Thread: Add proper planner support for ORDER BY / DISTINCT aggregates
A few years ago I wrote a patch to implement the missing aggregate combine functions for array_agg and string_agg [1]. In the end, the patch was rejected due to some concern [2] that if we allow these aggregates to run in parallel then it might mess up the order in which values are being aggregated by some unsuspecting user who didn't include an ORDER BY clause in the aggregate. It was mentioned at the time that due to nodeAgg.c performing so terribly with ORDER BY aggregates that we couldn't possibly ask users who were upset by this change to include an ORDER BY in their aggregate functions. I'd still quite like to finish off the remaining aggregate functions that still don't have a combine function, so to get that going again I've written some code that gets the query planner onboard with picking a plan that allows nodeAgg.c to skip doing any internal sorts when the input results are already sorted according to what's required by the aggregate function. Of course, the query could have many aggregates all with differing ORDER BY clauses. Since we reuse the same input for each, it might not be possible to feed each aggregate with suitably sorted input. When the input is not sorted, nodeAgg.c still must perform the sort as it does today. So unfortunately we can't remove the nodeAgg.c code for that. The best I could come up with is just picking a sort order that suits the first ORDER BY aggregate, then spin through the remaining ones to see if there's any with a more strict order requirement that we can use to suit that one and the first one. The planner does something similar for window functions already, although it's not quite as comprehensive to look beyond the first window for windows with a more strict sort requirement. This allows us to give presorted input to both aggregates in the following case: SELECT agg(a ORDER BY a),agg2(a ORDER BY a,b) ... but just the first agg in this one: SELECT agg(a ORDER BY a),agg2(a ORDER BY c) ... In order to make DISTINCT work, I had to add a new expression evaluation operator to allow filtering if the current value is the same as the last value. The current unpatched code implements distinct when reading back the sorted tuplestore data. Since I don't have a tuplestore with the pre-sorted version, I needed to cache the last Datum, or last tuple somewhere. I ended up putting that in the AggStatePerTransData struct. I'm not quite sure if I like that, but I don't really see where else it could go. When testing the performance of all this I found that when a suitable index exists to provide pre-sorted input for the aggregation that the performance does improve. Unfortunately, it looks like things get more complex when no index exists. In this case, since we're setting pathkeys to tell the planner we need a plan that provides pre-sorted input to the aggregates, the planner will add a sort below the aggregate node. I initially didn't see any problem with that as it just moves the sort to a Sort node rather than having it done implicitly inside nodeAgg.c. The problem is, it just does not perform as well. I guess this is because when the sort is done inside nodeAgg.c that the transition function is called in a tight loop while reading records back from the tuplestore. In the patched version, there's an additional node transition in between nodeAgg and nodeSort and that causes slower performance. For now, I'm not quite sure what to do about that. We set the plan pathkeys well before we could possibly decide if asking for pre-sorted input for the aggregates would be a good idea or not. Please find attached my WIP patch. It's WIP due to what I mentioned in the above paragraph and also because I've not bothered to add JIT support for the new expression evaluation steps. I'll add this to the July commitfest. David [1] https://www.postgresql.org/message-id/CAKJS1f9sx_6GTcvd6TMuZnNtCh0VhBzhX6FZqw17TgVFH-ga_A%40mail.gmail.com [2] https://www.postgresql.org/message-id/flat/6538.1522096067%40sss.pgh.pa.us#c228ed67026faa15209c76dada035da4
Attachment
> > This allows us to give presorted input to both aggregates in the following > case: > > SELECT agg(a ORDER BY a),agg2(a ORDER BY a,b) ... > > but just the first agg in this one: > > SELECT agg(a ORDER BY a),agg2(a ORDER BY c) ... I don't know if it's acceptable, but in the case where you add both an aggregate with an ORDER BY clause, and another aggregate without the clause, the output for the unordered one will change and use the same ordering, maybe suprising the unsuspecting user. Would that be acceptable ? > When testing the performance of all this I found that when a suitable > index exists to provide pre-sorted input for the aggregation that the > performance does improve. Unfortunately, it looks like things get more > complex when no index exists. In this case, since we're setting > pathkeys to tell the planner we need a plan that provides pre-sorted > input to the aggregates, the planner will add a sort below the > aggregate node. I initially didn't see any problem with that as it > just moves the sort to a Sort node rather than having it done > implicitly inside nodeAgg.c. The problem is, it just does not perform > as well. I guess this is because when the sort is done inside > nodeAgg.c that the transition function is called in a tight loop while > reading records back from the tuplestore. In the patched version, > there's an additional node transition in between nodeAgg and nodeSort > and that causes slower performance. For now, I'm not quite sure what > to do about that. We set the plan pathkeys well before we could > possibly decide if asking for pre-sorted input for the aggregates > would be a good idea or not. I was curious about the performance implication of that additional transition, and could not reproduce a signifcant difference. I may be doing something wrong: how did you highlight it ? Regards, -- Ronan Dunklau
On Fri, 2 Jul 2021 at 19:54, Ronan Dunklau <ronan.dunklau@aiven.io> wrote: > I don't know if it's acceptable, but in the case where you add both an > aggregate with an ORDER BY clause, and another aggregate without the clause, > the output for the unordered one will change and use the same ordering, maybe > suprising the unsuspecting user. Would that be acceptable ? That's a good question. There was an argument in [1] that mentions that there might be a group of people who rely on aggregation being done in a certain order where they're not specifying an ORDER BY clause in the aggregate. If that group of people exists, then it's possible they might be upset in the scenario that you describe. I also think that it's going to be pretty hard to make significant gains in this area if we are too scared to make changes to undefined behaviour. You wouldn't have to look too hard in the pgsql-general mailing list to find someone complaining that their query output is in the wrong order on some query that does not have an ORDER BY. We pretty much always tell those people that the order is undefined without an ORDER BY. I'm not too sure why Tom in [1] classes the ORDER BY aggregate people any differently. We'll be stuck forever here and in many other areas if we're too scared to change the order of aggregation. You could argue that something like parallelism has changed that for people already. I think the multi-batch Hash Aggregate code could also change this. > I was curious about the performance implication of that additional transition, > and could not reproduce a signifcant difference. I may be doing something > wrong: how did you highlight it ? It was pretty basic. I just created a table with two columns and no index and did something like SELECT a,SUM(b ORDER BY b) from ab GROUP BY 1; the new code will include a Sort due to lack of any index and the old code would have done a sort inside nodeAgg.c. I imagine that the overhead comes from the fact that in the patched version nodeAgg.c must ask its subnode (nodeSort.c) for the next tuple each time, whereas unpatched nodeAgg.c already has all the tuples in a tuplestore and can fetch them very quickly in a tight loop. David [1] https://www.postgresql.org/message-id/6538.1522096067%40sss.pgh.pa.us
On 2/07/21 8:39 pm, David Rowley wrote: > On Fri, 2 Jul 2021 at 19:54, Ronan Dunklau <ronan.dunklau@aiven.io> wrote: >> I don't know if it's acceptable, but in the case where you add both an >> aggregate with an ORDER BY clause, and another aggregate without the clause, >> the output for the unordered one will change and use the same ordering, maybe >> suprising the unsuspecting user. Would that be acceptable ? > That's a good question. There was an argument in [1] that mentions > that there might be a group of people who rely on aggregation being > done in a certain order where they're not specifying an ORDER BY > clause in the aggregate. If that group of people exists, then it's > possible they might be upset in the scenario that you describe. [...] I've always worked on the assumption that if I do not specify an ORDER BY clause then the rdbms is expected to present rows in the order most efficient for it to do so. If pg orders rows when not requested then this could add extra elapsed time to the query, which might be significant for large queries. I don't know of any rdbms that guarantees the order of returned rows when an ORDER BY clause is not used. So I think that pg has no obligation to protect the sensibilities of naive users in this case, especially at the expense of users that want queries to complete as quickly as possible. IMHO Cheers, Gavin
Gavin Flower <GavinFlower@archidevsys.co.nz> writes:
> On 2/07/21 8:39 pm, David Rowley wrote:
>> That's a good question. There was an argument in [1] that mentions
>> that there might be a group of people who rely on aggregation being
>> done in a certain order where they're not specifying an ORDER BY
>> clause in the aggregate. If that group of people exists, then it's
>> possible they might be upset in the scenario that you describe.
> So I think that pg has no obligation to protect the sensibilities of
> naive users in this case, especially at the expense of users that want
> queries to complete as quickly as possible. IMHO
I agree. We've broken such expectations in the past and I don't
have much hesitation about breaking them again.
regards, tom lane
Le vendredi 2 juillet 2021, 10:39:44 CEST David Rowley a écrit : > On Fri, 2 Jul 2021 at 19:54, Ronan Dunklau <ronan.dunklau@aiven.io> wrote: > > I don't know if it's acceptable, but in the case where you add both an > > aggregate with an ORDER BY clause, and another aggregate without the > > clause, the output for the unordered one will change and use the same > > ordering, maybe suprising the unsuspecting user. Would that be acceptable > > ? > > That's a good question. There was an argument in [1] that mentions > that there might be a group of people who rely on aggregation being > done in a certain order where they're not specifying an ORDER BY > clause in the aggregate. If that group of people exists, then it's > possible they might be upset in the scenario that you describe. > > I also think that it's going to be pretty hard to make significant > gains in this area if we are too scared to make changes to undefined > behaviour. You wouldn't have to look too hard in the pgsql-general > mailing list to find someone complaining that their query output is in > the wrong order on some query that does not have an ORDER BY. We > pretty much always tell those people that the order is undefined > without an ORDER BY. I'm not too sure why Tom in [1] classes the ORDER > BY aggregate people any differently. We'll be stuck forever here and > in many other areas if we're too scared to change the order of > aggregation. You could argue that something like parallelism has > changed that for people already. I think the multi-batch Hash > Aggregate code could also change this. I would agree with that. > > > I was curious about the performance implication of that additional > > transition, and could not reproduce a signifcant difference. I may be > > doing something wrong: how did you highlight it ? > > It was pretty basic. I just created a table with two columns and no > index and did something like SELECT a,SUM(b ORDER BY b) from ab GROUP > BY 1; the new code will include a Sort due to lack of any index and > the old code would have done a sort inside nodeAgg.c. I imagine that > the overhead comes from the fact that in the patched version nodeAgg.c > must ask its subnode (nodeSort.c) for the next tuple each time, > whereas unpatched nodeAgg.c already has all the tuples in a tuplestore > and can fetch them very quickly in a tight loop. Ok, I reproduced that case, just not using a group by: by adding the group by a sort node is added in both cases (master and your patch), except that with your patch we sort on both keys and that doesn't really incur a performance penalty. I think the overhead occurs because in the ExecAgg case, we use the tuplesort_*_datum API as an optimization when we have a single column as an input, which the ExecSort code doesn't. Maybe it would be worth it to try to use that API in sort nodes too, when it can be done. > > David > > [1] https://www.postgresql.org/message-id/6538.1522096067%40sss.pgh.pa.us -- Ronan Dunklau
> Ok, I reproduced that case, just not using a group by: by adding the group > by a sort node is added in both cases (master and your patch), except that > with your patch we sort on both keys and that doesn't really incur a > performance penalty. > > I think the overhead occurs because in the ExecAgg case, we use the > tuplesort_*_datum API as an optimization when we have a single column as an > input, which the ExecSort code doesn't. Maybe it would be worth it to try to > use that API in sort nodes too, when it can be done. Please find attached a POC patch to do just that. The switch to the single-datum tuplesort is done when there is only one attribute, it is byval (to avoid having to deal with copy of the references everywhere) and we are not in bound mode (to also avoid having to move things around). A naive run on make check pass on this, but I may have overlooked things. Should I add this separately to the commitfest ? For the record, the times I got on my laptop, on master VS david's patch VS both. Values are an average of 100 runs, as reported by pgbench --no-vacuum -f <file.sql> -t 100. There is a good amount of noise, but the simple "select one ordered column case" seems worth the optimization. Only shared_buffers and work_mem have been set to 2GB each. Setup 1: single table, 1 000 000 tuples, no index CREATE TABLE tbench ( a int, b int ); INSERT INTO tbench (a, b) SELECT a, b FROM generate_series(1, 100) a, generate_series(1, 10000) b; Test 1: Single-column ordered select (order by b since the table is already sorted by a) select b from tbench order by b; master: 303.661ms with mine: 148.571ms Test 2: Ordered sum (using b so that the input is not presorted) select sum(b order by b) from tbench; master: 112.379ms with david's patch: 144.469ms with david's patch + mine: 97ms Test 3: Ordered sum + group by select b, sum(a order by a) from tbench GROUP BY b; master: 316.117ms with david's patch: 297.079 with david's patch + mine: 294.601 Setup 2: same as before, but adding an index on (b, a) CREATE INDEX ON tbench (b, a); Test 2: Ordered sum: select sum(a order by a) from tbench; master: 111.847 ms with david's patch: 48.088 with david's patch + mine: 47.678 ms Test 3: Ordered sum + group by: select a, sum(b order by b) from tbench GROUP BY a; master: 76.873 ms with david's patch: 61.105 with david's patch + mine: 62.672 ms -- Ronan Dunklau
Attachment
>Please find attached a POC patch to do just that.
>The switch to the single-datum tuplesort is done when there is only one
>attribute, it is byval (to avoid having to deal with copy of the references
>everywhere) and we are not in bound mode (to also avoid having to move things
>around).
Hi, nice results!
I have a few suggestions and questions to your patch:
1. Why do you moved the declaration of variable *plannode?
I think this is unnecessary, extend the scope.
2. Why do you declare a new variable TupleDesc out_tuple_desc at ExecInitSort?
I think this is unnecessary too, maybe I didn't notice something.
3. I inverted the order of check at this line, I think "!node-bounded" is more cheap that TupleDescAttr(tupDesc, 0) ->attbyval
4. Once that you changed the order of execution, this test is unlikely that happens, so add unlikely helps the branch.
5. I think that you add a invariant inside the loop "if(node->is_single_val)"?
Would not be better two fors?
For you convenience, I attached a v2 version (with styles changes), please take a look and can you repeat yours tests?
regards,
Ranier Vilela
Attachment
Le lundi 5 juillet 2021, 16:51:59 CEST Ranier Vilela a écrit : > >Please find attached a POC patch to do just that. > > > >The switch to the single-datum tuplesort is done when there is only one > >attribute, it is byval (to avoid having to deal with copy of the > > references > > >everywhere) and we are not in bound mode (to also avoid having to move > > things > > >around). > > Hi, nice results! > > I have a few suggestions and questions to your patch: Thank you for those ! > > 1. Why do you moved the declaration of variable *plannode? > I think this is unnecessary, extend the scope. Sorry, I should have cleaned it up before sending. > > 2. Why do you declare a new variable TupleDesc out_tuple_desc at > ExecInitSort? > I think this is unnecessary too, maybe I didn't notice something. Same as the above, thanks for the two. > > 3. I inverted the order of check at this line, I think "!node-bounded" is > more cheap that TupleDescAttr(tupDesc, 0) ->attbyval I'm not sure it matters since it's done once per sort but Ok > > 4. Once that you changed the order of execution, this test is unlikely that > happens, so add unlikely helps the branch. Ok. > > 5. I think that you add a invariant inside the loop > "if(node->is_single_val)"? > Would not be better two fors? Ok for me. > > For you convenience, I attached a v2 version (with styles changes), please > take a look and can you repeat yours tests? Tested it quickly, and did not see any change performance wise that cannot be attributed to noise on my laptop but it's fine. Thank you for the fixes ! > > regards, > Ranier Vilela -- Ronan Dunklau
Em seg., 5 de jul. de 2021 às 12:07, Ronan Dunklau <ronan.dunklau@aiven.io> escreveu:
Le lundi 5 juillet 2021, 16:51:59 CEST Ranier Vilela a écrit :
> >Please find attached a POC patch to do just that.
> >
> >The switch to the single-datum tuplesort is done when there is only one
> >attribute, it is byval (to avoid having to deal with copy of the
>
> references
>
> >everywhere) and we are not in bound mode (to also avoid having to move
>
> things
>
> >around).
>
> Hi, nice results!
>
> I have a few suggestions and questions to your patch:
Thank you for those !
>
> 1. Why do you moved the declaration of variable *plannode?
> I think this is unnecessary, extend the scope.
Sorry, I should have cleaned it up before sending.
>
> 2. Why do you declare a new variable TupleDesc out_tuple_desc at
> ExecInitSort?
> I think this is unnecessary too, maybe I didn't notice something.
Same as the above, thanks for the two.
>
> 3. I inverted the order of check at this line, I think "!node-bounded" is
> more cheap that TupleDescAttr(tupDesc, 0) ->attbyval
I'm not sure it matters since it's done once per sort but Ok
>
> 4. Once that you changed the order of execution, this test is unlikely that
> happens, so add unlikely helps the branch.
Ok.
>
> 5. I think that you add a invariant inside the loop
> "if(node->is_single_val)"?
> Would not be better two fors?
Ok for me.
>
> For you convenience, I attached a v2 version (with styles changes), please
> take a look and can you repeat yours tests?
Tested it quickly, and did not see any change performance wise that cannot be
attributed to noise on my laptop but it's fine.
Thanks for testing again.
Thank you for the fixes !
You are welcome.
regards,
Ranier Vilela
On Sat, Jun 12, 2021 at 11:07 AM David Rowley <dgrowleyml@gmail.com> wrote: > > A few years ago I wrote a patch to implement the missing aggregate > combine functions for array_agg and string_agg [1]. In the end, the > patch was rejected due to some concern [2] that if we allow these > aggregates to run in parallel then it might mess up the order in which > values are being aggregated by some unsuspecting user who didn't > include an ORDER BY clause in the aggregate. It was mentioned at the > time that due to nodeAgg.c performing so terribly with ORDER BY > aggregates that we couldn't possibly ask users who were upset by this > change to include an ORDER BY in their aggregate functions. > > I'd still quite like to finish off the remaining aggregate functions > that still don't have a combine function, so to get that going again > I've written some code that gets the query planner onboard with > picking a plan that allows nodeAgg.c to skip doing any internal sorts > when the input results are already sorted according to what's required > by the aggregate function. > > Of course, the query could have many aggregates all with differing > ORDER BY clauses. Since we reuse the same input for each, it might not > be possible to feed each aggregate with suitably sorted input. When > the input is not sorted, nodeAgg.c still must perform the sort as it > does today. So unfortunately we can't remove the nodeAgg.c code for > that. > > The best I could come up with is just picking a sort order that suits > the first ORDER BY aggregate, then spin through the remaining ones to > see if there's any with a more strict order requirement that we can > use to suit that one and the first one. The planner does something > similar for window functions already, although it's not quite as > comprehensive to look beyond the first window for windows with a more > strict sort requirement. I think this is a reasonable choice. I could imagine a more complex method, say, counting the number of aggregates benefiting from a given sort, and choosing the one that benefits the most (and this could be further complicated by ranking based on "cost" -- not costing in the normal sense since we don't have that at this point), but I think it'd take a lot of convincing that that was valuable. > This allows us to give presorted input to both aggregates in the following case: > > SELECT agg(a ORDER BY a),agg2(a ORDER BY a,b) ... > > but just the first agg in this one: > > SELECT agg(a ORDER BY a),agg2(a ORDER BY c) ... > > In order to make DISTINCT work, I had to add a new expression > evaluation operator to allow filtering if the current value is the > same as the last value. The current unpatched code implements > distinct when reading back the sorted tuplestore data. Since I don't > have a tuplestore with the pre-sorted version, I needed to cache the > last Datum, or last tuple somewhere. I ended up putting that in the > AggStatePerTransData struct. I'm not quite sure if I like that, but I > don't really see where else it could go. That sounds like what nodeIncrementalSort.c's isCurrentGroup() does, except it's just implemented inline. Not anything you need to change in this patch, but noting it in case it triggered a thought valuable for you for me later on. > When testing the performance of all this I found that when a suitable > index exists to provide pre-sorted input for the aggregation that the > performance does improve. Unfortunately, it looks like things get more > complex when no index exists. In this case, since we're setting > pathkeys to tell the planner we need a plan that provides pre-sorted > input to the aggregates, the planner will add a sort below the > aggregate node. I initially didn't see any problem with that as it > just moves the sort to a Sort node rather than having it done > implicitly inside nodeAgg.c. The problem is, it just does not perform > as well. I guess this is because when the sort is done inside > nodeAgg.c that the transition function is called in a tight loop while > reading records back from the tuplestore. In the patched version, > there's an additional node transition in between nodeAgg and nodeSort > and that causes slower performance. For now, I'm not quite sure what > to do about that. We set the plan pathkeys well before we could > possibly decide if asking for pre-sorted input for the aggregates > would be a good idea or not. This opens up another path for significant plan benefits too: if there's now an explicit sort node, then it's possible for that node to be an incremental sort node, which isn't something nodeAgg is capable of utilizing currently. > Please find attached my WIP patch. It's WIP due to what I mentioned > in the above paragraph and also because I've not bothered to add JIT > support for the new expression evaluation steps. I looked this over (though didn't get a chance to play with it). I'm wondering about the changes to the test output in tuplesort.out. It looks like where a merge join used to be proceeding with an explicit sort with DESC it's now sorting with (implicit) ASC, and then an explicit sort node using DESC is above the merge join node. Two thoughts: 1. It seems like losing the "proper" sort order in the JOIN node isn't preferable. Given both are full sorts, it may not actually be a significant performance difference on its own (it can't short circuit), but it means precluding using incremental sort in the new sort node. 2. In an ideal world we'd push the more complex sort down into the merge join rather than doing a sort on "col1" and then a sort on "col1, col2". That's likely beyond this patch, but I haven't investigated at all. Thanks for your work on this; both this patch and the original one you're trying to enable seem like great additions. James
On Mon, Jul 5, 2021 at 8:08 AM Ronan Dunklau <ronan.dunklau@aiven.io> wrote: > > > Ok, I reproduced that case, just not using a group by: by adding the group > > by a sort node is added in both cases (master and your patch), except that > > with your patch we sort on both keys and that doesn't really incur a > > performance penalty. > > > > I think the overhead occurs because in the ExecAgg case, we use the > > tuplesort_*_datum API as an optimization when we have a single column as an > > input, which the ExecSort code doesn't. Maybe it would be worth it to try to > > use that API in sort nodes too, when it can be done. > > Please find attached a POC patch to do just that. > > The switch to the single-datum tuplesort is done when there is only one > attribute, it is byval (to avoid having to deal with copy of the references > everywhere) and we are not in bound mode (to also avoid having to move things > around). > > A naive run on make check pass on this, but I may have overlooked things. > > Should I add this separately to the commitfest ? It seems like a pretty obvious win on its own, and, I'd expect, will need less discussion than David's patch, so my vote is to make it a separate thread. The patch tester wants the full series attached each time, and even without that it's difficult to discuss multiple patches on a single thread. If you make a separate thread and CF entry, please CC me and add me as a reviewer on the CF entry. One thing from a quick read through of the patch: your changes near the end of ExecSort, in ExecInitSort, and in execnodes.h need indentation fixes. Thanks, James
> If you make a separate thread and CF entry, please CC me and add me as > a reviewer on the CF entry. Ok, I started a new thread and added it to the next CF: https:// commitfest.postgresql.org/34/3237/ -- Ronan Dunklau
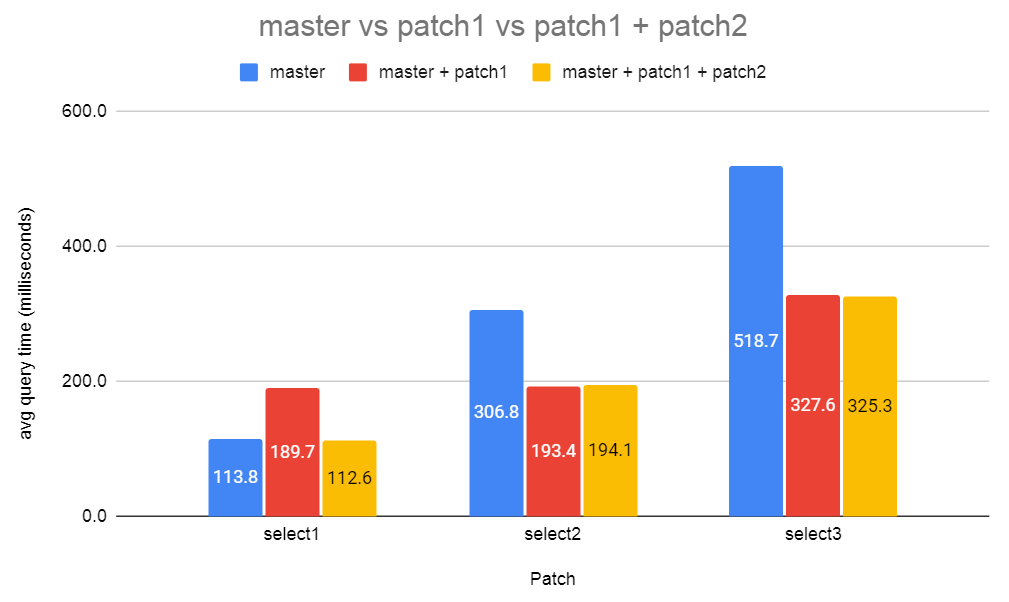
On Mon, 5 Jul 2021 at 18:38, Ronan Dunklau <ronan.dunklau@aiven.io> wrote: > I think the overhead occurs because in the ExecAgg case, we use the > tuplesort_*_datum API as an optimization when we have a single column as an > input, which the ExecSort code doesn't. Maybe it would be worth it to try to > use that API in sort nodes too, when it can be done. That's a really great find! Looks like I was wrong to assume that the extra overhead was from transitioning between nodes. I ran the performance results locally here with: create table t1(a int not null); create table t2(a int not null, b int not null); create table t3(a int not null, b int not null, c int not null); insert into t1 select x from generate_Series(1,1000000)x; insert into t2 select x,x from generate_Series(1,1000000)x; insert into t3 select x,x,1 from generate_Series(1,1000000)x; vacuum freeze analyze t1,t2,t3; select1: select sum(a order by a) from t1; select2: select sum(a order by b) from t2; select3: select c,sum(a order by b) from t3 group by c; master = https://git.postgresql.org/gitweb/?p=postgresql.git;a=commit;h=8aafb02616753f5c6c90bbc567636b73c0cbb9d4 patch1 = https://www.postgresql.org/message-id/attachment/123546/wip_planner_support_for_orderby_distinct_aggs_v0.patch patch2 = https://www.postgresql.org/message-id/attachment/124238/0001-Allow-Sort-nodes-to-use-the-fast-single-datum-tuples.patch The attached graph shows the results. It's very good to see that with both patches applied there's no regression. I'm a bit surprised there's much performance gain here given that I didn't add any indexes to provide any presorted input. David
Attachment
{kind=link}
On Sun, 13 Jun 2021 at 03:07, David Rowley <dgrowleyml@gmail.com> wrote: > > Please find attached my WIP patch. It's WIP due to what I mentioned > in the above paragraph and also because I've not bothered to add JIT > support for the new expression evaluation steps. I've split this patch into two parts. 0001 Adds planner support for ORDER BY aggregates. 0002 is a WIP patch for DISTINCT support. This still lacks JIT support and I'm still not certain of the best where to store the previous value or tuple to determine if the current one is distinct from it. The 0001 patch is fairly simple and does not require much in the way of changes in the planner aside from standard_qp_callback(). Surprisingly the executor does not need a great deal of work here either. It's just mostly about skipping the normal agg(.. ORDER BY) code when the Aggref is presorted. David
Attachment
Em seg., 12 de jul. de 2021 às 09:04, David Rowley <dgrowleyml@gmail.com> escreveu:
On Sun, 13 Jun 2021 at 03:07, David Rowley <dgrowleyml@gmail.com> wrote:
>
> Please find attached my WIP patch. It's WIP due to what I mentioned
> in the above paragraph and also because I've not bothered to add JIT
> support for the new expression evaluation steps.
I've split this patch into two parts.
Hi, I'll take a look.
0001 Adds planner support for ORDER BY aggregates.
/* Normal transition function without ORDER BY / DISTINCT. */
Is it possible to avoid entering to initialize args if 'argno >= pertrans->numTransInputs'?
Like this:
if (!pertrans->aggsortrequired && argno < pertrans->numTransInputs)
And if argos is '>' that pertrans->numTransInputs?
The test shouldn't be, inside the loop?
+ /*
+ * Don't initialize args for any ORDER BY clause that might
+ * exist in a presorted aggregate.
+ */
+ if (argno >= pertrans->numTransInputs)
+ break;
+ * Don't initialize args for any ORDER BY clause that might
+ * exist in a presorted aggregate.
+ */
+ if (argno >= pertrans->numTransInputs)
+ break;
I think that or can reduce the scope of variable 'sortlist' or simply remove it?
a)
+ /* Determine pathkeys for aggregate functions with an ORDER BY */
+ if (parse->groupingSets == NIL && root->numOrderedAggs > 0 &&
+ (qp_extra->groupClause == NIL || root->group_pathkeys))
+ {
+ ListCell *lc;
+ List *pathkeys = NIL;
+
+ foreach(lc, root->agginfos)
+ {
+ AggInfo *agginfo = (AggInfo *) lfirst(lc);
+ Aggref *aggref = agginfo->representative_aggref;
+ List *sortlist;
+
+ if (parse->groupingSets == NIL && root->numOrderedAggs > 0 &&
+ (qp_extra->groupClause == NIL || root->group_pathkeys))
+ {
+ ListCell *lc;
+ List *pathkeys = NIL;
+
+ foreach(lc, root->agginfos)
+ {
+ AggInfo *agginfo = (AggInfo *) lfirst(lc);
+ Aggref *aggref = agginfo->representative_aggref;
+ List *sortlist;
+
or better
b)
+ /* Determine pathkeys for aggregate functions with an ORDER BY */
+ if (parse->groupingSets == NIL && root->numOrderedAggs > 0 &&
+ (qp_extra->groupClause == NIL || root->group_pathkeys))
+ {
+ ListCell *lc;
+ List *pathkeys = NIL;
+
+ foreach(lc, root->agginfos)
+ {
+ AggInfo *agginfo = (AggInfo *) lfirst(lc);
+ Aggref *aggref = agginfo->representative_aggref;
+
+ if (AGGKIND_IS_ORDERED_SET(aggref->aggkind))
+ continue;
+
+ /* DISTINCT aggregates not yet supported by the planner */
+ if (aggref->aggdistinct != NIL)
+ continue;
+
+ if (aggref->aggorder == NIL)
+ continue;
+
+ /*
+ * Find the pathkeys with the most sorted derivative of the first
+ * Aggref. For example, if we determine the pathkeys for the first
+ * Aggref to be {a}, and we find another with {a,b}, then we use
+ * {a,b} since it's useful for more Aggrefs than just {a}. We
+ * currently ignore anything that might have a longer list of
+ * pathkeys than the first Aggref if it is not contained in the
+ * pathkeys for the first agg. We can't practically plan for all
+ * orders of each Aggref, so this seems like the best compromise.
+ */
+ if (pathkeys == NIL)
+ {
+ pathkeys = make_pathkeys_for_sortclauses(root, aggref->aggorder ,
+ aggref->args);
+ aggref->aggpresorted = true;
+ }
+ else
+ {
+ List *pathkeys2 = make_pathkeys_for_sortclauses(root,
+ aggref->aggorder,
+ aggref->args);
+ if (parse->groupingSets == NIL && root->numOrderedAggs > 0 &&
+ (qp_extra->groupClause == NIL || root->group_pathkeys))
+ {
+ ListCell *lc;
+ List *pathkeys = NIL;
+
+ foreach(lc, root->agginfos)
+ {
+ AggInfo *agginfo = (AggInfo *) lfirst(lc);
+ Aggref *aggref = agginfo->representative_aggref;
+
+ if (AGGKIND_IS_ORDERED_SET(aggref->aggkind))
+ continue;
+
+ /* DISTINCT aggregates not yet supported by the planner */
+ if (aggref->aggdistinct != NIL)
+ continue;
+
+ if (aggref->aggorder == NIL)
+ continue;
+
+ /*
+ * Find the pathkeys with the most sorted derivative of the first
+ * Aggref. For example, if we determine the pathkeys for the first
+ * Aggref to be {a}, and we find another with {a,b}, then we use
+ * {a,b} since it's useful for more Aggrefs than just {a}. We
+ * currently ignore anything that might have a longer list of
+ * pathkeys than the first Aggref if it is not contained in the
+ * pathkeys for the first agg. We can't practically plan for all
+ * orders of each Aggref, so this seems like the best compromise.
