Thread: heavily contended lwlocks with long wait queues scale badly
Hi,
I am working on posting a patch series making relation extension more
scalable. As part of that I was running some benchmarks for workloads that I
thought should not or just positively impacted - but I was wrong, there was
some very significant degradation at very high client counts. After pulling my
hair out for quite a while to try to understand that behaviour, I figured out
that it's just a side-effect of *removing* some other contention. This
morning, turns out sleeping helps, I managed to reproduce it in an unmodified
postgres.
$ cat ~/tmp/txid.sql
SELECT txid_current();
$ for c in 1 2 4 8 16 32 64 128 256 512 768 1024 2048 4096; do echo -n "$c ";pgbench -n -M prepared -f ~/tmp/txid.sql
-c$c-j$c -T5 2>&1|grep '^tps'|awk '{print $3}';done
1 60174
2 116169
4 208119
8 373685
16 515247
32 554726
64 497508
128 415097
256 334923
512 243679
768 192959
1024 157734
2048 82904
4096 32007
(I didn't properly round TPS, but that doesn't matter here)
Performance completely falls off a cliff starting at ~256 clients. There's
actually plenty CPU available here, so this isn't a case of running out of
CPU time.
Rather, the problem is very bad contention on the "spinlock" for the lwlock
wait list. I realized that something in that direction was off when trying to
investigate why I was seeing spin delays of substantial duration (>100ms).
The problem isn't a fundamental issue with lwlocks, it's that
LWLockDequeueSelf() does this:
LWLockWaitListLock(lock);
/*
* Can't just remove ourselves from the list, but we need to iterate over
* all entries as somebody else could have dequeued us.
*/
proclist_foreach_modify(iter, &lock->waiters, lwWaitLink)
{
if (iter.cur == MyProc->pgprocno)
{
found = true;
proclist_delete(&lock->waiters, iter.cur, lwWaitLink);
break;
}
}
I.e. it iterates over the whole waitlist to "find itself". The longer the
waitlist gets, the longer this takes. And the longer it takes for
LWLockWakeup() to actually wake up all waiters, the more likely it becomes
that LWLockDequeueSelf() needs to be called.
We can't make the trivial optimization and use proclist_contains(), because
PGPROC->lwWaitLink is also used for the list of processes to wake up in
LWLockWakeup().
But I think we can solve that fairly reasonably nonetheless. We can change
PGPROC->lwWaiting to not just be a boolean, but have three states:
0: not waiting
1: waiting in waitlist
2: waiting to be woken up
which we then can use in LWLockDequeueSelf() to only remove ourselves from the
list if we're on it. As removal from that list is protected by the wait list
lock, there's no race to worry about.
client patched HEAD
1 60109 60174
2 112694 116169
4 214287 208119
8 377459 373685
16 524132 515247
32 565772 554726
64 587716 497508
128 581297 415097
256 550296 334923
512 486207 243679
768 449673 192959
1024 410836 157734
2048 326224 82904
4096 250252 32007
Not perfect with the patch, but not awful either.
I suspect this issue might actually explain quite a few odd performance
behaviours we've seen at the larger end in the past. I think it has gotten a
bit worse with the conversion of lwlock.c to proclists (I see lots of
expensive multiplications to deal with sizeof(PGPROC)), but otherwise likely
exists at least as far back as ab5194e6f61, in 9.5.
I guess there's an argument for considering this a bug that we should
backpatch a fix for? But given the vintage, probably not? The only thing that
gives me pause is that this is quite hard to pinpoint as happening.
I've attached my quick-and-dirty patch. Obviously it'd need a few defines etc,
but I wanted to get this out to discuss before spending further time.
Greetings,
Andres Freund
Attachment
At Thu, 27 Oct 2022 09:59:14 -0700, Andres Freund <andres@anarazel.de> wrote in > But I think we can solve that fairly reasonably nonetheless. We can change > PGPROC->lwWaiting to not just be a boolean, but have three states: > 0: not waiting > 1: waiting in waitlist > 2: waiting to be woken up > > which we then can use in LWLockDequeueSelf() to only remove ourselves from the > list if we're on it. As removal from that list is protected by the wait list > lock, there's no race to worry about. Since LWLockDequeueSelf() is defined to be called in some restricted situation, there's no chance that the proc to remove is in another lock waiters list at the time the function is called. So it seems to work well. It is simple and requires no additional memory or cycles... No. It enlarges PRPC by 8 bytes, but changing lwWaiting to int8/uint8 keeps the size as it is. (Rocky8/x86-64) It just shaves off looping cycles. So +1 for what the patch does. > client patched HEAD > 1 60109 60174 > 2 112694 116169 > 4 214287 208119 > 8 377459 373685 > 16 524132 515247 > 32 565772 554726 > 64 587716 497508 > 128 581297 415097 > 256 550296 334923 > 512 486207 243679 > 768 449673 192959 > 1024 410836 157734 > 2048 326224 82904 > 4096 250252 32007 > > Not perfect with the patch, but not awful either. Fairly good? Agreed. The performance peak is improved by 6% and shifted to larger number of clients (32->128). > I suspect this issue might actually explain quite a few odd performance > behaviours we've seen at the larger end in the past. I think it has gotten a > bit worse with the conversion of lwlock.c to proclists (I see lots of > expensive multiplications to deal with sizeof(PGPROC)), but otherwise likely > exists at least as far back as ab5194e6f61, in 9.5. > > I guess there's an argument for considering this a bug that we should > backpatch a fix for? But given the vintage, probably not? The only thing that > gives me pause is that this is quite hard to pinpoint as happening. I don't think this is a bug but I think it might be back-patchable since it doesn't change memory footprint (if adjusted), causes no additional cost or interfarce breakage, thus it might be ok to backpatch. Since this "bug" has the nature of positive-feedback so reducing the coefficient is benetifical than the direct cause of the change. > I've attached my quick-and-dirty patch. Obviously it'd need a few defines etc, > but I wanted to get this out to discuss before spending further time. regards. -- Kyotaro Horiguchi NTT Open Source Software Center
On Mon, Oct 31, 2022 at 11:03 AM Kyotaro Horiguchi <horikyota.ntt@gmail.com> wrote: > > At Thu, 27 Oct 2022 09:59:14 -0700, Andres Freund <andres@anarazel.de> wrote in > > But I think we can solve that fairly reasonably nonetheless. We can change > > PGPROC->lwWaiting to not just be a boolean, but have three states: > > 0: not waiting > > 1: waiting in waitlist > > 2: waiting to be woken up > > > > which we then can use in LWLockDequeueSelf() to only remove ourselves from the > > list if we're on it. As removal from that list is protected by the wait list > > lock, there's no race to worry about. This looks like a good idea. > No. It enlarges PRPC by 8 bytes, but changing lwWaiting to int8/uint8 > keeps the size as it is. (Rocky8/x86-64) I agree > It just shaves off looping cycles. So +1 for what the patch does. > > > > client patched HEAD > > 1 60109 60174 > > 2 112694 116169 > > 4 214287 208119 > > 8 377459 373685 > > 16 524132 515247 > > 32 565772 554726 > > 64 587716 497508 > > 128 581297 415097 > > 256 550296 334923 > > 512 486207 243679 > > 768 449673 192959 > > 1024 410836 157734 > > 2048 326224 82904 > > 4096 250252 32007 > > > > Not perfect with the patch, but not awful either. > > Fairly good? Agreed. The performance peak is improved by 6% and > shifted to larger number of clients (32->128). > The performance result is promising so +1 -- Regards, Dilip Kumar EnterpriseDB: http://www.enterprisedb.com
