Thread: Initial 9.2 pgbench write results
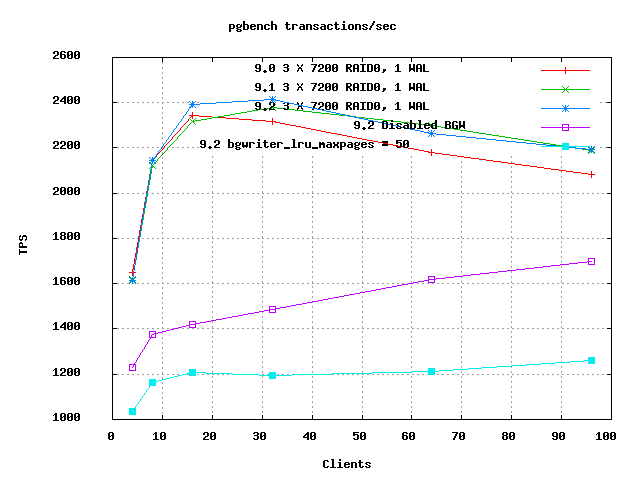
Last year at this time, I was investigating things like ext3 vs xfs, how well Linux's dirty_bytes parameter worked, and how effective a couple of patches were on throughput & latency. The only patch that ended up applied for 9.1 was for fsync compaction. That was measurably better in terms of eliminating backend syncs altogether, and it also pulled up average TPS a bit on the database scales I picked out to test it on. That rambling group of test sets is available at http://highperfpostgres.com/pgbench-results/index.htm For the first round of 9.2 testing under a write-heavy load, I started with 9.0 via the yum.postgresql.org packages for SL6, upgraded to 9.1 from there, and then used a source code build of 9.2 HEAD as of Feb 11 (58a9596ed4a509467e1781b433ff9c65a4e5b5ce). Attached is an Excel spreadsheet showing the major figures, along with a CSV formatted copy of that data too. Results that are ready so far are available at http://highperfpostgres.com/results-write-9.2-cf4/index.htm Most of that is good; here's the best and worst parts of the news in compact form: scale=500, db is 46% of RAM Version Avg TPS 9.0 1961 9.1 2255 9.2 2525 scale=1000, db is 94% of RAM; clients=4 Version TPS 9.0 535 9.1 491 (-8.4% relative to 9.0) 9.2 338 (-31.2% relative to 9.1) There's usually a tipping point with pgbench results, where the characteristics change quite a bit as the database exceeds total RAM size. You can see the background writer statistics change quite a bit around there too. Last year the sharpest part of that transition happened when exceeding total RAM; now it's happening just below that. This test set takes about 26 hours to run in the stripped down form I'm comparing, which doesn't even bother trying larger than RAM scales like 2000 or 3000 that might also be helpful. Most of the runtime time is spent on the larger scale database tests, which unfortunately are the interesting ones this year. I'm torn at this point between chasing down where this regression came from, moving forward with testing the new patches proposed for this CF, and seeing if this regression also holds with SSD storage. Obvious big commit candidates to bisect this over are the bgwriter/checkpointer split (Nov 1) and the group commit changes (Jan 30). Now I get to pay for not having set this up to run automatically each week since earlier in the 9.2 development cycle. If someone else wants to try and replicate the bad part of this, best guess for how is using the same minimal postgresql.conf changes I have here, and picking your database scale so that the test database just barely fits into RAM. pgbench gives rough 16MB of data per unit of scale, and scale=1000 is 15GB; percentages above are relative to the 16GB of RAM in my server. Client count should be small, number of physical cores is probably a good starter point (that's 4 in my system, I didn't test below that). At higher client counts, the general scalability improvements in 9.2 negate some of this downside. = Server config = The main change to the 8 hyperthreaded core test server (Intel i7-870) for this year is bumping it from 8GB to 16GB of RAM, which effectively doubles the scale I can reach before things slow dramatically. It's also been updated to run Scientific Linux 6.0, giving a slightly later kernel. That kernel does have different defaults for dirty_background_ratio and dirty_ratio, they're 10% and 20% now (compared to 5%/10% in last year's tests). Drive set for tests I'm publishing so far is basically the same: 4-port Areca card with 256MB battery-backed cache, 3 disk RAID0 for the database, single disk for the WAL, all cheap 7200 RPM drives. The OS is a separate drive, not connected to the caching controller. That's also where the pgbench latency data is writing to. Idea is that this will be similar to having around 10 drives in a production server, where you'll also be using RAID1 for redundancy. I have some numbers brewing for this system running with an Intel 320 series SSD, too, but they're not ready yet. = Test setup = pgbench-tools has been upgraded to break down its graphs per test set now, and there's even a configuration option to use client-side Javascript to put that into a tab-like interface available. Thanks to Ben Bleything for that one. Minimal changes were made to the postgresql.conf. shared_buffers=2GB, checkpoint_segments=64, and I left wal_buffers at its default so that 9.1 got credit for that going up. See http://highperfpostgres.com/results-write-9.2-cf4/541/pg_settings.txt for a full list of changes, drive mount options, and important kernel settings. Much of that data wasn't collected in last year's pgbench-tools runs. = Results commentary = For the most part the 9.2 results are quite good. The increase at high client counts is solid, as expected from all the lock refactoring this release has gotten. The smaller than RAM results that particularly benefited from the 9.1 changes, particularly the scale=500 ones, leaped as much in 9.2 as they did in 9.1. scale=500 and clients=96 is up 58% from 9.0 to 9.2 so far. The problems are all around the higher scales. scale=4000 (58GB) was detuned an average of 1.7% in 9.1, which seemed a fair trade for how much the fsync compaction helped with worse case behavior. It drops another 7.2% on average in 9.2 so far though. The really bad one is scale=1000 (15GB, so barely fitting in RAM now; very different from scale=1000 last year). With this new kernel/more RAM/etc., I'm seeing an average of a 7% TPS drop for the 9.1 changes. The drop from 9.1 to 9.2 is another 26%. -- Greg Smith 2ndQuadrant US greg@2ndQuadrant.com Baltimore, MD PostgreSQL Training, Services, and 24x7 Support www.2ndQuadrant.com
Attachment
On 02/14/2012 01:45 PM, Greg Smith wrote: > scale=1000, db is 94% of RAM; clients=4 > Version TPS > 9.0 535 > 9.1 491 (-8.4% relative to 9.0) > 9.2 338 (-31.2% relative to 9.1) A second pass through this data noted that the maximum number of buffers cleaned by the background writer is <=2785 in 9.0/9.1, while it goes as high as 17345 times in 9.2. The background writer is so busy now it hits the max_clean limit around 147 times in the slower[1] of the 9.2 runs. That's an average of once every 4 seconds, quite frequent. Whereas max_clean rarely happens in the comparable 9.0/9.1 results. This is starting to point my finger more toward this being an unintended consequence of the background writer/checkpointer split. Thinking out loud, about solutions before the problem is even nailed down, I wonder if we should consider lowering bgwriter_lru_maxpages now in the default config? In older versions, the page cleaning work had at most a 50% duty cycle; it was only running when checkpoints were not. If we wanted to keep the ceiling on background writer cleaning at the same level in the default configuration, that would require dropping bgwriter_lru_maxpages from 100 to 50. That would be roughly be the same amount of maximum churn. It's obviously more complicated than that, but I think there's a defensible position along those lines to consider. As a historical aside, I wonder how much this behavior might have been to blame for my failing to get spread checkpoints to show a positive outcome during 9.1 development. The way that was written also kept the cleaner running during checkpoints. I didn't measure those two changes individually as much as I did the