Thread: Should AT TIME ZONE be volatile?
Greetings hackers.
It seems that PostgreSQL 14 allows using the AT TIME ZONE operator within generated column definitions; according to the docs, that means the operator is considered immutable. However, unless I'm mistaken, the result of AT TIME ZONE depends on the time zone database, which is external and can change. I think that means that generated column data can become out-of-date upon tz database changes.
Sample table creation DDL:
CREATE TABLE events (
id integer PRIMARY KEY GENERATED BY DEFAULT AS IDENTITY,
local_timestamp timestamp without time zone NOT NULL,
utc_timestamp timestamp with time zone GENERATED ALWAYS AS (local_timestamp AT TIME ZONE time_zone_id) STORED,
time_zone_id text NULL
);
id integer PRIMARY KEY GENERATED BY DEFAULT AS IDENTITY,
local_timestamp timestamp without time zone NOT NULL,
utc_timestamp timestamp with time zone GENERATED ALWAYS AS (local_timestamp AT TIME ZONE time_zone_id) STORED,
time_zone_id text NULL
);
For comparison, SQL Server does consider AT TIME ZONE to be non-deterministic, and therefore does not allow it in stored generated columns (it does allow it in non-stored ones).
Shay
Greetings hackers:
I have a Synology NAS, and there is a PostgreSQL version 11.11 on it. I tried to modify pg_hba.conf file and add a new rule for external access.
But there is a strange thing, the $PGDATA is /var/services/pgsql, so changing the file on $PGDATA/pg_hba.conf maybe ok, but not. See below:
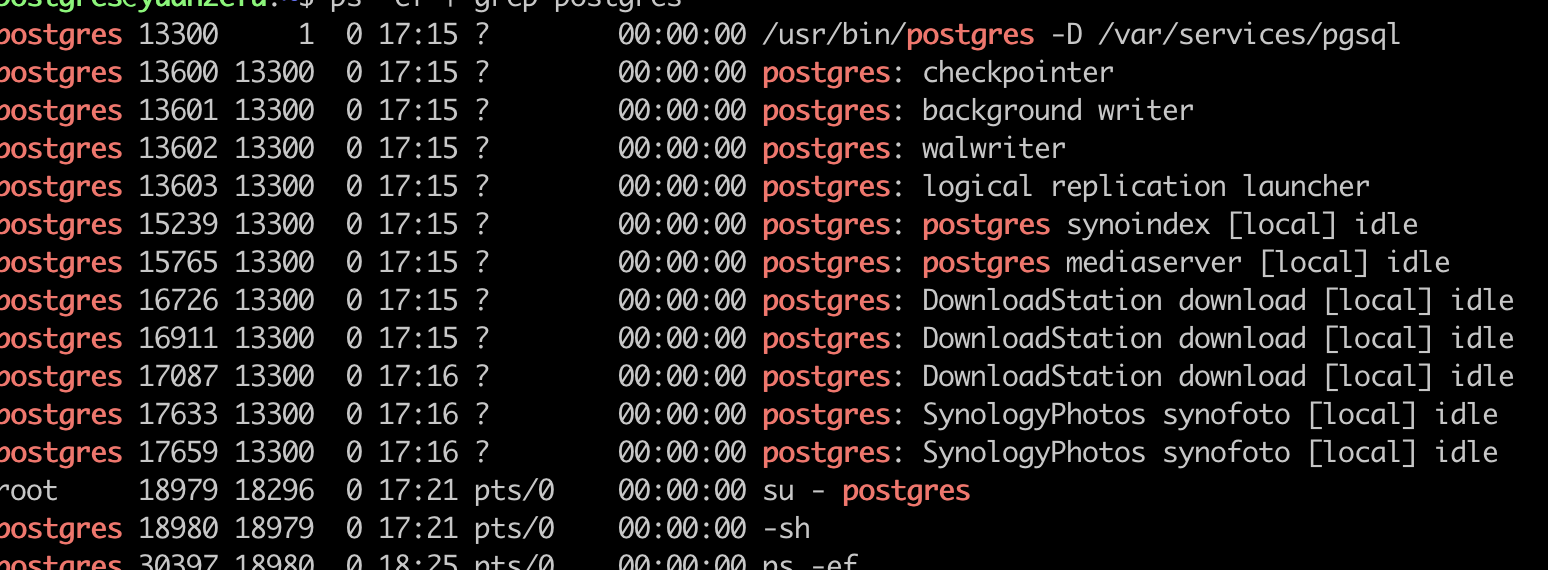
Then I tried to find the pg_hba.conf file, there is another one on /etc/postgresql/pg_hba.conf, this is actually the right file.My question is that PostgreSQL usually use $PGDATA/pg_hba.conf as the access control file, is there other way to specify conf file in other place?Best regards,Chris
Attachment
Wow, thanks so much, I checked it and there is a config on postgresql.conf.
