Thread: Proposal: Filter irrelevant change before reassemble transactions during logical decoding
Proposal: Filter irrelevant change before reassemble transactions during logical decoding
From
li jie
Date:
Hi,
During logical decoding, if there is a large write transaction, some
spill files will be written to disk,
depending on the setting of max_changes_in_memory.
This behavior can effectively avoid OOM, but if the transaction
generates a lot of change before commit,
a large number of files may fill the disk. For example, you can update
a TB-level table.
Of course, this is also inevitable.
But I found an inelegant phenomenon. If the updated large table is not
published, its changes will also
be written with a large number of spill files. Look at an example below:
publisher:
```
create table tbl_pub(id int, val1 text, val2 text,val3 text);
create table tbl_t1(id int, val1 text, val2 text,val3 text);
CREATE PUBLICATION mypub FOR TABLE public.tbl_pub;
```
subscriber:
```
create table tbl_pub(id int, val1 text, val2 text,val3 text);
create table tbl_t1(id int, val1 text, val2 text,val3 text);
CREATE SUBSCRIPTION mysub CONNECTION 'host=127.0.0.1 port=5432
user=postgres dbname=postgres' PUBLICATION mypub;
```
publisher:
```
begin;
insert into tbl_t1 select i,repeat('xyzzy', i),repeat('abcba',
i),repeat('dfds', i) from generate_series(0,999999) i;
```
Later you will see a large number of spill files in the
"/$PGDATA/pg_replslot/mysub/" directory.
```
$ll -sh
total 4.5G
4.0K -rw------- 1 postgres postgres 200 Nov 30 09:24 state
17M -rw------- 1 postgres postgres 17M Nov 30 08:22 xid-750-lsn-0-10000000.spill
12M -rw------- 1 postgres postgres 12M Nov 30 08:20 xid-750-lsn-0-1000000.spill
17M -rw------- 1 postgres postgres 17M Nov 30 08:23 xid-750-lsn-0-11000000.spill
......
```
We can see that table tbl_t1 is not published in mypub. It is also not
sent downstream because it is subscribed.
After the transaction is reorganized, the pgoutput decoding plug-in
filters out these change of unpublished relation
when sending logical changes. see function pgoutput_change.
Above all, if after constructing a change and before queuing a change
into a transaction, we filter out unpublished
relation-related changes, will it make logical decoding less laborious
and avoid disk growth as much as possible?
This is just an immature idea. I haven't started to implement it yet.
Maybe it was designed this way because there
are key factors that I didn't consider. So I want to hear everyone's
opinions, especially the designers of logic decoding.
Re: Proposal: Filter irrelevant change before reassemble transactions during logical decoding
From
li jie
Date:
> This is just an immature idea. I haven't started to implement it yet.
> Maybe it was designed this way because there
> are key factors that I didn't consider. So I want to hear everyone's
> opinions, especially the designers of logic decoding.
Attached is the patch I used to implement this optimization.
The main designs are as follows:
1. Added a callback LogicalDecodeFilterByRelCB for the output plugin.
2. Added this callback function pgoutput_table_filter for the pgoutput plugin.
Its main implementation is based on the table filter in the
pgoutput_change function.
3. After constructing a change and before Queue a change into a transaction,
use RelidByRelfilenumber to obtain the relation associated with the change,
just like obtaining the relation in the ReorderBufferProcessTXN function.
4. Relation may be a toast, and there is no good way to get its real
table relation
based on toast relation. Here, I get the real table oid through
toast relname, and
then get the real table relation.
5. This filtering takes into account INSERT/UPDATE/INSERT. Other
changes have not
been considered yet and can be expanded in the future.
6. The table filter in pgoutput_change and the get relation in
ReorderBufferProcessTXN
can be deleted. This has not been done yet. This is the next step.
Sincerely look forward to your feedback.
Regards, lijie
Attachment
Re: Proposal: Filter irrelevant change before reassemble transactions during logical decoding
From
Amit Kapila
Date:
On Fri, Dec 1, 2023 at 1:55 PM li jie <ggysxcq@gmail.com> wrote: > > > This is just an immature idea. I haven't started to implement it yet. > > Maybe it was designed this way because there > > are key factors that I didn't consider. So I want to hear everyone's > > opinions, especially the designers of logic decoding. > > Attached is the patch I used to implement this optimization. > The main designs are as follows: > 1. Added a callback LogicalDecodeFilterByRelCB for the output plugin. > > 2. Added this callback function pgoutput_table_filter for the pgoutput plugin. > Its main implementation is based on the table filter in the > pgoutput_change function. > > 3. After constructing a change and before Queue a change into a transaction, > use RelidByRelfilenumber to obtain the relation associated with the change, > just like obtaining the relation in the ReorderBufferProcessTXN function. > > 4. Relation may be a toast, and there is no good way to get its real > table relation > based on toast relation. Here, I get the real table oid through > toast relname, and > then get the real table relation. > This may be helpful for the case you have mentioned but how about cases where there is nothing to filter by relation? It will add overhead related to the transaction start/end and others for each change. Currently, we do that just once for all the changes that need to be processed. I wonder why the spilling can't be avoided with GUC logical_decoding_work_mem? -- With Regards, Amit Kapila.
Re: Proposal: Filter irrelevant change before reassemble transactions during logical decoding
From
li jie
Date:
> > This may be helpful for the case you have mentioned but how about > cases where there is nothing to filter by relation? You can see the complete antecedent in the email [1]. Relation that has not been published will also generate changes and put them into the entire transaction group, which will increase invalid memory or disk space. > It will add > overhead related to the transaction start/end and others for each > change. Currently, we do that just once for all the changes that need > to be processed. Yes, it will only be processed once at present. It is done when applying each change when the transaction is committed. This patch hopes to advance it to the time when constructing the change, and determines the change queue into a based on whether the relation is published. > I wonder why the spilling can't be avoided with GUC > logical_decoding_work_mem? Of course you can, but this will only convert disk space into memory space. For details, please see the case in Email [1]. Regards, lijie
Re: Proposal: Filter irrelevant change before reassemble transactions during logical decoding
From
li jie
Date:
> This may be helpful for the case you have mentioned but how about > cases where there is nothing to filter by relation? You can see the complete antecedent in the email [1]. Relation that has not been published will also generate changes and put them into the entire transaction group, which will increase invalid memory or disk space. > It will add > overhead related to the transaction start/end and others for each > change. Currently, we do that just once for all the changes that need > to be processed. Yes, it will only be processed once at present. It is done when applying each change when the transaction is committed. This patch hopes to advance it to the time when constructing the change, and determines the change queue into a based on whether the relation is published. > I wonder why the spilling can't be avoided with GUC > logical_decoding_work_mem? Of course you can, but this will only convert disk space into memory space. For details, please see the case in Email [1]. [1] https://www.postgresql.org/message-id/CAGfChW51P944nM5h0HTV9HistvVfwBxNaMt_s-OZ9t%3DuXz%2BZbg%40mail.gmail.com Regards, lijie Amit Kapila <amit.kapila16@gmail.com> 于2023年12月2日周六 12:11写道: > > On Fri, Dec 1, 2023 at 1:55 PM li jie <ggysxcq@gmail.com> wrote: > > > > > This is just an immature idea. I haven't started to implement it yet. > > > Maybe it was designed this way because there > > > are key factors that I didn't consider. So I want to hear everyone's > > > opinions, especially the designers of logic decoding. > > > > Attached is the patch I used to implement this optimization. > > The main designs are as follows: > > 1. Added a callback LogicalDecodeFilterByRelCB for the output plugin. > > > > 2. Added this callback function pgoutput_table_filter for the pgoutput plugin. > > Its main implementation is based on the table filter in the > > pgoutput_change function. > > > > 3. After constructing a change and before Queue a change into a transaction, > > use RelidByRelfilenumber to obtain the relation associated with the change, > > just like obtaining the relation in the ReorderBufferProcessTXN function. > > > > 4. Relation may be a toast, and there is no good way to get its real > > table relation > > based on toast relation. Here, I get the real table oid through > > toast relname, and > > then get the real table relation. > > > > This may be helpful for the case you have mentioned but how about > cases where there is nothing to filter by relation? It will add > overhead related to the transaction start/end and others for each > change. Currently, we do that just once for all the changes that need > to be processed. I wonder why the spilling can't be avoided with GUC > logical_decoding_work_mem? > > -- > With Regards, > Amit Kapila.
Re: Proposal: Filter irrelevant change before reassemble transactions during logical decoding
From
Ajin Cherian
Date:
Of course you can, but this will only convert disk space into memory space.
For details, please see the case in Email [1].
[1] https://www.postgresql.org/message-id/CAGfChW51P944nM5h0HTV9HistvVfwBxNaMt_s-OZ9t%3DuXz%2BZbg%40mail.gmail.com
Regards, lijie
Hi lijie,
Overall, I think the patch is a good improvement. Some comments from first run through of patch:
1. The patch no longer applies cleanly, please rebase.
2. While testing the patch, I saw something strange. If I try to truncate a table that is published. I still see the message:
2024-03-18 22:25:51.243 EDT [29385] LOG: logical filter change by table pg_class
2024-03-18 22:25:51.243 EDT [29385] LOG: logical filter change by table pg_class
This gives the impression that the truncate operation on the published table has been filtered but it hasn't. Also the log message needs to be reworded. Maybe, "Logical filtering change by non-published table <relation_name>"
3. Below code:
@@ -1201,11 +1343,14 @@ DecodeMultiInsert(LogicalDecodingContext *ctx, XLogRecordBuffer *buf)
+
+ if (FilterByTable(ctx, change))
+ continue;;
@@ -1201,11 +1343,14 @@ DecodeMultiInsert(LogicalDecodingContext *ctx, XLogRecordBuffer *buf)
+
+ if (FilterByTable(ctx, change))
+ continue;;
extra semi-colon after continue.
4. I am not sure if this is possible, but is there a way to avoid the overhead in the patch if the publication publishes "ALL TABLES"?
5. In function: pgoutput_table_filter() - this code appears to be filtering out not just unpublished tables but also applying row based filters on published tables as well. Is this really within the scope of the feature?
regards,
Ajin Cherian
Fujitsu Australia
RE: Proposal: Filter irrelevant change before reassemble transactions during logical decoding
From
"Hayato Kuroda (Fujitsu)"
Date:
Dear Li,
Thanks for proposing and sharing the PoC. Here are my high-level comments.
1.
What if ALTER PUBLICATION ... ADD is executed in parallel?
Should we publish added tables if the altering is done before the transaction is
committed? The current patch seems unable to do so because changes for added
tables have not been queued at COMMIT.
If we should not publish such tables, why?
2.
This patch could not apply as-is. Please rebase.
3. FilterByTable()
```
+ if (ctx->callbacks.filter_by_origin_cb == NULL)
+ return false;
```
filter_by_table_cb should be checked instead of filter_by_origin_cb.
Current patch crashes if the filter_by_table_cb() is not implemented.
4. DecodeSpecConfirm()
```
+ if (FilterByTable(ctx, change))
+ return;
+
```
I'm not sure it is needed. Can you explain the reason why you added?
5. FilterByTable
```
+ switch (change->action)
+ {
+ /* intentionally fall through */
+ case REORDER_BUFFER_CHANGE_INSERT:
+ case REORDER_BUFFER_CHANGE_UPDATE:
+ case REORDER_BUFFER_CHANGE_DELETE:
+ break;
+ default:
+ return false;
+ }
```
IIUC, REORDER_BUFFER_CHANGE_TRUNCATE also targes the user table, so I think
it should be accepted. Thought?
6.
I got strange errors when I tested the feature. I thought this implied there were
bugs in your patch.
1. implemented no-op filter atop test_decoding like attached
2. ran `make check` for test_decoding modle
3. some tests failed. Note that "filter" was a test added by me.
regression.diffs was also attached.
```
not ok 1 - ddl 970 ms
ok 2 - xact 36 ms
not ok 3 - rewrite 525 ms
not ok 4 - toast 736 ms
ok 5 - permissions 50 ms
ok 6 - decoding_in_xact 39 ms
not ok 7 - decoding_into_rel 57 ms
ok 8 - binary 21 ms
not ok 9 - prepared 33 ms
ok 10 - replorigin 93 ms
ok 11 - time 25 ms
ok 12 - messages 47 ms
ok 13 - spill 8063 ms
ok 14 - slot 124 ms
ok 15 - truncate 37 ms
not ok 16 - stream 60 ms
ok 17 - stats 157 ms
ok 18 - twophase 122 ms
not ok 19 - twophase_stream 57 ms
not ok 20 - filter 20 ms
```
Currently I'm not 100% sure the reason, but I think it may read the latest system
catalog even if ALTER SUBSCRIPTION is executed after changes.
In below example, an attribute is altered text->somenum, after inserting data.
But get_changes() outputs as somenum.
```
BEGIN
- table public.replication_example: INSERT: id[integer]:1 somedata[integer]:1 text[character varying]:'1'
- table public.replication_example: INSERT: id[integer]:2 somedata[integer]:1 text[character varying]:'2'
+ table public.replication_example: INSERT: id[integer]:1 somedata[integer]:1 somenum[character varying]:'1'
+ table public.replication_example: INSERT: id[integer]:2 somedata[integer]:1 somenum[character varying]:'2'
COMMIT
```
Also, if the relfilenuber of the relation is changed, an ERROR is raised.
```
SELECT data FROM pg_logical_slot_get_changes('regression_slot', NULL, NULL, 'include-xids', '0', 'skip-empty-xacts',
'1');
- data
-----------------------------------------------------------------------------
- BEGIN
- table public.tr_pkey: INSERT: id2[integer]:2 data[integer]:1 id[integer]:2
- COMMIT
- BEGIN
- table public.tr_pkey: DELETE: id[integer]:1
- table public.tr_pkey: DELETE: id[integer]:2
- COMMIT
-(7 rows)
-
+ERROR: could not map filenumber "base/16384/16397" to relation OID
```
Best Regards,
Hayato Kuroda
FUJITSU LIMITED
https://www.fujitsu.com/
Attachment
Re: Proposal: Filter irrelevant change before reassemble transactions during logical decoding
From
Ajin Cherian
Date:
On Tue, Mar 19, 2024 at 1:49 PM Ajin Cherian <itsajin@gmail.com> wrote:
Of course you can, but this will only convert disk space into memory space.
For details, please see the case in Email [1].
