Thread: Skip partition tuple routing with constant partition key
Hi,
When loading some data into a partitioned table for testing purpose,
I found even if I specified constant value for the partition key[1], it still do
the tuple routing for each row.
[1]---------------------
UPDATE partitioned set part_key = 2 , …
INSERT into partitioned(part_key, ...) select 1, …
---------------------
I saw such SQLs automatically generated by some programs,
So , personally, It’d be better to skip the tuple routing for this case.
IMO, we can use the following steps to skip the tuple routing:
1) collect the column that has constant value in the targetList.
2) compare the constant column with the columns used in partition key.
3) if all the columns used in key are constant then we cache the routed partition
and do not do the tuple routing again.
In this approach, I did some simple and basic performance tests:
----For plain single column partition key.(partition by range(col)/list(a)...)
When loading 100000000 rows into the table, I can see about 5-7% performance gain
for both cross-partition UPDATE and INSERT if specified constant for the partition key.
----For more complicated expression partition key(partition by range(UDF_func(col)+x)…)
When loading 100000000 rows into the table, it will bring more performance gain.
About > 20% performance gain
Besides, I did not see noticeable performance degradation for other cases(small data set).
Attaching a POC patch about this improvement.
Thoughts ?
Best regards,
houzj
Attachment
On Mon, May 17, 2021 at 8:37 PM houzj.fnst@fujitsu.com <houzj.fnst@fujitsu.com> wrote: > When loading some data into a partitioned table for testing purpose, > > I found even if I specified constant value for the partition key[1], it still do > > the tuple routing for each row. > > > [1]--------------------- > > UPDATE partitioned set part_key = 2 , … > > INSERT into partitioned(part_key, ...) select 1, … > > --------------------- > > I saw such SQLs automatically generated by some programs, Hmm, does this seem common enough for the added complexity to be worthwhile? For an example of what's previously been considered worthwhile for a project like this, see what 0d5f05cde0 did. The cases it addressed are common enough -- a file being loaded into a (time range-) partitioned table using COPY FROM tends to have lines belonging to the same partition consecutively placed. -- Amit Langote EDB: http://www.enterprisedb.com
On Tue, 18 May 2021 at 01:31, Amit Langote <amitlangote09@gmail.com> wrote: > Hmm, does this seem common enough for the added complexity to be worthwhile? I'd also like to know if there's some genuine use case for this. For testing purposes does not seem to be quite a good enough reason. A slightly different optimization that I have considered and even written patches before was to have ExecFindPartition() cache the last routed to partition and have it check if the new row can go into that one on the next call. I imagined there might be a use case for speeding that up for RANGE partitioned tables since it seems fairly likely that most use cases, at least for time series ranges will always hit the same partition most of the time. Since RANGE requires a binary search there might be some savings there. I imagine that optimisation would never be useful for HASH partitioning since it seems most likely that we'll be routing to a different partition each time and wouldn't save much since routing to hash partitions are cheaper than other types. LIST partitioning I'm not so sure about. It seems much less likely than RANGE to hit the same partition twice in a row. IIRC, the patch did something like call ExecPartitionCheck() on the new tuple with the previously routed to ResultRelInfo. I think the last used partition was cached somewhere like relcache (which seems a bit questionable). Likely this would speed up the example case here a bit. Not as much as the proposed patch, but it would likely apply in many more cases. I don't think I ever posted the patch to the list, and if so I no longer have access to it, so it would need to be done again. David
> > Hmm, does this seem common enough for the added complexity to be > worthwhile? > > I'd also like to know if there's some genuine use case for this. For testing > purposes does not seem to be quite a good enough reason. Thanks for the response. For some big data scenario, we sometimes transfer data from one table(only store not expired data) to another table(historical data) for future analysis. In this case, we import data into historical table regularly(could be one day or half a day), And the data is likely to be imported with date label specified, then all of the data to be imported this time belong to the same partition which partition by time range. So, personally, It will be nice if postgres can skip tuple routing for each row in this scenario. > A slightly different optimization that I have considered and even written > patches before was to have ExecFindPartition() cache the last routed to > partition and have it check if the new row can go into that one on the next call. > I imagined there might be a use case for speeding that up for RANGE > partitioned tables since it seems fairly likely that most use cases, at least for > time series ranges will > always hit the same partition most of the time. Since RANGE requires > a binary search there might be some savings there. I imagine that > optimisation would never be useful for HASH partitioning since it seems most > likely that we'll be routing to a different partition each time and wouldn't save > much since routing to hash partitions are cheaper than other types. LIST > partitioning I'm not so sure about. It seems much less likely than RANGE to hit > the same partition twice in a row. I think your approach looks good too, and it seems does not conflict with the approach proposed here. Best regards, houzj
On Tue, May 18, 2021 at 01:27:48PM +1200, David Rowley wrote: > A slightly different optimization that I have considered and even > written patches before was to have ExecFindPartition() cache the last > routed to partition and have it check if the new row can go into that > one on the next call. I imagined there might be a use case for > speeding that up for RANGE partitioned tables since it seems fairly > likely that most use cases, at least for time series ranges will > always hit the same partition most of the time. Since RANGE requires > a binary search there might be some savings there. I imagine that > optimisation would never be useful for HASH partitioning since it > seems most likely that we'll be routing to a different partition each > time and wouldn't save much since routing to hash partitions are > cheaper than other types. LIST partitioning I'm not so sure about. It > seems much less likely than RANGE to hit the same partition twice in a > row. It depends a lot on the schema used and the load pattern, but I'd like to think that a similar argument can be made in favor of LIST partitioning here. -- Michael
Attachment
On Tue, May 18, 2021 at 10:28 AM David Rowley <dgrowleyml@gmail.com> wrote:
> On Tue, 18 May 2021 at 01:31, Amit Langote <amitlangote09@gmail.com> wrote:
> > Hmm, does this seem common enough for the added complexity to be worthwhile?
>
> I'd also like to know if there's some genuine use case for this. For
> testing purposes does not seem to be quite a good enough reason.
>
> A slightly different optimization that I have considered and even
> written patches before was to have ExecFindPartition() cache the last
> routed to partition and have it check if the new row can go into that
> one on the next call. I imagined there might be a use case for
> speeding that up for RANGE partitioned tables since it seems fairly
> likely that most use cases, at least for time series ranges will
> always hit the same partition most of the time. Since RANGE requires
> a binary search there might be some savings there. I imagine that
> optimisation would never be useful for HASH partitioning since it
> seems most likely that we'll be routing to a different partition each
> time and wouldn't save much since routing to hash partitions are
> cheaper than other types. LIST partitioning I'm not so sure about. It
> seems much less likely than RANGE to hit the same partition twice in a
> row.
>
> IIRC, the patch did something like call ExecPartitionCheck() on the
> new tuple with the previously routed to ResultRelInfo. I think the
> last used partition was cached somewhere like relcache (which seems a
> bit questionable). Likely this would speed up the example case here
> a bit. Not as much as the proposed patch, but it would likely apply in
> many more cases.
>
> I don't think I ever posted the patch to the list, and if so I no
> longer have access to it, so it would need to be done again.
I gave a shot to implementing your idea and ended up with the attached
PoC patch, which does pass make check-world.
I do see some speedup:
-- creates a range-partitioned table with 1000 partitions
create unlogged table foo (a int) partition by range (a);
select 'create unlogged table foo_' || i || ' partition of foo for
values from (' || (i-1)*100000+1 || ') to (' || i*100000+1 || ');'
from generate_series(1, 1000) i;
\gexec
-- generates a 100 million record file
copy (select generate_series(1, 100000000)) to '/tmp/100m.csv' csv;
Times for loading that file compare as follows:
HEAD:
postgres=# copy foo from '/tmp/100m.csv' csv;
COPY 100000000
Time: 31813.964 ms (00:31.814)
postgres=# copy foo from '/tmp/100m.csv' csv;
COPY 100000000
Time: 31972.942 ms (00:31.973)
postgres=# copy foo from '/tmp/100m.csv' csv;
COPY 100000000
Time: 32049.046 ms (00:32.049)
Patched:
postgres=# copy foo from '/tmp/100m.csv' csv;
COPY 100000000
Time: 26151.158 ms (00:26.151)
postgres=# copy foo from '/tmp/100m.csv' csv;
COPY 100000000
Time: 28161.082 ms (00:28.161)
postgres=# copy foo from '/tmp/100m.csv' csv;
COPY 100000000
Time: 26700.908 ms (00:26.701)
I guess it would be nice if we could fit in a solution for the use
case that houjz mentioned as a special case. BTW, houjz, could you
please check if a patch like this one helps the case you mentioned?
--
Amit Langote
EDB: http://www.enterprisedb.com
Attachment
On Tue, May 18, 2021 at 11:11 AM houzj.fnst@fujitsu.com <houzj.fnst@fujitsu.com> wrote: > > > Hmm, does this seem common enough for the added complexity to be > > worthwhile? > > > > I'd also like to know if there's some genuine use case for this. For testing > > purposes does not seem to be quite a good enough reason. > > Thanks for the response. > > For some big data scenario, we sometimes transfer data from one table(only store not expired data) > to another table(historical data) for future analysis. > In this case, we import data into historical table regularly(could be one day or half a day), > And the data is likely to be imported with date label specified, then all of the data to be > imported this time belong to the same partition which partition by time range. Is directing that data directly into the appropriate partition not an acceptable solution to address this particular use case? Yeah, I know we should avoid encouraging users to perform DML directly on partitions, but... -- Amit Langote EDB: http://www.enterprisedb.com
RE: Skip partition tuple routing with constant partition key
From: Amit Langote <amitlangote09@gmail.com> > On Tue, May 18, 2021 at 11:11 AM houzj.fnst@fujitsu.com > <houzj.fnst@fujitsu.com> wrote: > > For some big data scenario, we sometimes transfer data from one table(only > store not expired data) > > to another table(historical data) for future analysis. > > In this case, we import data into historical table regularly(could be one day or > half a day), > > And the data is likely to be imported with date label specified, then all of the > data to be > > imported this time belong to the same partition which partition by time range. > > Is directing that data directly into the appropriate partition not an > acceptable solution to address this particular use case? Yeah, I know > we should avoid encouraging users to perform DML directly on > partitions, but... Yes, I want to make/keep it possible that application developers can be unaware of partitions. I believe that's why David-san,Alvaro-san, and you have made great efforts to improve partitioning performance. So, I'm +1 for what Hou-san istrying to achieve. Is there something you're concerned about? The amount and/or complexity of added code? Regards Takayuki Tsunakawa
On Thu, 20 May 2021 at 01:17, Amit Langote <amitlangote09@gmail.com> wrote: > I gave a shot to implementing your idea and ended up with the attached > PoC patch, which does pass make check-world. I only had a quick look at this. + if ((dispatch->key->strategy == PARTITION_STRATEGY_RANGE || + dispatch->key->strategy == PARTITION_STRATEGY_RANGE)) + dispatch->lastPartInfo = rri; I think you must have meant to have one of these as PARTITION_STRATEGY_LIST? Wondering what your thoughts are on, instead of caching the last used ResultRelInfo from the last call to ExecFindPartition(), to instead cached the last looked up partition index in PartitionDescData? That way we could cache lookups between statements. Right now your caching is not going to help for single-row INSERTs, for example. For multi-level partition hierarchies that would still require looping and checking the cached value at each level. I've not studied the code that builds and rebuilds PartitionDescData, so there may be some reason that we shouldn't do that. I know that's changed a bit recently with DETACH CONCURRENTLY. However, providing the cached index is not outside the bounds of the oids array, it shouldn't really matter if the cached value happens to end up pointing to some other partition. If that happens, we'll just fail the ExecPartitionCheck() and have to look for the correct partition. David
On Thu, 20 May 2021 at 12:20, tsunakawa.takay@fujitsu.com <tsunakawa.takay@fujitsu.com> wrote: > Yes, I want to make/keep it possible that application developers can be unaware of partitions. I believe that's why David-san,Alvaro-san, and you have made great efforts to improve partitioning performance. So, I'm +1 for what Hou-san istrying to achieve. > > Is there something you're concerned about? The amount and/or complexity of added code? It would be good to see how close Amit's patch gets to the performance of the original patch on this thread. As far as I can see, the difference is, aside from the setup code to determine if the partition is constant, that Amit's patch just requires an additional ExecPartitionCheck() call per row. That should be pretty cheap when compared to the binary search to find the partition for a RANGE or LIST partitioned table. Houzj didn't mention how the table in the test was partitioned, so it's hard to speculate how many comparisons would be done during a binary search. Or maybe it was HASH partitioned and there was no binary search. David
On Thu, May 20, 2021 at 9:31 AM David Rowley <dgrowleyml@gmail.com> wrote: > On Thu, 20 May 2021 at 01:17, Amit Langote <amitlangote09@gmail.com> wrote: > > I gave a shot to implementing your idea and ended up with the attached > > PoC patch, which does pass make check-world. > > I only had a quick look at this. > > + if ((dispatch->key->strategy == PARTITION_STRATEGY_RANGE || > + dispatch->key->strategy == PARTITION_STRATEGY_RANGE)) > + dispatch->lastPartInfo = rri; > > I think you must have meant to have one of these as PARTITION_STRATEGY_LIST? Oops, of course. Fixed in the attached. > Wondering what your thoughts are on, instead of caching the last used > ResultRelInfo from the last call to ExecFindPartition(), to instead > cached the last looked up partition index in PartitionDescData? That > way we could cache lookups between statements. Right now your caching > is not going to help for single-row INSERTs, for example. Hmm, addressing single-row INSERTs with something like you suggest might help time-range partitioning setups, because each of those INSERTs are likely to be targeting the same partition most of the time. Is that case what you had in mind? Although, in the cases where that doesn't help, we'd end up making a ResultRelInfo for the cached partition to check the partition constraint, only then to be thrown away because the new row belongs to a different partition. That overhead would not be free for sure. > For multi-level partition hierarchies that would still require looping > and checking the cached value at each level. Yeah, there's no getting around that, though maybe that's not a big problem. > I've not studied the code that builds and rebuilds PartitionDescData, > so there may be some reason that we shouldn't do that. I know that's > changed a bit recently with DETACH CONCURRENTLY. However, providing > the cached index is not outside the bounds of the oids array, it > shouldn't really matter if the cached value happens to end up pointing > to some other partition. If that happens, we'll just fail the > ExecPartitionCheck() and have to look for the correct partition. Yeah, as long as ExecFindPartition performs ExecPartitionCheck() on before returning a given cached partition, there's no need to worry about the cached index getting stale for whatever reason. -- Amit Langote EDB: http://www.enterprisedb.com
Attachment
On Thu, May 20, 2021 at 9:20 AM tsunakawa.takay@fujitsu.com <tsunakawa.takay@fujitsu.com> wrote: > From: Amit Langote <amitlangote09@gmail.com> > > On Tue, May 18, 2021 at 11:11 AM houzj.fnst@fujitsu.com > > <houzj.fnst@fujitsu.com> wrote: > > > For some big data scenario, we sometimes transfer data from one table(only > > store not expired data) > > > to another table(historical data) for future analysis. > > > In this case, we import data into historical table regularly(could be one day or > > half a day), > > > And the data is likely to be imported with date label specified, then all of the > > data to be > > > imported this time belong to the same partition which partition by time range. > > > > Is directing that data directly into the appropriate partition not an > > acceptable solution to address this particular use case? Yeah, I know > > we should avoid encouraging users to perform DML directly on > > partitions, but... > > Yes, I want to make/keep it possible that application developers can be unaware of partitions. I believe that's why David-san,Alvaro-san, and you have made great efforts to improve partitioning performance. So, I'm +1 for what Hou-san istrying to achieve. I'm very glad to see such discussions on the list, because it means the partitioning feature is being stretched to cover wider set of use cases. > Is there something you're concerned about? The amount and/or complexity of added code? IMHO, a patch that implements caching more generally would be better even if it adds some complexity. Hou-san's patch seemed centered around the use case where all rows being loaded in a given command route to the same partition, a very specialized case I'd say. Maybe we can extract the logic in Hou-san's patch to check the constant-ness of the targetlist producing the rows to insert and find a way to add it to the patch I posted such that the generality of the latter's implementation is not lost. -- Amit Langote EDB: http://www.enterprisedb.com
On Thu, 20 May 2021 at 20:49, Amit Langote <amitlangote09@gmail.com> wrote: > > On Thu, May 20, 2021 at 9:31 AM David Rowley <dgrowleyml@gmail.com> wrote: > > Wondering what your thoughts are on, instead of caching the last used > > ResultRelInfo from the last call to ExecFindPartition(), to instead > > cached the last looked up partition index in PartitionDescData? That > > way we could cache lookups between statements. Right now your caching > > is not going to help for single-row INSERTs, for example. > > Hmm, addressing single-row INSERTs with something like you suggest > might help time-range partitioning setups, because each of those > INSERTs are likely to be targeting the same partition most of the > time. Is that case what you had in mind? Yeah, I thought it would possibly be useful for RANGE partitioning. I was a bit undecided with LIST. There seemed to be bigger risk there that the usage pattern would route to a different partition each time. In my imagination, RANGE partitioning seems more likely to see subsequent tuples heading to the same partition as the last tuple. > Although, in the cases > where that doesn't help, we'd end up making a ResultRelInfo for the > cached partition to check the partition constraint, only then to be > thrown away because the new row belongs to a different partition. > That overhead would not be free for sure. Yeah, there's certainly above zero overhead to getting it wrong. It would be good to see benchmarks to find out what that overhead is. David
From: Amit Langote <amitlangote09@gmail.com>
Sent: Wednesday, May 19, 2021 9:17 PM
> I gave a shot to implementing your idea and ended up with the attached PoC
> patch, which does pass make check-world.