On Thu, Oct 27, 2022 at 10:29 PM Andres Freund <andres@anarazel.de> wrote: > > But I think we can solve that fairly reasonably nonetheless. We can change > PGPROC->lwWaiting to not just be a boolean, but have three states: > 0: not waiting > 1: waiting in waitlist > 2: waiting to be woken up > > which we then can use in LWLockDequeueSelf() to only remove ourselves from the > list if we're on it. As removal from that list is protected by the wait list > lock, there's no race to worry about. > > client patched HEAD > 1 60109 60174 > 2 112694 116169 > 4 214287 208119 > 8 377459 373685 > 16 524132 515247 > 32 565772 554726 > 64 587716 497508 > 128 581297 415097 > 256 550296 334923 > 512 486207 243679 > 768 449673 192959 > 1024 410836 157734 > 2048 326224 82904 > 4096 250252 32007 > > Not perfect with the patch, but not awful either. Here are results from my testing [1]. Results look impressive with the patch at a higher number of clients, for instance, on HEAD TPS with 1024 clients is 103587 whereas it is 248702 with the patch. HEAD, run 1: 1 34534 2 72088 4 135249 8 213045 16 243507 32 304108 64 375148 128 390658 256 345503 512 284510 768 146417 1024 103587 2048 34702 4096 12450 HEAD, run 2: 1 34110 2 72403 4 134421 8 211263 16 241606 32 295198 64 353580 128 385147 256 341672 512 295001 768 142341 1024 97721 2048 30229 4096 13179 PATCHED, run 1: 1 34412 2 71733 4 139141 8 211526 16 241692 32 308198 64 406198 128 385643 256 338464 512 295559 768 272639 1024 248702 2048 191402 4096 112074 PATCHED, run 2: 1 34087 2 73567 4 135624 8 211901 16 242819 32 310534 64 352663 128 381780 256 342483 512 301968 768 272596 1024 251014 2048 184939 4096 108186 > I've attached my quick-and-dirty patch. Obviously it'd need a few defines etc, > but I wanted to get this out to discuss before spending further time. Just for the record, here are some review comments posted in the other thread - https://www.postgresql.org/message-id/CALj2ACXktNbG%3DK8Xi7PSqbofTZozavhaxjatVc14iYaLu4Maag%40mail.gmail.com.. BTW, I've seen a sporadic crash (SEGV) with the patch in bg writer with the same set up [1], I'm not sure if it's really because of the patch. I'm unable to reproduce it now and unfortunately I didn't capture further details when it occurred. [1] ./configure --prefix=$PWD/inst/ --enable-tap-tests CFLAGS="-O3" > install.log && make -j 8 install > install.log 2>&1 & shared_buffers = 8GB max_wal_size = 32GB max_connections = 4096 checkpoint_timeout = 10min ubuntu: cat << EOF >> txid.sql SELECT txid_current(); EOF ubuntu: for c in 1 2 4 8 16 32 64 128 256 512 768 1024 2048 4096; do echo -n "$c ";./pgbench -n -M prepared -U ubuntu postgres -f txid.sql -c$c -j$c -T5 2>&1|grep '^tps'|awk '{print $3}';done -- Bharath Rupireddy PostgreSQL Contributors Team RDS Open Source Databases Amazon Web Services: https://aws.amazon.com
I was working on optimizing the LWLock queue in a little different way and I also did a benchmarking of Andres' original patch from this thread. [1] The results are quite impressive, indeed. Please feel free to see the results and join the discussion in [1] if you want. Best regards, Pavel [1] https://www.postgresql.org/message-id/flat/CALT9ZEEz%2B%3DNepc5eti6x531q64Z6%2BDxtP3h-h_8O5HDdtkJcPw%40mail.gmail.com
Hi Andres, Thank you for your patch. The results are impressive. On Mon, Oct 31, 2022 at 2:10 PM Pavel Borisov <pashkin.elfe@gmail.com> wrote: > > I was working on optimizing the LWLock queue in a little different way > and I also did a benchmarking of Andres' original patch from this > thread. [1] > The results are quite impressive, indeed. Please feel free to see the > results and join the discussion in [1] if you want. > > Best regards, > Pavel > > [1] https://www.postgresql.org/message-id/flat/CALT9ZEEz%2B%3DNepc5eti6x531q64Z6%2BDxtP3h-h_8O5HDdtkJcPw%40mail.gmail.com Pavel posted a patch implementing a lock-less queue for LWLock. The results are interesting indeed, but slightly lower than your current patch have. The current Pavel's patch probably doesn't utilize the full potential of lock-less idea. I wonder what do you think about this direction? We would be grateful for your guidance. Thank you. ------ Regards, Alexander Korotkov
On Thu, Oct 27, 2022 at 12:59 PM Andres Freund <andres@anarazel.de> wrote: > After pulling my > hair out for quite a while to try to understand that behaviour, I figured out > that it's just a side-effect of *removing* some other contention. I've seen this kind of pattern on multiple occasions. I don't know if they were all caused by this, or what, but I certainly like the idea of making it better. -- Robert Haas EDB: http://www.enterprisedb.com
Hi, On 2022-10-31 16:21:06 +0530, Bharath Rupireddy wrote: > BTW, I've seen a sporadic crash (SEGV) with the patch in bg writer > with the same set up [1], I'm not sure if it's really because of the > patch. I'm unable to reproduce it now and unfortunately I didn't > capture further details when it occurred. That's likely because the prototype patch I submitted in this thread missed updating LWLockUpdateVar(). Updated patch attached. Greetings, Andres Freund
Attachment
On Mon, Oct 31, 2022 at 4:51 PM Andres Freund <andres@anarazel.de> wrote:
Hi,
On 2022-10-31 16:21:06 +0530, Bharath Rupireddy wrote:
> BTW, I've seen a sporadic crash (SEGV) with the patch in bg writer
> with the same set up [1], I'm not sure if it's really because of the
> patch. I'm unable to reproduce it now and unfortunately I didn't
> capture further details when it occurred.
That's likely because the prototype patch I submitted in this thread missed
updating LWLockUpdateVar().
Updated patch attached.
Greetings,
Andres Freund
Hi,
Minor comment:
+ uint8 lwWaiting; /* see LWLockWaitState */
Why not declare `lwWaiting` of type LWLockWaitState ?
Cheers
Hi, On 2022-10-31 17:17:03 -0700, Zhihong Yu wrote: > On Mon, Oct 31, 2022 at 4:51 PM Andres Freund <andres@anarazel.de> wrote: > > > Hi, > > > > On 2022-10-31 16:21:06 +0530, Bharath Rupireddy wrote: > > > BTW, I've seen a sporadic crash (SEGV) with the patch in bg writer > > > with the same set up [1], I'm not sure if it's really because of the > > > patch. I'm unable to reproduce it now and unfortunately I didn't > > > capture further details when it occurred. > > > > That's likely because the prototype patch I submitted in this thread missed > > updating LWLockUpdateVar(). > > > > Updated patch attached. > > > > Greetings, > > > > Andres Freund > > > > Hi, > Minor comment: > > + uint8 lwWaiting; /* see LWLockWaitState */ > > Why not declare `lwWaiting` of type LWLockWaitState ? Unfortunately C99 (*) doesn't allow to specify the width of an enum field. With most compilers we'd end up using 4 bytes. Greetings, Andres Freund (*) C++ has allowed specifying this for quite a few years now and I think C23 will support it too, but that doesn't help us at this point.