Regards,
Chris
On 11/10/2021 18:38,Sergei Kornilov<sk@zsrv.org> wrote:
Hellopostgresql uses hba_file configuration parameter: https://www.postgresql.org/docs/current/runtime-config-file-locations.htmlSo could be changed in postgresql.confregards, Sergei
Shay Rojansky <roji@roji.org> writes:
> It seems that PostgreSQL 14 allows using the AT TIME ZONE operator within
> generated column definitions; according to the docs, that means the
> operator is considered immutable. However, unless I'm mistaken, the result
> of AT TIME ZONE depends on the time zone database, which is external and
> can change. I think that means that generated column data can become
> out-of-date upon tz database changes.
Yeah, we generally don't take such hazards into account. The poster
child here is that if we were strict about this, text comparisons
couldn't be immutable, because the underlying collation rules can
(and do) change from time to time. That's obviously unworkable.
I'm not sure how big a deal this really is for timestamps. The actual
stored time is either UTC or local time, and those are generally pretty
well-defined. If you make the wrong choice of which one to store for
your use-case, you might be unhappy.
FWIW, I believe the text search operators are also labeled as if the
underlying configurations won't change, which of course isn't really true.
regards, tom lane
> > It seems that PostgreSQL 14 allows using the AT TIME ZONE operator within
> > generated column definitions; according to the docs, that means the> > operator is considered immutable. However, unless I'm mistaken, the result
> > of AT TIME ZONE depends on the time zone database, which is external and
> > can change. I think that means that generated column data can become
> > out-of-date upon tz database changes.
>
> Yeah, we generally don't take such hazards into account. The poster
> child here is that if we were strict about this, text comparisons
> couldn't be immutable, because the underlying collation rules can
> (and do) change from time to time. That's obviously unworkable.
Thanks for the explanation Tom. I get the logic, though I think there may be a difference between "dependent on external rules which may theoretically change but almost never actually do" and "dependent on something that really does change frequently"... Countries really do change their daylight savings quite frequently, whereas I'm assuming collation rules are relatively immutable and changes are very rare.
> stored time is either UTC or local time, and those are generally pretty
> well-defined. If you make the wrong choice of which one to store for
> your use-case, you might be unhappy.
The example I'm working with, is storing a user-provided local timestamp and time zone ID, but also having an index generated column in UTC, to be able to order all rows on the global timeline regardless of time zone (see this blog post by Jon Skeet for some context). If the time zone database changes after the generated column is computed, the UTC timestamp is out of sync with regards to the reality. This seems unsafe.
On the other hand, it could be argued that this should be allowed, and that it should be the user's responsibility to update generated columns when the time zone database changes (or periodically, or whatever). Users always have the option to define a trigger anyway, so we may as well make this easier via a generated column.
In any case, if this is the intended behavior, no problem - I was a bit surprised by it, and found the difference with SQL Server interesting.
Shay
Shay Rojansky <roji@roji.org> writes:
>> Yeah, we generally don't take such hazards into account. The poster
>> child here is that if we were strict about this, text comparisons
>> couldn't be immutable, because the underlying collation rules can
>> (and do) change from time to time. That's obviously unworkable.
> Thanks for the explanation Tom. I get the logic, though I think there may
> be a difference between "dependent on external rules which may
> theoretically change but almost never actually do" and "dependent on
> something that really does change frequently"... Countries really do change
> their daylight savings quite frequently, whereas I'm assuming collation
> rules are relatively immutable and changes are very rare.
