Thread: New GUC autovacuum_max_threshold ?
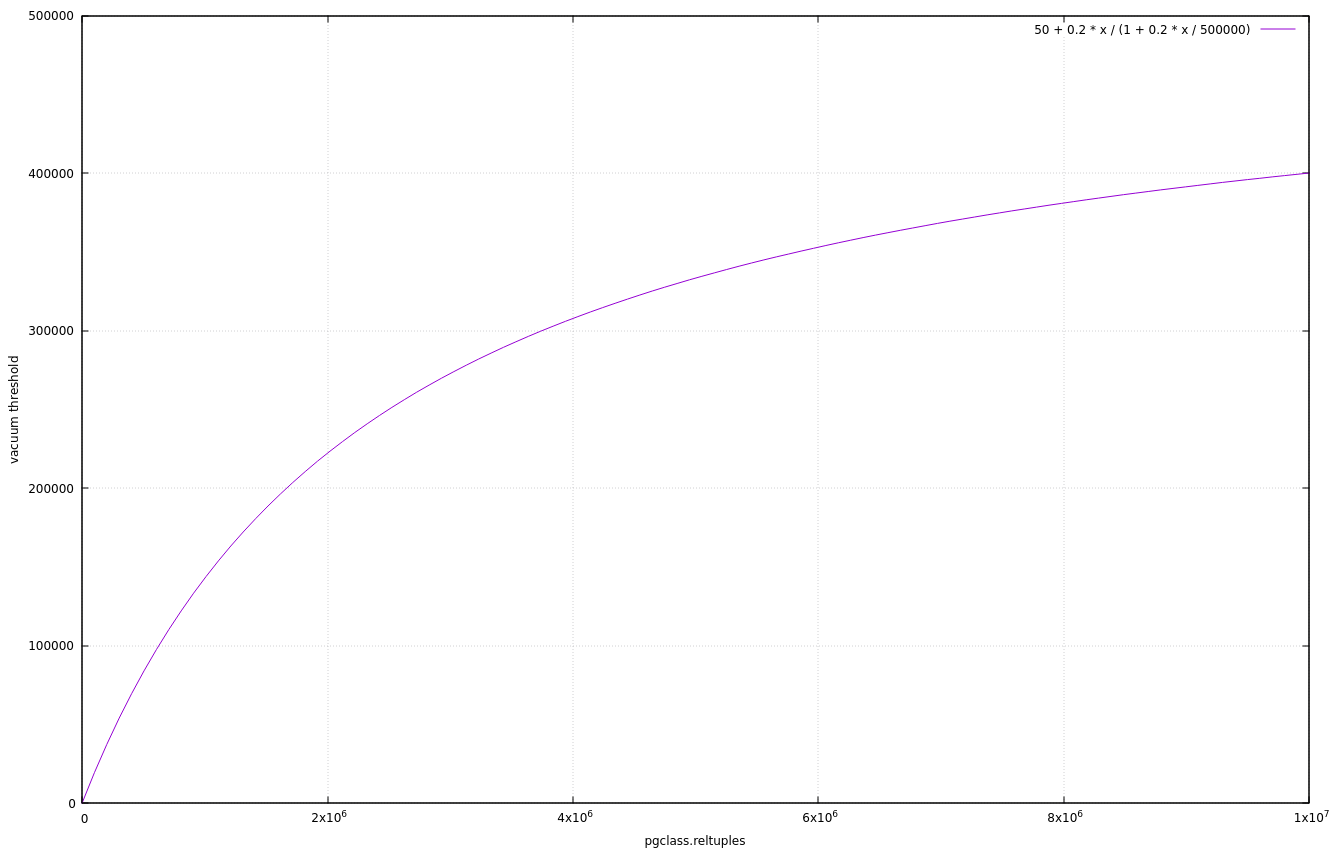
Hello, I would like to suggest a new parameter, autovacuum_max_threshold, which would set an upper limit on the number of tuples to delete/update/insert prior to vacuum/analyze. A good default might be 500000. The idea would be to replace the following calculation : vacthresh = (float4) vac_base_thresh + vac_scale_factor * reltuples; with this one : vacthresh = (float4) vac_base_thresh + vac_scale_factor * reltuples / (1 + vac_scale_factor * reltuples / autovacuum_max_threshold) (and the same for the others, vacinsthresh and anlthresh). The attached graph plots vacthresh against pgclass.reltuples, with default settings : autovacuum_vacuum_threshold = 50 autovacuum_vacuum_scale_factor = 0.2 and autovacuum_max_threshold = 500000 (the suggested default) Thus, for small tables, vacthresh is only slightly smaller than 0.2 * pgclass.reltuples, but it grows towards 500000 when reltuples → ∞ The idea is to reduce the need for autovacuum tuning. The attached (draft) patch further illustrates the idea. My guess is that a similar proposal has already been submitted... and rejected 🙂 If so, I'm very sorry for the useless noise. Best regards, Frédéric
Attachment
{kind=link}
On Wed, Apr 24, 2024 at 8:08 AM Frédéric Yhuel <frederic.yhuel@dalibo.com> wrote: > > Hello, > > I would like to suggest a new parameter, autovacuum_max_threshold, which > would set an upper limit on the number of tuples to delete/update/insert > prior to vacuum/analyze. Hi Frédéric, thanks for the proposal! You are tackling a very tough problem. I would also find it useful to know more about what led you to suggest this particular solution. I am very interested in user stories around difficulties with what tables are autovacuumed and when. Am I correct in thinking that one of the major goals here is for a very large table to be more likely to be vacuumed? > The idea would be to replace the following calculation : > > vacthresh = (float4) vac_base_thresh + vac_scale_factor * reltuples; > > with this one : > > vacthresh = (float4) vac_base_thresh + vac_scale_factor * reltuples / (1 > + vac_scale_factor * reltuples / autovacuum_max_threshold) > > (and the same for the others, vacinsthresh and anlthresh). My first thought when reviewing the GUC and how it is used is wondering if its description is a bit misleading. autovacuum_vacuum_threshold is the "minimum number of updated or deleted tuples needed to trigger a vacuum". That is, if this many tuples are modified, it *may* trigger a vacuum, but we also may skip vacuuming the table for other reasons or due to other factors. autovacuum_max_threshold's proposed definition is the upper limit/maximum number of tuples to insert/update/delete prior to vacuum/analyze. This implies that if that many tuples have been modified or inserted, the table will definitely be vacuumed -- which isn't true. Maybe that is okay, but I thought I would bring it up. > The attached (draft) patch further illustrates the idea. Thanks for including a patch! > My guess is that a similar proposal has already been submitted... and > rejected 🙂 If so, I'm very sorry for the useless noise. I rooted around in the hackers archive and couldn't find any threads on this specific proposal. I copied some other hackers I knew of who have worked on this problem and thought about it in the past, in case they know of some existing threads or prior work on this specific topic. - Melanie
On Wed, Apr 24, 2024 at 03:10:27PM -0400, Melanie Plageman wrote:
> On Wed, Apr 24, 2024 at 8:08 AM Frédéric Yhuel
> <frederic.yhuel@dalibo.com> wrote:
>> I would like to suggest a new parameter, autovacuum_max_threshold, which
>> would set an upper limit on the number of tuples to delete/update/insert
>> prior to vacuum/analyze.
>
> Hi Frédéric, thanks for the proposal! You are tackling a very tough
> problem. I would also find it useful to know more about what led you
> to suggest this particular solution. I am very interested in user
> stories around difficulties with what tables are autovacuumed and
> when.
>
> Am I correct in thinking that one of the major goals here is for a
> very large table to be more likely to be vacuumed?
If this is indeed the goal, +1 from me for doing something along these
lines.
>> The idea would be to replace the following calculation :
>>
>> vacthresh = (float4) vac_base_thresh + vac_scale_factor * reltuples;
>>
>> with this one :
>>
>> vacthresh = (float4) vac_base_thresh + vac_scale_factor * reltuples / (1
>> + vac_scale_factor * reltuples / autovacuum_max_threshold)
>>
>> (and the same for the others, vacinsthresh and anlthresh).
>
> My first thought when reviewing the GUC and how it is used is
> wondering if its description is a bit misleading.
Yeah, I'm having trouble following the proposed mechanics for this new GUC,
and it's difficult to understand how users would choose a value. If we
just want to cap the number of tuples required before autovacuum takes
action, perhaps we could simplify it to something like
vacthresh = (float4) vac_base_thresh + vac_scale_factor * reltuples;
vacthresh = Min(vacthres, vac_max_thresh);
This would effectively cause autovacuum_vacuum_scale_factor to be
overridden for large tables where the scale factor would otherwise cause
the calculated threshold to be extremely high.
>> My guess is that a similar proposal has already been submitted... and
>> rejected 🙂 If so, I'm very sorry for the useless noise.
>
> I rooted around in the hackers archive and couldn't find any threads
> on this specific proposal. I copied some other hackers I knew of who
> have worked on this problem and thought about it in the past, in case
> they know of some existing threads or prior work on this specific
> topic.
FWIW I have heard about this problem in the past, too.
--
Nathan Bossart
Amazon Web Services: https://aws.amazon.com
Le 24/04/2024 à 21:10, Melanie Plageman a écrit : > On Wed, Apr 24, 2024 at 8:08 AM Frédéric Yhuel > <frederic.yhuel@dalibo.com> wrote: >> >> Hello, >> >> I would like to suggest a new parameter, autovacuum_max_threshold, which >> would set an upper limit on the number of tuples to delete/update/insert >> prior to vacuum/analyze. > > Hi Frédéric, thanks for the proposal! You are tackling a very tough > problem. I would also find it useful to know more about what led you > to suggest this particular solution. I am very interested in user > stories around difficulties with what tables are autovacuumed and > when. > Hi Melanie! I can certainly start compiling user stories about that. Recently, one of my colleagues wrote an email to our DBA team saying something along these lines: « Hey, here is our suggested settings for per table autovacuum configuration: | *autovacuum* | L < 1 million | L >= 1 million | L >= 5 millions | L >= 10 millions | |:---------------------|--------------:|---------------:|----------------:|-----------------:| |`vacuum_scale_factor` | 0.2 (défaut) | 0.1 | 0.05 | 0.0 | |`vacuum_threshold` | 50 (défaut) | 50 (défaut) | 50 (défaut) | 500 000 | |`analyze_scale_factor`| 0.1 (défaut) | 0.1 (défaut) | 0.05 | 0.0 | |`analyze_threshold` | 50 (défaut) | 50 (défaut) | 50 (défaut) | 500 000 | Let's update this table with values for the vacuum_insert_* parameters. » I wasn't aware that we had this table, and although the settings made sense to me, I thought it was rather ugly and cumbersome for the user, and I started thinking about how postgres could make his life easier. > Am I correct in thinking that one of the major goals here is for a > very large table to be more likely to be vacuumed? > Absolutely. >> The idea would be to replace the following calculation : >> >> vacthresh = (float4) vac_base_thresh + vac_scale_factor * reltuples; >> >> with this one : >> >> vacthresh = (float4) vac_base_thresh + vac_scale_factor * reltuples / (1 >> + vac_scale_factor * reltuples / autovacuum_max_threshold) >> >> (and the same for the others, vacinsthresh and anlthresh). > > My first thought when reviewing the GUC and how it is used is > wondering if its description is a bit misleading. > > autovacuum_vacuum_threshold is the "minimum number of updated or > deleted tuples needed to trigger a vacuum". That is, if this many > tuples are modified, it *may* trigger a vacuum, but we also may skip > vacuuming the table for other reasons or due to other factors. > autovacuum_max_threshold's proposed definition is the upper > limit/maximum number of tuples to insert/update/delete prior to > vacuum/analyze. This implies that if that many tuples have been > modified or inserted, the table will definitely be vacuumed -- which > isn't true. Maybe that is okay, but I thought I would bring it up. > I'm not too sure I understand. What are the reasons it might by skipped? I can think of a concurrent index creation on the same table, or anything holding a SHARE UPDATE EXCLUSIVE lock or above. Is this the sort of thing you are talking about? Perhaps a better name for the GUC would be autovacuum_asymptotic_limit... or something like that? >> The attached (draft) patch further illustrates the idea. > > Thanks for including a patch! > >> My guess is that a similar proposal has already been submitted... and >> rejected 🙂 If so, I'm very sorry for the useless noise. > > I rooted around in the hackers archive and couldn't find any threads > on this specific proposal. I copied some other hackers I knew of who > have worked on this problem and thought about it in the past, in case > they know of some existing threads or prior work on this specific > topic. > Thanks!
