Thread: Spin Lock sleep resolution
While stracing a process that was contending for a spinlock, I noticed that the sleep time would often have a longish sequence of 1 and 2 msec sleep times, rather than the rapidly but randomly increasing sleep time intended. (At first it looked like it was sleeping on a different attempt each time, rather than re-sleeping, but some additional logging showed this was not the case, it was re-sleeping on the same lock attempt.)
The problem is that the state is maintained only to an integer number of milliseconds starting at 1, so it can take a number of attempts for the random increment to jump from 1 to 2, and then from 2 to 3.
If the state was instead maintained to an integer number of microseconds starting at 1000, this granularity of the jump would not be a problem.
And once the state is kept to microseconds, I see no point in not passing the microsecond precision to pg_usleep.
The attached patch changes the resolution of the state variable to microseconds, but keeps the starting value at 1msec, i.e. 1000 usec.
Arguably the MIN_DELAY_USEC value should be reduced from 1000 as well given current hardware, but I'll leave that as a separate issue.
There is the comment:
* The pg_usleep() delays are measured in milliseconds because 1 msec is a
* common resolution limit at the OS level for newer platforms. On older
* platforms the resolution limit is usually 10 msec, in which case the
* total delay before timeout will be a bit more.
I think the first sentence is out of date (CentOS 6.3 on "Intel(R) Xeon(R) CPU E5-2650 0 @ 2.00GHz" not exactly bleeding edge, seems to have a resolution of 100 usec), and also somewhat bogus (what benefit do we get by preemptively rounding to some level just because some common platforms will do so anyway?). I've just removed the whole comment, though maybe some version of the last sentence needs to be put back.
I have no evidence that the current granularity of the random escalation is actually causing performance problems, only that is causes confusion problems for people following along. But I think the change can be justified based purely on it being cleaner code and more future proof.
This could be made obsolete by changing to futexes, but I doubt that that is going to happen soon, and certainly not for all platforms.
I will add to commitfest Next
Cheers,
Jeff
Jeff Janes <jeff.janes@gmail.com> writes:
> The problem is that the state is maintained only to an integer number of
> milliseconds starting at 1, so it can take a number of attempts for the
> random increment to jump from 1 to 2, and then from 2 to 3.
Hm ... fair point, if you assume that the underlying OS has a sleep
resolution finer than 1ms. Otherwise it would not matter.
> The attached patch changes the resolution of the state variable to
> microseconds, but keeps the starting value at 1msec, i.e. 1000 usec.
No patch seen here ...
regards, tom lane
On Tue, Apr 2, 2013 at 1:24 AM, Tom Lane <tgl@sss.pgh.pa.us> wrote: > Jeff Janes <jeff.janes@gmail.com> writes: >> The problem is that the state is maintained only to an integer number of >> milliseconds starting at 1, so it can take a number of attempts for the >> random increment to jump from 1 to 2, and then from 2 to 3. > > Hm ... fair point, if you assume that the underlying OS has a sleep > resolution finer than 1ms. Otherwise it would not matter. I would guess it does matter for the cumulative error when re-sleeping several times. In any case, the resolution is limited on tick-based kernels, which are few nowadays. However, I've found evidence[0] that FreeBSD is still on that boat. [0] http://lists.freebsd.org/pipermail/freebsd-arch/2012-March/012423.html
On Monday, April 1, 2013, Tom Lane wrote:
Jeff Janes <jeff.janes@gmail.com> writes:
> The problem is that the state is maintained only to an integer number of
> milliseconds starting at 1, so it can take a number of attempts for the
> random increment to jump from 1 to 2, and then from 2 to 3.
Hm ... fair point, if you assume that the underlying OS has a sleep
resolution finer than 1ms. Otherwise it would not matter.
Let's say you get a long stretch of increments that are all a ratio of <1.5 fold, for simplicity let's say they are all 1.3 fold. When you do intermediate truncations of the state variable, it never progresses at all.
perl -le '$foo=1; foreach (1..10) {$foo*=1.3; print int $foo}'
perl -le '$foo=1; foreach (1..10) {$foo*=1.3; $foo=int $foo; print int $foo}'
Obviously the true stochastic case is not quite that stark.
No patch seen here ...
Sorry. I triple checked that the patch was there, but it seems like if you save a draft with an attachment, when you come back later to finish and send it, the attachment may not be there anymore. The Gmail Offline teams still has a ways to go. Hopefully it is actually there this time.
