Thread: Re: [HACKERS] Fix performance of generic atomics
A bit cleaner version of a patch.
Sokolov Yura писал 2017-05-25 15:22:
> Good day, everyone.
>
> I've been played with pgbench on huge machine.
> (72 cores, 56 for postgresql, enough memory to fit base
> both into shared_buffers and file cache)
> (pgbench scale 500, unlogged tables, fsync=off,
> synchronous commit=off, wal_writer_flush_after=0).
>
> With 200 clients performance is around 76000tps and main
> bottleneck in this dumb test is LWLockWaitListLock.
>
> I added gcc specific implementation for pg_atomic_fetch_or_u32_impl
> (ie using __sync_fetch_and_or) and performance became 83000tps.
>
> It were a bit strange at a first look, cause __sync_fetch_and_or
> compiles to almost same CAS loop.
>
> Looking closely, I noticed that intrinsic performs doesn't do
> read in the loop body, but at loop initialization. It is correct
> behavior cause `lock cmpxchg` instruction stores old value in EAX
> register.
>
> It is expected behavior, and pg_compare_and_exchange_*_impl does
> the same in all implementations. So there is no need to re-read
> value in the loop body:
>
> Example diff for pg_atomic_exchange_u32_impl:
>
> static inline uint32
> pg_atomic_exchange_u32_impl(volatile pg_atomic_uint32 *ptr, uint32
> xchg_)
> {
> uint32 old;
> + old = pg_atomic_read_u32_impl(ptr);
> while (true)
> {
> - old = pg_atomic_read_u32_impl(ptr);
> if (pg_atomic_compare_exchange_u32_impl(ptr, &old, xchg_))
> break;
> }
> return old;
> }
>
> After applying this change to all generic atomic functions
> (and for pg_atomic_fetch_or_u32_impl ), performance became
> equal to __sync_fetch_and_or intrinsic.
>
> Attached patch contains patch for all generic atomic
> functions, and also __sync_fetch_and_(or|and) for gcc, cause
> I believe GCC optimize code around intrinsic better than
> around inline assembler.
> (final performance is around 86000tps, but difference between
> 83000tps and 86000tps is not so obvious in NUMA system).
>
> With regards,
--
Sokolov Yura aka funny_falcon
Postgres Professional: https://postgrespro.ru
The Russian Postgres Company
--
Sent via pgsql-hackers mailing list (pgsql-hackers@postgresql.org)
To make changes to your subscription:
http://www.postgresql.org/mailpref/pgsql-hackers
Attachment
Sokolov Yura <funny.falcon@postgrespro.ru> writes:
@@ -382,12 +358,8 @@ static inline uint64pg_atomic_fetch_and_u64_impl(volatile pg_atomic_uint64 *ptr, uint64 and_){
uint64old;
- while (true)
- {
- old = pg_atomic_read_u64_impl(ptr);
- if (pg_atomic_compare_exchange_u64_impl(ptr, &old, old & and_))
- break;
- }
+ old = pg_atomic_read_u64_impl(ptr);
+ while (!pg_atomic_compare_exchange_u64_impl(ptr, &old, old & and_)); return old;}#endif
FWIW, I do not think that writing the loops like that is good style.
It looks like a typo and will confuse readers. You could perhaps
write the same code with better formatting, eg
while (!pg_atomic_compare_exchange_u64_impl(ptr, &old, old & and_)) /* skip */ ;
but why not leave the formulation with while(true) and a break alone?
(I take no position on whether moving the read of "old" outside the
loop is a valid optimization.)
regards, tom lane
Hello, Tom.
I agree that lonely semicolon looks bad.
Applied your suggestion for empty loop body (/* skip */).
Patch in first letter had while(true), but I removed it cause
I think it is uglier:
- `while(true)` was necessary for grouping read with `if`,
- but now there is single statement in a loop body and it is
condition for loop exit, so it is clearly just a loop.
Optimization is valid cause compare_exchange always store old value
in `old` variable in a same atomic manner as atomic read.
Tom Lane wrote 2017-05-25 17:39:
> Sokolov Yura <funny.falcon@postgrespro.ru> writes:
> @@ -382,12 +358,8 @@ static inline uint64
> pg_atomic_fetch_and_u64_impl(volatile pg_atomic_uint64 *ptr, uint64
> and_)
> {
> uint64 old;
> - while (true)
> - {
> - old = pg_atomic_read_u64_impl(ptr);
> - if (pg_atomic_compare_exchange_u64_impl(ptr, &old, old & and_))
> - break;
> - }
> + old = pg_atomic_read_u64_impl(ptr);
> + while (!pg_atomic_compare_exchange_u64_impl(ptr, &old, old & and_));
> return old;
> }
> #endif
>
> FWIW, I do not think that writing the loops like that is good style.