[1] https://www.postgresql.org/message-id/CAGfChW51P944nM5h0HTV9HistvVfwBxNaMt_s-OZ9t%3DuXz%2BZbg%40mail.gmail.com
Regards, lijie
In some testing, I see a crash:
(gdb) bt
#0 0x00007fa5bcbfd277 in raise () from /lib64/libc.so.6
#1 0x00007fa5bcbfe968 in abort () from /lib64/libc.so.6
#2 0x00000000009e0940 in ExceptionalCondition (
conditionName=conditionName@entry=0x7fa5ab8b9842 "RelationSyncCache != NULL",
fileName=fileName@entry=0x7fa5ab8b9820 "pgoutput.c", lineNumber=lineNumber@entry=1991)
at assert.c:66
#3 0x00007fa5ab8b7804 in get_rel_sync_entry (data=data@entry=0x2492288,
relation=relation@entry=0x7fa5be30a768) at pgoutput.c:1991
#4 0x00007fa5ab8b7cda in pgoutput_table_filter (ctx=<optimized out>, relation=0x7fa5be30a768,
change=0x24c5c20) at pgoutput.c:1671
#5 0x0000000000813761 in filter_by_table_cb_wrapper (ctx=ctx@entry=0x2491fd0,
relation=relation@entry=0x7fa5be30a768, change=change@entry=0x24c5c20) at logical.c:1268
#6 0x000000000080e20f in FilterByTable (ctx=ctx@entry=0x2491fd0, change=change@entry=0x24c5c20)
at decode.c:690
#7 0x000000000080e8e3 in DecodeInsert (ctx=ctx@entry=0x2491fd0, buf=buf@entry=0x7fff0db92550)
at decode.c:1070
#8 0x000000000080f43d in heap_decode (ctx=ctx@entry=0x2491fd0, buf=buf@entry=0x7fff0db92550)
at decode.c:485
#9 0x000000000080eca6 in LogicalDecodingProcessRecord (ctx=ctx@entry=0x2491fd0, record=0x2492368)
at decode.c:118
#10 0x000000000081338f in DecodingContextFindStartpoint (ctx=ctx@entry=0x2491fd0) at logical.c:672
#11 0x000000000083c650 in CreateReplicationSlot (cmd=cmd@entry=0x2490970) at walsender.c:1323
#12 0x000000000083fd48 in exec_replication_command (
cmd_string=cmd_string@entry=0x239c880 "CREATE_REPLICATION_SLOT \"pg_16387_sync_16384_7371301304766135621\" LOGICAL pgoutput (SNAPSHOT 'use')") at walsender.c:2116
(gdb) bt
#0 0x00007fa5bcbfd277 in raise () from /lib64/libc.so.6
#1 0x00007fa5bcbfe968 in abort () from /lib64/libc.so.6
#2 0x00000000009e0940 in ExceptionalCondition (
conditionName=conditionName@entry=0x7fa5ab8b9842 "RelationSyncCache != NULL",
fileName=fileName@entry=0x7fa5ab8b9820 "pgoutput.c", lineNumber=lineNumber@entry=1991)
at assert.c:66
#3 0x00007fa5ab8b7804 in get_rel_sync_entry (data=data@entry=0x2492288,
relation=relation@entry=0x7fa5be30a768) at pgoutput.c:1991
#4 0x00007fa5ab8b7cda in pgoutput_table_filter (ctx=<optimized out>, relation=0x7fa5be30a768,
change=0x24c5c20) at pgoutput.c:1671
#5 0x0000000000813761 in filter_by_table_cb_wrapper (ctx=ctx@entry=0x2491fd0,
relation=relation@entry=0x7fa5be30a768, change=change@entry=0x24c5c20) at logical.c:1268
#6 0x000000000080e20f in FilterByTable (ctx=ctx@entry=0x2491fd0, change=change@entry=0x24c5c20)
at decode.c:690
#7 0x000000000080e8e3 in DecodeInsert (ctx=ctx@entry=0x2491fd0, buf=buf@entry=0x7fff0db92550)
at decode.c:1070
#8 0x000000000080f43d in heap_decode (ctx=ctx@entry=0x2491fd0, buf=buf@entry=0x7fff0db92550)
at decode.c:485
#9 0x000000000080eca6 in LogicalDecodingProcessRecord (ctx=ctx@entry=0x2491fd0, record=0x2492368)
at decode.c:118
#10 0x000000000081338f in DecodingContextFindStartpoint (ctx=ctx@entry=0x2491fd0) at logical.c:672
#11 0x000000000083c650 in CreateReplicationSlot (cmd=cmd@entry=0x2490970) at walsender.c:1323
#12 0x000000000083fd48 in exec_replication_command (
cmd_string=cmd_string@entry=0x239c880 "CREATE_REPLICATION_SLOT \"pg_16387_sync_16384_7371301304766135621\" LOGICAL pgoutput (SNAPSHOT 'use')") at walsender.c:2116
The reason for the crash is that the RelationSyncCache was NULL prior to reaching a consistent point.
Hi li jie, I see that you created a new thread with an updated version of this patch [1]. I used that patch and addressed the crash seen above, rebased the patch and addressed a few other comments.
Hi li jie, I see that you created a new thread with an updated version of this patch [1]. I used that patch and addressed the crash seen above, rebased the patch and addressed a few other comments.
I'm happy to help you with this patch and address comments if you are not available.
regards,
Ajin Cherian
Fujitsu Australia
Attachment
Re: Proposal: Filter irrelevant change before reassemble transactions during logical decoding
From
Ajin Cherian
Date:
On Wed, May 22, 2024 at 2:17 PM Ajin Cherian <itsajin@gmail.com> wrote:
The reason for the crash is that the RelationSyncCache was NULL prior to reaching a consistent point.
Hi li jie, I see that you created a new thread with an updated version of this patch [1]. I used that patch and addressed the crash seen above, rebased the patch and addressed a few other comments.I'm happy to help you with this patch and address comments if you are not available.regards,Ajin CherianFujitsu Australia
I was discussing this with Kuroda-san who made a patch to add a table filter with test_decoding plugin. The filter does nothing, just returns false( doesn't filter anything) and I see that 8 test_decoding tests fail. In my analysis, I could see that some of the failures were because the new filter logic was accessing the relation cache using the latest snapshot for relids which was getting incorrect relation information while decoding attribute values.
for eg:
CREATE TABLE replication_example(id SERIAL PRIMARY KEY, somedata int, text varchar(120));
BEGIN;
INSERT INTO replication_example(somedata, text) VALUES (1, 1);
INSERT INTO replication_example(somedata, text) VALUES (1, 2);
COMMIT;
ALTER TABLE replication_example RENAME COLUMN text TO somenum;
SELECT data FROM pg_logical_slot_get_changes('regression_slot', NULL, NULL, 'include-xids', '0', 'skip-empty-xacts', '1');
Here, after decoding, the changes for the INSERT, were reflecting the new column name (somenum) which was altered in a later transaction. This is because the new Filterby Table() logic was getting relcache with latest snapshot and does not use a historic snapshot like logical decoding should be doing. This is because the changes are at the decode.c level and not the reorderbuffer level and does not have access to the txn from the reorderbuffer. This problem could be fixed by invalidating the cache in the FilterByTable() logic, but this does not solve other problems like the table name itself is changed in a later transaction. I think the patch has a fundamental problem that the table filter logic does not respect the snapshot of the transaction being decoded. The historic snapshot is currently only set up when the actual changes are committed or streamed at ReorderBufferProcessTXN().
If the purpose of the patch is to filter out unnecessary changes prior to actual decode, then it will use an invalid snapshot and have lots of problems. Otherwise this logic has to be moved to the reorderbuffer level and there will be a big overhead of extracting reorderbuffer while each change is queued in memory/disk. regards,
regards,
for eg:
CREATE TABLE replication_example(id SERIAL PRIMARY KEY, somedata int, text varchar(120));
BEGIN;
INSERT INTO replication_example(somedata, text) VALUES (1, 1);
INSERT INTO replication_example(somedata, text) VALUES (1, 2);
COMMIT;
ALTER TABLE replication_example RENAME COLUMN text TO somenum;
SELECT data FROM pg_logical_slot_get_changes('regression_slot', NULL, NULL, 'include-xids', '0', 'skip-empty-xacts', '1');
Here, after decoding, the changes for the INSERT, were reflecting the new column name (somenum) which was altered in a later transaction. This is because the new Filterby Table() logic was getting relcache with latest snapshot and does not use a historic snapshot like logical decoding should be doing. This is because the changes are at the decode.c level and not the reorderbuffer level and does not have access to the txn from the reorderbuffer. This problem could be fixed by invalidating the cache in the FilterByTable() logic, but this does not solve other problems like the table name itself is changed in a later transaction. I think the patch has a fundamental problem that the table filter logic does not respect the snapshot of the transaction being decoded. The historic snapshot is currently only set up when the actual changes are committed or streamed at ReorderBufferProcessTXN().
If the purpose of the patch is to filter out unnecessary changes prior to actual decode, then it will use an invalid snapshot and have lots of problems. Otherwise this logic has to be moved to the reorderbuffer level and there will be a big overhead of extracting reorderbuffer while each change is queued in memory/disk.
Ajin Cherian
Fujitsu Australia
Re: Proposal: Filter irrelevant change before reassemble transactions during logical decoding
From
Peter Smith
Date:
Hi Ajin, Some review comments for patch v12-0001. ====== Commit message 1. Track transactions which have snapshot changes with a new flag RBTXN_HAS_SNAPSHOT_CHANGES ~ The commit message only says *what* it does, but not *why* this patch even exists. TBH, I don't understand why this patch needs to be separated from your patch 0002, because 0001 makes no independent use of the flag, nor is it separately tested. Anyway, if it is going to remain separated then IMO at least the the message should explain the intended purpose e.g. why the subsequent patches require this flagged info and how they will use it. ====== src/include/replication/reorderbuffer.h 2. +/* Does this transaction have snapshot changes? */ +#define rbtxn_has_snapshot_changes(txn) \ +( \ + ((txn)->txn_flags & RBTXN_HAS_SNAPSHOT_CHANGES) != 0 \ +) + Is the below wording maybe a more plain way to say that: /* Does this transaction make changes to the current snapshot? */ ====== Kind Regards, Peter Smith. Fujitsu Australia
Re: Proposal: Filter irrelevant change before reassemble transactions during logical decoding
From
Peter Smith
Date:
Hi Ajin,
Some review comments for the patch v13-0002.
======
src/backend/replication/logical/reorderbuffer.c
1. GENERAL
I felt that a summary/overview of how all this filter/cache logic
works should be given in the large file header comment at the top of
this file. There may be some overlap with comments that are already in
the "RelFileLocator filtering" section.
~~~
ReorderBufferRelFileLocatorEnt:
2.
+/* entry for hash table we use to track if the relation can be filtered */
+typedef struct ReorderBufferRelFileLocatorEnt
/* Hash table entry used to determine if the relation can be filtered. */
~~~
ReorderBufferQueueChange:
3.
+ /*
+ * If we're not filtering and we've crossed the change threshold,
+ * attempt to filter again
+ */
SUGGESTION
If filtering was suspended, and we've crossed the change threshold
then reenable filtering.
~~~
ReorderBufferGetRelation:
4.
+static Relation
+ReorderBufferGetRelation(ReorderBuffer *rb, RelFileLocator *rlocator,
+ bool has_tuple)
Would a better name be ReorderBufferGetRelationForDecoding(). Yeah,
it's a bit long but perhaps it explains the context/purpose better.
~~~
5.
+ if (filterable)
+ {
+ RelationClose(relation);
+ return NULL;
+ }
I wonder if some small descriptive comment would be helpful here just
to say we are returning NULL to indicate that this relation is not
needed and yada yada...
~~~
RelFileLocatorCacheInvalidateCallback:
6.
+ /* slightly inefficient algorithm but not performance critical path */
+ while ((entry = (ReorderBufferRelFileLocatorEnt *)
hash_seq_search(&status)) != NULL)
+ {
+ /*
+ * If relid is InvalidOid, signaling a complete reset, we must remove
+ * all entries, otherwise just remove the specific relation's entry.
+ * Always remove negative cache entries.
+ */
+ if (relid == InvalidOid || /* complete reset */
+ entry->relid == InvalidOid || /* negative cache entry */
+ entry->relid == relid) /* individual flushed relation */
6a.
Maybe uppercase that 1st comment.
~
6b.
It seems a bit unusual to be referring to "negative cache entries". I
thought it should be described in terms of InvalidOid since that is
what it is using in the condition.
~
6c.
If the relid parameter can take special values like "If relid is
InvalidOid, signaling a complete reset" that sounds like the kind of
thing that should be documented in the function comment.
~~~
ReorderBufferFilterByRelFileLocator
7.
Despite the extra indenting required, I wondered if the logic may be
easier to read (e.g. it shows the association of the
rb->can_filter_change and entry->filterable more clearly) if this is
refactored slightly by sharing a single common return like below:
BEFORE
...
+ key.reltablespace = rlocator->spcOid;
+ key.relfilenumber = rlocator->relNumber;
+ entry = hash_search(RelFileLocatorFilterCache, &key, HASH_ENTER, &found);
+
+ if (found)
+ {
+ rb->can_filter_change = entry->filterable;
+ return entry->filterable;
+ }
...
+ rb->can_filter_change = entry->filterable;
...
+ return entry->filterable;
+}
AFTER
...
+ key.reltablespace = rlocator->spcOid;
+ key.relfilenumber = rlocator->relNumber;
+ entry = hash_search(RelFileLocatorFilterCache, &key, HASH_ENTER, &found);
+
+ if (!found)
+ {
...
+ }
+
+ rb->can_filter_change = entry->filterable;
+ return entry->filterable;
+}
======
src/include/replication/reorderbuffer.h
8.
+ /* should we try to filter the change? */
+ bool can_filter_change;
+
I think most of my difficulty reading this patch was due to this field
name 'can_filter_change'.
'can_filter_change' somehow sounded to me like it is past tense. e.g.
like as if we already found some change and we yes, we CAN filter it.
But AFAICT the real meaning is simply that (when the flag is true) we
are ALLOWED to check to see if there is anything filterable. In fact,
the change may or may not be filterable.
Can this be renamed to something more "correct"? e.g.
- 'allow_change_filtering'
- 'enable_change_filtering'
- etc.
~~
9.
+ /* number of changes after a failed attempt at filtering */
+ int8 processed_changes;
Maybe 'unfiltered_changes_count' is a better name for this field?
~~~
10.
+extern bool ReorderBufferCanFilterChanges(ReorderBuffer *rb);
Should match the 'can_filter_change' field name, so if you change that
(see comment #8), then change this too.
======
Kind Regards,
Peter Smith.
Fujitsu Australia
Re: Proposal: Filter irrelevant change before reassemble transactions during logical decoding
From
Amit Kapila
Date:
On Wed, Feb 12, 2025 at 10:41 AM Ajin Cherian <itsajin@gmail.com> wrote: > > On Wed, Jan 29, 2025 at 9:31 AM Peter Smith <smithpb2250@gmail.com> wrote: > > Hi Ajin, > > Some review comments for patch v12-0001. > > ====== > Commit message > > 1. > Track transactions which have snapshot changes with a new flag > RBTXN_HAS_SNAPSHOT_CHANGES > > ~ > > The commit message only says *what* it does, but not *why* this patch > even exists. TBH, I don't understand why this patch needs to be > separated from your patch 0002, because 0001 makes no independent use > of the flag, nor is it separately tested. > > Anyway, if it is going to remain separated then IMO at least the the > message should explain the intended purpose e.g. why the subsequent > patches require this flagged info and how they will use it. > > > Fixed. > I still can't get from 0001's commit message the reason for tracking the snapshot changes separately. Also, please find my comments for 0002's commit message. > When most changes in a transaction are unfilterable, the overhead of starting a transaction for each record is significant. > Can you tell what is the exact overhead by testing it? IIRC, that was the initial approach. It is better if you can mention in the commit message what was overhead. It will be easier for reviewers. > To reduce this overhead a hash cache of relation file locators is created. Even then a hash search for every record before recording has considerable overhead especially for use cases where most tables in an instance are published. > Again, can you share the link of performance data for this overhead and if you have not published then please share it and also mention it in commit message? > To further reduce this overhead a simple approach is used to suspend filtering for a certain number of changes (100) when an unfilterable change is encountered. In other words, continue filtering changes if the last record was filtered out. If an unfilterable change is found, skip filtering the next 100 changes. > Can we try different thresholds for this like 10, 50, 100, 200, etc. to decide what is a good threshold value to skip filtering changes? -- With Regards, Amit Kapila.
