Thread: [HACKERS] WIP: BRIN multi-range indexes
Hi all, A couple of days ago I've shared a WIP patch [1] implementing BRIN indexes based on bloom filters. One inherent limitation of that approach is that it can only support equality conditions - that's perfectly fine in many cases (e.g. with UUIDs it's rare to use range queries, etc.). [1] https://www.postgresql.org/message-id/5d78b774-7e9c-c94e-12cf-fef51cc89b1a%402ndquadrant.com But in other cases that restriction is pretty unacceptable, e.g. with timestamps that are queried mostly using range conditions. A common issue is that while the data is initially well correlated (giving us nice narrow min/max ranges in the BRIN index), this degrades over time (typically due to DELETE/UPDATE and then new rows routed to free space). There are not many options to prevent this, and fixing it pretty much requires CLUSTER on the table. This patch addresses this by BRIN indexes with more complex "summary". Instead of keeping just a single "minmax interval", we maintain a list of "minmax intervals", which allows us to track "gaps" in the data. To illustrate the improvement, consider this table: create table a (val float8) with (fillfactor = 90); insert into a select i::float from generate_series(1,10000000) s(i); update a set val = 1 where random() < 0.01; update a set val = 10000000 where random() < 0.01; Which means the column 'val' is almost perfectly correlated with the position in the table (which would be great for BRIN minmax indexes), but then 1% of the values is set to 1 and 10.000.000. That means pretty much every range will be [1,10000000], which makes this BRIN index mostly useless, as illustrated by these explain plans: create index on a using brin (val) with (pages_per_range = 16); explain analyze select * from a where val = 100; QUERY PLAN -------------------------------------------------------------------- Bitmap Heap Scan on a (cost=54.01..10691.02 rows=8 width=8) (actual time=5.901..785.520 rows=1 loops=1) Recheck Cond: (val = '100'::double precision) Rows Removed by Index Recheck: 9999999 Heap Blocks: lossy=49020 -> Bitmap Index Scan on a_val_idx (cost=0.00..54.00 rows=3400 width=0) (actual time=5.792..5.792 rows=490240 loops=1) Index Cond: (val = '100'::double precision) Planning time: 0.119 ms Execution time: 785.583 ms (8 rows) explain analyze select * from a where val between 100 and 10000; QUERY PLAN ------------------------------------------------------------------ Bitmap Heap Scan on a (cost=55.94..25132.00 rows=7728 width=8) (actual time=5.939..858.125 rows=9695 loops=1) Recheck Cond: ((val >= '100'::double precision) AND (val <= '10000'::double precision)) Rows Removed by Index Recheck: 9990305 Heap Blocks: lossy=49020 -> Bitmap Index Scan on a_val_idx (cost=0.00..54.01 rows=10200 width=0) (actual time=5.831..5.831 rows=490240 loops=1) Index Cond: ((val >= '100'::double precision) AND (val <= '10000'::double precision)) Planning time: 0.139 ms Execution time: 871.132 ms (8 rows) Obviously, the queries do scan the whole table and then eliminate most of the rows in "Index Recheck". Decreasing pages_per_range does not really make a measurable difference in this case - it eliminates maybe 10% of the rechecks, but most pages still have very wide minmax range. With the patch, it looks about like this: create index on a using brin (val float8_minmax_multi_ops) with (pages_per_range = 16); explain analyze select * from a where val = 100; QUERY PLAN ------------------------------------------------------------------- Bitmap Heap Scan on a (cost=830.01..11467.02 rows=8 width=8) (actual time=7.772..8.533 rows=1 loops=1) Recheck Cond: (val = '100'::double precision) Rows Removed by Index Recheck: 3263 Heap Blocks: lossy=16 -> Bitmap Index Scan on a_val_idx (cost=0.00..830.00 rows=3400 width=0) (actual time=7.729..7.729 rows=160 loops=1) Index Cond: (val = '100'::double precision) Planning time: 0.124 ms Execution time: 8.580 ms (8 rows) explain analyze select * from a where val between 100 and 10000; QUERY PLAN ------------------------------------------------------------------ Bitmap Heap Scan on a (cost=831.94..25908.00 rows=7728 width=8) (actual time=9.318..23.715 rows=9695 loops=1) Recheck Cond: ((val >= '100'::double precision) AND (val <= '10000'::double precision)) Rows Removed by Index Recheck: 3361 Heap Blocks: lossy=64 -> Bitmap Index Scan on a_val_idx (cost=0.00..830.01 rows=10200 width=0) (actual time=9.274..9.274 rows=640 loops=1) Index Cond: ((val >= '100'::double precision) AND (val <= '10000'::double precision)) Planning time: 0.138 ms Execution time: 36.100 ms (8 rows) That is, the timings drop from 785ms/871ms to 9ms/36s. The index is a bit larger (1700kB instead of 150kB), but it's still orders of magnitudes smaller than btree index (which is ~214MB in this case). The index build is slower than the regular BRIN indexes (about comparable to btree), but I'm sure it can be significantly improved. Also, I'm sure it's not bug-free. Two additional notes: 1) The patch does break the current BRIN indexes, because it requires passing all SearchKeys to the "consistent" BRIN function at once (otherwise we couldn't eliminate individual intervals in the summary), while currently the BRIN only deals with one SearchKey at a time. And I haven't modified the existing brin_minmax_consistent() function (yeah, I'm lazy, but this should be enough for interested people to try it out I believe). 2) It only works with float8 (and also timestamp data types) for now, but it should be straightforward to add support for additional data types. Most of that will be about adding catalog definitions anyway. regards -- Tomas Vondra http://www.2ndQuadrant.com PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services -- Sent via pgsql-hackers mailing list (pgsql-hackers@postgresql.org) To make changes to your subscription: http://www.postgresql.org/mailpref/pgsql-hackers
Attachment
Apparently I've managed to botch the git format-patch thing :-( Attached are both patches (the first one adding BRIN bloom indexes, the other one adding the BRIN multi-range). Hopefully I got it right this time ;-) regards -- Tomas Vondra http://www.2ndQuadrant.com PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services -- Sent via pgsql-hackers mailing list (pgsql-hackers@postgresql.org) To make changes to your subscription: http://www.postgresql.org/mailpref/pgsql-hackers
Attachment
Hi, attached is a patch series that includes both the BRIN multi-range minmax indexes discussed in this thread, and the BRIN bloom indexes initially posted in [1]. It seems easier to just deal with a single patch series, although we may end up adding just one of those proposed opclasses. There are 4 parts: 0001 - Modifies bringetbitmap() to pass all scan keys to the consistent function at once. This is actually needed by the multi-minmax indexes, but not really required for the others. I'm wondering if this is a safechange, considering it affects the BRIN interface. I.e. custom BRIN opclasses (perhaps in extensions) will be broken by this change. Maybe we should extend the BRIN API to support two versions of the consistent function - one that processes scan keys one by one, and the other one that processes all of them at once. 0002 - Adds BRIN bloom indexes, along with opclasses for all built-in data types (or at least those that also have regular BRIN opclasses). 0003 - Adds BRIN multi-minmax indexes, but only with float8 opclasses (which also includes timestamp etc.). That should be good enough for now, but adding support for other data types will require adding some sort of "distance" operator which is needed for merging ranges (to pick the two "closest" ones). For float8 it's simply a subtraction. 0004 - Moves dealing with IS [NOT] NULL search keys from opclasses to bringetbitmap(). The code was exactly the same in all opclasses, so moving it to bringetbitmap() seems right. It also allows some nice optimizations where we can skip the consistent() function entirely, although maybe that's useless. Also, maybe the there are opclasses that actually need to deal with the NULL values in consistent() function? regards [1] https://www.postgresql.org/message-id/5d78b774-7e9c-c94e-12cf-fef51cc89b1a%402ndquadrant.com -- Tomas Vondra http://www.2ndQuadrant.com PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services -- Sent via pgsql-hackers mailing list (pgsql-hackers@postgresql.org) To make changes to your subscription: http://www.postgresql.org/mailpref/pgsql-hackers
Attachment
Hi, Apparently there was some minor breakage due to duplicate OIDs, so here is the patch series updated to current master. regards -- Tomas Vondra http://www.2ndQuadrant.com PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
Attachment
On Sun, Nov 19, 2017 at 5:45 AM, Tomas Vondra <tomas.vondra@2ndquadrant.com> wrote: > Apparently there was some minor breakage due to duplicate OIDs, so here > is the patch series updated to current master. Moved to CF 2018-01. -- Michael
> On Nov 18, 2017, at 12:45 PM, Tomas Vondra <tomas.vondra@2ndquadrant.com> wrote: > > Hi, > > Apparently there was some minor breakage due to duplicate OIDs, so here > is the patch series updated to current master. > > regards > > -- > Tomas Vondra http://www.2ndQuadrant.com > PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services > <0001-Pass-all-keys-to-BRIN-consistent-function-at-once.patch.gz><0002-BRIN-bloom-indexes.patch.gz><0003-BRIN-multi-range-minmax-indexes.patch.gz><0004-Move-IS-NOT-NULL-checks-to-bringetbitmap.patch.gz> After applying these four patches to my copy of master, the regression tests fail for F_SATISFIES_HASH_PARTITION 5028 as attached. mark
Attachment
On 12/19/2017 08:38 PM, Mark Dilger wrote: > >> On Nov 18, 2017, at 12:45 PM, Tomas Vondra <tomas.vondra@2ndquadrant.com> wrote: >> >> Hi, >> >> Apparently there was some minor breakage due to duplicate OIDs, so here >> is the patch series updated to current master. >> >> regards >> >> -- >> Tomas Vondra http://www.2ndQuadrant.com >> PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services >> <0001-Pass-all-keys-to-BRIN-consistent-function-at-once.patch.gz><0002-BRIN-bloom-indexes.patch.gz><0003-BRIN-multi-range-minmax-indexes.patch.gz><0004-Move-IS-NOT-NULL-checks-to-bringetbitmap.patch.gz> > > > After applying these four patches to my copy of master, the regression > tests fail for F_SATISFIES_HASH_PARTITION 5028 as attached. > D'oh! There was an incorrect OID referenced in pg_opclass, which was also used by the satisfies_hash_partition() function. Fixed patches attached. regards -- Tomas Vondra http://www.2ndQuadrant.com PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
Attachment
> On Dec 19, 2017, at 5:16 PM, Tomas Vondra <tomas.vondra@2ndquadrant.com> wrote: > > > > On 12/19/2017 08:38 PM, Mark Dilger wrote: >> >>> On Nov 18, 2017, at 12:45 PM, Tomas Vondra <tomas.vondra@2ndquadrant.com> wrote: >>> >>> Hi, >>> >>> Apparently there was some minor breakage due to duplicate OIDs, so here >>> is the patch series updated to current master. >>> >>> regards >>> >>> -- >>> Tomas Vondra http://www.2ndQuadrant.com >>> PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services >>> <0001-Pass-all-keys-to-BRIN-consistent-function-at-once.patch.gz><0002-BRIN-bloom-indexes.patch.gz><0003-BRIN-multi-range-minmax-indexes.patch.gz><0004-Move-IS-NOT-NULL-checks-to-bringetbitmap.patch.gz> >> >> >> After applying these four patches to my copy of master, the regression >> tests fail for F_SATISFIES_HASH_PARTITION 5028 as attached. >> > > D'oh! There was an incorrect OID referenced in pg_opclass, which was > also used by the satisfies_hash_partition() function. Fixed patches > attached. Thanks! These fix the regression test failures. On my mac, all tests are now passing. I have not yet looked any further into the merits of these patches, however. mark
> On Dec 19, 2017, at 5:16 PM, Tomas Vondra <tomas.vondra@2ndquadrant.com> wrote: > > > > On 12/19/2017 08:38 PM, Mark Dilger wrote: >> >>> On Nov 18, 2017, at 12:45 PM, Tomas Vondra <tomas.vondra@2ndquadrant.com> wrote: >>> >>> Hi, >>> >>> Apparently there was some minor breakage due to duplicate OIDs, so here >>> is the patch series updated to current master. >>> >>> regards >>> >>> -- >>> Tomas Vondra http://www.2ndQuadrant.com >>> PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services >>> <0001-Pass-all-keys-to-BRIN-consistent-function-at-once.patch.gz><0002-BRIN-bloom-indexes.patch.gz><0003-BRIN-multi-range-minmax-indexes.patch.gz><0004-Move-IS-NOT-NULL-checks-to-bringetbitmap.patch.gz> >> >> >> After applying these four patches to my copy of master, the regression >> tests fail for F_SATISFIES_HASH_PARTITION 5028 as attached. >> > > D'oh! There was an incorrect OID referenced in pg_opclass, which was > also used by the satisfies_hash_partition() function. Fixed patches > attached. Your use of type ScanKey in src/backend/access/brin/brin.c is a bit confusing. A ScanKey is defined elsewhere as a pointer to ScanKeyData. When you define an array of ScanKeys, you use pointer-to-pointer style: + ScanKey **keys, + **nullkeys; But when you allocate space for the array, you don't treat it that way: + keys = palloc0(sizeof(ScanKey) * bdesc->bd_tupdesc->natts); + nullkeys = palloc0(sizeof(ScanKey) * bdesc->bd_tupdesc->natts); But then again when you use nullkeys, you treat it as a two-dimensional array: + nullkeys[keyattno - 1][nnullkeys[keyattno - 1]] = key; and likewise when you allocate space within keys: + keys[keyattno - 1] = palloc0(sizeof(ScanKey) * scan->numberOfKeys); Could you please clarify? I have been awake a bit too long; hopefully, I am not merely missing the obvious. mark
On 12/20/2017 03:37 AM, Mark Dilger wrote: > >> On Dec 19, 2017, at 5:16 PM, Tomas Vondra <tomas.vondra@2ndquadrant.com> wrote: >> >> >> >> On 12/19/2017 08:38 PM, Mark Dilger wrote: >>> >>>> On Nov 18, 2017, at 12:45 PM, Tomas Vondra <tomas.vondra@2ndquadrant.com> wrote: >>>> >>>> Hi, >>>> >>>> Apparently there was some minor breakage due to duplicate OIDs, so here >>>> is the patch series updated to current master. >>>> >>>> regards >>>> >>>> -- >>>> Tomas Vondra http://www.2ndQuadrant.com >>>> PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services >>>> <0001-Pass-all-keys-to-BRIN-consistent-function-at-once.patch.gz><0002-BRIN-bloom-indexes.patch.gz><0003-BRIN-multi-range-minmax-indexes.patch.gz><0004-Move-IS-NOT-NULL-checks-to-bringetbitmap.patch.gz> >>> >>> >>> After applying these four patches to my copy of master, the regression >>> tests fail for F_SATISFIES_HASH_PARTITION 5028 as attached. >>> >> >> D'oh! There was an incorrect OID referenced in pg_opclass, which was >> also used by the satisfies_hash_partition() function. Fixed patches >> attached. > > Your use of type ScanKey in src/backend/access/brin/brin.c is a bit confusing. A > ScanKey is defined elsewhere as a pointer to ScanKeyData. When you define > an array of ScanKeys, you use pointer-to-pointer style: > > + ScanKey **keys, > + **nullkeys; > > But when you allocate space for the array, you don't treat it that way: > > + keys = palloc0(sizeof(ScanKey) * bdesc->bd_tupdesc->natts); > + nullkeys = palloc0(sizeof(ScanKey) * bdesc->bd_tupdesc->natts); > > But then again when you use nullkeys, you treat it as a two-dimensional array: > > + nullkeys[keyattno - 1][nnullkeys[keyattno - 1]] = key; > > and likewise when you allocate space within keys: > > + keys[keyattno - 1] = palloc0(sizeof(ScanKey) * scan->numberOfKeys); > > Could you please clarify? I have been awake a bit too long; hopefully, I am > not merely missing the obvious. > Yeah, that's wrong - it should be "sizeof(ScanKey *)" instead. It's harmless, though, because ScanKey itself is a pointer, so the size is the same. Attached is an updated version of the patch series, significantly reworking and improving the multi-minmax part (the rest of the patch is mostly as it was before). I've significantly refactored and cleaned up the multi-minmax part, and I'm much happier with it - no doubt there's room for further improvement but overall it's much better. I've also added proper sgml docs for this part, and support for more data types including variable-length ones (all integer types, numeric, float-based types including timestamps, uuid, and a couple of others). At the API level, I needed to add one extra support procedure that measures distance between two values of the data type. This is needed so because we only keep a limited number of intervals for each range, and once in a while we need to decide which of them to "merge" (and we simply merge the closest ones). I've passed the indexes through significant testing and fixed a couple of silly bugs / memory leaks. Let's see if there are more. Performance-wise, the CREATE INDEX seems a bit slow - it's about an order of magnitude slower than regular BRIN. Some of that is expected (we simply need to do more stuff to maintain multiple ranges), but perhaps there's room for additional improvements - that's something I'd like to work on next. regards -- Tomas Vondra http://www.2ndQuadrant.com PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
Attachment
This stuff sounds pretty nice. However, have a look at this report: https://codecov.io/gh/postgresql-cfbot/postgresql/commit/2aa632dae3066900e15d2d42a4aad811dec11f08 it seems to me that the new code is not tested at all. Shouldn't you add a few more tests? I think 0004 should apply to unpatched master (except for the parts that concern files not in master); sounds like a good candidate for first apply. Then 0001, which seems mostly just refactoring. 0002 and 0003 are the really interesting ones (minus the code removed by 0004). -- Álvaro Herrera https://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On 01/23/2018 09:05 PM, Alvaro Herrera wrote: > This stuff sounds pretty nice. However, have a look at this report: > > https://codecov.io/gh/postgresql-cfbot/postgresql/commit/2aa632dae3066900e15d2d42a4aad811dec11f08 > > it seems to me that the new code is not tested at all. Shouldn't you > add a few more tests? > I have a hard time reading the report, but you're right I haven't added any tests for the new opclasses (bloom and minmax_multi). I agree that's something that needs to be addressed. > I think 0004 should apply to unpatched master (except for the parts > that concern files not in master); sounds like a good candidate for > first apply. Then 0001, which seems mostly just refactoring. 0002 and > 0003 are the really interesting ones (minus the code removed by > 0004). > That sounds like a reasonable plan. I'll reorder the patch series along those lines in the next few days. regards -- Tomas Vondra http://www.2ndQuadrant.com PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On 01/23/2018 10:07 PM, Tomas Vondra wrote: > > > On 01/23/2018 09:05 PM, Alvaro Herrera wrote: >> This stuff sounds pretty nice. However, have a look at this report: >> >> https://codecov.io/gh/postgresql-cfbot/postgresql/commit/2aa632dae3066900e15d2d42a4aad811dec11f08 >> >> it seems to me that the new code is not tested at all. Shouldn't you >> add a few more tests? >> > > I have a hard time reading the report, but you're right I haven't added > any tests for the new opclasses (bloom and minmax_multi). I agree that's > something that needs to be addressed. > >> I think 0004 should apply to unpatched master (except for the parts >> that concern files not in master); sounds like a good candidate for >> first apply. Then 0001, which seems mostly just refactoring. 0002 and >> 0003 are the really interesting ones (minus the code removed by >> 0004). >> > > That sounds like a reasonable plan. I'll reorder the patch series along > those lines in the next few days. > And here we go. Attached is a reworked patch series that moves the IS NULL tweak to the beginning of the series, and also adds proper regression tests both for the bloom and multi-minmax opclasses. I've simply copied the brin.sql tests and tweaked it for the new opclasses. I've also added a bunch of missing multi-minmax opclasses. At this point all data types that have minmax opclass should also have multi-minmax one, except for these types: * bytea * char * name * text * bpchar * bit * varbit The reason is that I'm not quite sure how to define the 'distance' function, which is needed when picking ranges to merge when building/updating the index. BTW while working on the regression tests, I've noticed that brin.sql fails to test a couple of minmax opclasses (e.g. abstime/reltime). Is that intentional or is that something we should fix eventually? regards -- Tomas Vondra http://www.2ndQuadrant.com PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
Attachment
> BTW while working on the regression tests, I've noticed that brin.sql > fails to test a couple of minmax opclasses (e.g. abstime/reltime). Is > that intentional or is that something we should fix eventually? I believe abstime/reltime are deprecated. Perhaps nobody wanted to bother adding test coverage for deprecated classes? There was another thread that discussed removing these types. The consensus seemed to be in favor of removing them, though I have not seen a patch for that yet. mark
On 02/05/2018 09:27 PM, Mark Dilger wrote: > >> BTW while working on the regression tests, I've noticed that brin.sql >> fails to test a couple of minmax opclasses (e.g. abstime/reltime). Is >> that intentional or is that something we should fix eventually? > > I believe abstime/reltime are deprecated. Perhaps nobody wanted to > bother adding test coverage for deprecated classes? There was another > thread that discussed removing these types. The consensus seemed to > be in favor of removing them, though I have not seen a patch for that yet. > Yeah, that's what I've been wondering about too. There's also this comment in nabstime.h: /* * Although time_t generally is a long int on 64 bit systems, these two * types must be 4 bytes, because that's what pg_type.h assumes. They * should be yanked (long) before 2038 and be replaced by timestamp and * interval. */ But then why adding BRIN opclasses at all? And if adding them, why not to test them? We all know how long deprecation takes, particularly for data types. For me the question is whether to bother with adding the multi-minmax opclasses, of course. regards -- Tomas Vondra http://www.2ndQuadrant.com PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
Tomas Vondra <tomas.vondra@2ndquadrant.com> writes:
> Yeah, that's what I've been wondering about too. There's also this
> comment in nabstime.h:
> /*
> * Although time_t generally is a long int on 64 bit systems, these two
> * types must be 4 bytes, because that's what pg_type.h assumes. They
> * should be yanked (long) before 2038 and be replaced by timestamp and
> * interval.
> */
> But then why adding BRIN opclasses at all? And if adding them, why not
> to test them? We all know how long deprecation takes, particularly for
> data types.
There was some pretty recent chatter about removing these types; IIRC
Andres was annoyed about their lack of overflow checks.
I would definitely vote against adding any BRIN support for these types,
or indeed doing any work on them at all other than removal.
regards, tom lane
On 02/06/2018 12:40 AM, Tom Lane wrote: > Tomas Vondra <tomas.vondra@2ndquadrant.com> writes: >> Yeah, that's what I've been wondering about too. There's also this >> comment in nabstime.h: > >> /* >> * Although time_t generally is a long int on 64 bit systems, these two >> * types must be 4 bytes, because that's what pg_type.h assumes. They >> * should be yanked (long) before 2038 and be replaced by timestamp and >> * interval. >> */ > >> But then why adding BRIN opclasses at all? And if adding them, why not >> to test them? We all know how long deprecation takes, particularly for >> data types. > > There was some pretty recent chatter about removing these types; > IIRC Andres was annoyed about their lack of overflow checks. > > I would definitely vote against adding any BRIN support for these > types, or indeed doing any work on them at all other than removal. > Works for me. Ripping out the two opclasses from the patch is trivial. regards -- Tomas Vondra http://www.2ndQuadrant.com PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
Hi, Attached is an updated patch series, fixing duplicate OIDs and removing opclasses for reltime/abstime data types, as discussed. regards -- Tomas Vondra http://www.2ndQuadrant.com PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
Attachment
Hi,
On 2018-02-25 01:30:47 +0100, Tomas Vondra wrote:
> Note: Currently, this only works with float8-based data types.
> Supporting additional data types is not a big issue, but will
> require extending the opclass with "subtract" operator (used to
> compute distance between values when merging ranges).
Based on Tom's past stances I'm a bit doubtful he'd be happy with such a
restriction. Note that something similar-ish also has come up in
0a459cec96.
I kinda wonder if there's any way to not have two similar but not equal
types of logic here?
That problem is
resolved here by adding the ability for btree operator classes to provide
an "in_range" support function that defines how to add or subtract the
RANGE offset value. Factoring it this way also allows the operator class
to avoid overflow problems near the ends of the datatype's range, if it
wishes to expend effort on that. (In the committed patch, the integer
opclasses handle that issue, but it did not seem worth the trouble to
avoid overflow failures for datetime types.)
- Andres
Andres Freund <andres@anarazel.de> writes:
> On 2018-02-25 01:30:47 +0100, Tomas Vondra wrote:
>> Note: Currently, this only works with float8-based data types.
>> Supporting additional data types is not a big issue, but will
>> require extending the opclass with "subtract" operator (used to
>> compute distance between values when merging ranges).
> Based on Tom's past stances I'm a bit doubtful he'd be happy with such a
> restriction. Note that something similar-ish also has come up in
> 0a459cec96.
> I kinda wonder if there's any way to not have two similar but not equal
> types of logic here?
Hm. I wonder what the patch intends to do with subtraction overflow,
or infinities, or NaNs. Just as with the RANGE patch, it does not
seem to me that failure is really an acceptable option. Indexes are
supposed to be able to index whatever the column datatype can store.
regards, tom lane
On 03/02/2018 05:08 AM, Tom Lane wrote: > Andres Freund <andres@anarazel.de> writes: >> On 2018-02-25 01:30:47 +0100, Tomas Vondra wrote: >>> Note: Currently, this only works with float8-based data types. >>> Supporting additional data types is not a big issue, but will >>> require extending the opclass with "subtract" operator (used to >>> compute distance between values when merging ranges). > >> Based on Tom's past stances I'm a bit doubtful he'd be happy with such a >> restriction. Note that something similar-ish also has come up in >> 0a459cec96. > That restriction was lifted quite a long time ago, so now both index types support pretty much the same data types as the original BRIN (with the reltime/abstime exception, discussed in this thread earlier). >> I kinda wonder if there's any way to not have two similar but not >> equal types of logic here? > > Hm. I wonder what the patch intends to do with subtraction overflow, > or infinities, or NaNs. Just as with the RANGE patch, it does not > seem to me that failure is really an acceptable option. Indexes are > supposed to be able to index whatever the column datatype can store. > I admit that's something I haven't thought about very much. I'll look into that, of course, but the indexes are only using the deltas to pick which ranges to merge, so I think in the worst case it may results in sub-optimal index. But let me check what the RANGE patch did. regards -- Tomas Vondra http://www.2ndQuadrant.com PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
Hi,
Attached is a patch version fixing breakage due to pg_proc changes
commited in fd1a421fe661.
On 03/02/2018 05:08 AM, Tom Lane wrote:
> Andres Freund <andres@anarazel.de> writes:
>> On 2018-02-25 01:30:47 +0100, Tomas Vondra wrote:
>>> Note: Currently, this only works with float8-based data types.
>>> Supporting additional data types is not a big issue, but will
>>> require extending the opclass with "subtract" operator (used to
>>> compute distance between values when merging ranges).
>
>> Based on Tom's past stances I'm a bit doubtful he'd be happy with
>> such a restriction. Note that something similar-ish also has come
>> up in 0a459cec96.
>
>> I kinda wonder if there's any way to not have two similar but not
>> equal types of logic here?
>
I don't think it's very similar to what 0a459cec96 is doing. It's true
both deal with ranges of values, but that's about it - I don't see how
this patch could reuse some bits from 0a459cec96.
To elaborate, 0a459cec96 only really needs to know "does this value fall
into this range" while this patch needs to compare ranges by length.
That is, given a bunch of ranges (summary of values for a section of a
table), it needs to decide which ranges to merge - and it picks the
ranges with the smallest gap.
So for example with ranges [1,10], [15,20], [30,200], [250,300] it would
merge [1,10] and [15,20] because the gap between them is only 5, which
is shorter than the other gaps. This is used when the summary for a
range of pages gets "full" (the patch only keeps up to 32 ranges or so).
Not sure how I could reuse 0a459cec96 to do this.
> Hm. I wonder what the patch intends to do with subtraction overflow,
> or infinities, or NaNs. Just as with the RANGE patch, it does not
> seem to me that failure is really an acceptable option. Indexes are
> supposed to be able to index whatever the column datatype can store.
>
I've been thinking about this after looking at 0a459cec96, and I don't
think this patch has the same issues. One reason is that just like the
original minmax opclass, it does not really mess with the data it
stores. It only does min/max on the values, and stores that, so if there
was NaN or Infinity, it will index NaN or Infinity.
The subtraction is used only to decide which ranges to merge first, and
if the subtraction returns Infinity/NaN the ranges will be considered
very distant and merged last. Which is pretty much the desired behavior,
because it means -Infinity, Infinity and NaN will be keps as individual
"points" as long as possible.
Perhaps there is some other danger/thinko here, that I don't see?
The one overflow issue I found in the patch is that the numeric
"distance" function does this:
d = DirectFunctionCall2(numeric_sub, a2, a1); /* a2 - a1 */
PG_RETURN_FLOAT8(DirectFunctionCall1(numeric_float8, d));
which can overflow, of course. But that is not fatal - the index may get
inefficient due to non-optimal merging of ranges, but it will still
return correct results. But I think this can be easily improved by
passing not only the two values, but also minimum and maximum, and use
that to normalize the values to [0,1].
regards
--
Tomas Vondra http://www.2ndQuadrant.com
PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
Attachment
On 03/04/2018 01:14 AM, Tomas Vondra wrote: > ... > > The one overflow issue I found in the patch is that the numeric > "distance" function does this: > > d = DirectFunctionCall2(numeric_sub, a2, a1); /* a2 - a1 */ > > PG_RETURN_FLOAT8(DirectFunctionCall1(numeric_float8, d)); > > which can overflow, of course. But that is not fatal - the index may get > inefficient due to non-optimal merging of ranges, but it will still > return correct results. But I think this can be easily improved by > passing not only the two values, but also minimum and maximum, and use > that to normalize the values to [0,1]. > Attached is an updated patch series, addressing this possible overflow the way I proposed - by computing (a2 - a1) / (b2 - b1), which is guaranteed to produce a value between 0 and 1. The two new arguments are ignored for most "distance" functions, because those can't overflow or underflow in double precision AFAICS. regards -- Tomas Vondra http://www.2ndQuadrant.com PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
Attachment
Hi,
attached is updated and slightly improved version of the two BRIN
opclasses (bloom and multi-range minmax). Given the lack of reviews I
think it's likely to get bumped to 2018-09, which I guess is OK - it
surely needs more feedback regarding some decisions. So let me share
some thoughts about those, before I forget all of it, and some test
results showing the pros/cons of those indexes.
1) index parameters
The main improvement of this version is an introduction of a couple of
BRIN index parameters, next to pages_per_range and autosummarize.
a) n_distinct_per_range - used to size Bloom index
b) false_positive_rate - used to size Bloom index
c) values_per_range - number of values in the minmax-multi summary
Until now those parameters were pretty much hard-coded, this allows easy
customization depending on the data set. There are some basic rules to
to clamp the values (e.g. not to allow ndistinct to be less than 128 or
more than MaxHeapTuplesPerPage * page_per_range), but that's about it.
I'm sure we could devise more elaborate heuristics (e.g. when building
index on an existing table, we could inspect table statistics first),
but the patch does not do that.
One disadvantage is that those parameters are per-index. It's possible
to define multi-column BRIN index, possibly with different opclasses:
CREATE INDEX ON t USING brin (a int4_bloom_ops,
b int8_bloom_ops,
c int4_minmax_multi_ops,
d int8_minmax_multi_ops)
WITH (false_positive_rate = 0.01,
n_distinct_per_range = 1024,
values_per_range = 32);
in which case the parameters apply to all columns (with the relevant
opclass type). So for example false_positive_rate applies to both "a"
and "b".
This is somewhat unfortunate, but I don't think it's worth inventing
more complex solution. If you need to specify different parameters, you
can simply build separate indexes, and it's more practical anyway
because all the summaries must fit on the same index page which limits
the per-column space. So people are more likely to define single-column
bloom indexes anyway.
There's a room for improvement when it comes to validating the
parameters. For example, it's possible to specify parameters that would
produce bloom filters larger than 8kB, which may lead with over-sized
index rows later. For minmax-multi indexes this should be relatively
safe (maximum number of values is 256, which is low enough for all
fixed-length types). Of course, varlena columns can break it, but we
can't really validate those anyway.
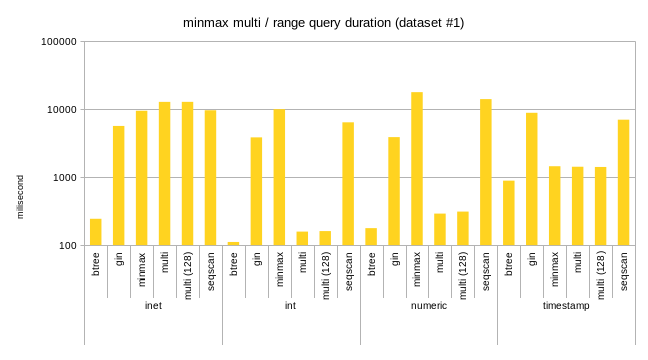
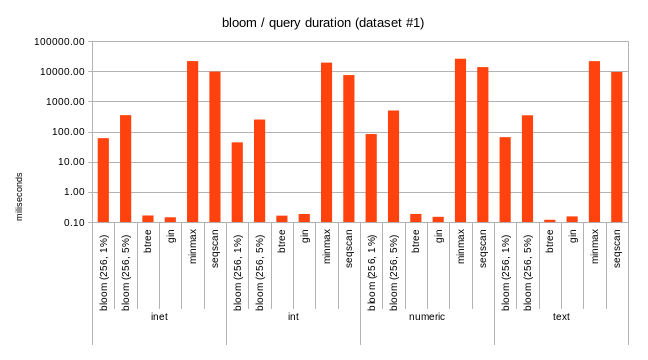
2) test results
The attached spreadsheet shows results comparing these opclasses to
existing BRIN indexes, and also to BTREE/GIN. Clearly, the dataset were
picked to show advantages of those approaches, e.g. on data sets where
regular minmax fails to deliver any benefits.
Overall I think it looks nice - the indexes are larger than minmax
(expected, the summaries are larger), but still orders of magnitude
smaller than BTREE or even GIN. For bloom the build time is comparable
to minmax, for minmax-multi it's somewhat slower - again, I'm sure
there's room for improvements.
For query performance, it's clearly better than plain minmax (but well,
the datasets were constructed to demonstrate that, so no surprise here).
One interesting thing I haven't realized initially is the relationship
between false positive rate for Bloom indexes, and the fraction of table
scanned by a query on average. Essentially, a bloom index with 1% false
positive rate is expected to scan about 1% of table on average. That
pretty accurately determines the performance of bloom indexes.
regards
--
Tomas Vondra http://www.2ndQuadrant.com
PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
Attachment
- 0001-Pass-all-keys-to-BRIN-consistent-function-a-20180403.patch.gz
- 0002-Move-IS-NOT-NULL-checks-to-bringetbitmap-20180403.patch.gz
- 0003-BRIN-bloom-indexes-20180403.patch.gz
- 0004-BRIN-multi-range-minmax-indexes-20180403.patch.gz
- brin-results.ods
- minmax-multi-queries.png
- bloom-queries.png
- bloom.sql
- minmax-multi.sql
{kind=link}
{kind=link}
Hi,
Attached is rebased version of this BRIN patch series, fixing mostly the
breakage due to 372728b0 (aka initial-catalog-data format changes). As
2018-07 CF is meant for almost-ready patches, this is more a 2018-09
material. But perhaps someone would like to take a look - and I'd have
to fix it anyway ...
At the pgcon dev meeting I suggested that long-running patches should
have a "summary" post once in a while, so that reviewers don't have to
reread the whole thread and follow all the various discussions. So let
me start with this thread, although it's not a particularly long or
complex one, nor does it have a long discussion. But anyway ...
The patches introduce two new BRIN opclasses - minmax-multi and bloom.
minmax-multi
============
minmax-multi is a variant of the current minmax opclass that handles
cases where the plain minmax opclass degrades due to outlier values.
Imagine almost perfectly correlated data (say, timestamps in a log
table) - that works great with regular minmax indexes. But if you go and
delete a bunch of historical messages (for whatever reason), new rows
with new timestamps will be routed to the empty space and the minmax
indexes will degrade because the ranges will get much "wider" due to the
new values.
The minmax-multi indexes deal with that by maintaining not a single
minmax range, but several of them. That allows tracking the outlier
values separately, without constructing one wide minmax range.
Consider this artificial example:
create table t (a bigint, b int);
alter t set (fillfactor=95);
insert into t select i + 1000*random(), i+1000*random()
from generate_series(1,100000000) s(i);
update t set a = 1, b = 1 where random() < 0.001;
update t set a = 100000000, b = 100000000 where random() < 0.001;
Now if you create a regular minmax index, it's going to perform
terribly, because pretty much every minmax range is [1,100000000] thanks
to the update of 0.1% of rows.
create index on t using brin (a);
explain analyze select * from t
where a between 1923300::int and 1923600::int;
QUERY PLAN
-----------------------------------------------------------------
Bitmap Heap Scan on t (cost=75.11..75884.45 rows=319 width=12)
(actual time=948.906..101739.892 rows=308 loops=1)
Recheck Cond: ((a >= 1923300) AND (a <= 1923600))
Rows Removed by Index Recheck: 99999692
Heap Blocks: lossy=568182
-> Bitmap Index Scan on t_a_idx (cost=0.00..75.03 rows=22587
width=0) (actual time=89.357..89.357 rows=5681920 loops=1)
Index Cond: ((a >= 1923300) AND (a <= 1923600))
Planning Time: 2.161 ms
Execution Time: 101740.776 ms
(8 rows)
But with the minmax-multi opclass, this is not an issue:
create index on t using brin (a int8_minmax_multi_ops);
QUERY PLAN
-------------------------------------------------------------------
Bitmap Heap Scan on t (cost=1067.11..76876.45 rows=319 width=12)
(actual time=38.906..49.763 rows=308 loops=1)
Recheck Cond: ((a >= 1923300) AND (a <= 1923600))
Rows Removed by Index Recheck: 22220
Heap Blocks: lossy=128
-> Bitmap Index Scan on t_a_idx (cost=0.00..1067.03 rows=22587
width=0) (actual time=28.069..28.069 rows=1280 loops=1)
Index Cond: ((a >= 1923300) AND (a <= 1923600))
Planning Time: 1.715 ms
Execution Time: 50.866 ms
(8 rows)
Which is clearly a big improvement.
Doing this required some changes to how BRIN evaluates conditions on
page ranges. With a single minmax range it was enough to evaluate them
one by one, but minmax-multi needs to see all of them at once (to match
them against the partial ranges).
Most of the complexity is in building the summary, particularly picking
which values (partial ranges) to merge. The max number of values in the
summary is specified as values_per_range index reloption, and by default
it's set to 64, so there can be either 64 points or 32 intervals or some
combination of those.
I've been thinking about some automated way to tune this (either
globally or for each page range independently), but so far I have not
been very successful. The challenge is that making good decisions
requires global information about values in the column (e.g. global
minimum and maximum). I think the reloption with 64 as a default is a
good enough solution for now.
Perhaps the stats from pg_statistic would be useful for improving this
in the future, but I'm not sure.
bloom
=====
As the name suggests, this opclass uses bloom filter for the summary.
Compared to the minmax-multi it's a bit more experimental idea, but I
believe the foundations are safe.
Using bloom filter means that the index can only support equalities, but
for many use cases that's an acceptable limitation - UUID, IP addresses,
... (various identifiers in general).
Of course, how to size the bloom filter? It's worth noting the false
positive rate of the filter is essentially the fraction of a table that
will be scanned every time.
Similarly to the minmax-multi, parameters for computing optimal filter
size are set as reloptions (false_positive_rate, n_distinct_per_range)
with some reasonable defaults (1% false positive rate and distinct
values 10% of maximum heap tuples in a page range).
Note: When building the filter, we don't compute the hashes from the
original values, but we first use the type-specific hash function (the
same we'd use for hash indexes or hash joins) and then use the hash a as
an input for the bloom filter. This generally works fine, but if "our"
hash function generates a lot of collisions, it increases false positive
ratio of the whole filter. I'm not aware of a case where this would be
an issue, though.
What further complicates sizing of the bloom filter is available space -
the whole bloom filter needs to fit onto an 8kB page, and "full" bloom
filters with about 1/2 the bits set are pretty non-compressible. So
there's maybe ~8000 bytes for the bitmap. So for columns with many
distinct values, it may be necessary to make the page range smaller, to
reduce the number of distinct values in it.
And of course it requires good ndistinct estimates, not just for the
column as a whole, but for a single page range (because that's what
matters for sizing the bloom filter). Which is not a particularly
reliable estimate, I'm afraid.
So reloptions seem like a sufficient solution, at least for now.
open questions
==============
* I suspect the definition of cross-type opclasses (int2 vs. int8) are
not entirely correct. That probably needs another look.
