Blog: PostgreSQL , p.5
Well, we've already discussed isolation and made a digression regarding the low-level data structure. And we've finally reached the most fascinating thing, that is, row versions (tuples).
Tuple header
As already mentioned, several versions of each row can be simultaneously available in the database. And we need to somehow distinguish one version from another one. To this end, each version is labeled with its effective "time" (xmin) and expiration "time" (xmax). Quotation marks denote that a special incrementing counter is used rather than the time itself. And this counter is the transaction identifier.
(As usual, in reality this is more complicated: the transaction ID cannot always increment due to a limited bit depth of the counter. But we will explore more details of this when our discussion reaches freezing.)
When a row is created, the value of xmin is set equal to the ID of the transaction that performed the INSERT command, while xmax is not filled in.
When a row is deleted, the xmax value of the current version is labeled with the ID of the transaction that performed DELETE.
An UPDATE command actually performs two subsequent operations: DELETE and INSERT. In the current version of the row, xmax is set equal to the ID of the transaction that performed UPDATE. Then a new version of the same row is created, in which the value of xmin is the same as xmax of the previous version.
Last time we talked about data consistency, looked at the difference between levels of transaction isolation from the point of view of the user and figured out why this is important to know. Now we are starting to explore how PostgreSQL implements snapshot isolation and multiversion concurrency.
In this article, we will look at how data is physically laid out in files and pages. This takes us away from discussing isolation, but such a digression is necessary to understand what follows. We will need to figure out how the data storage is organized at a low level.
Relations
If you look inside tables and indexes, it turns out that they are organized in a similar way. Both are database objects that contain some data consisting of rows.
There is no doubt that a table consists of rows, but this is less obvious for an index. However, imagine a B-tree: it consists of nodes that contain indexed values and references to other nodes or table rows. It's these nodes that can be considered index rows, and in fact, they are.
Actually, a few more objects are organized in a similar way: sequences (essentially single-row tables) and materialized views (essentially, tables that remember the query). And there are also regular views, which do not store data themselves, but are in all other senses similar to tables.
All these objects in PostgreSQL are called the common word relation. This word is extremely improper because it is a term from the relational theory. You can draw a parallel between a relation and a table (view), but certainly not between a relation and an index. But it just so happened: the academic origin of PostgreSQL manifests itself. It seems to me that it's tables and views that were called so first, and the rest swelled over time.
With this article I start a series about the internal structure of PostgreSQL.
The material will be based on our training courses on database administration that Pavel Luzanov and I are creating. Not everyone likes to watch video (I definitely do not), and reading slides, even with comments, is no good at all.
We strongly recommend you to get familiar with our 2-Day Introduction to PostgreSQL 11.
Of course, the articles will not be exactly the same as the content of the courses. I will talk only about how everything is organized, omitting the administration itself, but I will try to do it in more detail and more thoroughly. And I believe that the knowledge like this is as useful to an application developer as it is to an administrator.
I will target those who already have some experience in using PostgreSQL and at least in general understand what is what. The text will be too difficult for beginners. For example, I will not say a word about how to install PostgreSQL and run psql.
The stuff in question does not vary much from version to version, but I will use PostgreSQL 11.
The first series deals with issues related to isolation and multiversion concurrency, and the plan of the series is as follows:
- Isolation as understood by the standard and PostgreSQL (this article).
- Forks, files, pages — what is happening at the physical level.
- Row versions, virtual transactions and subtransactions.
- Data snapshots and the visibility of row versions; the event horizon.
- In-page vacuum and HOT updates.
- Normal vacuum.
- Autovacuum.
- Transaction id wraparound and freezing.
Off we go!

Parallelism in PostgreSQL: treatment of trees and conscience

Database scaling is a continually coming future. DBMS get improved and better scaled on hardware platforms, while the hardware platforms themselves increase the performance, number of cores, and memory - Achilles is trying to catch up with the turtle, but has not caught up yet. The database scaling challenge manifests itself in all its magnitude.
