Thread: Use simplehash.h instead of dynahash in SMgr
Hackers, Last year, when working on making compactify_tuples() go faster for 19c60ad69, I did quite a bit of benchmarking of the recovery process. The next thing that was slow after compactify_tuples() was the hash lookups done in smgropen(). Currently, we use dynahash hash tables to store the SMgrRelation so we can perform fast lookups by RelFileNodeBackend. However, I had in mind that a simplehash table might perform better. So I tried it... The attached converts the hash table lookups done in smgr.c to use simplehash instead of dynahash. This does require a few changes in simplehash.h to make it work. The reason being is that RelationData.rd_smgr points directly into the hash table entries. This works ok for dynahash as that hash table implementation does not do any reallocations of existing items or move any items around in the table, however, simplehash moves entries around all the time, so we can't point any pointers directly at the hash entries and expect them to be valid after adding or removing anything else from the table. To work around that, I've just made an additional type that serves as the hash entry type that has a pointer to the SMgrRelationData along with the hash status and hash value. It's just 16 bytes (or 12 on 32-bit machines). I opted to keep the hash key in the SMgrRelationData rather than duplicating it as it keeps the SMgrEntry struct nice and small. We only need to dereference the SMgrRelation pointer when we find an entry with the same hash value. The chances are quite good that an entry with the same hash value is the one that we want, so any additional dereferences to compare the key are not going to happen very often. I did experiment with putting the hash key in SMgrEntry and found it to be quite a bit slower. I also did try to use hash_bytes() but found building a hash function that uses murmurhash32 to be quite a bit faster. Benchmarking =========== I did some of that. It made my test case about 10% faster. The test case was basically inserting 100 million rows one at a time into a hash partitioned table with 1000 partitions and 2 int columns and a primary key on one of those columns. It was about 12GB of WAL. I used a hash partitioned table in the hope to create a fairly random-looking SMgr hash table access pattern. Hopefully something similar to what might happen in the real world. Over 10 runs of recovery, master took an average of 124.89 seconds. The patched version took 113.59 seconds. About 10% faster. I bumped shared_buffers up to 10GB, max_wal_size to 20GB and checkpoint_timeout to 60 mins. To make the benchmark more easily to repeat I patched with the attached recovery_panic.patch.txt. This just PANICs at the end of recovery so that the database shuts down before performing the end of recovery checkpoint. Just start the database up again to do another run. I did 10 runs. The end of recovery log message reported: master (aa271209f) CPU: user: 117.89 s, system: 5.70 s, elapsed: 123.65 s CPU: user: 117.81 s, system: 5.74 s, elapsed: 123.62 s CPU: user: 119.39 s, system: 5.75 s, elapsed: 125.20 s CPU: user: 117.98 s, system: 4.39 s, elapsed: 122.41 s CPU: user: 117.92 s, system: 4.79 s, elapsed: 122.76 s CPU: user: 119.84 s, system: 4.75 s, elapsed: 124.64 s CPU: user: 120.60 s, system: 5.82 s, elapsed: 126.49 s CPU: user: 118.74 s, system: 5.71 s, elapsed: 124.51 s CPU: user: 124.29 s, system: 6.79 s, elapsed: 131.14 s CPU: user: 118.73 s, system: 5.67 s, elapsed: 124.47 s master + v1 patch CPU: user: 106.90 s, system: 4.45 s, elapsed: 111.39 s CPU: user: 107.31 s, system: 5.98 s, elapsed: 113.35 s CPU: user: 107.14 s, system: 5.58 s, elapsed: 112.77 s CPU: user: 105.79 s, system: 5.64 s, elapsed: 111.48 s CPU: user: 105.78 s, system: 5.80 s, elapsed: 111.63 s CPU: user: 113.18 s, system: 6.21 s, elapsed: 119.45 s CPU: user: 107.74 s, system: 4.57 s, elapsed: 112.36 s CPU: user: 107.42 s, system: 4.62 s, elapsed: 112.09 s CPU: user: 106.54 s, system: 4.65 s, elapsed: 111.24 s CPU: user: 113.24 s, system: 6.86 s, elapsed: 120.16 s I wrote this patch a few days ago. I'm only posting it now as I know a couple of other people have expressed an interest in working on this. I didn't really want any duplicate efforts, so thought I'd better post it now before someone else goes and writes a similar patch. I'll park this here and have another look at it when the PG15 branch opens. David
Attachment
David Rowley писал 2021-04-24 18:58:
> Hackers,
>
> Last year, when working on making compactify_tuples() go faster for
> 19c60ad69, I did quite a bit of benchmarking of the recovery process.
> The next thing that was slow after compactify_tuples() was the hash
> lookups done in smgropen().
>
> Currently, we use dynahash hash tables to store the SMgrRelation so we
> can perform fast lookups by RelFileNodeBackend. However, I had in mind
> that a simplehash table might perform better. So I tried it...
>
> The attached converts the hash table lookups done in smgr.c to use
> simplehash instead of dynahash.
>
> This does require a few changes in simplehash.h to make it work. The
> reason being is that RelationData.rd_smgr points directly into the
> hash table entries. This works ok for dynahash as that hash table
> implementation does not do any reallocations of existing items or move
> any items around in the table, however, simplehash moves entries
> around all the time, so we can't point any pointers directly at the
> hash entries and expect them to be valid after adding or removing
> anything else from the table.
>
> To work around that, I've just made an additional type that serves as
> the hash entry type that has a pointer to the SMgrRelationData along
> with the hash status and hash value. It's just 16 bytes (or 12 on
> 32-bit machines). I opted to keep the hash key in the
> SMgrRelationData rather than duplicating it as it keeps the SMgrEntry
> struct nice and small. We only need to dereference the SMgrRelation
> pointer when we find an entry with the same hash value. The chances
> are quite good that an entry with the same hash value is the one that
> we want, so any additional dereferences to compare the key are not
> going to happen very often.
>
> I did experiment with putting the hash key in SMgrEntry and found it
> to be quite a bit slower. I also did try to use hash_bytes() but
> found building a hash function that uses murmurhash32 to be quite a
> bit faster.
>
> Benchmarking
> ===========
>
> I did some of that. It made my test case about 10% faster.
>
> The test case was basically inserting 100 million rows one at a time
> into a hash partitioned table with 1000 partitions and 2 int columns
> and a primary key on one of those columns. It was about 12GB of WAL. I
> used a hash partitioned table in the hope to create a fairly
> random-looking SMgr hash table access pattern. Hopefully something
> similar to what might happen in the real world.
>
> Over 10 runs of recovery, master took an average of 124.89 seconds.
> The patched version took 113.59 seconds. About 10% faster.
>
> I bumped shared_buffers up to 10GB, max_wal_size to 20GB and
> checkpoint_timeout to 60 mins.
>
> To make the benchmark more easily to repeat I patched with the
> attached recovery_panic.patch.txt. This just PANICs at the end of
> recovery so that the database shuts down before performing the end of
> recovery checkpoint. Just start the database up again to do another
> run.
>
> I did 10 runs. The end of recovery log message reported:
>
> master (aa271209f)
> CPU: user: 117.89 s, system: 5.70 s, elapsed: 123.65 s
> CPU: user: 117.81 s, system: 5.74 s, elapsed: 123.62 s
> CPU: user: 119.39 s, system: 5.75 s, elapsed: 125.20 s
> CPU: user: 117.98 s, system: 4.39 s, elapsed: 122.41 s
> CPU: user: 117.92 s, system: 4.79 s, elapsed: 122.76 s
> CPU: user: 119.84 s, system: 4.75 s, elapsed: 124.64 s
> CPU: user: 120.60 s, system: 5.82 s, elapsed: 126.49 s
> CPU: user: 118.74 s, system: 5.71 s, elapsed: 124.51 s
> CPU: user: 124.29 s, system: 6.79 s, elapsed: 131.14 s
> CPU: user: 118.73 s, system: 5.67 s, elapsed: 124.47 s
>
> master + v1 patch
> CPU: user: 106.90 s, system: 4.45 s, elapsed: 111.39 s
> CPU: user: 107.31 s, system: 5.98 s, elapsed: 113.35 s
> CPU: user: 107.14 s, system: 5.58 s, elapsed: 112.77 s
> CPU: user: 105.79 s, system: 5.64 s, elapsed: 111.48 s
> CPU: user: 105.78 s, system: 5.80 s, elapsed: 111.63 s
> CPU: user: 113.18 s, system: 6.21 s, elapsed: 119.45 s
> CPU: user: 107.74 s, system: 4.57 s, elapsed: 112.36 s
> CPU: user: 107.42 s, system: 4.62 s, elapsed: 112.09 s
> CPU: user: 106.54 s, system: 4.65 s, elapsed: 111.24 s
> CPU: user: 113.24 s, system: 6.86 s, elapsed: 120.16 s
>
> I wrote this patch a few days ago. I'm only posting it now as I know a
> couple of other people have expressed an interest in working on this.
> I didn't really want any duplicate efforts, so thought I'd better post
> it now before someone else goes and writes a similar patch.
>
> I'll park this here and have another look at it when the PG15 branch
> opens.
>
> David
Hi, David
It is quite interesting result. Simplehash being open-addressing with
linear probing is friendly for cpu cache. I'd recommend to define
SH_FILLFACTOR with value lower than default (0.9). I believe 0.75 is
suitable most for such kind of hash table.
> + /* rotate hashkey left 1 bit at each step */
> + hashkey = (hashkey << 1) | ((hashkey & 0x80000000) ? 1 : 0);
> + hashkey ^= murmurhash32((uint32) rnode->node.dbNode);
Why do you use so strange rotation expression? I know compillers are
able
to translage `h = (h << 1) | (h >> 31)` to single rotate instruction.
Do they recognize construction in your code as well?
Your construction looks more like "multiplate-modulo" operation in 32bit
Galois field . It is widely used operation in cryptographic, but it is
used modulo some primitive polynomial, and 0x100000001 is not such
polynomial. 0x1000000c5 is, therefore it should be:
hashkey = (hashkey << 1) | ((hashkey & 0x80000000) ? 0xc5 : 0);
or
hashkey = (hashkey << 1) | ((uint32)((int32)hashkey >> 31) & 0xc5);
But why don't just use hash_combine(uint32 a, uint32 b) instead (defined
in hashfn.h)? Yep, it could be a bit slower, but is it critical?
> - * smgrclose() -- Close and delete an SMgrRelation object.
> + * smgrclose() -- Close and delete an SMgrRelation object but don't
> + * remove from the SMgrRelationHash table.
I believe `smgrclose_internal()` should be in this comment.
Still I don't believe it worth to separate smgrclose_internal from
smgrclose. Is there measurable performance improvement from this
change? Even if there is, it will be lesser with SH_FILLFACTOR 0.75 .
As well I don't support modification simplehash.h for
SH_ENTRY_INITIALIZER,
SH_ENTRY_CLEANUP and SH_TRUNCATE. The initialization could comfortably
live in smgropen and the cleanup in smgrclose. And then SH_TRUNCATE
doesn't mean much.