* The bloom filter now works in two modes - sorted (where in the sorted
mode it stores the hashes directly) and hashed (the usual bloom filter
behavior). The idea is that for ranges with significantly fewer distinct
values, we only store those to save space (instead of allocating the
whole bloom filter with mostly 0 bits).
regards
--
Tomas Vondra http://www.2ndQuadrant.com
PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
Attachment
On Sun, Jun 24, 2018 at 2:01 PM, Tomas Vondra <tomas.vondra@2ndquadrant.com> wrote: > Attached is rebased version of this BRIN patch series, fixing mostly the > breakage due to 372728b0 (aka initial-catalog-data format changes). As > 2018-07 CF is meant for almost-ready patches, this is more a 2018-09 > material. But perhaps someone would like to take a look - and I'd have > to fix it anyway ... Hi Tomas, FYI Windows doesn't like this: src/backend/access/brin/brin_bloom.c(146): warning C4013: 'round' undefined; assuming extern returning int [C:\projects\postgresql\postgres.vcxproj] brin_bloom.obj : error LNK2019: unresolved external symbol round referenced in function bloom_init [C:\projects\postgresql\postgres.vcxproj] -- Thomas Munro http://www.enterprisedb.com
On 06/24/2018 11:39 PM, Thomas Munro wrote: > On Sun, Jun 24, 2018 at 2:01 PM, Tomas Vondra > <tomas.vondra@2ndquadrant.com> wrote: >> Attached is rebased version of this BRIN patch series, fixing mostly the >> breakage due to 372728b0 (aka initial-catalog-data format changes). As >> 2018-07 CF is meant for almost-ready patches, this is more a 2018-09 >> material. But perhaps someone would like to take a look - and I'd have >> to fix it anyway ... > > Hi Tomas, > > FYI Windows doesn't like this: > > src/backend/access/brin/brin_bloom.c(146): warning C4013: 'round' > undefined; assuming extern returning int > [C:\projects\postgresql\postgres.vcxproj] > > brin_bloom.obj : error LNK2019: unresolved external symbol round > referenced in function bloom_init > [C:\projects\postgresql\postgres.vcxproj] > Thanks, I've noticed the failure before, but was not sure what's the exact cause. It seems there's still no 'round' on Windows, so I'll probably fix that by using rint() instead, or something like that. regards -- Tomas Vondra http://www.2ndQuadrant.com PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On 06/25/2018 12:31 AM, Tomas Vondra wrote: > On 06/24/2018 11:39 PM, Thomas Munro wrote: >> On Sun, Jun 24, 2018 at 2:01 PM, Tomas Vondra >> <tomas.vondra@2ndquadrant.com> wrote: >>> Attached is rebased version of this BRIN patch series, fixing mostly the >>> breakage due to 372728b0 (aka initial-catalog-data format changes). As >>> 2018-07 CF is meant for almost-ready patches, this is more a 2018-09 >>> material. But perhaps someone would like to take a look - and I'd have >>> to fix it anyway ... >> >> Hi Tomas, >> >> FYI Windows doesn't like this: >> >> src/backend/access/brin/brin_bloom.c(146): warning C4013: 'round' >> undefined; assuming extern returning int >> [C:\projects\postgresql\postgres.vcxproj] >> >> brin_bloom.obj : error LNK2019: unresolved external symbol round >> referenced in function bloom_init >> [C:\projects\postgresql\postgres.vcxproj] >> > > Thanks, I've noticed the failure before, but was not sure what's the > exact cause. It seems there's still no 'round' on Windows, so I'll > probably fix that by using rint() instead, or something like that. > OK, here is a version tweaked to use floor()/ceil() instead of round(). Let's see if the Windows machine likes that more. regards -- Tomas Vondra http://www.2ndQuadrant.com PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
Attachment
Hi Tomas, On Mon, Jun 25, 2018 at 02:14:20AM +0200, Tomas Vondra wrote: > OK, here is a version tweaked to use floor()/ceil() instead of round(). > Let's see if the Windows machine likes that more. The latest patch set does not apply cleanly. Could you rebase it? I have moved the patch to CF 2018-10 for now, waiting on author. -- Michael
Attachment
On Tue, Oct 02, 2018 at 11:49:05AM +0900, Michael Paquier wrote: > The latest patch set does not apply cleanly. Could you rebase it? I > have moved the patch to CF 2018-10 for now, waiting on author. It's been some time since that request, so I am marking the patch as returned with feedback. -- Michael
Attachment
On 2/4/19 6:54 AM, Michael Paquier wrote: > On Tue, Oct 02, 2018 at 11:49:05AM +0900, Michael Paquier wrote: >> The latest patch set does not apply cleanly. Could you rebase it? I >> have moved the patch to CF 2018-10 for now, waiting on author. > > It's been some time since that request, so I am marking the patch as > returned with feedback. But that's not the most recent version of the patch. On 28/12 I've submitted an updated / rebased patch. regards -- Tomas Vondra http://www.2ndQuadrant.com PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On 2019-Feb-04, Tomas Vondra wrote: > On 2/4/19 6:54 AM, Michael Paquier wrote: > > On Tue, Oct 02, 2018 at 11:49:05AM +0900, Michael Paquier wrote: > >> The latest patch set does not apply cleanly. Could you rebase it? I > >> have moved the patch to CF 2018-10 for now, waiting on author. > > > > It's been some time since that request, so I am marking the patch as > > returned with feedback. > > But that's not the most recent version of the patch. On 28/12 I've > submitted an updated / rebased patch. Moved to next commitfest instead. -- Álvaro Herrera https://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
Apparently cputube did not pick the last version of the patches I've submitted in December (and I don't see the message in the thread in archive either), so it's listed as broken. So here we go again, hopefully this time everything will go through ... regards On 12/28/18 12:45 AM, Tomas Vondra wrote: > Hi all, > > Attached is an updated/rebased version of the patch series. There are no > changes to behavior, but let me briefly summarize the current state: > > 0001 and 0002 > ------------- > > The first two parts are "just" refactoring the existing code to pass all > scankeys to the opclass at once - this is needed by the new minmax-like > opclass, but per discussion with Alvaro it seems worthwhile even > independently. I tend to agree with that. Similarly for the second part, > which moves all IS NULL checks entirely to bringetbimap(). > > 0003 bloom opclass > ------------------ > > The first new opclasss, based on bloom filters. For each page range > (i.e. 1MB by default) a small bloom filter is built (with hash values of > the original values as inputs), and then used to evaluate equality > queries. A small optimization is that initially the actual (hash) values > are kept until reaching the bloom filter size. This improves behavior in > low-cardinality data sets. > > Picking the bloom filter parameters is the tricky part - we don't have a > reliable source of such information (namely number of distinct values > per range), and e.g. the false positive rate actually has to be picked > by the user because it's a compromise between index size and accuracy. > Essentially, false positive rate is the fraction of the table that has > to be scanned for a random value (on average). But it also makes the > index larger, because the per-range bloom filters will be larger. > > Another reason why this needs to be defined by the user is that the > space for index tuple is limited by one page (8kB by default), so we > can't allow the bloom filter to be larger (we have to assume it's > non-compressible, because in the optimal fill it's 50% 0s and 1s). But > the BRIN index may be multi-column, and the limit applies to the whole > tuple. And we don't know what the opclasses or parameters of other > columns are. > > So the patch simply adds two reloptions > > a) n_distinct_per_range - number of distinct values per range > b) false_positive_rate - false positive rate of the filter > > There are some simple heuristics to ensure the values are reasonable > (e.g. upper limit for number of distinct values, etc.) and perhaps we > might consider stats from the underlying table (when not empty), but the > patch does not do that. > > > 0004 multi-minmax opclass > ------------------------- > > The second opclass addresses a common issue for minmax indexes, where > the table is initially nicely correlated with the index, and it works > fine. But then deletes/updates route data into other parts of the table > making the ranges very wide ad rendering the BRIN index inefficient. > > One way to deal improve this would be considering the index(es) while > routing the new tuple, i.e. looking not only for page with enough free > space, but for pages in already matching ranges (or close to it). > > A partitioning is a possible approach so segregate the data. But it's > certainly much higher overhead, both in terms of maintenance and > planning (particularly with 1:1 of ranges vs. partitions). > > So the new multi-minmax opclass takes a different approach, replacing > the one minmax range with multiple ranges (64 boundary values or 32 > ranges by default). Initially individual values are stored, and after > reaching the maximum number of values the values are merged into ranges > by distance. This allows handling outliers very efficiently, because > they will not be merged with the "main" range for as long as possible. > > Similarly to the bloom opclass, the main challenge here is deciding the > parameter - in this case, it's "number of values per range". Again, it's > a compromise vs. index size and efficiency. The default (64 values) is > fairly reasonable, but ultimately it's up to the user - there is a new > reloption "values_per_range". > > > > regards > -- Tomas Vondra http://www.2ndQuadrant.com PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
Attachment
Hi! I'm starting to look at this patchset. In the general, I think it's very cool! We definitely need this. On Tue, Apr 3, 2018 at 10:51 PM Tomas Vondra <tomas.vondra@2ndquadrant.com> wrote: > 1) index parameters > > The main improvement of this version is an introduction of a couple of > BRIN index parameters, next to pages_per_range and autosummarize. > > a) n_distinct_per_range - used to size Bloom index > b) false_positive_rate - used to size Bloom index > c) values_per_range - number of values in the minmax-multi summary > > Until now those parameters were pretty much hard-coded, this allows easy > customization depending on the data set. There are some basic rules to > to clamp the values (e.g. not to allow ndistinct to be less than 128 or > more than MaxHeapTuplesPerPage * page_per_range), but that's about it. > I'm sure we could devise more elaborate heuristics (e.g. when building > index on an existing table, we could inspect table statistics first), > but the patch does not do that. > > One disadvantage is that those parameters are per-index. For me, the main disadvantage of this solution is that we put opclass-specific parameters into access method. And this is generally bad design. So, user can specify such parameter if even not using corresponding opclass, that may cause a confuse (if even we forbid that, it needs to be hardcoded). Also, extension opclasses can't do the same thing. Thus, it appears that extension opclasses are not first class citizens anymore. Have you take a look at opclass parameters patch [1]? I think it's proper solution of this problem. I think we should postpone this parameterization until we push opclass parameters patch. 1. https://www.postgresql.org/message-id/d22c3a18-31c7-1879-fc11-4c1ce2f5e5af%40postgrespro.ru ------ Alexander Korotkov Postgres Professional: http://www.postgrespro.com The Russian Postgres Company
On Sun, Mar 4, 2018 at 3:15 AM Tomas Vondra <tomas.vondra@2ndquadrant.com> wrote: > I've been thinking about this after looking at 0a459cec96, and I don't > think this patch has the same issues. One reason is that just like the > original minmax opclass, it does not really mess with the data it > stores. It only does min/max on the values, and stores that, so if there > was NaN or Infinity, it will index NaN or Infinity. FWIW, I think the closest similar functionality is subtype_diff function of range type. But I don't think we should require range type here just in order to fetch subtype_diff function out of it. So, opclass distance function looks OK for me, assuming it's not AM-defined function, but function used for inter-opclass compatibility. ------ Alexander Korotkov Postgres Professional: http://www.postgrespro.com The Russian Postgres Company
On 3/2/19 10:05 AM, Alexander Korotkov wrote: > On Sun, Mar 4, 2018 at 3:15 AM Tomas Vondra > <tomas.vondra@2ndquadrant.com> wrote: >> I've been thinking about this after looking at 0a459cec96, and I don't >> think this patch has the same issues. One reason is that just like the >> original minmax opclass, it does not really mess with the data it >> stores. It only does min/max on the values, and stores that, so if there >> was NaN or Infinity, it will index NaN or Infinity. > > FWIW, I think the closest similar functionality is subtype_diff > function of range type. But I don't think we should require range > type here just in order to fetch subtype_diff function out of it. So, > opclass distance function looks OK for me, OK, agreed. > assuming it's not AM-defined function, but function used for > inter-opclass compatibility. > I'm not sure I understand what you mean by this. Can you elaborate? Does the current implementation (i.e. distance function being implemented as an opclass support procedure) work for you or not? Thanks for looking at the patch! cheers -- Tomas Vondra http://www.2ndQuadrant.com PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On 3/2/19 10:00 AM, Alexander Korotkov wrote: > Hi! > > I'm starting to look at this patchset. In the general, I think it's > very cool! We definitely need this. > > On Tue, Apr 3, 2018 at 10:51 PM Tomas Vondra > <tomas.vondra@2ndquadrant.com> wrote: >> 1) index parameters >> >> The main improvement of this version is an introduction of a couple of >> BRIN index parameters, next to pages_per_range and autosummarize. >> >> a) n_distinct_per_range - used to size Bloom index >> b) false_positive_rate - used to size Bloom index >> c) values_per_range - number of values in the minmax-multi summary >> >> Until now those parameters were pretty much hard-coded, this allows easy >> customization depending on the data set. There are some basic rules to >> to clamp the values (e.g. not to allow ndistinct to be less than 128 or >> more than MaxHeapTuplesPerPage * page_per_range), but that's about it. >> I'm sure we could devise more elaborate heuristics (e.g. when building >> index on an existing table, we could inspect table statistics first), >> but the patch does not do that. >> >> One disadvantage is that those parameters are per-index. > > For me, the main disadvantage of this solution is that we put > opclass-specific parameters into access method. And this is generally > bad design. So, user can specify such parameter if even not using > corresponding opclass, that may cause a confuse (if even we forbid > that, it needs to be hardcoded). Also, extension opclasses can't do > the same thing. Thus, it appears that extension opclasses are not > first class citizens anymore. Have you take a look at opclass > parameters patch [1]? I think it's proper solution of this problem. > I think we should postpone this parameterization until we push opclass > parameters patch. > > 1. https://www.postgresql.org/message-id/d22c3a18-31c7-1879-fc11-4c1ce2f5e5af%40postgrespro.ru > I've looked at that patch only very briefly so far, but I agree it's likely a better solution than what my patch does at the moment (which I agree is a misuse of the AM-level options). I'll take a closer look. I agree it makes sense to re-use that infrastructure for this patch, but I'm hesitant to rebase it on top of that patch right away. Because it would mean this thread dependent on it, which would confuse cputube, make it bitrot faster etc. So I suggest we ignore this aspect of the patch for now, and let's talk about the other bits first. regards -- Tomas Vondra http://www.2ndQuadrant.com PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On Sun, Mar 3, 2019 at 12:25 AM Tomas Vondra <tomas.vondra@2ndquadrant.com> wrote: > I've looked at that patch only very briefly so far, but I agree it's > likely a better solution than what my patch does at the moment (which I > agree is a misuse of the AM-level options). I'll take a closer look. > > I agree it makes sense to re-use that infrastructure for this patch, but > I'm hesitant to rebase it on top of that patch right away. Because it > would mean this thread dependent on it, which would confuse cputube, > make it bitrot faster etc. > > So I suggest we ignore this aspect of the patch for now, and let's talk > about the other bits first. Works for me. We don't need to make the whole work made by this patch to be dependent on opclass parameters. It's OK to ignore this aspect for now and come back when opclass parameters get committed. ------ Alexander Korotkov Postgres Professional: http://www.postgrespro.com The Russian Postgres Company
On Sun, Mar 3, 2019 at 12:12 AM Tomas Vondra <tomas.vondra@2ndquadrant.com> wrote: > On 3/2/19 10:05 AM, Alexander Korotkov wrote: > > assuming it's not AM-defined function, but function used for > > inter-opclass compatibility. > > I'm not sure I understand what you mean by this. Can you elaborate? Does > the current implementation (i.e. distance function being implemented as > an opclass support procedure) work for you or not? I mean that unlike other index access methods BRIN allow opclasses to define custom support procedures. These support procedures are not directly called from AM, but might be called from other opclass support procedures. That allows to re-use the same high-level support procedures in multiple opclasses. So, distance support procedure is not directly called from AM. We don't have to change the interface between AM and opclass for that. This is why I'm OK with that. ------ Alexander Korotkov Postgres Professional: http://www.postgrespro.com The Russian Postgres Company
Hi! I have looked at this patch set too, but so far only at first two infrastructure patches. First of all, I agree that opclass parameters patch is needed here. 0001. Pass all keys to BRIN consistent function at once. I think that changing the signature of consistent function is bad, because then the authors of existing BRIN opclasses will need to maintain two variants of the function for different version of PosgreSQL. Moreover, we can easily distinguish two variants by the number of parameters. So I returned back a call to old 3-argument variant of consistent() in bringetbitmap(). Also I fixed brinvalidate() adding support for new 4-argument variant, and fixed catalog entries for brin_minmax_consistent() and brin_inclusion_consistent() which remained 3-argument. And also I removed unneeded indentation shift in these two functions, which makes it difficult to compare changes, by extracting subroutines minmax_consistent_key() and inclusion_consistent_key(). 0002. Move IS NOT NULL checks to bringetbitmap() I believe that removing duplicate code is always good. But in this case it seems a bit inconsistent to refactor only bringetbitmap(). I think we can't guarantee that existing opclasses work with null flags in add_value() and union() in the expected way. So I refactored the work with BrinValues flags in other places in patch 0003. I added flag BrinOpcInfp.oi_regular_nulls which enables regular processing of NULLs before calling of support functions. Now support functions don't need to care about bv_hasnulls at all. add_value(), for example, works now only with non-NULL values. Patches 0002 and 0003 should be merged, I put 0003 in a separate patch just for ease of review. 0004. BRIN bloom indexes 0005. BRIN multi-range minmax indexes I have not looked carefully at these packs yet, but fixed only catalog entries and removed NULLs processing according to patch 0003. I also noticed that the following functions contain a lot of duplicated code, which needs to be extracted into common subroutine: inclusion_get_procinfo() bloom_get_procinfo() minmax_multi_get_procinfo() Attached patches with all my changes. -- Nikita Glukhov Postgres Professional: http://www.postgrespro.com The Russian Postgres Company
Attachment
- 0001-Pass-all-keys-to-BRIN-consistent-function-at-once-20190312.patch.gz
- 0002-Move-IS-NOT-NULL-checks-to-bringetbitmap-20190312.patch.gz
- 0003-Move-processing-of-NULLs-from-BRIN-support-functions-20190312.patch.gz
- 0004-BRIN-bloom-indexes-20190312.patch.gz
- 0005-BRIN-multi-range-minmax-indexes-20190312.patch.gz
Hi Nikita, Thanks for looking at the patch. On 3/12/19 11:33 AM, Nikita Glukhov wrote: > Hi! > > I have looked at this patch set too, but so far only at first two > infrastructure patches. > > First of all, I agree that opclass parameters patch is needed here. > OK. > > 0001. Pass all keys to BRIN consistent function at once. > > I think that changing the signature of consistent function is bad, because then > the authors of existing BRIN opclasses will need to maintain two variants of > the function for different version of PosgreSQL. Moreover, we can easily > distinguish two variants by the number of parameters. So I returned back a > call to old 3-argument variant of consistent() in bringetbitmap(). Also I > fixed brinvalidate() adding support for new 4-argument variant, and fixed > catalog entries for brin_minmax_consistent() and brin_inclusion_consistent() > which remained 3-argument. And also I removed unneeded indentation shift in > these two functions, which makes it difficult to compare changes, by extracting > subroutines minmax_consistent_key() and inclusion_consistent_key(). > Hmmm. I admit I rather dislike functions that change the signature based on the number of arguments, for some reason. But maybe it's better than changing the consistent function. Not sure. > > 0002. Move IS NOT NULL checks to bringetbitmap() > > I believe that removing duplicate code is always good. But in this case it > seems a bit inconsistent to refactor only bringetbitmap(). I think we can't > guarantee that existing opclasses work with null flags in add_value() and > union() in the expected way. > > So I refactored the work with BrinValues flags in other places in patch 0003. > I added flag BrinOpcInfp.oi_regular_nulls which enables regular processing of > NULLs before calling of support functions. Now support functions don't need to > care about bv_hasnulls at all. add_value(), for example, works now only with > non-NULL values. > That seems like unnecessary complexity to me. We can't really guarantee much about opclasses in extensions anyway. I don't know if there's some sort of precedent but IMHO it's reasonable to expect the opclasses to be updated accordingly. > Patches 0002 and 0003 should be merged, I put 0003 in a separate patch just > for ease of review. > Thanks. > > 0004. BRIN bloom indexes > 0005. BRIN multi-range minmax indexes > > I have not looked carefully at these packs yet, but fixed only catalog entries > and removed NULLs processing according to patch 0003. I also noticed that the > following functions contain a lot of duplicated code, which needs to be > extracted into common subroutine: > inclusion_get_procinfo() > bloom_get_procinfo() > minmax_multi_get_procinfo() > Yes. The reason for the duplicate code is that initially this was submitted as two separate patches, so there was no obvious need for sharing code. regards -- Tomas Vondra http://www.2ndQuadrant.com PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On Tue, Mar 12, 2019 at 8:15 PM Tomas Vondra <tomas.vondra@2ndquadrant.com> wrote: > > 0001. Pass all keys to BRIN consistent function at once. > > > > I think that changing the signature of consistent function is bad, because then > > the authors of existing BRIN opclasses will need to maintain two variants of > > the function for different version of PosgreSQL. Moreover, we can easily > > distinguish two variants by the number of parameters. So I returned back a > > call to old 3-argument variant of consistent() in bringetbitmap(). Also I > > fixed brinvalidate() adding support for new 4-argument variant, and fixed > > catalog entries for brin_minmax_consistent() and brin_inclusion_consistent() > > which remained 3-argument. And also I removed unneeded indentation shift in > > these two functions, which makes it difficult to compare changes, by extracting > > subroutines minmax_consistent_key() and inclusion_consistent_key(). > > > > Hmmm. I admit I rather dislike functions that change the signature based > on the number of arguments, for some reason. But maybe it's better than > changing the consistent function. Not sure. I also kind of dislike signature change based on the number of arguments. But it's still good to let extensions use old interface if needed. What do you think about invention new consistent method, so that extension can implement one of them? We did similar thing for GIN (bistate consistent vs tristate consistent). ------ Alexander Korotkov Postgres Professional: http://www.postgrespro.com The Russian Postgres Company
On 3/13/19 9:15 AM, Alexander Korotkov wrote: > On Tue, Mar 12, 2019 at 8:15 PM Tomas Vondra > <tomas.vondra@2ndquadrant.com> wrote: >>> 0001. Pass all keys to BRIN consistent function at once. >>> >>> I think that changing the signature of consistent function is bad, because then >>> the authors of existing BRIN opclasses will need to maintain two variants of >>> the function for different version of PosgreSQL. Moreover, we can easily >>> distinguish two variants by the number of parameters. So I returned back a >>> call to old 3-argument variant of consistent() in bringetbitmap(). Also I >>> fixed brinvalidate() adding support for new 4-argument variant, and fixed >>> catalog entries for brin_minmax_consistent() and brin_inclusion_consistent() >>> which remained 3-argument. And also I removed unneeded indentation shift in >>> these two functions, which makes it difficult to compare changes, by extracting >>> subroutines minmax_consistent_key() and inclusion_consistent_key(). >>> >> >> Hmmm. I admit I rather dislike functions that change the signature based >> on the number of arguments, for some reason. But maybe it's better than >> changing the consistent function. Not sure. > > I also kind of dislike signature change based on the number of > arguments. But it's still good to let extensions use old interface if > needed. What do you think about invention new consistent method, so > that extension can implement one of them? We did similar thing for > GIN (bistate consistent vs tristate consistent). > Possibly. The other annoyance of course is that to support the current consistent method we'll have to keep all the code I guess :-( regards -- Tomas Vondra http://www.2ndQuadrant.com PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On Wed, Mar 13, 2019 at 12:52 PM Tomas Vondra <tomas.vondra@2ndquadrant.com> wrote: > On 3/13/19 9:15 AM, Alexander Korotkov wrote: > > On Tue, Mar 12, 2019 at 8:15 PM Tomas Vondra > > <tomas.vondra@2ndquadrant.com> wrote: > >>> 0001. Pass all keys to BRIN consistent function at once. > >>> > >>> I think that changing the signature of consistent function is bad, because then > >>> the authors of existing BRIN opclasses will need to maintain two variants of > >>> the function for different version of PosgreSQL. Moreover, we can easily > >>> distinguish two variants by the number of parameters. So I returned back a > >>> call to old 3-argument variant of consistent() in bringetbitmap(). Also I > >>> fixed brinvalidate() adding support for new 4-argument variant, and fixed > >>> catalog entries for brin_minmax_consistent() and brin_inclusion_consistent() > >>> which remained 3-argument. And also I removed unneeded indentation shift in > >>> these two functions, which makes it difficult to compare changes, by extracting > >>> subroutines minmax_consistent_key() and inclusion_consistent_key(). > >>> > >> > >> Hmmm. I admit I rather dislike functions that change the signature based > >> on the number of arguments, for some reason. But maybe it's better than > >> changing the consistent function. Not sure. > > > > I also kind of dislike signature change based on the number of > > arguments. But it's still good to let extensions use old interface if > > needed. What do you think about invention new consistent method, so > > that extension can implement one of them? We did similar thing for > > GIN (bistate consistent vs tristate consistent). > > > > Possibly. The other annoyance of course is that to support the current > consistent method we'll have to keep all the code I guess :-( Yes, because incompatible change of opclass support function signature is the thing we never did before. We have to add new optional arguments to GiST functions, but that was compatible change. If we do incompatible change of opclass interface, it becomes unclear to do pg_upgrade with extension installed. Imagine, if we don't require function signature to match, we could easily get segfault because of extension incompatibility. If we do require function signature to match, extension upgrade would become complex. It would be required to not only adjust C-code, but also write some custom script, which changes opclass (and users would have to run this script manually?). ------ Alexander Korotkov Postgres Professional: http://www.postgrespro.com The Russian Postgres Company
On Sun, Mar 03, 2019 at 07:29:26AM +0300, Alexander Korotkov wrote:
>On Sun, Mar 3, 2019 at 12:25 AM Tomas Vondra
><tomas.vondra@2ndquadrant.com> wrote:
>> I've looked at that patch only very briefly so far, but I agree it's
>> likely a better solution than what my patch does at the moment (which I
>> agree is a misuse of the AM-level options). I'll take a closer look.
>>
>> I agree it makes sense to re-use that infrastructure for this patch, but
>> I'm hesitant to rebase it on top of that patch right away. Because it
>> would mean this thread dependent on it, which would confuse cputube,
>> make it bitrot faster etc.
>>
>> So I suggest we ignore this aspect of the patch for now, and let's talk
>> about the other bits first.
>
>Works for me. We don't need to make the whole work made by this patch
>to be dependent on opclass parameters. It's OK to ignore this aspect
>for now and come back when opclass parameters get committed.
>
Attached is this patch series, rebased on top of current master and the
opclass parameters patch [1]. I previously planned to keep those two
efforts separate for a while, but I decided to give it a try and the
breakage is fairly minor so I'll keep it this way - this patch has zero
chance of getting committed with the opclass parameters patch anyway.
Aside from rebase and changes due to adopting opclass parameters, the
patch is otherwise unchanged.
0001-0004 are just the opclass parameters patch series.
0005 adds opclass parameters to BRIN indexes (similarly to what the
preceding parts to for GIN/GiST indexes).
0006-0010 are the original patch series (BRIN tweaks, bloom and
multi-minmax) rebased and switched to opclass parameters.
So now, we can do things like this:
CREATE INDEX x ON t USING brin (
col1 int4_bloom_ops(false_positive_rate = 0.05),
col2 int4_minmax_multi_ops(values_per_range = 16)
) WITH (pages_per_range = 32);
and so on. I think the patch [1] works fine - I only have some minor
comments, that I'll post to that thread.
The other challenges (e.g. how to pick the values for opclass parameters
automatically, based on the data) are still open.
regards
[1] https://www.postgresql.org/message-id/flat/d22c3a18-31c7-1879-fc11-4c1ce2f5e5af%40postgrespro.ru
--
Tomas Vondra http://www.2ndQuadrant.com
PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
Attachment
- 0001-Add-opclass-parameters-20190611.patch
- 0002-Add-opclass-parameters-to-GiST-20190611.patch
- 0003-Add-opclass-parameters-to-GIN-20190611.patch
- 0004-Add-opclass-parameters-to-GiST-tsvector_ops-20190611.patch
- 0005-Add-opclass-parameters-to-BRIN-20190611.patch
- 0006-Pass-all-keys-to-BRIN-consistent-function-a-20190611.patch
- 0007-Move-IS-NOT-NULL-checks-to-bringetbitmap-20190611.patch
- 0008-Move-processing-of-NULLs-from-BRIN-support--20190611.patch
- 0009-BRIN-bloom-indexes-20190611.patch
- 0010-BRIN-multi-range-minmax-indexes-20190611.patch
On 2019-Jun-11, Tomas Vondra wrote: > Attached is this patch series, rebased on top of current master and the > opclass parameters patch [1]. I previously planned to keep those two > efforts separate for a while, but I decided to give it a try and the > breakage is fairly minor so I'll keep it this way - this patch has zero > chance of getting committed with the opclass parameters patch anyway. > > Aside from rebase and changes due to adopting opclass parameters, the > patch is otherwise unchanged. This patch series doesn't apply, but I'm leaving it alone since the brokenness is the opclass part, for which I have pinged the other thread. Thanks, -- Álvaro Herrera https://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
Hi, Tomas! I took a look at this patchset. On Tue, Jun 11, 2019 at 8:31 PM Tomas Vondra <tomas.vondra@2ndquadrant.com> wrote: > Attached is this patch series, rebased on top of current master and the > opclass parameters patch [1]. I previously planned to keep those two > efforts separate for a while, but I decided to give it a try and the > breakage is fairly minor so I'll keep it this way - this patch has zero > chance of getting committed with the opclass parameters patch anyway. Great. You can notice, Nikita updated opclass parameters patchset providing uniform way of passing opclass parameters for all index access methods. We would appreciate if you share feedback on that. > Aside from rebase and changes due to adopting opclass parameters, the > patch is otherwise unchanged. > > 0001-0004 are just the opclass parameters patch series. > > 0005 adds opclass parameters to BRIN indexes (similarly to what the > preceding parts to for GIN/GiST indexes). I see this patch change validation and catalog entries for addvalue, consistent and union procs. However, I don't see additional argument to be passed to those functions in this patch. 0009 adds argument to addvalue. Regarding consistent and union, new argument seems not be added in any patch. It's probably not so important if you're going to rebase to current version of opclass parameters, because it provides new way of passing opclass parameters to support functions. ------ Alexander Korotkov Postgres Professional: http://www.postgrespro.com The Russian Postgres Company
On Tue, Sep 03, 2019 at 06:05:04PM -0400, Alvaro Herrera wrote: >On 2019-Jun-11, Tomas Vondra wrote: > >> Attached is this patch series, rebased on top of current master and the >> opclass parameters patch [1]. I previously planned to keep those two >> efforts separate for a while, but I decided to give it a try and the >> breakage is fairly minor so I'll keep it this way - this patch has zero >> chance of getting committed with the opclass parameters patch anyway. >> >> Aside from rebase and changes due to adopting opclass parameters, the >> patch is otherwise unchanged. > >This patch series doesn't apply, but I'm leaving it alone since the >brokenness is the opclass part, for which I have pinged the other >thread. > Attached is an updated version of this patch series, rebased on top of the opclass parameter patches, shared by Nikita a couple of days ago. There's one extra fixup patch, addressing a bug in those patches. Firstly, while I have some comments on the opclass parameters patches (shared in the other thread), I think that patch series is moving in the right direction. After rebase the code is somewhat simpler and easier to read, which is good. I'm sure there's some more work needed on the APIs and so on, but I'm optimistic about that. The rest of this patch series (0007-0011) is mostly unchanged. I've fixed a couple of bugs and added some comments (particularly to the bloom opclass), but that's about it. regards -- Tomas Vondra http://www.2ndQuadrant.com PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
Attachment
- 0001-Introduce-opclass-parameters.patch.gz
- 0002-Introduce-amattoptions.patch.gz
- 0003-Use-amattoptions-in-contrib-bloom.patch.gz
- 0004-Use-opclass-parameters-in-GiST-tsvector_ops.patch.gz
- 0005-Remove-pg_index.indoption.patch.gz
- 0006-fix-amvalidate.patch.gz
- 0007-Pass-all-keys-to-BRIN-consistent-function-at-once.patch.gz
- 0008-Move-IS-NOT-NULL-checks-to-bringetbitmap.patch.gz
- 0009-Move-processing-of-NULLs-from-BRIN-support-functions.patch.gz
- 0010-BRIN-bloom-indexes.patch.gz
- 0011-BRIN-multi-range-minmax-indexes.patch.gz
This patch fails to apply (or the opclass params one, maybe). Please update. -- Álvaro Herrera https://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On Wed, Sep 25, 2019 at 05:07:48PM -0300, Alvaro Herrera wrote: >This patch fails to apply (or the opclass params one, maybe). Please >update. > Yeah, the opclass params patches got broken by 773df883e adding enum reloptions. The breakage is somewhat extensive so I'll leave it up to Nikita to fix it in [1]. Until that happens, apply the patches on top of caba97a9d9 for review. Thanks [1] https://commitfest.postgresql.org/24/2183/ -- Tomas Vondra http://www.2ndQuadrant.com PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On Thu, Sep 26, 2019 at 09:01:48PM +0200, Tomas Vondra wrote: > Yeah, the opclass params patches got broken by 773df883e adding enum > reloptions. The breakage is somewhat extensive so I'll leave it up to > Nikita to fix it in [1]. Until that happens, apply the patches on > top of caba97a9d9 for review. This has been close to two months now, so I have the patch as RwF. Feel free to update if you think that's incorrect. -- Michael
Attachment
On Sun, Dec 01, 2019 at 10:55:02AM +0900, Michael Paquier wrote: >On Thu, Sep 26, 2019 at 09:01:48PM +0200, Tomas Vondra wrote: >> Yeah, the opclass params patches got broken by 773df883e adding enum >> reloptions. The breakage is somewhat extensive so I'll leave it up to >> Nikita to fix it in [1]. Until that happens, apply the patches on >> top of caba97a9d9 for review. > >This has been close to two months now, so I have the patch as RwF. >Feel free to update if you think that's incorrect. I see the opclass parameters patch got committed a couple days ago, so I've rebased the patch series on top of it. The pach was marked RwF since 2019-11, so I'll add it to the next CF. regards -- Tomas Vondra http://www.2ndQuadrant.com PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
Attachment
Hi! On Thu, Apr 2, 2020 at 5:29 AM Tomas Vondra <tomas.vondra@2ndquadrant.com> wrote: > On Sun, Dec 01, 2019 at 10:55:02AM +0900, Michael Paquier wrote: > >On Thu, Sep 26, 2019 at 09:01:48PM +0200, Tomas Vondra wrote: > >> Yeah, the opclass params patches got broken by 773df883e adding enum > >> reloptions. The breakage is somewhat extensive so I'll leave it up to > >> Nikita to fix it in [1]. Until that happens, apply the patches on > >> top of caba97a9d9 for review. > > > >This has been close to two months now, so I have the patch as RwF. > >Feel free to update if you think that's incorrect. > > I see the opclass parameters patch got committed a couple days ago, so > I've rebased the patch series on top of it. The pach was marked RwF > since 2019-11, so I'll add it to the next CF. I think this patchset was marked RwF mainly because slow progress on opclass parameters. Now we got opclass parameters committed, and I think this patchset is in a pretty good shape. Moreover, opclass parameters patch comes with very small examples. This patchset would be great showcase for opclass parameters. I'd like to give this patchset a chance for v13. I'm going to make another pass trough this patchset. If I wouldn't find serious issues, I'm going to commit it. Any objections? ------ Alexander Korotkov Postgres Professional: http://www.postgrespro.com The Russian Postgres Company
Alexander Korotkov <a.korotkov@postgrespro.ru> writes:
> I'd like to give this patchset a chance for v13. I'm going to make
> another pass trough this patchset. If I wouldn't find serious issues,
> I'm going to commit it. Any objections?
I think it is way too late to be reviving major features that nobody
has been looking at for months, that indeed were never even listed
in the final CF. At this point in the cycle I think we should just be
trying to get small stuff over the line, not shove in major patches
and figure they can be stabilized later.
In this particular case, the last serious work on the patchset seems
to have been Tomas' revision of 2019-09-14, and he specifically stated
then that the APIs still needed work. That doesn't sound like
"it's about ready to commit" to me.
regards, tom lane
On Sun, Apr 05, 2020 at 06:29:15PM +0300, Alexander Korotkov wrote: >Hi! > >On Thu, Apr 2, 2020 at 5:29 AM Tomas Vondra ><tomas.vondra@2ndquadrant.com> wrote: >> On Sun, Dec 01, 2019 at 10:55:02AM +0900, Michael Paquier wrote: >> >On Thu, Sep 26, 2019 at 09:01:48PM +0200, Tomas Vondra wrote: >> >> Yeah, the opclass params patches got broken by 773df883e adding enum >> >> reloptions. The breakage is somewhat extensive so I'll leave it up to >> >> Nikita to fix it in [1]. Until that happens, apply the patches on >> >> top of caba97a9d9 for review. >> > >> >This has been close to two months now, so I have the patch as RwF. >> >Feel free to update if you think that's incorrect. >> >> I see the opclass parameters patch got committed a couple days ago, so >> I've rebased the patch series on top of it. The pach was marked RwF >> since 2019-11, so I'll add it to the next CF. > >I think this patchset was marked RwF mainly because slow progress on >opclass parameters. Now we got opclass parameters committed, and I >think this patchset is in a pretty good shape. Moreover, opclass >parameters patch comes with very small examples. This patchset would >be great showcase for opclass parameters. > >I'd like to give this patchset a chance for v13. I'm going to make >another pass trough this patchset. If I wouldn't find serious issues, >I'm going to commit it. Any objections? > I'm an author of the patchset and I'd love to see it committed, but I think that might be a bit too rushed and unfair (considering it was not included in the current CF at all). I think the code is correct and I'm not aware of any bugs, but I'm not sure there was sufficient discussion about things like costing, choosing parameter values (e.g. number of values in the multi-minmax or bloom filter parameters). That being said, I think the first couple of patches (that modify how BRIN deals with multi-key scans and IS NULL clauses) are simple enough and non-controversial, so maybe we could get 0001-0003 committed, and leave the bloom/multi-minmax opclasses for v14. regards -- Tomas Vondra http://www.2ndQuadrant.com PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On Sun, Apr 5, 2020 at 6:51 PM Tom Lane <tgl@sss.pgh.pa.us> wrote: > Alexander Korotkov <a.korotkov@postgrespro.ru> writes: > > I'd like to give this patchset a chance for v13. I'm going to make > > another pass trough this patchset. If I wouldn't find serious issues, > > I'm going to commit it. Any objections? > > I think it is way too late to be reviving major features that nobody > has been looking at for months, that indeed were never even listed > in the final CF. At this point in the cycle I think we should just be > trying to get small stuff over the line, not shove in major patches > and figure they can be stabilized later. > > In this particular case, the last serious work on the patchset seems > to have been Tomas' revision of 2019-09-14, and he specifically stated > then that the APIs still needed work. That doesn't sound like > "it's about ready to commit" to me. OK, got it. Thank you for the feedback. ------ Alexander Korotkov Postgres Professional: http://www.postgrespro.com The Russian Postgres Company
On Sun, Apr 5, 2020 at 6:53 PM Tomas Vondra <tomas.vondra@2ndquadrant.com> wrote: > On Sun, Apr 05, 2020 at 06:29:15PM +0300, Alexander Korotkov wrote: > >On Thu, Apr 2, 2020 at 5:29 AM Tomas Vondra > ><tomas.vondra@2ndquadrant.com> wrote: > >> On Sun, Dec 01, 2019 at 10:55:02AM +0900, Michael Paquier wrote: > >> >On Thu, Sep 26, 2019 at 09:01:48PM +0200, Tomas Vondra wrote: > >> >> Yeah, the opclass params patches got broken by 773df883e adding enum > >> >> reloptions. The breakage is somewhat extensive so I'll leave it up to > >> >> Nikita to fix it in [1]. Until that happens, apply the patches on > >> >> top of caba97a9d9 for review. > >> > > >> >This has been close to two months now, so I have the patch as RwF. > >> >Feel free to update if you think that's incorrect. > >> > >> I see the opclass parameters patch got committed a couple days ago, so > >> I've rebased the patch series on top of it. The pach was marked RwF > >> since 2019-11, so I'll add it to the next CF. > > > >I think this patchset was marked RwF mainly because slow progress on > >opclass parameters. Now we got opclass parameters committed, and I > >think this patchset is in a pretty good shape. Moreover, opclass > >parameters patch comes with very small examples. This patchset would > >be great showcase for opclass parameters. > > > >I'd like to give this patchset a chance for v13. I'm going to make > >another pass trough this patchset. If I wouldn't find serious issues, > >I'm going to commit it. Any objections? > > > > I'm an author of the patchset and I'd love to see it committed, but I > think that might be a bit too rushed and unfair (considering it was not > included in the current CF at all). > > I think the code is correct and I'm not aware of any bugs, but I'm not > sure there was sufficient discussion about things like costing, choosing > parameter values (e.g. number of values in the multi-minmax or bloom > filter parameters). Ok! > That being said, I think the first couple of patches (that modify how > BRIN deals with multi-key scans and IS NULL clauses) are simple enough > and non-controversial, so maybe we could get 0001-0003 committed, and > leave the bloom/multi-minmax opclasses for v14. Regarding 0001-0003 I've couple of notes: 1) They should revise BRIN extensibility documentation section. 2) I think 0002 and 0003 should be merged. NULL ScanKeys should be still passed to consistent function when oi_regular_nulls == false. Assuming we're not going to get 0001-0003 into v13, I'm not so inclined to rush on these three as well. But you're willing to commit them, you can count round of review on me. ------ Alexander Korotkov Postgres Professional: http://www.postgrespro.com The Russian Postgres Company
On Sun, Apr 05, 2020 at 07:33:40PM +0300, Alexander Korotkov wrote: >On Sun, Apr 5, 2020 at 6:53 PM Tomas Vondra ><tomas.vondra@2ndquadrant.com> wrote: >> On Sun, Apr 05, 2020 at 06:29:15PM +0300, Alexander Korotkov wrote: >> >On Thu, Apr 2, 2020 at 5:29 AM Tomas Vondra >> ><tomas.vondra@2ndquadrant.com> wrote: >> >> On Sun, Dec 01, 2019 at 10:55:02AM +0900, Michael Paquier wrote: >> >> >On Thu, Sep 26, 2019 at 09:01:48PM +0200, Tomas Vondra wrote: >> >> >> Yeah, the opclass params patches got broken by 773df883e adding enum >> >> >> reloptions. The breakage is somewhat extensive so I'll leave it up to >> >> >> Nikita to fix it in [1]. Until that happens, apply the patches on >> >> >> top of caba97a9d9 for review. >> >> > >> >> >This has been close to two months now, so I have the patch as RwF. >> >> >Feel free to update if you think that's incorrect. >> >> >> >> I see the opclass parameters patch got committed a couple days ago, so >> >> I've rebased the patch series on top of it. The pach was marked RwF >> >> since 2019-11, so I'll add it to the next CF. >> > >> >I think this patchset was marked RwF mainly because slow progress on >> >opclass parameters. Now we got opclass parameters committed, and I >> >think this patchset is in a pretty good shape. Moreover, opclass >> >parameters patch comes with very small examples. This patchset would >> >be great showcase for opclass parameters. >> > >> >I'd like to give this patchset a chance for v13. I'm going to make >> >another pass trough this patchset. If I wouldn't find serious issues, >> >I'm going to commit it. Any objections? >> > >> >> I'm an author of the patchset and I'd love to see it committed, but I >> think that might be a bit too rushed and unfair (considering it was not >> included in the current CF at all). >> >> I think the code is correct and I'm not aware of any bugs, but I'm not >> sure there was sufficient discussion about things like costing, choosing >> parameter values (e.g. number of values in the multi-minmax or bloom >> filter parameters). > >Ok! > >> That being said, I think the first couple of patches (that modify how >> BRIN deals with multi-key scans and IS NULL clauses) are simple enough >> and non-controversial, so maybe we could get 0001-0003 committed, and >> leave the bloom/multi-minmax opclasses for v14. > >Regarding 0001-0003 I've couple of notes: >1) They should revise BRIN extensibility documentation section. >2) I think 0002 and 0003 should be merged. NULL ScanKeys should be >still passed to consistent function when oi_regular_nulls == false. > >Assuming we're not going to get 0001-0003 into v13, I'm not so >inclined to rush on these three as well. But you're willing to commit >them, you can count round of review on me. > I have no intention to get 0001-0003 committed. I think those changes are beneficial on their own, but the primary reason was to support the new opclasses (which require those changes). And those parts are not going to make it into v13 ... regards -- Tomas Vondra http://www.2ndQuadrant.com PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On Sun, Apr 5, 2020 at 8:00 PM Tomas Vondra <tomas.vondra@2ndquadrant.com> wrote: > On Sun, Apr 05, 2020 at 07:33:40PM +0300, Alexander Korotkov wrote: > >On Sun, Apr 5, 2020 at 6:53 PM Tomas Vondra > ><tomas.vondra@2ndquadrant.com> wrote: > >> On Sun, Apr 05, 2020 at 06:29:15PM +0300, Alexander Korotkov wrote: > >> >On Thu, Apr 2, 2020 at 5:29 AM Tomas Vondra > >> ><tomas.vondra@2ndquadrant.com> wrote: > >> >> On Sun, Dec 01, 2019 at 10:55:02AM +0900, Michael Paquier wrote: > >> >> >On Thu, Sep 26, 2019 at 09:01:48PM +0200, Tomas Vondra wrote: > >> >> >> Yeah, the opclass params patches got broken by 773df883e adding enum > >> >> >> reloptions. The breakage is somewhat extensive so I'll leave it up to > >> >> >> Nikita to fix it in [1]. Until that happens, apply the patches on > >> >> >> top of caba97a9d9 for review. > >> >> > > >> >> >This has been close to two months now, so I have the patch as RwF. > >> >> >Feel free to update if you think that's incorrect. > >> >> > >> >> I see the opclass parameters patch got committed a couple days ago, so > >> >> I've rebased the patch series on top of it. The pach was marked RwF > >> >> since 2019-11, so I'll add it to the next CF. > >> > > >> >I think this patchset was marked RwF mainly because slow progress on > >> >opclass parameters. Now we got opclass parameters committed, and I > >> >think this patchset is in a pretty good shape. Moreover, opclass > >> >parameters patch comes with very small examples. This patchset would > >> >be great showcase for opclass parameters. > >> > > >> >I'd like to give this patchset a chance for v13. I'm going to make > >> >another pass trough this patchset. If I wouldn't find serious issues, > >> >I'm going to commit it. Any objections? > >> > > >> > >> I'm an author of the patchset and I'd love to see it committed, but I > >> think that might be a bit too rushed and unfair (considering it was not > >> included in the current CF at all). > >> > >> I think the code is correct and I'm not aware of any bugs, but I'm not > >> sure there was sufficient discussion about things like costing, choosing > >> parameter values (e.g. number of values in the multi-minmax or bloom > >> filter parameters). > > > >Ok! > > > >> That being said, I think the first couple of patches (that modify how > >> BRIN deals with multi-key scans and IS NULL clauses) are simple enough > >> and non-controversial, so maybe we could get 0001-0003 committed, and > >> leave the bloom/multi-minmax opclasses for v14. > > > >Regarding 0001-0003 I've couple of notes: > >1) They should revise BRIN extensibility documentation section. > >2) I think 0002 and 0003 should be merged. NULL ScanKeys should be > >still passed to consistent function when oi_regular_nulls == false. > > > >Assuming we're not going to get 0001-0003 into v13, I'm not so > >inclined to rush on these three as well. But you're willing to commit > >them, you can count round of review on me. > > > > I have no intention to get 0001-0003 committed. I think those changes > are beneficial on their own, but the primary reason was to support the > new opclasses (which require those changes). And those parts are not > going to make it into v13 ... OK, no problem. Let's do this for v14. ------ Alexander Korotkov Postgres Professional: http://www.postgrespro.com The Russian Postgres Company
Hi, here is an updated patch series, fixing duplicate OIDs etc. regards -- Tomas Vondra http://www.2ndQuadrant.com PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
Attachment
On Sun, Apr 05, 2020 at 08:01:50PM +0300, Alexander Korotkov wrote: >On Sun, Apr 5, 2020 at 8:00 PM Tomas Vondra ><tomas.vondra@2ndquadrant.com> wrote: ... >> > >> >Assuming we're not going to get 0001-0003 into v13, I'm not so >> >inclined to rush on these three as well. But you're willing to commit >> >them, you can count round of review on me. >> > >> >> I have no intention to get 0001-0003 committed. I think those changes >> are beneficial on their own, but the primary reason was to support the >> new opclasses (which require those changes). And those parts are not >> going to make it into v13 ... > >OK, no problem. >Let's do this for v14. > Hi Alexander, Are you still interested in reviewing those patches? I'll take a look at 0001-0003 to check that your previous feedback was addressed. Do you have any comments about 0004 / 0005, which I think are the more interesting parts of this series? Attached is a rebased version - I realized I forgot to include 0005 in the last update, for some reason. regards -- Tomas Vondra http://www.2ndQuadrant.com PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
Attachment
On Fri, 3 Jul 2020 at 09:58, Tomas Vondra <tomas.vondra@2ndquadrant.com> wrote:
>
> On Sun, Apr 05, 2020 at 08:01:50PM +0300, Alexander Korotkov wrote:
> >On Sun, Apr 5, 2020 at 8:00 PM Tomas Vondra
> ><tomas.vondra@2ndquadrant.com> wrote:
> ...