On Mon, Oct 31, 2022 at 5:19 PM Andres Freund <andres@anarazel.de> wrote:
Hi,
On 2022-10-31 17:17:03 -0700, Zhihong Yu wrote:
> On Mon, Oct 31, 2022 at 4:51 PM Andres Freund <andres@anarazel.de> wrote:
>
> > Hi,
> >
> > On 2022-10-31 16:21:06 +0530, Bharath Rupireddy wrote:
> > > BTW, I've seen a sporadic crash (SEGV) with the patch in bg writer
> > > with the same set up [1], I'm not sure if it's really because of the
> > > patch. I'm unable to reproduce it now and unfortunately I didn't
> > > capture further details when it occurred.
> >
> > That's likely because the prototype patch I submitted in this thread missed
> > updating LWLockUpdateVar().
> >
> > Updated patch attached.
> >
> > Greetings,
> >
> > Andres Freund
> >
>
> Hi,
> Minor comment:
>
> + uint8 lwWaiting; /* see LWLockWaitState */
>
> Why not declare `lwWaiting` of type LWLockWaitState ?
Unfortunately C99 (*) doesn't allow to specify the width of an enum
field. With most compilers we'd end up using 4 bytes.
Greetings,
Andres Freund
(*) C++ has allowed specifying this for quite a few years now and I think C23
will support it too, but that doesn't help us at this point.
Hi,
Thanks for the response.
If possible, it would be better to put your explanation in the code comment (so that other people know the reasoning).
On Tue, Nov 1, 2022 at 5:21 AM Andres Freund <andres@anarazel.de> wrote:
>
> On 2022-10-31 16:21:06 +0530, Bharath Rupireddy wrote:
> > BTW, I've seen a sporadic crash (SEGV) with the patch in bg writer
> > with the same set up [1], I'm not sure if it's really because of the
> > patch. I'm unable to reproduce it now and unfortunately I didn't
> > capture further details when it occurred.
>
> That's likely because the prototype patch I submitted in this thread missed
> updating LWLockUpdateVar().
>
> Updated patch attached.
Thanks. It looks good to me. However, some minor comments on the v3 patch:
1.
- if (MyProc->lwWaiting)
+ if (MyProc->lwWaiting != LW_WS_NOT_WAITING)
elog(PANIC, "queueing for lock while waiting on another one");
Can the above condition be MyProc->lwWaiting == LW_WS_WAITING ||
MyProc->lwWaiting == LW_WS_PENDING_WAKEUP for better readability?
Or add an assertion Assert(MyProc->lwWaiting != LW_WS_WAITING &&
MyProc->lwWaiting != LW_WS_PENDING_WAKEUP); before setting
LW_WS_WAITING?
2.
/* Awaken any waiters I removed from the queue. */
proclist_foreach_modify(iter, &wakeup, lwWaitLink)
{
@@ -1044,7 +1052,7 @@ LWLockWakeup(LWLock *lock)
* another lock.
*/
pg_write_barrier();
- waiter->lwWaiting = false;
+ waiter->lwWaiting = LW_WS_NOT_WAITING;
PGSemaphoreUnlock(waiter->sem);
}
/*
* Awaken any waiters I removed from the queue.
*/
proclist_foreach_modify(iter, &wakeup, lwWaitLink)
{
PGPROC *waiter = GetPGProcByNumber(iter.cur);
proclist_delete(&wakeup, iter.cur, lwWaitLink);
/* check comment in LWLockWakeup() about this barrier */
pg_write_barrier();
waiter->lwWaiting = LW_WS_NOT_WAITING;
Can we add an assertion Assert(waiter->lwWaiting ==
LW_WS_PENDING_WAKEUP) in the above two places? We prepare the wakeup
list and set the LW_WS_NOT_WAITING flag in above loops, having an
assertion is better here IMO.
Below are test results with v3 patch. +1 for back-patching it.
HEAD PATCHED
1 34142 34289
2 72760 69720
4 136300 131848
8 210809 210192
16 240718 242744
32 297587 297354
64 341939 343036
128 383615 383801
256 342094 337680
512 263194 288629
768 145526 261553
1024 107267 241811
2048 35716 188389
4096 12415 120300
PG15 PATCHED
1 34503 34078
2 73708 72054
4 139415 133321
8 212396 211390
16 242227 242584
32 303441 309288
64 362680 339211
128 378645 344291
256 340016 344291
512 290044 293337
768 140277 264618
1024 96191 247636
2048 35158 181488
4096 12164 118610
--
Bharath Rupireddy
PostgreSQL Contributors Team
RDS Open Source Databases
Amazon Web Services: https://aws.amazon.com
On Tue, Nov 1, 2022 at 3:17 AM Bharath Rupireddy <bharath.rupireddyforpostgres@gmail.com> wrote: > Below are test results with v3 patch. +1 for back-patching it. The problem with back-patching stuff like this is that it can have unanticipated consequences. I think that the chances of something like this backfiring are less than for a patch that changes plans, but I don't think that they're nil, either. It could turn out that this patch, which has really promising results on the workloads we've tested, harms some other workload due to some other contention pattern we can't foresee. It could also turn out that improving performance at the database level actually has negative consequences for some application using the database, because the application could be unknowingly relying on the database to throttle its activity. It's hard for me to estimate exactly what the risk of a patch like this is. I think that if we back-patched this, and only this, perhaps the chances of something bad happening aren't incredibly high. But if we get into the habit of back-patching seemingly-innocuous performance improvements, it's only a matter of time before one of them turns out not to be so innocuous as we thought. I would guess that the number of times we have to back-patch something like this before somebody starts complaining about a regression is likely to be somewhere between 3 and 5. It's possible that I'm too pessimistic, though. -- Robert Haas EDB: http://www.enterprisedb.com
On 11/1/22 8:37 AM, Robert Haas wrote: > On Tue, Nov 1, 2022 at 3:17 AM Bharath Rupireddy > <bharath.rupireddyforpostgres@gmail.com> wrote: >> Below are test results with v3 patch. +1 for back-patching it. First, awesome find and proposed solution! > The problem with back-patching stuff like this is that it can have > unanticipated consequences. I think that the chances of something like > this backfiring are less than for a patch that changes plans, but I > don't think that they're nil, either. It could turn out that this > patch, which has really promising results on the workloads we've > tested, harms some other workload due to some other contention pattern > we can't foresee. It could also turn out that improving performance at > the database level actually has negative consequences for some > application using the database, because the application could be > unknowingly relying on the database to throttle its activity. If someone is using the database to throttle activity for their app, I have a bunch of follow up questions to understand why. > It's hard for me to estimate exactly what the risk of a patch like > this is. I think that if we back-patched this, and only this, perhaps > the chances of something bad happening aren't incredibly high. But if > we get into the habit of back-patching seemingly-innocuous performance > improvements, it's only a matter of time before one of them turns out > not to be so innocuous as we thought. I would guess that the number of > times we have to back-patch something like this before somebody starts > complaining about a regression is likely to be somewhere between 3 and > 5. Having the privilege of reading through the release notes for every update release, on average 1-2 "performance improvements" in each release. I believe they tend to be more negligible, though. I do understand the concerns. Say you discover your workload does have a regression with this patch and then there's a CVE that you want to accept -- what do you do? Reading the thread / patch, it seems as if this is a lower risk "performance fix", but still nonzero. While this does affect all supported versions, we could also consider backpatching only for PG15. That at least 1/ limits impact on users running older versions (opting into a major version upgrade) and 2/ we're still very early in the major upgrade cycle for PG15 that it's lower risk if there are issues. Users are generally happy when they can perform a simple upgrade and get a performance boost, particularly the set of users that this patch affects most (high throughput, high connection count). This is the type of fix that would make headlines in a major release announcement (10x TPS improvement w/4096 connections?!). That is also part of the tradeoff of backpatching this, is that we may lose some of the higher visibility marketing opportunities to discuss this (though I'm sure there will be plenty of blog posts, etc.) Andres: when you suggested backpatching, were you thinking of the Nov 2022 release or the Feb 2023 release? Thanks, Jonathan