Summary:
regards,
Yura Sokolov
Attachment
Thanks for having a look at this. "On Sun, 25 Apr 2021 at 10:27, Yura Sokolov <y.sokolov@postgrespro.ru> wrote: > > It is quite interesting result. Simplehash being open-addressing with > linear probing is friendly for cpu cache. I'd recommend to define > SH_FILLFACTOR with value lower than default (0.9). I believe 0.75 is > suitable most for such kind of hash table. You might be right there, although, with the particular benchmark I'm using the size of the table does not change as a result of that. I'd need to experiment with varying numbers of relations to see if dropping the fillfactor helps or hinders performance. FWIW, the hash stats at the end of recovery are: LOG: redo done at 3/C6E34F0 system usage: CPU: user: 107.00 s, system: 5.61 s, elapsed: 112.67 s LOG: size: 4096, members: 2032, filled: 0.496094, total chain: 997, max chain: 5, avg chain: 0.490650, total_collisions: 422, max_collisions: 3, avg_collisions: 0.207677 Perhaps if try using a number of relations somewhere between 2048 * 0.75 and 2048 * 0.9 then I might see some gains. Because I have 2032, the hash table grew up to 4096 buckets. I did a quick test dropping the fillfactor down to 0.4. The aim there was just to see if having 8192 buckets in this test would make it faster or slower LOG: redo done at 3/C6E34F0 system usage: CPU: user: 109.61 s, system: 4.28 s, elapsed: 113.93 s LOG: size: 8192, members: 2032, filled: 0.248047, total chain: 303, max chain: 2, avg chain: 0.149114, total_collisions: 209, max_collisions: 2, avg_collisions: 0.102854 it was slightly slower. I guess since the SMgrEntry is just 16 bytes wide that 4 of these will sit on each cache line which means there is a 75% chance that the next bucket over is on the same cache line. Since the average chain length is just 0.49 then we'll mostly just need to look at a single cache line to find the entry with the correct hash key. > > + /* rotate hashkey left 1 bit at each step */ > > + hashkey = (hashkey << 1) | ((hashkey & 0x80000000) ? 1 : 0); > > + hashkey ^= murmurhash32((uint32) rnode->node.dbNode); > > Why do you use so strange rotation expression? I know compillers are > able > to translage `h = (h << 1) | (h >> 31)` to single rotate instruction. > Do they recognize construction in your code as well? Not sure about all compilers, I only checked the earliest version of clang and gcc at godbolt.org and they both use a single "rol" instruction. https://godbolt.org/z/1GqdE6T3q > Your construction looks more like "multiplate-modulo" operation in 32bit > Galois field . It is widely used operation in cryptographic, but it is > used modulo some primitive polynomial, and 0x100000001 is not such > polynomial. 0x1000000c5 is, therefore it should be: > > hashkey = (hashkey << 1) | ((hashkey & 0x80000000) ? 0xc5 : 0); > or > hashkey = (hashkey << 1) | ((uint32)((int32)hashkey >> 31) & 0xc5); That does not really make sense to me. If you're shifting a 32-bit variable left 31 places then why would you AND with 0xc5? The only possible result is 1 or 0 depending on if the most significant bit is on or off. I see gcc and clang are unable to optimise that into an "rol" instruction. If I swap the "0xc5" for "1", then they're able to optimise the expression. > But why don't just use hash_combine(uint32 a, uint32 b) instead (defined > in hashfn.h)? Yep, it could be a bit slower, but is it critical? I had that function in the corner of my eye when writing this, but TBH, the hash function performance was just too big a factor to slow it down any further by using the more expensive hash_combine() function. I saw pretty good performance gains from writing my own hash function rather than using hash_bytes(). I didn't want to detract from that by using hash_combine(). Rotating the bits left 1 slot seems good enough for hash join and hash aggregate, so I don't have any reason to believe it's a bad way to combine the hash values. Do you? If you grep the source for "hashkey = (hashkey << 1) | ((hashkey & 0x80000000) ? 1 : 0);", then you'll see where else we do the same rotate left trick. > > - * smgrclose() -- Close and delete an SMgrRelation object. > > + * smgrclose() -- Close and delete an SMgrRelation object but don't > > + * remove from the SMgrRelationHash table. > > I believe `smgrclose_internal()` should be in this comment. Oops. Yeah, that's a mistake. > Still I don't believe it worth to separate smgrclose_internal from > smgrclose. Is there measurable performance improvement from this > change? Even if there is, it will be lesser with SH_FILLFACTOR 0.75 . The reason I did that is due to the fact that smgrcloseall() loops over the entire hash table and removes each entry one by one. The problem is that if I do a smgrtable_delete or smgrtable_delete_item in that loop then I'd need to restart the loop each time. Be aware that a simplehash delete can move entries earlier in the table, so it might cause us to miss entries during the loop. Restarting the loop each iteration is not going to be very efficient, so instead, I opted to make a version of smgrclose() that does not remove from the table so that I can just wipe out all table entries at the end of the loop. I called that smgrclose_internal(). Maybe there's a better name, but I don't really see any realistic way of not having some version that skips the hash table delete. I was hoping the 5 line comment I added to smgrcloseall() would explain the reason for the code being written way. An additional small benefit is that smgrclosenode() can get away with a single hashtable lookup rather than having to lookup the entry again with smgrtable_delete(). Using smgrtable_delete_item() deletes by bucket rather than key value which should be a good bit faster in many cases. I think the SH_ENTRY_CLEANUP macro is quite useful here as I don't need to worry about NULLing out the smgr_owner in yet another location where I do a hash delete. > As well I don't support modification simplehash.h for > SH_ENTRY_INITIALIZER, > SH_ENTRY_CLEANUP and SH_TRUNCATE. The initialization could comfortably > live in smgropen and the cleanup in smgrclose. And then SH_TRUNCATE > doesn't mean much. Can you share what you've got in mind here? The problem I'm solving with SH_ENTRY_INITIALIZER is the fact that in SH_INSERT_HASH_INTERNAL(), when we add a new item, we do entry->SH_KEY = key; to set the new entries key. Since I have SH_KEY defined as: #define SH_KEY data->smgr_rnode then I need some way to allocate the memory for ->data before the key is set. Doing that in smrgopen() is too late. We've already crashed by then for referencing uninitialised memory. I did try putting the key in SMgrEntry but found the performance to be quite a bit worse than keeping the SMgrEntry down to 16 bytes. That makes sense to me as we only need to compare the key when we find an entry with the same hash value as the one we're looking for. There's a pretty high chance of that being the entry we want. If I got my hash function right then the odds are about 1 in 4 billion of it not being the one we want. The only additional price we pay when we get two entries with the same hash value is an additional pointer dereference and a key comparison. David
David Rowley писал 2021-04-25 05:23: > Thanks for having a look at this. > > "On Sun, 25 Apr 2021 at 10:27, Yura Sokolov <y.sokolov@postgrespro.ru> > wrote: >> >> It is quite interesting result. Simplehash being open-addressing with >> linear probing is friendly for cpu cache. I'd recommend to define >> SH_FILLFACTOR with value lower than default (0.9). I believe 0.75 is >> suitable most for such kind of hash table. > > You might be right there, although, with the particular benchmark I'm > using the size of the table does not change as a result of that. I'd > need to experiment with varying numbers of relations to see if > dropping the fillfactor helps or hinders performance. > > FWIW, the hash stats at the end of recovery are: > > LOG: redo done at 3/C6E34F0 system usage: CPU: user: 107.00 s, > system: 5.61 s, elapsed: 112.67 s > LOG: size: 4096, members: 2032, filled: 0.496094, total chain: 997, > max chain: 5, avg chain: 0.490650, total_collisions: 422, > max_collisions: 3, avg_collisions: 0.207677 > > Perhaps if try using a number of relations somewhere between 2048 * > 0.75 and 2048 * 0.9 then I might see some gains. Because I have 2032, > the hash table grew up to 4096 buckets. > > I did a quick test dropping the fillfactor down to 0.4. The aim there > was just to see if having 8192 buckets in this test would make it > faster or slower > > LOG: redo done at 3/C6E34F0 system usage: CPU: user: 109.61 s, > system: 4.28 s, elapsed: 113.93 s > LOG: size: 8192, members: 2032, filled: 0.248047, total chain: 303, > max chain: 2, avg chain: 0.149114, total_collisions: 209, > max_collisions: 2, avg_collisions: 0.102854 > > it was slightly slower. Certainly. That is because in unmodified case you've got fillfactor 0.49 because table just grew. Below somewhat near 0.6 there is no gain in lower fillfactor. But if you test it when it closer to upper bound, you will notice difference. Try to test it with 3600 nodes, for example, if going down to 1800 nodes is not possible. >> > + /* rotate hashkey left 1 bit at each step */ >> > + hashkey = (hashkey << 1) | ((hashkey & 0x80000000) ? 1 : 0); >> > + hashkey ^= murmurhash32((uint32) rnode->node.dbNode); >> >> Why do you use so strange rotation expression? I know compillers are >> able >> to translage `h = (h << 1) | (h >> 31)` to single rotate instruction. >> Do they recognize construction in your code as well? > > Not sure about all compilers, I only checked the earliest version of > clang and gcc at godbolt.org and they both use a single "rol" > instruction. https://godbolt.org/z/1GqdE6T3q Yep, looks like all compilers recognize such construction with single exception of old icc compiler (both 13.0.1 and 16.0.3): https://godbolt.org/z/qsrjY5Eof and all compilers recognize `(h << 1) | (h >> 31)` well >> Your construction looks more like "multiplate-modulo" operation in >> 32bit >> Galois field . It is widely used operation in cryptographic, but it is >> used modulo some primitive polynomial, and 0x100000001 is not such >> polynomial. 0x1000000c5 is, therefore it should be: >> >> hashkey = (hashkey << 1) | ((hashkey & 0x80000000) ? 0xc5 : 0); >> or >> hashkey = (hashkey << 1) | ((uint32)((int32)hashkey >> 31) & >> 0xc5); > > That does not really make sense to me. If you're shifting a 32-bit > variable left 31 places then why would you AND with 0xc5? The only > possible result is 1 or 0 depending on if the most significant bit is > on or off. That is why there is cast to signed int before shifting: `(int32)hashkey >> 31`. Shift is then also signed ie arithmetic, and results are 0 or 0xffffffff. >> But why don't just use hash_combine(uint32 a, uint32 b) instead >> (defined >> in hashfn.h)? Yep, it could be a bit slower, but is it critical? > > I had that function in the corner of my eye when writing this, but > TBH, the hash function performance was just too big a factor to slow > it down any further by using the more expensive hash_combine() > function. I saw pretty good performance gains from writing my own hash > function rather than using hash_bytes(). I didn't want to detract from > that by using hash_combine(). Rotating the bits left 1 slot seems > good enough for hash join and hash aggregate, so I don't have any > reason to believe it's a bad way to combine the hash values. Do you? Well, if think a bit more, this hash values could be combined with using just addition: `hash(a) + hash(b) + hash(c)`. I thought more about consistency in a codebase. But looks like both ways (`hash_combine(a,b)` and `rotl(a,1)^b`) are used in a code. - hash_combine is in one time/three lines in hashTupleDesc at tupledesc.c - rotl+xor six times: -- three times/three lines in execGrouping.c with construction like yours -- three times in jsonb_util.c, multirangetypes.c and rangetypes.c with `(h << 1) | (h >> 31)`. Therefore I step down on recommendation in this place. Looks like it is possibility for micropatch to unify hash combining :-) > > If you grep the source for "hashkey = (hashkey << 1) | ((hashkey & > 0x80000000) ? 1 : 0);", then you'll see where else we do the same > rotate left trick. > >> > - * smgrclose() -- Close and delete an SMgrRelation object. >> > + * smgrclose() -- Close and delete an SMgrRelation object but don't >> > + * remove from the SMgrRelationHash table. >> >> I believe `smgrclose_internal()` should be in this comment. > > Oops. Yeah, that's a mistake. > >> Still I don't believe it worth to separate smgrclose_internal from >> smgrclose. Is there measurable performance improvement from this >> change? Even if there is, it will be lesser with SH_FILLFACTOR 0.75 . > > The reason I did that is due to the fact that smgrcloseall() loops > over the entire hash table and removes each entry one by one. The > problem is that if I do a smgrtable_delete or smgrtable_delete_item in > that loop then I'd need to restart the loop each time. Be aware that > a simplehash delete can move entries earlier in the table, so it might > cause us to miss entries during the loop. Restarting the loop each > iteration is not going to be very efficient, so instead, I opted to > make a version of smgrclose() that does not remove from the table so > that I can just wipe out all table entries at the end of the loop. I > called that smgrclose_internal(). If you read comments in SH_START_ITERATE, you'll see: * Search for the first empty element. As deletions during iterations are * supported, we want to start/end at an element that cannot be affected * by elements being shifted. * Iterate backwards, that allows the current element to be deleted, even * if there are backward shifts Therefore, it is safe to delete during iteration, and it doesn't lead nor require loop restart. > > An additional small benefit is that smgrclosenode() can get away with > a single hashtable lookup rather than having to lookup the entry again > with smgrtable_delete(). Using smgrtable_delete_item() deletes by > bucket rather than key value which should be a good bit faster in many > cases. I think the SH_ENTRY_CLEANUP macro is quite useful here as I > don't need to worry about NULLing out the smgr_owner in yet another > location where I do a hash delete. Doubtfully it makes sense since smgrclosenode is called only in LocalExecuteInvalidationMessage, ie when other backend drops some relation. There is no useful performance gain from it. > >> As well I don't support modification simplehash.h for >> SH_ENTRY_INITIALIZER, >> SH_ENTRY_CLEANUP and SH_TRUNCATE. The initialization could comfortably >> live in smgropen and the cleanup in smgrclose. And then SH_TRUNCATE >> doesn't mean much. > > Can you share what you've got in mind here? > > The problem I'm solving with SH_ENTRY_INITIALIZER is the fact that in > SH_INSERT_HASH_INTERNAL(), when we add a new item, we do entry->SH_KEY > = key; to set the new entries key. Since I have SH_KEY defined as: > > #define SH_KEY data->smgr_rnode > > then I need some way to allocate the memory for ->data before the key > is set. Doing that in smrgopen() is too late. We've already crashed by > then for referencing uninitialised memory. Oh, now I see. I could suggest work-around: - use entry->hash as a whole key value and manually resolve hash collision with chaining. But it looks ugly: use hash table and still manually resolve collisions. Therefore perhaps SH_ENTRY_INITIALIZER has sense. But SH_ENTRY_CLEANUP is abused in the patch: it is not symmetric to SH_ENTRY_INITIALIZER. It smells bad. `smgr_owner` is better cleaned in a way it is cleaned now in smgrclose because it is less obscure. And SH_ENTRY_CLEANUP should be just `pfree(a->data)`. And still no reason to have SH_TRUNCATE. > I did try putting the key in SMgrEntry but found the performance to be > quite a bit worse than keeping the SMgrEntry down to 16 bytes. That > makes sense to me as we only need to compare the key when we find an > entry with the same hash value as the one we're looking for. There's a > pretty high chance of that being the entry we want. If I got my hash > function right then the odds are about 1 in 4 billion of it not being > the one we want. The only additional price we pay when we get two > entries with the same hash value is an additional pointer dereference > and a key comparison. It has sense: whole benefit of simplehash is cache locality, and it is gained with smaller entry. regards, Yura Sokolov
On Sun, 25 Apr 2021 at 18:48, Yura Sokolov <y.sokolov@postgrespro.ru> wrote: > If you read comments in SH_START_ITERATE, you'll see: > > * Search for the first empty element. As deletions during iterations > are > * supported, we want to start/end at an element that cannot be > affected > * by elements being shifted. > > * Iterate backwards, that allows the current element to be deleted, > even > * if there are backward shifts > > Therefore, it is safe to delete during iteration, and it doesn't lead > nor > require loop restart. I had only skimmed that with a pre-loaded assumption that it wouldn't be safe. I didn't do a very good job of reading it as I failed to notice the lack of guarantees were about deleting items other than the current one. I didn't consider the option of finding a free bucket then looping backwards to avoid missing entries that are moved up during a delete. With that, I changed the patch to get rid of the SH_TRUNCATE and got rid of the smgrclose_internal which skips the hash delete. The code is much more similar to how it was now. In regards to the hashing stuff. I added a new function to pg_bitutils.h to rotate left and I'm using that instead of the other expression that was taken from nodeHash.c For the hash function, I've done some further benchmarking with: 1) The attached v2 patch 2) The attached + plus use_hash_combine.patch.txt which uses hash_combine() instead of pg_rotate_left32()ing the hashkey each time. 3) The attached v2 with use_hash_bytes.patch.txt applied. 4) Master I've also included the hash stats from each version of the hash function. I hope the numbers help indicate the reason I picked the hash function that I did. 1) v2 patch. CPU: user: 108.23 s, system: 6.97 s, elapsed: 115.63 s CPU: user: 114.78 s, system: 6.88 s, elapsed: 121.71 s CPU: user: 107.53 s, system: 5.70 s, elapsed: 113.28 s CPU: user: 108.43 s, system: 5.73 s, elapsed: 114.22 s CPU: user: 106.18 s, system: 5.73 s, elapsed: 111.96 s CPU: user: 108.04 s, system: 5.29 s, elapsed: 113.39 s CPU: user: 107.64 s, system: 5.64 s, elapsed: 113.34 s CPU: user: 106.64 s, system: 5.58 s, elapsed: 112.27 s CPU: user: 107.91 s, system: 5.40 s, elapsed: 113.36 s CPU: user: 115.35 s, system: 6.60 s, elapsed: 122.01 s Median = 113.375 s LOG: size: 4096, members: 2032, filled: 0.496094, total chain: 997, max chain: 5, avg chain: 0.490650, total_collisions: 422, max_collisions: 3, avg_collisions: 0.207677 2) v2 patch + use_hash_combine.patch.txt CPU: user: 113.22 s, system: 5.52 s, elapsed: 118.80 s CPU: user: 116.63 s, system: 5.87 s, elapsed: 122.56 s CPU: user: 115.33 s, system: 5.73 s, elapsed: 121.12 s CPU: user: 113.11 s, system: 5.61 s, elapsed: 118.78 s CPU: user: 112.56 s, system: 5.51 s, elapsed: 118.13 s CPU: user: 114.55 s, system: 5.80 s, elapsed: 120.40 s CPU: user: 121.79 s, system: 6.45 s, elapsed: 128.29 s CPU: user: 113.98 s, system: 4.50 s, elapsed: 118.52 s CPU: user: 113.24 s, system: 5.63 s, elapsed: 118.93 s CPU: user: 114.11 s, system: 5.60 s, elapsed: 119.78 s Median = 119.355 s LOG: size: 4096, members: 2032, filled: 0.496094, total chain: 971, max chain: 6, avg chain: 0.477854, total_collisions: 433, max_collisions: 4, avg_collisions: 0.213091 3) v2 patch + use_hash_bytes.patch.txt CPU: user: 120.87 s, system: 6.69 s, elapsed: 127.62 s CPU: user: 112.40 s, system: 4.68 s, elapsed: 117.14 s CPU: user: 113.19 s, system: 5.44 s, elapsed: 118.69 s CPU: user: 112.15 s, system: 4.73 s, elapsed: 116.93 s CPU: user: 111.10 s, system: 5.59 s, elapsed: 116.74 s CPU: user: 112.03 s, system: 5.74 s, elapsed: 117.82 s CPU: user: 113.69 s, system: 4.33 s, elapsed: 118.07 s CPU: user: 113.30 s, system: 4.19 s, elapsed: 117.55 s CPU: user: 112.77 s, system: 5.57 s, elapsed: 118.39 s CPU: user: 112.25 s, system: 4.59 s, elapsed: 116.88 s Median = 117.685 s LOG: size: 4096, members: 2032, filled: 0.496094, total chain: 900, max chain: 4, avg chain: 0.442913, total_collisions: 415, max_collisions: 4, avg_collisions: 0.204232 4) master CPU: user: 117.89 s, system: 5.7 s, elapsed: 123.65 s CPU: user: 117.81 s, system: 5.74 s, elapsed: 123.62 s CPU: user: 119.39 s, system: 5.75 s, elapsed: 125.2 s CPU: user: 117.98 s, system: 4.39 s, elapsed: 122.41 s CPU: user: 117.92 s, system: 4.79 s, elapsed: 122.76 s CPU: user: 119.84 s, system: 4.75 s, elapsed: 124.64 s CPU: user: 120.6 s, system: 5.82 s, elapsed: 126.49 s CPU: user: 118.74 s, system: 5.71 s, elapsed: 124.51 s CPU: user: 124.29 s, system: 6.79 s, elapsed: 131.14 s CPU: user: 118.73 s, system: 5.67 s, elapsed: 124.47 s Median = 124.49 s You can see that the bare v2 patch is quite a bit faster than any of the alternatives. We'd be better of with hash_bytes than using hash_combine() both for performance and for the seemingly better job the hash function does at reducing the hash collisions. David
Attachment
David Rowley писал 2021-04-25 16:36:
> On Sun, 25 Apr 2021 at 18:48, Yura Sokolov <y.sokolov@postgrespro.ru>
> wrote:
>> If you read comments in SH_START_ITERATE, you'll see:
>>
>> * Search for the first empty element. As deletions during
>> iterations
>> are
>> * supported, we want to start/end at an element that cannot be
>> affected
>> * by elements being shifted.