Re: Proposal: Filter irrelevant change before reassemble transactions during logical decoding
From
Peter Smith
Date:
Hi Ajin. FYI - Patch set v13* no longer applies cleanly. Needs rebasing. ====== Kind Regards, Peter Smith. Fujitsu Australia
Re: Proposal: Filter irrelevant change before reassemble transactions during logical decoding
From
Ajin Cherian
Date:
On Fri, Feb 14, 2025 at 6:18 PM Amit Kapila <amit.kapila16@gmail.com> wrote: > > On Wed, Feb 12, 2025 at 10:41 AM Ajin Cherian <itsajin@gmail.com> wrote: > > > > On Wed, Jan 29, 2025 at 9:31 AM Peter Smith <smithpb2250@gmail.com> wrote: > > > > Hi Ajin, > > > > Some review comments for patch v12-0001. > > > > ====== > > Commit message > > > > 1. > > Track transactions which have snapshot changes with a new flag > > RBTXN_HAS_SNAPSHOT_CHANGES > > > > ~ > > > > The commit message only says *what* it does, but not *why* this patch > > even exists. TBH, I don't understand why this patch needs to be > > separated from your patch 0002, because 0001 makes no independent use > > of the flag, nor is it separately tested. > > > > Anyway, if it is going to remain separated then IMO at least the the > > message should explain the intended purpose e.g. why the subsequent > > patches require this flagged info and how they will use it. > > > > > > Fixed. > > > > I still can't get from 0001's commit message the reason for tracking > the snapshot changes separately. Also, please find my comments for > 0002's commit message. > > > When most changes in a transaction are unfilterable, the overhead of > starting a transaction for each record is significant. > > > > Can you tell what is the exact overhead by testing it? IIRC, that was > the initial approach. It is better if you can mention in the commit > message what was overhead. It will be easier for reviewers. > > > > To reduce this overhead a hash cache of relation file locators is > created. Even then a hash search for every record before recording has > considerable overhead especially for use cases where most tables in an > instance are published. > > > > Again, can you share the link of performance data for this overhead > and if you have not published then please share it and also mention it > in commit message? > I compared the patch 1 which does not employ a hash cache and has the overhead of starting a transaction every time the filter is checked. I created a test setup of 10 million inserts in 3 different scenarios: 1. All inserts on unpublished tables 2. Half of the inserts on unpublished table and half on pupblished table 3. All inserts on published tables. The percentage improvement in the new optimized patch compared to the old patch is: No transactions in publication: 85.39% improvement Half transactions in publication: 72.70% improvement All transactions in publication: 48.47% improvement Attaching a graph to show the difference. > > > To further reduce this overhead a simple approach is used to suspend > filtering for a certain number of changes (100) when an unfilterable > change is encountered. In other words, continue filtering changes if > the last record was filtered out. If an unfilterable change is found, > skip filtering the next 100 changes. > > > > Can we try different thresholds for this like 10, 50, 100, 200, etc. > to decide what is a good threshold value to skip filtering changes? > Of Course this performance might vary from setup to setup but I tried the above setup to compare the 4 different threshold levels Conclusions: Lower throttling values yield better performance, particularly when transactions are included in the publication. Increasing the throttle limit to 200 transactions causes significant performance degradation, particularly when half or all transactions are included. For optimal performance, a moderate throttling value (100 transactions) may be the best balance between performance and processing efficiency. Attaching the graph to show the difference. I'm also attaching the test script that I used. regards, Ajin Cherian Fujitsu Australia
Attachment
Re: Proposal: Filter irrelevant change before reassemble transactions during logical decoding
From
Ajin Cherian
Date:
On Thu, Feb 20, 2025 at 1:30 PM Ajin Cherian <itsajin@gmail.com> wrote: > > On Fri, Feb 14, 2025 at 6:18 PM Amit Kapila <amit.kapila16@gmail.com> wrote: > > > > On Wed, Feb 12, 2025 at 10:41 AM Ajin Cherian <itsajin@gmail.com> wrote: > > > > > > On Wed, Jan 29, 2025 at 9:31 AM Peter Smith <smithpb2250@gmail.com> wrote: > > > > > > Hi Ajin, > > > > > > Some review comments for patch v12-0001. > > > > > > ====== > > > Commit message > > > > > > 1. > > > Track transactions which have snapshot changes with a new flag > > > RBTXN_HAS_SNAPSHOT_CHANGES > > > > > > ~ > > > > > > The commit message only says *what* it does, but not *why* this patch > > > even exists. TBH, I don't understand why this patch needs to be > > > separated from your patch 0002, because 0001 makes no independent use > > > of the flag, nor is it separately tested. > > > > > > Anyway, if it is going to remain separated then IMO at least the the > > > message should explain the intended purpose e.g. why the subsequent > > > patches require this flagged info and how they will use it. > > > > > > > > > Fixed. > > > > > > > I still can't get from 0001's commit message the reason for tracking > > the snapshot changes separately. Also, please find my comments for > > 0002's commit message. > > > > > When most changes in a transaction are unfilterable, the overhead of > > starting a transaction for each record is significant. > > > > > > > Can you tell what is the exact overhead by testing it? IIRC, that was > > the initial approach. It is better if you can mention in the commit > > message what was overhead. It will be easier for reviewers. > > > > > > > To reduce this overhead a hash cache of relation file locators is > > created. Even then a hash search for every record before recording has > > considerable overhead especially for use cases where most tables in an > > instance are published. > > > > > > > Again, can you share the link of performance data for this overhead > > and if you have not published then please share it and also mention it > > in commit message? > > > > I compared the patch 1 which does not employ a hash cache and has the > overhead of starting a transaction every time the filter is checked. > Just to clarify, by patch 1, I mean the first patch in this thread (v1) posted by Lie Jie here - (1) 1 - https://www.postgresql.org/message-id/CAGfChW5Qo2SrjJ7rU9YYtZbRaWv6v-Z8MJn=dQNx4uCSqDEOHA@mail.gmail.com regards, Ajin Cherian Fujitsu Australia
RE: Proposal: Filter irrelevant change before reassemble transactions during logical decoding
From
"Hayato Kuroda (Fujitsu)"
Date:
Dear Ajin, > I compared the patch 1 which does not employ a hash cache and has the > overhead of starting a transaction every time the filter is checked. > > I created a test setup of 10 million inserts in 3 different scenarios: > 1. All inserts on unpublished tables > 2. Half of the inserts on unpublished table and half on pupblished table > 3. All inserts on published tables. > > The percentage improvement in the new optimized patch compared to the > old patch is: > > No transactions in publication: 85.39% improvement > Half transactions in publication: 72.70% improvement > All transactions in publication: 48.47% improvement > > Attaching a graph to show the difference. I could not find any comparisons with HEAD. Can you clarify the throughput/latency/memory usage with HEAD? Best regards, Hayato Kuroda FUJITSU LIMITED
RE: Proposal: Filter irrelevant change before reassemble transactions during logical decoding
From
"Hayato Kuroda (Fujitsu)"
Date:
Dear Ajin,
Here are my comments. I must play with patches to understand more.
01.
```
extern bool ReorderBufferFilterByRelFileLocator(ReorderBuffer *rb, TransactionId xid,
XLogRecPtr lsn, RelFileLocator *rlocator,
ReorderBufferChangeType change_type,
bool has_tuple);
```
Can you explain why "has_tuple is needed? All callers is set to true.
02.
```
static Relation
ReorderBufferGetRelation(ReorderBuffer *rb, RelFileLocator *rlocator,
bool has_tuple)
```
Hmm, the naming is bit confusing for me. This operation is mostly not related with
the reorder buffer. How about "GetPossibleDecodableRelation" or something?
03.
```
if (IsToastRelation(relation))
{
Oid real_reloid = InvalidOid;
char *toast_name = RelationGetRelationName(relation);
/* pg_toast_ len is 9 */
char *start_ch = &toast_name[9];
real_reloid = pg_strtoint32(start_ch);
entry->relid = real_reloid;
}
```
It is bit hacky for me. How about using sscanf like attached?
04.
IIUC, toast tables always require the filter_change() call twice, is it right?
I understood like below:
1. ReorderBufferFilterByRelFileLocator() tries to filter the change at outside the
transaction. The OID indicates the pg_toast_xxx table.
2. pgoutput_filter_change() cannot find the table from the hash. It returns false
with cache_valid=false.
3. ReorderBufferFilterByRelFileLocator() starts a transaction and get its relation.
4. The function recognizes the relation seems toast and get parent oid.
5. The function tries to filter the change in the transaction, with the parent oid.
6. pgoutput_filter_change()->get_rel_sync_entry() enters the parent relation to the
hash and return determine the filtable or not.
7. After sometime, the same table is modified. But the toast table is not stored in
the hash so that whole 1-6 steps are required.
I feel this may affect the perfomance when many toast is modified. How about skiping
the check for toasted ones? ISTM IsToastNamespace() can be used for the decision.
Best regards,
Hayato Kuroda
FUJITSU LIMITED
Re: Proposal: Filter irrelevant change before reassemble transactions during logical decoding
From
Shlok Kyal
Date:
On Mon, 17 Feb 2025 at 16:20, Ajin Cherian <itsajin@gmail.com> wrote:
>
> On Mon, Feb 17, 2025 at 10:08 AM Peter Smith <smithpb2250@gmail.com> wrote:
> >
> > Hi Ajin.
> >
> > FYI - Patch set v13* no longer applies cleanly. Needs rebasing.
> >
> I've rebased the patch. I've also merged patch 1 into patch 2 as the
> functionality of the changes in patch 1 are only n patch 2.
>
> On Mon, Feb 17, 2025 at 10:08 AM Peter Smith <smithpb2250@gmail.com> wrote:
> >
> > Hi Ajin.
> >
> > FYI - Patch set v13* no longer applies cleanly. Needs rebasing.
> >
> I've rebased the patch. I've also merged patch 1 into patch 2 as the
> functionality of the changes in patch 1 are only in patch 2. So only 2
> patches in this version.
>
>
> On Fri, Feb 14, 2025 at 6:18 PM Amit Kapila <amit.kapila16@gmail.com> wrote:
> >
> > Again, can you share the link of performance data for this overhead
> > and if you have not published then please share it and also mention it
> > in commit message?
>
> I will run the performance tests and post an update with the results.
>
> > Can we try different thresholds for this like 10, 50, 100, 200, etc.
> > to decide what is a good threshold value to skip filtering changes?
> >
> Ok, will do this. For this patch, I reset the count to 0, else the
> test case fails as filtering could be skipped due to throttling. I
> think we need a way for the user to set this threshold via a GUC and
> that can be used for testing.
>
Hi Ajin,
I have reviewed the v14-0001 patch, I have following comment:
1. We need to initialize the 'rb->unfiltered_changes_count = 0', initially
inside function 'ReorderBufferAllocate', otherwise it will get set to garbage
value. While debugging I found out it was setting to 128 by default, so
'++rb->unfiltered_changes_count' was setting it to '-127'. As a result it
might not enter the if condition here for some initial inserts:
+ /*
+ * If filtering was suspended and we've crossed the change threshold,
+ * attempt to filter again
+ */
+ if (!rb->can_filter_change && (++rb->unfiltered_changes_count
+ >= CHANGES_THRESHOLD_FOR_FILTER))
+ {
+ rb->can_filter_change = true;
+ rb->unfiltered_changes_count = 0;
+ }
2. After applying only 0001 patch, then I tried to insert in a published table.
I am getting following error:
postgres=# insert into s1.t1 values(15);
INSERT 0 1
postgres=# insert into s1.t1 values(15);
WARNING: terminating connection because of crash of another server process
DETAIL: The postmaster has commanded this server process to roll back
the current transaction and exit, because another server process
exited abnormally and possibly corrupted shared memory.
HINT: In a moment you should be able to reconnect to the database and
repeat your command.
server closed the connection unexpectedly
This probably means the server terminated abnormally
before or while processing the request.
postgres=?#
Stack trace:
#0 __pthread_kill_implementation (no_tid=0, signo=6,
threadid=132913961858944) at ./nptl/pthread_kill.c:44
#1 __pthread_kill_internal (signo=6, threadid=132913961858944) at
./nptl/pthread_kill.c:78
#2 __GI___pthread_kill (threadid=132913961858944,
signo=signo@entry=6) at ./nptl/pthread_kill.c:89
#3 0x000078e270c42476 in __GI_raise (sig=sig@entry=6) at
../sysdeps/posix/raise.c:26
#4 0x000078e270c287f3 in __GI_abort () at ./stdlib/abort.c:79
#5 0x00005c9c56842f53 in ExceptionalCondition
(conditionName=0x5c9c56c10ed5 "MemoryContextIsValid(context)",
fileName=0x5c9c56c10d5f "mcxt.c",
lineNumber=1323) at assert.c:66
#6 0x00005c9c5690e99c in palloc (size=48) at mcxt.c:1323
#7 0x00005c9c55277564 in systable_beginscan
(heapRelation=0x78e2716561d8, indexId=2685, indexOK=true,
snapshot=0x0, nkeys=1, key=0x7ffd9a4446b0)
at genam.c:403
#8 0x00005c9c567cb6ca in SearchCatCacheMiss (cache=0x5c9c58af0e80,
nkeys=1, hashValue=1393055558, hashIndex=6, v1=16384, v2=0, v3=0,
v4=0)
at catcache.c:1533
#9 0x00005c9c567cb43d in SearchCatCacheInternal
(cache=0x5c9c58af0e80, nkeys=1, v1=16384, v2=0, v3=0, v4=0) at
catcache.c:1464
#10 0x00005c9c567cabd8 in SearchCatCache1 (cache=0x5c9c58af0e80,
v1=16384) at catcache.c:1332
#11 0x00005c9c5682a055 in SearchSysCache1 (cacheId=38, key1=16384) at
syscache.c:228
#12 0x00005c9c567e3b6f in get_namespace_name (nspid=16384) at lsyscache.c:3397
#13 0x00005c9c5608eb5e in logicalrep_write_namespace
(out=0x5c9c58b5d5c8, nspid=16384) at proto.c:1033
#14 0x00005c9c5608d0c2 in logicalrep_write_rel (out=0x5c9c58b5d5c8,
xid=0, rel=0x78e27167ede0, columns=0x0,
include_gencols_type=PUBLISH_GENCOLS_NONE) at proto.c:683
#15 0x000078e270fc9301 in send_relation_and_attrs
(relation=0x78e27167ede0, xid=0, ctx=0x5c9c58b4d8f0,
relentry=0x5c9c58b92278) at pgoutput.c:798
#16 0x000078e270fc8ed9 in maybe_send_schema (ctx=0x5c9c58b4d8f0,
change=0x5c9c58b8f2e0, relation=0x78e27167ede0,
relentry=0x5c9c58b92278)
at pgoutput.c:752
#17 0x000078e270fce338 in pgoutput_change (ctx=0x5c9c58b4d8f0,
txn=0x5c9c58b8b2c0, relation=0x78e27167ede0, change=0x5c9c58b8f2e0)
at pgoutput.c:1572
#18 0x00005c9c5607b265 in change_cb_wrapper (cache=0x5c9c58b4f900,
txn=0x5c9c58b8b2c0, relation=0x78e27167ede0, change=0x5c9c58b8f2e0)
at logical.c:1116
#19 0x00005c9c560a2cff in ReorderBufferApplyChange (rb=0x5c9c58b4f900,
txn=0x5c9c58b8b2c0, relation=0x78e27167ede0, change=0x5c9c58b8f2e0,
streaming=false) at reorderbuffer.c:2175
#20 0x00005c9c560a4856 in ReorderBufferProcessTXN (rb=0x5c9c58b4f900,
txn=0x5c9c58b8b2c0, commit_lsn=8380824, snapshot_now=0x5c9c58b736b8,
command_id=0, streaming=false) at reorderbuffer.c:2511
#21 0x00005c9c560a6aef in ReorderBufferReplay (txn=0x5c9c58b8b2c0,
rb=0x5c9c58b4f900, xid=752, commit_lsn=8380824, end_lsn=8380872,
commit_time=793368288662227, origin_id=0, origin_lsn=0) at
reorderbuffer.c:2973
#22 0x00005c9c560a6b71 in ReorderBufferCommit (rb=0x5c9c58b4f900,
xid=752, commit_lsn=8380824, end_lsn=8380872,
commit_time=793368288662227,
origin_id=0, origin_lsn=0) at reorderbuffer.c:2997
#23 0x00005c9c5606804a in DecodeCommit (ctx=0x5c9c58b4d8f0,
buf=0x7ffd9a445010, parsed=0x7ffd9a444e90, xid=752, two_phase=false)
at decode.c:730
#24 0x00005c9c56064d04 in xact_decode (ctx=0x5c9c58b4d8f0,
buf=0x7ffd9a445010) at decode.c:242
#25 0x00005c9c56063fe2 in LogicalDecodingProcessRecord
(ctx=0x5c9c58b4d8f0, record=0x5c9c58b4dd18) at decode.c:116
#26 0x00005c9c56135980 in XLogSendLogical () at walsender.c:3382
#27 0x00005c9c56133895 in WalSndLoop (send_data=0x5c9c56135836
<XLogSendLogical>) at walsender.c:2788
#28 0x00005c9c56130762 in StartLogicalReplication (cmd=0x5c9c58ab9a10)
at walsender.c:1496
#29 0x00005c9c56131ec3 in exec_replication_command (
cmd_string=0x5c9c58a83b90 "START_REPLICATION SLOT \"test1\"
LOGICAL 0/0 (proto_version '4', streaming 'parallel', origin 'any',
publication_names '\"pub1\"')") at walsender.c:2119
#30 0x00005c9c562abbe8 in PostgresMain (dbname=0x5c9c58abd598
"postgres", username=0x5c9c58abd580 "ubuntu") at postgres.c:4687
Thanks and Regards,
Shlok Kyal
Re: Proposal: Filter irrelevant change before reassemble transactions during logical decoding
From
Ajin Cherian
Date:
On Thu, Feb 20, 2025 at 3:08 PM Hayato Kuroda (Fujitsu) <kuroda.hayato@fujitsu.com> wrote: > > Dear Ajin, > > > I compared the patch 1 which does not employ a hash cache and has the > > overhead of starting a transaction every time the filter is checked. > > > > I created a test setup of 10 million inserts in 3 different scenarios: > > 1. All inserts on unpublished tables > > 2. Half of the inserts on unpublished table and half on pupblished table > > 3. All inserts on published tables. > > > > The percentage improvement in the new optimized patch compared to the > > old patch is: > > > > No transactions in publication: 85.39% improvement > > Half transactions in publication: 72.70% improvement > > All transactions in publication: 48.47% improvement > > > > Attaching a graph to show the difference. > > I could not find any comparisons with HEAD. Can you clarify the throughput/latency/memory > usage with HEAD? Here's the difference in latency with head. Again 10 million inserts in 3 scenarios: All transactions on unpublished tables, half of the transactions on unpublished tables and all transactions on published tables Conclusion: The patched code with 100 transaction throttling significantly improves performance, reducing execution time by ~69% when no published transactions are involved, ~43% with partial published transactions, and ~15% in all published transactions. Attaching a graph showing the performance differences. I will run tests comparing memory and throughput as well. regards, Ajin Cherian Fujitsu Australia
Attachment
{kind=link}
Re: Proposal: Filter irrelevant change before reassemble transactions during logical decoding
From
Ajin Cherian
Date:
On Fri, Feb 21, 2025 at 12:57 PM Ajin Cherian <itsajin@gmail.com> wrote: > > On Thu, Feb 20, 2025 at 3:08 PM Hayato Kuroda (Fujitsu) > <kuroda.hayato@fujitsu.com> wrote: > > > > Dear Ajin, > > > > > I compared the patch 1 which does not employ a hash cache and has the > > > overhead of starting a transaction every time the filter is checked. > > > > > > I created a test setup of 10 million inserts in 3 different scenarios: > > > 1. All inserts on unpublished tables > > > 2. Half of the inserts on unpublished table and half on pupblished table > > > 3. All inserts on published tables. > > > > > > The percentage improvement in the new optimized patch compared to the > > > old patch is: > > > > > > No transactions in publication: 85.39% improvement > > > Half transactions in publication: 72.70% improvement > > > All transactions in publication: 48.47% improvement > > > > > > Attaching a graph to show the difference. > > > > I could not find any comparisons with HEAD. Can you clarify the throughput/latency/memory > > usage with HEAD? > > Here's the difference in latency with head. Again 10 million inserts > in 3 scenarios: All transactions on unpublished tables, half of the > transactions on unpublished tables and all transactions on published > tables > Conclusion: > The patched code with 100 transaction throttling significantly > improves performance, reducing execution time by ~69% when no > published transactions are involved, ~43% with partial published > transactions, and ~15% in all published transactions. > Attaching a graph showing the performance differences. > In these tests, I also see an increased performance with the patch even when all transactions are published. I will investigate why this happens and update. regards, Ajin Cherian Fujitsu Australia
Re: Proposal: Filter irrelevant change before reassemble transactions during logical decoding
From
Amit Kapila
Date:
On Fri, Feb 21, 2025 at 7:57 AM Ajin Cherian <itsajin@gmail.com> wrote: > > On Fri, Feb 21, 2025 at 12:57 PM Ajin Cherian <itsajin@gmail.com> wrote: > > > > Conclusion: > > The patched code with 100 transaction throttling significantly > > improves performance, reducing execution time by ~69% when no > > published transactions are involved, ~43% with partial published > > transactions, and ~15% in all published transactions. > > Attaching a graph showing the performance differences. > > > > In these tests, I also see an increased performance with the patch > even when all transactions are published. I will investigate why this > happens and update. > Yes, it is important to investigate this because in the best case, it should match with HEAD. One thing you can verify is whether the changes processed on the server are exactly for the published table, it shouldn't happen that it is processing both published and unpublished changes. If the server is processing for both tables then it is expected that the patch performs better. I think you can verify before starting each test and after finishing each test whether the slot is pointing at the appropriate location for the next test or create a new slot for each with the required location. -- With Regards, Amit Kapila.