Hi Nathan, thanks for your review. Le 24/04/2024 à 21:57, Nathan Bossart a écrit : > Yeah, I'm having trouble following the proposed mechanics for this new GUC, > and it's difficult to understand how users would choose a value. If we > just want to cap the number of tuples required before autovacuum takes > action, perhaps we could simplify it to something like > > vacthresh = (float4) vac_base_thresh + vac_scale_factor * reltuples; > vacthresh = Min(vacthres, vac_max_thresh); > > This would effectively cause autovacuum_vacuum_scale_factor to be > overridden for large tables where the scale factor would otherwise cause > the calculated threshold to be extremely high. This would indeed work, and the parameter would be easier to define in the user documentation. I prefer a continuous function... but that is personal taste. It seems to me that autovacuum tuning is quite hard anyway, and that it wouldn't be that much difficult with this kind of asymptotic limit parameter. But I think the most important thing is to avoid per-table configuration for most of the users, or event autovacuum tuning at all, so either of these two formulas would do.
On Thu, Apr 25, 2024 at 09:13:07AM +0200, Frédéric Yhuel wrote: > Le 24/04/2024 à 21:57, Nathan Bossart a écrit : >> Yeah, I'm having trouble following the proposed mechanics for this new GUC, >> and it's difficult to understand how users would choose a value. If we >> just want to cap the number of tuples required before autovacuum takes >> action, perhaps we could simplify it to something like >> >> vacthresh = (float4) vac_base_thresh + vac_scale_factor * reltuples; >> vacthresh = Min(vacthres, vac_max_thresh); >> >> This would effectively cause autovacuum_vacuum_scale_factor to be >> overridden for large tables where the scale factor would otherwise cause >> the calculated threshold to be extremely high. > > This would indeed work, and the parameter would be easier to define in the > user documentation. I prefer a continuous function... but that is personal > taste. It seems to me that autovacuum tuning is quite hard anyway, and that > it wouldn't be that much difficult with this kind of asymptotic limit > parameter. I do think this is a neat idea, but would the two approaches really be much different in practice? The scale factor parameters already help keep the limit smaller for small tables and larger for large ones, so it strikes me as needless complexity. I think we'd need some sort of tangible reason to think the asymptotic limit is better. > But I think the most important thing is to avoid per-table configuration for > most of the users, or event autovacuum tuning at all, so either of these two > formulas would do. Yeah, I agree with the goal of minimizing the need for per-table configurations. -- Nathan Bossart Amazon Web Services: https://aws.amazon.com
On Thu, Apr 25, 2024 at 2:52 AM Frédéric Yhuel <frederic.yhuel@dalibo.com> wrote: > > Le 24/04/2024 à 21:10, Melanie Plageman a écrit : > > On Wed, Apr 24, 2024 at 8:08 AM Frédéric Yhuel > > <frederic.yhuel@dalibo.com> wrote: > >> > >> Hello, > >> > >> I would like to suggest a new parameter, autovacuum_max_threshold, which > >> would set an upper limit on the number of tuples to delete/update/insert > >> prior to vacuum/analyze. > > > > Hi Frédéric, thanks for the proposal! You are tackling a very tough > > problem. I would also find it useful to know more about what led you > > to suggest this particular solution. I am very interested in user > > stories around difficulties with what tables are autovacuumed and > > when. > > > > Hi Melanie! I can certainly start compiling user stories about that. Cool! That would be very useful. > >> The idea would be to replace the following calculation : > >> > >> vacthresh = (float4) vac_base_thresh + vac_scale_factor * reltuples; > >> > >> with this one : > >> > >> vacthresh = (float4) vac_base_thresh + vac_scale_factor * reltuples / (1 > >> + vac_scale_factor * reltuples / autovacuum_max_threshold) > >> > >> (and the same for the others, vacinsthresh and anlthresh). > > > > My first thought when reviewing the GUC and how it is used is > > wondering if its description is a bit misleading. > > > > autovacuum_vacuum_threshold is the "minimum number of updated or > > deleted tuples needed to trigger a vacuum". That is, if this many > > tuples are modified, it *may* trigger a vacuum, but we also may skip > > vacuuming the table for other reasons or due to other factors. > > autovacuum_max_threshold's proposed definition is the upper > > limit/maximum number of tuples to insert/update/delete prior to > > vacuum/analyze. This implies that if that many tuples have been > > modified or inserted, the table will definitely be vacuumed -- which > > isn't true. Maybe that is okay, but I thought I would bring it up. > > > > I'm not too sure I understand. What are the reasons it might by skipped? > I can think of a concurrent index creation on the same table, or > anything holding a SHARE UPDATE EXCLUSIVE lock or above. Is this the > sort of thing you are talking about? No, I was thinking more literally that, if reltuples (assuming reltuples is modified/inserted tuples) > autovacuum_max_threshold, I would expect the table to be vacuumed. However, with your formula, that wouldn't necessarily be true. I think there are values of reltuples and autovacuum_max_threshold at which reltuples > autovacuum_max_threshold but reltuples <= vac_base_thresh + vac_scale_factor * reltuples / (1 + vac_scale_factor * reltuples / autovacuum_max_threshold) I tried to reduce the formula to come up with a precise definition of the range of values for which this is true, however I wasn't able to reduce it to something nice. Here is just an example of a case: vac_base_thresh = 2000 vac_scale_factor = 0.9 reltuples = 3200 autovacuum_max_threshold = 2500 total_thresh = vac_base_thresh + vac_scale_factor * reltuples / (1 + vac_scale_factor * reltuples / autovacuum_max_threshold) total_thresh: 3338. dead tuples: 3200. autovacuum_max_threshold: 2500 so there are more dead tuples than the max threshold, so it should trigger a vacuum, but it doesn't because the total calculated threshold is higher than the number of dead tuples. This of course may not be a realistic scenario in practice. It works best the closer scale factor is to 1 (wish I had derived the formula successfully) and when autovacuum_max_threshold > 2 * vac_base_thresh. So, maybe it is not an issue. > Perhaps a better name for the GUC would be > autovacuum_asymptotic_limit... or something like that? If we keep the asymptotic part, that makes sense. I wonder if we have to add another "vacuum" in there (e.g. autovacuum_vacuum_max_threshold) to be consistent with the other gucs. I don't really know why they have that extra "vacuum" in them, though. Makes the names so long. - Melanie
On Wed, Apr 24, 2024 at 3:57 PM Nathan Bossart <nathandbossart@gmail.com> wrote: > Yeah, I'm having trouble following the proposed mechanics for this new GUC, > and it's difficult to understand how users would choose a value. If we > just want to cap the number of tuples required before autovacuum takes > action, perhaps we could simplify it to something like > > vacthresh = (float4) vac_base_thresh + vac_scale_factor * reltuples; > vacthresh = Min(vacthres, vac_max_thresh); > > This would effectively cause autovacuum_vacuum_scale_factor to be > overridden for large tables where the scale factor would otherwise cause > the calculated threshold to be extremely high. +1 for this. It seems a lot easier to understand than the original proposal. And in fact, when I was working on my 2024.pgconf.dev presentation, I suggested exactly this idea on one of my slides. I believe that the underlying problem here can be summarized in this way: just because I'm OK with 2MB of bloat in my 10MB table doesn't mean that I'm OK with 2TB of bloat in my 10TB table. One reason for this is simply that I can afford to waste 2MB much more easily than I can afford to waste 2TB -- and that applies both on disk and in memory. Another reason, at least in existing releases, is that at some point index vacuuming hits a wall because we run out of space for dead tuples. We *most definitely* want to do index vacuuming before we get to the point where we're going to have to do multiple cycles of index vacuuming. That latter problem should be fixed in v17 by the recent dead TID storage changes. But even so, you generally want to contain bloat before too many pages get added to your tables or indexes, because you can't easily get rid of them again afterward, so I think there's still a good case for preventing autovacuum from scaling the threshold out to infinity. What does surprise me is that Frédéric suggests a default value of 500,000. If half a million tuples (proposed default) is 20% of your table (default value of autovacuum_vacuum_scale_factor) then your table has 2.5 million tuples. Unless those tuples are very wide, that table isn't even 1GB in size. I'm not aware that there's any problem at all with the current formula on a table of that size, or even ten times that size. I think you need to have tables that are hundreds of gigabytes in size at least before this starts to become a serious problem. Looking at this from another angle, in existing releases, the maximum usable amount of autovacuum_work_mem is 1GB, which means we can store one-sixth of a billion dead TIDs, or roughly 166 million. And that limit has been a source of occasional complaints for years. So we have those complaints on the one hand, suggesting that 166 million is not enough, and then we have this proposal, saying that more than half a million is too much. That's really strange; my initial hunch is that the value should be 100-500x higher than what Frédéric proposed. I'm also sort of wondering how much the tuple width matters here. I'm not quite sure. -- Robert Haas EDB: http://www.enterprisedb.com
On Thu, Apr 25, 2024 at 02:33:05PM -0400, Robert Haas wrote: > What does surprise me is that Frédéric suggests a default value of > 500,000. If half a million tuples (proposed default) is 20% of your > table (default value of autovacuum_vacuum_scale_factor) then your > table has 2.5 million tuples. Unless those tuples are very wide, that > table isn't even 1GB in size. I'm not aware that there's any problem > at all with the current formula on a table of that size, or even ten > times that size. I think you need to have tables that are hundreds of > gigabytes in size at least before this starts to become a serious > problem. Looking at this from another angle, in existing releases, the > maximum usable amount of autovacuum_work_mem is 1GB, which means we > can store one-sixth of a billion dead TIDs, or roughly 166 million. > And that limit has been a source of occasional complaints for years. > So we have those complaints on the one hand, suggesting that 166 > million is not enough, and then we have this proposal, saying that > more than half a million is too much. That's really strange; my > initial hunch is that the value should be 100-500x higher than what > Frédéric proposed. Agreed, the default should probably be on the order of 100-200M minimum. The original proposal also seems to introduce one parameter that would affect all three of autovacuum_vacuum_threshold, autovacuum_vacuum_insert_threshold, and autovacuum_analyze_threshold. Is that okay? Or do we need to introduce a "limit" GUC for each? I guess the question is whether we anticipate any need to have different values for these limits, which might be unlikely. -- Nathan Bossart Amazon Web Services: https://aws.amazon.com