>>
>> * Iterate backwards, that allows the current element to be deleted,
>> even
>> * if there are backward shifts
>>
>> Therefore, it is safe to delete during iteration, and it doesn't lead
>> nor
>> require loop restart.
>
> I had only skimmed that with a pre-loaded assumption that it wouldn't
> be safe. I didn't do a very good job of reading it as I failed to
> notice the lack of guarantees were about deleting items other than the
> current one. I didn't consider the option of finding a free bucket
> then looping backwards to avoid missing entries that are moved up
> during a delete.
>
> With that, I changed the patch to get rid of the SH_TRUNCATE and got
> rid of the smgrclose_internal which skips the hash delete. The code
> is much more similar to how it was now.
>
> In regards to the hashing stuff. I added a new function to
> pg_bitutils.h to rotate left and I'm using that instead of the other
> expression that was taken from nodeHash.c
>
> For the hash function, I've done some further benchmarking with:
>
> 1) The attached v2 patch
> 2) The attached + plus use_hash_combine.patch.txt which uses
> hash_combine() instead of pg_rotate_left32()ing the hashkey each time.
> 3) The attached v2 with use_hash_bytes.patch.txt applied.
> 4) Master
>
> I've also included the hash stats from each version of the hash
> function.
>
> I hope the numbers help indicate the reason I picked the hash function
> that I did.
>
> 1) v2 patch.
> Median = 113.375 s
>
> LOG: size: 4096, members: 2032, filled: 0.496094, total chain: 997,
> max chain: 5, avg chain: 0.490650, total_collisions: 422,
> max_collisions: 3, avg_collisions: 0.207677
>
> 2) v2 patch + use_hash_combine.patch.txt
> Median = 119.355 s
>
> LOG: size: 4096, members: 2032, filled: 0.496094, total chain: 971,
> max chain: 6, avg chain: 0.477854, total_collisions: 433,
> max_collisions: 4, avg_collisions: 0.213091
>
> 3) v2 patch + use_hash_bytes.patch.txt
> Median = 117.685 s
>
> LOG: size: 4096, members: 2032, filled: 0.496094, total chain: 900,
> max chain: 4, avg chain: 0.442913, total_collisions: 415,
> max_collisions: 4, avg_collisions: 0.204232
>
> 4) master
> Median = 124.49 s
>
> You can see that the bare v2 patch is quite a bit faster than any of
> the alternatives. We'd be better of with hash_bytes than using
> hash_combine() both for performance and for the seemingly better job
> the hash function does at reducing the hash collisions.
>
> David
Looks much better! Simpler is almost always better.
Minor remarks:
Comment for SH_ENTRY_INITIALIZER e. May be like:
- SH_ENTRY_INITIALIZER(a) - if defined, this macro is called for new
entries
before key or hash is stored in. For example, it can be used to make
necessary memory allocations.
`pg_rotate_left32(x, 1) == pg_rotate_right(x, 31)`, therefore there's
no need to add `pg_rotate_left32` at all. More over, for hash combining
there's no much difference between `pg_rotate_left32(x, 1)` and
`pg_rotate_right(x, 1)`. (To be honestly, there is a bit of difference
due to murmur construction, but it should not be very big.)
If your test so sensitive to hash function speed, then I'd suggest
to try something even simpler:
static inline uint32
relfilenodebackend_hash(RelFileNodeBackend *rnode)
{
uint32 h = 0;
#define step(x) h ^= (uint32)(x) * 0x85ebca6b; h = pg_rotate_right(h,
11); h *= 9;
step(rnode->node.relNode);
step(rnode->node.spcNode); // spcNode could be different for same
relNode only
// during table movement. Does it pay
to hash it?
step(rnode->node.dbNode);
step(rnode->backend); // does it matter to hash backend?
// It equals to InvalidBackendId for
non-temporary relations
// and temporary relations in same
database never have same
// relNode (have they?).
return murmurhash32(hashkey);
}
I'd like to see benchmark code. It quite interesting this place became
measurable at all.
regards,
Yura Sokolov.
Attachment
On Mon, 26 Apr 2021 at 05:03, Yura Sokolov <y.sokolov@postgrespro.ru> wrote:
> If your test so sensitive to hash function speed, then I'd suggest
> to try something even simpler:
>
> static inline uint32
> relfilenodebackend_hash(RelFileNodeBackend *rnode)
> {
> uint32 h = 0;
> #define step(x) h ^= (uint32)(x) * 0x85ebca6b; h = pg_rotate_right(h,
> 11); h *= 9;
> step(rnode->node.relNode);
> step(rnode->node.spcNode); // spcNode could be different for same
> relNode only
> // during table movement. Does it pay
> to hash it?
> step(rnode->node.dbNode);
> step(rnode->backend); // does it matter to hash backend?
> // It equals to InvalidBackendId for
> non-temporary relations
> // and temporary relations in same
> database never have same
> // relNode (have they?).
> return murmurhash32(hashkey);
> }
I tried that and it got a median result of 113.795 seconds over 14
runs with this recovery benchmark test.
LOG: size: 4096, members: 2032, filled: 0.496094, total chain: 1014,
max chain: 6, avg chain: 0.499016, total_collisions: 428,
max_collisions: 3, avg_collisions: 0.210630
I also tried the following hash function just to see how much
performance might be left from speeding it up:
static inline uint32
relfilenodebackend_hash(RelFileNodeBackend *rnode)
{
uint32 h;
h = pg_rotate_right32((uint32) rnode->node.relNode, 16) ^ ((uint32)
rnode->node.dbNode);
return murmurhash32(h);
}
I got a median of 112.685 seconds over 14 runs with:
LOG: size: 4096, members: 2032, filled: 0.496094, total chain: 1044,
max chain: 7, avg chain: 0.513780, total_collisions: 438,
max_collisions: 3, avg_collisions: 0.215551
So it looks like there might not be too much left given that v2 was
113.375 seconds (median over 10 runs)
> I'd like to see benchmark code. It quite interesting this place became
> measurable at all.
Sure.
$ cat recoverybench_insert_hash.sh
#!/bin/bash
pg_ctl stop -D pgdata -m smart
pg_ctl start -D pgdata -l pg.log -w
psql -f setup1.sql postgres > /dev/null
psql -c "create table log_wal (lsn pg_lsn not null);" postgres > /dev/null
psql -c "insert into log_wal values(pg_current_wal_lsn());" postgres > /dev/null
psql -c "insert into hp select x,0 from generate_series(1,100000000)
x;" postgres > /dev/null
psql -c "insert into log_wal values(pg_current_wal_lsn());" postgres > /dev/null
psql -c "select 'Used ' ||
pg_size_pretty(pg_wal_lsn_diff(pg_current_wal_lsn(), lsn)) || ' of
WAL' from log_wal limit 1;" postgres
pg_ctl stop -D pgdata -m immediate -w
echo Starting Postgres...
pg_ctl start -D pgdata -l pg.log
$ cat setup1.sql
drop table if exists hp;
create table hp (a int primary key, b int not null) partition by hash(a);
select 'create table hp'||x|| ' partition of hp for values with
(modulus 1000, remainder '||x||');' from generate_Series(0,999) x;
\gexec
config:
shared_buffers = 10GB
checkpoint_timeout = 60min
max_wal_size = 20GB
min_wal_size = 20GB
For subsequent runs, if you apply the patch that does the PANIC at the
end of recovery, you'll just need to start the database up again to
perform recovery again. You can then just tail -f on your postgres
logs to watch for the "redo done" message which will show you the time
spent doing recovery.
David.
Hi,
On 2021-04-25 01:27:24 +0300, Yura Sokolov wrote:
> It is quite interesting result. Simplehash being open-addressing with
> linear probing is friendly for cpu cache. I'd recommend to define
> SH_FILLFACTOR with value lower than default (0.9). I believe 0.75 is
> suitable most for such kind of hash table.
It's not a "plain" linear probing hash table (although it is on the lookup
side). During insertions collisions are reordered so that the average distance
from the "optimal" position is ~even ("robin hood hashing"). That allows a
higher load factor than a plain linear probed hash table (for which IIRC
there's data to show 0.75 to be a good default load factor).
There of course may still be a benefit in lowering the load factor, but I'd
not start there.
David's test aren't really suited to benchmarking the load factor, but to me
the stats he showed didn't highlight a need to lower the load factor. Lowering
the fill factor does influence the cache hit ratio...
Greetings,
Andres Freund
Andres Freund писал 2021-04-26 21:46:
> Hi,
>
> On 2021-04-25 01:27:24 +0300, Yura Sokolov wrote:
>> It is quite interesting result. Simplehash being open-addressing with
>> linear probing is friendly for cpu cache. I'd recommend to define
>> SH_FILLFACTOR with value lower than default (0.9). I believe 0.75 is
>> suitable most for such kind of hash table.
>
> It's not a "plain" linear probing hash table (although it is on the
> lookup
> side). During insertions collisions are reordered so that the average
> distance
> from the "optimal" position is ~even ("robin hood hashing"). That
> allows a
> higher load factor than a plain linear probed hash table (for which
> IIRC
> there's data to show 0.75 to be a good default load factor).
Even for Robin Hood hashing 0.9 fill factor is too high. It leads to too
much movements on insertion/deletion and longer average collision chain.
Note that Robin Hood doesn't optimize average case. Indeed, usually
Robin Hood
has worse (longer) average collision chain than simple linear probing.
Robin Hood hashing optimizes worst case, ie it guarantees there is no
unnecessary
long collision chain.
See discussion on Rust hash table fill factor when it were Robin Hood:
https://github.com/rust-lang/rust/issues/38003
>
> There of course may still be a benefit in lowering the load factor, but
> I'd
> not start there.
>
> David's test aren't really suited to benchmarking the load factor, but
> to me
> the stats he showed didn't highlight a need to lower the load factor.
> Lowering
> the fill factor does influence the cache hit ratio...
>
> Greetings,
>
> Andres Freund
regards,
Yura.
