Thread: Use generation memory context for tuplestore.c
(40af10b57 did this for tuplesort.c, this is the same, but for tuplestore.c)
I was looking at the tuplestore.c code a few days ago and noticed that
it allocates tuples in the memory context that tuplestore_begin_heap()
is called in, which for nodeMaterial.c, is ExecutorState.
I didn't think this was great because:
1. Allocating many chunks in ExecutorState can bloat the context with
many blocks worth of free'd chunks, stored on freelists that might
never be reused for anything.
2. To clean up the memory, pfree must be meticulously called on each
allocated tuple
3. ExecutorState is an aset.c context which isn't the most efficient
allocator for this purpose.
I've attached 2 patches:
0001: Adds memory tracking to Materialize nodes, which looks like:
-> Materialize (actual time=0.033..9.157 rows=10000 loops=2)
Storage: Memory Maximum Storage: 10441kB
0002: Creates a Generation MemoryContext for storing tuples in tuplestore.
Using generation has the following advantages:
1. It does not round allocations up to the next power of 2. Using
generation will save an average of 25% memory for tuplestores or allow
an average of 25% more tuples before going to disk.
2. Allocation patterns in tuplestore.c are FIFO, which is exactly what
generation was designed to handle best.
3. Generation is faster to palloc/pfree than aset. (See [1]. Compare
the 4-bit times between aset_palloc_pfree.png and
generation_palloc_pfree.png)
4. tuplestore_clear() and tuplestore_end() can reset or delete the
tuple context instead of pfreeing every tuple one by one.
5. Higher likelihood of neighbouring tuples being stored consecutively
in memory, resulting in better CPU memory prefetching.
6. Generation has a page-level freelist, so is able to reuse pages
instead of freeing and mallocing another if tuplestore_trim() is used
to continually remove no longer needed tuples. aset.c can only
efficiently do this if the tuples are all in the same size class.
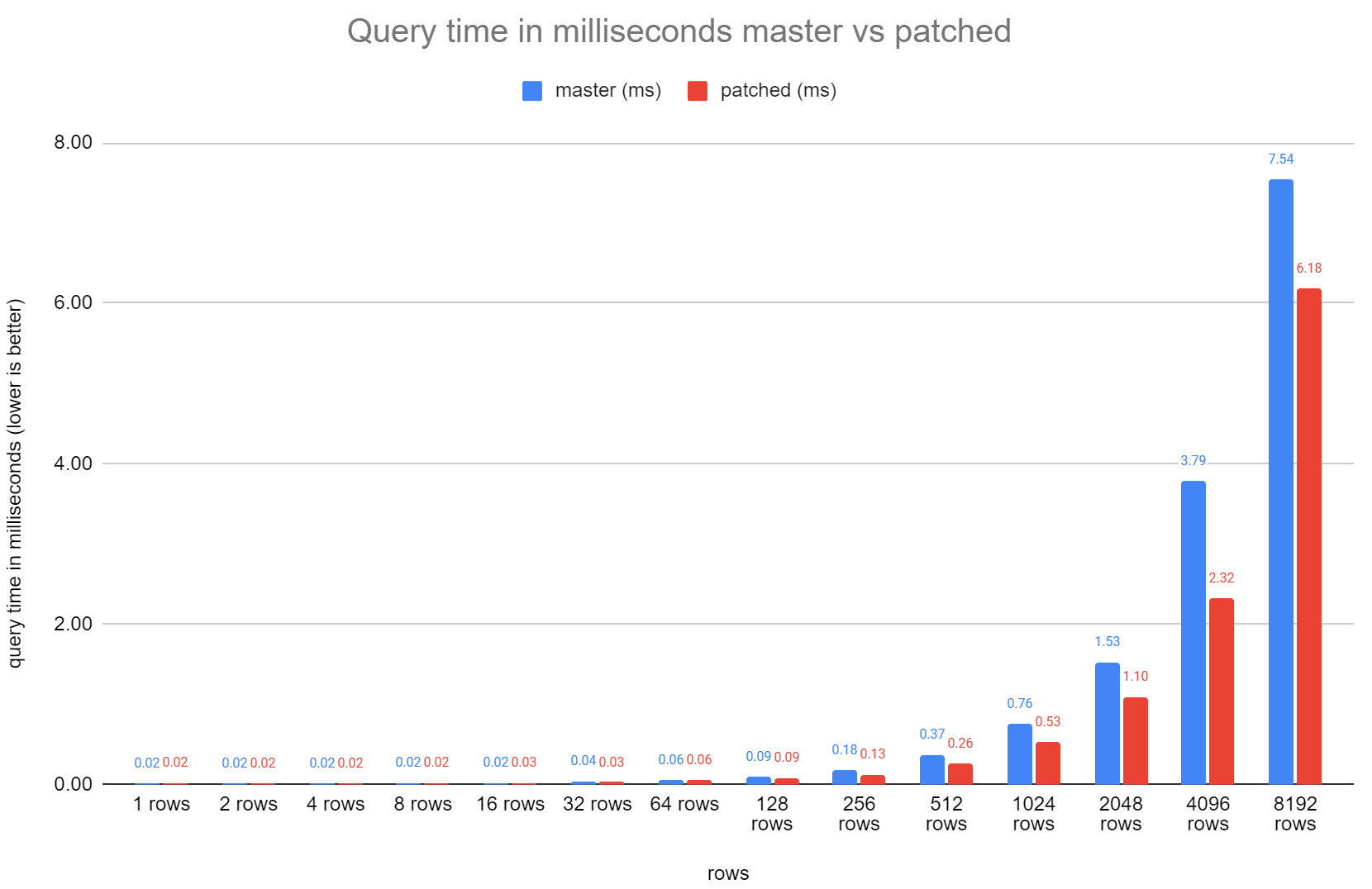
The attached bench.sh.txt tests the performance of this change and
result_chart.png shows the results I got when running on an AMD 3990x
master @ 8f0a97dff vs patched.
The script runs benchmarks for various tuple counts stored in the
tuplestore -- 1 to 8192 in power-2 increments.
The script does output the memory consumed by the tuplestore for each
query. Here are the results for the 8192 tuple test:
master @ 8f0a97dff
Storage: Memory Maximum Storage: 16577kB
patched:
Storage: Memory Maximum Storage: 8577kB
Which is roughly half, but I did pad the tuple to just over 1024
bytes, so the alloc set allocations would have rounded up to 2048
bytes.
Some things I've *not* done:
1. Gone over other executor nodes which use tuplestore to add the same
additional EXPLAIN output. CTE Scan, Recursive Union, Window Agg
could get similar treatment.
2. Given much consideration for the block sizes to use for
GenerationContextCreate(). (Maybe using ALLOCSET_SMALL_INITSIZE for
the start size is a good idea.)
3. A great deal of testing.
I'll park this here until we branch for v18.
David
[1] https://www.postgresql.org/message-id/CAApHDvqUWhOMkUjYXzq95idAwpiPdJLCxxRbf8kV6PYcW5y=Cg@mail.gmail.com
Attachment
{kind=link}