Meh. Yeah, there are some banana republics that change their DST rules
at the drop of a hat. More serious governments realize that there are
costs to that. For comparison's sake, glibc have modified their
collation rules significantly (enough for us to hear complaints about
it) at least twice in the past decade. That's considerably *more*
frequent than DST law changes where I live.
> On the other hand, it could be argued that this should be allowed, and that
> it should be the user's responsibility to update generated columns when the
> time zone database changes (or periodically, or whatever). Users always
> have the option to define a trigger anyway, so we may as well make this
> easier via a generated column.
Yeah, it's not clear that forbidding this would make anyone's life any
better. If you want an index on the UTC equivalent of a local time,
you're going to have to find a way to cope with potential mapping
changes. But refusing to let you use a generated column doesn't
seem to help that.
regards, tom lane
> Yeah, it's not clear that forbidding this would make anyone's life any
> better. If you want an index on the UTC equivalent of a local time,
> you're going to have to find a way to cope with potential mapping
> changes. But refusing to let you use a generated column doesn't
> seem to help that.
> better. If you want an index on the UTC equivalent of a local time,
> you're going to have to find a way to cope with potential mapping
> changes. But refusing to let you use a generated column doesn't
> seem to help that.
Makes sense, thanks Tom.
On Wed, Nov 10, 2021 at 6:03 PM Tom Lane <tgl@sss.pgh.pa.us> wrote: > For comparison's sake, glibc have modified their > collation rules significantly (enough for us to hear complaints about > it) at least twice in the past decade. That's considerably *more* > frequent than DST law changes where I live. Yes. It seems to be extremely common for people to get hosed by collation changes. Different major versions of RHEL ship with different collations. Different minor versions of RHEL ship with different collations. Tiny little changes in very end of the glibc version number include collation changes. I believe that it's been explicitly stated by Ulrich Drepper that you should not rely on collation definitions not to change at any time, and that relying on them for any sort of on-disk ordering is nuts. Which seems like an insane idea, because (1) surely the only point of such definitions is to help you sort your data, and you probably don't want to resort it in a continuous loop in case somebody decided to change the collation definition under you and (2) how important can it be to continually tinker with the sorting rules? I'm not really convinced that ICU is better, either. I think it's more that it isn't used as much. I don't have any constructive proposal for what to do about any of this. It sure is frustrating, though. -- Robert Haas EDB: http://www.enterprisedb.com
Robert Haas <robertmhaas@gmail.com> writes:
> I'm not really convinced that ICU is better, either. I think it's more
> that it isn't used as much.
Well, at least ICU has a notion of attaching versions to collations.
How mindful they are of bumping the version number when necessary
remains to be seen. But the POSIX locale APIs don't even offer the
opportunity to get it right.
> I don't have any constructive proposal for what to do about any of
> this. It sure is frustrating, though.
Yup. If we had reliable ways to detect changes in this sort of
environment-supplied data, maybe we could do something about it
(a la the work that's been happening on attaching collation versions
to indexes). But personally I can't summon the motivation to work
on that, when ICU is the *only* such infrastructure that offers
readily program-readable versioning.
regards, tom lane
On Thu, 2021-11-11 at 09:52 -0500, Tom Lane wrote: > Robert Haas <robertmhaas@gmail.com> writes: > > I'm not really convinced that ICU is better, either. I think it's more > > that it isn't used as much. > > Well, at least ICU has a notion of attaching versions to collations. > How mindful they are of bumping the version number when necessary > remains to be seen. But the POSIX locale APIs don't even offer the > opportunity to get it right. Also, it is much easier *not* to upgrade libicu than it is to *not* upgrade libc, which an essential component of the operating system. > > I don't have any constructive proposal for what to do about any of > > this. It sure is frustrating, though. > > Yup. If we had reliable ways to detect changes in this sort of > environment-supplied data, maybe we could do something about it > (a la the work that's been happening on attaching collation versions > to indexes). But personally I can't summon the motivation to work > on that, when ICU is the *only* such infrastructure that offers > readily program-readable versioning. Nobody will want to hear that, but the only really good solution would be for PostgreSQL to have its own built-in collations. Yours, Laurenz Albe
Laurenz Albe <laurenz.albe@cybertec.at> writes:
> On Thu, 2021-11-11 at 09:52 -0500, Tom Lane wrote:
>> Yup. If we had reliable ways to detect changes in this sort of
>> environment-supplied data, maybe we could do something about it
>> (a la the work that's been happening on attaching collation versions
>> to indexes). But personally I can't summon the motivation to work
>> on that, when ICU is the *only* such infrastructure that offers
>> readily program-readable versioning.
