Thread: General purpose hashing func in pgbench
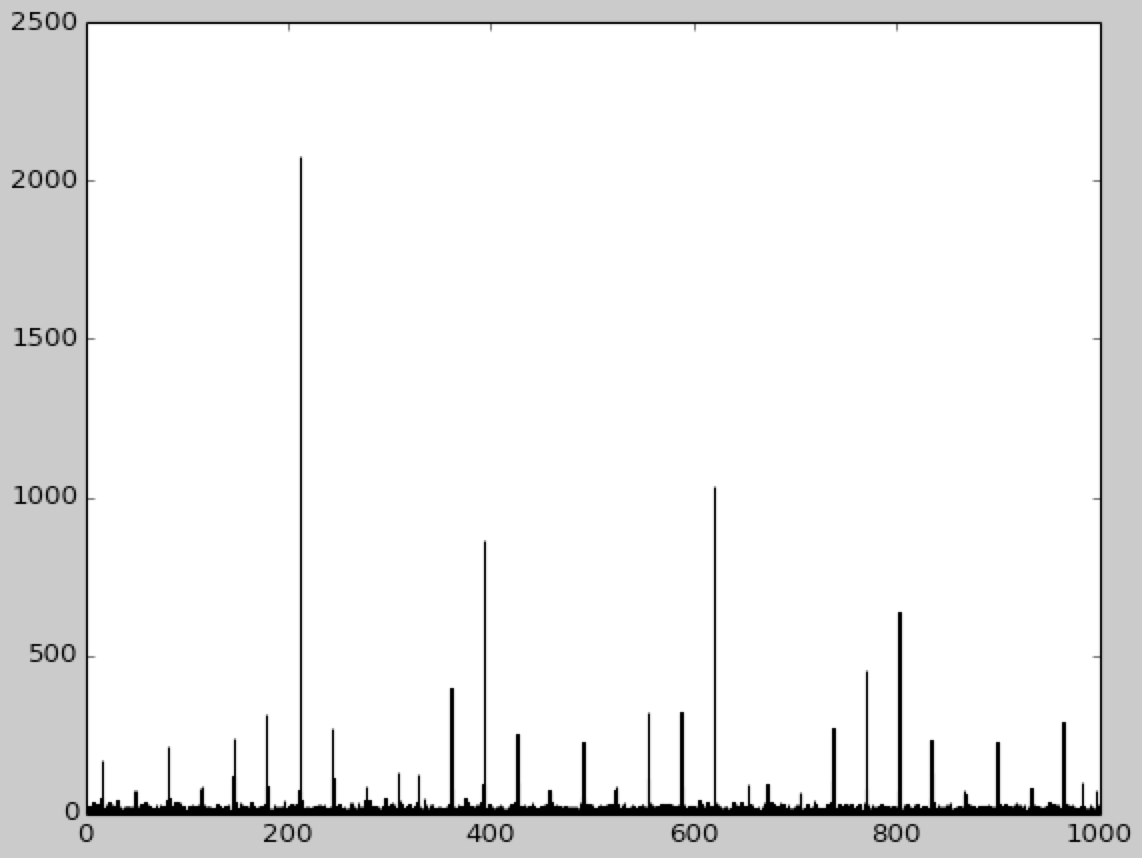
Hi hackers, Following up the recent discussion on zipfian distribution I was trying to reproduce some YCSB-like workloads. As this paper [1] describes, YCSB uses zipfian distribution to generate keys in order simulate intensive load on small number of records as it happens in real world applications (e.g. blogs). One problem is that most popular records keys are clustered together. To scatter them across the keyspace authors use hashing, the FNV-1a hash function in particular [2]. I've read Fabien Coelho's thread on additional operators and functions. Generally it could be possible to implement some basic hashing algorithms right in a pgbench script using just bitwise and arithmetic operators. But should we probably provide users with some general purpose hash function? The attached patch introduces hash() function which implements FNV-1a as an example of such hashing algorithm. There are also couple of images in the attachement that I have got from visualizing original zipfian distribution and the hashed one. Usage example: In psql: create table abc as select generate_series(0, 999) as a, 0 as b; pgbench script: \set rnd random_zipfian(0, 1000000, 0.99) \set key abs(hash(:rnd)) % 1000 begin; update abc set b = b + 1 where a = :key; end; Any thoughts or suggestions? [1] http://www.brianfrankcooper.net/home/publications/ycsb.pdf [2] https://en.wikipedia.org/wiki/Fowler–Noll–Vo_hash_function Thanks! -- Ildar Musin Postgres Professional: http://www.postgrespro.com Russian Postgres Company
Attachment
{kind=link}
{kind=link}
Hello Ildar, > Following up the recent discussion on zipfian distribution I was trying > to reproduce some YCSB-like workloads. As this paper [1] describes, YCSB > uses zipfian distribution to generate keys in order simulate intensive > load on small number of records as it happens in real world applications > (e.g. blogs). One problem is that most popular records keys are > clustered together. To scatter them across the keyspace authors use > hashing, the FNV-1a hash function in particular [2]. Yes, clustering is an issue for realistic load tests and may influence the resulting measured performance unduly. > I've read Fabien Coelho's thread on additional operators and functions. > Generally it could be possible to implement some basic hashing > algorithms right in a pgbench script using just bitwise and arithmetic > operators. But should we probably provide users with some general > purpose hash function? The problem I see with hash functions is that it generates collisions, which is an undesirable effect when dealing with keys as it biases the initial randomization. Thus I intend to submit a parametric pseudo-random permutation function, some day. As I foresaw that it might require some arguing I did not include the function in the operators and functions collection I submitted, so as not to slow down the inclusion process. Given that the patch was submitted over 20 months ago and is still stuck in the CF, that was a misjudgement:-) This is no no way a point against including one/some hash functions, especially if they actually appear in a benchmark. > The attached patch introduces hash() function which implements FNV-1a as > an example of such hashing algorithm. There are also couple of images in > the attachement that I have got from visualizing original zipfian > distribution and the hashed one. Usage example: > In psql: > create table abc as select generate_series(0, 999) as a, 0 as b; > > pgbench script: > \set rnd random_zipfian(0, 1000000, 0.99) > \set key abs(hash(:rnd)) % 1000 > begin; > update abc set b = b + 1 where a = :key; > end; > > Any thoughts or suggestions? As there may be several hash functions included in the long run. I'd suggest that the hash function should be named more precisely, eg "hash_fnv1a". The image looks like the distribution is more regularly scattered than actually randomized... Maybe this is because the first highest 256 values are really scattered by the process multiply/modulo process. Or maybe this is an optical effect? ISTM that there are undesired utf8 chars in a comment. Should be kept ASCII. I would put the actual hash computation in a separate function rather than inlined in the evaluator. Add the submission to the next CF? -- Fabien.