> >> >
> >> >Assuming we're not going to get 0001-0003 into v13, I'm not so
> >> >inclined to rush on these three as well. But you're willing to commit
> >> >them, you can count round of review on me.
> >> >
> >>
> >> I have no intention to get 0001-0003 committed. I think those changes
> >> are beneficial on their own, but the primary reason was to support the
> >> new opclasses (which require those changes). And those parts are not
> >> going to make it into v13 ...
> >
> >OK, no problem.
> >Let's do this for v14.
> >
>
> Hi Alexander,
>
> Are you still interested in reviewing those patches? I'll take a look at
> 0001-0003 to check that your previous feedback was addressed. Do you
> have any comments about 0004 / 0005, which I think are the more
> interesting parts of this series?
>
>
> Attached is a rebased version - I realized I forgot to include 0005 in
> the last update, for some reason.
>
I've done a quick test with this patch set. I wonder if we can improve
brin_page_items() SQL function in pageinspect as well. Currently,
brin_page_items() is hard-coded to support only normal brin indexes.
When we pass brin-bloom or brin-multi-range to that function the
binary values are shown in 'value' column but it seems not helpful for
users. For instance, here is an output of brin_page_items() with a
brin-multi-range index:
postgres(1:12801)=# select * from brin_page_items(get_raw_page('mul',
2), 'mul');
-[ RECORD 1
]----------------------------------------------------------------------------------------------------------------------
-----------------------------------------------------------------------------------------------------------------------------------
----------------------------
itemoffset | 1
blknum | 0
attnum | 1
allnulls | f
hasnulls | f
placeholder | f
value |
{\x010000001b0000002000000001000000e5700000e6700000e7700000e8700000e9700000ea700000eb700000ec700000ed700000ee700000ef
700000f0700000f1700000f2700000f3700000f4700000f5700000f6700000f7700000f8700000f9700000fa700000fb700000fc700000fd700000fe700000ff700
00000710000}
Also, I got an assertion failure when setting false_positive_rate reloption:
postgres(1:12448)=# create index blm on t using brin (c int4_bloom_ops
(false_positive_rate = 1));
TRAP: FailedAssertion("(false_positive_rate > 0) &&
(false_positive_rate < 1.0)", File: "brin_bloom.c", Line: 300)
I'll look at the code in depth and let you know if I find a problem.
Regards,
--
Masahiko Sawada http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On Fri, Jul 10, 2020 at 06:01:58PM +0900, Masahiko Sawada wrote:
>On Fri, 3 Jul 2020 at 09:58, Tomas Vondra <tomas.vondra@2ndquadrant.com> wrote:
>>
>> On Sun, Apr 05, 2020 at 08:01:50PM +0300, Alexander Korotkov wrote:
>> >On Sun, Apr 5, 2020 at 8:00 PM Tomas Vondra
>> ><tomas.vondra@2ndquadrant.com> wrote:
>> ...
>> >> >
>> >> >Assuming we're not going to get 0001-0003 into v13, I'm not so
>> >> >inclined to rush on these three as well. But you're willing to commit
>> >> >them, you can count round of review on me.
>> >> >
>> >>
>> >> I have no intention to get 0001-0003 committed. I think those changes
>> >> are beneficial on their own, but the primary reason was to support the
>> >> new opclasses (which require those changes). And those parts are not
>> >> going to make it into v13 ...
>> >
>> >OK, no problem.
>> >Let's do this for v14.
>> >
>>
>> Hi Alexander,
>>
>> Are you still interested in reviewing those patches? I'll take a look at
>> 0001-0003 to check that your previous feedback was addressed. Do you
>> have any comments about 0004 / 0005, which I think are the more
>> interesting parts of this series?
>>
>>
>> Attached is a rebased version - I realized I forgot to include 0005 in
>> the last update, for some reason.
>>
>
>I've done a quick test with this patch set. I wonder if we can improve
>brin_page_items() SQL function in pageinspect as well. Currently,
>brin_page_items() is hard-coded to support only normal brin indexes.
>When we pass brin-bloom or brin-multi-range to that function the
>binary values are shown in 'value' column but it seems not helpful for
>users. For instance, here is an output of brin_page_items() with a
>brin-multi-range index:
>
>postgres(1:12801)=# select * from brin_page_items(get_raw_page('mul',
>2), 'mul');
>-[ RECORD 1
]----------------------------------------------------------------------------------------------------------------------
>-----------------------------------------------------------------------------------------------------------------------------------
>----------------------------
>itemoffset | 1
>blknum | 0
>attnum | 1
>allnulls | f
>hasnulls | f
>placeholder | f
>value |
{\x010000001b0000002000000001000000e5700000e6700000e7700000e8700000e9700000ea700000eb700000ec700000ed700000ee700000ef
>700000f0700000f1700000f2700000f3700000f4700000f5700000f6700000f7700000f8700000f9700000fa700000fb700000fc700000fd700000fe700000ff700
>00000710000}
>
Hmm. I'm not sure we can do much better, without making the function
much more complicated. I mean, even with regular BRIN indexes we don't
really know if the value is plain min/max, right?
>Also, I got an assertion failure when setting false_positive_rate reloption:
>
>postgres(1:12448)=# create index blm on t using brin (c int4_bloom_ops
>(false_positive_rate = 1));
>TRAP: FailedAssertion("(false_positive_rate > 0) &&
>(false_positive_rate < 1.0)", File: "brin_bloom.c", Line: 300)
>
>I'll look at the code in depth and let you know if I find a problem.
>
Yeah, the assert should say (f_p_r <= 1.0).
But I'm not convinced we should allow values up to 1.0, really. The
f_p_r is the fraction of the table that will get matched always, so 1.0
would mean we get to scan the whole table. Seems kinda pointless. So
maybe we should cap it to something like 0.1 or so, but I agree the
value seems kinda arbitrary.
regards
--
Tomas Vondra http://www.2ndQuadrant.com
PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
Tomas Vondra <tomas.vondra@2ndquadrant.com> schrieb am Fr., 10. Juli 2020, 14:09:
On Fri, Jul 10, 2020 at 06:01:58PM +0900, Masahiko Sawada wrote:
>On Fri, 3 Jul 2020 at 09:58, Tomas Vondra <tomas.vondra@2ndquadrant.com> wrote:
>>
>> On Sun, Apr 05, 2020 at 08:01:50PM +0300, Alexander Korotkov wrote:
>> >On Sun, Apr 5, 2020 at 8:00 PM Tomas Vondra
>> ><tomas.vondra@2ndquadrant.com> wrote:
>> ...
>> >> >
>> >> >Assuming we're not going to get 0001-0003 into v13, I'm not so
>> >> >inclined to rush on these three as well. But you're willing to commit
>> >> >them, you can count round of review on me.
>> >> >
>> >>
>> >> I have no intention to get 0001-0003 committed. I think those changes
>> >> are beneficial on their own, but the primary reason was to support the
>> >> new opclasses (which require those changes). And those parts are not
>> >> going to make it into v13 ...
>> >
>> >OK, no problem.
>> >Let's do this for v14.
>> >
>>
>> Hi Alexander,
>>
>> Are you still interested in reviewing those patches? I'll take a look at
>> 0001-0003 to check that your previous feedback was addressed. Do you
>> have any comments about 0004 / 0005, which I think are the more
>> interesting parts of this series?
>>
>>
>> Attached is a rebased version - I realized I forgot to include 0005 in
>> the last update, for some reason.
>>
>
>I've done a quick test with this patch set. I wonder if we can improve
>brin_page_items() SQL function in pageinspect as well. Currently,
>brin_page_items() is hard-coded to support only normal brin indexes.
>When we pass brin-bloom or brin-multi-range to that function the
>binary values are shown in 'value' column but it seems not helpful for
>users. For instance, here is an output of brin_page_items() with a
>brin-multi-range index:
>
>postgres(1:12801)=# select * from brin_page_items(get_raw_page('mul',
>2), 'mul');
>-[ RECORD 1 ]----------------------------------------------------------------------------------------------------------------------
>-----------------------------------------------------------------------------------------------------------------------------------
>----------------------------
>itemoffset | 1
>blknum | 0
>attnum | 1
>allnulls | f
>hasnulls | f
>placeholder | f
>value | {\x010000001b0000002000000001000000e5700000e6700000e7700000e8700000e9700000ea700000eb700000ec700000ed700000ee700000ef
>700000f0700000f1700000f2700000f3700000f4700000f5700000f6700000f7700000f8700000f9700000fa700000fb700000fc700000fd700000fe700000ff700
>00000710000}
>
Hmm. I'm not sure we can do much better, without making the function
much more complicated. I mean, even with regular BRIN indexes we don't
really know if the value is plain min/max, right?
You can be sure with the next node. The value is in can be false positiv. The value is out is clear. You can detect the change between in and out.
>Also, I got an assertion failure when setting false_positive_rate reloption:
>
>postgres(1:12448)=# create index blm on t using brin (c int4_bloom_ops
>(false_positive_rate = 1));
>TRAP: FailedAssertion("(false_positive_rate > 0) &&
>(false_positive_rate < 1.0)", File: "brin_bloom.c", Line: 300)
>
>I'll look at the code in depth and let you know if I find a problem.
>
Yeah, the assert should say (f_p_r <= 1.0).
But I'm not convinced we should allow values up to 1.0, really. The
f_p_r is the fraction of the table that will get matched always, so 1.0
would mean we get to scan the whole table. Seems kinda pointless. So
maybe we should cap it to something like 0.1 or so, but I agree the
value seems kinda arbitrary.
regards
--
Tomas Vondra http://www.2ndQuadrant.com
PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On Fri, Jul 10, 2020 at 04:44:41PM +0200, Sascha Kuhl wrote:
>Tomas Vondra <tomas.vondra@2ndquadrant.com> schrieb am Fr., 10. Juli 2020,
>14:09:
>
>> On Fri, Jul 10, 2020 at 06:01:58PM +0900, Masahiko Sawada wrote:
>> >On Fri, 3 Jul 2020 at 09:58, Tomas Vondra <tomas.vondra@2ndquadrant.com>
>> wrote:
>> >>
>> >> On Sun, Apr 05, 2020 at 08:01:50PM +0300, Alexander Korotkov wrote:
>> >> >On Sun, Apr 5, 2020 at 8:00 PM Tomas Vondra
>> >> ><tomas.vondra@2ndquadrant.com> wrote:
>> >> ...
>> >> >> >
>> >> >> >Assuming we're not going to get 0001-0003 into v13, I'm not so
>> >> >> >inclined to rush on these three as well. But you're willing to
>> commit
>> >> >> >them, you can count round of review on me.
>> >> >> >
>> >> >>
>> >> >> I have no intention to get 0001-0003 committed. I think those changes
>> >> >> are beneficial on their own, but the primary reason was to support
>> the
>> >> >> new opclasses (which require those changes). And those parts are not
>> >> >> going to make it into v13 ...
>> >> >
>> >> >OK, no problem.
>> >> >Let's do this for v14.
>> >> >
>> >>
>> >> Hi Alexander,
>> >>
>> >> Are you still interested in reviewing those patches? I'll take a look at
>> >> 0001-0003 to check that your previous feedback was addressed. Do you
>> >> have any comments about 0004 / 0005, which I think are the more
>> >> interesting parts of this series?
>> >>
>> >>
>> >> Attached is a rebased version - I realized I forgot to include 0005 in
>> >> the last update, for some reason.
>> >>
>> >
>> >I've done a quick test with this patch set. I wonder if we can improve
>> >brin_page_items() SQL function in pageinspect as well. Currently,
>> >brin_page_items() is hard-coded to support only normal brin indexes.
>> >When we pass brin-bloom or brin-multi-range to that function the
>> >binary values are shown in 'value' column but it seems not helpful for
>> >users. For instance, here is an output of brin_page_items() with a
>> >brin-multi-range index:
>> >
>> >postgres(1:12801)=# select * from brin_page_items(get_raw_page('mul',
>> >2), 'mul');
>> >-[ RECORD 1
>>
]----------------------------------------------------------------------------------------------------------------------
>>
>>
>-----------------------------------------------------------------------------------------------------------------------------------
>> >----------------------------
>> >itemoffset | 1
>> >blknum | 0
>> >attnum | 1
>> >allnulls | f
>> >hasnulls | f
>> >placeholder | f
>> >value |
>>
{\x010000001b0000002000000001000000e5700000e6700000e7700000e8700000e9700000ea700000eb700000ec700000ed700000ee700000ef
>>
>>
>700000f0700000f1700000f2700000f3700000f4700000f5700000f6700000f7700000f8700000f9700000fa700000fb700000fc700000fd700000fe700000ff700
>> >00000710000}
>> >
>>
>> Hmm. I'm not sure we can do much better, without making the function
>> much more complicated. I mean, even with regular BRIN indexes we don't
>> really know if the value is plain min/max, right?
>>
>You can be sure with the next node. The value is in can be false positiv.
>The value is out is clear. You can detect the change between in and out.
>
I'm sorry, I don't understand what you're suggesting. How is any of this
related to false positive rate, etc?
The problem here is that while plain BRIN opclasses have fairly simple
summary that can be stored using a fixed number of simple data types
(e.g. minmax will store two values with the same data types as the
indexd column)
result = palloc0(MAXALIGN(SizeofBrinOpcInfo(2)) +
sizeof(MinmaxOpaque));
result->oi_nstored = 2;
result->oi_opaque = (MinmaxOpaque *)
MAXALIGN((char *) result + SizeofBrinOpcInfo(2));
result->oi_typcache[0] = result->oi_typcache[1] =
lookup_type_cache(typoid, 0);
The opclassed introduced here have somewhat more complex summary, stored
as a single bytea value - which is what gets printed by brin_page_items.
To print something easier to read (for humans) we'd either have to teach
brin_page_items about the diffrent opclasses (multi-range, bloom) end
how to parse the summary bytea, or we'd have to extend the opclasses
with a function formatting the summary. Or rework how the summary is
stored, but that seems like the worst option.
regards
--
Tomas Vondra http://www.2ndQuadrant.com
PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
Tomas Vondra <tomas.vondra@2ndquadrant.com> schrieb am Sa., 11. Juli 2020, 13:24:
On Fri, Jul 10, 2020 at 04:44:41PM +0200, Sascha Kuhl wrote:
>Tomas Vondra <tomas.vondra@2ndquadrant.com> schrieb am Fr., 10. Juli 2020,
>14:09:
>
>> On Fri, Jul 10, 2020 at 06:01:58PM +0900, Masahiko Sawada wrote:
>> >On Fri, 3 Jul 2020 at 09:58, Tomas Vondra <tomas.vondra@2ndquadrant.com>
>> wrote:
>> >>
>> >> On Sun, Apr 05, 2020 at 08:01:50PM +0300, Alexander Korotkov wrote:
>> >> >On Sun, Apr 5, 2020 at 8:00 PM Tomas Vondra
>> >> ><tomas.vondra@2ndquadrant.com> wrote:
>> >> ...
>> >> >> >
>> >> >> >Assuming we're not going to get 0001-0003 into v13, I'm not so
>> >> >> >inclined to rush on these three as well. But you're willing to
>> commit
>> >> >> >them, you can count round of review on me.
>> >> >> >
>> >> >>
>> >> >> I have no intention to get 0001-0003 committed. I think those changes
>> >> >> are beneficial on their own, but the primary reason was to support
>> the
>> >> >> new opclasses (which require those changes). And those parts are not
>> >> >> going to make it into v13 ...
>> >> >
>> >> >OK, no problem.
>> >> >Let's do this for v14.
>> >> >
>> >>
>> >> Hi Alexander,
>> >>
>> >> Are you still interested in reviewing those patches? I'll take a look at
>> >> 0001-0003 to check that your previous feedback was addressed. Do you
>> >> have any comments about 0004 / 0005, which I think are the more
>> >> interesting parts of this series?
>> >>
>> >>
>> >> Attached is a rebased version - I realized I forgot to include 0005 in
>> >> the last update, for some reason.
>> >>
>> >
>> >I've done a quick test with this patch set. I wonder if we can improve
>> >brin_page_items() SQL function in pageinspect as well. Currently,
>> >brin_page_items() is hard-coded to support only normal brin indexes.
>> >When we pass brin-bloom or brin-multi-range to that function the
>> >binary values are shown in 'value' column but it seems not helpful for
>> >users. For instance, here is an output of brin_page_items() with a
>> >brin-multi-range index:
>> >
>> >postgres(1:12801)=# select * from brin_page_items(get_raw_page('mul',
>> >2), 'mul');
>> >-[ RECORD 1
>> ]----------------------------------------------------------------------------------------------------------------------
>>
>> >-----------------------------------------------------------------------------------------------------------------------------------
>> >----------------------------
>> >itemoffset | 1
>> >blknum | 0
>> >attnum | 1
>> >allnulls | f
>> >hasnulls | f
>> >placeholder | f
>> >value |
>> {\x010000001b0000002000000001000000e5700000e6700000e7700000e8700000e9700000ea700000eb700000ec700000ed700000ee700000ef
>>
>> >700000f0700000f1700000f2700000f3700000f4700000f5700000f6700000f7700000f8700000f9700000fa700000fb700000fc700000fd700000fe700000ff700
>> >00000710000}
>> >
>>
>> Hmm. I'm not sure we can do much better, without making the function
>> much more complicated. I mean, even with regular BRIN indexes we don't
>> really know if the value is plain min/max, right?
>>
>You can be sure with the next node. The value is in can be false positiv.
>The value is out is clear. You can detect the change between in and out.
>
I'm sorry, I don't understand what you're suggesting. How is any of this
related to false positive rate, etc?
Hi,
You check by the bloom filter if a value you're searching is part of the node, right?
In case, the value is in the bloom filter you could be mistaken, because another value could have the same hash profile, no?
However if the value is out, the filter can not react. You can be sure that the value is out.
If you looking for a range or many ranges of values, you traverse many nodes. By knowing the value is out, you can state a clear set of nodes that form the range. However the border is somehow unsharp because of the false positives.
I am not sure if we write about the same. Please confirm, this can be needed. Please.
I will try to understand what you write. Interesting
Sascha
The problem here is that while plain BRIN opclasses have fairly simple
summary that can be stored using a fixed number of simple data types
(e.g. minmax will store two values with the same data types as the
indexd column)
result = palloc0(MAXALIGN(SizeofBrinOpcInfo(2)) +
sizeof(MinmaxOpaque));
result->oi_nstored = 2;
result->oi_opaque = (MinmaxOpaque *)
MAXALIGN((char *) result + SizeofBrinOpcInfo(2));
result->oi_typcache[0] = result->oi_typcache[1] =
lookup_type_cache(typoid, 0);
The opclassed introduced here have somewhat more complex summary, stored
as a single bytea value - which is what gets printed by brin_page_items.
To print something easier to read (for humans) we'd either have to teach
brin_page_items about the diffrent opclasses (multi-range, bloom) end
how to parse the summary bytea, or we'd have to extend the opclasses
with a function formatting the summary. Or rework how the summary is
stored, but that seems like the worst option.
regards
--
Tomas Vondra http://www.2ndQuadrant.com
PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
Sorry, my topic is different
Sascha Kuhl <yogidabanli@gmail.com> schrieb am Sa., 11. Juli 2020, 15:32:
Tomas Vondra <tomas.vondra@2ndquadrant.com> schrieb am Sa., 11. Juli 2020, 13:24:On Fri, Jul 10, 2020 at 04:44:41PM +0200, Sascha Kuhl wrote:
>Tomas Vondra <tomas.vondra@2ndquadrant.com> schrieb am Fr., 10. Juli 2020,
>14:09:
>
>> On Fri, Jul 10, 2020 at 06:01:58PM +0900, Masahiko Sawada wrote:
>> >On Fri, 3 Jul 2020 at 09:58, Tomas Vondra <tomas.vondra@2ndquadrant.com>
>> wrote:
>> >>
>> >> On Sun, Apr 05, 2020 at 08:01:50PM +0300, Alexander Korotkov wrote:
>> >> >On Sun, Apr 5, 2020 at 8:00 PM Tomas Vondra
>> >> ><tomas.vondra@2ndquadrant.com> wrote:
>> >> ...
>> >> >> >
>> >> >> >Assuming we're not going to get 0001-0003 into v13, I'm not so
>> >> >> >inclined to rush on these three as well. But you're willing to
>> commit
>> >> >> >them, you can count round of review on me.
>> >> >> >
>> >> >>
>> >> >> I have no intention to get 0001-0003 committed. I think those changes
>> >> >> are beneficial on their own, but the primary reason was to support
>> the
>> >> >> new opclasses (which require those changes). And those parts are not
>> >> >> going to make it into v13 ...
>> >> >
>> >> >OK, no problem.
>> >> >Let's do this for v14.
>> >> >
>> >>
>> >> Hi Alexander,
>> >>
>> >> Are you still interested in reviewing those patches? I'll take a look at
>> >> 0001-0003 to check that your previous feedback was addressed. Do you
>> >> have any comments about 0004 / 0005, which I think are the more
>> >> interesting parts of this series?
>> >>
>> >>
>> >> Attached is a rebased version - I realized I forgot to include 0005 in
>> >> the last update, for some reason.
>> >>
>> >
>> >I've done a quick test with this patch set. I wonder if we can improve
>> >brin_page_items() SQL function in pageinspect as well. Currently,
>> >brin_page_items() is hard-coded to support only normal brin indexes.
>> >When we pass brin-bloom or brin-multi-range to that function the
>> >binary values are shown in 'value' column but it seems not helpful for
>> >users. For instance, here is an output of brin_page_items() with a
>> >brin-multi-range index:
>> >
>> >postgres(1:12801)=# select * from brin_page_items(get_raw_page('mul',
>> >2), 'mul');
>> >-[ RECORD 1
>> ]----------------------------------------------------------------------------------------------------------------------
>>
>> >-----------------------------------------------------------------------------------------------------------------------------------
>> >----------------------------
>> >itemoffset | 1
>> >blknum | 0
>> >attnum | 1
>> >allnulls | f
>> >hasnulls | f
>> >placeholder | f
>> >value |
>> {\x010000001b0000002000000001000000e5700000e6700000e7700000e8700000e9700000ea700000eb700000ec700000ed700000ee700000ef
>>
>> >700000f0700000f1700000f2700000f3700000f4700000f5700000f6700000f7700000f8700000f9700000fa700000fb700000fc700000fd700000fe700000ff700
>> >00000710000}
>> >
>>
>> Hmm. I'm not sure we can do much better, without making the function
>> much more complicated. I mean, even with regular BRIN indexes we don't
>> really know if the value is plain min/max, right?
>>
>You can be sure with the next node. The value is in can be false positiv.
>The value is out is clear. You can detect the change between in and out.
>
I'm sorry, I don't understand what you're suggesting. How is any of this
related to false positive rate, etc?Hi,You check by the bloom filter if a value you're searching is part of the node, right?In case, the value is in the bloom filter you could be mistaken, because another value could have the same hash profile, no?However if the value is out, the filter can not react. You can be sure that the value is out.If you looking for a range or many ranges of values, you traverse many nodes. By knowing the value is out, you can state a clear set of nodes that form the range. However the border is somehow unsharp because of the false positives.I am not sure if we write about the same. Please confirm, this can be needed. Please.I will try to understand what you write. InterestingSascha
The problem here is that while plain BRIN opclasses have fairly simple
summary that can be stored using a fixed number of simple data types
(e.g. minmax will store two values with the same data types as the
indexd column)
result = palloc0(MAXALIGN(SizeofBrinOpcInfo(2)) +
sizeof(MinmaxOpaque));
result->oi_nstored = 2;
result->oi_opaque = (MinmaxOpaque *)
MAXALIGN((char *) result + SizeofBrinOpcInfo(2));
result->oi_typcache[0] = result->oi_typcache[1] =
lookup_type_cache(typoid, 0);
The opclassed introduced here have somewhat more complex summary, stored
as a single bytea value - which is what gets printed by brin_page_items.
To print something easier to read (for humans) we'd either have to teach
brin_page_items about the diffrent opclasses (multi-range, bloom) end
how to parse the summary bytea, or we'd have to extend the opclasses
with a function formatting the summary. Or rework how the summary is
stored, but that seems like the worst option.
regards
--
Tomas Vondra http://www.2ndQuadrant.com
PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On Sat, Jul 11, 2020 at 03:32:43PM +0200, Sascha Kuhl wrote:
>Tomas Vondra <tomas.vondra@2ndquadrant.com> schrieb am Sa., 11. Juli 2020,
>13:24:
>
>> On Fri, Jul 10, 2020 at 04:44:41PM +0200, Sascha Kuhl wrote:
>> >Tomas Vondra <tomas.vondra@2ndquadrant.com> schrieb am Fr., 10. Juli
>> 2020,
>> >14:09:
>> >
>> >> On Fri, Jul 10, 2020 at 06:01:58PM +0900, Masahiko Sawada wrote:
>> >> >On Fri, 3 Jul 2020 at 09:58, Tomas Vondra <
>> tomas.vondra@2ndquadrant.com>
>> >> wrote:
>> >> >>
>> >> >> On Sun, Apr 05, 2020 at 08:01:50PM +0300, Alexander Korotkov wrote:
>> >> >> >On Sun, Apr 5, 2020 at 8:00 PM Tomas Vondra
>> >> >> ><tomas.vondra@2ndquadrant.com> wrote:
>> >> >> ...
>> >> >> >> >
>> >> >> >> >Assuming we're not going to get 0001-0003 into v13, I'm not so
>> >> >> >> >inclined to rush on these three as well. But you're willing to
>> >> commit
>> >> >> >> >them, you can count round of review on me.
>> >> >> >> >
>> >> >> >>
>> >> >> >> I have no intention to get 0001-0003 committed. I think those
>> changes
>> >> >> >> are beneficial on their own, but the primary reason was to support
>> >> the
>> >> >> >> new opclasses (which require those changes). And those parts are
>> not
>> >> >> >> going to make it into v13 ...
>> >> >> >
>> >> >> >OK, no problem.
>> >> >> >Let's do this for v14.
>> >> >> >
>> >> >>
>> >> >> Hi Alexander,
>> >> >>
>> >> >> Are you still interested in reviewing those patches? I'll take a
>> look at
>> >> >> 0001-0003 to check that your previous feedback was addressed. Do you
>> >> >> have any comments about 0004 / 0005, which I think are the more
>> >> >> interesting parts of this series?
>> >> >>
>> >> >>
>> >> >> Attached is a rebased version - I realized I forgot to include 0005
>> in
>> >> >> the last update, for some reason.
>> >> >>
>> >> >
>> >> >I've done a quick test with this patch set. I wonder if we can improve
>> >> >brin_page_items() SQL function in pageinspect as well. Currently,
>> >> >brin_page_items() is hard-coded to support only normal brin indexes.
>> >> >When we pass brin-bloom or brin-multi-range to that function the
>> >> >binary values are shown in 'value' column but it seems not helpful for
>> >> >users. For instance, here is an output of brin_page_items() with a
>> >> >brin-multi-range index:
>> >> >
>> >> >postgres(1:12801)=# select * from brin_page_items(get_raw_page('mul',
>> >> >2), 'mul');
>> >> >-[ RECORD 1
>> >>
>>
]----------------------------------------------------------------------------------------------------------------------
>> >>
>> >>
>>
>-----------------------------------------------------------------------------------------------------------------------------------
>> >> >----------------------------
>> >> >itemoffset | 1
>> >> >blknum | 0
>> >> >attnum | 1
>> >> >allnulls | f
>> >> >hasnulls | f
>> >> >placeholder | f
>> >> >value |
>> >>
>>
{\x010000001b0000002000000001000000e5700000e6700000e7700000e8700000e9700000ea700000eb700000ec700000ed700000ee700000ef
>> >>
>> >>
>>
>700000f0700000f1700000f2700000f3700000f4700000f5700000f6700000f7700000f8700000f9700000fa700000fb700000fc700000fd700000fe700000ff700
>> >> >00000710000}
>> >> >
>> >>
>> >> Hmm. I'm not sure we can do much better, without making the function
>> >> much more complicated. I mean, even with regular BRIN indexes we don't
>> >> really know if the value is plain min/max, right?
>> >>
>> >You can be sure with the next node. The value is in can be false positiv.
>> >The value is out is clear. You can detect the change between in and out.
>> >
>>
>> I'm sorry, I don't understand what you're suggesting. How is any of this
>> related to false positive rate, etc?
>>
>
>Hi,
>
>You check by the bloom filter if a value you're searching is part of the
>node, right?
>
>In case, the value is in the bloom filter you could be mistaken, because
>another value could have the same hash profile, no?
>
>However if the value is out, the filter can not react. You can be sure that
>the value is out.
>
>If you looking for a range or many ranges of values, you traverse many
>nodes. By knowing the value is out, you can state a clear set of nodes that
>form the range. However the border is somehow unsharp because of the false
>positives.
>
>I am not sure if we write about the same. Please confirm, this can be
>needed. Please.
>
Probably not. Masahiko-san pointed out that pageinspect (which also has
a function to print pages from a BRIN index) does not understand the
summary of the new opclasses and just prints the bytea verbatim.
That has nothing to do with inspecting the bloom filter, or anything
like that. So I think there's some confusion ...
regards
--
Tomas Vondra http://www.2ndQuadrant.com
PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
Thanks, I see there is some understanding, though.
Tomas Vondra <tomas.vondra@2ndquadrant.com> schrieb am So., 12. Juli 2020, 01:30:
On Sat, Jul 11, 2020 at 03:32:43PM +0200, Sascha Kuhl wrote:
>Tomas Vondra <tomas.vondra@2ndquadrant.com> schrieb am Sa., 11. Juli 2020,
>13:24:
>
>> On Fri, Jul 10, 2020 at 04:44:41PM +0200, Sascha Kuhl wrote:
>> >Tomas Vondra <tomas.vondra@2ndquadrant.com> schrieb am Fr., 10. Juli
>> 2020,
>> >14:09:
>> >
>> >> On Fri, Jul 10, 2020 at 06:01:58PM +0900, Masahiko Sawada wrote:
>> >> >On Fri, 3 Jul 2020 at 09:58, Tomas Vondra <
>> tomas.vondra@2ndquadrant.com>
>> >> wrote:
>> >> >>
>> >> >> On Sun, Apr 05, 2020 at 08:01:50PM +0300, Alexander Korotkov wrote:
>> >> >> >On Sun, Apr 5, 2020 at 8:00 PM Tomas Vondra
>> >> >> ><tomas.vondra@2ndquadrant.com> wrote:
>> >> >> ...
>> >> >> >> >
>> >> >> >> >Assuming we're not going to get 0001-0003 into v13, I'm not so
>> >> >> >> >inclined to rush on these three as well. But you're willing to
>> >> commit
>> >> >> >> >them, you can count round of review on me.
>> >> >> >> >
>> >> >> >>
>> >> >> >> I have no intention to get 0001-0003 committed. I think those
>> changes
>> >> >> >> are beneficial on their own, but the primary reason was to support
>> >> the
>> >> >> >> new opclasses (which require those changes). And those parts are
>> not
>> >> >> >> going to make it into v13 ...
>> >> >> >
>> >> >> >OK, no problem.
>> >> >> >Let's do this for v14.
>> >> >> >
>> >> >>
>> >> >> Hi Alexander,
>> >> >>
>> >> >> Are you still interested in reviewing those patches? I'll take a
>> look at
>> >> >> 0001-0003 to check that your previous feedback was addressed. Do you
>> >> >> have any comments about 0004 / 0005, which I think are the more
>> >> >> interesting parts of this series?
>> >> >>
>> >> >>
>> >> >> Attached is a rebased version - I realized I forgot to include 0005
>> in
>> >> >> the last update, for some reason.
>> >> >>
>> >> >
>> >> >I've done a quick test with this patch set. I wonder if we can improve
>> >> >brin_page_items() SQL function in pageinspect as well. Currently,
>> >> >brin_page_items() is hard-coded to support only normal brin indexes.
>> >> >When we pass brin-bloom or brin-multi-range to that function the
>> >> >binary values are shown in 'value' column but it seems not helpful for
>> >> >users. For instance, here is an output of brin_page_items() with a
>> >> >brin-multi-range index:
>> >> >
>> >> >postgres(1:12801)=# select * from brin_page_items(get_raw_page('mul',
>> >> >2), 'mul');
>> >> >-[ RECORD 1
>> >>
>> ]----------------------------------------------------------------------------------------------------------------------
>> >>
>> >>
>> >-----------------------------------------------------------------------------------------------------------------------------------
>> >> >----------------------------
>> >> >itemoffset | 1
>> >> >blknum | 0
>> >> >attnum | 1
>> >> >allnulls | f
>> >> >hasnulls | f
>> >> >placeholder | f
>> >> >value |
>> >>
>> {\x010000001b0000002000000001000000e5700000e6700000e7700000e8700000e9700000ea700000eb700000ec700000ed700000ee700000ef
>> >>
>> >>
>> >700000f0700000f1700000f2700000f3700000f4700000f5700000f6700000f7700000f8700000f9700000fa700000fb700000fc700000fd700000fe700000ff700
>> >> >00000710000}
>> >> >
>> >>
>> >> Hmm. I'm not sure we can do much better, without making the function
>> >> much more complicated. I mean, even with regular BRIN indexes we don't
>> >> really know if the value is plain min/max, right?
>> >>
>> >You can be sure with the next node. The value is in can be false positiv.
>> >The value is out is clear. You can detect the change between in and out.
>> >
>>
>> I'm sorry, I don't understand what you're suggesting. How is any of this
>> related to false positive rate, etc?
>>
>
>Hi,
>
>You check by the bloom filter if a value you're searching is part of the
>node, right?
>
>In case, the value is in the bloom filter you could be mistaken, because
>another value could have the same hash profile, no?
>
>However if the value is out, the filter can not react. You can be sure that
>the value is out.
>
>If you looking for a range or many ranges of values, you traverse many
>nodes. By knowing the value is out, you can state a clear set of nodes that
>form the range. However the border is somehow unsharp because of the false
>positives.
>
>I am not sure if we write about the same. Please confirm, this can be
>needed. Please.
>
Probably not. Masahiko-san pointed out that pageinspect (which also has
a function to print pages from a BRIN index) does not understand the
summary of the new opclasses and just prints the bytea verbatim.
That has nothing to do with inspecting the bloom filter, or anything
like that. So I think there's some confusion ...
regards
--
Tomas Vondra http://www.2ndQuadrant.com
PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On 2020-Jul-10, Tomas Vondra wrote:
> > postgres(1:12801)=# select * from brin_page_items(get_raw_page('mul',
> > 2), 'mul');
> > -[ RECORD 1
]----------------------------------------------------------------------------------------------------------------------
> >
-----------------------------------------------------------------------------------------------------------------------------------
> > ----------------------------
> > itemoffset | 1
> > blknum | 0
> > attnum | 1
> > allnulls | f
> > hasnulls | f
> > placeholder | f
> > value |
{\x010000001b0000002000000001000000e5700000e6700000e7700000e8700000e9700000ea700000eb700000ec700000ed700000ee700000ef
> >
700000f0700000f1700000f2700000f3700000f4700000f5700000f6700000f7700000f8700000f9700000fa700000fb700000fc700000fd700000fe700000ff700
> > 00000710000}
>
> Hmm. I'm not sure we can do much better, without making the function
> much more complicated. I mean, even with regular BRIN indexes we don't
> really know if the value is plain min/max, right?
Maybe we can try to handle this with some other function that interprets
the bytea in 'value' and returns a user-readable text. I think it'd
have to be a superuser-only function, because otherwise you could easily
cause a crash by passing a value of a different opclass. But since this
seems a developer-only thing, that restriction seems fine to me.
(I don't know what's a good way to represent a bloom filter, mind.)
--
Álvaro Herrera https://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On Sun, Jul 12, 2020 at 07:58:54PM -0400, Alvaro Herrera wrote:
>On 2020-Jul-10, Tomas Vondra wrote:
>
>> > postgres(1:12801)=# select * from brin_page_items(get_raw_page('mul',
>> > 2), 'mul');
>> > -[ RECORD 1
]----------------------------------------------------------------------------------------------------------------------
>> >
-----------------------------------------------------------------------------------------------------------------------------------
>> > ----------------------------
>> > itemoffset | 1
>> > blknum | 0
>> > attnum | 1
>> > allnulls | f
>> > hasnulls | f
>> > placeholder | f
>> > value |
{\x010000001b0000002000000001000000e5700000e6700000e7700000e8700000e9700000ea700000eb700000ec700000ed700000ee700000ef
>> >
700000f0700000f1700000f2700000f3700000f4700000f5700000f6700000f7700000f8700000f9700000fa700000fb700000fc700000fd700000fe700000ff700
>> > 00000710000}
>>
>> Hmm. I'm not sure we can do much better, without making the function
>> much more complicated. I mean, even with regular BRIN indexes we don't
>> really know if the value is plain min/max, right?
>
>Maybe we can try to handle this with some other function that interprets
>the bytea in 'value' and returns a user-readable text. I think it'd
>have to be a superuser-only function, because otherwise you could easily
>cause a crash by passing a value of a different opclass. But since this
>seems a developer-only thing, that restriction seems fine to me.
>
Ummm, I disagree a superuser check is sufficient protection from a
segfault or similar issues. If we really want to print something nicer,
I'd say it needs to be a special function in the BRIN opclass.
>(I don't know what's a good way to represent a bloom filter, mind.)