>
> I do see some speedup:
>
> -- creates a range-partitioned table with 1000 partitions create unlogged table
> foo (a int) partition by range (a); select 'create unlogged table foo_' || i || '
> partition of foo for values from (' || (i-1)*100000+1 || ') to (' || i*100000+1 || ');'
> from generate_series(1, 1000) i;
> \gexec
>
> -- generates a 100 million record file
> copy (select generate_series(1, 100000000)) to '/tmp/100m.csv' csv;
>
> Times for loading that file compare as follows:
>
> HEAD:
>
> postgres=# copy foo from '/tmp/100m.csv' csv; COPY 100000000
> Time: 31813.964 ms (00:31.814)
> postgres=# copy foo from '/tmp/100m.csv' csv; COPY 100000000
> Time: 31972.942 ms (00:31.973)
> postgres=# copy foo from '/tmp/100m.csv' csv; COPY 100000000
> Time: 32049.046 ms (00:32.049)
>
> Patched:
>
> postgres=# copy foo from '/tmp/100m.csv' csv; COPY 100000000
> Time: 26151.158 ms (00:26.151)
> postgres=# copy foo from '/tmp/100m.csv' csv; COPY 100000000
> Time: 28161.082 ms (00:28.161)
> postgres=# copy foo from '/tmp/100m.csv' csv; COPY 100000000
> Time: 26700.908 ms (00:26.701)
>
> I guess it would be nice if we could fit in a solution for the use case that houjz
> mentioned as a special case. BTW, houjz, could you please check if a patch like
> this one helps the case you mentioned?
Thanks for the patch!
I did some test on it(using the table you provided above):
1): Test plain column in partition key.
SQL: insert into foo select 1 from generate_series(1, 10000000);
HEAD:
Time: 5493.392 ms (00:05.493)
AFTER PATCH(skip constant partition key)
Time: 4198.421 ms (00:04.198)
AFTER PATCH(cache the last partition)
Time: 4484.492 ms (00:04.484)
The test results of your patch in this case looks good.
It can fit many more cases and the performance gain is nice.
-----------
2) Test expression in partition key
create or replace function partition_func(i int) returns int as $$
begin
return i;
end;
$$ language plpgsql immutable parallel restricted;
create unlogged table foo (a int) partition by range (partition_func(a));
SQL: insert into foo select 1 from generate_series(1, 10000000);
HEAD
Time: 8595.120 ms (00:08.595)
AFTER PATCH(skip constant partition key)
Time: 4198.421 ms (00:04.198)
AFTER PATCH(cache the last partition)
Time: 12829.800 ms (00:12.830)
If add a user defined function in the partition key, it seems have
performance degradation after the patch.
I did some analysis on it, for the above testcase , ExecPartitionCheck
executed three expression 1) key is null 2) key > low 3) key < top
In this case, the "key" contains a funcexpr and the funcexpr will be executed
three times for each row, so, it bring extra overhead which cause the performance degradation.
IMO, improving the ExecPartitionCheck seems a better solution to it, we can
Calculate the key value in advance and use the value to do the bound check.
Thoughts ?
------------
Besides, are we going to add a reloption or guc to control this cache behaviour if we more forward with this approach
?
Because, If most of the rows to be inserted are routing to a different partition each time, then I think the extra
ExecPartitionCheck
will become the overhead. Maybe it's better to apply both two approaches(cache the last partition and skip constant
partitionkey)
which can achieve the best performance results.
Best regards,
houzj
Hou-san, On Thu, May 20, 2021 at 7:35 PM houzj.fnst@fujitsu.com <houzj.fnst@fujitsu.com> wrote: > From: Amit Langote <amitlangote09@gmail.com> > Sent: Wednesday, May 19, 2021 9:17 PM > > I guess it would be nice if we could fit in a solution for the use case that houjz > > mentioned as a special case. BTW, houjz, could you please check if a patch like > > this one helps the case you mentioned? > > Thanks for the patch! > I did some test on it(using the table you provided above): Thanks a lot for doing that. > 1): Test plain column in partition key. > SQL: insert into foo select 1 from generate_series(1, 10000000); > > HEAD: > Time: 5493.392 ms (00:05.493) > > AFTER PATCH(skip constant partition key) > Time: 4198.421 ms (00:04.198) > > AFTER PATCH(cache the last partition) > Time: 4484.492 ms (00:04.484) > > The test results of your patch in this case looks good. > It can fit many more cases and the performance gain is nice. Hmm yeah, not too bad. > 2) Test expression in partition key > > create or replace function partition_func(i int) returns int as $$ > begin > return i; > end; > $$ language plpgsql immutable parallel restricted; > create unlogged table foo (a int) partition by range (partition_func(a)); > > SQL: insert into foo select 1 from generate_series(1, 10000000); > > HEAD > Time: 8595.120 ms (00:08.595) > > AFTER PATCH(skip constant partition key) > Time: 4198.421 ms (00:04.198) > > AFTER PATCH(cache the last partition) > Time: 12829.800 ms (00:12.830) > > If add a user defined function in the partition key, it seems have > performance degradation after the patch. Oops. > I did some analysis on it, for the above testcase , ExecPartitionCheck > executed three expression 1) key is null 2) key > low 3) key < top > In this case, the "key" contains a funcexpr and the funcexpr will be executed > three times for each row, so, it bring extra overhead which cause the performance degradation. > > IMO, improving the ExecPartitionCheck seems a better solution to it, we can > Calculate the key value in advance and use the value to do the bound check. > Thoughts ? This one seems bit tough. ExecPartitionCheck() uses the generic expression evaluation machinery like a black box, which means execPartition.c can't really tweal/control the time spent evaluating partition constraints. Given that, we may have to disable the caching when key->partexprs != NIL, unless we can reasonably do what you are suggesting. > Besides, are we going to add a reloption or guc to control this cache behaviour if we more forward with this approach ? > Because, If most of the rows to be inserted are routing to a different partition each time, then I think the extra ExecPartitionCheck > will become the overhead. Maybe it's better to apply both two approaches(cache the last partition and skip constant partitionkey) > which can achieve the best performance results. A reloption will have to be a last resort is what I can say about this at the moment. -- Amit Langote EDB: http://www.enterprisedb.com
From: Amit Langote <amitlangote09@gmail.com>
Sent: Thursday, May 20, 2021 8:23 PM
>
> Hou-san,
>
> On Thu, May 20, 2021 at 7:35 PM houzj.fnst@fujitsu.com
> <houzj.fnst@fujitsu.com> wrote:
> > 2) Test expression in partition key
> >
> > create or replace function partition_func(i int) returns int as $$
> > begin
> > return i;
> > end;
> > $$ language plpgsql immutable parallel restricted; create unlogged
> > table foo (a int) partition by range (partition_func(a));
> >
> > SQL: insert into foo select 1 from generate_series(1, 10000000);
> >
> > HEAD
> > Time: 8595.120 ms (00:08.595)
> >
> > AFTER PATCH(skip constant partition key)
> > Time: 4198.421 ms (00:04.198)
> >
> > AFTER PATCH(cache the last partition)
> > Time: 12829.800 ms (00:12.830)
> >
> > If add a user defined function in the partition key, it seems have
> > performance degradation after the patch.
>
> Oops.
>
> > I did some analysis on it, for the above testcase , ExecPartitionCheck
> > executed three expression 1) key is null 2) key > low 3) key < top In
> > this case, the "key" contains a funcexpr and the funcexpr will be
> > executed three times for each row, so, it bring extra overhead which cause
> the performance degradation.
> >
> > IMO, improving the ExecPartitionCheck seems a better solution to it,
> > we can Calculate the key value in advance and use the value to do the bound
> check.
> > Thoughts ?
>
> This one seems bit tough. ExecPartitionCheck() uses the generic expression
> evaluation machinery like a black box, which means execPartition.c can't really
> tweal/control the time spent evaluating partition constraints. Given that, we
> may have to disable the caching when key->partexprs != NIL, unless we can
> reasonably do what you are suggesting.[]
I did some research on the CHECK expression that ExecPartitionCheck() execute.
Currently for a normal RANGE partition key it will first generate a CHECK expression
like : [Keyexpression IS NOT NULL AND Keyexpression > lowboud AND Keyexpression < lowboud].
In this case, Keyexpression will be re-executed which will bring some overhead.
Instead, I think we can try to do the following step:
1)extract the Keyexpression from the CHECK expression
2)evaluate the key expression in advance
3)pass the result of key expression to do the partition CHECK.
In this way ,we only execute the key expression once which looks more efficient.
Attaching a POC patch about this approach.
I did some performance test with my laptop for this patch:
------------------------------------test cheap partition key expression
create unlogged table test_partitioned_inner (a int) partition by range ((abs(a) + a/50));
create unlogged table test_partitioned_inner_1 partition of test_partitioned_inner for values from (1) to (50);
create unlogged table test_partitioned_inner_2 partition of test_partitioned_inner for values from ( 50 ) to (100);
insert into test_partitioned_inner_1 select (i%48)+1 from generate_series(1,10000000,1) t(i);
BEFORE patch:
Execution Time: 6120.706 ms
AFTER patch:
Execution Time: 5705.967 ms
------------------------------------test expensive partition key expression
create or replace function partfunc(i int) returns int as
$$
begin
return i;
end;
$$ language plpgsql IMMUTABLE;
create unlogged table test_partitioned_inner (a int) partition by range (partfunc (a));
create unlogged table test_partitioned_inner_1 partition of test_partitioned_inner for values from (1) to (50);
create unlogged table test_partitioned_inner_2 partition of test_partitioned_inner for values from ( 50 ) to (100);
I think this can be a independent improvement for partitioncheck.
before patch:
Execution Time: 14048.551 ms
after patch:
Execution Time: 8810.518 ms
I think this patch can solve the performance degradation of key expression
after applying the [Save the last partition] patch.
Besides, this could be a separate patch which can improve some more cases.
Thoughts ?
Best regards,
houzj
Attachment
RE: Skip partition tuple routing with constant partition key
From: houzj.fnst@fujitsu.com <houzj.fnst@fujitsu.com> > I think this patch can solve the performance degradation of key expression after > applying the [Save the last partition] patch. > Besides, this could be a separate patch which can improve some more cases. > Thoughts ? Thank you for proposing an impressive improvement so quickly! Yes, I'm in the mood for adopting Amit-san's patch as a basebecause it's compact and readable, and plus add this patch of yours to complement the partition key function case. But ... * Applying your patch alone produced a compilation error. I'm sorry I mistakenly deleted the compile log, but it said somethinglike "There's a redeclaration of PartKeyContext in partcache.h; the original definition is in partdef.h" * Hmm, this may be too much to expect, but I wonder if we can make the patch more compact... Regards Takayuki Tsunakawa
From: Tsunakawa, Takayuki <tsunakawa.takay@fujitsu.com> Sent: Monday, May 24, 2021 3:34 PM > > From: houzj.fnst@fujitsu.com <houzj.fnst@fujitsu.com> > > I think this patch can solve the performance degradation of key > > expression after applying the [Save the last partition] patch. > > Besides, this could be a separate patch which can improve some more cases. > > Thoughts ? > > Thank you for proposing an impressive improvement so quickly! Yes, I'm in > the mood for adopting Amit-san's patch as a base because it's compact and > readable, and plus add this patch of yours to complement the partition key > function case. Thanks for looking into this. > But ... > > * Applying your patch alone produced a compilation error. I'm sorry I > mistakenly deleted the compile log, but it said something like "There's a > redeclaration of PartKeyContext in partcache.h; the original definition is in > partdef.h" It seems a little strange, I have compiled it alone in two different linux machine and did not find such an error. Did you compile it on a windows machine ? > * Hmm, this may be too much to expect, but I wonder if we can make the patch > more compact... Of course, I will try to simplify the patch. Best regards, houzj
RE: Skip partition tuple routing with constant partition key
From: Hou, Zhijie/侯 志杰 <houzj.fnst@fujitsu.com> > It seems a little strange, I have compiled it alone in two different linux machine > and did > not find such an error. Did you compile it on a windows machine ? On Linux, it produces: gcc -std=gnu99 -Wall -Wmissing-prototypes -Wpointer-arith -Wdeclaration-after-s\ tatement -Werror=vla -Wendif-labels -Wmissing-format-attribute -Wformat-securit\ y -fno-strict-aliasing -fwrapv -g -O0 -I../../../src/include -D_GNU_SOURCE -\ c -o heap.o heap.c -MMD -MP -MF .deps/heap.Po In file included from heap.c:86: ../../../src/include/utils/partcache.h:54: error: redefinition of typedef 'Part\ KeyContext' ../../../src/include/partitioning/partdefs.h:26: note: previous declaration of \ 'PartKeyContext' was here Regards Takayuki Tsunakawa
From: houzj.fnst@fujitsu.com <houzj.fnst@fujitsu.com> Sent: Monday, May 24, 2021 3:58 PM > > From: Tsunakawa, Takayuki <mailto:tsunakawa.takay@fujitsu.com> > Sent: Monday, May 24, 2021 3:34 PM > > > > From: mailto:houzj.fnst@fujitsu.com <mailto:houzj.fnst@fujitsu.com> > > > I think this patch can solve the performance degradation of key > > > expression after applying the [Save the last partition] patch. > > > Besides, this could be a separate patch which can improve some more > cases. > > > Thoughts ? > > > > Thank you for proposing an impressive improvement so quickly! Yes, > > I'm in the mood for adopting Amit-san's patch as a base because it's > > compact and readable, and plus add this patch of yours to complement > > the partition key function case. > > Thanks for looking into this. > > > But ... > > > > * Applying your patch alone produced a compilation error. I'm sorry I > > mistakenly deleted the compile log, but it said something like > > "There's a redeclaration of PartKeyContext in partcache.h; the > > original definition is in partdef.h" > > It seems a little strange, I have compiled it alone in two different linux machine > and did not find such an error. Did you compile it on a windows machine ? Ah, Maybe I found the issue. Attaching a new patch, please have a try on this patch. Best regards, houzj
Attachment
Hou-san, On Mon, May 24, 2021 at 10:31 AM houzj.fnst@fujitsu.com <houzj.fnst@fujitsu.com> wrote: > From: Amit Langote <amitlangote09@gmail.com> > Sent: Thursday, May 20, 2021 8:23 PM > > This one seems bit tough. ExecPartitionCheck() uses the generic expression > > evaluation machinery like a black box, which means execPartition.c can't really > > tweal/control the time spent evaluating partition constraints. Given that, we > > may have to disable the caching when key->partexprs != NIL, unless we can > > reasonably do what you are suggesting.[] > > I did some research on the CHECK expression that ExecPartitionCheck() execute. Thanks for looking into this and writing the patch. Your idea does sound promising. > Currently for a normal RANGE partition key it will first generate a CHECK expression > like : [Keyexpression IS NOT NULL AND Keyexpression > lowboud AND Keyexpression < lowboud]. > In this case, Keyexpression will be re-executed which will bring some overhead. > > Instead, I think we can try to do the following step: > 1)extract the Keyexpression from the CHECK expression > 2)evaluate the key expression in advance > 3)pass the result of key expression to do the partition CHECK. > In this way ,we only execute the key expression once which looks more efficient. I would have preferred this not to touch anything but ExecPartitionCheck(), at least in the first version. Especially, seeing that your patch touches partbounds.c makes me a bit nervous, because the logic there is pretty complicated to begin with. How about we start with something like the attached? It's the same idea AFAICS, but implemented with a smaller footprint. We can consider teaching relcache about this as the next step, if at all. I haven't measured the performance, but maybe it's not as fast as yours, so will need some fine-tuning. Can you please give it a read? -- Amit Langote EDB: http://www.enterprisedb.com
Attachment
RE: Skip partition tuple routing with constant partition key