> Nobody will want to hear that, but the only really good solution would
> be for PostgreSQL to have its own built-in collations.
And our own tzdb too? Maybe an outfit like Oracle has the resources
and will to maintain their own copies of such data, but I can't see
us wanting to do it.
tzdb has an additional problem, which is that not updating is not an
option: if you're affected by a DST law change, you want that update,
and you frequently need it yesterday. We're definitely not set up
to handle that sort of update process, which is why we recommend
--with-system-tzdata.
regards, tom lane
On Thu, Nov 11, 2021 at 11:16 AM Laurenz Albe <laurenz.albe@cybertec.at> wrote: > Nobody will want to hear that, but the only really good solution would > be for PostgreSQL to have its own built-in collations. +1. I agree with Tom that it sounds like a lot of work. And to be honest it's work that I don't really feel very excited about. It would be necessary to understand not only the bona fide sorting rules of every human language out there, which might actually be sort of fun at least for a while, but also to decide - probably according to some incomprehensible standard - how Japanese katakana ought to sort in comparison to, say, box-drawing characters, the Mongolian alphabet, and smiley-face emojis. I think it's not particularly likely that there are a whole lot of documents out there that include all of those things, but the comparison algorithm has to return something, and probably there are people who have strong feelings about what the right answers are. That's a pretty unappealing thing to tackle, and I am not volunteering. On the other hand, if we don't do it, I'm suspicious that things will never get any better. And that would be sad. -- Robert Haas EDB: http://www.enterprisedb.com
Robert Haas <robertmhaas@gmail.com> writes:
> I agree with Tom that it sounds like a lot of work. And to be honest
> it's work that I don't really feel very excited about.
Even if you were excited about it, would maintaining such data be
a good use of project resources? It's not like we lack other things
we ought to be doing. I agree that the lack of reliable versioning
info is a problem, but I can't see that "let's fork ICU and tzdb too"
is a good answer.
regards, tom lane
>Laurenz Albe <laurenz.albe@cybertec.at> writes: >> On Thu, 2021-11-11 at 09:52 -0500, Tom Lane wrote: >>> Yup. If we had reliable ways to detect changes in this sort of >>> environment-supplied data, maybe we could do something about it >>> (a la the work that's been happening on attaching collation versions >>> to indexes). But personally I can't summon the motivation to work >>> on that, when ICU is the *only* such infrastructure that offers >>> readily program-readable versioning. >> Nobody will want to hear that, but the only really good solution would >> be for PostgreSQL to have its own built-in collations. >And our own tzdb too? Maybe an outfit like Oracle has the resources >and will to maintain their own copies of such data, but I can't see >us wanting to do it. >tzdb has an additional problem, which is that not updating is not an >option: if you're affected by a DST law change, you want that update, >and you frequently need it yesterday. We're definitely not set up >to handle that sort of update process, which is why we recommend >--with-system-tzdata. Where in the docs is this recommended? The only place I can find it is here: https://www.postgresql.org/docs/current/install-procedure.html Regards Daniel
On Thu, Nov 11, 2021 at 1:38 PM Tom Lane <tgl@sss.pgh.pa.us> wrote: > Even if you were excited about it, would maintaining such data be > a good use of project resources? It's not like we lack other things > we ought to be doing. I agree that the lack of reliable versioning > info is a problem, but I can't see that "let's fork ICU and tzdb too" > is a good answer. You might be right, but I think it's hard to say for certain. I don't think this is one of our top 10 problems, but it's probably one of our top 1000 problems, and it might be one of our top 100 problems. It's entirely subjective, and people are likely to disagree, but based on those numbers I'd say it's not worth 2% of our resources but it might well be worth 0.02% of our resources. Everybody's going to have their own opinion, though. I'm not sure how relevant those opinions are in the end, though. The community has little power to force anybody to work on anything; people work on what they want to work on, or what they get paid to work on, not what somebody else in the community decides is most important. Anyway, from my point of view, if some well-respected community member showed up and wanted to add a new kind of collation that is provided by PostgreSQL itself and had some well-thought-out candidates for initial integration, I don't know that it would be smart to turn that down because solving the whole problem for every case might be more work than anyone's willing to do. The only real issue for the project is if somebody makes a drive-by contribution of something that's going to need continuous updating. That sort of thing would be bad on multiple fronts: not only do we not want to get forced into spending ongoing maintenance effort on something like this, but we want collation definitions that *actually don't change*. -- Robert Haas EDB: http://www.enterprisedb.com
