Thread: Proposal for CSN based snapshots
Given the recent ideas being thrown about changing how freezing and clog is handled and MVCC catalog access I thought I would write out the ideas that I have had about speeding up snapshots in case there is an interesting tie in with the current discussions. To refresh your memory the basic idea is to change visibility determination to be based on a commit sequence number (CSN for short) - a 8 byte number incremented on every commit representing the total ordering of commits. To take a snapshot in this scheme you only need to know the value of last assigned CSN, all transactions with XID less than or equal to that number were commited at the time of the snapshots, everything above wasn't committed. Besides speeding up snapshot taking, this scheme can also be a building block for consistent snapshots in a multi-master environment with minimal communication. Google's Spanner database uses snapshots based on a similar scheme. The main tricky part about this scheme is finding the CSN that was assigned to each XIDs in face of arbitrarily long transactions and snapshots using only a bounded amount of shared memory. The secondary tricky part is doing this in a way that doesn't need locks for visibility determination as that would kill any hope of a performance gain. We need to keep around CSN slots for all currently running transactions and CSN slots of transactions that are concurrent with any active CSN based snapshot (xid.csn > min(snapshot.csn)). To do this I propose the following datastructures to do the XID-to-CSN mapping. For most recently assigned XIDs there is a ringbuffer of slots that contain the CSN values of the XIDs or special CSN values for transactions that haven't completed yet, aborted transactions or subtransactions. I call this the dense CSN map. Looking up a CSN of a XID from the ringbuffer is just a trivial direct indexing into the ring buffer. For long running transactions the ringbuffer may do a full circle before a transaction commits. Such CSN slots along with slots that are needed for older snapshots are evicted from the dense buffer into a sorted array of XID-CSN pairs, or the sparse mapping. For locking purposes there are two sparse buffers, one of them being active the other inactive, more on that later. Looking up the CSN value of a XID that has been evicted into the sparse mapping is a matter of performing a binary search to find the slot and reading the CSN value. Because snapshots can remain active for an unbounded amount of time and there can be unbounded amount of active snapshots, even the sparse mapping can fill up. To handle that case, each backend advertises its lowest snapshot number csn_min. When values need to be evicted from the sparse mapping, they are evicted in CSN order and written into the CSN log - a series of CSN-XID pairs. Backends that may still be concerned about those values are then notified that values that they might need to use have been evicted. Backends with invalidated snapshots can then convert their snapshots to regular list of concurrent XIDs snapshots at their leisure. To convert a CSN based snapshot to XID based, a backend would first scan the shared memory structures for xids up to snapshot.xmax for CSNs that are concurrent to the snapshot and insert the XIDs into the snapshot, then read in the CSN log starting from snapshots CSN, looking for xid's less than the snapshots xmax. After this the snapshot can be handled like current snapshots are handled. A more detailed view of synchronization primitives required for common operations follows. Taking a new snapshot --------------------- Taking a CSN based snapshot under this scheme would consist of reading xmin, csn and xmax from global variables, unlocked and in that order with read barriers in between each load. If this is our oldest snapshot we write our csn_min into pgproc, do a full memory barrier and check from a global variable if the CSN we used is still guaranteed to not be evicted (exceedingly unlikely but cannot be ruled out). The read barrier between reading xmin and csn is needed so the guarantee applies that no transaction with tx.xid < ss.xmin could have committed with tx.csn >= ss.csn, so xmin can be used to safely exclude csn lookups. Read barrier between reading csn and xmax is needed to guarantee that if tx.xid >= ss.xmax, then it's known that tx.csn >= ss.csn. From the write side, there needs to be at least one full memory barrier between GetNewTransactionId updating nextXid and CommitTransaction updating nextCsn, which is quite easily satisfied. Updating global xmin without races is slightly trickier but doable. Checking visibility ------------------- XidInMVCCSnapshot will need to switch on the type of snapshot used after checking xmin and xmax. For list-of-XIDs snapshots the current logic applies. CSN based snapshots need to first do an unlocked read from a backend specific global variable to check if we have been instructed to convert our snapshots to xid based, if so the snapshot is converted (more on that separately). Otherwise we look up the CSN of the xid. To map xid to csn, first the value from the csn slot corresponding to the xid is read in from dense map (just a plain denseCSNMap[xid % denseMapSize]), then after issuing a read barrier, the dense map eviction horizon is checked to verify that the value that we read in was in fact valid, if it is, it can be compared to the snapshot csn value to get the result, if not continue to check the sparse map. To check the sparse map, we read in the sparse map version counter value and use it to determine which one of the two maps is currently active (an optimistic locking scheme). We use linear or binary search to look up the slot for the XID. If the XID is not found we know that it wasn't committed after taking the snapshot, we then have to check the clog if it was committed or not. Otherwise compare the value against our snapshots csn to determine visibility. Finally after issuing a read barrier, check the sparse map version counter to see if the result is valid. Checking from the dense map can omit clog checks as we can use special values to signify aborted and uncommitted values. Even more so, we can defer clog updates until the corresponding slots are evicted from the dense map. Assigning XIDs and evicting from CSN buffers -------------------------------------------- XID assignment will need an additional step to allocate a CSN slot for the transaction. If the dense map ring buffer has filled up, this might require evicting some entries from the dense CSN map. For less contention and better efficiency it would be a good idea to do evictions larger blocks at a time. One 8th or 16th of the dense map at a time might be a good balance here. Eviction will be done under a new CSNEvictionLock. First we publish the point up to which we are evicting from dense to notify committing backends of the hazard. We then read the current nextCSN value and publish it as the largest possible global_csn_min value we can arrive at, so if there is a backend in the middle of taking a snapshot that has fetched a CSN but hasn't yet updated procarray entry will notice that it is at risk and will retry. Using nextCSN is being very conservative, but as far as I can see the invalidations will be rare and cheap. We have to issue a full memory barrier here so either the snapshot take sees our value or we see its csn min. If there is enough space, we just use global_csn_min as the sparse map eviction horizon. If there is not enough free space in the current active sparse map to guarantee that dense map will fit, we scan both the active sparse array and the to-be-evicted block, collecting the missing space worth xid-csn pairs with smallest CSN values to a heap, reducing the heap size for every xid,csn we omit due to not being needed either because the transaction was aborted or because it is visible to all active snapshots. When we finish scanning and the heap isn't empty, then the largest value in the heap is the sparse map eviction horizon. After arriving at the correct sparse map eviction horizon, we iterate through the sparse map and the dense map block to be evicted, copying all active or not-all-visible CSN slots to the inactive sparse map. We also update clog for every committed transaction that we found in the dense map. If we decided to evict some values, we write them to the CSN log here and update the sparse map eviction horizon with the CSN we arrived at. At this point the state in the current active sparse map and the evictable dense map block are duplicated into the inactive sparse map and CSN log. We now need to make the new state visible to visibility checkers in a safe order, issuing a write barrier before each step so the previous changes are visible: * Notify all backends that have csn_min <= sparse map eviction horizon that their snapshots are invalid and at what CSN log location they can start to read to find concurrent xids. * Increment sparse map version counter to switch sparse maps. * Raise the dense map eviction horizon, to free up the dense map block. * Overwrite the dense map block with special UncommittedCSN values that are tagged with their XID (more on that later) At this point we can consider the block cleared up for further use. Because we don't want to lock shared structures for snapshotting we need to maintain a global xmin value. To do this we acquire a spinlock on the global xmin value, and check if it's empty, if no other transaction is running we replace it with our xid. At this point we know the minimum CSN of any unconverted snapshots, so it's also a good time to clean up unnecessary CSN log. Finally we are done, so we can release CSNEvictionLock and XIDGenLock. Committing a transaction ------------------------ Most of the commit sequence remains the same, but where we currently do ProcArrayEndTransaction, we will acquire a new LWLock protecting the nextCSN value, I'll call it the CSNGenLock for now. We first read the dense array eviction horizon, then stamp all our non-overflowed or still in dense map subtransaction slots with special SubcommittedCSN value, then stamp the top level xid with nextCSN. We then issue a full memory barrier, and check the soon-to-be-evicted pointer into the dense map. If it overlaps with any of the XIDs we just tagged then the backend doing the eviction might have missed our update, we have to wait for CSNEvictionLock to become free and go and restamp the relevant XIDs in the sparse map. To stamp a XID with the commit CSN, we compare the XID to the dense map eviction horizon. If the XID still maps to the dense array, we do CAS and swap out UncommittedCSN(xid) with the value that we needed. If the CAS fails, then between when we read the dense array horizon and the actual stamping an eviction process replaced our slot with a newer one. If we didn't tag the slots with the XID value, then we might accidentally stamp another transactions slot. If the XID maps to the sparse array, we have to take the CSNEvictionLock so the sparse array doesn't get swapped out underneath us, and then look up the slot and stamp it and then update the CLOG before releasing the lock. Lock contention shouldn't be a problem here as only long running transactions map to the sparse array. When done with the stamping we will check the global xmin value, if it's our xid, we grab the spinlock, scan through the procarray for the next xmin value, update and release it. Rolling back a transaction -------------------------- Rolling back a transaction is basically the same as committing, but the CSN slots need to be stamped with a AbortedCSN. Subtransactions --------------- Because of limited size of the sparse array, we cannot keep open CSN slots for all of the potentially unbounded number of subtransactions there. I propose something similar to what is done currently with PGPROC_MAX_CACHED_SUBXIDS. When we assign xids to subtransactions that are above this limit, we tag them in the dense array with a special OverflowedSubxidCSN value. When evicting subtransactions from dense array, non-overflowed subtransaction slots are handled like regular slots. We discard the overflowed slots when evicting from the dense map. We also keep track of the lowest subxid that was overflowed and the latest subxid that was overflowed, lowest overflowed subxid is reset when before eviction the highest overflowed subxid is lower than the smallest xid in the sparse array (i.e. we know that the XID region convered by the sparse array doesn't contain any overflowed subxids). When constructing the regular snapshot we can then detect that we don't have the full information about subtransactions and can correctly set the overflowed flag on the snapshot. Similarly visibility checks can omit subxid lookups for xids missing from the sparse array when they know that the xid can't be overflowed. Prepared transactions --------------------- Prepared transactions are handled basically like regular transactions, when starting up with prepared transactions, they are inserted into the sparse array, when they are committed they get stamped with CSNs and become visible like usual. We just need to account for them when sizing the sparse array. Crash safety and checkpoints ---------------------------- Because clog updating is delayed for transactions in the dense map, checkpoints need to flush the dense array before writing out clog. Otherwise the datastructures are fully transient and don't need any special treatment. Hot standby ----------- I haven't yet worked out how CSN based snapshots best integrate with hot standby. As far as I can tell, we could just use the current KnownAssignedXidsGetAndSetXmin mechanism and get regular snapshots. But I think there is an opportunity here to get rid of most of or all of the KnownAssignedXids mechanism if we WAL log the CSNs that are assigned to commits (or use a side channel as proposed by Robert). The extra write is not great, but might not be a large problem after the WAL insertion scaling work is done. Another option would be to use the LSN of commit record as the next CSN value. The locking in that case requires some further thought to guarantee that commits are stamped in the same order as WAL records are inserted without holding WALInsertLock for too long. That seems doable by inserting commiting backends into a queue under WALInsertLock and then have them wait for the transaction in front of them to commit when WALInsertLock has been released. Serializable transactions ------------------------- I won't pretend to be familiar with SSI code, but as far as I can tell serializable transactions don't need any modifications to work with the CSN based snapshot scheme. There actually already is a commit sequence number in the SSI code that could be replaced by the actual CSN. IIRC one of the problems with serializable transactions on hot standby was that transaction visibility order on the standby is different from the master. If we use CSNs for visibility on the slave then we can actually provide identical visibility order. Required atomic primitives -------------------------- Besides the copious amount of memory barriers that are required for correctness. We will need the following lockless primitives: * 64bit atomic read * 64bit atomic write * 64bit CAS Are there any supported platforms where it would be impossible to have those? AFAIK everything from 32bit x86 through POWER and MIPS to ARM can do it. If there are any platforms that can't handle 64bit atomics, would it be ok to run on them with reduced concurrency/performance? Sizing the CSN maps ------------------- CSN maps need to sized to accomodate the number of backends. Dense array size should be picked so that most xids commit before being evicted from the dense map and sparse array will contain slots necessary for either long running transactions or for long snapshots not yet converted to XID based snapshots. I did a few quick simulations to measure the dynamics. If we assume a power law distribution of transaction lengths and snapshots for the full length of transactions with no think time, then 16 slots per backend is enough to make the probability of eviction before commit less than 1e-6 and being needed at eviction due to a snapshot about 1:10000. In the real world very long transactions are more likely than predicted model, but at least the normal variation is mostly buffered by this size. 16 slots = 128bytes per backend ends up at a 12.5KB buffer for the default value of 100 backends, or 125KB for 1000 backends. Sparse buffer needs to be at least big enough to fit CSN slots for the xids of all active transactions and non-overflowed subtransactions. At the current level PGPROC_MAX_CACHED_SUBXIDS=64, the minimum comes out at 16 bytes * (64 + 1) slots * 100 = backends = 101.6KB per buffer, or 203KB total in the default configuration. Performance discussion ---------------------- Taking a snapshot is extremely cheap in this scheme, I think the cost will be mostly for publishing the csnmin and rechecking validity after it. Taking snapshots in the shadow of another snapshot (often the case for the proposed MVCC catalog access) will be even cheaper as we don't have to advertise the new snapshot. The delayed XID based snapshot construction should be unlikely, but even if it isn't the costs are similar to GetSnapshotData, but we don't need to hold a lock. Visibility checking will also be simpler as for the cases where the snapshot is covered by the dense array it only requires two memory lookups and comparisons. The main extra work for writing transactions is the eviction process. The amortized worst case extra work per xid is dominated by copying the sparse buffer back and forth and spooling out the csn log. We need to write out 16 bytes per xid and copy sparse buffer size / eviction block size sparse buffer slots. If we evict 1/8th of dense map at each eviction it works out as 520 bytes copied per xid assigned. About the same ballpark as GetSnapshotData is now. With the described scheme, long snapshots will cause the sparse buffer to quickly fill up and then spool out until the backend wakes up, converts its snapshots and releases the eviction process to free up the log. It would be more efficient to be slightly more proactive and tell them to convert the snapshots earlier so if they manage to be timely with their conversion we can avoid writing any CSN log. I'm not particularly pleased about the fact that both xid assignment and committing can block behind the eviction lock. On the other hand, plugging in some numbers, with 100 backends doing 100k xid assignments/s the lock will be acquired 1000 times per second for less than 100us at a time. The contention might not be bad enough to warrant extra complexity to deal with it. If it does happen to be a problem, then I have some ideas how to cope with it. Having to do CSN log writes while holding a LWLock might not be the best of ideas, to combat that we can either add one more buffer so we can do the actual write syscall after we release CSNEvictionLock, or we can reuse the SLRU machinery to handle this. Overall it looks to be a big win for typical workloads. Workloads using large amounts of subtransactions might not be as well off, but I doubt there will be a regression. At this point I don't see any major issues with this approach. If the ensuing discussion doesn't find any major showstoppers then I will start to work on a patch bit-by-bit. It might take a while though as my free hacking time has been severely cut down since we have a small one in the family. Regards, Ants Aasma -- Cybertec Schönig & Schönig GmbH Gröhrmühlgasse 26 A-2700 Wiener Neustadt Web: http://www.postgresql-support.de
Ants, On 06/07/2013 12:42 AM, Ants Aasma wrote: > Given the recent ideas being thrown about changing how freezing and > clog is handled and MVCC catalog access I thought I would write out > the ideas that I have had about speeding up snapshots in case there is > an interesting tie in with the current discussions. Thanks for this write-up. > To refresh your memory the basic idea is to change visibility > determination to be based on a commit sequence number (CSN for short) > - a 8 byte number incremented on every commit representing the total > ordering of commits. To take a snapshot in this scheme you only need > to know the value of last assigned CSN, all transactions with XID less You mean with a *CSN* less than or equal to that number? There's certainly no point in comparing a CSN with an XID. > than or equal to that number were commited at the time of the > snapshots, everything above wasn't committed. Besides speeding up > snapshot taking, this scheme can also be a building block for > consistent snapshots in a multi-master environment with minimal > communication. Agreed. Postgres-R uses a CommitOrderId, which is very similar in concept, for example. > The main tricky part about this scheme is finding the CSN that was > assigned to each XIDs in face of arbitrarily long transactions and > snapshots using only a bounded amount of shared memory. The secondary > tricky part is doing this in a way that doesn't need locks for > visibility determination as that would kill any hope of a performance > gain. Agreed. Para-phrasing, you can also say that CSNs can only ever identify completed transactions, where XIDs can be used to identify transactions in progress as well. [ We cannot possibly get rid of XIDs entirely for that reason. And the mapping between CSNs and XIDs has some additional cost. ] > We need to keep around CSN slots for all currently running > transactions and CSN slots of transactions that are concurrent with > any active CSN based snapshot (xid.csn > min(snapshot.csn)). To do > this I propose the following datastructures to do the XID-to-CSN > mapping. For most recently assigned XIDs there is a ringbuffer of > slots that contain the CSN values of the XIDs or special CSN values > for transactions that haven't completed yet, aborted transactions or > subtransactions. I call this the dense CSN map. Looking up a CSN of a > XID from the ringbuffer is just a trivial direct indexing into the > ring buffer. > > For long running transactions the ringbuffer may do a full circle > before a transaction commits. Such CSN slots along with slots that are > needed for older snapshots are evicted from the dense buffer into a > sorted array of XID-CSN pairs, or the sparse mapping. For locking > purposes there are two sparse buffers, one of them being active the > other inactive, more on that later. Looking up the CSN value of a XID > that has been evicted into the sparse mapping is a matter of > performing a binary search to find the slot and reading the CSN value. I like this idea of dense and sparse "areas". Seems like a simple enough, yet reasonably compact representation that might work well in practice. > Because snapshots can remain active for an unbounded amount of time > and there can be unbounded amount of active snapshots, even the sparse > mapping can fill up. I don't think the number of active snapshots matters - after all, they could all refer the same CSN. So that number shouldn't have any influence on the size of the sparse mapping. What does matter is the number of transactions referenced by such a sparse map. You are of course correct in that this number is equally unbounded. > To handle that case, each backend advertises its > lowest snapshot number csn_min. When values need to be evicted from > the sparse mapping, they are evicted in CSN order and written into the > CSN log - a series of CSN-XID pairs. Backends that may still be > concerned about those values are then notified that values that they > might need to use have been evicted. Backends with invalidated > snapshots can then convert their snapshots to regular list of > concurrent XIDs snapshots at their leisure. > > To convert a CSN based snapshot to XID based, a backend would first > scan the shared memory structures for xids up to snapshot.xmax for > CSNs that are concurrent to the snapshot and insert the XIDs into the > snapshot, then read in the CSN log starting from snapshots CSN, > looking for xid's less than the snapshots xmax. After this the > snapshot can be handled like current snapshots are handled. Hm, I dislike the requirement to maintain two different snapshot formats. Also mind that snapshot conversions - however unlikely you choose to make them - may well result in bursts as multiple processes may need to do such a conversion, all starting at the same point in time. > Rolling back a transaction > -------------------------- > > Rolling back a transaction is basically the same as committing, but > the CSN slots need to be stamped with a AbortedCSN. Is that really necessary? After all, an aborted transaction behaves pretty much the same as a transaction in progress WRT visibility: it's simply not visible. Or why do you need to tell apart aborted from in-progress transactions by CSN? > Sizing the CSN maps > ------------------- > > CSN maps need to sized to accomodate the number of backends. > > Dense array size should be picked so that most xids commit before > being evicted from the dense map and sparse array will contain slots > necessary for either long running transactions or for long snapshots > not yet converted to XID based snapshots. I did a few quick > simulations to measure the dynamics. If we assume a power law > distribution of transaction lengths and snapshots for the full length > of transactions with no think time, then 16 slots per backend is > enough to make the probability of eviction before commit less than > 1e-6 and being needed at eviction due to a snapshot about 1:10000. In > the real world very long transactions are more likely than predicted > model, but at least the normal variation is mostly buffered by this > size. 16 slots = 128bytes per backend ends up at a 12.5KB buffer for > the default value of 100 backends, or 125KB for 1000 backends. Sounds reasonable to me. > Sparse buffer needs to be at least big enough to fit CSN slots for the > xids of all active transactions and non-overflowed subtransactions. At > the current level PGPROC_MAX_CACHED_SUBXIDS=64, the minimum comes out > at 16 bytes * (64 + 1) slots * 100 = backends = 101.6KB per buffer, > or 203KB total in the default configuration. A CSN is 8 bytes, the XID 4, resulting in 12 bytes per slot. So I guess the given 16 bytes includes alignment to 8 byte boundaries. Sounds good. > Performance discussion > ---------------------- > > Taking a snapshot is extremely cheap in this scheme, I think the cost > will be mostly for publishing the csnmin and rechecking validity after > it. Taking snapshots in the shadow of another snapshot (often the case > for the proposed MVCC catalog access) will be even cheaper as we don't > have to advertise the new snapshot. The delayed XID based snapshot > construction should be unlikely, but even if it isn't the costs are > similar to GetSnapshotData, but we don't need to hold a lock. > > Visibility checking will also be simpler as for the cases where the > snapshot is covered by the dense array it only requires two memory > lookups and comparisons. Keep in mind, though, that both of these lookups are into shared memory. Especially the dense ring buffer may well turn into a point of contention. Or at least the cache lines holding the most recent XIDs within that ring buffer. Where as currently, the snapshot's xip array resides in process-local memory. (Granted, often enough, the proc array also is a point of contention.) > At this point I don't see any major issues with this approach. If the > ensuing discussion doesn't find any major showstoppers then I will > start to work on a patch bit-by-bit. Bit-by-bit? Reminds me of punched cards. I don't think we accept patches in that format. :-) > we have a small one in the family. Congratulations on that one. Regards Markus Wanner
On Thu, Jun 6, 2013 at 11:42 PM, Ants Aasma <ants@cybertec.at> wrote: > To refresh your memory the basic idea is to change visibility > determination to be based on a commit sequence number (CSN for short) > - a 8 byte number incremented on every commit representing the total > ordering of commits I think we would just use the LSN of the commit record which is effectively the same but doesn't require a new counter. I don't think this changes anything though. -- greg