Re: Proposal: Filter irrelevant change before reassemble transactions during logical decoding
From
Peter Smith
Date:
Hi Ajin,
Some review comments for patch v14-0001.
======
src/backend/replication/logical/reorderbuffer.c
1.
+ * We also try and filter changes that are not relevant for logical decoding
+ * as well as give the option for plugins to filter changes in advance.
+ * Determining whether to filter a change requires information about the
+ * relation from the catalog, requring a transaction to be started.
+ * When most changes in a transaction are unfilterable, the overhead of
+ * starting a transaction for each record is significant. To reduce this
+ * overhead a hash cache of relation file locators is created. Even then a
+ * hash search for every record before recording has considerable overhead
+ * especially for use cases where most tables in an instance are
not filtered.
+ * To further reduce this overhead a simple approach is used to suspend
+ * filtering for a certain number of changes CHANGES_THRESHOLD_FOR_FILTER
+ * when an unfilterable change is encountered. In other words, continue
+ * filtering changes if the last record was filtered out. If an unfilterable
+ * change is found, skip filtering the next CHANGES_THRESHOLD_FOR_FILTER
+ * changes.
+ *
1a.
/try and filter/try to filter/
~
1b.
There is some leading whitespace problem happening (spaces instead of tabs?)
~
1c.
Minor rewording
SUGGESTION (e.g. anyway this should be identical to the commit message text)
Determining whether to filter a change requires information about the
relation and the publication from the catalog, which means a
transaction must be started. But, the overhead of starting a
transaction for each record is significant. To reduce this overhead a
hash cache of relation file locators is used to remember which
relations are filterable.
Even so, doing a hash search for every record has considerable
overhead, especially for scenarios where most tables in an instance
are published. To further reduce overheads a simple approach is used:
When an unfilterable change is encountered we suspend filtering for a
certain number (CHANGES_THRESHOLD_FOR_FILTER) of subsequent changes.
In other words, continue filtering until an unfilterable change is
encountered; then skip filtering the next CHANGES_THRESHOLD_FOR_FILTER
changes, before attempting filtering again.
~~~
2.
+/*
+ * After encountering a change that cannot be filtered out, filtering is
+ * temporarily suspended. Filtering resumes after processing every 100 changes.
+ * This strategy helps to minimize the overhead of performing a hash table
+ * search for each record, especially when most changes are not filterable.
+ */
+#define CHANGES_THRESHOLD_FOR_FILTER 100
Maybe you can explain where this magic number comes from.
SUGGESTION
The CHANGES_THRESHOLD_FOR_FILTER value of 100 was chosen as the best
trade-off value after performance tests were carried out using
candidate values 10, 50, 100, and 200.
~~~
ReorderBufferQueueChange:
3.
+ /*
+ * If filtering was suspended and we've crossed the change threshold,
+ * attempt to filter again
+ */
+ if (!rb->can_filter_change && (++rb->unfiltered_changes_count
+ >= CHANGES_THRESHOLD_FOR_FILTER))
+ {
+ rb->can_filter_change = true;
+ rb->unfiltered_changes_count = 0;
+ }
+
/If filtering was suspended/If filtering is currently suspended/
~~~
ReorderBufferGetRelation:
4.
+static Relation
+ReorderBufferGetRelation(ReorderBuffer *rb, RelFileLocator *rlocator,
+ bool has_tuple)
My suggested [2-#4] name change 'ReorderBufferGetRelationForDecoding'
is not done yet. I saw Kuroda-san also said this name was confusing
[1-#02], and suggested something similar
'GetPossibleDecodableRelation'.
~~~
RelFileLocatorCacheInvalidateCallback:
5.
+ /*
+ * If relid is InvalidOid, signaling a complete reset, we must remove
+ * all entries, otherwise just remove the specific relation's entry.
+ * Always remove negative cache entries.
+ */
+ if (relid == InvalidOid || /* complete reset */
+ entry->relid == InvalidOid || /* invalid cache entry */
+ entry->relid == relid) /* individual flushed relation */
+ {
+ if (hash_search(RelFileLocatorFilterCache,
+ &entry->key,
+ HASH_REMOVE,
+ NULL) == NULL)
+ elog(ERROR, "hash table corrupted");
+ }
5a.
IMO the relid *parameter* should be mentioned explicitly to
disambiguate relid from the entry->relid.
/If relid is InvalidOid, signaling a complete reset,/If a complete
reset is requested (when 'relid' parameter is InvalidOid),/
~
5b.
/Always remove negative cache entries./Remove any invalid cache
entries (these are indicated by invalid entry->relid)/
~~~
ReorderBufferFilterByRelFileLocator:
6.
I previously [2-#7] had suggested this function code could be
refactored to share some common return logic. It is not done, but OTOH
there is no reply, so I don't know if it was overlooked or simply
rejected.
======
src/include/replication/reorderbuffer.h
7.
+ /* should we try to filter the change? */
+ bool can_filter_change;
+
+ /* number of changes after a failed attempt at filtering */
+ int8 unfiltered_changes_count;
+
The potential renaming of that 'can_filter_change' field to something
better is still an open item IMO [2-#8] pending consensus on what a
better name for this might be.
======
[1]
https://www.postgresql.org/message-id/OSCPR01MB14966021B3390856464C5E27FF5C42%40OSCPR01MB14966.jpnprd01.prod.outlook.com
[2] https://www.postgresql.org/message-id/CAHut%2BPtrLu%3DYrxo_YQ-LC%2BLSOEUYmuFo2brjCQ18JM9-Vi2DwQ%40mail.gmail.com
Kind Regards,
Peter Smith.
Fujitsu Australia
Re: Proposal: Filter irrelevant change before reassemble transactions during logical decoding
From
Peter Smith
Date:
Hi Ajin, Some review comments for v14-0002. ====== src/backend/replication/logical/decode.c 1. There is lots of nearly duplicate code checking to see if a change is filterable DecodeInsert: + /* + * When filtering changes, determine if the relation associated with the change + * can be skipped. This could be because the relation is unlogged or because + * the plugin has opted to exclude this relation from decoding. + */ + if (FilterChangeIsEnabled(ctx) && ReorderBufferFilterByRelFileLocator(ctx->reorder, XLogRecGetXid(r), - buf->origptr, &target_locator, true)) + buf->origptr, &target_locator, + REORDER_BUFFER_CHANGE_INSERT, + true)) DecodeUpdate: + /* + * When filtering changes, determine if the relation associated with the change + * can be skipped. This could be because the relation is unlogged or because + * the plugin has opted to exclude this relation from decoding. + */ + if (FilterChangeIsEnabled(ctx) && + ReorderBufferFilterByRelFileLocator(ctx->reorder, XLogRecGetXid(r), + buf->origptr, &target_locator, + REORDER_BUFFER_CHANGE_UPDATE, + true)) + return; + DecodeDelete: + /* + * When filtering changes, determine if the relation associated with the change + * can be skipped. This could be because the relation is unlogged or because + * the plugin has opted to exclude this relation from decoding. + */ + if (FilterChangeIsEnabled(ctx) && + ReorderBufferFilterByRelFileLocator(ctx->reorder, XLogRecGetXid(r), + buf->origptr, &target_locator, + REORDER_BUFFER_CHANGE_DELETE, + true)) + return; + DecodeMultiInsert: /* + * When filtering changes, determine if the relation associated with the change + * can be skipped. This could be because the relation is unlogged or because + * the plugin has opted to exclude this relation from decoding. + */ + if (FilterChangeIsEnabled(ctx) && + ReorderBufferFilterByRelFileLocator(ctx->reorder, XLogRecGetXid(r), + buf->origptr, &rlocator, + REORDER_BUFFER_CHANGE_INSERT, + true)) + return; + DecodeSpecConfirm: + /* + * When filtering changes, determine if the relation associated with the change + * can be skipped. This could be because the relation is unlogged or because + * the plugin has opted to exclude this relation from decoding. + */ + if (FilterChangeIsEnabled(ctx) && + ReorderBufferFilterByRelFileLocator(ctx->reorder, XLogRecGetXid(r), + buf->origptr, &target_locator, + REORDER_BUFFER_CHANGE_INSERT, + true)) + return; + Can't all those code fragments (DecodeInsert, DecodeUpdate, DecodeDelete, DecodeMultiInsert, DecodeSpecConfirm) delegate to a new/common 'SkipThisChange(...)' function? ====== src/backend/replication/logical/reorderbuffer.c 2. /* * After encountering a change that cannot be filtered out, filtering is - * temporarily suspended. Filtering resumes after processing every 100 changes. + * temporarily suspended. Filtering resumes after processing CHANGES_THRESHOLD_FOR_FILTER + * changes. * This strategy helps to minimize the overhead of performing a hash table * search for each record, especially when most changes are not filterable. */ -#define CHANGES_THRESHOLD_FOR_FILTER 100 +#define CHANGES_THRESHOLD_FOR_FILTER 0 Why is this defined as 0? Some accidental residue from performance testing different values? ====== src/test/subscription/t/001_rep_changes.pl 3. +# Check that an unpublished change is filtered out. +$logfile = slurp_file($node_publisher->logfile, $log_location); +ok($logfile =~ qr/Filtering INSERT/, + 'unpublished INSERT is filtered'); + +ok($logfile =~ qr/Filtering UPDATE/, + 'unpublished UPDATE is filtered'); + +ok($logfile =~ qr/Filtering DELETE/, + 'unpublished DELETE is filtered'); + AFAICT these are probably getting filtered out because the entire table is not published at all. Should you also add different tests where you do operations on a table that IS partially replicated but only some of the *operations* are not published. e.g. test the different 'pubactions' of the PUBLICATION 'publish' parameter. Maybe you need different log checks to distinguish the different causes for the filtering. ====== Kind Regards, Peter Smith. Fujitsu Australia
RE: Proposal: Filter irrelevant change before reassemble transactions during logical decoding
From
"Hayato Kuroda (Fujitsu)"
Date:
> 03.
> ```
> if (IsToastRelation(relation))
> {
> Oid real_reloid = InvalidOid;
> char *toast_name =
> RelationGetRelationName(relation);
> /* pg_toast_ len is 9 */
> char *start_ch = &toast_name[9];
>
> real_reloid = pg_strtoint32(start_ch);
> entry->relid = real_reloid;
> }
> ```
>
> It is bit hacky for me. How about using sscanf like attached?
I forgot to attach :-(.
