Thread: spinlocks on HP-UX
I was able to obtain access to a 32-core HP-UX server. I repeated the
pgbench -S testing that I have previously done on Linux, and found
that the results were not too good. Here are the results at scale
factor 100, on 9.2devel, with various numbers of clients. Five minute
runs, shared_buffers=8GB.
1:tps = 5590.070816 (including connections establishing)
8:tps = 37660.233932 (including connections establishing)
16:tps = 67366.099286 (including connections establishing)
32:tps = 82781.624665 (including connections establishing)
48:tps = 18589.995074 (including connections establishing)
64:tps = 16424.661371 (including connections establishing)
And just for comparison, here are the numbers at scale factor 1000:
1:tps = 4751.768608 (including connections establishing)
8:tps = 33621.474490 (including connections establishing)
16:tps = 58959.043171 (including connections establishing)
32:tps = 78801.265189 (including connections establishing)
48:tps = 21635.234969 (including connections establishing)
64:tps = 18611.863567 (including connections establishing)
After mulling over the vmstat output for a bit, I began to suspect
spinlock contention. I took a look at document called "Implementing
Spinlocks on the Intel Itanium Architecture and PA-RISC", by Tor
Ekqvist and David Graves and available via the HP web site, which
states that when spinning on a spinlock on these machines, you should
use a regular, unlocked test first and use the atomic test only when
the unlocked test looks OK. I tried implementing this in two ways,
and both produced results which are FAR superior to our current
implementation. First, I did this:
--- a/src/include/storage/s_lock.h
+++ b/src/include/storage/s_lock.h
@@ -726,7 +726,7 @@ tas(volatile slock_t *lock)typedef unsigned int slock_t;
#include <ia64/sys/inline.h>
-#define TAS(lock) _Asm_xchg(_SZ_W, lock, 1, _LDHINT_NONE)
+#define TAS(lock) (*(lock) ? 1 : _Asm_xchg(_SZ_W, lock, 1, _LDHINT_NONE))
#endif /* HPUX on IA64, non gcc */
That resulted in these numbers. Scale factor 100:
1:tps = 5569.911714 (including connections establishing)
8:tps = 37365.364468 (including connections establishing)
16:tps = 63596.261875 (including connections establishing)
32:tps = 95948.157678 (including connections establishing)
48:tps = 90708.253920 (including connections establishing)
64:tps = 100109.065744 (including connections establishing)
Scale factor 1000:
1:tps = 4878.332996 (including connections establishing)
8:tps = 33245.469907 (including connections establishing)
16:tps = 56708.424880 (including connections establishing)
48:tps = 69652.232635 (including connections establishing)
64:tps = 70593.208637 (including connections establishing)
Then, I did this:
--- a/src/backend/storage/lmgr/s_lock.c
+++ b/src/backend/storage/lmgr/s_lock.c
@@ -96,7 +96,7 @@ s_lock(volatile slock_t *lock, const char *file, int line) int delays = 0;
int cur_delay = 0;
- while (TAS(lock))
+ while (*lock ? 1 : TAS(lock)) { /* CPU-specific delay each time through the loop */
SPIN_DELAY();
That resulted in these numbers, at scale factor 100:
1:tps = 5564.059494 (including connections establishing)
8:tps = 37487.090798 (including connections establishing)
16:tps = 66061.524760 (including connections establishing)
32:tps = 96535.523905 (including connections establishing)
48:tps = 92031.618360 (including connections establishing)
64:tps = 106813.631701 (including connections establishing)
And at scale factor 1000:
1:tps = 4980.338246 (including connections establishing)
8:tps = 33576.680072 (including connections establishing)
16:tps = 55618.677975 (including connections establishing)
32:tps = 73589.442746 (including connections establishing)
48:tps = 70987.026228 (including connections establishing)
Note sure why I am missing the 64-client results for that last set of
tests, but no matter.
Of course, we can't apply the second patch as it stands, because I
tested it on x86 and it loses. But it seems pretty clear we need to
do it at least for this architecture...
--
Robert Haas
EnterpriseDB: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
Pity that this patch works only on hpux :(. But i have an idea: maybe when executor stop at locked row, it should process next row instead of wait. Of course if query not contain "order by" or windowing functions. -- ------------ pasman
Robert Haas <robertmhaas@gmail.com> writes:
> First, I did this:
> -#define TAS(lock) _Asm_xchg(_SZ_W, lock, 1, _LDHINT_NONE)
> +#define TAS(lock) (*(lock) ? 1 : _Asm_xchg(_SZ_W, lock, 1, _LDHINT_NONE))
Seems reasonable, and similar to x86 logic.
> Then, I did this:
> - while (TAS(lock))
> + while (*lock ? 1 : TAS(lock))
Er, what? That sure looks like a manual application of what you'd
already done in the TAS macro.
> Of course, we can't apply the second patch as it stands, because I
> tested it on x86 and it loses. But it seems pretty clear we need to
> do it at least for this architecture...
Please clarify: when you say "this architecture", are you talking about
IA64 or PA-RISC? Is there any reason to think that this is specific to
HP-UX rather than any other system on the same architecture? (I'm sure
I can get access to some IA64 clusters at Red Hat, though maybe not
64-core ones.)
I don't have an objection to the TAS macro change, but I do object to
fooling with the hardware-independent code in s_lock.c ... especially
when the additional improvement seems barely above the noise threshold.
You ought to be able to do whatever you need inside the TAS macro.
regards, tom lane
On Sun, Aug 28, 2011 at 11:35 AM, Tom Lane <tgl@sss.pgh.pa.us> wrote: > Robert Haas <robertmhaas@gmail.com> writes: >> First, I did this: > >> -#define TAS(lock) _Asm_xchg(_SZ_W, lock, 1, _LDHINT_NONE) >> +#define TAS(lock) (*(lock) ? 1 : _Asm_xchg(_SZ_W, lock, 1, _LDHINT_NONE)) > > Seems reasonable, and similar to x86 logic. > >> Then, I did this: > >> - while (TAS(lock)) >> + while (*lock ? 1 : TAS(lock)) > > Er, what? That sure looks like a manual application of what you'd > already done in the TAS macro. Sorry, I blew through that a little too blithely. If you change TAS() itself, then even the very first attempt to acquire the lock will try the unlocked instruction first, whereas changing s_lock() allows you to do something different in the contended case than you do in the uncontended case. We COULD just change the TAS() macro since, in this case, it seems to make only a minor difference, but what I was thinking is that we could change s_lock.h to define two macros, TAS() and TAS_SPIN(). If a particular architecture defines TAS() but not TAS_SPIN(), then we define TAS_SPIN(x) to be TAS(x). Then, S_LOCK() can stay as-is - calling TAS() - but s_lock() can call TAS_SPIN(), which will normally be the same as TAS() but can be made different on any architecture where the retry loop should do something different than the initial attempt. > Please clarify: when you say "this architecture", are you talking about > IA64 or PA-RISC? Is there any reason to think that this is specific to > HP-UX rather than any other system on the same architecture? (I'm sure > I can get access to some IA64 clusters at Red Hat, though maybe not > 64-core ones.) I tested on IA64; I don't currently have access to a PA-RISC box. The documentation I'm looking at implies that the same approach would be desirable there, but that's just an unsubstantiated rumor at this point.... -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
Robert Haas <robertmhaas@gmail.com> writes:
> On Sun, Aug 28, 2011 at 11:35 AM, Tom Lane <tgl@sss.pgh.pa.us> wrote:
>> Robert Haas <robertmhaas@gmail.com> writes:
>>> Then, I did this:
>>>
>>> - � � � while (TAS(lock))
>>> + � � � while (*lock ? 1 : TAS(lock))
>> Er, what? �That sure looks like a manual application of what you'd
>> already done in the TAS macro.
> Sorry, I blew through that a little too blithely. If you change TAS()
> itself, then even the very first attempt to acquire the lock will try
> the unlocked instruction first, whereas changing s_lock() allows you
> to do something different in the contended case than you do in the
> uncontended case.
Yeah, I figured out that was probably what you meant a little while
later. I found a 64-CPU IA64 machine in Red Hat's test labs and am
currently trying to replicate your results; report to follow.
> We COULD just change the TAS() macro since, in this
> case, it seems to make only a minor difference, but what I was
> thinking is that we could change s_lock.h to define two macros, TAS()
> and TAS_SPIN().
Yeah, I was thinking along the same lines, though perhaps the name of
the new macro could use a little bikeshedding.
The comments in s_lock.h note that the unlocked test in x86 TAS is of
uncertain usefulness. It seems entirely possible to me that we ought
to use a similar design on x86, ie, use the unlocked test only once
we've entered the delay loop.
>> Please clarify: when you say "this architecture", are you talking about
>> IA64 or PA-RISC? �Is there any reason to think that this is specific to
>> HP-UX rather than any other system on the same architecture? �(I'm sure
>> I can get access to some IA64 clusters at Red Hat, though maybe not
>> 64-core ones.)
> I tested on IA64; I don't currently have access to a PA-RISC box. The
> documentation I'm looking at implies that the same approach would be
> desirable there, but that's just an unsubstantiated rumor at this
> point....
Well, I've got a PA-RISC box, but it's only a single processor so it's
not gonna prove much. Anybody?
regards, tom lane
I wrote:
> Yeah, I figured out that was probably what you meant a little while
> later. I found a 64-CPU IA64 machine in Red Hat's test labs and am
> currently trying to replicate your results; report to follow.
OK, these results are on a 64-processor SGI IA64 machine (AFAICT, 64
independent sockets, no hyperthreading or any funny business); 124GB
in 32 NUMA nodes; running RHEL5.7, gcc 4.1.2. I built today's git
head with --enable-debug (but not --enable-cassert) and ran with all
default configuration settings except shared_buffers = 8GB and
max_connections = 200. The test database is initialized at -s 100.
I did not change the database between runs, but restarted the postmaster
and then did this to warm the caches a tad:
pgbench -c 1 -j 1 -S -T 30 bench
Per-run pgbench parameters are as shown below --- note in particular
that I assigned one pgbench thread per 8 backends.
The numbers are fairly variable even with 5-minute runs; I did each
series twice so you could get a feeling for how much.
Today's git head:
pgbench -c 1 -j 1 -S -T 300 bench tps = 5835.213934 (including ...
pgbench -c 2 -j 1 -S -T 300 bench tps = 8499.223161 (including ...
pgbench -c 8 -j 1 -S -T 300 bench tps = 15197.126952 (including ...
pgbench -c 16 -j 2 -S -T 300 bench tps = 30803.255561 (including ...
pgbench -c 32 -j 4 -S -T 300 bench tps = 65795.356797 (including ...
pgbench -c 64 -j 8 -S -T 300 bench tps = 81644.914241 (including ...
pgbench -c 96 -j 12 -S -T 300 bench tps = 40059.202836 (including ...
pgbench -c 128 -j 16 -S -T 300 bench tps = 21309.615001 (including ...
run 2:
pgbench -c 1 -j 1 -S -T 300 bench tps = 5787.310115 (including ...
pgbench -c 2 -j 1 -S -T 300 bench tps = 8747.104236 (including ...
pgbench -c 8 -j 1 -S -T 300 bench tps = 14655.369995 (including ...
pgbench -c 16 -j 2 -S -T 300 bench tps = 28287.254924 (including ...
pgbench -c 32 -j 4 -S -T 300 bench tps = 61614.715187 (including ...
pgbench -c 64 -j 8 -S -T 300 bench tps = 79754.640518 (including ...
pgbench -c 96 -j 12 -S -T 300 bench tps = 40334.994324 (including ...
pgbench -c 128 -j 16 -S -T 300 bench tps = 23285.271257 (including ...
