Thread: replication primary writting infinite number of WAL files
Hello,
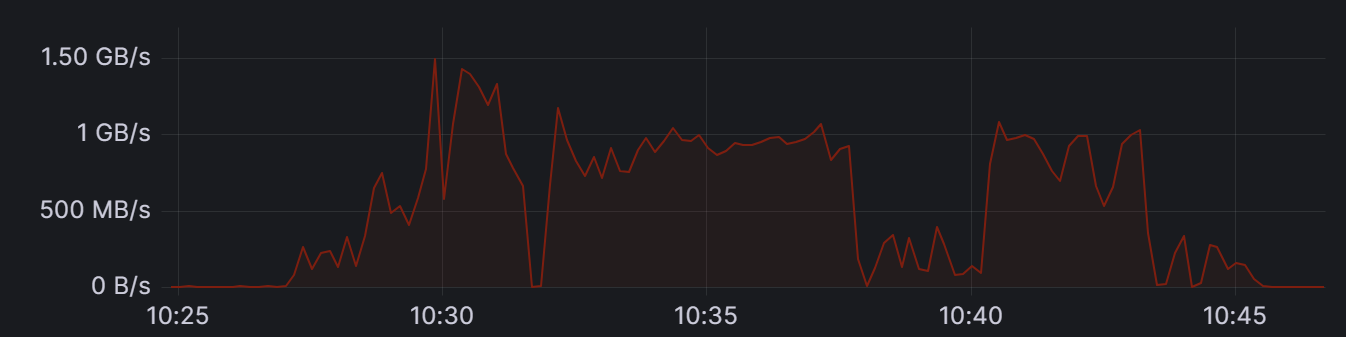
Yesterday we were faced with a problem that we do not understand and cannot solve ourselves. We have a postgresql cluster using repmgr, which has three members. The version of all instances (currently) is "PostgreSQL 14.5 (Debian 14.5-2.pgdg110+2) on x86_64-pc-linux-gnu, compiled by gcc (Debian 10.2.1-6) 10.2.1 20210110, 64-bit.". Under normal circumstances, the number of write operations is relatively low, with an average of 4-5 MB/sec total write speed on the disk associated with the data directory. Yesterday, the primary server suddenly started writing to the pg_wal directory at a crazy pace, 1.5GB/sec, but sometimes it went up to over 3GB/sec. The pg_wal started fattening up and didn't stop until it ran out of disk space. It happened so fast that we didn't have time to react. We then stopped all applications (postgresql clients) because we thought one of them was causing the problem. We then increased the disk size and restarted the primary. The primary finished recovery and started working "normally" for a little while, but then started filling up the disk again. In the meantime, we found out that the WAL files to one of the standbys were not going through. Originally, the (streaming replication) connection was lost due to a network error, later it slowed down and the standby could not keep up with the primary. We then unregistered and disconnected this standby and deleted its replication slot. This caused the primary to delete the unnecessary files from pg_wal and start working normally again. Upon further analysis of the database, we found that we did not see any mass data changes in any of the tables. The only exception is a sequence value that was moved millions of steps within a single minute. Of particular interest is that the sequence value did not increase afterwards; but even though we restarted the primary (without connecting normal clients), it continued to write endless WAL files until we deleted that standby replication slot. It is also interesting that there were two standbys, and dropping one of them "solved" the problem. The other standby could keep up with the writes, and it was also writing out 1.5GB/sec to its disk. Since we needed the third standby, we created a new one (using a fresh pg_basebackup) after completely deleting the old one. This new instance worked for about 12 hours. This morning, the error occurred again, in the same form. Based on our previous experience, we immediately deleted the standby and its replication slot, and the problem resolved itself (except that the standby had to be deleted again). Without rebooting or restarting anything else, the problem went away. I managed to save small part of the pg_wal before deleting the slot. We looked into this, we saw something like this:

We looked at the PostgreSQL release history, and we see some bug fixes in version 14.7 that might have something to do with this:
https://www.postgresql.org/docs/release/14.7/
> Ignore invalidated logical-replication slots while determining oldest catalog xmin (Sirisha Chamarthi) A replication slot could prevent cleanup of dead tuples in the system catalogs even after it becomes invalidated due to exceeding max_slot_wal_keep_size. Thus, failure of a replication consumer could lead to indefinitely-large catalog bloat.
This might not be the problem after all. We don't have enough knowledge and experience to determine the cause of the problem. It is a production system and we should somehow ensure that this won't happen in the future. Also, we would like to add another standby, but we do not want to do this right now, because it seems to be causing the problem (or at least it is strongly correlated).
Thank you,
Laszlo
Attachment
Am 24.11.23 um 12:39 schrieb Les: > > Hello, > > Yesterday we were faced with a problem that we do not understand and > cannot solve ourselves. We have a postgresql cluster using repmgr, > which has three members. The version of all instances (currently) is > "PostgreSQL 14.5 (Debian 14.5-2.pgdg110+2) on x86_64-pc-linux-gnu, > compiled by gcc (Debian 10.2.1-6) 10.2.1 20210110, 64-bit.". Under > normal circumstances, the number of write operations is relatively > low, with an average of 4-5 MB/sec total write speed on the disk > associated with the data directory. Yesterday, the primary server > suddenly started writing to the pg_wal directory at a crazy pace, > 1.5GB/sec, but sometimes it went up to over 3GB/sec. The pg_wal > started fattening up and didn't stop until it ran out of disk space. > please check the database log, a VACUUM can also lead to massive wal generation. Can you find other related messages? by the way, the picture is hard to read, please post text instead of pictures. Regards, Andreas -- Andreas Kretschmer - currently still (garden leave) Technical Account Manager (TAM) www.enterprisedb.com
Am 24.11.23 um 12:39 schrieb Les:
>
> Hello,
>
please check the database log, a VACUUM can also lead to massive wal
generation. Can you find other related messages? by the way, the picture
is hard to read, please post text instead of pictures.
Am 24.11.23 um 13:52 schrieb Les: > > > Andreas Kretschmer <andreas@a-kretschmer.de> wrote (2023. nov. 24., P, > 13:22): > > > > Am 24.11.23 um 12:39 schrieb Les: > > > > Hello, > > > > please check the database log, a VACUUM can also lead to massive wal > generation. Can you find other related messages? by the way, the > picture > is hard to read, please post text instead of pictures. > > > First I was also thinking about vacuum. But removing a replication > slot should have no effect on vacuum on the primary (AFAIK). Please > correct me if I'm wrong. > yeah, depends. there are 2 processes: * 1 process generating the wal's, maybe a VACUUM * an inactive slot holding the wals For instance, if a standby not reachable the wal's will accumulated within the slot, till the standby is reachable again. Andreas -- Andreas Kretschmer - currently still (garden leave) Technical Account Manager (TAM) www.enterprisedb.com
> First I was also thinking about vacuum. But removing a replication
> slot should have no effect on vacuum on the primary (AFAIK). Please
> correct me if I'm wrong.
>
yeah, depends. there are 2 processes:
* 1 process generating the wal's, maybe a VACUUM
* an inactive slot holding the wals
For instance, if a standby not reachable the wal's will accumulated
within the slot, till the standby is reachable again.
On Fri, 2023-11-24 at 12:39 +0100, Les wrote: > Under normal circumstances, the number of write operations is relatively low, with an > average of 4-5 MB/sec total write speed on the disk associated with the data directory. > Yesterday, the primary server suddenly started writing to the pg_wal directory at a > crazy pace, 1.5GB/sec, but sometimes it went up to over 3GB/sec. > [...] > Upon further analysis of the database, we found that we did not see any mass data > changes in any of the tables. The only exception is a sequence value that was moved > millions of steps within a single minute. That looks like some application went crazy and inserted millions of rows, but the inserts were rolled back. But it is hard to be certain with the clues given. Yours, Laurenz Albe
On Fri, 2023-11-24 at 12:39 +0100, Les wrote:
> Under normal circumstances, the number of write operations is relatively low, with an
> average of 4-5 MB/sec total write speed on the disk associated with the data directory.
> Yesterday, the primary server suddenly started writing to the pg_wal directory at a
> crazy pace, 1.5GB/sec, but sometimes it went up to over 3GB/sec.
> [...]
> Upon further analysis of the database, we found that we did not see any mass data
> changes in any of the tables. The only exception is a sequence value that was moved
> millions of steps within a single minute.
That looks like some application went crazy and inserted millions of rows, but the
inserts were rolled back. But it is hard to be certain with the clues given.
Writing of WAL files continued after we shut down all clients, and restarted the primary PostgreSQL server.The order was:1. shut down all clients2. stop the primary3. start the primary4. primary started to write like mad again5. removed replication slot6. primary stopped madness and deleted all WAL files (except for a few)How can the primary server generate more and more WAL files (writes) after all clients have been shut down and the server was restarted? My only bet was the autovacuum. But I ruled that out, because removing a replication slot has no effect on the autovacuum (am I wrong?). Now you are saying that this looks like a huge rollback. Does rolling back changes require even more data to be written to the WAL after server restart? As far as I know, if something was not written to the WAL, then it is not something that can be rolled back. Does removing a replication slot lessen the amount of data needed to be written for a rollback (or for anything else)? It is a fact that the primary stopped writing at 1.5GB/sec the moment we removed the slot.I'm not saying that you are wrong. Maybe there was a crazy application. I'm just saying that a crazy application cannot be the whole picture. It cannot explain this behaviour as a whole. Or maybe I have a deep misunderstanding about how WAL files work. On the second occasion, the primary was running for a few minutes when pg_wal started to increase. We noticed that early, and shut down all clients, then restarted the primary server. After the restart, the primary was writing out more WAL files for many more minutes, until we dropped the slot again. E.g. it was writing much more data after the restart than before the restart; and it only stopped (exactly) when we removed the slot.
On Fri, Nov 24, 2023 at 11:00 AM Les <nagylzs@gmail.com> wrote:[snip]Writing of WAL files continued after we shut down all clients, and restarted the primary PostgreSQL server.The order was:1. shut down all clients2. stop the primary3. start the primary4. primary started to write like mad again5. removed replication slot6. primary stopped madness and deleted all WAL files (except for a few)How can the primary server generate more and more WAL files (writes) after all clients have been shut down and the server was restarted? My only bet was the autovacuum. But I ruled that out, because removing a replication slot has no effect on the autovacuum (am I wrong?). Now you are saying that this looks like a huge rollback. Does rolling back changes require even more data to be written to the WAL after server restart? As far as I know, if something was not written to the WAL, then it is not something that can be rolled back. Does removing a replication slot lessen the amount of data needed to be written for a rollback (or for anything else)? It is a fact that the primary stopped writing at 1.5GB/sec the moment we removed the slot.I'm not saying that you are wrong. Maybe there was a crazy application. I'm just saying that a crazy application cannot be the whole picture. It cannot explain this behaviour as a whole. Or maybe I have a deep misunderstanding about how WAL files work. On the second occasion, the primary was running for a few minutes when pg_wal started to increase. We noticed that early, and shut down all clients, then restarted the primary server. After the restart, the primary was writing out more WAL files for many more minutes, until we dropped the slot again. E.g. it was writing much more data after the restart than before the restart; and it only stopped (exactly) when we removed the slot.pg_stat_activity will tell you something about what's happening even after you think "all clients have been shut down".I'd crank up the logging.to at least:log_error_verbosity = verboselog_statement = alltrack_activity_query_size = 10240client_min_messages = noticelog_line_prefix = '%m\t%r\t%u\t%d\t%p\t%i\t%a\t%e\t'
On 11/24/23 03:39, Les wrote: > Hello, > Yesterday, the primary server suddenly started > writing to the pg_wal directory at a crazy pace, 1.5GB/sec, but > sometimes it went up to over 3GB/sec. The pg_wal started fattening up > and didn't stop until it ran out of disk space. It happened so fast that > we didn't have time to react. We then stopped all applications > (postgresql clients) because we thought one of them was causing the > problem. > The only exception is a sequence > value that was moved millions of steps within a single minute. Of Did you determine this by looking at select * from some_seq? > This new instance worked for about 12 hours. This morning, the > error occurred again, in the same form. Based on our previous > experience, we immediately deleted the standby and its replication slot, > and the problem resolved itself (except that the standby had to be > deleted again). Without rebooting or restarting anything else, the > problem went away. I managed to save small part of the pg_wal before > deleting the slot. We looked into this, we saw something like this: Are the servers open to the world and if so have you explored whether there has been an intrusion? Do you have logs that cover the period from when it transitioned from working normally to going haywire? > We looked at the PostgreSQL release history, and we see some bug fixes > in version 14.7 that might have something to do with this: > > https://www.postgresql.org/docs/release/14.7/ > <https://www.postgresql.org/docs/release/14.7/> > > > Ignore invalidated logical-replication slots while determining oldest > catalog xmin (Sirisha Chamarthi) A replication slot could prevent > cleanup of dead tuples in the system catalogs even after it becomes > invalidated due to exceeding max_slot_wal_keep_size. Thus, failure of a > replication consumer could lead to indefinitely-large catalog bloat. > You are using repmgr which as I understand it uses streaming not logical replication. > Thank you, > > Laszlo > > -- Adrian Klaver adrian.klaver@aklaver.com
On Fri, 2023-11-24 at 16:59 +0100, Les wrote: > > > Laurenz Albe <laurenz.albe@cybertec.at> (2023. nov. 24., P, 16:00): > > On Fri, 2023-11-24 at 12:39 +0100, Les wrote: > > > Under normal circumstances, the number of write operations is relatively low, with an > > > average of 4-5 MB/sec total write speed on the disk associated with the data directory. > > > Yesterday, the primary server suddenly started writing to the pg_wal directory at a > > > crazy pace, 1.5GB/sec, but sometimes it went up to over 3GB/sec. > > > [...] > > > Upon further analysis of the database, we found that we did not see any mass data > > > changes in any of the tables. The only exception is a sequence value that was moved > > > millions of steps within a single minute. > > > > That looks like some application went crazy and inserted millions of rows, but the > > inserts were rolled back. But it is hard to be certain with the clues given. > > Writing of WAL files continued after we shut down all clients, and restarted the primary PostgreSQL server. > > How can the primary server generate more and more WAL files (writes) after all clients have > been shut down and the server was restarted? My only bet was the autovacuum. But I ruled > that out, because removing a replication slot has no effect on the autovacuum (am I wrong?). It must have been autovacuum. Removing a replication slot has an influence, since then autovacuum can do more work. If the problem stopped when you dropped the replication slot, it could be a coincidence. > Now you are saying that this looks like a huge rollback. It could have been many small rollbacks. > Does rolling back changes require even more data to be written to the WAL after server > restart? No. My assumption would be that something generated lots of INSERTs that were all rolled back. That creates WAL, even though you see no change in the table data. > Does removing a replication slot lessen the amount of data needed to be written for > a rollback (or for anything else)? No: the WAL is generated by whatever precedes the ROLLBACK, and the ROLLBACK does not create a lot of WAL. > It is a fact that the primary stopped writing at 1.5GB/sec the moment we removed the slot. I have no explanation for that, except a coincidence. Replication slots don't generate WAL. Yours, Laurenz Albe