Postgres Professional had to face the scaling problem not only theoretically, but also in practice: through their customers. Even more than once. It's one of these real-life cases that this article
will discuss.
Many thanks to Elena Indrupskaya for the translation. Russian version is here.



What is Baked in the Baker's Dozen?
On April 8, PostgreSQL feature freeze took place, so only features committed earlier will get into version PostgreSQL 13. Probably, this version can hardly be considered revolutionary, since it has no conceptual changes. Some of critical patches were late to get into it, such as Table and Functions for the JSON/SQL standard, which had been desirable to be part of PostgreSQL 12, along with the JSONPath patch; plug-in warehouses did not appear either — only the interface is being finalized. The list of improvements is still impressive. We prepared a pretty complete overview of the patches included in the Baker's Dozen.
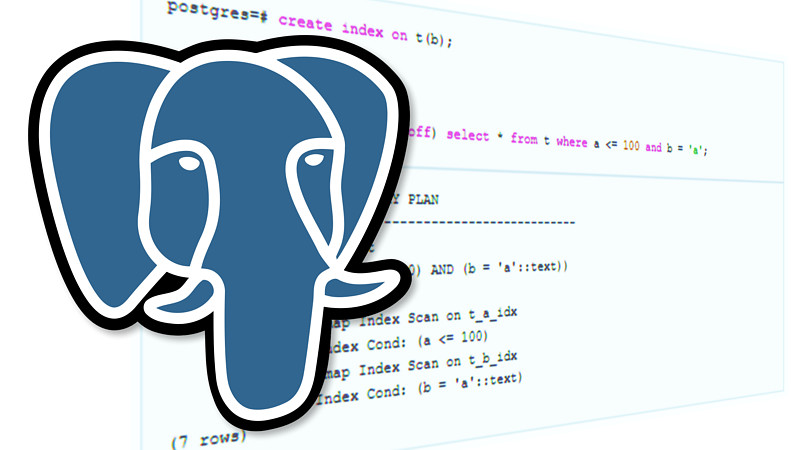
Indexes in PostgreSQL — 10 (Bloom)
In the previous articles we discussed PostgreSQL indexing engine and the interface of access methods, as well as B-trees, GiST, SP-GiST, GIN, RUM, and BRIN. But we still need to look at Bloom indexes.
Bloom
General concept
A classical Bloom filter is a data structure that enables us to quickly check membership of an element in a set. The filter is highly compact, but allows false positives: it can mistakenly consider an element to be a member of a set (false positive), but it is not permitted to consider an element of a set not to be a member (false negative).
The filter is an array of m bits (also called a signature) that is initially filled with zeros. k different hash functions are chosen that map any element of the set to k bits of the signature. To add an element to the set, we need to set each of these bits in the signature to one. Consequently, if all the bits corresponding to an element are set to one, the element can be a member of the set, but if at least one bit equals zero, the element is not in the set for sure.
In the case of a DBMS, we actually have N separate filters built for each index row. As a rule, several fields are included in the index, and it's values of these fields that compose the set of elements for each row.
By choosing the length of the signature m, we can find a trade-off between the index size and the probability of false positives. The application area for Bloom index is large, considerably "wide" tables to be queried using filters on each of the fields. This access method, like BRIN, can be regarded as an accelerator of sequential scan: all the matches found by the index must be rechecked with the table, but there is a chance to avoid considering most of the rows at all.
Indexes in PostgreSQL — 9 (BRIN)
In the previous articles we discussed PostgreSQL indexing engine, the interface of access methods, and the following methods: B-trees, GiST, SP-GiST, GIN, and RUM. The topic of this article is BRIN indexes.
BRIN
General concept
Unlike indexes with which we've already got acquainted, the idea of BRIN is to avoid looking through definitely unsuited rows rather than quickly find the matching ones. This is always an inaccurate index: it does not contain TIDs of table rows at all.
Simplistically, BRIN works fine for columns where values correlate with their physical location in the table. In other words, if a query without ORDER BY clause returns the column values virtually in the increasing or decreasing order (and there are no indexes on that column).
