> On Sat, May 04, 2024 at 01:55:22AM +1200, David Rowley wrote:
> (40af10b57 did this for tuplesort.c, this is the same, but for tuplestore.c)
An interesting idea, thanks. I was able to reproduce the results of your
benchmark and get similar conclusions from the results.
> Using generation has the following advantages:
>
> [...]
>
> 2. Allocation patterns in tuplestore.c are FIFO, which is exactly what
> generation was designed to handle best.
Do I understand correctly, that the efficiency of generation memory
context could be measured directly via counting number of malloc/free
calls? In those experiments I've conducted the numbers were indeed
visibly lower for the patched version (~30%), but I would like to
confirm my interpretation of this difference.
> 5. Higher likelihood of neighbouring tuples being stored consecutively
> in memory, resulting in better CPU memory prefetching.
I guess this roughly translates into better CPU cache utilization.
Measuring cache hit ratio for unmodified vs patched versions in my case
indeed shows about 10% less cache misses.
> The attached bench.sh.txt tests the performance of this change and
> result_chart.png shows the results I got when running on an AMD 3990x
> master @ 8f0a97dff vs patched.
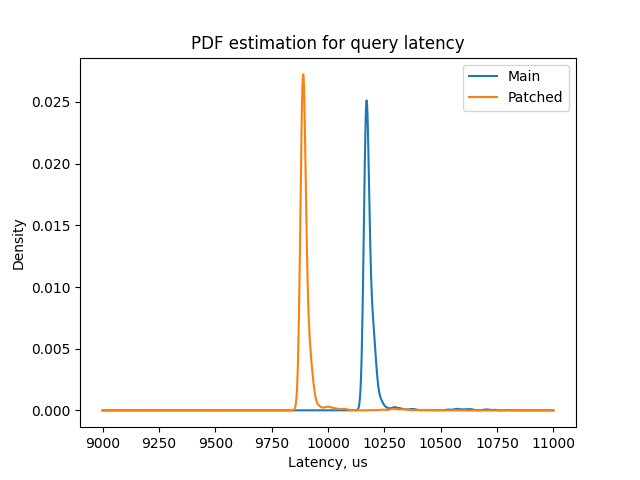
The query you use in the benchmark, is it something like a "best-case"
scenario for generation memory context? I was experimenting with
different size of the b column, lower values seems to produce less
difference between generation and aset (although still generation
context is distinctly faster regarding final query latencies, see the
attached PDF estimation, ran for 8192 rows). I'm curious what could be a
"worst-case" workload type for this patch?
I've also noticed the first patch disables materialization in some tests.
--- a/src/test/regress/sql/partition_prune.sql
+++ b/src/test/regress/sql/partition_prune.sql
+set enable_material = 0;
+
-- UPDATE on a partition subtree has been seen to have problems.
insert into ab values (1,2);
explain (analyze, costs off, summary off, timing off)
Is it due to the volatility of Maximum Storage values? If yes, could it
be covered with something similar to COSTS OFF instead?
{kind=link}