On Thu, Apr 25, 2024 at 3:21 PM Nathan Bossart <nathandbossart@gmail.com> wrote: > Agreed, the default should probably be on the order of 100-200M minimum. > > The original proposal also seems to introduce one parameter that would > affect all three of autovacuum_vacuum_threshold, > autovacuum_vacuum_insert_threshold, and autovacuum_analyze_threshold. Is > that okay? Or do we need to introduce a "limit" GUC for each? I guess the > question is whether we anticipate any need to have different values for > these limits, which might be unlikely. I don't think we should make the same limit apply to more than one of those. I would phrase the question in the opposite way that you did: is there any particular reason to believe that the limits should be the same? I don't see one. I think it would be OK to introduce limits for some and leave the others uncapped, but I don't like the idea of reusing the same limit for different things. My intuition is strongest for the vacuum threshold -- that's such an expensive operation, takes so long, and has such dire consequences if it isn't done. We need to force the table to be vacuumed before it bloats out of control. Maybe essentially the same logic applies to the insert threshold, namely, that we should vacuum before the number of not-all-visible pages gets too large, but I think it's less clear. It's just not nearly as bad if that happens. Sure, it may not be great when vacuum eventually runs and hits a ton of pages all at once, but it's not even close to being as catastrophic as the vacuum case. The analyze case, I feel, is really murky. autovacuum_analyze_scale_factor stands for the proposition that as the table becomes larger, analyze doesn't need to be done as often. If what you're concerned about is the frequency estimates, that's true: an injection of a million new rows can shift frequencies dramatically in a small table, but the effect is blunted in a large one. But a lot of the cases I've seen have involved the histogram boundaries. If you're inserting data into a table in increasing order, every new million rows shifts the boundary of the last histogram bucket by the same amount. You either need those rows included in the histogram to get good query plans, or you don't. If you do, the frequency with which you need to analyze does not change as the table grows. If you don't, then it probably does. But the answer doesn't really depend on how big the table is already, but on your workload. So it's unclear to me that the proposed parameter is the right idea here at all. It's also unclear to me that the existing system is the right idea. :-) So overall I guess I'd lean toward just introducing a cap for the "vacuum" case and leave the "insert" and "analyze" cases as ideas for possible future consideration, but I'm not 100% sure. -- Robert Haas EDB: http://www.enterprisedb.com
Le 25/04/2024 à 21:21, Nathan Bossart a écrit : > On Thu, Apr 25, 2024 at 02:33:05PM -0400, Robert Haas wrote: >> What does surprise me is that Frédéric suggests a default value of >> 500,000. If half a million tuples (proposed default) is 20% of your >> table (default value of autovacuum_vacuum_scale_factor) then your >> table has 2.5 million tuples. Unless those tuples are very wide, that >> table isn't even 1GB in size. I'm not aware that there's any problem >> at all with the current formula on a table of that size, or even ten >> times that size. I think you need to have tables that are hundreds of >> gigabytes in size at least before this starts to become a serious >> problem. Looking at this from another angle, in existing releases, the >> maximum usable amount of autovacuum_work_mem is 1GB, which means we >> can store one-sixth of a billion dead TIDs, or roughly 166 million. >> And that limit has been a source of occasional complaints for years. >> So we have those complaints on the one hand, suggesting that 166 >> million is not enough, and then we have this proposal, saying that >> more than half a million is too much. That's really strange; my >> initial hunch is that the value should be 100-500x higher than what >> Frédéric proposed. > > Agreed, the default should probably be on the order of 100-200M minimum. > I'm not sure... 500000 comes from the table given in a previous message. It may not be large enough. But vacuum also updates the visibility map, and a few hundred thousand heap fetches can already hurt the performance of an index-only scan, even if most of the blocs are read from cache. > The original proposal also seems to introduce one parameter that would > affect all three of autovacuum_vacuum_threshold, > autovacuum_vacuum_insert_threshold, and autovacuum_analyze_threshold. Is > that okay? Or do we need to introduce a "limit" GUC for each? I guess the > question is whether we anticipate any need to have different values for > these limits, which might be unlikely. > I agree with you, it seems unlikely. This is also an answer to Melanie's question about the name of the GUC : I deliberately left out the other "vacuum" because I thought we only needed one parameter for these three thresholds. Now I have just read Robert's new message, and I understand his point. But is there a real problem with triggering analyze after every 500000 (or more) modifications in the table anyway?
Le 25/04/2024 à 18:51, Melanie Plageman a écrit : >> I'm not too sure I understand. What are the reasons it might by skipped? >> I can think of a concurrent index creation on the same table, or >> anything holding a SHARE UPDATE EXCLUSIVE lock or above. Is this the >> sort of thing you are talking about? > No, I was thinking more literally that, if reltuples (assuming > reltuples is modified/inserted tuples) > autovacuum_max_threshold, I > would expect the table to be vacuumed. However, with your formula, > that wouldn't necessarily be true. > > I think there are values of reltuples and autovacuum_max_threshold at > which reltuples > autovacuum_max_threshold but reltuples <= > vac_base_thresh + vac_scale_factor * reltuples / (1 + vac_scale_factor > * reltuples / autovacuum_max_threshold) > > I tried to reduce the formula to come up with a precise definition of > the range of values for which this is true, however I wasn't able to > reduce it to something nice. > > Here is just an example of a case: > > vac_base_thresh = 2000 > vac_scale_factor = 0.9 > reltuples = 3200 > autovacuum_max_threshold = 2500 > > total_thresh = vac_base_thresh + vac_scale_factor * reltuples / (1 + > vac_scale_factor * reltuples / autovacuum_max_threshold) > > total_thresh: 3338. dead tuples: 3200. autovacuum_max_threshold: 2500 > > so there are more dead tuples than the max threshold, so it should > trigger a vacuum, but it doesn't because the total calculated > threshold is higher than the number of dead tuples. > OK, thank you! I got it. > This of course may not be a realistic scenario in practice. It works > best the closer scale factor is to 1 (wish I had derived the formula > successfully) and when autovacuum_max_threshold > 2 * vac_base_thresh. > So, maybe it is not an issue. I haven't thought much about this yet. I hope we can avoid such an extreme scenario by imposing some kind of constraint on this parameter, in relation to the others. Anyway, with Nathan and Robert upvoting the simpler formula, this will probably become irrelevant anyway :-)
On Thu, Apr 25, 2024 at 4:57 PM Frédéric Yhuel <frederic.yhuel@dalibo.com> wrote: > Now I have just read Robert's new message, and I understand his point. > But is there a real problem with triggering analyze after every 500000 > (or more) modifications in the table anyway? It depends on the situation, but even on a laptop, you can do that number of modifications in one second. You could easily have a moderate large number of tables that hit that threshold every minute, and thus get auto-analyzed every minute when an autovacuum worker is launched in that database. Now, in some situations, that could be a good thing, because I suspect it's not very hard to construct a workload where constantly analyzing all of your busy tables is necessary to maintain query performance. But in general I think what would happen with such a low threshold is that you'd end up with autovacuum spending an awful lot of its available resources on useless analyze operations, which would waste I/O and CPU time, and more importantly, interfere with its ability to get vacuums done. To put it another way, suppose my tables contain 10 million tuples each, which is not particularly large. The analyze scale factor is 10%, so currently I'd analyze after a million table modifications. Your proposal drops that to half a million, so I'm going to start analyzing 20 times more often. If you start doing ANYTHING to a database twenty times more often, it can cause a problem. Twenty times more selects, twenty times more checkpoints, twenty times more vacuuming, whatever. It's just a lot of resources to spend on something if that thing isn't actually necessary. -- Robert Haas EDB: http://www.enterprisedb.com
On Thu, 2024-04-25 at 14:33 -0400, Robert Haas wrote: > I believe that the underlying problem here can be summarized in this > way: just because I'm OK with 2MB of bloat in my 10MB table doesn't > mean that I'm OK with 2TB of bloat in my 10TB table. One reason for > this is simply that I can afford to waste 2MB much more easily than I > can afford to waste 2TB -- and that applies both on disk and in > memory. I don't find that convincing. Why are 2TB of wasted space in a 10TB table worse than 2TB of wasted space in 100 tables of 100GB each? > Another reason, at least in existing releases, is that at some > point index vacuuming hits a wall because we run out of space for dead > tuples. We *most definitely* want to do index vacuuming before we get > to the point where we're going to have to do multiple cycles of index > vacuuming. That is more convincing. But do we need a GUC for that? What about making a table eligible for autovacuum as soon as the number of dead tuples reaches 90% of what you can hold in "autovacuum_work_mem"? Yours, Laurenz Albe
Le 26/04/2024 à 04:24, Laurenz Albe a écrit : > On Thu, 2024-04-25 at 14:33 -0400, Robert Haas wrote: >> I believe that the underlying problem here can be summarized in this >> way: just because I'm OK with 2MB of bloat in my 10MB table doesn't >> mean that I'm OK with 2TB of bloat in my 10TB table. One reason for >> this is simply that I can afford to waste 2MB much more easily than I >> can afford to waste 2TB -- and that applies both on disk and in >> memory. > > I don't find that convincing. Why are 2TB of wasted space in a 10TB > table worse than 2TB of wasted space in 100 tables of 100GB each? > Good point, but another way of summarizing the problem would be that the autovacuum_*_scale_factor parameters work well as long as we have a more or less evenly distributed access pattern in the table. Suppose my very large table gets updated only for its 1% most recent rows. We probably want to decrease autovacuum_analyze_scale_factor and autovacuum_vacuum_scale_factor for this one. Partitioning would be a good solution, but IMHO postgres should be able to handle this case anyway, ideally without per-table configuration.