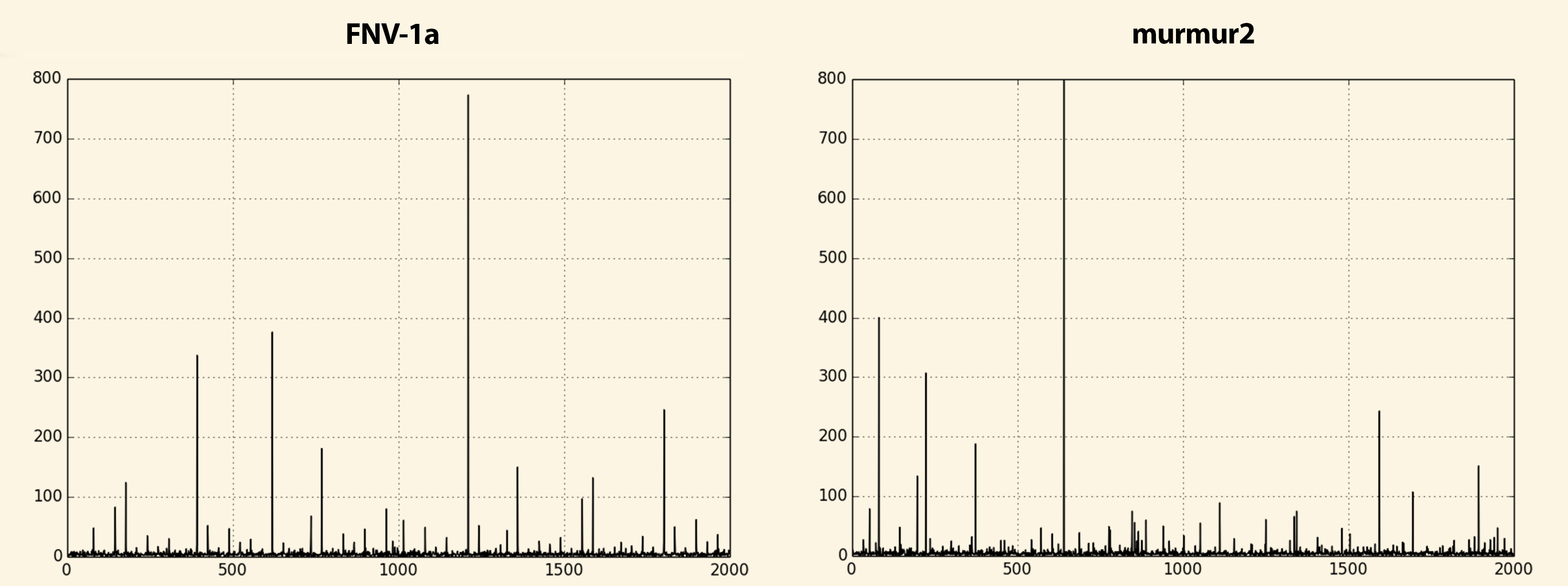
Hello Fabien, 20/12/2017 10:36, Fabien COELHO пишет: > As there may be several hash functions included in the long run. I'd > suggest that the hash function should be named more precisely, eg > "hash_fnv1a". Done. Added "hash_murmur2" too, see below. > The image looks like the distribution is more regularly scattered than > actually randomized... Maybe this is because the first highest 256 > values are really scattered by the process multiply/modulo process. Or > maybe this is an optical effect? > After your comment I searched the internet for different hashing algorithms comparison wrt randomness and found an interesting post at stackexchange [1]. According to author's research the murmur2 algorithm has the best randomness rate (among those he tested). So I implemented it (using original code by Austin Appleby as a reference [2]) and conducted few experiments. Results are in attachement. Indeed, comparing to murmur2 the FNV distribution seems pretty regular. > ISTM that there are undesired utf8 chars in a comment. Should be kept > ASCII. Oops, I copy-pasted the algorithm name from wikipedia, didn't notice there were some fancy unicode hyphens. > I would put the actual hash computation in a separate function rather > than inlined in the evaluator. Done. > Add the submission to the next CF? I think it is not commitfest ready yet -- I need to add some documentation and tests first. [1] https://softwareengineering.stackexchange.com/questions/49550/which-hashing-algorithm-is-best-for-uniqueness-and-speed [2] https://github.com/aappleby/smhasher/blob/master/src/MurmurHash2.cpp -- Ildar Musin Postgres Professional: http://www.postgrespro.com Russian Postgres Company
Attachment
{kind=link}
{kind=link}
>> Add the submission to the next CF? > I think it is not commitfest ready yet -- I need to add some > documentation and tests first. It just helps to that the thread is referenced, and the review process has started anyway. -- Fabien.
21/12/2017 15:44, Fabien COELHO пишет: > >>> Add the submission to the next CF? >> I think it is not commitfest ready yet -- I need to add some >> documentation and tests first. > > It just helps to that the thread is referenced, and the review process > has started anyway. > You are right, I've submitted the patch to upcoming commitfest. Thanks! -- Ildar Musin Postgres Professional: http://www.postgrespro.com Russian Postgres Company
> I think it is not commitfest ready yet -- I need to add some > documentation and tests first. Yes, doc & test are missing. From your figures, the murmur2 algorithm output looks way better. I'm wondering whether it makes sense to provide a bad hash function if a good/better one is available, unless the bad one actually appears in some benchmark... So I would suggest to remove fnv1a. One implementation put constants in defines, the other one uses "const int". The practice in pgbench seems to use defines (eg MIN_GAUSSIAN_PARAM...), so I would suggest to stick to this style. I'm wondering whether "hash" should be a shorthand for one hash functions, as a provided default chosen for its quality and efficiency. -- Fabien.
21/12/2017 18:26, Fabien COELHO пишет: > >> I think it is not commitfest ready yet -- I need to add some >> documentation and tests first. > > Yes, doc & test are missing. > > From your figures, the murmur2 algorithm output looks way better. I'm > wondering whether it makes sense to provide a bad hash function if a > good/better one is available, unless the bad one actually appears in > some benchmark... So I would suggest to remove fnv1a. Actually the "bad" one appears in YCSB. But if we should choose the only one I would stick to murmur too given it provides better results while having similar computational complexity. > > One implementation put constants in defines, the other one uses "const > int". The practice in pgbench seems to use defines (eg > MIN_GAUSSIAN_PARAM...), so I would suggest to stick to this style. That had been my intention from the start until I coded it that way and it looked ugly and hard to read (IMHO), like: k *= MURMUR2_M; k ^= k >> MURMUR2_R; k *= MURMUR2_M; result ^= k; result *= MURMUR2_M; ...etc. And besides it is not a parameter to be tuned and not something someone would ever want to change; it appears in just a single function. So I'd better leave it the way it is. Actually I was thinking to do the same to fnv1a too : ) -- Ildar Musin Postgres Professional: http://www.postgrespro.com Russian Postgres Company
Hello Ildar,
> Actually the "bad" one appears in YCSB.
Fine. Then it must be kept, whatever its quality.
> But if we should choose the only one I would stick to murmur too given
> it provides better results while having similar computational
> complexity.
No. Keep both as there is a justification for the bad one. Just make
"hash()" default to a good one.
>> One implementation put constants in defines, the other one uses "const
>> int". [...]
> [...] it looked ugly and hard to read (IMHO), like:
>
> k *= MURMUR2_M;
> k ^= k >> MURMUR2_R;
> k *= MURMUR2_M;
> result ^= k;
> result *= MURMUR2_M;
Yep. The ugliness is significantly linked to the choice of name. With
MM2_MUL and MM2_ROT ISTM that it is more readable:
> k *= MM2_MUL;
> k ^= k >> MM2_ROT;
> k *= MM2_MUL;
> result ^= k;
> result *= MM2_MUL;
> [...] So I'd better leave it the way it is. Actually I was thinking to
> do the same to fnv1a too : )
I think that the implementation style should be homogeneous, so I'd
suggest at least to stick to one style.
I noticed from the source of all human knowledege (aka Wikipedia:-) that
there seems to be a murmur3 successor. Have you considered it? One good
reason to skip it would be that the implementation is long and complex.
I'm not sure about a 8-byte input simplified version.
Just a question: Have you looked at SipHash24?
https://en.wikipedia.org/wiki/SipHash
The interesting point is that it can use a key and seems somehow
cryptographically secure, for a similar cost. However the how to decide
for/control the key is unclear.
--
Fabien.
Hello Fabien, 24/12/2017 11:12, Fabien COELHO пишет: > > Yep. The ugliness is significantly linked to the choice of name. With > MM2_MUL and MM2_ROT ISTM that it is more readable: > >> k *= MM2_MUL; >> k ^= k >> MM2_ROT; >> k *= MM2_MUL; >> result ^= k; >> result *= MM2_MUL; Ok, will do. > >> [...] So I'd better leave it the way it is. Actually I was thinking >> to do the same to fnv1a too : ) > > I think that the implementation style should be homogeneous, so I'd > suggest at least to stick to one style. > > I noticed from the source of all human knowledege (aka Wikipedia:-) > that there seems to be a murmur3 successor. Have you considered it? > One good reason to skip it would be that the implementation is long > and complex. I'm not sure about a 8-byte input simplified version. Murmur2 naturally supports 8-byte data. Murmur3 has 32- and 128-bit versions. So to handle int64 I could 1) split input value into two halfs and combine somehow the results of 32 bit version or 2) use 128-bit version and discard higher bytes. Btw, postgres core already has a 32bit murmur3 implementation, but it only uses the finalization part of algorithm (see murmurhash32). As my colleague Yura Sokolov told me in a recent conversation it alone provides pretty good randomization. I haven't tried it yet though. > > Just a question: Have you looked at SipHash24? > > https://en.wikipedia.org/wiki/SipHash > > The interesting point is that it can use a key and seems somehow > cryptographically secure, for a similar cost. However the how to > decide for/control the key is unclear. > Not yet. As I can understand from the wiki its main feature is to prevent attacks with crafted input data. How can it be useful in benchmarking? Unless it shows superior performance and randomization. -- Ildar Musin Postgres Professional: http://www.postgrespro.com Russian Postgres Company
Hello, >> I noticed from the source of all human knowledege (aka Wikipedia:-) >> that there seems to be a murmur3 successor. Have you considered it? >> One good reason to skip it would be that the implementation is long >> and complex. I'm not sure about a 8-byte input simplified version. > Murmur2 naturally supports 8-byte data. Murmur3 has 32- and 128-bit > versions. Ok. So it would make sense to keep the 64 bit murmur2 version. Pgbench ints are 64 bits, seems logical to keep them that way, so 32 bits versions do not look too interesting. >> Just a question: Have you looked at SipHash24? > > Not yet. As I can understand from the wiki its main feature is to > prevent attacks with crafted input data. How can it be useful in > benchmarking? No and yes:-) The attack prevention is pretty useless in the context. However, the key can be used if controlled so that different values do not have the same randomization in different part of the script, so as to avoid using the same patterns for different things if not desirable. For the pgbench pseudo-random permutation I'm looking at, the key can be specified to control whether the same pattern or not should be used. -- Fabien.
25/12/2017 17:12, Fabien COELHO пишет: > > However, the key can be used if controlled so that different values do > not have the same randomization in different part of the script, so as > to avoid using the same patterns for different things if not desirable. Original murmur algorithm accepts seed as a parameter, which can be used for this purpose. I used value itself as a seed in the patch, but I can turn it into a function argument. > > For the pgbench pseudo-random permutation I'm looking at, the key can > be specified to control whether the same pattern or not should be used. > Just curious, which algorithm are you intended to choose? -- Ildar Musin Postgres Professional: http://www.postgrespro.com Russian Postgres Company
Hello, >> However, the key can be used if controlled so that different values do >> not have the same randomization in different part of the script, so as >> to avoid using the same patterns for different things if not desirable. > > Original murmur algorithm accepts seed as a parameter, which can be used > for this purpose. I used value itself as a seed in the patch, but I can > turn it into a function argument. Hmmm. Possibly. However it needs a default, something like x = hash(v[, key]) with key some pseudo-random value? >> For the pgbench pseudo-random permutation I'm looking at, the key can >> be specified to control whether the same pattern or not should be used. >> > Just curious, which algorithm are you intended to choose? I have found nothing convincing, so I'm inventing. Most "permutation" functions are really cryptographic cyphers which are quite expensive, and require powers of two, which is not what is needed. ISTM that there are some constructs to deal with arbitrary sizes based on cryptographic functions, but that would make it too expensive for the purpose. Currently I use the key as a seed for a cheap a prng, two rounds of overlapping (to deal with non power of two) xor (from the prng output) and prime-multiply-modulo to scatter the value. See attached work in progress. If you have a pointer for a good and cheap generic (any size) keyed permutation, feel free to share it. -- Fabien.
Attachment
Fabien COELHO wrote: > Most "permutation" functions are really cryptographic cyphers which are > quite expensive, and require powers of two, which is not what is needed. > ISTM that there are some constructs to deal with arbitrary sizes based on > cryptographic functions, but that would make it too expensive for the > purpose. FWIW, you might have a look at the permuteseq extension: https://pgxn.org/dist/permuteseq It permutes an arbitrary range of 64-bit integers into itself, with a user-supplied key as the seed. Outputs are coerced into the desired range by using the smallest possible power of two for the Feistel cypher's block size, and then cycle-walking over the results. Best regards, -- Daniel Vérité PostgreSQL-powered mailer: http://www.manitou-mail.org Twitter: @DanielVerite
Bonjour Daniel, >> Most "permutation" functions are really cryptographic cyphers which are >> quite expensive, and require powers of two, which is not what is needed. >> ISTM that there are some constructs to deal with arbitrary sizes based on >> cryptographic functions, but that would make it too expensive for the >> purpose. > > FWIW, you might have a look at the permuteseq extension: > https://pgxn.org/dist/permuteseq > It permutes an arbitrary range of 64-bit integers into itself, > with a user-supplied key as the seed. > Outputs are coerced into the desired range by using the > smallest possible power of two for the Feistel cypher's > block size, and then cycle-walking over the results. Thanks for the pointer. I must admit that I do not like much the iterative "cycle walking" approach because it can be much more expensive for some values, and it makes the cost non uniform. Without that point, the overall encryption looks quite costly. For testing purposes, I'm looking for "pretty cheap" and "good enough", and for that I'm ready to forsake "cryptographic":-) Thanks again, it made an interesting read! -- Fabien.
Greetings Ildar, * Fabien COELHO (coelho@cri.ensmp.fr) wrote: > >>I noticed from the source of all human knowledege (aka Wikipedia:-) > >>that there seems to be a murmur3 successor. Have you considered it? > >>One good reason to skip it would be that the implementation is long > >>and complex. I'm not sure about a 8-byte input simplified version. > >Murmur2 naturally supports 8-byte data. Murmur3 has 32- and 128-bit > >versions. > > Ok. > > So it would make sense to keep the 64 bit murmur2 version. > > Pgbench ints are 64 bits, seems logical to keep them that way, so 32 bits > versions do not look too interesting. This sounds like it was settled and the patch needs updating with these changes, and with documentation and tests added. While the commitfest is still pretty early on, I would suggest trying to find time soon to update the patch and resubmit it, so it can get another review and hopefully be included during this commitfest. Also, I've not checked myself, but the patch appears to be failing for http://commitfest.cputube.org/ so it likely also needs a rebase. Thanks! Stephen
Attachment
Hello Fabien, 25/12/2017 19:17, Fabien COELHO пишет: > >>> However, the key can be used if controlled so that different values do >>> not have the same randomization in different part of the script, so as >>> to avoid using the same patterns for different things if not desirable. >> >> Original murmur algorithm accepts seed as a parameter, which can be used >> for this purpose. I used value itself as a seed in the patch, but I can >> turn it into a function argument. > > Hmmm. Possibly. However it needs a default, something like > > x = hash(v[, key]) > > with key some pseudo-random value? > Sorry for a long delay. I've added hash() function which is just an alias for murmur2. I've also utilized variable arguments feature from least()/greates() functions to make optional seed parameter, but I consider this as a hack. Should we probably add some infrastructure for optional arguments? Docs and tests are on their way. Thanks! -- Ildar Musin Postgres Professional: http://www.postgrespro.com Russian Postgres Company
Attachment
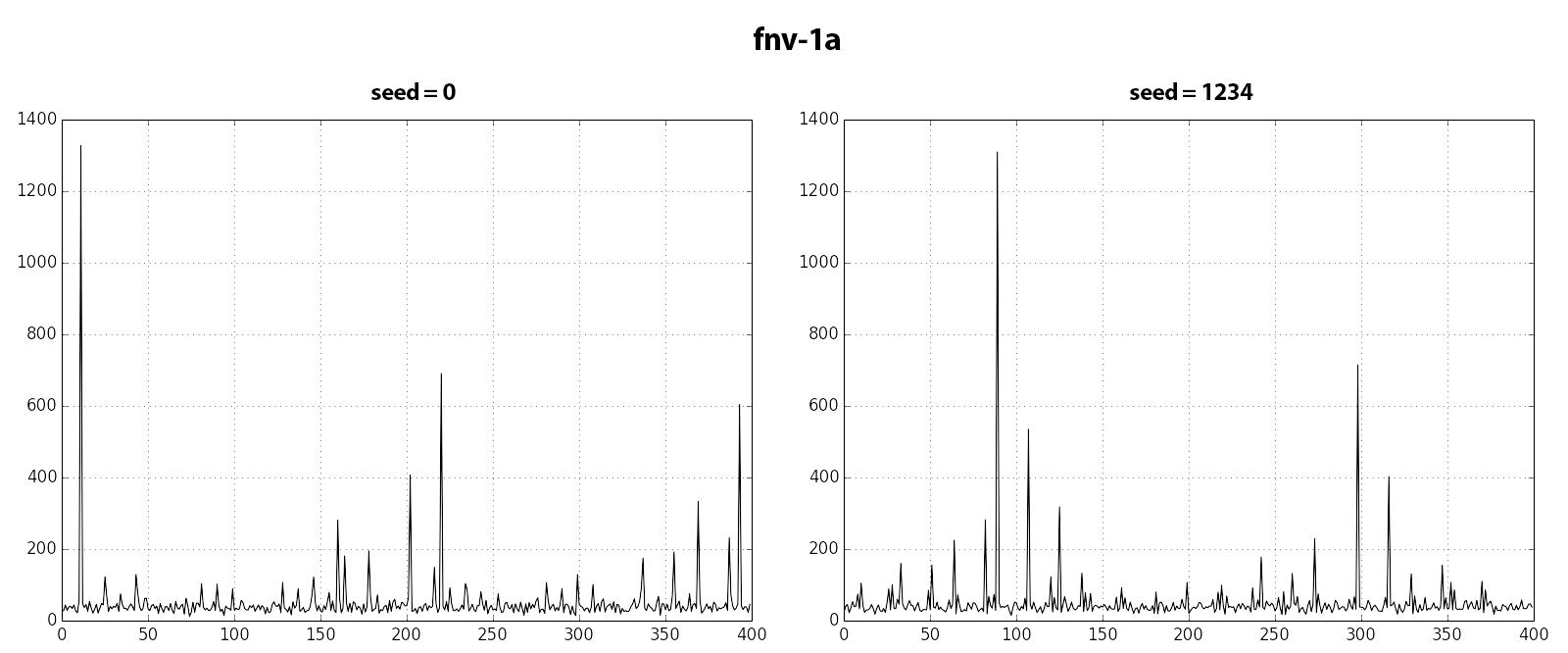
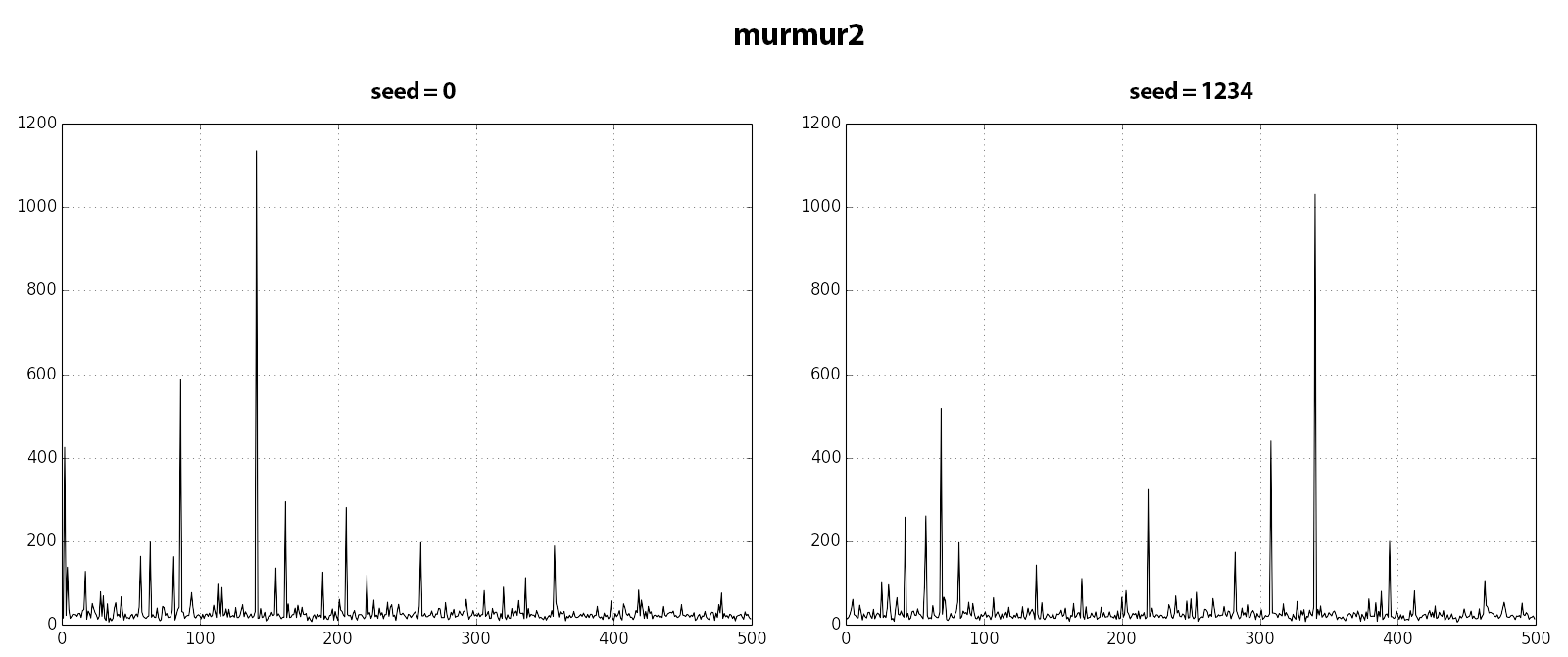