>
Me neither, but I guess we could print either some stats (size, number
of bits set, etc.) and/or then the bitmap.
regards
--
Tomas Vondra http://www.2ndQuadrant.com
PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On 2020-Jul-13, Tomas Vondra wrote: > On Sun, Jul 12, 2020 at 07:58:54PM -0400, Alvaro Herrera wrote: > > Maybe we can try to handle this with some other function that interprets > > the bytea in 'value' and returns a user-readable text. I think it'd > > have to be a superuser-only function, because otherwise you could easily > > cause a crash by passing a value of a different opclass. But since this > > seems a developer-only thing, that restriction seems fine to me. > > Ummm, I disagree a superuser check is sufficient protection from a > segfault or similar issues. My POV there is that it's the user's responsibility to call the right function; and if they fail to do so, it's their fault. I agree it's not ideal, but frankly these pageinspect things are not critical to get 100% user-friendly. > If we really want to print something nicer, I'd say it needs to be a > special function in the BRIN opclass. If that can be done, then +1. We just need to ensure that the function knows and can verify the type of index that the value comes from. I guess we can pass the index OID so that it can extract the opclass from catalogs to verify. -- Álvaro Herrera https://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On Mon, 13 Jul 2020 at 09:33, Alvaro Herrera <alvherre@2ndquadrant.com> wrote: > > On 2020-Jul-13, Tomas Vondra wrote: > > > On Sun, Jul 12, 2020 at 07:58:54PM -0400, Alvaro Herrera wrote: > > > > Maybe we can try to handle this with some other function that interprets > > > the bytea in 'value' and returns a user-readable text. I think it'd > > > have to be a superuser-only function, because otherwise you could easily > > > cause a crash by passing a value of a different opclass. But since this > > > seems a developer-only thing, that restriction seems fine to me. > > > > Ummm, I disagree a superuser check is sufficient protection from a > > segfault or similar issues. > > My POV there is that it's the user's responsibility to call the right > function; and if they fail to do so, it's their fault. I agree it's not > ideal, but frankly these pageinspect things are not critical to get 100% > user-friendly. > > > If we really want to print something nicer, I'd say it needs to be a > > special function in the BRIN opclass. > > If that can be done, then +1. We just need to ensure that the function > knows and can verify the type of index that the value comes from. I > guess we can pass the index OID so that it can extract the opclass from > catalogs to verify. +1 from me, too. Perhaps we can have it as optional. If a BRIN opclass doesn't have it, the 'values' can be null. Regards, -- Masahiko Sawada http://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On Mon, Jul 13, 2020 at 02:54:56PM +0900, Masahiko Sawada wrote: >On Mon, 13 Jul 2020 at 09:33, Alvaro Herrera <alvherre@2ndquadrant.com> wrote: >> >> On 2020-Jul-13, Tomas Vondra wrote: >> >> > On Sun, Jul 12, 2020 at 07:58:54PM -0400, Alvaro Herrera wrote: >> >> > > Maybe we can try to handle this with some other function that interprets >> > > the bytea in 'value' and returns a user-readable text. I think it'd >> > > have to be a superuser-only function, because otherwise you could easily >> > > cause a crash by passing a value of a different opclass. But since this >> > > seems a developer-only thing, that restriction seems fine to me. >> > >> > Ummm, I disagree a superuser check is sufficient protection from a >> > segfault or similar issues. >> >> My POV there is that it's the user's responsibility to call the right >> function; and if they fail to do so, it's their fault. I agree it's not >> ideal, but frankly these pageinspect things are not critical to get 100% >> user-friendly. >> >> > If we really want to print something nicer, I'd say it needs to be a >> > special function in the BRIN opclass. >> >> If that can be done, then +1. We just need to ensure that the function >> knows and can verify the type of index that the value comes from. I >> guess we can pass the index OID so that it can extract the opclass from >> catalogs to verify. > >+1 from me, too. Perhaps we can have it as optional. If a BRIN opclass >doesn't have it, the 'values' can be null. > I'd say that if the opclass does not have it, then we should print the bytea value (or whatever the opclass uses to store the summary) using the type functions. regards -- Tomas Vondra http://www.2ndQuadrant.com PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On Mon, Jul 13, 2020 at 5:59 PM Tomas Vondra <tomas.vondra@2ndquadrant.com> wrote: > >> > If we really want to print something nicer, I'd say it needs to be a > >> > special function in the BRIN opclass. > >> > >> If that can be done, then +1. We just need to ensure that the function > >> knows and can verify the type of index that the value comes from. I > >> guess we can pass the index OID so that it can extract the opclass from > >> catalogs to verify. > > > >+1 from me, too. Perhaps we can have it as optional. If a BRIN opclass > >doesn't have it, the 'values' can be null. > > > > I'd say that if the opclass does not have it, then we should print the > bytea value (or whatever the opclass uses to store the summary) using > the type functions. I've read the recent messages in this thread and I'd like to share my thoughts. I think the way brin_page_items() displays values is not really generic. It uses a range-like textual representation of an array of values, while that array doesn't necessarily have range semantics. However, I think it's good that brin_page_items() uses a type output function to display values. So, it's not necessary to introduce a new BRIN opclass function in order to get values displayed in a human-readable way. Instead, we could just make a standard of BRIN value to be human readable. I see at least two possibilities for that. 1. Use standard container data-types to represent BRIN values. For instance we could use an array of ranges instead of bytea for multirange. Not about how convenient/performant it would be. 2. Introduce new data-type to represent values in BRIN index. And for that type we can define output function with user-readable output. We did similar things for GiST. For instance, pg_trgm defines gtrgm type, which has no input and no output. But for BRIN opclass we can define type with just output. BTW, I've applied the patchset to the current master, but I got a lot of duplicate oids. Could you please resolve these conflicts. I think it would be good to use high oid numbers to evade conflicts during development/review, and rely on committer to set final oids (as discussed in [1]). Links 1. https://www.postgresql.org/message-id/CAH2-WzmMTGMcPuph4OvsO7Ykut0AOCF_i-%3DeaochT0dd2BN9CQ%40mail.gmail.com ------ Regards, Alexander Korotkov
On Wed, Jul 15, 2020 at 05:34:05AM +0300, Alexander Korotkov wrote: >On Mon, Jul 13, 2020 at 5:59 PM Tomas Vondra ><tomas.vondra@2ndquadrant.com> wrote: >> >> > If we really want to print something nicer, I'd say it needs to be a >> >> > special function in the BRIN opclass. >> >> >> >> If that can be done, then +1. We just need to ensure that the function >> >> knows and can verify the type of index that the value comes from. I >> >> guess we can pass the index OID so that it can extract the opclass from >> >> catalogs to verify. >> > >> >+1 from me, too. Perhaps we can have it as optional. If a BRIN opclass >> >doesn't have it, the 'values' can be null. >> > >> >> I'd say that if the opclass does not have it, then we should print the >> bytea value (or whatever the opclass uses to store the summary) using >> the type functions. > >I've read the recent messages in this thread and I'd like to share my thoughts. > >I think the way brin_page_items() displays values is not really >generic. It uses a range-like textual representation of an array of >values, while that array doesn't necessarily have range semantics. > >However, I think it's good that brin_page_items() uses a type output >function to display values. So, it's not necessary to introduce a new >BRIN opclass function in order to get values displayed in a >human-readable way. Instead, we could just make a standard of BRIN >value to be human readable. I see at least two possibilities for >that. >1. Use standard container data-types to represent BRIN values. For >instance we could use an array of ranges instead of bytea for >multirange. Not about how convenient/performant it would be. >2. Introduce new data-type to represent values in BRIN index. And for >that type we can define output function with user-readable output. We >did similar things for GiST. For instance, pg_trgm defines gtrgm >type, which has no input and no output. But for BRIN opclass we can >define type with just output. > I think there's a number of weak points in this approach. Firstly, it assumes the summaries can be represented as arrays of built-in types, which I'm not really sure about. It clearly is not true for the bloom opclasses, for example. But even for minmax oclasses it's going to be tricky because the ranges may be on different data types so presumably we'd need somewhat nested data structure. Moreover, multi-minmax summary contains either points or intervals, which requires additional fields/flags to indicate that. That further complicates the things ... maybe we could decompose that into separate arrays or something, but honestly it seems somewhat premature - there are far more important aspects to discuss, I think (e.g. how the ranges are built/merged in multi-minmax, or whether bloom opclasses are useful at all). >BTW, I've applied the patchset to the current master, but I got a lot >of duplicate oids. Could you please resolve these conflicts. I think >it would be good to use high oid numbers to evade conflicts during >development/review, and rely on committer to set final oids (as >discussed in [1]). > >Links >1. https://www.postgresql.org/message-id/CAH2-WzmMTGMcPuph4OvsO7Ykut0AOCF_i-%3DeaochT0dd2BN9CQ%40mail.gmail.com > Did you use the patchset from 2020/07/03? I don't get any duplicate OIDs with it, and it's already using quite high OIDs (part 4 uses >= 8000, part 5 uses >= 9000). regards -- Tomas Vondra http://www.2ndQuadrant.com PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
Hi, Tomas! Sorry for the late reply. On Sun, Jul 19, 2020 at 6:19 PM Tomas Vondra <tomas.vondra@2ndquadrant.com> wrote: > I think there's a number of weak points in this approach. > > Firstly, it assumes the summaries can be represented as arrays of > built-in types, which I'm not really sure about. It clearly is not true > for the bloom opclasses, for example. But even for minmax oclasses it's > going to be tricky because the ranges may be on different data types so > presumably we'd need somewhat nested data structure. > > Moreover, multi-minmax summary contains either points or intervals, > which requires additional fields/flags to indicate that. That further > complicates the things ... > > maybe we could decompose that into separate arrays or something, but > honestly it seems somewhat premature - there are far more important > aspects to discuss, I think (e.g. how the ranges are built/merged in > multi-minmax, or whether bloom opclasses are useful at all). I see. But there is at least a second option to introduce a new datatype with just an output function. In the similar way gist/tsvector_ops uses gtsvector key type. I think it would be more transparent than using just bytea. Also, this is the way we already use in the core. > >BTW, I've applied the patchset to the current master, but I got a lot > >of duplicate oids. Could you please resolve these conflicts. I think > >it would be good to use high oid numbers to evade conflicts during > >development/review, and rely on committer to set final oids (as > >discussed in [1]). > > > >Links > >1. https://www.postgresql.org/message-id/CAH2-WzmMTGMcPuph4OvsO7Ykut0AOCF_i-%3DeaochT0dd2BN9CQ%40mail.gmail.com > > Did you use the patchset from 2020/07/03? I don't get any duplicate OIDs > with it, and it's already using quite high OIDs (part 4 uses >= 8000, > part 5 uses >= 9000). Yep, it appears that I was using the wrong version of patchset. Patchset from 2020/07/03 works good on the current master. ------ Regards, Alexander Korotkov
On Tue, Aug 04, 2020 at 05:36:51PM +0300, Alexander Korotkov wrote: >Hi, Tomas! > >Sorry for the late reply. > >On Sun, Jul 19, 2020 at 6:19 PM Tomas Vondra ><tomas.vondra@2ndquadrant.com> wrote: >> I think there's a number of weak points in this approach. >> >> Firstly, it assumes the summaries can be represented as arrays of >> built-in types, which I'm not really sure about. It clearly is not true >> for the bloom opclasses, for example. But even for minmax oclasses it's >> going to be tricky because the ranges may be on different data types so >> presumably we'd need somewhat nested data structure. >> >> Moreover, multi-minmax summary contains either points or intervals, >> which requires additional fields/flags to indicate that. That further >> complicates the things ... >> >> maybe we could decompose that into separate arrays or something, but >> honestly it seems somewhat premature - there are far more important >> aspects to discuss, I think (e.g. how the ranges are built/merged in >> multi-minmax, or whether bloom opclasses are useful at all). > >I see. But there is at least a second option to introduce a new >datatype with just an output function. In the similar way >gist/tsvector_ops uses gtsvector key type. I think it would be more >transparent than using just bytea. Also, this is the way we already >use in the core. > So you're proposing to have a new data types "brin_minmax_multi_summary" and "brin_bloom_summary" (or some other names), with output functions printing something nicer? I suppose that could work, and we could even add pageinspect functions returning the value as raw bytea. Good idea! >> >BTW, I've applied the patchset to the current master, but I got a lot >> >of duplicate oids. Could you please resolve these conflicts. I think >> >it would be good to use high oid numbers to evade conflicts during >> >development/review, and rely on committer to set final oids (as >> >discussed in [1]). >> > >> >Links >> >1. https://www.postgresql.org/message-id/CAH2-WzmMTGMcPuph4OvsO7Ykut0AOCF_i-%3DeaochT0dd2BN9CQ%40mail.gmail.com >> >> Did you use the patchset from 2020/07/03? I don't get any duplicate OIDs >> with it, and it's already using quite high OIDs (part 4 uses >= 8000, >> part 5 uses >= 9000). > >Yep, it appears that I was using the wrong version of patchset. >Patchset from 2020/07/03 works good on the current master. > OK, good. regards -- Tomas Vondra http://www.2ndQuadrant.com PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On Tue, Aug 04, 2020 at 05:17:43PM +0200, Tomas Vondra wrote:
>On Tue, Aug 04, 2020 at 05:36:51PM +0300, Alexander Korotkov wrote:
>>Hi, Tomas!
>>
>>Sorry for the late reply.
>>
>>On Sun, Jul 19, 2020 at 6:19 PM Tomas Vondra
>><tomas.vondra@2ndquadrant.com> wrote:
>>>I think there's a number of weak points in this approach.
>>>
>>>Firstly, it assumes the summaries can be represented as arrays of
>>>built-in types, which I'm not really sure about. It clearly is not true
>>>for the bloom opclasses, for example. But even for minmax oclasses it's
>>>going to be tricky because the ranges may be on different data types so
>>>presumably we'd need somewhat nested data structure.
>>>
>>>Moreover, multi-minmax summary contains either points or intervals,
>>>which requires additional fields/flags to indicate that. That further
>>>complicates the things ...
>>>
>>>maybe we could decompose that into separate arrays or something, but
>>>honestly it seems somewhat premature - there are far more important
>>>aspects to discuss, I think (e.g. how the ranges are built/merged in
>>>multi-minmax, or whether bloom opclasses are useful at all).
>>
>>I see. But there is at least a second option to introduce a new
>>datatype with just an output function. In the similar way
>>gist/tsvector_ops uses gtsvector key type. I think it would be more
>>transparent than using just bytea. Also, this is the way we already
>>use in the core.
>>
>
>So you're proposing to have a new data types "brin_minmax_multi_summary"
>and "brin_bloom_summary" (or some other names), with output functions
>printing something nicer? I suppose that could work, and we could even
>add pageinspect functions returning the value as raw bytea.
>
>Good idea!
>
Attached is an updated version of the patch series, implementing this.
Adding the extra data types was fairly simple, because both bloom and
minmax-multi indexes already used "struct as varlena" approach, so all
that needed was a bunch of in/out functions and catalog records.
I've left the changes in separate patches for clarity, ultimately it'll
get merged into the other parts.
This reminded me that the current costing may not quite work, because
it depends on how well the index is correlated to the table. That may
be OK for minmax-multi in most cases, but for bloom it makes almost no
sense - correlation does not really matter for bloom filters, what
matters is the number of values in each range.
Consider this example:
create table t (a int);
insert into t select x from (
select (i/10) as x from generate_series(1,10000000) s(i)
order by random()
) foo;
create index on t using brin(
a int4_bloom_ops(n_distinct_per_range=6000,
false_positive_rate=0.05))
with (pages_per_range = 16);
vacuum analyze t;
test=# explain analyze select * from t where a = 10000;
QUERY PLAN
-----------------------------------------------------------------------------------------------------
Seq Scan on t (cost=0.00..169247.71 rows=10 width=4) (actual time=38.088..513.654 rows=10 loops=1)
Filter: (a = 10000)
Rows Removed by Filter: 9999990
Planning Time: 0.060 ms
Execution Time: 513.719 ms
(5 rows)
test=# set enable_seqscan = off;
SET
test=# explain analyze select * from t where a = 10000;
QUERY PLAN
----------------------------------------------------------------------------------------------------------------------------
Bitmap Heap Scan on t (cost=5553.07..174800.78 rows=10 width=4) (actual time=7.790..27.585 rows=10 loops=1)
Recheck Cond: (a = 10000)
Rows Removed by Index Recheck: 224182
Heap Blocks: lossy=992
-> Bitmap Index Scan on t_a_idx (cost=0.00..5553.06 rows=9999977 width=0) (actual time=7.006..7.007 rows=9920
loops=1)
Index Cond: (a = 10000)
Planning Time: 0.052 ms
Execution Time: 27.658 ms
(8 rows)
Clearly, the main problem is in brincostestimate relying on correlation
to tweak the selectivity estimates, leading to an estimate of almost the
whole table, when in practice we only scan a tiny fraction.
Part 0008 is an experimental tweaks the logic to ignore correlation for
bloom and minmax-multi opclasses, producing this plan:
test=# explain analyze select * from t where a = 10000;
QUERY PLAN
---------------------------------------------------------------------------------------------------------------------------
Bitmap Heap Scan on t (cost=5542.01..16562.95 rows=10 width=4) (actual time=12.013..34.705 rows=10 loops=1)
Recheck Cond: (a = 10000)
Rows Removed by Index Recheck: 224182
Heap Blocks: lossy=992
-> Bitmap Index Scan on t_a_idx (cost=0.00..5542.00 rows=3615 width=0) (actual time=11.108..11.109 rows=9920
loops=1)
Index Cond: (a = 10000)
Planning Time: 0.386 ms
Execution Time: 34.778 ms
(8 rows)
which is way closer to reality, of course. I'm not entirely sure it
behaves correctly for multi-column BRIN indexes, but I think as a PoC
it's sufficient.
For bloom, I think we can be a bit smarter - we could use the false
positive rate as the "minimum expected selectivity" or something like
that. After all, the false positive rate essentially means "Given a
random value, what's the chance that a bloom filter matches?" So given a
table with N ranges, we expect about (N * fpr) to match. Of course, the
problem is that this only works for "full" bloom filters. Ranges with
fewer distinct values will have much lower probability, and ranges with
unexpectedly many distinct values will have much higher probability.
But I think we can ignore that, assume the index was created with good
parameters, so the bloom filters won't degrade and the target fpr is
probably a defensive value.
For minmax-multi, we probably should not ignore correlation entirely.
It does handle imperfect correlation much more gracefully than plain
minmax, but it still depends on reasonably ordered data.
A possible improvement would be to compute average "covering" of ranges,
i.e. given the length of a column domain
D = MAX(column) - MIN(column)
compute what fraction of that is covered by a range by summing lengths
of intervals in the range, and dividing it by D. And then averaging it
over all BRIN ranges.
This would allow us to estimate how many ranges are matched by a random
value from the column domain, I think. But this requires extending what
data analyze collects for indexes - I don't think there are any stats
specific to BRIN-specific collected at the moment.
regards
--
Tomas Vondra http://www.2ndQuadrant.com
PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
Attachment
- 0001-Pass-all-keys-to-BRIN-consistent-function-a-20200807.patch
- 0002-Move-IS-NOT-NULL-checks-to-bringetbitmap-20200807.patch
- 0003-Move-processing-of-NULLs-from-BRIN-support--20200807.patch
- 0004-BRIN-bloom-indexes-20200807.patch
- 0005-add-special-pg_brin_bloom_summary-data-type-20200807.patch
- 0006-BRIN-multi-range-minmax-indexes-20200807.patch
- 0007-add-special-pg_brin_minmax_multi_summary-da-20200807.patch
- 0008-tweak-costing-for-bloom-minmax-multi-indexe-20200807.patch
On Fri, Aug 07, 2020 at 06:27:01PM +0200, Tomas Vondra wrote: > Attached is an updated version of the patch series, implementing this. > Adding the extra data types was fairly simple, because both bloom and > minmax-multi indexes already used "struct as varlena" approach, so all > that needed was a bunch of in/out functions and catalog records. > > I've left the changes in separate patches for clarity, ultimately it'll > get merged into the other parts. This fails to apply per the CF bot, so please provide a rebase. -- Michael
Attachment
On Sat, Sep 05, 2020 at 10:46:48AM +0900, Michael Paquier wrote: >On Fri, Aug 07, 2020 at 06:27:01PM +0200, Tomas Vondra wrote: >> Attached is an updated version of the patch series, implementing this. >> Adding the extra data types was fairly simple, because both bloom and >> minmax-multi indexes already used "struct as varlena" approach, so all >> that needed was a bunch of in/out functions and catalog records. >> >> I've left the changes in separate patches for clarity, ultimately it'll >> get merged into the other parts. > >This fails to apply per the CF bot, so please provide a rebase. OK, here is a rebased version. Most of the breakage was due to changes to the BRIN sgml docs. regards -- Tomas Vondra http://www.2ndQuadrant.com PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
Attachment
- 0001-Pass-all-keys-to-BRIN-consistent-function-a-20200906.patch
- 0002-Move-IS-NOT-NULL-checks-to-bringetbitmap-20200906.patch
- 0003-Move-processing-of-NULLs-from-BRIN-support--20200906.patch
- 0004-BRIN-bloom-indexes-20200906.patch
- 0005-add-special-pg_brin_bloom_summary-data-type-20200906.patch
- 0006-BRIN-minmax-multi-indexes-20200906.patch
- 0007-add-special-pg_brin_minmax_multi_summary-da-20200906.patch
- 0008-tweak-costing-for-bloom-minmax-multi-indexe-20200906.patch
On Sat, Sep 5, 2020 at 7:21 PM Tomas Vondra
<tomas.vondra@2ndquadrant.com> wrote:
>
> OK, here is a rebased version. Most of the breakage was due to changes
> to the BRIN sgml docs.
Hi Tomas,
I plan on trying some different queries on different data
distributions to get a sense of when the planner chooses a
multi-minmax index, and whether the choice is good.
Just to start, I used the artificial example in [1], but scaled down a
bit to save time. Config is at the default except for:
shared_buffers = 1GB
random_page_cost = 1.1;
effective_cache_size = 4GB;
create table t (a bigint, b int) with (fillfactor=95);
insert into t select i + 1000*random(), i+1000*random()
from generate_series(1,10000000) s(i);
update t set a = 1, b = 1 where random() < 0.001;
update t set a = 10000000, b = 10000000 where random() < 0.001;
analyze t;
create index on t using brin (a);
CREATE INDEX
Time: 1631.452 ms (00:01.631)
explain analyze select * from t
where a between 1923300::int and 1923600::int;
QUERY PLAN
--------------------------------------------------------------------------------------------------------------------------
Bitmap Heap Scan on t (cost=16.10..43180.43 rows=291 width=12)
(actual time=217.770..1131.366 rows=288 loops=1)
Recheck Cond: ((a >= 1923300) AND (a <= 1923600))
Rows Removed by Index Recheck: 9999712
Heap Blocks: lossy=56819
-> Bitmap Index Scan on t_a_idx (cost=0.00..16.03 rows=22595
width=0) (actual time=3.054..3.055 rows=568320 loops=1)
Index Cond: ((a >= 1923300) AND (a <= 1923600))
Planning Time: 0.328 ms
Execution Time: 1131.411 ms
(8 rows)
Now add the multi-minmax:
create index on t using brin (a int8_minmax_multi_ops);
CREATE INDEX
Time: 6521.026 ms (00:06.521)
The first interesting thing is, with both BRIN indexes available, the
planner still chooses the conventional BRIN index. Only when I disable
it, does it choose the multi-minmax index:
explain analyze select * from t
where a between 1923300::int and 1923600::int;
QUERY PLAN
-------------------------------------------------------------------------------------------------------------------------
Bitmap Heap Scan on t (cost=68.10..43160.86 rows=291 width=12)
(actual time=1.835..4.196 rows=288 loops=1)
Recheck Cond: ((a >= 1923300) AND (a <= 1923600))
Rows Removed by Index Recheck: 22240
Heap Blocks: lossy=128
-> Bitmap Index Scan on t_a_idx1 (cost=0.00..68.03 rows=22523
width=0) (actual time=0.691..0.691 rows=1280 loops=1)
Index Cond: ((a >= 1923300) AND (a <= 1923600))
Planning Time: 0.250 ms
Execution Time: 4.244 ms
(8 rows)
I wonder if this is a clue that something in the costing unfairly
penalizes a multi-minmax index. Maybe not enough to matter in
practice, since I wouldn't expect a user to put different kinds of
index on the same column.
The second thing is, with parallel seq scan, the query is faster than
a BRIN bitmap scan, with this pathological data distribution, but the
planner won't choose it unless forced to:
set enable_bitmapscan = 'off';
explain analyze select * from t
where a between 1923300::int and 1923600::int;
QUERY PLAN
-----------------------------------------------------------------------------------------------------------------------
Gather (cost=1000.00..120348.10 rows=291 width=12) (actual
time=372.766..380.364 rows=288 loops=1)
Workers Planned: 2
Workers Launched: 2
-> Parallel Seq Scan on t (cost=0.00..119319.00 rows=121
width=12) (actual time=268.326..366.228 rows=96 loops=3)
Filter: ((a >= 1923300) AND (a <= 1923600))
Rows Removed by Filter: 3333237
Planning Time: 0.089 ms
Execution Time: 380.434 ms
(8 rows)
And just to compare size:
BRIN 32kB
BRIN multi 136kB
Btree 188MB
[1] https://www.postgresql.org/message-id/459eef3e-48c7-0f5a-8356-992442a78bb6%402ndquadrant.com
--
John Naylor https://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On Wed, Sep 09, 2020 at 12:04:28PM -0400, John Naylor wrote:
>On Sat, Sep 5, 2020 at 7:21 PM Tomas Vondra
><tomas.vondra@2ndquadrant.com> wrote:
>>
>> OK, here is a rebased version. Most of the breakage was due to changes
>> to the BRIN sgml docs.
>
>Hi Tomas,
>
>I plan on trying some different queries on different data
>distributions to get a sense of when the planner chooses a
>multi-minmax index, and whether the choice is good.
>
>Just to start, I used the artificial example in [1], but scaled down a
>bit to save time. Config is at the default except for:
>shared_buffers = 1GB
>random_page_cost = 1.1;
>effective_cache_size = 4GB;
>
>create table t (a bigint, b int) with (fillfactor=95);
>
>insert into t select i + 1000*random(), i+1000*random()
> from generate_series(1,10000000) s(i);
>
>update t set a = 1, b = 1 where random() < 0.001;
>update t set a = 10000000, b = 10000000 where random() < 0.001;
>
>analyze t;
>
>create index on t using brin (a);
>CREATE INDEX
>Time: 1631.452 ms (00:01.631)
>
>explain analyze select * from t
> where a between 1923300::int and 1923600::int;
>
> QUERY PLAN
>--------------------------------------------------------------------------------------------------------------------------
> Bitmap Heap Scan on t (cost=16.10..43180.43 rows=291 width=12)
>(actual time=217.770..1131.366 rows=288 loops=1)
> Recheck Cond: ((a >= 1923300) AND (a <= 1923600))
> Rows Removed by Index Recheck: 9999712
> Heap Blocks: lossy=56819
> -> Bitmap Index Scan on t_a_idx (cost=0.00..16.03 rows=22595
>width=0) (actual time=3.054..3.055 rows=568320 loops=1)
> Index Cond: ((a >= 1923300) AND (a <= 1923600))
> Planning Time: 0.328 ms
> Execution Time: 1131.411 ms
>(8 rows)
>
>Now add the multi-minmax:
>
>create index on t using brin (a int8_minmax_multi_ops);
>CREATE INDEX
>Time: 6521.026 ms (00:06.521)
>
>The first interesting thing is, with both BRIN indexes available, the
>planner still chooses the conventional BRIN index. Only when I disable
>it, does it choose the multi-minmax index:
>
>explain analyze select * from t
> where a between 1923300::int and 1923600::int;
>
> QUERY PLAN
>-------------------------------------------------------------------------------------------------------------------------
> Bitmap Heap Scan on t (cost=68.10..43160.86 rows=291 width=12)
>(actual time=1.835..4.196 rows=288 loops=1)
> Recheck Cond: ((a >= 1923300) AND (a <= 1923600))
> Rows Removed by Index Recheck: 22240
> Heap Blocks: lossy=128
> -> Bitmap Index Scan on t_a_idx1 (cost=0.00..68.03 rows=22523
>width=0) (actual time=0.691..0.691 rows=1280 loops=1)
> Index Cond: ((a >= 1923300) AND (a <= 1923600))
> Planning Time: 0.250 ms
> Execution Time: 4.244 ms
>(8 rows)
>
>I wonder if this is a clue that something in the costing unfairly
>penalizes a multi-minmax index. Maybe not enough to matter in
>practice, since I wouldn't expect a user to put different kinds of
>index on the same column.
>
I think this is much more an estimation issue than a costing one. Notice
that in the "regular" BRIN minmax index we have this:
-> Bitmap Index Scan on t_a_idx (cost=0.00..16.03 rows=22595
width=0) (actual time=3.054..3.055 rows=568320 loops=1)
while for the multi-minmax we have this:
-> Bitmap Index Scan on t_a_idx1 (cost=0.00..68.03 rows=22523
width=0) (actual time=0.691..0.691 rows=1280 loops=1)
So yes, the multi-minmax index is costed a bit higher, mostly because
the index is a bit larger. (There's also a tweak to the correlation, but
that does not make much difference because it's just 0.99 vs. 1.0.)
The main difference is that for minmax the bitmap index scan actually
matches ~586k rows (a bit confusing, considering the heap scan has to
process almost 10M rows during recheck). But the multi-minmax only
matches ~1300 rows, with a recheck of 22k.
I'm not sure how to consider this during costing, as we only see these
numbers at execution time. One way would be to also consider "size" of
the ranges (i.e. max-min) vs. range of the whole column. But that's not
something we already have.
I'm not sure how troublesome this issue really is - I don't think people
are very likely to have both minmax and multi-minmax indexes on the same
column.
>The second thing is, with parallel seq scan, the query is faster than
>a BRIN bitmap scan, with this pathological data distribution, but the
>planner won't choose it unless forced to:
>
>set enable_bitmapscan = 'off';
>explain analyze select * from t
> where a between 1923300::int and 1923600::int;
> QUERY PLAN
>-----------------------------------------------------------------------------------------------------------------------
> Gather (cost=1000.00..120348.10 rows=291 width=12) (actual
>time=372.766..380.364 rows=288 loops=1)
> Workers Planned: 2
> Workers Launched: 2
> -> Parallel Seq Scan on t (cost=0.00..119319.00 rows=121
>width=12) (actual time=268.326..366.228 rows=96 loops=3)
> Filter: ((a >= 1923300) AND (a <= 1923600))
> Rows Removed by Filter: 3333237
> Planning Time: 0.089 ms
> Execution Time: 380.434 ms
>(8 rows)
>
I think this is the same root cause - the planner does not realize how
bad the minmax index actually is in this case, so it uses a bit too
optimistic estimate for costing. And then it has to do essentially
seqscan with extra work for bitmap index/heap scan.
regards
--
Tomas Vondra http://www.2ndQuadrant.com
PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On 2020-Sep-09, John Naylor wrote: > create index on t using brin (a); > CREATE INDEX > Time: 1631.452 ms (00:01.631) > create index on t using brin (a int8_minmax_multi_ops); > CREATE INDEX > Time: 6521.026 ms (00:06.521) It seems strange that the multi-minmax index takes so much longer to build. I wonder if there's some obvious part of the algorithm that can be improved? > The second thing is, with parallel seq scan, the query is faster than > a BRIN bitmap scan, with this pathological data distribution, but the > planner won't choose it unless forced to: > > set enable_bitmapscan = 'off'; > explain analyze select * from t > where a between 1923300::int and 1923600::int; This is probably explained by the fact that you likely have the whole table in shared buffers, or at least in OS cache. I'm not sure if the costing should necessarily account for this. -- Álvaro Herrera https://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On Wed, Sep 09, 2020 at 03:40:41PM -0300, Alvaro Herrera wrote: >On 2020-Sep-09, John Naylor wrote: > >> create index on t using brin (a); >> CREATE INDEX >> Time: 1631.452 ms (00:01.631) > >> create index on t using brin (a int8_minmax_multi_ops); >> CREATE INDEX >> Time: 6521.026 ms (00:06.521) > >It seems strange that the multi-minmax index takes so much longer to >build. I wonder if there's some obvious part of the algorithm that can >be improved? > There are some minor optimizations possible - for example I noticed we call minmax_multi_get_strategy_procinfo often because it happens in a loop, and we could easily do it just once. But that saves only about 10% or so, it's not a ground-breaking optimization. The main reason for the slowness is that we pass the values one by one to brin_minmax_multi_add_value - and on each call we need to deserialize (and then sometimes also serialize) the summary, which may be quite expensive. The regular minmax does not have this issue, it just swaps the Datum value and that's it. I see two possible optimizations - firstly, adding some sort of batch variant of the add_value function, which would get a bunch of values instead of just a single one, amortizing the serialization costs. Another option would be to teach add_value to keep the deserialized summary somewhere, and then force serialization at the end of the BRIN page range. The end result would be roughly the same, I think. regards -- Tomas Vondra http://www.2ndQuadrant.com PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On 2020-Sep-09, Tomas Vondra wrote: > There are some minor optimizations possible - for example I noticed we > call minmax_multi_get_strategy_procinfo often because it happens in a > loop, and we could easily do it just once. But that saves only about 10% > or so, it's not a ground-breaking optimization. Well, I guess this kind of thing should be fixed regardless while we still know it's there, just to avoid an obvious inefficiency. > The main reason for the slowness is that we pass the values one by one > to brin_minmax_multi_add_value - and on each call we need to deserialize > (and then sometimes also serialize) the summary, which may be quite > expensive. The regular minmax does not have this issue, it just swaps > the Datum value and that's it. Ah, right, that's more interesting. The original dumb BRIN code separates BrinMemTuple from BrinTuple so that things can be operated efficiently in memory. Maybe something similar can be done in this case, which also sounds like your second suggestion: > Another option would be to teach add_value to keep the deserialized > summary somewhere, and then force serialization at the end of the BRIN > page range. The end result would be roughly the same, I think. Also, I think you could get a few initial patches pushed soon, since they look like general improvements rather than specific to multi-range. On a differen train of thought, I wonder if we shouldn't drop the idea of there being two minmax opclasses; just have one (still called "minmax") and have the multi-range version be the v2 of it. We would still need to keep code to operate on the old one, but if you ever REINDEX then your index is upgraded to the new one. I see no reason to keep the dumb minmax version around, assuming the performance is roughly similar. -- Álvaro Herrera https://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On Wed, Sep 09, 2020 at 04:53:30PM -0300, Alvaro Herrera wrote: >On 2020-Sep-09, Tomas Vondra wrote: > >> There are some minor optimizations possible - for example I noticed we >> call minmax_multi_get_strategy_procinfo often because it happens in a >> loop, and we could easily do it just once. But that saves only about 10% >> or so, it's not a ground-breaking optimization. > >Well, I guess this kind of thing should be fixed regardless while we >still know it's there, just to avoid an obvious inefficiency. > Sure. I was just suggesting it's not something that'd make this very close to plain minmax opclass. >> The main reason for the slowness is that we pass the values one by one >> to brin_minmax_multi_add_value - and on each call we need to deserialize >> (and then sometimes also serialize) the summary, which may be quite >> expensive. The regular minmax does not have this issue, it just swaps >> the Datum value and that's it. > >Ah, right, that's more interesting. The original dumb BRIN code >separates BrinMemTuple from BrinTuple so that things can be operated >efficiently in memory. Maybe something similar can be done in this >case, which also sounds like your second suggestion: > >> Another option would be to teach add_value to keep the deserialized >> summary somewhere, and then force serialization at the end of the BRIN >> page range. The end result would be roughly the same, I think. > Well, the patch already has Ranges (memory) and SerializedRanges (disk) but it's not very clear to me where to stash the in-memory data and where to make the conversion. > >Also, I think you could get a few initial patches pushed soon, since >they look like general improvements rather than specific to multi-range. > Yeah, I agree. I plan to review those once again in a couple days and then push them. > >On a differen train of thought, I wonder if we shouldn't drop the idea >of there being two minmax opclasses; just have one (still called >"minmax") and have the multi-range version be the v2 of it. We would >still need to keep code to operate on the old one, but if you ever >REINDEX then your index is upgraded to the new one. I see no reason to >keep the dumb minmax version around, assuming the performance is roughly >similar. > I'm not a huge fan of that. I think it's unlikely we'll ever make this new set of oplasses just as fast as the plain minmax, and moreover it does have some additional requirements (e.g. the distance proc, which may not make sense for some data types). regards -- Tomas Vondra http://www.2ndQuadrant.com PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On Wed, Sep 09, 2020 at 10:26:00PM +0200, Tomas Vondra wrote: >On Wed, Sep 09, 2020 at 04:53:30PM -0300, Alvaro Herrera wrote: >>On 2020-Sep-09, Tomas Vondra wrote: >> >>>There are some minor optimizations possible - for example I noticed we >>>call minmax_multi_get_strategy_procinfo often because it happens in a >>>loop, and we could easily do it just once. But that saves only about 10% >>>or so, it's not a ground-breaking optimization. >> >>Well, I guess this kind of thing should be fixed regardless while we >>still know it's there, just to avoid an obvious inefficiency. >> > >Sure. I was just suggesting it's not something that'd make this very >close to plain minmax opclass. > >>>The main reason for the slowness is that we pass the values one by one >>>to brin_minmax_multi_add_value - and on each call we need to deserialize >>>(and then sometimes also serialize) the summary, which may be quite >>>expensive. The regular minmax does not have this issue, it just swaps >>>the Datum value and that's it. >> >>Ah, right, that's more interesting. The original dumb BRIN code >>separates BrinMemTuple from BrinTuple so that things can be operated >>efficiently in memory. Maybe something similar can be done in this >>case, which also sounds like your second suggestion: >> >>>Another option would be to teach add_value to keep the deserialized >>>summary somewhere, and then force serialization at the end of the BRIN >>>page range. The end result would be roughly the same, I think. >> > >Well, the patch already has Ranges (memory) and SerializedRanges (disk) >but it's not very clear to me where to stash the in-memory data and >where to make the conversion. > I've spent a bit of time experimenting with this. My idea was to allow keeping an "expanded" version of the summary somewhere. As the addValue function only receives BrinValues I guess one option would be to just add bv_mem_values field. Or do you have a better idea? Of course, more would need to be done: 1) We'd need to also pass the right memory context (bt_context seems like the right thing, but that's not something addValue sees now). 2) We'd also need to specify some sort of callback that serializes the in-memory value into bt_values. That's not something addValue can do, because it doesn't know whether it's the last value in the range etc. I guess one option would be to add yet another support proc, but I guess a simple callback would be enough. I've hacked together an experimental version of this to see how much would it help, and it reduces the duration from ~4.6s to ~3.3s. Which is nice, but plain minmax is ~1.1s. I suppose there's room for further improvements in compare_combine_ranges/reduce_combine_ranges and so on, but I still think there'll always be a gap compared to plain minmax. regards -- Tomas Vondra http://www.2ndQuadrant.com PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On 2020-Sep-10, Tomas Vondra wrote: > I've spent a bit of time experimenting with this. My idea was to allow > keeping an "expanded" version of the summary somewhere. As the addValue > function only receives BrinValues I guess one option would be to just > add bv_mem_values field. Or do you have a better idea? Maybe it's okay to pass the BrinMemTuple to the add_value function, and keep something there. Or maybe that's pointless and just a new field in BrinValues is okay. > Of course, more would need to be done: > > 1) We'd need to also pass the right memory context (bt_context seems > like the right thing, but that's not something addValue sees now). You could use GetMemoryChunkContext() for that. > 2) We'd also need to specify some sort of callback that serializes the > in-memory value into bt_values. That's not something addValue can do, > because it doesn't know whether it's the last value in the range etc. I > guess one option would be to add yet another support proc, but I guess a > simple callback would be enough. Hmm. > I've hacked together an experimental version of this to see how much > would it help, and it reduces the duration from ~4.6s to ~3.3s. Which is > nice, but plain minmax is ~1.1s. I suppose there's room for further > improvements in compare_combine_ranges/reduce_combine_ranges and so on, > but I still think there'll always be a gap compared to plain minmax. The main reason I'm talking about desupporting plain minmax is that, even if it's amazingly fast, it loses quite quickly in real-world cases because of loss of correlation. Minmax's build time is pretty much determined by speed at which you can seqscan the table. I don't think we lose much if we add overhead in order to create an index that is 100x more useful. -- Álvaro Herrera https://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
Ok, here's an attempt at a somewhat more natural test, to see what
happens after bulk updates and deletes, followed by more inserts. The
short version is that multi-minmax is resilient to a change that
causes a 4x degradation for simple minmax.
shared_buffers = 1GB
random_page_cost = 1.1
effective_cache_size = 4GB
work_mem = 64MB
maintenance_work_mem = 512MB
create unlogged table iot (
id bigint generated by default as identity primary key,
num double precision not null,
create_dt timestamptz not null,
stuff text generated always as (md5(id::text)) stored
)
with (fillfactor = 95);
insert into iot (num, create_dt)
select random(), x
from generate_series(
'2020-01-01 0:00'::timestamptz,
'2020-01-01 0:00'::timestamptz +'49000999 seconds'::interval,
'2 seconds'::interval) x;
INSERT 0 24500500
(01:18s, 2279 MB)
-- done in separate tests so the planner can choose each in turn
create index cd_single on iot using brin(create_dt);
6.7s
create index cd_multi on iot using brin(create_dt timestamptz_minmax_multi_ops);
34s
vacuum analyze;
-- aggregate February
-- single minmax and multi-minmax same plan and same Heap Blocks
below, so only one plan shown
-- query times between the opclasses within noise of variation
explain analyze select date_trunc('day', create_dt), avg(num)
from iot
where create_dt >= '2020-02-01 0:00' and create_dt < '2020-03-01 0:00'
group by 1;
QUERY PLAN
--------------------------------------------------------------------------------------------------------------------------------------------------------------------
HashAggregate (cost=357664.79..388181.83 rows=1232234 width=16)
(actual time=559.805..561.649 rows=29 loops=1)
Group Key: date_trunc('day'::text, create_dt)
Planned Partitions: 4 Batches: 1 Memory Usage: 24601kB
-> Bitmap Heap Scan on iot (cost=323.74..313622.05 rows=1232234
width=16) (actual time=1.787..368.256 rows=1252800 loops=1)
Recheck Cond: ((create_dt >= '2020-02-01
00:00:00-04'::timestamp with time zone) AND (create_dt < '2020-03-01
00:00:00-04'::timestamp with time zone))
Rows Removed by Index Recheck: 15936
Heap Blocks: lossy=15104
-> Bitmap Index Scan on cd_single (cost=0.00..15.68
rows=1236315 width=0) (actual time=0.933..0.934 rows=151040 loops=1)
Index Cond: ((create_dt >= '2020-02-01
00:00:00-04'::timestamp with time zone) AND (create_dt < '2020-03-01
00:00:00-04'::timestamp with time zone))
Planning Time: 0.118 ms
Execution Time: 568.653 ms
(11 rows)
-- delete first month and hi/lo values to create some holes in the table
delete from iot
where create_dt < '2020-02-01 0:00'::timestamptz;
DELETE 1339200
delete from iot
where num < 0.05
or num > 0.95;
DELETE 2316036
vacuum analyze iot;
-- add add back first month, but with double density (1s step rather
than 2s) so it spills over into other parts of the table, causing more
block ranges to have a lower bound with this month.
