis patch represents only 10 calls to ACITree.itemData out of 176 that are spread around our codeIn Depth look on the process behind the patch:We started writing this patch with the idea that we need to decouple pgAdmin4 from ACITree, because ACITree is no longer supported, the documentation is non existent and ACITree is no longer being actively developed.Our process:1. We "randomly" selected a function that is part of the ACITree. From this point we decided to replace that function with our own version. The function that we choose was "itemData".The function gives us all the "data" that a specific node of the tree find.Given in order to replace the tree we would need to have a function that would give us the same information. We had 2 options:a) Create a tree with a function called itemDataPros:- At first view this was the simpler solution- Would keep the status quoCons:- Not a OOP approach- Not very flexibleb) Create a tree that would return a node given an ID and then the node would be responsible for giving it's data.Pros:- OOP Approach- More flexible and we do not need to bring the tree around, just a nodeCons:- Break the current status quoGiven these 2 options we decided to go for a more OOP approach creating a Tree and a TreeNode classes, that in the future will be renamed to ACITreeWrapper and TreeNode.2. After we decided on the starting point we searched for occurrences of the function "itemData" and we found out that there were 303 occurrences of "itemData" in the code and roughly 176 calls to the function itself (some of the hits were variable names).3. We selected the first file on the search and found the function that was responsible for calling the itemData function.4. Extracted the function to a separate file5. Wrap this function with tests6. Refactor the function to ES6, give more declarative names to variables and break the functions into smaller chunks7. When all the tests were passing we replaced ACITree with our Tree8. We ensured that all tests were passing9. Remove function from the original file and use the new function10. Ensure everything still works11. Find the next function and execute from step 4 until all the functions are replaced, refactored and tested.As you can see by the process this is a pretty huge undertake, because of the number of calls to the function. This is just the first step on the direction of completely isolating the ACITree so that we can solve the problem with a large number of elements on the tree.What is on our radar that we need to address:- Finish the complete decoupling of the ACITree- Performance of the current tree implementation- Tweak the naming of the Tree class to explicitly tell us this is to use only with ACITree.ThanksJoao
Hello KhushbooOn Mon, Apr 9, 2018 at 1:59 AM Khushboo Vashi <khushboo.vashi@enterprisedb.com> wrote:Hi Joao,I have reviewed your patch and have some suggestions.On Sat, Apr 7, 2018 at 12:43 AM, Joao De Almeida Pereira <jdealmeidapereira@pivotal.io> wrote:Hello Murtuza/Dave,
Yes now the extracted functions are spread into different files. The intent would be to make the files as small as possible, and also to group and name them in a way that would be easy to understand what each file is doing without the need of opening it.
As a example:static/js/backupwill contain all the backup related functionality inside of this folder we can see the file:
menu_utils.jsAt this moment in time we decided to group all the functions that are related to the menu, but we can split that also if we believe it is easier to see.It's really very good to see the separated code for backup module. As we have done for backup, we would like do it for other PG utilities like restore, maintenance etc.Considering this, we should separate the code in a way that some of the common functionalities can be used for other modules like menu (as you have mentioned above), dialogue factory etc.Also, I think these functionalities should be in their respective static folder instead of pgadmin/static.About the location of the files. The move of the files to pgadmin/static/js was made on purpose in order to clearly separate Javascript from python code.The rational behind it was- Create a clear separation between the backend and frontend- Having Javascript code concentrated in a single place, hopefully, will encourage to developers to look for a functionality, that is already implemented in another modules, because they are right there. (When we started this journey we realized that the 'nodes' have a big groups of code that could be shared, but because the Javascript is spread everywhere it is much harder to look for it)There are some drawbacks of this separation:- When creating a new module we will need to put the javascript in a separate location from the backend code
static/js/datagridfolder contains all the datagrid related functionalitySame as backup module, this should be in it's respective static/js folder.Inside of the folder we can see the files:
get_panel_title.jsis responsible for retrieving the name of the panelshow_data.jsis responsible for showing the datagridshow_query_tool.jsis responsible for showing the query toolDoes this structure make sense?
Can you give an example of a comment that you think is missing and that could help?As a personal note, unless the algorithm is very obscure or very complicated, I believe that if the code needs comments it is a signal that something needs to change in terms of naming, structure of the part in question. This being said, I am open to add some comments that might help people.
You are right, with the help of naming convention and structure of the code, any one can get the idea about the code. But it is very useful to understand the codevery easily with the proper comments especially when there are multiple developers working on a single project.I found some of the places where it would be great to have comments.- treeMenu: new tree.Tree() in a browser.js- tree.js (especially Tree class)About the comment point I need a more clear understanding on what kind of comments you are looking for. Because when you read the function names you understand the intent, what they are doing. The parameters also explain what you need to pass into them.If what you are looking for in these comments is the reasoning being the change itself, then that should be present in the commit message. Specially because this is going to be a very big patch with a very big number of changes.Thanks
JoaoThanks,KhushbooOn Fri, Apr 6, 2018 at 4:48 AM Murtuza Zabuawala <murtuza.zabuawala@enterprisedb.com> wrote:Hi Joao,Patch looks good and working as expected.I also agree with Dave, Can we please add some comments in each file which can help us to understand the flow, I'm saying because now the code is segregated in so many separate files it will be hard to keep track of the flow from one file to another when debugging.--Regards,On Thu, Apr 5, 2018 at 7:08 PM, Joao De Almeida Pereira <jdealmeidapereira@pivotal.io> wrote:Hi Khushboo,Attached you can find both patches rebasedThanksOn Thu, Apr 5, 2018 at 6:31 AM Khushboo Vashi <khushboo.vashi@enterprisedb.com> wrote:Hi Joao,Can you please rebase the second patch?Thanks,KhushbooOn Tue, Apr 3, 2018 at 12:15 AM, Joao De Almeida Pereira <jdealmeidapereira@pivotal.io> wrote:Hi Hackers,Attached you can find the patch that will start to decouple pgAdmin from ACITree library.This patch is intended to be merged after 3.0, because we do not want to cause any entropy or delay the release, but we want to start the discussion and show some code.This job that we started is a massive tech debt chore that will take some time to finalize and we would love the help of the community to do it.Summary of the patch:0001 patch:- Creates a new tree that will allow us to create a separation between the application and ACI Tree- Creates a Fake Tree (Test double, for reference on the available test doubles: https://martinfowler.com/bliki/TestDouble.html) that can be used to inplace to replace the ACITree and also encapsulate the new tree behavior on our tests- Adds tests for all the tree functionalities0002 patch:- Extracts, refactors, adds tests and remove dependency from ACI Tree on:- getTreeNodeHierarchy
- on backup.js: menu_enabled, menu_enabled_server, start_backup_global_server, backup_objects
- on datagrid.js: show_data_grid, get_panel_title, show_query_tool- Start using sprintf-js as Underscore.String is deprecating sprintf functionThis patch represents only 10 calls to ACITree.itemData out of 176 that are spread around our codeIn Depth look on the process behind the patch:We started writing this patch with the idea that we need to decouple pgAdmin4 from ACITree, because ACITree is no longer supported, the documentation is non existent and ACITree is no longer being actively developed.Our process:1. We "randomly" selected a function that is part of the ACITree. From this point we decided to replace that function with our own version. The function that we choose was "itemData".The function gives us all the "data" that a specific node of the tree find.Given in order to replace the tree we would need to have a function that would give us the same information. We had 2 options:a) Create a tree with a function called itemDataPros:- At first view this was the simpler solution- Would keep the status quoCons:- Not a OOP approach- Not very flexibleb) Create a tree that would return a node given an ID and then the node would be responsible for giving it's data.Pros:- OOP Approach- More flexible and we do not need to bring the tree around, just a nodeCons:- Break the current status quoGiven these 2 options we decided to go for a more OOP approach creating a Tree and a TreeNode classes, that in the future will be renamed to ACITreeWrapper and TreeNode.2. After we decided on the starting point we searched for occurrences of the function "itemData" and we found out that there were 303 occurrences of "itemData" in the code and roughly 176 calls to the function itself (some of the hits were variable names).3. We selected the first file on the search and found the function that was responsible for calling the itemData function.4. Extracted the function to a separate file5. Wrap this function with tests6. Refactor the function to ES6, give more declarative names to variables and break the functions into smaller chunks7. When all the tests were passing we replaced ACITree with our Tree8. We ensured that all tests were passing9. Remove function from the original file and use the new function10. Ensure everything still works11. Find the next function and execute from step 4 until all the functions are replaced, refactored and tested.As you can see by the process this is a pretty huge undertake, because of the number of calls to the function. This is just the first step on the direction of completely isolating the ACITree so that we can solve the problem with a large number of elements on the tree.What is on our radar that we need to address:- Finish the complete decoupling of the ACITree- Performance of the current tree implementation- Tweak the naming of the Tree class to explicitly tell us this is to use only with ACITree.ThanksJoao
Hi Hackers,Any other comment about this patch?ThanksJoaoOn Tue, Apr 10, 2018 at 12:00 PM Joao De Almeida Pereira <jdealmeidapereira@pivotal.io> wrote:Hello KhushbooOn Mon, Apr 9, 2018 at 1:59 AM Khushboo Vashi <khushboo.vashi@enterprisedb.com> wrote:Hi Joao,I have reviewed your patch and have some suggestions.On Sat, Apr 7, 2018 at 12:43 AM, Joao De Almeida Pereira <jdealmeidapereira@pivotal.io> wrote:Hello Murtuza/Dave,
Yes now the extracted functions are spread into different files. The intent would be to make the files as small as possible, and also to group and name them in a way that would be easy to understand what each file is doing without the need of opening it.
As a example:static/js/backupwill contain all the backup related functionality inside of this folder we can see the file:
menu_utils.jsAt this moment in time we decided to group all the functions that are related to the menu, but we can split that also if we believe it is easier to see.It's really very good to see the separated code for backup module. As we have done for backup, we would like do it for other PG utilities like restore, maintenance etc.Considering this, we should separate the code in a way that some of the common functionalities can be used for other modules like menu (as you have mentioned above), dialogue factory etc.Also, I think these functionalities should be in their respective static folder instead of pgadmin/static.About the location of the files. The move of the files to pgadmin/static/js was made on purpose in order to clearly separate Javascript from python code.The rational behind it was- Create a clear separation between the backend and frontend- Having Javascript code concentrated in a single place, hopefully, will encourage to developers to look for a functionality, that is already implemented in another modules, because they are right there. (When we started this journey we realized that the 'nodes' have a big groups of code that could be shared, but because the Javascript is spread everywhere it is much harder to look for it)There are some drawbacks of this separation:- When creating a new module we will need to put the javascript in a separate location from the backend code
static/js/datagridfolder contains all the datagrid related functionalitySame as backup module, this should be in it's respective static/js folder.Inside of the folder we can see the files:
get_panel_title.jsis responsible for retrieving the name of the panelshow_data.jsis responsible for showing the datagridshow_query_tool.jsis responsible for showing the query toolDoes this structure make sense?
Can you give an example of a comment that you think is missing and that could help?As a personal note, unless the algorithm is very obscure or very complicated, I believe that if the code needs comments it is a signal that something needs to change in terms of naming, structure of the part in question. This being said, I am open to add some comments that might help people.
You are right, with the help of naming convention and structure of the code, any one can get the idea about the code. But it is very useful to understand the codevery easily with the proper comments especially when there are multiple developers working on a single project.I found some of the places where it would be great to have comments.- treeMenu: new tree.Tree() in a browser.js- tree.js (especially Tree class)About the comment point I need a more clear understanding on what kind of comments you are looking for. Because when you read the function names you understand the intent, what they are doing. The parameters also explain what you need to pass into them.If what you are looking for in these comments is the reasoning being the change itself, then that should be present in the commit message. Specially because this is going to be a very big patch with a very big number of changes.Thanks
JoaoThanks,KhushbooOn Fri, Apr 6, 2018 at 4:48 AM Murtuza Zabuawala <murtuza.zabuawala@enterprisedb.com> wrote:Hi Joao,Patch looks good and working as expected.I also agree with Dave, Can we please add some comments in each file which can help us to understand the flow, I'm saying because now the code is segregated in so many separate files it will be hard to keep track of the flow from one file to another when debugging.--Regards,On Thu, Apr 5, 2018 at 7:08 PM, Joao De Almeida Pereira <jdealmeidapereira@pivotal.io> wrote:Hi Khushboo,Attached you can find both patches rebasedThanksOn Thu, Apr 5, 2018 at 6:31 AM Khushboo Vashi <khushboo.vashi@enterprisedb.com> wrote:Hi Joao,Can you please rebase the second patch?Thanks,KhushbooOn Tue, Apr 3, 2018 at 12:15 AM, Joao De Almeida Pereira <jdealmeidapereira@pivotal.io> wrote:Hi Hackers,Attached you can find the patch that will start to decouple pgAdmin from ACITree library.This patch is intended to be merged after 3.0, because we do not want to cause any entropy or delay the release, but we want to start the discussion and show some code.This job that we started is a massive tech debt chore that will take some time to finalize and we would love the help of the community to do it.Summary of the patch:0001 patch:- Creates a new tree that will allow us to create a separation between the application and ACI Tree- Creates a Fake Tree (Test double, for reference on the available test doubles: https://martinfowler.com/bliki/TestDouble.html) that can be used to inplace to replace the ACITree and also encapsulate the new tree behavior on our tests- Adds tests for all the tree functionalities0002 patch:- Extracts, refactors, adds tests and remove dependency from ACI Tree on:- getTreeNodeHierarchy
- on backup.js: menu_enabled, menu_enabled_server, start_backup_global_server, backup_objects
- on datagrid.js: show_data_grid, get_panel_title, show_query_tool- Start using sprintf-js as Underscore.String is deprecating sprintf functionThis patch represents only 10 calls to ACITree.itemData out of 176 that are spread around our codeIn Depth look on the process behind the patch:We started writing this patch with the idea that we need to decouple pgAdmin4 from ACITree, because ACITree is no longer supported, the documentation is non existent and ACITree is no longer being actively developed.Our process:1. We "randomly" selected a function that is part of the ACITree. From this point we decided to replace that function with our own version. The function that we choose was "itemData".The function gives us all the "data" that a specific node of the tree find.Given in order to replace the tree we would need to have a function that would give us the same information. We had 2 options:a) Create a tree with a function called itemDataPros:- At first view this was the simpler solution- Would keep the status quoCons:- Not a OOP approach- Not very flexibleb) Create a tree that would return a node given an ID and then the node would be responsible for giving it's data.Pros:- OOP Approach- More flexible and we do not need to bring the tree around, just a nodeCons:- Break the current status quoGiven these 2 options we decided to go for a more OOP approach creating a Tree and a TreeNode classes, that in the future will be renamed to ACITreeWrapper and TreeNode.2. After we decided on the starting point we searched for occurrences of the function "itemData" and we found out that there were 303 occurrences of "itemData" in the code and roughly 176 calls to the function itself (some of the hits were variable names).3. We selected the first file on the search and found the function that was responsible for calling the itemData function.4. Extracted the function to a separate file5. Wrap this function with tests6. Refactor the function to ES6, give more declarative names to variables and break the functions into smaller chunks7. When all the tests were passing we replaced ACITree with our Tree8. We ensured that all tests were passing9. Remove function from the original file and use the new function10. Ensure everything still works11. Find the next function and execute from step 4 until all the functions are replaced, refactored and tested.As you can see by the process this is a pretty huge undertake, because of the number of calls to the function. This is just the first step on the direction of completely isolating the ACITree so that we can solve the problem with a large number of elements on the tree.What is on our radar that we need to address:- Finish the complete decoupling of the ACITree- Performance of the current tree implementation- Tweak the naming of the Tree class to explicitly tell us this is to use only with ACITree.ThanksJoao
Hi Hackers,Can someone review and merge this patch?ThanksJoaoOn Wed, Apr 18, 2018 at 10:23 AM Joao De Almeida Pereira <jdealmeidapereira@pivotal.io> wrote:Hi Hackers,Any other comment about this patch?ThanksJoaoOn Tue, Apr 10, 2018 at 12:00 PM Joao De Almeida Pereira <jdealmeidapereira@pivotal.io> wrote:Hello KhushbooOn Mon, Apr 9, 2018 at 1:59 AM Khushboo Vashi <khushboo.vashi@enterprisedb.com> wrote: Hi Joao,I have reviewed your patch and have some suggestions.On Sat, Apr 7, 2018 at 12:43 AM, Joao De Almeida Pereira <jdealmeidapereira@pivotal.io> wrote:Hello Murtuza/Dave,
Yes now the extracted functions are spread into different files. The intent would be to make the files as small as possible, and also to group and name them in a way that would be easy to understand what each file is doing without the need of opening it.
As a example:static/js/backupwill contain all the backup related functionality inside of this folder we can see the file:
menu_utils.jsAt this moment in time we decided to group all the functions that are related to the menu, but we can split that also if we believe it is easier to see.It's really very good to see the separated code for backup module. As we have done for backup, we would like do it for other PG utilities like restore, maintenance etc.Considering this, we should separate the code in a way that some of the common functionalities can be used for other modules like menu (as you have mentioned above), dialogue factory etc.Also, I think these functionalities should be in their respective static folder instead of pgadmin/static.About the location of the files. The move of the files to pgadmin/static/js was made on purpose in order to clearly separate Javascript from python code.The rational behind it was- Create a clear separation between the backend and frontend- Having Javascript code concentrated in a single place, hopefully, will encourage to developers to look for a functionality, that is already implemented in another modules, because they are right there. (When we started this journey we realized that the 'nodes' have a big groups of code that could be shared, but because the Javascript is spread everywhere it is much harder to look for it)There are some drawbacks of this separation:- When creating a new module we will need to put the javascript in a separate location from the backend code
static/js/datagridfolder contains all the datagrid related functionalitySame as backup module, this should be in it's respective static/js folder.Inside of the folder we can see the files:
get_panel_title.jsis responsible for retrieving the name of the panelshow_data.jsis responsible for showing the datagridshow_query_tool.jsis responsible for showing the query toolDoes this structure make sense?
Can you give an example of a comment that you think is missing and that could help?As a personal note, unless the algorithm is very obscure or very complicated, I believe that if the code needs comments it is a signal that something needs to change in terms of naming, structure of the part in question. This being said, I am open to add some comments that might help people.
You are right, with the help of naming convention and structure of the code, any one can get the idea about the code. But it is very useful to understand the codevery easily with the proper comments especially when there are multiple developers working on a single project.I found some of the places where it would be great to have comments.- treeMenu: new tree.Tree() in a browser.js- tree.js (especially Tree class)About the comment point I need a more clear understanding on what kind of comments you are looking for. Because when you read the function names you understand the intent, what they are doing. The parameters also explain what you need to pass into them.If what you are looking for in these comments is the reasoning being the change itself, then that should be present in the commit message. Specially because this is going to be a very big patch with a very big number of changes.Thanks
JoaoThanks,KhushbooOn Fri, Apr 6, 2018 at 4:48 AM Murtuza Zabuawala <murtuza.zabuawala@enterprisedb.com> wrote: Hi Joao,Patch looks good and working as expected.I also agree with Dave, Can we please add some comments in each file which can help us to understand the flow, I'm saying because now the code is segregated in so many separate files it will be hard to keep track of the flow from one file to another when debugging.--Regards,On Thu, Apr 5, 2018 at 7:08 PM, Joao De Almeida Pereira <jdealmeidapereira@pivotal.io> wrote:Hi Khushboo,Attached you can find both patches rebasedThanksOn Thu, Apr 5, 2018 at 6:31 AM Khushboo Vashi <khushboo.vashi@enterprisedb.com> wrote: Hi Joao,Can you please rebase the second patch?Thanks,KhushbooOn Tue, Apr 3, 2018 at 12:15 AM, Joao De Almeida Pereira <jdealmeidapereira@pivotal.io> wrote:Hi Hackers,Attached you can find the patch that will start to decouple pgAdmin from ACITree library.This patch is intended to be merged after 3.0, because we do not want to cause any entropy or delay the release, but we want to start the discussion and show some code.This job that we started is a massive tech debt chore that will take some time to finalize and we would love the help of the community to do it.Summary of the patch:0001 patch:- Creates a new tree that will allow us to create a separation between the application and ACI Tree- Creates a Fake Tree (Test double, for reference on the available test doubles: https://martinfowler.com/bliki/TestDouble.html) that can be used to inplace to replace the ACITree and also encapsulate the new tree behavior on our tests - Adds tests for all the tree functionalities0002 patch:- Extracts, refactors, adds tests and remove dependency from ACI Tree on:- getTreeNodeHierarchy
- on backup.js: menu_enabled, menu_enabled_server, start_backup_global_server, backup_objects
- on datagrid.js: show_data_grid, get_panel_title, show_query_tool- Start using sprintf-js as Underscore.String is deprecating sprintf functionThis patch represents only 10 calls to ACITree.itemData out of 176 that are spread around our codeIn Depth look on the process behind the patch:We started writing this patch with the idea that we need to decouple pgAdmin4 from ACITree, because ACITree is no longer supported, the documentation is non existent and ACITree is no longer being actively developed.Our process:1. We "randomly" selected a function that is part of the ACITree. From this point we decided to replace that function with our own version. The function that we choose was "itemData".The function gives us all the "data" that a specific node of the tree find.Given in order to replace the tree we would need to have a function that would give us the same information. We had 2 options:a) Create a tree with a function called itemDataPros:- At first view this was the simpler solution- Would keep the status quoCons:- Not a OOP approach- Not very flexibleb) Create a tree that would return a node given an ID and then the node would be responsible for giving it's data.Pros:- OOP Approach- More flexible and we do not need to bring the tree around, just a nodeCons:- Break the current status quoGiven these 2 options we decided to go for a more OOP approach creating a Tree and a TreeNode classes, that in the future will be renamed to ACITreeWrapper and TreeNode.2. After we decided on the starting point we searched for occurrences of the function "itemData" and we found out that there were 303 occurrences of "itemData" in the code and roughly 176 calls to the function itself (some of the hits were variable names).3. We selected the first file on the search and found the function that was responsible for calling the itemData function.4. Extracted the function to a separate file5. Wrap this function with tests6. Refactor the function to ES6, give more declarative names to variables and break the functions into smaller chunks7. When all the tests were passing we replaced ACITree with our Tree8. We ensured that all tests were passing9. Remove function from the original file and use the new function10. Ensure everything still works11. Find the next function and execute from step 4 until all the functions are replaced, refactored and tested.As you can see by the process this is a pretty huge undertake, because of the number of calls to the function. This is just the first step on the direction of completely isolating the ACITree so that we can solve the problem with a large number of elements on the tree.What is on our radar that we need to address:- Finish the complete decoupling of the ACITree- Performance of the current tree implementation- Tweak the naming of the Tree class to explicitly tell us this is to use only with ACITree.ThanksJoao
Blog: http://pgsnake.blogspot.com
Twitter: @pgsnake
EnterpriseDB UK: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
Ashesh; you had agreed to work on this early this week. Please ensure you do so today.Thanks.--On Tue, Apr 24, 2018 at 8:13 PM, Joao De Almeida Pereira <jdealmeidapereira@pivotal.io> wrote:Hi Hackers,Can someone review and merge this patch?ThanksJoaoOn Wed, Apr 18, 2018 at 10:23 AM Joao De Almeida Pereira <jdealmeidapereira@pivotal.io> wrote:Hi Hackers,Any other comment about this patch?ThanksJoaoOn Tue, Apr 10, 2018 at 12:00 PM Joao De Almeida Pereira <jdealmeidapereira@pivotal.io> wrote:Hello KhushbooOn Mon, Apr 9, 2018 at 1:59 AM Khushboo Vashi <khushboo.vashi@enterprisedb.com> wrote: Hi Joao,I have reviewed your patch and have some suggestions.On Sat, Apr 7, 2018 at 12:43 AM, Joao De Almeida Pereira <jdealmeidapereira@pivotal.io> wrote:Hello Murtuza/Dave,
Yes now the extracted functions are spread into different files. The intent would be to make the files as small as possible, and also to group and name them in a way that would be easy to understand what each file is doing without the need of opening it.
As a example:static/js/backupwill contain all the backup related functionality inside of this folder we can see the file:
menu_utils.jsAt this moment in time we decided to group all the functions that are related to the menu, but we can split that also if we believe it is easier to see.It's really very good to see the separated code for backup module. As we have done for backup, we would like do it for other PG utilities like restore, maintenance etc.Considering this, we should separate the code in a way that some of the common functionalities can be used for other modules like menu (as you have mentioned above), dialogue factory etc.Also, I think these functionalities should be in their respective static folder instead of pgadmin/static.About the location of the files. The move of the files to pgadmin/static/js was made on purpose in order to clearly separate Javascript from python code.The rational behind it was- Create a clear separation between the backend and frontend- Having Javascript code concentrated in a single place, hopefully, will encourage to developers to look for a functionality, that is already implemented in another modules, because they are right there. (When we started this journey we realized that the 'nodes' have a big groups of code that could be shared, but because the Javascript is spread everywhere it is much harder to look for it)There are some drawbacks of this separation:- When creating a new module we will need to put the javascript in a separate location from the backend code
static/js/datagridfolder contains all the datagrid related functionalitySame as backup module, this should be in it's respective static/js folder.Inside of the folder we can see the files:
get_panel_title.jsis responsible for retrieving the name of the panelshow_data.jsis responsible for showing the datagridshow_query_tool.jsis responsible for showing the query toolDoes this structure make sense?
Can you give an example of a comment that you think is missing and that could help?As a personal note, unless the algorithm is very obscure or very complicated, I believe that if the code needs comments it is a signal that something needs to change in terms of naming, structure of the part in question. This being said, I am open to add some comments that might help people.
You are right, with the help of naming convention and structure of the code, any one can get the idea about the code. But it is very useful to understand the codevery easily with the proper comments especially when there are multiple developers working on a single project.I found some of the places where it would be great to have comments.- treeMenu: new tree.Tree() in a browser.js- tree.js (especially Tree class)About the comment point I need a more clear understanding on what kind of comments you are looking for. Because when you read the function names you understand the intent, what they are doing. The parameters also explain what you need to pass into them.If what you are looking for in these comments is the reasoning being the change itself, then that should be present in the commit message. Specially because this is going to be a very big patch with a very big number of changes.Thanks
JoaoThanks,KhushbooOn Fri, Apr 6, 2018 at 4:48 AM Murtuza Zabuawala <murtuza.zabuawala@enterprisedb.com> wrote: Hi Joao,Patch looks good and working as expected.I also agree with Dave, Can we please add some comments in each file which can help us to understand the flow, I'm saying because now the code is segregated in so many separate files it will be hard to keep track of the flow from one file to another when debugging.--Regards,On Thu, Apr 5, 2018 at 7:08 PM, Joao De Almeida Pereira <jdealmeidapereira@pivotal.io> wrote:Hi Khushboo,Attached you can find both patches rebasedThanksOn Thu, Apr 5, 2018 at 6:31 AM Khushboo Vashi <khushboo.vashi@enterprisedb.com> wrote: Hi Joao,Can you please rebase the second patch?Thanks,KhushbooOn Tue, Apr 3, 2018 at 12:15 AM, Joao De Almeida Pereira <jdealmeidapereira@pivotal.io> wrote:Hi Hackers,Attached you can find the patch that will start to decouple pgAdmin from ACITree library.This patch is intended to be merged after 3.0, because we do not want to cause any entropy or delay the release, but we want to start the discussion and show some code.This job that we started is a massive tech debt chore that will take some time to finalize and we would love the help of the community to do it.Summary of the patch:0001 patch:- Creates a new tree that will allow us to create a separation between the application and ACI Tree- Creates a Fake Tree (Test double, for reference on the available test doubles: https://martinfowler.com/bliki/TestDouble.html) that can be used to inplace to replace the ACITree and also encapsulate the new tree behavior on our tests - Adds tests for all the tree functionalities0002 patch:- Extracts, refactors, adds tests and remove dependency from ACI Tree on:- getTreeNodeHierarchy
- on backup.js: menu_enabled, menu_enabled_server, start_backup_global_server, backup_objects
- on datagrid.js: show_data_grid, get_panel_title, show_query_tool- Start using sprintf-js as Underscore.String is deprecating sprintf functionThis patch represents only 10 calls to ACITree.itemData out of 176 that are spread around our codeIn Depth look on the process behind the patch:We started writing this patch with the idea that we need to decouple pgAdmin4 from ACITree, because ACITree is no longer supported, the documentation is non existent and ACITree is no longer being actively developed.Our process:1. We "randomly" selected a function that is part of the ACITree. From this point we decided to replace that function with our own version. The function that we choose was "itemData".The function gives us all the "data" that a specific node of the tree find.Given in order to replace the tree we would need to have a function that would give us the same information. We had 2 options:a) Create a tree with a function called itemDataPros:- At first view this was the simpler solution- Would keep the status quoCons:- Not a OOP approach- Not very flexibleb) Create a tree that would return a node given an ID and then the node would be responsible for giving it's data.Pros:- OOP Approach- More flexible and we do not need to bring the tree around, just a nodeCons:- Break the current status quoGiven these 2 options we decided to go for a more OOP approach creating a Tree and a TreeNode classes, that in the future will be renamed to ACITreeWrapper and TreeNode.2. After we decided on the starting point we searched for occurrences of the function "itemData" and we found out that there were 303 occurrences of "itemData" in the code and roughly 176 calls to the function itself (some of the hits were variable names).3. We selected the first file on the search and found the function that was responsible for calling the itemData function.4. Extracted the function to a separate file5. Wrap this function with tests6. Refactor the function to ES6, give more declarative names to variables and break the functions into smaller chunks7. When all the tests were passing we replaced ACITree with our Tree8. We ensured that all tests were passing9. Remove function from the original file and use the new function10. Ensure everything still works11. Find the next function and execute from step 4 until all the functions are replaced, refactored and tested.As you can see by the process this is a pretty huge undertake, because of the number of calls to the function. This is just the first step on the direction of completely isolating the ACITree so that we can solve the problem with a large number of elements on the tree.What is on our radar that we need to address:- Finish the complete decoupling of the ACITree- Performance of the current tree implementation- Tweak the naming of the Tree class to explicitly tell us this is to use only with ACITree.ThanksJoaoDave Page
Blog: http://pgsnake.blogspot.com
Twitter: @pgsnake
EnterpriseDB UK: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
Blog: http://pgsnake.blogspot.com
Twitter: @pgsnake
EnterpriseDB UK: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
How is your work on this going Ashesh? Will you be committing today?On Wed, Apr 25, 2018 at 8:52 AM, Dave Page <dpage@pgadmin.org> wrote:Ashesh; you had agreed to work on this early this week. Please ensure you do so today.Thanks.--On Tue, Apr 24, 2018 at 8:13 PM, Joao De Almeida Pereira <jdealmeidapereira@pivotal.io> wrote:Hi Hackers,Can someone review and merge this patch?ThanksJoaoOn Wed, Apr 18, 2018 at 10:23 AM Joao De Almeida Pereira <jdealmeidapereira@pivotal.io> wrote:Hi Hackers,Any other comment about this patch?ThanksJoaoOn Tue, Apr 10, 2018 at 12:00 PM Joao De Almeida Pereira <jdealmeidapereira@pivotal.io> wrote:Hello KhushbooOn Mon, Apr 9, 2018 at 1:59 AM Khushboo Vashi <khushboo.vashi@enterprisedb.com> wrote:Hi Joao,I have reviewed your patch and have some suggestions.On Sat, Apr 7, 2018 at 12:43 AM, Joao De Almeida Pereira <jdealmeidapereira@pivotal.io> wrote:Hello Murtuza/Dave,
Yes now the extracted functions are spread into different files. The intent would be to make the files as small as possible, and also to group and name them in a way that would be easy to understand what each file is doing without the need of opening it.
As a example:static/js/backupwill contain all the backup related functionality inside of this folder we can see the file:
menu_utils.jsAt this moment in time we decided to group all the functions that are related to the menu, but we can split that also if we believe it is easier to see.It's really very good to see the separated code for backup module. As we have done for backup, we would like do it for other PG utilities like restore, maintenance etc.Considering this, we should separate the code in a way that some of the common functionalities can be used for other modules like menu (as you have mentioned above), dialogue factory etc.Also, I think these functionalities should be in their respective static folder instead of pgadmin/static.About the location of the files. The move of the files to pgadmin/static/js was made on purpose in order to clearly separate Javascript from python code.The rational behind it was- Create a clear separation between the backend and frontend- Having Javascript code concentrated in a single place, hopefully, will encourage to developers to look for a functionality, that is already implemented in another modules, because they are right there. (When we started this journey we realized that the 'nodes' have a big groups of code that could be shared, but because the Javascript is spread everywhere it is much harder to look for it)There are some drawbacks of this separation:- When creating a new module we will need to put the javascript in a separate location from the backend code
static/js/datagridfolder contains all the datagrid related functionalitySame as backup module, this should be in it's respective static/js folder.Inside of the folder we can see the files:
get_panel_title.jsis responsible for retrieving the name of the panelshow_data.jsis responsible for showing the datagridshow_query_tool.jsis responsible for showing the query toolDoes this structure make sense?
Can you give an example of a comment that you think is missing and that could help?As a personal note, unless the algorithm is very obscure or very complicated, I believe that if the code needs comments it is a signal that something needs to change in terms of naming, structure of the part in question. This being said, I am open to add some comments that might help people.
You are right, with the help of naming convention and structure of the code, any one can get the idea about the code. But it is very useful to understand the codevery easily with the proper comments especially when there are multiple developers working on a single project.I found some of the places where it would be great to have comments.- treeMenu: new tree.Tree() in a browser.js- tree.js (especially Tree class)About the comment point I need a more clear understanding on what kind of comments you are looking for. Because when you read the function names you understand the intent, what they are doing. The parameters also explain what you need to pass into them.If what you are looking for in these comments is the reasoning being the change itself, then that should be present in the commit message. Specially because this is going to be a very big patch with a very big number of changes.Thanks
JoaoThanks,KhushbooOn Fri, Apr 6, 2018 at 4:48 AM Murtuza Zabuawala <murtuza.zabuawala@enterprisedb.com> wrote:Hi Joao,Patch looks good and working as expected.I also agree with Dave, Can we please add some comments in each file which can help us to understand the flow, I'm saying because now the code is segregated in so many separate files it will be hard to keep track of the flow from one file to another when debugging.--Regards,On Thu, Apr 5, 2018 at 7:08 PM, Joao De Almeida Pereira <jdealmeidapereira@pivotal.io> wrote:Hi Khushboo,Attached you can find both patches rebasedThanksOn Thu, Apr 5, 2018 at 6:31 AM Khushboo Vashi <khushboo.vashi@enterprisedb.com> wrote:Hi Joao,Can you please rebase the second patch?Thanks,KhushbooOn Tue, Apr 3, 2018 at 12:15 AM, Joao De Almeida Pereira <jdealmeidapereira@pivotal.io> wrote:Hi Hackers,Attached you can find the patch that will start to decouple pgAdmin from ACITree library.This patch is intended to be merged after 3.0, because we do not want to cause any entropy or delay the release, but we want to start the discussion and show some code.This job that we started is a massive tech debt chore that will take some time to finalize and we would love the help of the community to do it.Summary of the patch:0001 patch:- Creates a new tree that will allow us to create a separation between the application and ACI Tree- Creates a Fake Tree (Test double, for reference on the available test doubles: https://martinfowler.com/bliki/TestDouble.html) that can be used to inplace to replace the ACITree and also encapsulate the new tree behavior on our tests- Adds tests for all the tree functionalities0002 patch:- Extracts, refactors, adds tests and remove dependency from ACI Tree on:- getTreeNodeHierarchy
- on backup.js: menu_enabled, menu_enabled_server, start_backup_global_server, backup_objects
- on datagrid.js: show_data_grid, get_panel_title, show_query_tool- Start using sprintf-js as Underscore.String is deprecating sprintf functionThis patch represents only 10 calls to ACITree.itemData out of 176 that are spread around our codeIn Depth look on the process behind the patch:We started writing this patch with the idea that we need to decouple pgAdmin4 from ACITree, because ACITree is no longer supported, the documentation is non existent and ACITree is no longer being actively developed.Our process:1. We "randomly" selected a function that is part of the ACITree. From this point we decided to replace that function with our own version. The function that we choose was "itemData".The function gives us all the "data" that a specific node of the tree find.Given in order to replace the tree we would need to have a function that would give us the same information. We had 2 options:a) Create a tree with a function called itemDataPros:- At first view this was the simpler solution- Would keep the status quoCons:- Not a OOP approach- Not very flexibleb) Create a tree that would return a node given an ID and then the node would be responsible for giving it's data.Pros:- OOP Approach- More flexible and we do not need to bring the tree around, just a nodeCons:- Break the current status quoGiven these 2 options we decided to go for a more OOP approach creating a Tree and a TreeNode classes, that in the future will be renamed to ACITreeWrapper and TreeNode.2. After we decided on the starting point we searched for occurrences of the function "itemData" and we found out that there were 303 occurrences of "itemData" in the code and roughly 176 calls to the function itself (some of the hits were variable names).3. We selected the first file on the search and found the function that was responsible for calling the itemData function.4. Extracted the function to a separate file5. Wrap this function with tests6. Refactor the function to ES6, give more declarative names to variables and break the functions into smaller chunks7. When all the tests were passing we replaced ACITree with our Tree8. We ensured that all tests were passing9. Remove function from the original file and use the new function10. Ensure everything still works11. Find the next function and execute from step 4 until all the functions are replaced, refactored and tested.As you can see by the process this is a pretty huge undertake, because of the number of calls to the function. This is just the first step on the direction of completely isolating the ACITree so that we can solve the problem with a large number of elements on the tree.What is on our radar that we need to address:- Finish the complete decoupling of the ACITree- Performance of the current tree implementation- Tweak the naming of the Tree class to explicitly tell us this is to use only with ACITree.ThanksJoaoDave Page
Blog: http://pgsnake.blogspot.com
Twitter: @pgsnake
EnterpriseDB UK: http://www.enterprisedb.com
The Enterprise PostgreSQL Company--Dave Page
Blog: http://pgsnake.blogspot.com
Twitter: @pgsnake
EnterpriseDB UK: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
As you are aware we kept on working on the patch, so we are attaching to this email a new version of the patch.
This new version contains all the changes in the previous one plus more extractions of functions and refactoring of code.
The objective of this patch is to create a separation between pgAdmin and the ACI Tree. We are doing this because we realized that at this point in time we have the ACI Tree all over the code of pgAdmin. I found a very interesting article that really talks about this: https://medium.freecodecamp.org/code-dependencies-are-the-devil-35ed28b556d
What does each patch contain:
New Tree abstraction. This patch contains the new Tree that works as an adaptor for ACI Tree and is going to be used on all the extractions that we are doing
I have quite a few comments for the patch.I will send them soon.On Fri, Apr 27, 2018, 14:45 Dave Page <dpage@pgadmin.org> wrote:How is your work on this going Ashesh? Will you be committing today?On Wed, Apr 25, 2018 at 8:52 AM, Dave Page <dpage@pgadmin.org> wrote:Ashesh; you had agreed to work on this early this week. Please ensure you do so today.Thanks.--On Tue, Apr 24, 2018 at 8:13 PM, Joao De Almeida Pereira <jdealmeidapereira@pivotal.io> wrote:Hi Hackers,Can someone review and merge this patch?ThanksJoaoOn Wed, Apr 18, 2018 at 10:23 AM Joao De Almeida Pereira <jdealmeidapereira@pivotal.io> wrote:Hi Hackers,Any other comment about this patch?ThanksJoaoOn Tue, Apr 10, 2018 at 12:00 PM Joao De Almeida Pereira <jdealmeidapereira@pivotal.io> wrote:Hello KhushbooOn Mon, Apr 9, 2018 at 1:59 AM Khushboo Vashi <khushboo.vashi@enterprisedb.com> wrote:Hi Joao,I have reviewed your patch and have some suggestions.On Sat, Apr 7, 2018 at 12:43 AM, Joao De Almeida Pereira <jdealmeidapereira@pivotal.io> wrote:Hello Murtuza/Dave,
Yes now the extracted functions are spread into different files. The intent would be to make the files as small as possible, and also to group and name them in a way that would be easy to understand what each file is doing without the need of opening it.
As a example:static/js/backupwill contain all the backup related functionality inside of this folder we can see the file:
menu_utils.jsAt this moment in time we decided to group all the functions that are related to the menu, but we can split that also if we believe it is easier to see.It's really very good to see the separated code for backup module. As we have done for backup, we would like do it for other PG utilities like restore, maintenance etc.Considering this, we should separate the code in a way that some of the common functionalities can be used for other modules like menu (as you have mentioned above), dialogue factory etc.Also, I think these functionalities should be in their respective static folder instead of pgadmin/static.About the location of the files. The move of the files to pgadmin/static/js was made on purpose in order to clearly separate Javascript from python code.The rational behind it was- Create a clear separation between the backend and frontend- Having Javascript code concentrated in a single place, hopefully, will encourage to developers to look for a functionality, that is already implemented in another modules, because they are right there. (When we started this journey we realized that the 'nodes' have a big groups of code that could be shared, but because the Javascript is spread everywhere it is much harder to look for it)There are some drawbacks of this separation:- When creating a new module we will need to put the javascript in a separate location from the backend code
static/js/datagridfolder contains all the datagrid related functionalitySame as backup module, this should be in it's respective static/js folder.Inside of the folder we can see the files:
get_panel_title.jsis responsible for retrieving the name of the panelshow_data.jsis responsible for showing the datagridshow_query_tool.jsis responsible for showing the query toolDoes this structure make sense?
Can you give an example of a comment that you think is missing and that could help?As a personal note, unless the algorithm is very obscure or very complicated, I believe that if the code needs comments it is a signal that something needs to change in terms of naming, structure of the part in question. This being said, I am open to add some comments that might help people.
You are right, with the help of naming convention and structure of the code, any one can get the idea about the code. But it is very useful to understand the codevery easily with the proper comments especially when there are multiple developers working on a single project.I found some of the places where it would be great to have comments.- treeMenu: new tree.Tree() in a browser.js- tree.js (especially Tree class)About the comment point I need a more clear understanding on what kind of comments you are looking for. Because when you read the function names you understand the intent, what they are doing. The parameters also explain what you need to pass into them.If what you are looking for in these comments is the reasoning being the change itself, then that should be present in the commit message. Specially because this is going to be a very big patch with a very big number of changes.Thanks
JoaoThanks,KhushbooOn Fri, Apr 6, 2018 at 4:48 AM Murtuza Zabuawala <murtuza.zabuawala@enterprisedb.com> wrote:Hi Joao,Patch looks good and working as expected.I also agree with Dave, Can we please add some comments in each file which can help us to understand the flow, I'm saying because now the code is segregated in so many separate files it will be hard to keep track of the flow from one file to another when debugging.--Regards,On Thu, Apr 5, 2018 at 7:08 PM, Joao De Almeida Pereira <jdealmeidapereira@pivotal.io> wrote:Hi Khushboo,Attached you can find both patches rebasedThanksOn Thu, Apr 5, 2018 at 6:31 AM Khushboo Vashi <khushboo.vashi@enterprisedb.com> wrote:Hi Joao,Can you please rebase the second patch?Thanks,KhushbooOn Tue, Apr 3, 2018 at 12:15 AM, Joao De Almeida Pereira <jdealmeidapereira@pivotal.io> wrote:Hi Hackers,Attached you can find the patch that will start to decouple pgAdmin from ACITree library.This patch is intended to be merged after 3.0, because we do not want to cause any entropy or delay the release, but we want to start the discussion and show some code.This job that we started is a massive tech debt chore that will take some time to finalize and we would love the help of the community to do it.Summary of the patch:0001 patch:- Creates a new tree that will allow us to create a separation between the application and ACI Tree- Creates a Fake Tree (Test double, for reference on the available test doubles: https://martinfowler.com/bliki/TestDouble.html) that can be used to inplace to replace the ACITree and also encapsulate the new tree behavior on our tests- Adds tests for all the tree functionalities0002 patch:- Extracts, refactors, adds tests and remove dependency from ACI Tree on:- getTreeNodeHierarchy
- on backup.js: menu_enabled, menu_enabled_server, start_backup_global_server, backup_objects
- on datagrid.js: show_data_grid, get_panel_title, show_query_tool- Start using sprintf-js as Underscore.String is deprecating sprintf functionThis patch represents only 10 calls to ACITree.itemData out of 176 that are spread around our codeIn Depth look on the process behind the patch:We started writing this patch with the idea that we need to decouple pgAdmin4 from ACITree, because ACITree is no longer supported, the documentation is non existent and ACITree is no longer being actively developed.Our process:1. We "randomly" selected a function that is part of the ACITree. From this point we decided to replace that function with our own version. The function that we choose was "itemData".The function gives us all the "data" that a specific node of the tree find.Given in order to replace the tree we would need to have a function that would give us the same information. We had 2 options:a) Create a tree with a function called itemDataPros:- At first view this was the simpler solution- Would keep the status quoCons:- Not a OOP approach- Not very flexibleb) Create a tree that would return a node given an ID and then the node would be responsible for giving it's data.Pros:- OOP Approach- More flexible and we do not need to bring the tree around, just a nodeCons:- Break the current status quoGiven these 2 options we decided to go for a more OOP approach creating a Tree and a TreeNode classes, that in the future will be renamed to ACITreeWrapper and TreeNode.2. After we decided on the starting point we searched for occurrences of the function "itemData" and we found out that there were 303 occurrences of "itemData" in the code and roughly 176 calls to the function itself (some of the hits were variable names).3. We selected the first file on the search and found the function that was responsible for calling the itemData function.4. Extracted the function to a separate file5. Wrap this function with tests6. Refactor the function to ES6, give more declarative names to variables and break the functions into smaller chunks7. When all the tests were passing we replaced ACITree with our Tree8. We ensured that all tests were passing9. Remove function from the original file and use the new function10. Ensure everything still works11. Find the next function and execute from step 4 until all the functions are replaced, refactored and tested.As you can see by the process this is a pretty huge undertake, because of the number of calls to the function. This is just the first step on the direction of completely isolating the ACITree so that we can solve the problem with a large number of elements on the tree.What is on our radar that we need to address:- Finish the complete decoupling of the ACITree- Performance of the current tree implementation- Tweak the naming of the Tree class to explicitly tell us this is to use only with ACITree.ThanksJoaoDave Page
Blog: http://pgsnake.blogspot.com
Twitter: @pgsnake
EnterpriseDB UK: http://www.enterprisedb.com
The Enterprise PostgreSQL Company--Dave Page
Blog: http://pgsnake.blogspot.com
Twitter: @pgsnake
EnterpriseDB UK: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
Attachment
Hi Hackers,
As you are aware we kept on working on the patch, so we are attaching to this email a new version of the patch.
This new version contains all the changes in the previous one plus more extractions of functions and refactoring of code.
The objective of this patch is to create a separation between pgAdmin and the ACI Tree. We are doing this because we realized that at this point in time we have the ACI Tree all over the code of pgAdmin. I found a very interesting article that really talks about this: https://medium.freecodecamp.org/code-dependencies-are-the- devil-35ed28b556d In this patch there are some visions and ideas about the location of the code, the way to organize it and also try to pave the future for a application that is stable, easy to develop on and that can be release at a times notice.We are investing a big chunk of our time in doing this refactoring, but while doing that we also try to respond to the patches sent to the mailing list. We would like the feedback from the community because we believe this is a changing point for the application. The idea is to change the way we develop this application, instead of only correcting a bug of developing a feature, with every commit we should correct the bug or develop a feature but leave the code a little better than we found it (Refactoring, refactoring, refactoring). This is hard work but that is what the users from pgAdmin expect from this community of developers.======It is a huge patch86 files changed, 5492 inserts, 1840 deletionsand we would like to get your feedback as soon as possible, because we are continuing to work on it which means it is going to grow in size.At this point in time we still have 124 of 176 calls to the function itemData from ACITree.
What does each patch contain:0001:Very simple patch, we found out that the linter was not looking into all the javascript test files, so this patch will ensure it is0002:
New Tree abstraction. This patch contains the new Tree that works as an adaptor for ACI Tree and is going to be used on all the extractions that we are doing0003:Code that extracts, wrap with tests and replace ACI Tree invocations.We start creating new pattern for the location of Javascript files and their structure.Create patterns for creation of dialogs (backup and restore)
ThanksJoaoI have quite a few comments for the patch.I will send them soon.On Fri, Apr 27, 2018, 14:45 Dave Page <dpage@pgadmin.org> wrote:How is your work on this going Ashesh? Will you be committing today?On Wed, Apr 25, 2018 at 8:52 AM, Dave Page <dpage@pgadmin.org> wrote:Ashesh; you had agreed to work on this early this week. Please ensure you do so today.Thanks.--On Tue, Apr 24, 2018 at 8:13 PM, Joao De Almeida Pereira <jdealmeidapereira@pivotal.io> wrote:Hi Hackers,Can someone review and merge this patch?ThanksJoaoOn Wed, Apr 18, 2018 at 10:23 AM Joao De Almeida Pereira <jdealmeidapereira@pivotal.io> wrote:Hi Hackers,Any other comment about this patch?ThanksJoaoOn Tue, Apr 10, 2018 at 12:00 PM Joao De Almeida Pereira <jdealmeidapereira@pivotal.io> wrote:Hello KhushbooOn Mon, Apr 9, 2018 at 1:59 AM Khushboo Vashi <khushboo.vashi@enterprisedb.com> wrote: Hi Joao,I have reviewed your patch and have some suggestions.On Sat, Apr 7, 2018 at 12:43 AM, Joao De Almeida Pereira <jdealmeidapereira@pivotal.io> wrote:Hello Murtuza/Dave,
Yes now the extracted functions are spread into different files. The intent would be to make the files as small as possible, and also to group and name them in a way that would be easy to understand what each file is doing without the need of opening it.
As a example:static/js/backupwill contain all the backup related functionality inside of this folder we can see the file:
menu_utils.jsAt this moment in time we decided to group all the functions that are related to the menu, but we can split that also if we believe it is easier to see.It's really very good to see the separated code for backup module. As we have done for backup, we would like do it for other PG utilities like restore, maintenance etc.Considering this, we should separate the code in a way that some of the common functionalities can be used for other modules like menu (as you have mentioned above), dialogue factory etc.Also, I think these functionalities should be in their respective static folder instead of pgadmin/static.About the location of the files. The move of the files to pgadmin/static/js was made on purpose in order to clearly separate Javascript from python code.The rational behind it was- Create a clear separation between the backend and frontend- Having Javascript code concentrated in a single place, hopefully, will encourage to developers to look for a functionality, that is already implemented in another modules, because they are right there. (When we started this journey we realized that the 'nodes' have a big groups of code that could be shared, but because the Javascript is spread everywhere it is much harder to look for it)There are some drawbacks of this separation:- When creating a new module we will need to put the javascript in a separate location from the backend code
static/js/datagridfolder contains all the datagrid related functionalitySame as backup module, this should be in it's respective static/js folder.Inside of the folder we can see the files:
get_panel_title.jsis responsible for retrieving the name of the panelshow_data.jsis responsible for showing the datagridshow_query_tool.jsis responsible for showing the query toolDoes this structure make sense?
Can you give an example of a comment that you think is missing and that could help?As a personal note, unless the algorithm is very obscure or very complicated, I believe that if the code needs comments it is a signal that something needs to change in terms of naming, structure of the part in question. This being said, I am open to add some comments that might help people.