Hi, On 2021-04-26 22:44:13 +0300, Yura Sokolov wrote: > Even for Robin Hood hashing 0.9 fill factor is too high. It leads to too > much movements on insertion/deletion and longer average collision chain. That's true for modification heavy cases - but most hash tables in PG, including the smgr one, are quite read heavy. For workloads where there's a lot of smgr activity, the other overheads in relation creation/drop handling are magnitudes more expensive than the collision handling. Note that simplehash.h also grows when the distance gets too big and when there are too many elements to move, not just based on the fill factor. I kinda wish we had a chained hashtable implementation with the same interface as simplehash. It's very use-case dependent which approach is better, and right now we might be forcing some users to choose linear probing because simplehash.h is still faster than dynahash, even though chaining would actually be more appropriate. > Note that Robin Hood doesn't optimize average case. Right. > See discussion on Rust hash table fill factor when it were Robin Hood: > https://github.com/rust-lang/rust/issues/38003 The first sentence actually confirms my point above, about it being a question of read vs write heavy. Greetings, Andres Freund
David Rowley писал 2021-04-26 09:43:
> I tried that and it got a median result of 113.795 seconds over 14
> runs with this recovery benchmark test.
>
> LOG: size: 4096, members: 2032, filled: 0.496094, total chain: 1014,
> max chain: 6, avg chain: 0.499016, total_collisions: 428,
> max_collisions: 3, avg_collisions: 0.210630
>
> I also tried the following hash function just to see how much
> performance might be left from speeding it up:
>
> static inline uint32
> relfilenodebackend_hash(RelFileNodeBackend *rnode)
> {
> uint32 h;
>
> h = pg_rotate_right32((uint32) rnode->node.relNode, 16) ^ ((uint32)
> rnode->node.dbNode);
> return murmurhash32(h);
> }
>
> I got a median of 112.685 seconds over 14 runs with:
>
> LOG: size: 4096, members: 2032, filled: 0.496094, total chain: 1044,
> max chain: 7, avg chain: 0.513780, total_collisions: 438,
> max_collisions: 3, avg_collisions: 0.215551
The best result is with just:
return (uint32)rnode->node.relNode;
ie, relNode could be taken without mixing at all.
relNode is unique inside single database, and almost unique among whole
cluster
since it is Oid.
>> I'd like to see benchmark code. It quite interesting this place became
>> measurable at all.
>
> Sure.
>
> $ cat recoverybench_insert_hash.sh
> ....
>
> David.
So, I've repeated benchmark with different number of partitons (I tried
to catch higher fillfactor) and less amount of inserted data (since I
don't
want to stress my SSD).
partitions/ | dynahash | dynahash + | simplehash | simplehash + |
fillfactor | | simple func | | simple func |
------------+----------+-------------+--------------+
3500/0.43 | 3.73s | 3.54s | 3.58s | 3.34s |
3200/0.78 | 3.64s | 3.46s | 3.47s | 3.25s |
1500/0.74 | 3.18s | 2.97s | 3.03s | 2.79s |
Fillfactor is effective fillfactor in simplehash with than number of
partitions.
I wasn't able to measure with fillfactor close to 0.9 since looks like
simplehash tends to grow much earlier due to SH_GROW_MAX_MOVE.
Simple function is hash function that returns only rnode->node.relNode.
I've test it both with simplehash and dynahash.
For dynahash also custom match function were made.
Conclusion:
- trivial hash function gives better results for both simplehash and
dynahash,
- simplehash improves performance for both complex and trivial hash
function,
- simplehash + trivial function perform best.
I'd like to hear other's people comments on trivial hash function. But
since
generation of relation's Oid are not subject of human interventions, I'd
recommend
to stick with trivial.
Since patch is simple, harmless and gives measurable improvement,
I think it is ready for commit fest.
regards,
Yura Sokolov.
Postgres Proffesional https://www.postgrespro.com
PS. David, please send patch once again since my mail client reattached
files in
previous messages, and commit fest robot could think I'm author.
On Thu, 29 Apr 2021 at 00:28, Yura Sokolov <y.sokolov@postgrespro.ru> wrote: > The best result is with just: > > return (uint32)rnode->node.relNode; > > ie, relNode could be taken without mixing at all. > relNode is unique inside single database, and almost unique among whole > cluster > since it is Oid. I admit to having tried that too just to almost eliminate the cost of hashing. I just didn't consider it something we'd actually do. The system catalogues are quite likely to all have the same relfilenode in all databases, so for workloads that have a large number of databases, looking up WAL records that touch the catalogues is going to be pretty terrible. The simplified hash function I wrote with just the relNode and dbNode would be the least I'd be willing to entertain. However, I just wouldn't be surprised if there was a good reason for that being bad too. > So, I've repeated benchmark with different number of partitons (I tried > to catch higher fillfactor) and less amount of inserted data (since I > don't > want to stress my SSD). > > partitions/ | dynahash | dynahash + | simplehash | simplehash + | > fillfactor | | simple func | | simple func | > ------------+----------+-------------+--------------+ > 3500/0.43 | 3.73s | 3.54s | 3.58s | 3.34s | > 3200/0.78 | 3.64s | 3.46s | 3.47s | 3.25s | > 1500/0.74 | 3.18s | 2.97s | 3.03s | 2.79s | > > Fillfactor is effective fillfactor in simplehash with than number of > partitions. > I wasn't able to measure with fillfactor close to 0.9 since looks like > simplehash tends to grow much earlier due to SH_GROW_MAX_MOVE. Thanks for testing that. I also ran some tests last night to test the 0.75 vs 0.9 fillfactor to see if it made a difference. The test was similar to last time, but I trimmed the number of rows inserted from 100 million down to 25 million. Last time I tested with 1000 partitions, this time with each of: 100 200 300 400 500 600 700 800 900 1000 partitions. There didn't seem to be any point of testing lower than that as the minimum hash table size is 512. The averages over 10 runs were: nparts ff75 ff90 100 21.898 22.226 200 23.105 25.493 300 25.274 24.251 400 25.139 25.611 500 25.738 25.454 600 26.656 26.82 700 27.577 27.102 800 27.608 27.546 900 27.284 28.186 1000 29 28.153 Or to summarise a bit, we could just look at the sum of all the results per fillfactor: sum ff75 2592.79 sum ff90 2608.42 100.6% fillfactor 75 did come out slightly faster, but only just. It seems close enough that it might be better just to keep the 90 to save a little memory and improve caching elsewhere. Also, from below, you can see that for 300, 500, 600, 700, 1000 tables tests, the hash tables ended up the same size, yet there's a bit of variability in the timing result. So the 0.6% gain might just be noise. I don't think it's worth making the fillfactor 75. drowley@amd3990x:~/recoverylogs$ grep -rH -m 1 "collisions" ff75_tb100.log:LOG: size: 1024, members: 231, filled: 0.225586, total chain: 33, max chain: 2, avg chain: 0.142857, total_collisions: 20, max_collisions: 2, avg_collisions: 0.086580 ff90_tb100.log:LOG: size: 512, members: 231, filled: 0.451172, total chain: 66, max chain: 2, avg chain: 0.285714, total_collisions: 36, max_collisions: 2, avg_collisions: 0.155844 ff75_tb200.log:LOG: size: 1024, members: 431, filled: 0.420898, total chain: 160, max chain: 4, avg chain: 0.371230, total_collisions: 81, max_collisions: 3, avg_collisions: 0.187935 ff90_tb200.log:LOG: size: 512, members: 431, filled: 0.841797, total chain: 942, max chain: 9, avg chain: 2.185615, total_collisions: 134, max_collisions: 3, avg_collisions: 0.310905 ff90_tb300.log:LOG: size: 1024, members: 631, filled: 0.616211, total chain: 568, max chain: 9, avg chain: 0.900158, total_collisions: 158, max_collisions: 4, avg_collisions: 0.250396 ff75_tb300.log:LOG: size: 1024, members: 631, filled: 0.616211, total chain: 568, max chain: 9, avg chain: 0.900158, total_collisions: 158, max_collisions: 4, avg_collisions: 0.250396 ff75_tb400.log:LOG: size: 2048, members: 831, filled: 0.405762, total chain: 341, max chain: 4, avg chain: 0.410349, total_collisions: 162, max_collisions: 3, avg_collisions: 0.194946 ff90_tb400.log:LOG: size: 1024, members: 831, filled: 0.811523, total chain: 1747, max chain: 15, avg chain: 2.102286, total_collisions: 269, max_collisions: 3, avg_collisions: 0.323706 ff75_tb500.log:LOG: size: 2048, members: 1031, filled: 0.503418, total chain: 568, max chain: 5, avg chain: 0.550921, total_collisions: 219, max_collisions: 4, avg_collisions: 0.212415 ff90_tb500.log:LOG: size: 2048, members: 1031, filled: 0.503418, total chain: 568, max chain: 5, avg chain: 0.550921, total_collisions: 219, max_collisions: 4, avg_collisions: 0.212415 ff75_tb600.log:LOG: size: 2048, members: 1231, filled: 0.601074, total chain: 928, max chain: 7, avg chain: 0.753859, total_collisions: 298, max_collisions: 4, avg_collisions: 0.242080 ff90_tb600.log:LOG: size: 2048, members: 1231, filled: 0.601074, total chain: 928, max chain: 7, avg chain: 0.753859, total_collisions: 298, max_collisions: 4, avg_collisions: 0.242080 ff75_tb700.log:LOG: size: 2048, members: 1431, filled: 0.698730, total chain: 1589, max chain: 9, avg chain: 1.110412, total_collisions: 391, max_collisions: 4, avg_collisions: 0.273235 ff90_tb700.log:LOG: size: 2048, members: 1431, filled: 0.698730, total chain: 1589, max chain: 9, avg chain: 1.110412, total_collisions: 391, max_collisions: 4, avg_collisions: 0.273235 ff75_tb800.log:LOG: size: 4096, members: 1631, filled: 0.398193, total chain: 628, max chain: 6, avg chain: 0.385040, total_collisions: 296, max_collisions: 3, avg_collisions: 0.181484 ff90_tb800.log:LOG: size: 2048, members: 1631, filled: 0.796387, total chain: 2903, max chain: 12, avg chain: 1.779890, total_collisions: 515, max_collisions: 3, avg_collisions: 0.315757 ff75_tb900.log:LOG: size: 4096, members: 1831, filled: 0.447021, total chain: 731, max chain: 5, avg chain: 0.399235, total_collisions: 344, max_collisions: 3, avg_collisions: 0.187875 ff90_tb900.log:LOG: size: 2048, members: 1831, filled: 0.894043, total chain: 6364, max chain: 14, avg chain: 3.475696, total_collisions: 618, max_collisions: 4, avg_collisions: 0.337520 ff75_tb1000.log:LOG: size: 4096, members: 2031, filled: 0.495850, total chain: 1024, max chain: 6, avg chain: 0.504185, total_collisions: 416, max_collisions: 3, avg_collisions: 0.204825 ff90_tb1000.log:LOG: size: 4096, members: 2031, filled: 0.495850, total chain: 1024, max chain: 6, avg chain: 0.504185, total_collisions: 416, max_collisions: 3, avg_collisions: 0.204825 Another line of thought for making it go faster would be to do something like get rid of the hash status field from SMgrEntry. That could be either coded into a single bit we'd borrow from the hash value, or it could be coded into the least significant bit of the data field. A pointer to palloc'd memory should always be MAXALIGNed, which means at least the lower two bits are always zero. We'd just need to make sure and do something like "data & ~((uintptr_t) 3)" to trim off the hash status bits before dereferencing the pointer. That would make the SMgrEntry 12 bytes on a 64-bit machine. However, it would also mean that some entries would span 2 cache lines, which might affect performance a bit. > PS. David, please send patch once again since my mail client reattached > files in > previous messages, and commit fest robot could think I'm author. Authors are listed manually in the CF app. The app will pickup .patch files from the latest email in the thread and the CF bot will test those. So it does pay to be pretty careful when attaching patches to threads that are in the CF app. That's the reason I added the .txt extension to the recovery panic patch. The CF bot machines would have complained about that.
David Rowley писал 2021-04-29 02:51:
> On Thu, 29 Apr 2021 at 00:28, Yura Sokolov <y.sokolov@postgrespro.ru>
> wrote:
>> The best result is with just:
>>
>> return (uint32)rnode->node.relNode;
>>
>> ie, relNode could be taken without mixing at all.
>> relNode is unique inside single database, and almost unique among
>> whole
>> cluster
>> since it is Oid.
>
> I admit to having tried that too just to almost eliminate the cost of
> hashing. I just didn't consider it something we'd actually do.
>
> The system catalogues are quite likely to all have the same
> relfilenode in all databases, so for workloads that have a large
> number of databases, looking up WAL records that touch the catalogues
> is going to be pretty terrible.
Single workload that could touch system catalogues in different
databases is recovery (and autovacuum?). Client backends couldn't
be connected to more than one database.
But netherless, you're right. I oversimplified it intentionally.
I wrote originally:
hashcode = (uint32)rnode->node.dbNode * 0xc2b2ae35;
hashcode ^= (uint32)rnode->node.relNode;
return hashcode;
But before sending mail I'd cut dbNode part.
Still, main point: relNode could be put unmixed into final value.
This way less collisions happen.
>
> The simplified hash function I wrote with just the relNode and dbNode
> would be the least I'd be willing to entertain. However, I just
> wouldn't be surprised if there was a good reason for that being bad
> too.
>
>
>> So, I've repeated benchmark with different number of partitons (I
>> tried
>> to catch higher fillfactor) and less amount of inserted data (since I
>> don't
>> want to stress my SSD).
>>
>> partitions/ | dynahash | dynahash + | simplehash | simplehash + |
>> fillfactor | | simple func | | simple func |
>> ------------+----------+-------------+--------------+
>> 3500/0.43 | 3.73s | 3.54s | 3.58s | 3.34s |
>> 3200/0.78 | 3.64s | 3.46s | 3.47s | 3.25s |
>> 1500/0.74 | 3.18s | 2.97s | 3.03s | 2.79s |
>>
>> Fillfactor is effective fillfactor in simplehash with than number of
>> partitions.
>> I wasn't able to measure with fillfactor close to 0.9 since looks like
>> simplehash tends to grow much earlier due to SH_GROW_MAX_MOVE.
>
> Thanks for testing that.
>
> I also ran some tests last night to test the 0.75 vs 0.9 fillfactor to
> see if it made a difference. The test was similar to last time, but I
> trimmed the number of rows inserted from 100 million down to 25
> million. Last time I tested with 1000 partitions, this time with each
> of: 100 200 300 400 500 600 700 800 900 1000 partitions. There didn't
> seem to be any point of testing lower than that as the minimum hash
> table size is 512.