From: Hou, Zhijie/侯 志杰 <houzj.fnst@fujitsu.com> > Ah, Maybe I found the issue. > Attaching a new patch, please have a try on this patch. Thanks, it has compiled perfectly without any warning. Regards Takayuki Tsunakawa
Hi Amit-san, From: Amit Langote <amitlangote09@gmail.com> Sent: Monday, May 24, 2021 4:27 PM > Hou-san, > > On Mon, May 24, 2021 at 10:31 AM houzj.fnst@fujitsu.com > <houzj.fnst@fujitsu.com> wrote: > > From: Amit Langote <amitlangote09@gmail.com> > > Sent: Thursday, May 20, 2021 8:23 PM > > > This one seems bit tough. ExecPartitionCheck() uses the generic > > > expression evaluation machinery like a black box, which means > > > execPartition.c can't really tweal/control the time spent evaluating > > > partition constraints. Given that, we may have to disable the > > > caching when key->partexprs != NIL, unless we can reasonably do what > > > you are suggesting.[] > > > > I did some research on the CHECK expression that ExecPartitionCheck() > execute. > > Thanks for looking into this and writing the patch. Your idea does sound > promising. > > > Currently for a normal RANGE partition key it will first generate a > > CHECK expression like : [Keyexpression IS NOT NULL AND Keyexpression > > lowboud AND Keyexpression < lowboud]. > > In this case, Keyexpression will be re-executed which will bring some > overhead. > > > > Instead, I think we can try to do the following step: > > 1)extract the Keyexpression from the CHECK expression 2)evaluate the > > key expression in advance 3)pass the result of key expression to do > > the partition CHECK. > > In this way ,we only execute the key expression once which looks more > efficient. > > I would have preferred this not to touch anything but ExecPartitionCheck(), at > least in the first version. Especially, seeing that your patch touches > partbounds.c makes me a bit nervous, because the logic there is pretty > complicated to begin with. Agreed. > How about we start with something like the attached? It's the same idea > AFAICS, but implemented with a smaller footprint. We can consider teaching > relcache about this as the next step, if at all. I haven't measured the > performance, but maybe it's not as fast as yours, so will need some fine-tuning. > Can you please give it a read? Thanks for the patch and It looks more compact than mine. After taking a quick look at the patch, I found a possible issue. Currently, the patch does not search the parent's partition key expression recursively. For example, If we have multi-level partition: Table A is partition of Table B, Table B is partition of Table C. It looks like if insert into Table A , then we did not replace the key expression which come from Table C. If we want to get the Table C, we might need to use pg_inherit, but it costs too much to me. Instead, maybe we can use the existing logic which already scanned the pg_inherit in function generate_partition_qual(). Although this change is out of ExecPartitionCheck(). I think we'd better replace all the parents and grandparent...'s key expression. Attaching a demo patch based on the patch you posted earlier. I hope it will help. Best regards, houzj
Attachment
Hou-san, On Mon, May 24, 2021 at 10:15 PM houzj.fnst@fujitsu.com <houzj.fnst@fujitsu.com> wrote: > From: Amit Langote <amitlangote09@gmail.com> > Sent: Monday, May 24, 2021 4:27 PM > > On Mon, May 24, 2021 at 10:31 AM houzj.fnst@fujitsu.com > > <houzj.fnst@fujitsu.com> wrote: > > > Currently for a normal RANGE partition key it will first generate a > > > CHECK expression like : [Keyexpression IS NOT NULL AND Keyexpression > > > lowboud AND Keyexpression < lowboud]. > > > In this case, Keyexpression will be re-executed which will bring some > > overhead. > > > > > > Instead, I think we can try to do the following step: > > > 1)extract the Keyexpression from the CHECK expression 2)evaluate the > > > key expression in advance 3)pass the result of key expression to do > > > the partition CHECK. > > > In this way ,we only execute the key expression once which looks more > > efficient. > > > > I would have preferred this not to touch anything but ExecPartitionCheck(), at > > least in the first version. Especially, seeing that your patch touches > > partbounds.c makes me a bit nervous, because the logic there is pretty > > complicated to begin with. > > Agreed. > > > How about we start with something like the attached? It's the same idea > > AFAICS, but implemented with a smaller footprint. We can consider teaching > > relcache about this as the next step, if at all. I haven't measured the > > performance, but maybe it's not as fast as yours, so will need some fine-tuning. > > Can you please give it a read? > > Thanks for the patch and It looks more compact than mine. > > After taking a quick look at the patch, I found a possible issue. > Currently, the patch does not search the parent's partition key expression recursively. > For example, If we have multi-level partition: > Table A is partition of Table B, Table B is partition of Table C. > It looks like if insert into Table A , then we did not replace the key expression which come from Table C. Good catch! Although, I was relieved to realize that it's not *wrong* per se, as in it does not produce an incorrect result, but only *slower* than if the patch was careful enough to replace all the parents' key expressions. > If we want to get the Table C, we might need to use pg_inherit, but it costs too much to me. > Instead, maybe we can use the existing logic which already scanned the pg_inherit in function > generate_partition_qual(). Although this change is out of ExecPartitionCheck(). I think we'd better > replace all the parents and grandparent...'s key expression. Attaching a demo patch based on the > patch you posted earlier. I hope it will help. Thanks. Though again, I think we can do this without changing the relcache interface, such as RelationGetPartitionQual(). PartitionTupleRouting has all the information that's needed here. Each partitioned table involved in routing a tuple to the leaf partition has a PartitionDispatch struct assigned to it. That struct contains the PartitionKey and we can access partexprs from there. We can arrange to assemble them into a single list that is saved to a given partition's ResultRelInfo, that is, after converting the expressions to have partition attribute numbers. I tried that in the attached updated patch; see the 0002-* patch. Regarding the first patch to make ExecFindPartition() cache last used partition, I noticed that it only worked for the bottom-most parent in a multi-level partition tree, because only leaf partitions were assigned to dispatch->lastPartitionInfo. I have fixed the earlier patch to also save non-leaf partitions and their corresponding PartitionDispatch structs so that parents of all levels can use this caching feature. The patch has to become somewhat complex as a result, but hopefully not too unreadable. -- Amit Langote EDB: http://www.enterprisedb.com
Attachment
Hi Amit-san From: Amit Langote <amitlangote09@gmail.com> Sent: Tuesday, May 25, 2021 10:06 PM > Hou-san, > > Thanks for the patch and It looks more compact than mine. > > > > After taking a quick look at the patch, I found a possible issue. > > Currently, the patch does not search the parent's partition key expression > recursively. > > For example, If we have multi-level partition: > > Table A is partition of Table B, Table B is partition of Table C. > > It looks like if insert into Table A , then we did not replace the key expression > which come from Table C. > > Good catch! Although, I was relieved to realize that it's not *wrong* per se, as > in it does not produce an incorrect result, but only > *slower* than if the patch was careful enough to replace all the parents' key > expressions. > > > If we want to get the Table C, we might need to use pg_inherit, but it costs > too much to me. > > Instead, maybe we can use the existing logic which already scanned the > > pg_inherit in function generate_partition_qual(). Although this change > > is out of ExecPartitionCheck(). I think we'd better replace all the > > parents and grandparent...'s key expression. Attaching a demo patch based > on the patch you posted earlier. I hope it will help. > > Thanks. > > Though again, I think we can do this without changing the relcache interface, > such as RelationGetPartitionQual(). > > PartitionTupleRouting has all the information that's needed here. > Each partitioned table involved in routing a tuple to the leaf partition has a > PartitionDispatch struct assigned to it. That struct contains the PartitionKey > and we can access partexprs from there. We can arrange to assemble them > into a single list that is saved to a given partition's ResultRelInfo, that is, after > converting the expressions to have partition attribute numbers. I tried that in > the attached updated patch; see the 0002-* patch. Thanks for the explanation ! Yeah, we can get all the parent table info from PartitionTupleRouting when INSERT into a partitioned table. But I have two issues about using the information from PartitionTupleRouting to get the parent table's key expression: 1) It seems we do not initialize the PartitionTupleRouting when directly INSERT into a partition(not a partitioned table). I think it will be better we let the pre-compute-key_expression feature to be used in all the possible cases, because it could bring nice performance improvement. 2) When INSERT into a partitioned table which is also a partition, the PartitionTupleRouting is initialized after the ExecPartitionCheck. For example: create unlogged table parttable1 (a int, b int, c int, d int) partition by range (partition_func(a)); create unlogged table parttable1_a partition of parttable1 for values from (0) to (5000); create unlogged table parttable1_b partition of parttable1 for values from (5000) to (10000); create unlogged table parttable2 (a int, b int, c int, d int) partition by range (partition_func1(b)); create unlogged table parttable2_a partition of parttable2 for values from (0) to (5000); create unlogged table parttable2_b partition of parttable2 for values from (5000) to (10000); ---When INSERT into parttable2, the code do partitioncheck before initialize the PartitionTupleRouting. insert into parttable2 select 10001,100,10001,100; Best regards, houzj
Hou-san, On Wed, May 26, 2021 at 10:05 AM houzj.fnst@fujitsu.com <houzj.fnst@fujitsu.com> wrote: > From: Amit Langote <amitlangote09@gmail.com> > Sent: Tuesday, May 25, 2021 10:06 PM > > Though again, I think we can do this without changing the relcache interface, > > such as RelationGetPartitionQual(). > > > > PartitionTupleRouting has all the information that's needed here. > > Each partitioned table involved in routing a tuple to the leaf partition has a > > PartitionDispatch struct assigned to it. That struct contains the PartitionKey > > and we can access partexprs from there. We can arrange to assemble them > > into a single list that is saved to a given partition's ResultRelInfo, that is, after > > converting the expressions to have partition attribute numbers. I tried that in > > the attached updated patch; see the 0002-* patch. > > Thanks for the explanation ! > Yeah, we can get all the parent table info from PartitionTupleRouting when INSERT into a partitioned table. > > But I have two issues about using the information from PartitionTupleRouting to get the parent table's key expression: > 1) It seems we do not initialize the PartitionTupleRouting when directly INSERT into a partition(not a partitioned table). > I think it will be better we let the pre-compute-key_expression feature to be used in all the possible cases, because it > could bring nice performance improvement. > > 2) When INSERT into a partitioned table which is also a partition, the PartitionTupleRouting is initialized after the ExecPartitionCheck. Hmm, do we really need to optimize ExecPartitionCheck() when partitions are directly inserted into? As also came up earlier in the thread, we want to discourage users from doing that to begin with, so it doesn't make much sense to spend our effort on that case. Optimizing ExecPartitionCheck(), specifically your idea of pre-computing the partition key expressions, only came up after finding that the earlier patch to teach ExecFindPartition() to cache partitions may benefit from it. IOW, optimizing ExecPartitionCheck() for its own sake does not seem worthwhile, especially not if we'd need to break module boundaries to make that happen. Thoughts? -- Amit Langote EDB: http://www.enterprisedb.com
Hi, Amit:
Hi amit-san From: Amit Langote <amitlangote09@gmail.com> Sent: Wednesday, May 26, 2021 9:38 AM > > Hou-san, > > On Wed, May 26, 2021 at 10:05 AM houzj.fnst@fujitsu.com > <houzj.fnst@fujitsu.com> wrote: > > > > Thanks for the explanation ! > > Yeah, we can get all the parent table info from PartitionTupleRouting when > INSERT into a partitioned table. > > > > But I have two issues about using the information from PartitionTupleRouting > to get the parent table's key expression: > > 1) It seems we do not initialize the PartitionTupleRouting when directly > INSERT into a partition(not a partitioned table). > > I think it will be better we let the pre-compute-key_expression > > feature to be used in all the possible cases, because it could bring nice > performance improvement. > > > > 2) When INSERT into a partitioned table which is also a partition, the > PartitionTupleRouting is initialized after the ExecPartitionCheck. > > Hmm, do we really need to optimize ExecPartitionCheck() when partitions are > directly inserted into? As also came up earlier in the thread, we want to > discourage users from doing that to begin with, so it doesn't make much sense > to spend our effort on that case. > > Optimizing ExecPartitionCheck(), specifically your idea of pre-computing the > partition key expressions, only came up after finding that the earlier patch to > teach ExecFindPartition() to cache partitions may benefit from it. IOW, > optimizing ExecPartitionCheck() for its own sake does not seem worthwhile, > especially not if we'd need to break module boundaries to make that happen. > > Thoughts? OK, I see the point, thanks for the explanation. Let try to move forward. About teaching relcache about caching the target partition. David-san suggested cache the partidx in PartitionDesc. And it will need looping and checking the cached value at each level. I was thinking can we cache a partidx list[1, 2 ,3], and then we can follow the list to get the last partition and do the partition CHECK only for the last partition. If any unexpected thing happen, we can return to the original table and redo the tuple routing without using the cached index. What do you think ? Best regards, houzj
Hi,
On Thu, May 27, 2021 at 2:30 AM Zhihong Yu <zyu@yugabyte.com> wrote:
>>
>> Hi, Amit:
>
>
> For ConvertTupleToPartition() in 0001-ExecFindPartition-cache-last-used-partition-v3.patch:
>
> + if (tempslot != NULL)
> + ExecClearTuple(tempslot);
>
> If tempslot and parent_slot point to the same slot, should ExecClearTuple() still be called ?
Yeah, we decided back in 1c9bb02d8ec that it's necessary to free the
slot if it's the same slot as a parent partition's
PartitionDispatch->tupslot ("freeing parent's copy of the tuple").
Maybe we don't need this parent-slot-clearing anymore due to code
restructuring over the last 3 years, but that will have to be a
separate patch.
I hope the attached updated patch makes it a bit more clear what's
going on. I refactored more of the code in ExecFindPartition() to
make this patch more a bit more readable.
--
Amit Langote
EDB: http://www.enterprisedb.com
Attachment
Hi,
On Thu, May 27, 2021 at 2:30 AM Zhihong Yu <zyu@yugabyte.com> wrote:
>>
>> Hi, Amit:
>
>
> For ConvertTupleToPartition() in 0001-ExecFindPartition-cache-last-used-partition-v3.patch:
>
> + if (tempslot != NULL)
> + ExecClearTuple(tempslot);
>
> If tempslot and parent_slot point to the same slot, should ExecClearTuple() still be called ?
Yeah, we decided back in 1c9bb02d8ec that it's necessary to free the
slot if it's the same slot as a parent partition's
PartitionDispatch->tupslot ("freeing parent's copy of the tuple").
Maybe we don't need this parent-slot-clearing anymore due to code
restructuring over the last 3 years, but that will have to be a
separate patch.
I hope the attached updated patch makes it a bit more clear what's
going on. I refactored more of the code in ExecFindPartition() to
make this patch more a bit more readable.