09/01/2018 19:22, Ildar Musin пишет: > Hello Fabien, > > > 25/12/2017 19:17, Fabien COELHO пишет: >>>> However, the key can be used if controlled so that different values do >>>> not have the same randomization in different part of the script, so as >>>> to avoid using the same patterns for different things if not desirable. >>> Original murmur algorithm accepts seed as a parameter, which can be used >>> for this purpose. I used value itself as a seed in the patch, but I can >>> turn it into a function argument. >> Hmmm. Possibly. However it needs a default, something like >> >> x = hash(v[, key]) >> >> with key some pseudo-random value? >> > Sorry for a long delay. I've added hash() function which is just an > alias for murmur2. I've also utilized variable arguments feature from > least()/greates() functions to make optional seed parameter, but I > consider this as a hack. Should we probably add some infrastructure for > optional arguments? Docs and tests are on their way. > > Thanks! > I forgot to attach couple of fresh charts that show how distribution changes with respect to seed. -- Ildar Musin Postgres Professional: http://www.postgrespro.com Russian Postgres Company
Attachment
{kind=link}
{kind=link}
Hello Ildar, > Sorry for a long delay. I've added hash() function which is just an > alias for murmur2. I've also utilized variable arguments feature from > least()/greates() functions to make optional seed parameter, but I > consider this as a hack. Patch needs a rebase after Teodor push for a set of pgbench functions. > Should we probably add some infrastructure for optional arguments? You can look at the handling of "CASE" which may or may not have an "ELSE" clause. I'd suggest you use a new negative argument with the special meaning for hash, and create the seed value when missing when building the function, so as to simplify the executor code. Instead of 0, I'd consider providing a random default so that the hashing behavior is not the same from one run to the next. What do you think? Like the previous version, murmur2 with seed looks much more random than fnv with seed... -- Fabien.
09/01/2018 23:11, Fabien COELHO пишет: > > Hello Ildar, > >> Sorry for a long delay. I've added hash() function which is just an >> alias for murmur2. I've also utilized variable arguments feature from >> least()/greates() functions to make optional seed parameter, but I >> consider this as a hack. > > Patch needs a rebase after Teodor push for a set of pgbench functions. Done. Congratulations on your patch finally being committed : ) > >> Should we probably add some infrastructure for optional arguments? > > You can look at the handling of "CASE" which may or may not have an > "ELSE" clause. > > I'd suggest you use a new negative argument with the special meaning > for hash, and create the seed value when missing when building the > function, so as to simplify the executor code. Added a new nargs option -3 for hash functions and moved arguments check to parser. It's starting to look a bit odd and I'm thinking about replacing bare numbers (-1, -2, -3) with #defined macros. E.g.: #define PGBENCH_NARGS_VARIABLE (-1) #define PGBENCH_NARGS_CASE (-2) #define PGBENCH_NARGS_HASH (-3) > > Instead of 0, I'd consider providing a random default so that the > hashing behavior is not the same from one run to the next. What do you > think? > Makes sence since each thread is also initializes its random_state with random numbers before start. So I added global variable 'hash_seed' and initialize it with random() before threads spawned. > Like the previous version, murmur2 with seed looks much more random > than fnv with seed... > -- Ildar Musin Postgres Professional: http://www.postgrespro.com Russian Postgres Company
10/01/2018 16:35, Ildar Musin пишет: > 09/01/2018 23:11, Fabien COELHO пишет: >> Hello Ildar, >> >>> Sorry for a long delay. I've added hash() function which is just an >>> alias for murmur2. I've also utilized variable arguments feature from >>> least()/greates() functions to make optional seed parameter, but I >>> consider this as a hack. >> Patch needs a rebase after Teodor push for a set of pgbench functions. > Done. Congratulations on your patch finally being committed : ) >>> Should we probably add some infrastructure for optional arguments? >> You can look at the handling of "CASE" which may or may not have an >> "ELSE" clause. >> >> I'd suggest you use a new negative argument with the special meaning >> for hash, and create the seed value when missing when building the >> function, so as to simplify the executor code. > Added a new nargs option -3 for hash functions and moved arguments check > to parser. It's starting to look a bit odd and I'm thinking about > replacing bare numbers (-1, -2, -3) with #defined macros. E.g.: > > #define PGBENCH_NARGS_VARIABLE (-1) > #define PGBENCH_NARGS_CASE (-2) > #define PGBENCH_NARGS_HASH (-3) >> Instead of 0, I'd consider providing a random default so that the >> hashing behavior is not the same from one run to the next. What do you >> think? >> > Makes sence since each thread is also initializes its random_state with > random numbers before start. So I added global variable 'hash_seed' and > initialize it with random() before threads spawned. >> Like the previous version, murmur2 with seed looks much more random >> than fnv with seed... >> Sorry, here is the patch -- Ildar Musin Postgres Professional: http://www.postgrespro.com Russian Postgres Company
Attachment
Hello Ildar, >> Patch needs a rebase after Teodor push for a set of pgbench functions. > Done. Congratulations on your patch finally being committed : ) Over 21 months... I hope that pgbench will have hash functions sooner:-) >>> Should we probably add some infrastructure for optional arguments? >> >> You can look at the handling of "CASE" which may or may not have an >> "ELSE" clause. >> >> I'd suggest you use a new negative argument with the special meaning >> for hash, and create the seed value when missing when building the >> function, so as to simplify the executor code. > Added a new nargs option -3 for hash functions and moved arguments check > to parser. It's starting to look a bit odd and I'm thinking about > replacing bare numbers (-1, -2, -3) with #defined macros. E.g.: > > #define PGBENCH_NARGS_VARIABLE (-1) > #define PGBENCH_NARGS_CASE (-2) > #define PGBENCH_NARGS_HASH (-3) Yes, I'm more than fine with improving readability. >> Instead of 0, I'd consider providing a random default so that the >> hashing behavior is not the same from one run to the next. What do you >> think? > > Makes sence since each thread is also initializes its random_state with > random numbers before start. So I added global variable 'hash_seed' and > initialize it with random() before threads spawned. Hmm. I do not think that we should want a shared seed value. The seed should be different for each call so as to avoid undesired correlations. If wanted, correlation could be obtained by using an explicit identical seed. ISTM that the best way to add the seed is to call random() when the second arg is missing in make_func. Also, this means that the executor would always get its two arguments, so it would simplify the code there. -- Fabien.