On 11/24/23 09:32, Les wrote: Please Reply All to include list Ccing list to get information back there. > > > Adrian Klaver <adrian.klaver@aklaver.com > <mailto:adrian.klaver@aklaver.com>> (2023. nov. 24., P, 17:50): > > On 11/24/23 03:39, Les wrote: > > The only exception is a sequence > > value that was moved millions of steps within a single minute. Of > > Did you determine this by looking at select * from some_seq? > > > select dd, (select max(id) from some_frequently_changed_table where > created < dd) as id > FROM generate_series > ( '2023-11-24 10:50'::timestamp > , '2023-11-22 10:30'::timestamp > , '-1 minute'::interval) dd > ; > > Here is a fragment from the first occasion: > > 2023-11-24 10:31:00.000|182920700600| > 2023-11-24 10:30:00.000|182920700500| > 2023-11-24 10:29:00.000|182920699900| > 2023-11-24 10:28:00.000|182920699900| > 2023-11-24 10:27:00.000|182920699900| > 2023-11-24 10:26:00.000|182920663400| > 2023-11-24 10:25:00.000|182920663400| > 2023-11-24 10:24:00.000|176038405400| > 2023-11-24 10:23:00.000|176038405400| > 2023-11-24 10:22:00.000|176038405400| > 2023-11-24 10:21:00.000|176038405400| > 2023-11-24 10:20:00.000|169819538300| > 2023-11-24 10:19:00.000|169819538300| > 2023-11-24 10:18:00.000|169819538300| > 2023-11-24 10:17:00.000|167912236800| > 2023-11-24 10:16:00.000|164226477100| > 2023-11-24 10:15:00.000|164226477100| > 2023-11-24 10:14:00.000|153516704200| > 2023-11-24 10:13:00.000|153516704200| > 2023-11-24 10:12:00.000|153516704200| > 2023-11-24 10:11:00.000|153516704200| > 2023-11-24 10:10:00.000|153516704200| > 2023-11-24 10:09:00.000|144613764500| > 2023-11-24 10:08:00.000|144613764500| > 2023-11-24 10:07:00.000|144613764500| > 2023-11-24 10:06:00.000|144613764500| > 2023-11-24 10:05:00.000|144312488400| > > Sequence is incremented by 100, so for example, between 2023-11-24 > 10:20:00 and 2023-11-24 10:21:00 it went up 62188671 steps. I think it > is not possible to insert 62188671 rows into a table. A psql function > might be able to increment a sequence 62M times / minute, I'm not sure. > > On the second occasion, there these were the biggest: > > dd |id | > -----------------------+------------+ > 2023-11-24 10:50:00.000|182921196400| > 2023-11-24 10:49:00.000|182921196400| > 2023-11-24 10:48:00.000|182921196400| > 2023-11-24 10:47:00.000|182921196400| > 2023-11-24 10:46:00.000|182921192500| > 2023-11-24 10:45:00.000|182921192500| > 2023-11-24 10:44:00.000|182921192500| > 2023-11-24 10:43:00.000|182921191900| > 2023-11-24 10:42:00.000|182921191300| > 2023-11-24 10:41:00.000|182921189900| > 2023-11-24 10:40:00.000|182921189900| > 2023-11-24 10:39:00.000|182921188100| > 2023-11-24 10:38:00.000|182921188100| > 2023-11-24 10:37:00.000|182921188100| > 2023-11-24 10:36:00.000|182921188100| > 2023-11-24 10:35:00.000|182920838600| > 2023-11-24 10:34:00.000|182920838600| > 2023-11-24 10:33:00.000|182920838600| > 2023-11-24 10:32:00.000|182920838600| > 2023-11-24 10:31:00.000|182920700600| > 2023-11-24 10:30:00.000|182920700500| > > > > Are the servers open to the world and if so have you explored whether > there has been an intrusion? > > They are not open to the world. We did not see any sign of intrusion, > but of course this is possible. > > We are using dev databases that are created from snapshots of the > standby. There is a possibility that a dev database instance (created > from a snapshot of the standby) might have connected the primary just > before it was reconfigured to be standalone. Can this be a problem? > > > Do you have logs that cover the period from when it transitioned from > working normally to going haywire? > > Yes. That log only contains messages saying that "checkpoints are > happening too frequently", nothing else. > > > > > You are using repmgr which as I understand it uses streaming not > logical > replication. > > Yes, we are using streaming replication. -- Adrian Klaver adrian.klaver@aklaver.com
I have no explanation for that, except a coincidence.
Replication slots don't generate WAL.
On 11/24/23 09:51, Adrian Klaver wrote: > On 11/24/23 09:32, Les wrote: > > Please Reply All to include list > Ccing list to get information back there. > >> >> >> Adrian Klaver <adrian.klaver@aklaver.com >> <mailto:adrian.klaver@aklaver.com>> (2023. nov. 24., P, 17:50): >> >> On 11/24/23 03:39, Les wrote: >> > The only exception is a sequence >> > value that was moved millions of steps within a single minute. Of >> >> Did you determine this by looking at select * from some_seq? >> >> >> select dd, (select max(id) from some_frequently_changed_table where >> created < dd) as id >> FROM generate_series >> ( '2023-11-24 10:50'::timestamp >> , '2023-11-22 10:30'::timestamp >> , '-1 minute'::interval) dd >> ; >> >> Here is a fragment from the first occasion: >> >> 2023-11-24 10:31:00.000|182920700600| >> 2023-11-24 10:30:00.000|182920700500| >> 2023-11-24 10:29:00.000|182920699900| >> 2023-11-24 10:28:00.000|182920699900| >> 2023-11-24 10:27:00.000|182920699900| >> 2023-11-24 10:26:00.000|182920663400| >> 2023-11-24 10:25:00.000|182920663400| >> 2023-11-24 10:24:00.000|176038405400| >> 2023-11-24 10:23:00.000|176038405400| >> 2023-11-24 10:22:00.000|176038405400| >> 2023-11-24 10:21:00.000|176038405400| >> 2023-11-24 10:20:00.000|169819538300| >> 2023-11-24 10:19:00.000|169819538300| >> 2023-11-24 10:18:00.000|169819538300| >> 2023-11-24 10:17:00.000|167912236800| >> 2023-11-24 10:16:00.000|164226477100| >> 2023-11-24 10:15:00.000|164226477100| >> 2023-11-24 10:14:00.000|153516704200| >> 2023-11-24 10:13:00.000|153516704200| >> 2023-11-24 10:12:00.000|153516704200| >> 2023-11-24 10:11:00.000|153516704200| >> 2023-11-24 10:10:00.000|153516704200| >> 2023-11-24 10:09:00.000|144613764500| >> 2023-11-24 10:08:00.000|144613764500| >> 2023-11-24 10:07:00.000|144613764500| >> 2023-11-24 10:06:00.000|144613764500| >> 2023-11-24 10:05:00.000|144312488400| >> >> Sequence is incremented by 100, so for example, between 2023-11-24 >> 10:20:00 and 2023-11-24 10:21:00 it went up 62188671 steps. I think it >> is not possible to insert 62188671 rows into a table. A psql function >> might be able to increment a sequence 62M times / minute, I'm not sure. Am I correct in assuming id has as it's default nextval(<the_sequence>)? If so it would seem to me something was doing a lot of INSERTS between 2023-11-24 10:20:00.000 and 2023-11-24 10:21:00.000. And there is nothing in the logs in that time period besides "checkpoints are happening too frequently"? Do you have: https://www.postgresql.org/docs/current/runtime-config-logging.html#RUNTIME-CONFIG-LOGGING-WHAT log_statement set to at least 'mod'? >> We are using dev databases that are created from snapshots of the >> standby. There is a possibility that a dev database instance (created >> from a snapshot of the standby) might have connected the primary just >> before it was reconfigured to be standalone. Can this be a problem? Was your original report for the dev databases also? How are the snapshots being taken? -- Adrian Klaver adrian.klaver@aklaver.com
>> Sequence is incremented by 100, so for example, between 2023-11-24
>> 10:20:00 and 2023-11-24 10:21:00 it went up 62188671 steps. I think it
>> is not possible to insert 62188671 rows into a table. A psql function
>> might be able to increment a sequence 62M times / minute, I'm not sure.
Am I correct in assuming id has as it's default nextval(<the_sequence>)?
If so it would seem to me something was doing a lot of INSERTS between
2023-11-24 10:20:00.000 and 2023-11-24 10:21:00.000.
And there is nothing in the logs in that time period besides "checkpoints are happening too frequently"?
nov 24 10:18:02 docker02 33d8b96b9062[1200]: 2023-11-24 10:18:02.836 CET [296607] WARNING: SET TRANSACTION can only be used in transaction blocks
nov 24 10:18:02 docker02 33d8b96b9062[1200]: 2023-11-24 10:18:02.911 CET [286342] WARNING: SET TRANSACTION can only be used in transaction blocks
nov 24 10:18:02 docker02 33d8b96b9062[1200]: 2023-11-24 10:18:02.990 CET [286342] WARNING: SET TRANSACTION can only be used in transaction blocks
nov 24 10:18:03 docker02 33d8b96b9062[1200]: 2023-11-24 10:18:03.150 CET [296607] WARNING: SET TRANSACTION can only be used in transaction blocks
nov 24 10:18:03 docker02 33d8b96b9062[1200]: 2023-11-24 10:18:03.733 CET [294644] WARNING: SET TRANSACTION can only be used in transaction blocks
nov 24 10:18:03 docker02 33d8b96b9062[1200]: 2023-11-24 10:18:03.741 CET [294644] WARNING: SET TRANSACTION can only be used in transaction blocks
nov 24 10:18:04 docker02 33d8b96b9062[1200]: 2023-11-24 10:18:04.517 CET [35] LOG: checkpoints are occurring too frequently (22 seconds apart)
nov 24 10:18:04 docker02 33d8b96b9062[1200]: 2023-11-24 10:18:04.517 CET [35] HINT: Consider increasing the configuration parameter "max_wal_size".