You are right, with the help of naming convention and structure of the code, any one can get the idea about the code. But it is very useful to understand the codevery easily with the proper comments especially when there are multiple developers working on a single project.I found some of the places where it would be great to have comments.- treeMenu: new tree.Tree() in a browser.js- tree.js (especially Tree class)About the comment point I need a more clear understanding on what kind of comments you are looking for. Because when you read the function names you understand the intent, what they are doing. The parameters also explain what you need to pass into them.If what you are looking for in these comments is the reasoning being the change itself, then that should be present in the commit message. Specially because this is going to be a very big patch with a very big number of changes.Thanks
JoaoThanks,KhushbooOn Fri, Apr 6, 2018 at 4:48 AM Murtuza Zabuawala <murtuza.zabuawala@enterprisedb.com> wrote: Hi Joao,Patch looks good and working as expected.I also agree with Dave, Can we please add some comments in each file which can help us to understand the flow, I'm saying because now the code is segregated in so many separate files it will be hard to keep track of the flow from one file to another when debugging.--Regards,On Thu, Apr 5, 2018 at 7:08 PM, Joao De Almeida Pereira <jdealmeidapereira@pivotal.io> wrote:Hi Khushboo,Attached you can find both patches rebasedThanksOn Thu, Apr 5, 2018 at 6:31 AM Khushboo Vashi <khushboo.vashi@enterprisedb.com> wrote: Hi Joao,Can you please rebase the second patch?Thanks,KhushbooOn Tue, Apr 3, 2018 at 12:15 AM, Joao De Almeida Pereira <jdealmeidapereira@pivotal.io> wrote:Hi Hackers,Attached you can find the patch that will start to decouple pgAdmin from ACITree library.This patch is intended to be merged after 3.0, because we do not want to cause any entropy or delay the release, but we want to start the discussion and show some code.This job that we started is a massive tech debt chore that will take some time to finalize and we would love the help of the community to do it.Summary of the patch:0001 patch:- Creates a new tree that will allow us to create a separation between the application and ACI Tree- Creates a Fake Tree (Test double, for reference on the available test doubles: https://martinfowler.com/bliki/TestDouble.html) that can be used to inplace to replace the ACITree and also encapsulate the new tree behavior on our tests - Adds tests for all the tree functionalities0002 patch:- Extracts, refactors, adds tests and remove dependency from ACI Tree on:- getTreeNodeHierarchy
- on backup.js: menu_enabled, menu_enabled_server, start_backup_global_server, backup_objects
- on datagrid.js: show_data_grid, get_panel_title, show_query_tool- Start using sprintf-js as Underscore.String is deprecating sprintf functionThis patch represents only 10 calls to ACITree.itemData out of 176 that are spread around our codeIn Depth look on the process behind the patch:We started writing this patch with the idea that we need to decouple pgAdmin4 from ACITree, because ACITree is no longer supported, the documentation is non existent and ACITree is no longer being actively developed.Our process:1. We "randomly" selected a function that is part of the ACITree. From this point we decided to replace that function with our own version. The function that we choose was "itemData".The function gives us all the "data" that a specific node of the tree find.Given in order to replace the tree we would need to have a function that would give us the same information. We had 2 options:a) Create a tree with a function called itemDataPros:- At first view this was the simpler solution- Would keep the status quoCons:- Not a OOP approach- Not very flexibleb) Create a tree that would return a node given an ID and then the node would be responsible for giving it's data.Pros:- OOP Approach- More flexible and we do not need to bring the tree around, just a nodeCons:- Break the current status quoGiven these 2 options we decided to go for a more OOP approach creating a Tree and a TreeNode classes, that in the future will be renamed to ACITreeWrapper and TreeNode.2. After we decided on the starting point we searched for occurrences of the function "itemData" and we found out that there were 303 occurrences of "itemData" in the code and roughly 176 calls to the function itself (some of the hits were variable names).3. We selected the first file on the search and found the function that was responsible for calling the itemData function.4. Extracted the function to a separate file5. Wrap this function with tests6. Refactor the function to ES6, give more declarative names to variables and break the functions into smaller chunks7. When all the tests were passing we replaced ACITree with our Tree8. We ensured that all tests were passing9. Remove function from the original file and use the new function10. Ensure everything still works11. Find the next function and execute from step 4 until all the functions are replaced, refactored and tested.As you can see by the process this is a pretty huge undertake, because of the number of calls to the function. This is just the first step on the direction of completely isolating the ACITree so that we can solve the problem with a large number of elements on the tree.What is on our radar that we need to address:- Finish the complete decoupling of the ACITree- Performance of the current tree implementation- Tweak the naming of the Tree class to explicitly tell us this is to use only with ACITree.ThanksJoaoDave Page
Blog: http://pgsnake.blogspot.com
Twitter: @pgsnake
EnterpriseDB UK: http://www.enterprisedb.com
The Enterprise PostgreSQL Company--Dave Page
Blog: http://pgsnake.blogspot.com
Twitter: @pgsnake
EnterpriseDB UK: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
On Sat, Apr 28, 2018 at 3:55 AM, Joao De Almeida Pereira <jdealmeidapereira@pivotal.io> wrote:Hi Hackers,
As you are aware we kept on working on the patch, so we are attaching to this email a new version of the patch.
This new version contains all the changes in the previous one plus more extractions of functions and refactoring of code.
The objective of this patch is to create a separation between pgAdmin and the ACI Tree. We are doing this because we realized that at this point in time we have the ACI Tree all over the code of pgAdmin. I found a very interesting article that really talks about this: https://medium.freecodecamp.org/code-dependencies-are-the-de vil-35ed28b556d In this patch there are some visions and ideas about the location of the code, the way to organize it and also try to pave the future for a application that is stable, easy to develop on and that can be release at a times notice.We are investing a big chunk of our time in doing this refactoring, but while doing that we also try to respond to the patches sent to the mailing list. We would like the feedback from the community because we believe this is a changing point for the application. The idea is to change the way we develop this application, instead of only correcting a bug of developing a feature, with every commit we should correct the bug or develop a feature but leave the code a little better than we found it (Refactoring, refactoring, refactoring). This is hard work but that is what the users from pgAdmin expect from this community of developers.======It is a huge patch86 files changed, 5492 inserts, 1840 deletionsand we would like to get your feedback as soon as possible, because we are continuing to work on it which means it is going to grow in size.At this point in time we still have 124 of 176 calls to the function itemData from ACITree.
What does each patch contain:0001:Very simple patch, we found out that the linter was not looking into all the javascript test files, so this patch will ensure it is0002:
New Tree abstraction. This patch contains the new Tree that works as an adaptor for ACI Tree and is going to be used on all the extractions that we are doing0003:Code that extracts, wrap with tests and replace ACI Tree invocations.We start creating new pattern for the location of Javascript files and their structure.Create patterns for creation of dialogs (backup and restore)Do you have some TODO left for the same?Or, is this the final one? Because - it gives us the better understanding during reviewing the patch.-- Thanks, AsheshThanksJoaoI have quite a few comments for the patch.I will send them soon.On Fri, Apr 27, 2018, 14:45 Dave Page <dpage@pgadmin.org> wrote:How is your work on this going Ashesh? Will you be committing today?On Wed, Apr 25, 2018 at 8:52 AM, Dave Page <dpage@pgadmin.org> wrote:Ashesh; you had agreed to work on this early this week. Please ensure you do so today.Thanks.--On Tue, Apr 24, 2018 at 8:13 PM, Joao De Almeida Pereira <jdealmeidapereira@pivotal.io> wrote:Hi Hackers,Can someone review and merge this patch?ThanksJoaoOn Wed, Apr 18, 2018 at 10:23 AM Joao De Almeida Pereira <jdealmeidapereira@pivotal.io> wrote:Hi Hackers,Any other comment about this patch?ThanksJoaoOn Tue, Apr 10, 2018 at 12:00 PM Joao De Almeida Pereira <jdealmeidapereira@pivotal.io> wrote:Hello KhushbooOn Mon, Apr 9, 2018 at 1:59 AM Khushboo Vashi <khushboo.vashi@enterprisedb.com> wrote: Hi Joao,I have reviewed your patch and have some suggestions.On Sat, Apr 7, 2018 at 12:43 AM, Joao De Almeida Pereira <jdealmeidapereira@pivotal.io> wrote:Hello Murtuza/Dave,
Yes now the extracted functions are spread into different files. The intent would be to make the files as small as possible, and also to group and name them in a way that would be easy to understand what each file is doing without the need of opening it.
As a example:static/js/backupwill contain all the backup related functionality inside of this folder we can see the file:
menu_utils.jsAt this moment in time we decided to group all the functions that are related to the menu, but we can split that also if we believe it is easier to see.It's really very good to see the separated code for backup module. As we have done for backup, we would like do it for other PG utilities like restore, maintenance etc.Considering this, we should separate the code in a way that some of the common functionalities can be used for other modules like menu (as you have mentioned above), dialogue factory etc.Also, I think these functionalities should be in their respective static folder instead of pgadmin/static.About the location of the files. The move of the files to pgadmin/static/js was made on purpose in order to clearly separate Javascript from python code.The rational behind it was- Create a clear separation between the backend and frontend- Having Javascript code concentrated in a single place, hopefully, will encourage to developers to look for a functionality, that is already implemented in another modules, because they are right there. (When we started this journey we realized that the 'nodes' have a big groups of code that could be shared, but because the Javascript is spread everywhere it is much harder to look for it)There are some drawbacks of this separation:- When creating a new module we will need to put the javascript in a separate location from the backend code
static/js/datagridfolder contains all the datagrid related functionalitySame as backup module, this should be in it's respective static/js folder.Inside of the folder we can see the files:
get_panel_title.jsis responsible for retrieving the name of the panelshow_data.jsis responsible for showing the datagridshow_query_tool.jsis responsible for showing the query toolDoes this structure make sense?
Can you give an example of a comment that you think is missing and that could help?As a personal note, unless the algorithm is very obscure or very complicated, I believe that if the code needs comments it is a signal that something needs to change in terms of naming, structure of the part in question. This being said, I am open to add some comments that might help people.
You are right, with the help of naming convention and structure of the code, any one can get the idea about the code. But it is very useful to understand the codevery easily with the proper comments especially when there are multiple developers working on a single project.I found some of the places where it would be great to have comments.- treeMenu: new tree.Tree() in a browser.js- tree.js (especially Tree class)About the comment point I need a more clear understanding on what kind of comments you are looking for. Because when you read the function names you understand the intent, what they are doing. The parameters also explain what you need to pass into them.If what you are looking for in these comments is the reasoning being the change itself, then that should be present in the commit message. Specially because this is going to be a very big patch with a very big number of changes.Thanks
JoaoThanks,KhushbooOn Fri, Apr 6, 2018 at 4:48 AM Murtuza Zabuawala <murtuza.zabuawala@enterprisedb.com> wrote: Hi Joao,Patch looks good and working as expected.I also agree with Dave, Can we please add some comments in each file which can help us to understand the flow, I'm saying because now the code is segregated in so many separate files it will be hard to keep track of the flow from one file to another when debugging.--Regards,On Thu, Apr 5, 2018 at 7:08 PM, Joao De Almeida Pereira <jdealmeidapereira@pivotal.io> wrote:Hi Khushboo,Attached you can find both patches rebasedThanksOn Thu, Apr 5, 2018 at 6:31 AM Khushboo Vashi <khushboo.vashi@enterprisedb.com> wrote: Hi Joao,Can you please rebase the second patch?Thanks,KhushbooOn Tue, Apr 3, 2018 at 12:15 AM, Joao De Almeida Pereira <jdealmeidapereira@pivotal.io> wrote:Hi Hackers,Attached you can find the patch that will start to decouple pgAdmin from ACITree library.This patch is intended to be merged after 3.0, because we do not want to cause any entropy or delay the release, but we want to start the discussion and show some code.This job that we started is a massive tech debt chore that will take some time to finalize and we would love the help of the community to do it.Summary of the patch:0001 patch:- Creates a new tree that will allow us to create a separation between the application and ACI Tree- Creates a Fake Tree (Test double, for reference on the available test doubles: https://martinfowler.com/bliki/TestDouble.html) that can be used to inplace to replace the ACITree and also encapsulate the new tree behavior on our tests - Adds tests for all the tree functionalities0002 patch:- Extracts, refactors, adds tests and remove dependency from ACI Tree on:- getTreeNodeHierarchy
- on backup.js: menu_enabled, menu_enabled_server, start_backup_global_server, backup_objects
- on datagrid.js: show_data_grid, get_panel_title, show_query_tool- Start using sprintf-js as Underscore.String is deprecating sprintf functionThis patch represents only 10 calls to ACITree.itemData out of 176 that are spread around our codeIn Depth look on the process behind the patch:We started writing this patch with the idea that we need to decouple pgAdmin4 from ACITree, because ACITree is no longer supported, the documentation is non existent and ACITree is no longer being actively developed.Our process:1. We "randomly" selected a function that is part of the ACITree. From this point we decided to replace that function with our own version. The function that we choose was "itemData".The function gives us all the "data" that a specific node of the tree find.Given in order to replace the tree we would need to have a function that would give us the same information. We had 2 options:a) Create a tree with a function called itemDataPros:- At first view this was the simpler solution- Would keep the status quoCons:- Not a OOP approach- Not very flexibleb) Create a tree that would return a node given an ID and then the node would be responsible for giving it's data.Pros:- OOP Approach- More flexible and we do not need to bring the tree around, just a nodeCons:- Break the current status quoGiven these 2 options we decided to go for a more OOP approach creating a Tree and a TreeNode classes, that in the future will be renamed to ACITreeWrapper and TreeNode.2. After we decided on the starting point we searched for occurrences of the function "itemData" and we found out that there were 303 occurrences of "itemData" in the code and roughly 176 calls to the function itself (some of the hits were variable names).3. We selected the first file on the search and found the function that was responsible for calling the itemData function.4. Extracted the function to a separate file5. Wrap this function with tests6. Refactor the function to ES6, give more declarative names to variables and break the functions into smaller chunks7. When all the tests were passing we replaced ACITree with our Tree8. We ensured that all tests were passing9. Remove function from the original file and use the new function10. Ensure everything still works11. Find the next function and execute from step 4 until all the functions are replaced, refactored and tested.As you can see by the process this is a pretty huge undertake, because of the number of calls to the function. This is just the first step on the direction of completely isolating the ACITree so that we can solve the problem with a large number of elements on the tree.What is on our radar that we need to address:- Finish the complete decoupling of the ACITree- Performance of the current tree implementation- Tweak the naming of the Tree class to explicitly tell us this is to use only with ACITree.ThanksJoaoDave Page
Blog: http://pgsnake.blogspot.com
Twitter: @pgsnake
EnterpriseDB UK: http://www.enterprisedb.com
The Enterprise PostgreSQL Company--Dave Page
Blog: http://pgsnake.blogspot.com
Twitter: @pgsnake
EnterpriseDB UK: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
Hi there,Yes, there's a lot of TODO that we intend for this effort - to be submitted. We'd like to remove as much direct invocations on the ACI Tree library, as it causes a lot of coupling to the library. It is not the final patch, but we cannot come up with a definitive list of the things we intend to do, at this time.
On Mon, Apr 30, 2018 at 2:16 AM, Ashesh Vashi <ashesh.vashi@enterprisedb.com> wrote: On Sat, Apr 28, 2018 at 3:55 AM, Joao De Almeida Pereira <jdealmeidapereira@pivotal.io> wrote:Hi Hackers,
As you are aware we kept on working on the patch, so we are attaching to this email a new version of the patch.
This new version contains all the changes in the previous one plus more extractions of functions and refactoring of code.
The objective of this patch is to create a separation between pgAdmin and the ACI Tree. We are doing this because we realized that at this point in time we have the ACI Tree all over the code of pgAdmin. I found a very interesting article that really talks about this: https://medium.freecodecamp.org/code-dependencies-are-the-de vil-35ed28b556d In this patch there are some visions and ideas about the location of the code, the way to organize it and also try to pave the future for a application that is stable, easy to develop on and that can be release at a times notice.We are investing a big chunk of our time in doing this refactoring, but while doing that we also try to respond to the patches sent to the mailing list. We would like the feedback from the community because we believe this is a changing point for the application. The idea is to change the way we develop this application, instead of only correcting a bug of developing a feature, with every commit we should correct the bug or develop a feature but leave the code a little better than we found it (Refactoring, refactoring, refactoring). This is hard work but that is what the users from pgAdmin expect from this community of developers.======It is a huge patch86 files changed, 5492 inserts, 1840 deletionsand we would like to get your feedback as soon as possible, because we are continuing to work on it which means it is going to grow in size.At this point in time we still have 124 of 176 calls to the function itemData from ACITree.
What does each patch contain:0001:Very simple patch, we found out that the linter was not looking into all the javascript test files, so this patch will ensure it is0002:
New Tree abstraction. This patch contains the new Tree that works as an adaptor for ACI Tree and is going to be used on all the extractions that we are doing0003:Code that extracts, wrap with tests and replace ACI Tree invocations.We start creating new pattern for the location of Javascript files and their structure.Create patterns for creation of dialogs (backup and restore)Do you have some TODO left for the same?Or, is this the final one? Because - it gives us the better understanding during reviewing the patch.-- Thanks, AsheshThanksJoaoI have quite a few comments for the patch.I will send them soon.On Fri, Apr 27, 2018, 14:45 Dave Page <dpage@pgadmin.org> wrote:How is your work on this going Ashesh? Will you be committing today?On Wed, Apr 25, 2018 at 8:52 AM, Dave Page <dpage@pgadmin.org> wrote:Ashesh; you had agreed to work on this early this week. Please ensure you do so today.Thanks.--On Tue, Apr 24, 2018 at 8:13 PM, Joao De Almeida Pereira <jdealmeidapereira@pivotal.io> wrote:Hi Hackers,Can someone review and merge this patch?ThanksJoaoOn Wed, Apr 18, 2018 at 10:23 AM Joao De Almeida Pereira <jdealmeidapereira@pivotal.io> wrote:Hi Hackers,Any other comment about this patch?ThanksJoaoOn Tue, Apr 10, 2018 at 12:00 PM Joao De Almeida Pereira <jdealmeidapereira@pivotal.io> wrote:Hello KhushbooOn Mon, Apr 9, 2018 at 1:59 AM Khushboo Vashi <khushboo.vashi@enterprisedb.com> wrote: Hi Joao,I have reviewed your patch and have some suggestions.On Sat, Apr 7, 2018 at 12:43 AM, Joao De Almeida Pereira <jdealmeidapereira@pivotal.io> wrote:Hello Murtuza/Dave,
Yes now the extracted functions are spread into different files. The intent would be to make the files as small as possible, and also to group and name them in a way that would be easy to understand what each file is doing without the need of opening it.
As a example:static/js/backupwill contain all the backup related functionality inside of this folder we can see the file:
menu_utils.jsAt this moment in time we decided to group all the functions that are related to the menu, but we can split that also if we believe it is easier to see.It's really very good to see the separated code for backup module. As we have done for backup, we would like do it for other PG utilities like restore, maintenance etc.Considering this, we should separate the code in a way that some of the common functionalities can be used for other modules like menu (as you have mentioned above), dialogue factory etc.Also, I think these functionalities should be in their respective static folder instead of pgadmin/static.About the location of the files. The move of the files to pgadmin/static/js was made on purpose in order to clearly separate Javascript from python code.The rational behind it was- Create a clear separation between the backend and frontend- Having Javascript code concentrated in a single place, hopefully, will encourage to developers to look for a functionality, that is already implemented in another modules, because they are right there. (When we started this journey we realized that the 'nodes' have a big groups of code that could be shared, but because the Javascript is spread everywhere it is much harder to look for it)There are some drawbacks of this separation:- When creating a new module we will need to put the javascript in a separate location from the backend code
static/js/datagridfolder contains all the datagrid related functionalitySame as backup module, this should be in it's respective static/js folder.Inside of the folder we can see the files:
get_panel_title.jsis responsible for retrieving the name of the panelshow_data.jsis responsible for showing the datagridshow_query_tool.jsis responsible for showing the query toolDoes this structure make sense?
Can you give an example of a comment that you think is missing and that could help?As a personal note, unless the algorithm is very obscure or very complicated, I believe that if the code needs comments it is a signal that something needs to change in terms of naming, structure of the part in question. This being said, I am open to add some comments that might help people.
You are right, with the help of naming convention and structure of the code, any one can get the idea about the code. But it is very useful to understand the codevery easily with the proper comments especially when there are multiple developers working on a single project.I found some of the places where it would be great to have comments.- treeMenu: new tree.Tree() in a browser.js- tree.js (especially Tree class)About the comment point I need a more clear understanding on what kind of comments you are looking for. Because when you read the function names you understand the intent, what they are doing. The parameters also explain what you need to pass into them.If what you are looking for in these comments is the reasoning being the change itself, then that should be present in the commit message. Specially because this is going to be a very big patch with a very big number of changes.Thanks
JoaoThanks,KhushbooOn Fri, Apr 6, 2018 at 4:48 AM Murtuza Zabuawala <murtuza.zabuawala@enterprisedb.com> wrote: Hi Joao,Patch looks good and working as expected.I also agree with Dave, Can we please add some comments in each file which can help us to understand the flow, I'm saying because now the code is segregated in so many separate files it will be hard to keep track of the flow from one file to another when debugging.--Regards,On Thu, Apr 5, 2018 at 7:08 PM, Joao De Almeida Pereira <jdealmeidapereira@pivotal.io> wrote:Hi Khushboo,Attached you can find both patches rebasedThanksOn Thu, Apr 5, 2018 at 6:31 AM Khushboo Vashi <khushboo.vashi@enterprisedb.com> wrote: Hi Joao,Can you please rebase the second patch?Thanks,KhushbooOn Tue, Apr 3, 2018 at 12:15 AM, Joao De Almeida Pereira <jdealmeidapereira@pivotal.io> wrote:Hi Hackers,Attached you can find the patch that will start to decouple pgAdmin from ACITree library.This patch is intended to be merged after 3.0, because we do not want to cause any entropy or delay the release, but we want to start the discussion and show some code.This job that we started is a massive tech debt chore that will take some time to finalize and we would love the help of the community to do it.Summary of the patch:0001 patch:- Creates a new tree that will allow us to create a separation between the application and ACI Tree- Creates a Fake Tree (Test double, for reference on the available test doubles: https://martinfowler.com/bliki/TestDouble.html) that can be used to inplace to replace the ACITree and also encapsulate the new tree behavior on our tests - Adds tests for all the tree functionalities0002 patch:- Extracts, refactors, adds tests and remove dependency from ACI Tree on:- getTreeNodeHierarchy
- on backup.js: menu_enabled, menu_enabled_server, start_backup_global_server, backup_objects
- on datagrid.js: show_data_grid, get_panel_title, show_query_tool- Start using sprintf-js as Underscore.String is deprecating sprintf functionThis patch represents only 10 calls to ACITree.itemData out of 176 that are spread around our codeIn Depth look on the process behind the patch:We started writing this patch with the idea that we need to decouple pgAdmin4 from ACITree, because ACITree is no longer supported, the documentation is non existent and ACITree is no longer being actively developed.Our process:1. We "randomly" selected a function that is part of the ACITree. From this point we decided to replace that function with our own version. The function that we choose was "itemData".The function gives us all the "data" that a specific node of the tree find.Given in order to replace the tree we would need to have a function that would give us the same information. We had 2 options:a) Create a tree with a function called itemDataPros:- At first view this was the simpler solution- Would keep the status quoCons:- Not a OOP approach- Not very flexibleb) Create a tree that would return a node given an ID and then the node would be responsible for giving it's data.Pros:- OOP Approach- More flexible and we do not need to bring the tree around, just a nodeCons:- Break the current status quoGiven these 2 options we decided to go for a more OOP approach creating a Tree and a TreeNode classes, that in the future will be renamed to ACITreeWrapper and TreeNode.2. After we decided on the starting point we searched for occurrences of the function "itemData" and we found out that there were 303 occurrences of "itemData" in the code and roughly 176 calls to the function itself (some of the hits were variable names).3. We selected the first file on the search and found the function that was responsible for calling the itemData function.4. Extracted the function to a separate file5. Wrap this function with tests6. Refactor the function to ES6, give more declarative names to variables and break the functions into smaller chunks7. When all the tests were passing we replaced ACITree with our Tree8. We ensured that all tests were passing9. Remove function from the original file and use the new function10. Ensure everything still works11. Find the next function and execute from step 4 until all the functions are replaced, refactored and tested.As you can see by the process this is a pretty huge undertake, because of the number of calls to the function. This is just the first step on the direction of completely isolating the ACITree so that we can solve the problem with a large number of elements on the tree.What is on our radar that we need to address:- Finish the complete decoupling of the ACITree- Performance of the current tree implementation- Tweak the naming of the Tree class to explicitly tell us this is to use only with ACITree.ThanksJoaoDave Page
Blog: http://pgsnake.blogspot.com
Twitter: @pgsnake
EnterpriseDB UK: http://www.enterprisedb.com
The Enterprise PostgreSQL Company--Dave Page
Blog: http://pgsnake.blogspot.com
Twitter: @pgsnake
EnterpriseDB UK: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
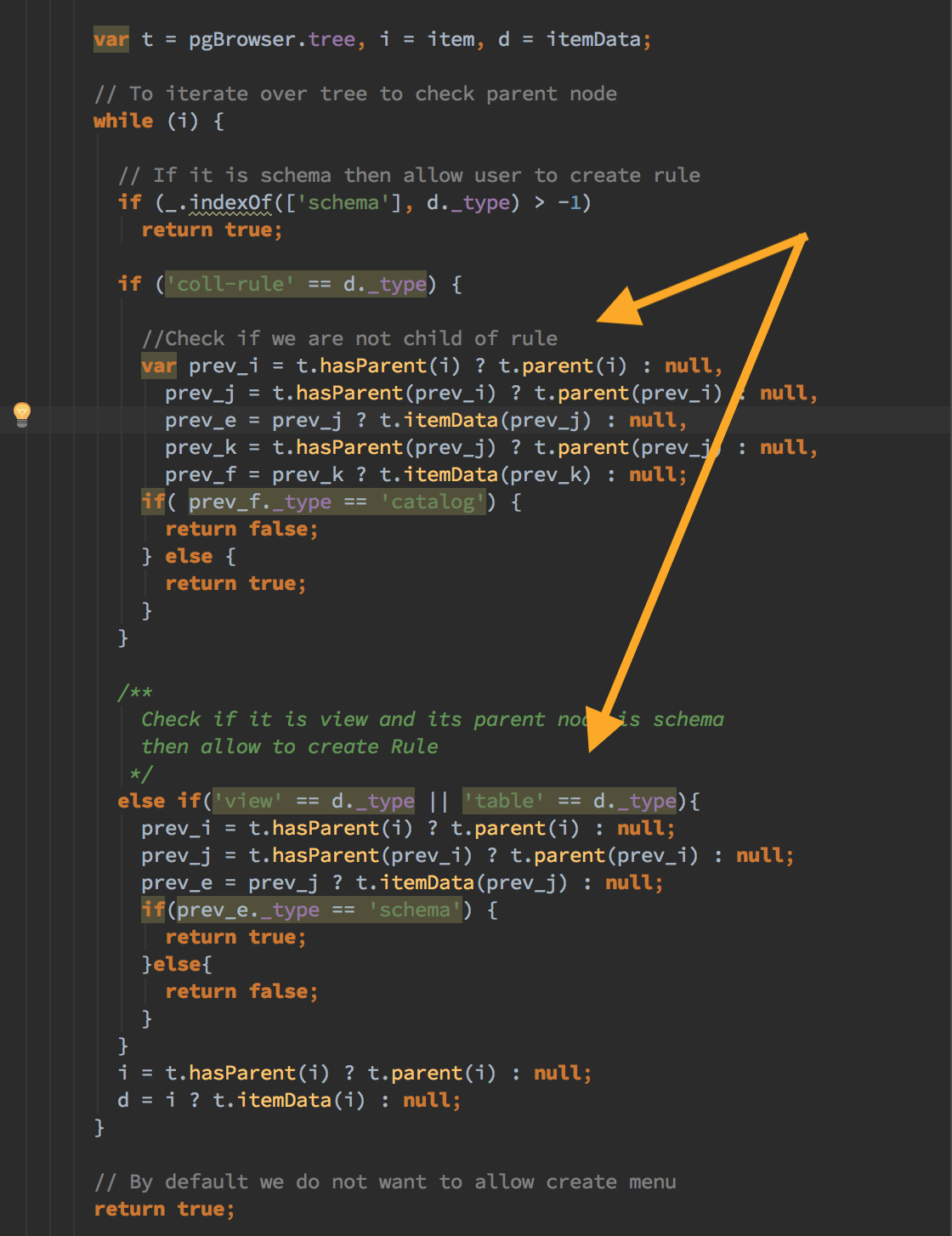
On Mon, Apr 30, 2018 at 3:51 PM, Anthony Emengo <aemengo@pivotal.io> wrote:Hi there,Yes, there's a lot of TODO that we intend for this effort - to be submitted. We'd like to remove as much direct invocations on the ACI Tree library, as it causes a lot of coupling to the library. It is not the final patch, but we cannot come up with a definitive list of the things we intend to do, at this time.Is there any known TODO list?So that - I can help you figure out (if any more).-- Thanks, AsheshOn Mon, Apr 30, 2018 at 2:16 AM, Ashesh Vashi <ashesh.vashi@enterprisedb.com> wrote:On Sat, Apr 28, 2018 at 3:55 AM, Joao De Almeida Pereira <jdealmeidapereira@pivotal.io> wrote:Hi Hackers,
As you are aware we kept on working on the patch, so we are attaching to this email a new version of the patch.
This new version contains all the changes in the previous one plus more extractions of functions and refactoring of code.
The objective of this patch is to create a separation between pgAdmin and the ACI Tree. We are doing this because we realized that at this point in time we have the ACI Tree all over the code of pgAdmin. I found a very interesting article that really talks about this: https://medium.freecodecamp.org/code-dependencies-are-the-devil-35ed28b556dIn this patch there are some visions and ideas about the location of the code, the way to organize it and also try to pave the future for a application that is stable, easy to develop on and that can be release at a times notice.We are investing a big chunk of our time in doing this refactoring, but while doing that we also try to respond to the patches sent to the mailing list. We would like the feedback from the community because we believe this is a changing point for the application. The idea is to change the way we develop this application, instead of only correcting a bug of developing a feature, with every commit we should correct the bug or develop a feature but leave the code a little better than we found it (Refactoring, refactoring, refactoring). This is hard work but that is what the users from pgAdmin expect from this community of developers.======It is a huge patch86 files changed, 5492 inserts, 1840 deletionsand we would like to get your feedback as soon as possible, because we are continuing to work on it which means it is going to grow in size.At this point in time we still have 124 of 176 calls to the function itemData from ACITree.
What does each patch contain:0001:Very simple patch, we found out that the linter was not looking into all the javascript test files, so this patch will ensure it is0002:
New Tree abstraction. This patch contains the new Tree that works as an adaptor for ACI Tree and is going to be used on all the extractions that we are doing0003:Code that extracts, wrap with tests and replace ACI Tree invocations.We start creating new pattern for the location of Javascript files and their structure.Create patterns for creation of dialogs (backup and restore)Do you have some TODO left for the same?Or, is this the final one? Because - it gives us the better understanding during reviewing the patch.-- Thanks, AsheshThanksJoaoOn Fri, Apr 27, 2018 at 5:34 AM Ashesh Vashi <ashesh.vashi@enterprisedb.com> wrote:I have quite a few comments for the patch.I will send them soon.On Fri, Apr 27, 2018, 14:45 Dave Page <dpage@pgadmin.org> wrote:How is your work on this going Ashesh? Will you be committing today?On Wed, Apr 25, 2018 at 8:52 AM, Dave Page <dpage@pgadmin.org> wrote:Ashesh; you had agreed to work on this early this week. Please ensure you do so today.Thanks.--On Tue, Apr 24, 2018 at 8:13 PM, Joao De Almeida Pereira <jdealmeidapereira@pivotal.io> wrote:Hi Hackers,Can someone review and merge this patch?ThanksJoaoOn Wed, Apr 18, 2018 at 10:23 AM Joao De Almeida Pereira <jdealmeidapereira@pivotal.io> wrote:Hi Hackers,Any other comment about this patch?ThanksJoaoOn Tue, Apr 10, 2018 at 12:00 PM Joao De Almeida Pereira <jdealmeidapereira@pivotal.io> wrote:Hello KhushbooOn Mon, Apr 9, 2018 at 1:59 AM Khushboo Vashi <khushboo.vashi@enterprisedb.com> wrote:Hi Joao,I have reviewed your patch and have some suggestions.On Sat, Apr 7, 2018 at 12:43 AM, Joao De Almeida Pereira <jdealmeidapereira@pivotal.io> wrote:Hello Murtuza/Dave,
Yes now the extracted functions are spread into different files. The intent would be to make the files as small as possible, and also to group and name them in a way that would be easy to understand what each file is doing without the need of opening it.
As a example:static/js/backupwill contain all the backup related functionality inside of this folder we can see the file:
menu_utils.jsAt this moment in time we decided to group all the functions that are related to the menu, but we can split that also if we believe it is easier to see.It's really very good to see the separated code for backup module. As we have done for backup, we would like do it for other PG utilities like restore, maintenance etc.Considering this, we should separate the code in a way that some of the common functionalities can be used for other modules like menu (as you have mentioned above), dialogue factory etc.Also, I think these functionalities should be in their respective static folder instead of pgadmin/static.About the location of the files. The move of the files to pgadmin/static/js was made on purpose in order to clearly separate Javascript from python code.The rational behind it was- Create a clear separation between the backend and frontend- Having Javascript code concentrated in a single place, hopefully, will encourage to developers to look for a functionality, that is already implemented in another modules, because they are right there. (When we started this journey we realized that the 'nodes' have a big groups of code that could be shared, but because the Javascript is spread everywhere it is much harder to look for it)There are some drawbacks of this separation:- When creating a new module we will need to put the javascript in a separate location from the backend code
static/js/datagridfolder contains all the datagrid related functionalitySame as backup module, this should be in it's respective static/js folder.Inside of the folder we can see the files:
get_panel_title.jsis responsible for retrieving the name of the panelshow_data.jsis responsible for showing the datagridshow_query_tool.jsis responsible for showing the query toolDoes this structure make sense?
Can you give an example of a comment that you think is missing and that could help?As a personal note, unless the algorithm is very obscure or very complicated, I believe that if the code needs comments it is a signal that something needs to change in terms of naming, structure of the part in question. This being said, I am open to add some comments that might help people.
You are right, with the help of naming convention and structure of the code, any one can get the idea about the code. But it is very useful to understand the codevery easily with the proper comments especially when there are multiple developers working on a single project.I found some of the places where it would be great to have comments.- treeMenu: new tree.Tree() in a browser.js- tree.js (especially Tree class)About the comment point I need a more clear understanding on what kind of comments you are looking for. Because when you read the function names you understand the intent, what they are doing. The parameters also explain what you need to pass into them.If what you are looking for in these comments is the reasoning being the change itself, then that should be present in the commit message. Specially because this is going to be a very big patch with a very big number of changes.Thanks
JoaoThanks,KhushbooOn Fri, Apr 6, 2018 at 4:48 AM Murtuza Zabuawala <murtuza.zabuawala@enterprisedb.com> wrote:Hi Joao,Patch looks good and working as expected.I also agree with Dave, Can we please add some comments in each file which can help us to understand the flow, I'm saying because now the code is segregated in so many separate files it will be hard to keep track of the flow from one file to another when debugging.--Regards,On Thu, Apr 5, 2018 at 7:08 PM, Joao De Almeida Pereira <jdealmeidapereira@pivotal.io> wrote:Hi Khushboo,Attached you can find both patches rebasedThanksOn Thu, Apr 5, 2018 at 6:31 AM Khushboo Vashi <khushboo.vashi@enterprisedb.com> wrote:Hi Joao,Can you please rebase the second patch?Thanks,KhushbooOn Tue, Apr 3, 2018 at 12:15 AM, Joao De Almeida Pereira <jdealmeidapereira@pivotal.io> wrote:Hi Hackers,Attached you can find the patch that will start to decouple pgAdmin from ACITree library.This patch is intended to be merged after 3.0, because we do not want to cause any entropy or delay the release, but we want to start the discussion and show some code.This job that we started is a massive tech debt chore that will take some time to finalize and we would love the help of the community to do it.Summary of the patch:0001 patch:- Creates a new tree that will allow us to create a separation between the application and ACI Tree- Creates a Fake Tree (Test double, for reference on the available test doubles: https://martinfowler.com/bliki/TestDouble.html) that can be used to inplace to replace the ACITree and also encapsulate the new tree behavior on our tests- Adds tests for all the tree functionalities0002 patch:- Extracts, refactors, adds tests and remove dependency from ACI Tree on:- getTreeNodeHierarchy
- on backup.js: menu_enabled, menu_enabled_server, start_backup_global_server, backup_objects
- on datagrid.js: show_data_grid, get_panel_title, show_query_tool- Start using sprintf-js as Underscore.String is deprecating sprintf functionThis patch represents only 10 calls to ACITree.itemData out of 176 that are spread around our codeIn Depth look on the process behind the patch:We started writing this patch with the idea that we need to decouple pgAdmin4 from ACITree, because ACITree is no longer supported, the documentation is non existent and ACITree is no longer being actively developed.Our process:1. We "randomly" selected a function that is part of the ACITree. From this point we decided to replace that function with our own version. The function that we choose was "itemData".The function gives us all the "data" that a specific node of the tree find.Given in order to replace the tree we would need to have a function that would give us the same information. We had 2 options:a) Create a tree with a function called itemDataPros:- At first view this was the simpler solution- Would keep the status quoCons:- Not a OOP approach- Not very flexibleb) Create a tree that would return a node given an ID and then the node would be responsible for giving it's data.Pros:- OOP Approach- More flexible and we do not need to bring the tree around, just a nodeCons:- Break the current status quoGiven these 2 options we decided to go for a more OOP approach creating a Tree and a TreeNode classes, that in the future will be renamed to ACITreeWrapper and TreeNode.2. After we decided on the starting point we searched for occurrences of the function "itemData" and we found out that there were 303 occurrences of "itemData" in the code and roughly 176 calls to the function itself (some of the hits were variable names).3. We selected the first file on the search and found the function that was responsible for calling the itemData function.4. Extracted the function to a separate file5. Wrap this function with tests6. Refactor the function to ES6, give more declarative names to variables and break the functions into smaller chunks7. When all the tests were passing we replaced ACITree with our Tree8. We ensured that all tests were passing9. Remove function from the original file and use the new function10. Ensure everything still works11. Find the next function and execute from step 4 until all the functions are replaced, refactored and tested.As you can see by the process this is a pretty huge undertake, because of the number of calls to the function. This is just the first step on the direction of completely isolating the ACITree so that we can solve the problem with a large number of elements on the tree.What is on our radar that we need to address:- Finish the complete decoupling of the ACITree- Performance of the current tree implementation- Tweak the naming of the Tree class to explicitly tell us this is to use only with ACITree.ThanksJoaoDave Page
Blog: http://pgsnake.blogspot.com
Twitter: @pgsnake
EnterpriseDB UK: http://www.enterprisedb.com
The Enterprise PostgreSQL Company--Dave Page
Blog: http://pgsnake.blogspot.com
Twitter: @pgsnake
EnterpriseDB UK: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
Attachment
Hi Hackers,
As you are aware we kept on working on the patch, so we are attaching to this email a new version of the patch.
This new version contains all the changes in the previous one plus more extractions of functions and refactoring of code.
The objective of this patch is to create a separation between pgAdmin and the ACI Tree. We are doing this because we realized that at this point in time we have the ACI Tree all over the code of pgAdmin. I found a very interesting article that really talks about this: https://medium.freecodecamp.org/code-dependencies-are-the- devil-35ed28b556d In this patch there are some visions and ideas about the location of the code, the way to organize it and also try to pave the future for a application that is stable, easy to develop on and that can be release at a times notice.We are investing a big chunk of our time in doing this refactoring, but while doing that we also try to respond to the patches sent to the mailing list. We would like the feedback from the community because we believe this is a changing point for the application. The idea is to change the way we develop this application, instead of only correcting a bug of developing a feature, with every commit we should correct the bug or develop a feature but leave the code a little better than we found it (Refactoring, refactoring, refactoring). This is hard work but that is what the users from pgAdmin expect from this community of developers.======It is a huge patch86 files changed, 5492 inserts, 1840 deletionsand we would like to get your feedback as soon as possible, because we are continuing to work on it which means it is going to grow in size.At this point in time we still have 124 of 176 calls to the function itemData from ACITree.
What does each patch contain:0001:Very simple patch, we found out that the linter was not looking into all the javascript test files, so this patch will ensure it is
0002:
New Tree abstraction. This patch contains the new Tree that works as an adaptor for ACI Tree and is going to be used on all the extractions that we are doing.
0003:Code that extracts, wrap with tests and replace ACI Tree invocations.
We start creating new pattern for the location of Javascript files and their structure.
Create patterns for creation of dialogs (backup and restore)
ThanksJoaoI have quite a few comments for the patch.I will send them soon.On Fri, Apr 27, 2018, 14:45 Dave Page <dpage@pgadmin.org> wrote:How is your work on this going Ashesh? Will you be committing today?On Wed, Apr 25, 2018 at 8:52 AM, Dave Page <dpage@pgadmin.org> wrote:Ashesh; you had agreed to work on this early this week. Please ensure you do so today.Thanks.--On Tue, Apr 24, 2018 at 8:13 PM, Joao De Almeida Pereira <jdealmeidapereira@pivotal.io> wrote:Hi Hackers,Can someone review and merge this patch?ThanksJoaoOn Wed, Apr 18, 2018 at 10:23 AM Joao De Almeida Pereira <jdealmeidapereira@pivotal.io> wrote:Hi Hackers,Any other comment about this patch?ThanksJoaoOn Tue, Apr 10, 2018 at 12:00 PM Joao De Almeida Pereira <jdealmeidapereira@pivotal.io> wrote:Hello KhushbooOn Mon, Apr 9, 2018 at 1:59 AM Khushboo Vashi <khushboo.vashi@enterprisedb.com> wrote: Hi Joao,I have reviewed your patch and have some suggestions.On Sat, Apr 7, 2018 at 12:43 AM, Joao De Almeida Pereira <jdealmeidapereira@pivotal.io> wrote:Hello Murtuza/Dave,
Yes now the extracted functions are spread into different files. The intent would be to make the files as small as possible, and also to group and name them in a way that would be easy to understand what each file is doing without the need of opening it.
As a example:static/js/backupwill contain all the backup related functionality inside of this folder we can see the file:
menu_utils.jsAt this moment in time we decided to group all the functions that are related to the menu, but we can split that also if we believe it is easier to see.It's really very good to see the separated code for backup module. As we have done for backup, we would like do it for other PG utilities like restore, maintenance etc.Considering this, we should separate the code in a way that some of the common functionalities can be used for other modules like menu (as you have mentioned above), dialogue factory etc.Also, I think these functionalities should be in their respective static folder instead of pgadmin/static.About the location of the files. The move of the files to pgadmin/static/js was made on purpose in order to clearly separate Javascript from python code.The rational behind it was- Create a clear separation between the backend and frontend- Having Javascript code concentrated in a single place, hopefully, will encourage to developers to look for a functionality, that is already implemented in another modules, because they are right there. (When we started this journey we realized that the 'nodes' have a big groups of code that could be shared, but because the Javascript is spread everywhere it is much harder to look for it)There are some drawbacks of this separation:- When creating a new module we will need to put the javascript in a separate location from the backend code
static/js/datagridfolder contains all the datagrid related functionalitySame as backup module, this should be in it's respective static/js folder.Inside of the folder we can see the files:
get_panel_title.jsis responsible for retrieving the name of the panelshow_data.jsis responsible for showing the datagridshow_query_tool.jsis responsible for showing the query toolDoes this structure make sense?
Can you give an example of a comment that you think is missing and that could help?As a personal note, unless the algorithm is very obscure or very complicated, I believe that if the code needs comments it is a signal that something needs to change in terms of naming, structure of the part in question. This being said, I am open to add some comments that might help people.
You are right, with the help of naming convention and structure of the code, any one can get the idea about the code. But it is very useful to understand the codevery easily with the proper comments especially when there are multiple developers working on a single project.I found some of the places where it would be great to have comments.- treeMenu: new tree.Tree() in a browser.js- tree.js (especially Tree class)About the comment point I need a more clear understanding on what kind of comments you are looking for. Because when you read the function names you understand the intent, what they are doing. The parameters also explain what you need to pass into them.If what you are looking for in these comments is the reasoning being the change itself, then that should be present in the commit message. Specially because this is going to be a very big patch with a very big number of changes.Thanks
JoaoThanks,KhushbooOn Fri, Apr 6, 2018 at 4:48 AM Murtuza Zabuawala <murtuza.zabuawala@enterprisedb.com> wrote: Hi Joao,Patch looks good and working as expected.I also agree with Dave, Can we please add some comments in each file which can help us to understand the flow, I'm saying because now the code is segregated in so many separate files it will be hard to keep track of the flow from one file to another when debugging.--Regards,On Thu, Apr 5, 2018 at 7:08 PM, Joao De Almeida Pereira <jdealmeidapereira@pivotal.io> wrote:Hi Khushboo,Attached you can find both patches rebasedThanksOn Thu, Apr 5, 2018 at 6:31 AM Khushboo Vashi <khushboo.vashi@enterprisedb.com> wrote: Hi Joao,Can you please rebase the second patch?Thanks,KhushbooOn Tue, Apr 3, 2018 at 12:15 AM, Joao De Almeida Pereira <jdealmeidapereira@pivotal.io> wrote:Hi Hackers,Attached you can find the patch that will start to decouple pgAdmin from ACITree library.This patch is intended to be merged after 3.0, because we do not want to cause any entropy or delay the release, but we want to start the discussion and show some code.This job that we started is a massive tech debt chore that will take some time to finalize and we would love the help of the community to do it.Summary of the patch:0001 patch:- Creates a new tree that will allow us to create a separation between the application and ACI Tree- Creates a Fake Tree (Test double, for reference on the available test doubles: https://martinfowler.com/bliki/TestDouble.html) that can be used to inplace to replace the ACITree and also encapsulate the new tree behavior on our tests - Adds tests for all the tree functionalities0002 patch:- Extracts, refactors, adds tests and remove dependency from ACI Tree on:- getTreeNodeHierarchy
- on backup.js: menu_enabled, menu_enabled_server, start_backup_global_server, backup_objects
- on datagrid.js: show_data_grid, get_panel_title, show_query_tool- Start using sprintf-js as Underscore.String is deprecating sprintf functionThis patch represents only 10 calls to ACITree.itemData out of 176 that are spread around our codeIn Depth look on the process behind the patch:We started writing this patch with the idea that we need to decouple pgAdmin4 from ACITree, because ACITree is no longer supported, the documentation is non existent and ACITree is no longer being actively developed.Our process:1. We "randomly" selected a function that is part of the ACITree. From this point we decided to replace that function with our own version. The function that we choose was "itemData".The function gives us all the "data" that a specific node of the tree find.Given in order to replace the tree we would need to have a function that would give us the same information. We had 2 options:a) Create a tree with a function called itemDataPros:- At first view this was the simpler solution- Would keep the status quoCons:- Not a OOP approach- Not very flexibleb) Create a tree that would return a node given an ID and then the node would be responsible for giving it's data.Pros:- OOP Approach- More flexible and we do not need to bring the tree around, just a nodeCons:- Break the current status quoGiven these 2 options we decided to go for a more OOP approach creating a Tree and a TreeNode classes, that in the future will be renamed to ACITreeWrapper and TreeNode.2. After we decided on the starting point we searched for occurrences of the function "itemData" and we found out that there were 303 occurrences of "itemData" in the code and roughly 176 calls to the function itself (some of the hits were variable names).3. We selected the first file on the search and found the function that was responsible for calling the itemData function.4. Extracted the function to a separate file5. Wrap this function with tests6. Refactor the function to ES6, give more declarative names to variables and break the functions into smaller chunks7. When all the tests were passing we replaced ACITree with our Tree8. We ensured that all tests were passing9. Remove function from the original file and use the new function10. Ensure everything still works11. Find the next function and execute from step 4 until all the functions are replaced, refactored and tested.As you can see by the process this is a pretty huge undertake, because of the number of calls to the function. This is just the first step on the direction of completely isolating the ACITree so that we can solve the problem with a large number of elements on the tree.What is on our radar that we need to address:- Finish the complete decoupling of the ACITree- Performance of the current tree implementation- Tweak the naming of the Tree class to explicitly tell us this is to use only with ACITree.ThanksJoaoDave Page
Blog: http://pgsnake.blogspot.com
Twitter: @pgsnake
EnterpriseDB UK: http://www.enterprisedb.com
The Enterprise PostgreSQL Company--Dave Page
Blog: http://pgsnake.blogspot.com
Twitter: @pgsnake
EnterpriseDB UK: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
On Sat, Apr 28, 2018 at 3:55 AM, Joao De Almeida Pereira <jdealmeidapereira@pivotal.io> wrote:Hi Hackers,
As you are aware we kept on working on the patch, so we are attaching to this email a new version of the patch.
This new version contains all the changes in the previous one plus more extractions of functions and refactoring of code.
The objective of this patch is to create a separation between pgAdmin and the ACI Tree. We are doing this because we realized that at this point in time we have the ACI Tree all over the code of pgAdmin. I found a very interesting article that really talks about this: https://medium.freecodecamp.org/code-dependencies-are-the-de vil-35ed28b556d In this patch there are some visions and ideas about the location of the code, the way to organize it and also try to pave the future for a application that is stable, easy to develop on and that can be release at a times notice.We are investing a big chunk of our time in doing this refactoring, but while doing that we also try to respond to the patches sent to the mailing list. We would like the feedback from the community because we believe this is a changing point for the application. The idea is to change the way we develop this application, instead of only correcting a bug of developing a feature, with every commit we should correct the bug or develop a feature but leave the code a little better than we found it (Refactoring, refactoring, refactoring). This is hard work but that is what the users from pgAdmin expect from this community of developers.======It is a huge patch86 files changed, 5492 inserts, 1840 deletionsand we would like to get your feedback as soon as possible, because we are continuing to work on it which means it is going to grow in size.At this point in time we still have 124 of 176 calls to the function itemData from ACITree.
What does each patch contain:0001:Very simple patch, we found out that the linter was not looking into all the javascript test files, so this patch will ensure it isCommitted the patch along with the regression introduced because of this patch.0002:
New Tree abstraction. This patch contains the new Tree that works as an adaptor for ACI Tree and is going to be used on all the extractions that we are doing.I was expecting a separate layer between the tree implementation, and aciTree adaptor.Please find the patch for the example.It will separate the two layers, and easy to replace with the new implemenation in future.
0003:Code that extracts, wrap with tests and replace ACI Tree invocations.There are many small cases left in the patches.Hence - I would like to know the TODO list created by you.e.g. When we remove any of the object from the database server, we're not yet removing the respective node from the new implementation, and its children.We start creating new pattern for the location of Javascript files and their structure.I would not like to see that changes in this patch.I would like us to come up with the actual design about the hot pluggability before going in this direction.Create patterns for creation of dialogs (backup and restore)It's better - we don't change the directory structure at the moment.I am not against dividing the big javascript files in small chunks, but - I would like us to discuss first about the hot plugins design first.-- Thanks, AsheshThanksJoaoI have quite a few comments for the patch.I will send them soon.On Fri, Apr 27, 2018, 14:45 Dave Page <dpage@pgadmin.org> wrote:How is your work on this going Ashesh? Will you be committing today?On Wed, Apr 25, 2018 at 8:52 AM, Dave Page <dpage@pgadmin.org> wrote:Ashesh; you had agreed to work on this early this week. Please ensure you do so today.Thanks.--On Tue, Apr 24, 2018 at 8:13 PM, Joao De Almeida Pereira <jdealmeidapereira@pivotal.io> wrote:Hi Hackers,Can someone review and merge this patch?ThanksJoaoOn Wed, Apr 18, 2018 at 10:23 AM Joao De Almeida Pereira <jdealmeidapereira@pivotal.io> wrote:Hi Hackers,Any other comment about this patch?ThanksJoaoOn Tue, Apr 10, 2018 at 12:00 PM Joao De Almeida Pereira <jdealmeidapereira@pivotal.io> wrote:Hello KhushbooOn Mon, Apr 9, 2018 at 1:59 AM Khushboo Vashi <khushboo.vashi@enterprisedb.com> wrote: Hi Joao,I have reviewed your patch and have some suggestions.On Sat, Apr 7, 2018 at 12:43 AM, Joao De Almeida Pereira <jdealmeidapereira@pivotal.io> wrote:Hello Murtuza/Dave,
Yes now the extracted functions are spread into different files. The intent would be to make the files as small as possible, and also to group and name them in a way that would be easy to understand what each file is doing without the need of opening it.
As a example:static/js/backupwill contain all the backup related functionality inside of this folder we can see the file:
menu_utils.jsAt this moment in time we decided to group all the functions that are related to the menu, but we can split that also if we believe it is easier to see.It's really very good to see the separated code for backup module. As we have done for backup, we would like do it for other PG utilities like restore, maintenance etc.Considering this, we should separate the code in a way that some of the common functionalities can be used for other modules like menu (as you have mentioned above), dialogue factory etc.Also, I think these functionalities should be in their respective static folder instead of pgadmin/static.About the location of the files. The move of the files to pgadmin/static/js was made on purpose in order to clearly separate Javascript from python code.The rational behind it was- Create a clear separation between the backend and frontend- Having Javascript code concentrated in a single place, hopefully, will encourage to developers to look for a functionality, that is already implemented in another modules, because they are right there. (When we started this journey we realized that the 'nodes' have a big groups of code that could be shared, but because the Javascript is spread everywhere it is much harder to look for it)There are some drawbacks of this separation:- When creating a new module we will need to put the javascript in a separate location from the backend code
static/js/datagridfolder contains all the datagrid related functionalitySame as backup module, this should be in it's respective static/js folder.Inside of the folder we can see the files:
get_panel_title.jsis responsible for retrieving the name of the panelshow_data.jsis responsible for showing the datagridshow_query_tool.jsis responsible for showing the query toolDoes this structure make sense?