Attachment
Hi, On 2022-11-01 08:37:39 -0400, Robert Haas wrote: > On Tue, Nov 1, 2022 at 3:17 AM Bharath Rupireddy > <bharath.rupireddyforpostgres@gmail.com> wrote: > > Below are test results with v3 patch. +1 for back-patching it. > > The problem with back-patching stuff like this is that it can have > unanticipated consequences. I think that the chances of something like > this backfiring are less than for a patch that changes plans, but I > don't think that they're nil, either. It could turn out that this > patch, which has really promising results on the workloads we've > tested, harms some other workload due to some other contention pattern > we can't foresee. It could also turn out that improving performance at > the database level actually has negative consequences for some > application using the database, because the application could be > unknowingly relying on the database to throttle its activity. > > It's hard for me to estimate exactly what the risk of a patch like > this is. I think that if we back-patched this, and only this, perhaps > the chances of something bad happening aren't incredibly high. But if > we get into the habit of back-patching seemingly-innocuous performance > improvements, it's only a matter of time before one of them turns out > not to be so innocuous as we thought. I would guess that the number of > times we have to back-patch something like this before somebody starts > complaining about a regression is likely to be somewhere between 3 and > 5. In general I agree, we shouldn't default to backpatching performance fixes. The reason I am even considering it in this case, is that it's a readily reproducible issue, leading to a quadratic behaviour that's extremely hard to pinpoint. There's no increase in CPU usage, no wait event for spinlocks, the system doesn't even get stuck (because the wait list lock is held after the lwlock lock release). I don't think users have a decent chance at figuring out that this is the issue. I'm not at all convinced we should backpatch either, just to be clear. Greetings, Andres Freund
Hi, On 2022-11-01 11:19:02 -0400, Jonathan S. Katz wrote: > This is the type of fix that would make headlines in a major release > announcement (10x TPS improvement w/4096 connections?!). That is also part > of the tradeoff of backpatching this, is that we may lose some of the higher > visibility marketing opportunities to discuss this (though I'm sure there > will be plenty of blog posts, etc.) (read the next paragraph with the caveat that results below prove it somewhat wrong) I don't think the fix is as big a deal as the above make it sound - you need to do somewhat extreme things to hit the problem. Yes, it drastically improves the scalability of e.g. doing SELECT txid_current() across as many sessions as possible - but that's not something you normally do (it was a good candidate to show the problem because it's a single lock but doesn't trigger WAL flushes at commit). You can probably hit the problem with many concurrent single-tx INSERTs, but you'd need to have synchronous_commit=off or fsync=off (or a very expensive server class SSD with battery backup) and the effect is likely smaller. > Andres: when you suggested backpatching, were you thinking of the Nov 2022 > release or the Feb 2023 release? I wasn't thinking that concretely. Even if we decide to backpatch, I'd be very hesitant to do it in a few days. <goes and runs test while in meeting> I tested with browser etc running, so this is plenty noisy. I used the best of the two pgbench -T21 -P5 tps, after ignoring the first two periods (they're too noisy). I used an ok-ish NVMe SSD, rather than the the expensive one that has "free" fsync. synchronous_commit=on: clients master fix 16 6196 6202 64 25716 25545 256 90131 90240 1024 128556 151487 2048 59417 157050 4096 32252 178823 synchronous_commit=off: clients master fix 16 409828 409016 64 454257 455804 256 304175 452160 1024 135081 334979 2048 66124 291582 4096 27019 245701 Hm. That's a bigger effect than I anticipated. I guess sc=off isn't actually required, due to the level of concurrency making group commit very effective. This is without an index, serial column or anything. But a quick comparison for just 4096 clients shows that to still be a big difference if I create an serial primary key: master: 26172 fix: 155813 Greetings, Andres Freund
On 11/1/22 1:41 PM, Andres Freund wrote: >> Andres: when you suggested backpatching, were you thinking of the Nov 2022 >> release or the Feb 2023 release? > > I wasn't thinking that concretely. Even if we decide to backpatch, I'd be very > hesitant to do it in a few days. Yeah this was my thinking (and also why I took a few days to reply given the lack of urgency for this release). It would at least give some more time for others to test it to feel confident that we're not introducing noticeable regressions. > <goes and runs test while in meeting> > > > I tested with browser etc running, so this is plenty noisy. I used the best of > the two pgbench -T21 -P5 tps, after ignoring the first two periods (they're > too noisy). I used an ok-ish NVMe SSD, rather than the the expensive one that > has "free" fsync. > > synchronous_commit=on: > > clients master fix > 16 6196 6202 > 64 25716 25545 > 256 90131 90240 > 1024 128556 151487 > 2048 59417 157050 > 4096 32252 178823 > > > synchronous_commit=off: > > clients master fix > 16 409828 409016 > 64 454257 455804 > 256 304175 452160 > 1024 135081 334979 > 2048 66124 291582 > 4096 27019 245701 > > > Hm. That's a bigger effect than I anticipated. I guess sc=off isn't actually > required, due to the level of concurrency making group commit very > effective. > > This is without an index, serial column or anything. But a quick comparison > for just 4096 clients shows that to still be a big difference if I create an > serial primary key: > master: 26172 > fix: 155813 🤯 (seeing if my exploding head makes it into the archives). Given the lack of ABI changes (hesitant to say low-risk until after more testing, but seemingly low-risk), I can get behind backpatching esp if we're targeting Feb 2023 so we can tests some more. With my advocacy hat on, it bums me that we may not get as much buzz about this change given it's not in a major release, but 1/ it'll fix an issue that will help users with high-concurrency and 2/ users would be able to perform a simpler update to get the change. Thanks, Jonathan
Attachment
On Tue, Nov 1, 2022 at 12:46 PM Bharath Rupireddy
<bharath.rupireddyforpostgres@gmail.com> wrote:
>
> > Updated patch attached.
>
> Thanks. It looks good to me. However, some minor comments on the v3 patch:
>
> 1.
> - if (MyProc->lwWaiting)
> + if (MyProc->lwWaiting != LW_WS_NOT_WAITING)
> elog(PANIC, "queueing for lock while waiting on another one");
>
> Can the above condition be MyProc->lwWaiting == LW_WS_WAITING ||
> MyProc->lwWaiting == LW_WS_PENDING_WAKEUP for better readability?
>
> Or add an assertion Assert(MyProc->lwWaiting != LW_WS_WAITING &&
> MyProc->lwWaiting != LW_WS_PENDING_WAKEUP); before setting
> LW_WS_WAITING?
>
> 2.
> /* Awaken any waiters I removed from the queue. */
> proclist_foreach_modify(iter, &wakeup, lwWaitLink)
> {
>
> @@ -1044,7 +1052,7 @@ LWLockWakeup(LWLock *lock)
> * another lock.
> */
> pg_write_barrier();
> - waiter->lwWaiting = false;
> + waiter->lwWaiting = LW_WS_NOT_WAITING;
> PGSemaphoreUnlock(waiter->sem);
> }
>
> /*
> * Awaken any waiters I removed from the queue.