> It looks like a typo and will confuse readers. You could perhaps
> write the same code with better formatting, eg
>
> while (!pg_atomic_compare_exchange_u64_impl(ptr, &old, old & and_))
> /* skip */ ;
>
> but why not leave the formulation with while(true) and a break alone?
>
> (I take no position on whether moving the read of "old" outside the
> loop is a valid optimization.)
>
> regards, tom lane
With regards,
--
Sokolov Yura aka funny_falcon
Postgres Professional: https://postgrespro.ru
The Russian Postgres Company
--
Sent via pgsql-hackers mailing list (pgsql-hackers@postgresql.org)
To make changes to your subscription:
http://www.postgresql.org/mailpref/pgsql-hackers
Attachment
Good day, every one.
I'm just posting benchmark numbers for atomics patch.
Hardware: 4 socket 72 core (144HT) x86_64 Centos 7.1
postgresql.conf tuning:
shared_buffers = 32GB
fsync = on
synchronous_commit = on
full_page_writes = off
wal_buffers = 16MB
wal_writer_flush_after = 16MB
commit_delay = 2
max_wal_size = 16GB
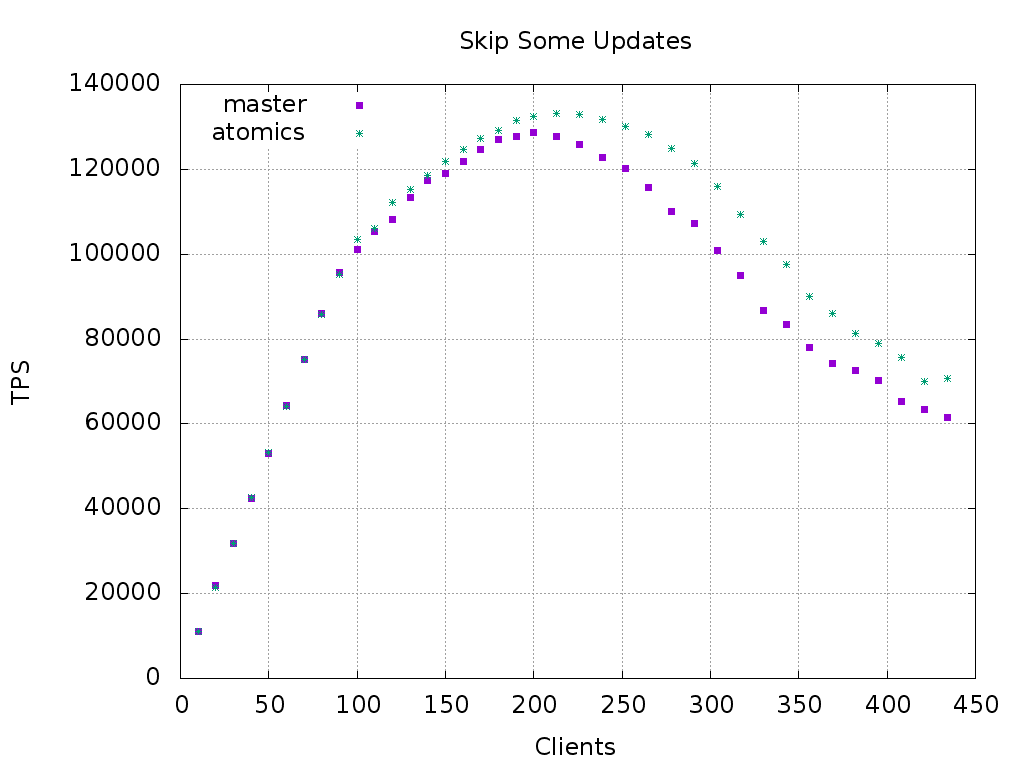
Results:
pgbench -i -s 300 + pgbench --skip-some-updates
Clients | master | atomics
========+=========+=======
50 | 53.1k | 53.2k
100 | 101.2k | 103.5k
150 | 119.1k | 121.9k
200 | 128.7k | 132.5k
252 | 120.2k | 130.0k
304 | 100.8k | 115.9k
356 | 78.1k | 90.1k
395 | 70.2k | 79.0k
434 | 61.6k | 70.7k
Also graph with more points attached.
On 2017-05-25 18:12, Sokolov Yura wrote:
> Hello, Tom.
>
> I agree that lonely semicolon looks bad.
> Applied your suggestion for empty loop body (/* skip */).
>
> Patch in first letter had while(true), but I removed it cause
> I think it is uglier:
> - `while(true)` was necessary for grouping read with `if`,
> - but now there is single statement in a loop body and it is
> condition for loop exit, so it is clearly just a loop.
>
> Optimization is valid cause compare_exchange always store old value
> in `old` variable in a same atomic manner as atomic read.