Can you give an example of a comment that you think is missing and that could help?As a personal note, unless the algorithm is very obscure or very complicated, I believe that if the code needs comments it is a signal that something needs to change in terms of naming, structure of the part in question. This being said, I am open to add some comments that might help people.
You are right, with the help of naming convention and structure of the code, any one can get the idea about the code. But it is very useful to understand the codevery easily with the proper comments especially when there are multiple developers working on a single project.I found some of the places where it would be great to have comments.- treeMenu: new tree.Tree() in a browser.js- tree.js (especially Tree class)About the comment point I need a more clear understanding on what kind of comments you are looking for. Because when you read the function names you understand the intent, what they are doing. The parameters also explain what you need to pass into them.If what you are looking for in these comments is the reasoning being the change itself, then that should be present in the commit message. Specially because this is going to be a very big patch with a very big number of changes.Thanks
JoaoThanks,KhushbooOn Fri, Apr 6, 2018 at 4:48 AM Murtuza Zabuawala <murtuza.zabuawala@enterprisedb.com> wrote: Hi Joao,Patch looks good and working as expected.I also agree with Dave, Can we please add some comments in each file which can help us to understand the flow, I'm saying because now the code is segregated in so many separate files it will be hard to keep track of the flow from one file to another when debugging.--Regards,On Thu, Apr 5, 2018 at 7:08 PM, Joao De Almeida Pereira <jdealmeidapereira@pivotal.io> wrote:Hi Khushboo,Attached you can find both patches rebasedThanksOn Thu, Apr 5, 2018 at 6:31 AM Khushboo Vashi <khushboo.vashi@enterprisedb.com> wrote: Hi Joao,Can you please rebase the second patch?Thanks,KhushbooOn Tue, Apr 3, 2018 at 12:15 AM, Joao De Almeida Pereira <jdealmeidapereira@pivotal.io> wrote:Hi Hackers,Attached you can find the patch that will start to decouple pgAdmin from ACITree library.This patch is intended to be merged after 3.0, because we do not want to cause any entropy or delay the release, but we want to start the discussion and show some code.This job that we started is a massive tech debt chore that will take some time to finalize and we would love the help of the community to do it.Summary of the patch:0001 patch:- Creates a new tree that will allow us to create a separation between the application and ACI Tree- Creates a Fake Tree (Test double, for reference on the available test doubles: https://martinfowler.com/bliki/TestDouble.html) that can be used to inplace to replace the ACITree and also encapsulate the new tree behavior on our tests - Adds tests for all the tree functionalities0002 patch:- Extracts, refactors, adds tests and remove dependency from ACI Tree on:- getTreeNodeHierarchy
- on backup.js: menu_enabled, menu_enabled_server, start_backup_global_server, backup_objects
- on datagrid.js: show_data_grid, get_panel_title, show_query_tool- Start using sprintf-js as Underscore.String is deprecating sprintf functionThis patch represents only 10 calls to ACITree.itemData out of 176 that are spread around our codeIn Depth look on the process behind the patch:We started writing this patch with the idea that we need to decouple pgAdmin4 from ACITree, because ACITree is no longer supported, the documentation is non existent and ACITree is no longer being actively developed.Our process:1. We "randomly" selected a function that is part of the ACITree. From this point we decided to replace that function with our own version. The function that we choose was "itemData".The function gives us all the "data" that a specific node of the tree find.Given in order to replace the tree we would need to have a function that would give us the same information. We had 2 options:a) Create a tree with a function called itemDataPros:- At first view this was the simpler solution- Would keep the status quoCons:- Not a OOP approach- Not very flexibleb) Create a tree that would return a node given an ID and then the node would be responsible for giving it's data.Pros:- OOP Approach- More flexible and we do not need to bring the tree around, just a nodeCons:- Break the current status quoGiven these 2 options we decided to go for a more OOP approach creating a Tree and a TreeNode classes, that in the future will be renamed to ACITreeWrapper and TreeNode.2. After we decided on the starting point we searched for occurrences of the function "itemData" and we found out that there were 303 occurrences of "itemData" in the code and roughly 176 calls to the function itself (some of the hits were variable names).3. We selected the first file on the search and found the function that was responsible for calling the itemData function.4. Extracted the function to a separate file5. Wrap this function with tests6. Refactor the function to ES6, give more declarative names to variables and break the functions into smaller chunks7. When all the tests were passing we replaced ACITree with our Tree8. We ensured that all tests were passing9. Remove function from the original file and use the new function10. Ensure everything still works11. Find the next function and execute from step 4 until all the functions are replaced, refactored and tested.As you can see by the process this is a pretty huge undertake, because of the number of calls to the function. This is just the first step on the direction of completely isolating the ACITree so that we can solve the problem with a large number of elements on the tree.What is on our radar that we need to address:- Finish the complete decoupling of the ACITree- Performance of the current tree implementation- Tweak the naming of the Tree class to explicitly tell us this is to use only with ACITree.ThanksJoaoDave Page
Blog: http://pgsnake.blogspot.com
Twitter: @pgsnake
EnterpriseDB UK: http://www.enterprisedb.com
The Enterprise PostgreSQL Company--Dave Page
Blog: http://pgsnake.blogspot.com
Twitter: @pgsnake
EnterpriseDB UK: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
Attachment
I was expecting a separate layer between the tree implementation, and aciTree adaptor.
Please find the patch for the example.
It will separate the two layers, and easy to replace with the new implementation in future.
I would not like to see that changes in this patch.
I would like us to come up with the actual design about the hot pluggability before going in this direction.
On Mon, Apr 30, 2018 at 8:30 PM, Ashesh Vashi <ashesh.vashi@enterprisedb.com> wrote: On Sat, Apr 28, 2018 at 3:55 AM, Joao De Almeida Pereira <jdealmeidapereira@pivotal.io> wrote:Hi Hackers,
As you are aware we kept on working on the patch, so we are attaching to this email a new version of the patch.
This new version contains all the changes in the previous one plus more extractions of functions and refactoring of code.
The objective of this patch is to create a separation between pgAdmin and the ACI Tree. We are doing this because we realized that at this point in time we have the ACI Tree all over the code of pgAdmin. I found a very interesting article that really talks about this: https://medium.freecodecamp.org/code-dependencies-are-the-de vil-35ed28b556d In this patch there are some visions and ideas about the location of the code, the way to organize it and also try to pave the future for a application that is stable, easy to develop on and that can be release at a times notice.We are investing a big chunk of our time in doing this refactoring, but while doing that we also try to respond to the patches sent to the mailing list. We would like the feedback from the community because we believe this is a changing point for the application. The idea is to change the way we develop this application, instead of only correcting a bug of developing a feature, with every commit we should correct the bug or develop a feature but leave the code a little better than we found it (Refactoring, refactoring, refactoring). This is hard work but that is what the users from pgAdmin expect from this community of developers.======It is a huge patch86 files changed, 5492 inserts, 1840 deletionsand we would like to get your feedback as soon as possible, because we are continuing to work on it which means it is going to grow in size.At this point in time we still have 124 of 176 calls to the function itemData from ACITree.
What does each patch contain:0001:Very simple patch, we found out that the linter was not looking into all the javascript test files, so this patch will ensure it isCommitted the patch along with the regression introduced because of this patch.0002:
New Tree abstraction. This patch contains the new Tree that works as an adaptor for ACI Tree and is going to be used on all the extractions that we are doing.I was expecting a separate layer between the tree implementation, and aciTree adaptor.Please find the patch for the example.It will separate the two layers, and easy to replace with the new implemenation in future.Oops forgot to attach the patch.Please find the patch attached.-- Thanks, Ashesh0003:Code that extracts, wrap with tests and replace ACI Tree invocations.There are many small cases left in the patches.Hence - I would like to know the TODO list created by you.e.g. When we remove any of the object from the database server, we're not yet removing the respective node from the new implementation, and its children.We start creating new pattern for the location of Javascript files and their structure.I would not like to see that changes in this patch.I would like us to come up with the actual design about the hot pluggability before going in this direction.Create patterns for creation of dialogs (backup and restore)It's better - we don't change the directory structure at the moment.I am not against dividing the big javascript files in small chunks, but - I would like us to discuss first about the hot plugins design first.-- Thanks, AsheshThanksJoaoI have quite a few comments for the patch.I will send them soon.On Fri, Apr 27, 2018, 14:45 Dave Page <dpage@pgadmin.org> wrote:How is your work on this going Ashesh? Will you be committing today?On Wed, Apr 25, 2018 at 8:52 AM, Dave Page <dpage@pgadmin.org> wrote:Ashesh; you had agreed to work on this early this week. Please ensure you do so today.Thanks.--On Tue, Apr 24, 2018 at 8:13 PM, Joao De Almeida Pereira <jdealmeidapereira@pivotal.io> wrote:Hi Hackers,Can someone review and merge this patch?ThanksJoaoOn Wed, Apr 18, 2018 at 10:23 AM Joao De Almeida Pereira <jdealmeidapereira@pivotal.io> wrote:Hi Hackers,Any other comment about this patch?ThanksJoaoOn Tue, Apr 10, 2018 at 12:00 PM Joao De Almeida Pereira <jdealmeidapereira@pivotal.io> wrote:Hello KhushbooOn Mon, Apr 9, 2018 at 1:59 AM Khushboo Vashi <khushboo.vashi@enterprisedb.com> wrote: Hi Joao,I have reviewed your patch and have some suggestions.On Sat, Apr 7, 2018 at 12:43 AM, Joao De Almeida Pereira <jdealmeidapereira@pivotal.io> wrote:Hello Murtuza/Dave,
Yes now the extracted functions are spread into different files. The intent would be to make the files as small as possible, and also to group and name them in a way that would be easy to understand what each file is doing without the need of opening it.
As a example:static/js/backupwill contain all the backup related functionality inside of this folder we can see the file:
menu_utils.jsAt this moment in time we decided to group all the functions that are related to the menu, but we can split that also if we believe it is easier to see.It's really very good to see the separated code for backup module. As we have done for backup, we would like do it for other PG utilities like restore, maintenance etc.Considering this, we should separate the code in a way that some of the common functionalities can be used for other modules like menu (as you have mentioned above), dialogue factory etc.Also, I think these functionalities should be in their respective static folder instead of pgadmin/static.About the location of the files. The move of the files to pgadmin/static/js was made on purpose in order to clearly separate Javascript from python code.The rational behind it was- Create a clear separation between the backend and frontend- Having Javascript code concentrated in a single place, hopefully, will encourage to developers to look for a functionality, that is already implemented in another modules, because they are right there. (When we started this journey we realized that the 'nodes' have a big groups of code that could be shared, but because the Javascript is spread everywhere it is much harder to look for it)There are some drawbacks of this separation:- When creating a new module we will need to put the javascript in a separate location from the backend code
static/js/datagridfolder contains all the datagrid related functionalitySame as backup module, this should be in it's respective static/js folder.Inside of the folder we can see the files:
get_panel_title.jsis responsible for retrieving the name of the panelshow_data.jsis responsible for showing the datagridshow_query_tool.jsis responsible for showing the query toolDoes this structure make sense?
Can you give an example of a comment that you think is missing and that could help?As a personal note, unless the algorithm is very obscure or very complicated, I believe that if the code needs comments it is a signal that something needs to change in terms of naming, structure of the part in question. This being said, I am open to add some comments that might help people.
You are right, with the help of naming convention and structure of the code, any one can get the idea about the code. But it is very useful to understand the codevery easily with the proper comments especially when there are multiple developers working on a single project.I found some of the places where it would be great to have comments.- treeMenu: new tree.Tree() in a browser.js- tree.js (especially Tree class)About the comment point I need a more clear understanding on what kind of comments you are looking for. Because when you read the function names you understand the intent, what they are doing. The parameters also explain what you need to pass into them.If what you are looking for in these comments is the reasoning being the change itself, then that should be present in the commit message. Specially because this is going to be a very big patch with a very big number of changes.Thanks
JoaoThanks,KhushbooOn Fri, Apr 6, 2018 at 4:48 AM Murtuza Zabuawala <murtuza.zabuawala@enterprisedb.com> wrote: Hi Joao,Patch looks good and working as expected.I also agree with Dave, Can we please add some comments in each file which can help us to understand the flow, I'm saying because now the code is segregated in so many separate files it will be hard to keep track of the flow from one file to another when debugging.--Regards,On Thu, Apr 5, 2018 at 7:08 PM, Joao De Almeida Pereira <jdealmeidapereira@pivotal.io> wrote:Hi Khushboo,Attached you can find both patches rebasedThanksOn Thu, Apr 5, 2018 at 6:31 AM Khushboo Vashi <khushboo.vashi@enterprisedb.com> wrote: Hi Joao,Can you please rebase the second patch?Thanks,KhushbooOn Tue, Apr 3, 2018 at 12:15 AM, Joao De Almeida Pereira <jdealmeidapereira@pivotal.io> wrote:Hi Hackers,Attached you can find the patch that will start to decouple pgAdmin from ACITree library.This patch is intended to be merged after 3.0, because we do not want to cause any entropy or delay the release, but we want to start the discussion and show some code.This job that we started is a massive tech debt chore that will take some time to finalize and we would love the help of the community to do it.Summary of the patch:0001 patch:- Creates a new tree that will allow us to create a separation between the application and ACI Tree- Creates a Fake Tree (Test double, for reference on the available test doubles: https://martinfowler.com/bliki/TestDouble.html) that can be used to inplace to replace the ACITree and also encapsulate the new tree behavior on our tests - Adds tests for all the tree functionalities0002 patch:- Extracts, refactors, adds tests and remove dependency from ACI Tree on:- getTreeNodeHierarchy
- on backup.js: menu_enabled, menu_enabled_server, start_backup_global_server, backup_objects
- on datagrid.js: show_data_grid, get_panel_title, show_query_tool- Start using sprintf-js as Underscore.String is deprecating sprintf functionThis patch represents only 10 calls to ACITree.itemData out of 176 that are spread around our codeIn Depth look on the process behind the patch:We started writing this patch with the idea that we need to decouple pgAdmin4 from ACITree, because ACITree is no longer supported, the documentation is non existent and ACITree is no longer being actively developed.Our process:1. We "randomly" selected a function that is part of the ACITree. From this point we decided to replace that function with our own version. The function that we choose was "itemData".The function gives us all the "data" that a specific node of the tree find.Given in order to replace the tree we would need to have a function that would give us the same information. We had 2 options:a) Create a tree with a function called itemDataPros:- At first view this was the simpler solution- Would keep the status quoCons:- Not a OOP approach- Not very flexibleb) Create a tree that would return a node given an ID and then the node would be responsible for giving it's data.Pros:- OOP Approach- More flexible and we do not need to bring the tree around, just a nodeCons:- Break the current status quoGiven these 2 options we decided to go for a more OOP approach creating a Tree and a TreeNode classes, that in the future will be renamed to ACITreeWrapper and TreeNode.2. After we decided on the starting point we searched for occurrences of the function "itemData" and we found out that there were 303 occurrences of "itemData" in the code and roughly 176 calls to the function itself (some of the hits were variable names).3. We selected the first file on the search and found the function that was responsible for calling the itemData function.4. Extracted the function to a separate file5. Wrap this function with tests6. Refactor the function to ES6, give more declarative names to variables and break the functions into smaller chunks7. When all the tests were passing we replaced ACITree with our Tree8. We ensured that all tests were passing9. Remove function from the original file and use the new function10. Ensure everything still works11. Find the next function and execute from step 4 until all the functions are replaced, refactored and tested.As you can see by the process this is a pretty huge undertake, because of the number of calls to the function. This is just the first step on the direction of completely isolating the ACITree so that we can solve the problem with a large number of elements on the tree.What is on our radar that we need to address:- Finish the complete decoupling of the ACITree- Performance of the current tree implementation- Tweak the naming of the Tree class to explicitly tell us this is to use only with ACITree.ThanksJoaoDave Page
Blog: http://pgsnake.blogspot.com
Twitter: @pgsnake
EnterpriseDB UK: http://www.enterprisedb.com
The Enterprise PostgreSQL Company--Dave Page
Blog: http://pgsnake.blogspot.com
Twitter: @pgsnake
EnterpriseDB UK: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
I was expecting a separate layer between the tree implementation, and aciTree adaptor.
Please find the patch for the example.
It will separate the two layers, and easy to replace with the new implementation in future.In general, we want defer the separation of the layers for now. Even though we might assume that this is the direction we want to go in. It's simply too early to be making such an architectural leap. For right now, we just know that we need the decoupling, but don't know what if we'd need the 2 layers as implemented. The principle we're adhering to here is the Last Responsible Moment principle, which states that you only make the changes that you feel is necessary for the given problems you're facing: https://blog.codinghorror.com/the-last- responsible-moment/ I would not like to see that changes in this patch.
I would like us to come up with the actual design about the hot pluggability before going in this direction.In our point of view these 2 changes are not related. One thing is the internal code organization of the application, other thing is allowing third party to drop code in the application and it just work. These 2 should be talked separately, but the hot pluggability is not something that will be address by this work we are doing right now.
Anthony && JoaoOn Mon, Apr 30, 2018 at 11:03 AM, Ashesh Vashi <ashesh.vashi@enterprisedb.com> wrote: On Mon, Apr 30, 2018 at 8:30 PM, Ashesh Vashi <ashesh.vashi@enterprisedb.com> wrote: On Sat, Apr 28, 2018 at 3:55 AM, Joao De Almeida Pereira <jdealmeidapereira@pivotal.io> wrote:Hi Hackers,
As you are aware we kept on working on the patch, so we are attaching to this email a new version of the patch.
This new version contains all the changes in the previous one plus more extractions of functions and refactoring of code.
The objective of this patch is to create a separation between pgAdmin and the ACI Tree. We are doing this because we realized that at this point in time we have the ACI Tree all over the code of pgAdmin. I found a very interesting article that really talks about this: https://medium.freecodecamp.org/code-dependencies-are-the-de vil-35ed28b556d In this patch there are some visions and ideas about the location of the code, the way to organize it and also try to pave the future for a application that is stable, easy to develop on and that can be release at a times notice.We are investing a big chunk of our time in doing this refactoring, but while doing that we also try to respond to the patches sent to the mailing list. We would like the feedback from the community because we believe this is a changing point for the application. The idea is to change the way we develop this application, instead of only correcting a bug of developing a feature, with every commit we should correct the bug or develop a feature but leave the code a little better than we found it (Refactoring, refactoring, refactoring). This is hard work but that is what the users from pgAdmin expect from this community of developers.======It is a huge patch86 files changed, 5492 inserts, 1840 deletionsand we would like to get your feedback as soon as possible, because we are continuing to work on it which means it is going to grow in size.At this point in time we still have 124 of 176 calls to the function itemData from ACITree.
What does each patch contain:0001:Very simple patch, we found out that the linter was not looking into all the javascript test files, so this patch will ensure it isCommitted the patch along with the regression introduced because of this patch.0002:
New Tree abstraction. This patch contains the new Tree that works as an adaptor for ACI Tree and is going to be used on all the extractions that we are doing.I was expecting a separate layer between the tree implementation, and aciTree adaptor.Please find the patch for the example.It will separate the two layers, and easy to replace with the new implemenation in future.Oops forgot to attach the patch.Please find the patch attached.-- Thanks, Ashesh0003:Code that extracts, wrap with tests and replace ACI Tree invocations.There are many small cases left in the patches.Hence - I would like to know the TODO list created by you.e.g. When we remove any of the object from the database server, we're not yet removing the respective node from the new implementation, and its children.We start creating new pattern for the location of Javascript files and their structure.I would not like to see that changes in this patch.I would like us to come up with the actual design about the hot pluggability before going in this direction.Create patterns for creation of dialogs (backup and restore)It's better - we don't change the directory structure at the moment.I am not against dividing the big javascript files in small chunks, but - I would like us to discuss first about the hot plugins design first.-- Thanks, AsheshThanksJoaoI have quite a few comments for the patch.I will send them soon.On Fri, Apr 27, 2018, 14:45 Dave Page <dpage@pgadmin.org> wrote:How is your work on this going Ashesh? Will you be committing today?On Wed, Apr 25, 2018 at 8:52 AM, Dave Page <dpage@pgadmin.org> wrote:Ashesh; you had agreed to work on this early this week. Please ensure you do so today.Thanks.--On Tue, Apr 24, 2018 at 8:13 PM, Joao De Almeida Pereira <jdealmeidapereira@pivotal.io> wrote:Hi Hackers,Can someone review and merge this patch?ThanksJoaoOn Wed, Apr 18, 2018 at 10:23 AM Joao De Almeida Pereira <jdealmeidapereira@pivotal.io> wrote:Hi Hackers,Any other comment about this patch?ThanksJoaoOn Tue, Apr 10, 2018 at 12:00 PM Joao De Almeida Pereira <jdealmeidapereira@pivotal.io> wrote:Hello KhushbooOn Mon, Apr 9, 2018 at 1:59 AM Khushboo Vashi <khushboo.vashi@enterprisedb.com> wrote: Hi Joao,I have reviewed your patch and have some suggestions.On Sat, Apr 7, 2018 at 12:43 AM, Joao De Almeida Pereira <jdealmeidapereira@pivotal.io> wrote:Hello Murtuza/Dave,
Yes now the extracted functions are spread into different files. The intent would be to make the files as small as possible, and also to group and name them in a way that would be easy to understand what each file is doing without the need of opening it.
As a example:static/js/backupwill contain all the backup related functionality inside of this folder we can see the file:
menu_utils.jsAt this moment in time we decided to group all the functions that are related to the menu, but we can split that also if we believe it is easier to see.It's really very good to see the separated code for backup module. As we have done for backup, we would like do it for other PG utilities like restore, maintenance etc.Considering this, we should separate the code in a way that some of the common functionalities can be used for other modules like menu (as you have mentioned above), dialogue factory etc.Also, I think these functionalities should be in their respective static folder instead of pgadmin/static.About the location of the files. The move of the files to pgadmin/static/js was made on purpose in order to clearly separate Javascript from python code.The rational behind it was- Create a clear separation between the backend and frontend- Having Javascript code concentrated in a single place, hopefully, will encourage to developers to look for a functionality, that is already implemented in another modules, because they are right there. (When we started this journey we realized that the 'nodes' have a big groups of code that could be shared, but because the Javascript is spread everywhere it is much harder to look for it)There are some drawbacks of this separation:- When creating a new module we will need to put the javascript in a separate location from the backend code
static/js/datagridfolder contains all the datagrid related functionalitySame as backup module, this should be in it's respective static/js folder.Inside of the folder we can see the files:
get_panel_title.jsis responsible for retrieving the name of the panelshow_data.jsis responsible for showing the datagridshow_query_tool.jsis responsible for showing the query toolDoes this structure make sense?
Can you give an example of a comment that you think is missing and that could help?As a personal note, unless the algorithm is very obscure or very complicated, I believe that if the code needs comments it is a signal that something needs to change in terms of naming, structure of the part in question. This being said, I am open to add some comments that might help people.
You are right, with the help of naming convention and structure of the code, any one can get the idea about the code. But it is very useful to understand the codevery easily with the proper comments especially when there are multiple developers working on a single project.I found some of the places where it would be great to have comments.- treeMenu: new tree.Tree() in a browser.js- tree.js (especially Tree class)About the comment point I need a more clear understanding on what kind of comments you are looking for. Because when you read the function names you understand the intent, what they are doing. The parameters also explain what you need to pass into them.If what you are looking for in these comments is the reasoning being the change itself, then that should be present in the commit message. Specially because this is going to be a very big patch with a very big number of changes.Thanks
JoaoThanks,KhushbooOn Fri, Apr 6, 2018 at 4:48 AM Murtuza Zabuawala <murtuza.zabuawala@enterprisedb.com> wrote: Hi Joao,Patch looks good and working as expected.I also agree with Dave, Can we please add some comments in each file which can help us to understand the flow, I'm saying because now the code is segregated in so many separate files it will be hard to keep track of the flow from one file to another when debugging.--Regards,On Thu, Apr 5, 2018 at 7:08 PM, Joao De Almeida Pereira <jdealmeidapereira@pivotal.io> wrote:Hi Khushboo,Attached you can find both patches rebasedThanksOn Thu, Apr 5, 2018 at 6:31 AM Khushboo Vashi <khushboo.vashi@enterprisedb.com> wrote: Hi Joao,Can you please rebase the second patch?Thanks,KhushbooOn Tue, Apr 3, 2018 at 12:15 AM, Joao De Almeida Pereira <jdealmeidapereira@pivotal.io> wrote:Hi Hackers,Attached you can find the patch that will start to decouple pgAdmin from ACITree library.This patch is intended to be merged after 3.0, because we do not want to cause any entropy or delay the release, but we want to start the discussion and show some code.This job that we started is a massive tech debt chore that will take some time to finalize and we would love the help of the community to do it.Summary of the patch:0001 patch:- Creates a new tree that will allow us to create a separation between the application and ACI Tree- Creates a Fake Tree (Test double, for reference on the available test doubles: https://martinfowler.com/bliki/TestDouble.html) that can be used to inplace to replace the ACITree and also encapsulate the new tree behavior on our tests - Adds tests for all the tree functionalities0002 patch:- Extracts, refactors, adds tests and remove dependency from ACI Tree on:- getTreeNodeHierarchy
- on backup.js: menu_enabled, menu_enabled_server, start_backup_global_server, backup_objects
- on datagrid.js: show_data_grid, get_panel_title, show_query_tool- Start using sprintf-js as Underscore.String is deprecating sprintf functionThis patch represents only 10 calls to ACITree.itemData out of 176 that are spread around our codeIn Depth look on the process behind the patch:We started writing this patch with the idea that we need to decouple pgAdmin4 from ACITree, because ACITree is no longer supported, the documentation is non existent and ACITree is no longer being actively developed.Our process:1. We "randomly" selected a function that is part of the ACITree. From this point we decided to replace that function with our own version. The function that we choose was "itemData".The function gives us all the "data" that a specific node of the tree find.Given in order to replace the tree we would need to have a function that would give us the same information. We had 2 options:a) Create a tree with a function called itemDataPros:- At first view this was the simpler solution- Would keep the status quoCons:- Not a OOP approach- Not very flexibleb) Create a tree that would return a node given an ID and then the node would be responsible for giving it's data.Pros:- OOP Approach- More flexible and we do not need to bring the tree around, just a nodeCons:- Break the current status quoGiven these 2 options we decided to go for a more OOP approach creating a Tree and a TreeNode classes, that in the future will be renamed to ACITreeWrapper and TreeNode.2. After we decided on the starting point we searched for occurrences of the function "itemData" and we found out that there were 303 occurrences of "itemData" in the code and roughly 176 calls to the function itself (some of the hits were variable names).3. We selected the first file on the search and found the function that was responsible for calling the itemData function.4. Extracted the function to a separate file5. Wrap this function with tests6. Refactor the function to ES6, give more declarative names to variables and break the functions into smaller chunks7. When all the tests were passing we replaced ACITree with our Tree8. We ensured that all tests were passing9. Remove function from the original file and use the new function10. Ensure everything still works11. Find the next function and execute from step 4 until all the functions are replaced, refactored and tested.As you can see by the process this is a pretty huge undertake, because of the number of calls to the function. This is just the first step on the direction of completely isolating the ACITree so that we can solve the problem with a large number of elements on the tree.What is on our radar that we need to address:- Finish the complete decoupling of the ACITree- Performance of the current tree implementation- Tweak the naming of the Tree class to explicitly tell us this is to use only with ACITree.ThanksJoaoDave Page
Blog: http://pgsnake.blogspot.com
Twitter: @pgsnake
EnterpriseDB UK: http://www.enterprisedb.com
The Enterprise PostgreSQL Company--Dave Page
Blog: http://pgsnake.blogspot.com
Twitter: @pgsnake
EnterpriseDB UK: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
On Mon, Apr 30, 2018 at 8:58 PM, Anthony Emengo <aemengo@pivotal.io> wrote:I was expecting a separate layer between the tree implementation, and aciTree adaptor.
Please find the patch for the example.
It will separate the two layers, and easy to replace with the new implementation in future.In general, we want defer the separation of the layers for now. Even though we might assume that this is the direction we want to go in. It's simply too early to be making such an architectural leap. For right now, we just know that we need the decoupling, but don't know what if we'd need the 2 layers as implemented. The principle we're adhering to here is the Last Responsible Moment principle, which states that you only make the changes that you feel is necessary for the given problems you're facing: https://blog.codinghorror.com/the-last-responsible- moment/ I would not like to see that changes in this patch.
I would like us to come up with the actual design about the hot pluggability before going in this direction.In our point of view these 2 changes are not related. One thing is the internal code organization of the application, other thing is allowing third party to drop code in the application and it just work. These 2 should be talked separately, but the hot pluggability is not something that will be address by this work we are doing right now.Neither - it should be part of this change.It should be addressed separately, and discussed.
-- Thanks, AsheshAnthony && JoaoOn Mon, Apr 30, 2018 at 11:03 AM, Ashesh Vashi <ashesh.vashi@enterprisedb.com> wrote: On Mon, Apr 30, 2018 at 8:30 PM, Ashesh Vashi <ashesh.vashi@enterprisedb.com> wrote: On Sat, Apr 28, 2018 at 3:55 AM, Joao De Almeida Pereira <jdealmeidapereira@pivotal.io> wrote:Hi Hackers,
As you are aware we kept on working on the patch, so we are attaching to this email a new version of the patch.
This new version contains all the changes in the previous one plus more extractions of functions and refactoring of code.
The objective of this patch is to create a separation between pgAdmin and the ACI Tree. We are doing this because we realized that at this point in time we have the ACI Tree all over the code of pgAdmin. I found a very interesting article that really talks about this: https://medium.freecodecamp.org/code-dependencies-are-the-de vil-35ed28b556d In this patch there are some visions and ideas about the location of the code, the way to organize it and also try to pave the future for a application that is stable, easy to develop on and that can be release at a times notice.We are investing a big chunk of our time in doing this refactoring, but while doing that we also try to respond to the patches sent to the mailing list. We would like the feedback from the community because we believe this is a changing point for the application. The idea is to change the way we develop this application, instead of only correcting a bug of developing a feature, with every commit we should correct the bug or develop a feature but leave the code a little better than we found it (Refactoring, refactoring, refactoring). This is hard work but that is what the users from pgAdmin expect from this community of developers.======It is a huge patch86 files changed, 5492 inserts, 1840 deletionsand we would like to get your feedback as soon as possible, because we are continuing to work on it which means it is going to grow in size.At this point in time we still have 124 of 176 calls to the function itemData from ACITree.
What does each patch contain:0001:Very simple patch, we found out that the linter was not looking into all the javascript test files, so this patch will ensure it isCommitted the patch along with the regression introduced because of this patch.0002:
New Tree abstraction. This patch contains the new Tree that works as an adaptor for ACI Tree and is going to be used on all the extractions that we are doing.I was expecting a separate layer between the tree implementation, and aciTree adaptor.Please find the patch for the example.It will separate the two layers, and easy to replace with the new implemenation in future.Oops forgot to attach the patch.Please find the patch attached.-- Thanks, Ashesh0003:Code that extracts, wrap with tests and replace ACI Tree invocations.There are many small cases left in the patches.Hence - I would like to know the TODO list created by you.e.g. When we remove any of the object from the database server, we're not yet removing the respective node from the new implementation, and its children.We start creating new pattern for the location of Javascript files and their structure.I would not like to see that changes in this patch.I would like us to come up with the actual design about the hot pluggability before going in this direction.Create patterns for creation of dialogs (backup and restore)It's better - we don't change the directory structure at the moment.I am not against dividing the big javascript files in small chunks, but - I would like us to discuss first about the hot plugins design first.-- Thanks, AsheshThanksJoaoI have quite a few comments for the patch.I will send them soon.On Fri, Apr 27, 2018, 14:45 Dave Page <dpage@pgadmin.org> wrote:How is your work on this going Ashesh? Will you be committing today?On Wed, Apr 25, 2018 at 8:52 AM, Dave Page <dpage@pgadmin.org> wrote:Ashesh; you had agreed to work on this early this week. Please ensure you do so today.Thanks.--On Tue, Apr 24, 2018 at 8:13 PM, Joao De Almeida Pereira <jdealmeidapereira@pivotal.io> wrote:Hi Hackers,Can someone review and merge this patch?ThanksJoaoOn Wed, Apr 18, 2018 at 10:23 AM Joao De Almeida Pereira <jdealmeidapereira@pivotal.io> wrote:Hi Hackers,Any other comment about this patch?ThanksJoaoOn Tue, Apr 10, 2018 at 12:00 PM Joao De Almeida Pereira <jdealmeidapereira@pivotal.io> wrote:Hello KhushbooOn Mon, Apr 9, 2018 at 1:59 AM Khushboo Vashi <khushboo.vashi@enterprisedb.com> wrote: Hi Joao,I have reviewed your patch and have some suggestions.On Sat, Apr 7, 2018 at 12:43 AM, Joao De Almeida Pereira <jdealmeidapereira@pivotal.io> wrote:Hello Murtuza/Dave,
Yes now the extracted functions are spread into different files. The intent would be to make the files as small as possible, and also to group and name them in a way that would be easy to understand what each file is doing without the need of opening it.
As a example:static/js/backupwill contain all the backup related functionality inside of this folder we can see the file:
menu_utils.jsAt this moment in time we decided to group all the functions that are related to the menu, but we can split that also if we believe it is easier to see.It's really very good to see the separated code for backup module. As we have done for backup, we would like do it for other PG utilities like restore, maintenance etc.Considering this, we should separate the code in a way that some of the common functionalities can be used for other modules like menu (as you have mentioned above), dialogue factory etc.Also, I think these functionalities should be in their respective static folder instead of pgadmin/static.About the location of the files. The move of the files to pgadmin/static/js was made on purpose in order to clearly separate Javascript from python code.The rational behind it was- Create a clear separation between the backend and frontend- Having Javascript code concentrated in a single place, hopefully, will encourage to developers to look for a functionality, that is already implemented in another modules, because they are right there. (When we started this journey we realized that the 'nodes' have a big groups of code that could be shared, but because the Javascript is spread everywhere it is much harder to look for it)There are some drawbacks of this separation:- When creating a new module we will need to put the javascript in a separate location from the backend code
static/js/datagridfolder contains all the datagrid related functionalitySame as backup module, this should be in it's respective static/js folder.Inside of the folder we can see the files:
get_panel_title.jsis responsible for retrieving the name of the panelshow_data.jsis responsible for showing the datagridshow_query_tool.jsis responsible for showing the query toolDoes this structure make sense?
Can you give an example of a comment that you think is missing and that could help?As a personal note, unless the algorithm is very obscure or very complicated, I believe that if the code needs comments it is a signal that something needs to change in terms of naming, structure of the part in question. This being said, I am open to add some comments that might help people.
You are right, with the help of naming convention and structure of the code, any one can get the idea about the code. But it is very useful to understand the codevery easily with the proper comments especially when there are multiple developers working on a single project.I found some of the places where it would be great to have comments.- treeMenu: new tree.Tree() in a browser.js- tree.js (especially Tree class)About the comment point I need a more clear understanding on what kind of comments you are looking for. Because when you read the function names you understand the intent, what they are doing. The parameters also explain what you need to pass into them.If what you are looking for in these comments is the reasoning being the change itself, then that should be present in the commit message. Specially because this is going to be a very big patch with a very big number of changes.Thanks
JoaoThanks,KhushbooOn Fri, Apr 6, 2018 at 4:48 AM Murtuza Zabuawala <murtuza.zabuawala@enterprisedb.com> wrote: Hi Joao,Patch looks good and working as expected.I also agree with Dave, Can we please add some comments in each file which can help us to understand the flow, I'm saying because now the code is segregated in so many separate files it will be hard to keep track of the flow from one file to another when debugging.--Regards,On Thu, Apr 5, 2018 at 7:08 PM, Joao De Almeida Pereira <jdealmeidapereira@pivotal.io> wrote:Hi Khushboo,Attached you can find both patches rebasedThanksOn Thu, Apr 5, 2018 at 6:31 AM Khushboo Vashi <khushboo.vashi@enterprisedb.com> wrote: Hi Joao,Can you please rebase the second patch?Thanks,KhushbooOn Tue, Apr 3, 2018 at 12:15 AM, Joao De Almeida Pereira <jdealmeidapereira@pivotal.io> wrote:Hi Hackers,Attached you can find the patch that will start to decouple pgAdmin from ACITree library.This patch is intended to be merged after 3.0, because we do not want to cause any entropy or delay the release, but we want to start the discussion and show some code.This job that we started is a massive tech debt chore that will take some time to finalize and we would love the help of the community to do it.Summary of the patch:0001 patch:- Creates a new tree that will allow us to create a separation between the application and ACI Tree- Creates a Fake Tree (Test double, for reference on the available test doubles: https://martinfowler.com/bliki/TestDouble.html) that can be used to inplace to replace the ACITree and also encapsulate the new tree behavior on our tests - Adds tests for all the tree functionalities0002 patch:- Extracts, refactors, adds tests and remove dependency from ACI Tree on:- getTreeNodeHierarchy
- on backup.js: menu_enabled, menu_enabled_server, start_backup_global_server, backup_objects
- on datagrid.js: show_data_grid, get_panel_title, show_query_tool- Start using sprintf-js as Underscore.String is deprecating sprintf functionThis patch represents only 10 calls to ACITree.itemData out of 176 that are spread around our codeIn Depth look on the process behind the patch:We started writing this patch with the idea that we need to decouple pgAdmin4 from ACITree, because ACITree is no longer supported, the documentation is non existent and ACITree is no longer being actively developed.Our process:1. We "randomly" selected a function that is part of the ACITree. From this point we decided to replace that function with our own version. The function that we choose was "itemData".The function gives us all the "data" that a specific node of the tree find.Given in order to replace the tree we would need to have a function that would give us the same information. We had 2 options:a) Create a tree with a function called itemDataPros:- At first view this was the simpler solution- Would keep the status quoCons:- Not a OOP approach- Not very flexibleb) Create a tree that would return a node given an ID and then the node would be responsible for giving it's data.Pros:- OOP Approach- More flexible and we do not need to bring the tree around, just a nodeCons:- Break the current status quoGiven these 2 options we decided to go for a more OOP approach creating a Tree and a TreeNode classes, that in the future will be renamed to ACITreeWrapper and TreeNode.2. After we decided on the starting point we searched for occurrences of the function "itemData" and we found out that there were 303 occurrences of "itemData" in the code and roughly 176 calls to the function itself (some of the hits were variable names).3. We selected the first file on the search and found the function that was responsible for calling the itemData function.4. Extracted the function to a separate file5. Wrap this function with tests6. Refactor the function to ES6, give more declarative names to variables and break the functions into smaller chunks7. When all the tests were passing we replaced ACITree with our Tree8. We ensured that all tests were passing9. Remove function from the original file and use the new function10. Ensure everything still works11. Find the next function and execute from step 4 until all the functions are replaced, refactored and tested.As you can see by the process this is a pretty huge undertake, because of the number of calls to the function. This is just the first step on the direction of completely isolating the ACITree so that we can solve the problem with a large number of elements on the tree.What is on our radar that we need to address:- Finish the complete decoupling of the ACITree- Performance of the current tree implementation- Tweak the naming of the Tree class to explicitly tell us this is to use only with ACITree.ThanksJoaoDave Page
Blog: http://pgsnake.blogspot.com
Twitter: @pgsnake
EnterpriseDB UK: http://www.enterprisedb.com
The Enterprise PostgreSQL Company--Dave Page
Blog: http://pgsnake.blogspot.com
Twitter: @pgsnake
EnterpriseDB UK: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
Blog: http://pgsnake.blogspot.com
Twitter: @pgsnake
EnterpriseDB UK: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
On Mon, Apr 30, 2018 at 4:33 PM, Ashesh Vashi <ashesh.vashi@enterprisedb.com> wrote: On Mon, Apr 30, 2018 at 8:58 PM, Anthony Emengo <aemengo@pivotal.io> wrote:I was expecting a separate layer between the tree implementation, and aciTree adaptor.
Please find the patch for the example.
It will separate the two layers, and easy to replace with the new implementation in future.In general, we want defer the separation of the layers for now. Even though we might assume that this is the direction we want to go in. It's simply too early to be making such an architectural leap. For right now, we just know that we need the decoupling, but don't know what if we'd need the 2 layers as implemented. The principle we're adhering to here is the Last Responsible Moment principle, which states that you only make the changes that you feel is necessary for the given problems you're facing: https://blog.codinghorror.com/the-last-responsible-m oment/ I would not like to see that changes in this patch.
I would like us to come up with the actual design about the hot pluggability before going in this direction.In our point of view these 2 changes are not related. One thing is the internal code organization of the application, other thing is allowing third party to drop code in the application and it just work. These 2 should be talked separately, but the hot pluggability is not something that will be address by this work we are doing right now.Neither - it should be part of this change.It should be addressed separately, and discussed.I agree. As long as this work doesn't make the pluggability problem worse, that problem should be considered separately.So given Anthony's comments, are you happy with this patch?
-- Thanks, AsheshAnthony && JoaoOn Mon, Apr 30, 2018 at 11:03 AM, Ashesh Vashi <ashesh.vashi@enterprisedb.com> wrote: On Mon, Apr 30, 2018 at 8:30 PM, Ashesh Vashi <ashesh.vashi@enterprisedb.com> wrote: On Sat, Apr 28, 2018 at 3:55 AM, Joao De Almeida Pereira <jdealmeidapereira@pivotal.io> wrote:Hi Hackers,
As you are aware we kept on working on the patch, so we are attaching to this email a new version of the patch.
This new version contains all the changes in the previous one plus more extractions of functions and refactoring of code.
The objective of this patch is to create a separation between pgAdmin and the ACI Tree. We are doing this because we realized that at this point in time we have the ACI Tree all over the code of pgAdmin. I found a very interesting article that really talks about this: https://medium.freecodecamp.org/code-dependencies-are-the-de vil-35ed28b556d In this patch there are some visions and ideas about the location of the code, the way to organize it and also try to pave the future for a application that is stable, easy to develop on and that can be release at a times notice.We are investing a big chunk of our time in doing this refactoring, but while doing that we also try to respond to the patches sent to the mailing list. We would like the feedback from the community because we believe this is a changing point for the application. The idea is to change the way we develop this application, instead of only correcting a bug of developing a feature, with every commit we should correct the bug or develop a feature but leave the code a little better than we found it (Refactoring, refactoring, refactoring). This is hard work but that is what the users from pgAdmin expect from this community of developers.======It is a huge patch86 files changed, 5492 inserts, 1840 deletionsand we would like to get your feedback as soon as possible, because we are continuing to work on it which means it is going to grow in size.At this point in time we still have 124 of 176 calls to the function itemData from ACITree.
What does each patch contain:0001:Very simple patch, we found out that the linter was not looking into all the javascript test files, so this patch will ensure it isCommitted the patch along with the regression introduced because of this patch.0002:
New Tree abstraction. This patch contains the new Tree that works as an adaptor for ACI Tree and is going to be used on all the extractions that we are doing.I was expecting a separate layer between the tree implementation, and aciTree adaptor.Please find the patch for the example.It will separate the two layers, and easy to replace with the new implemenation in future.Oops forgot to attach the patch.Please find the patch attached.-- Thanks, Ashesh0003:Code that extracts, wrap with tests and replace ACI Tree invocations.There are many small cases left in the patches.Hence - I would like to know the TODO list created by you.e.g. When we remove any of the object from the database server, we're not yet removing the respective node from the new implementation, and its children.We start creating new pattern for the location of Javascript files and their structure.I would not like to see that changes in this patch.I would like us to come up with the actual design about the hot pluggability before going in this direction.Create patterns for creation of dialogs (backup and restore)It's better - we don't change the directory structure at the moment.I am not against dividing the big javascript files in small chunks, but - I would like us to discuss first about the hot plugins design first.-- Thanks, AsheshThanksJoaoI have quite a few comments for the patch.I will send them soon.On Fri, Apr 27, 2018, 14:45 Dave Page <dpage@pgadmin.org> wrote:How is your work on this going Ashesh? Will you be committing today?On Wed, Apr 25, 2018 at 8:52 AM, Dave Page <dpage@pgadmin.org> wrote:Ashesh; you had agreed to work on this early this week. Please ensure you do so today.Thanks.--On Tue, Apr 24, 2018 at 8:13 PM, Joao De Almeida Pereira <jdealmeidapereira@pivotal.io> wrote:Hi Hackers,Can someone review and merge this patch?ThanksJoaoOn Wed, Apr 18, 2018 at 10:23 AM Joao De Almeida Pereira <jdealmeidapereira@pivotal.io> wrote:Hi Hackers,Any other comment about this patch?ThanksJoaoOn Tue, Apr 10, 2018 at 12:00 PM Joao De Almeida Pereira <jdealmeidapereira@pivotal.io> wrote:Hello KhushbooOn Mon, Apr 9, 2018 at 1:59 AM Khushboo Vashi <khushboo.vashi@enterprisedb.com> wrote: Hi Joao,I have reviewed your patch and have some suggestions.On Sat, Apr 7, 2018 at 12:43 AM, Joao De Almeida Pereira <jdealmeidapereira@pivotal.io> wrote:Hello Murtuza/Dave,
Yes now the extracted functions are spread into different files. The intent would be to make the files as small as possible, and also to group and name them in a way that would be easy to understand what each file is doing without the need of opening it.
As a example:static/js/backupwill contain all the backup related functionality inside of this folder we can see the file:
menu_utils.jsAt this moment in time we decided to group all the functions that are related to the menu, but we can split that also if we believe it is easier to see.It's really very good to see the separated code for backup module. As we have done for backup, we would like do it for other PG utilities like restore, maintenance etc.Considering this, we should separate the code in a way that some of the common functionalities can be used for other modules like menu (as you have mentioned above), dialogue factory etc.Also, I think these functionalities should be in their respective static folder instead of pgadmin/static.About the location of the files. The move of the files to pgadmin/static/js was made on purpose in order to clearly separate Javascript from python code.The rational behind it was- Create a clear separation between the backend and frontend- Having Javascript code concentrated in a single place, hopefully, will encourage to developers to look for a functionality, that is already implemented in another modules, because they are right there. (When we started this journey we realized that the 'nodes' have a big groups of code that could be shared, but because the Javascript is spread everywhere it is much harder to look for it)There are some drawbacks of this separation:- When creating a new module we will need to put the javascript in a separate location from the backend code
static/js/datagridfolder contains all the datagrid related functionalitySame as backup module, this should be in it's respective static/js folder.Inside of the folder we can see the files:
get_panel_title.jsis responsible for retrieving the name of the panelshow_data.jsis responsible for showing the datagridshow_query_tool.jsis responsible for showing the query toolDoes this structure make sense?
Can you give an example of a comment that you think is missing and that could help?As a personal note, unless the algorithm is very obscure or very complicated, I believe that if the code needs comments it is a signal that something needs to change in terms of naming, structure of the part in question. This being said, I am open to add some comments that might help people.
You are right, with the help of naming convention and structure of the code, any one can get the idea about the code. But it is very useful to understand the codevery easily with the proper comments especially when there are multiple developers working on a single project.I found some of the places where it would be great to have comments.- treeMenu: new tree.Tree() in a browser.js- tree.js (especially Tree class)About the comment point I need a more clear understanding on what kind of comments you are looking for. Because when you read the function names you understand the intent, what they are doing. The parameters also explain what you need to pass into them.If what you are looking for in these comments is the reasoning being the change itself, then that should be present in the commit message. Specially because this is going to be a very big patch with a very big number of changes.Thanks
JoaoThanks,KhushbooOn Fri, Apr 6, 2018 at 4:48 AM Murtuza Zabuawala <murtuza.zabuawala@enterprisedb.com> wrote: Hi Joao,Patch looks good and working as expected.I also agree with Dave, Can we please add some comments in each file which can help us to understand the flow, I'm saying because now the code is segregated in so many separate files it will be hard to keep track of the flow from one file to another when debugging.--Regards,On Thu, Apr 5, 2018 at 7:08 PM, Joao De Almeida Pereira <jdealmeidapereira@pivotal.io> wrote:Hi Khushboo,Attached you can find both patches rebasedThanksOn Thu, Apr 5, 2018 at 6:31 AM Khushboo Vashi <khushboo.vashi@enterprisedb.com> wrote: Hi Joao,Can you please rebase the second patch?Thanks,KhushbooOn Tue, Apr 3, 2018 at 12:15 AM, Joao De Almeida Pereira <jdealmeidapereira@pivotal.io> wrote:Hi Hackers,Attached you can find the patch that will start to decouple pgAdmin from ACITree library.This patch is intended to be merged after 3.0, because we do not want to cause any entropy or delay the release, but we want to start the discussion and show some code.This job that we started is a massive tech debt chore that will take some time to finalize and we would love the help of the community to do it.Summary of the patch:0001 patch:- Creates a new tree that will allow us to create a separation between the application and ACI Tree- Creates a Fake Tree (Test double, for reference on the available test doubles: https://martinfowler.com/bliki/TestDouble.html) that can be used to inplace to replace the ACITree and also encapsulate the new tree behavior on our tests - Adds tests for all the tree functionalities0002 patch:- Extracts, refactors, adds tests and remove dependency from ACI Tree on:- getTreeNodeHierarchy
- on backup.js: menu_enabled, menu_enabled_server, start_backup_global_server, backup_objects
- on datagrid.js: show_data_grid, get_panel_title, show_query_tool- Start using sprintf-js as Underscore.String is deprecating sprintf functionThis patch represents only 10 calls to ACITree.itemData out of 176 that are spread around our codeIn Depth look on the process behind the patch:We started writing this patch with the idea that we need to decouple pgAdmin4 from ACITree, because ACITree is no longer supported, the documentation is non existent and ACITree is no longer being actively developed.Our process:1. We "randomly" selected a function that is part of the ACITree. From this point we decided to replace that function with our own version. The function that we choose was "itemData".The function gives us all the "data" that a specific node of the tree find.Given in order to replace the tree we would need to have a function that would give us the same information. We had 2 options:a) Create a tree with a function called itemDataPros:- At first view this was the simpler solution- Would keep the status quoCons:- Not a OOP approach- Not very flexibleb) Create a tree that would return a node given an ID and then the node would be responsible for giving it's data.Pros:- OOP Approach- More flexible and we do not need to bring the tree around, just a nodeCons:- Break the current status quoGiven these 2 options we decided to go for a more OOP approach creating a Tree and a TreeNode classes, that in the future will be renamed to ACITreeWrapper and TreeNode.2. After we decided on the starting point we searched for occurrences of the function "itemData" and we found out that there were 303 occurrences of "itemData" in the code and roughly 176 calls to the function itself (some of the hits were variable names).3. We selected the first file on the search and found the function that was responsible for calling the itemData function.4. Extracted the function to a separate file5. Wrap this function with tests6. Refactor the function to ES6, give more declarative names to variables and break the functions into smaller chunks7. When all the tests were passing we replaced ACITree with our Tree8. We ensured that all tests were passing9. Remove function from the original file and use the new function10. Ensure everything still works11. Find the next function and execute from step 4 until all the functions are replaced, refactored and tested.As you can see by the process this is a pretty huge undertake, because of the number of calls to the function. This is just the first step on the direction of completely isolating the ACITree so that we can solve the problem with a large number of elements on the tree.What is on our radar that we need to address:- Finish the complete decoupling of the ACITree- Performance of the current tree implementation- Tweak the naming of the Tree class to explicitly tell us this is to use only with ACITree.ThanksJoaoDave Page
Blog: http://pgsnake.blogspot.com
Twitter: @pgsnake
EnterpriseDB UK: http://www.enterprisedb.com
The Enterprise PostgreSQL Company--Dave Page
Blog: http://pgsnake.blogspot.com
Twitter: @pgsnake
EnterpriseDB UK: http://www.enterprisedb.com
The Enterprise PostgreSQL Company--Dave Page
Blog: http://pgsnake.blogspot.com
Twitter: @pgsnake
EnterpriseDB UK: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
On Mon, Apr 30, 2018 at 9:07 PM, Dave Page <dpage@pgadmin.org> wrote:On Mon, Apr 30, 2018 at 4:33 PM, Ashesh Vashi <ashesh.vashi@enterprisedb.com> wrote:On Mon, Apr 30, 2018 at 8:58 PM, Anthony Emengo <aemengo@pivotal.io> wrote:I was expecting a separate layer between the tree implementation, and aciTree adaptor.