On Fri, Jun 7, 2013 at 2:59 PM, Markus Wanner <markus@bluegap.ch> wrote: >> To refresh your memory the basic idea is to change visibility >> determination to be based on a commit sequence number (CSN for short) >> - a 8 byte number incremented on every commit representing the total >> ordering of commits. To take a snapshot in this scheme you only need >> to know the value of last assigned CSN, all transactions with XID less > > You mean with a *CSN* less than or equal to that number? There's > certainly no point in comparing a CSN with an XID. That was what I meant. I guess my coffee hadn't kicked in yet there. >> than or equal to that number were commited at the time of the >> snapshots, everything above wasn't committed. Besides speeding up >> snapshot taking, this scheme can also be a building block for >> consistent snapshots in a multi-master environment with minimal >> communication. > > Agreed. Postgres-R uses a CommitOrderId, which is very similar in > concept, for example. Do you think having this snapshot scheme would be helpful for Postgres-R? >> Because snapshots can remain active for an unbounded amount of time >> and there can be unbounded amount of active snapshots, even the sparse >> mapping can fill up. > > I don't think the number of active snapshots matters - after all, they > could all refer the same CSN. So that number shouldn't have any > influence on the size of the sparse mapping. > > What does matter is the number of transactions referenced by such a > sparse map. You are of course correct in that this number is equally > unbounded. Yes, that is what I meant to say but for some reason didn't. >> To handle that case, each backend advertises its >> lowest snapshot number csn_min. When values need to be evicted from >> the sparse mapping, they are evicted in CSN order and written into the >> CSN log - a series of CSN-XID pairs. Backends that may still be >> concerned about those values are then notified that values that they >> might need to use have been evicted. Backends with invalidated >> snapshots can then convert their snapshots to regular list of >> concurrent XIDs snapshots at their leisure. >> >> To convert a CSN based snapshot to XID based, a backend would first >> scan the shared memory structures for xids up to snapshot.xmax for >> CSNs that are concurrent to the snapshot and insert the XIDs into the >> snapshot, then read in the CSN log starting from snapshots CSN, >> looking for xid's less than the snapshots xmax. After this the >> snapshot can be handled like current snapshots are handled. > > Hm, I dislike the requirement to maintain two different snapshot formats. > > Also mind that snapshot conversions - however unlikely you choose to > make them - may well result in bursts as multiple processes may need to > do such a conversion, all starting at the same point in time. I agree that two snapshot formats is not great. On the other hand, the additional logic is confined to XidInMVCCSnapshot and is reasonably simple. If we didn't convert the snapshots we would have to keep spooling out CSN log and look up XIDs for each visibility check. We could add a cache for XIDs that were deemed concurrent, but that is in effect just lazily constructing the same datastructure. The work needed to convert is reasonably well bounded, can be done without holding global locks and in most circumstances should only be necessary for snapshots that are used for a long time and will amortize the cost. I'm not worried about the bursts because the conversion is done lockless and starting at the same point in time leads to better cache utilization. >> Rolling back a transaction >> -------------------------- >> >> Rolling back a transaction is basically the same as committing, but >> the CSN slots need to be stamped with a AbortedCSN. > > Is that really necessary? After all, an aborted transaction behaves > pretty much the same as a transaction in progress WRT visibility: it's > simply not visible. > > Or why do you need to tell apart aborted from in-progress transactions > by CSN? I need to detect aborted transactions so they can be discared during the eviction process, otherwise the sparse array will fill up. They could also be filtered out by cross-referencing uncommitted slots with the procarray. Having the abort case do some additional work to make xid assigment cheaper looks like a good tradeoff. >> Sparse buffer needs to be at least big enough to fit CSN slots for the >> xids of all active transactions and non-overflowed subtransactions. At >> the current level PGPROC_MAX_CACHED_SUBXIDS=64, the minimum comes out >> at 16 bytes * (64 + 1) slots * 100 = backends = 101.6KB per buffer, >> or 203KB total in the default configuration. > > A CSN is 8 bytes, the XID 4, resulting in 12 bytes per slot. So I guess > the given 16 bytes includes alignment to 8 byte boundaries. Sounds good. 8 byte alignment for CSNs is needed for atomic if not something else. I think the size could be cut in half by using a base value for CSNs if we assume that no xid is active for longer than 2B transactions as is currently the case. I didn't want to include the complication in the first iteration, so I didn't verify if that would have any gotchas. >> Performance discussion >> ---------------------- >> >> Taking a snapshot is extremely cheap in this scheme, I think the cost >> will be mostly for publishing the csnmin and rechecking validity after >> it. Taking snapshots in the shadow of another snapshot (often the case >> for the proposed MVCC catalog access) will be even cheaper as we don't >> have to advertise the new snapshot. The delayed XID based snapshot >> construction should be unlikely, but even if it isn't the costs are >> similar to GetSnapshotData, but we don't need to hold a lock. >> >> Visibility checking will also be simpler as for the cases where the >> snapshot is covered by the dense array it only requires two memory >> lookups and comparisons. > > Keep in mind, though, that both of these lookups are into shared memory. > Especially the dense ring buffer may well turn into a point of > contention. Or at least the cache lines holding the most recent XIDs > within that ring buffer. > > Where as currently, the snapshot's xip array resides in process-local > memory. (Granted, often enough, the proc array also is a point of > contention.) Visibility checks are done lock free so they don't cause any contention. The number of times each cache line can be invalidated is bounded by 8. Overall I think actual performance tests are needed to see if there is a problem, or perhaps if having the data shared actually helps with cache hit rates. >> At this point I don't see any major issues with this approach. If the >> ensuing discussion doesn't find any major showstoppers then I will >> start to work on a patch bit-by-bit. > > Bit-by-bit? Reminds me of punched cards. I don't think we accept patches > in that format. :-) > >> we have a small one in the family. > > Congratulations on that one. Thanks, Ants Aasma -- Cybertec Schönig & Schönig GmbH Gröhrmühlgasse 26 A-2700 Wiener Neustadt Web: http://www.postgresql-support.de
On Fri, Jun 7, 2013 at 3:47 PM, Greg Stark <stark@mit.edu> wrote: > On Thu, Jun 6, 2013 at 11:42 PM, Ants Aasma <ants@cybertec.at> wrote: >> To refresh your memory the basic idea is to change visibility >> determination to be based on a commit sequence number (CSN for short) >> - a 8 byte number incremented on every commit representing the total >> ordering of commits > > I think we would just use the LSN of the commit record which is > effectively the same but doesn't require a new counter. > I don't think this changes anything though. I briefly touched on that point in the Hot Standby section. This has some consequences for locking in CommitTransaction, but otherwise LSN is as good as any other monotonically increasing value. Regards, Ants Aasma -- Cybertec Schönig & Schönig GmbH Gröhrmühlgasse 26 A-2700 Wiener Neustadt Web: http://www.postgresql-support.de
Ants Aasma <ants@cybertec.at> wrote: > Serializable transactions > ------------------------- > > I won't pretend to be familiar with SSI code, but as far as I can > tell serializable transactions don't need any modifications to > work with the CSN based snapshot scheme. There actually already > is a commit sequence number in the SSI code that could be > replaced by the actual CSN. That seems quite likely to work, and may be good for performance. > IIRC one of the problems with serializable transactions on hot > standby was that transaction visibility order on the standby is > different from the master. Pretty much. Technically what SSI does is to ensure that every serializable transaction's view of the data is consistent with some serial (one-at-a time) exection of serializable transactions. That "apparent order of execution" does not always match commit order. The problem is that without further work a hot standby query could see a state which would not have been possible for it to see on the master. For example, a batch is closed but a transaction has not yet committed which is part of that batch. For an example, see: http://wiki.postgresql.org/wiki/SSI#Read_Only_Transactions As that example demonstrates, as long as no serializable transaction *sees* the incomplete batch with knowledge (or at least potential knowledge) of the batch being closed, the pending transaction affecting the batch is allowed to commit. If the conflicting state is exposed by even a read-only query, the transaction with the pending change to the batch is canceled. A hot standby can't cancel the pending transaction -- at least not without adding additional communications channels and latency. The ideas which have been bandied about have had to do with allowing serializable transactions on a hot standby to use snapshots which are known to be "safe" -- that is, they cannot expose any such state. It might be possible to identify known safe points in the commit stream on the master and pass that information along in the WAL stream. The down side is that the hot standby would need to either remember the last such safe snapshot or wait for the next one, and while these usually come up fairly quickly in most workloads, there is no actual bounding on how long that could take. A nicer solution, if we can manage it, is to allow snapshots on the hot standby which are not based exclusively on the commit order, but use the apparent order of execution from the master. It seems non-trivial to get that right. > If we use CSNs for visibility on the slave then we can actually > provide identical visibility order. As the above indicates, that's not really true without using "apparent order of execution" instead of "commit order". In the absence of serializable transactions those are always the same (I think), but to provide a way to allow serializable transactions on the hot standby the order would need to be subject to rearrangement based on read-write conflicts among transactions on the master, or snapshots which could expose serialization anomalies would need to be prohibited. -- Kevin Grittner EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
Ants, the more I think about this, the more I start to like it. On 06/07/2013 02:50 PM, Ants Aasma wrote: > On Fri, Jun 7, 2013 at 2:59 PM, Markus Wanner <markus@bluegap.ch> wrote: >> Agreed. Postgres-R uses a CommitOrderId, which is very similar in >> concept, for example. > > Do you think having this snapshot scheme would be helpful for Postgres-R? Yeah, it could help to reduce patch size, after a rewrite to use such a CSN. >> Or why do you need to tell apart aborted from in-progress transactions >> by CSN? > > I need to detect aborted transactions so they can be discared during > the eviction process, otherwise the sparse array will fill up. They > could also be filtered out by cross-referencing uncommitted slots with > the procarray. Having the abort case do some additional work to make > xid assigment cheaper looks like a good tradeoff. I see. >>> Sparse buffer needs to be at least big enough to fit CSN slots for the >>> xids of all active transactions and non-overflowed subtransactions. At >>> the current level PGPROC_MAX_CACHED_SUBXIDS=64, the minimum comes out >>> at 16 bytes * (64 + 1) slots * 100 = backends = 101.6KB per buffer, >>> or 203KB total in the default configuration. >> >> A CSN is 8 bytes, the XID 4, resulting in 12 bytes per slot. So I guess >> the given 16 bytes includes alignment to 8 byte boundaries. Sounds good. > > 8 byte alignment for CSNs is needed for atomic if not something else. Oh, right, atomic writes. > I think the size could be cut in half by using a base value for CSNs > if we assume that no xid is active for longer than 2B transactions as > is currently the case. I didn't want to include the complication in > the first iteration, so I didn't verify if that would have any > gotchas. In Postgres-R, I effectively used a 32-bit order id which wraps around. In this case, I guess adjusting the base value will get tricky. Wrapping could probably be used as well, instead. > The number of times each cache line can be invalidated is > bounded by 8. Hm.. good point. Regards Markus Wanner
On 11th June 2013, Markus Wanner wrote: > >> Agreed. Postgres-R uses a CommitOrderId, which is very similar in > >> concept, for example. > > > > Do you think having this snapshot scheme would be helpful for > Postgres-R? > > Yeah, it could help to reduce patch size, after a rewrite to use such a > CSN. > > >> Or why do you need to tell apart aborted from in-progress > >> transactions by CSN? > > > > I need to detect aborted transactions so they can be discared during > > the eviction process, otherwise the sparse array will fill up. They > > could also be filtered out by cross-referencing uncommitted slots > with > > the procarray. Having the abort case do some additional work to make > > xid assigment cheaper looks like a good tradeoff. > > I see. > > >>> Sparse buffer needs to be at least big enough to fit CSN slots for > >>> the xids of all active transactions and non-overflowed > >>> subtransactions. At the current level PGPROC_MAX_CACHED_SUBXIDS=64, > >>> the minimum comes out at 16 bytes * (64 + 1) slots * 100 = > backends > >>> = 101.6KB per buffer, or 203KB total in the default configuration. > >> > >> A CSN is 8 bytes, the XID 4, resulting in 12 bytes per slot. So I > >> guess the given 16 bytes includes alignment to 8 byte boundaries. > Sounds good. > > > > 8 byte alignment for CSNs is needed for atomic if not something else. > > Oh, right, atomic writes. > > > I think the size could be cut in half by using a base value for CSNs > > if we assume that no xid is active for longer than 2B transactions as > > is currently the case. I didn't want to include the complication in > > the first iteration, so I didn't verify if that would have any > > gotchas. > > In Postgres-R, I effectively used a 32-bit order id which wraps around. > > In this case, I guess adjusting the base value will get tricky. > Wrapping could probably be used as well, instead. > > > The number of times each cache line can be invalidated is bounded by > > 8. > > Hm.. good point. > We are also planning to implement CSN based snapshot. So I am curious to know whether any further development is happening on this. If not then what is the reason? Am I missing something? Thanks and Regards, Kumar Rajeev Rastogi
On 01/24/2014 02:10 PM, Rajeev rastogi wrote: > We are also planning to implement CSN based snapshot. > So I am curious to know whether any further development is happening on this. I started looking into this, and plan to work on this for 9.5. It's a big project, so any help is welcome. The design I have in mind is to use the LSN of the commit record as the CSN (as Greg Stark suggested). Some problems and solutions I have been thinking of: The core of the design is to store the LSN of the commit record in pg_clog. Currently, we only store 2 bits per transaction there, indicating if the transaction committed or not, but the patch will expand it to 64 bits, to store the LSN. To check the visibility of an XID in a snapshot, the XID's commit LSN is looked up in pg_clog, and compared with the snapshot's LSN. Currently, before consulting the clog for an XID's status, it is necessary to first check if the transaction is still in progress by scanning the proc array. To get rid of that requirement, just before writing the commit record in the WAL, the backend will mark the clog slot with a magic value that says "I'm just about to commit". After writing the commit record, it is replaced with the record's actual LSN. If a backend sees the magic value in the clog, it will wait for the transaction to finish the insertion, and then check again to get the real LSN. I'm thinking of just using XactLockTableWait() for that. This mechanism makes the insertion of a commit WAL record and updating the clog appear atomic to the rest of the system. With this mechanism, taking a snapshot is just a matter of reading the current WAL insertion point. There is no need to scan the proc array, which is good. However, it probably still makes sense to record an xmin and an xmax in SnapshotData, for performance reasons. An xmax, in particular, will allow us to skip checking the clog for transactions that will surely not be visible. We will no longer track the latest completed XID or the xmin like we do today, but we can use SharedVariableCache->nextXid as a conservative value for xmax, and keep a cached global xmin value in shared memory, updated when convenient, that can be just copied to the snapshot. In theory, we could use a snapshot LSN as the cutoff-point for HeapTupleSatisfiesVisibility(). Maybe it's just because this is new, but that makes me feel uneasy. In any case, I think we'll need a cut-off point defined as an XID rather than an LSN for freezing purposes. In particular, we need a cut-off XID to determine how far the pg_clog can be truncated, and to store in relfrozenxid. So, we will still need the concept of a global oldest xmin. When a snapshot is just an LSN, taking a snapshot can no longer calculate an xmin, like we currently do (there will be a snapshot LSN in place of an xmin in the proc array). So we will need a new mechanism to calculate the global oldest xmin. First scan the proc array to find the oldest still in-progress XID. That - 1 will become the new oldest global xmin, after all currently active snapshots have finished. We don't want to sleep in GetOldestXmin(), waiting for the snapshots to finish, so we should periodically advance a system-wide oldest xmin value, for example whenever the walwrite process wakes up, so that when we need an oldest-xmin value, we will always have a fairly recently calculated value ready in shared memory. - Heikki
On 2014-05-12 16:56:51 +0300, Heikki Linnakangas wrote: > On 01/24/2014 02:10 PM, Rajeev rastogi wrote: > >We are also planning to implement CSN based snapshot. > >So I am curious to know whether any further development is happening on this. > > I started looking into this, and plan to work on this for 9.5. It's a big > project, so any help is welcome. The design I have in mind is to use the LSN > of the commit record as the CSN (as Greg Stark suggested). Cool. I haven't fully thought it through but I think it should make some of the decoding code simpler. And it should greatly simplify the hot standby code. Some of the stuff in here will be influence whether your freezing replacement patch gets in. Do you plan to further pursue that one? > The core of the design is to store the LSN of the commit record in pg_clog. > Currently, we only store 2 bits per transaction there, indicating if the > transaction committed or not, but the patch will expand it to 64 bits, to > store the LSN. To check the visibility of an XID in a snapshot, the XID's > commit LSN is looked up in pg_clog, and compared with the snapshot's LSN. We'll continue to need some of the old states? You plan to use values that can never be valid lsns for them? I.e. 0/0 IN_PROGRESS, 0/1 ABORTED etc? How do you plan to deal with subtransactions? > Currently, before consulting the clog for an XID's status, it is necessary > to first check if the transaction is still in progress by scanning the proc > array. To get rid of that requirement, just before writing the commit record > in the WAL, the backend will mark the clog slot with a magic value that says > "I'm just about to commit". After writing the commit record, it is replaced > with the record's actual LSN. If a backend sees the magic value in the clog, > it will wait for the transaction to finish the insertion, and then check > again to get the real LSN. I'm thinking of just using XactLockTableWait() > for that. This mechanism makes the insertion of a commit WAL record and > updating the clog appear atomic to the rest of the system. So it's quite possible that clog will become more of a contention point due to the doubled amount of writes. > In theory, we could use a snapshot LSN as the cutoff-point for > HeapTupleSatisfiesVisibility(). Maybe it's just because this is new, but > that makes me feel uneasy. It'd possibly also end up being less efficient because you'd visit the clog for potentially quite some transactions to get the LSN. Greetings, Andres Freund
On 05/12/2014 05:41 PM, Andres Freund wrote: > I haven't fully thought it through but I think it should make some of > the decoding code simpler. And it should greatly simplify the hot > standby code. Cool. I was worried it might conflict with the logical decoding stuff in some fundamental way, as I'm not really familiar with it. > Some of the stuff in here will be influence whether your freezing > replacement patch gets in. Do you plan to further pursue that one? Not sure. I got to the point where it seemed to work, but I got a bit of a cold feet proceeding with it. I used the page header's LSN field to define the "epoch" of the page, but I started to feel uneasy about it. I would be much more comfortable with an extra field in the page header, even though that uses more disk space. And requires dealing with pg_upgrade. >> The core of the design is to store the LSN of the commit record in pg_clog. >> Currently, we only store 2 bits per transaction there, indicating if the >> transaction committed or not, but the patch will expand it to 64 bits, to >> store the LSN. To check the visibility of an XID in a snapshot, the XID's >> commit LSN is looked up in pg_clog, and compared with the snapshot's LSN. > > We'll continue to need some of the old states? You plan to use values > that can never be valid lsns for them? I.e. 0/0 IN_PROGRESS, 0/1 ABORTED > etc? Exactly. Using 64 bits per XID instead of just 2 will obviously require a lot more disk space, so we might actually want to still support the old clog format too, as an "archive" format. The clog for old transactions could be converted to the more compact 2-bits per XID format (or even just 1 bit). > How do you plan to deal with subtransactions? pg_subtrans will stay unchanged. We could possibly merge it with pg_clog, reserving some 32-bit chunk of values that are not valid LSNs to mean an uncommitted subtransaction, with the parent XID. That assumes that you never need to look up the parent of an already-committed subtransaction. I thought that was true at first, but I think the SSI code looks up the parent of a committed subtransaction, to find its predicate locks. Perhaps it could be changed, but seems best to leave it alone for now; there will be a lot code churn anyway. I think we can get rid of the sub-XID array in PGPROC. It's currently used to speed up TransactionIdIsInProgress(), but with the patch it will no longer be necessary to call TransactionIdIsInProgress() every time you check the visibility of an XID, so it doesn't need to be so fast anymore. With the new "commit-in-progress" status in clog, we won't need the sub-committed clog status anymore. The "commit-in-progress" status will achieve the same thing. >> Currently, before consulting the clog for an XID's status, it is necessary >> to first check if the transaction is still in progress by scanning the proc >> array. To get rid of that requirement, just before writing the commit record >> in the WAL, the backend will mark the clog slot with a magic value that says >> "I'm just about to commit". After writing the commit record, it is replaced >> with the record's actual LSN. If a backend sees the magic value in the clog, >> it will wait for the transaction to finish the insertion, and then check >> again to get the real LSN. I'm thinking of just using XactLockTableWait() >> for that. This mechanism makes the insertion of a commit WAL record and >> updating the clog appear atomic to the rest of the system. > > So it's quite possible that clog will become more of a contention point > due to the doubled amount of writes. Yeah. OTOH, each transaction will take more space in the clog, which will spread the contention across more pages. And I think there are ways to mitigate contention in clog, if it becomes a problem. We could make the locking more fine-grained than one lock per page, use atomic 64-bit reads/writes on platforms that support it, etc. >> In theory, we could use a snapshot LSN as the cutoff-point for >> HeapTupleSatisfiesVisibility(). Maybe it's just because this is new, but >> that makes me feel uneasy. > > It'd possibly also end up being less efficient because you'd visit the > clog for potentially quite some transactions to get the LSN. True. - Heikki
On Mon, May 12, 2014 at 10:41 AM, Andres Freund <andres@2ndquadrant.com> wrote: > On 2014-05-12 16:56:51 +0300, Heikki Linnakangas wrote: >> On 01/24/2014 02:10 PM, Rajeev rastogi wrote: >> >We are also planning to implement CSN based snapshot. >> >So I am curious to know whether any further development is happening on this. >> >> I started looking into this, and plan to work on this for 9.5. It's a big >> project, so any help is welcome. The design I have in mind is to use the LSN >> of the commit record as the CSN (as Greg Stark suggested). > > Cool. Yes, very cool. I remember having some concerns about using the LSN of the commit record as the CSN. I think the biggest one was the need to update clog with the CSN before the commit record had been written, which your proposal to store a temporary sentinel value there until the commit has completed might address. However, I wonder what happens if you write the commit record and then the attempt to update pg_clog fails. I think you'll have to PANIC, which kind of sucks. It would be nice to pin the pg_clog page into the SLRU before writing the commit record so that we don't have to fear needing to re-read it afterwards, but the SLRU machinery doesn't currently have that notion. Another thing to think about is that LSN = CSN will make things much more difficult if we ever want to support multiple WAL streams with a separate LSN sequence for each. Perhaps you'll say that's a pipe dream anyway, and I agree it's probably 5 years out, but I think it may be something we'll want eventually. With synthetic CSNs those systems are more decoupled. OTOH, one advantage of LSN = CSN is that the commit order as seen on the standby would always match the commit order as seen on the master, which is currently not true, and would be a very nice property to have. I think we're likely to find that system performance is quite sensitive to any latency in updating the global-xmin. One thing about the present system is that if you take a snapshot while a very "old" transaction is still running, you're going to use that as your global-xmin for the entire lifetime of your transaction. It might be possible, with some of the rejiggering you're thinking about, to arrange things so that there are opportunities for processes to roll forward their notion of the global-xmin, making HOT pruning more efficient. Whether anything good happens there or not is sort of a side issue, but we need to make sure the efficiency of HOT pruning doesn't regress. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On Mon, May 12, 2014 at 4:56 PM, Heikki Linnakangas <hlinnakangas@vmware.com> wrote: > On 01/24/2014 02:10 PM, Rajeev rastogi wrote: >> >> We are also planning to implement CSN based snapshot. >> So I am curious to know whether any further development is happening on >> this. > > > I started looking into this, and plan to work on this for 9.5. It's a big > project, so any help is welcome. The design I have in mind is to use the LSN > of the commit record as the CSN (as Greg Stark suggested). I did do some coding work on this, but the free time I used to work on this basically disappeared with a child in the family. I guess what I have has bitrotted beyond recognition. However I may still have some insight that may be of use. From your comments I presume that you are going with the original, simpler approach proposed by Robert to simply keep the XID-CSN map around for ever and probe it for all visibility lookups that lie outside of the xmin-xmax range? As opposed to the more complex hybrid approach I proposed that keeps a short term XID-CSN map and lazily builds conventional list-of-concurrent-XIDs snapshots for long lived snapshots. I think that would be prudent, as the simpler approach needs mostly the same ground work and if turns out to work well enough, simpler is always better. Regards, Ants Aasma -- Cybertec Schönig & Schönig GmbH Gröhrmühlgasse 26 A-2700 Wiener Neustadt Web: http://www.postgresql-support.de
On 2014-05-12 18:01:59 +0300, Heikki Linnakangas wrote: > On 05/12/2014 05:41 PM, Andres Freund wrote: > >I haven't fully thought it through but I think it should make some of > >the decoding code simpler. And it should greatly simplify the hot > >standby code. > > Cool. I was worried it might conflict with the logical decoding stuff in > some fundamental way, as I'm not really familiar with it. My gut feeling is that it should be possible to make it work. I'm too deep into the last week of a project to properly analyze it, but I am sure we'll find a place to grab a drink and discuss it next week. Essentially all it needs is to be able to represent snapshots from the past including (and that's the hard part) a snapshot from somewhere in the midst of an xact. The latter is done by loggin cmin/cmax for all catalog tuples and building a lookup table when looking inside an xact. That shouldn't change much for CSN based snapshots. I think. > >Some of the stuff in here will be influence whether your freezing > >replacement patch gets in. Do you plan to further pursue that one? > > Not sure. I got to the point where it seemed to work, but I got a bit of a > cold feet proceeding with it. I used the page header's LSN field to define > the "epoch" of the page, but I started to feel uneasy about it. Yea. I don't think the approach is fundamentally broken but it touches a *lot* of arcane places... Or at least it needs to touch many and the trick is finding them all :) > I would be > much more comfortable with an extra field in the page header, even though > that uses more disk space. And requires dealing with pg_upgrade. Maybe we can reclaim pagesize_version and prune_xid in some way? It seems to be prune_xid could be represented as an LSN with CSN snapshots combined with your freezing approach and we probably don't need the last two bytes of the lsn for that purpose... > Using 64 bits per XID instead of just 2 will obviously require a lot more > disk space, so we might actually want to still support the old clog format > too, as an "archive" format. The clog for old transactions could be > converted to the more compact 2-bits per XID format (or even just 1 bit). Wouldn't it make more sense to have two slrus then? A SRLU with dynamic width doesn't seem easily doable. > >How do you plan to deal with subtransactions? > > pg_subtrans will stay unchanged. We could possibly merge it with pg_clog, > reserving some 32-bit chunk of values that are not valid LSNs to mean an > uncommitted subtransaction, with the parent XID. That assumes that you never > need to look up the parent of an already-committed subtransaction. I thought > that was true at first, but I think the SSI code looks up the parent of a > committed subtransaction, to find its predicate locks. Perhaps it could be > changed, but seems best to leave it alone for now; there will be a lot code > churn anyway. > > I think we can get rid of the sub-XID array in PGPROC. It's currently used > to speed up TransactionIdIsInProgress(), but with the patch it will no > longer be necessary to call TransactionIdIsInProgress() every time you check > the visibility of an XID, so it doesn't need to be so fast anymore. Whether it can be removed depends on how the whole hot standby stuff is dealt with... Also, there's some other callsites that do TransactionIdIsInProgress() at some frequency. Just think about all the multixact business :( > With the new "commit-in-progress" status in clog, we won't need the > sub-committed clog status anymore. The "commit-in-progress" status will > achieve the same thing. Wouldn't that cause many spurious waits? Because commit-in-progress needs to be waited on, but a sub-committed xact surely not? > >So it's quite possible that clog will become more of a contention point > >due to the doubled amount of writes. > > Yeah. OTOH, each transaction will take more space in the clog, which will > spread the contention across more pages. And I think there are ways to > mitigate contention in clog, if it becomes a problem. I am not opposed, more wondering if you'd thought about it. I don't think spreading the contention works very well with the current implementation of slru.c. It's already very prone to throwing away the wrong page. Widening it will just make that worse. > We could make the > locking more fine-grained than one lock per page, use atomic 64-bit > reads/writes on platforms that support it, etc. We *really* need an atomics abstraction layer... There's more and more stuff coming that needs it. This is going to be a *large* patch. Greetings, Andres Freund