"Daniel Westermann (DWE)" <daniel.westermann@dbi-services.com> writes: > On Thu, 2021-11-11 at 09:52 -0500, Tom Lane wrote: >> tzdb has an additional problem, which is that not updating is not an >> option: if you're affected by a DST law change, you want that update, >> and you frequently need it yesterday. We're definitely not set up >> to handle that sort of update process, which is why we recommend >> --with-system-tzdata. > Where in the docs is this recommended? The only place I can find it is here: > https://www.postgresql.org/docs/current/install-procedure.html Yup, that's exactly the text I was thinking of. Maybe the recommendation should be more enthusiastic --- it was written back when it was still rather questionable whether a platform would have an up-to-date copy of tzdata. (Maybe it still is, at least for the "up-to-date" part.) regards, tom lane
Robert Haas <robertmhaas@gmail.com> writes:
> ... but we want
> collation definitions that *actually don't change*.
Um ... how would that work? Unicode is a moving target. Even without
their continual addition of stuff, I'm not convinced that social rules
about how to sort are engraved on stone tablets. The need for collation
updates may not be as predictable as the need for timezone updates,
but I doubt that we can just freeze the data forever.
regards, tom lane
On Thu, Nov 11, 2021 at 2:23 PM Tom Lane <tgl@sss.pgh.pa.us> wrote: > Robert Haas <robertmhaas@gmail.com> writes: > > ... but we want > > collation definitions that *actually don't change*. > > Um ... how would that work? Unicode is a moving target. Even without > their continual addition of stuff, I'm not convinced that social rules > about how to sort are engraved on stone tablets. The need for collation > updates may not be as predictable as the need for timezone updates, > but I doubt that we can just freeze the data forever. I don't know, but I think the social rules that actually matter change extremely slowly. To my knowledge, the alphabet song has not changed since I was in kindergarten. Now I agree that in some countries it probably has ... but I doubt those events are super-common, because a country does change its definition of alphabetical order, there's a heck of a lot more updating to do than just reindexing your PostgreSQL databases. The signs saying A-L go to the left and M-Z go to the right will need revision if we decide M comes before L. I feel like it has to be the case that most of the updates that are being made involve things like how obscure characters compare to other obscure characters, or what to do in corner-case situations involving multiple diacritical marks. I know I've seen collation changes on Macs that changed the order in which en_US.UTF8 strings sorted. But it wasn't that the rules about English sorting have actually changed. It was that somebody somewhere decided that the algorithm should be more or less case-sensitive, or that we ought to ignore the amount of whitespace between words instead of not ignoring it, or I don't know exactly, but not anything that people universally agree on. Tinkering with obscure rules that actual human beings wouldn't agree on and prioritizing that over a stable algorithm is, IMHO, ridiculous. If the Unicode consortium introduces a new emoji for "annoyed PostgreSQL hacker," I really do not care whether that collates before or after the existing symbol for "floral heart bullet, reversed rotated." I care much more about whether it collates the same way after the next minor release as it does the day it's released. And I seriously doubt that I am alone in that. -- Robert Haas EDB: http://www.enterprisedb.com
On Thu, 11 Nov 2021 at 14:42, Robert Haas <robertmhaas@gmail.com> wrote:
diacritical marks. I know I've seen collation changes on Macs that
changed the order in which en_US.UTF8 strings sorted. But it wasn't
that the rules about English sorting have actually changed. It was
that somebody somewhere decided that the algorithm should be more or
less case-sensitive, or that we ought to ignore the amount of
whitespace between words instead of not ignoring it, or I don't know
exactly, but not anything that people universally agree on. Tinkering
with obscure rules that actual human beings wouldn't agree on and
prioritizing that over a stable algorithm is, IMHO, ridiculous.
