On Tue, 22 Jun 2021 at 14:49, Thomas Munro <thomas.munro@gmail.com> wrote:
> One idea I had at the time is that the right number of hash table
> implementations in our tree is two: one for chaining (like dynahash)
> and one for open addressing/probing (like simplehash), and that
> everything else should be hoisted out (locking, partitioning) or made
> into template parameters through the generic programming technique
> that simplehash.h has demonstrated (allocators, magic pointer type for
> internal pointers, plus of course the inlinable ops). But that was
> before we'd really fully adopted the idea of this style of template
> code. (I also assumed the weird memory stuff would be temporary and
> we'd move to threads, but that's another topic for another thread.)
> It seems like you'd disagree with this, and you'd say the right number
> is three. But it's also possible to argue for one...
I guess we could also ask ourselves how many join algorithms we need.
We have 3.something. None of which is perfect for every job. That's
why we have multiple. I wonder why this is different.
Just for anyone who missed it, the reason I wrote generichash and
didn't just use simplehash is that it's not possible to point any
other pointers to a simplehash table because these get shuffled around
during insert/delete. For the locallock stuff over on [1] we need the
LOCALLOCK object to be stable as we point to these from the resource
manager. Likewise here for SMgr, we point to SMgrRelationData objects
from RelationData. We can't have the hash table implementation swap
these out from under us.
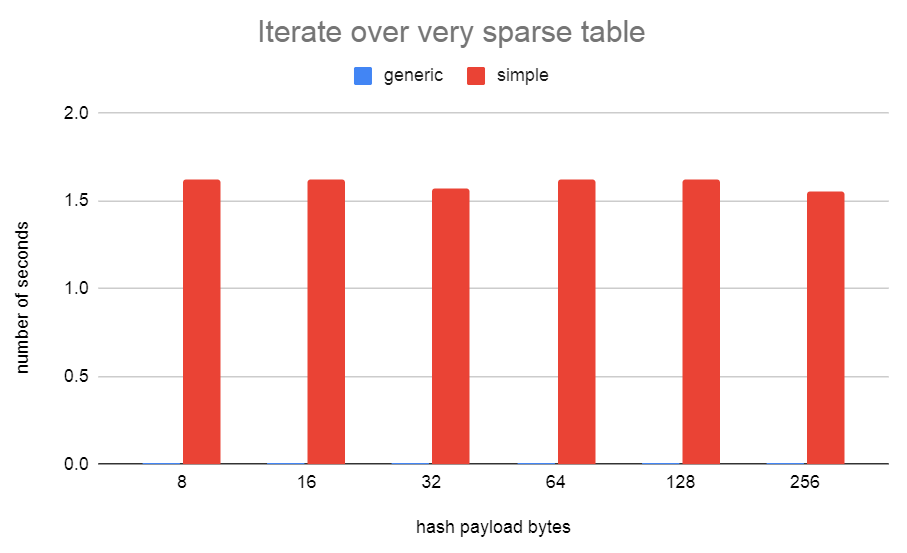
Additionally, I coded generichash to fix the very slow hash seq scan
problem that we have in LockReleaseAll() when a transaction has run in
the backend that took lots of locks and caused the locallock hash
table to bloat. Later when we run transactions that just grab a few
locks it takes us a relatively long time to do LockReleaseAll()
because we have to skip all those empty hash table buckets in the
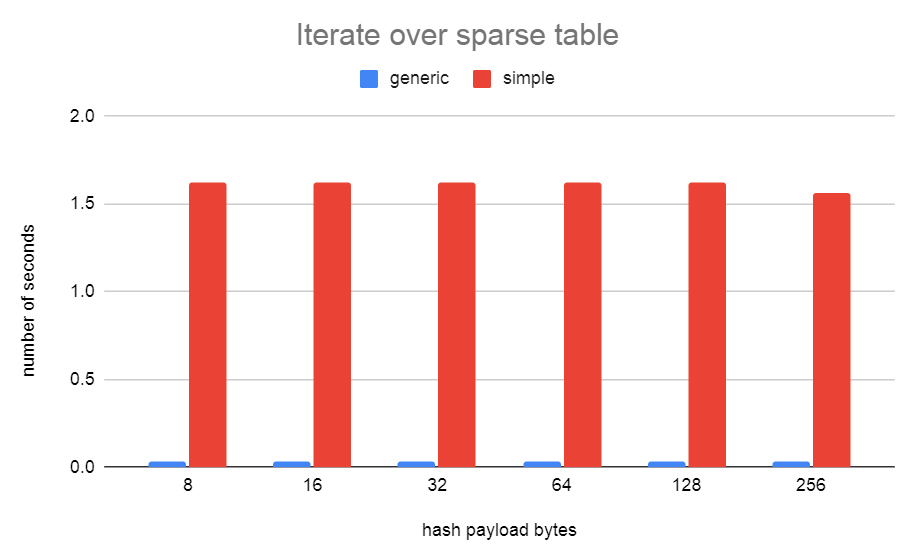
bloated table. (See iterate_sparse_table.png and
iterate_very_sparse_table.png)
I just finished writing a benchmark suite for comparing simplehash to
generichash. I did this as a standalone C program. See the attached
hashbench.tar.gz. You can run the tests with just ./test.sh. Just be
careful if compiling manually as test.sh passes -DHAVE__BUILTIN_CTZ
-DHAVE_LONG_INT_64 which have quite a big effect on the performance of
generichash due to it using pg_rightmost_one_pos64() when searching
the bitmaps for used items.
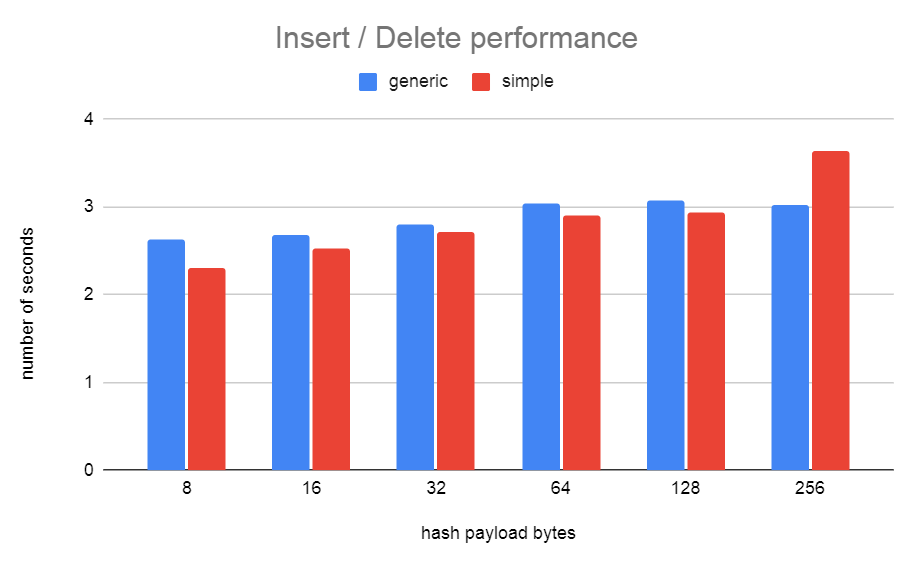
I've attached graphs showing the results I got from running test.sh on
my AMD 3990x machine. Because the size of the struct being hashed
matters a lot to the performance of simplehash, I ran tests with 8,
16, 32, 64, 128, 256-byte structs. This matters because simplehash
does memcpy() on this when moving stuff around during insert/delere.
The size of the "payload" matters a bit less to generichash.