>>> Patch needs a rebase after Teodor push for a set of pgbench functions. >> Done. Congratulations on your patch finally being committed : ) I forgot: please provide a doc & some coverage tests as well! -- Fabien.
Hello Fabien, 10/01/2018 21:42, Fabien COELHO пишет: >>>> Should we probably add some infrastructure for optional arguments? >>> >>> You can look at the handling of "CASE" which may or may not have an >>> "ELSE" clause. >>> >>> I'd suggest you use a new negative argument with the special meaning >>> for hash, and create the seed value when missing when building the >>> function, so as to simplify the executor code. > >> Added a new nargs option -3 for hash functions and moved arguments check >> to parser. It's starting to look a bit odd and I'm thinking about >> replacing bare numbers (-1, -2, -3) with #defined macros. E.g.: >> >> #define PGBENCH_NARGS_VARIABLE (-1) >> #define PGBENCH_NARGS_CASE (-2) >> #define PGBENCH_NARGS_HASH (-3) > > Yes, I'm more than fine with improving readability. > Added macros. >>> Instead of 0, I'd consider providing a random default so that the >>> hashing behavior is not the same from one run to the next. What do you >>> think? >> >> Makes sence since each thread is also initializes its random_state with >> random numbers before start. So I added global variable 'hash_seed' and >> initialize it with random() before threads spawned. > > Hmm. I do not think that we should want a shared seed value. The seed > should be different for each call so as to avoid undesired > correlations. If wanted, correlation could be obtained by using an > explicit identical seed. Probably I'm missing something but I cannot see the point. If we change seed on every invokation then we get uniform-like distribution (see attached image). And we don't get the same hash value for the same input which is the whole point of hash functions. Maybe I didn't understand you correctly. Anyway I've attached a new version with some tests and docs added. -- Ildar Musin Postgres Professional: http://www.postgrespro.com Russian Postgres Company
Attachment
{kind=link}
10/01/2018 21:42, Fabien COELHO пишет: > > Hmm. I do not think that we should want a shared seed value. The seed > should be different for each call so as to avoid undesired > correlations. If wanted, correlation could be obtained by using an > explicit identical seed. > > ISTM that the best way to add the seed is to call random() when the > second arg is missing in make_func. Also, this means that the executor > would always get its two arguments, so it would simplify the code there. > Ok, I think I understand what you meant. You meant the case like following: \set x random(1, 100) \set h1 hash(:x) \set h2 hash(:x) -- will have different seed from h1 so that different instances of hash function within one script would have different seeds. Yes, that is a good idea, I can do that. -- Ildar Musin Postgres Professional: http://www.postgrespro.com Russian Postgres Company
Hello Fabien, 11/01/2018 19:21, Ildar Musin пишет: > > 10/01/2018 21:42, Fabien COELHO пишет: >> Hmm. I do not think that we should want a shared seed value. The seed >> should be different for each call so as to avoid undesired >> correlations. If wanted, correlation could be obtained by using an >> explicit identical seed. >> >> ISTM that the best way to add the seed is to call random() when the >> second arg is missing in make_func. Also, this means that the executor >> would always get its two arguments, so it would simplify the code there. >> > Ok, I think I understand what you meant. You meant the case like following: > > \set x random(1, 100) > \set h1 hash(:x) > \set h2 hash(:x) -- will have different seed from h1 > > so that different instances of hash function within one script would > have different seeds. Yes, that is a good idea, I can do that. > Added this feature in attached patch. But on a second thought this could be something that user won't expect. For example, they may want to run pgbench with two scripts: - the first one updates row by key that is a hashed random_zipfian value; - the second one reads row by key generated the same way (that is actually what YCSB workloads A and B do) It feels natural to write something like this: \set rnd random_zipfian(0, 1000000, 0.99) \set key abs(hash(:rnd)) % 1000 in both scripts and expect that they both would have the same distribution. But they wouldn't. We could of course describe this implicit behaviour in documentation, but ISTM that shared seed would be more clear. Thanks! -- Ildar Musin Postgres Professional: http://www.postgrespro.com Russian Postgres Company
Attachment
Hello Ildar, >> Hmm. I do not think that we should want a shared seed value. The seed >> should be different for each call so as to avoid undesired >> correlations. If wanted, correlation could be obtained by using an >> explicit identical seed. > > Probably I'm missing something but I cannot see the point. If we change > seed on every invokation then we get uniform-like distribution (see > attached image). And we don't get the same hash value for the same input > which is the whole point of hash functions. Maybe I didn't understand > you correctly. I suggest to fix the seed when parsing the script, so that it is the same seed on each script for a given pgbench invocation, so that for one run it runs with the same seed for each hash call, but changes if pgbench is re-invoked so that the results would be different. Also, if hash(:i) and hash(:j) appears in two distinct scripts, ISTM that we do not necessarily want the same seed, otherwise i == j would correlate to hash(i) == hash(j), which may not be a desirable property for some use case. Maybe it would be desirable for other use cases, though. > Anyway I've attached a new version with some tests and docs added. -- Fabien.
>> Hmm. I do not think that we should want a shared seed value. The seed >> should be different for each call so as to avoid undesired >> correlations. If wanted, correlation could be obtained by using an >> explicit identical seed. >> >> ISTM that the best way to add the seed is to call random() when the >> second arg is missing in make_func. Also, this means that the executor >> would always get its two arguments, so it would simplify the code there. >> > Ok, I think I understand what you meant. You meant the case like following: > > \set x random(1, 100) > \set h1 hash(:x) > \set h2 hash(:x) -- will have different seed from h1 > > so that different instances of hash function within one script would > have different seeds. Yes, that is a good idea, I can do that. Yes, exactly. What is desirable may depend on the use case, though. -- Fabien.
Hello Ildar,
>> so that different instances of hash function within one script would
>> have different seeds. Yes, that is a good idea, I can do that.
>>
> Added this feature in attached patch. But on a second thought this could
> be something that user won't expect. For example, they may want to run
> pgbench with two scripts:
> - the first one updates row by key that is a hashed random_zipfian value;
> - the second one reads row by key generated the same way
> (that is actually what YCSB workloads A and B do)
>
> It feels natural to write something like this:
> \set rnd random_zipfian(0, 1000000, 0.99)
> \set key abs(hash(:rnd)) % 1000
> in both scripts and expect that they both would have the same
> distribution. But they wouldn't. We could of course describe this
> implicit behaviour in documentation, but ISTM that shared seed would be
> more clear.
I think that it depends on the use case, that both can be useful, so there
should be a way to do either.