On Mon, May 12, 2014 at 6:09 PM, Robert Haas <robertmhaas@gmail.com> wrote: > However, I wonder what > happens if you write the commit record and then the attempt to update > pg_clog fails. I think you'll have to PANIC, which kind of sucks. CLOG IO error while commiting is already a PANIC, SimpleLruReadPage() does SlruReportIOError(), which in turn does ereport(ERROR), while inside a critical section initiated in RecordTransactionCommit(). Regards, Ants Aasma -- Cybertec Schönig & Schönig GmbH Gröhrmühlgasse 26 A-2700 Wiener Neustadt Web: http://www.postgresql-support.de
On Mon, May 12, 2014 at 2:56 PM, Heikki Linnakangas <hlinnakangas@vmware.com> wrote: > Currently, before consulting the clog for an XID's status, it is necessary > to first check if the transaction is still in progress by scanning the proc > array. To get rid of that requirement, just before writing the commit record > in the WAL, the backend will mark the clog slot with a magic value that says > "I'm just about to commit". After writing the commit record, it is replaced > with the record's actual LSN. If a backend sees the magic value in the clog, > it will wait for the transaction to finish the insertion, and then check > again to get the real LSN. I'm thinking of just using XactLockTableWait() > for that. This mechanism makes the insertion of a commit WAL record and > updating the clog appear atomic to the rest of the system. Would it be useful to store the current WAL insertion point along with the "about to commit" flag so it's effectively a promise that this transaction will commit no earlier than XXX. That should allow most transactions to decide if those records are visible or not unless they're very recent transactions which started in that short window while the committing transaction was in the process of committing. -- greg
On 05/12/2014 06:26 PM, Andres Freund wrote: >> >With the new "commit-in-progress" status in clog, we won't need the >> >sub-committed clog status anymore. The "commit-in-progress" status will >> >achieve the same thing. > Wouldn't that cause many spurious waits? Because commit-in-progress > needs to be waited on, but a sub-committed xact surely not? Ah, no. Even today, a subxid isn't marked as sub-committed, until you commit the top-level transaction. The sub-commit state is a very transient state during the commit process, used to make the commit of the sub-transactions and the top-level transaction appear atomic. The commit-in-progress state would be a similarly short-lived state. You mark the subxids and the top xid as commit-in-progress just before the XLogInsert() of the commit record, and you replace them with the real LSNs right after XLogInsert(). - Heikki
On 2014-05-12 19:14:55 +0300, Heikki Linnakangas wrote: > On 05/12/2014 06:26 PM, Andres Freund wrote: > >>>With the new "commit-in-progress" status in clog, we won't need the > >>>sub-committed clog status anymore. The "commit-in-progress" status will > >>>achieve the same thing. > >Wouldn't that cause many spurious waits? Because commit-in-progress > >needs to be waited on, but a sub-committed xact surely not? > > Ah, no. Even today, a subxid isn't marked as sub-committed, until you commit > the top-level transaction. The sub-commit state is a very transient state > during the commit process, used to make the commit of the sub-transactions > and the top-level transaction appear atomic. The commit-in-progress state > would be a similarly short-lived state. You mark the subxids and the top xid > as commit-in-progress just before the XLogInsert() of the commit record, and > you replace them with the real LSNs right after XLogInsert(). Ah, right. Forgot that detail... Greetings, Andres Freund -- Andres Freund http://www.2ndQuadrant.com/PostgreSQL Development, 24x7 Support, Training & Services
On Mon, May 12, 2014 at 7:10 PM, Greg Stark <stark@mit.edu> wrote: > Would it be useful to store the current WAL insertion point along with > the "about to commit" flag so it's effectively a promise that this > transaction will commit no earlier than XXX. That should allow most > transactions to decide if those records are visible or not unless > they're very recent transactions which started in that short window > while the committing transaction was in the process of committing. I don't believe this is worth the complexity. The contention window is extremely short here. Regards, Ants Aasma -- Cybertec Schönig & Schönig GmbH Gröhrmühlgasse 26 A-2700 Wiener Neustadt Web: http://www.postgresql-support.de
On 12 May 2014 19:27, Heikki Linnakangas Wrote: > On 01/24/2014 02:10 PM, Rajeev rastogi wrote: > > We are also planning to implement CSN based snapshot. > > So I am curious to know whether any further development is happening > on this. > > I started looking into this, and plan to work on this for 9.5. It's a > big project, so any help is welcome. The design I have in mind is to > use the LSN of the commit record as the CSN (as Greg Stark suggested). Great ! > Some problems and solutions I have been thinking of: > > The core of the design is to store the LSN of the commit record in > pg_clog. Currently, we only store 2 bits per transaction there, > indicating if the transaction committed or not, but the patch will > expand it to 64 bits, to store the LSN. To check the visibility of an > XID in a snapshot, the XID's commit LSN is looked up in pg_clog, and > compared with the snapshot's LSN. Isn't it will be bit in-efficient to look in to pg_clog to read XID's commit LSN for every visibility check? > With this mechanism, taking a snapshot is just a matter of reading the > current WAL insertion point. There is no need to scan the proc array, > which is good. However, it probably still makes sense to record an xmin > and an xmax in SnapshotData, for performance reasons. An xmax, in > particular, will allow us to skip checking the clog for transactions > that will surely not be visible. We will no longer track the latest > completed XID or the xmin like we do today, but we can use > SharedVariableCache->nextXid as a conservative value for xmax, and keep > a cached global xmin value in shared memory, updated when convenient, > that can be just copied to the snapshot. I think we can update xmin, whenever transaction with its XID equal to xmin gets committed (i.e. in ProcArrayEndTransaction). Thanks and Regards, Kumar Rajeev Rastogi
On Mon, May 12, 2014 at 7:26 PM, Heikki Linnakangas <hlinnakangas@vmware.com> wrote: > In theory, we could use a snapshot LSN as the cutoff-point for > HeapTupleSatisfiesVisibility(). Maybe it's just because this is new, but > that makes me feel uneasy. To accomplish this won't XID-CSN map table be required and how will it be maintained (means when to clear and add a entry to that map table)? With Regards, Amit Kapila. EnterpriseDB: http://www.enterprisedb.com
On 05/13/2014 09:44 AM, Amit Kapila wrote: > On Mon, May 12, 2014 at 7:26 PM, Heikki Linnakangas > <hlinnakangas@vmware.com> wrote: >> In theory, we could use a snapshot LSN as the cutoff-point for >> HeapTupleSatisfiesVisibility(). Maybe it's just because this is new, but >> that makes me feel uneasy. > > To accomplish this won't XID-CSN map table be required and how will > it be maintained (means when to clear and add a entry to that map table)? Not sure I understand. The clog is a mapping from XID to CSN. What vacuum needs to know is whether the xmin and/or xmax is visible to everyone (and whether they committed or aborted). To determine that, it needs the oldest still active snapshot LSN. That can be found by scanning the proc array. It's pretty much the same as a regular MVCC visibility check, but using the oldest still-active snapshot. - Heikki
On 05/13/2014 08:08 AM, Rajeev rastogi wrote: >> >The core of the design is to store the LSN of the commit record in >> >pg_clog. Currently, we only store 2 bits per transaction there, >> >indicating if the transaction committed or not, but the patch will >> >expand it to 64 bits, to store the LSN. To check the visibility of an >> >XID in a snapshot, the XID's commit LSN is looked up in pg_clog, and >> >compared with the snapshot's LSN. > Isn't it will be bit in-efficient to look in to pg_clog to read XID's commit > LSN for every visibility check? Maybe. If no hint bit is set on the tuple, you have to check the clog anyway to determine if the tuple is committed. And if for XIDs older than xmin or newer than xmax, you don't need to check pg_clog. But it's true that for tuples with hint bit set, and xmin < XID < xmax, you have to check the pg_clog in the new system, when currently you only need to do a binary search of the local array in the snapshot. My gut feeling is that it won't be significantly slower in practice. If it becomes a problem, some rearrangement pg_clog code might help, or you could build a cache of XID->CSN mappings that you've alread looked up in SnapshotData. So I don't think that's going to be a show-stopper. - Heikki
On Tue, May 13, 2014 at 1:59 PM, Heikki Linnakangas <hlinnakangas@vmware.com> wrote: > On 05/13/2014 09:44 AM, Amit Kapila wrote: >> >> To accomplish this won't XID-CSN map table be required and how will >> it be maintained (means when to clear and add a entry to that map table)? > > > Not sure I understand. The clog is a mapping from XID to CSN. The case I was referring is for xmin < XID < xmax, which you have mentioned below that you are planing to directly refer pg_clog. This is I think one of the main place where new design can have impact on performance, but as you said it is better to first do the implementation based on pg_clog rather than directly jumping to optimize by maintaining XID to CSN mapping. With Regards, Amit Kapila. EnterpriseDB: http://www.enterprisedb.com
On 13 May 2014 14:06, Heikki Linnakangas > >> >The core of the design is to store the LSN of the commit record in > >> >pg_clog. Currently, we only store 2 bits per transaction there, > >> >indicating if the transaction committed or not, but the patch will > >> >expand it to 64 bits, to store the LSN. To check the visibility of > >> >an XID in a snapshot, the XID's commit LSN is looked up in pg_clog, > >> >and compared with the snapshot's LSN. > > Isn't it will be bit in-efficient to look in to pg_clog to read XID's > > commit LSN for every visibility check? > > Maybe. If no hint bit is set on the tuple, you have to check the clog > anyway to determine if the tuple is committed. And if for XIDs older > than xmin or newer than xmax, you don't need to check pg_clog. But it's > true that for tuples with hint bit set, and xmin < XID < xmax, you have > to check the pg_clog in the new system, when currently you only need to > do a binary search of the local array in the snapshot. My gut feeling > is that it won't be significantly slower in practice. If it becomes a > problem, some rearrangement pg_clog code might help, or you could build > a cache of XID->CSN mappings that you've alread looked up in > SnapshotData. So I don't think that's going to be a show-stopper. Yes definitely it should not be not show-stopper. This can be optimized later by method as you mentioned and also by some cut-off technique based on which we can decide that a XID beyond a certain range will be always visible, and thereby avoiding look-up in pg_clog. Thanks and Regards, Kumar Rajeev Rastogi
On Mon, May 12, 2014 at 06:01:59PM +0300, Heikki Linnakangas wrote: > >Some of the stuff in here will be influence whether your freezing > >replacement patch gets in. Do you plan to further pursue that one? > > Not sure. I got to the point where it seemed to work, but I got a > bit of a cold feet proceeding with it. I used the page header's LSN > field to define the "epoch" of the page, but I started to feel > uneasy about it. I would be much more comfortable with an extra > field in the page header, even though that uses more disk space. And > requires dealing with pg_upgrade. FYI, pg_upgrade copies pg_clog from the old cluster, so there will be a pg_upgrade issue anyway. I am not excited about a 32x increase in clog size, especially since we already do freezing at 200M transactions to allow for more aggressive clog trimming. Extrapolating that out, it means we would freeze every 6.25M transactions. -- Bruce Momjian <bruce@momjian.us> http://momjian.us EnterpriseDB http://enterprisedb.com + Everyone has their own god. +
On Thu, May 15, 2014 at 2:34 PM, Bruce Momjian <bruce@momjian.us> wrote: > On Mon, May 12, 2014 at 06:01:59PM +0300, Heikki Linnakangas wrote: >> >Some of the stuff in here will be influence whether your freezing >> >replacement patch gets in. Do you plan to further pursue that one? >> >> Not sure. I got to the point where it seemed to work, but I got a >> bit of a cold feet proceeding with it. I used the page header's LSN >> field to define the "epoch" of the page, but I started to feel >> uneasy about it. I would be much more comfortable with an extra >> field in the page header, even though that uses more disk space. And >> requires dealing with pg_upgrade. > > FYI, pg_upgrade copies pg_clog from the old cluster, so there will be a > pg_upgrade issue anyway. > > I am not excited about a 32x increase in clog size, especially since we > already do freezing at 200M transactions to allow for more aggressive > clog trimming. Extrapolating that out, it means we would freeze every > 6.25M transactions. It seems better to allow clog to grow larger than to force more-frequent freezing. If the larger clog size is a show-stopper (and I'm not sure I have an intelligent opinion on that just yet), one way to get around the problem would be to summarize CLOG entries after-the-fact. Once an XID precedes the xmin of every snapshot, we don't need to know the commit LSN any more. So we could read the old pg_clog files and write new summary files. Since we don't need to care about subcommitted transactions either, we could get by with just 1 bit per transaction, 1 = committed, 0 = aborted. Once we've written and fsync'd the summary files, we could throw away the original files. That might leave us with a smaller pg_clog than what we have today. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On 2014-05-15 15:40:06 -0400, Robert Haas wrote: > On Thu, May 15, 2014 at 2:34 PM, Bruce Momjian <bruce@momjian.us> wrote: > > On Mon, May 12, 2014 at 06:01:59PM +0300, Heikki Linnakangas wrote: > >> >Some of the stuff in here will be influence whether your freezing > >> >replacement patch gets in. Do you plan to further pursue that one? > >> > >> Not sure. I got to the point where it seemed to work, but I got a > >> bit of a cold feet proceeding with it. I used the page header's LSN > >> field to define the "epoch" of the page, but I started to feel > >> uneasy about it. I would be much more comfortable with an extra > >> field in the page header, even though that uses more disk space. And > >> requires dealing with pg_upgrade. > > > > FYI, pg_upgrade copies pg_clog from the old cluster, so there will be a > > pg_upgrade issue anyway. > > > > I am not excited about a 32x increase in clog size, especially since we > > already do freezing at 200M transactions to allow for more aggressive > > clog trimming. Extrapolating that out, it means we would freeze every > > 6.25M transactions. The default setting imo is far too low for a database of any relevant activity. If I had the stomach for the fight around it I'd suggest increasing it significantly by default. People with small databases won't be hurt significantly because they simply don't have that many transactions and autovacuum will get around to cleanup long before normally. > It seems better to allow clog to grow larger than to force > more-frequent freezing. Yes. > If the larger clog size is a show-stopper (and I'm not sure I have an > intelligent opinion on that just yet), one way to get around the > problem would be to summarize CLOG entries after-the-fact. Once an > XID precedes the xmin of every snapshot, we don't need to know the > commit LSN any more. So we could read the old pg_clog files and write > new summary files. Since we don't need to care about subcommitted > transactions either, we could get by with just 1 bit per transaction, > 1 = committed, 0 = aborted. Once we've written and fsync'd the > summary files, we could throw away the original files. That might > leave us with a smaller pg_clog than what we have today. I think the easiest way for now would be to have pg_clog with the same format as today and a rangewise much smaller pg_csn storing the lsns that are needed. That'll leave us with pg_upgrade'ability without needing to rewrite pg_clog during the upgrade. Greetings, Andres Freund -- Andres Freund http://www.2ndQuadrant.com/PostgreSQL Development, 24x7 Support, Training & Services
On Thu, May 15, 2014 at 10:06:32PM +0200, Andres Freund wrote: > > If the larger clog size is a show-stopper (and I'm not sure I have an > > intelligent opinion on that just yet), one way to get around the > > problem would be to summarize CLOG entries after-the-fact. Once an > > XID precedes the xmin of every snapshot, we don't need to know the > > commit LSN any more. So we could read the old pg_clog files and write > > new summary files. Since we don't need to care about subcommitted > > transactions either, we could get by with just 1 bit per transaction, > > 1 = committed, 0 = aborted. Once we've written and fsync'd the > > summary files, we could throw away the original files. That might > > leave us with a smaller pg_clog than what we have today. > > I think the easiest way for now would be to have pg_clog with the same > format as today and a rangewise much smaller pg_csn storing the lsns > that are needed. That'll leave us with pg_upgrade'ability without > needing to rewrite pg_clog during the upgrade. Yes, I like the idea of storing the CSN separately. One reason the 2-bit clog is so good is that we know we have atomic 1-byte writes on all platforms. Can we assume atomic 64-bit writes? -- Bruce Momjian <bruce@momjian.us> http://momjian.us EnterpriseDB http://enterprisedb.com + Everyone has their own god. +
On 2014-05-15 16:13:49 -0400, Bruce Momjian wrote: > On Thu, May 15, 2014 at 10:06:32PM +0200, Andres Freund wrote: > > > If the larger clog size is a show-stopper (and I'm not sure I have an > > > intelligent opinion on that just yet), one way to get around the > > > problem would be to summarize CLOG entries after-the-fact. Once an > > > XID precedes the xmin of every snapshot, we don't need to know the > > > commit LSN any more. So we could read the old pg_clog files and write > > > new summary files. Since we don't need to care about subcommitted > > > transactions either, we could get by with just 1 bit per transaction, > > > 1 = committed, 0 = aborted. Once we've written and fsync'd the > > > summary files, we could throw away the original files. That might > > > leave us with a smaller pg_clog than what we have today. > > > > I think the easiest way for now would be to have pg_clog with the same > > format as today and a rangewise much smaller pg_csn storing the lsns > > that are needed. That'll leave us with pg_upgrade'ability without > > needing to rewrite pg_clog during the upgrade. > > Yes, I like the idea of storing the CSN separately. One reason the > 2-bit clog is so good is that we know we have atomic 1-byte writes on > all platforms. I don't think we rely on that anywhere. And in fact we don't have the ability to do so for arbitrary bytes - lots of platforms can do that only on specifically aligned bytes. We rely on being able to atomically (as in either before/after no torn value) write/read TransactionIds, but that's it I think? > Can we assume atomic 64-bit writes? Not on 32bit platforms. Greetings, Andres Freund -- Andres Freund http://www.2ndQuadrant.com/PostgreSQL Development, 24x7 Support, Training & Services
Andres Freund wrote: > On 2014-05-15 15:40:06 -0400, Robert Haas wrote: > > On Thu, May 15, 2014 at 2:34 PM, Bruce Momjian <bruce@momjian.us> wrote: > > If the larger clog size is a show-stopper (and I'm not sure I have an > > intelligent opinion on that just yet), one way to get around the > > problem would be to summarize CLOG entries after-the-fact. Once an > > XID precedes the xmin of every snapshot, we don't need to know the > > commit LSN any more. So we could read the old pg_clog files and write > > new summary files. Since we don't need to care about subcommitted > > transactions either, we could get by with just 1 bit per transaction, > > 1 = committed, 0 = aborted. Once we've written and fsync'd the > > summary files, we could throw away the original files. That might > > leave us with a smaller pg_clog than what we have today. > > I think the easiest way for now would be to have pg_clog with the same > format as today and a rangewise much smaller pg_csn storing the lsns > that are needed. That'll leave us with pg_upgrade'ability without > needing to rewrite pg_clog during the upgrade. Err, we're proposing a patch to add timestamps to each commit, http://www.postgresql.org/message-id/20131022221600.GE4987@eldon.alvh.no-ip.org which does so in precisely this way. The idea that pg_csn or pg_committs can be truncated much earlier than pg_clog has its merit, no doubt. If we can make sure that the atomicity is sane, +1 from me. -- Álvaro Herrera http://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Training & Services
On 2014-05-15 17:37:14 -0400, Alvaro Herrera wrote: > Andres Freund wrote: > > On 2014-05-15 15:40:06 -0400, Robert Haas wrote: > > > On Thu, May 15, 2014 at 2:34 PM, Bruce Momjian <bruce@momjian.us> wrote: > > > > If the larger clog size is a show-stopper (and I'm not sure I have an > > > intelligent opinion on that just yet), one way to get around the > > > problem would be to summarize CLOG entries after-the-fact. Once an > > > XID precedes the xmin of every snapshot, we don't need to know the > > > commit LSN any more. So we could read the old pg_clog files and write > > > new summary files. Since we don't need to care about subcommitted > > > transactions either, we could get by with just 1 bit per transaction, > > > 1 = committed, 0 = aborted. Once we've written and fsync'd the > > > summary files, we could throw away the original files. That might > > > leave us with a smaller pg_clog than what we have today. > > > > I think the easiest way for now would be to have pg_clog with the same > > format as today and a rangewise much smaller pg_csn storing the lsns > > that are needed. That'll leave us with pg_upgrade'ability without > > needing to rewrite pg_clog during the upgrade. > > Err, we're proposing a patch to add timestamps to each commit, > http://www.postgresql.org/message-id/20131022221600.GE4987@eldon.alvh.no-ip.org > which does so in precisely this way. I am not sure where my statements above conflict with committs? Greetings, Andres Freund -- Andres Freund http://www.2ndQuadrant.com/PostgreSQL Development, 24x7 Support, Training & Services
Andres Freund wrote: > On 2014-05-15 17:37:14 -0400, Alvaro Herrera wrote: > > Andres Freund wrote: > > > On 2014-05-15 15:40:06 -0400, Robert Haas wrote: > > > > On Thu, May 15, 2014 at 2:34 PM, Bruce Momjian <bruce@momjian.us> wrote: > > > > > > If the larger clog size is a show-stopper (and I'm not sure I have an > > > > intelligent opinion on that just yet), one way to get around the > > > > problem would be to summarize CLOG entries after-the-fact. Once an > > > > XID precedes the xmin of every snapshot, we don't need to know the > > > > commit LSN any more. So we could read the old pg_clog files and write > > > > new summary files. Since we don't need to care about subcommitted > > > > transactions either, we could get by with just 1 bit per transaction, > > > > 1 = committed, 0 = aborted. Once we've written and fsync'd the > > > > summary files, we could throw away the original files. That might > > > > leave us with a smaller pg_clog than what we have today. > > > > > > I think the easiest way for now would be to have pg_clog with the same > > > format as today and a rangewise much smaller pg_csn storing the lsns > > > that are needed. That'll leave us with pg_upgrade'ability without > > > needing to rewrite pg_clog during the upgrade. > > > > Err, we're proposing a patch to add timestamps to each commit, > > http://www.postgresql.org/message-id/20131022221600.GE4987@eldon.alvh.no-ip.org > > which does so in precisely this way. > > I am not sure where my statements above conflict with committs? I didn't say it did ... -- Álvaro Herrera http://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Training & Services
So, here's a first version of the patch. Still very much WIP. One thorny issue came up in discussions with other hackers on this in PGCon: When a transaction is committed asynchronously, it becomes visible to other backends before the commit WAL record is flushed. With CSN-based snapshots, the order that transactions become visible is always based on the LSNs of the WAL records. This is a problem when there is a mix of synchronous and asynchronous commits: If transaction A commits synchronously with commit LSN 1, and transaction B commits asynchronously with commit LSN 2, B cannot become visible before A. And we cannot acknowledge B as committed to the client until it's visible to other transactions. That means that B will have to wait for A's commit record to be flushed to disk, before it can return, even though it was an asynchronous commit. I personally think that's annoying, but we can live with it. The most common usage of synchronous_commit=off is to run a lot of transactions in that mode, setting it in postgresql.conf. And it wouldn't completely defeat the purpose of mixing synchronous and asynchronous commits either: an asynchronous commit still only needs to wait for any already-logged synchronous commits to be flushed to disk, not the commit record of the asynchronous transaction itself. Ants' original design with a separate commit-sequence-number that's different from the commit LSN would not have this problem, because that would allow the commits to become visible to others in out-of-WAL-order. However, the WAL order == commit order is a nice and simple property, with other advantages. Some bigger TODO items: * Logical decoding is broken. I hacked on it enough that it looks roughly sane and it compiles, but didn't spend more time to debug. * I expanded pg_clog to 64-bits per XID, but people suggested keeping pg_clog as is, with two bits per commit, and adding a new SLRU for the commit LSNs beside it. Probably will need to do something like that to avoid bloating the clog. * Add some kind of backend-private caching of clog, to make it faster to access. The visibility checks are now hitting the clog a lot more heavily than before, as you need to check the clog even if the hint bits are set, if the XID falls between xmin and xmax of the snapshot. * Transactions currently become visible immediately when a WAL record is inserted, before it's flushed. That's wrong, but shouldn't be difficult to fix (except for the async commit issue explained above). - Heikki
Attachment
On Fri, May 30, 2014 at 3:59 PM, Heikki Linnakangas <hlinnakangas@vmware.com> wrote: > If transaction A commits synchronously with commit LSN 1, and transaction B > commits asynchronously with commit LSN 2, B cannot become visible before A. > And we cannot acknowledge B as committed to the client until it's visible to > other transactions. That means that B will have to wait for A's commit > record to be flushed to disk, before it can return, even though it was an > asynchronous commit. I thought that's what happens now. What's more of a concern is synchronousl replication. We currently have a hack that makes transactions committed locally invisible to other transactions even though they've committed and synced to disk until the slave responds that it's received the transaction. (I think this is bogus personally, it just shifts the failure modes around. If we wanted to do it properly we would have to do two-phase commit.) I guess it still works because we don't support having synchronous replication for just some transactions and not others. It would be nice to support that but I think it would mean making it work like local synchronous commit. It would only affect how long the commit blocks, not when other transactions see the committed data. -- greg
On 05/30/2014 06:09 PM, Greg Stark wrote: > On Fri, May 30, 2014 at 3:59 PM, Heikki Linnakangas > <hlinnakangas@vmware.com> wrote: >> If transaction A commits synchronously with commit LSN 1, and transaction B >> commits asynchronously with commit LSN 2, B cannot become visible before A. >> And we cannot acknowledge B as committed to the client until it's visible to >> other transactions. That means that B will have to wait for A's commit >> record to be flushed to disk, before it can return, even though it was an >> asynchronous commit. > > > I thought that's what happens now. > > What's more of a concern is synchronousl replication. We currently > have a hack that makes transactions committed locally invisible to > other transactions even though they've committed and synced to disk > until the slave responds that it's received the transaction. (I think > this is bogus personally, it just shifts the failure modes around. If > we wanted to do it properly we would have to do two-phase commit.) Yeah. To recap, the failure mode is that if the master crashes and restarts, the transaction becomes visible in the master even though it was never replicated. > I guess it still works because we don't support having synchronous > replication for just some transactions and not others. It would be > nice to support that but I think it would mean making it work like > local synchronous commit. It would only affect how long the commit > blocks, not when other transactions see the committed data. Actually, we do support that, see synchronous_commit=local. - Heikki