combination. [1] I normally do 3 runs of every scale/client combination, and find that more useful than a single run lasting 3X as long. The first out of each of the 3 runs I do at any scale is usually a bit faster than the later two, presumably due to table and/or disk fragmentation. I've tried to make this less of a factor in pgbench-tools by iterating through all requested client counts first, before beginning a second run of those scale/client combination. So if the two client counts were 4 and 8, it would be 4/8/4/8/4/8, which works much better than 4/4/4/8/8/8 in terms of fragmentation impacting the average result. Whether it would be better or worse to eliminate this difference by rebuilding the whole database multiple times for each scale is complicated. I happen to like seeing the results with a bit more fragmentation mixed in, see how they compare with the fresh database. Since more rebuilds would also make these tests take much longer than they already do, that's the tie-breaker that's led to the current testing schedule being the preferred one. -- Greg Smith 2ndQuadrant US greg@2ndQuadrant.com Baltimore, MD PostgreSQL Training, Services, and 24x7 Support www.2ndQuadrant.com
On Tue, Feb 14, 2012 at 3:25 PM, Greg Smith <greg@2ndquadrant.com> wrote: > On 02/14/2012 01:45 PM, Greg Smith wrote: >> >> scale=1000, db is 94% of RAM; clients=4 >> Version TPS >> 9.0 535 >> 9.1 491 (-8.4% relative to 9.0) >> 9.2 338 (-31.2% relative to 9.1) > > A second pass through this data noted that the maximum number of buffers > cleaned by the background writer is <=2785 in 9.0/9.1, while it goes as high > as 17345 times in 9.2. The background writer is so busy now it hits the > max_clean limit around 147 times in the slower[1] of the 9.2 runs. That's > an average of once every 4 seconds, quite frequent. Whereas max_clean > rarely happens in the comparable 9.0/9.1 results. This is starting to point > my finger more toward this being an unintended consequence of the background > writer/checkpointer split. I guess the question that occurs to me is: why is it busier? It may be that the changes we've made to reduce lock contention are allowing foreground processes to get work done faster. When they get work done faster, they dirty more buffers, and therefore the background writer gets busier. Also, if the background writer is more reliably cleaning pages even during checkpoints, that could have the same effect. Backends write fewer of their own pages, therefore they get more real work done, which of course means dirtying more pages. But I'm just speculating here. > Thinking out loud, about solutions before the problem is even nailed down, I > wonder if we should consider lowering bgwriter_lru_maxpages now in the > default config? In older versions, the page cleaning work had at most a 50% > duty cycle; it was only running when checkpoints were not. Is this really true? I see CheckpointWriteDelay calling BgBufferSync in 9.1. Background writing would stop during the sync phase and perhaps slow down a bit during checkpoint writing, but I don't think it was stopped completely. I'm curious what vmstat output looks like during your test. I've found that's a good way to know whether the system is being limited by I/O, CPU, or locks. It'd also be interesting to know what the % utilization figures for the disks looked like. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On Sat, Feb 18, 2012 at 7:35 PM, Robert Haas <robertmhaas@gmail.com> wrote: > On Tue, Feb 14, 2012 at 3:25 PM, Greg Smith <greg@2ndquadrant.com> wrote: >> On 02/14/2012 01:45 PM, Greg Smith wrote: >>> >>> scale=1000, db is 94% of RAM; clients=4 >>> Version TPS >>> 9.0 535 >>> 9.1 491 (-8.4% relative to 9.0) >>> 9.2 338 (-31.2% relative to 9.1) >> >> A second pass through this data noted that the maximum number of buffers >> cleaned by the background writer is <=2785 in 9.0/9.1, while it goes as high >> as 17345 times in 9.2. The background writer is so busy now it hits the >> max_clean limit around 147 times in the slower[1] of the 9.2 runs. That's >> an average of once every 4 seconds, quite frequent. Whereas max_clean >> rarely happens in the comparable 9.0/9.1 results. This is starting to point >> my finger more toward this being an unintended consequence of the background >> writer/checkpointer split. > > I guess the question that occurs to me is: why is it busier? > > It may be that the changes we've made to reduce lock contention are > allowing foreground processes to get work done faster. When they get > work done faster, they dirty more buffers, and therefore the > background writer gets busier. Also, if the background writer is more > reliably cleaning pages even during checkpoints, that could have the > same effect. Backends write fewer of their own pages, therefore they > get more real work done, which of course means dirtying more pages. The checkpointer/bgwriter split allows the bgwriter to do more work, which is the desired outcome, not an unintended consequence. The general increase in performance means there is more work to do. So both things mean there is more bgwriter activity. -- Simon Riggs http://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Training & Services
On Sat, Feb 18, 2012 at 3:00 PM, Simon Riggs <simon@2ndquadrant.com> wrote: > On Sat, Feb 18, 2012 at 7:35 PM, Robert Haas <robertmhaas@gmail.com> wrote: >> On Tue, Feb 14, 2012 at 3:25 PM, Greg Smith <greg@2ndquadrant.com> wrote: >>> On 02/14/2012 01:45 PM, Greg Smith wrote: >>>> >>>> scale=1000, db is 94% of RAM; clients=4 >>>> Version TPS >>>> 9.0 535 >>>> 9.1 491 (-8.4% relative to 9.0) >>>> 9.2 338 (-31.2% relative to 9.1) >>> >>> A second pass through this data noted that the maximum number of buffers >>> cleaned by the background writer is <=2785 in 9.0/9.1, while it goes as high >>> as 17345 times in 9.2. The background writer is so busy now it hits the >>> max_clean limit around 147 times in the slower[1] of the 9.2 runs. That's >>> an average of once every 4 seconds, quite frequent. Whereas max_clean >>> rarely happens in the comparable 9.0/9.1 results. This is starting to point >>> my finger more toward this being an unintended consequence of the background >>> writer/checkpointer split. >> >> I guess the question that occurs to me is: why is it busier? >> >> It may be that the changes we've made to reduce lock contention are >> allowing foreground processes to get work done faster. When they get >> work done faster, they dirty more buffers, and therefore the >> background writer gets busier. Also, if the background writer is more >> reliably cleaning pages even during checkpoints, that could have the >> same effect. Backends write fewer of their own pages, therefore they >> get more real work done, which of course means dirtying more pages. > > The checkpointer/bgwriter split allows the bgwriter to do more work, > which is the desired outcome, not an unintended consequence. > > The general increase in performance means there is more work to do. So > both things mean there is more bgwriter activity. I think you're saying pretty much the same thing I was saying, so I agree. Here's what's bugging me. Greg seemed to be assuming that the business of the background writer might be the cause of the performance drop-off he measured on certain test cases. But you and I both seem to feel that the business of the background writer is intentional and desirable. Supposing we're right, where's the drop-off