insert into iot (num, create_dt)
select random(), x
from generate_series(
'2020-01-01 0:00'::timestamptz,
'2020-01-31 23:59'::timestamptz,
'1 second'::interval) x;
INSERT 0 2678341
vacuum analyze;
-- aggregate February again
explain analyze select date_trunc('day', create_dt), avg(num)
from iot
where create_dt >= '2020-02-01 0:00' and create_dt < '2020-03-01 0:00'
group by 1;
-- simple minmax:
QUERY PLAN
--------------------------------------------------------------------------------------------------------------------------------------------------------------------
HashAggregate (cost=354453.63..383192.38 rows=1160429 width=16)
(actual time=2375.075..2376.982 rows=29 loops=1)
Group Key: date_trunc('day'::text, create_dt)
Planned Partitions: 4 Batches: 1 Memory Usage: 24601kB
-> Bitmap Heap Scan on iot (cost=305.85..312977.36 rows=1160429
width=16) (actual time=8.162..2201.547 rows=1127668 loops=1)
Recheck Cond: ((create_dt >= '2020-02-01
00:00:00-04'::timestamp with time zone) AND (create_dt < '2020-03-01
00:00:00-04'::timestamp with time zone))
Rows Removed by Index Recheck: 12278985
Heap Blocks: lossy=159616
-> Bitmap Index Scan on cd_single (cost=0.00..15.74
rows=1206496 width=0) (actual time=7.177..7.178 rows=1596160 loops=1)
Index Cond: ((create_dt >= '2020-02-01
00:00:00-04'::timestamp with time zone) AND (create_dt < '2020-03-01
00:00:00-04'::timestamp with time zone))
Planning Time: 0.117 ms
Execution Time: 2383.685 ms
(11 rows)
-- multi minmax:
QUERY PLAN
--------------------------------------------------------------------------------------------------------------------------------------------------------------------
HashAggregate (cost=354089.57..382932.46 rows=1164634 width=16)
(actual time=535.773..537.731 rows=29 loops=1)
Group Key: date_trunc('day'::text, create_dt)
Planned Partitions: 4 Batches: 1 Memory Usage: 24601kB
-> Bitmap Heap Scan on iot (cost=376.07..312463.00 rows=1164634
width=16) (actual time=3.731..363.116 rows=1127117 loops=1)
Recheck Cond: ((create_dt >= '2020-02-01
00:00:00-04'::timestamp with time zone) AND (create_dt < '2020-03-01
00:00:00-04'::timestamp with time zone))
Rows Removed by Index Recheck: 141619
Heap Blocks: lossy=15104
-> Bitmap Index Scan on cd_multi (cost=0.00..84.92
rows=1166823 width=0) (actual time=3.048..3.048 rows=151040 loops=1)
Index Cond: ((create_dt >= '2020-02-01
00:00:00-04'::timestamp with time zone) AND (create_dt < '2020-03-01
00:00:00-04'::timestamp with time zone))
Planning Time: 0.117 ms
Execution Time: 545.246 ms
(11 rows)
--
John Naylor https://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On Thu, Sep 10, 2020 at 05:01:37PM -0300, Alvaro Herrera wrote: >On 2020-Sep-10, Tomas Vondra wrote: > >> I've spent a bit of time experimenting with this. My idea was to allow >> keeping an "expanded" version of the summary somewhere. As the addValue >> function only receives BrinValues I guess one option would be to just >> add bv_mem_values field. Or do you have a better idea? > >Maybe it's okay to pass the BrinMemTuple to the add_value function, and >keep something there. Or maybe that's pointless and just a new field in >BrinValues is okay. > OK. I don't like changing the add_value API very much, so for the experimental version I simply added three new fields into the BrinValues struct - the deserialized value, serialization callback and the memory context. This seems to be working good enough for a WIP version. With the original (non-batched) patch version a build of an index took about 4s. With the minmax_multi_get_strategy_procinfo optimization and batch build it now takes ~2.6s, which is quite nice. It's still ~2.5x as much compared to plain minmax though. I think there's still room for a bit more improvement (in how we merge the ranges etc.) and maybe we can get to ~2s or something like that. >> Of course, more would need to be done: >> >> 1) We'd need to also pass the right memory context (bt_context seems >> like the right thing, but that's not something addValue sees now). > >You could use GetMemoryChunkContext() for that. > Maybe, although I prefer to just pass the memory context explicitly. >> 2) We'd also need to specify some sort of callback that serializes the >> in-memory value into bt_values. That's not something addValue can do, >> because it doesn't know whether it's the last value in the range etc. I >> guess one option would be to add yet another support proc, but I guess a >> simple callback would be enough. > >Hmm. > I added a simple serialization callback. It works but it's a bit weird that twe have most functions defined as support procedures, and then this extra C callback. >> I've hacked together an experimental version of this to see how much >> would it help, and it reduces the duration from ~4.6s to ~3.3s. Which is >> nice, but plain minmax is ~1.1s. I suppose there's room for further >> improvements in compare_combine_ranges/reduce_combine_ranges and so on, >> but I still think there'll always be a gap compared to plain minmax. > >The main reason I'm talking about desupporting plain minmax is that, >even if it's amazingly fast, it loses quite quickly in real-world cases >because of loss of correlation. Minmax's build time is pretty much >determined by speed at which you can seqscan the table. I don't think >we lose much if we add overhead in order to create an index that is 100x >more useful. > I understand. I just feel a bit uneasy about replacing an index with something that may or may not be better for a certain use case. I mean, if you have data set for which regular minmax works fine, wouldn't you be annoyed if we just switched it for something slower? regards -- Tomas Vondra http://www.2ndQuadrant.com PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
Attachment
- 0001-Pass-all-keys-to-BRIN-consistent-function-a-20200911.patch
- 0002-Move-IS-NOT-NULL-checks-to-bringetbitmap-20200911.patch
- 0003-Move-processing-of-NULLs-from-BRIN-support--20200911.patch
- 0004-BRIN-bloom-indexes-20200911.patch
- 0005-add-special-pg_brin_bloom_summary-data-type-20200911.patch
- 0006-BRIN-minmax-multi-indexes-20200911.patch
- 0007-add-special-pg_brin_minmax_multi_summary-da-20200911.patch
- 0008-tweak-costing-for-bloom-minmax-multi-indexe-20200911.patch
- 0009-WIP-batch-build-20200911.patch
- 0010-WIP-simplify-reduce_combine_ranges-20200911.patch
On Fri, Sep 11, 2020 at 6:14 AM Tomas Vondra <tomas.vondra@2ndquadrant.com> wrote: > I understand. I just feel a bit uneasy about replacing an index with > something that may or may not be better for a certain use case. I mean, > if you have data set for which regular minmax works fine, wouldn't you > be annoyed if we just switched it for something slower? How about making multi minmax the default for new indexes, and those who know their data will stay very well correlated can specify simple minmax ops for speed? Upgraded indexes would stay the same, and only new ones would have the risk of slowdown if not attended to. Also, I wonder if the slowdown in building a new index is similar to the slowdown for updates. I'd like to run some TCP-H tests (that will take some time). -- John Naylor https://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On Fri, Sep 11, 2020 at 10:08:15AM -0400, John Naylor wrote: >On Fri, Sep 11, 2020 at 6:14 AM Tomas Vondra ><tomas.vondra@2ndquadrant.com> wrote: > >> I understand. I just feel a bit uneasy about replacing an index with >> something that may or may not be better for a certain use case. I mean, >> if you have data set for which regular minmax works fine, wouldn't you >> be annoyed if we just switched it for something slower? > >How about making multi minmax the default for new indexes, and those >who know their data will stay very well correlated can specify simple >minmax ops for speed? Upgraded indexes would stay the same, and only >new ones would have the risk of slowdown if not attended to. > That might work, I think. I like that it's an explicit choice, i.e. we may change what the default opclass is, but the behavior won't change unexpectedly during REINDEX etc. It might still be a bit surprising after dump/restore, but that's probably fine. It would be ideal if the opclasses were binary compatible, allowing a more seamless transition. Unfortunately that seems impossible, because plain minmax uses two Datums to store the range, while multi-minmax uses a more complex structure. >Also, I wonder if the slowdown in building a new index is similar to >the slowdown for updates. I'd like to run some TCP-H tests (that will >take some time). > It might be, because it needs to deserialize/serialize the summary too, and there's no option to amortize the costs over many inserts. OTOH the insert probably needs to do various other things, so maybe it's won't be that bad. But yeah, testing and benchmarking it would be nice. Do you plan to test just the minmax-multi opclass, or will you look at the bloom one too? Attached is a slightly improved version - I've merged the various pieces into the "main" patches, and made some minor additional optimizations. I've left the cost tweak as a separate part for now, though. regards -- Tomas Vondra http://www.2ndQuadrant.com PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
Attachment
- 0001-Pass-all-keys-to-BRIN-consistent-function--20200911b.patch
- 0002-Move-IS-NOT-NULL-checks-to-bringetbitmap-20200911b.patch
- 0003-Move-processing-of-NULLs-from-BRIN-support-20200911b.patch
- 0004-BRIN-bloom-indexes-20200911b.patch
- 0005-BRIN-minmax-multi-indexes-20200911b.patch
- 0006-tweak-costing-for-bloom-minmax-multi-index-20200911b.patch
On Fri, Sep 11, 2020 at 2:05 PM Tomas Vondra <tomas.vondra@2ndquadrant.com> wrote: > that bad. But yeah, testing and benchmarking it would be nice. Do you > plan to test just the minmax-multi opclass, or will you look at the > bloom one too? Yeah, I'll start looking at bloom next week, and I'll include it when I do perf testing. -- John Naylor https://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On Fri, Sep 11, 2020 at 03:19:58PM -0400, John Naylor wrote: >On Fri, Sep 11, 2020 at 2:05 PM Tomas Vondra ><tomas.vondra@2ndquadrant.com> wrote: >> that bad. But yeah, testing and benchmarking it would be nice. Do you >> plan to test just the minmax-multi opclass, or will you look at the >> bloom one too? > >Yeah, I'll start looking at bloom next week, and I'll include it when >I do perf testing. > OK. Here is a slightly improved version of the patch series, with better commit messages and comments, and with the two patches tweaking handling of NULL values merged into one. As mentioned in my reply to Alvaro, I'm hoping to get the first two parts (general improvements) committed soon, so that we can focus on the new opclasses. I now recall why I was postponing pushing those parts because it's primarily "just" a preparation for the new opclasses. Both the scan keys and NULL handling tweaks are not going to help existing opclasses very much, I think. The NULL-handling might help a bit, but the scan key changes are mostly irrelevant. So I'm wondering if we should even change the two existing opclasses, instead of keeping them as they are (the code actually supports that by checking number of arguments of the constitent function). Opinions? regards -- Tomas Vondra http://www.2ndQuadrant.com PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
Attachment
Hi, while running some benchmarks to see if the first two patches cause any regressions, I found a bug in 0002 which reworks the NULL handling. The code failed to eliminate ranges early using the IS NULL scan keys, resulting in expensive recheck. The attached version fixes that. I also noticed that some of the queries seem to be slightly slower, most likely due to bringetbitmap having to split the scan keys per attribute, which also requires some allocations etc. The regression is fairly small might be just noise (less than 2-3% in most cases), but it seems just allocating everything in a single chunk eliminates most of it - this is what the new 0003 patch does. OTOH the rework also helps in other cases - I've measured ~2-3% speedups for cases where moving the IS NULL handling to bringetbitmap eliminates calls to the consistent function (e.g. IS NULL queries on columns with no NULL values). These results seems very dependent on the hardware (especially CPU), though, and the differences are pretty small in general (1-2%). regards -- Tomas Vondra http://www.2ndQuadrant.com PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
Attachment
On Sun, Sep 13, 2020 at 12:40 PM Tomas Vondra
<tomas.vondra@2ndquadrant.com> wrote:
> <20200913 patch set>
Hi Tomas,
The cfbot fails to apply this, but with 0001 from 0912 it works on my
end, so going with that.
One problem I have is I don't get success with the new reloptions:
create index cd_multi on iot using brin(create_dt
timestamptz_minmax_multi_ops) with (values_per_range = 64);
ERROR: unrecognized parameter "values_per_range"
create index on iot using brin(create_dt timestamptz_bloom_ops) with
(n_distinct_per_range = 16);
ERROR: unrecognized parameter "n_distinct_per_range"
Aside from that, I'm going to try to understand the code, and ask
questions. Some of the code might still change, but I don't think it's
too early to do some comment and docs proofreading. I'll do this in
separate emails for bloom and multi-minmax to keep it from being too
long. Perf testing will come sometime later.
Bloom
-----
+ greater than 0.0 and smaller than 1.0. The default values is 0.01,
+ rows per block). The default values is <literal>-0.1</literal>, and
s/values/value/
+ the minimum number of distinct non-null values is <literal>128</literal>.
I don't see 128 in the code, but I do see this, is this the intention?:
#define BLOOM_MIN_NDISTINCT_PER_RANGE 16
+ * Bloom filters allow efficient test whether a given page range contains
+ * a particular value. Therefore, if we summarize each page range into a
+ * bloom filter, we can easily and cheaply test wheter it containst values
+ * we get later.
s/test/testing/
s/wheter it containst/whether it contains/
+ * The index only supports equality operator, similarly to hash indexes.
s/operator/operators/
+ * The number of distinct elements (in a page range) depends on the data,
+ * we can consider it fixed. This simplifies the trade-off to just false
+ * positive rate vs. size.
Sounds like the first sentence should start with "although".
+ * of distinct items to be stored in the filter. We can't quite the input
+ * data, of course, but we may make the BRIN page ranges smaller - instead
I think you accidentally a word.
+ * Of course, good sizing decisions depend on having the necessary data,
+ * i.e. number of distinct values in a page range (of a given size) and
+ * table size (to estimate cost change due to change in false positive
+ * rate due to having larger index vs. scanning larger indexes). We may
+ * not have that data - for example when building an index on empty table
+ * it's not really possible. And for some data we only have estimates for
+ * the whole table and we can only estimate per-range values (ndistinct).
and
+ * The current logic, implemented in brin_bloom_get_ndistinct, attempts to
+ * make some basic sizing decisions, based on the table ndistinct estimate.
+ * XXX We might also fetch info about ndistinct estimate for the column,
+ * and compute the expected number of distinct values in a range. But
Maybe I'm missing something, but the first two comments don't match
the last one -- I don't see where we get table ndistinct, which I take
to mean from the stats catalog?
+ * To address these issues, the opclass stores the raw values directly, and
+ * only switches to the actual bloom filter after reaching the same space
+ * requirements.
IIUC, it's after reaching a certain size (BLOOM_MAX_UNSORTED * 4), so
"same" doesn't make sense here.
+ /*
+ * The 1% value is mostly arbitrary, it just looks nice.
+ */
+#define BLOOM_DEFAULT_FALSE_POSITIVE_RATE 0.01 /* 1% fp rate */
I think we'd want better stated justification for this default, even
if just precedence in other implementations. Maybe I can test some
other values here?
+ * XXX Perhaps we could save a few bytes by using different data types, but
+ * considering the size of the bitmap, the difference is negligible.
Yeah, I think it's obvious enough to leave out.
+ m = ceil((ndistinct * log(false_positive_rate)) / log(1.0 /
(pow(2.0, log(2.0)))));
I find this pretty hard to read and pgindent is going to mess it up
further. I would have a comment with the formula in math notation
(note that you can dispense with the reciprocal and just use
negation), but in code fold the last part to a constant. That might go
against project style, though:
m = ceil(ndistinct * log(false_positive_rate) * -2.08136);
+ * XXX Maybe the 64B min size is not really needed?
Something to figure out before commit?
+ /* assume 'not updated' by default */
+ Assert(filter);
I don't see how these are related.
+ big_h = ((uint32) DatumGetInt64(hash_uint32(value)));
I'm curious about the Int64 part -- most callers use the bare value or
with DatumGetUInt32().
Also, is there a reference for the algorithm for hash values that
follows? I didn't see anything like it in my cursory reading of the
topic. Might be good to include it in the comments.
+ * Tweak the ndistinct value based on the pagesPerRange value. First,
Nitpick: "Tweak" to my mind means to adjust an existing value. The
above is only true if ndistinct is negative, but we're really not
tweaking, but using it as a scale factor. Otherwise it's not adjusted,
only clamped.
+ * XXX We can only do this when the pagesPerRange value was supplied.
+ * If it wasn't, it has to be a read-only access to the index, in which
+ * case we don't really care. But perhaps we should fall-back to the
+ * default pagesPerRange value?
I don't understand this.
+static double
+brin_bloom_get_fp_rate(BrinDesc *bdesc, BloomOptions *opts)
+{
+ return BloomGetFalsePositiveRate(opts);
+}
The body of the function is just a macro not used anywhere else -- is
there a reason for having the macro? Also, what's the first parameter
for?
Similarly, BloomGetNDistinctPerRange could just be inlined or turned
into a function for readability.
+ * or null if it is not exists.
s/is not exists/does not exist/
+ /*
+ * XXX not sure the detoasting is necessary (probably not, this
+ * can only be in an index).
+ */
Something to find out before commit?
+ /* TODO include the sorted/unsorted values */
Patch TODO or future TODO?
--
John Naylor https://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On Thu, Sep 17, 2020 at 10:33:06AM -0400, John Naylor wrote:
>On Sun, Sep 13, 2020 at 12:40 PM Tomas Vondra
><tomas.vondra@2ndquadrant.com> wrote:
>> <20200913 patch set>
>
>Hi Tomas,
>
>The cfbot fails to apply this, but with 0001 from 0912 it works on my
>end, so going with that.
>
Hmm, it seems to fail because of some whitespace errors. Attached is an
updated version resolving that.
>One problem I have is I don't get success with the new reloptions:
>
>create index cd_multi on iot using brin(create_dt
>timestamptz_minmax_multi_ops) with (values_per_range = 64);
>ERROR: unrecognized parameter "values_per_range"
>
>create index on iot using brin(create_dt timestamptz_bloom_ops) with
>(n_distinct_per_range = 16);
>ERROR: unrecognized parameter "n_distinct_per_range"
>
But those are opclass parameters, so the parameters are not specified in
WITH clause, but right after the opclass name:
CREATE INDEX idx ON table USING brin (
bigint_col int8_minmax_multi_ops(values_per_range = 15)
);
>
>Aside from that, I'm going to try to understand the code, and ask
>questions. Some of the code might still change, but I don't think it's
>too early to do some comment and docs proofreading. I'll do this in
>separate emails for bloom and multi-minmax to keep it from being too
>long. Perf testing will come sometime later.
>
OK.
>
>Bloom
>-----
>
>+ greater than 0.0 and smaller than 1.0. The default values is 0.01,
>
>+ rows per block). The default values is <literal>-0.1</literal>, and
>
>s/values/value/
>
>+ the minimum number of distinct non-null values is <literal>128</literal>.
>
>I don't see 128 in the code, but I do see this, is this the intention?:
>
>#define BLOOM_MIN_NDISTINCT_PER_RANGE 16
>
Ah, that's right - I might have lowered the default after writing the
comment. Will fix.
>+ * Bloom filters allow efficient test whether a given page range contains
>+ * a particular value. Therefore, if we summarize each page range into a
>+ * bloom filter, we can easily and cheaply test wheter it containst values
>+ * we get later.
>
>s/test/testing/
>s/wheter it containst/whether it contains/
>
OK, will reword.
>+ * The index only supports equality operator, similarly to hash indexes.
>
>s/operator/operators/
>
Hmmm, are there really multiple equality operators?
>+ * The number of distinct elements (in a page range) depends on the data,
>+ * we can consider it fixed. This simplifies the trade-off to just false
>+ * positive rate vs. size.
>
>Sounds like the first sentence should start with "although".
>
Yeah, probably. Or maybe there should be "but" at the beginning of the
second sentence.
>+ * of distinct items to be stored in the filter. We can't quite the input
>+ * data, of course, but we may make the BRIN page ranges smaller - instead
>
>I think you accidentally a word.
>
Seems like that.
>+ * Of course, good sizing decisions depend on having the necessary data,
>+ * i.e. number of distinct values in a page range (of a given size) and
>+ * table size (to estimate cost change due to change in false positive
>+ * rate due to having larger index vs. scanning larger indexes). We may
>+ * not have that data - for example when building an index on empty table
>+ * it's not really possible. And for some data we only have estimates for
>+ * the whole table and we can only estimate per-range values (ndistinct).
>
>and
>
>+ * The current logic, implemented in brin_bloom_get_ndistinct, attempts to
>+ * make some basic sizing decisions, based on the table ndistinct estimate.
>
>+ * XXX We might also fetch info about ndistinct estimate for the column,
>+ * and compute the expected number of distinct values in a range. But
>
>Maybe I'm missing something, but the first two comments don't match
>the last one -- I don't see where we get table ndistinct, which I take
>to mean from the stats catalog?
>
Ah, right. The part suggesting we're looking at the table n_distinct
estimate is obsolete - some older version of the patch attempted to do
that, but I decided to remove it at some point. We can add it in the
future, but I'll fix the comment for now.
>+ * To address these issues, the opclass stores the raw values directly, and
>+ * only switches to the actual bloom filter after reaching the same space
>+ * requirements.
>
>IIUC, it's after reaching a certain size (BLOOM_MAX_UNSORTED * 4), so
>"same" doesn't make sense here.
>
Ummm, no. BLOOM_MAX_UNSORTED has nothing to do with the switch from
sorted mode to hashing (which is storing an actual bloom filter).
BLOOM_MAX_UNSORTED only determines number of new items that may not
be sorted - we don't sort after each insertion, but only once in a while
to amortize the costs. So for example you may have 1000 sorted values
and then we allow adding 32 new ones before sorting the array again
(using a merge sort). But all of this is in the "sorted" mode.
The number of items the comment refers to is this:
/* how many uint32 hashes can we fit into the bitmap */
int maxvalues = filter->nbits / (8 * sizeof(uint32));
where nbits is the size of the bloom filter. So I think the "same" is
quite right here.
>+ /*
>+ * The 1% value is mostly arbitrary, it just looks nice.
>+ */
>+#define BLOOM_DEFAULT_FALSE_POSITIVE_RATE 0.01 /* 1% fp rate */
>
>I think we'd want better stated justification for this default, even
>if just precedence in other implementations. Maybe I can test some
>other values here?
>
Well, I don't know how to pick a better default :-( Ultimately it's a
tarde-off between larger indexes and scanning larger fraction of a table
due to lower false positive. Then there's the restriction that the whole
index tuple needs to fit into a single 8kB page.
>+ * XXX Perhaps we could save a few bytes by using different data types, but
>+ * considering the size of the bitmap, the difference is negligible.
>
>Yeah, I think it's obvious enough to leave out.
>
>+ m = ceil((ndistinct * log(false_positive_rate)) / log(1.0 /
>(pow(2.0, log(2.0)))));
>
>I find this pretty hard to read and pgindent is going to mess it up
>further. I would have a comment with the formula in math notation
>(note that you can dispense with the reciprocal and just use
>negation), but in code fold the last part to a constant. That might go
>against project style, though:
>
>m = ceil(ndistinct * log(false_positive_rate) * -2.08136);
>
Hmm, maybe. I've mostly just copied this out from some bloom filter
paper, but maybe it's not readable.
>+ * XXX Maybe the 64B min size is not really needed?
>
>Something to figure out before commit?
>
Probably. I think this optimization is somewhat pointless and we should
just allocate the right amount of space, and repalloc if needed.
>+ /* assume 'not updated' by default */
>+ Assert(filter);
>
I think they are not related, although the formatting might make it seem
like that.
>I don't see how these are related.
>
>+ big_h = ((uint32) DatumGetInt64(hash_uint32(value)));
>
>I'm curious about the Int64 part -- most callers use the bare value or
>with DatumGetUInt32().
>
Yeah, that formula should use DatumGetUInt32.
>Also, is there a reference for the algorithm for hash values that
>follows? I didn't see anything like it in my cursory reading of the
>topic. Might be good to include it in the comments.
>
This was suggested by Yura Sokolov [1] in 2017. The post refers to a
paper [2] but I don't recall which part describes "our" algorithm.
[1] https://www.postgresql.org/message-id/94c173b54a0aef6ae9b18157ef52f03e@postgrespro.ru
[2] https://www.eecs.harvard.edu/~michaelm/postscripts/rsa2008.pdf
>+ * Tweak the ndistinct value based on the pagesPerRange value. First,
>
>Nitpick: "Tweak" to my mind means to adjust an existing value. The
>above is only true if ndistinct is negative, but we're really not
>tweaking, but using it as a scale factor. Otherwise it's not adjusted,
>only clamped.
>
OK. Perhaps 'adjust' would be a better term?
>+ * XXX We can only do this when the pagesPerRange value was supplied.
>+ * If it wasn't, it has to be a read-only access to the index, in which
>+ * case we don't really care. But perhaps we should fall-back to the
>+ * default pagesPerRange value?
>
>I don't understand this.
>
IIRC I thought there were situations when pagesPerRange value is not
defined, e.g. in read-only access. But I'm not sure about this, and
cosidering the code actally does not check for that (in fact, it has an
assert enforcing valid block number) I think it's a stale comment.
>+static double
>+brin_bloom_get_fp_rate(BrinDesc *bdesc, BloomOptions *opts)
>+{
>+ return BloomGetFalsePositiveRate(opts);
>+}
>
>The body of the function is just a macro not used anywhere else -- is
>there a reason for having the macro? Also, what's the first parameter
>for?
>
No reason. I think the function used to be more complicated at some
point, but it got simpler.
>Similarly, BloomGetNDistinctPerRange could just be inlined or turned
>into a function for readability.
>
Same story.
>+ * or null if it is not exists.
>
>s/is not exists/does not exist/
>
>+ /*
>+ * XXX not sure the detoasting is necessary (probably not, this
>+ * can only be in an index).
>+ */
>
>Something to find out before commit?
>
>+ /* TODO include the sorted/unsorted values */
>
This was simplemented as part of the discussion about pageinspect, and
I wanted some confirmation if the approach is acceptable or not before
spending more time on it. Also, the values are really just hashes of the
column values, so I'm not quite sure it makes sense to include that.
What would you suggest?
regards
--
Tomas Vondra http://www.2ndQuadrant.com
PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
Attachment
- 0001-Pass-all-scan-keys-to-BRIN-consistent-funct-20200917.patch
- 0002-Move-IS-NOT-NULL-handling-from-BRIN-support-20200917.patch
- 0003-optimize-allocations-20200917.patch
- 0004-BRIN-bloom-indexes-20200917.patch
- 0005-BRIN-minmax-multi-indexes-20200917.patch
- 0006-Ignore-correlation-for-new-BRIN-opclasses-20200917.patch
OK, cfbot was not quite happy with the last version either - there was a bug in 0003 part, allocating smaller chunk of memory than needed. Attached is a version fixing that, hopefully cfbot will be happy with this one. regards -- Tomas Vondra http://www.2ndQuadrant.com PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
Attachment
- 0001-Pass-all-scan-keys-to-BRIN-consistent-func-20200917b.patch
- 0002-Move-IS-NOT-NULL-handling-from-BRIN-suppor-20200917b.patch
- 0003-optimize-allocations-20200917b.patch
- 0004-BRIN-bloom-indexes-20200917b.patch
- 0005-BRIN-minmax-multi-indexes-20200917b.patch
- 0006-Ignore-correlation-for-new-BRIN-opclasses-20200917b.patch
On Thu, Sep 17, 2020 at 12:34 PM Tomas Vondra <tomas.vondra@2ndquadrant.com> wrote: > > On Thu, Sep 17, 2020 at 10:33:06AM -0400, John Naylor wrote: > >On Sun, Sep 13, 2020 at 12:40 PM Tomas Vondra > ><tomas.vondra@2ndquadrant.com> wrote: > >> <20200913 patch set> > But those are opclass parameters, so the parameters are not specified in > WITH clause, but right after the opclass name: > > CREATE INDEX idx ON table USING brin ( > bigint_col int8_minmax_multi_ops(values_per_range = 15) > ); D'oh! > >+ * The index only supports equality operator, similarly to hash indexes. > > > >s/operator/operators/ > > > > Hmmm, are there really multiple equality operators? Ah, I see what you meant -- then "_the_ equality operator" is what we want. > The number of items the comment refers to is this: > > /* how many uint32 hashes can we fit into the bitmap */ > int maxvalues = filter->nbits / (8 * sizeof(uint32)); > > where nbits is the size of the bloom filter. So I think the "same" is > quite right here. Ok, I get it now. > >+ /* > >+ * The 1% value is mostly arbitrary, it just looks nice. > >+ */ > >+#define BLOOM_DEFAULT_FALSE_POSITIVE_RATE 0.01 /* 1% fp rate */ > > > >I think we'd want better stated justification for this default, even > >if just precedence in other implementations. Maybe I can test some > >other values here? > > > > Well, I don't know how to pick a better default :-( Ultimately it's a > tarde-off between larger indexes and scanning larger fraction of a table > due to lower false positive. Then there's the restriction that the whole > index tuple needs to fit into a single 8kB page. Well, it might be a perfectly good default, and it seems common in articles on the topic, but the comment is referring to aesthetics. :-) I still intend to test some cases. > >Also, is there a reference for the algorithm for hash values that > >follows? I didn't see anything like it in my cursory reading of the > >topic. Might be good to include it in the comments. > > > > This was suggested by Yura Sokolov [1] in 2017. The post refers to a > paper [2] but I don't recall which part describes "our" algorithm. > > [1] https://www.postgresql.org/message-id/94c173b54a0aef6ae9b18157ef52f03e@postgrespro.ru > [2] https://www.eecs.harvard.edu/~michaelm/postscripts/rsa2008.pdf Hmm, I came across that paper while doing background reading. Okay, now I get that "% (filter->nbits - 1)" is the second hash function in that scheme. But now I wonder if that second function should actually act on the passed "value" (the original hash), so that they are actually independent, as required. In the language of that paper, the patch seems to have g(x) = h1(x) + i*h2(h1(x)) + f(i) instead of g(x) = h1(x) + i*h2(x) + f(i) Concretely, I'm wondering if it should be: big_h = DatumGetUint32(hash_uint32(value)); h = big_h % filter->nbits; -d = big_h % (filter->nbits - 1); +d = value % (filter->nbits - 1); But I could be wrong. Also, I take it that f(i) = 1 in the patch, hence the increment here: + h += d++; But it's a little hidden. That might be worth commenting, if I haven't completely missed something. > >+ * Tweak the ndistinct value based on the pagesPerRange value. First, > > > >Nitpick: "Tweak" to my mind means to adjust an existing value. The > >above is only true if ndistinct is negative, but we're really not > >tweaking, but using it as a scale factor. Otherwise it's not adjusted, > >only clamped. > > > > OK. Perhaps 'adjust' would be a better term? I felt like rewriting the whole thing, but your original gets the point across ok, really. "If the passed ndistinct value is positive, we can just use that, but we also clamp the value to prevent over-sizing the bloom filter unnecessarily. If it's negative, it represents a multiplier to apply to the maximum number of tuples in the range (assuming each page gets MaxHeapTuplesPerPage tuples, which is likely a significant over-estimate), similar to the corresponding value in table statistics." > >+ /* TODO include the sorted/unsorted values */ > > > > This was simplemented as part of the discussion about pageinspect, and > I wanted some confirmation if the approach is acceptable or not before > spending more time on it. Also, the values are really just hashes of the > column values, so I'm not quite sure it makes sense to include that. > What would you suggest? My gut feeling is the hashes are not useful for this purpose, but I don't feel strongly either way. -- John Naylor https://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
I wrote: > Hmm, I came across that paper while doing background reading. Okay, > now I get that "% (filter->nbits - 1)" is the second hash function in > that scheme. But now I wonder if that second function should actually > act on the passed "value" (the original hash), so that they are > actually independent, as required. In the language of that paper, the > patch seems to have > > g(x) = h1(x) + i*h2(h1(x)) + f(i) > > instead of > > g(x) = h1(x) + i*h2(x) + f(i) > > Concretely, I'm wondering if it should be: > > big_h = DatumGetUint32(hash_uint32(value)); > h = big_h % filter->nbits; > -d = big_h % (filter->nbits - 1); > +d = value % (filter->nbits - 1); > > But I could be wrong. I'm wrong -- if we use different operands to the moduli, we throw away the assumption of co-primeness. But I'm still left wondering why we have to re-hash the hash for this to work. In any case, there should be some more documentation around the core algorithm, so that future readers are not left scratching their heads. -- John Naylor https://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On Thu, Sep 17, 2020 at 05:42:59PM -0400, John Naylor wrote: >On Thu, Sep 17, 2020 at 12:34 PM Tomas Vondra ><tomas.vondra@2ndquadrant.com> wrote: >> >> On Thu, Sep 17, 2020 at 10:33:06AM -0400, John Naylor wrote: >> >On Sun, Sep 13, 2020 at 12:40 PM Tomas Vondra >> ><tomas.vondra@2ndquadrant.com> wrote: >> >> <20200913 patch set> >> But those are opclass parameters, so the parameters are not specified in >> WITH clause, but right after the opclass name: >> >> CREATE INDEX idx ON table USING brin ( >> bigint_col int8_minmax_multi_ops(values_per_range = 15) >> ); > >D'oh! > >> >+ * The index only supports equality operator, similarly to hash indexes. >> > >> >s/operator/operators/ >> > >> >> Hmmm, are there really multiple equality operators? > >Ah, I see what you meant -- then "_the_ equality operator" is what we want. > >> The number of items the comment refers to is this: >> >> /* how many uint32 hashes can we fit into the bitmap */ >> int maxvalues = filter->nbits / (8 * sizeof(uint32)); >> >> where nbits is the size of the bloom filter. So I think the "same" is >> quite right here. > >Ok, I get it now. > >> >+ /* >> >+ * The 1% value is mostly arbitrary, it just looks nice. >> >+ */ >> >+#define BLOOM_DEFAULT_FALSE_POSITIVE_RATE 0.01 /* 1% fp rate */ >> > >> >I think we'd want better stated justification for this default, even >> >if just precedence in other implementations. Maybe I can test some >> >other values here? >> > >> >> Well, I don't know how to pick a better default :-( Ultimately it's a >> tarde-off between larger indexes and scanning larger fraction of a table >> due to lower false positive. Then there's the restriction that the whole >> index tuple needs to fit into a single 8kB page. > >Well, it might be a perfectly good default, and it seems common in >articles on the topic, but the comment is referring to aesthetics. :-) >I still intend to test some cases. > I think we may formulate this as a question of how much I/O we need to do for a random query, and pick the false positive rate minimizing that. For a single BRIN range an approximation might look like this: bloom_size(fpr, ...) + (fpr * range_size) + (selectivity * range_size) The "selectivity" shows the true selectivity of ranges, and it might be esimated from a per-row selectivity I guess. But it does not matter much because this is constant and independent of the false-positive rate, so we can ignore it. Which leaves us with bloom_size(fpr, ...) + (fpr * range_size) We might solve this for fixed parameters (range_size, ndistinct, ...), either analytically or by brute force, giving us the "optimal" fpr. The trouble is the bloom_size is restricted, and we don't really know the limit - the whole index tuple needs to fit on a single 8kB page, and there may be other BRIN summaries etc. So I've opted to use a somewhat defensive default for the false positive rate. >> >Also, is there a reference for the algorithm for hash values that >> >follows? I didn't see anything like it in my cursory reading of the >> >topic. Might be good to include it in the comments. >> > >> >> This was suggested by Yura Sokolov [1] in 2017. The post refers to a >> paper [2] but I don't recall which part describes "our" algorithm. >> >> [1] https://www.postgresql.org/message-id/94c173b54a0aef6ae9b18157ef52f03e@postgrespro.ru >> [2] https://www.eecs.harvard.edu/~michaelm/postscripts/rsa2008.pdf > >Hmm, I came across that paper while doing background reading. Okay, >now I get that "% (filter->nbits - 1)" is the second hash function in >that scheme. But now I wonder if that second function should actually >act on the passed "value" (the original hash), so that they are >actually independent, as required. In the language of that paper, the >patch seems to have > >g(x) = h1(x) + i*h2(h1(x)) + f(i) > >instead of > >g(x) = h1(x) + i*h2(x) + f(i) > >Concretely, I'm wondering if it should be: > > big_h = DatumGetUint32(hash_uint32(value)); > h = big_h % filter->nbits; >-d = big_h % (filter->nbits - 1); >+d = value % (filter->nbits - 1); > >But I could be wrong. > >Also, I take it that f(i) = 1 in the patch, hence the increment here: > >+ h += d++; > >But it's a little hidden. That might be worth commenting, if I haven't >completely missed something. > OK >> >+ * Tweak the ndistinct value based on the pagesPerRange value. First, >> > >> >Nitpick: "Tweak" to my mind means to adjust an existing value. The >> >above is only true if ndistinct is negative, but we're really not >> >tweaking, but using it as a scale factor. Otherwise it's not adjusted, >> >only clamped. >> > >> >> OK. Perhaps 'adjust' would be a better term? > >I felt like rewriting the whole thing, but your original gets the >point across ok, really. > >"If the passed ndistinct value is positive, we can just use that, but >we also clamp the value to prevent over-sizing the bloom filter >unnecessarily. If it's negative, it represents a multiplier to apply >to the maximum number of tuples in the range (assuming each page gets >MaxHeapTuplesPerPage tuples, which is likely a significant >over-estimate), similar to the corresponding value in table >statistics." > >> >+ /* TODO include the sorted/unsorted values */ >> > >> >> This was simplemented as part of the discussion about pageinspect, and >> I wanted some confirmation if the approach is acceptable or not before >> spending more time on it. Also, the values are really just hashes of the >> column values, so I'm not quite sure it makes sense to include that. >> What would you suggest? > >My gut feeling is the hashes are not useful for this purpose, but I >don't feel strongly either way. > OK. I share this feeling. regards -- Tomas Vondra http://www.2ndQuadrant.com PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On Thu, Sep 17, 2020 at 06:48:11PM -0400, John Naylor wrote: >I wrote: > >> Hmm, I came across that paper while doing background reading. Okay, >> now I get that "% (filter->nbits - 1)" is the second hash function in >> that scheme. But now I wonder if that second function should actually >> act on the passed "value" (the original hash), so that they are >> actually independent, as required. In the language of that paper, the >> patch seems to have >> >> g(x) = h1(x) + i*h2(h1(x)) + f(i) >> >> instead of >> >> g(x) = h1(x) + i*h2(x) + f(i) >> >> Concretely, I'm wondering if it should be: >> >> big_h = DatumGetUint32(hash_uint32(value)); >> h = big_h % filter->nbits; >> -d = big_h % (filter->nbits - 1); >> +d = value % (filter->nbits - 1); >> >> But I could be wrong. > >I'm wrong -- if we use different operands to the moduli, we throw away >the assumption of co-primeness. But I'm still left wondering why we >have to re-hash the hash for this to work. In any case, there should >be some more documentation around the core algorithm, so that future >readers are not left scratching their heads. > Hmm, good question. I think we don't really need to hash it twice. It does not rally achieve anything - it won't reduce number of collisions or anything like that. regards -- Tomas Vondra http://www.2ndQuadrant.com PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On Fri, Sep 18, 2020 at 7:40 AM Tomas Vondra <tomas.vondra@2ndquadrant.com> wrote: > > On Thu, Sep 17, 2020 at 06:48:11PM -0400, John Naylor wrote: > >I wrote: > > > >> Hmm, I came across that paper while doing background reading. Okay, > >> now I get that "% (filter->nbits - 1)" is the second hash function in > >> that scheme. But now I wonder if that second function should actually > >> act on the passed "value" (the original hash), so that they are > >> actually independent, as required. In the language of that paper, the > >> patch seems to have > >> > >> g(x) = h1(x) + i*h2(h1(x)) + f(i) > >> > >> instead of > >> > >> g(x) = h1(x) + i*h2(x) + f(i) > >> > >> Concretely, I'm wondering if it should be: > >> > >> big_h = DatumGetUint32(hash_uint32(value)); > >> h = big_h % filter->nbits; > >> -d = big_h % (filter->nbits - 1); > >> +d = value % (filter->nbits - 1); > >> > >> But I could be wrong. > > > >I'm wrong -- if we use different operands to the moduli, we throw away > >the assumption of co-primeness. But I'm still left wondering why we > >have to re-hash the hash for this to work. In any case, there should > >be some more documentation around the core algorithm, so that future > >readers are not left scratching their heads. > > > > Hmm, good question. I think we don't really need to hash it twice. It > does not rally achieve anything - it won't reduce number of collisions > or anything like that. Yeah, looking back at the discussion you linked previously, I think it's a holdover from when the uint32 was rehashed with k different seeds. Anyway, after thinking about it some more, I still have doubts about the mapping algorithm. There are two stages to a hash mapping -- hashing and modulus. I don't think a single hash function (whether rehashed or not) can be turned into two independent functions via a choice of second modulus. At least, that's not what the Kirsch & Mitzenmacher paper is claiming. Since we're not actually applying two independent hash functions on the scan key, we're kind of shooting in the dark. It turns out there is something called a one-hash bloom filter, and the paper in [1] has a straightforward algorithm. Since we can implement it exactly as stated in the paper, that gives me more confidence in the real-world false positive rate. It goes like this: Partition the filter bitmap into k partitions of similar but unequal length, corresponding to consecutive prime numbers. Use the primes for moduli of the uint32 value and map it to the bit of the corresponding partition. For a simple example, let's use 7, 11, 13 for partitions in a filter of size 31. The three bits are: value % 7 7 + (value % 11) 7 + 11 + (value % 13) We could store a const array of the first 256 primes. The largest such prime is 1613, so with k=7 we can support up to ~11k bits, which is more than we'd like to store anyway. Then we store the array index of the largest prime in the 8bits of padding we currently have in BloomFilter struct. One wrinkle is that the sum of k primes is not going to match m exactly. If the sum is too small, we can trim a few bits off of the filter bitmap. If the sum is too large, the last partition can spill into the front of the first one. This shouldn't matter much in the common case since we need to round m to the nearest byte anyway. This should be pretty straightforward to turn into code and I can take a stab at it. Thoughts? [1] https://www.researchgate.net/publication/284283336_One-Hashing_Bloom_Filter -- John Naylor https://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On Fri, Sep 18, 2020 at 05:06:49PM -0400, John Naylor wrote:
>On Fri, Sep 18, 2020 at 7:40 AM Tomas Vondra
><tomas.vondra@2ndquadrant.com> wrote:
>>
>> On Thu, Sep 17, 2020 at 06:48:11PM -0400, John Naylor wrote:
>> >I wrote:
>> >
>> >> Hmm, I came across that paper while doing background reading. Okay,
>> >> now I get that "% (filter->nbits - 1)" is the second hash function in
>> >> that scheme. But now I wonder if that second function should actually
>> >> act on the passed "value" (the original hash), so that they are
>> >> actually independent, as required. In the language of that paper, the
>> >> patch seems to have
>> >>
>> >> g(x) = h1(x) + i*h2(h1(x)) + f(i)
>> >>
>> >> instead of
>> >>
>> >> g(x) = h1(x) + i*h2(x) + f(i)
>> >>
>> >> Concretely, I'm wondering if it should be:
>> >>
>> >> big_h = DatumGetUint32(hash_uint32(value));
>> >> h = big_h % filter->nbits;
>> >> -d = big_h % (filter->nbits - 1);
>> >> +d = value % (filter->nbits - 1);
>> >>
>> >> But I could be wrong.
>> >
>> >I'm wrong -- if we use different operands to the moduli, we throw away
>> >the assumption of co-primeness. But I'm still left wondering why we
>> >have to re-hash the hash for this to work. In any case, there should
>> >be some more documentation around the core algorithm, so that future
>> >readers are not left scratching their heads.
>> >
>>
>> Hmm, good question. I think we don't really need to hash it twice. It
>> does not rally achieve anything - it won't reduce number of collisions
>> or anything like that.
>
>Yeah, looking back at the discussion you linked previously, I think
>it's a holdover from when the uint32 was rehashed with k different
>seeds. Anyway, after thinking about it some more, I still have doubts
>about the mapping algorithm. There are two stages to a hash mapping --
>hashing and modulus. I don't think a single hash function (whether
>rehashed or not) can be turned into two independent functions via a
>choice of second modulus. At least, that's not what the Kirsch &
>Mitzenmacher paper is claiming. Since we're not actually applying two
>independent hash functions on the scan key, we're kind of shooting in
>the dark.
>
OK. I admit the modulo by nbits and (nbits - 1) is a bit suspicious, so
you may be right this is not quite correct construction.
The current scheme was meant to reduce the number of expensive hashing
calls (especially for low fpr values we may require quite a few of
those, easily 10 or more.
But maybe we could still use this scheme by actually computing
h1 = hash_uint32_extended(value, seed1);
h2 = hash_uint32_extended(value, seed2);
and then use this as the independent hash functions. I think that would
meet the requirements of the paper.
>It turns out there is something called a one-hash bloom filter, and
>the paper in [1] has a straightforward algorithm. Since we can
>implement it exactly as stated in the paper, that gives me more
>confidence in the real-world false positive rate. It goes like this:
>
>Partition the filter bitmap into k partitions of similar but unequal
>length, corresponding to consecutive prime numbers. Use the primes for
>moduli of the uint32 value and map it to the bit of the corresponding
>partition. For a simple example, let's use 7, 11, 13 for partitions in
>a filter of size 31. The three bits are:
>
>value % 7
>7 + (value % 11)
>7 + 11 + (value % 13)
>
>We could store a const array of the first 256 primes. The largest such
>prime is 1613, so with k=7 we can support up to ~11k bits, which is
>more than we'd like to store anyway. Then we store the array index of
>the largest prime in the 8bits of padding we currently have in
>BloomFilter struct.
