Thread: [PoC] pgstattuple2: block sampling to reduce physical read
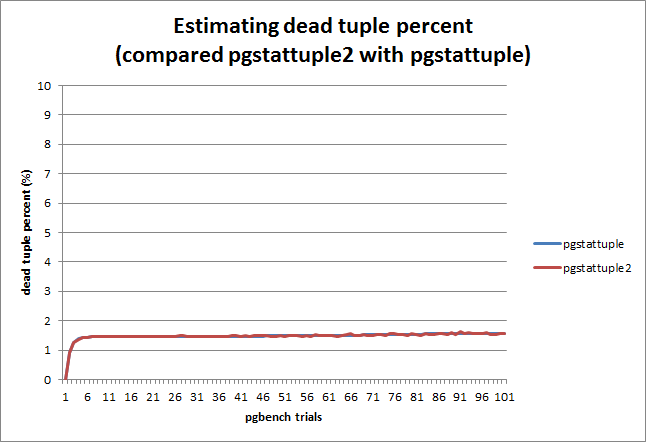
Hi, I've been working on new pgstattuple function to allow block sampling [1] in order to reduce block reads while scanning a table. A PoC patch is attached. [1] Re: [RFC] pgstattuple/pgstatindex enhancement http://www.postgresql.org/message-id/CA+TgmoaxJhGZ2c4AYfbr9muUVNhGWU4co-cthqpZRwwDtamvhw@mail.gmail.com This new function, pgstattuple2(), samples only 3,000 blocks (which accounts 24MB) from the table randomly, and estimates several parameters of the entire table. The function calculates the averages of the samples, estimates the parameters (averages and SDs), and shows "standard errors (SE)" to allow estimating status of the table with statistical approach. And, of course, it reduces number of physical block reads while scanning a bigger table. The following example shows that new pgstattuple2 function runs x100 faster than the original pgstattuple function with well-estimated results. ---------------------------------------------- postgres=# select * from pgstattuple('pgbench_accounts'); -[ RECORD 1 ]------+----------- table_len | 1402642432 tuple_count | 10000000 tuple_len | 1210000000 tuple_percent | 86.27 dead_tuple_count | 182895 dead_tuple_len | 22130295 dead_tuple_percent | 1.58 free_space | 21012328 free_percent | 1.5 Time: 1615.651 ms postgres=# select * from pgstattuple2('pgbench_accounts'); NOTICE: pgstattuple2: SE tuple_count 2376.47, tuple_len 287552.58, dead_tuple_count 497.63, dead_tuple_len 60213.08, free_space 289752.38 -[ RECORD 1 ]------+----------- table_len | 1402642432 tuple_count | 9978074 tuple_len | 1207347074 tuple_percent | 86.08 dead_tuple_count | 187315 dead_tuple_len | 22665208 dead_tuple_percent | 1.62 free_space | 23400431 free_percent | 1.67 Time: 15.026 ms postgres=# ---------------------------------------------- In addition to that, see attached chart to know how pgstattuple2 estimates well during repeating (long-running) pgbench. I understand that pgbench would generate "random" transactions, and those update operations might not have any skew over the table, so estimating table status seems to be easy in this test. However, I'm still curious to know whether it would work in "real-world" worklaod. Is it worth having this? Any comment or suggestion? Regards, -- Satoshi Nagayasu <snaga@uptime.jp> Uptime Technologies, LLC. http://www.uptime.jp
Attachment
{kind=link}
On 7/23/13 2:16 AM, Satoshi Nagayasu wrote: > I've been working on new pgstattuple function to allow > block sampling [1] in order to reduce block reads while > scanning a table. A PoC patch is attached. Take a look at all of the messages linked in https://commitfest.postgresql.org/action/patch_view?id=778 Jaime and I tried to do what you're working on then, including a random block sampling mechanism modeled on the stats_target mechanism. We didn't do that as part of pgstattuple though, which was a mistake. Noah created some test cases as part of his thorough review that were not computing the correct results. Getting the results correct for all of the various types of PostgreSQL tables and indexes ended up being much harder than the sampling part. See http://www.postgresql.org/message-id/20120222052747.GE8592@tornado.leadboat.com in particular for that. > This new function, pgstattuple2(), samples only 3,000 blocks > (which accounts 24MB) from the table randomly, and estimates > several parameters of the entire table. There should be an input parameter to the function for how much sampling to do, and if it's possible to make the scale for it to look like ANALYZE that's helpful too. I have a project for this summer that includes reviving this topic and making sure it works on some real-world systems. If you want to work on this too, I can easily combine that project into what you're doing. -- Greg Smith 2ndQuadrant US greg@2ndQuadrant.com Baltimore, MD PostgreSQL Training, Services, and 24x7 Support www.2ndQuadrant.com
