Thread: Proposal: scan key push down to heap [WIP]
Hi Hackers,
I would like to propose a patch for pushing down the scan key to heap.
Currently only in case of system table scan keys are pushed down. I
have implemented the POC patch to do the same for normal table scan.
This patch will extract the expression from qual and prepare the scan
keys. Currently in POC version I have only supported "var OP const"
type of qual, because these type of quals can be pushed down using
existing framework.
Purpose of this work is to first implement the basic functionality and
analyze the results. If results are good then we can extend it for
other type of expressions.
However in future when we try to expand the support for complex
expressions, then we need to be very careful while selecting
pushable expression. It should not happen that we push something very
complex, which may cause contention with other write operation (as
HeapKeyTest is done under page lock).
Performance Test: (test done in local machine, with all default setting).
Setup:
----------
create table test(a int, b varchar, c varchar, d int);
insert into test values(generate_series(1,10000000), repeat('x', 30),
repeat('y', 30), generate_series(1,10000000));
analyze test;
Test query:
--------------
select count(*) from test where a < $1;
Results: (execution time in ms)
------------
Selectivity Head(ms) Patch(ms) gain
0.01 612 307 49%
0.1 623 353 43%
0.2 645 398 38%
0.5 780 535 31%
0.8 852 590 30%
1 913 730 20%
Instructions: (Cpu instructions measured with callgrind tool):
Quary : select count(*) from test where a < 100000;
Head: 10,815,730,925
Patch: 4,780,047,331
Summary:
--------------
1. ~50% reduction in both instructions as well as execution time.
2. Here we can see ~ 20% execution time reduction even at selectivity
1 (when all tuples are selected). And, reasoning for the same can be
that HeapKeyTest is much simplified compared to ExecQual. It's
possible that in future when we try to support more variety of keys,
gain at high selectivity may come down.
WIP patch attached..
Thoughts ?
--
Regards,
Dilip Kumar
EnterpriseDB: http://www.enterprisedb.com
Attachment
{kind=link}
On Tue, Oct 11, 2016 at 4:57 AM, Dilip Kumar <dilipbalaut@gmail.com> wrote: > This patch will extract the expression from qual and prepare the scan > keys. Currently in POC version I have only supported "var OP const" > type of qual, because these type of quals can be pushed down using > existing framework. > > Purpose of this work is to first implement the basic functionality and > analyze the results. If results are good then we can extend it for > other type of expressions. > > However in future when we try to expand the support for complex > expressions, then we need to be very careful while selecting > pushable expression. It should not happen that we push something very > complex, which may cause contention with other write operation (as > HeapKeyTest is done under page lock). I seriously doubt that this should EVER be supported for anything other than "var op const", and even then only for very simple operators. For example, texteq() is probably too complicated, because it might de-TOAST, and that might involve doing a LOT of work while holding the buffer content lock. But int4eq() would be OK. Part of the trick if we want to make this work is going to be figuring out how we'll identify which operators are safe. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On Thu, Oct 13, 2016 at 6:05 AM, Robert Haas <robertmhaas@gmail.com> wrote: > I seriously doubt that this should EVER be supported for anything > other than "var op const", and even then only for very simple > operators. Yes, with existing key push down infrastructure only "var op const", but If we extend that I think we can cover many other simple expressions, i.e Unary Operator : ISNULL, NOTNULL Other Simple expression : "Var op Const", "Var op Var", "Var op SimpleExpr(Var, Const)" .. We can not push down function expression because we can not guarantee that they are safe, but can we pushdown inbuilt functions ? (I think we can identify their safety based on their data type, but I am not too sure about this point). For example, texteq() is probably too complicated, because > it might de-TOAST, and that might involve doing a LOT of work while > holding the buffer content lock. But int4eq() would be OK. > > Part of the trick if we want to make this work is going to be figuring > out how we'll identify which operators are safe. Yes, I agree that's the difficult part. Can't we process full qual list and decide decide the operator are safe or not based on their datatype ? What I mean to say is instead of checking safety of each operator like texteq(), text_le()... we can directly discard any operator involving such kind of data types. -- Regards, Dilip Kumar EnterpriseDB: http://www.enterprisedb.com
Dilip Kumar <dilipbalaut@gmail.com> writes:
> On Thu, Oct 13, 2016 at 6:05 AM, Robert Haas <robertmhaas@gmail.com> wrote:
>> I seriously doubt that this should EVER be supported for anything
>> other than "var op const", and even then only for very simple
>> operators.
> Yes, with existing key push down infrastructure only "var op const",
> but If we extend that I think we can cover many other simple
> expressions, i.e
I think it is a mistake to let this idea drive any additional
complication of the ScanKey data structure. That will have negative
impacts on indexscan performance, not to mention require touching
quite a lot of unrelated code. And as Robert points out, we do not
want to execute anything expensive while holding the buffer LWLock.
>> Part of the trick if we want to make this work is going to be figuring
>> out how we'll identify which operators are safe.
> Yes, I agree that's the difficult part. Can't we process full qual
> list and decide decide the operator are safe or not based on their
> datatype ?
Possibly restricting it to builtin, immutable functions on non-toastable
data types would do. Or for more safety, only allow pass-by-value data
types. But I have a feeling that there might still be counterexamples.
regards, tom lane
Hi,
On 2016-10-11 17:27:56 +0530, Dilip Kumar wrote:
> I would like to propose a patch for pushing down the scan key to heap.
I think that makes sense. Both because scankey eval is faster than
generic expression eval, and because it saves a lot of function calls in
heavily filtered cases.
> However in future when we try to expand the support for complex
> expressions, then we need to be very careful while selecting
> pushable expression. It should not happen that we push something very
> complex, which may cause contention with other write operation (as
> HeapKeyTest is done under page lock).
I don't think it's a good idea to do this under the content lock in any
case. But luckily I don't think we have to do so at all.