+ */
+ if (pathkeys == NIL)
+ {
+ pathkeys = make_pathkeys_for_sortclauses(root, aggref->aggorder ,
+ aggref->args);
+ aggref->aggpresorted = true;
+ }
+ else
+ {
+ List *pathkeys2 = make_pathkeys_for_sortclauses(root,
+ aggref->aggorder,
+ aggref->args);
0002 is a WIP patch for DISTINCT support. This still lacks JIT
support and I'm still not certain of the best where to store the
previous value or tuple to determine if the current one is distinct
from it.
In the patch 0002, I think that can reduce the scope of variable 'aggstate'?
+ EEO_CASE(EEOP_AGG_PRESORTED_DISTINCT_SINGLE)
+ {
+ AggStatePerTrans pertrans = op->d.agg_presorted_distinctcheck.pertrans;
+ Datum value = pertrans->transfn_fcinfo->args[1].value;
+ bool isnull = pertrans->transfn_fcinfo->args[1].isnull;
+
+ if (!pertrans->haslast ||
+ pertrans->lastisnull != isnull ||
+ !DatumGetBool(FunctionCall2Coll(&pertrans->equalfnOne,
+ pertrans->aggCollation,
+ pertrans->lastdatum, value)))
+ {
+ if (pertrans->haslast && !pertrans->inputtypeByVal)
+ pfree(DatumGetPointer(pertrans->lastdatum));
+
+ pertrans->haslast = true;
+ if (!isnull)
+ {
+ AggState *aggstate = castNode(AggState, state->parent);
+ {
+ AggStatePerTrans pertrans = op->d.agg_presorted_distinctcheck.pertrans;
+ Datum value = pertrans->transfn_fcinfo->args[1].value;
+ bool isnull = pertrans->transfn_fcinfo->args[1].isnull;
+
+ if (!pertrans->haslast ||
+ pertrans->lastisnull != isnull ||
+ !DatumGetBool(FunctionCall2Coll(&pertrans->equalfnOne,
+ pertrans->aggCollation,
+ pertrans->lastdatum, value)))
+ {
+ if (pertrans->haslast && !pertrans->inputtypeByVal)
+ pfree(DatumGetPointer(pertrans->lastdatum));
+
+ pertrans->haslast = true;
+ if (!isnull)
+ {
+ AggState *aggstate = castNode(AggState, state->parent);
+
+ /*
+ * XXX is it worth having a dedicted ByVal version of this
+ * operation so that we can skip switching memory contexts
+ * and do a simple assign rather than datumCopy below?
+ */
+ MemoryContext oldContext;
+
+ oldContext = MemoryContextSwitchTo(aggstate->curaggcontext->ecxt_per_tuple_memory);
+ * XXX is it worth having a dedicted ByVal version of this
+ * operation so that we can skip switching memory contexts
+ * and do a simple assign rather than datumCopy below?
+ */
+ MemoryContext oldContext;
+
+ oldContext = MemoryContextSwitchTo(aggstate->curaggcontext->ecxt_per_tuple_memory);
regards,
Ranier Vilela
Thanks for having a look at this. On Tue, 13 Jul 2021 at 11:04, Ranier Vilela <ranier.vf@gmail.com> wrote: >> 0001 Adds planner support for ORDER BY aggregates. > > /* Normal transition function without ORDER BY / DISTINCT. */ > Is it possible to avoid entering to initialize args if 'argno >= pertrans->numTransInputs'? > Like this: > > if (!pertrans->aggsortrequired && argno < pertrans->numTransInputs) > > And if argos is '>' that pertrans->numTransInputs? > The test shouldn't be, inside the loop? > > + /* > + * Don't initialize args for any ORDER BY clause that might > + * exist in a presorted aggregate. > + */ > + if (argno >= pertrans->numTransInputs) > + break; The idea is to stop the loop before processing any Aggref arguments that might belong to the ORDER BY clause. We must still process other arguments up to the ORDER BY args though, so we can't skip this loop. Note that we're doing argno++ inside the loop. If we had a for_each_to() macro, similar to for_each_from(), but allowed us to specify an end element then we could use that instead, but we don't and we still must initialize the transition arguments. > I think that or can reduce the scope of variable 'sortlist' or simply remove it? I've adjusted the scope of this. I didn't want to remove it because it's kinda useful to have it that way otherwise the 0002 patch would need to add it. >> 0002 is a WIP patch for DISTINCT support. This still lacks JIT >> support and I'm still not certain of the best where to store the >> previous value or tuple to determine if the current one is distinct >> from it. > > In the patch 0002, I think that can reduce the scope of variable 'aggstate'? > > + EEO_CASE(EEOP_AGG_PRESORTED_DISTINCT_SINGLE) Yeah, that could be done. I've attached the updated patches. David
Attachment
Em ter., 13 de jul. de 2021 às 01:44, David Rowley <dgrowleyml@gmail.com> escreveu:
Thanks for having a look at this.
On Tue, 13 Jul 2021 at 11:04, Ranier Vilela <ranier.vf@gmail.com> wrote:
>> 0001 Adds planner support for ORDER BY aggregates.
>
> /* Normal transition function without ORDER BY / DISTINCT. */
> Is it possible to avoid entering to initialize args if 'argno >= pertrans->numTransInputs'?
> Like this:
>
> if (!pertrans->aggsortrequired && argno < pertrans->numTransInputs)
>
> And if argos is '>' that pertrans->numTransInputs?
> The test shouldn't be, inside the loop?
>
> + /*
> + * Don't initialize args for any ORDER BY clause that might
> + * exist in a presorted aggregate.
> + */
> + if (argno >= pertrans->numTransInputs)
> + break;
The idea is to stop the loop before processing any Aggref arguments
that might belong to the ORDER BY clause.
Yes, I get the idea.
We must still process other
arguments up to the ORDER BY args though,
I may have misunderstood, but the other arguments are under pertrans->numTransInputs?
so we can't skip this loop.
The question not answered is if *argno* can '>=' that pertrans->numTransInputs,
before entering the loop?
If *can*, the loop might be useless in that case.
Note that we're doing argno++ inside the loop.
Another question is, if *argno* can '>' that pertrans->numTransInputs,
before the loop, the test will fail?
if (argno == pertrans->numTransInputs)
> I think that or can reduce the scope of variable 'sortlist' or simply remove it?
I've adjusted the scope of this. I didn't want to remove it because
it's kinda useful to have it that way otherwise the 0002 patch would
need to add it.
Nice.
>> 0002 is a WIP patch for DISTINCT support. This still lacks JIT
>> support and I'm still not certain of the best where to store the
>> previous value or tuple to determine if the current one is distinct
>> from it.
>
> In the patch 0002, I think that can reduce the scope of variable 'aggstate'?
>
> + EEO_CASE(EEOP_AGG_PRESORTED_DISTINCT_SINGLE)
Yeah, that could be done.
I've attached the updated patches.
Thanks.
regards,
Ranier Vilela
On Tue, 13 Jul 2021 at 23:45, Ranier Vilela <ranier.vf@gmail.com> wrote: > The question not answered is if *argno* can '>=' that pertrans->numTransInputs, > before entering the loop? > If *can*, the loop might be useless in that case. > >> >> >> Note that we're doing argno++ inside the loop. > > Another question is, if *argno* can '>' that pertrans->numTransInputs, > before the loop, the test will fail? > if (argno == pertrans->numTransInputs) argno is *always* 0 before the loop starts. David
Em ter., 13 de jul. de 2021 às 22:15, David Rowley <dgrowleyml@gmail.com> escreveu:
On Tue, 13 Jul 2021 at 23:45, Ranier Vilela <ranier.vf@gmail.com> wrote:
> The question not answered is if *argno* can '>=' that pertrans->numTransInputs,
> before entering the loop?
> If *can*, the loop might be useless in that case.
>
>>
>>
>> Note that we're doing argno++ inside the loop.
>
> Another question is, if *argno* can '>' that pertrans->numTransInputs,
> before the loop, the test will fail?
> if (argno == pertrans->numTransInputs)
argno is *always* 0 before the loop starts.
Good. Thanks.
regards,
Ranier Vilela
Le mardi 13 juillet 2021, 06:44:12 CEST David Rowley a écrit : > I've attached the updated patches. The approach of building a pathkey for the first order by we find, then appending to it as needed seems sensible but I'm a bit worried about users starting to rely on this as an optimization. Even if we don't document it, people may start to change the order of their target lists to "force" a specific sort on the lower nodes. How confident are we that we won't change this or that we will be willing to break it ? Generating all possible pathkeys and costing the resulting plans would be too expensive, but maybe a more "stable" (and limited) approach would be fine, like generating the pathkeys only if every ordered aggref shares the same prefix. I don't think there would be any ambiguity here. -- Ronan Dunklau
On Fri, 16 Jul 2021 at 01:02, Ronan Dunklau <ronan.dunklau@aiven.io> wrote: > The approach of building a pathkey for the first order by we find, then > appending to it as needed seems sensible but I'm a bit worried about users > starting to rely on this as an optimization. Even if we don't document it, > people may start to change the order of their target lists to "force" a > specific sort on the lower nodes. How confident are we that we won't change this > or that we will be willing to break it ? That's a good question. I mainly did it that way because Windowing functions work similarly based on the position of items in the targetlist. The situation there is slightly more complex as it depends on the SortGroupClause->tleSortGroupRef. > Generating all possible pathkeys and costing the resulting plans would be too > expensive, but maybe a more "stable" (and limited) approach would be fine, like > generating the pathkeys only if every ordered aggref shares the same prefix. I > don't think there would be any ambiguity here. I think that's a bad idea as it would leave a lot on the table. I don't see any reason to make it that restrictive. Remember that before this that every Aggref with a sort clause must perform their own sort. So it's not like we'll ever increase the number of sorts here as a result. What we maybe could consider instead would be to pick the first Aggref then look for the most sorted derivative of that then tally up the number of Aggrefs that can be sorted using those pathkeys, then repeat that process for the remaining Aggrefs that didn't have the same prefix then use the pathkeys for the set with the most Aggrefs. We could still tiebreak on the targetlist position so at least it's not random which ones we pick. Now that we have a list of Aggrefs that are deduplicated in the planner thanks to 0a2bc5d61e it should be fairly easy to do that. David
On Fri, 16 Jul 2021 at 18:04, David Rowley <dgrowleyml@gmail.com> wrote: > What we maybe could consider instead would be to pick the first Aggref > then look for the most sorted derivative of that then tally up the > number of Aggrefs that can be sorted using those pathkeys, then repeat > that process for the remaining Aggrefs that didn't have the same > prefix then use the pathkeys for the set with the most Aggrefs. We > could still tiebreak on the targetlist position so at least it's not > random which ones we pick. Now that we have a list of Aggrefs that are > deduplicated in the planner thanks to 0a2bc5d61e it should be fairly > easy to do that. I've attached a patch which does as I mention above. I'm still not sold on if this is better than just going with the order of the first aggregate. The problem might be that a plan could change as new aggregates are added to the end of the target list. It feels like there might be a bit less control over it than the previous version. Remember that suiting more aggregates is not always better as there might be an index that could provide presorted input for another set of aggregates which would overall reduce the number of sorts. However, maybe it's not too big an issue as for any aggregates that are not presorted we're left doing 1 sort per Aggref, so reducing the number of those might be more important than selecting the order that has an index to support it. I've left off the 0002 patch this time as I think the lack of JIT support for DISTINCT was causing the CF bot to fail. I'd quite like to confirm that theory. David
Attachment
On Fri, 16 Jul 2021 at 22:00, David Rowley <dgrowleyml@gmail.com> wrote: > > On Fri, 16 Jul 2021 at 18:04, David Rowley <dgrowleyml@gmail.com> wrote: > > What we maybe could consider instead would be to pick the first Aggref > > then look for the most sorted derivative of that then tally up the > > number of Aggrefs that can be sorted using those pathkeys, then repeat > > that process for the remaining Aggrefs that didn't have the same > > prefix then use the pathkeys for the set with the most Aggrefs. We > > could still tiebreak on the targetlist position so at least it's not > > random which ones we pick. Now that we have a list of Aggrefs that are > > deduplicated in the planner thanks to 0a2bc5d61e it should be fairly > > easy to do that. > > I've attached a patch which does as I mention above. Looks like I did a sloppy job of that. I messed up the condition in standard_qp_callback() that sets the ORDER BY aggregate pathkeys so that it accidentally set them when there was an unsortable GROUP BY clause, as highlighted by the postgres_fdw tests failing. I've now added a comment to explain why the condition is the way it is so that I don't forget again. Here's a cleaned-up version that passes make check-world. David
Attachment
> Looks like I did a sloppy job of that. I messed up the condition in
> standard_qp_callback() that sets the ORDER BY aggregate pathkeys so
> that it accidentally set them when there was an unsortable GROUP BY
> clause, as highlighted by the postgres_fdw tests failing. I've now
> added a comment to explain why the condition is the way it is so that
> I don't forget again.
>
> Here's a cleaned-up version that passes make check-world.
>
I've noticed that when the ORDER BY is a grouping key (which to be honest
doesn't seem to make much sense to me), the sort key is duplicated, as
demonstrated by one of the modified tests (partition_aggregate.sql).
This leads to additional sort nodes being added when there is no necessity to
do so. In the case of sort and index pathes, the duplicate keys are not
considered, I think the same should apply here.
It means the logic for appending the order by pathkeys to the existing group
by pathkeys would ideally need to remove the redundant group by keys from the
order by keys, considering this example:
regression=# explain select sum(unique1 order by ten, two), sum(unique1 order
by four), sum(unique1 order by two, four) from tenk2 group by ten;
QUERY PLAN
------------------------------------------------------------------------
GroupAggregate (cost=1109.39..1234.49 rows=10 width=28)
Group Key: ten
-> Sort (cost=1109.39..1134.39 rows=10000 width=16)
Sort Key: ten, ten, two
-> Seq Scan on tenk2 (cost=0.00..445.00 rows=10000 width=16)
We would ideally like to sort on ten, two, four to satisfy the first and last
aggref at once. Stripping the common prefix (ten) would eliminate this problem.
Also, existing regression tests cover the first problem (order by a grouping
key) but I feel like they should be extended with a case similar as the above
to check which pathkeys are used in the "multiple ordered aggregates + group
by" cases.
