Thread: Proposed patch: Smooth replication during VACUUM FULL
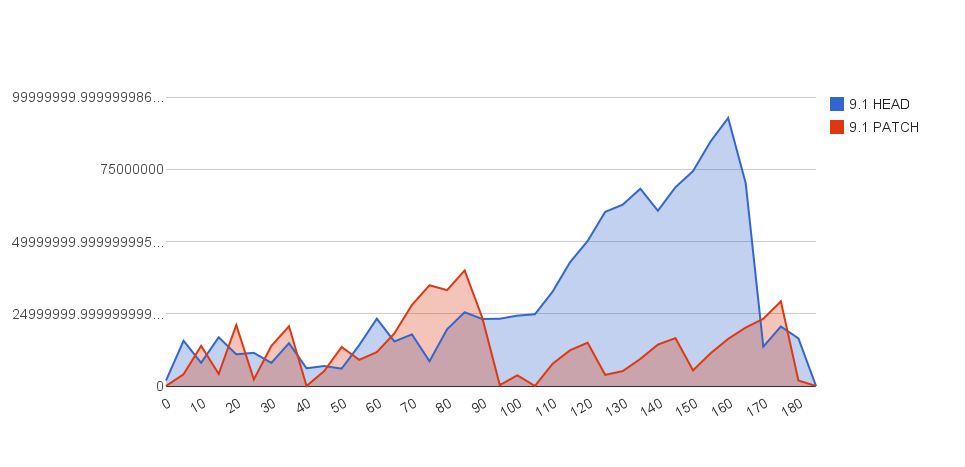
Hi guys, I have noticed that during VACUUM FULL on reasonably big tables, replication lag climbs. In order to smooth down the replication lag, I propose the attached patch which enables vacuum delay for VACUUM FULL. Please find attached the patch and below more information on this specific issue. Cheers, Gabriele == Scenario I have setup a simple SyncRep scenario with one master and one standby on the same server. On the master I have setup vacuum_cost_delay = 10 milliseconds. I have created a scale 50 pgbench database, which produces a 640MB pgbench_accounts table (about 82k pages). I have then launched a 60 seconds pgbench activity with 4 concurrent clients with the goal to make some changes to the pgbench table (approximately 1800 changes on my laptop). == Problem observed Replication lag climbs during VACUUM FULL. == Proposed change Enable vacuum delay for VACUUM FULL (and CLUSTER). == Test I have then launched a VACUUM FULL operation on the pgbench_accounts table and measured the lag in bytes every 5 seconds, by calculating the difference between the current location and the sent location. Here is a table with lag values. The first column (sec) is the sampling time (every 5 seconds for the sake of simplicity here), the second column (mlag) is the master lag on the current HEAD instance, the third column (mlagpatch) is the lag measured on the patched Postgres instance. sec | mlag | mlagpatch -----+-----------+----------- 0 | 1896424 | 0 5 | 15654912 | 4055040 10 | 8019968 | 13893632 15 | 16850944 | 4177920 20 | 10969088 | 21102592 25 | 11468800 | 2277376 30 | 7995392 | 13893632 35 | 14811136 | 20660224 40 | 6127616 | 0 45 | 6914048 | 5136384 50 | 5996544 | 13500416 55 | 14155776 | 9043968 60 | 23298048 | 11722752 65 | 15400960 | 18202624 70 | 17858560 | 28049408 75 | 8560640 | 34865152 80 | 19628032 | 33161216 85 | 25526272 | 39976960 90 | 23183360 | 23683072 95 | 23265280 | 303104 100 | 24346624 | 3710976 105 | 24813568 | 0 110 | 32587776 | 7651328 115 | 42827776 | 12369920 120 | 50167808 | 14991360 125 | 60260352 | 3850240 130 | 62750720 | 5160960 135 | 68255744 | 9355264 140 | 60653568 | 14336000 145 | 68780032 | 16564224 150 | 74342400 | 5398528 155 | 84639744 | 11321344 160 | 92741632 | 16302080 165 | 70123520 | 20234240 170 | 13606912 | 23248896 175 | 20586496 | 29278208 180 | 16482304 | 1900544 185 | 0 | 0 As you can see, replication lag on HEAD's PostgreSQL reaches 92MB (160 seconds) before starting to decrease (when the operation terminates). The test result is consistent with the expected behaviour of cost-based vacuum delay. -- Gabriele Bartolini - 2ndQuadrant Italia PostgreSQL Training, Services and Support gabriele.bartolini@2ndQuadrant.it | www.2ndQuadrant.it
Attachment