Please find the patch for the example.
It will separate the two layers, and easy to replace with the new implementation in future.In general, we want defer the separation of the layers for now. Even though we might assume that this is the direction we want to go in. It's simply too early to be making such an architectural leap. For right now, we just know that we need the decoupling, but don't know what if we'd need the 2 layers as implemented. The principle we're adhering to here is the Last Responsible Moment principle, which states that you only make the changes that you feel is necessary for the given problems you're facing: https://blog.codinghorror.com/the-last-responsible-moment/I would not like to see that changes in this patch.
I would like us to come up with the actual design about the hot pluggability before going in this direction.In our point of view these 2 changes are not related. One thing is the internal code organization of the application, other thing is allowing third party to drop code in the application and it just work. These 2 should be talked separately, but the hot pluggability is not something that will be address by this work we are doing right now.Neither - it should be part of this change.It should be addressed separately, and discussed.I agree. As long as this work doesn't make the pluggability problem worse, that problem should be considered separately.So given Anthony's comments, are you happy with this patch?I liked the design so far.But - as Khushboo mentioned ealier - it is missing at some places.I had to read through the code to understand the execution flow for some.And, there is still a lot missing bits, and pieces to consider for commit in the repo.-- Thanks, Ashesh-- Thanks, AsheshAnthony && JoaoOn Mon, Apr 30, 2018 at 11:03 AM, Ashesh Vashi <ashesh.vashi@enterprisedb.com> wrote:On Mon, Apr 30, 2018 at 8:30 PM, Ashesh Vashi <ashesh.vashi@enterprisedb.com> wrote:On Sat, Apr 28, 2018 at 3:55 AM, Joao De Almeida Pereira <jdealmeidapereira@pivotal.io> wrote:Hi Hackers,
As you are aware we kept on working on the patch, so we are attaching to this email a new version of the patch.
This new version contains all the changes in the previous one plus more extractions of functions and refactoring of code.
The objective of this patch is to create a separation between pgAdmin and the ACI Tree. We are doing this because we realized that at this point in time we have the ACI Tree all over the code of pgAdmin. I found a very interesting article that really talks about this: https://medium.freecodecamp.org/code-dependencies-are-the-devil-35ed28b556dIn this patch there are some visions and ideas about the location of the code, the way to organize it and also try to pave the future for a application that is stable, easy to develop on and that can be release at a times notice.We are investing a big chunk of our time in doing this refactoring, but while doing that we also try to respond to the patches sent to the mailing list. We would like the feedback from the community because we believe this is a changing point for the application. The idea is to change the way we develop this application, instead of only correcting a bug of developing a feature, with every commit we should correct the bug or develop a feature but leave the code a little better than we found it (Refactoring, refactoring, refactoring). This is hard work but that is what the users from pgAdmin expect from this community of developers.======It is a huge patch86 files changed, 5492 inserts, 1840 deletionsand we would like to get your feedback as soon as possible, because we are continuing to work on it which means it is going to grow in size.At this point in time we still have 124 of 176 calls to the function itemData from ACITree.
What does each patch contain:0001:Very simple patch, we found out that the linter was not looking into all the javascript test files, so this patch will ensure it isCommitted the patch along with the regression introduced because of this patch.0002:
New Tree abstraction. This patch contains the new Tree that works as an adaptor for ACI Tree and is going to be used on all the extractions that we are doing.I was expecting a separate layer between the tree implementation, and aciTree adaptor.Please find the patch for the example.It will separate the two layers, and easy to replace with the new implemenation in future.Oops forgot to attach the patch.Please find the patch attached.-- Thanks, Ashesh0003:Code that extracts, wrap with tests and replace ACI Tree invocations.There are many small cases left in the patches.Hence - I would like to know the TODO list created by you.e.g. When we remove any of the object from the database server, we're not yet removing the respective node from the new implementation, and its children.We start creating new pattern for the location of Javascript files and their structure.I would not like to see that changes in this patch.I would like us to come up with the actual design about the hot pluggability before going in this direction.Create patterns for creation of dialogs (backup and restore)It's better - we don't change the directory structure at the moment.I am not against dividing the big javascript files in small chunks, but - I would like us to discuss first about the hot plugins design first.-- Thanks, AsheshThanksJoaoOn Fri, Apr 27, 2018 at 5:34 AM Ashesh Vashi <ashesh.vashi@enterprisedb.com> wrote:I have quite a few comments for the patch.I will send them soon.On Fri, Apr 27, 2018, 14:45 Dave Page <dpage@pgadmin.org> wrote:How is your work on this going Ashesh? Will you be committing today?On Wed, Apr 25, 2018 at 8:52 AM, Dave Page <dpage@pgadmin.org> wrote:Ashesh; you had agreed to work on this early this week. Please ensure you do so today.Thanks.--On Tue, Apr 24, 2018 at 8:13 PM, Joao De Almeida Pereira <jdealmeidapereira@pivotal.io> wrote:Hi Hackers,Can someone review and merge this patch?ThanksJoaoOn Wed, Apr 18, 2018 at 10:23 AM Joao De Almeida Pereira <jdealmeidapereira@pivotal.io> wrote:Hi Hackers,Any other comment about this patch?ThanksJoaoOn Tue, Apr 10, 2018 at 12:00 PM Joao De Almeida Pereira <jdealmeidapereira@pivotal.io> wrote:Hello KhushbooOn Mon, Apr 9, 2018 at 1:59 AM Khushboo Vashi <khushboo.vashi@enterprisedb.com> wrote:Hi Joao,I have reviewed your patch and have some suggestions.On Sat, Apr 7, 2018 at 12:43 AM, Joao De Almeida Pereira <jdealmeidapereira@pivotal.io> wrote:Hello Murtuza/Dave,
Yes now the extracted functions are spread into different files. The intent would be to make the files as small as possible, and also to group and name them in a way that would be easy to understand what each file is doing without the need of opening it.
As a example:static/js/backupwill contain all the backup related functionality inside of this folder we can see the file:
menu_utils.jsAt this moment in time we decided to group all the functions that are related to the menu, but we can split that also if we believe it is easier to see.It's really very good to see the separated code for backup module. As we have done for backup, we would like do it for other PG utilities like restore, maintenance etc.Considering this, we should separate the code in a way that some of the common functionalities can be used for other modules like menu (as you have mentioned above), dialogue factory etc.Also, I think these functionalities should be in their respective static folder instead of pgadmin/static.About the location of the files. The move of the files to pgadmin/static/js was made on purpose in order to clearly separate Javascript from python code.The rational behind it was- Create a clear separation between the backend and frontend- Having Javascript code concentrated in a single place, hopefully, will encourage to developers to look for a functionality, that is already implemented in another modules, because they are right there. (When we started this journey we realized that the 'nodes' have a big groups of code that could be shared, but because the Javascript is spread everywhere it is much harder to look for it)There are some drawbacks of this separation:- When creating a new module we will need to put the javascript in a separate location from the backend code
static/js/datagridfolder contains all the datagrid related functionalitySame as backup module, this should be in it's respective static/js folder.Inside of the folder we can see the files:
get_panel_title.jsis responsible for retrieving the name of the panelshow_data.jsis responsible for showing the datagridshow_query_tool.jsis responsible for showing the query toolDoes this structure make sense?
Can you give an example of a comment that you think is missing and that could help?As a personal note, unless the algorithm is very obscure or very complicated, I believe that if the code needs comments it is a signal that something needs to change in terms of naming, structure of the part in question. This being said, I am open to add some comments that might help people.
You are right, with the help of naming convention and structure of the code, any one can get the idea about the code. But it is very useful to understand the codevery easily with the proper comments especially when there are multiple developers working on a single project.I found some of the places where it would be great to have comments.- treeMenu: new tree.Tree() in a browser.js- tree.js (especially Tree class)About the comment point I need a more clear understanding on what kind of comments you are looking for. Because when you read the function names you understand the intent, what they are doing. The parameters also explain what you need to pass into them.If what you are looking for in these comments is the reasoning being the change itself, then that should be present in the commit message. Specially because this is going to be a very big patch with a very big number of changes.Thanks
JoaoThanks,KhushbooOn Fri, Apr 6, 2018 at 4:48 AM Murtuza Zabuawala <murtuza.zabuawala@enterprisedb.com> wrote:Hi Joao,Patch looks good and working as expected.I also agree with Dave, Can we please add some comments in each file which can help us to understand the flow, I'm saying because now the code is segregated in so many separate files it will be hard to keep track of the flow from one file to another when debugging.--Regards,On Thu, Apr 5, 2018 at 7:08 PM, Joao De Almeida Pereira <jdealmeidapereira@pivotal.io> wrote:Hi Khushboo,Attached you can find both patches rebasedThanksOn Thu, Apr 5, 2018 at 6:31 AM Khushboo Vashi <khushboo.vashi@enterprisedb.com> wrote:Hi Joao,Can you please rebase the second patch?Thanks,KhushbooOn Tue, Apr 3, 2018 at 12:15 AM, Joao De Almeida Pereira <jdealmeidapereira@pivotal.io> wrote:Hi Hackers,Attached you can find the patch that will start to decouple pgAdmin from ACITree library.This patch is intended to be merged after 3.0, because we do not want to cause any entropy or delay the release, but we want to start the discussion and show some code.This job that we started is a massive tech debt chore that will take some time to finalize and we would love the help of the community to do it.Summary of the patch:0001 patch:- Creates a new tree that will allow us to create a separation between the application and ACI Tree- Creates a Fake Tree (Test double, for reference on the available test doubles: https://martinfowler.com/bliki/TestDouble.html) that can be used to inplace to replace the ACITree and also encapsulate the new tree behavior on our tests- Adds tests for all the tree functionalities0002 patch:- Extracts, refactors, adds tests and remove dependency from ACI Tree on:- getTreeNodeHierarchy
- on backup.js: menu_enabled, menu_enabled_server, start_backup_global_server, backup_objects
- on datagrid.js: show_data_grid, get_panel_title, show_query_tool- Start using sprintf-js as Underscore.String is deprecating sprintf functionThis patch represents only 10 calls to ACITree.itemData out of 176 that are spread around our codeIn Depth look on the process behind the patch:We started writing this patch with the idea that we need to decouple pgAdmin4 from ACITree, because ACITree is no longer supported, the documentation is non existent and ACITree is no longer being actively developed.Our process:1. We "randomly" selected a function that is part of the ACITree. From this point we decided to replace that function with our own version. The function that we choose was "itemData".The function gives us all the "data" that a specific node of the tree find.Given in order to replace the tree we would need to have a function that would give us the same information. We had 2 options:a) Create a tree with a function called itemDataPros:- At first view this was the simpler solution- Would keep the status quoCons:- Not a OOP approach- Not very flexibleb) Create a tree that would return a node given an ID and then the node would be responsible for giving it's data.Pros:- OOP Approach- More flexible and we do not need to bring the tree around, just a nodeCons:- Break the current status quoGiven these 2 options we decided to go for a more OOP approach creating a Tree and a TreeNode classes, that in the future will be renamed to ACITreeWrapper and TreeNode.2. After we decided on the starting point we searched for occurrences of the function "itemData" and we found out that there were 303 occurrences of "itemData" in the code and roughly 176 calls to the function itself (some of the hits were variable names).3. We selected the first file on the search and found the function that was responsible for calling the itemData function.4. Extracted the function to a separate file5. Wrap this function with tests6. Refactor the function to ES6, give more declarative names to variables and break the functions into smaller chunks7. When all the tests were passing we replaced ACITree with our Tree8. We ensured that all tests were passing9. Remove function from the original file and use the new function10. Ensure everything still works11. Find the next function and execute from step 4 until all the functions are replaced, refactored and tested.As you can see by the process this is a pretty huge undertake, because of the number of calls to the function. This is just the first step on the direction of completely isolating the ACITree so that we can solve the problem with a large number of elements on the tree.What is on our radar that we need to address:- Finish the complete decoupling of the ACITree- Performance of the current tree implementation- Tweak the naming of the Tree class to explicitly tell us this is to use only with ACITree.ThanksJoaoDave Page
Blog: http://pgsnake.blogspot.com
Twitter: @pgsnake
EnterpriseDB UK: http://www.enterprisedb.com
The Enterprise PostgreSQL Company--Dave Page
Blog: http://pgsnake.blogspot.com
Twitter: @pgsnake
EnterpriseDB UK: http://www.enterprisedb.com
The Enterprise PostgreSQL Company--Dave Page
Blog: http://pgsnake.blogspot.com
Twitter: @pgsnake
EnterpriseDB UK: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
You've lost us with the last reply. We'd love to know what we'd have to do to get this patch committed. You mention that "some things are missing at some places" and that "there are missing bits".
Please note that this is not a complete solution that we've offered so far.
But only one step in a grander effort to effect a more cleaner, more maintainable, more testable, code base.
As per my understading comments are required for better understanding, and makes the code more maintainable.
ThanksJoao and Anthony.On Mon, Apr 30, 2018 at 9:07 PM, Dave Page <dpage@pgadmin.org> wrote:On Mon, Apr 30, 2018 at 4:33 PM, Ashesh Vashi <ashesh.vashi@enterprisedb.com> wrote: On Mon, Apr 30, 2018 at 8:58 PM, Anthony Emengo <aemengo@pivotal.io> wrote:I was expecting a separate layer between the tree implementation, and aciTree adaptor.
Please find the patch for the example.
It will separate the two layers, and easy to replace with the new implementation in future.In general, we want defer the separation of the layers for now. Even though we might assume that this is the direction we want to go in. It's simply too early to be making such an architectural leap. For right now, we just know that we need the decoupling, but don't know what if we'd need the 2 layers as implemented. The principle we're adhering to here is the Last Responsible Moment principle, which states that you only make the changes that you feel is necessary for the given problems you're facing: https://blog.codinghorror.com/the-last- responsible-moment/ I would not like to see that changes in this patch.
I would like us to come up with the actual design about the hot pluggability before going in this direction.In our point of view these 2 changes are not related. One thing is the internal code organization of the application, other thing is allowing third party to drop code in the application and it just work. These 2 should be talked separately, but the hot pluggability is not something that will be address by this work we are doing right now.Neither - it should be part of this change.It should be addressed separately, and discussed.I agree. As long as this work doesn't make the pluggability problem worse, that problem should be considered separately.So given Anthony's comments, are you happy with this patch?I liked the design so far.But - as Khushboo mentioned ealier - it is missing at some places.I had to read through the code to understand the execution flow for some.And, there is still a lot missing bits, and pieces to consider for commit in the repo.-- Thanks, Ashesh-- Thanks, AsheshAnthony && JoaoOn Mon, Apr 30, 2018 at 11:03 AM, Ashesh Vashi <ashesh.vashi@enterprisedb.com> wrote: On Mon, Apr 30, 2018 at 8:30 PM, Ashesh Vashi <ashesh.vashi@enterprisedb.com> wrote: On Sat, Apr 28, 2018 at 3:55 AM, Joao De Almeida Pereira <jdealmeidapereira@pivotal.io> wrote:Hi Hackers,
As you are aware we kept on working on the patch, so we are attaching to this email a new version of the patch.
This new version contains all the changes in the previous one plus more extractions of functions and refactoring of code.
The objective of this patch is to create a separation between pgAdmin and the ACI Tree. We are doing this because we realized that at this point in time we have the ACI Tree all over the code of pgAdmin. I found a very interesting article that really talks about this: https://medium.freecodecamp.org/code-dependencies-are-the- devil-35ed28b556d In this patch there are some visions and ideas about the location of the code, the way to organize it and also try to pave the future for a application that is stable, easy to develop on and that can be release at a times notice.We are investing a big chunk of our time in doing this refactoring, but while doing that we also try to respond to the patches sent to the mailing list. We would like the feedback from the community because we believe this is a changing point for the application. The idea is to change the way we develop this application, instead of only correcting a bug of developing a feature, with every commit we should correct the bug or develop a feature but leave the code a little better than we found it (Refactoring, refactoring, refactoring). This is hard work but that is what the users from pgAdmin expect from this community of developers.======It is a huge patch86 files changed, 5492 inserts, 1840 deletionsand we would like to get your feedback as soon as possible, because we are continuing to work on it which means it is going to grow in size.At this point in time we still have 124 of 176 calls to the function itemData from ACITree.
What does each patch contain:0001:Very simple patch, we found out that the linter was not looking into all the javascript test files, so this patch will ensure it isCommitted the patch along with the regression introduced because of this patch.0002:
New Tree abstraction. This patch contains the new Tree that works as an adaptor for ACI Tree and is going to be used on all the extractions that we are doing.I was expecting a separate layer between the tree implementation, and aciTree adaptor.Please find the patch for the example.It will separate the two layers, and easy to replace with the new implemenation in future.Oops forgot to attach the patch.Please find the patch attached.-- Thanks, Ashesh0003:Code that extracts, wrap with tests and replace ACI Tree invocations.There are many small cases left in the patches.Hence - I would like to know the TODO list created by you.e.g. When we remove any of the object from the database server, we're not yet removing the respective node from the new implementation, and its children.We start creating new pattern for the location of Javascript files and their structure.I would not like to see that changes in this patch.I would like us to come up with the actual design about the hot pluggability before going in this direction.Create patterns for creation of dialogs (backup and restore)It's better - we don't change the directory structure at the moment.I am not against dividing the big javascript files in small chunks, but - I would like us to discuss first about the hot plugins design first.-- Thanks, AsheshThanksJoaoI have quite a few comments for the patch.I will send them soon.On Fri, Apr 27, 2018, 14:45 Dave Page <dpage@pgadmin.org> wrote:How is your work on this going Ashesh? Will you be committing today?On Wed, Apr 25, 2018 at 8:52 AM, Dave Page <dpage@pgadmin.org> wrote:Ashesh; you had agreed to work on this early this week. Please ensure you do so today.Thanks.--On Tue, Apr 24, 2018 at 8:13 PM, Joao De Almeida Pereira <jdealmeidapereira@pivotal.io> wrote:Hi Hackers,Can someone review and merge this patch?ThanksJoaoOn Wed, Apr 18, 2018 at 10:23 AM Joao De Almeida Pereira <jdealmeidapereira@pivotal.io> wrote:Hi Hackers,Any other comment about this patch?ThanksJoaoOn Tue, Apr 10, 2018 at 12:00 PM Joao De Almeida Pereira <jdealmeidapereira@pivotal.io> wrote:Hello KhushbooOn Mon, Apr 9, 2018 at 1:59 AM Khushboo Vashi <khushboo.vashi@enterprisedb.com> wrote: Hi Joao,I have reviewed your patch and have some suggestions.On Sat, Apr 7, 2018 at 12:43 AM, Joao De Almeida Pereira <jdealmeidapereira@pivotal.io> wrote:Hello Murtuza/Dave,
Yes now the extracted functions are spread into different files. The intent would be to make the files as small as possible, and also to group and name them in a way that would be easy to understand what each file is doing without the need of opening it.
As a example:static/js/backupwill contain all the backup related functionality inside of this folder we can see the file:
menu_utils.jsAt this moment in time we decided to group all the functions that are related to the menu, but we can split that also if we believe it is easier to see.It's really very good to see the separated code for backup module. As we have done for backup, we would like do it for other PG utilities like restore, maintenance etc.Considering this, we should separate the code in a way that some of the common functionalities can be used for other modules like menu (as you have mentioned above), dialogue factory etc.Also, I think these functionalities should be in their respective static folder instead of pgadmin/static.About the location of the files. The move of the files to pgadmin/static/js was made on purpose in order to clearly separate Javascript from python code.The rational behind it was- Create a clear separation between the backend and frontend- Having Javascript code concentrated in a single place, hopefully, will encourage to developers to look for a functionality, that is already implemented in another modules, because they are right there. (When we started this journey we realized that the 'nodes' have a big groups of code that could be shared, but because the Javascript is spread everywhere it is much harder to look for it)There are some drawbacks of this separation:- When creating a new module we will need to put the javascript in a separate location from the backend code
static/js/datagridfolder contains all the datagrid related functionalitySame as backup module, this should be in it's respective static/js folder.Inside of the folder we can see the files:
get_panel_title.jsis responsible for retrieving the name of the panelshow_data.jsis responsible for showing the datagridshow_query_tool.jsis responsible for showing the query toolDoes this structure make sense?
Can you give an example of a comment that you think is missing and that could help?As a personal note, unless the algorithm is very obscure or very complicated, I believe that if the code needs comments it is a signal that something needs to change in terms of naming, structure of the part in question. This being said, I am open to add some comments that might help people.
You are right, with the help of naming convention and structure of the code, any one can get the idea about the code. But it is very useful to understand the codevery easily with the proper comments especially when there are multiple developers working on a single project.I found some of the places where it would be great to have comments.- treeMenu: new tree.Tree() in a browser.js- tree.js (especially Tree class)About the comment point I need a more clear understanding on what kind of comments you are looking for. Because when you read the function names you understand the intent, what they are doing. The parameters also explain what you need to pass into them.If what you are looking for in these comments is the reasoning being the change itself, then that should be present in the commit message. Specially because this is going to be a very big patch with a very big number of changes.Thanks
JoaoThanks,KhushbooOn Fri, Apr 6, 2018 at 4:48 AM Murtuza Zabuawala <murtuza.zabuawala@enterprisedb.com> wrote: Hi Joao,Patch looks good and working as expected.I also agree with Dave, Can we please add some comments in each file which can help us to understand the flow, I'm saying because now the code is segregated in so many separate files it will be hard to keep track of the flow from one file to another when debugging.--Regards,On Thu, Apr 5, 2018 at 7:08 PM, Joao De Almeida Pereira <jdealmeidapereira@pivotal.io> wrote:Hi Khushboo,Attached you can find both patches rebasedThanksOn Thu, Apr 5, 2018 at 6:31 AM Khushboo Vashi <khushboo.vashi@enterprisedb.com> wrote: Hi Joao,Can you please rebase the second patch?Thanks,KhushbooOn Tue, Apr 3, 2018 at 12:15 AM, Joao De Almeida Pereira <jdealmeidapereira@pivotal.io> wrote:Hi Hackers,Attached you can find the patch that will start to decouple pgAdmin from ACITree library.This patch is intended to be merged after 3.0, because we do not want to cause any entropy or delay the release, but we want to start the discussion and show some code.This job that we started is a massive tech debt chore that will take some time to finalize and we would love the help of the community to do it.Summary of the patch:0001 patch:- Creates a new tree that will allow us to create a separation between the application and ACI Tree- Creates a Fake Tree (Test double, for reference on the available test doubles: https://martinfowler.com/bliki/TestDouble.html) that can be used to inplace to replace the ACITree and also encapsulate the new tree behavior on our tests - Adds tests for all the tree functionalities0002 patch:- Extracts, refactors, adds tests and remove dependency from ACI Tree on:- getTreeNodeHierarchy
- on backup.js: menu_enabled, menu_enabled_server, start_backup_global_server, backup_objects
- on datagrid.js: show_data_grid, get_panel_title, show_query_tool- Start using sprintf-js as Underscore.String is deprecating sprintf functionThis patch represents only 10 calls to ACITree.itemData out of 176 that are spread around our codeIn Depth look on the process behind the patch:We started writing this patch with the idea that we need to decouple pgAdmin4 from ACITree, because ACITree is no longer supported, the documentation is non existent and ACITree is no longer being actively developed.Our process:1. We "randomly" selected a function that is part of the ACITree. From this point we decided to replace that function with our own version. The function that we choose was "itemData".The function gives us all the "data" that a specific node of the tree find.Given in order to replace the tree we would need to have a function that would give us the same information. We had 2 options:a) Create a tree with a function called itemDataPros:- At first view this was the simpler solution- Would keep the status quoCons:- Not a OOP approach- Not very flexibleb) Create a tree that would return a node given an ID and then the node would be responsible for giving it's data.Pros:- OOP Approach- More flexible and we do not need to bring the tree around, just a nodeCons:- Break the current status quoGiven these 2 options we decided to go for a more OOP approach creating a Tree and a TreeNode classes, that in the future will be renamed to ACITreeWrapper and TreeNode.2. After we decided on the starting point we searched for occurrences of the function "itemData" and we found out that there were 303 occurrences of "itemData" in the code and roughly 176 calls to the function itself (some of the hits were variable names).3. We selected the first file on the search and found the function that was responsible for calling the itemData function.4. Extracted the function to a separate file5. Wrap this function with tests6. Refactor the function to ES6, give more declarative names to variables and break the functions into smaller chunks7. When all the tests were passing we replaced ACITree with our Tree8. We ensured that all tests were passing9. Remove function from the original file and use the new function10. Ensure everything still works11. Find the next function and execute from step 4 until all the functions are replaced, refactored and tested.As you can see by the process this is a pretty huge undertake, because of the number of calls to the function. This is just the first step on the direction of completely isolating the ACITree so that we can solve the problem with a large number of elements on the tree.What is on our radar that we need to address:- Finish the complete decoupling of the ACITree- Performance of the current tree implementation- Tweak the naming of the Tree class to explicitly tell us this is to use only with ACITree.ThanksJoaoDave Page
Blog: http://pgsnake.blogspot.com
Twitter: @pgsnake
EnterpriseDB UK: http://www.enterprisedb.com
The Enterprise PostgreSQL Company--Dave Page
Blog: http://pgsnake.blogspot.com
Twitter: @pgsnake
EnterpriseDB UK: http://www.enterprisedb.com
The Enterprise PostgreSQL Company--Dave Page
Blog: http://pgsnake.blogspot.com
Twitter: @pgsnake
EnterpriseDB UK: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
On Mon, Apr 30, 2018 at 11:27 PM, Joao De Almeida Pereira <jdealmeidapereira@pivotal.io> wrote:You've lost us with the last reply. We'd love to know what we'd have to do to get this patch committed. You mention that "some things are missing at some places" and that "there are missing bits".I've already mentioned few of them in the earlier mails about them.Please note that this is not a complete solution that we've offered so far.I know and, hence - asked for your understanding of the code (and, asked for the TODOs.)But only one step in a grander effort to effect a more cleaner, more maintainable, more testable, code base.Yes - we all want cleaner, maintainable, and testable code base.
As per my understading comments are required for better understanding, and makes the code more maintainable.But - if we're going to change everything in one go, it is difficult to understand the changes.Let's avoid mix match multiple things in a single patch. And, concerntrate one functionality at a time.
-- Thanks, AsheshThanksJoao and Anthony.On Mon, Apr 30, 2018 at 9:07 PM, Dave Page <dpage@pgadmin.org> wrote:On Mon, Apr 30, 2018 at 4:33 PM, Ashesh Vashi <ashesh.vashi@enterprisedb.com> wrote: On Mon, Apr 30, 2018 at 8:58 PM, Anthony Emengo <aemengo@pivotal.io> wrote:I was expecting a separate layer between the tree implementation, and aciTree adaptor.
Please find the patch for the example.
It will separate the two layers, and easy to replace with the new implementation in future.In general, we want defer the separation of the layers for now. Even though we might assume that this is the direction we want to go in. It's simply too early to be making such an architectural leap. For right now, we just know that we need the decoupling, but don't know what if we'd need the 2 layers as implemented. The principle we're adhering to here is the Last Responsible Moment principle, which states that you only make the changes that you feel is necessary for the given problems you're facing: https://blog.codinghorror.com/the-last-responsible- moment/ I would not like to see that changes in this patch.
I would like us to come up with the actual design about the hot pluggability before going in this direction.In our point of view these 2 changes are not related. One thing is the internal code organization of the application, other thing is allowing third party to drop code in the application and it just work. These 2 should be talked separately, but the hot pluggability is not something that will be address by this work we are doing right now.Neither - it should be part of this change.It should be addressed separately, and discussed.I agree. As long as this work doesn't make the pluggability problem worse, that problem should be considered separately.So given Anthony's comments, are you happy with this patch?I liked the design so far.But - as Khushboo mentioned ealier - it is missing at some places.I had to read through the code to understand the execution flow for some.And, there is still a lot missing bits, and pieces to consider for commit in the repo.-- Thanks, Ashesh-- Thanks, AsheshAnthony && JoaoOn Mon, Apr 30, 2018 at 11:03 AM, Ashesh Vashi <ashesh.vashi@enterprisedb.com> wrote: On Mon, Apr 30, 2018 at 8:30 PM, Ashesh Vashi <ashesh.vashi@enterprisedb.com> wrote: On Sat, Apr 28, 2018 at 3:55 AM, Joao De Almeida Pereira <jdealmeidapereira@pivotal.io> wrote:Hi Hackers,
As you are aware we kept on working on the patch, so we are attaching to this email a new version of the patch.
This new version contains all the changes in the previous one plus more extractions of functions and refactoring of code.
The objective of this patch is to create a separation between pgAdmin and the ACI Tree. We are doing this because we realized that at this point in time we have the ACI Tree all over the code of pgAdmin. I found a very interesting article that really talks about this: https://medium.freecodecamp.org/code-dependencies-are-the-de vil-35ed28b556d In this patch there are some visions and ideas about the location of the code, the way to organize it and also try to pave the future for a application that is stable, easy to develop on and that can be release at a times notice.We are investing a big chunk of our time in doing this refactoring, but while doing that we also try to respond to the patches sent to the mailing list. We would like the feedback from the community because we believe this is a changing point for the application. The idea is to change the way we develop this application, instead of only correcting a bug of developing a feature, with every commit we should correct the bug or develop a feature but leave the code a little better than we found it (Refactoring, refactoring, refactoring). This is hard work but that is what the users from pgAdmin expect from this community of developers.======It is a huge patch86 files changed, 5492 inserts, 1840 deletionsand we would like to get your feedback as soon as possible, because we are continuing to work on it which means it is going to grow in size.At this point in time we still have 124 of 176 calls to the function itemData from ACITree.
What does each patch contain:0001:Very simple patch, we found out that the linter was not looking into all the javascript test files, so this patch will ensure it isCommitted the patch along with the regression introduced because of this patch.0002:
New Tree abstraction. This patch contains the new Tree that works as an adaptor for ACI Tree and is going to be used on all the extractions that we are doing.I was expecting a separate layer between the tree implementation, and aciTree adaptor.Please find the patch for the example.It will separate the two layers, and easy to replace with the new implemenation in future.Oops forgot to attach the patch.Please find the patch attached.-- Thanks, Ashesh0003:Code that extracts, wrap with tests and replace ACI Tree invocations.There are many small cases left in the patches.Hence - I would like to know the TODO list created by you.e.g. When we remove any of the object from the database server, we're not yet removing the respective node from the new implementation, and its children.We start creating new pattern for the location of Javascript files and their structure.I would not like to see that changes in this patch.I would like us to come up with the actual design about the hot pluggability before going in this direction.Create patterns for creation of dialogs (backup and restore)It's better - we don't change the directory structure at the moment.I am not against dividing the big javascript files in small chunks, but - I would like us to discuss first about the hot plugins design first.-- Thanks, AsheshThanksJoaoI have quite a few comments for the patch.I will send them soon.On Fri, Apr 27, 2018, 14:45 Dave Page <dpage@pgadmin.org> wrote:How is your work on this going Ashesh? Will you be committing today?On Wed, Apr 25, 2018 at 8:52 AM, Dave Page <dpage@pgadmin.org> wrote:Ashesh; you had agreed to work on this early this week. Please ensure you do so today.Thanks.--On Tue, Apr 24, 2018 at 8:13 PM, Joao De Almeida Pereira <jdealmeidapereira@pivotal.io> wrote:Hi Hackers,Can someone review and merge this patch?ThanksJoaoOn Wed, Apr 18, 2018 at 10:23 AM Joao De Almeida Pereira <jdealmeidapereira@pivotal.io> wrote:Hi Hackers,Any other comment about this patch?ThanksJoaoOn Tue, Apr 10, 2018 at 12:00 PM Joao De Almeida Pereira <jdealmeidapereira@pivotal.io> wrote:Hello KhushbooOn Mon, Apr 9, 2018 at 1:59 AM Khushboo Vashi <khushboo.vashi@enterprisedb.com> wrote: Hi Joao,I have reviewed your patch and have some suggestions.On Sat, Apr 7, 2018 at 12:43 AM, Joao De Almeida Pereira <jdealmeidapereira@pivotal.io> wrote:Hello Murtuza/Dave,
Yes now the extracted functions are spread into different files. The intent would be to make the files as small as possible, and also to group and name them in a way that would be easy to understand what each file is doing without the need of opening it.
As a example:static/js/backupwill contain all the backup related functionality inside of this folder we can see the file:
menu_utils.jsAt this moment in time we decided to group all the functions that are related to the menu, but we can split that also if we believe it is easier to see.It's really very good to see the separated code for backup module. As we have done for backup, we would like do it for other PG utilities like restore, maintenance etc.Considering this, we should separate the code in a way that some of the common functionalities can be used for other modules like menu (as you have mentioned above), dialogue factory etc.Also, I think these functionalities should be in their respective static folder instead of pgadmin/static.About the location of the files. The move of the files to pgadmin/static/js was made on purpose in order to clearly separate Javascript from python code.The rational behind it was- Create a clear separation between the backend and frontend- Having Javascript code concentrated in a single place, hopefully, will encourage to developers to look for a functionality, that is already implemented in another modules, because they are right there. (When we started this journey we realized that the 'nodes' have a big groups of code that could be shared, but because the Javascript is spread everywhere it is much harder to look for it)There are some drawbacks of this separation:- When creating a new module we will need to put the javascript in a separate location from the backend code
static/js/datagridfolder contains all the datagrid related functionalitySame as backup module, this should be in it's respective static/js folder.Inside of the folder we can see the files:
get_panel_title.jsis responsible for retrieving the name of the panelshow_data.jsis responsible for showing the datagridshow_query_tool.jsis responsible for showing the query toolDoes this structure make sense?
Can you give an example of a comment that you think is missing and that could help?As a personal note, unless the algorithm is very obscure or very complicated, I believe that if the code needs comments it is a signal that something needs to change in terms of naming, structure of the part in question. This being said, I am open to add some comments that might help people.
You are right, with the help of naming convention and structure of the code, any one can get the idea about the code. But it is very useful to understand the codevery easily with the proper comments especially when there are multiple developers working on a single project.I found some of the places where it would be great to have comments.- treeMenu: new tree.Tree() in a browser.js- tree.js (especially Tree class)About the comment point I need a more clear understanding on what kind of comments you are looking for. Because when you read the function names you understand the intent, what they are doing. The parameters also explain what you need to pass into them.If what you are looking for in these comments is the reasoning being the change itself, then that should be present in the commit message. Specially because this is going to be a very big patch with a very big number of changes.Thanks
JoaoThanks,KhushbooOn Fri, Apr 6, 2018 at 4:48 AM Murtuza Zabuawala <murtuza.zabuawala@enterprisedb.com> wrote: Hi Joao,Patch looks good and working as expected.I also agree with Dave, Can we please add some comments in each file which can help us to understand the flow, I'm saying because now the code is segregated in so many separate files it will be hard to keep track of the flow from one file to another when debugging.--Regards,On Thu, Apr 5, 2018 at 7:08 PM, Joao De Almeida Pereira <jdealmeidapereira@pivotal.io> wrote:Hi Khushboo,Attached you can find both patches rebasedThanksOn Thu, Apr 5, 2018 at 6:31 AM Khushboo Vashi <khushboo.vashi@enterprisedb.com> wrote: Hi Joao,Can you please rebase the second patch?Thanks,KhushbooOn Tue, Apr 3, 2018 at 12:15 AM, Joao De Almeida Pereira <jdealmeidapereira@pivotal.io> wrote:Hi Hackers,Attached you can find the patch that will start to decouple pgAdmin from ACITree library.This patch is intended to be merged after 3.0, because we do not want to cause any entropy or delay the release, but we want to start the discussion and show some code.This job that we started is a massive tech debt chore that will take some time to finalize and we would love the help of the community to do it.Summary of the patch:0001 patch:- Creates a new tree that will allow us to create a separation between the application and ACI Tree- Creates a Fake Tree (Test double, for reference on the available test doubles: https://martinfowler.com/bliki/TestDouble.html) that can be used to inplace to replace the ACITree and also encapsulate the new tree behavior on our tests - Adds tests for all the tree functionalities0002 patch:- Extracts, refactors, adds tests and remove dependency from ACI Tree on:- getTreeNodeHierarchy
- on backup.js: menu_enabled, menu_enabled_server, start_backup_global_server, backup_objects
- on datagrid.js: show_data_grid, get_panel_title, show_query_tool- Start using sprintf-js as Underscore.String is deprecating sprintf functionThis patch represents only 10 calls to ACITree.itemData out of 176 that are spread around our codeIn Depth look on the process behind the patch:We started writing this patch with the idea that we need to decouple pgAdmin4 from ACITree, because ACITree is no longer supported, the documentation is non existent and ACITree is no longer being actively developed.Our process:1. We "randomly" selected a function that is part of the ACITree. From this point we decided to replace that function with our own version. The function that we choose was "itemData".The function gives us all the "data" that a specific node of the tree find.Given in order to replace the tree we would need to have a function that would give us the same information. We had 2 options:a) Create a tree with a function called itemDataPros:- At first view this was the simpler solution- Would keep the status quoCons:- Not a OOP approach- Not very flexibleb) Create a tree that would return a node given an ID and then the node would be responsible for giving it's data.Pros:- OOP Approach- More flexible and we do not need to bring the tree around, just a nodeCons:- Break the current status quoGiven these 2 options we decided to go for a more OOP approach creating a Tree and a TreeNode classes, that in the future will be renamed to ACITreeWrapper and TreeNode.2. After we decided on the starting point we searched for occurrences of the function "itemData" and we found out that there were 303 occurrences of "itemData" in the code and roughly 176 calls to the function itself (some of the hits were variable names).3. We selected the first file on the search and found the function that was responsible for calling the itemData function.4. Extracted the function to a separate file5. Wrap this function with tests6. Refactor the function to ES6, give more declarative names to variables and break the functions into smaller chunks7. When all the tests were passing we replaced ACITree with our Tree8. We ensured that all tests were passing9. Remove function from the original file and use the new function10. Ensure everything still works11. Find the next function and execute from step 4 until all the functions are replaced, refactored and tested.As you can see by the process this is a pretty huge undertake, because of the number of calls to the function. This is just the first step on the direction of completely isolating the ACITree so that we can solve the problem with a large number of elements on the tree.What is on our radar that we need to address:- Finish the complete decoupling of the ACITree- Performance of the current tree implementation- Tweak the naming of the Tree class to explicitly tell us this is to use only with ACITree.ThanksJoaoDave Page
Blog: http://pgsnake.blogspot.com
Twitter: @pgsnake
EnterpriseDB UK: http://www.enterprisedb.com
The Enterprise PostgreSQL Company--Dave Page
Blog: http://pgsnake.blogspot.com
Twitter: @pgsnake
EnterpriseDB UK: http://www.enterprisedb.com
The Enterprise PostgreSQL Company--Dave Page
Blog: http://pgsnake.blogspot.com
Twitter: @pgsnake
EnterpriseDB UK: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
Blog: http://pgsnake.blogspot.com
Twitter: @pgsnake
EnterpriseDB UK: http://www.enterprisedb.com
The Enterprise PostgreSQL Company

But - if we're going to change everything in one go, it is difficult to understand the changes.
Let's avoid mix match multiple things in a single patch. And, concerntrate one functionality at a time.
On Wed, May 2, 2018 at 6:30 AM, Ashesh Vashi <ashesh.vashi@enterprisedb.com> wrote:On Mon, Apr 30, 2018 at 11:27 PM, Joao De Almeida Pereira <jdealmeidapereira@pivotal.io> wrote:You've lost us with the last reply. We'd love to know what we'd have to do to get this patch committed. You mention that "some things are missing at some places" and that "there are missing bits".I've already mentioned few of them in the earlier mails about them.Please note that this is not a complete solution that we've offered so far.I know and, hence - asked for your understanding of the code (and, asked for the TODOs.)But only one step in a grander effort to effect a more cleaner, more maintainable, more testable, code base.Yes - we all want cleaner, maintainable, and testable code base.
As per my understading comments are required for better understanding, and makes the code more maintainable.But - if we're going to change everything in one go, it is difficult to understand the changes.Let's avoid mix match multiple things in a single patch. And, concerntrate one functionality at a time.So if I understand you correctly, your concerns are:- The changes should cover specific units of code at once.- There should be high-level comments to help guide new or less experienced developers.The first I agree with - and I think (if I understand correctly, so do Joao and Anthony). That's why they've concentrated on itemData first.The second I also agree with. It's one thing being able to follow a simple function without comments, but that doesn't give you an easy to understand high level view of how it all ties together without non-trivial amounts of work. I'll be the first to admit that we're not the best at that either, but we do try, and I'd like us to get better.-- Thanks, AsheshThanksJoao and Anthony.On Mon, Apr 30, 2018 at 11:45 AM Ashesh Vashi <ashesh.vashi@enterprisedb.com> wrote:On Mon, Apr 30, 2018 at 9:07 PM, Dave Page <dpage@pgadmin.org> wrote:On Mon, Apr 30, 2018 at 4:33 PM, Ashesh Vashi <ashesh.vashi@enterprisedb.com> wrote:On Mon, Apr 30, 2018 at 8:58 PM, Anthony Emengo <aemengo@pivotal.io> wrote:I was expecting a separate layer between the tree implementation, and aciTree adaptor.
Please find the patch for the example.
It will separate the two layers, and easy to replace with the new implementation in future.In general, we want defer the separation of the layers for now. Even though we might assume that this is the direction we want to go in. It's simply too early to be making such an architectural leap. For right now, we just know that we need the decoupling, but don't know what if we'd need the 2 layers as implemented. The principle we're adhering to here is the Last Responsible Moment principle, which states that you only make the changes that you feel is necessary for the given problems you're facing: https://blog.codinghorror.com/the-last-responsible-moment/I would not like to see that changes in this patch.
I would like us to come up with the actual design about the hot pluggability before going in this direction.In our point of view these 2 changes are not related. One thing is the internal code organization of the application, other thing is allowing third party to drop code in the application and it just work. These 2 should be talked separately, but the hot pluggability is not something that will be address by this work we are doing right now.Neither - it should be part of this change.It should be addressed separately, and discussed.I agree. As long as this work doesn't make the pluggability problem worse, that problem should be considered separately.So given Anthony's comments, are you happy with this patch?I liked the design so far.But - as Khushboo mentioned ealier - it is missing at some places.I had to read through the code to understand the execution flow for some.And, there is still a lot missing bits, and pieces to consider for commit in the repo.-- Thanks, Ashesh-- Thanks, AsheshAnthony && JoaoOn Mon, Apr 30, 2018 at 11:03 AM, Ashesh Vashi <ashesh.vashi@enterprisedb.com> wrote:On Mon, Apr 30, 2018 at 8:30 PM, Ashesh Vashi <ashesh.vashi@enterprisedb.com> wrote:On Sat, Apr 28, 2018 at 3:55 AM, Joao De Almeida Pereira <jdealmeidapereira@pivotal.io> wrote:Hi Hackers,
As you are aware we kept on working on the patch, so we are attaching to this email a new version of the patch.
This new version contains all the changes in the previous one plus more extractions of functions and refactoring of code.
The objective of this patch is to create a separation between pgAdmin and the ACI Tree. We are doing this because we realized that at this point in time we have the ACI Tree all over the code of pgAdmin. I found a very interesting article that really talks about this: https://medium.freecodecamp.org/code-dependencies-are-the-devil-35ed28b556dIn this patch there are some visions and ideas about the location of the code, the way to organize it and also try to pave the future for a application that is stable, easy to develop on and that can be release at a times notice.We are investing a big chunk of our time in doing this refactoring, but while doing that we also try to respond to the patches sent to the mailing list. We would like the feedback from the community because we believe this is a changing point for the application. The idea is to change the way we develop this application, instead of only correcting a bug of developing a feature, with every commit we should correct the bug or develop a feature but leave the code a little better than we found it (Refactoring, refactoring, refactoring). This is hard work but that is what the users from pgAdmin expect from this community of developers.======It is a huge patch86 files changed, 5492 inserts, 1840 deletionsand we would like to get your feedback as soon as possible, because we are continuing to work on it which means it is going to grow in size.At this point in time we still have 124 of 176 calls to the function itemData from ACITree.
What does each patch contain:0001:Very simple patch, we found out that the linter was not looking into all the javascript test files, so this patch will ensure it isCommitted the patch along with the regression introduced because of this patch.0002:
New Tree abstraction. This patch contains the new Tree that works as an adaptor for ACI Tree and is going to be used on all the extractions that we are doing.I was expecting a separate layer between the tree implementation, and aciTree adaptor.Please find the patch for the example.It will separate the two layers, and easy to replace with the new implemenation in future.Oops forgot to attach the patch.Please find the patch attached.-- Thanks, Ashesh0003:Code that extracts, wrap with tests and replace ACI Tree invocations.There are many small cases left in the patches.Hence - I would like to know the TODO list created by you.e.g. When we remove any of the object from the database server, we're not yet removing the respective node from the new implementation, and its children.We start creating new pattern for the location of Javascript files and their structure.I would not like to see that changes in this patch.I would like us to come up with the actual design about the hot pluggability before going in this direction.Create patterns for creation of dialogs (backup and restore)It's better - we don't change the directory structure at the moment.I am not against dividing the big javascript files in small chunks, but - I would like us to discuss first about the hot plugins design first.-- Thanks, AsheshThanksJoaoOn Fri, Apr 27, 2018 at 5:34 AM Ashesh Vashi <ashesh.vashi@enterprisedb.com> wrote:I have quite a few comments for the patch.I will send them soon.On Fri, Apr 27, 2018, 14:45 Dave Page <dpage@pgadmin.org> wrote:How is your work on this going Ashesh? Will you be committing today?On Wed, Apr 25, 2018 at 8:52 AM, Dave Page <dpage@pgadmin.org> wrote:Ashesh; you had agreed to work on this early this week. Please ensure you do so today.Thanks.--On Tue, Apr 24, 2018 at 8:13 PM, Joao De Almeida Pereira <jdealmeidapereira@pivotal.io> wrote:Hi Hackers,Can someone review and merge this patch?ThanksJoaoOn Wed, Apr 18, 2018 at 10:23 AM Joao De Almeida Pereira <jdealmeidapereira@pivotal.io> wrote:Hi Hackers,Any other comment about this patch?ThanksJoaoOn Tue, Apr 10, 2018 at 12:00 PM Joao De Almeida Pereira <jdealmeidapereira@pivotal.io> wrote:Hello KhushbooOn Mon, Apr 9, 2018 at 1:59 AM Khushboo Vashi <khushboo.vashi@enterprisedb.com> wrote:Hi Joao,I have reviewed your patch and have some suggestions.On Sat, Apr 7, 2018 at 12:43 AM, Joao De Almeida Pereira <jdealmeidapereira@pivotal.io> wrote:Hello Murtuza/Dave,
Yes now the extracted functions are spread into different files. The intent would be to make the files as small as possible, and also to group and name them in a way that would be easy to understand what each file is doing without the need of opening it.
As a example:static/js/backupwill contain all the backup related functionality inside of this folder we can see the file:
menu_utils.jsAt this moment in time we decided to group all the functions that are related to the menu, but we can split that also if we believe it is easier to see.It's really very good to see the separated code for backup module. As we have done for backup, we would like do it for other PG utilities like restore, maintenance etc.Considering this, we should separate the code in a way that some of the common functionalities can be used for other modules like menu (as you have mentioned above), dialogue factory etc.Also, I think these functionalities should be in their respective static folder instead of pgadmin/static.About the location of the files. The move of the files to pgadmin/static/js was made on purpose in order to clearly separate Javascript from python code.The rational behind it was- Create a clear separation between the backend and frontend- Having Javascript code concentrated in a single place, hopefully, will encourage to developers to look for a functionality, that is already implemented in another modules, because they are right there. (When we started this journey we realized that the 'nodes' have a big groups of code that could be shared, but because the Javascript is spread everywhere it is much harder to look for it)There are some drawbacks of this separation:- When creating a new module we will need to put the javascript in a separate location from the backend code
static/js/datagridfolder contains all the datagrid related functionalitySame as backup module, this should be in it's respective static/js folder.Inside of the folder we can see the files:
get_panel_title.jsis responsible for retrieving the name of the panelshow_data.jsis responsible for showing the datagridshow_query_tool.jsis responsible for showing the query toolDoes this structure make sense?
Can you give an example of a comment that you think is missing and that could help?As a personal note, unless the algorithm is very obscure or very complicated, I believe that if the code needs comments it is a signal that something needs to change in terms of naming, structure of the part in question. This being said, I am open to add some comments that might help people.
You are right, with the help of naming convention and structure of the code, any one can get the idea about the code. But it is very useful to understand the codevery easily with the proper comments especially when there are multiple developers working on a single project.I found some of the places where it would be great to have comments.- treeMenu: new tree.Tree() in a browser.js- tree.js (especially Tree class)About the comment point I need a more clear understanding on what kind of comments you are looking for. Because when you read the function names you understand the intent, what they are doing. The parameters also explain what you need to pass into them.If what you are looking for in these comments is the reasoning being the change itself, then that should be present in the commit message. Specially because this is going to be a very big patch with a very big number of changes.Thanks
JoaoThanks,KhushbooOn Fri, Apr 6, 2018 at 4:48 AM Murtuza Zabuawala <murtuza.zabuawala@enterprisedb.com> wrote:Hi Joao,Patch looks good and working as expected.I also agree with Dave, Can we please add some comments in each file which can help us to understand the flow, I'm saying because now the code is segregated in so many separate files it will be hard to keep track of the flow from one file to another when debugging.--Regards,On Thu, Apr 5, 2018 at 7:08 PM, Joao De Almeida Pereira <jdealmeidapereira@pivotal.io> wrote:Hi Khushboo,Attached you can find both patches rebasedThanksOn Thu, Apr 5, 2018 at 6:31 AM Khushboo Vashi <khushboo.vashi@enterprisedb.com> wrote:Hi Joao,Can you please rebase the second patch?Thanks,KhushbooOn Tue, Apr 3, 2018 at 12:15 AM, Joao De Almeida Pereira <jdealmeidapereira@pivotal.io> wrote:Hi Hackers,Attached you can find the patch that will start to decouple pgAdmin from ACITree library.This patch is intended to be merged after 3.0, because we do not want to cause any entropy or delay the release, but we want to start the discussion and show some code.This job that we started is a massive tech debt chore that will take some time to finalize and we would love the help of the community to do it.Summary of the patch:0001 patch:- Creates a new tree that will allow us to create a separation between the application and ACI Tree- Creates a Fake Tree (Test double, for reference on the available test doubles: https://martinfowler.com/bliki/TestDouble.html) that can be used to inplace to replace the ACITree and also encapsulate the new tree behavior on our tests- Adds tests for all the tree functionalities0002 patch:- Extracts, refactors, adds tests and remove dependency from ACI Tree on:- getTreeNodeHierarchy
- on backup.js: menu_enabled, menu_enabled_server, start_backup_global_server, backup_objects
- on datagrid.js: show_data_grid, get_panel_title, show_query_tool- Start using sprintf-js as Underscore.String is deprecating sprintf functionThis patch represents only 10 calls to ACITree.itemData out of 176 that are spread around our codeIn Depth look on the process behind the patch:We started writing this patch with the idea that we need to decouple pgAdmin4 from ACITree, because ACITree is no longer supported, the documentation is non existent and ACITree is no longer being actively developed.Our process:1. We "randomly" selected a function that is part of the ACITree. From this point we decided to replace that function with our own version. The function that we choose was "itemData".The function gives us all the "data" that a specific node of the tree find.Given in order to replace the tree we would need to have a function that would give us the same information. We had 2 options:a) Create a tree with a function called itemDataPros:- At first view this was the simpler solution- Would keep the status quoCons:- Not a OOP approach- Not very flexibleb) Create a tree that would return a node given an ID and then the node would be responsible for giving it's data.Pros:- OOP Approach- More flexible and we do not need to bring the tree around, just a nodeCons:- Break the current status quoGiven these 2 options we decided to go for a more OOP approach creating a Tree and a TreeNode classes, that in the future will be renamed to ACITreeWrapper and TreeNode.2. After we decided on the starting point we searched for occurrences of the function "itemData" and we found out that there were 303 occurrences of "itemData" in the code and roughly 176 calls to the function itself (some of the hits were variable names).3. We selected the first file on the search and found the function that was responsible for calling the itemData function.4. Extracted the function to a separate file5. Wrap this function with tests6. Refactor the function to ES6, give more declarative names to variables and break the functions into smaller chunks7. When all the tests were passing we replaced ACITree with our Tree8. We ensured that all tests were passing9. Remove function from the original file and use the new function10. Ensure everything still works11. Find the next function and execute from step 4 until all the functions are replaced, refactored and tested.As you can see by the process this is a pretty huge undertake, because of the number of calls to the function. This is just the first step on the direction of completely isolating the ACITree so that we can solve the problem with a large number of elements on the tree.What is on our radar that we need to address:- Finish the complete decoupling of the ACITree- Performance of the current tree implementation- Tweak the naming of the Tree class to explicitly tell us this is to use only with ACITree.ThanksJoaoDave Page
Blog: http://pgsnake.blogspot.com
Twitter: @pgsnake
EnterpriseDB UK: http://www.enterprisedb.com
The Enterprise PostgreSQL Company--Dave Page
Blog: http://pgsnake.blogspot.com
Twitter: @pgsnake
EnterpriseDB UK: http://www.enterprisedb.com
The Enterprise PostgreSQL Company--Dave Page
Blog: http://pgsnake.blogspot.com
Twitter: @pgsnake
EnterpriseDB UK: http://www.enterprisedb.com
The Enterprise PostgreSQL Company--Dave Page
Blog: http://pgsnake.blogspot.com
Twitter: @pgsnake
EnterpriseDB UK: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
Attachment
Hi Hackers,
Be prepared this is going to be a big email.