Due to pagemode - which is used by pretty much everything iterating over
heaps, and definitely seqscans - the key test already happens without
the content lock held, in heapgettup_pagemode():
/** ----------------* heapgettup_pagemode - fetch next heap tuple in page-at-a-time mode** Same API as
heapgettup,but used in page-at-a-time mode** The internal logic is much the same as heapgettup's too, but there are
some*differences: *****we do not take the buffer content lock**** (that only needs to* happen inside heapgetpage), and
weiterate through just the tuples listed* in rs_vistuples[] rather than all tuples on the page. Notice that* lineindex
is0-based, where the corresponding loop variable lineoff in* heapgettup is 1-based.* ----------------*/
static void
heapgettup_pagemode(HeapScanDesc scan, ScanDirection dir, int nkeys,
ScanKeykey)
.../* * advance the scan until we find a qualifying tuple or run out of stuff * to scan */for (;;){ while (linesleft
>0) { lineoff = scan->rs_vistuples[lineindex]; lpp = PageGetItemId(dp, lineoff);
Assert(ItemIdIsNormal(lpp));
... /* * if current tuple qualifies, return it. */ if (key != NULL) {
bool valid;
HeapKeyTest(tuple, RelationGetDescr(scan->rs_rd), nkeys, key, valid); if
(valid) { scan->rs_cindex = lineindex; return; } }
> Instructions: (Cpu instructions measured with callgrind tool):
Note that callgrind's numbers aren't very meaningful in these days. CPU
pipelining and speculative execution/reordering makes them very
inaccurate.
Greetings,
Andres Freund
On Fri, Oct 14, 2016 at 11:54 AM, Andres Freund <andres@anarazel.de> wrote: > I don't think it's a good idea to do this under the content lock in any > case. But luckily I don't think we have to do so at all. > > Due to pagemode - which is used by pretty much everything iterating over > heaps, and definitely seqscans - the key test already happens without > the content lock held, in heapgettup_pagemode(): Yes, you are right. Now after this clarification, it's clear that even we push down the key we are not evaluating it under buffer content lock. As of now, I have done my further analysis by keeping in mind only pushing 'var op const'. Below are my observations. #1. If we process the qual in executor, all temp memory allocation are under "per_tuple_context" which get reset after each tuple process. But, on other hand if we do that in heap, then that will be under "per_query_context". This restrict us to pushdown any qual which need to do memory allocations like "toastable" field. Is there any other way to handle this ? #2. Currently quals are ordered based on cost (refer order_qual_clauses), But once we pushdown some of the quals, then those quals will always be executed first. Can this create problem ? consider below example.. create or replace function f1(anyelement) returns bool as $$ begin raise notice '%', $1; return true; end; $$ LANGUAGE plpgsql cost 0.01; select * from t3 where a>1 and f1(b); In this case "f1(b)" will always be executed as first qual (cost is set very low by user) hence it will raise notice for all the tuple. But if we pushdown "a>1" qual to heap then only qualified tuple will be passed to "f1(b)". Is it behaviour change ? I know that, it can also impact the performance, because when user has given some function with very low cost then that should be executed first as it may discard most of the tuple. One solution to this can be.. 1. Only pushdown if either all quals are of same cost. 2. Pushdown all quals until we find first non pushable qual (this way we can maintain the same qual execution order what is there in existing system). -- Regards, Dilip Kumar EnterpriseDB: http://www.enterprisedb.com
Dilip Kumar wrote: > #2. Currently quals are ordered based on cost (refer > order_qual_clauses), But once we pushdown some of the quals, then > those quals will always be executed first. Can this create problem ? We don't promise order of execution (which is why we can afford to sort on cost), but I think it makes sense to keep a rough ordering based on cost, and not let this push-down affect those ordering decisions too much. I think it's fine to push-down quals that are within the same order of magnitude of the cost of a pushable condition, while keeping any other much-costlier qual (which could otherwise be pushed down) together with non-pushable conditions; this would sort-of guarantee within-order-of- magnitude order of execution of quals. Hopefully an example clarifies what I mean. Let's suppose you have three quals, where qual2 is non-pushable but 1 and 3 are. cost(1)=10, cost(2)=11, cost(3)=12. Currently, they are executed in that order. If you were to compare costs in the straightforward way, you would push only 1 (because 3 is costlier than 2 which is not push-down-able). With fuzzy comparisons, you'd push both 1 and 3, because cost of 3 is close enough to that of qual 2. But if cost(3)=100 then only push qual 1, and let qual 3 be evaluated together with 2 outside the scan node. BTW, should we cost push-down-able quals differently, say discount some fraction of the cost, to reflect the fact that they are cheaper to run? However, since the decision of which ones to push down depends on the cost, and the cost would depend on which ones we push down, it looks rather messy. -- Álvaro Herrera https://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
Alvaro Herrera <alvherre@2ndquadrant.com> writes:
> BTW, should we cost push-down-able quals differently, say discount some
> fraction of the cost, to reflect the fact that they are cheaper to run?
> However, since the decision of which ones to push down depends on the
> cost, and the cost would depend on which ones we push down, it looks
> rather messy.
I don't think our cost model is anywhere near refined enough to make it
worth trying to distinguish that. (Frankly, I'm pretty skeptical of this
entire patch being worth the trouble...)
regards, tom lane
On Tue, Oct 25, 2016 at 10:35 PM, Alvaro Herrera <alvherre@2ndquadrant.com> wrote: > We don't promise order of execution (which is why we can afford to sort > on cost), but I think it makes sense to keep a rough ordering based on > cost, and not let this push-down affect those ordering decisions too > much. Ok, Thanks for clarification. > > I think it's fine to push-down quals that are within the same order of > magnitude of the cost of a pushable condition, while keeping any other > much-costlier qual (which could otherwise be pushed down) together with > non-pushable conditions; this would sort-of guarantee within-order-of- > magnitude order of execution of quals. > > Hopefully an example clarifies what I mean. Let's suppose you have > three quals, where qual2 is non-pushable but 1 and 3 are. cost(1)=10, > cost(2)=11, cost(3)=12. Currently, they are executed in that order. > > If you were to compare costs in the straightforward way, you would push > only 1 (because 3 is costlier than 2 which is not push-down-able). With > fuzzy comparisons, you'd push both 1 and 3, because cost of 3 is close > enough to that of qual 2. > > But if cost(3)=100 then only push qual 1, and let qual 3 be evaluated > together with 2 outside the scan node. After putting more thought on this, IMHO it need not to be so complicated. Currently we are talking about pushing only "var op const", and cost of all such functions are very low and fixed "1". Do we really need to take care of any user defined function which is declared with very low cost ? Because while building index conditions also we don't take care of such things. Index conditions will always we evaluated first then only filter will be applied. Am I missing something ? -- Regards, Dilip Kumar EnterpriseDB: http://www.enterprisedb.com
On 2016-10-25 13:18:47 -0400, Tom Lane wrote: > (Frankly, I'm pretty skeptical of this entire patch being worth the > trouble...) The gains are quite noticeable in some cases. So if we can make it work without noticeable downsides... What I'm worried about though is that this, afaics, will quite noticeably *increase* total cost in cases with a noticeable number of columns and a not that selective qual. The reason for that being that HeapKeyTest() uses heap_getattr(), whereas upper layers use slot_getattr(). The latter "caches" repeated deforms, the former doesn't... That'll lead to deforming being essentially done twice, and it's quite often already a major cost of query processing.
On Wed, Oct 26, 2016 at 12:01 PM, Andres Freund <andres@anarazel.de> wrote: > On 2016-10-25 13:18:47 -0400, Tom Lane wrote: >> (Frankly, I'm pretty skeptical of this entire patch being worth the >> trouble...) > > The gains are quite noticeable in some cases. So if we can make it work > without noticeable downsides... > +1. > What I'm worried about though is that this, afaics, will quite > noticeably *increase* total cost in cases with a noticeable number of > columns and a not that selective qual. The reason for that being that > HeapKeyTest() uses heap_getattr(), whereas upper layers use > slot_getattr(). The latter "caches" repeated deforms, the former > doesn't... That'll lead to deforming being essentially done twice, and > it's quite often already a major cost of query processing. > heap_getattr() also has some caching mechanism to cache the tuple offset , however it might not be as good as slot_getattr(). I think if we decide to form the scan key from a qual only when qual refers to fixed length column and that column is before any varlen column, the increased cost will be alleviated. Do you have any other idea to alleviate such cost? -- With Regards, Amit Kapila. EnterpriseDB: http://www.enterprisedb.com
On 2016-10-28 11:23:22 +0530, Amit Kapila wrote: > On Wed, Oct 26, 2016 at 12:01 PM, Andres Freund <andres@anarazel.de> wrote: > > What I'm worried about though is that this, afaics, will quite > > noticeably *increase* total cost in cases with a noticeable number of > > columns and a not that selective qual. The reason for that being that > > HeapKeyTest() uses heap_getattr(), whereas upper layers use > > slot_getattr(). The latter "caches" repeated deforms, the former > > doesn't... That'll lead to deforming being essentially done twice, and > > it's quite often already a major cost of query processing. > > > > heap_getattr() also has some caching mechanism to cache the tuple > offset , however it might not be as good as slot_getattr(). It's most definitely not as good. In fact, my measurements show it to be a net negative in a number of cases. > I think if we decide to form the scan key from a qual only when qual > refers to fixed length column and that column is before any varlen > column, the increased cost will be alleviated. Do you have any other > idea to alleviate such cost? Well, that'll also make the feature not particularly useful :(. My suspicion is that the way to suceed here isn't to rely more on testing as part of the scan, but create a more general fastpath for qual evaluation, which atm is a *LOT* more heavyweight than what HeapKeyTest() does. But maybe I'm biased since I'm working on the latter... Andres
On Fri, Oct 28, 2016 at 12:16 PM, Andres Freund <andres@anarazel.de> wrote: > On 2016-10-28 11:23:22 +0530, Amit Kapila wrote: > >> I think if we decide to form the scan key from a qual only when qual >> refers to fixed length column and that column is before any varlen >> column, the increased cost will be alleviated. Do you have any other >> idea to alleviate such cost? > > Well, that'll also make the feature not particularly useful :(. > Yeah, the number of cases it can benefit will certainly reduce, but still it can be a win wherever it can be used which is not bad. Another thing that can be considered here is to evaluate if we can use selectivity as a measure to decide if we can push the quals down. If the quals are selective, then I think the non-effective caching impact can be negated and we can in turn see benefits. For example, we can consider a table with 20 to 40 columns having large number of rows and try to use different columns in quals and then test it for different selectivity to see how the performance varies with this patch. -- With Regards, Amit Kapila. EnterpriseDB: http://www.enterprisedb.com
On Wed, Oct 26, 2016 at 12:01 PM, Andres Freund <andres@anarazel.de> wrote:
> The gains are quite noticeable in some cases. So if we can make it work
> without noticeable downsides...
>
> What I'm worried about though is that this, afaics, will quite
> noticeably *increase* total cost in cases with a noticeable number of
> columns and a not that selective qual. The reason for that being that
> HeapKeyTest() uses heap_getattr(), whereas upper layers use
> slot_getattr(). The latter "caches" repeated deforms, the former
> doesn't... That'll lead to deforming being essentially done twice, and
> it's quite often already a major cost of query processing.
What about putting slot reference inside HeapScanDesc ?. I know it
will make ,heap layer use executor structure but just a thought.
I have quickly hacked this way where we use slot reference in
HeapScanDesc and directly use
slot_getattr inside HeapKeyTest (only if we have valid slot otherwise
use _heap_getattr) and measure the worst case performance (what you
have mentioned above.)
My Test: (21 column table with varchar in beginning + qual is on last
few column + varying selectivity )
postgres=# \d test
Table "public.test"
Column | Type | Modifiers
--------+-------------------+-----------
f1 | integer |
f2 | character varying |
f3 | integer |
f4 | integer |
f5 | integer |
f6 | integer |
f7 | integer |
f8 | integer |
f9 | integer |
f10 | integer |
f11 | integer |
f12 | integer |
f13 | integer |
f14 | integer |
f15 | integer |
f16 | integer |
f17 | integer |
f18 | integer |
f19 | integer |
f20 | integer |
f21 | integer |
tuple count : 10000000 (10 Million)
explain analyze select * from test where f21< $1 and f20 < $1 and f19
< $1 and f15 < $1 and f10 < $1; ($1 vary from 1Million to 1Million).
Target code base:
-----------------------
1. Head
2. Heap_scankey_pushdown_v1
3. My hack for keeping slot reference in HeapScanDesc
(v1+use_slot_in_HeapKeyTest)
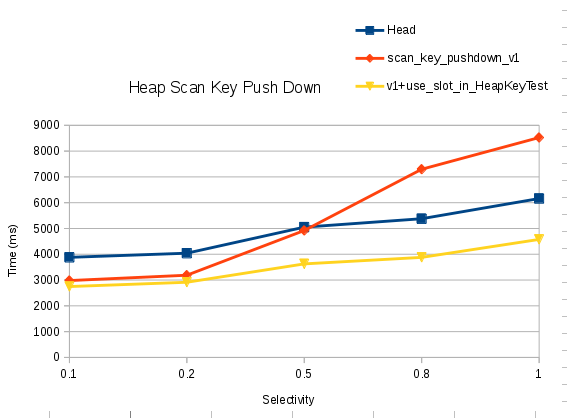
Result:
Selectivity Head scan_key_pushdown_v1 v1+use_slot_in_HeapKeyTest
0.1 3880 2980 2747
0.2 4041 3187 2914
0.5 5051 4921 3626
0.8 5378 7296 3879
1.0 6161 8525 4575
Performance graph is attached in the mail..