Best regards,
Hayato Kuroda
FUJITSU LIMITED
Attachment
Re: Proposal: Filter irrelevant change before reassemble transactions during logical decoding
From
Ajin Cherian
Date:
On Fri, Feb 21, 2025 at 2:24 PM Amit Kapila <amit.kapila16@gmail.com> wrote: > > On Fri, Feb 21, 2025 at 7:57 AM Ajin Cherian <itsajin@gmail.com> wrote: > > In these tests, I also see an increased performance with the patch > > even when all transactions are published. I will investigate why this > > happens and update. > > > > Yes, it is important to investigate this because in the best case, it > should match with HEAD. One thing you can verify is whether the > changes processed on the server are exactly for the published table, > it shouldn't happen that it is processing both published and > unpublished changes. If the server is processing for both tables then > it is expected that the patch performs better. I think you can verify > before starting each test and after finishing each test whether the > slot is pointing at the appropriate location for the next test or > create a new slot for each with the required location. Yes, you are right, I modified the tests to drop the slot and create a new slot advance to current_lsn and now I see a fractionally better performance in head code when all transactions are published. Graph attached. regards, Ajin Cherian Fujitsu Australia
Attachment
{kind=link}
Re: Proposal: Filter irrelevant change before reassemble transactions during logical decoding
From
Ajin Cherian
Date:
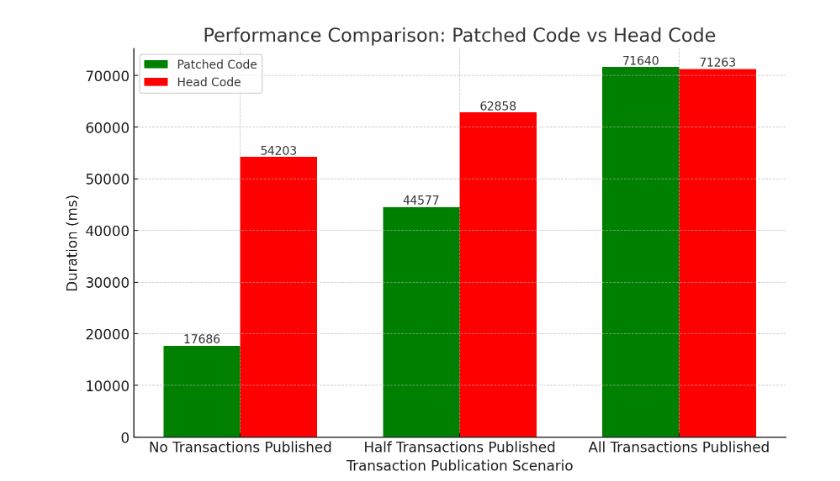
On Tue, Feb 25, 2025 at 3:26 PM Ajin Cherian <itsajin@gmail.com> wrote: > > On Fri, Feb 21, 2025 at 2:24 PM Amit Kapila <amit.kapila16@gmail.com> wrote: > > > > On Fri, Feb 21, 2025 at 7:57 AM Ajin Cherian <itsajin@gmail.com> wrote: > > > In these tests, I also see an increased performance with the patch > > > even when all transactions are published. I will investigate why this > > > happens and update. > > > > > > > Yes, it is important to investigate this because in the best case, it > > should match with HEAD. One thing you can verify is whether the > > changes processed on the server are exactly for the published table, > > it shouldn't happen that it is processing both published and > > unpublished changes. If the server is processing for both tables then > > it is expected that the patch performs better. I think you can verify > > before starting each test and after finishing each test whether the > > slot is pointing at the appropriate location for the next test or > > create a new slot for each with the required location. > > Yes, you are right, I modified the tests to drop the slot and create a > new slot advance to current_lsn and now I see a fractionally better > performance in head code when all transactions are published. > Graph attached. > Just to summarize and clarify: The patched code significantly improves performance when no transactions are published, reducing execution time from ~54,100 ms (head code) to ~17,700 ms—a nearly 70% improvement. When half of the transactions are published, the patched code also shows a notable performance gain, reducing execution time from ~62,800 ms to ~44,500 ms (~29% faster). When all transactions are published, the patched code is only 0.53% slower than the head code, indicating a negligible performance degradation. regards, Ajin Cherian Fujitsu Australia
Re: Proposal: Filter irrelevant change before reassemble transactions during logical decoding
From
Ajin Cherian
Date:
On Thu, Feb 20, 2025 at 8:42 PM Hayato Kuroda (Fujitsu)
<kuroda.hayato@fujitsu.com> wrote:
>
> Dear Ajin,
>
> Here are my comments. I must play with patches to understand more.
>
> 01.
> ```
> extern bool ReorderBufferFilterByRelFileLocator(ReorderBuffer *rb, TransactionId xid,
> XLogRecPtr lsn,
RelFileLocator*rlocator,
>
ReorderBufferChangeTypechange_type,
> bool has_tuple);
> ```
>
> Can you explain why "has_tuple is needed? All callers is set to true.
>
It is not needed. Removed.
> 02.
> ```
> static Relation
> ReorderBufferGetRelation(ReorderBuffer *rb, RelFileLocator *rlocator,
> bool has_tuple)
> ```
>
> Hmm, the naming is bit confusing for me. This operation is mostly not related with
> the reorder buffer. How about "GetPossibleDecodableRelation" or something?
>
> 03.
> ```
> if (IsToastRelation(relation))
> {
> Oid real_reloid = InvalidOid;
> char *toast_name = RelationGetRelationName(relation);
> /* pg_toast_ len is 9 */
> char *start_ch = &toast_name[9];
>
> real_reloid = pg_strtoint32(start_ch);
> entry->relid = real_reloid;
> }
> ```
>
> It is bit hacky for me. How about using sscanf like attached?
>
I have used the code that you shared to modify this.
> 04.
>
> IIUC, toast tables always require the filter_change() call twice, is it right?
> I understood like below:
>
> 1. ReorderBufferFilterByRelFileLocator() tries to filter the change at outside the
> transaction. The OID indicates the pg_toast_xxx table.
> 2. pgoutput_filter_change() cannot find the table from the hash. It returns false
> with cache_valid=false.
> 3. ReorderBufferFilterByRelFileLocator() starts a transaction and get its relation.
> 4. The function recognizes the relation seems toast and get parent oid.
> 5. The function tries to filter the change in the transaction, with the parent oid.
> 6. pgoutput_filter_change()->get_rel_sync_entry() enters the parent relation to the
> hash and return determine the filtable or not.
> 7. After sometime, the same table is modified. But the toast table is not stored in
> the hash so that whole 1-6 steps are required.
>
> I feel this may affect the perfomance when many toast is modified. How about skiping
> the check for toasted ones? ISTM IsToastNamespace() can be used for the decision.
>
I understand your concern but I also think that the benefits are
higher for toast changes
On Fri, Feb 21, 2025 at 6:26 PM Peter Smith <smithpb2250@gmail.com> wrote:
>
> Hi Ajin,
>
> Some review comments for patch v14-0001.
>
> ======
> src/backend/replication/logical/reorderbuffer.c
>
> 1.
> + * We also try and filter changes that are not relevant for logical decoding
> + * as well as give the option for plugins to filter changes in advance.
> + * Determining whether to filter a change requires information about the
> + * relation from the catalog, requring a transaction to be started.
> + * When most changes in a transaction are unfilterable, the overhead of
> + * starting a transaction for each record is significant. To reduce this
> + * overhead a hash cache of relation file locators is created. Even then a
> + * hash search for every record before recording has considerable overhead
> + * especially for use cases where most tables in an instance are
> not filtered.
> + * To further reduce this overhead a simple approach is used to suspend
> + * filtering for a certain number of changes CHANGES_THRESHOLD_FOR_FILTER
> + * when an unfilterable change is encountered. In other words, continue
> + * filtering changes if the last record was filtered out. If an unfilterable
> + * change is found, skip filtering the next CHANGES_THRESHOLD_FOR_FILTER
> + * changes.
> + *
>
> 1a.
> /try and filter/try to filter/
>
> ~
>
> 1b.
> There is some leading whitespace problem happening (spaces instead of tabs?)
>
> ~
>
> 1c.
> Minor rewording
>
> SUGGESTION (e.g. anyway this should be identical to the commit message text)
>
> Determining whether to filter a change requires information about the
> relation and the publication from the catalog, which means a
> transaction must be started. But, the overhead of starting a
> transaction for each record is significant. To reduce this overhead a
> hash cache of relation file locators is used to remember which
> relations are filterable.
>
> Even so, doing a hash search for every record has considerable
> overhead, especially for scenarios where most tables in an instance
> are published. To further reduce overheads a simple approach is used:
> When an unfilterable change is encountered we suspend filtering for a
> certain number (CHANGES_THRESHOLD_FOR_FILTER) of subsequent changes.
> In other words, continue filtering until an unfilterable change is
> encountered; then skip filtering the next CHANGES_THRESHOLD_FOR_FILTER
> changes, before attempting filtering again.
>
> ~~~
>
I have modified the whole commit message and these comments based on
inputs from Hou-san.
> 2.
> +/*
> + * After encountering a change that cannot be filtered out, filtering is
> + * temporarily suspended. Filtering resumes after processing every 100 changes.
> + * This strategy helps to minimize the overhead of performing a hash table
> + * search for each record, especially when most changes are not filterable.
> + */
> +#define CHANGES_THRESHOLD_FOR_FILTER 100
>
> Maybe you can explain where this magic number comes from.
>
> SUGGESTION
> The CHANGES_THRESHOLD_FOR_FILTER value of 100 was chosen as the best
> trade-off value after performance tests were carried out using
> candidate values 10, 50, 100, and 200.
>
I am not so sure as my test scenarios where very limited, I don't
think that I can say that 100 is the best value for all scenarios.
Which is why i suggest changing this as a user changable GUC variable
if others agree.
> ~~~
>
> ReorderBufferQueueChange:
>
> 3.
> + /*
> + * If filtering was suspended and we've crossed the change threshold,
> + * attempt to filter again
> + */
> + if (!rb->can_filter_change && (++rb->unfiltered_changes_count
> + >= CHANGES_THRESHOLD_FOR_FILTER))
> + {
> + rb->can_filter_change = true;
> + rb->unfiltered_changes_count = 0;
> + }
> +
>
> /If filtering was suspended/If filtering is currently suspended/
>
> ~~~
Fixed.
>
> ReorderBufferGetRelation:
>
> 4.
> +static Relation
> +ReorderBufferGetRelation(ReorderBuffer *rb, RelFileLocator *rlocator,
> + bool has_tuple)
>
> My suggested [2-#4] name change 'ReorderBufferGetRelationForDecoding'
> is not done yet. I saw Kuroda-san also said this name was confusing
> [1-#02], and suggested something similar
> 'GetPossibleDecodableRelation'.
>
Changed it to GetDecodableRelation()
> ~~~
>
> RelFileLocatorCacheInvalidateCallback:
>
> 5.
> + /*
> + * If relid is InvalidOid, signaling a complete reset, we must remove
> + * all entries, otherwise just remove the specific relation's entry.
> + * Always remove negative cache entries.
> + */
> + if (relid == InvalidOid || /* complete reset */
> + entry->relid == InvalidOid || /* invalid cache entry */
> + entry->relid == relid) /* individual flushed relation */
> + {
> + if (hash_search(RelFileLocatorFilterCache,
> + &entry->key,
> + HASH_REMOVE,
> + NULL) == NULL)
> + elog(ERROR, "hash table corrupted");
> + }
>
>
> 5a.
> IMO the relid *parameter* should be mentioned explicitly to
> disambiguate relid from the entry->relid.
>
> /If relid is InvalidOid, signaling a complete reset,/If a complete
> reset is requested (when 'relid' parameter is InvalidOid),/
>
> ~
>
> 5b.
> /Always remove negative cache entries./Remove any invalid cache
> entries (these are indicated by invalid entry->relid)/
>
> ~~~
Fixed
>
> ReorderBufferFilterByRelFileLocator:
>
> 6.
> I previously [2-#7] had suggested this function code could be
> refactored to share some common return logic. It is not done, but OTOH
> there is no reply, so I don't know if it was overlooked or simply
> rejected.
>
I had considered this but I felt that it is better readable this way.
> ======
> src/include/replication/reorderbuffer.h
>
> 7.
> + /* should we try to filter the change? */
> + bool can_filter_change;
> +
> + /* number of changes after a failed attempt at filtering */
> + int8 unfiltered_changes_count;
> +
>
> The potential renaming of that 'can_filter_change' field to something
> better is still an open item IMO [2-#8] pending consensus on what a
> better name for this might be.
>
I haven't changed this.
On Sun, Feb 23, 2025 at 2:19 PM Peter Smith <smithpb2250@gmail.com> wrote:
>
> Hi Ajin,
>
> Some review comments for v14-0002.
>
> ======
> src/backend/replication/logical/decode.c
>
> 1.
> There is lots of nearly duplicate code checking to see if a change is filterable
>
> DecodeInsert:
> + /*
> + * When filtering changes, determine if the relation associated with the change
> + * can be skipped. This could be because the relation is unlogged or because
> + * the plugin has opted to exclude this relation from decoding.
> + */
> + if (FilterChangeIsEnabled(ctx) &&
> ReorderBufferFilterByRelFileLocator(ctx->reorder, XLogRecGetXid(r),
> - buf->origptr, &target_locator, true))
> + buf->origptr, &target_locator,
> + REORDER_BUFFER_CHANGE_INSERT,
> + true))
>
>
> DecodeUpdate:
> + /*
> + * When filtering changes, determine if the relation associated with the change
> + * can be skipped. This could be because the relation is unlogged or because
> + * the plugin has opted to exclude this relation from decoding.
> + */
> + if (FilterChangeIsEnabled(ctx) &&
> + ReorderBufferFilterByRelFileLocator(ctx->reorder, XLogRecGetXid(r),
> + buf->origptr, &target_locator,
> + REORDER_BUFFER_CHANGE_UPDATE,
> + true))
> + return;
> +
>
> DecodeDelete:
> + /*
> + * When filtering changes, determine if the relation associated with the change
> + * can be skipped. This could be because the relation is unlogged or because
> + * the plugin has opted to exclude this relation from decoding.
> + */
> + if (FilterChangeIsEnabled(ctx) &&
> + ReorderBufferFilterByRelFileLocator(ctx->reorder, XLogRecGetXid(r),
> + buf->origptr, &target_locator,
> + REORDER_BUFFER_CHANGE_DELETE,
> + true))
> + return;
> +
>
> DecodeMultiInsert:
> /*
> + * When filtering changes, determine if the relation associated with the change
> + * can be skipped. This could be because the relation is unlogged or because
> + * the plugin has opted to exclude this relation from decoding.
> + */
> + if (FilterChangeIsEnabled(ctx) &&
> + ReorderBufferFilterByRelFileLocator(ctx->reorder, XLogRecGetXid(r),
> + buf->origptr, &rlocator,
> + REORDER_BUFFER_CHANGE_INSERT,
> + true))
> + return;
> +
>
> DecodeSpecConfirm:
> + /*
> + * When filtering changes, determine if the relation associated with the change
> + * can be skipped. This could be because the relation is unlogged or because
> + * the plugin has opted to exclude this relation from decoding.
> + */
> + if (FilterChangeIsEnabled(ctx) &&
> + ReorderBufferFilterByRelFileLocator(ctx->reorder, XLogRecGetXid(r),
> + buf->origptr, &target_locator,
> + REORDER_BUFFER_CHANGE_INSERT,
> + true))
> + return;
> +
>
> Can't all those code fragments (DecodeInsert, DecodeUpdate,
> DecodeDelete, DecodeMultiInsert, DecodeSpecConfirm) delegate to a
> new/common 'SkipThisChange(...)' function?
>
Fixed this accordingly.
> ======
> src/backend/replication/logical/reorderbuffer.c
>
> 2.
> /*
> * After encountering a change that cannot be filtered out, filtering is
> - * temporarily suspended. Filtering resumes after processing every 100 changes.
> + * temporarily suspended. Filtering resumes after processing
> CHANGES_THRESHOLD_FOR_FILTER
> + * changes.
> * This strategy helps to minimize the overhead of performing a hash table
> * search for each record, especially when most changes are not filterable.
> */
> -#define CHANGES_THRESHOLD_FOR_FILTER 100
> +#define CHANGES_THRESHOLD_FOR_FILTER 0
>
> Why is this defined as 0? Some accidental residue from performance
> testing different values?
>
I need it to remain 0 for my tests to work. I have mooved out these
changes and tests to a new patch 0003.
> ======
> src/test/subscription/t/001_rep_changes.pl
>
> 3.
> +# Check that an unpublished change is filtered out.
> +$logfile = slurp_file($node_publisher->logfile, $log_location);
> +ok($logfile =~ qr/Filtering INSERT/,
> + 'unpublished INSERT is filtered');
> +
> +ok($logfile =~ qr/Filtering UPDATE/,
> + 'unpublished UPDATE is filtered');
> +
> +ok($logfile =~ qr/Filtering DELETE/,
> + 'unpublished DELETE is filtered');
> +
>
> AFAICT these are probably getting filtered out because the entire
> table is not published at all.
>
> Should you also add different tests where you do operations on a table
> that IS partially replicated but only some of the *operations* are not
> published. e.g. test the different 'pubactions' of the PUBLICATION
> 'publish' parameter. Maybe you need different log checks to
> distinguish the different causes for the filtering.
>
I've modified the commit message in 0001 based on inputs from Hou-san.