On Sat, Apr 30, 2011 at 1:19 PM, Gabriele Bartolini <gabriele.bartolini@2ndquadrant.it> wrote: > Hi guys, > > I have noticed that during VACUUM FULL on reasonably big tables, replication > lag climbs. In order to smooth down the replication lag, I propose the > attached patch which enables vacuum delay for VACUUM FULL. > AFAICS, the problem is that those operations involve the rebuild of tables, so we can't simply stop in the middle and wait because we will need to hold a strong lock more time... also the patch seems to be only doing something for CLUSTER and not for VACUUM FULL. or am i missing something? -- Jaime Casanova www.2ndQuadrant.com Professional PostgreSQL: Soporte y capacitación de PostgreSQL
--On 30. April 2011 20:19:36 +0200 Gabriele Bartolini <gabriele.bartolini@2ndQuadrant.it> wrote: > I have noticed that during VACUUM FULL on reasonably big tables, replication > lag climbs. In order to smooth down the replication lag, I propose the > attached patch which enables vacuum delay for VACUUM FULL. Hmm, but this will move one problem into another. You need to hold exclusive locks longer than necessary and given that we discourage the regular use of VACUUM FULL i cannot see a real benefit of it... -- Thanks Bernd
Jaime Casanova <jaime@2ndquadrant.com> writes:
> On Sat, Apr 30, 2011 at 1:19 PM, Gabriele Bartolini
>> I have noticed that during VACUUM FULL on reasonably big tables, replication
>> lag climbs. In order to smooth down the replication lag, I propose the
>> attached patch which enables vacuum delay for VACUUM FULL.
> AFAICS, the problem is that those operations involve the rebuild of
> tables, so we can't simply stop in the middle and wait because we will
> need to hold a strong lock more time... also the patch seems to be
> only doing something for CLUSTER and not for VACUUM FULL.
> or am i missing something?
No, actually it would have no effect on CLUSTER because VacuumCostActive
wouldn't be set. I think this is basically fixing an oversight in the
patch that changed VACUUM FULL into a variant of CLUSTER. We used to
use vacuum_delay_point() in the main loops in old-style VACUUM FULL,
but forgot to consider doing so in the CLUSTER-ish implementation.
The argument about holding locks longer doesn't seem relevant to me:
enabling delays during VACUUM FULL would've had that effect in the old
implementation, too, but nobody ever complained about that, and besides
the feature isn't enabled by default.
A bigger objection to this patch is that it seems quite incomplete.
I'm not sure there's much point in adding delays to the first loop of
copy_heap_data() without also providing for delays inside the sorting
code and the eventual index rebuilds; which will make the patch
significantly more complicated and invasive.
Another question is whether this is the right place to be looking
at all. If Gabriele's setup can't keep up with replication when a
VAC FULL is running, then it can't keep up when under load, period.
This seems like a pretty band-aid-ish response to that sort of problem.