Observation:
----------------
1. Heap_scankey_pushdown_v1, start degrading after very high
selectivity (this behaviour is only visible if table have 20 or more
columns, I tested with 10 columns but with that I did not see any
regression in v1).
2. (v1+use_slot_in_HeapKeyTest) is always winner, even at very high selectivity.
--
Regards,
Dilip Kumar
EnterpriseDB: http://www.enterprisedb.com
Attachment
{kind=link}
On Fri, Oct 28, 2016 at 2:46 AM, Andres Freund <andres@anarazel.de> wrote: > Well, that'll also make the feature not particularly useful :(. My > suspicion is that the way to suceed here isn't to rely more on testing > as part of the scan, but create a more general fastpath for qual > evaluation, which atm is a *LOT* more heavyweight than what > HeapKeyTest() does. But maybe I'm biased since I'm working on the > latter... I think you might be right, but I'm not very clear on what the timeline for your work is. It would be easier to say, sure, let's put this on hold if we knew that in a month or two we could come back and retest after you've made some progress. But I don't know whether we're talking about months or years. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On 2016-10-31 09:28:00 -0400, Robert Haas wrote: > On Fri, Oct 28, 2016 at 2:46 AM, Andres Freund <andres@anarazel.de> wrote: > > Well, that'll also make the feature not particularly useful :(. My > > suspicion is that the way to suceed here isn't to rely more on testing > > as part of the scan, but create a more general fastpath for qual > > evaluation, which atm is a *LOT* more heavyweight than what > > HeapKeyTest() does. But maybe I'm biased since I'm working on the > > latter... > > I think you might be right, but I'm not very clear on what the > timeline for your work is. Me neither. But I think if we can stomach Dilip's approach of using a slot in heapam, then I think my concerns are addressed, and this is probably going go to be a win regardless of faster expression evaluation and/or batching. > It would be easier to say, sure, let's put > this on hold if we knew that in a month or two we could come back and > retest after you've made some progress. But I don't know whether > we're talking about months or years. I sure hope it's months. Andres
> -----Original Message----- > From: pgsql-hackers-owner@postgresql.org > [mailto:pgsql-hackers-owner@postgresql.org] On Behalf Of Dilip Kumar > Sent: Saturday, October 29, 2016 3:48 PM > To: Andres Freund > Cc: Tom Lane; Alvaro Herrera; pgsql-hackers > Subject: Re: [HACKERS] Proposal: scan key push down to heap [WIP] > > On Wed, Oct 26, 2016 at 12:01 PM, Andres Freund <andres@anarazel.de> wrote: > > The gains are quite noticeable in some cases. So if we can make it work > > without noticeable downsides... > > > > What I'm worried about though is that this, afaics, will quite > > noticeably *increase* total cost in cases with a noticeable number of > > columns and a not that selective qual. The reason for that being that > > HeapKeyTest() uses heap_getattr(), whereas upper layers use > > slot_getattr(). The latter "caches" repeated deforms, the former > > doesn't... That'll lead to deforming being essentially done twice, and > > it's quite often already a major cost of query processing. > > What about putting slot reference inside HeapScanDesc ?. I know it > will make ,heap layer use executor structure but just a thought. > > I have quickly hacked this way where we use slot reference in > HeapScanDesc and directly use > slot_getattr inside HeapKeyTest (only if we have valid slot otherwise > use _heap_getattr) and measure the worst case performance (what you > have mentioned above.) > > My Test: (21 column table with varchar in beginning + qual is on last > few column + varying selectivity ) > > postgres=# \d test > Table "public.test" > Column | Type | Modifiers > --------+-------------------+----------- > f1 | integer | > f2 | character varying | > f3 | integer | > f4 | integer | > f5 | integer | > f6 | integer | > f7 | integer | > f8 | integer | > f9 | integer | > f10 | integer | > f11 | integer | > f12 | integer | > f13 | integer | > f14 | integer | > f15 | integer | > f16 | integer | > f17 | integer | > f18 | integer | > f19 | integer | > f20 | integer | > f21 | integer | > > tuple count : 10000000 (10 Million) > explain analyze select * from test where f21< $1 and f20 < $1 and f19 > < $1 and f15 < $1 and f10 < $1; ($1 vary from 1Million to 1Million). > > Target code base: > ----------------------- > 1. Head > 2. Heap_scankey_pushdown_v1 > 3. My hack for keeping slot reference in HeapScanDesc > (v1+use_slot_in_HeapKeyTest) > > Result: > Selectivity Head scan_key_pushdown_v1 v1+use_slot_in_HeapKeyTest > 0.1 3880 2980 2747 > 0.2 4041 3187 2914 > 0.5 5051 4921 3626 > 0.8 5378 7296 3879 > 1.0 6161 8525 4575 > > Performance graph is attached in the mail.. > > Observation: > ---------------- > 1. Heap_scankey_pushdown_v1, start degrading after very high > selectivity (this behaviour is only visible if table have 20 or more > columns, I tested with 10 columns but with that I did not see any > regression in v1). > > 2. (v1+use_slot_in_HeapKeyTest) is always winner, even at very high selectivity. > Prior to this interface change, it may be a starting point to restrict scan key pushdown only when OpExpr references the column with static attcacheoff. This type of column does not need walks on tuples from the head, thus, tuple deforming cost will not be a downside. By the way, I'm a bit skeptical whether this enhancement is really beneficial than works for this enhancement, because we can now easily increase the number of processor cores to run seq-scan with qualifier, especially, when it has high selectivity. How about your thought? Thanks, -- NEC OSS Promotion Center / PG-Strom Project KaiGai Kohei <kaigai@ak.jp.nec.com>