>
> Tom Lane wrote 2017-05-25 17:39:
>> Sokolov Yura <funny.falcon@postgrespro.ru> writes:
>> @@ -382,12 +358,8 @@ static inline uint64
>> pg_atomic_fetch_and_u64_impl(volatile pg_atomic_uint64 *ptr, uint64
>> and_)
>> {
>> uint64 old;
>> - while (true)
>> - {
>> - old = pg_atomic_read_u64_impl(ptr);
>> - if (pg_atomic_compare_exchange_u64_impl(ptr, &old, old & and_))
>> - break;
>> - }
>> + old = pg_atomic_read_u64_impl(ptr);
>> + while (!pg_atomic_compare_exchange_u64_impl(ptr, &old, old & and_));
>> return old;
>> }
>> #endif
>>
>> FWIW, I do not think that writing the loops like that is good style.
>> It looks like a typo and will confuse readers. You could perhaps
>> write the same code with better formatting, eg
>>
>> while (!pg_atomic_compare_exchange_u64_impl(ptr, &old, old & and_))
>> /* skip */ ;
>>
>> but why not leave the formulation with while(true) and a break alone?
>>
>> (I take no position on whether moving the read of "old" outside the
>> loop is a valid optimization.)
>>
>> regards, tom lane
With regards,
--
Sokolov Yura aka funny_falcon
Postgres Professional: https://postgrespro.ru
The Russian Postgres Company
--
Sent via pgsql-hackers mailing list (pgsql-hackers@postgresql.org)
To make changes to your subscription:
http://www.postgresql.org/mailpref/pgsql-hackers
Attachment
{kind=link}
Hi, On 05/25/2017 11:12 AM, Sokolov Yura wrote: > I agree that lonely semicolon looks bad. > Applied your suggestion for empty loop body (/* skip */). > > Patch in first letter had while(true), but I removed it cause > I think it is uglier: > - `while(true)` was necessary for grouping read with `if`, > - but now there is single statement in a loop body and it is > condition for loop exit, so it is clearly just a loop. > > Optimization is valid cause compare_exchange always store old value > in `old` variable in a same atomic manner as atomic read. > I have tested this patch on a 2-socket machine, but don't see any performance change in the various runs. However, there is no regression either in all cases. As such, I have marked the entry "Ready for Committer". Remember to add a version postfix to your patches such that is easy to identify which is the latest version. Best regards, Jesper
Hi, On 05/25/2017 11:12 AM, Sokolov Yura wrote: > I agree that lonely semicolon looks bad. > Applied your suggestion for empty loop body (/* skip */). > > Patch in first letter had while(true), but I removed it cause > I think it is uglier: > - `while(true)` was necessary for grouping read with `if`, > - but now there is single statement in a loop body and it is > condition for loop exit, so it is clearly just a loop. > > Optimization is valid cause compare_exchange always store old value > in `old` variable in a same atomic manner as atomic read. > I have tested this patch on a 2-socket machine, but don't see any performance change in the various runs. However, there is no regression either in all cases. As such, I have marked the entry "Ready for Committer". Remember to add a version postfix to your patches such that is easy to identify which is the latest version. Best regards, Jesper
Jesper Pedersen <jesper.pedersen@redhat.com> writes:
> I have tested this patch on a 2-socket machine, but don't see any
> performance change in the various runs. However, there is no regression
> either in all cases.
Hm, so if we can't demonstrate a performance win, it's hard to justify
risking touching this code. What test case(s) did you use?
regards, tom lane
On 09/05/2017 02:24 PM, Tom Lane wrote: > Jesper Pedersen <jesper.pedersen@redhat.com> writes: >> I have tested this patch on a 2-socket machine, but don't see any >> performance change in the various runs. However, there is no regression >> either in all cases. > > Hm, so if we can't demonstrate a performance win, it's hard to justify > risking touching this code. What test case(s) did you use? > I ran pgbench (-M prepared) with synchronous_commit 'on' and 'off' using both logged and unlogged tables. Also ran an internal benchmark which didn't show anything either. Setting the entry back to "Needs Review" for additional feedback from others. Best regards, Jesper
Jesper Pedersen <jesper.pedersen@redhat.com> writes:
> On 09/05/2017 02:24 PM, Tom Lane wrote:
>> Hm, so if we can't demonstrate a performance win, it's hard to justify
>> risking touching this code. What test case(s) did you use?
> I ran pgbench (-M prepared) with synchronous_commit 'on' and 'off' using
> both logged and unlogged tables. Also ran an internal benchmark which
> didn't show anything either.
That may just mean that pgbench isn't stressing any atomic ops very
hard (at least in the default scenario).
I'm tempted to write a little C function that just hits the relevant
atomic ops in a tight loop, and see how long it takes to do a few
million iterations. That would be erring in the opposite direction,
of overstating the importance of atomic ops to real-world scenarios
--- but if we didn't get any win that way, then it's surely in the noise.
regards, tom lane
On Tue, Sep 5, 2017 at 11:39 AM, Jesper Pedersen <jesper.pedersen@redhat.com> wrote:
What scale factor and client count? How many cores per socket? It looks like Sokolov was just starting to see gains at 200 clients on 72 cores, using -N transaction.