This access method was created in scope of Axle, the European project for extremely large analytical databases, with an eye on tables that are several terabyte or dozens of terabytes large. An important feature of BRIN that enables us to create indexes on such tables is a small size and minimal overhead costs of maintenance.
This works as follows. The table is split into ranges that are several pages large (or several blocks large, which is the same) - hence the name: Block Range Index, BRIN. The index stores summary information on the data in each range. As a rule, this is the minimal and maximal values, but it happens to be different, as shown further. Assume that a query is performed that contains the condition for a column; if the sought values do not get into the interval, the whole range can be skipped; but if they do get, all rows in all blocks will have to be looked through to choose the matching ones among them.
It will not be a mistake to treat BRIN not as an index, but as an accelerator of sequential scan. We can regard BRIN as an alternative to partitioning if we consider each range as a "virtual" partition.
Now let's discuss the structure of the index in more detail.
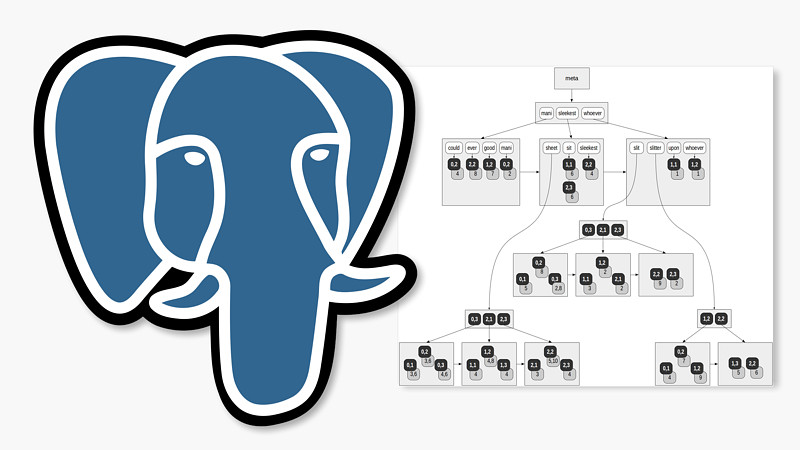
Indexes in PostgreSQL — 8 (RUM)
We have already discussed PostgreSQL indexing engine, the interface of access methods, and main access methods, such as: hash indexes, B-trees, GiST, SP-GiST, and GIN. In this article, we will watch how gin turns into rum.
RUM
Although the authors claim that gin is a powerful genie, the theme of drinks has eventually won: next-generation GIN has been called RUM.
This access method expands the concept that underlies GIN and enables us to perform full-text search even faster. In this series of articles, this is the only method that is not included in a standard PostgreSQL delivery and is an external extension. Several installation options are available for it:
- Take "yum" or "apt" package from the PGDG repository. For example, if you installed PostgreSQL from "postgresql-10" package, also install "postgresql-10-rum".
- Build from source code on github and install on your own (the instruction is there as well).
- Use as a part of Postgres Pro Enterprise (or at least read the documentation from there).
Limitations of GIN
What limitations of GIN does RUM enable us to transcend?
First, "tsvector" data type contains not only lexemes, but also information on their positions inside the document. As we observed last time, GIN index does not store this information. For this reason, operations to search for phrases, which appeared in version 9.6, are supported by GIN index inefficiently and have to access the original data for recheck.
Second, search systems usually return the results sorted by relevance (whatever that means). We can use ranking functions "ts_rank" and "ts_rank_cd" to this end, but they have to be computed for each row of the result, which is certainly slow.
To a first approximation, RUM access method can be considered as GIN that additionally stores position information and can return the results in a needed order (like GiST can return nearest neighbors). Let's move step by step.