(2013/07/23 20:02), Greg Smith wrote: > On 7/23/13 2:16 AM, Satoshi Nagayasu wrote: >> I've been working on new pgstattuple function to allow >> block sampling [1] in order to reduce block reads while >> scanning a table. A PoC patch is attached. > > Take a look at all of the messages linked in > https://commitfest.postgresql.org/action/patch_view?id=778 > > Jaime and I tried to do what you're working on then, including a random > block sampling mechanism modeled on the stats_target mechanism. We > didn't do that as part of pgstattuple though, which was a mistake. > > Noah created some test cases as part of his thorough review that were > not computing the correct results. Getting the results correct for all > of the various types of PostgreSQL tables and indexes ended up being > much harder than the sampling part. See > http://www.postgresql.org/message-id/20120222052747.GE8592@tornado.leadboat.com > in particular for that. Thanks for the info. I have read the previous discussion. I'm looking forward to seeing more feedback on this approach, in terms of design and performance improvement. So, I have submitted this for the next CF. >> This new function, pgstattuple2(), samples only 3,000 blocks >> (which accounts 24MB) from the table randomly, and estimates >> several parameters of the entire table. > > There should be an input parameter to the function for how much sampling > to do, and if it's possible to make the scale for it to look like > ANALYZE that's helpful too. > > I have a project for this summer that includes reviving this topic and > making sure it works on some real-world systems. If you want to work on > this too, I can easily combine that project into what you're doing. Yeah, I'm interested in that. Something can be shared? Regards, -- Satoshi Nagayasu <snaga@uptime.jp> Uptime Technologies, LLC. http://www.uptime.jp
On Sat, 2013-09-14 at 16:18 +0900, Satoshi Nagayasu wrote: > I'm looking forward to seeing more feedback on this approach, > in terms of design and performance improvement. > So, I have submitted this for the next CF. Your patch fails to build: pgstattuple.c: In function ‘pgstat_heap_sample’: pgstattuple.c:737:13: error: ‘SnapshotNow’ undeclared (first use in this function) pgstattuple.c:737:13: note: each undeclared identifier is reported only once for each function it appears in
(2013/09/15 11:07), Peter Eisentraut wrote: > On Sat, 2013-09-14 at 16:18 +0900, Satoshi Nagayasu wrote: >> I'm looking forward to seeing more feedback on this approach, >> in terms of design and performance improvement. >> So, I have submitted this for the next CF. > > Your patch fails to build: > > pgstattuple.c: In function ‘pgstat_heap_sample’: > pgstattuple.c:737:13: error: ‘SnapshotNow’ undeclared (first use in this function) > pgstattuple.c:737:13: note: each undeclared identifier is reported only once for each function it appears in Thanks for checking. Fixed to eliminate SnapshotNow. Regards, -- Satoshi Nagayasu <snaga@uptime.jp> Uptime Technologies, LLC. http://www.uptime.jp
Attachment
<div class="moz-cite-prefix">On 16/09/13 16:20, Satoshi Nagayasu wrote:<br /></div><blockquote
cite="mid:52368724.6050706@uptime.jp"type="cite">(2013/09/15 11:07), Peter Eisentraut wrote: <br /><blockquote
type="cite">OnSat, 2013-09-14 at 16:18 +0900, Satoshi Nagayasu wrote: <br /><blockquote type="cite">I'm looking forward
toseeing more feedback on this approach, <br /> in terms of design and performance improvement. <br /> So, I have
submittedthis for the next CF. <br /></blockquote><br /> Your patch fails to build: <br /><br /> pgstattuple.c: In
function‘pgstat_heap_sample’: <br /> pgstattuple.c:737:13: error: ‘SnapshotNow’ undeclared (first use in this function)
<br/> pgstattuple.c:737:13: note: each undeclared identifier is reported only once for each function it appears in <br
/></blockquote><br/> Thanks for checking. Fixed to eliminate SnapshotNow. <br /><br /></blockquote><br /> This seems
likea cool idea! I took a quick look, and initally replicated the sort of improvement you saw:<br /><br /><br
/><tt>bench=#explain analyze select * from pgstattuple('pgbench_accounts');<br />
QUERY PLAN <br />
<br/> --------------------------------------------------------------------------------<br /> Function Scan on
pgstattuple (cost=0.00..0.01 rows=1 width=72) (actual time=786.368..786.369 rows=1 loops=1)<br /> Total runtime:
786.384ms<br /> (2 rows)<br /><br /> bench=# explain analyze select * from pgstattuple2('pgbench_accounts');<br />
NOTICE: pgstattuple2: SE tuple_count 0.00, tuple_len 0.00, dead_tuple_count 0.00, dead_tuple_len 0.00, free_space
0.00<br/> QUERY PLAN <br />
<br /> --------------------------------------------------------------------------------<br
/> Function Scan on pgstattuple2 (cost=0.00..0.01 rows=1 width=72) (actual time=12.004..12.005 rows=1 loops=1)<br />
Totalruntime: 12.019 ms<br /> (2 rows)<br /><br /><br /></tt><tt><br /><font face="sans-serif"><tt><font
face="sans-serif">Iwondered what sort of difference eliminating caching wo<tt><font face="sans-serif">uld make:<br
/><br/><tt><font face="sans-serif">$ sudo sysctl -w vm.drop_caches=3</font></tt><br /><br /><tt><font
face="sans-serif"><tt><fontface="sans-serif">Repeatin<tt><font face="sans-serif">g the above quer<tt><font