--
Ronan Dunklau
On Mon, 19 Jul 2021 at 18:32, Ronan Dunklau <ronan.dunklau@aiven.io> wrote: > It means the logic for appending the order by pathkeys to the existing group > by pathkeys would ideally need to remove the redundant group by keys from the > order by keys, considering this example: > > regression=# explain select sum(unique1 order by ten, two), sum(unique1 order > by four), sum(unique1 order by two, four) from tenk2 group by ten; > QUERY PLAN > ------------------------------------------------------------------------ > GroupAggregate (cost=1109.39..1234.49 rows=10 width=28) > Group Key: ten > -> Sort (cost=1109.39..1134.39 rows=10000 width=16) > Sort Key: ten, ten, two > -> Seq Scan on tenk2 (cost=0.00..445.00 rows=10000 width=16) > > > We would ideally like to sort on ten, two, four to satisfy the first and last > aggref at once. Stripping the common prefix (ten) would eliminate this problem. hmm, yeah. That's not great. This comes from the way I'm doing list_concat on the pathkeys from the GROUP BY with the ones from the ordered aggregates. If it were possible to use make_pathkeys_for_sortclauses() to make these in one go, that would fix the problem since pathkey_is_redundant() would skip the 2nd "ten". Unfortunately, it's not possible to pass the combined list of SortGroupClauses to make_pathkeys_for_sortclauses since they're not from the same targetlist. Aggrefs have their own targetlist and the SortGroupClauses for the Aggref reference that tlist. I think to do this we'd need something like pathkeys_append() in pathkeys.c which had a loop and appended the pathkey only if pathkey_is_redundant returns false. > Also, existing regression tests cover the first problem (order by a grouping > key) but I feel like they should be extended with a case similar as the above > to check which pathkeys are used in the "multiple ordered aggregates + group > by" cases. It does seem like a bit of a weird case to go to a lot of effort to make work, but it would be nice if it did work without having to contort the code too much. David
On Mon, 19 Jul 2021 at 18:32, Ronan Dunklau <ronan.dunklau@aiven.io> wrote: > regression=# explain select sum(unique1 order by ten, two), sum(unique1 order > by four), sum(unique1 order by two, four) from tenk2 group by ten; > QUERY PLAN > ------------------------------------------------------------------------ > GroupAggregate (cost=1109.39..1234.49 rows=10 width=28) > Group Key: ten > -> Sort (cost=1109.39..1134.39 rows=10000 width=16) > Sort Key: ten, ten, two > -> Seq Scan on tenk2 (cost=0.00..445.00 rows=10000 width=16) > > > We would ideally like to sort on ten, two, four to satisfy the first and last > aggref at once. Stripping the common prefix (ten) would eliminate this problem. Thanks for finding this. I've made a few changes to make this case work as you describe. Please see attached v6 patches. Because I had to add additional code to take the GROUP BY pathkeys into account when choosing the best ORDER BY agg pathkeys, the function that does that became a little bigger. To try to reduce the complexity of it, I got rid of all the processing from the initial loop and instead it now uses the logic from the 2nd loop to find the best pathkeys. The reason I'd not done that in the first place was because I'd thought I could get away without building an additional Bitmapset for simple cases, but that's probably fairly cheap compared to building Pathkeys. With the additional complexity for the GROUP BY pathkeys, the extra code seemed not worth it. The 0001 patch is the ORDER BY aggregate code. 0002 is to fix up some broken regression tests in postgres_fdw that 0001 caused. It appears that 0001 uncovered a bug in the postgres_fdw code. I've reported that in [1]. If that turns out to be a bug then it'll need to be fixed before this can progress. David [1] https://www.postgresql.org/message-id/CAApHDvr4OeC2DBVY--zVP83-K=bYrTD7F8SZDhN4g+pj2f2S-A@mail.gmail.com
Attachment
Le mercredi 21 juillet 2021, 04:52:43 CEST David Rowley a écrit : > Thanks for finding this. I've made a few changes to make this case > work as you describe. Please see attached v6 patches. > > Because I had to add additional code to take the GROUP BY pathkeys > into account when choosing the best ORDER BY agg pathkeys, the > function that does that became a little bigger. To try to reduce the > complexity of it, I got rid of all the processing from the initial > loop and instead it now uses the logic from the 2nd loop to find the > best pathkeys. The reason I'd not done that in the first place was > because I'd thought I could get away without building an additional > Bitmapset for simple cases, but that's probably fairly cheap compared > to building Pathkeys. With the additional complexity for the GROUP > BY pathkeys, the extra code seemed not worth it. > > The 0001 patch is the ORDER BY aggregate code. 0002 is to fix up some > broken regression tests in postgres_fdw that 0001 caused. It appears > that 0001 uncovered a bug in the postgres_fdw code. I've reported > that in [1]. If that turns out to be a bug then it'll need to be fixed > before this can progress. I tested the 0001 patch against both HEAD and my proposed bugfix for postgres_fdw. There is a problem that the ordered aggregate is not pushed down anymore. The underlying Sort node is correctly pushed down though. This comes from the fact that postgres_fdw grouping path never contains any pathkey. Since the cost is fuzzily the same between the pushed-down aggregate and the locally performed one, the tie is broken against the pathkeys. Ideally we would add the group pathkeys to the grouping path, but this would add an additional ORDER BY expression matching the GROUP BY. Moreover, some triaging of the pathkeys would be necessary since we now mix the sort-in- aggref pathkeys with the group_pathkeys. -- Ronan Dunklau
On Thu, 22 Jul 2021 at 02:01, Ronan Dunklau <ronan.dunklau@aiven.io> wrote: > I tested the 0001 patch against both HEAD and my proposed bugfix for > postgres_fdw. > > There is a problem that the ordered aggregate is not pushed down anymore. The > underlying Sort node is correctly pushed down though. > > This comes from the fact that postgres_fdw grouping path never contains any > pathkey. Since the cost is fuzzily the same between the pushed-down aggregate > and the locally performed one, the tie is broken against the pathkeys. I think this might be more down to a lack of any penalty cost for fetching foreign tuples. Looking at create_foreignscan_path(), I don't see anything that adds anything to account for fetching the tuples from the foreign server. If there was something like that then there'd be more of a preference to perform the remote aggregation so that fewer rows must arrive from the remote server. I tested by adding: total_cost += cpu_tuple_cost * rows * 100; in create_foreignscan_path() and I got the plan with the remote aggregation. That's a fairly large penalty of 1.0 per row. Much bigger than parallel_tuple_cost's default value. I'm a bit undecided on how much this patch needs to get involved in adjusting foreign scan costs. The problem is that we've given the executor a new path to consider and nobody has done any proper costings for the foreign scan so that it properly prefers paths that have to pull fewer foreign tuples. This is a pretty similar problem to what parallel_tuple_cost aims to fix. Also similar to how we had to add APPEND_CPU_COST_MULTIPLIER to have partition-wise aggregates prefer grouping at the partition level rather than at the partitioned table level. > Ideally we would add the group pathkeys to the grouping path, but this would > add an additional ORDER BY expression matching the GROUP BY. Moreover, some > triaging of the pathkeys would be necessary since we now mix the sort-in- > aggref pathkeys with the group_pathkeys. I think you're talking about passing pathkeys into create_foreign_upper_path in add_foreign_grouping_paths. If so, I don't really see how it would be safe to add pathkeys to the foreign grouping path. What if the foreign server did a Hash Aggregate? The rows might come back in any random order. I kinda think that to fix this properly would need a new foreign server option such as foreign_tuple_cost. I'd feel better about something like that with some of the people with a vested interest in the FDW code were watching more closely. So far we've not managed to entice any of them with the bug report yet, but it's maybe early days yet. David
Le jeudi 22 juillet 2021, 09:38:50 CEST David Rowley a écrit : > On Thu, 22 Jul 2021 at 02:01, Ronan Dunklau <ronan.dunklau@aiven.io> wrote: > > I tested the 0001 patch against both HEAD and my proposed bugfix for > > postgres_fdw. > > > > There is a problem that the ordered aggregate is not pushed down anymore. > > The underlying Sort node is correctly pushed down though. > > > > This comes from the fact that postgres_fdw grouping path never contains > > any > > pathkey. Since the cost is fuzzily the same between the pushed-down > > aggregate and the locally performed one, the tie is broken against the > > pathkeys. > I think this might be more down to a lack of any penalty cost for > fetching foreign tuples. Looking at create_foreignscan_path(), I don't > see anything that adds anything to account for fetching the tuples > from the foreign server. If there was something like that then there'd > be more of a preference to perform the remote aggregation so that > fewer rows must arrive from the remote server. > > I tested by adding: total_cost += cpu_tuple_cost * rows * 100; in > create_foreignscan_path() and I got the plan with the remote > aggregation. That's a fairly large penalty of 1.0 per row. Much bigger > than parallel_tuple_cost's default value. > > I'm a bit undecided on how much this patch needs to get involved in > adjusting foreign scan costs. The problem is that we've given the > executor a new path to consider and nobody has done any proper > costings for the foreign scan so that it properly prefers paths that > have to pull fewer foreign tuples. This is a pretty similar problem > to what parallel_tuple_cost aims to fix. Also similar to how we had to > add APPEND_CPU_COST_MULTIPLIER to have partition-wise aggregates > prefer grouping at the partition level rather than at the partitioned > table level. > > > Ideally we would add the group pathkeys to the grouping path, but this > > would add an additional ORDER BY expression matching the GROUP BY. > > Moreover, some triaging of the pathkeys would be necessary since we now > > mix the sort-in- aggref pathkeys with the group_pathkeys. > > I think you're talking about passing pathkeys into > create_foreign_upper_path in add_foreign_grouping_paths. If so, I > don't really see how it would be safe to add pathkeys to the foreign > grouping path. What if the foreign server did a Hash Aggregate? The > rows might come back in any random order. Yes, I was suggesting to add a new path with the pathkeys factored in, which if chosen over the non-ordered path would result in an additional ORDER BY clause to prevent a HashAggregate. But that doesn't seem a good idea after all. > > I kinda think that to fix this properly would need a new foreign > server option such as foreign_tuple_cost. I'd feel better about > something like that with some of the people with a vested interest in > the FDW code were watching more closely. So far we've not managed to > entice any of them with the bug report yet, but it's maybe early days > yet. We already have that in the form of fdw_tuple_cost as a server option if I'm not mistaken ? It works as expected when the number of tuples is notably reduced by the foreign group by. The problem arise when the cardinality of the groups is equal to the input's cardinality. I think even in that case we should try to use a remote aggregate since it's a computation that will not happen on the local server. I also think we're more likely to have up to date statistics remotely than the ones collected locally on the foreign tables, and the estimated number of groups would be more accurate on the remote side than the local one. -- Ronan Dunklau
Le jeudi 22 juillet 2021, 10:42:49 CET Ronan Dunklau a écrit : > Le jeudi 22 juillet 2021, 09:38:50 CEST David Rowley a écrit : > > On Thu, 22 Jul 2021 at 02:01, Ronan Dunklau <ronan.dunklau@aiven.io> wrote: > > > I tested the 0001 patch against both HEAD and my proposed bugfix for > > > postgres_fdw. > > > > > > There is a problem that the ordered aggregate is not pushed down > > > anymore. > > > The underlying Sort node is correctly pushed down though. > > > > > > This comes from the fact that postgres_fdw grouping path never contains > > > any > > > pathkey. Since the cost is fuzzily the same between the pushed-down > > > aggregate and the locally performed one, the tie is broken against the > > > pathkeys. > > > > I think this might be more down to a lack of any penalty cost for > > fetching foreign tuples. Looking at create_foreignscan_path(), I don't > > see anything that adds anything to account for fetching the tuples > > from the foreign server. If there was something like that then there'd > > be more of a preference to perform the remote aggregation so that > > fewer rows must arrive from the remote server. > > > > I tested by adding: total_cost += cpu_tuple_cost * rows * 100; in > > create_foreignscan_path() and I got the plan with the remote > > aggregation. That's a fairly large penalty of 1.0 per row. Much bigger > > than parallel_tuple_cost's default value. > > > > I'm a bit undecided on how much this patch needs to get involved in > > adjusting foreign scan costs. The problem is that we've given the > > executor a new path to consider and nobody has done any proper > > costings for the foreign scan so that it properly prefers paths that > > have to pull fewer foreign tuples. This is a pretty similar problem > > to what parallel_tuple_cost aims to fix. Also similar to how we had to > > add APPEND_CPU_COST_MULTIPLIER to have partition-wise aggregates > > prefer grouping at the partition level rather than at the partitioned > > table level. > > > > > Ideally we would add the group pathkeys to the grouping path, but this > > > would add an additional ORDER BY expression matching the GROUP BY. > > > Moreover, some triaging of the pathkeys would be necessary since we now > > > mix the sort-in- aggref pathkeys with the group_pathkeys. > > > > I think you're talking about passing pathkeys into > > create_foreign_upper_path in add_foreign_grouping_paths. If so, I > > don't really see how it would be safe to add pathkeys to the foreign > > grouping path. What if the foreign server did a Hash Aggregate? The > > rows might come back in any random order. > > Yes, I was suggesting to add a new path with the pathkeys factored in, which > if chosen over the non-ordered path would result in an additional ORDER BY > clause to prevent a HashAggregate. But that doesn't seem a good idea after > all. > > > I kinda think that to fix this properly would need a new foreign > > server option such as foreign_tuple_cost. I'd feel better about > > something like that with some of the people with a vested interest in > > the FDW code were watching more closely. So far we've not managed to > > entice any of them with the bug report yet, but it's maybe early days > > yet. > > We already have that in the form of fdw_tuple_cost as a server option if I'm > not mistaken ? It works as expected when the number of tuples is notably > reduced by the foreign group by. > > The problem arise when the cardinality of the groups is equal to the input's > cardinality. I think even in that case we should try to use a remote > aggregate since it's a computation that will not happen on the local > server. I also think we're more likely to have up to date statistics > remotely than the ones collected locally on the foreign tables, and the > estimated number of groups would be more accurate on the remote side than > the local one. I took some time to toy with this again. At first I thought that charging a discount in foreign grouping paths for Aggref targets (since they are computed remotely) would be a good idea, similar to what is done for the grouping keys. But in the end, it's probably not something we would like to do. Yes, the group planning will be more accurate on the remote side generally (better statistics than locally for estimating the number of groups) but executing the grouping locally when the number of groups is close to the input's cardinality (ex: group by unique_key) gives us a form of parallelism which can actually perform better. For the other cases where there is fewer output than input tuples, that is, when an actual grouping takes place, adjusting fdw_tuple_cost might be enough to tune the behavior to what is desirable. -- Ronan Dunklau
This patch is now failing in the sqljson regression test. It looks like it's just the ordering of the elements in json_arrayagg() calls which may actually be a faulty test that needs more ORDER BY clauses rather than any issues with the code. Nonetheless it's something that needs to be addressed before this patch could be applied. Given it's gotten some feedback from Ronan and this regression test failure I'll move it to Waiting on Author but we're near the end of the CF and it'll probably be moved forward soon. On Thu, 4 Nov 2021 at 04:00, Ronan Dunklau <ronan.dunklau@aiven.io> wrote: > > Le jeudi 22 juillet 2021, 10:42:49 CET Ronan Dunklau a écrit : > > Le jeudi 22 juillet 2021, 09:38:50 CEST David Rowley a écrit : > > > On Thu, 22 Jul 2021 at 02:01, Ronan Dunklau <ronan.dunklau@aiven.io> > wrote: > > > > I tested the 0001 patch against both HEAD and my proposed bugfix for > > > > postgres_fdw. > > > > > > > > There is a problem that the ordered aggregate is not pushed down > > > > anymore. > > > > The underlying Sort node is correctly pushed down though. > > > > > > > > This comes from the fact that postgres_fdw grouping path never contains > > > > any > > > > pathkey. Since the cost is fuzzily the same between the pushed-down > > > > aggregate and the locally performed one, the tie is broken against the > > > > pathkeys. > > > > > > I think this might be more down to a lack of any penalty cost for > > > fetching foreign tuples. Looking at create_foreignscan_path(), I don't > > > see anything that adds anything to account for fetching the tuples > > > from the foreign server. If there was something like that then there'd > > > be more of a preference to perform the remote aggregation so that > > > fewer rows must arrive from the remote server. > > > > > > I tested by adding: total_cost += cpu_tuple_cost * rows * 100; in > > > create_foreignscan_path() and I got the plan with the remote > > > aggregation. That's a fairly large penalty of 1.0 per row. Much bigger > > > than parallel_tuple_cost's default value. > > > > > > I'm a bit undecided on how much this patch needs to get involved in > > > adjusting foreign scan costs. The problem is that we've given the > > > executor a new path to consider and nobody has done any proper > > > costings for the foreign scan so that it properly prefers paths that > > > have to pull fewer foreign tuples. This is a pretty similar problem > > > to what parallel_tuple_cost aims to fix. Also similar to how we had to > > > add APPEND_CPU_COST_MULTIPLIER to have partition-wise aggregates > > > prefer grouping at the partition level rather than at the partitioned > > > table level. > > > > > > > Ideally we would add the group pathkeys to the grouping path, but this > > > > would add an additional ORDER BY expression matching the GROUP BY. > > > > Moreover, some triaging of the pathkeys would be necessary since we now > > > > mix the sort-in- aggref pathkeys with the group_pathkeys. > > > > > > I think you're talking about passing pathkeys into > > > create_foreign_upper_path in add_foreign_grouping_paths. If so, I > > > don't really see how it would be safe to add pathkeys to the foreign > > > grouping path. What if the foreign server did a Hash Aggregate? The > > > rows might come back in any random order. > > > > Yes, I was suggesting to add a new path with the pathkeys factored in, which > > if chosen over the non-ordered path would result in an additional ORDER BY > > clause to prevent a HashAggregate. But that doesn't seem a good idea after > > all. > > > > > I kinda think that to fix this properly would need a new foreign > > > server option such as foreign_tuple_cost. I'd feel better about > > > something like that with some of the people with a vested interest in > > > the FDW code were watching more closely. So far we've not managed to > > > entice any of them with the bug report yet, but it's maybe early days > > > yet. > > > > We already have that in the form of fdw_tuple_cost as a server option if I'm > > not mistaken ? It works as expected when the number of tuples is notably > > reduced by the foreign group by. > > > > The problem arise when the cardinality of the groups is equal to the input's > > cardinality. I think even in that case we should try to use a remote > > aggregate since it's a computation that will not happen on the local > > server. I also think we're more likely to have up to date statistics > > remotely than the ones collected locally on the foreign tables, and the > > estimated number of groups would be more accurate on the remote side than > > the local one. > > I took some time to toy with this again. > > At first I thought that charging a discount in foreign grouping paths for > Aggref targets (since they are computed remotely) would be a good idea, > similar to what is done for the grouping keys. > > But in the end, it's probably not something we would like to do. Yes, the > group planning will be more accurate on the remote side generally (better > statistics than locally for estimating the number of groups) but executing the > grouping locally when the number of groups is close to the input's cardinality > (ex: group by unique_key) gives us a form of parallelism which can actually > perform better. > > For the other cases where there is fewer output than input tuples, that is, > when an actual grouping takes place, adjusting fdw_tuple_cost might be enough > to tune the behavior to what is desirable. > > > -- > Ronan Dunklau > > > > -- greg
On Thu, 31 Mar 2022 at 06:36, Greg Stark <stark@mit.edu> wrote: > > This patch is now failing in the sqljson regression test. It looks > like it's just the ordering of the elements in json_arrayagg() calls > which may actually be a faulty test that needs more ORDER BY clauses > rather than any issues with the code. Nonetheless it's something that > needs to be addressed before this patch could be applied. > > Given it's gotten some feedback from Ronan and this regression test > failure I'll move it to Waiting on Author but we're near the end of > the CF and it'll probably be moved forward soon. Thanks for mentioning this and for keeping tabs on it. This patch in general is more than there's realistic time for in this CF. I'd very much like to get the DISTINCT part working too. Not just the ORDER BY. I've pushed this one out to July's CF now. David
On Thu, 4 Nov 2021 at 20:59, Ronan Dunklau <ronan.dunklau@aiven.io> wrote: > I took some time to toy with this again. > > At first I thought that charging a discount in foreign grouping paths for > Aggref targets (since they are computed remotely) would be a good idea, > similar to what is done for the grouping keys. I've been working on this patch again. There was a bit of work to do to rebase it atop db0d67db2. The problem there was that since this patch appends pathkeys to suit ORDER BY / DISTINCT aggregates to the query's group_pathkeys, db0d67db2 goes and tries to rearrange those, but fails to find the SortGroupClause corresponding to the PathKey in group_pathkeys. I wish the code I came up with to make that work was a bit nicer, but what's there at least seems to work. There are a few more making copies of Lists than I'd like. I've also went and added LLVM support to make JIT work with the new DISTINCT expression evaluation step types. Also, James mentioned in [1] about the Merge Join plan change that this patch was causing in an existing test. I looked into that and found the cause. The plan change is not really the fault of this patch, so I've proposed a fix for to make that work more efficiently in [2]. The basics there are that select_outer_pathkeys_for_merge() pre-dates Incremental Sorts and didn't consider prefixes of the query_pathkeys after matching all the join quals. The patch on that thread relaxes that rule and makes this patch produce an Incremental Sort plan for the query in question. Another annoying part of this patch is that I've added an "aggpresorted" field to Aggref, which the planner sets. That's a parse node type and it would be nicer not to have the planner mess around with those. We maybe could wrap up the Aggrefs in some planner struct and pass those to the executor instead. That would require a bit more churn than what I've got in the attached. I've attached the v7 patch. David [1] https://www.postgresql.org/message-id/CAAaqYe-yxXkXVPJkRw1nDA=CJBw28jvhACRyDcU10dAOcdSj=Q@mail.gmail.com [2] https://www.postgresql.org/message-id/CAApHDvrtZu0PHVfDPFM4Yx3jNR2Wuwosv+T2zqa7LrhhBr2rRg@mail.gmail.com
Attachment
On Thu, 4 Nov 2021 at 20:59, Ronan Dunklau <ronan.dunklau@aiven.io> wrote:
> I took some time to toy with this again.