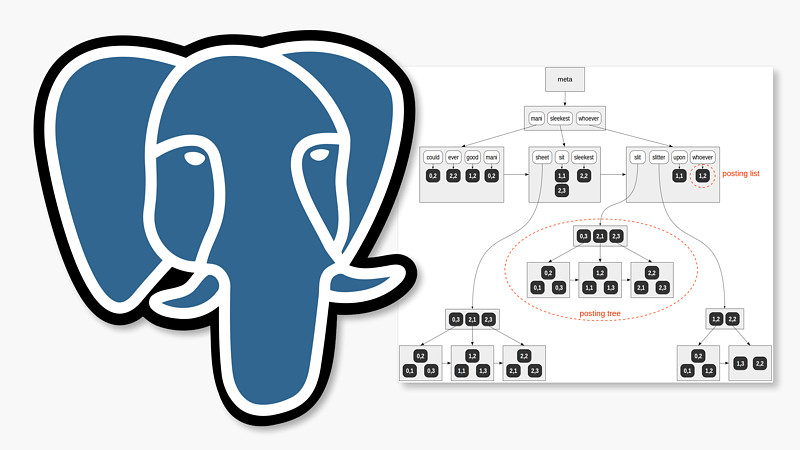
Indexes in PostgreSQL — 7 (GIN)
We have already got acquainted with PostgreSQL indexing engine and the interface of access methods and discussed hash indexes, B-trees, as well as GiST and SP-GiST indexes. And this article will feature GIN index.
GIN
"Gin?.. Gin is, it seems, such an American liquor?.."
"I'm not a drink, oh, inquisitive boy!" again the old man flared up, again he realized himself and again took himself in hand. "I am not a drink, but a powerful and undaunted spirit, and there is no such magic in the world that I would not be able to do."
— Lazar Lagin, "Old Khottabych".
Gin stands for Generalized Inverted Index and should be considered as a genie, not a drink.
— README
General concept
GIN is the abbreviated Generalized Inverted Index. This is a so-called inverted index. It manipulates data types whose values are not atomic, but consist of elements. We will call these types compound. And these are not the values that get indexed, but individual elements; each element references the values in which it occurs.
A good analogy to this method is the index at the end of a book, which for each term, provides a list of pages where this term occurs. The access method must ensure fast search of indexed elements, just like the index in a book. Therefore, these elements are stored as a familiar B-tree (a different, simpler, implementation is used for it, but it does not matter in this case). An ordered set of references to table rows that contain compound values with the element is linked to each element. Orderliness is inessential for data retrieval (the sort order of TIDs does not mean much), but important for the internal structure of the index.
Storing arbitrary PostgreSQL data types in JSONB
Last month Alvaro Hernandez-Tortosa published a blog post discussing how the existing JSON features in PostgreSQL can be improved. The main request was about increasing the number of data types supported in JSONB. We addressed this concern and are ready to share our development team’s commentary.

Indexes in PostgreSQL — 6 (SP-GiST)
We've already discussed PostgreSQL indexing engine, the interface of access methods, and three methods: hash index, B-tree, and GiST. In this article, we will describe SP-GiST.
SP-GiST
First, a few words about this name. The "GiST" part alludes to some similarity with the same-name access method. The similarity does exist: both are generalized search trees that provide a framework for building various access methods.
"SP" stands for space partitioning. The space here is often just what we are used to call a space, for example, a two-dimensional plane. But we will see that any search space is meant, that is, actually any value domain.
SP-GiST is suitable for structures where the space can be recursively split into non-intersecting areas. This class comprises quadtrees, k-dimensional trees (k-D trees), and radix trees.
Structure
So, the idea of SP-GiST access method is to split the value domain into non-overlapping subdomains each of which, in turn, can also be split. Partitioning like this induces non-balanced trees (unlike B-trees and regular GiST).
The trait of being non-intersecting simplifies decision-making during insertion and search. On the other hand, as a rule, the trees induced are of low branching. For example, a node of a quadtree usually has four child nodes (unlike B-trees, where the nodes amount to hundreds) and larger depth. Trees like these well suit the work in RAM, but the index is stored on a disk and therefore, to reduce the number of I/O operations, nodes have to be packed into pages, and it is not easy to do this efficiently. Besides, the time it takes to find different values in the index, may vary because of differences in branch depths.