>
> The averages over 10 runs were:
>
> nparts ff75 ff90
> 100 21.898 22.226
> 200 23.105 25.493
> 300 25.274 24.251
> 400 25.139 25.611
> 500 25.738 25.454
> 600 26.656 26.82
> 700 27.577 27.102
> 800 27.608 27.546
> 900 27.284 28.186
> 1000 29 28.153
>
> Or to summarise a bit, we could just look at the sum of all the
> results per fillfactor:
>
> sum ff75 2592.79
> sum ff90 2608.42 100.6%
>
> fillfactor 75 did come out slightly faster, but only just. It seems
> close enough that it might be better just to keep the 90 to save a
> little memory and improve caching elsewhere. Also, from below, you
> can see that for 300, 500, 600, 700, 1000 tables tests, the hash
> tables ended up the same size, yet there's a bit of variability in the
> timing result. So the 0.6% gain might just be noise.
>
> I don't think it's worth making the fillfactor 75.
To be clear: I didn't change SH_FILLFACTOR. It were equal to 0.9 .
I just were not able to catch table with fill factor more than 0.78.
Looks like you've got it with 900 partitions :-)
>
> Another line of thought for making it go faster would be to do
> something like get rid of the hash status field from SMgrEntry. That
> could be either coded into a single bit we'd borrow from the hash
> value, or it could be coded into the least significant bit of the data
> field. A pointer to palloc'd memory should always be MAXALIGNed,
> which means at least the lower two bits are always zero. We'd just
> need to make sure and do something like "data & ~((uintptr_t) 3)" to
> trim off the hash status bits before dereferencing the pointer. That
> would make the SMgrEntry 12 bytes on a 64-bit machine. However, it
> would also mean that some entries would span 2 cache lines, which
> might affect performance a bit.
Then data pointer will be itself unaligned to 8 bytes. While x86 is
mostly indifferent to this, doubtfully this memory economy will pay
off.
regards,
Yura Sokolov.
On Thu, 29 Apr 2021 at 12:30, Yura Sokolov <y.sokolov@postgrespro.ru> wrote: > > David Rowley писал 2021-04-29 02:51: > > Another line of thought for making it go faster would be to do > > something like get rid of the hash status field from SMgrEntry. That > > could be either coded into a single bit we'd borrow from the hash > > value, or it could be coded into the least significant bit of the data > > field. A pointer to palloc'd memory should always be MAXALIGNed, > > which means at least the lower two bits are always zero. We'd just > > need to make sure and do something like "data & ~((uintptr_t) 3)" to > > trim off the hash status bits before dereferencing the pointer. That > > would make the SMgrEntry 12 bytes on a 64-bit machine. However, it > > would also mean that some entries would span 2 cache lines, which > > might affect performance a bit. > > Then data pointer will be itself unaligned to 8 bytes. While x86 is > mostly indifferent to this, doubtfully this memory economy will pay > off. Actually, I didn't think very hard about that. The struct would still be 16 bytes and just have padding so the data pointer was aligned to 8 bytes (assuming a 64-bit machine). David
I've attached an updated patch. I forgot to call SH_ENTRY_CLEANUP, when it's defined during SH_RESET. I also tided up a couple of comments and change the code to use pg_rotate_right32(.., 31) instead of adding a new function for pg_rotate_left32 and calling that to shift left 1 bit. David
Attachment
Hi David, You're probably aware of this, but just to make it explicit: Jakub Wartak was testing performance of recovery, and one of the bottlenecks he found in some of his cases was dynahash as used by SMgr. It seems quite possible that this work would benefit some of his test workloads. He last posted about it here: https://postgr.es/m/VI1PR0701MB69608CBCE44D80857E59572EF6CA0@VI1PR0701MB6960.eurprd07.prod.outlook.com though the fraction of dynahash-from-SMgr is not as high there as in some of other reports I saw. -- Álvaro Herrera Valdivia, Chile
Hi David, Alvaro, -hackers > Hi David, > > You're probably aware of this, but just to make it explicit: Jakub Wartak was > testing performance of recovery, and one of the bottlenecks he found in > some of his cases was dynahash as used by SMgr. It seems quite possible > that this work would benefit some of his test workloads. I might be a little bit out of the loop, but as Alvaro stated - Thomas did plenty of excellent job related to recovery performancein that thread. In my humble opinion and if I'm not mistaken (I'm speculating here) it might be *not* how Smgrhash works, but how often it is being exercised and that would also explain relatively lower than expected(?) gains here.There are at least two very important emails from him that I'm aware that are touching the topic of reordering/compacting/batchingcalls to Smgr: https://www.postgresql.org/message-id/CA%2BhUKG%2B2Vw3UAVNJSfz5_zhRcHUWEBDrpB7pyQ85Yroep0AKbw%40mail.gmail.com https://www.postgresql.org/message-id/flat/CA%2BhUKGK4StQ%3DeXGZ-5hTdYCmSfJ37yzLp9yW9U5uH6526H%2BUeg%40mail.gmail.com Another potential option that we've discussed is that the redo generation itself is likely a brake of efficient recoveryperformance today (e.g. INSERT-SELECT on table with indexes, generates interleaved WAL records that touch often limitedset of blocks that usually put Smgr into spotlight). -Jakub Wartak.
Hi Jakub, On Wed, 5 May 2021 at 20:16, Jakub Wartak <Jakub.Wartak@tomtom.com> wrote: > I might be a little bit out of the loop, but as Alvaro stated - Thomas did plenty of excellent job related to recoveryperformance in that thread. In my humble opinion and if I'm not mistaken (I'm speculating here) it might be *not*how Smgr hash works, but how often it is being exercised and that would also explain relatively lower than expected(?)gains here. There are at least two very important emails from him that I'm aware that are touching the topic ofreordering/compacting/batching calls to Smgr: > https://www.postgresql.org/message-id/CA%2BhUKG%2B2Vw3UAVNJSfz5_zhRcHUWEBDrpB7pyQ85Yroep0AKbw%40mail.gmail.com > https://www.postgresql.org/message-id/flat/CA%2BhUKGK4StQ%3DeXGZ-5hTdYCmSfJ37yzLp9yW9U5uH6526H%2BUeg%40mail.gmail.com I'm not much of an expert here and I didn't follow the recovery prefetching stuff closely. So, with that in mind, I think there are lots that could be done along the lines of what Thomas is mentioning. Batching WAL records up by filenode then replaying each filenode one by one when our batching buffer is full. There could be some sort of parallel options there too, where workers replay a filenode each. However, that wouldn't really work for recovery on a hot-standby though. We'd need to ensure we replay the commit record for each transaction last. I think you'd have to batch by filenode and transaction in that case. Each batch might be pretty small on a typical OLTP workload, so it might not help much there, or it might hinder. But having said that, I don't think any of those possibilities should stop us speeding up smgropen(). > Another potential option that we've discussed is that the redo generation itself is likely a brake of efficient recoveryperformance today (e.g. INSERT-SELECT on table with indexes, generates interleaved WAL records that touch often limitedset of blocks that usually put Smgr into spotlight). I'm not quite sure if I understand what you mean here. Is this queuing up WAL records up during transactions and flush them out to WAL every so often after rearranging them into an order that's more optimal for replay? David
Hey David, > I think you'd have to batch by filenode and transaction in that case. Each batch might be pretty small on a typical OLTPworkload, so it might not help much there, or it might hinder. True, it is very workload dependent (I was chasing mainly INSERTs multiValues, INSERT-SELECT) that often hit the same $block,certainly not OLTP. I would even say that INSERT-as-SELECT would be more suited for DWH-like processing. > But having said that, I don't think any of those possibilities should stop us speeding up smgropen(). Of course! I've tried a couple of much more smaller ideas, but without any big gains. I was able to squeeze like 300-400kfunction calls per second (WAL records/s), that was the point I think where I think smgropen() got abused. > > Another potential option that we've discussed is that the redo generation > itself is likely a brake of efficient recovery performance today (e.g. INSERT- > SELECT on table with indexes, generates interleaved WAL records that touch > often limited set of blocks that usually put Smgr into spotlight). > > I'm not quite sure if I understand what you mean here. Is this queuing up > WAL records up during transactions and flush them out to WAL every so > often after rearranging them into an order that's more optimal for replay? Why not both? 😉 We were very concentrated on standby side, but on primary side one could also change how WAL records aregenerated: 1) Minimalization of records towards same repeated $block eg. Heap2 table_multi_insert() API already does this and it mattersto generate more optimal stream for replay: postgres@test=# create table t (id bigint primary key); postgres@test=# insert into t select generate_series(1, 10); results in many calls due to interleave heap with btree records for the same block from Smgr perspective (this is especiallyvisible on highly indexed tables) => rmgr: Btree len (rec/tot): 64/ 64, tx: 17243284, lsn: 4/E7000108, prev 4/E70000A0, desc: INSERT_LEAF off 1,blkref #0: rel 1663/16384/32794 blk 1 rmgr: Heap len (rec/tot): 63/ 63, tx: 17243284, lsn: 4/E7000148, prev 4/E7000108, desc: INSERT off 2 flags0x00, blkref #0: rel 1663/16384/32791 blk 0 rmgr: Btree len (rec/tot): 64/ 64, tx: 17243284, lsn: 4/E7000188, prev 4/E7000148, desc: INSERT_LEAF off 2,blkref #0: rel 1663/16384/32794 blk 1 rmgr: Heap len (rec/tot): 63/ 63, tx: 17243284, lsn: 4/E70001C8, prev 4/E7000188, desc: INSERT off 3 flags0x00, blkref #0: rel 1663/16384/32791 blk 0 rmgr: Btree len (rec/tot): 64/ 64, tx: 17243284, lsn: 4/E7000208, prev 4/E70001C8, desc: INSERT_LEAF off 3,blkref #0: rel 1663/16384/32794 blk 1 rmgr: Heap len (rec/tot): 63/ 63, tx: 17243284, lsn: 4/E7000248, prev 4/E7000208, desc: INSERT off 4 flags0x00, blkref #0: rel 1663/16384/32791 blk 0 rmgr: Btree len (rec/tot): 64/ 64, tx: 17243284, lsn: 4/E7000288, prev 4/E7000248, desc: INSERT_LEAF off 4,blkref #0: rel 1663/16384/32794 blk 1 rmgr: Heap len (rec/tot): 63/ 63, tx: 17243284, lsn: 4/E70002C8, prev 4/E7000288, desc: INSERT off 5 flags0x00, blkref #0: rel 1663/16384/32791 blk 0 [..] Similar stuff happens for UPDATE. It basically prevents recent-buffer optimization that avoid repeated calls to smgropen(). And here's already existing table_multi_inserts v2 API (Heap2) sample with obvious elimination of unnecessary individualcalls to smgopen() via one big MULTI_INSERT instead (for CTAS/COPY/REFRESH MV) : postgres@test=# create table t (id bigint primary key); postgres@test=# copy (select generate_series (1, 10)) to '/tmp/t'; postgres@test=# copy t from '/tmp/t'; => rmgr: Heap2 len (rec/tot): 210/ 210, tx: 17243290, lsn: 4/E9000028, prev 4/E8004410, desc: MULTI_INSERT+INIT10 tuples flags 0x02, blkref #0: rel 1663/16384/32801 blk 0 rmgr: Btree len (rec/tot): 102/ 102, tx: 17243290, lsn: 4/E9000100, prev 4/E9000028, desc: NEWROOT lev 0, blkref#0: rel 1663/16384/32804 blk 1, blkref #2: rel 1663/16384/32804 blk 0 rmgr: Btree len (rec/tot): 64/ 64, tx: 17243290, lsn: 4/E9000168, prev 4/E9000100, desc: INSERT_LEAF off 1,blkref #0: rel 1663/16384/32804 blk 1 rmgr: Btree len (rec/tot): 64/ 64, tx: 17243290, lsn: 4/E90001A8, prev 4/E9000168, desc: INSERT_LEAF off 2,blkref #0: rel 1663/16384/32804 blk 1 rmgr: Btree len (rec/tot): 64/ 64, tx: 17243290, lsn: 4/E90001E8, prev 4/E90001A8, desc: INSERT_LEAF off 3,blkref #0: rel 1663/16384/32804 blk 1 [..] Here Btree it is very localized (at least when concurrent sessions are not generating WAL) and it enables Thomas's recent-bufferto kick in DELETE is much more simple (thanks to not chewing out those Btree records) and also thanks to Thomas's recent-buffer shouldtheoretically put much less stress on smgropen() already: rmgr: Heap len (rec/tot): 54/ 54, tx: 17243296, lsn: 4/ED000028, prev 4/EC002800, desc: DELETE off 1 flags0x00 KEYS_UPDATED , blkref #0: rel 1663/16384/32808 blk 0 rmgr: Heap len (rec/tot): 54/ 54, tx: 17243296, lsn: 4/ED000060, prev 4/ED000028, desc: DELETE off 2 flags0x00 KEYS_UPDATED , blkref #0: rel 1663/16384/32808 blk 0 rmgr: Heap len (rec/tot): 54/ 54, tx: 17243296, lsn: 4/ED000098, prev 4/ED000060, desc: DELETE off 3 flags0x00 KEYS_UPDATED , blkref #0: rel 1663/16384/32808 blk 0 rmgr: Heap len (rec/tot): 54/ 54, tx: 17243296, lsn: 4/ED0000D0, prev 4/ED000098, desc: DELETE off 4 flags0x00 KEYS_UPDATED , blkref #0: rel 1663/16384/32808 blk 0 [..] 2) So what's missing - I may be wrong on this one - something like "index_multi_inserts" Btree2 API to avoid repeatedly overwhelmingsmgropen() on recovery side for same index's $buffer. Not sure it is worth the effort, though especially recent-bufferfixes that: rmgr: Btree len (rec/tot): 64/ 64, tx: 17243290, lsn: 4/E9000168, prev 4/E9000100, desc: INSERT_LEAF off 1,blkref #0: rel 1663/16384/32804 blk 1 rmgr: Btree len (rec/tot): 64/ 64, tx: 17243290, lsn: 4/E90001A8, prev 4/E9000168, desc: INSERT_LEAF off 2,blkref #0: rel 1663/16384/32804 blk 1 rmgr: Btree len (rec/tot): 64/ 64, tx: 17243290, lsn: 4/E90001E8, prev 4/E90001A8, desc: INSERT_LEAF off 3,blkref #0: rel 1663/16384/32804 blk 1 right? 3) Concurrent DML sessions mixing WAL records: the buffering on backend's side of things (on private "thread" of WAL - inprivate memory - that would be simply "copied" into logwriter's main WAL buffer when committing/buffer full) - it wouldseem like an very interesting idea to limit interleaving concurrent sessions WAL records between each other and exploitthe recent-buffer enhancement to avoid repeating the same calls to Smgr, wouldn't it? (I'm just mentioning it as Isaw you were benchmarking it here and called out this idea). I could be wrong though with many of those simplifications, in any case please consult with Thomas as he knows much betterand is much more trusted source than me 😉 -J.