On Fri, 3 May 2024 at 15:55, David Rowley <dgrowleyml@gmail.com> wrote: > > (40af10b57 did this for tuplesort.c, this is the same, but for tuplestore.c) > > I was looking at the tuplestore.c code a few days ago and noticed that > it allocates tuples in the memory context that tuplestore_begin_heap() > is called in, which for nodeMaterial.c, is ExecutorState. > > I didn't think this was great because: > 1. Allocating many chunks in ExecutorState can bloat the context with > many blocks worth of free'd chunks, stored on freelists that might > never be reused for anything. > 2. To clean up the memory, pfree must be meticulously called on each > allocated tuple > 3. ExecutorState is an aset.c context which isn't the most efficient > allocator for this purpose. Agreed on all counts. > I've attached 2 patches: > > 0001: Adds memory tracking to Materialize nodes, which looks like: > > -> Materialize (actual time=0.033..9.157 rows=10000 loops=2) > Storage: Memory Maximum Storage: 10441kB > > 0002: Creates a Generation MemoryContext for storing tuples in tuplestore. > > Using generation has the following advantages: [...] > 6. Generation has a page-level freelist, so is able to reuse pages > instead of freeing and mallocing another if tuplestore_trim() is used > to continually remove no longer needed tuples. aset.c can only > efficiently do this if the tuples are all in the same size class. Was a bump context considered? If so, why didn't it make the cut? If tuplestore_trim is the only reason why the type of context in patch 2 is a generation context, then couldn't we make the type of context conditional on state->eflags & EXEC_FLAG_REWIND, and use a bump context if we require rewind capabilities (i.e. where _trim is never effectively executed)? > master @ 8f0a97dff > Storage: Memory Maximum Storage: 16577kB > > patched: > Storage: Memory Maximum Storage: 8577kB Those are some impressive numbers. Kind regards, Matthias van de Meent Neon (https://neon.tech) On Fri, 3 May 2024 at 15:55, David Rowley <dgrowleyml@gmail.com> wrote: > > (40af10b57 did this for tuplesort.c, this is the same, but for tuplestore.c) > > I was looking at the tuplestore.c code a few days ago and noticed that > it allocates tuples in the memory context that tuplestore_begin_heap() > is called in, which for nodeMaterial.c, is ExecutorState. > > I didn't think this was great because: > 1. Allocating many chunks in ExecutorState can bloat the context with > many blocks worth of free'd chunks, stored on freelists that might > never be reused for anything. > 2. To clean up the memory, pfree must be meticulously called on each > allocated tuple > 3. ExecutorState is an aset.c context which isn't the most efficient > allocator for this purpose. > > I've attached 2 patches: > > 0001: Adds memory tracking to Materialize nodes, which looks like: > > -> Materialize (actual time=0.033..9.157 rows=10000 loops=2) > Storage: Memory Maximum Storage: 10441kB > > 0002: Creates a Generation MemoryContext for storing tuples in tuplestore. > > Using generation has the following advantages: > > 1. It does not round allocations up to the next power of 2. Using > generation will save an average of 25% memory for tuplestores or allow > an average of 25% more tuples before going to disk. > 2. Allocation patterns in tuplestore.c are FIFO, which is exactly what > generation was designed to handle