Modified and added new tests in patch 0003
regards,
Ajin Cherian
Fujitsu Australia
Attachment
Re: Proposal: Filter irrelevant change before reassemble transactions during logical decoding
From
Ajin Cherian
Date:
On Mon, Mar 3, 2025 at 9:10 PM Ajin Cherian <itsajin@gmail.com> wrote: > > On Thu, Feb 20, 2025 at 8:42 PM Hayato Kuroda (Fujitsu) > <kuroda.hayato@fujitsu.com> wrote: > > I confirmed with tests that with the patch, a lot less disk space is used when there are lots of unpublished changes and the subscription is not configured to be streaming. HEAD code: Initial disk usage in replication slot directory: 4.0K /home/ajin/dataoss/pg_replslot/mysub BEGIN INSERT 0 1000000 COMMIT Final disk usage in replication slot directory: 212M /home/ajin/dataoss/pg_replslot/mysub Patched code: Initial disk usage in replication slot directory: 4.0K /home/ajin/dataoss/pg_replslot/mysub BEGIN INSERT 0 1000000 COMMIT Final disk usage in replication slot directory: 4.0K /home/ajin/dataoss/pg_replslot/mysub Attaching the test script used. Regards, Ajin Cherian Fujitsu Australia
Attachment
Re: Proposal: Filter irrelevant change before reassemble transactions during logical decoding
From
Ajin Cherian
Date:
Moving this patch to the next CF as this patch needs more design level inputs which may not be feasible in this CF but do continue to review the patch. regards, Ajin Cherian Fujitsu Australia
Re: Proposal: Filter irrelevant change before reassemble transactions during logical decoding
From
Ajin Cherian
Date:
On Thu, Mar 13, 2025 at 5:49 PM Ajin Cherian <itsajin@gmail.com> wrote: > > Moving this patch to the next CF as this patch needs more design level > inputs which may not be feasible in this CF but do continue to review > the patch. > > regards, > Ajin Cherian > Fujitsu Australia Rebased the patch as it no longer applied. regards, Ajin Cherian Fujitsu Australia
Attachment
Re: Proposal: Filter irrelevant change before reassemble transactions during logical decoding
From
Shlok Kyal
Date:
On Thu, 20 Mar 2025 at 18:09, Ajin Cherian <itsajin@gmail.com> wrote:
>
> On Thu, Mar 13, 2025 at 5:49 PM Ajin Cherian <itsajin@gmail.com> wrote:
> >
> > Moving this patch to the next CF as this patch needs more design level
> > inputs which may not be feasible in this CF but do continue to review
> > the patch.
> >
> > regards,
> > Ajin Cherian
> > Fujitsu Australia
>
> Rebased the patch as it no longer applied.
>
Hi Ajin,
I have reviewed patch v16-0001, here are my comments:
1. There are some places where comments are more than 80 columns
window. I think it should be <=80 as per [1].
a. initial comment in reorderbuffer.c
+ * Filtering is temporarily suspended for a sequence of changes
(set to 100
+ * changes) when an unfilterable change is encountered. This
strategy minimizes
+ * the overhead of hash searching for every record, which is
beneficial when the
+ * majority of tables in an instance are published and thus
unfilterable. The
+ * threshold of 100 was determined to be the optimal balance
based on performance
+ * tests.
+ *
+ * Additionally, filtering is paused for transactions
containing WAL records
+ * (INTERNAL_SNAPSHOT, COMMAND_ID, or INVALIDATION) that modify
the historical
+ * snapshot constructed during logical decoding. This pause is
necessary because
+ * constructing a correct historical snapshot for searching publication
+ * information requires processing these WAL records.
b.
+ if (!has_tuple)
+ {
+ /*
+ * Mapped catalog tuple without data, emitted while catalog table was in
+ * the process of being rewritten. We can fail to look up the
+ * relfilenumber, because the relmapper has no "historic" view, in
+ * contrast to the normal catalog during decoding. Thus repeated rewrites
+ * can cause a lookup failure. That's OK because we do not decode catalog
+ * changes anyway. Normally such tuples would be skipped over below, but
+ * we can't identify whether the table should be logically logged without
+ * mapping the relfilenumber to the oid.
+ */
+ return NULL;
+ }
2. I think, 'rb->unfiltered_changes_count' should be initialised in
the function 'ReorderBufferAllocate'. While debugging I found that the
initial value of rb->unfiltered_changes_count is 127. I think it
should be set to '0' inside 'ReorderBufferAllocate'. Am I missing
something here?
I have also added the same comment in point 1. in [2].
Also, please ignore point 2. in email [2] a crash happened because I
was testing it without doing a clean build. Sorry for the
inconvenience.
[1]: https://www.postgresql.org/docs/devel/source-format.html
[2]: https://www.postgresql.org/message-id/CANhcyEUF1HzDRj_fJAGCqBqNg7xGVoATR7XgR311xq8UvBg9tg%40mail.gmail.com
Thanks and Regards,
Shlok Kyal
Re: Proposal: Filter irrelevant change before reassemble transactions during logical decoding
From
Shlok Kyal
Date:
On Thu, 20 Mar 2025 at 18:09, Ajin Cherian <itsajin@gmail.com> wrote: > > On Thu, Mar 13, 2025 at 5:49 PM Ajin Cherian <itsajin@gmail.com> wrote: > > > > Moving this patch to the next CF as this patch needs more design level > > inputs which may not be feasible in this CF but do continue to review > > the patch. > > > > regards, > > Ajin Cherian > > Fujitsu Australia > > Rebased the patch as it no longer applied. > Hi Ajin, I reviewed v16-0002 patch, here are my comments: 1. Guc CHANGES_THRESHOLD_FOR_FILTER was introduced in 0001 patch, should this change be in 0001 patch? - * temporarily suspended. Filtering resumes after processing every 100 changes. + * temporarily suspended. Filtering resumes after processing CHANGES_THRESHOLD_FOR_FILTER + * changes. 2. Following comment is repeated inside DecodeInsert, DecodeUpdate, DecodeDelete, DecodeMultiInsert, DecodeSpecConfirm + /* + * When filtering changes, determine if the relation associated with the change + * can be skipped. This could be because the relation is unlogged or because + * the plugin has opted to exclude this relation from decoding. + */ + if (SkipThisChange(ctx, buf->origptr, XLogRecGetXid(r), &target_locator, Since this comment is the same, should we remove it from the above functions and add this where function 'SkipThisChange' is defined? Thanks and Regards, Shlok Kyal
Re: Proposal: Filter irrelevant change before reassemble transactions during logical decoding
From
Peter Smith
Date:
Hi Ajin. Some review comments for patch v16-0001. ====== Commit message 1. A hash cache of relation file locators is implemented to cache whether a relation is filterable or not. This ensures that we only need to retrieve ~ /hash cache/hash table/ (AFAICT you called this a hash table elsewhere in all code comments) ~~~ 2. Additionally, filtering is paused for transactions containing WAL records (INTERNAL_SNAPSHOT, COMMAND_ID, or INVALIDATION) that modify the historical snapshot constructed during logical decoding. This pause is necessary because constructing a correct historical snapshot for searching publication information requires processing these WAL records. ~ IIUC, the "pause" here is really referring to the 100 changes following an unfilterable txn. So, I don't think what you are describing here is a "pause" -- it is just another reason for the tx to be marked unfilterable, and the pause logic will take care of itself. So, maybe it should be worded more like SUGGESTION Additionally, transactions containing WAL records (INTERNAL_SNAPSHOT, COMMAND_ID, or INVALIDATION) that modify the historical snapshot constructed during logical decoding are deemed unfilterable. This is necessary because constructing a correct historical snapshot for searching publication information requires processing these WAL records. ====== src/backend/replication/logical/reorderbuffer.c 3. Header comment. If you change the commit message based on previous suggestions, then change the comment here also to match it. ~~~ 4. +/* + * After encountering a change that cannot be filtered out, filtering is + * temporarily suspended. Filtering resumes after processing every 100 changes. + * This strategy helps to minimize the overhead of performing a hash table + * search for each record, especially when most changes are not filterable. + */ +#define CHANGES_THRESHOLD_FOR_FILTER 100 /every 100/the next 100/ ~~~ +ReorderBufferFilterByRelFileLocator: 5. + * if we are decoding a transaction without these records. See comment on top + * of GetDecodableRelation() to see list of relations that are not + * decoded by the reorderbuffer. /to see list of relations/to see the kinds of relation/ ====== Kind Regards, Peter Smith. Fujitsu Australia
Re: Proposal: Filter irrelevant change before reassemble transactions during logical decoding
From
Peter Smith
Date:
Hi Ajin, Here is another general review comment for patch 0001. ~~~ I keep getting confused by the distinction between the 2 member fields that are often found working hand-in-hand: entry->filterable rb->can_filter_change Unfortunately, because the names are very similar I keep blurring the meanings, and then nothing makes sense. IIUC, the meanings are actually like: entry->filterable. This means filtering is *possible* for this kind of relation; it doesn't mean it will happen though. rb->can_filter_change. This means the plugin will *try* to filter the change; it might do nothing if entry->filterable is false; can_filter_change bool is used for the 100 change "temporary suspension" logic (e.g. so it if is false we won't even try to filter despite entry->filterable is true). If those meanings are accurate I think some better member names might be: entry->filterable rb->try_to_filter_change Also these explanations/distinctions need to be made more clearly in the commit message and/of file head comments, as well as where those members are defined. ====== Kind Regards, Peter Smith. Fujitsu Australia.
Re: Proposal: Filter irrelevant change before reassemble transactions during logical decoding
From
Peter Smith
Date:
Hi Ajin,
Some review comments for patch v16-0002.
======
doc/src/sgml/logicaldecoding.sgml
1.
+ To indicate that decoding can be skipped for the given change
+ <parameter>change_type</parameter>, return <literal>true</literal>;
+ <literal>false</literal> otherwise.
/change <parameter>change_type</parameter>/<parameter>change_type</parameter>/
(don't need to say "change" twice)
======
src/backend/replication/logical/decode.c
SkipThisChange:
2.
+/* Function to determine whether to skip the change */
+static bool SkipThisChange(LogicalDecodingContext *ctx, XLogRecPtr
origptr, TransactionId xid,
+ RelFileLocator *target_locator, ReorderBufferChangeType change_type)
+{
+ return (FilterChangeIsEnabled(ctx) &&
+ ReorderBufferFilterByRelFileLocator(ctx->reorder, xid, origptr,
target_locator,
+ change_type));
+}
2a.
By convention the function return should be on its own line.
~
2b.
Probably this should be declared *inline* like other functions similar to this?
~
2c.
Consider renaming this function to FilterChange(...). I think that
might align better with the other functions like
FilterChangeIsEnabled, FilterByOrigin etc which all refer to
"filtering" instead of "skipping".
~~~
3.
+ /*
+ * When filtering changes, determine if the relation associated with the change
+ * can be skipped. This could be because the relation is unlogged or because
+ * the plugin has opted to exclude this relation from decoding.
+ */
+ if (SkipThisChange(ctx, buf->origptr, XLogRecGetXid(r), &target_locator,
+ REORDER_BUFFER_CHANGE_INSERT))
All these block comments prior to the calls to SkipThisChange seem
slightly overkill (I think Shlok also reports this). IMO this comment
can be much simpler:
e.g.
Can the relation associated with this change be skipped?
This is repeated in multiple places: DecodeInsert, DecodeUpdate,
DecodeDelete, DecodeMultiInsert, DecodeSpecConfirm
======
src/backend/replication/logical/logical.c
filter_change_cb_wrapper:
4.
+ /* check if the filter change callback is supported */
+ if (ctx->callbacks.filter_change_cb == NULL)
+ return false;
+
Other optional callbacks are more terse and just say like below, with
no comment.
if (!ctx->callbacks.truncate_cb)
return;
SUGGESTION (do the same here)
if (!ctx->callbacks.filter_change_cb)
return false;
======
src/backend/replication/logical/reorderbuffer.c
5.
/*
* After encountering a change that cannot be filtered out, filtering is
- * temporarily suspended. Filtering resumes after processing every 100 changes.
+ * temporarily suspended. Filtering resumes after processing
CHANGES_THRESHOLD_FOR_FILTER
+ * changes.
* This strategy helps to minimize the overhead of performing a hash table
* search for each record, especially when most changes are not filterable.
*/
I agree with Shlok. This change seems to belong in patch 0001.
~~~
ReorderBufferFilterByRelFileLocator
6.
ReorderBufferFilterByRelFileLocator(ReorderBuffer *rb, TransactionId xid,
XLogRecPtr lsn, RelFileLocator *rlocator,
ReorderBufferChangeType change_type)
~
The function comment for this says "Returns true if the relation can
be filtered; otherwise, false.". I'm not sure that it is strictly
correct. IMO the comment should explain more about how the return
boolean depends also on the *change_type*. e.g. IIUC you could be able
to filter INSERTS but not filter DELETES even for the same relation.
======
Kind Regards,
Peter Smith.
Fujitsu Australia
Re: Proposal: Filter irrelevant change before reassemble transactions during logical decoding
From
Peter Smith
Date:
Hi Ajin,
Some review comments for patch v16-0003.
======
Patch
1.
mode change 100644 => 100755 src/test/subscription/t/001_rep_changes.pl
What's this mode change for?
======
Commit message
2. missing commit message
======
src/backend/replication/logical/reorderbuffer.c
3.
-#define CHANGES_THRESHOLD_FOR_FILTER 100
+#define CHANGES_THRESHOLD_FOR_FILTER 0
Hmm. You cannot leave a thing like this in the patch because it seems
like just a temporary hack and means the patch cannot be committed in
this form. It needs some kind of more permanent testing solution,
allowing the tests of this patch can executed efficiently, and the
patch pushed, all without impacting the end-user. Maybe consider if
it's possible to have some injection point so the text can "inject" a
zero here (??).
======
src/test/subscription/t/001_rep_changes.pl
4.
# Create new tables on publisher and subscriber
$node_publisher->safe_psql('postgres', "CREATE TABLE pub_table (id int
primary key, data text)");
$node_publisher->safe_psql('postgres', "CREATE TABLE unpub_table (id
int primary key, data text)");
$node_publisher->safe_psql('postgres', "CREATE TABLE insert_only_table
(id int primary key, data text)");
$node_publisher->safe_psql('postgres', "CREATE TABLE delete_only_table
(id int primary key, data text)");
You could combine all those DDLs.
~~~
5.
$node_subscriber->safe_psql('postgres', "CREATE TABLE pub_table (id
int primary key, data text)");
$node_subscriber->safe_psql('postgres', "CREATE TABLE unpub_table (id
int primary key, data text)");
$node_subscriber->safe_psql('postgres', "CREATE TABLE
insert_only_table (id int primary key, data text)");
$node_subscriber->safe_psql('postgres', "CREATE TABLE
delete_only_table (id int primary key, data text)");
5a.
You could combine all those DDLs.
~
5b.
There are double blank lines here.
~~~
6.
# Setup logical replication publications
$node_publisher->safe_psql('postgres', "CREATE PUBLICATION pub_all FOR
TABLE pub_table");
$node_publisher->safe_psql('postgres', "CREATE PUBLICATION
pub_insert_only FOR TABLE insert_only_table WITH (publish = insert)");
$node_publisher->safe_psql('postgres', "CREATE PUBLICATION
pub_delete_only FOR TABLE delete_only_table WITH (publish = delete)");
You could combine all those DDLs.
~~~
7.
# Setup logical replication subscription
$node_subscriber->safe_psql('postgres', "CREATE SUBSCRIPTION sub_all
CONNECTION '$publisher_connstr' PUBLICATION pub_all");
$node_subscriber->safe_psql('postgres', "CREATE SUBSCRIPTION
sub_insert_only CONNECTION '$publisher_connstr' PUBLICATION
pub_insert_only");
$node_subscriber->safe_psql('postgres', "CREATE SUBSCRIPTION
sub_delete_only CONNECTION '$publisher_connstr' PUBLICATION
pub_delete_only");
7a.
comment should be plural /subscription/subscriptions/
~
7b.
You could combine all those DDL.
~~~
8.