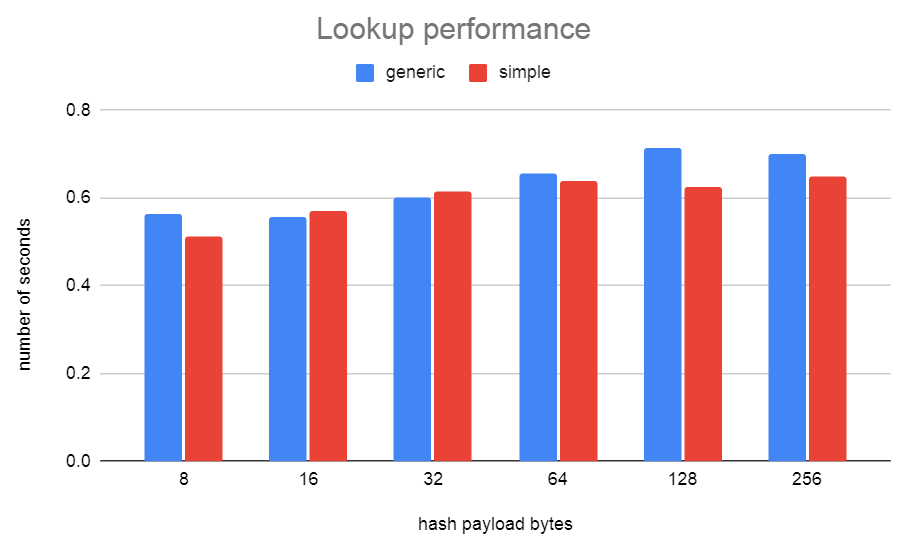
You can see that the lookup performance of generichash very similar to
simplehash. The insert/delete test shows the generichash is very
slightly slower from 8-128 bytes but wins when simplehash has to
tackle 256 bytes of data.
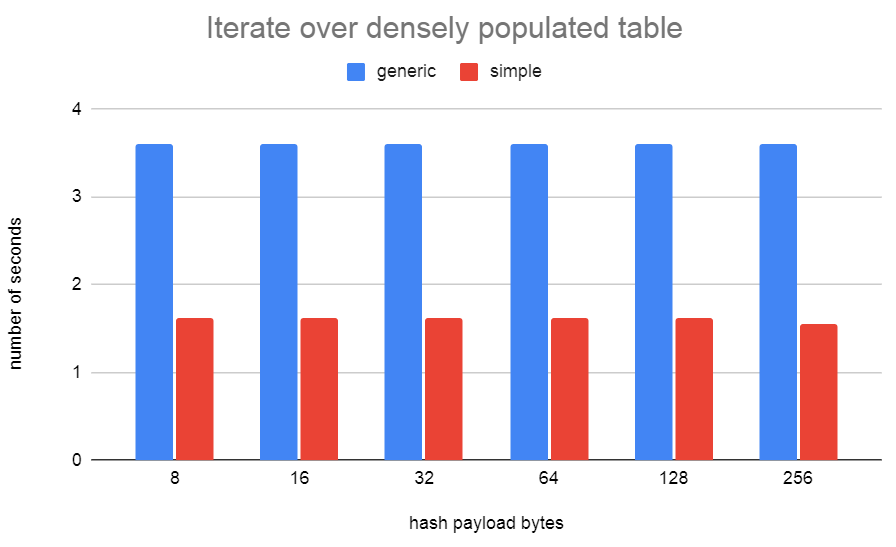
The seq scan tests show that simplehash is better when the table is
full of items, but it's terrible when bucket array is only sparsely
populated. I needed generichash to be fast at this for
LockReleaseAll(). I might be able to speed up generichash iteration
when the table is full a bit more by checking if the segment is full
and skipping to the next item rather than consulting the bitmap. That
will slow down the sparse case a bit though. Not sure if it's worth
it.
Anyway, what I hope to show here is that there is no one-size-fits-all
hash table.
David
[1] https://www.postgresql.org/message-id/CAApHDvoKqWRxw5nnUPZ8+mAJKHPOPxYGoY1gQdh0WeS4+biVhg@mail.gmail.com
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}