coming from? *scratches head* -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On Sun, Feb 19, 2012 at 4:17 AM, Robert Haas <robertmhaas@gmail.com> wrote: > Here's what's bugging me. Greg seemed to be assuming that the > business of the background writer might be the cause of the > performance drop-off he measured on certain test cases. But you and I > both seem to feel that the business of the background writer is > intentional and desirable. Supposing we're right, where's the > drop-off coming from? *scratches head* Any source of logical I/O becomes physical I/O when we run short of memory. So if we're using more memory for any reason that will cause more swapping. Or if we are doing things like consulting the vmap that would also cause a problem. I notice the issue is not as bad for 9.2 in the scale 4000 case, so it seems more likely that we're just hitting the tipping point earlier on 9.2 and that scale 1000 is right in the middle of the tipping point. What it does show quite clearly is that the extreme high end response time variability is still there. It also shows that insufficient performance testing has been done on this release so far. We may have "solved" some scalability problems but we've completely ignored real world performance issues and as Greg says, we now get to pray the price for not having done that earlier. I've argued previously that we should have a performance tuning phase at the end of the release cycle, now it looks that has become a necessity. Which will turn out to be a good thing in the end, I'm sure, even if its a little worrying right now. -- Simon Riggs http://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Training & Services
On Tue, Feb 14, 2012 at 6:45 PM, Greg Smith <greg@2ndquadrant.com> wrote: > Minimal changes were made to the postgresql.conf. shared_buffers=2GB, > checkpoint_segments=64, and I left wal_buffers at its default so that 9.1 > got credit for that going up. See > http://highperfpostgres.com/results-write-9.2-cf4/541/pg_settings.txt for a > full list of changes, drive mount options, and important kernel settings. > Much of that data wasn't collected in last year's pgbench-tools runs. Please retest with wal_buffers 128MB, checkpoint_segments 1024 Best to remove any tunable resource bottlenecks before we attempt further analysis. -- Simon Riggs http://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Training & Services
On 02/18/2012 02:35 PM, Robert Haas wrote: > I see CheckpointWriteDelay calling BgBufferSync > in 9.1. Background writing would stop during the sync phase and > perhaps slow down a bit during checkpoint writing, but I don't think > it was stopped completely. The sync phase can be pretty long here--that's where the worst-case latency figures lasting many seconds are coming from. When checkpoints are happening every 60 seconds as in some of these cases, that can represent a decent percentage of time. Similarly, when the OS cache fills, the write phase might block for a larger period of time than normally expected. But, yes, you're right that my "BGW is active twice as much in 9.2" comments are overstating the reality here. I'm collecting one last bit of data before posting another full set of results, but I'm getting more comfortable the issue here is simply changes in the BGW behavior. The performance regression tracks the background writer maximum intensity. I can match the original 9.1 performance just by dropping bgwriter_lru_maxpages, in cases where TPS drops significantly between 9.2 and 9.1. At the same time, some cases that improve between 9.1 and 9.2 perform worse if I do that. If whether 9.2 gains or loses compared to 9.1 is adjustable with a tunable parameter, with some winning and other losing at the defaults, that path forward is reasonable to deal with. The fact that pgbench is an unusual write workload is well understood, and I can write something documenting this possibility before 9.2 is officially released. I'm a lot less stressed that there's really a problem here now. -- Greg Smith 2ndQuadrant US greg@2ndQuadrant.com Baltimore, MD PostgreSQL Training, Services, and 24x7 Support www.2ndQuadrant.com
On 02/19/2012 05:37 AM, Simon Riggs wrote: > Please retest with wal_buffers 128MB, checkpoint_segments 1024 The test parameters I'm using aim to run through several checkpoint cycles in 10 minutes of time. Bumping up against the ugly edges of resource bottlenecks is part of the test. Increasing checkpoint_segments like that would lead to time driven checkpoints, either 1 or 2 of them during 10 minutes. I'd have to increase the total testing time by at least 5X to get an equal workout of the system. That would be an interesting data point to collect if I had a few weeks to focus just on that test. I think that's more than pgbench testing deserves though. -- Greg Smith 2ndQuadrant US greg@2ndQuadrant.com Baltimore, MD PostgreSQL Training, Services, and 24x7 Support www.2ndQuadrant.com
On Sun, Feb 19, 2012 at 11:12 PM, Greg Smith <greg@2ndquadrant.com> wrote: > I'm collecting one last bit of data before posting another full set of > results, but I'm getting more comfortable the issue here is simply changes > in the BGW behavior. The performance regression tracks the background > writer maximum intensity. That's really quite fascinating... but it seems immensely counterintuitive. Any idea why? BufFreelist contention between the background writer and regular backends leading to buffer allocation stalls, maybe? -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
I've updated http://highperfpostgres.com/results-write-9.2-cf4/index.htm with more data including two alternate background writer configurations. Since the sensitive part of the original results was scales of 500 and 1000, I've also gone back and added scale=750 runs to all results. Quick summary is that I'm not worried about 9.2 performance now, I'm increasingly confident that the earlier problems I reported on are just bad interactions between the reinvigorated background writer and workloads that are tough to write to disk. I'm satisfied I understand these test results well enough to start evaluating the pending 9.2 changes in the CF queue I wanted to benchmark. Attached are now useful client and scale graphs. All of 9.0, 9.1, and 9.2 have been run now with exactly the same scales and clients loads, so the graphs of all three versions can be compared. The two 9.2 variations with alternate parameters were only run at some scales, which means you can't compare them usefully on the clients graph; only on the scaling one. They are very obviously in a whole different range of that graph, just ignore the two that are way below the rest. Here's a repeat of the interesting parts of the data set with new points. Here "9.2N" is without no background writer, while "9.2H" has a background writer set to half strength: bgwriter_lru_maxpages = 50 I picked one middle client level out of the result=750 results just to focus better, relative results are not sensitive to that: scale=500, db is 46% of RAM Version Avg TPS 9.0 1961 9.1 2255 9.2 2525 9.2N 2267 9.2H 2300 scale=750, db is 69% of RAM; clients=16 Version Avg TPS 9.0 1298 9.1 1387 9.2 1477 9.2N 1489 9.2H 943 scale=1000, db is 94% of RAM; clients=4 Version TPS 9.0 535 9.1 491 (-8.4% relative to 9.0) 9.2 338 (-31.2% relative to 9.1) 9.2N 516 9.2H 400 The fact that almost all the performance regression against 9.2 goes away if the background writer is