Objectives of this patch:
- Start the work to split ACI from pgAdmin code
- Add more tests around the front end components
- Start the discussion on application architecture
1. Start the work to split ACI from pgAdmin code
Why
This journey started on our first attempt to store state of the current tree, so that when a user accessed again pgAdmin
there would be no need to reopen all the nodes and make the flow better. Another problem users brought to us was related
to the UI behavior when the number of objects was too big.
In order to do implement this features we would have to play around with aciTree or some functions from our code that
called and leveraged the aciTree functionalities. To do this we needed to have some confidence that our changes would
implement correctly the new feature and it would not break the current functionality.
The process that we used was first extract the functions that interacted with the tree, wrap them with
tests and then refactor them in some way. While doing this work we realized that the tree started spreading roots
throughout the majority of the application.
How
Options:
- Rewrite the front end
- One bang replace ACI Tree without change on the application
- Create an abstraction layer between ACI Tree and the application
1. Rewrite the front end
| Pros | Const |
|---|---|
| Achieve decoupling by recreating the frontend | Cost is too high |
| Do not rely on deprecated or unmaintained libraries | Turn around is too long |
| One shot change |
2. One bang replace ACI Tree
| Pros | Const |
|---|---|
| Achieve decoupling by recreating the frontend | Cost is too high |
| Does not achieve the decoupling unless we change the application | |
| Need to create an adaptor | |
| No garantee of success | |
| One shot change |
3. Create an abstraction layer between ACI Tree and the application
| Pros | Const |
|---|---|
| Achieve decoupling of the application and the tree | 90% of the time on Code archaeology |
| Lower cost | |
| Ability to change or keep ACI Tree, decision TBD | |
| Can be done in a iterative way |
We decided that options 3 looked more attractive specially because we could do it in a iterative way.
The next image depicts the current state of the interactions between the application and the ACI and the place we want
to be in.
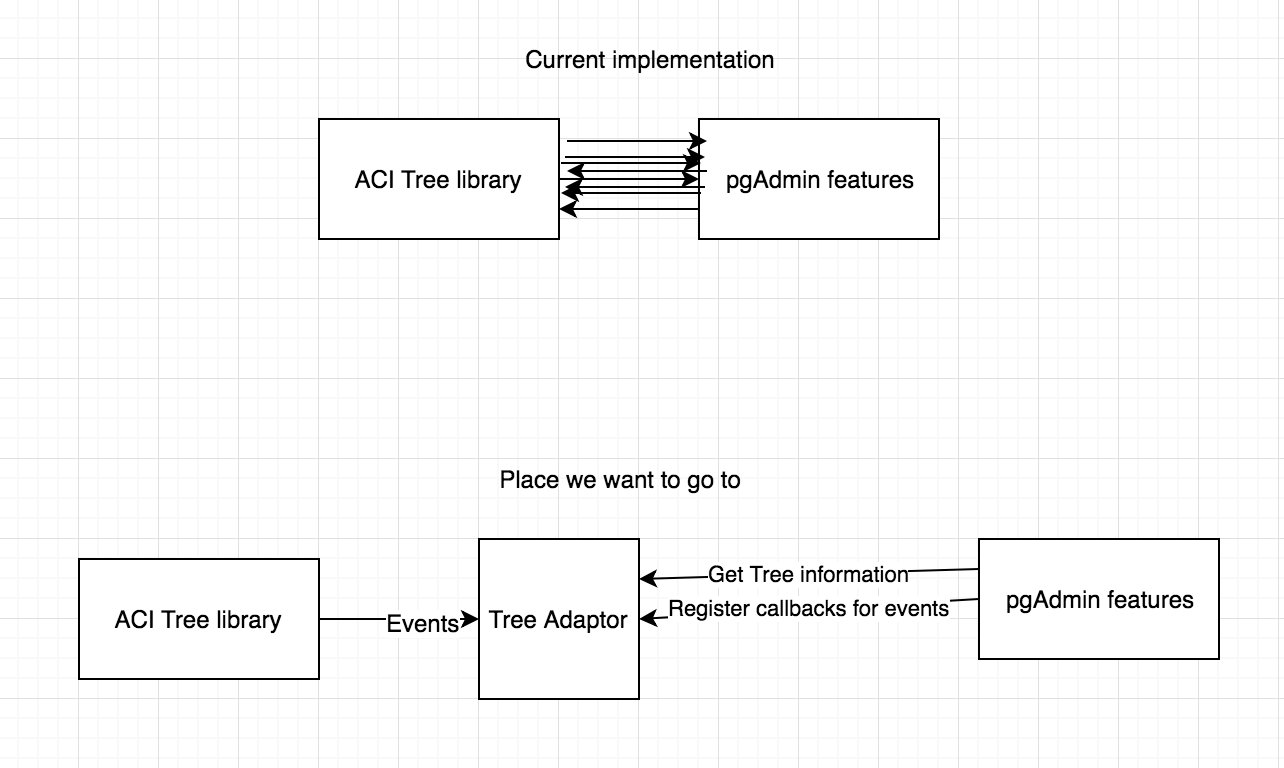
for retrieving of data from the ACI Tree that then is used in different ways.
Because we are doing this in a iterative process we need to keep the current tree working and create our adaptor next
to it. In order to do that we created a new property on PGBrowser class called treeMenu and when ACI Tree receives
the node information we also populate the new Tree with all the needed information.
This approach allow us not to worry, for now, with data retrieval, URL system and other issues that should be addressed
in the future when the adaptor is done.
This first patch tries to deal with the low hanging fruit, functions that are triggered by events from ACI Tree.
Cases like registering to events and triggering events need to be handled in the future as well.
2. Add more tests around the front end components
Why
Go Fast Forever: https://builttoadapt.io/why-tdd-489fdcdda05e
I think this is a very good summary of why do we need tests in our applications.
3. Start the discussion on application architecture
Why should we care about location of files inside a our application?
Why is this way better the another?
These are 2 good questions that have very lengthy answers. Trying to more or less summarize the answers we care about
the location of the files, because we want our application to communicate intent and there are always pros and cons
on all the decisions that we make.
At this point the application structure follows our menu, this approach eventually make is easier to follow the code
but at the same time if the menu changes down the line, will we change the structure of our folders?
The proposal that we do with the last diff of this patch is to change to a structure that slices vertically the
application. This way we can understand intent behind the code and more easily find what we are looking for.
In the current structure if you want to see the tables code you need to go topgAdmin/browser/server_groups/servers/databases/schemas/tables/ this is a huge path to remember and to get to. What
do we win with this? If we open pgAdmin we know which nodes to click in order to get to tables. But for development
every time that you are looking for a specific functionality you need to run the application, navigate the menu so that
you know where you can find the code. This doesn’t sound very appealing.
What if our structure would look like this:
- web - tables - controller - get_nodes.py - get_sql.py - __init__.py - frontend - component - ddl_component.js - services - table-service.js - schemas - servers - ....
This would saves us time because all the information that we need is what are we working on and everything is right there.
| Menu driven structure | Intent Driven Structure |
|---|---|
| Pros: | Pros: |
| Already in place | Explicitly shows features |
| Self contained features | Self contained features |
| Support for drop in features | Support for drop in features |
| Cons: | Cons: |
| Follows the menu, and it could change | Need to change current code |
| Hard to find features | Some additional plumbing might be needed |
| Drop in features need to be placed in a specific location according to the menu location |
What are your thought about this architecture?
Around minute 7 of this video Uncle Bob shows an application written
in rails to talk about architecture. It is a long KeyNote if you are curious I would advise you to see the full video.
His approach to architecture of the application is pretty interesting.
Patches
0001 Change the order of the shims on the shim file
Simple change that orders the shims inside the shim file
0002 New tree implementation
This is the first version of our Tree implementation. At this point is a very simple tree without no abstractions and
with code that eventually is not very performant, but this is only the first iteration and we are trying to follow the
Last Responsible Moment Principle.
What can you find in this patch:
- Creation of
PGBrowser.treeMenu - Initial version of the Tree Adaptor
web/pgadmin/static/js/tree/tree.js - TreeFake test double that can replace the Tree for testing purposes
- Tests. As an interesting asside because Fake’s need to behave like the real object you will noticed that there are
tests for this type of double and they the same as of the real object.
0003 Extract, Test and Refactor Methods
This is the patch that contains the change that we talked a in the objectives. It touches in a subset of the places
where itemData function is called. To have a sense of progress the following image depicts, on the left all places
where this functions can be found in the code and on the right the places where it still remains after this patch.
But this patch is not only related to the ACI Tree, it also creates some abstractions from code that we found repeated.
Some examples of this are the dialogs for Backup and Restore, where the majority of the logic was common, so we created
in web/pgadmin/static/js/alertify/ 3 different objects:
A Factory DialogFactory that is responsible for creating new Dialog and these dialogs will use the DialogWrapper.
This is also a good example of the Last Responsible Moment Principle,
in Dialog there are still some functions that are used in a Recover and Backup scenario. When we have more examples
we will be able to, if we want, to extract that into another function.
While doing some code refactoring we found out that the Right Click Menu as some checks that can be centralized. Examples
of these are checks for Enable/Disable of an option of the display of the Create/Edit/Drop option in some menus.
Check web/pgadmin/static/js/menu/ for more information. This simplified code like:
canCreate: function(itemData, item, data) {
- //If check is false then , we will allow create menu
- if (data && data.check == false)
- return true;
-
- var t = pgBrowser.tree, i = item, d = itemData;
- // To iterate over tree to check parent node
- while (i) {
- // If it is schema then allow user to create domain
- if (_.indexOf(['schema'], d._type) > -1)
- return true;
-
- if ('coll-domain' == d._type) {
- //Check if we are not child of catalog
- var prev_i = t.hasParent(i) ? t.parent(i) : null,
- prev_d = prev_i ? t.itemData(prev_i) : null;
- if( prev_d._type == 'catalog') {
- return false;
- } else {
- return true;
- }
- }
- i = t.hasParent(i) ? t.parent(i) : null;
- d = i ? t.itemData(i) : null;
- }
- // by default we do not want to allow create menu
- return true;
+ return canCreate.canCreate(pgBrowser, 'coll-domain', item, data); }
This refactor was made in a couple of places throughout the code.
Another refactor that had to be done was the creation of the functions getTreeNodeHierarchyFromElement andgetTreeNodeHierarchyFromIdentifier that replace the old getTreeNodeHierarchy. This implementation was done
because for the time being we have 2 different types of trees and calls to them.
The rest of the changes resulted from our process of refactoring that we are following:
- Find a location where
itemDatais used - Extract that into a function outside of the current code
- Wrap it with tests
- When we have enough confidence on the tests, we refactor the function to use the new Tree
- We refactor the function to become more readable
- Start over
0004 Architecture
The proposed structure is our vision for the application, this is not the state we will be in when this patch lands.
For now the only change we are doing is move the javascript into static/js/FEATURE_NAME. This is a first step in the
direction that we would like to see the product heading.
Even if we decide to keep using the same architecture the move of Javascript to a centralized place will
not break any plugability as webpack can retrieve all the Javascript from any place in the code.
Have a nice weekend
Joao
Attachment
Hi Hackers,
Be prepared this is going to be a big email.
Objectives of this patch:
- Start the work to split ACI from pgAdmin code
- Add more tests around the front end components
- Start the discussion on application architecture
1. Start the work to split ACI from pgAdmin code
Why
This journey started on our first attempt to store state of the current tree, so that when a user accessed again pgAdmin
there would be no need to reopen all the nodes and make the flow better. Another problem users brought to us was related
to the UI behavior when the number of objects was too big.In order to do implement this features we would have to play around with aciTree or some functions from our code that
called and leveraged the aciTree functionalities. To do this we needed to have some confidence that our changes would
implement correctly the new feature and it would not break the current functionality.
The process that we used was first extract the functions that interacted with the tree, wrap them with
tests and then refactor them in some way. While doing this work we realized that the tree started spreading roots
throughout the majority of the application.How
Options:
- Rewrite the front end
- One bang replace ACI Tree without change on the application
- Create an abstraction layer between ACI Tree and the application
1. Rewrite the front end
Pros Const Achieve decoupling by recreating the frontend Cost is too high Do not rely on deprecated or unmaintained libraries Turn around is too long One shot change 2. One bang replace ACI Tree
Pros Const Achieve decoupling by recreating the frontend Cost is too high Does not achieve the decoupling unless we change the application Need to create an adaptor No garantee of success One shot change 3. Create an abstraction layer between ACI Tree and the application
Pros Const Achieve decoupling of the application and the tree 90% of the time on Code archaeology Lower cost Ability to change or keep ACI Tree, decision TBD Can be done in a iterative way We decided that options 3 looked more attractive specially because we could do it in a iterative way.
The next image depicts the current state of the interactions between the application and the ACI and the place we want
to be in.
for retrieving of data from the ACI Tree that then is used in different ways.
Because we are doing this in a iterative process we need to keep the current tree working and create our adaptor next
to it. In order to do that we created a new property onPGBrowserclass calledtreeMenuand when ACI Tree receives
the node information we also populate the new Tree with all the needed information.This approach allow us not to worry, for now, with data retrieval, URL system and other issues that should be addressed
in the future when the adaptor is done.This first patch tries to deal with the low hanging fruit, functions that are triggered by events from ACI Tree.
Cases like registering to events and triggering events need to be handled in the future as well.2. Add more tests around the front end components
Why
Go Fast Forever: https://builttoadapt.io/why-tdd-489fdcdda05e
I think this is a very good summary of why do we need tests in our applications.3. Start the discussion on application architecture
Why should we care about location of files inside a our application?
Why is this way better the another?
These are 2 good questions that have very lengthy answers. Trying to more or less summarize the answers we care about
the location of the files, because we want our application to communicate intent and there are always pros and cons
on all the decisions that we make.At this point the application structure follows our menu, this approach eventually make is easier to follow the code
but at the same time if the menu changes down the line, will we change the structure of our folders?The proposal that we do with the last diff of this patch is to change to a structure that slices vertically the
application. This way we can understand intent behind the code and more easily find what we are looking for.In the current structure if you want to see the tables code you need to go to
pgAdmin/browser/server_groups/servers/databases/schemas/tables/this is a huge path to remember and to get to. What
do we win with this? If we open pgAdmin we know which nodes to click in order to get to tables. But for development
every time that you are looking for a specific functionality you need to run the application, navigate the menu so that
you know where you can find the code. This doesn’t sound very appealing.What if our structure would look like this:
- web - tables - controller - get_nodes.py - get_sql.py - __init__.py - frontend - component - ddl_component.js - services - table-service.js - schemas - servers - ....This would saves us time because all the information that we need is what are we working on and everything is right there.
Menu driven structure Intent Driven Structure Pros: Pros: Already in place Explicitly shows features Self contained features Self contained features Support for drop in features Support for drop in features Cons: Cons: Follows the menu, and it could change Need to change current code Hard to find features Some additional plumbing might be needed Drop in features need to be placed in a specific location according to the menu location What are your thought about this architecture?
Around minute 7 of this video Uncle Bob shows an application written
in rails to talk about architecture. It is a long KeyNote if you are curious I would advise you to see the full video.
His approach to architecture of the application is pretty interesting.Patches
0001 Change the order of the shims on the shim file
Simple change that orders the shims inside the shim file
0002 New tree implementation
This is the first version of our Tree implementation. At this point is a very simple tree without no abstractions and
with code that eventually is not very performant, but this is only the first iteration and we are trying to follow the
Last Responsible Moment Principle.What can you find in this patch:
- Creation of
PGBrowser.treeMenu- Initial version of the Tree Adaptor
web/pgadmin/static/js/tree/tree.js- TreeFake test double that can replace the Tree for testing purposes
- Tests. As an interesting asside because Fake’s need to behave like the real object you will noticed that there are
tests for this type of double and they the same as of the real object.0003 Extract, Test and Refactor Methods
This is the patch that contains the change that we talked a in the objectives. It touches in a subset of the places
whereitemDatafunction is called. To have a sense of progress the following image depicts, on the left all places
where this functions can be found in the code and on the right the places where it still remains after this patch.But this patch is not only related to the ACI Tree, it also creates some abstractions from code that we found repeated.
Some examples of this are the dialogs for Backup and Restore, where the majority of the logic was common, so we created
inweb/pgadmin/static/js/alertify/3 different objects:
A FactoryDialogFactorythat is responsible for creating newDialogand these dialogs will use theDialogWrapper.This is also a good example of the Last Responsible Moment Principle,
inDialogthere are still some functions that are used in a Recover and Backup scenario. When we have more examples
we will be able to, if we want, to extract that into another function.While doing some code refactoring we found out that the Right Click Menu as some checks that can be centralized. Examples
of these are checks for Enable/Disable of an option of the display of the Create/Edit/Drop option in some menus.
Checkweb/pgadmin/static/js/menu/for more information. This simplified code like:canCreate: function(itemData, item, data) { - //If check is false then , we will allow create menu - if (data && data.check == false) - return true; - - var t = pgBrowser.tree, i = item, d = itemData; - // To iterate over tree to check parent node - while (i) { - // If it is schema then allow user to create domain - if (_.indexOf(['schema'], d._type) > -1) - return true; - - if ('coll-domain' == d._type) { - //Check if we are not child of catalog - var prev_i = t.hasParent(i) ? t.parent(i) : null, - prev_d = prev_i ? t.itemData(prev_i) : null; - if( prev_d._type == 'catalog') { - return false; - } else { - return true; - } - } - i = t.hasParent(i) ? t.parent(i) : null; - d = i ? t.itemData(i) : null; - } - // by default we do not want to allow create menu - return true; + return canCreate.canCreate(pgBrowser, 'coll-domain', item, data); }This refactor was made in a couple of places throughout the code.
Another refactor that had to be done was the creation of the functions
getTreeNodeHierarchyFromElementandgetTreeNodeHierarchyFromIdentifierthat replace the oldgetTreeNodeHierarchy. This implementation was done
because for the time being we have 2 different types of trees and calls to them.The rest of the changes resulted from our process of refactoring that we are following:
- Find a location where
itemDatais used- Extract that into a function outside of the current code
- Wrap it with tests
- When we have enough confidence on the tests, we refactor the function to use the new Tree
- We refactor the function to become more readable
- Start over
0004 Architecture
The proposed structure is our vision for the application, this is not the state we will be in when this patch lands.
For now the only change we are doing is move the javascript intostatic/js/FEATURE_NAME. This is a first step in the
direction that we would like to see the product heading.Even if we decide to keep using the same architecture the move of Javascript to a centralized place will
not break any plugability as webpack can retrieve all the Javascript from any place in the code.Have a nice weekend
Joao

Attachment
And now the patches......On Fri, May 4, 2018 at 6:01 PM Joao De Almeida Pereira <jdealmeidapereira@pivotal.io> wrote:Hi Hackers,
Be prepared this is going to be a big email.
Objectives of this patch:
- Start the work to split ACI from pgAdmin code
- Add more tests around the front end components
- Start the discussion on application architecture
1. Start the work to split ACI from pgAdmin code
Why
This journey started on our first attempt to store state of the current tree, so that when a user accessed again pgAdmin
there would be no need to reopen all the nodes and make the flow better. Another problem users brought to us was related
to the UI behavior when the number of objects was too big.In order to do implement this features we would have to play around with aciTree or some functions from our code that
called and leveraged the aciTree functionalities. To do this we needed to have some confidence that our changes would
implement correctly the new feature and it would not break the current functionality.
The process that we used was first extract the functions that interacted with the tree, wrap them with
tests and then refactor them in some way. While doing this work we realized that the tree started spreading roots
throughout the majority of the application.How
Options:
- Rewrite the front end
- One bang replace ACI Tree without change on the application
- Create an abstraction layer between ACI Tree and the application
1. Rewrite the front end
Pros Const Achieve decoupling by recreating the frontend Cost is too high Do not rely on deprecated or unmaintained libraries Turn around is too long One shot change 2. One bang replace ACI Tree
Pros Const Achieve decoupling by recreating the frontend Cost is too high Does not achieve the decoupling unless we change the application Need to create an adaptor No garantee of success One shot change 3. Create an abstraction layer between ACI Tree and the application
Pros Const Achieve decoupling of the application and the tree 90% of the time on Code archaeology Lower cost Ability to change or keep ACI Tree, decision TBD Can be done in a iterative way We decided that options 3 looked more attractive specially because we could do it in a iterative way.
The next image depicts the current state of the interactions between the application and the ACI and the place we want
to be in.
for retrieving of data from the ACI Tree that then is used in different ways.
Because we are doing this in a iterative process we need to keep the current tree working and create our adaptor next
to it. In order to do that we created a new property onPGBrowserclass calledtreeMenuand when ACI Tree receives
the node information we also populate the new Tree with all the needed information.This approach allow us not to worry, for now, with data retrieval, URL system and other issues that should be addressed
in the future when the adaptor is done.This first patch tries to deal with the low hanging fruit, functions that are triggered by events from ACI Tree.
Cases like registering to events and triggering events need to be handled in the future as well.2. Add more tests around the front end components
Why
Go Fast Forever: https://builttoadapt.io/why-tdd-489fdcdda05e
I think this is a very good summary of why do we need tests in our applications.3. Start the discussion on application architecture
Why should we care about location of files inside a our application?
Why is this way better the another?
These are 2 good questions that have very lengthy answers. Trying to more or less summarize the answers we care about
the location of the files, because we want our application to communicate intent and there are always pros and cons
on all the decisions that we make.At this point the application structure follows our menu, this approach eventually make is easier to follow the code
but at the same time if the menu changes down the line, will we change the structure of our folders?The proposal that we do with the last diff of this patch is to change to a structure that slices vertically the
application. This way we can understand intent behind the code and more easily find what we are looking for.In the current structure if you want to see the tables code you need to go to
pgAdmin/browser/server_groups/servers/databases/schemas/tables/this is a huge path to remember and to get to. What
do we win with this? If we open pgAdmin we know which nodes to click in order to get to tables. But for development
every time that you are looking for a specific functionality you need to run the application, navigate the menu so that
you know where you can find the code. This doesn’t sound very appealing.What if our structure would look like this:
- web - tables - controller - get_nodes.py - get_sql.py - __init__.py - frontend - component - ddl_component.js - services - table-service.js - schemas - servers - ....This would saves us time because all the information that we need is what are we working on and everything is right there.
Menu driven structure Intent Driven Structure Pros: Pros: Already in place Explicitly shows features Self contained features Self contained features Support for drop in features Support for drop in features Cons: Cons: Follows the menu, and it could change Need to change current code Hard to find features Some additional plumbing might be needed Drop in features need to be placed in a specific location according to the menu location What are your thought about this architecture?
Around minute 7 of this video Uncle Bob shows an application written
in rails to talk about architecture. It is a long KeyNote if you are curious I would advise you to see the full video.
His approach to architecture of the application is pretty interesting.Patches
0001 Change the order of the shims on the shim file
Simple change that orders the shims inside the shim file
0002 New tree implementation
This is the first version of our Tree implementation. At this point is a very simple tree without no abstractions and
with code that eventually is not very performant, but this is only the first iteration and we are trying to follow the
Last Responsible Moment Principle.What can you find in this patch:
- Creation of
PGBrowser.treeMenu- Initial version of the Tree Adaptor
web/pgadmin/static/js/tree/tree.js- TreeFake test double that can replace the Tree for testing purposes
- Tests. As an interesting asside because Fake’s need to behave like the real object you will noticed that there are
tests for this type of double and they the same as of the real object.0003 Extract, Test and Refactor Methods
This is the patch that contains the change that we talked a in the objectives. It touches in a subset of the places
whereitemDatafunction is called. To have a sense of progress the following image depicts, on the left all places
where this functions can be found in the code and on the right the places where it still remains after this patch.But this patch is not only related to the ACI Tree, it also creates some abstractions from code that we found repeated.
Some examples of this are the dialogs for Backup and Restore, where the majority of the logic was common, so we created
inweb/pgadmin/static/js/alertify/3 different objects:
A FactoryDialogFactorythat is responsible for creating newDialogand these dialogs will use theDialogWrapper.This is also a good example of the Last Responsible Moment Principle,
inDialogthere are still some functions that are used in a Recover and Backup scenario. When we have more examples
we will be able to, if we want, to extract that into another function.While doing some code refactoring we found out that the Right Click Menu as some checks that can be centralized. Examples
of these are checks for Enable/Disable of an option of the display of the Create/Edit/Drop option in some menus.
Checkweb/pgadmin/static/js/menu/for more information. This simplified code like:canCreate: function(itemData, item, data) { - //If check is false then , we will allow create menu - if (data && data.check == false) - return true; - - var t = pgBrowser.tree, i = item, d = itemData; - // To iterate over tree to check parent node - while (i) { - // If it is schema then allow user to create domain - if (_.indexOf(['schema'], d._type) > -1) - return true; - - if ('coll-domain' == d._type) { - //Check if we are not child of catalog - var prev_i = t.hasParent(i) ? t.parent(i) : null, - prev_d = prev_i ? t.itemData(prev_i) : null; - if( prev_d._type == 'catalog') { - return false; - } else { - return true; - } - } - i = t.hasParent(i) ? t.parent(i) : null; - d = i ? t.itemData(i) : null; - } - // by default we do not want to allow create menu - return true; + return canCreate.canCreate(pgBrowser, 'coll-domain', item, data); }This refactor was made in a couple of places throughout the code.
Another refactor that had to be done was the creation of the functions
getTreeNodeHierarchyFromElementandgetTreeNodeHierarchyFromIdentifierthat replace the oldgetTreeNodeHierarchy. This implementation was done
because for the time being we have 2 different types of trees and calls to them.The rest of the changes resulted from our process of refactoring that we are following:
- Find a location where
itemDatais used- Extract that into a function outside of the current code
- Wrap it with tests
- When we have enough confidence on the tests, we refactor the function to use the new Tree
- We refactor the function to become more readable
- Start over
0004 Architecture
The proposed structure is our vision for the application, this is not the state we will be in when this patch lands.
For now the only change we are doing is move the javascript intostatic/js/FEATURE_NAME. This is a first step in the
direction that we would like to see the product heading.Even if we decide to keep using the same architecture the move of Javascript to a centralized place will
not break any plugability as webpack can retrieve all the Javascript from any place in the code.Have a nice weekend
Joao
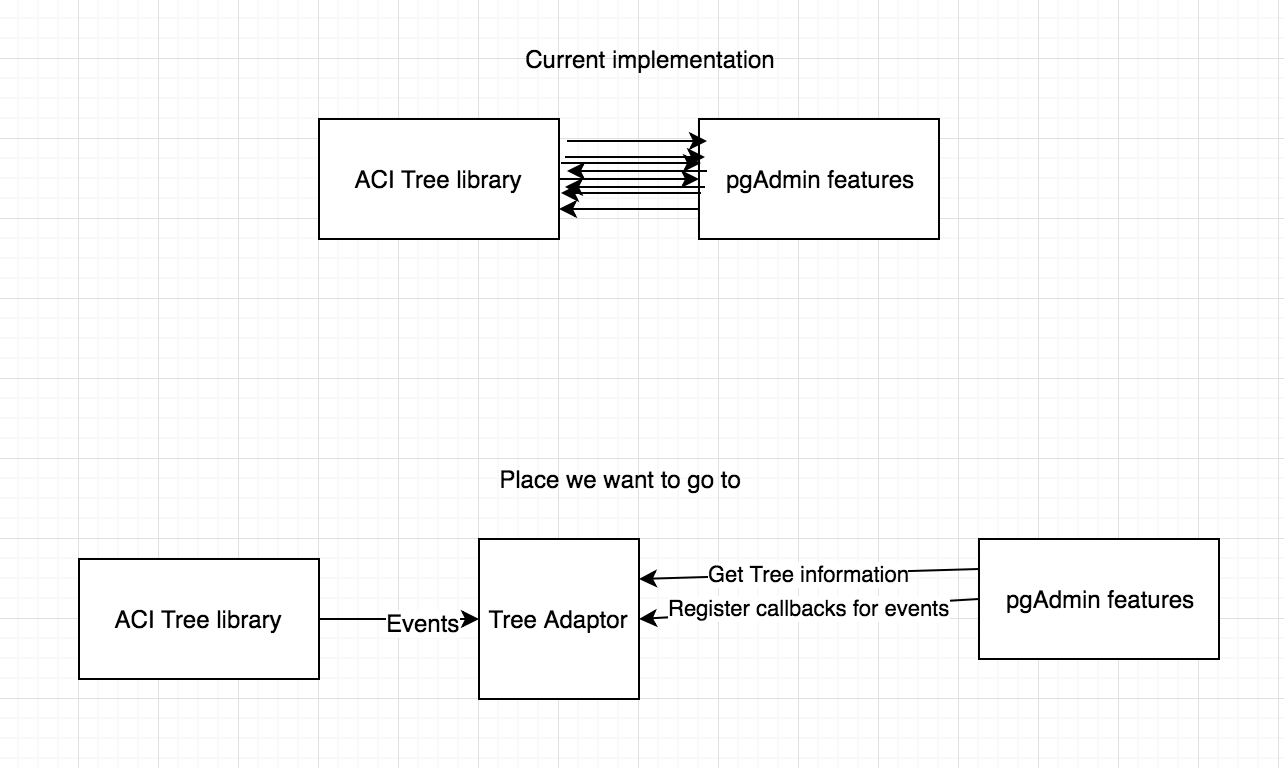
Attachment
Hi Hackers,We noticed that some of the latest changes created some conflicts with this patch. So you can find attached the patch rebased on the new master.ThanksVictoria && JoaoOn Fri, May 4, 2018 at 6:03 PM Joao De Almeida Pereira <jdealmeidapereira@pivotal.io> wrote:And now the patches......On Fri, May 4, 2018 at 6:01 PM Joao De Almeida Pereira <jdealmeidapereira@pivotal.io> wrote:Hi Hackers,
Be prepared this is going to be a big email.
Objectives of this patch:
- Start the work to split ACI from pgAdmin code
- Add more tests around the front end components
- Start the discussion on application architecture
1. Start the work to split ACI from pgAdmin code
Why
This journey started on our first attempt to store state of the current tree, so that when a user accessed again pgAdmin
there would be no need to reopen all the nodes and make the flow better. Another problem users brought to us was related
to the UI behavior when the number of objects was too big.In order to do implement this features we would have to play around with aciTree or some functions from our code that
called and leveraged the aciTree functionalities. To do this we needed to have some confidence that our changes would
implement correctly the new feature and it would not break the current functionality.
The process that we used was first extract the functions that interacted with the tree, wrap them with
tests and then refactor them in some way. While doing this work we realized that the tree started spreading roots
throughout the majority of the application.How
Options:
- Rewrite the front end
- One bang replace ACI Tree without change on the application
- Create an abstraction layer between ACI Tree and the application
1. Rewrite the front end
Pros Const Achieve decoupling by recreating the frontend Cost is too high Do not rely on deprecated or unmaintained libraries Turn around is too long One shot change 2. One bang replace ACI Tree
Pros Const Achieve decoupling by recreating the frontend Cost is too high Does not achieve the decoupling unless we change the application Need to create an adaptor No garantee of success One shot change 3. Create an abstraction layer between ACI Tree and the application
Pros Const Achieve decoupling of the application and the tree 90% of the time on Code archaeology Lower cost Ability to change or keep ACI Tree, decision TBD Can be done in a iterative way We decided that options 3 looked more attractive specially because we could do it in a iterative way.
The next image depicts the current state of the interactions between the application and the ACI and the place we want
to be in.
for retrieving of data from the ACI Tree that then is used in different ways.
Because we are doing this in a iterative process we need to keep the current tree working and create our adaptor next
to it. In order to do that we created a new property onPGBrowserclass calledtreeMenuand when ACI Tree receives
the node information we also populate the new Tree with all the needed information.This approach allow us not to worry, for now, with data retrieval, URL system and other issues that should be addressed
in the future when the adaptor is done.This first patch tries to deal with the low hanging fruit, functions that are triggered by events from ACI Tree.
Cases like registering to events and triggering events need to be handled in the future as well.2. Add more tests around the front end components
Why
Go Fast Forever: https://builttoadapt.io/why-
tdd-489fdcdda05e
I think this is a very good summary of why do we need tests in our applications.3. Start the discussion on application architecture
Why should we care about location of files inside a our application?
Why is this way better the another?
These are 2 good questions that have very lengthy answers. Trying to more or less summarize the answers we care about
the location of the files, because we want our application to communicate intent and there are always pros and cons
on all the decisions that we make.At this point the application structure follows our menu, this approach eventually make is easier to follow the code
but at the same time if the menu changes down the line, will we change the structure of our folders?The proposal that we do with the last diff of this patch is to change to a structure that slices vertically the
application. This way we can understand intent behind the code and more easily find what we are looking for.In the current structure if you want to see the tables code you need to go to
pgAdmin/browser/server_groups/this is a huge path to remember and to get to. Whatservers/databases/schemas/ tables/
do we win with this? If we open pgAdmin we know which nodes to click in order to get to tables. But for development
every time that you are looking for a specific functionality you need to run the application, navigate the menu so that
you know where you can find the code. This doesn’t sound very appealing.What if our structure would look like this:
- web - tables - controller - get_nodes.py - get_sql.py - __init__.py - frontend - component - ddl_component.js - services - table-service.js - schemas - servers - ....This would saves us time because all the information that we need is what are we working on and everything is right there.
Menu driven structure Intent Driven Structure Pros: Pros: Already in place Explicitly shows features Self contained features Self contained features Support for drop in features Support for drop in features Cons: Cons: Follows the menu, and it could change Need to change current code Hard to find features Some additional plumbing might be needed Drop in features need to be placed in a specific location according to the menu location What are your thought about this architecture?
Around minute 7 of this video Uncle Bob shows an application written
in rails to talk about architecture. It is a long KeyNote if you are curious I would advise you to see the full video.
His approach to architecture of the application is pretty interesting.Patches
0001 Change the order of the shims on the shim file
Simple change that orders the shims inside the shim file
0002 New tree implementation
This is the first version of our Tree implementation. At this point is a very simple tree without no abstractions and
with code that eventually is not very performant, but this is only the first iteration and we are trying to follow the
Last Responsible Moment Principle.What can you find in this patch:
- Creation of
PGBrowser.treeMenu- Initial version of the Tree Adaptor
web/pgadmin/static/js/tree/tree.js - TreeFake test double that can replace the Tree for testing purposes
- Tests. As an interesting asside because Fake’s need to behave like the real object you will noticed that there are
tests for this type of double and they the same as of the real object.0003 Extract, Test and Refactor Methods
This is the patch that contains the change that we talked a in the objectives. It touches in a subset of the places
whereitemDatafunction is called. To have a sense of progress the following image depicts, on the left all places
where this functions can be found in the code and on the right the places where it still remains after this patch.But this patch is not only related to the ACI Tree, it also creates some abstractions from code that we found repeated.
Some examples of this are the dialogs for Backup and Restore, where the majority of the logic was common, so we created
inweb/pgadmin/static/js/3 different objects:alertify/
A FactoryDialogFactorythat is responsible for creating newDialogand these dialogs will use theDialogWrapper.This is also a good example of the Last Responsible Moment Principle,
inDialogthere are still some functions that are used in a Recover and Backup scenario. When we have more examples
we will be able to, if we want, to extract that into another function.While doing some code refactoring we found out that the Right Click Menu as some checks that can be centralized. Examples
of these are checks for Enable/Disable of an option of the display of the Create/Edit/Drop option in some menus.
Checkweb/pgadmin/static/js/menu/for more information. This simplified code like:canCreate: function(itemData, item, data) { - //If check is false then , we will allow create menu - if (data && data.check == false) - return true; - - var t = pgBrowser.tree, i = item, d = itemData; - // To iterate over tree to check parent node - while (i) { - // If it is schema then allow user to create domain - if (_.indexOf(['schema'], d._type) > -1) - return true; - - if ('coll-domain' == d._type) { - //Check if we are not child of catalog - var prev_i = t.hasParent(i) ? t.parent(i) : null, - prev_d = prev_i ? t.itemData(prev_i) : null; - if( prev_d._type == 'catalog') { - return false; - } else { - return true; - } - } - i = t.hasParent(i) ? t.parent(i) : null; - d = i ? t.itemData(i) : null; - } - // by default we do not want to allow create menu - return true; + return canCreate.canCreate(pgBrowser, 'coll-domain', item, data); }This refactor was made in a couple of places throughout the code.
Another refactor that had to be done was the creation of the functions
getTreeNodeHierarchyFromElemenandt getTreeNodeHierarchyFromIdentithat replace the oldfier getTreeNodeHierarchy. This implementation was done
because for the time being we have 2 different types of trees and calls to them.The rest of the changes resulted from our process of refactoring that we are following:
- Find a location where
itemDatais used- Extract that into a function outside of the current code
- Wrap it with tests
- When we have enough confidence on the tests, we refactor the function to use the new Tree
- We refactor the function to become more readable
- Start over
0004 Architecture
The proposed structure is our vision for the application, this is not the state we will be in when this patch lands.
For now the only change we are doing is move the javascript intostatic/js/FEATURE_NAME. This is a first step in the
direction that we would like to see the product heading.Even if we decide to keep using the same architecture the move of Javascript to a centralized place will
not break any plugability as webpack can retrieve all the Javascript from any place in the code.Have a nice weekend
Joao
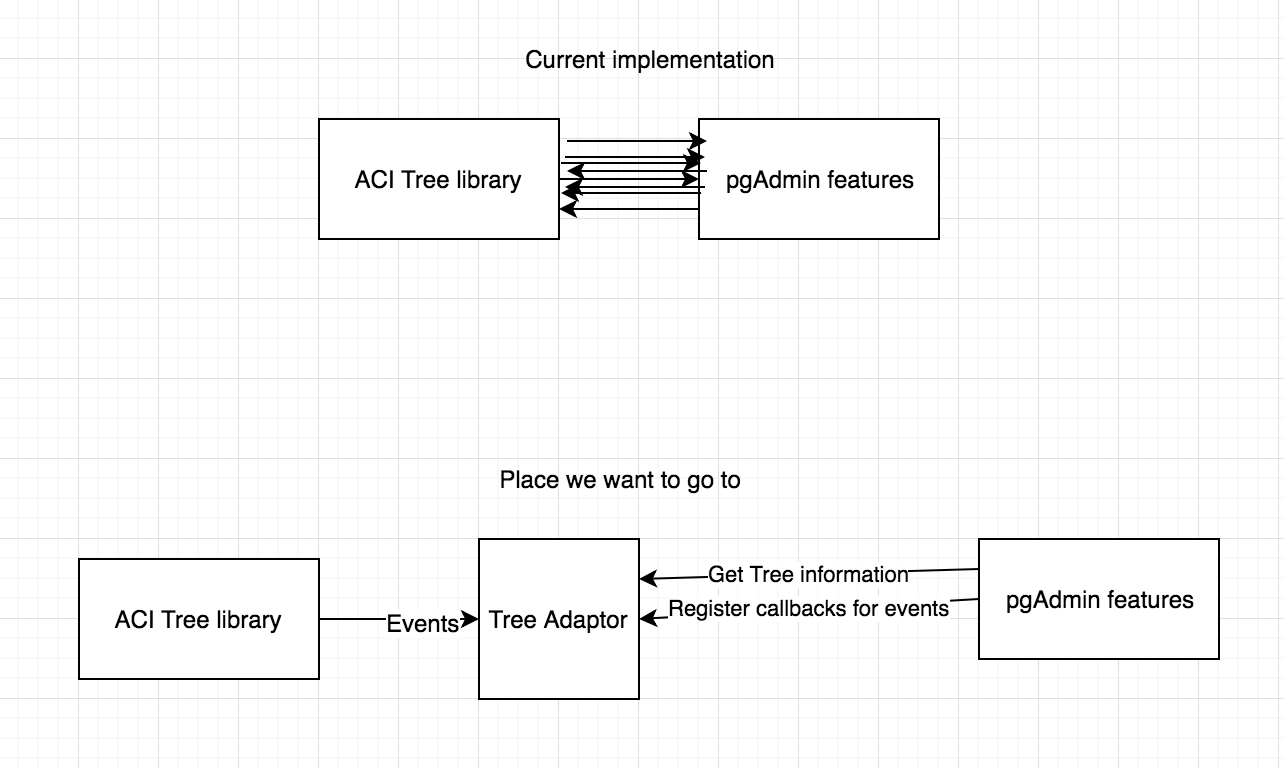
Attachment
- In menu/can_create.js, "parentCatalogOfTableChild" function name is unable to understand.
- Below code is bit confusing in terms of naming convention canCreate.canCreate inside "canCreate".
canCreate: function(itemData, item, data) {return canCreate.canCreate(pgBrowser, 'coll-collation', item, data);}Can we have something like "menuCreator.canCreate"?
- Why we have "menu_utils.js" for Backup, Maintenance, Restore and Grant Wizard? Can we have one single file with all the supported node for respective module? Also I have seen that the folder hierarchy for grant wizard is "/web/pgadmin/static/js/grant/wizard/menu_utils.js" why there are two separate folders grant and wizard (sub folder of grant)?
Hi Joao,Patch 0001 & 0002 (esp the new tree implementation) look good to me.Patch 0003 - I have some concerns regarding the approach taken to separate out the PG utilities. The dialogue factory is responsible for creating the dialogue which uses dialogue wrapper. So, any module should call the dialogue factory to create a new dialogue instance. Here dialogue itself call the dialogue factory for creating it.In the enable_disable_triggers.js file, can we just import alertifyjs instead of passing in all the functions?Patch 0004 - Right now with the new proposed architecture only JS files are re-arranged. To maintain the pluggability I would also like to have some discussion on the back end side. Right now, the code maintains everything. Let say I want to add any node under schema I will just drop the related folder and files in that hierarchy and it will work. But with the proposed architecture I can not visualize the backend architecture and this should not be ended with only JS restructuring.Thanks,KhushbooOn Tue, May 8, 2018 at 12:31 AM, Joao De Almeida Pereira <jdealmeidapereira@pivotal.io> wrote:Hi Hackers,We noticed that some of the latest changes created some conflicts with this patch. So you can find attached the patch rebased on the new master.ThanksVictoria && JoaoOn Fri, May 4, 2018 at 6:03 PM Joao De Almeida Pereira <jdealmeidapereira@pivotal.io> wrote:And now the patches......On Fri, May 4, 2018 at 6:01 PM Joao De Almeida Pereira <jdealmeidapereira@pivotal.io> wrote:Hi Hackers,
Be prepared this is going to be a big email.
Objectives of this patch:
- Start the work to split ACI from pgAdmin code
- Add more tests around the front end components
- Start the discussion on application architecture
1. Start the work to split ACI from pgAdmin code
Why
This journey started on our first attempt to store state of the current tree, so that when a user accessed again pgAdmin
there would be no need to reopen all the nodes and make the flow better. Another problem users brought to us was related
to the UI behavior when the number of objects was too big.In order to do implement this features we would have to play around with aciTree or some functions from our code that
called and leveraged the aciTree functionalities. To do this we needed to have some confidence that our changes would
implement correctly the new feature and it would not break the current functionality.
The process that we used was first extract the functions that interacted with the tree, wrap them with
tests and then refactor them in some way. While doing this work we realized that the tree started spreading roots
throughout the majority of the application.How
Options:
- Rewrite the front end
- One bang replace ACI Tree without change on the application
- Create an abstraction layer between ACI Tree and the application
1. Rewrite the front end
Pros Const Achieve decoupling by recreating the frontend Cost is too high Do not rely on deprecated or unmaintained libraries Turn around is too long One shot change 2. One bang replace ACI Tree
Pros Const Achieve decoupling by recreating the frontend Cost is too high Does not achieve the decoupling unless we change the application Need to create an adaptor No garantee of success One shot change 3. Create an abstraction layer between ACI Tree and the application
Pros Const Achieve decoupling of the application and the tree 90% of the time on Code archaeology Lower cost Ability to change or keep ACI Tree, decision TBD Can be done in a iterative way We decided that options 3 looked more attractive specially because we could do it in a iterative way.
The next image depicts the current state of the interactions between the application and the ACI and the place we want
to be in.
for retrieving of data from the ACI Tree that then is used in different ways.
Because we are doing this in a iterative process we need to keep the current tree working and create our adaptor next
to it. In order to do that we created a new property onPGBrowserclass calledtreeMenuand when ACI Tree receives
the node information we also populate the new Tree with all the needed information.This approach allow us not to worry, for now, with data retrieval, URL system and other issues that should be addressed
in the future when the adaptor is done.This first patch tries to deal with the low hanging fruit, functions that are triggered by events from ACI Tree.
Cases like registering to events and triggering events need to be handled in the future as well.2. Add more tests around the front end components
Why
Go Fast Forever: https://builttoadapt.io/why-td
d-489fdcdda05e
I think this is a very good summary of why do we need tests in our applications.3. Start the discussion on application architecture
Why should we care about location of files inside a our application?
Why is this way better the another?
These are 2 good questions that have very lengthy answers. Trying to more or less summarize the answers we care about
the location of the files, because we want our application to communicate intent and there are always pros and cons
on all the decisions that we make.At this point the application structure follows our menu, this approach eventually make is easier to follow the code
but at the same time if the menu changes down the line, will we change the structure of our folders?The proposal that we do with the last diff of this patch is to change to a structure that slices vertically the
application. This way we can understand intent behind the code and more easily find what we are looking for.In the current structure if you want to see the tables code you need to go to
pgAdmin/browser/server_groups/this is a huge path to remember and to get to. Whatservers/databases/schemas/tabl es/
do we win with this? If we open pgAdmin we know which nodes to click in order to get to tables. But for development
every time that you are looking for a specific functionality you need to run the application, navigate the menu so that
you know where you can find the code. This doesn’t sound very appealing.What if our structure would look like this:
- web - tables - controller - get_nodes.py - get_sql.py - __init__.py - frontend - component - ddl_component.js - services - table-service.js - schemas - servers - ....This would saves us time because all the information that we need is what are we working on and everything is right there.
Menu driven structure Intent Driven Structure Pros: Pros: Already in place Explicitly shows features Self contained features Self contained features Support for drop in features Support for drop in features Cons: Cons: Follows the menu, and it could change Need to change current code Hard to find features Some additional plumbing might be needed Drop in features need to be placed in a specific location according to the menu location What are your thought about this architecture?
Around minute 7 of this video Uncle Bob shows an application written
in rails to talk about architecture. It is a long KeyNote if you are curious I would advise you to see the full video.
His approach to architecture of the application is pretty interesting.Patches
0001 Change the order of the shims on the shim file
Simple change that orders the shims inside the shim file
0002 New tree implementation
This is the first version of our Tree implementation. At this point is a very simple tree without no abstractions and
with code that eventually is not very performant, but this is only the first iteration and we are trying to follow the
Last Responsible Moment Principle.What can you find in this patch:
- Creation of
PGBrowser.treeMenu- Initial version of the Tree Adaptor
web/pgadmin/static/js/tree/tree.js - TreeFake test double that can replace the Tree for testing purposes
- Tests. As an interesting asside because Fake’s need to behave like the real object you will noticed that there are
tests for this type of double and they the same as of the real object.0003 Extract, Test and Refactor Methods
This is the patch that contains the change that we talked a in the objectives. It touches in a subset of the places
whereitemDatafunction is called. To have a sense of progress the following image depicts, on the left all places
where this functions can be found in the code and on the right the places where it still remains after this patch.But this patch is not only related to the ACI Tree, it also creates some abstractions from code that we found repeated.
Some examples of this are the dialogs for Backup and Restore, where the majority of the logic was common, so we created
inweb/pgadmin/static/js/alertify3 different objects:/
A FactoryDialogFactorythat is responsible for creating newDialogand these dialogs will use theDialogWrapper.This is also a good example of the Last Responsible Moment Principle,
inDialogthere are still some functions that are used in a Recover and Backup scenario. When we have more examples
we will be able to, if we want, to extract that into another function.While doing some code refactoring we found out that the Right Click Menu as some checks that can be centralized. Examples
of these are checks for Enable/Disable of an option of the display of the Create/Edit/Drop option in some menus.
Checkweb/pgadmin/static/js/menu/for more information. This simplified code like:canCreate: function(itemData, item, data) { - //If check is false then , we will allow create menu - if (data && data.check == false) - return true; - - var t = pgBrowser.tree, i = item, d = itemData; - // To iterate over tree to check parent node - while (i) { - // If it is schema then allow user to create domain - if (_.indexOf(['schema'], d._type) > -1) - return true; - - if ('coll-domain' == d._type) { - //Check if we are not child of catalog - var prev_i = t.hasParent(i) ? t.parent(i) : null, - prev_d = prev_i ? t.itemData(prev_i) : null; - if( prev_d._type == 'catalog') { - return false; - } else { - return true; - } - } - i = t.hasParent(i) ? t.parent(i) : null; - d = i ? t.itemData(i) : null; - } - // by default we do not want to allow create menu - return true; + return canCreate.canCreate(pgBrowser, 'coll-domain', item, data); }This refactor was made in a couple of places throughout the code.
Another refactor that had to be done was the creation of the functions
getTreeNodeHierarchyFromElemenandt getTreeNodeHierarchyFromIdentithat replace the oldfier getTreeNodeHierarchy. This implementation was done
because for the time being we have 2 different types of trees and calls to them.The rest of the changes resulted from our process of refactoring that we are following:
- Find a location where
itemDatais used- Extract that into a function outside of the current code
- Wrap it with tests
- When we have enough confidence on the tests, we refactor the function to use the new Tree
- We refactor the function to become more readable
- Start over
0004 Architecture
The proposed structure is our vision for the application, this is not the state we will be in when this patch lands.
For now the only change we are doing is move the javascript intostatic/js/FEATURE_NAME. This is a first step in the
direction that we would like to see the product heading.Even if we decide to keep using the same architecture the move of Javascript to a centralized place will
not break any plugability as webpack can retrieve all the Javascript from any place in the code.Have a nice weekend
Joao
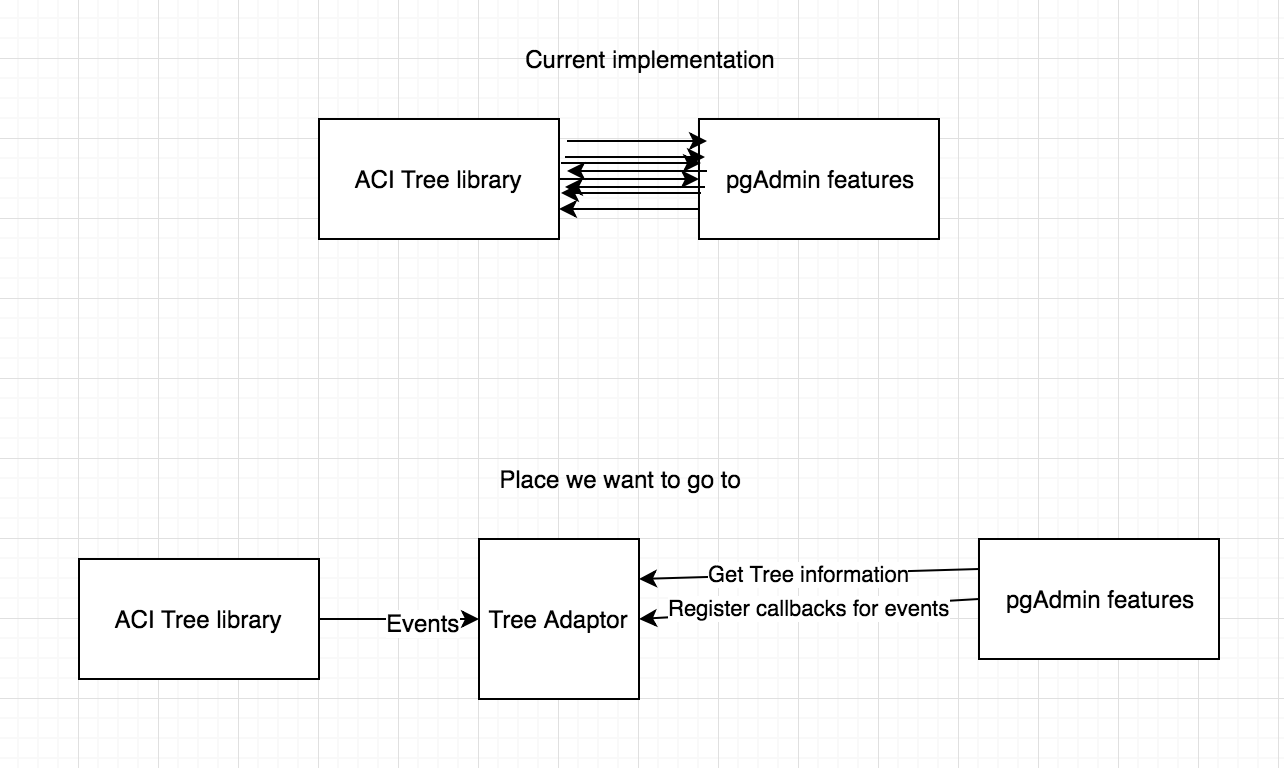
Mobile: +91 976-788-8246
Attachment
Patch 0003 - I have some concerns regarding the approach taken to separate out the PG utilities. The dialogue factory is responsible for creating the dialogue which uses dialogue wrapper. So, any module should call the dialogue factory to create a new dialogue instance. Here dialogue itself call the dialogue factory for creating it.