The following review has been posted through the commitfest application: make installcheck-world: tested, passed Implements feature: tested, passed Spec compliant: tested, passed Documentation: not tested I believe it is ready for committer. The new status of this patch is: Ready for Committer
I'd been thinking of this patch again. When testing with simplehash, I found that the width of the hash bucket type was fairly critical for getting good performance from simplehash.h. With simplehash.h I didn't manage to narrow this any more than 16 bytes. I needed to store the 32-bit hash value and a pointer to the data. On a 64-bit machine, with padding, that's 16-bytes. I've been thinking about a way to narrow this down further to just 8 bytes and also solve the stable pointer problem at the same time... I've come up with a new hash table implementation that I've called generichash. It works similarly to simplehash in regards to the linear probing, only instead of storing the data in the hash bucket, we just store a uint32 index that indexes off into an array. To keep the pointers in that array stable, we cannot resize the array as the table grows. Instead, I just allocate another array of the same size. Since these arrays are always sized as powers of 2, it's very fast to index into them using the uint32 index that's stored in the bucket. Unused buckets just store the special index of 0xFFFFFFFF. I've also proposed to use this hash table implementation over in [1] to speed up LockReleaseAll(). The 0001 patch here is just the same as the patch from [1]. The 0002 patch includes using a generichash hash table for SMgr. The performance using generichash.h is about the same as the simplehash.h version of the patch. Although, the test was not done on the same version of master. Master (97b713418) drowley@amd3990x:~$ tail -f pg.log | grep "redo done" CPU: user: 124.85 s, system: 6.83 s, elapsed: 131.74 s CPU: user: 115.01 s, system: 4.76 s, elapsed: 119.83 s CPU: user: 122.13 s, system: 6.41 s, elapsed: 128.60 s CPU: user: 113.85 s, system: 6.11 s, elapsed: 120.02 s CPU: user: 121.40 s, system: 6.28 s, elapsed: 127.74 s CPU: user: 113.71 s, system: 5.80 s, elapsed: 119.57 s CPU: user: 113.96 s, system: 5.90 s, elapsed: 119.92 s CPU: user: 122.74 s, system: 6.21 s, elapsed: 129.01 s CPU: user: 122.00 s, system: 6.38 s, elapsed: 128.44 s CPU: user: 113.06 s, system: 6.14 s, elapsed: 119.25 s CPU: user: 114.42 s, system: 4.35 s, elapsed: 118.82 s Median: 120.02 s master + v1 + v2 drowley@amd3990x:~$ tail -n 0 -f pg.log | grep "redo done" CPU: user: 107.75 s, system: 4.61 s, elapsed: 112.41 s CPU: user: 108.07 s, system: 4.49 s, elapsed: 112.61 s CPU: user: 106.89 s, system: 5.55 s, elapsed: 112.49 s CPU: user: 107.42 s, system: 5.64 s, elapsed: 113.12 s CPU: user: 106.85 s, system: 4.42 s, elapsed: 111.31 s CPU: user: 107.36 s, system: 4.76 s, elapsed: 112.16 s CPU: user: 107.20 s, system: 4.47 s, elapsed: 111.72 s CPU: user: 106.94 s, system: 5.89 s, elapsed: 112.88 s CPU: user: 115.32 s, system: 6.12 s, elapsed: 121.49 s CPU: user: 108.02 s, system: 4.48 s, elapsed: 112.54 s CPU: user: 106.93 s, system: 4.54 s, elapsed: 111.51 s Median: 112.49 s So about a 6.69% speedup David [1] https://www.postgresql.org/message-id/CAApHDvoKqWRxw5nnUPZ8+mAJKHPOPxYGoY1gQdh0WeS4+biVhg@mail.gmail.com
Attachment
On Mon, Jun 21, 2021 at 10:15 AM David Rowley <dgrowleyml@gmail.com> wrote: > I've come up with a new hash table implementation that I've called > generichash. At the risk of kibitzing the least-important detail of this proposal, I'm not very happy with the names of our hash implementations. simplehash is not especially simple, and dynahash is not particularly dynamic, especially now that the main place we use it is for shared-memory hash tables that can't be resized. Likewise, generichash doesn't really give any kind of clue about how this hash table is different from any of the others. I don't know how possible it is to do better here; naming things is one of the two hard problems in computer science. In a perfect world, though, our hash table implementations would be named in such a way that somebody might be able to look at the names and guess on that basis which one is best-suited to a given task. -- Robert Haas EDB: http://www.enterprisedb.com
Robert Haas <robertmhaas@gmail.com> writes:
> On Mon, Jun 21, 2021 at 10:15 AM David Rowley <dgrowleyml@gmail.com> wrote:
>> I've come up with a new hash table implementation that I've called
>> generichash.
> At the risk of kibitzing the least-important detail of this proposal,
> I'm not very happy with the names of our hash implementations.
I kind of wonder if we really need four different hash table
implementations (this being the third "generic" one, plus hash join
has its own, and I may have forgotten others). Should we instead
think about revising simplehash to gain the benefits of this patch?
regards, tom lane
On Tue, 22 Jun 2021 at 02:53, Robert Haas <robertmhaas@gmail.com> wrote: > At the risk of kibitzing the least-important detail of this proposal, > I'm not very happy with the names of our hash implementations. > simplehash is not especially simple, and dynahash is not particularly > dynamic, especially now that the main place we use it is for > shared-memory hash tables that can't be resized. Likewise, generichash > doesn't really give any kind of clue about how this hash table is > different from any of the others. I don't know how possible it is to > do better here; naming things is one of the two hard problems in > computer science. In a perfect world, though, our hash table > implementations would be named in such a way that somebody might be > able to look at the names and guess on that basis which one is > best-suited to a given task. I'm certainly open to better names. I did almost call it stablehash, in regards to the pointers to elements not moving around like they do with simplehash. I think more generally, hash table implementations are complex enough that it's pretty much impossible to give them a short enough meaningful name. Most papers just end up assigning a name to some technique. e.g Robinhood, Cuckoo etc. Both simplehash and generichash use a variant of Robinhood hashing. simplehash uses open addressing and generichash does not. Instead of Andres naming it simplehash, if he'd instead called it "robinhoodhash", then someone might come along and complain that his implementation is broken because it does not implement tombstoning. Maybe Andres thought he'd avoid that by not claiming that it's an implementation of a Robinhood hash table. That seems pretty wise to me. Naming it simplehash was a pretty simple way of avoiding that problem. Anyway, I'm open to better names, but I don't think the name should drive the implementation. If the implementation does not fit the name perfectly, then the name should change rather than the implementation. Personally, I think we should call it RowleyHash, but I think others might object. ;-) David
On Tue, 22 Jun 2021 at 03:43, Tom Lane <tgl@sss.pgh.pa.us> wrote: > I kind of wonder if we really need four different hash table > implementations (this being the third "generic" one, plus hash join > has its own, and I may have forgotten others). Should we instead > think about revising simplehash to gain the benefits of this patch? hmm, yeah. I definitely agree with trying to have as much reusable code as we can when we can. It certainly reduces maintenance and bugs tend to be found more quickly too. It's a very worthy cause. I did happen to think of this when I was copying swathes of code out of simplehash.h. However, I decided that the two implementations are sufficiently different that if I tried to merge them both into one .h file, we'd have some unreadable and unmaintainable mess. I just don't think their DNA is compatible enough for the two to be mated successfully. For example, simplehash uses open addressing and generichash does not. This means that things like iterating over the table works completely differently. Lookups in generichash need to perform an extra step to fetch the actual data from the segment arrays. I think it would certainly be possible to merge the two, but I just don't think it would be easy code to work on if we did that. The good thing is that that the API between the two is very similar and it's quite easy to swap one for the other. I did make changes around memory allocation due to me being too cheap to zero memory when I didn't need to and simplehash not having any means of allocating memory without zeroing it. I also think that there's just no one-size-fits-all hash table type. simplehash will not perform well when the size of the stored element is very large. There's simply too much memcpying to move data around during insert/delete. simplehash will also have terrible iteration performance in sparsely populated tables. However, simplehash will be pretty much unbeatable for lookups where the element type is very small, e.g single Datum, or an int. The CPU cache efficiency there will be pretty much unbeatable. I tried to document the advantages of each in the file header comments. I should probably also add something to simplehash.h's comments to mention generichash.h David
On Tue, Jun 22, 2021 at 1:55 PM David Rowley <dgrowleyml@gmail.com> wrote: > On Tue, 22 Jun 2021 at 03:43, Tom Lane <tgl@sss.pgh.pa.us> wrote: > > I kind of wonder if we really need four different hash table > > implementations (this being the third "generic" one, plus hash join > > has its own, and I may have forgotten others). Should we instead > > think about revising simplehash to gain the benefits of this patch? > > hmm, yeah. I definitely agree with trying to have as much reusable > code as we can when we can. It certainly reduces maintenance and bugs > tend to be found more quickly too. It's a very worthy cause. It is indeed really hard to decide when you have a new thing, and when you need a new way to parameterise the existing generic thing. I wondered about this how-many-hash-tables-does-it-take question a lot when writing dshash.c (a chaining hash table that can live in weird dsa.c memory, backed by DSM segments created on the fly that may be mapped at different addresses in each backend, and has dynahash-style partition locking), and this was around the time Andres was talking about simplehash. In retrospect, I'd probably kick out the built-in locking and partitions and instead let callers create their own partitioning scheme on top from N tables, and that'd remove one quirk, leaving only the freaky pointers and allocator. I recall from a previous life that Boost's unordered_map template is smart enough to support running in shared memory mapped at different addresses just through parameterisation that controls the way it deals with internal pointers (boost::unordered_map<..., ShmemAllocator>), which seemed pretty clever to me, and it might be achievable to do the same with a generic hash table for us that could take over dshash's specialness. One idea I had at the time is that the right number of hash table implementations in our tree is two: one for chaining (like dynahash) and one for open addressing/probing (like simplehash), and that everything else should be hoisted out (locking, partitioning) or made into template parameters through the generic programming technique that simplehash.h has demonstrated (allocators, magic pointer type for internal pointers, plus of course the inlinable ops). But that was before we'd really fully adopted the idea of this style of template code. (I also assumed the weird memory stuff would be temporary and we'd move to threads, but that's another topic for another thread.) It seems like you'd disagree with this, and you'd say the right number is three. But it's also possible to argue for one... A more superficial comment: I don't like calling hash tables "hash". I blame perl.