best. > 3. Generation is faster to palloc/pfree than aset. (See [1]. Compare > the 4-bit times between aset_palloc_pfree.png and > generation_palloc_pfree.png) > 4. tuplestore_clear() and tuplestore_end() can reset or delete the > tuple context instead of pfreeing every tuple one by one. > 5. Higher likelihood of neighbouring tuples being stored consecutively > in memory, resulting in better CPU memory prefetching. > 6. Generation has a page-level freelist, so is able to reuse pages > instead of freeing and mallocing another if tuplestore_trim() is used > to continually remove no longer needed tuples. aset.c can only > efficiently do this if the tuples are all in the same size class. > > The attached bench.sh.txt tests the performance of this change and > result_chart.png shows the results I got when running on an AMD 3990x > master @ 8f0a97dff vs patched. > The script runs benchmarks for various tuple counts stored in the > tuplestore -- 1 to 8192 in power-2 increments. > > The script does output the memory consumed by the tuplestore for each > query. Here are the results for the 8192 tuple test: > > master @ 8f0a97dff > Storage: Memory Maximum Storage: 16577kB > > patched: > Storage: Memory Maximum Storage: 8577kB > > Which is roughly half, but I did pad the tuple to just over 1024 > bytes, so the alloc set allocations would have rounded up to 2048 > bytes. > > Some things I've *not* done: > > 1. Gone over other executor nodes which use tuplestore to add the same > additional EXPLAIN output. CTE Scan, Recursive Union, Window Agg > could get similar treatment. > 2. Given much consideration for the block sizes to use for > GenerationContextCreate(). (Maybe using ALLOCSET_SMALL_INITSIZE for > the start size is a good idea.) > 3. A great deal of testing. > > I'll park this here until we branch for v18. > > David > > [1] https://www.postgresql.org/message-id/CAApHDvqUWhOMkUjYXzq95idAwpiPdJLCxxRbf8kV6PYcW5y=Cg@mail.gmail.com
On Sat, 4 May 2024 at 03:51, Matthias van de Meent <boekewurm+postgres@gmail.com> wrote: > Was a bump context considered? If so, why didn't it make the cut? > If tuplestore_trim is the only reason why the type of context in patch > 2 is a generation context, then couldn't we make the type of context > conditional on state->eflags & EXEC_FLAG_REWIND, and use a bump > context if we require rewind capabilities (i.e. where _trim is never > effectively executed)? I didn't really want to raise all this here, but to answer why I didn't use bump... There's a bit more that would need to be done to allow bump to work in use-cases where no trim support is needed. Namely, if you look at writetup_heap(), you'll see a heap_free_minimal_tuple(), which is pfreeing the memory that was allocated for the tuple in either tuplestore_puttupleslot(), tuplestore_puttuple() or tuplestore_putvalues(). So basically, what happens if we're still loading the tuplestore and we've spilled to disk, once the tuplestore_put* function is called, we allocate memory for the tuple that might get stored in RAM (we don't know yet), but then call tuplestore_puttuple_common() which decides if the tuple goes to RAM or disk, then because we're spilling to disk, the write function pfree's the memory we allocate in the tuplestore_put function after the tuple is safely written to the disk