Cheers,
Jeff
Attachment
On Tue, 2 Apr 2013 09:01:36 -0700 Jeff Janes <jeff.janes@gmail.com> wrote: > Sorry. I triple checked that the patch was there, but it seems like if you > save a draft with an attachment, when you come back later to finish and > send it, the attachment may not be there anymore. The Gmail Offline teams > still has a ways to go. Hopefully it is actually there this time. I'll give the patch a try, I have a workload that is impacted by spinlocks fairly heavily sometimes and this might help or at least give me more information. Thanks! -dg -- David Gould daveg@sonic.net If simplicity worked, the world would be overrun with insects.
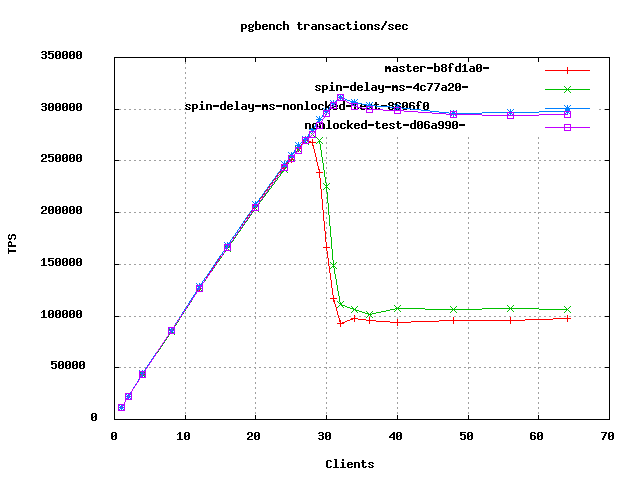
Hi David, On 02.04.2013 22:58, David Gould wrote: > On Tue, 2 Apr 2013 09:01:36 -0700 > Jeff Janes<jeff.janes@gmail.com> wrote: > >> Sorry. I triple checked that the patch was there, but it seems like if you >> save a draft with an attachment, when you come back later to finish and >> send it, the attachment may not be there anymore. The Gmail Offline teams >> still has a ways to go. Hopefully it is actually there this time. > > I'll give the patch a try, I have a workload that is impacted by spinlocks > fairly heavily sometimes and this might help or at least give me more > information. Thanks! Did you ever get around to test this? I repeated these pgbench tests I did earlier: http://www.postgresql.org/message-id/5190E17B.9060804@vmware.com I concluded in that thread that on this platform, the TAS_SPIN macro really needs a non-locked test before the locked one. That fixes the big fall in performance with more than 28 clients. So I repeated that test with four versions: master - no patch spin-delay-ms - Jeff's patch nonlocked-test - master with the non-locked test added to TAS_SPIN spin-delay-ms-nonlocked-test - both patches Jeff's patch seems to somewhat alleviate the huge fall in performance I'm otherwise seeing without the nonlocked-test patch. With the nonlocked-test patch, if you squint you can see a miniscule benefit. I wasn't expecting much of a gain from this, just wanted to verify that it's not making things worse. So looks good to me. - Heikki
Attachment
{kind=link}
On Tue, 18 Jun 2013 10:09:55 +0300 Heikki Linnakangas <hlinnakangas@vmware.com> wrote: > On 02.04.2013 22:58, David Gould wrote: > > I'll give the patch a try, I have a workload that is impacted by spinlocks > > fairly heavily sometimes and this might help or at least give me more > > information. Thanks! > > Did you ever get around to test this? > > I repeated these pgbench tests I did earlier: > > http://www.postgresql.org/message-id/5190E17B.9060804@vmware.com > > I concluded in that thread that on this platform, the TAS_SPIN macro > really needs a non-locked test before the locked one. That fixes the big > fall in performance with more than 28 clients. ... > I wasn't expecting much of a gain from this, just wanted to verify that > it's not making things worse. So looks good to me. Thanks for the followup, and I really like your graph, it looks exactly like what we were hitting. My client ended up configuring around it and adding more hosts so the urgency to run more tests sort of declined, although I think we still hit it from time to time. If you would like to point me at or send me the latest flavor of the patch it may be timely for me to test again. Especially if this is a more or less finished version, we are about to roll out a new build to all these hosts and I'd be happy to try to incorporate this patch and get some production experience with it on 80 core hosts. -dg -- David Gould 510 282 0869 daveg@sonic.net If simplicity worked, the world would be overrun with insects.