On 09/05/2017 02:24 PM, Tom Lane wrote:Jesper Pedersen <jesper.pedersen@redhat.com> writes:I have tested this patch on a 2-socket machine, but don't see any
performance change in the various runs. However, there is no regression
either in all cases.
Hm, so if we can't demonstrate a performance win, it's hard to justify
risking touching this code. What test case(s) did you use?
I ran pgbench (-M prepared) with synchronous_commit 'on' and 'off' using both logged and unlogged tables. Also ran an internal benchmark which didn't show anything either.
Cheers,
Jeff
Jeff Janes <jeff.janes@gmail.com> writes: > What scale factor and client count? How many cores per socket? It looks > like Sokolov was just starting to see gains at 200 clients on 72 cores, > using -N transaction. I spent some time poking at this with the test scaffolding I showed at https://www.postgresql.org/message-id/17694.1504665058%40sss.pgh.pa.us AFAICT, there are not huge differences between different coding methods even for two processes in direct competition in the tightest possible atomic-ops loops. So if you're testing SQL operations, you're definitely not going to see anything without a whole lot of concurrent processes. Moreover, it matters which primitive you're testing, on which platform, with which compiler, because we have a couple of layers of atomic ops implementations. I started out testing pg_atomic_fetch_add_u32(), as shown in the above- mentioned message. On x86_x64 with gcc, that is implemented by the code for it in src/include/port/atomics/arch-x86.h. If you dike out that support, it falls back to the version in atomics/generic-gcc.h, which seems no worse and possibly better. Only if you also dike out generic-gcc.h do you get to the version in atomics/generic.h that this patch wants to change. However, at that point you're also down to a spinlock-based implementation of the underlying pg_atomic_read_u32_impl and pg_atomic_compare_exchange_u32_impl, which means that performance is going to be less than great anyway. No platform that we consider well-supported ought to be hitting the spinlock paths. This means that Sokolov's proposed changes in atomics/generic.h ought to be uninteresting for performance on any platform we care about --- at least for pg_atomic_fetch_add_u32(). However, Sokolov also proposes adding gcc-intrinsic support for pg_atomic_fetch_and_xxx and pg_atomic_fetch_or_xxx. This is a different kettle of fish. I repeated the experiments I'd done for pg_atomic_fetch_add_u32(), per the above message, using the "or" primitive, and found largely the same results as for "add": it's slightly better under contention than the generic code, and significantly better if the result value of the atomic op isn't needed. So I think we should definitely take the part of the patch that changes generic-gcc.h --- and we should check to see if we're missing out on any other gcc primitives we should be using there. I'm less excited about the proposed changes in generic.h. There's nothing wrong with them in principle, but they mostly shouldn't make any performance difference on any platform we care about, because we shouldn't get to that code in the first place on any platform we care about. If we are getting to that code for any specific primitive, then either there's a gap in the platform-specific or compiler-specific support, or it's debatable that we ought to consider that primitive to be very primitive. regards, tom lane
On 2017-09-06 07:23, Tom Lane wrote: > Jeff Janes <jeff.janes@gmail.com> writes: >> What scale factor and client count? How many cores per socket? It >> looks >> like Sokolov was just starting to see gains at 200 clients on 72 >> cores, >> using -N transaction. > This means that Sokolov's proposed changes in atomics/generic.h > ought to be uninteresting for performance on any platform we care about > --- at > least for pg_atomic_fetch_add_u32(). May I cite you this way: "Tom Lane says PostgreSQL core team doesn't care for 4 socket 72 core Intel Xeon servers" ??? To be honestly, I didn't measure exact impact of changing pg_atomic_fetch_add_u32. I found issue with pg_atomic_fetch_or_u32, cause it is highly contended both in LWLock, and in buffer page state management. I found changing loop for generic pg_atomic_fetch_or_u32 already gives improvement. And I changed loop for other generic atomic functions to make all functions uniform. It is bad style guide not to changing worse (but correct) code into better (and also correct) just because you can't measure difference (in my opinion. Perhaps i am mistaken). (and yes: gcc intrinsic gives more improvement). -- With regards, Sokolov Yura aka funny_falcon Postgres Professional: https://postgrespro.ru The Russian Postgres Company
On 2017-09-06 14:54, Sokolov Yura wrote: > On 2017-09-06 07:23, Tom Lane wrote: >> Jeff Janes <jeff.janes@gmail.com> writes: >>> What scale factor and client count? How many cores per socket? It >>> looks >>> like Sokolov was just starting to see gains at 200 clients on 72 >>> cores, >>> using -N transaction. >> This means that Sokolov's proposed changes in atomics/generic.h >> ought to be uninteresting for performance on any platform we care >> about --- at >> least for pg_atomic_fetch_add_u32(). > > May I cite you this way: I apologize for tone of my previous message. My tongue is my enemy. -- Sokolov Yura aka funny_falcon Postgres Professional: https://postgrespro.ru The Russian Postgres Company
On 5 September 2017 at 21:23, Tom Lane <tgl@sss.pgh.pa.us> wrote: > Jeff Janes <jeff.janes@gmail.com> writes: >> What scale factor and client count? How many cores per socket? It looks >> like Sokolov was just starting to see gains at 200 clients on 72 cores, >> using -N transaction. ... > Moreover, it matters which primitive you're testing, on which platform, > with which compiler, because we have a couple of layers of atomic ops > implementations. ... I think Sokolov was aiming at 4-socket servers specifically, rather than as a general performance gain. If there is no gain on 2-socket, at least there is no loss either. -- Simon Riggs http://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
Simon Riggs <simon@2ndquadrant.com> writes:
> On 5 September 2017 at 21:23, Tom Lane <tgl@sss.pgh.pa.us> wrote:
>> Moreover, it matters which primitive you're testing, on which platform,
>> with which compiler, because we have a couple of layers of atomic ops
>> implementations.