With modified TAS macro (see patch 1 below):
pgbench -c 1 -j 1 -S -T 300 bench tps = 6171.454468 (including ...
pgbench -c 2 -j 1 -S -T 300 bench tps = 8709.003728 (including ...
pgbench -c 8 -j 1 -S -T 300 bench tps = 14902.731035 (including ...
pgbench -c 16 -j 2 -S -T 300 bench tps = 29789.744482 (including ...
pgbench -c 32 -j 4 -S -T 300 bench tps = 59991.549128 (including ...
pgbench -c 64 -j 8 -S -T 300 bench tps = 117369.287466 (including ...
pgbench -c 96 -j 12 -S -T 300 bench tps = 112583.144495 (including ...
pgbench -c 128 -j 16 -S -T 300 bench tps = 110231.305282 (including ...
run 2:
pgbench -c 1 -j 1 -S -T 300 bench tps = 5670.097936 (including ...
pgbench -c 2 -j 1 -S -T 300 bench tps = 8230.786940 (including ...
pgbench -c 8 -j 1 -S -T 300 bench tps = 14785.952481 (including ...
pgbench -c 16 -j 2 -S -T 300 bench tps = 29335.875139 (including ...
pgbench -c 32 -j 4 -S -T 300 bench tps = 59605.433837 (including ...
pgbench -c 64 -j 8 -S -T 300 bench tps = 108884.294519 (including ...
pgbench -c 96 -j 12 -S -T 300 bench tps = 110387.439978 (including ...
pgbench -c 128 -j 16 -S -T 300 bench tps = 109046.121191 (including ...
With unlocked test in s_lock.c delay loop only (patch 2 below):
pgbench -c 1 -j 1 -S -T 300 bench tps = 5426.491088 (including ...
pgbench -c 2 -j 1 -S -T 300 bench tps = 8787.939425 (including ...
pgbench -c 8 -j 1 -S -T 300 bench tps = 15720.801359 (including ...
pgbench -c 16 -j 2 -S -T 300 bench tps = 33711.102718 (including ...
pgbench -c 32 -j 4 -S -T 300 bench tps = 61829.180234 (including ...
pgbench -c 64 -j 8 -S -T 300 bench tps = 109781.655020 (including ...
pgbench -c 96 -j 12 -S -T 300 bench tps = 107132.848280 (including ...
pgbench -c 128 -j 16 -S -T 300 bench tps = 106533.630986 (including ...
run 2:
pgbench -c 1 -j 1 -S -T 300 bench tps = 5705.283316 (including ...
pgbench -c 2 -j 1 -S -T 300 bench tps = 8442.798662 (including ...
pgbench -c 8 -j 1 -S -T 300 bench tps = 14423.723837 (including ...
pgbench -c 16 -j 2 -S -T 300 bench tps = 29112.751995 (including ...
pgbench -c 32 -j 4 -S -T 300 bench tps = 62258.984033 (including ...
pgbench -c 64 -j 8 -S -T 300 bench tps = 107741.988800 (including ...
pgbench -c 96 -j 12 -S -T 300 bench tps = 107138.968981 (including ...
pgbench -c 128 -j 16 -S -T 300 bench tps = 106110.215138 (including ...
So this pretty well confirms Robert's results, in particular that all of
the win from an unlocked test comes from using it in the delay loop.
Given the lack of evidence that a general change in TAS() is beneficial,
I'm inclined to vote against it, on the grounds that the extra test is
surely a loss at some level when there is not contention.
(IOW, +1 for inventing a second macro to use in the delay loop only.)
We ought to do similar tests on other architectures. I found some
lots-o-processors x86_64 machines at Red Hat, but they don't seem to
own any PPC systems with more than 8 processors. Anybody have big
iron with other non-Intel chips?
regards, tom lane
Patch 1: change TAS globally, non-HPUX code:
*** src/include/storage/s_lock.h.orig Sat Jan 1 13:27:24 2011
--- src/include/storage/s_lock.h Sun Aug 28 13:32:47 2011
***************
*** 228,233 ****
--- 228,240 ---- { long int ret;
+ /*
+ * Use a non-locking test before the locking instruction proper. This
+ * appears to be a very significant win on many-core IA64.
+ */
+ if (*lock)
+ return 1;
+ __asm__ __volatile__( " xchg4 %0=%1,%2 \n" : "=r"(ret), "+m"(*lock)
***************
*** 243,248 ****
--- 250,262 ---- { int ret;
+ /*
+ * Use a non-locking test before the locking instruction proper. This
+ * appears to be a very significant win on many-core IA64.
+ */
+ if (*lock)
+ return 1;
+ ret = _InterlockedExchange(lock,1); /* this is a xchg asm macro */ return ret;
Patch 2: change s_lock only (same as Robert's quick hack):
*** src/backend/storage/lmgr/s_lock.c.orig Sat Jan 1 13:27:09 2011
--- src/backend/storage/lmgr/s_lock.c Sun Aug 28 14:02:29 2011
***************
*** 96,102 **** int delays = 0; int cur_delay = 0;
! while (TAS(lock)) { /* CPU-specific delay each time through the loop */ SPIN_DELAY();
--- 96,102 ---- int delays = 0; int cur_delay = 0;
! while (*lock ? 1 : TAS(lock)) { /* CPU-specific delay each time through the loop */
SPIN_DELAY();
On Sun, Aug 28, 2011 at 7:19 PM, Tom Lane <tgl@sss.pgh.pa.us> wrote: > So this pretty well confirms Robert's results, in particular that all of > the win from an unlocked test comes from using it in the delay loop. > Given the lack of evidence that a general change in TAS() is beneficial, > I'm inclined to vote against it, on the grounds that the extra test is > surely a loss at some level when there is not contention. > (IOW, +1 for inventing a second macro to use in the delay loop only.) Beautiful. Got a naming preference for that second macro? I suggested TAS_SPIN() because it's what you use when you spin, as opposed to what you use in the uncontended case, but I'm not attached to that. > We ought to do similar tests on other architectures. I found some > lots-o-processors x86_64 machines at Red Hat, but they don't seem to > own any PPC systems with more than 8 processors. Anybody have big > iron with other non-Intel chips? Aside from PPC, it would probably be worth testing SPARC and ARM if we can find machines. Anything else is probably too old or too marginal to get excited about. AFAIK these effects don't manifest with <32 cores, so I suspect that a lot of what's in s_lock.h is irrelevant just because many of those architectures are too old to exist in 32-core versions. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
Robert Haas <robertmhaas@gmail.com> writes:
> On Sun, Aug 28, 2011 at 7:19 PM, Tom Lane <tgl@sss.pgh.pa.us> wrote:
>> (IOW, +1 for inventing a second macro to use in the delay loop only.)
> Beautiful. Got a naming preference for that second macro? I
> suggested TAS_SPIN() because it's what you use when you spin, as
> opposed to what you use in the uncontended case, but I'm not attached
> to that.
I had been thinking TAS_CONTENDED, but on reflection there's not a
strong argument for that over TAS_SPIN. Do what you will.
regards, tom lane
2011/8/28 pasman pasmański <pasman.p@gmail.com>: > Pity that this patch works only on hpux :(. Well, not really. x86 is already well-behaved. On a 32-core x86 box running Linux, performs seems to plateau and level off, and then fall off gradually. But on ia64, performance just collapses after about 24 cores. The fact that we don't have that problem everywhere is a good thing, not a bad thing... > But i have an idea: maybe when executor stop at locked row, it should > process next row instead of wait. > > Of course if query not contain "order by" or windowing functions. That wouldn't really help, first of all because you'd then have to remember to go back to that row (and chances are it would still be contended then), and second because these aren't row-level locks anyway. They're locks on various global data structures, such as the ProcArray. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On Sun, Aug 28, 2011 at 8:00 PM, Tom Lane <tgl@sss.pgh.pa.us> wrote:
> Robert Haas <robertmhaas@gmail.com> writes:
>> On Sun, Aug 28, 2011 at 7:19 PM, Tom Lane <tgl@sss.pgh.pa.us> wrote:
>>> (IOW, +1 for inventing a second macro to use in the delay loop only.)
>
>> Beautiful. Got a naming preference for that second macro? I
>> suggested TAS_SPIN() because it's what you use when you spin, as
>> opposed to what you use in the uncontended case, but I'm not attached
>> to that.
>
> I had been thinking TAS_CONTENDED, but on reflection there's not a
> strong argument for that over TAS_SPIN. Do what you will.
OK, done. I think while we're tidying up here we ought to do
something about this comment:
* ANOTHER CAUTION: be sure that TAS(), TAS_SPIN(), and
S_UNLOCK() represent* sequence points, ie, loads and stores of other values must not be moved* across a lock
orunlock. In most cases it suffices to make
the operation* be done through a "volatile" pointer.
IIUC, this is basically total nonsense. volatile only constrains the
optimizer, not the CPU; and only with regard to the ordering of one
volatile access vs. another, NOT the ordering of volatile accesses
with any non-volatile accesses that may be floating around. So its
practical utility for synchronization purposes seems to be nearly
zero. I think what this should say is that we expect these operations
to act as a full memory fence. Note that in some other worlds (e.g.
Linux) a spinlock acquisition or release is only required to act as a
half-fence; that is, other loads and stores are allowed to bleed into
the critical section but not out. However, I think we have been
assuming full-fence behavior. In either case, claiming that the use
of a volatile pointer is all that's needed here strikes me as pretty
misleading.
In the department of loose ends, there are a bunch of other things
that maybe need cleanup here: (1) the gcc/intel compiler cases on
ia64, (2) PA-RISC, (3) ARM, (4) PowerPC... and we should also perhaps
reconsider the 32-bit x86 case. Right now TAS() says:
/* * Use a non-locking test before asserting the bus lock. Note that the * extra test appears to
bea small loss on some x86 platforms
and a small * win on others; it's by no means clear that we should keep it. */
I can't get too excited about spending a lot of effort optimizing
32-bit PostgreSQL on any architecture at this point, but if someone
else is, we might want to check whether it makes more sense to do the
non-locking test only in TAS_SPIN().
--
Robert Haas
EnterpriseDB: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
Robert Haas <robertmhaas@gmail.com> writes:
> OK, done. I think while we're tidying up here we ought to do
> something about this comment:
> * ANOTHER CAUTION: be sure that TAS(), TAS_SPIN(), and
> S_UNLOCK() represent
> * sequence points, ie, loads and stores of other values must not be moved
> * across a lock or unlock. In most cases it suffices to make
> the operation
> * be done through a "volatile" pointer.
> IIUC, this is basically total nonsense.
It could maybe be rewritten for more clarity, but it's far from being
nonsense. The responsibility for having an actual hardware memory fence
instruction lies with the author of the TAS macro. But the
responsibility for keeping the compiler from reordering stuff around the
TAS call is that of the *user* of the TAS macro (or spinlock), and in
most cases the way to do that is to make sure that both the spinlock and
the shared data structure are referenced through volatile pointers.
This isn't academic; we've seen bugs from failure to do that. (BTW,
the reason for not being equivalently tense about LWLock-protected
structures is that the compiler generally won't try to move operations
around an out-of-line function call. It's the fact that spinlocks are
inline-able that creates the risk here.)
> In the department of loose ends, there are a bunch of other things
> that maybe need cleanup here: (1) the gcc/intel compiler cases on
> ia64, (2) PA-RISC, (3) ARM, (4) PowerPC... and we should also perhaps
> reconsider the 32-bit x86 case.
The results I got yesterday seem sufficient basis to change the
gcc/intel cases for IA64, so I will go do that if you didn't already.