disabled is an interesting point. That results actually get worse at scale=500 without the background writer is another. That pair of observations makes me feel better that there's a tuning trade-off here being implicitly made by having a more active background writer in 9.2; it helps on some cases, hurts others. That I can deal with. Everything lines up perfectly at scale=500: if I reorder on TPS: scale=500, db is 46% of RAM Version Avg TPS 9.2 2525 9.2H 2300 9.2N 2267 9.1 2255 9.0 1961 That makes you want to say "the more background writer the better", right? The new scale=750 numbers are weird though, and they keep this from being so clear. I ran the parts that were most weird twice just because they seemed so odd, and it was repeatable. Just like scale=500, with scale=750 the 9.2/no background writer has the best performance of any run. But the half-intensity one has the worst! It would be nice if it fell between the 9.2 and 9.2N results, instead it's at the other edge. The only lesson I can think to draw here is that once we're in the area where performance is dominated by the trivia around exactly how writes are scheduled, the optimal ordering of writes is just too complicated to model that easily. The rest of this is all speculation on how to fit some ideas to this data. Going back to 8.3 development, one of the design trade-offs I was very concerned about was not wasting resources by having the BGW run too often. Even then it was clear that for these simple pgbench tests, there were situations where letting backends do their own writes was better than speculative writes from the background writer. The BGW constantly risks writing a page that will be re-dirtied before it goes to disk. That can't be too common though in the current design, since it avoids things with high usage counts. (The original BGW wrote things that were used recently, and that was a measurable problem by 8.3) I think an even bigger factor now is that the BGW writes can disturb write ordering/combining done at the kernel and storage levels. It's painfully obvious now how much PostgreSQL relies on that to get good performance. All sorts of things break badly if we aren't getting random writes scheduled to optimize seek times, in as many contexts as possible. It doesn't seem unreasonable that background writer writes can introduce some delay into the checkpoint writes, just by adding more random components to what is already a difficult to handle write/sync series. That's what I think what these results are showing is that background writer writes can deoptimize other forms of write. A second fact that's visible from the TPS graphs over the test run, and obvious if you think about it, is that BGW writes force data to physical disk earlier than they otherwise might go there. That's a subtle pattern in the graphs. I expect that though, given one element to "do I write this?" in Linux is how old the write is. Wondering about this really emphasises that I need to either add graphing of vmstat/iostat data to these graphs or switch to a benchmark that does that already. I think I've got just enough people using pgbench-tools to justify the feature even if I plan to use the program less. I also have a good answer to "why does this only happen at these scales?" now. At scales below here, the database is so small relative to RAM that it just all fits all the time. That includes the indexes being very small, so not many writes generated by their dirty blocks. At higher scales, the write volume becomes seek bound, and the result is so low that checkpoints become timeout based. So there are significantly less of them. At the largest scales and client counts here, there isn't a single checkpoint actually finished at some of these 10 minute long runs. One doesn't even start until 5 minutes have gone by, and the checkpoint writes are so slow they take longer than 5 minutes to trickle out and sync, with all the competing I/O from backends mixed in. Note that the "clients-sets" graph still shows a strong jump from 9.0 to 9.1 at high client counts; I'm pretty sure that's the fsync compaction at work. -- Greg Smith 2ndQuadrant US greg@2ndQuadrant.com Baltimore, MD PostgreSQL Training, Services, and 24x7 Support www.2ndQuadrant.com
Attachment
{kind=link}
{kind=link}
On Thu, Feb 23, 2012 at 11:17 AM, Greg Smith <greg@2ndquadrant.com> wrote:
> A second fact that's visible from the TPS graphs over the test run, and
> obvious if you think about it, is that BGW writes force data to physical
> disk earlier than they otherwise might go there. That's a subtle pattern in
> the graphs. I expect that though, given one element to "do I write this?"
> in Linux is how old the write is. Wondering about this really emphasises
> that I need to either add graphing of vmstat/iostat data to these graphs or
> switch to a benchmark that does that already. I think I've got just enough
> people using pgbench-tools to justify the feature even if I plan to use the
> program less.
For me, that is the key point.
For the test being performed there is no value in things being written
earlier, since doing so merely overexercises the I/O.
We should note that there is no feedback process in the bgwriter to do
writes only when the level of dirty writes by backends is high enough
to warrant the activity. Note that Linux has a demand paging
algorithm, it doesn't just clean all of the time. That's the reason
you still see some swapping, because that activity is what wakes the
pager. We don't count the number of dirty writes by backends, we just
keep cleaning even when nobody wants it.
Earlier, I pointed out that bgwriter is being woken any time a user
marks a buffer dirty. That is overkill. The bgwriter should stay
asleep until a threshold number (TBD) of dirty writes is reached, then
it should wake up and do some cleaning. Having a continuously active
bgwriter is pointless, for some workloads whereas for others, it
helps. So having a sleeping bgwriter isn't just a power management
issue its a performance issue in some cases.
/*
* Even in cases where there's been little or no buffer allocation
* activity, we want to make a small amount of progress through the buffer
* cache so that as many reusable buffers as possible are clean after an
* idle period.
*
* (scan_whole_pool_milliseconds / BgWriterDelay) computes how many times
* the BGW will be called during the scan_whole_pool time; slice the
* buffer pool into that many sections.
*/
Since scan_whole_pool_milliseconds is set to 2 minutes we scan the
whole bufferpool every 2 minutes, no matter how big the bufferpool,
even when nothing else is happening. Not cool.
I think it would be sensible to have bgwriter stop when 10% of
shared_buffers are clean, rather than keep going even when no dirty
writes are happening.
So my suggestion is that we put in an additional clause into
BgBufferSync() to allow min_scan_buffers to fall to zero when X% of
shared buffers is clean. After that bgwriter should sleep. And be
woken again only by a dirty write by a user backend. That sounds like
clean ratio will flip between 0 and X% but first dirty write will
occur long before we git zero, so that will cause bgwriter to attempt
to maintain a reasonably steady state clean ratio.
I would also take a wild guess that the 750 results are due to
freelist contention. To assess that, I post again the patch shown on
other threads designed to assess the overall level of freelist lwlock
contention.