> If there is no gain on 2-socket, at least there is no loss either.
The point I'm trying to make is that if tweaking generic.h improves
performance then it's an indicator of missed cases in the less-generic
atomics code, and the latter is where our attention should be focused.
I think basically all of the improvement Sokolov got was from upgrading
the coverage of generic-gcc.h.
regards, tom lane
On 2017-09-06 15:56, Tom Lane wrote: > Simon Riggs <simon@2ndquadrant.com> writes: >> On 5 September 2017 at 21:23, Tom Lane <tgl@sss.pgh.pa.us> wrote: >>> Moreover, it matters which primitive you're testing, on which >>> platform, >>> with which compiler, because we have a couple of layers of atomic ops >>> implementations. > >> If there is no gain on 2-socket, at least there is no loss either. > > The point I'm trying to make is that if tweaking generic.h improves > performance then it's an indicator of missed cases in the less-generic > atomics code, and the latter is where our attention should be focused. > I think basically all of the improvement Sokolov got was from upgrading > the coverage of generic-gcc.h. > > regards, tom lane Not exactly. I've checked, that new version of generic pg_atomic_fetch_or_u32 loop also gives improvement. Without that check I'd not suggest to fix generic atomic functions. Of course, gcc intrinsic gives more gain. -- Sokolov Yura aka funny_falcon Postgres Professional: https://postgrespro.ru The Russian Postgres Company
Sokolov Yura <funny.falcon@postgrespro.ru> writes:
> On 2017-09-06 15:56, Tom Lane wrote:
>> The point I'm trying to make is that if tweaking generic.h improves
>> performance then it's an indicator of missed cases in the less-generic
>> atomics code, and the latter is where our attention should be focused.
>> I think basically all of the improvement Sokolov got was from upgrading
>> the coverage of generic-gcc.h.
> Not exactly. I've checked, that new version of generic
> pg_atomic_fetch_or_u32
> loop also gives improvement.
But once you put in the generic-gcc version, that's not reached anymore.
regards, tom lane
On 2017-09-06 16:36, Tom Lane wrote: > Sokolov Yura <funny.falcon@postgrespro.ru> writes: >> On 2017-09-06 15:56, Tom Lane wrote: >>> The point I'm trying to make is that if tweaking generic.h improves >>> performance then it's an indicator of missed cases in the >>> less-generic >>> atomics code, and the latter is where our attention should be >>> focused. >>> I think basically all of the improvement Sokolov got was from >>> upgrading >>> the coverage of generic-gcc.h. > >> Not exactly. I've checked, that new version of generic >> pg_atomic_fetch_or_u32 >> loop also gives improvement. > > But once you put in the generic-gcc version, that's not reached > anymore. > Yes, you're right. But I think, generic version still should be "fixed". If generic version is not reached on any platform, then why it is kept? If it is reached somewhere, then it should be improved. -- Sokolov Yura aka funny_falcon Postgres Professional: https://postgrespro.ru The Russian Postgres Company
On Wed, Sep 6, 2017 at 9:42 AM, Sokolov Yura <funny.falcon@postgrespro.ru> wrote: > Yes, you're right. > > But I think, generic version still should be "fixed". > If generic version is not reached on any platform, then why it is kept? > If it is reached somewhere, then it should be improved. This seems like a pretty sound argument to me. I think Tom's probably right that the changes in generic-gcc.h are the important ones, but I'm not sure that's an argument against patching generics.h. Given that pg_atomic_compare_exchange_u32_impl is defined to update *old there seems to be no reason to call pg_atomic_read_u32_impl every time through the loop. Whether doing so hurts performance in practice is likely to depend on a bunch of stuff, but we don't normally refuse to remove unnecessary code on the grounds that it will rarely be reached. Given that CPUs are weird, it's possible that there is some system where throwing an extra read of a value we already have into the loop works out to a win, but in the absence of evidence I'm reluctant to presume it. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
Robert Haas <robertmhaas@gmail.com> writes:
> On Wed, Sep 6, 2017 at 9:42 AM, Sokolov Yura
> <funny.falcon@postgrespro.ru> wrote:
>> But I think, generic version still should be "fixed".