regards, tom lane
On Sat, Apr 30, 2011 at 5:48 PM, Tom Lane <tgl@sss.pgh.pa.us> wrote: > Jaime Casanova <jaime@2ndquadrant.com> writes: >> On Sat, Apr 30, 2011 at 1:19 PM, Gabriele Bartolini >>> I have noticed that during VACUUM FULL on reasonably big tables, replication >>> lag climbs. In order to smooth down the replication lag, I propose the >>> attached patch which enables vacuum delay for VACUUM FULL. > >> AFAICS, the problem is that those operations involve the rebuild of >> tables, so we can't simply stop in the middle and wait because we will >> need to hold a strong lock more time... also the patch seems to be >> only doing something for CLUSTER and not for VACUUM FULL. >> or am i missing something? > [...] > The argument about holding locks longer doesn't seem relevant to me: > enabling delays during VACUUM FULL would've had that effect in the old > implementation, too, but nobody ever complained about that, you mean, no complaints except the usual: "don't use VACUUM FULL"? -- Jaime Casanova www.2ndQuadrant.com Professional PostgreSQL: Soporte y capacitación de PostgreSQL
On Sat, Apr 30, 2011 at 11:48 PM, Tom Lane <tgl@sss.pgh.pa.us> wrote: > Jaime Casanova <jaime@2ndquadrant.com> writes: >> On Sat, Apr 30, 2011 at 1:19 PM, Gabriele Bartolini >>> I have noticed that during VACUUM FULL on reasonably big tables, replication >>> lag climbs. In order to smooth down the replication lag, I propose the >>> attached patch which enables vacuum delay for VACUUM FULL. > >> AFAICS, the problem is that those operations involve the rebuild of >> tables, so we can't simply stop in the middle and wait because we will >> need to hold a strong lock more time... also the patch seems to be >> only doing something for CLUSTER and not for VACUUM FULL. >> or am i missing something? > > No, actually it would have no effect on CLUSTER because VacuumCostActive > wouldn't be set. Ah, good point, so the patch is accurate even though very short. > I think this is basically fixing an oversight in the > patch that changed VACUUM FULL into a variant of CLUSTER. We used to > use vacuum_delay_point() in the main loops in old-style VACUUM FULL, > but forgot to consider doing so in the CLUSTER-ish implementation. > The argument about holding locks longer doesn't seem relevant to me: > enabling delays during VACUUM FULL would've had that effect in the old > implementation, too, but nobody ever complained about that, and besides > the feature isn't enabled by default. > > A bigger objection to this patch is that it seems quite incomplete. > I'm not sure there's much point in adding delays to the first loop of > copy_heap_data() without also providing for delays inside the sorting > code and the eventual index rebuilds; which will make the patch > significantly more complicated and invasive. The patch puts the old behaviour of vacuum delay back into VACUUM FULL and seems worth backpatching to 9.0 and 9.1 to me, since it is so simple. Previously there wasn't any delay in the sort or indexing either, so it's a big ask to put that in now and it would also make backpatching harder. I think we should backpatch this now, but work on an additional delay in sort and index for 9.2 to "complete" this thought. ISTM a good idea for us to add similar delay code to all "maintenance" commands, should the user wish to use it (9.2+). > Another question is whether this is the right place to be looking > at all. If Gabriele's setup can't keep up with replication when a > VAC FULL is running, then it can't keep up when under load, period. > This seems like a pretty band-aid-ish response to that sort of problem. This isn't about whether the system can cope with the load, its about whether replication lag is affected by the load. -- Simon Riggs http://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Training & Services
Simon Riggs <simon@2ndQuadrant.com> writes:
> On Sat, Apr 30, 2011 at 11:48 PM, Tom Lane <tgl@sss.pgh.pa.us> wrote:
>> A bigger objection to this patch is that it seems quite incomplete.
>> I'm not sure there's much point in adding delays to the first loop of
>> copy_heap_data() without also providing for delays inside the sorting
>> code and the eventual index rebuilds; which will make the patch
>> significantly more complicated and invasive.
> The patch puts the old behaviour of vacuum delay back into VACUUM FULL
> and seems worth backpatching to 9.0 and 9.1 to me, since it is so
> simple.
No, it does perhaps 1% of what's needed to make the new implementation
react to vacuum_cost_delay in a useful way. I see no point in applying
this as-is, let alone back-patching it.
> Previously there wasn't any delay in the sort or indexing either, so
> it's a big ask to put that in now and it would also make backpatching
> harder.
You're missing the point: there wasn't any sort or reindex in the old
implementation of VACUUM FULL. The CLUSTER-based implementation makes
use of very large chunks of code that were simply never used before
by VACUUM.
>> Another question is whether this is the right place to be looking
>> at all. �If Gabriele's setup can't keep up with replication when a
>> VAC FULL is running, then it can't keep up when under load, period.
>> This seems like a pretty band-aid-ish response to that sort of problem.
> This isn't about whether the system can cope with the load, its about
> whether replication lag is affected by the load.