face="sans-serif">ies:<br/><br /><br
/></font></tt></font></tt></font></tt></font></tt></font></tt></font></tt></font><tt><tt><tt><tt><tt><tt><tt>bench=#
explainanalyze select * from pgstattuple('pgbench_accounts');</tt><tt><br
/></tt><tt> QUERY PLAN </tt><tt><br
/></tt><tt> </tt><tt><br
/></tt><tt>--------------------------------------------------------------------------------</tt><tt><br
/></tt><tt> FunctionScan on pgstattuple (cost=0.00..0.01 rows=1 width=72) (actual time=95</tt><tt>03.774..9503.776
rows=1loops=1)</tt><tt><br /></tt><tt> Total runtime: 9504.523 ms</tt><tt><br /></tt><tt>(2 rows)</tt><tt><br
/></tt><tt><br/></tt><tt><tt>bench=# explain analyze select * from pgstattuple2('pgbench_accounts');</tt><tt><br
/></tt><tt>NOTICE: pgstattuple2: SE tuple_count 0.00, tuple_len 0.00, dead_tuple_count 0.00, dead_tuple_len 0.00,
free_space0.00</tt><tt><br /></tt><tt> QUERY PLAN
</tt><tt><br/></tt><tt> </tt><tt><br
/></tt><tt>--------------------------------------------------------------------------------</tt><tt><br
/></tt><tt> FunctionScan on pgstattuple2 (cost=0.00..0.01 rows=1 width=72) (actual time=1</tt><tt>2330.630..12330.631
rows=1loops=1)</tt><tt><br /></tt><tt> Total runtime: 12331.353 ms</tt><tt><br /></tt><tt>(2
rows)</tt></tt></tt></tt></tt></tt></tt></tt><fontface="sans-serif"><tt><font face="sans-serif"><tt><font
face="sans-serif"><tt><fontface="sans-serif"><tt><font face="sans-serif"><tt><font face="sans-serif"><tt><font
face="sans-serif"><tt><fontface="sans-serif"><br /></font></tt><br /><br
/></font></tt></font></tt></font></tt></font></tt></font></tt></font></tt></font></tt>Sothe sampling code seems
*slower*when the cache is completely cold - is that expected? (I have not looked at how the code works yet - I'll dive
inlater if I get a chance)!<br /><br /> Regards<br /><br /> Mark<br /><tt><br /></tt>
On 11/10/13 11:09, Mark Kirkwood wrote:
> On 16/09/13 16:20, Satoshi Nagayasu wrote:
>> (2013/09/15 11:07), Peter Eisentraut wrote:
>>> On Sat, 2013-09-14 at 16:18 +0900, Satoshi Nagayasu wrote:
>>>> I'm looking forward to seeing more feedback on this approach,
>>>> in terms of design and performance improvement.
>>>> So, I have submitted this for the next CF.
>>> Your patch fails to build:
>>>
>>> pgstattuple.c: In function ‘pgstat_heap_sample’:
>>> pgstattuple.c:737:13: error: ‘SnapshotNow’ undeclared (first use in
>>> this function)
>>> pgstattuple.c:737:13: note: each undeclared identifier is reported
>>> only once for each function it appears in
>> Thanks for checking. Fixed to eliminate SnapshotNow.
>>
> This seems like a cool idea! I took a quick look, and initally
> replicated the sort of improvement you saw:
>
>
> bench=# explain analyze select * from pgstattuple('pgbench_accounts');
> QUERY PLAN
>
> --------------------------------------------------------------------------------
> Function Scan on pgstattuple (cost=0.00..0.01 rows=1 width=72) (actual
> time=786.368..786.369 rows=1 loops=1)
> Total runtime: 786.384 ms
> (2 rows)
>
> bench=# explain analyze select * from pgstattuple2('pgbench_accounts');
> NOTICE: pgstattuple2: SE tuple_count 0.00, tuple_len 0.00,
> dead_tuple_count 0.00, dead_tuple_len 0.00, free_space 0.00
> QUERY PLAN
>
> --------------------------------------------------------------------------------
> Function Scan on pgstattuple2 (cost=0.00..0.01 rows=1 width=72) (actual
> time=12.004..12.005 rows=1 loops=1)
> Total runtime: 12.019 ms
> (2 rows)
>
>
>
> I wondered what sort of difference eliminating caching would make:
>
> $ sudo sysctl -w vm.drop_caches=3
>
> Repeating the above queries:
>
>
> bench=# explain analyze select * from pgstattuple('pgbench_accounts');
> QUERY PLAN
>
> --------------------------------------------------------------------------------
> Function Scan on pgstattuple (cost=0.00..0.01 rows=1 width=72) (actual
> time=9503.774..9503.776 rows=1 loops=1)
> Total runtime: 9504.523 ms
> (2 rows)
>
> bench=# explain analyze select * from pgstattuple2('pgbench_accounts');
> NOTICE: pgstattuple2: SE tuple_count 0.00, tuple_len 0.00,
> dead_tuple_count 0.00, dead_tuple_len 0.00, free_space 0.00
> QUERY PLAN
>
> --------------------------------------------------------------------------------
> Function Scan on pgstattuple2 (cost=0.00..0.01 rows=1 width=72) (actual
> time=12330.630..12330.631 rows=1 loops=1)
> Total runtime: 12331.353 ms
> (2 rows)
>
>
> So the sampling code seems *slower* when the cache is completely cold -
> is that expected? (I have not looked at how the code works yet - I'll
> dive in later if I get a chance)!
>
Quietly replying to myself - looking at the code the sampler does 3000
random page reads... I guess this is slower than 163935 (number of pages
in pgbench_accounts) sequential page reads thanks to os readahead on my
type of disk (WD Velociraptor). Tweaking the number of random reads (i.e
the sample size) down helps - but obviously that can impact estimation
accuracy.
Thinking about this a bit more, I guess the elapsed runtime is not the
*only* theng to consider - the sampling code will cause way less
disruption to the os page cache (3000 pages vs possibly lots more than
3000 for reading an entire ralation).
Thoughts?
Cheers
Mark
(2013/10/11 7:32), Mark Kirkwood wrote:
> On 11/10/13 11:09, Mark Kirkwood wrote:
>> On 16/09/13 16:20, Satoshi Nagayasu wrote:
>>> (2013/09/15 11:07), Peter Eisentraut wrote:
>>>> On Sat, 2013-09-14 at 16:18 +0900, Satoshi Nagayasu wrote:
>>>>> I'm looking forward to seeing more feedback on this approach,
>>>>> in terms of design and performance improvement.
>>>>> So, I have submitted this for the next CF.
>>>> Your patch fails to build:
>>>>
>>>> pgstattuple.c: In function ‘pgstat_heap_sample’:
>>>> pgstattuple.c:737:13: error: ‘SnapshotNow’ undeclared (first use in
>>>> this function)
>>>> pgstattuple.c:737:13: note: each undeclared identifier is reported
>>>> only once for each function it appears in
>>> Thanks for checking. Fixed to eliminate SnapshotNow.
>>>
>> This seems like a cool idea! I took a quick look, and initally
>> replicated the sort of improvement you saw:
>>
>>
>> bench=# explain analyze select * from pgstattuple('pgbench_accounts');
>> QUERY PLAN
>>
>> --------------------------------------------------------------------------------
>> Function Scan on pgstattuple (cost=0.00..0.01 rows=1 width=72) (actual
>> time=786.368..786.369 rows=1 loops=1)
>> Total runtime: 786.384 ms
>> (2 rows)
>>
>> bench=# explain analyze select * from pgstattuple2('pgbench_accounts');
>> NOTICE: pgstattuple2: SE tuple_count 0.00, tuple_len 0.00,
>> dead_tuple_count 0.00, dead_tuple_len 0.00, free_space 0.00
>> QUERY PLAN
>>
>> --------------------------------------------------------------------------------
>> Function Scan on pgstattuple2 (cost=0.00..0.01 rows=1 width=72) (actual
>> time=12.004..12.005 rows=1 loops=1)
>> Total runtime: 12.019 ms
>> (2 rows)
>>
>>
>>
>> I wondered what sort of difference eliminating caching would make:
>>
>> $ sudo sysctl -w vm.drop_caches=3
>>
>> Repeating the above queries:
>>
>>
>> bench=# explain analyze select * from pgstattuple('pgbench_accounts');
>> QUERY PLAN
>>
>> --------------------------------------------------------------------------------
>> Function Scan on pgstattuple (cost=0.00..0.01 rows=1 width=72) (actual
>> time=9503.774..9503.776 rows=1 loops=1)
>> Total runtime: 9504.523 ms
>> (2 rows)
>>
>> bench=# explain analyze select * from pgstattuple2('pgbench_accounts');
>> NOTICE: pgstattuple2: SE tuple_count 0.00, tuple_len 0.00,
>> dead_tuple_count 0.00, dead_tuple_len 0.00, free_space 0.00
>> QUERY PLAN
>>
>> --------------------------------------------------------------------------------
>> Function Scan on pgstattuple2 (cost=0.00..0.01 rows=1 width=72) (actual
>> time=12330.630..12330.631 rows=1 loops=1)
>> Total runtime: 12331.353 ms
>> (2 rows)
>>
>>
>> So the sampling code seems *slower* when the cache is completely cold -
>> is that expected? (I have not looked at how the code works yet - I'll
>> dive in later if I get a chance)!