>> If generic version is not reached on any platform, then why it is kept?
>> If it is reached somewhere, then it should be improved.
> This seems like a pretty sound argument to me. I think Tom's probably
> right that the changes in generic-gcc.h are the important ones, but
> I'm not sure that's an argument against patching generics.h. Given
> that pg_atomic_compare_exchange_u32_impl is defined to update *old
> there seems to be no reason to call pg_atomic_read_u32_impl every time
> through the loop.
Probably not. I'm not quite 100% convinced of that, because of my
observation that gcc is capable of generating different and better
code for some of these primitives if it can prove that the return
value is not needed. It's not clear that that could apply in any
of these uses of pg_atomic_compare_exchange_u32_impl, though.
In any case, by my own argument, it shouldn't matter, because if
any of these are really performance-critical then we should be
looking for better ways.
regards, tom lane
On Wed, Sep 6, 2017 at 12:01 PM, Tom Lane <tgl@sss.pgh.pa.us> wrote: >> This seems like a pretty sound argument to me. I think Tom's probably >> right that the changes in generic-gcc.h are the important ones, but >> I'm not sure that's an argument against patching generics.h. Given >> that pg_atomic_compare_exchange_u32_impl is defined to update *old >> there seems to be no reason to call pg_atomic_read_u32_impl every time >> through the loop. > > Probably not. I'm not quite 100% convinced of that, because of my > observation that gcc is capable of generating different and better > code for some of these primitives if it can prove that the return > value is not needed. It's not clear that that could apply in any > of these uses of pg_atomic_compare_exchange_u32_impl, though. > In any case, by my own argument, it shouldn't matter, because if > any of these are really performance-critical then we should be > looking for better ways. It's not a question of whether the return value is used, but of whether the updated value of *old is used. Unless I'm confused. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
Robert Haas <robertmhaas@gmail.com> writes:
> It's not a question of whether the return value is used, but of
> whether the updated value of *old is used.
Right, but if we re-read "old" in the loop, and if the primitive
doesn't return "old" (or does, but call site ignores it) then in
principle the CAS might be strength-reduced a bit. Whether that
can win enough to be better than removing the unlocked read,
I dunno.
In the case at hand, looking at a loop like
while (count-- > 0){ (void) pg_atomic_fetch_or_u32(myptr, 1);}
with our HEAD code and RHEL6's gcc I get this for the inner loop:
.L9:movl (%rdx), %eaxmovl %eax, %ecxorl $1, %ecxlock cmpxchgl %ecx,(%rdx) setz %cl
testb %cl, %clje .L9subq $1, %rbxtestq %rbx, %rbxjg .L9
Applying the proposed generic.h patch, it becomes
.L10:movl (%rsi), %eax
.L9:movl %eax, %ecxorl $1, %ecxlock cmpxchgl %ecx,(%rdx) setz %cl testb
%cl,%clje .L9subq $1, %rbxtestq %rbx, %rbxjg .L10
Note that in both cases the cmpxchgl is coming out of the asm construct in
pg_atomic_compare_exchange_u32_impl from atomics/arch-x86.h, so that even
if a simpler assembly instruction were possible given that we don't need
%eax to be updated, there's no chance of that actually happening. This
gets back to the point I made in the other thread that maybe the
arch-x86.h asm sequences are not an improvement over the gcc intrinsics.
The code is the same if the loop is modified to use the result of
pg_atomic_fetch_or_u32, so I won't bother showing that.
Adding the proposed generic-gcc.h patch, the loop reduces to
.L11:lock orl $1, (%rax)subq $1, %rbxtestq %rbx, %rbxjg .L11
or if we make the loop do junk += pg_atomic_fetch_or_u32(myptr, 1);
then we get
.L13:movl (%rsi), %eax
.L10:movl %eax, %edimovl %eax, %ecxorl $1, %ecxlock cmpxchgl %ecx, (%rdx)jne .L10addl %edi, %r8dsubq
$1, %rbxtestq %rbx, %rbxjg .L13
So that last is slightly better than the generic.h + asm CAS version,
perhaps not meaningfully so --- but it's definitely better when
the compiler can see the result isn't used.
In short then, given the facts on the ground here, in particular the
asm-based CAS primitive at the heart of these loops, it's clear that
taking the read out of the loop can't hurt. But that should be read
as a rather narrow conclusion. With a different compiler and/or a
different version of pg_atomic_compare_exchange_u32_impl, maybe the
answer would be different. And of course it's moot once the
generic-gcc.h patch is applied.