I am also currently running tests on x86_64 and PPC using Red Hat test
machines --- expect results later today. Red Hat doesn't seem to own
any many-CPU machines that are 32-bit-only, and I rather wonder if there
are any. It might be that it only makes sense to optimize the x86 paths
for a few CPUs, in which case this test methodology may not be very
helpful.
regards, tom lane
On Mon, Aug 29, 2011 at 11:07 AM, Tom Lane <tgl@sss.pgh.pa.us> wrote: > Robert Haas <robertmhaas@gmail.com> writes: >> OK, done. I think while we're tidying up here we ought to do >> something about this comment: > >> * ANOTHER CAUTION: be sure that TAS(), TAS_SPIN(), and >> S_UNLOCK() represent >> * sequence points, ie, loads and stores of other values must not be moved >> * across a lock or unlock. In most cases it suffices to make >> the operation >> * be done through a "volatile" pointer. > >> IIUC, this is basically total nonsense. > > It could maybe be rewritten for more clarity, but it's far from being > nonsense. The responsibility for having an actual hardware memory fence > instruction lies with the author of the TAS macro. Right... but the comment implies that you probably don't need one, and doesn't even mention that you MIGHT need one. >> In the department of loose ends, there are a bunch of other things >> that maybe need cleanup here: (1) the gcc/intel compiler cases on >> ia64, (2) PA-RISC, (3) ARM, (4) PowerPC... and we should also perhaps >> reconsider the 32-bit x86 case. > > The results I got yesterday seem sufficient basis to change the > gcc/intel cases for IA64, so I will go do that if you didn't already. I did not; please go ahead. I wasn't relishing the idea trying to figure out how to install gcc to test that case. > I am also currently running tests on x86_64 and PPC using Red Hat test > machines --- expect results later today. Red Hat doesn't seem to own > any many-CPU machines that are 32-bit-only, and I rather wonder if there > are any. It might be that it only makes sense to optimize the x86 paths > for a few CPUs, in which case this test methodology may not be very > helpful. FWIW, I tried spinning unlocked on x86_64 at 32 cores and got a regression. Don't have any PPC gear at present. I think optimizing spinlocks for machines with only a few CPUs is probably pointless. Based on what I've seen so far, spinlock contention even at 16 CPUs is negligible pretty much no matter what you do. Whether your implementation is fast or slow isn't going to matter, because even an inefficient implementation will account for only a negligible percentage of the total CPU time - much less than 1% - as opposed to a 64-core machine, where it's not that hard to find cases where spin-waits consume the *majority* of available CPU time (recall previous discussion of lseek). So I'm disinclined to spend the time it would take to tinker with the 32-bit code, because it will not matter; for that platform we're better off spending our time installing a hash table in ScanKeywordLookup(). And there's always a possibility that AMD and Intel chips could be different, or there could even be differences between different chip generations from the same manufacturer, so all in all it seems like a pretty unrewarding exercise. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
Robert Haas <robertmhaas@gmail.com> writes:
> On Mon, Aug 29, 2011 at 11:07 AM, Tom Lane <tgl@sss.pgh.pa.us> wrote:
>> Robert Haas <robertmhaas@gmail.com> writes:
>>> IIUC, this is basically total nonsense.
>> It could maybe be rewritten for more clarity, but it's far from being
>> nonsense. �The responsibility for having an actual hardware memory fence
>> instruction lies with the author of the TAS macro.
> Right... but the comment implies that you probably don't need one, and
> doesn't even mention that you MIGHT need one.
I think maybe we need to split it into two paragraphs, one addressing
the TAS author and the other for the TAS user. I'll have a go at that.
> I think optimizing spinlocks for machines with only a few CPUs is
> probably pointless. Based on what I've seen so far, spinlock
> contention even at 16 CPUs is negligible pretty much no matter what
> you do.
We did find significant differences several years ago, testing on
machines that probably had no more than four cores; that's where the
existing comments in s_lock.h came from. Whether those tests are
still relevant for today's source code is not obvious though.
regards, tom lane
On Mon, Aug 29, 2011 at 11:42 AM, Tom Lane <tgl@sss.pgh.pa.us> wrote: > Robert Haas <robertmhaas@gmail.com> writes: >> On Mon, Aug 29, 2011 at 11:07 AM, Tom Lane <tgl@sss.pgh.pa.us> wrote: >>> Robert Haas <robertmhaas@gmail.com> writes: >>>> IIUC, this is basically total nonsense. > >>> It could maybe be rewritten for more clarity, but it's far from being >>> nonsense. The responsibility for having an actual hardware memory fence >>> instruction lies with the author of the TAS macro. > >> Right... but the comment implies that you probably don't need one, and >> doesn't even mention that you MIGHT need one. > > I think maybe we need to split it into two paragraphs, one addressing > the TAS author and the other for the TAS user. I'll have a go at that. OK. >> I think optimizing spinlocks for machines with only a few CPUs is >> probably pointless. Based on what I've seen so far, spinlock >> contention even at 16 CPUs is negligible pretty much no matter what >> you do. > > We did find significant differences several years ago, testing on > machines that probably had no more than four cores; that's where the > existing comments in s_lock.h came from. Whether those tests are > still relevant for today's source code is not obvious though. Hmm, OK. I guess if you want to put energy into it, I'm not going to complain too much... just not sure it's the best use of time. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On Mon, Aug 29, 2011 at 4:07 PM, Tom Lane <tgl@sss.pgh.pa.us> wrote: >> * ANOTHER CAUTION: be sure that TAS(), TAS_SPIN(), and >> S_UNLOCK() represent >> * sequence points, ie, loads and stores of other values must not be moved >> * across a lock or unlock. In most cases it suffices to make >> the operation >> * be done through a "volatile" pointer. > >> IIUC, this is basically total nonsense. > > It could maybe be rewritten for more clarity, but it's far from being > nonsense. The confusion for me is that it's talking about sequence points and volatile pointers in the same breath as if one implies the other. Making something a volatile pointer dose not create a sequence point. It requires that the compiler not move the access or store across any sequence points that are already there. It might be helpful to include the actual bug that the comment is trying to warn against because iirc it was a real case that caused you to add the volatile modifiers. -- greg
Greg Stark <stark@mit.edu> writes:
> The confusion for me is that it's talking about sequence points and
> volatile pointers in the same breath as if one implies the other.
> Making something a volatile pointer dose not create a sequence point.
> It requires that the compiler not move the access or store across any
> sequence points that are already there.
Well, no, I don't think that's the useful way to think about it. Modern
compilers seem to only honor sequence points in terms of the semantics
seen by the executing program; they don't believe that they can't
reorder loads/stores freely. And as long as the memory in question is
only used by the given program, they're right. But for memory locations
shared with other threads of execution, you have to be careful about the
order of accesses to those locations. My understanding of "volatile"
is that the compiler is forbidden from altering the order of
volatile-qualified loads and stores *relative to each other*, or from
optimizing away a load or store that seems redundant in the context of
the given program. That's got nothing to do with sequence points per se.
> It might be helpful to include the actual bug that the comment is
> trying to warn against because iirc it was a real case that caused you
> to add the volatile modifiers.
Well, if there were one and only one bug involved here, it wouldn't be
such a critical problem ...
regards, tom lane
On Mon, Aug 29, 2011 at 12:00 PM, Tom Lane <tgl@sss.pgh.pa.us> wrote: > Greg Stark <stark@mit.edu> writes: >> The confusion for me is that it's talking about sequence points and >> volatile pointers in the same breath as if one implies the other. >> Making something a volatile pointer dose not create a sequence point. >> It requires that the compiler not move the access or store across any >> sequence points that are already there. > > Well, no, I don't think that's the useful way to think about it. Modern > compilers seem to only honor sequence points in terms of the semantics > seen by the executing program; they don't believe that they can't > reorder loads/stores freely. This discussion seems to miss the fact that there are two levels of reordering that can happen. First, the compiler can move things around. Second, the CPU can move things around. Even on x86, for example, a sequence like this can be reordered: LOAD A STORE A LOAD B Even though the compiler may emit those instructions in exactly that order, an x86 CPU can, IIUC, decide to load B before it finishes storing A, so that the actual apparent execution order as seen by other CPUs will be either the above, or the above with the last two instructions reversed. On a weakly ordered CPU, the load of B could be moved back even further, before the LOAD of A. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
Robert Haas <robertmhaas@gmail.com> writes:
> This discussion seems to miss the fact that there are two levels of
> reordering that can happen. First, the compiler can move things
> around. Second, the CPU can move things around.
Right, I think that's exactly the problem with the previous wording of
that comment; it doesn't address the two logical levels involved.
I've rewritten it, see what you think.
* Another caution for users of these macros is that it is the caller's* responsibility to ensure that the
compilerdoesn't re-order accesses* to shared memory to precede the actual lock acquisition, or follow the* lock
release. Typically we handle this by using volatile-qualified* pointers to refer to both the spinlock itself and the
shareddata* structure being accessed within the spinlocked critical section.* That fixes it because compilers are
notallowed to re-order accesses* to volatile objects relative to other such accesses.** On platforms with weak
memoryordering, the TAS(), TAS_SPIN(), and* S_UNLOCK() macros must further include hardware-level memory fence*
instructionsto prevent similar re-ordering at the hardware level.* TAS() and TAS_SPIN() must guarantee that loads
andstores issued after* the macro are not executed until the lock has been obtained. Conversely,* S_UNLOCK()
mustguarantee that loads and stores issued before the macro* have been executed before the lock is released.
regards, tom lane
On Mon, Aug 29, 2011 at 5:53 PM, Robert Haas <robertmhaas@gmail.com> wrote: > Even though the compiler may emit those instructions in exactly that > order, an x86 CPU can, IIUC, decide to load B before it finishes > storing A, so that the actual apparent execution order as seen by > other CPUs will be either the above, or the above with the last two > instructions reversed. On a weakly ordered CPU, the load of B could > be moved back even further, before the LOAD of A. My understanding of what the comment meant is that there is already a full memory barrier as far as the CPU is concerned due to the TAS or whatever, but it's important that there also be a sequence point there so that the volatile memory access isn't reordered by the compiler to occur before the memory barrier. I was going to say the same thing as Tom that sequence points and volatile pointers have nothing at all to do with each other. However my brief searching online actually seemed to indicate that in fact the compiler isn't supposed to reorder volatile memory accesses across sequence points. That seemed to make sense since I couldn't think of any other way to rigorously describe the constraints the compiler should operate under. -- greg
On Mon, Aug 29, 2011 at 1:24 PM, Tom Lane <tgl@sss.pgh.pa.us> wrote: > Robert Haas <robertmhaas@gmail.com> writes: >> This discussion seems to miss the fact that there are two levels of >> reordering that can happen. First, the compiler can move things >> around. Second, the CPU can move things around. > > Right, I think that's exactly the problem with the previous wording of > that comment; it doesn't address the two logical levels involved. > I've rewritten it, see what you think. > > * Another caution for users of these macros is that it is the caller's > * responsibility to ensure that the compiler doesn't re-order accesses > * to shared memory to precede the actual lock acquisition, or follow the > * lock release. Typically we handle this by using volatile-qualified > * pointers to refer to both the spinlock itself and the shared data > * structure being accessed within the spinlocked critical section. > * That fixes it because compilers are not allowed to re-order accesses > * to volatile objects relative to other such accesses. > * > * On platforms with weak memory ordering, the TAS(), TAS_SPIN(), and > * S_UNLOCK() macros must further include hardware-level memory fence > * instructions to prevent similar re-ordering at the hardware level. > * TAS() and TAS_SPIN() must guarantee that loads and stores issued after > * the macro are not executed until the lock has been obtained. Conversely, > * S_UNLOCK() must guarantee that loads and stores issued before the macro > * have been executed before the lock is released. That's definitely an improvement. I'm actually not convinced that we're entirely consistent here about what we require the semantics of acquiring and releasing a spinlock to be. For example, on x86 and x86_64, we acquire the lock using xchgb, which acts a full memory barrier. But when we release the lock, we just zero out the memory address, which is NOT a full memory barrier. Stores can't cross it, but non-dependent loads of different locations can back up over it. That's pretty close to a full barrier, but it isn't, quite. Now, I don't see why that should really cause any problem, at least for common cases like LWLockAcquire(). If the CPU prefetches the data protected by the lwlock after we know we've got the lock before we've actually released the spinlock and returned from LWLockAcquire(), that should be fine, even good (for performance). The real problem with being squiffy here is that it's not clear how weak we can make the fence instruction on weakly ordered architectures that support multiple types. Right now we're pretty conservative, but I think that may be costing us. I might be wrong; more research is needed here; but I think that we should at least start to get our head about what semantics we actually need. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
I wrote:
> I am also currently running tests on x86_64 and PPC using Red Hat test
> machines --- expect results later today.
OK, I ran some more tests. These are not directly comparable to my
previous results with IA64, because (a) I used RHEL6.2 and gcc 4.4.6;
(b) I used half as many pgbench threads as backends, rather than one
thread per eight backends. Testing showed that pgbench cannot saturate
more than two backends per thread in this test environment, as shown
for example by this series:
pgbench -c 8 -j 1 -S -T 300 bench tps = 22091.461409 (including ...
pgbench -c 8 -j 2 -S -T 300 bench tps = 42587.661755 (including ...
pgbench -c 8 -j 4 -S -T 300 bench tps = 77515.057885 (including ...
pgbench -c 8 -j 8 -S -T 300 bench tps = 75830.463821 (including ...