With "always different" default seed, distinct distributions are achieved
with:
-- DIFF distinct seeds inside and between runs
\set i1 abs(hash(:r1)) % 1000
\set j1 abs(hash(:r2)) % 1000
and the same distribution can be done with an explicit seed:
-- DIFF same seed inside and between runs
\set i1 abs(hash(:r1), 5432) % 1000
\set j1 abs(hash(:r2), 5432) % 1000
The drawback is that the same seed is used between runs in this case,
which is not desirable. This could be circumvented by adding the random
seed as an automatic variable and using it, eg:
-- DIFF same seed inside run, distinct between runs
\set i1 abs(hash(:r1), :random_seed + 5432) % 1000
\set j1 abs(hash(:r2), :random_seed + 2345) % 1000
Now with a shared hash_seed the same distribution is by default:
-- SHARED same underlying hash_seed inside run, distinct between runs
\set i1 abs(hash(:r1)) % 1000
\set j1 abs(hash(:r2)) % 1000
However some trick is needed now to get distinct seeds. With
-- SHARED distinct seed inside run, but same between runs
\set i1 abs(hash(:r1, 5432)) % 1000
\set j1 abs(hash(:r2, 2345)) % 1000
We are back to the same issue has the previous case because then the
distribution is the same from one run to the next, which is not desirable.
I found this workaround trick:
-- SHARED distinct seeds inside and between runs
\set i1 abs(hash(:r1, hash(5432))) % 1000
\set j1 abs(hash(:r2, hash(2345))) % 1000
Or with a new :hash_seed or :random_seed automatic variable, we could also
have:
-- SHARED distinct seeds inside and between runs
\set i1 abs(hash(:r1, :hash_seed + 5432)) % 1000
\set j1 abs(hash(:r2, :hash_seed + 2345)) % 1000
It provides controllable distinct seeds between runs but equal one between
if desired, by reusing the same value to be hashed as a seed.
I also agree with your argument that the user may reasonably expect that
hash(5432) == hash(5432) inside and between scripts, at least on the same
run, so would be surprised that it is not the case.
So I've changed my mind, I'm sorry for making you going back and forth on
the subject. I'm now okay with one shared 64 bit hash seed, with a clear
documentation about the fact, and an outline of the trick to achieve
distinct distributions inside a run if desired and why it would be
desirable to avoid correlations. Also, I think that providing the seed as
automatic variable (:hash_seed or :hseed or whatever) would make some
sense as well. Maybe this could be used as a way to fix the seed
explicitely, eg:
pgbench -D hash_seed=1234 ...
Would use this value instead of the random generated one. Also, with that
the default inserted second argument could be simply ":hash_seed", which
would simplify the executor which would not have to do check for an
optional second argument.
--
Fabien.
Hi Fabien, 13/01/2018 11:16, Fabien COELHO пишет: > > Hello Ildar, > >>> so that different instances of hash function within one script would >>> have different seeds. Yes, that is a good idea, I can do that. >>> >> Added this feature in attached patch. But on a second thought this could >> be something that user won't expect. For example, they may want to run >> pgbench with two scripts: >> - the first one updates row by key that is a hashed random_zipfian >> value; >> - the second one reads row by key generated the same way >> (that is actually what YCSB workloads A and B do) >> >> It feels natural to write something like this: >> \set rnd random_zipfian(0, 1000000, 0.99) >> \set key abs(hash(:rnd)) % 1000 >> in both scripts and expect that they both would have the same >> distribution. But they wouldn't. We could of course describe this >> implicit behaviour in documentation, but ISTM that shared seed would be >> more clear. > > I think that it depends on the use case, that both can be useful, so > there should be a way to do either. > > With "always different" default seed, distinct distributions are achieved > with: > > -- DIFF distinct seeds inside and between runs > \set i1 abs(hash(:r1)) % 1000 > \set j1 abs(hash(:r2)) % 1000 > > and the same distribution can be done with an explicit seed: > > -- DIFF same seed inside and between runs > \set i1 abs(hash(:r1), 5432) % 1000 > \set j1 abs(hash(:r2), 5432) % 1000 > > The drawback is that the same seed is used between runs in this case, > which is not desirable. This could be circumvented by adding the > random seed as an automatic variable and using it, eg: > > -- DIFF same seed inside run, distinct between runs > \set i1 abs(hash(:r1), :random_seed + 5432) % 1000 > \set j1 abs(hash(:r2), :random_seed + 2345) % 1000 > > > Now with a shared hash_seed the same distribution is by default: > > -- SHARED same underlying hash_seed inside run, distinct between runs > \set i1 abs(hash(:r1)) % 1000 > \set j1 abs(hash(:r2)) % 1000 > > However some trick is needed now to get distinct seeds. With > > -- SHARED distinct seed inside run, but same between runs > \set i1 abs(hash(:r1, 5432)) % 1000 > \set j1 abs(hash(:r2, 2345)) % 1000 > > We are back to the same issue has the previous case because then the > distribution is the same from one run to the next, which is not > desirable. I found this workaround trick: > > -- SHARED distinct seeds inside and between runs > \set i1 abs(hash(:r1, hash(5432))) % 1000 > \set j1 abs(hash(:r2, hash(2345))) % 1000 > > Or with a new :hash_seed or :random_seed automatic variable, we could > also have: > > -- SHARED distinct seeds inside and between runs > \set i1 abs(hash(:r1, :hash_seed + 5432)) % 1000 > \set j1 abs(hash(:r2, :hash_seed + 2345)) % 1000 > > It provides controllable distinct seeds between runs but equal one > between if desired, by reusing the same value to be hashed as a seed. > > I also agree with your argument that the user may reasonably expect > that hash(5432) == hash(5432) inside and between scripts, at least on > the same run, so would be surprised that it is not the case. > > So I've changed my mind, I'm sorry for making you going back and forth > on the subject. I'm now okay with one shared 64 bit hash seed, with a > clear documentation about the fact, and an outline of the trick to > achieve distinct distributions inside a run if desired and why it > would be desirable to avoid correlations. Also, I think that providing > the seed as automatic variable (:hash_seed or :hseed or whatever) > would make some sense as well. Maybe this could be used as a way to > fix the seed explicitely, eg: > > pgbench -D hash_seed=1234 ... > > Would use this value instead of the random generated one. Also, with > that the default inserted second argument could be simply > ":hash_seed", which would simplify the executor which would not have > to do check for an optional second argument. > Here is a new version of patch. I've splitted it into two parts. The first one is almost the same as v4 from [1] with some refactoring. The second part introduces random_seed variable as you proposed. I didn't do the executor simplification thing yet because I'm a little concerned about inventive users, who may want to change random_seed variable in runtime (which is possible since pgbench doesn't have read only variables aka constants AFAIK). [1] https://www.postgresql.org/message-id/43a8fbbb-32fa-6478-30a9-f64041adf019%40postgrespro.ru -- Ildar Musin Postgres Professional: http://www.postgrespro.com Russian Postgres Company
Attachment
Hello Ildar,
> Here is a new version of patch. I've splitted it into two parts. The
> first one is almost the same as v4 from [1] with some refactoring. The
> second part introduces random_seed variable as you proposed.
Patch 1 applies. Compilations fails, there are two "hash_seed" declared in
"pgbench.c".
Patch 2 applies cleanly on top of the previous patch and compiles, because
the variable is removed...
If an ":hash_seed" pgbench variable is used, ISTM that there is no need
for a global variable at all, so the two patches are going back and forth,
which is unhelpful. ISTM better to provide just one combined patch for the
feature.
If the hash_seed variable really needs to be kept, it should be an "int64"
variable, like other pgbench values. Calling random just usually
initializes about 31 bits, so random should be called 2 or maybe 3 times?
Or maybe use the internal getrand which has 48 pseudorandom bits?
For me "random seed" is what is passed to srandom, so the variable should
rather be named hash_seed because there could also be a random seed
(actually, there is in another parallel patch:-). Moreover, this seed may
or may not be random if set, so calling it "random_seed" is not desirable.
The len < 1 || len > 2 is checked twice, once in the "switch", on in an
"if" just after the "switch". Once is enough.
> I didn't do the executor simplification thing yet because I'm a little
> concerned about inventive users, who may want to change random_seed
> variable in runtime (which is possible since pgbench doesn't have read
> only variables aka constants AFAIK).
If the user choses to overide hash_seed in their script, it is their
decision, the documentation has only to be clear about :hash_seed being
the default seed. I see no clear reason to work around this possibility by
evaluating the seed at parse time, especially as the variable may not have
its final value yet depending on the option order. I'd suggest to just use
make_variable("hash_seed") for the default second argument and simplify
the executor.