--
Simon Riggs http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Training & Services
Attachment
On 02/23/2012 07:36 AM, Simon Riggs wrote: > Since scan_whole_pool_milliseconds is set to 2 minutes we scan the > whole bufferpool every 2 minutes, no matter how big the bufferpool, > even when nothing else is happening. Not cool. It's not quite that bad. Once the BGW has circled around the whole buffer pool, such that it's swept so far ahead it's reached the clock sweep strategy point, it stops. So when the system is idle, it creeps forward until it's scanned the pool once. Then, it still wakes up regularly, but the computation of the bufs_to_lap lap number will reach 0. That aborts running the main buffer scanning loop, so it only burns a bit of CPU time and a lock on BufFreelistLock each time it wakes--both of which are surely to spare if the system is idle. I can agree with your power management argument, I don't see much of a performance win from eliminating this bit. The goals was to end up with a fully cleaned pool ready to absorb going from idle to a traffic spike. The logic behind where the "magic constants" controlling it came from was all laid out at http://archives.postgresql.org/pgsql-hackers/2007-09/msg00214.php There's a bunch of code around that whole computation that only executes if you enable BGW_DEBUG. I left that in there in case somebody wanted to fiddle with this specific tuning work again, since it took so long to get right. That was the last feature change made to the 8.3 background writer tuning work. I was content at that time to cut the minimal activity level in half relative to what it was in 8.2, and that measured well enough. It's hard to find compelling benchmark workloads where the background writer really works well though. I hope to look at this set of interesting cases I found here more, now that I seem to have both positive and negative results for background writer involvement. As for free list contention, I wouldn't expect that to be a major issue in the cases I was testing. The background writer is just one of many backends all contending for that. When there's dozens of backends all grabbing, I'd think that its individual impact would be a small slice of the total activity. I will of course reserve arguing that point until I've benchmarked to support it though. -- Greg Smith 2ndQuadrant US greg@2ndQuadrant.com Baltimore, MD PostgreSQL Training, Services, and 24x7 Support www.2ndQuadrant.com
On Thu, Feb 23, 2012 at 8:44 PM, Greg Smith <greg@2ndquadrant.com> wrote: > On 02/23/2012 07:36 AM, Simon Riggs wrote: >> >> Since scan_whole_pool_milliseconds is set to 2 minutes we scan the >> whole bufferpool every 2 minutes, no matter how big the bufferpool, >> even when nothing else is happening. Not cool. > > > It's not quite that bad. Once the BGW has circled around the whole buffer > pool, such that it's swept so far ahead it's reached the clock sweep > strategy point, it stops. So when the system is idle, it creeps forward > until it's scanned the pool once. Then, it still wakes up regularly, but > the computation of the bufs_to_lap lap number will reach 0. That aborts > running the main buffer scanning loop, so it only burns a bit of CPU time > and a lock on BufFreelistLock each time it wakes--both of which are surely > to spare if the system is idle. I can agree with your power management > argument, I don't see much of a performance win from eliminating this bit. The behaviour is wrong though, because we're scanning for too long when the system goes quiet and then we wake up again too quickly - as soon as a new buffer allocation happens. We don't need to clean the complete bufferpool in 2 minutes. That's exactly the thing checkpoint does and we slowed that down so it didn't do that. So we're still writing way too much. So the proposal was to make it scan only 10% of the bufferpool, not 100%, then sleep. We only need some clean buffers, we don't need *all* buffers clean, especially on very large shared_buffers. And we should wake up only when we see an effect on user backends, i.e. a dirty write - which is the event the bgwriter is designed to avoid. The last bit is the key - waking up only when a dirty write occurs. If they aren't happening we literally don't need the bgwriter - as your tests show. -- Simon Riggs http://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Training & Services
On Thu, Feb 23, 2012 at 3:44 PM, Greg Smith <greg@2ndquadrant.com> wrote: > It's not quite that bad. Once the BGW has circled around the whole buffer > pool, such that it's swept so far ahead it's reached the clock sweep > strategy point, it stops. So when the system is idle, it creeps forward > until it's scanned the pool once. Then, it still wakes up regularly, but > the computation of the bufs_to_lap lap number will reach 0. That aborts > running the main buffer scanning loop, so it only burns a bit of CPU time > and a lock on BufFreelistLock each time it wakes--both of which are surely > to spare if the system is idle. I can agree with your power management > argument, I don't see much of a performance win from eliminating this bit I think that goal of ending up with a clean buffer pool is a good one, and I'm loathe to give it up. On the other hand, I agree with Simon that it does seem a bit wasteful to scan the entire buffer arena because there's one dirty buffer somewhere. But maybe we should look at that as a reason to improve the way we find dirty buffers, rather than a reason not to worry about writing them out. There's got to be a better way than scanning the whole buffer pool. Honestly, though, that feels like 9.3 material. So far there's no evidence that we've introduced any regressions that can't be compensated for by tuning, and this doesn't feel like the right time to embark on a bunch of new engineering projects. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On Thu, Feb 23, 2012 at 11:59 PM, Robert Haas <robertmhaas@gmail.com> wrote: > this doesn't feel like the right time to embark on a bunch of new > engineering projects. IMHO this is exactly the right time to do full system tuning. Only when we have major projects committed can we move towards measuring things and correcting deficiencies. Doing tuning last is a natural consequence of the first rule of tuning: Don't. That means we have to wait and see what problems emerge and then fix them, so there has to be a time period when this is allowed. This is exactly the same on any commercial implementation project - you do tuning at the end before release. I fully accept that this is not a time for heavy lifting. But it is a time when we can apply a few low-invasive patches to improve things. Tweaking the bgwriter is not exactly a big or complex thing. We will be making many other small tweaks and fixes for months yet, so lets just regard tuning as performance bug fixing and get on with it, please. -- Simon Riggs http://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Training & Services
On Tue, Feb 14, 2012 at 12:25 PM, Greg Smith <greg@2ndquadrant.com> wrote: > On 02/14/2012 01:45 PM, Greg Smith wrote: >> >> scale=1000, db is 94% of RAM; clients=4 >> Version TPS >> 9.0 535 >> 9.1 491 (-8.4% relative to 9.0) >> 9.2 338 (-31.2% relative to 9.1) > > > A second pass through this data noted that the maximum number of buffers > cleaned by the background writer is <=2785 in 9.0/9.1, while it goes as high > as 17345 times in 9.2. There is something strange about the data for Set 4 (9.1) at scale 1000. The number of buf_alloc varies a lot from run to run in that series (by a factor of 60 from max to min). But the TPS doesn't vary by very much. How can that be? If a transaction needs a page that is not in the cache, it needs to allocate a buffer. So the only thing that could lower the allocation would be a higher cache hit rate, right? How could there be so much variation in the cache hit rate from run to run at the same scale? Cheers, Jeff