>
Why would 11k bits be more than we'd like to store? Assuming we could
use the whole 8kB page for the bloom filter, that'd be about 64k bits.
In practice there'd be a bit of overhead (page header ...) but it's
still much more than 11k bits. But I guess we can simply make the table
of primes a bit larger, right?
FWIW I don't think we need to be that careful about the space to store
stuff in padding etc. If we can - great, but compared to the size of the
filter it's negligible and I'd prioritize simplicity over a byte or two.
>One wrinkle is that the sum of k primes is not going to match m
>exactly. If the sum is too small, we can trim a few bits off of the
>filter bitmap. If the sum is too large, the last partition can spill
>into the front of the first one. This shouldn't matter much in the
>common case since we need to round m to the nearest byte anyway.
>
AFAIK the paper simply says that as long as the sum of partitions is
close to the requested nbits, it's good enough. So I guess we could just
roll with that, no need to trim/wrap or something like that.
>This should be pretty straightforward to turn into code and I can take
>a stab at it. Thoughts?
>
Sure, go ahead. I'm happy someone is actually looking at those patches
and proposing alternative solutions, and this might easily be a better
hashing scheme.
regards
--
Tomas Vondra http://www.2ndQuadrant.com
PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On Fri, Sep 18, 2020 at 6:27 PM Tomas Vondra <tomas.vondra@2ndquadrant.com> wrote: > But maybe we could still use this scheme by actually computing > > h1 = hash_uint32_extended(value, seed1); > h2 = hash_uint32_extended(value, seed2); > > and then use this as the independent hash functions. I think that would > meet the requirements of the paper. Yeah, that would work algorithmically. It would be trivial to add to the patch, too of course. There'd be a higher up-front cpu cost. Also, I'm a bit cautious of rehashing hashes, and whether the two values above are independent enough. I'm not sure either of these points matters. My guess is the partition approach is more sound, but it has some minor organizational challenges (see below). > Why would 11k bits be more than we'd like to store? Assuming we could > use the whole 8kB page for the bloom filter, that'd be about 64k bits. > In practice there'd be a bit of overhead (page header ...) but it's > still much more than 11k bits. Brain fade -- I guess I thought we were avoiding being toasted, but now I see that's not possible for BRIN storage. So, we'll want to guard against this: ERROR: index row size 8160 exceeds maximum 8152 for index "bar_num_idx" While playing around with the numbers I had an epiphany: At the defaults, the filter already takes up ~4.3kB, over half the page. There is no room for another tuple, so if we're only indexing one column, we might as well take up the whole page. Here MT = max tuples per 128 8k pages, or 37120, so default ndistinct is 3712. n k m p MT/10 7 35580 0.01 MT/10 7 64000 0.0005 MT/10 12 64000 0.00025 Assuming ndistinct isn't way off reality, we get 20x-40x lower false positive rate almost for free, and it'd be trivial to code! Keeping k at 7 would be more robust, since it's equivalent to starting with n = ~6000, p = 0.006, which is still almost 2x less false positives than you asked for. It also means nearly doubling the number of sorted values before switching. Going the other direction, capping nbits to 64k bits when ndistinct gets too high, the false positive rate we can actually support starts to drop. Here, the user requested 0.001 fpr. n k p 4500 9 0.001 6000 7 0.006 7500 6 0.017 15000 3 0.129 (probably useless by now) MT 1 0.440 64000 1 0.63 (possible with > 128 pages per range) I imagine smaller pages_per_range settings are going to be useful for skinny tables (note to self -- test). Maybe we could provide a way for the user to see that their combination of pages_per_range, false positive rate, and ndistinct is supportable, like brin_bloom_get_supported_fpr(). Or document to check with page_inspect. And that's not even considering multi-column indexes, like you mentioned. > But I guess we can simply make the table > of primes a bit larger, right? If we want to support all the above cases without falling down entirely, it would have to go up to 32k to be safe (When k = 1 we could degenerate to one modulus on the whole filter). That would be a table of about 7kB, which we could binary search. [thinks for a moment]...Actually, if we wanted to be clever, maybe we could precalculate the primes needed for the 64k bit cases and stick them at the end of the array. The usual algorithm will find them. That way, we could keep the array around 2kB. However, for >8kB block size, we couldn't adjust the 64k number, which might be okay, but not really project policy. We could also generate the primes via a sieve instead, which is really fast (and more code). That would be more robust, but that would require the filter to store the actual primes used, so 20 more bytes at max k = 10. We could hard-code space for that, or to keep from hard-coding maximum k and thus lowest possible false positive rate, we'd need more bookkeeping. So, with the partition approach, we'd likely have to set in stone either max nbits, or min target false positive rate. The latter option seems more principled, not only for the block size, but also since the target fp rate is already fixed by the reloption, and as I've demonstrated, we can often go above and beyond the reloption even without changing k. > >One wrinkle is that the sum of k primes is not going to match m > >exactly. If the sum is too small, we can trim a few bits off of the > >filter bitmap. If the sum is too large, the last partition can spill > >into the front of the first one. This shouldn't matter much in the > >common case since we need to round m to the nearest byte anyway. > > > > AFAIK the paper simply says that as long as the sum of partitions is > close to the requested nbits, it's good enough. So I guess we could just > roll with that, no need to trim/wrap or something like that. Hmm, I'm not sure I understand you. I can see not caring to trim wasted bits, but we can't set/read off the end of the filter. If we don't wrap, we could just skip reading/writing that bit. So a tiny portion of access would be at k - 1. The paper is not clear on what to do here, but they are explicit in minimizing the absolute value, which could go on either side. Also I found a bug: + add_local_real_reloption(relopts, "false_positive_rate", + "desired false-positive rate for the bloom filters", + BLOOM_DEFAULT_FALSE_POSITIVE_RATE, + 0.001, 1.0, offsetof(BloomOptions, falsePositiveRate)); When I set fp to 1.0, the reloption code is okay with that, but then later the assertion gets triggered. -- John Naylor https://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On Mon, Sep 21, 2020 at 01:42:34PM -0400, John Naylor wrote:
>On Fri, Sep 18, 2020 at 6:27 PM Tomas Vondra
><tomas.vondra@2ndquadrant.com> wrote:
>
>> But maybe we could still use this scheme by actually computing
>>
>> h1 = hash_uint32_extended(value, seed1);
>> h2 = hash_uint32_extended(value, seed2);
>>
>> and then use this as the independent hash functions. I think that would
>> meet the requirements of the paper.
>
>Yeah, that would work algorithmically. It would be trivial to add to
>the patch, too of course. There'd be a higher up-front cpu cost. Also,
>I'm a bit cautious of rehashing hashes, and whether the two values
>above are independent enough. I'm not sure either of these points
>matters. My guess is the partition approach is more sound, but it has
>some minor organizational challenges (see below).
>
OK. I don't think rehashing hashes is an issue as long as the original
hash has sufficiently low collision rate (and while we know it's not
perfect we know it works well enough for hash indexes etc.). And I doubt
the cost of the extra hash of uint32 would be noticeable.
That being said the partitioning approach might be more sound and it's
definitely worth giving it a try.
>> Why would 11k bits be more than we'd like to store? Assuming we could
>> use the whole 8kB page for the bloom filter, that'd be about 64k bits.
>> In practice there'd be a bit of overhead (page header ...) but it's
>> still much more than 11k bits.
>
>Brain fade -- I guess I thought we were avoiding being toasted, but
>now I see that's not possible for BRIN storage. So, we'll want to
>guard against this:
>
>ERROR: index row size 8160 exceeds maximum 8152 for index "bar_num_idx"
>
>While playing around with the numbers I had an epiphany: At the
>defaults, the filter already takes up ~4.3kB, over half the page.
>There is no room for another tuple, so if we're only indexing one
>column, we might as well take up the whole page.
Hmm, yeah. I may be wrong but IIRC indexes don't support external
storage but compression is still allowed. So even if those defaults are
a bit higher than needed that should make the bloom filters a bit more
compressible, and thus fit multiple BRIN tuples on a single page.
>Here MT = max tuples per 128 8k pages, or 37120, so default ndistinct
>is 3712.
>
>n k m p
>MT/10 7 35580 0.01
>MT/10 7 64000 0.0005
>MT/10 12 64000 0.00025
>
>Assuming ndistinct isn't way off reality, we get 20x-40x lower false
>positive rate almost for free, and it'd be trivial to code! Keeping k
>at 7 would be more robust, since it's equivalent to starting with n =
>~6000, p = 0.006, which is still almost 2x less false positives than
>you asked for. It also means nearly doubling the number of sorted
>values before switching.
>
>Going the other direction, capping nbits to 64k bits when ndistinct
>gets too high, the false positive rate we can actually support starts
>to drop. Here, the user requested 0.001 fpr.
>
>n k p
>4500 9 0.001
>6000 7 0.006
>7500 6 0.017
>15000 3 0.129 (probably useless by now)
>MT 1 0.440
>64000 1 0.63 (possible with > 128 pages per range)
>
>I imagine smaller pages_per_range settings are going to be useful for
>skinny tables (note to self -- test). Maybe we could provide a way for
>the user to see that their combination of pages_per_range, false
>positive rate, and ndistinct is supportable, like
>brin_bloom_get_supported_fpr(). Or document to check with page_inspect.
>And that's not even considering multi-column indexes, like you
>mentioned.
>
I agree giving users visibility into this would be useful.
Not sure about how much we want to rely on these optimizations, though,
considering multi-column indexes kinda break this.
>> But I guess we can simply make the table of primes a bit larger,
>> right?
>
>If we want to support all the above cases without falling down
>entirely, it would have to go up to 32k to be safe (When k = 1 we could
>degenerate to one modulus on the whole filter). That would be a table
>of about 7kB, which we could binary search. [thinks for a
>moment]...Actually, if we wanted to be clever, maybe we could
>precalculate the primes needed for the 64k bit cases and stick them at
>the end of the array. The usual algorithm will find them. That way, we
>could keep the array around 2kB. However, for >8kB block size, we
>couldn't adjust the 64k number, which might be okay, but not really
>project policy.
>
>We could also generate the primes via a sieve instead, which is really
>fast (and more code). That would be more robust, but that would require
>the filter to store the actual primes used, so 20 more bytes at max k =
>10. We could hard-code space for that, or to keep from hard-coding
>maximum k and thus lowest possible false positive rate, we'd need more
>bookkeeping.
>
I don't think the efficiency of this code matters too much - it's only
used once when creating the index, so the simpler the better. Certainly
for now, while testing the partitioning approach.
>So, with the partition approach, we'd likely have to set in stone
>either max nbits, or min target false positive rate. The latter option
>seems more principled, not only for the block size, but also since the
>target fp rate is already fixed by the reloption, and as I've
>demonstrated, we can often go above and beyond the reloption even
>without changing k.
>
That seems like a rather annoying limitation, TBH.
>> >One wrinkle is that the sum of k primes is not going to match m
>> >exactly. If the sum is too small, we can trim a few bits off of the
>> >filter bitmap. If the sum is too large, the last partition can spill
>> >into the front of the first one. This shouldn't matter much in the
>> >common case since we need to round m to the nearest byte anyway.
>> >
>>
>> AFAIK the paper simply says that as long as the sum of partitions is
>> close to the requested nbits, it's good enough. So I guess we could
>> just roll with that, no need to trim/wrap or something like that.
>
>Hmm, I'm not sure I understand you. I can see not caring to trim wasted
>bits, but we can't set/read off the end of the filter. If we don't
>wrap, we could just skip reading/writing that bit. So a tiny portion of
>access would be at k - 1. The paper is not clear on what to do here,
>but they are explicit in minimizing the absolute value, which could go
>on either side.
>
What I meant is that is that the paper says this:
Given a planned overall length mp for a Bloom filter, we usually
cannot get k prime numbers to make their sum mf to be exactly mp. As
long as the difference between mp and mf is small enough, it neither
causes any trouble for the software implementation nor noticeably
shifts the false positive ratio.
Which I think means we can pick mp, generate k primes with sum mf close
to mp, and just use that with mf bits.
>Also I found a bug:
>
>+ add_local_real_reloption(relopts, "false_positive_rate", + "desired
>false-positive rate for the bloom filters", +
>BLOOM_DEFAULT_FALSE_POSITIVE_RATE, + 0.001, 1.0, offsetof(BloomOptions,
>falsePositiveRate));
>
>When I set fp to 1.0, the reloption code is okay with that, but then
>later the assertion gets triggered.
>
Hmm, yeah. I wonder what to do about that, considering indexes with fp
1.0 are essentially useless.
regards
--
Tomas Vondra http://www.2ndQuadrant.com
PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On Mon, Sep 21, 2020 at 3:56 PM Tomas Vondra <tomas.vondra@2ndquadrant.com> wrote: > > On Mon, Sep 21, 2020 at 01:42:34PM -0400, John Naylor wrote: > >While playing around with the numbers I had an epiphany: At the > >defaults, the filter already takes up ~4.3kB, over half the page. > >There is no room for another tuple, so if we're only indexing one > >column, we might as well take up the whole page. > > Hmm, yeah. I may be wrong but IIRC indexes don't support external > storage but compression is still allowed. So even if those defaults are > a bit higher than needed that should make the bloom filters a bit more > compressible, and thus fit multiple BRIN tuples on a single page. > Not sure about how much we want to rely on these optimizations, though, > considering multi-column indexes kinda break this. Yeah. Okay, then it sounds like we should go in the other direction, as the block comment at the top of brin_bloom.c implies. Indexes with multiple bloom-indexed columns already don't fit in one 8kB page, so I think every documented example should have a much lower pages_per_range. Using 32 pages per range with max tuples gives n = 928. With default p, that's about 1.1 kB per brin tuple, so one brin page can index 224 pages, much more than with the default 128. Hmm, how ugly would it be to change the default range size depending on the opclass? If indexes don't support external storage, that sounds like a pain to add. Also, with very small fpr, you can easily get into many megabytes of filter space, which kind of defeats the purpose of brin in the first place. There is already this item from the brin readme: * Different-size page ranges? In the current design, each "index entry" in a BRIN index covers the same number of pages. There's no hard reason for this; it might make sense to allow the index to self-tune so that some index entries cover smaller page ranges, if this allows the summary values to be more compact. This would incur larger BRIN overhead for the index itself, but might allow better pruning of page ranges during scan. In the limit of one index tuple per page, the index itself would occupy too much space, even though we would be able to skip reading the most heap pages, because the summary values are tight; in the opposite limit of a single tuple that summarizes the whole table, we wouldn't be able to prune anything even though the index is very small. This can probably be made to work by using the range map as an index in itself. This sounds like a lot of work, but would be robust. Anyway, given that this is a general problem and not specific to the prime partition algorithm, I'll leave that out of the attached patch, named as a .txt to avoid confusing the cfbot. > >We could also generate the primes via a sieve instead, which is really > >fast (and more code). That would be more robust, but that would require > >the filter to store the actual primes used, so 20 more bytes at max k = > >10. We could hard-code space for that, or to keep from hard-coding > >maximum k and thus lowest possible false positive rate, we'd need more > >bookkeeping. > > > > I don't think the efficiency of this code matters too much - it's only > used once when creating the index, so the simpler the better. Certainly > for now, while testing the partitioning approach. To check my understanding, isn't bloom_init() called for every tuple? Agreed on simplicity so done this way. > >So, with the partition approach, we'd likely have to set in stone > >either max nbits, or min target false positive rate. The latter option > >seems more principled, not only for the block size, but also since the > >target fp rate is already fixed by the reloption, and as I've > >demonstrated, we can often go above and beyond the reloption even > >without changing k. > > > > That seems like a rather annoying limitation, TBH. I don't think the latter is that bad. I've capped k at 10 for demonstration's sake.: (928 is from using 32 pages per range) n k m p 928 7 8895 0.01 928 10 13343 0.001 (lowest p supported in patch set) 928 13 17790 0.0001 928 10 18280 0.0001 (still works with lower k, needs higher m) 928 10 17790 0.00012 (even keeping m from row #3, capping k doesn't degrade p much) Also, k seems pretty robust against small changes as long as m isn't artificially constrained and as long as p is small. So I *think* it's okay to cap k at 10 or 12, and not bother with adjusting m, which worsens space issues. As I found before, lowering k raises target fpr, but seems more robust to overshooting ndistinct. In any case, we only need k * 2 bytes to store the partition lengths. The only way I see to avoid any limitation is to make the array of primes variable length, which could be done by putting the filter offset calculation into a macro. But having two variable-length arrays seems messy. > >Hmm, I'm not sure I understand you. I can see not caring to trim wasted > >bits, but we can't set/read off the end of the filter. If we don't > >wrap, we could just skip reading/writing that bit. So a tiny portion of > >access would be at k - 1. The paper is not clear on what to do here, > >but they are explicit in minimizing the absolute value, which could go > >on either side. > > > > What I meant is that is that the paper says this: > > Given a planned overall length mp for a Bloom filter, we usually > cannot get k prime numbers to make their sum mf to be exactly mp. As > long as the difference between mp and mf is small enough, it neither > causes any trouble for the software implementation nor noticeably > shifts the false positive ratio. > > Which I think means we can pick mp, generate k primes with sum mf close > to mp, and just use that with mf bits. Oh, I see. When I said "trim" I meant exactly that (when mf < mp). Yeah, we can bump it up as well for the other case. I've done it that way. > >+ add_local_real_reloption(relopts, "false_positive_rate", + "desired > >false-positive rate for the bloom filters", + > >BLOOM_DEFAULT_FALSE_POSITIVE_RATE, + 0.001, 1.0, offsetof(BloomOptions, > >falsePositiveRate)); > > > >When I set fp to 1.0, the reloption code is okay with that, but then > >later the assertion gets triggered. > > > > Hmm, yeah. I wonder what to do about that, considering indexes with fp > 1.0 are essentially useless. Not just useless -- they're degenerate. When p = 1.0, m = k = 0 -- We cannot accept this value from the user. Looking up thread, 0.1 was suggested as a limit. That might be a good starting point. This is interesting work! Having gone this far, I'm going to put more attention to the multi-minmax patch and actually start performance testing. -- John Naylor https://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
Attachment
On Thu, Sep 24, 2020 at 05:18:03PM -0400, John Naylor wrote: >On Mon, Sep 21, 2020 at 3:56 PM Tomas Vondra ><tomas.vondra@2ndquadrant.com> wrote: >> >> On Mon, Sep 21, 2020 at 01:42:34PM -0400, John Naylor wrote: > >> >While playing around with the numbers I had an epiphany: At the >> >defaults, the filter already takes up ~4.3kB, over half the page. >> >There is no room for another tuple, so if we're only indexing one >> >column, we might as well take up the whole page. >> >> Hmm, yeah. I may be wrong but IIRC indexes don't support external >> storage but compression is still allowed. So even if those defaults are >> a bit higher than needed that should make the bloom filters a bit more >> compressible, and thus fit multiple BRIN tuples on a single page. > >> Not sure about how much we want to rely on these optimizations, though, >> considering multi-column indexes kinda break this. > >Yeah. Okay, then it sounds like we should go in the other direction, >as the block comment at the top of brin_bloom.c implies. Indexes with >multiple bloom-indexed columns already don't fit in one 8kB page, so I >think every documented example should have a much lower >pages_per_range. Using 32 pages per range with max tuples gives n = >928. With default p, that's about 1.1 kB per brin tuple, so one brin >page can index 224 pages, much more than with the default 128. > >Hmm, how ugly would it be to change the default range size depending >on the opclass? > Not sure. What would happen for multi-column BRIN indexes with different opclasses? >If indexes don't support external storage, that sounds like a pain to >add. Also, with very small fpr, you can easily get into many megabytes >of filter space, which kind of defeats the purpose of brin in the >first place. > True. >There is already this item from the brin readme: > >* Different-size page ranges? > In the current design, each "index entry" in a BRIN index covers the same > number of pages. There's no hard reason for this; it might make sense to > allow the index to self-tune so that some index entries cover smaller page > ranges, if this allows the summary values to be more compact. This >would incur > larger BRIN overhead for the index itself, but might allow better pruning of > page ranges during scan. In the limit of one index tuple per page, the index > itself would occupy too much space, even though we would be able to skip > reading the most heap pages, because the summary values are tight; in the > opposite limit of a single tuple that summarizes the whole table, we wouldn't > be able to prune anything even though the index is very small. This can > probably be made to work by using the range map as an index in itself. > >This sounds like a lot of work, but would be robust. > Yeah. I think it's a fairly independent / orthogonal project. >Anyway, given that this is a general problem and not specific to the >prime partition algorithm, I'll leave that out of the attached patch, >named as a .txt to avoid confusing the cfbot. > >> >We could also generate the primes via a sieve instead, which is really >> >fast (and more code). That would be more robust, but that would require >> >the filter to store the actual primes used, so 20 more bytes at max k = >> >10. We could hard-code space for that, or to keep from hard-coding >> >maximum k and thus lowest possible false positive rate, we'd need more >> >bookkeeping. >> > >> >> I don't think the efficiency of this code matters too much - it's only >> used once when creating the index, so the simpler the better. Certainly >> for now, while testing the partitioning approach. > >To check my understanding, isn't bloom_init() called for every tuple? >Agreed on simplicity so done this way. > No, it's only called for the first non-NULL value in the page range (unless I made a boo boo when writing that code). >> >So, with the partition approach, we'd likely have to set in stone >> >either max nbits, or min target false positive rate. The latter option >> >seems more principled, not only for the block size, but also since the >> >target fp rate is already fixed by the reloption, and as I've >> >demonstrated, we can often go above and beyond the reloption even >> >without changing k. >> > >> >> That seems like a rather annoying limitation, TBH. > >I don't think the latter is that bad. I've capped k at 10 for >demonstration's sake.: > >(928 is from using 32 pages per range) > >n k m p >928 7 8895 0.01 >928 10 13343 0.001 (lowest p supported in patch set) >928 13 17790 0.0001 >928 10 18280 0.0001 (still works with lower k, needs higher m) >928 10 17790 0.00012 (even keeping m from row #3, capping k doesn't >degrade p much) > >Also, k seems pretty robust against small changes as long as m isn't >artificially constrained and as long as p is small. > >So I *think* it's okay to cap k at 10 or 12, and not bother with >adjusting m, which worsens space issues. As I found before, lowering k >raises target fpr, but seems more robust to overshooting ndistinct. In >any case, we only need k * 2 bytes to store the partition lengths. > >The only way I see to avoid any limitation is to make the array of >primes variable length, which could be done by putting the filter >offset calculation into a macro. But having two variable-length arrays >seems messy. > Hmmm. I wonder how would these limitations impact the conclusions from the one-hashing paper? Or was this just for the sake of a demonstration? I'd suggest we just do the simplest thing possible (be it a hard-coded table of primes or a sieve) and then evaluate if we need to do something more sophisticated. >> >Hmm, I'm not sure I understand you. I can see not caring to trim wasted >> >bits, but we can't set/read off the end of the filter. If we don't >> >wrap, we could just skip reading/writing that bit. So a tiny portion of >> >access would be at k - 1. The paper is not clear on what to do here, >> >but they are explicit in minimizing the absolute value, which could go >> >on either side. >> > >> >> What I meant is that is that the paper says this: >> >> Given a planned overall length mp for a Bloom filter, we usually >> cannot get k prime numbers to make their sum mf to be exactly mp. As >> long as the difference between mp and mf is small enough, it neither >> causes any trouble for the software implementation nor noticeably >> shifts the false positive ratio. >> >> Which I think means we can pick mp, generate k primes with sum mf close >> to mp, and just use that with mf bits. > >Oh, I see. When I said "trim" I meant exactly that (when mf < mp). >Yeah, we can bump it up as well for the other case. I've done it that >way. > OK >> >+ add_local_real_reloption(relopts, "false_positive_rate", + "desired >> >false-positive rate for the bloom filters", + >> >BLOOM_DEFAULT_FALSE_POSITIVE_RATE, + 0.001, 1.0, offsetof(BloomOptions, >> >falsePositiveRate)); >> > >> >When I set fp to 1.0, the reloption code is okay with that, but then >> >later the assertion gets triggered. >> > >> >> Hmm, yeah. I wonder what to do about that, considering indexes with fp >> 1.0 are essentially useless. > >Not just useless -- they're degenerate. When p = 1.0, m = k = 0 -- We >cannot accept this value from the user. Looking up thread, 0.1 was >suggested as a limit. That might be a good starting point. > Makes sense, I'll fix it that way. >This is interesting work! Having gone this far, I'm going to put more >attention to the multi-minmax patch and actually start performance >testing. > Cool, thanks! I'll take a look at your one-hashing patch tomorrow. regards -- Tomas Vondra http://www.2ndQuadrant.com PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On Thu, Sep 24, 2020 at 7:50 PM Tomas Vondra <tomas.vondra@2ndquadrant.com> wrote: > > On Thu, Sep 24, 2020 at 05:18:03PM -0400, John Naylor wrote: > >Hmm, how ugly would it be to change the default range size depending > >on the opclass? > > > > Not sure. What would happen for multi-column BRIN indexes with different > opclasses? Sounds like a can of worms. In any case I suspect if there is no more graceful way to handle too-large filters than ERROR out the first time trying to write to the index, this feature might meet some resistance. Not sure what to suggest, though. > >> I don't think the efficiency of this code matters too much - it's only > >> used once when creating the index, so the simpler the better. Certainly > >> for now, while testing the partitioning approach. > > > >To check my understanding, isn't bloom_init() called for every tuple? > >Agreed on simplicity so done this way. > > > > No, it's only called for the first non-NULL value in the page range > (unless I made a boo boo when writing that code). Ok, then I basically understood -- by tuple I meant BRIN tuple, pardon my ambiguity. After thinking about it, I agree that CPU cost is probably trivial (and if not, something is seriously wrong). > >n k m p > >928 7 8895 0.01 > >928 10 13343 0.001 (lowest p supported in patch set) > >928 13 17790 0.0001 > >928 10 18280 0.0001 (still works with lower k, needs higher m) > >928 10 17790 0.00012 (even keeping m from row #3, capping k doesn't > >degrade p much) > > > >Also, k seems pretty robust against small changes as long as m isn't > >artificially constrained and as long as p is small. > > > >So I *think* it's okay to cap k at 10 or 12, and not bother with > >adjusting m, which worsens space issues. As I found before, lowering k > >raises target fpr, but seems more robust to overshooting ndistinct. In > >any case, we only need k * 2 bytes to store the partition lengths. > > > >The only way I see to avoid any limitation is to make the array of > >primes variable length, which could be done by putting the filter > >offset calculation into a macro. But having two variable-length arrays > >seems messy. > > > > Hmmm. I wonder how would these limitations impact the conclusions from > the one-hashing paper? Or was this just for the sake of a demonstration? Using "10" in the patch is a demonstration, which completely supports the current fpr allowed by the reloption, and showing what happens if fpr is allowed to go lower. But for your question, I *think* this consideration is independent from the conclusions. The n, k, m values give a theoretical false positive rate, assuming a completely perfect hashing scheme. The numbers I'm playing with show consequences in the theoretical fpr. The point of the paper (and others like it) is how to get the real fpr as close as possible to the fpr predicted by the theory. My understanding anyway. -- John Naylor https://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On Mon, Sep 28, 2020 at 04:42:39PM -0400, John Naylor wrote:
>On Thu, Sep 24, 2020 at 7:50 PM Tomas Vondra
><tomas.vondra@2ndquadrant.com> wrote:
>>
>> On Thu, Sep 24, 2020 at 05:18:03PM -0400, John Naylor wrote:
>
>> >Hmm, how ugly would it be to change the default range size depending
>> >on the opclass?
>> >
>>
>> Not sure. What would happen for multi-column BRIN indexes with different
>> opclasses?
>
>Sounds like a can of worms. In any case I suspect if there is no more
>graceful way to handle too-large filters than ERROR out the first time
>trying to write to the index, this feature might meet some resistance.
>Not sure what to suggest, though.
>
Is it actually all that different from the existing BRIN indexes?
Consider this example:
create table x (a text, b text, c text);
create index on x using brin (a,b,c);
create or replace function random_str(p_len int) returns text as $$
select string_agg(x, '') from (select chr(1 + (254 * random())::int ) as x from generate_series(1,$1)) foo;
$$ language sql;
test=# insert into x select random_str(1000), random_str(1000), random_str(1000);
ERROR: index row size 9056 exceeds maximum 8152 for index "x_a_b_c_idx"
I'm a bit puzzled, though, because both of these things seem to work:
1) insert before creating the index
create table x (a text, b text, c text);
insert into x select random_str(1000), random_str(1000), random_str(1000);
create index on x using brin (a,b,c);
-- and there actually is a non-empty summary with real data
select * from brin_page_items(get_raw_page('x_a_b_c_idx', 2), 'x_a_b_c_idx'::regclass);
2) insert "small" row before inserting the over-sized one
create table x (a text, b text, c text);
insert into x select random_str(10), random_str(10), random_str(10);
insert into x select random_str(1000), random_str(1000), random_str(1000);
create index on x using brin (a,b,c);
-- and there actually is a non-empty summary with the "big" values
select * from brin_page_items(get_raw_page('x_a_b_c_idx', 2), 'x_a_b_c_idx'::regclass);
I find this somewhat strange - how come we don't fail here too?
regards
--
Tomas Vondra http://www.2ndQuadrant.com
PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On Mon, Sep 28, 2020 at 10:12 PM Tomas Vondra <tomas.vondra@2ndquadrant.com> wrote: > Is it actually all that different from the existing BRIN indexes? > Consider this example: > > create table x (a text, b text, c text); > > create index on x using brin (a,b,c); > > create or replace function random_str(p_len int) returns text as $$ > select string_agg(x, '') from (select chr(1 + (254 * random())::int ) as x from generate_series(1,$1)) foo; > $$ language sql; > > test=# insert into x select random_str(1000), random_str(1000), random_str(1000); > ERROR: index row size 9056 exceeds maximum 8152 for index "x_a_b_c_idx" Hmm, okay. As for which comes first, insert or index creation, I'm baffled, too. I also would expect the example above would take up a bit over 6000 bytes, but not 9000. -- John Naylor https://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On Wed, Sep 30, 2020 at 07:57:19AM -0400, John Naylor wrote:
>On Mon, Sep 28, 2020 at 10:12 PM Tomas Vondra
><tomas.vondra@2ndquadrant.com> wrote:
>
>> Is it actually all that different from the existing BRIN indexes?
>> Consider this example:
>>
>> create table x (a text, b text, c text);
>>
>> create index on x using brin (a,b,c);
>>
>> create or replace function random_str(p_len int) returns text as $$
>> select string_agg(x, '') from (select chr(1 + (254 * random())::int ) as x from generate_series(1,$1)) foo;
>> $$ language sql;
>>
>> test=# insert into x select random_str(1000), random_str(1000), random_str(1000);
>> ERROR: index row size 9056 exceeds maximum 8152 for index "x_a_b_c_idx"
>
>Hmm, okay. As for which comes first, insert or index creation, I'm
>baffled, too. I also would expect the example above would take up a
>bit over 6000 bytes, but not 9000.
>
OK, so this seems like a data corruption bug in BRIN, actually.
The ~9000 bytes is actually about right, because the strings are in
UTF-8 so roughly 1.5B per character seems about right. And we have 6
values to store (3 columns, min/max for each), so 6 * 1500 = 9000.
The real question is how come INSERT + CREATE INDEX actually manages to
create an index tuple. And the answer is pretty simple - brin_form_tuple
kinda ignores toasting, happily building index tuples where some values
are toasted.
Consider this:
create table x (a text, b text, c text);
insert into x select random_str(1000), random_str(1000), random_str(1000);
create index on x using brin (a,b,c);
delete from x;
vacuum x;
set enable_seqscan=off;
insert into x select random_str(10), random_str(10), random_str(10);
ERROR: missing chunk number 0 for toast value 16530 in pg_toast_16525
explain analyze select * from x where a = 'xxx';
ERROR: missing chunk number 0 for toast value 16530 in pg_toast_16525
select * from brin_page_items(get_raw_page('x_a_b_c_idx', 2), 'x_a_b_c_idx'::regclass);
ERROR: missing chunk number 0 for toast value 16547 in pg_toast_16541
Interestingly enough, running the select before the insert seems to be
working - not sure why.
Anyway, it behaves like this since 9.5 :-(
regards
--
Tomas Vondra http://www.2ndQuadrant.com
PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On 2020-Oct-01, Tomas Vondra wrote: > OK, so this seems like a data corruption bug in BRIN, actually. Oh crap. You're right -- the data needs to be detoasted before being put in the index. I'll have a look at how this can be fixed.
Status update for a commitfest entry. According to cfbot the patch no longer compiles. Tomas, can you send an update, please? I also see that a few last messages mention a data corruption bug. Sounds pretty serious. Alvaro, have you had a chance to look at it? I don't see anything committed yet, nor any active discussion in other threads.
On Mon, Nov 02, 2020 at 06:05:27PM +0000, Anastasia Lubennikova wrote: >Status update for a commitfest entry. > >According to cfbot the patch no longer compiles. Tomas, can you send >an update, please? > Yep, here's an updated patch series. It got broken by f90149e6285aa which disallowed OID macros in pg_type, but fixing it was simple. I've also included the patch adopting the one-hash bloom, as implemented by John Naylor. I didn't have time to do any testing / evaluation yet, so I've kept it as a separate part - ultimately we should either merge it into the other bloom patch or discard it. >I also see that a few last messages mention a data corruption bug. >Sounds pretty serious. Alvaro, have you had a chance to look at it? I >don't see anything committed yet, nor any active discussion in other >threads. Yeah, I'm not aware of any fix addressing this - my understanding was Alvaro plans to handle that, but amybe I misinterpreted his response. Anyway, I think the fix is simple - we need to de-TOAST the data while adding the data to index, and we need to consider what to do with existing possibly-broken indexes. regards -- Tomas Vondra http://www.2ndQuadrant.com PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
Attachment
- 0001-Pass-all-scan-keys-to-BRIN-consistent-funct-20201103.patch
- 0002-Move-IS-NOT-NULL-handling-from-BRIN-support-20201103.patch
- 0003-optimize-allocations-20201103.patch
- 0004-BRIN-bloom-indexes-20201103.patch
- 0005-use-one-hash-bloom-variant-20201103.patch
- 0006-BRIN-minmax-multi-indexes-20201103.patch
- 0007-Ignore-correlation-for-new-BRIN-opclasses-20201103.patch
Hi,
Here's a rebased version of the patch series, to keep the cfbot happy.
I've also restricted the false positive rate to [0.001, 0.1] instead of
the original [0.0, 1.0], per discussion on this thread.
I've done a bunch of experiments, comparing the "regular" bloom indexes
with the one-hashing scheme proposed by John Naylor. I've been wondering
if there's some measurable difference, especially in:
* efficiency (query duration)
* false positive rate depending on the fill factor
So I ran a bunch of tests on synthetic data sets, varying parameters
affecting the BRIN bloom indexes:
1) different pages_per_range
2) number of distinct values per range
3) fill factor of the bloom filter (66%, 100%, 200%)
Attached is a script I used to test this, and a simple spreadsheet
summarizing the results, comparing the results for each combination of
parameters. For each combination it shows average query duration (over
10 runs) and scan fraction (what fraction of table was scanned).
Overall, I think there's very little difference, particularly in the
"match" cases when we're searching for a value that we know is in the
table. The one-hash variant seems to perform a bit better, but the
difference is fairly small.
In the "mismatch" cases (searching for value that is not in the table)
the differences are more significant, but it might be noise. It does
seem much more "green" than "red", i.e. the one-hash variant seems to be
faster (although this does depend on the values for formatting).
To sum this up, I think the one-hash approach seems interesting. It's
not going to give us huge speedups because we're only hashing int32
values anyway (not the source data), but it's worth exploring.
I've started looking at the one-hash code changes, and I've discovered a
couple issues. I've been wondering how expensive the naive prime sieve
is - it's not extremely hot code path, as we're only running it for each
page range. But still. So my plan was to create the largest bloom filter
possible, and see how much time generate_primes() takes.
So I initialized a cluster with 32kB blocks and tried to do this:
create index on t
using brin (a int4_bloom_ops(n_distinct_per_range=120000,
false_positive_rate=0.1));
which ends up using nbits=575104 (which is 2x the page size, but let's
ignore that) and nhashes=3. That however crashes and burns, because:
a) set_bloom_partitions does this:
while (primes[pidx + nhashes - 1] <= target && primes[pidx] > 0)
pidx++;
which is broken, because the second part of the condition only checks
the current index - we may end up using nhashes primes after that, and
some of them may be 0. So this needs to be:
while (primes[pidx + nhashes - 1] <= target &&
primes[pidx + nhashes] > 0)
pidx++;
(We know there's always at least one 0 at the end, so it's OK not to
check the length explicitly.)
b) set_bloom_partitions does this to generate primes:
/*
* Increase the limit to ensure we have some primes higher than
* the target partition length. The 100 value is arbitrary, but
* should be well over what we need.
*/
primes = generate_primes(target_partlen + 100);
It's not clear to me why 100 is sufficient, particularly for large page
sizes. AFAIK the primes get more and more sparse, so how does this
guarantee we'll get enough "sufficiently large" primes?
c) generate_primes uses uint16 to store the primes, so it can only
generate primes up to 32768. That's (probably) enough for 8kB pages, but
for 32kB pages it's clearly insufficient.
I've fixes these issues in a separate WIP patch, with some simple
debugging logging.
As for the original question how expensive this naive sieve is, I
haven't been able to measure any significant timings. The logging aroung
generate_primes usually looks like this:
2020-11-07 20:36:10.614 CET [232789] LOG: generating primes nbits
575104 nhashes 3 target_partlen 191701
2020-11-07 20:36:10.614 CET [232789] LOG: primes generated
So it takes 0.000 second for this extreme page size. I don't think we
need to invent anything more elaborate.
regards
--
Tomas Vondra
EnterpriseDB: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
Attachment
- i5.ods
- 0001-Pass-all-scan-keys-to-BRIN-consistent-funct-20201107.patch
- 0002-Move-IS-NOT-NULL-handling-from-BRIN-support-20201107.patch
- 0003-Optimize-allocations-in-bringetbitmap-20201107.patch
- 0004-BRIN-bloom-indexes-20201107.patch
- 0005-use-one-hash-bloom-variant-20201107.patch
- 0006-one-hash-tweaks-20201107.patch
- 0007-BRIN-minmax-multi-indexes-20201107.patch
- 0008-Ignore-correlation-for-new-BRIN-opclasses-20201107.patch
- bloom-test.sh
Seems I forgot to replace uint16 with uint32 in couple places when fixing the one-hash code, so it was triggering SIGFPE because of division by 0. Here's a fixed patch series. regards -- Tomas Vondra EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
Attachment
- 0001-Pass-all-scan-keys-to-BRIN-consistent-funct-20201108.patch
- 0002-Move-IS-NOT-NULL-handling-from-BRIN-support-20201108.patch
- 0003-Optimize-allocations-in-bringetbitmap-20201108.patch
- 0004-BRIN-bloom-indexes-20201108.patch
- 0005-use-one-hash-bloom-variant-20201108.patch
- 0006-one-hash-tweaks-20201108.patch
- 0007-BRIN-minmax-multi-indexes-20201108.patch
- 0008-Ignore-correlation-for-new-BRIN-opclasses-20201108.patch
On Sat, Nov 7, 2020 at 4:38 PM Tomas Vondra <tomas.vondra@enterprisedb.com> wrote:
> Overall, I think there's very little difference, particularly in the
> "match" cases when we're searching for a value that we know is in the
> table. The one-hash variant seems to perform a bit better, but the
> difference is fairly small.
>
> In the "mismatch" cases (searching for value that is not in the table)
> the differences are more significant, but it might be noise. It does
> seem much more "green" than "red", i.e. the one-hash variant seems to be
> faster (although this does depend on the values for formatting).
>
> To sum this up, I think the one-hash approach seems interesting. It's
> not going to give us huge speedups because we're only hashing int32
> values anyway (not the source data), but it's worth exploring.
Thanks for testing! It seems you tested against the version with two moduli, and not the alternative discussed in
> Overall, I think there's very little difference, particularly in the
> "match" cases when we're searching for a value that we know is in the
> table. The one-hash variant seems to perform a bit better, but the
> difference is fairly small.
>
> In the "mismatch" cases (searching for value that is not in the table)
> the differences are more significant, but it might be noise. It does
> seem much more "green" than "red", i.e. the one-hash variant seems to be
> faster (although this does depend on the values for formatting).
>
> To sum this up, I think the one-hash approach seems interesting. It's
> not going to give us huge speedups because we're only hashing int32
> values anyway (not the source data), but it's worth exploring.
Thanks for testing! It seems you tested against the version with two moduli, and not the alternative discussed in
which would in fact be rehashing the 32 bit values. I think that would be the way to go if we don't use the one-hashing approach.
> a) set_bloom_partitions does this:
>
> while (primes[pidx + nhashes - 1] <= target && primes[pidx] > 0)
> pidx++;
>
> which is broken, because the second part of the condition only checks
> the current index - we may end up using nhashes primes after that, and
> some of them may be 0. So this needs to be:
>
> while (primes[pidx + nhashes - 1] <= target &&
> primes[pidx + nhashes] > 0)
> pidx++;
Good catch.
> b) set_bloom_partitions does this to generate primes:
>
> /*
> * Increase the limit to ensure we have some primes higher than
> * the target partition length. The 100 value is arbitrary, but
> * should be well over what we need.
> */
> primes = generate_primes(target_partlen + 100);
>
> It's not clear to me why 100 is sufficient, particularly for large page
> sizes. AFAIK the primes get more and more sparse, so how does this
> guarantee we'll get enough "sufficiently large" primes?
This value is not rigorous and should be improved, but I started with that by looking at the table in section 3 in
https://primes.utm.edu/notes/gaps.html
I see two ways to make a stronger guarantee:
1. Take the average gap between primes near n, which is log(n), and multiply that by BLOOM_MAX_NUM_PARTITIONS. Adding that to the target seems a better heuristic than a constant, and is still simple to calculate.
With the pathological example you gave of n=575104, k=3 (target_partlen = 191701), the number to add is log(191701) * 10 = 122. By the table referenced above, the largest prime gap under 360653 is 95, so we're guaranteed to find at least one prime in the space of 122 above the target. That will likely be enough to find the closest-to-target filter size for k=3. Even if it weren't, nbits is so large that the relative difference is tiny. I'd say a heuristic like this is most likely to be off precisely when it matters the least. At this size, even if we find zero primes above our target, the relative filter size is close to
(575104 - 3 * 95) / 575104 = 0.9995
For a more realistic bad-case target partition length, log(1327) * 10 = 72. There are 33 composites after 1327, the largest such gap below 9551. That would give five primes larger than the target
1361 1367 1373 1381 1399
which is more than enough for k<=10:
1297 + 1301 + 1303 + 1307 + 1319 + 1321 + 1327 + 1361 + 1367 + 1373 = 13276
2. Use a "segmented range" algorithm for the sieve and iterate until we get k*2 primes, half below and half above the target. This would be an absolute guarantee, but also more code, so I'm inclined against that.