Hi, On 2014-05-30 17:59:23 +0300, Heikki Linnakangas wrote: > So, here's a first version of the patch. Still very much WIP. Cool. > One thorny issue came up in discussions with other hackers on this in PGCon: > > When a transaction is committed asynchronously, it becomes visible to other > backends before the commit WAL record is flushed. With CSN-based snapshots, > the order that transactions become visible is always based on the LSNs of > the WAL records. This is a problem when there is a mix of synchronous and > asynchronous commits: > > If transaction A commits synchronously with commit LSN 1, and transaction B > commits asynchronously with commit LSN 2, B cannot become visible before A. > And we cannot acknowledge B as committed to the client until it's visible to > other transactions. That means that B will have to wait for A's commit > record to be flushed to disk, before it can return, even though it was an > asynchronous commit. > I personally think that's annoying, but we can live with it. The most common > usage of synchronous_commit=off is to run a lot of transactions in that > mode, setting it in postgresql.conf. And it wouldn't completely defeat the > purpose of mixing synchronous and asynchronous commits either: an > asynchronous commit still only needs to wait for any already-logged > synchronous commits to be flushed to disk, not the commit record of the > asynchronous transaction itself. I have a hard time believing that users won't hate us for such a regression. It's pretty common to mix both sorts of transactions and this will - by my guesstimate - dramatically reduce throughput for the async backends. > * Logical decoding is broken. I hacked on it enough that it looks roughly > sane and it compiles, but didn't spend more time to debug. I think we can live with it not working for the first few iterations. I'll look into it once the patch has stabilized a bit. > * I expanded pg_clog to 64-bits per XID, but people suggested keeping > pg_clog as is, with two bits per commit, and adding a new SLRU for the > commit LSNs beside it. Probably will need to do something like that to avoid > bloating the clog. It also influences how on-disk compatibility is dealt with. So: How are you planning to deal with on-disk compatibility? > * Add some kind of backend-private caching of clog, to make it faster to > access. The visibility checks are now hitting the clog a lot more heavily > than before, as you need to check the clog even if the hint bits are set, if > the XID falls between xmin and xmax of the snapshot. That'll hurt a lot in concurrent scenarios :/. Have you measured how 'wide' xmax-xmin usually is? I wonder if we could just copy a range of values from the clog when we start scanning.... Greetings, Andres Freund -- Andres Freund http://www.2ndQuadrant.com/PostgreSQL Development, 24x7 Support, Training & Services
On 05/30/2014 06:27 PM, Andres Freund wrote: > On 2014-05-30 17:59:23 +0300, Heikki Linnakangas wrote: >> One thorny issue came up in discussions with other hackers on this in PGCon: >> >> When a transaction is committed asynchronously, it becomes visible to other >> backends before the commit WAL record is flushed. With CSN-based snapshots, >> the order that transactions become visible is always based on the LSNs of >> the WAL records. This is a problem when there is a mix of synchronous and >> asynchronous commits: >> >> If transaction A commits synchronously with commit LSN 1, and transaction B >> commits asynchronously with commit LSN 2, B cannot become visible before A. >> And we cannot acknowledge B as committed to the client until it's visible to >> other transactions. That means that B will have to wait for A's commit >> record to be flushed to disk, before it can return, even though it was an >> asynchronous commit. > >> I personally think that's annoying, but we can live with it. The most common >> usage of synchronous_commit=off is to run a lot of transactions in that >> mode, setting it in postgresql.conf. And it wouldn't completely defeat the >> purpose of mixing synchronous and asynchronous commits either: an >> asynchronous commit still only needs to wait for any already-logged >> synchronous commits to be flushed to disk, not the commit record of the >> asynchronous transaction itself. > > I have a hard time believing that users won't hate us for such a > regression. It's pretty common to mix both sorts of transactions and > this will - by my guesstimate - dramatically reduce throughput for the > async backends. Yeah, it probably would. Not sure how many people would care. For an asynchronous commit, we could store the current WAL flush location as the commit LSN, instead of the location of the commit record. That would break the property that LSN == commit order, but that property is fundamentally incompatible with having async commits become visible without flushing previous transactions. Or we could even make it configurable, it would be fairly easy to support both behaviors. >> * Logical decoding is broken. I hacked on it enough that it looks roughly >> sane and it compiles, but didn't spend more time to debug. > > I think we can live with it not working for the first few > iterations. I'll look into it once the patch has stabilized a bit. Thanks! >> * I expanded pg_clog to 64-bits per XID, but people suggested keeping >> pg_clog as is, with two bits per commit, and adding a new SLRU for the >> commit LSNs beside it. Probably will need to do something like that to avoid >> bloating the clog. > > It also influences how on-disk compatibility is dealt with. So: How are > you planning to deal with on-disk compatibility? > >> * Add some kind of backend-private caching of clog, to make it faster to >> access. The visibility checks are now hitting the clog a lot more heavily >> than before, as you need to check the clog even if the hint bits are set, if >> the XID falls between xmin and xmax of the snapshot. > > That'll hurt a lot in concurrent scenarios :/. Have you measured how > 'wide' xmax-xmin usually is? That depends entirely on the workload. The worst case is a mix of a long-running transaction and a lot of short transaction. It could grow to millions of transactions or more in that case. > I wonder if we could just copy a range of > values from the clog when we start scanning.... I don't think that's practical, if the xmin-xmax gap is wide. Perhaps we should take the bull by the horns and make clog faster to look up. If we e.g. mmapped the clog file into backend-private address space, we could all the locking overhead of an SLRU. On platforms with atomic 64-bit instructions, you could read the clog with just a memory barrier. Even on other architectures, you'd only need a spinlock. - Heikki
(forgot to answer this question) On 05/30/2014 06:27 PM, Andres Freund wrote: > On 2014-05-30 17:59:23 +0300, Heikki Linnakangas wrote: >> * I expanded pg_clog to 64-bits per XID, but people suggested keeping >> pg_clog as is, with two bits per commit, and adding a new SLRU for the >> commit LSNs beside it. Probably will need to do something like that to avoid >> bloating the clog. > > It also influences how on-disk compatibility is dealt with. So: How are > you planning to deal with on-disk compatibility? Have pg_upgrade read the old clog and write it out in the new format. - Heikki
On Fri, May 30, 2014 at 2:38 PM, Heikki Linnakangas <hlinnakangas@vmware.com> wrote: > (forgot to answer this question) > > On 05/30/2014 06:27 PM, Andres Freund wrote: >> >> On 2014-05-30 17:59:23 +0300, Heikki Linnakangas wrote: >>> >>> * I expanded pg_clog to 64-bits per XID, but people suggested keeping >>> pg_clog as is, with two bits per commit, and adding a new SLRU for the >>> commit LSNs beside it. Probably will need to do something like that to >>> avoid >>> bloating the clog. >> >> >> It also influences how on-disk compatibility is dealt with. So: How are >> you planning to deal with on-disk compatibility? > > > Have pg_upgrade read the old clog and write it out in the new format. That doesn't address Bruce's concern about CLOG disk consumption. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On Tue, Jun 3, 2014 at 2:55 PM, Robert Haas <robertmhaas@gmail.com> wrote: > That doesn't address Bruce's concern about CLOG disk consumption. Well we would only need the xid->lsn mapping for transactions since globalxmin. Anything older we would just need the committed bit. So we could maintain two structures, one like our current clog going back until the freeze_max_age and one with 32-bits (or 64 bits?) per xid but only going back as far as the globalxmin. There are a myriad of compression techniques we could use on a sequence of mostly similar mostly increasing numbers in a small range too. But I suspect they wouldn't really be necessary. Here's another thought. I don't see how to make this practical but it would be quite convenient if it could be made so. The first time an xid is looked up and is determined to be committed then all we'll ever need in the future is the lsn. If we could replace the xid with the LSN of the commit record right there in the page then future viewers would be able to determine if it's visible without looking in the clog or this new clog xid->lsn mapping. If that was the full LSN it would never need to be frozen either. The problem with this is that the LSN is big and actually moves faster than the xid. We could play the same games with putting the lsn segment in the page header but it's actually entirely feasible to have a snapshot that extends over several segments. Way easier than a snapshot that extends over several xid epochs. (This does make having a CSN like Oracle kind of tempting after all) -- greg
On 06/03/2014 05:53 PM, Greg Stark wrote: > On Tue, Jun 3, 2014 at 2:55 PM, Robert Haas <robertmhaas@gmail.com> wrote: >> That doesn't address Bruce's concern about CLOG disk consumption. > > Well we would only need the xid->lsn mapping for transactions since > globalxmin. Anything older we would just need the committed bit. So we > could maintain two structures, one like our current clog going back > until the freeze_max_age and one with 32-bits (or 64 bits?) per xid > but only going back as far as the globalxmin. There are a myriad of > compression techniques we could use on a sequence of mostly similar > mostly increasing numbers in a small range too. But I suspect they > wouldn't really be necessary. Yeah, that seems like a better design, after all. Attached is a new patch. It now keeps the current pg_clog unchanged, but adds a new pg_csnlog besides it. pg_csnlog is more similar to pg_subtrans than pg_clog: it's not WAL-logged, is reset at startup, and segments older than GlobalXmin can be truncated. This addresses the disk space consumption, and simplifies pg_upgrade. There are no other significant changes in this new version, so it's still very much WIP. But please take a look! - Heikki
Attachment
On 05/30/2014 11:14 PM, Heikki Linnakangas wrote: > > Yeah. To recap, the failure mode is that if the master crashes and > restarts, the transaction becomes visible in the master even though it > was never replicated. Wouldn't another pg_clog bit for the transaction be able to sort that out? -- Craig Ringer http://www.2ndQuadrant.com/PostgreSQL Development, 24x7 Support, Training & Services
On Mon, Jun 16, 2014 at 12:58 AM, Craig Ringer <craig@2ndquadrant.com> wrote: > On 05/30/2014 11:14 PM, Heikki Linnakangas wrote: >> Yeah. To recap, the failure mode is that if the master crashes and >> restarts, the transaction becomes visible in the master even though it >> was never replicated. > > Wouldn't another pg_clog bit for the transaction be able to sort that out? How? -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On 06/18/2014 12:41 AM, Robert Haas wrote: > On Mon, Jun 16, 2014 at 12:58 AM, Craig Ringer <craig@2ndquadrant.com> wrote: >> > On 05/30/2014 11:14 PM, Heikki Linnakangas wrote: >>> >> Yeah. To recap, the failure mode is that if the master crashes and >>> >> restarts, the transaction becomes visible in the master even though it >>> >> was never replicated. >> > >> > Wouldn't another pg_clog bit for the transaction be able to sort that out? > How? A flag to indicate that the tx is locally committed but hasn't been confirmed by a streaming synchronous replica, so it must not become visible until the replica confirms it or SR is disabled. Then scan pg_clog on start / replica connect and ask the replica to confirm local commit for those tx's. No? -- Craig Ringer http://www.2ndQuadrant.com/PostgreSQL Development, 24x7 Support, Training & Services
On Tue, Jun 17, 2014 at 9:00 PM, Craig Ringer <craig@2ndquadrant.com> wrote: > On 06/18/2014 12:41 AM, Robert Haas wrote: >> On Mon, Jun 16, 2014 at 12:58 AM, Craig Ringer <craig@2ndquadrant.com> wrote: >>> > On 05/30/2014 11:14 PM, Heikki Linnakangas wrote: >>>> >> Yeah. To recap, the failure mode is that if the master crashes and >>>> >> restarts, the transaction becomes visible in the master even though it >>>> >> was never replicated. >>> > >>> > Wouldn't another pg_clog bit for the transaction be able to sort that out? >> How? > > A flag to indicate that the tx is locally committed but hasn't been > confirmed by a streaming synchronous replica, so it must not become > visible until the replica confirms it or SR is disabled. > > Then scan pg_clog on start / replica connect and ask the replica to > confirm local commit for those tx's. > > No? No. Otherwise, one of those bits could get changed after a backend takes a snapshot and before it finishes using it - so that the transaction snapshot is in effect changing underneath it. You could avoid that by memorizing the contents of CLOG when taking a snapshot, but that would defeat the whole purpose of CSN-based snapshots, which is to make the small and fixed-size. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On 06/18/2014 09:12 PM, Robert Haas wrote: > No. Otherwise, one of those bits could get changed after a backend > takes a snapshot and before it finishes using it - so that the > transaction snapshot is in effect changing underneath it. You could > avoid that by memorizing the contents of CLOG when taking a snapshot, > but that would defeat the whole purpose of CSN-based snapshots, which > is to make the small and fixed-size. Ah. Thankyou. I appreciate the explanation. -- Craig Ringer http://www.2ndQuadrant.com/PostgreSQL Development, 24x7 Support, Training & Services
Hi, On Fri, Jun 13, 2014 at 7:24 PM, Heikki Linnakangas <hlinnakangas@vmware.com> wrote: > Yeah, that seems like a better design, after all. > > Attached is a new patch. It now keeps the current pg_clog unchanged, but > adds a new pg_csnlog besides it. pg_csnlog is more similar to pg_subtrans > than pg_clog: it's not WAL-logged, is reset at startup, and segments older > than GlobalXmin can be truncated. > > This addresses the disk space consumption, and simplifies pg_upgrade. > > There are no other significant changes in this new version, so it's still > very much WIP. But please take a look! > Thanks for working on this important patch. I know this patch is still largely a WIP but I would like to report an observation. I applied this patch and did a few pgbench runs with 32 clients (this is on a not so powerful VM, by the way) . Perhaps you suspect such a thing already but I observed a relatively larger percentage of time being spent in XLogInsert(). Perhaps XLogCtlInsert.insertpos_lck contention via GetXLogInsertRecPtr()? -- Amit
On 12 May 2014 17:14, Heikki Linnakangas <hlinnakangas@vmware.com> wrote: > On 05/12/2014 06:26 PM, Andres Freund wrote: >>> >>> >With the new "commit-in-progress" status in clog, we won't need the >>> >sub-committed clog status anymore. The "commit-in-progress" status will >>> >achieve the same thing. >> >> Wouldn't that cause many spurious waits? Because commit-in-progress >> needs to be waited on, but a sub-committed xact surely not? > > > Ah, no. Even today, a subxid isn't marked as sub-committed, until you commit > the top-level transaction. The sub-commit state is a very transient state > during the commit process, used to make the commit of the sub-transactions > and the top-level transaction appear atomic. The commit-in-progress state > would be a similarly short-lived state. You mark the subxids and the top xid > as commit-in-progress just before the XLogInsert() of the commit record, and > you replace them with the real LSNs right after XLogInsert(). My understanding is that we aim to speed up the rate of Snapshot reads. Which may make it feasible to store autonomous transactions in shared memory, hopefully DSM. The above mechanism sounds like it might slow down transaction commit. Could we prototype that and measure the speed? More generally, do we have any explicit performance goals or acceptance criteria for this patch? -- Simon Riggs http://www.2ndQuadrant.com/PostgreSQL Development, 24x7 Support, Training & Services
Heikki Linnakangas wrote:
> Attached is a new patch. It now keeps the current pg_clog unchanged,
> but adds a new pg_csnlog besides it. pg_csnlog is more similar to
> pg_subtrans than pg_clog: it's not WAL-logged, is reset at startup,
> and segments older than GlobalXmin can be truncated.
>
> This addresses the disk space consumption, and simplifies pg_upgrade.
>
> There are no other significant changes in this new version, so it's
> still very much WIP. But please take a look!
Thanks. I've been looking at this. It needs a rebase; I had to apply
to commit 89cf2d52030 (Wed Jul 2 13:11:05 2014 -0400) because of
conflicts with the commit after that; it applies with some fuzz. I read
the discussion in this thread and the README, to try to understand how
this is supposed to work. It looks pretty good.
One thing not quite clear to me is the now-static RecentXmin,
GetRecentXmin(), AdvanceGlobalRecentXmin, and the like. I found the
whole thing pretty confusing. I noticed that ShmemVariableCache->recentXmin
is read without a lock in GetSnapshotData(), but exclusive ProcArrayLock
is taken to write to it in GetRecentXmin(). I think we can write it
without a lock also, since we assume that storing an xid is atomic.
With that change, I think you can make the acquisition of ProcArray Lock
to walk the pgproc list use shared mode, not exclusive.
Another point is that RecentXmin is no longer used directly, except in
TransactionIdIsActive(). But that routine is only used for an Assert()
now, so I think it's fine to just have GetRecentXmin() return the value
and not set RecentXmin as a side effect; my point is that ISTM
RecentXmin can be removed altogether, which makes that business simpler.
As far as GetOldestXmin() is concerned, that routine now ignores its
arguments. Is that okay? I imagine it's just a natural consequence of
how things work now. [ ... reads some more code ... ] Oh, now it's
only used to determine a freeze limit. I think you should just remove
the arguments and make that whole thing simpler. I was going to suggest
that AdvanceRecentGlobalXmin() could receive a possibly-NULL Relation
argument to pass down to GetOldestSnapshotGuts() which can make use of
it for a tigther limit, but since OldestXmin is only for freezing, maybe
there is no point in this extra complication.
Regarding the pendingGlobalXmin stuff, I didn't find any documentation.
I think you just need to write a very long comment on top of
AdvanceRecentGlobalXmin() to explain what it's doing. After going over
the code half a dozen times I think I understand what's idea, and it
seems sound.
Not sure about the advancexmin_counter thing. Maybe in some cases
sessions will only run 9 transactions or less and then finish, in which
case it will only get advanced at checkpoint time, which would be way
too seldom. Maybe it would work to place the counter in shared memory:
acquire(spinlock);
if (ShmemVariableCache->counter++ >= some_number)
{
SI don't understand this:hmemVariableCache->counter = 0;
do_update = true;
}
release(spinlock);
if (do_update)
AdvanceRecentGlobalXmin();
(Maybe we can forgo the spinlock altogether? If the value gets out of
hand once in a while, it shouldn't really matter) Perhaps the "some
number" should be scaled to some fraction of MaxBackends, but not less
than X (32?) and no more than Y (128?). Or maybe just use constant 10,
as the current code does. But it'd be total number of transactions, not
transaction in the current backend.
I think it'd be cleaner to have a distinct typedef to use when
XLogRecPtr is used as a snapshot representation. Right now there is no
clarity on whether we're interested in the xlog position itself or it's
a snapshot value.
HeapTupleSatisfiesVacuum[X]() and various callers needs update to their
comments: when OldestXmin is mentioned, it should be OldestSnapshot.
I noticed that SubTransGetTopmostTransaction() is now only called from
predicate.c, and it's pretty constrained in what it wants. I'm not
implying that we want to do anything in your patch about it, other than
perhaps add a note to it that we may want to examine it later for
possible changes.
I haven't gone over the transam.c, clog.c changes yet.
I attach a couple of minor tweaks to the README, mostly for clarity (but
also update clog -> csnlog in a couple of places).
--
Álvaro Herrera http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Training & Services
Attachment
On Fri, 2014-06-13 at 13:24 +0300, Heikki Linnakangas wrote: > Attached is a new patch. It now keeps the current pg_clog unchanged, but > adds a new pg_csnlog besides it. pg_csnlog is more similar to > pg_subtrans than pg_clog: it's not WAL-logged, is reset at startup, and > segments older than GlobalXmin can be truncated. It appears that this patch weakens the idea of hint bits. Even if HEAP_XMIN_COMMITTED is set, it still needs to find out if it's in the snapshot. That's fast if the xid is less than snap->xmin, but otherwise it needs to do a fetch from the csnlog, which is exactly what the hint bits are designed to avoid. And we can't get around this, because the whole point of this patch is to remove the xip array from the snapshot. If the transaction was committed a long time ago, then we could set PD_ALL_VISIBLE and the VM bit, and a scan wouldn't even look at the hint bit. If it was committed recently, then it's probably greater than the recentXmin. I think there's still room for a hint bit to technically be useful, but it seems quite narrow unless I'm missing something (and a narrowly-useful hint bit doesn't seem to be useful at all). I'm not complaining, and I hope this is not a showstopper for this patch, but I think it's worth discussing. Regards,Jeff Davis
On 08/26/2014 12:03 PM, Jeff Davis wrote: > On Fri, 2014-06-13 at 13:24 +0300, Heikki Linnakangas wrote: >> Attached is a new patch. It now keeps the current pg_clog unchanged, but >> adds a new pg_csnlog besides it. pg_csnlog is more similar to >> pg_subtrans than pg_clog: it's not WAL-logged, is reset at startup, and >> segments older than GlobalXmin can be truncated. > > It appears that this patch weakens the idea of hint bits. Even if > HEAP_XMIN_COMMITTED is set, it still needs to find out if it's in the > snapshot. > > That's fast if the xid is less than snap->xmin, but otherwise it needs > to do a fetch from the csnlog, which is exactly what the hint bits are > designed to avoid. And we can't get around this, because the whole point > of this patch is to remove the xip array from the snapshot. Yeah. This patch in the current state is likely much much slower than unpatched master, except in extreme cases where you have thousands of connections and short transactions so that without the patch, you spend most of the time acquiring snapshots. My current thinking is that access to the csnlog will need to be made faster. Currently, it's just another SLRU, but I'm sure we can do better than that. Or add a backend-private cache on top of it; that might already alleviate it enough.. - Heikki
On Tue, 2014-08-26 at 13:45 +0300, Heikki Linnakangas wrote: > My current thinking is that access to the csnlog will need to be made > faster. Currently, it's just another SLRU, but I'm sure we can do better > than that. Or add a backend-private cache on top of it; that might > already alleviate it enough.. Aren't those the same ideas that have been proposed for eliminating hint bits? If this patch makes taking snapshots much faster, then perhaps it's enough incentive to follow through on one of those ideas. I am certainly open to removing hint bits (which was probably clear from earlier discussions) if there are significant wins elsewhere and the penalty is not too great. To continue the discussion on this patch, let's assume that we make TransactionIdGetCommitLSN sufficiently fast. If that's the case, can't we make HeapTupleSatisfiesMVCC look more like: LsnMin = TransactionIdGetCommitLSN(xmin); if (!COMMITLSN_IS_COMMITTED(LsnMin)) LsnMin = BIG_LSN; LsnMin = TransactionIdGetCommitLSN(xmin); if (!COMMITLSN_IS_COMMITTED(LsnMin)) LsnMin = BIG_LSN; return (snapshot->snapshotlsn >= LsnMin && snapshot->snapshotlsn < LsnMax); There would need to be some handling for locked tuples, or tuples related to the current transaction, of course. But I still think it would turn out simpler; perhaps by enough to save a few cycles. Regards,Jeff Davis
On Tue, Aug 26, 2014 at 11:45 AM, Heikki Linnakangas <hlinnakangas@vmware.com> wrote: >> It appears that this patch weakens the idea of hint bits. Even if >> HEAP_XMIN_COMMITTED is set, it still needs to find out if it's in the >> snapshot. >> >> That's fast if the xid is less than snap->xmin, but otherwise it needs >> to do a fetch from the csnlog, which is exactly what the hint bits are >> designed to avoid. And we can't get around this, because the whole point >> of this patch is to remove the xip array from the snapshot. > > > Yeah. This patch in the current state is likely much much slower than > unpatched master, except in extreme cases where you have thousands of > connections and short transactions so that without the patch, you spend most > of the time acquiring snapshots. Interesting analysis. I suppose the equivalent of hint bits would be to actually write the CSN of the transaction into the record when the hint bit is set. I don't immediately see how to make that practical. One thought would be to have a list of xids in the page header with their corresponding csn -- which starts to sound a lot like Oralce's "Interested Transaction List". But I don't see how to make that work for the hundreds of possible xids on the page. The worst case for visibility resolution is you have a narrow table that has random access DDL happening all the time, each update is a short transaction and there are a very high rate of such transactions spread out uniformly over a very large table. That means any given page has over 200 rows with random xids spread over a very large range of xids. Currently the invariant hint bits give us is that each xid needs to be looked up in the clog only a more or less fixed number of times, in that scenario only once since the table is very large and the transactions short lived. -- greg
On Tue, 2014-08-26 at 19:25 +0100, Greg Stark wrote: > I don't immediately see how to make that practical. One thought would > be to have a list of xids in the page header with their corresponding > csn -- which starts to sound a lot like Oralce's "Interested > Transaction List". But I don't see how to make that work for the > hundreds of possible xids on the page. I feel like that's moving in the wrong direction. That's still causing a lot of modifications to a data page when the data is not changing, and that's bad for a lot of cases that I'm interested in (checksums are one example). We are mixing two kinds of data: user data and visibility information. Each is changed under different circumstances and has different characteristics, and I'm beginning to think they shouldn't be mixed at all. What if we just devised a structure specially designed to hold visibility information, put all of the visibility information there, and data pages would only change where there is a real, user-initiated I/U/D. Vacuum could still clear out dead tuples from the data area, but it would do the rest of its work on the visibility structure. It could even be a clever structure that could compress away large static areas until they become active again. Maybe this wouldn't work for all tables, but could be an option for big tables with low update rates. > The worst case for visibility resolution is you have a narrow table > that has random access DDL happening all the time, each update is a > short transaction and there are a very high rate of such transactions > spread out uniformly over a very large table. That means any given > page has over 200 rows with random xids spread over a very large range > of xids. That's not necessarily a bad case, unless the CLOG/CSNLOG lookup is a significant fraction of the effort to update a tuple. That would be a bad case if you introduce scans into the equation as well, but that's not a problem if the all-visible bit is set. > Currently the invariant hint bits give us is that each xid needs to be > looked up in the clog only a more or less fixed number of times, in > that scenario only once since the table is very large and the > transactions short lived. A backend-local cache might accomplish that, as well (would still need to do a lookup, but no locks or contention). There would be some challenges around invalidation (for xid wraparound) and pre-warming the cache (so establishing a lot of connections doesn't cause a lot of CLOG access). Regards,Jeff Davis
On Tue, Aug 26, 2014 at 8:32 PM, Jeff Davis <pgsql@j-davis.com> wrote: > We are mixing two kinds of data: user data and visibility information. > Each is changed under different circumstances and has different > characteristics, and I'm beginning to think they shouldn't be mixed at > all. > > What if we just devised a structure specially designed to hold > visibility information, put all of the visibility information there, and > data pages would only change where there is a real, user-initiated > I/U/D. Vacuum could still clear out dead tuples from the data area, but > it would do the rest of its work on the visibility structure. It could > even be a clever structure that could compress away large static areas > until they become active again. Well fundamentally the reason the visibility information is with the user data is so that we don't need to do two i/os to access the data. The whole point of hint bits is to guarantee that after some amount of time you can read data directly out of the heap page and use it without doing any additional I/O. -- greg
On Tue, 2014-08-26 at 21:00 +0100, Greg Stark wrote: > Well fundamentally the reason the visibility information is with the > user data is so that we don't need to do two i/os to access the data. > The whole point of hint bits is to guarantee that after some amount of > time you can read data directly out of the heap page and use it > without doing any additional I/O. If the data is that static, then the visibility information would be highly compressible, and surely in shared_buffers already. (Yes, it would need to be pinned, which has a cost.) Regards,Jeff Davis
On Tue, Aug 26, 2014 at 11:55 PM, Greg Stark <stark@mit.edu> wrote:
> Interesting analysis.