I find this entirely astonishing, BTW; the backend is surely doing far
more than twice as much work per query as pgbench. We need to look into
why pgbench is apparently still such a dog. However, that's not
tremendously relevant to the question of whether we need an unlocked
test in spinlocks.
These tests were run on a 32-CPU Opteron machine (Sun Fire X4600 M2,
8 quad-core sockets). Test conditions the same as my IA64 set, except
for the OS and the -j switches:
Stock git head:
pgbench -c 1 -j 1 -S -T 300 bench tps = 9515.435401 (including ...
pgbench -c 2 -j 1 -S -T 300 bench tps = 20239.289880 (including ...
pgbench -c 8 -j 4 -S -T 300 bench tps = 78628.371372 (including ...
pgbench -c 16 -j 8 -S -T 300 bench tps = 143065.596555 (including ...
pgbench -c 32 -j 16 -S -T 300 bench tps = 227349.424654 (including ...
pgbench -c 64 -j 32 -S -T 300 bench tps = 269016.946095 (including ...
pgbench -c 96 -j 48 -S -T 300 bench tps = 253884.095190 (including ...
pgbench -c 128 -j 64 -S -T 300 bench tps = 269235.253012 (including ...
Non-locked test in TAS():
pgbench -c 1 -j 1 -S -T 300 bench tps = 9316.195621 (including ...
pgbench -c 2 -j 1 -S -T 300 bench tps = 19852.444846 (including ...
pgbench -c 8 -j 4 -S -T 300 bench tps = 77701.546927 (including ...
pgbench -c 16 -j 8 -S -T 300 bench tps = 138926.775553 (including ...
pgbench -c 32 -j 16 -S -T 300 bench tps = 188485.669320 (including ...
pgbench -c 64 -j 32 -S -T 300 bench tps = 253602.490286 (including ...
pgbench -c 96 -j 48 -S -T 300 bench tps = 251181.310600 (including ...
pgbench -c 128 -j 64 -S -T 300 bench tps = 260812.933702 (including ...
Non-locked test in TAS_SPIN() only:
pgbench -c 1 -j 1 -S -T 300 bench tps = 9283.944739 (including ...
pgbench -c 2 -j 1 -S -T 300 bench tps = 20213.208443 (including ...
pgbench -c 8 -j 4 -S -T 300 bench tps = 78824.247744 (including ...
pgbench -c 16 -j 8 -S -T 300 bench tps = 141027.072774 (including ...
pgbench -c 32 -j 16 -S -T 300 bench tps = 201658.416366 (including ...
pgbench -c 64 -j 32 -S -T 300 bench tps = 271035.843105 (including ...
pgbench -c 96 -j 48 -S -T 300 bench tps = 261337.324585 (including ...
pgbench -c 128 -j 64 -S -T 300 bench tps = 271272.921058 (including ...
So basically there is no benefit to the unlocked test on this hardware.
But it doesn't cost much either, which is odd because the last time we
did this type of testing, adding an unlocked test was a "huge loss" on
Opteron. Apparently AMD improved their handling of the case, and/or
the other changes we've made change the usage pattern completely.
I am hoping to do a similar test on another machine with $bignum Xeon
processors, to see if Intel hardware reacts any differently. But that
machine is in the Westford office which is currently without power,
so it will have to wait a few days. (I can no longer get at either
of the machines cited in this mail, either, so if you want to see
more test cases it'll have to wait.)
These tests were run on a 32-processor PPC64 machine (IBM 8406-71Y,
POWER7 architecture; I think it might be 16 cores with hyperthreading,
not sure). The machine has "only" 6GB of RAM so I set shared_buffers to
4GB, other test conditions the same:
Stock git head:
pgbench -c 1 -j 1 -S -T 300 bench tps = 8746.076443 (including ...
pgbench -c 2 -j 1 -S -T 300 bench tps = 12297.297308 (including ...
pgbench -c 8 -j 4 -S -T 300 bench tps = 48697.392492 (including ...
pgbench -c 16 -j 8 -S -T 300 bench tps = 94133.227472 (including ...
pgbench -c 32 -j 16 -S -T 300 bench tps = 126822.857978 (including ...
pgbench -c 64 -j 32 -S -T 300 bench tps = 129364.417801 (including ...
pgbench -c 96 -j 48 -S -T 300 bench tps = 125728.697772 (including ...
pgbench -c 128 -j 64 -S -T 300 bench tps = 131566.394880 (including ...
Non-locked test in TAS():
pgbench -c 1 -j 1 -S -T 300 bench tps = 8810.484890 (including ...
pgbench -c 2 -j 1 -S -T 300 bench tps = 12336.612804 (including ...
pgbench -c 8 -j 4 -S -T 300 bench tps = 49023.435650 (including ...
pgbench -c 16 -j 8 -S -T 300 bench tps = 96306.706556 (including ...
pgbench -c 32 -j 16 -S -T 300 bench tps = 131731.475778 (including ...
pgbench -c 64 -j 32 -S -T 300 bench tps = 133451.416612 (including ...
pgbench -c 96 -j 48 -S -T 300 bench tps = 110076.269474 (including ...
pgbench -c 128 -j 64 -S -T 300 bench tps = 111339.797242 (including ...
Non-locked test in TAS_SPIN() only:
pgbench -c 1 -j 1 -S -T 300 bench tps = 8726.269726 (including ...
pgbench -c 2 -j 1 -S -T 300 bench tps = 12228.415466 (including ...
pgbench -c 8 -j 4 -S -T 300 bench tps = 48227.623829 (including ...
pgbench -c 16 -j 8 -S -T 300 bench tps = 93302.510254 (including ...
pgbench -c 32 -j 16 -S -T 300 bench tps = 130661.097475 (including ...
pgbench -c 64 -j 32 -S -T 300 bench tps = 133009.181697 (including ...
pgbench -c 96 -j 48 -S -T 300 bench tps = 128710.757986 (including ...
pgbench -c 128 -j 64 -S -T 300 bench tps = 133063.460934 (including ...
So basically no value to an unlocked test on this platform either.
regards, tom lane
Robert Haas <robertmhaas@gmail.com> writes:
> I'm actually not convinced that we're entirely consistent here about
> what we require the semantics of acquiring and releasing a spinlock to
> be. For example, on x86 and x86_64, we acquire the lock using xchgb,
> which acts a full memory barrier. But when we release the lock, we
> just zero out the memory address, which is NOT a full memory barrier.
> Stores can't cross it, but non-dependent loads of different locations
> can back up over it. That's pretty close to a full barrier, but it
> isn't, quite.
Right. That's why I wrote the comment as I did; it says what the actual
requirement is. There probably are cases where our implementations are
more restrictive than necessary (I hope none where they are weaker).
regards, tom lane
On Mon, Aug 29, 2011 at 2:15 PM, Tom Lane <tgl@sss.pgh.pa.us> wrote: > These tests were run on a 32-CPU Opteron machine (Sun Fire X4600 M2, > 8 quad-core sockets). Test conditions the same as my IA64 set, except > for the OS and the -j switches: > > Stock git head: > > pgbench -c 1 -j 1 -S -T 300 bench tps = 9515.435401 (including ... > pgbench -c 32 -j 16 -S -T 300 bench tps = 227349.424654 (including ... > > These tests were run on a 32-processor PPC64 machine (IBM 8406-71Y, > POWER7 architecture; I think it might be 16 cores with hyperthreading, > not sure). The machine has "only" 6GB of RAM so I set shared_buffers to > 4GB, other test conditions the same: > > Stock git head: > > pgbench -c 1 -j 1 -S -T 300 bench tps = 8746.076443 (including ... > pgbench -c 32 -j 16 -S -T 300 bench tps = 126822.857978 (including ... Stepping beyond the immediate issue of whether we want an unlocked test in there or not (and I agree that based on these numbers we don't), there's a clear and puzzling difference between those sets of numbers. The Opteron test is showing 32 clients getting about 23.9 times the throughput of a single client, which is not exactly linear but is at least respectable, whereas the PPC64 test is showing 32 clients getting just 14.5 times the throughput of a single client, which is pretty significantly less good. Moreover, cranking it up to 64 clients is squeezing a significant amount of additional work out on Opteron, but not on PPC64. The HP-UX/Itanium numbers in my OP give a ratio of 17.3x - a little better than your PPC64 numbers, but certainly not great. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
Greg Stark <stark@mit.edu> writes:
> I was going to say the same thing as Tom that sequence points and
> volatile pointers have nothing at all to do with each other. However
> my brief searching online actually seemed to indicate that in fact the
> compiler isn't supposed to reorder volatile memory accesses across
> sequence points. That seemed to make sense since I couldn't think of
> any other way to rigorously describe the constraints the compiler
> should operate under.
It's a bit confusing. I agree that if the code is written such that
there are two volatile accesses with no intervening sequence point,
the compiler is at liberty to do them in either order; for instance in
foo(*x, *y);
there are no guarantees about which value is fetched first, even if x
and y are volatile-qualified. What's bothering me is that in, say,
*x = 0;*y = 1;*z = 2;
if x and z are volatile-qualified but y isn't, I believe the compilers
think they are only required to store into *x before *z, and can reorder
the store to *y around either of the others. So this makes the notion
of a sequence point pretty squishy in itself.
regards, tom lane
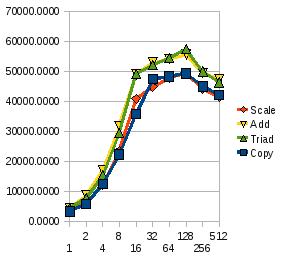
Robert Haas <robertmhaas@gmail.com> wrote: > Stepping beyond the immediate issue of whether we want an unlocked > test in there or not (and I agree that based on these numbers we > don't), there's a clear and puzzling difference between those sets > of numbers. The Opteron test is showing 32 clients getting about > 23.9 times the throughput of a single client, which is not exactly > linear but is at least respectable, whereas the PPC64 test is > showing 32 clients getting just 14.5 times the throughput of a > single client, which is pretty significantly less good. Moreover, > cranking it up to 64 clients is squeezing a significant amount of > additional work out on Opteron, but not on PPC64. The > HP-UX/Itanium numbers in my OP give a ratio of 17.3x - a little > better than your PPC64 numbers, but certainly not great. I wouldn't make too much of that without comparing to a STREAM test (properly configured -- the default array size is likely not to be large enough for these machines). On a recently delivered 32 core machine with 256 GB RAM, I saw numbers like this for just RAM access: Threads Copy Scale Add Triad 1 3332.3721 3374.8146 4500.1954 4309.7392 2 5822.8107 6158.4621 8563.3236 7756.9050 4 12474.9646 12282.3401 16960.7216 15399.2406 8 22353.6013 23502.4389 31911.5206 29574.8124 16 35760.8782 40946.6710 49108.4386 49264.6576 32 47567.3882 44935.4608 52983.9355 52278.1373 64 48428.9939 47851.7320 54141.8830 54560.0520 128 49354.4303 49586.6092 55663.2606 57489.5798 256 45081.3601 44303.1032 49561.3815 50073.3530 512 42271.9688 41689.8609 47362.4190 46388.9720 Graph attached for those who are visually inclined and have support for the display of JPEG files. Note that this is a machine which is *not* configured to be blazingly fast for a single connection, but to scale up well for a large number of concurrent processes: http://www.redbooks.ibm.com/redpapers/pdfs/redp4650.pdf Unless your benchmarks are falling off a lot faster than the STREAM test on that hardware, I wouldn't worry. -Kevin
Attachment
{kind=link}
"Kevin Grittner" <Kevin.Grittner@wicourts.gov> writes:
> Robert Haas <robertmhaas@gmail.com> wrote:
>> Stepping beyond the immediate issue of whether we want an unlocked
>> test in there or not (and I agree that based on these numbers we
>> don't), there's a clear and puzzling difference between those sets
>> of numbers. The Opteron test is showing 32 clients getting about
>> 23.9 times the throughput of a single client, which is not exactly
>> linear but is at least respectable, whereas the PPC64 test is
>> showing 32 clients getting just 14.5 times the throughput of a
>> single client, which is pretty significantly less good.