In the enable_disable_triggers.js file, can we just import alertifyjs instead of passing in all the functions?
Patch 0004 - Right now with the new proposed architecture only JS files are re-arranged. To maintain the pluggability I would also like to have some discussion on the back end side. Right now, the code maintains everything. Let say I want to add any node under schema I will just drop the related folder and files in that hierarchy and it will work. But with the proposed architecture I can not visualize the backend architecture and this should not be ended with only JS restructuring.
In menu/can_create.js, "parentCatalogOfTableChild" function name is unable to understand.
Below code is bit confusing in terms of naming convention canCreate.canCreate inside "canCreate".
Why we have "menu_utils.js" for Backup, Maintenance, Restore and Grant Wizard? Can we have one single file with all the supported node for respective module?
Also I have seen that the folder hierarchy for grant wizard is "/web/pgadmin/static/js/grant/wizard/menu_utils.js" why there are two separate folders grant and wizard (sub folder of grant)?
Hi JoaoBelow are my review comments:
- In menu/can_create.js, "parentCatalogOfTableChild" function name is unable to understand.
- Below code is bit confusing in terms of naming convention canCreate.canCreate inside "canCreate".
canCreate: function(itemData, item, data) {return canCreate.canCreate(pgBrowser, 'coll-collation', item, data);}Can we have something like "menuCreator.canCreate"?
- Why we have "menu_utils.js" for Backup, Maintenance, Restore and Grant Wizard? Can we have one single file with all the supported node for respective module? Also I have seen that the folder hierarchy for grant wizard is "/web/pgadmin/static/js/grant/wizard/menu_utils.js" why there are two separate folders grant and wizard (sub folder of grant)?
On Wed, May 9, 2018 at 4:32 PM, Khushboo Vashi <khushboo.vashi@enterprisedb.com> wrote:Hi Joao,Patch 0001 & 0002 (esp the new tree implementation) look good to me.Patch 0003 - I have some concerns regarding the approach taken to separate out the PG utilities. The dialogue factory is responsible for creating the dialogue which uses dialogue wrapper. So, any module should call the dialogue factory to create a new dialogue instance. Here dialogue itself call the dialogue factory for creating it.In the enable_disable_triggers.js file, can we just import alertifyjs instead of passing in all the functions?Patch 0004 - Right now with the new proposed architecture only JS files are re-arranged. To maintain the pluggability I would also like to have some discussion on the back end side. Right now, the code maintains everything. Let say I want to add any node under schema I will just drop the related folder and files in that hierarchy and it will work. But with the proposed architecture I can not visualize the backend architecture and this should not be ended with only JS restructuring.Thanks,KhushbooOn Tue, May 8, 2018 at 12:31 AM, Joao De Almeida Pereira <jdealmeidapereira@pivotal.io> wrote:Hi Hackers,We noticed that some of the latest changes created some conflicts with this patch. So you can find attached the patch rebased on the new master.ThanksVictoria && JoaoOn Fri, May 4, 2018 at 6:03 PM Joao De Almeida Pereira <jdealmeidapereira@pivotal.io> wrote:And now the patches......On Fri, May 4, 2018 at 6:01 PM Joao De Almeida Pereira <jdealmeidapereira@pivotal.io> wrote:Hi Hackers,
Be prepared this is going to be a big email.
Objectives of this patch:
- Start the work to split ACI from pgAdmin code
- Add more tests around the front end components
- Start the discussion on application architecture
1. Start the work to split ACI from pgAdmin code
Why
This journey started on our first attempt to store state of the current tree, so that when a user accessed again pgAdmin
there would be no need to reopen all the nodes and make the flow better. Another problem users brought to us was related
to the UI behavior when the number of objects was too big.In order to do implement this features we would have to play around with aciTree or some functions from our code that
called and leveraged the aciTree functionalities. To do this we needed to have some confidence that our changes would
implement correctly the new feature and it would not break the current functionality.
The process that we used was first extract the functions that interacted with the tree, wrap them with
tests and then refactor them in some way. While doing this work we realized that the tree started spreading roots
throughout the majority of the application.How
Options:
- Rewrite the front end
- One bang replace ACI Tree without change on the application
- Create an abstraction layer between ACI Tree and the application
1. Rewrite the front end
Pros Const Achieve decoupling by recreating the frontend Cost is too high Do not rely on deprecated or unmaintained libraries Turn around is too long One shot change 2. One bang replace ACI Tree
Pros Const Achieve decoupling by recreating the frontend Cost is too high Does not achieve the decoupling unless we change the application Need to create an adaptor No garantee of success One shot change 3. Create an abstraction layer between ACI Tree and the application
Pros Const Achieve decoupling of the application and the tree 90% of the time on Code archaeology Lower cost Ability to change or keep ACI Tree, decision TBD Can be done in a iterative way We decided that options 3 looked more attractive specially because we could do it in a iterative way.
The next image depicts the current state of the interactions between the application and the ACI and the place we want
to be in.
for retrieving of data from the ACI Tree that then is used in different ways.
Because we are doing this in a iterative process we need to keep the current tree working and create our adaptor next
to it. In order to do that we created a new property onPGBrowserclass calledtreeMenuand when ACI Tree receives
the node information we also populate the new Tree with all the needed information.This approach allow us not to worry, for now, with data retrieval, URL system and other issues that should be addressed
in the future when the adaptor is done.This first patch tries to deal with the low hanging fruit, functions that are triggered by events from ACI Tree.
Cases like registering to events and triggering events need to be handled in the future as well.2. Add more tests around the front end components
Why
Go Fast Forever: https://builttoadapt.io/why-tdd-489fdcdda05e
I think this is a very good summary of why do we need tests in our applications.3. Start the discussion on application architecture
Why should we care about location of files inside a our application?
Why is this way better the another?
These are 2 good questions that have very lengthy answers. Trying to more or less summarize the answers we care about
the location of the files, because we want our application to communicate intent and there are always pros and cons
on all the decisions that we make.At this point the application structure follows our menu, this approach eventually make is easier to follow the code
but at the same time if the menu changes down the line, will we change the structure of our folders?The proposal that we do with the last diff of this patch is to change to a structure that slices vertically the
application. This way we can understand intent behind the code and more easily find what we are looking for.In the current structure if you want to see the tables code you need to go to
pgAdmin/browser/server_groups/servers/databases/schemas/tables/this is a huge path to remember and to get to. What
do we win with this? If we open pgAdmin we know which nodes to click in order to get to tables. But for development
every time that you are looking for a specific functionality you need to run the application, navigate the menu so that
you know where you can find the code. This doesn’t sound very appealing.What if our structure would look like this:
- web - tables - controller - get_nodes.py - get_sql.py - __init__.py - frontend - component - ddl_component.js - services - table-service.js - schemas - servers - ....This would saves us time because all the information that we need is what are we working on and everything is right there.
Menu driven structure Intent Driven Structure Pros: Pros: Already in place Explicitly shows features Self contained features Self contained features Support for drop in features Support for drop in features Cons: Cons: Follows the menu, and it could change Need to change current code Hard to find features Some additional plumbing might be needed Drop in features need to be placed in a specific location according to the menu location What are your thought about this architecture?
Around minute 7 of this video Uncle Bob shows an application written
in rails to talk about architecture. It is a long KeyNote if you are curious I would advise you to see the full video.
His approach to architecture of the application is pretty interesting.Patches
0001 Change the order of the shims on the shim file
Simple change that orders the shims inside the shim file
0002 New tree implementation
This is the first version of our Tree implementation. At this point is a very simple tree without no abstractions and
with code that eventually is not very performant, but this is only the first iteration and we are trying to follow the
Last Responsible Moment Principle.What can you find in this patch:
- Creation of
PGBrowser.treeMenu- Initial version of the Tree Adaptor
web/pgadmin/static/js/tree/tree.js- TreeFake test double that can replace the Tree for testing purposes
- Tests. As an interesting asside because Fake’s need to behave like the real object you will noticed that there are
tests for this type of double and they the same as of the real object.0003 Extract, Test and Refactor Methods
This is the patch that contains the change that we talked a in the objectives. It touches in a subset of the places
whereitemDatafunction is called. To have a sense of progress the following image depicts, on the left all places
where this functions can be found in the code and on the right the places where it still remains after this patch.But this patch is not only related to the ACI Tree, it also creates some abstractions from code that we found repeated.
Some examples of this are the dialogs for Backup and Restore, where the majority of the logic was common, so we created
inweb/pgadmin/static/js/alertify/3 different objects:
A FactoryDialogFactorythat is responsible for creating newDialogand these dialogs will use theDialogWrapper.This is also a good example of the Last Responsible Moment Principle,
inDialogthere are still some functions that are used in a Recover and Backup scenario. When we have more examples
we will be able to, if we want, to extract that into another function.While doing some code refactoring we found out that the Right Click Menu as some checks that can be centralized. Examples
of these are checks for Enable/Disable of an option of the display of the Create/Edit/Drop option in some menus.
Checkweb/pgadmin/static/js/menu/for more information. This simplified code like:canCreate: function(itemData, item, data) { - //If check is false then , we will allow create menu - if (data && data.check == false) - return true; - - var t = pgBrowser.tree, i = item, d = itemData; - // To iterate over tree to check parent node - while (i) { - // If it is schema then allow user to create domain - if (_.indexOf(['schema'], d._type) > -1) - return true; - - if ('coll-domain' == d._type) { - //Check if we are not child of catalog - var prev_i = t.hasParent(i) ? t.parent(i) : null, - prev_d = prev_i ? t.itemData(prev_i) : null; - if( prev_d._type == 'catalog') { - return false; - } else { - return true; - } - } - i = t.hasParent(i) ? t.parent(i) : null; - d = i ? t.itemData(i) : null; - } - // by default we do not want to allow create menu - return true; + return canCreate.canCreate(pgBrowser, 'coll-domain', item, data); }This refactor was made in a couple of places throughout the code.
Another refactor that had to be done was the creation of the functions
getTreeNodeHierarchyFromElementandgetTreeNodeHierarchyFromIdentifierthat replace the oldgetTreeNodeHierarchy. This implementation was done
because for the time being we have 2 different types of trees and calls to them.The rest of the changes resulted from our process of refactoring that we are following:
- Find a location where
itemDatais used- Extract that into a function outside of the current code
- Wrap it with tests
- When we have enough confidence on the tests, we refactor the function to use the new Tree
- We refactor the function to become more readable
- Start over
0004 Architecture
The proposed structure is our vision for the application, this is not the state we will be in when this patch lands.
For now the only change we are doing is move the javascript intostatic/js/FEATURE_NAME. This is a first step in the
direction that we would like to see the product heading.Even if we decide to keep using the same architecture the move of Javascript to a centralized place will
not break any plugability as webpack can retrieve all the Javascript from any place in the code.Have a nice weekend
Joao--Akshay JoshiSr. Software ArchitectPhone: +91 20-3058-9517
Mobile: +91 976-788-8246
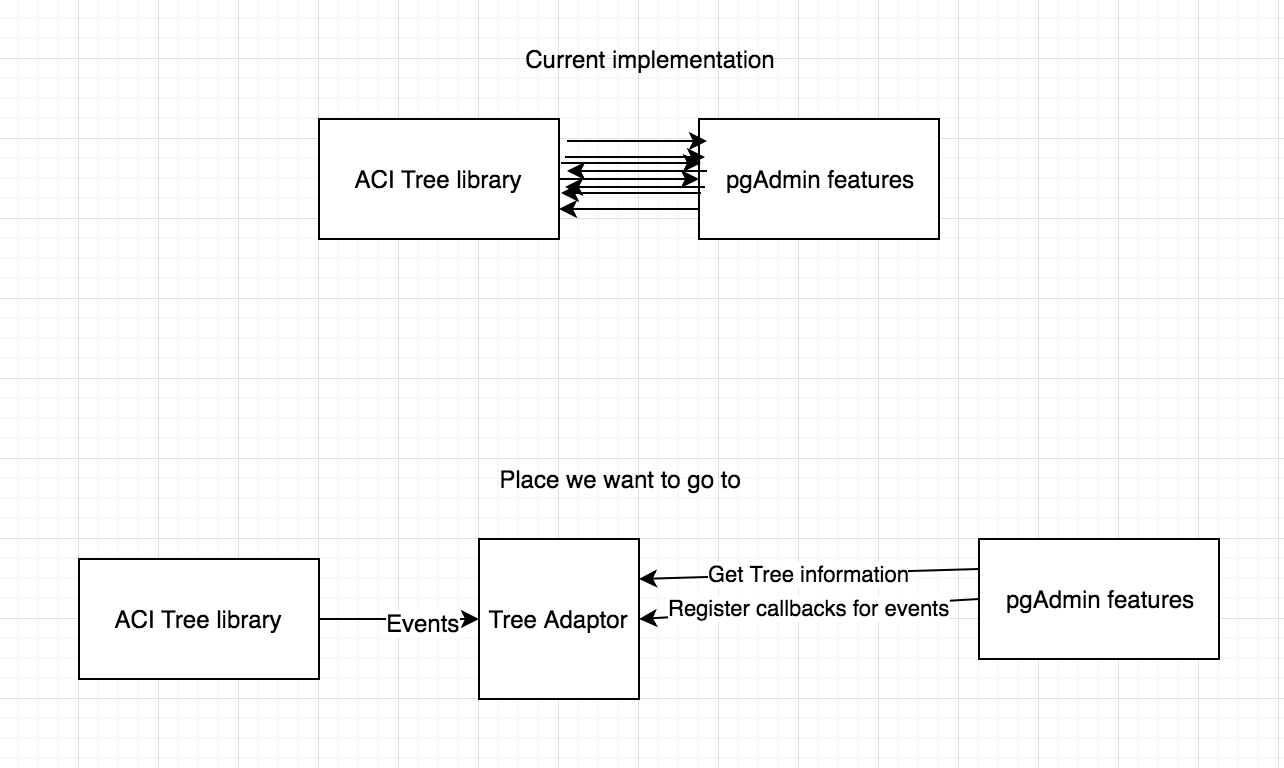
Attachment
Hi HackersThere were very good points raised. Do you think that these are blockers for 0001, 0002, and 0003 getting committed? In general, we felt like there were points made about very specific issues, were there any broader concerns about the patches? We don't need an agreement on architecture yet for patches 0001, 0002, and 0003.
Patch 0003 - I have some concerns regarding the approach taken to separate out the PG utilities. The dialogue factory is responsible for creating the dialogue which uses dialogue wrapper. So, any module should call the dialogue factory to create a new dialogue instance. Here dialogue itself call the dialogue factory for creating it.We did not fully understand what your concern is on this point.If you are concerned that we have a dialogWrapper and a dialog class and don't understand the difference between the two?We don't feel too strongly about this decision. It seemed easier at the time (to test) because the wrapper represents what will be passed into the alertify library. We're certainly open to having this implementation change in the future.In the enable_disable_triggers.js file, can we just import alertifyjs instead of passing in all the functions?We made this decision to make testing of the functionality easier to test, by using a principle called dependency injection. https://martinfowler.com/articles/injection.html. If we import alertifyjs directly, then we can't stub out its functionality. Patch 0004 - Right now with the new proposed architecture only JS files are re-arranged. To maintain the pluggability I would also like to have some discussion on the back end side. Right now, the code maintains everything. Let say I want to add any node under schema I will just drop the related folder and files in that hierarchy and it will work. But with the proposed architecture I can not visualize the backend architecture and this should not be ended with only JS restructuring.This patch in fact only moves Javascript files from one folder structure to a different folder structure. The process we are following is an iterative process and will be built upon itself. The end vision that we have for the product is as depicted in the previous email an Intent Driven Structure and in this structure each folder will contain a Feature that will be self contained (Backend + Frontend). The major difference between what we have now and what we envision this application to look like is that these folders can live at the same level so that we know at a glance what this application is capable of doing. This structure will also make it easier to onboard someone that is looking to help building any feature because they will have access to all of the features in the "same screen" instead of having to do a deep dive into the application code in order to find the place to start.As of right now we haven't though very deep on the backend side of things. But looking at the current structure moving from a hierarchical file structure into a horizontal one, doesn't look like a lot of plumbing. Nevertheless this is something that we should address when we get there and we believe we are not there yet.In menu/can_create.js, "parentCatalogOfTableChild" function name is unable to understand. The intent behind this function is to retrieve all the tree child node that matches a given type argument and has a direct parent of the catalog type. The name was in a hurry and could certainly be improved. Any suggestions are welcome. How about **matchesTypeAndHasCatalogParent(self, arg)**? Below code is bit confusing in terms of naming convention canCreate.canCreate inside "canCreate".That sounds great. Let's do that.Why we have "menu_utils.js" for Backup, Maintenance, Restore and Grant Wizard? Can we have one single file with all the supported node for respective module?It was for expressing developer intent. The menu_utils.js that were placed in discrete packages have functionality that pertain only to its package. If we thought that the functionality were shared, we wouldn't have put them in the shared folder `pgadmin4/web/pgadmin/static/js/menu/...` Also I have seen that the folder hierarchy for grant wizard is "/web/pgadmin/static/js/grant/wizard/menu_utils.js" why there are two separate folders grant and wizard (sub folder of grant)? It makes sense to think of the wizard as separate entity from grants. You could imagine that when we add additional functionality for grants, that we'd want it alongside the wizard functionality. You could call it premature at this point.We understand that our vision for the application is quite bold and if we, as a community, decide that this is the way to go it is going to take some time to accomplish and will involve effort. But we believe this will take the code into a better place.Patches 1,2 and 3 are our priority at this point, because there are features that we want to implement that depend on the separation from ACI Tree, and we would like to see these in master as soon as possible.Joao and AnthonyHi JoaoBelow are my review comments:
- In menu/can_create.js, "parent
CatalogOfTableChild" function name is unable to understand. - Below code is bit confusing in terms of naming convention canCreate.canCreate inside "canCreate".
canCreate: function(itemData, item, data) {return canCreate.canCreate(pgBrowser, 'coll-collation', item, data);}Can we have something like "menuCreator.canCreate"?
- Why we have "menu_utils.js" for Backup, Maintenance, Restore and Grant Wizard? Can we have one single file with all the supported node for respective module? Also I have seen that the folder hierarchy for grant wizard is "/web/pgadmin/static/js/grant/
wizard/menu_utils.js" why there are two separate folders grant and wizard (sub folder of grant)? On Wed, May 9, 2018 at 4:32 PM, Khushboo Vashi <khushboo.vashi@enterprisedb.com> wrote: Hi Joao,Patch 0001 & 0002 (esp the new tree implementation) look good to me.Patch 0003 - I have some concerns regarding the approach taken to separate out the PG utilities. The dialogue factory is responsible for creating the dialogue which uses dialogue wrapper. So, any module should call the dialogue factory to create a new dialogue instance. Here dialogue itself call the dialogue factory for creating it.In the enable_disable_triggers.js file, can we just import alertifyjs instead of passing in all the functions?Patch 0004 - Right now with the new proposed architecture only JS files are re-arranged. To maintain the pluggability I would also like to have some discussion on the back end side. Right now, the code maintains everything. Let say I want to add any node under schema I will just drop the related folder and files in that hierarchy and it will work. But with the proposed architecture I can not visualize the backend architecture and this should not be ended with only JS restructuring.Thanks,KhushbooOn Tue, May 8, 2018 at 12:31 AM, Joao De Almeida Pereira <jdealmeidapereira@pivotal.io> wrote:Hi Hackers,We noticed that some of the latest changes created some conflicts with this patch. So you can find attached the patch rebased on the new master.ThanksVictoria && JoaoOn Fri, May 4, 2018 at 6:03 PM Joao De Almeida Pereira <jdealmeidapereira@pivotal.io> wrote:And now the patches......On Fri, May 4, 2018 at 6:01 PM Joao De Almeida Pereira <jdealmeidapereira@pivotal.io> wrote:Hi Hackers,
Be prepared this is going to be a big email.
Objectives of this patch:
- Start the work to split ACI from pgAdmin code
- Add more tests around the front end components
- Start the discussion on application architecture
1. Start the work to split ACI from pgAdmin code
Why
This journey started on our first attempt to store state of the current tree, so that when a user accessed again pgAdmin
there would be no need to reopen all the nodes and make the flow better. Another problem users brought to us was related
to the UI behavior when the number of objects was too big.In order to do implement this features we would have to play around with aciTree or some functions from our code that
called and leveraged the aciTree functionalities. To do this we needed to have some confidence that our changes would
implement correctly the new feature and it would not break the current functionality.
The process that we used was first extract the functions that interacted with the tree, wrap them with
tests and then refactor them in some way. While doing this work we realized that the tree started spreading roots
throughout the majority of the application.How
Options:
- Rewrite the front end
- One bang replace ACI Tree without change on the application
- Create an abstraction layer between ACI Tree and the application
1. Rewrite the front end
Pros Const Achieve decoupling by recreating the frontend Cost is too high Do not rely on deprecated or unmaintained libraries Turn around is too long One shot change 2. One bang replace ACI Tree
Pros Const Achieve decoupling by recreating the frontend Cost is too high Does not achieve the decoupling unless we change the application Need to create an adaptor No garantee of success One shot change 3. Create an abstraction layer between ACI Tree and the application
Pros Const Achieve decoupling of the application and the tree 90% of the time on Code archaeology Lower cost Ability to change or keep ACI Tree, decision TBD Can be done in a iterative way We decided that options 3 looked more attractive specially because we could do it in a iterative way.
The next image depicts the current state of the interactions between the application and the ACI and the place we want
to be in.
for retrieving of data from the ACI Tree that then is used in different ways.
Because we are doing this in a iterative process we need to keep the current tree working and create our adaptor next
to it. In order to do that we created a new property onPGBrowserclass calledtreeMenuand when ACI Tree receives
the node information we also populate the new Tree with all the needed information.This approach allow us not to worry, for now, with data retrieval, URL system and other issues that should be addressed
in the future when the adaptor is done.This first patch tries to deal with the low hanging fruit, functions that are triggered by events from ACI Tree.
Cases like registering to events and triggering events need to be handled in the future as well.2. Add more tests around the front end components
Why
Go Fast Forever: https://builttoadapt.io/why-td
d-489fdcdda05e
I think this is a very good summary of why do we need tests in our applications.3. Start the discussion on application architecture
Why should we care about location of files inside a our application?
Why is this way better the another?
These are 2 good questions that have very lengthy answers. Trying to more or less summarize the answers we care about
the location of the files, because we want our application to communicate intent and there are always pros and cons
on all the decisions that we make.At this point the application structure follows our menu, this approach eventually make is easier to follow the code
but at the same time if the menu changes down the line, will we change the structure of our folders?The proposal that we do with the last diff of this patch is to change to a structure that slices vertically the
application. This way we can understand intent behind the code and more easily find what we are looking for.In the current structure if you want to see the tables code you need to go to
pgAdmin/browser/server_groups/this is a huge path to remember and to get to. Whatservers/databases/schemas/tabl es/
do we win with this? If we open pgAdmin we know which nodes to click in order to get to tables. But for development
every time that you are looking for a specific functionality you need to run the application, navigate the menu so that
you know where you can find the code. This doesn’t sound very appealing.What if our structure would look like this:
- web - tables - controller - get_nodes.py - get_sql.py - __init__.py - frontend - component - ddl_component.js - services - table-service.js - schemas - servers - ....This would saves us time because all the information that we need is what are we working on and everything is right there.
Menu driven structure Intent Driven Structure Pros: Pros: Already in place Explicitly shows features Self contained features Self contained features Support for drop in features Support for drop in features Cons: Cons: Follows the menu, and it could change Need to change current code Hard to find features Some additional plumbing might be needed Drop in features need to be placed in a specific location according to the menu location What are your thought about this architecture?
Around minute 7 of this video Uncle Bob shows an application written
in rails to talk about architecture. It is a long KeyNote if you are curious I would advise you to see the full video.
His approach to architecture of the application is pretty interesting.Patches
0001 Change the order of the shims on the shim file
Simple change that orders the shims inside the shim file
0002 New tree implementation
This is the first version of our Tree implementation. At this point is a very simple tree without no abstractions and
with code that eventually is not very performant, but this is only the first iteration and we are trying to follow the
Last Responsible Moment Principle.What can you find in this patch:
- Creation of
PGBrowser.treeMenu- Initial version of the Tree Adaptor
web/pgadmin/static/js/tree/tree.js - TreeFake test double that can replace the Tree for testing purposes
- Tests. As an interesting asside because Fake’s need to behave like the real object you will noticed that there are
tests for this type of double and they the same as of the real object.0003 Extract, Test and Refactor Methods
This is the patch that contains the change that we talked a in the objectives. It touches in a subset of the places
whereitemDatafunction is called. To have a sense of progress the following image depicts, on the left all places
where this functions can be found in the code and on the right the places where it still remains after this patch.But this patch is not only related to the ACI Tree, it also creates some abstractions from code that we found repeated.
Some examples of this are the dialogs for Backup and Restore, where the majority of the logic was common, so we created
inweb/pgadmin/static/js/alertify3 different objects:/
A FactoryDialogFactorythat is responsible for creating newDialogand these dialogs will use theDialogWrapper.This is also a good example of the Last Responsible Moment Principle,
inDialogthere are still some functions that are used in a Recover and Backup scenario. When we have more examples
we will be able to, if we want, to extract that into another function.While doing some code refactoring we found out that the Right Click Menu as some checks that can be centralized. Examples
of these are checks for Enable/Disable of an option of the display of the Create/Edit/Drop option in some menus.
Checkweb/pgadmin/static/js/menu/for more information. This simplified code like:canCreate: function(itemData, item, data) { - //If check is false then , we will allow create menu - if (data && data.check == false) - return true; - - var t = pgBrowser.tree, i = item, d = itemData; - // To iterate over tree to check parent node - while (i) { - // If it is schema then allow user to create domain - if (_.indexOf(['schema'], d._type) > -1) - return true; - - if ('coll-domain' == d._type) { - //Check if we are not child of catalog - var prev_i = t.hasParent(i) ? t.parent(i) : null, - prev_d = prev_i ? t.itemData(prev_i) : null; - if( prev_d._type == 'catalog') { - return false; - } else { - return true; - } - } - i = t.hasParent(i) ? t.parent(i) : null; - d = i ? t.itemData(i) : null; - } - // by default we do not want to allow create menu - return true; + return canCreate.canCreate(pgBrowser, 'coll-domain', item, data); }This refactor was made in a couple of places throughout the code.
Another refactor that had to be done was the creation of the functions
getTreeNodeHierarchyFromElemenandt getTreeNodeHierarchyFromIdentithat replace the oldfier getTreeNodeHierarchy. This implementation was done
because for the time being we have 2 different types of trees and calls to them.The rest of the changes resulted from our process of refactoring that we are following:
- Find a location where
itemDatais used- Extract that into a function outside of the current code
- Wrap it with tests
- When we have enough confidence on the tests, we refactor the function to use the new Tree
- We refactor the function to become more readable
- Start over
0004 Architecture
The proposed structure is our vision for the application, this is not the state we will be in when this patch lands.
For now the only change we are doing is move the javascript intostatic/js/FEATURE_NAME. This is a first step in the
direction that we would like to see the product heading.Even if we decide to keep using the same architecture the move of Javascript to a centralized place will
not break any plugability as webpack can retrieve all the Javascript from any place in the code.Have a nice weekend
Joao--Akshay JoshiSr. Software ArchitectPhone: +91 20-3058-9517
Mobile: +91 976-788-8246
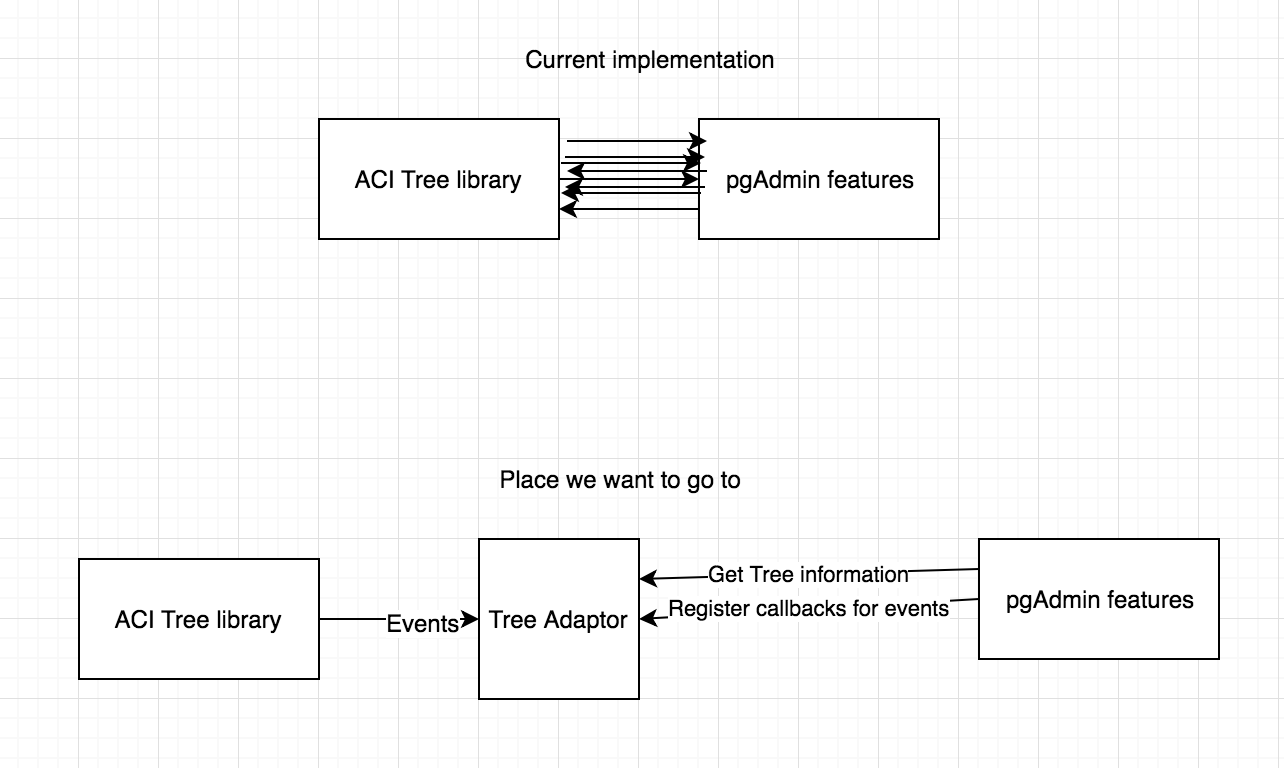
Attachment
1. In TreeNode, we're keepging the reference of DOMElement, do we really need it?
As of right now, our Tree abstraction acts as an adapter to the aciTree library. The aciTree library needs the domElement for most of its functions (setInode, unload, etc). Thus this is the easiest way to introduce our abstraction and keep the functionality as before - at least until we decide that whether we want to switch out the library or not.
2. Are you expecting the tree class to be a singleton class
Since this tree is referenced throughout the codebase, considering it to be a singleton seems like the most appropriate pattern for this usecase. It is very much the same way how we create a single instance of the aciTree library and use that throughout the codebase. Moreover, it opens up opportunities to improve performance, for example caching lockups of nodes. I’m not a fan of singletons myself, but I feel like we’re simply keeping the architecture the same in the instance.
Attachment
1. In TreeNode, we're keepging the reference of DOMElement, do we really need it?As of right now, our
Treeabstraction acts as an adapter to the aciTree library. The aciTree library needs the domElement for most of its functions (setInode, unload, etc). Thus this is the easiest way to introduce our abstraction and keep the functionality as before - at least until we decide that whether we want to switch out the library or not.
2. Are you expecting the tree class to be a singleton classSince this tree is referenced throughout the codebase, considering it to be a singleton seems like the most appropriate pattern for this usecase. It is very much the same way how we create a single instance of the aciTree library and use that throughout the codebase. Moreover, it opens up opportunities to improve performance, for example caching lockups of nodes. I’m not a fan of singletons myself, but I feel like we’re simply keeping the architecture the same in the instance.
Sincerely,Anthony and Victoria
1. In TreeNode, we're keepging the reference of DOMElement, do we really need it?As of right now, ourTreeabstraction acts as an adapter to the aciTree library. The aciTree library needs the domElement for most of its functions (setInode, unload, etc). Thus this is the easiest way to introduce our abstraction and keep the functionality as before - at least until we decide that whether we want to switch out the library or not.
I understand that. But - I've not seen any reference of domElement the code yet, hence - pointed that out.
If you look at the function: reload, unload you will see that domNode is used to communicate with the ACITree
2. Are you expecting the tree class to be a singleton classSince this tree is referenced throughout the codebase, considering it to be a singleton seems like the most appropriate pattern for this usecase. It is very much the same way how we create a single instance of the aciTree library and use that throughout the codebase. Moreover, it opens up opportunities to improve performance, for example caching lockups of nodes. I’m not a fan of singletons myself, but I feel like we’re simply keeping the architecture the same in the instance.
Yeah - I don't see any usage of tree object from anywhere.
And, we're already creating new object in browser.js (and, not utitlizing that instance anywhere.)
You are right, we do not need to export tree as a singleton for now. The line that exports the variable tree can be remove when applying the patch number 2.
On Thu, May 10, 2018 at 8:08 PM, Anthony Emengo <aemengo@pivotal.io> wrote:1. In TreeNode, we're keepging the reference of DOMElement, do we really need it?As of right now, our
Treeabstraction acts as an adapter to the aciTree library. The aciTree library needs the domElement for most of its functions (setInode, unload, etc). Thus this is the easiest way to introduce our abstraction and keep the functionality as before - at least until we decide that whether we want to switch out the library or not.I understand that. But - I've not seen any reference of domElement the code yet, hence - pointed that out.2. Are you expecting the tree class to be a singleton classSince this tree is referenced throughout the codebase, considering it to be a singleton seems like the most appropriate pattern for this usecase. It is very much the same way how we create a single instance of the aciTree library and use that throughout the codebase. Moreover, it opens up opportunities to improve performance, for example caching lockups of nodes. I’m not a fan of singletons myself, but I feel like we’re simply keeping the architecture the same in the instance.
Yeah - I don't see any usage of tree object from anywhere.And, we're already creating new object in browser.js (and, not utitlizing that instance anywhere.)-- Thanks, AsheshSincerely,Anthony and Victoria
Hello Ashesh,1. In TreeNode, we're keepging the reference of DOMElement, do we really need it?As of right now, ourTreeabstraction acts as an adapter to the aciTree library. The aciTree library needs the domElement for most of its functions (setInode, unload, etc). Thus this is the easiest way to introduce our abstraction and keep the functionality as before - at least until we decide that whether we want to switch out the library or not.I understand that. But - I've not seen any reference of domElement the code yet, hence - pointed that out.If you look at the function:
reload,unloadyou will see thatdomNodeis used to communicate with the ACITree2. Are you expecting the tree class to be a singleton classSince this tree is referenced throughout the codebase, considering it to be a singleton seems like the most appropriate pattern for this usecase. It is very much the same way how we create a single instance of the aciTree library and use that throughout the codebase. Moreover, it opens up opportunities to improve performance, for example caching lockups of nodes. I’m not a fan of singletons myself, but I feel like we’re simply keeping the architecture the same in the instance.Yeah - I don't see any usage of tree object from anywhere.
And, we're already creating new object in browser.js (and, not utitlizing that instance anywhere.)You are right, we do not need to export tree as a singleton for now. The line that exports the variable
treecan be remove when applying the patch number 2.I think we addressed all the concern raised about this patch. Does this mean that the patch is going to get committed?
We are looking forward to continue the development on this track of work, but as you know, we are blocked until it gets committed into master. We hope that this gets unblocked soon because this is a very big track of work and the longer it is blocked, the longer it will take to get finalized.ThanksJoaoOn Fri, May 11, 2018 at 2:32 AM Ashesh Vashi <ashesh.vashi@enterprisedb.com> wrote:On Thu, May 10, 2018 at 8:08 PM, Anthony Emengo <aemengo@pivotal.io> wrote:1. In TreeNode, we're keepging the reference of DOMElement, do we really need it?As of right now, our
Treeabstraction acts as an adapter to the aciTree library. The aciTree library needs the domElement for most of its functions (setInode, unload, etc). Thus this is the easiest way to introduce our abstraction and keep the functionality as before - at least until we decide that whether we want to switch out the library or not.I understand that. But - I've not seen any reference of domElement the code yet, hence - pointed that out.2. Are you expecting the tree class to be a singleton classSince this tree is referenced throughout the codebase, considering it to be a singleton seems like the most appropriate pattern for this usecase. It is very much the same way how we create a single instance of the aciTree library and use that throughout the codebase. Moreover, it opens up opportunities to improve performance, for example caching lockups of nodes. I’m not a fan of singletons myself, but I feel like we’re simply keeping the architecture the same in the instance.
Yeah - I don't see any usage of tree object from anywhere.And, we're already creating new object in browser.js (and, not utitlizing that instance anywhere.)-- Thanks, AsheshSincerely,Anthony and Victoria
On Sat, May 12, 2018, 02:58 Joao De Almeida Pereira <jdealmeidapereira@pivotal.io> wrote:Hello Ashesh,1. In TreeNode, we're keepging the reference of DOMElement, do we really need it?As of right now, ourTreeabstraction acts as an adapter to the aciTree library. The aciTree library needs the domElement for most of its functions (setInode, unload, etc). Thus this is the easiest way to introduce our abstraction and keep the functionality as before - at least until we decide that whether we want to switch out the library or not.I understand that. But - I've not seen any reference of domElement the code yet, hence - pointed that out.If you look at the function:
reload,unloadyou will see thatdomNodeis used to communicate with the ACITree2. Are you expecting the tree class to be a singleton classSince this tree is referenced throughout the codebase, considering it to be a singleton seems like the most appropriate pattern for this usecase. It is very much the same way how we create a single instance of the aciTree library and use that throughout the codebase. Moreover, it opens up opportunities to improve performance, for example caching lockups of nodes. I’m not a fan of singletons myself, but I feel like we’re simply keeping the architecture the same in the instance.Yeah - I don't see any usage of tree object from anywhere.
And, we're already creating new object in browser.js (and, not utitlizing that instance anywhere.)You are right, we do not need to export tree as a singleton for now. The line that exports the variable
treecan be remove when applying the patch number 2.I think we addressed all the concern raised about this patch. Does this mean that the patch is going to get committed?Yes - from me for 0002.
Blog: http://pgsnake.blogspot.com
Twitter: @pgsnake
EnterpriseDB UK: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
On Sat, May 12, 2018 at 12:10 AM, Ashesh Vashi <ashesh.vashi@enterprisedb.com> wrote: On Sat, May 12, 2018, 02:58 Joao De Almeida Pereira <jdealmeidapereira@pivotal.io> wrote:Hello Ashesh,1. In TreeNode, we're keepging the reference of DOMElement, do we really need it?As of right now, ourTreeabstraction acts as an adapter to the aciTree library. The aciTree library needs the domElement for most of its functions (setInode, unload, etc). Thus this is the easiest way to introduce our abstraction and keep the functionality as before - at least until we decide that whether we want to switch out the library or not.I understand that. But - I've not seen any reference of domElement the code yet, hence - pointed that out.If you look at the function:
reload,unloadyou will see thatdomNodeis used to communicate with the ACITree2. Are you expecting the tree class to be a singleton classSince this tree is referenced throughout the codebase, considering it to be a singleton seems like the most appropriate pattern for this usecase. It is very much the same way how we create a single instance of the aciTree library and use that throughout the codebase. Moreover, it opens up opportunities to improve performance, for example caching lockups of nodes. I’m not a fan of singletons myself, but I feel like we’re simply keeping the architecture the same in the instance.Yeah - I don't see any usage of tree object from anywhere.
And, we're already creating new object in browser.js (and, not utitlizing that instance anywhere.)You are right, we do not need to export tree as a singleton for now. The line that exports the variable
treecan be remove when applying the patch number 2.I think we addressed all the concern raised about this patch. Does this mean that the patch is going to get committed?Yes - from me for 0002.Can you do that today?
--Dave Page
Blog: http://pgsnake.blogspot.com
Twitter: @pgsnake
EnterpriseDB UK: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
On Mon, May 14, 2018 at 2:59 PM, Dave Page <dpage@pgadmin.org> wrote:On Sat, May 12, 2018 at 12:10 AM, Ashesh Vashi <ashesh.vashi@enterprisedb.com> wrote: On Sat, May 12, 2018, 02:58 Joao De Almeida Pereira <jdealmeidapereira@pivotal.io> wrote:Hello Ashesh,1. In TreeNode, we're keepging the reference of DOMElement, do we really need it?As of right now, ourTreeabstraction acts as an adapter to the aciTree library. The aciTree library needs the domElement for most of its functions (setInode, unload, etc). Thus this is the easiest way to introduce our abstraction and keep the functionality as before - at least until we decide that whether we want to switch out the library or not.I understand that. But - I've not seen any reference of domElement the code yet, hence - pointed that out.If you look at the function:
reload,unloadyou will see thatdomNodeis used to communicate with the ACITree2. Are you expecting the tree class to be a singleton classSince this tree is referenced throughout the codebase, considering it to be a singleton seems like the most appropriate pattern for this usecase. It is very much the same way how we create a single instance of the aciTree library and use that throughout the codebase. Moreover, it opens up opportunities to improve performance, for example caching lockups of nodes. I’m not a fan of singletons myself, but I feel like we’re simply keeping the architecture the same in the instance.Yeah - I don't see any usage of tree object from anywhere.
And, we're already creating new object in browser.js (and, not utitlizing that instance anywhere.)You are right, we do not need to export tree as a singleton for now. The line that exports the variable
treecan be remove when applying the patch number 2.I think we addressed all the concern raised about this patch. Does this mean that the patch is going to get committed?Yes - from me for 0002.Can you do that today?Done.
Blog: http://pgsnake.blogspot.com
Twitter: @pgsnake
EnterpriseDB UK: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
On Mon, May 14, 2018 at 1:38 PM, Ashesh Vashi <ashesh.vashi@enterprisedb.com> wrote: On Mon, May 14, 2018 at 2:59 PM, Dave Page <dpage@pgadmin.org> wrote:On Sat, May 12, 2018 at 12:10 AM, Ashesh Vashi <ashesh.vashi@enterprisedb.com> wrote: On Sat, May 12, 2018, 02:58 Joao De Almeida Pereira <jdealmeidapereira@pivotal.io> wrote:Hello Ashesh,1. In TreeNode, we're keepging the reference of DOMElement, do we really need it?As of right now, ourTreeabstraction acts as an adapter to the aciTree library. The aciTree library needs the domElement for most of its functions (setInode, unload, etc). Thus this is the easiest way to introduce our abstraction and keep the functionality as before - at least until we decide that whether we want to switch out the library or not.I understand that. But - I've not seen any reference of domElement the code yet, hence - pointed that out.If you look at the function:
reload,unloadyou will see thatdomNodeis used to communicate with the ACITree2. Are you expecting the tree class to be a singleton classSince this tree is referenced throughout the codebase, considering it to be a singleton seems like the most appropriate pattern for this usecase. It is very much the same way how we create a single instance of the aciTree library and use that throughout the codebase. Moreover, it opens up opportunities to improve performance, for example caching lockups of nodes. I’m not a fan of singletons myself, but I feel like we’re simply keeping the architecture the same in the instance.Yeah - I don't see any usage of tree object from anywhere.
And, we're already creating new object in browser.js (and, not utitlizing that instance anywhere.)You are right, we do not need to export tree as a singleton for now. The line that exports the variable
treecan be remove when applying the patch number 2.I think we addressed all the concern raised about this patch. Does this mean that the patch is going to get committed?Yes - from me for 0002.Can you do that today?Done.Great, thanks!On to patch 0003 then :-)
--Dave Page
Blog: http://pgsnake.blogspot.com
Twitter: @pgsnake
EnterpriseDB UK: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
On Mon, May 14, 2018 at 6:10 PM, Dave Page <dpage@pgadmin.org> wrote:On Mon, May 14, 2018 at 1:38 PM, Ashesh Vashi <ashesh.vashi@enterprisedb.com> wrote: On Mon, May 14, 2018 at 2:59 PM, Dave Page <dpage@pgadmin.org> wrote:On Sat, May 12, 2018 at 12:10 AM, Ashesh Vashi <ashesh.vashi@enterprisedb.com> wrote: On Sat, May 12, 2018, 02:58 Joao De Almeida Pereira <jdealmeidapereira@pivotal.io> wrote:Hello Ashesh,1. In TreeNode, we're keepging the reference of DOMElement, do we really need it?As of right now, ourTreeabstraction acts as an adapter to the aciTree library. The aciTree library needs the domElement for most of its functions (setInode, unload, etc). Thus this is the easiest way to introduce our abstraction and keep the functionality as before - at least until we decide that whether we want to switch out the library or not.I understand that. But - I've not seen any reference of domElement the code yet, hence - pointed that out.If you look at the function:
reload,unloadyou will see thatdomNodeis used to communicate with the ACITree2. Are you expecting the tree class to be a singleton classSince this tree is referenced throughout the codebase, considering it to be a singleton seems like the most appropriate pattern for this usecase. It is very much the same way how we create a single instance of the aciTree library and use that throughout the codebase. Moreover, it opens up opportunities to improve performance, for example caching lockups of nodes. I’m not a fan of singletons myself, but I feel like we’re simply keeping the architecture the same in the instance.Yeah - I don't see any usage of tree object from anywhere.
And, we're already creating new object in browser.js (and, not utitlizing that instance anywhere.)You are right, we do not need to export tree as a singleton for now. The line that exports the variable
treecan be remove when applying the patch number 2.I think we addressed all the concern raised about this patch. Does this mean that the patch is going to get committed?Yes - from me for 0002.Can you do that today?Done.Great, thanks!On to patch 0003 then :-)Yes - already working on it! :-)
-- Thanks, Ashesh--Dave Page
Blog: http://pgsnake.blogspot.com
Twitter: @pgsnake
EnterpriseDB UK: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
Attachment
Can you explain the reasoning behind the change you did on the canCreate function?
Bind creates a new instance of a function, do we really need that?isValidTreeNodeData- If it is not Null or Undefined it really means that the data is Valid? Shouldn’t it be
isDataDefined? - This looks like a generic function that could be used with objects of any type not specific to TreeNodeData. So the file location doesn’t look correct.
- If it is not Null or Undefined it really means that the data is Valid? Shouldn’t it be
The tree folder is just a Tree that we use to store information. The menu uses a Tree but the 2 things should be separated.
In our point of view the current entanglement of the ACITree into our code came from missing concepts into a single place (Menu + Storage of information).
The idea behind having the Tree as a separate block was to ensure that we do not have the Menu and Tree coupling.supportedNodesMenu.enabledwhat it does it check if a Node Menu should be enabled or not. The name of it maybe should benodeMenu.enabled?
Hi Joao,On Mon, May 14, 2018 at 6:11 PM, Ashesh Vashi <ashesh.vashi@enterprisedb.com> wrote:On Mon, May 14, 2018 at 6:10 PM, Dave Page <dpage@pgadmin.org> wrote:On Mon, May 14, 2018 at 1:38 PM, Ashesh Vashi <ashesh.vashi@enterprisedb.com> wrote:On Mon, May 14, 2018 at 2:59 PM, Dave Page <dpage@pgadmin.org> wrote:On Sat, May 12, 2018 at 12:10 AM, Ashesh Vashi <ashesh.vashi@enterprisedb.com> wrote:On Sat, May 12, 2018, 02:58 Joao De Almeida Pereira <jdealmeidapereira@pivotal.io> wrote:Hello Ashesh,1. In TreeNode, we're keepging the reference of DOMElement, do we really need it?As of right now, ourTreeabstraction acts as an adapter to the aciTree library. The aciTree library needs the domElement for most of its functions (setInode, unload, etc). Thus this is the easiest way to introduce our abstraction and keep the functionality as before - at least until we decide that whether we want to switch out the library or not.I understand that. But - I've not seen any reference of domElement the code yet, hence - pointed that out.If you look at the function:
reload,unloadyou will see thatdomNodeis used to communicate with the ACITree2. Are you expecting the tree class to be a singleton classSince this tree is referenced throughout the codebase, considering it to be a singleton seems like the most appropriate pattern for this usecase. It is very much the same way how we create a single instance of the aciTree library and use that throughout the codebase. Moreover, it opens up opportunities to improve performance, for example caching lockups of nodes. I’m not a fan of singletons myself, but I feel like we’re simply keeping the architecture the same in the instance.Yeah - I don't see any usage of tree object from anywhere.
And, we're already creating new object in browser.js (and, not utitlizing that instance anywhere.)You are right, we do not need to export tree as a singleton for now. The line that exports the variable
treecan be remove when applying the patch number 2.I think we addressed all the concern raised about this patch. Does this mean that the patch is going to get committed?Yes - from me for 0002.Can you do that today?Done.Great, thanks!On to patch 0003 then :-)Yes - already working on it! :-)Majority part of the 0003 patch looks good to me.Except choice of the path of some of the file, and name of the functions.Please find the updated patch.I've moved files under the 'pgadmin/static/js/menu' directory under the 'pgadmin/static/js/tree', as they're using tree functionalities directly.Please review it, and let me know your concern.-- Thanks, Ashesh-- Thanks, Ashesh--Dave Page
Blog: http://pgsnake.blogspot.com
Twitter: @pgsnake
EnterpriseDB UK: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
Hello Ashesh,These are our comments to the patch:
Can you explain the reasoning behind the change you did on the canCreate function?
Bind creates a new instance of a function, do we really need that?
isValidTreeNodeData
- If it is not Null or Undefined it really means that the data is Valid? Shouldn’t it be
isDataDefined?- This looks like a generic function that could be used with objects of any type not specific to TreeNodeData. So the file location doesn’t look correct.
- The tree folder is just a Tree that we use to store information. The menu uses a Tree but the 2 things should be separated.
In our point of view the current entanglement of the ACITree into our code came from missing concepts into a single place (Menu + Storage of information).
The idea behind having the Tree as a separate block was to ensure that we do not have the Menu and Tree coupling.
supportedNodesMenu.enabledwhat it does it check if a Node Menu should be enabled or not. The name of it maybe should benodeMenu.enabled?