Anyway, I don't have a big objection to applying this. My concern
is more that we need to be taking a harder look at other parts of
the atomics infrastructure, because tweaks there are likely to buy
much more.
regards, tom lane
Hi Jeff, On 09/05/2017 03:47 PM, Jeff Janes wrote: >> I ran pgbench (-M prepared) with synchronous_commit 'on' and 'off' using >> both logged and unlogged tables. Also ran an internal benchmark which >> didn't show anything either. >> > > What scale factor and client count? How many cores per socket? It looks > like Sokolov was just starting to see gains at 200 clients on 72 cores, > using -N transaction. I have done a run with scale factor 300, and another with 3000 on a 2S/28C/56T/256Gb w/ 2 x RAID10 SSD machine; up to 200 clients. I would consider the runs as "noise" as I'm seeing +-1% for all client counts, so nothing like Yura is seeing in [1] for the higher client counts. I did a run with -N too using scale factor 300, using the settings in [1], but with same result (+-1%). [1] https://www.postgresql.org/message-id/d62d7d9d473d07e172d799d5a57e70be@postgrespro.ru Best regards, Jesper
I wrote:
> Anyway, I don't have a big objection to applying this. My concern
> is more that we need to be taking a harder look at other parts of
> the atomics infrastructure, because tweaks there are likely to buy
> much more.
I went ahead and pushed these patches, adding __sync_fetch_and_sub
since gcc seems to provide that on the same footing as these other
functions.
Looking at these generic functions a bit closer, I notice that
most of them are coded like
old = pg_atomic_read_u32_impl(ptr);while (!pg_atomic_compare_exchange_u32_impl(ptr, &old, old | or_)) /* skip */;
but there's an exception: pg_atomic_exchange_u64_impl just does
old = ptr->value;while (!pg_atomic_compare_exchange_u64_impl(ptr, &old, xchg_)) /* skip */;
That's interesting. Why not pg_atomic_read_u64_impl there?
I think that the simple read is actually okay as it stands: if we
are unlucky enough to get a torn read, the first compare/exchange
will fail to compare equal, and it will replace "old" with a valid
atomically-read value, and then the next loop iteration has a chance
to succeed. Therefore there's no need to pay the extra cost of a
locked read instead of an unlocked one.
However, if that's the reasoning, why don't we make all of these
use simple reads? It seems unlikely that a locked read is free.
If there's actually a reason for pg_atomic_exchange_u64_impl to be
different from the rest, it needs to have a comment explaining why.
regards, tom lane
Hi, On 2017-09-06 14:31:26 -0400, Tom Lane wrote: > I wrote: > > Anyway, I don't have a big objection to applying this. My concern > > is more that we need to be taking a harder look at other parts of > > the atomics infrastructure, because tweaks there are likely to buy > > much more. > > I went ahead and pushed these patches, adding __sync_fetch_and_sub > since gcc seems to provide that on the same footing as these other > functions. > > Looking at these generic functions a bit closer, I notice that > most of them are coded like > > old = pg_atomic_read_u32_impl(ptr); > while (!pg_atomic_compare_exchange_u32_impl(ptr, &old, old | or_)) > /* skip */; > > but there's an exception: pg_atomic_exchange_u64_impl just does > > old = ptr->value; > while (!pg_atomic_compare_exchange_u64_impl(ptr, &old, xchg_)) > /* skip */; > > That's interesting. Why not pg_atomic_read_u64_impl there? Because our platforms don't generally guaranatee that 64bit reads: /* * 64 bit reads aren't safe on all platforms. In the generic * implementation implement them as a compare/exchange with0. That'll * fail or succeed, but always return the old value. Possible might store * a 0, but only if the prev. valuealso was a 0 - i.e. harmless. */pg_atomic_compare_exchange_u64_impl(ptr, &old, 0); so I *guess* I decided doing an unnecessary cmpxchg wasn't useful. But since then we've added an optimization for platforms where we know 64bit reads have single copy atomicity. So we could change that now. > I think that the simple read is actually okay as it stands: if we > are unlucky enough to get a torn read, the first compare/exchange > will fail to compare equal, and it will replace "old" with a valid > atomically-read value, and then the next loop iteration has a chance > to succeed. Therefore there's no need to pay the extra cost of a > locked read instead of an unlocked one. > > However, if that's the reasoning, why don't we make all of these > use simple reads? It seems unlikely that a locked read is free. We don't really use locked reads? All the _atomic_ wrapper forces is an actual read from memory rather than a register. Greetings, Andres Freund
Andres Freund <andres@anarazel.de> writes:
> On 2017-09-06 14:31:26 -0400, Tom Lane wrote:
>> However, if that's the reasoning, why don't we make all of these
>> use simple reads? It seems unlikely that a locked read is free.
> We don't really use locked reads? All the _atomic_ wrapper forces is an
> actual read from memory rather than a register.