nov 24 10:18:06 docker02 33d8b96b9062[1200]: 2023-11-24 10:18:06.831 CET [294595] WARNING: SET TRANSACTION can only be used in transaction blocks
nov 24 10:18:07 docker02 33d8b96b9062[1200]: 2023-11-24 10:18:07.096 CET [294595] WARNING: SET TRANSACTION can only be used in transaction blocks
nov 24 10:18:07 docker02 33d8b96b9062[1200]: 2023-11-24 10:18:07.541 CET [271126] WARNING: SET TRANSACTION can only be used in transaction blocks
nov 24 10:18:07 docker02 33d8b96b9062[1200]: 2023-11-24 10:18:07.549 CET [271126] WARNING: SET TRANSACTION can only be used in transaction blocks
nov 24 10:18:17 docker02 33d8b96b9062[1200]: 2023-11-24 10:18:17.335 CET [293994] WARNING: SET TRANSACTION can only be used in transaction blocks
nov 24 10:18:17 docker02 33d8b96b9062[1200]: 2023-11-24 10:18:17.930 CET [293994] WARNING: SET TRANSACTION can only be used in transaction blocks
nov 24 10:18:18 docker02 33d8b96b9062[1200]: 2023-11-24 10:18:18.743 CET [271126] WARNING: SET TRANSACTION can only be used in transaction blocks
nov 24 10:18:18 docker02 33d8b96b9062[1200]: 2023-11-24 10:18:18.750 CET [271126] WARNING: SET TRANSACTION can only be used in transaction blocks
nov 24 10:18:20 docker02 33d8b96b9062[1200]: 2023-11-24 10:18:20.612 CET [296546] WARNING: SET TRANSACTION can only be used in transaction blocks
nov 24 10:18:20 docker02 33d8b96b9062[1200]: 2023-11-24 10:18:20.622 CET [286567] WARNING: SET TRANSACTION can only be used in transaction blocks
nov 24 10:18:20 docker02 33d8b96b9062[1200]: 2023-11-24 10:18:20.623 CET [286567] ERROR: SET TRANSACTION ISOLATION LEVEL must be called before any query
nov 24 10:18:20 docker02 33d8b96b9062[1200]: 2023-11-24 10:18:20.623 CET [286567] STATEMENT: SET TRANSACTION ISOLATION LEVEL REPEATABLE READ
nov 24 10:18:20 docker02 33d8b96b9062[1200]: 2023-11-24 10:18:20.915 CET [296546] WARNING: SET TRANSACTION can only be used in transaction blocks
nov 24 10:18:21 docker02 33d8b96b9062[1200]: 2023-11-24 10:18:21.706 CET [296760] WARNING: SET TRANSACTION can only be used in transaction blocks
nov 24 10:18:21 docker02 33d8b96b9062[1200]: 2023-11-24 10:18:21.890 CET [296760] WARNING: SET TRANSACTION can only be used in transaction blocks
nov 24 10:18:26 docker02 33d8b96b9062[1200]: 2023-11-24 10:18:26.776 CET [35] LOG: checkpoints are occurring too frequently (22 seconds apart)
nov 24 10:18:26 docker02 33d8b96b9062[1200]: 2023-11-24 10:18:26.776 CET [35] HINT: Consider increasing the configuration parameter "max_wal_size".
nov 24 10:18:33 docker02 33d8b96b9062[1200]: 2023-11-24 10:18:33.692 CET [294644] WARNING: SET TRANSACTION can only be used in transaction blocks
nov 24 10:18:33 docker02 33d8b96b9062[1200]: 2023-11-24 10:18:33.701 CET [294644] WARNING: SET TRANSACTION can only be used in transaction blocks
nov 24 10:18:34 docker02 33d8b96b9062[1200]: 2023-11-24 10:18:34.842 CET [292587] WARNING: SET TRANSACTION can only be used in transaction blocks
nov 24 10:18:34 docker02 33d8b96b9062[1200]: 2023-11-24 10:18:34.863 CET [292587] WARNING: SET TRANSACTION can only be used in transaction blocks
nov 24 10:18:36 docker02 33d8b96b9062[1200]: 2023-11-24 10:18:36.709 CET [296759] WARNING: SET TRANSACTION can only be used in transaction blocks
nov 24 10:18:36 docker02 33d8b96b9062[1200]: 2023-11-24 10:18:36.964 CET [296759] WARNING: SET TRANSACTION can only be used in transaction blocks
nov 24 10:18:48 docker02 33d8b96b9062[1200]: 2023-11-24 10:18:48.739 CET [294644] WARNING: SET TRANSACTION can only be used in transaction blocks
nov 24 10:18:48 docker02 33d8b96b9062[1200]: 2023-11-24 10:18:48.750 CET [294644] WARNING: SET TRANSACTION can only be used in transaction blocks
nov 24 10:18:49 docker02 33d8b96b9062[1200]: 2023-11-24 10:18:49.002 CET [35] LOG: checkpoints are occurring too frequently (22 seconds apart)
nov 24 10:18:49 docker02 33d8b96b9062[1200]: 2023-11-24 10:18:49.002 CET [35] HINT: Consider increasing the configuration parameter "max_wal_size".
nov 24 10:18:51 docker02 33d8b96b9062[1200]: 2023-11-24 10:18:51.687 CET [291236] WARNING: SET TRANSACTION can only be used in transaction blocks
nov 24 10:18:51 docker02 33d8b96b9062[1200]: 2023-11-24 10:18:51.897 CET [291236] WARNING: SET TRANSACTION can only be used in transaction blocks
nov 24 10:19:02 docker02 33d8b96b9062[1200]: 2023-11-24 10:19:02.353 CET [269128] WARNING: SET TRANSACTION can only be used in transaction blocks
nov 24 10:19:02 docker02 33d8b96b9062[1200]: 2023-11-24 10:19:02.619 CET [269128] WARNING: SET TRANSACTION can only be used in transaction blocks
nov 24 10:19:04 docker02 33d8b96b9062[1200]: 2023-11-24 10:19:04.463 CET [288875] WARNING: SET TRANSACTION can only be used in transaction blocks
nov 24 10:19:04 docker02 33d8b96b9062[1200]: 2023-11-24 10:19:04.645 CET [288875] WARNING: SET TRANSACTION can only be used in transaction blocks
nov 24 10:19:06 docker02 33d8b96b9062[1200]: 2023-11-24 10:19:06.755 CET [294593] WARNING: SET TRANSACTION can only be used in transaction blocks
nov 24 10:19:06 docker02 33d8b96b9062[1200]: 2023-11-24 10:19:06.974 CET [294593] WARNING: SET TRANSACTION can only be used in transaction blocks
nov 24 10:19:08 docker02 33d8b96b9062[1200]: 2023-11-24 10:19:08.079 CET [296583] WARNING: SET TRANSACTION can only be used in transaction blocks
nov 24 10:19:08 docker02 33d8b96b9062[1200]: 2023-11-24 10:19:08.395 CET [296583] WARNING: SET TRANSACTION can only be used in transaction blocks
nov 24 10:19:11 docker02 33d8b96b9062[1200]: 2023-11-24 10:19:11.320 CET [35] LOG: checkpoints are occurring too frequently (23 seconds apart)
nov 24 10:19:11 docker02 33d8b96b9062[1200]: 2023-11-24 10:19:11.320 CET [35] HINT: Consider increasing the configuration parameter "max_wal_size".