--
Amit Langote
EDB: http://www.enterprisedb.com
On Thu, May 27, 2021 at 1:55 PM Zhihong Yu <zyu@yugabyte.com> wrote: > For CanUseSavedPartitionForTuple, nit: you can check !dispatch->savedPartResultInfo at the beginning and return early. > This would save some indentation. Sure, see the attached. -- Amit Langote EDB: http://www.enterprisedb.com
Attachment
On Thu, May 27, 2021 at 11:47 AM houzj.fnst@fujitsu.com <houzj.fnst@fujitsu.com> wrote: > About teaching relcache about caching the target partition. > > David-san suggested cache the partidx in PartitionDesc. > And it will need looping and checking the cached value at each level. > I was thinking can we cache a partidx list[1, 2 ,3], and then we can follow > the list to get the last partition and do the partition CHECK only for the last > partition. If any unexpected thing happen, we can return to the original table > and redo the tuple routing without using the cached index. > What do you think ? Where are you thinking to cache the partidx list? Inside PartitionDesc or some executor struct? -- Amit Langote EDB: http://www.enterprisedb.com
From: Amit Langote <amitlangote09@gmail.com> Sent: Thursday, May 27, 2021 1:54 PM > On Thu, May 27, 2021 at 11:47 AM houzj.fnst@fujitsu.com > <houzj.fnst@fujitsu.com> wrote: > > About teaching relcache about caching the target partition. > > > > David-san suggested cache the partidx in PartitionDesc. > > And it will need looping and checking the cached value at each level. > > I was thinking can we cache a partidx list[1, 2 ,3], and then we can > > follow the list to get the last partition and do the partition CHECK > > only for the last partition. If any unexpected thing happen, we can > > return to the original table and redo the tuple routing without using the > cached index. > > What do you think ? > > Where are you thinking to cache the partidx list? Inside PartitionDesc or some > executor struct? I was thinking cache the partidx list in PartitionDescData which is in relcache, if possible, we can use the cached partition between statements. Best regards, houzj
Hou-san, On Thu, May 27, 2021 at 3:56 PM houzj.fnst@fujitsu.com <houzj.fnst@fujitsu.com> wrote: > From: Amit Langote <amitlangote09@gmail.com> > Sent: Thursday, May 27, 2021 1:54 PM > > On Thu, May 27, 2021 at 11:47 AM houzj.fnst@fujitsu.com > > <houzj.fnst@fujitsu.com> wrote: > > > About teaching relcache about caching the target partition. > > > > > > David-san suggested cache the partidx in PartitionDesc. > > > And it will need looping and checking the cached value at each level. > > > I was thinking can we cache a partidx list[1, 2 ,3], and then we can > > > follow the list to get the last partition and do the partition CHECK > > > only for the last partition. If any unexpected thing happen, we can > > > return to the original table and redo the tuple routing without using the > > cached index. > > > What do you think ? > > > > Where are you thinking to cache the partidx list? Inside PartitionDesc or some > > executor struct? > > I was thinking cache the partidx list in PartitionDescData which is in relcache, if possible, we can > use the cached partition between statements. Ah, okay. I thought you were talking about a different idea. How and where would you determine that a cached partidx value is indeed the correct one for a given row? Anyway, do you want to try writing a patch to see how it might work? -- Amit Langote EDB: http://www.enterprisedb.com
Hi Amit-san From: Amit Langote <amitlangote09@gmail.com> Sent: Thursday, May 27, 2021 4:46 PM > Hou-san, > > On Thu, May 27, 2021 at 3:56 PM houzj.fnst@fujitsu.com > <houzj.fnst@fujitsu.com> wrote: > > From: Amit Langote <amitlangote09@gmail.com> > > Sent: Thursday, May 27, 2021 1:54 PM > > > On Thu, May 27, 2021 at 11:47 AM houzj.fnst@fujitsu.com > > > <houzj.fnst@fujitsu.com> wrote: > > > > About teaching relcache about caching the target partition. > > > > > > > > David-san suggested cache the partidx in PartitionDesc. > > > > And it will need looping and checking the cached value at each level. > > > > I was thinking can we cache a partidx list[1, 2 ,3], and then we > > > > can follow the list to get the last partition and do the partition > > > > CHECK only for the last partition. If any unexpected thing happen, > > > > we can return to the original table and redo the tuple routing > > > > without using the > > > cached index. > > > > What do you think ? > > > > > > Where are you thinking to cache the partidx list? Inside > > > PartitionDesc or some executor struct? > > > > I was thinking cache the partidx list in PartitionDescData which is in > > relcache, if possible, we can use the cached partition between statements. > Ah, okay. I thought you were talking about a different idea. > How and where would you determine that a cached partidx value is indeed the correct one for > a given row? > Anyway, do you want to try writing a patch to see how it might work? Yeah, the different idea here is to see if it is possible to share the cached partition info between statements efficiently. But, after some research, I found something not as expected: Currently, we tried to use ExecPartitionCheck to check the if the cached partition is the correct one. And if we want to share the cached partition between statements, we need to Invoke ExecPartitionCheck for single-row INSERT, but the first time ExecPartitionCheck call will need to build expression state tree for the partition. From some simple performance tests, the cost to build the state tree could be more than the cached partition saved which could bring performance degradation. So, If we want to share the cached partition between statements, we seems cannot use ExecPartitionCheck. Instead, I tried directly invoke the partition support function(partsupfunc) to check If the cached info is correct. In this approach I tried cache the *bound offset* in PartitionDescData, and we can use the bound offset to get the bound datum from PartitionBoundInfoData and invoke the partsupfunc to do the CHECK. Attach a POC patch about it. Just to share an idea about sharing cached partition info between statements. Best regards, houzj
Attachment
Hou-san, On Tue, Jun 1, 2021 at 5:43 PM houzj.fnst@fujitsu.com <houzj.fnst@fujitsu.com> wrote: > From: Amit Langote <amitlangote09@gmail.com> > > > > Where are you thinking to cache the partidx list? Inside > > > > PartitionDesc or some executor struct? > > > > > > I was thinking cache the partidx list in PartitionDescData which is in > > > relcache, if possible, we can use the cached partition between statements. > > > > Ah, okay. I thought you were talking about a different idea. > > How and where would you determine that a cached partidx value is indeed the correct one for > > a given row? > > Anyway, do you want to try writing a patch to see how it might work? > > Yeah, the different idea here is to see if it is possible to share the cached > partition info between statements efficiently. > > But, after some research, I found something not as expected: Thanks for investigating this. > Currently, we tried to use ExecPartitionCheck to check the if the cached > partition is the correct one. And if we want to share the cached partition > between statements, we need to Invoke ExecPartitionCheck for single-row INSERT, > but the first time ExecPartitionCheck call will need to build expression state > tree for the partition. From some simple performance tests, the cost to build > the state tree could be more than the cached partition saved which could bring > performance degradation. Yeah, using the executor in the lower layer will defeat the whole point of caching in that layer. > So, If we want to share the cached partition between statements, we seems cannot > use ExecPartitionCheck. Instead, I tried directly invoke the partition support > function(partsupfunc) to check If the cached info is correct. In this approach I > tried cache the *bound offset* in PartitionDescData, and we can use the bound offset > to get the bound datum from PartitionBoundInfoData and invoke the partsupfunc > to do the CHECK. > > Attach a POC patch about it. Just to share an idea about sharing cached partition info > between statements. I have not looked at your patch yet, but yeah that's what I would imagine doing it. -- Amit Langote EDB: http://www.enterprisedb.com
On Thu, Jun 3, 2021 at 8:48 PM Amit Langote <amitlangote09@gmail.com> wrote: > On Tue, Jun 1, 2021 at 5:43 PM houzj.fnst@fujitsu.com > <houzj.fnst@fujitsu.com> wrote: > > So, If we want to share the cached partition between statements, we seems cannot > > use ExecPartitionCheck. Instead, I tried directly invoke the partition support > > function(partsupfunc) to check If the cached info is correct. In this approach I > > tried cache the *bound offset* in PartitionDescData, and we can use the bound offset > > to get the bound datum from PartitionBoundInfoData and invoke the partsupfunc > > to do the CHECK. > > > > Attach a POC patch about it. Just to share an idea about sharing cached partition info > > between statements. > > I have not looked at your patch yet, but yeah that's what I would > imagine doing it. Just read it and think it looks promising. On code, I wonder why not add the rechecking-cached-offset code directly in get_partiiton_for_tuple(), instead of adding a whole new function for that. Can you please check the attached revised version? -- Amit Langote EDB: http://www.enterprisedb.com
Attachment
On Fri, Jun 4, 2021 at 4:38 PM Amit Langote <amitlangote09@gmail.com> wrote: > On Thu, Jun 3, 2021 at 8:48 PM Amit Langote <amitlangote09@gmail.com> wrote: > > On Tue, Jun 1, 2021 at 5:43 PM houzj.fnst@fujitsu.com > > <houzj.fnst@fujitsu.com> wrote: > > > So, If we want to share the cached partition between statements, we seems cannot > > > use ExecPartitionCheck. Instead, I tried directly invoke the partition support > > > function(partsupfunc) to check If the cached info is correct. In this approach I > > > tried cache the *bound offset* in PartitionDescData, and we can use the bound offset > > > to get the bound datum from PartitionBoundInfoData and invoke the partsupfunc > > > to do the CHECK. > > > > > > Attach a POC patch about it. Just to share an idea about sharing cached partition info > > > between statements. > > > > I have not looked at your patch yet, but yeah that's what I would > > imagine doing it. > > Just read it and think it looks promising. > > On code, I wonder why not add the rechecking-cached-offset code > directly in get_partiiton_for_tuple(), instead of adding a whole new > function for that. Can you please check the attached revised version? Here's another, slightly more polished version of that. Also, I added a check_cached parameter to get_partition_for_tuple() to allow the caller to disable checking the cached version. -- Amit Langote EDB: http://www.enterprisedb.com
Attachment
On Fri, Jun 4, 2021 at 6:05 PM Amit Langote <amitlangote09@gmail.com> wrote: > On Fri, Jun 4, 2021 at 4:38 PM Amit Langote <amitlangote09@gmail.com> wrote: > > On Thu, Jun 3, 2021 at 8:48 PM Amit Langote <amitlangote09@gmail.com> wrote: > > > On Tue, Jun 1, 2021 at 5:43 PM houzj.fnst@fujitsu.com > > > <houzj.fnst@fujitsu.com> wrote: > > > > So, If we want to share the cached partition between statements, we seems cannot > > > > use ExecPartitionCheck. Instead, I tried directly invoke the partition support > > > > function(partsupfunc) to check If the cached info is correct. In this approach I > > > > tried cache the *bound offset* in PartitionDescData, and we can use the bound offset > > > > to get the bound datum from PartitionBoundInfoData and invoke the partsupfunc > > > > to do the CHECK. > > > > > > > > Attach a POC patch about it. Just to share an idea about sharing cached partition info > > > > between statements. > > > > > > I have not looked at your patch yet, but yeah that's what I would > > > imagine doing it. > > > > Just read it and think it looks promising. > > > > On code, I wonder why not add the rechecking-cached-offset code > > directly in get_partiiton_for_tuple(), instead of adding a whole new > > function for that. Can you please check the attached revised version? I should have clarified a bit more on why I think a new function looked unnecessary to me. The thing about that function that bothered me was that it appeared to duplicate a lot of code fragments of get_partition_for_tuple(). That kind of duplication often leads to bugs of omission later if something from either function needs to change. -- Amit Langote EDB: http://www.enterprisedb.com
Hi Amit-san From: Amit Langote <amitlangote09@gmail.com> > On Fri, Jun 4, 2021 at 6:05 PM Amit Langote <amitlangote09@gmail.com> > wrote: > > On Fri, Jun 4, 2021 at 4:38 PM Amit Langote <amitlangote09@gmail.com> > wrote: > > > On Thu, Jun 3, 2021 at 8:48 PM Amit Langote <amitlangote09@gmail.com> > wrote: > > > > On Tue, Jun 1, 2021 at 5:43 PM houzj.fnst@fujitsu.com > > > > <houzj.fnst@fujitsu.com> wrote: > > > > > So, If we want to share the cached partition between statements, > > > > > we seems cannot use ExecPartitionCheck. Instead, I tried > > > > > directly invoke the partition support > > > > > function(partsupfunc) to check If the cached info is correct. In > > > > > this approach I tried cache the *bound offset* in > > > > > PartitionDescData, and we can use the bound offset to get the > > > > > bound datum from PartitionBoundInfoData and invoke the > partsupfunc to do the CHECK. > > > > > > > > > > Attach a POC patch about it. Just to share an idea about sharing > > > > > cached partition info between statements. > > > > > > > > I have not looked at your patch yet, but yeah that's what I would > > > > imagine doing it. > > > > > > Just read it and think it looks promising. > > > > > > On code, I wonder why not add the rechecking-cached-offset code > > > directly in get_partiiton_for_tuple(), instead of adding a whole new > > > function for that. Can you please check the attached revised version? > > I should have clarified a bit more on why I think a new function looked > unnecessary to me. The thing about that function that bothered me was that > it appeared to duplicate a lot of code fragments of get_partition_for_tuple(). > That kind of duplication often leads to bugs of omission later if something from > either function needs to change. Thanks for the patch and explanation, I think you are right that it’s better add the rechecking-cached-offset code directly in get_partiiton_for_tuple(). And now, I think maybe it's time to try to optimize the performance. Currently, if every row to be inserted in a statement belongs to different partition, then the cache check code will bring a slight performance degradation(AFAICS: 2% ~ 4%). So, If we want to solve this, then we may need 1) a reloption to let user control whether use the cache. Or, 2) introduce some simple strategy to control whether use cache automatically. I have not write a patch about 1) reloption, because I think it will be nice if we can enable this cache feature by default. So, I attached a WIP patch about approach 2). The rough idea is to check the average batch number every 1000 rows. If the average batch num is greater than 1, then we enable the cache check, if not, disable cache check. This is similar to what 0d5f05cde0 did. Thoughts ? Best regards, houzj
Attachment
Hou-san, On Mon, Jun 7, 2021 at 8:38 PM houzj.fnst@fujitsu.com <houzj.fnst@fujitsu.com> wrote: > Thanks for the patch and explanation, I think you are right that it’s better add > the rechecking-cached-offset code directly in get_partiiton_for_tuple(). > > And now, I think maybe it's time to try to optimize the performance. > Currently, if every row to be inserted in a statement belongs to different > partition, then the cache check code will bring a slight performance > degradation(AFAICS: 2% ~ 4%). > > So, If we want to solve this, then we may need 1) a reloption to let user control whether use the cache. > Or, 2) introduce some simple strategy to control whether use cache automatically. > > I have not write a patch about 1) reloption, because I think it will be nice if we can > enable this cache feature by default. So, I attached a WIP patch about approach 2). > > The rough idea is to check the average batch number every 1000 rows. > If the average batch num is greater than 1, then we enable the cache check, > if not, disable cache check. This is similar to what 0d5f05cde0 did. Thanks for sharing the idea and writing a patch for it. I considered a simpler heuristic where we enable/disable caching of a given offset if it is found by the binary search algorithm at least N consecutive times. But your idea to check the ratio of the number of tuples inserted over partition/bound offset changes every N tuples inserted may be more adaptive. Please find attached a revised version of your patch, where I tried to make it a bit easier to follow, hopefully. While doing so, I realized that caching the bound offset across queries makes little sense now, so I decided to keep the changes confined to execPartition.c. Do you have a counter-argument to that? -- Amit Langote EDB: http://www.enterprisedb.com
Attachment
On Wed, Jun 16, 2021 at 4:27 PM Amit Langote <amitlangote09@gmail.com> wrote: > On Mon, Jun 7, 2021 at 8:38 PM houzj.fnst@fujitsu.com > <houzj.fnst@fujitsu.com> wrote: > > The rough idea is to check the average batch number every 1000 rows. > > If the average batch num is greater than 1, then we enable the cache check, > > if not, disable cache check. This is similar to what 0d5f05cde0 did. > > Thanks for sharing the idea and writing a patch for it. > > I considered a simpler heuristic where we enable/disable caching of a > given offset if it is found by the binary search algorithm at least N > consecutive times. But your idea to check the ratio of the number of > tuples inserted over partition/bound offset changes every N tuples > inserted may be more adaptive. > > Please find attached a revised version of your patch, where I tried to > make it a bit easier to follow, hopefully. While doing so, I realized > that caching the bound offset across queries makes little sense now, > so I decided to keep the changes confined to execPartition.c. Do you > have a counter-argument to that? Attached a slightly revised version of that patch, with a commit message this time. -- Amit Langote EDB: http://www.enterprisedb.com
Attachment
On Wed, Jun 16, 2021 at 4:27 PM Amit Langote <amitlangote09@gmail.com> wrote:
> On Mon, Jun 7, 2021 at 8:38 PM houzj.fnst@fujitsu.com
> <houzj.fnst@fujitsu.com> wrote:
> > The rough idea is to check the average batch number every 1000 rows.
> > If the average batch num is greater than 1, then we enable the cache check,
> > if not, disable cache check. This is similar to what 0d5f05cde0 did.
>
> Thanks for sharing the idea and writing a patch for it.
>
> I considered a simpler heuristic where we enable/disable caching of a
> given offset if it is found by the binary search algorithm at least N
> consecutive times. But your idea to check the ratio of the number of
> tuples inserted over partition/bound offset changes every N tuples
> inserted may be more adaptive.
>
> Please find attached a revised version of your patch, where I tried to
> make it a bit easier to follow, hopefully. While doing so, I realized
> that caching the bound offset across queries makes little sense now,
> so I decided to keep the changes confined to execPartition.c. Do you
> have a counter-argument to that?
Attached a slightly revised version of that patch, with a commit
message this time.
--
Amit Langote
EDB: http://www.enterprisedb.com
+ {
Hi,
Thanks for reading the patch.
On Thu, Jun 17, 2021 at 1:46 PM Zhihong Yu <zyu@yugabyte.com> wrote:
> On Wed, Jun 16, 2021 at 9:29 PM Amit Langote <amitlangote09@gmail.com> wrote:
>> Attached a slightly revised version of that patch, with a commit
>> message this time.
>
> + int n_tups_inserted;
> + int n_offset_changed;
>
> Since tuples appear in plural, maybe offset should be as well: offsets.