Yes, I thought the point here was to nail down each change as a separate version. So for example maybe I'm running Universal Compare Everything Collation v1.2435 while your database is running Universal Compare Everything Collation v1.2436, with the only difference being whether e diaresis circumflex comes before or after e circumflex diaresis. If I do a system upgrade I won't just silently corrupt any indexes with those characters; instead I'll be told that my collation is out of date and then I can decide whether to stick with the old collation or rebuild my indexes and upgrade.
There is however one kind of change at least that I think can be made safely: adding a new character in between existing characters. That shouldn't affect any existing indexes.
If the Unicode consortium introduces a new emoji for "annoyed
PostgreSQL hacker," I really do not care whether that collates before
or after the existing symbol for "floral heart bullet, reversed
rotated." I care much more about whether it collates the same way
after the next minor release as it does the day it's released. And I
seriously doubt that I am alone in that.
On Thu, Nov 11, 2021 at 3:45 PM Isaac Morland <isaac.morland@gmail.com> wrote: > There is however one kind of change at least that I think can be made safely: adding a new character in between existingcharacters. That shouldn't affect any existing indexes. Only if you can guarantee that said character is not present already. I don't think we update the end of the acceptable code point range every time that Unicode adds new stuff, so probably those things are subject to some default rule unless and until someone installs something more specific. Therefore I doubt that even this case is truly safe. -- Robert Haas EDB: http://www.enterprisedb.com
On Thu, 11 Nov 2021 at 16:08, Robert Haas <robertmhaas@gmail.com> wrote:
On Thu, Nov 11, 2021 at 3:45 PM Isaac Morland <isaac.morland@gmail.com> wrote:
> There is however one kind of change at least that I think can be made safely: adding a new character in between existing characters. That shouldn't affect any existing indexes.
Only if you can guarantee that said character is not present already.
I don't think we update the end of the acceptable code point range
every time that Unicode adds new stuff, so probably those things are
subject to some default rule unless and until someone installs
something more specific. Therefore I doubt that even this case is
truly safe.
Wouldn't an existing index only have characters that were already part of the collation? Attempting to use one not covered by the collation I would have expected to cause an error at insert time. But definitely I agree I wouldn't feel confident about the safety of any change.
On Thu, Nov 11, 2021 at 5:04 PM Isaac Morland <isaac.morland@gmail.com> wrote: > Wouldn't an existing index only have characters that were already part of the collation? Attempting to use one not coveredby the collation I would have expected to cause an error at insert time. But definitely I agree I wouldn't feel confidentabout the safety of any change. I mean it's not like we are updating the definition of pg_utf8_verifychar() every time they define a new code point. -- Robert Haas EDB: http://www.enterprisedb.com
On Fri, Nov 12, 2021 at 12:09 PM Robert Haas <robertmhaas@gmail.com> wrote: > On Thu, Nov 11, 2021 at 5:04 PM Isaac Morland <isaac.morland@gmail.com> wrote: > > Wouldn't an existing index only have characters that were already part of the collation? Attempting to use one not coveredby the collation I would have expected to cause an error at insert time. But definitely I agree I wouldn't feel confidentabout the safety of any change. > > I mean it's not like we are updating the definition of > pg_utf8_verifychar() every time they define a new code point. Right, and there may be other systems that do this. That is, reject invalid code points, because they have no sort order. You can see some sign of this in the major and minor collation version numbers reported by Windows (though I'm not sure if this was lost with the recent move to ICU): if only the minor version changes, the documentation says it means "we only added new code points, no existing code points changed", so a sufficiently clever program doesn't need to rebuild its persistent ordered data structures, if it never allowed any unknown code points into the structure before. Not only does PostgreSQL not have the logic for that, it also doesn't have the data: the set of existing code points has to be the one used by the collation provider, and the collection providers we have don't reject unknown code points on comparison.