> I wouldn't make too much of that without comparing to a STREAM test
> (properly configured -- the default array size is likely not to be
> large enough for these machines).
Yeah. One point I didn't mention is that the Opteron machine's memory
is split across 8 NUMA nodes, whereas the PPC machine's isn't. I would
bet there's a significant difference in aggregate available memory
bandwidth.
Also, if the PPC machine really is hyperthreaded (the internal webpage
for it says "Hyper? True" but /proc/cpuinfo doesn't provide any clear
indications), that might mean it's not going to scale too well past 16x
the single-thread case.
regards, tom lane
Sorry, forgot to cc the list. On Mon, Aug 29, 2011 at 10:12 PM, Tom Lane <tgl@sss.pgh.pa.us> wrote: > Also, if the PPC machine really is hyperthreaded (the internal webpage > for it says "Hyper? True" but /proc/cpuinfo doesn't provide any clear > indications), that might mean it's not going to scale too well past 16x > the single-thread case. According to IBM docs [1], 8406-71Y contains one 8 core POWER7 chip that is 4-way multi-threaded and has 4 memory channels. X4600M2 should have 16 memory channels, although at 2/3 the transfer rate. 6GB of memory is a strange amount for the IBM, according to specs it should take 4 or 8GB DIMMs in pairs. Sounds like the server is split into multiple partitions. -- Ants Aasma [1] http://www.redbooks.ibm.com/redpapers/pdfs/redp4655.pdf
Ants Aasma <ants.aasma@eesti.ee> writes: > On Mon, Aug 29, 2011 at 10:12 PM, Tom Lane <tgl@sss.pgh.pa.us> wrote: >> Also, if the PPC machine really is hyperthreaded (the internal webpage >> for it says "Hyper? True" but /proc/cpuinfo doesn't provide any clear >> indications), that might mean it's not going to scale too well past 16x >> the single-thread case. > According to IBM docs [1], 8406-71Y contains one 8 core POWER7 chip > that is 4-way multi-threaded and has 4 memory channels. Yeah, I looked at the docs. "Multi threading" is IBM's term for hyperthreading, that is several instruction streams competing for use of a single processor core's pipelines. So the 32 virtual processors on the machine only really represent 8 physically independent cores, squaring with the hardware designation. I found an IBM doc http://www-03.ibm.com/systems/resources/pwrsysperf_SMT4OnP7.pdf suggesting that the throughput benefit of 4-way SMT is typically 1.5 to 2X, that is you max out at 1.5 to 2X as much work as you'd get with just 8 virtual processors on the same 8 cores. So I'd say we're really doing quite well to get the numbers I got. (The paper also implies that you get more benefit from SMT with workloads that incur more memory-access stalls, so the relatively large working set of this test case is helping it look good.) > 6GB of > memory is a strange amount for the IBM, according to specs it should take > 4 or 8GB DIMMs in pairs. Sounds like the server is split into multiple > partitions. I'm confused about that too. There definitely seemed to be only 6GB of available RAM, but there's no way I can see that memory might be partitioned across different blades. The blades look pretty independent ... regards, tom lane
I wrote:
> I am hoping to do a similar test on another machine with $bignum Xeon
> processors, to see if Intel hardware reacts any differently. But that
> machine is in the Westford office which is currently without power,
> so it will have to wait a few days.
OK, the lights are on again in Westford, so here are some results from
an 8-socket Fujitsu PRIMEQUEST 1800 with 10-core Xeon E7-8870 processors,
hyperthreading enabled for a total of 160 virtual processors.
All test conditions the same as from my Opteron runs yesterday,
except just for the heck of it I ran it up to 160 backends.
Stock git head (of a couple of days ago now):
pgbench -c 1 -j 1 -S -T 300 bench tps = 4401.589257 (including ...
pgbench -c 2 -j 1 -S -T 300 bench tps = 8585.789827 (including ...
pgbench -c 8 -j 4 -S -T 300 bench tps = 36315.227334 (including ...
pgbench -c 16 -j 8 -S -T 300 bench tps = 73841.195884 (including ...
pgbench -c 32 -j 16 -S -T 300 bench tps = 155309.526039 (including ...
pgbench -c 64 -j 32 -S -T 300 bench tps = 77477.101725 (including ...
pgbench -c 96 -j 48 -S -T 300 bench tps = 41301.481915 (including ...
pgbench -c 128 -j 64 -S -T 300 bench tps = 30443.815506 (including ...
pgbench -c 160 -j 80 -S -T 300 bench tps = 24600.584202 (including ...
Non-locked test in TAS():
pgbench -c 1 -j 1 -S -T 300 bench tps = 4412.336573 (including ...
pgbench -c 2 -j 1 -S -T 300 bench tps = 8739.900806 (including ...
pgbench -c 8 -j 4 -S -T 300 bench tps = 32957.710818 (including ...
pgbench -c 16 -j 8 -S -T 300 bench tps = 71538.032629 (including ...
pgbench -c 32 -j 16 -S -T 300 bench tps = 153892.469308 (including ...
pgbench -c 64 -j 32 -S -T 300 bench tps = 127786.277182 (including ...
pgbench -c 96 -j 48 -S -T 300 bench tps = 92108.895423 (including ...
pgbench -c 128 -j 64 -S -T 300 bench tps = 75382.131814 (including ...
pgbench -c 160 -j 80 -S -T 300 bench tps = 67277.057981 (including ...
Non-locked test in TAS_SPIN() only:
pgbench -c 1 -j 1 -S -T 300 bench tps = 4006.626861 (including ...
pgbench -c 2 -j 1 -S -T 300 bench tps = 9020.124850 (including ...
pgbench -c 8 -j 4 -S -T 300 bench tps = 36507.582318 (including ...
pgbench -c 16 -j 8 -S -T 300 bench tps = 69668.921550 (including ...
pgbench -c 32 -j 16 -S -T 300 bench tps = 150886.395754 (including ...
pgbench -c 64 -j 32 -S -T 300 bench tps = 216697.745497 (including ...
pgbench -c 96 -j 48 -S -T 300 bench tps = 171013.266643 (including ...
pgbench -c 128 -j 64 -S -T 300 bench tps = 115205.718495 (including ...
pgbench -c 160 -j 80 -S -T 300 bench tps = 92073.704665 (including ...
This suggests that (1) an unlocked test in TAS_SPIN might be a good idea
on x86_64 after all, and (2) this test scenario may not be pushing the
system hard enough to expose limitations of the spinlock implementation.
I am now thinking that the reason we saw clear differences in spinlock
implementations years ago, and now are not seeing them except on insane
hardware, is mainly that we've managed to reduce contention at higher
levels of the system. That doesn't mean spinlocks have become
uninteresting, just that "pgbench -S" isn't the ideal test case for
stressing them. I'm thinking maybe we need a test scenario that
generates sinval traffic, for example, or forces snapshots to be taken
more often. Ideas anyone?
regards, tom lane
On Tue, Aug 30, 2011 at 4:05 PM, Tom Lane <tgl@sss.pgh.pa.us> wrote: > This suggests that (1) an unlocked test in TAS_SPIN might be a good idea > on x86_64 after all, and (2) this test scenario may not be pushing the > system hard enough to expose limitations of the spinlock implementation. > > I am now thinking that the reason we saw clear differences in spinlock > implementations years ago, and now are not seeing them except on insane > hardware, is mainly that we've managed to reduce contention at higher > levels of the system. That doesn't mean spinlocks have become > uninteresting, just that "pgbench -S" isn't the ideal test case for > stressing them. I'm thinking maybe we need a test scenario that > generates sinval traffic, for example, or forces snapshots to be taken > more often. Ideas anyone? On current sources, with a workload that fits into shared_buffers, pgbench -S hammers the spinlock protecting ProcArrayLock extremely hard. I'm sure it's possible to come up with a test case that hammers them harder, but using a real workload can expose issues (like aggregate memory bandwidth) that you might not see otherwise. I am a bit surprised by your test results, because I also tried x86_64 with an unlocked test, also on pgbench -S, and I am pretty sure I got a regression. Maybe I'll try rerunning that. It seems possible that the x86_64 results depend on the particular sub-architecture and/or whether HT is in use, which would be kind of a nuisance. Also, did you happen to measure the amount of user time vs. system time that your test runs used? If this is on Linux, I am surprised that you didn't get killed by the lseek() contention problem on a machine with that many cores. I found it to be visible at 32 and crippling at 64, so I can't even imagine what it would be like at 160. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
Robert Haas <robertmhaas@gmail.com> writes:
> I am a bit surprised by your test results, because I also tried x86_64
> with an unlocked test, also on pgbench -S, and I am pretty sure I got
> a regression. Maybe I'll try rerunning that. It seems possible that
> the x86_64 results depend on the particular sub-architecture and/or
> whether HT is in use, which would be kind of a nuisance.
Well, if you consider Opteron as a sub-architecture of x86_64, that was
already true the last time we did this. So far there have not been
cases where something really good for one implementation was really bad
for another, but someday we'll probably hit that.
> Also, did you happen to measure the amount of user time vs. system
> time that your test runs used?
Did not think about that. I was considering how to measure the average
context swap rate over each run, so that we could keep an eye out for
the "context swap storm" behavior that's the usual visible-in-top
symptom of these sorts of problems. But it'd have to be automated;
I'm not going to keep my eyes glued to "top" output for several hours.
I'd be happy to re-run these tests with any RHEL-compatible measurement
scaffolding somebody else provides, but if I have to write it, it
probably won't happen very soon.
> If this is on Linux, I am surprised
> that you didn't get killed by the lseek() contention problem on a
> machine with that many cores.
Hm ... now that you mention it, all of these tests have been using
the latest-and-greatest unreleased RHEL kernels. Maybe Red Hat already
fixed that contention problem in their kernel? Have you got a RH
bugzilla number for the issue?
regards, tom lane
On Tue, Aug 30, 2011 at 4:37 PM, Tom Lane <tgl@sss.pgh.pa.us> wrote: >> If this is on Linux, I am surprised >> that you didn't get killed by the lseek() contention problem on a >> machine with that many cores. > > Hm ... now that you mention it, all of these tests have been using > the latest-and-greatest unreleased RHEL kernels. Maybe Red Hat already > fixed that contention problem in their kernel? Have you got a RH > bugzilla number for the issue? No, I haven't had much luck filing bugs against Red Hat releases, so I've sort of given up on that. I did have some off-list correspondence with a Red Hat engineer who red my blog post, though. It should be pretty easy to figure it out, though. Just fire up pgbench with lots of clients (say, 160) and run vmstat in another window. If the machine reports 10% system time, it's fixed. If it reports 90% system time, it's not. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
Robert Haas <robertmhaas@gmail.com> writes:
> On Tue, Aug 30, 2011 at 4:37 PM, Tom Lane <tgl@sss.pgh.pa.us> wrote:
>>> If this is on Linux, I am surprised
>>> that you didn't get killed by the lseek() contention problem on a
>>> machine with that many cores.
>> Hm ... now that you mention it, all of these tests have been using
>> the latest-and-greatest unreleased RHEL kernels.
> It should be pretty easy to figure it out, though. Just fire up
> pgbench with lots of clients (say, 160) and run vmstat in another
> window. If the machine reports 10% system time, it's fixed. If it
> reports 90% system time, it's not.
I ran it up to "pgbench -c 200 -j 200 -S -T 300 bench" and still see
vmstat numbers around 50% user time, 12% system time, 38% idle.