I was hoping one would read that as "the number of times the offset
changed" while inserting "that many tuples", so the singular form
makes more sense to me.
Actually, I even considered naming the variable n_offsets_seen, in
which case the plural form makes sense, but I chose not to go with
that name.
> + part_index = get_cached_list_partition(pd, boundinfo, key,
> + values);
>
> nit:either put values on the same line, or align the 4 parameters on different lines.
Not sure pgindent requires us to follow that style, but I too prefer
the way you suggest. It does make the patch a bit longer though.
> + if (part_index < 0)
> + {
> + bound_offset = partition_range_datum_bsearch(key->partsupfunc,
>
> Do we need to check the value of equal before computing part_index ?
Just in case you didn't notice, this is not new code, but appears as a
diff hunk due to indenting.
As for whether the code should be checking 'equal', I don't think the
logic at this particular site should do that. Requiring 'equal' to be
true would mean that this code would only accept tuples that exactly
match the bound that partition_range_datum_bsearch() returned.
Updated patch attached. Aside from addressing your 2nd point, I fixed
a typo in a comment.
--
Amit Langote
EDB: http://www.enterprisedb.com
Attachment
Hi,
Thanks for reading the patch.
On Thu, Jun 17, 2021 at 1:46 PM Zhihong Yu <zyu@yugabyte.com> wrote:
> On Wed, Jun 16, 2021 at 9:29 PM Amit Langote <amitlangote09@gmail.com> wrote:
>> Attached a slightly revised version of that patch, with a commit
>> message this time.
>
> + int n_tups_inserted;
> + int n_offset_changed;
>
> Since tuples appear in plural, maybe offset should be as well: offsets.
I was hoping one would read that as "the number of times the offset
changed" while inserting "that many tuples", so the singular form
makes more sense to me.
Actually, I even considered naming the variable n_offsets_seen, in
which case the plural form makes sense, but I chose not to go with
that name.
> + part_index = get_cached_list_partition(pd, boundinfo, key,
> + values);
>
> nit:either put values on the same line, or align the 4 parameters on different lines.
Not sure pgindent requires us to follow that style, but I too prefer
the way you suggest. It does make the patch a bit longer though.
> + if (part_index < 0)
> + {
> + bound_offset = partition_range_datum_bsearch(key->partsupfunc,
>
> Do we need to check the value of equal before computing part_index ?
Just in case you didn't notice, this is not new code, but appears as a
diff hunk due to indenting.
As for whether the code should be checking 'equal', I don't think the
logic at this particular site should do that. Requiring 'equal' to be
true would mean that this code would only accept tuples that exactly
match the bound that partition_range_datum_bsearch() returned.
Updated patch attached. Aside from addressing your 2nd point, I fixed
a typo in a comment.
--
Amit Langote
EDB: http://www.enterprisedb.com
On Thu, Jun 17, 2021 at 4:18 PM Zhihong Yu <zyu@yugabyte.com> wrote:
> On Wed, Jun 16, 2021 at 10:37 PM Amit Langote <amitlangote09@gmail.com> wrote:
>> > + if (part_index < 0)
>> > + {
>> > + bound_offset = partition_range_datum_bsearch(key->partsupfunc,
>> >
>> > Do we need to check the value of equal before computing part_index ?
>>
>> Just in case you didn't notice, this is not new code, but appears as a
>> diff hunk due to indenting.
>>
>> As for whether the code should be checking 'equal', I don't think the
>> logic at this particular site should do that. Requiring 'equal' to be
>> true would mean that this code would only accept tuples that exactly
>> match the bound that partition_range_datum_bsearch() returned.
>
> Hi, Amit:
> Thanks for the quick response.
> w.r.t. the last point, since variable equal is defined within the case of PARTITION_STRATEGY_RANGE,
> I wonder if it can be named don_t_care or something like that.
> That way, it would be clearer to the reader that its value is purposefully not checked.
Normally, we write a comment in such cases, like
/* The value returned in 'equal' is ignored! */
Though I forgot to do that when I first wrote this code. :(
> It is fine to leave the variable as is since this was existing code.
Yeah, maybe there's not much to be gained by doing something about
that now, unless of course a committer insists that we do.
--
Amit Langote
EDB: http://www.enterprisedb.com
I noticed that there is no CF entry for this, so created one in the next CF: https://commitfest.postgresql.org/34/3270/ Rebased patch attached.
Attachment
There are a whole lot of different patches in this thread. However this last one https://commitfest.postgresql.org/37/3270/ created by Amit seems like a fairly straightforward optimization that can be evaluated on its own separately from the others and seems quite mature. I'm actually inclined to set it to "Ready for Committer". Incidentally a quick read-through of the patch myself and the only question I have is how the parameters of the adaptive algorithm were chosen. They seem ludicrously conservative to me and a bit of simple arguments about how expensive an extra check is versus the time saved in the boolean search should be easy enough to come up with to justify whatever values make sense.
Hi Greg, On Wed, Mar 16, 2022 at 6:54 AM Greg Stark <stark@mit.edu> wrote: > There are a whole lot of different patches in this thread. > > However this last one https://commitfest.postgresql.org/37/3270/ > created by Amit seems like a fairly straightforward optimization that > can be evaluated on its own separately from the others and seems quite > mature. I'm actually inclined to set it to "Ready for Committer". Thanks for taking a look at it. > Incidentally a quick read-through of the patch myself and the only > question I have is how the parameters of the adaptive algorithm were > chosen. They seem ludicrously conservative to me Do you think CACHE_BOUND_OFFSET_THRESHOLD_TUPS (1000) is too high? I suspect maybe you do. Basically, the way this works is that once set, cached_bound_offset is not reset until encountering a tuple for which cached_bound_offset doesn't give the correct partition, so the threshold doesn't matter when the caching is active. However, once reset, it is not again set till the threshold number of tuples have been processed and that too only if the binary searches done during that interval appear to have returned the same bound offset in succession a number of times. Maybe waiting a 1000 tuples to re-assess that is a bit too conservative, yes. I guess even as small a number as 10 is fine here? I've attached an updated version of the patch, though I haven't changed the threshold constant. -- Amit Langote EDB: http://www.enterprisedb.com On Wed, Mar 16, 2022 at 6:54 AM Greg Stark <stark@mit.edu> wrote: > > There are a whole lot of different patches in this thread. > > However this last one https://commitfest.postgresql.org/37/3270/ > created by Amit seems like a fairly straightforward optimization that > can be evaluated on its own separately from the others and seems quite > mature. I'm actually inclined to set it to "Ready for Committer". > > Incidentally a quick read-through of the patch myself and the only > question I have is how the parameters of the adaptive algorithm were > chosen. They seem ludicrously conservative to me and a bit of simple > arguments about how expensive an extra check is versus the time saved > in the boolean search should be easy enough to come up with to justify > whatever values make sense. -- Amit Langote EDB: http://www.enterprisedb.com
Attachment
Hi Greg,
On Wed, Mar 16, 2022 at 6:54 AM Greg Stark <stark@mit.edu> wrote:
> There are a whole lot of different patches in this thread.
>
> However this last one https://commitfest.postgresql.org/37/3270/
> created by Amit seems like a fairly straightforward optimization that
> can be evaluated on its own separately from the others and seems quite
> mature. I'm actually inclined to set it to "Ready for Committer".
Thanks for taking a look at it.
> Incidentally a quick read-through of the patch myself and the only
> question I have is how the parameters of the adaptive algorithm were
> chosen. They seem ludicrously conservative to me
Do you think CACHE_BOUND_OFFSET_THRESHOLD_TUPS (1000) is too high? I
suspect maybe you do.
Basically, the way this works is that once set, cached_bound_offset is
not reset until encountering a tuple for which cached_bound_offset
doesn't give the correct partition, so the threshold doesn't matter
when the caching is active. However, once reset, it is not again set
till the threshold number of tuples have been processed and that too
only if the binary searches done during that interval appear to have
returned the same bound offset in succession a number of times. Maybe
waiting a 1000 tuples to re-assess that is a bit too conservative,
yes. I guess even as small a number as 10 is fine here?
I've attached an updated version of the patch, though I haven't
changed the threshold constant.
--
Amit Langote
EDB: http://www.enterprisedb.com
On Wed, Mar 16, 2022 at 6:54 AM Greg Stark <stark@mit.edu> wrote:
>
> There are a whole lot of different patches in this thread.
>
> However this last one https://commitfest.postgresql.org/37/3270/
> created by Amit seems like a fairly straightforward optimization that
> can be evaluated on its own separately from the others and seems quite
> mature. I'm actually inclined to set it to "Ready for Committer".
>
> Incidentally a quick read-through of the patch myself and the only
> question I have is how the parameters of the adaptive algorithm were
> chosen. They seem ludicrously conservative to me and a bit of simple
> arguments about how expensive an extra check is versus the time saved
> in the boolean search should be easy enough to come up with to justify
> whatever values make sense.
On Thu, Mar 24, 2022 at 1:55 AM Zhihong Yu <zyu@yugabyte.com> wrote:
> On Wed, Mar 23, 2022 at 5:52 AM Amit Langote <amitlangote09@gmail.com> wrote:
>> I've attached an updated version of the patch, though I haven't
>> changed the threshold constant.
> + * Threshold of the number of tuples to need to have been processed before
> + * maybe_cache_partition_bound_offset() (re-)assesses whether caching must be
>
> The first part of the comment should be:
>
> Threshold of the number of tuples which need to have been processed
Sounds the same to me, so leaving it as it is.
> + (double) pd->n_tups_inserted / pd->n_offset_changed > 1)
>
> I think division can be avoided - the condition can be written as:
>
> pd->n_tups_inserted > pd->n_offset_changed
>
> + /* Check if the value is below the high bound */
>
> high bound -> upper bound
Both done, thanks.
In the attached updated patch, I've also lowered the threshold number
of tuples to wait before re-enabling caching from 1000 down to 10.
AFAICT, it only makes things better for the cases in which the
proposed caching is supposed to help, while not affecting the cases in
which caching might actually make things worse.
I've repeated the benchmark mentioned in [1]:
-- creates a range-partitioned table with 1000 partitions
create unlogged table foo (a int) partition by range (a);
select 'create unlogged table foo_' || i || ' partition of foo for
values from (' || (i-1)*100000+1 || ') to (' || i*100000+1 || ');'
from generate_series(1, 1000) i;
\gexec
-- generates a 100 million record file
copy (select generate_series(1, 100000000)) to '/tmp/100m.csv' csv;
HEAD:
postgres=# copy foo from '/tmp/100m.csv' csv; truncate foo;
COPY 100000000
Time: 39445.421 ms (00:39.445)
TRUNCATE TABLE
Time: 381.570 ms
postgres=# copy foo from '/tmp/100m.csv' csv; truncate foo;
COPY 100000000
Time: 38779.235 ms (00:38.779)
Patched:
postgres=# copy foo from '/tmp/100m.csv' csv; truncate foo;
COPY 100000000
Time: 33136.202 ms (00:33.136)
TRUNCATE TABLE
Time: 394.939 ms
postgres=# copy foo from '/tmp/100m.csv' csv; truncate foo;
COPY 100000000
Time: 33914.856 ms (00:33.915)
TRUNCATE TABLE
Time: 407.451 ms
So roughly, 38 seconds with HEAD vs. 33 seconds with the patch applied.
(Curiously, the numbers with both HEAD and patched look worse this
time around, because they were 31 seconds with HEAD vs. 26 seconds
with patched back in May 2021. Unless that's measurement noise, maybe
something to look into.)
--
Amit Langote
EDB: http://www.enterprisedb.com
[1] https://www.postgresql.org/message-id/CA%2BHiwqFbMSLDMinPRsGQVn_gfb-bMy0J2z_rZ0-b9kSfxXF%2BAg%40mail.gmail.com
Attachment
Is this a problem with the patch or its tests?
[18:14:20.798] # poll_query_until timed out executing this query:
[18:14:20.798] # SELECT count(1) = 0 FROM pg_subscription_rel WHERE
srsubstate NOT IN ('r', 's');
[18:14:20.798] # expecting this output:
[18:14:20.798] # t
[18:14:20.798] # last actual query output:
[18:14:20.798] # f
[18:14:20.798] # with stderr:
[18:14:20.798] # Tests were run but no plan was declared and
done_testing() was not seen.
[18:14:20.798] # Looks like your test exited with 60 just after 31.
[18:14:20.798] [18:12:21] t/013_partition.pl .................
[18:14:20.798] Dubious, test returned 60 (wstat 15360, 0x3c00)
...
[18:14:20.798] Test Summary Report
[18:14:20.798] -------------------
[18:14:20.798] t/013_partition.pl (Wstat: 15360 Tests: 31 Failed: 0)
[18:14:20.798] Non-zero exit status: 60
[18:14:20.798] Parse errors: No plan found in TAP output
[18:14:20.798] Files=32, Tests=328, 527 wallclock secs ( 0.16 usr 0.09
sys + 99.81 cusr 87.08 csys = 187.14 CPU)
[18:14:20.798] Result: FAIL
On Sun, Apr 3, 2022 at 10:31 PM Greg Stark <stark@mit.edu> wrote:
> Is this a problem with the patch or its tests?
>
> [18:14:20.798] # poll_query_until timed out executing this query:
> [18:14:20.798] # SELECT count(1) = 0 FROM pg_subscription_rel WHERE
> srsubstate NOT IN ('r', 's');
> [18:14:20.798] # expecting this output:
> [18:14:20.798] # t
> [18:14:20.798] # last actual query output:
> [18:14:20.798] # f
> [18:14:20.798] # with stderr:
> [18:14:20.798] # Tests were run but no plan was declared and
> done_testing() was not seen.
> [18:14:20.798] # Looks like your test exited with 60 just after 31.
> [18:14:20.798] [18:12:21] t/013_partition.pl .................
> [18:14:20.798] Dubious, test returned 60 (wstat 15360, 0x3c00)
> ...