>
> I suppose the equivalent of hint bits would be to actually write the
> CSN of the transaction into the record when the hint bit is set.
>
> I don't immediately see how to make that practical. One thought would
> be to have a list of xids in the page header with their corresponding
> csn -- which starts to sound a lot like Oralce's "Interested
> Transaction List". But I don't see how to make that work for the
> hundreds of possible xids on the page.
> Interesting analysis.
>
> I suppose the equivalent of hint bits would be to actually write the
> CSN of the transaction into the record when the hint bit is set.
>
> I don't immediately see how to make that practical. One thought would
> be to have a list of xids in the page header with their corresponding
> csn -- which starts to sound a lot like Oralce's "Interested
> Transaction List". But I don't see how to make that work for the
> hundreds of possible xids on the page.
Here we can limit the number of such entries (xid-csn pair) that
can exist in block header and incase it starts to overflow, it can
use some alternate location. Another idea could be that reserve
the space whenever new transaction starts to operate in block
and update the CSN for the same later and incase the maximum
number of available slots gets filled up, we can either use alternate
location or may be block the new transaction until such a slot is
available, here I am assuming that Vacuum would clear the slots
in blocks as and when such transactions become visible to
everyone or may be the transaction which didn't find any slot can
also try to clear such slots.
On Tue, 2014-08-26 at 13:45 +0300, Heikki Linnakangas wrote: > Yeah. This patch in the current state is likely much much slower than > unpatched master, except in extreme cases where you have thousands of > connections and short transactions so that without the patch, you spend > most of the time acquiring snapshots. What else are you looking to accomplish with this patch during this 'fest? Bug finding? Design review? Performance testing? I haven't had a good track record with my performance testing recently, so I'm unlikely to be much help there. It seems a bit early for bug hunting, unless you think it will raise possible design issues. I think there's already at least one design issue to consider, which is whether we care about CLOG/CSNLOG access for hinted records where the xid > snapshot->xmin (that is, accesses that previously would have looked at xip). Would more discussion help here or do we need to wait for performance numbers? Regards,Jeff Davis
On 08/27/2014 08:23 AM, Jeff Davis wrote: > On Tue, 2014-08-26 at 13:45 +0300, Heikki Linnakangas wrote: >> Yeah. This patch in the current state is likely much much slower than >> unpatched master, except in extreme cases where you have thousands of >> connections and short transactions so that without the patch, you spend >> most of the time acquiring snapshots. > > What else are you looking to accomplish with this patch during this > 'fest? Bug finding? Design review? Performance testing? Design review, mostly. I know the performance still sucks. Although if you can foresee some performance problems, aside from the extra CSNLOG lookups, it would be good to know. > I think there's already at least one design issue to consider, which is > whether we care about CLOG/CSNLOG access for hinted records where the > xid > snapshot->xmin (that is, accesses that previously would have > looked at xip). Would more discussion help here or do we need to wait > for performance numbers? I think my current plan is to try to make that CSNLOG lookup fast. In essence, rewrite SLRUs to be more performant. That would help with the current clog, too, which would make it more feasible to set hint bits less often. In particular, avoid dirtying pages just to set hint bits. I'm not sure if that's enough - you can't beat checking a single hint bit in the same cache line as the XID - but I think it's worth a try. - Heikki
On 08/27/2014 09:40 AM, Heikki Linnakangas wrote: > On 08/27/2014 08:23 AM, Jeff Davis wrote: >> On Tue, 2014-08-26 at 13:45 +0300, Heikki Linnakangas wrote: >>> Yeah. This patch in the current state is likely much much slower than >>> unpatched master, except in extreme cases where you have thousands of >>> connections and short transactions so that without the patch, you spend >>> most of the time acquiring snapshots. >> >> What else are you looking to accomplish with this patch during this >> 'fest? Bug finding? Design review? Performance testing? > > Design review, mostly. I know the performance still sucks. Although if > you can foresee some performance problems, aside from the extra CSNLOG > lookups, it would be good to know. I think for this commitfest, I've gotten as much review of this patch that I can hope for. Marking as "Returned with Feedback". But of course, feel free to continue reviewing and commenting ;-). - Heikki
On Wed, Aug 27, 2014 at 10:42 AM, Heikki Linnakangas <hlinnakangas@vmware.com> wrote:
On 08/27/2014 09:40 AM, Heikki Linnakangas wrote:On 08/27/2014 08:23 AM, Jeff Davis wrote:On Tue, 2014-08-26 at 13:45 +0300, Heikki Linnakangas wrote:Yeah. This patch in the current state is likely much much slower than
unpatched master, except in extreme cases where you have thousands of
connections and short transactions so that without the patch, you spend
most of the time acquiring snapshots.
What else are you looking to accomplish with this patch during this
'fest? Bug finding? Design review? Performance testing?
Design review, mostly. I know the performance still sucks. Although if
you can foresee some performance problems, aside from the extra CSNLOG
lookups, it would be good to know.
I think for this commitfest, I've gotten as much review of this patch that I can hope for. Marking as "Returned with Feedback". But of course, feel free to continue reviewing and commenting ;-).
What is current state of this patch? Does community want CSN based snapshots?
Last email in lists was in August 2014. Huawei did talk about their further research on this idea at PGCon and promised to publish their patch in open source.
However, it isn't published yet, and we don't know how long we could wait for it.
Now, our company have resources to work on CSN based snapshots for 9.6. If Huawei will not publish their patch, we can pick up this work from last community version of this patch.
------
Alexander Korotkov
Postgres Professional: http://www.postgrespro.com
The Russian Postgres Company
Alexander Korotkov
Postgres Professional: http://www.postgrespro.com
The Russian Postgres Company
On 24 July 2015 at 14:43, Alexander Korotkov <a.korotkov@postgrespro.ru> wrote:
--
What is current state of this patch? Does community want CSN based snapshots?
CSN snapshots could give us
1. More scalable GetSnapshotData() calls
2. Faster GetSnapshotData() calls
3. Smaller snapshots which could be passed around more usefully between distributed servers
It depends on the exact design we use to get that. Certainly we do not want them if they cause a significant performance regression.
Now, our company have resources to work on CSN based snapshots for 9.6. If Huawei will not publish their patch, we can pick up this work from last community version of this patch.
Sounds good.
Simon Riggs http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On Fri, Jul 24, 2015 at 1:00 PM, Simon Riggs <simon@2ndquadrant.com> wrote: > It depends on the exact design we use to get that. Certainly we do not want > them if they cause a significant performance regression. Yeah. I think the performance worries expressed so far are: - Currently, if you see an XID that is between the XMIN and XMAX of the snapshot, you hit CLOG only on first access. After that, the tuple is hinted. With this approach, the hint bit doesn't avoid needing to hit CLOG anymore, because it's not enough to know whether or not the tuple committed; you have to know the CSN at which it committed, which means you have to look that up in CLOG (or whatever SLRU stores this data). Heikki mentioned adding some caching to ameliorate this problem, but it sounds like he was worried that the impact might still be significant. - Mixing synchronous_commit=on and synchronous_commit=off won't work as well, because if the LSN ordering of commit records matches the order in which transactions become visible, then an async-commit transaction can't become visible before a later sync-commit transaction. I expect we might just decide we can live with this, but it's worth discussing in case people feel otherwise. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On 2015-07-24 14:21:39 -0400, Robert Haas wrote: > - Mixing synchronous_commit=on and synchronous_commit=off won't work > as well, because if the LSN ordering of commit records matches the > order in which transactions become visible, then an async-commit > transaction can't become visible before a later sync-commit > transaction. I expect we might just decide we can live with this, but > it's worth discussing in case people feel otherwise. I'm not following this anymore. Even though a couple months back I apparently did. Heikki's description of the problem was: On 2014-05-30 17:59:23 +0300, Heikki Linnakangas wrote: > One thorny issue came up in discussions with other hackers on this in PGCon: > > When a transaction is committed asynchronously, it becomes visible to other > backends before the commit WAL record is flushed. With CSN-based snapshots, > the order that transactions become visible is always based on the LSNs of > the WAL records. This is a problem when there is a mix of synchronous and > asynchronous commits: > > If transaction A commits synchronously with commit LSN 1, and transaction B > commits asynchronously with commit LSN 2, B cannot become visible before A. > And we cannot acknowledge B as committed to the client until it's visible to > other transactions. That means that B will have to wait for A's commit > record to be flushed to disk, before it can return, even though it was an > asynchronous commit. Afacs the xlog insertion order isn't changed relevantly by the patch? Right now the order for sync commit = on is: XactLogCommitRecord(); XLogFlush(); TransactionIdCommitTree(); ProcArrayEndTransaction(); and for sync commit = off it's: XactLogCommitRecord(); TransactionIdAsyncCommitTree(); ProcArrayEndTransaction(); with the CSN patch it's: sync on: TransactionIdSetCommitting(); XactLogCommitRecord(); XLogFlush(XactLastRecEnd); TransactionIdCommitTree(); sync off: TransactionIdSetCommitting(); XactLogCommitRecord(); TransactionIdCommitTree(); How does this cause the above described problem? Yes, mixing sync/async commits can give somewhat weird visibility semantics, but that's not really new, is it? Regards, Andres
On 24 July 2015 at 19:21, Robert Haas <robertmhaas@gmail.com> wrote:
--
On Fri, Jul 24, 2015 at 1:00 PM, Simon Riggs <simon@2ndquadrant.com> wrote:
> It depends on the exact design we use to get that. Certainly we do not want
> them if they cause a significant performance regression.
Yeah. I think the performance worries expressed so far are:
- Currently, if you see an XID that is between the XMIN and XMAX of
the snapshot, you hit CLOG only on first access. After that, the
tuple is hinted. With this approach, the hint bit doesn't avoid
needing to hit CLOG anymore, because it's not enough to know whether
or not the tuple committed; you have to know the CSN at which it
committed, which means you have to look that up in CLOG (or whatever
SLRU stores this data). Heikki mentioned adding some caching to
ameliorate this problem, but it sounds like he was worried that the
impact might still be significant.
This seems like the heart of the problem. Changing a snapshot from a list of xids into one number is easy. Making XidInMVCCSnapshot() work is the hard part because there needs to be a translation/lookup from CSN to determine if it contains the xid.
That turns CSN into a reference to a cached snapshot, or a reference by which a snapshot can be derived on demand.
- Mixing synchronous_commit=on and synchronous_commit=off won't work
as well, because if the LSN ordering of commit records matches the
order in which transactions become visible, then an async-commit
transaction can't become visible before a later sync-commit
transaction. I expect we might just decide we can live with this, but
it's worth discussing in case people feel otherwise.
Using the Commit LSN as CSN seems interesting, but it is not the only choice.
Commit LSN is not the precise order in which commits become visible because of the race condition between marking commit in WAL and marking commit in clog. That problem is accentuated by mixing async and sync, but that is not the only source of racing.
Simon Riggs http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On Sat, Jul 25, 2015 at 11:39 AM, Simon Riggs <simon@2ndquadrant.com> wrote:
On 24 July 2015 at 19:21, Robert Haas <robertmhaas@gmail.com> wrote:On Fri, Jul 24, 2015 at 1:00 PM, Simon Riggs <simon@2ndquadrant.com> wrote:
> It depends on the exact design we use to get that. Certainly we do not want
> them if they cause a significant performance regression.
Yeah. I think the performance worries expressed so far are:
- Currently, if you see an XID that is between the XMIN and XMAX of
the snapshot, you hit CLOG only on first access. After that, the
tuple is hinted. With this approach, the hint bit doesn't avoid
needing to hit CLOG anymore, because it's not enough to know whether
or not the tuple committed; you have to know the CSN at which it
committed, which means you have to look that up in CLOG (or whatever
SLRU stores this data). Heikki mentioned adding some caching to
ameliorate this problem, but it sounds like he was worried that the
impact might still be significant.This seems like the heart of the problem. Changing a snapshot from a list of xids into one number is easy. Making XidInMVCCSnapshot() work is the hard part because there needs to be a translation/lookup from CSN to determine if it contains the xid.That turns CSN into a reference to a cached snapshot, or a reference by which a snapshot can be derived on demand.
I got the problem. Currently, once we set hint bits don't have to visit CLOG anymore. With CSN snapshots that is not so. We still have to translate XID into CSN in order to compare it with snapshot CSN. In version of CSN patch in this thread we still have XMIN and XMAX in the snapshot. AFAICS with CSN snapshots XMIN and XMAX are not necessary required to express snapshot, they were kept for optimization. That restricts usage of XID => CSN map with given range of XIDs. However, with long running transactions [XMIN; XMAX] range could be very wide and we could use XID => CSN map heavily in wide range of XIDs.
As I can see in Huawei PGCon talk "Dense Map" in shared memory is proposed for XID => CSN transformation. Having large enough "Dense Map" we can do most of XID => CSN transformations with single shared memory access. PGCon talk gives us result of pgbench. However, pgbench doesn't run any long transactions. With long running transaction we can run out of "Dense Map" for significant part of XID => CSN transformations. Dilip, did you test your patch with long transactions?
I'm also thinking about different option for optimizing this. When we set hint bits we can also change XMIN/XMAX with CSN. In this case we wouldn't need to do XID => CSN transformation for this tuple anymore. However, we have 32-bit XIDs for now. We could also have 32-bit CSNs. However, that would doubles our troubles with wraparound: we will have 2 counters that could wraparound. That could return us to thoughts about 64-bit XIDs.
Alexander Korotkov
Postgres Professional: http://www.postgrespro.com
The Russian Postgres Company
(Reviving an old thread) I spent some time dusting off this old patch, to implement CSN snapshots. Attached is a new patch, rebased over current master, and with tons of comments etc. cleaned up. There's more work to be done here, I'm posting this to let people know I'm working on this again. And to have a backup on the 'net :-). I switched to using a separate counter for CSNs. CSN is no longer the same as the commit WAL record's LSN. While I liked the conceptual simplicity of CSN == LSN a lot, and the fact that the standby would see the same commit order as master, I couldn't figure out how to make async commits to work. Next steps: * Hot standby feedback is broken, now that CSN != LSN again. Will have to switch this back to using an "oldest XID", rather than a CSN. * I plan to replace pg_subtrans with a special range of CSNs in the csnlog. Something like, start the CSN counter at 2^32 + 1, and use CSNs < 2^32 to mean "this is a subtransaction, parent is XXX". One less SLRU to maintain. * Put per-proc xmin back into procarray. I removed it, because it's not necessary for snapshots or GetOldestSnapshot() (which replaces GetOldestXmin()) anymore. But on second thoughts, we still need it for deciding when it's safe to truncate the csnlog. * In this patch, HeapTupleSatisfiesVacuum() is rewritten to use an "oldest CSN", instead of "oldest xmin", but that's not strictly necessary. To limit the size of the patch, I might revert those changes for now. * Rewrite the way RecentGlobalXmin is updated. As Alvaro pointed out in his review comments two years ago, that was quite complicated. And I'm worried that the lazy scheme I had might not allow pruning fast enough. I plan to make it more aggressive, so that whenever the currently oldest transaction finishes, it's responsible for advancing the "global xmin" in shared memory. And the way it does that, is by scanning the csnlog, starting from the current "global xmin", until the next still in-progress XID. That could be a lot, if you have a very long-running transaction that ends, but we'll see how it performs. * Performance testing. Clearly this should have a performance benefit, at least under some workloads, to be worthwhile. And not regress. - Heikki
Attachment
On Tue, Aug 9, 2016 at 3:16 PM, Heikki Linnakangas <hlinnaka@iki.fi> wrote: > (Reviving an old thread) > > I spent some time dusting off this old patch, to implement CSN snapshots. > Attached is a new patch, rebased over current master, and with tons of > comments etc. cleaned up. There's more work to be done here, I'm posting > this to let people know I'm working on this again. And to have a backup on > the 'net :-). Great to hear. I hope to find some time to review this. In the meanwhile here is a brain dump of my thoughts on the subject. > I switched to using a separate counter for CSNs. CSN is no longer the same > as the commit WAL record's LSN. While I liked the conceptual simplicity of > CSN == LSN a lot, and the fact that the standby would see the same commit > order as master, I couldn't figure out how to make async commits to work. I had an idea how that would work. In short lastCommitSeqNo would be a vector clock. Each tier of synchronization requiring different amount of waiting between xlog insert and visibility would get a position in the vector. Commits then need to be ordered only with respect to other commits within the same tier. The vector position also needs to be stored in the CSN log, probably by appropriating a couple of bits from the CSN value. I'm not sure if doing it this way would be worth the complexity, but as far as I can see it would work. However I think keeping CSN and LSN separate is a good idea, as it keeps the door open to using an external source for the CSN value, enabling stuff like cheap multi master globally consistent snapshots. > Next steps: > > * Hot standby feedback is broken, now that CSN != LSN again. Will have to > switch this back to using an "oldest XID", rather than a CSN. > > * I plan to replace pg_subtrans with a special range of CSNs in the csnlog. > Something like, start the CSN counter at 2^32 + 1, and use CSNs < 2^32 to > mean "this is a subtransaction, parent is XXX". One less SLRU to maintain. That's a great idea. I had a similar idea to enable lock-free writing into data structures, have 2^32 COMMITSEQNO_INPROGRESS values that embed the xid owning the slot. This way a writer can just blindly CAS into data structures without worrying about overwriting useful stuff due to race conditions. > * Put per-proc xmin back into procarray. I removed it, because it's not > necessary for snapshots or GetOldestSnapshot() (which replaces > GetOldestXmin()) anymore. But on second thoughts, we still need it for > deciding when it's safe to truncate the csnlog. > > * In this patch, HeapTupleSatisfiesVacuum() is rewritten to use an "oldest > CSN", instead of "oldest xmin", but that's not strictly necessary. To limit > the size of the patch, I might revert those changes for now. > > * Rewrite the way RecentGlobalXmin is updated. As Alvaro pointed out in his > review comments two years ago, that was quite complicated. And I'm worried > that the lazy scheme I had might not allow pruning fast enough. I plan to > make it more aggressive, so that whenever the currently oldest transaction > finishes, it's responsible for advancing the "global xmin" in shared memory. > And the way it does that, is by scanning the csnlog, starting from the > current "global xmin", until the next still in-progress XID. That could be a > lot, if you have a very long-running transaction that ends, but we'll see > how it performs. I had a similar idea. This would be greatly improved by a hybrid snapshot scheme that could make the tail end of the CSN log a lot sparser. More on that below. > * Performance testing. Clearly this should have a performance benefit, at > least under some workloads, to be worthwhile. And not regress. I guess this is the main question. GetSnapshotData is probably going to be faster, but the second important benefit that I saw was the possibility of reducing locking around common activities. This of course needs to guided by profiling - evils of premature optimization and all that. But that said, my gut tells me that the most important spots are: * Looking up CSNs for XidVisibleInSnashot. Current version gets a shared lock on CSNLogControlLock. That might get nasty, for example when two concurrent sequential scans running on different cores or sockets hit a patch of transactions within their xmin-xmax interval. * GetSnapshotData. With tps on read only queries potentially pushing into the millions, it would be awfully nice if contending on a single cache line could be avoided. Currently it acquires ProcArrayLock and CommitSeqNoLock to atomically update MyPgXact->snapshotcsn. The pattern I had in mind to make this lock free would be to read a CSN, publish value, check against latest OldestGlobalSnapshot value and loop if necessary, and on the other side, calculate optimistic oldest snapshot, publish and then recheck, if necessary, republish. * While commits are not as performance critical it may still be beneficial to defer clog updates and perform them in larger batches to reduce clog lock traffic. I think I have achieved some clarity on my idea of snapshots that migrate between being CSN and XID based. The essential problem with old CSN based snapshots is that the CSN log for their xmin-xmax interval needs to be kept around in a quick to access datastructure. And the problem with long running transactions is twofold, first is that they need a well defined location where to publish the visibility info for their xids and secondly, they enlarge the xmin-xmax interval of all concurrent snapshots, needing a potentially huge amount of CSN log to be kept around. One way to deal with it is to just accept it and use a SLRU as in this patch. My new insight is that a snapshot doesn't need to be either-or CSN or XIP (xid in progress) array based, but it can also be a hybrid. There would be a sorted array of in progress xids and a non-overlapping CSN xmin-xmax interval where CSN log needs to be consulted. As snapshots age they scan the CSN log and incrementally build their XIP array, basically lazily constructing same data structure used in snapshots today. Old in progress xids need a slot for themselves to be kept around, but all new snapshots being taken would immediately classify them as old, store them in XIP and not include them in their CSN xmin. Under this scheme the amount of CSN log strictly needed is a reasonably sized ring buffer for recent xids (probably sized based on max conn), a sparse map for long transactions (bounded by max conn) and some slack for snapshots still being converted. A SLRU or similar is still needed because there is no way to ensure timely conversion of all snapshots, but by properly timing the notification the probability of actually using it should be extremely low. Datastructure maintenance operations occur naturally on xid assignment and are easily batched. Long running transactions still affect all snapshots, but the effect is small and not dependent on transaction age, old snapshots only affect themselves. Subtransactions are still a pain, and would need something similar to the current suboverflowed scheme. On the plus side, it seems like the number of subxids to overflow could be global, not per backend. In short: * A directly mapped ring buffer for recent xids could be accessed lock free, would take care most of the traffic in most of the cases. Looks like it would be a good trade-off for complexity/performance. * To keep workloads with wildly varying transaction lengths in bounded amount of memory, a significantly more complex hybrid snapshot scheme is needed. It remains to be seen if these workloads are actually a significant issue. But if they are, the approach described might provide a way out. Regards, Ants Aasma
On 08/10/2016 01:03 PM, Ants Aasma wrote: > On Tue, Aug 9, 2016 at 3:16 PM, Heikki Linnakangas <hlinnaka@iki.fi> wrote: >> (Reviving an old thread) >> >> I spent some time dusting off this old patch, to implement CSN snapshots. >> Attached is a new patch, rebased over current master, and with tons of >> comments etc. cleaned up. There's more work to be done here, I'm posting >> this to let people know I'm working on this again. And to have a backup on >> the 'net :-). > > Great to hear. I hope to find some time to review this. In the > meanwhile here is a brain dump of my thoughts on the subject. Thanks! >> * Performance testing. Clearly this should have a performance benefit, at >> least under some workloads, to be worthwhile. And not regress. > > I guess this is the main question. GetSnapshotData is probably going > to be faster, but the second important benefit that I saw was the > possibility of reducing locking around common activities. This of > course needs to guided by profiling - evils of premature optimization > and all that. Yep. For the record, one big reason I'm excited about this is that a snapshot can be represented as small fixed-size value. And the reason that's exciting is that it makes it more feasible for each backend to publish their snapshots, which in turn makes it possible to vacuum old tuples more aggressively. In particular, if you have one very long-running transaction (think pg_dump), and a stream of transactions, you could vacuum away tuples that were inserted after the long-running transaction started and deleted before any of the shorter transactions started. You could do that without CSN snapshots, but it's a lot simpler with them. But that's a separate story. > But that said, my gut tells me that the most important spots are: > > * Looking up CSNs for XidVisibleInSnashot. Current version gets a > shared lock on CSNLogControlLock. That might get nasty, for example > when two concurrent sequential scans running on different cores or > sockets hit a patch of transactions within their xmin-xmax interval. I'm not too worried about that particular case. Shared LWLocks scale pretty well these days, thanks to Andres Freund's work in this area. A mix of updates and reads on the csnlog might become a scalability problem though. We'll find out once we start testing. > * GetSnapshotData. With tps on read only queries potentially pushing > into the millions, it would be awfully nice if contending on a single > cache line could be avoided. Currently it acquires ProcArrayLock and > CommitSeqNoLock to atomically update MyPgXact->snapshotcsn. The > pattern I had in mind to make this lock free would be to read a CSN, > publish value, check against latest OldestGlobalSnapshot value and > loop if necessary, and on the other side, calculate optimistic oldest > snapshot, publish and then recheck, if necessary, republish. Yeah, I haven't spent any serious effort into optimizing this yet. For the final version, should definitely do something like that. > * While commits are not as performance critical it may still be > beneficial to defer clog updates and perform them in larger batches to > reduce clog lock traffic. Hmm. I doubt batching them is going to help much. But it should be straightforward to use atomic operations here too, to reduce locking. > I think I have achieved some clarity on my idea of snapshots that > migrate between being CSN and XID based. The essential problem with > old CSN based snapshots is that the CSN log for their xmin-xmax > interval needs to be kept around in a quick to access datastructure. > And the problem with long running transactions is twofold, first is > that they need a well defined location where to publish the visibility > info for their xids and secondly, they enlarge the xmin-xmax interval > of all concurrent snapshots, needing a potentially huge amount of CSN > log to be kept around. One way to deal with it is to just accept it > and use a SLRU as in this patch. > > My new insight is that a snapshot doesn't need to be either-or CSN or > XIP (xid in progress) array based, but it can also be a hybrid. There > would be a sorted array of in progress xids and a non-overlapping CSN > xmin-xmax interval where CSN log needs to be consulted. As snapshots > age they scan the CSN log and incrementally build their XIP array, > basically lazily constructing same data structure used in snapshots > today. Old in progress xids need a slot for themselves to be kept > around, but all new snapshots being taken would immediately classify > them as old, store them in XIP and not include them in their CSN xmin. > Under this scheme the amount of CSN log strictly needed is a > reasonably sized ring buffer for recent xids (probably sized based on > max conn), a sparse map for long transactions (bounded by max conn) > and some slack for snapshots still being converted. A SLRU or similar > is still needed because there is no way to ensure timely conversion of > all snapshots, but by properly timing the notification the probability > of actually using it should be extremely low. Datastructure > maintenance operations occur naturally on xid assignment and are > easily batched. Long running transactions still affect all snapshots, > but the effect is small and not dependent on transaction age, old > snapshots only affect themselves. Subtransactions are still a pain, > and would need something similar to the current suboverflowed scheme. > On the plus side, it seems like the number of subxids to overflow > could be global, not per backend. Yeah, if the csnlog access turns out to be too expensive, we could do something like this. In theory, you can always convert a CSN snapshot into an old-style list of XIDs, by scanning the csnlog between the xmin and xmax. That could be expensive if the distance between xmin and xmax is large, of course. But as you said, you can have various hybrid forms, where you use a list of XIDs of some range as a cache, for example. I'm hopeful that we can simply make the csnlog access fast enough, though. Looking up an XID in a sorted array is O(log n), while looking up an XID in the csnlog is O(1). That ignores all locking and different constant factors, of course, but it's not a given that accessing the csnlog has to be slower than a binary search of an XID array. - Heikki
On Tue, Aug 9, 2016 at 3:16 PM, Heikki Linnakangas <hlinnaka@iki.fi> wrote:
(Reviving an old thread)
I spent some time dusting off this old patch, to implement CSN snapshots. Attached is a new patch, rebased over current master, and with tons of comments etc. cleaned up. There's more work to be done here, I'm posting this to let people know I'm working on this again. And to have a backup on the 'net :-).