nov 24 10:19:17 docker02 33d8b96b9062[1200]: 2023-11-24 10:19:17.226 CET [300760] WARNING: SET TRANSACTION can only be used in transaction blocks
nov 24 10:19:17 docker02 33d8b96b9062[1200]: 2023-11-24 10:19:17.924 CET [300760] WARNING: SET TRANSACTION can only be used in transaction blocks
nov 24 10:19:19 docker02 33d8b96b9062[1200]: 2023-11-24 10:19:19.351 CET [296581] WARNING: SET TRANSACTION can only be used in transaction blocks
nov 24 10:19:19 docker02 33d8b96b9062[1200]: 2023-11-24 10:19:19.593 CET [296581] WARNING: SET TRANSACTION can only be used in transaction blocks
nov 24 10:19:21 docker02 33d8b96b9062[1200]: 2023-11-24 10:19:21.502 CET [286342] WARNING: SET TRANSACTION can only be used in transaction blocks
nov 24 10:19:21 docker02 33d8b96b9062[1200]: 2023-11-24 10:19:21.602 CET [286342] WARNING: SET TRANSACTION can only be used in transaction blocks
nov 24 10:19:21 docker02 33d8b96b9062[1200]: 2023-11-24 10:19:21.734 CET [286342] WARNING: SET TRANSACTION can only be used in transaction blocks
nov 24 10:19:22 docker02 33d8b96b9062[1200]: 2023-11-24 10:19:22.016 CET [286342] WARNING: SET TRANSACTION can only be used in transaction blocks
nov 24 10:19:23 docker02 33d8b96b9062[1200]: 2023-11-24 10:19:23.541 CET [296982] WARNING: SET TRANSACTION can only be used in transaction blocks
nov 24 10:19:23 docker02 33d8b96b9062[1200]: 2023-11-24 10:19:23.550 CET [296982] WARNING: SET TRANSACTION can only be used in transaction blocks
nov 24 10:19:23 docker02 33d8b96b9062[1200]: 2023-11-24 10:19:23.669 CET [296604] WARNING: SET TRANSACTION can only be used in transaction blocks
nov 24 10:19:24 docker02 33d8b96b9062[1200]: 2023-11-24 10:19:24.032 CET [296604] WARNING: SET TRANSACTION can only be used in transaction blocks
nov 24 10:19:33 docker02 33d8b96b9062[1200]: 2023-11-24 10:19:33.953 CET [288875] WARNING: SET TRANSACTION can only be used in transaction blocks
nov 24 10:19:34 docker02 33d8b96b9062[1200]: 2023-11-24 10:19:34.012 CET [288875] WARNING: SET TRANSACTION can only be used in transaction blocks
nov 24 10:19:34 docker02 33d8b96b9062[1200]: 2023-11-24 10:19:34.058 CET [35] LOG: checkpoints are occurring too frequently (23 seconds apart)
nov 24 10:19:34 docker02 33d8b96b9062[1200]: 2023-11-24 10:19:34.058 CET [35] HINT: Consider increasing the configuration parameter "max_wal_size".
nov 24 10:19:34 docker02 33d8b96b9062[1200]: 2023-11-24 10:19:34.850 CET [292587] WARNING: SET TRANSACTION can only be used in transaction blocks
nov 24 10:19:34 docker02 33d8b96b9062[1200]: 2023-11-24 10:19:34.867 CET [292587] WARNING: SET TRANSACTION can only be used in transaction blocks
nov 24 10:19:36 docker02 33d8b96b9062[1200]: 2023-11-24 10:19:36.675 CET [286342] WARNING: SET TRANSACTION can only be used in transaction blocks
nov 24 10:19:36 docker02 33d8b96b9062[1200]: 2023-11-24 10:19:36.909 CET [286342] WARNING: SET TRANSACTION can only be used in transaction blocks
nov 24 10:19:49 docker02 33d8b96b9062[1200]: 2023-11-24 10:19:49.198 CET [296604] WARNING: SET TRANSACTION can only be used in transaction blocks
nov 24 10:19:49 docker02 33d8b96b9062[1200]: 2023-11-24 10:19:49.258 CET [296604] WARNING: SET TRANSACTION can only be used in transaction blocks
nov 24 10:19:51 docker02 33d8b96b9062[1200]: 2023-11-24 10:19:51.698 CET [296760] WARNING: SET TRANSACTION can only be used in transaction blocks
nov 24 10:19:51 docker02 33d8b96b9062[1200]: 2023-11-24 10:19:51.977 CET [296760] WARNING: SET TRANSACTION can only be used in transaction blocks
nov 24 10:19:56 docker02 33d8b96b9062[1200]: 2023-11-24 10:19:56.160 CET [35] LOG: checkpoints are occurring too frequently (22 seconds apart)
nov 24 10:19:56 docker02 33d8b96b9062[1200]: 2023-11-24 10:19:56.160 CET [35] HINT: Consider increasing the configuration parameter "max_wal_size".
nov 24 10:20:02 docker02 33d8b96b9062[1200]: 2023-11-24 10:20:02.333 CET [296583] WARNING: SET TRANSACTION can only be used in transaction blocks
nov 24 10:20:02 docker02 33d8b96b9062[1200]: 2023-11-24 10:20:02.635 CET [296583] WARNING: SET TRANSACTION can only be used in transaction blocks
nov 24 10:20:04 docker02 33d8b96b9062[1200]: 2023-11-24 10:20:04.151 CET [286569] WARNING: SET TRANSACTION can only be used in transaction blocks
nov 24 10:20:04 docker02 33d8b96b9062[1200]: 2023-11-24 10:20:04.484 CET [286569] WARNING: SET TRANSACTION can only be used in transaction blocks
nov 24 10:20:06 docker02 33d8b96b9062[1200]: 2023-11-24 10:20:06.768 CET [297731] WARNING: SET TRANSACTION can only be used in transaction blocks
nov 24 10:20:07 docker02 33d8b96b9062[1200]: 2023-11-24 10:20:07.044 CET [297731] WARNING: SET TRANSACTION can only be used in transaction blocks
nov 24 10:20:07 docker02 33d8b96b9062[1200]: 2023-11-24 10:20:07.560 CET [292587] WARNING: SET TRANSACTION can only be used in transaction blocks
nov 24 10:20:07 docker02 33d8b96b9062[1200]: 2023-11-24 10:20:07.571 CET [292587] WARNING: SET TRANSACTION can only be used in transaction blocks
nov 24 10:20:17 docker02 33d8b96b9062[1200]: 2023-11-24 10:20:17.070 CET [297731] WARNING: SET TRANSACTION can only be used in transaction blocks
nov 24 10:20:17 docker02 33d8b96b9062[1200]: 2023-11-24 10:20:17.238 CET [297731] WARNING: SET TRANSACTION can only be used in transaction blocks
nov 24 10:20:18 docker02 33d8b96b9062[1200]: 2023-11-24 10:20:18.740 CET [271750] WARNING: SET TRANSACTION can only be used in transaction blocks
nov 24 10:20:18 docker02 33d8b96b9062[1200]: 2023-11-24 10:20:18.751 CET [271750] WARNING: SET TRANSACTION can only be used in transaction blocks
nov 24 10:20:19 docker02 33d8b96b9062[1200]: 2023-11-24 10:20:19.691 CET [35] LOG: checkpoints are occurring too frequently (23 seconds apart)
nov 24 10:20:19 docker02 33d8b96b9062[1200]: 2023-11-24 10:20:19.691 CET [35] HINT: Consider increasing the configuration parameter "max_wal_size".
nov 24 10:20:20 docker02 33d8b96b9062[1200]: 2023-11-24 10:20:20.241 CET [274723] WARNING: SET TRANSACTION can only be used in transaction blocks
nov 24 10:20:20 docker02 33d8b96b9062[1200]: 2023-11-24 10:20:20.289 CET [296982] WARNING: SET TRANSACTION can only be used in transaction blocks
nov 24 10:20:20 docker02 33d8b96b9062[1200]: 2023-11-24 10:20:20.293 CET [274723] WARNING: SET TRANSACTION can only be used in transaction blocks
nov 24 10:20:20 docker02 33d8b96b9062[1200]: 2023-11-24 10:20:20.361 CET [296982] WARNING: SET TRANSACTION can only be used in transaction blocks
nov 24 10:20:21 docker02 33d8b96b9062[1200]: 2023-11-24 10:20:21.707 CET [291236] WARNING: SET TRANSACTION can only be used in transaction blocks
nov 24 10:20:21 docker02 33d8b96b9062[1200]: 2023-11-24 10:20:21.919 CET [291236] WARNING: SET TRANSACTION can only be used in transaction blocks
nov 24 10:20:33 docker02 33d8b96b9062[1200]: 2023-11-24 10:20:33.742 CET [293629] WARNING: SET TRANSACTION can only be used in transaction blocks
nov 24 10:20:33 docker02 33d8b96b9062[1200]: 2023-11-24 10:20:33.756 CET [293629] WARNING: SET TRANSACTION can only be used in transaction blocks
nov 24 10:20:34 docker02 33d8b96b9062[1200]: 2023-11-24 10:20:34.921 CET [294144] WARNING: SET TRANSACTION can only be used in transaction blocks
nov 24 10:20:35 docker02 33d8b96b9062[1200]: 2023-11-24 10:20:35.062 CET [294144] WARNING: SET TRANSACTION can only be used in transaction blocks
nov 24 10:20:36 docker02 33d8b96b9062[1200]: 2023-11-24 10:20:36.796 CET [286342] WARNING: SET TRANSACTION can only be used in transaction blocks
nov 24 10:20:37 docker02 33d8b96b9062[1200]: 2023-11-24 10:20:37.102 CET [286342] WARNING: SET TRANSACTION can only be used in transaction blocks
nov 24 10:20:40 docker02 33d8b96b9062[1200]: 2023-11-24 10:20:40.229 CET [286342] WARNING: SET TRANSACTION can only be used in transaction blocks
nov 24 10:20:40 docker02 33d8b96b9062[1200]: 2023-11-24 10:20:40.399 CET [286342] WARNING: SET TRANSACTION can only be used in transaction blocks
nov 24 10:20:42 docker02 33d8b96b9062[1200]: 2023-11-24 10:20:42.938 CET [35] LOG: checkpoints are occurring too frequently (23 seconds apart)
nov 24 10:20:42 docker02 33d8b96b9062[1200]: 2023-11-24 10:20:42.938 CET [35] HINT: Consider increasing the configuration parameter "max_wal_size".