# Insert, delete, and update tests for restricted publication tables
$log_location = -s $node_publisher->logfile;
$node_publisher->safe_psql('postgres', "INSERT INTO insert_only_table
VALUES (1, 'to be inserted')");
$node_publisher->safe_psql('postgres', "UPDATE insert_only_table SET
data = 'updated' WHERE id = 1");
$logfile = slurp_file($node_publisher->logfile, $log_location);
ok($logfile =~ qr/Filtering UPDATE/,
'unpublished UPDATE is filtered');
$log_location = -s $node_publisher->logfile;
$node_publisher->safe_psql('postgres', "DELETE FROM insert_only_table
WHERE id = 1");
$logfile = slurp_file($node_publisher->logfile, $log_location);
ok($logfile =~ qr/Filtering DELETE/,
'unpublished DELETE is filtered');
$log_location = -s $node_publisher->logfile;
$node_publisher->safe_psql('postgres', "INSERT INTO delete_only_table
VALUES (1, 'to be deleted')");
$logfile = slurp_file($node_publisher->logfile, $log_location);
ok($logfile =~ qr/Filtering INSERT/,
'unpublished INSERT is filtered');
~
8a.
Maybe it is clearer to say "...for publications with restricted pubactions"
~
8b.
Change the comment or rearrange the tests so they are in the same
order as described
~
8c.
Looking at the expected logs I wondered if it might be nicer for the
pgoutput_filter_change doing this logging to also emit the relation
name.
~~~
9.
+$node_subscriber->safe_psql('postgres', "DROP SUBSCRIPTION sub_all");
+$node_subscriber->safe_psql('postgres', "DROP SUBSCRIPTION sub_insert_only");
+$node_subscriber->safe_psql('postgres', "DROP SUBSCRIPTION sub_delete_only");
+
9a.
You could combine all those DDL
~
9b.
Add some simple comment like "# cleanup"
~
9c.
Any reason why you dropped the subscriptions but not the publications?
======
Kind Regards,
Peter Smith.
Fujitsu Australia
Re: Proposal: Filter irrelevant change before reassemble transactions during logical decoding
From
Ajin Cherian
Date:
On Thu, Apr 3, 2025 at 11:01 PM Shlok Kyal <shlok.kyal.oss@gmail.com> wrote:
>
> Hi Ajin,
>
> I have reviewed patch v16-0001, here are my comments:
>
> 1. There are some places where comments are more than 80 columns
> window. I think it should be <=80 as per [1].
Fixed.
>
> 2. I think, 'rb->unfiltered_changes_count' should be initialised in
> the function 'ReorderBufferAllocate'. While debugging I found that the
> initial value of rb->unfiltered_changes_count is 127. I think it
> should be set to '0' inside 'ReorderBufferAllocate'. Am I missing
> something here?
> I have also added the same comment in point 1. in [2].
>
Fixed.
On Sat, Apr 5, 2025 at 12:34 AM Shlok Kyal <shlok.kyal.oss@gmail.com> wrote:
>
> On Thu, 20 Mar 2025 at 18:09, Ajin Cherian <itsajin@gmail.com> wrote:
> >
> > On Thu, Mar 13, 2025 at 5:49 PM Ajin Cherian <itsajin@gmail.com> wrote:
> > >
> > > Moving this patch to the next CF as this patch needs more design level
> > > inputs which may not be feasible in this CF but do continue to review
> > > the patch.
> > >
> > > regards,
> > > Ajin Cherian
> > > Fujitsu Australia
> >
> > Rebased the patch as it no longer applied.
> >
>
> Hi Ajin,
>
> I reviewed v16-0002 patch, here are my comments:
>
> 1. Guc CHANGES_THRESHOLD_FOR_FILTER was introduced in 0001 patch,
> should this change be in 0001 patch?
>
Fixed.
> - * temporarily suspended. Filtering resumes after processing every 100 changes.
> + * temporarily suspended. Filtering resumes after processing
> CHANGES_THRESHOLD_FOR_FILTER
> + * changes.
>
> 2. Following comment is repeated inside DecodeInsert, DecodeUpdate,
> DecodeDelete, DecodeMultiInsert, DecodeSpecConfirm
> + /*
> + * When filtering changes, determine if the relation associated with the change
> + * can be skipped. This could be because the relation is unlogged or because
> + * the plugin has opted to exclude this relation from decoding.
> + */
> + if (SkipThisChange(ctx, buf->origptr, XLogRecGetXid(r), &target_locator,
>
> Since this comment is the same, should we remove it from the above
> functions and add this where function 'SkipThisChange' is defined?
>
reworded this.
On Thu, Apr 10, 2025 at 2:26 PM Peter Smith <smithpb2250@gmail.com> wrote:
>
> Hi Ajin.
>
> Some review comments for patch v16-0001.
>
> ======
> Commit message
>
> 1.
> A hash cache of relation file locators is implemented to cache whether a
> relation is filterable or not. This ensures that we only need to retrieve
>
> ~
>
> /hash cache/hash table/
>
> (AFAICT you called this a hash table elsewhere in all code comments)
Fixed.
>
> ~~~
>
> 2.
> Additionally, filtering is paused for transactions containing WAL records
> (INTERNAL_SNAPSHOT, COMMAND_ID, or INVALIDATION) that modify the historical
> snapshot constructed during logical decoding. This pause is necessary because
> constructing a correct historical snapshot for searching publication
> information requires processing these WAL records.
>
> ~
>
> IIUC, the "pause" here is really referring to the 100 changes
> following an unfilterable txn. So, I don't think what you are
> describing here is a "pause" -- it is just another reason for the tx
> to be marked unfilterable, and the pause logic will take care of
> itself. So, maybe it should be worded more like
>
> SUGGESTION
> Additionally, transactions containing WAL records (INTERNAL_SNAPSHOT,
> COMMAND_ID, or INVALIDATION) that modify the historical
> snapshot constructed during logical decoding are deemed unfilterable.
> This is necessary because constructing a correct historical snapshot
> for searching publication information requires processing these WAL
> records.
>
Fixed.
> ======
> src/backend/replication/logical/reorderbuffer.c
>
> 3. Header comment.
>
> If you change the commit message based on previous suggestions, then
> change the comment here also to match it.
>
> ~~~
>
> 4.
> +/*
> + * After encountering a change that cannot be filtered out, filtering is
> + * temporarily suspended. Filtering resumes after processing every 100 changes.
> + * This strategy helps to minimize the overhead of performing a hash table
> + * search for each record, especially when most changes are not filterable.
> + */
> +#define CHANGES_THRESHOLD_FOR_FILTER 100
>
> /every 100/the next 100/
>
> ~~~
>
> +ReorderBufferFilterByRelFileLocator:
>
> 5.
> + * if we are decoding a transaction without these records. See comment on top
> + * of GetDecodableRelation() to see list of relations that are not
> + * decoded by the reorderbuffer.
>
> /to see list of relations/to see the kinds of relation/
>
Fixed.
On Fri, Apr 11, 2025 at 1:15 PM Peter Smith <smithpb2250@gmail.com> wrote:
>
> Hi Ajin,
>
> Here is another general review comment for patch 0001.
>
> ~~~
>
> I keep getting confused by the distinction between the 2 member fields
> that are often found working hand-in-hand:
> entry->filterable
> rb->can_filter_change
>
> Unfortunately, because the names are very similar I keep blurring the
> meanings, and then nothing makes sense.
>
> IIUC, the meanings are actually like:
>
> entry->filterable. This means filtering is *possible* for this kind of
> relation; it doesn't mean it will happen though.
>
> rb->can_filter_change. This means the plugin will *try* to filter the
> change; it might do nothing if entry->filterable is false;
> can_filter_change bool is used for the 100 change "temporary
> suspension" logic (e.g. so it if is false we won't even try to filter
> despite entry->filterable is true).
>
> If those meanings are accurate I think some better member names might be:
> entry->filterable
> rb->try_to_filter_change
>
> Also these explanations/distinctions need to be made more clearly in
> the commit message and/of file head comments, as well as where those
> members are defined.
Fixed as recommended.
On Fri, Apr 11, 2025 at 2:21 PM Peter Smith <smithpb2250@gmail.com> wrote:
>
> Hi Ajin,
>
> Some review comments for patch v16-0002.
>
> ======
> doc/src/sgml/logicaldecoding.sgml
>
> 1.
> + To indicate that decoding can be skipped for the given change
> + <parameter>change_type</parameter>, return <literal>true</literal>;
> + <literal>false</literal> otherwise.
>
> /change <parameter>change_type</parameter>/<parameter>change_type</parameter>/
>
> (don't need to say "change" twice)
Fixed.
>
> ======
> src/backend/replication/logical/decode.c
>
> SkipThisChange:
>
> 2.
> +/* Function to determine whether to skip the change */
> +static bool SkipThisChange(LogicalDecodingContext *ctx, XLogRecPtr
> origptr, TransactionId xid,
> + RelFileLocator *target_locator, ReorderBufferChangeType change_type)
> +{
> + return (FilterChangeIsEnabled(ctx) &&
> + ReorderBufferFilterByRelFileLocator(ctx->reorder, xid, origptr,
> target_locator,
> + change_type));
> +}
>
> 2a.
> By convention the function return should be on its own line.
>
> ~
>
> 2b.
> Probably this should be declared *inline* like other functions similar to this?
>
Fixed.
> ~
>
> 2c.
> Consider renaming this function to FilterChange(...). I think that
> might align better with the other functions like
> FilterChangeIsEnabled, FilterByOrigin etc which all refer to
> "filtering" instead of "skipping".
>
Fixed.
> ~~~
>
> 3.
> + /*
> + * When filtering changes, determine if the relation associated with the change
> + * can be skipped. This could be because the relation is unlogged or because
> + * the plugin has opted to exclude this relation from decoding.
> + */
> + if (SkipThisChange(ctx, buf->origptr, XLogRecGetXid(r), &target_locator,
> + REORDER_BUFFER_CHANGE_INSERT))
>
> All these block comments prior to the calls to SkipThisChange seem
> slightly overkill (I think Shlok also reports this). IMO this comment
> can be much simpler:
> e.g.
> Can the relation associated with this change be skipped?
>
> This is repeated in multiple places: DecodeInsert, DecodeUpdate,
> DecodeDelete, DecodeMultiInsert, DecodeSpecConfirm
Fixed.
>
> ======
> src/backend/replication/logical/logical.c
>
> filter_change_cb_wrapper:
>
> 4.
> + /* check if the filter change callback is supported */
> + if (ctx->callbacks.filter_change_cb == NULL)
> + return false;
> +
>
> Other optional callbacks are more terse and just say like below, with
> no comment.
> if (!ctx->callbacks.truncate_cb)
> return;
> SUGGESTION (do the same here)
> if (!ctx->callbacks.filter_change_cb)
> return false;
>
> ======
> src/backend/replication/logical/reorderbuffer.c
>
> 5.
> /*
> * After encountering a change that cannot be filtered out, filtering is
> - * temporarily suspended. Filtering resumes after processing every 100 changes.
> + * temporarily suspended. Filtering resumes after processing
> CHANGES_THRESHOLD_FOR_FILTER
> + * changes.
> * This strategy helps to minimize the overhead of performing a hash table
> * search for each record, especially when most changes are not filterable.
> */
>
> I agree with Shlok. This change seems to belong in patch 0001.
>
Fixed.
> ~~~
>
> ReorderBufferFilterByRelFileLocator
>
> 6.
> ReorderBufferFilterByRelFileLocator(ReorderBuffer *rb, TransactionId xid,
> XLogRecPtr lsn, RelFileLocator *rlocator,
> ReorderBufferChangeType change_type)
> ~
>
> The function comment for this says "Returns true if the relation can
> be filtered; otherwise, false.". I'm not sure that it is strictly
> correct. IMO the comment should explain more about how the return
> boolean depends also on the *change_type*. e.g. IIUC you could be able
> to filter INSERTS but not filter DELETES even for the same relation.
>
Reworded.
On Fri, Apr 11, 2025 at 4:06 PM Peter Smith <smithpb2250@gmail.com> wrote:
>
> Hi Ajin,
>
> Some review comments for patch v16-0003.
>
> ======
> Patch
>
> 1.
> mode change 100644 => 100755 src/test/subscription/t/001_rep_changes.pl
>
> What's this mode change for?
>
Fixed.
> ======
> Commit message
>
> 2. missing commit message
>
> ======
> src/backend/replication/logical/reorderbuffer.c
Fixed.
>
> 3.
> -#define CHANGES_THRESHOLD_FOR_FILTER 100
> +#define CHANGES_THRESHOLD_FOR_FILTER 0
>
> Hmm. You cannot leave a thing like this in the patch because it seems
> like just a temporary hack and means the patch cannot be committed in
> this form. It needs some kind of more permanent testing solution,
> allowing the tests of this patch can executed efficiently, and the
> patch pushed, all without impacting the end-user. Maybe consider if
> it's possible to have some injection point so the text can "inject" a
> zero here (??).
>
Yes, this is currently just a hack before we decide whether throttling
buffer value is correct and whether it should be user configurable.
> ======
> src/test/subscription/t/001_rep_changes.pl
>
> 4.
> # Create new tables on publisher and subscriber
> $node_publisher->safe_psql('postgres', "CREATE TABLE pub_table (id int
> primary key, data text)");
> $node_publisher->safe_psql('postgres', "CREATE TABLE unpub_table (id
> int primary key, data text)");
> $node_publisher->safe_psql('postgres', "CREATE TABLE insert_only_table
> (id int primary key, data text)");
> $node_publisher->safe_psql('postgres', "CREATE TABLE delete_only_table
> (id int primary key, data text)");
>
> You could combine all those DDLs.
>
Fixed all these.
Attached patch v17
regards,
Ajin Cherian
Fujitsu Australia
Attachment
Re: Proposal: Filter irrelevant change before reassemble transactions during logical decoding
From
Peter Smith
Date:
Hi Ajin,
Some review comments for patch v17-0001
======
Commit message
1.
Additionally, transactions containing WAL records (INTERNAL_SNAPSHOT,
COMMAND_ID, or INVALIDATION) that modify the historical snapshot
constructed during logical decoding are deemed unfilterable. This
is necessary because constructing a correct historical snapshot
for searching publication information requires processing these WAL record.
~
/these WAL record./these WAL records./
======
src/backend/replication/logical/reorderbuffer.c
ReorderBufferFilterByRelFileLocator:
2.
+ if (found)
+ {
+ rb->try_to_filter_change = entry->filterable;
+ return entry->filterable;
+ }
+
Bad indentation.
======
src/include/replication/reorderbuffer.h
3.
+extern bool ReorderBufferCanFilterChanges(ReorderBuffer *rb);
+
Why is this extern here? This function is not implemented in patch 0001.
======
Kind Regards,
Peter Smith.
Fujitsu Australia
Re: Proposal: Filter irrelevant change before reassemble transactions during logical decoding
From
Peter Smith
Date:
Hi Ajin,
Some review comments for patch v17-0002.
======
src/backend/replication/logical/decode.c
1.
/*
+ * Check if filtering changes before decoding is supported and we're
not suppressing filter
+ * changes currently.
+ */
+static inline bool
+FilterChangeIsEnabled(LogicalDecodingContext *ctx)
+{
+ return (ctx->callbacks.filter_change_cb != NULL &&
+ ctx->reorder->try_to_filter_change);
+}
+
I still have doubts about the need for/benefits of this to be a
separate function.
It is only called from *one* place within the other static function,
FilterChange.
Just putting that code inline seems just as readable as maintaining
the separate function for it.
SUGGESTION:
static inline bool
FilterChange(LogicalDecodingContext *ctx, XLogRecPtr origptr, TransactionId xid,
RelFileLocator *target_locator, ReorderBufferChangeType
change_type)
{
return
ctx->callbacks.filter_change_cb &&
ctx->reorder->try_to_filter_change &&
ReorderBufferFilterByRelFileLocator(ctx->reorder, xid, origptr,
target_locator,
change_type));
}
======
src/backend/replication/logical/reorderbuffer.c
RelFileLocatorCacheInvalidateCallback:
2.
if (hash_search(RelFileLocatorFilterCache,
- &entry->key,
- HASH_REMOVE,
- NULL) == NULL)
+ &entry->key,
+ HASH_REMOVE,
+ NULL) == NULL)
elog(ERROR, "hash table corrupted");
I think this whitespace change belongs back in patch 0001 where this
function was introduced, not here in patch 0002.
~~~
ReorderBufferFilterByRelFileLocator:
3.
+ /*
+ * Quick return if we already know that the relation is not to be
+ * decoded. These are for special relations that are unlogged and for
+ * sequences and catalogs.