On Fri, Feb 24, 2012 at 5:35 AM, Simon Riggs <simon@2ndquadrant.com> wrote: > On Thu, Feb 23, 2012 at 11:59 PM, Robert Haas <robertmhaas@gmail.com> wrote: >> this doesn't feel like the right time to embark on a bunch of new >> engineering projects. > > IMHO this is exactly the right time to do full system tuning. Only > when we have major projects committed can we move towards measuring > things and correcting deficiencies. Ideally we should measure things as we do them. Of course there will be cases that we fail to test which slip through the cracks, as Greg is now finding, and I agree we should try to fix any problems that we turn up during testing. But, as I said before, so far Greg hasn't turned up anything that can't be fixed by adjusting settings, so I don't see a compelling case for change on that basis. As a side point, there's no obvious reason why the problems Greg is identifying here couldn't have been identified before committing the background writer/checkpointer split. The fact that we didn't find them then suggests to me that we need to be more not less cautious in making further changes in this area. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On Mon, Feb 27, 2012 at 5:13 AM, Robert Haas <robertmhaas@gmail.com> wrote: > On Fri, Feb 24, 2012 at 5:35 AM, Simon Riggs <simon@2ndquadrant.com> wrote: >> On Thu, Feb 23, 2012 at 11:59 PM, Robert Haas <robertmhaas@gmail.com> wrote: >>> this doesn't feel like the right time to embark on a bunch of new >>> engineering projects. >> >> IMHO this is exactly the right time to do full system tuning. Only >> when we have major projects committed can we move towards measuring >> things and correcting deficiencies. > > Ideally we should measure things as we do them. Of course there will > be cases that we fail to test which slip through the cracks, as Greg > is now finding, and I agree we should try to fix any problems that we > turn up during testing. But, as I said before, so far Greg hasn't > turned up anything that can't be fixed by adjusting settings, so I > don't see a compelling case for change on that basis. That isn't the case. We have evidence that the current knobs are hugely ineffective in some cases. Turning the bgwriter off is hardly "adjusting a setting", its admitting that there is no useful setting. I've suggested changes that aren't possible by tuning the current knobs. > As a side point, there's no obvious reason why the problems Greg is > identifying here couldn't have been identified before committing the > background writer/checkpointer split. The fact that we didn't find > them then suggests to me that we need to be more not less cautious in > making further changes in this area. The split was essential to avoid the bgwriter action being forcibly turned off during checkpoint sync. The fact that forcibly turning it off is in some cases a benefit doesn't alter the fact that it was in many cases a huge negative. If its on you can always turn it off, but if it was not available at all there was no tuning option. I see no negative aspect to the split. -- Simon Riggs http://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Training & Services
On Mon, Feb 27, 2012 at 3:50 AM, Simon Riggs <simon@2ndquadrant.com> wrote: > That isn't the case. We have evidence that the current knobs are > hugely ineffective in some cases. > > Turning the bgwriter off is hardly "adjusting a setting", its > admitting that there is no useful setting. > > I've suggested changes that aren't possible by tuning the current knobs. OK, fair point. But I don't think any of us - Greg included - have an enormously clear idea why turning the background writer off is improving performance in some cases. I think we need to understand that better before we start changing things. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On Mon, Feb 27, 2012 at 1:08 PM, Robert Haas <robertmhaas@gmail.com> wrote: > On Mon, Feb 27, 2012 at 3:50 AM, Simon Riggs <simon@2ndquadrant.com> wrote: >> That isn't the case. We have evidence that the current knobs are >> hugely ineffective in some cases. >> >> Turning the bgwriter off is hardly "adjusting a setting", its >> admitting that there is no useful setting. >> >> I've suggested changes that aren't possible by tuning the current knobs. > > OK, fair point. But I don't think any of us - Greg included - have an > enormously clear idea why turning the background writer off is > improving performance in some cases. I think we need to understand > that better before we start changing things. I wasn't suggesting we make a change without testing. The theory that the bgwriter is doing too much work needs to be tested, so we need a proposal for how to reduce that work in a coherent way so we can test, which is what I've given. Other proposals are also possible. -- Simon Riggs http://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Training & Services
On 02/27/2012 08:08 AM, Robert Haas wrote: > OK, fair point. But I don't think any of us - Greg included - have an > enormously clear idea why turning the background writer off is > improving performance in some cases. I think we need to understand > that better before we start changing things. Check out http://archives.postgresql.org/pgsql-hackers/2007-08/msg00895.php for proof this is not a new observation. The fact that there are many workloads where the background writer just gets in the way was clear since the 8.3 development four years ago. One of my guiding principles then was to err on the side of doing less in the default configuration. The defaults in 8.3 usually do less than the 8.2 configuration, given a reasonable shared_buffers size. Since then we've found a few cases where it measurably helps. The examples on my recent graphs have a few such tests. Simon has mentioned seeing big gains during recovery from having 2 processes pushing I/O out. One of the reasons I drilled right into this spot is because of fears that running the writer more often would sprout regressions in TPS. I can't explain exactly why exactly having backends write their own buffers out at the latest possible moment works significantly better in some cases here. But that fact isn't new to 9.2; it's just has a slightly higher potential to get in the way, now that the writing happens during the sync phase. -- Greg Smith 2ndQuadrant US greg@2ndQuadrant.com Baltimore, MD PostgreSQL Training, Services, and 24x7 Support www.2ndQuadrant.com
<p><br /> On Feb 27, 2012 10:36 PM, "Greg Smith" <<a href="mailto:greg@2ndquadrant.com">greg@2ndquadrant.com</a>> wrote:<br/> > One of the reasons I drilled right into this spot is because of fears that running the writer more oftenwould sprout regressions in TPS. I can't explain exactly why exactly having backends write their own buffers out atthe latest possible moment works significantly better in some cases here. But that fact isn't new to 9.2; it's just hasa slightly higher potential to get in the way, now that the writing happens during the sync phase.<p>My hypothesis forthe TPS regression is that it is due to write combining. When the workload is mainly bound by I/O, every little bit thatcan be saved helps the bottomline. Larger scalefactors don't get the benefit because there is less write combining goingon overall.<p>Anyway, most people don't run their databases at 100% load. At lesser loads bgwriter should help end userlatency. Is there a standard benchmark to measure that?<p>--<br /> Ants Aasma