> c) generate_primes uses uint16 to store the primes, so it can only
> generate primes up to 32768. That's (probably) enough for 8kB pages, but
> for 32kB pages it's clearly insufficient.
Okay.
> As for the original question how expensive this naive sieve is, I
> haven't been able to measure any significant timings. The logging aroung
> generate_primes usually looks like this:
>
> 2020-11-07 20:36:10.614 CET [232789] LOG: generating primes nbits
> 575104 nhashes 3 target_partlen 191701
> 2020-11-07 20:36:10.614 CET [232789] LOG: primes generated
>
> So it takes 0.000 second for this extreme page size. I don't think we
> need to invent anything more elaborate.
Okay, good to know. If we were concerned about memory, we could have it check only odd numbers. That's a common feature of sieves, but also makes the code a bit harder to understand if you haven't seen it before.
Also to fill in something I left for later, the reference for this
/* upper bound of number of primes below limit */
/* WIP: reference for this number */
int numprimes = 1.26 * limit / log(limit);
is
Rosser, J. Barkley; Schoenfeld, Lowell (1962). "Approximate formulas for some functions of prime numbers". Illinois J. Math. 6: 64–94. doi:10.1215/ijm/1255631807
More precisely, it's 30*log(113)/113 rounded up.
--
John Naylor
EnterpriseDB: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
> a) set_bloom_partitions does this:
>
> while (primes[pidx + nhashes - 1] <= target && primes[pidx] > 0)
> pidx++;
>
> which is broken, because the second part of the condition only checks
> the current index - we may end up using nhashes primes after that, and
> some of them may be 0. So this needs to be:
>
> while (primes[pidx + nhashes - 1] <= target &&
> primes[pidx + nhashes] > 0)
> pidx++;
Good catch.
> b) set_bloom_partitions does this to generate primes:
>
> /*
> * Increase the limit to ensure we have some primes higher than
> * the target partition length. The 100 value is arbitrary, but
> * should be well over what we need.
> */
> primes = generate_primes(target_partlen + 100);
>
> It's not clear to me why 100 is sufficient, particularly for large page
> sizes. AFAIK the primes get more and more sparse, so how does this
> guarantee we'll get enough "sufficiently large" primes?
This value is not rigorous and should be improved, but I started with that by looking at the table in section 3 in
https://primes.utm.edu/notes/gaps.html
I see two ways to make a stronger guarantee:
1. Take the average gap between primes near n, which is log(n), and multiply that by BLOOM_MAX_NUM_PARTITIONS. Adding that to the target seems a better heuristic than a constant, and is still simple to calculate.
With the pathological example you gave of n=575104, k=3 (target_partlen = 191701), the number to add is log(191701) * 10 = 122. By the table referenced above, the largest prime gap under 360653 is 95, so we're guaranteed to find at least one prime in the space of 122 above the target. That will likely be enough to find the closest-to-target filter size for k=3. Even if it weren't, nbits is so large that the relative difference is tiny. I'd say a heuristic like this is most likely to be off precisely when it matters the least. At this size, even if we find zero primes above our target, the relative filter size is close to
(575104 - 3 * 95) / 575104 = 0.9995
For a more realistic bad-case target partition length, log(1327) * 10 = 72. There are 33 composites after 1327, the largest such gap below 9551. That would give five primes larger than the target
1361 1367 1373 1381 1399
which is more than enough for k<=10:
1297 + 1301 + 1303 + 1307 + 1319 + 1321 + 1327 + 1361 + 1367 + 1373 = 13276
2. Use a "segmented range" algorithm for the sieve and iterate until we get k*2 primes, half below and half above the target. This would be an absolute guarantee, but also more code, so I'm inclined against that.
> c) generate_primes uses uint16 to store the primes, so it can only
> generate primes up to 32768. That's (probably) enough for 8kB pages, but
> for 32kB pages it's clearly insufficient.
Okay.
> As for the original question how expensive this naive sieve is, I
> haven't been able to measure any significant timings. The logging aroung
> generate_primes usually looks like this:
>
> 2020-11-07 20:36:10.614 CET [232789] LOG: generating primes nbits
> 575104 nhashes 3 target_partlen 191701
> 2020-11-07 20:36:10.614 CET [232789] LOG: primes generated
>
> So it takes 0.000 second for this extreme page size. I don't think we
> need to invent anything more elaborate.
Okay, good to know. If we were concerned about memory, we could have it check only odd numbers. That's a common feature of sieves, but also makes the code a bit harder to understand if you haven't seen it before.
Also to fill in something I left for later, the reference for this
/* upper bound of number of primes below limit */
/* WIP: reference for this number */
int numprimes = 1.26 * limit / log(limit);
is
Rosser, J. Barkley; Schoenfeld, Lowell (1962). "Approximate formulas for some functions of prime numbers". Illinois J. Math. 6: 64–94. doi:10.1215/ijm/1255631807
More precisely, it's 30*log(113)/113 rounded up.
--
John Naylor
EnterpriseDB: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
On 11/9/20 3:29 PM, John Naylor wrote: > On Sat, Nov 7, 2020 at 4:38 PM Tomas Vondra > <tomas.vondra@enterprisedb.com <mailto:tomas.vondra@enterprisedb.com>> > wrote: > >> Overall, I think there's very little difference, particularly in the >> "match" cases when we're searching for a value that we know is in the >> table. The one-hash variant seems to perform a bit better, but the >> difference is fairly small. >> >> In the "mismatch" cases (searching for value that is not in the table) >> the differences are more significant, but it might be noise. It does >> seem much more "green" than "red", i.e. the one-hash variant seems to be >> faster (although this does depend on the values for formatting). >> >> To sum this up, I think the one-hash approach seems interesting. It's >> not going to give us huge speedups because we're only hashing int32 >> values anyway (not the source data), but it's worth exploring. > > Thanks for testing! It seems you tested against the version with two > moduli, and not the alternative discussed in > > https://www.postgresql.org/message-id/20200918222702.omsieaphfj3ctqg3%40development > <https://www.postgresql.org/message-id/20200918222702.omsieaphfj3ctqg3%40development> > > which would in fact be rehashing the 32 bit values. I think that would > be the way to go if we don't use the one-hashing approach. > Yeah. I forgot about this detail, and I may try again with the two-hash variant, but I wonder how much difference would it make, considering the results match the expected results (that is, the scan fraction" results for fill_factor=100 match the target fpr almost perfectly). I think there's a possibly-more important omission in the testing - I forgot about the "sort mode" used initially, when the filter keeps the actual hash values and only switches to hashing later. I wonder if that plays role for some of the cases. I'll investigate this a bit in the next round of tests. >> a) set_bloom_partitions does this: >> >> while (primes[pidx + nhashes - 1] <= target && primes[pidx] > 0) >> pidx++; >> >> which is broken, because the second part of the condition only checks >> the current index - we may end up using nhashes primes after that, and >> some of them may be 0. So this needs to be: >> >> while (primes[pidx + nhashes - 1] <= target && >> primes[pidx + nhashes] > 0) >> pidx++; > > Good catch. > >> b) set_bloom_partitions does this to generate primes: >> >> /* >> * Increase the limit to ensure we have some primes higher than >> * the target partition length. The 100 value is arbitrary, but >> * should be well over what we need. >> */ >> primes = generate_primes(target_partlen + 100); >> >> It's not clear to me why 100 is sufficient, particularly for large page >> sizes. AFAIK the primes get more and more sparse, so how does this >> guarantee we'll get enough "sufficiently large" primes? > > This value is not rigorous and should be improved, but I started with > that by looking at the table in section 3 in > > https://primes.utm.edu/notes/gaps.html > <https://primes.utm.edu/notes/gaps.html> > > I see two ways to make a stronger guarantee: > > 1. Take the average gap between primes near n, which is log(n), and > multiply that by BLOOM_MAX_NUM_PARTITIONS. Adding that to the target > seems a better heuristic than a constant, and is still simple to calculate. > > With the pathological example you gave of n=575104, k=3 (target_partlen > = 191701), the number to add is log(191701) * 10 = 122. By the table > referenced above, the largest prime gap under 360653 is 95, so we're > guaranteed to find at least one prime in the space of 122 above the > target. That will likely be enough to find the closest-to-target filter > size for k=3. Even if it weren't, nbits is so large that the relative > difference is tiny. I'd say a heuristic like this is most likely to be > off precisely when it matters the least. At this size, even if we find > zero primes above our target, the relative filter size is close to > > (575104 - 3 * 95) / 575104 = 0.9995 > > For a more realistic bad-case target partition length, log(1327) * 10 = > 72. There are 33 composites after 1327, the largest such gap below 9551. > That would give five primes larger than the target > 1361 1367 1373 1381 1399 > > which is more than enough for k<=10: > > 1297 + 1301 + 1303 + 1307 + 1319 + 1321 + 1327 + 1361 + 1367 + > 1373 = 13276 > > 2. Use a "segmented range" algorithm for the sieve and iterate until we > get k*2 primes, half below and half above the target. This would be an > absolute guarantee, but also more code, so I'm inclined against that. > Thanks, that makes sense. While investigating the failures, I've tried increasing the values a lot, without observing any measurable increase in runtime. IIRC I've even used (10 * target_partlen) or something like that. That tells me it's not very sensitive part of the code, so I'd suggest to simply use something that we know is large enough to be safe. For example, the largest bloom filter we can have is 32kB, i.e. 262kb, at which point the largest gap is less than 95 (per the gap table). And we may use up to BLOOM_MAX_NUM_PARTITIONS, so let's just use BLOOM_MAX_NUM_PARTITIONS * 100 on the basis that we may need BLOOM_MAX_NUM_PARTITIONS partitions before/after the target. We could consider the actual target being lower (essentially 1/npartions of the nbits) which decreases the maximum gap, but I don't think that's the extra complexity here. FWIW I wonder if we should do something about bloom filters that we know can get larger than page size. In the example I used, we know that nbits=575104 is larger than page, so as the filter gets more full (and thus more random and less compressible) it won't possibly fit. Maybe we should reject that right away, instead of "delaying it" until later, on the basis that it's easier to fix at CREATE INDEX time (compared to when inserts/updates start failing at a random time). The problem with this is of course that if the index is multi-column, this may not be strict enough (i.e. each filter would fit independently, but the whole index row is too large). But it's probably better to do at least something, and maybe improve that later with some whole-row check. >> c) generate_primes uses uint16 to store the primes, so it can only >> generate primes up to 32768. That's (probably) enough for 8kB pages, but >> for 32kB pages it's clearly insufficient. > > Okay. > >> As for the original question how expensive this naive sieve is, I >> haven't been able to measure any significant timings. The logging aroung >> generate_primes usually looks like this: >> >> 2020-11-07 20:36:10.614 CET [232789] LOG: generating primes nbits >> 575104 nhashes 3 target_partlen 191701 >> 2020-11-07 20:36:10.614 CET [232789] LOG: primes generated >> >> So it takes 0.000 second for this extreme page size. I don't think we >> need to invent anything more elaborate. > > Okay, good to know. If we were concerned about memory, we could have it > check only odd numbers. That's a common feature of sieves, but also > makes the code a bit harder to understand if you haven't seen it before. > IMO if we were concerned about memory we'd use Bitmapset instead of an array of bools. That's 1:8 compression, not just 1:2. > Also to fill in something I left for later, the reference for this > > /* upper bound of number of primes below limit */ > /* WIP: reference for this number */ > int numprimes = 1.26 * limit / log(limit); > > is > > Rosser, J. Barkley; Schoenfeld, Lowell (1962). "Approximate formulas for > some functions of prime numbers". Illinois J. Math. 6: 64–94. > doi:10.1215/ijm/1255631807 > > More precisely, it's 30*log(113)/113 rounded up. > Thanks, I was wondering where that came from. -- Tomas Vondra EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On Mon, Nov 9, 2020 at 1:39 PM Tomas Vondra <tomas.vondra@enterprisedb.com> wrote:
>
>
> While investigating the failures, I've tried increasing the values a
> lot, without observing any measurable increase in runtime. IIRC I've
> even used (10 * target_partlen) or something like that. That tells me
> it's not very sensitive part of the code, so I'd suggest to simply use
> something that we know is large enough to be safe.
Okay, then it's not worth being clever.
> For example, the largest bloom filter we can have is 32kB, i.e. 262kb,
> at which point the largest gap is less than 95 (per the gap table). And
> we may use up to BLOOM_MAX_NUM_PARTITIONS, so let's just use
> BLOOM_MAX_NUM_PARTITIONS * 100
Sure.
> FWIW I wonder if we should do something about bloom filters that we know
> can get larger than page size. In the example I used, we know that
> nbits=575104 is larger than page, so as the filter gets more full (and
> thus more random and less compressible) it won't possibly fit. Maybe we
> should reject that right away, instead of "delaying it" until later, on
> the basis that it's easier to fix at CREATE INDEX time (compared to when
> inserts/updates start failing at a random time).
Yeah, I'd be inclined to reject that right away.
> The problem with this is of course that if the index is multi-column,
> this may not be strict enough (i.e. each filter would fit independently,
> but the whole index row is too large). But it's probably better to do at
> least something, and maybe improve that later with some whole-row check.
A whole-row check would be nice, but I don't know how hard that would be.
As a Devil's advocate proposal, how awful would it be to not allow multicolumn brin-bloom indexes?
--
John Naylor
EnterpriseDB: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
>
>
> While investigating the failures, I've tried increasing the values a
> lot, without observing any measurable increase in runtime. IIRC I've
> even used (10 * target_partlen) or something like that. That tells me
> it's not very sensitive part of the code, so I'd suggest to simply use
> something that we know is large enough to be safe.
Okay, then it's not worth being clever.
> For example, the largest bloom filter we can have is 32kB, i.e. 262kb,
> at which point the largest gap is less than 95 (per the gap table). And
> we may use up to BLOOM_MAX_NUM_PARTITIONS, so let's just use
> BLOOM_MAX_NUM_PARTITIONS * 100
Sure.
> FWIW I wonder if we should do something about bloom filters that we know
> can get larger than page size. In the example I used, we know that
> nbits=575104 is larger than page, so as the filter gets more full (and
> thus more random and less compressible) it won't possibly fit. Maybe we
> should reject that right away, instead of "delaying it" until later, on
> the basis that it's easier to fix at CREATE INDEX time (compared to when
> inserts/updates start failing at a random time).
Yeah, I'd be inclined to reject that right away.
> The problem with this is of course that if the index is multi-column,
> this may not be strict enough (i.e. each filter would fit independently,
> but the whole index row is too large). But it's probably better to do at
> least something, and maybe improve that later with some whole-row check.
A whole-row check would be nice, but I don't know how hard that would be.
As a Devil's advocate proposal, how awful would it be to not allow multicolumn brin-bloom indexes?
--
John Naylor
EnterpriseDB: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
Hi, Attached is an updated version of the patch series, rebased on current master, and results for benchmark comparing the various bloom variants. The improvements are fairly minor: 1) Rejecting bloom filters that are clearly too large (larger than page) early. This is imperfect, as it works for individual index keys, not the whole row. But per discussion it seems useful. 2) I've added sort_mode opclass parameter, allowing disabling the sorted mode the bloom indexes start in by default. I'm not convinced we should commit this, I've needed this for the benchmarking. The benchmarking compares the three parts with different Bloom variants: 0004 - single hash with mod by (nbits) and (nbits-1) 0005 - two independent hashes (two random seeds) 0006 - partitioned approach, proposed by John Naylor I'm attaching the shell script used to run the benchmark, and a summary of the results. The 0004 is used as a baseline, and the comparisons show speedups for 0005 and 0006 relative to that (if you scroll to the right). Essentially, green means "faster than 0004" while red means slower. I don't think any of those approaches comes as a clearly superior. The results for most queries are within 2%, which is mostly just noise. There are cases where the differences are more significant (~10%), but it's in either direction and if you compare duration of the whole benchmark (by summing per-query averages) it's within 1% again. For the "mismatch" case (i.e. looking for values not contained in the table) the differences are larger, but that's mostly due to luck and hitting false positives for that particular query - on average the differences are negligible, just like for the "match" case. So based on this I'm tempted to just use the version with two hashes, as implemented in 0005. It's much simpler than the partitioning scheme, does not need any of the logic to generate primes etc. regards -- Tomas Vondra EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
Attachment
- 0008-Ignore-correlation-for-new-BRIN-opclasses-20201220.patch
- 0007-BRIN-minmax-multi-indexes-20201220.patch
- 0006-use-one-hash-bloom-variant-20201220.patch
- 0005-use-two-independent-hashes-20201220.patch
- 0004-BRIN-bloom-indexes-20201220.patch
- 0003-Optimize-allocations-in-bringetbitmap-20201220.patch
- 0002-Move-IS-NOT-NULL-handling-from-BRIN-support-20201220.patch
- 0001-Pass-all-scan-keys-to-BRIN-consistent-funct-20201220.patch
- results.ods
- brin-bloom-test.sh
On Sun, Dec 20, 2020 at 1:16 PM Tomas Vondra <tomas.vondra@enterprisedb.com> wrote: > Attached is an updated version of the patch series, rebased on current > master, and results for benchmark comparing the various bloom variants. Perhaps src/include/utils/inet.h needs to include <sys/socket.h>, because FreeBSD says: brin_minmax_multi.c:1693:24: error: use of undeclared identifier 'AF_INET' if (ip_family(ipa) == PGSQL_AF_INET) ^ ../../../../src/include/utils/inet.h:39:24: note: expanded from macro 'PGSQL_AF_INET' #define PGSQL_AF_INET (AF_INET + 0) ^
Hi, On 1/2/21 7:42 AM, Thomas Munro wrote: > On Sun, Dec 20, 2020 at 1:16 PM Tomas Vondra > <tomas.vondra@enterprisedb.com> wrote: >> Attached is an updated version of the patch series, rebased on current >> master, and results for benchmark comparing the various bloom variants. > > Perhaps src/include/utils/inet.h needs to include <sys/socket.h>, > because FreeBSD says: > > brin_minmax_multi.c:1693:24: error: use of undeclared identifier 'AF_INET' > if (ip_family(ipa) == PGSQL_AF_INET) > ^ > ../../../../src/include/utils/inet.h:39:24: note: expanded from macro > 'PGSQL_AF_INET' > #define PGSQL_AF_INET (AF_INET + 0) > ^ Not sure. The other files using PGSQL_AF_INET just include sys/socket.h directly, so maybe this should just do the same thing ... regards -- Tomas Vondra EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On Sat, Dec 19, 2020 at 8:15 PM Tomas Vondra <tomas.vondra@enterprisedb.com> wrote:
> [12-20 version]
Hi Tomas,
The measurements look good. In case it fell through the cracks, my earlier review comments for Bloom BRIN indexes regarding minor details don't seem to have been addressed in this version. I'll point to earlier discussion for convenience:
https://www.postgresql.org/message-id/CACPNZCt%3Dx-fOL0CUJbjR3BFXKgcd9HMPaRUVY9cwRe58hmd8Xg%40mail.gmail.com
https://www.postgresql.org/message-id/CACPNZCuqpkCGt8%3DcywAk1kPu0OoV_TjPXeV-J639ABQWyViyug%40mail.gmail.com
> The improvements are fairly minor:
>
> 1) Rejecting bloom filters that are clearly too large (larger than page)
> early. This is imperfect, as it works for individual index keys, not the
> whole row. But per discussion it seems useful.
I think this is good enough.
> So based on this I'm tempted to just use the version with two hashes, as
> implemented in 0005. It's much simpler than the partitioning scheme,
> does not need any of the logic to generate primes etc.
Sounds like the best engineering decision.
Circling back to multi-minmax build times, I ran a couple quick tests on bigger hardware, and found that not only is multi-minmax slower than minmax, which is to be expected, but also slower than btree. (unlogged table ~12GB in size, maintenance_work_mem = 1GB, median of three runs)
btree 38.3s
minmax 26.2s
multi-minmax 110s
Since btree indexes are much larger, I imagine something algorithmic is involved. Is it worth digging further to see if some code path is taking more time than we would expect?
--
John Naylor
EDB: http://www.enterprisedb.com
Hi Tomas,
The measurements look good. In case it fell through the cracks, my earlier review comments for Bloom BRIN indexes regarding minor details don't seem to have been addressed in this version. I'll point to earlier discussion for convenience:
https://www.postgresql.org/message-id/CACPNZCt%3Dx-fOL0CUJbjR3BFXKgcd9HMPaRUVY9cwRe58hmd8Xg%40mail.gmail.com
https://www.postgresql.org/message-id/CACPNZCuqpkCGt8%3DcywAk1kPu0OoV_TjPXeV-J639ABQWyViyug%40mail.gmail.com
> The improvements are fairly minor:
>
> 1) Rejecting bloom filters that are clearly too large (larger than page)
> early. This is imperfect, as it works for individual index keys, not the
> whole row. But per discussion it seems useful.
I think this is good enough.
> So based on this I'm tempted to just use the version with two hashes, as
> implemented in 0005. It's much simpler than the partitioning scheme,
> does not need any of the logic to generate primes etc.
Sounds like the best engineering decision.
Circling back to multi-minmax build times, I ran a couple quick tests on bigger hardware, and found that not only is multi-minmax slower than minmax, which is to be expected, but also slower than btree. (unlogged table ~12GB in size, maintenance_work_mem = 1GB, median of three runs)
btree 38.3s
minmax 26.2s
multi-minmax 110s
Since btree indexes are much larger, I imagine something algorithmic is involved. Is it worth digging further to see if some code path is taking more time than we would expect?
--
John Naylor
EDB: http://www.enterprisedb.com
On 1/12/21 6:28 PM, John Naylor wrote: > On Sat, Dec 19, 2020 at 8:15 PM Tomas Vondra > <tomas.vondra@enterprisedb.com <mailto:tomas.vondra@enterprisedb.com>> > wrote: > > [12-20 version] > > Hi Tomas, > > The measurements look good. In case it fell through the cracks, my > earlier review comments for Bloom BRIN indexes regarding minor details > don't seem to have been addressed in this version. I'll point to earlier > discussion for convenience: > > https://www.postgresql.org/message-id/CACPNZCt%3Dx-fOL0CUJbjR3BFXKgcd9HMPaRUVY9cwRe58hmd8Xg%40mail.gmail.com > <https://www.postgresql.org/message-id/CACPNZCt%3Dx-fOL0CUJbjR3BFXKgcd9HMPaRUVY9cwRe58hmd8Xg%40mail.gmail.com> > > https://www.postgresql.org/message-id/CACPNZCuqpkCGt8%3DcywAk1kPu0OoV_TjPXeV-J639ABQWyViyug%40mail.gmail.com > <https://www.postgresql.org/message-id/CACPNZCuqpkCGt8%3DcywAk1kPu0OoV_TjPXeV-J639ABQWyViyug%40mail.gmail.com> > Whooops :-( I'll go through those again, thanks for reminding me. > > The improvements are fairly minor: > > > > 1) Rejecting bloom filters that are clearly too large (larger than page) > > early. This is imperfect, as it works for individual index keys, not the > > whole row. But per discussion it seems useful. > > I think this is good enough. > > > So based on this I'm tempted to just use the version with two hashes, as > > implemented in 0005. It's much simpler than the partitioning scheme, > > does not need any of the logic to generate primes etc. > > Sounds like the best engineering decision. > > Circling back to multi-minmax build times, I ran a couple quick tests on > bigger hardware, and found that not only is multi-minmax slower than > minmax, which is to be expected, but also slower than btree. (unlogged > table ~12GB in size, maintenance_work_mem = 1GB, median of three runs) > > btree 38.3s > minmax 26.2s > multi-minmax 110s > > Since btree indexes are much larger, I imagine something algorithmic is > involved. Is it worth digging further to see if some code path is taking > more time than we would expect? > I suspect it'd due to minmax having to decide which "ranges" to merge, which requires repeated sorting, etc. I certainly don't dare to claim the current algorithm is perfect. I wouldn't have expected such big difference, though - so definitely worth investigating. regards -- Tomas Vondra EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On 1/12/21 6:28 PM, John Naylor wrote: > On Sat, Dec 19, 2020 at 8:15 PM Tomas Vondra > <tomas.vondra@enterprisedb.com <mailto:tomas.vondra@enterprisedb.com>> > wrote: > > [12-20 version] > > Hi Tomas, > > The measurements look good. In case it fell through the cracks, my > earlier review comments for Bloom BRIN indexes regarding minor details > don't seem to have been addressed in this version. I'll point to earlier > discussion for convenience: > > https://www.postgresql.org/message-id/CACPNZCt%3Dx-fOL0CUJbjR3BFXKgcd9HMPaRUVY9cwRe58hmd8Xg%40mail.gmail.com > <https://www.postgresql.org/message-id/CACPNZCt%3Dx-fOL0CUJbjR3BFXKgcd9HMPaRUVY9cwRe58hmd8Xg%40mail.gmail.com> > > https://www.postgresql.org/message-id/CACPNZCuqpkCGt8%3DcywAk1kPu0OoV_TjPXeV-J639ABQWyViyug%40mail.gmail.com > <https://www.postgresql.org/message-id/CACPNZCuqpkCGt8%3DcywAk1kPu0OoV_TjPXeV-J639ABQWyViyug%40mail.gmail.com> > Attached is a patch, addressing those issues - particularly those from the first link, the second one is mostly a discussion about how to do the hashing properly etc. It also switches to the two-hash variant, as discussed earlier. I've changed the range to allow false positives between 0.0001 and 0.25, instead the original range (0.001 and 0.1). The default (0.01) remains the same. I was worried that the original range was too narrow, and would prevent even sensible combinations of parameter values. But now that we reject bloom filters that are obviously too large, it's less of an issue I think. I'm not entirely convinced the sort_mode option should be committed. It was meant only to allow benchmarking the hash approaches. In fact, I'm thinking about removing the sorted mode entirely - if the bloom filter contains only a few distinct values: a) it's going to be almost entirely 0 bits, so easy to compress b) it does not eliminate collisions entirely (we store hashes, not the original values) regards -- Tomas Vondra EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
Attachment
- 0001-Pass-all-scan-keys-to-BRIN-consistent-funct-20210112.patch
- 0002-Move-IS-NOT-NULL-handling-from-BRIN-support-20210112.patch
- 0003-Optimize-allocations-in-bringetbitmap-20210112.patch
- 0004-BRIN-bloom-indexes-20210112.patch
- 0005-bloom-fixes-and-tweaks-20210112.patch
- 0006-add-sort_mode-opclass-parameter-20210112.patch
- 0007-BRIN-minmax-multi-indexes-20210112.patch
- 0008-Ignore-correlation-for-new-BRIN-opclasses-20210112.patch
Here is a slightly improved version of the patch series. Firstly, I realized the PG_DETOAST_DATUM() in brin_bloom_summary_out is actually needed - the value can't be toasted, but it might be stored with just 1B header. So we need to expand it to 4B, because the struct has int32 as the first field. I've also removed the sort mode from bloom filters. I've thought about this for a long time, and ultimately concluded that it's not worth the extra complexity. It might work for ranges with very few distinct values, but that also means the bloom filter will be mostly 0 and thus easy to compress (and with very low false-positive rate). There probably are cases where it might be a bit better/smaller, but I had a hard time constructing such cases. So I ditched it for now. I've kept the "flags" which is unused and reserved for future, to allow such improvements. regards -- Tomas Vondra EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
Attachment
- 0001-Pass-all-scan-keys-to-BRIN-consistent-funct-20210114.patch
- 0002-Move-IS-NOT-NULL-handling-from-BRIN-support-20210114.patch
- 0003-Optimize-allocations-in-bringetbitmap-20210114.patch
- 0004-BRIN-bloom-indexes-20210114.patch
- 0005-BRIN-minmax-multi-indexes-20210114.patch
- 0006-Ignore-correlation-for-new-BRIN-opclasses-20210114.patch
A version (hopefully) fixing the issue with build on FreeBSD, identified by commitfest.cputube.org. regards -- Tomas Vondra EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
Attachment
- 0001-Pass-all-scan-keys-to-BRIN-consistent-fun-20210114-2.patch
- 0002-Move-IS-NOT-NULL-handling-from-BRIN-suppo-20210114-2.patch
- 0003-Optimize-allocations-in-bringetbitmap-20210114-2.patch
- 0004-BRIN-bloom-indexes-20210114-2.patch
- 0005-BRIN-minmax-multi-indexes-20210114-2.patch
- 0006-Ignore-correlation-for-new-BRIN-opclasses-20210114-2.patch
On Tue, Jan 12, 2021 at 1:42 PM Tomas Vondra <tomas.vondra@enterprisedb.com> wrote:
> I suspect it'd due to minmax having to decide which "ranges" to merge,
> which requires repeated sorting, etc. I certainly don't dare to claim
> the current algorithm is perfect. I wouldn't have expected such big
> difference, though - so definitely worth investigating.
It seems that monotonically increasing (or decreasing) values in a table are a worst case scenario for multi-minmax indexes, or basically, unique values within a range. I'm guessing it's because it requires many passes to fit all the values into a limited number of ranges. I tried using smaller pages_per_range numbers, 32 and 8, and that didn't help.
Now, with a different data distribution, using only 10 values that repeat over and over, the results are much more sympathetic to multi-minmax:
insert into iot (num, create_dt)
select random(), '2020-01-01 0:00'::timestamptz + (x % 10 || ' seconds')::interval
from generate_series(1,5*365*24*60*60) x;
create index cd_single on iot using brin(create_dt);
27.2s
create index cd_multi on iot using brin(create_dt timestamptz_minmax_multi_ops);
30.4s
create index cd_bt on iot using btree(create_dt);
61.8s
Circling back to the monotonic case, I tried running a simple perf record on a backend creating a multi-minmax index on a timestamptz column and these were the highest non-kernel calls:
+ 21.98% 21.91% postgres postgres [.] FunctionCall2Coll
+ 9.31% 9.29% postgres postgres [.] compare_combine_ranges
+ 8.60% 8.58% postgres postgres [.] qsort_arg
+ 5.68% 5.66% postgres postgres [.] brin_minmax_multi_add_value
+ 5.63% 5.60% postgres postgres [.] timestamp_lt
+ 4.73% 4.71% postgres postgres [.] reduce_combine_ranges
+ 3.80% 0.00% postgres [unknown] [.] 0x0320016800040000
+ 3.51% 3.50% postgres postgres [.] timestamp_eq
There's no one place that's pathological enough to explain the 4x slowness over traditional BRIN and nearly 3x slowness over btree when using a large number of unique values per range, so making progress here would have to involve a more holistic approach.
--
John Naylor
EDB: http://www.enterprisedb.com
> I suspect it'd due to minmax having to decide which "ranges" to merge,
> which requires repeated sorting, etc. I certainly don't dare to claim
> the current algorithm is perfect. I wouldn't have expected such big
> difference, though - so definitely worth investigating.
It seems that monotonically increasing (or decreasing) values in a table are a worst case scenario for multi-minmax indexes, or basically, unique values within a range. I'm guessing it's because it requires many passes to fit all the values into a limited number of ranges. I tried using smaller pages_per_range numbers, 32 and 8, and that didn't help.
Now, with a different data distribution, using only 10 values that repeat over and over, the results are much more sympathetic to multi-minmax:
insert into iot (num, create_dt)
select random(), '2020-01-01 0:00'::timestamptz + (x % 10 || ' seconds')::interval
from generate_series(1,5*365*24*60*60) x;
create index cd_single on iot using brin(create_dt);
27.2s
create index cd_multi on iot using brin(create_dt timestamptz_minmax_multi_ops);
30.4s
create index cd_bt on iot using btree(create_dt);
61.8s
Circling back to the monotonic case, I tried running a simple perf record on a backend creating a multi-minmax index on a timestamptz column and these were the highest non-kernel calls:
+ 21.98% 21.91% postgres postgres [.] FunctionCall2Coll
+ 9.31% 9.29% postgres postgres [.] compare_combine_ranges
+ 8.60% 8.58% postgres postgres [.] qsort_arg
+ 5.68% 5.66% postgres postgres [.] brin_minmax_multi_add_value
+ 5.63% 5.60% postgres postgres [.] timestamp_lt
+ 4.73% 4.71% postgres postgres [.] reduce_combine_ranges
+ 3.80% 0.00% postgres [unknown] [.] 0x0320016800040000
+ 3.51% 3.50% postgres postgres [.] timestamp_eq
There's no one place that's pathological enough to explain the 4x slowness over traditional BRIN and nearly 3x slowness over btree when using a large number of unique values per range, so making progress here would have to involve a more holistic approach.
--
John Naylor
EDB: http://www.enterprisedb.com
On 1/19/21 9:44 PM, John Naylor wrote: > On Tue, Jan 12, 2021 at 1:42 PM Tomas Vondra > <tomas.vondra@enterprisedb.com <mailto:tomas.vondra@enterprisedb.com>> > wrote: > > I suspect it'd due to minmax having to decide which "ranges" to merge, > > which requires repeated sorting, etc. I certainly don't dare to claim > > the current algorithm is perfect. I wouldn't have expected such big > > difference, though - so definitely worth investigating. > > It seems that monotonically increasing (or decreasing) values in a table > are a worst case scenario for multi-minmax indexes, or basically, unique > values within a range. I'm guessing it's because it requires many passes > to fit all the values into a limited number of ranges. I tried using > smaller pages_per_range numbers, 32 and 8, and that didn't help. > > Now, with a different data distribution, using only 10 values that > repeat over and over, the results are muchs more sympathetic to multi-minmax: > > insert into iot (num, create_dt) > select random(), '2020-01-01 0:00'::timestamptz + (x % 10 || ' > seconds')::interval > from generate_series(1,5*365*24*60*60) x; > > create index cd_single on iot using brin(create_dt); > 27.2s > > create index cd_multi on iot using brin(create_dt > timestamptz_minmax_multi_ops); > 30.4s > > create index cd_bt on iot using btree(create_dt); > 61.8s > > Circling back to the monotonic case, I tried running a simple perf > record on a backend creating a multi-minmax index on a timestamptz > column and these were the highest non-kernel calls: > + 21.98% 21.91% postgres postgres [.] > FunctionCall2Coll > + 9.31% 9.29% postgres postgres [.] > compare_combine_ranges > + 8.60% 8.58% postgres postgres [.] qsort_arg > + 5.68% 5.66% postgres postgres [.] > brin_minmax_multi_add_value > + 5.63% 5.60% postgres postgres [.] timestamp_lt > + 4.73% 4.71% postgres postgres [.] > reduce_combine_ranges > + 3.80% 0.00% postgres [unknown] [.] > 0x0320016800040000 > + 3.51% 3.50% postgres postgres [.] timestamp_eq > > There's no one place that's pathological enough to explain the 4x > slowness over traditional BRIN and nearly 3x slowness over btree when > using a large number of unique values per range, so making progress here > would have to involve a more holistic approach. > Yeah. This very much seems like the primary problem is in how we build the ranges incrementally - with monotonic sequences, we end up having to merge the ranges over and over again. I don't know what was the structure of the table, but I guess it was kinda narrow (very few columns), which exacerbates the problem further, because the number of rows per range will be way higher than in real-world. I do think the solution to this might be to allow more values during batch index creation, and only "compress" to the requested number at the very end (when serializing to on-disk format). There are a couple additional comments about possibly replacing sequential scan with a binary search, that could help a bit too. regards -- Tomas Vondra EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On 1/20/21 1:07 AM, Tomas Vondra wrote:
> On 1/19/21 9:44 PM, John Naylor wrote:
>> On Tue, Jan 12, 2021 at 1:42 PM Tomas Vondra
>> <tomas.vondra@enterprisedb.com <mailto:tomas.vondra@enterprisedb.com>>
>> wrote:
>> > I suspect it'd due to minmax having to decide which "ranges" to merge,
>> > which requires repeated sorting, etc. I certainly don't dare to claim
>> > the current algorithm is perfect. I wouldn't have expected such big
>> > difference, though - so definitely worth investigating.
>>
>> It seems that monotonically increasing (or decreasing) values in a
>> table are a worst case scenario for multi-minmax indexes, or
>> basically, unique values within a range. I'm guessing it's because it
>> requires many passes to fit all the values into a limited number of
>> ranges. I tried using smaller pages_per_range numbers, 32 and 8, and
>> that didn't help.
>>
>> Now, with a different data distribution, using only 10 values that
>> repeat over and over, the results are muchs more sympathetic to
>> multi-minmax:
>>
>> insert into iot (num, create_dt)
>> select random(), '2020-01-01 0:00'::timestamptz + (x % 10 || '
>> seconds')::interval
>> from generate_series(1,5*365*24*60*60) x;
>>
>> create index cd_single on iot using brin(create_dt);
>> 27.2s
>>
>> create index cd_multi on iot using brin(create_dt
>> timestamptz_minmax_multi_ops);
>> 30.4s
>>
>> create index cd_bt on iot using btree(create_dt);
>> 61.8s
>>
>> Circling back to the monotonic case, I tried running a simple perf
>> record on a backend creating a multi-minmax index on a timestamptz
>> column and these were the highest non-kernel calls:
>> + 21.98% 21.91% postgres postgres [.]
>> FunctionCall2Coll
>> + 9.31% 9.29% postgres postgres [.]
>> compare_combine_ranges
>> + 8.60% 8.58% postgres postgres [.] qsort_arg
>> + 5.68% 5.66% postgres postgres [.]
>> brin_minmax_multi_add_value
>> + 5.63% 5.60% postgres postgres [.]
>> timestamp_lt
>> + 4.73% 4.71% postgres postgres [.]
>> reduce_combine_ranges
>> + 3.80% 0.00% postgres [unknown] [.]
>> 0x0320016800040000
>> + 3.51% 3.50% postgres postgres [.]
>> timestamp_eq
>>
>> There's no one place that's pathological enough to explain the 4x
>> slowness over traditional BRIN and nearly 3x slowness over btree when
>> using a large number of unique values per range, so making progress
>> here would have to involve a more holistic approach.
>>
>
> Yeah. This very much seems like the primary problem is in how we build
> the ranges incrementally - with monotonic sequences, we end up having to
> merge the ranges over and over again. I don't know what was the
> structure of the table, but I guess it was kinda narrow (very few
> columns), which exacerbates the problem further, because the number of
> rows per range will be way higher than in real-world.
>
> I do think the solution to this might be to allow more values during
> batch index creation, and only "compress" to the requested number at the
> very end (when serializing to on-disk format).
> > There are a couple additional comments about possibly replacing
> sequential scan with a binary search, that could help a bit too.
>
OK, I took a look at this, and I came up with two optimizations that
improve this for the pathological cases. I've kept this as patches on
top of the last patch, to allow easier review of the changes.
0007 - This reworks how the ranges are reduced by merging the closest
ranges. Instead of doing that iteratively in a fairly expensive loop,
the new reduce reduce_combine_ranges() uses much simpler approach.
There's a couple more optimizations (skipping expensive code when not
needed, etc.) which should help a bit too.
0008 - This is a WIP version of the batch mode. Originally, when
building an index we'd "fill" the small buffer, combine some of the
ranges to free ~25% of space for new values. And we'd do this over and
over. This involves some expensive steps (sorting etc.) and for some
pathologic cases (like monotonic sequences) this performed particularly
poorly. The new code simply collects all values in the range, and then
does the expensive stuff only once.
Note: These parts are fairly new, with minimal testing so far.
When measured on a table with 10M rows with a number of data sets with
different patterns, the results look like this:
dataset btree minmax unpatched patched diff
--------------------------------------------------------------
monotonic-100-asc 3023 1002 1281 1722 1.34
monotonic-100-desc 3245 1042 1363 1674 1.23
monotonic-10000-asc 2597 1028 2469 2272 0.92
monotonic-10000-desc 2591 1021 2157 2246 1.04
monotonic-asc 1863 968 4884 1106 0.23
monotonic-desc 2546 1017 3520 2337 0.66
random-100 3648 1133 1594 1797 1.13
random-10000 3507 1124 1651 2657 1.61
The btree and minmax are the current indexes. unpatched means minmax
multi from the previous patch version, patched is with 0007 and 0008
applied. The diff shows patched/unpatched. The benchmarking script is
attached.
The pathological case (monotonic-asc) is now 4x faster, roughly equal to
regular minmax index build. The opposite (monotonic-desc) is about 33%
faster, roughly in line with btree.
There are a couple cases where it's actually a bit slower - those are
the cases with very few distinct values per range. I believe this
happens because in the batch mode the code does not check if the summary
already contains this value, adds it to the buffer and the last step
ends up being more expensive than this.
I believe there's some "compromise" between those two extremes, i.e. we
should use buffer that is too small or too large, but something in
between, so that the reduction happens once in a while but not too often
(as with the original aggressive approach).
FWIW, none of this is likely to be an issue in practice, because (a)
tables usually don't have such strictly monotonic patterns, (b) people
should stick to plain minmax for cases that do. And (c) regular tables
tend to have much wider rows, so there are fewer values per range (so
that other stuff is likely more expensive that building BRIN).
regards
--
Tomas Vondra
EnterpriseDB: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
Attachment
- 0001-Pass-all-scan-keys-to-BRIN-consistent-funct-20210122.patch
- 0002-Move-IS-NOT-NULL-handling-from-BRIN-support-20210122.patch
- 0003-Optimize-allocations-in-bringetbitmap-20210122.patch
- 0004-BRIN-bloom-indexes-20210122.patch
- 0005-BRIN-minmax-multi-indexes-20210122.patch
- 0006-Ignore-correlation-for-new-BRIN-opclasses-20210122.patch
- 0007-patched-2-20210122.patch
- 0008-batch-build-20210122.patch
- brin.sh
On Thu, Jan 21, 2021 at 9:06 PM Tomas Vondra <tomas.vondra@enterprisedb.com> wrote:
> [wip optimizations]
> The pathological case (monotonic-asc) is now 4x faster, roughly equal to
> regular minmax index build. The opposite (monotonic-desc) is about 33%
> faster, roughly in line with btree.
Those numbers look good. I get similar results, shown below. I've read 0007-8 briefly but not in depth.
> There are a couple cases where it's actually a bit slower - those are
> the cases with very few distinct values per range. I believe this
> happens because in the batch mode the code does not check if the summary
> already contains this value, adds it to the buffer and the last step
> ends up being more expensive than this.
I think if it's worst case a bit faster than btree and best case a bit slower than traditional minmax, that's acceptable.
> I believe there's some "compromise" between those two extremes, i.e. we
> should use buffer that is too small or too large, but something in
> between, so that the reduction happens once in a while but not too often
> (as with the original aggressive approach).
This sounds good also.
> FWIW, none of this is likely to be an issue in practice, because (a)
> tables usually don't have such strictly monotonic patterns, (b) people
> should stick to plain minmax for cases that do.
Still, it would be great if multi-minmax can be a drop in replacement. I know there was a sticking point of a distance function not being available on all types, but I wonder if that can be remedied or worked around somehow.
And (c) regular tables
> tend to have much wider rows, so there are fewer values per range (so
> that other stuff is likely more expensive than building BRIN).
True. I'm still puzzled that it didn't help to use 8 pages per range, but it's moot now.