The seed variable is not tested explicitely in the script, you could add
a "hash(5432) == hash(5432, :hash_seed)" for instance.
It would be nice if an native English speaker could proofread the
documentation text. I'd suggest: "*an* optional seed parameter". "In case
*the* seed...". "<literal>:hash_seed</literal>". "shared for" -> "shared
by". "following listing" -> "following pgbench script". "few accounts
generates" -> "few accounts generate".
For the document example, I'd use larger values for the random & modulo,
eg 100000000 and 1000000. The drawback is that zipfian does a costly
computation of the generalized harmonic number when the parameter is lower
than 1.0. For cities, the parameter found by Zipf was 1.07 (says
Wikipedia). Maybe use this historical value. Or maybe use an exponential
distribution in the example.
--
Fabien.
Hello Fabien,
17/01/2018 10:52, Fabien COELHO пишет:
>> Here is a new version of patch. I've splitted it into two parts. The
>> first one is almost the same as v4 from [1] with some refactoring.
>> The second part introduces random_seed variable as you proposed.
>
> Patch 1 applies. Compilations fails, there are two "hash_seed"
> declared in "pgbench.c".
>
> Patch 2 applies cleanly on top of the previous patch and compiles,
> because the variable is removed...
>
> If an ":hash_seed" pgbench variable is used, ISTM that there is no
> need for a global variable at all, so the two patches are going back
> and forth, which is unhelpful. ISTM better to provide just one
> combined patch for the feature.
>
> If the hash_seed variable really needs to be kept, it should be an
> "int64" variable, like other pgbench values.
>
> The len < 1 || len > 2 is checked twice, once in the "switch", on in
> an "if" just after the "switch". Once is enough.
I totally messed up doing git rebase and didn't double check the code.
*facepalm* There shouldn't be hash_seed variable and the second 'len < 1
|| len > 2' check. Sorry for that, fixed in the attached patch.
> Calling random just usually initializes about 31 bits, so random
> should be called 2 or maybe 3 times? Or maybe use the internal getrand
> which has 48 pseudorandom bits?
Done. I used code from get_random_uint64() as an example.
>
> For me "random seed" is what is passed to srandom, so the variable
> should rather be named hash_seed because there could also be a random
> seed (actually, there is in another parallel patch:-). Moreover, this
> seed may or may not be random if set, so calling it "random_seed" is
> not desirable.
>
My intention was to introduce seed variable which potentially could be
used in different contexts, not only for hash functions. I renamed it to
'hash_seed' for now. But what do you think about naming it simply 'seed'
or choosing some other general name?
>> I didn't do the executor simplification thing yet because I'm a
>> little concerned about inventive users, who may want to change
>> random_seed variable in runtime (which is possible since pgbench
>> doesn't have read only variables aka constants AFAIK).
>
> If the user choses to overide hash_seed in their script, it is their
> decision, the documentation has only to be clear about :hash_seed
> being the default seed. I see no clear reason to work around this
> possibility by evaluating the seed at parse time, especially as the
> variable may not have its final value yet depending on the option
> order. I'd suggest to just use make_variable("hash_seed") for the
> default second argument and simplify the executor.
That is a great idea, I didn't see that possibility. Done.
>
> The seed variable is not tested explicitely in the script, you could add
> a "hash(5432) == hash(5432, :hash_seed)" for instance.
>
> It would be nice if an native English speaker could proofread the
> documentation text. I'd suggest: "*an* optional seed parameter". "In
> case *the* seed...". "<literal>:hash_seed</literal>". "shared for" ->
> "shared by". "following listing" -> "following pgbench script". "few
> accounts generates" -> "few accounts generate".
>
Done as well.
> For the document example, I'd use larger values for the random &
> modulo, eg 100000000 and 1000000. The drawback is that zipfian does a
> costly computation of the generalized harmonic number when the
> parameter is lower than 1.0. For cities, the parameter found by Zipf
> was 1.07 (says Wikipedia). Maybe use this historical value. Or maybe
> use an exponential distribution in the example.
>
Changed parameter to 1.07.
Thanks!
--
Ildar Musin
Postgres Professional: http://www.postgrespro.com
Russian Postgres Company
Attachment
Hello Ildar,
Patch v8 applies cleanly and compiles. Global and local "make check ok".
Doc build ok.
>> For me "random seed" is what is passed to srandom, so the variable
>> should rather be named hash_seed because there could also be a random
>> seed (actually, there is in another parallel patch:-). Moreover, this
>> seed may or may not be random if set, so calling it "random_seed" is
>> not desirable.
>
> My intention was to introduce seed variable which potentially could be
> used in different contexts, not only for hash functions.
Yes, good point. I'd need it for the pseudo-random permutation function.
> I renamed it to 'hash_seed' for now. But what do you think about naming
> it simply 'seed' or choosing some other general name?
ISTM "seed" that is prone to being used for something else in a script.
What about ":default_seed", which says it all?
Some minor suggestions:
In "make_func", I'd assert that nargs is positive in the default branch.
The default seed may be created with just one assignment instead of
repeated |= ops. Or not:-)
In evalStandardFunc, I'd suggest to avoid the ? construction and use an
if and a direct setIntValue in both case, removing the "result"
variable, as done in other branches (eg bitwise operators...). Maybe
something like:
if (func == murmur2)
setIntValue(retval, getHashXXX(val, seed));
else if (...)
...
else
Assert(0);
so that it is structurally ready for other hash functions if needed.
Documentation:
In the table, use official names in the description, and add wikipedia
links, something like:
FNV hash ->
<ulink url="https://en.wikipedia.org/wiki/Fowler%E2%80%93Noll%E2%80%93Vo_hash_function">FNV-1a hash</ulink>
murmur2 hash ->
<ulink url="https://en.wikipedia.org/wiki/MurmurHash">MurmurHash2 hash</ulink>
In the text:
"Hash functions accepts" -> "Hash functions
<literal>hash</literal>, <......> and <....> accept*NO S*"
"... provided hash_seed value is used" => "... provided the value of
<literal>:hash_seed</literal> is used, which is initialized randomly
unless set by the command-line <literal>-D</literal> option."
ISTM that the Automatic Variable table should be in alphabetical order.
--
Fabien.
Hello Fabien, On 18.01.2018 12:06, Fabien COELHO wrote: >> My intention was to introduce seed variable which potentially could be >> used in different contexts, not only for hash functions. > > Yes, good point. I'd need it for the pseudo-random permutation function. > >> I renamed it to 'hash_seed' for now. But what do you think about >> naming it simply 'seed' or choosing some other general name? > > ISTM "seed" that is prone to being used for something else in a script. > What about ":default_seed", which says it all? > Sounds good, renamed to "default_seed". > > Some minor suggestions: > > In "make_func", I'd assert that nargs is positive in the default branch. Added assert for non-negative nargs (since there is pi() function with zero arguments). > > The default seed may be created with just one assignment instead of > repeated |= ops. Or not:-) > Tried this, but after applying pgindent it turns into a mess : ) So I left it in the initial form. > In evalStandardFunc, I'd suggest to avoid the ? construction and use an > if and a direct setIntValue in both case, removing the "result" > variable, as done in other branches (eg bitwise operators...). Maybe > something like: > > if (func == murmur2) > setIntValue(retval, getHashXXX(val, seed)); > else if (...) > ... > else > Assert(0); > > so that it is structurally ready for other hash functions if needed. > Done. Probably if more functions are added it would make sense to change it to "switch". > Documentation: > > In the table, use official names in the description, and add wikipedia > links, something like: > > FNV hash -> > <ulink > url="https://en.wikipedia.org/wiki/Fowler%E2%80%93Noll%E2%80%93Vo_hash_function">FNV-1a > hash</ulink> > > murmur2 hash -> > <ulink url="https://en.wikipedia.org/wiki/MurmurHash">MurmurHash2 > hash</ulink> > > > In the text: > > "Hash functions accepts" -> "Hash functions <literal>hash</literal>, > <......> and <....> accept*NO S*" > > "... provided hash_seed value is used" => "... provided the value of > <literal>:hash_seed</literal> is used, which is initialized randomly > unless set by the command-line <literal>-D</literal> option." > > ISTM that the Automatic Variable table should be in alphabetical order. > Updated the documentation. Thanks! -- Ildar Musin i.musin@postgrespro.ru
Attachment
Hello Ildar, Applies, compiles, runs. I still have a few very minor comments, sorry for this (hopefully) last iteration from my part. I'm kind of iterative... The XML documentation source should avoid a paragraph on one very long line, but rather be indented like other sections. I'd propose simplify the second part: Hash functions can be used, for example, to modify the distribution of <literal>random_zipfian</literal> or <literal>random_exponential</literal> functions in order to obtain scattered distribution. Thus the following pgbench script simulates possible real world workload typical for social media and blogging platforms where few accounts generate excessive load: -> Hash functions can be used to scatter the distribution of random functions such as <literal>random_zipfian</literal> or <literal>random_exponential</literal>. For instance, the following pgbench script simulates possible real world workload typical for social media and blogging platforms where few accounts generate excessive load: Comment the Assert(0) as an internal error that cannot happen. I'd suggest to compact the execution code by declaring int64 variable and coerce to int in one go, like the integer bitwise functions. I'm in favor to keeping them in their own case and not reuse this one. -- Fabien.