It looks to me like two of the three implementations promise no such
thing. Even if they somehow do, it hardly matters given that the cmpxchg
loop would be self-correcting. Mostly, though, I'm looking at the
fallback pg_atomic_read_u64_impl implementation (with a CAS), which
seems far more expensive than can be justified for this.
regards, tom lane
On 2017-09-06 15:12:13 -0400, Tom Lane wrote: > Andres Freund <andres@anarazel.de> writes: > > On 2017-09-06 14:31:26 -0400, Tom Lane wrote: > >> However, if that's the reasoning, why don't we make all of these > >> use simple reads? It seems unlikely that a locked read is free. > > > We don't really use locked reads? All the _atomic_ wrapper forces is an > > actual read from memory rather than a register. > > It looks to me like two of the three implementations promise no such > thing. They're volatile vars, so why not? > Even if they somehow do, it hardly matters given that the cmpxchg loop > would be self-correcting. Well, in this one instance maybe, hardly in others. > Mostly, though, I'm looking at the fallback pg_atomic_read_u64_impl > implementation (with a CAS), which seems far more expensive than can > be justified for this. What are you suggesting as an alternative? - Andres
Andres Freund <andres@anarazel.de> writes:
> On 2017-09-06 15:12:13 -0400, Tom Lane wrote:
>> It looks to me like two of the three implementations promise no such
>> thing.
> They're volatile vars, so why not?
Yeah, but so are the caller's variables. That is, in
pg_atomic_exchange_u64_impl(volatile pg_atomic_uint64 *ptr, uint64 xchg_)
{uint64 old;old = ptr->value;
ISTM that the compiler is required to actually fetch ptr->value, not
rely on some previous read of it. I do not think that (the first
version of) pg_atomic_read_u64_impl is adding any guarantee that wasn't
there already.
>> Even if they somehow do, it hardly matters given that the cmpxchg loop
>> would be self-correcting.
> Well, in this one instance maybe, hardly in others.
All the functions involved use nigh-identical cmpxchg loops.
> What are you suggesting as an alternative?
I think we can just use "old = ptr->value" to set up for the cmpxchg
loop in every generic.h function that uses such a loop.
regards, tom lane
On 2017-09-06 15:25:20 -0400, Tom Lane wrote:
> Andres Freund <andres@anarazel.de> writes:
> > On 2017-09-06 15:12:13 -0400, Tom Lane wrote:
> >> It looks to me like two of the three implementations promise no such
> >> thing.
>
> > They're volatile vars, so why not?
>
> Yeah, but so are the caller's variables. That is, in
>
> pg_atomic_exchange_u64_impl(volatile pg_atomic_uint64 *ptr, uint64 xchg_)
> {
> uint64 old;
> old = ptr->value;
>
> ISTM that the compiler is required to actually fetch ptr->value, not
> rely on some previous read of it. I do not think that (the first
> version of) pg_atomic_read_u64_impl is adding any guarantee that wasn't
> there already.
>
> >> Even if they somehow do, it hardly matters given that the cmpxchg loop
> >> would be self-correcting.
>
> > Well, in this one instance maybe, hardly in others.
>
> All the functions involved use nigh-identical cmpxchg loops.
>
> > What are you suggesting as an alternative?
>
> I think we can just use "old = ptr->value" to set up for the cmpxchg
> loop in every generic.h function that uses such a loop.
I think we might have been talking past each other - I thought you were
talking about changing the pg_atomic_read_u64_impl implementation for
external users.
Greetings,
Andres Freund
Andres Freund <andres@anarazel.de> writes:
> On 2017-09-06 15:25:20 -0400, Tom Lane wrote:
>> I think we can just use "old = ptr->value" to set up for the cmpxchg
>> loop in every generic.h function that uses such a loop.
> I think we might have been talking past each other - I thought you were
> talking about changing the pg_atomic_read_u64_impl implementation for
> external users.
Ah. I was not thinking of touching pg_atomic_read_u32/u64_impl,
although now that you mention it, it's not clear to me why we
couldn't simplify
- return *(&ptr->value);
+ return ptr->value;
AFAIK, the compiler is entitled to, and does, simplify away that
take-a-pointer-and-immediately-dereference-it dance. If it did
not, a whole lot of standard array locutions would be much less
efficient than they should be. What matters here is the volatile
qualifier, which we've already got.
regards, tom lane
I wrote:
> Ah. I was not thinking of touching pg_atomic_read_u32/u64_impl,
> although now that you mention it, it's not clear to me why we
> couldn't simplify
> - return *(&ptr->value);
> + return ptr->value;
Just to check, I applied that change to pg_atomic_read_u32_impl and
pg_atomic_read_u64_impl, and recompiled. I get bit-for-bit the
same backend executable. Maybe it would have an effect on some
other compiler, but I doubt it, except perhaps at -O0.
regards, tom lane