On Tue, 22 Jun 2021 at 14:49, Thomas Munro <thomas.munro@gmail.com> wrote: > One idea I had at the time is that the right number of hash table > implementations in our tree is two: one for chaining (like dynahash) > and one for open addressing/probing (like simplehash), and that > everything else should be hoisted out (locking, partitioning) or made > into template parameters through the generic programming technique > that simplehash.h has demonstrated (allocators, magic pointer type for > internal pointers, plus of course the inlinable ops). But that was > before we'd really fully adopted the idea of this style of template > code. (I also assumed the weird memory stuff would be temporary and > we'd move to threads, but that's another topic for another thread.) > It seems like you'd disagree with this, and you'd say the right number > is three. But it's also possible to argue for one... I guess we could also ask ourselves how many join algorithms we need. We have 3.something. None of which is perfect for every job. That's why we have multiple. I wonder why this is different. Just for anyone who missed it, the reason I wrote generichash and didn't just use simplehash is that it's not possible to point any other pointers to a simplehash table because these get shuffled around during insert/delete. For the locallock stuff over on [1] we need the LOCALLOCK object to be stable as we point to these from the resource manager. Likewise here for SMgr, we point to SMgrRelationData objects from RelationData. We can't have the hash table implementation swap these out from under us. Additionally, I coded generichash to fix the very slow hash seq scan problem that we have in LockReleaseAll() when a transaction has run in the backend that took lots of locks and caused the locallock hash table to bloat. Later when we run transactions that just grab a few locks it takes us a relatively long time to do LockReleaseAll() because we have to skip all those empty hash table buckets in the bloated table. (See iterate_sparse_table.png and iterate_very_sparse_table.png) I just finished writing a benchmark suite for comparing simplehash to generichash. I did this as a standalone C program. See the attached hashbench.tar.gz. You can run the tests with just ./test.sh. Just be careful if compiling manually as test.sh passes -DHAVE__BUILTIN_CTZ -DHAVE_LONG_INT_64 which have quite a big effect on the performance of generichash due to it using pg_rightmost_one_pos64() when searching the bitmaps for used items. I've attached graphs showing the results I got from running test.sh on my AMD 3990x machine. Because the size of the struct being hashed matters a lot to the performance of simplehash, I ran tests with 8, 16, 32, 64, 128, 256-byte structs. This matters because simplehash does memcpy() on this when moving stuff around during insert/delere. The size of the "payload" matters a bit less to generichash. You can see that the lookup performance of generichash very similar to simplehash. The insert/delete test shows the generichash is very slightly slower from 8-128 bytes but wins when simplehash has to tackle 256 bytes of data. The seq scan tests show that simplehash is better when the table is full of items, but it's terrible when bucket array is only sparsely populated. I needed generichash to be fast at this for LockReleaseAll(). I might be able to speed up generichash iteration when the table is full a bit more by checking if the segment is full and skipping to the next item rather than consulting the bitmap. That will slow down the sparse case a bit though. Not sure if it's worth it. Anyway, what I hope to show here is that there is no one-size-fits-all hash table. David [1] https://www.postgresql.org/message-id/CAApHDvoKqWRxw5nnUPZ8+mAJKHPOPxYGoY1gQdh0WeS4+biVhg@mail.gmail.com
Attachment
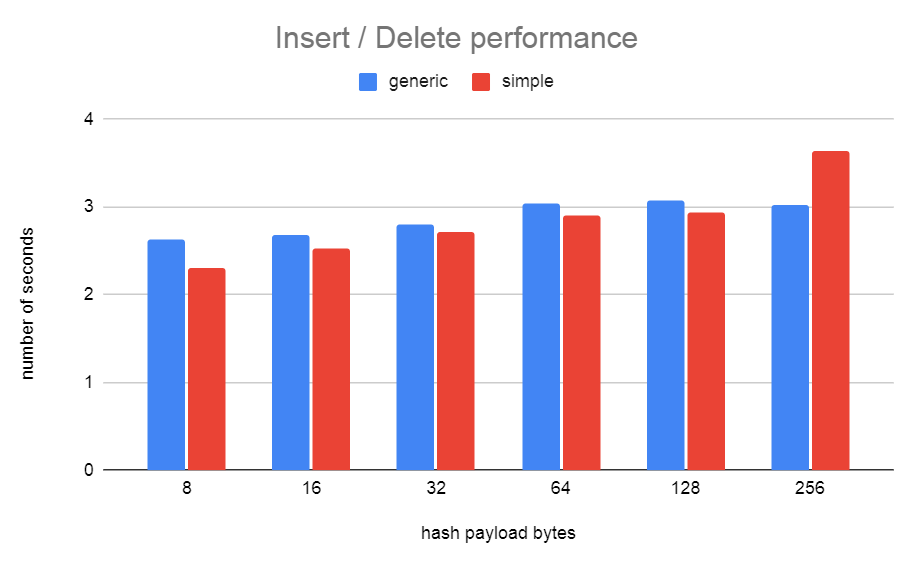{kind=link}
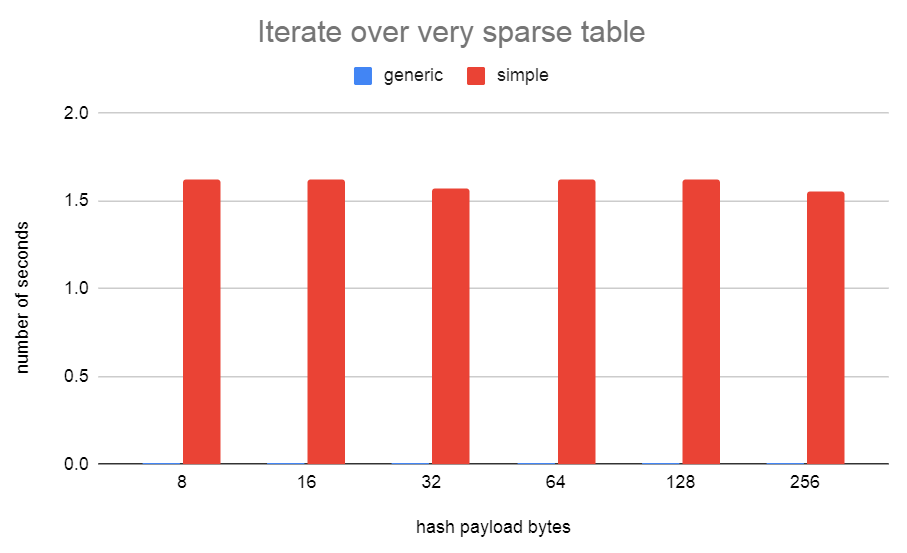{kind=link}
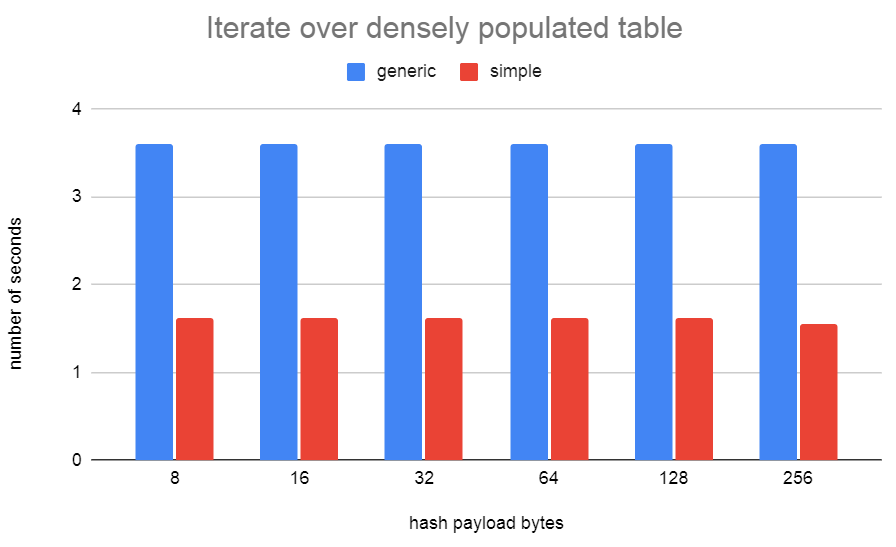{kind=link}
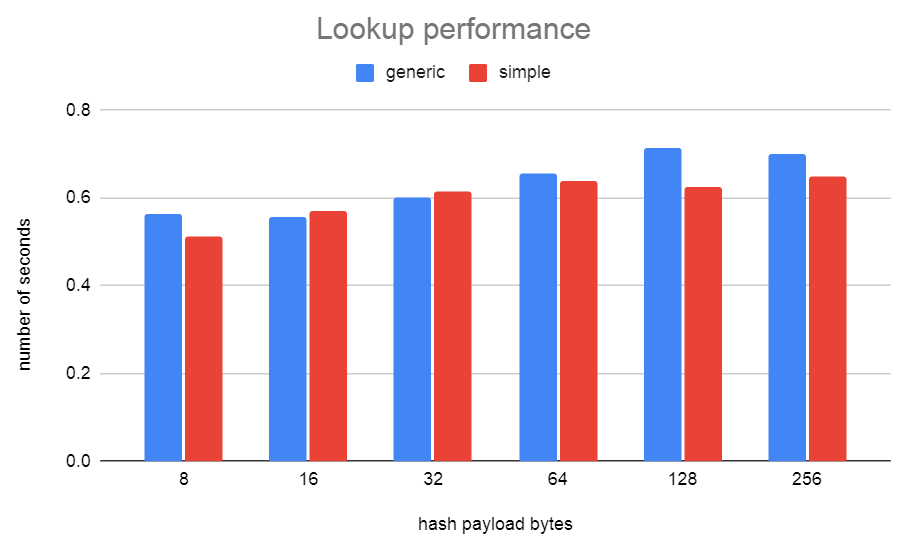{kind=link}
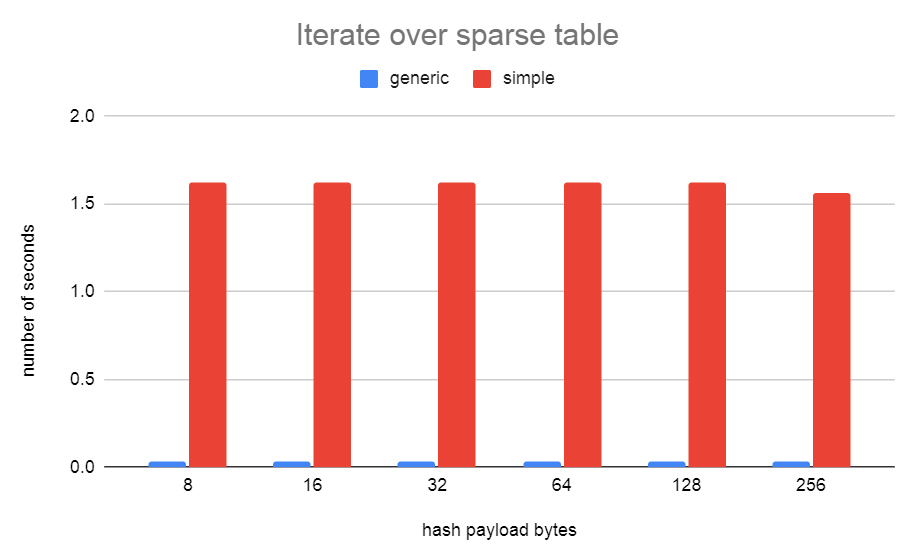{kind=link}
On Tue, Jun 22, 2021 at 6:51 PM David Rowley <dgrowleyml@gmail.com> wrote: > I guess we could also ask ourselves how many join algorithms we need. David and I discussed this a bit off-list, and I just wanted to share how I understand the idea so far in case it helps someone else. There are essentially three subcomponents working together: 1. A data structure similar in some ways to a C++ std::deque<T>, which gives O(1) access to elements by index, is densely packed to enable cache-friendly scanning of all elements, has stable addresses (as long as you only add new elements at the end or overwrite existing slots), and is internally backed by an array of pointers to a set of chunks. 2. A bitmapset that tracks unused elements in 1, making it easy to find the lowest-index hole when looking for a place to put a new one by linear search for a 1 bit, so that we tend towards maximum density despite having random frees from time to time (seems good, the same idea is used in kernels to allocate the lowest unused file descriptor number). 3. A hash table that has as elements indexes into 1. It somehow hides the difference between keys (what callers look things up with) and keys reachable by following an index into 1 (where elements' keys live). One thought is that you could do 1 as a separate component as the "primary" data structure, and use a plain old simplehash for 3 as a kind of index into it, but use pointers (rather than indexes) to objects in 1 as elements. I don't know if it's better.
On Wed, 23 Jun 2021 at 12:17, Thomas Munro <thomas.munro@gmail.com> wrote: > > David and I discussed this a bit off-list, and I just wanted to share > how I understand the idea so far in case it helps someone else. There > are essentially three subcomponents working together: Thanks for taking an interest in this. I started looking at your idea and I've now changed my mind from just not liking it to thinking that the whole idea is just completely horrible :-( It gets really messy with all the nested pre-processor stuff around fetching the element from the segmented array inside simplehash. One problem is that simplehash needs the address of the segments despite simplehash not knowing anything about segments. I've tried to make that work by passing in the generic hash struct as simplehash's private_data. This ends up with deeply nested macros all defined in different files. I pitty the future person debugging that. There is also a problem of how to reference simplehash functions inside the generichash code. It's not possible to do things like SH_CREATE() because all those macros are undefined at the end of simplehash.h. It's no good to hardcode the names either as GH_PREFIX must be used, else it wouldn't be possible to use more than 1 differenrly defined hash table per .c file. Fixing this means either modifying simplehash.h to not undefine all the name macros at the end maybe with SH_NOUNDEF or creating another set of macros to build the names for the simplehash functions inside the generic hash code. I don't like either of those ideas. There are also a bunch of changes / API breakages that need to be done to make this work with simplehash.h. 1) Since I really need 8-byte buckets in the hash table to make this as fast as possible, I want to use the array index for the hash status and that means changing the simplehash API to allow that to work. This requires something like SH_IS_BUCKET_INUSE, SH_SET_BUCKET_INUSE, SH_SET_BUCKET_EMPTY. 2) I need to add a new memory allocation function to not zero the memory. At the moment all hash buckets are emptied when creating a table by zeroing the bucket memory. If someone defines SH_SET_BUCKET_EMPTY to do something that says 0 memory is not empty, then that won't work. So I need to allocate the bucket memory then call SH_SET_BUCKET_EMPTY on each bucket. 3) I'll need to replace SH_KEY with something more complex. Since the simplehash bucket will just have a uint32 hashvalue and uint32 index, the hash key is not stored in the bucket, it's stored over in the segment. I'll need to replace SH_KEY with SH_GETKEY and SH_SETKEY. These will need to consult the simplehash's private_data so that the element can be found in the segmented array. Also, simplehash internally manages when the hash table needs to grow. I'll need to perform separate checks to see if the segmented array also must grow. It's a bit annoying to double up those checks as they're in a very hot path as they're done everytime someone inserts into the table. > 2. A bitmapset that tracks unused elements in 1, making it easy to > find the lowest-index hole when looking for a place to put a new one > by linear search for a 1 bit, so that we tend towards maximum density > despite having random frees from time to time (seems good, the same > idea is used in kernels to allocate the lowest unused file descriptor > number). I didn't use Bitmapsets. I wanted the bitmaps to be allocated in the same chunk of memory as the segments of the array. Also, because bitmapset's nwords is variable, then they can't really do any loop unrolling. Since in my implementation the number of bitmap words are known at compile-time, the compiler has the flexibility to do loop unrolling. The bitmap manipulation is one of the biggest overheads in generichash.h. I'd prefer to keep that as fast as possible. > 3. A hash table that has as elements indexes into 1. It somehow hides > the difference between keys (what callers look things up with) and > keys reachable by following an index into 1 (where elements' keys > live). I think that can be done, but it would require looking up the segmented array twice instead of once. The first time would be when we compare the keys after seeing the hash values match. The final time would be in the calling code to translate the index to the pointer. Hopefully the compiler would be able to optimize that to a single lookup. > One thought is that you could do 1 as a separate component as the > "primary" data structure, and use a plain old simplehash for 3 as a > kind of index into it, but use pointers (rather than indexes) to > objects in 1 as elements. I don't know if it's better. Using pointers would double the bucket width on a 64 bit machine. I don't want to do that. Also, to be able to determine the segment from the pointer it would require looping over each segment to check if the pointer belongs there. With the index we can determine the segment directly with bit-shifting the index. So, with all that. I really don't think it's a great idea to try and have this use simplehash.h code. I plan to pursue the idea I proposed with having seperate hash table code that is coded properly to have stable pointers into the data rather than trying to contort simplehash's code into working that way. David
On Wed, Jun 30, 2021 at 11:14 PM David Rowley <dgrowleyml@gmail.com> wrote: > On Wed, 23 Jun 2021 at 12:17, Thomas Munro <thomas.munro@gmail.com> wrote: > Thanks for taking an interest in this. I started looking at your idea > and I've now changed my mind from just not liking it to thinking that > the whole idea is just completely horrible :-( Hah. I accept that trying to make a thing that "wraps" these data structures and provides a simple interface is probably really quite horrible with preprocessor voodoo. I was mainly questioning how bad it would be if we had a generic segmented array component (seems like a great idea, which I'm sure would find other uses, I recall wanting to write that myself before), and then combined that with the presence map idea to make a dense object pool (ditto), but then, in each place where we need something like this, just used a plain old hash table to point directly to objects in it whenever we needed that, open coding the logic to keep it in sync (I mean, just the way that people usually use hash tables). That way, the object pool can give you very fast scans over all objects in cache friendly order (no linked lists), and the hash table doesn't know/care about its existence. In other words, small reusable components that each do one thing well and are not coupled together. I think I understand now that you really, really want small index numbers and not 64 bit pointers in the hash table. Hmm. > It gets really messy with all the nested pre-processor stuff around > fetching the element from the segmented array inside simplehash. One > problem is that simplehash needs the address of the segments despite > simplehash not knowing anything about segments. I've tried to make > that work by passing in the generic hash struct as simplehash's > private_data. This ends up with deeply nested macros all defined in > different files. I pitty the future person debugging that. Yeah, that sounds terrible. > There are also a bunch of changes / API breakages that need to be done > to make this work with simplehash.h. > > 1) Since I really need 8-byte buckets in the hash table to make this > as fast as possible, I want to use the array index for the hash status > and that means changing the simplehash API to allow that to work. > This requires something like SH_IS_BUCKET_INUSE, SH_SET_BUCKET_INUSE, > SH_SET_BUCKET_EMPTY. +1 for doing customisable "is in use" checks on day anyway, as a separate project. Not sure if any current users could shrink their structs in practice because, at a glance, the same amount of space might be used by padding anyway, but when a case like that shows up... > > 2. A bitmapset that tracks unused elements in 1, making it easy to > > find the lowest-index hole when looking for a place to put a new one > > by linear search for a 1 bit, so that we tend towards maximum density > > despite having random frees from time to time (seems good, the same > > idea is used in kernels to allocate the lowest unused file descriptor > > number). > > I didn't use Bitmapsets. I wanted the bitmaps to be allocated in the > same chunk of memory as the segments of the array. Also, because > bitmapset's nwords is variable, then they can't really do any loop > unrolling. Since in my implementation the number of bitmap words are > known at compile-time, the compiler has the flexibility to do loop > unrolling. The bitmap manipulation is one of the biggest overheads in > generichash.h. I'd prefer to keep that as fast as possible. I think my hands autocompleted "bitmapset", I really meant to write just "bitmap" as I didn't think you were using the actual thing called bitmapset, but point taken. > So, with all that. I really don't think it's a great idea to try and > have this use simplehash.h code. I plan to pursue the idea I proposed > with having seperate hash table code that is coded properly to have > stable pointers into the data rather than trying to contort > simplehash's code into working that way. Fair enough. It's not that I don't believe it's a good idea to be able to perform cache-friendly iteration over densely packed objects... that part sounds great... it's just that it's not obvious to me that it should be a *hashtable's* job to provide that access path. Perhaps I lack imagination and we'll have to agree to differ.