buffer. This is a fairly inefficient design. While, we do need to still form a tuple and store it somewhere for tuplestore_putvalues(), we don't need to do that for a heap tuple. I think it should be possible to write directly from the table's page. Overall tuplestore.c seems quite confused as to how it's meant to work. You have tuplestore_begin_heap() function, which is the *only* external function to create a tuplestore. We then pretend we're agnostic about how we store tuples that won't fit in memory by providing callbacks for read/write/copy, but we only have 1 set of functions for those and instead of having some other begin method we use when not dealing with heap tuples, we use some other tuplestore_put* function. It seems like another pass is required to fix all this and I think that should be: 1. Get rid of the function pointers and just hardcode which static functions we call to read/write/copy. 2. Rename tuplestore_begin_heap() to tuplestore_begin(). 3. See if we can rearrange the code so that the copying to the tuple context is only done when we are in TSS_INMEM. I'm not sure what that would look like, but it's required before we could use bump so we don't pfree a bump allocated chunk. Or maybe there's a way to fix this by adding other begin functions and making it work more like tuplesort. I've not really looked into that. I'd rather tackle these problems independently and I believe there are much bigger wins to moving from aset to generation than generation to bump, so that's where I've started. Thanks for having a look at the patch. David
> On Sat, May 04, 2024 at 01:55:22AM +1200, David Rowley wrote:
> (40af10b57 did this for tuplesort.c, this is the same, but for tuplestore.c)
An interesting idea, thanks. I was able to reproduce the results of your
benchmark and get similar conclusions from the results.
> Using generation has the following advantages:
>
> [...]
>
> 2. Allocation patterns in tuplestore.c are FIFO, which is exactly what
> generation was designed to handle best.
Do I understand correctly, that the efficiency of generation memory
context could be measured directly via counting number of malloc/free
calls? In those experiments I've conducted the numbers were indeed
visibly lower for the patched version (~30%), but I would like to
confirm my interpretation of this difference.
> 5. Higher likelihood of neighbouring tuples being stored consecutively
> in memory, resulting in better CPU memory prefetching.
I guess this roughly translates into better CPU cache utilization.
Measuring cache hit ratio for unmodified vs patched versions in my case
indeed shows about 10% less cache misses.
> The attached bench.sh.txt tests the performance of this change and
> result_chart.png shows the results I got when running on an AMD 3990x
> master @ 8f0a97dff vs patched.
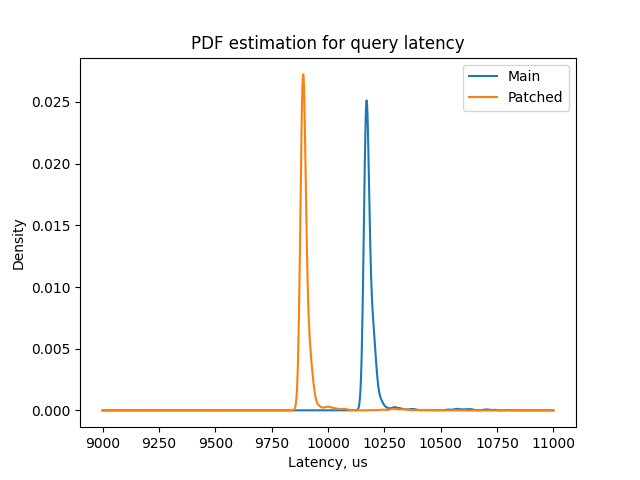
The query you use in the benchmark, is it something like a "best-case"
scenario for generation memory context? I was experimenting with
different size of the b column, lower values seems to produce less
difference between generation and aset (although still generation
context is distinctly faster regarding final query latencies, see the
attached PDF estimation, ran for 8192 rows). I'm curious what could be a
"worst-case" workload type for this patch?