So no lseek problem here, boss. Kernel calls itself 2.6.32-192.el6.x86_64.
regards, tom lane
On Tue, Aug 30, 2011 at 6:33 PM, Tom Lane <tgl@sss.pgh.pa.us> wrote: > Robert Haas <robertmhaas@gmail.com> writes: >> On Tue, Aug 30, 2011 at 4:37 PM, Tom Lane <tgl@sss.pgh.pa.us> wrote: >>>> If this is on Linux, I am surprised >>>> that you didn't get killed by the lseek() contention problem on a >>>> machine with that many cores. > >>> Hm ... now that you mention it, all of these tests have been using >>> the latest-and-greatest unreleased RHEL kernels. > >> It should be pretty easy to figure it out, though. Just fire up >> pgbench with lots of clients (say, 160) and run vmstat in another >> window. If the machine reports 10% system time, it's fixed. If it >> reports 90% system time, it's not. > > I ran it up to "pgbench -c 200 -j 200 -S -T 300 bench" and still see > vmstat numbers around 50% user time, 12% system time, 38% idle. > So no lseek problem here, boss. Kernel calls itself 2.6.32-192.el6.x86_64. Eh, wait a minute. 38% idle time? Did you use a scale factor that doesn't fit in shared_buffers? If so you're probably testing how fast you pass BufFreelistLock around... -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
Robert Haas <robertmhaas@gmail.com> writes:
> On Tue, Aug 30, 2011 at 6:33 PM, Tom Lane <tgl@sss.pgh.pa.us> wrote:
>> I ran it up to "pgbench -c 200 -j 200 -S -T 300 bench" and still see
>> vmstat numbers around 50% user time, 12% system time, 38% idle.
>> So no lseek problem here, boss. Kernel calls itself 2.6.32-192.el6.x86_64.
> Eh, wait a minute. 38% idle time? Did you use a scale factor that
> doesn't fit in shared_buffers?
Nope: -s 100, 8GB shared_buffers, same as all the other tests.
Typical strace of one backend looks like
recvfrom(9, "Q\0\0\0?SELECT abalance FROM pgbenc"..., 8192, 0, NULL, NULL) = 64
lseek(10, 0, SEEK_END) = 269213696
lseek(11, 0, SEEK_END) = 224641024
sendto(9, "T\0\0\0!\0\1abalance\0\0\0\241\267\0\3\0\0\0\27\0\4\377\377\377\377"..., 66, 0, NULL, 0) = 66
recvfrom(9, "Q\0\0\0?SELECT abalance FROM pgbenc"..., 8192, 0, NULL, NULL) = 64
lseek(10, 0, SEEK_END) = 269213696
lseek(11, 0, SEEK_END) = 224641024
sendto(9, "T\0\0\0!\0\1abalance\0\0\0\241\267\0\3\0\0\0\27\0\4\377\377\377\377"..., 66, 0, NULL, 0) = 66
recvfrom(9, "Q\0\0\0?SELECT abalance FROM pgbenc"..., 8192, 0, NULL, NULL) = 64
select(0, NULL, NULL, NULL, {0, 1000}) = 0 (Timeout)
lseek(10, 0, SEEK_END) = 269213696
lseek(11, 0, SEEK_END) = 224641024
select(0, NULL, NULL, NULL, {0, 1000}) = 0 (Timeout)
select(0, NULL, NULL, NULL, {0, 1000}) = 0 (Timeout)
sendto(9, "T\0\0\0!\0\1abalance\0\0\0\241\267\0\3\0\0\0\27\0\4\377\377\377\377"..., 66, 0, NULL, 0) = 66
recvfrom(9, "Q\0\0\0?SELECT abalance FROM pgbenc"..., 8192, 0, NULL, NULL) = 64
lseek(10, 0, SEEK_END) = 269213696
lseek(11, 0, SEEK_END) = 224641024
select(0, NULL, NULL, NULL, {0, 1000}) = 0 (Timeout)
sendto(9, "T\0\0\0!\0\1abalance\0\0\0\241\267\0\3\0\0\0\27\0\4\377\377\377\377"..., 66, 0, NULL, 0) = 66
No I/O anywhere. I'm thinking the reported idle time must correspond to
spinlock delays that are long enough to reach the select() calls in
s_lock. If so, 38% is depressingly high, but it's not out of line with
what we've seen in the past in tests designed to provoke spinlock
contention.
(BTW, this is with the unlocked test added to TAS_SPIN.)
regards, tom lane
On Tue, Aug 30, 2011 at 7:21 PM, Tom Lane <tgl@sss.pgh.pa.us> wrote:
> Robert Haas <robertmhaas@gmail.com> writes:
>> On Tue, Aug 30, 2011 at 6:33 PM, Tom Lane <tgl@sss.pgh.pa.us> wrote:
>>> I ran it up to "pgbench -c 200 -j 200 -S -T 300 bench" and still see
>>> vmstat numbers around 50% user time, 12% system time, 38% idle.
>>> So no lseek problem here, boss. Kernel calls itself 2.6.32-192.el6.x86_64.
>
>> Eh, wait a minute. 38% idle time? Did you use a scale factor that
>> doesn't fit in shared_buffers?
>
> Nope: -s 100, 8GB shared_buffers, same as all the other tests.
>
> Typical strace of one backend looks like
>
> recvfrom(9, "Q\0\0\0?SELECT abalance FROM pgbenc"..., 8192, 0, NULL, NULL) = 64
> lseek(10, 0, SEEK_END) = 269213696
> lseek(11, 0, SEEK_END) = 224641024
> sendto(9, "T\0\0\0!\0\1abalance\0\0\0\241\267\0\3\0\0\0\27\0\4\377\377\377\377"..., 66, 0, NULL, 0) = 66
> recvfrom(9, "Q\0\0\0?SELECT abalance FROM pgbenc"..., 8192, 0, NULL, NULL) = 64
> lseek(10, 0, SEEK_END) = 269213696
> lseek(11, 0, SEEK_END) = 224641024
> sendto(9, "T\0\0\0!\0\1abalance\0\0\0\241\267\0\3\0\0\0\27\0\4\377\377\377\377"..., 66, 0, NULL, 0) = 66
> recvfrom(9, "Q\0\0\0?SELECT abalance FROM pgbenc"..., 8192, 0, NULL, NULL) = 64
> select(0, NULL, NULL, NULL, {0, 1000}) = 0 (Timeout)
> lseek(10, 0, SEEK_END) = 269213696
> lseek(11, 0, SEEK_END) = 224641024
> select(0, NULL, NULL, NULL, {0, 1000}) = 0 (Timeout)
> select(0, NULL, NULL, NULL, {0, 1000}) = 0 (Timeout)
> sendto(9, "T\0\0\0!\0\1abalance\0\0\0\241\267\0\3\0\0\0\27\0\4\377\377\377\377"..., 66, 0, NULL, 0) = 66
> recvfrom(9, "Q\0\0\0?SELECT abalance FROM pgbenc"..., 8192, 0, NULL, NULL) = 64
> lseek(10, 0, SEEK_END) = 269213696
> lseek(11, 0, SEEK_END) = 224641024
> select(0, NULL, NULL, NULL, {0, 1000}) = 0 (Timeout)
> sendto(9, "T\0\0\0!\0\1abalance\0\0\0\241\267\0\3\0\0\0\27\0\4\377\377\377\377"..., 66, 0, NULL, 0) = 66
>
> No I/O anywhere. I'm thinking the reported idle time must correspond to
> spinlock delays that are long enough to reach the select() calls in
> s_lock. If so, 38% is depressingly high, but it's not out of line with
> what we've seen in the past in tests designed to provoke spinlock
> contention.
>
> (BTW, this is with the unlocked test added to TAS_SPIN.)
Well, that is mighty interesting. That strace looks familiar, but I
have never seen a case where the idle time was more than a few
percentage points on this test (well, assuming you're using 9.2
sources, anyway).
--
Robert Haas
EnterpriseDB: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
I wrote:
> No I/O anywhere. I'm thinking the reported idle time must correspond to
> spinlock delays that are long enough to reach the select() calls in
> s_lock. If so, 38% is depressingly high, but it's not out of line with
> what we've seen in the past in tests designed to provoke spinlock
> contention.
I tried increasing MAX_SPINS_PER_DELAY from 1000 to 10000. (Again, this
is with the unlocked test added to TAS_SPIN.) This resulted in a very
significant drop in the reported idle-time percentage, down to 10% or so
at full load; but unfortunately the TPS numbers got worse for the higher
end of the curve:
pgbench -c 1 -j 1 -S -T 300 bench tps = 4526.914824 (including ...
pgbench -c 2 -j 1 -S -T 300 bench tps = 8183.815526 (including ...
pgbench -c 8 -j 4 -S -T 300 bench tps = 34637.075173 (including ...
pgbench -c 16 -j 8 -S -T 300 bench tps = 68792.550304 (including ...
pgbench -c 32 -j 16 -S -T 300 bench tps = 159195.038317 (including ...
pgbench -c 64 -j 32 -S -T 300 bench tps = 220544.912947 (including ...
pgbench -c 96 -j 48 -S -T 300 bench tps = 147367.793544 (including ...
pgbench -c 128 -j 64 -S -T 300 bench tps = 79187.042252 (including ...
pgbench -c 160 -j 80 -S -T 300 bench tps = 43957.912879 (including ...
So that confirms the idea that the reported idle time corresponds to
s_lock select() sleeps. Unfortunately, it doesn't appear to lead to
anything that would result in increasing performance. I suppose the
reason that performance gets worse, even though we've presumably
eliminated some process context swaps, is that we have more cache line
contention for whichever spinlock(s) they're all fighting over.