Thanks for testing that. It would be very helpful to improve the
performance.
> Quietly replying to myself - looking at the code the sampler does 3000
> random page reads... I guess this is slower than 163935 (number of pages
> in pgbench_accounts) sequential page reads thanks to os readahead on my
> type of disk (WD Velociraptor). Tweaking the number of random reads (i.e
> the sample size) down helps - but obviously that can impact estimation
> accuracy.
>
> Thinking about this a bit more, I guess the elapsed runtime is not the
> *only* theng to consider - the sampling code will cause way less
> disruption to the os page cache (3000 pages vs possibly lots more than
> 3000 for reading an entire ralation).
>
> Thoughts?
I think it could be improved by sorting sample block numbers
*before* physical block reads in order to eliminate random access
on the disk.
pseudo code:
--------------------------------------
for (i=0 ; i<SAMPLE_SIZE ; i++)
{ sample_block[i] = random();
}
qsort(sample_block);
for (i=0 ; i<SAMPLE_SIZE ; i++)
{ buf = ReadBuffer(rel, sample_block[i]);
do_some_stats_stuff(buf);
}
--------------------------------------
I guess it would be helpful for reducing random access thing.
Any comments?
--
Satoshi Nagayasu <snaga@uptime.jp>
Uptime Technologies, LLC. http://www.uptime.jp
On Thu, Oct 10, 2013 at 5:32 PM, Mark Kirkwood <mark.kirkwood@catalyst.net.nz> wrote: > > Quietly replying to myself - looking at the code the sampler does 3000 > random page reads... FWIW, something that bothers me is that there is 3000 random page reads... i mean, why 3000? how do you get that number as absolute for good accuracy in every relation? why not a percentage, maybe an argument to the function? also the name pgstattuple2, doesn't convince me... maybe you can use pgstattuple() if you use a second argument (percentage of the sample) to overload the function -- Jaime Casanova www.2ndQuadrant.com Professional PostgreSQL: Soporte 24x7 y capacitación Phone: +593 4 5107566 Cell: +593 987171157
On 11/10/13 17:08, Satoshi Nagayasu wrote:
> (2013/10/11 7:32), Mark Kirkwood wrote:
>> On 11/10/13 11:09, Mark Kirkwood wrote:
>>> On 16/09/13 16:20, Satoshi Nagayasu wrote:
>>>> (2013/09/15 11:07), Peter Eisentraut wrote:
>>>>> On Sat, 2013-09-14 at 16:18 +0900, Satoshi Nagayasu wrote:
>>>>>> I'm looking forward to seeing more feedback on this approach,
>>>>>> in terms of design and performance improvement.
>>>>>> So, I have submitted this for the next CF.
>>>>> Your patch fails to build:
>>>>>
>>>>> pgstattuple.c: In function ‘pgstat_heap_sample’:
>>>>> pgstattuple.c:737:13: error: ‘SnapshotNow’ undeclared (first use in
>>>>> this function)
>>>>> pgstattuple.c:737:13: note: each undeclared identifier is reported
>>>>> only once for each function it appears in
>>>> Thanks for checking. Fixed to eliminate SnapshotNow.
>>>>
>>> This seems like a cool idea! I took a quick look, and initally
>>> replicated the sort of improvement you saw:
>>>
>>>
>>> bench=# explain analyze select * from pgstattuple('pgbench_accounts');
>>> QUERY PLAN
>>>
>>> --------------------------------------------------------------------------------
>>> Function Scan on pgstattuple (cost=0.00..0.01 rows=1 width=72) (actual
>>> time=786.368..786.369 rows=1 loops=1)
>>> Total runtime: 786.384 ms
>>> (2 rows)
>>>
>>> bench=# explain analyze select * from pgstattuple2('pgbench_accounts');
>>> NOTICE: pgstattuple2: SE tuple_count 0.00, tuple_len 0.00,
>>> dead_tuple_count 0.00, dead_tuple_len 0.00, free_space 0.00
>>> QUERY PLAN
>>>
>>> --------------------------------------------------------------------------------
>>> Function Scan on pgstattuple2 (cost=0.00..0.01 rows=1 width=72) (actual
>>> time=12.004..12.005 rows=1 loops=1)
>>> Total runtime: 12.019 ms
>>> (2 rows)
>>>
>>>
>>>
>>> I wondered what sort of difference eliminating caching would make:
>>>
>>> $ sudo sysctl -w vm.drop_caches=3
>>>
>>> Repeating the above queries:
>>>
>>>
>>> bench=# explain analyze select * from pgstattuple('pgbench_accounts');
>>> QUERY PLAN
>>>
>>> --------------------------------------------------------------------------------
>>> Function Scan on pgstattuple (cost=0.00..0.01 rows=1 width=72) (actual
>>> time=9503.774..9503.776 rows=1 loops=1)
>>> Total runtime: 9504.523 ms
>>> (2 rows)
>>>
>>> bench=# explain analyze select * from pgstattuple2('pgbench_accounts');
>>> NOTICE: pgstattuple2: SE tuple_count 0.00, tuple_len 0.00,
>>> dead_tuple_count 0.00, dead_tuple_len 0.00, free_space 0.00
>>> QUERY PLAN
>>>
>>> --------------------------------------------------------------------------------
>>> Function Scan on pgstattuple2 (cost=0.00..0.01 rows=1 width=72) (actual
>>> time=12330.630..12330.631 rows=1 loops=1)
>>> Total runtime: 12331.353 ms
>>> (2 rows)
>>>
>>>
>>> So the sampling code seems *slower* when the cache is completely cold -
>>> is that expected? (I have not looked at how the code works yet - I'll
>>> dive in later if I get a chance)!