I've also noticed the first patch disables materialization in some tests.
--- a/src/test/regress/sql/partition_prune.sql
+++ b/src/test/regress/sql/partition_prune.sql
+set enable_material = 0;
+
-- UPDATE on a partition subtree has been seen to have problems.
insert into ab values (1,2);
explain (analyze, costs off, summary off, timing off)
Is it due to the volatility of Maximum Storage values? If yes, could it
be covered with something similar to COSTS OFF instead?
Attachment
{kind=link}
On Sat, 4 May 2024 at 04:02, David Rowley <dgrowleyml@gmail.com> wrote: > > On Sat, 4 May 2024 at 03:51, Matthias van de Meent > <boekewurm+postgres@gmail.com> wrote: > > Was a bump context considered? If so, why didn't it make the cut? > > If tuplestore_trim is the only reason why the type of context in patch > > 2 is a generation context, then couldn't we make the type of context > > conditional on state->eflags & EXEC_FLAG_REWIND, and use a bump > > context if we require rewind capabilities (i.e. where _trim is never > > effectively executed)? > > I didn't really want to raise all this here, but to answer why I > didn't use bump... > > There's a bit more that would need to be done to allow bump to work in > use-cases where no trim support is needed. Namely, if you look at > writetup_heap(), you'll see a heap_free_minimal_tuple(), which is > pfreeing the memory that was allocated for the tuple in either > tuplestore_puttupleslot(), tuplestore_puttuple() or > tuplestore_putvalues(). So basically, what happens if we're still > loading the tuplestore and we've spilled to disk, once the > tuplestore_put* function is called, we allocate memory for the tuple > that might get stored in RAM (we don't know yet), but then call > tuplestore_puttuple_common() which decides if the tuple goes to RAM or > disk, then because we're spilling to disk, the write function pfree's > the memory we allocate in the tuplestore_put function after the tuple > is safely written to the disk buffer. Thanks, that's exactly the non-obvious issue I was looking for, but couldn't find immediately. > This is a fairly inefficient design. While, we do need to still form > a tuple and store it somewhere for tuplestore_putvalues(), we don't > need to do that for a heap tuple. I think it should be possible to > write directly from the table's page. [...] > I'd rather tackle these problems independently and I believe there are > much bigger wins to moving from aset to generation than generation to > bump, so that's where I've started. That's entirely reasonable, and I wouldn't ask otherwise. Thanks, Matthias van de Meent
Thanks for having a look at this. On Sat, 11 May 2024 at 04:34, Dmitry Dolgov <9erthalion6@gmail.com> wrote: > Do I understand correctly, that the efficiency of generation memory > context could be measured directly via counting number of malloc/free > calls? In those experiments I've conducted the numbers were indeed > visibly lower for the patched version (~30%), but I would like to > confirm my interpretation of this difference. For the test case I had in the script, I imagine the reduction in malloc/free is just because of the elimination of the power-of-2 roundup. If the test case had resulted in tuplestore_trim() being used, e.g if Material was used to allow mark and restore for a Merge Join or WindowAgg, then the tuplestore_trim() would result in pfree()ing of tuples and further reduce malloc of new blocks. This is true because AllocSet records pfree'd non-large chunks in a freelist element and makes no attempt to free() blocks. In the tuplestore_trim() scenario with the patched version, the pfree'ing of chunks is in a first-in-first-out order which allows an entire block to become empty of palloc'd chunks which allows it to become the freeblock and be reused rather than malloc'ing another block when there's not enough space on the current block. If the scenario is that tuplestore_trim() always manages to keep the number of tuples down to something that can fit on one GenerationBlock, then we'll only malloc() 2 blocks and the generation code will just alternate between the two, reusing the empty one when it needs a new block rather than calling malloc. > > 5. Higher likelihood of neighbouring tuples being stored consecutively > > in memory, resulting in better CPU memory prefetching. > > I guess this roughly translates into better CPU cache utilization. > Measuring cache hit ratio for unmodified vs patched versions in my case > indeed shows about 10% less cache misses. Thanks for testing that. In simple test cases that's likely to come from removing the power-of-2 round-up behaviour of AllocSet allowing the allocations to be more dense. In more complex cases when allocations are making occasional use of chunks from AllowSet's freelist[], the access pattern will be more predictable and allow the CPU to prefetch memory more efficiently, resulting in a better CPU cache hit ratio. > The query you use in the benchmark, is it something like a "best-case" > scenario for generation memory context? I was experimenting with > different size of the b column, lower values seems to produce less > difference between generation and aset (although still generation > context is distinctly faster regarding final query latencies, see the > attached PDF estimation, ran for 8192 rows). I'm curious what could be a > "worst-case" workload type for this patch? It's not purposefully "best-case". Likely there'd be more improvement if I'd scanned the Material node more than twice. However, the tuple size I picked is close to the best case as it's just over 1024 bytes. Generation will just round the size up to the next 8-byte alignment boundary, whereas AllocSet will round that up to 2048 bytes. A case where the patched version would be even better would be where the unpatched version spilled to disk but the patched version did not. I imagine there's room for hundreds of percent speedup for that case. > I've also noticed the first patch disables materialization in some tests. > > --- a/src/test/regress/sql/partition_prune.sql > +++ b/src/test/regress/sql/partition_prune.sql > > +set enable_material = 0; > + > -- UPDATE on a partition subtree has been seen to have problems. > insert into ab values (1,2); > explain (analyze, costs off, summary off, timing off) > > Is it due to the volatility of Maximum Storage values? If yes, could it > be covered with something similar to COSTS OFF instead? I don't think not showing this with COSTS OFF is very consistent with Sort and Memoize's memory stats output. I opted to disable the Material node for that plan as it seemed like the easiest way to make the output stable. There are other ways that could be done. See explain_memoize() in memoize.sql. I thought about doing that, but it seemed like overkill when there was a much more simple way to get what I wanted. I'd certainly live to regret that if disabling Material put the Nested Loop costs dangerously close to the costs of some other join method and the plan became unstable on the buildfarm. David
On Sat, 4 May 2024 at 03:51, Matthias van de Meent
<boekewurm+postgres@gmail.com> wrote:
>
> On Fri, 3 May 2024 at 15:55, David Rowley <dgrowleyml@gmail.com> wrote:
> > master @ 8f0a97dff
> > Storage: Memory Maximum Storage: 16577kB
> >
> > patched:
> > Storage: Memory Maximum Storage: 8577kB
>
> Those are some impressive numbers.
This patch needed to be rebased, so updated patches are attached.
I was also reflecting on what Bruce wrote in [1] about having to parse
performance numbers from the commit messages, so I decided to adjust
the placeholder commit message I'd written to make performance numbers
more clear to Bruce, or whoever does the next major version release
notes. That caused me to experiment with finding the best case for
this patch. I could scale the improvement much further than I have,
but here's something I came up with that's easy to reproduce.
create table winagg (a int, b text);
insert into winagg select a,repeat('a', 1024) from generate_series(1,10000000)a;
set work_mem = '1MB';
set jit=0;
explain (analyze, timing off) select sum(l1),sum(l2) from (select
length(b) l1,length(lag(b, 800) over ()) as l2 from winagg limit
1600);
master:
Execution Time: 6585.685 ms
patched:
Execution Time: 4.159 ms
1583x faster.
I've effectively just exploited the spool_tuples() behaviour of what
it does when the tuplestore goes to disk to have it spool the entire
remainder of the partition, which is 10 million rows. I'm just taking
a tiny portion of those with the LIMIT 1600. I just set work_mem to
something that the patched version won't have the tuplestore spill to
disk so that spool_tuples() only spools what's needed in the patched
version. So, artificial is a word you could use, but certainly,
someone could find this performance cliff in the wild and be prevented
from falling off it by this patch.
David
[1] https://www.postgresql.org/message-id/Zk5r2XyI0BhXLF8h%40momjian.us
Attachment
On Fri, 31 May 2024 at 05:26, David Rowley <dgrowleyml@gmail.com> wrote:
>
> On Sat, 4 May 2024 at 03:51, Matthias van de Meent
> <boekewurm+postgres@gmail.com> wrote:
> >
> > On Fri, 3 May 2024 at 15:55, David Rowley <dgrowleyml@gmail.com> wrote:
> > > master @ 8f0a97dff
> > > Storage: Memory Maximum Storage: 16577kB
> > >
> > > patched:
> > > Storage: Memory Maximum Storage: 8577kB
> >
> > Those are some impressive numbers.