> */
> proclist_foreach_modify(iter, &wakeup, lwWaitLink)
> {
> PGPROC *waiter = GetPGProcByNumber(iter.cur);
>
> proclist_delete(&wakeup, iter.cur, lwWaitLink);
> /* check comment in LWLockWakeup() about this barrier */
> pg_write_barrier();
> waiter->lwWaiting = LW_WS_NOT_WAITING;
>
> Can we add an assertion Assert(waiter->lwWaiting ==
> LW_WS_PENDING_WAKEUP) in the above two places? We prepare the wakeup
> list and set the LW_WS_NOT_WAITING flag in above loops, having an
> assertion is better here IMO.
>
> Below are test results with v3 patch. +1 for back-patching it.
>
> HEAD PATCHED
> 1 34142 34289
> 2 72760 69720
> 4 136300 131848
> 8 210809 210192
> 16 240718 242744
> 32 297587 297354
> 64 341939 343036
> 128 383615 383801
> 256 342094 337680
> 512 263194 288629
> 768 145526 261553
> 1024 107267 241811
> 2048 35716 188389
> 4096 12415 120300
>
> PG15 PATCHED
> 1 34503 34078
> 2 73708 72054
> 4 139415 133321
> 8 212396 211390
> 16 242227 242584
> 32 303441 309288
> 64 362680 339211
> 128 378645 344291
> 256 340016 344291
> 512 290044 293337
> 768 140277 264618
> 1024 96191 247636
> 2048 35158 181488
> 4096 12164 118610
I looked at the v3 patch again today and ran some performance tests.
The results look impressive as they were earlier. Andres, any plans to
get this in?
pgbench with SELECT txid_current();:
Clients HEAD PATCHED
1 34613 33611
2 72634 70546
4 137885 136911
8 216470 216076
16 242535 245392
32 299952 304740
64 329788 347401
128 378296 386873
256 344939 343832
512 292196 295839
768 144212 260102
1024 101525 250263
2048 35594 185878
4096 11842 104227
pgbench with insert into pgbench_accounts table:
Clients HEAD PATCHED
1 1660 1600
2 1848 1746
4 3547 3395
8 7330 6754
16 13103 13613
32 26011 26372
64 52331 52594
128 93313 95526
256 127373 126182
512 126712 127857
768 116765 119227
1024 111464 112499
2048 58838 92756
4096 26066 60543
--
Bharath Rupireddy
PostgreSQL Contributors Team
RDS Open Source Databases
Amazon Web Services: https://aws.amazon.com
Hi,
On 2022-11-09 15:54:16 +0530, Bharath Rupireddy wrote:
> On Tue, Nov 1, 2022 at 12:46 PM Bharath Rupireddy
> <bharath.rupireddyforpostgres@gmail.com> wrote:
> >
> > > Updated patch attached.
> >
> > Thanks. It looks good to me. However, some minor comments on the v3 patch:
> >
> > 1.
> > - if (MyProc->lwWaiting)
> > + if (MyProc->lwWaiting != LW_WS_NOT_WAITING)
> > elog(PANIC, "queueing for lock while waiting on another one");
> >
> > Can the above condition be MyProc->lwWaiting == LW_WS_WAITING ||
> > MyProc->lwWaiting == LW_WS_PENDING_WAKEUP for better readability?
> >
> > Or add an assertion Assert(MyProc->lwWaiting != LW_WS_WAITING &&
> > MyProc->lwWaiting != LW_WS_PENDING_WAKEUP); before setting
> > LW_WS_WAITING?
I don't think that's a good idea - it'll just mean we have to modify more
places if we add another state, without making anything more robust.
> > 2.
> > /* Awaken any waiters I removed from the queue. */
> > proclist_foreach_modify(iter, &wakeup, lwWaitLink)
> > {
> >
> > @@ -1044,7 +1052,7 @@ LWLockWakeup(LWLock *lock)
> > * another lock.
> > */
> > pg_write_barrier();
> > - waiter->lwWaiting = false;
> > + waiter->lwWaiting = LW_WS_NOT_WAITING;
> > PGSemaphoreUnlock(waiter->sem);
> > }
> >
> > /*
> > * Awaken any waiters I removed from the queue.
> > */
> > proclist_foreach_modify(iter, &wakeup, lwWaitLink)
> > {
> > PGPROC *waiter = GetPGProcByNumber(iter.cur);
> >
> > proclist_delete(&wakeup, iter.cur, lwWaitLink);
> > /* check comment in LWLockWakeup() about this barrier */
> > pg_write_barrier();
> > waiter->lwWaiting = LW_WS_NOT_WAITING;
> >
> > Can we add an assertion Assert(waiter->lwWaiting ==
> > LW_WS_PENDING_WAKEUP) in the above two places? We prepare the wakeup
> > list and set the LW_WS_NOT_WAITING flag in above loops, having an
> > assertion is better here IMO.
I guess it can't hurt - but it's not really related to the changes in the
patch, no?
> I looked at the v3 patch again today and ran some performance tests.
> The results look impressive as they were earlier. Andres, any plans to
> get this in?
I definitely didn't want to backpatch before this point release. But it seems
we haven't quite got to an agreement what to do about backpatching. It's
probably best to just commit it to HEAD and let the backpatch discussion
happen concurrently.
I'm on a hike, without any connectivity, Thu afternoon - Sun. I think it's OK
to push it to HEAD if I get it done in the next few hours. Bigger issues,
which I do not expect, should show up before tomorrow afternoon. Smaller
things could wait till Sunday if necessary.
Greetings,
Andres Freund
On 2022-11-09 09:38:08 -0800, Andres Freund wrote: > I'm on a hike, without any connectivity, Thu afternoon - Sun. I think it's OK > to push it to HEAD if I get it done in the next few hours. Bigger issues, > which I do not expect, should show up before tomorrow afternoon. Smaller > things could wait till Sunday if necessary. I didn't get to it in time, so I'll leave it for when I'm back.
Hi, On 2022-11-09 17:03:13 -0800, Andres Freund wrote: > On 2022-11-09 09:38:08 -0800, Andres Freund wrote: > > I'm on a hike, without any connectivity, Thu afternoon - Sun. I think it's OK > > to push it to HEAD if I get it done in the next few hours. Bigger issues, > > which I do not expect, should show up before tomorrow afternoon. Smaller > > things could wait till Sunday if necessary. > > I didn't get to it in time, so I'll leave it for when I'm back. Took a few days longer, partially because I encountered an independent issue (see 8c954168cff) while testing. I pushed it to HEAD now. I still think it might be worth to backpatch in a bit, but so far the votes on that weren't clear enough on that to feel comfortable. Regards, Andres
On 11/20/22 2:56 PM, Andres Freund wrote: > Hi, > > On 2022-11-09 17:03:13 -0800, Andres Freund wrote: >> On 2022-11-09 09:38:08 -0800, Andres Freund wrote: >>> I'm on a hike, without any connectivity, Thu afternoon - Sun. I think it's OK >>> to push it to HEAD if I get it done in the next few hours. Bigger issues, >>> which I do not expect, should show up before tomorrow afternoon. Smaller >>> things could wait till Sunday if necessary. >> >> I didn't get to it in time, so I'll leave it for when I'm back. > > Took a few days longer, partially because I encountered an independent issue > (see 8c954168cff) while testing. > > I pushed it to HEAD now. Thanks! > I still think it might be worth to backpatch in a bit, but so far the votes on > that weren't clear enough on that to feel comfortable. My general feeling is "yes" on backpatching, particularly if this is a bug and it's fixable without ABI breaks. My comments were around performing additional workload benchmarking just to ensure people feel comfortable that we're not introducing any performance regressions, and to consider the Feb 2023 release as the time to introduce this (vs. Nov 2022). That gives us ample time to determine if there are any performance regressions introduced. Thanks, Jonathan
Attachment
On Mon, Nov 21, 2022 at 10:31:14AM -0500, Jonathan S. Katz wrote: > On 11/20/22 2:56 PM, Andres Freund wrote: >> I still think it might be worth to backpatch in a bit, but so far the votes on >> that weren't clear enough on that to feel comfortable. > > My general feeling is "yes" on backpatching, particularly if this is a bug > and it's fixable without ABI breaks. Now that commit a4adc31 has had some time to bake and concerns about unintended consequences may have abated, I wanted to revive this back-patching discussion. I see a few possibly-related reports [0] [1] [2], and I'm now seeing this in the field, too. While it is debatable whether this is a bug, it's a quite nasty issue for users, and it's both difficult to detect and difficult to work around. Thoughts? [0] https://postgr.es/m/CAM527d-uDn5osa6QPKxHAC6srOfBH3M8iXUM%3DewqHV6n%3Dw1u8Q%40mail.gmail.com [1] https://postgr.es/m/VI1PR05MB620666631A41186ACC3FC91ACFC70%40VI1PR05MB6206.eurprd05.prod.outlook.com [2] https://postgr.es/m/dd0e070809430a31f7ddd8483fbcce59%40mail.gmail.com -- Nathan Bossart Amazon Web Services: https://aws.amazon.com
On Wed, Jan 10, 2024 at 09:17:47PM -0600, Nathan Bossart wrote: > Now that commit a4adc31 has had some time to bake and concerns about > unintended consequences may have abated, I wanted to revive this > back-patching discussion. I see a few possibly-related reports [0] [1] > [2], and I'm now seeing this in the field, too. While it is debatable > whether this is a bug, it's a quite nasty issue for users, and it's both > difficult to detect and difficult to work around. +1, I've seen this becoming a PITA for a few things. Knowing that the size of PGPROC does not change at all, I would be in favor for a backpatch, especially since it's been in the tree for more than 1 year, and even more knowing that we have 16 released with this stuff in. -- Michael
Attachment