Hi, On Fri, Apr 26, 2024 at 04:24:45AM +0200, Laurenz Albe wrote: > On Thu, 2024-04-25 at 14:33 -0400, Robert Haas wrote: > > Another reason, at least in existing releases, is that at some > > point index vacuuming hits a wall because we run out of space for dead > > tuples. We *most definitely* want to do index vacuuming before we get > > to the point where we're going to have to do multiple cycles of index > > vacuuming. > > That is more convincing. But do we need a GUC for that? What about > making a table eligible for autovacuum as soon as the number of dead > tuples reaches 90% of what you can hold in "autovacuum_work_mem"? Due to the improvements in v17, this would basically never trigger accordings to my understanding, or at least only after an excessive amount of bloat has been accumulated. Michael
Le 25/04/2024 à 22:21, Robert Haas a écrit : > The analyze case, I feel, is really murky. > autovacuum_analyze_scale_factor stands for the proposition that as the > table becomes larger, analyze doesn't need to be done as often. If > what you're concerned about is the frequency estimates, that's true: > an injection of a million new rows can shift frequencies dramatically > in a small table, but the effect is blunted in a large one. But a lot > of the cases I've seen have involved the histogram boundaries. If > you're inserting data into a table in increasing order, every new > million rows shifts the boundary of the last histogram bucket by the > same amount. You either need those rows included in the histogram to > get good query plans, or you don't. If you do, the frequency with > which you need to analyze does not change as the table grows. If you > don't, then it probably does. But the answer doesn't really depend on > how big the table is already, but on your workload. So it's unclear to > me that the proposed parameter is the right idea here at all. It's > also unclear to me that the existing system is the right idea. 🙂 This is very interesting. And what about ndistinct? I believe it could be problematic, too, in some (admittedly rare or pathological) cases. For example, suppose that the actual number of distinct values grows from 1000 to 200000 after a batch of insertions, for a particular column. OK, in such a case, the default analyze sampling isn't large enough to compute a ndistinct close enough to reality anyway. But without any analyze at all, it can lead to very bad planning - think of a Nested Loop with a parallel seq scan for the outer table instead of a simple efficient index scan, because the index scan of the inner table is overestimated (each index scan cost and number or rows returned).
On Fri, 2024-04-26 at 09:35 +0200, Frédéric Yhuel wrote: > > Le 26/04/2024 à 04:24, Laurenz Albe a écrit : > > On Thu, 2024-04-25 at 14:33 -0400, Robert Haas wrote: > > > I believe that the underlying problem here can be summarized in this > > > way: just because I'm OK with 2MB of bloat in my 10MB table doesn't > > > mean that I'm OK with 2TB of bloat in my 10TB table. One reason for > > > this is simply that I can afford to waste 2MB much more easily than I > > > can afford to waste 2TB -- and that applies both on disk and in > > > memory. > > > > I don't find that convincing. Why are 2TB of wasted space in a 10TB > > table worse than 2TB of wasted space in 100 tables of 100GB each? > > Good point, but another way of summarizing the problem would be that the > autovacuum_*_scale_factor parameters work well as long as we have a more > or less evenly distributed access pattern in the table. > > Suppose my very large table gets updated only for its 1% most recent > rows. We probably want to decrease autovacuum_analyze_scale_factor and > autovacuum_vacuum_scale_factor for this one. > > Partitioning would be a good solution, but IMHO postgres should be able > to handle this case anyway, ideally without per-table configuration. I agree that you may well want autovacuum and autoanalyze treat your large table differently from your small tables. But I am reluctant to accept even more autovacuum GUCs. It's not like we don't have enough of them, rather the opposite. You can slap on more GUCs to treat more special cases, but we will never reach the goal of having a default that will make everybody happy. I believe that the defaults should work well in moderately sized databases with moderate usage characteristics. If you have large tables or a high number of transactions per second, you can be expected to make the effort and adjust the settings for your case. Adding more GUCs makes life *harder* for the users who are trying to understand and configure how autovacuum works. Yours, Laurenz Albe
Hi, On Fri, Apr 26, 2024 at 10:18:00AM +0200, Laurenz Albe wrote: > On Fri, 2024-04-26 at 09:35 +0200, Frédéric Yhuel wrote: > > Le 26/04/2024 à 04:24, Laurenz Albe a écrit : > > > On Thu, 2024-04-25 at 14:33 -0400, Robert Haas wrote: > > > > I believe that the underlying problem here can be summarized in this > > > > way: just because I'm OK with 2MB of bloat in my 10MB table doesn't > > > > mean that I'm OK with 2TB of bloat in my 10TB table. One reason for > > > > this is simply that I can afford to waste 2MB much more easily than I > > > > can afford to waste 2TB -- and that applies both on disk and in > > > > memory. > > > > > > I don't find that convincing. Why are 2TB of wasted space in a 10TB > > > table worse than 2TB of wasted space in 100 tables of 100GB each? > > > > Good point, but another way of summarizing the problem would be that the > > autovacuum_*_scale_factor parameters work well as long as we have a more > > or less evenly distributed access pattern in the table. > > > > Suppose my very large table gets updated only for its 1% most recent > > rows. We probably want to decrease autovacuum_analyze_scale_factor and > > autovacuum_vacuum_scale_factor for this one. > > > > Partitioning would be a good solution, but IMHO postgres should be able > > to handle this case anyway, ideally without per-table configuration. > > I agree that you may well want autovacuum and autoanalyze treat your large > table differently from your small tables. > > But I am reluctant to accept even more autovacuum GUCs. It's not like > we don't have enough of them, rather the opposite. You can slap on more > GUCs to treat more special cases, but we will never reach the goal of > having a default that will make everybody happy. > > I believe that the defaults should work well in moderately sized databases > with moderate usage characteristics. If you have large tables or a high > number of transactions per second, you can be expected to make the effort > and adjust the settings for your case. Adding more GUCs makes life *harder* > for the users who are trying to understand and configure how autovacuum works. Well, I disagree to some degree. I agree that the defaults should work well in moderately sized databases with moderate usage characteristics. But I also think we can do better than telling DBAs to they have to manually fine-tune autovacuum for large tables (and frequenlty implementing by hand what this patch is proposed, namely setting autovacuum_vacuum_scale_factor to 0 and autovacuum_vacuum_threshold to a high number), as this is cumbersome and needs adult supervision that is not always available. Of course, it would be great if we just slap some AI into the autovacuum launcher that figures things out automagically, but I don't think we are there, yet. So this proposal (probably along with a higher default threshold than 500000, but IMO less than what Robert and Nathan suggested) sounds like a stop forward to me. DBAs can set the threshold lower if they want, or maybe we can just turn it off by default if we cannot agree on a sane default, but I think this (using the simplified formula from Nathan) is a good approach that takes some pain away from autovacuum tuning and reserves that for the really difficult cases. Michael
On 4/26/24 04:43, Michael Banck wrote: > So this proposal (probably along with a higher default threshold than > 500000, but IMO less than what Robert and Nathan suggested) sounds like > a stop forward to me. DBAs can set the threshold lower if they want, or > maybe we can just turn it off by default if we cannot agree on a sane > default, but I think this (using the simplified formula from Nathan) is > a good approach that takes some pain away from autovacuum tuning and > reserves that for the really difficult cases. +1 to the above Although I don't think 500000 is necessarily too small. In my view, having autovac run very quickly, even if more frequently, provides an overall better user experience. -- Joe Conway PostgreSQL Contributors Team RDS Open Source Databases Amazon Web Services: https://aws.amazon.com
On Thu, Apr 25, 2024 at 10:24 PM Laurenz Albe <laurenz.albe@cybertec.at> wrote: > I don't find that convincing. Why are 2TB of wasted space in a 10TB > table worse than 2TB of wasted space in 100 tables of 100GB each? It's not worse, but it's more avoidable. No matter what you do, any table that suffers a reasonable number of updates and/or deletes is going to have some wasted space. When a tuple is deleted or update, the old one has to stick around until its xmax is all-visible, and then after that until the page is HOT pruned which may not happen immediately, and then even after that the line pointer sticks around until the next vacuum which doesn't happen instantly either. No matter how aggressive you make autovacuum, or even no matter how aggressively you vacuum manually, non-insert-only tables are always going to end up containing some bloat. But how much? Well, it's basically given by RATE_AT_WHICH_SPACE_IS_WASTED * AVERAGE_TIME_UNTIL_SPACE_IS_RECLAIMED. Which, you'll note, does not really depend on the table size. It does a little bit, because the time until a tuple is fully removed, including the line pointer, depends on how long vacuum takes, and vacuum takes larger on a big table than a small one. But the effect is much less than linear, I believe, because you can HOT-prune as soon as the xmax is all-visible, which reclaims most of the space instantly. So in practice, the minimum feasible steady-state bloat for a table depends a great deal on how fast updates and deletes are happening, but only weakly on the size of the table. Which, in plain English, means that you should be able to vacuum a 10TB table often enough that it doesn't accumulate 2TB of bloat, if you want to. It's going to be harder to vacuum a 10GB table often enough that it doesn't accumulate 2GB of bloat. And it's going to be *really* hard to vacuum a 10MB table often enough that it doesn't accumulate 2MB of bloat. The only way you're going to be able to do that last one at all is if the update rate is very low. > > Another reason, at least in existing releases, is that at some > > point index vacuuming hits a wall because we run out of space for dead > > tuples. We *most definitely* want to do index vacuuming before we get > > to the point where we're going to have to do multiple cycles of index > > vacuuming. > > That is more convincing. But do we need a GUC for that? What about > making a table eligible for autovacuum as soon as the number of dead > tuples reaches 90% of what you can hold in "autovacuum_work_mem"? That would have been a good idea to do in existing releases, a long time before now, but we didn't. However, the new dead TID store changes the picture, because if I understand John Naylor's remarks correctly, the new TID store can hold so many TIDs so efficiently that you basically won't run out of memory. So now I think this wouldn't be effective - yet I still think it's wrong to let the vacuum threshold scale without bound as the table size increases. -- Robert Haas EDB: http://www.enterprisedb.com
On Fri, Apr 26, 2024 at 9:22 AM Joe Conway <mail@joeconway.com> wrote: > Although I don't think 500000 is necessarily too small. In my view, > having autovac run very quickly, even if more frequently, provides an > overall better user experience. Can you elaborate on why you think that? I mean, to me, that's almost equivalent to removing autovacuum_vacuum_scale_factor entirely, because only for very small tables will that calculation produce a value lower than 500k. We might need to try to figure out some test cases here. My intuition is that this is going to vacuum large tables insanely aggressively. -- Robert Haas EDB: http://www.enterprisedb.com
On Fri, Apr 26, 2024 at 4:43 AM Michael Banck <mbanck@gmx.net> wrote: > > I believe that the defaults should work well in moderately sized databases > > with moderate usage characteristics. If you have large tables or a high > > number of transactions per second, you can be expected to make the effort > > and adjust the settings for your case. Adding more GUCs makes life *harder* > > for the users who are trying to understand and configure how autovacuum works. > > Well, I disagree to some degree. I agree that the defaults should work > well in moderately sized databases with moderate usage characteristics. > But I also think we can do better than telling DBAs to they have to > manually fine-tune autovacuum for large tables (and frequenlty > implementing by hand what this patch is proposed, namely setting > autovacuum_vacuum_scale_factor to 0 and autovacuum_vacuum_threshold to a > high number), as this is cumbersome and needs adult supervision that is > not always available. Of course, it would be great if we just slap some > AI into the autovacuum launcher that figures things out automagically, > but I don't think we are there, yet. > > So this proposal (probably along with a higher default threshold than > 500000, but IMO less than what Robert and Nathan suggested) sounds like > a stop forward to me. DBAs can set the threshold lower if they want, or > maybe we can just turn it off by default if we cannot agree on a sane > default, but I think this (using the simplified formula from Nathan) is > a good approach that takes some pain away from autovacuum tuning and > reserves that for the really difficult cases. I agree with this. If having an extra setting substantially reduces the number of cases that require manual tuning, it's totally worth it. And I think it will. To be clear, I don't think this is the biggest problem with the autovacuum algorithm, not by quite a bit. But it's a relatively easy one to fix. -- Robert Haas EDB: http://www.enterprisedb.com
On 4/26/24 09:31, Robert Haas wrote: > On Fri, Apr 26, 2024 at 9:22 AM Joe Conway <mail@joeconway.com> wrote: >> Although I don't think 500000 is necessarily too small. In my view, >> having autovac run very quickly, even if more frequently, provides an >> overall better user experience. > > Can you elaborate on why you think that? I mean, to me, that's almost > equivalent to removing autovacuum_vacuum_scale_factor entirely, > because only for very small tables will that calculation produce a > value lower than 500k. If I understood Nathan's proposed calc, for small tables you would still get (thresh + sf * numtuples). Once that number exceeds the new limit parameter, then the latter would kick in. So small tables would retain the current behavior and large enough tables would be clamped. > We might need to try to figure out some test cases here. My intuition > is that this is going to vacuum large tables insanely aggressively. It depends on workload to be sure. Just because a table is large, it doesn't mean that dead rows are generated that fast. Admittedly it has been quite a while since I looked at all this that closely, but if A/V runs on some large busy table for a few milliseconds once every few minutes, that is far less disruptive than A/V running for tens of seconds once every few hours or for minutes ones every few days -- or whatever. The key thing to me is the "few milliseconds" runtime. The short duration means that no one notices an impact, and the longer duration almost guarantees that an impact will be felt. -- Joe Conway PostgreSQL Contributors Team RDS Open Source Databases Amazon Web Services: https://aws.amazon.com
On Fri, Apr 26, 2024 at 9:40 AM Joe Conway <mail@joeconway.com> wrote: > > Can you elaborate on why you think that? I mean, to me, that's almost > > equivalent to removing autovacuum_vacuum_scale_factor entirely, > > because only for very small tables will that calculation produce a > > value lower than 500k. > > If I understood Nathan's proposed calc, for small tables you would still > get (thresh + sf * numtuples). Once that number exceeds the new limit > parameter, then the latter would kick in. So small tables would retain > the current behavior and large enough tables would be clamped. Right. But with a 500k threshold, "large enough" is not very large at all. The default scale factor is 20%, so the crossover point is at 2.5 million tuples. That's pgbench scale factor 25, which is a 320MB table. > It depends on workload to be sure. Just because a table is large, it > doesn't mean that dead rows are generated that fast. That is true, as far as it goes. > Admittedly it has been quite a while since I looked at all this that > closely, but if A/V runs on some large busy table for a few milliseconds > once every few minutes, that is far less disruptive than A/V running for > tens of seconds once every few hours or for minutes ones every few days > -- or whatever. The key thing to me is the "few milliseconds" runtime. > The short duration means that no one notices an impact, and the longer > duration almost guarantees that an impact will be felt. Sure, I mean, I totally agree with that, but how is a vacuum on a large table going to run for milliseconds? If it can skip index vacuuming, sure, then it's quick, because it only needs to scan the heap pages that are not all-visible. But as soon as index vacuuming is triggered, it's going to take a while. You can't afford to trigger that constantly. Let's compare the current situation to the situation post-patch with a cap of 500k. Consider a table 1024 times larger than the one I mentioned above, so pgbench scale factor 25600, size on disk 320GB. Currently, that table will be vacuumed for bloat when the number of dead tuples exceeds 20% of the table size, because that's the default value of autovacuum_vacuum_scale_factor. The table has 2.56 billion tuples, so that means that we're going to vacuum it when there are more than 510 million dead tuples. Post-patch, we will vacuum when we have 500 thousand dead tuples. Suppose a uniform workload that slowly updates rows in the table. If we were previously autovacuuming the table once per day (1440 minutes) we're now going to try to vacuum it almost every minute (1440 minutes / 1024 = 84 seconds). Unless I'm missing something major, that's completely bonkers. It might be true that it would be a good idea to vacuum such a table more often than we do at present, but there's no shot that we want to do it that much more often. The pgbench_accounts_pkey index will, I believe, be on the order of 8-10GB at that scale. We can't possibly want to incur that much extra I/O every minute, and I don't think it's going to finish in milliseconds, either. -- Robert Haas EDB: http://www.enterprisedb.com
I've been following this discussion and would like to add my 2 cents. > Unless I'm missing something major, that's completely bonkers. It > might be true that it would be a good idea to vacuum such a table more > often than we do at present, but there's no shot that we want to do it > that much more often. This is really an important point. Too small of a threshold and a/v will constantly be vacuuming a fairly large and busy table with many indexes. If the threshold is large, say 100 or 200 million, I question if you want autovacuum to be doing the work of cleanup here? That long of a period without a autovacuum on a table means there maybe something misconfigured in your autovacuum settings. At that point aren't you just better off performing a manual vacuum and taking advantage of parallel index scans? Regards, Sami Imseih Amazon Web Services (AWS)
On Wed, May 1, 2024 at 2:19 PM Imseih (AWS), Sami <simseih@amazon.com> wrote: > > Unless I'm missing something major, that's completely bonkers. It > > might be true that it would be a good idea to vacuum such a table more > > often than we do at present, but there's no shot that we want to do it > > that much more often. > > This is really an important point. > > Too small of a threshold and a/v will constantly be vacuuming a fairly large > and busy table with many indexes. > > If the threshold is large, say 100 or 200 million, I question if you want autovacuum > to be doing the work of cleanup here? That long of a period without a autovacuum > on a table means there maybe something misconfigured in your autovacuum settings. > > At that point aren't you just better off performing a manual vacuum and > taking advantage of parallel index scans? As far as that last point goes, it would be good if we taught autovacuum about several things it doesn't currently know about; parallelism is one. IMHO, it's probably not the most important one, but it's certainly on the list. I think, though, that we should confine ourselves on this thread to talking about what the threshold ought to be. And as far as that goes, I'd like you - and others - to spell out more precisely why you think 100 or 200 million tuples is too much. It might be, or maybe it is in some cases but not in others. To me, that's not a terribly large amount of data. Unless your tuples are very wide, it's a few tens of gigabytes. That is big enough that I can believe that you *might* want autovacuum to run when you hit that threshold, but it's definitely not *obvious* to me that you want autovacuum to run when you hit that threshold. To make that concrete: If the table is 10TB, do you want to vacuum to reclaim 20GB of bloat? You might be vacuuming 5TB of indexes to reclaim 20GB of heap space - is that the right thing to do? If yes, why? I do think it's interesting that other people seem to think we should be vacuuming more often on tables that are substantially smaller than the ones that seem like a big problem to me. I'm happy to admit that my knowledge of this topic is not comprehensive and I'd like to learn from the experience of others. But I think it's clearly and obviously unworkable to multiply the current frequency of vacuuming for large tables by a three or four digit number. Possibly what we need here is something other than a cap, where, say, we vacuum a 10GB table twice as often as now, a 100GB table four times as often, and a 1TB table eight times as often. Or whatever the right answer is. But we can't just pull numbers out of the air like that: we need to be able to justify our choices. I think we all agree that big tables need to be vacuumed more often than the current formula does, but we seem to be rather far apart on the values of "big" and "more". -- Robert Haas EDB: http://www.enterprisedb.com
On Sat, 27 Apr 2024 at 02:13, Robert Haas <robertmhaas@gmail.com> wrote: > Let's compare the current situation to the situation post-patch with a > cap of 500k. Consider a table 1024 times larger than the one I > mentioned above, so pgbench scale factor 25600, size on disk 320GB. > Currently, that table will be vacuumed for bloat when the number of > dead tuples exceeds 20% of the table size, because that's the default > value of autovacuum_vacuum_scale_factor. The table has 2.56 billion > tuples, so that means that we're going to vacuum it when there are > more than 510 million dead tuples. Post-patch, we will vacuum when we > have 500 thousand dead tuples. Suppose a uniform workload that slowly > updates rows in the table. If we were previously autovacuuming the > table once per day (1440 minutes) we're now going to try to vacuum it > almost every minute (1440 minutes / 1024 = 84 seconds). I've not checked your maths, but if that's true, that's not going to work. I think there are fundamental problems with the parameters that drive autovacuum that need to be addressed before we can consider a patch like this one. Here are some of the problems that I know about: 1. Autovacuum has exactly zero forward vision and operates reactively rather than proactively. This "blind operating" causes tables to either not need vacuumed or suddenly need vacuumed without any consideration of how busy autovacuum is at that current moment. 2. There is no prioritisation for the order in which tables are autovacuumed. 3. With the default scale factor, the larger a table becomes, the more infrequent the autovacuums. 4. Autovacuum is more likely to trigger when the system is busy because more transaction IDs are being consumed and there is more DML occurring. This results in autovacuum having less work to do during quiet periods when there are more free resources to be doing the vacuum work. In my opinion, the main problem with Frédéric's proposed GUC/reloption is that it increases the workload that autovacuum is responsible for and, because of #2, it becomes more likely that autovacuum works on some table that isn't the highest priority table to work on which can result in autovacuum starvation of tables that are more important to vacuum now. I think we need to do a larger overhaul of autovacuum to improve points 1-4 above. I also think that there's some work coming up that might force us into this sooner than we think. As far as I understand it, AIO will break vacuum_cost_page_miss because everything (providing IO keeps up) will become vacuum_cost_page_hit. Maybe that's not that important as that costing is quite terrible anyway. Here's a sketch of an idea that's been in my head for a while: Round 1: 1a) Give autovacuum forward vision (#1 above) and instead of vacuuming a table when it (atomically) crosses some threshold, use the existing scale_factors and autovacuum_freeze_max_age to give each table an autovacuum "score", which could be a number from 0-100, where 0 means do nothing and 100 means nuclear meltdown. Let's say a table gets 10 points for the dead tuples meeting the current scale_factor and maybe an additional point for each 10% of proportion the size of the table is according to the size of the database (gives some weight to space recovery for larger tables). For relfrozenxid, make the score the maximum of dead tuple score vs the percentage of the age(relfrozenxid) is to 2 billion. Use a similar maximum score calc for age(relminmxid) 2 billion. 1b) Add a new GUC that defines the minimum score a table must reach before autovacuum will consider it. 1c) Change autovacuum to vacuum the tables with the highest scores first. Round 2: 2a) Have autovacuum monitor the score of the highest scoring table over time with buckets for each power of 2 seconds in history from now. Let's say 20 buckets, about 12 days of history. Migrate scores into older buckets to track the score over time. 2b) Have autovacuum cost limits adapt according to the history so that if the maximum score of any table is trending upwards, that autovacuum speeds up until the score buckets trend downwards towards the present. 2c) Add another GUC to define the minimum score that autovacuum will be "proactive". Must be less than the minimum score to consider autovacuum (or at least, ignored unless it is.). This GUC would not cause an autovacuum speedup due to 2b) as we'd only consider tables which meet the GUC added in 1b) in the score history array in 2a). This stops autovacuum running faster than autovacuum_cost_limit when trying to be proactive. While the above isn't well a well-baked idea. The exact way to calculate the scores isn't well thought through, certainly. However, I do think it's an idea that we should consider and improve upon. I believe 2c) helps solve the problem of large tables becoming bloated as autovacuum could get to these sooner when the workload is low enough for it to run proactively. I think we need at least 1a) before we can give autovacuum more work to do, especially if we do something like multiply its workload by 1024x, per your comment above. David