nov 24 10:20:48 docker02 33d8b96b9062[1200]: 2023-11-24 10:20:48.702 CET [293629] WARNING: SET TRANSACTION can only be used in transaction blocks
nov 24 10:20:48 docker02 33d8b96b9062[1200]: 2023-11-24 10:20:48.721 CET [293629] WARNING: SET TRANSACTION can only be used in transaction blocks
nov 24 10:20:50 docker02 33d8b96b9062[1200]: 2023-11-24 10:20:50.570 CET [286342] WARNING: SET TRANSACTION can only be used in transaction blocks
nov 24 10:20:50 docker02 33d8b96b9062[1200]: 2023-11-24 10:20:50.621 CET [286342] WARNING: SET TRANSACTION can only be used in transaction blocks
nov 24 10:20:51 docker02 33d8b96b9062[1200]: 2023-11-24 10:20:51.694 CET [297732] WARNING: SET TRANSACTION can only be used in transaction blocks
nov 24 10:20:52 docker02 33d8b96b9062[1200]: 2023-11-24 10:20:52.041 CET [297732] WARNING: SET TRANSACTION can only be used in transaction blocks
nov 24 10:18:26 docker02 33d8b96b9062[1200]: 2023-11-24 10:18:26.776 CET [35] LOG: checkpoints are occurring too frequently (22 seconds apart)
nov 24 10:18:49 docker02 33d8b96b9062[1200]: 2023-11-24 10:18:49.002 CET [35] LOG: checkpoints are occurring too frequently (22 seconds apart)
nov 24 10:19:11 docker02 33d8b96b9062[1200]: 2023-11-24 10:19:11.320 CET [35] LOG: checkpoints are occurring too frequently (23 seconds apart)
nov 24 10:19:34 docker02 33d8b96b9062[1200]: 2023-11-24 10:19:34.058 CET [35] LOG: checkpoints are occurring too frequently (23 seconds apart)
nov 24 10:19:56 docker02 33d8b96b9062[1200]: 2023-11-24 10:19:56.160 CET [35] LOG: checkpoints are occurring too frequently (22 seconds apart)
nov 24 10:20:19 docker02 33d8b96b9062[1200]: 2023-11-24 10:20:19.691 CET [35] LOG: checkpoints are occurring too frequently (23 seconds apart)
nov 24 10:20:42 docker02 33d8b96b9062[1200]: 2023-11-24 10:20:42.938 CET [35] LOG: checkpoints are occurring too frequently (23 seconds apart)
nov 24 10:21:06 docker02 33d8b96b9062[1200]: 2023-11-24 10:21:06.356 CET [35] LOG: checkpoints are occurring too frequently (24 seconds apart)
nov 24 10:21:28 docker02 33d8b96b9062[1200]: 2023-11-24 10:21:28.590 CET [35] LOG: checkpoints are occurring too frequently (22 seconds apart)
nov 24 10:21:51 docker02 33d8b96b9062[1200]: 2023-11-24 10:21:51.617 CET [35] LOG: checkpoints are occurring too frequently (23 seconds apart)
nov 24 10:22:14 docker02 33d8b96b9062[1200]: 2023-11-24 10:22:14.530 CET [35] LOG: checkpoints are occurring too frequently (23 seconds apart)
nov 24 10:22:39 docker02 33d8b96b9062[1200]: 2023-11-24 10:22:39.058 CET [35] LOG: checkpoints are occurring too frequently (25 seconds apart)
nov 24 10:23:02 docker02 33d8b96b9062[1200]: 2023-11-24 10:23:02.064 CET [35] LOG: checkpoints are occurring too frequently (23 seconds apart)
nov 24 10:23:25 docker02 33d8b96b9062[1200]: 2023-11-24 10:23:25.382 CET [35] LOG: checkpoints are occurring too frequently (23 seconds apart)
nov 24 10:23:49 docker02 33d8b96b9062[1200]: 2023-11-24 10:23:49.410 CET [35] LOG: checkpoints are occurring too frequently (24 seconds apart)
nov 24 10:28:34 docker02 33d8b96b9062[1200]: 2023-11-24 10:28:34.128 CET [35] LOG: checkpoints are occurring too frequently (19 seconds apart)
nov 24 10:28:49 docker02 33d8b96b9062[1200]: 2023-11-24 10:28:49.073 CET [35] LOG: checkpoints are occurring too frequently (15 seconds apart)
nov 24 10:29:12 docker02 33d8b96b9062[1200]: 2023-11-24 10:29:12.887 CET [35] LOG: checkpoints are occurring too frequently (23 seconds apart)
nov 24 10:29:32 docker02 33d8b96b9062[1200]: 2023-11-24 10:29:32.667 CET [35] LOG: checkpoints are occurring too frequently (20 seconds apart)
nov 24 10:29:43 docker02 33d8b96b9062[1200]: 2023-11-24 10:29:43.824 CET [35] LOG: checkpoints are occurring too frequently (11 seconds apart)
nov 24 10:29:51 docker02 33d8b96b9062[1200]: 2023-11-24 10:29:51.326 CET [35] LOG: checkpoints are occurring too frequently (8 seconds apart)
nov 24 10:30:09 docker02 33d8b96b9062[1200]: 2023-11-24 10:30:09.215 CET [35] LOG: checkpoints are occurring too frequently (18 seconds apart)
nov 24 10:30:16 docker02 33d8b96b9062[1200]: 2023-11-24 10:30:16.547 CET [35] LOG: checkpoints are occurring too frequently (7 seconds apart)
nov 24 10:30:25 docker02 33d8b96b9062[1200]: 2023-11-24 10:30:25.162 CET [35] LOG: checkpoints are occurring too frequently (9 seconds apart)
nov 24 10:30:33 docker02 33d8b96b9062[1200]: 2023-11-24 10:30:33.967 CET [35] LOG: checkpoints are occurring too frequently (8 seconds apart)
nov 24 10:30:43 docker02 33d8b96b9062[1200]: 2023-11-24 10:30:43.040 CET [35] LOG: checkpoints are occurring too frequently (10 seconds apart)
nov 24 10:30:53 docker02 33d8b96b9062[1200]: 2023-11-24 10:30:53.033 CET [35] LOG: checkpoints are occurring too frequently (10 seconds apart)
nov 24 10:31:01 docker02 33d8b96b9062[1200]: 2023-11-24 10:31:01.964 CET [35] LOG: checkpoints are occurring too frequently (8 seconds apart)
nov 24 10:31:16 docker02 33d8b96b9062[1200]: 2023-11-24 10:31:16.476 CET [35] LOG: checkpoints are occurring too frequently (15 seconds apart)
nov 24 10:32:04 docker02 33d8b96b9062[1200]: 2023-11-24 10:32:04.206 CET [35] LOG: checkpoints are occurring too frequently (6 seconds apart)
nov 24 10:32:14 docker02 33d8b96b9062[1200]: 2023-11-24 10:32:14.133 CET [35] LOG: checkpoints are occurring too frequently (10 seconds apart)
nov 24 10:32:24 docker02 33d8b96b9062[1200]: 2023-11-24 10:32:24.615 CET [35] LOG: checkpoints are occurring too frequently (10 seconds apart)
nov 24 10:32:37 docker02 33d8b96b9062[1200]: 2023-11-24 10:32:37.079 CET [35] LOG: checkpoints are occurring too frequently (13 seconds apart)
nov 24 10:32:48 docker02 33d8b96b9062[1200]: 2023-11-24 10:32:48.132 CET [35] LOG: checkpoints are occurring too frequently (11 seconds apart)
nov 24 10:32:59 docker02 33d8b96b9062[1200]: 2023-11-24 10:32:59.177 CET [35] LOG: checkpoints are occurring too frequently (11 seconds apart)
nov 24 10:33:10 docker02 33d8b96b9062[1200]: 2023-11-24 10:33:10.534 CET [35] LOG: checkpoints are occurring too frequently (11 seconds apart)
nov 24 10:33:22 docker02 33d8b96b9062[1200]: 2023-11-24 10:33:22.633 CET [35] LOG: checkpoints are occurring too frequently (12 seconds apart)