On 11.11.21 18:32, Robert Haas wrote: > I agree with Tom that it sounds like a lot of work. And to be honest > it's work that I don't really feel very excited about. It would be > necessary to understand not only the bona fide sorting rules of every > human language out there, which might actually be sort of fun at least > for a while, but also to decide - probably according to some > incomprehensible standard - how Japanese katakana ought to sort in > comparison to, say, box-drawing characters, the Mongolian alphabet, > and smiley-face emojis. I think it's not particularly likely that > there are a whole lot of documents out there that include all of those > things, but the comparison algorithm has to return something, and > probably there are people who have strong feelings about what the > right answers are. That's a pretty unappealing thing to tackle, and I > am not volunteering. > > On the other hand, if we don't do it, I'm suspicious that things will > never get any better. And that would be sad. There are standards for sort order, and the major hiccups we had in the past were mostly moving from older versions of those standards to newer versions. So at some point this should stabilize.
On Fri, Nov 12, 2021 at 8:42 AM Peter Eisentraut <peter.eisentraut@enterprisedb.com> wrote: > There are standards for sort order, and the major hiccups we had in the > past were mostly moving from older versions of those standards to newer > versions. So at some point this should stabilize. Only if they don't keep making new versions of the standards. -- Robert Haas EDB: http://www.enterprisedb.com
On Thu, Nov 11, 2021 at 09:52:52AM -0500, Tom Lane wrote: > Robert Haas <robertmhaas@gmail.com> writes: > > I'm not really convinced that ICU is better, either. I think it's more > > that it isn't used as much. > > Well, at least ICU has a notion of attaching versions to collations. > How mindful they are of bumping the version number when necessary > remains to be seen. But the POSIX locale APIs don't even offer the > opportunity to get it right. > > > I don't have any constructive proposal for what to do about any of > > this. It sure is frustrating, though. > > Yup. If we had reliable ways to detect changes in this sort of > environment-supplied data, maybe we could do something about it > (a la the work that's been happening on attaching collation versions > to indexes). But personally I can't summon the motivation to work Theoretically there are versions attached to collations already: the collation in index is an oid referencing the pg_collation. And the pg_collation already has versions. Currently for glibc the version looks like glibc version at initdb, and that doesn't seem very reliable, but that could be a different task (to find LC_COLLATE file and put hash of the usuable data into version string, for example). Currently, it is questionable how to work with the different versions of collations -- but that could be solved e.g. via ap- propriate naming. Perhaps "collation@ver" ? But if the version would contain a hash, a full version could be a bit dubious. And some database maintainance task could check that all the old collations are available, rename them as needed, and create a set the new ones. Automatically invalidating all the indexes, unfortunately. > on that, when ICU is the *only* such infrastructure that offers > readily program-readable versioning. > > regards, tom lane >
On Sat, Nov 13, 2021 at 11:47 AM Ilya Anfimov <ilan@tzirechnoy.com> wrote: > Currently for glibc the version looks like glibc version at > initdb, and that doesn't seem very reliable, but that could be a > different task (to find LC_COLLATE file and put hash of the > usuable data into version string, for example). Yeah, I had a system exactly like that working (that is, a way to run arbitrary commands to capture version strings, that could be used to hash your collation definition files, patches somewhere in the archives), but then we thought it'd be better to use glibc versions, and separately, to perhaps try to ask the glibc people to expose a version. FreeBSD (at my request), Windows and ICU do expose versions in a straightforward way, and we capture those. > Currently, it is questionable how to work with the different > versions of collations -- but that could be solved e.g. via ap- > propriate naming. Perhaps "collation@ver" ? But if the version > would contain a hash, a full version could be a bit dubious. > And some database maintainance task could check that all the old > collations are available, rename them as needed, and create a set > the new ones. > Automatically invalidating all the indexes, unfortunately. We built a system that at least detected the changes on a per-index level, but failed to ship it in release 14. See revert commit, and links back to previous commits and discussion: https://git.postgresql.org/gitweb/?p=postgresql.git;a=commitdiff;h=ec48314708262d8ea6cdcb83f803fc83dd89e721 It didn't invalidate indexes, but complained about each individual index on first access in each session, until you REINDEXed it. We will try again :-) In the archives you can find discussions of how to make a system that tolerates multiple version existing at the same time as I think you're getting at, like DB2 does. It's tricky, because it's code and data. DB2 ships with N copies of ICU in it.