> [18:14:20.798] Test Summary Report
> [18:14:20.798] -------------------
> [18:14:20.798] t/013_partition.pl (Wstat: 15360 Tests: 31 Failed: 0)
> [18:14:20.798] Non-zero exit status: 60
> [18:14:20.798] Parse errors: No plan found in TAP output
> [18:14:20.798] Files=32, Tests=328, 527 wallclock secs ( 0.16 usr 0.09
> sys + 99.81 cusr 87.08 csys = 187.14 CPU)
> [18:14:20.798] Result: FAIL
Hmm, make check-world passes for me after rebasing the patch (v10) to
the latest HEAD (clean), nor do I see a failure on cfbot:
http://cfbot.cputube.org/amit-langote.html
--
Amit Langote
EDB: http://www.enterprisedb.com
Amit Langote <amitlangote09@gmail.com> writes: > On Sun, Apr 3, 2022 at 10:31 PM Greg Stark <stark@mit.edu> wrote: >> Is this a problem with the patch or its tests? >> [18:14:20.798] Test Summary Report >> [18:14:20.798] ------------------- >> [18:14:20.798] t/013_partition.pl (Wstat: 15360 Tests: 31 Failed: 0) > Hmm, make check-world passes for me after rebasing the patch (v10) to > the latest HEAD (clean), nor do I see a failure on cfbot: > http://cfbot.cputube.org/amit-langote.html 013_partition.pl has been failing regularly in the buildfarm, most recently here: https://buildfarm.postgresql.org/cgi-bin/show_log.pl?nm=florican&dt=2022-03-31%2000%3A49%3A45 I don't think there's room to blame any uncommitted patches for that. Somebody broke it a short time before here: https://buildfarm.postgresql.org/cgi-bin/show_log.pl?nm=wrasse&dt=2022-03-17%2016%3A08%3A19 regards, tom lane
Hi, On 2022-04-06 00:07:07 -0400, Tom Lane wrote: > Amit Langote <amitlangote09@gmail.com> writes: > > On Sun, Apr 3, 2022 at 10:31 PM Greg Stark <stark@mit.edu> wrote: > >> Is this a problem with the patch or its tests? > >> [18:14:20.798] Test Summary Report > >> [18:14:20.798] ------------------- > >> [18:14:20.798] t/013_partition.pl (Wstat: 15360 Tests: 31 Failed: 0) > > > Hmm, make check-world passes for me after rebasing the patch (v10) to > > the latest HEAD (clean), nor do I see a failure on cfbot: > > http://cfbot.cputube.org/amit-langote.html > > 013_partition.pl has been failing regularly in the buildfarm, > most recently here: > > https://buildfarm.postgresql.org/cgi-bin/show_log.pl?nm=florican&dt=2022-03-31%2000%3A49%3A45 Just failed locally on my machine as well. > I don't think there's room to blame any uncommitted patches > for that. Somebody broke it a short time before here: > > https://buildfarm.postgresql.org/cgi-bin/show_log.pl?nm=wrasse&dt=2022-03-17%2016%3A08%3A19 The obvious thing to point a finger at is commit c91f71b9dc91ef95e1d50d6d782f477258374fc6 Author: Tomas Vondra <tomas.vondra@postgresql.org> Date: 2022-03-16 16:42:47 +0100 Fix publish_as_relid with multiple publications Greetings, Andres Freund
Hi, On Thu, Apr 7, 2022 at 4:37 PM Andres Freund <andres@anarazel.de> wrote: > > Hi, > > On 2022-04-06 00:07:07 -0400, Tom Lane wrote: > > Amit Langote <amitlangote09@gmail.com> writes: > > > On Sun, Apr 3, 2022 at 10:31 PM Greg Stark <stark@mit.edu> wrote: > > >> Is this a problem with the patch or its tests? > > >> [18:14:20.798] Test Summary Report > > >> [18:14:20.798] ------------------- > > >> [18:14:20.798] t/013_partition.pl (Wstat: 15360 Tests: 31 Failed: 0) > > > > > Hmm, make check-world passes for me after rebasing the patch (v10) to > > > the latest HEAD (clean), nor do I see a failure on cfbot: > > > http://cfbot.cputube.org/amit-langote.html > > > > 013_partition.pl has been failing regularly in the buildfarm, > > most recently here: > > > > https://buildfarm.postgresql.org/cgi-bin/show_log.pl?nm=florican&dt=2022-03-31%2000%3A49%3A45 > > Just failed locally on my machine as well. > > > > I don't think there's room to blame any uncommitted patches > > for that. Somebody broke it a short time before here: > > > > https://buildfarm.postgresql.org/cgi-bin/show_log.pl?nm=wrasse&dt=2022-03-17%2016%3A08%3A19 > > The obvious thing to point a finger at is > > commit c91f71b9dc91ef95e1d50d6d782f477258374fc6 > Author: Tomas Vondra <tomas.vondra@postgresql.org> > Date: 2022-03-16 16:42:47 +0100 > > Fix publish_as_relid with multiple publications > I've not managed to reproduce this issue on my machine but while reviewing the code and the server logs[1] I may have found possible bugs: 2022-04-08 12:59:30.701 EDT [91997:1] LOG: logical replication apply worker for subscription "sub2" has started 2022-04-08 12:59:30.702 EDT [91998:3] 013_partition.pl LOG: statement: ALTER SUBSCRIPTION sub2 SET PUBLICATION pub_lower_level, pub_all 2022-04-08 12:59:30.733 EDT [91998:4] 013_partition.pl LOG: disconnection: session time: 0:00:00.036 user=buildfarm database=postgres host=[local] 2022-04-08 12:59:30.740 EDT [92001:1] LOG: logical replication table synchronization worker for subscription "sub2", table "tab4_1" has started 2022-04-08 12:59:30.744 EDT [91997:2] LOG: logical replication apply worker for subscription "sub2" will restart because of a parameter change 2022-04-08 12:59:30.750 EDT [92003:1] LOG: logical replication table synchronization worker for subscription "sub2", table "tab3" has started The logs say that the apply worker for "sub2" finished whereas the tablesync workers for "tab4_1" and "tab3" started. After these logs, there are no logs that these tablesync workers finished and the apply worker for "sub2" restarted, until the timeout. While reviewing the code, I realized that the tablesync workers can advance its relstate even without the apply worker intervention. After a tablesync worker copies the table it sets SUBREL_STATE_SYNCWAIT to its relstate, then it waits for the apply worker to update the relstate to SUBREL_STATE_CATCHUP. If the apply worker has already died, it breaks from the wait loop and returns false: wait_for_worker_state_change(): for (;;) { LogicalRepWorker *worker; : /* * Bail out if the apply worker has died, else signal it we're * waiting. */ LWLockAcquire(LogicalRepWorkerLock, LW_SHARED); worker = logicalrep_worker_find(MyLogicalRepWorker->subid, InvalidOid, false); if (worker && worker->proc) logicalrep_worker_wakeup_ptr(worker); LWLockRelease(LogicalRepWorkerLock); if (!worker) break; : } return false; However, the caller doesn't check the return value at all: /* * We are done with the initial data synchronization, update the state. */ SpinLockAcquire(&MyLogicalRepWorker->relmutex); MyLogicalRepWorker->relstate = SUBREL_STATE_SYNCWAIT; MyLogicalRepWorker->relstate_lsn = *origin_startpos; SpinLockRelease(&MyLogicalRepWorker->relmutex); /* * Finally, wait until the main apply worker tells us to catch up and then * return to let LogicalRepApplyLoop do it. */ wait_for_worker_state_change(SUBREL_STATE_CATCHUP); return slotname; Therefore, the tablesync worker started logical replication while keeping its relstate as SUBREL_STATE_SYNCWAIT. Given the server logs, it's likely that both tablesync workers for "tab4_1" and "tab3" were in this situation. That is, there were two tablesync workers who were applying changes for the target relation but the relstate was SUBREL_STATE_SYNCWAIT. When it comes to starting the apply worker, probably it didn't happen since there are already running tablesync workers as much as max_sync_workers_per_subscription (2 by default): logicalrep_worker_launch(): /* * If we reached the sync worker limit per subscription, just exit * silently as we might get here because of an otherwise harmless race * condition. */ if (nsyncworkers >= max_sync_workers_per_subscription) { LWLockRelease(LogicalRepWorkerLock); return; } This scenario seems possible in principle but I've not managed to reproduce this issue so I might be wrong. Especially, according to the server logs, it seems like the tablesync workers were launched before the apply worker restarted due to parameter change and this is a common pattern among other failure logs. But I'm not sure how it could really happen. IIUC the apply worker always re-reads subscription (and exits if there is parameter change) and then requests to launch tablesync workers accordingly. Also, the fact that we don't check the return value of wiat_for_worker_state_change() is not a new thing; we have been living with this behavior since v10. So I'm not really sure why this problem appeared recently if my hypothesis is correct. Regards, [1] https://buildfarm.postgresql.org/cgi-bin/show_stage_log.pl?nm=grassquit&dt=2022-04-08%2014%3A13%3A27&stg=subscription-check -- Masahiko Sawada EDB: https://www.enterprisedb.com/
On Tue, Apr 12, 2022 at 6:16 AM Masahiko Sawada <sawada.mshk@gmail.com> wrote: > > Hi, > > On Thu, Apr 7, 2022 at 4:37 PM Andres Freund <andres@anarazel.de> wrote: > > > > Hi, > > > > On 2022-04-06 00:07:07 -0400, Tom Lane wrote: > > > Amit Langote <amitlangote09@gmail.com> writes: > > > > On Sun, Apr 3, 2022 at 10:31 PM Greg Stark <stark@mit.edu> wrote: > > > >> Is this a problem with the patch or its tests? > > > >> [18:14:20.798] Test Summary Report > > > >> [18:14:20.798] ------------------- > > > >> [18:14:20.798] t/013_partition.pl (Wstat: 15360 Tests: 31 Failed: 0) > > > > > > > Hmm, make check-world passes for me after rebasing the patch (v10) to > > > > the latest HEAD (clean), nor do I see a failure on cfbot: > > > > http://cfbot.cputube.org/amit-langote.html > > > > > > 013_partition.pl has been failing regularly in the buildfarm, > > > most recently here: > > > > > > https://buildfarm.postgresql.org/cgi-bin/show_log.pl?nm=florican&dt=2022-03-31%2000%3A49%3A45 > > > > Just failed locally on my machine as well. > > > > > > > I don't think there's room to blame any uncommitted patches > > > for that. Somebody broke it a short time before here: > > > > > > https://buildfarm.postgresql.org/cgi-bin/show_log.pl?nm=wrasse&dt=2022-03-17%2016%3A08%3A19 > > > > The obvious thing to point a finger at is > > > > commit c91f71b9dc91ef95e1d50d6d782f477258374fc6 > > Author: Tomas Vondra <tomas.vondra@postgresql.org> > > Date: 2022-03-16 16:42:47 +0100 > > > > Fix publish_as_relid with multiple publications > > > > I've not managed to reproduce this issue on my machine but while > reviewing the code and the server logs[1] I may have found possible > bugs: > > 2022-04-08 12:59:30.701 EDT [91997:1] LOG: logical replication apply > worker for subscription "sub2" has started > 2022-04-08 12:59:30.702 EDT [91998:3] 013_partition.pl LOG: > statement: ALTER SUBSCRIPTION sub2 SET PUBLICATION pub_lower_level, > pub_all > 2022-04-08 12:59:30.733 EDT [91998:4] 013_partition.pl LOG: > disconnection: session time: 0:00:00.036 user=buildfarm > database=postgres host=[local] > 2022-04-08 12:59:30.740 EDT [92001:1] LOG: logical replication table > synchronization worker for subscription "sub2", table "tab4_1" has > started > 2022-04-08 12:59:30.744 EDT [91997:2] LOG: logical replication apply > worker for subscription "sub2" will restart because of a parameter > change > 2022-04-08 12:59:30.750 EDT [92003:1] LOG: logical replication table > synchronization worker for subscription "sub2", table "tab3" has > started > > The logs say that the apply worker for "sub2" finished whereas the > tablesync workers for "tab4_1" and "tab3" started. After these logs, > there are no logs that these tablesync workers finished and the apply > worker for "sub2" restarted, until the timeout. While reviewing the > code, I realized that the tablesync workers can advance its relstate > even without the apply worker intervention. > > After a tablesync worker copies the table it sets > SUBREL_STATE_SYNCWAIT to its relstate, then it waits for the apply > worker to update the relstate to SUBREL_STATE_CATCHUP. If the apply > worker has already died, it breaks from the wait loop and returns > false: > > wait_for_worker_state_change(): > > for (;;) > { > LogicalRepWorker *worker; > > : > > /* > * Bail out if the apply worker has died, else signal it we're > * waiting. > */ > LWLockAcquire(LogicalRepWorkerLock, LW_SHARED); > worker = logicalrep_worker_find(MyLogicalRepWorker->subid, > InvalidOid, false); > if (worker && worker->proc) > logicalrep_worker_wakeup_ptr(worker); > LWLockRelease(LogicalRepWorkerLock); > if (!worker) > break; > > : > } > > return false; > > However, the caller doesn't check the return value at all: > > /* > * We are done with the initial data synchronization, update the state. > */ > SpinLockAcquire(&MyLogicalRepWorker->relmutex); > MyLogicalRepWorker->relstate = SUBREL_STATE_SYNCWAIT; > MyLogicalRepWorker->relstate_lsn = *origin_startpos; > SpinLockRelease(&MyLogicalRepWorker->relmutex); > > /* > * Finally, wait until the main apply worker tells us to catch up and then > * return to let LogicalRepApplyLoop do it. > */ > wait_for_worker_state_change(SUBREL_STATE_CATCHUP); > return slotname; > > Therefore, the tablesync worker started logical replication while > keeping its relstate as SUBREL_STATE_SYNCWAIT. > > Given the server logs, it's likely that both tablesync workers for > "tab4_1" and "tab3" were in this situation. That is, there were two > tablesync workers who were applying changes for the target relation > but the relstate was SUBREL_STATE_SYNCWAIT. > > When it comes to starting the apply worker, probably it didn't happen > since there are already running tablesync workers as much as > max_sync_workers_per_subscription (2 by default): > > logicalrep_worker_launch(): > > /* > * If we reached the sync worker limit per subscription, just exit > * silently as we might get here because of an otherwise harmless race > * condition. > */ > if (nsyncworkers >= max_sync_workers_per_subscription) > { > LWLockRelease(LogicalRepWorkerLock); > return; > } > > This scenario seems possible in principle but I've not managed to > reproduce this issue so I might be wrong. > This is exactly the same analysis I have done in the original thread where that patch was committed. I have found some crude ways to reproduce it with a different test as well. See emails [1][2][3]. > Especially, according to the > server logs, it seems like the tablesync workers were launched before > the apply worker restarted due to parameter change and this is a > common pattern among other failure logs. But I'm not sure how it could > really happen. IIUC the apply worker always re-reads subscription (and > exits if there is parameter change) and then requests to launch > tablesync workers accordingly. > Is there any rule/documentation which ensures that we must re-read the subscription parameter change before trying to launch sync workers? Actually, it would be better if we discuss this problem on another thread [1] to avoid hijacking this thread. So, it would be good if you respond there with your thoughts. Thanks for looking into this. [1] - https://www.postgresql.org/message-id/CAA4eK1LpBFU49Ohbnk%3Ddv_v9YP%2BKqh1%2BSf8i%2B%2B_s-QhD1Gy4Qw%40mail.gmail.com [2] - https://www.postgresql.org/message-id/CAA4eK1JzzoE61CY1qi9Vcdi742JFwG4YA3XpoMHwfKNhbFic6g%40mail.gmail.com [3] - https://www.postgresql.org/message-id/CAA4eK1JcQRQw0G-U4A%2BvaGaBWSvggYMMDJH4eDtJ0Yf2eUYXyA%40mail.gmail.com -- With Regards, Amit Kapila.