>
> This patch needed to be rebased, so updated patches are attached.
Here's a review for the V2 patch:
I noticed this change to buffile.c shows up in both v1 and v2 of the
patchset, but I can't trace the reasoning why it changed with this
patch (rather than a separate bugfix):
> +++ b/src/backend/storage/file/buffile.c
> @@ -867,7 +867,7 @@ BufFileSize(BufFile *file)
> {
> int64 lastFileSize;
>
> - Assert(file->fileset != NULL);
> + Assert(file->files != NULL);
> +++ b/src/backend/commands/explain.c
> [...]
> +show_material_info(MaterialState *mstate, ExplainState *es)
> + spaceUsedKB = (tuplestore_space_used(tupstore) + 1023) / 1024;
I think this should use the BYTES_TO_KILOBYTES macro for consistency.
Lastly, I think this would benefit from a test in
regress/sql/explain.sql, as the test changes that were included
removed the only occurrance of a Materialize node from the regression
tests' EXPLAIN outputs.
Kind regards,
Matthias van de Meent
Thank you for having another look at this. On Wed, 3 Jul 2024 at 00:20, Matthias van de Meent <boekewurm+postgres@gmail.com> wrote: > I noticed this change to buffile.c shows up in both v1 and v2 of the > patchset, but I can't trace the reasoning why it changed with this > patch (rather than a separate bugfix): I didn't explain that very well here, did I. I took up the discussion about that in [1]. (Which you've now seen) > > +show_material_info(MaterialState *mstate, ExplainState *es) > > + spaceUsedKB = (tuplestore_space_used(tupstore) + 1023) / 1024; > > I think this should use the BYTES_TO_KILOBYTES macro for consistency. Yes, that needs to be done. Thank you. > Lastly, I think this would benefit from a test in > regress/sql/explain.sql, as the test changes that were included > removed the only occurrance of a Materialize node from the regression > tests' EXPLAIN outputs. I've modified the tests where the previous patch disabled enable_material to enable it again and mask out the possibly unstable part. Do you think that's an ok level of testing? David [1] https://postgr.es/m/CAApHDvofgZT0VzydhyGH5MMb-XZzNDqqAbzf1eBZV5HDm3%2BosQ%40mail.gmail.com
Attachment
Hello David, 03.07.2024 13:41, David Rowley wrote: > >> Lastly, I think this would benefit from a test in >> regress/sql/explain.sql, as the test changes that were included >> removed the only occurrance of a Materialize node from the regression >> tests' EXPLAIN outputs. > I've modified the tests where the previous patch disabled > enable_material to enable it again and mask out the possibly unstable > part. Do you think that's an ok level of testing? Please look at a segfault crash introduced with 1eff8279d: CREATE TABLE t1(i int); CREATE TABLE t2(i int) PARTITION BY RANGE (i); CREATE TABLE t2p PARTITION OF t2 FOR VALUES FROM (1) TO (2); EXPLAIN ANALYZE SELECT * FROM t1 JOIN t2 ON t1.i > t2.i; Leads to: Core was generated by `postgres: law regression [local] EXPLAIN '. Program terminated with signal SIGSEGV, Segmentation fault. #0 0x000055c36dbac2f7 in tuplestore_storage_type_name (state=0x0) at tuplestore.c:1476 1476 if (state->status == TSS_INMEM) Best regards, Alexander
On Fri, 5 Jul 2024 at 16:00, Alexander Lakhin <exclusion@gmail.com> wrote: > Please look at a segfault crash introduced with 1eff8279d: > CREATE TABLE t1(i int); > CREATE TABLE t2(i int) PARTITION BY RANGE (i); > CREATE TABLE t2p PARTITION OF t2 FOR VALUES FROM (1) TO (2); > > EXPLAIN ANALYZE SELECT * FROM t1 JOIN t2 ON t1.i > t2.i; > > Leads to: > Core was generated by `postgres: law regression [local] EXPLAIN '. > Program terminated with signal SIGSEGV, Segmentation fault. > > #0 0x000055c36dbac2f7 in tuplestore_storage_type_name (state=0x0) at tuplestore.c:1476 > 1476 if (state->status == TSS_INMEM) Thanks for the report. I've just pushed a fix in 53abb1e0e. David
On Wed, 3 Jul 2024 at 22:41, David Rowley <dgrowleyml@gmail.com> wrote: > > On Wed, 3 Jul 2024 at 00:20, Matthias van de Meent > > Lastly, I think this would benefit from a test in > > regress/sql/explain.sql, as the test changes that were included > > removed the only occurrance of a Materialize node from the regression > > tests' EXPLAIN outputs. > > I've modified the tests where the previous patch disabled > enable_material to enable it again and mask out the possibly unstable > part. Do you think that's an ok level of testing? I spent quite a bit more time today looking at these patches. Mostly that amounted to polishing comments more. I've pushed them both now. Thank you both of you for reviewing these. David
05.07.2024 07:57, David Rowley wrote:
> Thanks for the report. I've just pushed a fix in 53abb1e0e.
Thank you, David!
Please look at another anomaly introduced with 590b045c3:
echo "
CREATE TABLE t(f int, t int);
INSERT INTO t VALUES (1, 1);
WITH RECURSIVE sg(f, t) AS (
SELECT * FROM t t1
UNION ALL
SELECT t2.* FROM t t2, sg WHERE t2.f = sg.t
) SEARCH DEPTH FIRST BY f, t SET seq
SELECT * FROM sg;
" | timeout 60 psql
triggers
TRAP: failed Assert("chunk->requested_size < oldsize"), File: "generation.c", Line: 842, PID: 830294
Best regards,
Alexander
On Sat, 6 Jul 2024 at 02:00, Alexander Lakhin <exclusion@gmail.com> wrote:
> CREATE TABLE t(f int, t int);
> INSERT INTO t VALUES (1, 1);
>
> WITH RECURSIVE sg(f, t) AS (
> SELECT * FROM t t1
> UNION ALL
> SELECT t2.* FROM t t2, sg WHERE t2.f = sg.t
> ) SEARCH DEPTH FIRST BY f, t SET seq
> SELECT * FROM sg;
> " | timeout 60 psql
>
> triggers
> TRAP: failed Assert("chunk->requested_size < oldsize"), File: "generation.c", Line: 842, PID: 830294
This seems to be a bug in GenerationRealloc().
What's happening is when we palloc(4) for the files array in
makeBufFile(), that palloc uses GenerationAlloc() and since we have
MEMORY_CONTEXT_CHECKING, the code does:
/* ensure there's always space for the sentinel byte */
chunk_size = MAXALIGN(size + 1);
resulting in chunk_size == 8. When extendBufFile() effectively does
the repalloc(file->files, 8), we call GenerationRealloc() with those 8
bytes and go into the "if (oldsize >= size)" path thinking we have
enough space already. Here both values are 8, which would be fine on
non-MEMORY_CONTEXT_CHECKING builds, but there's no space for the
sentinel byte here. set_sentinel(pointer, size) stomps on some memory,
but no crash from that. It's only a problem when extendBufFile() asks
for 12 bytes that we come back into GenerationRealloc() and trigger
the Assert(chunk->requested_size < oldsize). Both of these values are
8. The oldsize should have been large enough to store the sentinel
byte, it isn't due to the problem caused during GenerationRealloc with
8 bytes.
I also had not intended that the buffile.c stuff would use the
generation context. I'll need to fix that too, but I think I'll fix
the GenerationRealloc() first.
The attached fixes the issue. I'll stare at it a bit more and try to
decide if that's the best way to fix it.
David
Attachment
On Sat, 6 Jul 2024 at 12:08, David Rowley <dgrowleyml@gmail.com> wrote: > The attached fixes the issue. I'll stare at it a bit more and try to > decide if that's the best way to fix it. I did that staring work and thought about arranging the code to reduce the number of #ifdefs. In the end, I decided it was better to keep the two "if" checks close together so that it's easy to see that one does > and the other >=. Someone else's tastes may vary. I adjusted the comment to remove the >= mention and pushed the resulting patch and backpatched to 16, where I broke this in 0e480385e. Thanks for the report. David David
On Sat, 6 Jul 2024 at 12:08, David Rowley <dgrowleyml@gmail.com> wrote: > I also had not intended that the buffile.c stuff would use the > generation context. I'll need to fix that too, but I think I'll fix > the GenerationRealloc() first. I've pushed a fix for that now too. David