On Sat, Oct 29, 2016 at 12:17 PM, Dilip Kumar <dilipbalaut@gmail.com> wrote: > What about putting slot reference inside HeapScanDesc ?. I know it > will make ,heap layer use executor structure but just a thought. > > I have quickly hacked this way where we use slot reference in > HeapScanDesc and directly use > slot_getattr inside HeapKeyTest (only if we have valid slot otherwise > use _heap_getattr) and measure the worst case performance (what you > have mentioned above.) > > My Test: (21 column table with varchar in beginning + qual is on last > few column + varying selectivity ) > > postgres=# \d test > Table "public.test" > Column | Type | Modifiers > --------+-------------------+----------- > f1 | integer | > f2 | character varying | > f3 | integer | > f4 | integer | > f5 | integer | > f6 | integer | > f7 | integer | > f8 | integer | > f9 | integer | > f10 | integer | > f11 | integer | > f12 | integer | > f13 | integer | > f14 | integer | > f15 | integer | > f16 | integer | > f17 | integer | > f18 | integer | > f19 | integer | > f20 | integer | > f21 | integer | > > tuple count : 10000000 (10 Million) > explain analyze select * from test where f21< $1 and f20 < $1 and f19 > < $1 and f15 < $1 and f10 < $1; ($1 vary from 1Million to 1Million). > > Target code base: > ----------------------- > 1. Head > 2. Heap_scankey_pushdown_v1 > 3. My hack for keeping slot reference in HeapScanDesc > (v1+use_slot_in_HeapKeyTest) > > Result: > Selectivity Head scan_key_pushdown_v1 v1+use_slot_in_HeapKeyTest > 0.1 3880 2980 2747 > 0.2 4041 3187 2914 > 0.5 5051 4921 3626 > 0.8 5378 7296 3879 > 1.0 6161 8525 4575 > > Performance graph is attached in the mail.. > > Observation: > ---------------- > 1. Heap_scankey_pushdown_v1, start degrading after very high > selectivity (this behaviour is only visible if table have 20 or more > columns, I tested with 10 columns but with that I did not see any > regression in v1). > > 2. (v1+use_slot_in_HeapKeyTest) is always winner, even at very high selectivity. The patch is attached for this (storing slot reference in HeapScanDesc).. -- Regards, Dilip Kumar EnterpriseDB: http://www.enterprisedb.com
Attachment
On Tue, Nov 1, 2016 at 8:31 PM, Kouhei Kaigai <kaigai@ak.jp.nec.com> wrote: > By the way, I'm a bit skeptical whether this enhancement is really beneficial > than works for this enhancement, because we can now easily increase the number > of processor cores to run seq-scan with qualifier, especially, when it has high > selectivity. > How about your thought? Are you saying we don't need to both making sequential scans faster because we could just use parallel sequential scan instead? That doesn't sound right to me. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
I have done performance analysis for TPCH queries, I saw visible gain
in 5 queries (10-25%).
Performance Data:
Benchmark : TPCH (S.F. 10)
shared_buffer : 20GB
work_mem : 50MB
Machine : POWER
Results are median of three run (explain analyze results for both
head/patch are attached in TPCH_out.tar).
Query Execution Time in (ms)
Head Patch Improvement
Q3 18475 16558 10%
Q4 7526 5856 22%
Q7 19386 17425 10%
Q10 16994 15019 11%
Q12 13852 10117 26%
Currently we had two major problems about this patch..
Problem1: As Andres has mentioned, HeapKeyTest uses heap_getattr,
whereas ExecQual use slot_getattr().So we can have worst case
performance problem when very less tuple are getting filter out and we
have table with many columns with qual on most of the columns.
Problem2. In HeapKeyTest we are under per_query_ctx, whereas in
ExecQual we are under per_tuple_ctx , so in former we can not afford
to have any palloc.
In this patch I have address both the concern by exposing executor
information to heap (I exposed per_tuple_ctx and slot to HeapDesc),
which is not a very good design.
I have other ideas in mind for solving these concerns, please provide
your thoughts..
For problem1 :
I think it's better to give task of key push down to optimizer, there
we can actually take the decision mostly based on two parameters.
1. Selectivity.
2. Column number on which qual is given.
For problem2 :
I think for solving this we need to limit the number of datatype we
pushdown to heap (I mean we can push all datatype which don't need
palloc in qual test).
1. Don't push down datatype with variable length.
2. Some other datatype with fixed length like 'name' can also
palloc (i.e nameregexeq). so we need to block them as well.
*Note: For exactly understanding which key is pushed down in below
attached exact analyze output, refer this example..
without patch:
-> Parallel Seq Scan on orders (cost=0.00..369972.00 rows=225038
width=20) (actual time=0.025..3216.157 rows=187204 loops=3)
Filter: ((o_orderdate >= '1995-01-01'::date) AND
(o_orderdate < '1995-04-01 00:00:00'::timestamp without time zone))
Rows Removed by Filter: 4812796
with patch:
-> Parallel Seq Scan on orders (cost=0.00..369972.00 rows=225038
width=20) (actual time=0.015..1884.993 rows=187204 loops=3)
Filter: ((o_orderdate >= '1995-01-01'::date) AND
(o_orderdate < '1995-04-01 00:00:00'::timestamp without time zone))
1. So basically on head it shows how many rows are discarded by filter
(Rows Removed by Filter: 4812796), Now if we pushdown all the keys
then it will not show this value.
2. We can also check how much actual time reduced in the SeqScan node.
(i.e in above example on head it was 3216.157 whereas with patch it
was 1884.993).
--
Regards,
Dilip Kumar
EnterpriseDB: http://www.enterprisedb.com
On Thu, Nov 3, 2016 at 7:29 PM, Robert Haas <robertmhaas@gmail.com> wrote:
> On Tue, Nov 1, 2016 at 8:31 PM, Kouhei Kaigai <kaigai@ak.jp.nec.com> wrote:
>> By the way, I'm a bit skeptical whether this enhancement is really beneficial
>> than works for this enhancement, because we can now easily increase the number
>> of processor cores to run seq-scan with qualifier, especially, when it has high
>> selectivity.
>> How about your thought?
>
> Are you saying we don't need to both making sequential scans faster
> because we could just use parallel sequential scan instead? That
> doesn't sound right to me.
>
> --
> Robert Haas
> EnterpriseDB: http://www.enterprisedb.com
> The Enterprise PostgreSQL Company
--
Regards,
Dilip Kumar
EnterpriseDB: http://www.enterprisedb.com
Attachment
On Sun, Nov 13, 2016 at 12:16 AM, Dilip Kumar <dilipbalaut@gmail.com> wrote: > Problem1: As Andres has mentioned, HeapKeyTest uses heap_getattr, > whereas ExecQual use slot_getattr().So we can have worst case > performance problem when very less tuple are getting filter out and we > have table with many columns with qual on most of the columns. > > Problem2. In HeapKeyTest we are under per_query_ctx, whereas in > ExecQual we are under per_tuple_ctx , so in former we can not afford > to have any palloc. Couldn't we just change the current memory context before calling heap_getnext()? And then change back? Also, what if we abandoned the idea of pushing qual evaluation all the way down into the heap and just tried to do HeapKeyTest in SeqNext itself? Would that be almost as fast, or would it give up most of the benefits? -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On Mon, Nov 14, 2016 at 9:30 PM, Robert Haas <robertmhaas@gmail.com> wrote: > Couldn't we just change the current memory context before calling > heap_getnext()? And then change back? Right, seems like it will not have any problem.. > > Also, what if we abandoned the idea of pushing qual evaluation all the > way down into the heap and just tried to do HeapKeyTest in SeqNext > itself? Would that be almost as fast, or would it give up most of the > benefits? This we can definitely test. I will test and post the data. Thanks for the suggestion. -- Regards, Dilip Kumar EnterpriseDB: http://www.enterprisedb.com
On Mon, Nov 14, 2016 at 9:44 PM, Dilip Kumar <dilipbalaut@gmail.com> wrote:
>> Also, what if we abandoned the idea of pushing qual evaluation all the
>> way down into the heap and just tried to do HeapKeyTest in SeqNext
>> itself? Would that be almost as fast, or would it give up most of the
>> benefits?
> This we can definitely test. I will test and post the data.
>
> Thanks for the suggestion.
Here are some results with this approach...
create table test(a int, b varchar, c varchar, d int);
insert into test values(generate_series(1,10000000), repeat('x', 30),
repeat('y', 30), generate_series(1,10000000));
analyze test;
query: explain analyze select * from test where a < $1;
selectivity head patch1 patch2 patch3
10.00% 840 460 582 689
20.00% 885 563 665 752
50.00% 1076 786 871 910
80.00% 1247 988 1055 1099
100.00% 1386 1123 1193 1237
patch1: Original patch (heap_scankey_pushdown_v1.patch), only
supported for fixed length datatype and use heap_getattr.
patch2: Switches memory context in HeapKeyTest + Store tuple in slot
and use slot_getattr instead of heap_getattr.
patch3: call HeapKeyTest in SeqNext after storing slot, and also
switch memory context before calling HeapKeyTest.
Summary: (performance data)
----------------------------------------
1. At 10% selectivity patch1 shows > 40% gain which reduced to 30% in
patch2 and finally it drops to 17% in patch3.
2. I think patch1 wins over patch2, because patch1 avoid call to ExecStoreTuple.
3. Patch2 wins over patch3 because patch2 can reject tuple in
heapgettup_pagemode whereas patch3 can do it in SeqNext, so patch2 can
avoid some function calls instructions.
Summary (various patches and problems)
-----------------------------------------------------
Patch1:
problem1: This approach has performance problem in some cases (quals
on many columns of the table + high selectivity (>50%)).
problem2: HeapKeyTest uses ExecutorContext so we need to block any
datatype which needs memory allocation during eval functions.
Patch2: Patch2 solves both the problems of patch1, but exposes
executor items to heap and it's not a good design.
Patch3: This solves all the problems exists in patch1+patch2, but
performance is significantly less.
I haven't yet tested patch3 with TPCH, I will do that once machine is available.
--
Regards,
Dilip Kumar
EnterpriseDB: http://www.enterprisedb.com
On Sat, Nov 19, 2016 at 6:48 PM, Dilip Kumar <dilipbalaut@gmail.com> wrote: > patch1: Original patch (heap_scankey_pushdown_v1.patch), only > supported for fixed length datatype and use heap_getattr. > > patch2: Switches memory context in HeapKeyTest + Store tuple in slot > and use slot_getattr instead of heap_getattr. > > patch3: call HeapKeyTest in SeqNext after storing slot, and also > switch memory context before calling HeapKeyTest. > > I haven't yet tested patch3 with TPCH, I will do that once machine is available. As promised, I have taken the performance with TPCH benchmark and still result are quite good. However this are less compared to older version (which was exposing expr ctx and slot to heap). Query Head [1] Patch3 Improvement Q3 36122.425 32285.608 10% Q4 6797 5763.871 15% Q10 17996.104 15878.505 11% Q12 12399.651 9969.489 19% [1] heap_scankey_pushdown_POC_V3.patch : attached with the mail. -- Regards, Dilip Kumar EnterpriseDB: http://www.enterprisedb.com
Attachment
On Mon, Nov 28, 2016 at 3:00 PM, Dilip Kumar <dilipbalaut@gmail.com> wrote: > As promised, I have taken the performance with TPCH benchmark and > still result are quite good. However this are less compared to older > version (which was exposing expr ctx and slot to heap). > > Query Head [1] Patch3 Improvement > Q3 36122.425 32285.608 10% > Q4 6797 5763.871 15% > Q10 17996.104 15878.505 11% > Q12 12399.651 9969.489 19% > > [1] heap_scankey_pushdown_POC_V3.patch : attached with the mail. I forgot to mention the configuration parameter in last mail.. TPCH-scale factor 10. work mem 20MB Power, 4 socket machine Shared Buffer 1GB -- Regards, Dilip Kumar EnterpriseDB: http://www.enterprisedb.com