> Thanks for testing that. It would be very helpful to improve the
> performance.
>
>> Quietly replying to myself - looking at the code the sampler does 3000
>> random page reads... I guess this is slower than 163935 (number of pages
>> in pgbench_accounts) sequential page reads thanks to os readahead on my
>> type of disk (WD Velociraptor). Tweaking the number of random reads (i.e
>> the sample size) down helps - but obviously that can impact estimation
>> accuracy.
>>
>> Thinking about this a bit more, I guess the elapsed runtime is not the
>> *only* theng to consider - the sampling code will cause way less
>> disruption to the os page cache (3000 pages vs possibly lots more than
>> 3000 for reading an entire ralation).
>>
>> Thoughts?
> I think it could be improved by sorting sample block numbers
> *before* physical block reads in order to eliminate random access
> on the disk.
>
> pseudo code:
> --------------------------------------
> for (i=0 ; i<SAMPLE_SIZE ; i++)
> {
> sample_block[i] = random();
> }
>
> qsort(sample_block);
>
> for (i=0 ; i<SAMPLE_SIZE ; i++)
> {
> buf = ReadBuffer(rel, sample_block[i]);
>
> do_some_stats_stuff(buf);
> }
> --------------------------------------
>
> I guess it would be helpful for reducing random access thing.
>
> Any comments?
Ah yes - that's a good idea (rough patch to your patch attached)!
bench=# explain analyze select * from pgstattuple2('pgbench_accounts');
NOTICE: pgstattuple2: SE tuple_count 0.00, tuple_len 0.00,
dead_tuple_count 0.00, dead_tuple_len 0.00, free_space 0.00
QUERY PLAN
--------------------------------------------------------------------------------
Function Scan on pgstattuple2 (cost=0.00..0.01 rows=1 width=72) (actual
time=9968.318..9968.319 rows=1 loops=1)
Total runtime: 9968.443 ms
(2 rows)
It would appear that we are now not any worse than a complete sampling...
Cheers
Mark
Attachment
On 11/10/13 17:33, Jaime Casanova wrote: > On Thu, Oct 10, 2013 at 5:32 PM, Mark Kirkwood > <mark.kirkwood@catalyst.net.nz> wrote: >> Quietly replying to myself - looking at the code the sampler does 3000 >> random page reads... > FWIW, something that bothers me is that there is 3000 random page > reads... i mean, why 3000? how do you get that number as absolute for > good accuracy in every relation? why not a percentage, maybe an > argument to the function? Right, Looking at http://en.wikipedia.org/wiki/Sample_size_determination maybe it is not such a bad setting - tho 400 or 1000 seem to be good magic numbers too (if we are gonna punt on single number that is). Perhaps it should reuse (some of) the code from acquire_sample_rows in src/commands/analyze.c (we can't use exactly the same logic, as we need to keep block data together in this case). Cheers Mark
On 11/10/13 17:49, Mark Kirkwood wrote:
> On 11/10/13 17:08, Satoshi Nagayasu wrote:
>> (2013/10/11 7:32), Mark Kirkwood wrote:
>>> On 11/10/13 11:09, Mark Kirkwood wrote:
>>>> On 16/09/13 16:20, Satoshi Nagayasu wrote:
>>>>> (2013/09/15 11:07), Peter Eisentraut wrote:
>>>>>> On Sat, 2013-09-14 at 16:18 +0900, Satoshi Nagayasu wrote:
>>>>>>> I'm looking forward to seeing more feedback on this approach,
>>>>>>> in terms of design and performance improvement.
>>>>>>> So, I have submitted this for the next CF.
>>>>>> Your patch fails to build:
>>>>>>
>>>>>> pgstattuple.c: In function ‘pgstat_heap_sample’:
>>>>>> pgstattuple.c:737:13: error: ‘SnapshotNow’ undeclared (first use in
>>>>>> this function)
>>>>>> pgstattuple.c:737:13: note: each undeclared identifier is reported
>>>>>> only once for each function it appears in
>>>>> Thanks for checking. Fixed to eliminate SnapshotNow.