On 1/10/24 10:45 PM, Michael Paquier wrote: > On Wed, Jan 10, 2024 at 09:17:47PM -0600, Nathan Bossart wrote: >> Now that commit a4adc31 has had some time to bake and concerns about >> unintended consequences may have abated, I wanted to revive this >> back-patching discussion. I see a few possibly-related reports [0] [1] >> [2], and I'm now seeing this in the field, too. While it is debatable >> whether this is a bug, it's a quite nasty issue for users, and it's both >> difficult to detect and difficult to work around. > > +1, I've seen this becoming a PITA for a few things. Knowing that the > size of PGPROC does not change at all, I would be in favor for a > backpatch, especially since it's been in the tree for more than 1 > year, and even more knowing that we have 16 released with this stuff > in. I have similar data sources to Nathan/Michael and I'm trying to avoid piling on, but one case that's interesting occurred after a major version upgrade from PG10 to PG14 on a database supporting a very active/highly concurrent workload. On inspection, it seems like backpatching would help this particularly case. With 10/11 EOL, I do wonder if we'll see more of these reports on upgrade to < PG16. (I was in favor of backpatching prior; opinion is unchanged). Thanks, Jonathan
Attachment
On Thu, Jan 11, 2024 at 09:47:33AM -0500, Jonathan S. Katz wrote: > I have similar data sources to Nathan/Michael and I'm trying to avoid piling > on, but one case that's interesting occurred after a major version upgrade > from PG10 to PG14 on a database supporting a very active/highly concurrent > workload. On inspection, it seems like backpatching would help this > particularly case. > > With 10/11 EOL, I do wonder if we'll see more of these reports on upgrade to > < PG16. > > (I was in favor of backpatching prior; opinion is unchanged). Hearing nothing, I have prepared a set of patches for v12~v15, checking all the lwlock paths for all the branches. At the end the set of changes look rather sane to me regarding the queue handlings. I have also run some numbers on all the branches, and the test case posted upthread falls off dramatically after 512 concurrent connections at the top of all the stable branches :( For example on REL_12_STABLE with and without the patch attached: num v12 v12+patch 1 29717.151665 29096.707588 2 63257.709301 61889.476318 4 127921.873393 124575.901330 8 231400.571662 230562.725174 16 343911.185351 312432.897015 32 291748.985280 281011.787701 64 268998.728648 269975.605115 128 297332.597018 286449.176950 256 243902.817657 240559.122309 512 190069.602270 194510.718508 768 58915.650225 165714.707198 1024 39920.950552 149433.836901 2048 16922.391688 108164.301054 4096 6229.063321 69032.338708 I'd like to apply that, just let me know if you have any comments and/or objections. -- Michael
Attachment
On 1/16/24 1:11 AM, Michael Paquier wrote: > On Thu, Jan 11, 2024 at 09:47:33AM -0500, Jonathan S. Katz wrote: >> I have similar data sources to Nathan/Michael and I'm trying to avoid piling >> on, but one case that's interesting occurred after a major version upgrade >> from PG10 to PG14 on a database supporting a very active/highly concurrent >> workload. On inspection, it seems like backpatching would help this >> particularly case. >> >> With 10/11 EOL, I do wonder if we'll see more of these reports on upgrade to >> < PG16. >> >> (I was in favor of backpatching prior; opinion is unchanged). > > Hearing nothing, I have prepared a set of patches for v12~v15, > checking all the lwlock paths for all the branches. At the end the > set of changes look rather sane to me regarding the queue handlings. > > I have also run some numbers on all the branches, and the test case > posted upthread falls off dramatically after 512 concurrent > connections at the top of all the stable branches :( > > For example on REL_12_STABLE with and without the patch attached: > num v12 v12+patch > 1 29717.151665 29096.707588 > 2 63257.709301 61889.476318 > 4 127921.873393 124575.901330 > 8 231400.571662 230562.725174 > 16 343911.185351 312432.897015 > 32 291748.985280 281011.787701 > 64 268998.728648 269975.605115 > 128 297332.597018 286449.176950 > 256 243902.817657 240559.122309 > 512 190069.602270 194510.718508 > 768 58915.650225 165714.707198 > 1024 39920.950552 149433.836901 > 2048 16922.391688 108164.301054 > 4096 6229.063321 69032.338708 > > I'd like to apply that, just let me know if you have any comments > and/or objections. Wow. All I can say is that my opinion remains unchanged on going forward with backpatching. Looking at the code, I understand an argument for not backpatching given we modify the struct, but this does seem low-risk/high-reward and should help PostgreSQL to run better on this higher throughput workloads. Thanks, Jonathan
Attachment
On Tue, Jan 16, 2024 at 11:24:49PM -0500, Jonathan S. Katz wrote: > On 1/16/24 1:11 AM, Michael Paquier wrote: >> I'd like to apply that, just let me know if you have any comments >> and/or objections. > > Looking at the code, I understand an argument for not backpatching given we > modify the struct, but this does seem low-risk/high-reward and should help > PostgreSQL to run better on this higher throughput workloads. Just to be clear here. I have repeated tests on all the stable branches yesterday, and the TPS falls off drastically around 256 concurrent sessions for all of them with patterns similar to what I've posted for 12, getting back a lot of performance for the cases with more than 1k connections. -- Michael
Attachment
On Tue, Jan 16, 2024 at 03:11:48PM +0900, Michael Paquier wrote: > I'd like to apply that, just let me know if you have any comments > and/or objections. And done on 12~15. While on it, I have also looked at source code references on github and debian that involve lwWaiting, and all of them rely on lwWaiting when not waiting, making LW_WS_NOT_WAITING an equivalent. -- Michael
Attachment
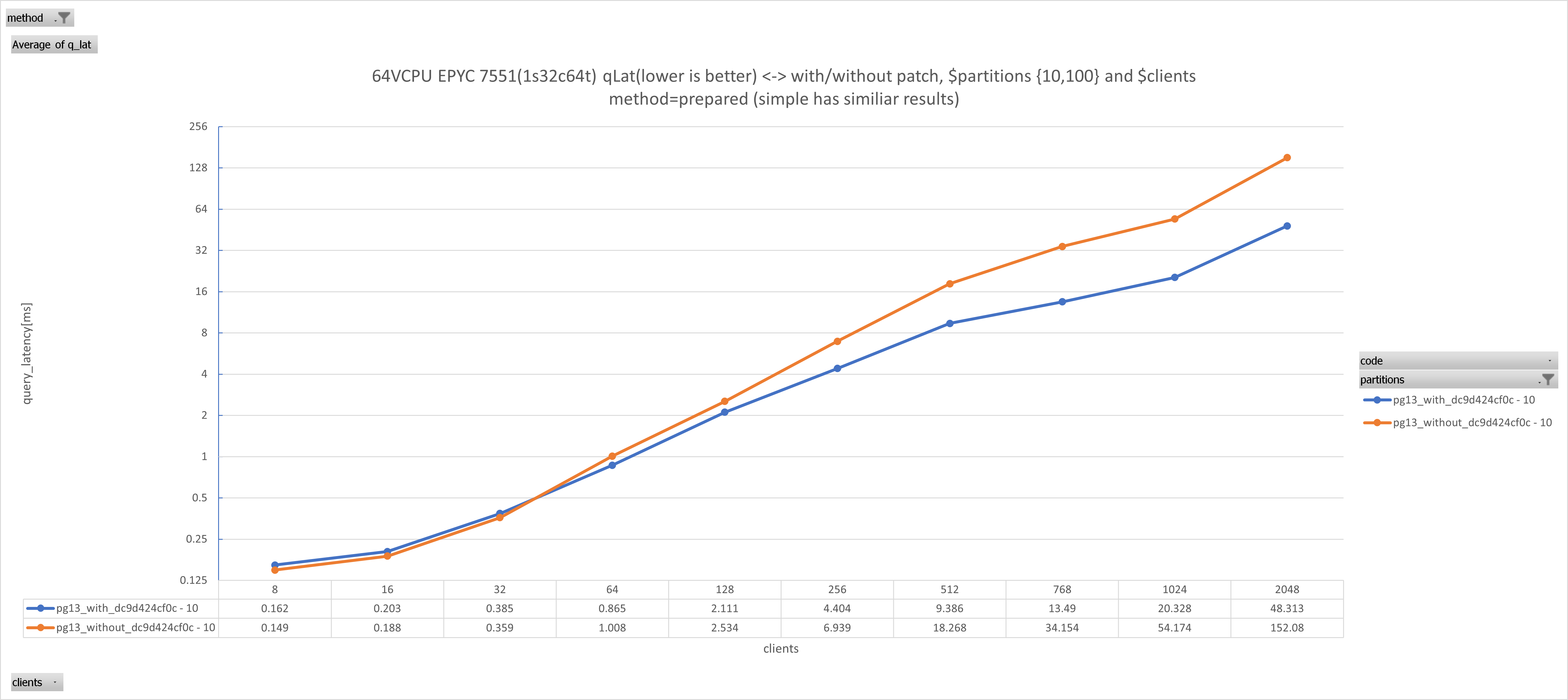
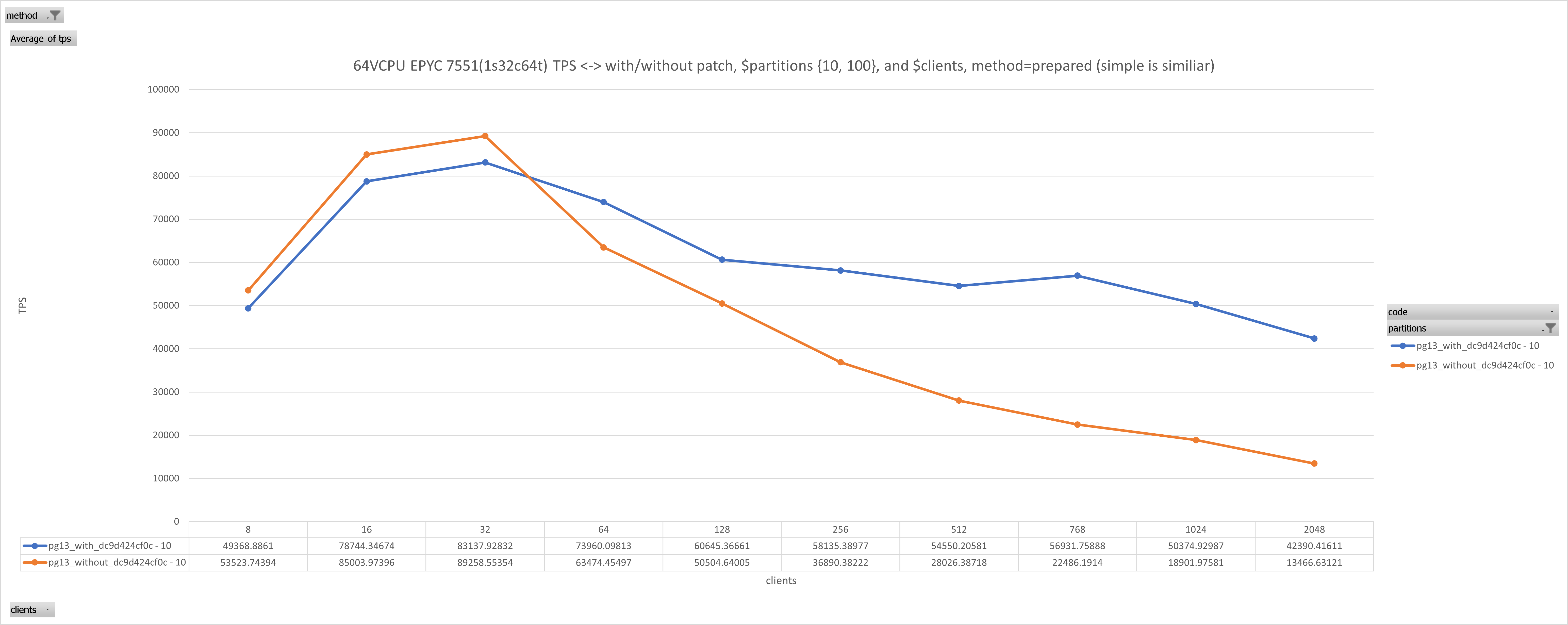
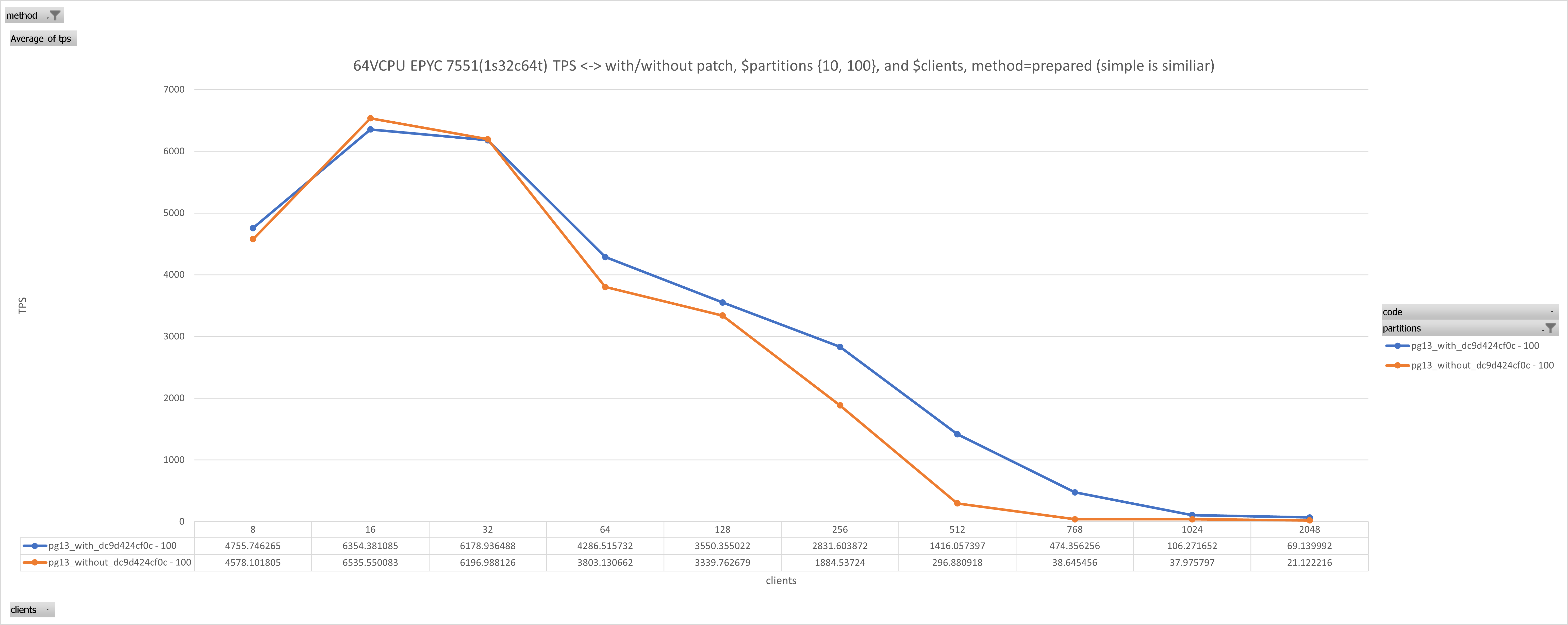
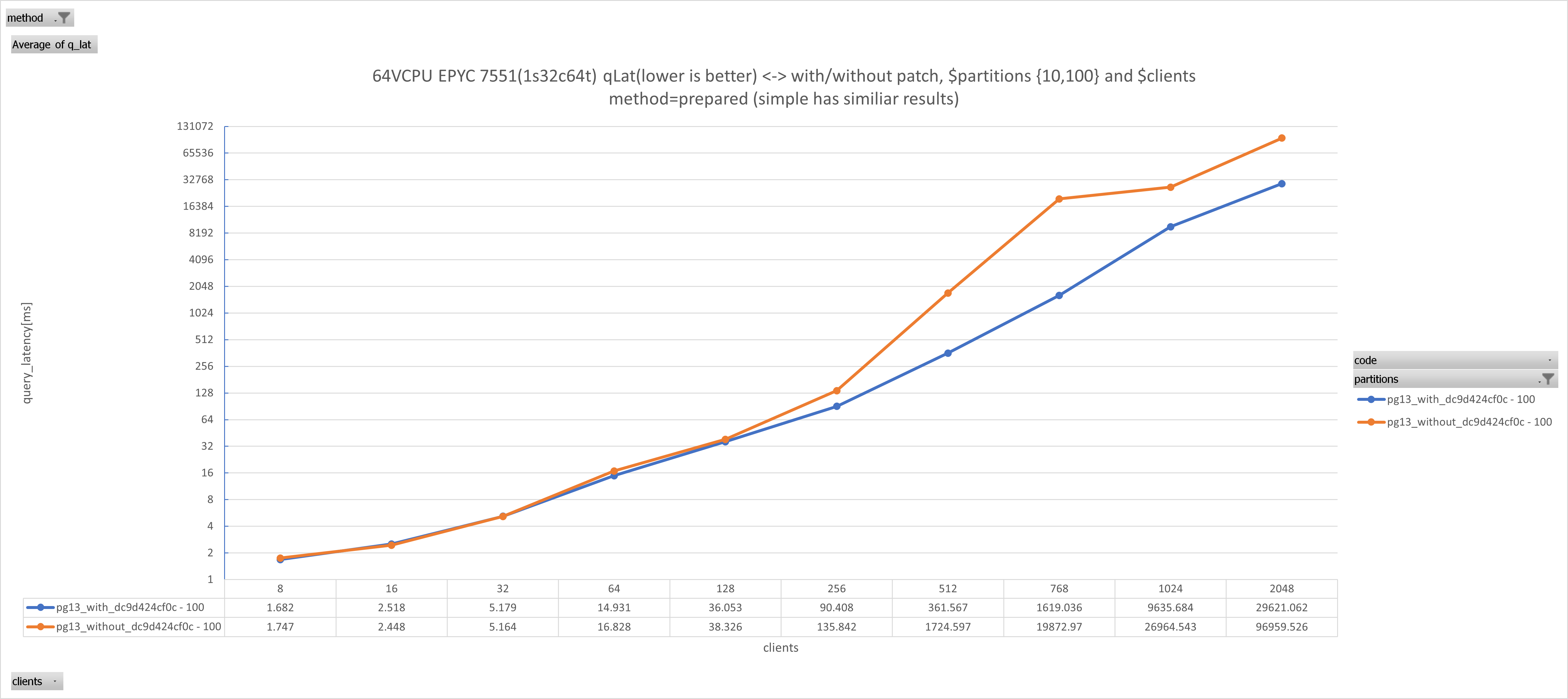
On Thu, Jan 18, 2024 at 7:17 AM Michael Paquier <michael@paquier.xyz> wrote: > > On Tue, Jan 16, 2024 at 03:11:48PM +0900, Michael Paquier wrote: > > I'd like to apply that, just let me know if you have any comments > > and/or objections. > > And done on 12~15. Hi Michael, just to reassure you that it is a good thing. We have a customer who reported much better performance on 16.x than on 13~15 in very heavy duty LWLock/lockmanager scenarios (ofc, before that was committed/released), so I gave it a try here today to see how much can be attributed to that single commit. Given: # $s=10, $p=10,100, DURATION=10s, m=prepared,simple, no reruns , just single $DURATION run to save time pgbench -i -s $s --partitions $p $DBNAME ALTER TABLE pgbench_accounts ADD COLUMN aid_parent INT; UPDATE pgbench_accounts SET aid_parent = aid CREATE INDEX ON pgbench_accounts(aid_parent) pgbench -n -M $m -T $DURATION -c $c -j $c -f join.sql $DBNAME join.sql was: \set aid random(1, 100000 * :scale) select * from pgbench_accounts pa join pgbench_branches pb on pa.bid = pb.bid where pa.aid_parent = :aid; see attached results.The benefits are observable (at least when active working sessions >= VCPUs [threads not cores]) and give up to ~2.65x boost in certain cases at least for this testcase. Hopefully others will find it useful. -J.
Attachment
{kind=link}
{kind=link}
{kind=link}
{kind=link}
On Fri, Jan 19, 2024 at 01:49:59PM +0100, Jakub Wartak wrote: > Hi Michael, just to reassure you that it is a good thing. We have a > customer who reported much better performance on 16.x than on 13~15 in > very heavy duty LWLock/lockmanager scenarios (ofc, before that was > committed/released), so I gave it a try here today to see how much can > be attributed to that single commit. Ahh. Thanks for the feedback. -- Michael