ThanksVictoria & JoaoHi Joao,On Mon, May 14, 2018 at 6:11 PM, Ashesh Vashi <ashesh.vashi@enterprisedb.com> wrote: On Mon, May 14, 2018 at 6:10 PM, Dave Page <dpage@pgadmin.org> wrote:On Mon, May 14, 2018 at 1:38 PM, Ashesh Vashi <ashesh.vashi@enterprisedb.com> wrote: On Mon, May 14, 2018 at 2:59 PM, Dave Page <dpage@pgadmin.org> wrote:On Sat, May 12, 2018 at 12:10 AM, Ashesh Vashi <ashesh.vashi@enterprisedb.com> wrote: On Sat, May 12, 2018, 02:58 Joao De Almeida Pereira <jdealmeidapereira@pivotal.io> wrote:Hello Ashesh,1. In TreeNode, we're keepging the reference of DOMElement, do we really need it?As of right now, ourTreeabstraction acts as an adapter to the aciTree library. The aciTree library needs the domElement for most of its functions (setInode, unload, etc). Thus this is the easiest way to introduce our abstraction and keep the functionality as before - at least until we decide that whether we want to switch out the library or not.I understand that. But - I've not seen any reference of domElement the code yet, hence - pointed that out.If you look at the function:
reload,unloadyou will see thatdomNodeis used to communicate with the ACITree2. Are you expecting the tree class to be a singleton classSince this tree is referenced throughout the codebase, considering it to be a singleton seems like the most appropriate pattern for this usecase. It is very much the same way how we create a single instance of the aciTree library and use that throughout the codebase. Moreover, it opens up opportunities to improve performance, for example caching lockups of nodes. I’m not a fan of singletons myself, but I feel like we’re simply keeping the architecture the same in the instance.Yeah - I don't see any usage of tree object from anywhere.
And, we're already creating new object in browser.js (and, not utitlizing that instance anywhere.)You are right, we do not need to export tree as a singleton for now. The line that exports the variable
treecan be remove when applying the patch number 2.I think we addressed all the concern raised about this patch. Does this mean that the patch is going to get committed?Yes - from me for 0002.Can you do that today?Done.Great, thanks!On to patch 0003 then :-)Yes - already working on it! :-)Majority part of the 0003 patch looks good to me.Except choice of the path of some of the file, and name of the functions.Please find the updated patch.I've moved files under the 'pgadmin/static/js/menu' directory under the 'pgadmin/static/js/tree', as they're using tree functionalities directly.Please review it, and let me know your concern.-- Thanks, Ashesh-- Thanks, Ashesh--Dave Page
Blog: http://pgsnake.blogspot.com
Twitter: @pgsnake
EnterpriseDB UK: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
export function canCreate(pgBrowser, childOfCatalogType) { return canCreateObject.bind({ browser: pgBrowser, childOfCatalogType: childOfCatalogType, });
}
With respect to the above code: this bind pattern looks good and seems like the idiomatic way to handle this in JavaScript. On a lighter node, I don’t even see the need for an additional method to wrap it. The invocation could have easily been like canCreate: canCreateObject.bind({ browser: pgBrowser, childOfCatalogType: childOfCatalogType }), I don’t feel too strongly here.
I renamed it as isValidTreeNodeData, because - we were using it in for testing the tree data. Please suggest me the right place, and name.
We’re not sure; maybe after continued refactoring, we will come across more generic functions. At that point we can revisit this and create a utils.js file.
The original patch was separating them in different places, but - still uses some of the functionalities directly from the tree, which was happening because we have contextual menu.
To give a better solution, I can think of putting the menus related code understand ‘sources/tree/menu’ directory.
We’re particularly worried because we’re trying to avoid the coupling that we see in the code base today. We want to decouple application state from business domain logic as much as we can - because this makes the code much easier to understand. We achieve lower coupling by have more suitable interfaces to retrieve application state like: anyParent (the menu doesn’t care how this happens). This is the direction that we’re trying to move towards, we just don’t want the package structure to undermine that developer intent.
How about nodeMenu.isSupportedNode(…)?
Naming is one of the hardest problems in programming. I don’t feel too strongly about this one. For now, let’s keep it as is
Thanks
Anthony && Victoria
Hey all,We haven't heard from you all in a while regarding our last statements. Is there any thing that I need to clarify? We feel left in the dark here and just want to know what we can do help.Cheers!Anthony && Joao
Blog: http://pgsnake.blogspot.com
Twitter: @pgsnake
EnterpriseDB UK: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
Ashesh, please prioritise this so we can move on.Thanks.On Mon, May 21, 2018 at 2:46 PM, Anthony Emengo <aemengo@pivotal.io> wrote:Hey all,We haven't heard from you all in a while regarding our last statements. Is there any thing that I need to clarify? We feel left in the dark here and just want to know what we can do help.Cheers!Anthony && Joao--Dave Page
Blog: http://pgsnake.blogspot.com
Twitter: @pgsnake
EnterpriseDB UK: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
Hello Hackers,Just to remind that if you need some more information from our side you can ping us.Can we expect and email tomorrow morning with the commit?ThanksVictoria & JoaoOn Mon, May 21, 2018 at 9:56 AM Dave Page <dpage@pgadmin.org> wrote:Ashesh, please prioritise this so we can move on.Thanks.On Mon, May 21, 2018 at 2:46 PM, Anthony Emengo <aemengo@pivotal.io> wrote:Hey all,We haven't heard from you all in a while regarding our last statements. Is there any thing that I need to clarify? We feel left in the dark here and just want to know what we can do help.Cheers!Anthony && Joao--Dave Page
Blog: http://pgsnake.blogspot.com
Twitter: @pgsnake
EnterpriseDB UK: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
Blog: http://pgsnake.blogspot.com
Twitter: @pgsnake
EnterpriseDB UK: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
export function canCreate(pgBrowser, childOfCatalogType) { return canCreateObject.bind({ browser: pgBrowser, childOfCatalogType: childOfCatalogType, }); }With respect to the above code: this bind pattern looks good and seems like the idiomatic way to handle this in JavaScript. On a lighter node, I don’t even see the need for an additional method to wrap it. The invocation could have easily been like
canCreate: canCreateObject.bind({ browser: pgBrowser, childOfCatalogType: childOfCatalogType }),I don’t feel too strongly here.
I renamed it as isValidTreeNodeData, because - we were using it in for testing the tree data. Please suggest me the right place, and name.
We’re not sure; maybe after continued refactoring, we will come across more generic functions. At that point we can revisit this and create a
utils.jsfile.
The original patch was separating them in different places, but - still uses some of the functionalities directly from the tree, which was happening because we have contextual menu.
To give a better solution, I can think of putting the menus related code understand ‘sources/tree/menu’ directory.We’re particularly worried because we’re trying to avoid the coupling that we see in the code base today. We want to decouple application state from business domain logic as much as we can - because this makes the code much easier to understand. We achieve lower coupling by have more suitable interfaces to retrieve application state like:
anyParent(the menu doesn’t care how this happens). This is the direction that we’re trying to move towards, we just don’t want the package structure to undermine that developer intent.
How about nodeMenu.isSupportedNode(…)?
Naming is one of the hardest problems in programming. I don’t feel too strongly about this one. For now, let’s keep it as is
Thanks
Anthony && Victoria
Attachment
Sorry for the late reply.On Wed, May 16, 2018 at 8:55 PM, Anthony Emengo <aemengo@pivotal.io> wrote:export function canCreate(pgBrowser, childOfCatalogType) { return canCreateObject.bind({ browser: pgBrowser, childOfCatalogType: childOfCatalogType, }); }With respect to the above code: this bind pattern looks good and seems like the idiomatic way to handle this in JavaScript. On a lighter node, I don’t even see the need for an additional method to wrap it. The invocation could have easily been like
canCreate: canCreateObject.bind({ browser: pgBrowser, childOfCatalogType: childOfCatalogType }),I don’t feel too strongly here.I do agree - we can handle the same problem many ways.I prefer object oriented pardigm more in general.Any way - I have modified the code with some other changes.I renamed it as isValidTreeNodeData, because - we were using it in for testing the tree data. Please suggest me the right place, and name.
We’re not sure; maybe after continued refactoring, we will come across more generic functions. At that point we can revisit this and create a
utils.jsfile.Sure.The original patch was separating them in different places, but - still uses some of the functionalities directly from the tree, which was happening because we have contextual menu.
To give a better solution, I can think of putting the menus related code understand ‘sources/tree/menu’ directory.We’re particularly worried because we’re trying to avoid the coupling that we see in the code base today. We want to decouple application state from business domain logic as much as we can - because this makes the code much easier to understand. We achieve lower coupling by have more suitable interfaces to retrieve application state like:
anyParent(the menu doesn’t care how this happens). This is the direction that we’re trying to move towards, we just don’t want the package structure to undermine that developer intent.I realized after revisiting the code, menu/can_create.js was only applicable to the children of the schema/catalog nodes, same as 'can_drop_child'.We should have put both scripts in the same directory.Please find the updated patch for the same.Please review it, and let me know your concerns.-- Thanks, AsheshHow about nodeMenu.isSupportedNode(…)?
Naming is one of the hardest problems in programming. I don’t feel too strongly about this one. For now, let’s keep it as is
Thanks
Anthony && Victoria
Are there any ideas as to how we can meaningfully move forward with the goal of allowing the tree view to support a very large number of tables?
Hey, Thanks so much for the reply.We've noticed that you've made several modifications on top of our original patch. Unfortunately, we've found it very hard to follow. Could we please get a brief synopsis of the changes you have made - just so we can better understand the rationale behind them? Just like we've done for you previously.Let's keep in mind that the original intent was simply to introduce this abstraction into the code base, which is a big enough task. I'd hate for the scope of the changes we're making to expand beyond that.ThanksJoao && AnthonySorry for the late reply.On Wed, May 16, 2018 at 8:55 PM, Anthony Emengo <aemengo@pivotal.io> wrote:export function canCreate(pgBrowser, childOfCatalogType) { return canCreateObject.bind({ browser: pgBrowser, childOfCatalogType: childOfCatalogType, }); }With respect to the above code: this bind pattern looks good and seems like the idiomatic way to handle this in JavaScript. On a lighter node, I don’t even see the need for an additional method to wrap it. The invocation could have easily been like
canCreate: canCreateObject.bind({ browser: pgBrowser, childOfCatalogType: childOfCatalogType }),I don’t feel too strongly here.I do agree - we can handle the same problem many ways.I prefer object oriented pardigm more in general.Any way - I have modified the code with some other changes.I renamed it as isValidTreeNodeData, because - we were using it in for testing the tree data. Please suggest me the right place, and name.
We’re not sure; maybe after continued refactoring, we will come across more generic functions. At that point we can revisit this and create a
utils.jsfile.Sure.The original patch was separating them in different places, but - still uses some of the functionalities directly from the tree, which was happening because we have contextual menu.
To give a better solution, I can think of putting the menus related code understand ‘sources/tree/menu’ directory.We’re particularly worried because we’re trying to avoid the coupling that we see in the code base today. We want to decouple application state from business domain logic as much as we can - because this makes the code much easier to understand. We achieve lower coupling by have more suitable interfaces to retrieve application state like:
anyParent(the menu doesn’t care how this happens). This is the direction that we’re trying to move towards, we just don’t want the package structure to undermine that developer intent.I realized after revisiting the code, menu/can_create.js was only applicable to the children of the schema/catalog nodes, same as 'can_drop_child'.We should have put both scripts in the same directory.Please find the updated patch for the same.Please review it, and let me know your concerns.-- Thanks, AsheshHow about nodeMenu.isSupportedNode(…)?
Naming is one of the hardest problems in programming. I don’t feel too strongly about this one. For now, let’s keep it as is
Thanks
Anthony && Victoria
All,These patches were first proposed on April 2 and the meaningful changes have yet to be committed. ~8 weeks is long enough that my assumption now is that these aren't going to be committed.The goal of these patches is to begin to separate out the ACI tree in order to allow us to do feature work on that chunk of the code. Are there any alternate suggestions for this work?
Are there any ideas as to how we can meaningfully move forward with the goal of allowing the tree view to support a very large number of tables?-- RobOn Thu, May 24, 2018 at 10:43 AM, Joao De Almeida Pereira <jdealmeidapereira@pivotal.io> wrote:Hey, Thanks so much for the reply.We've noticed that you've made several modifications on top of our original patch. Unfortunately, we've found it very hard to follow. Could we please get a brief synopsis of the changes you have made - just so we can better understand the rationale behind them? Just like we've done for you previously.Let's keep in mind that the original intent was simply to introduce this abstraction into the code base, which is a big enough task. I'd hate for the scope of the changes we're making to expand beyond that.ThanksJoao && AnthonySorry for the late reply.On Wed, May 16, 2018 at 8:55 PM, Anthony Emengo <aemengo@pivotal.io> wrote:export function canCreate(pgBrowser, childOfCatalogType) { return canCreateObject.bind({ browser: pgBrowser, childOfCatalogType: childOfCatalogType, }); }With respect to the above code: this bind pattern looks good and seems like the idiomatic way to handle this in JavaScript. On a lighter node, I don’t even see the need for an additional method to wrap it. The invocation could have easily been like
canCreate: canCreateObject.bind({ browser: pgBrowser, childOfCatalogType: childOfCatalogType }),I don’t feel too strongly here.I do agree - we can handle the same problem many ways.I prefer object oriented pardigm more in general.Any way - I have modified the code with some other changes.I renamed it as isValidTreeNodeData, because - we were using it in for testing the tree data. Please suggest me the right place, and name.
We’re not sure; maybe after continued refactoring, we will come across more generic functions. At that point we can revisit this and create a
utils.jsfile.Sure.The original patch was separating them in different places, but - still uses some of the functionalities directly from the tree, which was happening because we have contextual menu.
To give a better solution, I can think of putting the menus related code understand ‘sources/tree/menu’ directory.We’re particularly worried because we’re trying to avoid the coupling that we see in the code base today. We want to decouple application state from business domain logic as much as we can - because this makes the code much easier to understand. We achieve lower coupling by have more suitable interfaces to retrieve application state like:
anyParent(the menu doesn’t care how this happens). This is the direction that we’re trying to move towards, we just don’t want the package structure to undermine that developer intent.I realized after revisiting the code, menu/can_create.js was only applicable to the children of the schema/catalog nodes, same as 'can_drop_child'.We should have put both scripts in the same directory.Please find the updated patch for the same.Please review it, and let me know your concerns.-- Thanks, AsheshHow about nodeMenu.isSupportedNode(…)?
Naming is one of the hardest problems in programming. I don’t feel too strongly about this one. For now, let’s keep it as is
Thanks
Anthony && Victoria
Blog: http://pgsnake.blogspot.com
Twitter: @pgsnake
EnterpriseDB UK: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
Hey, Thanks so much for the reply.We've noticed that you've made several modifications on top of our original patch. Unfortunately, we've found it very hard to follow. Could we please get a brief synopsis of the changes you have made - just so we can better understand the rationale behind them? Just like we've done for you previously.
M webpack.shim.js M webpack.test.config.js
- In order to specify the fake_browser in regression tests, we need to use 'pgbrowser/browser' in the 'schema_child_tree_node.js' script. D pgadmin/browser/server_groups/servers/databases/schemas/ static/js/can_drop_child.js
- We don't need this with the new implementation.C pgadmin/browser/server_groups/servers/databases/schemas/ static/js/child.js
- All the children of schema node have common properties as 'parent_type', 'canDrop', 'canDropCascase', 'canCreate'.
Hence - instead of defining them in each node, we have created a base node, which will have all these properties.
And, modified all schema children node to inherit from it.C pgadmin/browser/server_groups/servers/databases/schemas/ static/js/schema_child_tree_ node.js
- In this script, we're defining three functions 'childCreateMenuEnabled', 'isTreeItemOfChildOfSchema', & 'isTreeNodeOfSchemaChild', which are used by the 'SchemaChildNode' objects.M pgadmin/browser/static/js/collection.js
- Fixed an issue related to wrongly defined 'error' function for the Collection object.D pgadmin/static/js/menu/can_create.js
- It defined the function, which was defining a check for creation of a schema child node, or not by looking at the parent node (i.e. a schema/catalog node).
The file was not defintely placed under the wrong directory, because - the similar logic was under 'can_drop_child.js', and it was defined under 'pgadmin/browser/server_groups/servers/databases/schemas/ static/js' directory. D pgadmin/static/js/menu/menu_enabled.js C pgadmin/static/js/nodes/supported_database_node.js
- Used by the external tools for checking whether the 'selected' tree-node is:
+ 'database' node, and it is allowed to connect it.
+ Or, it is one of the schema child (and, not 'catalog' child).
- Finding the correct location was difficult for this, as there is no defined pattern, also it can be used by other functions too. Hence - moved it out of 'pgadmin/static/js/menu' directory.M pgadmin/static/js/tree/tree.js
- Introduced a function, which returns the ancestor node object, fow which the condition is true.D regression/javascript/menu/can_create_spec.js D regression/javascript/menu/ menu_enabled_spec.js D regression/javascript/schema/ can_drop_child_spec.js C regression/javascript/fake_ browser/browser.js
C regression/javascript/nodes/schema/child_menu_spec.js
- Modified the regression to test the new functionalies.M pgadmin/browser/server_groups/servers/databases/schemas/**/*.js
- Extending the schema child nodes from the 'SchemaChildNode' class defined in 'pgadmin/.../schemas/static/js/child.js' script.
Let's keep in mind that the original intent was simply to introduce this abstraction into the code base, which is a big enough task. I'd hate for the scope of the changes we're making to expand beyond that.
ThanksJoao && AnthonySorry for the late reply.On Wed, May 16, 2018 at 8:55 PM, Anthony Emengo <aemengo@pivotal.io> wrote:export function canCreate(pgBrowser, childOfCatalogType) { return canCreateObject.bind({ browser: pgBrowser, childOfCatalogType: childOfCatalogType, }); }With respect to the above code: this bind pattern looks good and seems like the idiomatic way to handle this in JavaScript. On a lighter node, I don’t even see the need for an additional method to wrap it. The invocation could have easily been like
canCreate: canCreateObject.bind({ browser: pgBrowser, childOfCatalogType: childOfCatalogType }),I don’t feel too strongly here.I do agree - we can handle the same problem many ways.I prefer object oriented pardigm more in general.Any way - I have modified the code with some other changes.I renamed it as isValidTreeNodeData, because - we were using it in for testing the tree data. Please suggest me the right place, and name.
We’re not sure; maybe after continued refactoring, we will come across more generic functions. At that point we can revisit this and create a
utils.jsfile.Sure.The original patch was separating them in different places, but - still uses some of the functionalities directly from the tree, which was happening because we have contextual menu.
To give a better solution, I can think of putting the menus related code understand ‘sources/tree/menu’ directory.We’re particularly worried because we’re trying to avoid the coupling that we see in the code base today. We want to decouple application state from business domain logic as much as we can - because this makes the code much easier to understand. We achieve lower coupling by have more suitable interfaces to retrieve application state like:
anyParent(the menu doesn’t care how this happens). This is the direction that we’re trying to move towards, we just don’t want the package structure to undermine that developer intent.I realized after revisiting the code, menu/can_create.js was only applicable to the children of the schema/catalog nodes, same as 'can_drop_child'.We should have put both scripts in the same directory.Please find the updated patch for the same.Please review it, and let me know your concerns.-- Thanks, AsheshHow about nodeMenu.isSupportedNode(…)?
Naming is one of the hardest problems in programming. I don’t feel too strongly about this one. For now, let’s keep it as is
Thanks
Anthony && Victoria
Hey Ashesh,
Thanks for the explanation. It was great and it really helped!
C pgadmin/browser/server_groups/servers/databases/schemas/static/js/child.js
C pgadmin/browser/server_groups/servers/databases/schemas/static/js/schema_child_tree_node.js
It makes sense to remove duplication by extracting these attributes out and setting the canDrop and canCreate functions here. But is it possible to combine these two files into one since they are related so we don’t need to import schema_child_tree_node?
M pgadmin/static/js/tree/tree.js
The creation of the ancestorNode function feels like a pre-optimization. That function is not used any where outside of the tree.js file, so it’s more confusing to have it defined. On a lighter note, could we avoid the !! syntax when possible? For example, instead of return !!obj, we could do something like return obj === undefined or return _.isUndefined(obj) as this is more intuitive.
https://softwareengineering.stackexchange.com/a/80092
In addition, please update this patch as it is out of sync with the latest commit on the master branch. Otherwise, everything looks good!
On Thu, May 24, 2018 at 8:13 PM, Joao De Almeida Pereira <jdealmeidapereira@pivotal.io> wrote:Hey, Thanks so much for the reply.We've noticed that you've made several modifications on top of our original patch. Unfortunately, we've found it very hard to follow. Could we please get a brief synopsis of the changes you have made - just so we can better understand the rationale behind them? Just like we've done for you previously.Please find the changes from your original patch:M webpack.shim.js M webpack.test.config.js
- In order to specify the fake_browser in regression tests, we need to use 'pgbrowser/browser' in the 'schema_child_tree_node.js' script.D pgadmin/browser/server_groups/servers/databases/schemas/static/js/can_drop_child.js
- We don't need this with the new implementation.C pgadmin/browser/server_groups/servers/databases/schemas/static/js/child.js
- All the children of schema node have common properties as 'parent_type', 'canDrop', 'canDropCascase', 'canCreate'.
Hence - instead of defining them in each node, we have created a base node, which will have all these properties.
And, modified all schema children node to inherit from it.C pgadmin/browser/server_groups/servers/databases/schemas/static/js/schema_child_tree_node.js
- In this script, we're defining three functions 'childCreateMenuEnabled', 'isTreeItemOfChildOfSchema', & 'isTreeNodeOfSchemaChild', which are used by the 'SchemaChildNode' objects.M pgadmin/browser/static/js/collection.js
- Fixed an issue related to wrongly defined 'error' function for the Collection object.D pgadmin/static/js/menu/can_create.js
- It defined the function, which was defining a check for creation of a schema child node, or not by looking at the parent node (i.e. a schema/catalog node).
The file was not defintely placed under the wrong directory, because - the similar logic was under 'can_drop_child.js', and it was defined under 'pgadmin/browser/server_groups/servers/databases/schemas/static/js' directory.D pgadmin/static/js/menu/menu_enabled.jsC pgadmin/static/js/nodes/supported_database_node.js
- Used by the external tools for checking whether the 'selected' tree-node is:
+ 'database' node, and it is allowed to connect it.
+ Or, it is one of the schema child (and, not 'catalog' child).
- Finding the correct location was difficult for this, as there is no defined pattern, also it can be used by other functions too. Hence - moved it out of 'pgadmin/static/js/menu' directory.M pgadmin/static/js/tree/tree.js
- Introduced a function, which returns the ancestor node object, fow which the condition is true.D regression/javascript/menu/can_create_spec.js D regression/javascript/menu/menu_enabled_spec.js D regression/javascript/schema/can_drop_child_spec.js C regression/javascript/fake_browser/browser.js
C regression/javascript/nodes/schema/child_menu_spec.js
- Modified the regression to test the new functionalies.M pgadmin/browser/server_groups/servers/databases/schemas/**/*.js
- Extending the schema child nodes from the 'SchemaChildNode' class defined in 'pgadmin/.../schemas/static/js/child.js' script.Let me know if you need more information.Let's keep in mind that the original intent was simply to introduce this abstraction into the code base, which is a big enough task. I'd hate for the scope of the changes we're making to expand beyond that.I have the mutual feeling.-- Thanks, AsheshThanksJoao && AnthonyOn Thu, May 24, 2018 at 2:59 AM Ashesh Vashi <ashesh.vashi@enterprisedb.com> wrote:Sorry for the late reply.On Wed, May 16, 2018 at 8:55 PM, Anthony Emengo <aemengo@pivotal.io> wrote:export function canCreate(pgBrowser, childOfCatalogType) { return canCreateObject.bind({ browser: pgBrowser, childOfCatalogType: childOfCatalogType, }); }With respect to the above code: this bind pattern looks good and seems like the idiomatic way to handle this in JavaScript. On a lighter node, I don’t even see the need for an additional method to wrap it. The invocation could have easily been like
canCreate: canCreateObject.bind({ browser: pgBrowser, childOfCatalogType: childOfCatalogType }),I don’t feel too strongly here.I do agree - we can handle the same problem many ways.I prefer object oriented pardigm more in general.Any way - I have modified the code with some other changes.I renamed it as isValidTreeNodeData, because - we were using it in for testing the tree data. Please suggest me the right place, and name.
We’re not sure; maybe after continued refactoring, we will come across more generic functions. At that point we can revisit this and create a
utils.jsfile.Sure.The original patch was separating them in different places, but - still uses some of the functionalities directly from the tree, which was happening because we have contextual menu.
To give a better solution, I can think of putting the menus related code understand ‘sources/tree/menu’ directory.We’re particularly worried because we’re trying to avoid the coupling that we see in the code base today. We want to decouple application state from business domain logic as much as we can - because this makes the code much easier to understand. We achieve lower coupling by have more suitable interfaces to retrieve application state like:
anyParent(the menu doesn’t care how this happens). This is the direction that we’re trying to move towards, we just don’t want the package structure to undermine that developer intent.I realized after revisiting the code, menu/can_create.js was only applicable to the children of the schema/catalog nodes, same as 'can_drop_child'.We should have put both scripts in the same directory.Please find the updated patch for the same.Please review it, and let me know your concerns.-- Thanks, AsheshHow about nodeMenu.isSupportedNode(…)?
Naming is one of the hardest problems in programming. I don’t feel too strongly about this one. For now, let’s keep it as is
Thanks
Anthony && Victoria
Hey Ashesh,
Thanks for the explanation. It was great and it really helped!
C pgadmin/browser/server_groups/servers/databases/schemas/static/js/child.js C pgadmin/browser/server_groups/servers/databases/schemas/static/js/schema_child_tree_node.jsIt makes sense to remove duplication by extracting these attributes out and setting the
canDropandcanCreatefunctions here. But is it possible to combine these two files into one since they are related so we don’t need to importschema_child_tree_node?M pgadmin/static/js/tree/tree.jsThe creation of the
ancestorNodefunction feels like a pre-optimization. That function is not used any where outside of thetree.jsfile, so it’s more confusing to have it defined. On a lighter note, could we avoid the !! syntax when possible? For example, instead ofreturn !!obj, we could do something likereturn obj === undefinedorreturn _.isUndefined(obj)as this is more intuitive.https://softwareengineering.stackexchange.com/a/80092
In addition, please update this patch as it is out of sync with the latest commit on the master branch. Otherwise, everything looks good!
ThanksAnthony && VictoriaOn Fri, Jun 1, 2018 at 7:52 AM Ashesh Vashi <ashesh.vashi@enterprisedb.com> wrote:On Thu, May 24, 2018 at 8:13 PM, Joao De Almeida Pereira <jdealmeidapereira@pivotal.io> wrote:Hey, Thanks so much for the reply.We've noticed that you've made several modifications on top of our original patch. Unfortunately, we've found it very hard to follow. Could we please get a brief synopsis of the changes you have made - just so we can better understand the rationale behind them? Just like we've done for you previously.Please find the changes from your original patch:M webpack.shim.js M webpack.test.config.js
- In order to specify the fake_browser in regression tests, we need to use 'pgbrowser/browser' in the 'schema_child_tree_node.js' script.D pgadmin/browser/server_groups/servers/databases/schemas/static/js/can_drop_child.js
- We don't need this with the new implementation.C pgadmin/browser/server_groups/servers/databases/schemas/static/js/child.js
- All the children of schema node have common properties as 'parent_type', 'canDrop', 'canDropCascase', 'canCreate'.
Hence - instead of defining them in each node, we have created a base node, which will have all these properties.
And, modified all schema children node to inherit from it.C pgadmin/browser/server_groups/servers/databases/schemas/static/js/schema_child_tree_node.js
- In this script, we're defining three functions 'childCreateMenuEnabled', 'isTreeItemOfChildOfSchema', & 'isTreeNodeOfSchemaChild', which are used by the 'SchemaChildNode' objects.M pgadmin/browser/static/js/collection.js
- Fixed an issue related to wrongly defined 'error' function for the Collection object.D pgadmin/static/js/menu/can_create.js
- It defined the function, which was defining a check for creation of a schema child node, or not by looking at the parent node (i.e. a schema/catalog node).
The file was not defintely placed under the wrong directory, because - the similar logic was under 'can_drop_child.js', and it was defined under 'pgadmin/browser/server_groups/servers/databases/schemas/static/js' directory.D pgadmin/static/js/menu/menu_enabled.jsC pgadmin/static/js/nodes/supported_database_node.js
- Used by the external tools for checking whether the 'selected' tree-node is:
+ 'database' node, and it is allowed to connect it.
+ Or, it is one of the schema child (and, not 'catalog' child).
- Finding the correct location was difficult for this, as there is no defined pattern, also it can be used by other functions too. Hence - moved it out of 'pgadmin/static/js/menu' directory.M pgadmin/static/js/tree/tree.js
- Introduced a function, which returns the ancestor node object, fow which the condition is true.D regression/javascript/menu/can_create_spec.js D regression/javascript/menu/menu_enabled_spec.js D regression/javascript/schema/can_drop_child_spec.js C regression/javascript/fake_browser/browser.js
C regression/javascript/nodes/schema/child_menu_spec.js
- Modified the regression to test the new functionalies.M pgadmin/browser/server_groups/servers/databases/schemas/**/*.js
- Extending the schema child nodes from the 'SchemaChildNode' class defined in 'pgadmin/.../schemas/static/js/child.js' script.Let me know if you need more information.Let's keep in mind that the original intent was simply to introduce this abstraction into the code base, which is a big enough task. I'd hate for the scope of the changes we're making to expand beyond that.I have the mutual feeling.-- Thanks, AsheshThanksJoao && AnthonyOn Thu, May 24, 2018 at 2:59 AM Ashesh Vashi <ashesh.vashi@enterprisedb.com> wrote:Sorry for the late reply.On Wed, May 16, 2018 at 8:55 PM, Anthony Emengo <aemengo@pivotal.io> wrote:export function canCreate(pgBrowser, childOfCatalogType) { return canCreateObject.bind({ browser: pgBrowser, childOfCatalogType: childOfCatalogType, }); }With respect to the above code: this bind pattern looks good and seems like the idiomatic way to handle this in JavaScript. On a lighter node, I don’t even see the need for an additional method to wrap it. The invocation could have easily been like
canCreate: canCreateObject.bind({ browser: pgBrowser, childOfCatalogType: childOfCatalogType }),I don’t feel too strongly here.I do agree - we can handle the same problem many ways.I prefer object oriented pardigm more in general.Any way - I have modified the code with some other changes.I renamed it as isValidTreeNodeData, because - we were using it in for testing the tree data. Please suggest me the right place, and name.
We’re not sure; maybe after continued refactoring, we will come across more generic functions. At that point we can revisit this and create a
utils.jsfile.Sure.The original patch was separating them in different places, but - still uses some of the functionalities directly from the tree, which was happening because we have contextual menu.
To give a better solution, I can think of putting the menus related code understand ‘sources/tree/menu’ directory.We’re particularly worried because we’re trying to avoid the coupling that we see in the code base today. We want to decouple application state from business domain logic as much as we can - because this makes the code much easier to understand. We achieve lower coupling by have more suitable interfaces to retrieve application state like:
anyParent(the menu doesn’t care how this happens). This is the direction that we’re trying to move towards, we just don’t want the package structure to undermine that developer intent.I realized after revisiting the code, menu/can_create.js was only applicable to the children of the schema/catalog nodes, same as 'can_drop_child'.We should have put both scripts in the same directory.Please find the updated patch for the same.Please review it, and let me know your concerns.-- Thanks, AsheshHow about nodeMenu.isSupportedNode(…)?
Naming is one of the hardest problems in programming. I don’t feel too strongly about this one. For now, let’s keep it as is
Thanks
Anthony && Victoria
Hi Ashesh,We just attempted to apply your patch over master but it did not work. We don't want to introduce any bugs or break any functionality. Please update the patch to make sure it is synced up with the master branch.
Sincerely,VictoriaOn Fri, Jun 1, 2018 at 11:18 AM Anthony Emengo <aemengo@pivotal.io> wrote:Hey Ashesh,
Thanks for the explanation. It was great and it really helped!
C pgadmin/browser/server_groups/servers/databases/schemas/stat ic/js/child.js C pgadmin/browser/server_groups/ servers/databases/schemas/stat ic/js/schema_child_tree_node. js It makes sense to remove duplication by extracting these attributes out and setting the
canDropandcanCreatefunctions here. But is it possible to combine these two files into one since they are related so we don’t need to importschema_child_tree_node?
M pgadmin/static/js/tree/tree.jsThe creation of the
ancestorNodefunction feels like a pre-optimization. That function is not used any where outside of thetree.jsfile, so it’s more confusing to have it defined.
On a lighter note, could we avoid the !! syntax when possible? For example, instead of
return !!obj, we could do something likereturn obj === undefinedorreturn _.isUndefined(obj)as this is more intuitive.
In addition, please update this patch as it is out of sync with the latest commit on the master branch. Otherwise, everything looks good!
ThanksAnthony && VictoriaOn Thu, May 24, 2018 at 8:13 PM, Joao De Almeida Pereira <jdealmeidapereira@pivotal.io> wrote:Hey, Thanks so much for the reply.We've noticed that you've made several modifications on top of our original patch. Unfortunately, we've found it very hard to follow. Could we please get a brief synopsis of the changes you have made - just so we can better understand the rationale behind them? Just like we've done for you previously.Please find the changes from your original patch:M webpack.shim.js M webpack.test.config.js
- In order to specify the fake_browser in regression tests, we need to use 'pgbrowser/browser' in the 'schema_child_tree_node.js' script.D pgadmin/browser/server_groups/servers/databases/schemas/stat ic/js/can_drop_child.js
- We don't need this with the new implementation.C pgadmin/browser/server_groups/servers/databases/schemas/stat ic/js/child.js
- All the children of schema node have common properties as 'parent_type', 'canDrop', 'canDropCascase', 'canCreate'.
Hence - instead of defining them in each node, we have created a base node, which will have all these properties.
And, modified all schema children node to inherit from it.C pgadmin/browser/server_groups/servers/databases/schemas/stat ic/js/schema_child_tree_node. js
- In this script, we're defining three functions 'childCreateMenuEnabled', 'isTreeItemOfChildOfSchema', & 'isTreeNodeOfSchemaChild', which are used by the 'SchemaChildNode' objects.M pgadmin/browser/static/js/collection.js
- Fixed an issue related to wrongly defined 'error' function for the Collection object.D pgadmin/static/js/menu/can_create.js
- It defined the function, which was defining a check for creation of a schema child node, or not by looking at the parent node (i.e. a schema/catalog node).
The file was not defintely placed under the wrong directory, because - the similar logic was under 'can_drop_child.js', and it was defined under 'pgadmin/browser/server_groups/servers/databases/schemas/sta tic/js' directory. D pgadmin/static/js/menu/menu_enabled.js C pgadmin/static/js/nodes/supported_database_node.js
- Used by the external tools for checking whether the 'selected' tree-node is:
+ 'database' node, and it is allowed to connect it.
+ Or, it is one of the schema child (and, not 'catalog' child).
- Finding the correct location was difficult for this, as there is no defined pattern, also it can be used by other functions too. Hence - moved it out of 'pgadmin/static/js/menu' directory.M pgadmin/static/js/tree/tree.js
- Introduced a function, which returns the ancestor node object, fow which the condition is true.D regression/javascript/menu/can_create_spec.js D regression/javascript/menu/men u_enabled_spec.js D regression/javascript/schema/c an_drop_child_spec.js C regression/javascript/fake_bro wser/browser.js
C regression/javascript/nodes/schema/child_menu_spec.js
- Modified the regression to test the new functionalies.M pgadmin/browser/server_groups/servers/databases/schemas/**/* .js
- Extending the schema child nodes from the 'SchemaChildNode' class defined in 'pgadmin/.../schemas/static/js/child.js' script. Let me know if you need more information.Let's keep in mind that the original intent was simply to introduce this abstraction into the code base, which is a big enough task. I'd hate for the scope of the changes we're making to expand beyond that.I have the mutual feeling.-- Thanks, AsheshThanksJoao && AnthonySorry for the late reply.On Wed, May 16, 2018 at 8:55 PM, Anthony Emengo <aemengo@pivotal.io> wrote:export function canCreate(pgBrowser, childOfCatalogType) { return canCreateObject.bind({ browser: pgBrowser, childOfCatalogType: childOfCatalogType, }); }With respect to the above code: this bind pattern looks good and seems like the idiomatic way to handle this in JavaScript. On a lighter node, I don’t even see the need for an additional method to wrap it. The invocation could have easily been like
canCreate: canCreateObject.bind({ browser: pgBrowser, childOfCatalogType: childOfCatalogType }),I don’t feel too strongly here.I do agree - we can handle the same problem many ways.I prefer object oriented pardigm more in general.Any way - I have modified the code with some other changes.I renamed it as isValidTreeNodeData, because - we were using it in for testing the tree data. Please suggest me the right place, and name.
We’re not sure; maybe after continued refactoring, we will come across more generic functions. At that point we can revisit this and create a
utils.jsfile.Sure.The original patch was separating them in different places, but - still uses some of the functionalities directly from the tree, which was happening because we have contextual menu.
To give a better solution, I can think of putting the menus related code understand ‘sources/tree/menu’ directory.We’re particularly worried because we’re trying to avoid the coupling that we see in the code base today. We want to decouple application state from business domain logic as much as we can - because this makes the code much easier to understand. We achieve lower coupling by have more suitable interfaces to retrieve application state like:
anyParent(the menu doesn’t care how this happens). This is the direction that we’re trying to move towards, we just don’t want the package structure to undermine that developer intent.I realized after revisiting the code, menu/can_create.js was only applicable to the children of the schema/catalog nodes, same as 'can_drop_child'.We should have put both scripts in the same directory.Please find the updated patch for the same.Please review it, and let me know your concerns.-- Thanks, AsheshHow about nodeMenu.isSupportedNode(…)?
Naming is one of the hardest problems in programming. I don’t feel too strongly about this one. For now, let’s keep it as is
Thanks
Anthony && Victoria
Attachment
On Fri, Jun 1, 2018 at 10:09 PM, Victoria Henry <vhenry@pivotal.io> wrote:Hi Ashesh,We just attempted to apply your patch over master but it did not work. We don't want to introduce any bugs or break any functionality. Please update the patch to make sure it is synced up with the master branch.Please find the updated patch.Sincerely,VictoriaOn Fri, Jun 1, 2018 at 11:18 AM Anthony Emengo <aemengo@pivotal.io> wrote:Hey Ashesh,
Thanks for the explanation. It was great and it really helped!
C pgadmin/browser/server_groups/servers/databases/schemas/static/js/child.js C pgadmin/browser/server_groups/servers/databases/schemas/static/js/schema_child_tree_node.jsIt makes sense to remove duplication by extracting these attributes out and setting the
canDropandcanCreatefunctions here. But is it possible to combine these two files into one since they are related so we don’t need to importschema_child_tree_node?That was the original plan, but 'pgadmin/browser/static/js//node.js' script has too many dependecies, which are not easily portable.And - that may lead to change the scope of the patch.Hence - I decided to use the separate file to make sure we have enough test coverage (which is more imprortant than changing the scope).M pgadmin/static/js/tree/tree.jsThe creation of the
ancestorNodefunction feels like a pre-optimization. That function is not used any where outside of thetree.jsfile, so it’s more confusing to have it defined.It is being used in the latest changes. :-)On a lighter note, could we avoid the !! syntax when possible? For example, instead of
return !!obj, we could do something likereturn obj === undefinedorreturn _.isUndefined(obj)as this is more intuitive.I am kind of disagree here. But - I have changed it anyway.In addition, please update this patch as it is out of sync with the latest commit on the master branch. Otherwise, everything looks good!
Here - you go!-- Thanks, AsheshThanksAnthony && VictoriaOn Fri, Jun 1, 2018 at 7:52 AM Ashesh Vashi <ashesh.vashi@enterprisedb.com> wrote:On Thu, May 24, 2018 at 8:13 PM, Joao De Almeida Pereira <jdealmeidapereira@pivotal.io> wrote:Hey, Thanks so much for the reply.We've noticed that you've made several modifications on top of our original patch. Unfortunately, we've found it very hard to follow. Could we please get a brief synopsis of the changes you have made - just so we can better understand the rationale behind them? Just like we've done for you previously.Please find the changes from your original patch:M webpack.shim.js M webpack.test.config.js
- In order to specify the fake_browser in regression tests, we need to use 'pgbrowser/browser' in the 'schema_child_tree_node.js' script.D pgadmin/browser/server_groups/servers/databases/schemas/static/js/can_drop_child.js
- We don't need this with the new implementation.C pgadmin/browser/server_groups/servers/databases/schemas/static/js/child.js
- All the children of schema node have common properties as 'parent_type', 'canDrop', 'canDropCascase', 'canCreate'.
Hence - instead of defining them in each node, we have created a base node, which will have all these properties.
And, modified all schema children node to inherit from it.C pgadmin/browser/server_groups/servers/databases/schemas/static/js/schema_child_tree_node.js
- In this script, we're defining three functions 'childCreateMenuEnabled', 'isTreeItemOfChildOfSchema', & 'isTreeNodeOfSchemaChild', which are used by the 'SchemaChildNode' objects.M pgadmin/browser/static/js/collection.js
- Fixed an issue related to wrongly defined 'error' function for the Collection object.D pgadmin/static/js/menu/can_create.js
- It defined the function, which was defining a check for creation of a schema child node, or not by looking at the parent node (i.e. a schema/catalog node).
The file was not defintely placed under the wrong directory, because - the similar logic was under 'can_drop_child.js', and it was defined under 'pgadmin/browser/server_groups/servers/databases/schemas/static/js' directory.D pgadmin/static/js/menu/menu_enabled.jsC pgadmin/static/js/nodes/supported_database_node.js
- Used by the external tools for checking whether the 'selected' tree-node is:
+ 'database' node, and it is allowed to connect it.
+ Or, it is one of the schema child (and, not 'catalog' child).
- Finding the correct location was difficult for this, as there is no defined pattern, also it can be used by other functions too. Hence - moved it out of 'pgadmin/static/js/menu' directory.M pgadmin/static/js/tree/tree.js
- Introduced a function, which returns the ancestor node object, fow which the condition is true.D regression/javascript/menu/can_create_spec.js D regression/javascript/menu/menu_enabled_spec.js D regression/javascript/schema/can_drop_child_spec.js C regression/javascript/fake_browser/browser.js
C regression/javascript/nodes/schema/child_menu_spec.js
- Modified the regression to test the new functionalies.M pgadmin/browser/server_groups/servers/databases/schemas/**/*.js
- Extending the schema child nodes from the 'SchemaChildNode' class defined in 'pgadmin/.../schemas/static/js/child.js' script.Let me know if you need more information.Let's keep in mind that the original intent was simply to introduce this abstraction into the code base, which is a big enough task. I'd hate for the scope of the changes we're making to expand beyond that.I have the mutual feeling.-- Thanks, AsheshThanksJoao && AnthonyOn Thu, May 24, 2018 at 2:59 AM Ashesh Vashi <ashesh.vashi@enterprisedb.com> wrote:Sorry for the late reply.On Wed, May 16, 2018 at 8:55 PM, Anthony Emengo <aemengo@pivotal.io> wrote:export function canCreate(pgBrowser, childOfCatalogType) { return canCreateObject.bind({ browser: pgBrowser, childOfCatalogType: childOfCatalogType, }); }With respect to the above code: this bind pattern looks good and seems like the idiomatic way to handle this in JavaScript. On a lighter node, I don’t even see the need for an additional method to wrap it. The invocation could have easily been like
canCreate: canCreateObject.bind({ browser: pgBrowser, childOfCatalogType: childOfCatalogType }),I don’t feel too strongly here.I do agree - we can handle the same problem many ways.I prefer object oriented pardigm more in general.Any way - I have modified the code with some other changes.I renamed it as isValidTreeNodeData, because - we were using it in for testing the tree data. Please suggest me the right place, and name.
We’re not sure; maybe after continued refactoring, we will come across more generic functions. At that point we can revisit this and create a
utils.jsfile.Sure.The original patch was separating them in different places, but - still uses some of the functionalities directly from the tree, which was happening because we have contextual menu.
To give a better solution, I can think of putting the menus related code understand ‘sources/tree/menu’ directory.We’re particularly worried because we’re trying to avoid the coupling that we see in the code base today. We want to decouple application state from business domain logic as much as we can - because this makes the code much easier to understand. We achieve lower coupling by have more suitable interfaces to retrieve application state like:
anyParent(the menu doesn’t care how this happens). This is the direction that we’re trying to move towards, we just don’t want the package structure to undermine that developer intent.I realized after revisiting the code, menu/can_create.js was only applicable to the children of the schema/catalog nodes, same as 'can_drop_child'.We should have put both scripts in the same directory.Please find the updated patch for the same.Please review it, and let me know your concerns.-- Thanks, AsheshHow about nodeMenu.isSupportedNode(…)?
Naming is one of the hardest problems in programming. I don’t feel too strongly about this one. For now, let’s keep it as is
Thanks
Anthony && Victoria
Hey Ashesh,LGTM! The some of the CI tests failed but it looks like a flake. But you can go ahead and merge this.Sincerely,VictoriaOn Fri, Jun 1, 2018 at 10:09 PM, Victoria Henry <vhenry@pivotal.io> wrote:Hi Ashesh,We just attempted to apply your patch over master but it did not work. We don't want to introduce any bugs or break any functionality. Please update the patch to make sure it is synced up with the master branch.Please find the updated patch.Sincerely,VictoriaOn Fri, Jun 1, 2018 at 11:18 AM Anthony Emengo <aemengo@pivotal.io> wrote:Hey Ashesh,
Thanks for the explanation. It was great and it really helped!
C pgadmin/browser/server_groups/servers/databases/schemas/ static/js/child.js C pgadmin/browser/server_groups/ servers/databases/schemas/ static/js/schema_child_tree_ node.js It makes sense to remove duplication by extracting these attributes out and setting the
canDropandcanCreatefunctions here. But is it possible to combine these two files into one since they are related so we don’t need to importschema_child_tree_node?That was the original plan, but 'pgadmin/browser/static/js//node.js' script has too many dependecies, which are not easily portable. And - that may lead to change the scope of the patch.Hence - I decided to use the separate file to make sure we have enough test coverage (which is more imprortant than changing the scope).M pgadmin/static/js/tree/tree.jsThe creation of the
ancestorNodefunction feels like a pre-optimization. That function is not used any where outside of thetree.jsfile, so it’s more confusing to have it defined.It is being used in the latest changes. :-)On a lighter note, could we avoid the !! syntax when possible? For example, instead of
return !!obj, we could do something likereturn obj === undefinedorreturn _.isUndefined(obj)as this is more intuitive.I am kind of disagree here. But - I have changed it anyway.In addition, please update this patch as it is out of sync with the latest commit on the master branch. Otherwise, everything looks good!
Here - you go!-- Thanks, AsheshThanksAnthony && VictoriaOn Thu, May 24, 2018 at 8:13 PM, Joao De Almeida Pereira <jdealmeidapereira@pivotal.io> wrote:Hey, Thanks so much for the reply.We've noticed that you've made several modifications on top of our original patch. Unfortunately, we've found it very hard to follow. Could we please get a brief synopsis of the changes you have made - just so we can better understand the rationale behind them? Just like we've done for you previously.Please find the changes from your original patch:M webpack.shim.js M webpack.test.config.js
- In order to specify the fake_browser in regression tests, we need to use 'pgbrowser/browser' in the 'schema_child_tree_node.js' script.D pgadmin/browser/server_groups/servers/databases/schemas/ static/js/can_drop_child.js
- We don't need this with the new implementation.C pgadmin/browser/server_groups/servers/databases/schemas/stat ic/js/child.js
- All the children of schema node have common properties as 'parent_type', 'canDrop', 'canDropCascase', 'canCreate'.
Hence - instead of defining them in each node, we have created a base node, which will have all these properties.
And, modified all schema children node to inherit from it.C pgadmin/browser/server_groups/servers/databases/schemas/ static/js/schema_child_tree_ node.js
- In this script, we're defining three functions 'childCreateMenuEnabled', 'isTreeItemOfChildOfSchema', & 'isTreeNodeOfSchemaChild', which are used by the 'SchemaChildNode' objects.M pgadmin/browser/static/js/collection.js
- Fixed an issue related to wrongly defined 'error' function for the Collection object.D pgadmin/static/js/menu/can_create.js
- It defined the function, which was defining a check for creation of a schema child node, or not by looking at the parent node (i.e. a schema/catalog node).
The file was not defintely placed under the wrong directory, because - the similar logic was under 'can_drop_child.js', and it was defined under 'pgadmin/browser/server_groups/servers/databases/ schemas/static/js' directory. D pgadmin/static/js/menu/menu_enabled.js C pgadmin/static/js/nodes/supported_database_node.js
- Used by the external tools for checking whether the 'selected' tree-node is:
+ 'database' node, and it is allowed to connect it.
+ Or, it is one of the schema child (and, not 'catalog' child).
- Finding the correct location was difficult for this, as there is no defined pattern, also it can be used by other functions too. Hence - moved it out of 'pgadmin/static/js/menu' directory.M pgadmin/static/js/tree/tree.js
- Introduced a function, which returns the ancestor node object, fow which the condition is true.D regression/javascript/menu/can_create_spec.js D regression/javascript/menu/ menu_enabled_spec.js D regression/javascript/schema/ can_drop_child_spec.js C regression/javascript/fake_bro wser/browser.js
C regression/javascript/nodes/schema/child_menu_spec.js
- Modified the regression to test the new functionalies.M pgadmin/browser/server_groups/servers/databases/schemas/**/* .js
- Extending the schema child nodes from the 'SchemaChildNode' class defined in 'pgadmin/.../schemas/static/js/child.js' script. Let me know if you need more information.Let's keep in mind that the original intent was simply to introduce this abstraction into the code base, which is a big enough task. I'd hate for the scope of the changes we're making to expand beyond that.I have the mutual feeling.-- Thanks, AsheshThanksJoao && AnthonySorry for the late reply.On Wed, May 16, 2018 at 8:55 PM, Anthony Emengo <aemengo@pivotal.io> wrote:export function canCreate(pgBrowser, childOfCatalogType) { return canCreateObject.bind({ browser: pgBrowser, childOfCatalogType: childOfCatalogType, }); }With respect to the above code: this bind pattern looks good and seems like the idiomatic way to handle this in JavaScript. On a lighter node, I don’t even see the need for an additional method to wrap it. The invocation could have easily been like
canCreate: canCreateObject.bind({ browser: pgBrowser, childOfCatalogType: childOfCatalogType }),I don’t feel too strongly here.I do agree - we can handle the same problem many ways.I prefer object oriented pardigm more in general.Any way - I have modified the code with some other changes.I renamed it as isValidTreeNodeData, because - we were using it in for testing the tree data. Please suggest me the right place, and name.
We’re not sure; maybe after continued refactoring, we will come across more generic functions. At that point we can revisit this and create a
utils.jsfile.Sure.The original patch was separating them in different places, but - still uses some of the functionalities directly from the tree, which was happening because we have contextual menu.
To give a better solution, I can think of putting the menus related code understand ‘sources/tree/menu’ directory.We’re particularly worried because we’re trying to avoid the coupling that we see in the code base today. We want to decouple application state from business domain logic as much as we can - because this makes the code much easier to understand. We achieve lower coupling by have more suitable interfaces to retrieve application state like:
anyParent(the menu doesn’t care how this happens). This is the direction that we’re trying to move towards, we just don’t want the package structure to undermine that developer intent.I realized after revisiting the code, menu/can_create.js was only applicable to the children of the schema/catalog nodes, same as 'can_drop_child'.We should have put both scripts in the same directory.Please find the updated patch for the same.Please review it, and let me know your concerns.-- Thanks, AsheshHow about nodeMenu.isSupportedNode(…)?
Naming is one of the hardest problems in programming. I don’t feel too strongly about this one. For now, let’s keep it as is
Thanks
Anthony && Victoria
1) Why don't we start using webpack alias's instead of using absolute path. For eg,
import {RestoreDialogWrapper} from '../../../pgadmin/static/js/restore/restore_dialog_wrapper';
can be used as import {RestoreDialogWrapper} from 'pgadmin_static/js/restore/restore_dialog_wrapper';
by adding pgadmin_static alias to webpack config.
2) Few of the js are left behind, the ones which are used in python __init__.py. Can't we move them too ? It would be nicer to not to leave behind a single js.
Hi Anthony/Victoria/Joao,I know I am very late to review on patch 004. The idea of moving js files from tools to static folder looks good, but I have a few suggestions:1) Why don't we start using webpack alias's instead of using absolute path. For eg,import {RestoreDialogWrapper} from '../../../pgadmin/static/js/restore/restore_dialog_wrapper';can be used as import {RestoreDialogWrapper} from 'pgadmin_static/js/restore/restore_dialog_wrapper';by adding pgadmin_static alias to webpack config.2) Few of the js are left behind, the ones which are used in python __init__.py. Can't we move them too ? It would be nicer to not to leave behind a single js.Kindly let me know your views on this.Thanks and Regards,Aditya ToshniwalSoftware Engineer | EnterpriseDB Software Solutions | Pune"Don't Complain about Heat, Plant a tree"On Sat, Jun 2, 2018 at 12:47 AM, Victoria Henry <vhenry@pivotal.io> wrote:Hey Ashesh,LGTM! The some of the CI tests failed but it looks like a flake. But you can go ahead and merge this.Sincerely,VictoriaOn Fri, Jun 1, 2018 at 2:36 PM Ashesh Vashi <ashesh.vashi@enterprisedb.com> wrote:On Fri, Jun 1, 2018 at 10:09 PM, Victoria Henry <vhenry@pivotal.io> wrote:Hi Ashesh,We just attempted to apply your patch over master but it did not work. We don't want to introduce any bugs or break any functionality. Please update the patch to make sure it is synced up with the master branch.Please find the updated patch.Sincerely,VictoriaOn Fri, Jun 1, 2018 at 11:18 AM Anthony Emengo <aemengo@pivotal.io> wrote:Hey Ashesh,
Thanks for the explanation. It was great and it really helped!