>
> At first I thought that charging a discount in foreign grouping paths for
> Aggref targets (since they are computed remotely) would be a good idea,
> similar to what is done for the grouping keys.
>
> But in the end, it's probably not something we would like to do. Yes, the
> group planning will be more accurate on the remote side generally (better
> statistics than locally for estimating the number of groups) but executing the
> grouping locally when the number of groups is close to the input's cardinality
> (ex: group by unique_key) gives us a form of parallelism which can actually
> perform better.
>
> For the other cases where there is fewer output than input tuples, that is,
> when an actual grouping takes place, adjusting fdw_tuple_cost might be enough
> to tune the behavior to what is desirable.
I've now looked into this issue. With the patched code, the remote
aggregate path loses out in add_path() due to the fact that the local
aggregate path compares fuzzily the same as the remote aggregate path.
Since the local aggregate path is now fetching the rows from the
foreign server with a SQL query containing an ORDER BY clause (per my
change to query_pathkeys being picked up in
get_useful_pathkeys_for_relation()), add_path now prefers that path
due to it having pathkeys and the remote aggregate query not having
any (PATHKEYS_BETTER2).
It seems what's going on is that quite simply the default
fdw_tuple_cost is unrealistically low. Let's look.
#define DEFAULT_FDW_TUPLE_COST 0.01
Which is even lower than DEFAULT_PARALLEL_TUPLE_COST (0.1) and the
same as cpu_tuple_cost!
After some debugging, I see add_path() switches to the, seemingly
better, remote aggregate plan again if I multiple fdw_tuple_cost by
28. Anything below that sticks to the (inferior) local aggregate plan.
There's also another problem going on that would make that situation
better. The query planner expects the following query to produce 6
rows:
SELECT array_agg("C 1" ORDER BY "C 1" USING OPERATOR(public.<^) NULLS
LAST), c2 FROM "S 1"."T 1" WHERE (("C 1" < 100)) AND ((c2 = 6)) GROUP
BY c2;
You might expect the planner to think there'd just be 1 row due to the
"c2 = 6" and "GROUP BY c2", but it thinks there will be more than
that. If estimate_num_groups() knew about EquivalenceClasses and
checked ec_has_const, then it might be able to do better, but it
doesn't, so:
GroupAggregate (cost=11.67..11.82 rows=6 width=36)
If I force that estimate to be 1 row instead of 6, then I only need a
fdw_tuple_cost to be 12 times the default to get it to switch to the
remote aggregate plan.
I think we should likely just patch master and change
DEFAULT_FDW_TUPLE_COST to at the very least 0.2, which is 20x higher
than today's setting. I'd be open to a much higher setting such as 0.5
(50x).
David
On Wed, Jul 20, 2022 at 1:27 PM David Rowley <dgrowleyml@gmail.com> wrote:
I've been working on this patch again. There was a bit of work to do
to rebase it atop db0d67db2. The problem there was that since this
patch appends pathkeys to suit ORDER BY / DISTINCT aggregates to the
query's group_pathkeys, db0d67db2 goes and tries to rearrange those,
but fails to find the SortGroupClause corresponding to the PathKey in
group_pathkeys. I wish the code I came up with to make that work was a
bit nicer, but what's there at least seems to work. There are a few
more making copies of Lists than I'd like.
record we've found pathkeys for an aggregate, because 'currpathkeys' may
include pathkeys for some latter aggregates. I can see this problem with
the query below:
select max(b order by b), max(a order by a) from t group by a;
When processing the first aggregate, we compose the 'currpathkeys' as
{a, b} and mark this aggregate in 'aggindexes'. When it comes to the
second aggregate, we compose its pathkeys as {a} and decide that it is
not stronger than 'currpathkeys'. So the second aggregate is not
recorded in 'aggindexes'. As a result, we fail to mark aggpresorted for
the second aggregate.
Thanks
Richard
On Fri, 22 Jul 2022 at 21:33, Richard Guo <guofenglinux@gmail.com> wrote:
> I can see this problem with
> the query below:
>
> select max(b order by b), max(a order by a) from t group by a;
>
> When processing the first aggregate, we compose the 'currpathkeys' as
> {a, b} and mark this aggregate in 'aggindexes'. When it comes to the
> second aggregate, we compose its pathkeys as {a} and decide that it is
> not stronger than 'currpathkeys'. So the second aggregate is not
> recorded in 'aggindexes'. As a result, we fail to mark aggpresorted for
> the second aggregate.
Yeah, you're right. I have a missing check to see if currpathkeys are
better than the pathkeys for the current aggregate. In your example
case we'd have still processed the 2nd aggregate the old way instead
of realising we could take the new pre-sorted path for faster
processing.
I've adjusted that in the attached to make it properly include the
case where currpathkeys are better.
Thanks for the review.
David
Attachment
On Mon, Jul 25, 2022 at 4:39 PM David Rowley <dgrowleyml@gmail.com> wrote:
On Fri, 22 Jul 2022 at 21:33, Richard Guo <guofenglinux@gmail.com> wrote:
> I can see this problem with
> the query below:
>
> select max(b order by b), max(a order by a) from t group by a;
>
> When processing the first aggregate, we compose the 'currpathkeys' as
> {a, b} and mark this aggregate in 'aggindexes'. When it comes to the
> second aggregate, we compose its pathkeys as {a} and decide that it is
> not stronger than 'currpathkeys'. So the second aggregate is not
> recorded in 'aggindexes'. As a result, we fail to mark aggpresorted for
> the second aggregate.
Yeah, you're right. I have a missing check to see if currpathkeys are
better than the pathkeys for the current aggregate. In your example
case we'd have still processed the 2nd aggregate the old way instead
of realising we could take the new pre-sorted path for faster
processing.
I've adjusted that in the attached to make it properly include the
case where currpathkeys are better.
Thanks for the review.
David
Hi,
sort order the the planner chooses is simply : there is duplicate `the`
+ /* mark this aggregate is covered by 'currpathkeys' */
is covered by -> as covered by
Cheers
On Tue, Jul 26, 2022 at 7:38 AM David Rowley <dgrowleyml@gmail.com> wrote:
On Fri, 22 Jul 2022 at 21:33, Richard Guo <guofenglinux@gmail.com> wrote:
> I can see this problem with
> the query below:
>
> select max(b order by b), max(a order by a) from t group by a;
>
> When processing the first aggregate, we compose the 'currpathkeys' as
> {a, b} and mark this aggregate in 'aggindexes'. When it comes to the
> second aggregate, we compose its pathkeys as {a} and decide that it is
> not stronger than 'currpathkeys'. So the second aggregate is not
> recorded in 'aggindexes'. As a result, we fail to mark aggpresorted for
> the second aggregate.
Yeah, you're right. I have a missing check to see if currpathkeys are
better than the pathkeys for the current aggregate. In your example
case we'd have still processed the 2nd aggregate the old way instead
of realising we could take the new pre-sorted path for faster
processing.
I've adjusted that in the attached to make it properly include the
case where currpathkeys are better.
Also I'm wondering if it's possible to take into consideration the
ordering indicated by existing indexes when determining the pathkeys. So
that for the query below we can avoid the Incremental Sort node if we
consider that there is an index on t(a, c):
# explain (costs off) select max(b order by b), max(c order by c) from t group by a;
QUERY PLAN
---------------------------------------------
GroupAggregate
Group Key: a
-> Incremental Sort
Sort Key: a, b
Presorted Key: a
-> Index Scan using t_a_c_idx on t
(6 rows)
Thanks
Richard
On Tue, 26 Jul 2022 at 12:01, Zhihong Yu <zyu@yugabyte.com> wrote: > sort order the the planner chooses is simply : there is duplicate `the` I think the first "the" should be "that" > + /* mark this aggregate is covered by 'currpathkeys' */ > > is covered by -> as covered by I think it was shortened from "mark that this aggregate", but I dropped "that" to get the comment to fit on a single line. Swapping "is" for "as" makes it better. Thanks. David
On Tue, 26 Jul 2022 at 19:39, Richard Guo <guofenglinux@gmail.com> wrote: > Also I'm wondering if it's possible to take into consideration the > ordering indicated by existing indexes when determining the pathkeys. So > that for the query below we can avoid the Incremental Sort node if we > consider that there is an index on t(a, c): > > # explain (costs off) select max(b order by b), max(c order by c) from t group by a; > QUERY PLAN > --------------------------------------------- > GroupAggregate > Group Key: a > -> Incremental Sort > Sort Key: a, b > Presorted Key: a > -> Index Scan using t_a_c_idx on t > (6 rows) That would be nice but I'm not going to add anything to this patch which does anything like that. I think the patch, as it is, is a good meaningful step forward to improve the performance of ordered aggregates. There are other things in the planner that could gain from what you talk about. For example, choosing the evaluation order of WindowFuncs. Perhaps it would be better to try to tackle those two problems together rather than try to sneak something half-baked along with this patch. David
On Wed, Jul 27, 2022 at 6:46 AM David Rowley <dgrowleyml@gmail.com> wrote:
On Tue, 26 Jul 2022 at 19:39, Richard Guo <guofenglinux@gmail.com> wrote:
> Also I'm wondering if it's possible to take into consideration the
> ordering indicated by existing indexes when determining the pathkeys. So
> that for the query below we can avoid the Incremental Sort node if we
> consider that there is an index on t(a, c):
>
> # explain (costs off) select max(b order by b), max(c order by c) from t group by a;
> QUERY PLAN
> ---------------------------------------------
> GroupAggregate
> Group Key: a
> -> Incremental Sort
> Sort Key: a, b
> Presorted Key: a
> -> Index Scan using t_a_c_idx on t
> (6 rows)
That would be nice but I'm not going to add anything to this patch
which does anything like that. I think the patch, as it is, is a good
meaningful step forward to improve the performance of ordered
aggregates.
Concur with that.
There are other things in the planner that could gain from what you
talk about. For example, choosing the evaluation order of WindowFuncs.
Perhaps it would be better to try to tackle those two problems
together rather than try to sneak something half-baked along with this
patch.
Thanks
Richard
On Wed, 27 Jul 2022 at 15:16, Richard Guo <guofenglinux@gmail.com> wrote: > That makes sense. The patch looks in a good shape to me in this part. Thanks for giving it another look. I'm also quite happy with the patch now. The 2 plan changes are explained. I have a patch on another thread [1] for the change in the Merge Join plan. I'd like to consider that separately from this patch. The postgres_fdw changes are explained in [2]. This can be fixed by setting fdw_tuple_cost to something more realistic in the foreign server settings on the test. I'd like to take a serious look at pushing this patch on the first few days of August, so if anyone is following along here that might have objections, can you do so before then? David [1] https://www.postgresql.org/message-id/CAApHDvrtZu0PHVfDPFM4Yx3jNR2Wuwosv+T2zqa7LrhhBr2rRg@mail.gmail.com [2] https://www.postgresql.org/message-id/CAApHDvpXiXLxg4TsA8P_4etnuGQqAAbHWEOM4hGe=DCaXmi_jA@mail.gmail.com
David Rowley <dgrowleyml@gmail.com> writes:
> I'd like to take a serious look at pushing this patch on the first few
> days of August, so if anyone is following along here that might have
> objections, can you do so before then?
Are you going to push the other patch (adjusting
select_outer_pathkeys_for_merge) first, so that we can see the residual
plan changes that this patch creates? I'm not entirely comfortable
with the regression test changes as posted. Likewise, it might be
better to fix DEFAULT_FDW_TUPLE_COST beforehand, to detangle what
the effects of that are.
Also, I think it's bad style to rely on aggpresorted defaulting to false.
You should explicitly initialize it anywhere that an Aggref node is
constructed. It looks like there are just two places to fix
(parse_expr.c and parse_func.c).