+ */
+ if (entry->filterable)
+ return true;
/These are for/This is for/
~~~
4.
if (RelationIsValid(relation))
{
- entry->relid = RelationGetRelid(relation);
+ if (IsToastRelation(relation))
+ {
+ char *toast_name = RelationGetRelationName(relation);
+ int n PG_USED_FOR_ASSERTS_ONLY;
+
+ n = sscanf(toast_name, "pg_toast_%u", &entry->relid);
+
+ Assert(n == 1);
+ }
+ else
+ entry->relid = RelationGetRelid(relation);
+
entry->filterable = false;
+ rb->try_to_filter_change = rb->filter_change(rb, entry->relid, change_type,
+ true, &cache_valid);
RelationClose(relation);
}
else
{
entry->relid = InvalidOid;
- entry->filterable = true;
+ rb->try_to_filter_change = entry->filterable = true;
}
rb->try_to_filter_change = entry->filterable;
~
Something seems fishy here. AFAICT, the rb->try_to_filter_change will
already be assigned in both the *if* and the *else* blocks. So, why is
it being overwritten again outside that if/else?
======
Kind Regards,
Peter Smith.
Fujitsu Australia
Re: Proposal: Filter irrelevant change before reassemble transactions during logical decoding
From
Peter Smith
Date:
Hi Ajin.
Here are some v17-0003 review comments (aka some v16-0003 comments
that were not yet addressed or rejected)
On Fri, Apr 11, 2025 at 4:05 PM Peter Smith <smithpb2250@gmail.com> wrote:
...
> ======
> Commit message
>
> 2. missing commit message
Not yet addressed.
> ~~~
>
> 8.
> # Insert, delete, and update tests for restricted publication tables
> $log_location = -s $node_publisher->logfile;
> $node_publisher->safe_psql('postgres', "INSERT INTO insert_only_table
> VALUES (1, 'to be inserted')");
> $node_publisher->safe_psql('postgres', "UPDATE insert_only_table SET
> data = 'updated' WHERE id = 1");
> $logfile = slurp_file($node_publisher->logfile, $log_location);
> ok($logfile =~ qr/Filtering UPDATE/,
> 'unpublished UPDATE is filtered');
>
> $log_location = -s $node_publisher->logfile;
> $node_publisher->safe_psql('postgres', "DELETE FROM insert_only_table
> WHERE id = 1");
> $logfile = slurp_file($node_publisher->logfile, $log_location);
> ok($logfile =~ qr/Filtering DELETE/,
> 'unpublished DELETE is filtered');
>
> $log_location = -s $node_publisher->logfile;
> $node_publisher->safe_psql('postgres', "INSERT INTO delete_only_table
> VALUES (1, 'to be deleted')");
> $logfile = slurp_file($node_publisher->logfile, $log_location);
> ok($logfile =~ qr/Filtering INSERT/,
> 'unpublished INSERT is filtered');
>
> ~
...
> 8b.
> Change the comment or rearrange the tests so they are in the same
> order as described
>
The comment was changed, and now says "Insert, update, and delete
tests ..." but still, the "Filtering INSERT" test is last. IMO, that
test should come first to match the comment.
> ~
>
> 8c.
> Looking at the expected logs I wondered if it might be nicer for the
> pgoutput_filter_change doing this logging to also emit the relation
> name.
>
Not yet addressed
======
Kind Regards,
Peter Smith.
Fujitsu Australia
Re: Proposal: Filter irrelevant change before reassemble transactions during logical decoding
From
Ajin Cherian
Date:
On Tue, Apr 22, 2025 at 5:00 PM Peter Smith <smithpb2250@gmail.com> wrote:
>
> Hi Ajin,
>
> Some review comments for patch v17-0001
>
> ======
> Commit message
>
> 1.
> Additionally, transactions containing WAL records (INTERNAL_SNAPSHOT,
> COMMAND_ID, or INVALIDATION) that modify the historical snapshot
> constructed during logical decoding are deemed unfilterable. This
> is necessary because constructing a correct historical snapshot
> for searching publication information requires processing these WAL record.
>
> ~
>
> /these WAL record./these WAL records./
>
Fixed.
> ======
> src/backend/replication/logical/reorderbuffer.c
>
> ReorderBufferFilterByRelFileLocator:
>
> 2.
> + if (found)
> + {
> + rb->try_to_filter_change = entry->filterable;
> + return entry->filterable;
> + }
> +
>
> Bad indentation.
>
Fixed.
> ======
> src/include/replication/reorderbuffer.h
>
> 3.
> +extern bool ReorderBufferCanFilterChanges(ReorderBuffer *rb);
> +
>
> Why is this extern here? This function is not implemented in patch 0001.
>
Fixed.
On Wed, Apr 23, 2025 at 1:11 PM Peter Smith <smithpb2250@gmail.com> wrote:
>
> Hi Ajin,
>
> Some review comments for patch v17-0002.
>
> ======
> src/backend/replication/logical/decode.c
>
> 1.
> /*
> + * Check if filtering changes before decoding is supported and we're
> not suppressing filter
> + * changes currently.
> + */
> +static inline bool
> +FilterChangeIsEnabled(LogicalDecodingContext *ctx)
> +{
> + return (ctx->callbacks.filter_change_cb != NULL &&
> + ctx->reorder->try_to_filter_change);
> +}
> +
>
> I still have doubts about the need for/benefits of this to be a
> separate function.
>
> It is only called from *one* place within the other static function,
> FilterChange.
>
> Just putting that code inline seems just as readable as maintaining
> the separate function for it.
>
> SUGGESTION:
> static inline bool
> FilterChange(LogicalDecodingContext *ctx, XLogRecPtr origptr, TransactionId xid,
> RelFileLocator *target_locator, ReorderBufferChangeType
> change_type)
> {
> return
> ctx->callbacks.filter_change_cb &&
> ctx->reorder->try_to_filter_change &&
> ReorderBufferFilterByRelFileLocator(ctx->reorder, xid, origptr,
> target_locator,
> change_type));
> }
>
>
Fixed.
> ======
> src/backend/replication/logical/reorderbuffer.c
>
> RelFileLocatorCacheInvalidateCallback:
>
> 2.
> if (hash_search(RelFileLocatorFilterCache,
> - &entry->key,
> - HASH_REMOVE,
> - NULL) == NULL)
> + &entry->key,
> + HASH_REMOVE,
> + NULL) == NULL)
> elog(ERROR, "hash table corrupted");
>
> I think this whitespace change belongs back in patch 0001 where this
> function was introduced, not here in patch 0002.
>
Fixed.
> ~~~
>
> ReorderBufferFilterByRelFileLocator:
>
> 3.
> + /*
> + * Quick return if we already know that the relation is not to be
> + * decoded. These are for special relations that are unlogged and for
> + * sequences and catalogs.
> + */
> + if (entry->filterable)
> + return true;
>
> /These are for/This is for/
Fixed.
>
> ~~~
>
> 4.
> if (RelationIsValid(relation))
> {
> - entry->relid = RelationGetRelid(relation);
> + if (IsToastRelation(relation))
> + {
> + char *toast_name = RelationGetRelationName(relation);
> + int n PG_USED_FOR_ASSERTS_ONLY;
> +
> + n = sscanf(toast_name, "pg_toast_%u", &entry->relid);
> +
> + Assert(n == 1);
> + }
> + else
> + entry->relid = RelationGetRelid(relation);
> +
> entry->filterable = false;
> + rb->try_to_filter_change = rb->filter_change(rb, entry->relid, change_type,
> + true, &cache_valid);
> RelationClose(relation);
> }
> else
> {
> entry->relid = InvalidOid;
> - entry->filterable = true;
> + rb->try_to_filter_change = entry->filterable = true;
> }
>
> rb->try_to_filter_change = entry->filterable;
> ~
>
> Something seems fishy here. AFAICT, the rb->try_to_filter_change will
> already be assigned in both the *if* and the *else* blocks. So, why is
> it being overwritten again outside that if/else?
>
Fixed.
On Wed, Apr 23, 2025 at 1:49 PM Peter Smith <smithpb2250@gmail.com> wrote:
>
> Hi Ajin.
>
> Here are some v17-0003 review comments (aka some v16-0003 comments
> that were not yet addressed or rejected)
>
> On Fri, Apr 11, 2025 at 4:05 PM Peter Smith <smithpb2250@gmail.com> wrote:
> ...
> > ======
> > Commit message
> >
> > 2. missing commit message
>
> Not yet addressed.
Fixed.
>
> > ~~~
> >
> > 8.
> > # Insert, delete, and update tests for restricted publication tables
> > $log_location = -s $node_publisher->logfile;
> > $node_publisher->safe_psql('postgres', "INSERT INTO insert_only_table
> > VALUES (1, 'to be inserted')");
> > $node_publisher->safe_psql('postgres', "UPDATE insert_only_table SET
> > data = 'updated' WHERE id = 1");
> > $logfile = slurp_file($node_publisher->logfile, $log_location);
> > ok($logfile =~ qr/Filtering UPDATE/,
> > 'unpublished UPDATE is filtered');
> >
> > $log_location = -s $node_publisher->logfile;
> > $node_publisher->safe_psql('postgres', "DELETE FROM insert_only_table
> > WHERE id = 1");
> > $logfile = slurp_file($node_publisher->logfile, $log_location);
> > ok($logfile =~ qr/Filtering DELETE/,
> > 'unpublished DELETE is filtered');
> >
> > $log_location = -s $node_publisher->logfile;
> > $node_publisher->safe_psql('postgres', "INSERT INTO delete_only_table
> > VALUES (1, 'to be deleted')");
> > $logfile = slurp_file($node_publisher->logfile, $log_location);
> > ok($logfile =~ qr/Filtering INSERT/,
> > 'unpublished INSERT is filtered');
> >
> > ~
> ...
> > 8b.
> > Change the comment or rearrange the tests so they are in the same
> > order as described
> >
>
> The comment was changed, and now says "Insert, update, and delete
> tests ..." but still, the "Filtering INSERT" test is last. IMO, that
> test should come first to match the comment.
>
> > ~
Fixed.
> >
> > 8c.
> > Looking at the expected logs I wondered if it might be nicer for the
> > pgoutput_filter_change doing this logging to also emit the relation
> > name.
> >
>
pgoutupt_filter does not have relation name, I have added a debug
message in reorderbuffer.c and modified the test accordingly.
Updated patchset v18 addressing review comments.
regards,
Ajin Cherian
Fujitsu Australia
Attachment
Re: Proposal: Filter irrelevant change before reassemble transactions during logical decoding
From
Peter Smith
Date:
Hi Ajin.
One comment for the patch set v18-0003..
======
1.
+$log_location = -s $node_publisher->logfile;
+$node_publisher->safe_psql('postgres', "DELETE FROM insert_only_table
WHERE id = 1");
+$node_publisher->wait_for_catchup('sub_all');
+
+$logfile = slurp_file($node_publisher->logfile, $log_location);
+ok($logfile =~ qr/Filtering DELETE/,
+ 'unpublished DELETE is filtered');
+
For this delete filter test, shouldn't there be another log file check
missing here which names the filtered relation? -- e.g. something like
+ok($logfile =~ qr/Filtering change for relation "insert_only_table"/,
+ 'delete for relation insert_only_table is filtered');
======
Kind Regards,
Peter Smith.
Fujitsu Australia
Re: Proposal: Filter irrelevant change before reassemble transactions during logical decoding
From
Ajin Cherian
Date:
Hello, I ran a series of tests using both streaming and non-streaming logical replication modes with the patch. In non-streaming mode, the patch showed a significant performance improvement — up to +68% in the best case, with a -6% regression in the worst case. In contrast, results in streaming mode were more modest. With the default logical_decoding_work_mem of 64MB, I observed a +11.6% improvement at best and a -6.7% degradation at worst. Increasing the work memory provided some incremental improvements: At 128MB: +14.43% (best), -0.65% (worst) At 256MB: +12.55% (best), -0.03% (worst) At 512MB: +16.98% (best), -2.48% (worst) It's worth noting that streaming mode is enabled by default in logical decoding, and as such, it's likely the mode most users and applications are operating in. Non-streaming mode is typically only used in more specialized setups or older deployments. Given this, the broader benefit of the patch - especially considering its complexity, may depend on how widely non-streaming mode is used in practice. I'm sharing these findings in case others are interested in evaluating the patch further. I believe the worst-case performance degradation can be reduced with better code optimization. Feedback is welcome if people believe it’s worthwhile to continue development based on these results. regards, Ajin Cherian Fujitsu Australia
Attachment
{kind=link}
{kind=link}
Re: Proposal: Filter irrelevant change before reassemble transactions during logical decoding
From
Amit Kapila
Date:
On Fri, May 30, 2025 at 4:41 PM Ajin Cherian <itsajin@gmail.com> wrote: > > I ran a series of tests using both streaming and non-streaming logical > replication modes with the patch. In non-streaming mode, the patch > showed a significant performance improvement — up to +68% in the best > case, with a -6% regression in the worst case. > > In contrast, results in streaming mode were more modest. With the > default logical_decoding_work_mem of 64MB, I observed a +11.6% > improvement at best and a -6.7% degradation at worst. Increasing the > work memory provided some incremental improvements: > > At 128MB: +14.43% (best), -0.65% (worst) > > At 256MB: +12.55% (best), -0.03% (worst) > > At 512MB: +16.98% (best), -2.48% (worst) > > It's worth noting that streaming mode is enabled by default in logical > decoding, and as such, it's likely the mode most users and > applications are operating in. Non-streaming mode is typically only > used in more specialized setups or older deployments. Given this, the > broader benefit of the patch - especially considering its complexity, > may depend on how widely non-streaming mode is used in practice. > You haven't shared the exact test scenario, but I am assuming the above tests are for very large transactions, as you are comparing streaming and non-streaming modes. Can we see results with short transaction size (say one insert or one update, or one delete) as well? -- With Regards, Amit Kapila.
Re: Proposal: Filter irrelevant change before reassemble transactions during logical decoding
From
Ajin Cherian
Date:
On Tue, Jun 3, 2025 at 4:25 PM Ajin Cherian <itsajin@gmail.com> wrote: > > On Tue, Jun 3, 2025 at 3:55 PM Amit Kapila <amit.kapila16@gmail.com> wrote: > > > > > > You haven't shared the exact test scenario, but I am assuming the > > above tests are for very large transactions, as you are comparing > > streaming and non-streaming modes. Can we see results with short > > transaction size (say one insert or one update, or one delete) as > > well? > > > > Attaching the scripts I used for my tests. Yes, I used transactions > with large inserts. I will redo the tests with short single inserts > and share the results here. I redid the tests with 10k small transactions (single inserts) and the results are not great with the patch: No transactions published: Patched code performs 12.33% faster than head code. Half transactions published: Patched code is 4.97% slower than head. All transactions published: Patched code is 6.70% slower than head. Attaching the script and the bar graph. regards, Ajin Cherian Fujitsu Australia
Attachment
{kind=link}
Re: Proposal: Filter irrelevant change before reassemble transactions during logical decoding
From
Ajin Cherian
Date:
On Wed, Jun 4, 2025 at 8:22 PM Ajin Cherian <itsajin@gmail.com> wrote: > > On Tue, Jun 3, 2025 at 4:25 PM Ajin Cherian <itsajin@gmail.com> wrote: > > > > On Tue, Jun 3, 2025 at 3:55 PM Amit Kapila <amit.kapila16@gmail.com> wrote: > > > > > > > > > You haven't shared the exact test scenario, but I am assuming the > > > above tests are for very large transactions, as you are comparing > > > streaming and non-streaming modes. Can we see results with short > > > transaction size (say one insert or one update, or one delete) as > > > well? > > > > > > > Attaching the scripts I used for my tests. Yes, I used transactions > > with large inserts. I will redo the tests with short single inserts > > and share the results here. > > I redid the tests with 10k small transactions (single inserts) and the > results are not great with the patch: I did some more tests with 20k and 30k transactions. Results attached. 20k Small Transactions No transactions published: +13.9% improvement Half transactions published: +0.9% improvement All transactions published: +1.4% improvement 30k Small Transactions No transactions published: +15.9% improvement Half transactions published: −1.3% degradation All transactions published: +1.3% improvement regards, Ajin Cherian Fujitsu Australia
{kind=link}