Great! It's very nice seeing that you're working on this patch.
After PGCON I've your patch rebased to the master, but you already did much more.
I switched to using a separate counter for CSNs. CSN is no longer the same as the commit WAL record's LSN. While I liked the conceptual simplicity of CSN == LSN a lot, and the fact that the standby would see the same commit order as master, I couldn't figure out how to make async commits to work.
I didn't get async commits problem at first glance. AFAICS, the difference between sync commit and async is only that async commit doesn't wait WAL log to flush. But async commit still receives LSN.
Could you describe it in more details?
------
Alexander Korotkov
Postgres Professional: http://www.postgrespro.com
The Russian Postgres Company
Alexander Korotkov
Postgres Professional: http://www.postgrespro.com
The Russian Postgres Company
On Wed, Aug 10, 2016 at 2:10 PM, Heikki Linnakangas <hlinnaka@iki.fi> wrote:
------
Alexander Korotkov
Postgres Professional: http://www.postgrespro.com
Yeah, if the csnlog access turns out to be too expensive, we could do something like this. In theory, you can always convert a CSN snapshot into an old-style list of XIDs, by scanning the csnlog between the xmin and xmax. That could be expensive if the distance between xmin and xmax is large, of course. But as you said, you can have various hybrid forms, where you use a list of XIDs of some range as a cache, for example.
I'm hopeful that we can simply make the csnlog access fast enough, though. Looking up an XID in a sorted array is O(log n), while looking up an XID in the csnlog is O(1). That ignores all locking and different constant factors, of course, but it's not a given that accessing the csnlog has to be slower than a binary search of an XID array.
FYI, I'm still fan of idea to rewrite XID with CSN in tuple in the same way we're writing hint bits now.
I'm going to make prototype of this approach which would be enough for performance measurements.
------
Alexander Korotkov
Postgres Professional: http://www.postgrespro.com
The Russian Postgres Company
On 08/10/2016 04:34 PM, Alexander Korotkov wrote: > On Tue, Aug 9, 2016 at 3:16 PM, Heikki Linnakangas <hlinnaka@iki.fi> wrote: > >> I switched to using a separate counter for CSNs. CSN is no longer the same >> as the commit WAL record's LSN. While I liked the conceptual simplicity of >> CSN == LSN a lot, and the fact that the standby would see the same commit >> order as master, I couldn't figure out how to make async commits to work. > > I didn't get async commits problem at first glance. AFAICS, the difference > between sync commit and async is only that async commit doesn't wait WAL > log to flush. But async commit still receives LSN. > Could you describe it in more details? Imagine that you have a stream of normal, synchronous, commits. They get assigned LSNs: 1, 2, 3, 4. They become visible to other transactions in that order. The way I described this scheme in the first emails on this thread, was to use the current WAL insertion position as the snapshot. That's not correct, though: you have to use the current WAL *flush* position as the snapshot. Otherwise you would see the results of a transaction that hasn't been flushed to disk yet, i.e. which might still get lost, if you pull the power plug before the flush happens. So you have to use the last flush position as the snapshot. Now, if you do an asynchronous commit, the effects of that should become visible immediately, without waiting for the next flush. You can't do that, if its CSN == LSN. Perhaps you could make an exception for async commits, so that the CSN of an async commit is not the commit record's LSN, but the current WAL flush position, so that it becomes visible to others immediately. But then, how do you distinguish two async transactions that commit roughly at the same time, so that the flush position at time of commit is the same for both? And now you've given up on the CSN == LSN property, for async commits, anyway. - Heikki
Heikki Linnakangas <hlinnaka@iki.fi> writes:
> Imagine that you have a stream of normal, synchronous, commits. They get
> assigned LSNs: 1, 2, 3, 4. They become visible to other transactions in
> that order.
> The way I described this scheme in the first emails on this thread, was
> to use the current WAL insertion position as the snapshot. That's not
> correct, though: you have to use the current WAL *flush* position as the
> snapshot. Otherwise you would see the results of a transaction that
> hasn't been flushed to disk yet, i.e. which might still get lost, if you
> pull the power plug before the flush happens. So you have to use the
> last flush position as the snapshot.
Uh, what? That's not the semantics we have today, and I don't see why
it's necessary or a good idea. Once the commit is in the WAL stream,
any action taken on the basis of seeing the commit must be later in
the WAL stream. So what's the problem?
> Now, if you do an asynchronous commit, the effects of that should become
> visible immediately, without waiting for the next flush. You can't do
> that, if its CSN == LSN.
This distinction is completely arbitrary, and unlike the way it works now.
regards, tom lane
On 08/10/2016 05:09 PM, Tom Lane wrote: > Heikki Linnakangas <hlinnaka@iki.fi> writes: >> Imagine that you have a stream of normal, synchronous, commits. They get >> assigned LSNs: 1, 2, 3, 4. They become visible to other transactions in >> that order. > >> The way I described this scheme in the first emails on this thread, was >> to use the current WAL insertion position as the snapshot. That's not >> correct, though: you have to use the current WAL *flush* position as the >> snapshot. Otherwise you would see the results of a transaction that >> hasn't been flushed to disk yet, i.e. which might still get lost, if you >> pull the power plug before the flush happens. So you have to use the >> last flush position as the snapshot. > > Uh, what? That's not the semantics we have today, and I don't see why > it's necessary or a good idea. Once the commit is in the WAL stream, > any action taken on the basis of seeing the commit must be later in > the WAL stream. So what's the problem? I was talking about synchronous commits in the above. A synchronous commit is not made visible to other transactions, until the commit WAL record is flushed to disk. You could argue that that doesn't need to be so, because indeed any action taken on the basis of seeing the commit must be later in the WAL stream. But that's what asynchronous commits are for. For synchronous commits, we have a higher standard. - Heikki
Heikki Linnakangas <hlinnaka@iki.fi> writes:
> On 08/10/2016 05:09 PM, Tom Lane wrote:
>> Uh, what? That's not the semantics we have today, and I don't see why
>> it's necessary or a good idea. Once the commit is in the WAL stream,
>> any action taken on the basis of seeing the commit must be later in
>> the WAL stream. So what's the problem?
> I was talking about synchronous commits in the above. A synchronous
> commit is not made visible to other transactions, until the commit WAL
> record is flushed to disk.
[ thinks for a bit... ] Oh, OK, that's because we don't treat a
transaction as committed until its clog bit is set *and* it's not
marked as running in the PGPROC array. And sync transactions will
flush WAL in between.
Still, having to invent CSNs seems like a huge loss for this design.
Personally I'd give up async commit first. If we had only sync commit,
the rule could be "xact LSN less than snapshot threshold and less than
WAL flush position", and we'd not need CSNs. I know some people like
async commit, but it's there because it was easy and cheap in our old
design, not because it's the world's greatest feature and worth giving
up performance for.
regards, tom lane
On 08/10/2016 05:51 PM, Tom Lane wrote: > Heikki Linnakangas <hlinnaka@iki.fi> writes: >> On 08/10/2016 05:09 PM, Tom Lane wrote: >>> Uh, what? That's not the semantics we have today, and I don't see why >>> it's necessary or a good idea. Once the commit is in the WAL stream, >>> any action taken on the basis of seeing the commit must be later in >>> the WAL stream. So what's the problem? > >> I was talking about synchronous commits in the above. A synchronous >> commit is not made visible to other transactions, until the commit WAL >> record is flushed to disk. > > [ thinks for a bit... ] Oh, OK, that's because we don't treat a > transaction as committed until its clog bit is set *and* it's not > marked as running in the PGPROC array. And sync transactions will > flush WAL in between. Right. > Still, having to invent CSNs seems like a huge loss for this design. > Personally I'd give up async commit first. If we had only sync commit, > the rule could be "xact LSN less than snapshot threshold and less than > WAL flush position", and we'd not need CSNs. I know some people like > async commit, but it's there because it was easy and cheap in our old > design, not because it's the world's greatest feature and worth giving > up performance for. I don't think that's a very popular opinion (I disagree, for one). Asynchronous commits are a huge performance boost for some applications. The alternative is fsync=off, and I don't want to see more people doing that. SSDs have made the penalty of an fsync much smaller, but it's still there. Hmm. There's one more possible way this could all work. Let's have CSN == LSN, also for asynchronous commits. A snapshot is the current insert position, but also make note of the current flush position, when you take a snapshot. Now, when you use the snapshot, if you ever see an XID that committed between the snapshot's insert position and the flush position, wait for the WAL to be flushed up to the snapshot's insert position at that point. With that scheme, an asynchronous commit could return to the application without waiting for a flush, but if someone actually looks at the changes the transaction made, then that transaction would have to wait. Furthermore, we could probably skip that waiting too, if the reading transaction is also using synchronous_commit=off. That's slightly different from the current behaviour. A transaction that runs with synchronous_commit=on, and reads data that was modified by an asynchronous transaction, would take a hit. But I think that would be acceptable. - Heikki
On Wed, Aug 10, 2016 at 11:09 AM, Heikki Linnakangas <hlinnaka@iki.fi> wrote: >> Still, having to invent CSNs seems like a huge loss for this design. >> Personally I'd give up async commit first. If we had only sync commit, >> the rule could be "xact LSN less than snapshot threshold and less than >> WAL flush position", and we'd not need CSNs. I know some people like >> async commit, but it's there because it was easy and cheap in our old >> design, not because it's the world's greatest feature and worth giving >> up performance for. > > I don't think that's a very popular opinion (I disagree, for one). > Asynchronous commits are a huge performance boost for some applications. The > alternative is fsync=off, and I don't want to see more people doing that. > SSDs have made the penalty of an fsync much smaller, but it's still there. Uh, yeah. Asynchronous commit can be 100 times faster on some realistic workloads. If we remove it, many people will have to decide between running with fsync=off and abandoning PostgreSQL altogether. That doesn't strike me as a remotely possible line of attack. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On 08/10/2016 08:28 AM, Robert Haas wrote: > On Wed, Aug 10, 2016 at 11:09 AM, Heikki Linnakangas <hlinnaka@iki.fi> wrote: >>> Still, having to invent CSNs seems like a huge loss for this design. >>> Personally I'd give up async commit first. If we had only sync commit, >>> the rule could be "xact LSN less than snapshot threshold and less than >>> WAL flush position", and we'd not need CSNs. I know some people like >>> async commit, but it's there because it was easy and cheap in our old >>> design, not because it's the world's greatest feature and worth giving >>> up performance for. >> >> I don't think that's a very popular opinion (I disagree, for one). >> Asynchronous commits are a huge performance boost for some applications. The >> alternative is fsync=off, and I don't want to see more people doing that. >> SSDs have made the penalty of an fsync much smaller, but it's still there. > > Uh, yeah. Asynchronous commit can be 100 times faster on some > realistic workloads. If we remove it, many people will have to decide > between running with fsync=off and abandoning PostgreSQL altogether. > That doesn't strike me as a remotely possible line of attack. +1 for Robert here, removing async commit is a non-starter. It is PostgreSQL performance 101 that you disable synchronous commit unless you have a specific data/business requirement that needs it. Specifically because of how much faster Pg is with async commit. Sincerely, jD > -- Command Prompt, Inc. http://the.postgres.company/ +1-503-667-4564 PostgreSQL Centered full stack support, consulting and development. Everyone appreciates your honesty, until you are honest with them. Unless otherwise stated, opinions are my own.
* Joshua D. Drake (jd@commandprompt.com) wrote: > +1 for Robert here, removing async commit is a non-starter. It is > PostgreSQL performance 101 that you disable synchronous commit > unless you have a specific data/business requirement that needs it. > Specifically because of how much faster Pg is with async commit. I agree that we don't want to get rid of async commit, but, for the archive, I wouldn't recommend using it unless you specifically understand and accept that trade-off, so I wouldn't lump it into a "PostgreSQL performance 101" group- that's increasing work_mem, shared_buffers, WAL size, etc. Accepting that you're going to lose *committed* transactions on a crash requires careful thought and consideration of what you're going to do when that happens, not the other way around. Thanks! Stephen
On 08/10/2016 09:04 AM, Stephen Frost wrote: > * Joshua D. Drake (jd@commandprompt.com) wrote: >> +1 for Robert here, removing async commit is a non-starter. It is >> PostgreSQL performance 101 that you disable synchronous commit >> unless you have a specific data/business requirement that needs it. >> Specifically because of how much faster Pg is with async commit. > > I agree that we don't want to get rid of async commit, but, for the > archive, I wouldn't recommend using it unless you specifically understand > and accept that trade-off, so I wouldn't lump it into a "PostgreSQL > performance 101" group- that's increasing work_mem, shared_buffers, WAL > size, etc. Accepting that you're going to lose *committed* transactions > on a crash requires careful thought and consideration of what you're > going to do when that happens, not the other way around. Yes Stephen, you are correct which is why I said, "unless you have a specific data/business requirement that needs it". Thanks! jD > > Thanks! > > Stephen > -- Command Prompt, Inc. http://the.postgres.company/ +1-503-667-4564 PostgreSQL Centered full stack support, consulting and development. Everyone appreciates your honesty, until you are honest with them. Unless otherwise stated, opinions are my own.
On Wed, Aug 10, 2016 at 6:09 PM, Heikki Linnakangas <hlinnaka@iki.fi> wrote: > Hmm. There's one more possible way this could all work. Let's have CSN == > LSN, also for asynchronous commits. A snapshot is the current insert > position, but also make note of the current flush position, when you take a > snapshot. Now, when you use the snapshot, if you ever see an XID that > committed between the snapshot's insert position and the flush position, > wait for the WAL to be flushed up to the snapshot's insert position at that > point. With that scheme, an asynchronous commit could return to the > application without waiting for a flush, but if someone actually looks at > the changes the transaction made, then that transaction would have to wait. > Furthermore, we could probably skip that waiting too, if the reading > transaction is also using synchronous_commit=off. > > That's slightly different from the current behaviour. A transaction that > runs with synchronous_commit=on, and reads data that was modified by an > asynchronous transaction, would take a hit. But I think that would be > acceptable. My proposal of vector clocks would allow for pretty much exactly current behavior. To simplify, there would be lastSyncCommitSeqNo and lastAsyncCommitSeqNo variables in ShmemVariableCache. Transaction commit would choose which one to update based on synchronous_commit setting and embed the value of the setting into CSN log. Snapshots would contain both values, when checking for CSN visibility use the value of the looked up synchronous_commit setting to decide which value to compare against. Standby's replaying commit records would just update both values, resulting in transactions becoming visible in xlog order, as they do today. The scheme would allow for inventing a new xlog record/replication message communicating visibility ordering. However I don't see why inventing a separate CSN concept is a large problem. Quite the opposite, unless there is a good reason that I'm missing, it seems better to not unnecessarily conflate commit record durability and transaction visibility ordering. Not having them tied together allows for an external source to provide CSN values, allowing for interesting distributed transaction implementations. E.g. using a timestamp as the CSN a'la Google Spanner and the TrueTime API. Regards, Ants Aasma
On Wed, Aug 10, 2016 at 6:09 PM, Heikki Linnakangas <hlinnaka@iki.fi> wrote:
On 08/10/2016 05:51 PM, Tom Lane wrote:Heikki Linnakangas <hlinnaka@iki.fi> writes:On 08/10/2016 05:09 PM, Tom Lane wrote:Uh, what? That's not the semantics we have today, and I don't see why
it's necessary or a good idea. Once the commit is in the WAL stream,
any action taken on the basis of seeing the commit must be later in
the WAL stream. So what's the problem?I was talking about synchronous commits in the above. A synchronous
commit is not made visible to other transactions, until the commit WAL
record is flushed to disk.
[ thinks for a bit... ] Oh, OK, that's because we don't treat a
transaction as committed until its clog bit is set *and* it's not
marked as running in the PGPROC array. And sync transactions will
flush WAL in between.
Right.Still, having to invent CSNs seems like a huge loss for this design.
Personally I'd give up async commit first. If we had only sync commit,
the rule could be "xact LSN less than snapshot threshold and less than
WAL flush position", and we'd not need CSNs. I know some people like
async commit, but it's there because it was easy and cheap in our old
design, not because it's the world's greatest feature and worth giving
up performance for.
I don't think that's a very popular opinion (I disagree, for one). Asynchronous commits are a huge performance boost for some applications. The alternative is fsync=off, and I don't want to see more people doing that. SSDs have made the penalty of an fsync much smaller, but it's still there.
Hmm. There's one more possible way this could all work. Let's have CSN == LSN, also for asynchronous commits. A snapshot is the current insert position, but also make note of the current flush position, when you take a snapshot. Now, when you use the snapshot, if you ever see an XID that committed between the snapshot's insert position and the flush position, wait for the WAL to be flushed up to the snapshot's insert position at that point. With that scheme, an asynchronous commit could return to the application without waiting for a flush, but if someone actually looks at the changes the transaction made, then that transaction would have to wait. Furthermore, we could probably skip that waiting too, if the reading transaction is also using synchronous_commit=off.
That's slightly different from the current behaviour. A transaction that runs with synchronous_commit=on, and reads data that was modified by an asynchronous transaction, would take a hit. But I think that would be acceptable.
Oh, I found that I underestimated complexity of async commit... :)
Do I understand right that now async commit right as follows?
1) Async transaction confirms commit before flushing WAL.
2) Other transactions sees effect of async transaction only when its WAL flushed.
3) In the session which just committed async transaction, effect of this transaction is visible immediately (before WAL flushed). Is it true?
------
Alexander Korotkov
Postgres Professional: http://www.postgrespro.com
The Russian Postgres Company
Alexander Korotkov
Postgres Professional: http://www.postgrespro.com
The Russian Postgres Company
On 08/10/2016 07:54 PM, Alexander Korotkov wrote: > Do I understand right that now async commit right as follows? > 1) Async transaction confirms commit before flushing WAL. Yes. > 2) Other transactions sees effect of async transaction only when its WAL > flushed. No. Other transactions also see the effects of the async transaction before it's flushed. > 3) In the session which just committed async transaction, effect of this > transaction is visible immediately (before WAL flushed). Is it true? Yes. (The same session is not a special case, per previous point. All sessions see the async transaction as committed, even before it's flushed.) - Heikki
On Wed, Aug 10, 2016 at 5:54 PM, Alexander Korotkov <a.korotkov@postgrespro.ru> wrote: > Oh, I found that I underestimated complexity of async commit... :) Indeed. I think Tom's attitude was right even if the specific conclusion was wrong. While I don't think removing async commit is viable I think it would be a laudable goal if we can remove some of the complication in it. I normally describe async commit as "just like a normal commit but don't block on the commit" but it's actually a bit more complicated. AIUI the additional complexity is that while async commits are visible to everyone immediately other non-async transactions can be committed but then be in limbo for a while before they are visible to others. So other sessions will see the async commit "jump ahead" of any non-async transactions even if those other transactions were committed first. Any standbys will see the non-async transaction in the logs before the async transaction and in a crash it's possible to lose the async transaction even though it was visible but not the sync transaction that wasn't. Complexity like this makes it hard to implement other features such as CSNs. IIRC this already bit hot standby as well. I think it would be a big improvement if we had a clear, well defined commit order that was easy to explain and easy to reason about when new changes are being made. -- greg
On Wed, Aug 10, 2016 at 7:54 PM, Alexander Korotkov <a.korotkov@postgrespro.ru> wrote: > Oh, I found that I underestimated complexity of async commit... :) > > Do I understand right that now async commit right as follows? > 1) Async transaction confirms commit before flushing WAL. > 2) Other transactions sees effect of async transaction only when its WAL > flushed. > 3) In the session which just committed async transaction, effect of this > transaction is visible immediately (before WAL flushed). Is it true? Current code simplified: XactLogCommitRecord() if (synchronous_commit) XLogFlush() ProcArrayEndTransaction() // Become visible The issue we are discussing is that with CSNs, the "become visible" portion must occur in CSN order. If CSN == LSN, then async transactions that have their commit record after a sync record must wait for the sync record to flush and become visible. Simplest solution is to not require CSN == LSN and just assign a CSN value immediately before becoming visible. Regards, Ants Aasma
On Wed, Aug 10, 2016 at 12:26 PM, Greg Stark <stark@mit.edu> wrote: > Complexity like this makes it hard to implement other features such as > CSNs. IIRC this already bit hot standby as well. I think it would be a > big improvement if we had a clear, well defined commit order that was > easy to explain and easy to reason about when new changes are being > made. And here I was getting concerned that there was no mention of "apparent order of execution" for serializable transactions -- which does not necessarily match either the order of LSNs from commit records nor CSNs. The order in which transactions become visible is clearly a large factor in determining AOoE, but it is secondary to looking at whether a transaction modified data based on reading the "before" image of a data set modified by a concurrent transaction. I still think that our best bet for avoiding anomalies when using logical replication in complex environments is for logical replication to apply transactions in apparent order of execution. -- Kevin Grittner EDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On Wed, Aug 10, 2016 at 8:26 PM, Greg Stark <stark@mit.edu> wrote:
Heikki, Ants, Greg, thank you for the explanation. You restored order in my personal world.
On Wed, Aug 10, 2016 at 5:54 PM, Alexander Korotkov
<a.korotkov@postgrespro.ru> wrote:
> Oh, I found that I underestimated complexity of async commit... :)
Indeed. I think Tom's attitude was right even if the specific
conclusion was wrong. While I don't think removing async commit is
viable I think it would be a laudable goal if we can remove some of
the complication in it. I normally describe async commit as "just like
a normal commit but don't block on the commit" but it's actually a bit
more complicated.
AIUI the additional complexity is that while async commits are visible
to everyone immediately other non-async transactions can be committed
but then be in limbo for a while before they are visible to others. So
other sessions will see the async commit "jump ahead" of any non-async
transactions even if those other transactions were committed first.
Any standbys will see the non-async transaction in the logs before the
async transaction and in a crash it's possible to lose the async
transaction even though it was visible but not the sync transaction
that wasn't.