>>>>>
>>>> This seems like a cool idea! I took a quick look, and initally
>>>> replicated the sort of improvement you saw:
>>>>
>>>>
>>>> bench=# explain analyze select * from pgstattuple('pgbench_accounts');
>>>> QUERY PLAN
>>>>
>>>> --------------------------------------------------------------------------------
>>>> Function Scan on pgstattuple (cost=0.00..0.01 rows=1 width=72) (actual
>>>> time=786.368..786.369 rows=1 loops=1)
>>>> Total runtime: 786.384 ms
>>>> (2 rows)
>>>>
>>>> bench=# explain analyze select * from pgstattuple2('pgbench_accounts');
>>>> NOTICE: pgstattuple2: SE tuple_count 0.00, tuple_len 0.00,
>>>> dead_tuple_count 0.00, dead_tuple_len 0.00, free_space 0.00
>>>> QUERY PLAN
>>>>
>>>> --------------------------------------------------------------------------------
>>>> Function Scan on pgstattuple2 (cost=0.00..0.01 rows=1 width=72) (actual
>>>> time=12.004..12.005 rows=1 loops=1)
>>>> Total runtime: 12.019 ms
>>>> (2 rows)
>>>>
>>>>
>>>>
>>>> I wondered what sort of difference eliminating caching would make:
>>>>
>>>> $ sudo sysctl -w vm.drop_caches=3
>>>>
>>>> Repeating the above queries:
>>>>
>>>>
>>>> bench=# explain analyze select * from pgstattuple('pgbench_accounts');
>>>> QUERY PLAN
>>>>
>>>> --------------------------------------------------------------------------------
>>>> Function Scan on pgstattuple (cost=0.00..0.01 rows=1 width=72) (actual
>>>> time=9503.774..9503.776 rows=1 loops=1)
>>>> Total runtime: 9504.523 ms
>>>> (2 rows)
>>>>
>>>> bench=# explain analyze select * from pgstattuple2('pgbench_accounts');
>>>> NOTICE: pgstattuple2: SE tuple_count 0.00, tuple_len 0.00,
>>>> dead_tuple_count 0.00, dead_tuple_len 0.00, free_space 0.00
>>>> QUERY PLAN
>>>>
>>>> --------------------------------------------------------------------------------
>>>> Function Scan on pgstattuple2 (cost=0.00..0.01 rows=1 width=72) (actual
>>>> time=12330.630..12330.631 rows=1 loops=1)
>>>> Total runtime: 12331.353 ms
>>>> (2 rows)
>>>>
>>>>
>>>> So the sampling code seems *slower* when the cache is completely cold -
>>>> is that expected? (I have not looked at how the code works yet - I'll
>>>> dive in later if I get a chance)!
>> Thanks for testing that. It would be very helpful to improve the
>> performance.
>>
>>> Quietly replying to myself - looking at the code the sampler does 3000
>>> random page reads... I guess this is slower than 163935 (number of pages
>>> in pgbench_accounts) sequential page reads thanks to os readahead on my
>>> type of disk (WD Velociraptor). Tweaking the number of random reads (i.e
>>> the sample size) down helps - but obviously that can impact estimation
>>> accuracy.
>>>
>>> Thinking about this a bit more, I guess the elapsed runtime is not the
>>> *only* theng to consider - the sampling code will cause way less
>>> disruption to the os page cache (3000 pages vs possibly lots more than
>>> 3000 for reading an entire ralation).
>>>
>>> Thoughts?
>> I think it could be improved by sorting sample block numbers
>> *before* physical block reads in order to eliminate random access
>> on the disk.
>>
>> pseudo code:
>> --------------------------------------
>> for (i=0 ; i<SAMPLE_SIZE ; i++)
>> {
>> sample_block[i] = random();
>> }
>>
>> qsort(sample_block);
>>
>> for (i=0 ; i<SAMPLE_SIZE ; i++)
>> {
>> buf = ReadBuffer(rel, sample_block[i]);
>>
>> do_some_stats_stuff(buf);
>> }
>> --------------------------------------
>>
>> I guess it would be helpful for reducing random access thing.
>>
>> Any comments?
> Ah yes - that's a good idea (rough patch to your patch attached)!