On Wed, Apr 13, 2022 at 2:39 PM Amit Kapila <amit.kapila16@gmail.com> wrote: > > On Tue, Apr 12, 2022 at 6:16 AM Masahiko Sawada <sawada.mshk@gmail.com> wrote: > > > > Hi, > > > > On Thu, Apr 7, 2022 at 4:37 PM Andres Freund <andres@anarazel.de> wrote: > > > > > > Hi, > > > > > > On 2022-04-06 00:07:07 -0400, Tom Lane wrote: > > > > Amit Langote <amitlangote09@gmail.com> writes: > > > > > On Sun, Apr 3, 2022 at 10:31 PM Greg Stark <stark@mit.edu> wrote: > > > > >> Is this a problem with the patch or its tests? > > > > >> [18:14:20.798] Test Summary Report > > > > >> [18:14:20.798] ------------------- > > > > >> [18:14:20.798] t/013_partition.pl (Wstat: 15360 Tests: 31 Failed: 0) > > > > > > > > > Hmm, make check-world passes for me after rebasing the patch (v10) to > > > > > the latest HEAD (clean), nor do I see a failure on cfbot: > > > > > http://cfbot.cputube.org/amit-langote.html > > > > > > > > 013_partition.pl has been failing regularly in the buildfarm, > > > > most recently here: > > > > > > > > https://buildfarm.postgresql.org/cgi-bin/show_log.pl?nm=florican&dt=2022-03-31%2000%3A49%3A45 > > > > > > Just failed locally on my machine as well. > > > > > > > > > > I don't think there's room to blame any uncommitted patches > > > > for that. Somebody broke it a short time before here: > > > > > > > > https://buildfarm.postgresql.org/cgi-bin/show_log.pl?nm=wrasse&dt=2022-03-17%2016%3A08%3A19 > > > > > > The obvious thing to point a finger at is > > > > > > commit c91f71b9dc91ef95e1d50d6d782f477258374fc6 > > > Author: Tomas Vondra <tomas.vondra@postgresql.org> > > > Date: 2022-03-16 16:42:47 +0100 > > > > > > Fix publish_as_relid with multiple publications > > > > > > > I've not managed to reproduce this issue on my machine but while > > reviewing the code and the server logs[1] I may have found possible > > bugs: > > > > 2022-04-08 12:59:30.701 EDT [91997:1] LOG: logical replication apply > > worker for subscription "sub2" has started > > 2022-04-08 12:59:30.702 EDT [91998:3] 013_partition.pl LOG: > > statement: ALTER SUBSCRIPTION sub2 SET PUBLICATION pub_lower_level, > > pub_all > > 2022-04-08 12:59:30.733 EDT [91998:4] 013_partition.pl LOG: > > disconnection: session time: 0:00:00.036 user=buildfarm > > database=postgres host=[local] > > 2022-04-08 12:59:30.740 EDT [92001:1] LOG: logical replication table > > synchronization worker for subscription "sub2", table "tab4_1" has > > started > > 2022-04-08 12:59:30.744 EDT [91997:2] LOG: logical replication apply > > worker for subscription "sub2" will restart because of a parameter > > change > > 2022-04-08 12:59:30.750 EDT [92003:1] LOG: logical replication table > > synchronization worker for subscription "sub2", table "tab3" has > > started > > > > The logs say that the apply worker for "sub2" finished whereas the > > tablesync workers for "tab4_1" and "tab3" started. After these logs, > > there are no logs that these tablesync workers finished and the apply > > worker for "sub2" restarted, until the timeout. While reviewing the > > code, I realized that the tablesync workers can advance its relstate > > even without the apply worker intervention. > > > > After a tablesync worker copies the table it sets > > SUBREL_STATE_SYNCWAIT to its relstate, then it waits for the apply > > worker to update the relstate to SUBREL_STATE_CATCHUP. If the apply > > worker has already died, it breaks from the wait loop and returns > > false: > > > > wait_for_worker_state_change(): > > > > for (;;) > > { > > LogicalRepWorker *worker; > > > > : > > > > /* > > * Bail out if the apply worker has died, else signal it we're > > * waiting. > > */ > > LWLockAcquire(LogicalRepWorkerLock, LW_SHARED); > > worker = logicalrep_worker_find(MyLogicalRepWorker->subid, > > InvalidOid, false); > > if (worker && worker->proc) > > logicalrep_worker_wakeup_ptr(worker); > > LWLockRelease(LogicalRepWorkerLock); > > if (!worker) > > break; > > > > : > > } > > > > return false; > > > > However, the caller doesn't check the return value at all: > > > > /* > > * We are done with the initial data synchronization, update the state. > > */ > > SpinLockAcquire(&MyLogicalRepWorker->relmutex); > > MyLogicalRepWorker->relstate = SUBREL_STATE_SYNCWAIT; > > MyLogicalRepWorker->relstate_lsn = *origin_startpos; > > SpinLockRelease(&MyLogicalRepWorker->relmutex); > > > > /* > > * Finally, wait until the main apply worker tells us to catch up and then > > * return to let LogicalRepApplyLoop do it. > > */ > > wait_for_worker_state_change(SUBREL_STATE_CATCHUP); > > return slotname; > > > > Therefore, the tablesync worker started logical replication while > > keeping its relstate as SUBREL_STATE_SYNCWAIT. > > > > Given the server logs, it's likely that both tablesync workers for > > "tab4_1" and "tab3" were in this situation. That is, there were two > > tablesync workers who were applying changes for the target relation > > but the relstate was SUBREL_STATE_SYNCWAIT. > > > > When it comes to starting the apply worker, probably it didn't happen > > since there are already running tablesync workers as much as > > max_sync_workers_per_subscription (2 by default): > > > > logicalrep_worker_launch(): > > > > /* > > * If we reached the sync worker limit per subscription, just exit > > * silently as we might get here because of an otherwise harmless race > > * condition. > > */ > > if (nsyncworkers >= max_sync_workers_per_subscription) > > { > > LWLockRelease(LogicalRepWorkerLock); > > return; > > } > > > > This scenario seems possible in principle but I've not managed to > > reproduce this issue so I might be wrong. > > > > This is exactly the same analysis I have done in the original thread > where that patch was committed. I have found some crude ways to > reproduce it with a different test as well. See emails [1][2][3]. Great. I didn't realize there is a discussion there. > > > Especially, according to the > > server logs, it seems like the tablesync workers were launched before > > the apply worker restarted due to parameter change and this is a > > common pattern among other failure logs. But I'm not sure how it could > > really happen. IIUC the apply worker always re-reads subscription (and > > exits if there is parameter change) and then requests to launch > > tablesync workers accordingly. > > > > Is there any rule/documentation which ensures that we must re-read the > subscription parameter change before trying to launch sync workers? No, but as far as I read the code I could not find any path of that. > > Actually, it would be better if we discuss this problem on another > thread [1] to avoid hijacking this thread. So, it would be good if you > respond there with your thoughts. Thanks for looking into this. Agreed. I'll respond there. Regards, -- Masahiko Sawada EDB: https://www.enterprisedb.com/
I've spent some time looking at the v10 patch, and to be honest, I don't really like the look of it :( 1. I think we should be putting the cache fields in PartitionDescData rather than PartitionDispatch. Having them in PartitionDescData allows caching between statements. 2. The function name maybe_cache_partition_bound_offset() fills me with dread. It's very unconcise. I don't think anyone should ever use that word in a function or variable name. 3. I'm not really sure why there's a field named n_tups_inserted. That would lead me to believe that ExecFindPartition is only executed for INSERTs. UPDATEs need to know the partition too. 4. The fields you're adding to PartitionDispatch are very poorly documented. I'm not really sure what n_offset_changed means. Why can't you just keep track by recording the last used partition, the last index into the datum array, and then just a count of the number of times we've found the last used partition in a row? When the found partition does not match the last partition, just reset the counter and when the counter reaches the cache threshold, use the cache path. I've taken a go at rewriting this, from scratch, into what I think it should look like. I then looked at what I came up with and decided the logic for finding partitions should all be kept in a single function. That way there's much less chance of someone forgetting to update the double-checking logic during cache hits when they update the logic for finding partitions without the cache. The 0001 patch is my original attempt. I then rewrote it and came up with 0002 (applies on top of 0001). After writing a benchmark script, I noticed that the performance of 0002 was quite a bit worse than 0001. I noticed that the benchmark where the partition changes each time got much worse with 0002. I can only assume that's due to the increased code size, so I played around with likely() and unlikely() to see if I could use those to shift the code layout around in such a way to make 0002 faster. Surprisingly using likely() for the cache hit path make it faster. I'd have assumed it would be unlikely() that would work. cache_partition_bench.png shows the results. I tested with master @ a5f9f1b88. The "Amit" column is your v10 patch. copybench.sh is the script I used to run the benchmarks. This tries all 3 partitioning strategies and performs 2 COPY FROMs, one with the rows arriving in partition order and another where the next row always goes into a different partition. I'm expecting to see the "ordered" case get better for LIST and RANGE partitions and the "unordered" case not to get any slower. With all of the attached patches applied, it does seem like I've managed to slightly speed up all of the unordered cases slightly. This might be noise, but I did manage to remove some redundant code that needlessly checked if the HASH partitioned table had a DEFAULT partition, which it cannot. This may account for some of the increase in performance. I do need to stare at the patch a bit more before I'm confident that it's correct. I just wanted to share it before I go and do that. David
Attachment
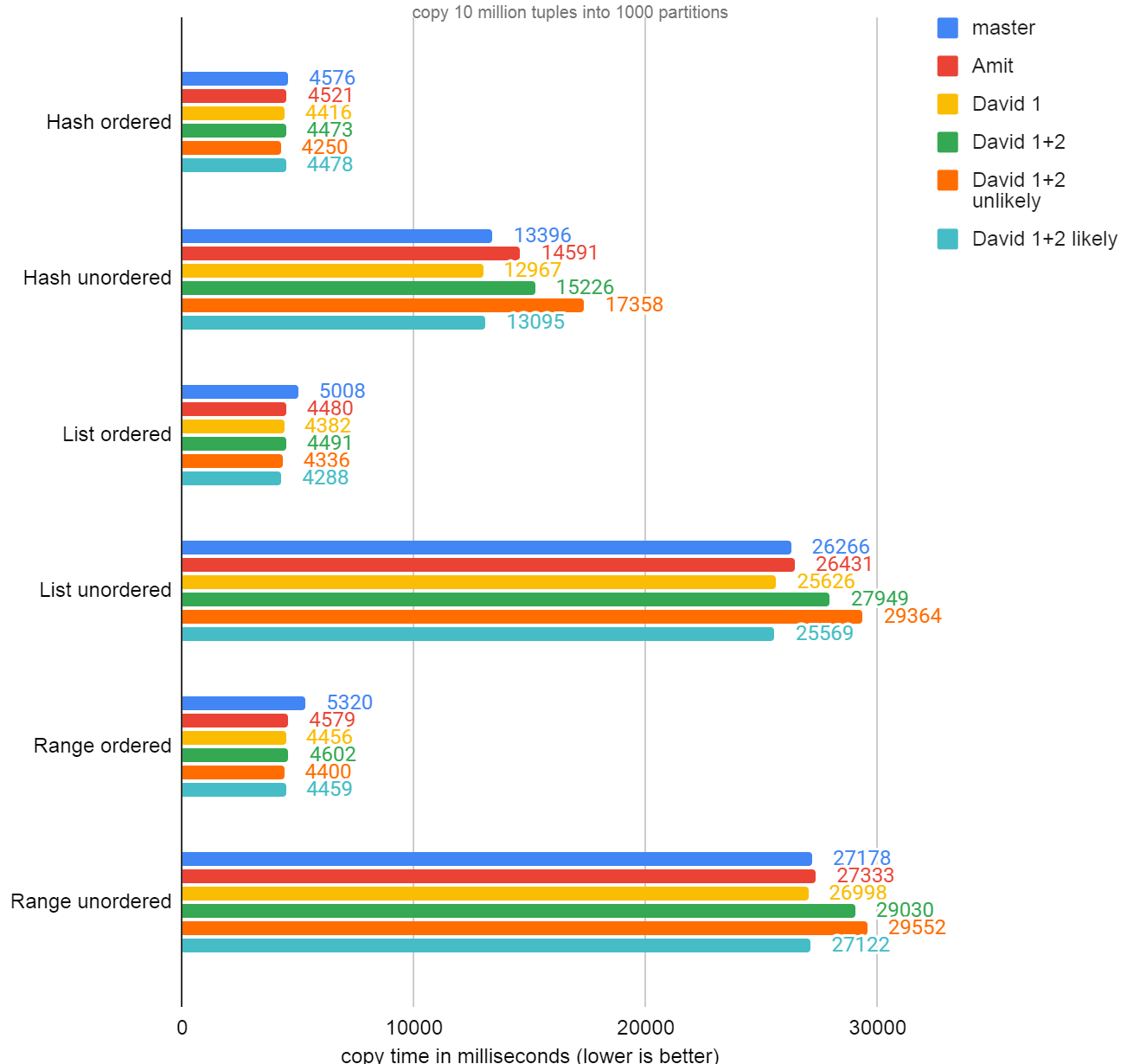{kind=link}
On Thu, Jul 14, 2022 at 2:31 PM David Rowley <dgrowleyml@gmail.com> wrote:
> I've spent some time looking at the v10 patch, and to be honest, I
> don't really like the look of it :(
Thanks for the review and sorry for the delay in replying.
> 1. I think we should be putting the cache fields in PartitionDescData
> rather than PartitionDispatch. Having them in PartitionDescData allows
> caching between statements.
Looking at your patch, yes, that makes sense. Initially, I didn't see
much point in having the ability to cache between (supposedly simple
OLTP) statements, because the tuple routing binary search is such a
minuscule portion of their execution, but now I agree why not.
> 2. The function name maybe_cache_partition_bound_offset() fills me
> with dread. It's very unconcise. I don't think anyone should ever use
> that word in a function or variable name.
Yeah, we can live without this one for sure as your patch
demonstrates, but to be fair, it's not like we don't have "maybe_"
used in variables and functions in arguably even trickier parts of our
code, like those you can find with `git grep maybe_`.
> 3. I'm not really sure why there's a field named n_tups_inserted.
> That would lead me to believe that ExecFindPartition is only executed
> for INSERTs. UPDATEs need to know the partition too.
Hmm, (cross-partition) UPDATEs internally use an INSERT that does
ExecFindPartition(). I don't see ExecUpdate() directly calling
ExecFindPartition(). Well, yes, apply_handle_tuple_routing() in a way
does, but apparently I didn't worry about that function.
> 4. The fields you're adding to PartitionDispatch are very poorly
> documented. I'm not really sure what n_offset_changed means.
My intention with that variable was to count the number of partition
switches that happened over the course of inserting N tuples. The
theory was that if the ratio of the number of partition switches and
the number of tuples inserted is too close to 1, the dataset being
loaded is not really in an order that'd benefit from caching. That
was an attempt to get some kind of adaptability to account for the
cases where the ordering in the dataset is not consistent, but it
seems like your approach is just as adaptive. And your code is much
simpler.
> Why
> can't you just keep track by recording the last used partition, the
> last index into the datum array, and then just a count of the number
> of times we've found the last used partition in a row? When the found
> partition does not match the last partition, just reset the counter
> and when the counter reaches the cache threshold, use the cache path.
Yeah, it makes sense and is easier to understand.
> I've taken a go at rewriting this, from scratch, into what I think it
> should look like. I then looked at what I came up with and decided
> the logic for finding partitions should all be kept in a single
> function. That way there's much less chance of someone forgetting to
> update the double-checking logic during cache hits when they update
> the logic for finding partitions without the cache.
>
> The 0001 patch is my original attempt. I then rewrote it and came up
> with 0002 (applies on top of 0001).
Thanks for these patches. I've been reading and can't really find
anything to complain about at a high level.
> After writing a benchmark script, I noticed that the performance of
> 0002 was quite a bit worse than 0001. I noticed that the benchmark
> where the partition changes each time got much worse with 0002. I can
> only assume that's due to the increased code size, so I played around
> with likely() and unlikely() to see if I could use those to shift the
> code layout around in such a way to make 0002 faster. Surprisingly
> using likely() for the cache hit path make it faster. I'd have assumed
> it would be unlikely() that would work.
Hmm, I too would think that unlikely() on that condition, not
likely(), would have helped the unordered case better.
> cache_partition_bench.png shows the results. I tested with master @
> a5f9f1b88. The "Amit" column is your v10 patch.
> copybench.sh is the script I used to run the benchmarks. This tries
> all 3 partitioning strategies and performs 2 COPY FROMs, one with the
> rows arriving in partition order and another where the next row always
> goes into a different partition. I'm expecting to see the "ordered"
> case get better for LIST and RANGE partitions and the "unordered" case
> not to get any slower.
>
> With all of the attached patches applied, it does seem like I've
> managed to slightly speed up all of the unordered cases slightly.
> This might be noise, but I did manage to remove some redundant code
> that needlessly checked if the HASH partitioned table had a DEFAULT
> partition, which it cannot. This may account for some of the increase
> in performance.
>
> I do need to stare at the patch a bit more before I'm confident that
> it's correct. I just wanted to share it before I go and do that.
The patch looks good to me. I thought some about whether the cache
fields in PartitionDesc may ever be "wrong". For example, the index
values becoming out-of-bound after partition DETACHes. Even though
there's some PartitionDesc-preserving cases in
RelationClearRelation(), I don't think that a preserved PartitionDesc
would ever contain a wrong value.
Here are some comments.
PartitionBoundInfo boundinfo; /* collection of partition bounds */
+ int last_found_datum_index; /* Index into the owning
+ * PartitionBoundInfo's datum array
+ * for the last found partition */
What does "owning PartitionBoundInfo's" mean? Maybe the "owning" is
unnecessary?
+ int last_found_part_index; /* Partition index of the last found
+ * partition or -1 if none have been
+ * found yet or if we've failed to
+ * find one */
-1 if none *has* been...?
+ int last_found_count; /* Number of times in a row have we found
+ * values to match the partition
Number of times in a row *that we have* found.
+ /*
+ * The Datum has changed. Zero the number of times we've
+ * found last_found_datum_index in a row.
+ */
+ partdesc->last_found_count = 0;
+ /* Zero the "winning streak" on the cache hit count */
+ partdesc->last_found_count = 0;
Might it be better for the two comments to say the same thing? Also,
I wonder which one do you intend as the resetting of last_found_count:
setting it to 0 or 1? I can see that the stanza at the end of the
function sets to 1 to start a new cycle.
+ /* Check if the value is equal to the lower bound */
+ cmpval = partition_rbound_datum_cmp(key->partsupfunc,
+ key->partcollation,
+ lastDatums,
+ kind,
+ values,
+ key->partnatts);
The function does not merely check for equality, so maybe better to
say the following instead:
Check if the value is >= the lower bound.
Perhaps, just like you've done in the LIST stanza even mention that
the lower bound is same as the last found one, like:
Check if the value >= the last found lower bound.
And likewise, change the nearby comment that says this:
+ /* Check if the value is below the upper bound */
to say:
Now check if the value is below the corresponding [to last found lower
bound] upper bound.
+ * No caching of partitions is done when the last found partition is th
the
+ * Calling this function can be quite expensive for LIST and RANGE partitioned
+ * tables have many partitions.
having many partitions
Many of the use cases for LIST and RANGE
+ * partitioned tables mean that the same partition is likely to be found in
mean -> are such that
we record the partition index we've found in the
+ * PartitionDesc
we record the partition index we've found *for given values* in the
PartitionDesc
--
Thanks, Amit Langote
EDB: http://www.enterprisedb.com
Thank for looking at this. On Sat, 23 Jul 2022 at 01:23, Amit Langote <amitlangote09@gmail.com> wrote: > + /* > + * The Datum has changed. Zero the number of times we've > + * found last_found_datum_index in a row. > + */ > + partdesc->last_found_count = 0; > > + /* Zero the "winning streak" on the cache hit count */ > + partdesc->last_found_count = 0; > > Might it be better for the two comments to say the same thing? Also, > I wonder which one do you intend as the resetting of last_found_count: > setting it to 0 or 1? I can see that the stanza at the end of the > function sets to 1 to start a new cycle. I think I've addressed all of your comments. The above one in particular caused me to make some larger changes. The reason I was zeroing the last_found_count in LIST partitioned tables when the Datum was not equal to the previous found Datum was due to the fact that the code at the end of the function was only checking the partition indexes matched rather than the bound_offset vs last_found_datum_index. The reason I wanted to zero this was that if you had a partition FOR VALUES IN(1,2), and you received rows with values alternating between 1 and 2 then we'd match to the same partition each time, however the equality test with the current 'values' and the Datum at last_found_datum_index would have been false each time. If we didn't zero the last_found_count we'd have kept using the cache path even though the Datum and last Datum wouldn't have been equal each time. That would have resulted in always doing the cache check and failing, then doing the binary search anyway. I've now changed the code so that instead of checking the last found partition is the same as the last one, I'm now checking if bound_offset is the same as last_found_datum_index. This will be false in the "values alternating between 1 and 2" case from above. This caused me to have to change how the caching works for LIST partitions with a NULL partition which is receiving NULL values. I've coded things now to just skip the cache for that case. Finding the correct LIST partition for a NULL value is cheap and no need to cache that. I've also moved all the code which updates the cache fields to the bottom of get_partition_for_tuple(). I'm only expecting to do that when bound_offset is set by the lookup code in the switch statement. Any paths, e.g. HASH partitioning lookup and LIST or RANGE with NULL values shouldn't reach the code which updates the partition fields. I've added an Assert(bound_offset >= 0) to ensure that stays true. There's probably a bit more to optimise here too, but not much. I don't think the partdesc->last_found_part_index = -1; is needed when we're in the code block that does return boundinfo->default_index; However, that only might very slightly speedup the case when we're inserting continuously into the DEFAULT partition. That code path is also used when we fail to find any matching partition. That's not one we need to worry about making go faster. I also ran the benchmarks again and saw that most of the use of likely() and unlikely() no longer did what I found them to do earlier. So the weirdness we saw there most likely was just down to random code layout changes. In this patch, I just dropped the use of either of those two macros. David
Attachment
Thank for looking at this.
On Sat, 23 Jul 2022 at 01:23, Amit Langote <amitlangote09@gmail.com> wrote:
> + /*
> + * The Datum has changed. Zero the number of times we've
> + * found last_found_datum_index in a row.
> + */
> + partdesc->last_found_count = 0;
>
> + /* Zero the "winning streak" on the cache hit count */
> + partdesc->last_found_count = 0;
>
> Might it be better for the two comments to say the same thing? Also,
> I wonder which one do you intend as the resetting of last_found_count:
> setting it to 0 or 1? I can see that the stanza at the end of the
> function sets to 1 to start a new cycle.
I think I've addressed all of your comments. The above one in
particular caused me to make some larger changes.
The reason I was zeroing the last_found_count in LIST partitioned
tables when the Datum was not equal to the previous found Datum was
due to the fact that the code at the end of the function was only
checking the partition indexes matched rather than the bound_offset vs
last_found_datum_index. The reason I wanted to zero this was that if
you had a partition FOR VALUES IN(1,2), and you received rows with
values alternating between 1 and 2 then we'd match to the same
partition each time, however the equality test with the current
'values' and the Datum at last_found_datum_index would have been false
each time. If we didn't zero the last_found_count we'd have kept
using the cache path even though the Datum and last Datum wouldn't
have been equal each time. That would have resulted in always doing
the cache check and failing, then doing the binary search anyway.
I've now changed the code so that instead of checking the last found
partition is the same as the last one, I'm now checking if
bound_offset is the same as last_found_datum_index. This will be
false in the "values alternating between 1 and 2" case from above.
This caused me to have to change how the caching works for LIST
partitions with a NULL partition which is receiving NULL values. I've
coded things now to just skip the cache for that case. Finding the
correct LIST partition for a NULL value is cheap and no need to cache
that. I've also moved all the code which updates the cache fields to
the bottom of get_partition_for_tuple(). I'm only expecting to do that
when bound_offset is set by the lookup code in the switch statement.
Any paths, e.g. HASH partitioning lookup and LIST or RANGE with NULL
values shouldn't reach the code which updates the partition fields.
I've added an Assert(bound_offset >= 0) to ensure that stays true.
There's probably a bit more to optimise here too, but not much. I
don't think the partdesc->last_found_part_index = -1; is needed when
we're in the code block that does return boundinfo->default_index;
However, that only might very slightly speedup the case when we're
inserting continuously into the DEFAULT partition. That code path is
also used when we fail to find any matching partition. That's not one
we need to worry about making go faster.
I also ran the benchmarks again and saw that most of the use of
likely() and unlikely() no longer did what I found them to do earlier.
So the weirdness we saw there most likely was just down to random code
layout changes. In this patch, I just dropped the use of either of
those two macros.
David
+
On Wed, Jul 27, 2022 at 7:28 AM David Rowley <dgrowleyml@gmail.com> wrote:
> On Sat, 23 Jul 2022 at 01:23, Amit Langote <amitlangote09@gmail.com> wrote:
> > + /*
> > + * The Datum has changed. Zero the number of times we've
> > + * found last_found_datum_index in a row.
> > + */
> > + partdesc->last_found_count = 0;
> >
> > + /* Zero the "winning streak" on the cache hit count */
> > + partdesc->last_found_count = 0;
> >
> > Might it be better for the two comments to say the same thing? Also,
> > I wonder which one do you intend as the resetting of last_found_count:
> > setting it to 0 or 1? I can see that the stanza at the end of the
> > function sets to 1 to start a new cycle.
>
> I think I've addressed all of your comments. The above one in
> particular caused me to make some larger changes.
>
> The reason I was zeroing the last_found_count in LIST partitioned
> tables when the Datum was not equal to the previous found Datum was
> due to the fact that the code at the end of the function was only
> checking the partition indexes matched rather than the bound_offset vs
> last_found_datum_index. The reason I wanted to zero this was that if
> you had a partition FOR VALUES IN(1,2), and you received rows with
> values alternating between 1 and 2 then we'd match to the same
> partition each time, however the equality test with the current
> 'values' and the Datum at last_found_datum_index would have been false
> each time. If we didn't zero the last_found_count we'd have kept
> using the cache path even though the Datum and last Datum wouldn't
> have been equal each time. That would have resulted in always doing
> the cache check and failing, then doing the binary search anyway.
Thanks for the explanation. So, in a way the caching scheme works for
LIST partitioning only if the same value appears consecutively in the
input set, whereas it does not for *a set of* values belonging to the
same partition appearing consecutively. Maybe that's a reasonable
restriction for now.
> I've now changed the code so that instead of checking the last found
> partition is the same as the last one, I'm now checking if
> bound_offset is the same as last_found_datum_index. This will be
> false in the "values alternating between 1 and 2" case from above.
> This caused me to have to change how the caching works for LIST
> partitions with a NULL partition which is receiving NULL values. I've
> coded things now to just skip the cache for that case. Finding the
> correct LIST partition for a NULL value is cheap and no need to cache
> that. I've also moved all the code which updates the cache fields to
> the bottom of get_partition_for_tuple(). I'm only expecting to do that
> when bound_offset is set by the lookup code in the switch statement.
> Any paths, e.g. HASH partitioning lookup and LIST or RANGE with NULL
> values shouldn't reach the code which updates the partition fields.
> I've added an Assert(bound_offset >= 0) to ensure that stays true.
Looks good.
> There's probably a bit more to optimise here too, but not much. I
> don't think the partdesc->last_found_part_index = -1; is needed when
> we're in the code block that does return boundinfo->default_index;
> However, that only might very slightly speedup the case when we're
> inserting continuously into the DEFAULT partition. That code path is
> also used when we fail to find any matching partition. That's not one
> we need to worry about making go faster.
So this is about:
if (part_index < 0)
- part_index = boundinfo->default_index;
+ {
+ /*
+ * Since we don't do caching for the default partition or failed
+ * lookups, we'll just wipe the cache fields back to their initial
+ * values. The count becomes 0 rather than 1 as 1 means it's the
+ * first time we've found a partition we're recording for the cache.
+ */
+ partdesc->last_found_datum_index = -1;
+ partdesc->last_found_part_index = -1;
+ partdesc->last_found_count = 0;
+
+ return boundinfo->default_index;
+ }
I wonder why not to leave the cache untouched in this case? It's
possible that erratic rows only rarely occur in the input sets.
> I also ran the benchmarks again and saw that most of the use of
> likely() and unlikely() no longer did what I found them to do earlier.
> So the weirdness we saw there most likely was just down to random code
> layout changes. In this patch, I just dropped the use of either of
> those two macros.
Ah, using either seems to be trying to fit the code one or the other
pattern in the input set anyway, so seems fine to keep them out for
now.
Some minor comments:
+ * The number of times the same partition must be found in a row before we
+ * switch from a search for the given values to just checking if the values
How about:
switch from using a binary search for the given values to...
Should the comment update above get_partition_for_tuple() mention
something like the cached path is basically O(1) and the non-cache
path O (log N) as I can see in comments in some other modules, like
pairingheap.c?
+ * so bump the count by one. If all goes well we'll eventually reach
Maybe a comma is needed after "well", because I got tricked into
thinking the "well" is duplicated.
+ * PARTITION_CACHED_FIND_THRESHOLD and we'll try the cache path next time
"we'll" sounds redundant with the one in the previous line.
+ * found yet, the last found was the DEFAULT partition, or there was no
Adding "if" to both sentence fragments might make this sound better.
--
Thanks, Amit Langote
EDB: http://www.enterprisedb.com
On Thu, 28 Jul 2022 at 00:50, Amit Langote <amitlangote09@gmail.com> wrote:
> So, in a way the caching scheme works for
> LIST partitioning only if the same value appears consecutively in the
> input set, whereas it does not for *a set of* values belonging to the
> same partition appearing consecutively. Maybe that's a reasonable
> restriction for now.
I'm not really seeing another cheap enough way of doing that. Any LIST
partition could allow any number of values. We've only space to record
1 of those values by way of recording which element in the
PartitionBound that it was located.
> if (part_index < 0)
> - part_index = boundinfo->default_index;
> + {
> + /*
> + * Since we don't do caching for the default partition or failed
> + * lookups, we'll just wipe the cache fields back to their initial
> + * values. The count becomes 0 rather than 1 as 1 means it's the
> + * first time we've found a partition we're recording for the cache.
> + */
> + partdesc->last_found_datum_index = -1;
> + partdesc->last_found_part_index = -1;
> + partdesc->last_found_count = 0;
> +
> + return boundinfo->default_index;
> + }
>
> I wonder why not to leave the cache untouched in this case? It's
> possible that erratic rows only rarely occur in the input sets.
I looked into that and I ended up just removing the code to reset the
cache. It now works similarly to a LIST partitioned table's NULL
partition.
> Should the comment update above get_partition_for_tuple() mention
> something like the cached path is basically O(1) and the non-cache
> path O (log N) as I can see in comments in some other modules, like
> pairingheap.c?
I adjusted for the other things you mentioned but I didn't add the big
O stuff. I thought the comment was clear enough.
I'd quite like to push this patch early next week, so if anyone else
is following along that might have any objections, could they do so
before then?
David
Attachment
On Thu, Jul 28, 2022 at 11:59 AM David Rowley <dgrowleyml@gmail.com> wrote:
> On Thu, 28 Jul 2022 at 00:50, Amit Langote <amitlangote09@gmail.com> wrote:
> > So, in a way the caching scheme works for
> > LIST partitioning only if the same value appears consecutively in the
> > input set, whereas it does not for *a set of* values belonging to the
> > same partition appearing consecutively. Maybe that's a reasonable
> > restriction for now.
>
> I'm not really seeing another cheap enough way of doing that. Any LIST
> partition could allow any number of values. We've only space to record
> 1 of those values by way of recording which element in the
> PartitionBound that it was located.
Yeah, no need to complicate the implementation for the LIST case.
> > if (part_index < 0)
> > - part_index = boundinfo->default_index;
> > + {
> > + /*
> > + * Since we don't do caching for the default partition or failed
> > + * lookups, we'll just wipe the cache fields back to their initial
> > + * values. The count becomes 0 rather than 1 as 1 means it's the
> > + * first time we've found a partition we're recording for the cache.
> > + */
> > + partdesc->last_found_datum_index = -1;
> > + partdesc->last_found_part_index = -1;
> > + partdesc->last_found_count = 0;
> > +
> > + return boundinfo->default_index;
> > + }
> >
> > I wonder why not to leave the cache untouched in this case? It's
> > possible that erratic rows only rarely occur in the input sets.
>
> I looked into that and I ended up just removing the code to reset the
> cache. It now works similarly to a LIST partitioned table's NULL
> partition.
+1
> > Should the comment update above get_partition_for_tuple() mention
> > something like the cached path is basically O(1) and the non-cache
> > path O (log N) as I can see in comments in some other modules, like
> > pairingheap.c?
>
> I adjusted for the other things you mentioned but I didn't add the big
> O stuff. I thought the comment was clear enough.
WFM.
> I'd quite like to push this patch early next week, so if anyone else
> is following along that might have any objections, could they do so
> before then?
I have no more comments.
--
Thanks, Amit Langote
EDB: http://www.enterprisedb.com
On Thursday, July 28, 2022 10:59 AM David Rowley <dgrowleyml@gmail.com> wrote:
> On Thu, 28 Jul 2022 at 00:50, Amit Langote <amitlangote09@gmail.com>
> wrote:
> > So, in a way the caching scheme works for LIST partitioning only if
> > the same value appears consecutively in the input set, whereas it does
> > not for *a set of* values belonging to the same partition appearing
> > consecutively. Maybe that's a reasonable restriction for now.
>
> I'm not really seeing another cheap enough way of doing that. Any LIST
> partition could allow any number of values. We've only space to record
> 1 of those values by way of recording which element in the PartitionBound that
> it was located.
>
> > if (part_index < 0)
> > - part_index = boundinfo->default_index;
> > + {
> > + /*
> > + * Since we don't do caching for the default partition or failed
> > + * lookups, we'll just wipe the cache fields back to their initial
> > + * values. The count becomes 0 rather than 1 as 1 means it's the
> > + * first time we've found a partition we're recording for the cache.
> > + */
> > + partdesc->last_found_datum_index = -1;
> > + partdesc->last_found_part_index = -1;
> > + partdesc->last_found_count = 0;
> > +
> > + return boundinfo->default_index;
> > + }
> >
> > I wonder why not to leave the cache untouched in this case? It's
> > possible that erratic rows only rarely occur in the input sets.
>
> I looked into that and I ended up just removing the code to reset the cache. It
> now works similarly to a LIST partitioned table's NULL partition.
>
> > Should the comment update above get_partition_for_tuple() mention
> > something like the cached path is basically O(1) and the non-cache
> > path O (log N) as I can see in comments in some other modules, like
> > pairingheap.c?
>
> I adjusted for the other things you mentioned but I didn't add the big O stuff. I
> thought the comment was clear enough.
>
> I'd quite like to push this patch early next week, so if anyone else is following
> along that might have any objections, could they do so before then?
Thanks for the patch. The patch looks good to me.
Only a minor nitpick:
+ /*
+ * For LIST partitioning, this is the number of times in a row that the
+ * the datum we're looking
It seems a duplicate 'the' word in this comment.
"the the datum".
Best regards,
Hou Zhijie
On Thu, 28 Jul 2022 at 19:37, Amit Langote <amitlangote09@gmail.com> wrote: > > On Thu, Jul 28, 2022 at 11:59 AM David Rowley <dgrowleyml@gmail.com> wrote: > > I'd quite like to push this patch early next week, so if anyone else > > is following along that might have any objections, could they do so > > before then? > > I have no more comments. Thank you both for the reviews. I've now pushed this. David
On Tue, Aug 2, 2022 at 6:58 AM David Rowley <dgrowleyml@gmail.com> wrote: > On Thu, 28 Jul 2022 at 19:37, Amit Langote <amitlangote09@gmail.com> wrote: > > > > On Thu, Jul 28, 2022 at 11:59 AM David Rowley <dgrowleyml@gmail.com> wrote: > > > > I'd quite like to push this patch early next week, so if anyone else > > > is following along that might have any objections, could they do so > > > before then? > > > > I have no more comments. > > Thank you both for the reviews. > > I've now pushed this. Thank you for working on this. -- Thanks, Amit Langote EDB: http://www.enterprisedb.com