On Mon, Nov 28, 2016 at 4:30 AM, Dilip Kumar <dilipbalaut@gmail.com> wrote: > On Sat, Nov 19, 2016 at 6:48 PM, Dilip Kumar <dilipbalaut@gmail.com> wrote: >> patch1: Original patch (heap_scankey_pushdown_v1.patch), only >> supported for fixed length datatype and use heap_getattr. >> >> patch2: Switches memory context in HeapKeyTest + Store tuple in slot >> and use slot_getattr instead of heap_getattr. >> >> patch3: call HeapKeyTest in SeqNext after storing slot, and also >> switch memory context before calling HeapKeyTest. >> >> I haven't yet tested patch3 with TPCH, I will do that once machine is available. > > As promised, I have taken the performance with TPCH benchmark and > still result are quite good. However this are less compared to older > version (which was exposing expr ctx and slot to heap). > > Query Head [1] Patch3 Improvement > Q3 36122.425 32285.608 10% > Q4 6797 5763.871 15% > Q10 17996.104 15878.505 11% > Q12 12399.651 9969.489 19% > > [1] heap_scankey_pushdown_POC_V3.patch : attached with the mail. I think we should go with this approach. I don't think it's a good idea to have the heapam layer know about executor slots. Even though it's a little sad to pass up an opportunity for a larger performance improvement, this improvement is still quite good. However, there's a fair amount of this patch that doesn't look right: - The changes to heapam.c shouldn't be needed any more. Ditto valid.h, relscan.h, catcache.c and maybe some other stuff. - get_scankey_from_qual() should be done at plan time, not execution time. Just as index scans already divide up quals between "Index Cond" and "Filter" (see ExplainNode), I think Seq Scans are now going to need to something similar. Obviously, "Index Cond" isn't an appropriate name for things that we test via HeapKeyTest, but maybe "Heap Cond" would be suitable. That's going to be a fair amount of refactoring, since the "typedef Scan SeqScan" in plannodes.h is going to need to be replaced by an actual new structure definition. - get_scankey_from_qual()'s prohibition on variable-width columns is presumably no longer necessary with this approach, right? - Anything tested in SeqNext() will also need to be retested in SeqRecheck(); otherwise, the test will be erroneously skipped during EPQ rechecks. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On Mon, Nov 28, 2016 at 8:25 PM, Robert Haas <robertmhaas@gmail.com> wrote: > I think we should go with this approach. I don't think it's a good > idea to have the heapam layer know about executor slots. Even though > it's a little sad to pass up an opportunity for a larger performance > improvement, this improvement is still quite good. I agree. However, there's a > fair amount of this patch that doesn't look right: > > - The changes to heapam.c shouldn't be needed any more. Ditto > valid.h, relscan.h, catcache.c and maybe some other stuff. Actually we want to call slot_getattr instead heap_getattr, because of problem mentioned by Andres upthread and we also saw in test results. Should we make a copy of HeapKeyTest lets say ExecKeyTest and keep it under executor ? ExecKeyTest will be same as HeapKeyTest but it will call slot_getattr instead of heap_getattr. > > - get_scankey_from_qual() should be done at plan time, not execution > time. Just as index scans already divide up quals between "Index > Cond" and "Filter" (see ExplainNode), I think Seq Scans are now going > to need to something similar. Obviously, "Index Cond" isn't an > appropriate name for things that we test via HeapKeyTest, but maybe > "Heap Cond" would be suitable. That's going to be a fair amount of > refactoring, since the "typedef Scan SeqScan" in plannodes.h is going > to need to be replaced by an actual new structure definition. > Okay. > - get_scankey_from_qual()'s prohibition on variable-width columns is > presumably no longer necessary with this approach, right? Correct. > > - Anything tested in SeqNext() will also need to be retested in > SeqRecheck(); otherwise, the test will be erroneously skipped during > EPQ rechecks. Okay.. -- Regards, Dilip Kumar EnterpriseDB: http://www.enterprisedb.com
On 2016-11-28 09:55:00 -0500, Robert Haas wrote: > I think we should go with this approach. I don't think it's a good > idea to have the heapam layer know about executor slots. I agree that that's not pretty. > Even though > it's a little sad to pass up an opportunity for a larger performance > improvement, this improvement is still quite good. It's imo not primarily about a larger performance improvement, but about avoid possible regressions. Doubling deforming of wide tuples will have noticeable impact on some workloads. I don't think we can disregard that. Andres
On Mon, Nov 28, 2016 at 11:25 PM, Andres Freund <andres@anarazel.de> wrote: > On 2016-11-28 09:55:00 -0500, Robert Haas wrote: >> I think we should go with this approach. I don't think it's a good >> idea to have the heapam layer know about executor slots. > > I agree that that's not pretty. > >> Even though >> it's a little sad to pass up an opportunity for a larger performance >> improvement, this improvement is still quite good. > > It's imo not primarily about a larger performance improvement, but about > avoid possible regressions. Doubling deforming of wide tuples will have > noticeable impact on some workloads. I don't think we can disregard > that. I wasn't proposing to disregard that. I'm saying hoist the tests up into nodeSeqScan.c where they can use the slot without breaking the abstraction. It's not quite as fast but it's a lot cleaner. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On Mon, Nov 28, 2016 at 11:17 PM, Dilip Kumar <dilipbalaut@gmail.com> wrote: > Actually we want to call slot_getattr instead heap_getattr, because of > problem mentioned by Andres upthread and we also saw in test results. Ah, right. > Should we make a copy of HeapKeyTest lets say ExecKeyTest and keep it > under executor ? Sure. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On Tue, Nov 29, 2016 at 11:21 PM, Robert Haas <robertmhaas@gmail.com> wrote:
> On Mon, Nov 28, 2016 at 11:17 PM, Dilip Kumar <dilipbalaut@gmail.com> wrote:
>> Actually we want to call slot_getattr instead heap_getattr, because of
>> problem mentioned by Andres upthread and we also saw in test results.
>
> Ah, right.
>
>> Should we make a copy of HeapKeyTest lets say ExecKeyTest and keep it
>> under executor ?
>
> Sure.
I have worked on the idea you suggested upthread. POC patch is attached.
Todo:
1. Comments.
2. Test.
3. Some regress output will change as we are adding some extra
information to analyze output.
I need some suggestion..
1. As we decided to separate scankey and qual during planning time. So
I am doing it at create_seqscan_path. My question is currently we
don't have path node for seqscan, so where should we store scankey ?
In Path node, or create new SeqScanPath node ?. In attached patch I
have stored in Path node.
2. This is regarding instrumentation information for scan key, after
my changes currently explain analyze result will look like this.
postgres=# explain (analyze, costs off) select * from lineitem
where l_shipmode in ('MAIL', 'AIR')
and l_receiptdate >= date '1994-01-01';
QUERY PLAN
--------------------------------------------------------------------------
Seq Scan on lineitem (actual time=0.022..12179.946 rows=6238212 loops=1)
Scan Key: (l_receiptdate >= '1994-01-01'::date)
Filter: (l_shipmode = ANY ('{MAIL,AIR}'::bpchar[]))
Rows Removed by Scan Key: 8162088
Rows Removed by Filter: 15599495
Planning time: 0.182 ms
Execution time: 12410.529 ms
My question is, how should we show pushdown filters ?