nov 24 10:33:34 docker02 33d8b96b9062[1200]: 2023-11-24 10:33:34.379 CET [35] LOG: checkpoints are occurring too frequently (12 seconds apart)
nov 24 10:33:44 docker02 33d8b96b9062[1200]: 2023-11-24 10:33:44.377 CET [35] LOG: checkpoints are occurring too frequently (10 seconds apart)
nov 24 10:33:53 docker02 33d8b96b9062[1200]: 2023-11-24 10:33:53.592 CET [35] LOG: checkpoints are occurring too frequently (9 seconds apart)
nov 24 10:34:04 docker02 33d8b96b9062[1200]: 2023-11-24 10:34:04.271 CET [35] LOG: checkpoints are occurring too frequently (11 seconds apart)
nov 24 10:34:13 docker02 33d8b96b9062[1200]: 2023-11-24 10:34:13.725 CET [35] LOG: checkpoints are occurring too frequently (9 seconds apart)
nov 24 10:34:22 docker02 33d8b96b9062[1200]: 2023-11-24 10:34:22.886 CET [35] LOG: checkpoints are occurring too frequently (9 seconds apart)
nov 24 10:34:32 docker02 33d8b96b9062[1200]: 2023-11-24 10:34:32.705 CET [35] LOG: checkpoints are occurring too frequently (10 seconds apart)
nov 24 10:34:42 docker02 33d8b96b9062[1200]: 2023-11-24 10:34:42.025 CET [35] LOG: checkpoints are occurring too frequently (10 seconds apart)
nov 24 10:34:51 docker02 33d8b96b9062[1200]: 2023-11-24 10:34:51.517 CET [35] LOG: checkpoints are occurring too frequently (9 seconds apart)
nov 24 10:35:01 docker02 33d8b96b9062[1200]: 2023-11-24 10:35:01.632 CET [35] LOG: checkpoints are occurring too frequently (10 seconds apart)
nov 24 10:35:12 docker02 33d8b96b9062[1200]: 2023-11-24 10:35:12.685 CET [35] LOG: checkpoints are occurring too frequently (11 seconds apart)
nov 24 10:35:22 docker02 33d8b96b9062[1200]: 2023-11-24 10:35:22.923 CET [35] LOG: checkpoints are occurring too frequently (10 seconds apart)
nov 24 10:35:32 docker02 33d8b96b9062[1200]: 2023-11-24 10:35:32.703 CET [35] LOG: checkpoints are occurring too frequently (10 seconds apart)
nov 24 10:35:42 docker02 33d8b96b9062[1200]: 2023-11-24 10:35:42.797 CET [35] LOG: checkpoints are occurring too frequently (10 seconds apart)
nov 24 10:35:52 docker02 33d8b96b9062[1200]: 2023-11-24 10:35:52.731 CET [35] LOG: checkpoints are occurring too frequently (10 seconds apart)
nov 24 10:36:02 docker02 33d8b96b9062[1200]: 2023-11-24 10:36:02.355 CET [35] LOG: checkpoints are occurring too frequently (10 seconds apart)
nov 24 10:36:11 docker02 33d8b96b9062[1200]: 2023-11-24 10:36:11.812 CET [35] LOG: checkpoints are occurring too frequently (9 seconds apart)
nov 24 10:36:21 docker02 33d8b96b9062[1200]: 2023-11-24 10:36:21.161 CET [35] LOG: checkpoints are occurring too frequently (10 seconds apart)
nov 24 10:36:30 docker02 33d8b96b9062[1200]: 2023-11-24 10:36:30.837 CET [35] LOG: checkpoints are occurring too frequently (9 seconds apart)
nov 24 10:36:40 docker02 33d8b96b9062[1200]: 2023-11-24 10:36:40.895 CET [35] LOG: checkpoints are occurring too frequently (10 seconds apart)
nov 24 10:36:50 docker02 33d8b96b9062[1200]: 2023-11-24 10:36:50.593 CET [35] LOG: checkpoints are occurring too frequently (10 seconds apart)
nov 24 10:36:59 docker02 33d8b96b9062[1200]: 2023-11-24 10:36:59.814 CET [35] LOG: checkpoints are occurring too frequently (9 seconds apart)
nov 24 10:37:09 docker02 33d8b96b9062[1200]: 2023-11-24 10:37:09.199 CET [35] LOG: checkpoints are occurring too frequently (10 seconds apart)
nov 24 10:37:19 docker02 33d8b96b9062[1200]: 2023-11-24 10:37:19.601 CET [35] LOG: checkpoints are occurring too frequently (10 seconds apart)
nov 24 10:37:29 docker02 33d8b96b9062[1200]: 2023-11-24 10:37:29.818 CET [35] LOG: checkpoints are occurring too frequently (10 seconds apart)
nov 24 10:37:39 docker02 33d8b96b9062[1200]: 2023-11-24 10:37:39.895 CET [35] LOG: checkpoints are occurring too frequently (10 seconds apart)
nov 24 10:40:21 docker02 33d8b96b9062[1200]: 2023-11-24 10:40:21.692 CET [35] LOG: checkpoints are occurring too frequently (10 seconds apart)
nov 24 10:40:33 docker02 33d8b96b9062[1200]: 2023-11-24 10:40:33.105 CET [35] LOG: checkpoints are occurring too frequently (12 seconds apart)
nov 24 10:40:44 docker02 33d8b96b9062[1200]: 2023-11-24 10:40:44.801 CET [35] LOG: checkpoints are occurring too frequently (11 seconds apart)
nov 24 10:40:57 docker02 33d8b96b9062[1200]: 2023-11-24 10:40:57.440 CET [35] LOG: checkpoints are occurring too frequently (13 seconds apart)
nov 24 10:41:07 docker02 33d8b96b9062[1200]: 2023-11-24 10:41:07.943 CET [35] LOG: checkpoints are occurring too frequently (10 seconds apart)
nov 24 10:41:21 docker02 33d8b96b9062[1200]: 2023-11-24 10:41:21.356 CET [35] LOG: checkpoints are occurring too frequently (14 seconds apart)
nov 24 10:41:36 docker02 33d8b96b9062[1200]: 2023-11-24 10:41:36.391 CET [35] LOG: checkpoints are occurring too frequently (15 seconds apart)
nov 24 10:41:49 docker02 33d8b96b9062[1200]: 2023-11-24 10:41:49.293 CET [35] LOG: checkpoints are occurring too frequently (13 seconds apart)
nov 24 10:42:00 docker02 33d8b96b9062[1200]: 2023-11-24 10:42:00.720 CET [35] LOG: checkpoints are occurring too frequently (11 seconds apart)
nov 24 10:42:12 docker02 33d8b96b9062[1200]: 2023-11-24 10:42:12.392 CET [35] LOG: checkpoints are occurring too frequently (12 seconds apart)
nov 24 10:42:30 docker02 33d8b96b9062[1200]: 2023-11-24 10:42:30.657 CET [35] LOG: checkpoints are occurring too frequently (18 seconds apart)
nov 24 10:42:46 docker02 33d8b96b9062[1200]: 2023-11-24 10:42:46.338 CET [35] LOG: checkpoints are occurring too frequently (16 seconds apart)
nov 24 10:42:57 docker02 33d8b96b9062[1200]: 2023-11-24 10:42:57.103 CET [35] LOG: checkpoints are occurring too frequently (11 seconds apart)
nov 24 10:43:09 docker02 33d8b96b9062[1200]: 2023-11-24 10:43:09.618 CET [35] LOG: checkpoints are occurring too frequently (12 seconds apart)
Do you have:
https://www.postgresql.org/docs/current/runtime-config-logging.html#RUNTIME-CONFIG-LOGGING-WHAT
log_statement
set to at least 'mod'?
>> We are using dev databases that are created from snapshots of the
>> standby. There is a possibility that a dev database instance (created
>> from a snapshot of the standby) might have connected the primary just
>> before it was reconfigured to be standalone. Can this be a problem?
Was your original report for the dev databases also?
How are the snapshots being taken?