And I think you're missing the point here too. Even if we cluttered
the system to the extent of making all steps of VACUUM FULL honor
vacuum_cost_delay, it wouldn't fix Gabriele's problem, because any other
I/O-intensive query would produce the same effect. We could further
clutter everything else that someone defines as a "maintenance query",
and it *still* wouldn't fix the problem. It would be much more
profitable to attack the performance of replication directly. I don't
really feel a need to put cost_delay stuff into anything that's not used
by autovacuum.
regards, tom lane
On Sun, May 1, 2011 at 6:51 PM, Tom Lane <tgl@sss.pgh.pa.us> wrote: > Simon Riggs <simon@2ndQuadrant.com> writes: >> On Sat, Apr 30, 2011 at 11:48 PM, Tom Lane <tgl@sss.pgh.pa.us> wrote: >>> A bigger objection to this patch is that it seems quite incomplete. >>> I'm not sure there's much point in adding delays to the first loop of >>> copy_heap_data() without also providing for delays inside the sorting >>> code and the eventual index rebuilds; which will make the patch >>> significantly more complicated and invasive. > >> The patch puts the old behaviour of vacuum delay back into VACUUM FULL >> and seems worth backpatching to 9.0 and 9.1 to me, since it is so >> simple. > > No, it does perhaps 1% of what's needed to make the new implementation > react to vacuum_cost_delay in a useful way. I see no point in applying > this as-is, let alone back-patching it. Gabriele's test results show the opposite. It is clearly very effective. Please look again at the test results. I'm surprised that the reaction isn't "good catch" and the patch quickly applied. >> Previously there wasn't any delay in the sort or indexing either, so >> it's a big ask to put that in now and it would also make backpatching >> harder. > > You're missing the point: there wasn't any sort or reindex in the old > implementation of VACUUM FULL. The CLUSTER-based implementation makes > use of very large chunks of code that were simply never used before > by VACUUM. > >>> Another question is whether this is the right place to be looking >>> at all. If Gabriele's setup can't keep up with replication when a >>> VAC FULL is running, then it can't keep up when under load, period. >>> This seems like a pretty band-aid-ish response to that sort of problem. > >> This isn't about whether the system can cope with the load, its about >> whether replication lag is affected by the load. > > And I think you're missing the point here too. Even if we cluttered > the system to the extent of making all steps of VACUUM FULL honor > vacuum_cost_delay, it wouldn't fix Gabriele's problem, because any other > I/O-intensive query would produce the same effect. We could further > clutter everything else that someone defines as a "maintenance query", > and it *still* wouldn't fix the problem. It would be much more > profitable to attack the performance of replication directly. I don't think the performance of replication is at issue. This is about resource control. The point is that replication is quite likely to be a high priority, especially with sync rep. Speeding up replication is not the same thing as rate limiting other users to enforce a lower priority, which is what vacuum_delay does. > I don't > really feel a need to put cost_delay stuff into anything that's not used > by autovacuum. It seems reasonable to me to hope that one day we might be able to specify that certain tasks have a lower rate of resource usage than others. -- Simon Riggs http://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Training & Services
On Sun, May 1, 2011 at 9:31 PM, Simon Riggs <simon@2ndquadrant.com> wrote: > I don't think the performance of replication is at issue. This is > about resource control. > The unspoken question here is why would replication be affected by i/o load anyways? It's reading data file buffers that have only recently been written and should be in cache. I wonder if this system has chosen O_DIRECT or something like that for writing out wal? -- greg
On Mon, May 2, 2011 at 7:44 AM, Greg Stark <gsstark@mit.edu> wrote: > On Sun, May 1, 2011 at 9:31 PM, Simon Riggs <simon@2ndquadrant.com> wrote: >> I don't think the performance of replication is at issue. This is >> about resource control. >> > > The unspoken question here is why would replication be affected by i/o > load anyways? It's reading data file buffers that have only recently > been written and should be in cache. I wonder if this system has > chosen O_DIRECT or something like that for writing out wal? It's not, that is a misunderstanding in the thread. It appears that the sheer volume of WAL being generated slows down replication. I would guess it's the same effect as noticing a slow down on web traffic when somebody is watching streaming video. The requested solution is the same as the network case: rate limit the task using too much resource, if the user requests that. I can't see the objection to replacing something inadvertently removed in 9.0, especially since it is a 1 line patch and is accompanied by copious technical evidence. Sure, we can do an even better job in a later release. -- Simon Riggs http://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Training & Services
Simon Riggs <simon@2ndQuadrant.com> writes:
> I can't see the objection to replacing something inadvertently removed
> in 9.0, especially since it is a 1 line patch and is accompanied by
> copious technical evidence.
I am not sure which part of "this isn't a substitute for what happened
before 9.0" you fail to understand.
As for "copious technical evidence", I saw no evidence provided
whatsoever that this patch really did anything much to fix the
reported problem. Yeah, it would help during the initial scan
of the old rel, but not during the sort or reindex steps.
(And as for the thoroughness of the technical analysis, the patch
doesn't even catch the second CHECK_FOR_INTERRUPTS in copy_heap_data;
which would at least provide some relief for the sort part of the
problem, though only in the last pass of sorting.)
regards, tom lane
Excerpts from Bernd Helmle's message of sáb abr 30 19:40:00 -0300 2011: > > > --On 30. April 2011 20:19:36 +0200 Gabriele Bartolini > <gabriele.bartolini@2ndQuadrant.it> wrote: > > > I have noticed that during VACUUM FULL on reasonably big tables, replication > > lag climbs. In order to smooth down the replication lag, I propose the > > attached patch which enables vacuum delay for VACUUM FULL. > > Hmm, but this will move one problem into another. You need to hold exclusive > locks longer than necessary and given that we discourage the regular use of > VACUUM FULL i cannot see a real benefit of it... With the 8.4 code you had the possibility of doing so, if you so wished. It wasn't enabled by default. (Say you want to vacuum a very large table that is not critical to operation; so you can lock it for a long time without trouble, but you can't have this vacuum operation cause delays in the rest of the system due to excessive I/O.) The argument seems sane to me. I didn't look into the details of the patch though. -- Álvaro Herrera <alvherre@commandprompt.com> The PostgreSQL Company - Command Prompt, Inc. PostgreSQL Replication, Consulting, Custom Development, 24x7 support
On Mon, May 2, 2011 at 3:37 PM, Tom Lane <tgl@sss.pgh.pa.us> wrote: > As for "copious technical evidence", I saw no evidence provided > whatsoever that this patch really did anything much to fix the > reported problem. Yeah, it would help during the initial scan > of the old rel, but not during the sort or reindex steps. > Well if Simon's right that it's a question of generating an overwhelming amount of wal rather than saturating the local i/o then the sort isn't relevant. I'm not sure of what the scale of wal from the reindex operation is compared to the table rebuild. Of course you would have same problem doing a COPY load or even just doing a sequential scan of a recently loaded table. Or is there something about table rebuilds that is particularly nasty? -- greg
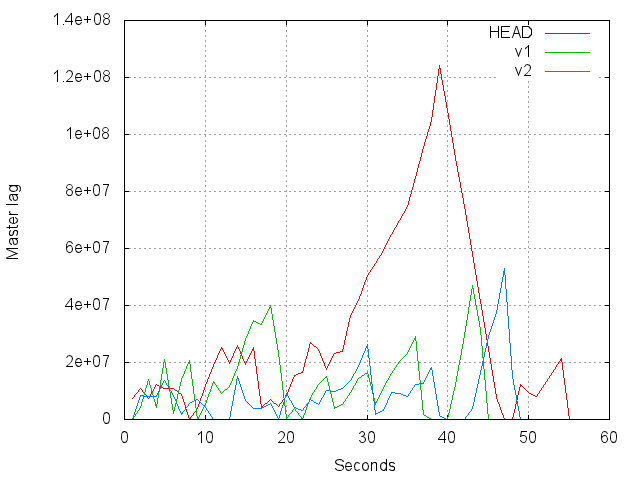
On Mon, May 2, 2011 at 3:37 PM, Tom Lane <tgl@sss.pgh.pa.us> wrote: > Simon Riggs <simon@2ndQuadrant.com> writes: >> I can't see the objection to replacing something inadvertently removed >> in 9.0, especially since it is a 1 line patch and is accompanied by >> copious technical evidence. > > I am not sure which part of "this isn't a substitute for what happened > before 9.0" you fail to understand. > > As for "copious technical evidence", I saw no evidence provided > whatsoever that this patch really did anything much to fix the > reported problem. Just so we're looking at the same data, graph attached. > Yeah, it would help during the initial scan > of the old rel, but not during the sort or reindex steps. As Greg points out, the sort is not really of concern (for now). > (And as for the thoroughness of the technical analysis, the patch > doesn't even catch the second CHECK_FOR_INTERRUPTS in copy_heap_data; > which would at least provide some relief for the sort part of the > problem, though only in the last pass of sorting.) I'm sure Gabriele can add those things as well - that also looks like another 1 line change. I'm just observing that the patch as-is appears effective and I feel it is important. -- Simon Riggs http://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Training & Services
Attachment
{kind=link}
On Mon, May 2, 2011 at 5:20 PM, Simon Riggs <simon@2ndquadrant.com> wrote: >> Yeah, it would help during the initial scan >> of the old rel, but not during the sort or reindex steps. > > As Greg points out, the sort is not really of concern (for now). Though I was surprised the reindex isn't an equally big problem. It might matter a lot what the shape of the schema is. If you have lots of indexes the index wal might be larger than the table rebuild. -- greg
Il 02/05/11 18:20, Simon Riggs ha scritto: > I'm sure Gabriele can add those things as well - that also looks like > another 1 line change. Yes, today we have performed some tests with that patch as well (attached is version 2). The version 2 of the patch (which includes the change Tom suggested on Saturday), smooths the process even more. You can look at the attached graph for now - even though we are currently relaunching a test with all 3 different versions from scratch (unpatched, patch v1 and patch v2), with larger data in order to confirm this behaviour. > I'm just observing that the patch as-is appears effective and I feel > it is important. Exactly. One thing also important to note as well is that with the vacuum delay being honoured, "vacuum full" operations in a SyncRep scenario take less time as well - as the load is more distributed over time. You can easily spot in the graphs the point where VACUUM FULL terminates, then it is just a matter of flushing the WAL delay for replication. Anyway, I hope I can give you more detailed information tomorrow. Thanks. Cheers, Gabriele -- Gabriele Bartolini - 2ndQuadrant Italia PostgreSQL Training, Services and Support gabriele.bartolini@2ndQuadrant.it | www.2ndQuadrant.it
Attachment
{kind=link}
On Mon, May 2, 2011 at 6:15 PM, Gabriele Bartolini <gabriele.bartolini@2ndquadrant.it> wrote: > You can easily spot in the graphs the point where VACUUM FULL terminates, > then it is just a matter of flushing the WAL delay for replication. Agreed. > Anyway, I hope I can give you more detailed information tomorrow. Thanks. Did you find anything else of note, or is your patch ready to commit? -- Simon Riggs http://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Training & Services
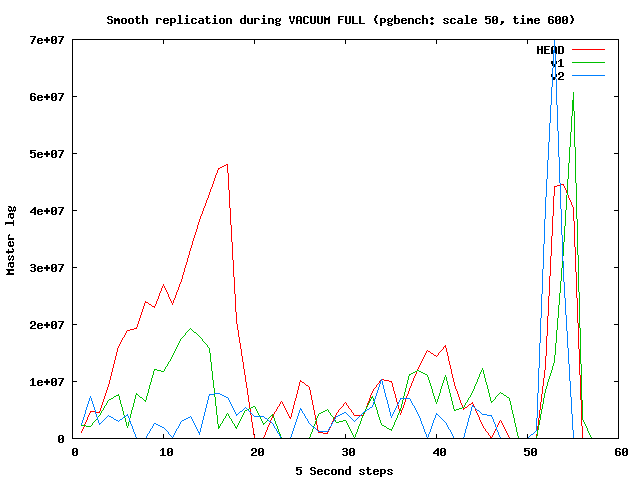
Il 09/05/11 09:14, Simon Riggs ha scritto: >> Anyway, I hope I can give you more detailed information tomorrow. Thanks. > Did you find anything else of note, or is your patch ready to commit? Unfortunately I did not have much time to run further tests. The ones I have done so far show that it mostly works (see attached graph), but there are some unresolved spikes that will require further work in 9.2. Cheers, Gabriele -- Gabriele Bartolini - 2ndQuadrant Italia PostgreSQL Training, Services and Support gabriele.bartolini@2ndQuadrant.it | www.2ndQuadrant.it
{kind=link}