C pgadmin/browser/server_groups/servers/databases/schemas/static/js/child.js C pgadmin/browser/server_groups/servers/databases/schemas/static/js/schema_child_tree_node.jsIt makes sense to remove duplication by extracting these attributes out and setting the
canDropandcanCreatefunctions here. But is it possible to combine these two files into one since they are related so we don’t need to importschema_child_tree_node?That was the original plan, but 'pgadmin/browser/static/js//node.js' script has too many dependecies, which are not easily portable.And - that may lead to change the scope of the patch.Hence - I decided to use the separate file to make sure we have enough test coverage (which is more imprortant than changing the scope).M pgadmin/static/js/tree/tree.jsThe creation of the
ancestorNodefunction feels like a pre-optimization. That function is not used any where outside of thetree.jsfile, so it’s more confusing to have it defined.It is being used in the latest changes. :-)On a lighter note, could we avoid the !! syntax when possible? For example, instead of
return !!obj, we could do something likereturn obj === undefinedorreturn _.isUndefined(obj)as this is more intuitive.I am kind of disagree here. But - I have changed it anyway.In addition, please update this patch as it is out of sync with the latest commit on the master branch. Otherwise, everything looks good!
Here - you go!-- Thanks, AsheshThanksAnthony && VictoriaOn Fri, Jun 1, 2018 at 7:52 AM Ashesh Vashi <ashesh.vashi@enterprisedb.com> wrote:On Thu, May 24, 2018 at 8:13 PM, Joao De Almeida Pereira <jdealmeidapereira@pivotal.io> wrote:Hey, Thanks so much for the reply.We've noticed that you've made several modifications on top of our original patch. Unfortunately, we've found it very hard to follow. Could we please get a brief synopsis of the changes you have made - just so we can better understand the rationale behind them? Just like we've done for you previously.Please find the changes from your original patch:M webpack.shim.js M webpack.test.config.js
- In order to specify the fake_browser in regression tests, we need to use 'pgbrowser/browser' in the 'schema_child_tree_node.js' script.D pgadmin/browser/server_groups/servers/databases/schemas/static/js/can_drop_child.js
- We don't need this with the new implementation.C pgadmin/browser/server_groups/servers/databases/schemas/static/js/child.js
- All the children of schema node have common properties as 'parent_type', 'canDrop', 'canDropCascase', 'canCreate'.
Hence - instead of defining them in each node, we have created a base node, which will have all these properties.
And, modified all schema children node to inherit from it.C pgadmin/browser/server_groups/servers/databases/schemas/static/js/schema_child_tree_node.js
- In this script, we're defining three functions 'childCreateMenuEnabled', 'isTreeItemOfChildOfSchema', & 'isTreeNodeOfSchemaChild', which are used by the 'SchemaChildNode' objects.M pgadmin/browser/static/js/collection.js
- Fixed an issue related to wrongly defined 'error' function for the Collection object.D pgadmin/static/js/menu/can_create.js
- It defined the function, which was defining a check for creation of a schema child node, or not by looking at the parent node (i.e. a schema/catalog node).
The file was not defintely placed under the wrong directory, because - the similar logic was under 'can_drop_child.js', and it was defined under 'pgadmin/browser/server_groups/servers/databases/schemas/static/js' directory.D pgadmin/static/js/menu/menu_enabled.jsC pgadmin/static/js/nodes/supported_database_node.js
- Used by the external tools for checking whether the 'selected' tree-node is:
+ 'database' node, and it is allowed to connect it.
+ Or, it is one of the schema child (and, not 'catalog' child).
- Finding the correct location was difficult for this, as there is no defined pattern, also it can be used by other functions too. Hence - moved it out of 'pgadmin/static/js/menu' directory.M pgadmin/static/js/tree/tree.js
- Introduced a function, which returns the ancestor node object, fow which the condition is true.D regression/javascript/menu/can_create_spec.js D regression/javascript/menu/menu_enabled_spec.js D regression/javascript/schema/can_drop_child_spec.js C regression/javascript/fake_browser/browser.js
C regression/javascript/nodes/schema/child_menu_spec.js
- Modified the regression to test the new functionalies.M pgadmin/browser/server_groups/servers/databases/schemas/**/*.js
- Extending the schema child nodes from the 'SchemaChildNode' class defined in 'pgadmin/.../schemas/static/js/child.js' script.Let me know if you need more information.Let's keep in mind that the original intent was simply to introduce this abstraction into the code base, which is a big enough task. I'd hate for the scope of the changes we're making to expand beyond that.I have the mutual feeling.-- Thanks, AsheshThanksJoao && AnthonyOn Thu, May 24, 2018 at 2:59 AM Ashesh Vashi <ashesh.vashi@enterprisedb.com> wrote:Sorry for the late reply.On Wed, May 16, 2018 at 8:55 PM, Anthony Emengo <aemengo@pivotal.io> wrote:export function canCreate(pgBrowser, childOfCatalogType) { return canCreateObject.bind({ browser: pgBrowser, childOfCatalogType: childOfCatalogType, }); }With respect to the above code: this bind pattern looks good and seems like the idiomatic way to handle this in JavaScript. On a lighter node, I don’t even see the need for an additional method to wrap it. The invocation could have easily been like
canCreate: canCreateObject.bind({ browser: pgBrowser, childOfCatalogType: childOfCatalogType }),I don’t feel too strongly here.I do agree - we can handle the same problem many ways.I prefer object oriented pardigm more in general.Any way - I have modified the code with some other changes.I renamed it as isValidTreeNodeData, because - we were using it in for testing the tree data. Please suggest me the right place, and name.
We’re not sure; maybe after continued refactoring, we will come across more generic functions. At that point we can revisit this and create a
utils.jsfile.Sure.The original patch was separating them in different places, but - still uses some of the functionalities directly from the tree, which was happening because we have contextual menu.
To give a better solution, I can think of putting the menus related code understand ‘sources/tree/menu’ directory.We’re particularly worried because we’re trying to avoid the coupling that we see in the code base today. We want to decouple application state from business domain logic as much as we can - because this makes the code much easier to understand. We achieve lower coupling by have more suitable interfaces to retrieve application state like:
anyParent(the menu doesn’t care how this happens). This is the direction that we’re trying to move towards, we just don’t want the package structure to undermine that developer intent.I realized after revisiting the code, menu/can_create.js was only applicable to the children of the schema/catalog nodes, same as 'can_drop_child'.We should have put both scripts in the same directory.Please find the updated patch for the same.Please review it, and let me know your concerns.-- Thanks, AsheshHow about nodeMenu.isSupportedNode(…)?
Naming is one of the hardest problems in programming. I don’t feel too strongly about this one. For now, let’s keep it as is
Thanks
Anthony && Victoria
Hi Aditya,1) Why don't we start using webpack alias's instead of using absolute path. For eg,
import {RestoreDialogWrapper} from '../../../pgadmin/static/js/restore/restore_dialog_ wrapper';
can be used as import {RestoreDialogWrapper} from 'pgadmin_static/js/restore/restore_dialog_wrapper';
by adding pgadmin_static alias to webpack config.Great point. In some areas of the code, we began making this change. There is already an alias in webpack shims for `../../../pgadmin/static/js` called `sources`. You can find an example of this in import statements for `supported_database_node.js`2) Few of the js are left behind, the ones which are used in python __init__.py. Can't we move them too ? It would be nicer to not to leave behind a single js.I'm not sure what you mean. Could you point to an example of a single js file?
Sincerely,VictoriaOn Wed, Jun 6, 2018 at 7:07 AM Aditya Toshniwal <aditya.toshniwal@enterprisedb.com> wrote: Hi Anthony/Victoria/Joao,I know I am very late to review on patch 004. The idea of moving js files from tools to static folder looks good, but I have a few suggestions:1) Why don't we start using webpack alias's instead of using absolute path. For eg,import {RestoreDialogWrapper} from '../../../pgadmin/static/js/restore/restore_dialog_ wrapper'; can be used as import {RestoreDialogWrapper} from 'pgadmin_static/js/restore/restore_dialog_wrapper'; by adding pgadmin_static alias to webpack config.2) Few of the js are left behind, the ones which are used in python __init__.py. Can't we move them too ? It would be nicer to not to leave behind a single js.Kindly let me know your views on this.Thanks and Regards,Aditya ToshniwalSoftware Engineer | EnterpriseDB Software Solutions | Pune"Don't Complain about Heat, Plant a tree"On Sat, Jun 2, 2018 at 12:47 AM, Victoria Henry <vhenry@pivotal.io> wrote:Hey Ashesh,LGTM! The some of the CI tests failed but it looks like a flake. But you can go ahead and merge this.Sincerely,VictoriaOn Fri, Jun 1, 2018 at 10:09 PM, Victoria Henry <vhenry@pivotal.io> wrote:Hi Ashesh,We just attempted to apply your patch over master but it did not work. We don't want to introduce any bugs or break any functionality. Please update the patch to make sure it is synced up with the master branch.Please find the updated patch.Sincerely,VictoriaOn Fri, Jun 1, 2018 at 11:18 AM Anthony Emengo <aemengo@pivotal.io> wrote:Hey Ashesh,
Thanks for the explanation. It was great and it really helped!
C pgadmin/browser/server_groups/servers/databases/schemas/ static/js/child.js C pgadmin/browser/server_groups/ servers/databases/schemas/ static/js/schema_child_tree_ node.js It makes sense to remove duplication by extracting these attributes out and setting the
canDropandcanCreatefunctions here. But is it possible to combine these two files into one since they are related so we don’t need to importschema_child_tree_node?That was the original plan, but 'pgadmin/browser/static/js//node.js' script has too many dependecies, which are not easily portable. And - that may lead to change the scope of the patch.Hence - I decided to use the separate file to make sure we have enough test coverage (which is more imprortant than changing the scope).M pgadmin/static/js/tree/tree.jsThe creation of the
ancestorNodefunction feels like a pre-optimization. That function is not used any where outside of thetree.jsfile, so it’s more confusing to have it defined.It is being used in the latest changes. :-)On a lighter note, could we avoid the !! syntax when possible? For example, instead of
return !!obj, we could do something likereturn obj === undefinedorreturn _.isUndefined(obj)as this is more intuitive.I am kind of disagree here. But - I have changed it anyway.In addition, please update this patch as it is out of sync with the latest commit on the master branch. Otherwise, everything looks good!
Here - you go!-- Thanks, AsheshThanksAnthony && VictoriaOn Thu, May 24, 2018 at 8:13 PM, Joao De Almeida Pereira <jdealmeidapereira@pivotal.io> wrote:Hey, Thanks so much for the reply.We've noticed that you've made several modifications on top of our original patch. Unfortunately, we've found it very hard to follow. Could we please get a brief synopsis of the changes you have made - just so we can better understand the rationale behind them? Just like we've done for you previously.Please find the changes from your original patch:M webpack.shim.js M webpack.test.config.js
- In order to specify the fake_browser in regression tests, we need to use 'pgbrowser/browser' in the 'schema_child_tree_node.js' script.D pgadmin/browser/server_groups/servers/databases/schemas/ static/js/can_drop_child.js
- We don't need this with the new implementation.C pgadmin/browser/server_groups/servers/databases/schemas/stat ic/js/child.js
- All the children of schema node have common properties as 'parent_type', 'canDrop', 'canDropCascase', 'canCreate'.
Hence - instead of defining them in each node, we have created a base node, which will have all these properties.
And, modified all schema children node to inherit from it.C pgadmin/browser/server_groups/servers/databases/schemas/ static/js/schema_child_tree_ node.js
- In this script, we're defining three functions 'childCreateMenuEnabled', 'isTreeItemOfChildOfSchema', & 'isTreeNodeOfSchemaChild', which are used by the 'SchemaChildNode' objects.M pgadmin/browser/static/js/collection.js
- Fixed an issue related to wrongly defined 'error' function for the Collection object.D pgadmin/static/js/menu/can_create.js
- It defined the function, which was defining a check for creation of a schema child node, or not by looking at the parent node (i.e. a schema/catalog node).
The file was not defintely placed under the wrong directory, because - the similar logic was under 'can_drop_child.js', and it was defined under 'pgadmin/browser/server_groups/servers/databases/ schemas/static/js' directory. D pgadmin/static/js/menu/menu_enabled.js C pgadmin/static/js/nodes/supported_database_node.js
- Used by the external tools for checking whether the 'selected' tree-node is:
+ 'database' node, and it is allowed to connect it.
+ Or, it is one of the schema child (and, not 'catalog' child).
- Finding the correct location was difficult for this, as there is no defined pattern, also it can be used by other functions too. Hence - moved it out of 'pgadmin/static/js/menu' directory.M pgadmin/static/js/tree/tree.js
- Introduced a function, which returns the ancestor node object, fow which the condition is true.D regression/javascript/menu/can_create_spec.js D regression/javascript/menu/ menu_enabled_spec.js D regression/javascript/schema/ can_drop_child_spec.js C regression/javascript/fake_bro wser/browser.js
C regression/javascript/nodes/schema/child_menu_spec.js
- Modified the regression to test the new functionalies.M pgadmin/browser/server_groups/servers/databases/schemas/**/* .js
- Extending the schema child nodes from the 'SchemaChildNode' class defined in 'pgadmin/.../schemas/static/js/child.js' script. Let me know if you need more information.Let's keep in mind that the original intent was simply to introduce this abstraction into the code base, which is a big enough task. I'd hate for the scope of the changes we're making to expand beyond that.I have the mutual feeling.-- Thanks, AsheshThanksJoao && AnthonySorry for the late reply.On Wed, May 16, 2018 at 8:55 PM, Anthony Emengo <aemengo@pivotal.io> wrote:export function canCreate(pgBrowser, childOfCatalogType) { return canCreateObject.bind({ browser: pgBrowser, childOfCatalogType: childOfCatalogType, }); }With respect to the above code: this bind pattern looks good and seems like the idiomatic way to handle this in JavaScript. On a lighter node, I don’t even see the need for an additional method to wrap it. The invocation could have easily been like
canCreate: canCreateObject.bind({ browser: pgBrowser, childOfCatalogType: childOfCatalogType }),I don’t feel too strongly here.I do agree - we can handle the same problem many ways.I prefer object oriented pardigm more in general.Any way - I have modified the code with some other changes.I renamed it as isValidTreeNodeData, because - we were using it in for testing the tree data. Please suggest me the right place, and name.
We’re not sure; maybe after continued refactoring, we will come across more generic functions. At that point we can revisit this and create a
utils.jsfile.Sure.The original patch was separating them in different places, but - still uses some of the functionalities directly from the tree, which was happening because we have contextual menu.
To give a better solution, I can think of putting the menus related code understand ‘sources/tree/menu’ directory.We’re particularly worried because we’re trying to avoid the coupling that we see in the code base today. We want to decouple application state from business domain logic as much as we can - because this makes the code much easier to understand. We achieve lower coupling by have more suitable interfaces to retrieve application state like:
anyParent(the menu doesn’t care how this happens). This is the direction that we’re trying to move towards, we just don’t want the package structure to undermine that developer intent.I realized after revisiting the code, menu/can_create.js was only applicable to the children of the schema/catalog nodes, same as 'can_drop_child'.We should have put both scripts in the same directory.Please find the updated patch for the same.Please review it, and let me know your concerns.-- Thanks, AsheshHow about nodeMenu.isSupportedNode(…)?
Naming is one of the hardest problems in programming. I don’t feel too strongly about this one. For now, let’s keep it as is
Thanks
Anthony && Victoria
Hi Hackers,
Be prepared this is going to be a big email.
Objectives of this patch:
- Start the work to split ACI from pgAdmin code
- Add more tests around the front end components
- Start the discussion on application architecture
1. Start the work to split ACI from pgAdmin code
Why
This journey started on our first attempt to store state of the current tree, so that when a user accessed again pgAdmin
there would be no need to reopen all the nodes and make the flow better. Another problem users brought to us was related
to the UI behavior when the number of objects was too big.In order to do implement this features we would have to play around with aciTree or some functions from our code that
called and leveraged the aciTree functionalities. To do this we needed to have some confidence that our changes would
implement correctly the new feature and it would not break the current functionality.
The process that we used was first extract the functions that interacted with the tree, wrap them with
tests and then refactor them in some way. While doing this work we realized that the tree started spreading roots
throughout the majority of the application.How
Options:
- Rewrite the front end
- One bang replace ACI Tree without change on the application
- Create an abstraction layer between ACI Tree and the application
1. Rewrite the front end
Pros Const Achieve decoupling by recreating the frontend Cost is too high Do not rely on deprecated or unmaintained libraries Turn around is too long One shot change 2. One bang replace ACI Tree
Pros Const Achieve decoupling by recreating the frontend Cost is too high Does not achieve the decoupling unless we change the application Need to create an adaptor No garantee of success One shot change 3. Create an abstraction layer between ACI Tree and the application
Pros Const Achieve decoupling of the application and the tree 90% of the time on Code archaeology Lower cost Ability to change or keep ACI Tree, decision TBD Can be done in a iterative way We decided that options 3 looked more attractive specially because we could do it in a iterative way.
The next image depicts the current state of the interactions between the application and the ACI and the place we want
to be in.
for retrieving of data from the ACI Tree that then is used in different ways.
Because we are doing this in a iterative process we need to keep the current tree working and create our adaptor next
to it. In order to do that we created a new property onPGBrowserclass calledtreeMenuand when ACI Tree receives
the node information we also populate the new Tree with all the needed information.This approach allow us not to worry, for now, with data retrieval, URL system and other issues that should be addressed
in the future when the adaptor is done.This first patch tries to deal with the low hanging fruit, functions that are triggered by events from ACI Tree.
Cases like registering to events and triggering events need to be handled in the future as well.2. Add more tests around the front end components
Why
Go Fast Forever: https://builttoadapt.io/why-
tdd-489fdcdda05e
I think this is a very good summary of why do we need tests in our applications.3. Start the discussion on application architecture
Why should we care about location of files inside a our application?
Why is this way better the another?
These are 2 good questions that have very lengthy answers. Trying to more or less summarize the answers we care about
the location of the files, because we want our application to communicate intent and there are always pros and cons
on all the decisions that we make.At this point the application structure follows our menu, this approach eventually make is easier to follow the code
but at the same time if the menu changes down the line, will we change the structure of our folders?
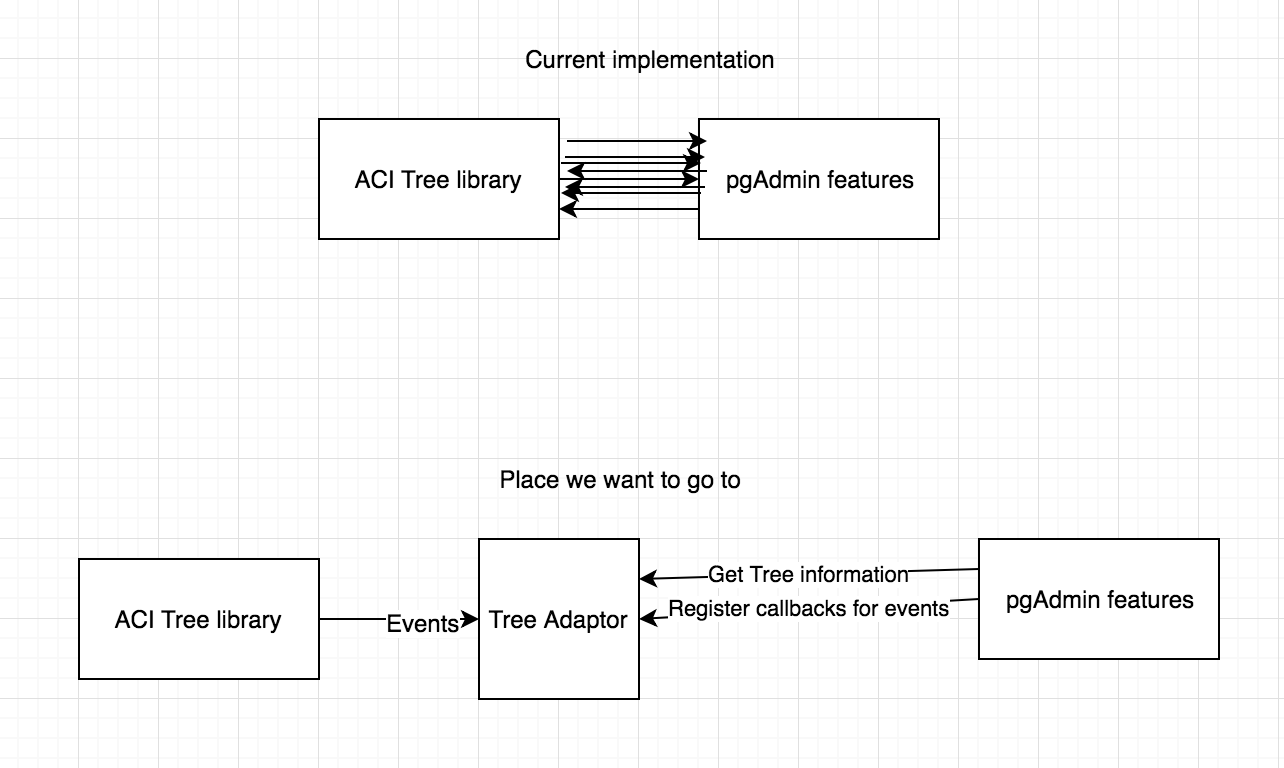
{kind=link}
{kind=link}
The proposal that we do with the last diff of this patch is to change to a structure that slices vertically the
application. This way we can understand intent behind the code and more easily find what we are looking for.In the current structure if you want to see the tables code you need to go to
pgAdmin/browser/server_groups/this is a huge path to remember and to get to. Whatservers/databases/schemas/ tables/
do we win with this? If we open pgAdmin we know which nodes to click in order to get to tables. But for development
every time that you are looking for a specific functionality you need to run the application, navigate the menu so that
you know where you can find the code. This doesn’t sound very appealing.What if our structure would look like this:
- web - tables - controller - get_nodes.py - get_sql.py - __init__.py - frontend - component - ddl_component.js - services - table-service.js - schemas - servers - ....
This would saves us time because all the information that we need is what are we working on and everything is right there.
Menu driven structure Intent Driven Structure Pros: Pros: Already in place Explicitly shows features Self contained features Self contained features Support for drop in features Support for drop in features Cons: Cons: Follows the menu, and it could change Need to change current code Hard to find features Some additional plumbing might be needed Drop in features need to be placed in a specific location according to the menu location What are your thought about this architecture?
Around minute 7 of this video Uncle Bob shows an application written
in rails to talk about architecture. It is a long KeyNote if you are curious I would advise you to see the full video.
His approach to architecture of the application is pretty interesting.
Patches
0001 Change the order of the shims on the shim file
Simple change that orders the shims inside the shim file
0002 New tree implementation
This is the first version of our Tree implementation. At this point is a very simple tree without no abstractions and
with code that eventually is not very performant, but this is only the first iteration and we are trying to follow the
Last Responsible Moment Principle.What can you find in this patch:
- Creation of
PGBrowser.treeMenu- Initial version of the Tree Adaptor
web/pgadmin/static/js/tree/tree.js - TreeFake test double that can replace the Tree for testing purposes
- Tests. As an interesting asside because Fake’s need to behave like the real object you will noticed that there are
tests for this type of double and they the same as of the real object.0003 Extract, Test and Refactor Methods
This is the patch that contains the change that we talked a in the objectives. It touches in a subset of the places
whereitemDatafunction is called. To have a sense of progress the following image depicts, on the left all places
where this functions can be found in the code and on the right the places where it still remains after this patch.But this patch is not only related to the ACI Tree, it also creates some abstractions from code that we found repeated.
Some examples of this are the dialogs for Backup and Restore, where the majority of the logic was common, so we created
inweb/pgadmin/static/js/3 different objects:alertify/
A FactoryDialogFactorythat is responsible for creating newDialogand these dialogs will use theDialogWrapper.This is also a good example of the Last Responsible Moment Principle,
inDialogthere are still some functions that are used in a Recover and Backup scenario. When we have more examples
we will be able to, if we want, to extract that into another function.While doing some code refactoring we found out that the Right Click Menu as some checks that can be centralized. Examples
of these are checks for Enable/Disable of an option of the display of the Create/Edit/Drop option in some menus.
Checkweb/pgadmin/static/js/menu/for more information. This simplified code like:canCreate: function(itemData, item, data) { - //If check is false then , we will allow create menu - if (data && data.check == false) - return true; - - var t = pgBrowser.tree, i = item, d = itemData; - // To iterate over tree to check parent node - while (i) { - // If it is schema then allow user to create domain - if (_.indexOf(['schema'], d._type) > -1) - return true; - - if ('coll-domain' == d._type) { - //Check if we are not child of catalog - var prev_i = t.hasParent(i) ? t.parent(i) : null, - prev_d = prev_i ? t.itemData(prev_i) : null; - if( prev_d._type == 'catalog') { - return false; - } else { - return true; - } - } - i = t.hasParent(i) ? t.parent(i) : null; - d = i ? t.itemData(i) : null; - } - // by default we do not want to allow create menu - return true; + return canCreate.canCreate(pgBrowser, 'coll-domain', item, data); }This refactor was made in a couple of places throughout the code.
Another refactor that had to be done was the creation of the functions
getTreeNodeHierarchyFromElemenandt getTreeNodeHierarchyFromIdentithat replace the oldfier getTreeNodeHierarchy. This implementation was done
because for the time being we have 2 different types of trees and calls to them.The rest of the changes resulted from our process of refactoring that we are following:
- Find a location where
itemDatais used- Extract that into a function outside of the current code
- Wrap it with tests
- When we have enough confidence on the tests, we refactor the function to use the new Tree
- We refactor the function to become more readable
- Start over
0004 Architecture
The proposed structure is our vision for the application, this is not the state we will be in when this patch lands.
For now the only change we are doing is move the javascript intostatic/js/FEATURE_NAME. This is a first step in the
direction that we would like to see the product heading.Even if we decide to keep using the same architecture the move of Javascript to a centralized place will
not break any plugability as webpack can retrieve all the Javascript from any place in the code.Have a nice weekend
Joao
Attachment
Hi Aditya
Sure. I did not find moving web/pgadmin/tools/datagrid/static/js/datagrid.js. Please correct me if I am missing anything.
Generally speaking, I agree with moving/deleting files if it makes sense. But in regards to web/pgadmin/tools/datagrid/static/js/datagrid.js, it looks like this is still being used in web/pgadmin/tools/sqleditor/static/js/sqleditor.js with Datagrid.create_transaction
Sincerely,
Victoria
Hi Victoria,On Wed, Jun 6, 2018 at 8:55 PM, Victoria Henry <vhenry@pivotal.io> wrote:Hi Aditya,1) Why don't we start using webpack alias's instead of using absolute path. For eg,
import {RestoreDialogWrapper} from '../../../pgadmin/static/js/restore/restore_dialog_wrapper';
can be used as import {RestoreDialogWrapper} from 'pgadmin_static/js/restore/restore_dialog_wrapper';
by adding pgadmin_static alias to webpack config.Great point. In some areas of the code, we began making this change. There is already an alias in webpack shims for `../../../pgadmin/static/js` called `sources`. You can find an example of this in import statements for `supported_database_node.js`2) Few of the js are left behind, the ones which are used in python __init__.py. Can't we move them too ? It would be nicer to not to leave behind a single js.I'm not sure what you mean. Could you point to an example of a single js file?Sure. I did not find moving web/pgadmin/tools/datagrid/static/js/datagrid.js. Please correct me if I am missing anything.Sincerely,VictoriaOn Wed, Jun 6, 2018 at 7:07 AM Aditya Toshniwal <aditya.toshniwal@enterprisedb.com> wrote:Hi Anthony/Victoria/Joao,I know I am very late to review on patch 004. The idea of moving js files from tools to static folder looks good, but I have a few suggestions:1) Why don't we start using webpack alias's instead of using absolute path. For eg,import {RestoreDialogWrapper} from '../../../pgadmin/static/js/restore/restore_dialog_wrapper';can be used as import {RestoreDialogWrapper} from 'pgadmin_static/js/restore/restore_dialog_wrapper';by adding pgadmin_static alias to webpack config.2) Few of the js are left behind, the ones which are used in python __init__.py. Can't we move them too ? It would be nicer to not to leave behind a single js.Kindly let me know your views on this.Thanks and Regards,Aditya ToshniwalSoftware Engineer | EnterpriseDB Software Solutions | Pune"Don't Complain about Heat, Plant a tree"On Sat, Jun 2, 2018 at 12:47 AM, Victoria Henry <vhenry@pivotal.io> wrote:Hey Ashesh,LGTM! The some of the CI tests failed but it looks like a flake. But you can go ahead and merge this.Sincerely,VictoriaOn Fri, Jun 1, 2018 at 2:36 PM Ashesh Vashi <ashesh.vashi@enterprisedb.com> wrote:On Fri, Jun 1, 2018 at 10:09 PM, Victoria Henry <vhenry@pivotal.io> wrote:Hi Ashesh,We just attempted to apply your patch over master but it did not work. We don't want to introduce any bugs or break any functionality. Please update the patch to make sure it is synced up with the master branch.Please find the updated patch.Sincerely,VictoriaOn Fri, Jun 1, 2018 at 11:18 AM Anthony Emengo <aemengo@pivotal.io> wrote:Hey Ashesh,
Thanks for the explanation. It was great and it really helped!
C pgadmin/browser/server_groups/servers/databases/schemas/static/js/child.js C pgadmin/browser/server_groups/servers/databases/schemas/static/js/schema_child_tree_node.jsIt makes sense to remove duplication by extracting these attributes out and setting the
canDropandcanCreatefunctions here. But is it possible to combine these two files into one since they are related so we don’t need to importschema_child_tree_node?That was the original plan, but 'pgadmin/browser/static/js//node.js' script has too many dependecies, which are not easily portable.And - that may lead to change the scope of the patch.Hence - I decided to use the separate file to make sure we have enough test coverage (which is more imprortant than changing the scope).M pgadmin/static/js/tree/tree.jsThe creation of the
ancestorNodefunction feels like a pre-optimization. That function is not used any where outside of thetree.jsfile, so it’s more confusing to have it defined.It is being used in the latest changes. :-)On a lighter note, could we avoid the !! syntax when possible? For example, instead of
return !!obj, we could do something likereturn obj === undefinedorreturn _.isUndefined(obj)as this is more intuitive.I am kind of disagree here. But - I have changed it anyway.In addition, please update this patch as it is out of sync with the latest commit on the master branch. Otherwise, everything looks good!
Here - you go!-- Thanks, AsheshThanksAnthony && VictoriaOn Fri, Jun 1, 2018 at 7:52 AM Ashesh Vashi <ashesh.vashi@enterprisedb.com> wrote:On Thu, May 24, 2018 at 8:13 PM, Joao De Almeida Pereira <jdealmeidapereira@pivotal.io> wrote:Hey, Thanks so much for the reply.We've noticed that you've made several modifications on top of our original patch. Unfortunately, we've found it very hard to follow. Could we please get a brief synopsis of the changes you have made - just so we can better understand the rationale behind them? Just like we've done for you previously.Please find the changes from your original patch:M webpack.shim.js M webpack.test.config.js
- In order to specify the fake_browser in regression tests, we need to use 'pgbrowser/browser' in the 'schema_child_tree_node.js' script.D pgadmin/browser/server_groups/servers/databases/schemas/static/js/can_drop_child.js
- We don't need this with the new implementation.C pgadmin/browser/server_groups/servers/databases/schemas/static/js/child.js
- All the children of schema node have common properties as 'parent_type', 'canDrop', 'canDropCascase', 'canCreate'.
Hence - instead of defining them in each node, we have created a base node, which will have all these properties.
And, modified all schema children node to inherit from it.C pgadmin/browser/server_groups/servers/databases/schemas/static/js/schema_child_tree_node.js
- In this script, we're defining three functions 'childCreateMenuEnabled', 'isTreeItemOfChildOfSchema', & 'isTreeNodeOfSchemaChild', which are used by the 'SchemaChildNode' objects.M pgadmin/browser/static/js/collection.js
- Fixed an issue related to wrongly defined 'error' function for the Collection object.D pgadmin/static/js/menu/can_create.js
- It defined the function, which was defining a check for creation of a schema child node, or not by looking at the parent node (i.e. a schema/catalog node).
The file was not defintely placed under the wrong directory, because - the similar logic was under 'can_drop_child.js', and it was defined under 'pgadmin/browser/server_groups/servers/databases/schemas/static/js' directory.D pgadmin/static/js/menu/menu_enabled.jsC pgadmin/static/js/nodes/supported_database_node.js
- Used by the external tools for checking whether the 'selected' tree-node is:
+ 'database' node, and it is allowed to connect it.
+ Or, it is one of the schema child (and, not 'catalog' child).
- Finding the correct location was difficult for this, as there is no defined pattern, also it can be used by other functions too. Hence - moved it out of 'pgadmin/static/js/menu' directory.M pgadmin/static/js/tree/tree.js
- Introduced a function, which returns the ancestor node object, fow which the condition is true.D regression/javascript/menu/can_create_spec.js D regression/javascript/menu/menu_enabled_spec.js D regression/javascript/schema/can_drop_child_spec.js C regression/javascript/fake_browser/browser.js
C regression/javascript/nodes/schema/child_menu_spec.js
- Modified the regression to test the new functionalies.M pgadmin/browser/server_groups/servers/databases/schemas/**/*.js
- Extending the schema child nodes from the 'SchemaChildNode' class defined in 'pgadmin/.../schemas/static/js/child.js' script.Let me know if you need more information.Let's keep in mind that the original intent was simply to introduce this abstraction into the code base, which is a big enough task. I'd hate for the scope of the changes we're making to expand beyond that.I have the mutual feeling.-- Thanks, AsheshThanksJoao && AnthonyOn Thu, May 24, 2018 at 2:59 AM Ashesh Vashi <ashesh.vashi@enterprisedb.com> wrote:Sorry for the late reply.On Wed, May 16, 2018 at 8:55 PM, Anthony Emengo <aemengo@pivotal.io> wrote:export function canCreate(pgBrowser, childOfCatalogType) { return canCreateObject.bind({ browser: pgBrowser, childOfCatalogType: childOfCatalogType, }); }With respect to the above code: this bind pattern looks good and seems like the idiomatic way to handle this in JavaScript. On a lighter node, I don’t even see the need for an additional method to wrap it. The invocation could have easily been like
canCreate: canCreateObject.bind({ browser: pgBrowser, childOfCatalogType: childOfCatalogType }),I don’t feel too strongly here.I do agree - we can handle the same problem many ways.I prefer object oriented pardigm more in general.Any way - I have modified the code with some other changes.I renamed it as isValidTreeNodeData, because - we were using it in for testing the tree data. Please suggest me the right place, and name.
We’re not sure; maybe after continued refactoring, we will come across more generic functions. At that point we can revisit this and create a
utils.jsfile.Sure.The original patch was separating them in different places, but - still uses some of the functionalities directly from the tree, which was happening because we have contextual menu.
To give a better solution, I can think of putting the menus related code understand ‘sources/tree/menu’ directory.We’re particularly worried because we’re trying to avoid the coupling that we see in the code base today. We want to decouple application state from business domain logic as much as we can - because this makes the code much easier to understand. We achieve lower coupling by have more suitable interfaces to retrieve application state like:
anyParent(the menu doesn’t care how this happens). This is the direction that we’re trying to move towards, we just don’t want the package structure to undermine that developer intent.I realized after revisiting the code, menu/can_create.js was only applicable to the children of the schema/catalog nodes, same as 'can_drop_child'.We should have put both scripts in the same directory.Please find the updated patch for the same.Please review it, and let me know your concerns.-- Thanks, AsheshHow about nodeMenu.isSupportedNode(…)?
Naming is one of the hardest problems in programming. I don’t feel too strongly about this one. For now, let’s keep it as is
Thanks
Anthony && Victoria
Hi Aditya
Sure. I did not find moving web/pgadmin/tools/datagrid/static/js/datagrid.js. Please correct me if I am missing anything. Generally speaking, I agree with moving/deleting files if it makes sense. But in regards to
web/pgadmin/tools/datagrid/, it looks like this is still being used instatic/js/datagrid.js web/pgadmin/tools/sqleditor/withstatic/js/sqleditor.js Datagrid.create_transaction
Sincerely,
Victoria
On Thu, Jun 7, 2018 at 12:35 AM Aditya Toshniwal <aditya.toshniwal@enterprisedb.com> wrote: Hi Victoria,On Wed, Jun 6, 2018 at 8:55 PM, Victoria Henry <vhenry@pivotal.io> wrote:Hi Aditya,1) Why don't we start using webpack alias's instead of using absolute path. For eg,
import {RestoreDialogWrapper} from '../../../pgadmin/static/js/restore/restore_dialog_ wrapper';
can be used as import {RestoreDialogWrapper} from 'pgadmin_static/js/restore/restore_dialog_wrapper';
by adding pgadmin_static alias to webpack config.Great point. In some areas of the code, we began making this change. There is already an alias in webpack shims for `../../../pgadmin/static/js` called `sources`. You can find an example of this in import statements for `supported_database_node.js`2) Few of the js are left behind, the ones which are used in python __init__.py. Can't we move them too ? It would be nicer to not to leave behind a single js.I'm not sure what you mean. Could you point to an example of a single js file?Sure. I did not find moving web/pgadmin/tools/datagrid/static/js/datagrid.js. Please correct me if I am missing anything. Sincerely,VictoriaOn Wed, Jun 6, 2018 at 7:07 AM Aditya Toshniwal <aditya.toshniwal@enterprisedb.com> wrote: Hi Anthony/Victoria/Joao,I know I am very late to review on patch 004. The idea of moving js files from tools to static folder looks good, but I have a few suggestions:1) Why don't we start using webpack alias's instead of using absolute path. For eg,import {RestoreDialogWrapper} from '../../../pgadmin/static/js/restore/restore_dialog_ wrapper'; can be used as import {RestoreDialogWrapper} from 'pgadmin_static/js/restore/restore_dialog_wrapper'; by adding pgadmin_static alias to webpack config.2) Few of the js are left behind, the ones which are used in python __init__.py. Can't we move them too ? It would be nicer to not to leave behind a single js.Kindly let me know your views on this.Thanks and Regards,Aditya ToshniwalSoftware Engineer | EnterpriseDB Software Solutions | Pune"Don't Complain about Heat, Plant a tree"On Sat, Jun 2, 2018 at 12:47 AM, Victoria Henry <vhenry@pivotal.io> wrote:Hey Ashesh,LGTM! The some of the CI tests failed but it looks like a flake. But you can go ahead and merge this.Sincerely,VictoriaOn Fri, Jun 1, 2018 at 10:09 PM, Victoria Henry <vhenry@pivotal.io> wrote:Hi Ashesh,We just attempted to apply your patch over master but it did not work. We don't want to introduce any bugs or break any functionality. Please update the patch to make sure it is synced up with the master branch.Please find the updated patch.Sincerely,VictoriaOn Fri, Jun 1, 2018 at 11:18 AM Anthony Emengo <aemengo@pivotal.io> wrote:Hey Ashesh,
Thanks for the explanation. It was great and it really helped!
C pgadmin/browser/server_groups/servers/databases/schemas/ static/js/child.js C pgadmin/browser/server_groups/ servers/databases/schemas/ static/js/schema_child_tree_ node.js It makes sense to remove duplication by extracting these attributes out and setting the
canDropandcanCreatefunctions here. But is it possible to combine these two files into one since they are related so we don’t need to importschema_child_tree_node?That was the original plan, but 'pgadmin/browser/static/js//node.js' script has too many dependecies, which are not easily portable. And - that may lead to change the scope of the patch.Hence - I decided to use the separate file to make sure we have enough test coverage (which is more imprortant than changing the scope).M pgadmin/static/js/tree/tree.jsThe creation of the
ancestorNodefunction feels like a pre-optimization. That function is not used any where outside of thetree.jsfile, so it’s more confusing to have it defined.It is being used in the latest changes. :-)On a lighter note, could we avoid the !! syntax when possible? For example, instead of
return !!obj, we could do something likereturn obj === undefinedorreturn _.isUndefined(obj)as this is more intuitive.I am kind of disagree here. But - I have changed it anyway.In addition, please update this patch as it is out of sync with the latest commit on the master branch. Otherwise, everything looks good!
Here - you go!-- Thanks, AsheshThanksAnthony && VictoriaOn Thu, May 24, 2018 at 8:13 PM, Joao De Almeida Pereira <jdealmeidapereira@pivotal.io> wrote:Hey, Thanks so much for the reply.We've noticed that you've made several modifications on top of our original patch. Unfortunately, we've found it very hard to follow. Could we please get a brief synopsis of the changes you have made - just so we can better understand the rationale behind them? Just like we've done for you previously.Please find the changes from your original patch:M webpack.shim.js M webpack.test.config.js
- In order to specify the fake_browser in regression tests, we need to use 'pgbrowser/browser' in the 'schema_child_tree_node.js' script.D pgadmin/browser/server_groups/servers/databases/schemas/ static/js/can_drop_child.js
- We don't need this with the new implementation.C pgadmin/browser/server_groups/servers/databases/schemas/stat ic/js/child.js
- All the children of schema node have common properties as 'parent_type', 'canDrop', 'canDropCascase', 'canCreate'.
Hence - instead of defining them in each node, we have created a base node, which will have all these properties.
And, modified all schema children node to inherit from it.C pgadmin/browser/server_groups/servers/databases/schemas/ static/js/schema_child_tree_ node.js
- In this script, we're defining three functions 'childCreateMenuEnabled', 'isTreeItemOfChildOfSchema', & 'isTreeNodeOfSchemaChild', which are used by the 'SchemaChildNode' objects.M pgadmin/browser/static/js/collection.js
- Fixed an issue related to wrongly defined 'error' function for the Collection object.D pgadmin/static/js/menu/can_create.js
- It defined the function, which was defining a check for creation of a schema child node, or not by looking at the parent node (i.e. a schema/catalog node).
The file was not defintely placed under the wrong directory, because - the similar logic was under 'can_drop_child.js', and it was defined under 'pgadmin/browser/server_groups/servers/databases/ schemas/static/js' directory. D pgadmin/static/js/menu/menu_enabled.js C pgadmin/static/js/nodes/supported_database_node.js
- Used by the external tools for checking whether the 'selected' tree-node is:
+ 'database' node, and it is allowed to connect it.
+ Or, it is one of the schema child (and, not 'catalog' child).
- Finding the correct location was difficult for this, as there is no defined pattern, also it can be used by other functions too. Hence - moved it out of 'pgadmin/static/js/menu' directory.M pgadmin/static/js/tree/tree.js
- Introduced a function, which returns the ancestor node object, fow which the condition is true.D regression/javascript/menu/can_create_spec.js D regression/javascript/menu/ menu_enabled_spec.js D regression/javascript/schema/ can_drop_child_spec.js C regression/javascript/fake_bro wser/browser.js
C regression/javascript/nodes/schema/child_menu_spec.js
- Modified the regression to test the new functionalies.M pgadmin/browser/server_groups/servers/databases/schemas/**/* .js
- Extending the schema child nodes from the 'SchemaChildNode' class defined in 'pgadmin/.../schemas/static/js/child.js' script. Let me know if you need more information.Let's keep in mind that the original intent was simply to introduce this abstraction into the code base, which is a big enough task. I'd hate for the scope of the changes we're making to expand beyond that.I have the mutual feeling.-- Thanks, AsheshThanksJoao && AnthonySorry for the late reply.On Wed, May 16, 2018 at 8:55 PM, Anthony Emengo <aemengo@pivotal.io> wrote:export function canCreate(pgBrowser, childOfCatalogType) { return canCreateObject.bind({ browser: pgBrowser, childOfCatalogType: childOfCatalogType, }); }With respect to the above code: this bind pattern looks good and seems like the idiomatic way to handle this in JavaScript. On a lighter node, I don’t even see the need for an additional method to wrap it. The invocation could have easily been like
canCreate: canCreateObject.bind({ browser: pgBrowser, childOfCatalogType: childOfCatalogType }),I don’t feel too strongly here.I do agree - we can handle the same problem many ways.I prefer object oriented pardigm more in general.Any way - I have modified the code with some other changes.I renamed it as isValidTreeNodeData, because - we were using it in for testing the tree data. Please suggest me the right place, and name.
We’re not sure; maybe after continued refactoring, we will come across more generic functions. At that point we can revisit this and create a
utils.jsfile.Sure.The original patch was separating them in different places, but - still uses some of the functionalities directly from the tree, which was happening because we have contextual menu.
To give a better solution, I can think of putting the menus related code understand ‘sources/tree/menu’ directory.We’re particularly worried because we’re trying to avoid the coupling that we see in the code base today. We want to decouple application state from business domain logic as much as we can - because this makes the code much easier to understand. We achieve lower coupling by have more suitable interfaces to retrieve application state like:
anyParent(the menu doesn’t care how this happens). This is the direction that we’re trying to move towards, we just don’t want the package structure to undermine that developer intent.I realized after revisiting the code, menu/can_create.js was only applicable to the children of the schema/catalog nodes, same as 'can_drop_child'.We should have put both scripts in the same directory.Please find the updated patch for the same.Please review it, and let me know your concerns.-- Thanks, AsheshHow about nodeMenu.isSupportedNode(…)?
Naming is one of the hardest problems in programming. I don’t feel too strongly about this one. For now, let’s keep it as is
Thanks
Anthony && Victoria
...
3. Start the discussion on application architecture
Why should we care about location of files inside a our application?
Why is this way better the another?
These are 2 good questions that have very lengthy answers. Trying to more or less summarize the answers we care about
the location of the files, because we want our application to communicate intent and there are always pros and cons
on all the decisions that we make.
At this point the application structure follows our menu, this approach eventually make is easier to follow the code
but at the same time if the menu changes down the line, will we change the structure of our folders?
The proposal that we do with the last diff of this patch is to change to a structure that slices vertically the
application. This way we can understand intent behind the code and more easily find what we are looking for.
In the current structure if you want to see the tables code you need to go to
pgAdmin/browser/server_groups/this is a huge path to remember and to get to. Whatservers/databases/schemas/tabl es/
do we win with this?
If we open pgAdmin we know which nodes to click in order to get to tables. But for development
every time that you are looking for a specific functionality you need to run the application, navigate the menu so that
you know where you can find the code. This doesn’t sound very appealing.
What if our structure would look like this:
- web - tables - controller - get_nodes.py - get_sql.py - __init__.py - frontend - component - ddl_component.js - services - table-service.js - schemas - servers - ....
This would saves us time because all the information that we need is what are we working on and everything is right there.
Menu driven structure Intent Driven Structure Pros: Pros: Already in place Explicitly shows features Self contained features Self contained features Support for drop in features Support for drop in features Cons: Cons: Follows the menu, and it could change Need to change current code Hard to find features Some additional plumbing might be needed Drop in features need to be placed in a specific location according to the menu location What are your thought about this architecture?
NOTE:pgadmin/ - database_objects/ - server/ - __init__.py - create.py - get.py - sql.py - update.py - static/ - img/ - server.svg - server_bad.svg - javascripts/ - server.js - ui_schema.js - database/ - templates ... ... + schema/ ... - tests/ - api/ ... - gui/ ... - karma/ ... - browser/ + pgagents/ - server_groups/ - servers/ - databases/ - __init__.py - node.py - schemas ... ... ... ... + tests/ - tools/ + sqleditor/ + dataviewer/ + debugger/ - misc/ + sql/ + statistics/ ...
Around minute 7 of this video Uncle Bob shows an application written
in rails to talk about architecture. It is a long KeyNote if you are curious I would advise you to see the full video.
His approach to architecture of the application is pretty interesting.
Hi Team,On Sat, May 5, 2018 at 3:31 AM, Joao De Almeida Pereira <jdealmeidapereira@pivotal.io> wrote:...
3. Start the discussion on application architecture
Why should we care about location of files inside a our application?
Why is this way better the another?
These are 2 good questions that have very lengthy answers. Trying to more or less summarize the answers we care about
the location of the files, because we want our application to communicate intent and there are always pros and cons
on all the decisions that we make.To be honest, it depends on how do you see the application, and its expectations.That question leads me to another question "What do we want from pgAdmin 4?"At this point the application structure follows our menu, this approach eventually make is easier to follow the code
but at the same time if the menu changes down the line, will we change the structure of our folders?To be honest not menu driven. (Probably a wrong choice of word 'Menu'.)But - only under 'browser' (You can also call it object browser/tree), it is driven by the database object relation model.And, each module maintains the parent-child relationship.The proposal that we do with the last diff of this patch is to change to a structure that slices vertically the
application. This way we can understand intent behind the code and more easily find what we are looking for.In the current structure if you want to see the tables code you need to go to
pgAdmin/browser/server_groups/this is a huge path to remember and to get to. Whatservers/databases/schemas/tabl es/
do we win with this?I agree - it is too deep structure.But - it gives me the idea what's the structure of the database objection relationship.Does it hurt, I would say no?Because - as a database developer, I know whats the relationship of objects, and where I can find them.(Until I heard Dave saying it is about to touch the limit of maximum file system path.)
If we open pgAdmin we know which nodes to click in order to get to tables. But for development
every time that you are looking for a specific functionality you need to run the application, navigate the menu so that
you know where you can find the code. This doesn’t sound very appealing.What if our structure would look like this:
- web - tables - controller - get_nodes.py - get_sql.py - __init__.py - frontend - component - ddl_component.js - services - table-service.js - schemas - servers - ....I think - there is nothing wrong with the current module structure. It is more appealing to me than the above one.The python package contains the backend code, and static contains all your frontend.I am not saying, we should not change anything.We can definitely divide them in smaller chunks for both backend, and frontend side.This would saves us time because all the information that we need is what are we working on and everything is right there.
Menu driven structure Intent Driven Structure Pros: Pros: Already in place Explicitly shows features Self contained features Self contained features Support for drop in features Support for drop in features Cons: Cons: Follows the menu, and it could change Need to change current code Hard to find features Some additional plumbing might be needed Drop in features need to be placed in a specific location according to the menu location What are your thought about this architecture?
I am not a fan of flat file structure in application.There are many reasons - why we need namespace in C++, same applies here.Let me start from the question "What do we want from pgAdmin 4?"* A object browser* Miscallenous operations associated with the object shown in the object browser+ Reversed Enginering query (if any)+ Properties Viewer+ Edit/Create Viewer+ Staticis+ List of dependencies+ List of dependents* Query tool* Data Viewer (table/view)* Function debugger* Extendability/PluggabilityAccording to me - these as the intent of the application, and not objects assiciated with them.I do agree, there is no boundry (or, very thin) between data & presentation at the moment.We can start from there.I can think of the following directory structure ( which is not too different from the current, but - still will give the developers a lot more comfort as per your complain :-) ).NOTE:pgadmin/ - database_objects/ - server/ - __init__.py - create.py - get.py - sql.py - update.py - static/ - img/ - server.svg - server_bad.svg - javascripts/ - server.js - ui_schema.js - database/ - templates ... ... + schema/ ... - tests/ - api/ ... - gui/ ... - karma/ ... - browser/ + pgagents/ - server_groups/ - servers/ - databases/ - __init__.py - node.py - schemas ... ... ... ... + tests/ - tools/ + sqleditor/ + dataviewer/ + debugger/ - misc/ + sql/ + statistics/ ...We also need to think about the facts that.These changes may lead to a lot of night mare packagers to make changes in the installers in upgrade mode.Also - when I say pluggability/extendability, we should be able to create plugins on top of pgAdmin 4.Just take an example of this feature (Geospatial Query Viewer).I think - it is best implemented as an plugin, as not every pgAdmin user will benificiary.We need ability to load the modules as pluggable module same as we used to have before we introduced the webpack to bundle everything as modules.We also need to start thinking about it.-- Thanks, AsheshAround minute 7 of this video Uncle Bob shows an application written
in rails to talk about architecture. It is a long KeyNote if you are curious I would advise you to see the full video.
His approach to architecture of the application is pretty interesting.