>
> bench=# explain analyze select * from pgstattuple2('pgbench_accounts');
> NOTICE: pgstattuple2: SE tuple_count 0.00, tuple_len 0.00,
> dead_tuple_count 0.00, dead_tuple_len 0.00, free_space 0.00
> QUERY PLAN
>
> --------------------------------------------------------------------------------
> Function Scan on pgstattuple2 (cost=0.00..0.01 rows=1 width=72) (actual
> time=9968.318..9968.319 rows=1 loops=1)
> Total runtime: 9968.443 ms
> (2 rows)
>
Actually - correcting my compare function to sort the blocks in
*increasing* order (doh), gets a better result:
bench=# explain analyze select * from pgstattuple2('pgbench_accounts');
NOTICE: pgstattuple2: SE tuple_count 0.00, tuple_len 0.00,
dead_tuple_count 0.00, dead_tuple_len 0.00, free_space 0.00
QUERY PLAN
------------------------------------------------------------------------------------------------------------------
Function Scan on pgstattuple2 (cost=0.00..0.01 rows=1 width=72) (actual
time=7055.840..7055.841 rows=1 loops=1)
Total runtime: 7055.954 ms
(2 rows)
On 11/10/13 17:33, Jaime Casanova wrote: > also the name pgstattuple2, doesn't convince me... maybe you can use > pgstattuple() if you use a second argument (percentage of the sample) > to overload the function +1, that seems much nicer. Regards Mark
On 16/10/13 11:51, Mark Kirkwood wrote: > On 11/10/13 17:33, Jaime Casanova wrote: >> also the name pgstattuple2, doesn't convince me... maybe you can use >> pgstattuple() if you use a second argument (percentage of the sample) >> to overload the function > > +1, that seems much nicer. > Oh - and if you produce a new version I'd be happy to review it (I guess it will need to go in the next CF, given the discussion happening now). Regards Mark
<div class="WordSection1"><p class="MsoNormal">On 16/09/13 16:20, Satoshi Nagayasu wrote:<p class="MsoNormal">> Thanksfor checking. Fixed to eliminate SnapshotNow.<p class="MsoNormal"> <p class="MsoNormal">Looking forward to get a newpatch, incorporating the comments, that are already given in the following mails:<p class="MsoNormal"> <p class="MsoNormal">1.Jaime Casanova: "The name pgstattuple2, doesn't convince me... maybe you can use pgstattuple() if youuse a second argument (percentage of the sample) to overload the function". <p class="MsoNormal">(<a href="http://www.postgresql.org/message-id/5265AD16.3090704@catalyst.net.nz">http://www.postgresql.org/message-id/5265AD16.3090704@catalyst.net.nz</a>) <pclass="MsoNormal"> <p class="MsoNormal">The comment related to having an argument, to mention the sampling number, is alsogiven by Greg Smith: “There should be an input parameter to the function for how much sampling to do”<p class="MsoNormal">(<a href="http://www.postgresql.org/message-id/51EE62D4.7020401@2ndQuadrant.com">http://www.postgresql.org/message-id/51EE62D4.7020401@2ndQuadrant.com</a>) <pclass="MsoNormal"> <p class="MsoNormal">2. Yourself: "I think it could be improved by sorting sample block numbers beforephysical block reads in order to eliminate random access on the disk." <p class="MsoNormal">(<a href="http://www.postgresql.org/message-id/525779C5.2020608@uptime.jp">http://www.postgresql.org/message-id/525779C5.2020608@uptime.jp</a>) forwhich, Mark Kirkwood , has given a rough patch.<p class="MsoNormal"> <p class="MsoNormal">Regards,<p class="MsoNormal">FirozEV</div>
<div class="WordSection1"><p class="MsoNormal"> <p class="MsoNormal">On 16/09/13 16:20, Satoshi Nagayasu wrote:<p class="MsoNormal">>Thanks for checking. Fixed to eliminate SnapshotNow.<p class="MsoNormal"> <p class="MsoNormal">Lookingforward to get a new patch, incorporating the comments, that are already given in the followingmails:<p class="MsoNormal"> <p class="MsoNormal">1. Jaime Casanova: "The name pgstattuple2, doesn't convince me...maybe you can use pgstattuple() if you use a second argument (percentage of the sample) to overload the function". <pclass="MsoNormal">(<a href="http://www.postgresql.org/message-id/5265AD16.3090704@catalyst.net.nz">http://www.postgresql.org/message-id/5265AD16.3090704@catalyst.net.nz</a>) <pclass="MsoNormal"> <p class="MsoNormal">The comment related to having an argument, to mention the sampling number, is alsogiven by Greg Smith: “There should be an input parameter to the function for how much sampling to do”<p class="MsoNormal">(<a href="http://www.postgresql.org/message-id/51EE62D4.7020401@2ndQuadrant.com">http://www.postgresql.org/message-id/51EE62D4.7020401@2ndQuadrant.com</a>) <pclass="MsoNormal"> <p class="MsoNormal">2. Yourself: "I think it could be improved by sorting sample block numbers beforephysical block reads in order to eliminate random access on the disk." <p class="MsoNormal">(<a href="http://www.postgresql.org/message-id/525779C5.2020608@uptime.jp">http://www.postgresql.org/message-id/525779C5.2020608@uptime.jp</a>) forwhich, Mark Kirkwood , has given a rough patch.<p class="MsoNormal"> <p class="MsoNormal">Regards,<p class="MsoNormal">FirozEV<p class="MsoNormal"> </div>