Complexity like this makes it hard to implement other features such as
CSNs. IIRC this already bit hot standby as well. I think it would be a
big improvement if we had a clear, well defined commit order that was
easy to explain and easy to reason about when new changes are being
made.
Now I see that introduction of own sequence of CSN which is not equal to LSN makes sense.
The Russian Postgres Company
And here's a new patch version. Still lots of work to do, especially in performance testing, and minimizing the worst-case performance hit. On 08/09/2016 03:16 PM, Heikki Linnakangas wrote: > Next steps: > > * Hot standby feedback is broken, now that CSN != LSN again. Will have > to switch this back to using an "oldest XID", rather than a CSN. > > * I plan to replace pg_subtrans with a special range of CSNs in the > csnlog. Something like, start the CSN counter at 2^32 + 1, and use CSNs > < 2^32 to mean "this is a subtransaction, parent is XXX". One less SLRU > to maintain. > > * Put per-proc xmin back into procarray. I removed it, because it's not > necessary for snapshots or GetOldestSnapshot() (which replaces > GetOldestXmin()) anymore. But on second thoughts, we still need it for > deciding when it's safe to truncate the csnlog. > > * In this patch, HeapTupleSatisfiesVacuum() is rewritten to use an > "oldest CSN", instead of "oldest xmin", but that's not strictly > necessary. To limit the size of the patch, I might revert those changes > for now. I did all of the above. This patch is now much smaller, as I didn't change all the places that used to deal with global-xmin's, like I did earlier. The oldest-xmin is now computed pretty like it always has been. > * Rewrite the way RecentGlobalXmin is updated. As Alvaro pointed out in > his review comments two years ago, that was quite complicated. And I'm > worried that the lazy scheme I had might not allow pruning fast enough. > I plan to make it more aggressive, so that whenever the currently oldest > transaction finishes, it's responsible for advancing the "global xmin" > in shared memory. And the way it does that, is by scanning the csnlog, > starting from the current "global xmin", until the next still > in-progress XID. That could be a lot, if you have a very long-running > transaction that ends, but we'll see how it performs. I ripped out all that, and created a GetRecentGlobalXmin() function that computes a global-xmin value when needed, like GetOldestXmin() does. Seems most straightforward. Since we no longer get a RecentGlobalXmin value essentially for free in GetSnapshotData(), as we no longer scan the proc array, it's better to compute the value only when needed. > * Performance testing. Clearly this should have a performance benefit, > at least under some workloads, to be worthwhile. And not regress. I wrote a little C module to create a "worst-case" table. Every row in the table has a different xmin, and the xmin values are shuffled across the table, to defeat any caching. A sequential scan of a table like that with 10 million rows took about 700 ms on my laptop, when the hint bits are set, without this patch. With this patch, if there's a snapshot holding back the xmin horizon, so that we need to check the CSN log for every XID, it took about 30000 ms. So we have some optimization work to do :-). I'm not overly worried about that right now, as I think there's a lot of room for improvement in the SLRU code. But that's the next thing I'm going to work. - Heikki
On 08/22/2016 07:35 PM, Heikki Linnakangas wrote: > And here's a new patch version... And here's the attachment I forgot, *sigh*.. - Heikki
Attachment
Nice to see you working on this again. On Mon, Aug 22, 2016 at 12:35 PM, Heikki Linnakangas <hlinnaka@iki.fi> wrote: > A sequential scan of a table like that with 10 million rows took about 700 > ms on my laptop, when the hint bits are set, without this patch. With this > patch, if there's a snapshot holding back the xmin horizon, so that we need > to check the CSN log for every XID, it took about 30000 ms. So we have some > optimization work to do :-). I'm not overly worried about that right now, as > I think there's a lot of room for improvement in the SLRU code. But that's > the next thing I'm going to work. So the worst case for this patch is obviously bad right now and, as you say, that means that some optimization work is needed. But what about the best case? If we create a scenario where there are no open read-write transactions at all and (somehow) lots and lots of ProcArrayLock contention, how much does this help? Because there's only a purpose to trying to minimize the losses if there are some gains to which we can look forward. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On 08/22/2016 07:49 PM, Robert Haas wrote: > Nice to see you working on this again. > > On Mon, Aug 22, 2016 at 12:35 PM, Heikki Linnakangas <hlinnaka@iki.fi> wrote: >> A sequential scan of a table like that with 10 million rows took about 700 >> ms on my laptop, when the hint bits are set, without this patch. With this >> patch, if there's a snapshot holding back the xmin horizon, so that we need >> to check the CSN log for every XID, it took about 30000 ms. So we have some >> optimization work to do :-). I'm not overly worried about that right now, as >> I think there's a lot of room for improvement in the SLRU code. But that's >> the next thing I'm going to work. > > So the worst case for this patch is obviously bad right now and, as > you say, that means that some optimization work is needed. > > But what about the best case? If we create a scenario where there are > no open read-write transactions at all and (somehow) lots and lots of > ProcArrayLock contention, how much does this help? I ran some quick pgbench tests on my laptop, but didn't see any meaningful benefit. I think the best I could see is about 5% speedup, when running "pgbench -S", with 900 idle connections sitting in the background. On the positive side, I didn't see much slowdown either. (Sorry, I didn't record the details of those tests, as I was testing many different options and I didn't see a clear difference either way.) It seems that Amit's PGPROC batch clearing patch was very effective. I remember seeing ProcArrayLock contention very visible earlier, but I can't hit that now. I suspect you'd still see contention on bigger hardware, though, my laptop has oly 4 cores. I'll have to find a real server for the next round of testing. > Because there's only a purpose to trying to minimize the losses if > there are some gains to which we can look forward. Aside from the potential performance gains, this slashes a lot of complicated code: 70 files changed, 2429 insertions(+), 6066 deletions(-) That removed code is quite mature at this point, and I'm sure we'll add some code back to this patch as it evolves, but still. Also, I'm looking forward for a follow-up patch, to track snapshots in backends at a finer level, so that vacuum could remove tuples more aggressively, if you have pg_dump running for days. CSN snapshots isn't a strict requirement for that, but it makes it simpler, when you can represent a snapshot with a small fixed-size integer. Yes, seeing some direct performance gains would be nice too. - Heikki
Hi, On 2016-08-22 20:32:42 +0300, Heikki Linnakangas wrote: > I ran some quick pgbench tests on my laptop, but didn't see any meaningful > benefit. I think the best I could see is about 5% speedup, when running > "pgbench -S", with 900 idle connections sitting in the background. On the > positive side, I didn't see much slowdown either. (Sorry, I didn't record > the details of those tests, as I was testing many different options and I > didn't see a clear difference either way.) Hm. Does the picture change if those are idle in transaction, after assigning an xid. > It seems that Amit's PGPROC batch clearing patch was very effective. It usually breaks down if you have a mixed read/write workload - might be worthehile prototyping that. > I > remember seeing ProcArrayLock contention very visible earlier, but I can't > hit that now. I suspect you'd still see contention on bigger hardware, > though, my laptop has oly 4 cores. I'll have to find a real server for the > next round of testing. Yea, I think that's true. I can just about see ProcArrayLock contention on my more powerful laptop, to see it really bad you need bigger hardware / higher concurrency. Greetings, Andres Freund
On Mon, Aug 22, 2016 at 1:32 PM, Heikki Linnakangas <hlinnaka@iki.fi> wrote: >> But what about the best case? If we create a scenario where there are >> no open read-write transactions at all and (somehow) lots and lots of >> ProcArrayLock contention, how much does this help? > > I ran some quick pgbench tests on my laptop, but didn't see any meaningful > benefit. I think the best I could see is about 5% speedup, when running > "pgbench -S", with 900 idle connections sitting in the background. On the > positive side, I didn't see much slowdown either. (Sorry, I didn't record > the details of those tests, as I was testing many different options and I > didn't see a clear difference either way.) That's not very exciting. > It seems that Amit's PGPROC batch clearing patch was very effective. I > remember seeing ProcArrayLock contention very visible earlier, but I can't > hit that now. I suspect you'd still see contention on bigger hardware, > though, my laptop has oly 4 cores. I'll have to find a real server for the > next round of testing. It's good that those patches were effective, and I bet that approach could be further refined, too. However, I think Amit may have mentioned in an internal meeting that he was able to generate some pretty serious ProcArrayLock contention with some of his hash index patches applied. I don't remember the details, though. >> Because there's only a purpose to trying to minimize the losses if >> there are some gains to which we can look forward. > > Aside from the potential performance gains, this slashes a lot of > complicated code: > > 70 files changed, 2429 insertions(+), 6066 deletions(-) > > That removed code is quite mature at this point, and I'm sure we'll add some > code back to this patch as it evolves, but still. That's interesting, but it might just mean we're replacing well-tested code with new, buggy code. By the time you fix all the performance regressions, those numbers could be a lot closer together. > Also, I'm looking forward for a follow-up patch, to track snapshots in > backends at a finer level, so that vacuum could remove tuples more > aggressively, if you have pg_dump running for days. CSN snapshots isn't a > strict requirement for that, but it makes it simpler, when you can represent > a snapshot with a small fixed-size integer. That would certainly be nice, but I think we need to be careful not to sacrifice too much trying to get there. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On 2016-08-22 13:41:57 -0400, Robert Haas wrote: > On Mon, Aug 22, 2016 at 1:32 PM, Heikki Linnakangas <hlinnaka@iki.fi> wrote: > >> But what about the best case? If we create a scenario where there are > >> no open read-write transactions at all and (somehow) lots and lots of > >> ProcArrayLock contention, how much does this help? > > > > I ran some quick pgbench tests on my laptop, but didn't see any meaningful > > benefit. I think the best I could see is about 5% speedup, when running > > "pgbench -S", with 900 idle connections sitting in the background. On the > > positive side, I didn't see much slowdown either. (Sorry, I didn't record > > the details of those tests, as I was testing many different options and I > > didn't see a clear difference either way.) > > That's not very exciting. I think it's neither exciting nor worrying - the benefit of the pgproc batch clearing itself wasn't apparent on small hardware either...
On Mon, Aug 22, 2016 at 11:11 PM, Robert Haas <robertmhaas@gmail.com> wrote: > On Mon, Aug 22, 2016 at 1:32 PM, Heikki Linnakangas <hlinnaka@iki.fi> wrote: >>> But what about the best case? If we create a scenario where there are >>> no open read-write transactions at all and (somehow) lots and lots of >>> ProcArrayLock contention, how much does this help? >> >> I ran some quick pgbench tests on my laptop, but didn't see any meaningful >> benefit. I think the best I could see is about 5% speedup, when running >> "pgbench -S", with 900 idle connections sitting in the background. On the >> positive side, I didn't see much slowdown either. (Sorry, I didn't record >> the details of those tests, as I was testing many different options and I >> didn't see a clear difference either way.) > > That's not very exciting. > >> It seems that Amit's PGPROC batch clearing patch was very effective. I >> remember seeing ProcArrayLock contention very visible earlier, but I can't >> hit that now. I suspect you'd still see contention on bigger hardware, >> though, my laptop has oly 4 cores. I'll have to find a real server for the >> next round of testing. > > It's good that those patches were effective, and I bet that approach > could be further refined, too. However, I think Amit may have > mentioned in an internal meeting that he was able to generate some > pretty serious ProcArrayLock contention with some of his hash index > patches applied. I don't remember the details, though. > Yes, thats right. We are seeing ProcArrayLock as a bottleneck at high-concurrency for hash-index reads. On a quick look, it seems patch still acquires ProcArrayLock in shared mode in GetSnapshotData() although duration is reduced. I think it is worth to try the workload where we are seeing ProcArrayLock as bottleneck, but not sure if it can drastically improves the situation, because as per our initial analysis, lock acquisition and release itself causes problem. -- With Regards, Amit Kapila. EnterpriseDB: http://www.enterprisedb.com
On 08/22/2016 08:38 PM, Andres Freund wrote: > On 2016-08-22 20:32:42 +0300, Heikki Linnakangas wrote: >> I >> remember seeing ProcArrayLock contention very visible earlier, but I can't >> hit that now. I suspect you'd still see contention on bigger hardware, >> though, my laptop has oly 4 cores. I'll have to find a real server for the >> next round of testing. > > Yea, I think that's true. I can just about see ProcArrayLock contention > on my more powerful laptop, to see it really bad you need bigger > hardware / higher concurrency. As soon as I sent my previous post, Vladimir Borodin kindly offered access to a 32-core server for performance testing. Thanks Vladimir! I installed Greg Smith's pgbench-tools kit on that server, and ran some tests. I'm seeing some benefit on "pgbench -N" workload, but only after modifying the test script to use "-M prepared", and using Unix domain sockets instead of TCP to connect. Apparently those things add enough overhead to mask out the little difference. Attached is a graph with the results. Full results are available at https://hlinnaka.iki.fi/temp/csn-4-results/. In short, the patch improved throughput, measured in TPS, with >= 32 or so clients. The biggest difference was with 44 clients, which saw about 5% improvement. So, not phenomenal, but it's something. I suspect that with more cores, the difference would become more clear. Like on a cue, Alexander Korotkov just offered access to a 72-core system :-). Thanks! I'll run the same tests on that. - Heikki
Attachment
{kind=link}
On 2016-08-23 18:18:57 +0300, Heikki Linnakangas wrote: > I installed Greg Smith's pgbench-tools kit on that server, and ran some > tests. I'm seeing some benefit on "pgbench -N" workload, but only after > modifying the test script to use "-M prepared", and using Unix domain > sockets instead of TCP to connect. Apparently those things add enough > overhead to mask out the little difference. To make the problem more apparent, how are the differences for something as extreme as just a SELECT 1; or a SELECT 1 FROM pgbench_accounts WHERE aid = 1; Greetings, Andres Freund
On 08/23/2016 06:18 PM, Heikki Linnakangas wrote: > On 08/22/2016 08:38 PM, Andres Freund wrote: >> On 2016-08-22 20:32:42 +0300, Heikki Linnakangas wrote: >>> I >>> remember seeing ProcArrayLock contention very visible earlier, but I can't >>> hit that now. I suspect you'd still see contention on bigger hardware, >>> though, my laptop has oly 4 cores. I'll have to find a real server for the >>> next round of testing. >> >> Yea, I think that's true. I can just about see ProcArrayLock contention >> on my more powerful laptop, to see it really bad you need bigger >> hardware / higher concurrency. > > As soon as I sent my previous post, Vladimir Borodin kindly offered > access to a 32-core server for performance testing. Thanks Vladimir! > > I installed Greg Smith's pgbench-tools kit on that server, and ran some > tests. I'm seeing some benefit on "pgbench -N" workload, but only after > modifying the test script to use "-M prepared", and using Unix domain > sockets instead of TCP to connect. Apparently those things add enough > overhead to mask out the little difference. > > Attached is a graph with the results. Full results are available at > https://hlinnaka.iki.fi/temp/csn-4-results/. In short, the patch > improved throughput, measured in TPS, with >= 32 or so clients. The > biggest difference was with 44 clients, which saw about 5% improvement. > > So, not phenomenal, but it's something. I suspect that with more cores, > the difference would become more clear. > > Like on a cue, Alexander Korotkov just offered access to a 72-core > system :-). Thanks! I'll run the same tests on that. And here are the results on the 72 core machine (thanks again, Alexander!). The test setup was the same as on the 32-core machine, except that I ran it with more clients since the system has more CPU cores. In summary, in the best case, the patch increases throughput by about 10%. That peak is with 64 clients. Interestingly, as the number of clients increases further, the gain evaporates, and the CSN version actually performs worse than unpatched master. I don't know why that is. One theory that by eliminating one bottleneck, we're now hitting another bottleneck which doesn't degrade as gracefully when there's contention. Full results are available at https://hlinnaka.iki.fi/temp/csn-4-72core-results/. - Heikki
Attachment
{kind=link}
On Wed, Aug 24, 2016 at 11:54 AM, Heikki Linnakangas <hlinnaka@iki.fi> wrote:
And here are the results on the 72 core machine (thanks again, Alexander!). The test setup was the same as on the 32-core machine, except that I ran it with more clients since the system has more CPU cores. In summary, in the best case, the patch increases throughput by about 10%. That peak is with 64 clients. Interestingly, as the number of clients increases further, the gain evaporates, and the CSN version actually performs worse than unpatched master. I don't know why that is. One theory that by eliminating one bottleneck, we're now hitting another bottleneck which doesn't degrade as gracefully when there's contention.On 08/23/2016 06:18 PM, Heikki Linnakangas wrote:On 08/22/2016 08:38 PM, Andres Freund wrote:On 2016-08-22 20:32:42 +0300, Heikki Linnakangas wrote:I
remember seeing ProcArrayLock contention very visible earlier, but I can't
hit that now. I suspect you'd still see contention on bigger hardware,
though, my laptop has oly 4 cores. I'll have to find a real server for the
next round of testing.
Yea, I think that's true. I can just about see ProcArrayLock contention
on my more powerful laptop, to see it really bad you need bigger
hardware / higher concurrency.
As soon as I sent my previous post, Vladimir Borodin kindly offered
access to a 32-core server for performance testing. Thanks Vladimir!
I installed Greg Smith's pgbench-tools kit on that server, and ran some
tests. I'm seeing some benefit on "pgbench -N" workload, but only after
modifying the test script to use "-M prepared", and using Unix domain
sockets instead of TCP to connect. Apparently those things add enough
overhead to mask out the little difference.
Attached is a graph with the results. Full results are available at
https://hlinnaka.iki.fi/temp/csn-4-results/. In short, the patch
improved throughput, measured in TPS, with >= 32 or so clients. The
biggest difference was with 44 clients, which saw about 5% improvement.
So, not phenomenal, but it's something. I suspect that with more cores,
the difference would become more clear.
Like on a cue, Alexander Korotkov just offered access to a 72-core
system :-). Thanks! I'll run the same tests on that.
Did you try to identify this second bottleneck with perf or something?
It would be nice to also run pgbench -S. Also, it would be nice to check something like 10% of writes, 90% of reads (which is quite typical workload in real life I believe).