Le 01/05/2024 à 20:50, Robert Haas a écrit : > Possibly what we need here is > something other than a cap, where, say, we vacuum a 10GB table twice > as often as now, a 100GB table four times as often, and a 1TB table > eight times as often. Or whatever the right answer is. IMO, it would make more sense. So maybe something like this: vacthresh = Min(vac_base_thresh + vac_scale_factor * reltuples, vac_base_thresh + vac_scale_factor * sqrt(reltuples) * 1000); (it could work to compute a score, too, like in David's proposal)
> And as far as that goes, I'd like you - and others - to spell out more > precisely why you think 100 or 200 million tuples is too much. It > might be, or maybe it is in some cases but not in others. To me, > that's not a terribly large amount of data. Unless your tuples are > very wide, it's a few tens of gigabytes. That is big enough that I can > believe that you *might* want autovacuum to run when you hit that > threshold, but it's definitely not *obvious* to me that you want > autovacuum to run when you hit that threshold. Vacuuming the heap alone gets faster the more I do it, thanks to the visibility map. However, the more indexes I have, and the larger ( in the TBs), the indexes become, autovacuum workers will be monopolized vacuuming these indexes. At 500k tuples, I am constantly vacuuming large indexes and monopolizing autovacuum workers. At 100 or 200 million tuples, I will also monopolize autovacuum workers as they vacuums indexes for many minutes or hours. At 100 or 200 million, the monopolization will occur less often, but it will still occur leading an operator to maybe have to terminate the autovacuum an kick of a manual vacuum. I am not convinced a new tuple based threshold will address this, but I may also may be misunderstanding the intention of this GUC. > To make that concrete: If the table is 10TB, do you want to vacuum to > reclaim 20GB of bloat? You might be vacuuming 5TB of indexes to > reclaim 20GB of heap space - is that the right thing to do? If yes, > why? No, I would not want to run autovacuum on 5TB indexes to reclaim a small amount of bloat. Regards, Sami
On Wed, May 1, 2024 at 10:03 PM David Rowley <dgrowleyml@gmail.com> wrote: > Here are some of the problems that I know about: > > 1. Autovacuum has exactly zero forward vision and operates reactively > rather than proactively. This "blind operating" causes tables to > either not need vacuumed or suddenly need vacuumed without any > consideration of how busy autovacuum is at that current moment. > 2. There is no prioritisation for the order in which tables are autovacuumed. > 3. With the default scale factor, the larger a table becomes, the more > infrequent the autovacuums. > 4. Autovacuum is more likely to trigger when the system is busy > because more transaction IDs are being consumed and there is more DML > occurring. This results in autovacuum having less work to do during > quiet periods when there are more free resources to be doing the > vacuum work. I agree with all of these points. For a while now, I've been thinking that we really needed a prioritization scheme, so that we don't waste our time on low-priority tasks when there are high-priority tasks that need to be completed. But lately I've started to think that what matters most is the rate at which autovacuum work is happening overall. I feel like prioritization is mostly going to matter when we're not keeping up, and I think the primary goal should be to keep up. I think we could use the same data to make both decisions -- if autovacuum were proactive rather than reactive, that would mean that we know something about what is going to happen in the future, and I think that data could be used both to decide whether we're keeping up, and also to prioritize. But if I had to pick a first target, I'd forget about trying to make things happen in the right order and just try to make sure we get all the things done. > I think we need at least 1a) before we can give autovacuum more work > to do, especially if we do something like multiply its workload by > 1024x, per your comment above. I guess I view it differently. It seems to me that right now, we're not vacuuming large tables often enough. We should fix that, independently of anything else. If the result is that small and medium sized tables get vacuumed less often, then that just means there were never enough resources to go around in the first place. We haven't taken a system that was working fine and broken it: we've just moved the problem from one category of tables (the big ones) to a different category of tables. If the user wants to solve that problem, they need to bump up the cost limit or add hardware. I don't see that we have any particular reason to believe such users will be worse off on average than they are today. On the other hand, users who do have a sufficiently high cost limit and enough hardware will be better off, because we'll start doing all the vacuuming work that needs to be done instead of only some of it. Now, if we start vacuuming any class of table whatsoever 1024x as often as we do today, we are going to lose. But that would still be true even if we did everything on your list. Large tables need to be vacuumed more frequently than we now do, but not THAT much more frequently. Any system that produces that result is just using a wrong algorithm, or wrong constants, or something. Even if all the necessary resources are available, nobody is going to thank us for vacuuming gigantic tables in a tight loop. The problem with such a large increase is not that we don't have prioritization, but that such a large increase is fundamentally the wrong thing to do. On the other hand, I think a more modest increase is the right thing to do, and I think it's the right thing to do whether we have prioritization or not. -- Robert Haas EDB: http://www.enterprisedb.com
On Tue, May 07, 2024 at 10:31:00AM -0400, Robert Haas wrote: > On Wed, May 1, 2024 at 10:03 PM David Rowley <dgrowleyml@gmail.com> wrote: >> I think we need at least 1a) before we can give autovacuum more work >> to do, especially if we do something like multiply its workload by >> 1024x, per your comment above. > > I guess I view it differently. It seems to me that right now, we're > not vacuuming large tables often enough. We should fix that, > independently of anything else. If the result is that small and medium > sized tables get vacuumed less often, then that just means there were > never enough resources to go around in the first place. We haven't > taken a system that was working fine and broken it: we've just moved > the problem from one category of tables (the big ones) to a different > category of tables. If the user wants to solve that problem, they need > to bump up the cost limit or add hardware. I don't see that we have > any particular reason to believe such users will be worse off on > average than they are today. On the other hand, users who do have a > sufficiently high cost limit and enough hardware will be better off, > because we'll start doing all the vacuuming work that needs to be done > instead of only some of it. > > Now, if we start vacuuming any class of table whatsoever 1024x as > often as we do today, we are going to lose. But that would still be > true even if we did everything on your list. Large tables need to be > vacuumed more frequently than we now do, but not THAT much more > frequently. Any system that produces that result is just using a wrong > algorithm, or wrong constants, or something. Even if all the necessary > resources are available, nobody is going to thank us for vacuuming > gigantic tables in a tight loop. The problem with such a large > increase is not that we don't have prioritization, but that such a > large increase is fundamentally the wrong thing to do. On the other > hand, I think a more modest increase is the right thing to do, and I > think it's the right thing to do whether we have prioritization or > not. This is about how I feel, too. In any case, I +1'd a higher default because I think we need to be pretty conservative with these changes, at least until we have a better prioritization strategy. While folks may opt to set this value super low, I think that's more likely to lead to some interesting secondary effects. If the default is high, hopefully these secondary effects will be minimized or avoided. -- Nathan Bossart Amazon Web Services: https://aws.amazon.com
> This is about how I feel, too. In any case, I +1'd a higher default > because I think we need to be pretty conservative with these changes, at > least until we have a better prioritization strategy. While folks may opt > to set this value super low, I think that's more likely to lead to some > interesting secondary effects. If the default is high, hopefully these > secondary effects will be minimized or avoided. There is also an alternative of making this GUC -1 by default, which means it has not effect and any value larger will be used in the threshold calculation of autovacuunm. A user will have to be careful not to set it too low, but that is going to be a concern either way. This idea maybe worth considering as it does not change the default behavior of the autovac threshold calculation, and if a user has cases in which they have many tables with a few billion tuples that they wish to see autovacuumed more often, they now have a GUC to make that possible and potentially avoid per-table threshold configuration. Also, I think coming up with a good default will be challenging, and perhaps this idea is a good middle ground. Regards, Sami
On Wed, May 8, 2024 at 1:30 PM Imseih (AWS), Sami <simseih@amazon.com> wrote: > There is also an alternative of making this GUC -1 by default, which > means it has not effect and any value larger will be used in the threshold > calculation of autovacuunm. A user will have to be careful not to set it too low, > but that is going to be a concern either way. Personally, I'd much rather ship it with a reasonable default. If we ship it disabled, most people won't end up using it at all, which sucks, and those who do will be more likely to set it to a ridiculous value, which also sucks. If we ship it with a value that has a good chance of being within 2x or 3x of the optimal value on a given user's system, then a lot more people will benefit from it. > Also, I think coming up with a good default will be challenging, > and perhaps this idea is a good middle ground. Maybe. I freely admit that I don't know exactly what the optimal value is here, and I think there is some experimentation that is needed to try to get some better intuition there. At what table size does the current system actually result in too little vacuuming, and how can we demonstrate that? Does the point at which that happens depend more on the table size in gigabytes, or more on the number of rows? These are things that someone can research and about which they can present data. As I see it, a lot of the lack of agreement up until now is people just not understanding the math. Since I think I've got the right idea about the math, I attribute this to other people being confused about what is going to happen and would tend to phrase it as: some people don't understand how catastrophically bad it will be if you set this value too low. However, another possibility is that it is I who am misunderstanding the math. In that case, the correct phrasing is probably something like: Robert wants a completely useless and worthless value for this parameter that will be of no help to anyone. Regardless, at least some of us are confused. If we can reduce that confusion, then people's ideas about what values for this parameter might be suitable should start to come closer together. I tend to feel like the disagreement here is not really about whether it's a good idea to increase the frequency of vacuuming on large tables by three orders of magnitude compared to what we do now, but rather than about whether that's actually going to happen. -- Robert Haas EDB: http://www.enterprisedb.com
Le 09/05/2024 à 16:58, Robert Haas a écrit : > As I see it, a lot of the lack of agreement up until now is people > just not understanding the math. Since I think I've got the right idea > about the math, I attribute this to other people being confused about > what is going to happen and would tend to phrase it as: some people > don't understand how catastrophically bad it will be if you set this > value too low. FWIW, I do agree with your math. I found your demonstration convincing. 500000 was selected with the wet finger. Using the formula I suggested earlier: vacthresh = Min(vac_base_thresh + vac_scale_factor * reltuples, vac_base_thresh + vac_scale_factor * sqrt(reltuples) * 1000); your table of 2.56 billion tuples will be vacuumed if there are more than 10 million dead tuples (every 28 minutes). If we want to stick with the simple formula, we should probably choose a very high default, maybe 100 million, as you suggested earlier. However, it would be nice to have the visibility map updated more frequently than every 100 million dead tuples. I wonder if this could be decoupled from the vacuum process?