>> Sequence is incremented by 100, so for example, between 2023-11-24
>> 10:20:00 and 2023-11-24 10:21:00 it went up 62188671 steps. I think it
>> is not possible to insert 62188671 rows into a table. A psql function
>> might be able to increment a sequence 62M times / minute, I'm not sure.
Am I correct in assuming id has as it's default nextval(<the_sequence>)?All primary keys are "id int8 NOT NULL". They don't have a default, but all of these identifiers are generated from the same (global) sequence. We are using a single global sequence, because there are only a few writes. 99% of I/O operations are read.
A single sequence for all id columns across all tables?
How is the sequence value landing in the id column?
If so it would seem to me something was doing a lot of INSERTS between
2023-11-24 10:20:00.000 and 2023-11-24 10:21:00.000.Yes. But is it possible to insert 62M rows within 1 minute?
Is has not been determined yet that 62 million inserts where done, just that the sequence jumped by that number of steps.
It might be possible to "select nextval" 1M times per second from an Pl/SQL function that does nothing else in an infinite loop. But that would not write too much data on the disk.
On an old laptop:
create table insert_test(id int);
insert into insert_test select val from generate_series(1, 1000000) as t(val);
INSERT 0 1000000
Time: 943.918 ms
I would say there is more then just the id being inserted, unless all the other fields allow NULL.
And there is nothing in the logs in that time period besides "checkpoints are happening too frequently"?The "set transaction" warning is due to a bug in an application that calls SET TRANSACTION before starting a transaction.
And what is that app doing when it does SET TRANSACTION?
https://www.postgresql.org/docs/current/runtime-config-logging.html#RUNTIME-CONFIG-LOGGING-WHAT
log_statement
set to at least 'mod'?Unfortunately we don't, but now that you asked, we will turn this on.
>> We are using dev databases that are created from snapshots of the
>> standby. There is a possibility that a dev database instance (created
>> from a snapshot of the standby) might have connected the primary just
>> before it was reconfigured to be standalone. Can this be a problem?
Was your original report for the dev databases also?No, every log and metric was for the prod db.
So how do the dev databases enter into this"
How are the snapshots being taken?zfs snapshot is taken on the standby, then zfs clone is created on the snapshot, and a new postgresql instance is started on top of the clone. It recovers within one minute. In a very few cases (two or three times in a year), it fails to recover. Then we use a different snapshot. When the dev instance starts up, then we immediately delete everything from repmgr nodes, and disable repmgr completely. Today we noticed that the dev db was created in a network that made it possible to connect to the prod primary. (dev db's network was not separated from the prod db's network, fixed today). The dev db might have connected to the prod/primary after startup. But that dev instance was created 7 days ago, so probably it is not related.
What I know about ZFS would fit in the navel of flea, so someone else will have to comment on this.
Dev connected to prod/primary how?
Actually, we need this standby because we are using zfs snapshots for making frequent database backups. Without this standby, we can't make frequent backups. (The primary and the other standby are not using zfs.)Thanks,Laszlo
A single sequence for all id columns across all tables?
How is the sequence value landing in the id column?
It might be possible to "select nextval" 1M times per second from an Pl/SQL function that does nothing else in an infinite loop. But that would not write too much data on the disk.On an old laptop:
create table insert_test(id int);
insert into insert_test select val from generate_series(1, 1000000) as t(val);
INSERT 0 1000000
Time: 943.918 ms
I would say there is more then just the id being inserted, unless all the other fields allow NULL.
And there is nothing in the logs in that time period besides "checkpoints are happening too frequently"?The "set transaction" warning is due to a bug in an application that calls SET TRANSACTION before starting a transaction.And what is that app doing when it does SET TRANSACTION?
How are the snapshots being taken?zfs snapshot is taken on the standby, then zfs clone is created on the snapshot, and a new postgresql instance is started on top of the clone. It recovers within one minute. In a very few cases (two or three times in a year), it fails to recover. Then we use a different snapshot. When the dev instance starts up, then we immediately delete everything from repmgr nodes, and disable repmgr completely. Today we noticed that the dev db was created in a network that made it possible to connect to the prod primary. (dev db's network was not separated from the prod db's network, fixed today). The dev db might have connected to the prod/primary after startup. But that dev instance was created 7 days ago, so probably it is not related.What I know about ZFS would fit in the navel of flea, so someone else will have to comment on this.
Dev connected to prod/primary how?
On 11/24/23 14:01, Les wrote: > > A single sequence for all id columns across all tables? > > How is the sequence value landing in the id column? > > In most cases it is by using "nextval(seq_name)" in the SQL statement. > But sometimes the sequence value is taken first, and then multiple > inserts are sent with fixed increasing values. (Sometimes records > reference each other, such records are inserted within a short > transaction with deferred foreign key constraints.) Leaving the reasoning behind this alone, the important part is that in order for the id values to jump like they did there was intensive processing of queries going on. That would be one thing you should track down, what kicked that off and why? > It is the main app that is using the database, using jdbc. Multiple > instances were running when the sequence jumped. Multiple instances of the app or something else? What where the instances doing? > When the dev db starts up (from the cloned data directory), it still has > the old repmgr conf. That config is deleted, and repmgr is disabled > right after the startup, but there is the possibility that the dev db > has connected the primary when it was cloned (7 days ago), because at > the beginning of startup, it is the exact clone of the standby from a > previous point of time. Hmm, that does not look good. At this point I would create a new post/thread where you organize the bits an pieces that you have posted over the course of this thread into a something more coherent. In particular a time line of the whole cloning/replication process. > > Laszlo -- Adrian Klaver adrian.klaver@aklaver.com
On 2023-11-24 22:05:12 +0100, Les wrote:
> And there is nothing in the logs in that time period besides "checkpoints
> are happening too frequently"?
>
>
>
> Here are all the logs we have from that minute.
>
> ╰─# journalctl CONTAINER_ID=33d8b96b9062 --since '2023-11-24 10:18:00' --until
> '2023-11-24 10:21:00.000'
[citing only the "checkpoints are occurring too frequently" entries:]
> nov 24 10:18:04 docker02 33d8b96b9062[1200]: 2023-11-24 10:18:04.517 CET [35] > LOG: checkpoints are occurring too
frequently(22 seconds apart)
> nov 24 10:18:26 docker02 33d8b96b9062[1200]: 2023-11-24 10:18:26.776 CET [35] > LOG: checkpoints are occurring too
frequently(22 seconds apart)
> nov 24 10:18:49 docker02 33d8b96b9062[1200]: 2023-11-24 10:18:49.002 CET [35] > LOG: checkpoints are occurring too
frequently(22 seconds apart)
> nov 24 10:19:11 docker02 33d8b96b9062[1200]: 2023-11-24 10:19:11.320 CET [35] > LOG: checkpoints are occurring too
frequently(23 seconds apart)
> nov 24 10:19:34 docker02 33d8b96b9062[1200]: 2023-11-24 10:19:34.058 CET [35] > LOG: checkpoints are occurring too
frequently(23 seconds apart)
> nov 24 10:19:56 docker02 33d8b96b9062[1200]: 2023-11-24 10:19:56.160 CET [35] > LOG: checkpoints are occurring too
frequently(22 seconds apart)
> nov 24 10:20:19 docker02 33d8b96b9062[1200]: 2023-11-24 10:20:19.691 CET [35] > LOG: checkpoints are occurring too
frequently(23 seconds apart)
> nov 24 10:20:42 docker02 33d8b96b9062[1200]: 2023-11-24 10:20:42.938 CET [35] > LOG: checkpoints are occurring too
frequently(23 seconds apart)
Interesting. If the database writes 1.5 GB/s of WALs and max_wal_size is
the default of 1GB, shouldn't there be a checkpoint about every 0.7
seconds instead of just every 22 seconds?
hp
--
_ | Peter J. Holzer | Story must make more sense than reality.
|_|_) | |
| | | hjp@hjp.at | -- Charles Stross, "Creative writing
__/ | http://www.hjp.at/ | challenge!"
Attachment
> nov 24 10:20:19 docker02 33d8b96b9062[1200]: 2023-11-24 10:20:19.691 CET [35] > LOG: checkpoints are occurring too frequently (23 seconds apart)
> nov 24 10:20:42 docker02 33d8b96b9062[1200]: 2023-11-24 10:20:42.938 CET [35] > LOG: checkpoints are occurring too frequently (23 seconds apart)
Interesting. If the database writes 1.5 GB/s of WALs and max_wal_size is
the default of 1GB, shouldn't there be a checkpoint about every 0.7
seconds instead of just every 22 seconds?