Indexes in PostgreSQL — 5 (GiST)
In the previous articles, we discussed PostgreSQL indexing engine, the interface of access methods, and two access methods: hash index and B-tree. In this article, we will describe GiST indexes.
GiST
GiST is an abbreviation of "generalized search tree". This is a balanced search tree, just like "b-tree" discussed earlier.
What is the difference? "btree" index is strictly connected to the comparison semantics: support of "greater", "less", and "equal" operators is all it is capable of (but very capable!) However, modern databases store data types for which these operators just make no sense: geodata, text documents, images, ...
GiST index method comes to our aid for these data types. It permits defining a rule to distribute data of an arbitrary type across a balanced tree and a method to use this representation for access by some operator. For example, GiST index can "accommodate" R-tree for spatial data with support of relative position operators (located on the left, on the right, contains, etc.) or RD-tree for sets with support of intersection or inclusion operators.
Thanks to extensibility, a totally new method can be created from scratch in PostgreSQL: to this end, an interface with the indexing engine must be implemented. But this requires premeditation of not only the indexing logic, but also mapping data structures to pages, efficient implementation of locks, and support of a write-ahead log. All this assumes high developer skills and a large human effort. GiST simplifies the task by taking over low-level problems and offering its own interface: several functions pertaining not to techniques, but to the application domain. In this sense, we can regard GiST as a framework for building new access methods.

Indexes in PostgreSQL — 4 (Btree)
We've already discussed PostgreSQL indexing engine and interface of access methods, as well as hash index, one of access methods. We will now consider B-tree, the most traditional and widely used index. This article is large, so be patient.
Btree
Structure
B-tree index type, implemented as "btree" access method, is suitable for data that can be sorted. In other words, "greater", "greater or equal", "less", "less or equal", and "equal" operators must be defined for the data type. Note that the same data can sometimes be sorted differently, which takes us back to the concept of operator family.
As always, index rows of the B-tree are packed into pages. In leaf pages, these rows contain data to be indexed (keys) and references to table rows (TIDs). In internal pages, each row references a child page of the index and contains the minimal value in this page.
B-trees have a few important traits:
- B-trees are balanced, that is, each leaf page is separated from the root by the same number of internal pages. Therefore, search for any value takes the same time.
- B-trees are multi-branched, that is, each page (usually 8 KB) contains a lot of (hundreds) TIDs. As a result, the depth of B-trees is pretty small, actually up to 4–5 for very large tables.
- Data in the index is sorted in nondecreasing order (both between pages and inside each page), and same-level pages are connected to one another by a bidirectional list. Therefore, we can get an ordered data set just by a list walk one or the other direction without returning to the root each time.
Below is a simplified example of the index on one field with integer keys.

Indexes in PostgreSQL — 3 (Hash)
The first article described PostgreSQL indexing engine, the second one dealt with the interface of access methods, and now we are ready to discuss specific types of indexes. Let's start with hash index.
Hash
Structure
General theory
Plenty of modern programming languages include hash tables as the base data type. On the outside, a hash table looks like a regular array that is indexed with any data type (for example, string) rather than with an integer number. Hash index in PostgreSQL is structured in a similar way. How does this work?
As a rule, data types have very large ranges of permissible values: how many different strings can we potentially envisage in a column of type "text"? At the same time, how many different values are actually stored in a text column of some table? Usually, not so many of them.
The idea of hashing is to associate a small number (from 0 to N−1, N values in total) with a value of any data type. Association like this is called a hash function. The number obtained can be used as an index of a regular array where references to table rows (TIDs) will be stored. Elements of this array are called hash table buckets - one bucket can store several TIDs if the same indexed value appears in different rows.
The more uniformly a hash function distributes source values by buckets, the better it is. But even a good hash function will sometimes produce equal results for different source values - this is called a collision. So, one bucket can store TIDs corresponding to different keys, and therefore, TIDs obtained from the index need to be rechecked.