On Thu, Feb 23, 2012 at 3:17 AM, Greg Smith <greg@2ndquadrant.com> wrote: > I think an even bigger factor now is that the BGW writes can disturb write > ordering/combining done at the kernel and storage levels. It's painfully > obvious now how much PostgreSQL relies on that to get good performance. All > sorts of things break badly if we aren't getting random writes scheduled to > optimize seek times, in as many contexts as possible. It doesn't seem > unreasonable that background writer writes can introduce some delay into the > checkpoint writes, just by adding more random components to what is already > a difficult to handle write/sync series. That's what I think what these > results are showing is that background writer writes can deoptimize other > forms of write. How hard would it be to dummy up a bgwriter which, every time it wakes up, it forks off a child process to actually do the write, and then the real one just waits for the child to exit? If it didn't have to correctly handle signals, SINVAL, and such, it should be just a few lines of code, but I don't know how much we can ignore signals and such even just for testing purposes. My thought here is that the kernel is getting in a snit over one process doing all the writing on the system, and is punishing that process in a way that ruins things for everyone. > > A second fact that's visible from the TPS graphs over the test run, and > obvious if you think about it, is that BGW writes force data to physical > disk earlier than they otherwise might go there. On a busy system like you are testing, the BGW should only be writing out data a fraction of a second before the backends would otherwise be doing it, unless the "2 minutes to circle the buffer pool" logic is in control rather than the bgwriter_lru_multiplier and bgwriter_lru_maxpages logic. From the data reported, we can see how many buffer-allocations there are but not how many circles of the pool it took to find them) It doesn't seem likely that small shifts in timing are having that effect, compared to the possible effect of who is doing the writing. If the timing is truly the issue, lowering bgwriter_delay might smooth the timing out and bring closer to what the backends would do for themselves. Cheers, Jeff
On Tue, Feb 28, 2012 at 1:15 AM, Ants Aasma <ants.aasma@eesti.ee> wrote: > My hypothesis for the TPS regression is that it is due to write combining. > When the workload is mainly bound by I/O, every little bit that can be saved > helps the bottomline. Larger scalefactors don't get the benefit because > there is less write combining going on overall. This is an interesting hypothesis which I think we can test. I'm thinking of writing a quick patch (just for testing, not for commit) to set a new buffer flag BM_BGWRITER_CLEANED to every buffer the background writer cleans. Then we can keep a count of how often such buffers are dirtied before they're evicted, vs. how often they're evicted before they're dirtied. If any significant percentage of them are redirtied before they're evicted, that would confirm this hypothesis. At any rate I think the numbers would be interesting to see. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On Tue, Feb 28, 2012 at 11:36 AM, Jeff Janes <jeff.janes@gmail.com> wrote: > How hard would it be to dummy up a bgwriter which, every time it wakes > up, it forks off a child process to actually do the write, and then > the real one just waits for the child to exit? If it didn't have to > correctly handle signals, SINVAL, and such, it should be just a few > lines of code, but I don't know how much we can ignore signals and > such even just for testing purposes. My thought here is that the > kernel is getting in a snit over one process doing all the writing on > the system, and is punishing that process in a way that ruins things > for everyone. I would assume the only punishment that the kernel would inflict would be to put the bgwriter to sleep. That would make the bgwriter less effective, of course, but it shouldn't make it worse than no bgwriter at all. Unless it does it some really stupid way, like making bgwriter sleep while it holds some lock. But maybe I'm missing something - what do you have in mind? -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
----- Цитат от Robert Haas (robertmhaas@gmail.com), на 28.02.2012 в 19:25 ----- <br /><br />> On Tue, Feb 28, 2012 at11:36 AM, Jeff Janes wrote: <br />>> How hard would it be to dummy up a bgwriter which, every time it wakes <br/>>> up, it forks off a child process to actually do the write, and then <br />>> the real one just waitsfor the child to exit? If it didn't have to <br />>> correctly handle signals, SINVAL, and such, it should bejust a few <br />>> lines of code, but I don't know how much we can ignore signals and <br />>> such even justfor testing purposes. My thought here is that the <br />>> kernel is getting in a snit over one process doingall the writing on <br />>> the system, and is punishing that process in a way that ruins things <br />>>for everyone. <br />> <br />> I would assume the only punishment that the kernel would inflict would <br/>> be to put the bgwriter to sleep. That would make the bgwriter less <br />> effective, of course, but it shouldn'tmake it worse than no bgwriter <br />> at all. Unless it does it some really stupid way, like making <br />>bgwriter sleep while it holds some lock. <br />> <br />> But maybe I'm missing something - what do you have inmind? <br />> <br />> -- <br />> Robert Haas <br />> EnterpriseDB: http://www.enterprisedb.com <br />> TheEnterprise PostgreSQL Company <br />> <br />> -- <br />> Sent via pgsql-hackers mailing list (pgsql-hackers@postgresql.org)<br />> To make changes to your subscription: <br />> http://www.postgresql.org/mailpref/pgsql-hackers<br />> <br />> <br /><br />-- <br />Luben Karavelov
On Tue, Feb 28, 2012 at 11:46 AM, Robert Haas <robertmhaas@gmail.com> wrote: > On Tue, Feb 28, 2012 at 1:15 AM, Ants Aasma <ants.aasma@eesti.ee> wrote: >> My hypothesis for the TPS regression is that it is due to write combining. >> When the workload is mainly bound by I/O, every little bit that can be saved >> helps the bottomline. Larger scalefactors don't get the benefit because >> there is less write combining going on overall. > > This is an interesting hypothesis which I think we can test. I'm > thinking of writing a quick patch (just for testing, not for commit) > to set a new buffer flag BM_BGWRITER_CLEANED to every buffer the > background writer cleans. Then we can keep a count of how often such > buffers are dirtied before they're evicted, vs. how often they're > evicted before they're dirtied. If any significant percentage of them > are redirtied before they're evicted, that would confirm this > hypothesis. At any rate I think the numbers would be interesting to > see. Patch attached. I tried it on my laptop with a 60-second pgbench run at scale factor 100, and got this: LOG: bgwriter_clean: 1387 evict-before-dirty, 10 dirty-before-evict LOG: bgwriter_clean: 1372 evict-before-dirty, 10 dirty-before-evict LOG: bgwriter_clean: 1355 evict-before-dirty, 10 dirty-before-evict LOG: bgwriter_clean: 1344 evict-before-dirty, 8 dirty-before-evict LOG: bgwriter_clean: 1418 evict-before-dirty, 8 dirty-before-evict LOG: bgwriter_clean: 1345 evict-before-dirty, 7 dirty-before-evict LOG: bgwriter_clean: 1339 evict-before-dirty, 6 dirty-before-evict LOG: bgwriter_clean: 1362 evict-before-dirty, 9 dirty-before-evict That doesn't look bad at all. Then I reset the stats, tried it again, and got this: LOG: bgwriter_clean: 3863 evict-before-dirty, 198 dirty-before-evict LOG: bgwriter_clean: 3861 evict-before-dirty, 199 dirty-before-evict LOG: bgwriter_clean: 3978 evict-before-dirty, 218 dirty-before-evict LOG: bgwriter_clean: 3928 evict-before-dirty, 204 dirty-before-evict LOG: bgwriter_clean: 3956 evict-before-dirty, 207 dirty-before-evict LOG: bgwriter_clean: 3906 evict-before-dirty, 222 dirty-before-evict LOG: bgwriter_clean: 3912 evict-before-dirty, 197 dirty-before-evict LOG: bgwriter_clean: 3853 evict-before-dirty, 200 dirty-before-evict OK, that's not so good, but I don't know why it's different. I'm not sure I can reproduce the exact same scenario Greg is seeing - this is totally different hardware - but I'll play around with it a little bit more. Greg, if you happen to feel like testing this on one of your problem cases I'd be interested in seeing what it spits out. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
Attachment
Jeff Janes <jeff.janes@gmail.com> writes:
> How hard would it be to dummy up a bgwriter which, every time it wakes
> up, it forks off a child process to actually do the write, and then
> the real one just waits for the child to exit? If it didn't have to
> correctly handle signals, SINVAL, and such, it should be just a few
> lines of code, but I don't know how much we can ignore signals and
> such even just for testing purposes. My thought here is that the
> kernel is getting in a snit over one process doing all the writing on
> the system, and is punishing that process in a way that ruins things
> for everyone.
If that is the case (which I don't know one way or the other), I'm not
sure that having subprocesses do the work would be an improvement.