Hello Fabien, 26/01/2018 09:28, Fabien COELHO пишет: > > Hello Ildar, > > Applies, compiles, runs. > > I still have a few very minor comments, sorry for this (hopefully) > last iteration from my part. I'm kind of iterative... > > The XML documentation source should avoid a paragraph on one very long > line, but rather be indented like other sections. > > I'd propose simplify the second part: > > Hash functions can be used, for example, to modify the distribution of > <literal>random_zipfian</literal> or > <literal>random_exponential</literal> > functions in order to obtain scattered distribution. > Thus the following pgbench script simulates possible real world > workload > typical for social media and blogging platforms where few accounts > generate excessive load: > > -> > > Hash functions can be used to scatter the distribution of random > functions such as <literal>random_zipfian</literal> or > <literal>random_exponential</literal>. > For instance, the following pgbench script simulates possible real > world workload typical for social media and blogging platforms where > few accounts generate excessive load: > > Comment the Assert(0) as an internal error that cannot happen. > > I'd suggest to compact the execution code by declaring int64 variable > and coerce to int in one go, like the integer bitwise functions. I'm > in favor to keeping them in their own case and not reuse this one. > I did everything you mention here and attached a new version on the patch. Thank you! -- Ildar Musin Postgres Professional: http://www.postgrespro.com Russian Postgres Company
Attachment
Hello Ildar, > I did everything you mention here and attached a new version on the patch. Patch applies, compiles, runs ok. Alas, I still have a few more very minor comments about the doc, sorry again: + <entry> <literal>default_seed</literal> </entry> + <entry>random seed used in hash functions by default</entry> s/random //: the seed may or may not be random. The "In some cases several distinct distributions..." paragraph is also just one line in the xml source file. It should be justified at about 80 columns like others. -- Fabien.
Hi Fabien, On 28.01.2018 11:10, Fabien COELHO wrote: > > Hello Ildar, > >> I did everything you mention here and attached a new version on the >> patch. > > Patch applies, compiles, runs ok. > > Alas, I still have a few more very minor comments about the doc, sorry > again: No problem : ) > > + <entry> <literal>default_seed</literal> </entry> > + <entry>random seed used in hash functions by default</entry> > > s/random //: the seed may or may not be random. > > The "In some cases several distinct distributions..." paragraph is also > just one line in the xml source file. It should be justified at about 80 > columns like others. > Fixed the doc, attached the patch. Thanks! -- Ildar Musin i.musin@postgrespro.ru
Attachment
Hello Ildar, > Fixed the doc, attached the patch. Thanks! Patch applies, compiles, pgbench & global "make check" ok, doc built ok. Ok for me, switched to "Ready". -- Fabien.
On 29.01.2018 15:03, Fabien COELHO wrote: > > Patch applies, compiles, pgbench & global "make check" ok, doc built ok. > > Ok for me, switched to "Ready". > Thank you for the thorough review! -- Ildar Musin i.musin@postgrespro.ru
>> Patch applies, compiles, pgbench & global "make check" ok, doc built ok. Agree. If I understand upthread correctly, implementation of Murmur hash algorithm based on Austin Appleby work https://github.com/aappleby/smhasher/blob/master/src/MurmurHash2.cpp If so, I have notice and objections: 1) Seems, it's good idea to add credits to Austin Appleby to comments. 2) Reference implementaion directly says (link above): // 2. It will not produce the same results on little-endian and big-endian // machines. I don't think that is good thing for testing and benchmarking for several reasons: it could produce different data collection, different selects, different distribution. 3) Again, from comments of reference implementation: // Note - This code makes a few assumptions about how your machine behaves - // 1. We can read a 4-byte value from any address without crashing It's not true for all supported platforms. Any box with strict aligment will SIGBUSed here. -- Teodor Sigaev E-mail: teodor@sigaev.ru WWW: http://www.sigaev.ru/
Hello Teodor, Thank you for reviewing this patch. On 06.03.2018 15:53, Teodor Sigaev wrote: >>> Patch applies, compiles, pgbench & global "make check" ok, doc >>> built ok. > > Agree. > > If I understand upthread correctly, implementation of Murmur hash > algorithm based on Austin Appleby work > https://github.com/aappleby/smhasher/blob/master/src/MurmurHash2.cpp > > If so, I have notice and objections: > > 1) Seems, it's good idea to add credits to Austin Appleby to > comments. > Sounds fair, I'll send an updated version soon. > 2) Reference implementaion directly says (link above): // 2. It will > not produce the same results on little-endian and big-endian // > machines. > > I don't think that is good thing for testing and benchmarking for > several reasons: it could produce different data collection, > different selects, different distribution. > > 3) Again, from comments of reference implementation: // Note - This > code makes a few assumptions about how your machine behaves - // 1. > We can read a 4-byte value from any address without crashing > > It's not true for all supported platforms. Any box with strict > aligment will SIGBUSed here. > I think that both points refer to the fact that original algorithm accepts a byte string as an input, slices it up by 8 bytes and form unsigned int values from it. In that case the order of bytes in the input string does matter since it may result in different integers on different architectures. And it is also fair requirement for a byte string to be aligned as some architectures cannot handle unaligned data. In this patch though I slightly modified the original algorithm in a way that it takes unsigned ints as an input (not byte string), so neither of this points should be a problem as it seems to me. But I'll double check it on big-endian machine with strict alignment (Sparc). Thanks! -- Ildar Musin i.musin@postgrespro.ru
Hello Teodor, >> 1) Seems, it's good idea to add credits to Austin Appleby to >> comments. >> Done. Also rebased to the latest master. > > I think that both points refer to the fact that original algorithm > accepts a byte string as an input, slices it up by 8 bytes and form > unsigned int values from it. In that case the order of bytes in the > input string does matter since it may result in different integers on > different architectures. And it is also fair requirement for a byte > string to be aligned as some architectures cannot handle unaligned data. > In this patch though I slightly modified the original algorithm in a way > that it takes unsigned ints as an input (not byte string), so neither of > this points should be a problem as it seems to me. But I'll double check > it on big-endian machine with strict alignment (Sparc). Turned out that the only big-endian machine I could run test on is out of order. Maybe someone has access to a big-endian machine? If so, could you please run some basic test and send me the resulting file? I've attached initialization script and pgbench script which could be run as follows: psql postgres -f hash_init.sql pgbench postgres -T60 -f hash_run.sql psql postgres -c "copy abc to '/tmp/hash_results.csv'" Thanks! -- Ildar Musin i.musin@postgrespro.ru
Attachment
Hello Teodor, On 07.03.2018 16:21, Ildar Musin wrote: > Turned out that the only big-endian machine I could run test on is > out of order. I finally managed to perform this test on sparc v9 machine which is 64 bit big-endian architecture. I run pgbench script (see previous message) with default_seed=123 on both x86-64 and sparc machines and visualized the results. You can find them in the attached chart. Both images showed the same distribution. So endianness isn't a concern here. Thanks! -- Ildar Musin i.musin@postgrespro.ru
Attachment
{kind=link}
> I finally managed to perform this test on sparc v9 machine which is 64
> bit big-endian architecture. I run pgbench script (see previous message)
> with default_seed=123 on both x86-64 and sparc machines and visualized
> the results. You can find them in the attached chart. Both images showed
> the same distribution. So endianness isn't a concern here.
Agree, pushed.
But I have a notice about number of arguments. Seems, special values for hash
and greatest/least functions is not actually needed. If we split nargs option to
n mandatory arguments and n optional ones then special values for that functions
will go away: hash will have 1 mandatory and 1 optional, greatest/least will
have one mandatory and infinite number of optional. Not sure for now about
CASE/WHEN case. But seems it's a deal for separate refactoring.
--
Teodor Sigaev E-mail: teodor@sigaev.ru
WWW: http://www.sigaev.ru/