In above plan I am showing as "Scan Key: ", does this look fine or we
should name it something else ?
--
Regards,
Dilip Kumar
EnterpriseDB: http://www.enterprisedb.com
Attachment
On Wed, Nov 30, 2016 at 5:41 AM, Dilip Kumar <dilipbalaut@gmail.com> wrote:
> 1. As we decided to separate scankey and qual during planning time. So
> I am doing it at create_seqscan_path. My question is currently we
> don't have path node for seqscan, so where should we store scankey ?
> In Path node, or create new SeqScanPath node ?. In attached patch I
> have stored in Path node.
Well, Path should obviously only contain those things that are common
across all kinds of paths, so I would think you'd need to invent
SeqScanPath.
> 2. This is regarding instrumentation information for scan key, after
> my changes currently explain analyze result will look like this.
>
> postgres=# explain (analyze, costs off) select * from lineitem
> where l_shipmode in ('MAIL', 'AIR')
> and l_receiptdate >= date '1994-01-01';
> QUERY PLAN
> --------------------------------------------------------------------------
> Seq Scan on lineitem (actual time=0.022..12179.946 rows=6238212 loops=1)
> Scan Key: (l_receiptdate >= '1994-01-01'::date)
> Filter: (l_shipmode = ANY ('{MAIL,AIR}'::bpchar[]))
> Rows Removed by Scan Key: 8162088
> Rows Removed by Filter: 15599495
> Planning time: 0.182 ms
> Execution time: 12410.529 ms
>
> My question is, how should we show pushdown filters ?
> In above plan I am showing as "Scan Key: ", does this look fine or we
> should name it something else ?
Seems OK to me, but I'm open to better ideas if anybody has any.
--
Robert Haas
EnterpriseDB: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
On 2016-11-30 16:11:23 +0530, Dilip Kumar wrote: > On Tue, Nov 29, 2016 at 11:21 PM, Robert Haas <robertmhaas@gmail.com> wrote: > > On Mon, Nov 28, 2016 at 11:17 PM, Dilip Kumar <dilipbalaut@gmail.com> wrote: > >> Actually we want to call slot_getattr instead heap_getattr, because of > >> problem mentioned by Andres upthread and we also saw in test results. > > > > Ah, right. > > > >> Should we make a copy of HeapKeyTest lets say ExecKeyTest and keep it > >> under executor ? > > > > Sure. > > I have worked on the idea you suggested upthread. POC patch is > attached. Hm. I'm more than a bit doubful about this approach. Shouldn't we just *always* do this as part of expression evaluation, instead of special-casing for seqscans? I.e. during planning recognize that an OpExpr can be evaluated as a scankey and then emit different qual evaluation instructions? Because then the benefit can be everywhere, instead of just seqscans. I'll post my new expression evaluation stuff - which doesn't do this atm, but makes ExecQual faster in other ways - later this week. If we could get the planner (or parse-analysis?) to set an OpExpr flag that signals that the expression can be evaluated as a scankey, that'd be easy. Greetings, Andres Freund
On Fri, Dec 2, 2016 at 8:41 AM, Andres Freund <andres@anarazel.de> wrote:
On 2016-11-30 16:11:23 +0530, Dilip Kumar wrote:
> On Tue, Nov 29, 2016 at 11:21 PM, Robert Haas <robertmhaas@gmail.com> wrote:
> > On Mon, Nov 28, 2016 at 11:17 PM, Dilip Kumar <dilipbalaut@gmail.com> wrote:
> >> Actually we want to call slot_getattr instead heap_getattr, because of
> >> problem mentioned by Andres upthread and we also saw in test results.
> >
> > Ah, right.
> >
> >> Should we make a copy of HeapKeyTest lets say ExecKeyTest and keep it
> >> under executor ?
> >
> > Sure.
>
> I have worked on the idea you suggested upthread. POC patch is
> attached.
Hm. I'm more than a bit doubful about this approach. Shouldn't we just
*always* do this as part of expression evaluation, instead of
special-casing for seqscans?
I.e. during planning recognize that an OpExpr can be evaluated as a
scankey and then emit different qual evaluation instructions? Because
then the benefit can be everywhere, instead of just seqscans.
I'll post my new expression evaluation stuff - which doesn't do this
atm, but makes ExecQual faster in other ways - later this week. If we
could get the planner (or parse-analysis?) to set an OpExpr flag that
signals that the expression can be evaluated as a scankey, that'd be
easy.
Moved to next CF with "waiting on author" status.
Regards,
Hari Babu
Fujitsu Australia
On Fri, Dec 2, 2016 at 3:11 AM, Andres Freund <andres@anarazel.de> wrote: > Hm. I'm more than a bit doubful about this approach. Shouldn't we just > *always* do this as part of expression evaluation, instead of > special-casing for seqscans? That make sense, we can actually do this as part of expression evaluation and we can cover more cases. > > I.e. during planning recognize that an OpExpr can be evaluated as a > scankey and then emit different qual evaluation instructions? Because > then the benefit can be everywhere, instead of just seqscans. I will experiment with this.. > > I'll post my new expression evaluation stuff - which doesn't do this > atm, but makes ExecQual faster in other ways - later this week. If we > could get the planner (or parse-analysis?) to set an OpExpr flag that > signals that the expression can be evaluated as a scankey, that'd be > easy. Isn't it better to directly make two separate lists during planning itself, one for regular qual and other which can be converted to scankey. Instead of keeping the flag in OpExpr ? -- Regards, Dilip Kumar EnterpriseDB: http://www.enterprisedb.com
On Sat, Dec 3, 2016 at 10:30 AM, Dilip Kumar <dilipbalaut@gmail.com> wrote: >> I'll post my new expression evaluation stuff - which doesn't do this >> atm, but makes ExecQual faster in other ways - later this week. If we >> could get the planner (or parse-analysis?) to set an OpExpr flag that >> signals that the expression can be evaluated as a scankey, that'd be >> easy. > > Isn't it better to directly make two separate lists during planning > itself, one for regular qual and other which can be converted to > scankey. Instead of keeping the flag in OpExpr ? Well, I certainly think that in the end we need them in two separate lists. But it's possible that a flag in the OpExpr could somehow be useful in constructing those lists cheaply. I'm not sure I see what Andres has in mind, though. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company