Here are some numbers (median of 3) with a similar scenario as before, repeated here with some added details. I didn't bother with what you call "unpatched":
btree minmax multi
monotonic-asc 44.4 26.5 27.8
mono-del-ins 38.7 24.6 30.4
mono-10-asc 61.8 25.6 33.5
create unlogged table iot (
id bigint generated by default as identity primary key,
num double precision not null,
create_dt timestamptz not null,
stuff text generated always as (md5(id::text)) stored
)
with (fillfactor = 95);
-- monotonic-asc:
insert into iot (num, create_dt)
select random(), x
from generate_series(
'2020-01-01 0:00'::timestamptz,
'2020-01-01 0:00'::timestamptz +'5 years'::interval,
'1 second'::interval) x;
-- mono-del-ins:
-- Here I deleted a few values from (likely) each page in the above table, and reinserted values that shouldn't be in existing ranges:
delete from iot1
where num < 0.05
or num > 0.95;
vacuum iot1;
insert into iot (num, create_dt)
select random(), x
from generate_series(
'2020-01-01 0:00'::timestamptz,
'2020-02-01 23:59'::timestamptz,
'1 second'::interval) x;
-- mono-10-asc
truncate table iot;
insert into iot (num, create_dt)
select random(), '2020-01-01 0:00'::timestamptz + (x % 10 || ' seconds')::interval
from generate_series(1,5*365*24*60*60) x;
--
John Naylor
EDB: http://www.enterprisedb.com
> [wip optimizations]
> The pathological case (monotonic-asc) is now 4x faster, roughly equal to
> regular minmax index build. The opposite (monotonic-desc) is about 33%
> faster, roughly in line with btree.
Those numbers look good. I get similar results, shown below. I've read 0007-8 briefly but not in depth.
> There are a couple cases where it's actually a bit slower - those are
> the cases with very few distinct values per range. I believe this
> happens because in the batch mode the code does not check if the summary
> already contains this value, adds it to the buffer and the last step
> ends up being more expensive than this.
I think if it's worst case a bit faster than btree and best case a bit slower than traditional minmax, that's acceptable.
> I believe there's some "compromise" between those two extremes, i.e. we
> should use buffer that is too small or too large, but something in
> between, so that the reduction happens once in a while but not too often
> (as with the original aggressive approach).
This sounds good also.
> FWIW, none of this is likely to be an issue in practice, because (a)
> tables usually don't have such strictly monotonic patterns, (b) people
> should stick to plain minmax for cases that do.
Still, it would be great if multi-minmax can be a drop in replacement. I know there was a sticking point of a distance function not being available on all types, but I wonder if that can be remedied or worked around somehow.
And (c) regular tables
> tend to have much wider rows, so there are fewer values per range (so
> that other stuff is likely more expensive than building BRIN).
True. I'm still puzzled that it didn't help to use 8 pages per range, but it's moot now.
Here are some numbers (median of 3) with a similar scenario as before, repeated here with some added details. I didn't bother with what you call "unpatched":
btree minmax multi
monotonic-asc 44.4 26.5 27.8
mono-del-ins 38.7 24.6 30.4
mono-10-asc 61.8 25.6 33.5
create unlogged table iot (
id bigint generated by default as identity primary key,
num double precision not null,
create_dt timestamptz not null,
stuff text generated always as (md5(id::text)) stored
)
with (fillfactor = 95);
-- monotonic-asc:
insert into iot (num, create_dt)
select random(), x
from generate_series(
'2020-01-01 0:00'::timestamptz,
'2020-01-01 0:00'::timestamptz +'5 years'::interval,
'1 second'::interval) x;
-- mono-del-ins:
-- Here I deleted a few values from (likely) each page in the above table, and reinserted values that shouldn't be in existing ranges:
delete from iot1
where num < 0.05
or num > 0.95;
vacuum iot1;
insert into iot (num, create_dt)
select random(), x
from generate_series(
'2020-01-01 0:00'::timestamptz,
'2020-02-01 23:59'::timestamptz,
'1 second'::interval) x;
-- mono-10-asc
truncate table iot;
insert into iot (num, create_dt)
select random(), '2020-01-01 0:00'::timestamptz + (x % 10 || ' seconds')::interval
from generate_series(1,5*365*24*60*60) x;
--
John Naylor
EDB: http://www.enterprisedb.com
On 1/23/21 12:27 AM, John Naylor wrote:
> On Thu, Jan 21, 2021 at 9:06 PM Tomas Vondra
> <tomas.vondra@enterprisedb.com <mailto:tomas.vondra@enterprisedb.com>>
> wrote:
> > [wip optimizations]
>
> > The pathological case (monotonic-asc) is now 4x faster, roughly equal to
> > regular minmax index build. The opposite (monotonic-desc) is about 33%
> > faster, roughly in line with btree.
>
> Those numbers look good. I get similar results, shown below. I've read
> 0007-8 briefly but not in depth.
> > > There are a couple cases where it's actually a bit slower - those are
> > the cases with very few distinct values per range. I believe this
> > happens because in the batch mode the code does not check if the summary
> > already contains this value, adds it to the buffer and the last step
> > ends up being more expensive than this.
>
> I think if it's worst case a bit faster than btree and best case a bit
> slower than traditional minmax, that's acceptable.
>
> > I believe there's some "compromise" between those two extremes, i.e. we
> > should use buffer that is too small or too large, but something in
> > between, so that the reduction happens once in a while but not too often
> > (as with the original aggressive approach).
>
> This sounds good also.
>
Yeah, I agree.
I think the reason why some of the cases got a bit slower is that in
those cases the original approach (ranges being built fairly frequently,
not just once at the end) we quickly built something that represented
the whole range, so adding a new value was often no-op. The add_value
callback found the range already "includes" the new value, etc.
With the batch mode, that's no longer true - we accumulate everything,
so we have to sort it etc. Which I guess may be fairly expensive, thanks
to calling comparator functions etc. I wonder if this could be optimized
a bit, e.g. by first "deduplicating" the values using memcmp() or so.
But ultimately, I think the right solution will be to limit the buffer
size to something like 10x the target, and roll with that. Typically,
increasing the buffer size from e.g. 100B to 1000B brings much clearer
improvement than increasing it from 1000B to 10000B. I'd bet this
follows the pattern.
> > FWIW, none of this is likely to be an issue in practice, because (a)
> > tables usually don't have such strictly monotonic patterns, (b) people
> > should stick to plain minmax for cases that do.
>
> Still, it would be great if multi-minmax can be a drop in replacement. I
> know there was a sticking point of a distance function not being
> available on all types, but I wonder if that can be remedied or worked
> around somehow.
>
Hmm. I think Alvaro also mentioned he'd like to use this as a drop-in
replacement for minmax (essentially, using these opclasses as the
default ones, with the option to switch back to plain minmax). I'm not
convinced we should do that - though. Imagine you have minmax indexes in
your existing DB, it's working perfectly fine, and then we come and just
silently change that during dump/restore. Is there some past example
when we did something similar and it turned it to be OK?
As for the distance functions, I'm pretty sure there are data types
without "natural" distance - like most strings, for example. We could
probably invent something, but the question is how much we can rely on
it working well enough in practice.
Of course, is minmax even the right index type for such data types?
Strings are usually "labels" and not queried using range queries,
although sometimes people encode stuff as strings (but then it's very
unlikely we'll define the distance definition well). So maybe for those
types a hash / bloom would be a better fit anyway.
But I do have an idea - maybe we can do without distances, in those
cases. Essentially, the primary issue of minmax indexes are outliers, so
what if we simply sort the values, keep one range in the middle and as
many single points on each tail?
Imagine we have N values, and we want to represent this by K values. We
simply sort the N values, keep (k-2)/2 values on each tail as outliers,
and use 2 values for the values in between.
Example:
input: [1, 2, 100, 110, 111, ..., 120, , ..., 130, 201, 202]
Given k = 6, we would keep 2 values on tails, and range for the rest:
[1, 2, (100, 130), 201, 202]
Of course, this does not optimize for the same thing as when we have
distance - in that case we try to minimize the "covering" of the input
data, something like
sum(length(r) for r in ranges) / (max(ranges) - min(ranges))
But maybe it's good enough when there's no distance function ...
> And (c) regular tables
> > tend to have much wider rows, so there are fewer values per range (so
> > that other stuff is likely more expensive than building BRIN).
>
> True. I'm still puzzled that it didn't help to use 8 pages per range,
> but it's moot now.
>
I'd bet that even with just 8 pages, there were quite a few values in
the range - possibly hundreds per page. I haven't tried if the patches
help with smaller ranges, so maybe we should check.
>
> Here are some numbers (median of 3) with a similar scenario as before,
> repeated here with some added details. I didn't bother with what you
> call "unpatched":
>
> btree minmax multi
> monotonic-asc 44.4 26.5 27.8
> mono-del-ins 38.7 24.6 30.4
> mono-10-asc 61.8 25.6 33.5
>
Thanks. Those numbers seem reasonable.
--
Tomas Vondra
EnterpriseDB: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
Hi Tomas,
I took another look through the Bloom opclass portion (0004) with sorted_mode omitted, and it looks good to me code-wise. I think this part is close to commit-ready. I also did one more proofreading pass for minor details.
+ rows per block). The default values is <literal>-0.1</literal>, and
+ greater than 0.0 and smaller than 1.0. The default values is 0.01,
s/values/value/
+ * bloom filter, we can easily and cheaply test wheter it contains values
s/wheter/whether/
+ * XXX We assume the bloom filters have the same parameters fow now. In the
s/fow/for/
+ * or null if it does not exists.
s/exists/exist/
+ * We do expect the bloom filter to eventually switch to hashing mode,
+ * and it's bound to be almost perfectly random, so not compressible.
Leftover from when it started out in sorted mode.
+ if ((m/8) > BLCKSZ)
It seems we need something more safe, to account for page header and tuple header at least. As the comment before says, the filter will eventually not be compressible. I remember we can't be exact here, with the possibility of multiple columns, but we can leave a little slack space.
-- + rows per block). The default values is <literal>-0.1</literal>, and
+ greater than 0.0 and smaller than 1.0. The default values is 0.01,
s/values/value/
+ * bloom filter, we can easily and cheaply test wheter it contains values
s/wheter/whether/
+ * XXX We assume the bloom filters have the same parameters fow now. In the
s/fow/for/
+ * or null if it does not exists.
s/exists/exist/
+ * We do expect the bloom filter to eventually switch to hashing mode,
+ * and it's bound to be almost perfectly random, so not compressible.
Leftover from when it started out in sorted mode.
+ if ((m/8) > BLCKSZ)
It seems we need something more safe, to account for page header and tuple header at least. As the comment before says, the filter will eventually not be compressible. I remember we can't be exact here, with the possibility of multiple columns, but we can leave a little slack space.
On Fri, Jan 22, 2021 at 10:59 PM Tomas Vondra <tomas.vondra@enterprisedb.com> wrote:
>
>
> On 1/23/21 12:27 AM, John Naylor wrote:
> > Still, it would be great if multi-minmax can be a drop in replacement. I
> > know there was a sticking point of a distance function not being
> > available on all types, but I wonder if that can be remedied or worked
> > around somehow.
> >
>
> Hmm. I think Alvaro also mentioned he'd like to use this as a drop-in
> replacement for minmax (essentially, using these opclasses as the
> default ones, with the option to switch back to plain minmax). I'm not
> convinced we should do that - though. Imagine you have minmax indexes in
> your existing DB, it's working perfectly fine, and then we come and just
> silently change that during dump/restore. Is there some past example
> when we did something similar and it turned it to be OK?
I was assuming pg_dump can be taught to insert explicit opclasses for minmax indexes, so that upgrade would not cause surprises. If that's true, only new indexes would have the different default opclass.
> As for the distance functions, I'm pretty sure there are data types
> without "natural" distance - like most strings, for example. We could
> probably invent something, but the question is how much we can rely on
> it working well enough in practice.
>
> Of course, is minmax even the right index type for such data types?
> Strings are usually "labels" and not queried using range queries,
> although sometimes people encode stuff as strings (but then it's very
> unlikely we'll define the distance definition well). So maybe for those
> types a hash / bloom would be a better fit anyway.
Right.
> But I do have an idea - maybe we can do without distances, in those
> cases. Essentially, the primary issue of minmax indexes are outliers, so
> what if we simply sort the values, keep one range in the middle and as
> many single points on each tail?
That's an interesting idea. I think it would be a nice bonus to try to do something along these lines. On the other hand, I'm not the one volunteering to do the work, and the patch is useful as is.
--
John Naylor
EDB: http://www.enterprisedb.com
>
>
> On 1/23/21 12:27 AM, John Naylor wrote:
> > Still, it would be great if multi-minmax can be a drop in replacement. I
> > know there was a sticking point of a distance function not being
> > available on all types, but I wonder if that can be remedied or worked
> > around somehow.
> >
>
> Hmm. I think Alvaro also mentioned he'd like to use this as a drop-in
> replacement for minmax (essentially, using these opclasses as the
> default ones, with the option to switch back to plain minmax). I'm not
> convinced we should do that - though. Imagine you have minmax indexes in
> your existing DB, it's working perfectly fine, and then we come and just
> silently change that during dump/restore. Is there some past example
> when we did something similar and it turned it to be OK?
I was assuming pg_dump can be taught to insert explicit opclasses for minmax indexes, so that upgrade would not cause surprises. If that's true, only new indexes would have the different default opclass.
> As for the distance functions, I'm pretty sure there are data types
> without "natural" distance - like most strings, for example. We could
> probably invent something, but the question is how much we can rely on
> it working well enough in practice.
>
> Of course, is minmax even the right index type for such data types?
> Strings are usually "labels" and not queried using range queries,
> although sometimes people encode stuff as strings (but then it's very
> unlikely we'll define the distance definition well). So maybe for those
> types a hash / bloom would be a better fit anyway.
Right.
> But I do have an idea - maybe we can do without distances, in those
> cases. Essentially, the primary issue of minmax indexes are outliers, so
> what if we simply sort the values, keep one range in the middle and as
> many single points on each tail?
That's an interesting idea. I think it would be a nice bonus to try to do something along these lines. On the other hand, I'm not the one volunteering to do the work, and the patch is useful as is.
--
John Naylor
EDB: http://www.enterprisedb.com
On 1/26/21 7:52 PM, John Naylor wrote: > On Fri, Jan 22, 2021 at 10:59 PM Tomas Vondra > <tomas.vondra@enterprisedb.com <mailto:tomas.vondra@enterprisedb.com>> > wrote: > > > > > > On 1/23/21 12:27 AM, John Naylor wrote: > > > > Still, it would be great if multi-minmax can be a drop in > replacement. I > > > know there was a sticking point of a distance function not being > > > available on all types, but I wonder if that can be remedied or worked > > > around somehow. > > > > > > > Hmm. I think Alvaro also mentioned he'd like to use this as a drop-in > > replacement for minmax (essentially, using these opclasses as the > > default ones, with the option to switch back to plain minmax). I'm not > > convinced we should do that - though. Imagine you have minmax indexes in > > your existing DB, it's working perfectly fine, and then we come and just > > silently change that during dump/restore. Is there some past example > > when we did something similar and it turned it to be OK? > > I was assuming pg_dump can be taught to insert explicit opclasses for > minmax indexes, so that upgrade would not cause surprises. If that's > true, only new indexes would have the different default opclass. > Maybe, I suppose we could do that. But I always found such changes happening silently in the background a bit suspicious, because it may be quite confusing. I certainly wouldn't expect such difference between creating a new index and index created by dump/restore. Did we do such changes in the past? That might be a precedent, but I don't recall any example ... > > As for the distance functions, I'm pretty sure there are data types > > without "natural" distance - like most strings, for example. We could > > probably invent something, but the question is how much we can rely on > > it working well enough in practice. > > > > Of course, is minmax even the right index type for such data types? > > Strings are usually "labels" and not queried using range queries, > > although sometimes people encode stuff as strings (but then it's very > > unlikely we'll define the distance definition well). So maybe for those > > types a hash / bloom would be a better fit anyway. > > Right. > > > But I do have an idea - maybe we can do without distances, in those > > cases. Essentially, the primary issue of minmax indexes are outliers, so > > what if we simply sort the values, keep one range in the middle and as > > many single points on each tail? > > That's an interesting idea. I think it would be a nice bonus to try to > do something along these lines. On the other hand, I'm not the one > volunteering to do the work, and the patch is useful as is. > IMO it's fairly small amount of code, so I'll take a stab at in in the next version of the patch. regards -- Tomas Vondra EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On Tue, Jan 26, 2021 at 6:59 PM Tomas Vondra <tomas.vondra@enterprisedb.com> wrote:
>
>
>
> On 1/26/21 7:52 PM, John Naylor wrote:
> > On Fri, Jan 22, 2021 at 10:59 PM Tomas Vondra
> > <tomas.vondra@enterprisedb.com <mailto:tomas.vondra@enterprisedb.com>>
> > wrote:
> > > Hmm. I think Alvaro also mentioned he'd like to use this as a drop-in
> > > replacement for minmax (essentially, using these opclasses as the
> > > default ones, with the option to switch back to plain minmax). I'm not
> > > convinced we should do that - though. Imagine you have minmax indexes in
> > > your existing DB, it's working perfectly fine, and then we come and just
> > > silently change that during dump/restore. Is there some past example
> > > when we did something similar and it turned it to be OK?
> >
> > I was assuming pg_dump can be taught to insert explicit opclasses for
> > minmax indexes, so that upgrade would not cause surprises. If that's
> > true, only new indexes would have the different default opclass.
> >
>
> Maybe, I suppose we could do that. But I always found such changes
> happening silently in the background a bit suspicious, because it may be
> quite confusing. I certainly wouldn't expect such difference between
> creating a new index and index created by dump/restore. Did we do such
> changes in the past? That might be a precedent, but I don't recall any
> example ...
I couldn't think of a comparable example either. It comes down to evaluating risk. On the one hand it's nice if users get an enhancement without having to know about it, on the other hand if there is some kind of noticeable regression, that's bad.
--
John Naylor
EDB: http://www.enterprisedb.com
>
>
>
> On 1/26/21 7:52 PM, John Naylor wrote:
> > On Fri, Jan 22, 2021 at 10:59 PM Tomas Vondra
> > <tomas.vondra@enterprisedb.com <mailto:tomas.vondra@enterprisedb.com>>
> > wrote:
> > > Hmm. I think Alvaro also mentioned he'd like to use this as a drop-in
> > > replacement for minmax (essentially, using these opclasses as the
> > > default ones, with the option to switch back to plain minmax). I'm not
> > > convinced we should do that - though. Imagine you have minmax indexes in
> > > your existing DB, it's working perfectly fine, and then we come and just
> > > silently change that during dump/restore. Is there some past example
> > > when we did something similar and it turned it to be OK?
> >
> > I was assuming pg_dump can be taught to insert explicit opclasses for
> > minmax indexes, so that upgrade would not cause surprises. If that's
> > true, only new indexes would have the different default opclass.
> >
>
> Maybe, I suppose we could do that. But I always found such changes
> happening silently in the background a bit suspicious, because it may be
> quite confusing. I certainly wouldn't expect such difference between
> creating a new index and index created by dump/restore. Did we do such
> changes in the past? That might be a precedent, but I don't recall any
> example ...
I couldn't think of a comparable example either. It comes down to evaluating risk. On the one hand it's nice if users get an enhancement without having to know about it, on the other hand if there is some kind of noticeable regression, that's bad.
--
John Naylor
EDB: http://www.enterprisedb.com
Hi,
Here's an updated and significantly improved version of the patch
series, particularly the multi-minmax part. I've fixed a number of
stupid bugs in that, discovered by either valgrind or stress-tests.
I was surprised by some of the bugs, or rather that the existing
regression tests failed to crash on them, so it's probably worth briefly
discussing the details. There were two main classes of such bugs:
1) missing datumCopy
AFAICS this happened because there were a couple missing datumCopy
calls, and BRIN covers multiple pages, so with by-ref data types we
added a pointer but the buffer might have gone away unexpectedly.
Regular regression tests passed just fine, because brin_multi runs
almost separately, so the chance of the buffer being evicted was low.
Valgrind reported this (with a rather enigmatic message, as usual), and
so did a simple stress-test creating many indexes concurrently. Anything
causing aggressive eviction of buffer would do the trick, I think,
triggering segfaults, asserts, etc.
2) bogus opclass definitions
There were a couple opclasses referencing incorrect distance function,
intended for a different data type. I was scratching my head WTH the
regression tests pass, as there is a table to build multi-minmax index
on all supported data types. The reason is pretty silly - the table is
very small, just 100 rows, with very low fillfactor (so only couple
values per page), and the index was created with pages_per_range=1. So
the compaction was not triggered and the distance function was never
actually called. I've decided to build the indexes on a larger data set
first, to test this. But maybe this needs somewhat different approach.
BLOOM
-----
The attached patch series addresses comments from the last review. As
for the size limit, I've defined a new macro
#define BloomMaxFilterSize \
MAXALIGN_DOWN(BLCKSZ - \
(MAXALIGN(SizeOfPageHeaderData + \
sizeof(ItemIdData)) + \
MAXALIGN(sizeof(BrinSpecialSpace)) + \
SizeOfBrinTuple))
and use that to determine if the bloom filter is too large. IMO that's
close enough, considering that this is a best-effort check anyway (due
to not being able to consider multi-column indexes).
MINMAX-MULTI
------------
As mentioned, there's a lot of fixes and improvements in this part, but
the basic principle is still the same. I've kept it split into three
parts with different approaches to building, so that it's possible to do
benchmarks and comparisons, and pick the best one.
a) 0005 - Aggressively compacts the summary, by always keeping it within
the limit defined by values_per_range. So if the range contains more
values, this may trigger compaction very often in some cases (e.g. for
monotonic series).
One drawback is that the more often the compactions happen, the less
optimal the result is - the algorithm is kinda greedy, picking something
like local optimums in each step.
b) 0006 - Batch build, exactly the opposite of 0005. Accumulates all
values in a buffer, then does a single round of compaction at the very
end. This obviously doesn't have the "greediness" issues, but it may
consume quite a bit of memory for some data types and/or indexes with
large BRIN ranges.
c) 0007 - A hybrid approach, using a buffer that is multiple of the
user-specified value, with some safety min/max limits. IMO this is what
we should use, although perhaps with some tuning of the exact limits.
Attached is a spreadsheet with benchmark results for each of those three
approaches, on different data types (byval/byref), data set types, index
parameters (pages/values per range) etc. I think 0007 is a reasonable
compromise overall, with performance somewhere in betwen 0005 and 0006.
Of course, there are cases where it's somewhat slow, e.g. for data types
with expensive comparisons and data sets forcing frequent compactions,
in which case it's ~10x slower compared to regular minmax (in most cases
it's ~1.5x). Compared to btree, it's usually much faster - ~2-3x as fast
(except for some extreme cases, of course).
As for the opclasses for indexes without "natural" distance function,
implemented in 0008, I think we should drop it. In theory it works, but
I'm far from convinced it's actually useful in practice. Essentially, if
you have a data type with ordering but without a meaningful concept of a
distance, it's hard to say what is an outlier. I'd bet most of those
data types are used as "labels" where even the ordering is kinda
useless, i.e. hardly anyone uses range queries on things like names,
it's all just equality searches. Which means the bloom indexes are a
much better match for this use case.
The other thing we were considering was using the new multi-minmax
opclasses as default ones, replacing the existing minmax ones. IMHO we
shouldn't do that either. For existing minmax indexes that's useless
(the opclass seems to be working, otherwise the index would be dropped).
But even for new indexes I'm not sure it's the right thing, so I don't
plan to change this.
I'm also attaching the stress-test that I used to test the hell out of
this, creating indexes on various data sets, data types, with varying
index parameters, etc.
regards
--
Tomas Vondra
EnterpriseDB: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
Attachment
- 0009-Ignore-correlation-for-new-BRIN-opclasses-20210203.patch
- 0008-Define-multi-minmax-oclasses-for-types-with-20210203.patch
- 0007-Remove-the-special-batch-mode-use-a-larger--20210203.patch
- 0006-Batch-mode-when-building-new-BRIN-multi-min-20210203.patch
- 0005-BRIN-minmax-multi-indexes-20210203.patch
- 0004-BRIN-bloom-indexes-20210203.patch
- 0003-Optimize-allocations-in-bringetbitmap-20210203.patch
- 0002-Move-IS-NOT-NULL-handling-from-BRIN-support-20210203.patch
- 0001-Pass-all-scan-keys-to-BRIN-consistent-funct-20210203.patch
- brin-bench.ods
- brin-stress-test.tgz
- brin-bench.tgz
Hi,
For 0007-Remove-the-special-batch-mode-use-a-larger--20210203.patch :
+ /* same as preceding value, so store it */
+ if (compare_values(&range->values[start + i - 1],
+ &range->values[start + i],
+ (void *) &cxt) == 0)
+ continue;
+
+ range->values[start + n] = range->values[start + i];
+ if (compare_values(&range->values[start + i - 1],
+ &range->values[start + i],
+ (void *) &cxt) == 0)
+ continue;
+
+ range->values[start + n] = range->values[start + i];
It seems the comment doesn't match the code: the value is stored when subsequent value is different from the previous.
For has_matching_range():
+ int midpoint = (start + end) / 2;
I think the standard notion for midpoint is start + (end-start)/2.
+ /* this means we ran out of ranges in the last step */
+ if (start > end)
+ return false;
+ if (start > end)
+ return false;
It seems the above should be ahead of computation of midpoint.
Similar comment for the code in AssertCheckRanges().
Cheers
On Wed, Feb 3, 2021 at 3:55 PM Tomas Vondra <tomas.vondra@enterprisedb.com> wrote:
Hi,
Here's an updated and significantly improved version of the patch
series, particularly the multi-minmax part. I've fixed a number of
stupid bugs in that, discovered by either valgrind or stress-tests.
I was surprised by some of the bugs, or rather that the existing
regression tests failed to crash on them, so it's probably worth briefly
discussing the details. There were two main classes of such bugs:
1) missing datumCopy
AFAICS this happened because there were a couple missing datumCopy
calls, and BRIN covers multiple pages, so with by-ref data types we
added a pointer but the buffer might have gone away unexpectedly.
Regular regression tests passed just fine, because brin_multi runs
almost separately, so the chance of the buffer being evicted was low.
Valgrind reported this (with a rather enigmatic message, as usual), and
so did a simple stress-test creating many indexes concurrently. Anything
causing aggressive eviction of buffer would do the trick, I think,
triggering segfaults, asserts, etc.
2) bogus opclass definitions
There were a couple opclasses referencing incorrect distance function,
intended for a different data type. I was scratching my head WTH the
regression tests pass, as there is a table to build multi-minmax index
on all supported data types. The reason is pretty silly - the table is
very small, just 100 rows, with very low fillfactor (so only couple
values per page), and the index was created with pages_per_range=1. So
the compaction was not triggered and the distance function was never
actually called. I've decided to build the indexes on a larger data set
first, to test this. But maybe this needs somewhat different approach.
BLOOM
-----
The attached patch series addresses comments from the last review. As
for the size limit, I've defined a new macro
#define BloomMaxFilterSize \
MAXALIGN_DOWN(BLCKSZ - \
(MAXALIGN(SizeOfPageHeaderData + \
sizeof(ItemIdData)) + \
MAXALIGN(sizeof(BrinSpecialSpace)) + \
SizeOfBrinTuple))
and use that to determine if the bloom filter is too large. IMO that's
close enough, considering that this is a best-effort check anyway (due
to not being able to consider multi-column indexes).
MINMAX-MULTI
------------
As mentioned, there's a lot of fixes and improvements in this part, but
the basic principle is still the same. I've kept it split into three
parts with different approaches to building, so that it's possible to do
benchmarks and comparisons, and pick the best one.
a) 0005 - Aggressively compacts the summary, by always keeping it within
the limit defined by values_per_range. So if the range contains more
values, this may trigger compaction very often in some cases (e.g. for
monotonic series).
One drawback is that the more often the compactions happen, the less
optimal the result is - the algorithm is kinda greedy, picking something
like local optimums in each step.
b) 0006 - Batch build, exactly the opposite of 0005. Accumulates all
values in a buffer, then does a single round of compaction at the very
end. This obviously doesn't have the "greediness" issues, but it may
consume quite a bit of memory for some data types and/or indexes with
large BRIN ranges.
c) 0007 - A hybrid approach, using a buffer that is multiple of the
user-specified value, with some safety min/max limits. IMO this is what
we should use, although perhaps with some tuning of the exact limits.
Attached is a spreadsheet with benchmark results for each of those three
approaches, on different data types (byval/byref), data set types, index
parameters (pages/values per range) etc. I think 0007 is a reasonable
compromise overall, with performance somewhere in betwen 0005 and 0006.
Of course, there are cases where it's somewhat slow, e.g. for data types
with expensive comparisons and data sets forcing frequent compactions,
in which case it's ~10x slower compared to regular minmax (in most cases
it's ~1.5x). Compared to btree, it's usually much faster - ~2-3x as fast
(except for some extreme cases, of course).
As for the opclasses for indexes without "natural" distance function,
implemented in 0008, I think we should drop it. In theory it works, but
I'm far from convinced it's actually useful in practice. Essentially, if
you have a data type with ordering but without a meaningful concept of a
distance, it's hard to say what is an outlier. I'd bet most of those
data types are used as "labels" where even the ordering is kinda
useless, i.e. hardly anyone uses range queries on things like names,
it's all just equality searches. Which means the bloom indexes are a
much better match for this use case.
The other thing we were considering was using the new multi-minmax
opclasses as default ones, replacing the existing minmax ones. IMHO we
shouldn't do that either. For existing minmax indexes that's useless
(the opclass seems to be working, otherwise the index would be dropped).
But even for new indexes I'm not sure it's the right thing, so I don't
plan to change this.
I'm also attaching the stress-test that I used to test the hell out of
this, creating indexes on various data sets, data types, with varying
index parameters, etc.
regards
--
Tomas Vondra
EnterpriseDB: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
On 2/4/21 1:49 AM, Zhihong Yu wrote: > Hi, > For 0007-Remove-the-special-batch-mode-use-a-larger--20210203.patch : > > + /* same as preceding value, so store it */ > + if (compare_values(&range->values[start + i - 1], > + &range->values[start + i], > + (void *) &cxt) == 0) > + continue; > + > + range->values[start + n] = range->values[start + i]; > > It seems the comment doesn't match the code: the value is stored when > subsequent value is different from the previous. > Yeah, you're right the comment is wrong - the code is doing exactly the opposite. I'll need to go through this more carefully. > For has_matching_range(): > + int midpoint = (start + end) / 2; > > I think the standard notion for midpoint is start + (end-start)/2. > > + /* this means we ran out of ranges in the last step */ > + if (start > end) > + return false; > > It seems the above should be ahead of computation of midpoint. > Not sure why would that be an issue, as we're not using the value and the values are just plain integers (so no overflows ...). regards -- Tomas Vondra EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
Hi,
bq. Not sure why would that be an issue
Moving the (start > end) check is up to your discretion.
But the midpoint computation should follow text book :-)
Cheers
On Wed, Feb 3, 2021 at 4:59 PM Tomas Vondra <tomas.vondra@enterprisedb.com> wrote:
On 2/4/21 1:49 AM, Zhihong Yu wrote:
> Hi,
> For 0007-Remove-the-special-batch-mode-use-a-larger--20210203.patch :
>
> + /* same as preceding value, so store it */
> + if (compare_values(&range->values[start + i - 1],
> + &range->values[start + i],
> + (void *) &cxt) == 0)
> + continue;
> +
> + range->values[start + n] = range->values[start + i];
>
> It seems the comment doesn't match the code: the value is stored when
> subsequent value is different from the previous.
>
Yeah, you're right the comment is wrong - the code is doing exactly the
opposite. I'll need to go through this more carefully.
> For has_matching_range():
> + int midpoint = (start + end) / 2;
>
> I think the standard notion for midpoint is start + (end-start)/2.
>
> + /* this means we ran out of ranges in the last step */
> + if (start > end)
> + return false;
>
> It seems the above should be ahead of computation of midpoint.
>
Not sure why would that be an issue, as we're not using the value and
the values are just plain integers (so no overflows ...).
regards
--
Tomas Vondra
EnterpriseDB: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
On Wed, Feb 3, 2021 at 7:54 PM Tomas Vondra <tomas.vondra@enterprisedb.com> wrote:
>
> [v-20210203]
Hi Tomas,
I have some random comments from reading the patch, but haven't gone into detail in the newer aspects. I'll do so in the near future.
The cfbot seems to crash on this patch during make check, but it doesn't crash for me. I'm not even sure what date that cfbot status is from.
> BLOOM
> -----
Looks good, but make sure you change the commit message -- it still refers to sorted mode.
+ * not entirely clear how to distrubute the space between those columns.
s/distrubute/distribute/
> MINMAX-MULTI
> ------------
> c) 0007 - A hybrid approach, using a buffer that is multiple of the
> user-specified value, with some safety min/max limits. IMO this is what
> we should use, although perhaps with some tuning of the exact limits.
That seems like a good approach.
+#include "access/hash.h" /* XXX strange that it fails because of BRIN_AM_OID without this */
I think you want #include "catalog/pg_am.h" here.
> Attached is a spreadsheet with benchmark results for each of those three
> approaches, on different data types (byval/byref), data set types, index
> parameters (pages/values per range) etc. I think 0007 is a reasonable
> compromise overall, with performance somewhere in betwen 0005 and 0006.
> Of course, there are cases where it's somewhat slow, e.g. for data types
> with expensive comparisons and data sets forcing frequent compactions,
> in which case it's ~10x slower compared to regular minmax (in most cases
> it's ~1.5x). Compared to btree, it's usually much faster - ~2-3x as fast
> (except for some extreme cases, of course).
>
>
> As for the opclasses for indexes without "natural" distance function,
> implemented in 0008, I think we should drop it. In theory it works, but
Sounds reasonable.
> The other thing we were considering was using the new multi-minmax
> opclasses as default ones, replacing the existing minmax ones. IMHO we
> shouldn't do that either. For existing minmax indexes that's useless
> (the opclass seems to be working, otherwise the index would be dropped).
> But even for new indexes I'm not sure it's the right thing, so I don't
> plan to change this.
Okay.
--
John Naylor
EDB: http://www.enterprisedb.com
>
> [v-20210203]
Hi Tomas,
I have some random comments from reading the patch, but haven't gone into detail in the newer aspects. I'll do so in the near future.
The cfbot seems to crash on this patch during make check, but it doesn't crash for me. I'm not even sure what date that cfbot status is from.
> BLOOM
> -----
Looks good, but make sure you change the commit message -- it still refers to sorted mode.
+ * not entirely clear how to distrubute the space between those columns.
s/distrubute/distribute/
> MINMAX-MULTI
> ------------
> c) 0007 - A hybrid approach, using a buffer that is multiple of the
> user-specified value, with some safety min/max limits. IMO this is what
> we should use, although perhaps with some tuning of the exact limits.
That seems like a good approach.
+#include "access/hash.h" /* XXX strange that it fails because of BRIN_AM_OID without this */
I think you want #include "catalog/pg_am.h" here.
> Attached is a spreadsheet with benchmark results for each of those three
> approaches, on different data types (byval/byref), data set types, index
> parameters (pages/values per range) etc. I think 0007 is a reasonable
> compromise overall, with performance somewhere in betwen 0005 and 0006.
> Of course, there are cases where it's somewhat slow, e.g. for data types
> with expensive comparisons and data sets forcing frequent compactions,
> in which case it's ~10x slower compared to regular minmax (in most cases
> it's ~1.5x). Compared to btree, it's usually much faster - ~2-3x as fast
> (except for some extreme cases, of course).
>
>
> As for the opclasses for indexes without "natural" distance function,
> implemented in 0008, I think we should drop it. In theory it works, but
Sounds reasonable.
> The other thing we were considering was using the new multi-minmax
> opclasses as default ones, replacing the existing minmax ones. IMHO we
> shouldn't do that either. For existing minmax indexes that's useless
> (the opclass seems to be working, otherwise the index would be dropped).
> But even for new indexes I'm not sure it's the right thing, so I don't
> plan to change this.
Okay.
--
John Naylor
EDB: http://www.enterprisedb.com
On 2/9/21 3:46 PM, John Naylor wrote:
> On Wed, Feb 3, 2021 at 7:54 PM Tomas Vondra
> <tomas.vondra@enterprisedb.com <mailto:tomas.vondra@enterprisedb.com>>
> wrote:
> >
> > [v-20210203]
>
> Hi Tomas,
>
> I have some random comments from reading the patch, but haven't gone
> into detail in the newer aspects. I'll do so in the near future.
>
> The cfbot seems to crash on this patch during make check, but it doesn't
> crash for me. I'm not even sure what date that cfbot status is from.
>
Yeah, I noticed that too, and I'm investigating.
I tried running the regression tests on a 32-bit machine (rpi4), which
sometimes uncovers strange failures, and that indeed fails. There are
two or three bugs.
Firstly, the allocation optimization patch does this:
MAXALIGN(sizeof(ScanKey) * scan->numberOfKeys * natts)
instead of
MAXALIGN(sizeof(ScanKey) * scan->numberOfKeys) * natts
and that sometimes produces the wrong result, triggering an assert.
Secondly, there seems to be an issue with cross-type bloom indexes.
Imagine you have an int8 column, with a bloom index on it, and then you
do this:
WHERE column = '122'::int4;
Currently, we end up passing this to the consistent function, which
tries to call hashint8 on the int4 datum - that succeeds on 64 bits
(because both types are byval), but fails on 32-bits (where int8 is
byref, so it fails on int4). Which causes a segfault.
I think I included those cross-type operators as a copy-paste from
minmax indexes, but I see hash indexes don't allow this. And removing
those cross-type rows from pg_amop.dat makes the crashes go away.
It's also possible I simplified the get_strategy_procinfo a bit too
much. I see the minmax variant has subtype, so maybe we could do this
instead (I recall the integer types should have "compatible" results).
There are a couple failues where the index does not produce the right
number of results, though. I haven't investigated that yet. Once I fix
this, I'll post an updated patch - hopefully that'll make cfbot happy.
regards
--
Tomas Vondra
EnterpriseDB: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
Hi,
Attached is an updated version of the patch series, addressing all the
failures on cfbot (at least I hope so). This turned out to be more fun
than I expected, as the issues went unnoticed on 64-bits and only failed
on 32-bits. That's also why I'm not entirely sure this will make cfbot
happy as that seems to be x86_64, but the issues are real so let's see.
1) I already outlined the issue in the previous message:
MAXALIGN(a * b) != MAXALIGN(a) * b
and there's an assert that we used exactly the same amount of memory we
allocated, so this caused a crash. Strange that it'd fail on 32-bits and
not 64-bits, but perhaps there's some math reason for that, or maybe it
was just pure luck.
2) The rest of the issues generally boils down to types that are byval
on 64-bits, but byref on 32-bits. Like int8 or float8 for example. The
first place causing issues were cross-type operators, i.e. the bloom
opclasses did things like this in pg_amop.dat:
{ amopfamily => 'brin/integer_bloom_ops', amoplefttype => 'int2',
amoprighttype => 'int8', amopstrategy => '1',
amopopr => '=(int2,int8)', amopmethod => 'brin' },
so it was possible to do this:
WHERE int8column = 1234::int2
in which case we used the int8 opclass, so the consistent function
thought it's working with int8, and used the hash function defined for
that opclass in pg_amproc. That's hashint8 of course, but we called that
on Datum storing int2. Clearly, dereferencing that pointer is guaranteed
to fail with a segfault.
I think there are two options to fix this. Firstly, we can remove the
cross-type operators, so that the left/right type is always the same.
That'll work fine for most cases, and it's pretty simple. It's also what
the hash_ops opclasses do, so I've done that.
An alternative would be to do something like minmax does for stategies,
and consider the subtype (i.e. type of the right argument). It's trick a
bit tricky, though, because it assumes the hash functions for the two
types are "compatible" and produce the same hash for the same value.
AFAIK that's correct for the usual cases (int2/int4/int8) and it'd be
restricted by pg_amop. But hash_ops don't do that for some reason, so I
wonder what am I missing. (The other thing is where to define these hash
functions - right now pg_amproc only tracks hash function for the "base"
data type, and there may be multiple supported subtypes, so where to
store that? Perhaps we could use the hash function from the default hash
opclass for each type.)
Anyway, I've decided to keep this simple for now, and I've ripped-out
the cross-type operators. We can add that back later, if needed.
3) There were a couple byref failures in the distance functions, which
generally used "double" internally (which I'm not sure is guaranteed to
be 64-bit types) instead of float8, and used plain "return" instead of
PG_RETURN_FLOAT8() in a couple places. Silly mistakes.
4) A particulary funny mistake was in actually calculating the hashes
for bloom filter, which is using hash_uint32_extended (so that we can
seed it). The trouble is that while hash_uint32() returns uint32,
hash_uint32_extended returns ... uint64. So we calculated a hash, but
then used the *pointer* to the uint64 value, not the value. I have to
say, the "uint32" in the function name is somewhat misleading.
This passes all my tests, including valgrind on the 32-bit rpi4 machine,
the stress test (testing both the bloom and multi-minmax opclasses etc.)
regards
--
Tomas Vondra
EnterpriseDB: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
Attachment
- 0009-Ignore-correlation-for-new-BRIN-opclasses-20210211.patch
- 0008-Define-multi-minmax-oclasses-for-types-with-20210211.patch
- 0007-Remove-the-special-batch-mode-use-a-larger--20210211.patch
- 0006-Batch-mode-when-building-new-BRIN-multi-min-20210211.patch
- 0005-BRIN-minmax-multi-indexes-20210211.patch
- 0004-BRIN-bloom-indexes-20210211.patch
- 0003-Optimize-allocations-in-bringetbitmap-20210211.patch
- 0002-Move-IS-NOT-NULL-handling-from-BRIN-support-20210211.patch
- 0001-Pass-all-scan-keys-to-BRIN-consistent-funct-20210211.patch
On 2/11/21 3:51 PM, Tomas Vondra wrote: > > ... > > This passes all my tests, including valgrind on the 32-bit rpi4 machine, > the stress test (testing both the bloom and multi-minmax opclasses etc.) > OK, the cfbot seems happy with it, but I forgot to address the minor issues mentioned in the review from 2021/02/09, so here's a patch series addressing that. Overall, I think the plan is to eventually commit 0001-0004 as is, squash 0005-0007 (so the minmax-multi uses the "hybrid" approach). I don't intend to commit 0008, because I have doubts those opclasses are really useful for anything. As for 0009, I think it's a fairly small tweak - the correlation made sense for regular brin indexes, but those new oclasses are meant exactly for cases where the data is not well correlated. regards -- Tomas Vondra EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
Attachment
- 0001-Pass-all-scan-keys-to-BRIN-consistent-funct-20210215.patch
- 0002-Move-IS-NOT-NULL-handling-from-BRIN-support-20210215.patch
- 0003-Optimize-allocations-in-bringetbitmap-20210215.patch
- 0004-BRIN-bloom-indexes-20210215.patch
- 0005-BRIN-minmax-multi-indexes-20210215.patch
- 0006-Batch-mode-when-building-new-BRIN-multi-min-20210215.patch
- 0007-Remove-the-special-batch-mode-use-a-larger--20210215.patch
- 0008-Define-multi-minmax-oclasses-for-types-with-20210215.patch
- 0009-Ignore-correlation-for-new-BRIN-opclasses-20210215.patch