Nothing else jumped out at me in a quick scan.
regards, tom lane
On Mon, 1 Aug 2022 at 03:49, Tom Lane <tgl@sss.pgh.pa.us> wrote: > Are you going to push the other patch (adjusting > select_outer_pathkeys_for_merge) first, so that we can see the residual > plan changes that this patch creates? I'm not entirely comfortable > with the regression test changes as posted. Yes, I pushed that earlier. > Likewise, it might be > better to fix DEFAULT_FDW_TUPLE_COST beforehand, to detangle what > the effects of that are. I chatted to Andres and Thomas about this last week and their view made me think it might not be quite as clear-cut as "just bump it up a bunch because it's ridiculously low" that I had in mind. They mentioned about file_fdw and another one that appears to work on mmapped segments, which I don't recall if any names were mentioned. Certainly that's not a reason not to change it, but it's not quite as clear-cut as I thought. I'll open a thread with some reasonable evidence to get a topic going and see where we end up. In the meantime I've just coded it to do a temporary adjustment to the fdw_tuple_cost foreign server setting just before the test in question. > Also, I think it's bad style to rely on aggpresorted defaulting to false. > You should explicitly initialize it anywhere that an Aggref node is > constructed. It looks like there are just two places to fix > (parse_expr.c and parse_func.c). Ooops. I'm normally good at remembering that. Not this time! > Nothing else jumped out at me in a quick scan. Thanks for the quick scan. I did another few myself and adjusted a small number of things. Mostly comments and using things like lfirst_node and list_nth_node instead of lfirst and list_nth with a cast. I've now pushed the patch. Thank you to everyone who looked at this. David
David Rowley <dgrowleyml@gmail.com> writes:
> On Mon, 1 Aug 2022 at 03:49, Tom Lane <tgl@sss.pgh.pa.us> wrote:
>> Likewise, it might be
>> better to fix DEFAULT_FDW_TUPLE_COST beforehand, to detangle what
>> the effects of that are.
> I chatted to Andres and Thomas about this last week and their view
> made me think it might not be quite as clear-cut as "just bump it up a
> bunch because it's ridiculously low" that I had in mind. They
> mentioned about file_fdw and another one that appears to work on
> mmapped segments, which I don't recall if any names were mentioned.
Um ... DEFAULT_FDW_TUPLE_COST is postgres_fdw-specific, so I do not
see what connection some other FDW would have to it.
regards, tom lane
On Wed, 3 Aug 2022 at 01:19, Tom Lane <tgl@sss.pgh.pa.us> wrote: > > David Rowley <dgrowleyml@gmail.com> writes: > > I chatted to Andres and Thomas about this last week and their view > > made me think it might not be quite as clear-cut as "just bump it up a > > bunch because it's ridiculously low" that I had in mind. They > > mentioned about file_fdw and another one that appears to work on > > mmapped segments, which I don't recall if any names were mentioned. > > Um ... DEFAULT_FDW_TUPLE_COST is postgres_fdw-specific, so I do not > see what connection some other FDW would have to it. I should have devoted more brain cells to that one. Anyway, I started a thread at [1]. David [1] https://www.postgresql.org/message-id/CAApHDvopVjjfh5c1Ed2HRvDdfom2dEpMwwiu5-f1AnmYprJngA@mail.gmail.com
Hi, David:
I was looking at the final patch and noticed that setno field in agg_presorted_distinctcheck struct is never used.
Looks like it was copied from neighboring struct.
Can you take a look at the patch ?
Thanks
Attachment
On Tue, Aug 2, 2022 at 11:02 AM Zhihong Yu <zyu@yugabyte.com> wrote:
Hi, David:I was looking at the final patch and noticed that setno field in agg_presorted_distinctcheck struct is never used.Looks like it was copied from neighboring struct.Can you take a look at the patch ?Thanks
Looks like setoff field is not used either.
Cheers
Attachment
On Wed, 3 Aug 2022 at 07:31, Zhihong Yu <zyu@yugabyte.com> wrote: > On Tue, Aug 2, 2022 at 11:02 AM Zhihong Yu <zyu@yugabyte.com> wrote: >> I was looking at the final patch and noticed that setno field in agg_presorted_distinctcheck struct is never used. > Looks like setoff field is not used either. Thanks for the report. It seems transno was unused too. I just pushed a commit to remove all 3. David
On Tue, Aug 02, 2022 at 11:21:04PM +1200, David Rowley wrote:
> I've now pushed the patch.
I've not studied the patch at all.
But in a few places, it removes the locally-computed group_pathkeys:
- List *group_pathkeys = root->group_pathkeys;
However it doesn't do that here:
/*
* Instead of operating directly on the input relation, we can
* consider finalizing a partially aggregated path.
*/
if (partially_grouped_rel != NULL)
{
foreach(lc, partially_grouped_rel->pathlist)
{
ListCell *lc2;
Path *path = (Path *) lfirst(lc);
Path *path_original = path;
List *pathkey_orderings = NIL;
List *group_pathkeys = root->group_pathkeys;
I noticed because that creates a new shadow variable, which seems accidental.
make src/backend/optimizer/plan/planner.o COPT=-Wshadow=compatible-local
src/backend/optimizer/plan/planner.c:6642:14: warning: declaration of ‘group_pathkeys’ shadows a previous local
[-Wshadow=compatible-local]
6642 | List *group_pathkeys = root->group_pathkeys;
| ^~~~~~~~~~~~~~
src/backend/optimizer/plan/planner.c:6438:12: note: shadowed declaration is here
6438 | List *group_pathkeys;
--
Justin
On Wed, 17 Aug 2022 at 13:57, Justin Pryzby <pryzby@telsasoft.com> wrote: > But in a few places, it removes the locally-computed group_pathkeys: > > - List *group_pathkeys = root->group_pathkeys; > I noticed because that creates a new shadow variable, which seems accidental. Thanks for the report. I've just pushed a fix for this that basically just removes the line you quoted. Really I should have been using the version of group_pathkeys that stripped off the pathkeys from the ORDER BY / DISTINCT aggregates that is calculated earlier in that function. In practice, there was no actual bug here as the wrong variable was only being used in the code path that was handling partial paths. We never create any partial paths when there are aggregates with ORDER BY / DISTINCT clauses, so in that code path, the two versions of the group_pathkeys variable would have always been set to the same thing. It makes sense just to get rid of the shadowed variable since the value of it will be the same anyway. David
Hello, While playing with the patch I found a situation where the performance may be degraded compared to previous versions. The test case below. If you create a proper index for the query (a,c), version 16 wins. On my notebook, the query runs ~50% faster. But if there is no index (a,c), but only (a,b), in previous versions the planner uses it, but with this patch a full table scan is selected. create table t (a text, b text, c text); insert into t (a,b,c) select x,y,x from generate_series(1,100) as x, generate_series(1,10000) y; create index on t (a,b); vacuum analyze t; explain (analyze, buffers) select a, array_agg(c order by c) from t group by a; v 14.5 QUERY PLAN ------------------------------------------------------------------------------------------------------------------------------------- GroupAggregate (cost=0.42..46587.76 rows=100 width=34) (actual time=3.077..351.526 rows=100 loops=1) Group Key: a Buffers: shared hit=193387 read=2745 -> Index Scan using t_a_b_idx on t (cost=0.42..41586.51 rows=1000000 width=4) (actual time=0.014..155.095 rows=1000000 loops=1) Buffers: shared hit=193387 read=2745 Planning: Buffers: shared hit=9 Planning Time: 0.059 ms Execution Time: 351.581 ms (9 rows) v 16 QUERY PLAN ------------------------------------------------------------------------------------------------------------------------ GroupAggregate (cost=128728.34..136229.59 rows=100 width=34) (actual time=262.930..572.915 rows=100 loops=1) Group Key: a Buffers: shared hit=5396, temp read=1950 written=1964 -> Sort (cost=128728.34..131228.34 rows=1000000 width=4) (actual time=259.423..434.105 rows=1000000 loops=1) Sort Key: a, c Sort Method: external merge Disk: 15600kB Buffers: shared hit=5396, temp read=1950 written=1964 -> Seq Scan on t (cost=0.00..15396.00 rows=1000000 width=4) (actual time=0.005..84.104 rows=1000000 loops=1) Buffers: shared hit=5396 Planning: Buffers: shared hit=9 Planning Time: 0.055 ms Execution Time: 575.146 ms (13 rows) -- Pavel Luzanov Postgres Professional: https://postgrespro.com The Russian Postgres Company
Le samedi 5 novembre 2022, 09:51:23 CET Pavel Luzanov a écrit :
> While playing with the patch I found a situation where the performance
> may be degraded compared to previous versions.
>
> The test case below.
> If you create a proper index for the query (a,c), version 16 wins. On my
> notebook, the query runs ~50% faster.
> But if there is no index (a,c), but only (a,b), in previous versions the
> planner uses it, but with this patch a full table scan is selected.
Hello,
In your exact use case, the combo incremental-sort + Index scan is evaluated
to cost more than doing a full sort + seqscan.
If you try for example to create an index on (b, a) and group by b, you will
get the expected behaviour:
ro=# create index on t (b, a);
CREATE INDEX
ro=# explain select b, array_agg(c order by c) from t group by b;
QUERY PLAN
-----------------------------------------------------------------------------------------
GroupAggregate (cost=10.64..120926.80 rows=9970 width=36)
Group Key: b
-> Incremental Sort (cost=10.64..115802.17 rows=1000000 width=6)
Sort Key: b, c
Presorted Key: b
-> Index Scan using t_b_a_idx on t (cost=0.42..47604.12
rows=1000000 width=6)
(6 rows)
I think we can trace that back to incremental sort being pessimistic about
it's performance. If you try the same query, but with set enable_seqscan = off,
you will get a full sort over an index scan:
QUERY PLAN
-----------------------------------------------------------------------------------------
GroupAggregate (cost=154944.94..162446.19 rows=100 width=34)
Group Key: a
-> Sort (cost=154944.94..157444.94 rows=1000000 width=4)
Sort Key: a, c
-> Index Scan using t_a_b_idx on t (cost=0.42..41612.60
rows=1000000 width=4)
(5 rows)
This probably comes from the overly pessimistic behaviour that the number of
tuples per group will be 1.5 times as much as we should estimate:
/*
* Estimate average cost of sorting of one group where presorted
keys are
* equal. Incremental sort is sensitive to distribution of tuples
to the
* groups, where we're relying on quite rough assumptions. Thus,
we're
* pessimistic about incremental sort performance and increase its
average
* group size by half.
*/
I can't see why an incrementalsort could be more expensive than a full sort,
using the same presorted path. It looks to me that in that case we should
always prefer an incrementalsort. Maybe we should bound incremental sorts cost
to make sure they are never more expensive than the full sort ?
Also, prior to this commit I don't think it made a real difference, because
worst case scenario we would have missed an incremental sort, which we didn't
have beforehand. But with this patch, we may actually replace a "hidden"
incremental sort which was done in the agg codepath by a full sort.
Best regards,
--
Ronan Dunklau
Hi, On 07.11.2022 17:53, Ronan Dunklau wrote: > In your exact use case, the combo incremental-sort + Index scan is evaluated > to cost more than doing a full sort + seqscan. > I think we can trace that back to incremental sort being pessimistic about > it's performance. If you try the same query, but with set enable_seqscan = off, > you will get a full sort over an index scan: > > QUERY PLAN > ----------------------------------------------------------------------------------------- > GroupAggregate (cost=154944.94..162446.19 rows=100 width=34) > Group Key: a > -> Sort (cost=154944.94..157444.94 rows=1000000 width=4) > Sort Key: a, c > -> Index Scan using t_a_b_idx on t (cost=0.42..41612.60 > rows=1000000 width=4) > (5 rows) You are right. By disabling seq scan, we can get this plan. But compare it with the plan in v15: postgres@db(15.0)=# explain select a, array_agg(c order by c) from t group by a; QUERY PLAN ----------------------------------------------------------------------------------- GroupAggregate (cost=0.42..46667.56 rows=100 width=34) Group Key: a -> Index Scan using t_a_b_idx on t (cost=0.42..41666.31 rows=1000000 width=4) (3 rows) The total plan cost in v16 is ~4 times higher, while the index scan cost remains the same. > I can't see why an incrementalsort could be more expensive than a full sort, > using the same presorted path. The only reason I can see is the number of buffers to read. In the plan with incremental sort we read the whole index, ~190000 buffers. And the plan with seq scan only required ~5000 (I think due to buffer ring optimization). Perhaps this behavior is preferable. Especially when many concurrent queries are running. The less buffer cache is busy, the better. But in single-user mode this query is slower. -- Pavel Luzanov Postgres Professional: https://postgrespro.com The Russian Postgres Company
Le lundi 7 novembre 2022, 17:58:50 CET Pavel Luzanov a écrit : > > I can't see why an incrementalsort could be more expensive than a full > > sort, using the same presorted path. > > The only reason I can see is the number of buffers to read. In the plan > with incremental sort we read the whole index, ~190000 buffers. > And the plan with seq scan only required ~5000 (I think due to buffer > ring optimization). What I meant here is that disabling seqscans, the planner still chooses a full sort over a partial sort. The underlying index is the same, it is just a matter of choosing a Sort node over an IncrementalSort node. This, I think, is wrong: I can't see how it could be worse to use an incrementalsort in that case. It makes sense to prefer a SeqScan over an IndexScan if you are going to sort the whole table anyway. But in that case we shouldn't. What happened before is that some sort of incremental sort was always chosen, because it was hidden as an implementation detail of the agg node. But now it has to compete on a cost basis with the full sort, and that costing is wrong in that case. Maybe the original costing code for incremental sort was a bit too pessimistic. -- Ronan Dunklau
On 07.11.2022 20:30, Ronan Dunklau wrote: > What I meant here is that disabling seqscans, the planner still chooses a full > sort over a partial sort. The underlying index is the same, it is just a > matter of choosing a Sort node over an IncrementalSort node. This, I think, is > wrong: I can't see how it could be worse to use an incrementalsort in that > case. I finally get your point. And I agree with you. > Maybe the original costing code for incremental sort was a bit too > pessimistic. In this query, incremental sorting lost just a little bit in cost: 164468.95 vs 162504.23. QUERY PLAN ------------------------------------------------------------------------------------------------------------------------------------------- GroupAggregate (cost=155002.98..162504.23 rows=100 width=34) (actual time=296.591..568.270 rows=100 loops=1) Group Key: a -> Sort (cost=155002.98..157502.98 rows=1000000 width=4) (actual time=293.810..454.170 rows=1000000 loops=1) Sort Key: a, c Sort Method: external merge Disk: 15560kB -> Index Scan using t_a_b_idx on t (cost=0.42..41670.64 rows=1000000 width=4) (actual time=0.021..156.441 rows=1000000 loops=1) Settings: enable_seqscan = 'off' Planning Time: 0.074 ms Execution Time: 569.957 ms (9 rows) set enable_sort=off; SET QUERY PLAN ------------------------------------------------------------------------------------------------------------------------------------------- GroupAggregate (cost=1457.58..164468.95 rows=100 width=34) (actual time=6.623..408.833 rows=100 loops=1) Group Key: a -> Incremental Sort (cost=1457.58..159467.70 rows=1000000 width=4) (actual time=2.652..298.530 rows=1000000 loops=1) Sort Key: a, c Presorted Key: a Full-sort Groups: 100 Sort Method: quicksort Average Memory: 27kB Peak Memory: 27kB Pre-sorted Groups: 100 Sort Method: quicksort Average Memory: 697kB Peak Memory: 697kB -> Index Scan using t_a_b_idx on t (cost=0.42..41670.64 rows=1000000 width=4) (actual time=0.011..155.260 rows=1000000 loops=1) Settings: enable_seqscan = 'off', enable_sort = 'off' Planning Time: 0.044 ms Execution Time: 408.867 ms -- Pavel Luzanov Postgres Professional: https://postgrespro.com The Russian Postgres Company