We know for a fact that the OOM killer knows enough to blame memory
consumed by a child process on the parent. Resource limitations of
other sorts might work similarly.
But a bigger problem is that fork() is very very far from being zero
cost. I think doing one per write() would swamp any improvement you
could hope to get.
It does make sense that the bgwriter would get hit by niceness penalties
after it'd run up sufficient runtime. If we could get some hard numbers
about how long it takes for that to happen, we could consider letting
the bgwriter exit (and the postmaster spawn a new one) every so often.
This is just gaming the scheduler, and so one would like to think
there's a better way to do it, but I don't know of any
non-root-privilege way to stave off getting niced.
regards, tom lane
On Tue, Feb 28, 2012 at 9:49 AM, Robert Haas <robertmhaas@gmail.com> wrote: > On Tue, Feb 28, 2012 at 11:46 AM, Robert Haas <robertmhaas@gmail.com> wrote: >> >> This is an interesting hypothesis which I think we can test. I'm >> thinking of writing a quick patch (just for testing, not for commit) >> to set a new buffer flag BM_BGWRITER_CLEANED to every buffer the >> background writer cleans. Then we can keep a count of how often such >> buffers are dirtied before they're evicted, vs. how often they're >> evicted before they're dirtied. If any significant percentage of them >> are redirtied before they're evicted, that would confirm this >> hypothesis. At any rate I think the numbers would be interesting to >> see. > > Patch attached. > ... > That doesn't look bad at all. Then I reset the stats, tried it again, > and got this: > > LOG: bgwriter_clean: 3863 evict-before-dirty, 198 dirty-before-evict > LOG: bgwriter_clean: 3861 evict-before-dirty, 199 dirty-before-evict > LOG: bgwriter_clean: 3978 evict-before-dirty, 218 dirty-before-evict > LOG: bgwriter_clean: 3928 evict-before-dirty, 204 dirty-before-evict > LOG: bgwriter_clean: 3956 evict-before-dirty, 207 dirty-before-evict > LOG: bgwriter_clean: 3906 evict-before-dirty, 222 dirty-before-evict > LOG: bgwriter_clean: 3912 evict-before-dirty, 197 dirty-before-evict > LOG: bgwriter_clean: 3853 evict-before-dirty, 200 dirty-before-evict > > OK, that's not so good, but I don't know why it's different. I don't think reseting the stats has anything to do with it, it is just that the shared_buffers warmed up over time. On my testing, this dirty-before-evict is because the bgwriter is riding too far ahead of the clock sweep, because of scan_whole_pool_milliseconds. Because it is far ahead, that leaves a lot of run between the two pointers for re-dirtying cache hits to land. Not only is 2 minutes likely to be too small of a value for large shared_buffers, but min_scan_buffers doesn't live up to its name. It is not the minimum buffers to scan, it is the minimum to find/make reusable. If lots of buffers have a nonzero usagecount (and if your data doesn't fix in shared_buffers, it is hard to see how more than half of the buffers can have zero usagecount) or are pinned, you are scanning a lot more than min_scan_buffers. If I disable that, then the bgwriter remains "just in time", just slightly ahead of the clock-sweep, and the dirty-before-evict drops a lot. If scan_whole_pool_milliseconds is to be used at all, it seems like it should not be less than checkpoint_timeout. If I don't want checkpoints trashing my IO, why would I want someone else to do it instead? Cheers, Jeff
On Tue, Mar 6, 2012 at 4:35 PM, Jeff Janes <jeff.janes@gmail.com> wrote:
> I don't think reseting the stats has anything to do with it, it is
> just that the shared_buffers warmed up over time.
Yes.
> On my testing, this dirty-before-evict is because the bgwriter is
> riding too far ahead of the clock sweep, because of
> scan_whole_pool_milliseconds. Because it is far ahead, that leaves a
> lot of run between the two pointers for re-dirtying cache hits to
> land.
>
> Not only is 2 minutes likely to be too small of a value for large
> shared_buffers, but min_scan_buffers doesn't live up to its name. It
> is not the minimum buffers to scan, it is the minimum to find/make
> reusable. If lots of buffers have a nonzero usagecount (and if your
> data doesn't fix in shared_buffers, it is hard to see how more than
> half of the buffers can have zero usagecount) or are pinned, you are
> scanning a lot more than min_scan_buffers.
>
> If I disable that, then the bgwriter remains "just in time", just
> slightly ahead of the clock-sweep, and the dirty-before-evict drops a
> lot.
>
> If scan_whole_pool_milliseconds is to be used at all, it seems like it
> should not be less than checkpoint_timeout. If I don't want
> checkpoints trashing my IO, why would I want someone else to do it
> instead?
I'm not sure that 2 minutes is a bad value (although maybe it is) but
I think you've definitely got a good point as regards
min_scan_buffers. It seems like the main LRU scan that begins here:
while (num_to_scan > 0 && reusable_buffers < upcoming_alloc_est)
Ought to be doing something like this:
while (num_to_scan > 0 && (reusable_buffers <
upcoming_alloc_est || num_already_scanned < min_scan_buffers))
...and the logic that changes upcoming_alloc_est based on
min_scan_buffers ought to be ripped out. Unless I'm misunderstanding
this logic, this will cause the background writer to scan the buffer
pool considerably FASTER than once every two minutes when there are
lots of high-usage-count buffers.
--
Robert Haas
EnterpriseDB: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
On 03/06/2012 04:35 PM, Jeff Janes wrote: > On my testing, this dirty-before-evict is because the bgwriter is > riding too far ahead of the clock sweep, because of > scan_whole_pool_milliseconds. Because it is far ahead, that leaves a > lot of run between the two pointers for re-dirtying cache hits to > land. > > Not only is 2 minutes likely to be too small of a value for large > shared_buffers, but min_scan_buffers doesn't live up to its name. It > is not the minimum buffers to scan, it is the minimum to find/make > reusable. If lots of buffers have a nonzero usagecount (and if your > data doesn't fix in shared_buffers, it is hard to see how more than > half of the buffers can have zero usagecount) or are pinned, you are > scanning a lot more than min_scan_buffers. The naming could be better in spots. If I wanted to blame a past version of myself for predicting this but doing nothing, I could dig up disclaimer e-mails I wrote in 2007, about whether fragility to base "magic constants" in the proposed model was too much. 9.2 and current generation hardware seems to have finally pushed on enough soft spots to crack more of those assumptions. > If scan_whole_pool_milliseconds is to be used at all, it seems like it > should not be less than checkpoint_timeout. If I don't want > checkpoints trashing my IO, why would I want someone else to do it > instead? The idea of the BGW LRU scan is to find things that can be written usefully now due to low usage. The checkpoint one writes regardless of usage count. Your can find both opportunity and problem in that overlap. -- Greg Smith 2ndQuadrant US greg@2ndQuadrant.com Baltimore, MD PostgreSQL Training, Services, and 24x7 Support www.2ndQuadrant.com