regards, tom lane
Hi, I am interested in this thread because I may be able to borrow a big IBM machine and might be able to do some tests on it if it somewhat contributes enhancing PostgreSQL. Is there anything I can do for this? -- Tatsuo Ishii SRA OSS, Inc. Japan English: http://www.sraoss.co.jp/index_en.php Japanese: http://www.sraoss.co.jp > I was able to obtain access to a 32-core HP-UX server. I repeated the > pgbench -S testing that I have previously done on Linux, and found > that the results were not too good. Here are the results at scale > factor 100, on 9.2devel, with various numbers of clients. Five minute > runs, shared_buffers=8GB. > > 1:tps = 5590.070816 (including connections establishing) > 8:tps = 37660.233932 (including connections establishing) > 16:tps = 67366.099286 (including connections establishing) > 32:tps = 82781.624665 (including connections establishing) > 48:tps = 18589.995074 (including connections establishing) > 64:tps = 16424.661371 (including connections establishing) > > And just for comparison, here are the numbers at scale factor 1000: > > 1:tps = 4751.768608 (including connections establishing) > 8:tps = 33621.474490 (including connections establishing) > 16:tps = 58959.043171 (including connections establishing) > 32:tps = 78801.265189 (including connections establishing) > 48:tps = 21635.234969 (including connections establishing) > 64:tps = 18611.863567 (including connections establishing) > > After mulling over the vmstat output for a bit, I began to suspect > spinlock contention. I took a look at document called "Implementing > Spinlocks on the Intel Itanium Architecture and PA-RISC", by Tor > Ekqvist and David Graves and available via the HP web site, which > states that when spinning on a spinlock on these machines, you should > use a regular, unlocked test first and use the atomic test only when > the unlocked test looks OK. I tried implementing this in two ways, > and both produced results which are FAR superior to our current > implementation. First, I did this: > > --- a/src/include/storage/s_lock.h > +++ b/src/include/storage/s_lock.h > @@ -726,7 +726,7 @@ tas(volatile slock_t *lock) > typedef unsigned int slock_t; > > #include <ia64/sys/inline.h> > -#define TAS(lock) _Asm_xchg(_SZ_W, lock, 1, _LDHINT_NONE) > +#define TAS(lock) (*(lock) ? 1 : _Asm_xchg(_SZ_W, lock, 1, _LDHINT_NONE)) > > #endif /* HPUX on IA64, non gcc */ > > That resulted in these numbers. Scale factor 100: > > 1:tps = 5569.911714 (including connections establishing) > 8:tps = 37365.364468 (including connections establishing) > 16:tps = 63596.261875 (including connections establishing) > 32:tps = 95948.157678 (including connections establishing) > 48:tps = 90708.253920 (including connections establishing) > 64:tps = 100109.065744 (including connections establishing) > > Scale factor 1000: > > 1:tps = 4878.332996 (including connections establishing) > 8:tps = 33245.469907 (including connections establishing) > 16:tps = 56708.424880 (including connections establishing) > 48:tps = 69652.232635 (including connections establishing) > 64:tps = 70593.208637 (including connections establishing) > > Then, I did this: > > --- a/src/backend/storage/lmgr/s_lock.c > +++ b/src/backend/storage/lmgr/s_lock.c > @@ -96,7 +96,7 @@ s_lock(volatile slock_t *lock, const char *file, int line) > int delays = 0; > int cur_delay = 0; > > - while (TAS(lock)) > + while (*lock ? 1 : TAS(lock)) > { > /* CPU-specific delay each time through the loop */ > SPIN_DELAY(); > > That resulted in these numbers, at scale factor 100: > > 1:tps = 5564.059494 (including connections establishing) > 8:tps = 37487.090798 (including connections establishing) > 16:tps = 66061.524760 (including connections establishing) > 32:tps = 96535.523905 (including connections establishing) > 48:tps = 92031.618360 (including connections establishing) > 64:tps = 106813.631701 (including connections establishing) > > And at scale factor 1000: > > 1:tps = 4980.338246 (including connections establishing) > 8:tps = 33576.680072 (including connections establishing) > 16:tps = 55618.677975 (including connections establishing) > 32:tps = 73589.442746 (including connections establishing) > 48:tps = 70987.026228 (including connections establishing) > > Note sure why I am missing the 64-client results for that last set of > tests, but no matter. > > Of course, we can't apply the second patch as it stands, because I > tested it on x86 and it loses. But it seems pretty clear we need to > do it at least for this architecture... > > -- > Robert Haas > EnterpriseDB: http://www.enterprisedb.com > The Enterprise PostgreSQL Company > > -- > Sent via pgsql-hackers mailing list (pgsql-hackers@postgresql.org) > To make changes to your subscription: > http://www.postgresql.org/mailpref/pgsql-hackers
On Tue, Sep 6, 2011 at 4:33 AM, Tatsuo Ishii <ishii@postgresql.org> wrote: > I am interested in this thread because I may be able to borrow a big > IBM machine and might be able to do some tests on it if it somewhat > contributes enhancing PostgreSQL. Is there anything I can do for this? That would be great. What I've been using as a test case is pgbench -S -c $NUM_CPU_CORES -j $NUM_CPU_CORES with scale factor 100 and shared_buffers=8GB. I think what you'd want to compare is the performance of unpatched master, vs. the performance with this line added to s_lock.h for your architecture: #define TAS_SPIN(lock) (*(lock) ? 1 : TAS(lock)) We've now added that line for ia64 (the line is present in two different places in the file, one for GCC and the other for HP's compiler). So the question is whether we need it for any other architectures. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
> That would be great. What I've been using as a test case is pgbench > -S -c $NUM_CPU_CORES -j $NUM_CPU_CORES with scale factor 100 and > shared_buffers=8GB. > > I think what you'd want to compare is the performance of unpatched > master, vs. the performance with this line added to s_lock.h for your > architecture: > > #define TAS_SPIN(lock) (*(lock) ? 1 : TAS(lock)) > > We've now added that line for ia64 (the line is present in two > different places in the file, one for GCC and the other for HP's > compiler). So the question is whether we need it for any other > architectures. Ok. Let me talk to IBM guys... -- Tatsuo Ishii SRA OSS, Inc. Japan English: http://www.sraoss.co.jp/index_en.php Japanese: http://www.sraoss.co.jp
>> That would be great. What I've been using as a test case is pgbench >> -S -c $NUM_CPU_CORES -j $NUM_CPU_CORES with scale factor 100 and >> shared_buffers=8GB. >> >> I think what you'd want to compare is the performance of unpatched >> master, vs. the performance with this line added to s_lock.h for your >> architecture: >> >> #define TAS_SPIN(lock) (*(lock) ? 1 : TAS(lock)) >> >> We've now added that line for ia64 (the line is present in two >> different places in the file, one for GCC and the other for HP's >> compiler). So the question is whether we need it for any other >> architectures. > > Ok. Let me talk to IBM guys... With help from IBM Japan Ltd. we did some tests on a larger IBM machine than Tom Lane has used for his test(http://archives.postgresql.org/message-id/8292.1314641721@sss.pgh.pa.us). In his case it was IBM 8406-71Y, which has 8 physical cores and 4SMT(32 threadings). Ours is IBM Power 750 Express, which has 32 physical cores and 4SMT(128 threadings), 256GB RAM. The test method was same as the one in the article above. The differences are OS(RHEL 6.1), gcc version (4.4.5) and shared buffer size(8GB). We tested 3 methods to enhance spin lock contention: 1) Add "hint" parameter to lwarx op which is usable POWER6 or later architecure. 2) Add non-locked test in TAS() 3) #1 + #2 We saw small performance enhancement with #1, larger one with #2 and even better with #1+#2. Stock git head: pgbench -c 1 -j 1 -S -T 300 bench tps = 10356.306513 (including ... pgbench -c 2 -j 1 -S -T 300 bench tps = 21841.10285 (including ... pgbench -c 8 -j 4 -S -T 300 bench tps = 63800.868529 (including ... pgbench -c 16 -j 8 -S -T 300 bench tps = 144872.64726 (including ... pgbench -c 32 -j 16 -S -T 300 bench tps = 120943.238461 (including ... pgbench -c 64 -j 32 -S -T 300 bench tps = 108144.933981 (including ... pgbench -c 128 -j 64 -S -T 300 bench tps = 92202.782791 (including ... With hint (method #1): pgbench -c 1 -j 1 -S -T 300 bench tps = 11198.1872 (including ... pgbench -c 2 -j 1 -S -T 300 bench tps = 21390.592014 (including ... pgbench -c 8 -j 4 -S -T 300 bench tps = 74423.488089 (including ... pgbench -c 16 -j 8 -S -T 300 bench tps = 153766.351105 (including ... pgbench -c 32 -j 16 -S -T 300 bench tps = 134313.758113 (including ... pgbench -c 64 -j 32 -S -T 300 bench tps = 129392.154047 (including ... pgbench -c 128 -j 64 -S -T 300 bench tps = 105506.948058 (including ... Non-locked test in TAS() (method #2): pgbench -c 1 -j 1 -S -T 300 bench tps = 10537.893154 (including ... pgbench -c 2 -j 1 -S -T 300 bench tps = 22019.388666 (including ... pgbench -c 8 -j 4 -S -T 300 bench tps = 78763.930379 (including ... pgbench -c 16 -j 8 -S -T 300 bench tps = 142791.99724 (including ... pgbench -c 32 -j 16 -S -T 300 bench tps = 222008.903675 (including ... pgbench -c 64 -j 32 -S -T 300 bench tps = 209912.691058 (including ... pgbench -c 128 -j 64 -S -T 300 bench tps = 199437.23965 (including ... With hint and non-locked test in TAS (#1 + #2) pgbench -c 1 -j 1 -S -T 300 bench tps = 11419.881375 (including ... pgbench -c 2 -j 1 -S -T 300 bench tps = 21919.530209 (including ... pgbench -c 8 -j 4 -S -T 300 bench tps = 74788.242876 (including ... pgbench -c 16 -j 8 -S -T 300 bench tps = 156354.988564 (including ... pgbench -c 32 -j 16 -S -T 300 bench tps = 240521.495 (including ... pgbench -c 64 -j 32 -S -T 300 bench tps = 235709.272642 (including ... pgbench -c 128 -j 64 -S -T 300 bench tps = 220135.729663 (including ... Since each core usage is around 50% in the benchmark, there is room for further performance improvement by eliminating other contentions, tuning compiler option etc. -- Tatsuo Ishii SRA OSS, Inc. Japan English: http://www.sraoss.co.jp/index_en.php Japanese: http://www.sraoss.co.jp
On Tue, Oct 18, 2011 at 12:11 AM, Tatsuo Ishii <ishii@postgresql.org> wrote: >>> That would be great. What I've been using as a test case is pgbench >>> -S -c $NUM_CPU_CORES -j $NUM_CPU_CORES with scale factor 100 and >>> shared_buffers=8GB. >>> >>> I think what you'd want to compare is the performance of unpatched >>> master, vs. the performance with this line added to s_lock.h for your >>> architecture: >>> >>> #define TAS_SPIN(lock) (*(lock) ? 1 : TAS(lock)) >>> >>> We've now added that line for ia64 (the line is present in two >>> different places in the file, one for GCC and the other for HP's >>> compiler). So the question is whether we need it for any other >>> architectures. >> >> Ok. Let me talk to IBM guys... > > With help from IBM Japan Ltd. we did some tests on a larger IBM > machine than Tom Lane has used for his > test(http://archives.postgresql.org/message-id/8292.1314641721@sss.pgh.pa.us). > In his case it was IBM 8406-71Y, which has 8 physical cores and > 4SMT(32 threadings). Ours is IBM Power 750 Express, which has 32 > physical cores and 4SMT(128 threadings), 256GB RAM. > > The test method was same as the one in the article above. The > differences are OS(RHEL 6.1), gcc version (4.4.5) and shared buffer > size(8GB). > > We tested 3 methods to enhance spin lock contention: > > 1) Add "hint" parameter to lwarx op which is usable POWER6 or later > architecure. > > 2) Add non-locked test in TAS() > > 3) #1 + #2 > > We saw small performance enhancement with #1, larger one with #2 and > even better with #1+#2. Hmm, so you added the non-locked test in TAS()? Did you try adding it just to TAS_SPIN()? On Itanium, I found that it was slightly better to do it only in TAS_SPIN() - i.e. in the contended case. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
>> With help from IBM Japan Ltd. we did some tests on a larger IBM >> machine than Tom Lane has used for his >> test(http://archives.postgresql.org/message-id/8292.1314641721@sss.pgh.pa.us). >> In his case it was IBM 8406-71Y, which has 8 physical cores and >> 4SMT(32 threadings). Ours is IBM Power 750 Express, which has 32 >> physical cores and 4SMT(128 threadings), 256GB RAM. >> >> The test method was same as the one in the article above. The >> differences are OS(RHEL 6.1), gcc version (4.4.5) and shared buffer >> size(8GB). >> >> We tested 3 methods to enhance spin lock contention: >> >> 1) Add "hint" parameter to lwarx op which is usable POWER6 or later >> architecure. >> >> 2) Add non-locked test in TAS() >> >> 3) #1 + #2 >> >> We saw small performance enhancement with #1, larger one with #2 and >> even better with #1+#2. > > Hmm, so you added the non-locked test in TAS()? Did you try adding it > just to TAS_SPIN()? On Itanium, I found that it was slightly better > to do it only in TAS_SPIN() - i.e. in the contended case. The actual test was performed by one of our engineers in my company (Toshihiro Kitagawa). I think the answer to your question is yes, but let me talk to him to make it sure. -- Tatsuo Ishii SRA OSS, Inc. Japan English: http://www.sraoss.co.jp/index_en.php Japanese: http://www.sraoss.co.jp