On Tue, 8 Nov 2022 at 03:53, Ronan Dunklau <ronan.dunklau@aiven.io> wrote: > I can't see why an incrementalsort could be more expensive than a full sort, > using the same presorted path. It looks to me that in that case we should > always prefer an incrementalsort. Maybe we should bound incremental sorts cost > to make sure they are never more expensive than the full sort ? The only thing that I could think of that would cause incremental sort to be more expensive than sort is the tuplesort_reset() calls that are performed between sorts. However, I see cost_incremental_sort() accounts for those already with: run_cost += 2.0 * cpu_tuple_cost * input_groups; Also, I see at the top of incremental_sort.sql there's a comment claiming: -- When we have to sort the entire table, incremental sort will -- be slower than plain sort, so it should not be used. I'm just unable to verify that's true by doing the following: $ echo "select * from (select * from tenk1 order by four) t order by four, ten;" > bench.sql $ pgbench -n -f bench.sql -T 60 -M prepared regression | grep -E "^tps" tps = 102.136151 (without initial connection time) $ # disable sort so that the test performs Sort -> Incremental Sort rather $ # than Sort -> Sort $ psql -c "alter system set enable_sort=0;" regression $ psql -c "select pg_reload_conf();" regression $ pgbench -n -f bench.sql -T 60 -M prepared regression | grep -E "^tps" tps = 112.378761 (without initial connection time) When I disable sort, the plan changes to use Incremental Sort and execution becomes faster, not slower like the comment claims it will. Perhaps this was true during the development of Incremental sort and then something was changed to speed things up. I do recall reviewing that patch many years ago and hinting about the invention of tuplesort_reset(). I don't recall, but I assume the patch must have been creating a new tuplesort each group before that. Also, I was looking at add_paths_to_grouping_rel() and I saw that if presorted_keys > 0 that we'll create both a Sort and Incremental Sort path. If we assume Incremental Sort is always better when it can be done, then it seems useless to create the Sort path when Incremental Sort is possible. When working on making Incremental Sorts work for window functions I did things that way. Maybe we should just make add_paths_to_grouping_rel() work the same way. Regarding the 1.5 factor in cost_incremental_sort(), I assume this is for skewed groups. Imagine there's 1 huge group and 99 tiny ones. However, even if that were the case, I imagine the performance would still be around the same performance as the non-incremental variant of sort. I've been playing around with the attached patch which does: 1. Adjusts add_paths_to_grouping_rel so that we don't add a Sort path when we can add an Incremental Sort path instead. This removes quite a few redundant lines of code. 2. Removes the * 1.5 fuzz-factor in cost_incremental_sort() 3. Does various other code tidy stuff in cost_incremental_sort(). 4. Removes the test from incremental_sort.sql that was ensuring the inferior Sort -> Sort plan was being used instead of the superior Sort -> Incremental Sort plan. I'm not really that 100% confident in the removal of the * 1.5 thing. I wonder if there's some reason we're not considering that might cause a performance regression if we're to remove it. David
Attachment
On 08.11.2022 04:31, David Rowley wrote: > I've been playing around with the attached patch which does: > > 1. Adjusts add_paths_to_grouping_rel so that we don't add a Sort path > when we can add an Incremental Sort path instead. This removes quite a > few redundant lines of code. > 2. Removes the * 1.5 fuzz-factor in cost_incremental_sort() > 3. Does various other code tidy stuff in cost_incremental_sort(). > 4. Removes the test from incremental_sort.sql that was ensuring the > inferior Sort -> Sort plan was being used instead of the superior Sort > -> Incremental Sort plan. I can confirm that with this patch, the plan with incremental sorting beats the others. Here are the test results with my previous example. Script: create table t (a text, b text, c text); insert into t (a,b,c) select x,y,x from generate_series(1,100) as x, generate_series(1,10000) y; create index on t (a); vacuum analyze t; reset all; explain (settings, analyze) select a, array_agg(c order by c) from t group by a; \echo set enable_incremental_sort=off; set enable_incremental_sort=off; explain (settings, analyze) select a, array_agg(c order by c) from t group by a; \echo set enable_seqscan=off; set enable_seqscan=off; explain (settings, analyze) select a, array_agg(c order by c) from t group by a; Script output: CREATE TABLE INSERT 0 1000000 CREATE INDEX VACUUM RESET QUERY PLAN ----------------------------------------------------------------------------------------------------------------------------------------- GroupAggregate (cost=957.60..113221.24 rows=100 width=34) (actual time=6.088..381.777 rows=100 loops=1) Group Key: a -> Incremental Sort (cost=957.60..108219.99 rows=1000000 width=4) (actual time=2.387..272.332 rows=1000000 loops=1) Sort Key: a, c Presorted Key: a Full-sort Groups: 100 Sort Method: quicksort Average Memory: 27kB Peak Memory: 27kB Pre-sorted Groups: 100 Sort Method: quicksort Average Memory: 697kB Peak Memory: 697kB -> Index Scan using t_a_idx on t (cost=0.42..29279.42 rows=1000000 width=4) (actual time=0.024..128.083 rows=1000000 loops=1) Planning Time: 0.070 ms Execution Time: 381.815 ms (10 rows) set enable_incremental_sort=off; SET QUERY PLAN ------------------------------------------------------------------------------------------------------------------------ GroupAggregate (cost=128728.34..136229.59 rows=100 width=34) (actual time=234.044..495.537 rows=100 loops=1) Group Key: a -> Sort (cost=128728.34..131228.34 rows=1000000 width=4) (actual time=231.172..383.393 rows=1000000 loops=1) Sort Key: a, c Sort Method: external merge Disk: 15600kB -> Seq Scan on t (cost=0.00..15396.00 rows=1000000 width=4) (actual time=0.005..78.189 rows=1000000 loops=1) Settings: enable_incremental_sort = 'off' Planning Time: 0.041 ms Execution Time: 497.230 ms (9 rows) set enable_seqscan=off; SET QUERY PLAN ----------------------------------------------------------------------------------------------------------------------------------------- GroupAggregate (cost=142611.77..150113.02 rows=100 width=34) (actual time=262.250..527.260 rows=100 loops=1) Group Key: a -> Sort (cost=142611.77..145111.77 rows=1000000 width=4) (actual time=259.551..417.154 rows=1000000 loops=1) Sort Key: a, c Sort Method: external merge Disk: 15560kB -> Index Scan using t_a_idx on t (cost=0.42..29279.42 rows=1000000 width=4) (actual time=0.012..121.995 rows=1000000 loops=1) Settings: enable_incremental_sort = 'off', enable_seqscan = 'off' Planning Time: 0.041 ms Execution Time: 528.950 ms (9 rows) -- Pavel Luzanov Postgres Professional: https://postgrespro.com The Russian Postgres Company
On Tue, Nov 8, 2022 at 9:31 AM David Rowley <dgrowleyml@gmail.com> wrote:
I've been playing around with the attached patch which does:
1. Adjusts add_paths_to_grouping_rel so that we don't add a Sort path
when we can add an Incremental Sort path instead. This removes quite a
few redundant lines of code.
For unsorted paths, the original logic here is to explicitly add a Sort
path only for the cheapest-total path. This patch changes that and may
add a Sort path for other paths besides the cheapest-total path. I
think this may introduce in some unnecessary path candidates.
I think it's good that this patch removes redundant codes. ISTM we can
do the same when we try to finalize the partially aggregated paths from
partially_grouped_rel.
Thanks
Richard
path only for the cheapest-total path. This patch changes that and may
add a Sort path for other paths besides the cheapest-total path. I
think this may introduce in some unnecessary path candidates.
I think it's good that this patch removes redundant codes. ISTM we can
do the same when we try to finalize the partially aggregated paths from
partially_grouped_rel.
Thanks
Richard
Le mardi 8 novembre 2022, 02:31:12 CET David Rowley a écrit : > 1. Adjusts add_paths_to_grouping_rel so that we don't add a Sort path > when we can add an Incremental Sort path instead. This removes quite a > few redundant lines of code. This seems sensible > 2. Removes the * 1.5 fuzz-factor in cost_incremental_sort() > 3. Does various other code tidy stuff in cost_incremental_sort(). > 4. Removes the test from incremental_sort.sql that was ensuring the > inferior Sort -> Sort plan was being used instead of the superior Sort > -> Incremental Sort plan. > > I'm not really that 100% confident in the removal of the * 1.5 thing. > I wonder if there's some reason we're not considering that might cause > a performance regression if we're to remove it. I'm not sure about it either. It seems to me that we were afraid of regressions, and having this overcharged just made us miss a new optimization without changing existing plans. With ordered aggregates, the balance is a bit trickier and we are at risk of either regressing on aggregate plans, or more common ordered ones. -- Ronan Dunklau
On Tue, 8 Nov 2022 at 19:51, Richard Guo <guofenglinux@gmail.com> wrote: > For unsorted paths, the original logic here is to explicitly add a Sort > path only for the cheapest-total path. This patch changes that and may > add a Sort path for other paths besides the cheapest-total path. I > think this may introduce in some unnecessary path candidates. Yeah, you're right. The patch shouldn't change that. I've adjusted the attached patch so that part works more like it did before. v2 attached. Thanks David
Attachment
On Wed, 9 Nov 2022 at 14:58, David Rowley <dgrowleyml@gmail.com> wrote:
> v2 attached.
I've been looking at this again and this time around understand why
the * 1.5 pessimism factor was included in the incremental sort code.
If we create a table with a very large skew in the number of rows per
what will be our pre-sorted groups.
create table ab (a int not null, b int not null);
insert into ab select 0,x from generate_Series(1,999000)x union all
select x%1000+1,0 from generate_Series(999001,1000000)x;
Here the 0 group has close to 1 million rows, but the remaining groups
1-1000 have just 1 row each. The planner only knows there are about
1001 distinct values in "a" and assumes an even distribution of rows
between those values.
With:
explain (analyze, timing off) select * from ab order by a,b;
In master, the plan is:
QUERY PLAN
-----------------------------------------------------------------------------------------------------------------
Sort (cost=122490.27..124990.27 rows=1000000 width=8) (actual
rows=1000000 loops=1)
Sort Key: a, b
Sort Method: quicksort Memory: 55827kB
-> Index Scan using ab_a_idx on ab (cost=0.42..22832.42
rows=1000000 width=8) (actual rows=1000000 loops=1)
Planning Time: 0.069 ms
Execution Time: 155.469 ms
With the v2 patch it's:
QUERY PLAN
-----------------------------------------------------------------------------------------------------------------
Incremental Sort (cost=2767.38..109344.55 rows=1000000 width=8)
(actual rows=1000000 loops=1)
Sort Key: a, b
Presorted Key: a
Full-sort Groups: 33 Sort Method: quicksort Average Memory: 27kB
Peak Memory: 27kB
Pre-sorted Groups: 1 Sort Method: quicksort Average Memory:
55795kB Peak Memory: 55795kB
-> Index Scan using ab_a_idx on ab (cost=0.42..22832.42
rows=1000000 width=8) (actual rows=1000000 loops=1)
Planning Time: 0.072 ms
Execution Time: 163.614 ms
So there is a performance regression.
Sometimes teaching the planner new tricks means that it might use
those tricks at a bad time. Normally we put in an off switch for
these situations to allow users an escape hatch. We have
enable_incremental_sort for this. It seems like incremental sort has
tried to avoid this problem by always considering the same "Sort"
paths that we did prior to incremental sort, and also considers
incremental sort for pre-sorted paths with the 1.5 pessimism factor.
The v2 patch taking away the safety net.
I think what we need to do is: Do our best to give incremental sort
the most realistic costs we can and accept that it might choose a
worse plan in some cases. Users can turn it off if they really have no
other means to convince the planner it's wrong.
Additionally, I think what we also need to add a GUC such as
enable_presorted_aggregate. People can use that when their Index Scan
-> Incremental Sort -> Aggregate plan is worse than their previous Seq
Scan -> Sort -> Aggregate plan that they were getting in < 16.
Turning off enable_incremental_sort alone won't give them the same
aggregate plan that they had in pg15 as we always set the
query_pathkeys to request a sort order that will suit the order by /
distinct aggregates.
I'll draft up a patch for the enable_presorted_aggregate.
David
On Tue, 13 Dec 2022 at 20:53, David Rowley <dgrowleyml@gmail.com> wrote: > I think what we need to do is: Do our best to give incremental sort > the most realistic costs we can and accept that it might choose a > worse plan in some cases. Users can turn it off if they really have no > other means to convince the planner it's wrong. > > Additionally, I think what we also need to add a GUC such as > enable_presorted_aggregate. People can use that when their Index Scan > -> Incremental Sort -> Aggregate plan is worse than their previous Seq > Scan -> Sort -> Aggregate plan that they were getting in < 16. > Turning off enable_incremental_sort alone won't give them the same > aggregate plan that they had in pg15 as we always set the > query_pathkeys to request a sort order that will suit the order by / > distinct aggregates. > > I'll draft up a patch for the enable_presorted_aggregate. I've attached a patch series for this. v3-0001 can be ignored here. I've posted about that in [1]. Any discussion about that patch should take place over there. The patch is required to get the 0002 patch to pass isolation check v3-0002 removes the 1.5 x cost pessimism from incremental sort and also rewrites how we make incremental sort paths. I've now gone through the remaining places where we create an incremental sort path to give all those the same treatment that I'd added to add_paths_to_grouping_rel(). There was a 1 or 2 plan changes in the regression tests. One was the isolation test change, which I claim to be a broken test and should be fixed another way. The other was performing a Sort on the cheapest input path which had presorted keys. That plan now uses an Incremental Sort to make use of the presorted keys. I'm happy to see just how much redundant code this removes. About 200 lines. v3-0003 adds the enable_presorted_aggregate GUC. David [1] https://www.postgresql.org/message-id/CAApHDvrbDhObhLV+=U_K_-t+2Av2av1aL9d+2j_3AO-XndaviA@mail.gmail.com
Attachment
On Fri, 16 Dec 2022 at 00:10, David Rowley <dgrowleyml@gmail.com> wrote: > v3-0002 removes the 1.5 x cost pessimism from incremental sort and > also rewrites how we make incremental sort paths. I've now gone > through the remaining places where we create an incremental sort path > to give all those the same treatment that I'd added to > add_paths_to_grouping_rel(). There was a 1 or 2 plan changes in the > regression tests. One was the isolation test change, which I claim to > be a broken test and should be fixed another way. The other was > performing a Sort on the cheapest input path which had presorted keys. > That plan now uses an Incremental Sort to make use of the presorted > keys. I'm happy to see just how much redundant code this removes. > About 200 lines. I've now pushed this patch. Thanks for the report and everyone for all the useful discussion. Also Richard for the review. > v3-0003 adds the enable_presorted_aggregate GUC. This I've moved off to [1]. We tend to have lengthy discussions about GUCs, what to name them and if we actually need them. I didn't want to bury that discussion in this old and already long thread. David [1] https://postgr.es/m/CAApHDvqzuHerD8zN1Qu=d66e3bp1=9iFn09ZiQ3Zug_Phi6yLQ@mail.gmail.com
While doing some random testing, I noticed that the following is broken in HEAD: SELECT COUNT(DISTINCT random()) FROM generate_series(1,10); ERROR: ORDER/GROUP BY expression not found in targetlist It appears to have been broken by 1349d279, though I haven't looked at the details. I'm somewhat surprised that a case as simple as this wasn't covered by any pre-existing regression tests. Regards, Dean
On Tue, Jan 10, 2023 at 6:12 PM Dean Rasheed <dean.a.rasheed@gmail.com> wrote:
While doing some random testing, I noticed that the following is broken in HEAD:
SELECT COUNT(DISTINCT random()) FROM generate_series(1,10);
ERROR: ORDER/GROUP BY expression not found in targetlist
It appears to have been broken by 1349d279, though I haven't looked at
the details.
Yeah, this is definitely broken. For this query, we try to sort the
scan/join path by random() before performing the Aggregate, which is an
optimization implemented in 1349d2790b. However the scan/join plan's
tlist does not contain random(), which I think we need to fix.
Thanks
Richard
scan/join path by random() before performing the Aggregate, which is an
optimization implemented in 1349d2790b. However the scan/join plan's
tlist does not contain random(), which I think we need to fix.
Thanks
Richard
On Wed, 11 Jan 2023 at 15:46, Richard Guo <guofenglinux@gmail.com> wrote:
> However the scan/join plan's
> tlist does not contain random(), which I think we need to fix.
I was wondering if that's true and considered that we don't want to
evaluate random() for the sort then again when doing the aggregate
transitions, but I see that does not really work before 1349d279, per:
postgres=# set enable_presorted_aggregate=0;
SET
postgres=# select string_agg(random()::text, ',' order by random())
from generate_series(1,3);
string_agg
-----------------------------------------------------------
0.8659110018246505,0.15612649559563474,0.2022878955613403
(1 row)
I'd have expected those random numbers to be concatenated in ascending order.