On Thu, 1 Jul 2021 at 13:00, Thomas Munro <thomas.munro@gmail.com> wrote:
>
> On Wed, Jun 30, 2021 at 11:14 PM David Rowley <dgrowleyml@gmail.com> wrote:
> > 1) Since I really need 8-byte buckets in the hash table to make this
> > as fast as possible, I want to use the array index for the hash status
> > and that means changing the simplehash API to allow that to work.
> > This requires something like SH_IS_BUCKET_INUSE, SH_SET_BUCKET_INUSE,
> > SH_SET_BUCKET_EMPTY.
>
> +1 for doing customisable "is in use" checks on day anyway, as a
> separate project. Not sure if any current users could shrink their
> structs in practice because, at a glance, the same amount of space
> might be used by padding anyway, but when a case like that shows up...
Yeah, I did look at that when messing with simplehash when working on
Result Cache a few months ago. I found all current usages have at
least a free byte, so I wasn't motivated to allow custom statuses to
be defined.
There's probably a small tidy up to do in simplehash maybe along with
that patch. If you look at SH_GROW, for example, you'll see various
formations of:
if (oldentry->status != SH_STATUS_IN_USE)
if (oldentry->status == SH_STATUS_IN_USE)
if (newentry->status == SH_STATUS_EMPTY)
I'm not all that sure why there's a need to distinguish !=
SH_STATUS_IN_USE from == SH_STATUS_EMPTY. I can only imagine that
Andres was messing around with tombstoning and at one point had a 3rd
status in a development version. There are some minor inefficiencies
as a result of this, e.g in SH_DELETE, the code does:
if (entry->status == SH_STATUS_EMPTY)
return false;
if (entry->status == SH_STATUS_IN_USE &&
SH_COMPARE_KEYS(tb, hash, key, entry))
That SH_STATUS_IN_USE check is always true.
David
On Tue, Jun 22, 2021 at 02:15:26AM +1200, David Rowley wrote: [...] > > I've come up with a new hash table implementation that I've called > generichash. It works similarly to simplehash in regards to the Hi David, Are you planning to work on this in this CF? This is marked as "Ready for committer" but it doesn't apply anymore. -- Jaime Casanova Director de Servicios Profesionales SystemGuards - Consultores de PostgreSQL
On Fri, 24 Sept 2021 at 20:26, Jaime Casanova <jcasanov@systemguards.com.ec> wrote: > Are you planning to work on this in this CF? > This is marked as "Ready for committer" but it doesn't apply anymore. I've attached an updated patch. Since this patch is pretty different from the one that was marked as ready for committer, I'll move this to needs review. However, I'm a bit disinclined to go ahead with this patch at all. Thomas made it quite clear it's not for the patch, and on discussing the patch with Andres, it turned out he does not like the idea either. Andres' argument was along the lines of bitmaps being slow. The hash table uses bitmaps to record which items in each segment are in use. I don't really agree with him about that, so we'd likely need some more comments to help reach a consensus about if we want this or not. Maybe Andres has more comments, so I've included him here. David
Attachment
On Mon, Sep 27, 2021 at 04:30:25PM +1300, David Rowley wrote: > On Fri, 24 Sept 2021 at 20:26, Jaime Casanova > <jcasanov@systemguards.com.ec> wrote: > > Are you planning to work on this in this CF? > > This is marked as "Ready for committer" but it doesn't apply anymore. > > I've attached an updated patch. Since this patch is pretty different > from the one that was marked as ready for committer, I'll move this to > needs review. > > However, I'm a bit disinclined to go ahead with this patch at all. > Thomas made it quite clear it's not for the patch, and on discussing > the patch with Andres, it turned out he does not like the idea either. > Andres' argument was along the lines of bitmaps being slow. The hash > table uses bitmaps to record which items in each segment are in use. I > don't really agree with him about that, so we'd likely need some more > comments to help reach a consensus about if we want this or not. > > Maybe Andres has more comments, so I've included him here. > Hi David, Thanks for the updated patch. Based on your comments I will mark this patch as withdrawn at midday of my monday unless someone objects to that. -- Jaime Casanova Director de Servicios Profesionales SystemGuards - Consultores de PostgreSQL
On Mon, 4 Oct 2021 at 20:37, Jaime Casanova <jcasanov@systemguards.com.ec> wrote: > Based on your comments I will mark this patch as withdrawn at midday of > my monday unless someone objects to that. I really think we need a hash table implementation that's faster than dynahash and supports stable pointers to elements (simplehash does not have stable pointers). I think withdrawing this won't help us move towards getting that. Thomas voiced his concerns here about having an extra hash table implementation and then also concerns that I've coded the hash table code to be fast to iterate over the hashed items. To be honest, I think both Andres and Thomas must be misunderstanding the bitmap part. I get the impression that they both think the bitmap is solely there to make interations faster, but in reality it's primarily there as a compact freelist and can also be used to make iterations over sparsely populated tables fast. For the freelist we look for 0-bits, and we look for 1-bits during iteration. I think I'd much rather talk about the concerns here than just withdraw this. Even if what I have today just serves as something to aid discussion. It would also be good to get the points Andres raised with me off-list on this thread. I think his primary concern was that bitmaps are slow, but I don't really think maintaining full pointers into freed items is going to improve the performance of this. David
Good day, David and all.
В Вт, 05/10/2021 в 11:07 +1300, David Rowley пишет:
> On Mon, 4 Oct 2021 at 20:37, Jaime Casanova
> <jcasanov@systemguards.com.ec> wrote:
> > Based on your comments I will mark this patch as withdrawn at midday
> > of
> > my monday unless someone objects to that.
>
> I really think we need a hash table implementation that's faster than
> dynahash and supports stable pointers to elements (simplehash does not
> have stable pointers). I think withdrawing this won't help us move
> towards getting that.
Agree with you. I believe densehash could replace both dynahash and
simplehash. Shared memory usages of dynahash should be reworked to
other less dynamic hash structure. So there should be densehash for
local hashes and statichash for static shared memory.
densehash slight slowness compared to simplehash in some operations
doesn't worth keeping simplehash beside densehash.
> Thomas voiced his concerns here about having an extra hash table
> implementation and then also concerns that I've coded the hash table
> code to be fast to iterate over the hashed items. To be honest, I
> think both Andres and Thomas must be misunderstanding the bitmap part.
> I get the impression that they both think the bitmap is solely there
> to make interations faster, but in reality it's primarily there as a
> compact freelist and can also be used to make iterations over sparsely
> populated tables fast. For the freelist we look for 0-bits, and we
> look for 1-bits during iteration.
I think this part is overengineered. More below.
> I think I'd much rather talk about the concerns here than just
> withdraw this. Even if what I have today just serves as something to
> aid discussion.
>
> It would also be good to get the points Andres raised with me off-list
> on this thread. I think his primary concern was that bitmaps are
> slow, but I don't really think maintaining full pointers into freed
> items is going to improve the performance of this.
>
> David
First on "quirks" in the patch I was able to see:
DH_NEXT_ZEROBIT:
DH_BITMAP_WORD mask = (~(DH_BITMAP_WORD) 0) << DH_BITNUM(prevbit);
DH_BITMAP_WORD word = ~(words[wordnum] & mask); /* flip bits */
really should be
DH_BITMAP_WORD mask = (~(DH_BITMAP_WORD) 0) << DH_BITNUM(prevbit);
DH_BITMAP_WORD word = (~words[wordnum]) & mask; /* flip bits */
But it doesn't harm because DH_NEXT_ZEROBIT is always called with
`prevbit = -1`, which is incremented to `0`. Therefore `mask` is always
`0xffff...ff`.
DH_INDEX_TO_ELEMENT
/* ensure this segment is marked as used */
should be
/* ensure this item is marked as used in the segment */
DH_GET_NEXT_UNUSED_ENTRY
/* find the first segment with an unused item */
while (seg != NULL && seg->nitems == DH_ITEMS_PER_SEGMENT)
seg = tb->segments[++segidx];
No protection for `++segidx <= tb->nsegments` . I understand, it could
not happen due to `grow_threshold` is always lesser than
`nsegment * DH_ITEMS_PER_SEGMENT`. But at least comment should be
leaved about legality of absence of check.
Now architecture notes:
I don't believe there is need for configurable DH_ITEMS_PER_SEGMENT. I
don't event believe it should be not equal to 16 (or 8). Then segment
needs only one `used_items` word, which simplifies code a lot.
There is no much difference in overhead between 1/16 and 1/256.
And then I believe, segment doesn't need both `nitems` and `used_items`.
Condition "segment is full" will be equal to `used_items == 0xffff`.
Next, I think it is better to make real free list instead of looping to
search such one. Ie add `uint32 DH_SEGMENT->next` field and maintain
list starting from `first_free_segment`.
If concern were "allocate from lower-numbered segments first", than min-
heap could be created. It is possible to create very efficient non-
balanced "binary heap" with just two fields (`uint32 left, right`).
Algorithmic PoC in Ruby language is attached.
There is also allocation concern: AllocSet tends to allocate in power2
sizes. Use of power2 segments with header (nitems/used_items) certainly
will lead to wasted 2x space on every segment if element size is also
power2, and a bit lesser for other element sizes.
There could be two workarounds:
- make segment a bit less capable (15 elements instead of 16)
- move header from segment itself to `DH_TYPE->segments` array.
I think, second option is more prefered:
- `DH_TYPE->segments[x]` inevitable accessed on every operation,
therefore why not store some info here?
- if nitems/used_items will be in `DH_TYPE->segments[x]`, then
hashtable iteration doesn't need bitmap at all - there will be no need
in `DH_TYPE->used_segments` bitmap. Absence of this bitmap will
reduce overhead on usual operations (insert/delete) as well.
Hope I was useful.
regards
Yura Sokolov
y.sokolov@postgrespro.ru
funny.falcon@gmail.com
Attachment
On Tue, Oct 05, 2021 at 11:07:48AM +1300, David Rowley wrote: > I think I'd much rather talk about the concerns here than just > withdraw this. Even if what I have today just serves as something to > aid discussion. Hmm. This last update was two months ago, and the patch does not apply anymore. I am marking it as RwF for now. -- Michael
Attachment
Hi, On 2021-04-25 03:58:38 +1200, David Rowley wrote: > Currently, we use dynahash hash tables to store the SMgrRelation so we > can perform fast lookups by RelFileNodeBackend. However, I had in mind > that a simplehash table might perform better. So I tried it... > The test case was basically inserting 100 million rows one at a time > into a hash partitioned table with 1000 partitions and 2 int columns > and a primary key on one of those columns. It was about 12GB of WAL. I > used a hash partitioned table in the hope to create a fairly > random-looking SMgr hash table access pattern. Hopefully something > similar to what might happen in the real world. A potentially stupid question: Do we actually need to do smgr lookups in this path? Afaict nearly all of the buffer lookups here will end up as cache hits in shared buffers, correct? Afaict we'll do two smgropens in a lot of paths: 1) XLogReadBufferExtended() does smgropen so it can do smgrnblocks() 2) ReadBufferWithoutRelcache() does an smgropen() It's pretty sad that we constantly do two smgropen()s to start with. But in the cache hit path we don't actually need an smgropen in either case afaict. ReadBufferWithoutRelcache() does an smgropen, because that's ReadBuffer_common()'s API. Which in turn has that API because it wants to use RelationGetSmgr() when coming from ReadBufferExtended(). It doesn't seem awful to allow smgr to be NULL and to pass in the rlocator in addition. XLogReadBufferExtended() does an smgropen() so it can do smgrcreate() and smgrnblocks(). But neither is needed in the cache hit case, I think. We could do a "read-only" lookup in s_b, and only do the current logic in case that fails? Greetings, Andres Freund