Alexander Korotkov
Postgres Professional: http://www.postgrespro.com
The Russian Postgres Company
On Wed, Aug 24, 2016 at 2:24 PM, Heikki Linnakangas <hlinnaka@iki.fi> wrote: > > And here are the results on the 72 core machine (thanks again, Alexander!). > The test setup was the same as on the 32-core machine, except that I ran it > with more clients since the system has more CPU cores. In summary, in the > best case, the patch increases throughput by about 10%. That peak is with 64 > clients. Interestingly, as the number of clients increases further, the gain > evaporates, and the CSN version actually performs worse than unpatched > master. I don't know why that is. One theory that by eliminating one > bottleneck, we're now hitting another bottleneck which doesn't degrade as > gracefully when there's contention. > Quite possible and I think it could be either due CLOGControlLock or WALWriteLock. Are you planning to work on this for this release, if not do you think meanwhile we should pursue "caching the snapshot" idea of Andres? Last time Mithun did some benchmarks [1] after fixing some issues in the patch and he found noticeable performance increase. [1] - https://www.postgresql.org/message-id/CAD__Ouic1Tvnwqm6Wf6j7Cz1Kk1DQgmy0isC7%3DOgX%2B3JtfGk9g%40mail.gmail.com -- With Regards, Amit Kapila. EnterpriseDB: http://www.enterprisedb.com
On Wed, Aug 24, 2016 at 5:54 PM, Heikki Linnakangas <hlinnaka@iki.fi> wrote: > And here are the results on the 72 core machine (thanks again, Alexander!). > The test setup was the same as on the 32-core machine, except that I ran it > with more clients since the system has more CPU cores. In summary, in the > best case, the patch increases throughput by about 10%. That peak is with 64 > clients. Interestingly, as the number of clients increases further, the gain > evaporates, and the CSN version actually performs worse than unpatched > master. I don't know why that is. One theory that by eliminating one > bottleneck, we're now hitting another bottleneck which doesn't degrade as > gracefully when there's contention. > > Full results are available at > https://hlinnaka.iki.fi/temp/csn-4-72core-results/. There has not been much activity on this thread for some time, and I mentioned my intentions to some developers at the last PGCon. But I am planning to study more the work that has been done here, with as envisaged goal to present a patch for the first CF of PG11. Lots of fun ahead. -- Michael
On 21.06.2017 04:48, Michael Paquier wrote: > There has not been much activity on this thread for some time, and I > mentioned my intentions to some developers at the last PGCon. But I am > planning to study more the work that has been done here, with as > envisaged goal to present a patch for the first CF of PG11. Lots of > fun ahead. Hi Michael, Glad to see you working on this! I've been studying this topic too. Attached you can find a recently rebased version of Heikki's v4 patch. I also fixed a bug that appeared on report-receipts isolation test: XidIsConcurrent should report that a transaction is concurrent to ours when its csn equals our snapshotcsn. There is another bug where multiple tuples with the same primary key appear after a pgbench read-write test. Querying pgbench_branches with disabled index scans, I see several tuples with the same 'bid' value. Usually they do not touch the index so there are no errors. But sometimes HOT update is not possible and it errors out with violation of unique constraint, which is how I noticed it. I can't reproduce it on my machine and have to use a 72-core one. For now I can conclude that the oldestActiveXid is not always updated correctly. In TransactionIdAsyncCommitTree, just before the transaction sets clog status, its xid can be less than oldestActiveXid. Other transactions are seeing it as aborted for some time before it writes to clog (see TransactionIdGetCommitSeqNo). They can update a tuple it deleted, and that leads to duplication. Unfortunately, I didn't have time yet to investigate this further. -- Alexander Kuzmenkov Postgres Professional: http://www.postgrespro.com The Russian Postgres Company -- Sent via pgsql-hackers mailing list (pgsql-hackers@postgresql.org) To make changes to your subscription: http://www.postgresql.org/mailpref/pgsql-hackers
Attachment
On Wed, Jun 21, 2017 at 1:48 PM, Alexander Kuzmenkov <a.kuzmenkov@postgrespro.ru> wrote: > Glad to see you working on this! I've been studying this topic too. Attached > you can find a recently rebased version of Heikki's v4 patch. > I also fixed a bug that appeared on report-receipts isolation test: > XidIsConcurrent should report that a transaction is concurrent to ours when > its csn equals our snapshotcsn. I am finally looking at rebasing things properly now, and getting more familiar in order to come up with a patch for the upcoming coming fest (I can see some diff simplifications as well to impact less existing applications), and this v5 is very suspicious. You are adding code that should actually be removed. One such block can be found at the beginning of the patch: <indexterm> + <primary>txid_snapshot_xip</primary> + </indexterm> + + <indexterm> That's not actually a problem as I am reusing an older v4 from Heikki now for the future, but I wanted to let you know about that first. -- Michael
> That's not actually a problem as I am reusing an older v4 from Heikki > now for the future, but I wanted to let you know about that first. Thank you, I'll look into that. -- Alexander Kuzmenkov Postgres Professional: http://www.postgrespro.com The Russian Postgres Company
Hi all, So I did some more experiments on this patch. * I fixed the bug with duplicate tuples I mentioned in the previous letter. Indeed, the oldestActiveXid could be advanced past the transaction's xid before it set the clog status. This happened because the oldestActiveXid is calculated based on the CSN log contents, and we wrote to CSN log before writing to clog. The fix is to write to clog before CSN log (TransactionIdAsyncCommitTree) * We can remove the exclusive locking on CSNLogControlLock when setting the CSN for a transaction (CSNLogSetPageStatus). When we assign a CSN to a transaction and its children, the atomicity is guaranteed by using an intermediate state (COMMITSEQNO_COMMITTING), so it doesn't matter if this function is not atomic in itself. The shared lock should suffice here. * On throughputs of about 100k TPS, we allocate ~1k CSN log pages per second. This is done with exclusive locking on CSN control lock, and noticeably increases contention. To alleviate this, I allocate new pages in batches (ExtendCSNLOG). * When advancing oldestActiveXid, we scan CSN log to find an xid that is still in progress. To do that, we increment the xid and query its CSN using the high level function, acquiring and releasing the lock and looking up the log page for each xid. I wrote some code to acquire the lock only once and then scan the pages (CSNLogSetPageStatus). * On bigger buffers the linear page lookup code that the SLRU uses now becomes slow. I added a shared dynahash table to speed up this lookup. * I merged in recent changes from master (up to 7e1fb4). Unfortunately I didn't have enough time to fix the logical replication and snapshot import, so now it's completely broken. I ran some pgbench with these tweaks (tpcb-like, 72 cores, scale 500). The throughput is good on lower number of clients (on 50 clients it's 35% higher than on the master), but then it degrades steadily. After 250 clients it's already lower than master; see the attached graph. In perf reports the CSN-related things have almost vanished, and I see lots of time spent working with clog. This is probably the situation where by making some parts faster, the contention in other parts becomes worse and overall we have a performance loss. Hilariously, at some point I saw a big performance increase after adding some debug printfs. I wanted to try some things with the clog next, but for now I'm out of time. The new version of the patch is attached. Last time I apparently diff'ed it the other way around, now it should apply fine. -- Alexander Kuzmenkov Postgres Professional: http://www.postgrespro.com The Russian Postgres Company -- Sent via pgsql-hackers mailing list (pgsql-hackers@postgresql.org) To make changes to your subscription: http://www.postgresql.org/mailpref/pgsql-hackers
Attachment
{kind=link}
On Tue, Aug 1, 2017 at 7:41 PM, Alexander Kuzmenkov <a.kuzmenkov@postgrespro.ru> wrote: > Hi all, > > So I did some more experiments on this patch. > > * I fixed the bug with duplicate tuples I mentioned in the previous letter. > Indeed, the oldestActiveXid could be advanced past the transaction's xid > before it set the clog status. This happened because the oldestActiveXid is > calculated based on the CSN log contents, and we wrote to CSN log before > writing to clog. The fix is to write to clog before CSN log > (TransactionIdAsyncCommitTree) > > * We can remove the exclusive locking on CSNLogControlLock when setting the > CSN for a transaction (CSNLogSetPageStatus). When we assign a CSN to a > transaction and its children, the atomicity is guaranteed by using an > intermediate state (COMMITSEQNO_COMMITTING), so it doesn't matter if this > function is not atomic in itself. The shared lock should suffice here. > > * On throughputs of about 100k TPS, we allocate ~1k CSN log pages per > second. This is done with exclusive locking on CSN control lock, and > noticeably increases contention. To alleviate this, I allocate new pages in > batches (ExtendCSNLOG). > > * When advancing oldestActiveXid, we scan CSN log to find an xid that is > still in progress. To do that, we increment the xid and query its CSN using > the high level function, acquiring and releasing the lock and looking up the > log page for each xid. I wrote some code to acquire the lock only once and > then scan the pages (CSNLogSetPageStatus). > > * On bigger buffers the linear page lookup code that the SLRU uses now > becomes slow. I added a shared dynahash table to speed up this lookup. > > * I merged in recent changes from master (up to 7e1fb4). Unfortunately I > didn't have enough time to fix the logical replication and snapshot import, > so now it's completely broken. > > I ran some pgbench with these tweaks (tpcb-like, 72 cores, scale 500). The > throughput is good on lower number of clients (on 50 clients it's 35% higher > than on the master), but then it degrades steadily. After 250 clients it's > already lower than master; see the attached graph. In perf reports the > CSN-related things have almost vanished, and I see lots of time spent > working with clog. This is probably the situation where by making some parts > faster, the contention in other parts becomes worse and overall we have a > performance loss. Yeah, this happens sometimes and I have also observed this behavior. > Hilariously, at some point I saw a big performance > increase after adding some debug printfs. I wanted to try some things with > the clog next, but for now I'm out of time. > What problem exactly you are seeing in the clog, is it the contention around CLOGControlLock or generally accessing CLOG is slower. If former, then we already have a patch [1] to address it. [1] - https://commitfest.postgresql.org/14/358/ -- With Regards, Amit Kapila. EnterpriseDB: http://www.enterprisedb.com
> What problem exactly you are seeing in the clog, is it the contention > around CLOGControlLock or generally accessing CLOG is slower. If > former, then we already have a patch [1] to address it. It's the contention around CLogControlLock. Thank you for the pointer, next time I'll try it with the group clog update patch. -- Alexander Kuzmenkov Postgres Professional: http://www.postgrespro.com The Russian Postgres Company
Here is some news about the CSN patch. * I merged it with master (58bd60995f), which now has the clog group update. With this optimization, CSN is now faster than the master by about 15% on 100 to 400 clients (72 cores, pgbench tpcb-like, scale 500). It does not degrade faster than master as it did before. The numbers of clients greater than 400 were not measured. * Querying for CSN of subtransactions was not implemented in the previous version of the patch, so I added it. I tested the performance on the tpcb-like pgbench script with some savepoints added, and it was significantly worse than on the master. The main culprit seems to be the ProcArrayLock taken in GetSnapshotData, GetRecentGlobalXmin, ProcArrayEndTransaction. Although it is only taken in shared mode, just reading the current lock mode and writing the same value back takes about 10% CPU. Maybe we could do away with some of these locks, but there is some interplay with imported snapshots and replication slots which I don't understand well. I plan to investigate this next. I am attaching the latest version of the patch and the graphs of tps/clients for tpcb and tpcb with savepoints. -- Alexander Kuzmenkov Postgres Professional: http://www.postgrespro.com The Russian Postgres Company -- Sent via pgsql-hackers mailing list (pgsql-hackers@postgresql.org) To make changes to your subscription: http://www.postgresql.org/mailpref/pgsql-hackers
Attachment
{kind=link}
{kind=link}
On Mon, Sep 25, 2017 at 10:17 AM, Alexander Kuzmenkov <a.kuzmenkov@postgrespro.ru> wrote: > Here is some news about the CSN patch. > > * I merged it with master (58bd60995f), which now has the clog group update. > With this optimization, CSN is now faster than the master by about 15% on > 100 to 400 clients (72 cores, pgbench tpcb-like, scale 500). It does not > degrade faster than master as it did before. The numbers of clients greater > than 400 were not measured. Hmm, that's gratifying. > * Querying for CSN of subtransactions was not implemented in the previous > version of the patch, so I added it. I tested the performance on the > tpcb-like pgbench script with some savepoints added, and it was > significantly worse than on the master. The main culprit seems to be the > ProcArrayLock taken in GetSnapshotData, GetRecentGlobalXmin, > ProcArrayEndTransaction. Although it is only taken in shared mode, just > reading the current lock mode and writing the same value back takes about > 10% CPU. Maybe we could do away with some of these locks, but there is some > interplay with imported snapshots and replication slots which I don't > understand well. I plan to investigate this next. That's not so good, though. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company -- Sent via pgsql-hackers mailing list (pgsql-hackers@postgresql.org) To make changes to your subscription: http://www.postgresql.org/mailpref/pgsql-hackers
Hi hackers, Here is a new version of the patch with some improvements, rebased to 117469006b. Performance on pgbench tpcb with subtransactions is now slightly better than master. See the picture 'savepoints2'. This was achieved by removing unnecessary exclusive locking on CSNLogControlLock in SubTransSetParent. After that change, both versions are mostly waiting on XidGenLock in GetNewTransactionId. Performance on default pgbench tpcb is also improved. At scale 500, csn is at best 30% faster than master, see the picture 'tpcb500'. These improvements are due to slight optimizations of GetSnapshotData and refreshing RecentGlobalXmin less often. At scale 1500, csn is slightly faster at up to 200 clients, but then degrades steadily: see the picture 'tpcb1500'. Nevertheless, CSN-related code paths do not show up in perf profiles or LWLock wait statistics [1]. I think what we are seeing here is again that when some bottlenecks are removed, the fast degradation of LWLocks under contention leads to net drop in performance. With this in mind, I tried running the same benchmarks with patch from Yura Sokolov [2], which should improve LWLock performance on NUMA machines. Indeed, with this patch csn starts outperforming master on all numbers of clients measured, as you can see in the picture 'tpcb1500'. This LWLock change influences the csn a lot more than master, which also suggests that we are observing a superlinear degradation of LWLocks under increasing contention. After this I plan to improve the comments, since many of them have become out of date, and work on logical replication. [1] To collect LWLock wait statistics, I sample pg_stat_activity, and also use a bcc script by Andres Freund: https://www.postgresql.org/message-id/flat/20170622210845.d2hsbqv6rxu2tiye%40alap3.anarazel.de#20170622210845.d2hsbqv6rxu2tiye@alap3.anarazel.de [2] https://www.postgresql.org/message-id/flat/2968c0be065baab8865c4c95de3f435c@postgrespro.ru#2968c0be065baab8865c4c95de3f435c@postgrespro.ru -- Alexander Kuzmenkov Postgres Professional: http://www.postgrespro.com The Russian Postgres Company
Attachment
{kind=link}
{kind=link}
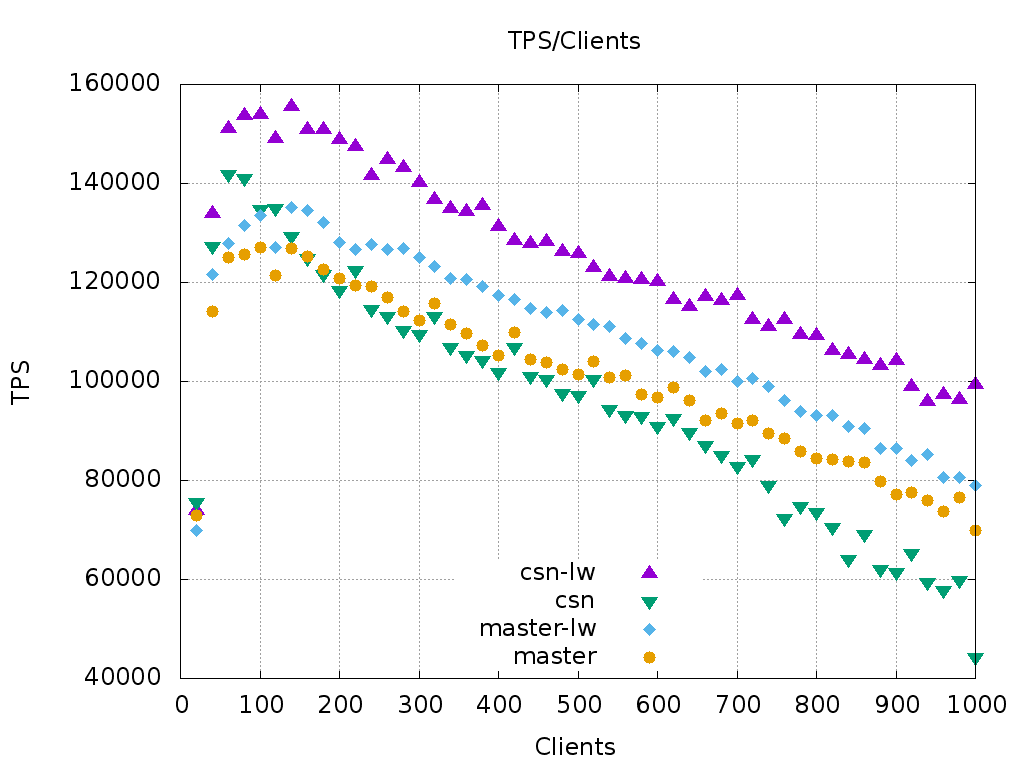{kind=link}
On Mon, Dec 4, 2017 at 6:07 PM, Alexander Kuzmenkov <a.kuzmenkov@postgrespro.ru> wrote:
Performance on pgbench tpcb with subtransactions is now slightly better than master. See the picture 'savepoints2'. This was achieved by removing unnecessary exclusive locking on CSNLogControlLock in SubTransSetParent. After that change, both versions are mostly waiting on XidGenLock in GetNewTransactionId.
Performance on default pgbench tpcb is also improved. At scale 500, csn is at best 30% faster than master, see the picture 'tpcb500'. These improvements are due to slight optimizations of GetSnapshotData and refreshing RecentGlobalXmin less often. At scale 1500, csn is slightly faster at up to 200 clients, but then degrades steadily: see the picture 'tpcb1500'. Nevertheless, CSN-related code paths do not show up in perf profiles or LWLock wait statistics [1]. I think what we are seeing here is again that when some bottlenecks are removed, the fast degradation of LWLocks under contention leads to net drop in performance. With this in mind, I tried running the same benchmarks with patch from Yura Sokolov [2], which should improve LWLock performance on NUMA machines. Indeed, with this patch csn starts outperforming master on all numbers of clients measured, as you can see in the picture 'tpcb1500'. This LWLock change influences the csn a lot more than master, which also suggests that we are observing a superlinear degradation of LWLocks under increasing contention.
These results look promising for me. Could you try benchmarking using more workloads including read-only and mixed mostly-read workloads?
You can try same benchmarks I used in my talk about CSN in pgconf.eu [1] slides 19-25 (and you're welcome to invent more benchmakrs yourself)
Also, I wonder how current version of CSN patch behaves in worst case when we have to scan the table with a lot of unique xid (and correspondingly have to do a lot of csnlog lookups)? See [1] slide 18. This worst case was significant part of my motivation to try "rewrite xid with csn" approach. Please, find simple extension I used to fill table with random xmins in the attachment.
------
Alexander Korotkov
Postgres Professional: http://www.
The Russian Postgres Company
Alexander Korotkov
Postgres Professional: http://www.
The Russian Postgres Company
Attachment
El 08/12/17 a las 14:59, Alexander Korotkov escribió:
Sure, here are some more benchmarks.
I've already had measured the "skip some updates" and "select-only" pgbench variants, and also a simple "select 1" query. These are for scale 1500 and for 20 to 1000 connections. The graphs are attached.
"select 1", which basically benchmarks snapshot taking, shows an impressive twofold increase in TPS over master, but this is to be expected. "select-only" stabilizes at 20% higher than master. Interesting to note is that these select-only scenarios almost do not degrade with growing client count.
For the "skip some updates" scenario, CSN is slightly slower than master, but this is improved by the LWLock patch I mentioned upthread.
I also replicated the setup from your slides 23 and 25. I used scale 500 and client counts 20-300, and probably the same 72-core Xeon.
Slide 23 shows 22% write and 78% read queries, that is "-b select-only@9 -b tpcb-like@1". The corresponding picture is called "random.png". The absolute numbers are somewhat lower for my run, but CSN is about 40% faster than master, like the CSN-rewrite variant.
Slide 25 is a custom script called "rrw" with extra 20 read queries. We can see that since your run the master has improved much, and the current CSN shows the same general behaviour as CSN-rewrite, although being slower in absolute numbers.
OK, let's summarize how the worst case in question works. It happens when the tuples have a wide range of xmins and no hint bits. All visibility checks have to go to clog then. Fortunately, on master we also set hint bits during these checks, and the subsequent scans can determine visibility using just the hint bits and the current snapshot. This makes the subsequent scans run much faster. With CSN, this is not enough, and the visibility checks always go to CSN log for all the transactions newer than global xmin. This can become very slow if there is a long-running transaction that holds back the global xmin.
I made a simple test to see these effects. The procedure is as follows. I start a transaction in psql; that will be our long-running transaction. Next, I run pgbench for a minute, and randomize the tuple xmins in "pgbench_accounts" using your extension. Then I run "select sum(abalance) from pgbench_accounts" twice, and record the durations.
Here is a table with the results (50M tuples, 1M transactions for master and 400k for CSN):
Branch scan 1, s scan 2, s
--------------------------------
CSN 80 80
master 13 3.5
So, we are indeed seeing the expected results. Significant slowdown with long-running transaction is an important problem for this patch. Even the first scan is much slower, because a CSN log page contains 16 times less transactions than a clog page, and we have the same number of buffers (max 128) for them. When the range of xids is wide, we spend most of the time loading and unloading the pages. I believe it can be improved by using more buffers for CSN log. I did some work in this direction, namely, made SLRUs use a dynahash table instead of linear search for page->buffer lookups. This is included in the v8 I posted earlier, but it should probably be done as a separate patch.
These results look promising for me. Could you try benchmarking using more workloads including read-only and mixed mostly-read workloads?You can try same benchmarks I used in my talk about CSN in pgconf.eu [1] slides 19-25 (and you're welcome to invent more benchmakrs yourself)
Sure, here are some more benchmarks.
I've already had measured the "skip some updates" and "select-only" pgbench variants, and also a simple "select 1" query. These are for scale 1500 and for 20 to 1000 connections. The graphs are attached.
"select 1", which basically benchmarks snapshot taking, shows an impressive twofold increase in TPS over master, but this is to be expected. "select-only" stabilizes at 20% higher than master. Interesting to note is that these select-only scenarios almost do not degrade with growing client count.
For the "skip some updates" scenario, CSN is slightly slower than master, but this is improved by the LWLock patch I mentioned upthread.
I also replicated the setup from your slides 23 and 25. I used scale 500 and client counts 20-300, and probably the same 72-core Xeon.
Slide 23 shows 22% write and 78% read queries, that is "-b select-only@9 -b tpcb-like@1". The corresponding picture is called "random.png". The absolute numbers are somewhat lower for my run, but CSN is about 40% faster than master, like the CSN-rewrite variant.
Slide 25 is a custom script called "rrw" with extra 20 read queries. We can see that since your run the master has improved much, and the current CSN shows the same general behaviour as CSN-rewrite, although being slower in absolute numbers.
Also, I wonder how current version of CSN patch behaves in worst case when we have to scan the table with a lot of unique xid (and correspondingly have to do a lot of csnlog lookups)? See [1] slide 18. This worst case was significant part of my motivation to try "rewrite xid with csn" approach. Please, find simple extension I used to fill table with random xmins in the attachment.
OK, let's summarize how the worst case in question works. It happens when the tuples have a wide range of xmins and no hint bits. All visibility checks have to go to clog then. Fortunately, on master we also set hint bits during these checks, and the subsequent scans can determine visibility using just the hint bits and the current snapshot. This makes the subsequent scans run much faster. With CSN, this is not enough, and the visibility checks always go to CSN log for all the transactions newer than global xmin. This can become very slow if there is a long-running transaction that holds back the global xmin.
I made a simple test to see these effects. The procedure is as follows. I start a transaction in psql; that will be our long-running transaction. Next, I run pgbench for a minute, and randomize the tuple xmins in "pgbench_accounts" using your extension. Then I run "select sum(abalance) from pgbench_accounts" twice, and record the durations.
Here is a table with the results (50M tuples, 1M transactions for master and 400k for CSN):
Branch scan 1, s scan 2, s
--------------------------------
CSN 80 80
master 13 3.5
So, we are indeed seeing the expected results. Significant slowdown with long-running transaction is an important problem for this patch. Even the first scan is much slower, because a CSN log page contains 16 times less transactions than a clog page, and we have the same number of buffers (max 128) for them. When the range of xids is wide, we spend most of the time loading and unloading the pages. I believe it can be improved by using more buffers for CSN log. I did some work in this direction, namely, made SLRUs use a dynahash table instead of linear search for page->buffer lookups. This is included in the v8 I posted earlier, but it should probably be done as a separate patch.
-- Alexander Kuzmenkov Postgres Professional: http://www.postgrespro.com The Russian Postgres Company
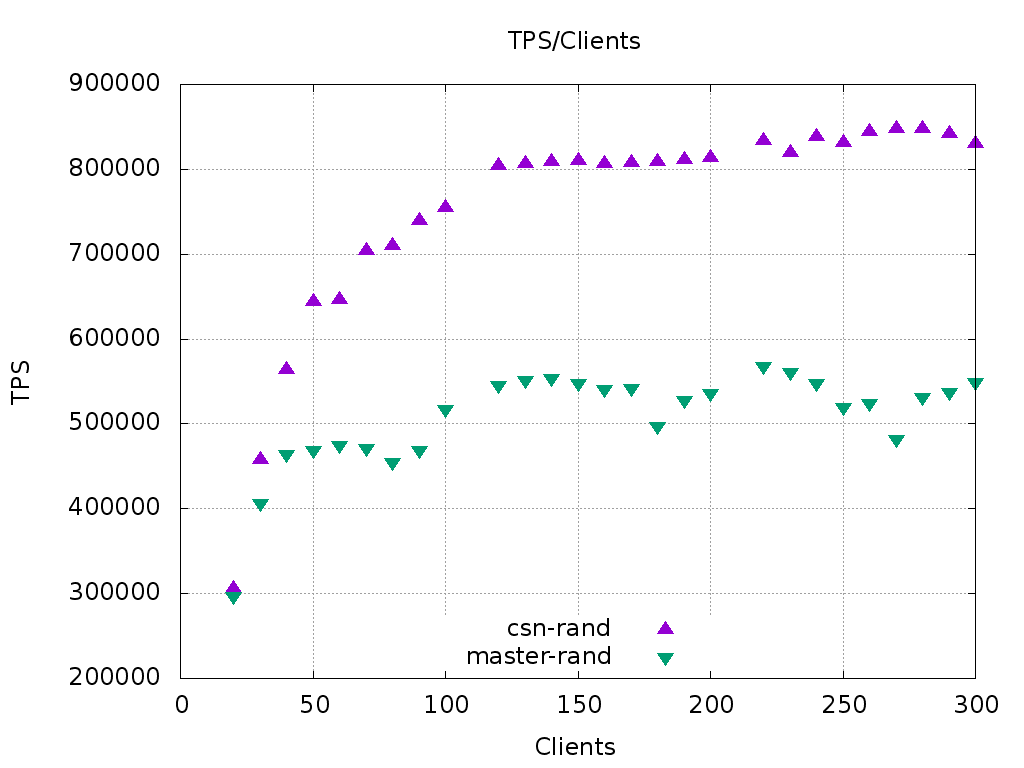{kind=link}
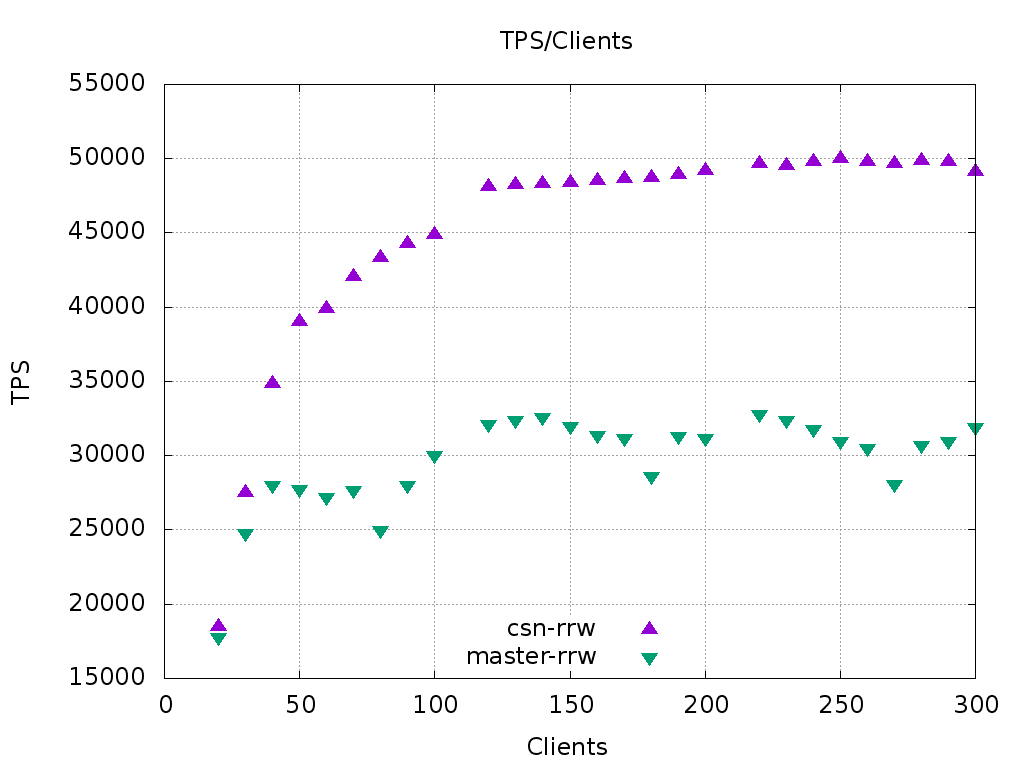{kind=link}
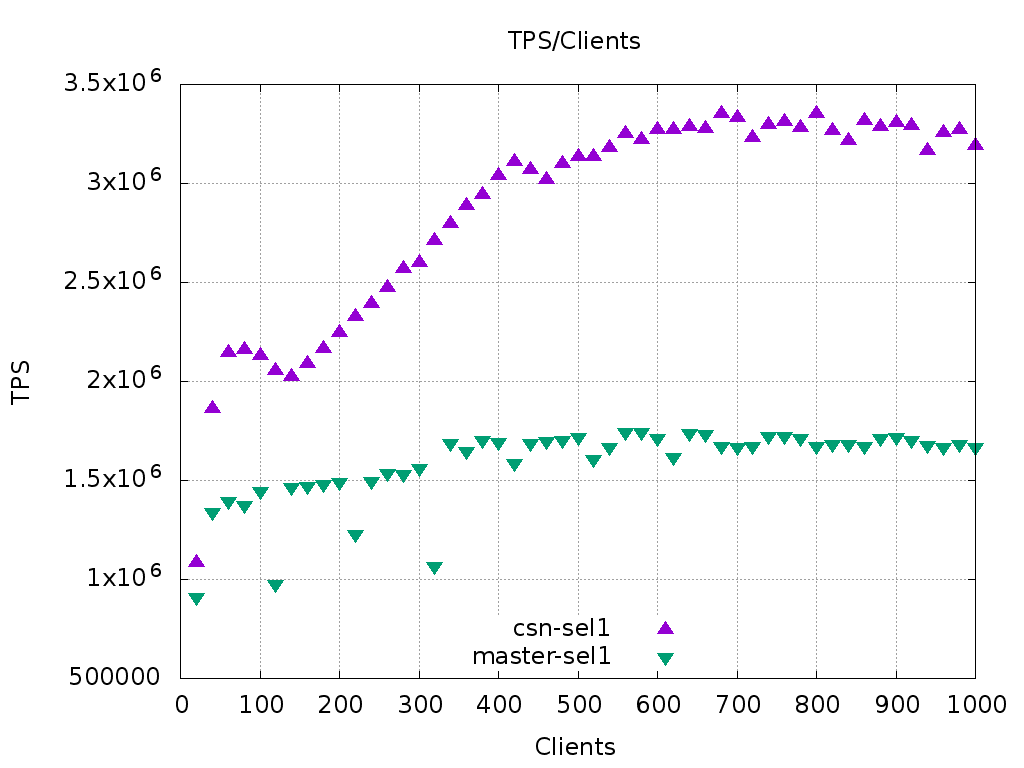{kind=link}
{kind=link}
{kind=link}