On Mon, May 13, 2024 at 11:14 AM Frédéric Yhuel <frederic.yhuel@dalibo.com> wrote: > FWIW, I do agree with your math. I found your demonstration convincing. > 500000 was selected with the wet finger. Good to know. > Using the formula I suggested earlier: > > vacthresh = Min(vac_base_thresh + vac_scale_factor * reltuples, > vac_base_thresh + vac_scale_factor * sqrt(reltuples) * 1000); > > your table of 2.56 billion tuples will be vacuumed if there are > more than 10 million dead tuples (every 28 minutes). Yeah, so that is about 50x what we do now (twice an hour vs. once a day). While that's a lot more reasonable than the behavior that we'd get from a 500k hard cap (every 84 seconds), I suspect it's still too aggressive. I find these things much easier to reason about in gigabytes than in time units. In that example, the table was 320GB and was getting vacuumed after accumulating 64GB of bloat. That seems like a lot. It means that the table can grow from 320GB all the way up until 384GB before we even think about starting to vacuum it, and then we might not start right away, depending on resource availability, and we may take some time to finish, possibly considerable time, depending on the number and size of indexes and the availability of I/O resources. So actually the table might very plausibly be well above 400GB before we get done processing it, or potentially even more. I think that's not aggressive enough. But how much would we like to push that 64GB of bloat number down for a table of this size? I would argue that if we're vacuuming the table when it's only got 1GB of bloat, or 2GB of bloat, that seems excessive. Unless the system is very lightly loaded and has no long-running transactions at all, we're unlikely to be able to vacuum aggressively enough to keep a 320GB table at a size of 321GB or 322GB. Without testing or doing any research, I'm going to guess that a realistic number is probably in the range of 10-20GB of bloat. If the table activity is very light, we might be able to get it even lower, like say 5GB, but the costs ramp up very quickly as you push the vacuuming threshold down. Also, if the table accumulates X amount of bloat during the time it takes to run one vacuum, you can never succeed in limiting bloat to a value less than X (and probably more like 1.5*X or 2*X or something). So without actually trying anything, which I do think somebody should do and report results, my guess is that for a 320GB table, you'd like to multiply the vacuum frequency by a value somewhere between 3 and 10, and probably much closer to 3 than to 10. Maybe even less than 3. Not sure exactly. Like I say, I think someone needs to try some different workloads and database sizes and numbers of indexes, and try to get a feeling for what actually works well in practice. > If we want to stick with the simple formula, we should probably choose a > very high default, maybe 100 million, as you suggested earlier. > > However, it would be nice to have the visibility map updated more > frequently than every 100 million dead tuples. I wonder if this could be > decoupled from the vacuum process? Yes, but if a page has had any non-HOT updates, it can't become all-visible again without vacuum. If it has had only HOT updates, then a HOT-prune could make it all-visible. I don't think we do that currently, but I think in theory we could. -- Robert Haas EDB: http://www.enterprisedb.com
I didn't see a commitfest entry for this, so I created one to make sure we
don't lose track of this:
https://commitfest.postgresql.org/48/5046/
--
nathan
Le 18/06/2024 à 05:06, Nathan Bossart a écrit : > I didn't see a commitfest entry for this, so I created one to make sure we > don't lose track of this: > > https://commitfest.postgresql.org/48/5046/ > OK thanks! By the way, I wonder if there were any off-list discussions after Robert's conference at PGConf.dev (and I'm waiting for the video of the conf).
I've attached a new patch to show roughly what I think this new GUC should look like. I'm hoping this sparks more discussion, if nothing else. On Tue, Jun 18, 2024 at 12:36:42PM +0200, Frédéric Yhuel wrote: > By the way, I wonder if there were any off-list discussions after Robert's > conference at PGConf.dev (and I'm waiting for the video of the conf). I don't recall any discussions about this idea, but Robert did briefly mention it in his talk [0]. [0] https://www.youtube.com/watch?v=RfTD-Twpvac -- nathan
Attachment
On 8/7/24 23:39, Nathan Bossart wrote: > I've attached a new patch to show roughly what I think this new GUC should > look like. I'm hoping this sparks more discussion, if nothing else. > Thank you. FWIW, I would prefer a sub-linear growth, so maybe something like this: vacthresh = Min(vac_base_thresh + vac_scale_factor * reltuples, vac_base_thresh + vac_scale_factor * pow(reltuples, 0.7) * 100); This would give : * 386M (instead of 5.1 billion currently) for a 25.6 billion tuples table ; * 77M for a 2.56 billion tuples table (Robert's example) ; * 15M (instead of 51M currently) for a 256M tuples table ; * 3M (instead of 5M currently) for a 25.6M tuples table. The other advantage is that you don't need another GUC. > On Tue, Jun 18, 2024 at 12:36:42PM +0200, Frédéric Yhuel wrote: >> By the way, I wonder if there were any off-list discussions after Robert's >> conference at PGConf.dev (and I'm waiting for the video of the conf). > > I don't recall any discussions about this idea, but Robert did briefly > mention it in his talk [0]. > > [0] https://www.youtube.com/watch?v=RfTD-Twpvac > Very interesting, thanks!
Hi frederic.yhuel
> Thank you. FWIW, I would prefer a sub-linear growth, so maybe something
> like this
> vacthresh = Min(vac_base_thresh + vac_scale_factor * reltuples,
> vac_base_thresh + vac_scale_factor * pow(reltuples, 0.7) * 100);
> This would give :
> * 386M (instead of 5.1 billion currently) for a 25.6 billion tuples table ;
> * 77M for a 2.56 billion tuples table (Robert's example) ;
> * 15M (instead of 51M currently) for a 256M tuples table ;
> * 3M (instead of 5M currently) for a 25.6M tuples table.
> The other advantage is that you don't need another GUC.
Argee ,We just need to change the calculation formula,But I prefer this formula because it calculates a smoother value.
vacthresh = (float4) fmin(vac_base_thresh + vac_scale_factor * reltuples,vac_base_thresh + vac_scale_factor * log2(reltuples) * 10000);
or
> Thank you. FWIW, I would prefer a sub-linear growth, so maybe something
> like this
> vacthresh = Min(vac_base_thresh + vac_scale_factor * reltuples,
> vac_base_thresh + vac_scale_factor * pow(reltuples, 0.7) * 100);
> This would give :
> * 386M (instead of 5.1 billion currently) for a 25.6 billion tuples table ;
> * 77M for a 2.56 billion tuples table (Robert's example) ;
> * 15M (instead of 51M currently) for a 256M tuples table ;
> * 3M (instead of 5M currently) for a 25.6M tuples table.
> The other advantage is that you don't need another GUC.
Argee ,We just need to change the calculation formula,But I prefer this formula because it calculates a smoother value.
vacthresh = (float4) fmin(vac_base_thresh + vac_scale_factor * reltuples,vac_base_thresh + vac_scale_factor * log2(reltuples) * 10000);
or
vacthresh = (float4) fmin(vac_base_thresh + (vac_scale_factor * reltuples) , sqrt(1000.0 * reltuples));
Frédéric Yhuel <frederic.yhuel@dalibo.com> 于2024年8月12日周一 21:41写道:
On 8/7/24 23:39, Nathan Bossart wrote:
> I've attached a new patch to show roughly what I think this new GUC should
> look like. I'm hoping this sparks more discussion, if nothing else.
>
Thank you. FWIW, I would prefer a sub-linear growth, so maybe something
like this:
vacthresh = Min(vac_base_thresh + vac_scale_factor * reltuples,
vac_base_thresh + vac_scale_factor * pow(reltuples, 0.7) * 100);
This would give :
* 386M (instead of 5.1 billion currently) for a 25.6 billion tuples table ;
* 77M for a 2.56 billion tuples table (Robert's example) ;
* 15M (instead of 51M currently) for a 256M tuples table ;
* 3M (instead of 5M currently) for a 25.6M tuples table.
The other advantage is that you don't need another GUC.
> On Tue, Jun 18, 2024 at 12:36:42PM +0200, Frédéric Yhuel wrote:
>> By the way, I wonder if there were any off-list discussions after Robert's
>> conference at PGConf.dev (and I'm waiting for the video of the conf).
>
> I don't recall any discussions about this idea, but Robert did briefly
> mention it in his talk [0].
>
> [0] https://www.youtube.com/watch?v=RfTD-Twpvac
>
Very interesting, thanks!
On Wed, Nov 06, 2024 at 08:51:07PM +0800, wenhui qiu wrote: >> Thank you. FWIW, I would prefer a sub-linear growth, so maybe something >> like this > >> vacthresh = Min(vac_base_thresh + vac_scale_factor * reltuples, >> vac_base_thresh + vac_scale_factor * pow(reltuples, 0.7) * 100); > >> This would give : > >> * 386M (instead of 5.1 billion currently) for a 25.6 billion tuples > table ; >> * 77M for a 2.56 billion tuples table (Robert's example) ; >> * 15M (instead of 51M currently) for a 256M tuples table ; >> * 3M (instead of 5M currently) for a 25.6M tuples table. >> The other advantage is that you don't need another GUC. > Argee ,We just need to change the calculation formula,But I prefer this > formula because it calculates a smoother value. > > vacthresh = (float4) fmin(vac_base_thresh + vac_scale_factor * > reltuples,vac_base_thresh > + vac_scale_factor * log2(reltuples) * 10000); > or > vacthresh = (float4) fmin(vac_base_thresh + (vac_scale_factor * reltuples) > , sqrt(1000.0 * reltuples)); I apologize for the curt response, but I don't understand how we could decide which of these three complicated formulas to use, let alone how we could expect users to reason about the behavior. -- nathan
On Sat, Nov 09, 2024 at 10:08:51PM +0800, wenhui qiu wrote: > Sorry ,I forgot to explain the reason in my last email,In fact, I > submitted the patch to the community,(frederic.yhuel@dalibo.com) told me > there has a same idea ,so , > Let me explain those two formulas here,about ( vacthresh = (float4) > fmin(vac_base_thresh + (vac_scale_factor * reltuples), sqrt(1000.0 * > reltuples)); A few days ago, I was looking at the sql server > documentation and found that sql server has optimized the algorithm related > to updating statistics in the 2016 ,version,I think we can also learn from > the implementation method of sql server to optimize the problem of > automatic vacuum triggered by large tables,The Document link( > https://learn.microsoft.com/en-us/sql/relational-databases/statistics/statistics?view=sql-server-ver16 > ),about ( vacthresh = (float4) fmin(vac_base_thresh + vac_scale_factor * > reltuples,vac_base_thresh+ vac_scale_factor * log2(reltuples) * 10000);)I > came to the conclusion by trying to draw a function graph,I personally > think it is a smooth formula AFAICT the main advantage of these formulas is that you don't need another GUC, but they also makes the existing ones more difficult to configure. Plus, there's no way to go back to the existing behavior. -- nathan
Hi Nathan Bossart
> AFAICT the main advantage of these formulas is that you don't need another
> GUC, but they also makes the existing ones more difficult to configure.
> Plus, there's no way to go back to the existing behavior.
There is indeed this problem,But I think this formula should not be a linear relationship in the first place,SQL Server was realized and optimized eight years ago. I think we can definitely draw on the experience of SQL Server.Maybe many people are worried that frequent vacuum will affect io performance, but we can learn from the experience of SQL Server in vacuum analysis .
> AFAICT the main advantage of these formulas is that you don't need another
> GUC, but they also makes the existing ones more difficult to configure.
> Plus, there's no way to go back to the existing behavior.
There is indeed this problem,But I think this formula should not be a linear relationship in the first place,SQL Server was realized and optimized eight years ago. I think we can definitely draw on the experience of SQL Server.Maybe many people are worried that frequent vacuum will affect io performance, but we can learn from the experience of SQL Server in vacuum analysis .
Nathan Bossart <nathandbossart@gmail.com> 于2024年11月9日周六 23:59写道:
On Sat, Nov 09, 2024 at 10:08:51PM +0800, wenhui qiu wrote:
> Sorry ,I forgot to explain the reason in my last email,In fact, I
> submitted the patch to the community,(frederic.yhuel@dalibo.com) told me
> there has a same idea ,so ,
> Let me explain those two formulas here,about ( vacthresh = (float4)
> fmin(vac_base_thresh + (vac_scale_factor * reltuples), sqrt(1000.0 *
> reltuples)); A few days ago, I was looking at the sql server
> documentation and found that sql server has optimized the algorithm related
> to updating statistics in the 2016 ,version,I think we can also learn from
> the implementation method of sql server to optimize the problem of
> automatic vacuum triggered by large tables,The Document link(
> https://learn.microsoft.com/en-us/sql/relational-databases/statistics/statistics?view=sql-server-ver16
> ),about ( vacthresh = (float4) fmin(vac_base_thresh + vac_scale_factor *
> reltuples,vac_base_thresh+ vac_scale_factor * log2(reltuples) * 10000);)I
> came to the conclusion by trying to draw a function graph,I personally
> think it is a smooth formula
AFAICT the main advantage of these formulas is that you don't need another
GUC, but they also makes the existing ones more difficult to configure.
Plus, there's no way to go back to the existing behavior.
--
nathan
On 11/9/24 16:59, Nathan Bossart wrote: > AFAICT the main advantage of these formulas is that you don't need another > GUC, but they also makes the existing ones more difficult to configure. I wouldn't say that's the main advantage. It doesn't seem very clean to me to cap to a fixed value. Because you could take Robert's demonstration with a bigger table, and come to the same conclusion: Let's compare the current situation to the situation post-Nathan's-patch with a cap of 100M. Consider a table 100 times larger than the one of Robert's previous example, so pgbench scale factor 2_560_000, size on disk 32TB. Currently, that table will be vacuumed for bloat when the number of dead tuples exceeds 20% of the table size, because that's the default value of autovacuum_vacuum_scale_factor. The table has 256 billion tuples, so that means that we're going to vacuum it when there are more than 51 billion dead tuples. Post-patch, we will vacuum when we have 100 million dead tuples. Suppose a uniform workload that slowly updates rows in the table. If we were previously autovacuuming the table once per day (1440 minutes) we're now going to try to vacuum it almost every minute (1440 minutes / 512 = 168 seconds). (compare with every 55 min with my formula) Of course, this a theoretical example that is probably unrealistic. I don't know, really. I don't know if Robert's example was realistic in the first place. In any case, we should do the tests that Robert suggested and/or come up with a good mathematical model, because we are in the dark at the moment. > Plus, there's no way to go back to the existing behavior. I think we should indeed provide a retro-compatible behaviour (so maybe another GUC after all).
HI
> In any case, we should do the tests that Robert suggested and/or come up
> with a good mathematical model, because we are in the dark at the moment.
I think SQL Server has given us great inspiration
>I think we should indeed provide a retro-compatible behaviour (so maybe
> another GUC after all).I am ready to implement a new guc parameter,Enable database administrators to configure appropriate calculation methods(The default value is the original calculation formula)
> In any case, we should do the tests that Robert suggested and/or come up
> with a good mathematical model, because we are in the dark at the moment.
I think SQL Server has given us great inspiration
>I think we should indeed provide a retro-compatible behaviour (so maybe
> another GUC after all).I am ready to implement a new guc parameter,Enable database administrators to configure appropriate calculation methods(The default value is the original calculation formula)
Frédéric Yhuel <frederic.yhuel@dalibo.com> 于2024年11月13日周三 18:03写道:
On 11/9/24 16:59, Nathan Bossart wrote:
> AFAICT the main advantage of these formulas is that you don't need another
> GUC, but they also makes the existing ones more difficult to configure.
I wouldn't say that's the main advantage. It doesn't seem very clean to
me to cap to a fixed value. Because you could take Robert's
demonstration with a bigger table, and come to the same conclusion:
Let's compare the current situation to the situation post-Nathan's-patch
with a cap of 100M. Consider a table 100 times larger than the one of
Robert's previous example, so pgbench scale factor 2_560_000, size on
disk 32TB.
Currently, that table will be vacuumed for bloat when the number of
dead tuples exceeds 20% of the table size, because that's the default
value of autovacuum_vacuum_scale_factor. The table has 256 billion
tuples, so that means that we're going to vacuum it when there are
more than 51 billion dead tuples. Post-patch, we will vacuum when we
have 100 million dead tuples. Suppose a uniform workload that slowly
updates rows in the table. If we were previously autovacuuming the
table once per day (1440 minutes) we're now going to try to vacuum it
almost every minute (1440 minutes / 512 = 168 seconds).
(compare with every 55 min with my formula)
Of course, this a theoretical example that is probably unrealistic. I
don't know, really. I don't know if Robert's example was realistic in
the first place.
In any case, we should do the tests that Robert suggested and/or come up
with a good mathematical model, because we are in the dark at the moment.
> Plus, there's no way to go back to the existing behavior.
I think we should indeed provide a retro-compatible behaviour (so maybe
another GUC after all).
On 1/7/25 23:57, Nathan Bossart wrote: > Here is a rebased patch for cfbot. AFAICT we are still pretty far from > consensus on which approach to take, unfortunately. > For what it's worth, although I would have preferred the sub-linear growth thing, I'd much rather have this than nothing. And I have to admit that the proposed formulas were either too convoluted or wrong. This very patch is more straightforward. Please let me know if I can help and how.
On Wed, Jan 8, 2025 at 8:01 PM Nathan Bossart <nathandbossart@gmail.com> wrote:
On Wed, Jan 08, 2025 at 02:48:10PM +0100, Frédéric Yhuel wrote:
> For what it's worth, although I would have preferred the sub-linear growth
> thing, I'd much rather have this than nothing.
+1, this is how I feel, too. But I also don't want to add something that
folks won't find useful.
> And I have to admit that the proposed formulas were either too convoluted or
> wrong.
>
> This very patch is more straightforward. Please let me know if I can help
> and how.
I read through the thread from the top, and it does seem like there is
reasonably strong support for the hard cap. Upon a closer review of the
patch, I noticed that the relopt was defined such that you couldn't disable
autovacuum_max_threshold on a per-table basis, so I fixed that in v4.
--
nathan
nathan,
Please also provide the tests on the new parameter you want to introduce.
Best,
vini
On Wed, Jan 8, 2025 at 3:01 PM Nathan Bossart <nathandbossart@gmail.com> wrote: > > On Wed, Jan 08, 2025 at 02:48:10PM +0100, Frédéric Yhuel wrote: > > For what it's worth, although I would have preferred the sub-linear growth > > thing, I'd much rather have this than nothing. > > +1, this is how I feel, too. But I also don't want to add something that > folks won't find useful. > > > And I have to admit that the proposed formulas were either too convoluted or > > wrong. > > > > This very patch is more straightforward. Please let me know if I can help > > and how. > > I read through the thread from the top, and it does seem like there is > reasonably strong support for the hard cap. Upon a closer review of the > patch, I noticed that the relopt was defined such that you couldn't disable > autovacuum_max_threshold on a per-table basis, so I fixed that in v4. > To be frank, this patch feels like a solution in search of a problem, and as I read back through the thread, it isn't clear what problem this is intended to fix. There is some talk of "simplifying" autovacuum configuration, but some noted that we already have a rather complex set of GUCs to deal with, and adding another one, along with more math, into the equation doesn't seem simpler to mel I'd like to think the bar should be that the problem should be clear. So what is the problem? Is the patch supposed to help with wraparound prevention? autovac_freeze_max_age already covers that, and when it doesn't vacuum_failsafe_age helps out. A couple of people mentioned issues around hitting the index wall when vacuuming large tables, but we believe that problem is mostly resolved due to radix based tid storage, so this doesn't solve that. (To the degree you don't think v17 has baked into enough production workloads to be sure, I'd agree, but that's also an argument against doing more work that might not be needed) Maybe the hope is that this setting will cause vacuum to run more often to help ameliorate i/o work from freeze vacuums kicking in, but I suspect that Melanie's nearby work on eager vacuuming is a smarter solution towards this problem (warning, it also may want to add more gucs), so I think we're not solving that, and in fact might be undercutting it. I guess that means this is supposed to help with bloat management? but only on large tables? I guess because you run vacuums more often? Except that the adages of running vacuums more often don't apply as cleanly to large tables, because those tables typically come with large indexes, and while we have a lot of machinery in place to help with repeated scans of the heap, that same machinery doesn't exist for scanning the indexes, which gives you sort of an exponential curve around vacuum times as table size (but actually index size) grows larger. On the upside, this does mean we're less likely to see a 50x boost in vacuums on large tables that some seemed concerned about, but on the downside its because we're probably going to increase the probability of vacuum worker starvation. But getting back to goals, if your goal is to help with bloat management, trying to tie that to a number that doesn't cleanly map to the meta information of the table in question is a poor way to do it. Meaning, to the degree that you are skeptical that vacuuming based on 20% of the rows of a table might not really be 20% of the size of the table, it's certainly going to be a closer map than 100million rows in a n number of tables of unknown (but presumably greater than 500million?) numbers of rows of unknown sizes. And again, we have a means to tackle these bloat cases already; lowering vacuum_scale_factor. This isn't to say the system is perfect; I do think there are some fundamental issues that need addressing, but adding this guc just feels a little less baked than usual. Robert Treat https://xzilla.net
Committed. -- nathan