On 18.06.2013 10:52, David Gould wrote: > On Tue, 18 Jun 2013 10:09:55 +0300 > Heikki Linnakangas<hlinnakangas@vmware.com> wrote: > >> I repeated these pgbench tests I did earlier: >> >> http://www.postgresql.org/message-id/5190E17B.9060804@vmware.com >> >> I concluded in that thread that on this platform, the TAS_SPIN macro >> really needs a non-locked test before the locked one. That fixes the big >> fall in performance with more than 28 clients. > ... >> I wasn't expecting much of a gain from this, just wanted to verify that >> it's not making things worse. So looks good to me. > > Thanks for the followup, and I really like your graph, it looks exactly > like what we were hitting. My client ended up configuring around it > and adding more hosts so the urgency to run more tests sort of declined, > although I think we still hit it from time to time. Oh, interesting. What kind of hardware are you running on? To be honest, I'm not sure what my test hardware is, it's managed by another team across the world, but /proc/cpuinfo says: model name : Intel(R) Xeon(R) CPU E5-4640 0 @ 2.40GHz And it's running in a virtual machine on VMware; that might also be a factor. It would be good to test the TAS_SPIN nonlocked patch on a variety of systems. The comments in s_lock.h say that on Opteron, the non-locked test is a huge loss. In particular, would be good to re-test that on a modern AMD system. > If you would like to point me at or send me the latest flavor of the patch > it may be timely for me to test again. Especially if this is a more or less > finished version, we are about to roll out a new build to all these hosts > and I'd be happy to try to incorporate this patch and get some production > experience with it on 80 core hosts. Jeff's patch is here: http://www.postgresql.org/message-id/CAMkU=1xtP+3UWL6dg10rDRtMA28zy-9ujrOxNuST_r3zOdpNxg@mail.gmail.com. My non-locked TAS_SPIN patch is the one-liner here: http://www.postgresql.org/message-id/519A938A.1070903@vmware.com Thanks! - Heikki
On Tue, 18 Jun 2013 11:41:06 +0300 Heikki Linnakangas <hlinnakangas@vmware.com> wrote: > Oh, interesting. What kind of hardware are you running on? To be honest, > I'm not sure what my test hardware is, it's managed by another team > across the world, but /proc/cpuinfo says: > > model name : Intel(R) Xeon(R) CPU E5-4640 0 @ 2.40GHz It claims to have 80 of these: model name : Intel(R) Xeon(R) CPU E7-L8867 @2.13GHz Postgres is on ramfs on these with unlogged tables. > And it's running in a virtual machine on VMware; that might also be a > factor. I'm not a fan of virtualization. It makes performance even harder to reason about. > It would be good to test the TAS_SPIN nonlocked patch on a variety of > systems. The comments in s_lock.h say that on Opteron, the non-locked > test is a huge loss. In particular, would be good to re-test that on a > modern AMD system. I'll see what I can do. However I don't have acces to any large modern AMD systems. -dg -- David Gould 510 282 0869 daveg@sonic.net If simplicity worked, the world would be overrun with insects.
On Tue, Jun 18, 2013 at 12:09 AM, Heikki Linnakangas <hlinnakangas@vmware.com> wrote:
Jeff's patch seems to somewhat alleviate the huge fall in performance I'm otherwise seeing without the nonlocked-test patch. With the nonlocked-test patch, if you squint you can see a miniscule benefit.
I wasn't expecting much of a gain from this, just wanted to verify that it's not making things worse. So looks good to me.
Hi Heikki,
Thanks for trying out the patch.
I see in the commitfest app it is set to "Waiting on Author" (but I don't know who "maiku41" is).
Based on the comments so far, I don't know what I should be doing on it at the moment, and I thought perhaps your comment above meant it should be "ready for committer".
If we think the patch has a risk of introducing subtle errors, then it probably can't be justified based on the small performance gains you saw.
But if we think it has little risk, then I think it is justified simply based on cleaner code, and less confusion for people who are tracing a problematic process. If we want it to do a random escalation, it should probably look like a random escalation to the interested observer.