Running: select random() from generate_Series(1,3) order by random();
gives me the results in the order I'd have expected.
I think whatever the fix is here, we should likely ensure that the
results are consistent regardless of which Aggrefs are the presorted
ones. Perhaps the easiest way to do that, and to ensure we call the
volatile functions are called the same number of times would just be
to never choose Aggrefs with volatile functions when doing
make_pathkeys_for_groupagg().
David
David Rowley <dgrowleyml@gmail.com> writes:
> I think whatever the fix is here, we should likely ensure that the
> results are consistent regardless of which Aggrefs are the presorted
> ones. Perhaps the easiest way to do that, and to ensure we call the
> volatile functions are called the same number of times would just be
> to never choose Aggrefs with volatile functions when doing
> make_pathkeys_for_groupagg().
There's existing logic in equivclass.c and other places that tries
to draw very tight lines around what we'll assume about volatile
sort expressions (pathkeys). It sounds like there's someplace in
this recent patch that didn't get that memo.
regards, tom lane
On Wed, 11 Jan 2023 at 17:32, Tom Lane <tgl@sss.pgh.pa.us> wrote: > > David Rowley <dgrowleyml@gmail.com> writes: > > I think whatever the fix is here, we should likely ensure that the > > results are consistent regardless of which Aggrefs are the presorted > > ones. Perhaps the easiest way to do that, and to ensure we call the > > volatile functions are called the same number of times would just be > > to never choose Aggrefs with volatile functions when doing > > make_pathkeys_for_groupagg(). > > There's existing logic in equivclass.c and other places that tries > to draw very tight lines around what we'll assume about volatile > sort expressions (pathkeys). It sounds like there's someplace in > this recent patch that didn't get that memo. I'm not sure I did a good job of communicating my thoughts there. What I mean is, having volatile functions in the aggregate's ORDER BY or DISTINCT clause didn't seem very well behaved prior to the presorted aggregates patch. If I go and fix the bug with the missing targetlist items, then a query such as: select string_agg(random()::text, ',' order by random()) from generate_series(1,3); should start putting the random() numbers in order where it didn't prior to 1349d279. Perhaps users might be happy that those are in order, however, if they then go and change the query to: select sum(a order by a),string_agg(random()::text, ',' order by random()) from generate_series(1,3); then they might become unhappy again that their string_agg is not ordered the way they specified because the planner opted to sort by "a" rather than "random()" after the initial scan. I'm wondering if 1349d279 should have just never opted to presort Aggrefs which have volatile functions so that the existing behaviour of unordered output is given always and nobody is fooled into thinking this works correctly only to be disappointed later when they add some other aggregate to their query or if we should fix both. Certainly, it seems much easier to do the former. David
On Wed, Jan 11, 2023 at 12:13 PM David Rowley <dgrowleyml@gmail.com> wrote:
postgres=# set enable_presorted_aggregate=0;
SET
postgres=# select string_agg(random()::text, ',' order by random())
from generate_series(1,3);
string_agg
-----------------------------------------------------------
0.8659110018246505,0.15612649559563474,0.2022878955613403
(1 row)
I'd have expected those random numbers to be concatenated in ascending order.
select string_agg(
random()::text, -- position 1
','
order by random() -- position 2
)
from generate_series(1,3);
I traced this query a bit and found that when executing the aggregation
the random() function in the aggregate expression (position 1) and in
the order by clause (position 2) are calculated separately. And the
sorting is performed based on the function results from the order by
clause. In the final output, what we see is the function results from
the aggregate expression. Thus we'll notice the output is not sorted.
I'm not sure if this is expected or broken though.
BTW, if we explicitly add ::text for random() in the order by clause, as
select string_agg(
random()::text,
','
order by random()::text
)
from generate_series(1,3);
The random() function will be calculated only once for each tuple, and
we can get a sorted output.
Thanks
Richard
random()::text, -- position 1
','
order by random() -- position 2
)
from generate_series(1,3);
I traced this query a bit and found that when executing the aggregation
the random() function in the aggregate expression (position 1) and in
the order by clause (position 2) are calculated separately. And the
sorting is performed based on the function results from the order by
clause. In the final output, what we see is the function results from
the aggregate expression. Thus we'll notice the output is not sorted.
I'm not sure if this is expected or broken though.
BTW, if we explicitly add ::text for random() in the order by clause, as
select string_agg(
random()::text,
','
order by random()::text
)
from generate_series(1,3);
The random() function will be calculated only once for each tuple, and
we can get a sorted output.
Thanks
Richard
On Wed, 11 Jan 2023 at 05:24, David Rowley <dgrowleyml@gmail.com> wrote:
>
> I'm wondering if 1349d279 should have just never opted to presort
> Aggrefs which have volatile functions so that the existing behaviour
> of unordered output is given always and nobody is fooled into thinking
> this works correctly only to be disappointed later when they add some
> other aggregate to their query or if we should fix both. Certainly,
> it seems much easier to do the former.
>
I took a look at this, and I agree that the best solution is probably
to have make_pathkeys_for_groupagg() ignore Aggrefs that contain
volatile functions. Not only is that the simplest solution, preserving
the old behaviour, I think it's required for correctness.
Aside from the fact that I don't think such aggregates would benefit
from the optimisation introduced by 1349d279, I think it would be
incorrect if there was more than one such aggregate having the same
sort expression, because I think that volatile sorting should be
evaluated separately for each aggregate. For example:
SELECT string_agg(a::text, ',' ORDER BY random()),
string_agg(a::text, ',' ORDER BY random())
FROM generate_series(1,3) s(a);
string_agg | string_agg
------------+------------
2,1,3 | 3,2,1
(1 row)
so pre-sorting wouldn't be right (or at least it would change existing
behaviour in a surprising way).
Regards,
Dean
On Tue, 17 Jan 2023 at 13:16, Dean Rasheed <dean.a.rasheed@gmail.com> wrote: > > On Wed, 11 Jan 2023 at 05:24, David Rowley <dgrowleyml@gmail.com> wrote: > > > > I'm wondering if 1349d279 should have just never opted to presort > > Aggrefs which have volatile functions so that the existing behaviour > > of unordered output is given always and nobody is fooled into thinking > > this works correctly only to be disappointed later when they add some > > other aggregate to their query or if we should fix both. Certainly, > > it seems much easier to do the former. > > > > I took a look at this, and I agree that the best solution is probably > to have make_pathkeys_for_groupagg() ignore Aggrefs that contain > volatile functions. Thanks for giving that some additional thought. I've just pushed a fix which adjusts things that way. David
On Tue, Jan 17, 2023 at 11:39 AM David Rowley <dgrowleyml@gmail.com> wrote:
On Tue, 17 Jan 2023 at 13:16, Dean Rasheed <dean.a.rasheed@gmail.com> wrote:
> I took a look at this, and I agree that the best solution is probably
> to have make_pathkeys_for_groupagg() ignore Aggrefs that contain
> volatile functions.
Thanks for giving that some additional thought. I've just pushed a
fix which adjusts things that way.
This makes a lot of sense. I agree that we shouldn't do pre-sorting for
volatile sort expressions, especially when there are multiple aggregates
with the same volatile sort expression.
Not related to this specific issue, but I find sorting by volatile
expression is confusing in different scenarios. Consider the two
queries given by David
Query 1:
select string_agg(random()::text, ',' order by random()) from generate_series(1,3);
Query 2:
select random()::text from generate_series(1,3) order by random();
Considering the targetlist as Aggref->args or Query->targetList, in both
queries we would add an additional TargetEntry (as resjunk column) for
the ORDER BY item 'random()', because it's not present in the existing
targetlist. Note that the existing TargetEntry for 'random()::text' is
a CoerceViaIO expression which is an explicit cast, so we cannot strip
it and match it to the ORDER BY item. Thus we would have two random()
FuncExprs in the final targetlist, for both queries.
In query 1 we call random() twice for each tuple, one for the original
TargetEntry 'random()::text', and one for the TargetEntry of the ORDER
BY item 'random()', and do the sorting according to the second call
results. Thus we would notice the final output is unsorted because it's
from the first random() call.
However, in query 2 we have the ORDER BY item 'random()' in the
scan/join node's targetlist. And then for the two random() FuncExprs in
the final targetlist, set_plan_references would adjust both of them to
refer to the outputs of the scan/join node. Thus random() is actually
called only once for each tuple and we would find the final output is
sorted.
It seems we fail to keep consistent about the behavior of sorting by
volatile expression in the two scenarios.
BTW, I wonder if we should have checked CoercionForm before
fix_upper_expr_mutator steps into CoerceViaIO->arg to adjust the expr
there. It seems parser checks it and only strips implicit coercions
when matching TargetEntry expr to ORDER BY item.
volatile sort expressions, especially when there are multiple aggregates
with the same volatile sort expression.
Not related to this specific issue, but I find sorting by volatile
expression is confusing in different scenarios. Consider the two
queries given by David
Query 1:
select string_agg(random()::text, ',' order by random()) from generate_series(1,3);
Query 2:
select random()::text from generate_series(1,3) order by random();
Considering the targetlist as Aggref->args or Query->targetList, in both
queries we would add an additional TargetEntry (as resjunk column) for
the ORDER BY item 'random()', because it's not present in the existing
targetlist. Note that the existing TargetEntry for 'random()::text' is
a CoerceViaIO expression which is an explicit cast, so we cannot strip
it and match it to the ORDER BY item. Thus we would have two random()
FuncExprs in the final targetlist, for both queries.
In query 1 we call random() twice for each tuple, one for the original
TargetEntry 'random()::text', and one for the TargetEntry of the ORDER
BY item 'random()', and do the sorting according to the second call
results. Thus we would notice the final output is unsorted because it's
from the first random() call.
However, in query 2 we have the ORDER BY item 'random()' in the
scan/join node's targetlist. And then for the two random() FuncExprs in
the final targetlist, set_plan_references would adjust both of them to
refer to the outputs of the scan/join node. Thus random() is actually
called only once for each tuple and we would find the final output is
sorted.
It seems we fail to keep consistent about the behavior of sorting by
volatile expression in the two scenarios.
BTW, I wonder if we should have checked CoercionForm before
fix_upper_expr_mutator steps into CoerceViaIO->arg to adjust the expr
there. It seems parser checks it and only strips implicit coercions
when matching TargetEntry expr to ORDER BY item.
Thanks
Richard
Richard
Richard Guo <guofenglinux@gmail.com> writes:
> BTW, I wonder if we should have checked CoercionForm before
> fix_upper_expr_mutator steps into CoerceViaIO->arg to adjust the expr
> there.
I will just quote what it says in primnodes.h:
* NB: equal() ignores CoercionForm fields, therefore this *must* not carry
* any semantically significant information.
If you think the planner should act differently for different values of
CoercionForm, you are mistaken. Maybe this is evidence of some
previous bit of brain-fade, but if so we need to fix that.
regards, tom lane
On Tue, Jan 17, 2023 at 3:05 PM Tom Lane <tgl@sss.pgh.pa.us> wrote:
Richard Guo <guofenglinux@gmail.com> writes:
> BTW, I wonder if we should have checked CoercionForm before
> fix_upper_expr_mutator steps into CoerceViaIO->arg to adjust the expr
> there.
I will just quote what it says in primnodes.h:
* NB: equal() ignores CoercionForm fields, therefore this *must* not carry
* any semantically significant information.
If you think the planner should act differently for different values of
CoercionForm, you are mistaken. Maybe this is evidence of some
previous bit of brain-fade, but if so we need to fix that.
According to this comment in primnodes.h, the planner is not supposed to
treat implicit and explicit casts differently. In this case
set_plan_references is doing its job correctly, to adjust both random()
FuncExprs in targetlist to refer to subplan's output for query 2. As a
consequence we would get a sorted output.
I'm still confused that when the same scenario happens with ORDER BY in
an aggregate function, like in query 1, the result is different in that
we would get an unsorted output.
I wonder if we should avoid this inconsistent behavior.
Thanks
Richard
treat implicit and explicit casts differently. In this case
set_plan_references is doing its job correctly, to adjust both random()
FuncExprs in targetlist to refer to subplan's output for query 2. As a
consequence we would get a sorted output.
I'm still confused that when the same scenario happens with ORDER BY in
an aggregate function, like in query 1, the result is different in that
we would get an unsorted output.
I wonder if we should avoid this inconsistent behavior.
Thanks
Richard
On Wed, 18 Jan 2023 at 22:37, Richard Guo <guofenglinux@gmail.com> wrote: > I'm still confused that when the same scenario happens with ORDER BY in > an aggregate function, like in query 1, the result is different in that > we would get an unsorted output. > > I wonder if we should avoid this inconsistent behavior. It certainly seems pretty strange that aggregates with an ORDER BY behave differently from the query's ORDER BY. I'd have expected that to be the same. I've not looked to see why there's a difference, but suspect that we thought about how we want it to work for the query's ORDER BY and when ORDER BY aggregates were added, that behaviour was not considered. Likely finding the code or location where that code should be would help us understand if something was just forgotten in the aggregate's case. It's probably another question as to if we should be adjusting this behaviour now. David
On Wed, 18 Jan 2023 at 09:49, David Rowley <dgrowleyml@gmail.com> wrote:
>
> On Wed, 18 Jan 2023 at 22:37, Richard Guo <guofenglinux@gmail.com> wrote:
> > I'm still confused that when the same scenario happens with ORDER BY in
> > an aggregate function, like in query 1, the result is different in that
> > we would get an unsorted output.
> >
> > I wonder if we should avoid this inconsistent behavior.
>
> It certainly seems pretty strange that aggregates with an ORDER BY
> behave differently from the query's ORDER BY. I'd have expected that
> to be the same. I've not looked to see why there's a difference, but
> suspect that we thought about how we want it to work for the query's
> ORDER BY and when ORDER BY aggregates were added, that behaviour was
> not considered.
>
I think the behaviour of an ORDER BY in the query can also be pretty
surprising. For example, consider:
SELECT ARRAY[random(), random(), random()]
FROM generate_series(1, 3);
array
-------------------------------------------------------------
{0.2335800863701647,0.14688842754711273,0.2975659224823368}
{0.10616525384762876,0.8371175798972244,0.2936178886154661}
{0.21679841321788262,0.5254761982948826,0.7789412240118161}
(3 rows)
which produces 9 different random values, as expected, and compare that to:
SELECT ARRAY[random(), random(), random()]
FROM generate_series(1, 3)
ORDER BY random();
array
---------------------------------------------------------------
{0.01952216253949679,0.01952216253949679,0.01952216253949679}
{0.6735145595500629,0.6735145595500629,0.6735145595500629}
{0.9406665780147616,0.9406665780147616,0.9406665780147616}
(3 rows)
which now only has 3 distinct random values. It's pretty
counterintuitive that adding an ORDER BY clause changes the contents
of the rows returned, not just their order.
The trouble is, if we tried to fix that, we'd risk changing some other
behaviour that users may have come to rely on.
Regards,
Dean
Dean Rasheed <dean.a.rasheed@gmail.com> writes:
> I think the behaviour of an ORDER BY in the query can also be pretty
> surprising.
Indeed. The fundamental question is this: in
> SELECT ARRAY[random(), random(), random()]
> FROM generate_series(1, 3)
> ORDER BY random();
are those four occurrences of random() supposed to refer to the
same value, or not? This only matters for volatile functions
of course; with stable or immutable functions, textually-equal
subexpressions should have the same value in any given row.
It is very clear what we are supposed to do for
SELECT random() FROM ... ORDER BY 1;
which sadly isn't legal SQL anymore. It gets fuzzy as soon
as we have
SELECT random() FROM ... ORDER BY random();
You could make an argument either way for those being the
same value or not, but historically we've concluded that
it's more useful to deem them the same value. Then the
behavior you show is not such a surprising extension,
although it could be argued that such matches should only
extend to identical top-level targetlist entries.
> The trouble is, if we tried to fix that, we'd risk changing some other
> behaviour that users may have come to rely on.
Yeah. I'm hesitant to try to adjust semantics here;
we're much more likely to get complaints than kudos.
regards, tom lane