On Tue, Oct 18, 2011 at 10:04 AM, Robert Haas <robertmhaas@gmail.com> wrote: > Hmm, so you added the non-locked test in TAS()? Did you try adding it > just to TAS_SPIN()? On Itanium, I found that it was slightly better > to do it only in TAS_SPIN() - i.e. in the contended case. > Would it be a good change for S_LOCK() to use TAS_SPIN() as well ? Thanks, Pavan -- Pavan Deolasee EnterpriseDB http://www.enterprisedb.com
On Tue, Oct 18, 2011 at 2:20 AM, Pavan Deolasee <pavan.deolasee@gmail.com> wrote: > On Tue, Oct 18, 2011 at 10:04 AM, Robert Haas <robertmhaas@gmail.com> wrote: >> Hmm, so you added the non-locked test in TAS()? Did you try adding it >> just to TAS_SPIN()? On Itanium, I found that it was slightly better >> to do it only in TAS_SPIN() - i.e. in the contended case. > > Would it be a good change for S_LOCK() to use TAS_SPIN() as well ? Well, that would be sort of missing the point of why we invented TAS_SPIN() in the first place. What we found on Itanium is that using the unlocked test always was better than never doing it, but what was even slightly better was to use the unlocked first test *only when spinning*. In other words, on the very first go-around, we use the atomic instruction right away. Only if that fails do we switch to using the unlocked test first. Now it's possible that on some other architecture it's better to do the unlocked test first every time. But it seems somewhat unlikely, because in the hopefully-common case where the spinlock is uncontended, it's just a waste. If you're having enough spinlock contention that the first TAS() is failing frequently, you need to fix the underlying cause of the spinlock contention... -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
>> With help from IBM Japan Ltd. we did some tests on a larger IBM >> machine than Tom Lane has used for his >> test(http://archives.postgresql.org/message-id/8292.1314641721@sss.pgh.pa.us). >> In his case it was IBM 8406-71Y, which has 8 physical cores and >> 4SMT(32 threadings). Ours is IBM Power 750 Express, which has 32 >> physical cores and 4SMT(128 threadings), 256GB RAM. >> >> The test method was same as the one in the article above. The >> differences are OS(RHEL 6.1), gcc version (4.4.5) and shared buffer >> size(8GB). >> >> We tested 3 methods to enhance spin lock contention: >> >> 1) Add "hint" parameter to lwarx op which is usable POWER6 or later >> architecure. >> >> 2) Add non-locked test in TAS() >> >> 3) #1 + #2 >> >> We saw small performance enhancement with #1, larger one with #2 and >> even better with #1+#2. > > Hmm, so you added the non-locked test in TAS()? Did you try adding it > just to TAS_SPIN()? On Itanium, I found that it was slightly better > to do it only in TAS_SPIN() - i.e. in the contended case. Here is new patch using TAS_SPIN(), created by Manabu Ori from IBM Japan. Also this patch deal with older Power architectures which do not have "hint" argument of lwarx opcode. According to him, the patch resulted in much better performance stock git head. Stock git head without patch: pgbench -c 1 -j 1 -S -T 300 tps = 11360.472691 (including ... pgbench -c 2 -j 1 -S -T 300 tps = 22173.943133 (including ... pgbench -c 4 -j 2 -S -T 300 tps = 43397.331641 (including ... pgbench -c 8 -j 4 -S -T 300 tps = 73469.073714 (including ... pgbench -c 16 -j 8 -S -T 300 tps = 151094.270443 (including ... pgbench -c 32 -j 16 -S -T 300 tps = 166752.637452 (including ... pgbench -c 64 -j 32 -S -T 300 tps = 148139.338204 (including ... pgbench -c 128 -j 64 -S -T 300 tps = 115412.622895 (including ... Stock git head with patch: pgbench -c 1 -j 1 -S -T 300 tps = 11103.370854 (including ... pgbench -c 2 -j 1 -S -T 300 tps = 22118.907582 (including ... pgbench -c 4 -j 2 -S -T 300 tps = 42608.641820 (including ... pgbench -c 8 -j 4 -S -T 300 tps = 77592.862639 (including ... pgbench -c 16 -j 8 -S -T 300 tps = 150469.841892 (including ... pgbench -c 32 -j 16 -S -T 300 tps = 267726.082168 (including ... pgbench -c 64 -j 32 -S -T 300 tps = 322582.271713 (including ... pgbench -c 128 -j 64 -S -T 300 tps = 273071.683663 (including ... (Graph is attached) Test environment: Power 750 (32 physical cores, virtually 128 cores using SMT4) mem: 256GB OS: RHEL6.1 kernel 2.6.32-131.0.15.el6.ppc64 gcc version 4.4.5 20110214 (Red Hat 4.4.5-6) PostgreSQL Git head (0510b62d91151b9d8c1fe1aa15c9cf3ffe9bf25b) -- Tatsuo Ishii SRA OSS, Inc. Japan English: http://www.sraoss.co.jp/index_en.php Japanese: http://www.sraoss.co.jp
On 28.12.2011 14:03, Tatsuo Ishii wrote: >>> With help from IBM Japan Ltd. we did some tests on a larger IBM >>> machine than Tom Lane has used for his >>> test(http://archives.postgresql.org/message-id/8292.1314641721@sss.pgh.pa.us). >>> In his case it was IBM 8406-71Y, which has 8 physical cores and >>> 4SMT(32 threadings). Ours is IBM Power 750 Express, which has 32 >>> physical cores and 4SMT(128 threadings), 256GB RAM. >>> >>> The test method was same as the one in the article above. The >>> differences are OS(RHEL 6.1), gcc version (4.4.5) and shared buffer >>> size(8GB). >>> >>> We tested 3 methods to enhance spin lock contention: >>> >>> 1) Add "hint" parameter to lwarx op which is usable POWER6 or later >>> architecure. >>> >>> 2) Add non-locked test in TAS() >>> >>> 3) #1 + #2 >>> >>> We saw small performance enhancement with #1, larger one with #2 and >>> even better with #1+#2. >> >> Hmm, so you added the non-locked test in TAS()? Did you try adding it >> just to TAS_SPIN()? On Itanium, I found that it was slightly better >> to do it only in TAS_SPIN() - i.e. in the contended case. > > Here is new patch using TAS_SPIN(), created by Manabu Ori from IBM > Japan. Also this patch deal with older Power architectures which do > not have "hint" argument of lwarx opcode. > > According to him, the patch resulted in much better performance stock > git head. Impressive results. config/c-compiler.m4 doesn't seem like the right place for the configure test. Would there be any harm in setting the lwarx hint always; what would happen on older ppc processors that don't support it? -- Heikki Linnakangas EnterpriseDB http://www.enterprisedb.com
> On 28.12.2011 14:03, Tatsuo Ishii wrote: >>>> With help from IBM Japan Ltd. we did some tests on a larger IBM >>>> machine than Tom Lane has used for his >>>> test(http://archives.postgresql.org/message-id/8292.1314641721@sss.pgh.pa.us). >>>> In his case it was IBM 8406-71Y, which has 8 physical cores and >>>> 4SMT(32 threadings). Ours is IBM Power 750 Express, which has 32 >>>> physical cores and 4SMT(128 threadings), 256GB RAM. >>>> >>>> The test method was same as the one in the article above. The >>>> differences are OS(RHEL 6.1), gcc version (4.4.5) and shared buffer >>>> size(8GB). >>>> >>>> We tested 3 methods to enhance spin lock contention: >>>> >>>> 1) Add "hint" parameter to lwarx op which is usable POWER6 or later >>>> architecure. >>>> >>>> 2) Add non-locked test in TAS() >>>> >>>> 3) #1 + #2 >>>> >>>> We saw small performance enhancement with #1, larger one with #2 and >>>> even better with #1+#2. >>> >>> Hmm, so you added the non-locked test in TAS()? Did you try adding it >>> just to TAS_SPIN()? On Itanium, I found that it was slightly better >>> to do it only in TAS_SPIN() - i.e. in the contended case. >> >> Here is new patch using TAS_SPIN(), created by Manabu Ori from IBM >> Japan. Also this patch deal with older Power architectures which do >> not have "hint" argument of lwarx opcode. >> >> According to him, the patch resulted in much better performance stock >> git head. > > Impressive results. > > config/c-compiler.m4 doesn't seem like the right place for the > configure test. Would there be any harm in setting the lwarx hint > always; what would happen on older ppc processors that don't support > it? I think the load module just fails to run in this case, but I'd like to confirm. Ori-san? -- Tatsuo Ishii SRA OSS, Inc. Japan English: http://www.sraoss.co.jp/index_en.php Japanese: http://www.sraoss.co.jp
Heikki Linnakangas <heikki.linnakangas@enterprisedb.com> writes:
> config/c-compiler.m4 doesn't seem like the right place for the configure
> test. Would there be any harm in setting the lwarx hint always; what
> would happen on older ppc processors that don't support it?
More to the point, a configure test only proves whether the
build machine can deal with the flag, not whether the machine
the executables will ultimately run on knows what the flag means.
We cannot assume that the build and execution boxes are the same.
(In general, AC_TRY_RUN tests are best avoided because of this.)
regards, tom lane
2011/12/29 Tatsuo Ishii <<a href="mailto:ishii@postgresql.org">ishii@postgresql.org</a>><br />> > Impressiveresults.<br />> ><br />> > config/c-compiler.m4 doesn't seem like the right place for the<br /> >> configure test. Would there be any harm in setting the lwarx hint<br />> > always; what would happen on olderppc processors that don't support<br />> > it?<br />><br />> I think the load module just fails to run inthis case, but I'd like<br /> > to confirm. Ori-san?<br /><br />I don't know where is the right config/*.m4 to placethis kind of<br />configure test. Do you have any idea?<br /><br />I believe lwarx hint would be no harm for recentPowerPC processors.<br /> What I tested are:<br /><br /> (1) Built postgres on POWER6 + RHEL5, which got lwarx hint<br/> included. Then copy these src tree to POWER5 + RHEL4 and<br /> run "make test", finished successfully.<br/><br /> (2) Lwarx test in configure failed on POWER5 + RHEL4.<br /><br />Note that POWER6 understands lwarxhint and POWER5 doesn't.<br />RHEL5 binutils supports lwarx hint and RHEL4 binutils doesn't.<br /><br />The only concernis for very old PowerPC.<br />Referring to Power Instruction Set Architecture manual(*1), on<br /> some processorsthat precede PowerISA v2.00, executing lwarx with<br />hint will cause the illegal instruction error.<br /><br/>Lwarx test in configure should fail on these kind of processors,<br />guessing from my test(2).<br /><br /> (*1) p.689of <a href="https://www.power.org/resources/downloads/PowerISA_V2.06B_V2_PUBLIC.pdf">https://www.power.org/resources/downloads/PowerISA_V2.06B_V2_PUBLIC.pdf</a><br /><br/>Regards,<br />Manabu Ori<br /><br />
On 29.12.2011 04:36, Manabu Ori wrote: > I believe lwarx hint would be no harm for recent PowerPC processors. > What I tested are: > > (1) Built postgres on POWER6 + RHEL5, which got lwarx hint > included. Then copy these src tree to POWER5 + RHEL4 and > run "make test", finished successfully. > > (2) Lwarx test in configure failed on POWER5 + RHEL4. > > Note that POWER6 understands lwarx hint and POWER5 doesn't. > RHEL5 binutils supports lwarx hint and RHEL4 binutils doesn't. > > The only concern is for very old PowerPC. > Referring to Power Instruction Set Architecture manual(*1), on > some processors that precede PowerISA v2.00, executing lwarx with > hint will cause the illegal instruction error. > > Lwarx test in configure should fail on these kind of processors, > guessing from my test(2). The Linux kernel does this (arch/powerpc/include/asm/ppc-opcode.h): > 127 /* > 128 * Only use the larx hint bit on 64bit CPUs. e500v1/v2 based CPUs will treat a > 129 * larx with EH set as an illegal instruction. > 130 */ > 131 #ifdef CONFIG_PPC64 > 132 #define __PPC_EH(eh) (((eh) & 0x1) << 0) > 133 #else > 134 #define __PPC_EH(eh) 0 > 135 #endif We can't copy-paste code from Linux directly, and I'm not sure I like that particular phrasing of the macro, but perhaps we should steal the idea and only use the hint on 64-bit PowerPC processors? I presume all the processors that support the hint are 64-bit, so the question is, is there any 64-bit PowerPC processors that would get upset about it? It's quite arbitrary to tie it to the word length, but if it works as a dividing line in practice, I'm fine with it. -- Heikki Linnakangas EnterpriseDB http://www.enterprisedb.com
Heikki Linnakangas <heikki.linnakangas@enterprisedb.com> writes:
> The Linux kernel does this (arch/powerpc/include/asm/ppc-opcode.h):
Yeah, I was looking at that too.
> We can't copy-paste code from Linux directly, and I'm not sure I like
> that particular phrasing of the macro, but perhaps we should steal the
> idea and only use the hint on 64-bit PowerPC processors?
The info that I've found says that the hint exists beginning in POWER6,
and there were certainly 64-bit Power machines before that. However,
it might be that the only machines that actually spit up on the hint bit
(rather than ignore it) were 32-bit, in which case this would be a
usable heuristic. Not sure how we can research that ... do we want to
just assume the kernel guys know what they're doing?
regards, tom lane