Thanks,
Jeff
Jeff Janes escribió: > I see in the commitfest app it is set to "Waiting on Author" (but I don't > know who "maiku41" is). Yeah, that guy is misterious. I'm guessing the Mike Blackwell person Josh mentioned in his "week 1" report. -- Álvaro Herrera http://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Training & Services
On 06/26/2013 02:49 PM, Jeff Janes wrote: > I see in the commitfest app it is set to "Waiting on Author" (but I don't > know who "maiku41" is). Mike Blackwell, who's helping track patches for the CommitFest. It's been our practice since the 9.3 cycle that patches which are still under contentious discussion which blocks commit are "waiting on author" rather than some other status. It was not clear to me (or to Mike) that the dicussion on this patch was concluded favorably. Is it? -- Josh Berkus PostgreSQL Experts Inc. http://pgexperts.com
On Wed, Jun 26, 2013 at 5:49 PM, Jeff Janes <jeff.janes@gmail.com> wrote: > On Tue, Jun 18, 2013 at 12:09 AM, Heikki Linnakangas > <hlinnakangas@vmware.com> wrote: >> Jeff's patch seems to somewhat alleviate the huge fall in performance I'm >> otherwise seeing without the nonlocked-test patch. With the nonlocked-test >> patch, if you squint you can see a miniscule benefit. >> >> I wasn't expecting much of a gain from this, just wanted to verify that >> it's not making things worse. So looks good to me. > > Hi Heikki, > > Thanks for trying out the patch. > > I see in the commitfest app it is set to "Waiting on Author" (but I don't > know who "maiku41" is). > > Based on the comments so far, I don't know what I should be doing on it at > the moment, and I thought perhaps your comment above meant it should be > "ready for committer". > > If we think the patch has a risk of introducing subtle errors, then it > probably can't be justified based on the small performance gains you saw. > > But if we think it has little risk, then I think it is justified simply > based on cleaner code, and less confusion for people who are tracing a > problematic process. If we want it to do a random escalation, it should > probably look like a random escalation to the interested observer. I think it has little risk. If it turns out to be worse for performance, we can always revert it, but I expect it'll be better or a wash, and the results so far seem to bear that out. Another interesting question is whether we should fool with the actual values for minimum and maximum delays, but that's a separate and much harder question, so I think we should just do this for now and call it good. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On 27.06.2013 17:30, Robert Haas wrote: > On Wed, Jun 26, 2013 at 5:49 PM, Jeff Janes<jeff.janes@gmail.com> wrote: >> If we think the patch has a risk of introducing subtle errors, then it >> probably can't be justified based on the small performance gains you saw. >> >> But if we think it has little risk, then I think it is justified simply >> based on cleaner code, and less confusion for people who are tracing a >> problematic process. If we want it to do a random escalation, it should >> probably look like a random escalation to the interested observer. > > I think it has little risk. If it turns out to be worse for > performance, we can always revert it, but I expect it'll be better or > a wash, and the results so far seem to bear that out. Another > interesting question is whether we should fool with the actual values > for minimum and maximum delays, but that's a separate and much harder > question, so I think we should just do this for now and call it good. My thoughts exactly. I wanted to see if David Gould would like to do some testing with it, but there's realy no need to hold off committing for that, I'm not expecting any surprises there. Committed. Jeff, in the patch you changed the datatype of cur_delay variable from int to long. AFAICS that makes no difference, so I kept it as int. Let me know if there was a reason for that change. - Heikki
On Fri, Jun 28, 2013 at 2:46 AM, Heikki Linnakangas <hlinnakangas@vmware.com> wrote:
On 27.06.2013 17:30, Robert Haas wrote:On Wed, Jun 26, 2013 at 5:49 PM, Jeff Janes<jeff.janes@gmail.com> wrote:If we think the patch has a risk of introducing subtle errors, then it
probably can't be justified based on the small performance gains you saw.
But if we think it has little risk, then I think it is justified simply
based on cleaner code, and less confusion for people who are tracing a
problematic process. If we want it to do a random escalation, it should
probably look like a random escalation to the interested observer.
I think it has little risk. If it turns out to be worse for
performance, we can always revert it, but I expect it'll be better or
a wash, and the results so far seem to bear that out. Another
interesting question is whether we should fool with the actual values
for minimum and maximum delays, but that's a separate and much harder
question, so I think we should just do this for now and call it good.
My thoughts exactly. I wanted to see if David Gould would like to do some testing with it, but there's realy no need to hold off committing for that, I'm not expecting any surprises there. Committed.
Thanks.
Jeff, in the patch you changed the datatype of cur_delay variable from int to long. AFAICS that makes no difference, so I kept it as int. Let me know if there was a reason for that change.
I think my thought process at the time was that since the old code multiplied by "1000L", not "1000" in the expression argument to pg_usleep, I wanted to keep the spirit of the L in place. It seemed safer than trying to prove to myself that it was not necessary.
If int suffices, should the L come out of the defines for MIN_DELAY_USEC and MAX_DELAY_USEC ?
Cheers,
Jeff