Re: Proposal: scan key push down to heap [WIP] - Mailing list pgsql-hackers
| From | Dilip Kumar |
|---|---|
| Subject | Re: Proposal: scan key push down to heap [WIP] |
| Date | |
| Msg-id | CAFiTN-uRWHftdO7Qyqz3EtQDr0hMh-+S3o2mxTvuqng+kXYJnw@mail.gmail.com Whole thread |
| In response to | Re: Proposal: scan key push down to heap [WIP] (Andres Freund <andres@anarazel.de>) |
| Responses |
Re: Proposal: scan key push down to heap [WIP]
Re: Proposal: scan key push down to heap [WIP] |
| List | pgsql-hackers |
On Wed, Oct 26, 2016 at 12:01 PM, Andres Freund <andres@anarazel.de> wrote:
> The gains are quite noticeable in some cases. So if we can make it work
> without noticeable downsides...
>
> What I'm worried about though is that this, afaics, will quite
> noticeably *increase* total cost in cases with a noticeable number of
> columns and a not that selective qual. The reason for that being that
> HeapKeyTest() uses heap_getattr(), whereas upper layers use
> slot_getattr(). The latter "caches" repeated deforms, the former
> doesn't... That'll lead to deforming being essentially done twice, and
> it's quite often already a major cost of query processing.
What about putting slot reference inside HeapScanDesc ?. I know it
will make ,heap layer use executor structure but just a thought.
I have quickly hacked this way where we use slot reference in
HeapScanDesc and directly use
slot_getattr inside HeapKeyTest (only if we have valid slot otherwise
use _heap_getattr) and measure the worst case performance (what you
have mentioned above.)
My Test: (21 column table with varchar in beginning + qual is on last
few column + varying selectivity )
postgres=# \d test
Table "public.test"
Column | Type | Modifiers
--------+-------------------+-----------
f1 | integer |
f2 | character varying |
f3 | integer |
f4 | integer |
f5 | integer |
f6 | integer |
f7 | integer |
f8 | integer |
f9 | integer |
f10 | integer |
f11 | integer |
f12 | integer |
f13 | integer |
f14 | integer |
f15 | integer |
f16 | integer |
f17 | integer |
f18 | integer |
f19 | integer |
f20 | integer |
f21 | integer |
tuple count : 10000000 (10 Million)
explain analyze select * from test where f21< $1 and f20 < $1 and f19
< $1 and f15 < $1 and f10 < $1; ($1 vary from 1Million to 1Million).
Target code base:
-----------------------
1. Head
2. Heap_scankey_pushdown_v1
3. My hack for keeping slot reference in HeapScanDesc
(v1+use_slot_in_HeapKeyTest)
Result:
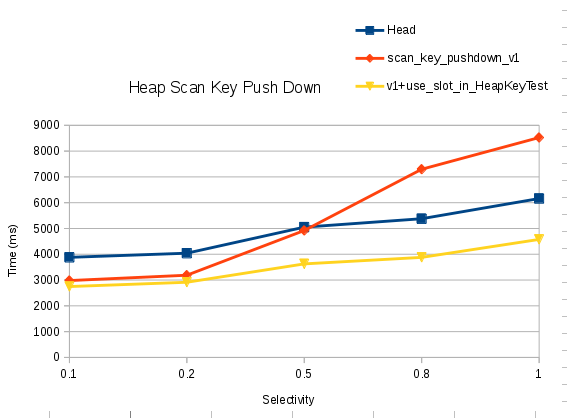
Selectivity Head scan_key_pushdown_v1 v1+use_slot_in_HeapKeyTest
0.1 3880 2980 2747
0.2 4041 3187 2914
0.5 5051 4921 3626
0.8 5378 7296 3879
1.0 6161 8525 4575
Performance graph is attached in the mail..
Observation:
----------------
1. Heap_scankey_pushdown_v1, start degrading after very high
selectivity (this behaviour is only visible if table have 20 or more
columns, I tested with 10 columns but with that I did not see any
regression in v1).
2. (v1+use_slot_in_HeapKeyTest) is always winner, even at very high selectivity.
--
Regards,
Dilip Kumar
EnterpriseDB: http://www.enterprisedb.com
Attachment
{kind=link}
pgsql-hackers by date: