On Mon, 5 Jul 2021 at 18:38, Ronan Dunklau <ronan.dunklau@aiven.io> wrote:
> I think the overhead occurs because in the ExecAgg case, we use the
> tuplesort_*_datum API as an optimization when we have a single column as an
> input, which the ExecSort code doesn't. Maybe it would be worth it to try to
> use that API in sort nodes too, when it can be done.
That's a really great find! Looks like I was wrong to assume that the
extra overhead was from transitioning between nodes.
I ran the performance results locally here with:
create table t1(a int not null);
create table t2(a int not null, b int not null);
create table t3(a int not null, b int not null, c int not null);
insert into t1 select x from generate_Series(1,1000000)x;
insert into t2 select x,x from generate_Series(1,1000000)x;
insert into t3 select x,x,1 from generate_Series(1,1000000)x;
vacuum freeze analyze t1,t2,t3;
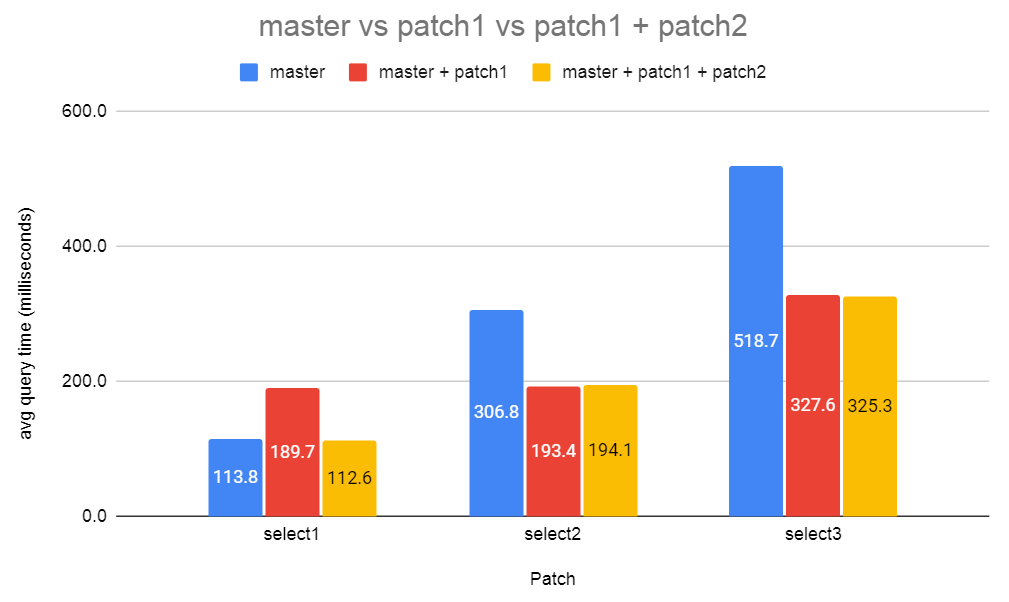
select1: select sum(a order by a) from t1;
select2: select sum(a order by b) from t2;
select3: select c,sum(a order by b) from t3 group by c;
master = https://git.postgresql.org/gitweb/?p=postgresql.git;a=commit;h=8aafb02616753f5c6c90bbc567636b73c0cbb9d4
patch1 =
https://www.postgresql.org/message-id/attachment/123546/wip_planner_support_for_orderby_distinct_aggs_v0.patch
patch2 =
https://www.postgresql.org/message-id/attachment/124238/0001-Allow-Sort-nodes-to-use-the-fast-single-datum-tuples.patch
The attached graph shows the results.
It's very good to see that with both patches applied there's no
regression. I'm a bit surprised there's much performance gain here
given that I didn't add any indexes to provide any presorted input.
David
{kind=link}